This article is more than one year old. Older articles may contain outdated content. Check that the information in the page has not become incorrect since its publication.
Announcing etcd 3.4
etcd 3.4 focuses on stability, performance and ease of operation, with features like pre-vote and non-voting member and improvements to storage backend and client balancer.
Please see CHANGELOG for full lists of changes.
Better Storage Backend
etcd v3.4 includes a number of performance improvements for large scale Kubernetes workloads.
In particular, etcd experienced performance issues with a large number of concurrent read transactions even when there is no write (e.g. “read-only range request ... took too long to execute”). Previously, the storage backend commit operation on pending writes blocks incoming read transactions, even when there was no pending write. Now, the commit does not block reads which improve long-running read transaction performance.
We further made backend read transactions fully concurrent. Previously, ongoing long-running read transactions block writes and upcoming reads. With this change, write throughput is increased by 70% and P99 write latency is reduced by 90% in the presence of long-running reads. We also ran Kubernetes 5000-node scalability test on GCE with this change and observed similar improvements. For example, in the very beginning of the test where there are a lot of long-running “LIST pods”, the P99 latency of “POST clusterrolebindings” is reduced by 97.4%.
More improvements have been made to lease storage. We enhanced lease expire/revoke performance by storing lease objects more efficiently, and made lease look-up operation non-blocking with current lease grant/revoke operation. And etcd v3.4 introduces lease checkpoint as an experimental feature to persist remaining time-to-live values through consensus. This ensures short-lived lease objects are not auto-renewed after leadership election. This also prevents lease object pile-up when the time-to-live value is relatively large (e.g. 1-hour TTL never expired in Kubernetes use case).
Improved Raft Voting Process
etcd server implements Raft consensus algorithm for data replication. Raft is a leader-based protocol. Data is replicated from leader to follower; a follower forwards proposals to a leader, and the leader decides what to commit or not. Leader persists and replicates an entry, once it has been agreed by the quorum of cluster. The cluster members elect a single leader, and all other members become followers. The elected leader periodically sends heartbeats to its followers to maintain its leadership, and expects responses from each follower to keep track of its progress.
In its simplest form, a Raft leader steps down to a follower when it receives a message with higher terms without any further cluster-wide health checks. This behavior can affect the overall cluster availability.
For instance, a flaky (or rejoining) member drops in and out, and starts campaign. This member ends up with higher terms, ignores all incoming messages with lower terms, and sends out messages with higher terms. When the leader receives this message of a higher term, it reverts back to follower.
This becomes more disruptive when there’s a network partition. Whenever the partitioned node regains its connectivity, it can possibly trigger the leader re-election. To address this issue, etcd Raft introduces a new node state pre-candidate with the pre-vote feature. The pre-candidate first asks other servers whether it's up-to-date enough to get votes. Only if it can get votes from the majority, it increments its term and starts an election. This extra phase improves the robustness of leader election in general. And helps the leader remain stable as long as it maintains its connectivity with the quorum of its peers.
Similarly, etcd availability can be affected when a restarting node has not received the leader heartbeats in time (e.g. due to slow network), which triggers the leader election. Previously, etcd fast-forwards election ticks on server start, with only one tick left for leader election. For example, when the election timeout is 1-second, the follower only waits 100ms for leader contacts before starting an election. This speeds up initial server start, by not having to wait for the election timeouts (e.g. election is triggered in 100ms instead of 1-second). Advancing election ticks is also useful for cross datacenter deployments with larger election timeouts. However, in many cases, the availability is more critical than the speed of initial leader election. To ensure better availability with rejoining nodes, etcd now adjusts election ticks with more than one tick left, thus more time for the leader to prevent a disruptive restart.
Raft Non-Voting Member, Learner
The challenge with membership reconfiguration is that it often leads to quorum size changes, which are prone to cluster unavailabilities. Even if it does not alter the quorum, clusters with membership change are more likely to experience other underlying problems. To improve the reliability and confidence of reconfiguration, a new role - learner is introduced in etcd 3.4 release.
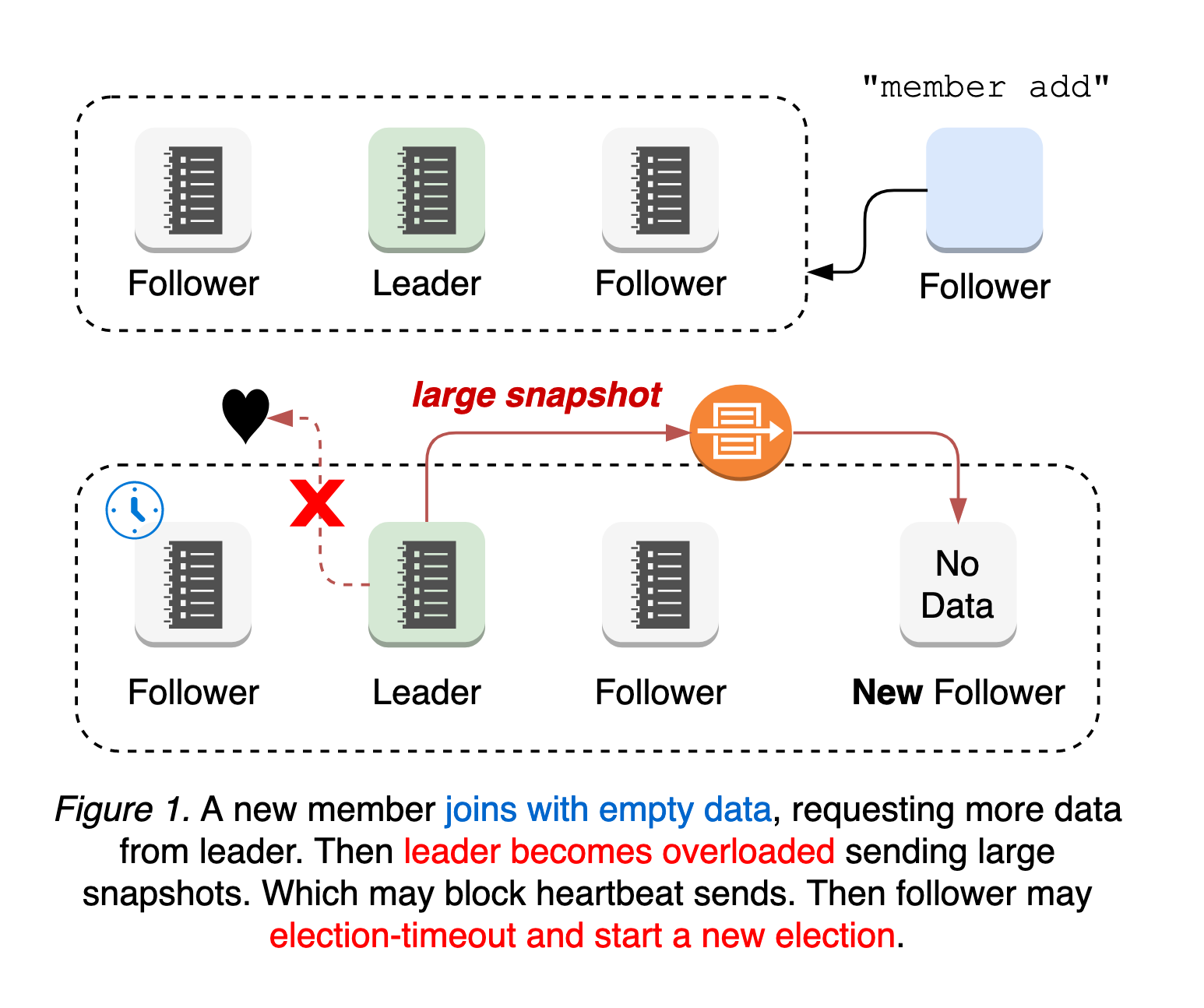
A new etcd member joins the cluster with no initial data, requesting all historical updates from the leader until it catches up to the leader’s logs. This means the leader’s network is more likely to be overloaded, blocking or dropping leader heartbeats to followers. In such cases, a follower may experience election-timeout and start a new leader election. That is, a cluster with a new member is more vulnerable to leader election. Both leader election and the subsequent update propagation to the new member are prone to causing periods of cluster unavailability (see Figure 1).
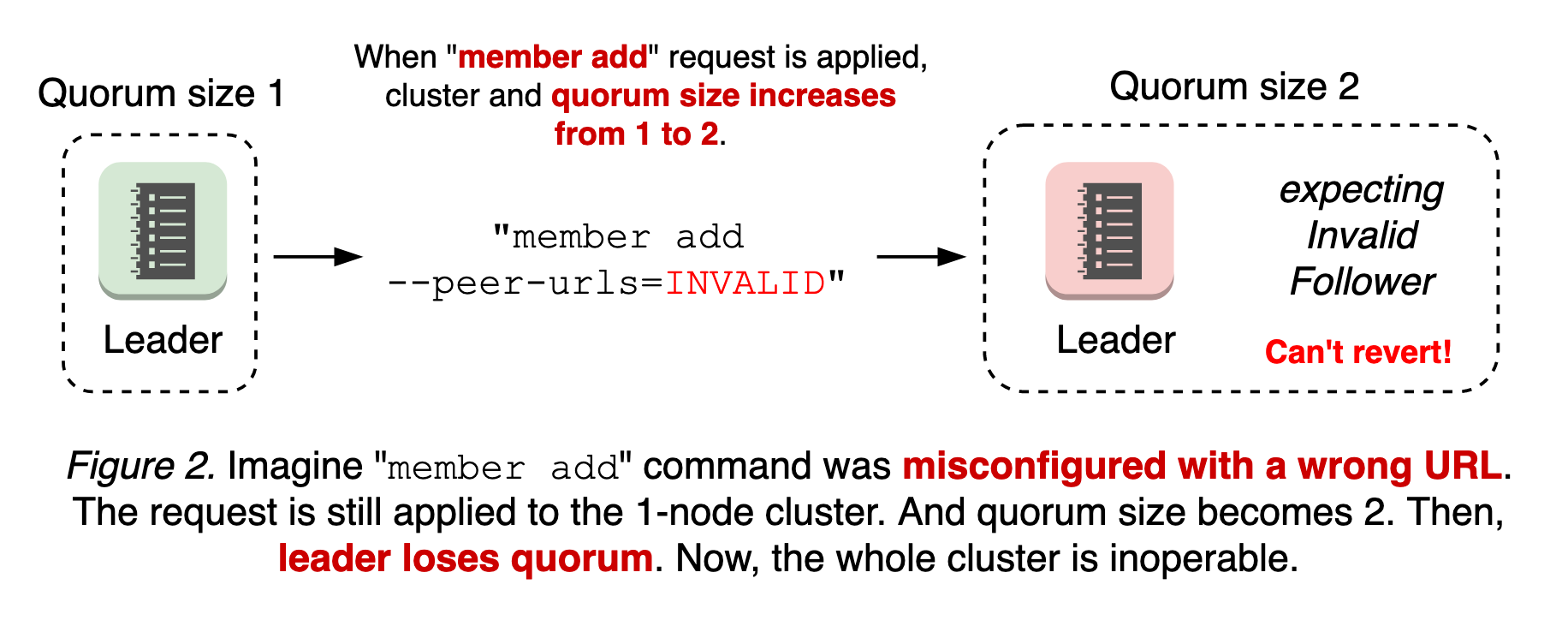
The worst case is a misconfigured membership add. Membership reconfiguration in etcd is a two-step process: etcdctl member add with peer URLs, and starting a new etcd to join the cluster. That is, member add command is applied whether the peer URL value is invalid or not. If the first step is to apply the invalid URLs and change the quorum size, it is possible that the cluster already loses the quorum until the new node connects. Since the node with invalid URLs will never become online and there’s no leader, it is impossible to revert the membership change (see Figure 2).
This becomes more complicated when there are partitioned nodes (see the design document for more).
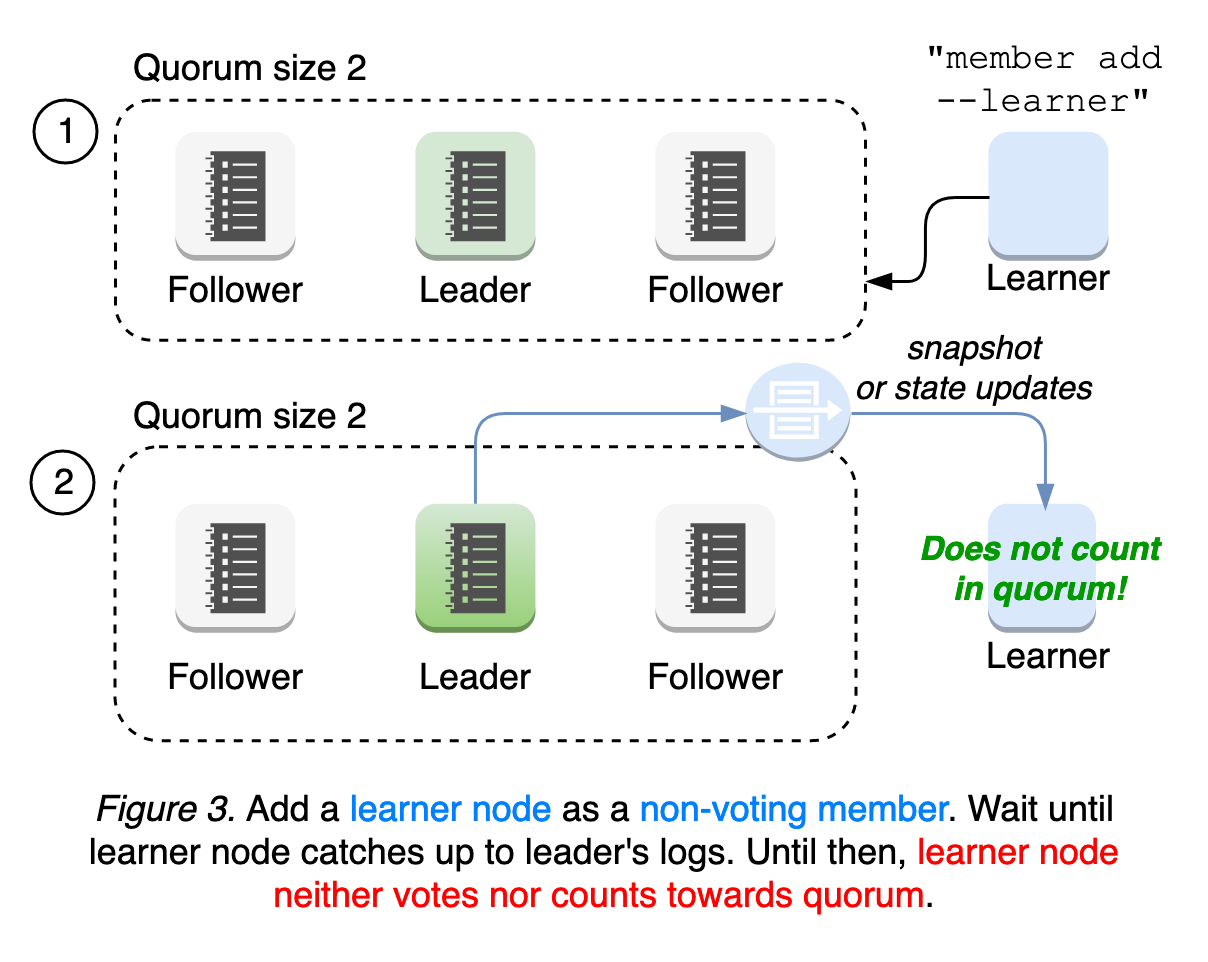
In order to address such failure modes, etcd introduces a new node state “Learner”, which joins the cluster as a non-voting member until it catches up to leader’s logs. This means the learner still receives all updates from leader, while it does not count towards the quorum, which is used by the leader to evaluate peer activeness. The learner only serves as a standby node until promoted. This relaxed requirements for quorum provides the better availability during membership reconfiguration and operational safety (see Figure 3).
We will further improve learner robustness, and explore auto-promote mechanisms for easier and more reliable operation. Please read our learner design documentation and runtime-configuration document for user guides.
New Client Balancer
etcd is designed to tolerate various system and network faults. By design, even if one node goes down, the cluster “appears” to be working normally, by providing one logical cluster view of multiple servers. But, this does not guarantee the liveness of the client. Thus, etcd client has implemented a different set of intricate protocols to guarantee its correctness and high availability under faulty conditions.
Historically, etcd client balancer heavily relied on old gRPC interface: every gRPC dependency upgrade broke client behavior. A majority of development and debugging efforts were devoted to fixing those client behavior changes. As a result, its implementation has become overly complicated with bad assumptions on server connectivity. The primary goal was to simplify balancer failover logic in etcd v3.4 client; instead of maintaining a list of unhealthy endpoints, which may be stale, simply roundrobin to the next endpoint whenever client gets disconnected from the current endpoint. It does not assume endpoint status. Thus, no more complicated status tracking is needed.
Furthermore, the new client now creates its own credential bundle to fix balancer failover against secure endpoints. This resolves the year-long bug, where kube-apiserver loses its connectivity to etcd cluster when the first etcd server becomes unavailable.
Please see client balancer design documentation for more.