This article is more than one year old. Older articles may contain outdated content. Check that the information in the page has not become incorrect since its publication.
Introducing the Resource Management Working Group
Why are we here?
Kubernetes has evolved to support diverse and increasingly complex classes of applications. We can onboard and scale out modern, cloud-native web applications based on microservices, batch jobs, and stateful applications with persistent storage requirements.
However, there are still opportunities to improve Kubernetes; for example, the ability to run workloads that require specialized hardware or those that perform measurably better when hardware topology is taken into account. These conflicts can make it difficult for application classes (particularly in established verticals) to adopt Kubernetes.
We see an unprecedented opportunity here, with a high cost if it’s missed. The Kubernetes ecosystem must create a consumable path forward to the next generation of system architectures by catering to needs of as-yet unserviced workloads in meaningful ways. The Resource Management Working Group, along with other SIGs, must demonstrate the vision customers want to see, while enabling solutions to run well in a fully integrated, thoughtfully planned end-to-end stack.
Kubernetes Working Groups are created when a particular challenge requires cross-SIG collaboration. The Resource Management Working Group, for example, works primarily with sig-node and sig-scheduling to drive support for additional resource management capabilities in Kubernetes. We make sure that key contributors from across SIGs are frequently consulted because working groups are not meant to make system-level decisions on behalf of any SIG.
An example and key benefit of this is the working group’s relationship with sig-node. We were able to ensure completion of several releases of node reliability work (complete in 1.6) before contemplating feature design on top. Those designs are use-case driven: research into technical requirements for a variety of workloads, then sorting based on measurable impact to the largest cross-section.
Target Workloads and Use-cases
One of the working group’s key design tenets is that user experience must remain clean and portable, while still surfacing infrastructure capabilities that are required by businesses and applications.
While not representing any commitment, we hope in the fullness of time that Kubernetes can optimally run financial services workloads, machine learning/training, grid schedulers, map-reduce, animation workloads, and more. As a use-case driven group, we account for potential application integration that can also facilitate an ecosystem of complementary independent software vendors to flourish on top of Kubernetes.
Why do this?
Kubernetes covers generic web hosting capabilities very well, so why go through the effort of expanding workload coverage for Kubernetes at all? The fact is that workloads elegantly covered by Kubernetes today, only represent a fraction of the world’s compute usage. We have a tremendous opportunity to safely and methodically expand upon the set of workloads that can run optimally on Kubernetes.
To date, there’s demonstrable progress in the areas of expanded workload coverage:
- Stateful applications such as Zookeeper, etcd, MySQL, Cassandra, ElasticSearch
- Jobs, such as timed events to process the day’s logs or any other batch processing
- Machine Learning and compute-bound workload acceleration through Alpha GPU support Collectively, the folks working on Kubernetes are hearing from their customers that we need to go further. Following the tremendous popularity of containers in 2014, industry rhetoric circled around a more modern, container-based, datacenter-level workload orchestrator as folks looked to plan their next architectures.
As a consequence, we began advocating for increasing the scope of workloads covered by Kubernetes, from overall concepts to specific features. Our aim is to put control and choice in users hands, helping them move with confidence towards whatever infrastructure strategy they choose. In this advocacy, we quickly found a large group of like-minded companies interested in broadening the types of workloads that Kubernetes can orchestrate. And thus the working group was born.
Genesis of the Resource Management Working Group
After extensive development/feature discussions during the Kubernetes Developer Summit 2016 after CloudNativeCon | KubeCon Seattle, we decided to formalize our loosely organized group. In January 2017, the Kubernetes Resource Management Working Group was formed. This group (led by Derek Carr from Red Hat and Vishnu Kannan from Google) was originally cast as a temporary initiative to provide guidance back to sig-node and sig-scheduling (primarily). However, due to the cross-cutting nature of the goals within the working group, and the depth of roadmap quickly uncovered, the Resource Management Working Group became its own entity within the first few months.
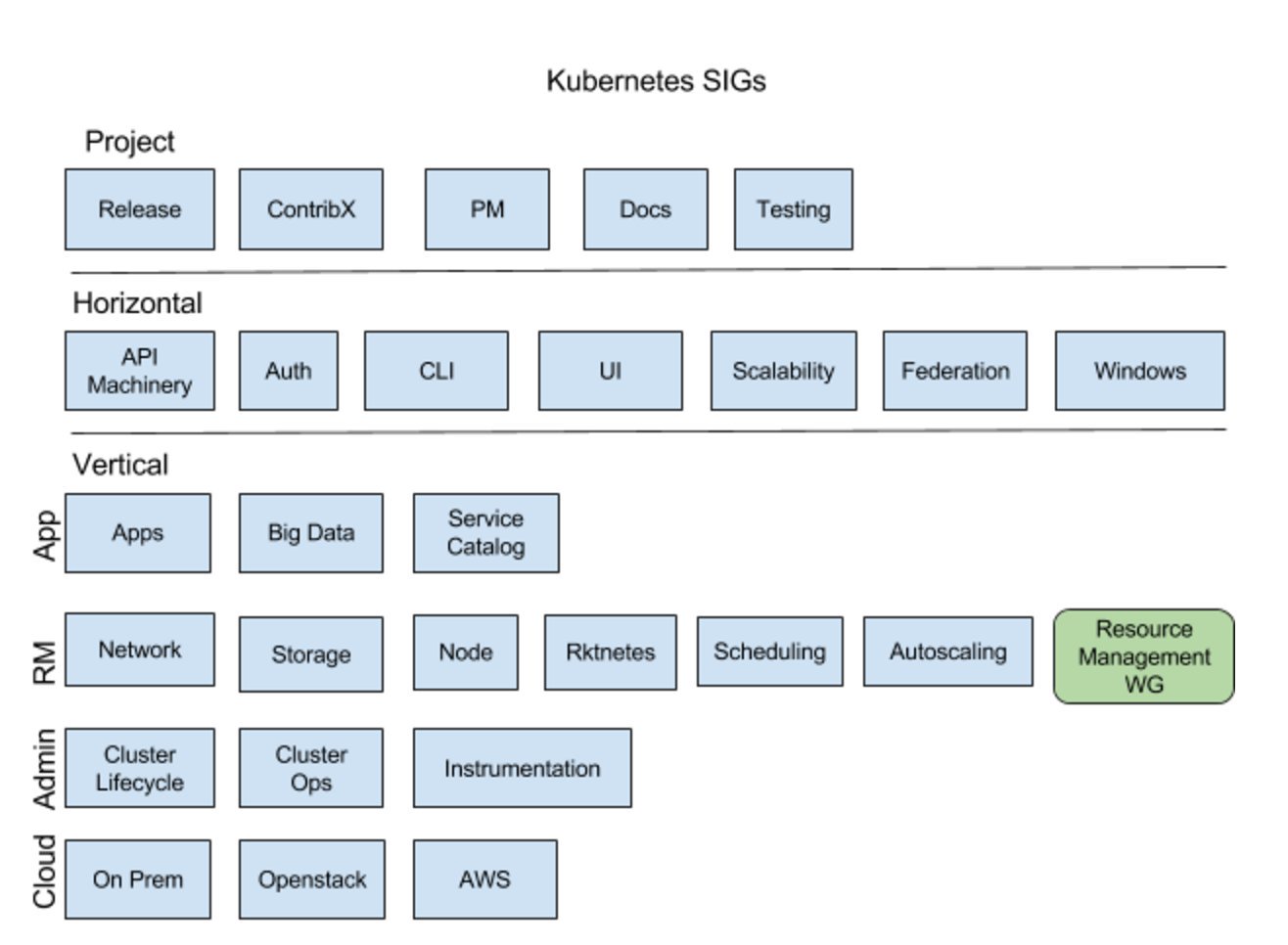
Recently, Brian Grant from Google (@bgrant0607) posted the following image on his Twitter feed. This image helps to explain the role of each SIG, and shows where the Resource Management Working Group fits into the overall project organization.
To help bootstrap this effort, the Resource Management Working Group had its first face-to-face kickoff meeting in May 2017. Thanks to Google for hosting!

Folks from Intel, NVIDIA, Google, IBM, Red Hat. and Microsoft (among others) participated.
You can read the outcomes of that 3-day meeting here.
The group’s prioritized list of features for increasing workload coverage on Kubernetes enumerated in the charter of the Resource Management Working group includes:
- Support for performance sensitive workloads (exclusive cores, cpu pinning strategies, NUMA)
- Integrating new hardware devices (GPUs, FPGAs, Infiniband, etc.)
- Improving resource isolation (local storage, hugepages, caches, etc.)
- Improving Quality of Service (performance SLOs)
- Performance benchmarking
- APIs and extensions related to the features mentioned above The discussions made it clear that there was tremendous overlap between needs for various workloads, and that we ought to de-duplicate requirements, and plumb generically.
Workload Characteristics
The set of initially targeted use-cases share one or more of the following characteristics:
- Deterministic performance (address long tail latencies)
- Isolation within a single node, as well as within groups of nodes sharing a control plane
- Requirements on advanced hardware and/or software capabilities
- Predictable, reproducible placement: applications need granular guarantees around placement The Resource Management Working Group is spearheading the feature design and development in support of these workload requirements. Our goal is to provide best practices and patterns for these scenarios.
Initial Scope
In the months leading up to our recent face-to-face, we had discussed how to safely abstract resources in a way that retains portability and clean user experience, while still meeting application requirements. The working group came away with a multi-release roadmap that included 4 short- to mid-term targets with great overlap between target workloads:
Device Manager (Plugin) Proposal
- Kubernetes should provide access to hardware devices such as NICs, GPUs, FPGA, Infiniband and so on.
- Kubernetes should provide a way for users to request static CPU assignment via the Guaranteed QoS tier. No support for NUMA in this phase.
HugePages support in Kubernetes
- Kubernetes should provide a way for users to consume huge pages of any size.
- Kubernetes should implement an abstraction layer (analogous to StorageClasses) for devices other than CPU and memory that allows a user to consume a resource in a portable way. For example, how can a pod request a GPU that has a minimum amount of memory?
Getting Involved & Summary
Our charter document includes a Contact Us section with links to our mailing list, Slack channel, and Zoom meetings. Recordings of previous meetings are uploaded to Youtube. We plan to discuss these topics and more at the 2017 Kubernetes Developer Summit at CloudNativeCon | KubeCon in Austin. Please come and join one of our meetings (users, customers, software and hardware vendors are all welcome) and contribute to the working group!