これは、このセクションの複数ページの印刷可能なビューです。 印刷するには、ここをクリックしてください.
Kubernetesブログ
- Kubernetes v1.36: ハル (Haru)
- Ingress2Gateway 1.0リリースのお知らせ: Gateway APIへの移行
- Kubernetes v1.35: Workload Aware Scheduling の導入
- Kubernetes v1.35: Timbernetes (The World Tree Release)
- よくあるKubernetesの7つの落とし穴(そして私がそれらを回避する方法をいかに学んだか)
- Kubernetes v1.34: Of Wind & Will (O' WaW)
- デバイスを持つPodでの障害への対処
- Kubernetes v1.33: 思い描いていたとおりに動作するようになったImage Pull Policy!
- Kubernetes v1.33: HorizontalPodAutoscalerの設定可能な許容値
- Kubernetes v1.33: EndpointsからEndpointSliceへの継続的な移行を進める
- Kubernetes v1.33: Octarine
- KubernetesのマルチコンテナPod: 概要
- kube-scheduler-simulatorの紹介
- Kubernetes v1.33の先行紹介
- Ingress-nginxの脆弱性CVE-2025-1974: 知っておくべきこと
- SIG Appsの取り組みの紹介
- SIG etcdの取り組みの紹介
- クラウドコントローラーマネージャーに関する「鶏が先か卵が先か」問題
- SIG Architecture: Enhancementsの取り組みの紹介
- Kubernetes v1.32: Penelope
- Kubernetes Upstream Training in Japanの取り組みの紹介
- Kubernetes 1.31: Fine-grained SupplementalGroups control
- Kubernetes 1.31: SPDYからWebSocketへのストリーミングの移行
- Kubernetes v1.31: キャッシュからの整合性のある読み込みによるクラスターパフォーマンスの向上
- Kubernetes v1.31: Elli
- Client-Goへのフィーチャーゲートの導入: 柔軟性と管理性を強化するために
- SIG Nodeの紹介
- Kubernetesの10年間の歴史
- Kubernetes史上最大の移行作業を完了
- Gateway API v1.1: サービスメッシュ、GRPCRoute、そして更なる進化
- DIY: Kubernetesで自分だけのクラウドを構築しよう(パート3)
- DIY: Kubernetesで自分だけのクラウドを構築しよう(パート2)
- DIY: Kubernetesで自分だけのクラウドを構築しよう(パート1)
- Kubernetes v1.30をそっと覗く
- CRI-O: OCIレジストリからのseccompプロファイルの適用
- SIG Cloud Providerの取り組みの紹介
- Kubernetesブッククラブを覗く
- Kubernetesでコンテナを別ファイルシステムに格納する設定方法
- SIG Releaseスポットライト(リリース・チーム・サブプロジェクト)
- フォレンジックコンテナ分析
- Kubernetes 1.26: PodDisruptionBudgetによって保護された不健全なPodに対する退避ポリシー
- Kubernetesにおけるフォレンジックコンテナチェックポイント処理
- 更新: dockershimの削除に関するFAQ
- Don't Panic: Kubernetes and Docker
Kubernetes v1.36: ハル (Haru)
編集者: Chad M. Crowell、Kirti Goyal、Sophia Ugochukwu、Swathi Rao、Utkarsh Umre
前回のリリースと同様に、Kubernetes v1.36のリリースでは新しいGA、ベータ、アルファの機能が導入されます。 高品質なリリースの継続的な提供は、私たちの開発サイクルの強さとコミュニティからの活発なサポートを示しています。
このリリースは70個の機能改善で構成されています。 それらのうち、GAへの昇格が18個、ベータへの移行が25個、アルファとしての導入が25個です。
また、このリリースにはいくつかの非推奨化と削除があります。 これらに必ず目を通してください。
リリースのテーマとロゴ

Kubernetes v1.36で2026年の幕を開けます。 このリリースは季節が移り変わり、山の光が変化する時に届きました。 ハルは日本語で多くの意味を持つ響きです。 その中で最も大切にしているのは、春、晴れ(澄んだ空)、そして遥か(遠く離れた)です。 季節と空と地平線。 この先にある内容には、その3つすべてが見つかるでしょう。
ロゴはavocadoneko / Natsuho Ideによって作成され、葛飾北斎の『富嶽三十六景』からインスピレーションを得ています。 これは『神奈川沖浪裏』を世界に送り出したのと同じシリーズです。 v1.36のロゴは、シリーズの中で最も有名な作品の一つである『凱風快晴』、赤富士とも呼ばれる作品を再解釈しています。 夏の夜明けに赤く染まった山が、長い雪解けの後に雪のない姿を見せる光景です。 三十六の景色はv1.36にふさわしい数であり、北斎もそこで止まらなかったことを思い起こさせます。1 その風景を見守るのはKubernetesの舵輪で、山の傍らの空に配置されています。
富士の麓にはStella(左)とNacho(右)という2匹の猫が座っています。 首輪にKubernetesの舵輪が付いた彼らは、日本の神社を守る一対の狛犬の役割を担っています。 一対であるのは、何事も一人では守れないからです。 StellaとNachoは、はるかに大きな仲間を代表しています。 SIGとワーキンググループ、メンテナーとレビュアー、ドキュメント、ブログ、翻訳の担当者、リリースチーム、初めての一歩を踏み出す新規コントリビューター、そして季節ごとに戻ってくる長年のコントリビューターです。 Kubernetes v1.36は、いつものように多くの手によって支えられています。
ロゴの赤富士の峰に沿って「晴れに翔け」という書が描かれています。 これは山に収まりきらなかった対句の前半です:
晴れに翔け、未来よ明け
「澄んだ空へ翔け、明日の夜明けに向かって」
これが、このリリースに込めた願いです。 澄んだ空へ翔けること。 リリースそのもののため、プロジェクトのため、そしてそれを共に届けるすべての人のために。 赤富士に差す朝日は終わりではなく、通過点です。 このリリースは次のリリースへ、そのリリースはまたその次へと、一つの視点では捉えきれない遥かな地平線に向かって続いていきます。
1. このシリーズは非常に人気があったため、北斎はさらに10枚の版画を追加し、合計46枚になりました。
主なアップデート情報
Kubernetes v1.36は新機能と改善点が満載です。 このセクションでは、リリースチームが特に注目して欲しい、選りすぐりのアップデート内容をご紹介します!
安定版: きめ細かなAPI認可
Kubernetes SIG AuthおよびSIG Nodeを代表して、きめ細かなkubelet API認可がKubernetes v1.36でGA(General Availability)に昇格したことをお知らせします!
KubeletFineGrainedAuthzフィーチャーゲートは、Kubernetes v1.32でオプトインのアルファ機能として導入され、v1.33でベータ(デフォルトで有効)に昇格しました。
現在、この機能はGAになりました。
この機能は、kubeletのHTTPS APIに対してより精密な最小権限のアクセス制御を可能にし、一般的な監視や可観測性のユースケースにおいて過度に広範なnodes/proxy権限を付与する必要性を排除します。
この取り組みは、SIG AuthとSIG Nodeが主導したKEP #2862の一環として行われました。
ベータ: リソースヘルスステータス
v1.34のリリース以前は、Kubernetesには割り当てられたデバイスの健全性を報告するネイティブな方法がなく、ハードウェア障害によるPodのクラッシュを診断することが困難でした。
Device Pluginに焦点を当てたv1.31での最初のアルファリリースを基に、Kubernetes v1.36では各Podの.status内のallocatedResourcesStatusフィールドをベータに昇格させることでこの機能を拡張しています。
このフィールドは、すべての専用ハードウェアに対する統一されたヘルスレポート機構を提供します。
ユーザーはkubectl describe podを実行して、コンテナのクラッシュループがUnhealthyまたはUnknownのデバイスステータスによるものかどうかを判断できるようになりました。
これは、ハードウェアが従来のプラグインまたは新しいDRAフレームワークのどちらで提供されているかに関係なく機能します。
この可視性の向上により、管理者と自動化されたコントローラーは故障したハードウェアを迅速に特定し、高性能ワークロードのリカバリを効率化できます。
この取り組みは、SIG Nodeが主導したKEP #4680の一環として行われました。
アルファ: Workload Aware Scheduling(WAS)機能
従来、KubernetesスケジューラーとJobコントローラーはPodを独立したユニットとして管理していたため、複雑な分散ワークロードにおいて断片的なスケジューリングやリソースの浪費が発生することがよくありました。 Kubernetes v1.36では、Workload Aware Scheduling(WAS)機能の包括的なスイートをアルファとして導入し、Jobコントローラーを改訂されたWorkload APIと新しい分離されたPodGroup APIにネイティブに統合することで、関連するPodを単一の論理エンティティとして扱えるようにしています。
Kubernetes v1.35では、Podがノードにバインドされる前にスケジュール可能な最小数のPodを要求することで、すでにGangスケジューリングをサポートしていました。 v1.36では、グループ全体をアトミックに評価する新しいPodGroupスケジューリングサイクルを導入し、さらに進化しています。 グループ内のすべてのPodがまとめてバインドされるか、一つもバインドされないかのどちらかです。
この取り組みは、SIG SchedulingとSIG Appsが主導した複数のKEP(#4671、#5547、#5832、#5732、#5710を含む)の一環として行われました。
GAに昇格した機能
これはv1.36リリース後にGAとなった改善点の一部です。
ボリュームグループスナップショット
数回のベータサイクルを経て、VolumeGroupSnapshotサポートがKubernetes v1.36でGA(General Availability)に到達しました。 この機能により、複数のPersistentVolumeClaimにわたるクラッシュ整合性のあるスナップショットを同時に取得できます。 ボリュームグループスナップショットのサポートは、グループスナップショット用の拡張APIのセットに依存しています。 これらのAPIにより、ユーザーは一連のボリュームに対してクラッシュ整合性のあるスナップショットを取得できます。 主な目的は、そのスナップショットのセットを新しいボリュームに復元し、クラッシュ整合性のあるリカバリポイントに基づいてワークロードを復旧できるようにすることです。
この取り組みは、SIG Storageが主導したKEP #3476の一環として行われました。
変更可能なボリュームアタッチ制限
Kubernetes v1.36では、変更可能なCSINodeのAllocatable 機能がGAに昇格しました。
この機能強化により、Container Storage Interface(CSI)ドライバーがノードで処理可能なボリュームの最大数を動的に更新できるようになります。
この更新により、kubeletはノードのボリューム制限と容量情報を動的に更新できるようになりました。
kubeletは、定期的なチェックまたはCSIドライバーからのリソース枯渇エラーに応じて、コンポーネントの再起動を必要とせずにこれらの制限を調整します。
これにより、Kubernetesスケジューラーはストレージの可用性に関する正確な情報を維持し、古いボリューム制限によるPodスケジューリングの失敗を防止します。
この取り組みは、SIG Storageが主導したKEP #4876の一環として行われました。
ServiceAccountトークンの外部署名API
Kubernetes v1.36では、ServiceAccountの 外部トークン署名 機能がGAに昇格し、Kubernetes APIとのクリーンな統合を維持しながらトークン署名を外部システムに委譲できるようになりました。 クラスターは、標準的なServiceAccountトークン形式に従うProjected ServiceAccountトークンの発行に外部JWT署名者を使用でき、必要に応じて延長された有効期限もサポートします。 これは、すでに外部のIDまたは鍵管理システムに依存しているクラスターにとって特に有用で、コントロールプレーン内で鍵管理を重複させることなくKubernetesを統合できます。
kube-apiserverは外部署名者から公開鍵を検出し、キャッシュし、自身が署名していないトークンを検証するように構成されているため、既存の認証・認可フローは期待通りに動作し続けます。 アルファおよびベータフェーズを通じて、外部署名者プラグインのAPIと設定、パス検証、およびOIDCディスカバリは、実際の本番環境のデプロイメントとローテーションパターンに安全に対応できるよう強化されました。
v1.36でのGA昇格により、外部ServiceAccountトークン署名は、IDと署名を一元管理するプラットフォームにとって完全にサポートされたオプションとなり、外部IAMシステムとの統合が簡素化され、コントロールプレーン内で署名鍵を直接管理する必要性が軽減されます。
この取り組みは、SIG Authが主導したKEP #740の一環として行われました。
GAに昇格したDRA機能
Dynamic Resource Allocation(DRA)エコシステムの一部が、Kubernetes v1.36で主要なガバナンスと選択機能のGA昇格により本番環境で利用可能な成熟度に達しました。 DRA管理者アクセス のGA移行により、クラスター管理者がハードウェアリソースにグローバルにアクセスして管理するための永続的でセキュアなフレームワークが提供され、優先順位付きリスト の安定化により、リソース選択ロジックがすべてのクラスター環境で一貫性と予測可能性を保つようになりました。
これにより、組織は長期的なAPIの安定性と後方互換性の保証のもとで、ミッションクリティカルなハードウェア自動化を安心してデプロイできます。 これらの機能により、大規模GPUクラスターやマルチテナントAIプラットフォームに不可欠な高度なリソース共有ポリシーと管理オーバーライドの実装が可能になり、次世代リソース管理のコアアーキテクチャ基盤の完成を示しています。
この取り組みは、SIG AuthとSIG Schedulingが主導したKEP #5018および#4816の一環として行われました。
Mutating Admissionポリシー
Kubernetes v1.36では、MutatingAdmissionPolicyのGA昇格により、宣言的なクラスター管理がより洗練されたものとなりました。 このマイルストーンは、管理者がCommon Expression Language(CEL)を使用してAPIサーバー内でリソースの変更を直接定義できるようにすることで、従来のWebhookに代わるネイティブで高性能な代替手段を提供し、多くの一般的なユースケースにおいて外部インフラストラクチャの必要性を完全に排除します。
これにより、クラスターオペレーターはカスタムAdmission Webhookの管理に伴うレイテンシや運用の複雑さなしに、受信リクエストを変更できます。 変更ロジックを宣言的でバージョン管理されたポリシーに移行することで、組織はより予測可能なクラスター動作、ネットワークオーバーヘッドの削減、そして長期的なAPIの安定性が完全に保証された堅牢なセキュリティモデルを実現できます。
この取り組みは、SIG API Machineryが主導したKEP #3962の一環として行われました。
validation-genによるKubernetesネイティブ型の宣言的バリデーション
Kubernetes v1.36では、宣言的バリデーション (validation-genを使用)のGA昇格により、カスタムリソースの開発がさらに効率的なものとなりました。
このマイルストーンは、Common Expression Language(CEL)を使用してGoの構造体タグ内に高度なバリデーションロジックを直接定義できるようにすることで、複雑なOpenAPIスキーマを手動で記述するという手間がかかりエラーが発生しやすい作業を置き換えます。
カスタムバリデーション関数を記述する代わりに、Kubernetesコントリビューターは+k8s:minimumや+k8s:enumなどのIDLマーカーコメントを使用して、APIの型定義(types.go)内にバリデーションルールを直接定義できるようになりました。
validation-genツールはこれらのコメントを解析し、コンパイル時に堅牢なAPIバリデーションコードを自動生成します。
これにより、メンテナンスのオーバーヘッドが削減され、APIバリデーションがソースコードと一貫性を保ち同期された状態を維持できます。
この取り組みは、SIG API Machineryが主導したKEP #5073の一環として行われました。
Kubernetes API型からのgogo/protobuf依存関係の削除
Kubernetes v1.36では、gogoprotobufの削除が完了し、Kubernetesコードベースのセキュリティと長期的な保守性が大きく前進しました。
この取り組みにより、メンテナンスされていないgogoprotobufライブラリへの重大な依存関係が排除されました。
このライブラリは、潜在的なセキュリティ脆弱性の原因となり、最新のGo言語機能の採用を妨げる要因となっていました。
Kubernetes API型に互換性のリスクをもたらす標準的なProtobuf生成への移行ではなく、プロジェクトは必要な生成ロジックをk8s.io/code-generator内にフォークして内部化することを選択しました。
このアプローチにより、既存のAPIの動作とシリアライゼーションの互換性を維持しながら、Kubernetesの依存関係グラフからメンテナンスされていないランタイム依存関係を排除することに成功しました。
Kubernetes APIをGo言語で利用する開発者にとって、この変更は技術的負債を削減し、標準protobufライブラリとの誤った併用を防止します。
この取り組みは、SIG API Machineryが主導したKEP #5589の一環として行われました。
ノードログクエリ
以前は、Kubernetesではコントロールプレーンやワーカーノードに関連する問題のデバッグのために、クラスター管理者がSSH経由でノードにログインするか、クライアント側のリーダーを実装する必要がありました。
特定の問題では依然として直接のノードアクセスが必要ですが、kube-proxyやkubeletの問題はログを検査することで診断できます。
ノードログは、Podやコンテナのデバッグと同様に、kubelet APIとkubectlプラグインを使用してノードにログインせずにトラブルシューティングを簡素化する方法をクラスター管理者に提供します。
この方法はオペレーティングシステムに依存せず、サービスまたはノードが/var/logにログを出力する必要があります。
この機能は、本番ワークロードでの徹底的なパフォーマンス検証を経てKubernetes v1.36でGAに到達し、NodeLogQueryフィーチャーゲートを通じてkubeletでデフォルトで有効になっています。
さらに、enableSystemLogQuery kubelet設定オプションも有効にする必要があります。
この取り組みは、SIG Windowsが主導したKEP #2258の一環として行われました。
Podにおけるユーザー名前空間のサポート
Kubernetes v1.36では、ユーザー名前空間のサポートがGAに昇格し、コンテナの分離とノードセキュリティが主要な成熟度のマイルストーンに到達しました。 この待望の機能は、コンテナのrootユーザーをホスト上の非特権ユーザーにマッピングすることで多層防御の重要なレイヤーを提供し、プロセスがコンテナから脱出したとしても、基盤となるノードに対する管理権限を持たないことを保証します。
これにより、クラスターオペレーターはコンテナブレイクアウトの脆弱性の影響を軽減するため、本番ワークロードに対してこの堅牢な分離を安心して有効にできます。 コンテナの内部IDをホストのIDから切り離すことで、Kubernetesはマルチテナント環境と機密性の高いインフラストラクチャを不正アクセスから保護するための堅牢で標準化されたメカニズムを提供し、すべて長期的なAPIの安定性が完全に保証されています。
この取り組みは、SIG Nodeが主導したKEP #127の一環として行われました。
cgroupv2ベースのPSIサポート
Kubernetes v1.36では、Pressure Stall Information(PSI)メトリクスのエクスポートがGAに昇格し、ノードリソース管理と可観測性がより精密になりました。 この機能は、CPU、メモリ、I/Oの「圧力」メトリクスを報告する能力をkubeletに提供し、従来の使用率メトリクスよりもきめ細かなリソース競合のビューを提供します。
クラスターオペレーターとオートスケーラーは、これらのメトリクスを使用して、単に処理が集中しているシステムとリソース枯渇により実際にストールしているシステムを区別できます。 これらのシグナルを活用することで、ユーザーはPodのリソースリクエストをより正確に調整し、垂直オートスケーリングの信頼性を向上させ、アプリケーションのパフォーマンス低下やノードの不安定化につながる前にノイジーネイバー効果を検出できます。
この取り組みは、SIG Nodeが主導したKEP #4205の一環として行われました。
VolumeSource: OCIアーティファクトおよびイメージ
Kubernetes v1.36では、OCIボリュームソース サポートがGAに昇格し、コンテナデータの配布がより柔軟になりました。 この機能は、外部ストレージプロバイダーやConfigMapからボリュームをマウントするという従来の要件を超え、kubeletがコンテナイメージやアーティファクトリポジトリなどのOCI準拠のレジストリからコンテンツを直接取得してマウントできるようにします。
これにより、開発者やプラットフォームエンジニアはアプリケーションデータ、モデル、静的アセットをOCIアーティファクトとしてパッケージ化し、コンテナイメージに使用しているのと同じレジストリとバージョニングワークフローを使用してPodに配信できます。 このイメージとボリューム管理の統合により、CI/CDパイプラインが簡素化され、読み取り専用コンテンツのための専用ストレージバックエンドへの依存が軽減され、データがどの環境でも移植可能かつセキュアにアクセス可能な状態を維持できます。
この取り組みは、SIG Nodeが主導したKEP #4639の一環として行われました。
ベータの新機能
これはv1.36リリース後にベータとなった改善点の一部です。
コントローラーの陳腐化の軽減
Kubernetesコントローラーにおける陳腐化は、多くのコントローラーに影響を及ぼし、コントローラーの動作に微妙な影響を与える可能性がある問題です。 通常、コントローラーの作成者による何らかの前提に起因して陳腐化が問題であることが発見されるのは、本番環境のコントローラーがすでに誤ったアクションを実行してしまった後、手遅れになってからです。 これにより、キャッシュの陳腐化時にコントローラーの調整において、競合する更新やデータの破損が発生する可能性がありました。
Kubernetes v1.36には、コントローラーの陳腐化を軽減し、コントローラーの動作のより良い可観測性を提供する新機能が含まれていることをお知らせします。 これにより、しばしば有害な動作につながる可能性がある、古いクラスター状態のビューに基づく調整が防止されます。
この取り組みは、SIG API Machineryが主導したKEP #5647の一環として行われました。
IP/CIDRバリデーションの改善
Kubernetes v1.36では、APIのIPおよびCIDRフィールドに対するStrictIPCIDRValidation機能がベータに昇格し、以前はすり抜けていた不正なアドレスやプレフィックスを検出するためにバリデーションが強化されました。
これにより、Service、Pod、NetworkPolicy、またはその他のリソースが無効なIPを参照するという微妙な設定バグを防止でき、混乱するランタイム動作やセキュリティ上の問題を回避できます。
コントローラーは、オブジェクトに書き戻すIPを正規化し、すでに保存されている不正な値に遭遇した場合に警告を出すように更新されているため、クラスターは段階的にクリーンで一貫性のあるデータに収束できます。
ベータでは、StrictIPCIDRValidationはより広範な使用の準備が整い、ネットワークやポリシーが時間とともに進化する中で、オペレーターにIP関連の設定に対するより信頼性の高いガードレールを提供します。
この取り組みは、SIG Networkが主導したKEP #4858の一環として行われました。
kubectlユーザー設定のクラスター設定からの分離
kubectlのユーザー設定をカスタマイズするための.kuberc機能は引き続きベータであり、デフォルトで有効になっています。
~/.kube/kubercファイルにより、ユーザーはクラスターのエンドポイントと認証情報を保持するkubeconfigファイルとは別に、エイリアス、デフォルトフラグ、その他の個人設定を保存できます。
この分離により、個人の設定がCIパイプラインや共有のkubeconfigファイルに干渉することを防ぎ、異なるクラスターやコンテキスト間で一貫したkubectlエクスペリエンスを維持できます。
Kubernetes v1.36では、.kubercに認証情報プラグインのポリシー(許可リストまたは拒否リスト)を定義する機能が追加され、より安全な認証プラクティスが強制されるようになりました。
必要に応じて、環境変数KUBECTL_KUBERC=falseまたはKUBERC=offを設定することでこの機能を無効にできます。
この取り組みは、SIG CLIが主導し、SIG Authの協力を得たKEP #3104の一環として行われました。
Job一時停止時の変更可能なコンテナリソース
Kubernetes v1.36では、MutablePodResourcesForSuspendedJobs機能がベータに昇格し、デフォルトで有効になりました。
この更新により、Jobのバリデーションが緩和され、Jobが一時停止中にコンテナのCPU、メモリ、GPU、および拡張リソースのリクエストと制限を更新できるようになりました。
この機能により、キューコントローラーやオペレーターはリアルタイムのクラスター条件に基づいてバッチワークロードの要件を調整できます。 例えば、キューイングシステムは受信したJobを一時停止し、利用可能な容量やクォータに合わせてリソース要件を調整してから、一時停止を解除できます。 この機能は、変更可能性を一時停止中のJob(または一時停止時にPodが終了されたJob)に厳密に制限し、アクティブに実行中のPodへの破壊的な変更を防止します。
この取り組みは、SIG Appsが主導したKEP #5440の一環として行われました。
制約付きなりすまし
Kubernetes v1.36では、ユーザーなりすましのConstrainedImpersonation機能がベータに昇格し、歴史的にオール・オア・ナッシングだったメカニズムを、実際に最小権限の原則に沿うものへと強化しています。
この機能が有効な場合、なりすましを行うユーザーは2つの異なる権限セットを持つ必要があります。1つは特定のアイデンティティになりすますための権限、もう1つはそのアイデンティティに代わって特定のアクションを実行するための権限です。
これにより、なりすましのRBACが誤って設定されている場合でも、サポートツール、コントローラー、またはノードエージェントがなりすましを使用して自身に許可されている以上のアクセス権を取得することを防止します。
既存のimpersonateルールは引き続き機能しますが、APIサーバーは新しい制約付きチェックを優先するため、移行は一斉切り替えではなく段階的に行われます。
v1.36のベータでは、ConstrainedImpersonationはテスト済みでドキュメント化されており、デバッグ、プロキシ、またはノードレベルのコントローラーにおいてなりすましに依存するプラットフォームチームによるより広範な採用の準備が整っています。
この取り組みは、SIG Authが主導したKEP #5284の一環として行われました。
ベータのDRA機能
Dynamic Resource Allocation(DRA)フレームワークは、Kubernetes v1.36で複数のコア機能がベータに昇格しデフォルトで有効になることで、さらなる成熟度のマイルストーンに到達しました。 この移行により、パーティション可能なデバイスとConsumable Capacityの昇格によってGPUなどのハードウェアのよりきめ細かな共有が可能になり、DRAは基本的な割り当てを超えて進化しています。 一方、デバイスのTaintとTolerationにより、専用リソースが適切なワークロードによってのみ使用されることが保証されます。
これにより、ユーザーはResourceClaimデバイスステータスとPodスケジューリング前のデバイスアタッチメントの保証を通じて、はるかに信頼性が高く可観測性の高いリソースライフサイクルの恩恵を受けられます。 これらの機能を拡張リソースサポートと統合することで、Kubernetesはレガシーなデバイスプラグインシステムに代わる堅牢な本番対応の代替手段を提供し、複雑なAIおよびHPCワークロードが前例のない精度と運用安全性でハードウェアを管理できるようにします。
この取り組みは、SIG SchedulingとSIG Nodeが主導した複数のKEP(#5004、#4817、#5055、#5075、#4815、#5007を含む)の一環として行われました。
KubernetesコンポーネントのStatusz
Kubernetes v1.36では、コアKubernetesコンポーネントのComponentStatuszフィーチャーゲートがベータに昇格し、各コンポーネントのリアルタイムのビルドおよびバージョン詳細を表示する/statuszエンドポイント(デフォルトで有効)が提供されます。
このオーバーヘッドの低いz-pageは、起動時刻、稼働時間、Goバージョン、バイナリバージョン、エミュレーションバージョン、最小互換バージョンなどの情報を公開し、オペレーターや開発者がログや設定を掘り下げることなく、実行中のものを正確に確認できるようにします。
エンドポイントはデフォルトで人間が読めるテキストビューを提供し、さらに明示的なコンテンツネゴシエーションを介してJSON、YAML、またはCBORでのプログラムアクセス用のバージョン管理された構造化API(config.k8s.io/v1beta1)も提供します。
アクセスはsystem:monitoringグループに付与され、ヘルスおよびメトリクスエンドポイントの既存の保護と整合し、機密データの露出を防止します。
ベータでは、ComponentStatuszはすべてのコアコントロールプレーンコンポーネントおよびノードエージェントでデフォルトで有効になり、ユニットテスト、統合テスト、E2Eテストにより本番環境での可観測性およびデバッグワークフローに安全に使用できます。
この取り組みは、SIG Instrumentationが主導したKEP #4827の一環として行われました。
KubernetesコンポーネントのFlagz
Kubernetes v1.36では、コアKubernetesコンポーネントのComponentFlagzフィーチャーゲートがベータに昇格し、各コンポーネントが起動時に指定された有効なコマンドラインフラグを公開する/flagzエンドポイントが標準化されました。
これにより、クラスターオペレーターと開発者はコンポーネントの設定をクラスター内でリアルタイムに確認できるようになり、予期しない動作のデバッグや、フラグのロールアウトが再起動後に実際に反映されたかの確認が、はるかに容易になります。
エンドポイントは人間が読めるテキストビューとバージョン管理された構造化API(当初はconfig.k8s.io/v1beta1)の両方をサポートしているため、インシデント中にcurlで確認することも、準備ができたら自動化ツールに組み込むこともできます。
アクセスはsystem:monitoringグループに付与され、機密値はマスクできるため、設定の可視化はヘルスおよびステータスエンドポイント周辺の既存のセキュリティプラクティスと整合しています。
ベータでは、ComponentFlagzはデフォルトで有効になり、すべてのコアコントロールプレーンコンポーネントおよびノードエージェントに実装され、ユニットテスト、統合テスト、E2Eテストにより本番クラスターでのエンドポイントの信頼性が確保されています。
この取り組みは、SIG Instrumentationが主導したKEP #4828の一環として行われました。
Mixed Versionプロキシ (別名: バージョン間相互運用プロキシ)
Kubernetes v1.36では、Mixed Versionプロキシ機能がベータに昇格し、v1.28でのアルファ導入を基に、混合バージョンクラスターに対してより安全なコントロールプレーンのアップグレードを提供します。 各APIリクエストは、リクエストされたグループ、バージョン、リソースを提供するapiserverインスタンスにルーティングできるようになり、バージョンの差異による404エラーや障害が軽減されます。
この機能はピア集約ディスカバリに依存しているため、apiserverはどのリソースとバージョンを公開しているかに関する情報を共有し、そのデータを使用して必要に応じてリクエストを透過的に再ルーティングします。 再ルーティングされたトラフィックとプロキシ動作に関する新しいメトリクスにより、オペレーターはリクエストが転送される頻度と転送先のピアを把握できます。 これらの変更により、マルチステップまたは部分的なコントロールプレーンのアップグレードを実行しながら、高可用性の混合バージョンAPIコントロールプレーンを本番環境で実行することがより容易になります。
この取り組みは、SIG API Machineryが主導したKEP #4020の一環として行われました。
cgroups v2によるメモリQoS
Kubernetesは、よりスマートで階層化されたメモリ保護により、Linux cgroup v2ノードでのメモリQoSを強化しました。
カーネルのコントロールをPodのリクエストと制限により適切に整合させ、同じノードを共有するワークロード間の干渉とスラッシングを軽減します。
このイテレーションでは、kubeletがmemory.highとmemory.minをプログラムする方法も改善され、ライブロックを回避するためのメトリクスとセーフガードが追加され、クラスターオペレーターが環境に合わせてメモリ保護の動作を調整できる設定オプションが導入されました。
この取り組みは、SIG Nodeが主導したKEP #2570の一環として行われました。
アルファの新機能
これはv1.36リリース後にアルファとなった改善点の一部です。
カスタムメトリクスに対するHPAのゼロへのスケール
これまでHorizontalPodAutoscaler(HPA)は、実行中のPodからのメトリクス(CPUやメモリなど)に基づいてのみスケーリングの必要性を計算できたため、最低1つのレプリカをアクティブに保つ必要がありました。 Kubernetes v1.36では、ObjectまたはExternalメトリクスを使用する場合に限り、ワークロードをゼロレプリカにスケールダウンできるようにするHPAのゼロへのスケール機能(デフォルトで無効)のアルファでの開発を継続しています。
ユーザーは、保留中のタスクがない場合にリソースを大量に消費するワークロードを完全にアイドル状態にすることで、インフラストラクチャのコストの大幅な削減を試せるようになります。
この機能はHPAScaleToZeroフィーチャーゲートの背後に残っていますが、ゼロの実行中PodでもHPAをアクティブに維持し、外部メトリクス(例: キューの長さ)が新しいタスクの到着を示すとすぐにDeploymentを自動的にスケールアップします。
この取り組みは、SIG Autoscalingが主導したKEP #2021の一環として行われました。
アルファのDRA機能
従来、Dynamic Resource Allocation(DRA)フレームワークは、高レベルのコントローラーとのシームレスな統合が欠如しており、デバイス固有のメタデータや可用性を把握する手段が限られていました。 Kubernetes v1.36では、ワークロード向けのネイティブResourceClaimサポートや、CPU管理にDRAの柔軟性を提供するDRAネイティブリソースなど、一連のDRA強化機能をアルファとして導入しています。
ユーザーはDownward APIを活用して、複雑なリソース属性をコンテナに直接公開できるようになりました。 これにより、リソースの可用性をより正確に把握でき、スケジューリングの予測可能性も向上します。 これらのアップデートは、デバイス属性におけるリスト型のサポートと組み合わさり、DRAを低レベルのプリミティブから、現代のAIおよびハイパフォーマンスコンピューティング(HPC)スタックの高度なネットワーキングとコンピューティング要件を処理できる堅牢なシステムへと変革します。
この取り組みは、SIG SchedulingとSIG Nodeが主導した複数のKEP(#5729、#5304、#5517、#5677、#5491を含む)にわたって行われました。
Kubernetesメトリクスのネイティブヒストグラムサポート
Kubernetes v1.36では、アルファとしてネイティブヒストグラムサポートが導入され、高解像度モニタリングが新たなマイルストーンに到達しました。 従来のPrometheusヒストグラムは事前定義された固定的なバケットに依存しており、データの精度とメモリ使用量の間でトレードオフを強いられることがしばしばありました。 今回のアップデートにより、コントロールプレーンはリアルタイムのデータに基づいて解像度を動的に調整するスパースヒストグラムをエクスポートできるようになります。
クラスターオペレーターは、手動のバケット管理のオーバーヘッドなしに、kube-apiserverやその他のコアコンポーネントの正確なレイテンシ分布をキャプチャできるようになりました。 このアーキテクチャの転換により、より信頼性の高いSLIとSLOを実現でき、予測の難しいワークロードのスパイク時でも精度を保つことが可能な高精度なヒートマップが利用可能になります。
この取り組みは、SIG Instrumentationが主導したKEP #5808の一環として行われました。
マニフェストベースのAdmission Control設定
Kubernetes v1.36では、アルファとしてマニフェストベースのAdmission Control設定が導入され、Admissionコントローラーの管理がより宣言的で一貫性のあるモデルに移行しました。 この変更は、管理者がAdmission Controlの望ましい状態を構造化されたマニフェストを通じて直接定義できるようにすることで、異なるコマンドラインフラグや個別の複雑な設定ファイルを通じてAdmissionプラグインを設定するという長年の課題に対処しています。
クラスターオペレーターは、他のKubernetesオブジェクトに使用されるのと同じバージョン管理された宣言的ワークフローでAdmissionプラグインの設定を管理できるようになり、クラスターアップグレード中の設定のドリフトや手動エラーのリスクが大幅に軽減されます。 これらの設定を統一されたマニフェストに集約することで、kube-apiserverの監査と自動化が容易になり、より安全で再現可能なクラスターデプロイメントへの道が開かれます。
この取り組みは、SIG API Machineryが主導したKEP #5793の一環として行われました。
CRIリストストリーミング
Kubernetes v1.36では、アルファとしてCRIリストストリーミングが導入され、新しい内部ストリーミング操作を使用するようになりました。
この改善は、kubeletとコンテナランタイム間の従来のモノリシックなListリクエストを、より効率的なサーバーサイドストリーミングRPCに置き換えることで、大規模ノードでよく見られるメモリ圧迫とレイテンシスパイクに対処しています。
すべてのコンテナまたはイメージデータを含む単一の大きなレスポンスを待つ代わりに、kubeletはストリーミングされた結果をインクリメンタルに処理できるようになりました。 この移行により、kubeletのピークメモリフットプリントが大幅に削減され、高密度ノードでの応答性が向上し、ノードあたりのコンテナ数が増え続けても流動的なクラスター管理が確保されます。
この取り組みは、SIG Nodeが主導したKEP #5825の一環として行われました。
その他の注目すべき変更点
Ingress NGINXの引退
エコシステムの安全性とセキュリティを優先するため、Kubernetes SIG NetworkとSecurity Response Committeeは2026年3月24日にIngress NGINXを引退させました。 この日以降、新たなリリース、バグ修正、発見されたセキュリティ脆弱性を解決するためのアップデートは行われません。 Ingress NGINXの既存のデプロイメントは引き続き機能し、Helmチャートやコンテナイメージなどのインストールアーティファクトは引き続き利用可能です。
詳細については公式の引退アナウンスをご覧ください。
ボリュームに対するSELinuxラベリングの高速化(GA)
Kubernetes v1.36では、SELinuxボリュームマウントの改善がGAに昇格しました。
この変更は、再帰的なファイルのラベル再設定をmount -o context=XYZオプションに置き換え、マウント時にボリューム全体に正しいSELinuxラベルを適用します。
これにより、より一貫したパフォーマンスが実現し、SELinuxが有効なシステムでのPod起動時の遅延が軽減されます。
この機能はv1.28でReadWriteOncePodボリュームに対するベータとして導入されました。
v1.32では、メトリクスと競合を検出するためのオプトアウトオプション(securityContext.seLinuxChangePolicy: Recursive)が追加されました。
v1.36では安定版に到達し、すべてのボリュームにデフォルトで適用され、PodまたはCSIDriverがspec.seLinuxMountを介してオプトインします。
ただし、この機能は将来のKubernetesリリースで破壊的変更のリスクを生み出す可能性があります。 これは、同じノード上で特権Podと非特権Podの間で1つのボリュームを共有する場合に発生する可能性があります。
開発者はPodにseLinuxChangePolicyフィールドとSELinuxボリュームラベルを設定する責任があります。
Deployment、StatefulSet、DaemonSet、またはPodテンプレートを含むカスタムリソースのいずれを作成する場合でも、これらの設定を慎重に行わないと、Podがボリュームを共有する際にPodが正しく起動しないなどの様々な問題が発生する可能性があります。
Kubernetes v1.36はクラスターを監査するのに最適なリリースです。 詳細についてはSELinux Volume Label Changes goes GA (and likely implications in v1.37)のブログ記事をご覧ください。
この機能強化の詳細については、KEP-1710: Speed up recursive SELinux label changeをご参照ください。
v1.36での昇格、非推奨、削除
GAへの昇格
これは安定版(一般提供、GAとも呼ばれる)に昇格したすべての機能を一覧にしたものです。 アルファからベータへの昇格や新機能を含む更新の完全なリストについては、リリースノートをご覧ください。
このリリースには、GAに昇格した合計18の機能強化が含まれています:
- PodにおけるUser Namespaceのサポート
- ServiceAccountトークンの外部署名API
- 再帰的なSELinuxラベル変更の高速化
- Portworxファイルのin-treeからCSIドライバーへの移行
- きめ細かなkubelet API認可
- Mutating Admissionポリシー
- ノードログクエリ
- VolumeGroupSnapshot
- 変更可能なCSINodeのAllocatableプロパティ
- DRA: デバイスリクエストにおける優先順位付き代替
- cgroupv2ベースのPSIサポート
- ProcMountオプションの追加
- DRA: Dynamic Resource AllocationのリソースをPodResourcesに含める拡張
- VolumeSource: OCIアーティファクトおよびイメージ
- CPU ManagerにおけるL3キャッシュトポロジー認識の分割
- DRA: ResourceClaimとResourceClaimTemplateのAdminAccess
- Kubernetes API型からのgogo protobuf依存関係の削除
- secretsフィールドを介したServiceAccountトークンのCSIドライバーオプトイン
非推奨、削除、コミュニティの更新
Kubernetesの開発と成熟に伴い、プロジェクト全体の健全性を向上させるために、機能が非推奨になったり、削除されたり、より良いものに置き換えられたりすることがあります。 このプロセスの詳細については、Kubernetesの非推奨と削除のポリシーをご覧ください。 Kubernetes v1.36にはいくつかの非推奨が含まれています。
Serviceの.spec.externalIPsの非推奨化
このリリースでは、Service specのexternalIPsフィールドが非推奨になりました。
これは、機能自体は存在しますが、Kubernetesの将来のバージョンでは機能しなくなることを意味します。
このフィールドに依存している場合は、移行を計画する必要があります。
このフィールドは長年にわたりセキュリティ上の既知の問題であり、CVE-2020-8554に記載されているように、クラスタートラフィックに対する中間者攻撃を可能にしていました。
Kubernetes v1.36以降、使用時に非推奨の警告が表示され、v1.43での完全な削除が計画されています。
ServiceがまだexternalIPsに依存している場合は、クラウドマネージドのIngressにはLoadBalancer Service、シンプルなポート公開にはNodePort、外部トラフィックをより柔軟かつ安全に処理するにはGateway APIの使用を検討してください。
このフィールドとその非推奨化の詳細については、External IPsまたはKEP-5707: Deprecate service.spec.externalIPsをご参照ください。
gitRepoボリュームドライバーの削除
gitRepoボリュームタイプはv1.11以降非推奨となっていました。
Kubernetes v1.36では、gitRepoボリュームプラグインが恒久的に無効化され、再度有効にすることはできません。
この変更は、gitRepoの使用により攻撃者がノード上でrootとしてコードを実行できるという重大なセキュリティの問題からクラスターを保護します。
gitRepoは長年にわたり非推奨であり、より良い代替手段が推奨されてきましたが、以前のリリースでは技術的にはまだ使用可能でした。
v1.36以降、その経路は完全に閉鎖されたため、gitRepoに依存している既存のワークロードは、Initコンテナや外部のgit-syncスタイルのツールなどのサポートされているアプローチに移行する必要があります。
この削除の詳細については、KEP-5040: Remove gitRepo volume driverをご参照ください。
リリースノート
Kubernetes v1.36リリースの詳細については、リリースノートをご覧ください。
入手方法
Kubernetes v1.36はGitHubまたはKubernetes公式サイトのダウンロードページからダウンロードできます。
Kubernetesを始めるには、インタラクティブチュートリアルをチェックするか、minikubeを使用してローカルKubernetesクラスターを実行してください。 また、kubeadmを使用して簡単にv1.36をインストールすることもできます。
リリースチーム
Kubernetesは、コミュニティの支援、コミットメント、献身的な努力なくしては成り立ちません。 各リリースチームは、皆さんが利用するKubernetesリリースを構成する様々な要素を協力して構築する、献身的なコミュニティボランティアで構成されています。 これを実現するには、コードそのものからドキュメント作成、プロジェクト管理に至るまで、コミュニティのあらゆる分野の専門スキルが必要です。
Kubernetes v1.36リリースをコミュニティに届けるために多くの時間を費やして取り組んでくれたリリースチーム全体に感謝します。 リリースチームには、初参加のShadow(見習い)から、複数のリリースサイクルで経験を積んだベテランのチームリードまで、様々なメンバーが参加しています。 リリースリードのRyota Sawadaに心より感謝します。 彼の実践的な課題解決のアプローチと、コミュニティを前進させる活力と情熱で、成功したリリースサイクルを導いてくれました。
プロジェクトの活動状況
CNCF K8sのDevStatsプロジェクトは、Kubernetesおよび様々なサブプロジェクトの活動状況に関する興味深いデータポイントを集計しています。 これには個人の貢献から貢献企業数まで含まれ、このエコシステムの発展に費やされる努力の深さと広さを示しています。
v1.36リリースサイクル(2026年1月12日から2026年4月22日までの15週間)において、Kubernetesには最大106の異なる企業と491人の個人から貢献がありました。 より広範なクラウドネイティブエコシステムでは、この数字は370社、合計2235人のコントリビューターに達しています。
なお、「貢献」とはコミットの作成、コードレビュー、コメント、IssueやPRの作成、PRのレビュー(ブログやドキュメントを含む)、またはIssueやPRへのコメントを行うことを指します。 貢献に興味がある場合は、コントリビューター向けWebサイトのはじめにをご覧ください。
データソース:
イベント情報
今後開催予定のKubernetesおよびクラウドネイティブイベント(KubeCon + CloudNativeCon、KCDなど)や、世界各地で開催される主要なカンファレンスについて紹介します。 Kubernetesコミュニティの最新情報を入手し、参加しましょう!
2026年4月
- KCD - Kubernetes Community Days: Guadalajara: 2026年4月18日 | メキシコ、グアダラハラ
2026年5月
- KCD - Kubernetes Community Days: Toronto: 2026年5月13日 | カナダ、トロント
- KCD - Kubernetes Community Days: Texas: 2026年5月15日 | アメリカ、オースティン
- KCD - Kubernetes Community Days: Istanbul: 2026年5月15日 | トルコ、イスタンブール
- KCD - Kubernetes Community Days: Helsinki: 2026年5月20日 | フィンランド、ヘルシンキ
- KCD - Kubernetes Community Days: Czech & Slovak: 2026年5月21日 | チェコ、プラハ
2026年6月
- KCD - Kubernetes Community Days: New York: 2026年6月10日 | アメリカ、ニューヨーク
- KubeCon + CloudNativeCon India 2026: 2026年6月18日-19日 | インド、ムンバイ
2026年7月
2026年9月
2026年10月
- KCD - Kubernetes Community Days: UK: 2026年10月19日 | イギリス、エディンバラ
2026年11月
- KCD - Kubernetes Community Days: Porto: 2026年11月19日 | ポルトガル、ポルト
- KubeCon + CloudNativeCon North America 2026: 2026年11月9日-12日 | アメリカ、ソルトレイクシティ
最新のイベント情報はこちらでご確認いただけます。
ウェビナーのご案内
Kubernetes v1.36リリースチームのメンバーと一緒に 2026年5月20日(水)午後4時(UTC) から、このリリースのハイライトについて学びましょう。 詳細および参加登録は、CNCFオンラインプログラム・サイトのイベントページをご覧ください。
参加方法
Kubernetesに関わる最も簡単な方法は、あなたの興味に合ったSpecial Interest Groups(SIGs)のいずれかに参加することです。 Kubernetesコミュニティに向けて何か発信したいことはありますか? 毎週のコミュニティミーティングや、以下のチャンネルであなたの声を共有してください。 継続的なフィードバックとサポートに感謝いたします。
- 最新情報はBlueskyの@kubernetes.ioをフォローしてください
- Discussでコミュニティディスカッションに参加してください
- Slackでコミュニティに参加してください
- Stack Overflowで質問したり、回答したりしてください
- あなたのKubernetesに関するストーリーを共有してください
- Kubernetesの最新情報はブログでさらに詳しく読むことができます
- リリースチームについての詳細はKubernetes Release Teamをご覧ください
Ingress2Gateway 1.0リリースのお知らせ: Gateway APIへの移行
Ingress-NGINXの廃止が2026年3月に予定されており、Kubernetesのネットワーキングは転換期を迎えています。 多くの組織にとって、問題はGateway APIに移行するかどうかではなく、いかに安全に移行するかです。
IngressからGateway APIへの移行は、API設計における根本的な転換です。 Gateway APIはモジュール式で拡張可能なAPIを提供し、KubernetesネイティブなRBACを強力にサポートしています。 一方、Ingress APIはシンプルですがIngress-NGINXのような実装では独自のアノテーション、ConfigMap、CRDを通じてAPIを拡張しています。 Ingress-NGINXのようなIngressコントローラーからの移行では、Ingressコントローラーのあらゆる細かな挙動を正確に把握し、それをGateway APIへ対応付けるという困難な作業が伴います。
Ingress2Gatewayは、チームがIngressからGateway APIへ安心して移行できるよう支援するツールです。 Ingressリソースやマニフェストを実装固有のアノテーションも含めてGateway APIへ変換します。また、変換できない設定については警告や代替案を提示します。
本日、SIG NetworkはIngress2Gatewayの1.0リリースを発表します。 このマイルストーンは、ネットワーキングスタックの刷新を検討しているチームに向けた、安定かつテスト済みの移行支援ツールの完成を意味します。
Ingress2Gateway 1.0
Ingress-NGINXアノテーションのサポート
1.0リリースにおける主な改善点は、Ingress-NGINXのより包括的なサポートです。 1.0リリース以前、Ingress2GatewayがサポートしていたIngress-NGINXのアノテーションはわずか3つでした。 1.0リリースでは、30以上の一般的なアノテーション(CORS、バックエンドTLS、正規表現マッチング、パスの書き換えなど)をサポートしています。
包括的なインテグレーションテスト
サポートされている各Ingress-NGINXアノテーション、および一般的なアノテーションの代表的な組み合わせには、コントローラーレベルのインテグレーションテストが用意されています。 これらのテストは、Ingress-NGINX設定と生成されたGateway APIの動作が同等であることを検証します。 これらのテストは、実際のクラスター上で実際のコントローラーを動作させ、YAML構造だけでなく、実行時の挙動(ルーティング、リダイレクト、書き換えなど)を比較します。
テストでは以下を行います:
- Ingress-NGINXコントローラーを起動する
- 複数のGateway APIコントローラーを起動する
- 実装固有の設定を含むIngressリソースを適用する
ingress2gatewayでIngressリソースをGateway APIに変換し、生成されたマニフェストを適用する- Gateway APIコントローラーとIngressコントローラーが同等の挙動を示すことを検証する
包括的なテストスイートは開発中のバグを検出するだけでなく、予期しないエッジケースや想定外のデフォルト値を考慮した変換の正確性を保証するため、本番環境で初めて問題に気づくという事態を防ぎます。
通知とエラーハンドリング
移行は「ワンクリック」で完了するものではありません。 サポートされている設定を変換することと同様に、細かな差異や変換できない挙動を明示することも重要です。 1.0リリースでは通知のフォーマットと内容が改善され、何が不足しているか、どのように修正すればよいかが明確にわかるようになりました。
Ingress2Gatewayの使い方
Ingress2Gatewayは移行支援ツールであり、一度きりの置き換えツールではありません。 その目的は以下の通りです。
- サポートされているIngressの設定と挙動を移行する
- サポートされていない設定を特定し、代替案を提示する
- 望ましくない設定を再評価し、必要に応じて破棄する
このセクションでは、以下のIngress-NGINX設定を安全に移行する方法を説明します。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/proxy-body-size: "1G"
nginx.ingress.kubernetes.io/use-regex: "true"
nginx.ingress.kubernetes.io/proxy-send-timeout: "1"
nginx.ingress.kubernetes.io/proxy-read-timeout: "1"
nginx.ingress.kubernetes.io/enable-cors: "true"
nginx.ingress.kubernetes.io/configuration-snippet: |
more_set_headers "Request-Id: $req_id";
name: my-ingress
namespace: my-ns
spec:
ingressClassName: nginx
rules:
- host: my-host.example.com
http:
paths:
- backend:
service:
name: website-service
port:
number: 80
path: /users/(\d+)
pathType: ImplementationSpecific
tls:
- hosts:
- my-host.example.com
secretName: my-secret
1. Ingress2Gatewayのインストール
Go環境がセットアップ済みであれば、以下のコマンドでIngress2Gatewayをインストールできます。
go install github.com/kubernetes-sigs/ingress2gateway@v1.0.0
または、以下のコマンドを使用します。
brew install ingress2gateway
GitHubからバイナリをダウンロードするか、ソースからビルドすることもできます。
2. Ingress2Gatewayの実行
Ingress2GatewayにはIngressマニフェストをファイルとして渡すか、クラスターから直接読み取らせることができます。
# マニフェストファイルを渡す
ingress2gateway print --input-file my-manifest.yaml,my-other-manifest.yaml --providers=ingress-nginx > gwapi.yaml
# クラスター内のNamespaceを指定する
ingress2gateway print --namespace my-api --providers=ingress-nginx > gwapi.yaml
# クラスター全体を対象にする
ingress2gateway print --providers=ingress-nginx --all-namespaces > gwapi.yaml
備考:
--emitter <agentgateway|envoy-gateway|kgateway>を渡すことで、実装固有の拡張を出力することもできます。3. 出力の確認
これが最も重要なステップです。
前のセクションのコマンドはGateway APIマニフェストをgwapi.yamlに出力するとともに、正確に変換できなかった箇所や手動で確認すべき点を説明する警告も出力します。
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
annotations:
gateway.networking.k8s.io/generator: ingress2gateway-dev
name: nginx
namespace: my-ns
spec:
gatewayClassName: nginx
listeners:
- hostname: my-host.example.com
name: my-host-example-com-http
port: 80
protocol: HTTP
- hostname: my-host.example.com
name: my-host-example-com-https
port: 443
protocol: HTTPS
tls:
certificateRefs:
- group: ""
kind: Secret
name: my-secret
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
annotations:
gateway.networking.k8s.io/generator: ingress2gateway-dev
name: my-ingress-my-host-example-com
namespace: my-ns
spec:
hostnames:
- my-host.example.com
parentRefs:
- name: nginx
port: 443
rules:
- backendRefs:
- name: website-service
port: 80
filters:
- cors:
allowCredentials: true
allowHeaders:
- DNT
- Keep-Alive
- User-Agent
- X-Requested-With
- If-Modified-Since
- Cache-Control
- Content-Type
- Range
- Authorization
allowMethods:
- GET
- PUT
- POST
- DELETE
- PATCH
- OPTIONS
allowOrigins:
- "*"
maxAge: 1728000
type: CORS
matches:
- path:
type: RegularExpression
value: (?i)/users/(\d+).*
name: rule-0
timeouts:
request: 10s
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
annotations:
gateway.networking.k8s.io/generator: ingress2gateway-dev
name: my-ingress-my-host-example-com-ssl-redirect
namespace: my-ns
spec:
hostnames:
- my-host.example.com
parentRefs:
- name: nginx
port: 80
rules:
- filters:
- requestRedirect:
scheme: https
statusCode: 308
type: RequestRedirect
Ingress2Gatewayは、一部のアノテーションをGateway APIの同等の機能へ正常に変換しました。
例えば、 nginx.ingress.kubernetes.io/enable-corsアノテーションはCORSフィルターに変換されています。
しかし詳しく見ると、 nginx.ingress.kubernetes.io/proxy-{read,send}-timeoutとnginx.ingress.kubernetes.io/proxy-body-sizeアノテーションは完全には対応付けられていません。
ログには、これらが省略された理由と変換の背景が示されています。
┌─ WARN ────────────────────────────────────────
│ Unsupported annotation nginx.ingress.kubernetes.io/configuration-snippet
│ source: INGRESS-NGINX
│ object: Ingress: my-ns/my-ingress
└─
┌─ INFO ────────────────────────────────────────
│ Using case-insensitive regex path matches. You may want to change this.
│ source: INGRESS-NGINX
│ object: HTTPRoute: my-ns/my-ingress-my-host-example-com
└─
┌─ WARN ────────────────────────────────────────
│ ingress-nginx only supports TCP-level timeouts; i2gw has made a best-effort translation to Gateway API timeouts.request. Please verify that this meets your needs. See documentation: https://gateway-api.sigs.k8s.io/guides/http-timeouts/
│ source: INGRESS-NGINX
│ object: HTTPRoute: my-ns/my-ingress-my-host-example-com
└─
┌─ WARN ────────────────────────────────────────
│ Failed to apply my-ns.my-ingress.metadata.annotations."nginx.ingress.kubernetes.io/proxy-body-size" from my-ns/my-ingress: Most Gateway API implementations have reasonable body size and buffering defaults
│ source: STANDARD_EMITTER
│ object: HTTPRoute: my-ns/my-ingress-my-host-example-com
└─
┌─ WARN ────────────────────────────────────────
│ Gateway API does not support configuring URL normalization (RFC 3986, Section 6). Please check if this matters for your use case and consult implementation-specific details.
│ source: STANDARD_EMITTER
└─
Ingress2Gatewayがnginx.ingress.kubernetes.io/configuration-snippetアノテーションをサポートしていないという警告が表示されています。
同等の挙動を実現する方法があるかどうか、使用しているGateway API実装のドキュメントを確認する必要があります。
また、Ingress-NGINXの正規表現マッチングは大文字小文字を区別しないプレフィックスマッチであることも通知されています。これが、マッチパターンが (?i)/users/(\d+).* となっている理由です。
ほとんどの組織では、パスパターンから先頭の (?i) と末尾の .* を削除して、大文字小文字を区別する完全一致に変更することが望ましいでしょう。
Ingress2Gatewayは、nginx.ingress.kubernetes.io/proxy-{send,read}-timeoutアノテーションからHTTPルートの10秒のリクエストタイムアウトへのベストエフォートな変換を行いました。
このServiceへのリクエストがもっと短い時間、例えば3秒で完了すべきであれば、Gateway APIマニフェストに対応する変更を加えてください。
また、 nginx.ingress.kubernetes.io/proxy-body-sizeにはGateway APIでの同等の機能がないため、変換されていません。
しかし、ほとんどのGateway API実装ではリクエストボディの最大サイズやバッファリングに適切なデフォルト値が設定されているため、実際には問題にならない可能性があります。
さらに、一部のエミッターでは実装固有の拡張を通じてこのアノテーションをサポートしている場合があります。
例えば、先ほどのingress2gateway printコマンドに--emitter agentgateway、--emitter envoy-gateway、または--emitter kgatewayフラグを追加すると、生成されるGateway APIマニフェストにボディサイズの設定を反映した実装固有の設定が追加されます。
URL正規化に関する警告も表示されています。 Agentgateway、Envoy Gateway、Kgateway、IstioなどのGateway API実装にはある程度のURL正規化機能がありますが、その挙動は実装によって異なり、標準のGateway APIを通じて設定することはできません。 使用しているGateway API実装のURL正規化の挙動を確認・テストし、ユースケースとの互換性を確保してください。
Ingress-NGINXのデフォルトの挙動に合わせるため、Ingress2Gatewayはポート80のリスナーと、HTTPトラフィックをHTTPSにリダイレクトするHTTPリクエストリダイレクトフィルターも追加しています。 HTTPトラフィックを一切処理しない場合は、ポート80のリスナーと対応するHTTPRouteを削除してください。
注意:
生成された出力とログを必ず確認してください。これらの変更を手動で適用した後、Gateway APIマニフェストは以下のようになります。
---
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
annotations:
gateway.networking.k8s.io/generator: ingress2gateway-dev
name: nginx
namespace: my-ns
spec:
gatewayClassName: nginx
listeners:
- hostname: my-host.example.com
name: my-host-example-com-https
port: 443
protocol: HTTPS
tls:
certificateRefs:
- group: ""
kind: Secret
name: my-secret
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
annotations:
gateway.networking.k8s.io/generator: ingress2gateway-dev
name: my-ingress-my-host-example-com
namespace: my-ns
spec:
hostnames:
- my-host.example.com
parentRefs:
- name: nginx
port: 443
rules:
- backendRefs:
- name: website-service
port: 80
filters:
- cors:
allowCredentials: true
allowHeaders:
- DNT
...
allowMethods:
- GET
...
allowOrigins:
- '*'
maxAge: 1728000
type: CORS
matches:
- path:
type: RegularExpression
value: /users/(\d+)
name: rule-0
timeouts:
request: 3s
4. 検証
Gateway APIマニフェストが用意できたら、開発クラスターで十分にテストしてください。 この例では、少なくともGateway API実装のリクエストボディの最大サイズのデフォルト値が適切であることと、3秒のタイムアウトが十分であることを確認してください。
開発クラスターで挙動を検証した後、既存のIngressと並行してGateway APIの設定をデプロイしてください。 その後、DNSの重み付けルーティング、クラウドロードバランサー、またはプラットフォームのトラフィック分割機能を使用して、トラフィックを段階的に移行することを強く推奨します。 こうすることで、テストをすり抜けた設定ミスから迅速に復旧できます。
最後に、すべてのトラフィックをGateway APIコントローラーに移行し終えたら、Ingressリソースを削除しIngressコントローラーをアンインストールしてください。
まとめ
Ingress2Gateway 1.0のリリースはまだ始まりに過ぎません。Ingress2Gatewayを活用してGateway APIへ安全に移行していただければ幸いです。 2026年3月のIngress-NGINX廃止が迫る中、設定の対応範囲の拡大、テストの拡充、UXの改善にご協力いただけるよう、コミュニティの皆さまに呼びかけます。
Gateway APIに関するリソース
Gateway APIの対象範囲は広大です。 Gateway APIを活用するために役立つリソースを以下に紹介します。
- Listener setsは、アプリケーション開発者がGatewayリスナーを管理できるようにする機能です。
gwctlは、アタッチメントやリンターエラーなど、Gatewayリソースの包括的なビューを提供します。- Gateway API Slack: Kubernetes Slackの
#sig-network-gateway-api - Ingress2Gateway Slack: Kubernetes Slackの
#sig-network-ingress2gateway - GitHub: kubernetes-sigs/ingress2gateway
Kubernetes v1.35: Workload Aware Scheduling の導入
大規模なワークロードのスケジューリングは、単一のPodをスケジューリングするよりもはるかに複雑で脆弱な操作です。 これは、各Podを独立してスケジューリングするのではなく、すべてのPodをまとめて考慮する必要があることが多いためです。 たとえば、機械学習のバッチジョブをスケジューリングする際には、プロセス全体を可能な限り効率的にするために、各ワーカーを同じラックに配置するなど、戦略的に配置する必要がよくあります。 同時に、このようなワークロードを構成するPodは、スケジューリングの観点からは非常に多くの場合同一であり、このプロセスのあるべき姿を根本的に変えるものです。
大規模ワークロードのスケジューリングを効率的に行うために適応されたカスタムスケジューラーは数多く存在しますが、特にユースケースが増加しているAI時代においては、こうしたワークロードのスケジューリングがKubernetesユーザーにとってどれほど一般的で重要であるかを考えると、大規模ワークロードのスケジューリングをkube-schedulerのファーストクラスの対象としてネイティブにサポートする時が来ています。
Workload aware scheduling
最近のKubernetes 1.35リリースでは、Workload aware scheduling の改善の第一弾が提供されました。 これらは、ワークロードのスケジューリングと管理を改善することを目的とした、より広範な取り組みの一部です。 この取り組みは複数のSIGとリリースにまたがり、最終目標に向けてシステムの機能を段階的に拡張していく予定です。 その目標とは、プリエンプションやオートスケーリングを含む(ただしこれらに限定されない)、Kubernetesにおけるシームレスなワークロードのスケジューリングと管理です。
Kubernetes v1.35では、ワークロードの望ましい構成やスケジューリング指向の要件を記述するために使用できるWorkload APIが導入されます。
また、Gang Podを オール・オア・ナッシング 方式でスケジューリングするようにkube-schedulerに指示する、Gangスケジューリング の初期実装が含まれています。
さらに、Opportunistic Batching処理 機能により、(通常Gangを構成する)同一Podのスケジューリングを高速化するための改善も行いました。
Workload API
新しいWorkload APIリソースはscheduling.k8s.io/v1alpha1
APIグループの一部です。
このリソースは、マルチPodアプリケーションのスケジューリング要件を構造化された機械可読な定義として機能します。
Jobのようなユーザー向けワークロードが何を実行するかを定義するのに対し、Workloadリソースは、Podのグループをどのようにスケジューリングし、そのライフサイクルを通じて配置をどのように管理すべきかを決定します。
Workloadを使用すると、Podのグループを定義し、それにスケジューリングポリシーを適用できます。
以下はGangスケジューリングの設定例です。workersという名前のpodGroupを定義し、minCountを4に設定したgangポリシーを適用します。
apiVersion: scheduling.k8s.io/v1alpha1
kind: Workload
metadata:
name: training-job-workload
namespace: some-ns
spec:
podGroups:
- name: workers
policy:
gang:
# 4つのPodが同時に実行できる場合にのみGangはスケジュール可能
minCount: 4
Podを作成する際には、新しいworkloadRefフィールドを使用してこのWorkloadにリンクします:
apiVersion: v1
kind: Pod
metadata:
name: worker-0
namespace: some-ns
spec:
workloadRef:
name: training-job-workload
podGroup: workers
...
Gangスケジューリングの仕組み
gangポリシーは オール・オア・ナッシング の配置を強制します。
Gangスケジューリングがなければ、Jobが部分的にスケジューリングされ、実行できないままリソースを消費し、リソースの浪費やデッドロックの可能性につながることがあります。
GangスケジューリングされたPodグループの一部であるPodを作成すると、スケジューラーのGangSchedulingプラグインが各Podグループ(またはレプリカキー)のライフサイクルを独立して管理します:
Podを作成すると(またはコントローラーが自動的に作成すると)、 スケジューラーは以下の条件が満たされるまでスケジューリングをブロックします:
- 参照先のWorkloadオブジェクトが作成されていること。
- 参照先のPodグループがWorkload内に存在すること。
- そのグループ内の待機中のPod数が
minCountを満たしていること。
十分な数のPodが到着すると、スケジューラーはそれらの配置を試みます。 ただし、すぐにNodeにバインドするのではなく、Podは
Permitゲートで待機します。スケジューラーは、グループ全体(少なくとも
minCount分)に対して有効な割り当てが見つかったかどうかを確認します。- グループの余地がある場合、ゲートが開き、すべてのPodがNodeにバインドされます。
- タイムアウト(5分に設定)以内にグループの一部のPodのみがスケジューリングされた場合、 スケジューラーはグループ内のすべてのPodを拒否します。 それらはキューに戻り、予約されたリソースが他のワークロードのために解放されます。
これは最初の実装ですが、Kubernetesプロジェクトは今後のリリースでGangスケジューリングアルゴリズムを改善・拡張することを明確に意図していることを指摘しておきます。 提供を目指している利点には、Gang全体の単一サイクルスケジューリングフェーズ、ワークロードレベルのプリエンプションなどが含まれ、最終目標に向かって進んでいきます。
Opportunistic Batching
明示的なGangスケジューリングに加えて、v1.35では Opportunistic Batching が導入されます。 これは、同一Podのスケジューリングレイテンシーを改善するベータ機能です。
Gangスケジューリングとは異なり、この機能はWorkload APIやユーザー側での明示的なオプトインを必要としません。 スケジューラー内でOpportunisticに動作し、同一のスケジューリング要件(コンテナイメージ、リソース要求、アフィニティなど)を持つPodを識別します。 スケジューラーがPodを処理する際に、キュー内の後続の同一Podに対して実行可能性の計算を再利用でき、プロセスを大幅に高速化します。
ほとんどのユーザーは、Podが以下の条件を満たしていれば、特別な手順を踏むことなく、この最適化の恩恵を自動的に受けることができます。
制約事項
Opportunistic Batching処理は特定の条件下で動作します。
kube-schedulerが配置を見つけるために使用するすべてのフィールドが、Pod間で同一である必要があります。
さらに、一部の機能を使用すると、正確性を確保するために、それらのPodに対するバッチ処理メカニズムが無効になります。
ワークロードに対してバッチ処理が暗黙的に無効になっていないことを確認するために、kube-schedulerの設定を確認する必要がある場合があることに注意してください。
制約事項の詳細については、ドキュメントを参照してください。
最終目標
プロジェクトには、ワークロード対応スケジューリングを実現するという広範な目標があります。 これらの新しいAPIとスケジューリングの拡張機能は、最初のステップに過ぎません。 近い将来、この取り組みは以下に取り組むことを目指しています:
- ワークロードスケジューリングフェーズの導入
- マルチノード DRA およびトポロジー対応スケジューリングのサポート改善
- ワークロードレベルのプリエンプション
- スケジューリングとオートスケーリングの統合改善
- 外部ワークロードスケジューラーとの連携改善
- ワークロードのライフサイクル全体を通じた配置管理
- マルチワークロードスケジューリングシミュレーション
他にもあります。これらの重点分野の優先順位と実装順序は変更される可能性があります。 今後の更新にご期待ください。
はじめに
ワークロード対応スケジューリングの改善を試すには:
- Workload API:
kube-apiserverとkube-schedulerの両方でGenericWorkloadフィーチャーゲートを有効にし、scheduling.k8s.io/v1alpha1APIグループが有効であることを確認してください。 - Gangスケジューリング:
kube-schedulerでGangSchedulingフィーチャーゲートを有効にしてください(Workload APIが有効である必要があります)。 - Opportunistic Batching処理: ベータ機能として、v1.35ではデフォルトで有効になっています。
必要に応じて、
kube-schedulerのOpportunisticBatchingフィーチャーゲートを使用して無効にできます。
テストクラスターでワークロード対応スケジューリングを試して、Kubernetesスケジューリングの将来を形作るために、ぜひ体験をお聞かせください。 フィードバックは以下の方法で送ることができます:
- Slack (#sig-scheduling)で連絡してください。
- ワークロード対応スケジューリングの追跡Issueにコメントしてください。
- Kubernetesリポジトリに新しいIssueを報告してください。
さらに詳しく
- Workload APIとGangスケジューリングおよび Opportunistic Batching処理のKEPをお読みください。
- 最近の更新については、ワークロード対応スケジューリングのIssueを追跡してください。
Kubernetes v1.35: Timbernetes (The World Tree Release)
編集者: Aakanksha Bhende, Arujjwal Negi, Chad M. Crowell, Graziano Casto, Swathi Rao
前回のリリースと同様に、Kubernetes v1.35のリリースでは新しいGA、ベータ版、アルファ版の機能が導入されます。 高品質なリリースの継続的な提供は、私たちの開発サイクルの強さとコミュニティからの活発なサポートを示しています。
このリリースは60個の機能改善で構成されています。 それらのうち、GAへの昇格が17個、ベータへの移行が19個、アルファとしての導入が22個です。
また、このリリースにはいくつかの非推奨化と削除があります。 これらに必ず目を通してください。
リリースのテーマとロゴ

2025年はOctarine: The Color of Magic(v1.33)の輝きで始まり、Of Wind & Will(v1.34)の風に乗って進んできました。 そして私たちは、多くの世界をつなぐ生命の木、北欧神話のユグドラシルにインスパイアされた「世界樹」に手を伸ばしながら、この一年を締めくくります。 偉大な木が年輪を重ねるように、Kubernetesもリリースを重ねて成長し、グローバルコミュニティの献身によって形作られています。
その中心には、地球を包み込むKubernetesの舵輪があります。 それを支えているのは、日々の仕事や人生の変化を乗り越えながら、着実にオープンソースの管理を続ける、粘り強いメンテナ、コントリビューター、そしてユーザーたちです。 彼らは古いAPIを剪定し、新しい機能を接ぎ木し、世界最大級のオープンソースプロジェクトの一つを健全に保っています。
ロゴには、3匹のリスが木を守る姿が描かれています。 レビュアーを象徴する、LGTMの巻物を持った魔法使い。 新しいブランチを切り出すリリースチームを象徴する、斧とKubernetesの盾を持った戦士。 そして、山積みのIssueに光をもたらすトリアージ担当者を象徴する、ランタンを持ったローグです。
彼らは、より大きな冒険パーティーを代表しています。 Kubernetes v1.35は、世界樹に新たな年輪を刻みます。 それは多くの手によって、多くの道を経て形作られた新鮮な一刻であり、根を深く張りながら枝をより高く伸ばし続けるコミュニティの証です。
主なアップデート情報
Kubernetes v1.35は新機能と改善点が満載です。 このセクションでは、リリースチームが特に注目して欲しい、選りすぐりのアップデート内容をご紹介します!
安定版: Podリソースのインプレース更新
Podリソースのインプレース更新機能がGA(General Availability)に昇格しました。 この機能により、Podやコンテナを再起動せずにCPUやメモリリソースを調整できます。 以前は、このような変更にはPodの再作成が必要で、特にステートフルアプリケーションやバッチアプリケーションでワークロードの中断を招く可能性がありました。 また、これまでのKubernetesリリースでは、既存のPodに対してインフラストラクチャのリソース設定(requestsとlimits)のみを変更することが許可されていました。 新しいインプレース機能により、中断のないスムーズな垂直スケーリングが可能になり、効率が向上し、開発もシンプルになります。
この取り組みは、SIG Nodeが主導したKEP #1287の一環として行われました。
ベータ: Workload IdentityとセキュリティのためのPod証明書
以前は、Podに証明書を配布するには外部コントローラー(cert-manager、SPIFFE/SPIRE)、CRDオーケストレーション、およびSecret管理が必要で証明書のローテーションはサイドカーやInitコンテナで処理されていました。 Kubernetes v1.35では、自動証明書ローテーションによるネイティブなWorkload Identityが可能になり、サービスメッシュやゼロトラストアーキテクチャが大幅に簡素化されます。
kubeletが鍵を生成し、PodCertificateRequestを介して証明書を要求し、クレデンシャルバンドルをPodのファイルシステムに直接書き込むようになりました。
kube-apiserverはアドミッション時にノード制限を強制し、サードパーティの署名者が誤ってノード分離の境界に違反するという最も一般的な落とし穴を排除します。
これにより、発行パスにBearerトークンを含まない純粋なmTLSフローが可能になります。
この取り組みは、SIG Authが主導したKEP #4317の一環として行われました。
アルファ: スケジューリング前のNode Declared Features
コントロールプレーンで新機能が有効になっていても、ノードが古いバージョンのままである場合(このような状況は、Kubernetesのスキューポリシーで許可されています)、スケジューラーはその機能を必要とするPodを、互換性のない古いノードに配置してしまうことがあります。
Node Declared Featuresというフレームワークにより、ノードは自身がサポートするKubernetes機能を宣言できるようになります。
この新しいアルファ機能を有効にすると、ノードは自身がサポートする機能を報告し、新しい.status.declaredFeaturesフィールドを介してこの情報をコントロールプレーンに公開します。
その後、kube-scheduler、アドミッションコントローラー、およびサードパーティコンポーネントがこれらの宣言を使用できます。
例えば、スケジューリングやAPI検証の制約を強制して、Podが互換性のあるノードでのみ実行されるようにできます。
この取り組みは、SIG Nodeが主導したKEP #5328の一環として行われました。
GAに昇格した機能
これはv1.35リリース後にGAとなった改善点の一部です。
PreferSameNodeによるトラフィック分散
ServiceのtrafficDistributionフィールドが更新され、トラフィックルーティングをより明示的に制御できるようになりました。
新しいオプションPreferSameNodeが導入され、ローカルノード上のエンドポイントが利用可能な場合はそれを厳密に優先し、利用できない場合にのみリモートエンドポイントにフォールバックするようにServiceを設定できます。
同時に、既存のPreferCloseオプションはPreferSameZoneに名称が変更されました。
この変更により、トラフィックが現在のアベイラビリティゾーン内で優先されることが明示され、APIが自己説明的になりました。
PreferCloseは後方互換性のために保持されていますが、PreferSameZoneがゾーンルーティングの標準となり、ノードレベルとゾーンレベルの優先設定が明確に区別されるようになりました。
この取り組みは、SIG Networkが主導したKEP #3015の一環として行われました。
Job APIのmanaged-byメカニズム
Job APIにmanagedByフィールドが追加され、外部コントローラーがJobのステータス同期を処理できるようになりました。
Kubernetes v1.35でGAに昇格したこの機能は、主にMultiKueueによって推進されています。
MultiKueueは、クラスター間でJobを分散実行するためのシステムです。
管理クラスターで作成したJobがワーカークラスターで実行され、その結果が管理クラスターに反映されます。
このワークフローを有効にするには、組み込みのJobコントローラーが特定のJobリソースに対してアクションを実行しないようにして、代わりにKueueコントローラーがステータス更新を管理できるようにする必要があります。
目的は、Jobの同期を別のコントローラーにクリーンに委譲できるようにすることです。 そのコントローラーにカスタムパラメーターを渡したり、CronJobの並行性ポリシーを変更したりすることは目的としていません。
この取り組みは、SIG Appsが主導したKEP #4368の一環として行われました。
.metadata.generationによる信頼性の高いPodの更新追跡
これまで、Pod APIにはDeploymentなどの他のKubernetesオブジェクトにあるmetadata.generationフィールドがありませんでした。
このフィールドがなかったため、コントローラーやユーザーはkubeletがPodの仕様に対する最新の変更を実際に処理したかどうかを確実に検証する方法がありませんでした。
この曖昧さは、Podリソースのインプレース更新で特に問題でした。
リソースのリサイズ要求がいつ適用されたのかを正確に知ることが困難だったためです。
Kubernetes v1.33では、アルファ機能としてPodに.metadata.generationフィールドが追加されました。
このフィールドはv1.35のPod APIでGAになりました。
これにより、Podのspecが更新されるたびに.metadata.generationの値がインクリメントされます。
この改善の一環として、Pod APIには.status.observedGenerationフィールドも追加されました。
このフィールドは、kubeletが正常に確認して処理したgenerationを報告します。
また、Podの各conditionにも個別のobservedGenerationフィールドが含まれるようになり、クライアントはこれを報告したり監視したりできます。
この機能はv1.35でGAに昇格したため、すべてのワークロードで利用可能です。
この取り組みは、SIG Nodeが主導したKEP #5067の一環として行われました。
トポロジーマネージャーのNUMAノード数制限の設定
トポロジーマネージャーは、アフィニティ計算時の状態爆発を防ぐため、サポートできるNUMAノードの最大数として8というハードコードされた制限を使用していました。 (ここで重要な点があります。NUMAノード はKubernetes APIのNodeとは異なります。) このNUMAノード数の制限により、8つを超えるNUMAノードを持つCPUアーキテクチャを搭載した最新のハイエンドサーバーをKubernetesで十分に活用できませんでした。
Kubernetes v1.31では、トポロジーマネージャーのポリシー設定に新しいベータオプションmax-allowable-numa-nodesが導入されました。
Kubernetes v1.35では、このオプションがGAになりました。
これを有効にすることで、クラスター管理者は8つを超えるNUMAノードを持つサーバーを使用できます。
この設定オプションはGAですが、Kubernetesコミュニティは大規模なNUMAホストでのパフォーマンスが低いことを認識しており、これを改善することを目的とした改善提案(KEP-5726)があります。 詳細については、ノードのトポロジー管理ポリシーを制御するをご覧ください。
この取り組みは、SIG Nodeが主導したKEP #4622の一環として行われました。
ベータの新機能
これはv1.35リリース後にベータとなった改善点の一部です。
Downward APIによるノードトポロジーラベルの公開
従来は、Pod内からリージョンやゾーンなどのノードトポロジー情報にアクセスするには、Kubernetes APIサーバーへのクエリが必要でした。 この方法は機能しますが、インフラストラクチャのメタデータを取得するためだけに広範なRBAC権限やサイドカーコンテナが必要となり、複雑さとセキュリティリスクが生じていました。 Kubernetes v1.35では、Downward APIを介してノードトポロジーラベルを直接公開する機能がベータに昇格しました。
kubeletは、topology.kubernetes.io/zoneやtopology.kubernetes.io/regionなどの標準トポロジーラベルを、環境変数またはProjected VolumeファイルとしてPodに注入できるようになりました。
主な利点は、ワークロードがトポロジーを認識するためのより安全で効率的な方法が提供されることです。
これにより、アプリケーションはAPIサーバーに依存することなく、アベイラビリティゾーンやリージョンにネイティブに適応できます。
最小権限の原則を守ることでセキュリティが強化され、クラスター設定も簡素化されます。
注意: Kubernetesは、Downward APIへの入力として使用できるように、利用可能なトポロジーラベルをすべてのPodに注入するようになりました。 v1.35へのアップグレードにより、ほとんどのクラスター管理者は各Podにいくつかの新しいラベルが追加されていることに気づくでしょう。 これは設計の一部として想定された動作です。
この取り組みは、SIG Nodeが主導したKEP #4742の一環として行われました。
Storage Version Migrationのネイティブサポート
Kubernetes v1.35では、Storage Version Migrationのネイティブサポートがベータに昇格し、デフォルトで有効になりました。 この変更により、マイグレーションロジックがKubernetesコントロールプレーンのコア(「in-tree」)に直接統合され、外部ツールへの依存がなくなりました。
これまで管理者は、スキーマの更新や保存データの再暗号化のために、手動の「読み取り/書き込みループ」(多くの場合kubectl getをkubectl replaceにパイプする方法)に頼っていました。
この方法は非効率で、特にSecretのような大規模なリソースでは競合が発生しやすいものでした。
このリリースでは、組み込みコントローラーが更新の競合と整合性トークンを自動的に処理し、最小限の運用オーバーヘッドで保存データを最新の状態に保つ、安全で効率的かつ信頼性の高い方法を提供します。
この取り組みは、SIG API Machineryが主導したKEP #4192の一環として行われました。
変更可能なボリュームアタッチ制限
CSI(Container Storage Interface)ドライバーは、ストレージシステムをコンテナ化されたワークロードに一貫した方法で公開するKubernetesプラグインです。
CSINodeオブジェクトは、ノードにインストールされているすべてのCSIドライバーの詳細を記録します。
しかし、ノードで報告されるアタッチ容量と実際の容量の間に不一致が生じることがあります。
CSIドライバーの起動後にボリュームスロットが消費されると、kube-schedulerは十分な容量がないノードにステートフルなPodを割り当ててしまい、最終的にContainerCreating状態で停止することがあります。
Kubernetes v1.35では、CSINode.spec.drivers[*].allocatable.countが変更可能になり、ノードで利用可能なボリュームアタッチ容量を動的に更新できるようになりました。
また、CSIDriverオブジェクトを介して設定可能な更新間隔を導入することで、CSIドライバーがすべてのノードでallocatable.count値を更新する頻度を制御できるようになりました。
さらに、容量不足によるボリュームアタッチの失敗を検出すると、CSINode.spec.drivers[*].allocatable.countを自動的に更新します。
この機能はv1.34でフィーチャーフラグMutableCSINodeAllocatableCountがデフォルトで無効の状態でベータに昇格しましたが、v1.35でもフィードバックを得る時間を確保するためベータのままです。
ただし、フィーチャーフラグはデフォルトで有効になっています。
この取り組みは、SIG Storageが主導したKEP #4876の一環として行われました。
効率的なバッチスケジューリング
従来、KubernetesスケジューラーはO(Pod数 × Node数)の時間計算量でPodを順次処理していたため、互換性のあるPodに対して冗長な計算が発生することがありました。
このKEPでは、Pod scheduling signature(Podのスケジューリング特性を表すシグネチャ)を使用して互換性のあるPodを識別し、それらをまとめてバッチ処理することでパフォーマンスを向上させる仕組みを導入しています。
これにより、フィルタリングとスコアリングの結果を複数のPod間で共有できます。
Podスケジューリング署名は、同じ署名を持つ2つのPodがスケジューリングの観点から「同一」であることを保証します。 この署名は、Podとノードの属性だけでなく、システム内の他のPodやPod配置に関するグローバルデータも考慮します。 つまり、同じ署名を持つPodは、任意のノード群に対して同じスコアや実行可能性の結果を得ることになります。
このバッチ処理の仕組みは、必要に応じて呼び出せる2つの操作(createとnominate)で構成されています。
createは、有効な署名を持つPodのスケジューリング結果から新しいバッチ情報のセットを作成します。
nominateは、createで作成されたバッチ情報を使用して、署名が基準となるPodの署名と一致する新しいPodに対して、nominatedノード名を設定します。
この取り組みは、SIG Schedulingが主導したKEP #5598の一環として行われました。
StatefulSetにおけるmaxUnavailable
StatefulSetはPodのグループを実行し、各Podに対して固定のアイデンティティを維持します。
これは、安定したネットワーク識別子や永続ストレージを必要とするステートフルなワークロードにとって重要です。
StatefulSetの.spec.updateStrategy.<type>がRollingUpdateに設定されている場合、StatefulSetコントローラーはStatefulSet内の各Podを削除して再作成します。
Pod終了時と同じ順序(最大の序数から最小へ)で進行し、一度に1つずつPodを更新します。
Kubernetes v1.24では、StatefulSetのrollingUpdate設定にmaxUnavailableという新しいアルファフィールドが追加されました。
このフィールドは、クラスター管理者が明示的にオプトインしない限り、Kubernetes APIの一部ではありませんでした。
Kubernetes v1.35では、このフィールドはベータになり、デフォルトで利用可能です。
これを使用して、更新中に利用不可にできるPodの最大数を定義できます。
この設定は、.spec.podManagementPolicyをParallelに設定した場合に最も効果的です。
maxUnavailableは正の数(例: 2)または希望するPod数の割合(例: 10%)として設定できます。
このフィールドが指定されていない場合、デフォルトは1となり、一度に1つのPodのみを更新する従来の動作が維持されます。
この改善により、複数のPodが同時に停止することを許容できるステートフルアプリケーションでは、更新を高速に完了できます。
この取り組みは、SIG Appsが主導したKEP #961の一環として行われました。
kubercにおける認証情報プラグインポリシーの設定
オプションのkubercファイルは、実行中のCIパイプラインを予期しない出力で中断することなく、サーバー設定とクラスター認証情報をユーザー設定から分離する方法です。
v1.35リリースの一環として、kubercに認証情報プラグインポリシーを設定できる機能が追加されました。
この変更により、すべてのプラグインを許可または拒否するcredentialPluginPolicyフィールドと、credentialPluginAllowlistを使用して許可するプラグインのリストを指定する機能の2つのフィールドが導入されました。
この取り組みは、SIG AuthとSIG CLIの協力によりKEP #3104の一環として行われました。
KYAML
YAMLは人間が読みやすいデータシリアライズ形式です。 Kubernetesでは、YAMLファイルはPod、Service、Deploymentなどのリソースを定義および設定するために使用されます。 しかし、複雑なYAMLは読みにくいという問題があります。 YAMLでは空白が意味を持つため、インデントとネストに注意が必要であり、文字列の引用符がオプションであることから予期しない型変換が発生することがあります(例: The Norway Bug)。 JSONは代替手段ですが、コメントをサポートしておらず、末尾のカンマやキーの引用符に厳格な要件があります。
KYAMLは、Kubernetes向けに特別に設計された、より安全で曖昧さの少ないYAMLのサブセットです。
v1.34でオプトインのアルファ機能として導入されたこの機能は、Kubernetes v1.35でベータに昇格し、デフォルトで有効になりました。
環境変数KUBECTL_KYAML=falseを設定することで無効にできます。
KYAMLはYAMLとJSONの両方が抱える課題に対処しています。 KYAMLファイルはすべて有効なYAMLファイルでもあるため、KYAMLで記述したマニフェストは任意のバージョンのkubectlで使用できます。 一方で、kubectlへの入力は厳密なKYAML形式である必要はなく、従来のYAMLもそのまま解析できます。
この取り組みは、SIG CLIが主導したKEP #5295の一環として行われました。
HorizontalPodAutoscalerの許容値の設定
Horizontal Pod Autoscaler(HPA)は、これまでスケーリングアクションに対して、グローバルに設定された固定の10%の許容値に依存していました。 このハードコードされた値の欠点は、5%の負荷増加でスケーリングが必要な高感度のワークロードではスケーリングがブロックされることが多い一方で、他のワークロードでは不必要に振動する可能性があることでした。
Kubernetes v1.35では、許容値を設定できる機能がベータに昇格し、デフォルトで有効になりました。
この機能強化により、HPAのbehaviorフィールド内でリソースごとにカスタムの許容値ウィンドウを定義できます。
特定の許容値を設定することで(例: 5%の場合は0.05に下げる)、オペレーターはオートスケーリングの感度を精密に制御でき、クラスター全体の設定変更を必要とせずに、重要なワークロードがメトリクスの小さな変化に素早く反応するようにできます。
この取り組みは、SIG Autoscalingが主導したKEP #4951の一環として行われました。
Podにおけるユーザー名前空間のサポート
Kubernetesにユーザー名前空間のサポートが追加され、Podはホストとユーザー/グループIDを共有する代わりに、分離されたIDマッピングで実行できるようになりました。 これにより、コンテナ内部ではrootとして動作しながら、実際にはホスト上の非特権ユーザーにマッピングされるため、侵害が発生した場合の権限昇格リスクが軽減されます。 この機能はPodレベルのセキュリティを向上させ、コンテナ内でrootが必要なワークロードをより安全に実行できるようにします。 時間の経過とともに、id-mappedマウントによりステートレスとステートフルの両方のPodにサポートが拡大されました。
この取り組みは、SIG Nodeが主導したKEP #127の一環として行われました。
VolumeSource: OCIアーティファクトおよびイメージ
Podを作成する際、コンテナにデータ、バイナリ、または設定ファイルを提供する必要があることがよくあります。
従来は、コンテンツをメインのコンテナイメージに含めるか、カスタムのInitコンテナを使用してファイルをダウンロードしemptyDirに展開する必要がありました。
これらのアプローチは現在も有効です。
Kubernetes v1.31ではimageボリュームタイプのサポートが追加され、PodがOCIコンテナイメージのアーティファクトを宣言的にプルしてボリュームに展開できるようになりました。
これにより、設定ファイル、バイナリ、機械学習モデルなどのデータのみのアーティファクトを、標準的なOCIレジストリツールを使用してパッケージ化し配布できます。
この機能により、データをコンテナイメージから完全に分離でき、追加のInitコンテナや起動スクリプトが不要になります。 imageボリュームタイプはv1.33からベータであり、v1.35ではデフォルトで有効になっています。 この機能を使用するには、containerd v2.1以降などの互換性のあるコンテナランタイムが必要です。
この取り組みは、SIG Nodeが主導したKEP #4639の一環として行われました。
キャッシュされたイメージに対するkubeletの認証情報検証の強制
imagePullPolicy: IfNotPresentの設定では、Pod自体がそのイメージを取得するための認証情報を持っていなくても、ノードにすでにキャッシュされているコンテナイメージを使用できます。
この動作の欠点は、マルチテナントクラスターでセキュリティの脆弱性を生むことです。
有効な認証情報を持つPodが機密性の高いプライベートイメージをノード上に取得すると、同じノード上の後続の未認可Podがローカルキャッシュに依存するだけで、そのイメージにアクセスできてしまいます。
このKEPでは、kubeletがキャッシュされたイメージに対して認証情報の検証を強制する仕組みを導入しています。
ローカルにキャッシュされたイメージをPodが使用することを許可する前に、kubeletはそのPodがイメージを取得するための有効な認証情報を持っているかどうかを確認します。
これにより、イメージがすでにノードに存在するかどうかに関係なく、認可されたワークロードのみがプライベートイメージを使用できるようになり、共有クラスターのセキュリティ体制が大幅に強化されます。
Kubernetes v1.35では、この機能はベータに昇格し、デフォルトで有効になっています。
KubeletEnsureSecretPulledImagesフィーチャーゲートをfalseに設定することで無効にすることもできます。
さらに、imagePullCredentialsVerificationPolicyフラグにより、オペレーターは後方互換性を優先するモードから最大限のセキュリティを提供する厳格な強制モードまで、希望するセキュリティレベルを設定できます。
この取り組みは、SIG Nodeが主導したKEP #2535の一環として行われました。
きめ細かなコンテナ再起動ルール
従来、restartPolicyフィールドはPodレベルでのみ定義されており、Pod内のすべてのコンテナに同じ動作を強制していました。
このグローバル設定の欠点は、AI/MLトレーニングジョブなどの複雑なワークロードに対する粒度の欠如でした。
これらのジョブでは、ジョブの完了を管理するためにPodにrestartPolicy: Neverが必要なことが多いですが、個々のコンテナは特定のリトライ可能なエラー(ネットワークの問題やGPU初期化の失敗など)に対してインプレース再起動の恩恵を受ける可能性がありました。
Kubernetes v1.35では、コンテナAPI自体でrestartPolicyとrestartPolicyRulesを有効にすることでこの問題に対処しています。
これにより、Podの全体的なポリシーとは独立して動作する、個々の通常コンテナとInitコンテナの再起動戦略を定義できます。
たとえば、コンテナが特定のエラーコードで終了した場合にのみ自動的に再起動するように設定でき、一時的な障害のためにPod全体を再スケジュールするコストの高いオーバーヘッドを回避できます。
このリリースでは、この機能はベータに昇格し、デフォルトで有効になっています。
ユーザーはコンテナの仕様でrestartPolicyRulesをすぐに活用して、Podの広範なライフサイクルロジックを変更することなく、長時間実行されるワークロードのリカバリ時間とリソース使用率を最適化できます。
この取り組みは、SIG Nodeが主導したKEP #5307の一環として行われました。
CSIドライバーがsecretsフィールドでServiceAccountトークンを受信可能に
Container Storage Interface(CSI)ドライバーにServiceAccountトークンを提供する方法は、従来はvolume_contextフィールドへの注入に依存していました。
このアプローチは重大なセキュリティリスクをもたらします。
volume_contextは機密性のない設定データを対象としており、ドライバーやデバッグツールによって平文でログに記録されることが多く、認証情報が漏洩する可能性があるためです。
Kubernetes v1.35では、CSIドライバーがNodePublishVolumeリクエストの専用secretsフィールドを介してServiceAccountトークンを受け取るためのオプトイン機構を導入しています。
ドライバーはCSIDriverオブジェクトでserviceAccountTokenInSecretsフィールドをtrueに設定することでこの動作を有効にでき、kubeletにトークンを安全に設定するよう指示します。
主な利点は、ログやエラーメッセージでの認証情報の意図しない露出を防止することです。 この変更により、機密性の高いワークロードIDが適切な安全なチャネルを介して処理されるようになり、既存のドライバーとの後方互換性を維持しながら、シークレット管理のベストプラクティスに沿った対応が可能になります。
この取り組みは、SIG AuthがSIG Storageと協力して主導したKEP #5538の一環として行われました。
Deploymentステータスの追加: 終了中のレプリカ数
従来、Deploymentのステータスは利用可能なレプリカと更新されたレプリカの詳細を提供していましたが、シャットダウン中のPodを明確に確認することはできませんでした。 この欠落の欠点は、ユーザーやコントローラーが、安定したDeploymentと、クリーンアップタスクを実行中または長い猶予期間に従っているPodがまだ存在するDeploymentを簡単に区別できないことでした。
Kubernetes v1.35では、Deploymentステータス内のterminatingReplicasフィールドがベータに昇格しました。
このフィールドは、削除タイムスタンプが設定されているがまだシステムから削除されていないPodの数を提供します。
この機能は、DeploymentがPodの置き換えを処理する方法を改善するより大きな取り組みの基礎的なステップであり、ロールアウト中に新しいPodをいつ作成するかに関する将来のポリシーの基盤を築いています。
主な利点は、ライフサイクル管理ツールやオペレーター向けの可観測性の向上です。 終了中のPodの数を公開することで、外部システムは個々のPodリストを手動でクエリしてフィルタリングすることなく、完全なシャットダウンを待ってから後続のタスクに進むなど、より適切な判断を下せるようになります。
この取り組みは、SIG Appsが主導したKEP #3973の一環として行われました。
アルファの新機能
これはv1.35リリース後にアルファとなった改善点の一部です。
KubernetesにおけるGangスケジューリングのサポート
AI/MLトレーニングジョブやHPCシミュレーションなどの相互依存するワークロードのスケジューリングは、デフォルトのKubernetesスケジューラーがPodを個別に配置するため、従来から困難でした。 これにより、一部のPodが開始される一方で他のPodがリソースを無期限に待機する部分的なスケジューリングが発生し、デッドロックやクラスター容量の浪費につながることがよくありました。
Kubernetes v1.35では、新しいWorkload APIとPodGroupコンセプトを介した、いわゆる「Gangスケジューリング」のネイティブサポートを導入しています。 この機能は「オール・オア・ナッシング (全か無か)」のスケジューリング戦略を実装し、定義されたPodのグループは、クラスターがグループ全体を同時に収容するのに十分なリソースを持っている場合にのみスケジュールされることを保証します。
主な利点は、バッチおよび並列ワークロードの信頼性と効率性の向上です。 部分的なデプロイメントを防ぐことで、リソースのデッドロックを排除し、完全なジョブが実行できる場合にのみ高価なクラスター容量が使用されるようになり、大規模なデータ処理タスクのオーケストレーションが大幅に最適化されます。
この取り組みは、SIG Schedulingが主導したKEP #4671の一環として行われました。
制約付きなりすまし
従来、Kubernetes RBACのimpersonate動詞はオール・オア・ナッシングの方式で機能していました。
ユーザーが対象のアイデンティティになりすますことを認可されると、関連するすべての権限を取得していました。
この広範な認可の欠点は、最小権限の原則に違反し、管理者がなりすましを行うユーザーを特定のアクションやリソースに制限できないことでした。
Kubernetes v1.35では、なりすましフローに二次的な認可チェックを追加する新しいアルファ機能、制約付きなりすましを導入しています。
ConstrainedImpersonationフィーチャーゲートを介して有効にすると、APIサーバーは基本的なimpersonate権限だけでなく、新しい動詞プレフィックス(例: impersonate-on:<mode>:<verb>)を使用して、なりすましを行うユーザーが特定のアクションに対して認可されているかどうかも確認します。
これにより、管理者はきめ細かなポリシーを定義できます。
たとえば、サポートエンジニアがログを表示するためだけにクラスター管理者になりすますことを許可し、完全な管理アクセス権を付与しないようにできます。
この取り組みは、SIG Authが主導したKEP #5284の一環として行われました。
KubernetesコンポーネントのFlagz
APIサーバーやkubeletなどのKubernetesコンポーネントのランタイム設定を検証するには、従来ホストノードへの特権アクセスやプロセス引数へのアクセスが必要でした。
これに対処するため、コマンドラインオプションをHTTP経由で公開する/flagzエンドポイントが導入されました。
しかし、その出力は当初プレーンテキストに限定されており、自動化ツールが設定を確実に解析して検証することが困難でした。
Kubernetes v1.35では、/flagzエンドポイントが機械可読な構造化JSON出力をサポートするように強化されました。
認可されたユーザーは、標準的なHTTPコンテンツネゴシエーションを使用してバージョン管理されたJSONレスポンスをリクエストできるようになり、元のプレーンテキスト形式も人間による検査用に引き続き利用可能です。
このアップデートにより、可観測性とコンプライアンスのワークフローが大幅に改善され、外部システムが脆弱なテキスト解析や直接的なインフラストラクチャアクセスなしに、コンポーネント設定をプログラムで監査できるようになります。
この取り組みは、SIG Instrumentationが主導したKEP #4828の一環として行われました。
KubernetesコンポーネントのStatusz
kube-apiserverやkubeletなどのKubernetesコンポーネントのトラブルシューティングには、従来、構造化されていないログやテキスト出力の解析が必要であり、これは脆弱で自動化が困難でした。
以前から基本的な/statuszエンドポイントは存在していましたが、標準化された機械可読形式がなく、外部監視システムでの有用性が制限されていました。
Kubernetes v1.35では、/statuszエンドポイントが機械可読な構造化JSON出力をサポートするように強化されました。
認可されたユーザーは、標準的なHTTPコンテンツネゴシエーションを使用してこの形式をリクエストし、バージョン情報やヘルスインジケーターなどの正確なステータスデータを、脆弱なテキスト解析に頼ることなく取得できます。
この改善により、すべてのコアコンポーネントにわたって、自動デバッグおよび可観測性ツールのための信頼性が高く一貫したインターフェースが提供されます。
この取り組みは、SIG Instrumentationが主導したKEP #4827の一環として行われました。
CCM: informerを使用したwatch-basedルートコントローラーの調整
クラウド環境内でのネットワークルートの管理は、従来Cloud Controller Manager(CCM)がクラウドプロバイダーのAPIを定期的にポーリングしてルートテーブルを検証および更新することに依存していました。 この固定間隔での調整アプローチは非効率になりがちで、大量の不要なAPI呼び出しを生成し、ノードの状態変化と対応するルート更新の間に遅延が生じることがよくありました。
Kubernetes v1.35リリースでは、cloud-controller-managerライブラリがルートコントローラー用のwatch-based調整戦略を導入しています。 タイマーに依存する代わりに、コントローラーはinformerを利用して、追加、削除、関連フィールドの更新などの特定のノードイベントを監視し、実際に変更が発生した場合にのみルート同期をトリガーします。
主な利点は、クラウドプロバイダーAPIの使用量が大幅に削減されることで、レート制限に達するリスクが低下し、運用オーバーヘッドが軽減されます。 さらに、このイベント駆動モデルは、クラスタートポロジーの変更後すぐにルートテーブルが更新されることを保証し、クラスターのネットワーク層の応答性を向上させます。
この取り組みは、SIG Cloud Providerが主導したKEP #5237の一環として行われました。
しきい値ベースの配置のための拡張toleration演算子
Kubernetes v1.35では、ワークロードが信頼性要件を表現できるようにすることで、SLA対応のスケジューリングを導入しています。 この機能はtolerationに数値比較演算子を追加し、サービス保証や障害ドメインの品質などのSLA指向のtaintに基づいて、Podがノードにマッチするか回避するかを制御できるようにします。
主な利点は、より正確な配置によるスケジューラーの強化です。 重要なワークロードは高SLAノードを要求でき、優先度の低いワークロードは低SLAノードを選択できます。 これにより、信頼性を損なうことなく使用率が向上し、コストが削減されます。
この取り組みは、SIG Schedulingが主導したKEP #5471の一環として行われました。
Job一時停止時の変更可能なコンテナリソース
バッチワークロードを実行する際に、リソース制限の設定で試行錯誤を伴うことがよくあります。 現在、Jobの仕様は不変であり、Jobがメモリ不足(OOM)エラーやCPU不足で失敗した場合、ユーザーは単にリソースを調整することができません。 Jobを削除して新しいJobを作成する必要があり、実行履歴とステータスが失われます。
Kubernetes v1.35では、一時停止状態のJobに対してリソースリクエストと制限を更新する機能を導入しています。
MutablePodResourcesForSuspendedJobsフィーチャーゲートを介して有効にすると、この機能強化により、ユーザーは失敗しているJobを一時停止し、適切なリソース値でPodテンプレートを変更してから、修正された設定で実行を再開できます。
主な利点は、設定ミスのあるJobに対するよりスムーズなリカバリワークフローです。 一時停止中にインプレースで修正できるようにすることで、ユーザーはJobのライフサイクルアイデンティティを中断したり完了ステータスを見失ったりすることなくリソースのボトルネックを解決でき、バッチ処理の開発者体験が大幅に向上します。
この取り組みは、SIG Appsが主導したKEP #5440の一環として行われました。
その他の注目すべき変更
Dynamic Resource Allocation(DRA)の継続的なイノベーション
コア機能はv1.34でGAに昇格し、無効にする機能が提供されていました。 v1.35では常に有効になっています。 いくつかのアルファ機能も大幅に改善され、テストの準備が整っています。 今後のリリースでベータへの昇格を目指すこれらの機能について、ぜひフィードバックをお寄せください。
DRAを介した拡張リソースリクエスト
Device Pluginを介した拡張リソースリクエストと比較していくつかの機能的な差分が対処されました。 たとえば、Initコンテナでのデバイスのスコアリングと再利用などです。
デバイスのTaintとToleration
新しい「None」エフェクトを使用すると、スケジューリングや実行中のPodに直ちに影響を与えることなく問題を報告できます。 DeviceTaintRuleは、進行中の退避に関するステータス情報を提供するようになりました。 「None」エフェクトは、実際にPodを退避する前の「ドライラン」として使用できます:
- 「effect: None」でDeviceTaintRuleを作成する
- ステータスを確認して、退避されるPodの数を確認する
- 「effect: None」を「effect: NoExecute」に置き換える
パーティション可能なデバイス
同じパーティション可能なデバイスに属するデバイスを、異なるResourceSliceで定義できるようになりました。 詳細については公式ドキュメントをご覧ください。
Consumable capacityとデバイスバインディング条件
いくつかのバグが修正され、テストが追加されました。 Consumable Capacityとバインディング条件の詳細については、公式ドキュメントをご覧ください。
比較可能なリソースバージョンのセマンティクス
Kubernetes v1.35では、クライアントがリソースバージョンを解釈する方法が変更されました。
v1.35より前は、クライアントがサポートできる唯一の比較は文字列の等価性チェックでした。 2つのリソースバージョンが等しければ、それらは同じでした。 クライアントはAPIサーバーにリソースバージョンを提供し、特定のリソースバージョン以降のすべてのイベントをストリーミングするなど、コントロールプレーンに内部比較を依頼することもできました。
v1.35では、すべてのin-treeリソースバージョンがより厳格な新しい定義を満たしています。 値は特殊な形式の10進数です。 そして、比較可能であるため、クライアントは2つの異なるリソースバージョンを比較する独自の操作を実行できます。 たとえば、クラッシュ後に再接続するクライアントは、更新があったが変更が失われていない場合と区別して、更新を失ったことを検出できます。
このセマンティクスの変更により、Storage Version Migration、 informer (クライアントヘルパーの概念)のパフォーマンス改善、コントローラーの信頼性など、他の重要なユースケースが可能になります。 これらのケースはすべて、あるリソースバージョンが別のリソースバージョンより新しいかどうかを知る必要があります。
この取り組みは、SIG API Machineryが主導したKEP #5504の一環として行われました。
v1.35での昇格、非推奨、削除
GAへの昇格
これは安定版(一般提供、GAとも呼ばれる)に昇格したすべての機能を一覧にしたものです。 アルファからベータへの昇格や新機能を含む更新の完全なリストについては、リリースノートをご覧ください。
このリリースには、GAに昇格した合計15の機能強化が含まれています:
- CPUManagerポリシーオプションの追加: reservedSystemCPUsをシステムデーモンと割り込み処理に制限
- Podのgeneration管理
- インバリアントテスト
- Podリソースのインプレース更新
- きめ細かなSupplementalGroupsの制御
- kubeletのドロップイン設定ディレクトリのサポート
- Kubernetes API型からのgogo/protobuf依存関係の削除
- kubeletの期限ベースイメージGC
- kubeletの並列イメージプル制限
- MaxAllowableNUMANodes用のTopologyManagerポリシーオプションの追加
- HTTPリクエストヘッダーへのkubectlコマンドメタデータの追加
- PreferSameNodeトラフィック分散(旧PreferLocalトラフィックポリシー/ノードレベルトポロジー)
- Job APIのmanaged-byメカニズム
- SPDYからWebSocketsへの移行
非推奨、削除、コミュニティの更新
Kubernetesの開発と成熟に伴い、プロジェクト全体の健全性を向上させるために、機能が非推奨になったり、削除されたり、より良いものに置き換えられたりすることがあります。 このプロセスの詳細については、Kubernetesの非推奨と削除のポリシーをご覧ください。 Kubernetes v1.35にはいくつかの非推奨が含まれています。
Ingress NGINXの引退
長年にわたり、Ingress NGINXコントローラーはKubernetesクラスターへのトラフィックルーティングにおいて人気のある選択肢でした。 柔軟性があり、広く採用され、数え切れないほどのアプリケーションの標準的なエントリーポイントとして機能してきました。
しかし、プロジェクトの維持が持続不可能になりました。 メンテナーの深刻な不足と増大する技術的負債により、コミュニティは最近、引退させるという難しい決断を下しました。 これは厳密にはv1.35リリースの一部ではありませんが、非常に重要な変更であるため、ここで強調したいと思います。
その結果、Kubernetesプロジェクトは、Ingress NGINXが2026年3月までベストエフォートのメンテナンスのみを受けることを発表しました。 この日以降、アーカイブされ、今後の更新は行われません。 推奨される移行先はGateway APIであり、トラフィック管理のためのより現代的で安全かつ拡張可能な標準を提供します。
詳細については公式ブログ記事をご覧ください。
cgroup v1サポートの削除
Linuxノードでのリソース管理において、Kubernetesは従来cgroups(コントロールグループ)に依存してきました。 オリジナルのcgroup v1は機能していましたが、一貫性がなく制限があることが多くありました。 そのため、Kubernetesはv1.25でcgroup v2のサポートを導入し、よりクリーンで統一された階層構造と優れたリソース分離を提供しました。
cgroup v2が現代の標準となったため、Kubernetesはv1.35でレガシーなcgroup v1サポートを廃止する準備が整いました。
これはクラスター管理者にとって重要なお知らせです。cgroup v2をサポートしていない古いLinuxディストリビューションでノードを実行している場合、kubeletは起動に失敗します。
ダウンタイムを回避するには、それらのノードをcgroup v2が有効になっているシステムに移行する必要があります。
詳細についてはcgroup v2についてをお読みください。
また、KEP-5573: Remove cgroup v1 supportで移行作業を追跡できます。
kube-proxyのipvsモードの非推奨化
数年前、Kubernetesは標準のiptablesよりも高速なロードバランシングを提供するために、kube-proxyにipvsモードを採用しました。
パフォーマンスの向上をもたらしましたが、進化するネットワーキング要件に対応し続けることで、過度の技術的負債と複雑さが生じました。
このメンテナンス負担のため、Kubernetes v1.35ではipvsモードが非推奨になりました。
このリリースでは、このipvsモードは引き続き利用可能ですが、kube-proxyはipvsを使用するよう設定されている場合、起動時に警告を出力するようになります。
目標はコードベースを合理化し、現代の標準に焦点を当てることです。
Linuxノードでは、現在推奨される代替手段であるnftablesへの移行を開始する必要があります。
詳細についてはKEP-5495: Deprecate ipvs mode in kube-proxyをご覧ください。
containerd v1.Xの最終サポート
Kubernetes v1.35は引き続きcontainerd 1.7およびその他のLTSリリースをサポートしていますが、これがそのようなサポートを提供する最後のバージョンです。 SIG Nodeコミュニティは、v1.35をcontainerd v1.Xシリーズをサポートする最後のリリースに指定しました。
これは重要なリマインダーです。次のKubernetesバージョンにアップグレードする前に、containerd 2.0以降に切り替える必要があります。
どのノードに対応が必要かを特定するために、クラスター内のkubelet_cri_losing_supportメトリクスを監視できます。
詳細については公式ブログ記事またはKEP-4033: Discover cgroup driver from CRIをご覧ください。
kubelet再起動時のPod安定性の向上
以前は、kubeletサービスの再起動により、Podステータスに一時的な中断が発生することがよくありました。
再起動中、kubeletはコンテナの状態をリセットし、アプリケーション自体が正常に実行されていても、正常なPodがNotReadyとしてマークされ、ロードバランサーから削除されていました。
この信頼性の問題に対処するため、シームレスなノードメンテナンスを確保するようにこの挙動が修正されました。
kubeletは起動時にランタイムから既存のコンテナの状態を適切に復元するようになりました。
これにより、kubeletの再起動やアップグレード中もワークロードはReady状態を維持し、トラフィックは中断されることなく流れ続けます。
詳細についてはKEP-4781: Fix inconsistent container ready state after kubelet restartをご覧ください。
リリースノート
Kubernetes v1.35リリースの詳細については、リリースノートをご覧ください。
入手方法
Kubernetes v1.35はGitHubまたはKubernetes公式サイトのダウンロードページからダウンロードできます。
Kubernetesを始めるには、インタラクティブチュートリアルをチェックするか、minikubeを使用してローカルKubernetesクラスターを実行してください。 また、kubeadmを使用して簡単にv1.35をインストールすることもできます。
リリースチーム
Kubernetesは、コミュニティの支援、コミットメント、献身的な努力なくしては成り立ちません。 各リリースチームは、皆さんが利用するKubernetesリリースを構成する様々な要素を協力して構築する、献身的なコミュニティボランティアで構成されています。 これを実現するには、コードそのものからドキュメント作成、プロジェクト管理に至るまで、コミュニティのあらゆる分野の専門スキルが必要です。
私たちは、技術的な卓越性と周囲を巻き込む情熱でKubernetesコミュニティに永続的な影響を残した、長年にわたるコントリビューターであり尊敬されるエンジニアであるHan Kangを追悼します。 HanはSIG InstrumentationとSIG API Machineryにおいて重要な存在であり、プロジェクトのコアの安定性に対する重要な貢献と持続的なコミットメントにより、2021 Kubernetes Contributor Awardを受賞しました。 技術的な貢献に加えて、Hanはメンターとしての寛大さと人々のつながりを築くことへの情熱で深く称賛されていました。 彼は、新しいコントリビューターの最初のPull Requestを導いたり、忍耐と優しさで同僚をサポートしたりと、他者のために「扉を開く」ことで知られていました。 Hanの遺志は、彼がインスパイアしたエンジニアたち、彼が構築を手助けした堅牢なシステム、そして彼がクラウドネイティブのエコシステム内で育んだ温かく協力的な精神を通じて生き続けています。
Kubernetes v1.35リリースをコミュニティに届けるために多くの時間を費やして取り組んでくれたリリースチーム全体に感謝します。 リリースチームには、初参加のShadow(見習い)から、複数のリリースサイクルで経験を積んだベテランのチームリードまで、様々なメンバーが参加しています。 リリースリードのDrew Hagenに心より感謝します。 彼の実践的な指導と活力あふれるエネルギーは、複雑な課題を乗り越える力となっただけでなく、この成功したリリースの背後にあるコミュニティ精神を燃え立たせました。
プロジェクトの活動状況
CNCF K8sのDevStatsプロジェクトは、Kubernetesおよび様々なサブプロジェクトの活動状況に関する興味深いデータポイントを集計しています。 これには個人の貢献から貢献企業数まで含まれ、このエコシステムの発展に費やされる努力の深さと広さを示しています。
v1.35リリースサイクル(2025年9月15日から2025年12月17日までの14週間)において、Kubernetesには最大85の異なる企業と419人の個人から貢献がありました。 より広範なクラウドネイティブエコシステムでは、この数字は281社、合計1769人のコントリビューターに達しています。
なお、「貢献」とはコミットの作成、コードレビュー、コメント、IssueやPRの作成、PRのレビュー(ブログやドキュメントを含む)、またはIssueやPRへのコメントを行うことを指します。
貢献に興味がある場合は、コントリビューター向けWebサイトのはじめにをご覧ください。
データソース:
イベント情報
今後開催予定のKubernetesおよびクラウドネイティブイベント(KubeCon + CloudNativeCon、KCDなど)や、世界各地で開催される主要なカンファレンスについて紹介します。 Kubernetesコミュニティの最新情報を入手し、参加しましょう!
2026年2月
- KCD - Kubernetes Community Days: New Delhi: 2026年2月21日 | インド、ニューデリー
- KCD - Kubernetes Community Days: Guadalajara: 2026年2月23日 | メキシコ、グアダラハラ
2026年3月
- KubeCon + CloudNativeCon Europe 2026: 2026年3月23日-26日 | オランダ、アムステルダム
2026年5月
- KCD - Kubernetes Community Days: Toronto: 2026年5月13日 | カナダ、トロント
- KCD - Kubernetes Community Days: Helsinki: 2026年5月20日 | フィンランド、ヘルシンキ
2026年6月
- KubeCon + CloudNativeCon China 2026: 2026年6月10日-11日 | 香港
- KubeCon + CloudNativeCon India 2026: 2026年6月18日-19日 | インド、ムンバイ
- KCD - Kubernetes Community Days: Kuala Lumpur: 2026年6月27日 | マレーシア、クアラルンプール
2026年7月
- KubeCon + CloudNativeCon Japan 2026: 2026年7月29日-30日 | 日本、横浜
最新のイベント情報はこちらでご確認いただけます。
ウェビナーのご案内
Kubernetes v1.35リリースチームのメンバーと一緒に 2026年1月14日(水)午後5時(UTC) から、このリリースのハイライトやアップグレードの計画に役立つ非推奨事項や削除事項について学びましょう。 詳細および参加登録は、CNCFオンラインプログラム・サイトのイベントページをご覧ください。
参加方法
Kubernetesに関わる最も簡単な方法は、あなたの興味に合ったSpecial Interest Groups(SIGs)のいずれかに参加することです。 Kubernetesコミュニティに向けて何か発信したいことはありますか? 毎週のコミュニティミーティングや、以下のチャンネルであなたの声を共有してください。 継続的なフィードバックとサポートに感謝いたします。
- 最新情報はBlueSkyの@kubernetes.ioをフォローしてください
- Discussでコミュニティディスカッションに参加してください
- Slackでコミュニティに参加してください
- Stack Overflowで質問したり、回答したりしてください
- あなたのKubernetesに関するストーリーを共有してください
- Kubernetesの最新情報はブログでさらに詳しく読むことができます
- リリースチームについての詳細はKubernetes Release Teamをご覧ください
よくあるKubernetesの7つの落とし穴(そして私がそれらを回避する方法をいかに学んだか)
Kubernetesが強力でありながら時にイライラさせられることは周知の事実です。 私がコンテナオーケストレーションに初めて手を出したとき、落とし穴のリスト全体をまとめるのに十分なほど多くの失敗をしました。 この投稿では、私が遭遇した(または他の人が遭遇するのを見た)7つの大きな落とし穴を順に説明し、それらを回避する方法についてのヒントを共有したいと思います。 Kubernetesを試し始めたばかりの方でも、すでに本番クラスターを管理している方でも、これらの洞察が余計なストレスを回避するのに役立つことを願っています。
1. リソースrequestsとlimitsの設定を怠る
落とし穴: Pod仕様でCPUとメモリの要件を指定しないこと。 これは通常、Kubernetesがこれらのフィールドを必須としておらず、ワークロードはこれらなしでも起動して実行できる場合が多いために発生します。 そのため、設定の初期段階や迅速なデプロイサイクルの最中に見過ごされがちです。
背景: Kubernetesでは、リソースのrequestsとlimitsは効率的なクラスター管理に不可欠です。 リソースのrequestsは、スケジューラーが各Podに適切な量のCPUとメモリを確保し、動作に必要なリソースを保証します。 リソースlimitsは、Podが使用できるCPUとメモリの量に上限を設け、単一のPodが過剰なリソースを消費して他のPodを枯渇状態にすることを防ぎます。 リソースrequestsとlimitsが設定されていない場合:
- リソース不足: Podが不十分なリソースしか得られず、パフォーマンスの低下や障害につながる可能性があります。 これは、Kubernetesがrequestsの値に基づきPodをスケジュールするためです。 requestsがないと、スケジューラーは単一のノードに過剰数のPodを配置する可能性があり、リソースの競合やパフォーマンスのボトルネックにつながります。
- リソースの占有: 逆に、limitsがないと、あるPodが公平な配分以上のリソースを消費し、同じノード上の他のPodのパフォーマンスと安定性に影響を与える可能性があります。 これにより、利用可能なメモリ不足のために他のPodが退避されたり、Out-Of-Memory(OOM)キラーによって強制終了されたりする問題が発生する可能性があります。
回避方法:
- 控えめな
requests(例えば100mCPU、128Miメモリ)から始めて、アプリの動作を確認します。 - 実際の使用状況を監視して値を調整します。HorizontalPodAutoscalerは、メトリクスに基づいてスケーリングを自動化するのに役立ちます。
kubectl top podsやログ/監視ツールを注視して、過剰または過小なプロビジョニングになっていないことを確認します。
私の実体験: 初期の頃、私はメモリ制限について考えたことがありませんでした。 ローカルクラスターでは問題なく見えました。 しかし、より大規模な環境では、Podが次々とOOMKilledされました。 教訓を得ました。 コンテナのリソースrequestsとlimitsを設定する詳細な手順については、コンテナおよびPodへのメモリリソースの割り当て(公式Kubernetesドキュメントの一部)を参照してください。
2. liveness probeとreadiness probeを軽視する
落とし穴: Kubernetesがコンテナの健全性や準備状態をチェックする方法を明示的に定義せずにコンテナをデプロイすること。 これは、Kubernetesが内部のプロセスが終了していない限りコンテナを「実行中」と見なすために起こりがちです。 追加のシグナルがないと、Kubernetesは、たとえ内部のアプリケーションが応答しない、初期化中、またはスタックしていても、ワークロードが機能していると想定してしまいます。
背景: liveness、readiness、startup probeは、Kubernetesがコンテナの健全性と可用性を監視するために使用するメカニズムです。
- Liveness probeは、アプリケーションがまだ生きているかどうかを判断します。 livenessチェックが失敗すると、コンテナは再起動されます。
- Readiness probeは、コンテナがトラフィックを処理する準備ができているかどうかを制御します。 readiness probeが合格するまで、コンテナはServiceエンドポイントから除外されます。
- Startup probeは、長い起動時間と実際の障害を区別するのに役立ちます。
回避方法:
- ヘルスエンドポイント(例えば
/healthz)をチェックするためのシンプルなHTTPlivenessProbeを追加して、Kubernetesがハングしたコンテナを再起動できるようにします。 readinessProbeを使用して、アプリがウォームアップされるまでトラフィックがアプリに到達しないようにします。- probeはシンプルに保ちます。 過度に複雑なチェックは、誤検知や不要な再起動を引き起こす可能性があります。
私の実体験: かつて、ロードに時間がかかるWebサービスのreadiness probeを忘れたことがあります。 ユーザーが早すぎるタイミングでアクセスして、奇妙なタイムアウトが発生し、何時間も頭を抱えました。 たった3行のreadiness probeがあれば、防げたはずでした。
コンテナのliveness、readiness、startup Probeを設定する包括的な手順については、公式KubernetesドキュメントのLiveness Probe、Readiness ProbeおよびStartup Probeを使用するを参照してください。
3. 「コンテナログを見ればいいだけ」(これが悲劇の始まり)
落とし穴: kubectl logsで取得したコンテナログのみに依存すること。
このコマンドは迅速かつ便利で、多くのセットアップにおいて、開発中や初期のトラブルシューティング中にログにアクセスできるように見えるため、これが起こりがちです。
しかし、kubectl logsは現在実行中または最近終了したコンテナからのログのみを取得し、それらのログはノードのローカルディスクに保存されます。
コンテナの削除、退避、またはノードの再起動が発生すると、すぐにログファイルはローテーションされるか、永久に失われる可能性があります。
回避方法:
- ログを集中管理するために、FluentdやFluent BitのようなCNCFツールを使用して、すべてのPodからの出力を集約します。
- OpenTelemetryを採用して、ログ、メトリクス、(必要に応じて)トレースの統合ビューを取得します。 これにより、インフラストラクチャイベントとアプリレベルの振る舞いとの相関関係を見つけることができます。
- ログとPrometheusメトリクスを連携し、アプリケーションログと並行してクラスターレベルのデータを追跡します。 分散トレーシングが必要な場合は、JaegerのようなCNCFプロジェクトを検討してください。
私の実体験: 突然の再起動によって初めてPodログを失ったとき、「kubectl logs」だけではいかに頼りないかを実感しました。 それ以来、重要な手がかりを見逃さないように、すべてのクラスターに適切なパイプラインをセットアップしています。
4. 開発環境と本番環境を完全に同じに扱う
落とし穴: 開発、ステージング、本番環境全体で同一の設定を持つ同じKubernetesマニフェストをデプロイすること。 これは、チームが一貫性と再利用性を目指すものの、環境固有の要因—トラフィックパターン、リソースの可用性、スケーリングのニーズ、またはアクセス制御など—が大きく異なりうることを見落としている場合によく起こります。 カスタマイズなしでは、ある環境向けに最適化された設定が別の環境では不安定性、パフォーマンス低下、またはセキュリティ欠陥を引き起こす可能性があります。
回避方法:
- 環境オーバーレイまたはkustomizeを使用して、共通ベースを維持しながら、各環境のリソースrequests、レプリカ、または設定をカスタマイズします。
- 環境固有の設定をConfigMapやSecretに切り出します。 機密データを管理するには、Sealed Secretsのような特化したツールを使用できます。
- 本番環境ではスケールを考慮した計画を。 開発クラスターは最小限のCPU/メモリで済むかもしれませんが、本番環境では大幅により多くのリソースが必要になる可能性があります。
私の実体験: ある時、小さな開発環境で「テスト」のためにreplicaCountを2から10にスケールアップしました。
すぐにリソース不足になり、後始末に半日を費やしました。
しまった。
5. 古いリソースを放置する
落とし穴: 未使用または古いリソース—Deployment、Service、ConfigMap、PersistentVolumeClaimなど—をクラスター内で実行したままにすること。 これは、Kubernetesが明示的に指示されない限りリソースを自動的に削除せず、所有権や有効期限を追跡する組み込みメカニズムがないためによく起こります。 時間の経過とともに、これらの忘れられたオブジェクトが蓄積し、クラスターリソースを消費し、クラウドコストを増加させます。 特に、古いServiceやLoadBalancerがトラフィックをルーティングし続けていると、運用上の混乱を引き起こす可能性があります。
回避方法:
- すべてにラベルを付ける: 目的や所有者のラベルを付けます。 そうすれば、不要になったリソースを簡単にクエリできます。
- 定期的にクラスターを監査する:
kubectl get all -n <namespace>を実行して、実際に実行されているものを確認し、すべてが正当であることを確認します。 - Kubernetesのガベージコレクションを採用する: K8sドキュメントは、依存オブジェクトを自動的に削除する方法を示しています。
- ポリシーの自動化を活用する: Kyvernoのようなツールは、一定期間後に古いリソースを自動的に削除またはブロックしたり、ライフサイクルポリシーを強制したりできます。 そのため、すべてのクリーンアップ手順をひとつひとつ覚えておく必要がありません。
私の実体験: ハッカソンの後、外部ロードバランサーに固定された「test-svc」を削除するのを忘れました。 3週間後、そのロードバランサーの料金をずっと支払っていたことに気づきました。 やってしまった。
6. ネットワークを早々に深掘りしすぎる
落とし穴: Kubernetesのネイティブなネットワークプリミティブを完全に理解する前に、高度なネットワークソリューション—サービスメッシュ、カスタムCNIプラグインやマルチクラスター通信—を導入すること。 これは、チームがコアのKubernetesネットワークの仕組み(Pod間通信、ClusterIP Service、DNS解決、基本的なIngressトラフィック処理を含む)を最初に習得せずに、外部ツールを使用してトラフィックルーティング、可観測性、mTLSなどの機能を実装する際によく発生します。 結果として、ネットワーク関連の問題のトラブルシューティングが難しくなります(特に、オーバーレイが追加の抽象化や障害点をもたらす場合)。
回避方法:
- 小さく始める: Deployment、Service、そしてNGINXをベースとするような基本的なIngressコントローラー(例: Ingress-NGINX)を使用します。
- クラスター内でのトラフィックの流れ、サービスディスカバリの仕組み、DNSの設定方法を理解していることを確認します。
- 本格的なメッシュや高度なCNI機能は、実際に必要な場合にのみ移行します。 複雑なネットワークはオーバーヘッドを増加させます。
私の実体験: かつて、小さな内部アプリでIstioを試したところ、実際のアプリよりもIstio自体のデバッグに多くの時間を費やしました。 最終的に一歩引いてIstioを削除したところ、すべてが正常に機能しました。
7. セキュリティとRBACを軽視する
落とし穴: 安全でない設定でワークロードをデプロイすること。
例えば、rootユーザーとしてコンテナを実行する、latestイメージタグを使用する、セキュリティコンテキストを無効にする、cluster-adminのような過度に広範なRBACロールを割り当てるなど。
これらの慣習が根強く残っているのは、Kubernetesが初期状態では厳格なセキュリティデフォルトを強制せず、プラットフォームが意見を押し付けるのではなく柔軟に設計されているためです。
明示的なセキュリティポリシーが設定されていない場合、クラスターはコンテナエスケープ、不正な権限昇格、あるいはバージョン固定されていないイメージによる意図しない本番環境の変更といったリスクにさらされ続ける可能性があります。
回避方法:
- RBACを使用して、Kubernetes内でロールと権限を定義します。 RBACはデフォルトであり最も広くサポートされている認可メカニズムですが、Kubernetesは代替の認可メカニズムの使用も許可しています。 より高度または外部ポリシーのニーズについては、OPA Gatekeeper(Regoベース)、Kyverno、またはCELやCedarのようなポリシー言語を使用したカスタムWebhookなどのソリューションを検討してください。
- イメージを特定のバージョンに固定しましょう(
:latestはもう使わない!)。 これにより、実際に何がデプロイされているかを把握しやすくなります。 - Podのセキュリティアドミッション(またはKyvernoのような他のソリューション)を活用して、非rootコンテナ、読み取り専用ファイルシステムなどを強制します。
私の実体験: 私は大きなセキュリティ侵害を経験したことはありませんが、教訓となる話は数多く聞いています。 対策を講じなければ、何か問題が起こるのは時間の問題です。
最後に
Kubernetesは素晴らしいですが、超能力者ではありません。 何が必要かを伝えなければ、魔法のように正しいことをしてくれるわけではありません。 これらの落とし穴を心に留めておくことで、多くの悩みの種と無駄な時間を避けられます。 失敗は起こります(信じてください、私も十分失敗しました)が、それぞれがKubernetesの仕組みをより深く学ぶチャンスです。 より深く掘り下げたい場合は、公式ドキュメントとコミュニティSlackが次のステップとして最適です。 そしてもちろん、あなた自身の失敗談や成功のヒントを自由に共有してください。 結局のところ、私たちは皆、このクラウドネイティブの冒険を一緒に歩んでいるのですから。
Happy Shipping!
Kubernetes v1.34: Of Wind & Will (O' WaW)
編集者: Agustina Barbetta, Alejandro Josue Leon Bellido, Graziano Casto, Melony Qin, Dipesh Rawat
前回のリリースと同様に、Kubernetes v1.34のリリースでは新しいGA、ベータ版、アルファ版の機能が導入されます。 高品質なリリースの継続的な提供は、私たちの開発サイクルの強さとコミュニティからの活発なサポートを示しています。
このリリースは58個の機能改善で構成されています。 それらのうち、GAへの昇格が23個、ベータへの移行が22個、アルファとしての導入が13個となっています。
また、このリリースにはいくつかの非推奨化と削除があります。 これらに必ず目を通してください。
リリースのテーマとロゴ

私たちを取り巻く風、そして私たちの内なる意志によって動かされるリリース。
訳注: このリリースでは、Kubernetesの開発を航海になぞらえています。
すべてのリリースサイクルで、私たちは実際にはコントロールできない「風」を受け継ぎます — ツールの状態、ドキュメント、そしてプロジェクトの歴史的な特性です。 時にこれらの風は私たちの帆を満たし、時に横に押し流し、時に凪いでしまいます。
Kubernetesを前進させ続けているのは完璧な風ではなく、船員たちの意志です。 彼らは帆を調整し、舵を取り、航路を定め、船を安定させます。 リリースが実現するのは条件が常に理想的だからではありません。 それを構築する人々、リリースする人々、そしてクマ^、猫、犬、魔法使い、好奇心に満ちた人々がいるからこそ実現するのです。 風がどの方向に吹いても、彼らはKubernetesを力強く前進させ続けています。
このリリース Of Wind & Will (O' WaW) は、私たちを形作ってきた風と、私たちを前進させる意志に敬意を表しています。
^ なぜクマなのか? その答えはご想像にお任せします!
主なアップデート情報
Kubernetes v1.34は新機能と改善点が満載です。 このセクションでは、リリースチームが特に注目して欲しい、選りすぐりのアップデート内容をご紹介します!
GA: DRAのコア機能
Dynamic Resource Allocation (DRA)は、GPU、TPU、NICおよびその他のデバイスを選択、割り当て、共有、設定するためのより強力な方法を提供します。
v1.30リリース以降、DRAは構造化パラメーターを使ってデバイスを要求する仕組みを採用しています。
これらのパラメーターはKubernetesのコアからは直接見えない形で処理されます。
この設計は、ストレージボリュームの動的プロビジョニングから着想を得ています。
構造化パラメーターを使用するDRAは、resource.k8s.io配下の以下のAPIに依存しています。ResourceClaim、DeviceClass、ResourceClaimTemplate、ResourceSlice。
また、Podの.specに新しいresourceClaimsフィールドを追加しています。resource.k8s.io/v1 APIはGAに昇格し、現在はデフォルトで利用可能です。
この作業はWG Device Managementが主導したKEP #4381の一環として行われました。
ベータ: kubeletイメージ認証プロバイダー向けのProjected ServiceAccountトークン
プライベートコンテナイメージを取得する際に使用されるkubeletの認証プロバイダーは、従来、ノードやクラスターに保存された長期間有効なSecretに依存していました。
この方法では、認証情報が特定のワークロードに紐付けられず、自動更新もされないため、セキュリティリスクと管理の手間が増大していました。
この問題を解決するため、kubeletがコンテナレジストリへの認証に、短期間のみ有効で特定の用途に限定されたServiceAccountトークンを要求できるようになりました。
これにより、ノード全体の認証情報ではなく、Pod固有のアイデンティティに基づいてイメージの取得を認可できます。
最大の利点はセキュリティの大幅な向上です。
イメージ取得のために長期間有効なSecretを保持する必要がなくなり、攻撃を受けるリスクが減少し、管理者と開発者の両方にとって認証情報の管理がシンプルになります。
この作業はSIG AuthとSIG Nodeが主導したKEP #4412の一環として行われました。
アルファ: KYAML(Kubernetes向けに最適化されたYAML形式)のサポート
KYAMLは、Kubernetes向けに最適化された、より安全で曖昧さの少ないYAMLのサブセットです。 Kubernetes v1.34以降、どのバージョンのKubernetesを使用していても、kubectlの新しい出力形式としてKYAMLを利用できます。
KYAMLは、YAMLとJSONそれぞれが抱える課題を解決します。 YAMLでは空白文字が重要な意味を持つため、インデントやネストに細心の注意が必要です。 また、文字列の引用符を省略できることで、予期しない型変換が発生することがあります(例: 「ノルウェー問題」)。 一方、JSONはコメントが書けず、末尾のカンマや引用符付きのキーに関して厳密なルールがあります。
KYAMLファイルはすべて有効なYAMLでもあるため、KYAMLで記述したファイルはどのバージョンのkubectlにも入力として渡せます。
v1.34のkubectlでは、環境変数KUBECTL_KYAML=trueを設定することで、KYAML形式での出力もリクエストできます(例: kubectl get -o kyaml ...)。
もちろん、従来通りJSONやYAML形式での出力も可能です。
この作業はSIG CLIが主導したKEP #5295の一環として行われました。
GAに昇格した機能
これはv1.34リリース後にGAとなった改善点の一部です。
Jobの代替Podの遅延作成
デフォルトでは、JobコントローラーはPodが終了処理を始めた時点で、すぐに代替となる新しいPodを作成します。
その結果、終了中の古いPodとまだ新しいPodが同時に存在し、両方がリソースを使用する状態になります。
リソースが限られたクラスターでは、古いPodが完全に終了してリソースを解放するまで、新しいPodが起動できずに待機状態となり、リソースの競合が発生します。
また、この状況により、クラスターオートスケーラーが不必要にノードを追加してしまうこともあります。
さらに、TensorFlowやJAXなどの機械学習フレームワークは、同じインデックスのPodが複数同時に動作することを許可しないため、この同時実行が問題となります。
この機能により、Jobに.spec.podReplacementPolicyが導入されます。
Podが完全に終了した後(.status.phase: Failedとなった後)にのみ代替Podを作成するよう設定できます。
これを行うには、.spec.podReplacementPolicy: Failedを設定します。
v1.28でアルファとして導入されたこの機能は、v1.34でGAに昇格しました。
この作業はSIG Appsが主導したKEP #3939の一環として行われました。
ボリューム拡張失敗からの復旧
この機能により、ストレージプロバイダーがサポートしていないサイズへのボリューム拡張が失敗した場合に、その拡張操作をキャンセルし、サポート範囲内のより小さなサイズで再度拡張を試みることができます。
v1.23でアルファとして導入されたこの機能は、v1.34でGAに昇格しました。
この作業はSIG Storageが主導したKEP #1790の一環として行われました。
ボリューム変更のためのVolumeAttributesClass
VolumeAttributesClassがv1.34でGAに昇格しました。
VolumeAttributesClassは、プロビジョニングされたIOなどのボリュームパラメーターを変更するための、汎用的なKubernetesネイティブなAPIです。
プロバイダーがサポートしている場合、ワークロードがコストとパフォーマンスのバランスを取りながら、稼働中にボリュームを垂直スケーリングできるようになります。
Kubernetesの他のすべての新しいボリューム機能と同様に、このAPIはContainer Storage Interface (CSI)を介して実装されています。
この機能を使用するには、お使いのプロビジョナー固有のCSIドライバーが、この機能のCSI側の実装である新しいModifyVolume APIをサポートしている必要があります。
この作業はSIG Storageが主導したKEP #3751の一環として行われました。
構造化された認証設定
Kubernetes v1.29では、APIサーバーのクライアント認証を管理する新しい方法が導入されました。 これまで多数のコマンドラインオプションで設定していた認証を、構造化された設定ファイルで管理できるようになりました。 AuthenticationConfigurationという新しいリソースにより、管理者は複数のJWT認証機構の設定、CEL式を使った柔軟な検証ルールの定義、そしてサーバーを再起動することなく設定を動的に再読み込みすることが可能になります。 この変更により、クラスターの認証設定がより管理しやすく、監査しやすくなりました。 この機能はv1.34でGAに昇格しています。
この作業はSIG Authが主導したKEP #3331の一環として行われました。
セレクターに基づく細かい認可
Kubernetesの認可機構(Webhook認可や組み込みのノード認可を含む)が、リクエストに含まれるフィールドセレクターやラベルセレクターの内容まで考慮して、より細かい認可判断を行えるようになりました。 list、watch、deletecollection といった一覧取得や削除のリクエストにセレクターが含まれている場合、認可レイヤーはその条件も含めてアクセス権限を評価します。
例えば、「特定のノード(.spec.nodeName)に割り当てられたPodのみを一覧表示できる」という認可ポリシーを作成できます。
この場合、クライアント(例: 特定ノード上のkubelet)は必要なフィールドセレクターを明示的に指定する必要があり、指定がない場合はリクエストが拒否されます。
この機能により、クライアントが制限事項を理解し適切にリクエストを送信できる環境であれば、最小権限の原則に基づいた厳密なアクセス制御が実現できます。
Kubernetes v1.34では、ノードごとのリソース分離やカスタムマルチテナント構成など、きめ細かい制御が必要な環境での運用がより安全になりました。
この作業はSIG Authが主導したKEP #4601の一環として行われました。
細かい制御による匿名リクエストの制限
匿名アクセスを完全に有効または無効にする代わりに、認証されていないリクエストを許可する特定のエンドポイントのリストを厳密に設定できるようになりました。
これにより、/healthz、/readyz、/livezなどのヘルスチェックやブートストラップ用エンドポイントへの匿名アクセスに依存するクラスターに対して、より安全な代替手段を提供します。
この機能により、匿名ユーザーに広範なアクセス権を誤って付与してしまうRBACの設定ミスを防ぐことができ、外部のプローブツールやブートストラップツールへの変更も不要です。
この作業はSIG Authが主導したKEP #4633の一環として行われました。
プラグイン固有のコールバックによる効率的な再キューイング
kube-schedulerが、以前スケジュールできなかったPodをいつ再試行すべきかについて、より正確な判断を下せるようになりました。
各スケジューリングプラグインが独自のコールバック関数を登録できるようになり、クラスターで発生したイベントが、以前拒否されたPodをスケジュール可能にする可能性があるかどうかをスケジューラーに通知します。
これにより、不要な再試行が削減され、スケジューリング全体のスループットが向上します。 特に動的リソース割り当て(DRA)を使用するクラスターで効果的です。 また、特定のプラグインが安全と判断した場合には、通常のバックオフ遅延をスキップできるようになり、特定のケースでスケジューリングがより高速化されます。
この作業はSIG Schedulingが主導したKEP #4247の一環として行われました。
順序付けられたNamespace削除
ランダムに近いリソース削除順序は、セキュリティギャップや意図しない動作を引き起こす可能性があります。
例えば、NetworkPolicyが削除された後もPodが残り続けるといった問題です。
この改善により、Kubernetes名前空間に対して、より構造化された削除プロセスが導入され、安全で決定的なリソース削除が保証されます。
論理的な依存関係やセキュリティの依存関係を尊重する削除順序を強制することで、Podが他のリソースよりも先に削除されることが保証されます。
この機能はKubernetes v1.33で導入され、v1.34でGAに昇格しました。
この昇格により、CVE-2024-7598で説明されている脆弱性を含む、非決定的な削除によるリスクを軽減し、セキュリティと信頼性が向上します。
この作業はSIG API Machineryが主導したKEP #5080の一環として行われました。
list 応答のストリーミング
Kubernetesで大規模なlist応答を処理することは、これまで大きなスケーラビリティの課題でした。
クライアントが数千のPodやカスタムリソースなどの大規模なリソースリストを要求した場合、APIサーバーは送信前にオブジェクトのコレクション全体を単一の大きなメモリバッファにシリアライズする必要がありました。
このプロセスは大量のメモリ負荷を生み出し、パフォーマンスの低下を引き起こし、クラスター全体の安定性に影響を与える可能性がありました。
この制限に対処するため、コレクション( list 応答)のストリーミングエンコーディングメカニズムが導入されました。
JSONおよびKubernetes Protobuf応答形式では、このストリーミングメカニズムが自動的に有効になり、関連するフィーチャーゲートはGAとなっています。
この方法の主な利点は、APIサーバーでの大規模なメモリ割り当てを回避し、メモリフットプリントをより小さく予測可能にすることです。
その結果、特に大規模なリソースリストの頻繁なリクエストが一般的な大規模環境において、クラスターの回復力とパフォーマンスが向上します。
この作業はSIG API Machineryが主導したKEP #5116の一環として行われました。
回復力のあるWatchキャッシュの初期化
Watchキャッシュは、etcdに保存されているクラスター状態の結果整合性を保つキャッシュレイヤーで、kube-apiserver内部で動作します。
これまで、kube-apiserverの起動時にWatchキャッシュがまだ初期化されていない場合や、Watchキャッシュの再初期化が必要な場合に問題が発生することがありました。
これらの問題に対処するため、Watchキャッシュの初期化プロセスが障害に対してより回復力のあるものに改善され、コントロールプレーンの堅牢性が向上し、コントローラーやクライアントが確実にWatchを確立できるようになりました。この改善はv1.31でベータとして導入され、現在はGAとなっています。
この作業はSIG API MachineryとSIG Scalabilityが主導したKEP #4568の一環として行われました。
DNS検索パス検証の緩和
これまで、PodのDNS searchパスに対する厳格な検証は、複雑なネットワーク環境やレガシーネットワーク環境での統合において問題が発生することがよくありました。
この制限により、組織のインフラストラクチャに必要な設定がブロックされ、管理者は困難な回避策の実装を強いられていました。
この問題に対処するため、緩和されたDNS検証がv1.32でアルファとして導入され、v1.34でGAに昇格しました。
一般的なユースケースとして、Podが内部のKubernetesサービスと外部ドメインの両方と通信する必要がある場合があります。
Podの.spec.dnsConfigのsearchesリストの最初のエントリに単一のドット(.)を設定することで、システムのリゾルバーがクラスターの内部検索ドメインを外部クエリに追加することを防げます。
これにより、外部ホスト名に対する不要な内部DNSサーバーへのDNSリクエストの生成を回避し、効率を向上させ、潜在的な名前解決エラーを防ぎます。
この作業はSIG Networkが主導したKEP #4427の一環として行われました。
Windows kube-proxyにおけるDirect Service Return(DSR)のサポート
DSRは、ロードバランサーを経由したリターントラフィックがロードバランサーをバイパスしてクライアントに直接応答できるようにすることで、パフォーマンスを最適化します。
これにより、ロードバランサーの負荷が軽減され、全体的なレイテンシーが改善されます。
Windows上のDSRの詳細については、Direct Server Return (DSR) in a nutshellをご覧ください。
v1.14で最初に導入されたこの機能は、v1.34でGAに昇格しました。
この作業はSIG Windowsが主導したKEP #5100の一環として行われました。
コンテナライフサイクルフックのSleepアクション
コンテナのPreStopおよびPostStartライフサイクルフックにSleepアクションが導入され、安全な終了の管理とコンテナライフサイクル管理全体を改善する簡単な方法が提供されました。
Sleepアクションにより、コンテナは起動後または終了前に指定された時間だけ一時停止できます。
負の値またはゼロのスリープ時間を使用すると、すぐに戻り、結果的に何も実行しない(no-op)動作となります。
Sleepアクションは、Kubernetes v1.29で導入され、v1.32でゼロ値のサポートが追加されました。
両方の機能がv1.34でGAに昇格しました。
この作業はSIG Nodeが主導したKEP #3960およびKEP #4818の一環として行われました。
Linuxノードでのスワップ機能のサポート
これまで、Kubernetesでスワップ機能サポートがなかったため、メモリ不足に陥ったノードではプロセスを突然終了させざるを得ず、ワークロードが不安定になることがよくありました。 この問題は特に、大容量だがアクセス頻度の低いメモリフットプリントを持つアプリケーションに影響し、より柔軟なリソース管理を妨げていました。
この問題に対処するため、ノードごとに設定可能なスワップ機能のサポートがv1.22で導入されました。
アルファ版とベータ版の段階を経て、v1.34でGAに昇格しました。
主要なモードであるLimitedSwapでは、Podが既存のメモリ制限内でスワップを使用でき、問題に対する直接的な解決策を提供します。
デフォルトでは、kubeletはNoSwapモードで設定されており、Kubernetesワークロードはスワップを使用できません。
この機能により、ワークロードの安定性が向上し、リソース使用率がより効率的になります。 リソースに制約のある環境で、より多様なアプリケーションをサポートできるようになりますが、管理者はスワップ使用による潜在的なパフォーマンスへの影響を考慮する必要があります。
この作業はSIG Nodeが主導したKEP #2400の一環として行われました。
環境変数での特殊文字の許可
Kubernetesの環境変数検証ルールが緩和され、=を除くほぼすべての印字可能なASCII文字を変数名で使用できるようになりました。
この変更により、非標準的な文字を変数名に必要とするワークロードのシナリオをサポートします。
例えば、.NET Coreのようなフレームワークでは、ネストされた設定キーを表すために:を使用します。
緩和された検証は、Pod仕様で直接定義された環境変数だけでなく、ConfigMapやSecretへのenvFrom参照を使用して注入された環境変数にも適用されます。
この作業はSIG Nodeが主導したKEP #4369の一環として行われました。
Taint管理のNodeライフサイクルからの分離
これまで、TaintManagerがノードの状態(NotReady、Unreachableなど)に基づいてNoScheduleやNoExecute taintを適用するロジックは、ノードのライフサイクルコントローラーと密接に結合していました。
この密結合により、コードの保守性とテストが困難になり、taintベースの退避メカニズムの柔軟性も制限されていました。
このKEPでは、TaintManagerをKubernetesコントローラーマネージャー内の独立したコントローラーとしてリファクタリングします。
これはコードのモジュール性と保守性を向上させるための内部的なアーキテクチャの改善です。
この変更により、taintベースの退避ロジックを独立してテストし、発展させることができるようになりますが、taintの使用方法に対するユーザー向けの直接的な影響はありません。
この作業はSIG SchedulingとSIG Nodeが主導したKEP #3902の一環として行われました。
ベータの新機能
これはv1.34のリリース後にベータとなった改善点の一部です。
Podレベルのリソース要求と制限
複数のコンテナを持つPodのリソース要求を定義することは、これまで困難でした。 要求と制限はコンテナごとにしか設定できなかったため、開発者は各コンテナに過剰なリソースを割り当てるか、必要なリソース総量を細かく分割する必要がありました。 これにより設定が複雑になり、非効率的なリソース割り当てにつながることがよくありました。 この問題を簡素化するため、Podレベルでリソース要求と制限を指定できる機能が導入されました。 これにより、開発者はPod全体のリソース予算を定義し、それを構成するコンテナ間で共有できます。 この機能はv1.32でアルファとして導入され、v1.34でベータに昇格し、HPAもPodレベルのリソース指定をサポートするようになりました。 主な利点は、マルチコンテナPodのリソース管理がより直感的で簡単になることです。 すべてのコンテナが使用するリソースの合計がPodの定義された制限を超えないことが保証されます。 これにより、リソース計画の改善、より正確なスケジューリング、そしてクラスターリソースの効率的な利用が実現されます。
この作業はSIG SchedulingとSIG Autoscalingが主導したKEP #2837の一環として行われました。
kubectl向けユーザー設定のための.kubercファイル
.kuberc設定ファイルにより、デフォルトオプションやコマンドエイリアスなど、kubectlの設定を定義できます。
kubeconfigファイルとは異なり、.kuberc設定ファイルにはクラスターの詳細、ユーザー名、パスワードは含まれません。
この機能はアルファとしてv1.33で導入され、環境変数KUBECTL_KUBERCで有効にすることで利用できます。
v1.34でベータに昇格し、デフォルトで有効になっています。
この作業はSIG CLIが主導したKEP #3104の一環として行われました。
外部ServiceAccountのトークン署名
これまで、KubernetesはServiceAccountトークンを、kube-apiserverの起動時にディスクから読み込まれる静的な署名鍵を使用して管理していました。
この機能では、プロセス外署名のためのExternalJWTSigner gRPCサービスが導入されます。
これにより、Kubernetesディストリビューションは、静的なディスクベースの鍵の代わりに外部鍵管理ソリューション(HSM、クラウドKMSなど)を使用してServiceAccountトークンの署名を行えるようになります。
v1.32でアルファとして導入されたこの外部JWTの署名機能は、v1.34でベータに進み、デフォルトで有効になっています。
この作業はSIG Authが主導したKEP #740の一環として行われました。
ベータ版のDRA機能
セキュアなリソースモニタリングのための管理者アクセス
DRAは、ResourceClaimまたはResourceClaimTemplateのadminAccessフィールドを通じて、制御された管理者アクセスをサポートします。
これにより、クラスター運用者は他のユーザーが使用中のデバイスにモニタリングや診断のためにアクセスできます。
この特権モードは、resource.k8s.io/admin-access: "true"でラベル付けされた名前空間でそのようなオブジェクトを作成する権限を持つユーザーに限定されます。
これにより、通常のワークロードは影響を受けません。
v1.34でベータに昇格したこの機能は、名前空間ベースの認可チェックを通じてワークロードの分離を保ちながら、セキュアな内部監視機能を提供します。
この作業はWG Device ManagementとSIG Authが主導したKEP #5018の一環として行われました。
ResourceClaimとResourceClaimTemplateにおける優先順位付きの代替案
ワークロードは単一の高性能GPUで最適に動作するかもしれませんが、2つの中級GPUでも動作可能な場合があります。
フィーチャーゲートのDRAPrioritizedList(現在はデフォルトで有効)により、ResourceClaimとResourceClaimTemplateに新しいfirstAvailableフィールドが追加されます。
このフィールドは順序付きリストで、リクエストが様々な方法で満たされる可能性があることを指定できます。
特定のハードウェアが利用できない場合は何も割り当てないという選択も含まれます。
スケジューラーはリスト内の代替案を順番に満たそうとするため、ワークロードにはクラスターで利用可能な最適なデバイスセットが割り当てられます。
この作業はWG Device Managementが主導したKEP #4816の一環として行われました。
kubeletによる割り当て済みDRAリソースの報告
kubeletのAPIが更新され、DRAを通じて割り当てられたPodリソースを報告できるようになりました。
これにより、ノードのモニタリングエージェントは、各ノードでPodに割り当てられているDRAリソースを検出できます。
さらに、ノードコンポーネントはPodResourcesAPIを使用してこのDRA情報を活用し、新しい機能や統合を開発できるようになります。
Kubernetes v1.34以降、この機能はデフォルトで有効になっています。
この作業はWG Device Managementが主導したKEP #3695の一環として行われました。
kube-schedulerの非ブロッキングAPIコール
kube-schedulerはスケジューリングサイクル中にブロッキングAPIコールを行い、パフォーマンスのボトルネックを生み出していました。
この機能では、リクエスト重複排除を備えた優先度付きキューシステムを通じた非同期API処理が導入されます。
これにより、スケジューラーはバックグラウンドでAPI操作が完了する間も、Podの処理を継続できます。
主な利点として、スケジューリングレイテンシーの削減、API遅延時のスケジューラースレッドの枯渇防止、スケジュール不可能なPodの即座の再試行機能があります。
この実装は後方互換性を維持し、保留中のAPI操作を監視するためのメトリクスも追加されます。
この作業はSIG Schedulingが主導したKEP #5229の一環として行われました。
Mutating Admission Policy
MutatingAdmissionPolicyは、Mutating Admission Webhookに対する宣言的でプロセス内の代替手段を提供します。
この機能はCELのオブジェクトインスタンス化とJSONのパッチ戦略を、Server-Side Applyのマージアルゴリズムと組み合わせて活用します。
これにより、管理者がAPIサーバー内で直接Mutationルールを定義できるようになり、アドミッション制御が大幅に簡素化されます。
v1.32でアルファとして導入されたMutating Admission Policyは、v1.34でベータに昇格しました。
この作業はSIG API Machineryが主導したKEP #3962の一環として行われました。
スナップショット可能なAPIサーバーのキャッシュ
kube-apiserverのキャッシュメカニズム(Watchキャッシュ)は、最新の観測状態に対するリクエストを効率的に処理します。
しかし、以前の状態に対する list リクエスト(ページネーションやresourceVersionの指定など)は、多くの場合このキャッシュをバイパスし、etcdから直接提供されます。
このetcdへの直接アクセスは、パフォーマンスコストを大幅に増加させ、特に大規模なリソースでは大量のデータ転送によるメモリ圧迫から安定性の問題を引き起こす可能性があります。ListFromCacheSnapshotフィーチャーゲートがデフォルトで有効になることで、kube-apiserverは要求されたresourceVersionより古いスナップショットが利用可能な場合、そこから応答を提供しようとします。
kube-apiserverは最初スナップショットがない状態で開始し、watchイベントごとに新しいスナップショットを作成します。
etcdがコンパクションされたことを検出するか、75秒より古いイベントでキャッシュがいっぱいになるまで、スナップショットを保持します。
指定されたresourceVersionが利用できない場合、サーバーはetcdにフォールバックします。
この作業はSIG API Machineryが主導したKEP #4988の一環として行われました。
Kubernetesネイティブ型の宣言的検証のためのツール
このリリース以前は、Kubernetesに組み込まれたAPIの検証ルールはすべて手作業で書かれており、メンテナーにとって発見、理解、改善、テストが困難でした。
APIに適用される可能性のあるすべての検証ルールを見つける統一的な方法も存在しませんでした。
宣言的検証 により、API開発、保守、レビューが容易になり、より良いツールとドキュメンテーションのためのプログラム的な検査も可能になります。
Kubernetesライブラリを使用して独自のコード(コントローラーなど)を書く開発者にとっても、複雑な検証関数ではなくIDLタグを通じて新しいフィールドを追加できるため、作業が簡素化されます。
この変更は検証用のボイラープレート(定型コード)を自動化してAPI作成を高速化し、バージョン管理された型で検証を実行することでより関連性の高いエラーメッセージを提供します。
この機能強化(v1.33でベータに昇格し、v1.34でもベータとして継続)は、ネイティブKubernetes型にCELベースの検証ルールをもたらし、型定義に直接、より細かく宣言的な検証を定義できるようにします。
これによりAPIの一貫性と開発者体験が向上します。
この作業はSIG API Machineryが主導したKEP #5073の一環として行われました。
list リクエスト用のストリーミングインフォーマー
v1.32以降ベータとなっているストリーミングインフォーマー機能は、v1.34でさらなるベータの改善をしました。 この機能により、list リクエストはetcdから直接ページ化された結果を組み立てるのではなく、APIサーバーのWatchキャッシュから継続的なオブジェクトのストリームとしてデータを返すことができます。 Watch操作に使用されるのと同じメカニズムを再利用することで、APIサーバーは安定したメモリ使用量を保ちながら大規模なデータセットを提供でき、安定性に影響を与える割り当てのスパイクを回避できます。
このリリースでは、kube-apiserverとkube-controller-managerの両方がデフォルトで新しいWatchListメカニズムを活用します。
kube-apiserverではlistリクエストがより効率的にストリーミングされ、kube-controller-managerはインフォーマーを扱うためのよりメモリ効率的で予測可能な方法の恩恵を受けます。
これらの改善により、大規模なlist操作中のメモリ圧迫が削減され、持続的な負荷下での信頼性が向上し、listストリーミングがより予測可能で効率的になります。
この作業はSIG API MachineryとSIG Scalabilityが主導したKEP #3157の一環として行われました。
Windowsノードの安全な終了
Windowsノード上のkubeletがシステムのシャットダウンイベントを検出し、実行中のPodの安全な終了を開始できるようになりました。
これはLinux上の既存の動作を反映しており、計画的なシャットダウンや再起動時にワークロードがクリーンに終了することを保証します。
システムがシャットダウンを開始すると、kubeletは標準的な終了ロジックを使用して反応します。
設定されたライフサイクルフックと猶予期間を尊重し、ノードが電源オフになる前にPodに停止する時間を与えます。
この機能はWindowsのプレシャットダウン通知に依存してこのプロセスを調整します。
この機能強化により、メンテナンス、再起動、またはシステムアップデート時のワークロードの信頼性が向上します。
現在ベータ版で、デフォルトで有効になっています。
この作業はSIG Windowsが主導したKEP #4802の一環として行われました。
インプレースなPodのリサイズ機能の改善
v1.33でベータに昇格しデフォルトで有効になったインプレースなPodのリサイズ機能は、v1.34でさらなる改善を受けています。 これには、メモリ使用量の削減のサポートとPodレベルリソースとの統合が含まれます。
この機能はv1.34でもベータのまま維持されています。 詳細な使用方法と例については、ドキュメントコンテナに割り当てられたCPUとメモリリソースのリサイズをご参照ください。
この作業はSIG NodeとSIG Autoscalingが主導したKEP #1287の一環として行われました。
アルファの新機能
これはv1.34リリース後にアルファとなった改善点の一部です。
mTLS認証のためのPodの証明書
クラスター内のワークロードの認証、特にAPIサーバーとの通信では、主にServiceAccountトークンに依存してきました。
効果的ではあるものの、これらのトークンは相互TLS(mTLS)のための強力で検証可能なアイデンティティを確立するには必ずしも理想的ではなく、証明書ベースの認証を期待する外部システムとの統合時に課題が生じることがあります。
Kubernetes v1.34では、PodCertificateRequestを介してPodがX.509証明書を取得するための組み込みメカニズムが導入されます。
kubeletはPod用の証明書を要求・管理でき、これらの証明書はmTLSを使用してKubernetes APIサーバーや他のサービスへの認証に使用できます。
主な利点は、Podのためのより堅牢で柔軟なアイデンティティメカニズムです。
Bearerトークンのみに依存することなく、強力なmTLS認証を実装するネイティブな方法を提供し、Kubernetesを標準的なセキュリティプラクティスに合わせ、証明書対応の可観測性やセキュリティツールとの統合を簡素化します。
この作業はSIG Authが主導したKEP #4317の一環として行われました。
「制限」Podのセキュリティ標準によるRemote Probeの禁止
Probeおよびライフサイクルハンドラー内のhostフィールドにより、ユーザーはkubeletがProbeする対象としてpodIP以外のエンティティを指定できます。
しかし、これは悪用や、セキュリティ制御をバイパスする攻撃の経路を開きます。
hostフィールドには、セキュリティ上重要な外部ホストやノード上のlocalhostを含む、任意の値を設定できるためです。
Kubernetes v1.34では、Podが制限Podのセキュリティ標準を満たすのは、hostフィールドを未設定のままにするか、このタイプのProbeを使用しない場合のみとなります。
この標準を強制するには、Podセキュリティアドミッション またはサードパーティソリューションを使用できます。
これらはセキュリティ制御であるため、選択した強制メカニズムの制限と動作を理解するためにドキュメントを確認してください。
この作業はSIG Authが主導したKEP #4940の一環として行われました。
Pod配置を表現するための.status.nominatedNodeNameの使用
kube-schedulerがPodをNodeにバインドするのに時間がかかる場合、クラスターオートスケーラーはPodが特定のNodeにバインドされることを理解できない場合があります。
その結果、Nodeを使用率が低いと誤判断し、削除してしまう可能性があります。
この問題に対処するため、kube-schedulerは.status.nominatedNodeNameを使用して、進行中のプリエンプションを示すだけでなく、Podの配置意図も表現できるようになります。
NominatedNodeNameForExpectationフィーチャーゲートを有効にすることで、スケジューラーはこのフィールドを使用してPodがどこにバインドされるかを示します。
これにより内部的な予約が公開され、外部コンポーネントが情報に基づいた判断を下せるようになります。
この作業はSIG Schedulingが主導したKEP #5278の一環として行われました。
アルファ版のDRA機能
DRAのリソースヘルス状態
Podが故障した、または一時的に異常なデバイスを使用している場合、それを把握することは困難です。
これによりPodのクラッシュのトラブルシューティングが難しく、時には不可能になります。
DRAのリソースヘルス状態機能は、Podに割り当てられたデバイスのヘルス状態をPodのステータスに公開することで、可観測性を向上させます。
これにより、異常なデバイスに関連するPodの問題の原因を特定しやすくなり、適切に対応できるようになります。
この機能を有効にするには、ResourceHealthStatusフィーチャーゲートを有効にし、DRAドライバーがDRAResourceHealth gRPCサービスを実装している必要があります。
この作業はWG Device Managementが主導したKEP #4680の一環として行われました。
拡張リソースマッピング
拡張リソースマッピングは、リソースの容量と消費量を記述するための簡単な方法を提供することで、DRAの表現力豊かで柔軟なアプローチよりもシンプルな代替手段となります。
これにより、クラスター管理者はDRAで管理しているリソースを拡張リソースとして公開でき、アプリケーション開発者や運用者は新しいDRA APIを学ぶことなく、従来通りコンテナの.spec.resourcesフィールドでこれらのリソースを要求できます。
この機能の最大の利点は、既存のワークロードを変更せずにDRAの恩恵を受けられることです。
アプリケーション開発者とクラスター管理者の両方にとって、DRAへの移行が大幅に簡単になります。
この作業はWG Device Managementが主導したKEP #5004の一環として行われました。
DRAの消費可能な容量
Kubernetes v1.33では、リソースドライバーがデバイス全体を一つの単位として扱うのではなく、利用可能なデバイスの一部分(スライス)を公開できるようになりました。
しかし、このアプローチでは、デバイスドライバーがユーザーの要求に基づいてデバイスリソースを細かく動的に分割する場合や、ResourceClaimの仕様と名前空間の制限を超えてリソースを共有する場合に対応できませんでした。DRAConsumableCapacityフィーチャーゲートを有効にすることで(v1.34でアルファとして導入)、リソースドライバーは同じデバイスやデバイスの一部を、複数のResourceClaimまたは複数のDeviceRequest間で共有できるようになります。
この機能はまた、capacityフィールドで定義されたデバイスリソースの一部を割り当てることをサポートするようスケジューラーを拡張します。
このDRA機能により、名前空間やクレーム間でのデバイス共有が改善され、Podのニーズに合わせた調整が可能になります。
ドライバーが容量制限を強制でき、スケジューリングが強化され、帯域幅を考慮したネットワーキングやマルチテナント共有などの新しいユースケースをサポートします。
この作業はWG Device Managementが主導したKEP #5075の一環として行われました。
デバイスのバインド条件
Kubernetesスケジューラーは、必要な外部リソース(アタッチ可能なデバイスやFPGAなど)が準備完了であることを確認するまで、PodのNodeへのバインディングを遅延させることで、より信頼性が向上します。
この遅延メカニズムは、スケジューリングフレームワークのPreBindフェーズで実装されます。
このフェーズ中に、スケジューラーは必要なすべてのデバイス条件が満たされているかを確認してから、バインディングを続行します。
これにより外部デバイスコントローラーとの調整が可能になり、より堅牢で予測可能なスケジューリングが実現します。
この作業はWG Device Managementが主導したKEP #5007の一環として行われました。
コンテナ再起動ルール
現在、Pod内のすべてのコンテナは、終了またはクラッシュ時に同じ.spec.restartPolicyに従います。
しかし、複数のコンテナを実行するPodでは、各コンテナに異なる再起動要件が必要な場合があります。
例えば、初期化を実行するために使用されるInitコンテナでは、失敗時に初期化を再試行したくない場合があります。
同様に長時間実行される訓練ワークロードを扱うML研究の環境では、再試行可能な終了コードで失敗したコンテナは、Pod全体を再作成して進行状況を失うのではなく、その場で素早く再起動すべきです。
Kubernetes v1.34ではContainerRestartRulesフィーチャーゲートを導入します。
有効にすると、Pod内の各コンテナに対してrestartPolicyを指定できます。
また、最後の終了コードに基づいてrestartPolicyを上書きするrestartPolicyRulesリストも定義できます。
これにより、複雑なシナリオに対処するために必要な細かい制御と、計算リソースのより良い利用が可能になります。
この作業はSIG Nodeが主導したKEP #5307の一環として行われました。
実行時に作成されたファイルからの環境変数の読み込み
アプリケーション開発者は長い間、環境変数宣言のより柔軟な方法を求めてきました。 これまで、環境変数は静的な値、ConfigMapまたはSecretを介してAPIサーバー側で宣言されていました。
EnvFilesフィーチャーゲートによって、Kubernetes v1.34では実行時に環境変数を宣言する機能を導入します。
あるコンテナ(通常はInitコンテナ)が変数を生成してファイルに保存し、後続のコンテナがそのファイルから環境変数を読み込んで起動できます。
このアプローチにより、対象コンテナのエントリポイントを「ラップ」する(起動コマンドを変更する)必要がなくなり、Pod内でのより柔軟なコンテナオーケストレーションが可能になります。
この機能は特にAI/MLトレーニングのワークロードに有益です。 訓練Job内の各Podが実行時に定義される値で初期化される必要がある場合に役立ちます。
この作業はSIG Nodeが主導したKEP #3721の一環として行われました。
v1.34での昇格、非推奨化、および削除
GAへの昇格
これは安定版(一般提供、GAとも呼ばれる)に昇格したすべての機能を一覧にしたものです。 アルファからベータへの昇格や新機能を含む更新の完全なリストについては、リリースノートをご覧ください。
このリリースには、GAに昇格した合計23の機能強化が含まれています:
- Allow almost all printable ASCII characters in environment variables
- Allow for recreation of pods once fully terminated in the job controller
- Allow zero value for Sleep Action of PreStop Hook
- API Server tracing
- AppArmor support
- Authorize with Field and Label Selectors
- Consistent Reads from Cache
- Decouple TaintManager from NodeLifecycleController
- Discover cgroup driver from CRI
- DRA: structured parameters
- Introducing Sleep Action for PreStop Hook
- Kubelet OpenTelemetry Tracing
- Kubernetes VolumeAttributesClass ModifyVolume
- Node memory swap support
- Only allow anonymous auth for configured endpoints
- Ordered namespace deletion
- Per-plugin callback functions for accurate requeueing in kube-scheduler
- Relaxed DNS search string validation
- Resilient Watchcache Initialization
- Streaming Encoding for LIST Responses
- Structured Authentication Config
- Support for Direct Service Return (DSR) and overlay networking in Windows kube-proxy
- Support recovery from volume expansion failure
非推奨化と削除
Kubernetesの開発と成熟に伴い、プロジェクト全体の健全性を向上させるために機能が非推奨化されたり、削除されたり、より良い機能に置き換えられたりすることがあります。 このプロセスに関する詳細は、Kubernetes非推奨ポリシーを参照してください。 Kubernetes v1.34にはいくつかの非推奨化が含まれています。
手動でのcgroupドライバー設定の非推奨化
これまで、正しいcgroupドライバーの設定は、Kubernetesクラスターを実行するユーザーにとって悩みの種でした。
Kubernetes v1.28では、kubeletがCRI実装に問い合わせて使用すべきcgroupドライバーを見つける方法が追加されました。
この自動検出が現在強く推奨されており、そのサポートはv1.34でGAに昇格しました。
お使いのCRIコンテナランタイムが必要なcgroupドライバーを報告する機能をサポートしていない場合は、コンテナランタイムをアップグレードまたは変更する必要があります。
kubelet設定ファイルのcgroupDriver設定は現在非推奨となっています。
対応するコマンドラインオプション--cgroup-driverは以前から非推奨となっており、Kubernetesでは設定ファイルの使用を推奨しています。
設定項目とコマンドラインオプションの両方は将来のリリースで削除される予定ですが、その削除はv1.36のマイナーリリースより前には行われません。
この作業はSIG Nodeが主導したKEP #4033の一環として行われました。
v1.36でのcontainerd 1.xサポート終了
Kubernetes v1.34はまだcontainerd 1.7やその他のLTSリリースをサポートしていますが、自動でのcgroupドライバー検出の結果として、Kubernetes SIG Nodeコミュニティはcontainerd v1.Xの最終サポートタイムラインについて正式に合意しました。
このサポートを提供する最後のKubernetesリリースはv1.35となります(containerd 1.7のEOLに合わせて)。
これは早期の警告です。
containerd 1.Xを使用している場合は、早急に2.0以降への切り替えを検討してください。
クラスター内のノードが、まもなくサポート対象外となるcontainerdバージョンを使用しているかどうかを判断するために、kubelet_cri_losing_supportメトリクスを監視できます。
この作業はSIG Nodeが主導したKEP #4033の一環として行われました。
PreferCloseトラフィック分散の非推奨化
Kubernetes Service内のspec.trafficDistributionフィールドにより、ユーザーはServiceエンドポイントへのトラフィックのルーティング方法に関する優先設定を指定できます。
KEP-3015ではPreferCloseを非推奨とし、2つの新しい値PreferSameZoneとPreferSameNodeを導入します。
PreferSameZoneは既存のPreferCloseのエイリアスで、その意味をより明確にします。
PreferSameNodeは可能な場合はローカルエンドポイントに接続を配信し、不可能な場合はリモートエンドポイントにフォールバックすることを可能にします。
この機能はPreferSameTrafficDistributionフィーチャーゲートの下でv1.33で導入されました。
v1.34でベータに昇格し、デフォルトで有効になっています。
この作業はSIG Networkが主導したKEP #3015の一環として行われました
リリースノート
Kubernetes v1.34リリースの詳細については、リリースノートをご覧ください。
入手方法
Kubernetes v1.34はGitHubまたはKubernetes公式サイトのダウンロードページからダウンロードできます。
Kubernetesを始めるには、チュートリアルをチェックするか、minikubeを使用してローカルKubernetesクラスターを実行してください。また、kubeadmを使用して簡単にv1.34をインストールすることもできます。
リリースチーム
Kubernetesは、コミュニティの支援と献身的な努力によって成り立っています。 各リリースチームは、皆さんが利用するKubernetesリリースを構成する様々な要素を協力して構築する、献身的なコミュニティボランティアで構成されています。 これを実現するには、コードそのものからドキュメント作成、プロジェクト管理に至るまで、コミュニティのあらゆる分野の専門スキルが必要です。
私たちは、技術とコミュニティ構築への情熱でKubernetesコミュニティに大きな足跡を残した献身的なコントリビューター、Rodolfo "Rodo" Martínez Vegaを追悼します。
Rodoは、v1.22-v1.23およびv1.25-v1.30を含む複数のリリースでKubernetesリリースチームのメンバーとして活動し、プロジェクトの成功と安定性に対する揺るぎない献身を示しました。
リリースチームでの活動に加え、RodoはCloud Native LATAMコミュニティの発展に深く関わり、この分野における言語と文化の壁を越える架け橋となりました。
Kubernetesドキュメントのスペイン語版やCNCF Glossaryでの活動は、世界中のスペイン語話者の開発者に知識を届けたいという彼の強い思いを体現していました。
Rodoが指導した数多くのコミュニティメンバー、彼が支えたリリース、そして彼が育んだ活気あるLATAM Kubernetesコミュニティを通じて、彼の遺産は今も生き続けています。
Kubernetes v1.34リリースをコミュニティに届けるために多くの時間を費やして取り組んでくれたリリースチーム全体に感謝します。 リリースチームには、初参加のShadow(見習い)から、複数のリリースサイクルで経験を積んだベテランのチームリードまで、様々なメンバーが参加しています。 リリースリードのVyom Yadavに心より感謝します。 彼は成功へと導くリーダーシップ、課題解決への実践的なアプローチ、そしてコミュニティを前進させる活力と思いやりを示してくれました。
プロジェクトの活動状況
CNCF K8sのDevStatsプロジェクトは、Kubernetesおよび様々なサブプロジェクトの活動状況に関する興味深いデータポイントを集計しています。 これには個人の貢献から貢献企業数まで含まれ、このエコシステムの発展に費やされる努力の深さと広さを示しています。
v1.34リリースサイクル(2025年5月19日から2025年8月27日までの15週間)において、Kubernetesには最大106の異なる企業と491人の個人から貢献がありました。 より広範なクラウドネイティブエコシステムでは、この数字は370社、合計2235人のコントリビューターに達しています。
なお、「貢献」とはコミットの作成、コードレビュー、コメント、IssueやPRの作成、PRのレビュー(ブログやドキュメントを含む)、またはIssueやPRへのコメントを行うことを指します。
貢献に興味がある場合は、コントリビューター向けWebサイトのはじめにをご覧ください。
データソース:
イベント情報
今後開催予定のKubernetesおよびクラウドネイティブイベント(KubeCon + CloudNativeCon、KCDなど)や、世界各地で開催される主要なカンファレンスについて紹介します。 Kubernetesコミュニティの最新情報を入手し、参加しましょう!
2025年8月
- KCD - Kubernetes Community Days: Colombia: 2025年8月28日 | コロンビア、ボゴタ
2025年9月
- CloudCon Sydney: 2025年9月9日-10日 | オーストラリア、シドニー
- KCD - Kubernetes Community Days: San Francisco Bay Area: 2025年9月9日 | アメリカ、サンフランシスコ
- KCD - Kubernetes Community Days: Washington DC: 2025年9月16日 | アメリカ、ワシントンD.C.
- KCD - Kubernetes Community Days: Sofia: 2025年9月18日 | ブルガリア、ソフィア
- KCD - Kubernetes Community Days: El Salvador: 2025年9月20日 | エルサルバドル、サンサルバドル
2025年10月
- KCD - Kubernetes Community Days: Warsaw: 2025年10月9日 | ポーランド、ワルシャワ
- KCD - Kubernetes Community Days: Edinburgh: 2025年10月21日 | イギリス、エディンバラ
- KCD - Kubernetes Community Days: Sri Lanka: 2025年10月26日 | スリランカ、コロンボ
2025年11月
- KCD - Kubernetes Community Days: Porto: 2025年11月3日 | ポルトガル、ポルト
- KubeCon + CloudNativeCon North America 2025: 2025年11月10日-13日 | アメリカ、アトランタ
- KCD - Kubernetes Community Days: Hangzhou: 2025年11月14日 | 中国、杭州
2025年12月
- KCD - Kubernetes Community Days: Suisse Romande: 2025年12月4日 | スイス、ジュネーブ
最新のイベント情報はこちらでご確認いただけます。
ウェビナーのご案内
Kubernetes v1.34リリースチームのメンバーと一緒に 2025年9月24日(水)午後4時(UTC) から、このリリースのハイライトやアップグレードの計画に役立つ非推奨事項や削除事項について学びましょう。 詳細および参加登録は、CNCFオンラインプログラム・サイトのイベントページをご覧ください。
参加方法
Kubernetesに関わる最も簡単な方法は、あなたの興味に合ったSpecial Interest Groups (SIGs)のいずれかに参加することです。 Kubernetesコミュニティに向けて何か発信したいことはありますか? 毎週のコミュニティミーティングや、以下のチャンネルであなたの声を共有してください。 継続的なフィードバックとサポートに感謝いたします。
- 最新情報はBlueSkyの@kubernetes.ioをフォローしてください
- Discussでコミュニティディスカッションに参加してください
- Slackでコミュニティに参加してください
- Stack Overflowで質問したり、回答したりしてください
- あなたのKubernetesに関するストーリーを共有してください
- Kubernetesの最新情報はブログでさらに詳しく読むことができます
- リリースチームについての詳細はKubernetes Release Teamをご覧ください
デバイスを持つPodでの障害への対処
Kubernetesはコンテナオーケストレーションのデファクトスタンダードですが、GPUやその他のアクセラレーターのような専用ハードウェアを扱うとなると、少し複雑になります。 この記事では、Kubernetesでデバイスを持つPodを運用する際の故障モード管理の課題について、KubeCon NA 2024でのSergey KanzhelevとMrunal Patelのセッションの知見に基づいて掘り下げます。 スライドと録画のリンクもご確認ください。
AI/MLブームとKubernetesへの影響
AI/MLワークロードの台頭は、Kubernetesに新たな課題をもたらしています。 これらのワークロードは専用ハードウェアに大きく依存することが多く、デバイスの故障はパフォーマンスに重大な影響を与え、腹立たしくなる中断につながる可能性があります。 2024年のLlama論文で強調されているように、ハードウェアの問題、特にGPUの故障はAI/MLトレーニングにおける中断の主要原因です。 また、Ryan HalliseyとPiotr ProkopによるKubeConセッション「All-Your-GPUs-Are-Belong-to-Us: An Inside Look at NVIDIA's Self-Healing GeForce NOW Infrastructure」(録画)からも、NVIDIAがデバイス障害とメンテナンスの処理にどれだけの労力をかけているかがわかります。 それによると、1000ノードあたり1日19件の修復リクエストが発生しているそうです! また、データセンターではスポット消費モデルを提供し電力を過剰に供給しているため、デバイスの故障が日常的なものとなり、ビジネスモデルの一部となっているケースも見られます。
しかし、Kubernetesのリソースに対する見方は依然として非常に静的です。 リソースは存在するか存在しないかのどちらかです。 存在する場合、それが完全に機能し続けると想定されています。 Kubernetesは、完全または部分的なハードウェア障害を処理するための適切なサポートを欠いています。 これらの以前からある前提と設定全体の複雑さが相まって、様々な故障モードが発生します。 本記事ではこれについて議論します。
AI/MLワークロードの理解
一般的に、すべてのAI/MLワークロードは専用ハードウェアを必要とし、スケジューリング要件が難しく、アイドル時にコストがかかります。 AI/MLワークロードは通常、トレーニングと推論の2つのカテゴリに分類されます。 以下は、これらのカテゴリの特性を非常に単純化した見方であり、Webサービスなどの従来のワークロードとは異なります:
- トレーニング
- これらのワークロードはリソース集約的で、しばしばマシン全体を消費し、Podのグループとして実行されます。 トレーニングジョブは通常「完了まで実行」されますが、それは数日、数週間、さらには数ヶ月かかることもあります。 単一のPodで障害が起こった場合もすべてのPodでステップ全体を再起動する必要があります。
- 推論
- これらのワークロードは通常、長時間実行されるか無限に実行されます。 ノードのデバイスのサブセットを消費する程度の小さなものでも、複数のノードにまたがるほど大きなものでもかまいません。 モデルの重みを含む巨大なファイルのダウンロードが必要になることがよくあります。
これらの類のワークロードは、特に多くの前提を覆します:
| 以前 | 現在 |
|---|---|
| より良いCPUを使えば、アプリはより速く動作する。 | 実行には特定のデバイス(またはデバイスクラス)が必要。 |
| 何かが動作しない場合は、再作成すればよい。 | 割り当てまたは再割り当ては高コスト。 |
| どのノードでも動作する。Pod間での調整は不要。 | 特別な方法でスケジュールされる - デバイスはしばしばノード間トポロジーで接続される。 |
| 各Podは、障害が発生した場合にプラグアンドプレイで置き換え可能。 | Podはより大きなタスクの一部。タスク全体のライフサイクルは各Podに依存する。 |
| コンテナイメージはスリムで簡単に利用可能。 | コンテナイメージは特別な処理が必要なほど大きい場合がある。 |
| 長時間の初期化は漸進的なロールアウトで相殺できる。 | 初期化は長くなる可能性があり最適化が必要。場合によっては複数のPodをまとめて最適化。 |
| コンピューティングノードはコモディティ化されており比較的安価であるため、アイドル時間は許容される。 | 専用ハードウェアを搭載したノードは、非搭載のノードよりも桁違いに高価である可能性があるため、アイドル時間は非常に無駄が多い。 |
既存の障害モデルは古い前提に基づいていました。 新しいワークロードタイプでもまだ機能する可能性がありますが、デバイスに関するナレッジが限られており、非常にコストがかかります。 場合によってはありえないほど高コストになることもあります。 この記事の後半でさらに多くの例をお見せします。
Kubernetesが依然として王者である理由
この記事では、AI/MLワークロードが従来のKubernetesワークロードと非常に異なるのに、なぜゼロから始めないのかという疑問については深く掘り下げません。 多くの課題があるにもかかわらず、Kubernetesは依然としてAI/MLワークロードのプラットフォームとして選ばれ続けています。 その成熟度、セキュリティ、豊富なツールエコシステムが、魅力的な選択肢となっています。 代替手段は存在しますが、それらの多くはKubernetesが提供する長年の開発と改良の成果には及びません。 そしてKubernetesの開発者たちは、本記事で指摘された課題やそれ以上の課題に積極的に取り組んでいます。
デバイス障害処理の現状
このセクションでは、さまざまな故障モードと今日使用されているベストプラクティス、そしてDIY(Do-It-Yourself)ソリューションの概要を説明します。 次のセッションでは、それらの故障モードの改善のロードマップを説明します。
故障モード: K8sインフラストラクチャ
Kubernetesインフラストラクチャに関連する障害を理解するには、ノード上でPodをスケジュールする際にどれほど多くの要素が関わっているかを理解する必要があります。 Podがノードにスケジュールされる際の一連のイベントは以下のとおりです:
- デバイスプラグインがノードにスケジュールされる
- ローカルgRPCを介してデバイスプラグインがkubeletに登録される
- Kubeletがデバイスプラグインを使用してデバイスを監視し、ノードの容量を更新する
- 更新された容量に基づいてスケジューラーがUser Podをノードに配置する
- デバイスプラグインにUser Podのデバイスを割り当てるよう、Kubeletが依頼する
- 割り当てられたデバイスが接続されたUser PodをKubeletが作成する
この図は、関与するアクターの一部を示しています:

多くのアクターが相互接続されているため、各アクターと各接続で中断が発生する可能性があります。 これは、しばしば障害と見なされる多くの例外的な状況につながり、深刻なワークロード中断を引き起こす可能性があります:
- Podがライフサイクルのさまざまな段階で受け入れに失敗する
- 完璧に正常なハードウェアでPodが実行できない
- スケジューリングに予想外に長い時間がかかる

Kubernetesの目標は、これらのコンポーネント間の中断を可能な限り信頼性の高いものにすることです。 Kubeletはすでにリトライ、終了前の猶予期間、その他の技術を実装してこれを改善しています。 ロードマップセクションでは、Kubernetesプロジェクトが追跡している他のエッジケースについて詳しく説明します。 ただし、これらの改善はすべて、これらのベストプラクティスに従った場合にのみ機能します:
- ワークロードを中断しないように、できるだけ早くkubeletとコンテナランタイム(containerdやCRI-Oなど)を設定して再起動する。
- デバイスプラグインの健全性を監視し、アップグレードを慎重に計画する。
- デバイスプラグインやその他のコンポーネントの中断を防ぐため、ノードを重要度の低いワークロードで過負荷にしない。
- ノードの準備状態の一時的な不安定さに対処するため、User Podのtolerationsを設定する。
- デバイスを長時間ブロックしないよう、適切な終了ロジックを慎重に設定・コーディングする。
Kubernetesインフラ関連の問題の別の類は、ドライバー関連です。 CPUやメモリなどの従来のリソースでは、アプリケーションとハードウェア間の互換性チェックは必要ありませんでした。 ハードウェアアクセラレーターのような専用デバイスでは新たな故障モードがあります。 ノードにインストールされているデバイスドライバーは以下を満たす必要があります:
- ハードウェアに適合していること
- アプリとの互換性があること
- 他のドライバー(ncclなど)と連携可能であること
ドライバーバージョンの処理に関するベストプラクティス:
- ドライバーインストーラーの健全性を監視する
- インフラストラクチャとPodのアップグレードを計画してバージョンを一致させる
- 可能な限りカナリアデプロイメントを使用する
このセクションのベストプラクティスに従い、信頼できるソースからのデバイスプラグインおよびデバイスドライバーインストーラーを使用することで、この種の障害は一般的に解消されます。 Kubernetesはこの領域をさらに改善するための取り組みを追跡しています。
故障モード: デバイスの障害
現在、Kubernetesではデバイス障害に関する処理がほとんどありません。 デバイスプラグインは、割り当て可能なデバイスの数を変更することによってのみデバイス障害を報告します。 また、Kubernetesは、liveness probeやコンテナ障害などの標準的なメカニズムを利用して、Podがkubeletに障害状態を伝達できるようにしています。 ただし、Kubernetesはデバイス障害とコンテナクラッシュを関連付けず、同じデバイスに接続されたままコンテナを再起動する以外の軽減策を提供しません。
これが、様々なシグナルに基づいてデバイス障害を処理する多くのプラグインとDIYソリューションが存在する理由です。
ヘルスコントローラー
多くの場合、故障したデバイスによって復旧不能になり、非常に高価なノードが何もできなくなってしまいます。 これに対するシンプルなDIYソリューションは、ノードヘルスコントローラー です。 コントローラーは、デバイスの割り当て可能数と容量を比較し、容量が大きい場合、タイマーを開始します。 タイマーがしきい値に達すると、ヘルスコントローラーはノードを強制終了して再作成します。
ヘルスコントローラー アプローチにはいくつかの問題があります:
- デバイス障害の根本原因は通常不明
- コントローラーはワークロードを認識しない
- 故障したデバイスが使われていないとしても、(ノードが再作成されることで)他のデバイスの稼働を継続できない
- 非常に汎用的であるため、検出が遅すぎる可能性がある
- ノードがより大きなノードセットの一部である可能性があり、他のノードとの連携なしでは単独で削除できない
上記の問題の一部を解決できるヘルスコントローラーのバリエーションもあります。 しかし、ここでの全体的なテーマは、故障したデバイスを最適に処理するには、特定のワークロード用のカスタマイズされた処理が必要であるということです。 Kubernetesは、デバイスがノード、クラスター、および割り当てられたPodにとってどれほど重要であるかを表現するのに十分な抽象化をまだ提供していません。
Pod失敗ポリシー
デバイス障害処理の別のDIYアプローチは、故障したデバイスに対するPodごとの対応です。 このアプローチは、Jobとして実装されたトレーニングワークロードに適用できます。
Podは、デバイス障害の特別なエラーコードを定義できます。 たとえば、デバイスが予期しない振る舞いをした場合、Podは特別な終了コードで終了します。 その後、Pod失敗ポリシーは、デバイス障害を特別な方法で処理できます。 詳細については、Pod失敗ポリシーによる再試行可能および再試行不可能なPod障害の処理を参照してください。
Jobに対する Pod失敗ポリシー アプローチにはいくつかの問題があります:
- よく知られた device failed 状態が存在しないため、このアプローチは一般的なPodケースでは機能しない
- エラーコードは慎重にコーディングする必要があり、場合によっては保証が難しい
- Pod失敗ポリシー機能の制限により、
restartPolicy: NeverのJobでのみ機能する
したがって、このソリューションは適用範囲が限られています。
カスタムPod watcher
より汎用的なアプローチは、DIYソリューションとしてPod watcherを実装するか、この機能を提供するサードパーティツールを使用することです。 Pod watcherは、推論ワークロードのデバイス障害を処理するためによく使用されます。
Kubernetesは、デバイスが不健全と報告されている場合でも、デバイスに割り当てられたPodを維持するだけであるため、Pod watcherでこの状況を検出し何らかの修復を適用するというアイデアです。 これは、ノード上のPod Resources APIを使用してデバイスの健全性ステータスとそのPodへのマッピングを取得することが多いです。 デバイスが故障した場合、修復措置として接続されたPodを削除できます。 レプリカセットが健全なデバイスでPodの再作成を処理します。
このwatcherを実装する他の理由:
- これがないと、Podは故障したデバイスにいつまでも割り当てられ続ける
restartPolicy=AlwaysのPodには スケジューリング解除 がされない- CrashLoopBackoff状態のPodを削除する組み込みコントローラーがない
カスタム Pod watcher の問題点:
- Pod watcherのシグナルを取得するのは高コストで、いくつかの特権的な操作が必要
- カスタムソリューションであり、Podに対するデバイスの重要性を前提としている
- Pod watcherは、Podの再スケジュールを外部コントローラーに依存している
デバイス障害や今後のメンテナンスを処理するためのDIYソリューションには、さらに多くのバリエーションがあります。 全体的に、Kubernetesにはこれらのソリューションを実装するのに十分な拡張ポイントがあります。 ただし、一部の拡張ポイントは、ユーザーの許容を超える高い特権を要求したり、あまりにも破壊的であったりします。 ロードマップセクションでは、デバイス障害の処理に関する特定の改善について詳しく説明します。
故障モード: コンテナコードの障害
コンテナコードが障害を起こしたり、メモリ不足などの問題が発生したりした場合、Kubernetesはそれらのケースに対処する方法を知っています。
コンテナを再起動するか、PodにrestartPolicy: Neverが設定されている場合はPodをクラッシュさせ、別のノードにスケジュールします。
Kubernetesは、何が障害であるか(たとえば、ゼロ以外の終了コードやliveness probeの失敗)と、そのような障害にどのように対応するか(たいてい常に再起動するか、すぐにPodを失敗させる)について表現力が限られています。
このレベルの表現力は、複雑なAI/MLワークロードにはしばしば不十分です。 AI/ML Podは、イメージを取得する時間とデバイス割り当てを節約できるため、ローカルで再スケジュールするか、その場で再スケジュールする方が適しています。 AI/ML Podはしばしば相互接続されており、一緒に再起動する必要があります。 これにより複雑さがさらに増しますが、これを最適化することで、AI/MLワークロードの実行コストを大幅に削減できる場合が多いです。
Pod障害のオーケストレーションを処理するための様々なDIYソリューションがあります。 最も典型的なものは、オーケストレーターによってコンテナ内のメイン実行可能ファイルをラップすることです。 このオーケストレーターは、他のPodで障害が起こったためにジョブを再起動する必要がある場合に、メイン実行可能ファイルを再起動できるようになります。
このようなソリューションは非常に脆弱で複雑です。 大規模なトレーニングジョブで使用する場合、通常のJobSetの削除/再作成サイクルと比較して、コスト削減の価値がある場合が多いです。 Kubernetesに新しいフックと拡張ポイントを開発することで、これらのソリューションの脆弱性を低減し効率化すれば、より小さなジョブにも簡単に適用でき、すべての人に利益をもたらします。
故障モード: デバイスの劣化
すべてのデバイス障害が、ワークロード全体やバッチジョブにとって致命的であるとは限りません。 ハードウェアスタックがますます複雑になるにつれて、ハードウェアスタックレイヤーのいずれかの設定ミスやドライバーの障害により、機能しているもののパフォーマンスが低下しているデバイスが生じる可能性があります。 遅くなっている1つのデバイスが、トレーニングジョブ全体を遅くする可能性があります。
このようなケースの報告はますます増えています。 Kubernetesには今日、このタイプの障害を表現する方法がなくこれが最新のタイプの故障モードであるため、ハードウェアベンダーから検出に関するベストプラクティスやこれらの状況の修復に関するサードパーティツールがほとんど提供されていません。
通常、これらの障害は、観測されたワークロード特性に基づいて検出されます。たとえば、特定のハードウェアでのAI/MLトレーニングステップの期待速度などです。 これらの問題の修復は、ワークロードのニーズに大きく依存します。
ロードマップ
上のセクションで概説したように、Kubernetesは多くの拡張ポイントを提供しており、それらを使用して様々なDIYソリューションを実装できます。 AI/MLの分野は、要件や使用パターンの変化に伴い、非常に急速に発展しています。 SIG Nodeは、特定のシナリオをサポートするための新しいセマンティクスの導入よりも、ワークロード固有のシナリオを実装するための拡張ポイントを増やすという慎重なアプローチを採用しています。 これは、一部のワークロードにしか適さない可能性のある障害に対する自動修復の実装よりも、障害に関する情報を容易に利用できるようにすることを優先するということです。
このアプローチによりワークロード処理に劇的な変更が加えられることがなくなり、既存の円滑なDIYソリューションや従来のワークロードの体験が損なわれることはありません。
今日使用されている多くのエラーハンドリング技術はAI/MLで機能しますが、非常に高コストです。 SIG Nodeは、AI/MLのコスト削減が重要であるという理解の下で、これらをより安価にするための拡張ポイントに投資します。
以下は、さまざまな故障モードに対して私たちが想定している具体的な投資事項です。
故障モードのロードマップ: K8sインフラストラクチャ
Kubernetesインフラストラクチャの領域は理解しやすく、デバイスプラグインからDRAへの今後の移行を正しく行うために非常に重要です。 SIG Nodeはこの領域で多くの作業項目を追跡しており、特に以下のものがあります:
- integrate kubelet with the systemd watchdog · Issue #127460
- DRA: detect stale DRA plugin sockets · Issue #128696
- Support takeover for devicemanager/device-plugin · Issue #127803
- Kubelet plugin registration reliability · Issue #127457
- Recreate the Device Manager gRPC server if failed · Issue #128167
- Pods that consume "devices" via Device Plugin always fail when Node reboots even if it implements plugins_registry interface · Issue #128043
基本的に、Kubernetesコンポーネントのすべての相互作用は、kubeletの改善またはプラグイン開発とデプロイメントのベストプラクティスを介して信頼性が確保される必要があります。
故障モードのロードマップ: デバイス故障
デバイス障害については、Kubernetesがサポートできる共通のシナリオでいくつかのパターンが既に現れています。 しかし、最初のステップは、故障したデバイスに関する情報をより簡単に利用できるようにすることです。 ここでの最初のステップは、KEP 4680(Add Resource Health Status to the Pod Status for Device Plugin and DRA)での作業です。
テストされる長期的なアイデアには以下が含まれます:
- デバイス障害をPod失敗ポリシーに統合する。
- ノードローカルのリトライポリシー、
restartPolicy=OnFailureのPodに対してPod失敗ポリシーを有効にし、さらにそれ以外のケースにも対応可能にする。 restartPolicy: Alwaysも対象とした、Podの スケジュール解除 機能。これにより、Podに新しいデバイスを割り当てることができる。- DRAでデバイスを表すために使用されるResourceSliceから、健全でないデバイスを単に削除するのではなく、ResourceSliceにデバイスの健全性情報を追加する。
故障モードのロードマップ: コンテナコードの障害
AI/MLワークロードのコンテナコード障害への対応における主な改善点は、すべて低コストなエラー処理とリカバリを目的としています。 低コスト化の主な要因は、事前に割り当てられたリソースを可能な限り再利用することにあります。 コンテナをその場で再起動することによるPodの再利用から、可能な限り再スケジューリングの代わりにノードローカルでのコンテナ再起動、スナップショットサポート、イメージ取得を節約するために同じノードを優先する再スケジューリングまでです。
次のシナリオを考えてみましょう: 512個のPodが必要な大きなトレーニングジョブがあります。 そして、そのうちの1つが故障しました。 これは、すべてのPodを中断し、故障したステップを再起動するために同期する必要があることを意味します。 これを達成する最も効率的な方法は、一般に、可能な限り多くのPodをその場で再起動することで再利用しながら、エラーをクリアするために問題のあったPodを置き換えることです。 以下に図を示します:

このシナリオを実装することは可能ですが、Kubernetesに特定の拡張ポイントが不足しているため、これを実装するすべてのソリューションは脆弱です。 このシナリオを実装するための拡張ポイントの追加は、Kubernetesのロードマップに組み込まれています。
故障モードのロードマップ: デバイスの劣化
この領域ではほとんど何も行われていません - 明確な検出シグナルがなく、トラブルシューティングツールが非常に限られており、Kubernetesで「劣化した」デバイスを表現する組み込みセマンティクスがありません。 DRAでデバイスを表現するために使用されるResourceSliceにデバイスのパフォーマンスや劣化に関するデータを追加することについての議論がありますが、まだ明確に定義されていません。 また、node-healthcheck-operatorのようなプロジェクトもあり、一部のシナリオで使用できます。
この領域では、ハードウェアベンダーとクラウドプロバイダーからの開発が期待されており、近い将来はDIYソリューションが主流になると予想しています。 AI/MLワークロードを利用するユーザーが増えるにつれて、この分野ではここで使用されているパターンに関するフィードバックが必要になります。
会話に参加する
Kubernetesコミュニティは、デバイス障害処理の未来を形作るためのフィードバックと参加を歓迎しています。 SIG Nodeに参加して、進行中の議論に貢献してください!
この記事では、Kubernetesにおけるデバイス障害管理の課題と今後の方向性について概説しました。 これらの課題に対処することで、KubernetesはAI/MLワークロードの主要プラットフォームとしての地位を確固たるものにし、特殊なハードウェアに依存するアプリケーションの耐障害性と信頼性を確保することができます。
Kubernetes v1.33: 思い描いていたとおりに動作するようになったImage Pull Policy!
思い描いていたとおりに動作するようになったImage Pull Policy!
Kubernetesには意外な挙動がいくつか存在しますが、imagePullPolicyの挙動もその一つかもしれません。
KubernetesがPodの実行を本質とするものであることを踏まえると、認証が必要なイメージに対してPodのアクセスを制限しようとする際に、10年以上前からissue 18787という形で注意点が存在していたことを知ると、意外に思うかもしれません。
この10年越しの問題が解決されるリリースは、非常に興奮すべきものです。
備考:
このブログ記事全体を通して「Podの認証情報」という用語が頻繁に使われます。 この文脈においては、この用語は、一般的にコンテナイメージのプルを認証するためにPodが利用できる認証情報全体を指します。IfNotPresent、たとえ本来持つべきでないとしても
この問題の要点は、imagePullPolicy: IfNotPresentという設定が、まさに文字通りの意味でしか動作せず、それ以上のことは一切行ってこなかったという点です。
ここで、とあるシナリオを考えてみましょう。
まず、Namespace X内のPod AがNode 1にスケジュールされ、プライベートリポジトリからimage Fooを必要とする状況を考えます。
イメージプル時の認証情報として、このPodはimagePullSecretsのSecret 1を参照しています。
Secret 1には、プライベートリポジトリからイメージをプルするために必要な認証情報が含まれています。
KubeletはPod Aから提供されたSecret 1の認証情報を使用し、レジストリからcontainer image Fooをプルすることになります。
これが意図した(かつ安全な)動作です。
しかし、ここからが興味深いところです。
Namespace Y内のPod Bも、たまたまNode 1にスケジュールされたとします。
このとき、予期しない(かつ潜在的に安全でない)事態が発生します。
Pod BはIfNotPresentのイメージプルポリシーを指定し、同じプライベートイメージを参照しているかもしれません。
しかし、Pod BはimagePullSecretsでSecret 1(あるいは本例では、いかなるSecretも)を指定していません。
KubeletがこのPodを実行しようとすると、IfNotPresentのポリシーが尊重されます。
Kubeletは、image Fooがすでにローカルに存在していることを確認し、そのimage FooをPod Bに提供します。
つまり、Pod Bはそもそも、そのイメージをプルする権限を示す認証情報を一切提供していないにもかかわらず、そのイメージを実行できてしまうのです。

異なるPodによってプルされたプライベートイメージを使用する
IfNotPresentは、イメージがノード上にすでに存在している場合にはimage Fooをプルすべきではありませんが、ノードにスケジュールされたすべてのPodが、過去にプルされたプライベートイメージへアクセスできてしまうというのは、セキュリティ上不適切な構成です。
これらのPodはそもそも、そのイメージをプルする権限を全く与えられていなかったのです。
IfNotPresent、ただし本来アクセス権がある場合に限る
Kubernetes v1.33では、SIG AuthとSIG Nodeがついにこの(非常に古くからある)問題への対応を開始し、適切な検証が行われるようになりました! 基本的な期待される挙動は変更されていません。 イメージが存在しない場合、Kubeletはそのイメージをプルしようとします。 その際には、各Podが提供する認証情報が使用されます。 この挙動は1.33以前と同様です。
イメージがすでに存在している場合、Kubeletの挙動は変化します。 これからは、KubeletはPodにそのイメージの使用を許可する前に、そのPodの認証情報を検証するようになります。
この機能の改修にあたっては、パフォーマンスとサービスの安定性も考慮されています。 同じ認証情報を使用するPodは、再認証を要求されることはありません。 これは、Podが同じKubernetesのSecretオブジェクトから認証情報を取得している場合には、たとえその認証情報がローテーションされていたとしても、当てはまります。
Never pull、ただし認証されている場合に限る
imagePullPolicy: Neverオプションは、イメージを取得しません。
ただし、コンテナイメージがすでにノード上に存在する場合、そのプライベートイメージを使用しようとするすべてのPodは、認証情報の提示が求められ、その認証情報は検証されます。
同じ認証情報を使用するPodは、再認証を要求されることはありません。 一方で、以前にそのイメージのプルに成功した認証情報を提示しないPodには、プライベートイメージの使用が許可されません。
Always pull、ただし認証されている場合に限る
imagePullPolicy: Alwaysは、これまでも意図おりに動作してきました。
イメージが要求されるたびに、そのリクエストはレジストリに送られ、レジストリ側で認証チェックが実行されます。
以前は、プライベートなコンテナイメージが、すでにイメージをプル済みのノード上で他のPodに再利用されないようにする唯一の手段は、Podのアドミッション時に強制的にAlwaysのイメージプルポリシーを適用することでした。
幸いにも、この方法はある程度パフォーマンスに優れていました。 プルされるのはイメージそのものではなく、イメージマニフェストだけだったからです。 しかしながら、それでもコストとリスクは存在していました。 新しいロールアウト、スケールアップ、またはPodの再起動の際には、イメージを提供するレジストリが認証チェックのために必ず利用可能でなければならず、その結果、クラスター内で稼働するサービスの安定性において、イメージレジストリがクリティカルパスに置かれることになります。
仕組みについて
この機能は、各ノードに存在する永続的なファイルベースのキャッシュに基づいて動作します。 以下は、この機能がどのように動作するかの簡略化された説明です。 完全な仕様については、KEP-2535をご参照ください。
初めてイメージをリクエストする際の処理の流れは、以下のとおりです:
- プライベートレジストリからイメージを要求するPodが、ノードにスケジュールされる。
- 要求されたイメージが、当該ノード上に存在しない。
- Kubeletは、そのイメージをプルしようとしている状態であることを示す記録を作成する。
- Kubeletは、Podにimage pull secretとして指定されたKubernetesのSecretから認証情報を抽出し、それを使用してプライベートレジストリからイメージを取得します。。
- イメージのプルに成功すると、Kubeletはその成功を記録する。この記録には、使用された認証情報(ハッシュ形式)および、それらの認証情報を取得するために使われたSecretの情報も含まれる。
- Kubeletは、元のプルしようとしている状態であることを示す記録を削除する。
- Kubeletは、プルに成功したことを示す記録を後の利用のために保持する。
後に、同じノードにスケジュールされた別のPodが、以前にプルされたプライベートイメージを要求した場合の処理は次のとおりです:
- Kubeletは、その新しいPodがプルのために提供した認証情報を確認する。
- その認証情報のハッシュ、またはその認証情報の元となったSecretが、以前のプル成功時に記録されたハッシュまたはSecretと一致する場合、そのPodには以前にプルされたイメージの使用が許可される。
- 認証情報またはその認証情報の元となるSecretが、そのイメージに関するプル成功記録の中に存在しない場合、Kubeletはその新しい認証情報を使ってリモートレジストリからの再プルを試み、認証フローを開始する。
試してみよう
Kubernetes v1.33では、この機能のアルファ版がリリースされました。
実際に試してみるには、バージョン1.33のKubeletにおいて、KubeletEnsureSecretPulledImagesフィーチャーゲートを有効にしてください。
この機能や追加のオプション設定の詳細については、Kubernetes公式ドキュメントのイメージの概要ページをご覧ください。
今後の予定
今後のリリースにおいて、以下の対応を予定しています:
- Kubeletイメージ認証プロバイダー用の投影サービスアカウントトークンとの連携を実現します。これにより、ワークロードに特化した新しいイメージプル認証情報の供給元が追加されます。
- この機能のパフォーマンスを計測し、将来的な変更の影響を評価するためのベンチマークスイートを作成します。
- 各イメージプル要求のたびにファイルを読み込む必要がなくなるように、インメモリキャッシュ層を実装します。
- 認証情報の有効期限をサポートし、以前に検証済みの認証情報でも強制的に再認証するようにします。
参加するには
これらの変更について詳しく理解するには、KEP-2535を読むのが最適です。
さらに関わりたい方は、Kubernetes Slackの#sig-auth-authenticators-devチャンネルで私たちにご連絡ください(招待を受けるにはhttps://slack.k8s.io/をご確認ください)。 また、隔週水曜日に開催されているSIG Authのミーティングへの参加も歓迎です。
Kubernetes v1.33: HorizontalPodAutoscalerの設定可能な許容値
この投稿では、Kubernetes 1.33で初めて利用可能になった新しいアルファ機能である、HorizontalPodAutoscalerの設定可能な許容値 について説明します。
これは何ですか?
水平Pod自動スケーリングは、Kubernetesのよく知られた機能であり、リソース使用率に基づいてレプリカを追加または削除することで、ワークロードのサイズを自動的に調整できます。
たとえば、Kubernetesクラスターで50個のレプリカを持つWebアプリケーションが稼働しているとします。 HorizontalPodAutoscaler(HPA)をCPU使用率に基づいてスケーリングするように構成し、目標使用率を75%に設定します。 現在の全レプリカにおけるCPU使用率が目標の75%を上回る90%であると仮定します。 このとき、HPAは次の式を使用して必要なレプリカ数を計算します。
この例の場合では、下記のようになります。
そのため、HPAは各Podの負荷を軽減するために、レプリカ数を50から60に増やします。 同様に、CPU使用率が75%を下回った場合は、HPAがそれに応じてレプリカ数を縮小します。 Kubernetesのドキュメントでは、スケーリングアルゴリズムの詳細な説明が提供されています。
小さなメトリクスの変動があるたびにレプリカが作成または削除されるのを防ぐために、Kubernetesはヒステリシスの仕組みを適用しています。 現在の値と目標値の差が10%を超えた場合にのみ、レプリカ数を変更します。 上記の例では、現在値と目標値の比率は\(90/75\)、すなわち目標を20%上回っており、10%の許容値を超えているため、スケールアップが実行されます。
この10%というデフォルトの許容値はクラスター全体に適用されるものであり、これまでのKubernetesのリリースでは細かく調整することができませんでした。 多くの用途には適していますが、10%の許容値が数十個のPodに相当するような大規模なデプロイメントには粗すぎます。 その結果、コミュニティでは、この値を調整可能にしてほしいという要望が以前から寄せられてきました。
Kubernetes v1.33では、これが可能になりました。
どうやって使うのか?
Kubernetes v1.33クラスターでHPAConfigurableToleranceフィーチャーゲートを有効にした後、HorizontalPodAutoscalerオブジェクトに対して希望する許容値を設定できます。
許容値はspec.behavior.scaleDownおよびspec.behavior.scaleUpフィールドの下に指定され、スケールアップとスケールダウンで異なる値を設定することが可能です。
典型的な使い方としては、スケールアップには小さな許容範囲(スパイクに素早く反応するため)、スケールダウンには大きな許容範囲(メトリクスの小さな変動に対してレプリカを過剰に追加・削除しないようにするため)を指定することが挙げられます。
たとえば、スケールダウンに対して5%の許容値を、スケールアップに対して許容値を指定しないHPAは、次のようになります。
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: my-app
spec:
...
behavior:
scaleDown:
tolerance: 0.05
scaleUp:
tolerance: 0
すべての詳細を知りたい!
すべての技術的な詳細については、KEP-4951を参照してください。 また、issue 4951をフォローすることで、この機能の安定版への移行についての通知を受け取ることができます。
Kubernetes v1.33: EndpointsからEndpointSliceへの継続的な移行を進める
EndpointSlice (KEP-752)がv1.15でアルファとして導入され、v1.21でGAとなって以来、Endpoints APIはKubernetesの中でほぼ使われず、埃を被っています。 デュアルスタックネットワークやトラフィック分散など、Serviceの新機能はEndpointSlice APIでのみサポートされているため、全てのサービスプロキシ、Gateway API実装、及び同様のコントローラーはEndpointsからEndpointSliceへの移行を余儀なくされました。 現時点のEndpoints APIは、未だにEndpointsを使っているエンドユーザーのワークロードやスクリプトの互換性を維持するための存在に過ぎません。
Kubernetes 1.33以降、Endpoints APIは正式に非推奨となり、Endpointsリソースを読み書きするユーザーに対して、EndpointSliceを使用するようAPIサーバーから警告が返されるようになりました。
最終的には、「ServiceとPodに基づいてEndpointsオブジェクトを生成する Endpointsコントローラー がクラスター内で実行されている」という基準をKubernetes Conformanceから除外することがKEP-4974にて計画されています。 これの実現によって、現代的なほとんどのクラスターにおいて不要な作業を回避することができます。
Kubernetes非推奨ポリシーに従うと、Endpointsタイプ自体が完全に廃止されることはおそらく無いですが、Endpoints APIを使うワークロードやスクリプトを保有しているユーザーはEndpointSliceへの移行が推奨されます。
EndpointsからEndpointSliceへの移行に関する注意点
EndpointSliceを利用する
エンドユーザーにとって、Endpoints APIとEndpointSlice APIの最大の違いは、selectorを持つ全てのServiceが自身と同じ名前のEndpointsオブジェクトを必ず1つずつ持つのに対し、1つのServiceに紐づけられるEndpointSliceは複数存在する可能性がある、という点です。
$ kubectl get endpoints myservice
Warning: v1 Endpoints is deprecated in v1.33+; use discovery.k8s.io/v1 EndpointSlice
NAME ENDPOINTS AGE
myservice 10.180.3.17:443 1h
$ kubectl get endpointslice -l kubernetes.io/service-name=myservice
NAME ADDRESSTYPE PORTS ENDPOINTS AGE
myservice-7vzhx IPv4 443 10.180.3.17 21s
myservice-jcv8s IPv6 443 2001:db8:0123::5 21s
この場合、Serviceがデュアルスタックであるため、EndpointSliceがIPv4アドレス用とIPv6アドレス用の2つ存在します。 (Endpoints APIはデュアルスタックをサポートしていないため、Endpointsオブジェクトにはクラスターのプライマリアドレスファミリーのアドレスのみが表示されています。)
複数のEndpointSliceを持つ 可能性 は、複数のエンドポイントが存在するあらゆるServiceにありますが、代表的なケースが3つ存在します。
EndpointSliceは単一のIPファミリーのエンドポイントしか表現できないため、デュアルスタックServiceの場合、IPv4用とIPv6用のEndpointSliceがそれぞれ作成されます。
単一のEndpointSlice内のエンドポイントは、全て同じポートを対象とする必要があります。例えば、エンドポイントとなるPodをロールアウトして、リッスンするポート番号を80から8080に更新する場合、ロールアウト中はServiceに2つのEndpointSliceが必要になります。1つはポート80をリッスンしているエンドポイント用、もう1つはポート8080をリッスンしているエンドポイント用です。
Serviceに100以上のエンドポイントが存在する場合、Endpointsコントローラーは1つの巨大なオブジェクトにエンドポイントを集約していましたが、EndpointSliceコントローラーはこれらを複数のEndpointSliceに分割します。
ServiceとEndpointSliceの間に予測可能な1対1の対応関係はないため、あるServiceに紐づけられるEndpointSliceリソースの実際の名前を事前に知ることはできません。
そのため、Serviceに紐づけられるEndpointSliceリソースを取得する際は、名前で取得するのではなく、"kubernetes.io/service-name"ラベルが目的のServiceを指しているEndpointSliceを全て取得する必要があります。
kubectl get endpointslice -l kubernetes.io/service-name=myservice
Goのコードでも同様の変更が必要です。 Endpointsを使用して次のように記述していたところは、
// `namespace`内の`name`という名前のEndpointsを取得する
endpoint, err := client.CoreV1().Endpoints(namespace).Get(ctx, name, metav1.GetOptions{})
if err != nil {
if apierrors.IsNotFound(err) {
// サービスに対応するEndpointsが(まだ)存在しない
...
}
// 他のエラーを処理
...
}
// `endpoint`を使った処理を続ける
...
EndpointSliceを使うと次のようになります。
// `namespace`内の`name`というServiceに紐づいた全てのEndpointSliceを取得する
slices, err := client.DiscoveryV1().EndpointSlices(namespace).List(ctx,
metav1.ListOptions{LabelSelector: discoveryv1.LabelServiceName + "=" + name})
if err != nil {
// エラーを処理
...
} else if len(slices.Items) == 0 {
// Serviceに対応するEndpointSliceが(まだ)存在しない
...
}
// `slices.Items`を使った処理を続ける
...
EndpointSliceを生成する
手作業でEndpointsを生成している箇所やコントローラーについては、複数のEndpointSliceを考慮しなくてもよい場合が多いため、比較的簡単にEndpointSliceへの移行ができます。 Endpointsから少し情報の整理の仕方は変わっていますが、単にEndpointSliceという新しい型を使用するようにYAMLやGoのコードを更新するだけで済みます。
例えばこのようなEndpointsオブジェクトの場合、
apiVersion: v1
kind: Endpoints
metadata:
name: myservice
subsets:
- addresses:
- ip: 10.180.3.17
nodeName: node-4
- ip: 10.180.5.22
nodeName: node-9
- ip: 10.180.18.2
nodeName: node-7
notReadyAddresses:
- ip: 10.180.6.6
nodeName: node-8
ports:
- name: https
protocol: TCP
port: 443
次のようなEndpointSliceオブジェクトになります。
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: myservice
labels:
kubernetes.io/service-name: myservice
addressType: IPv4
endpoints:
- addresses:
- 10.180.3.17
nodeName: node-4
- addresses:
- 10.180.5.22
nodeName: node-9
- addresses:
- 10.180.18.12
nodeName: node-7
- addresses:
- 10.180.6.6
nodeName: node-8
conditions:
ready: false
ports:
- name: https
protocol: TCP
port: 443
いくつか留意点があります。
この例では明示的に
nameを指定していますが、generateNameを使用することでAPIサーバーにユニークなサフィックスを付加させることもできます。重要なのは名前自体ではなく、Serviceを指す"kubernetes.io/service-name"ラベルです。明示的に
addressType: IPv4(またはIPv6)を指定する必要があります。EndpointSliceは、Endpointsの
"subsets"フィールドの一要素と類似しています。複数のsubsetsを持つEndpointsオブジェクトを表現する場合、基本的には異なる"ports"を持つ複数のEndpointSliceにする必要があります。endpointsフィールドとaddressesフィールドはどちらも配列ですが、慣習的にaddressesフィールドは1つの要素しか含みません。Serviceに複数のエンドポイントがある場合は、endpointsフィールドに複数の要素を持たせ、それぞれのaddressesフィールドには1つの要素のみを含める必要があります。Endpoints APIでは「ready」と「not-ready」のエンドポイントが別々に列挙されますが、EndpointSlice APIでは各エンドポイントに対してconditions(
ready: falseなど)を設定することができます。
もちろん、ひとたびEndpointSliceに移行すれば、topology hintsやterminating endpointsなどEndpointSlice特有の機能を活用できます。 詳細はEndpointSlice APIのドキュメントをご参照下さい。
Kubernetes v1.33: Octarine
編集者: Agustina Barbetta, Aakanksha Bhende, Udi Hofesh, Ryota Sawada, Sneha Yadav
前回のリリースと同様に、Kubernetes v1.33リリースでは新しいGA、ベータ、アルファの機能が導入されています。 高品質なリリースの継続的な提供は、私たちの開発サイクルの強さとコミュニティからの活発なサポートを示しています。
このリリースには64個の機能改善が含まれています。 それらのうち、GAへの昇格が18個、ベータへの移行が20個、アルファとしての導入が24個、機能の非推奨化及び撤回が2個となっています。
また、このリリースにはいくつかの注目すべき非推奨化と削除があります。 まだ古いバージョンのKubernetesを実行している場合は、これらに必ず目を通してください。
リリースのテーマとロゴ

Kubernetes v1.33のテーマはOctarine: 魔法の色1で、テリー・プラチェットの ディスクワールド シリーズに着想を得ています。
このリリースは、Kubernetesがエコシステム全体で可能にするオープンソースの魔法2を強調しています。
ディスクワールドの世界に詳しい方なら、"見えざる大学"の塔の上に止まった小さな沼ドラゴンが、アンク・モルポークの街の上に64の星3と共に浮かぶKubernetesの月を見上げる様子を思い浮かべていることでしょう。
Kubernetesが10年の節目を迎え新たな10年へ踏み出すにあたり、私たちはメンテナーの魔術、新しいコントリビューターの好奇心、そしてプロジェクトを推進する協力的な精神を祝福します。 v1.33リリースは、プラチェットが書いたように、「やり方を知っていても、それはまだ魔法だ」 ということを思い出させてくれます。 Kubernetesのコードベースの詳細をすべて知っていたとしても、リリースサイクルの終わりに立ち止まってみると、Kubernetesはまだ魔法のままであることがわかるでしょう。
Kubernetes v1.33は、真に卓越したものを生み出すために世界中の何百人ものコントリビューター4が協力する、オープンソースイノベーションの持続的な力の証です。 あらゆる新機能の背後には、プロジェクトを維持・改善したり、安全性や信頼性を担保したり、計画通りにリリースしたりといったKubernetesコミュニティの働きがあります。
1. Octarineはディスクワールド世界の神話上の8番目の色で、「蛍光の緑がかった黄紫色」と表現される架空の色です。
秘術に調律された人々—魔法使い、魔女、そしてもちろん猫にのみ見えます。
一般人は目を閉じた時のみこの色を感じることができるとされています。
そして時々、IPテーブルのルールを長時間見つめてきた人にも見えるようになります。
2. 「十分に発達した技術は魔法と区別がつかない」ですよね…?
3. v1.33にも64のKEP(Kubernetes Enhancement Proposals)が含まれていますが、これは偶然ではありません。
4. v1.33のプロジェクト活動状況セクションをご覧ください 🚀
主なアップデート情報
Kubernetes v1.33は新機能と改善点が満載です。 このセクションでは、リリースチームが特に注目して欲しい、選りすぐりのアップデート内容をご紹介します!
GA: サイドカーコンテナ
サイドカーパターンでは、ネットワーキング、ロギング、メトリクス収集などの分野における追加機能を処理するために、別途補助的なコンテナをデプロイする必要があります。 サイドカーコンテナはv1.33でGAに昇格しました。
Kubernetesでは、restartPolicy: Alwaysが設定された、特別な種類のinitコンテナとしてサイドカーを実装しています。
サイドカーは、アプリケーションコンテナより先に起動し、Podのライフサイクル全体を通じて実行され続け、アプリケーションコンテナの終了を待ってから自動的に終了することが保証されます。
さらに、サイドカーはprobe(startup、readiness、liveness)を使用して動作状態を通知できる他、メモリ不足時の早期終了を防ぐため、Out-Of-Memory(OOM)スコア調整がプライマリコンテナと揃えられています。
詳細については、サイドカーコンテナをお読みください。
この作業はSIG Nodeが主導したKEP-753: Sidecar Containersの一環として行われました。
ベータ: Podの垂直スケーリングのためのインプレースなリソースリサイズ
ワークロードはDeployment、StatefulSetなどのAPIを使用して定義できます。
これらはメモリやCPUリソース、また実行すべきPodの数(レプリカ数)を含む、実行されるべきPodのテンプレートを示しています。
ワークロードはPodのレプリカ数を更新することで水平方向にスケールしたり、Podのコンテナに必要なリソースを更新することで垂直方向にスケールしたりできます。
この機能改善が入る前、Podのspecで定義されたコンテナリソースは不変であり、これらの詳細をPodテンプレート内で更新するにはPodの置き換えが必要でした。
しかし、再起動無しで既存のPodのリソース設定を動的に更新できるとしたらどうでしょうか?
KEP-1287は、まさにそのようなインプレースPod更新を可能にするためのものです。 これはv1.27でアルファとしてリリースされ、v1.33でベータに昇格しました。 これにより、ステートフルなプロセスをダウンタイムなしで垂直方向にスケールアップしたり、トラフィックが少ない時シームレスにスケールダウンすることができます。 さらには起動時に大きなリソースを割り当てて、初期設定が完了したら削減したりするなど、さまざまな可能性が開かれます。
この作業はSIG NodeとSIG Autoscalingが主導したKEP-1287: In-Place Update of Pod Resourcesの一環として行われました。
アルファ: .kubercによるkubectl向けユーザー設定の新しい記述オプション
v1.33にて、kubectlは新しいアルファ機能として、ユーザー設定をクラスター設定と分けて明示的に記述するファイル、.kubercを導入します。
このファイルにはkubectlのエイリアスや上書き設定(例えばServer-Side Applyをデフォルトで使用するなど)を含めることができますが、クラスター認証情報やホスト情報はkubeconfigに残しておく必要があります。
この分離によって、対象クラスターや使用するkubeconfigに関わらず、kubectlの操作に関わるユーザー設定は同じ物を使い回せるようになります。
このアルファ機能を有効にするためには、環境変数KUBECTL_KUBERC=trueを設定し、.kuberc設定ファイルを作成して下さい。
デフォルトの状態では、kubectlは~/.kube/kubercにこのファイルが無いか探します。
--kubercフラグを使用すると、代わりの場所を指定することもできます。
例: kubectl --kuberc /var/kube/rc
この作業はSIG CLIが主導したKEP-3104: Separate kubectl user preferences from cluster configsの一環として行われました。
GAに昇格した機能
これはv1.33リリース後にGAとなった改善点の一部です。
インデックス付きJobのインデックスごとのバックオフ制限
このリリースでは、インデックス付きJobのインデックスごとにバックオフ制限を設定できる機能がGAに昇格しました。
従来、Kubernetes JobのbackoffLimitパラメーターは、Job全体が失敗とみなされる前の再試行回数を指定していました。
この機能強化により、インデックス付きJob内の各インデックスが独自のバックオフ制限を持つことができるようになり、個々のタスクの再試行動作をより細かく制御できるようになりました。
これにより、特定のインデックスの失敗がJob全体を早期に終了させることなく、他のインデックスが独立して処理を継続できるようになります。
この作業はSIG Appsが主導したKEP-3850: Backoff Limit Per Index For Indexed Jobsの一環として行われました。
Job成功ポリシー
.spec.successPolicyを使用してユーザーはどのPodインデックスが成功する必要があるか(succeededIndexes)、何個のPodが成功する必要があるか(succeededCount)、またはその両方の組み合わせを指定できます。
この機能は、部分的な完了で十分なシミュレーションやリーダーの成功だけがJobの全体的な結果を決定するリーダー・ワーカーパターンなど、さまざまなワークロードに利点をもたらします。
この作業はSIG Appsが主導したKEP-3998: Job success/completion policyの一環として行われました。
バインドされたServiceAccountトークンのセキュリティ改善
この機能強化では一意のトークン識別子(すなわちJWT IDクレーム、JTIとも呼ばれる)やノード情報をトークン内に含めることで、より正確な検証と監査を可能にする機能などが導入されました。 さらに、ノード固有の制限をサポートし、トークンが指定されたノードでのみ使用可能であることを保証することで、トークンの不正使用や潜在的なセキュリティ侵害のリスクを低減します。 これらの改善は現在一般提供され、Kubernetesクラスター内のサービスアカウントトークンの全体的なセキュリティ態勢を強化することを目的としています。
この作業はSIG Authが主導したKEP-4193: Bound service account token improvementsの一環として行われました。
kubectlでのサブリソースサポート
--subresource引数が現在kubectlのサブコマンド(get、patch、edit、apply、replaceなど)で一般提供されるようになり、ユーザーはそれらをサポートするすべてのリソースのサブリソースを取得および更新できるようになりました。
サポートされているサブリソースの詳細については、Subresourcesをご覧ください。
この作業はSIG CLIが主導したKEP-2590: Add subresource support to kubectlの一環として行われました。
複数のサービスCIDR
この機能強化では、サービスIPの割り当てロジックの新しい実装が導入されました。
クラスター全体で、type: ClusterIPの各サービスには一意のIPアドレスが割り当てられる必要があります。
既に割り当てられている特定のClusterIPでサービスを作成しようとすると、エラーが返されます。
更新されたIPアドレス割り当てロジックは、ServiceCIDRとIPAddressという2つの新しく安定化したAPIオブジェクトを使用します。
現在一般提供されているこれらのAPIにより、クラスター管理者は(新しいServiceCIDRオブジェクトを作成することで)type: ClusterIPサービスに利用可能なIPアドレスの数を動的に増やすことができます。
この作業はSIG Networkが主導したKEP-1880: Multiple Service CIDRsの一環として行われました。
kube-proxyのnftablesバックエンド
kube-proxyのnftablesバックエンドがGAになり、Kubernetesクラスター内のサービス実装のパフォーマンスとスケーラビリティを大幅に向上させる新しい実装が追加されました。
互換性の理由から、Linuxノードではデフォルトでiptablesのままです。
試してみたい場合はMigrating from iptables mode to nftablesをご確認ください。
この作業はSIG Networkが主導したKEP-3866: nftables kube-proxy backendの一環として行われました。
trafficDistribution: PreferCloseによるTopology Aware Routing
このリリースでは、Topology Aware Routingとトラフィック分散がGAに昇格し、マルチゾーンクラスターでのサービストラフィックを最適化できるようになりました。
EndpointSliceのTopology Aware Hintによりkube-proxyなどのコンポーネントは同じゾーン内のエンドポイントへのトラフィックルーティングを優先できるようになり、レイテンシーとクロスゾーンデータ転送コストが削減されます。
これを基に、Serviceの仕様にtrafficDistributionフィールドが追加され、PreferCloseオプションによりネットワークトポロジーに基づいて最も近い利用可能なエンドポイントにトラフィックが誘導されます。
この構成はゾーン間通信を最小限に抑えることでパフォーマンスとコスト効率を向上させます。
この作業はSIG Networkが主導したKEP-4444: Traffic Distribution for ServicesとKEP-2433: Topology Aware Routingの一環として行われました。
SMT非対応ワークロードを拒否するオプション
この機能はCPUマネージャーにポリシーオプションを追加し、Simultaneous Multithreading(SMT)構成に適合しないワークロードを拒否できるようにしました。 現在一般提供されているこの機能強化により、PodがCPUコアの排他的使用を要求する場合、CPUマネージャーはSMT対応システムで完全なコアペア(プライマリスレッドと兄弟スレッド両方を含む)の割り当てを強制できるようになり、ワークロードが意図しない方法でCPUリソースを共有するシナリオを防止します。
この作業はSIG Nodeが主導したKEP-2625: node: cpumanager: add options to reject non SMT-aligned workloadの一環として行われました。
matchLabelKeysとmismatchLabelKeysを使用したPodアフィニティまたはアンチアフィニティの定義
matchLabelKeysとmismatchLabelKeysフィールドがPodアフィニティ条件で利用可能になり、ユーザーはPodが共存する(アフィニティ)または共存しない(アンチアフィニティ)べき範囲を細かく制御できるようになりました。
これらの新しく安定化したオプションは、既存のlabelSelectorメカニズムを補完します。
affinityフィールドは、多用途なローリングアップデートの強化されたスケジューリングや、グローバル構成に基づいてツールやコントローラーによって管理されるサービスの分離を容易にします。
この作業はSIG Schedulingが主導したKEP-3633: Introduce MatchLabelKeys to Pod Affinity and Pod Anti Affinityの一環として行われました。
Podトポロジー分散制約スキューの計算時にtaintとtolerationを考慮する
この機能強化はPodTopologySpreadにnodeAffinityPolicyとnodeTaintsPolicyという2つのフィールドを導入しました。
これらのフィールドにより、ユーザーはノード間のPod分散のスキュー(偏り)を計算する際にノードアフィニティルールとノードテイントを考慮すべきかどうかを指定できます。
デフォルトでは、nodeAffinityPolicyはHonorに設定されており、Podのノードアフィニティまたはセレクターに一致するノードのみが分散計算に含まれることを意味します。
nodeTaintsPolicyはデフォルトでIgnoreに設定されており、指定されない限りノードテイントは考慮されないことを示します。
この機能強化によりPod配置のより細かい制御が可能になり、Podがアフィニティとテイント許容の両方の要件を満たすノードにスケジュールされることを保証し、制約を満たさないためにPodが保留状態のままになるシナリオを防止します。
この作業はSIG Schedulingが主導したKEP-3094: Take taints/tolerations into consideration when calculating PodTopologySpread skewの一環として行われました。
Volume Populators
v1.24でベータとしてリリースされた後、Volume Populators はv1.33でGAに昇格しました。
この新しく安定化した機能は、ユーザーがPersistentVolumeClaim(PVC)クローンやボリュームスナップショットだけでなく、様々なソースからのデータでボリュームを事前に準備する方法を提供します。
このメカニズムはPersistentVolumeClaim内のdataSourceRefフィールドに依存しています。
このフィールドは既存のdataSourceフィールドよりも柔軟性が高く、カスタムリソースをデータソースとして使用することができます。
特別なコントローラーであるvolume-data-source-validatorは、VolumePopulatorという名前のAPI種別のための新しく安定化したCustomResourceDefinition(CRD)と共に、これらのデータソース参照を検証します。
VolumePopulator APIにより、ボリュームポピュレーターコントローラーはサポートするデータソースのタイプを登録できます。
ボリュームポピュレーターを使用するには、適切なCRDでクラスターをセットアップする必要があります。
この作業はSIG Storageが主導したKEP-1495: Generic data populatorsの一環として行われました。
PersistentVolumeの再利用ポリシーを常に尊重する
この機能強化はPersistent Volume(PV)の再利用ポリシーが一貫して尊重されない問題に対処したもので、ストレージリソースのリークを防ぎます。
具体的にはPVがその関連するPersistent Volume Claim(PVC)より先に削除された場合、再利用ポリシー(Delete)が実行されず、基盤となるストレージアセットがそのまま残ってしまう可能性がありました。
これを緩和するために、Kubernetesは関連するPVにファイナライザーを設定し、削除順序に関係なく再利用ポリシーが適用されるようになりました。
この機能強化により、ストレージリソースの意図しない保持を防ぎ、PVライフサイクル管理の一貫性を維持します。
この作業はSIG Storageが主導したKEP-2644: Always Honor PersistentVolume Reclaim Policyの一環として行われました。
ベータの新機能
これはv1.33リリース後にベータとなった改善点の一部です。
Windowsのkube-proxyにおけるDirect Service Return (DSR)のサポート
DSRは、ロードバランサーを経由するリターントラフィックがロードバランサーをバイパスしてクライアントに直接応答できるようにすることでパフォーマンスを最適化します。 これによりロードバランサーの負荷が軽減され、全体的なレイテンシーも低減されます。 Windows上のDSRに関する情報は、Direct Server Return (DSR) in a nutshellをお読みください。
v1.14で最初に導入されたDSRのサポートは、KEP-5100: Support for Direct Service Return (DSR) and overlay networking in Windows kube-proxyの一環としてSIG Windowsによりベータに昇格しました。
構造化パラメーターのサポート
構造化パラメーターのサポートはKubernetes v1.33でベータ機能として継続される中、Dynamic Resource Allocation(DRA)のこの中核部分に大幅な改善が見られました。
新しいv1beta2バージョンはresource.k8s.io APIを簡素化し、名前空間クラスターのeditロールを持つ一般ユーザーが現在DRAを使用できるようになりました。
kubeletは現在シームレスなアップグレードサポートを含み、DaemonSetとしてデプロイされたドライバーがローリングアップデートメカニズムを使用できるようになっています。
DRA実装では、これによりResourceSliceの削除と再作成が防止され、アップグレード中も変更されないままにすることができます。
さらに、ドライバーの登録解除後にkubeletがクリーンアップを行う前に30秒の猶予期間が導入され、ローリングアップデートを使用しないドライバーのサポートが向上しました。
この作業はSIG Node、SIG Scheduling、SIG Autoscalingを含む機能横断チームであるWG Device ManagementによるKEP-4381: DRA: structured parametersの一環として行われました。
ネットワークインターフェース向けDynamic Resource Allocation(DRA)
v1.32で導入されたDRAによるネットワークインターフェースデータの標準化された報告がv1.33でベータに昇格しました。 これにより、よりネイティブなKubernetesネットワークの統合が可能になり、ネットワークデバイスの開発と管理が簡素化されます。 これについては以前にv1.32リリース発表ブログで説明されています。
この作業はSIG Network、SIG Node、およびWG Device Managementが主導したKEP-4817: DRA: Resource Claim Status with possible standardized network interface dataの一環として行われました。
スケジューラーがactiveQにPodを持たない場合に、スケジュールされていないPodを早期に処理
この機能はキュースケジューリングの動作を改善します。
裏側では、スケジューラーはactiveQが空の場合に、エラーによってバックオフされていないPodをbackoffQからポップすることでこれを実現しています。
以前は、activeQが空の場合でもスケジューラーはアイドル状態になってしまいましたが、この機能強化はそれを防止することでスケジューリング効率を向上させます。
この作業はSIG Schedulingが主導したKEP-5142: Pop pod from backoffQ when activeQ is emptyの一環として行われました。
Kubernetesスケジューラーにおける非同期プリエンプション
プリエンプションは、優先度の低いPodを退避させることで、優先度の高いPodが必要なリソースを確保できるようにします。 v1.32でアルファとして導入された非同期プリエンプションがv1.33でベータに昇格しました。 この機能強化により、Podを削除するためのAPIコールなどの重い操作が並行して処理されるようになり、スケジューラーは遅延なく他のPodのスケジューリングを継続できます。 この改善は特にPodの入れ替わりが激しいクラスターやスケジューリングの失敗が頻繁に発生するクラスターで有益であり、より効率的で回復力のあるスケジューリングプロセスを確保します。
この作業はSIG Schedulingが主導したKEP-4832: Asynchronous preemption in the schedulerの一環として行われました。
ClusterTrustBundle
X.509トラストアンカー(ルート証明書)を保持するために設計されたクラスタースコープリソースであるClusterTrustBundleがv1.33でベータに昇格しました。 このAPIにより、クラスター内の証明書署名者がX.509トラストアンカーをクラスターワークロードに公開および通信することが容易になります。
この作業はSIG Authが主導したKEP-3257: ClusterTrustBundles (previously Trust Anchor Sets)の一環として行われました。
きめ細かいSupplementalGroupsの制御
v1.31で導入されたこの機能はv1.33でベータに昇格し、現在はデフォルトで有効になっています。
クラスターでフィーチャーゲートのSupplementalGroupsPolicyが有効になっている場合、PodのsecurityContext内のsupplementalGroupsPolicyフィールドは2つのポリシーをサポートします:
デフォルトのMergeポリシーはコンテナイメージの/etc/groupファイルからのグループと指定されたグループを結合することで後方互換性を維持し、新しいStrictポリシーは明示的に定義されたグループのみを適用します。
この機能強化は、コンテナイメージからの暗黙的なグループメンバーシップが意図しないファイルアクセス権限につながり、ポリシー制御をバイパスする可能性があるセキュリティ上の懸念に対処するのに役立ちます。
この作業はSIG Nodeが主導したKEP-3619: Fine-grained SupplementalGroups controlの一環として行われました。
イメージをボリュームとしてマウントする機能をサポート
v1.31で導入されたPodでOpen Container Initiative(OCI)イメージをボリュームとして使用する機能のサポートがベータに昇格しました。 この機能により、ユーザーはPod内でイメージ参照をボリュームとして指定し、コンテナ内でボリュームマウントとして再利用できるようになります。 これにより、ボリュームデータを別々にパッケージ化し、メインイメージに含めることなくPod内のコンテナ間で共有する可能性が開かれ、脆弱性を減らしイメージ作成を簡素化します。
この作業はSIG NodeとSIG Storageが主導したKEP-4639: VolumeSource: OCI Artifact and/or Imageの一環として行われました。
Linux Podにおけるユーザー名前空間のサポート
執筆時点で最も古いオープンなKEPの1つであるKEP-127は、Pod用のLinuxユーザー名前空間を使用したPodセキュリティの改善です。 このKEPは2016年後半に最初に提案され、複数の改訂を経て、v1.25でアルファリリース、v1.30で初期ベータ(デフォルトでは無効)となり、v1.33の一部としてデフォルトで有効なベータに移行しました。
このサポートは、手動でpod.spec.hostUsersを指定してオプトインしない限り、既存のPodに影響を与えません。
v1.30の先行紹介ブログで強調されているように、これは脆弱性を軽減するための重要なマイルストーンです。
この作業はSIG Nodeが主導したKEP-127: Support User Namespaces in podsの一環として行われました。
PodのprocMountオプション
v1.12でアルファとして導入され、v1.31でデフォルト無効のベータだったprocMountオプションが、v1.33でデフォルト有効のベータに移行しました。
この機能強化はユーザーが/procファイルシステムへのアクセスを細かく調整できるようにすることでPod分離を改善します。
具体的には、PodのsecurityContextにフィールドを追加し、特定の/procパスをマスクしたり読み取り専用としてマークするデフォルトの動作をオーバーライドできるようにします。
これは特に、ユーザーがユーザー名前空間を使用してKubernetes Pod内で非特権コンテナを実行したい場合に便利です。
通常、コンテナランタイム(CRI実装を介して)は厳格な/procマウント設定で外部コンテナを起動します。
しかし、非特権Pod内でネストされたコンテナを正常に実行するには、ユーザーはそれらのデフォルト設定を緩和するメカニズムが必要であり、この機能はまさにそれを提供します。
この作業はSIG Nodeが主導したKEP-4265: add ProcMount optionの一環として行われました。
NUMAノード間でCPUを分散させるCPUManagerポリシー
この機能はCPUManagerに、単一ノードに集中させるのではなく非一様メモリアクセス(NUMA)ノード間でCPUを分散させる新しいポリシーオプションを追加します。 これにより複数のNUMAノード間でワークロードのバランスを取ることでCPUリソースの割り当てを最適化し、マルチNUMAシステムにおけるパフォーマンスとリソース使用率を向上させます。
この作業はSIG Nodeが主導したKEP-2902: Add CPUManager policy option to distribute CPUs across NUMA nodes instead of packing themの一環として行われました。
コンテナのPreStopフックのゼロ秒スリープ
Kubernetes 1.29ではPodのpreStopライフサイクルフックにSleepアクションが導入され、コンテナが終了する前に指定された時間だけ一時停止できるようになりました。
これにより、接続のドレイン(排出)やクリーンアップ操作などのタスクを容易にするコンテナのシャットダウンを遅らせるための簡単な方法が提供されます。
preStopフックのSleepアクションは、現在ベータ機能としてゼロ秒の時間を受け付けることができます。
これにより、preStopフックが必要だが遅延が不要な場合に便利な、無操作(no-op)のpreStopフックを定義できるようになります。
この作業はSIG Nodeが主導したKEP-3960: Introducing Sleep Action for PreStop HookおよびKEP-4818: Allow zero value for Sleep Action of PreStop Hookの一環として行われました。
Kubernetesネイティブ型の宣言的検証のための内部ツール
ひそかに、Kubernetesの内部はオブジェクトとオブジェクトへの変更を検証するための新しいメカニズムの使用を開始しています。
Kubernetes v1.33では、Kubernetesコントリビューターが宣言的な検証ルールを生成するために使用する内部ツールvalidation-genを導入しています。
全体的な目標は、開発者が検証制約を宣言的に指定できるようにすることでAPI検証の堅牢性と保守性を向上させ、手動コーディングエラーを減らし、コードベース全体での一貫性を確保することです。
この作業はSIG API Machineryが主導したKEP-5073: Declarative Validation Of Kubernetes Native Types With validation-genの一環として行われました。
アルファの新機能
これはv1.33リリース後にアルファとなった改善点の一部です。
HorizontalPodAutoscalerの設定可能な許容値
この機能は、HorizontalPodAutoscaler設定可能な許容値を導入し、小さなメトリクス変動に対するスケーリング反応を抑制します。
この作業はSIG Autoscalingが主導したKEP-4951: Configurable tolerance for Horizontal Pod Autoscalersの一環として行われました。
設定可能なコンテナの再起動遅延
CrashLoopBackOffの処理方法を微調整できる機能です。
この作業はSIG Nodeが主導したKEP-4603: Tune CrashLoopBackOffの一環として行われました。
カスタムコンテナの停止シグナル
Kubernetes v1.33より前では、停止シグナルはコンテナイメージ定義内でのみ設定可能でした(例えば、イメージメタデータのStopSignalフィールドを介して)。
終了動作を変更したい場合は、カスタムコンテナイメージをビルドする必要がありました。
Kubernetes v1.33で(アルファの)フィーチャーゲートであるContainerStopSignalsを有効にすることで、Pod仕様内で直接カスタム停止シグナルを定義できるようになりました。
これはコンテナのlifecycle.stopSignalフィールドで定義され、Podのspec.os.nameフィールドが存在する必要があります。
指定されない場合、コンテナはイメージで定義された停止シグナル(存在する場合)、またはコンテナランタイムのデフォルト(通常Linuxの場合はSIGTERM)にフォールバックします。
この作業はSIG Nodeが主導したKEP-4960: Container Stop Signalsの一環として行われました。
豊富なDRA機能強化
Kubernetes v1.33は、今日の複雑なインフラストラクチャ向けに設計された機能を備えたDynamic Resource Allocation (DRA)の開発を継続しています。 DRAはPod間およびPod内のコンテナ間でリソースを要求および共有するためのAPIです。 通常、それらのリソースはGPU、FPGA、ネットワークアダプターなどのデバイスです。
以下はv1.33で導入されたすべてのアルファのDRAのフィーチャーゲートです:
- ノードテイントと同様に、フィーチャーゲートの
DRADeviceTaintsを有効にすることで、デバイスはTaintとTolerationをサポートします。 管理者またはコントロールプレーンコンポーネントはデバイスにテイントを付けて使用を制限できます。 テイントが存在する間、それらのデバイスに依存するPodのスケジューリングを一時停止したり、テイントされたデバイスを使用するPodを退避させたりすることができます。 - フィーチャーゲートの
DRAPrioritizedListを有効にすることで、DeviceRequestsはfirstAvailableという新しいフィールドを取得します。 このフィールドは順序付けられたリストで、ユーザーが特定のハードウェアが利用できない場合に何も割り当てないことを含め、リクエストが異なる方法で満たされる可能性を指定できるようにします。 - フィーチャーゲートの
DRAAdminAccessを有効にすると、resource.k8s.io/admin-access: "true"でラベル付けされた名前空間内でResourceClaimまたはResourceClaimTemplateオブジェクトを作成する権限を持つユーザーのみがadminAccessフィールドを使用できます。 これにより、管理者以外のユーザーがadminAccess機能を誤用できないようになります。 - v1.31以降、デバイスパーティションの使用が可能でしたが、ベンダーはデバイスを事前にパーティション分割し、それに応じて通知する必要がありました。
v1.33でフィーチャーゲートの
DRAPartitionableDevicesを有効にすることで、デバイスベンダーは重複するものを含む複数のパーティションを通知できます。 Kubernetesスケジューラーはワークロード要求に基づいてパーティションを選択し、競合するパーティションの同時割り当てを防止します。 この機能により、ベンダーは割り当て時に動的にパーティションを作成する機能を持ちます。 割り当てと動的パーティショニングは自動的かつユーザーに透過的に行われ、リソース使用率の向上を可能にします。
これらのフィーチャーゲートは、フィーチャーゲートのDynamicResourceAllocationも有効にしない限り効果がありません。
この作業はSIG Node、SIG Scheduling、SIG Authが主導した KEP-5055: DRA: device taints and tolerations、 KEP-4816: DRA: Prioritized Alternatives in Device Requests、 KEP-5018: DRA: AdminAccess for ResourceClaims and ResourceClaimTemplates、 およびKEP-4815: DRA: Add support for partitionable devicesの一環として行われました。
IfNotPresentとNeverのイメージに対する認証を行う堅牢なimagePullPolicy
この機能により、ユーザーはイメージがノード上に既に存在するかどうかに関わらず、新しい資格情報セットごとにkubeletがイメージプル認証チェックを要求することを確実にできます。
この作業はSIG Authが主導したKEP-2535: Ensure secret pulled imagesの一環として行われました。
Downward APIを通じて利用可能なノードトポロジーラベル
この機能により、ノードトポロジーラベルがダウンワードAPIを通じて公開されるようになります。 Kubernetes v1.33より前では、基盤となるノードについてKubernetes APIに問い合わせるために初期化コンテナを使用する回避策が必要でした。 このアルファ機能により、ワークロードがノードトポロジー情報にアクセスする方法が簡素化されます。
この作業はSIG Nodeが主導したKEP-4742: Expose Node labels via downward APIの一環として行われました。
生成番号と観測された生成番号によるより良いPodステータス
この変更以前は、metadata.generationフィールドはPodでは使用されていませんでした。
metadata.generationをサポートするための拡張に加えて、この機能はstatus.observedGenerationを導入し、より明確なPodステータスを提供します。
この作業はSIG Nodeが主導したKEP-5067: Pod Generationの一環として行われました。
kubeletのCPU Managerによる分割レベル3キャッシュアーキテクチャのサポート
これまでのkubeletのCPU Managerは分割L3キャッシュアーキテクチャ(Last Level Cache、またはLLCとも呼ばれる)を認識せず、分割L3キャッシュを考慮せずにCPU割り当てを分散させる可能性があり、ノイジーネイバー問題を引き起こす可能性がありました。 このアルファ機能はCPU Managerを改善し、より良いパフォーマンスのためにCPUコアをより適切に割り当てます。
この作業はSIG Nodeが主導したKEP-5109: Split L3 Cache Topology Awareness in CPU Managerの一環として行われました。
スケジューリング改善のためのPSI(Pressure Stall Information)メトリクス
この機能は、Linuxノードにcgroupv2を使用してPSI統計とメトリクスを提供するサポートを追加します。 これによりリソース不足を検出し、Podスケジューリングのためのより細かい制御をノードに提供できます。
この作業はSIG Nodeが主導したKEP-4205: Support PSI based on cgroupv2の一環として行われました。
kubeletによるシークレットレスイメージPull
kubeletのオンディスク認証情報プロバイダーが、オプションでKubernetes ServiceAccount(SA)トークンの取得をサポートするようになりました。 これにより、クラウドプロバイダーはOIDC互換のアイデンティティソリューションとより適切に統合でき、イメージレジストリとの認証が簡素化されます。
この作業はSIG Authが主導したKEP-4412: Projected service account tokens for Kubelet image credential providersの一環として行われました。
v1.33での昇格、非推奨化、および削除
GAへの昇格
これは安定版(一般提供、GAとも呼ばれる)に昇格したすべての機能を一覧にしたものです。 アルファからベータへの昇格や新機能を含む更新の完全なリストについては、リリースノートをご覧ください。
このリリースには、GAに昇格した合計18の機能強化が含まれています:
- Take taints/tolerations into consideration when calculating PodTopologySpread skew
- Introduce
MatchLabelKeysto Pod Affinity and Pod Anti Affinity - Bound service account token improvements
- Generic data populators
- Multiple Service CIDRs
- Topology Aware Routing
- Portworx file in-tree to CSI driver migration
- Always Honor PersistentVolume Reclaim Policy
- nftables kube-proxy backend
- Deprecate status.nodeInfo.kubeProxyVersion field
- Add subresource support to kubectl
- Backoff Limit Per Index For Indexed Jobs
- Job success/completion policy
- Sidecar Containers
- CRD Validation Ratcheting
- node: cpumanager: add options to reject non SMT-aligned workload
- Traffic Distribution for Services
- Recursive Read-only (RRO) mounts
非推奨化と削除
Kubernetesの開発と成熟に伴い、プロジェクト全体の健全性を向上させるために機能が非推奨化されたり、削除されたり、より良い機能に置き換えられたりすることがあります。 このプロセスに関する詳細は、Kubernetes非推奨ポリシーを参照してください。 これらの非推奨化や削除の多くは、Kubernetes v1.33の先行紹介ブログで告知されました。
Endpoints APIの非推奨化
v1.21以降GAされたEndpointSlice APIは、元のEndpoint APIを事実上置き換えました。 元のEndpoint APIはシンプルで分かりやすかったものの、多数のネットワークエンドポイントへスケーリングする際にいくつかの課題がありました。 EndpointSlice APIにはデュアルスタックネットワーキングなどの新機能が導入され、これにより元のEndpoint APIは非推奨化されることになりました。
この非推奨化は、ワークロードやスクリプトからEndpoint APIを直接使用しているユーザーにのみ影響します。 これらのユーザーは代わりにEndpointSliceを使用するように移行する必要があります。 非推奨化による影響と移行計画に関する詳細を記載した専用のブログ記事が公開される予定です。
詳細はKEP-4974: Deprecate v1.Endpointsで確認できます。
Nodeステータスにおけるkube-proxyバージョン情報の削除
v1.31の「Deprecation of status.nodeInfo.kubeProxyVersion field for Nodes」で強調されているように、v1.31での非推奨化に続き、Nodeの.status.nodeInfo.kubeProxyVersionフィールドがv1.33で削除されました。
このフィールドはkubeletによって設定されていましたが、その値は一貫して正確ではありませんでした。 v1.31以降デフォルトで無効化されていたため、このフィールドはv1.33で完全に削除されました。
詳細はKEP-4004: Deprecate status.nodeInfo.kubeProxyVersion fieldで確認できます。
インツリーのgitRepoボリュームドライバーの削除
gitRepoボリュームタイプは、約7年前のv1.11から非推奨化されていました。
非推奨化されて以降、gitRepoボリュームタイプがノード上でrootとしてリモートコード実行を得るためにどのように悪用されうるかといった、セキュリティ上の懸念がありました。
v1.33では、インツリーのドライバーコードが削除されます。
代替手段としてgit-syncやinitコンテナがあります。
Kubernetes APIのgitVolumesは削除されないため、gitRepoボリュームを持つPodはkube-apiserverによって受け入れられます。
しかし、フィーチャーゲートのGitRepoVolumeDriverがfalseに設定されているkubeletはそれらを実行せず、ユーザーに適切なエラーを返します。
これにより、ユーザーはワークロードを修正するための十分な時間を確保するために、3バージョン分の期間、ドライバーの再有効化をオプトインできます。
kubeletのフィーチャーゲートとインツリーのプラグインコードは、v1.39リリースで削除される予定です。
詳細はKEP-5040: Remove gitRepo volume driverで確認できます。
Windows Podにおけるホストネットワークサポートの削除
Windows Podのネットワーキングは、コンテナがNodeのネットワーク名前空間を使用できるようにすることでLinuxとの機能パリティを達成し、クラスター密度を向上させることを目指していました。
元の実装はv1.26でアルファとして導入されましたが、予期せぬcontainerdの挙動に直面し、代替ソリューションが存在したため、Kubernetesプロジェクトは関連するKEPを取り下げることを決定しました。
サポートはv1.33で完全に削除されました。
これは、ホストネットワークおよびホストレベルのアクセスを提供するHostProcessコンテナには影響しないことに注意してください。 v1.33で取り下げられたKEPは、ホストネットワークのみを提供することに関するものでしたが、Windowsのネットワーキングロジックにおける技術的な制限のため、安定することはありませんでした。
詳細はKEP-3503: Host network support for Windows podsで確認できます。
リリースノート
Kubernetes v1.33リリースの詳細については、リリースノートをご覧ください。
入手方法
Kubernetes v1.33はGitHubまたはKubernetes公式サイトのダウンロードページからダウンロードできます。
Kubernetesを始めるには、チュートリアルをチェックするか、minikubeを使用してローカルKubernetesクラスターを実行してください。 また、kubeadmを使用して簡単にv1.33をインストールすることもできます。
リリースチーム
Kubernetesはそのコミュニティのサポート、コミットメント、そして懸命な働きによってのみ実現可能です。 リリースチームは、ユーザーが依存するKubernetesリリースを構成する多くの部分を構築するために協力する、献身的なコミュニティボランティアによって構成されています。 これには、コード自体からドキュメンテーションやプロジェクト管理まで、コミュニティのあらゆる分野の人々の専門的なスキルが必要です。
私たちは、Kubernetes v1.33リリースをコミュニティに提供するために熱心に取り組んだ時間について、リリースチーム全体に感謝します。 リリースチームのメンバーは、初めてのShadow(見習い)から、複数のリリースサイクルで培われた経験を持ち、復帰をしたチームリードまで幅広く存在します。 このリリースサイクルでは、リリースノートとDocsのサブチームを統合し、Docsサブチームに統一するという新しいチーム構造が採用されました。 新しいDocsチームから関連情報とリソースを整理する綿密な努力のおかげで、リリースノートとDocsの追跡は円滑かつ成功した移行を実現しました。 最後に、成功したリリースサイクルを通してのサポート、支援、誰もが効果的に貢献できるようにする取り組み、そしてリリースプロセスを改善するための課題に対して、リリースリードのNina Polshakovaに心より感謝します。
プロジェクトの活動状況
CNCF K8sのDevStatsプロジェクトは、Kubernetesおよび様々なサブプロジェクトの活動状況に関する興味深いデータポイントを集計しています。 これには個人の貢献から貢献企業数まで含まれ、このエコシステムの発展に費やされる努力の深さと広さを示しています。
v1.33リリースサイクル(2025年1月13日から4月23日までの15週間)において、Kubernetesには最大121の異なる企業と570人の個人から貢献がありました(執筆時点では、リリース日の数週間前の数値です)。 より広範なクラウドネイティブエコシステムでは、この数字は435社、合計2400人のコントリビューターに達しています。 データソースはこのダッシュボードで確認できます。 前回のリリースv1.32の活動データと比較すると、企業や個人からの貢献レベルは同様であり、コミュニティの関心と参加が引き続き強いことを示しています。
なお、「貢献」とはコミットの作成、コードレビュー、コメント、IssueやPRの作成、PRのレビュー(ブログやドキュメントを含む)、またはIssueやPRへのコメントを行うことを指します。 貢献に興味がある場合は、公式ドキュメントのコントリビューター向けのはじめにをご覧ください。
Kubernetesプロジェクトとコミュニティの全体的な活動状況についてさらに詳しく知るには、DevStatsをチェックしてください。
イベント情報
今後開催予定のKubernetesおよびクラウドネイティブイベント(KubeCon + CloudNativeCon、KCDなど)や、世界各地で開催される主要なカンファレンスについて紹介します。 Kubernetesコミュニティの最新情報を入手し、参加しましょう!
2025年5月
- KCD - Kubernetes Community Days: Costa Rica: 2025年5月3日 | コスタリカ、エレディア
- KCD - Kubernetes Community Days: Helsinki: 2025年5月6日 | フィンランド、ヘルシンキ
- KCD - Kubernetes Community Days: Texas Austin: 2025年5月15日 | アメリカ、オースティン
- KCD - Kubernetes Community Days: Seoul: 2025年5月22日 | 韓国、ソウル
- KCD - Kubernetes Community Days: Istanbul, Turkey: 2025年5月23日 | トルコ、イスタンブール
- KCD - Kubernetes Community Days: San Francisco Bay Area: 2025年5月28日 | アメリカ、サンフランシスコ
2025年6月
- KCD - Kubernetes Community Days: New York: 2025年6月4日 | アメリカ、ニューヨーク
- KCD - Kubernetes Community Days: Czech & Slovak: 2025年6月5日 | スロバキア、ブラチスラバ
- KCD - Kubernetes Community Days: Bengaluru: 2025年6月6日 | インド、バンガロール
- KubeCon + CloudNativeCon China 2025: 2025年6月10日-11日 | 香港
- KCD - Kubernetes Community Days: Antigua Guatemala: 2025年6月14日 | グアテマラ、アンティグア・グアテマラ
- KubeCon + CloudNativeCon Japan 2025: 2025年6月16日-17日 | 日本、東京
- KCD - Kubernetes Community Days: Nigeria, Africa: 2025年6月19日 | アフリカ、ナイジェリア
2025年7月
- KCD - Kubernetes Community Days: Utrecht: 2025年7月4日 | オランダ、ユトレヒト
- KCD - Kubernetes Community Days: Taipei: 2025年7月5日 | 台湾、台北
- KCD - Kubernetes Community Days: Lima, Peru: 2025年7月19日 | ペルー、リマ
2025年8月
- KubeCon + CloudNativeCon India 2025: 2025年8月6日-7日 | インド、ハイデラバード
- KCD - Kubernetes Community Days: Colombia: 2025年8月29日 | コロンビア、ボゴタ
最新のKCD情報はこちらでご確認いただけます。
ウェビナーのご案内
Kubernetes v1.33リリースチームのメンバーと一緒に 2025年5月16日(金)午後4時(UTC) から、このリリースのハイライトやアップグレードの計画に役立つ非推奨事項や削除事項について学びましょう。 詳細および参加登録は、CNCFオンラインプログラム・サイトのイベントページをご覧ください。
参加方法
Kubernetesに関わる最も簡単な方法は、あなたの興味に合ったSpecial Interest Groups (SIGs)のいずれかに参加することです。 Kubernetesコミュニティに向けて何か発信したいことはありますか? 毎週のコミュニティミーティングや、以下のチャンネルであなたの声を共有してください。 継続的なフィードバックとサポートに感謝いたします。
- 最新情報はBlueSkyの@kubernetes.ioをフォローしてください
- Discussでコミュニティディスカッションに参加してください
- Slackでコミュニティに参加してください
- Server FaultかStack Overflowで質問したり、回答したりしてください
- あなたのKubernetesに関するストーリーを共有してください
- Kubernetesの最新情報はブログでさらに詳しく読むことができます
- Kubernetes Release Teamについての詳細はこちらをご覧ください
KubernetesのマルチコンテナPod: 概要
クラウドネイティブアーキテクチャの進化が続く中、Kubernetesは複雑で分散したシステムをデプロイするための定番のプラットフォームとなってきました。 このエコシステムにおける最も強力でありながら繊細な設計パターンの一つがサイドカーパターンです。これは、開発者がソースコードに深く踏み込むことなく、アプリケーションの機能を拡張できる手法です。
サイドカーパターンの起源
サイドカーは、バイクに取り付ける信頼できる補助座席のようなものだと考えてみてください。 ITインフラストラクチャでは、重要な処理を担うために、補助的なサービスが従来から利用されてきました。 コンテナが登場する以前は、ロギング、モニタリング、ネットワーク処理を管理するために、バックグラウンドプロセスやヘルパーデーモンに依存していました。 マイクロサービスの革命により、このアプローチは変革され、サイドカーは体系的かつ意図的なアーキテクチャの選択肢となりました。 マイクロサービスの台頭に伴い、サイドカーパターンはより明確に定義されるようになり、開発者はメインサービスのコードを変更することなく、特定の責務を切り離せるようになりました。 IstioやLinkerdのようなサービスメッシュは、サイドカープロキシを普及させ、これらの補助的なコンテナが分散システムにおける可観測性、セキュリティ、トラフィック管理を洗練された方法で処理できることを示しました。
Kubernetesにおける実装
Kubernetesでは、サイドカーコンテナはメインのアプリケーションと同じPod内で動作し、通信やリソースの共有を可能にします。
これは、単にPod内に複数のコンテナを並列に定義することのように聞こえるかもしれません。
実際、その通りであり、Kubernetes v1.29.0でサイドカーのネイティブサポートが導入されるまでは、そのように実装する必要がありました。
現在では、Podマニフェスト内でspec.initContainersフィールドを使用してサイドカーコンテナを定義することができます。
これをサイドカーコンテナとして機能させるポイントは、restartPolicy: Alwaysを指定することです。
以下はその一例で、Kubernetesマニフェスト全体の一部を抜粋したものです。
initContainers:
- name: logshipper
image: alpine:latest
restartPolicy: Always
command: ['sh', '-c', 'tail -F /opt/logs.txt']
volumeMounts:
- name: data
mountPath: /opt
spec.initContainersというフィールド名は、混乱を招くかもしれません。
サイドカーコンテナを定義したいのに、なぜspec.initContainers配列にエントリを追加しなければならないのでしょうか?
spec.initContainersに定義されたコンテナは、メインアプリケーションが起動する直前に一度だけ実行され、完了すると終了します。
一方、サイドカーコンテナは通常、メインのアプリケーションコンテナと並行して動作し続けます。
Kubernetesにおけるネイティブなサイドカーコンテナは、spec.initContainersにrestartPolicy:Alwaysを指定することで、従来のInitコンテナとは異なる挙動を持ち、常に稼働し続けることが保証されます。
サイドカーを採用すべき場合と避けるべき場合
サイドカーパターンは多くのケースで有用ですが、正当化されるようなユースケースがない限り、一般的には推奨される手法ではありません。 サイドカーを追加すると、複雑性やリソース消費、ネットワーク遅延の可能性が増大します。 その代わりに、まずは組み込みライブラリや共通インフラなど、より単純な代替手段を検討すべきです。
サイドカーの導入が適しているのは次のような場合です:
- 元のコードに手を加えることなくアプリケーションの機能を拡張する必要がある場合
- ロギング、モニタリング、セキュリティなどの横断的な考慮が必要な実装をする場合
- モダンなネットワーク機能を必要とするレガシーアプリケーションを扱う場合
- 独立したスケーリングや更新が求められるマイクロサービスを設計する場合
次のような場合は慎重に検討してください:
- リソース効率を最優先したい場合
- 最小限のネットワーク遅延が重要な場合
- より単純な代替手段が存在する場合
- トラブルシューティングの複雑さを最小限に抑えたい場合
4つの重要なマルチコンテナパターン
Initコンテナパターン
Initコンテナパターンは、メインのアプリケーションコンテナが起動する前に(しばしば重要な)初期化処理を実行するために使用されます。 通常のコンテナと異なり、Initコンテナは処理が完了すると終了し、メインアプリケーションの前提条件が満たされることを保証します。
このパターンが適しているケース:
- 各種設定の準備
- シークレットの読み込み
- 依存関係の利用可能性の確認
- データベースマイグレーションの実行
Initコンテナを使用することで、アプリケーションのコードを変更することなく、予測可能で制御された環境下での起動を実現できます。
Ambassadorパターン
Ambassadorコンテナは、Pod内で動作する補助的なサービスを提供し、ネットワークサービスへのアクセスを簡易化します。 一般的に、Ambassadorコンテナはアプリケーションコンテナに代わってネットワークリクエストを送信し、サービス検出、ピアの識別検証、通信の暗号化といった処理を担います。
このパターンが特に有効なのは次のような場合です:
- クライアント接続に関する処理を切り離す場合
- 言語に依存しないネットワーク機能を実装する場合
- TLSなどのセキュリティ層を追加する場合
- 堅牢なサーキットブレーカーやリトライ機構を構築する場合
Configuration helper
configuration helper サイドカーは、アプリケーションに対して設定の更新を動的に提供し、サービスを中断させることなく常に最新の設定にアクセスできるようにします。 多くの場合、アプリケーションが正常に起動するためには、事前に初期設定を提供する必要があります。
ユースケース:
- 環境変数やシークレットの取得
- 設定変更のポーリング
- 設定管理とアプリケーションロジックの分離
Adapterパターン
adapter(または façade)コンテナは、メインのアプリケーションコンテナと外部サービスとの間の相互運用性を実現します。 これは、データ形式、プロトコル、またはAPIの変換を行うことで実現されます。
このパターンの強み:
- レガシーなデータ形式の変換
- 通信プロトコル間の橋渡し
- 互換性のないサービス間の統合促進
まとめ
サイドカーパターンは非常に高い柔軟性を提供してくれますが、銀の弾丸ではありません。 サイドカーを追加するたびに、複雑性が増し、リソースを消費し、運用負荷が高まる可能性があります。 まずは、より単純な代替手段を検討するようにしてください。 鍵となるのは、戦略的な実装です。 サイドカーは、あらゆる場面で使うデフォルトの方法ではなく、特定のアーキテクチャ上の課題を解決するための精密なツールとして活用すべきです。 適切に使用すれば、コンテナ化された環境において、セキュリティ、ネットワーキング、設定管理の向上に貢献できます。 賢明に選び、注意深く実装し、サイドカーを活用してコンテナエコシステムをさらに高めましょう。
kube-scheduler-simulatorの紹介
Kubernetesスケジューラーは、Podがどのノードで実行されるかを決定する、非常に重要なコントロールプレーンコンポーネントです。 そのため、Kubernetesを利用するすべてのユーザーは、スケジューラーに依存しています。
kube-scheduler-simulatorは、Kubernetesスケジューラーの シミュレーター であり、Google Summer of Code 2021において私(Kensei Nakada)が開発を開始し、その後多くのコントリビューションを受けてきたプロジェクトです。 このツールを使用すると、スケジューラーの動作や意思決定を詳細に観察することができます。
このシミュレーターは、スケジューリング制約(たとえば、Pod間のアフィニティ)を利用する一般ユーザーにとっても有用ですし、カスタムプラグインによってスケジューラーを拡張するエキスパートにとっても有用です。
動機
スケジューラーは、多くのプラグインで構成されており、それぞれが独自の観点でスケジューリングの意思決定に寄与しているため、しばしばブラックボックスのように見えます。 その動作を理解することは、考慮される要素が非常に多いため困難です。
たとえシンプルなテストクラスターにおいてPodが正しくスケジューリングされているように見えても、想定とは異なる計算に基づいてスケジューリングされている可能性があります。 このようなずれは、本番の大規模な環境において、予期しないスケジューリング結果を引き起こすことにつながりかねません。
また、スケジューラーをテストすることは非常に複雑な課題です。 実際のクラスター内では無数の操作パターンが存在し、有限な数のテストであらゆるシナリオを予測することは現実的ではありません。 多くの場合、スケジューラーを実際のクラスターにデプロイして初めてバグが発見されます。 実際、アップストリームのkube-schedulerであっても、リリース後にユーザーによって多くのバグが発見されています。
スケジューラー、あるいはどんなKubernetesコントローラーであっても、それらをテストするための開発環境やサンドボックス環境を用意することは、一般的なプラクティスです。 しかし、この方法では、本番クラスターで発生し得るすべてのシナリオを網羅するには不十分です。 というのも、開発クラスターは通常、本番に比べてはるかに小規模であり、ワークロードの規模やスケーリングの特性にも大きな違いがあるためです。 開発クラスターは本番環境とまったく同じ使われ方をすることはなく、同じ挙動を示すこともありません。
kube-scheduler-simulatorは、これらの問題を解決することを目的としています。 ユーザーは、このツールを用いてスケジューリング制約やスケジューラーの設定、カスタムプラグインをテストしつつ、スケジューリングの意思決定におけるあらゆる詳細な部分を確認することができます。 また、ユーザーは本番クラスターと同じリソースを使いながら、実際のワークロードに影響を与えることなく、スケジューラーをテストできるシミュレートされたクラスター環境を作成することも可能です。
kube-scheduler-simulatorの機能
kube-scheduler-simulatorのコア機能は、スケジューラーの内部的な意思決定を可視化できる点にあります。 スケジューラーはスケジューリングフレームワークに基づいて動作しており、さまざまな拡張ポイントで複数のプラグインを利用し、ノードのフィルタリング(Filterフェーズ)、スコア付け(Scoreフェーズ)を経て、最終的にPodに最適なノードを決定します。
このシミュレーターを用いることで、ユーザーはKubernetesリソースを作成し、各プラグインがPodのスケジューリングにどのように影響を与えているかを観察できます。 これにより、スケジューラーの仕組みを理解し、適切なスケジューリング制約を定義する助けとなります。
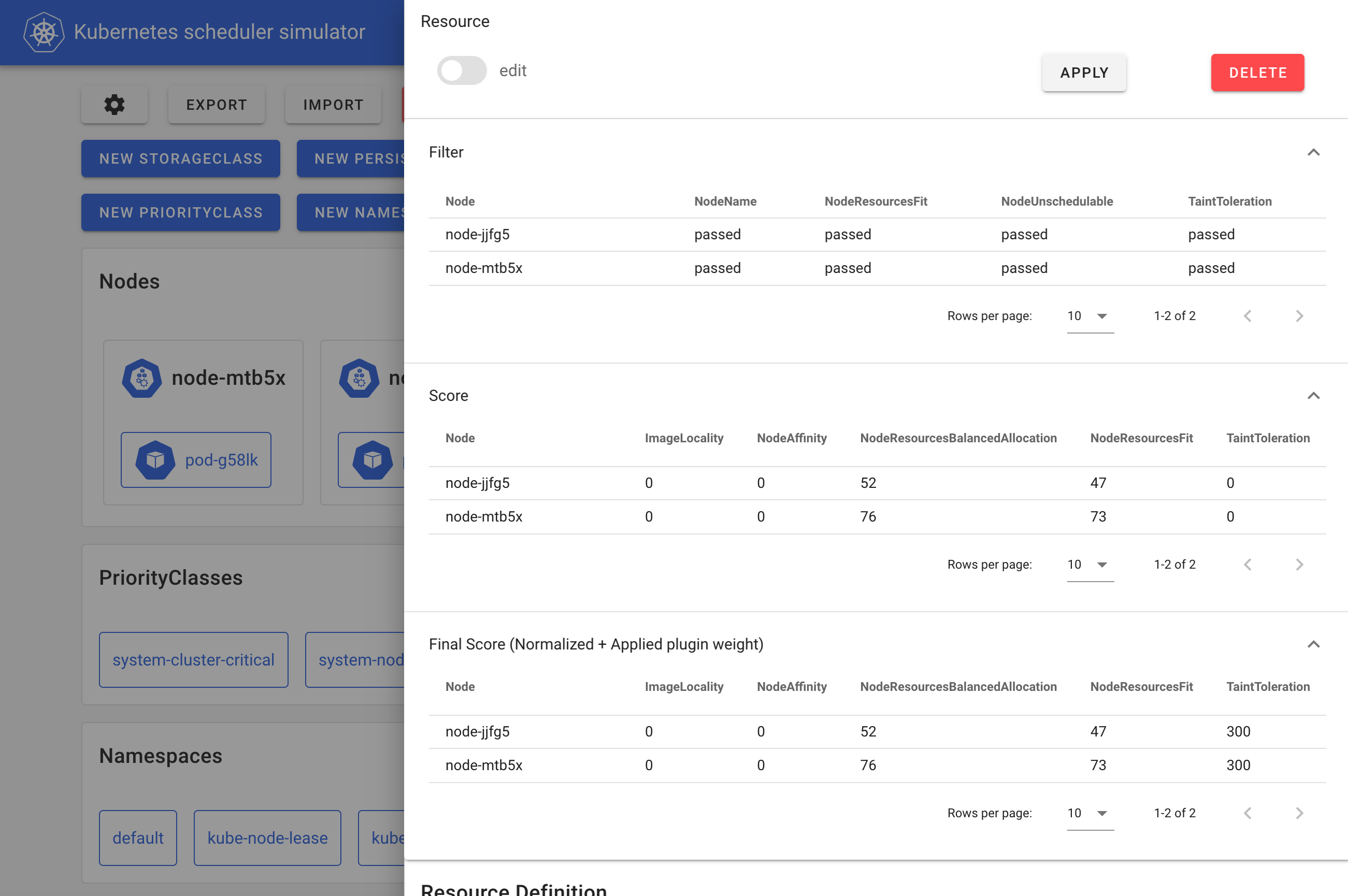
シミュレーターのwebフロントエンド
このシミュレーターの内部では、通常のスケジューラー(vanilla scheduler)ではなく、Debuggable Schedulerと呼ばれるデバッグを容易にするスケジューラーが動作します。 このDebuggable Schedulerは、各拡張ポイントにおける各スケジューラープラグインの結果を、以下のマニフェストに示すようにPodのアノテーションとして出力します。 webフロントエンドはこれらのアノテーションに基づいてスケジューリング結果を整形・可視化します。
kind: Pod
apiVersion: v1
metadata:
# このブログ投稿では、アノテーション内のJSONは見やすさのために手動で整形されています。
annotations:
kube-scheduler-simulator.sigs.k8s.io/bind-result: '{"DefaultBinder":"success"}'
kube-scheduler-simulator.sigs.k8s.io/filter-result: >-
{
"node-jjfg5":{
"NodeName":"passed",
"NodeResourcesFit":"passed",
"NodeUnschedulable":"passed",
"TaintToleration":"passed"
},
"node-mtb5x":{
"NodeName":"passed",
"NodeResourcesFit":"passed",
"NodeUnschedulable":"passed",
"TaintToleration":"passed"
}
}
kube-scheduler-simulator.sigs.k8s.io/finalscore-result: >-
{
"node-jjfg5":{
"ImageLocality":"0",
"NodeAffinity":"0",
"NodeResourcesBalancedAllocation":"52",
"NodeResourcesFit":"47",
"TaintToleration":"300",
"VolumeBinding":"0"
},
"node-mtb5x":{
"ImageLocality":"0",
"NodeAffinity":"0",
"NodeResourcesBalancedAllocation":"76",
"NodeResourcesFit":"73",
"TaintToleration":"300",
"VolumeBinding":"0"
}
}
kube-scheduler-simulator.sigs.k8s.io/permit-result: '{}'
kube-scheduler-simulator.sigs.k8s.io/permit-result-timeout: '{}'
kube-scheduler-simulator.sigs.k8s.io/postfilter-result: '{}'
kube-scheduler-simulator.sigs.k8s.io/prebind-result: '{"VolumeBinding":"success"}'
kube-scheduler-simulator.sigs.k8s.io/prefilter-result: '{}'
kube-scheduler-simulator.sigs.k8s.io/prefilter-result-status: >-
{
"AzureDiskLimits":"",
"EBSLimits":"",
"GCEPDLimits":"",
"InterPodAffinity":"",
"NodeAffinity":"",
"NodePorts":"",
"NodeResourcesFit":"success",
"NodeVolumeLimits":"",
"PodTopologySpread":"",
"VolumeBinding":"",
"VolumeRestrictions":"",
"VolumeZone":""
}
kube-scheduler-simulator.sigs.k8s.io/prescore-result: >-
{
"InterPodAffinity":"",
"NodeAffinity":"success",
"NodeResourcesBalancedAllocation":"success",
"NodeResourcesFit":"success",
"PodTopologySpread":"",
"TaintToleration":"success"
}
kube-scheduler-simulator.sigs.k8s.io/reserve-result: '{"VolumeBinding":"success"}'
kube-scheduler-simulator.sigs.k8s.io/result-history: >-
[
{
"kube-scheduler-simulator.sigs.k8s.io/bind-result":"{\"DefaultBinder\":\"success\"}",
"kube-scheduler-simulator.sigs.k8s.io/filter-result":"{\"node-jjfg5\":{\"NodeName\":\"passed\",\"NodeResourcesFit\":\"passed\",\"NodeUnschedulable\":\"passed\",\"TaintToleration\":\"passed\"},\"node-mtb5x\":{\"NodeName\":\"passed\",\"NodeResourcesFit\":\"passed\",\"NodeUnschedulable\":\"passed\",\"TaintToleration\":\"passed\"}}",
"kube-scheduler-simulator.sigs.k8s.io/finalscore-result":"{\"node-jjfg5\":{\"ImageLocality\":\"0\",\"NodeAffinity\":\"0\",\"NodeResourcesBalancedAllocation\":\"52\",\"NodeResourcesFit\":\"47\",\"TaintToleration\":\"300\",\"VolumeBinding\":\"0\"},\"node-mtb5x\":{\"ImageLocality\":\"0\",\"NodeAffinity\":\"0\",\"NodeResourcesBalancedAllocation\":\"76\",\"NodeResourcesFit\":\"73\",\"TaintToleration\":\"300\",\"VolumeBinding\":\"0\"}}",
"kube-scheduler-simulator.sigs.k8s.io/permit-result":"{}",
"kube-scheduler-simulator.sigs.k8s.io/permit-result-timeout":"{}",
"kube-scheduler-simulator.sigs.k8s.io/postfilter-result":"{}",
"kube-scheduler-simulator.sigs.k8s.io/prebind-result":"{\"VolumeBinding\":\"success\"}",
"kube-scheduler-simulator.sigs.k8s.io/prefilter-result":"{}",
"kube-scheduler-simulator.sigs.k8s.io/prefilter-result-status":"{\"AzureDiskLimits\":\"\",\"EBSLimits\":\"\",\"GCEPDLimits\":\"\",\"InterPodAffinity\":\"\",\"NodeAffinity\":\"\",\"NodePorts\":\"\",\"NodeResourcesFit\":\"success\",\"NodeVolumeLimits\":\"\",\"PodTopologySpread\":\"\",\"VolumeBinding\":\"\",\"VolumeRestrictions\":\"\",\"VolumeZone\":\"\"}",
"kube-scheduler-simulator.sigs.k8s.io/prescore-result":"{\"InterPodAffinity\":\"\",\"NodeAffinity\":\"success\",\"NodeResourcesBalancedAllocation\":\"success\",\"NodeResourcesFit\":\"success\",\"PodTopologySpread\":\"\",\"TaintToleration\":\"success\"}",
"kube-scheduler-simulator.sigs.k8s.io/reserve-result":"{\"VolumeBinding\":\"success\"}",
"kube-scheduler-simulator.sigs.k8s.io/score-result":"{\"node-jjfg5\":{\"ImageLocality\":\"0\",\"NodeAffinity\":\"0\",\"NodeResourcesBalancedAllocation\":\"52\",\"NodeResourcesFit\":\"47\",\"TaintToleration\":\"0\",\"VolumeBinding\":\"0\"},\"node-mtb5x\":{\"ImageLocality\":\"0\",\"NodeAffinity\":\"0\",\"NodeResourcesBalancedAllocation\":\"76\",\"NodeResourcesFit\":\"73\",\"TaintToleration\":\"0\",\"VolumeBinding\":\"0\"}}",
"kube-scheduler-simulator.sigs.k8s.io/selected-node":"node-mtb5x"
}
]
kube-scheduler-simulator.sigs.k8s.io/score-result: >-
{
"node-jjfg5":{
"ImageLocality":"0",
"NodeAffinity":"0",
"NodeResourcesBalancedAllocation":"52",
"NodeResourcesFit":"47",
"TaintToleration":"0",
"VolumeBinding":"0"
},
"node-mtb5x":{
"ImageLocality":"0",
"NodeAffinity":"0",
"NodeResourcesBalancedAllocation":"76",
"NodeResourcesFit":"73",
"TaintToleration":"0",
"VolumeBinding":"0"
}
}
kube-scheduler-simulator.sigs.k8s.io/selected-node: node-mtb5x
ユーザーはまた、自身のカスタムプラグインやextenderをこのDebuggable Schedulerに統合し、その結果を可視化することもできます。
このDebuggable Schedulerは、たとえば任意のKubernetesクラスター上や統合テスト内など、スタンドアローンで実行することも可能です。これは、自身のプラグインをテストしたり、実クラスター上でカスタムスケジューラーをよりデバッグしやすくしたいと考えるカスタムプラグイン開発者にとって有用です。
より優れた開発クラスターとしてのシミュレーター
前述のとおり、限られたテストだけでは実世界のクラスターで起こり得るすべてのシナリオを予測することは不可能です。 ユーザーはスケジューラーを本番環境にデプロイする前に、小規模な開発クラスターでテストし、問題が発生しないことを願うことしかできません。
そこで、シミュレーターのインポート機能を使うことで、本番環境に近い環境で、稼働中のワークロードに影響を与えることなくスケジューラーのシミュレーションをすることができます。
本番クラスターとシミュレーターの間で継続的に同期を行うことで、ユーザーは本番クラスターが対応するリソースと同じリソースを用いて、新しいバージョンのスケジューラーを安全にテストすることができます。 その動作に確信が持てた段階で本番環境へのデプロイに進むことができ、予期しない問題のリスクを低減できます。
ユースケースは?
- クラスターユーザー: スケジューリング制約(たとえば、PodAffinityやPodTopologySpreadなど)が意図した通りに機能しているかを検証する。
- クラスター管理者: スケジューラーの設定を変更した場合に、クラスターがどのように動作するかを評価する。
- スケジューラープラグイン開発者: カスタムスケジューラープラグインやスケジューラー拡張をテストする。Debuggable Schedulerを統合テストや開発クラスターで使用したり、本番環境に近い環境でのテストのために同期機能を活用したりする。
利用開始の手順
このシミュレーターを使用するには、マシンにDockerがインストールされていれば十分で、Kubernetesクラスターは必要ありません。
git clone git@github.com:kubernetes-sigs/kube-scheduler-simulator.git
cd kube-scheduler-simulator
make docker_up
http://localhost:3000でシミュレーターのweb UIにアクセスできます。
詳しくは、kube-scheduler-simulatorのリポジトリをご覧ください!
貢献するには
このシミュレーターは、Kubernetes SIG Schedulingによって開発されています。 フィードバックやコントリビューションは大歓迎です!
問題の報告やプルリクエストは、kube-scheduler-simulatorのリポジトリで行ってください。 また、Slackの#sig-schedulingチャンネルにもぜひご参加ください。
謝辞
このシミュレーターのプロジェクトは、熱意あるボランティアのエンジニアたちによってメンテナンスされ、多くの課題を乗り越えて現在の形に至りました。
素晴らしいコントリビューターの皆さんに心より感謝いたします!
Kubernetes v1.33の先行紹介
Kubernetes v1.33のリリースが近づく中で、Kubernetesプロジェクトは進化を続けています。 プロジェクト全体の健全性を高めるために、一部の機能が非推奨となったり、削除または置き換えられたりする可能性があります。 本ブログ記事では、v1.33リリースに向けて計画されている変更の一部を紹介します。 これらは、Kubernetes環境を安定して運用し、最新の開発動向を把握し続けるために、リリースチームが特に知っておくべきであると考えている情報です。 以下の情報は、v1.33リリースの現時点の状況に基づいており、正式リリースまでに変更される可能性があります。
Kubernetes APIの削除および非推奨プロセス
Kubernetesプロジェクトでは、機能の非推奨ポリシーが明確に文書化されています。 このポリシーでは、安定版のAPIを非推奨とするには同じAPIの新たな安定版が存在していることが条件とされています。 また、APIの安定性レベルごとに最低限のサポート期間が定められています。 非推奨となったAPIは、将来のKubernetesリリースで削除される予定であることを示しています。 削除までは引き続き動作しますが(非推奨から少なくとも1年間は利用可能です)、利用時には警告メッセージが表示されます。 削除されたAPIは現在のバージョンでは利用できなくなり、その時点で代替手段への移行が必須となります。
一般公開版(GA)または安定版のAPIバージョンが非推奨となる可能性はありますが、Kubernetesの同一のメジャーバージョン内で削除されてはなりません。
ベータ版やプレリリースのAPIバージョンは、非推奨となってから3つのリリース分はサポートされなければなりません。
アルファ版または実験的なAPIバージョンは、事前の非推奨通知なしに任意のリリースで削除される可能性があります。すでに同一の機能に対して別の実装が存在する場合、このプロセスは「撤回」と見なされることがあります。
機能がベータ版から安定版へ昇格した結果としてAPIが削除される場合でも、単にそのAPIが定着しなかった場合でも、すべての削除はこの非推奨ポリシーに準拠して実施されます。 APIが削除される際には、移行手段が非推奨ガイド内で案内されます。
Kubernetes v1.33における非推奨と削除
安定版Endpoints APIの非推奨化
EndpointSlices APIはv1.21から安定版となっており、実質的に従来のEndpoints APIを置き換える存在となっています。 元のEndpoints APIはシンプルで分かりやすい設計でしたが、大規模なネットワークエンドポイントにスケールする際に課題がありました。 EndpointSlices APIはデュアルスタックネットワーク対応などの新機能を導入しており、これにより従来のEndpoints APIは非推奨とする準備が整いました。
今回の非推奨は、ワークロードやスクリプトからEndpoints APIを直接使用しているユーザーのみに影響します。 これらのユーザーは、代わりにEndpointSliceの使用へ移行する必要があります。 非推奨による影響と移行計画の詳細については、今後数週間以内に専用のブログ記事が公開される予定です。
詳細はKEP-4974: Deprecate v1.Endpointsをご覧ください。
ノードステータスからのkube-proxyバージョン情報の削除
リリースアナウンスで示されたとおり、v1.31で非推奨となったstatus.nodeInfo.kubeProxyVersionフィールドは、v1.33で削除されます。
このフィールドはkubeletによって設定されていましたが、その値は一貫して正確とは限りませんでした。
v1.31以降、このフィールドはデフォルトで無効化されているため、v1.33では完全に削除されます。
詳細はKEP-4004: Deprecate status.nodeInfo.kubeProxyVersion fieldをご覧ください。
Windows Podにおけるホストネットワーク対応の削除
Windows Podのネットワーク機能は、Linuxと同等の機能を提供し、コンテナがノードのネットワーク名前空間を使用できるようにすることで、クラスター密度の向上を目指していました。 この機能の初期実装はv1.26でアルファ版として導入されましたが、containerdに関する予期せぬ挙動が確認され、また代替手段も存在していたことから、Kubernetesプロジェクトは関連するKEPの撤回を決定しました。 v1.33において、この機能のサポートは完全に削除される見込みです。
詳細はKEP-3503: Host network support for Windows podsをご覧ください。
Kubernetes v1.33の注目すべき変更点
本記事の執筆者として、私たちは特に注目すべき重要な改善点を1つ選びました!
Linux Podにおけるユーザー名前空間のサポート
現在もオープンなKEPの中で最も古いものの一つが、KEP-127「Podに対してLinuxユーザー名前空間を使用することによるセキュリティの改善」です。このKEPは2016年後半に初めて提案され、複数回の改訂を経てv1.25でアルファ版として登場し、v1.30で初めてベータ版が提供されました(この時点ではデフォルトで無効)。そしてv1.33では、この機能がデフォルトで有効な状態で提供される予定です。
この機能は、明示的にpod.spec.hostUsersを指定して有効化しない限り、既存のPodには影響しません。
Kubernetes v1.30をそっと覗くでも触れられているように、この機能は脆弱性の軽減に向けた重要なマイルストーンとなります。
詳細はKEP-127: Support User Namespaces in podsをご覧ください。
その他の注目すべきKubernetes v1.33の改善点
以下に挙げる改善項目は、今後リリース予定のv1.33に含まれる見込みのものです。 ただし、これらは確定事項ではなく、リリース内容は変更される可能性があります。
Podの垂直スケーリングに対応したリソースの動的リサイズ
Podをプロビジョニングする際には、DeploymentやStatefulSetなど、さまざまなリソースを利用できます。
スケーラビリティの要件によっては、Podのレプリカ数を更新する水平スケーリング、あるいはPod内のコンテナに割り当てるリソースを更新する垂直スケーリングが必要になる場合があります。
この改善が導入される以前は、Podのspecに定義されたコンテナリソースは変更できず、Podテンプレート内のリソースを更新するとPodの置き換えが発生していました。
しかし、既存のPodを再起動せずに、動的にリソース設定を更新できたらどうでしょうか?
KEP-1287は、まさにこのようなPodのインプレース更新を可能にするためのものです。 これにより、ステートフルなプロセスに対してダウンタイムなしでの垂直スケールアップや、トラフィックが少ないときのシームレスなスケールダウン、さらには起動時に一時的に大きなリソースを割り当て、初期処理が完了した後にそれを縮小するといったことも可能になります。 この機能はv1.27でアルファ版としてリリースされており、v1.33ではベータ版として提供される予定です。
詳細はKEP-1287: In-Place Update of Pod Resourcesをご覧ください。
DRAのResourceClaimにおけるデバイスステータスがベータに昇格
ResourceClaimのstatus内にあるdevicesフィールドは、v1.32リリースで導入された機能であり、v1.33でベータに昇格する見込みです。
このフィールドは、ドライバーがデバイスの状態情報を報告できるようにするもので、可観測性とトラブルシューティング能力の向上に貢献します。
例えば、ResourceClaimのステータスにネットワークインターフェースの名前、MACアドレス、IPアドレスを報告することは、ネットワークサービスの設定や管理、ならびにネットワーク関連の問題のデバッグに大いに役立ちます。この機能の詳細は、動的リソース割り当てのドキュメントをご覧ください。
また、計画中の拡張についてはKEP-4817: DRA: Resource Claim Status with possible standardized network interface dataに記載されています。
名前空間の順序付き削除
このKEPは、Kubernetesの名前空間に対して、より構造化された削除プロセスを導入することで、リソースの安全かつ決定論的な削除を実現することを目的としています。 現在の削除処理はほぼランダムな順序で行われるため、たとえばNetworkPolicyが先に削除されてPodが残るといった、セキュリティ上の問題や意図しない動作を引き起こす可能性があります。 論理的およびセキュリティ上の依存関係を考慮した構造化された削除順序を強制することで、このアプローチはPodが他のリソースより先に削除されることを保証します。 この設計は、非決定的な削除に関連するリスクを軽減することで、Kubernetesのセキュリティと信頼性を向上させます。
詳細はKEP-5080: Ordered namespace deletionをご覧ください。
Indexed Job管理の強化
これら2つのKEPは、ジョブの処理、特にIndexed Jobの信頼性を向上させるためにGAに昇格する予定です。 KEP-3850では、Indexed Jobに対してインデックスごとのバックオフ制限を提供しており、各インデックスが他のインデックスと完全に独立して動作できるようになります。 また、KEP-3998はJob APIを拡張し、すべてのインデックスが成功していない場合でもIndexed Jobを成功と見なすための条件を定義できるようにします。
詳細は、KEP-3850: Backoff Limit Per Index For Indexed JobsおよびKEP-3998: Job success/completion policyをご覧ください。
さらに詳しく知りたい方へ
新機能や非推奨の項目については、Kubernetesのリリースノートでもアナウンスされています。 Kubernetes v1.33の新機能については、該当リリースのCHANGELOGにて正式に発表される予定です。
Kubernetes v1.33のリリースは 2025年4月23日(水) を予定しています。 今後の更新情報にもぜひご注目ください!
以下のリリースノートでも、各バージョンにおける変更点のアナウンスを確認できます。
コミュニティへの参加方法
Kubernetesに関わるための最も簡単な方法は、関心のある分野に関連するSpecial Interest Groups(SIGs)のいずれかに参加することです。 Kubernetesコミュニティに向けて発信したい内容がありますか? もしあれば、毎週開催されているコミュニティミーティングや、下記の各種チャネルを通じて、ぜひ声を届けてください。 皆さまからの継続的なご意見とご支援に、心より感謝申し上げます。
- 最新情報はBlueskyの@kubernetes.ioでご確認ください
- Discussでコミュニティのディスカッションに参加しましょう
- Slackのコミュニティに参加しましょう
- Server FaultやStack Overflowに質問を投稿したり、他の質問に回答したりしましょう
- あなたのKubernetesストーリーを共有しましょう
- Kubernetesに関する最新情報はブログをご覧ください
- Kubernetesリリースチームについて学びましょう
Ingress-nginxの脆弱性CVE-2025-1974: 知っておくべきこと
本日、ingress-nginxのメンテナーは、攻撃者がKubernetesクラスターを乗っ取ることを容易にする可能性のある、一連の重大な脆弱性に対するパッチをリリースしました: ingress-nginx v1.12.1およびingress-nginx v1.11.5。 ingress-nginxは、Kubernetes管理者の40%超が利用しています。 もしあなたがそれに該当する場合は、ユーザーとデータを保護するために直ちに対応を行ってください。
背景
Ingressは、ワークロードPodを外部に公開して活用できるようにする、Kubernetesにおける従来の機能です。 実装に依存しない方法で、Kubernetesユーザーはアプリケーションをネットワーク上にどのように公開するかを定義できます。 次に、Ingressコントローラーがその定義に従い、ユーザーの状況やニーズに応じてローカルまたはクラウドのリソースを構成します。
さまざまなクラウドプロバイダーやロードバランサー製品に対応するために、多くのIngressコントローラーが利用可能です。 Ingress-nginxは、Kubernetesプロジェクトが提供するソフトウェアベースのIngressコントローラーです。 その柔軟性と使いやすさから、ingress-nginxは非常に人気があり、Kubernetesクラスターの40%超で導入されています!
Ingress-nginxは、Ingressオブジェクトの要件を、強力なオープンソースのWebサーバーデーモンであるnginxの設定に変換します。 その後、nginxはこの設定を用いて、Kubernetesクラスター内で稼働しているさまざまなアプリケーションへのリクエストを受け付け、ルーティングします。 これらのnginx設定パラメーターを適切に取り扱うことは極めて重要です。 なぜなら、ingress-nginxはユーザーに対して高い柔軟性を提供する必要がある一方で、nginxに対して不適切な動作を意図的または過失により誘発させないようにしなければならないためです。
本日修正された脆弱性
本日修正されたingress-nginxの脆弱性のうち4件は、特定のnginx設定の取り扱いに関する改善です。 これらの修正がない場合、特別に細工されたIngressオブジェクトによってnginxが不正な動作を引き起こす可能性があり、たとえば、ingress-nginxにとってアクセス可能なSecretの値が漏洩するなどの事態が発生します。 デフォルトでは、ingress-nginxはクラスター全体のSecretにアクセスできるため、Ingressを作成する権限を持つユーザーやエンティティがクラスター全体を乗っ取る事態につながるおそれがあります。
本日公開された脆弱性のうち最も深刻なものは、CVE-2025-1974です。 この脆弱性は9.8 CVSSと評価されており、ingress-nginxのValidating Admission Controller機能を通じて、Podネットワーク上の任意のエンティティが設定インジェクションの脆弱性を悪用できるというものです。 このため、通常であればクラスター内にIngressオブジェクトを作成する(比較的高い権限が必要な)操作が前提となる攻撃が、大幅に容易かつ危険なものになります。 さらに、今回の他の脆弱性と組み合わさることで、CVE-2025-1974により、Podネットワーク上に存在する任意のものが、認証情報や管理権限なしにKubernetesクラスターを乗っ取る可能性が高まります。 多くの一般的なシナリオでは、PodネットワークはクラウドVPC内のすべてのワークロード、あるいは企業ネットワークに接続しているすべてのユーザーからアクセス可能です! これは、非常に深刻な状況です。
本日、これら5件の脆弱性すべてに対する修正を含むingress-nginx v1.12.1およびingress-nginx v1.11.5をリリースしました。
次のステップ
まずは、クラスターでingress-nginxが使用されているかどうかを確認してください。
多くの場合、クラスター管理者権限を用いてkubectl get pods --all-namespaces --selector app.kubernetes.io/name=ingress-nginxを実行することで確認できます。
ingress-nginxを使用している場合は、直ちにこれらの脆弱性への対応を計画してください。
最も効果的かつ簡単な対処方法は、ingress-nginxの新しいパッチリリースにアップグレードすること です。 本日リリースされたパッチを適用することで、5件すべての脆弱性が修正されます。
すぐにアップグレードできない場合は、ingress-nginxのValidating Admission Controller機能を無効化することで、リスクを大幅に軽減することが可能です。
ingress-nginxをHelmでインストールしている場合
- Helmの設定値
controller.admissionWebhooks.enabled=falseを設定して再インストールしてください。
- Helmの設定値
ingress-nginxを手動でインストールしている場合
ingress-nginx-admissionという名前のValidatingWebhookConfigurationを削除してください。ingress-nginx-controllerのDeploymentまたはDaemonSetを編集し、controllerコンテナの引数から--validating-webhookを削除してください。
CVE-2025-1974に対する緩和策としてValidating Admission Controller機能を無効化した場合は、アップグレード後に必ず再び有効化することを忘れないでください。 この機能は、不正なIngress設定が適用される前に警告を出すことで、ユーザー体験を向上させる重要な役割を担っています。
結論、謝辞、およびさらなる情報
本日発表されたCVE-2025-1974を含むingress-nginxの脆弱性は、多くのKubernetesユーザーとそのデータに対して重大なリスクとなります。 ingress-nginxを利用している場合は、自身の安全を守るために直ちに対策を講じてください。
今回の脆弱性を適切に報告し、Kubernetesセキュリティ対応チーム(SRC)およびingress-nginxメンテナー(Marco Ebert氏、James Strong氏)と連携して効果的な修正に尽力いただいたWizのNir Ohfeld氏、Sagi Tzadik氏、Ronen Shustin氏、Hillai Ben-Sasson氏に感謝いたします。
ingress-nginxの今後の保守および将来に関する詳細は、このGitHub issueをご覧いただくか、James氏およびMarco氏によるKubeCon/CloudNativeCon EU 2025の講演にご参加ください。
本記事で取り上げた各脆弱性の詳細については、以下の然るべきGitHub Issueをご参照ください: CVE-2025-24513、CVE-2025-24514、CVE-2025-1097、CVE-2025-1098、CVE-2025-1974。
このブログ記事は、ハイパーリンクを更新するために2025年5月に改訂されました。
SIG Appsの取り組みの紹介
SIG Spotlightシリーズでは、さまざまなSpecial Interest Group(SIG)のリーダーへのインタビューを通じて、Kubernetesプロジェクトの核心に迫ります。 今回は、Kubernetes上におけるアプリケーションの開発、デプロイ、運用に関連するすべてを担当するグループである SIG Apps を取り上げます。 Sandipan Panda(DevZero)は、SIG AppsのチェアおよびテックリードであるMaciej Szulik(Defense Unicorns)とJanet Kuo(Google)にインタビューする機会を得ることができました。 彼らは、Kubernetesエコシステムにおけるアプリケーション管理の経験、課題、そして将来のビジョンについて共有してくれました。
はじめに
Sandipan: こんにちは。まずはご自身について、現在の役割や、SIG Appsにおける現在の役職に至るまでのKubernetesコミュニティでの歩みについて教えていただけますか?
Maciej: こんにちは。SIG Appsのリードを務めるMaciejです。この役割に加えて、SIG CLIでも活動しており、Steering Committeeメンバーのひとりでもあります。私は2014年後半から、コントローラー、apiserver、kubectlを含むさまざまな領域でKubernetesに貢献してきました。
Janet: もちろんです!私はJanetです。Googleでスタッフソフトウェアエンジニアを務めており、Kubernetesプロジェクトには初期の段階、2015年のバージョン1.0のリリース以前から深く関わってきました。これまでの道のりは本当に素晴らしいものでした!
Kubernetesコミュニティにおける私の現在の役割は、SIG Appsのチェア兼テックリードの一人です。SIG Appsとの関わりは自然な流れで始まりました。 私はまず、Deployment APIの構築やローリングアップデート機能の追加に取り組みました。 その中で自然とSIG Appsに引き寄せられ、次第に関与を深めていきました。 時が経つにつれて、より多くの責任を担うようになり、現在のリーダーシップの役割を務めるに至りました。
SIG Appsについて
以下の回答はすべてMaciejとJanetの共同によるものです。
Sandipan: ご存じない方のために、SIG Appsの使命と目的について概要を教えていただけますか?Kubernetesエコシステムの中で、どのような主要な課題の解決を目指しているのでしょうか?
charterに記載されているとおり、私たちはKubernetes上でアプリケーションを開発、デプロイ、運用することに関連する幅広い領域をカバーしています。 簡単に言えば、隔週で開催しているミーティングには誰でも自由に参加でき、Kubernetes上でアプリケーションを記述・デプロイする際の良かった点や困った点について議論することができます。
Sandipan: 現在、SIG Appsが取り組んでいる最も重要なプロジェクトやイニシアチブにはどのようなものがありますか?
現時点において、私たちのコントローラー開発を推進している主な要素は、さまざまなAI関連のワークロードを実行する際に生じる課題です。 ここで、私たちが過去数年間に渡って支援してきた2つのワーキンググループについて言及する価値があります。
The Batch Working Group: Kubernetes上でHPC、AI/ML、データ分析ジョブを実行することに取り組んでいます。
The Serving Working Group: ハードウェアアクセラレーションを用いたAI/ML推論に焦点を当てています。
ベストプラクティスと課題
Sandipan: SIG Appsは、Kubernetesにおけるアプリケーション管理のベストプラクティスの策定において重要な役割を担っています。これらのベストプラクティスの一部と、それがアプリケーションのライフサイクル管理にどのように役立つかを教えていただけますか?
ヘルスチェックとReadiness Probeを実装することで、アプリケーションが正常であり、トラフィックを処理する準備ができていることを確認できます。これにより、信頼性と稼働時間が向上します。これらに加えて、包括的なログ出力、モニタリング、トレーシングのソリューションを組み合わせることで、アプリケーションの動作に関するインサイトを得ることができ、問題の特定と解決を迅速に行うことが可能になります。
リソース使用量やカスタムメトリクスに基づいてアプリケーションをオートスケールすることで、リソースの使用を最適化し、変動する負荷に対応できるようにします。
ステートレスなアプリケーションにはDeploymentを、ステートフルなアプリケーションにはStatefulSetを、バッチワークロードにはJobやCronJobを、各ノードでデーモンを実行するにはDaemonSetを使用してください。また、OperatorやCRDを活用してKubernetes APIを拡張することで、複雑なアプリケーションのデプロイ・管理・ライフサイクルを自動化でき、運用が容易になり、手動による介入を減らすことができます。
Sandipan: SIG Appsが直面している一般的な課題にはどのようなものがありますか?また、それに対してどのように対処していますか?
私たちが常に直面している最大の課題は、多くの機能、アイデア、改善提案を却下しなければならないという点です。こうした判断の背景にある理由を説明するには、多くの規律と忍耐が必要となります。
Sandipan: Kubernetesの進化はSIG Appsの活動にどのような影響を与えましたか?最近の変更や今後の機能の中で、SIG Appsにとって特に関連性が高い、あるいは有益だと考えるものはありますか?
SIG Appsに関わる私たち自身、そしてコミュニティ全体にとっての主な利点は、カスタムリソースによってKubernetesを拡張できることです。 また、ユーザーが組み込みのコントローラーを活用して独自のカスタムコントローラーを構築し、私たちコアメンテナーが考慮していなかった、あるいはKubernetes内で効率的に対応できなかった高度なユースケースを実現できる点も重要です。
SIG Appsへの貢献
Sandipan: SIG Appsに関わりたいと考えている新しいコントリビューターには、どのような機会がありますか?また、どのようなアドバイスがありますか?
「最初に取り組むのにおすすめのissueはありますか?」という質問はとてもよく寄せられます:-) しかし、残念ながら簡単に答えられるものではありません。 私たちはいつも、「コアコントローラーへの貢献を始める最善の方法は、しばらく時間をかけて取り組みたいと思えるコントローラーを見つけることです」と皆さんに伝えています。 そのコントローラーのコードを読み、ユニットテストや統合テストを実行してみてください。 一度、全体の仕組みを理解できたら、あえて壊してみて、テストが失敗することを確認するのもよいでしょう。 その特定のコントローラーについて理解が深まり、自信がついてきたら、そのコントローラーに関連するオープンなissueを探してみるとよいでしょう。ユーザーが直面している問題について説明を加えたり、改善案を提案したり、あるいは最初の修正に挑戦してみるのも良いかもしれません。
先ほど述べたとおり、この道に近道はありません。 私たちが現在の状態に至るまでに徐々に積み重ねてきたすべてのエッジケースを理解するためには、コードベースと向き合って時間をかける必要があります。 1つのコントローラーでうまくいったら、そのプロセスを他のコントローラーでも再び繰り返す必要があります。
Sandipan: SIG Appsはコミュニティからどのようにフィードバックを収集しており、それをどのように活動へ反映しているのでしょうか?
私たちは常に、隔週で開催しているミーティングに参加し、ご自身の課題や解決策を発表していただくよう、皆さんに奨励しています。 Kubernetes上で興味深い問題に取り組んでおり、コアコントローラーに関する有用なフィードバックを提供できるのであれば、どなたからの声でも常に歓迎しています。
今後の展望
Sandipan: 今後を見据えたとき、Kubernetesにおけるアプリケーション管理に関して、SIG Appsが注目している主要な注力領域や今後のトレンドにはどのようなものがありますか?SIGはそれらのトレンドにどのように適応しているのでしょうか?
間違いなく、現在のAIブームが最大の推進要因です。 前述のとおり、私たちはそれぞれ異なる側面を扱う2つのワーキンググループを有しています。
Sandipan: このSIGに関して、気に入っている点があれば教えてください。
間違いなく、ミーティングやSlackに参加してくれている人々です。 彼らは、課題のトリアージやプルリクエストに絶え間なく貢献し、Kubernetesを素晴らしいものにするために(非常に頻繁に私的な時間を使って)多くの時間を費やしてくれています!
SIG Appsは、Kubernetesコミュニティにおける必要不可欠な構成要素であり、大規模なアプリケーションのデプロイと管理のあり方を形成する役割を担っています。 KubernetesのワークロードAPIの改善から、AI/MLアプリケーション管理におけるイノベーションの推進まで、SIG Appsは絶え間なく現代のアプリケーション開発者および運用者のニーズに応え続けています。 新しいコントリビューターであっても、経験豊富な開発者であっても、関与し、貢献する機会は常に存在します。
SIG Appsについてさらに学びたい方や、貢献に関心のある方は、SIG READMEをご確認のうえ、隔週で開催されているミーティングにぜひご参加ください。
SIG etcdの取り組みの紹介
今回のSIG etcd spotlightでは、このKubernetesのSpecial Interest Groupについてさらに理解を深めるため、James Blair氏、Marek Siarkowicz氏、Wenjia Zhang氏、Benjamin Wang氏にお話を伺いました。
SIG etcdの紹介
Frederico: こんにちは、お時間をいただきありがとうございます!まずは自己紹介から始めましょう。ご自身のこと、現在の役割、そしてKubernetesに関わるようになった経緯について教えてください。
Benjamin: こんにちは、Benjaminと申します。私はSIG etcdのテックリードであり、etcdのメンテナーのひとりです。私はBroadcomグループの一部であるVMwareに勤めています。Kubernetes、etcd、そしてCSI(Container Storage Interface)には、仕事を通じて、またオープンソースへの大きな情熱から関わるようになりました。2020年からKubernetes、etcd、(およびCSI)に取り組んでいます。
James: こんにちは、チームの皆さん。私はJamesです。SIG etcdの共同チェアであり、etcdのメンテナーを務めています。Red Hatに勤めており、スペシャリストアーキテクトとしてクラウドネイティブ技術の導入支援を行っています。Kubernetesエコシステムには2019年から関わるようになりました。2022年末頃、etcdコミュニティとプロジェクトが支援を必要としていることに気付き、できる限り頻繁に貢献を始めました。 私たちのコミュニティには「技術がきっかけで参加し、人とのつながりで留まる」という言葉がありますが、私にとってこれはまさにその通りです。 これまで素晴らしい旅路であり、これからもコミュニティを支えていけることを楽しみにしています。
Marek: 皆さんこんにちは、私はMarekです。SIG etcdのリードを務めています。Googleでは、GKEのetcdチームを率いており、すべてのGKEユーザーに対して安定かつ信頼性の高い体験を提供することを目指しています。 私のKubernetesとの関わりは、SIG Instrumentationから始まりました。 そこでは、Kubernetes Structured Logging effortを立ち上げ、主導しました。 現在も、Kubernetes Metrics Serverの主要なプロジェクトリードを務めており、Kubernetesにおけるオートスケーリングに必要な重要なシグナルを提供しています。 etcdには3年前、バージョン3.5のリリース時期から関わり始めました。 当初はいくつかの課題に直面しましたが、今ではetcdはこれまでで最もスケーラブルで信頼性の高い状態にあり、プロジェクト史上最多のコントリビューション数を記録しています。 このことに非常に興奮しています。 私は分散システム、エクストリーム・プログラミング、テストに情熱を持っています。
Wenjia: こんにちは、Wenjiaと申します。SIG etcdの共同チェアであり、etcdのメンテナーのひとりです。Googleでエンジニアリングマネージャーとして、GKE(Google Kubernetes Engine)およびGDC(Google Distributed Cloud)に取り組んでいます。 Kubernetes v1.10およびetcd v3.1のリリース時期から、オープンソースのKubernetesおよびetcdの分野で活動しています。 Kubernetesに関わるようになったきっかけは仕事でしたが、私をこの分野にとどめているのは、コンテナオーケストレーション技術の魅力、そしてさらに重要なことに、素晴らしいオープンソースコミュニティの存在です。
KubernetesのSpecial Interest Group(SIG)になるまで
Frederico: 素晴らしいです、ありがとうございます。まずはSIG自体の起源についてお聞きしたいと思います。SIG etcdは非常に新しいSIGですが、その設立の経緯と背景について簡単に教えていただけますか?
Marek: もちろんです!SIG etcdは、etcdがKubernetesのデータストアとして重要なコンポーネントであることから設立されました。しかし当時、etcdはメンテナーの入れ替わりや信頼性の問題など、いくつかの課題を抱えていました。専用のSIGを設立することで、これらの問題に集中して取り組み、開発・保守プロセスを改善し、クラウドネイティブの環境と連動してetcdを発展させていく体制が整いました。
Frederico: SIGになったことで、期待どおりの成果は得られましたか?さらに言えば、先ほど挙げられた動機は実際に解消されつつありますか?その達成度についても教えてください。
Marek: 全体的に見て非常にポジティブな変化でした。SIGになることで、etcdの開発により明確な構造と透明性がもたらされました。私たちは、KEP(Kubernetes Enhancement Proposals)やPRR(Production Readiness Reviews)といったKubernetesのプロセスを取り入れ、それにより機能開発やリリースサイクルが改善されています。
Frederico: それらに加えて、SIGになったことによって得られた最大のメリットを一つ選ぶならなんでしょうか?
Marek: 私にとって最大の利点は、ProwやTestGridといったツールのようなKubernetesのテスト基盤を採用できたことです。etcdのような大規模プロジェクトの場合、GitHub標準のツールとは到底比較になりません。使い慣れた、明確で扱いやすいツールがあることは、etcdにとって大きな強化となり、Kubernetesのコントリビューターがetcdにも貢献しやすくなります。
Wenjia: まったく同感です。課題は依然として残っていますが、SIGという枠組みがそれらに取り組むための確かな基盤を提供しており、etcdがKubernetesエコシステムの重要なコンポーネントとして今後も成功し続けることを確かなものにしてくれています。
コミュニティへのポジティブな影響もまた、SIG etcdの成功において強調しておきたい重要な側面です。 KubernetesのSIGという枠組みによって、etcdのコントリビューターを受け入れやすい環境が整い、より広いKubernetesコミュニティからの参加が増加しました。 また、SIG API Machinery、SIG Scalability、SIG Testing、SIG Cluster Lifecycleなど、他のSIGとの連携も強化されています。
このような連携のおかげで、etcdの開発が、より広いKubernetesエコシステムのニーズと確実に整合するようになっています。SIG etcdとSIG Cluster Lifecycleの共同の取り組みにより設立されたetcd Operator Working Groupは、このような成功した連携の好例であり、Kubernetesにおけるetcdの運用面を改善しようとする共通の取り組み姿勢を示しています。
Frederico: コラボレーションについて言及がありましたが、ここ数か月でコントリビューターやコミュニティの関与に変化は見られましたか?
James: はい、ユニークなPR作成者のデータにも示されているとおり、私たちは最近3月に過去最高を記録し、ポジティブな傾向が続いています。
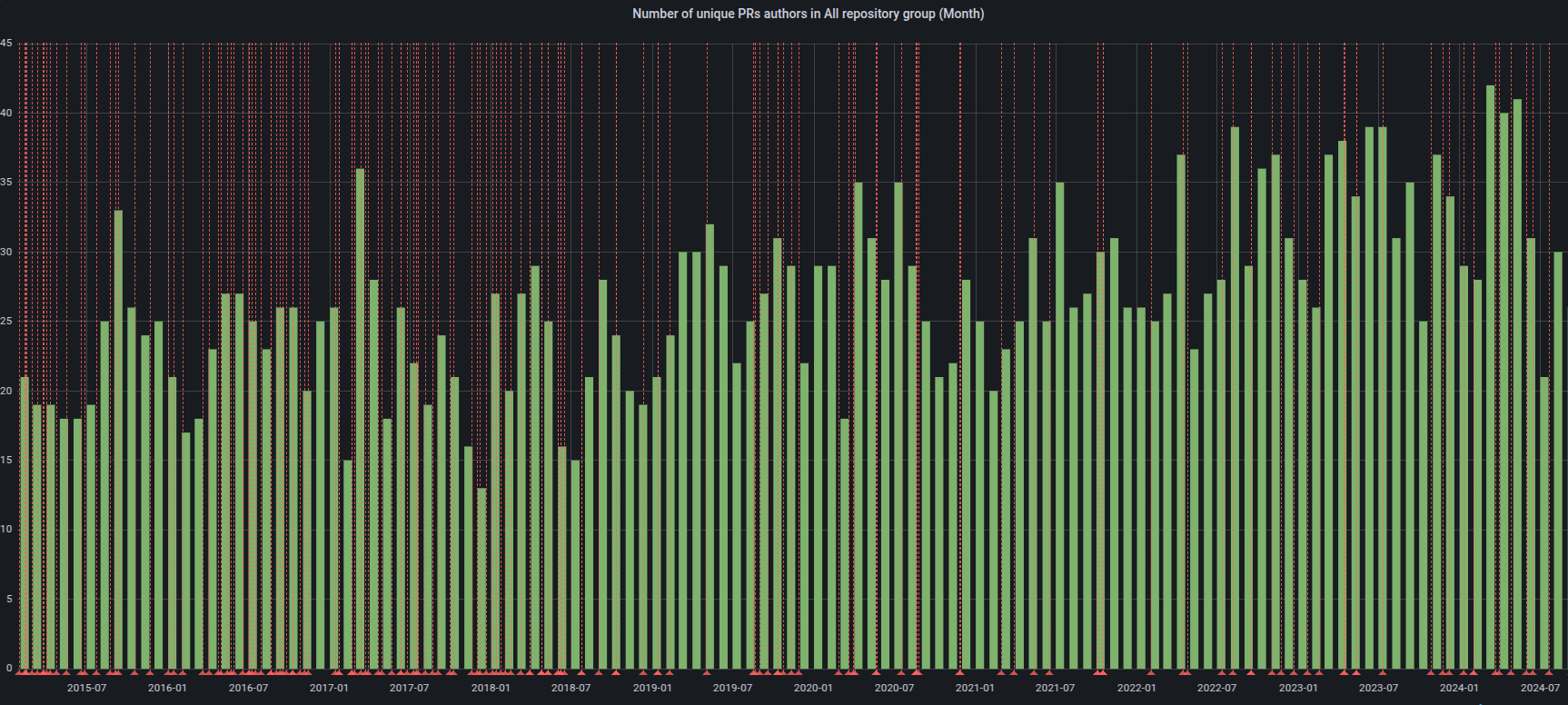
さらに、etcdプロジェクトの全リポジトリにおける全体的なコントリビューションを見ても、etcdプロジェクトの活動が再び活発化していることを示すポジティブな傾向を確認しています。
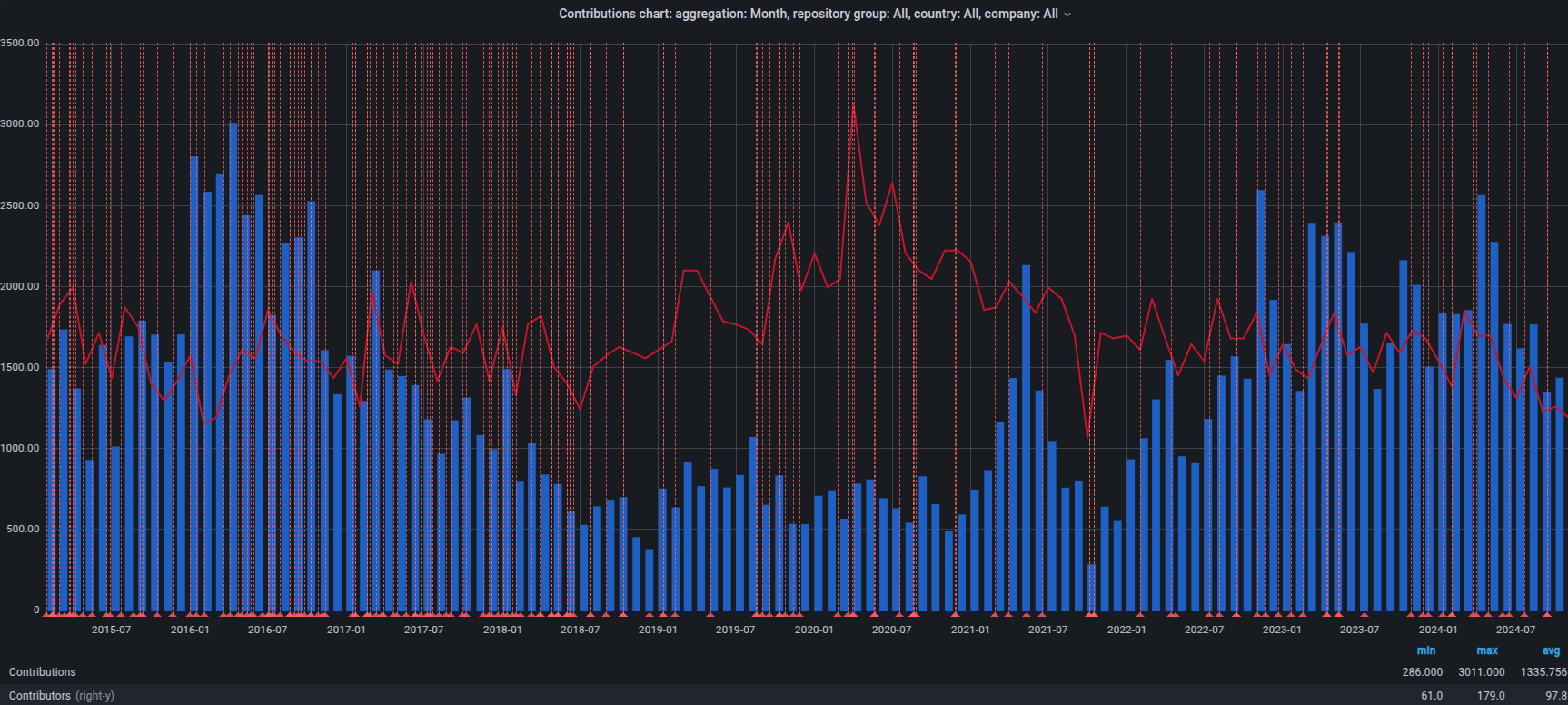
今後の展望
Frederico: 大変興味深い話でした、ありがとうございます。直近の話として、SIG etcdの現在の優先事項にはどのようなものがありますか?
Marek: 信頼性は常に最重要課題です。etcdが堅牢であることを確実にしなければなりません。また、オペレーターにとってetcdをより使いやすく、管理しやすくするための取り組みも進めています。さらに、etcdをKubernetesに限らず、インフラ管理のための現実的に利用可能なスタンドアロンの選択肢とすることも視野に入れています。そしてもちろん、スケーラビリティも重要です。クラウドネイティブの世界で拡大し続ける要求に対応できるようにする必要があります。
Benjamin: 信頼性を最優先の原則とすべきだという点には私も同意します。正確性だけでなく、互換性も確保する必要があります。加えて、etcdの理解しやすさと保守性を継続的に改善していくべきです。私たちが注力すべきは、コミュニティが最も関心を寄せているペインポイントの解消です。
Frederico: 特に緊密に連携しているSIGはありますか?
Marek: SIG API Machineryは間違いなく緊密に連携している相手です。彼らはetcdが保存するデータの構造を保有しているため、私たちは常に連携して取り組んでいます。また、SIG Cluster Lifecycleも重要です。etcdはKubernetesクラスターの重要な構成要素であるため、新たに設立されたetcd operator Working groupでも協働しています。
Wenjia: Marekが挙げたSIG API MachineryとSIG Cluster Lifecycle以外にも、SIG ScalabilityやSIG Testingとも密接に連携しています。
Frederico: より一般的な観点でお聞きしますが、クラウドネイティブ環境が進化する中で、SIG etcdにとっての主な課題は何だとお考えですか?
Marek: そうですね、重要なデータを扱っている以上、信頼性は常に課題です。クラウドネイティブの世界は非常に速いペースで進化しており、その要求に応えられるようなスケーラビリティを確保するには継続的な努力が必要です。
参加方法
Frederico: そろそろお話も終わりに近づいてきましたが、etcdに関心のある方はどのように関わることができますか?
Marek: ぜひ参加していただきたいです!最も良い始め方は、SIG etcdミーティングに参加し、etcd-devメーリングリストでの議論を追い、GitHubのIssueを確認することです。提案のレビュー、コードのテスト、ドキュメントの貢献など、常に協力してくださる方を歓迎しています。
Wenjia: この質問はとても嬉しいですね😀。SIG etcdへの貢献に関心のある方が関わり、影響を与える方法は数多くあります。以下は、皆さんが貢献できる主な分野の一部です。
コードでの貢献:
- バグ修正: etcdのコードベースの既知の問題に取り組みます。初心者に適したタスクを見つけるには、「good first issue」や「help wanted」とラベル付けされたIssueから始めるのが良いでしょう。
- 機能開発: 新機能や機能強化の開発に貢献します。etcdのロードマップやディスカッションを確認し、計画中の内容や自身のスキルが活かせる領域を探してください。
- テストとコードレビュー: テストの作成、コード変更のレビュー、フィードバックの提供を通じて、etcdの品質確保に貢献します。
- ドキュメント: 新しいコンテンツの追加、既存情報の明確化、誤記の修正などを通じて、etcdのドキュメントを改善します。明確で包括的なドキュメントは、ユーザーおよびコントリビューターの双方にとって不可欠です。
- コミュニティサポート: フォーラム、メーリングリスト、またはSlackチャンネルで質問に回答します。etcdの理解と利用を支援することも、価値のある貢献です。
参加方法:
- コミュニティに参加する: まずはSlack上のetcdコミュニティに参加し、SIGのミーティングに出席し、メーリングリストをフォローしましょう。プロジェクト、そのプロセス、関わっている人々について理解を深めることができます。
- メンターを見つける: オープンソースやetcdに不慣れな場合は、ガイド役として支援してくれるメンターを見つけることを検討してください。続報にご注目ください!第1期のメンタープログラムは大変成功を収めました。次回のメンタープログラムも近日開始予定です。
- 小さく始める: 小さな貢献から始めることを恐れないでください。たとえば、ドキュメントの誤字を修正したり、簡単なバグ修正を提案したりするだけでも、プロジェクトに参加するための素晴らしい第一歩となります。
etcdに貢献することで、クラウドネイティブエコシステムの重要な要素を改善する手助けとなるだけでなく、貴重な経験とスキルも得ることができます。 ぜひ飛び込んで、貢献を始めてみてください!
Frederico: 素晴らしいお話をありがとうございました。最後に、設立されたばかりの他のSIGに向けて、アドバイスをひとついただけますか?
Marek: もちろんです!私からのアドバイスは、Kubernetes全体のコミュニティで確立されているプロセスを積極的に取り入れ、他のSIGとの連携を優先し、強固なコミュニティの構築に注力することです。
Wenjia: 私自身のOSS活動の中でとても役立ったポイントをいくつか紹介します。
- 忍耐強くあること: オープンソース開発には時間がかかることがあります。貢献がすぐに受け入れられなかったり、困難に直面しても気落ちしないでください。
- 敬意を持つこと: etcdコミュニティでは協調と敬意が重視されています。他の人の意見に配慮し、共通の目標に向かって協力しましょう。
- 楽しむこと: オープンソースへの貢献は楽しいものであるべきです。自分の興味のある分野を見つけて、やりがいを感じられる方法で貢献してください。
Frederico: 素晴らしい締めくくりですね。皆さん、本日はありがとうございました!
詳細情報や各種リソースについては、以下をご覧ください。
- etcdの公式ウェブサイト: https://etcd.io/
- etcdのGitHubリポジトリ: https://github.com/etcd-io/etcd
- etcdコミュニティページ: https://etcd.io/community/
クラウドコントローラーマネージャーに関する「鶏が先か卵が先か」問題
Kubernetes 1.31において、Kubernetes史上最大の移行作業を完了し、in-treeのクラウドプロバイダーが削除されました。 コンポーネントの移行自体は完了したものの、ユーザーやインストーラープロジェクト(例えば、kOpsやCluster API)にとっては、いくつかの追加的な複雑さが残ることになりました。 これらの追加手順や障害ポイントについて説明し、クラスター管理者向けに推奨事項を示します。 この移行作業は非常に複雑で、いくつかのロジックはコアコンポーネントから分離する必要があり、4つの新しいサブシステムが構築されました。
- クラウドコントローラーマネージャー(KEP-2392)
- APIサーバーネットワークプロキシ(KEP-1281)
- kubeletクレデンシャルプロバイダープラグイン(KEP-2133)
- CSIを使用するストレージの移行(KEP-625)
クラウドコントローラーマネージャーはコントロールプレーンの一部です。 kube-controller-managerやkubeletに従来存在していた機能の一部を置き換える重要なコンポーネントです。

Kubernetesのコンポーネント
クラウドコントローラーマネージャーの中でも最も重要な機能のひとつがノードコントローラーで、ノードの初期化を担当しています。
以下の図に示すように、kubeletが起動すると、NodeオブジェクトをAPIサーバーに登録し、そのノードにTaintを付与することで、最初にcloud-controller-managerによって処理されるようにします。 初期状態のNodeには、ノードアドレスや、ノード、リージョン、インスタンスタイプなどのクラウドプロバイダー固有の情報を含むラベルといった、クラウドプロバイダー固有の情報が欠けています。

「鶏が先か卵が先か」問題のシーケンス図
この新しい初期化プロセスにより、ノードが準備完了となるまでに若干の遅延が発生します。
従来は、kubeletがノードを作成する際、同時にノードの初期化を行うことも可能でした。
しかし、その処理がcloud-controller-managerに移行されたことで、クラスターのブートストラップ時に「鶏が先か卵が先か」問題が発生する可能性があります。
これは、cloud-controller-managerを他のコントロールプレーンコンポーネントと同様にデプロイしていないKubernetesアーキテクチャ(たとえば、static Pod、スタンドアロンバイナリ、またはTaintを許容しhostNetworkを使用するDaemonSetやDeploymentなど)において特に問題となります(この点については後述します)。
依存関係の問題の具体例
前述のとおり、ブートストラップ時にcloud-controller-managerがスケジューリング不可となり、クラスターが正常に初期化されない可能性があります。 以下に、この問題がどのように表面化するか、またその原因となり得る根本的な要因の具体例を示します。
これらの例では、cloud-controller-managerをKubernetesリソース(たとえば、DeploymentやDaemonSetなど)として実行し、そのライフサイクルを管理していることを前提としています。 これらの方法では、cloud-controller-managerのスケジューリングがKubernetesに依存するため、確実にスケジューリングされるように注意が必要です。
例: 未初期化のTaintによりクラウドコントローラーマネージャーがスケジューリングされない
Kubernetesのドキュメントに記載されているとおり、--cloud-provider=externalフラグを付けてkubeletを起動した場合、対応するNodeオブジェクトにはnode.cloudprovider.kubernetes.io/uninitializedというNo Schedule Taintが追加されます。
そのNo Schedule Taintを除去するのはcloud-controller-managerの責任であるため、cloud-controller-managerをDeploymentやDaemonSetなどのKubernetesリソースで管理している場合、cloud-controller-manager自身がスケジューリングできないという状況が発生する可能性があります。
コントロールプレーンの初期化中にcloud-controller-managerがスケジューリングできないと、結果として作成されるすべてのNodeオブジェクトにnode.cloudprovider.kubernetes.io/uninitializedというNo Schedule Taintが付与されたままとなります。
また、このTaintの削除はcloud-controller-managerの責務であるため、cloud-controller-managerが実行されなければTaintは削除されません。
このNo Schedule Taintが除去されないと、コンテナネットワークインターフェースのコントローラーなどの重要なワークロードがスケジューリングされず、クラスターは正常な状態になりません。
例: Not-Ready Taintによりクラウドコントローラーマネージャーがスケジューリングされない
次の例は、コンテナネットワークインターフェース(CNI)がcloud-controller-manager(CCM)からのIPアドレス情報を待ち受けており、かつCCMがCNIによって除去されるはずのTaintを許容していない状況で発生する可能性があります。
Kubernetesのドキュメントでは、node.kubernetes.io/not-ready Taintについて次のように説明されています。
「Nodeコントローラーは、ノードの正常性を監視することでその状態を判断し、それに応じてこのTaintを追加または削除します。」
このTaintがNodeリソースに付与される条件の一つは、そのノード上でコンテナネットワークがまだ初期化されていない場合です。 cloud-controller-managerはNodeリソースにIPアドレスを追加する責任があり、コンテナネットワークコントローラーはコンテナネットワークを適切に構成するためにIPアドレスを必要とします。 したがって、場合によってはノードがNot Readyのまま初期化されず、恒久的にその状態にとどまることがあります。
この状況は最初の例と同様の理由で発生しますが、この場合はnode.kubernetes.io/not-ready TaintがNo Executeの効果とともに使用されているため、cloud-controller-managerはこのTaintが付与されたノード上で実行されません。
cloud-controller-managerが実行できない場合、ノードは初期化されません。
これはコンテナネットワークコントローラーが正常に動作できないことへと連鎖し、ノードはnode.cloudprovider.kubernetes.io/uninitializedとnode.kubernetes.io/not-readyの両方のTaintを保持することになり、クラスターは正常な状態ではなくなります。
推奨事項
cloud-controller-managerの実行方法に「これが正解」という唯一の方法はありません。 詳細はクラスター管理者およびユーザーの具体的なニーズに依存します。 クラスターおよびcloud-controller-managerのライフサイクルを計画する際には、以下のガイダンスを考慮してください。
cloud-controller-managerが管理対象と同じクラスター内で実行されている場合は、下記の推奨事項を考慮してください。
- Podネットワークではなく、ホストネットワークモードを使用してください。多くの場合、クラウドコントローラーマネージャーはインフラストラクチャに関連付けられたAPIサービスエンドポイントと通信する必要があります。"hostNetwork"をtrueに設定することで、クラウドコントローラーはコンテナネットワークではなくホストのネットワークを使用するようになり、ホストオペレーティングシステムと同じネットワークアクセスを持つことが保証されます。また、ネットワークプラグインへの依存もなくなります。これにより、クラウドコントローラーがインフラストラクチャのエンドポイントへアクセスできるようになります(ネットワーク構成がインフラストラクチャプロバイダーの指示と一致しているか必ず確認してください)。
- スケーラブルなリソースタイプを使用してください。
DeploymentやDaemonSetは、クラウドコントローラーのライフサイクルを管理するのに有用です。これらを使用することで、冗長性のために複数のインスタンスを実行したり、Kubernetesのスケジューリング機能によってクラスター内で適切に配置したりすることが容易になります。これらのプリミティブを使ってクラウドコントローラーのライフサイクルを管理し、複数のレプリカを実行する場合は、リーダー選出を有効にすることを忘れないでください。そうしないと、各コントローラーが互いに干渉し、クラスター内のノードが初期化されない可能性があります。 - コントローラーマネージャーのコンテナをコントロールプレーンに配置してください。他のコントローラー(たとえばAzureのノードマネージャーコントローラーなど)がコントロールプレーン外で実行される必要がある場合もありますが、コントローラーマネージャー自体はコントロールプレーンにデプロイするべきです。クラウドコントローラーをコントロールプレーン上で実行するように、nodeSelectorやaffinityスタンザを使用してスケジューリングを制御してください。これにより、クラウドコントローラーを保護された領域で実行できるようになります。クラウドコントローラーはKubernetesと物理インフラストラクチャとの間の接続を担い、クラスターへのノードの追加・削除に不可欠です。これらをコントロールプレーン上で実行することで、他のコアのクラスターコントローラーと同等の優先度で実行され、非特権ユーザーのワークロードとは分離されることが確保されます。
- クラウドコントローラーが同一のホスト上で実行されないようにするためのanti-affinityスタンザも、単一ノードの障害によってクラウドコントローラーのパフォーマンスが低下するのを防ぐうえで非常に有用であることは注目に値します。
- 運用が可能となるように、適切なTolerationを設定してください。クラウドコントローラーコンテナのマニフェストには、適切なノードにスケジューリングされるよう、またノードが初期化中であっても実行できるようにするためのTolerationを記述する必要があります。これは、クラウドコントローラーが
node.cloudprovider.kubernetes.io/uninitializedTaintを許容すべきであることを意味します。また、コントロールプレーンに関連付けられたTaint(たとえばnode-role.kubernetes.io/control-planeやnode-role.kubernetes.io/master)も許容すべきです。さらに、ノードがまだ正常性監視の利用ができない状態でもクラウドコントローラーが実行できるよう、node.kubernetes.io/not-readyTaintを許容することも有用です。
cloud-controller-managerを、管理対象のクラスター上ではなく、別のクラスター(たとえば、ホスト型コントロールプレーンを用いた構成)で実行する場合、その運用はcloud-controller-managerを実行しているクラスターの環境に依存するため、より厳しい制約を受けることになります。 自己管理型クラスター上での運用に関する推奨事項は、競合の種類やネットワーク制約が異なるため、適切でない場合があります。 このようなシナリオにおいては、ご利用のトポロジーに応じたアーキテクチャと要件を確認してください。
例
以下は、上記のガイダンスを反映したKubernetesのDeploymentの例です。 これはあくまでデモンストレーション用のものであり、実運用で使用する場合は必ずクラウドプロバイダーのドキュメントを参照してください。
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: cloud-controller-manager
name: cloud-controller-manager
namespace: kube-system
spec:
replicas: 2
selector:
matchLabels:
app.kubernetes.io/name: cloud-controller-manager
strategy:
type: Recreate
template:
metadata:
labels:
app.kubernetes.io/name: cloud-controller-manager
annotations:
kubernetes.io/description: Cloud controller manager for my infrastructure
spec:
containers: # コンテナの詳細は使用するクラウドコントローラーマネージャーに依存します
- name: cloud-controller-manager
command:
- /bin/my-infrastructure-cloud-controller-manager
- --leader-elect=true
- -v=1
image: registry/my-infrastructure-cloud-controller-manager@latest
resources:
requests:
cpu: 200m
memory: 50Mi
hostNetwork: true # これらのPodはコントロールプレーンの一部です
nodeSelector:
node-role.kubernetes.io/control-plane: ""
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: "kubernetes.io/hostname"
labelSelector:
matchLabels:
app.kubernetes.io/name: cloud-controller-manager
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
operator: Exists
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 120
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 120
- effect: NoSchedule
key: node.cloudprovider.kubernetes.io/uninitialized
operator: Exists
- effect: NoSchedule
key: node.kubernetes.io/not-ready
operator: Exists
クラウドコントローラーマネージャーのデプロイ方法を決定する際には、クラスターの規模やリソースに応じたPodのオートスケーリングは推奨されないことに注意してください。 クラウドコントローラーマネージャーのレプリカを複数実行することは、高可用性や冗長性を確保する上で有効な手法ですが、パフォーマンスの向上にはつながりません。 一般に、任意の時点でクラスターの整合性を保つ処理を行うのはクラウドコントローラーマネージャーのインスタンスのうち1つだけです。
SIG Architecture: Enhancementsの取り組みの紹介
これは、SIG Architecture Spotlightシリーズの第4回目のインタビューであり、今後もさまざまなサブプロジェクトを取り上げる予定です。 今回は、SIG Architecture: Enhancementsを特集します。
このSIG Architecture Spotlightでは、EnhancementsサブプロジェクトのリードであるKirsten Garrisonさんにお話を伺いました。
Enhancementsサブプロジェクト
Frederico(FSM): Kirstenさん、Enhancementsサブプロジェクトについてお話しできる機会をいただき、とてもうれしく思います。 まずは簡単に自己紹介とご自身の役割について教えてください。
Kirsten Garrison(KG): 私はSIG-ArchitectureのEnhancementsサブプロジェクトのリードを務めており、現在はGoogleに勤務しています。 最初はCarolyn Van Slyckさんの助けを借りながら、service-catalogプロジェクトへのコントリビュートを通じて関わり始めました。 その後、リリースチームに参加し、最終的にEnhancementsのリードおよびRelease Leadの補佐を務めることになりました。 リリースチームでは、私のチームの経験に基づき、各SIGやEnhancementsチームにとってより良いプロセスとなるよう(オプトインプロセスなどの)いくつかのアイデアに取り組みました。 最終的には、サブプロジェクトのミーティングに参加し、その作業にも貢献するようになりました。
FSM: Enhancementsサブプロジェクトについて言及されていましたが、その主な目的や関与する領域について説明していただけますか?
KG: Enhancementsサブプロジェクトは、主にKubernetes Enhancement Proposal(略して KEP)を扱っています。 KEPは、Kubernetesプロジェクトにおけるすべての新機能および重要な変更に必要となる「設計」ドキュメントです。
KEPとその影響
FSM: KEPプロセスの改善は、かつてから(そして現在も)、SIG Architectureが深く関与している取り組みの一つです。 このプロセスについて知らない方のために、説明していただけますか?
KG: 各リリースにおいて、各SIGはそのリリースに含めたいと考えている機能をリリースチームに共有します。 先ほど述べたとおり、これらの変更の前提となるのがKEPです。 KEPは標準化された設計ドキュメントであり、すべての作成者がリリースサイクルの最初の数週間で記入し、承認されなければなりません。 ほとんどの機能は、alpha、beta、最終的にはGAという3つのフェーズを経て進行します。 そのため、機能を承認するということは、SIGにとって大きな責任を伴う決定となります。
KEPは、ある機能に関する唯一の信頼できる情報源としての役割があります。 KEPテンプレートには、機能がどの段階にいるかに応じて異なる要件がありますが、一般的には設計や影響についての詳細な議論、安定性やパフォーマンスに関する成果物の提示が求められます。 KEPが承認されるまでには、作成者、SIGのレビュアー、APIレビューチーム、Production Readiness Reviewチーム1との間でかなりの反復的なやり取りが必要となります。 各レビュアーチームは、Kubernetesリリースが安定し、パフォーマンスに優れたものとなるよう、その提案が自分たちの基準を満たしているかを確認します。 すべての承認が得られて初めて作成者は次に進むことができ、Kubernetesのコードベースに自身の機能をマージすることができます。
FSM: なるほど、かなり多くの枠組みが追加されたのですね。 振り返ってみて、そのアプローチによる最も重要な改善点は何だったと思いますか?
KG: 概して、最も大きな影響を与えた改善点は、KEPの本来の意図に焦点を当てたことだと考えています。 KEPは単に設計を記録するために存在するのではなく、変更のさまざまな側面について議論し、合意に至るための構造化された手段を提供するものです。 KEPプロセスの中心にあるのは、コミュニケーションと配慮です。
その目的のために、いくつかの重要な変更は、より詳細でアクセスしやすいKEPテンプレートを中心に行われています。 現在のk/enhancementsリポジトリの形になるまでには、多くの時間をかけてかなりの作業が行われてきました。 具体的には、SIGごとに整理されたディレクトリ構成と、現行のKEPテンプレート(Proposal/Motivation/Design Detailsのサブセクションを含む)の枠組みが整えられました。 今では、この基本的な構造は当たり前のように感じられるかもしれませんが、実際にはこのプロセスの基盤を整えるために、多くの人々が長年にわたって取り組んできた成果を反映したものです。
Kubernetesが成熟するにつれて、単に1つの機能をマージするという最終的な目標だけでなく、安定性やパフォーマンス、ユーザーの期待の設定とそれに応えることなど、さらに多くの要素を考慮する必要が出てきました。 こうした点を意識する中で、テンプレートもより詳細なものへと発展してきました。 Production Readiness Reviewの追加や改善されたテスト要件(KEPのライフサイクルの段階ごとに異なります)も、大きな変更点でした。
現在の注力分野
FSM: 成熟の話といえば、最近Kubernetes v1.31をリリースし、v1.32の作業もすでに始まっています。Enhancementsサブプロジェクトが現在取り組んでいる内容の中で、今後の進め方に影響を与える可能性があるものはありますか?
KG: 現在、2つの取り組みを進めています。
- プロセス用KEPテンプレートの作成: 機能指向ではなくプロセス指向の重要な変更に対してもKEPプロセスを活用したいと考える人がいます。 私たちはこのような取り組みを支援したいと考えています。 というのも、変更を記録として残すことは重要であり、それを実現するためのより優れたツールを提供することで、さらなる議論と透明性の向上が促されるからです。
- KEPのバージョン管理: テンプレートの変更は可能な限り非破壊的に行うことを目指していますが、KEPテンプレートにバージョンを設け、バージョンに対応するポリシーを整備することで、変更をより適切に追跡・共有できるようになると考えています。
これらの機能はいずれも、正しく設計し、完全に展開するまでに時間を要しますが(まさにKEPの機能と同様です)、どちらもコミュニティ全体にとって有益な改善につながると信じています。
FSM: 改善点について言及されましたが、最近のリリースでEnhancementのトラッキング用にプロジェクトボードが導入され、非常に効果的で、リリースチームのメンバーからも満場一致で称賛されていたのを思い出します。 これは、サブプロジェクトとして特に注力していた分野だったのでしょうか?
KG: このサブプロジェクトは、リリースチームのEnhancementチームによるスプレッドシートからプロジェクトボードへの移行を支援しました。 Enhancementの収集とトラッキングは、常に運用上の課題でした。 私がリリースチームに所属していた頃には、SIGのリードがリリーストラッキングの対象とするKEPを「オプトイン」する方式への移行を支援しました。 これにより、KEPに対して重要な作業を開始する前に、作成者とSIGの間でより良いコミュニケーションが取れるようになり、Enhancementsチームの手間も軽減されました。 この変更では、コミュニティに一度に多くの変更を導入することを避けるため、既存のツールを活用しました。 その後、リリースチームが、Enhancementの収集プロセスをさらに改善するため、GitHubのプロジェクトボードを活用するというアイデアをこのサブプロジェクトに提案しました。 これは、複雑なスプレッドシートの使用をやめ、k/enhancementのIssueに付与されたリポジトリネイティブなラベルとプロジェクトボードを用いる方向への転換でした。
FSM: それは、間違いなくワークフローの簡素化に大きな影響を与えたことでしょうね…。
KG: 摩擦の原因を取り除き、明確なコミュニケーションを促進することは、Enhancementsサブプロジェクトにとって非常に重要です。 同時に、コミュニティ全体に影響を及ぼす意思決定については慎重に検討することも重要です。 変更によって利点が得られる一方で、展開時に後退や混乱を一切引き起こさないように、バランスの取れた対応となることを私たちは確実にしたいと考えています。 私たちは、アイデア出しからプロジェクトボードへの実際の移行作業に至るまで、リリースチームを支援しました。 これは大成功を収め、KEPプロセスに関わるすべての人々を助けるような高い影響を持つ変更をチームが実現するのを見るのは、とても刺激的なことでした!
参加方法
FSM: 興味を持って参加を検討している読者に向けて、このサブプロジェクトに関わるために必要なスキルについて教えていただけますか?
KG: KEPに関する知識があると役立ちます。 それは実際の経験から得たものであっても、kubernetes/enhancementsリポジトリを時間をかけて読み込んだ結果であっても構いません。 興味がある方は誰でも歓迎です。そこから一緒に進めていきましょう。
FSM: 素晴らしいです!お時間と貴重なお話を本当にありがとうございました。 最後に読者の皆さんに伝えたいことはありますか?
KG: Enhancementsプロセスは、Kubernetesにおける最も重要な要素の一つであり、それを成功させるためには、プロジェクト全体にわたる多くの人々やチームによる膨大な調整と協力が必要です。 プロジェクトをより良いものにするために、皆さんが継続的に努力し、尽力していることに心から感謝し、また大いに励まされています。 このコミュニティは本当に素晴らしいものです。
詳細については、このシリーズのProduction Readiness Review spotlight interviewを確認してみてください。 ↩︎
Kubernetes v1.32: Penelope
編集者: Matteo Bianchi, Edith Puclla, William Rizzo, Ryota Sawada, Rashan Smith
Kubernetes v1.32: Penelopeのリリースを発表します!
これまでのリリースと同様に、Kubernetes v1.32では新たなGA、ベータ、アルファの機能が導入されています。 継続的に高品質なリリースを提供できていることは、私たちの開発サイクルの強さと、活発なコミュニティのサポートを示すものです。 今回のリリースでは、44の機能強化が行われました。 そのうち、13の機能がGAに昇格し、12の機能がベータに移行し、19の機能がアルファとして導入されています。
リリースのテーマとロゴ

Kubernetes v1.32のリリーステーマは"Penelope"です。
Kubernetesが古代ギリシャ語で「パイロット」または「舵取り」を意味することから始め、このリリースではKubernetesの10年間とその成果を振り返ります。 各リリースサイクルは一つの旅路であり、「オデュッセイア」のペーネロペーが10年の間、昼に織ったものを夜になると解いていったように、各リリースでは新機能の追加と既存機能の削除を行います。 ただしここでは、Kubernetesを継続的に改善するというより明確な目的を持って行われています。 v1.32はKubernetesが10周年を迎える年の最後のリリースとなることから、クラウドネイティブの海の試練や課題を航海してきたグローバルなKubernetesクルーの一員として貢献してくださった全ての方々に敬意を表したいと思います。 これからも共にKubernetesの未来を紡いでいけることを願っています。
最近の主要な機能の更新
DRAの機能強化に関する注記
今回のリリースでは、前回のリリースと同様に、KubernetesプロジェクトはDynamic Resource Allocation(DRA)に対して多くの機能強化を提案し続けています。 DRAはKubernetesのリソース管理システムの主要なコンポーネントです。 これらの機能強化は、GPU、FPGA、ネットワークアダプターなどの特殊なハードウェアを必要とするワークロードに対するリソース割り当ての柔軟性と効率性を向上させることを目的としています。
これらの機能は、機械学習や高性能コンピューティングアプリケーションなどのユースケースで特に有用です。DRAのStructured parameterサポートを可能にするコア部分はベータに昇格しました。
ノードとサイドカーコンテナの更新における振る舞いの改善
SIG Nodeでは、KEPの範囲を超えて以下のような改善が行われています:
kubeletのヘルスチェックが失敗した際にkubeletを再起動するために、systemdのwatchdog機能が使用されるようになりました。 また、一定時間内の最大再起動回数も制限されます。 これによりkubeletの信頼性が向上します。 詳細についてはPull Requestの#127566をご覧ください。
イメージプルのバックオフエラーが発生した場合、Podのステータスに表示されるメッセージが改善され、より分かりやすくなり、Podがこの状態にある理由の詳細が示されるようになりました。 イメージプルのバックオフが発生すると、エラーはPod仕様の
status.containerStatuses[*].state.waiting.messageフィールドに追加され、reasonフィールドにはImagePullBackOffの値が設定されます。 この変更により、より多くのコンテキストが提供され、問題の根本原因を特定するのに役立ちます。 詳細については、Pull Requestの#127918をご覧ください。サイドカーコンテナ機能は、v1.33でStableへの昇格を目指しています。 残りの作業項目とユーザーからのフィードバックについては、Issueの#753のコメントをご覧ください。
GAに昇格した機能のハイライト
これは、v1.32のリリースに伴いGAとなった改善点の一部です。
カスタムリソースのフィールドセレクター
カスタムリソースのフィールドセレクターにより、開発者は組み込みのKubernetesオブジェクトで利用できる機能と同様に、カスタムリソースにフィールドセレクターを追加できるようになりました。 これにより、カスタムリソースのより効率的で正確なフィルタリングが可能になり、より良いAPI設計の実践を促進します。
この作業は、SIG API MachineryによりKEP #4358の一部として実施されました。
SizeMemoryBackedVolumesのサポート
この機能により、Podのリソース制限に基づいてメモリバックアップボリュームを動的にサイズ設定できるようになり、ワークロードの移植性とノードのリソース使用率の全体的な向上を実現します。
この作業は、SIG NodeによりKEP #1967の一部として実施されました。
バインドされたサービスアカウントトークンの改善
サービスアカウントトークンのクレームにノード名を含めることで、認可と認証(ValidatingAdmissionPolicy)の過程でこの情報を使用できるようになりました。 さらに、この改善によりサービスアカウントの認証情報がノードの権限昇格パスとなることを防ぎます。
この作業は、SIG AuthによりKEP #4193の一部として実施されました。
構造化された認可設定
APIサーバーに複数の認可機能を設定できるようになり、webhookでのCELマッチ条件をサポートすることで、構造化された認可の判断が可能になりました。
この作業は、SIG AuthによりKEP #3221の一部として実施されました。
StatefulSetによって作成されたPVCの自動削除
StatefulSetが作成したPersistentVolumeClaim(PVC)は、不要になると自動的に削除されるようになりました。 これはStatefulSetの更新やノードのメンテナンス時にもデータを確実に保持したまま削除処理を行います。 この機能により、StatefulSetのストレージ管理が容易になり、PVCが残されたままになるリスクも減少します。
この作業は、SIG AppsによりKEP #1847の一部として実施されました。
ベータに昇格した機能のハイライト
これは、v1.32のリリースに伴いベータとなった改善点の一部です。
JobのAPI管理メカニズム
JobのmanagedByフィールドがv1.32でベータに昇格しました。
この機能により、外部コントローラー(Kueueなど)がJobの同期を管理できるようになり、高度なワークロード管理システムとのより柔軟な統合が可能になります。
この作業は、SIG AppsによりKEP #4368の一部として実施されました。
設定されたエンドポイントのみの匿名認証を許可
この機能により、管理者は匿名リクエストを許可するエンドポイントを指定できるようになりました。
例えば、管理者は/healthz、/livez、/readyzなどのヘルスエンドポイントへの匿名アクセスのみを許可し、ユーザーがRBACを誤設定した場合でも、他のクラスターエンドポイントやリソースへの匿名アクセスを確実に防止できます。
この作業は、SIG AuthによりKEP #4633の一部として実施されました。
kube-schedulerにおけるプラグインごとの再スケジュール判断機能の改善
この機能は、プラグインごとのコールバック関数(QueueingHint)によってスケジューリングの再試行の判断をより効率的にすることで、スケジューリングのスループットを向上させます。 すべてのプラグインがQueueingHintsを持つようになりました。
この作業は、SIG SchedulingによりKEP #4247の一部として実施されました。
ボリューム拡張の失敗からのリカバリー
この機能により、ユーザーは小さいサイズで再試行することでボリューム拡張の失敗から回復できるようになりました。 この改善により、ボリューム拡張がより堅牢で信頼性の高いものとなり、プロセス中のデータ損失や破損のリスクが軽減されます。
この作業は、SIG StorageによりKEP #1790の一部として実施されました。
ボリュームグループスナップショット
この機能は、VolumeGroupSnapshot APIを導入し、ユーザーが複数のボリュームを同時にスナップショット取得できるようにすることで、ボリューム間のデータ整合性を確保します。
この作業は、SIG StorageによりKEP #3476の一部として実施されました。
構造化パラメーターのサポート
Dynamic Resource Allocation(DRA)のコア部分である構造化パラメーターのサポートがベータに昇格しました。 これにより、kube-schedulerとCluster Autoscalerはサードパーティドライバーを必要とせずに、直接クレームの割り当てをシミュレーションできるようになりました。
これらのコンポーネントは、実際に割り当てを確定することなく、クラスターの現在の状態に基づいてリソース要求が満たされるかどうかを予測できるようになりました。 サードパーティドライバーによる割り当ての検証やテストが不要になったことで、この機能はリソース分配の計画と意思決定を改善し、スケジューリングとスケーリングのプロセスをより効率的にします。
この作業は、WG Device Management(SIG Node、SIG Scheduling、SIG Autoscalingを含む機能横断チーム)によりKEP #4381の一部として実施されました。
ラベルとフィールドセレクターの認可
認可の判断にラベルとフィールドセレクターを使用できるようになりました。 ノードの認可機能は、これを自動的に活用してノードが自身のPodのみをリストやウォッチできるように制限します。 Webhookの認可機能は、使用されるラベルやフィールドセレクターに基づいてリクエストを制限するように更新できます。
この作業は、SIG AuthによりKEP #4601の一部として実施されました。
アルファとして導入された新機能
これは、v1.32のリリースでアルファとして導入された主な改善点の一部です。
Kubernetesスケジューラーにおける非同期プリエンプション
Kubernetesスケジューラーは、プリエンプション操作を非同期で処理することでスケジューリングのスループットを向上させる、非同期プリエンプション機能が強化されました。 プリエンプションは、優先度の低いPodを退避させることで、優先度の高いPodに必要なリソースを確保します。 しかし、これまでこのプロセスではPodを削除するためのAPIコールなどの重い操作が必要で、スケジューラーの速度低下を引き起こしていました。 この強化により、そのような処理が並列で実行されるようになり、スケジューラーは他のPodのスケジューリングを遅延なく継続できるようになりました。 この改善は、特にPodの入れ替わりが頻繁なクラスターや、スケジューリングの失敗が頻発するクラスターで有効で、より効率的で堅牢なスケジューリングプロセスを実現します。
この作業は、SIG SchedulingによりKEP #4832の一部として実施されました。
CEL式を使用したMutating Admission Policy
この機能は、CELのオブジェクトインスタンス化とJSONパッチ戦略を、Server Side Applyのマージアルゴリズムと組み合わせて活用します。 これにより、ポリシー定義が簡素化され、変更の競合が削減され、アドミッション制御のパフォーマンスが向上すると同時に、Kubernetesにおけるより堅牢で拡張可能なポリシーフレームワークの基盤が構築されます。
KubernetesのAPIサーバーは、Common Expression Language(CEL)ベースのMutating Admission Policyをサポートするようになり、Mutating Admission Webhookの軽量で効率的な代替手段を提供します。 この強化により、管理者はCELを使用して、ラベルの設定、フィールドのデフォルト値設定、サイドカーの注入といった変更を、シンプルな宣言的な式で定義できるようになりました。 このアプローチにより、運用の複雑さが軽減され、webhookの必要性が排除され、kube-apiserverと直接統合されることで、より高速で信頼性の高いプロセス内変更処理を実現します。
この作業は、SIG API MachineryによりKEP #3962の一部として実施されました。
Podレベルのリソース指定
この機能強化により、Podレベルでリソースの要求と制限を設定できるようになり、Pod内のすべてのコンテナが動的に使用できる共有プールを作成することで、Kubernetesのリソース管理が簡素化されます。 これは特に、リソース需要が変動的またはバースト的なコンテナを持つワークロードにとって有用で、過剰なプロビジョニングを最小限に抑え、全体的なリソース効率を向上させます。
KubernetesはPodレベルでLinuxのcgroup設定を活用することで、これらのリソース制限を確実に適用しながら、密結合したコンテナが人為的な制約に縛られることなく、より効果的に連携できるようにします。 重要なことに、この機能は既存のコンテナレベルのリソース設定との後方互換性を維持しており、ユーザーは現在のワークフローや既存の設定を中断することなく、段階的に採用できます。
これは、コンテナ間のリソース割り当て管理の運用複雑性を軽減するため、マルチコンテナPodにとって重要な改善となります。 また、コンテナがワークロードを共有したり、最適なパフォーマンスを発揮するために互いの可用性に依存したりするサイドカーアーキテクチャなどの密接に統合されたアプリケーションにおいて、パフォーマンスの向上をもたらします。
この作業は、SIG NodeによりKEP #2837の一部として実施されました。
PreStopフックのスリープアクションでゼロ値を許可
この機能強化により、KubernetesのPreStopライフサイクルフックで0秒のスリープ時間を設定できるようになり、リソースの検証とカスタマイズのためのより柔軟な無操作オプションを提供します。 これまでは、スリープアクションにゼロ値を設定しようとするとバリデーションエラーが発生し、その使用が制限されていました。 この更新により、ユーザーはゼロ秒の時間を有効なスリープ設定として設定でき、必要に応じて即時実行と終了の動作が可能になります。
この機能強化は後方互換性があり、PodLifecycleSleepActionAllowZeroフィーチャーゲートによって制御されるオプトイン機能として導入されています。
この変更は、実際のスリープ時間を必要とせずに、検証やAdmission Webhook処理のためにPreStopフックを必要とするシナリオで特に有効です。
Goのtime.After関数の機能に合わせることで、この更新はKubernetesワークロードの設定を簡素化し、使いやすさを向上させます。
この作業は、SIG NodeによりKEP #4818の一部として実施されました。
DRA:ResourceClaimステータスのための標準化されたネットワークインターフェースデータ
この機能強化により、ドライバーがResourceClaimの各割り当てオブジェクトに対して特定のデバイスステータスデータを報告できる新しいフィールドが追加されました。
また、ネットワークデバイス情報を表現するための標準的な方法も確立されました。
この作業は、SIG NetworkによりKEP #4817の一部として実施されました。
コアコンポーネントの新しいstatuszとflagzエンドポイント
コアコンポーネントに対して、2つの新しいHTTPエンドポイント(/statuszと/flagz)を有効にできるようになりました。
これらのエンドポイントは、コンポーネントが実行されているバージョン(Golangのバージョンなど)や、稼働時間、そのコンポーネントが実行された際のコマンドラインフラグの詳細を把握することで、クラスターのデバッグ性を向上させます。
これにより、実行時および設定の問題の診断が容易になります。
この作業は、SIG InstrumentationによりKEP #4827とKEP #4828の一部として実施されました。
Windowsの逆襲
Kubernetesクラスターにおいて、Windowsノードの正常なシャットダウンのサポートが追加されました。 このリリース以前、KubernetesはLinuxノードに対して正常なノードシャットダウン機能を提供していましたが、Windowsに対する同等のサポートは欠けていました。 この機能強化により、Windowsノード上のkubeletがシステムのシャットダウンイベントを適切に処理できるようになりました。 これにより、Windowsノード上で実行されているPodが正常に終了され、ワークロードの中断なしでの再スケジュールが可能になります。 この改善により、特に計画的なメンテナンスやシステム更新時において、Windowsノードを含むクラスターの信頼性と安定性が向上します。
さらに、CPUマネージャー、メモリマネージャー、トポロジーマネージャーの改善により、Windowsノードに対するCPUとメモリのアフィニティサポートが追加されました。
この作業は、SIG WindowsによりKEP #4802とKEP #4885の一部として実施されました。
1.32における機能の昇格、非推奨化、および削除
GAへの昇格
ここでは、GA(一般提供 とも呼ばれる)に昇格したすべての機能を紹介します。新機能やアルファからベータへの昇格を含む完全な更新リストについては、リリースノートをご覧ください。
このリリースでは、以下の13個の機能強化がGAに昇格しました:
- Structured Authorization Configuration
- Bound service account token improvements
- Custom Resource Field Selectors
- Retry Generate Name
- Make Kubernetes aware of the LoadBalancer behaviour
- Field
status.hostIPsadded for Pod - Custom profile in kubectl debug
- Memory Manager
- Support to size memory backed volumes
- Improved multi-numa alignment in Topology Manager
- Add job creation timestamp to job annotations
- Add Pod Index Label for StatefulSets and Indexed Jobs
- Auto remove PVCs created by StatefulSet
非推奨化と削除
Kubernetesの開発と成熟に伴い、プロジェクト全体の健全性のために、機能が非推奨化、削除、またはより良いものに置き換えられる場合があります。 このプロセスの詳細については、Kubernetesの非推奨化と削除のポリシーをご覧ください。
古いDRA実装の廃止
KEP #3063により、Kubernetes 1.26でDynamic Resource Allocation(DRA)が導入されました。
しかし、Kubernetes v1.32では、このDRAのアプローチが大幅に変更されます。元の実装に関連するコードは削除され、KEP #4381が「新しい」基本機能として残ります。
既存のアプローチを変更する決定は、リソースの可用性が不透明であったことによるクラスターオートスケーリングとの非互換性に起因しており、これによりCluster Autoscalerとコントローラーの両方の意思決定が複雑化していました。 新しく追加されたStructured Parameterモデルがその機能を置き換えます。
この削除により、Kubernetesはkube-apiserverとの双方向のAPIコールの複雑さを回避し、新しいハードウェア要件とリソースクレームをより予測可能な方法で処理できるようになります。
詳細については、KEP #3063をご覧ください。
API削除
Kubernetes v1.32では、以下のAPIが削除されます:
- FlowSchemaとPriorityLevelConfigurationの
flowcontrol.apiserver.k8s.io/v1beta3APIバージョンが削除されます。 これに備えるため、既存のマニフェストを編集し、v1.29以降で利用可能なflowcontrol.apiserver.k8s.io/v1 APIバージョンを使用するようにクライアントソフトウェアを書き換えることができます。 既存の永続化されたオブジェクトはすべて新しいAPIを通じてアクセス可能です。flowcontrol.apiserver.k8s.io/v1beta3における主な変更点として、PriorityLevelConfigurationのspec.limited.nominalConcurrencySharesフィールドは未指定の場合にのみデフォルトで30となり、明示的に0が指定された場合は30に変更されないようになりました。
詳細については、API廃止に関する移行ガイドを参照してください。
リリースノートとアップグレードに必要なアクション
Kubernetes v1.32リリースの詳細については、リリースノートをご確認ください。
入手方法
Kubernetes v1.32は、GitHubまたはKubernetesダウンロードページからダウンロードできます。
Kubernetesを始めるには、対話式のチュートリアルをチェックするか、minikubeを使用してローカルKubernetesクラスターを実行してください。 また、kubeadmを使用して簡単にv1.32をインストールすることもできます。
リリースチーム
Kubernetesは、そのコミュニティのサポート、献身、そして懸命な努力に支えられて実現しています。 各リリースチームは、皆様が頼りにしているKubernetesリリースを構成する多くの要素を構築するために協力して働く、献身的なコミュニティボランティアで構成されています。 これには、コード自体からドキュメンテーション、プロジェクト管理に至るまで、コミュニティのあらゆる分野から専門的なスキルを持つ人々が必要です。
私たちは、Kubernetes v1.32リリースをコミュニティに提供するために多くの時間を費やしてくださったリリースチーム全体に感謝の意を表します。 リリースチームのメンバーは、初めてShadowとして参加する人から、複数のリリースサイクルを経験したベテランのチームリーダーまで多岐にわたります。 リリースリードのFrederico Muñozには、リリースチームを見事に率いて、あらゆる事柄を細心の注意を払って処理し、このリリースを円滑かつ効率的に実行してくれたことに、特別な感謝の意を表します。 最後になりましたが、すべてのリリースメンバー(リードとShadowの双方)、そして14週間のリリース作業期間中に素晴らしい仕事と成果を上げてくれた以下のSIGsに、大きな感謝の意を表します:
- SIG Docs - ドキュメントとブログのレビューにおける基本的なサポートを提供し、リリースのコミュニケーションとドキュメントチームとの継続的な協力を行ってくれました。
- SIG K8s InfraとSIG Testing - 必要なすべてのインフラコンポーネントと共に、テストフレームワークを確実に維持するための素晴らしい仕事を行ってくれました。
- SIG Releaseとすべてのリリースマネージャー - リリース全体の調整を通じて素晴らしいサポートを提供し、最も困難な課題でも適切かつタイムリーに対応してくれました。
プロジェクトの進捗速度
CNCFのK8s DevStatsプロジェクトは、Kubernetesと様々なサブプロジェクトの進捗に関する興味深いデータポイントを集計しています。 これには、個人の貢献から貢献している企業の数まで、このエコシステムの進化に関わる取り組みの深さと広さを示す様々な情報が含まれています。
14週間(9月9日から12月11日まで)続いたv1.32リリースサイクルでは、125の異なる企業と559の個人がKubernetesに貢献しました。
クラウドネイティブエコシステム全体では、433の企業から合計2441人の貢献者がいます。 これは前回のリリースサイクルと比較して、全体の貢献が7%増加し、参加企業数も14%増加したことを示しており、クラウドネイティブプロジェクトに対する強い関心とコミュニティの支持が表れています。
このデータの出典:
ここでの貢献とは、コミットの作成、コードレビュー、コメント、IssueやPRの作成、PR(ブログやドキュメントを含む)のレビュー、もしくはIssueやPRへのコメントを指します。
コントリビューターウェブサイトのGetting Startedから、貢献を始める方法をご確認ください。
Kubernetesプロジェクトとコミュニティの全体的な活動状況の詳細については、DevStatsをご確認ください。
イベント情報
2025年3月から6月にかけて開催予定のKubernetesとクラウドネイティブ関連のイベントをご紹介します。 KubeCon、KCD、その他世界各地で開催される注目のカンファレンスが含まれています。 Kubernetesコミュニティの最新情報を入手し、交流を深めましょう。
2025年3月
- KCD - Kubernetes Community Days: Beijing, China: 3月 | 北京(中国)
- KCD - Kubernetes Community Days: Guadalajara, Mexico: 2025年3月16日 | グアダラハラ(メキシコ)
- KCD - Kubernetes Community Days: Rio de Janeiro, Brazil: 2025年3月22日 | リオデジャネイロ(ブラジル)
2025年4月
- KubeCon + CloudNativeCon Europe 2025: 2025年4月1日-4日 | ロンドン(イギリス)
- KCD - Kubernetes Community Days: Budapest, Hungary: 2025年4月23日 | ブダペスト(ハンガリー)
- KCD - Kubernetes Community Days: Chennai, India: 2025年4月26日 | チェンナイ(インド)
- KCD - Kubernetes Community Days: Auckland, New Zealand: 2025年4月28日 | オークランド(ニュージーランド)
2025年5月
- KCD - Kubernetes Community Days: Helsinki, Finland: 2025年5月6日 | ヘルシンキ(フィンランド)
- KCD - Kubernetes Community Days: San Francisco, USA: 2025年5月8日 | サンフランシスコ(アメリカ)
- KCD - Kubernetes Community Days: Austin, USA: 2025年5月15日 | オースティン(アメリカ)
- KCD - Kubernetes Community Days: Seoul, South Korea: 2025年5月22日 | ソウル(韓国)
- KCD - Kubernetes Community Days: Istanbul, Turkey: 2025年5月23日 | イスタンブール(トルコ)
- KCD - Kubernetes Community Days: Heredia, Costa Rica: 2025年5月31日 | エレディア(コスタリカ)
- KCD - Kubernetes Community Days: New York, USA: 2025年5月 | ニューヨーク(アメリカ)
2025年6月
- KCD - Kubernetes Community Days: Bratislava, Slovakia: 2025年6月5日 | ブラチスラバ(スロバキア)
- KCD - Kubernetes Community Days: Bangalore, India: 2025年6月6日 | バンガロール(インド)
- KubeCon + CloudNativeCon China 2025: 2025年6月10日-11日 | 香港
- KCD - Kubernetes Community Days: Antigua Guatemala, Guatemala: 2025年6月14日 | アンティグア グアテマラ(グアテマラ)
- KubeCon + CloudNativeCon Japan 2025: 2025年6月16日-17日 | 東京(日本)
- KCD - Kubernetes Community Days: Nigeria, Africa: 2025年6月19日 | ナイジェリア
次期リリースに関するウェビナーのお知らせ
2025年1月9日(木)午後5時(太平洋時間) に開催されるKubernetes v1.32リリースチームメンバーによるウェビナーにご参加ください。 このリリースの主要な機能や、アップグレード計画に役立つ非推奨化および削除された機能について学ぶことができます。 詳細および参加登録については、CNCFオンラインプログラムサイトのイベントページをご覧ください。
参加方法
Kubernetesに関わる最も簡単な方法は、あなたの興味に合ったSpecial Interest Groups(SIG)のいずれかに参加することです。 Kubernetesコミュニティに向けて何か発信したいことはありますか? 毎週のコミュニティミーティングや、以下のチャンネルであなたの声を共有してください。 継続的なフィードバックとサポートに感謝いたします。
- 最新情報はBlueskyの@Kubernetes.ioをフォローしてください
- Discussでコミュニティディスカッションに参加してください
- Slackでコミュニティに参加してください
- Stack Overflowで質問したり、回答したりしてください
- あなたのKubernetesに関するストーリーを共有してください
- Kubernetesの最新情報はブログでさらに詳しく読むことができます
- Kubernetesリリースチームについてもっと学んでください
Kubernetes Upstream Training in Japanの取り組みの紹介
私たちは、Kubernetes Upstream Training in Japanのオーガナイザーチームです。 チームは、Kubernetesへのコントリビューションを続けるメンバーで構成され、その中にはReviewerやApprover、Chairといった役割を担う人々も含まれています。
私たちの目標は、Kubernetesのコントリビューターを増やし、コミュニティの成長を促進することです。Kubernetesコミュニティは親切で協力的ですが、初めての貢献はややハードルが高いと感じる方もいます。私たちのトレーニングプログラムは、そのハードルを下げ、初心者でもスムーズに参加できる環境を提供することを目的としています。
Kubernetes Upstream Training in Japanとは?

Kubernetes Upstream Training in Japanは2019年から始まり、年に1〜2回のペースで開催されています。 当初、Kubernetes Upstream TrainingはKubeConのco-locatedイベント(Kubernetes Contributor Summit)の中で実施されていましたが、同様のイベントを日本でも行って日本人のコントリビューターを増やしたいという思いから、私たちはKubernetes Upstream Training in Japanを立ち上げました。
パンデミック以前は対面形式で行われていましたが、2020年以降はオンラインで開催しています。 トレーニングでは、Kubernetesにまだコントリビューションをしたことがない方々に向けて、以下のような内容を提供しています。
- Kubernetesコミュニティの紹介
- Kubernetesのコードベースの紹介と、PRの作成方法
- 言語など参加障壁を低減するための工夫や勇気付け
- 開発環境のセットアップ方法
- kubernetes-sigs/contributor-playgroundを使用したハンズオン
プログラムの最初に、なぜKubernetesにコントリビューションするのか、だれがKubernetesにコントリビューションできるのかを伝えます。 Kubernetesに貢献することは、世界中にインパクトのある貢献ができること、そしてKuberenetesコミュニティはみなさんからのコントリビューションを楽しみにしていることを伝えます!
KubernetesコミュニティやSIG、Working Groupについて説明します。 また、私たちが主にコミュニケーションのために用いるSlackやGitHub、メーリングリストについて説明します。 日本語を話す人の中には、英語によるコミュニケーションに障壁を感じる人もいます。 また、コミュニティに初めて参加する人は、どこでどのようなコミュニケーションが行われているのか知る必要があります。 もちろん、私たちがトレーニングの中で最も大切にしていることは第一歩を踏み出すことです!
次に、Member、Reviewer、Approver、Tech leadやChairといった役割や責任について説明します。
その後、Kubernetesのコードベースの構成、主要なリポジトリ、PRの作成方法、Prowを使ったCI/CDの仕組みなどを解説します。 PRが作成されてからマージされるまでのプロセスについて詳しく説明します。
いくつかの講義を行った後、実際に参加者には、kubernetes-sigs/contributor-playgroundを使用したハンズオンを行い、簡単なPRの作成を体験してもらいます。 これにより、Kubernetesへのコントリビューションの流れを実感してもらうことが目的です。
プログラムの最後には、ローカルでのクラスター構築、コードのビルド、効率的なテスト実行方法など、kubernetes/kubernetesリポジトリに貢献するための具体的な開発環境のセットアップについても解説します。
参加者へのインタビュー
私たちのトレーニングプログラムに参加した方々にインタビューを行いました。 参加した理由や感想、そして今後の目標について伺いました。
Keita Mochizukiさん(NTT DATA Group Corporation)
Keita Mochizukiさんは、Kubernetesや周辺のプロジェクトへ継続的に貢献しているコントリビューターです。 Keitaさんは、コンテナセキュリティのプロフェッショナルでもあり、最近は書籍の出版を行いました。 また、新規コントリビューターのためのロードマップを公開しており、これは新たなコントリビューターにとって非常に役立つものです。
Junya: なぜKubernetes Upstream Trainingに参加しようと思いましたか?
Keita: 実は私は2020年と2022年の2回参加しました。2020年はk8sに触れ始めたばかりで、社外活動に参加してみようと思い、偶然Twitterで見かけて申し込みました。しかし、当時は知識も浅く、OSSにPRを送ること自体が雲の上の存在のように感じていました。そのため、受講後の理解度は浅く、なんとなく「ふーん」という感覚でした。
2回目の2022年は、具体的にコントリビューションを始めようとしていたタイミングで、再度参加しました。この時は事前調査も行い、疑問点を講義中に解決できたので、非常に実りある時間を過ごせました。
Junya: 参加してみて、どのような感想を持ちましたか?
Keita: このトレーニングは参加者のスタンス次第でその意義が大きく変わるものだと感じました。トレーニング自体は一般的な解説と簡単なハンズオンで構成されていますが、このトレーニングに参加したからといって、すぐにコントリビューションができるかというと、そう簡単ではありません。しかし、もし事前に自分が今後コントリビューションを行うイメージをなんとなくでも持っていたり、具体的な疑問や課題を明確にしておくことができれば、講師の方々が実際にコミュニティで培った貴重なノウハウを活かして、それらに対して丁寧に応えてくれるため、大変有意義なトレーニングになると思います。
Junya: コントリビューションの目的は何ですか?
Keita: 最初のモチベーションは「Kubernetesの深い理解と実績の獲得」で、つまり「コントリビューションそのものが目的」でした。 現在はこれに加え、業務で発見したバグや制約への対応を目的にコントリビューションを行うこともあります。また、コントリビューション活動を通じて、ドキュメント化されていない仕様をソースコードから解析することへの抵抗が以前よりも少なくなりました。
Junya: コントリビューションをする中で、難しかったことは何ですか?
Keita: 最も難しかったのは、最初の一歩を踏み出すことでした。OSSへのコントリビューションには一定の知識やノウハウが必要となるため、本トレーニングをはじめ、さまざまなリソースの活用や人からのサポートが不可欠でした。その中で、「最初の一歩を踏み出すと、あとはどんどん前に進める」という言葉が強く印象に残っています。また、業務としてコントリビューションを続ける上で一番難しいのは、その成果を業績として示すことです。継続的に取り組むためには事業目標や戦略と関連付ける必要がありますが、UpstreamへのContributionは必ずしも短期的に業績に繋がるケースばかりではないため、そのことをマネージャーと十分に認識を合わせ、理解を得ることが重要であると考えています。
Junya: 今後の目標は何ですか?
Keita: よりインパクトのある領域にコントリビューションすることです。これまでは実績を得ることを主目的としていたため比較的小さな個々のバグ等を中心にコントリビューションを行うことが多かったのですが、今後はKubernetesのユーザーに対して影響度の高いものや、業務上の課題解決に繋がるものに挑戦の幅を広げたいと思っています。最近は自身がコードベースの開発や修正に携わった内容を公式ドキュメントに反映すると言うことも行っていますが、これも目標に向けての1歩だと考えています。
Junya: ありがとうございました!
Yoshiki Fujikaneさん(CyberAgent, Inc.)
Yoshiki Fujikaneさんは、CNCFのSandboxプロジェクトのひとりであるPipeCDのメンテナのひとりです。 PipeCDのKubernetesサポートに関する新機能の開発の他に、コミュニティ運営や、各種技術カンファレンスへの登壇も積極的に行っています。
Junya: なぜKubernetes Upstream Trainingに参加しようと思いましたか?
Yoshiki: 参加した当時はまだ学生時代でした。その時はEKSを軽く触っていただけでしたが、なんか難しいけどかっこいいな!とk8s自体に興味をふんわりと持っている状態でした。当時は本当にOSSは雲の上の存在で、ましてやk8sのupstreamの開発なんてすごすぎて手の届かない存在だと思ってました。OSSにはもともと興味があったのですが、何から始めればいいのかわからなかったです。そんな時にkubernetes upstream trainingの存在を知って、k8sへのコントリビューションに挑戦してみようと思いました。
Junya: 参加してみて、どのような感想を持ちましたか?
Yoshiki: OSSに関わるコミュニティがどんなものかを知るキッカケとしてとてもありがたいなと感じました。当時は英語力もそこまで高くなく、一次情報を見に行くことは自分にとって大きなハードルでした。 k8sは非常に大きなプロジェクトなので、コントリビューションに必要なことだけでなく、全体像があまりわかっていない状態でした。upstream trainingでは、コミュニティの構造を日本語で説明していただいたうえで、コントリビューションを実際に行うところまで一通り経験することができました。そこで、一次情報に関する情報を共有してくださったおかげで、その後自分なりにエントリーポイントとして利用しつつ追加で調査するキッカケづくりになって非常にありがたかったです。この経験から、一次情報を整理しつつ見る習慣を身につける必要があるなと思い、気になったものはGitHubのissueやdocsを漁りに見に行くようになりました。結果として、今はk8sのコントリビューション自体は行っていませんが、ここでの経験が別プロジェクトにコントリビューションするための素地となって役立っています。
Junya: 現在はどのような領域でコントリビューションを行っていますか?別のプロジェクトとはどのようなものでしょうか?
Yoshiki: 現在はk8sからは少し離れていて、CNCFのSandbox ProjectであるPipeCDのメンテナをやっています。PipeCDはCDツールの一つで、様々なアプリケーションプラットフォームに対してGitOpsスタイルでデプロイする機能を持っています。このツールは、元々サイバーエージェント内部で開発が始まりました。大小様々なチームが異なるプラットフォームを採用していた中で、統一的なUXで共通で利用できるCD基盤を実現するために開発が進められた背景があります。現在はk8s、AWS ECS、Lambda、Cloud Run、Terraformといったプラットフォームに対応しています。
Junya: PipeCDチームの中ではどのような役割ですか?
Yoshiki: 私はチーム内ではk8s周りの機能改善、開発をフルタイムの仕事として行っています。社内向けにPipeCDをSaaSとして提供しているため、そのサポートの一環として、新規機能の追加や既存機能の改善などを行うことが主な目的です。さらに、コード以外のコントリビューションとしては、PipeCD自体のコミュニティ拡大に向けて各種登壇であったり、コミュニティミーティングの運営を行っているところです。
Junya: Kubernetes周りの機能改善や開発とは具体的にどのようなものですか?
Yoshiki: PipeCDはKubernetesのGitOpsやProgressive Deliveryをサポートしていて、それらの機能開発などです。直近だと、マルチクラスター上へのデプロイを効率化するための機能開発を進めているところです。
Junya: OSSコントリビューションを行うなかで、難しかったことはありますか?
Yoshiki: 機能の汎用性を維持しつつ、ユーザーのユースケースを満たすように開発を進めることです。社内SaaSを運用する中で機能要望をいただいた際には、もちろん課題を解決するためにまずは機能追加を検討します。一方で、PipeCDはOSSとしてより多くのユーザーに使ってもらうことも考えて行きたいです。なので、あるユースケースをもとに別のユースケースとしても使えるかどうかを考え、ソフトウェアとして汎用性をもたせるように意識しています。
Junya: 今後の目標を教えてください!
Yoshiki: PipeCDの機能拡張に力を入れていきたいと考えています。PipeCDは現在One CD for All のスローガンのもと開発を進めています。先程お伝えした通り、k8s、AWS ECS、Lambda、Cloud Run、Terraform の5種類に対応していますが、これ以外にもプラットフォームは存在しますし、今後も新たなプラットフォームが台頭してくるかもしれません。そこで、PipeCDは現在ユーザーが独自に拡張できるようにプラグイン機構の開発を進めています。それに力を入れていきたいですね。また、k8sのマルチクラスターデプロイ向けの機能開発も進めているところで、これからもよりインパクトのあるコントリビューションをしていきたいと考えてます。
Junya: ありがとうございました!
Kubernetes Upstream Training の未来
私たちは、これからもKubernetes Upstream Training in Japanを継続して開催し、多くの新しいコントリビューターを迎えたいと考えています。 次回の開催は11月末のCloudNative Days Winter 2024の中での開催を予定しています。
また、私たちの目標は、これらのトレーニングプログラムを日本だけでなく、世界中に広げていくことです。 Kubernetesは今年で10周年を迎えましたが、コミュニティがこれまで以上に活発になるためには、世界中の人々が貢献し続けることが重要です。 現在、Upstream Trainingはいくつかの地域で開催されていますが、私たちはさらに多くの地域での開催を目指しています。
多くの人々がKubernetesコミュニティに参加し、貢献することで、私たちのコミュニティがますます活気づくことを楽しみにしています!
Kubernetes 1.31: Fine-grained SupplementalGroups control
この記事ではKubernetes 1.31の新機能である、Pod内のコンテナにおける補助グループ制御の改善機能について説明します。
動機: コンテナイメージ内の/etc/groupに定義される暗黙的なグループ情報
この挙動は多くのKubernetesクラスターのユーザー、管理者にとってあまり知られていないかもしれませんが、Kubernetesは、デフォルトでは、Podで定義された情報に加えて、コンテナイメージ内の/etc/groupのグループ情報を マージ します。
例を見てみましょう。このPodはsecurityContextでrunAsUser=1000、runAsGroup=3000、supplementalGroups=4000を指定しています。
apiVersion: v1
kind: Pod
metadata:
name: implicit-groups
spec:
securityContext:
runAsUser: 1000
runAsGroup: 3000
supplementalGroups: [4000]
containers:
- name: ctr
image: registry.k8s.io/e2e-test-images/agnhost:2.45
command: [ "sh", "-c", "sleep 1h" ]
securityContext:
allowPrivilegeEscalation: false
ctrコンテナでidコマンドを実行すると何が出力されるでしょうか?
# Podを作成してみましょう。
$ kubectl apply -f https://k8s.io/blog/2024-08-22-Fine-grained-SupplementalGroups-control/implicit-groups.yaml
# Podのコンテナが実行されていることを確認します。
$ kubectl get pod implicit-groups
# idコマンドを確認します。
$ kubectl exec implicit-groups -- id
出力は次のようになるでしょう。
uid=1000 gid=3000 groups=3000,4000,50000
Podマニフェストには50000は一切定義されていないにもかかわらず、補助グループ(groupsフィールド)に含まれているグループID50000は一体どこから来るのでしょうか? 答えはコンテナイメージの/etc/groupファイルです。
コンテナイメージの/etc/groupの内容が下記のようになっていることが確認できるでしょう。
$ kubectl exec implicit-groups -- cat /etc/group
...
user-defined-in-image:x:1000:
group-defined-in-image:x:50000:user-defined-in-image
なるほど!コンテナのプライマリユーザーであるユーザー(1000)がグループ(50000)に属していることが最後のエントリから確認出来ました。
このように、コンテナイメージ上の/etc/groupで定義される、コンテナのプライマリユーザーのグループ情報は、Podからの情報に加えて 暗黙的にマージ されます。ただし、この挙動は、現在のCRI実装がDockerから引き継いだ設計上の決定であり、コミュニティはこれまでこの挙動について再検討することはほとんどありませんでした。
何が悪いのか?
コンテナイメージの/etc/groupから 暗黙的にマージ されるグループ情報は、特にボリュームアクセスを行う際に、セキュリティ上の懸念を引き起こすことがあります(詳細はkubernetes/kubernetes#112879を参照してください)。なぜなら、Linuxにおいて、ファイルパーミッションはuid/gidで制御されているからです。更に悪いことに、/etc/groupに由来する暗黙的なgidは、マニフェストにグループ情報の手がかりが無いため、ポリシーエンジン等でチェック・検知をすることが出来ません。これはKubernetesセキュリティの観点からも懸念となります。
PodにおけるFine-grained(きめ細かい) SupplementalGroups control: SupplementaryGroupsPolicy
この課題を解決するために、Kubernetes 1.31はPodの.spec.securityContextに、新しくsupplementalGroupsPolicyフィールドを追加します。
このフィールドは、Pod内のコンテナプロセスに付与される補助グループを決定するを方法を制御できるようにします。有効なポリシーは次の2つです。
Merge:
/etc/groupで定義されている、コンテナのプライマリユーザーが所属するグループ情報をマージします。指定されていない場合、このポリシーがデフォルトです(後方互換性を考慮して既存の挙動と同様)。Strict:
fsGroup、supplementalGroups、runAsGroupフィールドで指定されたグループIDのみ補助グループに指定されます。つまり、/etc/groupで定義された、コンテナのプライマリユーザーのグループ情報はマージされません。
では、どのようにStrictポリシーが動作するか見てみましょう。
apiVersion: v1
kind: Pod
metadata:
name: strict-supplementalgroups-policy
spec:
securityContext:
runAsUser: 1000
runAsGroup: 3000
supplementalGroups: [4000]
supplementalGroupsPolicy: Strict
containers:
- name: ctr
image: registry.k8s.io/e2e-test-images/agnhost:2.45
command: [ "sh", "-c", "sleep 1h" ]
securityContext:
allowPrivilegeEscalation: false
# Podを作成してみましょう。
$ kubectl apply -f https://k8s.io/blog/2024-08-22-Fine-grained-SupplementalGroups-control/strict-supplementalgroups-policy.yaml
# Podのコンテナが実行されていることを確認します。
$ kubectl get pod strict-supplementalgroups-policy
# プロセスのユーザー、グループ情報を確認します。
kubectl exec -it strict-supplementalgroups-policy -- id
出力はこのようになります。
uid=1000 gid=3000 groups=3000,4000
Strictポリシーによってグループ50000がgroupsから除外されているのが確認できました!
このように、確実にsupplementalGroupsPolicy: Strictを設定する(ポリシーエンジン等によって強制する)ことで、暗黙的な補助グループを回避することが可能になります。
備考:
このフィールドの値を強制するだけでは不十分な場合もあります。なぜなら、プロセスが自分自身のユーザー、グループ情報を変更できる権限/ケーパビリティを持っている場合があるからです。詳細は次のセクションを参照してください。Podステータスにおける付与されたユーザー、グループ情報の確認
この機能は、Podのstatus.containerStatuses[].user.linuxフィールドでコンテナの最初のプロセスに付与されたユーザー、グループ情報を公開しています。暗黙的なグループIDが付与されているかどうかを確認するのに便利でしょう。
...
status:
containerStatuses:
- name: ctr
user:
linux:
gid: 3000
supplementalGroups:
- 3000
- 4000
uid: 1000
...
備考:
status.containerStatuses[].user.linuxフィールドで公開されているユーザー、グループ情報は、コンテナの最初のプロセスに、最初に付与された 情報であることに注意してください。
もしそのプロセスが、自身のユーザー、グループ情報を変更できるシステムコール(例えば setuid(2),
setgid(2),
setgroups(2)等)を実行する権限を持っている場合、プロセス自身で動的に変更が可能なためです。
つまり、実際にプロセスに付与されているユーザー、グループ情報は動的に変化します。この機能を利用するには
supplementalGroupsPolicyフィールドを有効化するには、下記のコンポーネントを利用する必要があります。
- Kubernetes: v1.31以降、かつ、
SupplementalGroupsPolicyフィーチャーゲートが有効化されていること。v1.31現在、このフィーチャーゲートはアルファです。 - CRI実装:
- containerd: v2.0以降
- CRI-O: v1.31以降
ノードの.status.features.supplementalGroupsPolicyフィールドでこの機能が利用可能かどうか確認出来ます。
apiVersion: v1
kind: Node
...
status:
features:
supplementalGroupsPolicy: true
将来の展望
Kubernetes SIG Nodeは、この機能が将来的なKubernetesのリリースでベータ版に昇格し、最終的には一般提供(GA)されることを望んでおり、期待しています。そうなれば、ユーザーはもはや機能ゲートを手動で有効にする必要がなくなります。
supplementalGroupsPolicyが指定されていない場合は、後方互換性のためにMergeポリシーが適用されます。
より学ぶには?
- Podとコンテナにセキュリティコンテキストを設定する(
supplementalGroupsPolicyの詳細) - KEP-3619: Fine-grained SupplementalGroups control
参加するには?
この機能はSIG Nodeコミュニティによって推進されています。コミュニティに参加して、上記の機能やそれ以外のアイデアやフィードバックを共有してください。皆さんからのご意見をお待ちしています!
Kubernetes 1.31: SPDYからWebSocketへのストリーミングの移行
Kubernetes 1.31では、kubectlがストリーミングする際に、SPDYに代わりWebSocketプロトコルをデフォルトで使用するようになりました。
この記事では、この変更が意味するところと、なぜこれらのストリーミングAPIが重要なのかについて説明します。
KubernetesのストリーミングAPI
Kubernetesでは、HTTPまたはRESTfulインターフェースとして公開される特定のエンドポイントが、ストリーミングプロトコルが必要な、ストリーミング接続にアップグレードされます。 リクエスト・レスポンス型プロトコルであるHTTPとは異なり、ストリーミングプロトコルは双方向・低遅延の永続的な接続を提供し、リアルタイムでの対話を可能にします。 ストリーミングプロトコルは、クライアントとサーバー間で同一の接続を介して、双方向でのデータの読み書きをサポートします。 このタイプの接続は、例えば、ローカルワークステーションから実行中のコンテナ内にシェルを作成し、そのコンテナ内でコマンドを実行する場合などに役立ちます。
なぜストリーミングプロトコルを変更するのか?
v1.31リリース以前は、Kubernetesはストリーミング接続をアップグレードする際に、デフォルトでSPDY/3.1プロトコルを使用していました。
SPDY/3.1は8年前に非推奨となっており、標準化されることはありませんでした。
多くの最新のプロキシ、ゲートウェイ、ロードバランサーは、このプロトコルをサポートしていません。
その結果、プロキシやゲートウェイを介してクラスターにアクセスしようとすると、kubectl cp、kubectl attach、kubectl exec、kubectl port-forwardなどのコマンドが機能しなくなることがあります。
Kubernetes v1.31以降、SIG API Machineryは、Kubernetesクライアント(kubectlなど)がこれらのコマンドに使用するストリーミングプロトコルを、よりモダンなWebSocketストリーミングプロトコルに変更しました。
WebSocketプロトコルは、現在サポートされている標準化されたストリーミングプロトコルであり、様々なコンポーネントやプログラミング言語間の互換性と相互運用性を保証します。
WebSocketプロトコルは、SPDYよりも最新のプロキシやゲートウェイで広くサポートされています。
ストリーミングAPIの仕組み
Kubernetesは、発信元のHTTPリクエストに特定のアップグレードヘッダーを追加することで、HTTP接続をストリーミング通信が可能な接続へと切り替えます。
例えば、クラスター内のnginxコンテナでdateコマンドを実行するためのHTTPアップグレードリクエストは、以下のようになります:
$ kubectl exec -v=8 nginx -- date
GET https://127.0.0.1:43251/api/v1/namespaces/default/pods/nginx/exec?command=date…
Request Headers:
Connection: Upgrade
Upgrade: websocket
Sec-Websocket-Protocol: v5.channel.k8s.io
User-Agent: kubectl/v1.31.0 (linux/amd64) kubernetes/6911225
コンテナランタイムがWebSocketストリーミングプロトコルと、少なくとも1つのサブプロトコルバージョン(例:v5.channel.k8s.io)をサポートしている場合、サーバーは成功を示す101 Switching Protocolsステータスと、ネゴシエートされたサブプロトコルバージョンを含めて応答します:
Response Status: 101 Switching Protocols in 3 milliseconds
Response Headers:
Upgrade: websocket
Connection: Upgrade
Sec-Websocket-Accept: j0/jHW9RpaUoGsUAv97EcKw8jFM=
Sec-Websocket-Protocol: v5.channel.k8s.io
この時点で、HTTPプロトコルに使用されていたTCP接続はストリーミング接続に変更されています。 この対話型シェルでのSTDIN、STDOUT、STDERR(ターミナルのリサイズ情報やプロセス終了コードも含む)データは、このアップグレードされた接続を通じてストリーミングされます。
新しいWebSocketストリーミングプロトコルの使用方法
クラスターとkubectlがバージョン1.29以降の場合、SPDYではなくWebSocketの使用を制御するための、2つのコントロールプレーンフィーチャーゲートと2つのkubectl環境変数があります。 Kubernetes 1.31では、以下のすべてのフィーチャーゲートがベータ版であり、デフォルトで有効になっています:
- フィーチャーゲート
TranslateStreamCloseWebsocketRequests.../exec.../attach
PortForwardWebsockets.../port-forward
- kubectlの機能を制御する環境変数
KUBECTL_REMOTE_COMMAND_WEBSOCKETSkubectl execkubectl cpkubectl attach
KUBECTL_PORT_FORWARD_WEBSOCKETSkubectl port-forward
古いバージョンのクラスターにおいても、フィーチャーゲート設定を管理できる場合であれば、TranslateStreamCloseWebsocketRequests(Kubernetes v1.29で追加)とPortForwardWebsockets(Kubernetes v1.30で追加)の両方を有効にして、この新しい動作を試すことができます。
バージョン1.31のkubectlは自動的に新しい動作を使用できますが、サーバー側の機能が明示的に有効になっているクラスターに接続する必要があります。
ストリーミングAPIについてさらに学ぶ
Kubernetes v1.31: キャッシュからの整合性のある読み込みによるクラスターパフォーマンスの向上
Kubernetesはコンテナ化されたアプリケーションの堅牢なオーケストレーションで知られていますが、クラスターの規模が拡大するにつれて、コントロールプレーンへの負荷がボトルネックとなる可能性があります。 特に大きな課題となっていたのは、etcdデータストアからのデータ読み込みの厳密な整合性を保証することです。 これを実現するには、リソースを大量に消費するクォーラム読み込みが必要でした。
本日、Kubernetesコミュニティは、大きな改善を発表できることを嬉しく思います。 Kubernetes v1.31において、「キャッシュからの整合性のある読み込み」がベータ版に移行しました。
なぜ整合性のある読み込みが重要なのか
Kubernetes コンポーネントがクラスターの最新状態を正確に把握するためには、整合性のある読み込みが不可欠です。 整合性のある読み込みを保証することで、Kubernetesの操作の正確性と信頼性が維持され、各コンポーネントは最新の情報に基づいて適切な判断を下すことができます。 しかし、大規模なクラスターでは、そのためのデータの取得と処理がパフォーマンスのボトルネックとなるおそれがあります。 特に、結果のフィルタリングを伴うリクエストでこの問題が顕著になります。 Kubernetesはetcd内で名前空間ごとにデータを直接フィルタリングできますが、ラベルやフィールドセレクタによるその他のフィルタリングでは、データセット全体をetcdから取得し、Kubernetes APIサーバーがメモリ上でフィルタリングを行う必要があります。 この問題は、特にkubeletなどのコンポーネントに大きな影響を与えます。 kubeletは自身のノードにスケジュールされたPodのみをリストするだけで足りるところを、これまでの仕組みでは、APIサーバーとetcdがクラスター内のすべてのPodを処理する必要がありました。
ブレイクスルー: 信頼性の高いキャッシング
Kubernetesは、読み込み操作を最適化するために、以前からWatchキャッシュを使用してきました。 Watchキャッシュはクラスターの状態のスナップショットを保存し、etcdのWatchを通じて更新情報を受け取ります。 しかし、これまではキャッシュが完全に最新の状態であることを保証できなかったため、整合性のある読み込みを直接提供することができませんでした。
「キャッシュからの整合性のある読み込み」機能は、etcdの進捗通知のメカニズムを活用してこの問題に対処します。 この通知により、Watchキャッシュは自身とetcdを比較し、データが最新かどうかを把握できます。 整合性のある読み込みが要求されると、システムはまずWatchキャッシュの内容が最新かどうかを確認します。 キャッシュが最新でない場合、システムはキャッシュの内容が完全に更新されたと確認できるまで、etcdに進捗通知を問い合わせ続けます。 そして準備が整うと、要求されたデータはキャッシュから直接読み取られ効率的に提供されます。 このため、特にetcdから大量のデータを取得する必要があるような場面で、パフォーマンスを大幅に向上させることができます。 以上のようにして、データをフィルタリングするリクエストをキャッシュから処理できるようになり、etcdから読み取る必要のあるメタデータは最小限に抑えられます。
重要な注意点: この機能を利用するには、Kubernetesクラスターでetcdバージョン3.4.31以降または3.5.13以降を実行している必要があります。 古いバージョンのetcdを使用している場合、etcdから直接整合性のある読み込みを行う方式に自動で切り替わります。
体感できるパフォーマンスの向上
この一見単純な変更は、Kubernetesのパフォーマンスとスケーラビリティに大きな影響を与えます。
- etcdの負荷軽減: Kubernetes v1.31では、etcdの作業負荷を軽減し、他の重要な操作のためにリソースを解放できます。
- レイテンシの短縮: キャッシュからの読み込みは、etcdからデータを取得して処理するよりもはるかに高速です。 これはコンポーネントへの応答が迅速になり、クラスター全体の応答性が向上することを意味します。
- スケーラビリティの向上: etcdの負荷軽減により、コントロールプレーンはパフォーマンスを犠牲にすることなくより多くのリクエストを処理できるようになるため、 数千ものノードとPodを持つような大規模なクラスターでは、最も大きなメリットが得られます。
5,000ノードのスケーラビリティテスト結果: 5,000ノードのクラスターで行われた最近のスケーラビリティテストでは、キャッシュからの整合性のある読み込みを有効にすることで、以下のような目覚ましい改善が見られました。
- kube-apiserverのCPU使用率が 30%削減
- etcdのCPU使用率が 25%削減
- PodのLISTリクエストの99パーセンタイルレイテンシが最大 3分の1に短縮 (5秒から1.5秒)
今後の予定
ベータ版への移行により、キャッシュからの整合性のある読み込みはデフォルトで有効になり、サポートされているetcdバージョンを実行しているすべてのKubernetesユーザーにシームレスなパフォーマンス向上を提供します。
私たちの旅はこれで終わりではありません。 Kubernetesコミュニティは、将来的にさらにパフォーマンスを最適化するために、Watchキャッシュでのページネーションのサポートを積極的に検討しています。
はじめ方
Kubernetes v1.31にアップグレードし、etcdバージョン3.4.31以降または3.5.13以降を使用していることを確認するのが、キャッシュからの整合性のある読み込みのメリットを体験する最も簡単な方法です。 ご質問やフィードバックがある場合は、Kubernetesコミュニティまでお気軽にお問い合わせください。
キャッシュからの整合性のある読み込みによって、あなたのKubernetes体験がどう変わったか、ぜひ教えてください!
この機能への貢献に対して、@ah8ad3 と @p0lyn0mial に特別な感謝を捧げます。
Kubernetes v1.31: Elli
編集者: Matteo Bianchi, Yigit Demirbas, Abigail McCarthy, Edith Puclla, Rashan Smith
Kubernetes v1.31: Elliのリリースを発表します!
これまでのリリースと同様に、Kubernetes v1.31では新たなGA、ベータ、アルファの機能が導入されています。 継続的に高品質なリリースを提供できていることは、私たちの開発サイクルの強さと、活発なコミュニティのサポートを示すものです。 今回のリリースでは、45の機能強化が行われました。 そのうち、11の機能がGAに昇格し、22の機能がベータに移行し、12の機能がアルファとして導入されています。
リリースのテーマとロゴ

Kubernetes v1.31のリリーステーマは"Elli"です。
Kubernetes v1.31のElliは、優しい心を持つ愛らしい犬で、かわいらしい船乗りの帽子をかぶっています。 これは、多様で大きなKubernetesコントリビューターファミリーへの遊び心あふれる敬意を表しています。
Kubernetes v1.31は、プロジェクトが10周年を祝った後の初めてのリリースです。 Kubernetesは誕生以来、長い道のりを歩んできました。 そして今もなお、各リリースで新たな方向に進化し続けています。 10年という節目を迎え、これを実現させた数え切れないほどのKubernetesコントリビューターたちの努力、献身、技術、知恵、そして地道な作業を振り返ると、深い感銘を受けずにはいられません。
プロジェクトの運営には膨大な労力が必要ですが、それにもかかわらず、熱意と笑顔を持って何度も貢献し、コミュニティの一員であることに誇りを感じる人々が絶えません。 新旧問わずコントリビューターから見られるこの「魂」こそが、活気に満ちた、まさに「喜びにあふれた」コミュニティの証なのです。
Kubernetes v1.31のElliは、まさにこの素晴らしい精神を祝福する存在なのです! Kubernetesの輝かしい次の10年に、みんなで乾杯しましょう!
GAに昇格した機能のハイライト
これは、v1.31のリリースに伴いGAとなった改善点の一部です。
AppArmorのサポートがGAに
KubernetesのAppArmorサポートがGAになりました。
コンテナのsecurityContext内のappArmorProfile.typeフィールドを設定することで、AppArmorを使用してコンテナを保護できます。
Kubernetes v1.30より前では、AppArmorはアノテーションで制御されていましたが、v1.30からはフィールドを使用して制御されるようになりました。
そのためアノテーションの使用をやめ、appArmorProfile.typeフィールドの使用に移行することをお勧めします。
詳細については、AppArmorのチュートリアルをご覧ください。 この機能は、SIG NodeによってKEP #24の一環として開発しました。
kube-proxyによる外部からの接続の安定性改善
kube-proxyを使用した外部からの接続の安定性が、v1.31で大きく改善されました。
Kubernetesのロードバランサーに関する一般的な課題の1つに、トラフィックの損失を防ぐための各コンポーネント間の連携があります。
この機能では、kube-proxyに新たな仕組みを導入し、type: LoadBalancerとexternalTrafficPolicy: Clusterを設定したサービスで公開される終了予定のNodeに対して、ロードバランサーが接続をスムーズに切り替えられるようにしています。
また、クラウドプロバイダーとKubernetesのロードバランサー実装における推奨プラクティスも確立しました。
この機能を利用するには、kube-proxyがクラスター上でデフォルトのサービスプロキシとして動作し、ロードバランサーが接続の切り替えをサポートしている必要があります。 特別な設定は不要で、v1.30からkube-proxyにデフォルトで組み込まれており、v1.31で正式にGAとなりました。
詳しくは、仮想IPとサービスプロキシのドキュメントをご覧ください。
この機能は、SIG NetworkがKEP #3836の一環として開発しました。
永続ボリュームの状態変化時刻の記録機能が正式リリース
永続ボリュームの状態変化時刻を記録する機能が、v1.31で正式にリリースされました。
この機能により、PersistentVolumeの状態が最後に変わった時刻を保存するPersistentVolumeStatusフィールドが追加されます。
機能が有効になると、すべてのPersistentVolumeオブジェクトに.status.lastTransitionTimeという新しいフィールドが設けられ、ボリュームの状態が最後に変わった時刻が記録されます。
ただし、この変更はすぐには反映されません。
Kubernetes v1.31にアップグレードした後、PersistentVolumeが更新され、状態(Pending、Bound、Released)が初めて変わったときに、新しいフィールドに時刻が記録されます。
この機能により、PersistentVolumeがPendingからBoundに変わるまでの時間を測定できるようになります。
また、様々な指標やSLOの設定にも活用できます。
詳しくは、永続ボリュームのドキュメントをご覧ください。
この機能は、SIG StorageがKEP #3762の一環として開発しました。
ベータに昇格した機能のハイライト
これは、v1.31のリリースに伴いベータとなった改善点の一部です。
kube-proxyでのnftablesバックエンドの導入
v1.31では、nftablesバックエンドがベータとして登場しました。
この機能はNFTablesProxyModeという設定で制御され、現在はデフォルトで有効になっています。
nftables APIは、iptables APIの次世代版として開発され、より高いパフォーマンスと拡張性を提供します。
nftablesプロキシモードは、iptablesモードと比べてサービスエンドポイントの変更をより迅速かつ効率的に処理できます。
また、カーネル内でのパケット処理も効率化されています(ただし、この効果は数万のサービスを持つ大規模クラスターでより顕著になります)。
Kubernetes v1.31の時点では、nftablesモードはまだ新しい機能のため、すべてのネットワークプラグインとの互換性が確認されているわけではありません。
お使いのネットワークプラグインのドキュメントで対応状況を確認してください。
このプロキシモードはLinux Nodeのみで利用可能で、カーネル5.13以降が必要です。
移行を検討する際は、特にNodePortサービスに関連する一部の機能が、iptablesモードとnftablesモードで完全に同じように動作しない点に注意が必要です。
デフォルト設定の変更が必要かどうかは、移行ガイドで確認してください。
この機能は、SIG NetworkがKEP #3866の一環として開発しました。
永続ボリュームのreclaimポリシーに関する変更
Kubernetes v1.31では、PersistentVolumeのreclaimポリシーを常に尊重する機能がベータになりました。 この機能強化により、関連するPersistentVolumeClaim(PVC)が削除された後でも、PersistentVolume(PV)のreclaimポリシーが確実に適用されるようになり、ボリュームの漏洩を防止します。
これまでは、PVとPVCのどちらが先に削除されたかによって、特定の条件下でPVに設定されたreclaimポリシーが無視されることがありました。 その結果、reclaimポリシーが"Delete"に設定されていても、外部インフラの対応するストレージリソースが削除されないケースがありました。 これにより、一貫性の欠如やリソースのリークが発生する可能性がありました。
この機能の導入により、PVとPVCの削除順序に関係なく、reclaimポリシーの"Delete"が確実に実行され、バックエンドインフラから基盤となるストレージオブジェクトが削除されることがKubernetesによって保証されるようになりました。
この機能は、SIG StorageがKEP #2644の一環として開発しました。
バインドされたサービスアカウントトークンの改善
ServiceAccountTokenNodeBinding機能が、v1.31でベータに昇格しました。
この機能により、PodではなくNodeにのみバインドされたトークンを要求できるようになりました。
このトークンには、Node情報が含まれており、トークンが使用される際にNodeの存在を検証します。
詳しくは、バインドされたサービスアカウントトークンのドキュメントをご覧ください。
この機能は、SIG AuthがKEP #4193の一環として開発しました。
複数のサービスCIDRのサポート
v1.31では、複数のサービスCIDRを持つクラスターのサポートがベータになりました(デフォルトでは無効)。
Kubernetesクラスターには、IPアドレスを使用する複数のコンポーネントがあります: Node、Pod、そしてServiceです。 NodeとPodのIP範囲は、それぞれインフラストラクチャやネットワークプラグインに依存するため、動的に変更できます。 しかし、サービスのIP範囲は、クラスター作成時にkube-apiserverのハードコードされたフラグとして定義されていました。 長期間運用されているクラスターや大規模なクラスターでは、管理者が割り当てられたサービスCIDR範囲を拡張、縮小、あるいは完全に置き換える必要があり、IPアドレスの枯渇が問題となっていました。 これらの操作は正式にサポートされておらず、複雑で繊細なメンテナンス作業を通じて行われ、しばしばクラスターのダウンタイムを引き起こしていました。 この新機能により、ユーザーとクラスター管理者はダウンタイムなしでサービスCIDR範囲を動的に変更できるようになります。
この機能の詳細については、仮想IPとサービスプロキシのドキュメントページをご覧ください。
この機能は、SIG NetworkがKEP #1880の一環として開発しました。
サービスのトラフィック分散機能
サービスのトラフィック分散機能が、v1.31でベータとなり、デフォルトで有効になりました。
SIG Networkingは、サービスネットワーキングにおける最適なユーザー体験とトラフィック制御機能を見出すため、何度も改良を重ねてきました。
その結果、サービス仕様にtrafficDistributionフィールドを実装しました。
このフィールドは、ルーティングの決定を行う際に、基盤となる実装が考慮すべき指針として機能します。
この機能の詳細については、1.30リリースブログをお読みいただくか、サービスのドキュメントページをご覧ください。
この機能は、SIG NetworkがKEP #4444の一環として開発しました。
Kubernetes VolumeAttributesClassによるボリューム修正機能
VolumeAttributesClass APIが、v1.31でベータになります。 VolumeAttributesClassは、プロビジョニングされたIOのような動的なボリュームパラメーターを修正するための、Kubernetes独自の汎用APIを提供します。 これにより、プロバイダーがサポートしている場合、ワークロードはコストとパフォーマンスのバランスを取るために、オンラインでボリュームを垂直スケーリングできるようになります。 この機能は、Kubernetes 1.29からアルファとして提供されていました。
この機能は、SIG Storageが主導し、KEP #3751の一環として開発しました。
アルファとして導入された新機能
これは、v1.31のリリースでアルファとして導入された主な改善点の一部です。
アクセラレータなどのハードウェア管理を改善する新しいDRA API
Kubernetes v1.31では、動的リソース割り当て(DRA)APIとその設計が更新されました。 この更新の主な焦点は構造化パラメーターにあります。 これにより、リソース情報とリクエストがKubernetesとクライアントに対して透明になり、クラスターのオートスケーリングなどの機能の実装が可能になります。 kubeletのDRAサポートも更新され、kubeletとコントロールプレーン間のバージョンの違いに対応できるようになりました。 構造化パラメーターにより、スケジューラはPodのスケジューリング時にResourceClaimを割り当てます。 DRAドライバーコントローラによる割り当ては、現在「クラシックDRA」と呼ばれる方法でも引き続きサポートされています。
Kubernetes v1.31では、クラシックDRAにDRAControlPlaneControllerという別のフィーチャーゲートが用意されており、これを明示的に有効にする必要があります。
このコントロールプレーンコントローラーを使用することで、DRAドライバーは構造化パラメーターではまだサポートされていない割り当てポリシーを実装できます。
この機能は、SIG NodeがKEP #3063の一環として開発しました。
イメージボリュームのサポート
Kubernetesコミュニティは、将来的に人工知能(AI)や機械学習(ML)のユースケースをより多く実現することを目指しています。
これらのユースケースを実現するための要件の1つは、Open Container Initiative(OCI)互換のイメージやアーティファクト(OCIオブジェクトと呼ばれる)を、ネイティブのボリュームソースとして直接サポートすることです。 これにより、ユーザーはOCI標準に集中でき、OCIレジストリを使用してあらゆるコンテンツを保存・配布できるようになります。
そこで、v1.31では、OCIイメージをPod内のボリュームとして使用できる新しいアルファ機能が追加されました。
この機能により、ユーザーはPod内でイメージ参照をボリュームとして指定し、それをコンテナ内のボリュームマウントとして再利用できます。
この機能を試すには、ImageVolumeフィーチャーゲートを有効にする必要があります。
この機能は、SIG NodeとSIG StorageがKEP #4639の一環として開発しました。
Podステータスを通じたデバイスの健全性情報の公開
Podステータスを通じてデバイスの健全性情報を公開する機能が、v1.31で新しいアルファ機能として追加されました。デフォルトでは無効になっています。
Kubernetes v1.31以前では、Podが故障したデバイスと関連付けられているかどうかを知る方法は、PodResources APIを使用することでした。
この機能を有効にすると、各Pod の.status内の各コンテナステータスにallocatedResourcesStatusフィールドが追加されます。
allocatedResourcesStatusフィールドは、コンテナに割り当てられた各デバイスの健全性情報を報告します。
この機能は、SIG NodeがKEP #4680の一環として開発しました。
セレクターに基づいたより細かな認可
この機能により、Webhookオーソライザーや将来の(現在は設計されていない)ツリー内オーソライザーが、ラベルやフィールドセレクターを使用するリクエストに限り、listとwatchリクエストを許可できるようになります。
例えば、オーソライザーは次のような表現が可能になります: このユーザーはすべてのPodをリストできないが、.spec.nodeNameが特定の値に一致するPodはリストできる。
あるいは、ユーザーが名前空間内のconfidential: trueとラベル付けされていないすべてのSecretを監視することを許可する。
CRDフィールドセレクター(これもv1.31でベータに移行)と組み合わせることで、より安全なNodeごとの拡張機能を作成することが可能になります。
この機能は、SIG AuthがKEP #4601の一環として開発しました。
匿名APIアクセスへの制限
AnonymousAuthConfigurableEndpointsフィーチャーゲートを有効にすることで、ユーザーは認証設定ファイルを使用して、匿名リクエストがアクセスできるエンドポイントを設定できるようになりました。
これにより、匿名ユーザーにクラスターへの広範なアクセスを与えてしまうようなRBAC設定ミスから、ユーザー自身を守ることができます。
この機能は、SIG AuthがKEP #4633の一環として開発しました。
1.31における機能の昇格、非推奨化、および削除
GAへの昇格
ここでは、GA(一般提供とも呼ばれる)に昇格したすべての機能を紹介します。新機能やアルファからベータへの昇格を含む完全な更新リストについては、リリースノートをご覧ください。
このリリースでは、以下の11個の機能強化がGAに昇格しました:
- PersistentVolume last phase transition time
- Metric cardinality enforcement
- Kube-proxy improved ingress connectivity reliability
- Add CDI devices to device plugin API
- Move cgroup v1 support into maintenance mode
- AppArmor support
- PodHealthyPolicy for PodDisruptionBudget
- Retriable and non-retriable Pod failures for Jobs
- Elastic Indexed Jobs
- Allow StatefulSet to control start replica ordinal numbering
- Random Pod selection on ReplicaSet downscaling
非推奨化と削除
Kubernetesの開発と成熟に伴い、プロジェクト全体の健全性のために、機能が非推奨化、削除、またはより良いものに置き換えられる場合があります。 このプロセスの詳細については、Kubernetesの非推奨化と削除のポリシーをご覧ください。
cgroup v1のメンテナンスモードへの移行
Kubernetesがコンテナオーケストレーションの変化に適応し続ける中、コミュニティはv1.31でcgroup v1のサポートをメンテナンスモードに移行することを決定しました。 この変更は、業界全体のcgroup v2への移行と歩調を合わせており、機能性、拡張性、そしてより一貫性のあるインターフェースの向上を提供します。 Kubernetesのメンテナンスモードとは、cgroup v1サポートに新機能が追加されないことを意味します。 重要なセキュリティ修正は引き続き提供されますが、バグ修正はベストエフォートとなり、重大なバグは可能な場合修正されますが、一部の問題は未解決のままとなる可能性があります。
できるだけ早くcgroup v2への移行を開始することをお勧めします。 この移行はアーキテクチャに依存し、基盤となるオペレーティングシステムとコンテナランタイムがcgroup v2をサポートしていることを確認し、ワークロードとアプリケーションがcgroup v2で正しく機能することを検証するためのテストを含みます。
問題が発生した場合は、issueを作成して報告してください。
この機能は、SIG NodeがKEP #4569の一環として開発しました。
SHA-1署名サポートに関する注意事項
go1.18(2022年3月リリース)以降、crypto/x509ライブラリはSHA-1ハッシュ関数で署名された証明書を拒否するようになりました。
SHA-1は安全でないことが確立されており、公的に信頼された認証局は2015年以降SHA-1証明書を発行していません。
Kubernetesのコンテキストでは、アグリケーションAPIサーバーやWebhookに使用される私的な認証局を通じてSHA-1ハッシュ関数で署名されたユーザー提供の証明書が依然として存在する可能性があります。
SHA-1ベースの証明書を使用している場合は、環境にGODEBUG=x509sha1=1を設定することで、明示的にそのサポートを有効にする必要があります。
GoのGODEBUGの互換性ポリシーに基づき、x509sha1 GODEBUGとSHA-1証明書のサポートは、go1.24で完全に削除される予定です。
go1.24は2025年前半にリリースされる予定です。
SHA-1証明書に依存している場合は、できるだけ早く移行を開始してください。
SHA-1サポートの終了時期、Kubernetesリリースがgo1.24を採用する計画、およびメトリクスと監査ログを通じてSHA-1証明書の使用を検出する方法の詳細については、Kubernetes issue #125689をご覧ください。
Nodeのstatus.nodeInfo.kubeProxyVersionフィールドの非推奨化(KEP 4004)
Kubernetes v1.31では、Nodeの.status.nodeInfo.kubeProxyVersionフィールドが非推奨となり、将来のリリースで削除される予定です。
このフィールドの値が正確ではなかった(そして現在も正確ではない)ため、非推奨化されています。
このフィールドはkubeletによって設定されますが、kubeletはkube-proxyのバージョンやkube-proxyが実行されているかどうかについて信頼できる情報を持っていません。
v1.31では、DisableNodeKubeProxyVersionフィーチャーゲートがデフォルトでtrueに設定され、kubeletは関連するNodeの.status.kubeProxyVersionフィールドを設定しなくなります。
クラウドプロバイダーとの全てのインツリー統合の削除
以前の記事で強調したように、クラウドプロバイダー統合の最後に残っていたインツリーサポートがv1.31リリースの一部として削除されました。 これは、クラウドプロバイダーと統合できなくなったという意味ではありません。 ただし、外部統合を使用する推奨アプローチを必ず使用する必要があります。 一部の統合はKubernetesプロジェクトの一部であり、他はサードパーティのソフトウェアです。
この節目は、Kubernetes v1.26から始まった、全てのクラウドプロバイダー統合のKubernetesコアからの外部化プロセスの完了を示しています(KEP-2395)。 この変更により、Kubernetesは真にベンダー中立なプラットフォームに近づきます。
クラウドプロバイダー統合の詳細については、v1.29 クラウドプロバイダー統合機能のブログ記事をお読みください。 インツリーのコード削除に関する追加の背景については、(v1.29 非推奨化ブログ)をご確認ください。
後者のブログには、v1.29以降のバージョンに移行する必要があるユーザーにとって有用な情報も含まれています。
インツリープロバイダーのフィーチャーゲートの削除
Kubernetes v1.31では、以下のアルファフィーチャーゲートが削除されました: InTreePluginAWSUnregister、InTreePluginAzureDiskUnregister、InTreePluginAzureFileUnregister、InTreePluginGCEUnregister、InTreePluginOpenStackUnregister、およびInTreePluginvSphereUnregister。
これらのフィーチャーゲートは、実際にコードベースから削除することなく、インツリーのボリュームプラグインが削除されたシナリオのテストを容易にするために導入されました。
Kubernetes 1.30でこれらのインツリーのボリュームプラグインが非推奨となったため、これらのフィーチャーゲートは冗長となり、もはや目的を果たさなくなりました。
唯一残っているCSIの移行ゲートはInTreePluginPortworxUnregisterで、これはPortworxのCSI移行が完了し、そのツリー内ボリュームプラグインの削除準備が整うまでアルファのままとなります。
kubeletの--keep-terminated-pod-volumesコマンドラインフラグの削除
2017年に非推奨となったkubeletのフラグ--keep-terminated-pod-volumesが、v1.31リリースの一部として削除されました。
詳細については、Pull Request #122082をご覧ください。
CephFSボリュームプラグインの削除
CephFSボリュームプラグインがこのリリースで削除され、cephfsボリュームタイプは機能しなくなりました。
代わりに、サードパーティのストレージドライバーとしてCephFS CSIドライバーを使用することをお勧めします。 クラスターバージョンをv1.31にアップグレードする前にCephFSボリュームプラグインを使用していた場合は、新しいドライバーを使用するようにアプリケーションを再デプロイする必要があります。
CephFSボリュームプラグインは、v1.28で正式に非推奨とマークされていました。
Ceph RBDボリュームプラグインの削除
v1.31リリースでは、Ceph RBDボリュームプラグインとそのCSI移行サポートが削除され、rbdボリュームタイプは機能しなくなりました。
代わりに、クラスターでRBD CSIドライバーを使用することをお勧めします。 クラスターバージョンをv1.31にアップグレードする前にCeph RBDボリュームプラグインを使用していた場合は、新しいドライバーを使用するようにアプリケーションを再デプロイする必要があります。
Ceph RBDボリュームプラグインは、v1.28で正式に非推奨とマークされていました。
kube-schedulerにおける非CSIボリューム制限プラグインの非推奨化
v1.31リリースでは、すべての非CSIボリューム制限スケジューラープラグインが非推奨となり、デフォルトプラグインから既に非推奨となっているいくつかのプラグインが削除されます。 これには以下が含まれます:
AzureDiskLimitsCinderLimitsEBSLimitsGCEPDLimits
これらのボリュームタイプはCSIに移行されているため、代わりにNodeVolumeLimitsプラグインを使用することをお勧めします。
NodeVolumeLimitsプラグインは、削除されたプラグインと同じ機能を処理できます。
スケジューラーの設定で明示的にこれらのプラグインを使用している場合は、非推奨のプラグインをNodeVolumeLimitsプラグインに置き換えてください。
AzureDiskLimits、CinderLimits、EBSLimits、GCEPDLimitsプラグインは将来のリリースで削除される予定です。
これらのプラグインは、Kubernetes v1.14以降非推奨となっていたため、デフォルトのスケジューラープラグインリストから削除されます。
リリースノートとアップグレードに必要なアクション
Kubernetes v1.31リリースの詳細については、リリースノートをご確認ください。
SchedulerQueueingHintsが有効な場合、スケジューラーはQueueingHintを使用するようになりました
スケジューラーに、Pod/Updatedイベントに登録されたQueueingHintを使用して、以前スケジュール不可能だったPodの更新がそれらをスケジュール可能にしたかどうかを判断するサポートが追加されました。
この新機能は、フィーチャーゲートSchedulerQueueingHintsが有効な場合に動作します。
これまで、スケジュール不可能なPodが更新された場合、スケジューラは常にPodをキュー(activeQ / backoffQ)に戻していました。
しかし、Podへのすべての更新がPodをスケジュール可能にするわけではありません。
特に、現在の多くのスケジューリング制約が不変であることを考慮すると、そうではありません。
新しい動作では、スケジュール不可能なPodが更新されると、スケジューリングキューはQueueingHint(s)を使用して、その更新がPodをスケジュール可能にする可能性があるかどうかをチェックします。
少なくとも1つのQueueingHintがQueueを返した場合にのみ、それらをactiveQまたはbackoffQに再度キューイングします。
カスタムスケジューラープラグイン開発者向けの必要なアクション:
プラグインからの拒否が、スケジュールされていないPod自体の更新によって解決される可能性がある場合、プラグインはPod/Updateイベントに対するQueueingHintを実装する必要があります。
例えばschedulable=falseラベルを持つPodを拒否するカスタムプラグインを開発したとします。
schedulable=falseラベルを持つPodは、schedulable=falseラベルが削除されるとスケジュール可能になります。このプラグインはPod/Updateイベントに対するQueueingHintを実装し、スケジュールされていないPodでそのようなラベルの変更が行われた場合にQueueを返すようにします。
詳細については、Pull Request #122234をご覧ください。
kubeletの--keep-terminated-pod-volumesコマンドラインフラグの削除
2017年に非推奨となったkubeletのフラグ--keep-terminated-pod-volumesが、v1.31リリースの一部として削除されました。
詳細については、Pull Request #122082をご覧ください。
入手方法
Kubernetes v1.31は、GitHubまたはKubernetesダウンロードページからダウンロードできます。
Kubernetesを始めるには、対話式のチュートリアルをチェックするか、minikubeを使用してローカルKubernetesクラスターを実行してください。 また、kubeadmを使用して簡単にv1.31をインストールすることもできます。
リリースチーム
Kubernetesは、そのコミュニティのサポート、献身、そして懸命な努力に支えられて実現しています。 各リリースチームは、皆様が頼りにしているKubernetesリリースを構成する多くの要素を構築するために協力して働く、献身的なコミュニティボランティアで構成されています。 これには、コード自体からドキュメンテーション、プロジェクト管理に至るまで、コミュニティのあらゆる分野から専門的なスキルを持つ人々が必要です。
私たちは、Kubernetes v1.31リリースをコミュニティに提供するために多くの時間を費やしてくださったリリースチーム全体に感謝の意を表します。 リリースチームのメンバーは、初めてShadowとして参加する人から、複数のリリースサイクルを経験したベテランのチームリーダーまで多岐にわたります。 特に、リリースリーダーのAngelos Kolaitisには特別な感謝の意を表します。 リリースサイクルを成功に導き、チーム全体をサポートし、各メンバーが最大限に貢献できる環境を整えると同時に、リリースプロセスの改善にも取り組んでくれました。
プロジェクトの進捗速度
CNCF K8s DevStatsプロジェクトは、Kubernetesと様々なサブプロジェクトの進捗に関する興味深いデータポイントを集計しています。 これには、個人の貢献から貢献している企業の数まで、このエコシステムの進化に関わる取り組みの深さと広さを示す様々な情報が含まれています。
14週間(5月7日から8月13日まで)続いたv1.31リリースサイクルでは、113の異なる企業と528の個人がKubernetesに貢献しました。
クラウドネイティブエコシステム全体では、379の企業から合計2268人の貢献者がいます。 これは、前回のリリースサイクルと比較して、貢献者数が驚異の63%増加しました!
このデータの出典:
ここでいう貢献とは、コミットの作成、コードレビュー、コメント、IssueやPRの作成、PRのレビュー(ブログやドキュメントを含む)、またはIssueやPRへのコメントを指します。
貢献に興味がある方は、このページを訪れて始めてください。
Kubernetesプロジェクトとコミュニティ全体の進捗速度についてもっと知りたい方は、DevStatsをチェックしてください。
イベント情報
2024年8月から11月にかけて開催予定のKubernetesとクラウドネイティブ関連のイベントをご紹介します。KubeCon、KCD、その他世界各地で開催される注目のカンファレンスが含まれています。Kubernetesコミュニティの最新情報を入手し、交流を深めましょう。
2024年8月
- KubeCon + CloudNativeCon + Open Source Summit China 2024: 2024年8月21日-23日 | 香港
- KubeDay Japan: 2024年8月27日 | 東京、日本
2024年9月
- KCD Lahore - Pakistan 2024: 2024年9月1日 | ラホール、パキスタン
- KuberTENes Birthday Bash Stockholm: 2024年9月5日 | ストックホルム、スウェーデン
- KCD Sydney '24: 2024年9月5日-6日 | シドニー、オーストラリア
- KCD Washington DC 2024: 2024年9月24日 | ワシントンDC、アメリカ合衆国
- KCD Porto 2024: 2024年9月27日-28日 | ポルト、ポルトガル
2024年10月
- KubeDay Australia: 2024年10月1日 | メルボルン、オーストラリア
- KCD Austria 2024: 2024年10月8日-10日 | ウィーン、オーストリア
- KCD UK - London 2024: 2024年10月22日-23日 | グレーターロンドン、イギリス
2024年11月
- KubeCon + CloudNativeCon North America 2024: 2024年11月12日-15日 | ソルトレイクシティ、アメリカ合衆国
- Kubernetes on EDGE Day North America: 2024年11月12日 | ソルトレイクシティ、アメリカ合衆国
次期リリースに関するウェビナーのお知らせ
2024年9月12日(木)午前10時(太平洋時間)に開催されるKubernetes v1.31リリースチームメンバーによるウェビナーにご参加ください。このリリースの主要な機能や、アップグレード計画に役立つ非推奨化および削除された機能について学ぶことができます。 詳細および登録については、CNCFオンラインプログラムサイトのイベントページをご覧ください。
参加方法
Kubernetesに関わる最も簡単な方法は、あなたの興味に合ったSpecial Interest Groups(SIG)のいずれかに参加することです。 Kubernetesコミュニティに向けて何か発信したいことはありますか? 毎週のコミュニティミーティングや、以下のチャンネルであなたの声を共有してください。 継続的なフィードバックとサポートに感謝いたします。
- 最新情報はX(旧Twitter)の@Kubernetesioをフォローしてください
- Discussでコミュニティディスカッションに参加してください
- Slackでコミュニティに参加してください
- Stack Overflowで質問したり、回答したりしてください
- あなたのKubernetesに関するストーリーを共有してください
- Kubernetesの最新情報はブログでさらに詳しく読むことができます
- Kubernetesリリースチームについてもっと学んでください
Client-Goへのフィーチャーゲートの導入: 柔軟性と管理性を強化するために
Kubernetesコンポーネントは フィーチャーゲート というオン/オフのスイッチを使うことで、新機能を追加する際のリスクを管理しています。 フィーチャーゲート の仕組みは、Alpha、Beta、GAといった各ステージを通じて、新機能の継続的な品質認定を可能にします。
kube-controller-managerやkube-schedulerのようなKubernetesコンポーネントは、client-goライブラリを使ってAPIとやりとりします。 Kubernetesエコシステムは、このライブラリをコントローラーやツール、Webhookなどをビルドするために利用しています。 最新のclient-goにはそれ自体にフィーチャーゲート機構があり、開発者やクラスター管理者は新たなクライアントの機能を採用するかどうかを制御することができます。
Kubernetesにおけるフィーチャーゲートについて深く知るには、フィーチャーゲートを参照してください。
動機
client-goのフィーチャーゲートが登場するまでは、それぞれの機能が独自のやり方で、 利用できる機能とその機能の有効化のための仕組みを区別していました。 client-goの新バージョンにアップデートすることで有効化できる機能もありました。 その他の機能については、利用するプログラムからいつでも設定できる状態にしておく必要がありました。 ごく一部の機能には環境変数を使って実行時に設定可能なものがありました。 kube-apiserverが提供するフィーチャーゲート機能を利用する場合、(設定や機能実装の時期が原因で)そうした機能をサポートしないクライアントサイドのフォールバック機構がしばしば必要になりました。 これらのフォールバック機構で明らかになった問題があれば、問題の影響を緩和するためにclient-goのバージョンを固定したり、ロールバックしたりする必要がありました。
これらのいずれのアプローチも、client-goを利用するいくつかのプログラムに対してのみデフォルトで機能を有効化する場合には、よい効果をもたらすものではありませんでした。
単一のコンポーネントに対して新機能を有効化するだけでも、標準設定の変更が直ちにすべてのKubernetesコンポーネントに伝搬し、影響範囲は甚大なものとなっていました。
client-goにおけるフィーチャーゲート
こうした課題に対処するため、client-goの個別機能は新しいフィーチャーゲート機構を使うフェーズに移行します。 Kubernetesコンポーネントのフィーチャーゲート使用経験があるなら、開発者やユーザーは誰もが慣れ親しんだやり方で機能を有効化/無効化できるようになります。
client-goの最近のバージョンを使うだけで、client-goを用いてビルドしたソフトウェアを利用する方々にとってはいくつかの利益があります。
- アーリーアダプターはデフォルトでは無効化されているclient-goの機能について、プロセス単位で有効化できます。
- 挙動がおかしな機能については、新たなバイナリをビルドせずに無効化できます。
- client-goのすべての既知のフィーチャーゲートは状態が記録されており、ユーザーは機能の挙動を調査することができます。
client-goを用いてビルドするソフトウェアを開発している方々にとっては、次のような利益があります。
- 環境変数から client-goのフィーチャーゲートのオーバーライドを指定することができます。 client-goの機能にバグが見つかった場合は、新しいリリースを待たずに機能を無効化できます。
- プログラムのデフォルトの挙動を変更する目的で、開発者は環境変数ベースのオーバーライドを他のソースからの読み込みで置き換えたり、実行時のオーバーライドを完全に無効化したりすることができます。
このカスタマイズ可能な振る舞いは、Kubernetesコンポーネントの既存の
--feature-gatesコマンドラインフラグや機能有効化メトリクス、ロギングを統合するのに利用します。
client-goのフィーチャーゲートをオーバーライドする
補足: ここではclient-goのフィーチャーゲートを実行時に上書きするデフォルトの方法について説明します。
client-goのフィーチャーゲートは、個々のプログラムの開発者がカスタマイズしたり、無効化したりすることができます。
Kubernetesコンポーネントではclient-goフィーチャーゲートの上書きを--feature-gatesフラグで制御します。
client-goの機能はKUBE_FEATUREから始まる名前の環境変数を設定することによって、有効化したり無効化したりすることができます。
例えば、MyFeatureという名前の機能を有効化するには、次のような環境変数を設定します。
KUBE_FEATURE_MyFeature=true
この機能を無効化したいときには、環境変数をfalseに設定します。
KUBE_FEATURE_MyFeature=false
補足: いくつかのオペレーティングシステムでは、環境変数は大文字小文字が区別されます。
したがってKUBE_FEATURE_MyFeatureとKUBE_FEATURE_MYFEATUREは異なる2つの変数として認識される場合があります。
client-goのフィーチャーゲートをカスタマイズする
標準のフィーチャーゲート上書き機能である環境変数ベースの仕組みは、Kubernetesエコシステムの多くのプログラムにとって十分なものと言え、特殊なインテグレーションが不要なやり方です。 異なる挙動を必要とするプログラムのために、この仕組みを独自のフィーチャーゲートプロバイダーで置き換えることもできます。 これにより、うまく動かないことが分かっている機能を強制的に無効化したり、フィーチャーゲートを直接外部の設定サービスから読み込んだり、コマンドラインオプションからフィーチャーゲートの上書きを指定したりすることができるようになります。
Kubernetesコンポーネントはclient-goの標準のフィーチャーゲートプロバイダーを、既存のKubernetesフィーチャーゲートプロバイダーに対する接ぎ木(shim)を使って置き換えます。
実用的な理由から、client-goのフィーチャーゲートは他のKubernetesのフィーチャーゲートと同様に取り扱われています。
(--feature-gatesコマンドラインフラグに落とし込まれた上で、機能有効化メトリクスに登録され、プログラム開始時にログがなされます)。
標準のフィーチャーゲートプロバイダーを置き換えるには、Gatesインターフェースを実装し、パッケージ初期化の際にReplaceFeatureGatesを呼ぶ必要があります。 以下は簡単な例です。
import (
“k8s.io/client-go/features”
)
type AlwaysEnabledGates struct{}
func (AlwaysEnabledGates) Enabled(features.Feature) bool {
return true
}
func init() {
features.ReplaceFeatureGates(AlwaysEnabledGates{})
}
定義済みのclient-goの機能の完全な一覧が必要な場合は、Registryインターフェースを実装してAddFeaturesToExistingFeatureGatesを呼ぶことで取得できます。
完全な例としてはKubernetesにおける使用方法を参考にしてください。
まとめ
client-go v1.30のフィーチャーゲートの導入により、client-goの新機能のロールアウトを安全かつ簡単に実施できるようになりました。 ユーザーや開発者はclient-goの新機能を採用するペースを管理できます。
Kubernetes APIの両側にまたがる機能の品質認定に関する共通のメカニズムができたことによって、Kubernetesコントリビューターの作業は効率化されつつあります。
SIG Nodeの紹介
コンテナオーケストレーションの世界で、Kubernetesは圧倒的な存在感を示しており、世界中で最も複雑で動的なアプリケーションの一部を動かしています。 その裏では、Special Interest Groups(SIG)のネットワークがKubernetesの革新と安定性を牽引しています。
今日は、SIG NodeのメンバーであるMatthias Bertschy、Gunju Kim、Sergey Kanzhelevにお話を伺い、彼らの役割、課題、そしてSIG Node内の注目すべき取り組みについて光を当てていきます。
複数の回答者による共同回答の場合は、回答者全員のイニシャルで表記します。
自己紹介
Arpit: 本日はお時間をいただき、ありがとうございます。まず、自己紹介とSIG Node内での役割について簡単に教えていただけますか?
Matthias: Matthias Bertschyと申します。フランス人で、フランスアルプスの近く、ジュネーブ湖のそばに住んでいます。2017年からKubernetesのコントリビューターとして活動し、SIG Nodeのレビュアー、そしてProwのメンテナーを務めています。現在は、ARMOというセキュリティスタートアップでシニアKubernetes開発者として働いています。ARMOは、KubescapeというプロジェクトをCNCFに寄贈しました。

Gunju: Gunju Kimと申します。NAVERでソフトウェアエンジニアとして働いており、検索サービス用のクラウドプラットフォームの開発に注力しています。2021年から空き時間を使ってKubernetesプロジェクトにコントリビュートしています。
Sergey: Sergey Kanzhelevと申します。3年間KubernetesとGoogle Kubernetes Engineに携わり、長年オープンソースプロジェクトに取り組んできました。現在はSIG Nodeの議長を務めています。
SIG Nodeについて
Arpit: ありがとうございます!Kubernetesエコシステム内でのSIG Nodeの責任について、読者の方々に概要を説明していただけますか?
M/G/S: SIG NodeはKubernetesで最初に、あるいは最初期に設立されたSIGの1つです。このSIGは、KubernetesとNodeリソースとのすべてのやり取り、そしてNode自体のメンテナンスに責任を持っています。これはかなり広範囲に及び、SIGはKubernetesのコードベースの大部分を所有しています。この広範な所有権のため、SIG NodeはSIG Network、SIG Storage、SIG Securityなど他のSIGと常に連絡を取り合っており、Kubernetesの新機能や開発のほとんどが何らかの形でSIG Nodeに関わっています。
Arpit: SIG NodeはKubernetesのパフォーマンスと安定性にどのように貢献していますか?
M/G/S: Kubernetesは、安価なハードウェアを搭載した小型の物理VMから、大規模なAI/ML最適化されたGPU搭載Nodeまで、さまざまなサイズと形状のNodeで動作します。Nodeは数か月オンラインのままの場合もあれば、クラウドプロバイダーの余剰コンピューティングで実行されているため、短命で任意のタイミングでプリエンプトされる可能性もあります。
Node上のKubernetesエージェントであるkubeletは、これらすべての環境で確実に動作する必要があります。
近年、kubeletの操作パフォーマンスの重要性が増しています。
その理由は二つあります。
一つは、Kubernetesが通信や小売業などの分野で、より小規模なNodeで使用されるようになってきており、可能な限り小さなリソース消費(フットプリント)で動作することが求められているからです。
もう一つは、AI/MLワークロードでは各Nodeが非常に高価なため、操作の遅延がわずか1秒でも計算コストに大きな影響を与える可能性があるからです。
課題と機会
Arpit: SIG Nodeが今後直面すると予想される課題や可能性について、どのようなものがあるでしょうか?
M/G/S: Kubernetesが誕生から10年を迎え、次の10年に向かう中で、新しい種類のワークロードへの対応が強く求められています。SIG Nodeはこの取り組みで重要な役割を果たすことになるでしょう。後ほど詳しく説明しますが、サイドカーのKEPは、こうした新しいタイプのワークロードをサポートするための取り組みの一例です。
今後数年間の主な課題は、既存の機能の品質と後方互換性を維持しつつ、いかに革新を続けていくかということです。 SIG Nodeは、これからもKubernetesの開発において中心的な役割を担い続けるでしょう。
Arpit: SIG Nodeで現在取り組んでいる研究や開発分野の中で、特に注目しているものはありますか?
M/G/S: 新しいタイプのワークロードへの対応は、私たちにとって非常に興味深い分野です。最近取り組んでいるサイドカーコンテナの研究はその好例といえるでしょう。サイドカーは、アプリケーションの中核となるコードを変更することなく、その機能を拡張できる柔軟なソリューションを提供します。
Arpit: SIG Nodeを維持する上で直面した課題と、それをどのように克服したかを教えてください。
M/G/S: SIG Nodeが直面する最大の課題は、その広範な責任範囲と数多くの機能要望への対応です。この課題に取り組むため、私たちは新たなレビュアーの参加を積極的に呼びかけています。また、常にプロセスの改善に努め、フィードバックに迅速に対応できる体制を整えています。さらに、各リリースの後にはSIG Nodeのミーティングでフィードバックセッションを開催し、問題点や改善が必要な分野を特定し、具体的な行動計画を立てています。
Arpit: SIG Nodeが現在注目している技術や、Kubernetesへの導入を検討している新しい機能などはありますか?
M/G/S: SIG Nodeは、Kubernetesが依存しているさまざまなコンポーネントの開発に積極的に関与し、その進展を注意深く見守っています。これには、コンテナランタイム(containerdやCRI-Oなど)やOSの機能が含まれます。例えば、現在 cgroup v1 の廃止と削除が迫っていますが、これに対してKubernetesユーザーが円滑に移行できるよう、SIG NodeとKubernetesプロジェクト全体で取り組んでいます。また、containerdがバージョン2.0をリリースする予定ですが、これには非推奨機能の削除が含まれており、Kubernetesユーザーにも影響が及ぶと考えられます。
Arpit: SIG Nodeのメンテナーとしての経験の中で、特に誇りに思う思い出深い経験や成果を共有していただけますか?
Mathias: 最高の瞬間は、私の最初のKEP(startupProbeの導入)がついにGA(General Availability)に昇格したときだと思います。また、私の貢献がコントリビューターによって日々使用されているのを見るのも楽しいです。例えば、スカッシュコミットにもかかわらずLGTMを保持するために使用されるGitHubツリーハッシュを含むコメントなどです。
サイドカーコンテナ
Arpit: Kubernetesの文脈におけるサイドカーコンテナの概念とその進化について、もう少し詳しく教えていただけますか?
M/G/S: サイドカーコンテナの概念は、Kubernetesが複合コンテナのアイデアを導入した2015年にさかのぼります。同じPod内でメインのアプリケーションコンテナと並行して実行されるこれらの追加コンテナは、コアのコードベースを変更することなくアプリケーションの機能を拡張・強化する方法として見られていました。サイドカーの初期の採用者はカスタムスクリプトと設定を使用して管理していましたが、このアプローチは一貫性とスケーラビリティの面で課題がありました。
Arpit: サイドカーコンテナが特に有益な具体的なユースケースや例を共有していただけますか?
M/G/S: サイドカーコンテナは、さまざまな方法でアプリケーションの機能を強化するために使用できる多用途なツールです:
- ロギングとモニタリング: サイドカーコンテナを使用して、Pod内の主要アプリケーションコンテナからログとメトリクスを収集し、中央のロギングおよびモニタリングシステムに送信できます。
- トラフィックのフィルタリングとルーティング: サイドカーコンテナを使用して、Pod内の主要アプリケーションコンテナとの間のトラフィックをフィルタリングおよびルーティングできます。
- 暗号化と復号化: サイドカーコンテナを使用して、Pod内の主要アプリケーションコンテナと外部サービスの間で流れるデータを暗号化および復号化できます。
- データ同期: サイドカーコンテナを使用して、Pod内の主要アプリケーションコンテナと外部データベースやサービスの間でデータを同期できます。
- フォールトインジェクション: サイドカーコンテナを使用して、Pod内の主要アプリケーションコンテナに障害を注入し、障害に対する耐性をテストできます。
Arpit: 提案によると、一部の企業がサイドカー機能を追加したKubernetesのフォークを使用しているそうです。この機能の採用状況やコミュニティの関心度について、何か見解をお聞かせいただけますか?
M/G/S: 採用率を測定する具体的な指標はありませんが、KEPはコミュニティから大きな関心を集めています。特にIstioのようなサービスメッシュベンダーは、アルファテストフェーズに積極的に参加しました。KEPの可視性は、多数のブログ投稿、インタビュー、講演、ワークショップを通じてさらに実証されています。KEPは、ネットワークプロキシ、ロギングシステム、セキュリティ対策など、KubernetesのPod内のメインコンテナと並行して追加機能を提供する需要の増加に対応しています。コミュニティは、この機能の広範な採用を促進するために、既存のワークロードに対する容易な移行パスを提供することの重要性を認識しています。
Arpit: 本番環境でサイドカーコンテナを使用している企業の注目すべき例や成功事例はありますか?
M/G/S: 本番環境での広範な採用を期待するにはまだ早すぎます。1.29リリースは2024年1月11日からGoogle Kubernetes Engine(GKE)で利用可能になったばかりで、ユニバーサルインジェクターを介して効果的に有効化し使用する方法に関する包括的なドキュメントがまだ必要です。人気のあるサービスメッシュプラットフォームであるIstioも、ネイティブサイドカーを有効にするための適切なドキュメントが不足しているため、開発者がこの新機能を使い始めるのが難しくなっています。しかし、ネイティブサイドカーのサポートが成熟し、ドキュメントが改善されるにつれて、本番環境でのこの技術のより広範な採用が期待できます。
Arpit: 提案では、サイドカー機能を実現するために初期化したコンテナにrestartPolicyフィールドを導入することが示されています。この方法で、先ほど挙げられた課題をどのように解決できるのか、詳しく教えていただけますか?
M/G/S: 初期化したコンテナにrestartPolicyフィールドを導入する提案は、既存のインフラストラクチャを活用し、サイドカーの管理を簡素化することで、概説された課題に対処します。このアプローチは、Podの仕様に新しいフィールドを追加することを避け、管理しやすさを保ちつつ、さらなる複雑さを回避します。既存の初期化したコンテナのメカニズムを利用することで、サイドカーはPodの起動時に通常の初期化コンテナと並行して実行でき、一貫した初期化の順序を確保します。ささらに、サイドカー用の初期化コンテナの再起動ポリシーをAlwaysに設定することで、メインアプリケーションコンテナが終了した後も、ロギングやモニタリングなどの継続的なサービスをワークロードの終了まで維持できます。
Arpit: 初期化したコンテナにrestartPolicyフィールドを導入することは、既存のKubernetes設定との後方互換性にどのような影響を与えますか?
M/G/S: 初期化したコンテナにrestartPolicyフィールドを導入しても、既存のKubernetes設定との後方互換性は維持されます。既存の初期化したコンテナは従来通りに機能し続け、新しいrestartPolicyフィールドは、明示的にサイドカーとして指定された初期化したコンテナにのみ適用されます。このアプローチにより、既存のアプリケーションやデプロイメントが新機能によって中断されることはなく、同時にサイドカーをより効果的に定義および管理する方法が提供されます。
SIG Nodeへの貢献
Arpit: 新しいメンバー、特に初心者が貢献するのに最適な方法は何でしょうか?
M/G/S: 新しいメンバーや初心者は、サイドカーに関するKEP(Kubernetes Enhancement Proposal)に対して、以下の方法で貢献できます:
- 認知度の向上: サイドカーの利点と使用例を紹介するコンテンツを作成します。これにより、他の人々にこの機能の理解を深めてもらい、採用を促すことができます。
- フィードバックの提供: サイドカーの使用経験(良い点も悪い点も)を共有してください。このフィードバックは、機能の改善や使いやすさの向上に役立ちます。
- ユースケースの共有: 本番環境でサイドカーを使用している場合は、その経験を他の人と共有してください。実際の使用例を示すことで、この機能の価値を実証し、他の人々の採用を促進できます。
- ドキュメントの改善: この機能のドキュメントの明確化や拡充にご協力ください。より分かりやすいドキュメントは、他の人々がサイドカーを理解し、活用する助けになります。
サイドカーに関するKEP以外にも、SIG Nodeではより多くの貢献者を必要としている分野があります:
テストカバレッジの向上: SIG Nodeでは、Kubernetesコンポーネントのテストカバレッジを継続的に改善する方法を模索しています。
CI(継続的インテグレーション)の維持: SIG Nodeは、Kubernetesコンポーネントが様々な状況下で期待通りに動作することを確認するため、一連のエンドツーエンド(e2e)テストを管理しています。
結論
SIG Nodeは、Kubernetesの発展において重要な役割を果たしています。 クラウドネイティブ・コンピューティングの絶えず変化する環境の中で、Kubernetesの信頼性と適応性を確保し続けています。 Matthias、Gunju、Sergeyといった献身的なメンバーが先頭に立ち、SIG Nodeは革新の最前線に立ち続けています。 彼らの努力により、Kubernetesは新たな地平を目指して前進し続けているのです。
Kubernetesの10年間の歴史

10年前の2014年6月6日、Kubernetesの最初のコミットがGitHubにプッシュされました。 Go、Bash、Markdownで書かれた250のファイルと47,501行のコードを含むその最初のコミットが、今日のKubernetesプロジェクトの始まりでした。 それから10年後の今日、Kubernetesが44か国から8,000社以上の企業、88,000人以上のコントリビューターを有する、これまでで最大のオープンソースプロジェクトの一つに成長するとは誰が予想したでしょうか。

このマイルストーンはKubernetesだけでなく、そこから生まれたクラウドネイティブエコシステムにとっても重要なものです。 CNCFには約200のプロジェクトがあり、240,000人以上のコントリビューターからのコントリビューションがあります。 また、より広いエコシステムの中でも数千人のコントリビューターがいます。 Kubernetesが今日の姿になれたのは、彼らや700万人以上の開発者、さらに多くのユーザーコミュニティがエコシステムを形作る手助けをしてくれたおかげです。
Kubernetesの始まり - 技術の収束
Kubernetesの元となるアイディアは、(2013年に登場した)最初のコミットや最初のプロトタイプの前から存在していました。 2000年代初頭、ムーアの法則が有効に機能していました。 コンピューティングハードウェアは非常に速い速度でますます強力になり、それに対応してアプリケーションもますます複雑化していきました。 このハードウェアのコモディティ化とアプリケーションの複雑化の組み合わせにより、ソフトウェアをハードウェアからさらに抽象化する必要が生じ、解決策が現れ始めました。
当時の多くの企業と同様にGoogleも急速に拡大しており、同社のエンジニアたちはLinuxカーネル内での隔離の形態を作り出すというアイデアに興味を持っていました。 Googleのエンジニア、Rohit Sethはそのコンセプトを2006年のメールで説明しました。
ワークロードのメモリやタスクなどのシステムリソースの使用を追跡し、課金する構造を示すためにコンテナという用語を使用します。

2013年3月、PyConでSolomon Hykesが行った5分間のライトニングトークThe future of Linux Containersでは、Linuxコンテナを作成および使用するためのオープンソースツールである「Docker」が紹介されました。 DockerはLinuxコンテナに使いやすさをもたらし、これまで以上に多くのユーザーが利用できるようになりました。 Dockerの人気が急上昇し、Linuxコンテナの抽象化を誰もが利用できるようにしたことで、アプリケーションをより移植性が高く、再現性のある方法で実行できるようになりました。 しかし、依然としてスケールの問題は残っていました。
Googleのアプリケーションオーケストレーションをスケールで管理するBorgシステムは、2000年代半ばにLinuxコンテナを採用しました。 その後、GoogleはOmegaと呼ばれるシステムの新バージョンの開発も開始しました。 BorgとOmegaシステムに精通していたGoogleのエンジニアたちは、Dockerによって駆動するコンテナ化の人気を目の当たりにしました。 そしてBrendan Burnsのブログで説明されているように、オープンソースのコンテナオーケストレーションシステムの必要性だけでなく、その「必然性」を認識しました。 この認識は2013年秋にJoe Beda、Brendan Burns、Craig McLuckie、Ville Aikas、Tim Hockin、Dawn Chen、Brian Grant、Daniel Smithを含む小さなチームにKubernetesのプロジェクトを始めるインスピレーションを与えました。
Kubernetesの10年間

Kubernetesの歴史は2014年6月6日のその歴史的なコミットと、2014年6月10日のDockerCon 2014でのGoogleエンジニアEric Brewerによる基調講演(およびそれに対応するGoogleブログ)でのプロジェクト発表から始まります。
その後の1年間で、主にGoogleとRed Hatからのコントリビューターによる小さなコミュニティがプロジェクトに取り組み、2015年7月21日にバージョン1.0のリリースに至りました。 1.0と同時に、GoogleはKubernetesをLinux Foundationの新たに設立された部門であるCloud Native Computing Foundation (CNCF)に寄贈することを発表しました。
1.0に到達したものの、Kubernetesプロジェクトは依然として使いにくく理解しにくいものでした。 KubernetesのコントリビューターであるKelsey Hightowerはプロジェクトの使いやすさの欠点に特に注目し、2016年7月7日に彼の有名な"Kubernetes the Hard Way"ガイドの最初のコミットをプッシュしました。
プロジェクトは最初の1.0リリース以来大きく変わり、いくつかの大きな成果を経験しました。 たとえば、1.16でのCustom Resource Definition (CRD)のGAや、1.23での完全なデュアルスタックサポートの開始などです。 また、1.22での広く使用されているベータ版APIの削除や、Dockershimの廃止から学んだコミュニティの「教訓」もあります。
1.0以降の注目すべきアップデート、マイルストーン、およびイベントには以下のものがあります。
- 2016年12月 - Kubernetes 1.5でCRIの最初のサポートとアルファ版Windowsノードサポートによるランタイムプラグイン機能が導入されました。また、OpenAPIが初めて登場し、クライアントが拡張されたAPIを認識できるようになりました。
- このリリースでは、StatefulSetとPodDisruptionBudgetがベータ版で導入されました。
- 2017年4月 - ロールベースアクセス制御(RBAC)の導入。
- 2017年6月 - Kubernetes 1.7でThirdPartyResource (TPR)がCustomResourceDefinition (CRD)に置き換えられました。
- 2017年12月 - Kubernetes 1.9ではWorkload APIがGA(一般提供)となりました。リリースブログには「Kubernetesで最もよく使用されるオブジェクトの一つであるDeploymentとReplicaSetは、1年以上の実際の使用とフィードバックを経て安定しました」と書かれています。
- 2018年12月 - Kubernetes 1.13でContainer Storage Interface (CSI)がGAに達しました。また最小限のクラスターをブートストラップするためのkubeadmツールがGAに達し、CoreDNSがデフォルトのDNSサーバーとなりました。
- 2019年9月 - Kubernetes 1.16でCustom Resource DefinitionがGAに達しました。
- 2020年8月 - Kubernetes 1.19でリリースのサポート期間が1年に延長されました。
- 2020年12月 - Kubernetes 1.20でDockershimが廃止されました。
- 2021年4月 - Kubernetesのリリース頻度が変更され、年間4回から3回に減少されました。
- 2021年7月 - 広く使用されているベータ版APIがKubernetes 1.22で削除されました。
- 2022年5月 - Kubernetes 1.24でベータ版APIがデフォルトで無効にされ、アップグレードの競合を減らすとともにDockershimが削除されました。その結果、多くのユーザーの混乱を引き起こしました(その後、コミュニケーションを改善しました)。
- 2022年12月 - Kubernetes 1.26ではAI/ML/バッチワークロードのサポートを強化するための大規模なバッチおよびJob APIのオーバーホールが行われました。
PS: プロジェクトがどれだけ進化したか自分で見てみたいですか? コミュニティメンバーのCarlos Santana、Amim Moises Salum Knabben、James Spurinが作成したKubernetes 1.0クラスターを立ち上げるためのチュートリアルをチェックしてみてください。
Kubernetesには数え切れないほどの拡張するポイントがあります。 もともとはDocker専用に設計されていましたが、現在ではCRI標準に準拠する任意のコンテナランタイムをプラグインできます。 他にもストレージ用のCSIやネットワーキング用のCNIなどのインターフェースがあります。 そしてこれはできることのほんの一部に過ぎません。 過去10年間で新しいパターンがいくつも登場しました。 例えば、Custom Resource Definition (CRD)を使用してサードパーティのコントローラーをサポートすることができます。 これは現在Kubernetesエコシステムの大きな一部となっています。
このプロジェクトを構築するコミュニティも、この10年間で非常に大きくなりました。 DevStatsを使用すると、この10年間でKubernetesを世界で2番目に大きなオープンソースプロジェクトにした驚異的なコントリビューションの量を確認できます。
- 88,474人のコントリビューター
- 15,121人のコードコミッター
- 4,228,347件のコントリビューション
- 158,530件のIssue
- 311,787件のPull Request
今日のKubernetes

初期の頃からこのプロジェクトは技術的能力、利用状況、およびコントリビューションの面で驚異的な成長を遂げてきました。 プロジェクトは今もなおユーザーにより良いサービスを提供するために積極的に改善に取り組んでいます。
次回の1.31リリースでは、長期にわたる重要なプロジェクトの完成を祝います。 それはインツリークラウドプロバイダーのコードの削除です。 このKubernetesの歴史上最大のマイグレーションでは、約150万行のコードが削除され、コアコンポーネントのバイナリサイズが約40%削減されました。 プロジェクトの初期には、拡張性が成功の鍵であることは明らかでした。 しかし、その拡張性をどのように実現するかは常に明確ではありませんでした。 このマイグレーションにより、Kubernetesの核となるコードベースからさまざまなベンダー固有の機能が削除されました。 ベンダー固有の機能は、今後はCustom Resource Definition (CRD)やGateway APIなどの他のプラグイン拡張機能やパターンによってよりよく提供されるようになります。
Kubernetesは、膨大なユーザーベースにサービスを提供する上で新たな課題にも直面しており、コミュニティはそれに適応しています。 その一例が、新しいコミュニティ所有のregistry.k8s.ioへのイメージホスティングの移行です。 ユーザーに事前コンパイル済みのバイナリイメージを提供するためのエグレスの帯域幅とコストは非常に大きなものとなっています。 この新しいレジストリの変更により、コミュニティはこれらの便利なイメージをよりコスト効率およびパフォーマンス効率の高い方法で提供し続けることができます。 必ずブログ記事をチェックし、registry.k8s.ioを使用するように更新してください!
Kubernetesの未来

10年が経ち、Kubernetesの未来は依然として明るく見えます。 コミュニティはユーザー体験の改善とプロジェクトの持続可能性を向上させる変更を優先しています。 アプリケーション開発の世界は進化し続けており、Kubernetesもそれに合わせて変化していく準備ができています。
2024年にはAIの登場がかつてニッチなワークロードタイプを重要なものへと変えました。 分散コンピューティングとワークロードスケジューリングは常に人工知能(AI)、機械学習(ML)、および高性能コンピューティング(HPC)ワークロードのリソース集約的なニーズと密接に関連してきました。 コントリビューターは、新しく開発されたワークロードのニーズとそれらにKubernetesがどのように最適に対応できるかに注目しています。 新しいServing Working Groupは、コミュニティがこれらのワークロードのニーズに対処するためにどのように組織化されているかの一例です。 今後数年でKubernetesがさまざまな種類のハードウェアを管理する能力や、ハードウェア全体でチャンクごとに実行される大規模なバッチスタイルのワークロードのスケジューリング能力に関して改善が見られるでしょう。
Kubernetesを取り巻くエコシステムは成長し続け、進化していきます。 将来的にはインツリーベンダーコードのマイグレーションやレジストリの変更など、プロジェクトの持続可能性を維持するための取り組みがますます重要になるでしょう。
Kubernetesの次の10年は、ユーザーとエコシステム、そして何よりもそれに貢献する人々によって導かれるでしょう。 コミュニティは新しいコントリビューターを歓迎しています。 コントリビューションに関する詳細は、新しいコントリビューター向けのガイドで確認できます。
Kubernetesの未来を一緒に築いていくことを楽しみにしています!

Kubernetes史上最大の移行作業を完了
Kubernetes v1.7以降、Kubernetesプロジェクトは、クラウドプロバイダーとの統合機能をKubernetesのコアコンポーネントから分離するという野心的な目標を追求してきました(KEP-2395)。 この統合機能はKubernetesの初期の開発と成長に重要な役割を果たしつつも、2つの重要な要因によってその分離が推進されました。 1つは、何百万行ものGoコードにわたってすべてのクラウドプロバイダーのネイティブサポートを維持することの複雑さが増大していたこと、もう1つは、Kubernetesを真にベンダーニュートラルなプラットフォームとして確立したいという願望です。
多くのリリースを経て、すべてのクラウドプロバイダー統合が、Kubernetesのコアリポジトリから外部プラグインに正常に移行されたことを喜ばしく思います。 当初の目的を達成したことに加えて、約150万行のコードを削除し、コアコンポーネントのバイナリサイズを約40%削減することで、Kubernetesを大幅に合理化しました。
この移行は、影響を受けるコンポーネントが多数あり、Google Cloud、AWS、Azure、OpenStack、vSphereの5つの初期クラウドプロバイダーの組み込み統合に依存していた重要なコードパスがあったため、複雑で長期にわたる作業となりました。 この移行を成功させるために、私たちは4つの新しいサブシステムを一から構築する必要がありました。
- クラウドコントローラーマネージャー (KEP-2392)
- APIサーバーネットワークプロキシ (KEP-1281)
- kubeletクレデンシャルプロバイダープラグイン (KEP-2133)
- CSIを使用するストレージの移行 (KEP-625)
各サブシステムは、組み込み機能と同等の機能を実現するために不可欠であり、安全で信頼できる移行パスを使用して各サブシステムをGAレベルの成熟度にするために、いくつかのリリースが必要でした。 以下に、各サブシステムの詳細を説明します。
クラウドコントローラーマネージャー
クラウドコントローラーマネージャーは、この取り組みで導入された最初の外部コンポーネントであり、kube-controller-managerとkubeletのうち、クラウドAPIと直接やり取りする機能を置き換えるものです。
この重要なコンポーネントは、ノードが実行されているクラウドのリージョンとゾーンを示すメタデータラベルや、クラウドプロバイダーのみが知っているIPアドレスを適用することにより、ノードを初期化する役割を担っています。
さらに、LoadBalancerタイプのServiceに対してクラウドロードバランサーをプロビジョニングするサービスコントローラーも実行します。
詳細については、Kubernetesドキュメントのクラウドコントローラーマネージャーを参照してください。
APIサーバーネットワークプロキシ
2018年にSIG API Machineryと共同で開始されたAPIサーバーネットワークプロキシプロジェクトは、kube-apiserver内のSSHトンネラー機能を置き換えることを目的としていました。
このトンネラーは、Kubernetesのコントロールプレーンとノードとのトラフィックを安全にプロキシするために使用されていましたが、これらのSSHトンネルを確立するために、kube-apiserver内に組み込まれたプロバイダー固有の実装の詳細に大きく依存していました。
現在、APIサーバーネットワークプロキシは、kube-apiserver内のGAレベルの拡張ポイントとなっています。
これは、APIサーバーからノードへのトラフィックを安全なプロキシを介してルーティングできる汎用的なプロキシメカニズムを提供し、APIサーバーが実行されているクラウドプロバイダーを認識する必要がなくなりました。
このプロジェクトでは、本番環境での採用が進んでいるKonnectivityプロジェクトも導入されました。
APIサーバーネットワークプロキシの詳細については、READMEを参照してください。
kubeletのクレデンシャルプロバイダープラグイン
kubeletのクレデンシャルプロバイダープラグインは、Google Cloud、AWS、またはAzureでホストされているイメージレジストリのクレデンシャルを動的に取得するkubeletの組み込み機能を置き換えるために開発されました。
従来の機能は便利で、kubeletがGCR、ECR、またはACRからイメージを取得するための短期間のトークンをシームレスに取得できるようにしていました。
しかし、Kubernetesの他の領域と同様に、これをサポートするには、kubeletが異なるクラウド環境とAPIについて特定の知識を持つ必要がありました。
2019年に導入されたクレデンシャルプロバイダープラグインメカニズムは、kubeletが様々なクラウドでホストされているイメージのクレデンシャルを動的に提供するプラグインバイナリを実行するための汎用的な拡張ポイントを提供します。
この拡張性により、kubeletの短期間のトークンを取得する機能が、最初の3つのクラウドプロバイダーを超えて拡張されました。
詳細については、認証されたイメージプルのためのkubeletクレデンシャルプロバイダーを参照してください。
ストレージプラグインのKubernetesコアからCSIへの移行
Container Storage Interface(CSI)は、Kubernetesやそのほかのコンテナオーケストレーターにおいてブロックおよびファイルストレージシステムを管理するためのコントロールプレーン標準であり、1.13でGAになりました。
これは、Kubernetesに直接組み込まれていたボリュームプラグインを、Kubernetesクラスター内のPodとして実行できるドライバーに置き換えるために設計されました。
これらのドライバーは、Kubernetes APIを介してkube-controller-managerストレージコントローラーと通信し、ローカルのgRPCエンドポイントを介してkubeletと通信します。
現在、すべての主要なクラウドとストレージベンダーにわたって100以上のCSIドライバーが利用可能であり、Kubernetesでステートフルなワークロードが現実のものとなっています。
ただし、KubernetesコアのボリュームAPIの既存のすべてのユーザーをどのように扱うかという大きな課題が残っていました。 APIの後方互換性を維持するために、Kubernetesコアのボリューム APIを同等のCSI APIに変換するAPIトランスレーション層をコントローラーに組み込みました。 これにより、すべてのストレージ操作をCSIドライバーにリダイレクトすることができ、APIを削除せずにKubernetesコアのボリュームプラグインのコードを削除する道が開けました。
Kubernetesコアのストレージの移行の詳細については、Kubernetes In-Tree to CSI Volume Migration Moves to Betaを参照してください。
今後の展望
この移行は、ここ数年のSIG Cloud Providerがもっとも注力してきたことでした。 この重要なマイルストーンを達成したことで、これまでに構築してきた外部サブシステムを活用して、Kubernetesとクラウドプロバイダーをより良く統合するための新しい革新的な方法を模索する取り組みにシフトしていきます。 これには、クラスター内のノードがパブリッククラウドとプライベートクラウドの両方で実行できるハイブリッド環境でKubernetesをより賢くすることや、外部プロバイダーの開発者が統合の取り組みを簡素化・合理化するためのより良いツールとフレームワークを提供することが含まれます。
新機能やツール、フレームワークの開発が進む一方で、SIG Cloud Providerはテストの重要性も忘れてはいません。 SIGの将来の活動のもう1つの重点分野は、より多くのプロバイダーを含めるためのクラウドコントローラーテストの改善です。 この取り組みの最終目標は、できるだけ多くのプロバイダーを含むテストフレームワークを作成し、Kubernetesコミュニティに対して、Kubernetes環境に関する最高レベルの信頼性を提供することです。
v1.29より前のバージョンのKubernetesを使用していて、まだ外部クラウドプロバイダーに移行していない場合は、以前のブログ記事Kubernetes 1.29: Cloud Provider Integrations Are Now Separate Componentsを確認することをおすすめします。 この記事では、私たちが行った変更について詳細な情報を提供し、外部プロバイダーへの移行方法についてガイダンスを提供しています。 v1.31以降、Kubernetesコアのクラウドプロバイダーは永続的に無効化され、Kubernetesのコアコンポーネントから削除されます。
貢献に興味がある方は、隔週のSIGミーティングにぜひご参加ください!
Gateway API v1.1: サービスメッシュ、GRPCRoute、そして更なる進化
![]()
昨年10月のGateway APIの正式リリース後、Kubernetes SIG NetworkはGateway APIのv1.1リリースを発表しました。 このリリースでは、いくつかの機能が 標準機能 (GA)に昇格しています。 特にサービスメッシュとGRPCRouteのサポートが含まれます。 また、セッション維持とクライアント証明書の検証を含む新しい実験的機能も導入しています。
新機能
GAへの昇格
このリリースでは、4つの待望の機能が標準機能に昇格しました。 これにより、これらの機能は実験的な段階を卒業したことになります。 GAへの昇格が行われたということは、APIの設計に対する高い信頼性を示すとともに、後方互換性を保証するものです。 他のKubernetes APIと同様に、GAへ昇格した機能も時間とともに後方互換性を保ちながら進化していきます。 今後もこれらの新機能のさらなる改良と改善が行われることを期待しています。 これらの仕組みについて詳しくは、Gateway APIのバージョニングポリシーをご覧ください。
サービスメッシュのサポート
Gateway APIのサービスメッシュサポートにより、サービスメッシュユーザーは同じAPIを使用してIngressトラフィックとメッシュトラフィックを管理することが可能になります。
これにより同じポリシーとルーティングインターフェースを再利用することができます。
また、Gateway API v1.1では、HTTPRouteなどのルートがServiceをparentRefとして持つことができるようになり、特定のサービスへのトラフィックの動作を制御できます。
詳細については、Gateway APIのサービスメッシュドキュメントをお読みいただくか、Gateway APIの実装リストをご覧ください。
例えば、アプリケーションのコールグラフの深部にあるワークロードに対して、HTTPRouteを使用してカナリアデプロイメントを行うことができます。 以下はその例です:
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: color-canary
namespace: faces
spec:
parentRefs:
- name: color
kind: Service
group: ""
port: 80
rules:
- backendRefs:
- name: color
port: 80
weight: 50
- name: color2
port: 80
weight: 50
これにより、名前空間faces内のcolorサービスに送信されるトラフィックが、元のcolorサービスとcolor2サービスの間で50対50に分割されます。
この設定は移植性が高く、あるメッシュから別のメッシュへ簡単に移行できます。
GRPCRoute
すでにGRPCRouteの実験的機能バージョンを使用している場合、使用しているコントローラーがGRPCRoute v1をサポートするようアップデートされるまで、標準バージョンのGRPCRouteへのアップグレードは控えることをお勧めします。
それまでは、v1alpha2とv1の両方のAPIバージョンを含むv1.1の実験的チャンネルバージョンのGRPCRouteにアップグレードしても問題ありません。
ParentReference Port
ParentReferenceにportフィールドが追加されました。 これにより、リソースをGatewayのリスナー、Service、あるいは他の親リソース(実装によって異なります)に関連付けることができるようになりました。 ポートにバインドすることで、複数のリスナーに一度に関連付けることも可能です。
例えば、HTTPRouteをGatewayの特定のリスナーに関連付ける際、リスナー名ではなくリスナーのポートを指定できるようになりました。 これにより、一つまたは複数の特定のリスナーに関連付けることができます。
詳細については、Gatewayへの関連付けを参照してください。
適合性プロファイルとレポート
適合性レポートのAPIが拡張され、実装の動作モードを指定するmodeフィールドと、Gateway APIのチャネル(標準版または実験的機能版)をしめすgatewayAPIChannelが追加されました。
gatewayAPIVersionとgatewayAPIChannelは、テスト結果の簡単な説明とともに、テストスイートの仕組みによって自動的に入力されるようになりました。
レポートの構成がより体系的に整理され、実装者はテストの実行方法に関する情報を追加し、再現手順を提供できるようになりました。
実験的機能版チャンネルへの新機能追加
Gatewayのクライアント証明書の検証
Gatewayの各リスナーでクライアント証明書の検証が設定できるようになりました。
これは、tls内に新しく追加されたfrontendValidationフィールドによって実現されています。
このフィールドでは、クライアントが提示する証明書を検証するための信頼アンカーとして使用できるCA証明書のリストを設定できます。
以下の例は、ConfigMapのfoo-example-com-ca-certに保存されているCA証明書を使用して、Gatewayリスナーのfoo-httpsに接続するクライアントの証明書を検証する方法を示しています。
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: client-validation-basic
spec:
gatewayClassName: acme-lb
listeners:
name: foo-https
protocol: HTTPS
port: 443
hostname: foo.example.com
tls:
certificateRefs:
kind: Secret
group: ""
name: foo-example-com-cert
frontendValidation:
caCertificateRefs:
kind: ConfigMap
group: ""
name: foo-example-com-ca-cert
セッション維持とBackendLBPolicy
Gateway APIにセッション維持機能が導入されました。 これは新しいポリシー(BackendLBPolicy)によってサービスレベルで設定でき、さらにHTTPRouteとGRPCRoute内のフィールドを使用してルートレベルでも設定可能です。 BackendLBPolicyとルートレベルのAPIは、セッションのタイムアウト、セッション名、セッションタイプ、クッキーの有効期間タイプなど、同じセッション維持の設定を提供します。
以下は、fooサービスにクッキーベースのセッション維持を有効にするBackendLBPolicyの設定例です。
セッション名をfoo-sessionに設定し、絶対タイムアウトとアイドルタイムアウトを定義し、クッキーをセッションクッキーとして設定しています:
apiVersion: gateway.networking.k8s.io/v1alpha2
kind: BackendLBPolicy
metadata:
name: lb-policy
namespace: foo-ns
spec:
targetRefs:
- group: core
kind: service
name: foo
sessionPersistence:
sessionName: foo-session
absoluteTimeout: 1h
idleTimeout: 30m
type: Cookie
cookieConfig:
lifetimeType: Session
その他の変更点
TLS関連用語の明確化
API全体でTLS関連の用語を統一する取り組みの一環として、BackendTLSPolicyに互換性のない変更を加えました。 これにより、新しいAPIバージョン(v1alpha3)が導入されました。 既存のv1alpha2を使用している場合は、データのバックアップや古いバージョンのアンインストールなど、適切な対応が必要です。
v1alpha2のBackendTLSPolicyフィールドへの参照は、v1alpha3に更新する必要があります。 主な変更点は以下の通りです:
targetRefがtargetRefsに変更(複数のターゲットへの適用が可能に)tlsがvalidationに変更tls.caCertRefsがvalidation.caCertificateRefsに変更tls.wellKnownCACertsがvalidation.wellKnownCACertificatesに変更
このリリースに含まれるすべての変更点については、v1.1.0リリースノートをご覧ください。
Gateway APIの背景
Gateway APIのアイデアは、2019年のKubeCon San Diegoで次世代のIngress APIとして最初に提案されました。 それ以来、すばらしいコミュニティが形成され、おそらくKubernetes史上最も協力的なAPIを開発してきました。 これまでに200人以上がこのAPIに貢献しており、その数は今も増え続けています。
メンテナーは、リポジトリへのコミット、議論、アイデア、あるいは一般的なサポートなど、あらゆる形でGateway APIに貢献してくださった 全ての方々 に感謝の意を表します。 このように献身的で活発なコミュニティのサポートなしでは、ここまで到達することはできませんでした。
実際に使ってみましょう
Gateway APIの特徴として、最新版を使用するためにKubernetesそのものを最新にする必要がありません。 Kubernetes 1.26以降であれば、このバージョンのGateway APIをすぐに利用開始できます。
APIを試すには、スタートガイドをご覧ください。
開発に参加しませんか
Ingressやサービスメッシュ向けのKubernetesルーティングAPIの未来を形作るチャンスがたくさんあります。
- ユーザーガイドで、対応可能なユースケースをチェックしてみてください。
- 既存のGatewayコントローラーを実際に試してみるのもおすすめです。
- さらに、コミュニティへの参加もお待ちしています。一緒にGateway APIの未来を築いていきましょう!
関連するKubernetesブログ記事
DIY: Kubernetesで自分だけのクラウドを構築しよう(パート3)
Kubernetesの中でKubernetesを実行するという最も興味深いフェーズに近づいています。 この記事では、KamajiやCluster APIなどのテクノロジーとそれらのKubeVirtとの統合について説明します。
以前の議論では、ベアメタル上でのKubernetesの準備と、Kubernetesを仮想マシン管理システムに変える方法について説明しました。 この記事では、上記のすべてを使用して、本格的な管理対象のKubernetesを構築し、ワンクリックで仮想Kubernetesクラスターを実行する方法を説明して、シリーズを締めくくります。
まず、Cluster APIについて詳しく見ていきましょう。
Cluster API
Cluster APIは、Kubernetesの拡張機能で、別のKubernetesクラスター内でカスタムリソースとしてKubernetesクラスターを管理できるようにするものです。
Cluster APIの主な目的は、Kubernetesクラスターの基本的なエンティティを記述し、そのライフサイクルを管理するための統一されたインターフェースを提供することです。 これにより、クラスターの作成、更新、削除のプロセスを自動化し、スケーリングとインフラストラクチャの管理を簡素化できます。
Cluster APIのコンテキストでは、管理クラスターとテナントクラスターの2つの用語があります。
- 管理クラスターは、他のクラスターのデプロイと管理に使用されるKubernetesクラスターです。 このクラスターには、必要なすべてのCluster APIコンポーネントが含まれており、テナントクラスターの記述、作成、更新を担当します。多くの場合、この目的でのみ使用されます。
- テナントクラスターは、ユーザークラスターまたはCluster APIを使用してデプロイされたクラスターです。 これらは、管理クラスターで関連するリソースを記述することで作成されます。その後、エンドユーザーがアプリケーションとサービスをデプロイするために使用されます。
テナントクラスターは、物理的に管理クラスターと同じインフラストラクチャ上で実行する必要は必ずしもないことを理解することが重要です。 むしろ多くの場合、それらは別の場所で実行されています。

Cluster APIを使用した管理KubernetesクラスターとテナントKubernetesクラスターの相互作用を示す図
Cluster APIは、その動作のために プロバイダー の概念を利用します。 プロバイダーは、作成されるクラスターの特定のコンポーネントを担当する個別のコントローラーです。 Cluster API内にはいくつかの種類のプロバイダーがあります。 主なものは次のとおりです。
- インフラストラクチャプロバイダー: 仮想マシンや物理サーバーなどのコンピューティングインフラストラクチャを提供する役割を担います。
- コントロールプレーンプロバイダー: kube-apiserver、kube-scheduler、kube-controller-managerなどのKubernetesコントロールプレーンを提供します。
- ブートストラッププロバイダー: 作成される仮想マシンやサーバー用のcloud-init設定の生成に使用されます。
始めるには、Cluster API自体と各種プロバイダーを1つずつインストールする必要があります。 サポートされているプロバイダーの完全なリストはプロジェクトのドキュメントで確認できます。
インストールにはclusterctlユーティリティや、より宣言的な方法としてCluster API Operatorを使用できます。
プロバイダーの選択
インフラストラクチャプロバイダー
KubeVirtを使用してKubernetesクラスターを実行するにはKubeVirt Infrastructure Providerをインストールする必要があります。 これにより、Cluster APIが動作する管理クラスターと同じ場所で、ワーカーノード用の仮想マシンをデプロイできるようになります。
コントロールプレーンプロバイダー
Kamajiプロジェクトは、管理クラスター内のコンテナとしてテナントクラスターのKubernetesコントロールプレーンを実行するためのソリューションを提供しています。 このアプローチには、いくつかの重要な利点があります。
- 費用対効果: コントロールプレーンをコンテナで実行することで、クラスターごとに個別のコントロールプレーンノードを使用する必要がなくなり、インフラストラクチャのコストを大幅に削減できます。
- 安定性: 複雑な多層デプロイメント方式を排除することでアーキテクチャを簡素化できます。 仮想マシンを順次起動してからその中にetcdとKubernetesコンポーネントをインストールするのではなく、Kubernetes内で通常のアプリケーションとしてデプロイおよび実行され、オペレーターによって管理されるシンプルなコントロールプレーンがあります。
- セキュリティ: クラスターのコントロールプレーンはエンドユーザーから隠されており、そのコンポーネントが侵害される可能性を減らし、クラスターの証明書ストアへのユーザーアクセスを排除します。ユーザーに見えないコントロールプレーンを構成するこのアプローチは、クラウドプロバイダーによって頻繁に使用されています。
ブートストラッププロバイダー
Kubeadmをブートストラッププロバイダーとして使用します。 これは、Cluster APIでクラスターを準備するための標準的な方法です。 このプロバイダーは、Cluster API自体の一部として開発されています。kubeletとkubeadmがインストールされた準備済みのシステムイメージのみが必要で、cloud-initとignitionの形式でコンフィグを生成できます。
Talos LinuxもCluster API経由でのプロビジョニングをサポートしており、そのためのプロバイダーが用意されていることは注目に値します。 前回の記事では、ベアメタルノードで管理クラスターをセットアップするためにTalos Linuxを使用する方法について説明しましたが、テナントクラスターをプロビジョニングするには、Kamaji+Kubeadmのアプローチの方が優れています。 コンテナへのKubernetesコントロールプレーンのデプロイを容易にするため、コントロールプレーンインスタンス用に個別の仮想マシンを用意する必要無くなります。 これにより、管理が簡素化され、コストが削減されます。
動作の仕組み
Cluster APIの主要なオブジェクトはClusterリソースで、他のすべてのリソースの親となります。 通常、このリソースは他の2つのリソースを参照します。 コントロールプレーンを記述するリソースとインフラストラクチャを記述するリソースです。 それぞれが個別のプロバイダーによって管理されます。
Clusterとは異なり、これら2つのリソースは標準化されておらず、そのリソースの種類は使用している特定のプロバイダーに依存します。

Cluster APIにおけるClusterリソースとそれがリンクするリソースの関係を示す図
Cluster APIには、MachineDeploymentという名前のリソースもあります。 これは物理サーバーか仮想マシンかにかかわらずノードのグループを記述するものです。 このリソースは、Deployment、ReplicaSet、Podなどの標準のKubernetesリソースと同様に機能し、ノードのグループを宣言的に記述し、自動的にスケーリングするためのメカニズムを提供します。
つまり、MachineDeploymentリソースを使用すると、クラスターのノードを宣言的に記述でき、指定されたパラメーターと要求されたレプリカ数に応じて、ノードの作成、削除、更新を自動化できます。

Cluster APIにおけるMachineDeploymentリソースとその子リソースの関係を示す図
マシンを作成するために、MachineDeploymentは、マシン自体を生成するためのテンプレートと、そのcloud-init設定を生成するためのテンプレートを参照します。

Cluster APIにおけるMachineDeploymentリソースとそれがリンクするリソースの関係を示す図
Cluster APIを使用して新しいKubernetesクラスターをデプロイするには、以下のリソースのセットを準備する必要があります。
- 一般的なClusterリソース
- Kamajiが運用するコントロールプレーンを担当するKamajiControlPlaneリソース
- KubeVirt内のクラスター設定を記述するKubevirtClusterリソース
- 仮想マシンテンプレートを担当するKubevirtMachineTemplateリソース
- トークンとcloud-initの生成を担当するKubeadmConfigTemplateリソース
- いくつかのワーカーを作成するための少なくとも1つのMachineDeployment
クラスターの仕上げ
ほとんどの場合これで十分ですが、使用するプロバイダーによっては、他のリソースも必要になる場合があります。 プロバイダーの種類ごとに作成されるリソースの例は、Kamajiプロジェクトのドキュメントで確認できます。
この段階ですでに使用可能なテナントKubernetesクラスターができていますが、これまでのところ、APIワーカーとあらゆるKubernetesクラスターのインストールに標準で含まれるいくつかのコアプラグイン(kube-proxyとCoreDNS)しか含まれていません。 完全に統合するには、さらにいくつかのコンポーネントをインストールする必要があります。
追加のコンポーネントをインストールするには、個別のCluster API Add-on Provider for Helmや、前の記事で説明したFluxCDを使用できます。
FluxCDでリソースを作成する際、Cluster APIによって生成されたkubeconfigを参照することでターゲットクラスターを指定できます。 そうするとインストールは直接そのクラスターに対して実行されます。 このように、FluxCDは管理クラスターとユーザーテナントクラスターの両方でリソースを管理するための汎用ツールになります。

管理クラスターとテナントKubernetesクラスターの両方にコンポーネントをインストールできるfluxcdの相互作用スキームを示す図
ここで議論されているコンポーネントとは何でしょうか?一般的に、そのセットには以下が含まれます。
CNIプラグイン
テナントKubernetesクラスター内のPod間の通信を確保するには、CNIプラグインをデプロイする必要があります。 このプラグインは、Pod同士が相互に通信できるようにする仮想ネットワークを作成し、従来はクラスターのワーカーノード上にDaemonsetとしてデプロイされます。 適切だと思うCNIプラグインを選んでインストールできます。

ネストされたKubernetesクラスターのスキームにおいて、テナントKubernetesクラスター内にインストールされたCNIプラグインを示す図
クラウドコントローラーマネージャー
この一部レスポンスについては、以下のようにMarkdown記法を修正するのが良いと思います。
クラウドコントローラーマネージャー(CCM)の主な役割は、Kubernetes をクラウドインフラストラクチャプロバイダーの環境(この場合は、テナントKubernetesのすべてのワーカーがプロビジョニングされている管理Kubernetesクラスター)と統合することです。 CCMが実行するタスクは次のとおりです。
- LoadBalancer タイプのサービスが作成されると、CCM はクラウドロードバランサーの作成プロセスを開始します。これにより、トラフィックが Kubernetes クラスターに誘導されます。
- クラウドインフラストラクチャからノードが削除された場合、CCM はクラスターからもそのノードを確実に削除し、クラスターの現在の状態を維持します。
- CCM を使用する場合、ノードは特別な taint (
node.cloudprovider.kubernetes.io/uninitialized) を付けてクラスターに追加されます。これにより、必要に応じて追加のビジネスロジックを処理できます。初期化が正常に完了すると、この taint がノードから削除されます。
クラウドプロバイダーによっては、CCM がテナントクラスターの内部と外部の両方で動作する場合があります。
KubeVirt Cloud Providerは、外部の親管理クラスターにインストールするように設計されています。 したがって、テナントクラスターでLoadBalancerタイプのサービスを作成すると親クラスターでLoadBalancerサービスの作成が開始され、トラフィックがテナントクラスターに誘導されます。

ネストされたKubernetesクラスターのスキームにおいて、テナントKubernetesクラスターの外部にインストールされたCloud Controller Managerと、それが管理する親から子へのKubernetesクラスター間のサービスのマッピングを示す図
CSIドライバー
Container Storage Interface(CSI)は、Kubernetesでストレージを操作するために、2つの主要な部分に分かれています。
- csi-controller: このコンポーネントは、クラウドプロバイダーのAPIと対話して、ボリュームの作成、削除、アタッチ、デタッチ、およびサイズ変更を行う責任があります。
- csi-node: このコンポーネントは各ノードで実行され、kubeletから要求されたPodへのボリュームのマウントを容易にします。
KubeVirt CSI Driverを使用するコンテキストでは、ユニークな機会が生まれます。 KubeVirtの仮想マシンは管理KubernetesクラスターでKubernetesのフル機能のAPIが利用できる環境で実行されるため、ユーザーのテナントクラスターの外部でcsi-controllerを実行する道が開かれます。 このアプローチはKubeVirtコミュニティで人気があり、いくつかの重要な利点があります。
- セキュリティ: この方法では、エンドユーザーからクラウドの内部APIを隠し、Kubernetesインターフェースを介してのみリソースへのアクセスを提供します。これにより、ユーザークラスターから管理クラスターへの直接アクセスのリスクが軽減されます。
- シンプルさと利便性: ユーザーは自分のクラスターで追加のコントローラーを管理する必要がないため、アーキテクチャが簡素化され、管理の負担が軽減されます。
ただし、csi-nodeは、各ノードのkubeletと直接やり取りするため、必然的にテナントクラスター内で実行する必要があります。 このコンポーネントは、Podへのボリュームのマウントとマウント解除を担当し、クラスターノードで直接発生するプロセスとの緊密な統合が必要です。
KubeVirt CSIドライバーは、ボリュームの要求のためのプロキシとして機能します。 テナントクラスター内でPVCが作成されると、管理クラスターにPVCが作成され、作成されたPVが仮想マシンに接続されます。

ネストされたKubernetesクラスターのスキームにおいて、テナントKubernetesクラスターの内部と外部の両方にインストールされたCSIプラグインのコンポーネントと、それが管理する親から子へのKubernetesクラスター間の永続ボリュームのマッピングを示す図
クラスターオートスケーラー
クラスターオートスケーラーは、さまざまなクラウドAPIと連携できる汎用的なコンポーネントであり、Cluster APIとの統合は利用可能な機能の1つに過ぎません。 適切に設定するには、2つのクラスターへのアクセスが必要です。 テナントクラスターではPodを追跡し、新しいノードを追加する必要性を判断し、管理するKubernetesクラスター(管理Kubernetesクラスター)ではMachineDeploymentリソースと対話し、レプリカ数を調整します。
Cluster Autoscalerは通常テナントKubernetesクラスター内で実行されますが、今回のケースでは、前述と同じ理由からクラスター外にインストールすることをお勧めします。 このアプローチは、テナントクラスターのユーザーが管理クラスターの管理APIにアクセスできないようにするため、メンテナンスがより簡単で、より安全です。

ネストされたKubernetesクラスターのスキームにおいて、テナントKubernetesクラスターの外部にインストールされたCluster Autoscalerを示す図
Konnectivity
もう1つ追加のコンポーネントについて言及したいと思います。 Konnectivityです。 後でテナントKubernetesクラスターでwebhookとAPIアグリゲーションレイヤーを動作させるために、おそらくこれが必要になるでしょう。 このトピックについては、私の以前の記事で詳しく説明しています。
上記のコンポーネントとは異なり、Kamajiでは、Konnectivityを簡単に有効にし、kube-proxyやCoreDNSと並んで、テナントクラスターのコアコンポーネントの1つとして管理できます。
まとめ
これで、動的スケーリング、ボリュームの自動プロビジョニング、ロードバランサーの機能を備えた、完全に機能するKubernetesクラスターができました。
今後は、テナントクラスターからのメトリクスやログの収集を検討するとよいでしょうが、それはこの記事の範囲を超えています。
もちろん、Kubernetesクラスターをデプロイするために必要なコンポーネントはすべて、1つのHelmチャートにパッケージ化し、統一されたアプリケーションとしてデプロイできます。 これは、オープンなPaaSプラットフォームであるCozystackで、ボタンをクリックするだけで管理対象のKubernetesクラスターのデプロイを整理する方法そのものです。 Cozystackでは、記事で説明したすべてのテクノロジーを無料で試すことができます。
DIY: Kubernetesで自分だけのクラウドを構築しよう(パート2)
Kubernetesエコシステムだけを使って自分だけのクラウドを構築する方法について、一連の記事を続けています。 前回の記事では、Talos LinuxとFlux CDをベースにした基本的なKubernetes ディストリビューションの準備方法を説明しました。 この記事では、Kubernetesにおけるさまざまな仮想化テクノロジーをいくつか紹介し、主にストレージとネットワークを中心に、Kubernetes内で仮想マシンを実行するために必要な環境を整えます。
KubeVirt、LINSTOR、Kube-OVNなどのテクノロジーについて取り上げる予定です。
しかし最初に、仮想マシンが必要な理由と、クラウドの構築にDockerコンテナを使用するだけでは不十分である理由を説明しましょう。 その理由は、コンテナが十分なレベルの分離を提供していないことにあります。 状況は年々改善されていますが、コンテナのサンドボックスから脱出してシステムの特権を昇格させる脆弱性が見つかることがよくあります。
一方、Kubernetesはもともとマルチテナントシステムとして設計されていなかったため、基本的な使用パターンでは、独立したプロジェクトや開発チームごとに別々のKubernetesクラスターを作成することが一般的です。
仮想マシンは、クラウド環境でテナント同士を分離するための主要な手段です。 仮想マシン内では、ユーザーは管理者権限でコードやプログラムを実行できますが、これは他のテナントや環境自体に影響を与えません。 つまり、仮想マシンはハードマルチテナンシー分離を実現し、テナント間で信頼関係がない環境でも安全に実行できます。
Kubernetes における仮想化テクノロジー
Kubernetesの世界に仮想化をもたらすテクノロジーはいくつかありますが、KubeVirtとKata Containersが最も一般的です。 ただし、これらの動作方式は異なることを理解しておく必要があります。
Kata Containersは、CRI(Container Runtime Interface)を実装しており、標準のコンテナを仮想マシン内で実行することで、追加の分離レベルを提供します。 ただし、これらは同一のKubernetesクラスター内で動作します。

コンテナを仮想マシン内で実行することにより、Kata Containersがコンテナの分離を確保する方法を示す図
KubeVirtは、Kubernetes APIを使用して従来の仮想マシンを実行できます。 KubeVirtの仮想マシンは、コンテナ内の通常のLinuxプロセスとして実行されます。 つまり、KubeVirtでは、コンテナが仮想マシン(QEMU)プロセスを実行するためのサンドボックスとして使用されます。 これは、以下の図で、KubeVirtにおける仮想マシンのライブマイグレーションの実装方法を見ると明らかです。 マイグレーションが必要な場合、仮想マシンはあるコンテナから別のコンテナに移動します。

KubeVirtにおいて、仮想マシンがあるコンテナから別のコンテナへライブマイグレーションする様子を示す図
Cloud-Hypervisorを使用した軽量な仮想化を実装し、初期からCluster APIを使用した仮想Kubernetesクラスターの実行に重点を置いている代替プロジェクトVirtinkもあります。
私たちの目標を考慮して、この分野で最も一般的なプロジェクトであるKubeVirtを使用することに決めました。 さらに、私たちはKubeVirtに関する豊富な専門知識を持ち、すでに多くの貢献をしています。
KubeVirtはインストールが簡単で、containerDisk機能を使用してすぐに仮想マシンを実行できます。 この機能により、VMイメージをコンテナイメージレジストリから直接OCIイメージとして保存および配布できます。 containerDiskを使用した仮想マシンは、Kubernetesワーカーノードやその他の状態の永続化を必要としない仮想マシンの作成に適しています。
永続データを管理するために、KubeVirtは別のツールであるContainerized Data Importer(CDI)を提供しています。 CDIを使用すると、PVCのクローンを作成し、ベースイメージからデータを取り込むことができます。 CDIは、仮想マシンの永続ボリュームを自動的にプロビジョニングする場合や、テナントKubernetesクラスターからの永続ボリューム要求を処理するために使用されるKubeVirt CSIドライバーにも必要となります。
しかし最初に、これらのデータをどこにどのように保存するかを決める必要があります。
Kubernetes上の仮想マシン用ストレージ
CSI(Container Storage Interface)の導入により、Kubernetesと統合できる幅広いテクノロジーが利用可能になりました。 実際、KubeVirtはCSIインターフェースを完全に活用しており、仮想化のためのストレージの選択肢はKubernetes自体のストレージの選択肢と密接に連携しています。 しかし、考慮すべき細かな差異があります。 通常、標準のファイルシステムを使用するコンテナとは異なり、仮想マシンにはブロックデバイスの方が効率的です。
KubernetesのCSIインターフェースでは、ファイルシステムとブロックデバイスの両方のタイプのボリュームを要求できますが、使用しているストレージバックエンドがこれをサポートしていることを確認することが重要です。
仮想マシンにブロックデバイスを使用すると、ファイルシステムなどの追加の抽象化レイヤーが不要になるため、パフォーマンスが向上し、ほとんどの場合で ReadWriteMany モードの使用が可能になります。 このモードでは、複数のノードから同時にボリュームにアクセスできるため、KubeVirtにおける仮想マシンのライブマイグレーションを有効にするための重要な機能です。
ストレージシステムは、外部または内部(ハイパーコンバージドインフラストラクチャの場合)にすることができます。 多くの場合、外部ストレージを使用するとデータが計算ノードから分離して保存されるため、システム全体の安定性が向上します。

計算ノードと通信する外部データストレージを示す図
外部ストレージソリューションは、エンタープライズシステムでよく使用されています。 このようなストレージは、多くの場合運用を担当する外部ベンダーによって提供されるためです。 Kubernetesとの統合には、クラスターにインストールされる小さなコンポーネントであるCSIドライバーのみが関与します。 このドライバーは、このストレージにボリュームをプロビジョニングし、Kubernetesによって実行されるPodにそれらをアタッチする役割を担います。 ただし、このようなストレージソリューションは、純粋にオープンソースのテクノロジーを使用して実装することもできます。 人気のあるソリューションの1つは、democratic-csiドライバーを使用したTrueNASです。

コンピュートノード上で実行されるローカルデータストレージを示す図
一方、ハイパーコンバージドシステムは、多くの場合、ローカルストレージ(レプリケーションが不要な場合)と、Rook/Ceph、OpenEBS、Longhorn、LINSTORなどのソフトウェアデファインドストレージを使用して実装されます。 これらは、多くの場合、Kubernetesに直接インストールされます。

コンピュートノード上で実行されるクラスター化データストレージを示す図
ハイパーコンバージドシステムには利点があります。 たとえば、データの局所性です。 データがローカルに保存されている場合、そのデータへのアクセスは高速になります。 しかし、このようなシステムは通常、管理と保守がより難しいという欠点があります。
Ænixでは、追加の外部ストレージを購入してセットアップする必要なく使用でき、速度とリソースの利用の点で最適な、すぐに使える解決策を提供したいと考えていました。 LINSTORがその解決策となりました。 バックエンドとして業界で人気のある実績あるテクノロジーであるLVMやZFSを使用していることで、データが安全に保存されていることに自信が持てます。 DRDBベースのレプリケーションは信じられないほど高速で、少ない計算リソースしか消費しません。
Kubernetes上でLINSTORをインストールするには、PiraeusプロジェクトがKubeVirtで使用できる既製のブロックストレージをすでに提供しています。
Kubernetes上の仮想マシン用ネットワーク
Kubernetesのネットワークアーキテクチャは同じようなインターフェースであるCNIを持っているにもかかわらず、実際にはより複雑で、通常、互いに直接接続されていない多くの独立したコンポーネントで構成されています。 実際、Kubernetesのネットワークは以下に説明する4つのレイヤーに分割できます。
ノードネットワーク (データセンターネットワーク)
ノードが相互に接続されるネットワークです。 このネットワークは通常、Kubernetesによって管理されませんが、これがないと何も機能しないため、重要なネットワークです。 実際には、ベアメタルインフラストラクチャには通常、複数のこのようなネットワークがあります。 例えば、ノード間通信用の1つ、ストレージレプリケーション用の2つ目、外部アクセス用の3つ目などです。

Kubernetesのネットワーク構成におけるノードネットワーク(データセンターネットワーク)の役割を示す図
ノード間の物理ネットワークの相互作用の設定は、ほとんどの状況でKubernetesが既存のネットワークインフラストラクチャを利用するため、この記事の範囲を超えています。
Podネットワーク
これは、CNIプラグインによって提供されるネットワークです。 CNIプラグインの役割は、クラスター内のすべてのコンテナとノード間の透過的な接続を確保することです。 ほとんどのCNIプラグインは、各ノードで使用するためにIPアドレスの個別のブロックが割り当てられるフラットネットワークを実装しています。

Kubernetesのネットワーク構成におけるPodネットワーク(CNIプラグイン)の役割を示す図
実際には、クラスターにはMultusによって管理される複数のCNIプラグインを持つことができます。 このアプローチは、RancherやOpenShiftなどのKubeVirtベースの仮想化ソリューションでよく使用されます。 プライマリCNIプラグインはKubernetesサービスとの統合に使用され、追加のCNIプラグインはプライベートネットワーク(VPC)の実装やデータセンターの物理ネットワークとの統合に使用されます。
デフォルトのCNIプラグインは、ブリッジまたは物理インターフェースの接続に使用できます。 さらに、パフォーマンスを向上させるために設計されたmacvtap-cniなどの専用プラグインもあります。
Kubernetes内で仮想マシンを実行する際に注意すべきもう1つの側面は、特にMultusによって提供されるセカンダリインターフェースに対するIPAM(IPアドレス管理)の必要性です。 これは通常、インフラストラクチャ内で動作するDHCPサーバーによって管理されます。 さらに、仮想マシンのMACアドレスの割り当ては、Kubemacpoolによって管理できます。
私たちのプラットフォームでは、別の方法を選択し、Kube-OVNに完全に頼ることにしました。 このCNIプラグインは、もともとOpenStack用に開発されたOVN(Open Virtual Network)をベースにしています。 Kube-OVNはKubernetes内の仮想マシン用の完全なネットワークソリューションを提供します。 IPとMACアドレスを管理するためのカスタムリソースを備え、ノード間でIPアドレスを保持したままライブマイグレーションをサポートし、テナント間の物理ネットワーク分離用のVPCの作成を可能にします。
Kube-OVNでは、名前空間全体に個別のサブネットを割り当てたり、Multusを使用して追加のネットワークインターフェースとして接続したりできます。
サービスネットワーク
CNIプラグインに加えて、Kubernetesにはサービスネットワークもあります。これは主にサービスディスカバリーに必要です。 従来の仮想マシンとは異なり、KubernetesはもともとランダムなアドレスでPodを実行するように設計されています。 そして、サービスネットワークは、トラフィックを常に正しいPodに誘導する便利な抽象化(安定したIPアドレスとDNS名)を提供します。 仮想マシンのIPは通常静的であるにもかかわらず、このアプローチはクラウド内の仮想マシンでも一般的に使用されています。

Kubernetesのネットワーク構成におけるサービスネットワーク(サービスネットワークプラグイン)の役割を示す図
Kubernetesでのサービスネットワークの実装は、サービスネットワークプラグインによって処理されます。 標準の実装はkube-proxyと呼ばれ、ほとんどのクラスターで使用されています。 しかし最近では、この機能はCNIプラグインの一部として提供されることがあります。 最も先進的な実装は、Ciliumプロジェクトによって提供されており、kube-proxyの代替モードで実行できます。
CiliumはeBPFテクノロジーに基づいており、Linuxネットワークスタックを効率的にオフロードできるため、iptablesベースの従来の方法と比較してパフォーマンスとセキュリティが向上します。
実際には、CiliumとKube-OVNを簡単に統合することが可能です。 これにより、仮想マシン向けにシームレスでマルチテナントのネットワーキングを提供する統合ソリューションを実現することができます。 また、高度なネットワークポリシーと統合されたサービスネットワーク機能も提供されます。
外部トラフィックのロードバランサー
この段階で、Kubernetes内で仮想マシンを実行するために必要なものはすべて揃っています。 しかし、実際にはもう1つ必要なものがあります。 クラスターの外部からサービスにアクセスする必要がまだあり、外部ロードバランサーがこれを整理するのに役立ちます。
ベアメタルのKubernetesクラスターには、いくつかの利用可能なロードバランサーがあります。 MetalLB、kube-vip、LoxiLBがあり、またCiliumとKube-OVNにはビルトインの実装が提供されています。
外部ロードバランサーの役割は、外部から利用可能な安定したアドレスを提供し、外部トラフィックをサービスネットワークに誘導することです。 サービスネットワークプラグインは、通常どおりそれをPodと仮想マシンに誘導します。

Kubernetesのネットワーク構成における外部ロードバランサーの役割を示す図
ほとんどの場合、ベアメタル上でのロードバランサーの設定は、クラスター内のノードにフローティングIPアドレスを作成し、ARP/NDPまたはBGPプロトコルを使用してそれを外部にアナウンスすることによって実現されます。
さまざまなオプションを検討した結果、MetalLBが最もシンプルで信頼性の高いソリューションであると判断しましたが、MetalLBの使用のみを厳密に強制しているわけではありません。
もう1つの利点は、L2モードでは、MetalLBスピーカーがメンバーリストプロトコルを使用してライブネスチェックを実行することにより、ネイバーの状態を継続的にチェックすることです。 これにより、Kubernetesコントロールプレーンとは独立して機能するフェイルオーバーが可能になります。
まとめ
ここまでが、Kubernetesにおける仮想化、ストレージ、ネットワークの概要になります。 ここで取り上げたテクノロジーは、Cozystackプラットフォームで利用可能であり、制限なくお試しいただけるよう事前に設定されています。
次の記事では、この上にボタンをクリックするだけで、完全に機能するKubernetesクラスターのプロビジョニングをどのように実装できるかを詳しく説明します。
DIY: Kubernetesで自分だけのクラウドを構築しよう(パート1)
Ænixでは、Kubernetesに対する深い愛着があり、近いうちにすべての最新テクノロジーがKubernetesの驚くべきパターンを活用し始めることを夢見ています。 自分だけのクラウドを構築することを考えたことはありませんか?きっと考えたことがあるでしょう。 しかし、快適なKubernetesエコシステムを離れることなく、最新のテクノロジーとアプローチのみを使ってそれを実現することは可能でしょうか? Cozystackの開発における私たちの経験は、その点を深く掘り下げる必要がありました。 自分だけのクラウドを構築することを考えたことはありませんか?
Kubernetesはこの目的のために設計されたものではなく、ベアメタルサーバー用にOpenStackを使用し、意図したとおりにその内部でKubernetesを実行すればよいのではないかと主張する人もいるかもしれません。 しかし、そうすることで、単に責任があなたの手からOpenStack管理者の手に移っただけです。 これにより、少なくとも1つの巨大で複雑なシステムがエコシステムに追加されることになります。
なぜ物事を複雑にするのでしょうか? 結局のところ、Kubernetesにはテナント用のKubernetesクラスターを実行するために必要なものがすべて揃っています。
Kubernetesをベースにしたクラウドプラットフォームの開発における私たちの経験を共有したいと思います。 私たち自身が使用しており、あなたの注目に値すると信じているオープンソースプロジェクトを紹介します。
この一連の記事では、オープンソースのテクノロジーのみを使用して、ベアメタルから管理されたKubernetesを準備する方法についての私たちの物語をお伝えします。 データセンターの準備、仮想マシンの実行、ネットワークの分離、フォールトトレラントなストレージのセットアップといった基本的なレベルから、動的なボリュームのプロビジョニング、ロードバランサー、オートスケーリングを備えた本格的なKubernetesクラスターのプロビジョニングまでを扱います。
この記事から、いくつかのパートで構成されるシリーズを開始します:
- パート1: 自分のクラウドの基礎を準備する。ベアメタル上でのKubernetesの準備と運用における課題、およびインフラストラクチャをプロビジョニングするための既成のレシピ。
- パート2: ネットワーク、ストレージ、仮想化。Kubernetesを仮想マシン起動のためのツールにする方法とそのために必要なもの。
- パート3: Cluster APIと、ボタンを押すだけでKubernetesクラスターのプロビジョニングを開始する方法。オートスケーリング、ボリュームの動的プロビジョニング、ロードバランサーの仕組み。
さまざまなテクノロジーをできるだけ独立して説明しようと思いますが、同時に、私たちの経験と、なぜある解決策に至ったのかを共有します。
まず、Kubernetesの主な利点と、それがクラウドリソースの使用へのアプローチをどのように変えたかを理解しましょう。
クラウドとベアメタルでは、Kubernetesの使い方が異なることを理解することが重要です。
クラウド上のKubernetes
クラウド上でKubernetesを運用する場合、永続ボリューム、クラウドロードバランサー、ノードのプロビジョニングプロセスを気にする必要はありません。 これらはすべて、Kubernetesオブジェクトの形式であなたのリクエストを受け入れるクラウドプロバイダーによって処理されます。 つまり、サーバー側は完全にあなたから隠されており、クラウドプロバイダーがどのように正確に実装しているかを知る必要はありません。 それはあなたの責任範囲ではないからです。

クラウド上のKubernetesを示す図。ロードバランシングとストレージはクラスターの外部で行われています
Kubernetesは、どこでも同じように機能する便利な抽象化を提供しているため、あらゆるクラウドのKubernetes上にアプリケーションをデプロイできます。
クラウドでは、Kubernetesコントロールプレーン、仮想マシン、永続ボリューム、ロードバランサーなど、いくつかの個別のエンティティを持つことが非常に一般的です。 これらのエンティティを使用することで、高度に動的な環境を作成できます。
Kubernetesのおかげで、仮想マシンは今やクラウドリソースを利用するための単なるユーティリティエンティティとしてのみ見られるようになりました。 もはや仮想マシンの中にデータを保存することはありません。 仮想マシンをすべて削除して、アプリケーションを壊すことなく再作成できます。 Kubernetesコントロールプレーンは、クラスター内で何が実行されるべきかについての情報を保持し続けます。 ロードバランサーは、新しいノードにトラフィックを送信するためにエンドポイントを変更するだけで、ワークロードにトラフィックを送信し続けます。 そして、データはクラウドが提供する外部の永続ボリュームに安全に保存されます。
このアプローチは、クラウドでKubernetesを使用する際の基本です。 その理由はかなり明白です。 システムが単純であるほど安定性が高くなり、このシンプルさのためにクラウドでKubernetesを選択するのです。
ベアメタル上のKubernetes
クラウドでKubernetesを使用することは本当に簡単で便利ですが、ベアメタルへのインストールについては同じことが言えません。 ベアメタルの世界では、Kubernetesは逆に非常に複雑になります。 まず、ネットワーク全体、バックエンドストレージ、クラウドバランサーなどは、通常、クラスターの外部ではなく内部で実行されるためです。 その結果、このようなシステムは更新と保守がはるかに難しくなります。

ベアメタル上のKubernetesを示す図。ロードバランシングとストレージはクラスターの内部で行われています
ご自身で判断してみてください。
クラウドでは、通常、ノードを更新するために仮想マシンを削除する(またはkubectl delete nodeを使用する)だけで、イミュータブルなイメージに基づいて新しいノードを作成することをノード管理ツールに任せることができます。
新しいノードはクラスターに参加し、Kubernetesの世界で非常にシンプルでよく使われるパターンに従って、ノードとして「そのまま動作」します。
多くのクラスターでは、安価なスポットインスタンスを利用できるため、数分ごとに新しい仮想マシンをオーダーしています。
しかし、物理サーバーを使用している場合は、簡単に削除して再作成することはできません。
まず、物理サーバーはクラスターサービスを実行していたり、データを保存していたりすることが多いため、その更新プロセスははるかに複雑になるからです。
この問題を解決するアプローチはさまざまです。 kubeadm、kubespray、k3sが行うようなインプレースアップデートから、Cluster APIとMetal3を通じた物理ノードのプロビジョニングの完全な自動化まで幅広くあります。
私は、Talos Linuxが提供するハイブリッドアプローチが気に入っています。 このアプローチでは、システム全体が単一の設定ファイルで記述されます。 このファイルのほとんどのパラメーターは、Kubernetesコントロールプレーンコンポーネントのバージョンを含め、ノードを再起動または再作成することなく適用できます。 それでも、Kubernetesの宣言的な性質を最大限に保持しています。 このアプローチは、ベアメタルノードを更新する際のクラスターサービスへの不要な影響を最小限に抑えます。 ほとんどの場合、マイナーアップデートの際に仮想マシンを移行したり、クラスターファイルシステムを再構築したりする必要はありません。
将来のクラウドの基盤を準備する
さて、自分だけのクラウドを構築することに決めたとしましょう。 まずは基盤となるレイヤーが必要です。 サーバーにKubernetesをインストールする方法だけでなく、それをどのように更新し、維持していくかについても考える必要があります。 カーネルの更新、必要なモジュールのインストール、パッケージやセキュリティパッチなどについても考えなければならないことを考慮してください。 クラウド上の既製のKubernetesを使用する際に気にする必要のないことをはるかに多く考えなければなりません。
もちろん、UbuntuやDebianのような標準的なディストリビューションを使用できますし、Flatcar Container Linux、Fedora Core、Talos Linuxのような特殊なディストリビューションを検討することもできます。 それぞれに長所と短所があります。
私たちのことですか? Ænixでは、ZFS、DRBD、OpenvSwitchなどのかなり特殊なカーネルモジュールを使用しているので、必要なモジュールをすべて事前に含んだシステムイメージを形成する方法を選びました。 この場合、Talos Linuxが私たちにとって最も便利であることがわかりました。 たとえば、次のような設定で、必要なカーネルモジュールをすべて含むシステムイメージを構築するのに十分です:
arch: amd64
platform: metal
secureboot: false
version: v1.6.4
input:
kernel:
path: /usr/install/amd64/vmlinuz
initramfs:
path: /usr/install/amd64/initramfs.xz
baseInstaller:
imageRef: ghcr.io/siderolabs/installer:v1.6.4
systemExtensions:
- imageRef: ghcr.io/siderolabs/amd-ucode:20240115
- imageRef: ghcr.io/siderolabs/amdgpu-firmware:20240115
- imageRef: ghcr.io/siderolabs/bnx2-bnx2x:20240115
- imageRef: ghcr.io/siderolabs/i915-ucode:20240115
- imageRef: ghcr.io/siderolabs/intel-ice-firmware:20240115
- imageRef: ghcr.io/siderolabs/intel-ucode:20231114
- imageRef: ghcr.io/siderolabs/qlogic-firmware:20240115
- imageRef: ghcr.io/siderolabs/drbd:9.2.6-v1.6.4
- imageRef: ghcr.io/siderolabs/zfs:2.1.14-v1.6.4
output:
kind: installer
outFormat: raw
dockerコマンドラインツールを使用して、OSイメージをビルドします:
cat config.yaml | docker run --rm -i -v /dev:/dev --privileged "ghcr.io/siderolabs/imager:v1.6.4" -
その結果、必要なものがすべて含まれたDockerコンテナイメージが得られます。 このイメージを使用して、サーバーにTalos Linuxをインストールできます。 同じことができます。このイメージには、必要なすべてのファームウェアとカーネルモジュールが含まれます。
しかし、新しく形成されたイメージをノードにどのように配信するかという問題が発生します。
しばらくの間、PXEブートのアイデアについて考えていました。 たとえば、2年前に記事を書いたKubefarmプロジェクトは、完全にこのアプローチを使用して構築されました。 しかし残念ながら、他のクラスターを保持する最初の親クラスターをデプロイするのに役立つわけではありません。 そこで今回、PXEアプローチを使用して同じことを行うのに役立つソリューションを用意しました。
基本的に必要なのは、コンテナ内で一時的なDHCPとPXEサーバーを実行することだけです。 そうすれば、ノードはあなたのイメージから起動し、Debianベースの簡単なスクリプトを使用して、ノードのブートストラップに役立てることができます。

talos-bootstrapスクリプトのソースコードはGitHubで入手できます。
このスクリプトを使用すると、ベアメタル上に5分でKubernetesをデプロイし、それにアクセスするためのkubeconfigを取得できます。 しかし、まだ多くの未解決の問題が残っています。
システムコンポーネントの配信
この段階では、さまざまなワークロードを実行できるKubernetesクラスターがすでに手に入っています。 しかし、まだ完全に機能しているわけではありません。 つまり、ネットワークとストレージを設定する必要があるだけでなく、仮想マシンを実行するためのKubeVirtや、監視スタックやその他のシステム全体のコンポーネントなど、必要なクラスター拡張機能をインストールする必要があります。
従来、これはHelmチャートをクラスターにインストールすることで解決されています。
ローカルでhelm installコマンドを実行することで実現できますが、アップデートを追跡したい場合や、複数のクラスターを持っていてそれらを均一に保ちたい場合、このアプローチは不便になります。
実際には、これを宣言的に行う方法はたくさんあります。
これを解決するには、最高のGitOpsプラクティスを使用することをお勧めします。
つまり、ArgoCDやFluxCDのようなツールを指します。
ArgoCDはグラフィカルインターフェースと中央コントロールプレーンを備えているため開発目的には便利ですが、一方でFluxCDはKubernetesディストリビューションの作成により適しています。 FluxCDを使用すると、どのチャートをどのパラメーターで起動すべきかを指定し、依存関係を記述できます。 そうすれば、FluxCDがすべてを処理してくれます。
新しく作成したクラスターにFluxCDを1回インストールし、適切に設定することをお勧めします。 これにより、FluxCDは必要不可欠なコンポーネントをすべて自動的にデプロイできるようになり、クラスターを目的の状態にアップグレードできます。 たとえば、私たちのプラットフォームをインストールすると、システムコンポーネントとともに次の事前設定されたHelmチャートが表示されます:
NAMESPACE NAME AGE READY STATUS
cozy-cert-manager cert-manager 4m1s True Release reconciliation succeeded
cozy-cert-manager cert-manager-issuers 4m1s True Release reconciliation succeeded
cozy-cilium cilium 4m1s True Release reconciliation succeeded
cozy-cluster-api capi-operator 4m1s True Release reconciliation succeeded
cozy-cluster-api capi-providers 4m1s True Release reconciliation succeeded
cozy-dashboard dashboard 4m1s True Release reconciliation succeeded
cozy-fluxcd cozy-fluxcd 4m1s True Release reconciliation succeeded
cozy-grafana-operator grafana-operator 4m1s True Release reconciliation succeeded
cozy-kamaji kamaji 4m1s True Release reconciliation succeeded
cozy-kubeovn kubeovn 4m1s True Release reconciliation succeeded
cozy-kubevirt-cdi kubevirt-cdi 4m1s True Release reconciliation succeeded
cozy-kubevirt-cdi kubevirt-cdi-operator 4m1s True Release reconciliation succeeded
cozy-kubevirt kubevirt 4m1s True Release reconciliation succeeded
cozy-kubevirt kubevirt-operator 4m1s True Release reconciliation succeeded
cozy-linstor linstor 4m1s True Release reconciliation succeeded
cozy-linstor piraeus-operator 4m1s True Release reconciliation succeeded
cozy-mariadb-operator mariadb-operator 4m1s True Release reconciliation succeeded
cozy-metallb metallb 4m1s True Release reconciliation succeeded
cozy-monitoring monitoring 4m1s True Release reconciliation succeeded
cozy-postgres-operator postgres-operator 4m1s True Release reconciliation succeeded
cozy-rabbitmq-operator rabbitmq-operator 4m1s True Release reconciliation succeeded
cozy-redis-operator redis-operator 4m1s True Release reconciliation succeeded
cozy-telepresence telepresence 4m1s True Release reconciliation succeeded
cozy-victoria-metrics-operator victoria-metrics-operator 4m1s True Release reconciliation succeeded
まとめ
結果として、誰にでも提供できる高い再現性を持つ環境を実現でき、意図したとおりに動作することがわかります。 これは、実際にCozystackプロジェクトが行っていることであり、あなた自身が無料で試すことができます。
次の記事では、仮想マシンを実行するためのKubernetesの準備方法とボタンをクリックするだけでKubernetesクラスターを実行する方法について説明します。 ご期待ください。きっと面白いはずです!
Kubernetes v1.30をそっと覗く
Kubernetes v1.30のおもしろい変更点をざっと見る
新しい年であり、新しいKubernetesのリリースです。 リリースサイクルの半分が終了し、v1.30ではかなりの数の興味深くおもしろい機能強化が行われます。 アルファ版の真新しい機能から、安定版へと進む既存の機能、そして待望の改良まで、このリリースには誰もが注目するものがあります!
正式リリースまでのつなぎとして、このリリースで我々がもっとも期待している機能強化をそっと覗いてみましょう!
Kubernetes v1.30の主な変更点
動的なリソース割り当てのための構造化パラメーター (KEP-4381)
動的なリソース割り当て(DRA)はv1.26でアルファ機能としてKubernetesに追加されました。 これは、サードパーティリソースへのアクセスを要求するための従来のデバイスプラグインAPIに代わるものを定義しています。 設計上、動的なリソース割り当て(DRA)では、Kubernetesの中心部に完全に不透明なリソースのパラメーターが使用されます。 このアプローチは、クラスターオートスケーラーや、Podのグループ(Jobスケジューラーなど)に対して決定を下す必要がある上位コントローラーにとって問題となります。 時間経過に伴う要求(claim)の割り当てや割り当て解除の効果をシミュレートできないのです。 これを行うための情報は、サードパーティのDRAドライバーのみが保有しています。
動的なリソース割り当て(DRA)の構造化パラメーターは、これらの要求(claim)パラメーターの不透明さがより少ないフレームワークを構築することによって、この問題に対処するための従来の実装の拡張になります。 すべての要求(claim)パラメーターのセマンティクスを自分で処理する代わりに、ドライバーはKubernetesによって事前定義された特定の"構造化モデル"を使用してリソースを記述し、管理できます。 これにより、この"構造化モデル"を認識しているコンポーネントは、サードパーティのコントローラーに委託することなく、これらのリソースに関する意思決定を行えます。 たとえば、スケジューラーは動的なリソース割り当て(DRA)ドライバーとやり取りを行うことなく、要求(claim)を迅速に割り当てることができます。 今回のリリースでは、さまざまな"構造化モデル"を実現するために必要なフレームワークの定義と"名前付きリソース"モデルの実装を中心に作業が行われました。 このモデルでは、個々のリソース・インスタンスをリストアップすることができ、従来のデバイスプラグインAPIと比較して、属性によってそれらのインスタンスを個別に選択する機能が追加されています。
Nodeのメモリスワップのサポート (KEP-2400)
Kubernetes v1.30では、Linux Nodeにおけるメモリスワップのサポートが、システムの安定性を向上させることに重点を置いて、その動作方法に大きな変更が加えられました。
以前のKubernetesバージョンでは、NodeSwapフィーチャーゲートはデフォルトで無効化されており、有効化された場合、デフォルトの動作としてUnlimitedSwap動作が使用されていました。
より良い安定性を達成するために、(Nodeの安定性を損なう可能性のある)UnlimitedSwap動作はv1.30で削除されます。
更新された、まだベータ版のLinux Nodeでのスワップのサポートは、デフォルトで利用できるようになります。
ただし、デフォルトの動作は、NoSwap(UnlimitedSwapではない)モードに設定されたNodeを実行することになります。
NoSwapモードでは、kubeletはスワップ領域が有効化されたNodeでの実行をサポートしますが、Podはページファイルを一切使用しません。
そのNodeでkubeletを実行するには、--fail-swap-on=falseを設定する必要があります。
ただ、大きな変更とはこのことではなく、もう1つのモードであるLimitedSwapです。
このモードでは、kubeletは実際にそのNodeのページファイルを使用し、Podが仮想メモリの一部をページアウトできるようにします。
コンテナ(およびその親Pod)はメモリ制限を超えてスワップにアクセスすることはできませんが、利用可能な場合はスワップ領域を使用できます。
KubernetesのNode Special Interest Group (SIG Node)は、エンドユーザー、貢献者、およびより広いKubernetesコミュニティからのフィードバックに基づいて、改訂された実装の使用方法を理解できるようにドキュメントも更新します。
KubernetesにおけるLinux Nodeのスワップ・サポートの詳細については、前回のブログ記事またはNodeのスワップ・ドキュメントを読んでください。
Podでユーザー名前空間のサポート (KEP-127)
ユーザー名前空間は、2024年1月に公開されたCVE-2024-21626を含むHigh/Criticalと評価された複数のCVEを防止、または緩和するために、Podをより適切に分離するLinux専用の機能です。 Kubernetes 1.30では、ユーザー名前空間のサポートがベータ版に移行し、ボリュームのあるPodとないPod、カスタムUID/GID範囲などがサポートされるようになりました!
構造化された認可設定 (KEP-3221)
構造化された認可設定のサポートはベータ版に移行し、デフォルトで有効になります。 この機能は、失敗時に明示的に拒否するなどのきめ細かな制御を可能にしたり、特定の順序でリクエストを検証する明確に定義されたパラメーターを持つ複数のWebhookによる認可チェーンの作成を可能にします。 設定ファイルのアプローチでは、リクエストがWebhookへ渡される前にCELルールを指定して事前にフィルタリングすることも可能で、不要なリクエストを防ぐのに役立ちます。 また、設定ファイルが変更されると、APIサーバーは自動的に認可チェーンを再読み込みします。
--authorization-configコマンドライン引数を使用して、その認可設定へのパスを指定する必要があります。
設定ファイルの代わりにコマンドラインフラグを使い続けたい場合、そのまま機能し続けます。
複数のWebhook、失敗ポリシー、事前フィルタールールなどの新しい認可Webhook機能にアクセスするには、--authorization-configファイルにオプションを記述するように切り替えます。
Kubernetes 1.30からは、設定ファイルのフォーマットがベータ段階であり、フィーチャーゲートがデフォルトで有効になっているため、--authorization-configを指定する必要があるだけです。
すべての可能な値を含む設定例は、認可ドキュメントで提供されています。
詳細については、認可ドキュメントを読んでください。
コンテナリソースをもとにしたPodの自動スケーリング (KEP-1610)
ContainerResourceメトリクスに基づく水平Pod自動スケーリングは、v1.30で安定版に移行します。
HorizontalPodAutoscalerのこの新しい動作により、Pod全体のリソース使用量ではなく、個々のコンテナのリソース使用量に基づいて自動スケーリングを設定できるようになります。
詳細については以前の記事を参照するか、コンテナリソースメトリクスを読んでください。
アドミッション・コントロールに対するCEL (KEP-3488)
Kubernetesのアドミッション・コントロールにCommon Expression Language (CEL)を統合することで、アドミッション・リクエストを評価するよりダイナミックで表現力豊かな方法が導入されます。 この機能により、複雑できめ細かなポリシーがKubernetes APIを通じて直接定義・適用できるようになり、パフォーマンスや柔軟性を損なうことなく、セキュリティとガバナンスの機能が強化されます。
CELがKubernetesのアドミッション・コントロールに追加されたことで、クラスター管理者はWebhookベースのアクセス・コントローラーに頼ることなく、クラスターの望ましい状態やポリシーに対してAPIリクエストの内容を評価できる複雑なルールを作成できます。 このレベルの制御は、クラスター運用の効率性、セキュリティ、整合性を維持するために極めて重要であり、Kubernetes環境をより堅牢にし、さまざまなユースケースや要件へ適応できるようにします。 アドミッション・コントロールにCELを使用する詳細については、ValidatingAdmissionPolicyのAPIドキュメントを参照してください。
私たちと同じようにこのリリースを楽しみにしていただければ幸いです。数週間後の公式のリリース記事で、さらなるハイライトをお見逃しなく!
CRI-O: OCIレジストリからのseccompプロファイルの適用
seccompはセキュアなコンピューティングモードを意味し、Linuxカーネルのバージョン2.6.12以降の機能として提供されました。 これは、プロセスの特権をサンドボックス化し、ユーザースペースからカーネルへの呼び出しを制限するために使用できます。 Kubernetesでは、ノードに読み込まれたseccompプロファイルをPodやコンテナに自動的に適用することができます。
しかし、Kubernetesでseccompプロファイルを配布することは大きな課題です。 なぜなら、JSONファイルがワークロードが実行可能なすべてのノードで利用可能でなければならないからです。 Security Profiles Operatorなどのプロジェクトは、クラスター内でデーモンとして実行することでこの問題を解決しています。 この設定から、コンテナランタイムがこの配布プロセスの一部を担当できるかどうかが興味深い点です。
通常、ランタイムはローカルパスからプロファイルを適用します。たとえば:
apiVersion: v1
kind: Pod
metadata:
name: pod
spec:
containers:
- name: container
image: nginx:1.25.3
securityContext:
seccompProfile:
type: Localhost
localhostProfile: nginx-1.25.3.json
プロファイルnginx-1.25.3.jsonはkubeletのルートディレクトリ内にseccompディレクトリを追加して利用可能でなければなりません。
これは、ディスク上のプロファイルのデフォルトの場所が/var/lib/kubelet/seccomp/nginx-1.25.3.jsonになることを指しています。
プロファイルが利用できない場合、ランタイムは次のようにコンテナの作成に失敗します。
kubectl get pods
NAME READY STATUS RESTARTS AGE
pod 0/1 CreateContainerError 0 38s
kubectl describe pod/pod | tail
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 117s default-scheduler Successfully assigned default/pod to 127.0.0.1
Normal Pulling 117s kubelet Pulling image "nginx:1.25.3"
Normal Pulled 111s kubelet Successfully pulled image "nginx:1.25.3" in 5.948s (5.948s including waiting)
Warning Failed 7s (x10 over 111s) kubelet Error: setup seccomp: unable to load local profile "/var/lib/kubelet/seccomp/nginx-1.25.3.json": open /var/lib/kubelet/seccomp/nginx-1.25.3.json: no such file or directory
Normal Pulled 7s (x9 over 111s) kubelet Container image "nginx:1.25.3" already present on machine
Localhostプロファイルを手動で配布する必要があるという大きな障害は、多くのエンドユーザーがRuntimeDefaultに戻るか、さらにはUnconfined(seccompが無効になっている)でワークロードを実行することになる可能性が高いということです。
CRI-Oが救世主
KubernetesのコンテナランタイムCRI-Oは、カスタムアノテーションを使用してさまざまな機能を提供しています。
v1.30のリリースでは、アノテーションの新しい集合であるseccomp-profile.kubernetes.cri-o.io/PODとseccomp-profile.kubernetes.cri-o.io/<CONTAINER>のサポートが追加されました。
これらのアノテーションを使用すると、以下を指定することができます:
- 特定のコンテナ用のseccompプロファイルは、次のように使用されます:
seccomp-profile.kubernetes.cri-o.io/<CONTAINER>(例:seccomp-profile.kubernetes.cri-o.io/webserver: 'registry.example/example/webserver:v1') - Pod内のすべてのコンテナに対するseccompプロファイルは、コンテナ名の接尾辞を使用せず、予約された名前
PODを使用して次のように使用されます:seccomp-profile.kubernetes.cri-o.io/POD - イメージ全体のseccompプロファイルは、イメージ自体がアノテーション
seccomp-profile.kubernetes.cri-o.io/PODまたはseccomp-profile.kubernetes.cri-o.io/<CONTAINER>を含んでいる場合に使用されます
CRI-Oは、ランタイムがそれを許可するように構成されている場合、およびUnconfinedとして実行されるワークロードに対してのみ、そのアノテーションを尊重します。
それ以外のすべてのワークロードは、引き続きsecurityContextからの値を優先して使用します。
アノテーション単体では、プロファイルの配布にはあまり役立ちませんが、それらの参照方法が役立ちます! たとえば、OCIアーティファクトを使用して、通常のコンテナイメージのようにseccompプロファイルを指定できるようになりました。
apiVersion: v1
kind: Pod
metadata:
name: pod
annotations:
seccomp-profile.kubernetes.cri-o.io/POD: quay.io/crio/seccomp:v2
spec: …
イメージquay.io/crio/seccomp:v2には、実際のプロファイル内容を含むseccomp.jsonファイルが含まれています。
ORASやSkopeoなどのツールを使用して、イメージの内容を検査できます。
oras pull quay.io/crio/seccomp:v2
Downloading 92d8ebfa89aa seccomp.json
Downloaded 92d8ebfa89aa seccomp.json
Pulled [registry] quay.io/crio/seccomp:v2
Digest: sha256:f0205dac8a24394d9ddf4e48c7ac201ca7dcfea4c554f7ca27777a7f8c43ec1b
jq . seccomp.json | head
{
"defaultAction": "SCMP_ACT_ERRNO",
"defaultErrnoRet": 38,
"defaultErrno": "ENOSYS",
"archMap": [
{
"architecture": "SCMP_ARCH_X86_64",
"subArchitectures": [
"SCMP_ARCH_X86",
"SCMP_ARCH_X32"
# イメージのプレーンマニフェストを調べる
skopeo inspect --raw docker://quay.io/crio/seccomp:v2 | jq .
{
"schemaVersion": 2,
"mediaType": "application/vnd.oci.image.manifest.v1+json",
"config":
{
"mediaType": "application/vnd.cncf.seccomp-profile.config.v1+json",
"digest": "sha256:ca3d163bab055381827226140568f3bef7eaac187cebd76878e0b63e9e442356",
"size": 3,
},
"layers":
[
{
"mediaType": "application/vnd.oci.image.layer.v1.tar",
"digest": "sha256:92d8ebfa89aa6dd752c6443c27e412df1b568d62b4af129494d7364802b2d476",
"size": 18853,
"annotations": { "org.opencontainers.image.title": "seccomp.json" },
},
],
"annotations": { "org.opencontainers.image.created": "2024-02-26T09:03:30Z" },
}
イメージマニフェストには、特定の必要な構成メディアタイプ(application/vnd.cncf.seccomp-profile.config.v1+json)への参照と、seccomp.jsonファイルを指す単一のレイヤー(application/vnd.oci.image.layer.v1.tar)が含まれています。
それでは、この新機能を試してみましょう!
特定のコンテナやPod全体に対してアノテーションを使用する
CRI-Oは、アノテーションを利用する前に適切に構成する必要があります。
これを行うには、ランタイムの allowed_annotations配列にアノテーションを追加します。
これは、次のようなドロップイン構成/etc/crio/crio.conf.d/10-crun.confを使用して行うことができます:
[crio.runtime]
default_runtime = "crun"
[crio.runtime.runtimes.crun]
allowed_annotations = [
"seccomp-profile.kubernetes.cri-o.io",
]
それでは、CRI-Oを最新のmainコミットから実行します。
これは、ソースからビルドするか、静的バイナリバンドルを使用するか、プレリリースパッケージを使用することで行うことができます。
これを実証するために、local-up-cluster.shを使って単一ノードのKubernetesクラスターをセットアップし、コマンドラインからcrioバイナリを実行しました。
クラスターが起動して実行されているので、seccomp Unconfinedとして実行されているアノテーションのないPodを試してみましょう:
cat pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod
spec:
containers:
- name: container
image: nginx:1.25.3
securityContext:
seccompProfile:
type: Unconfined
kubectl apply -f pod.yaml
ワークロードが起動して実行中です:
kubectl get pods
NAME READY STATUS RESTARTS AGE
pod 1/1 Running 0 15s
crictlを使用してコンテナを検査しても、seccompプロファイルが適用されていないことがわかります:
export CONTAINER_ID=$(sudo crictl ps --name container -q)
sudo crictl inspect $CONTAINER_ID | jq .info.runtimeSpec.linux.seccomp
null
では、Podを変更して、コンテナにプロファイルquay.io/crio/seccomp:v2を適用します:
apiVersion: v1
kind: Pod
metadata:
name: pod
annotations:
seccomp-profile.kubernetes.cri-o.io/container: quay.io/crio/seccomp:v2
spec:
containers:
- name: container
image: nginx:1.25.3
新しいseccompプロファイルを適用するには、Podを削除して再作成する必要があります。 再作成のみが新しいseccompプロファイルを適用するためです:
kubectl delete pod/pod
pod "pod" deleted
kubectl apply -f pod.yaml
pod/pod created
CRI-Oのログには、ランタイムがアーティファクトを取得したことが示されます:
WARN[…] Allowed annotations are specified for workload [seccomp-profile.kubernetes.cri-o.io]
INFO[…] Found container specific seccomp profile annotation: seccomp-profile.kubernetes.cri-o.io/container=quay.io/crio/seccomp:v2 id=26ddcbe6-6efe-414a-88fd-b1ca91979e93 name=/runtime.v1.RuntimeService/CreateContainer
INFO[…] Pulling OCI artifact from ref: quay.io/crio/seccomp:v2 id=26ddcbe6-6efe-414a-88fd-b1ca91979e93 name=/runtime.v1.RuntimeService/CreateContainer
INFO[…] Retrieved OCI artifact seccomp profile of len: 18853 id=26ddcbe6-6efe-414a-88fd-b1ca91979e93 name=/runtime.v1.RuntimeService/CreateContainer
And the container is finally using the profile:
そして、コンテナは最終的にプロファイルを使用しています:
export CONTAINER_ID=$(sudo crictl ps --name container -q)
sudo crictl inspect $CONTAINER_ID | jq .info.runtimeSpec.linux.seccomp | head
{
"defaultAction": "SCMP_ACT_ERRNO",
"defaultErrnoRet": 38,
"architectures": [
"SCMP_ARCH_X86_64",
"SCMP_ARCH_X86",
"SCMP_ARCH_X32"
],
"syscalls": [
{
ユーザーが接尾辞/containerを予約名/PODに置き換えると、Pod内のすべてのコンテナに対して同じことが機能します。
たとえば:
apiVersion: v1
kind: Pod
metadata:
name: pod
annotations:
seccomp-profile.kubernetes.cri-o.io/POD: quay.io/crio/seccomp:v2
spec:
containers:
- name: container
image: nginx:1.25.3
コンテナイメージにアノテーションを使用する
特定のワークロードにOCIアーティファクトとしてseccompプロファイルを指定する機能は素晴らしいですが、ほとんどのユーザーはseccompプロファイルを公開されたコンテナイメージに関連付けたいと考えています。 これは、コンテナイメージ自体に適用されるメタデータであるコンテナイメージアノテーションを使用して行うことができます。 たとえば、Podmanを使用して、イメージのビルド中に直接イメージアノテーションを追加することができます:
podman build \
--annotation seccomp-profile.kubernetes.cri-o.io=quay.io/crio/seccomp:v2 \
-t quay.io/crio/nginx-seccomp:v2 .
プッシュされたイメージには、そのアノテーションが含まれます:
skopeo inspect --raw docker://quay.io/crio/nginx-seccomp:v2 |
jq '.annotations."seccomp-profile.kubernetes.cri-o.io"'
"quay.io/crio/seccomp:v2"
そのイメージを使用して、CRI-OのテストPod定義に組み込む場合:
apiVersion: v1
kind: Pod
metadata:
name: pod
# Podのアノテーションが設定されていません
spec:
containers:
- name: container
image: quay.io/crio/nginx-seccomp:v2
その後、CRI-Oのログには、イメージのアノテーションが評価され、プロファイルが適用されたことが示されます:
kubectl delete pod/pod
pod "pod" deleted
kubectl apply -f pod.yaml
pod/pod created
INFO[…] Found image specific seccomp profile annotation: seccomp-profile.kubernetes.cri-o.io=quay.io/crio/seccomp:v2 id=c1f22c59-e30e-4046-931d-a0c0fdc2c8b7 name=/runtime.v1.RuntimeService/CreateContainer
INFO[…] Pulling OCI artifact from ref: quay.io/crio/seccomp:v2 id=c1f22c59-e30e-4046-931d-a0c0fdc2c8b7 name=/runtime.v1.RuntimeService/CreateContainer
INFO[…] Retrieved OCI artifact seccomp profile of len: 18853 id=c1f22c59-e30e-4046-931d-a0c0fdc2c8b7 name=/runtime.v1.RuntimeService/CreateContainer
INFO[…] Created container 116a316cd9a11fe861dd04c43b94f45046d1ff37e2ed05a4e4194fcaab29ee63: default/pod/container id=c1f22c59-e30e-4046-931d-a0c0fdc2c8b7 name=/runtime.v1.RuntimeService/CreateContainer
export CONTAINER_ID=$(sudo crictl ps --name container -q)
sudo crictl inspect $CONTAINER_ID | jq .info.runtimeSpec.linux.seccomp | head
{
"defaultAction": "SCMP_ACT_ERRNO",
"defaultErrnoRet": 38,
"architectures": [
"SCMP_ARCH_X86_64",
"SCMP_ARCH_X86",
"SCMP_ARCH_X32"
],
"syscalls": [
{
コンテナイメージの場合、アノテーションseccomp-profile.kubernetes.cri-o.ioはseccomp-profile.kubernetes.cri-o.io/PODと同様に扱われ、Pod全体に適用されます。
さらに、この機能は、イメージにコンテナ固有のアノテーションを使用する場合にも機能します。
たとえば、コンテナの名前がcontainer1の場合:
skopeo inspect --raw docker://quay.io/crio/nginx-seccomp:v2-container |
jq '.annotations."seccomp-profile.kubernetes.cri-o.io/container1"'
"quay.io/crio/seccomp:v2"
この機能の素晴らしい点は、ユーザーが特定のコンテナイメージ用のseccompプロファイルを作成し、同じレジストリ内に並べて保存できることです。 イメージをプロファイルにリンクすることで、アプリケーション全体のライフサイクルを通じてそれらを維持する柔軟性が提供されます。
ORASを使用してプロファイルをプッシュする
OCIオブジェクトを作成してseccompプロファイルを含めるには、ORASを使用する場合、もう少し作業が必要です。
将来的には、Podmanなどのツールが全体のプロセスをより簡略化することを期待しています。
現時点では、コンテナレジストリがOCI互換である必要があります。
これはQuay.ioの場合も同様です。
CRI-Oは、seccompプロファイルオブジェクトがコンテナイメージメディアタイプ(application/vnd.cncf.seccomp-profile.config.v1+json)を持っていることを期待していますが、ORASはデフォルトでapplication/vnd.oci.empty.v1+jsonを使用します。
これを実現するために、次のコマンドを実行できます:
echo "{}" > config.json
oras push \
--config config.json:application/vnd.cncf.seccomp-profile.config.v1+json \
quay.io/crio/seccomp:v2 seccomp.json
結果として得られるイメージには、CRI-Oが期待するmediaTypeが含まれています。
ORASは単一のレイヤーseccomp.json をレジストリにプッシュします。
プロファイルの名前はあまり重要ではありません。
CRI-Oは最初のレイヤーを選択し、それがseccompプロファイルとして機能するかどうかを確認します。
将来の作業
CRI-OはOCIアーティファクトを通常のファイルと同様に内部で管理しています。
これにより、それらを移動したり、使用されなくなった場合に削除したり、seccompプロファイル以外のデータを利用したりする利点が得られます。
これにより、OCIアーティファクトをベースにしたCRI-Oの将来の拡張が可能になります。
また、OCIアーティファクトの中に複数のレイヤーを持つことを考える上で、seccompプロファイルの積層も可能になります。
v1.30.xリリースではUnconfinedワークロードのみがサポートされているという制限は、将来CRI-Oが解決したい課題です。
セキュリティを損なうことなく、全体的なユーザーエクスペリエンスを簡素化することが、コンテナワークロードにおけるseccompの成功の鍵となるようです。
CRI-Oのメンテナーは、新機能に関するフィードバックや提案を歓迎します! このブログ投稿を読んでいただき、ぜひKubernetesのSlackチャンネル#crioを通じてメンテナーに連絡したり、GitHubリポジトリでIssueを作成したりしてください。
SIG Cloud Providerの取り組みの紹介
Kubernetes関連のサービスは、開発者にとってクラウドプロバイダー経由で利用するのが最も人気な方法の一つです。では、クラウドプロバイダーがどのようにしてKubernetesと連携しているのか、不思議に思ったことはありませんか?Kubernetesがさまざまなクラウドプロバイダーと統合される過程は、どのように実現されているのでしょうか?この疑問に答えるために、SIG Cloud Providerにスポットライトを当ててみましょう。
SIG Cloud Providerは、Kubernetesとさまざまなクラウドプロバイダーとのシームレスな統合を実現するために活動しています。彼らの使命は、Kubernetesエコシステムを誰にとっても公平かつオープンなものに保つことです。 明確な基準と要件を定めることで、どのクラウドプロバイダーもKubernetesと適切に連携できるようにしています。 クラウドプロバイダーとの連携を可能にするために、クラスター内の各コンポーネントを適切に構成することも彼らの重要な責務です。
SIG Spotlightシリーズの本記事では、Arujjwal NegiがMichael McCune(Red Hat)にインタビューを行いました。McCune氏は elmiko の名でも知られており、SIG Cloud Providerの共同チェアを務めています。このインタビューを通じて、本SIGの活動の実態に迫ります。
はじめに
Arujjwal: まずは、あなた自身について知るところから始めたいと思います。簡単に自己紹介をしていただけますか?また、どのようにしてKubernetesに関わるようになったのかも教えてください。
Michael:こんにちは、Michael McCuneです。コミュニティでは、多くの人が私のハンドルネームである elmiko と呼んでいます。私は長年ソフトウェア開発に携わっており(私が開発を始めた頃は、Windows 3.1が流行していました!)、キャリアのほとんどをオープンソースソフトウェアとともに歩んできました。Kubernetesに関わるようになったのは、機械学習やデータサイエンスのアプリケーション開発に取り組んでいたときです。当時所属していたチームでは、Apache Sparkなどの技術をKubernetes上で活用するチュートリアルやサンプルを作成していました。それとは別に、私は以前から分散システム全般に強い関心を持っており、Kubernetesの開発に直接取り組むチームに参加できるチャンスが訪れたときには、すぐに飛び込みました!
活動内容と運営体制
Arujjwal: SIG Cloud Providerがどのような活動を行っていて、どのように機能しているのか教えていただけますか?
Michael: SIG Cloud Providerは、Kubernetesがすべてのインフラプロバイダーに対して中立的な統合ポイントを提供できるようにすることを目的として設立されました。これまでで最大の取り組みは、Kubernetes本体(in-tree)に組み込まれていたクラウドコントローラーを、外部コンポーネント(out-of-tree)として切り出し、移行する作業です。SIGでは定期的にミーティングを行い、進捗状況や今後の作業について議論しています。あわせて、報告された質問やバグへの対応も行っています。さらに、クラウドプロバイダー向けのフレームワークや各種クラウドコントローラーの実装、Konnectivity proxy projectなど、クラウド関連サブプロジェクトの調整窓口としての役割も担っています。
Arujjwal: プロジェクトのREADMEを拝見し、SIG Cloud ProviderがKubernetesとクラウドプロバイダーとの統合に関わっていることを知りました。この統合プロセスは、具体的にどのように進められているのでしょうか?
Michael: Kubernetesを実行する最も一般的な方法の一つは、クラウド環境(AWS、Azure、GCPなど)にデプロイすることです。これらのクラウドインフラには、Kubernetesのパフォーマンスを高めるための機能が備わっていることがよくあります。例えば、Serviceオブジェクト向けのエラスティックロードバランシングを提供する機能などです。Kubernetesからクラウド固有のサービスを一貫して利用できるようにするために、Kubernetesコミュニティではクラウドコントローラーという仕組みを導入し、これらの統合ポイントに対応しています。クラウドプロバイダーは、SIGが管理しているフレームワークを利用するか、あるいはKubernetesのコードやドキュメントで定義されているAPIガイドラインに従うことで、独自のコントローラーを作成できます。ここでひとつ強調しておきたいのは、SIG Cloud ProviderはKubernetesクラスター内のノードのライフサイクル管理は担当していないという点です。このようなトピックについては、SIG Cluster Lifecycleや Cluster APIプロジェクトが適切な議論の場となります。
重要なサブプロジェクト
Arujjwal:このSIGには多くのサブプロジェクトが存在しています。その中でも特に重要なものと、それぞれが担っている役割について教えていただけますか?
Michael: 現在、最も重要だと考えているサブプロジェクトはcloud provider frameworkと、extraction/migration projectの2つです。cloud provider framework は、インフラ統合を担当する開発者が、自身のインフラ環境に対応したクラウドコントローラーを構築する際に役立つ共通ライブラリです。このプロジェクトは、新しくSIGに参加する人たちが最初に触れることの多い入り口でもあります。もう一つのextraction and migration projectは、このフレームワークの存在理由にも関わる、非常に大きなサブプロジェクトです。少し背景を説明すると、Kubernetesでは長い間、基盤となるインフラとの統合が必要とされてきました。その目的は、必ずしも機能を追加することではなく、たとえばインスタンスの終了といったクラウド上のイベントを把握するためでした。当初、クラウドプロバイダーとの統合機能はKubernetes本体のコードツリー内に直接組み込まれていました。これがいわゆる"in-tree"と呼ばれる形式の由来です(詳しくはこちらの記事をご覧ください)。しかし、プロバイダー固有のコードを Kubernetesのメインソースツリーで管理することは、コミュニティにとって望ましくないと見なされていました。そのため、"in-tree"のクラウドコントローラーを取り除き、"out-of-tree"で管理可能な独立コンポーネントへと移行するために、このextraction and migration projectが立ち上げられました。
Arujjwal: [cloud provider framework]が、新しく関わる人にとって良い出発点になるのはなぜでしょうか?初心者向けのタスクが継続的に用意されているのですか?あるとすれば、どのような内容ですか?
Michael: cloud provider frameworkは、クラウドコントローラーマネージャーに関するコミュニティの推奨される実装方法を反映しているため、新しく参加する人にとっては良い出発点だと思います。このフレームワークに取り組むことで、マネージャーが何を、どのように行っているのかをしっかりと理解できるはずです。ただ残念ながら、このコンポーネントに関しては、初心者向けのタスクが常に継続的に用意されているわけではありません。その理由の一つは、フレームワーク自体がすでに成熟していること、また各クラウドプロバイダー側の実装も同様に安定していることです。この分野にもっと関わってみたいという方には、Go言語の基本的な知識があると良いと思います。加えて、少なくとも1つのクラウドAPI(AWS、Azure、GCPなど)についての理解があると、なお良いです。個人的な意見ですが、SIG Cloud Providerに新しく参加することは簡単ではないと思います。というのも、このプロジェクトに関わるコードの多くは、特定のクラウドプロバイダーとの統合処理を直接扱っているからです。クラウドプロバイダー周りでより積極的に活動したいと考えている方への私のアドバイスは、まず1つか2つのクラウドAPIに慣れ親しむことです。その上で、該当するクラウド向けのコントローラーマネージャーにあるopen issueを探し、他のコントリビューターとできるだけ多くコミュニケーションを取るようにするのが良いでしょう。
成果
Arujjwal: SIG Cloud Providerの活動の中で、特に誇りに思っている成果があれば教えてくれますか?
Michael: 私がSIGに参加してから1年以上が経ちますが、その間にextraction and migrationサブプロジェクトを大きく前進させることができました。 当初は、定義されたKEPはアルファ版の段階でしたが、現在ではベータ版へと進み、Kubernetesのソースツリーから古いプロバイダーコードを削除するところまで近づいています。コミュニティのメンバーが積極的に関与してくれている様子を見ることができ、とても誇らしく感じています。クラウドコントローラーの切り出しに向けて、私たちが着実に前進してきたことを実感しています。おそらく、あと数回のリリースのうちに、in-treeのクラウドコントローラーは完全に削除され、このサブプロジェクトも完了するだろうと感じています。
新しいコントリビューターへのアドバイス
Arujjwal: SIG Cloud Providerに参加したいと考えている新しいコントリビューターに向けて、何か提案やアドバイスはありますか?
Michael: 個人的には、これは難しい質問だと思います。SIG Cloud Providerは、Kubernetesと基盤インフラとの間を統合するコード部分に焦点を当てたグループです。SIGのメンバーは、クラウドプロバイダーの公式な立場を代表していることが多いですが、必ずしもそうである必要はありません。Kubernetesのこの分野に関心がある方には、まずSIGのミーティングに参加して、私たちがどのように活動しているかを見てみることをおすすめします。あわせて、cloud provider frameworkプロジェクトを学ぶのも良いスタートになります。また、今後に向けた興味深いアイデアもいくつかあります。たとえば、すべてのクラウドプロバイダーに共通するテストフレームワークの構想です。これは、Kubernetesへの関与を広げたい方にとって、大きなチャンスになるでしょう。
Arujjwal: 現在、SIG Cloud Providerとして求めているスキルの中で、私たちが特に強調すべきものはありますか?私たちが所属するSIG ContribExから例を挙げると、たとえばHugoの専門知識がある方であれば、k8s.devの改善で常に力をお借りしたいと考えています!
Michael: 現在、SIGはextraction and migrationプロセスの最終段階に取り組んでいます。一方で、今後に向けた計画もすでに始めており、次に何を進めていくかを検討しています。その中でも大きな話題の一つがテストです。現時点では、各クラウドプロバイダーが自分たちのコントローラーマネージャーの動作を確認するために使える、汎用的で共通なテスト群は存在していません。もし、GinkgoやKubetestフレームワークに詳しい方がいれば、新しいテストの設計や実装にあたって、ぜひ力をお借りしたいと思います。
これでインタビューは終了です。SIG Cloud Providerの目的や活動内容について、少しでも理解を深めていただけたなら幸いです。今回ご紹介したのは、あくまでその一端に過ぎません。より詳しく知りたい方や実際に関わってみたい方は、こちらのミーティングに参加してみてください。
Kubernetesブッククラブを覗く
Kubernetesとそれを取り巻く技術のエコシステム全体を学ぶことは、課題がないわけではありません。 このインタビューでは、AWSのCarlos Santanaさんに、コミュニティベースの学習体験を利用するために、彼がどのようにしてKubernetesブッククラブを作ったのか、その会がどのような活動をするのか、そしてどのようにして参加するのかについて伺います。

Frederico Muñoz (FSM): こんにちはCarlosさん、時間をとってくれてありがとう。 まずはじめに、ご自身のことを少し教えていただけますか?
Carlos Santana (CS): もちろんです。 6年前に本番環境でKubernetesをデプロイした経験が、Knativeに参加するきっかけとなり、その後リリースチームを通じてKubernetesに貢献しました。 アップストリームのKubernetesでの作業は、私がオープンソースで得た最高の経験のひとつです。 過去2年間、AWSのシニア・スペシャリスト・ソリューション・アーキテクトとしての役割で、私は大企業がKubernetes上に内部開発者プラットフォーム(IDP)を構築することを支援してきました。 今後、私のオープンソースへの貢献は、ArgoやCrossplane、BackstageのようなCNCFのプロジェクトやCNOEを対象にしています。
ブッククラブの創設
FSM: それであなたがKubernetesに辿り着いたわけですが、その時点でブッククラブを始めた動機は何だったのでしょうか?
CS: Kubernetesブッククラブのアイデアは、TGIKのライブ配信での何気ない提案から生まれました。 私にとって、それは単に本を読むということ以上に、学習コミュニティを作るということでした。 このプラットフォームは知識の源であるだけでなく、特にパンデミックの困難な時期にはサポートシステムでもありました。 この取り組みが、メンバーたちの対処と成長に役立っていることを目の当たりにして、喜ばしいと思っています。 最初の本Production Kubernetesは、2021年3月5日に始めて36週間かかりました。 現在は、1冊の本をカバーするのにそれほど時間はかからず、1週間に1章か2章です。
FSM: Kubernetesブッククラブの仕組みについて教えてください。どのように本を選び、どのように読み進めるのですか?
CS: 私たちは、グループの関心とニーズに基づいて本を共同で選んでいます。 この実践的なアプローチは、メンバー、とくに初心者が複雑な概念をより簡単に理解するのに役立ちます。 毎週2つのシリーズがあり、EMEAのタイムゾーンのものと、私がUSで組織しているものです。 各オーガナイザーは共同ホストと協力してSlack上で本を選び、各章の議論するために、数週間に渡りホストのラインナップを整えます。
FSM: 私の記憶が間違っていなければ、Kubernetesブッククラブは17冊目に突入しています。 物事を活発に保つための秘密のレシピがあるのですか?
CS: ブッククラブを活発で魅力的なものに保つ秘訣は、いくつかの重要な要素にあります。
まず、一貫性が重要です。 休みの日やKubeConのような大きなイベントの時だけミーティングをキャンセルして、定期的なスケジュールを維持するよう努力しています。 この規則性は、メンバーの参加を維持し、信頼できるコミュニティを築くのに役立っています。
次に、セッションを面白く、対話式のものにすることが重要です。 たとえば、ミートアップ中にポップアップ・クイズを頻繁に導入します。これはメンバーの理解度をテストするだけでなく、楽しみの要素も加えています。 このアプローチによって内容の関連性が維持され、理論的な概念が実社会のシナリオでどのように適用されるかをメンバーが理解するのに役立ちます。
ブッククラブで扱うトピック
FSM: 書籍の主なトピックは、Kubernetes、GitOps、セキュリティ、SRE、オブザーバビリティになっています。 これはとくに人気という観点で、Cloud Native Landscapeの反映でしょうか?
CS: 私たちの旅は『Production Kubernetes』から始まり、実用的な本番環境向けのソリューションに焦点を当てる方向性を設定しました。 それ以来、私たちはCNCF Landscapeのさまざまな側面を掘り下げ、異なるテーマに沿って本を揃えています。 各テーマは、それがセキュリティであれ、オブザーバビリティであれ、サービスメッシュであれ、コミュニティ内の関連性と需要にもとづいて選択されています。 たとえば、Kubernetes認定に関する最近のテーマでは、書籍の著者を積極的なホストとして参加させ、彼らの専門知識で議論を充実させました。
FSM: プロジェクトに最近変化があったことは知っています。Cloud Native Community GroupとしてCNCFに統合されたことです。 この変更について少しお話いただけますか?
CS: CNCFはブッククラブをCloud Native Community Groupとして快く受け入れてくれました。 これは私たちの運営を合理化し、影響範囲を拡大する重要な進展です。 この連携はKubernetes Community Days (KCD)のミートアップで使用されているものと同様に、管理機能の強化に役立っています。 現在では、メンバーシップ、イベントのスケジューリング、メーリングリスト、Webカンファレンスの開催、セッションの記録など、より強固な体制が整っています。
FSM: CNCFとの関わりは、この半年間のKubernetesブッククラブの成長やエンゲージメントにどのような影響を与えましたか?
CS: 半年前にCNCFコミュニティの一員になって以来、Kubernetesブッククラブでは大きな定量的な変化を目の当たりにしてきました。 会員数は600人以上に急増し、この間に40以上のイベントを企画・実施することに成功しました。 さらに期待されるのは、1回のイベントに平均30人が参加するという安定した動員数です。 この成長とエンゲージメントは、コミュニティにおける影響やKubernetesブッククラブの影響範囲に関して、私たちのCNCF加盟が肯定的な影響である明確な指標です。
ブッククラブに参加する
FSM: 参加を希望する人は、どうすればいいのでしょうか?
CS: 参加するためには3つの段階があります。
- まず、Kubernetesブッククラブコミュニティに参加します
- 次に、コミュニティページ上のイベントに出欠連絡をします
- 最後に、CNCFのSlackチャンネル#kubernetes-book-clubに参加します
FSM: 素晴らしい、ありがとうございます!最後に何かコメントをお願いします。
CS: Kubernetesブッククラブは、単に本について議論する専門家のグループというだけではなく、それ以上です。 それは、Neependra Khareさん、Eric Smallingさん、Sevi Karakulakさん、Chad M. Crowellさん、そしてWalid (CNJ) Shaariさんの主催と企画を手伝ってくれる素晴らしいボランティアであり、活気のあるコミュニティです。 KubeConで私たちを見て、Kubernetesブッククラブのステッカーをゲットしてください!
Kubernetesでコンテナを別ファイルシステムに格納する設定方法
Kubernetesクラスターの稼働、運用する上でよくある問題は、ディスク容量が不足することです。
ノードがプロビジョニングされる際には、コンテナイメージと実行中のコンテナのために十分なストレージスペースを確保することが重要です。
通常、コンテナランタイムは/varに書き込みます。
これは別のパーティションとして、ルートファイルシステム上に配置できます。
CRI-Oはデフォルトで、コンテナとイメージを/var/lib/containersに書き込みますが、containerdはコンテナとイメージを/var/lib/containerdに書き込みます。
このブログ記事では、コンテナランタイムがデフォルトのパーティションとは別にコンテンツを保存する方法に注目したいと思います。 これにより、Kubernetesの設定をより柔軟に行うことができ、デフォルトのファイルシステムはそのままに、コンテナストレージ用に大きなディスクを追加する方法が提供されます。
もう少し説明が必要な領域は、Kubernetesがディスクに書き込む場所/内容です。
Kubernetesディスク使用状況を理解する
Kubernetesには永続(persistent)データと一時(ephemeral)データがあります。
kubeletとローカルのKubernetes固有ストレージのベースパスは設定可能ですが、通常は/var/lib/kubeletと想定されています。
Kubernetesのドキュメントでは、これは時々ルートファイルシステムまたはノードファイルシステムと呼ばれます。
このデータの大部分は、次のようにカテゴリー分けされます。
- エフェメラルストレージ
- ログ
- コンテナランタイム
ルート/ノード・ファイルシステムは/ではなく、/var/lib/kubeletがあるディスクのため、ほとんどのPOSIXシステムとは異なります。
エフェメラルストレージ
Podやコンテナは、動作に一時的または短期的なローカルストレージを必要とする場合があります。 エフェメラルストレージの寿命は個々のPodの寿命を超えず、エフェメラルストレージはPod間で共有することはできません。
ログ
デフォルトでは、Kubernetesは各実行中のコンテナのログを/var/log内のファイルとして保存します。
これらのログは一時的であり、ポッドが実行されている間に大きくなりすぎないようにkubeletによって監視されます。
各ノードのログローテーション設定をカスタマイズしてこれらのログのサイズを管理し、ノードローカルストレージに依存しないためにログの配信を設定することができます(サードパーティーのソリューションを使用)。
コンテナランタイム
コンテナランタイムには、コンテナとイメージのための2つの異なるストレージ領域があります。
読み取り専用レイヤー:イメージは通常、コンテナが実行されている間に変更されないため、読み取り専用レイヤーとして表されます。読み取り専用レイヤーには、複数のレイヤーが組み合わされて単一の読み取り専用レイヤーになることがあります。コンテナがファイルシステムに書き込んでいる場合、コンテナの上にはエフェメラルストレージを提供する薄いレイヤーがあります。
書き込み可能レイヤー:コンテナランタイムによっては、ローカルの書き込みがレイヤー化された書き込みメカニズム(たとえば、Linux上の
overlayfsやWindows上のCimFS)として実装されることがあります。これは書き込み可能レイヤーと呼ばれます。ローカルの書き込みは、コンテナイメージの完全なクローンで初期化された書き込み可能なファイルシステムを使用する場合もあります。これは、ハイパーバイザ仮想化に基づく一部のランタイムで使用されます。
コンテナランタイムのファイルシステムには、読み取り専用レイヤーと書き込み可能レイヤーの両方が含まれます。これはKubernetesドキュメントではimagefsと見なされています。
コンテナランタイムの構成
CRI-O
CRI-Oは、コンテナランタイムが永続データと一時データをどのように保存するかを制御するためのTOML形式のストレージ構成ファイルを使用します。
CRI-Oはストレージライブラリを利用します。
一部のLinuxディストリビューションには、ストレージに関するマニュアルエントリ(man 5 containers-storage.conf)があります。
ストレージの主な設定は、/etc/containers/storage.confにあり、一時データの場所やルートディレクトリを制御することができます。
ルートディレクトリは、CRI-Oが永続データを保存する場所です。
[storage]
# Default storage driver
driver = "overlay"
# Temporary storage location
runroot = "/var/run/containers/storage"
# Primary read/write location of container storage
graphroot = "/var/lib/containers/storage"
graphroot- コンテナランタイムから保存される永続データを指します
- SELinuxが有効になっている場合、これは
/var/lib/containers/storageと一致させる必要があります
runroot- コンテナに対する一時的な読み書きアクセスを提供します
- これは一時ファイルシステムに配置することを推奨します
ここでは、/var/lib/containers/storageに合うようにgraphrootディレクトリのラベルを変更する簡単な方法を紹介します:
semanage fcontext -a -e /var/lib/containers/storage <YOUR-STORAGE-PATH>
restorecon -R -v <YOUR-STORAGE-PATH>
containerd
コンテナランタイムであるcontainerdは、永続データと一時データの保存先を制御するためのTOML形式の構成ファイルを使用します。構成ファイルのデフォルトパスは、/etc/containerd/config.tomlにあります。
containerdストレージの関連フィールドは、rootとstateです。
root- containerdのメタデータのルートディレクトリ
- デフォルトは
/var/lib/containerdです - また、OSがそれを要求する場合は、ルートにSELinuxラベルも必要です
state- containerdの一時データ
- デフォルトは、
/run/containerdです
Kubernetesノードの圧迫による退避
Kubernetesは、コンテナファイルシステムがノードファイルシステムと分離されているかどうかを自動的に検出します。 ファイルシステムを分離する場合、Kubernetesはノードファイルシステムとコンテナランタイムファイルシステムの両方を監視する責任があります。 Kubernetesドキュメントでは、ノードファイルシステムとコンテナランタイムファイルシステムをそれぞれnodefsとimagefsと呼んでいます。 nodefsまたはimagefsのいずれかがディスク容量不足になると、ノード全体がディスク圧迫があると見なされます。 Kubernetesは、まず未使用のコンテナやイメージを削除してスペースを回収し、その後にポッドを追い出すことでスペースを再利用します。 nodefsとimagefsの両方を持つノードでは、kubeletはimagefs上の未使用のコンテナイメージをガベージコレクトし、nodefsからは終了したポッドとそれらのコンテナを削除します。 nodefsのみが存在する場合、Kubernetesのガベージコレクションには、終了したコンテナ、ポッド、そして未使用のイメージが含まれます。
Kubernetesでは、ディスクがいっぱいかどうかを判断するためのより多くの構成が可能です。
kubelet内の退避マネージャーには、関連する閾値を制御するいくつかの構成設定があります。
ファイルシステムの場合、関連する測定値はnodefs.available、nodefs.inodesfree、imagefs.available、およびimagefs.inodesfreeです。
コンテナランタイム用に専用のディスクがない場合、imagefsは無視されます。
ユーザーは、既存のデフォルト値を使用できます:
memory.available< 100MiBnodefs.available< 10%imagefs.available< 15%nodefs.inodesFree< 5% (Linuxノード)
Kubernetesでは、kubeletの構成ファイル内のEvictionHardとEvictionSoftにユーザー定義の値を設定することができます。
EvictionHard
限界値を定義します。これらの限界値を超えると、Grace Periodなしでポッドが追い出されます。
EvictionSoft
限界値を定義します。これらの限界値を超えると、Grace Periodが設定されたシグナルごとにポッドが追い出されます。
EvictionHardの値を指定すると、デフォルト値が置き換えられます。
したがって、すべてのシグナルを設定することが重要です。
たとえば、次に示すkubeletの設定は、退避シグナルと猶予期間オプションを設定するために使用できます。
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
address: "192.168.0.8"
port: 20250
serializeImagePulls: false
evictionHard:
memory.available: "100Mi"
nodefs.available: "10%"
nodefs.inodesFree: "5%"
imagefs.available: "15%"
imagefs.inodesFree: "5%"
evictionSoft:
memory.available: "100Mi"
nodefs.available: "10%"
nodefs.inodesFree: "5%"
imagefs.available: "15%"
imagefs.inodesFree: "5%"
evictionSoftGracePeriod:
memory.available: "1m30s"
nodefs.available: "2m"
nodefs.inodesFree: "2m"
imagefs.available: "2m"
imagefs.inodesFree: "2m"
evictionMaxPodGracePeriod: 60s
問題点
Kubernetesプロジェクトでは、退避のデフォルト設定を使用するか、退避に関連するすべてのフィールドを設定することをお勧めしています。
デフォルト設定を使用するか、独自のevictionHard設定を指定できます。
シグナルの設定を忘れると、Kubernetesはそのリソースを監視しません。
管理者やユーザーが遭遇する可能性のある一般的な設定ミスの1つは、新しいファイルシステムを/var/lib/containers/storageまたは/var/lib/containerdにマウントすることです。
Kubernetesは別のファイルシステムを検出するため、これを行った場合はimagefs.inodesfreeとimagefs.availableが必要に応じて設定に一致していることを確認する必要があります。
もう一つの混乱の領域は、イメージファイルシステムをノードに定義した場合でも、エフェメラルストレージの報告が変わらないことです。
イメージファイルシステム(imagefs)は、コンテナイメージのレイヤーを保存するために使用されます。
コンテナが自分自身のルートファイルシステムに書き込む場合、そのローカルな書き込みはコンテナイメージのサイズには含まれません。
コンテナランタイムがこれらのローカルな変更を保存する場所は、ランタイムによって定義されますが、通常はイメージファイルシステムです。
Pod内のコンテナがファイルシステムをバックエンドとするemptyDirボリュームに書き込んでいる場合、これはノードファイルシステムからスペースを使用します。
kubeletは常に、nodefsで表されるファイルシステムに基づいてエフェメラルストレージの容量と割り当てを報告します。
これは、実際には一時的な書き込みがイメージファイルシステムに行われている場合に混乱の原因となる可能性があります。
今後の課題
KEP-4191に取り組むことで、エフェメラルの報告の制限を解消し、コンテナランタイムにより多くの構成オプションを提供することが期待されています。 この提案では、Kubernetesは書き込み可能なレイヤーが読み取り専用のレイヤー(イメージ)と分離されているかどうかを検出します。 これにより、書き込み可能なレイヤーを含むすべてのエフェメラルストレージを同じディスクに配置することが可能になります。 また、イメージ用に別のディスクを使用することも可能になります。
参加するためにはどうすればよいですか?
参加したい場合は、KubernetesのSIG Nodeに参加することができます。
フィードバックを共有したい場合は、Slackチャンネルの#sig-nodeで行うことができます。 まだそのSlackワークスペースに参加していない場合は、https://slack.k8s.io/から招待状を取得できます。
素晴らしいレビューを提供し、貴重な洞察を共有し、トピックのアイデアを提案してくれたすべてのコントリビューターに特別な感謝を捧げます。
- Peter Hunt
- Mrunal Patel
- Ryan Phillips
- Gaurav Singh
SIG Releaseスポットライト(リリース・チーム・サブプロジェクト)
リリース・スペシャル・インタレスト・グループ(SIG Release)は、Kubernetesが4ヶ月ごとに最先端の機能とバグ修正でその刃を研ぐ場所です。Kubernetesのような大きなプロジェクトが、新バージョンをリリースするまでのタイムラインをどのように効率的に管理しているのか、またリリースチームの内部はどのようになっているのか、考えたことはありますか?このような疑問に興味がある方、もっと知りたい方、SIG Releaseの仕事に関わりたい方は、ぜひ読んでみてください!
SIG ReleaseはKubernetesの開発と進化において重要な役割を担っています。その主な責任は、Kubernetesの新バージョンのリリースプロセスを管理することです。通常3〜4ヶ月ごとの定期的なリリースサイクルで運営されています。このサイクルの間、Kubernetesリリースチームは他のSIGやコントリビューターと密接に連携し、円滑でうまく調整されたリリースを保証します。これには、リリーススケジュールの計画、コードフリーズとテストフェーズの期限の設定、バイナリ、ドキュメント、リリースノートなどのリリース成果物の作成が含まれます。
さらに読み進める前に、SIG Releaseにはリリース・エンジニアリングとリリース・チームという2つのサブプロジェクトがあることに注意してください。
このブログ記事では、Nitish KumarがSIG Releaseのテクニカル・リーダーであるVerónica López (PlanetScale)にインタビューし、Release Teamサブプロジェクトにスポットライトを当て、リリース・プロセスがどのように見えるか、そして参加する方法について説明します。
最初の計画から最終的なリリースまで、Kubernetesの新バージョンの典型的なリリースプロセスはどのようなものですか?スムーズなリリースを保証するために使用している特定の方法論やツールはありますか?
Kubernetesの新バージョンのリリースプロセスは、十分に構造化されたコミュニティ主導の取り組みです。私たちが従う特定の方法論やツールはありませんが、物事を整理しておくための一連の手順を記載したカレンダーはあります。完全なリリースプロセスは次のようになります:
リリースチームの立ち上げ: 新しいリリースのさまざまなコンポーネントの管理を担当するKubernetesコミュニティのボランティアを含むリリースチームの結成から始めます。これは通常、前のリリースが終了する前に行われます。チームが結成されると、リリースチームリーダーとブランチマネージャーが通常の成果物のカレンダーを提案する間に、新しいメンバーがオンボードされます。例として、SIG Releaseのリポジトリに作成されたv1.29チーム結成のissueを見てください。コントリビューターがリリースチームの一員になるには、通常リリースシャドウプログラムを通りますが、それがSIG Releaseに参加する唯一の方法というわけではありません。
初期段階: 各リリースサイクルの最初の数週間で、SIG ReleaseはKubernetes機能強化提案(KEPs)で概説された新機能や機能強化の進捗を熱心に追跡します。これらの機能のすべてがまったく新しいものではありませんが、多くの場合、アルファ段階から始まり、その後ベータ段階に進み、最終的には安定したステータスに到達します。
機能の成熟段階: 通常、コミュニティからのフィードバックを集めるため、実験的な新機能を含むアルファ・リリースを2、3回行い、その後、機能がより安定し、バグの修正が中心となるベータ・リリースを2、3回行います。この段階でのユーザーからのフィードバックは非常に重要で、この段階で発生する可能性のあるバグやその他の懸念に対処するために、追加のベータ・リリースを作成しなければならないこともあります。これがクリアされると、実際のリリースの前にリリース候補(RC)を作成します。このサイクルを通じて、リリースノートやユーザーガイドなどのドキュメントの更新や改善に努めます。
安定化段階: 新リリースの数週間前にコードフリーズを実施し、この時点以降は新機能の追加を禁止します。メインリリースと並行して、私たちはKubernetesの古い公式サポートバージョンのパッチを毎月作成し続けているので、Kubernetesバージョンのライフサイクルはその後数ヶ月に及ぶと言えます。完全なリリースサイクル全体を通して、リリースノートやユーザーガイドを含むドキュメントの更新と改善に努めます。

各リリースで安定性と新機能の導入のバランスをどのように扱っていますか?どのような基準で、どの機能をリリースに含めるかを決定するのですか?
終わりのないミッションですが、重要なのは私たちのプロセスとガイドラインを尊重することだと考えています。私たちのガイドラインは、このプロジェクトに豊富な知識と経験をもたらしてくれるコミュニティの何十人ものメンバーから、何時間にもわたって議論とフィードバックを重ねた結果です。もし厳格なガイドラインがなかったら、私たちの注意を必要とするもっと生産的な議題に時間を使う代わりに、同じ議論を何度も繰り返してしまうでしょう。すべての重要な例外は、チームメンバーの大半の合意を必要とするため、品質を確保することができます。
何がリリースになるかを決定するプロセスは、リリースチームがワークフローを引き継ぐずっと前から始まっています。各SIGと経験豊富なコントリビューターが、機能や変更を含めるかどうかを決定します。その後、リリースチームが、それらの貢献がドキュメント、テスト、後方互換性などの要件を満たしていることを確認し、正式に許可します。同様のプロセスは月例パッチリリースのチェリーピックでも行われ、完全なKEPを必要とするPRや、影響を受けるすべてのブランチを含まない修正は受け入れないという厳しいポリシーがあります。
Kubernetesの開発とリリース中に遭遇した最も大きな課題は何ですか?これらの課題をどのように克服しましたか?
リリースのサイクルごとに、さまざまな課題が発生します。新たに発見されたCVE(Common Vulnerabilities and Exposures)のような土壇場の問題に取り組んだり、内部ツール内のバグを解決したり、以前のリリースの機能によって引き起こされた予期せぬリグレッションに対処したりすることもあります。私たちがしばしば直面するもう1つの障害は、私たちのチームは大規模ですが、私たちのほとんどがボランティアベースで貢献していることです。時には人手が足りないと感じることもありますが、私たちは常に組織化し、うまくやりくりしています。
新しい貢献者として、SIG Releaseに参加するための理想的な道はどのようなものでしょうか?誰もが自分のタスクに忙殺されているコミュニティで、効果的に貢献するために適切なタスクを見つけるにはどうすればいいのでしょうか?
オープンソースコミュニティへの関わり方は人それぞれです。SIG Releaseは、リリースを出荷できるように自分たちでツールを書くという、自分勝手なチームです。SIG K8s Infraのような他のSIGとのコラボレーションも多いのですが、私たちが使用するツールはすべて、コストを削減しつつ、私たちの大規模な技術的ニーズに合わせて作られたものでなければなりません。このため、「単に」リリースを作成するだけでなく、さまざまなタイプのプロジェクトを手伝ってくれるボランティアを常に探しています。
私たちの現在のプロジェクトでは、Goプログラミング、Kubernetes内部の理解、Linuxパッケージング、サプライチェーンセキュリティ、テクニカルライティング、一般的なオープンソースプロジェクトのメンテナンスなどのスキルが必要です。このスキルセットは、プロジェクトの成長とともに常に進化しています。
理想的な道筋として、私たちはこう提案します:
- どのように機能が管理されているか、リリースカレンダー、リリースチームの全体的な構造など、コードに慣れる。
- Slack(#sig-release)などのKubernetesコミュニティのコミュニケーションチャンネルに参加する。
- コミュニティ全員が参加できるSIG Releaseウィークリーミーティングに参加する。これらのミーティングに参加することは、あなたのスキルセットや興味に関連すると思われる進行中のプロジェクトや将来のプロジェクトについて学ぶ素晴らしい方法です。
経験豊富な貢献者は皆、かつてあなたのような立場にあったことを忘れないでください。遠慮せずに質問し、議論に参加し、貢献するための小さな一歩を踏み出しましょう。

リリースシャドウプログラムとは何ですか?また、他の様々なSIGに含まれるシャドウプログラムとの違いは何ですか?
リリースシャドウプログラムは、Kubernetesのリリースサイクルを通して、リリースチームの経験豊富なメンバーをシャドウイングする機会を提供します。これは、Kubernetesのリリースに必要な、サブチームにまたがるすべての困難な仕事を見るまたとないチャンスです。多くの人は、私たちの仕事は3ヶ月ごとにリリースを切ることだけだと思っていますが、それは氷山の一角にすぎません。
私たちのプログラムは通常、特定のKubernetesリリースサイクルに沿っており、それは約3ヶ月の予測可能なタイムラインを持っています。このプログラムではKubernetesの新機能を書くことはありませんが、リリースチームは新リリースと何千人ものコントリビューターとの最後のステップであるため、高い責任感が求められます。
一般的に、次のKubernetesリリースのリリースシャドウ/リリースリードとしてボランティアに参加する人に求める資格は何ですか?
どの役割もある程度の技術的能力を必要としますが、Goの実践的な経験やKubernetes APIに精通していることを必要とするものもあれば、技術的な内容を明確かつ簡潔に伝えるのが得意な人を必要とするものもあります。技術的な専門知識よりも、熱意とコミットメントを重視しています。もしあなたが正しい姿勢を持っていて、Kubernetesやリリース・エンジニアリングの仕事を楽しんでいることが伝われば、たとえそれがあなたが余暇を利用して立ち上げた個人的なプロジェクトであったとしても、チームは必ずあなたを指導します。セルフスターターであること、そして質問をすることを恐れないことは、私たちのチームであなたを大きく前進させます。
リリースシャドープログラムに何度も不合格になった人に何を勧めますか?
応募し続けることです。
リリースサイクルごとに応募者数が飛躍的に増えているため、選ばれるのが難しくなり、落胆することもありますが、不採用になったからといって、あなたに才能がないというわけではないことを知っておいてください。すべての応募者を受け入れることは現実的に不可能です、しかし、ここに私たちが提案する代替案があります。:
毎週開催されるKubernetes SIGのリリースミーティングに参加して、自己紹介をし、チームや私たちが取り組んでいるプロジェクトに慣れてください。
リリースチームはSIG Releaseに参加する方法の1つですが、私たちは常に手伝ってくれる人を探しています。繰り返しになりますが、一定の技術的な能力に加えて、私たちが最も求めている特性は、信頼できる人であり、それには時間が必要です。

リリースチームがKubernetes v1.28に特に期待している進行中の取り組みや今後の機能について教えてください。これらの進歩は、Kubernetesの長期的なビジョンとどのように整合しているのでしょうか?
Kubernetesのパッケージをコミュニティインフラ上でついに公開できることに興奮しています。数年前からやりたいと思っていたことですが、移行する前に整えなければならない技術的な意味合いが多いプロジェクトです。それが終われば、生産性を向上させ、ワークフロー全体をコントロールできるようになります。
最後に
さて、この対談はここで終わりですが、学習はこれで終わりではありません。このインタビューが、SIG Releaseが何をしているのか、そしてどのように手助けを始めたらいいのか、ある程度わかっていただけたと思います。重要なこととして、この記事はSIG Releaseの最初のサブプロジェクトであるリリース・チームを取り上げています。次回のSIG Releaseのスポットライトブログでは、Release Engineeringサブプロジェクトにスポットライトを当て、その活動内容や参加方法について紹介します。最後に、SIG Releaseの運営方法についてより深く理解するために、SIG Release憲章をご覧ください。
フォレンジックコンテナ分析
前回投稿したKubernetesにおけるフォレンジックコンテナチェックポイント処理では、Kubernetesでのチェックポイントの作成や、それがどのようにセットアップされ、どのように使用されるのかを紹介しました。 機能の名前はフォレンジックコンテナチェックポイントですが、Kubernetesによって作成されたチェックポイントの実際の分析方法については、詳細を説明しませんでした。 この記事では、チェックポイントがどのように分析されるのかについての詳細を提供します。
チェックポイントの作成はまだKubernetesでalpha機能であり、この記事ではその機能が将来どのように動作するのかについてのプレビューを提供します。
準備
チェックポイント作成のサポートを有効にするためのKubernetesの設定方法や、基盤となるCRI実装方法についての詳細はKubernetesにおけるフォレンジックコンテナチェックポイント処理を参照してください。
一例として、この記事内でチェックポイントを作成し分析するコンテナイメージ(quay.io/adrianreber/counter:blog)を準備しました。
このコンテナはコンテナ内でファイルを作成することができ、後でチェックポイント内で探したい情報をメモリーに格納しておくこともできます。
コンテナを実行するためにはPodが必要であり、この例では下記のPodマニフェストを使用します。
apiVersion: v1
kind: Pod
metadata:
name: counters
spec:
containers:
- name: counter
image: quay.io/adrianreber/counter:blog
この結果、counterと呼ばれるコンテナがcountersと呼ばれるPod内で実行されます。
一度コンテナが実行されると、コンテナで下記アクションが行えます。
$ kubectl get pod counters --template '{{.status.podIP}}'
10.88.0.25
$ curl 10.88.0.25:8088/create?test-file
$ curl 10.88.0.25:8088/secret?RANDOM_1432_KEY
$ curl 10.88.0.25:8088
最初のアクセスはコンテナ内でtest-fileという内容でtest-fileと呼ばれるファイルを作成します。
次のアクセスで、コンテナのメモリー内のどこかにシークレット情報(RANDOM_1432_KEY)を記憶します。
最後のアクセスは内部のログファイルに1行追加するだけです。
チェックポイントを分析する前の最後のステップは、チェックポイントを作成することをKubernetesに指示することです。
前回の記事で説明したように、これにはkubelet限定のチェックポイントAPIエンドポイントへのアクセスを必要とします。
default名前空間内のcountersという名前のPod内のcounterという名前のコンテナに対して、kubelet APIエンドポイントが次の場所で到達可能です。
# Podが実行されているNode上で実行する
curl -X POST "https://localhost:10250/checkpoint/default/counters/counter"
厳密には、kubeletの自己署名証明書を許容しkubelet チェックポイントAPIの使用を認可するために、下記のcurlコマンドのオプションが必要です。
--insecure --cert /var/run/kubernetes/client-admin.crt --key /var/run/kubernetes/client-admin.key
チェックポイントの作成が終了すると、/var/lib/kubelet/checkpoints/checkpoint-<pod-name>_<namespace-name>-<container-name>-<timestamp>.tarでチェックポイントが利用可能になります。
この記事の後述のステップでは、チェックポイントアーカイブを分析する際にcheckpoint.tarという名前を使用します。
checkpointctlを使用したチェックポイントアーカイブの分析
チェックポイントが作成したコンテナに関するいくつかの初期情報を得るためには、このようにcheckpointctlを使用します。
$ checkpointctl show checkpoint.tar --print-stats
+-----------+----------------------------------+--------------+---------+---------------------+--------+------------+------------+-------------------+
| CONTAINER | IMAGE | ID | RUNTIME | CREATED | ENGINE | IP | CHKPT SIZE | ROOT FS DIFF SIZE |
+-----------+----------------------------------+--------------+---------+---------------------+--------+------------+------------+-------------------+
| counter | quay.io/adrianreber/counter:blog | 059a219a22e5 | runc | 2023-03-02T06:06:49 | CRI-O | 10.88.0.23 | 8.6 MiB | 3.0 KiB |
+-----------+----------------------------------+--------------+---------+---------------------+--------+------------+------------+-------------------+
CRIU dump statistics
+---------------+-------------+--------------+---------------+---------------+---------------+
| FREEZING TIME | FROZEN TIME | MEMDUMP TIME | MEMWRITE TIME | PAGES SCANNED | PAGES WRITTEN |
+---------------+-------------+--------------+---------------+---------------+---------------+
| 100809 us | 119627 us | 11602 us | 7379 us | 7800 | 2198 |
+---------------+-------------+--------------+---------------+---------------+---------------+
これによって、チェックポイントアーカイブ内のチェックポイントについてのいくつかの情報が、すでに取得できています。
コンテナの名前やコンテナランタイムやコンテナエンジンについての情報を見ることができます。
チェックポイントのサイズ(CHKPT SIZE)もリスト化されます。
これは大部分がチェックポイントに含まれるメモリーページのサイズですが、コンテナ内の全ての変更されたファイルのサイズ(ROOT FS DIFF SIZE)についての情報もあります。
追加のパラメーター--print-statsはチェックポイントアーカイブ内の情報を復号化し、2番目のテーブル(CRIU dump statistics)で表示します。
この情報はチェックポイント作成中に収集され、CRIUがコンテナ内のプロセスをチェックポイントするために必要な時間と、チェックポイント作成中に分析され書き込まれたメモリーページ数の概要を示します。
より深く掘り下げる
checkpointctlの助けを借りて、チェックポイントアーカイブについてのハイレベルな情報を得ることができます。
チェックポイントアーカイブをさらに分析するには、それを展開する必要があります。
チェックポイントアーカイブはtarアーカイブであり、tar xf checkpoint.tarの助けを借りて展開可能です。
チェックポイントアーカイブを展開すると、下記のファイルやディレクトリが作成されます。
bind.mounts- このファイルにはバインドマウントについての情報が含まれており、復元中に全ての外部ファイルとディレクトリを正しい場所にマウントするために必要になります。checkpoint/- このディレクトリにはCRIUによって作成された実際のチェックポイントが含まれています。config.dumpとspec.dump- これらのファイルには、復元中に必要とされるコンテナについてのメタデータが含まれています。dump.log- このファイルにはチェックポイント作成中に作成されたCRIUのデバッグ出力が含まれています。stats-dump- このファイルには、checkpointctlが--print-statsでダンプ統計情報を表示するために使用するデータが含まれています。rootfs-diff.tar- このファイルには、コンテナのファイルシステム上で変更された全てのファイルが含まれています。
ファイルシステムの変更 - rootfs-diff.tar
コンテナのチェックポイントをさらに分析するための最初のステップは、コンテナ内で変更されたファイルを見ることです。
これはrootfs-diff.tarファイルを参照することで行えます。
$ tar xvf rootfs-diff.tar
home/counter/logfile
home/counter/test-file
これでコンテナ内で変更されたファイルを調べられます。
$ cat home/counter/logfile
10.88.0.1 - - [02/Mar/2023 06:07:29] "GET /create?test-file HTTP/1.1" 200 -
10.88.0.1 - - [02/Mar/2023 06:07:40] "GET /secret?RANDOM_1432_KEY HTTP/1.1" 200 -
10.88.0.1 - - [02/Mar/2023 06:07:43] "GET / HTTP/1.1" 200 -
$ cat home/counter/test-file
test-file
このコンテナのベースになっているコンテナイメージ(quay.io/adrianreber/counter:blog)と比較すると、コンテナが提供するサービスへの全てのアクセス情報を含んだlogfileや予想通り作成されたtest-fileファイルを確認することができます。
rootfs-diff.tarの助けを借りることで、作成または変更された全てのファイルを、コンテナのベースイメージと比較して検査することが可能です。
チェックポイント処理したプロセスを分析する - checkpoint/
ディレクトリcheckpoint/はコンテナ内でプロセスをチェックポイントしている間にCRIUによって作成されたデータを含んでいます。
ディレクトリcheckpoint/の内容は、CRIUの一部として配布されているCRITツールを使用して分析できるさまざまなイメージファイルで構成されています。
まず、コンテナの内部プロセスの概要を取得してみましょう。
$ crit show checkpoint/pstree.img | jq .entries[].pid
1
7
8
この出力はコンテナのPID名前空間の内部に3つのプロセス(PIDが1と7と8)があることを意味しています。
これはコンテナのPID名前空間の内部からの視界を表示しているだけです。 復元中に正確にそれらのPIDが再作成されます。 コンテナのPID名前空間の外部からPIDは復元後に変更されます。
次のステップは、それらの3つのプロセスについての追加情報を取得することです。
$ crit show checkpoint/core-1.img | jq .entries[0].tc.comm
"bash"
$ crit show checkpoint/core-7.img | jq .entries[0].tc.comm
"counter.py"
$ crit show checkpoint/core-8.img | jq .entries[0].tc.comm
"tee"
これは、コンテナ内の3つのプロセスがbashとcounter.py(Pythonインタプリター)とteeであることを意味しています。
プロセスの親子関係についての詳細は、checkpoint/pstree.imgに分析するデータがさらにあります。
ここまでで収集した情報をまだ実行中のコンテナと比較してみましょう。
$ crictl inspect --output go-template --template "{{(index .info.pid)}}" 059a219a22e56
722520
$ ps auxf | grep -A 2 722520
fedora 722520 \_ bash -c /home/counter/counter.py 2>&1 | tee /home/counter/logfile
fedora 722541 \_ /usr/bin/python3 /home/counter/counter.py
fedora 722542 \_ /usr/bin/coreutils --coreutils-prog-shebang=tee /usr/bin/tee /home/counter/logfile
$ cat /proc/722520/comm
bash
$ cat /proc/722541/comm
counter.py
$ cat /proc/722542/comm
tee
この出力では、まずコンテナ内の最初のプロセスのPIDを取得しています。
そしてコンテナを実行しているシステム上で、そのPIDと子プロセスを探しています。
3つのプロセスが表示され、最初のものはコンテナPID名前空間の中でPID 1である"bash"です。
次に/proc/<PID>/commを見ると、チェックポイントイメージと正確に同じ値を見つけることができます。
覚えておく重要なことは、チェックポイントはコンテナのPID名前空間内の視界が含まれていることです。 なぜなら、これらの情報はプロセスを復元するために重要だからです。
critがコンテナについて教えてくれる最後の例は、UTS名前空間に関する情報です。
$ crit show checkpoint/utsns-12.img
{
"magic": "UTSNS",
"entries": [
{
"nodename": "counters",
"domainname": "(none)"
}
]
}
UTS名前空間内のホストネームがcountersであることを教えてくれます。
チェックポイント作成中に収集された各リソースCRIUについて、checkpoint/ディレクトリは対応するイメージファイルを含んでいます。
このイメージファイルはcritを使用することで分析可能です。
メモリーページを見る
CRITを使用して復号化できるCRIUからの情報に加えて、CRIUがディスクに書き込んだ生のメモリーページを含んでいるファイルもあります。
$ ls checkpoint/pages-*
checkpoint/pages-1.img checkpoint/pages-2.img checkpoint/pages-3.img
最初にコンテナを使用した際に、メモリー内のどこかにランダムキー(RANDOM_1432_KEY)を保存しました。
見つけることができるかどうか見てみましょう。
$ grep -ao RANDOM_1432_KEY checkpoint/pages-*
checkpoint/pages-2.img:RANDOM_1432_KEY
そして実際に、私のデータがあります。 この方法で、コンテナ内のプロセスの全てのメモリーページの内容を簡単に見ることができます。 しかし、チェックポイントアーカイブにアクセスできるなら誰でも、コンテナのプロセスのメモリー内に保存された全ての情報にアクセスできることを覚えておくことも重要です。
さらなる分析のためにgdbを使用する
チェックポイントイメージを見るための他の方法はgdbです。
CRIUリポジトリは、チェックポイントをコアダンプファイルに変換するcoredumpスクリプトを含んでいます。
$ /home/criu/coredump/coredump-python3
$ ls -al core*
core.1 core.7 core.8
coredump-python3スクリプトを実行すると、チェックポイントイメージがコンテナ内の各プロセスに対し1つのコアダンプファイルに変換されます。
gdbを使用してプロセスの詳細を見ることもできます。
$ echo info registers | gdb --core checkpoint/core.1 -q
[New LWP 1]
Core was generated by `bash -c /home/counter/counter.py 2>&1 | tee /home/counter/logfile'.
#0 0x00007fefba110198 in ?? ()
(gdb)
rax 0x3d 61
rbx 0x8 8
rcx 0x7fefba11019a 140667595587994
rdx 0x0 0
rsi 0x7fffed9c1110 140737179816208
rdi 0xffffffff 4294967295
rbp 0x1 0x1
rsp 0x7fffed9c10e8 0x7fffed9c10e8
r8 0x1 1
r9 0x0 0
r10 0x0 0
r11 0x246 582
r12 0x0 0
r13 0x7fffed9c1170 140737179816304
r14 0x0 0
r15 0x0 0
rip 0x7fefba110198 0x7fefba110198
eflags 0x246 [ PF ZF IF ]
cs 0x33 51
ss 0x2b 43
ds 0x0 0
es 0x0 0
fs 0x0 0
gs 0x0 0
この例では、チェックポイント中の全てのレジストリの値を見ることができ、コンテナのPID 1のプロセスの完全なコマンドライン(bash -c /home/counter/counter.py 2>&1 | tee /home/counter/logfile)を見ることもできます。
まとめ
コンテナチェックポイントを作成することで、コンテナを停止することやチェックポイントが作成されたことを知ることなく、実行中のコンテナのチェックポイントを作成することが可能です。
Kubernetesにおいてコンテナのチェックポイントを作成した結果がチェックポイントアーカイブです。
checkpointctlやtar、crit、gdbのような異なるツールを使用して、チェックポイントを分析できます。
grepのようなシンプルなツールでさえ、チェックポイントアーカイブ内の情報を見つけることが可能です。
この記事で示したチェックポイントの分析方法のさまざまな例は出発点にすぎません。 この記事ではチェックポイントの分析を始める方法を紹介しましたが、要件によってはかなり詳細に特定の物事を見ることも可能です。
参加するためにはどうすればよいですか?
SIG Nodeにはいくつかの方法でアクセスできます。
- Slack: #sig-node
- Slack: #sig-security
- メーリングリスト
Kubernetes 1.26: PodDisruptionBudgetによって保護された不健全なPodに対する退避ポリシー
アプリケーションの中断がその可用性に影響を与えないようにすることは、簡単な作業ではありません。 先月リリースされたKubernetes v1.26では、PodDisruptionBudget (PDB) に 不健全なPodの退避ポリシー を指定して、ノード管理操作中に可用性を維持できるようになりました。 この記事では、アプリケーション所有者が中断をより柔軟に管理できるようにするために、PDBにどのような変更が導入されたのかを詳しく説明します。
これはどのような問題を解決しますか?
APIによって開始されるPodの退避では、PodDisruptionBudget(PDB)が考慮されます。
これは、退避によるPodへの自発的な中断の要求は保護されたアプリケーションを中断してはならず、
PDBの.status.currentHealthyが.status.desiredHealthyを下回ってはいけないことを意味します。
Unhealthyな実行中のPodはPDBステータスにはカウントされませんが、
これらの退避はアプリケーションが中断されない場合にのみ可能です。
これにより、中断されたアプリケーションやまだ開始されていないアプリケーションが、退避によって追加のダウンタイムが発生することなく、できるだけ早く可用性を達成できるようになります。
残念ながら、これは手動の介入なしでノードをドレインしたいクラスター管理者にとって問題を引き起こします。
(バグまたは構成ミスにより)PodがCrashLoopBackOff状態になっているアプリケーション、または単に準備ができていないPodがあるアプリケーションが誤動作している場合、このタスクはさらに困難になります。
アプリケーションのすべてのPodが正常でない場合、PDBの違反により退避リクエストは失敗します。その場合、ノードのドレインは進行できません。
一方で、次の目的で従来の動作に依存するユーザーもいます。
- 基盤となるリソースまたはストレージを保護しているPodの削除によって引き起こされるデータ損失を防止する
- アプリケーションに対して可能な限り最高の可用性を実現する
Kubernetes 1.26では、PodDisruptionBudget APIに新しい実験的フィールド.spec.unhealthyPodEvictionPolicyが導入されました。
このフィールドを有効にすると、これらの要件の両方をサポートできるようになります。
どのように機能しますか?
APIによって開始される退避は、Podの安全な終了をトリガーするプロセスです。
このプロセスは、APIを直接呼び出すか、kubectl drainコマンドを使用するか、クラスター内の他のアクターを使用して開始できます。
このプロセス中に、十分な数のPodが常にクラスター内で実行されていることを確認するために、すべてのPodの削除が適切なPDBと照合されます。
次のポリシーにより、PDBの作成者は、プロセスが不健全なPodを処理する方法をより詳細に制御できるようになります。
IfHealthyBudgetとAlwaysAllowの2つのポリシーから選択できます。
前者のIfHealthyBudgetは、従来の動作に従って、デフォルトで得られる最高の可用性を実現します。
不健全なPodは、アプリケーションが利用可能な最小数の.status.desiredHealthyだけPodがある場合にのみ中断できます。
PDBのspec.unhealthyPodEvictionPolicyフィールドをAlwaysAllowに設定することにより、アプリケーションにとってベストエフォートの可用性を選択することになります。
このポリシーを使用すると、不健全なPodをいつでも削除できます。これにより、クラスターの保守とアップグレードが容易になります。
多くの場合、AlwaysAllowがより良い選択であると考えられますが、一部の重要なワークロードでは、
不健全なPodであってもノードドレインやAPIによって開始される他の形式の退避から保護する方が望ましい場合もあります。
どのように利用できますか?
これはアルファ機能であるため、kube-apiserverに対してコマンドライン引数--feature-gates=PDBUnhealthyPodEvictionPolicy=trueを指定して
PDBUnhealthyPodEvictionPolicyフィーチャーゲートを有効にする必要があります。
ここに例を示します。クラスターでフィーチャーゲートを有効にし、プレーンなWebサーバーを実行するDeploymentをすでに定義していると仮定します。
そのDeploymentのPodにapp: nginxというラベルを付けました。
回避可能な中断を制限したいと考えており、このアプリにはベストエフォートの可用性で十分であることがわかっています。
WebサーバーのPodが不健全な場合でも、退避を許可することにしました。
不健全なPodを排除するためのAlwaysAllowポリシーを使用して、このアプリケーションを保護するPDBを作成します。
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: nginx-pdb
spec:
selector:
matchLabels:
app: nginx
maxUnavailable: 1
unhealthyPodEvictionPolicy: AlwaysAllow
もっと学ぶには?
- KEPを読んでください: Unhealthy Pod Eviction Policy for PDBs
- PodDisruptionBudgetについてのドキュメントを読んでください: Unhealthy Pod Eviction Policy
- PodDisruptionBudget、draining of NodesおよびevictionsについてKubernetesドキュメントを確認してください
どうすれば参加できますか?
フィードバックがある場合は、Slackの#sig-apps チャンネル(必要な場合は https://slack.k8s.io/ にアクセスして招待を受けてください)、またはSIG Appsメーリングリストにご連絡ください。kubernetes-sig-apps@googlegroups.com
Kubernetesにおけるフォレンジックコンテナチェックポイント処理
フォレンジックコンテナチェックポイント処理はCheckpoint/Restore In Userspace (CRIU)に基づいており、コンテナがチェックポイントされていることを認識することなく、実行中のコンテナのステートフルコピーを作成することができます。 コンテナのコピーは、元のコンテナに気づかれることなく、サンドボックス環境で複数回の分析やリストアが可能です。 フォレンジックコンテナチェックポイント処理はKubernetes v1.25でalpha機能として導入されました。
どのように機能しますか?
CRIUを使用してコンテナのチェックポイントやリストアを行うことが可能です。 CRIUはruncやcrun、CRI-O、containerdと統合されており、Kubernetesで実装されているフォレンジックコンテナチェックポイント処理は、既存のCRIU統合を使用します。
なぜ重要なのか?
CRIUと対応する統合機能を使用することで、後でフォレンジック分析を行うために、ディスク上で実行中のコンテナに関する全ての情報と状態を取得することが可能です。 フォレンジック分析は、疑わしいコンテナを停止したり影響を与えることなく検査するために重要となる場合があります。 コンテナが本当に攻撃を受けている場合、攻撃者はコンテナを検査する処理を検知するかもしれません。 チェックポイントを取得しサンドボックス環境でコンテナを分析することは、元のコンテナや、おそらく攻撃者にも検査を認識されることなく、コンテナを検査することができる可能性があります。
フォレンジックコンテナチェックポイント処理のユースケースに加えて、内部状態を失うことなく、あるノードから他のノードにコンテナを移行することも可能です。 特に初期化時間の長いステートフルコンテナの場合、チェックポイントからリストアすることは再起動後の時間が節約されるか、起動時間がより早くなる可能性があります。
コンテナチェックポイント処理を利用するには?
機能はフィーチャーゲートで制限されているため、新しい機能を使用する前にContainerCheckpointを有効にしてください。
ランタイムがコンテナチェックポイント処理をサポートしている必要もあります。
- containerd: サポートは現在検討中です。詳細はcontainerdプルリクエスト#6965を見てください。
- CRI-O: v1.25はフォレンジックコンテナチェックポイント処理をサポートしています。
CRI-Oでの使用例
CRI-Oとの組み合わせでフォレンジックコンテナチェックポイント処理を使用するためには、ランタイムをコマンドラインオプション--enable-criu-support=trueで起動する必要があります。
Kubernetesでは、ContainerCheckpointフィーチャーゲートを有効にしたクラスターを実行する必要があります。
チェックポイント処理の機能はCRIUによって提供されているため、CRIUをインストールすることも必要となります。
通常、runcやcrunはCRIUに依存しているため、自動的にインストールされます。
執筆時点ではチェックポイント機能はCRI-OやKubernetesにおいてalpha機能としてみなされており、セキュリティ影響がまだ検討中であることに言及することも重要です。
コンテナとPodが実行されると、チェックポイントを作成することが可能になります。
チェックポイント処理はkubeletレベルでのみ公開されています。
コンテナをチェックポイントするためには、コンテナが実行されているノード上でcurlを実行し、チェックポイントをトリガーします。
curl -X POST "https://localhost:10250/checkpoint/namespace/podId/container"
default名前空間内のcountersと呼ばれるPod内のcounterと呼ばれるコンテナに対し、kubelet APIエンドポイントが次の場所で到達可能です。
curl -X POST "https://localhost:10250/checkpoint/default/counters/counter"
厳密には、kubeletの自己署名証明書を許容し、kubeletチェックポイントAPIの使用を認可するために、下記のcurlコマンドのオプションが必要です。
--insecure --cert /var/run/kubernetes/client-admin.crt --key /var/run/kubernetes/client-admin.key
このkubelet APIが実行されると、CRI-Oからチェックポイントの作成をリクエストします。
CRI-Oは低レベルランタイム(例えばrunc)からチェックポイントをリクエストします。
そのリクエストを確認すると、runcは実際のチェックポイントを行うためにcriuツールを呼び出します。
チェックポイント処理が終了すると、チェックポイントは/var/lib/kubelet/checkpoints/checkpoint-<pod-name>_<namespace-name>-<container-name>-<timestamp>.tarで利用可能になります。
その後、そのtarアーカイブを使用してコンテナを別の場所にリストアできます。
Kubernetesの外部でチェックポイントしたコンテナをリストアする(CRI-Oを使用)
チェックポイントtarアーカイブを使用すると、CRI-Oのサンドボックスインスタンス内のKubernetesの外部にコンテナをリストア可能です。 リストア中のより良いユーザーエクスペリエンスのために、main CRI-O GitHubブランチからCRI-Oのlatestバージョンを使用することを推奨します。 CRI-O v1.25を使用している場合、コンテナを開始する前にKubernetesが作成する特定のディレクトリを手動で作成する必要があります。
Kubernetesの外部にコンテナをリストアするための最初のステップは、crictlを使用してPodサンドボックスを作成することです。
crictl runp pod-config.json
次に、さきほどチェックポイントしたコンテナを新しく作成したPodサンドボックスにリストアします。
crictl create <POD_ID> container-config.json pod-config.json
container-config.jsonのレジストリでコンテナイメージを指定する代わりに、前に作成したチェックポイントアーカイブへのパスを指定する必要があります。
{
"metadata": {
"name": "counter"
},
"image":{
"image": "/var/lib/kubelet/checkpoints/<checkpoint-archive>.tar"
}
}
次に、そのコンテナを開始するためにcrictl start <CONTAINER_ID>を実行すると、さきほどチェックポイントしたコンテナのコピーが実行されているはずです。
Kubernetes内でチェックポイントしたコンテナをリストアする
先ほどチェックポイントしたコンテナをKubernetes内で直接リストアするためには、レジストリにプッシュできるイメージにチェックポイントアーカイブを変換する必要があります。
ローカルのチェックポイントアーカイブを変換するための方法として、buildahを使用した下記のステップが考えられます。
newcontainer=$(buildah from scratch)
buildah add $newcontainer /var/lib/kubelet/checkpoints/checkpoint-<pod-name>_<namespace-name>-<container-name>-<timestamp>.tar /
buildah config --annotation=io.kubernetes.cri-o.annotations.checkpoint.name=<container-name> $newcontainer
buildah commit $newcontainer checkpoint-image:latest
buildah rm $newcontainer
出来上がったイメージは標準化されておらず、CRI-Oとの組み合わせでのみ動作します。
このイメージはalphaにも満たないフォーマットであると考えてください。
このようなチェックポイントイメージのフォーマットを標準化するための議論が進行中です。
これはまだ標準化されたイメージフォーマットではなく、CRI-Oを--enable-criu-support=trueで起動した場合のみ動作することを忘れないでください。
CRIUサポートでCRI-Oを起動することのセキュリティ影響はまだ明確ではなく、そのため、イメージフォーマットだけでなく機能も気を付けて使用するべきです。
さて、そのイメージをコンテナイメージレジストリにプッシュする必要があります。 例えば以下のような感じです。
buildah push localhost/checkpoint-image:latest container-image-registry.example/user/checkpoint-image:latest
このチェックポイントイメージ(container-image-registry.example/user/checkpoint-image:latest)をリストアするために、イメージはPodの仕様(Specification)に記載する必要があります。
以下はマニフェストの例です。
apiVersion: v1
kind: Pod
metadata:
namePrefix: example-
spec:
containers:
- name: <container-name>
image: container-image-registry.example/user/checkpoint-image:latest
nodeName: <destination-node>
Kubernetesは新しいPodをノード上にスケジュールします。
そのノード上のKubeletは、registry/user/checkpoint-image:latestとして指定されたイメージをもとに、コンテナを作成し開始するようにコンテナランタイム(この例ではCRI-O)に指示をします。
CRI-Oはregistry/user/checkpoint-image:latestがコンテナイメージでなく、チェックポイントデータへの参照であることを検知します。
その時、コンテナを作成し開始する通常のステップの代わりに、CRI-Oはチェックポイントデータをフェッチし、指定されたチェックポイントからコンテナをリストアします。
Pod内のアプリケーションはチェックポイントを取得しなかったかのように実行し続けます。 コンテナ内では、アプリケーションはチェックポイントからリストアされず通常起動したコンテナのような見た目や動作をします。
これらのステップで、あるノードで動作しているPodを、別のノードで動作している新しい同等のPodに置き換えることができ、そのPod内のコンテナの状態を失うことはないです。
どのように参加すればよいですか?
SIG Nodeにはいくつかの手段でアクセスすることができます。
さらなる読み物
コンテナチェックポイントの分析方法に関する詳細は後続のブログForensic container analysisを参照してください。
更新: dockershimの削除に関するFAQ
この記事は2020年の後半に投稿されたオリジナルの記事Dockershim Deprecation FAQの更新版です。 この記事にはv1.24のリリースに関する更新を含みます。
この文書では、Kubernetesからの dockershim の削除に関するよくある質問について説明します。 この削除はKubernetes v1.20リリースの一部としてはじめて発表されたものです。 Kubernetes v1.24のリリースにおいてdockershimは実際にKubernetesから削除されました。
これが何を意味するかについては、ブログ記事Don't Panic: Kubernetes and Dockerをご覧ください。
dockershim削除の影響範囲を確認するをお読みいただくことで、 dockershimの削除があなたやあなたの組織に与える影響をご判断いただけます。
Kubernetes 1.24リリースに至るまでの間、Kubernetesコントリビューターはこの移行を円滑に行えるようにするために尽力してきました。
- 私たちのコミットメントと次のステップを詳述したブログ記事。
- 他のコンテナランタイムへの移行に大きな障害があるかどうかのチェック。
- dockershimからの移行ガイドの追加。
- dockershimの削除とCRI互換ランタイムの使用に関する記事一覧の作成。 このリストには、上に示した文書の一部が含まれており、また、厳選された外部の情報(ベンダーによるガイドを含む)もカバーしています。
dockershimはなぜKubernetesから削除されたのですか?
Kubernetesの初期のバージョンは、特定のコンテナランタイム上でのみ動作しました。 Docker Engineです。その後、Kubernetesは他のコンテナランタイムと連携するためのサポートを追加しました。 オーケストレーター(Kubernetesなど)と多くの異なるコンテナランタイムの間の相互運用を可能にするため、 CRI標準が作成されました。 Docker Engineはそのインターフェース(CRI)を実装していないため、Kubernetesプロジェクトは移行を支援する特別なコードを作成し、 その dockershim コードをKubernetes自身の一部としました。
dockershimコードは常に一時的な解決策であることを意図されていました(このためshimと名付けられています)。 コミュニティでの議論や計画については、dockershimの削除によるKubernetes改良の提案にてお読みいただけます。
実際、dockershimのメンテナンスはKubernetesメンテナーにとって大きな負担になっていました。
さらに、dockershimとほとんど互換性のなかった機能、たとえばcgroups v2やユーザーネームスペースなどが、 これらの新しいCRIランタイムに実装されています。Kubernetesからdockershimを削除することで、これらの分野でのさらなる開発が可能になります。
Dockerとコンテナは同じものですか?
DockerはLinuxのコンテナパターンを普及させ、その基盤技術の発展に寄与してきましたが、 Linuxのコンテナ技術そのものはかなり以前から存在しています。 また、コンテナエコシステムはDockerを超えてより広範に発展してきました。 OCIやCRIのような標準は、Dockerの機能の一部を置き換えたり、既存の機能を強化したりすることで、 私達のエコシステムの多くのツールの成長と繁栄を助けてきました。
既存のコンテナイメージは引き続き使えるのですか?
はい、docker buildから生成されるイメージは、全てのCRI実装で動作します。
既存のイメージも全く同じように動作します。
プライベートイメージについてはどうでしょうか?
はい、すべてのCRIランタイムはKubernetesで使われているものと同一のpull secretsをサポートしており、 PodSpecまたはService Accountを通して利用できます。
Kubernetes 1.23でDocker Engineを引き続き使用できますか?
はい、1.20で変更されたのは、Docker Engineランタイムを使用している場合に警告ログがkubelet起動時に出るようになったことだけです。 この警告は、1.23までのすべてのバージョンで表示されます。 dockershimの削除はKubernetes 1.24で行われました。
Kubernetes v1.24以降を実行している場合は、Docker Engineを引き続きコンテナランタイムとして利用できますか?をご覧ください。 (CRIがサポートされているKubernetesリリースを使用している場合、dockershimから切り替えることができることを忘れないでください。 リリースv1.24からはKubernetesにdockershimが含まれなくなったため、必ず切り替えなければなりません)。
どのCRIの実装を使うべきでしょうか?
これは難しい質問で、様々な要素に依存します。 もしDocker Engineがうまく動いているのであれば、containerdに移行するのは比較的簡単で、 性能もオーバーヘッドも確実に改善されるでしょう。 しかし、他の選択のほうがあなたの環境により適合する場合もありますので、 CNCF landscapeにあるすべての選択肢を検討されることをおすすめします。
Docker Engineを引き続きコンテナランタイムとして利用できますか?
第一に、ご自身のPCで開発やテスト用途でDockerを使用している場合、何も変わることはありません。 Kubernetesでどのコンテナランタイムを使っていても、Dockerをローカルで使い続けることができます。 コンテナではこのような相互運用性を実現できます。
MirantisとDockerは、Kubernetesから内蔵のdockershimが削除された後も、
Docker Engineの代替アダプターを維持することにコミットしています。
代替アダプターの名前はcri-dockerdです。
cri-dockerdをインストールして、kubeletをDocker Engineに接続するために使用することができます。
詳細については、Migrate Docker Engine nodes from dockershim to cri-dockerdを読んでください。
今現在でプロダクション環境に他のランタイムを使用している例はあるのでしょうか?
Kubernetesプロジェクトが生み出したすべての成果物(Kubernetesバイナリ)は、リリースごとに検証されています。
また、kindプロジェクトは以前からcontainerdを使っており、プロジェクトのユースケースにおいて安定性が向上してきています。 kindとcontainerdは、Kubernetesコードベースの変更を検証するために毎日何回も利用されています。 他の関連プロジェクトも同様のパターンを追っており、他のコンテナランタイムの安定性と使いやすさが示されています。 例として、OpenShift 4.xは2019年6月以降、CRI-Oランタイムをプロダクション環境で使っています。
他の事例や参考資料はについては、 containerdとCRI-O(Cloud Native Computing Foundation (CNCF)の2つのコンテナランタイム)の採用例をご覧ください。
OCIという単語をよく見るのですが、これは何ですか?
OCIはOpen Container Initiativeの略で、コンテナツールとテクノロジー間の数多くのインターフェースの標準化を行った団体です。 彼らはコンテナイメージをパッケージするための標準仕様(OCI image-spec)と、 コンテナを実行するための標準仕様(OCI runtime-spec)をメンテナンスしています。 また、runcという形でruntime-specの実装もメンテナンスしており、 これはcontainerdとCRI-Oの両方でデフォルトの下位ランタイムとなっています。 CRIはこれらの低レベル仕様に基づいて、コンテナを管理するためのエンドツーエンドの標準を提供します。
CRI実装を変更する際に注意すべきことは何ですか?
DockerとほとんどのCRI(containerdを含む)において、下位で使用されるコンテナ化コードは同じものですが、 いくつかの細かい違いが存在します。移行する際に考慮すべき一般的な事項は次のとおりです。
- ログ設定
- ランタイムリソースの制限
- ノード構成スクリプトでdockerコマンドやコントロールソケット経由でDocker Engineを使用しているもの
kubectlのプラグインでdockerCLIまたはDocker Engineコントロールソケットが必要なもの- KubernetesプロジェクトのツールでDocker Engineへの直接アクセスが必要なもの(例:廃止された
kube-imagepullerツール) registry-mirrorsやinsecureレジストリなどの機能の設定- その他の支援スクリプトやデーモンでDocker Engineが利用可能であることを想定していてKubernetes外で実行されるもの(モニタリング・セキュリティエージェントなど)
- GPUまたは特別なハードウェア、そしてランタイムおよびKubernetesとそれらハードウェアの統合方法
あなたがKubernetesのリソース要求/制限やファイルベースのログ収集DaemonSetを使用しているのであれば、それらは問題なく動作し続けますが、
dockerdの設定をカスタマイズしていた場合は、それを新しいコンテナランタイムに適合させる必要があるでしょう。
他に注意することとしては、システムメンテナンスを実行するようなものや、コンテナ内でイメージをビルドするようなものが動作しなくなります。
前者の場合は、crictlツールをdrop-inの置き換えとして使用できます(docker cliからcrictlへのマッピングを参照)。
後者の場合は、img、buildah、kaniko、buildkit-cli-for-kubectlのようなDockerを必要としない新しいコンテナビルドの選択肢を使用できます。
containerdを使っているのであれば、ドキュメントを参照して、移行するのにどのような構成が利用可能かを確認するところから始めるといいでしょう。
containerdとCRI-OをKubernetesで使用する方法に関しては、コンテナランタイムに関するKubernetesのドキュメントを参照してください。
さらに質問がある場合どうすればいいでしょうか?
ベンダーサポートのKubernetesディストリビューションを使用している場合、彼らの製品に対するアップグレード計画について尋ねることができます。 エンドユーザーの質問に関しては、エンドユーザーコミュニティフォーラムに投稿してください。
dockershimの削除に関する決定については、専用のGitHub issueで議論することができます。
変更点に関するより詳細な技術的な議論は、待ってください、DockerはKubernetesで非推奨になったのですか?という素晴らしいブログ記事も参照してください。
dockershimを使っているかどうかを検出できるツールはありますか?
はい!Detector for Docker Socket (DDS)というkubectlプラグインをインストールすることであなたのクラスターを確認していただけます。
DDSは、アクティブなKubernetesワークロードがDocker Engineソケット(docker.sock)をボリュームとしてマウントしているかを検出できます。
さらなる詳細と使用パターンについては、DDSプロジェクトのREADMEを参照してください。
ハグしていただけますか?
はい、私達は引き続きいつでもハグに応じています。🤗🤗🤗
Don't Panic: Kubernetes and Docker
Kubernetesはv1.20より新しいバージョンで、コンテナランタイムとしてDockerをサポートしません。
パニックを起こす必要はありません。これはそれほど抜本的なものではないのです。
概要: ランタイムとしてのDockerは、Kubernetesのために開発されたContainer Runtime Interface(CRI)を利用しているランタイムを選んだ結果としてサポートされなくなります。しかし、Dockerによって生成されたイメージはこれからも、今までもそうだったように、みなさんのクラスターで使用可能です。
もし、あなたがKubernetesのエンドユーザーであるならば、多くの変化はないでしょう。これはDockerの死を意味するものではありませんし、開発ツールとして今後Dockerを使用するべきでない、使用することは出来ないと言っているのでもありません。Dockerはコンテナを作成するのに便利なツールですし、docker buildコマンドで作成されたイメージはKubernetesクラスター上でこれからも動作可能なのです。
もし、GKE、EKS、AKSといったマネージドKubernetesサービス(それらはデフォルトでcontainerdを使用しています)を使っているのなら、ワーカーノードがサポート対象のランタイムを使用しているか、Dockerのサポートが将来のK8sバージョンで切れる前に確認しておく必要があるでしょう。 もし、ノードをカスタマイズしているのなら、環境やRuntimeの仕様に合わせて更新する必要があるでしょう。サービスプロバイダーと確認し、アップグレードのための適切なテストと計画を立ててください。
もし、ご自身でClusterを管理しているのなら、やはり問題が発生する前に必要な対応を行う必要があります。v1.20の時点で、Dockerの使用についての警告メッセージが表示されるようになります。将来のKubernetesリリース(現在の計画では2021年下旬のv1.22)でDockerのRuntimeとしての使用がサポートされなくなれば、containerdやCRI-Oといった他のサポート対象のRuntimeに切り替える必要があります。切り替える際、そのRuntimeが現在使用しているDocker Daemonの設定をサポートすることを確認してください。(Loggingなど)
では、なぜ混乱が生じ、誰もが恐怖に駆られているのか。
ここで議論になっているのは2つの異なる場面についてであり、それが混乱の原因になっています。Kubernetesクラスターの内部では、Container runtimeと呼ばれるものがあり、それはImageをPullし起動する役目を持っています。Dockerはその選択肢として人気があります(他にはcontainerdやCRI-Oが挙げられます)が、しかしDockerはそれ自体がKubernetesの一部として設計されているわけではありません。これが問題の原因となっています。
お分かりかと思いますが、ここで”Docker”と呼んでいるものは、ある1つのものではなく、その技術的な体系の全体であり、その一部には"containerd"と呼ばれるものもあり、これはそれ自体がハイレベルなContainer runtimeとなっています。Dockerは素晴らしいもので、便利です。なぜなら、多くのUXの改善がされており、それは人間が開発を行うための操作を簡単にしているのです。しかし、それらはKubernetesに必要なものではありません。Kubernetesは人間ではないからです。 このhuman-friendlyな抽象化レイヤーが作られたために、結果としてはKubernetesクラスターはDockershimと呼ばれるほかのツールを使い、本当に必要な機能つまりcontainerdを利用してきました。これは素晴らしいとは言えません。なぜなら、我々がメンテする必要のあるものが増えますし、それは問題が発生する要因ともなります。今回の変更で実際に行われることというのは、Dockershimを最も早い場合でv1.23のリリースでkubeletから除外することです。その結果として、Dockerのサポートがなくなるということなのです。 ここで、containerdがDockerに含まれているなら、なぜDockershimが必要なのかと疑問に思われる方もいるでしょう。
DockerはCRI(Container Runtime Interface)に準拠していません。もしそうであればshimは必要ないのですが、現実はそうでありません。 しかし、これは世界の終わりでありません、心配しないでください。みなさんはContainer runtimeをDockerから他のサポート対象であるContainer runtimeに切り替えるだけでよいのです。
1つ注意すべきことは、クラスターで行われる処理のなかでDocker socket(/var/run/docker.sock)に依存する部分がある場合、他のRuntimeへ切り替えるとこの部分が働かなくなるでしょう。このパターンはしばしばDocker in Dockerと呼ばれます。このような場合の対応方法はたくさんあります。kaniko、img、buildahなどです。
では開発者にとって、この変更は何を意味するのか。これからもDockerfileを使ってよいのか。これからもDockerでビルドを行ってよいのか。
この変更は、Dockerを直接操作している多くのみなさんとは別の場面に影響を与えるでしょう。 みなさんが開発を行う際に使用しているDockerと、Kubernetesクラスターの内部で使われているDocker runtimeは関係ありません。これがわかりにくいことは理解しています。開発者にとって、Dockerはこれからも便利なものであり、このアナウンスがあった前と変わらないでしょう。DockerでビルドされたImageは、決してDockerでだけ動作するというわけではありません。それはOCI(Open Container Initiative) Imageと呼ばれるものです。あらゆるOCI準拠のImageは、それを何のツールでビルドしたかによらず、Kubernetesから見れば同じものなのです。containerdもCRI-Oも、そのようなImageをPullし、起動することが出来ます。 これがコンテナの仕様について、共通の仕様を策定している理由なのです。
さて、この変更は決定しています。いくつかの問題は発生するかもしてませんが、決して壊滅的なものではなく、ほとんどの場合は良い変化となるでしょう。Kubernetesをどのように使用しているかによりますが、この変更が特に何の影響も及ぼさない人もいるでしょうし、影響がとても少ない場合もあります。長期的に見れば、物事を簡単にするのに役立つものです。 もし、この問題がまだわかりにくいとしても、心配しないでください。Kubernetesでは多くのものが変化しており、その全てに完璧に精通している人など存在しません。 経験の多寡や難易度にかかわらず、どんなことでも質問してください。我々の目標は、全ての人が将来の変化について、可能な限りの知識と理解を得られることです。 このブログが多くの質問の答えとなり、不安を和らげることができればと願っています。
別の情報をお探しであれば、dockershimの削除に関するFAQを参照してください。