1 - Kubernetesドキュメント Kubernetesは、コンテナ化されたアプリケーションの展開、スケーリング、また管理を自動化するためのオープンソースコンテナプラットフォームです。このオープンソースプロジェクトは、Cloud Native Computing Foundationによってホストされています。
1.1 - 利用可能なドキュメントバージョン 本ウェブサイトには、現行版とその直前4バージョンのKubernetesドキュメントがあります。
Kubernetesバージョンのドキュメントの入手性は、そのリリースが現在サポートされているかどうかで分かれます。
どのKubernetesバージョンが公式にどのくらいの期間サポートされるかについて知るには、サポート期間 を参照してください。
2 - はじめに このセクションではKubernetesをセットアップして動かすための複数のやり方について説明します。
Kubernetesをインストールする際には、メンテナンスの容易さ、セキュリティ、制御、利用可能なリソース、クラスターの運用および管理に必要な専門知識に基づいてインストレーションタイプを選んでください。
Kuerbetesクラスターをローカルマシン、クラウド、データセンターにデプロイするために、Kubernetesをダウンロード できます。
kube-apiserver やkube-proxy のようないくつかのKubernetesのコンポーネント も、コンテナイメージ としてクラスター内にデプロイできます。
可能であればコンテナイメージとしてKubernetesのコンポーネントを実行し、それらのコンポーネントをKubernetesで管理するようにすることを推奨 します。
コンテナを実行するコンポーネント(特にkubelet)は、このカテゴリーには含まれません。
Kubernetesクラスターを自分で管理するのを望まないなら、認定プラットフォーム をはじめとする、マネージドのサービスを選択することもできます。
複数のクラウドやベアメタル環境にまたがった、その他の標準あるいはカスタムのソリューションもあります。
環境について学ぶ Kubernetesについて学んでいる場合、Kubernetesコミュニティにサポートされているツールや、Kubernetesクラスターをローカルマシンにセットアップするエコシステム内のツールを使いましょう。
ツールのインストール を参照してください。
プロダクション環境 プロダクション環境 用のソリューションを評価する際には、Kubernetesクラスター(または抽象概念 )の運用においてどの部分を自分で管理し、どの部分をプロバイダーに任せるのかを考慮してください。
自分で管理するクラスターであれば、Kubernetesをデプロイするための公式にサポートされているツールはkubeadm です。
次の項目 Kubernetesは、そのコントロールプレーン がLinux上で実行されるよう設計されています。
クラスター内では、Linux上でも、Windowsを含めた別のオペレーティングシステム上でも、アプリケーションを実行できます。
2.1 - 学習環境 2.2 - プロダクション環境 プロダクション品質のKubernetesクラスターを作成します。
プロダクション環境向けのKubernetesクラスターには計画と準備が必要です。Kubernetesクラスターが重要なワークロードを動かしている場合、耐障害性のある構成にしなければいけません。このページはプロダクション環境で利用できるクラウターのセットアップをするための手順や既存のクラスターをプロダクション環境で利用できるように昇格するための手順を説明します。
既にプロダクション環境のセットアップを理解している場合、次の項目 に進んでください。
プロダクション環境の考慮事項 通常、プロダクション用のKubernetesクラスター環境は個人学習の環境や開発環境、テスト環境より多くの要件があります。プロダクション環境は多くのユーザーによるセキュアなアクセスや安定した可用性、変化する需要に適用するためのリソースが必要になる場合があります。
プロダクション用のKubernetes環境をどこに配置するか(オンプレミスまたはクラウド)、どの程度の管理を自分で行うか、それとも他に任せるかを決定する際には、以下の問題がKubernetesクラスターに対する要件にどのように影響を与えるかを考慮してください。
可用性 : 単一のマシンで動作するKubernetes学習環境 には単一障害点があります。高可用性のクラスターの作成するには下記の点を考慮する必要があります。
ワーカーノードからのコントロールプレーンの分離 複数ノードへのコントロールプレーンのレプリケーション クラスターのAPIサーバー へのトラフィックの負荷分散 変化するワークロードに応じて、十分な数のワーカーノードが利用可能であること、または迅速に利用可能になること スケール : プロダクション用のKubernetes環境が安定した要求を受けることが予測できる場合、必要なキャパシティをセットアップすることができるかもしれません。しかし、時間の経過と共に成長する需要やシーズンや特別なイベントのようなことで大幅な変化を予測する場合、コントロールプレーンやワーカーノードへの多くのリクエストにより増加する負荷を軽減するスケールの方法や未使用のリソースを削減するためのスケールダウンの方法を計画する必要があリます。
セキュリティやアクセス管理 : 自身のKubernetes学習クラスターでは全管理者権限を持っています。しかし、重要なワークロードを保持していたり、複数のユーザーが利用する共有クラスターでは、誰がどのクラスターのリソースに対してアクセスできるかをより制限されたアプローチを必要とします。ユーザーやワークロードが必要なリソースへアクセスできることを実現するロールベースアクセス制御(RBAC )や他のセキュリティメカニズムを使用し、ワークロードやクラスターを保護することができます。ポリシー やコンテナリソース を管理することによってユーザーやワークロードがアクセスできるリソースの制限を設定できます。
自身のプロダクション環境のKubernetesを構築する前に、ターンキークラウドソリューション や
プロバイダーや他のKubernetesパートナー へ仕事の一部や全てを委託することを考えてください。オプションには次のものが含まれます。
サーバーレス : クラスターを全く管理せずに第三者の設備上でワークロードを実行します。CPU使用量やメモリ、ディスクリクエストなどの利用に応じて課金します。マネージドコントロールプレーン : クラスターのコントロールプレーンのスケールと可用性やパッチとアップグレードの実行をプロバイダーに管理してもらいます。マネージドワーカーノード : 需要に合わせてノードのプールを構成し、プロバイダーがワーカーノードが利用可能であることを保証し、需要に応じたアップグレードを実施できるようにします。統合 : ストレージ、コンテナレジストリ、認証方法、開発ツールなどの他の必要なサービスとKubernetesを統合するプロバイダーも存在します。プロダクション用のKubernetesクラスターを自身で構築する場合でもパートナーと連携する場合でもクラスターのコントロールプレーン 、ワーカーノード 、ユーザーアクセス 、およびワークロードリソース に関連する要件を評価するために以下のセクションのレビューを行なってください。
プロダクション環境のクラスターのセットアップ プロダクション環境向けのKubernetesクラスターでは、コントロールプレーンが異なる方法で複数のコンピューターに分散されたサービスからクラスターを管理します。一方で、各ワーカーノードは単一のエンティティとして表され、KubernetesのPodを実行するように設定されています。
プロダクション環境のコントロールプレーン 最もシンプルなKubernetesクラスターはすべてのコントロールプレーンとワーカーノードサービスが同一のマシン上で稼働しています。Kubernetesコンポーネント の図に示すようにワーカーノードの追加によって環境をスケールさせることができます。クラスターが短時間の稼働や深刻な問題が起きたときに破棄してもよい場合は、同一マシン上での構成で要件を満たしているかもしれません。
永続性や高可用性のクラスターが必要であれば、コントロールプレーンの拡張方法を考えなければいけません。設計上、単一のマシンで動作するコントロールプレーンサービスは高可用性ではありません。クラスターを常に稼働させ、何か問題が発生した場合に修復できる保証が重要な場合は、以下のステップを考えてください。
デプロイツールの選択 : kubeadm、kopsやkubesprayなどのツールを使ってコントロールプレーンをデプロイできます。これらのデプロイメント方法を使用したプロダクション環境向けののデプロイのヒントを学ぶためにデプロイツールによるKubernetesのインストール をご覧になってください。異なるコンテナランタイム をデプロイに使用することができます。証明書の管理 : コントロールプレーンサービス間の安全な通信は証明書を使用して実装されています。証明書はデプロイ時に自動で生成したり、独自の認証局を使用し生成することができます。詳細はPKI証明書と要件 をご覧ください。APIサーバー用のロードバランサーの構成 : 外部からのAPIリクエストを異なるノード上で稼働しているAPIサーバーサービスインスタンスに分散させるためにロードバランサーを設定します。詳細は 外部ロードバランサーの作成 をご覧ください。etcdサービスの分離とバックアップ : etcdサービスは他のコントロールプレーンサービスと同じマシン上で動作させることも、追加のセキュリティと可用性のために別のマシン上で動作させることもできます。etcdはクラスターの構成データを格納しており、必要に応じてデータベースを修復できるようにするためにetcdデータベースのバックアップは定期的に行うべきです。etcdの構成と使用に関する詳細はetcd FAQ をご覧ください。また、Kubernetes向けのetcdクラスターの運用 とkubeadmを使用した高可用性etcdクラスターのセットアップ もご覧ください。複数のコントロールプレーンシステムの作成 : 高可用性のためにコントロールプレーンは単一のマシンに限定されるべきではありません。コントロールプレーンサービスはinitサービス(systemdなど)によって実行される場合、各サービスは少なくとも3台のマシンで実行されるべきです。しかし、Kubernetes内でPodとしてコントロールプレーンサービスを実行することで、リクエストしたサービスのレプリカ数が常に利用可能であることが保証されます。スケジューラーは耐障害性が備わっているべきですが、高可用性は必要ありません。一部のデプロイメントツールはKubernetesサービスのリーダー選出のためにRaft コンセンサスアルゴリズムを設定しています。プライマリが失われた場合、別のサービスが自らを選出して引き継ぎます。複数ゾーンへの配置 : クラスターを常に利用可能に保つことが重要である場合、複数のデータセンターにまたがって実行されるクラスターを作成することを検討してください。クラウド環境ではゾーンと呼ばれます。ゾーンのグループはリージョンと呼ばれます。同リージョンで複数のゾーンにクラスターを分散させることで、一つのゾーンが利用不可能になったとしても、クラスタが機能し続ける可能性を向上できます。詳細は、複数ゾーンでの稼働 をご覧ください。継続的な機能の管理 : クラスターを長期間稼働する計画がある場合、正常性とセキュリティを維持するために行うべきタスクがあります。例えば、kubeadmを使用してインストールした場合、証明書管理 やkubeadmによるクラスターのアップグレード を支援するドキュメントがあります。より多くのKubernetes管理タスクのリストについては、クラスターの管理 をご覧ください。コントロールプレーンサービスを実行する際の利用可能なオプションについて学ぶためには、kube-apiserver 、kube-controller-manager 、kube-scheduler のコンポーネントページをご覧ください。高可用性のコントロールプレーンの例については、高可用性トポロジーのオプション 、kubeadmを使用した高可用性クラスターの作成 、Kubernetes向けetcdクラスターの運用 をご覧ください。etcdクラスターのバックアップ計画の作成については、etcdクラスターのバックアップ をご覧ください。
プロダクション環境のワーカーノード プロダクション向けのワークロードとそのワークロードが依存するサービス(CoreDNSなど)は耐障害性を必要とします。自身でコントロールプレーンを管理するか、クラウドプロバイダーに任せるかに関わらず、ワーカーノード(単にノードとも呼ばれます)の管理方法を考える必要があります。
ノードの構成 : ノードは物理マシンもしくは仮想マシンになります。ノードを自身で作成し管理したい場合、サポートされてるオペレーティングシステムをインストールし、適切なノードサービス を追加し、実行します。
ノードをセットアップする際に、ワークロードの需要に合わせた適切なメモリ、CPU、ディスク速度、ストレージ容量を確保することを考えること 汎用コンピュータシステムで十分か、GPUプロセッサやWindowsノード、VMの分離を必要とするワークロードがあるかどうかを考えること ノードの検証 : ノードがKubernetesクラスターに参加するための要件を満たしていることを保証する方法についての情報は有効なノードのセットアップ をご覧ください。
クラスターへのノードの追加 : 自身でクラスターを管理している場合、自身のマシンをセットアップし手動で追加するか、または自動でクラスターのAPIサーバーに登録させることによってノードを追加できます。これらのKubernetesへノードを追加するためのセットアップ方法については、ノード セクションをご覧ください。
ノードのスケール : クラスターのキャパシティの拡張プランを作成することは最終的に必要になります。稼働させなければいけないPod数やコンテナ数を基にどのくらいのノード数が必要なのかを決定をするための助けとなる大規模クラスターの考慮事項 をご覧ください。自身でノードを管理する場合、自身で物理機材を購入し設置することを意味します。
ノードのオートスケーリング : ノードやノードが提供するキャパシティを自動的に管理するために利用できるツールについて学ぶために、クラスターのオートスケーリング をご覧ください。
ノードのヘルスチェックのセットアップ : 重要なワークロードのためにノード上で稼働しているノードとPodが正常であることを確認しなければいけません。Node Problem Detector デーモンを使用し、ノードが正常であることを保証してください。
プロダクション環境のユーザー管理 プロダクション環境では、自身または少人数の小さなグループがクラスターにアクセスするモデルから、数十人から数百人がアクセスする可能性のあるモデルへと移行するかもしれません。学習環境やプラットフォームのプロトタイプでは、すべての作業を行うための1つの管理アカウントを持っているかもしれません。プロダクション環境では、異なる名前空間へのアクセスレベルが異なる複数のアカウントを持つことになリます。
プロダクション環境向けのクラスターを運用することは、他のユーザーによるアクセスを選択的に許可する方法を決定することを意味します。特に、クラスターにアクセスをしようとするユーザーの身元を検証するための戦略を選択し(認証)、ユーザーが要求する操作に対して権限があるかどうかを決定する必要があります(認可)。:
認証 : APIサーバーはクライアント証明書、bearerトークン、認証プロキシまたはHTTPベーシック認証を使用し、ユーザーを認証できます。使用したい認証の方法を選択できます。プラグインを使用することで、APIサーバーはLDAPやKerberosなどの組織の既存の認証方法を活用できます。Kubernetesユーザーを認証する様々な方法の説明は認証 をご覧ください。認可 : 通常のユーザーを認可する際には、おそらくRBACとABACの認可方法のどちらかを選択することになります。様々なユーザーアカウントの認可方式(およびサービスアカウントによるクラスターがアクセスするための認可方式)を評価するために、認可の概要 をご覧ください。ロールベースアクセスコントロール : (RBAC ): 認証されたユーザーに特定の権限のセットを許可することによってクラスターへのアクセスを割り当てることができます。特定のNamespace(Role)やクラスター全体(ClusterRole)に権限を割り当てることができます。RoleBindingsやClusterRoleBindingsを使用することによって、権限を特定のユーザーに付与することができます。属性ベースアクセスコントロール (ABAC ): クラスターのリソース属性に基づいたポリシーを作成し、その属性に基づいてアクセスを許可または拒否することができます。ポリシーファイルの各行は、バージョニングプロパティ(apiVersionとkind)やsubject(ユーザーやグループ)に紐づくプロパティとリソースに紐づくプロパティとリソースに紐づかないプロパティ(/version or /apis)と読み取り専用プロパティを持つmapのspecプロパティを特定します。詳細は、Examples をご覧ください。プロダクション用のKubernetesクラスターの認証認可をセットアップするにあたって、いくつかの考慮事項があります。
認証モードの設定 : Kubernetes APIサーバー (kube-apiserver )の起動時に、--authorization-mode フラグを使用しサポートされた認証モードを設定しなければいけません。例えば、/etc/kubernetes/manifests 配下のkube-adminserver.yaml ファイルで*--authorization-mode*フラグにNodeやRBACを設定することで、認証されたリクエストに対してノードやRBACの認証を許可することができます。ユーザー証明書とロールバインディングの作成(RMAC) : RBAC認証を使用している場合、ユーザーはクラスター証明機関により署名された証明書署名要求(CSR)を作成でき、各ユーザーにRolesとClusterRolesをバインドすることができます。詳細は証明書署名要求 をご覧ください。属性を組み合わせたポリシーの作成(ABAC) : ABAC認証を使用している場合、特定のリソース(例えばPod)、Namespace、またはAPIグループにアクセスするために、選択されたユーザーやグループに属性の組み合わせで形成されたポリシーを割り当てることができます。より多くの情報はExamples をご覧ください。アドミッションコントローラーの考慮事項 : APIサーバーを経由してくるリクエストのための追加の認証形式にWebhookトークン認証 があります。Webhookや他の特別な認証形式はAPIサーバーへアドミッションコントローラーを追加し有効化される必要があります。ワークロードリソースの制限の設定 プロダクションワークロードからの要求はKubernetesのコントロールプレーンの内外の両方で負荷が生じる原因になります。クラスターのワークロードの需要に合わせて設定するためには、次の項目を考慮してください。
Namespaceの制限の設定 : メモリやCPUなどの項目のクォートをNamespaceごとに設定します。詳細については、メモリー、CPU、APIリソースの管理 をご覧ください。制限を継承するために階層型Namespace を設定することもできます。DNS要求のための準備 : ワークロードの急激なスケールアップを予測するのであれば、DNSサービスもスケールアップする準備をする必要があります。詳細については、クラスター内のDNSサービスのオートスケール をご覧ください。追加のサービスアカウントの作成 : ユーザーアカウントはクラスターで何ができるかを決定し、サービスアカウントは特定のNamespace内でのPodへのアクセスを定義します。
デフォルトでは、Podは名前空間のデフォルトのサービスアカウントを引き受けます。新規のサービスアカウントの作成についての情報はサービスアカウントの管理 をご覧ください。例えば、以下のようなことが考えられます:次の項目 2.2.1 - コンテナランタイム クラスター内の各ノードがPodを実行できるようにするため、コンテナランタイム をインストールする必要があります。
このページでは、ノードをセットアップするための概要と関連する作業について説明します。
Kubernetes 1.35においては、Container Runtime Interface (CRI)に準拠したランタイムを使用する必要があります。
詳しくはサポートするCRIのバージョン をご覧ください。
このページではいくつかの一般的なコンテナランタイムをKubernetesで使用する方法の概要を説明します。
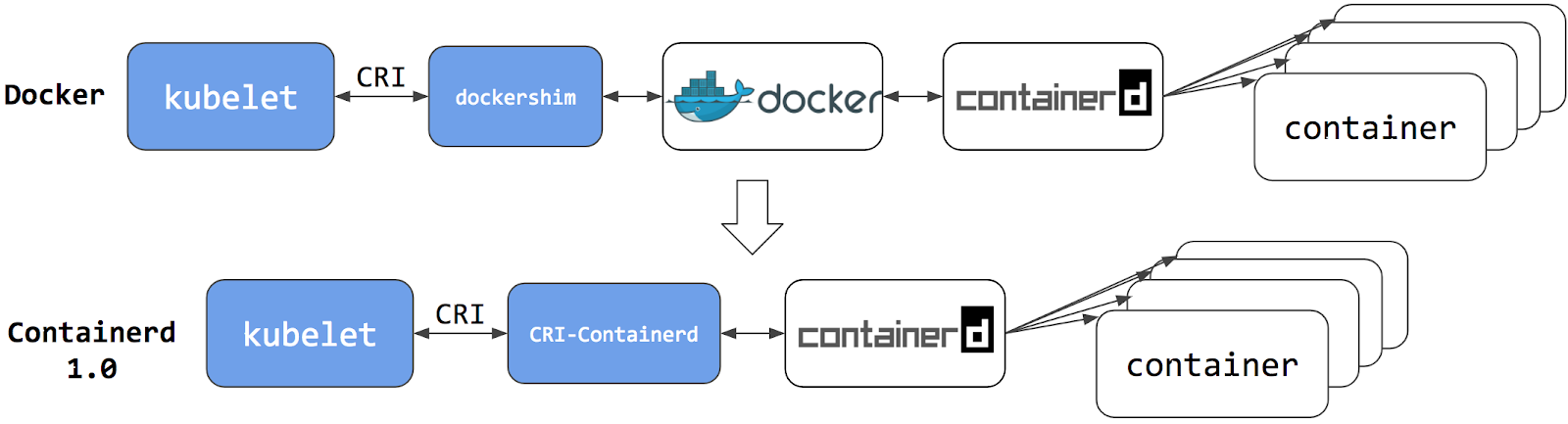
備考: v1.24以前のKubernetesリリースでは、 dockershim という名前のコンポーネントを使用したDocker Engineとの直接の統合が含まれていました。
この特別な直接統合は、もはやKubernetesの一部ではありません(この削除はv1.20リリースの一部として発表 されています)。
dockershimの廃止がどのような影響を与えるかについては、dockershim削除の影響範囲を確認する をご覧ください。
dockershimからの移行について知りたい場合、dockershimからの移行 を参照してください。
v1.35以外のバージョンのKubernetesを実行している場合、そのバージョンのドキュメントを確認してください。
インストールと設定の必須要件 以下の手順では、全コンテナランタイムに共通の設定をLinux上のKubernetesノードに適用します。
特定の設定が不要であることが分かっている場合、手順をスキップして頂いて構いません。
詳細については、Network Plugin Requirements または、特定のコンテナランタイムのドキュメントを参照してください。
IPv4フォワーディングを有効化し、iptablesからブリッジされたトラフィックを見えるようにする 以下のコマンドを実行します。
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
# この構成に必要なカーネルパラメーター、再起動しても値は永続します
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
# 再起動せずにカーネルパラメーターを適用
sudo sysctl --system
以下のコマンドを実行してbr_netfilterとoverlayモジュールが読み込まれていることを確認してください。
lsmod | grep br_netfilter
lsmod | grep overlay
以下のコマンドを実行して、net.bridge.bridge-nf-call-iptables、net.bridge.bridge-nf-call-ip6tables、net.ipv4.ip_forwardカーネルパラメーターが1に設定されていることを確認します。
sysctl net.bridge.bridge-nf-call-iptables net.bridge.bridge-nf-call-ip6tables net.ipv4.ip_forward
cgroupドライバー Linuxでは、プロセスに割り当てられるリソースを制約するためにcgroup が使用されます。
kubelet と基盤となるコンテナランタイムは、コンテナのリソース管理 を実施し、CPU/メモリーの要求や制限などのリソースを設定するため、cgroupとインターフェースする必要があります。
cgroupとインターフェースするために、kubeletおよびコンテナランタイムはcgroupドライバー を使用する必要があります。
この際、kubeletとコンテナランタイムが同一のcgroupドライバーを使用し、同一の設定を適用することが不可欠となります。
利用可能なcgroupドライバーは以下の2つです。
cgroupfsドライバー cgroupfsドライバーは、kubeletのデフォルトのcgroupドライバーです。
cgroupfsドライバーを使用すると、kubeletとコンテナランタイムはcgroupファイルシステムと直接インターフェースし、cgroupを設定します。
systemd がinitシステムである場合、cgroupfsドライバーは推奨されません 。
なぜなら、systemdはシステム上のcgroupマネージャーが単一であると想定しているからです。
また、cgroup v2 を使用している場合は、cgroupfsの代わりにsystemd cgroupドライバーを使用してください。
systemd cgroupドライバー Linuxディストリビューションのinitシステムにsystemd が選択されている場合、
initプロセスはルートcgroupを生成・消費し、cgroupマネージャーとして動作します。
systemdはcgroupと密接に連携しており、systemdユニットごとにcgroupを割り当てます。
その結果、initシステムにsystemdを使用した状態でcgroupfsドライバーを使用すると、
システムには2つの異なるcgroupマネージャーが存在することになります。
2つのcgroupマネージャーが存在することで、システムで利用可能なリソースおよび使用中のリソースに、2つの異なる見え方が与えられることになります。
特定の場合において、kubeletとコンテナランタイムにcgroupfsを、残りのプロセスにsystemdを使用するように設定されたノードが高負荷時に不安定になることがあります。
このような不安定性を緩和するためのアプローチは、systemdがinitシステムに採用されている場合にkubeletとコンテナランタイムのcgroupドライバーとしてsystemdを使用することです。
cgroupドライバーにsystemdを設定するには、以下のようにKubeletConfigurationcgroupDriverオプションを編集してsystemdを設定します。
apiVersion : kubelet.config.k8s.io/v1beta1
kind : KubeletConfiguration
...
cgroupDriver : systemd
kubelet用のcgroupドライバーとしてsystemdを設定する場合、コンテナランタイムのcgroupドライバーにもsystemdを設定する必要があります。
具体的な手順については、以下のリンクなどの、お使いのコンテナランタイムのドキュメントを参照してください。
注意: クラスターに参加したノードのcgroupドライバーを変更するのはデリケートな操作です。
kubeletが特定のcgroupドライバーのセマンティクスを使用してPodを作成していた場合、
コンテナランタイムを別のcgroupドライバーに変更すると、そのような既存のPodに対してPodサンドボックスを再作成しようとしたときにエラーが発生することがあります。
kubeletを再起動してもこのようなエラーは解決しない可能性があります。
もしあなたが適切な自動化の手段を持っているのであれば、更新された設定を使用してノードを別のノードに置き換えるか、自動化を使用して再インストールを行ってください。
kubeadmで管理されたクラスターでのsystemdドライバーへの移行 既存のkubeadm管理クラスターでsystemd cgroupドライバーに移行したい場合は、cgroupドライバーの設定 に従ってください。
サポートするCRIのバージョン コンテナランタイムは、Container Runtime Interfaceのv1alpha2以上をサポートする必要があります。
Kubernetes 1.35は、デフォルトでCRI APIのv1を使用します。
コンテナランタイムがv1 APIをサポートしていない場合、kubeletは代わりに(非推奨の)v1alpha2 APIにフォールバックします。
コンテナランタイム 備考: このセクションでは、Kubernetesが必要とする機能を提供するサードパーティープロジェクトにリンクしています。これらのプロジェクトはアルファベット順に記載されていて、Kubernetesプロジェクトの作者は責任を持ちません。このリストにプロジェクトを追加するには、変更を提出する前に
content guide をお読みください。
詳細はこちら。 containerd このセクションでは、CRIランタイムとしてcontainerdを使用するために必要な手順の概要を説明します。
以下のコマンドを使用して、システムにcontainerdをインストールします:
まずはcontainerdの使用を開始する の指示に従ってください。有効なconfig.toml設定ファイルを作成したら、このステップに戻ります。
このファイルはパス/etc/containerd/config.tomlにあります。
このファイルはC:\Program Files\containerd\config.tomlにあります。
Linuxでは、containerd用のデフォルトのCRIソケットは/run/containerd/containerd.sockです。
Windowsでは、デフォルトのCRIエンドポイントはnpipe://./pipe/containerd-containerdです。
systemd cgroupドライバーを構成する/etc/containerd/config.toml内でruncがsystemd cgroupドライバーを使うようにするには、Containerdのバージョンに基づいて以下の設定を行ってください。
Containerdバージョン1.x:
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
...
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true
Containerdバージョン2.x:
[plugins.'io.containerd.cri.v1.runtime'.containerd.runtimes.runc]
...
[plugins.'io.containerd.cri.v1.runtime'.containerd.runtimes.runc.options]
SystemdCgroup = true
cgroup v2 を使用する場合はsystemd cgroupドライバーの利用を推奨します。
備考: パッケージ(RPMや.debなど)からcontainerdをインストールした場合、
CRI統合プラグインがデフォルトで無効になっていることがあります。
Kubernetesでcontainerdを使用するには、CRIサポートを有効にする必要があります。
/etc/containerd/config.toml内のdisabled_pluginsリストにcriが含まれていないことを確認してください。
このファイルを変更した場合、containerdも再起動してください。
クラスターの初回構築後、またはCNIをインストールした後にコンテナのクラッシュループが発生した場合、
パッケージと共に提供されるcontainerdの設定に互換性のないパラメーターが含まれている可能性があります。
get-started.md にあるように、
containerd config default > /etc/containerd/config.tomlでcontainerdの設定をリセットした上で、
上記の設定パラメーターを使用することを検討してください。
この変更を適用した場合、必ずcontainerdを再起動してください。
sudo systemctl restart containerd
kubeadmを使用している場合、手動でkubelet cgroupドライバーの設定 を行ってください。
サンドボックス(pause)イメージの上書き containerdの設定 で以下の設定をすることで、サンドボックスのイメージを上書きすることができます。
[plugins."io.containerd.grpc.v1.cri" ]
sandbox_image = "registry.k8s.io/pause:3.2"
この場合も、設定ファイルの更新後にsystemctl restart containerdを実行してcontainerdも再起動する必要があるでしょう。
CRI-O 本セクションでは、コンテナランタイムとしてCRI-Oをインストールするために必要な手順を説明します。
CRI-Oをインストールするには、CRI-Oのインストール手順 に従ってください。
cgroupドライバー CRI-Oはデフォルトでsystemd cgroupドライバーを使用し、おそらく問題なく動作します。
cgroupfs cgroupドライバーに切り替えるには、/etc/crio/crio.conf を編集するか、
/etc/crio/crio.conf.d/02-cgroup-manager.confにドロップイン設定ファイルを置いて、以下のような設定を記述してください。
[crio.runtime]
conmon_cgroup = "pod"
cgroup_manager = "cgroupfs"
上記でconmon_cgroupも変更されていることに注意してください。
CRI-Oでcgroupfsを使用する場合、ここにはpodという値を設定する必要があります。
一般に、kubeletのcgroupドライバーの設定(通常はkubeadmによって行われます)とCRI-Oの設定は一致させる必要があります。
CRI-Oの場合、CRIソケットはデフォルトで/var/run/crio/crio.sockとなります。
サンドボックス(pause)イメージの上書き CRI-Oの設定 において、以下の値を設定することができます。
[crio.image]
pause_image="registry.k8s.io/pause:3.6"
このオプションはライブ設定リロードによる変更の適用に対応しています。
systemctl reload crioまたはcrioプロセスにSIGHUPを送信することで変更を適用できます。
Docker Engine 備考: この手順では、Docker EngineとKubernetesを統合するために
cri-dockerdアダプターを使用することを想定しています。
各ノードに、使用しているLinuxディストリビューション用のDockerをDocker Engineのインストール に従ってインストールします。
cri-dockerd
cri-dockerdの場合、CRIソケットはデフォルトで/run/cri-dockerd.sockになります。
Mirantis Container Runtime Mirantis Container Runtime (MCR)は、
以前はDocker Enterprise Editionとして知られていた、商業的に利用可能なコンテナランタイムです。
MCRに含まれるオープンソースのcri-dockerd
Mirantis Container Runtimeのインストール方法について知るには、MCRデプロイガイド を参照してください。
CRIソケットのパスを見つけるには、systemdのcri-docker.socketという名前のユニットを確認してください。
サンドボックス(pause)イメージを上書きする cri-dockerdアダプターは、Podインフラコンテナ("pause image")として使用するコンテナイメージを指定するためのコマンドライン引数を受け付けます。
使用するコマンドライン引数は --pod-infra-container-imageです。
次の項目 コンテナランタイムに加えて、クラスターには動作するネットワークプラグイン が必要です。
2.2.2 - Kubernetesをデプロイツールでインストールする
2.2.2.1 - kubeadmを使ってクラスターを構築する 2.2.2.1.1 - kubeadmのインストール このページではkubeadmコマンドをインストールする方法を示します。このインストール処理実行後にkubeadmを使用してクラスターを作成する方法については、kubeadmを使用したシングルマスタークラスターの作成 を参照してください。
始める前に 次のいずれかが動作しているマシンが必要ですUbuntu 16.04+ Debian 9+ CentOS 7 Red Hat Enterprise Linux (RHEL) 7 Fedora 25+ HypriotOS v1.0.1+ Container Linux (tested with 1800.6.0) 1台あたり2GB以上のメモリ(2GBの場合、アプリ用のスペースはほとんどありません) 2コア以上のCPU クラスター内のすべてのマシン間で通信可能なネットワーク(パブリックネットワークでもプライベートネットワークでも構いません) ユニークなhostname、MACアドレス、とproduct_uuidが各ノードに必要です。詳細はここ を参照してください。 マシン内の特定のポートが開いていること。詳細はここ を参照してください。 Swapがオフであること。kubeletが正常に動作するためにはswapは必ず オフでなければなりません。 MACアドレスとproduct_uuidが全てのノードでユニークであることの検証 ネットワークインターフェースのMACアドレスはip linkもしくはifconfig -aコマンドで取得できます。 product_uuidはsudo cat /sys/class/dmi/id/product_uuidコマンドで確認できます。 ハードウェアデバイスではユニークなアドレスが割り当てられる可能性が非常に高いですが、VMでは同じになることがあります。Kubernetesはこれらの値を使用して、クラスター内のノードを一意に識別します。これらの値が各ノードに固有ではない場合、インストール処理が失敗 することもあります。
ネットワークアダプタの確認 複数のネットワークアダプターがあり、Kubernetesコンポーネントにデフォルトで到達できない場合、IPルートを追加して、Kubernetesクラスターのアドレスが適切なアダプターを経由するように設定することをお勧めします。
必須ポートの確認 Kubernetesのコンポーネントが互いに通信するためには、これらの必要なポート が開いている必要があります。
netcat などのツールを使用することで、下記のようにポートが開いているかどうかを確認することが可能です。
nc 127.0.0.1 6443 -zv -w 2
使用するPodネットワークプラグインによっては、特定のポートを開く必要がある場合もあります。
これらは各Podネットワークプラグインによって異なるため、どのようなポートが必要かについては、プラグインのドキュメントを参照してください。
ランタイムのインストール Podのコンテナを実行するために、Kubernetesはコンテナランタイム を使用します。
デフォルトでは、Kubernetesは選択されたコンテナランタイムと通信するためにContainer Runtime Interface (CRI)を使用します。
ランタイムを指定しない場合、kubeadmはよく知られたUnixドメインソケットのリストをスキャンすることで、インストールされたコンテナランタイムの検出を試みます。
次の表がコンテナランタイムと関連するソケットのパスリストです。
コンテナランタイムとソケットパス ランタイム Unixドメインソケットのパス Docker /var/run/docker.sockcontainerd /run/containerd/containerd.sockCRI-O /var/run/crio/crio.sock
Dockerとcontainerdの両方が同時に検出された場合、Dockerが優先されます。Docker 18.09にはcontainerdが同梱されており、両方が検出可能であるため、この仕様が必要です。他の2つ以上のランタイムが検出された場合、kubeadmは適切なエラーメッセージで終了します。
kubeletは、組み込まれたdockershimCRIを通してDockerと連携します。
詳細は、コンテナランタイム を参照してください。
デフォルトでは、kubeadmはDocker をコンテナランタイムとして使用します。
kubeletは、組み込まれたdockershimCRIを通してDockerと連携します。
詳細は、コンテナランタイム を参照してください。
kubeadm、kubelet、kubectlのインストール 以下のパッケージをマシン上にインストールしてください
kubeadm: クラスターを起動するコマンドです。
kubelet: クラスター内のすべてのマシンで実行されるコンポーネントです。
Podやコンテナの起動などを行います。
kubectl: クラスターにアクセスするためのコマンドラインツールです。
kubeadmはkubeletやkubectlをインストールまたは管理しない ため、kubeadmにインストールするKubernetesコントロールプレーンのバージョンと一致させる必要があります。そうしないと、予期しないバグのある動作につながる可能性のあるバージョン差異(version skew)が発生するリスクがあります。ただし、kubeletとコントロールプレーン間のマイナーバージョン差異(minor version skew)は_1つ_サポートされていますが、kubeletバージョンがAPIサーバーのバージョンを超えることはできません。たとえば、1.7.0を実行するkubeletは1.8.0 APIサーバーと完全に互換性がありますが、その逆はできません。
kubectlのインストールに関する詳細情報は、kubectlのインストールおよびセットアップ を参照してください。
警告: これらの手順はシステムアップグレードによるすべてのKubernetesパッケージの更新を除きます。これはkubeadmとKubernetesが
アップグレードにおける特別な注意 を必要とするからです。
バージョン差異(version skew)に関しては下記を参照してください。
aptのパッケージ一覧を更新し、Kubernetesのaptリポジトリーを利用するのに必要なパッケージをインストールします:
sudo apt-get update
# apt-transport-httpsはダミーパッケージの可能性があります。その場合、そのパッケージはスキップできます
sudo apt-get install -y apt-transport-https ca-certificates curl gpg
Kubernetesパッケージリポジトリーの公開署名キーをダウンロードします。すべてのリポジトリーに同じ署名キーが使用されるため、URL内のバージョンは無視できます:
# `/etc/apt/keyrings`フォルダーが存在しない場合は、curlコマンドの前に作成する必要があります。下記の備考を参照してください。
# sudo mkdir -p -m 755 /etc/apt/keyrings
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.35/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
備考: Debian 12とUbuntu 22.04より古いリリースでは、/etc/apt/keyringsフォルダーはデフォルトでは存在しないため、curlコマンドの前に作成する必要があります。適切なKubernetes aptリポジトリーを追加します。このリポジトリーには、Kubernetes 1.35用のパッケージのみがあることに注意してください。他のKubernetesマイナーバージョンの場合は、目的のマイナーバージョンに一致するようにURL内のKubernetesマイナーバージョンを変更する必要があります(インストールする予定のKubernetesバージョンのドキュメントも読んでください):
# これにより、/etc/apt/sources.list.d/kubernetes.listにある既存の設定が上書きされます
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.35/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
aptのパッケージ一覧を更新し、kubelet、kubeadm、kubectlをインストールします。そしてバージョンを固定します:
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
# SELinuxをpermissiveモードに設定する(効果的に無効化する)
setenforce 0
sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
yum install -y kubelet kubeadm kubectl --disableexcludes= kubernetes
systemctl enable --now kubelet
Note:
setenforce 0およびsed ...を実行することによりSELinuxをpermissiveモードに設定し、効果的に無効化できます。
これはコンテナがホストのファイルシステムにアクセスするために必要です。例えば、Podのネットワークに必要とされます。
kubeletにおけるSELinuxのサポートが改善されるまでは、これを実行しなければなりません。
CNIプラグインをインストールする(ほとんどのPodのネットワークに必要です):
CNI_VERSION = "v0.8.2"
ARCH = "amd64"
mkdir -p /opt/cni/bin
curl -L "https://github.com/containernetworking/plugins/releases/download/ ${ CNI_VERSION } /cni-plugins-linux- ${ ARCH } - ${ CNI_VERSION } .tgz" | tar -C /opt/cni/bin -xz
crictlをインストールする (kubeadm / Kubelet Container Runtime Interface (CRI)に必要です)
CRICTL_VERSION = "v1.22.0"
ARCH = "amd64"
curl -L "https://github.com/kubernetes-sigs/cri-tools/releases/download/ ${ CRICTL_VERSION } /crictl- ${ CRICTL_VERSION } -linux- ${ ARCH } .tar.gz" | sudo tar -C $DOWNLOAD_DIR -xz
kubeadm、kubelet、kubectlをインストールしkubeletをsystemd serviceに登録します:
RELEASE = " $( curl -sSL https://dl.k8s.io/release/stable.txt) "
ARCH = "amd64"
mkdir -p /opt/bin
cd /opt/bin
curl -L --remote-name-all https://dl.k8s.io/release/${ RELEASE } /bin/linux/${ ARCH } /{ kubeadm,kubelet,kubectl}
chmod +x { kubeadm,kubelet,kubectl}
curl -sSL "https://raw.githubusercontent.com/kubernetes/kubernetes/ ${ RELEASE } /build/debs/kubelet.service" | sed "s:/usr/bin:/opt/bin:g" > /etc/systemd/system/kubelet.service
mkdir -p /etc/systemd/system/kubelet.service.d
curl -sSL "https://raw.githubusercontent.com/kubernetes/kubernetes/ ${ RELEASE } /build/debs/10-kubeadm.conf" | sed "s:/usr/bin:/opt/bin:g" > /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
kubeletを有効化し起動します:
systemctl enable --now kubelet
kubeadmが何をすべきか指示するまで、kubeletはクラッシュループで数秒ごとに再起動します。
コントロールプレーンノードのkubeletによって使用されるcgroupドライバーの設定 Dockerを使用した場合、kubeadmは自動的にkubelet向けのcgroupドライバーを検出し、それを実行時に/var/lib/kubelet/kubeadm-flags.envファイルに設定します。
もしあなたが異なるCRIを使用している場合、/etc/default/kubelet(CentOS、RHEL、Fedoraでは/etc/sysconfig/kubelet)ファイル内のcgroup-driverの値を以下のように変更する必要があります。
KUBELET_EXTRA_ARGS = --cgroup-driver= <value>
このファイルは、kubeletの追加のユーザー定義引数を取得するために、kubeadm initおよびkubeadm joinによって使用されます。
CRIのcgroupドライバーがcgroupfsでない場合にのみ それを行う必要があることに注意してください。なぜなら、これはすでにkubeletのデフォルト値であるためです。
kubeletをリスタートする方法:
systemctl daemon-reload
systemctl restart kubelet
CRI-Oやcontainerdといった他のコンテナランタイムのcgroup driverは実行中に自動的に検出されます。
トラブルシュート kubeadmで問題が発生した場合は、トラブルシューティング を参照してください。
次の項目 2.2.2.1.2 - kubeadmのトラブルシューティング どのプログラムでもそうですが、kubeadmのインストールや実行でエラーが発生することがあります。このページでは、一般的な失敗例をいくつか挙げ、問題を理解して解決するための手順を示しています。
本ページに問題が記載されていない場合は、以下の手順を行ってください:
RBACがないため、v1.18ノードをv1.17クラスターに結合できない v1.18では、同名のノードが既に存在する場合にクラスター内のノードに参加しないようにする機能を追加しました。これには、ブートストラップトークンユーザがNodeオブジェクトをGETできるようにRBACを追加する必要がありました。
しかし、これによりv1.18のkubeadm joinがkubeadm v1.17で作成したクラスターに参加できないという問題が発生します。
この問題を回避するには、次の2つの方法があります。
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRole
metadata :
name : kubeadm:get-nodes
rules :
apiGroups :
- ""
resources :
- nodes
verbs :
- get
---
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRoleBinding
metadata :
name : kubeadm:get-nodes
roleRef :
apiGroup : rbac.authorization.k8s.io
kind : ClusterRole
name : kubeadm:get-nodes
subjects :
apiGroup : rbac.authorization.k8s.io
kind : Group
name : system:bootstrappers:kubeadm:default-node-token
インストール中にebtablesもしくは他の似たような実行プログラムが見つからない kubeadm initの実行中に以下のような警告が表示された場合は、以降に記載するやり方を行ってください。
[ preflight] WARNING: ebtables not found in system path
[ preflight] WARNING: ethtool not found in system path
このような場合、ノード上にebtables, ethtoolなどの実行ファイルがない可能性があります。これらをインストールするには、以下のコマンドを実行します。
Ubuntu/Debianユーザーは、apt install ebtables ethtoolを実行してください。 CentOS/Fedoraユーザーは、yum install ebtables ethtoolを実行してください。 インストール中にkubeadmがコントロールプレーンを待ち続けて止まる 以下のを出力した後にkubeadm initが止まる場合は、kubeadm initを実行してください:
[ apiclient] Created API client, waiting for the control plane to become ready
これはいくつかの問題が原因となっている可能性があります。最も一般的なのは:
ネットワーク接続の問題が挙げられます。続行する前に、お使いのマシンがネットワークに完全に接続されていることを確認してください。
kubeletのデフォルトのcgroupドライバの設定がDockerで使用されているものとは異なっている場合も考えられます。
システムログファイル(例: /var/log/message)をチェックするか、journalctl -u kubeletの出力を調べてください:
error: failed to run Kubelet: failed to create kubelet:
misconfiguration: kubelet cgroup driver: "systemd" is different from docker cgroup driver: "cgroupfs"
以上のようなエラーが現れていた場合、cgroupドライバの問題を解決するには、以下の2つの方法があります:
ここ の指示に従ってDockerを再度インストールします。
Dockerのcgroupドライバに合わせてkubeletの設定を手動で変更します。その際は、マスターノード上でkubeletが使用するcgroupドライバを設定する を参照してください。
control plane Dockerコンテナがクラッシュループしたり、ハングしたりしています。これはdocker psを実行し、docker logsを実行して各コンテナを調査することで確認できます。 管理コンテナを削除する時にkubeadmが止まる Dockerが停止して、Kubernetesで管理されているコンテナを削除しないと、以下のようなことが起こる可能性があります:
sudo kubeadm reset
[ preflight] Running pre-flight checks
[ reset] Stopping the kubelet service
[ reset] Unmounting mounted directories in "/var/lib/kubelet"
[ reset] Removing kubernetes-managed containers
( block)
考えられる解決策は、Dockerサービスを再起動してからkubeadm resetを再実行することです:
sudo systemctl restart docker.service
sudo kubeadm reset
dockerのログを調べるのも有効な場合があります:
Podの状態がRunContainerError、CrashLoopBackOff、またはErrorとなる kubeadm initの直後には、これらの状態ではPodは存在しないはずです。
kubeadm initの 直後 にこれらの状態のいずれかにPodがある場合は、kubeadmのリポジトリにIssueを立ててください。ネットワークソリューションをデプロイするまではcoredns(またはkube-dns)はPending状態でなければなりません。ネットワークソリューションをデプロイしてもcoredns(またはkube-dns)に何も起こらない場合にRunContainerError、CrashLoopBackOff、Error`の状態でPodが表示された場合は、インストールしたPodネットワークソリューションが壊れている可能性が高いです。より多くのRBACの特権を付与するか、新しいバージョンを使用する必要があるかもしれません。PodネットワークプロバイダのイシュートラッカーにIssueを出して、そこで問題をトリアージしてください。 1.12.1よりも古いバージョンのDockerをインストールした場合は、systemdでdockerdを起動する際にMountFlags=slaveオプションを削除してdockerを再起動してください。マウントフラグは/usr/lib/systemd/system/docker.serviceで確認できます。MountFlagsはKubernetesがマウントしたボリュームに干渉し、PodsをCrashLoopBackOff状態にすることがあります。このエラーは、Kubernetesがvar/run/secrets/kubernetes.io/serviceaccountファイルを見つけられない場合に発生します。 coredns(もしくはkube-dns)がPending状態でスタックするkubeadmはネットワークプロバイダに依存しないため、管理者は選択したPodネットワークソリューションをインストール をする必要があります。CoreDNSを完全にデプロイする前にPodネットワークをインストールする必要があります。したがって、ネットワークがセットアップされる前の Pending状態になります。
HostPortサービスが動かないHostPortとHostIPの機能は、ご使用のPodネットワークプロバイダによって利用可能です。Podネットワークソリューションの作者に連絡して、HostPortとHostIP機能が利用可能かどうかを確認してください。
Calico、Canal、FlannelのCNIプロバイダは、HostPortをサポートしていることが確認されています。
詳細については、[CNI portmap documentation] (https://github.com/containernetworking/plugins/blob/master/plugins/meta/portmap/README.md ) を参照してください。
ネットワークプロバイダが portmap CNI プラグインをサポートしていない場合は、NodePortサービス を使用するか、HostNetwork=trueを使用してください。
サービスIP経由でPodにアクセスすることができない 多くのネットワークアドオンは、PodがサービスIPを介して自分自身にアクセスできるようにするヘアピンモード を有効にしていません。これはCNI に関連する問題です。ヘアピンモードのサポート状況については、ネットワークアドオンプロバイダにお問い合わせください。
VirtualBoxを使用している場合(直接またはVagrant経由)は、hostname -iがルーティング可能なIPアドレスを返すことを確認する必要があります。デフォルトでは、最初のインターフェースはルーティング可能でないホスト専用のネットワークに接続されています。これを回避するには/etc/hostsを修正する必要があります。例としてはこのVagrantfile を参照してください。
TLS証明書のエラー 以下のエラーは、証明書の不一致の可能性を示しています。
# kubectl get pods
Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of "crypto/rsa: verification error" while trying to verify candidate authority certificate "kubernetes")
HOME/.kube/configファイルに有効な証明書が含まれていることを確認し、必要に応じて証明書を再生成します。kubeconfigファイル内の証明書はbase64でエンコードされています。証明書をデコードするにはbase64 --decodeコマンドを、証明書情報を表示するにはopenssl x509 -text -nooutコマンドを用いてください。
環境変数KUBECONFIGの設定を解除するには以下のコマンドを実行するか:
設定をデフォルトのKUBECONFIGの場所に設定します:
export KUBECONFIG = /etc/kubernetes/admin.conf
もう一つの回避策は、既存のkubeconfigを"admin"ユーザに上書きすることです:
mv $HOME /.kube $HOME /.kube.bak
mkdir $HOME /.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME /.kube/config
sudo chown $( id -u) :$( id -g) $HOME /.kube/config
Vagrant内でPodネットワークとしてflannelを使用する時のデフォルトNIC 以下のエラーは、Podネットワークに何か問題があったことを示している可能性を示しています:
Error from server ( NotFound) : the server could not find the requested resource
Vagrant内のPodネットワークとしてflannelを使用している場合は、flannelのデフォルトのインターフェース名を指定する必要があります。
Vagrantは通常、2つのインターフェースを全てのVMに割り当てます。1つ目は全てのホストにIPアドレス10.0.2.15が割り当てられており、NATされる外部トラフィックのためのものです。
これは、ホストの最初のインターフェースをデフォルトにしているflannelの問題につながるかもしれません。これは、すべてのホストが同じパブリックIPアドレスを持っていると考えます。これを防ぐには、2番目のインターフェースが選択されるように --iface eth1フラグをflannelに渡してください。
公開されていないIPがコンテナに使われている 状況によっては、kubectl logsやkubectl runコマンドが以下のようなエラーを返すことがあります:
Error from server: Get https://10.19.0.41:10250/containerLogs/default/mysql-ddc65b868-glc5m/mysql: dial tcp 10.19.0.41:10250: getsockopt: no route to host
これには、おそらくマシンプロバイダのポリシーによって、一見同じサブネット上の他のIPと通信できないIPをKubernetesが使用している可能性があります。
DigitalOceanはパブリックIPとプライベートIPをeth0に割り当てていますが、kubeletはパブリックIPではなく、ノードのInternalIPとして後者を選択します。
ifconfigではエイリアスIPアドレスが表示されないため、ifconfigの代わりにip addr showを使用してこのシナリオをチェックしてください。あるいは、DigitalOcean専用のAPIエンドポイントを使用して、ドロップレットからアンカーIPを取得することもできます:
curl http://169.254.169.254/metadata/v1/interfaces/public/0/anchor_ipv4/address
回避策としては、--node-ipを使ってどのIPを使うかをkubeletに伝えることです。DigitalOceanを使用する場合、オプションのプライベートネットワークを使用したい場合は、パブリックIP(eth0に割り当てられている)かプライベートIP(eth1に割り当てられている)のどちらかを指定します。これにはkubeadm NodeRegistrationOptions構造体の KubeletExtraArgsセクション
kubeletを再起動してください:
systemctl daemon-reload
systemctl restart kubelet
corednsのPodがCrashLoopBackOffもしくはError状態になるSELinuxを実行しているノードで古いバージョンのDockerを使用している場合、coredns Podが起動しないということが起きるかもしれません。この問題を解決するには、以下のオプションのいずれかを試してみてください:
kubectl -n kube-system get deployment coredns -o yaml | \
's/allowPrivilegeEscalation: false/allowPrivilegeEscalation: true/g' | \
CoreDNSにCrashLoopBackOffが発生する別の原因は、KubernetesにデプロイされたCoreDNS Podがループを検出したときに発生します。CoreDNSがループを検出して終了するたびに、KubernetesがCoreDNS Podを再起動しようとするのを避けるために、いくつかの回避策 が用意されています。
警告: SELinuxを無効にするかallowPrivilegeEscalationをtrueに設定すると、クラスターのセキュリティが損なわれる可能性があります。etcdのpodが継続的に再起動する 以下のエラーが発生した場合は:
rpc error: code = 2 desc = oci runtime error: exec failed: container_linux.go:247: starting container process caused "process_linux.go:110: decoding init error from pipe caused \"read parent: connection reset by peer\""
この問題は、CentOS 7をDocker 1.13.1.84で実行した場合に表示されます。このバージョンのDockerでは、kubeletがetcdコンテナに実行されないようにすることができます。
この問題を回避するには、以下のいずれかのオプションを選択します:
1.13.1-75のような以前のバージョンのDockerにロールバックする yum downgrade docker-1.13.1-75.git8633870.el7.centos.x86_64 docker-client-1.13.1-75.git8633870.el7.centos.x86_64 docker-common-1.13.1-75.git8633870.el7.centos.x86_64
18.06のような最新の推奨バージョンをインストールする: sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum install docker-ce-18.06.1.ce-3.el7.x86_64
-component-extra-argsのようなkubeadm initフラグを使うと、kube-apiserverのようなコントロールプレーンコンポーネントにカスタム引数を渡すことができます。しかし、このメカニズムは値の解析に使われる基本的な型 (mapStringString) のために制限されています。
もし、--apiserver-extra-args "enable-admission plugins=LimitRanger,NamespaceExists"のようにカンマで区切られた複数の値をサポートする引数を渡した場合、このフラグはflag: malformed pair, expect string=stringで失敗します。これは--apiserver-extra-argsの引数リストがkey=valueのペアを期待しており、この場合NamespacesExistsは値を欠いたキーとみなされるためです。
別の方法として、key=valueのペアを以下のように分離してみることもできます:
--apiserver-extra-args "enable-admission-plugins=LimitRanger,enable-admission-plugins=NamespaceExists"しかし、この場合は、キーenable-admission-pluginsはNamespaceExistsの値しか持ちません。既知の回避策としては、kubeadm設定ファイル を使用することが挙げられます。
cloud-controller-managerによってノードが初期化される前にkube-proxyがスケジューリングされる クラウドプロバイダのシナリオでは、クラウドコントローラーマネージャがノードアドレスを初期化する前に、kube-proxyが新しいワーカーノードでスケジューリングされてしまうことがあります。これにより、kube-proxyがノードのIPアドレスを正しく拾えず、ロードバランサを管理するプロキシ機能に悪影響を及ぼします。
kube-proxy Podsでは以下のようなエラーが発生します:
server.go:610] Failed to retrieve node IP: host IP unknown; known addresses: []
proxier.go:340] invalid nodeIP, initializing kube-proxy with 127.0.0.1 as nodeIP
既知の解決策は、初期のガード条件が緩和されるまで他のノードから離しておき、条件に関係なくコントロールプレーンノード上でスケジューリングできるように、キューブプロキシDaemonSetにパッチを当てることです:
kubectl -n kube-system patch ds kube-proxy -p='{ "spec": { "template": { "spec": { "tolerations": [ { "key": "CriticalAddonsOnly", "operator": "Exists" }, { "effect": "NoSchedule", "key": "node-role.kubernetes.io/master" } ] } } } }'
Tこの問題のトラッキング問題はこちら 。
kubeadmの設定をマーシャリングする際、NodeRegistration.Taintsフィールドが省略される 注意: このIssue は、kubeadmタイプをマーシャルするツール(YAML設定ファイルなど)にのみ適用されます。これはkubeadm API v1beta2で修正される予定です。
デフォルトでは、kubeadmはコントロールプレーンノードにnode-role.kubernetes.io/master:NoScheduleのテイントを適用します。kubeadmがコントロールプレーンノードに影響を与えないようにし、InitConfiguration.NodeRegistration.Taintsを空のスライスに設定すると、マーシャリング時にこのフィールドは省略されます。フィールドが省略された場合、kubeadmはデフォルトのテイントを適用します。
少なくとも2つの回避策があります:
空のスライスの代わりにnode-role.kubernetes.io/master:PreferNoScheduleテイントを使用します。他のノードに容量がない限り、Podsはマスター上でスケジュールされます 。
kubeadm init終了後のテイントの除去:
kubectl taint nodes NODE_NAME node-role.kubernetes.io/master:NoSchedule-
ノード{#usr-mounted-read-only}に/usrが読み取り専用でマウントされる Fedora CoreOSなどのLinuxディストリビューションでは、ディレクトリ/usrが読み取り専用のファイルシステムとしてマウントされます。 flex-volumeサポート では、kubeletやkube-controller-managerのようなKubernetesコンポーネントはデフォルトで/usr/libexec/kubernetes/kubelet-plugins/volume/exec/のパスを使用していますが、この機能を動作させるためにはflex-volumeディレクトリは 書き込み可能 な状態でなければなりません。
この問題を回避するには、kubeadm設定ファイル を使用してflex-volumeディレクトリを設定します。
プライマリコントロールプレーンノード(kubeadm initで作成されたもの)上で、--configで以下のファイルを渡します:
apiVersion : kubeadm.k8s.io/v1beta2
kind : InitConfiguration
nodeRegistration :
kubeletExtraArgs :
volume-plugin-dir : "/opt/libexec/kubernetes/kubelet-plugins/volume/exec/"
---
apiVersion : kubeadm.k8s.io/v1beta2
kind : ClusterConfiguration
controllerManager :
extraArgs :
flex-volume-plugin-dir : "/opt/libexec/kubernetes/kubelet-plugins/volume/exec/"
ノードをジョインするには:
apiVersion : kubeadm.k8s.io/v1beta2
kind : JoinConfiguration
nodeRegistration :
kubeletExtraArgs :
volume-plugin-dir : "/opt/libexec/kubernetes/kubelet-plugins/volume/exec/"
あるいは、/usrマウントを書き込み可能にするために /etc/fstabを変更することもできますが、これはLinuxディストリビューションの設計原理を変更していることに注意してください。
kubeadm upgrade planがcontext deadline exceededエラーメッセージを表示するこのエラーメッセージは、外部etcdを実行している場合にkubeadmでKubernetesクラスターをアップグレードする際に表示されます。これは致命的なバグではなく、古いバージョンのkubeadmが外部etcdクラスターのバージョンチェックを行うために発生します。kubeadm upgrade apply ...で進めることができます。
この問題はバージョン1.19で修正されます。
2.2.2.1.3 - kubeadmを使用したクラスターの作成 kubeadmを使用すれば、Kubernetes Conformance tests に通るクラスターをセットアップすることができます。
kubeadmは、ブートストラップトークン やクラスターのアップグレードなどのその他のクラスターのライフサイクルの機能もサポートします。
kubeadmツールは、次のようなときに適しています。
新しいユーザーが初めてKubernetesを試すためのシンプルな方法が必要なとき。 既存のユーザーがクラスターのセットアップを自動化し、アプリケーションをテストする方法が必要なとき。 より大きなスコープで、他のエコシステムやインストーラーツールのビルディングブロックが必要なとき。 kubeadmは、ラップトップ、クラウドのサーバー群、Raspberry Piなどの様々なマシンにインストールして使えます。クラウドとオンプレミスのどちらにデプロイする場合でも、kubeadmはAnsibleやTerraformなどのプロビジョニングシステムに統合できます。
始める前に このガイドを進めるには、以下の環境が必要です。
UbuntuやCentOSなど、deb/rpmパッケージと互換性のあるLinux OSが動作している1台以上のマシンがあること。 マシンごとに2GiB以上のRAMが搭載されていること。それ以下の場合、アプリ実行用のメモリがほとんど残りません。 コントロールプレーンノードとして使用するマシンには、最低でも2CPU以上あること。 クラスター内の全マシン間に完全なネットワーク接続があること。パブリックネットワークとプライベートネットワークのいずれでも使えます。 また、新しいクラスターで使いたいKubernetesのバージョンをデプロイできるバージョンのkubeadmを使用する必要もあります。
Kubernetesのバージョンとバージョンスキューポリシー は、kubeadmにもKubernetes全体と同じように当てはまります。
Kubernetesとkubeadmがサポートするバージョンを理解するには、上記のポリシーを確認してください。このページは、Kubernetes v1.35向けに書かれています。
kubeadmツールの全体の機能の状態は、一般利用可能(GA)です。一部のサブ機能はまだ活発に開発が行われています。クラスター作成の実装は、ツールの進化に伴ってわずかに変わるかもしれませんが、全体の実装は非常に安定しているはずです。
備考: kubeadm alpha以下のすべてのコマンドは、定義通り、アルファレベルでサポートされています。目的 シングルコントロールプレーンのKubernetesクラスターをインストールします クラスター上にPodネットワークをインストールして、Podがお互いに通信できるようにします 手順 ホストの準備 コンポーネントのインストール コンテナランタイム と、kubeadmを全てのホストにインストールしてください。
インストールの詳細やその他の準備については、kubeadmのインストール を読んでください。
備考: すでにkubeadmがインストール済みである場合は、kubeadmのアップグレード手順についてはLinuxノードのアップグレード の最初の2ステップを確認してください。
アップグレード中、kubeletはクラッシュループによってkubeadmの指示を待つため、数秒ごとに再起動します。
このクラッシュループは想定内の正常な動作です。
コントロールプレーンの初期化が完了すれば、kubeletは正常に動作します。
ネットワークの設定 kubeadmは他のKubernetesコンポーネントと同様に、ホスト上のデフォルトゲートウェイとなっているネットワークインターフェースと関連づけられた利用可能なIPアドレスを探索します。
このIPアドレスは、コンポーネントによるアドバタイズや受信に使用されます。
Linuxのホスト上でこのIPを確認するには次のようにします:
ip route show # "default via"で始まる行を探してください。
備考: 2つ以上のデフォルトゲートウェイがホスト上に存在する場合、Kubernetesコンポーネントは、適切なグローバルユニキャストIPアドレスを持つ最初に検出したゲートウェイを使用しようとします。
この選択を行う際、ゲートウェイの正確な順序は、オペレーティングシステムやカーネルのバージョンにより異なる場合があります。Kubernetesコンポーネントはカスタムネットワークインターフェースをオプションとして受け入れないため、カスタム構成を必要とする全てのコンポーネントのインスタンスにカスタムIPアドレスをフラグとして渡す必要があります。
備考: ホストにデフォルトゲートウェイが存在せず、カスタムIPがKubernetesコンポーネントに渡されない場合、コンポーネントはエラーで終了する可能性があります。initおよびjoinで作成されたコントロールプレーンに対してAPIサーバーのアドバタイズアドレスを設定するには、--apiserver-advertise-addressフラグを使用します。
このオプションは、可能であればkubeadm API においてInitConfiguration.localAPIEndpointおよびJoinConfiguration.controlPlane.localAPIEndpointとして設定するのが望ましいです。
全てのノード上のkubeletに対して、--node-ipオプションはkubeadmの設定ファイル(InitConfigurationまたはJoinConfiguration)の.nodeRegistration.kubeletExtraArgsにて指定することができます。
デュアルスタックについては、kubeadmによるデュアルスタックのサポート を参照してください。
コントロールプレーンのコンポーネントに割り当てたIPアドレスは、X.509証明書のSubject Alternative Nameフィールドの一部になります。
これらのIPアドレスを変更するには、新しい証明書に署名し、影響を受けるコンポーネントを再起動する必要があります。
これにより、証明書ファイルの変更が反映されます。
詳細は、kubeadmによる証明書管理 を参照してください。
警告: Kubernetesプロジェクトは、このアプローチ(全てのコンポーネントのインスタンスにカスタムIPアドレスを設定すること)を推奨していません。
代わりに、Kubernetesメンテナーはホストネットワークを設定することを推奨しています。
これにより、KubernetesコンポーネントがデフォルトゲートウェイのIPを自動検出し使用できるようになります。
Linuxノード上では、ネットワーク設定にip routeのようなコマンドを使用できます。
また、オペレーティングシステムによってはより高レベルなネットワーク管理ツールが提供される場合もあります。
ノードのデフォルトゲートウェイがパブリックアドレスの場合、ノードやクラスターを保護するためにパケットフィルタリングなどのセキュリティ対策を行う必要があります。必要なコンテナイメージの準備 このステップは任意で、kubeadm initおよびkubeadm join実行時にregistry.k8s.ioに存在するデフォルトのコンテナイメージをダウンロードしない場合のみ行います。
kubeadmは、ノードにインターネット接続がない状態でクラスターを構築する際に、必要なイメージを事前に取得するのに役立つコマンドがあります。
詳細は、インターネット接続無しでのkubeadmの稼働 を参照してください。
kubeadmはカスタムイメージリポジトリから必要なイメージを使用することもできます。
詳細はカスタムイメージの使用 を参照してください。
コントロールプレーンノードの初期化 コントロールプレーンノードとは、etcd (クラスターのデータベース)やAPIサーバー (kubectl コマンドラインツールが通信する相手)などのコントロールプレーンのコンポーネントが実行されるマシンです。
(推奨)シングルコントロールプレーンのkubeadmクラスターを高可用性クラスター にアップグレードする予定がある場合、--control-plane-endpointを指定して、すべてのコントロールプレーンノードとエンドポイントを共有する必要があります。
エンドポイントにはDNS名やロードバランサーのIPアドレスが使用できます。 Podネットワークアドオンを選んで、kubeadm initに引数を渡す必要があるかどうか確認してください。
選んだサードパーティのプロバイダーによっては、--pod-network-cidrをプロバイダー固有の値に設定する必要がある場合があります。
詳しくは、Podネットワークアドオンのインストール を参照してください。 (オプション)kubeadmは既知のエンドポイントの一覧を用いて、コンテナランタイムの検出を試みます。
異なるコンテナランタイムを使用する場合やプロビジョニングするノードに2つ以上のランタイムがインストールされている場合、kubeadmに--cri-socket引数を指定してください。
詳しくは、ランタイムのインストール を参照してください。 コントロールプレーンノードを初期化するには、次のコマンドを実行します。
apiserver-advertise-addressとControlPlaneEndpointに関する検討 --apiserver-advertise-addressは、特定のコントロールプレーンノードのAPIサーバーがアドバタイズするアドレスを設定するために使用できます。
一方--control-plane-endpointは、すべてのコントロールプレーンノード共有のエンドポイントを設定するために使用できます。
--control-plane-endpointはIPアドレスと、IPアドレスへマッピングできるDNS名を使用できます。利用可能なソリューションをそうしたマッピングの観点から評価するには、ネットワーク管理者に相談してください。
以下にマッピングの例を示します。
192.168.0.102 cluster-endpoint
ここでは、192.168.0.102がこのノードのIPアドレスであり、cluster-endpointがこのIPアドレスへとマッピングされるカスタムDNS名です。
このように設定することで、--control-plane-endpoint=cluster-endpointをkubeadm initに渡せるようになり、kubeadm joinにも同じDNS名を渡せます。
後でcluster-endpointを修正して、高可用性が必要なシナリオでロードバランサーのアドレスを指すようにすることができます。
kubeadmでは、--control-plane-endpointを渡さずに構築したシングルコントロールプレーンのクラスターを高可用性クラスターに切り替えることはサポートされていません。
詳細な情報 kubeadm initの引数のより詳細な情報は、kubeadmリファレンスガイド を参照してください。
kubeadm initを設定ファイルにて設定するには、設定ファイルのドキュメント を参照してください。
コントロールプレーンコンポーネントやetcdサーバーのliveness probeへのオプションのIPv6の割り当てなど、コントロールプレーンのコンポーネントをカスタマイズしたい場合は、カスタムの引数 に示されている方法で各コンポーネントに追加の引数を与えてください。
既存のクラスターの再設定を行う場合は、kubeadmクラスターの再設定 を参照してください。
kubeadm initを再び実行する場合は、初めにクラスターの破棄 を行う必要があります。
もし異なるアーキテクチャのノードをクラスターにjoinさせたい場合は、デプロイしたDaemonSetがそのアーキテクチャ向けのコンテナイメージをサポートしているか確認してください。
初めにkubeadm initは、マシンがKubernetesを実行する準備ができているかを確認するための、一連の事前チェックを行います。
これらの事前チェックは、エラー発生時には警告を表示して終了します。
次に、kubeadm initはクラスターのコントロールプレーンのコンポーネントをダウンロードしてインストールします。
これには数分掛かるかもしれません。
これらが終了すると以下が出力されます。
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a Pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
/docs/concepts/cluster-administration/addons/
You can now join any number of machines by running the following on each node
as root:
kubeadm join <control-plane-host>:<control-plane-port> --token <token> --discovery-token-ca-cert-hash sha256:<hash>
kubectlをroot以外のユーザーでも実行できるようにするには、次のコマンドを実行します。これらのコマンドは、kubeadm initの出力の中にも書かれています。
mkdir -p $HOME /.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME /.kube/config
sudo chown $( id -u) :$( id -g) $HOME /.kube/config
rootユーザーの場合は、代わりに次のコマンドを実行します。
export KUBECONFIG = /etc/kubernetes/admin.conf
警告: kubeadm initによって生成されたkubeconfigファイルのadmin.confは、Subject: O = kubeadm:cluster-admins, CN = kubernetes-admin
の証明書を内包しています。
kubeadm:cluster-adminsグループは、ビルトインのClusterRoleであるcluster-adminと紐づいています。
admin.confは誰とも共有しないでください。
kubeadm initは、別のkubeconfigファイルであるsuper-admin.confも生成します。
これは、Subject: O = system:masters, CN = kubernetes-super-adminの証明書を内包しています。
system:mastersは認可のレイヤー(例: RBAC)をバイパスする、緊急用のスーパーユーザーグループです。
super-admin.confは誰とも共有しないでください。
このファイルは安全な場所に退避させることを推奨します。
追加ユーザーへkubeconfigファイルを生成するためにkubeadm kubeconfig userを実行するには、追加ユーザのためのkubeconfigファイルの生成 を参照してください。
kubeadm initが出力したkubeadm joinコマンドをメモしておいてください。クラスターにノードを追加する ために、このコマンドが必要です。
トークンは、コントロールプレーンノードと追加ノードの間の相互認証に使用します。ここに含まれるトークンには秘密の情報が含まれます。
このトークンを知っていれば、誰でもクラスターに認証済みノードを追加できてしまうため、取り扱いには注意してください。
kubeadm tokenコマンドを使用すると、これらのトークンの一覧、作成、削除ができます。
詳しくはkubeadmリファレンスガイド を参照してください。
Podネットワークアドオンのインストール 注意: このセクションには、ネットワークのセットアップとデプロイの順序に関する重要な情報が書かれています。
先に進む前に以下のすべてのアドバイスを熟読してください。
Pod同士が通信できるようにするには、Container Network Interface (CNI)をベースとするPodネットワークアドオンをデプロイしなければなりません。
ネットワークアドオンをインストールする前には、Cluster DNS(CoreDNS)は起動しません。
Podネットワークがホストネットワークと決して重ならないように気をつけてください。
もし重なると、様々な問題が起こってしまう可能性があります(ネットワークプラグインが優先するPodネットワークとホストのネットワークの一部が衝突することが分かった場合、適切な代わりのCIDRを考える必要があります。そして、kubeadm initの実行時に--pod-network-cidrにそのCIDRを指定し、ネットワークプラグインのYAMLでは代わりにそのCIDRを使用してください)。 デフォルトでは、kubeadmはRBAC (role based access control)の使用を強制します。
PodネットワークプラグインがRBACをサポートしており、またそのデプロイに使用するマニフェストもRBACをサポートしていることを確認してください。 クラスターでIPv6を使用したい場合、デュアルスタック、IPv6のみのシングルスタックのネットワークのいずれであっても、PodネットワークプラグインがIPv6をサポートしていることを確認してください。
IPv6のサポートは、CNIのv0.6.0 で追加されました。
備考: kubeadmはCNIに依存すべきではないため、CNIプロバイダーの検証は現在e2eテストの範囲外です。
CNIプラグインに関する問題を見つけた場合、kubeadmやKubernetesではなく、そのCNIプラグインの課題管理システムへ問題を報告してください。CNIを使用するKubernetes Podネットワークを提供する外部のプロジェクトがいくつかあります。一部のプロジェクトでは、ネットワークポリシー もサポートしています。
Kubernetesのネットワークモデル を実装したアドオンの一覧も確認してください。
Kubernetesでサポートされているネットワークアドオンの非網羅的な一覧については、アドオンのインストール のページを参照してください。
Podネットワークアドオンをインストールするには、コントロールプレーンノード上またはkubeconfigクレデンシャルを持っているノード上で、次のコマンドを実行します。
kubectl apply -f <add-on.yaml>
インストールできるPodネットワークは、クラスターごとに1つだけです。
Podネットワークがインストールされたら、kubectl get pods --all-namespacesの出力結果でCoreDNS PodがRunning状態であることをチェックすることで、ネットワークが動作していることを確認できます。そして、一度CoreDNS Podが動作すれば、続けてノードを追加できます。
ネットワークやCoreDNSがRunning状態にならない場合は、kubeadmのトラブルシューティングガイド をチェックしてください。
管理されたノードラベル デフォルトでは、kubeadmはNodeRestriction という、ノード登録時にkubeletが自己適用するラベルを制限するアドミッションコントローラーを有効化します。
このアドミッションコントローラーのドキュメントでは、kubeletの--node-labelsオプションで使用できるラベルについて説明しています。
node-role.kubernetes.io/control-planeは上記のような制限されたラベルであり、ノード作成後に特権クライアントを使用してkubeadmがマニュアルで適用します。
これを手動で行うには、kubeadm管理の/etc/kubernetes/admin.confのような特権kubeconfigを使用していることを確認し、kubectl labelコマンドを使用してください。
コントロールプレーンノードの隔離 デフォルトでは、セキュリティ上の理由により、クラスターはコントロールプレーンノードにPodをスケジューリングしません。
たとえば、開発用のKubernetesシングルマシンのクラスターなどで、Podをコントロールプレーンノードにスケジューリングしたい場合は、次のコマンドを実行します。
kubectl taint nodes --all node-role.kubernetes.io/control-plane-
出力は次のようになります。
node "test-01" untainted
...
このコマンドは、コントロールプレーンノードを含むすべてのノードからnode-role.kubernetes.io/control-plane:NoSchedule taintを削除します。
その結果、スケジューラーはどこにでもPodをスケジューリングできるようになります。
さらに、以下のコマンドを実行することでコントロールプレーンノードからnode.kubernetes.io/exclude-from-external-load-balancers
kubectl label nodes --all node.kubernetes.io/exclude-from-external-load-balancers-
コントロールプレーンノードの追加 コントロールプレーンノードの追加によって高可用性kubeadmクラスターを構築する手順は、kubeadmを使用した高可用性クラスターの作成 を参照してください。
ワーカーノードの追加 ワーカーノードは、ワークロード(コンテナやPodなど)が実行される場所です。
kubeadm joinコマンドを使用したLinux、Windowsワーカーノードの追加方法は、以下のページを参照してください。
(オプション)コントロールプレーンノード以外のマシンからのクラスター操作 他のコンピューター(例: ラップトップ)上のkubectlがクラスターと通信できるようにするためには、次のようにして管理者のkubeconfigファイルをコントロールプレーンノードから対象のコンピューター上にコピーする必要があります。
scp root@<control-plane-host>:/etc/kubernetes/admin.conf .
kubectl --kubeconfig ./admin.conf get nodes
備考: 上の例では、rootユーザーに対するSSH接続が有効であることを仮定しています。
そうでない場合は、admin.confファイルを他のユーザーからアクセスできるようにコピーした上で、代わりにそのユーザーを使ってscpしてください。
admin.confファイルはユーザーにクラスターに対する スーパーユーザー の権限を与えます。
そのため、このファイルは慎重に使用しなければなりません。
通常のユーザーには、明示的に許可した権限を持つユニークなクレデンシャルを生成することを推奨します。
これには、kubeadm kubeconfig user --client-name <CN>コマンドが使えます。
このコマンドを実行すると、KubeConfigファイルがSTDOUTに出力されるため、ファイルに保存してユーザーに配布します。
その後、kubectl create (cluster)rolebindingコマンドを使って権限を付与します。
(オプション)APIサーバーをlocalhostへプロキシする クラスターの外部からAPIサーバーに接続したいときは、次のようにkubectl proxyコマンドが使えます。
scp root@<control-plane-host>:/etc/kubernetes/admin.conf .
kubectl --kubeconfig ./admin.conf proxy
これで、ローカルのhttp://localhost:8001/api/v1からAPIサーバーにアクセスできるようになります。
クリーンアップ テストのためにクラスターに破棄可能なサーバーを使用した場合、サーバーのスイッチをオフにすれば、以降のクリーンアップの作業は必要ありません。
クラスターのローカルの設定を削除するには、kubectl config delete-clusterを実行します。
しかし、よりきれいにクラスターのプロビジョンをもとに戻したい場合は、初めにノードのdrain を行い、ノードが空になっていることを確認した後、ノードの設定を削除する必要があります。
ノードの削除 適切なクレデンシャルを使用してコントロールプレーンノードに指示を出します。次のコマンドを実行してください。
kubectl drain <node name> --delete-emptydir-data --force --ignore-daemonsets
ノードを削除する前に、kubeadmによってインストールされた状態をリセットします。
リセットプロセスでは、iptablesのルールやIPVS tablesのリセットやクリーンアップは行われません。
iptablesをリセットしたい場合は、次のように手動でコマンドを実行する必要があります。
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
IPVS tablesをリセットしたい場合は、次のコマンドを実行する必要があります。
ノードを削除します。
kubectl delete node <node name>
クラスターのセットアップを最初から始めたいときは、kubeadm initやkubeadm joinを適切な引数を付けて実行すればいいだけです。
コントロールプレーンのクリーンアップ コントロールホスト上でkubeadm resetを実行すると、ベストエフォートでのクリーンアップが実行できます。
このサブコマンドとオプションに関するより詳しい情報は、kubeadm reset
バージョンスキューポリシー kubeadmは、kubeadmが管理するコンポーネントに対してバージョンの差異を許容しますが、kubeadmのバージョンをコントロールプレーンのコンポーネント、kube-proxy、kubeletと一致させることを推奨します。
Kubernetesのバージョンに対するkubeadmのバージョンの差異 kubeadmは、kubeadmと同じバージョンか、1つ前のバージョンのKubernetesコンポーネントで使用できます。
Kubernetesのバージョンはkubeadm initの--kubernetes-version、もしくは--configを使用する場合のClusterConfiguration.kubernetesVersion
例:
kubeadmのバージョン: 1.35 kubernetesVersionは、1.35または1.34でなければならないkubeletに対するkubeadmのバージョンの差異 Kubernetesのバージョンと同様に、kubeadmは、kubeadmと同じバージョン、もしくは3つ前までのバージョンをkubeletに使用できます。
例:
kubeadmのバージョン: 1.35 ホスト上のkubeletのバージョンは、1.35、1.34、1.33、もしくは1.32でなければならない kubeadmに対するkubeadmのバージョンの差異 kubeadmによって管理されている既存のノードまたはクラスター全体を、kubeadmコマンドが操作するには一定の制限が存在します。
新たなノードをクラスターに参加させる場合、kubeadm joinを実行するkubeadmのバイナリは、kubeadm initによるクラスター構築、もしくはkubeadm upgradeによるノードのアップグレードのいずれかに使用されたkubeadmの最新バージョンと一致している必要があります。
同様の制限はkubeadm upgradeを除く他のkubeadmのコマンドにも適用されます。
kubeadm joinの例:
kubeadm initによるクラスター構築で使用したkubeadmのバージョン: 1.35参加するノードは、1.35のバージョンのkubeadmバイナリを使用しなければならない アップグレードするノードでは、そのノードの管理に使用しているkubeadmのバージョンと同じマイナーバージョン、もしくはマイナーバージョンが1つ新しいkubeadmを使用する必要があります。
kubeadm upgradeの例:
クラスター構築またはノードのアップグレードに使用されたkubeadmのバージョン: 1.34 ノードのアップグレードで使用するkubeadmのバージョンは、1.34または1.35でなければならない 異なるKubernetesコンポーネント間のバージョン差異についてさらに学ぶには、バージョンスキューポリシー を参照してください。
制限事項 クラスターの弾力性 ここで作られたクラスターは、1つのコントロールプレーンノードと、その上で動作する1つのetcdデータベースしか持ちません。
つまり、コントロールプレーンノードが故障した場合、クラスターのデータは失われ、クラスターを最初から作り直す必要がある可能性があります。
対処方法:
kubeadmのdeb/rpmパッケージおよびバイナリは、multi-platform proposal に従い、amd64、arm(32ビット)、arm64、ppc64le、およびs390x向けにビルドされています。
マルチプラットフォームのコントロールプレーンおよびアドオン用のコンテナイメージも、v1.12からサポートされています。
すべてのプラットフォーム向けのソリューションを提供しているネットワークプロバイダーは一部のみです。それぞれのプロバイダーが選択したプラットフォームをサポートしているかどうかを確認するには、前述のネットワークプロバイダーのリストを参照してください。
トラブルシューティング kubeadmに関する問題が起きたときは、トラブルシューティングドキュメント を確認してください。
次の項目 フィードバック 2.2.2.1.4 - kubeadmを使ったコントロールプレーンの設定のカスタマイズ FEATURE STATE:
Kubernetes 1.12 [stable]
kubeadmのClusterConfigurationオブジェクトはAPIServer、ControllerManager、およびSchedulerのようなコントロールプレーンの構成要素に渡されたデフォルトのフラグを上書きすることができる extraArgsの項目があります。
その構成要素は次の項目で定義されています。
apiServercontrollerManagerschedulerextraArgs の項目は キー: 値 のペアです。コントロールプレーンの構成要素のフラグを上書きするには:
設定内容に適切な項目を追加 フラグを追加して項目を上書き --config <任意の設定YAMLファイル>でkubeadm initを実行各設定項目のより詳細な情報はAPIリファレンスのページ を参照してください。
備考: kubeadm config print init-defaultsを実行し、選択したファイルに出力を保存することで、デフォルト値でClusterConfigurationオブジェクトを生成できます。APIServerフラグ 詳細はkube-apiserverのリファレンスドキュメント を参照してください。
使用例:
apiVersion : kubeadm.k8s.io/v1beta2
kind : ClusterConfiguration
kubernetesVersion : v1.16.0
apiServer :
extraArgs :
advertise-address : 192.168.0.103
anonymous-auth : "false"
enable-admission-plugins : AlwaysPullImages,DefaultStorageClass
audit-log-path : /home/johndoe/audit.log
ControllerManagerフラグ 詳細はkube-controller-managerのリファレンスドキュメント を参照してください。
使用例:
apiVersion : kubeadm.k8s.io/v1beta2
kind : ClusterConfiguration
kubernetesVersion : v1.16.0
controllerManager :
extraArgs :
cluster-signing-key-file : /home/johndoe/keys/ca.key
bind-address : 0.0.0.0
deployment-controller-sync-period : "50"
Schedulerフラグ 詳細はkube-schedulerのリファレンスドキュメント を参照してください。
使用例:
apiVersion : kubeadm.k8s.io/v1beta2
kind : ClusterConfiguration
kubernetesVersion : v1.16.0
scheduler :
extraArgs :
bind-address : 0.0.0.0
config : /home/johndoe/schedconfig.yaml
kubeconfig : /home/johndoe/kubeconfig.yaml
2.2.2.1.5 - 高可用性トポロジーのためのオプション このページでは、高可用性(HA)Kubernetesクラスターのトポロジーを設定するための2つのオプションについて説明します。
HAクラスターは次の方法で設定できます。
積層コントロールプレーンノードを使用する方法。こちらの場合、etcdノードはコントロールプレーンノードと同じ場所で動作します。 外部のetcdノードを使用する方法。こちらの場合、etcdがコントロールプレーンとは分離されたノードで動作します。 HAクラスターをセットアップする前に、各トポロジーの利点と欠点について注意深く考慮する必要があります。
備考: kubeadmは、etcdクラスターを静的にブートストラップします。
詳細については、etcd
クラスタリングガイド をご覧ください。
積層etcdトポロジー 積層HAクラスターは、コントロールプレーンのコンポーネントを実行する、kubeadmで管理されたノードで構成されるクラスターの上に、etcdにより提供される分散データストレージクラスターがあるようなトポロジー です。
各コントロールプレーンノードは、kube-apiserver、kube-scheduler、およびkube-controller-managerを実行します。kube-apiserver はロードバランサーを用いてワーカーノードに公開されます。
各コントロールプレーンノードはローカルのetcdメンバーを作り、このetcdメンバーはそのノードのkube-apiserverとだけ通信します。ローカルのkube-controller-managerとkube-schedulerのインスタンスも同様です。
このトポロジーは、同じノード上のコントロールプレーンとetcdのメンバーを結合します。外部のetcdノードを使用するクラスターよりはセットアップがシンプルで、レプリケーションの管理もシンプルです。
しかし、積層クラスターには、結合による故障のリスクがあります。1つのノードがダウンすると、etcdメンバーとコントロールプレーンのインスタンスの両方が失われ、冗長性が損なわれます。より多くのコントロールプレーンノードを追加することで、このリスクは緩和できます。
そのため、HAクラスターのためには、最低でも3台の積層コントロールプレーンノードを実行しなければなりません。
これがkubeadmのデフォルトのトポロジーです。kubeadm initやkubeadm join --control-placeを実行すると、ローカルのetcdメンバーがコントロールプレーンノード上に自動的に作成されます。
外部のetcdトポロジー 外部のetcdを持つHAクラスターは、コントロールプレーンコンポーネントを実行するノードで構成されるクラスターの外部に、etcdにより提供される分散データストレージクラスターがあるようなトポロジー です。
積層etcdトポロジーと同様に、外部のetcdトポロジーにおける各コントロールプレーンノードは、kube-apiserver、kube-scheduler、およびkube-controller-managerのインスタンスを実行します。そして、kube-apiserverは、ロードバランサーを使用してワーカーノードに公開されます。しかし、etcdメンバーは異なるホスト上で動作しており、各etcdホストは各コントロールプレーンノードのkube-api-serverと通信します。
このトポロジーは、コントロールプレーンとetcdメンバーを疎結合にします。そのため、コントロールプレーンインスタンスまたはetcdメンバーを失うことによる影響は少なく、積層HAトポロジーほどクラスターの冗長性に影響しないHAセットアップが実現します。
しかし、このトポロジーでは積層HAトポロジーの2倍の数のホストを必要とします。このトポロジーのHAクラスターのためには、最低でもコントロールプレーンのために3台のホストが、etcdノードのために3台のホストがそれぞれ必要です。
次の項目 2.2.2.1.6 - kubeadmを使用した高可用性クラスターの作成 このページでは、kubeadmを使用して、高可用性クラスターを作成する、2つの異なるアプローチを説明します:
積層コントロールプレーンノードを使う方法。こちらのアプローチは、必要なインフラストラクチャーが少ないです。etcdのメンバーと、コントロールプレーンノードは同じ場所に置かれます。 外部のetcdクラスターを使う方法。こちらのアプローチには、より多くのインフラストラクチャーが必要です。コントロールプレーンノードと、etcdのメンバーは分離されます。 先へ進む前に、どちらのアプローチがアプリケーションの要件と、環境に適合するか、慎重に検討してください。こちらの比較 が、それぞれの利点/欠点について概説しています。
高可用性クラスターの作成で問題が発生した場合は、kueadmのissue tracker でフィードバックを提供してください。
高可用性クラスターのアップグレード も参照してください。
注意: このページはクラウド上でクラスターを構築することには対応していません。ここで説明されているどちらのアプローチも、クラウド上で、LoadBalancerタイプのServiceオブジェクトや、動的なPersistentVolumeを利用して動かすことはできません。始める前に どちらの方法でも、以下のインフラストラクチャーが必要です:
master用に、kubeadmの最小要件 を満たす3台のマシン worker用に、kubeadmの最小要件 を満たす3台のマシン クラスター内のすべてのマシン間がフルにネットワーク接続可能であること(パブリック、もしくはプライベートネットワーク) すべてのマシンにおいて、sudo権限 あるデバイスから、システム内のすべてのノードに対しSSH接続できること kubeadmとkubeletがすべてのマシンにインストールされていること。 kubectlは任意です。外部etcdクラスターには、以下も必要です:
両手順における最初のステップ kube-apiserver用にロードバランサーを作成
備考: ロードバランサーには多くの設定項目があります。以下の例は、一選択肢に過ぎません。あなたのクラスター要件には、異なった設定が必要かもしれません。DNSで解決される名前で、kube-apiserver用ロードバランサーを作成する。
クラウド環境では、コントロールプレーンノードをTCPフォワーディングロードバランサーの後ろに置かなければなりません。このロードバランサーはターゲットリストに含まれる、すべての健全なコントロールプレーンノードにトラフィックを分配します。apiserverへのヘルスチェックはkube-apiserverがリッスンするポート(デフォルト値: :6443)に対する、TCPチェックです。
クラウド環境では、IPアドレスを直接使うことは推奨されません。
ロードバランサーは、apiserverポートで、全てのコントロールプレーンノードと通信できなければなりません。また、リスニングポートに対する流入トラフィックも許可されていなければなりません。
ロードバランサーのアドレスは、常にkubeadmのControlPlaneEndpointのアドレスと一致することを確認してください。
詳細はOptions for Software Load Balancing をご覧ください。
ロードバランサーに、最初のコントロールプレーンノードを追加し、接続をテストする:
nc -v LOAD_BALANCER_IP PORT
apiserverはまだ動いていないので、接続の拒否は想定通りです。しかし、タイムアウトしたのであれば、ロードバランサーはコントロールプレーンノードと通信できなかったことを意味します。もし、タイムアウトが起きたら、コントロールプレーンノードと通信できるように、ロードバランサーを再設定してください。 残りのコントロールプレーンノードを、ロードバランサーのターゲットグループに追加します。
積層コントロールプレーンとetcdノード 最初のコントロールプレーンノードの手順 最初のコントロールプレーンノードを初期化します:
sudo kubeadm init --control-plane-endpoint "LOAD_BALANCER_DNS:LOAD_BALANCER_PORT" --upload-certs
--kubernetes-versionフラグで使用するKubernetesのバージョンを設定できます。kubeadm、kubelet、kubectl、Kubernetesのバージョンを一致させることが推奨されます。--control-plane-endpointフラグは、ロードバランサーのIPアドレスまたはDNS名と、ポートが設定される必要があります。--upload-certsフラグは全てのコントロールプレーンノードで共有する必要がある証明書をクラスターにアップロードするために使用されます。代わりに、コントロールプレーンノード間で手動あるいは自動化ツールを使用して証明書をコピーしたい場合は、このフラグを削除し、以下の証明書の手動配布 のセクションを参照してください。備考: kubeadm initの
--configフラグと
--certificate-keyフラグは混在させることはできないため、
kubeadm configuration を使用する場合は
certificateKeyフィールドを適切な場所に追加する必要があります(
InitConfigurationと
JoinConfiguration: controlPlaneの配下)。
備考: いくつかのCNIネットワークプラグインはPodのIPのCIDRの指定など追加の設定を必要としますが、必要としないプラグインもあります。
CNIネットワークドキュメント を参照してください。PodにCIDRを設定するには、
ClusterConfigurationの
networkingオブジェクトに
podSubnet: 192.168.0.0/16フィールドを設定してください。
...
You can now join any number of control-plane node by running the following command on each as a root:
kubeadm join 192.168.0.200:6443 --token 9vr73a.a8uxyaju799qwdjv --discovery-token-ca-cert-hash sha256:7c2e69131a36ae2a042a339b33381c6d0d43887e2de83720eff5359e26aec866 --control-plane --certificate-key f8902e114ef118304e561c3ecd4d0b543adc226b7a07f675f56564185ffe0c07
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use kubeadm init phase upload-certs to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.0.200:6443 --token 9vr73a.a8uxyaju799qwdjv --discovery-token-ca-cert-hash sha256:7c2e69131a36ae2a042a339b33381c6d0d43887e2de83720eff5359e26aec866
この出力をテキストファイルにコピーします。あとで、他のコントロールプレーンノードとワーカーノードをクラスターに参加させる際に必要です。
--upload-certsフラグをkubeadm initで使用すると、プライマリコントロールプレーンの証明書が暗号化されて、kubeadm-certs Secretにアップロードされます。
証明書を再アップロードして新しい復号キーを生成するには、すでにクラスターに参加しているコントロールプレーンノードで次のコマンドを使用します:
sudo kubeadm init phase upload-certs --upload-certs
また、後でjoinで使用できるように、init中にカスタムした--certificate-keyを指定することもできます。このようなキーを生成するには、次のコマンドを使用します: kubeadm alpha certs certificate-key
備考: `kubeadm-certs`のSecretと復号キーは2時間で期限切れとなります。
注意: コマンド出力に記載されているように、証明書キーはクラスターの機密データへのアクセスを提供します。秘密にしてください!
使用するCNIプラグインを適用します:こちらの手順に従い CNIプロバイダーをインストールします。該当する場合は、kubeadmの設定で指定されたPodのCIDRに対応していることを確認してください。
Weave Netを使用する場合の例:
kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version= $( kubectl version | base64 | tr -d '\n' ) "
以下のコマンドを入力し、コンポーネントのPodが起動するのを確認します:
kubectl get pod -n kube-system -w
残りのコントロールプレーンノードの手順
備考: kubeadmバージョン1.15以降、複数のコントロールプレーンノードを並行してクラスターに参加させることができます。
このバージョンの前は、最初のノードの初期化が完了した後でのみ、新しいコントロールプレーンノードを順番にクラスターに参加させる必要があります。追加のコントロールプレーンノード毎に、以下の手順を行います。
kubeadm initを最初のノードで実行した際に取得したjoinコマンドを使って、新しく追加するコントロールプレーンノードでkubeadm joinを開始します。このようなコマンドになるはずです:
sudo kubeadm join 192.168.0.200:6443 --token 9vr73a.a8uxyaju799qwdjv --discovery-token-ca-cert-hash sha256:7c2e69131a36ae2a042a339b33381c6d0d43887e2de83720eff5359e26aec866 --control-plane --certificate-key f8902e114ef118304e561c3ecd4d0b543adc226b7a07f675f56564185ffe0c07
--control-planeフラグによって、kubeadm joinの実行は新しいコントロールプレーンを作成します。-certificate-key ...を指定したキーを使って、クラスターのkubeadm-certs Secretからダウンロードされたコントロールプレーンの証明書が復号されます。外部のetcdノード 外部のetcdノードを使ったクラスターの設定は、積層etcdの場合と似ていますが、最初にetcdを設定し、kubeadmの設定ファイルにetcdの情報を渡す必要があります。
etcdクラスターの構築 こちらの手順 にしたがって、etcdクラスターを構築してください。
こちらの手順 にしたがって、SSHを構築してください。
以下のファイルをクラスター内の任意のetcdノードから最初のコントロールプレーンノードにコピーしてください:
export CONTROL_PLANE = "ubuntu@10.0.0.7"
scp /etc/kubernetes/pki/etcd/ca.crt " ${ CONTROL_PLANE } " :
scp /etc/kubernetes/pki/apiserver-etcd-client.crt " ${ CONTROL_PLANE } " :
scp /etc/kubernetes/pki/apiserver-etcd-client.key " ${ CONTROL_PLANE } " :
CONTROL_PLANEの値を、最初のコントロールプレーンノードのuser@hostで置き換えます。最初のコントロールプレーンノードの構築 以下の内容で、kubeadm-config.yamlという名前の設定ファイルを作成します:
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
kubernetesVersion: stable
controlPlaneEndpoint: "LOAD_BALANCER_DNS:LOAD_BALANCER_PORT"
etcd:
external:
endpoints:
- https://ETCD_0_IP:2379
- https://ETCD_1_IP:2379
- https://ETCD_2_IP:2379
caFile: /etc/kubernetes/pki/etcd/ca.crt
certFile: /etc/kubernetes/pki/apiserver-etcd-client.crt
keyFile: /etc/kubernetes/pki/apiserver-etcd-client.key
備考: ここで、積層etcdと外部etcdの違いは、外部etcdの構成では`etcd`の`external`オブジェクトにetcdのエンドポイントが記述された設定ファイルが必要です。積層etcdトポロジーの場合、これは自動で管理されます。
以下の手順は、積層etcdの構築と同様です。
sudo kubeadm init --config kubeadm-config.yaml --upload-certsをこのノードで実行します。
表示されたjoinコマンドを、あとで使うためにテキストファイルに書き込みます。
使用するCNIプラグインを適用します。以下はWeave CNIの場合です:
kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version= $( kubectl version | base64 | tr -d '\n' ) "
残りのコントロールプレーンノードの手順 手順は、積層etcd構築の場合と同じです:
最初のコントロールプレーンノードが完全に初期化されているのを確認します。 テキストファイルに保存したjoinコマンドを使って、それぞれのコントロールプレーンノードをクラスターへ参加させます。コントロールプレーンノードは1台ずつクラスターへ参加させるのを推奨します。 --certificate-keyで指定する復号キーは、デフォルトで2時間で期限切れになることを忘れないでください。コントロールプレーン起動後の共通タスク workerのインストール kubeadm initコマンドから返されたコマンドを利用して、workerノードをクラスターに参加させることが可能です。
sudo kubeadm join 192.168.0.200:6443 --token 9vr73a.a8uxyaju799qwdjv --discovery-token-ca-cert-hash sha256:7c2e69131a36ae2a042a339b33381c6d0d43887e2de83720eff5359e26aec866
証明書の手動配布 --upload-certsフラグを指定してkubeadm initを実行しない場合、プライマリコントロールプレーンノードから他のコントロールプレーンノードへ証明書を手動でコピーする必要があります。
コピーを行うには多くの方法があります。次の例ではsshとscpを使用しています。
1台のマシンから全てのノードをコントロールしたいのであれば、SSHが必要です。
システム内の全ての他のノードにアクセスできるメインデバイスで、ssh-agentを有効にします
eval $(ssh-agent)
SSHの秘密鍵を、セッションに追加します:
ssh-add ~/.ssh/path_to_private_key
正常に接続できることを確認するために、ノード間でSSHします。
全てのノードでSSHを設定したら、kubeadm initを実行した後、最初のコントロールノードプレーンノードで次のスクリプトを実行します。このスクリプトは、最初のコントロールプレーンノードから残りのコントロールプレーンノードへ証明書ファイルをコピーします:
次の例の、CONTROL_PLANE_IPSを他のコントロールプレーンノードのIPアドレスに置き換えます。
USER = ubuntu # 環境に合わせる
CONTROL_PLANE_IPS = "10.0.0.7 10.0.0.8"
for host in ${ CONTROL_PLANE_IPS } ; do
scp /etc/kubernetes/pki/ca.crt " ${ USER } " @$host :
scp /etc/kubernetes/pki/ca.key " ${ USER } " @$host :
scp /etc/kubernetes/pki/sa.key " ${ USER } " @$host :
scp /etc/kubernetes/pki/sa.pub " ${ USER } " @$host :
scp /etc/kubernetes/pki/front-proxy-ca.crt " ${ USER } " @$host :
scp /etc/kubernetes/pki/front-proxy-ca.key " ${ USER } " @$host :
scp /etc/kubernetes/pki/etcd/ca.crt " ${ USER } " @$host :etcd-ca.crt
# 外部のetcdノード使用時はこちらのコマンドを実行
scp /etc/kubernetes/pki/etcd/ca.key " ${ USER } " @$host :etcd-ca.key
done
注意: 上のリストにある証明書だけをコピーしてください。kubeadmが、参加するコントロールプレーンノード用に、残りの証明書と必要なSANの生成を行います。間違って全ての証明書をコピーしてしまったら、必要なSANがないため、追加ノードの作成は失敗するかもしれません。
次に、クラスターに参加させる残りの各コントロールプレーンノードでkubeadm joinを実行する前に次のスクリプトを実行する必要があります。このスクリプトは、前の手順でコピーした証明書をホームディレクトリから/etc/kubernetes/pkiへ移動します:
USER = ubuntu # 環境に合わせる
mkdir -p /etc/kubernetes/pki/etcd
mv /home/${ USER } /ca.crt /etc/kubernetes/pki/
mv /home/${ USER } /ca.key /etc/kubernetes/pki/
mv /home/${ USER } /sa.pub /etc/kubernetes/pki/
mv /home/${ USER } /sa.key /etc/kubernetes/pki/
mv /home/${ USER } /front-proxy-ca.crt /etc/kubernetes/pki/
mv /home/${ USER } /front-proxy-ca.key /etc/kubernetes/pki/
mv /home/${ USER } /etcd-ca.crt /etc/kubernetes/pki/etcd/ca.crt
# 外部のetcdノード使用時はこちらのコマンドを実行
mv /home/${ USER } /etcd-ca.key /etc/kubernetes/pki/etcd/ca.key
2.2.2.1.7 - kubeadmを使用した高可用性etcdクラスターの作成 Kubeadm defaults to running a single member etcd cluster in a static pod managed
by the kubelet on the control plane node. This is not a high availability setup
as the etcd cluster contains only one member and cannot sustain any members
becoming unavailable. This task walks through the process of creating a high
availability etcd cluster of three members that can be used as an external etcd
when using kubeadm to set up a kubernetes cluster.
始める前に Three hosts that can talk to each other over ports 2379 and 2380. This
document assumes these default ports. However, they are configurable through
the kubeadm config file. Each host must have docker, kubelet, and kubeadm installed . Each host should have access to the Kubernetes container image registry (registry.k8s.io) or list/pull the required etcd image using kubeadm config images list/pull. This guide will setup etcd instances as static pods managed by a kubelet. Some infrastructure to copy files between hosts. For example ssh and scp
can satisfy this requirement. クラスターの構築 The general approach is to generate all certs on one node and only distribute
the necessary files to the other nodes.
備考: kubeadm contains all the necessary cryptographic machinery to generate
the certificates described below; no other cryptographic tooling is required for
this example.Configure the kubelet to be a service manager for etcd.
Since etcd was created first, you must override the service priority by creating a new unit file
that has higher precedence than the kubeadm-provided kubelet unit file.
cat << EOF > /etc/systemd/system/kubelet.service.d/20-etcd-service-manager.conf
[Service]
ExecStart=
# Replace "systemd" with the cgroup driver of your container runtime. The default value in the kubelet is "cgroupfs".
ExecStart=/usr/bin/kubelet --address=127.0.0.1 --pod-manifest-path=/etc/kubernetes/manifests --cgroup-driver=systemd
Restart=always
EOF
systemctl daemon-reload
systemctl restart kubelet
Create configuration files for kubeadm.
Generate one kubeadm configuration file for each host that will have an etcd
member running on it using the following script.
# Update HOST0, HOST1, and HOST2 with the IPs or resolvable names of your hosts
export HOST0 = 10.0.0.6
export HOST1 = 10.0.0.7
export HOST2 = 10.0.0.8
# Create temp directories to store files that will end up on other hosts.
mkdir -p /tmp/${ HOST0 } / /tmp/${ HOST1 } / /tmp/${ HOST2 } /
ETCDHOSTS =( ${ HOST0 } ${ HOST1 } ${ HOST2 } )
NAMES =( "infra0" "infra1" "infra2" )
for i in " ${ !ETCDHOSTS[@]} " ; do
HOST = ${ ETCDHOSTS [$i ]}
NAME = ${ NAMES [$i ]}
cat << EOF > /tmp/${HOST}/kubeadmcfg.yaml
apiVersion: "kubeadm.k8s.io/v1beta2"
kind: ClusterConfiguration
etcd:
local:
serverCertSANs:
- "${HOST}"
peerCertSANs:
- "${HOST}"
extraArgs:
initial-cluster: ${NAMES[0]}=https://${ETCDHOSTS[0]}:2380,${NAMES[1]}=https://${ETCDHOSTS[1]}:2380,${NAMES[2]}=https://${ETCDHOSTS[2]}:2380
initial-cluster-state: new
name: ${NAME}
listen-peer-urls: https://${HOST}:2380
listen-client-urls: https://${HOST}:2379
advertise-client-urls: https://${HOST}:2379
initial-advertise-peer-urls: https://${HOST}:2380
EOF
done
Generate the certificate authority
If you already have a CA then the only action that is copying the CA's crt and
key file to /etc/kubernetes/pki/etcd/ca.crt and
/etc/kubernetes/pki/etcd/ca.key. After those files have been copied,
proceed to the next step, "Create certificates for each member".
If you do not already have a CA then run this command on $HOST0 (where you
generated the configuration files for kubeadm).
kubeadm init phase certs etcd-ca
This creates two files
/etc/kubernetes/pki/etcd/ca.crt/etc/kubernetes/pki/etcd/ca.keyCreate certificates for each member
kubeadm init phase certs etcd-server --config= /tmp/${ HOST2 } /kubeadmcfg.yaml
kubeadm init phase certs etcd-peer --config= /tmp/${ HOST2 } /kubeadmcfg.yaml
kubeadm init phase certs etcd-healthcheck-client --config= /tmp/${ HOST2 } /kubeadmcfg.yaml
kubeadm init phase certs apiserver-etcd-client --config= /tmp/${ HOST2 } /kubeadmcfg.yaml
cp -R /etc/kubernetes/pki /tmp/${ HOST2 } /
# cleanup non-reusable certificates
find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete
kubeadm init phase certs etcd-server --config= /tmp/${ HOST1 } /kubeadmcfg.yaml
kubeadm init phase certs etcd-peer --config= /tmp/${ HOST1 } /kubeadmcfg.yaml
kubeadm init phase certs etcd-healthcheck-client --config= /tmp/${ HOST1 } /kubeadmcfg.yaml
kubeadm init phase certs apiserver-etcd-client --config= /tmp/${ HOST1 } /kubeadmcfg.yaml
cp -R /etc/kubernetes/pki /tmp/${ HOST1 } /
find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete
kubeadm init phase certs etcd-server --config= /tmp/${ HOST0 } /kubeadmcfg.yaml
kubeadm init phase certs etcd-peer --config= /tmp/${ HOST0 } /kubeadmcfg.yaml
kubeadm init phase certs etcd-healthcheck-client --config= /tmp/${ HOST0 } /kubeadmcfg.yaml
kubeadm init phase certs apiserver-etcd-client --config= /tmp/${ HOST0 } /kubeadmcfg.yaml
# No need to move the certs because they are for HOST0
# clean up certs that should not be copied off this host
find /tmp/${ HOST2 } -name ca.key -type f -delete
find /tmp/${ HOST1 } -name ca.key -type f -delete
Copy certificates and kubeadm configs
The certificates have been generated and now they must be moved to their
respective hosts.
USER = ubuntu
HOST = ${ HOST1 }
scp -r /tmp/${ HOST } /* ${ USER } @${ HOST } :
ssh ${ USER } @${ HOST }
USER@HOST $ sudo -Es
root@HOST $ chown -R root:root pki
root@HOST $ mv pki /etc/kubernetes/
Ensure all expected files exist
The complete list of required files on $HOST0 is:
/tmp/${HOST0}
└── kubeadmcfg.yaml
---
/etc/kubernetes/pki
├── apiserver-etcd-client.crt
├── apiserver-etcd-client.key
└── etcd
├── ca.crt
├── ca.key
├── healthcheck-client.crt
├── healthcheck-client.key
├── peer.crt
├── peer.key
├── server.crt
└── server.key
On $HOST1:
$HOME
└── kubeadmcfg.yaml
---
/etc/kubernetes/pki
├── apiserver-etcd-client.crt
├── apiserver-etcd-client.key
└── etcd
├── ca.crt
├── healthcheck-client.crt
├── healthcheck-client.key
├── peer.crt
├── peer.key
├── server.crt
└── server.key
On $HOST2
$HOME
└── kubeadmcfg.yaml
---
/etc/kubernetes/pki
├── apiserver-etcd-client.crt
├── apiserver-etcd-client.key
└── etcd
├── ca.crt
├── healthcheck-client.crt
├── healthcheck-client.key
├── peer.crt
├── peer.key
├── server.crt
└── server.key
Create the static pod manifests
Now that the certificates and configs are in place it's time to create the
manifests. On each host run the kubeadm command to generate a static manifest
for etcd.
root@HOST0 $ kubeadm init phase etcd local --config= /tmp/${ HOST0 } /kubeadmcfg.yaml
root@HOST1 $ kubeadm init phase etcd local --config= $HOME /kubeadmcfg.yaml
root@HOST2 $ kubeadm init phase etcd local --config= $HOME /kubeadmcfg.yaml
Optional: Check the cluster health
docker run --rm -it \
\
${ ETCD_TAG } etcdctl \
\
\
\
${ HOST0 } :2379 endpoint health --cluster
...
https://[ HOST0 IP] :2379 is healthy: successfully committed proposal: took = 16.283339ms
https://[ HOST1 IP] :2379 is healthy: successfully committed proposal: took = 19.44402ms
https://[ HOST2 IP] :2379 is healthy: successfully committed proposal: took = 35.926451ms
Set ${ETCD_TAG} to the version tag of your etcd image. For example 3.4.3-0. To see the etcd image and tag that kubeadm uses execute kubeadm config images list --kubernetes-version ${K8S_VERSION}, where ${K8S_VERSION} is for example v1.17.0 Set ${HOST0}to the IP address of the host you are testing. 次の項目 Once you have a working 3 member etcd cluster, you can continue setting up a
highly available control plane using the external etcd method with
kubeadm .
2.2.2.1.8 - kubeadmを使用したクラスター内の各kubeletの設定 FEATURE STATE:
Kubernetes 1.11 [stable]
kubeadm CLIツールのライフサイクルは、Kubernetesクラスター内の各ノード上で稼働するデーモンであるkubelet から分離しています。kubeadm CLIツールはKubernetesを初期化またはアップグレードする際にユーザーによって実行されます。一方で、kubeletは常にバックグラウンドで稼働しています。
kubeletはデーモンのため、何らかのinitシステムやサービスマネージャーで管理する必要があります。DEBパッケージやRPMパッケージからkubeletをインストールすると、systemdはkubeletを管理するように設定されます。代わりに別のサービスマネージャーを使用することもできますが、手動で設定する必要があります。
いくつかのkubeletの設定は、クラスターに含まれる全てのkubeletで同一である必要があります。一方で、特定のマシンの異なる特性(OS、ストレージ、ネットワークなど)に対応するために、kubeletごとに設定が必要なものもあります。手動で設定を管理することも可能ですが、kubeadmは一元的な設定管理 のためのKubeletConfigurationAPIを提供しています。
Kubeletの設定パターン 以下のセクションでは、kubeadmを使用したkubeletの設定パターンについて説明します。これは手動で各Nodeの設定を管理するよりも簡易に行うことができます。
各kubeletにクラスターレベルの設定を配布 kubeadm initおよびkubeadm joinコマンドを使用すると、kubeletにデフォルト値を設定することができます。興味深い例として、異なるCRIランタイムを使用したり、Serviceが使用するデフォルトのサブネットを設定したりすることができます。
Serviceが使用するデフォルトのサブネットとして10.96.0.0/12を設定する必要がある場合は、--service-cidrパラメーターを渡します。
kubeadm init --service-cidr 10.96.0.0/12
これによってServiceの仮想IPはこのサブネットから割り当てられるようになりました。また、--cluster-dnsフラグを使用し、kubeletが用いるDNSアドレスを設定する必要もあります。この設定はクラスター内の全てのマネージャーとNode上で同一である必要があります。kubeletは、kubeletのComponentConfig と呼ばれる、バージョン管理と構造化されたAPIオブジェクトを提供します。これはkubelet内のほとんどのパラメーターを設定し、その設定をクラスター内で稼働中の各kubeletへ適用することを可能にします。以下の例のように、キャメルケースのキーに値のリストとしてクラスターDNS IPアドレスなどのフラグを指定することができます。
apiVersion : kubelet.config.k8s.io/v1beta1
kind : KubeletConfiguration
clusterDNS :
10.96.0.10
ComponentConfigの詳細については、このセクション をご覧ください
インスタンス固有の設定内容を適用 いくつかのホストでは、ハードウェア、オペレーティングシステム、ネットワーク、その他ホスト固有のパラメーターの違いのため、特定のkubeletの設定を必要とします。以下にいくつかの例を示します。
DNS解決ファイルへのパスは--resolv-confフラグで指定することができますが、オペレーティングシステムやsystemd-resolvedを使用するかどうかによって異なる場合があります。このパスに誤りがある場合、そのNode上でのDNS解決は失敗します。 クラウドプロバイダーを使用していない場合、Node APIオブジェクト.metadata.nameはデフォルトでマシンのホスト名に設定されます。異なるNode名を指定する必要がある場合には、--hostname-overrideフラグによってこの挙動を書き換えることができます。 現在のところ、kubletはCRIランタイムが使用するcgroupドライバを自動で検知することができませんが、kubeletの稼働を保証するためには、--cgroup-driverの値はCRIランタイムが使用するcgroupドライバに一致していなければなりません。 クラスターが使用するCRIランタイムによっては、異なるフラグを指定する必要があるかもしれません。例えば、Dockerを使用している場合には、--network-plugin=cniのようなフラグを指定する必要があります。外部のランタイムを使用している場合には、--container-runtime=remoteと指定し、--container-runtime-endpoint=<path>のようにCRIエンドポイントを指定する必要があります。 これらのフラグは、systemdなどのサービスマネージャー内のkubeletの設定によって指定することができます。
kubeadm ... --config some-config-file.yamlのように、カスタムのKubeletConfigurationAPIオブジェクトを設定ファイルを介して渡すことで、kubeadmによって起動されるkubeletに設定を反映することができます。
kubeadm config print init-defaults --component-configs KubeletConfigurationを実行することによって、この構造体の全てのデフォルト値を確認することができます。
また、各フィールドの詳細については、kubelet ComponentConfigに関するAPIリファレンス を参照してください。
kubeadm init実行時の流れkubeadm initを実行した場合、kubeletの設定は/var/lib/kubelet/config.yamlに格納され、クラスターのConfigMapにもアップロードされます。ConfigMapはkubelet-config-1.Xという名前で、Xは初期化するKubernetesのマイナーバージョンを表します。またこの設定ファイルは、クラスター内の全てのkubeletのために、クラスター全体設定の基準と共に/etc/kubernetes/kubelet.confにも書き込まれます。この設定ファイルは、kubeletがAPIサーバと通信するためのクライアント証明書を指し示します。これは、各kubeletにクラスターレベルの設定を配布 することの必要性を示しています。
二つ目のパターンである、インスタンス固有の設定内容を適用 するために、kubeadmは環境ファイルを/var/lib/kubelet/kubeadm-flags.envへ書き出します。このファイルは以下のように、kubelet起動時に渡されるフラグのリストを含んでいます。
KUBELET_KUBEADM_ARGS = "--flag1=value1 --flag2=value2 ..."
kubelet起動時に渡されるフラグに加えて、このファイルはcgroupドライバーや異なるCRIランタイムソケットを使用するかどうか(--cri-socket)といった動的なパラメーターも含みます。
これら二つのファイルがディスク上に格納されると、systemdを使用している場合、kubeadmは以下の二つのコマンドを実行します。
systemctl daemon-reload && systemctl restart kubelet
リロードと再起動に成功すると、通常のkubeadm initのワークフローが続きます。
kubeadm join実行時の流れkubeadm joinを実行した場合、kubeadmはBootstrap Token証明書を使用してTLS bootstrapを行い、ConfigMapkubelet-config-1.Xをダウンロードするために必要なクレデンシャルを取得し、/var/lib/kubelet/config.yamlへ書き込みます。動的な環境ファイルは、kubeadm initの場合と全く同様の方法で生成されます。
次に、kubeadmは、kubeletに新たな設定を読み込むために、以下の二つのコマンドを実行します。
systemctl daemon-reload && systemctl restart kubelet
kubeletが新たな設定を読み込むと、kubeadmは、KubeConfigファイル/etc/kubernetes/bootstrap-kubelet.confを書き込みます。これは、CA証明書とBootstrap Tokenを含みます。これらはkubeletがTLS Bootstrapを行い/etc/kubernetes/kubelet.confに格納されるユニークなクレデンシャルを取得するために使用されます。ファイルが書き込まれると、kubeletはTLS Bootstrapを終了します。
kubelet用のsystemdファイル kubeadmには、systemdがどのようにkubeletを実行するかを指定した設定ファイルが同梱されています。
kubeadm CLIコマンドは決してこのsystemdファイルには触れないことに注意してください。
kubeadmのDEBパッケージ またはRPMパッケージ によってインストールされたこの設定ファイルは、/etc/systemd/system/kubelet.service.d/10-kubeadm.confに書き込まれ、systemdで使用されます。基本的なkubelet.service(RPM用 または、 DEB用 )を拡張します。
[Service]
Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf
--kubeconfig=/etc/kubernetes/kubelet.conf"
Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml"
# This is a file that "kubeadm init" and "kubeadm join" generate at runtime, populating
the KUBELET_KUBEADM_ARGS variable dynamically
EnvironmentFile=-/var/lib/kubelet/kubeadm-flags.env
# This is a file that the user can use for overrides of the kubelet args as a last resort. Preferably,
# the user should use the .NodeRegistration.KubeletExtraArgs object in the configuration files instead.
# KUBELET_EXTRA_ARGS should be sourced from this file.
EnvironmentFile=-/etc/default/kubelet
ExecStart=
ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS
このファイルは、kubeadmがkubelet用に管理する全ファイルが置かれるデフォルトの場所を指定します。
TLS Bootstrapに使用するKubeConfigファイルは/etc/kubernetes/bootstrap-kubelet.confですが、/etc/kubernetes/kubelet.confが存在しない場合にのみ使用します。 ユニークなkublet識別子を含むKubeConfigファイルは/etc/kubernetes/kubelet.confです。 kubeletのComponentConfigを含むファイルは/var/lib/kubelet/config.yamlです。 KUBELET_KUBEADM_ARGSを含む動的な環境ファイルは/var/lib/kubelet/kubeadm-flags.envから取得します。KUBELET_EXTRA_ARGSによるユーザー定義のフラグの上書きを格納できるファイルは/etc/default/kubelet(DEBの場合)、または/etc/sysconfig/kubelet(RPMの場合)から取得します。KUBELET_EXTRA_ARGSはフラグの連なりの最後に位置し、優先度が最も高いです。Kubernetesバイナリとパッケージの内容 Kubernetesに同梱されるDEB、RPMのパッケージは以下の通りです。
パッケージ名 説明 kubeadm/usr/bin/kubeadmCLIツールと、kubelet用のsystemdファイル をインストールします。kubeletkubeletバイナリを/usr/binに、CNIバイナリを/opt/cni/binにインストールします。 kubectl/usr/bin/kubectlバイナリをインストールします。cri-tools/usr/bin/crictlバイナリをcri-tools gitリポジトリ からインストールします。
2.2.2.1.9 - kubeadmによるデュアルスタックのサポート FEATURE STATE:
Kubernetes v1.23 [stable]
Kubernetesクラスターにはデュアルスタック ネットワークが含まれています。つまりクラスターネットワークではいずれかのアドレスファミリーを使用することができます。
クラスターでは、コントロールプレーンはIPv4アドレスとIPv6アドレスの両方を、単一のPod またはService に割り当てることができます。
始める前に kubeadmのインストール の手順に従って、kubeadm ツールをインストールしておく必要があります。
ノード として使用したいサーバーごとに、IPv6フォワーディングが許可されていることを確認してください。
Linuxでは、各サーバーでrootユーザーとしてsysctl -w net.ipv6.conf.all.forwarding=1を実行することで設定できます。
使用するにはIPv4およびIPv6アドレス範囲が必要です。
クラスター運用者は、通常はIPv4にはプライベートアドレス範囲を使用します。
IPv6では、通常は運用者が割り当てたアドレス範囲を使用して、2000::/3の範囲内からグローバルユニキャストアドレスブロックを選択します。
クラスターのIPアドレス範囲をパブリックインターネットにルーティングする必要はありません。
IPアドレス割り当てのサイズは、実行する予定のPodとServiceの数に適している必要があります。
備考: kubeadm upgradeコマンドを使用して既存のクラスターをアップグレードする場合、kubeadmはPodのIPアドレス範囲("クラスターCIDR")やクラスターのServiceのアドレス範囲("Service CIDR")の変更をサポートしません。デュアルスタッククラスターの作成 kubeadm initを使用してデュアルスタッククラスターを作成するには、以下の例のようにコマンドライン引数を渡します:
# これらのアドレス範囲は例です
kubeadm init --pod-network-cidr= 10.244.0.0/16,2001:db8:42:0::/56 --service-cidr= 10.96.0.0/16,2001:db8:42:1::/112
わかりやすいように、主要なデュアルスタックコントロールプレーンノードのkubeadm構成ファイル kubeadm-config.yamlの例を示します。
---
apiVersion : kubeadm.k8s.io/v1beta4
kind : ClusterConfiguration
networking :
podSubnet : 10.244.0.0 /16,2001:db8:42:0::/56
serviceSubnet : 10.96.0.0 /16,2001:db8:42:1::/112
---
apiVersion : kubeadm.k8s.io/v1beta4
kind : InitConfiguration
localAPIEndpoint :
advertiseAddress : "10.100.0.1"
bindPort : 6443
nodeRegistration :
kubeletExtraArgs :
- name : "node-ip"
value : "10.100.0.2,fd00:1:2:3::2
InitConfigurationのadvertiseAddressは、APIサーバーがリッスンしていることをアドバタイズするIPアドレスを指定します。
advertiseAddressの値はkubeadm initの--apiserver-advertise-addressフラグに相当します。
kubeadmを実行してデュアルスタックコントロールプレーンノードを初期化します:
kubeadm init --config= kubeadm-config.yaml
kube-controller-managerフラグ--node-cidr-mask-size-ipv4|--node-cidr-mask-size-ipv6はデフォルト値で設定されます。
IPv4/IPv6デュアルスタックの設定 を参照してください。
備考: --apiserver-advertise-addressフラグはデュアルスタックをサポートしません。デュアルスタッククラスターへのノード参加 ノードを参加させる前に、そのノードにIPv6ルーティングが可能なネットワークインターフェースがあり、IPv6フォワーディングが許可されていることを確認してください。
以下は、ワーカーノードをクラスターに参加させるためのkubeadm構成ファイル kubeadm-config.yamlの例です。
apiVersion : kubeadm.k8s.io/v1beta4
kind : JoinConfiguration
discovery :
bootstrapToken :
apiServerEndpoint : 10.100.0.1 :6443
token : "clvldh.vjjwg16ucnhp94qr"
caCertHashes :
- "sha256:a4863cde706cfc580a439f842cc65d5ef112b7b2be31628513a9881cf0d9fe0e"
# 上記の認証情報をクラスターの実際のトークンとCA証明書に一致するように変更
nodeRegistration :
kubeletExtraArgs :
- name : "node-ip"
value : "10.100.0.2,fd00:1:2:3::3"
また以下は、別のコントロールプレーンノードをクラスターに参加させるためのkubeadm構成ファイル kubeadm-config.yamlの例です。
apiVersion : kubeadm.k8s.io/v1beta4
kind : JoinConfiguration
controlPlane :
localAPIEndpoint :
advertiseAddress : "10.100.0.2"
bindPort : 6443
discovery :
bootstrapToken :
apiServerEndpoint : 10.100.0.1 :6443
token : "clvldh.vjjwg16ucnhp94qr"
caCertHashes :
- "sha256:a4863cde706cfc580a439f842cc65d5ef112b7b2be31628513a9881cf0d9fe0e"
# 上記の認証情報をクラスターの実際のトークンとCA証明書に一致するように変更
nodeRegistration :
kubeletExtraArgs :
- name : "node-ip"
value : "10.100.0.2,fd00:1:2:3::4"
JoinConfiguration.controlPlaneのadvertiseAddressは、APIサーバーがリッスンしていることをアドバタイズするIPアドレスを指定します。
advertiseAddressの値はkubeadm joinの--apiserver-advertise-addressフラグに相当します。
kubeadm join --config= kubeadm-config.yaml
シングルスタッククラスターの作成
備考: デュアルスタックのサポートは、デュアルスタックアドレスを使用する必要があるという意味ではありません。
デュアルスタックネットワーク機能が有効になっているシングルスタッククラスターをデプロイすることができます。よりわかりやすいように、シングルスタックコントロールプレーンノードのkubeadm構成ファイル kubeadm-config.yamlの例を示します。
apiVersion : kubeadm.k8s.io/v1beta4
kind : ClusterConfiguration
networking :
podSubnet : 10.244.0.0 /16
serviceSubnet : 10.96.0.0 /16
次の項目 2.2.2.1.10 - コントロールプレーンをセルフホストするようにkubernetesクラスターを構成する コントロールプレーンのセルフホスティング kubeadmを使用すると、セルフホスト型のKubernetesコントロールプレーンを実験的に作成できます。これはAPIサーバー、コントローラーマネージャー、スケジューラーなどの主要コンポーネントは、静的ファイルを介してkubeletで構成されたstatic pods ではなく、Kubernetes APIを介して構成されたDaemonSet pods として実行されることを意味します。
セルフホスト型クラスターを作成する場合はkubeadm alpha selfhosting pivot を参照してください。
警告
注意: この機能により、クラスターがサポートされていない状態になり、kubeadmがクラスターを管理できなくなります。これにはkubeadm upgradeが含まれます。1.8以降のセルフホスティングには、いくつかの重要な制限があります。特に、セルフホスト型クラスターは、手動の介入なしにコントロールプレーンのNode再起動から回復することはできません。
デフォルトでは、セルフホスト型のコントロールプレーンのPodは、hostPath
コントロールプレーンのセルフホストされた部分にはetcdが含まれていませんが、etcdは静的Podとして実行されます。
プロセス セルフホスティングのブートストラッププロセスは、kubeadm design
document に記載されています。
要約すると、kubeadm alpha selfhostingは次のように機能します。
静的コントロールプレーンのブートストラップが起動し、正常になるのを待ちます。これはkubeadm initのセルフホスティングを使用しないプロセスと同じです。
静的コントロールプレーンのPodのマニフェストを使用して、セルフホスト型コントロールプレーンを実行する一連のDaemonSetのマニフェストを構築します。また、必要に応じてこれらのマニフェストを変更します。たとえば、シークレット用の新しいボリュームを追加します。
kube-systemのネームスペースにDaemonSetを作成し、Podの結果が起動されるのを待ちます。
セルフホスト型のPodが操作可能になると、関連する静的Podが削除され、kubeadmは次のコンポーネントのインストールに進みます。これによりkubeletがトリガーされて静的Podが停止します。
元の静的なコントロールプレーンが停止すると、新しいセルフホスト型コントロールプレーンはリスニングポートにバインドしてアクティブになります。
2.2.3 - ターンキークラウドソリューション このページは、Kubernetes認定ソリューションプロバイダーのリストを提供します。
各プロバイダーのページから、本番環境でも利用可能なクラスターのインストール方法やセットアップ方法を学ぶことができます。
2.3 - ベストプラクティス 2.3.1 - 大規模クラスターの構築 クラスターはKubernetesのエージェントが動作する(物理もしくは仮想の)ノード の集合で、コントロールプレーン によって管理されます。
Kubernetes v1.35 では、最大5000ノードから構成されるクラスターをサポートします。
具体的には、Kubernetesは次の基準を 全て 満たす構成に対して適用できるように設計されています。
1ノードにつきPodが110個以上存在しない 5000ノード以上存在しない Podの総数が150000個以上存在しない コンテナの総数が300000個以上存在しない ノードを追加したり削除したりすることによって、クラスターをスケールできます。
これを行う方法は、クラスターがどのようにデプロイされたかに依存します。
クラウドプロバイダーのリソースクォータ クラウドプロバイダーのクォータの問題に遭遇することを避けるため、多数のノードを使ったクラスターを作成するときには次のようなことを考慮してください。
次のようなクラウドリソースの増加をリクエストするコンピューターインスタンス CPU ストレージボリューム 使用中のIPアドレス パケットフィルタリングのルールセット ロードバランサーの数 ネットワークサブネット ログストリーム クラウドプロバイダーによる新しいインスタンスの作成に対するレート制限のため、バッチで新しいノードを立ち上げるようなクラスターのスケーリング操作を通すためには、バッチ間ですこし休止を入れます。 コントロールプレーンのコンポーネント 大きなクラスターでは、十分な計算とその他のリソースを持ったコントロールプレーンが必要になります。
特に故障ゾーンあたり1つまたは2つのコントロールプレーンインスタンスを動かす場合、最初に垂直方向にインスタンスをスケールし、垂直方向のスケーリングの効果が低下するポイントに達したら水平方向にスケールします。
フォールトトレランスを備えるために、1つの故障ゾーンに対して最低1インスタンスを動かすべきです。
Kubernetesノードは、同一故障ゾーン内のコントロールプレーンエンドポイントに対して自動的にトラフィックが向かないようにします。
しかし、クラウドプロバイダーはこれを実現するための独自の機構を持っているかもしれません。
例えばマネージドなロードバランサーを使うと、故障ゾーン A にあるkubeletやPodから発生したトラフィックを、同じく故障ゾーン A にあるコントロールプレーンホストに対してのみ送るように設定します。もし1つのコントロールプレーンホストまたは故障ゾーン A のエンドポイントがオフラインになった場合、ゾーン A にあるノードについてすべてのコントロールプレーンのトラフィックはゾーンを跨いで送信されます。それぞれのゾーンで複数のコントロールプレーンホストを動作させることは、結果としてほとんどありません。
etcdストレージ 大きなクラスターの性能を向上させるために、他の専用のetcdインスタンスにイベントオブジェクトを保存できます。
クラスターを作るときに、(カスタムツールを使って)以下のようなことができます。
追加のetcdインスタンスを起動または設定する イベントを保存するためにAPIサーバ を設定する 大きなクラスターのためにetcdを設定・管理する詳細については、Operating etcd clusters for Kubernetes またはkubeadmを使用した高可用性etcdクラスターの作成 を見てください。
アドオンのリソース Kubernetesのリソース制限 は、メモリリークの影響やPodやコンテナが他のコンポーネントに与える他の影響を最小化することに役立ちます。
これらのリソース制限は、アプリケーションのワークロードに適用するのと同様に、アドオン のリソースにも適用されます。
例えば、ロギングコンポーネントに対してCPUやメモリ制限を設定できます。
...
containers :
- name : fluentd-cloud-logging
image : fluent/fluentd-kubernetes-daemonset:v1
resources :
limits :
cpu : 100m
memory : 200Mi
アドオンのデフォルト制限は、アドオンを小~中規模のKubernetesクラスターで動作させたときの経験から得られたデータに基づきます。
大規模のクラスターで動作させる場合は、アドオンはデフォルト制限よりも多くのリソースを消費することが多いです。
これらの値を調整せずに大規模のクラスターをデプロイした場合、メモリー制限に達し続けるため、アドオンが継続的に停止されるかもしれません。
あるいは、CPUのタイムスライス制限により性能がでない状態で動作するかもしれません。
クラスターのアドオンのリソース制限に遭遇しないために、多くのノードで構成されるクラスターを構築する場合は次のことを考慮します。
いくつかのアドオンは垂直方向にスケールします - クラスターに1つのレプリカ、もしくは故障ゾーン全体にサービングされるものがあります。このようなアドオンでは、クラスターをスケールアウトしたときにリクエストと制限を増やす必要があります。 数多くのアドオンは、水平方向にスケールします - より多くのPod数を動作させることで性能を向上できます - ただし、とても大きなクラスターではCPUやメモリの制限も少し引き上げる必要があるかもしれません。VerticalPodAutoscalerは、提案されたリクエストや制限の数値を提供する _recommender_ モードで動作可能です。 いくつかのアドオンはDaemonSet によって制御され、1ノードに1つ複製される形で動作します: 例えばノードレベルのログアグリゲーターです。水平方向にスケールするアドオンの場合と同様に、CPUやメモリ制限を少し引き上げる必要があるかもしれません。 次の項目 VerticalPodAutoscaler は、リソースのリクエストやPodの制限についての管理を手助けするためにクラスターへデプロイ可能なカスタムリソースです。
VerticalPodAutoscaler やクラスターで致命的なアドオンを含むクラスターコンポーネントをスケールする方法についてさらに知りたい場合はVertical Pod Autoscaler をご覧ください。
cluster autoscaler は、クラスターで要求されるリソース水準を満たす正確なノード数で動作できるよう、いくつかのクラウドプロバイダーと統合されています。
addon resizer は、クラスターのスケールが変化したときにアドオンの自動的なリサイズをお手伝いします。
2.3.2 - 複数のゾーンで動かす このページでは、複数のゾーンにまたがるKubernetesクラスターの実行について説明します。
背景 Kubernetesは、1つのKubernetesクラスターが複数のゾーンにまたがって実行できるように設計されており、通常これらのゾーンは リージョン と呼ばれる論理的なグループ内に収まります。主要なクラウドプロバイダーは、一貫した機能を提供するゾーン( アベイラビリティゾーン とも呼ばれる)の集合をリージョンと定義しており、リージョン内では各ゾーンが同じAPIとサービスを提供しています。
一般的なクラウドアーキテクチャは、あるゾーンでの障害が別のゾーンのサービスにも影響を与える可能性を最小限に抑えることを目的としています。
コントロールプレーンの動作 すべてのコントロールプレーンコンポーネント は、交換可能なリソースのプールとして実行され、コンポーネントごとに複製されることをサポートします。
クラスターコントロールプレーンをデプロイする場合は、複数のゾーンに渡ってコントロールプレーンコンポーネントのレプリカを配置します。可用性を重視する場合は、少なくとも3つのゾーンを選択し、個々のコントロールプレーンコンポーネント(APIサーバー、スケジューラー、etcd、クラスターコントローラーマネージャー)を少なくとも3つのゾーンに渡って複製します。クラウドコントローラーマネージャーを実行している場合は、選択したすべてのゾーンにまたがって複製する必要があります。
備考: KubernetesはAPIサーバーのエンドポイントに対してゾーンを跨いだ回復力を提供しません。クラスター内のAPIサーバーの可用性を向上させるためにDNSラウンドロビン、SRVレコード、またはヘルスチェックを備えたサードパーティの負荷分散ソリューションなど、さまざまな技術を使用できます。ノードの動作 Kubernetesは、(Deployment やStatefulSet のような)ワークロードリソース用のPodをクラスター内の異なるノードに自動的に分散します。この分散は、障害の影響を軽減するのに役立ちます。
ノードが起動すると、各ノードのkubeletは、Kubernetes APIで特定のkubeletを表すNodeオブジェクトにラベル を自動的に追加します。これらのラベルにはゾーン情報 を含めることができます。
クラスターが複数のゾーンまたはリージョンにまたがっている場合、ノードラベルとPod Topology Spread Constraints を組み合わせて使用することで、リージョン、ゾーン、さらには特定のノードといった障害ドメイン間でクラスター全体にPodをどのように分散させるかを制御できます。これらのヒントにより、スケジューラー は期待される可用性を高めてPodを配置し、関連する障害がワークロード全体に影響するリスクを低減できます
例えば、StatefulSetの3つのレプリカがすべて互いに異なるゾーンで実行されるように制約を設定できます。ワークロードごとにどのアベイラビリティゾーンを使用するかを明示的に定義しなくても、宣言的に定義できます。
ノードをゾーンに分散させる Kubernetesのコアがノードを作成してくれるわけではないため、自分で行うか、Cluster API などのツールを使ってノードの管理を代行する必要があります。
Cluster APIなどのツールを使用すると、複数の障害ドメインにわたってクラスターのワーカーノードとして実行するマシンのセットを定義したり、ゾーン全体のサービスが中断した場合にクラスターを自動的に復旧するルールを定義できます。
Podの手動ゾーン割り当て nodeSelectorの制約 は、作成したPodだけでなく、Deployment、StatefulSet、Jobなどのワークロードリソース内のPodテンプレートにも適用できます。
ゾーンのストレージアクセス Persistent Volumeが作成されると、Kubernetesは特定のゾーンにリンクされているすべてのPersistent Volumeにゾーンラベルを自動的に追加します。その後、スケジューラー は、NoVolumeZoneConflict条件を通じて、指定されたPersistent Volumeを要求するPodがそのボリュームと同じゾーンにのみ配置されるようにします。
ゾーンラベルの追加方法は、クラウドプロバイダーと使用しているストレージプロビジョナーによって異なる可能性があることに注意してください。正しい設定を行うために、常に利用している環境のドキュメントを参照してください。
Persistent Volume Claimには、そのクラス内のストレージが使用する障害ドメイン(ゾーン)を指定するStorageClass を指定できます。障害ドメインまたはゾーンを認識するStorageClassの構成については、許可されたトポロジー を参照してください。
ネットワーキング Kubernetes自体にはゾーンを意識したネットワーキングは含まれていません。ネットワークプラグインを使用してクラスターネットワーキングを設定できますが、そのネットワークソリューションにはゾーン固有の要素があるかもしれません。例えば、クラウドプロバイダーがtype=LoadBalancerのServiceをサポートしている場合、ロードバランサーは与えられた接続を処理するロードバランサーのコンポーネントと同じゾーンで動作しているPodにのみトラフィックを送信する可能性があります。詳しくはクラウドプロバイダーのドキュメントを確認してください。
カスタムまたはオンプレミスのデプロイメントの場合、同様の考慮事項が適用されます。Service およびIngress の動作は、異なるゾーンの処理を含め、クラスターのセットアップ方法によって異なります。
障害回復 クラスターをセットアップする際には、リージョン内のすべてのゾーンが同時にオフラインになった場合にセットアップがサービスを復旧できるかどうか、またどのように復旧させるかを考慮しておく必要があるかもしれません。例えば、ゾーン内にPodを実行できるノードが少なくとも1つあることに依存していますか?クラスタークリティカルな修復作業が、クラスター内に少なくとも1つの健全なノードがあることに依存していないことを確認してください。例えば、全てのノードが不健全な場合、少なくとも1つのノードを使用できるよう修復が完了するように、特別なtoleration で修復Jobを実行する必要があるかもしれません。
Kubernetesにはこの課題に対する答えはありませんが、検討すべきことです。
次の項目 設定された制約を守りつつ、スケジューラーがクラスターにPodを配置する方法については、スケジューリング、プリエンプションと退避 を参照してください。
2.3.3 - ノードのセットアップの検証 ノード適合テスト ノード適合テスト は、システムの検証とノードに対する機能テストを提供するコンテナ型のテストフレームワークです。このテストは、ノードがKubernetesの最小要件を満たしているかどうかを検証するもので、テストに合格したノードはKubernetesクラスターに参加する資格があることになります。
ノードの前提条件 適合テストを実行するにはノードは通常のKubernetesノードと同じ前提条件を満たしている必要があります。 最低でもノードに以下のデーモンがインストールされている必要があります:
コンテナランタイム (Docker) Kubelet ノード適合テストの実行 ノード適合テストを実行するには、以下の手順に従います:
kubeletの--kubeconfigオプションの値を調べます。例:--kubeconfig=/var/lib/kubelet/config.yaml。
このテストフレームワークはKubeletのテスト用にローカルコントロールプレーンを起動するため、APIサーバーのURLとしてhttp://localhost:8080を使用します。
他にも使用できるkubeletコマンドラインパラメーターがいくつかあります:
--cloud-provider: --cloud-provider=gceを指定している場合は、テストを実行する前にこのフラグを取り除いてください。以下のコマンドでノード適合テストを実行します:
# $CONFIG_DIRはKubeletのPodのマニフェストパスです。
# $LOG_DIRはテスト出力のパスです。
sudo docker run -it --rm --privileged --net= host \
$CONFIG_DIR :$CONFIG_DIR -v $LOG_DIR :/var/result \
他アーキテクチャ向けのノード適合テストの実行 Kubernetesは他のアーキテクチャ用のノード適合テストのdockerイメージを提供しています:
Arch Image amd64 node-test-amd64 arm node-test-arm arm64 node-test-arm64
選択したテストの実行 特定のテストを実行するには、環境変数FOCUSを実行したいテストの正規表現で上書きします。
sudo docker run -it --rm --privileged --net= host \
$CONFIG_DIR :$CONFIG_DIR -v $LOG_DIR :/var/result \
FOCUS = MirrorPod \ # MirrorPodテストのみを実行します
registry.k8s.io/node-test:0.2
特定のテストをスキップするには、環境変数SKIPをスキップしたいテストの正規表現で上書きします。
sudo docker run -it --rm --privileged --net= host \
$CONFIG_DIR :$CONFIG_DIR -v $LOG_DIR :/var/result \
SKIP = MirrorPod \ # MirrorPodテスト以外のすべてのノード適合テストを実行します
registry.k8s.io/node-test:0.2
ノード適合テストは、node e2e test のコンテナ化されたバージョンです。
デフォルトでは、すべての適合テストが実行されます。
理論的には、コンテナを構成し必要なボリュームを適切にマウントすれば、どのノードのe2eテストも実行できます。しかし、不適合テストを実行するためにはより複雑な設定が必要となるため、適合テストのみを実行することを強く推奨します 。
注意事項 このテストでは、ノード適合テストイメージや機能テストで使用されるコンテナのイメージなど、いくつかのdockerイメージがノード上に残ります。 このテストでは、ノード上にデッドコンテナが残ります。これらのコンテナは機能テスト中に作成されます。 2.3.4 - Podセキュリティ標準の強制 このページでは、Podセキュリティの標準 を強制する際のベストプラクティスの概要を説明します。
ビルトインPodセキュリティアドミッションコントローラーの使用 FEATURE STATE:
Kubernetes v1.25 [stable]
Podセキュリティアドミッションコントローラー は、非推奨のPodSecurityPolicyを置き換えます。
すべてのNamespaceに設定する 設定が全く無いNamespaceは、クラスターのセキュリティモデルにおいて重大な弱点とみなすべきです。
各Namespaceで発生するワークロードのタイプを時間をかけて分析し、Podセキュリティ標準を参照しながら、それぞれに適切なレベルを決定することを推奨します。
また、ラベルのないNamespaceは、まだ評価されていないことだけを示すべきです。
すべてのNamespaceのワークロードが同じセキュリティ要件を持つというシナリオでは、PodSecurityラベルを一括適用する方法を例 で説明しています。
最小特権の原則を採用する 理想的な世界では、すべてのNamespaceのPodがrestrictedポリシーの要件を満たすでしょう。
しかし、ワークロードの中には正当な理由で昇格した特権を必要とするものもあるため、それは不可能であり、現実的でもありません。
privilegedワークロードを許可するNamespaceは、適切なアクセス制御を確立し、実施すべきである。最小権限のNamespaceで実行されるワークロードについては、そのワークロードのセキュリティ要件に関するドキュメントを整備する。可能であれば、それらの要件がどのように制約される可能性があるのかを考慮する。 マルチモード戦略の採用 Podセキュリティアドミッションコントローラーのauditとwarnモードを使用すると、既存のワークロードを破壊することなく、Podに関する重要なセキュリティインサイトを簡単に収集できます。
すべてのNamespaceでこれらのモードを有効にし、最終的にenforceしたいレベルやバージョンに設定するのがよい方法です。
このフェーズで生成される警告と監査注釈は、その状態への指針となります。
ワークロード作成者が希望のレベルに収まるように変更することを期待している場合は、warnモードを有効にしてください。
監査ログを使用して、希望のレベルに収まるように変更を監視/推進することを期待している場合は、auditモードを有効にしてください。
enforceモードが希望通りの値に設定されている場合でも、これらのモードはいくつかの異なる方法で役立ちます。
warnをenforceと同じレベルに設定すると、バリデーションを通過しないPod(またはPodテンプレートを持つリソース)を作成しようとしたときに、クライアントが警告を受け取るようになります。これにより、対象のリソースを更新して準拠させることができます。enforceを特定の最新バージョンではないに固定するNamespaceでは、auditとwarnモードをenforceと同じレベルに設定するが、最新バージョンに対して設定することで、以前のバージョンでは許可されていたが、現在のベストプラクティスでは許可されていない設定を可視化することができます。サードパーティによる代替案 備考: このセクションでは、Kubernetesが必要とする機能を提供するサードパーティープロジェクトにリンクしています。これらのプロジェクトはアルファベット順に記載されていて、Kubernetesプロジェクトの作者は責任を持ちません。このリストにプロジェクトを追加するには、変更を提出する前に
content guide をお読みください。
詳細はこちら。 Kubernetesエコシステムでは、セキュリティプロファイルを強制するための他の選択肢も開発されています。
ビルトインソリューション(PodSecurityアドミッションコントローラーなど)とサードパーティツールのどちらを選ぶかは、あなたの状況次第です。
どのようなソリューションを評価する場合でも、サプライチェーンの信頼が非常に重要です。最終的には、前述のアプローチのどれを使っても、何もしないよりはましでしょう。
2.3.5 - PKI証明書とその要件 Kubernetesでは、TLS認証のためにPKI証明書が必要です。
kubeadm でKubernetesをインストールする場合、必要な証明書は自動で生成されます。
自身で証明書を作成することも可能です。例えば、秘密鍵をAPIサーバーに保持しないことで、管理をよりセキュアにする場合が挙げられます。
本ページでは、クラスターに必要な証明書について説明します。
クラスターではどのように証明書が使われているのか Kubernetesは下記の用途でPKIを必要とします:
kubeletがAPIサーバーの認証をするためのクライアント証明書 APIサーバーがkubeletと通信するためのkubeletのサーバー証明書 APIサーバーのエンドポイント用サーバー証明書 クラスターの管理者がAPIサーバーの認証を行うためのクライアント証明書 APIサーバーがkubeletと通信するためのクライアント証明書 APIサーバーがetcdと通信するためのクライアント証明書 controller managerがAPIサーバーと通信するためのクライアント証明書およびkubeconfig スケジューラーがAPIサーバーと通信するためのクライアント証明書およびkubeconfig front-proxy 用のクライアント証明書およびサーバー証明書さらに、etcdはクライアントおよびピア間の認証に相互TLS通信を実装しています。
証明書の保存場所 kubeadmを使用してKubernetesをインストールする場合、ほとんどの証明書は/etc/kubernetes/pkiに保存されます。このドキュメントの全てのパスは、そのディレクトリの相対パスを表します。
ただしユーザーアカウントの証明書に関しては、kubeadmは/etc/kubernetesに配置します。
手動で証明書を設定する もしkubeadmに必要な証明書の生成を望まない場合、それらを単一ルート認証局を使って作成するか、全ての証明書を提供することで作成できます。
自身の認証局を作成する詳細については、証明書を手動で生成する を参照してください。
証明書の管理についての詳細は、kubeadmによる証明書管理 を参照してください。
単一ルート認証局 管理者によりコントロールされた、単一ルート認証局の作成が可能です。このルート認証局は複数の中間認証局を作る事が可能で、作成はKubernetes自身に委ねます。
必要な認証局:
パス デフォルトCN 説明 ca.crt,key kubernetes-ca Kubernetes全体の認証局 etcd/ca.crt,key etcd-ca etcd用 front-proxy-ca.crt,key kubernetes-front-proxy-ca front-end proxy 用
上記の認証局に加えて、サービスアカウント管理用に公開鍵/秘密鍵のペア(sa.keyとsa.pub)を取得する事が必要です。
次の例は、前の表で示されたCAのキーと証明書を示しています:
/etc/kubernetes/pki/ca.crt
/etc/kubernetes/pki/ca.key
/etc/kubernetes/pki/etcd/ca.crt
/etc/kubernetes/pki/etcd/ca.key
/etc/kubernetes/pki/front-proxy-ca.crt
/etc/kubernetes/pki/front-proxy-ca.key
全ての証明書 CAの秘密鍵をクラスターにコピーしたくない場合、自身で全ての証明書を作成できます。
必要な証明書:
デフォルトCN 親認証局 組織 種類 ホスト名 (SAN) kube-etcd etcd-ca server, client <hostname>, <Host_IP>, localhost, 127.0.0.1kube-etcd-peer etcd-ca server, client <hostname>, <Host_IP>, localhost, 127.0.0.1kube-etcd-healthcheck-client etcd-ca client kube-apiserver-etcd-client etcd-ca client kube-apiserver kubernetes-ca server <hostname>, <Host_IP>, <advertise_IP>, [1]kube-apiserver-kubelet-client kubernetes-ca system:masters client front-proxy-client kubernetes-front-proxy-ca client
備考: kube-apiserver-kubelet-clientにスーパーユーザーグループsystem:mastersを使用する代わりに、より権限の低いグループを使用することができます。
そのために、kubeadmはkubeadm:cluster-adminsグループを使用します。[1]: クラスターに接続するIPおよびDNS名( kubeadm を使用する場合と同様、ロードバランサーのIPおよびDNS名、kubernetes、kubernetes.default、kubernetes.default.svc、kubernetes.default.svc.cluster、kubernetes.default.svc.cluster.local)
ここで種類は、一つまたは複数のx509の鍵用途にマッピングされており、これはCertificateSigningRequest の.spec.usagesにも記載されています:
種類 鍵の用途 server digital signature, key encipherment, server auth client digital signature, key encipherment, client auth
備考: 上記に挙げられたホスト名(SAN)は、クラスターを動作させるために推奨されるものです。
特別なセットアップが求められる場合、全てのサーバー証明書にSANを追加する事ができます。備考: kubeadm利用者のみ:
秘密鍵なしでCA証明書をクラスターにコピーするシナリオは、kubeadmドキュメントの外部認証局の項目で言及されています。 kubeadmでPKIを生成すると、kube-etcd、kube-etcd-peerおよび kube-etcd-healthcheck-client証明書は外部etcdを利用するケースでは生成されない事に留意してください。 証明書のパス 証明書は推奨パスに配置するべきです(kubeadm を使用する場合と同様)。
パスは場所に関係なく与えられた引数で特定されます。
デフォルトCN 鍵の推奨パス 証明書の推奨パス コマンド 鍵を指定する引数 証明書を指定する引数 etcd-ca etcd/ca.key etcd/ca.crt kube-apiserver --etcd-cafile kube-apiserver-etcd-client apiserver-etcd-client.key apiserver-etcd-client.crt kube-apiserver --etcd-keyfile --etcd-certfile kubernetes-ca ca.key ca.crt kube-apiserver --client-ca-file kubernetes-ca ca.key ca.crt kube-controller-manager --cluster-signing-key-file --client-ca-file, --root-ca-file, --cluster-signing-cert-file kube-apiserver apiserver.key apiserver.crt kube-apiserver --tls-private-key-file --tls-cert-file kube-apiserver-kubelet-client apiserver-kubelet-client.key apiserver-kubelet-client.crt kube-apiserver --kubelet-client-key --kubelet-client-certificate front-proxy-ca front-proxy-ca.key front-proxy-ca.crt kube-apiserver --requestheader-client-ca-file front-proxy-ca front-proxy-ca.key front-proxy-ca.crt kube-controller-manager --requestheader-client-ca-file front-proxy-client front-proxy-client.key front-proxy-client.crt kube-apiserver --proxy-client-key-file --proxy-client-cert-file etcd-ca etcd/ca.key etcd/ca.crt etcd --trusted-ca-file, --peer-trusted-ca-file kube-etcd etcd/server.key etcd/server.crt etcd --key-file --cert-file kube-etcd-peer etcd/peer.key etcd/peer.crt etcd --peer-key-file --peer-cert-file etcd-ca etcd/ca.crt etcdctl --cacert kube-etcd-healthcheck-client etcd/healthcheck-client.key etcd/healthcheck-client.crt etcdctl --key --cert
サービスアカウント用の鍵ペアについても同様です。
秘密鍵のパス 公開鍵のパス コマンド 引数 sa.key kube-controller-manager service-account-private sa.pub kube-apiserver service-account-key
次の例は、自分自身で全てのキーと証明書を生成している場合に提供する必要があるファイルパスを前の表 から示しています:
/etc/kubernetes/pki/etcd/ca.key
/etc/kubernetes/pki/etcd/ca.crt
/etc/kubernetes/pki/apiserver-etcd-client.key
/etc/kubernetes/pki/apiserver-etcd-client.crt
/etc/kubernetes/pki/ca.key
/etc/kubernetes/pki/ca.crt
/etc/kubernetes/pki/apiserver.key
/etc/kubernetes/pki/apiserver.crt
/etc/kubernetes/pki/apiserver-kubelet-client.key
/etc/kubernetes/pki/apiserver-kubelet-client.crt
/etc/kubernetes/pki/front-proxy-ca.key
/etc/kubernetes/pki/front-proxy-ca.crt
/etc/kubernetes/pki/front-proxy-client.key
/etc/kubernetes/pki/front-proxy-client.crt
/etc/kubernetes/pki/etcd/server.key
/etc/kubernetes/pki/etcd/server.crt
/etc/kubernetes/pki/etcd/peer.key
/etc/kubernetes/pki/etcd/peer.crt
/etc/kubernetes/pki/etcd/healthcheck-client.key
/etc/kubernetes/pki/etcd/healthcheck-client.crt
/etc/kubernetes/pki/sa.key
/etc/kubernetes/pki/sa.pub
ユーザーアカウント用に証明書を設定する 管理者アカウントおよびサービスアカウントは手動で設定しなければなりません。
ファイル名 クレデンシャル名 デフォルトCN O (in Subject) admin.conf default-admin kubernetes-admin <admin-group>super-admin.conf default-super-admin kubernetes-super-admin system:masters kubelet.conf default-auth system:node:<nodeName> (備考を参照) system:nodes controller-manager.conf default-controller-manager system:kube-controller-manager scheduler.conf default-scheduler system:kube-scheduler
備考: kubelet.confにおける
<nodeName>の値は
必ず APIサーバーに登録されたkubeletのノード名と一致しなければなりません。詳細は、
Node Authorization を参照してください。
備考: 上記の例での<admin-group>は実装に依存します。
一部のツールはデフォルトのadmin.conf内の証明書にsystem:mastersグループの一部として署名します。
system:mastersは緊急用のスーパーユーザーグループであり、RBACのようなKubernetesの認証レイヤーをバイパスすることができます。
また、一部のツールはこのスーパーユーザーグループに紐づけられた証明書を含むsuper-admin.confを生成しません。
kubeadmはkubeconfigファイル内に2つの別々の管理者証明書を生成します。
一つはadmin.conf内にあり、Subject: O = kubeadm:cluster-admins, CN = kubernetes-adminとなっています。
kubeadm:cluster-adminsはcluster-admin ClusterRoleに紐づけられたカスタムグループです。
このファイルは、kubeadmが管理する全てのコントロールプレーンマシン上で生成されます。
もう一つはsuper-admin.conf内にあり、Subject: O = system:masters, CN = kubernetes-super-adminとなっています。
このファイルはkubeadm initが呼び出されたノード上でのみ生成されます。
各コンフィグ毎に、CN名と組織を指定してx509証明書と鍵ペアを生成してください。
以下のように、各コンフィグでkubectlを実行してください。
KUBECONFIG = <filename> kubectl config set-cluster default-cluster --server= https://<host ip>:6443 --certificate-authority <path-to-kubernetes-ca> --embed-certs
KUBECONFIG = <filename> kubectl config set-credentials <credential-name> --client-key <path-to-key>.pem --client-certificate <path-to-cert>.pem --embed-certs
KUBECONFIG = <filename> kubectl config set-context default-system --cluster default-cluster --user <credential-name>
KUBECONFIG = <filename> kubectl config use-context default-system
これらのファイルは以下のように利用されます:
ファイル名 コマンド コメント admin.conf kubectl クラスターの管理者設定用 kubelet.conf kubelet クラスターの各ノードに1つ必要です。 controller-manager.conf kube-controller-manager manifests/kube-controller-manager.yamlのマニフェストファイルに追記する必要があります。scheduler.conf kube-scheduler manifests/kube-scheduler.yamlのマニフェストファイルに追記する必要があります。
以下のファイルは、前の表に挙げたファイルへの絶対パスを示しています:
/etc/kubernetes/admin.conf
/etc/kubernetes/super-admin.conf
/etc/kubernetes/kubelet.conf
/etc/kubernetes/controller-manager.conf
/etc/kubernetes/scheduler.conf
3 - コンセプト 本セクションは、Kubernetesシステムの各パートと、クラスター を表現するためにKubernetesが使用する抽象概念について学習し、Kubernetesの仕組みをより深く理解するのに役立ちます。
3.1 - 概要 Kubernetesは、宣言的な構成管理と自動化を促進し、コンテナ化されたワークロードやサービスを管理するための、ポータブルで拡張性のあるオープンソースのプラットフォームです。Kubernetesは巨大で急速に成長しているエコシステムを備えており、それらのサービス、サポート、ツールは幅広い形で利用可能です。
このページでは、Kubernetesの概要について説明します。
Kubernetesの名称は、ギリシャ語に由来し、操舵手やパイロットを意味しています。
"K"と"s"の間にある8つの文字を数えることから、K8sが略語として使われています。
Googleは2014年にKubernetesプロジェクトをオープンソース化しました。
Kubernetesは、本番環境で大規模なワークロードを稼働させたGoogleの15年以上の経験 と、コミュニティからの最高のアイディアや実践を組み合わせています。
Kubernetesが必要な理由と提供する機能 コンテナは、アプリケーションを集約して実行する良い方法です。本番環境では、アプリケーションを実行しダウンタイムが発生しないように、コンテナを管理する必要があります。例えば、コンテナがダウンした場合、他のコンテナを起動する必要があります。このような動作がシステムに組み込まれていると、管理が簡単になるのではないでしょうか?
そこを助けてくれるのがKubernetesです!Kubernetesは分散システムを弾力的に実行するフレームワークを提供してくれます。あなたのアプリケーションのためにスケーリングとフェイルオーバーの面倒を見てくれて、デプロイのパターンなどを提供します。例えば、Kubernetesはシステムにカナリアデプロイを簡単に管理することができます。
Kubernetesは以下を提供します。
サービスディスカバリと負荷分散
Kubernetesは、DNS名または独自のIPアドレスを使ってコンテナを公開することができます。コンテナへのトラフィックが多い場合は、Kubernetesは負荷分散し、ネットワークトラフィックを振り分けることができるため、デプロイが安定します。ストレージオーケストレーション
Kubernetesは、ローカルストレージやパブリッククラウドプロバイダーなど、選択したストレージシステムを自動でマウントすることができます。自動化されたロールアウトとロールバック
Kubernetesを使うとデプロイしたコンテナのあるべき状態を記述することができ、制御されたスピードで実際の状態をあるべき状態に変更することができます。例えば、アプリケーションのデプロイのために、新しいコンテナの作成や既存コンテナの削除、新しいコンテナにあらゆるリソースを適用する作業を、Kubernetesで自動化できます。自動ビンパッキング
コンテナ化されたタスクを実行するノードのクラスターをKubernetesへ提供します。各コンテナがどれくらいCPUやメモリ(RAM)を必要とするのかをKubernetesに宣言することができます。Kubernetesはコンテナをノードにあわせて調整することができ、リソースを最大限に活用してくれます。自己修復
Kubernetesは、処理が失敗したコンテナを再起動し、コンテナを入れ替え、定義したヘルスチェックに応答しないコンテナを強制終了します。処理の準備ができるまでは、クライアントに通知しません。機密情報と構成管理
Kubernetesは、パスワードやOAuthトークン、SSHキーなどの機密の情報を保持し、管理することができます。機密情報をデプロイし、コンテナイメージを再作成することなくアプリケーションの構成情報を更新することができます。スタック構成の中で機密情報を晒してしまうこともありません。バッチの実行
サービスに加えて、KubernetesはバッチやCIのワークロードを管理し、必要であれば障害が発生したコンテナを置き換えることもできます。水平スケーリング
簡単なコマンド、UI、あるいはCPU使用率に基づいて自動的に、アプリケーションをスケールイン、スケールアウトできます。IPv4/IPv6デュアルスタック
PodとServiceに、IPv4とIPv6アドレスを割り当てます。拡張性のある設計
アップストリームのソースコードを変更することなく、Kubernetesクラスターに機能を追加できます。Kubernetesにないもの Kubernetesは、従来型の全部入りなPaaS(Platform as a Service)のシステムではありません。Kubernetesはハードウェアレベルではなく、コンテナレベルで動作するため、デプロイ、スケーリング、負荷分散といったPaaSが提供するのと共通の機能をいくつか提供し、またユーザーはロギングやモニタリング及びアラートを行うソリューションを統合できます。また一方、Kubernetesはモノリシックでなく、標準のソリューションは選択が自由で、追加と削除が容易な構成になっています。Kubernetesは開発プラットフォーム構築のためにビルディングブロックを提供しますが、重要な部分はユーザーの選択と柔軟性を維持しています。
Kubernetesは...
サポートするアプリケーションの種類を制限しません。Kubernetesは、ステートレス、ステートフルやデータ処理のワークロードなど、非常に多様なワークロードをサポートすることを目的としています。アプリケーションがコンテナで実行できるのであれば、Kubernetes上で問題なく実行できるはずです。 ソースコードのデプロイやアプリケーションのビルドは行いません。継続的なインテグレーション、デリバリ、デプロイ(CI/CD)のワークフローは、技術的な要件だけでなく組織の文化や好みで決められます。 ミドルウェア(例:メッセージバス)、データ処理フレームワーク(例:Spark)、データベース(例:MySQL)、キャッシュ、クラスターストレージシステム(例:Ceph)といったアプリケーションレベルの機能を組み込んで提供しません。それらのコンポーネントは、Kubernetes上で実行することもできますし、Open Service Broker のようなポータブルメカニズムを経由してKubernetes上で実行されるアプリケーションからアクセスすることも可能です。 ロギング、モニタリングやアラートを行うソリューションは指定しません。PoCとしていくつかのインテグレーションとメトリクスを収集し出力するメカニズムを提供します。 構成言語/システム(例:Jsonnet)の提供も指示もしません。任意の形式の宣言型仕様の対象となる可能性のある宣言型APIを提供します。 統合的なマシンの構成、メンテナンス、管理、または自己修復を行うシステムは提供も採用も行いません。 さらに、Kubernetesは単なるオーケストレーションシステムではありません。実際には、オーケストレーションの必要性はありません。オーケストレーションの技術的な定義は、「最初にAを実行し、次にB、その次にCを実行」のような定義されたワークフローの実行です。対照的にKubernetesは、現在の状態から提示されたあるべき状態にあわせて継続的に維持するといった、独立していて構成可能な制御プロセスのセットを提供します。AからCへどのように移行するかは問題ではありません。集中管理も必要ありません。これにより、使いやすく、より強力で、堅牢で、弾力性と拡張性があるシステムが実現します。 Kubernetesの歴史的背景 過去を振り返って、Kubernetesがなぜこんなに便利なのかを見てみましょう。
仮想化ができる前の時代におけるデプロイ(Traditional deployment):
初期の頃は、組織は物理サーバー上にアプリケーションを実行させていました。物理サーバー上でアプリケーションのリソース制限を設定する方法がなかったため、リソースの割当問題が発生していました。例えば、複数のアプリケーションを実行させた場合、ひとつのアプリケーションがリソースの大半を消費してしまうと、他のアプリケーションのパフォーマンスが低下してしまうことがありました。この解決方法は、それぞれのアプリケーションを別々の物理サーバーで動かすことでした。しかし、リソースが十分に活用できなかったため、拡大しませんでした。また組織にとって多くの物理サーバーを維持することは費用がかかりました。
仮想化を使ったデプロイ(Virtualized deployment):
ひとつの解決方法として、仮想化が導入されました。1台の物理サーバーのCPU上で、複数の仮想マシン(VM)を実行させることができるようになりました。仮想化によりアプリケーションをVM毎に隔離することができ、ひとつのアプリケーションの情報が他のアプリケーションから自由にアクセスさせないといったセキュリティレベルを提供することができます。
仮想化により、物理サーバー内のリソース使用率が向上し、アプリケーションの追加や更新が容易になり、ハードウェアコストの削減などスケーラビリティが向上します。仮想化を利用すると、物理リソースのセットを使い捨て可能な仮想マシンのクラスターとして提示することができます。
各VMは、仮想ハードウェア上で各自のOSを含んだ全コンポーネントを実行する完全なマシンです。
コンテナを使ったデプロイ(Container deployment):
コンテナはVMと似ていますが、アプリケーション間でオペレーティングシステム(OS)を共有できる緩和された分離特性を持っています。そのため、コンテナは軽量だといわれます。VMと同じように、コンテナは各自のファイルシステム、CPUの共有、メモリ、プロセス空間等を持っています。基盤のインフラストラクチャから分離されているため、クラウドやOSディストリビューションを越えて移動することが可能です。
コンテナは、その他にも次のようなメリットを提供するため、人気が高まっています。
アジャイルアプリケーションの作成とデプロイ: VMイメージの利用時と比較して、コンテナイメージ作成の容易さと効率性が向上します。 継続的な開発、インテグレーションとデプロイ: 信頼できる頻繁なコンテナイメージのビルドと、素早く簡単にロールバックすることが可能なデプロイを提供します(イメージが不変であれば)。 開発者と運用者の関心を分離: アプリケーションコンテナイメージの作成は、デプロイ時ではなく、ビルド/リリース時に行います。それによって、インフラストラクチャとアプリケーションを分離します。 可観測性: OSレベルの情報とメトリクスだけではなく、アプリケーションの稼働状態やその他の警告も表示します。 開発、テスト、本番環境を越えた環境の一貫性: クラウドで実行させるのと同じようにノートPCでも実行させることができます。 クラウドとOSディストリビューションの可搬性: Ubuntu、RHEL、CoreOS上でも、オンプレミスも、主要なパブリッククラウドでも、それ以外のどんな環境でも、実行できます。 アプリケーション中心の管理: 仮想マシン上でOSを実行するレベルから、論理リソースを使用してOS上でアプリケーションを実行するレベルへと、抽象度を高めます。 疎結合、分散化、拡張性、柔軟性のあるマイクロサービス: アプリケーションを小さく、同時にデプロイと管理が可能な独立した部品に分割されます。1台の大きな単一目的のマシン上に実行するモノリシックなスタックではありません。 リソースの分割: アプリケーションのパフォーマンスが予測可能です。 リソースの効率的な利用: 高い効率性と集約性を実現できます。 次の項目 3.1.1 - Kubernetesのコンポーネント Kubernetesクラスターを構成するキーコンポーネントの概要。
このページでは、Kubernetesクラスターを構成する必須コンポーネントの概略を説明します。
Kubernetesクラスターのコンポーネント
コアコンポーネント Kubernetesクラスターは、コントロールプレーンと1つ以上のワーカーノードで構成されています。
以下に主要なコンポーネントの概要を簡単に説明します。
コントロールプレーンコンポーネント クラスター全体の状態を管理します:
kube-apiserver Kubernetes HTTP APIを公開するコアコンポーネントサーバーです。 etcd APIサーバーのすべてのデータを保存する、一貫性と高可用性を兼ね備えたキーバリューストアです。 kube-scheduler まだノードにバインドされていないPodを検出し、それぞれのPodを適切なノードに割り当てます。 kube-controller-manager コントローラー を実行して、Kubernetes APIの動作を実装します。cloud-controller-manager (オプション)基盤となるクラウドプロバイダーと統合します。 ノードコンポーネント すべてのノードで実行され、実行中のPodを維持し、Kubernetesランタイム環境を提供します。
kubelet コンテナを含むPodが稼働していることを保証します。 kube-proxy (オプション)ノード上のネットワークルールを維持し、Service を実装します。 コンテナランタイム コンテナを実行する役割を持つソフトウェアです。
詳細はコンテナランタイム を参照してください。 🛇 This item links to a third party project or product that is not part of Kubernetes itself.
More information クラスターによっては、各ノードに追加のソフトウェアが必要になる場合があります。
例えば、Linuxノード上でsystemd を実行してローカルコンポーネントを監督することもあります。
アドオン アドオンはKubernetesの機能を拡張します。
いくつかの重要な例は次のとおりです:
DNS クラスター全体のDNS解決のために使われます。 Web UI (ダッシュボード)ウェブインターフェースを通してクラスターを管理するために使われます。 Container Resource Monitoring コンテナのメトリクスを収集・保存するために使われます。 Cluster-level Logging コンテナのログを中央ログストアに保存するために使われます。 アーキテクチャの柔軟性 Kubernetesは、これらのコンポーネントのデプロイと管理方法に柔軟性を持たせることができます。
Kubernetesのアーキテクチャは、小規模な開発環境から大規模な本番環境への展開まで、様々なニーズに適応できます。
各コンポーネントの詳細情報や、クラスターのアーキテクチャを設定する様々な方法については、クラスターのアーキテクチャ のページをご覧ください。
3.1.2 - Kubernetes API Kubernetes APIを使用すると、Kubernetes内のオブジェクトの状態をクエリで操作できます。 Kubernetesのコントロールプレーンの中核は、APIサーバーとそれが公開するHTTP APIです。ユーザー、クラスターのさまざまな部分、および外部コンポーネントはすべて、APIサーバーを介して互いに通信します。
Kubernetesの中核である control plane はAPI server です。
APIサーバーは、エンドユーザー、クラスターのさまざまな部分、および外部コンポーネントが相互に通信できるようにするHTTP APIを公開します。
Kubernetes APIを使用すると、Kubernetes API内のオブジェクトの状態をクエリで操作できます(例:Pod、Namespace、ConfigMap、Events)。
ほとんどの操作は、APIを使用しているkubectl コマンドラインインターフェースもしくはkubeadm のような別のコマンドラインツールを通して実行できます。
RESTコールを利用して直接APIにアクセスすることも可能です。
Kubernetes APIを利用してアプリケーションを書いているのであれば、client libraries の利用を考えてみてください。
OpenAPI 仕様 完全なAPIの詳細は、OpenAPI を使用して文書化されています。
OpenAPI V2 Kubernetes APIサーバーは、/openapi/v2エンドポイントを介してOpenAPI v2仕様を提供します。
次のように要求ヘッダーを使用して、応答フォーマットを要求できます。
OpenAPI v2クエリの有効なリクエストヘッダー値 ヘッダー 取りうる値 備考 Accept-Encodinggzipこのヘッダーを使わないことも可能 Acceptapplication/com.github.proto-openapi.spec.v2@v1.0+protobuf主にクラスター内での使用 application/jsonデフォルト *application/jsonを提供
Kubernetesは、他の手段として主にクラスター間の連携用途向けのAPIに、Protocol buffersをベースにしたシリアライズフォーマットを実装しています。このフォーマットに関しては、Kubernetes Protobuf serialization デザイン提案を参照してください。また、各スキーマのInterface Definition Language(IDL)ファイルは、APIオブジェクトを定義しているGoパッケージ内に配置されています。
OpenAPI V3 FEATURE STATE:
Kubernetes v1.24 [beta]
Kubernetes v1.35では、OpenAPI v3によるAPI仕様をベータサポートとして提供しています。これは、デフォルトで有効化されているベータ機能です。kube-apiserverのOpenAPIV3というfeature gate を切ることにより、このベータ機能を無効化することができます。
/openapi/v3が、全ての利用可能なグループやバージョンの一覧を閲覧するためのディスカバリーエンドポイントとして提供されています。このエンドポイントは、JSONのみを返却します。利用可能なグループやバージョンは、次のような形式で提供されます。
{
"paths": {
...,
"api/v1": {
"serverRelativeURL": "/openapi/v3/api/v1?hash=CC0E9BFD992D8C59AEC98A1E2336F899E8318D3CF4C68944C3DEC640AF5AB52D864AC50DAA8D145B3494F75FA3CFF939FCBDDA431DAD3CA79738B297795818CF"
},
"apis/admissionregistration.k8s.io/v1": {
"serverRelativeURL": "/openapi/v3/apis/admissionregistration.k8s.io/v1?hash=E19CC93A116982CE5422FC42B590A8AFAD92CDE9AE4D59B5CAAD568F083AD07946E6CB5817531680BCE6E215C16973CD39003B0425F3477CFD854E89A9DB6597"
},
....
}
クライアントサイドのキャッシングを改善するために、相対URLはイミュータブルな(不変の)OpenAPI記述を指しています。
また、APIサーバーも、同様の目的で適切なHTTPキャッシュヘッダー(Expiresには1年先の日付、Cache-Controlにはimmutable)をセットします。廃止されたURLが使用された場合、APIサーバーは最新のURLへのリダイレクトを返します。
Kubernetes APIサーバーは、/openapi/v3/apis/<group>/<version>?hash=<hash>のエンドポイントにて、KubernetesのグループバージョンごとにOpenAPI v3仕様を公開しています。
受理されるリクエストヘッダーについては、以下の表の通りです。
OpenAPI v3において有効なリクエストヘッダー ヘッダー 取りうる値 備考 Accept-Encodinggzipこのヘッダーを使わないことも可能 Acceptapplication/com.github.proto-openapi.spec.v3@v1.0+protobuf主にクラスター内での使用 application/jsonデフォルト *application/jsonを提供
永続性 KubernetesはAPIリソースの観点からシリアル化された状態をetcd に書き込むことで保存します。
APIグループとバージョニング フィールドの削除やリソース表現の再構成を簡単に行えるようにするため、Kubernetesは複数のAPIバージョンをサポートしており、/api/v1や/apis/rbac.authorization.k8s.io/v1alpha1のように、それぞれ異なるAPIのパスが割り当てられています。
APIが、システムリソースと動作について明確かつ一貫したビューを提供し、サポート終了、実験的なAPIへのアクセス制御を有効にするために、リソースまたはフィールドレベルではなく、APIレベルでバージョンが行われます。
APIの発展や拡張を簡易に行えるようにするため、Kubernetesは有効もしくは無効 を行えるAPIグループ を実装しました。
APIリソースは、APIグループ、リソースタイプ、ネームスペース(namespacedリソースのための)、名前によって区別されます。APIサーバーは、APIバージョン間の変換を透過的に処理します。すべてのバージョンの違いは、実際のところ同じ永続データとして表現されます。APIサーバーは、同じ基本的なデータを複数のAPIバージョンで提供することができます。
例えば、同じリソースでv1とv1beta1の2つのバージョンが有ることを考えてみます。
v1beta1バージョンのAPIを利用しオブジェクトを最初に作成したとして、v1beta1バージョンが非推奨となり削除されるまで、v1beta1もしくはv1どちらのAPIバージョンを利用してもオブジェクトのread、update、deleteができます。
その時点では、v1 APIを使用してオブジェクトの修正やアクセスを継続することが可能です。
APIの変更 成功を収めているシステムはすべて、新しいユースケースの出現や既存の変化に応じて成長し、変化する必要があります。
したがって、Kubernetesには、Kubernetes APIを継続的に変更および拡張できる設計機能があります。
Kubernetesプロジェクトは、既存のクライアントとの互換性を破壊 しないこと 、およびその互換性を一定期間維持して、他のプロジェクトが適応する機会を提供することを目的としています。
基本的に、新しいAPIリソースと新しいリソースフィールドは追加することができます。
リソースまたはフィールドを削除するには、API非推奨ポリシー に従ってください。
Kubernetesは、通常はAPIバージョンv1として、公式のKubernetes APIが一度一般提供(GA)に達した場合、互換性を維持することを強く確約します。
さらに、Kubernetesは、公式Kubernetes APIの beta APIバージョン経由で永続化されたデータとの互換性を維持します。
そして、機能が安定したときにGA APIバージョン経由でデータを変換してアクセスできることを保証します。
beta APIを採用した場合、APIが卒業(Graduate)したら、後続のbetaまたはstable APIに移行する必要があります。
これを行うのに最適な時期は、オブジェクトが両方のAPIバージョンから同時にアクセスできるbeta APIの非推奨期間中です。
beta APIが非推奨期間を終えて提供されなくなったら、代替APIバージョンを使用する必要があります。
備考: Kubernetesは、 alpha APIバージョンについても互換性の維持に注力しますが、いくつかの事情により不可である場合もあります。
alpha APIバージョンを使っている場合、クラスターをアップグレードする時にKubernetesのリリースノートを確認してください。
APIが互換性のない方法で変更された場合は、アップグレードをする前に既存のalphaオブジェクトをすべて削除する必要があります。APIバージョンレベルの定義に関する詳細はAPIバージョンのリファレンス を参照してください。
APIの拡張 Kubernetes APIは2つの方法で拡張できます。
カスタムリソース は、APIサーバーが選択したリソースAPIをどのように提供するかを宣言的に定義します。アグリゲーションレイヤー を実装することでKubernetes APIを拡張することもできます。次の項目 3.1.3 - Kubernetesオブジェクトを利用する Kubernetesオブジェクトは、Kubernetes上で永続的なエンティティです。Kubernetesはこれらのエンティティを使い、クラスターの状態を表現します。 Kubernetesオブジェクトモデルと、これらのオブジェクトの利用方法について学びます。
3.1.3.1 - Kubernetesオブジェクトを理解する このページでは、KubernetesオブジェクトがKubernetes APIでどのように表現されているか、またそれらを.yamlフォーマットでどのように表現するかを説明します。
Kubernetesオブジェクトを理解する Kubernetesオブジェクト は、Kubernetes上で永続的なエンティティです。Kubernetesはこれらのエンティティを使い、クラスターの状態を表現します。具体的に言うと、下記のような内容が表現できます:
どのようなコンテナ化されたアプリケーションが稼働しているか(またそれらはどのノード上で動いているか) それらのアプリケーションから利用可能なリソース アプリケーションがどのように振る舞うかのポリシー、例えば再起動、アップグレード、耐障害性ポリシーなど Kubernetesオブジェクトは「意図の記録」です。一度オブジェクトを作成すると、Kubernetesは常にそのオブジェクトが存在し続けるように動きます。オブジェクトを作成することで、Kubernetesに対し効果的にあなたのクラスターのワークロードがこのようになっていて欲しいと伝えているのです。これが、あなたのクラスターの望ましい状態 です。
Kubernetesオブジェクトを操作するには、作成、変更、または削除に関わらずKubernetes API を使う必要があるでしょう。例えばkubectlコマンドラインインターフェースを使った場合、このCLIが処理に必要なKubernetes API命令を、あなたに代わり発行します。あなたのプログラムからクライアントライブラリ を利用し、直接Kubernetes APIを利用することも可能です。
オブジェクトのspec(仕様)とstatus(状態) ほとんどのKubernetesオブジェクトは、オブジェクトの設定を管理する2つの入れ子になったオブジェクトのフィールドを持っています。それはオブジェクト specstatusspecを持っているオブジェクトに関しては、オブジェクト作成時にspecを設定する必要があり、望ましい状態としてオブジェクトに持たせたい特徴を記述する必要があります。
status オブジェクトはオブジェクトの 現在の状態 を示し、その情報はKubernetesシステムとそのコンポーネントにより提供、更新されます。Kubernetesコントロールプレーン は、あなたから指定された望ましい状態と現在の状態が一致するよう常にかつ積極的に管理をします。
例えば、KubernetesのDeploymentはクラスター上で稼働するアプリケーションを表現するオブジェクトです。Deploymentを作成するとき、アプリケーションの複製を3つ稼働させるようDeploymentのspecで指定するかもしれません。KubernetesはDeploymentのspecを読み取り、指定されたアプリケーションを3つ起動し、現在の状態がspecに一致するようにします。もしこれらのインスタンスでどれかが落ちた場合(statusが変わる)、Kubernetesはspecと、statusの違いに反応し、修正しようとします。この場合は、落ちたインスタンスの代わりのインスタンスを立ち上げます。
spec、status、metadataに関するさらなる情報は、Kubernetes API Conventions をご確認ください。
Kubernetesオブジェクトを記述する Kubernetesでオブジェクトを作成する場合、オブジェクトの基本的な情報(例えば名前)と共に、望ましい状態を記述したオブジェクトのspecを渡さなければいけません。KubernetesAPIを利用しオブジェクトを作成する場合(直接APIを呼ぶか、kubectlを利用するかに関わらず)、APIリクエストはそれらの情報をJSON形式でリクエストのBody部に含んでいなければなりません。
ここで、KubernetesのDeploymentに必要なフィールドとオブジェクトのspecを記載した.yamlファイルの例を示します:
apiVersion : apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind : Deployment
metadata :
name : nginx-deployment
spec :
selector :
matchLabels :
app : nginx
replicas : 2 # tells deployment to run 2 pods matching the template
template :
metadata :
labels :
app : nginx
spec :
containers :
- name : nginx
image : nginx:1.14.2
ports :
- containerPort : 80
上に示した.yamlファイルを利用してDeploymentを作成するには、kubectlコマンドラインインターフェースに含まれているkubectl apply.yamlファイルを引数に指定し、実行します。ここで例を示します:
kubectl apply -f https://k8s.io/examples/application/deployment.yaml --record
出力結果は、下記に似た形になります:
deployment.apps/nginx-deployment created
必須フィールド Kubernetesオブジェクトを.yamlファイルに記載して作成する場合、下記に示すフィールドに値をセットしておく必要があります:
apiVersion - どのバージョンのKubernetesAPIを利用してオブジェクトを作成するかkind - どの種類のオブジェクトを作成するかmetadata - オブジェクトを一意に特定するための情報、文字列のname、UID、また任意のnamespaceが該当するspec - オブジェクトの望ましい状態specの正確なフォーマットは、Kubernetesオブジェクトごとに異なり、オブジェクトごとに特有な入れ子のフィールドを持っています。Kubernetes API リファレンス が、Kubernetesで作成できる全てのオブジェクトに関するspecのフォーマットを探すのに役立ちます。
例えば、Podオブジェクトに関するspecのフォーマットはPodSpec v1 core を、またDeploymentオブジェクトに関するspecのフォーマットはDeploymentSpec v1 apps をご確認ください。
次の項目 3.1.3.2 - Kubernetesオブジェクト管理 kubectlコマンドラインツールは、Kubernetesオブジェクトを作成、管理するためにいくつかの異なる方法をサポートしています。
このドキュメントでは、それらの異なるアプローチごとの概要を提供します。
Kubectlを使ったオブジェクト管理の詳細は、Kubectl book を参照してください。
管理手法
警告: Kubernetesのオブジェクトは、いずれか一つの手法で管理してください。
同じオブジェクトに対して、複数の手法を組み合わせた場合、未定義の挙動をもたらします。管理手法 何を対象にするか 推奨環境 サポートライター 学習曲線 命令型コマンド 現行のオブジェクト 開発用プロジェクト 1+ 緩やか 命令型オブジェクト設定 個々のファイル 本番用プロジェクト 1 中程度 宣言型オブジェクト設定 ファイルのディレクトリ 本番用プロジェクト 1+ 急
命令型コマンド 命令型コマンドを使う場合、ユーザーはクラスター内の現行のオブジェクトに対して処理を行います。
ユーザーはkubectlコマンドに処理内容を引数、もしくはフラグで指定します。
これはKubernetesの使い始め、またはクラスターに対して一度限りのタスクを行う際の最も簡単な手法です。
なぜなら、この手法は現行のオブジェクトに対して直接操作ができ、以前の設定履歴は提供されないからです。
例 Deploymentオブジェクトを作成し、nginxコンテナの単一インスタンスを起動します:
kubectl run nginx --image nginx
同じことを異なる構文で行います:
kubectl create deployment nginx --image nginx
トレードオフ オブジェクト設定手法に対する長所:
コマンドは簡潔、簡単に学ぶことができ、そして覚えやすいです コマンドではクラスターの設定を変えるのに、わずか1ステップしか必要としません オブジェクト設定手法に対する短所:
コマンドは変更レビュープロセスと連携しません コマンドは変更に伴う監査証跡を提供しません コマンドは現行がどうなっているかという情報を除き、レコードのソースを提供しません コマンドはオブジェクトを作成するためのテンプレートを提供しません 命令型オブジェクト設定 命令型オブジェクト設定では、kubectlコマンドに処理内容(create、replaceなど)、任意のフラグ、そして最低1つのファイル名を指定します。
指定されたファイルは、YAMLまたはJSON形式でオブジェクトの全ての定義情報を含んでいなければいけません。
オブジェクト定義の詳細は、APIリファレンス を参照してください。
警告: 命令型のreplaceコマンドは、既存の構成情報を新しく提供された設定に置き換え、設定ファイルに無いオブジェクトの全ての変更を削除します。
このアプローチは、構成情報が設定ファイルとは無関係に更新されるリソースタイプでは使用しないでください。
例えば、タイプがLoadBalancerのServiceオブジェクトにおけるexternalIPsフィールドは、設定ファイルとは無関係に、クラスターによって更新されます。例 設定ファイルに定義されたオブジェクトを作成します:
kubectl create -f nginx.yaml
設定ファイルに定義されたオブジェクトを削除します:
kubectl delete -f nginx.yaml -f redis.yaml
設定ファイルに定義された情報で、現行の設定を上書き更新します:
kubectl replace -f nginx.yaml
トレードオフ 命令型コマンド手法に対する長所:
オブジェクト設定をGitのような、ソースコード管理システムに格納することができます オブジェクト設定の変更内容をプッシュする前にレビュー、監査証跡を残すようなプロセスと連携することができます オブジェクト設定は新しいオブジェクトを作る際のテンプレートを提供します 命令型コマンド手法に対する短所:
オブジェクト設定ではオブジェクトスキーマの基礎的な理解が必要です オブジェクト設定ではYAMLファイルを書くという、追加のステップが必要です 宣言型オブジェクト設定手法に対する長所:
命令型オブジェクト設定の振る舞いは、よりシンプルで簡単に理解ができます Kubernetesバージョン1.5においては、命令型オブジェクト設定の方がより成熟しています 宣言型オブジェクト設定手法に対する短所:
命令型オブジェクト設定は各ファイルごとに設定を書くには最も適していますが、ディレクトリには適していません 現行オブジェクトの更新は設定ファイルに対して反映しなければなりません。反映されない場合、次の置き換え時に更新内容が失われてしまいます 宣言型オブジェクト設定 宣言型オブジェクト設定を利用する場合、ユーザーはローカルに置かれている設定ファイルを操作します。
しかし、ユーザーはファイルに対する操作内容を指定しません。作成、更新、そして削除といった操作はオブジェクトごとにkubectlが検出します。
この仕組みが、異なるオブジェクトごとに異なる操作をディレクトリに対して行うことを可能にしています。
備考: 宣言型オブジェクト設定は、他の人が行った変更が設定ファイルにマージされなかったとしても、それらの変更を保持します。
これは、replaceAPI操作のように、全てのオブジェクト設定を置き換えるわけではなく、patchAPI操作による、変更箇所のみの更新が可能にしています。例 configディレクトリ配下にある全てのオブジェクト設定ファイルを処理し、作成、または現行オブジェクトへのパッチを行います。
まず、diffでどのような変更が行われるかを確認した後に適用します:
kubectl diff -f configs/
kubectl apply -f configs/
再帰的にディレクトリを処理します:
kubectl diff -R -f configs/
kubectl apply -R -f configs/
トレードオフ 命令型オブジェクト設定手法に対する長所:
現行オブジェクトに直接行われた変更が、それらが設定ファイルに反映されていなかったとしても、保持されます 宣言型オブジェクト設定は、ディレクトリごとの処理をより良くサポートしており、自動的にオブジェクトごとに操作のタイプ(作成、パッチ、削除)を検出します 命令型オブジェクト設定手法に対する短所:
宣言型オブジェクト設定は、デバッグ、そして想定外の結果が出たときに理解するのが困難です 差分を利用した一部のみの更新は、複雑なマージ、パッチの操作が必要です 次の項目 3.1.3.3 - オブジェクトの名前とID クラスター内の各オブジェクトには、そのタイプのリソースに固有の名前 UID
たとえば、同じ名前空間 内にmyapp-1234という名前のPodは1つしか含められませんが、myapp-1234という名前の1つのPodと1つのDeploymentを含めることができます。
ユーザーが一意ではない属性を付与するために、Kubernetesはラベル とアノテーション を提供しています。
名前 クライアントから提供され、リソースURL内のオブジェクトを参照する文字列です。例えば/api/v1/pods/何らかの名前のようになります。
同じ種類のオブジェクトは、同じ名前を同時に持つことはできません。しかし、オブジェクトを削除することで、旧オブジェクトと同じ名前で新しいオブジェクトを作成できます。
次の3つの命名規則がよく使われます。
DNSサブドメイン名 ほとんどのリソースタイプには、RFC 1123 で定義されているDNSサブドメイン名として使用できる名前が必要です。
つまり、名前は次のとおりでなければなりません:
253文字以内 英小文字、数字、「-」または「.」のみを含む 英数字で始まる 英数字で終わる DNSラベル名 一部のリソースタイプでは、RFC 1123 で定義されているDNSラベル標準に従う名前が必要です。
つまり、名前は次のとおりでなければなりません:
63文字以内 英小文字、数字または「-」のみを含む 英数字で始まる 英数字で終わる パスセグメント名 一部のリソースタイプでは、名前をパスセグメントとして安全にエンコードできるようにする必要があります。
つまり、名前を「.」や「..」にすることはできず、名前に「/」または「%」を含めることはできません。
以下は、nginx-demoという名前のPodのマニフェストの例です。
apiVersion : v1
kind : Pod
metadata :
name : nginx-demo
spec :
containers :
- name : nginx
image : nginx:1.14.2
ports :
- containerPort : 80
備考: 一部のリソースタイプには、名前に追加の制限があります。UID オブジェクトを一意に識別するためのKubernetesが生成する文字列です。
Kubernetesクラスターの生存期間中にわたって生成された全てのオブジェクトは、異なるUIDを持っています。これは類似のエンティティの、同一時間軸での存在を区別するのが目的です。
Kubernetes UIDは、UUIDのことを指します。
UUIDは、ISO/IEC 9834-8およびITU-T X.667として標準化されています。
次の項目 3.1.3.4 - ラベル(Labels)とセレクター(Selectors) ラベル(Labels) はPodなどのオブジェクトに割り当てられたキーとバリューのペアです。
"metadata" : {
"labels" : {
"key1" : "value1" ,
"key2" : "value2"
}
}
ラベルは効率的な検索・閲覧を可能にし、UIやCLI上での利用に最適です。
識別用途でない情報は、アノテーション を用いて記録されるべきです。
ラベルを使う動機 ラベルは、クライアントにそのマッピング情報を保存することを要求することなく、ユーザー独自の組織構造をシステムオブジェクト上で疎結合にマッピングできます。
サービスデプロイメントとバッチ処理のパイプラインは多くの場合、多次元のエンティティとなります(例: 複数のパーティション、Deployment、リリーストラック、ティアー、ティアー毎のマイクロサービスなど)
ラベルの例:
"release" : "stable", "release" : "canary""environment" : "dev", "environment" : "qa", "environment" : "production""tier" : "frontend", "tier" : "backend", "tier" : "cache""partition" : "customerA", "partition" : "customerB""track" : "daily", "track" : "weekly"これらは単によく使われるラベルの例です。ユーザーは自由に規約を決めることができます。
ラベルのキーは、ある1つのオブジェクトに対してユニークである必要があることは覚えておかなくてはなりません。
構文と文字セット ラベルは、キーとバリューのベアです。正しいラベルキーは2つのセグメントを持ちます。/によって分割されたオプショナルなプレフィックスと名前です。[a-z0-9A-Z])で、文字列の間ではこれに加えてダッシュ(-)、アンダースコア(_)、ドット(.)を使うことができます。.)で区切られたDNSラベルのセットで、253文字以下である必要があり、最後にスラッシュ(/)が続きます。
もしプレフィックスが省略された場合、ラベルキーはそのユーザーに対してプライベートであると推定されます。kube-scheduler kube-controller-manager kube-apiserver kubectlやその他のサードパーティツール)は、プレフィックスを指定しなくてはなりません。
kubernetes.io/とk8s.io/プレフィックスは、Kubernetesコアコンポーネントのために予約されています。
正しいラベル値は63文字以下の長さで、空文字か、もしくは開始と終了が英数字([a-z0-9A-Z])で、文字列の間がダッシュ(-)、アンダースコア(_)、ドット(.)と英数字である文字列を使うことができます。
例えば、environment: productionとapp: nginxの2つのラベルを持つPodの設定ファイルは下記のようになります。
apiVersion : v1
kind : Pod
metadata :
name : label-demo
labels :
environment : production
app : nginx
spec :
containers :
- name : nginx
image : nginx:1.14.2
ports :
- containerPort : 80
ラベルセレクター 名前とUID とは異なり、ラベルはユニーク性を提供しません。通常、多くのオブジェクトが同じラベルを保持することを想定します。
ラベルセレクター を介して、クライアントとユーザーはオブジェクトのセットを指定できます。ラベルセレクターはKubernetesにおいてコアなグルーピング機能となります。
Kubernetes APIは現在2タイプのセレクターをサポートしています。等価ベース(equality-based) と集合ベース(set-based) です。要件(requirements) で構成されています。AND (&&)オペレーターと同様にふるまい、全ての要件を満たす必要があります。
空文字の場合や、指定なしのセレクターに関するセマンティクスは、コンテキストに依存します。
そしてセレクターを使うAPIタイプは、それらのセレクターの妥当性とそれらが示す意味をドキュメントに記載するべきです。
備考: ReplicaSetなど、いくつかのAPIタイプにおいて、2つのインスタンスのラベルセレクターは単一の名前空間において重複してはいけません。重複していると、コントローラーがそれらのラベルセレクターがコンフリクトした操作とみなし、どれだけの数のレプリカを稼働させるべきか決めることができなくなります。
注意: 等価ベース、集合ベースともに、論理OR (||) オペレーターは存在しません。フィルターステートメントが意図した通りになっていることを確認してください。等価ベース(Equality-based) の要件(requirement)等価ベース(Equality-based) もしくは不等ベース(Inequality-based) の要件は、ラベルキーとラベル値によるフィルタリングを可能にします。=、==、!=となります。=、==)は等価(Equality) を表現し(この2つは単なる同義語)、最後の1つ(!=)は不等(Inequality) を意味します。
environment = production
tier != frontend
最初の例は、キーがenvironmentで、値がproductionである全てのリソースを対象にします。tierで、値がfrontendとは異なるリソースと、tierという名前のキーを持たない全てのリソースを対象にします。,を使って、productionの中から、frontendのものを除外するようにフィルターすることもできます。environment=production,tier!=frontend
等価ベースのラベル要件の1つの使用シナリオとして、PodにおけるNodeの選択要件を指定するケースがあります。accelerator=nvidia-tesla-p100をもったNodeを選択します。
apiVersion : v1
kind : Pod
metadata :
name : cuda-test
spec :
containers :
- name : cuda-test
image : "registry.k8s.io/cuda-vector-add:v0.1"
resources :
limits :
nvidia.com/gpu : 1
nodeSelector :
accelerator : nvidia-tesla-p100
集合ベース(Set-based) の要件(requirement)集合ベース(Set-based) のラベルの要件は値のセットによってキーをフィルタリングします。in、notin、existsの3つのオペレーターをサポートしています(キーを特定するのみ)。
例えば:
environment in (production, qa)
tier notin (frontend, backend)
partition
!partition
最初の例では、キーがenvironmentで、値がproductionかqaに等しいリソースを全て選択します。 第2の例では、キーがtierで、値がfrontendとbackend以外のもの、そしてtierキーを持たないリソースを全て選択します。 第3の例では、partitionというキーをもつラベルを全て選択し、値はチェックしません。 第4の例では、partitionというキーを持たないラベルを全て選択し、値はチェックしません。 同様に、コンマセパレーターは、AND オペレーターと同様にふるまいます。そのため、partitionとenvironmentキーの値がともにqaでないラベルを選択するには、partition,environment notin (qa)と記述することで可能です。集合ベース のラベルセレクターは、environment=productionという記述がenvironment in (production)と等しいため、一般的な等価形式となります。 !=とnotinも同様に等価となります。
集合ベース の要件は、等価ベース の要件と混在できます。partition in (customerA, customerB),environment!=qa.
API LISTとWATCHによるフィルタリング LISTとWATCHオペレーションは、単一のクエリパラメーターを使うことによって返されるオブジェクトのセットをフィルターするためのラベルセレクターを指定できます。集合ベース と等価ベース のどちらの要件も許可されています(ここでは、URLクエリストリング内で出現します)。
等価ベース での要件: ?labelSelector=environment%3Dproduction,tier%3Dfrontend集合ベース での要件: ?labelSelector=environment+in+%28production%2Cqa%29%2Ctier+in+%28frontend%29上記の2つの形式のラベルセレクターはRESTクライアントを介してリストにしたり、もしくは確認するために使われます。kubectlによってapiserverをターゲットにし、等価ベース の要件でフィルターすると以下のように書けます。
kubectl get pods -l environment = production,tier= frontend
もしくは、集合ベース の要件を指定すると以下のようになります。
kubectl get pods -l 'environment in (production),tier in (frontend)'
すでに言及したように、集合ベース の要件は、等価ベース の要件より表現力があります。OR オペレーターを実装して以下のように書けます。
kubectl get pods -l 'environment in (production, qa)'
もしくは、notin オペレーターを介して、否定マッチングによる制限もできます。
kubectl get pods -l 'environment,environment notin (frontend)'
APIオブジェクトに参照を設定する ServiceReplicationControllerPod のような他のリソースのセットを指定するのにも使われます。
ServiceとReplicationController Serviceが対象とするPodの集合は、ラベルセレクターによって定義されます。ReplicationControllerが管理するべきPod数についてもラベルセレクターを使って定義されます。
それぞれのオブジェクトに対するラベルセレクターはマップを使ってjsonもしくはyaml形式のファイルで定義され、等価ベース のセレクターのみサポートされています。
"selector" : {
"component" : "redis" ,
}
もしくは
selector :
component : redis
このセレクター(それぞれjsonまたはyaml形式)は、component=redisまたはcomponent in (redis)と等価です。
集合ベース の要件指定をサポートするリソースJobDeploymentReplicaSetDaemonSet集合ベース での要件指定もサポートしています。
selector :
matchLabels :
component : redis
matchExpressions :
- {key: tier, operator: In, values : [cache]}
- {key: environment, operator: NotIn, values : [dev]}
matchLabelsは、{key,value}ペアのマップです。matchLabels内の単一の{key,value}は、matchExpressionsの要素と等しく、それは、keyフィールドがキー名で、operatorが"In"で、values配列は単に"値"を保持します。matchExpressionsはPodセレクター要件のリストです。対応しているオペレーターはIn、NotIn、ExistsとDoesNotExistです。valuesのセットは、InとNotInオペレーターにおいては空文字を許容しません。matchLabelsとmatchExpressionsの両方によって指定された全ての要件指定はANDで判定されます。つまり要件にマッチするには指定された全ての要件を満たす必要があります。
Nodeのセットを選択する ラベルを選択するための1つのユースケースはPodがスケジュールできるNodeのセットを制限することです。Node選定 のドキュメントを参照してください。
3.1.3.5 - Namespace(名前空間) Kubernetesは、同一の物理クラスター上で複数の仮想クラスターの動作をサポートします。
この仮想クラスターをNamespaceと呼びます。
複数のNamespaceを使う時 Namespaceは、複数のチーム・プロジェクトにまたがる多くのユーザーがいる環境での使用を目的としています。
数人から数十人しかユーザーのいないクラスターに対して、あなたはNamespaceを作成したり、考える必要は全くありません。
Kubernetesが提供するNamespaceの機能が必要となった時に、Namespaceの使用を始めてください。
Namespaceは名前空間のスコープを提供します。リソース名は単一のNamespace内ではユニークである必要がありますが、Namespace全体ではその必要はありません。Namespaceは相互にネストすることはできず、各Kubernetesリソースは1つのNamespaceにのみ存在できます。
Namespaceは、複数のユーザーの間でクラスターリソースを分割する方法です。(これはリソースクォータ を介して分割します。)
同じアプリケーションの異なるバージョンなど、少し違うリソースをただ分割するだけに、複数のNamespaceを使う必要はありません。
同一のNamespace内でリソースを区別するためにはラベル を使用してください。
Namespaceを利用する Namespaceの作成と削除方法はNamespaceの管理ガイドドキュメント に記載されています。
備考: プレフィックスkube-を持つNamespaceは、KubernetesシステムのNamespaceとして予約されているため利用は避けてください。Namespaceの表示 ユーザーは、以下の方法で単一クラスター内の現在のNamespaceの一覧を表示できます。
NAME STATUS AGE
default Active 1d
kube-node-lease Active 1d
kube-system Active 1d
kube-public Active 1d
Kubernetesの起動時には4つの初期Namespaceが作成されています。
default 他にNamespaceを持っていないオブジェクトのためのデフォルトNamespacekube-system Kubernetesシステムによって作成されたオブジェクトのためのNamespacekube-public このNamespaceは自動的に作成され、全てのユーザーから読み取り可能です。(認証されていないユーザーも含みます。)
このNamespaceは、リソースをクラスター全体を通じてパブリックに表示・読み取り可能にするため、ほとんどクラスターによって使用される用途で予約されます。 このNamespaceのパブリックな側面は単なる慣例であり、要件ではありません。kube-node-lease クラスターのスケールに応じたノードハートビートのパフォーマンスを向上させる各ノードに関連したLeaseオブジェクトのためのNamespace。Namespaceの設定 現在のリクエストのNamespaceを設定するには、--namespaceフラグを使用します。
例:
kubectl run nginx --image= nginx --namespace= <insert-namespace-name-here>
kubectl get pods --namespace= <insert-namespace-name-here>
Namespace設定の永続化 ユーザーはあるコンテキストのその後のコマンドで使うために、コンテキスト内で永続的にNamespaceを保存できます。
kubectl config set-context --current --namespace= <insert-namespace-name-here>
# Validate it
kubectl config view --minify | grep namespace:
NamespaceとDNS ユーザーがService を作成するとき、Serviceは対応するDNSエントリ を作成します。
このエントリは<service-name>.<namespace-name>.svc.cluster.localという形式になり、これはもしあるコンテナがただ<service-name>を指定していた場合、Namespace内のローカルのServiceに対して名前解決されます。
これはデベロップメント、ステージング、プロダクションといった複数のNamespaceをまたいで同じ設定を使う時に効果的です。
もしユーザーがNamespaceをまたいでアクセスしたい時、 完全修飾ドメイン名(FQDN)を指定する必要があります。
すべてのオブジェクトはNamespaceに属しているとは限らない ほとんどのKubernetesリソース(例えば、Pod、Service、ReplicationControllerなど)はいくつかのNamespaceにあります。
しかしNamespaceのリソースそれ自体は単一のNamespace内にありません。
そしてNode やPersistentVolumeのような低レベルのリソースはどのNamespaceにも属していません。
どのKubernetesリソースがNamespaceに属しているか、属していないかを見るためには、以下のコマンドで確認できます。
# Namespaceに属しているもの
kubectl api-resources --namespaced= true
# Namespaceに属していないもの
kubectl api-resources --namespaced= false
次の項目 3.1.3.6 - アノテーション(Annotations) ユーザーは、識別用途でない任意のメタデータをオブジェクトに割り当てるためにアノテーションを使用できます。ツールやライブラリなどのクライアントは、このメタデータを取得できます。
オブジェクトにメタデータを割り当てる ユーザーは、Kubernetesオブジェクトに対してラベルやアノテーションの両方またはどちらか一方を割り当てることができます。
ラベルはオブジェクトの選択や、特定の条件を満たしたオブジェクトの集合を探すことに使うことができます。
それと対照的に、アノテーションはオブジェクトを識別、または選択するために使用されません。
アノテーション内のメタデータは大小様々で、構造化されているものや、そうでないものも設定でき、ラベルでは許可されていない文字も含むことができます。
アノテーションは、ラベルと同様に、キーとバリューのマップとなります。
"metadata" : {
"annotations" : {
"key1" : "value1" ,
"key2" : "value2"
}
}
下記は、アノテーション内で記録できる情報の例です。
宣言的設定レイヤーによって管理されているフィールド。これらのフィールドをアノテーションとして割り当てることで、クライアントもしくはサーバによってセットされたデフォルト値、オートサイジングやオートスケーリングシステムによってセットされたフィールドや、自動生成のフィールドなどと区別することができます。
ビルド、リリースやタイムスタンプのようなイメージの情報、リリースID、gitのブランチ、PR番号、イメージハッシュ、レジストリアドレスなど
ロギング、監視、分析用のポインタ、もしくは監査用リポジトリ
デバッグ目的で使用されるためのクライアントライブラリやツールの情報。例えば、名前、バージョン、ビルド情報など。
他のエコシステムのコンポーネントからの関連オブジェクトのURLなど、ユーザーやツール、システムの出所情報。
軽量ロールアウトツールのメタデータ。例えば設定やチェックポイントなど。
情報をどこで確認できるかを示すためのもの。例えばチームのウェブサイト、責任者の電話番号や、ページャー番号やディレクトリエンティティなど。
システムのふるまいの変更や、標準ではない機能を利用可能にするために、エンドユーザーがシステムに対して指定する値
アノテーションを使用するかわりに、ユーザーはこのようなタイプの情報を外部のデータベースやディレクトリに保存することもできます。しかし、それによりデプロイ、管理、イントロスペクションを行うためのクライアンライブラリやツールの生成が非常に難しくなります。
構文と文字セット アノテーション はキーとバリューのペアです。有効なアノテーションのキーの形式は2つのセグメントがあります。
プレフィックス(オプション)と名前で、それらはスラッシュ/で区切られます。
名前セグメントは必須で、63文字以下である必要があり、文字列の最初と最後は英数字([a-z0-9A-Z])と、文字列の間にダッシュ(-)、アンダースコア(_)、ドット(.)を使うことができます。
プレフィックスはオプションです。もしプレフィックスが指定されていた場合、プレフィックスはDNSサブドメイン形式である必要があり、それはドット(.)で区切られたDNSラベルのセットで、253文字以下である必要があり、最後にスラッシュ(/)が続きます。
もしプレフィックスが除外された場合、アノテーションキーはそのユーザーに対してプライベートであると推定されます。
エンドユーザーのオブジェクトにアノテーションを追加するような自動化されたシステムコンポーネント(例: kube-scheduler kube-controller-manager kube-apiserver kubectlやその他のサードパーティツール)は、プレフィックスを指定しなくてはなりません。
kubernetes.io/とk8s.io/プレフィックスは、Kubernetesコアコンポーネントのために予約されています。
たとえば、imageregistry: https://hub.docker.com/というアノテーションが付いたPodの構成ファイルは次のとおりです:
apiVersion : v1
kind : Pod
metadata :
name : annotations-demo
annotations :
imageregistry : "https://hub.docker.com/"
spec :
containers :
- name : nginx
image : nginx:1.14.2
ports :
- containerPort : 80
次の項目 ラベルとセレクター について学習してください。
3.1.3.7 - フィールドセレクター(Field Selectors) フィールドセレクター(Field Selectors) は、1つかそれ以上のリソースフィールドの値を元にKubernetesリソースを選択 するためのものです。
metadata.name=my-servicemetadata.namespace!=defaultstatus.phase=Pending下記のkubectlコマンドは、status.phaseRunningである全てのPodを選択します。
kubectl get pods --field-selector status.phase= Running
備考: フィールドセレクターは本質的にリソースの フィルター となります。デフォルトでは、セレクター/フィルターが指定されていない場合は、全てのタイプのリソースが取得されます。これは、kubectlクエリのkubectl get podsとkubectl get pods --field-selector ""が同じであることを意味します。サポートされているフィールド サポートされているフィールドセレクターはKubernetesリソースタイプによって異なります。全てのリソースタイプはmetadata.nameとmetadata.namespaceフィールドをサポートしています。サポートされていないフィールドセレクターの使用をするとエラーとなります。
kubectl get ingress --field-selector foo.bar= baz
Error from server (BadRequest): Unable to find "ingresses" that match label selector "", field selector "foo.bar=baz": "foo.bar" is not a known field selector: only "metadata.name", "metadata.namespace"
サポートされているオペレーター ユーザーは、=、==や!=といったオペレーターをフィールドセレクターと組み合わせて使用できます。(=と==は同義)kubectlコマンドはdefaultネームスペースに属していない全てのKubernetes Serviceを選択します。
kubectl get services --all-namespaces --field-selector metadata.namespace!= default
連結されたセレクター ラベル や他のセレクターと同様に、フィールドセレクターはコンマ区切りのリストとして連結することができます。kubectlコマンドは、status.phaseがRunningでなく、かつspec.restartPolicyフィールドがAlwaysに等しいような全てのPodを選択します。
kubectl get pods --field-selector= status.phase!= Running,spec.restartPolicy= Always
複数のリソースタイプ ユーザーは複数のリソースタイプにまたがったフィールドセレクターを利用できます。kubectlコマンドは、defaultネームスペースに属していない全てのStatefulSetとServiceを選択します。
kubectl get statefulsets,services --field-selector metadata.namespace!= default
3.1.3.8 - ファイナライザー(Finalizers) ファイナライザーは、削除対象としてマークされたリソースを完全に削除する前に、特定の条件が満たされるまでKubernetesを待機させるための名前空間付きのキーです。
ファイナライザーは、削除されたオブジェクトが所有していたリソースをクリーンアップするようにコントローラー に警告します。
Kubernetesにファイナライザーが指定されたオブジェクトを削除するように指示すると、Kubernetes APIはそのオブジェクトに.metadata.deletionTimestampを追加し削除対象としてマークして、ステータスコード202(HTTP "Accepted")を返します。
コントロールプレーンやその他のコンポーネントがファイナライザーによって定義されたアクションを実行している間、対象のオブジェクトは終了中の状態のまま残っています。
それらのアクションが完了したら、そのコントローラーは関係しているファイナライザーを対象のオブジェクトから削除します。
metadata.finalizersフィールドが空になったら、Kubernetesは削除が完了したと判断しオブジェクトを削除します。
ファイナライザーはリソースのガベージコレクション を管理するために使うことができます。
例えば、コントローラーが対象のリソースを削除する前に関連するリソースやインフラをクリーンアップするためにファイナライザーを定義することができます。
ファイナライザーを利用すると、対象のリソースを削除する前に特定のクリーンアップを行うようにコントローラー に警告することで、ガベージコレクション を管理することができます。
大抵の場合ファイナライザーは実行されるコードを指定することはありません。
その代わり、一般的にはアノテーションのように特定のリソースに関するキーのリストになります。
Kubernetesはいくつかのファイナライザーを自動的に追加しますが、自分で追加することもできます。
ファイナライザーはどのように動作するか マニフェストファイルを使ってリソースを作るとき、metadata.finalizersフィールドの中でファイナライザーを指定することができます。
リソースを削除しようとするとき、削除リクエストを扱うAPIサーバーはfinalizersフィールドの値を確認し、以下のように扱います。
削除を開始した時間をオブジェクトのmetadata.deletionTimestampフィールドに設定します。 metadata.finalizersフィールドが空になるまでオブジェクトが削除されるのを阻止します。ステータスコード202(HTTP "Accepted")を返します。 ファイナライザーを管理しているコントローラーは、オブジェクトの削除がリクエストされたことを示すmetadata.deletionTimestampがオブジェクトに設定されたことを検知します。
するとコントローラーはリソースに指定されたファイナライザーの要求を満たそうとします。
ファイナライザーの条件が満たされるたびに、そのコントローラーはリソースのfinalizersフィールドの対象のキーを削除します。
finalizersフィールドが空になったとき、deletionTimestampフィールドが設定されたオブジェクトは自動的に削除されます。管理外のリソース削除を防ぐためにファイナライザーを利用することもできます。
ファイナライザーの一般的な例はkubernetes.io/pv-protectionで、これは PersistentVolumeオブジェクトが誤って削除されるのを防ぐためのものです。
PersistentVolumeオブジェクトをPodが利用中の場合、Kubernetesはpv-protectionファイナライザーを追加します。
PersistentVolumeを削除しようとするとTerminatingステータスになりますが、ファイナライザーが存在しているためコントローラーはボリュームを削除することができません。
PodがPersistentVolumeの利用を停止するとKubernetesはpv-protectionファイナライザーを削除し、コントローラーがボリュームを削除します。
オーナーリファレンス、ラベル、ファイナライザー ラベル のように、
オーナーリファレンス はKubernetesのオブジェクト間の関係性を説明しますが、利用される目的が異なります。
コントローラー がPodのようなオブジェクトを管理するとき、関連するオブジェクトのグループの変更を追跡するためにラベルを利用します。
例えば、Job がいくつかのPodを作成するとき、JobコントローラーはそれらのPodにラベルを付け、クラスター内の同じラベルを持つPodの変更を追跡します。
Jobコントローラーは、Podを作成したJobを指すオーナーリファレンス もそれらのPodに追加します。
Podが実行されているときにJobを削除すると、Kubernetesはオーナーリファレンス(ラベルではない)を使って、クリーンアップする必要のあるPodをクラスター内から探し出します。
また、Kubernetesは削除対象のリソースのオーナーリファレンスを認識して、ファイナライザーを処理します。
状況によっては、ファイナライザーが依存オブジェクトの削除をブロックしてしまい、対象のオーナーオブジェクトが完全に削除されず予想以上に長時間残ってしまうことがあります。
このような状況では、対象のオーナーと依存オブジェクトの、ファイナライザーとオーナーリファレンスを確認して問題を解決する必要があります。
備考: オブジェクトが削除中の状態で詰まってしまった場合、削除を続行するために手動でファイナライザーを削除することは避けてください。
通常、ファイナライザーは理由があってリソースに追加されているものであるため、強制的に削除してしまうとクラスターで何らかの問題を引き起こすことがあります。
そのファイナライザーの目的を理解しているかつ、別の方法で達成できる場合にのみ行うべきです(例えば、依存オブジェクトを手動で削除するなど)。次の項目 3.1.3.9 - オーナーと従属 Kubernetesでは、いくつかのオブジェクトは他のオブジェクトのオーナー になっています。
例えば、ReplicaSet はPodの集合のオーナーです。
これらの所有されているオブジェクトはオーナーに従属 しています。
オーナーシップはいくつかのリソースでも使われているラベルとセレクター とは仕組みが異なります。
例として、EndpointSliceオブジェクトを作成するServiceオブジェクトを考えてみます。
Serviceはラベルを使ってどのEndpointSliceがどのServiceに利用されているかをコントロールプレーンに判断させています。
ラベルに加えて、Serviceの代わりに管理される各EndpointSliceはオーナーリファレンスを持ちます。
オーナーリファレンスは、Kubernetesの様々な箇所で管理外のオブジェクトに干渉してしまうのを避けるのに役立ちます。
オブジェクト仕様におけるオーナーリファレンス 従属オブジェクトはオーナーオブジェクトを参照するためのmetadata.ownerReferencesフィールドを持っています。
有効なオーナーリファレンスは従属オブジェクトと同じ名前空間に存在するオブジェクトの名前とUIDで構成されます。
KubernetesはReplicaSet、DaemonSet、Deployment、Job、CronJob、ReplicationControllerのようなオブジェクトの従属オブジェクトに、自動的に値を設定します。
このフィールドの値を手動で変更することで、これらの関係性を自分で設定することもできます。
ただし、通常はその必要はなく、Kubernetesが自動で管理するようにすることができます。
従属オブジェクトは、オーナーオブジェクトが削除されたときにガベージコレクションをブロックするかどうかを管理する真偽値を取るownerReferences.blockOwnerDeletionフィールドも持っています。
Kubernetesは、コントローラー
(例:Deploymentコントローラー)がmetadata.ownerReferencesフィールドに値を設定している場合、自動的にこのフィールドをtrueに設定します。
blockOwnerDeletionフィールドに手動で値を設定することで、どの従属オブジェクトがガベージコレクションをブロックするかを設定することもできます。
Kubernetesのアドミッションコントローラーはオーナーの削除権限に基づいて、ユーザーが従属リソースのこのフィールドを変更できるかを管理しています。
これにより、認証されていないユーザーがオーナーオブジェクトの削除を遅らせることを防ぎます。
備考: 名前空間をまたぐオーナーリファレンスは仕様により許可されていません。
名前空間付き従属オブジェクトには、クラスタースコープ、または名前空間付きのオーナーを指定することができます。名前空間付きオーナーは必ず 従属オブジェクトと同じ名前空間に存在していなければなりません。
そうでない場合、オーナーリファレンスはないものとして扱われ、全てのオーナーがいなくなった時点で従属オブジェクトは削除対象となります。
クラスタースコープの従属オブジェクトはクラスタースコープのオーナーのみ指定できます。
v1.20以降では、クラスタースコープの従属オブジェクトが名前空間付きのオブジェクトをオーナーとした場合、
解決できないオーナーリファレンスを持っているものとして扱われ、ガベージコレクションの対象とすることができません。
v1.20以降で、ガベージコレクターが無効な名前空間またぎのownerReferenceや名前空間付きのオーナーに依存するクラスタースコープのオブジェクトなどを検知した場合、OwnerRefInvalidNamespaceを理由とした警告のEventを出し、involvedObjectで無効な従属オブジェクトを報告します。
kubectl get events -A --field-selector=reason=OwnerRefInvalidNamespaceを実行することで、この種類のEventを確認することができます。
オーナーシップとファイナライザー Kubernetesでリソースを削除するとき、APIサーバーはリソースを管理するコントローラーにファイナライザールール を処理させることができます。
ファイナライザー はクラスターが正しく機能するために必要なリソースを誤って削除してしまうことを防ぎます。
例えば、まだPodが使用中のPersistentVolumeを削除しようとするとき、PersistentVolumeが持っているkubernetes.io/pv-protectionファイナライザーにより、削除は即座には行われません。
その代わり、Kubernetesがファイナライザーを削除するまでボリュームはTerminatingステータスのまま残り、PersistentVolumeがPodにバインドされなくなった後で削除が行われます。
またKubernetesはフォアグラウンド、孤立したオブジェクトのカスケード削除 を行ったとき、オーナーリソースにファイナライザーを追加します。
フォアグラウンド削除では、foregroundファイナライザーを追加し、オーナーを削除する前にコントローラーがownerReferences.blockOwnerDeletion=trueを持っている従属リソースを削除するようにします。
孤立したオブジェクトの削除を行う場合、Kubernetesはorphanファイナライザーを追加し、オーナーオブジェクトを削除した後にコントローラーが従属リソースを無視するようにします。
次の項目 3.1.3.10 - 推奨ラベル(Recommended Labels) ユーザーはkubectlやダッシュボード以外に、多くのツールでKubernetesオブジェクトの管理と可視化ができます。共通のラベルセットにより、全てのツールにおいて解釈可能な共通のマナーに沿ってオブジェクトを表現することで、ツールの相互運用を可能にします。
ツール化に対するサポートに加えて、推奨ラベルはクエリ可能な方法でアプリケーションを表現します。
メタデータは、アプリケーション のコンセプトを中心に構成されています。KubernetesはPaaS(Platform as a Service)でなく、アプリケーションの公式な概念を持たず、またそれを強制することはありません。
そのかわり、アプリケーションは、非公式で、メタデータによって表現されています。単一のアプリケーションが有する項目に対する定義は厳密に決められていません。
備考: ラベルには推奨ラベルというものがあります。それらのラベルはアプリケーションの管理を容易にします。しかしコア機能のツール化において必須のものではありません。共有されたラベルとアノテーションは、app.kubernetes.ioという共通のプレフィックスを持ちます。プレフィックスの無いラベルはユーザーに対してプライベートなものになります。その共有されたプレフィックスは、共有ラベルがユーザーのカスタムラベルに干渉しないことを保証します。
ラベル これらの推奨ラベルの利点を最大限得るためには、全てのリソースオブジェクトに対して推奨ラベルが適用されるべきです。
キー 説明 例 型 app.kubernetes.io/nameアプリケーション名 mysql文字列 app.kubernetes.io/instanceアプリケーションのインスタンスを特定するための固有名 mysql-abcxzy文字列 app.kubernetes.io/versionアプリケーションの現在のバージョン (例: セマンティックバージョン、リビジョンのハッシュなど) 5.7.21文字列 app.kubernetes.io/componentアーキテクチャ内のコンポーネント database文字列 app.kubernetes.io/part-ofこのアプリケーションによって構成される上位レベルのアプリケーション wordpress文字列 app.kubernetes.io/managed-byこのアプリケーションの操作を管理するために使われているツール helm文字列
これらのラベルが実際にどう使われているかを表すために、下記のStatefulSetのオブジェクトを考えましょう。
apiVersion : apps/v1
kind : StatefulSet
metadata :
labels :
app.kubernetes.io/name : mysql
app.kubernetes.io/instance : mysql-abcxzy
app.kubernetes.io/version : "5.7.21"
app.kubernetes.io/component : database
app.kubernetes.io/part-of : wordpress
app.kubernetes.io/managed-by : helm
アプリケーションとアプリケーションのインスタンス 単一のアプリケーションは、Kubernetesクラスター内で、いくつかのケースでは同一の名前空間に対して1回または複数回インストールされることがあります。
例えば、WordPressは複数のウェブサイトがあれば、それぞれ別のWordPressが複数回インストールされることがあります。
アプリケーション名と、アプリケーションのインスタンス名はそれぞれ別に記録されます。
例えば、WordPressはapp.kubernetes.io/nameにwordpressと記述され、インスタンス名に関してはapp.kubernetes.io/instanceにwordpress-abcxzyと記述されます。この仕組みはアプリケーションと、アプリケーションのインスタンスを特定可能にします。全てのアプリケーションインスタンスは固有の名前を持たなければなりません。
ラベルの使用例 ここでは、ラベルの異なる使用例を示します。これらの例はそれぞれシステムの複雑さが異なります。
シンプルなステートレスサービス DeploymentとServiceオブジェクトを使って、シンプルなステートレスサービスをデプロイするケースを考えます。下記の2つのスニペットはラベルが最もシンプルな形式においてどのように使われるかをあらわします。
下記のDeploymentは、アプリケーションを稼働させるポッドを管理するのに使われます。
apiVersion : apps/v1
kind : Deployment
metadata :
labels :
app.kubernetes.io/name : myservice
app.kubernetes.io/instance : myservice-abcxzy
...
下記のServiceは、アプリケーションを公開するために使われます。
apiVersion : v1
kind : Service
metadata :
labels :
app.kubernetes.io/name : myservice
app.kubernetes.io/instance : myservice-abcxzy
...
データベースを使ったウェブアプリケーション 次にもう少し複雑なアプリケーションについて考えます。データベース(MySQL)を使ったウェブアプリケーション(WordPress)で、Helmを使ってインストールします。
下記のスニペットは、このアプリケーションをデプロイするために使うオブジェクト設定の出だし部分です。
はじめに下記のDeploymentは、WordPressのために使われます。
apiVersion : apps/v1
kind : Deployment
metadata :
labels :
app.kubernetes.io/name : wordpress
app.kubernetes.io/instance : wordpress-abcxzy
app.kubernetes.io/version : "4.9.4"
app.kubernetes.io/managed-by : helm
app.kubernetes.io/component : server
app.kubernetes.io/part-of : wordpress
...
下記のServiceは、WordPressを公開するために使われます。
apiVersion : v1
kind : Service
metadata :
labels :
app.kubernetes.io/name : wordpress
app.kubernetes.io/instance : wordpress-abcxzy
app.kubernetes.io/version : "4.9.4"
app.kubernetes.io/managed-by : helm
app.kubernetes.io/component : server
app.kubernetes.io/part-of : wordpress
...
MySQLはStatefulSetとして公開され、MySQL自身と、MySQLが属する親アプリケーションのメタデータを持ちます。
apiVersion : apps/v1
kind : StatefulSet
metadata :
labels :
app.kubernetes.io/name : mysql
app.kubernetes.io/instance : mysql-abcxzy
app.kubernetes.io/version : "5.7.21"
app.kubernetes.io/managed-by : helm
app.kubernetes.io/component : database
app.kubernetes.io/part-of : wordpress
...
このServiceはMySQLをWordPressアプリケーションの一部として公開します。
apiVersion : v1
kind : Service
metadata :
labels :
app.kubernetes.io/name : mysql
app.kubernetes.io/instance : mysql-abcxzy
app.kubernetes.io/version : "5.7.21"
app.kubernetes.io/managed-by : helm
app.kubernetes.io/component : database
app.kubernetes.io/part-of : wordpress
...
MySQLのStatefulSetとServiceにより、MySQLとWordPressに関するより広範な情報が含まれていることに気づくでしょう。
3.2 - クラスターのアーキテクチャ Kubernetesの背後にあるアーキテクチャのコンセプト。
Kubernetesクラスターのアーキテクチャ
3.2.1 - ノード Kubernetesはコンテナを Node 上で実行されるPodに配置することで、ワークロードを実行します。
ノードはクラスターによりますが、1つのVMまたは物理的なマシンです。
各ノードはPod やそれを制御するコントロールプレーン を実行するのに必要なサービスを含んでいます。
通常、1つのクラスターで複数のノードを持ちます。学習用途やリソースの制限がある環境では、1ノードかもしれません。
1つのノード上のコンポーネント には、kubelet 、コンテナランタイム 、kube-proxy が含まれます。
管理 ノードをAPIサーバー に加えるには2つの方法があります:
ノード上のkubeletが、コントロールプレーンに自己登録する。 あなた、もしくは他のユーザーが手動でNodeオブジェクトを追加する。 Nodeオブジェクトの作成、もしくはノード上のkubeletによる自己登録の後、コントロールプレーンはNodeオブジェクトが有効かチェックします。例えば、下記のjsonマニフェストでノードを作成してみましょう:
{
"kind" : "Node" ,
"apiVersion" : "v1" ,
"metadata" : {
"name" : "10.240.79.157" ,
"labels" : {
"name" : "my-first-k8s-node"
}
}
}
Kubernetesは内部的にNodeオブジェクトを作成します。 APIサーバーに登録したkubeletがノードのmetadata.nameフィールドが一致しているか検証します。ノードが有効な場合、つまり必要なサービスがすべて実行されている場合は、Podを実行する資格があります。それ以外の場合、該当ノードが有効になるまではいかなるクラスターの活動に対しても無視されます。
備考: Kubernetesは無効なNodeのオブジェクトを保持し、それが有効になるまで検証を続けます。
ヘルスチェックを止めるためには、あなた、もしくはコントローラー が明示的にNodeを削除する必要があります。
Nodeオブジェクトの名前は有効なDNSサブドメイン名 である必要があります。
ノードの自己登録 kubeletのフラグ --register-nodeがtrue(デフォルト)のとき、kubeletは自分自身をAPIサーバーに登録しようとします。これはほとんどのディストリビューションで使用されている推奨パターンです。
自己登録については、kubeletは以下のオプションを伴って起動されます:
--kubeconfig - 自分自身をAPIサーバーに対して認証するための資格情報へのパス--cloud-provider - 自身に関するメタデータを読むためにクラウドプロバイダー と会話する方法--register-node - 自身をAPIサーバーに自動的に登録--register-with-taints - 与えられたtaint のリストでノードを登録します (カンマ区切りの <key>=<value>:<effect>)。register-nodeがfalseの場合、このオプションは機能しません
--node-ip - ノードのIPアドレス--node-labels - ノードをクラスターに登録するときに追加するLabel (NodeRestriction許可プラグイン によって適用されるラベルの制限を参照)--node-status-update-frequency - kubeletがノードのステータスをマスターにPOSTする頻度の指定ノード認証モード およびNodeRestriction許可プラグイン が有効になっている場合、kubeletは自分自身のノードリソースを作成/変更することのみ許可されています。
手動によるノード管理 クラスター管理者はkubectl を使用してNodeオブジェクトを作成および変更できます。
管理者が手動でNodeオブジェクトを作成したい場合は、kubeletフラグ --register-node = falseを設定してください。
管理者は--register-nodeの設定に関係なくNodeオブジェクトを変更することができます。
例えば、ノードにラベルを設定し、それをunschedulableとしてマークすることが含まれます。
ノード上のラベルは、スケジューリングを制御するためにPod上のノードセレクターと組み合わせて使用できます。
例えば、Podをノードのサブセットでのみ実行する資格があるように制限します。
ノードをunschedulableとしてマークすると、新しいPodがそのノードにスケジュールされるのを防ぎますが、ノード上の既存のPodには影響しません。
これは、ノードの再起動などの前の準備ステップとして役立ちます。
ノードにスケジュール不可能のマークを付けるには、次のコマンドを実行します:
備考: DaemonSet によって作成されたPodはノード上のunschedulable属性を考慮しません。
これは、再起動の準備中にアプリケーションからアプリケーションが削除されている場合でも、DaemonSetがマシンに属していることを前提としているためです。
ノードのステータス ノードのステータスは以下の情報を含みます:
kubectlを使用し、ノードのステータスや詳細を確認できます:
kubectl describe node <ノード名をここに挿入>
出力情報の各箇所について、以下で説明します。
Addresses これらのフィールドの使い方は、お使いのクラウドプロバイダーやベアメタルの設定内容によって異なります。
HostName: ノードのカーネルによって伝えられたホスト名です。kubeletの--hostname-overrideパラメーターによって上書きすることができます。 ExternalIP: 通常は、外部にルーティング可能(クラスターの外からアクセス可能)なノードのIPアドレスです。 InternalIP: 通常は、クラスター内でのみルーティング可能なノードのIPアドレスです。 Conditions conditionsフィールドは全てのRunningなノードのステータスを表します。例として、以下のような状態を含みます:
ノードのConditionと、各condition適用時の概要 ノードのCondition 概要 Readyノードの状態が有効でPodを配置可能な場合にTrueになります。ノードの状態に問題があり、Podが配置できない場合にFalseになります。ノードコントローラーが、node-monitor-grace-periodで設定された時間内(デフォルトでは40秒)に該当ノードと疎通できない場合、Unknownになります。 DiskPressureノードのディスク容量が圧迫されているときにTrueになります。圧迫とは、ディスクの空き容量が少ないことを指します。それ以外のときはFalseです。 MemoryPressureノードのメモリが圧迫されているときにTrueになります。圧迫とは、メモリの空き容量が少ないことを指します。それ以外のときはFalseです。 PIDPressureプロセスが圧迫されているときにTrueになります。圧迫とは、プロセス数が多すぎることを指します。それ以外のときはFalseです。 NetworkUnavailableノードのネットワークが適切に設定されていない場合にTrueになります。それ以外のときはFalseです。
備考: コマンドラインを使用してcordonされたNodeを表示する場合、ConditionはSchedulingDisabledを含みます。
SchedulingDisabledはKubernetesのAPIにおけるConditionではありません;その代わり、cordonされたノードはUnschedulableとしてマークされます。Nodeの状態は、Nodeリソースの.statusの一部として表現されます。例えば、正常なノードの場合は以下のようなjson構造が表示されます。
"conditions" : [
{
"type" : "Ready" ,
"status" : "True" ,
"reason" : "KubeletReady" ,
"message" : "kubelet is posting ready status" ,
"lastHeartbeatTime" : "2019-06-05T18:38:35Z" ,
"lastTransitionTime" : "2019-06-05T11:41:27Z"
}
]
Ready conditionがpod-eviction-timeout(kube-controller-manager に渡された引数)に設定された時間を超えてもUnknownやFalseのままになっている場合、該当ノード上にあるPodはノードコントローラーによって削除がスケジュールされます。デフォルトの退役のタイムアウトの時間は5分 です。ノードが到達不能ないくつかの場合においては、APIサーバーが該当ノードのkubeletと疎通できない状態になっています。その場合、APIサーバーがkubeletと再び通信を確立するまでの間、Podの削除を行うことはできません。削除がスケジュールされるまでの間、削除対象のPodは切り離されたノードの上で稼働を続けることになります。
ノードコントローラーはクラスター内でPodが停止するのを確認するまでは強制的に削除しないようになりました。到達不能なノード上で動いているPodはTerminatingまたはUnknownのステータスになります。Kubernetesが基盤となるインフラストラクチャーを推定できない場合、クラスター管理者は手動でNodeオブジェクトを削除する必要があります。KubernetesからNodeオブジェクトを削除すると、そのノードで実行されているすべてのPodオブジェクトがAPIサーバーから削除され、それらの名前が解放されます。
ノードのライフサイクルコントローラーがconditionを表したtaint を自動的に生成します。
スケジューラーがPodをノードに割り当てる際、ノードのtaintを考慮します。Podが許容するtaintは例外です。
詳細は条件によるtaintの付与 を参照してください。
CapacityとAllocatable ノードで利用可能なリソース(CPU、メモリ、およびノードでスケジュールできる最大Pod数)について説明します。
capacityブロック内のフィールドは、ノードが持っているリソースの合計量を示します。
allocatableブロックは、通常のPodによって消費されるノード上のリソースの量を示します。
CapacityとAllocatableについて深く知りたい場合は、ノード上でどのようにコンピュートリソースが予約されるか を読みながら学ぶことができます。
Info カーネルのバージョン、Kubernetesのバージョン(kubeletおよびkube-proxyのバージョン)、(使用されている場合)Dockerのバージョン、OS名など、ノードに関する一般的な情報です。
この情報はノードからkubeletを通じて取得され、Kubernetes APIに公開されます。
ノードのハートビート ハートビートは、Kubernetesノードから送信され、ノードが利用可能か判断するのに役立ちます。
以下の2つのハートビートがあります:
Nodeの.statusの更新 Lease object です。
各ノードはkube-node-leaseというnamespace に関連したLeaseオブジェクトを持ちます。
Leaseは軽量なリソースで、クラスターのスケールに応じてノードのハートビートにおけるパフォーマンスを改善します。kubeletがNodeStatusとLeaseオブジェクトの作成および更新を担当します。
kubeletは、ステータスに変化があったり、設定した間隔の間に更新がない時にNodeStatusを更新します。NodeStatus更新のデフォルト間隔は5分です。(到達不能の場合のデフォルトタイムアウトである40秒よりもはるかに長いです) kubeletは10秒間隔(デフォルトの更新間隔)でLeaseオブジェクトの生成と更新を実施します。Leaseの更新はNodeStatusの更新とは独立されて行われます。Leaseの更新が失敗した場合、kubeletは200ミリ秒から始まり7秒を上限とした指数バックオフでリトライします。 ノードコントローラー ノードコントローラー は、ノードのさまざまな側面を管理するKubernetesのコントロールプレーンコンポーネントです。
ノードコントローラーは、ノードの存続期間中に複数の役割を果たします。1つ目は、ノードが登録されたときにCIDRブロックをノードに割り当てることです(CIDR割り当てがオンになっている場合)。
2つ目は、ノードコントローラーの内部ノードリストをクラウドの利用可能なマシンのリストと一致させることです。
クラウド環境で実行している場合、ノードに異常があると、ノードコントローラーはクラウドプロバイダーにそのNodeのVMがまだ使用可能かどうかを問い合わせます。
使用可能でない場合、ノードコントローラーはノードのリストから該当ノードを削除します。
3つ目は、ノードの状態を監視することです。
ノードが到達不能(例えば、ノードがダウンしているなどので理由で、ノードコントローラーがハートビートの受信を停止した場合)になると、ノードコントローラーは、NodeStatusのNodeReady conditionをConditionUnknownに変更する役割があります。その後も該当ノードが到達不能のままであった場合、Graceful Terminationを使って全てのPodを退役させます。デフォルトのタイムアウトは、ConditionUnknownの報告を開始するまで40秒、その後Podの追い出しを開始するまで5分に設定されています。
ノードコントローラーは、--node-monitor-periodに設定された秒数ごとに各ノードの状態をチェックします。
信頼性 ほとんどの場合、排除の速度は1秒あたり--node-eviction-rateに設定された数値(デフォルトは秒間0.1)です。つまり、10秒間に1つ以上のPodをノードから追い出すことはありません。
特定のアベイラビリティーゾーン内のノードのステータスが異常になると、ノード排除の挙動が変わります。ノードコントローラーは、ゾーン内のノードの何%が異常(NodeReady条件がConditionUnknownまたはConditionFalseである)であるかを同時に確認します。
異常なノードの割合が少なくとも --healthy-zone-thresholdに設定した値を下回る場合(デフォルトは0.55)であれば、退役率は低下します。クラスターが小さい場合(すなわち、 --large-cluster-size-thresholdの設定値よりもノード数が少ない場合。デフォルトは50)、退役は停止し、そうでない場合、退役率は秒間で--secondary-node-eviction-rateの設定値(デフォルトは0.01)に減少します。
これらのポリシーがアベイラビリティーゾーンごとに実装されているのは、1つのアベイラビリティーゾーンがマスターから分割される一方、他のアベイラビリティーゾーンは接続されたままになる可能性があるためです。
クラスターが複数のクラウドプロバイダーのアベイラビリティーゾーンにまたがっていない場合、アベイラビリティーゾーンは1つだけです(クラスター全体)。
ノードを複数のアベイラビリティゾーンに分散させる主な理由は、1つのゾーン全体が停止したときにワークロードを正常なゾーンに移動できることです。
したがって、ゾーン内のすべてのノードが異常である場合、ノードコントローラーは通常のレート --node-eviction-rateで退役します。
コーナーケースは、すべてのゾーンが完全にUnhealthyである(すなわち、クラスター内にHealthyなノードがない)場合です。
このような場合、ノードコントローラーはマスター接続に問題があると見なし、接続が回復するまですべての退役を停止します。
ノードコントローラーは、Podがtaintを許容しない場合、 NoExecuteのtaintを持つノード上で実行されているPodを排除する責務もあります。
さらに、ノードコントローラーはノードに到達できない、または準備ができていないなどのノードの問題に対応するtaint を追加する責務があります。これはスケジューラーが、問題のあるノードにPodを配置しない事を意味しています。
ノードのキャパシティ Nodeオブジェクトはノードのリソースキャパシティ(CPUの数とメモリの量)を監視します。
自己登録 したノードは、Nodeオブジェクトを作成するときにキャパシティを報告します。
手動によるノード管理 を実行している場合は、ノードを追加するときにキャパシティを設定する必要があります。
Kubernetesスケジューラー は、ノード上のすべてのPodに十分なリソースがあることを確認します。スケジューラーは、ノード上のコンテナが要求するリソースの合計がノードキャパシティ以下であることを確認します。
これは、kubeletによって管理されたすべてのコンテナを含みますが、コンテナランタイムによって直接開始されたコンテナやkubeletの制御外で実行されているプロセスは含みません。
ノードのトポロジー
FEATURE STATE:
Kubernetes v1.16 [alpha]
TopologyManagerの
フィーチャーゲート を有効にすると、
kubeletはリソースの割当を決定する際にトポロジーのヒントを利用できます。
詳細は、
ノードのトポロジー管理ポリシーを制御する を参照してください。
ノードの正常終了 FEATURE STATE:
Kubernetes v1.21 [beta]
kubeletは、ノードのシステムシャットダウンを検出すると、ノード上で動作しているPodを終了させます。
Kubelet は、ノードのシャットダウン時に、ポッドが通常の通常のポッド終了プロセス に従うようにします。
Graceful Node Shutdownはsystemdに依存しているため、systemd inhibitor locks を
利用してノードのシャットダウンを一定時間遅らせることができます。
Graceful Node Shutdownは、v1.21でデフォルトで有効になっているGracefulNodeShutdown フィーチャーゲート で制御されます。
なお、デフォルトでは、後述の設定オプションShutdownGracePeriodおよびShutdownGracePeriodCriticalPodsの両方がゼロに設定されているため、Graceful node shutdownは有効になりません。この機能を有効にするには、この2つのkubeletの設定を適切に設定し、ゼロ以外の値を設定する必要があります。
Graceful shutdownでは、kubeletは以下の2段階でPodを終了させます。
そのノード上で動作している通常のPodを終了させます。 そのノード上で動作しているcritical pods を終了させます。 Graceful Node Shutdownには、2つのKubeletConfiguration
ShutdownGracePeriod:ノードがシャットダウンを遅らせるべき合計期間を指定します。これは、通常のPodとcritical pods の両方のPod終了の合計猶予期間です。 ShutdownGracePeriodCriticalPods:ノードのシャットダウン時にcritical pods を終了させるために使用する期間を指定します。この値は、ShutdownGracePeriodよりも小さくする必要があります。 例えば、ShutdownGracePeriod=30s、ShutdownGracePeriodCriticalPods=10sとすると、
kubeletはノードのシャットダウンを30秒遅らせます。シャットダウンの間、最初の20(30-10)秒は通常のポッドを優雅に終了させるために確保され、
残りの10秒は重要なポッドを終了させるために確保されることになります。
備考: Graceful Node Shutdown中にPodが退避された場合、それらのPodの.statusはFailedになります。
kubectl get podsを実行すると、退避させられたPodのステータスが Shutdown と表示されます。
また、kubectl describe podを実行すると、ノードのシャットダウンのためにPodが退避されたことがわかります。
Status: Failed
Reason: Shutdown
Message: Node is shutting, evicting pods
失敗したポッドオブジェクトは、明示的に削除されるか、GCによってクリーンアップ されるまで保存されます。
これは、ノードが突然終了した場合とは異なった振る舞いです。
ノードの非正常終了 FEATURE STATE:
Kubernetes v1.26 [beta]
コマンドがkubeletのinhibitor locksメカニズムをトリガーしない場合や、ShutdownGracePeriodやShutdownGracePeriodCriticalPodsが適切に設定されていないといったユーザーによるミス等が原因で、ノードがシャットダウンしたことをkubeletのNode Shutdownマネージャーが検知できないことがあります。詳細は上記セクションノードの正常終了 を参照ください。
ノードのシャットダウンがkubeletのNode Shutdownマネージャーに検知されない場合、StatefulSetを構成するPodはシャットダウン状態のノード上でterminating状態のままになってしまい、他の実行中のノードに移動することができなくなってしまいます。これは、ノードがシャットダウンしているため、その上のkubeletがPodを削除できず、それにより、StatefulSetが新しいPodを同じ名前で作成できなくなってしまうためです。Podがボリュームを使用している場合、VolumeAttachmentsはシャットダウン状態のノードによって削除されないため、Podが使用しているボリュームは他の実行中のノードにアタッチすることができなくなってしまいます。その結果として、StatefulSet上で実行中のアプリケーションは適切に機能しなくなってしまいます。シャットダウンしていたノードが復旧した場合、そのノード上のPodはkubeletに削除され、他の実行中のノード上に作成されます。また、シャットダウン状態のノードが復旧できなかった場合は、そのノード上のPodは永久にterminating状態のままとなります。
上記の状況を脱却するには、ユーザーが手動でNoExecuteまたはNoSchedule effectを設定してnode.kubernetes.io/out-of-service taintをノードに付与することで、故障中の状態に設定することができます。kube-controller-manager において NodeOutOfServiceVolumeDetachフィーチャーゲート が有効になっており、かつノードがtaintによって故障中としてマークされている場合は、ノードに一致するtolerationがないPodは強制的に削除され、ノード上のterminating状態のPodに対するボリュームデタッチ操作が直ちに実行されます。これにより、故障中のノード上のPodを異なるノード上にすばやく復旧させることが可能になります。
non-graceful shutdownの間に、Podは以下の2段階で終了します:
一致するout-of-service tolerationを持たないPodを強制的に削除する。 上記のPodに対して即座にボリュームデタッチ操作を行う。 備考: node.kubernetes.io/out-of-service taintを付与する前に、ノードがシャットダウンしているか電源がオフになっていることを確認してください(再起動中ではないこと)。Podの別ノードへの移動後、シャットダウンしていたノードが回復した場合は、ユーザーが手動で付与したout-of-service taintをユーザー自ら手動で削除する必要があります。 スワップメモリの管理 FEATURE STATE:
Kubernetes v1.22 [alpha]
Kubernetes 1.22以前では、ノードはスワップメモリの使用をサポートしておらず、ノード上でスワップが検出された場合、
kubeletはデフォルトで起動に失敗していました。1.22以降では、スワップメモリのサポートをノードごとに有効にすることができます。
ノードでスワップを有効にするには、kubeletの NodeSwap フィーチャーゲート を有効にし、
--fail-swap-onコマンドラインフラグまたはfailSwapOnKubeletConfiguration を false に設定する必要があります。
ユーザーはオプションで、ノードがスワップメモリをどのように使用するかを指定するために、memorySwap.swapBehaviorを設定することもできます。ノードがスワップメモリをどのように使用するかを指定します。例えば、以下のようになります。
memorySwap :
swapBehavior : LimitedSwap
swapBehaviorで使用できる設定オプションは以下の通りです。:
LimitedSwap: Kubernetesのワークロードが、使用できるスワップ量に制限を設けます。Kubernetesが管理していないノード上のワークロードは、依然としてスワップを使用できます。UnlimitedSwap: Kubernetesのワークロードが使用できるスワップ量に制限を設けません。システムの限界まで、要求されただけのスワップメモリを使用することができます。memorySwapの設定が指定されておらず、フィーチャーゲート が有効な場合、デフォルトのkubeletはLimitedSwapの設定と同じ動作を適用します。
LimitedSwap設定の動作は、ノードがコントロールグループ(「cgroups」とも呼ばれる)のv1とv2のどちらで動作しているかによって異なります。
Kubernetesのワークロードでは、メモリとスワップを組み合わせて使用することができ、ポッドのメモリ制限が設定されている場合はその制限まで使用できます。
cgroupsv1: Kubernetesのワークロードは、メモリとスワップを組み合わせて使用することができ、ポッドのメモリ制限が設定されている場合はその制限まで使用できます。cgroupsv2: Kubernetesのワークロードは、スワップメモリを使用できません。詳しくは、KEP-2400 と
design proposal をご覧いただき、テストにご協力、ご意見をお聞かせください。
次の項目 3.2.2 - ノードとコントロールプレーン間の通信 本ドキュメントは、APIサーバー とKubernetesクラスター 間の通信経路をまとめたものです。
その目的は、信頼できないネットワーク上(またはクラウドプロバイダー上の完全なパブリックIP)でクラスターが実行できるよう、ユーザーがインストールをカスタマイズしてネットワーク構成を強固にできるようにすることです。
ノードからコントロールプレーンへの通信 Kubernetesには「ハブアンドスポーク」というAPIパターンがあります。ノード(またはノードが実行するPod)からのすべてのAPIの使用は、APIサーバーで終了します。他のコントロールプレーンコンポーネントは、どれもリモートサービスを公開するようには設計されていません。APIサーバーは、1つ以上の形式のクライアント認証 が有効になっている状態で、セキュアなHTTPSポート(通常は443)でリモート接続をリッスンするように設定されています。
特に匿名リクエスト やサービスアカウントトークン が許可されている場合は、1つ以上の認可 形式を有効にする必要があります。
ノードは、有効なクライアント認証情報とともに、APIサーバーに安全に接続できるように、クラスターのパブリックルート証明書 でプロビジョニングされる必要があります。適切なやり方は、kubeletに提供されるクライアント認証情報が、クライアント証明書の形式であることです。kubeletクライアント証明書の自動プロビジョニングについては、kubelet TLSブートストラップ を参照してください。
APIサーバーに接続したいPod は、サービスアカウントを利用することで、安全に接続することができます。これにより、Podのインスタンス化時に、Kubernetesはパブリックルート証明書と有効なBearerトークンを自動的にPodに挿入します。
kubernetesサービス(デフォルトの名前空間)は、APIサーバー上のHTTPSエンドポイントに(kube-proxy
また、コントロールプレーンのコンポーネントは、セキュアなポートを介してAPIサーバーとも通信します。
その結果、ノードやノード上で動作するPodからコントロールプレーンへの接続は、デフォルトでセキュアであり、信頼されていないネットワークやパブリックネットワークを介して実行することができます。
コントロールプレーンからノードへの通信 コントロールプレーン(APIサーバー)からノードへの主要な通信経路は2つあります。
1つ目は、APIサーバーからクラスター内の各ノードで実行されるkubelet プロセスへの通信経路です。
2つ目は、APIサーバーの プロキシ 機能を介した、APIサーバーから任意のノード、Pod、またはサービスへの通信経路です。
APIサーバーからkubeletへの通信 APIサーバーからkubeletへの接続は、以下の目的で使用されます:
Podのログの取得。 実行中のPodへのアタッチ(通常はkubectlを使用)。 kubeletのポート転送機能の提供。 これらの接続は、kubeletのHTTPSエンドポイントで終了します。デフォルトでは、APIサーバーはkubeletのサービング証明書を検証しないため、接続は中間者攻撃の対象となり、信頼されていないネットワークやパブリックネットワークを介して実行するのは安全ではありません 。
この接続を検証するには、--kubelet-certificate-authorityフラグを使用して、kubeletのサービング証明書を検証するために使用するルート証明書バンドルを、APIサーバーに提供します。
それができない場合は、信頼できないネットワークやパブリックネットワークを介した接続を回避するため、必要に応じてAPIサーバーとkubeletの間でSSHトンネル を使用します。
最後に、kubelet APIを保護するために、Kubelet認証/認可 を有効にする必要があります。
APIサーバーからノード、Pod、サービスへの通信 APIサーバーからノード、Pod、またはサービスへの接続は、デフォルトで平文のHTTP接続になるため、認証も暗号化もされません。API URL内のノード、Pod、サービス名にhttps:を付けることで、セキュアなHTTPS接続を介して実行できますが、HTTPSエンドポイントから提供された証明書を検証したり、クライアント認証情報を提供したりすることはありません。そのため、接続の暗号化はされますが、完全性の保証はありません。これらの接続を、信頼されていないネットワークやパブリックネットワークを介して実行するのは、現在のところ安全ではありません 。
SSHトンネル Kubernetesは、コントロールプレーンからノードへの通信経路を保護するために、SSHトンネル をサポートしています。この構成では、APIサーバーがクラスター内の各ノードへのSSHトンネルを開始(ポート22でリッスンしているSSHサーバーに接続)し、kubelet、ノード、Pod、またはサービス宛てのすべてのトラフィックをトンネル経由で渡します。
このトンネルにより、ノードが稼働するネットワークの外部にトラフィックが公開されないようになります。
備考: SSHトンネルは現在非推奨であるため、自分が何をしているのか理解していないのであれば、使用すべきではありません。この通信経路の代替となるものとして、
Konnectivityサービス があります。
Konnectivityサービス FEATURE STATE:
Kubernetes v1.18 [beta]
SSHトンネルの代替として、Konnectivityサービスは、コントロールプレーンからクラスターへの通信に、TCPレベルのプロキシを提供します。Konnectivityサービスは、コントロールプレーンネットワークのKonnectivityサーバーと、ノードネットワークのKonnectivityエージェントの、2つの部分で構成されています。
Konnectivityエージェントは、Konnectivityサーバーへの接続を開始し、ネットワーク接続を維持します。
Konnectivityサービスを有効にすると、コントロールプレーンからノードへのトラフィックは、すべてこの接続を経由するようになります。
Konnectivityサービスのセットアップ に従って、クラスターにKonnectivityサービスをセットアップしてください。
次の項目 3.2.3 - リース しばしば分散システムでは共有リソースをロックしたりノード間の活動を調整する機構として"リース"が必要になります。
Kubernetesでは、"リース"のコンセプトはcoordination.k8s.ioAPIグループのLeaseオブジェクトに表されていて、ノードのハートビートやコンポーネントレベルのリーダー選出といったシステムにとって重要な機能に利用されています。
ノードハートビート Kubernetesでは、kubeletのノードハートビートをKubernetes APIサーバーに送信するのにLease APIが使われています。
各Nodeごとに、kube-node-lease名前空間にノードとマッチする名前のLeaseオブジェクトが存在します。
内部的には、kubeletのハートビートはこのLeaseオブジェクトに対するUPDATEリクエストであり、Leaseのspec.renewTimeフィールドを更新しています。
Kubernetesのコントロールプレーンはこのフィールドのタイムスタンプを見て、Nodeが利用可能かを判断しています。
詳しくはNode Leaseオブジェクト をご覧ください。
リーダー選出 Kubernetesでは、あるコンポーネントのインスタンスが常に一つだけ実行されていることを保証するためにもリースが利用されています。
これはkube-controller-managerやkube-schedulerといったコントロールプレーンのコンポーネントで、一つのインスタンスのみがアクティブに実行され、その他のインスタンスをスタンバイ状態とする必要があるような冗長構成を組むために利用されています。
APIサーバーのアイデンティティー FEATURE STATE:
Kubernetes v1.26 [beta]
Kubernetes v1.26から、各kube-apiserverはLease APIを利用して自身のアイデンティティーをその他のシステムに向けて公開するようになりました。
それ自体は特に有用ではありませんが、何台のkube-apiserverがKubernetesコントロールプレーンを稼働させているのかをクライアントが知るためのメカニズムを提供します。
kube-apiserverリースが存在することで、各kube-apiserver間の調整が必要となる可能性がある将来の機能が使えるようになります。
kube-system名前空間のapiserver-<sha256-hash>という名前のリースオブジェクトを確認することで、各kube-apiserverが所有しているLeaseを確認することができます。
また、k8s.io/component=kube-apiserverラベルセレクターを利用することもできます。
$ kubectl -n kube-system get lease -l k8s.io/component= kube-apiserver
NAME HOLDER AGE
apiserver-c4vwjftbvpc5os2vvzle4qg27a kube-apiserver-c4vwjftbvpc5os2vvzle4qg27a_9cbf54e5-1136-44bd-8f9a-1dcd15c346b4 5m33s
apiserver-dz2dqprdpsgnm756t5rnov7yka kube-apiserver-dz2dqprdpsgnm756t5rnov7yka_84f2a85d-37c1-4b14-b6b9-603e62e4896f 4m23s
apiserver-fyloo45sdenffw2ugwaz3likua kube-apiserver-fyloo45sdenffw2ugwaz3likua_c5ffa286-8a9a-45d4-91e7-61118ed58d2e 4m43s
リースの名前に使われているSHA256ハッシュはkube-apiserverのOSホスト名に基づいています。各kube-apiserverはクラスター内で一意なホスト名を使用するように構成する必要があります。
同じホスト名を利用する新しいkube-apiserverインスタンスは、新しいリースオブジェクトを作成せずに、既存のLeaseを新しいインスタンスのアイデンティティーを利用して引き継ぎます。
kube-apiserverが使用するホスト名はkubernetes.io/hostnameラベルの値で確認できます。
$ kubectl -n kube-system get lease kube-apiserver-c4vwjftbvpc5os2vvzle4qg27a -o yaml
apiVersion : coordination.k8s.io/v1
kind : Lease
metadata :
creationTimestamp : "2022-11-30T15:37:15Z"
labels :
k8s.io/component : kube-apiserver
kubernetes.io/hostname : kind-control-plane
name : kube-apiserver-c4vwjftbvpc5os2vvzle4qg27a
namespace : kube-system
resourceVersion : "18171"
uid : d6c68901-4ec5-4385-b1ef-2d783738da6c
spec :
holderIdentity : kube-apiserver-c4vwjftbvpc5os2vvzle4qg27a_9cbf54e5-1136-44bd-8f9a-1dcd15c346b4
leaseDurationSeconds : 3600
renewTime : "2022-11-30T18:04:27.912073Z"
すでに存在しなくなったkube-apiserverの期限切れリースは、1時間後に新しいkube-apiserverによってガベージコレクションされます。
3.2.4 - コントローラー ロボット工学やオートメーションの分野において、 制御ループ とは、あるシステムの状態を制御する終了状態のないループのことです。
ここでは、制御ループの一例として、部屋の中にあるサーモスタットを挙げます。
あなたが温度を設定すると、それはサーモスタットに 目的の状態(desired state) を伝えることになります。実際の部屋の温度は 現在の状態 です。サーモスタットは、装置をオンまたはオフにすることによって、現在の状態を目的の状態に近づけるように動作します。
Kubernetesにおいて、コントローラーは
クラスター の状態を監視し、必要に応じて変更を加えたり要求したりする制御ループです。それぞれのコントローラーは現在のクラスターの状態を望ましい状態に近づけるように動作します。
コントローラーパターン コントローラーは少なくとも1種類のKubernetesのリソースを監視します。これらのオブジェクト には目的の状態を表すspecフィールドがあります。リソースのコントローラーは、現在の状態を目的の状態に近づける責務を持ちます。
コントローラーは自分自身でアクションを実行する場合もありますが、KubernetesではコントローラーがAPIサーバー に意味のある副作用を持つメッセージを送信することが一般的です。以下では、このような例を見ていきます。
APIサーバー経由でコントロールする Job コントローラーはKubernetesのビルトインのコントローラーの一例です。ビルトインのコントローラーは、クラスターのAPIサーバーとやりとりをして状態を管理します。
Jobは、1つ以上のPod を起動して、タスクを実行した後に停止する、Kubernetesのリソースです。
(1度スケジュール されると、Podオブジェクトはkubeletに対する目的の状態の一部になります。)
Jobコントローラーが新しいタスクを見つけると、その処理が完了するように、クラスター上のどこかで、一連のNode上のkubeletが正しい数のPodを実行することを保証します。ただし、Jobコントローラーは、自分自身でPodやコンテナを実行することはありません。代わりに、APIサーバーに対してPodの作成や削除を依頼します。コントロールプレーン 上の他のコンポーネントが(スケジュールして実行するべき新しいPodが存在するという)新しい情報を基に動作することによって、最終的に目的の処理が完了します。
新しいJobが作成されたとき、目的の状態は、そのJobが完了することです。JobコントローラーはそのJobに対する現在の状態を目的の状態に近づけるようにします。つまり、そのJobが行ってほしい処理を実行するPodを作成し、Jobが完了に近づくようにします。
コントローラーは、コントローラーを設定するオブジェクトも更新します。たとえば、あるJobが完了した場合、Jobコントローラーは、JobオブジェクトにFinishedというマークを付けます。
(これは、部屋が設定温度になったことを示すために、サーモスタットがランプを消灯するのに少し似ています。)
直接的なコントロール Jobとは対照的に、クラスターの外部に変更を加える必要があるコントローラーもあります。
たとえば、クラスターに十分な数のNode が存在することを保証する制御ループの場合、そのコントローラーは、必要に応じて新しいNodeをセットアップするために、現在のクラスターの外部とやりとりをする必要があります。
外部の状態とやりとりをするコントローラーは、目的の状態をAPIサーバーから取得した後、外部のシステムと直接通信し、現在の状態を目的の状態に近づけます。
(クラスター内のノードを水平にスケールさせるコントローラー が実際に存在します。)
ここで重要な点は、コントローラーが目的の状態を実現するために変更を加えてから、現在の状態をクラスターのAPIサーバーに報告することです。他の制御ループは、その報告されたデータを監視し、独自のアクションを実行できます。
サーモスタットの例では、部屋が非常に寒い場合、別のコントローラーが霜防止ヒーターをオンにすることもあります。Kubernetesクラスターを使用すると、コントロールプレーンは、Kubernetesを拡張して 実装することにより、IPアドレス管理ツールやストレージサービス、クラウドプロバイダーAPI、およびその他のサービスと間接的に連携します。
目的の状態 vs 現在の状態 Kubernetesはシステムに対してクラウドネイティブな見方をするため、常に変化し続けるような状態を扱えるように設計されています。
処理を実行したり、制御ループが故障を自動的に修正したりしているどの時点でも、クラスターは変化中である可能性があります。つまり、クラスターは決して安定した状態にならない可能性があるということです。
コントローラーがクラスターのために実行されていて、有用な変更が行われるのであれば、全体的な状態が安定しているかどうかは問題にはなりません。
設計 設計理念として、Kubernetesは多数のコントローラーを使用しており、各コントローラーはクラスターの状態の特定の側面をそれぞれ管理しています。最もよくあるパターンは、特定の制御ループ(コントローラー)が目的の状態として1種類のリソースを使用し、目的の状態を実現することを管理するために別の種類のリソースを用意するというものです。たとえば、Jobのコントローラーは、Jobオブジェクト(新しい処理を見つけるため)およびPodオブジェクト(Jobを実行し、処理が完了したか確認するため)を監視します。この場合、なにか別のものがJobを作成し、JobコントローラーはPodを作成します。
相互にリンクされた単一のモノリシックな制御ループよりは、複数の単純なコントローラーが存在する方が役に立ちます。コントローラーは故障することがあるため、Kubernetesは故障を許容するように設計されています。
備考: 同じ種類のオブジェクトを作成または更新するコントローラーが、複数存在する場合があります。実際には、Kubernetesコントローラーは、自分が制御するリソースに関連するリソースにのみ注意を払うように作られています。
たとえば、DeploymentとJobがありますが、これらは両方ともPodを作成するものです。しかし、JobコントローラーはDeploymentが作成したPodを削除することはありません。各コントローラーが2つのPodを区別できる情報(ラベル )が存在するためです。
コントローラーを実行する方法 Kubernetesには、kube-controller-manager 内部で動作する一組のビルトインのコントローラーが用意されています。これらビルトインのコントローラーは、コアとなる重要な振る舞いを提供します。
DeploymentコントローラーとJobコントローラーは、Kubernetes自体の一部として同梱されているコントローラーの例です(それゆえ「ビルトイン」のコントローラーと呼ばれます)。Kubernetesは回復性のあるコントロールプレーンを実行できるようにしているため、ビルトインのコントローラーの一部が故障しても、コントロールプレーンの別の部分が作業を引き継いでくれます。
Kubernetesを拡張するためにコントロールプレーンの外で動作するコントローラーもあります。もし望むなら、新しいコントローラーを自分で書くこともできます。自作のコントローラーをPodセットとして動作させたり、Kubernetesの外部で動作させることもできます。どのような動作方法が最も適しているかは、そのコントローラーがどのようなことを行うのかに依存します。
次の項目 3.2.5 - クラウドコントローラーマネージャー FEATURE STATE:
Kubernetes v1.11 [beta]
クラウドインフラストラクチャ技術により、パブリック、プライベート、ハイブリッドクラウド上でKubernetesを動かすことができます。Kubernetesは、コンポーネント間の密なつながりが不要な自動化されたAPI駆動インフラストラクチャを信条としています。
cloud-controller-managerは クラウド特有の制御ロジックを組み込むKubernetesのコントロールプレーン コンポーネントです。クラウドコントロールマネージャーは、クラスターをクラウドプロバイダーAPIとリンクし、クラスターのみで相互作用するコンポーネントからクラウドプラットフォームで相互作用するコンポーネントを分離します。
Kubernetesと基盤となるクラウドインフラストラクチャ間の相互運用ロジックを分離することで、クラウドプロバイダーはcloud-controller-managerコンポーネントにより、メインのKubernetesプロジェクトとは異なるペースで機能をリリースできるようになります。
cloud-controller-managerは、プラグイン機構を用い、異なるクラウドプロバイダーに対してそれぞれのプラットフォームとKubernetesの結合を可能にする構成になっています。
設計
クラウドコントローラーマネージャーは、複製されたプロセスの集合としてコントロールプレーンで実行されます(通常、Pod内のコンテナとなります)。各cloud-controller-managerは、シングルプロセスで複数のコントローラー を実装します。
備考: コントロールプレーンの一部ではなく、Kubernetesの
アドオン としてクラウドコントローラーマネージャーを実行することもできます。
クラウドコントローラーマネージャーの機能 クラウドコントローラーマネージャーのコントローラーは以下を含んでいます。
ノードコントローラー ノードコントローラーは、クラウドインフラストラクチャで新しいサーバーが作成された際に、Node オブジェクトを作成する責務を持ちます。ノードコントローラーは、クラウドプロバイダーのテナント内で動作しているホストの情報を取得します。ノードコントローラーは下記に示す機能を実行します:
Nodeオブジェクトを、コントローラーがクラウドプロバイダーAPIを通じて見つけた各サーバーで初期化する。 Nodeオブジェクトに、ノードがデプロイされているリージョンや利用可能なリソース(CPU、メモリなど)のようなクラウド特有な情報を注釈付けやラベル付けをする。 ノードのホスト名とネットワークアドレスを取得する。 ノードの正常性を検証する。ノードが応答しなくなった場合、クラウドプロバイダーのAPIを利用しサーバーがdeactivated / deleted / terminatedであるかを確認する。クラウドからノードが削除されていた場合、KubernetesクラスターからNodeオブジェクトを削除する。 いくつかのクラウドプロバイダーは、これをノードコントローラーと個別のノードライフサイクルコントローラーに分けて実装しています。
ルートコントローラー ルートコントローラーは、クラスター内の異なるノード上で稼働しているコンテナが相互に通信できるように、クラウド内のルートを適切に設定する責務を持ちます。
クラウドプロバイダーによっては、ルートコントローラーはPodネットワークのIPアドレスのブロックを割り当てることもあります。
サービスコントローラー Service は、マネージドロードバランサー、IPアドレスネットワークパケットフィルターや対象のヘルスチェックのようなクラウドインフラストラクチャコンポーネントとの統合を行います。サービスコントローラーは、ロードバランサーや他のインフラストラクチャコンポーネントを必要とするServiceリソースを宣言する際にそれらのコンポーネントを設定するため、クラウドプロバイダーのAPIと対話します。
認可 このセクションでは、クラウドコントローラーマネージャーが操作を行うために様々なAPIオブジェクトに必要な権限を分類します。
ノードコントローラー ノードコントローラーはNodeオブジェクトのみに対して働きます。Nodeオブジェクトに対して、readとmodifyの全権限が必要です。
v1/Node:
get list create update patch watch delete ルートコントローラー ルートコントローラーは、Nodeオブジェクトの作成を待ち受け、ルートを適切に設定します。Nodeオブジェクトについて、get権限が必要です。
v1/Node:
サービスコントローラー サービスコントローラーは、Serviceオブジェクトのcreate 、update 、delete イベントを待ち受け、その後、サービスのロードバランサーを適切に設定します。
Serviceにアクセスするため、list 、watch の権限が必要です。Serviceを更新するため、statusサブリソースへのpatch 、update の権限が必要です。
v1/Service:
その他 クラウドコントローラーマネージャーのコア機能の実装は、Eventオブジェクトのcreate権限と、セキュアな処理を保証するため、ServiceAccountのcreate権限が必要です。
v1/Event:
v1/ServiceAccount:
クラウドコントローラーマネージャーのRBAC ClusterRoleはこのようになります:
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRole
metadata :
name : cloud-controller-manager
rules :
apiGroups :
- ""
resources :
- events
verbs :
- create
- patch
- update
apiGroups :
- ""
resources :
- nodes
verbs :
- '*'
apiGroups :
- ""
resources :
- nodes/status
verbs :
- patch
apiGroups :
- ""
resources :
- services
verbs :
- list
- watch
apiGroups :
- ""
resources :
- services/status
verbs :
- patch
- update
apiGroups :
- ""
resources :
- serviceaccounts
verbs :
- create
apiGroups :
- ""
resources :
- persistentvolumes
verbs :
- get
- list
- update
- watch
次の項目 3.2.6 - cgroup v2について Linuxでは、コントロールグループ がプロセスに割り当てられるリソースを制限しています。
コンテナ化されたワークロードの、CPU/メモリーの要求と制限を含むPodとコンテナのリソース管理 を強制するために、
kubelet と基盤となるコンテナランタイムはcgroupをインターフェースとして接続する必要があります。
Linuxではcgroup v1とcgroup v2の2つのバージョンのcgroupがあります。
cgroup v2は新世代のcgroup APIです。
cgroup v2とは何か? FEATURE STATE:
Kubernetes v1.25 [stable]
cgroup v2はLinuxのcgroup APIの次のバージョンです。
cgroup v2はリソース管理機能を強化した統合制御システムを提供しています。
以下のように、cgroup v2はcgroup v1からいくつかの点を改善しています。
統合された単一階層設計のAPI より安全なコンテナへのサブツリーの移譲 Pressure Stall Information などの新機能強化されたリソース割り当て管理と複数リソース間の隔離異なるタイプのメモリー割り当ての統一(ネットワークメモリー、カーネルメモリーなど) ページキャッシュの書き戻しといった、非即時のリソース変更 Kubernetesのいくつかの機能では、強化されたリソース管理と隔離のためにcgroup v2のみを使用しています。
例えば、MemoryQoS 機能はメモリーQoSを改善し、cgroup v2の基本的な機能に依存しています。
cgroup v2を使う cgroup v2を使うおすすめの方法は、デフォルトでcgroup v2が有効で使うことができるLinuxディストリビューションを使うことです。
あなたのディストリビューションがcgroup v2を使っているかどうかを確認するためには、Linux Nodeのcgroupバージョンを特定する を参照してください。
必要要件 cgroup v2を使うには以下のような必要要件があります。
OSディストリビューションでcgroup v2が有効であること Linuxカーネルバージョンが5.8以上であること コンテナランタイムがcgroup v2をサポートしていること。例えば、 kubeletとコンテナランタイムがsystemd cgroupドライバー を使うように設定されていること Linuxディストリビューションのcgroup v2サポート cgroup v2を使っているLinuxディストリビューションの一覧はcgroup v2ドキュメント をご覧ください。
Container-Optimized OS (M97以降) Ubuntu (21.10以降, 22.04以降推奨) Debian GNU/Linux (Debian 11 bullseye以降) Fedora (31以降) Arch Linux (April 2021以降) RHEL and RHEL-like distributions (9以降) あなたのディストリビューションがcgroup v2を使っているかどうかを確認するためには、あなたのディストリビューションのドキュメントを参照するか、Linux Nodeのcgroupバージョンを特定する の説明に従ってください。
カーネルのcmdlineの起動時引数を修正することで、手動であなたのLinuxディストリビューションのcgroup v2を有効にすることもできます。
あなたのディストリビューションがGRUBを使っている場合は、
/etc/default/grubの中のGRUB_CMDLINE_LINUXにsystemd.unified_cgroup_hierarchy=1を追加し、sudo update-grubを実行してください。
ただし、おすすめの方法はデフォルトですでにcgroup v2が有効になっているディストリビューションを使うことです。
cgroup v2への移行 cgroup v2に移行するには、必要要件 を満たすことを確認し、
cgroup v2がデフォルトで有効であるカーネルバージョンにアップグレードします。
kubeletはOSがcgroup v2で動作していることを自動的に検出し、それに応じて処理を行うため、追加設定は必要ありません。
ノード上やコンテナ内からユーザーが直接cgroupファイルシステムにアクセスしない限り、cgroup v2に切り替えたときのユーザー体験に目立った違いはないはずです。
cgroup v2はcgroup v1とは違うAPIを利用しているため、cgroupファイルシステムに直接アクセスしているアプリケーションはcgroup v2をサポートしている新しいバージョンに更新する必要があります。例えば、
サードパーティーの監視またはセキュリティエージェントはcgroupファイルシステムに依存していることがあります。
エージェントをcgroup v2をサポートしているバージョンに更新してください。 Podやコンテナを監視するためにcAdvisor をスタンドアローンのDaemonSetとして起動している場合、v0.43.0以上に更新してください。 Javaアプリケーションをデプロイする場合は、完全にcgroup v2をサポートしているバージョンを利用してください: uber-go/automaxprocs パッケージを利用している場合は、利用するバージョンがv1.5.1以上であることを確認してください。Linux Nodeのcgroupバージョンを特定する cgroupバージョンは利用されているLinuxディストリビューションと、OSで設定されているデフォルトのcgroupバージョンに依存します。
あなたのディストリビューションがどちらのcgroupバージョンを利用しているのかを確認するには、stat -fc %T /sys/fs/cgroup/コマンドをノード上で実行してください。
stat -fc %T /sys/fs/cgroup/
cgroup v2では、cgroup2fsと出力されます。
cgroup v1では、tmpfsと出力されます。
次の項目 3.2.7 - Kubernetesの自己修復機能 Kubernetesは、ワークロードの健全性と可用性を維持するための自己修復機能を備えています。
ノードが使用不能になった際にはワークロードを再スケジュールし、障害の発生したコンテナを自動的に置き換え、システムの望ましい状態が維持されるようにします。
自己修復機能 コンテナレベルの再起動: Pod内のコンテナが失敗した場合、KubernetesはrestartPolicy
レプリカの置換: Deployment やStatefulSet に属するPodが失敗した場合、Kubernetesは指定されたレプリカ数を維持するために代替のPodを作成します。DaemonSet に属するPodが失敗した場合、コントロールプレーンが同じノード上で実行するための代替Podを作成します。
永続ストレージの復旧: PersistentVolume(PV)をアタッチしたPodが実行されているノードが障害を起こした場合、Kubernetesはそのボリュームを別のノード上の新しいPodに再アタッチできます。
Serviceにおける負荷分散: Service の背後にあるPodが失敗した場合、KubernetesはそのPodをServiceのエンドポイントから自動的に除外し、正常なPodのみにトラフィックをルーティングします。
Kubernetesの自己修復を実現する主なコンポーネントには、次のようなものがあります:
kubelet :
ReplicaSet、StatefulSet、DaemonSetコントローラー: Podの望ましいレプリカ数を維持します。
PersistentVolumeコントローラー: ステートフルなワークロードに対してボリュームのアタッチおよびデタッチを管理します。
考慮事項 次の項目 3.2.8 - コンテナランタイムインターフェース(CRI) CRIは、クラスターコンポーネントを再コンパイルすることなく、kubeletがさまざまなコンテナランタイムを使用できるようにするプラグインインターフェースです。
kubelet がPod とそのコンテナを起動できるように、クラスター内の各ノードで動作するcontainer runtime が必要です。
kubeletとContainerRuntime間の通信のメインプロトコルです。
Kubernetes Container Runtime Interface(CRI)は、クラスターコンポーネント kubelet とcontainer runtime 間の通信用のメインgRPC プロトコルを定義します。
API FEATURE STATE:
Kubernetes v1.23 [stable]
kubeletは、gRPCを介してコンテナランタイムに接続するときにクライアントとして機能します。ランタイムおよびイメージサービスエンドポイントは、コンテナランタイムで使用可能である必要があります。コンテナランタイムは、--image-service-endpointコマンドラインフラグ を使用して、kubelet内で個別に設定できます。
Kubernetes v1.35の場合、kubeletはCRI v1の使用を優先します。
コンテナランタイムがCRIのv1をサポートしていない場合、kubeletはサポートされている古いバージョンのネゴシエーションを試みます。
kubelet v1.35はCRI v1alpha2をネゴシエートすることもできますが、このバージョンは非推奨と見なされます。
kubeletがサポートされているCRIバージョンをネゴシエートできない場合、kubeletはあきらめて、ノードとして登録されません。
アップグレード Kubernetesをアップグレードする場合、kubeletはコンポーネントの再起動時に最新のCRIバージョンを自動的に選択しようとします。
それが失敗した場合、フォールバックは上記のように行われます。
コンテナランタイムがアップグレードされたためにgRPCリダイヤルが必要な場合は、コンテナランタイムも最初に選択されたバージョンをサポートする必要があります。
そうでない場合、リダイヤルは失敗することが予想されます。これには、kubeletの再起動が必要です。
次の項目 3.2.9 - ガベージコレクション ガベージコレクションは、Kubernetesがクラスターリソースをクリーンアップするために使用するさまざまなメカニズムの総称です。これにより、次のようなリソースのクリーンアップが可能になります:
オーナーの依存関係 Kubernetesの多くのオブジェクトは、owner reference
Ownershipは、一部のリソースでも使用されるラベルおよびセレクター メカニズムとは異なります。
たとえば、EndpointSliceオブジェクトを作成するService を考えます。
Serviceはラベル を使用して、コントロールプレーンがServiceに使用されているEndpointSliceオブジェクトを判別できるようにします。
ラベルに加えて、Serviceに代わって管理される各EndpointSliceには、owner referenceがあります。
owner referenceは、Kubernetesのさまざまな部分が制御していないオブジェクトへの干渉を回避するのに役立ちます。
備考: namespace間のowner referenceは、設計上許可されていません。
namespaceの依存関係は、クラスタースコープまたはnamespaceのオーナーを指定できます。
namespaceのオーナーは、依存関係と同じnamespaceに存在する必要があります 。
そうでない場合、owner referenceは不在として扱われ、すべてのオーナーが不在であることが確認されると、依存関係は削除される可能性があります。
クラスタースコープの依存関係は、クラスタースコープのオーナーのみを指定できます。
v1.20以降では、クラスタースコープの依存関係がnamespaceを持つkindをオーナーとして指定している場合、それは解決できないowner referenceを持つものとして扱われ、ガベージコレクションを行うことはできません。
V1.20以降では、ガベージコレクタは無効な名前空間間のownerReference、またはnamespaceのkindを参照するownerReferenceをもつクラスター・スコープの依存関係を検出した場合、無効な依存関係のOwnerRefInvalidNamespaceとinvolvedObjectを理由とする警告イベントが報告されます。
以下のコマンドを実行すると、そのようなイベントを確認できます。
kubectl get events -A --field-selector=reason=OwnerRefInvalidNamespace
カスケード削除 Kubernetesは、ReplicaSetを削除したときに残されたPodなど、owner referenceがなくなったオブジェクトをチェックして削除します。
オブジェクトを削除する場合、カスケード削除と呼ばれるプロセスで、Kubernetesがオブジェクトの依存関係を自動的に削除するかどうかを制御できます。
カスケード削除には、次の2つのタイプがあります。
フォアグラウンドカスケード削除 バックグラウンドカスケード削除 また、Kubernetes finalizer を使用して、ガベージコレクションがowner referenceを持つリソースを削除する方法とタイミングを制御することもできます。
フォアグラウンドカスケード削除 フォアグラウンドカスケード削除では、削除するオーナーオブジェクトは最初に削除進行中 の状態になります。
この状態では、オーナーオブジェクトに次のことが起こります。
Kubernetes APIサーバーは、オブジェクトのmetadata.deletionTimestampフィールドを、オブジェクトに削除のマークが付けられた時刻に設定します。 Kubernetes APIサーバーは、metadata.finalizersフィールドをforegroundDeletionに設定します。 オブジェクトは、削除プロセスが完了するまで、KubernetesAPIを介して表示されたままになります。 オーナーオブジェクトが削除進行中の状態に入ると、コントローラーは依存関係を削除します。
すべての依存関係オブジェクトを削除した後、コントローラーはオーナーオブジェクトを削除します。
この時点で、オブジェクトはKubernetesAPIに表示されなくなります。
フォアグラウンドカスケード削除中に、オーナーの削除をブロックする依存関係は、ownerReference.blockOwnerDeletion=trueフィールドを持つ依存関係のみです。
詳細については、フォアグラウンドカスケード削除の使用 を参照してください。
バックグラウンドカスケード削除 バックグラウンドカスケード削除では、Kubernetes APIサーバーがオーナーオブジェクトをすぐに削除し、コントローラーがバックグラウンドで依存オブジェクトをクリーンアップします。
デフォルトでは、フォアグラウンド削除を手動で使用するか、依存オブジェクトを孤立させることを選択しない限り、Kubernetesはバックグラウンドカスケード削除を使用します。
詳細については、バックグラウンドカスケード削除の使用 を参照してください。
孤立した依存関係 Kubernetesがオーナーオブジェクトを削除すると、残された依存関係はorphan オブジェクトと呼ばれます。
デフォルトでは、Kubernetesは依存関係オブジェクトを削除します。この動作をオーバーライドする方法については、オーナーオブジェクトの削除と従属オブジェクトの孤立 を参照してください。
未使用のコンテナとイメージのガベージコレクション kubelet は未使用のイメージに対して5分ごとに、未使用のコンテナに対して1分ごとにガベージコレクションを実行します。
外部のガベージコレクションツールは、kubeletの動作を壊し、存在するはずのコンテナを削除する可能性があるため、使用しないでください。
未使用のコンテナとイメージのガベージコレクションのオプションを設定するには、設定ファイル を使用してkubeletを調整し、KubeletConfiguration
コンテナイメージのライフサイクル Kubernetesは、kubeletの一部であるイメージマネージャー を通じて、cadvisor の協力を得て、すべてのイメージのライフサイクルを管理します。kubeletは、ガベージコレクションを決定する際に、次のディスク使用制限を考慮します。
HighThresholdPercentLowThresholdPercent設定されたHighThresholdPercent値を超えるディスク使用量はガベージコレクションをトリガーします。
ガベージコレクションは、最後に使用された時間に基づいて、最も古いものから順にイメージを削除します。
kubeletは、ディスク使用量がLowThresholdPercent値に達するまでイメージを削除します。
コンテナのガベージコレクション kubeletは、次の変数に基づいて未使用のコンテナをガベージコレクションします。
MinAge: kubeletがガベージコレクションできるコンテナの最低期間。0を設定すると無効化されます。MaxPerPodContainer: 各Podが持つことができるデッドコンテナの最大数。0未満に設定すると無効化されます。MaxContainers: クラスターが持つことができるデッドコンテナの最大数。0未満に設定すると無効化されます。これらの変数に加えて、kubeletは、通常、最も古いものから順に、定義されていない削除されたコンテナをガベージコレクションします。
MaxPerPodContainerとMaxContainersは、Podごとのコンテナの最大数(MaxPerPodContainer)を保持すると、グローバルなデッドコンテナの許容合計(MaxContainers)を超える状況で、互いに競合する可能性があります。
この状況では、kubeletはMaxPerPodContainerを調整して競合に対処します。最悪のシナリオは、MaxPerPodContainerを1にダウングレードし、最も古いコンテナを削除することです。
さらに、削除されたPodが所有するコンテナは、MinAgeより古くなると削除されます。
備考: kubeletがガベージコレクションするのは、自分が管理するコンテナのみです。ガベージコレクションの設定 これらのリソースを管理するコントローラーに固有のオプションを設定することにより、リソースのガベージコレクションを調整できます。次のページは、ガベージコレクションを設定する方法を示しています。
次の項目 3.2.10 - Mixed Version Proxy FEATURE STATE:
Kubernetes v1.28 [alpha](disabled by default)
Kubernetes 1.35には、APIサーバー が他の ピア APIサーバーにリソースリクエストをプロキシできるようにするアルファ機能が含まれています。
また、クライアントがディスカバリを通じてクラスター全体で提供されるリソースの全体像を取得することもできます。
これは、1つのクラスター内で異なるバージョンのKubernetesを実行する複数のAPIサーバーがある場合に役立ちます(例えば、Kubernetesの新しいリリースへの長期間にわたるロールアウト中など)。
これにより、クラスター管理者は、より安全にアップグレードできる高可用性クラスターを設定できます:
重要なタスクでリソースの包括的なリストを表示するためにディスカバリに依存するコントローラーが、常にすべてのリソースの完全なビューを取得できるようにします。
この完全なクラスター全体のディスカバリを ピア集約ディスカバリ と呼びます。 (アップグレード中に行われる)リソースリクエストを正しいkube-apiserverに転送します。
このプロキシにより、ユーザーはアップグレードプロセスに起因する予期しない404 Not Foundエラーを見ることがなくなります。
このメカニズムは Mixed Version Proxy と呼ばれます。 ピア集約ディスカバリとMixed Version Proxyの有効化 APIサーバー を起動する際に、UnknownVersionInteroperabilityProxyフィーチャーゲート が有効になっていることを確認してください:
kube-apiserver \
= UnknownVersionInteroperabilityProxy = true \
# この機能に必要なコマンドライン引数
--peer-ca-file= <kube-apiserver CA証明書へのパス>
--proxy-client-cert-file= <アグリゲータープロキシ証明書へのパス>,
--proxy-client-key-file= <アグリゲータープロキシ鍵へのパス>,
--requestheader-client-ca-file= <アグリゲーターCA証明書へのパス>,
# requestheader-allowed-namesは、任意のCommon Nameを許可するために空白に設定できます
--requestheader-allowed-names= <プロキシクライアント証明書を検証するための有効なCommon Names>,
# この機能のオプションフラグ
--peer-advertise-ip= ` ピアがリクエストをプロキシするために使用するこのkube-apiserverのIP`
--peer-advertise-port= ` ピアがリクエストをプロキシするために使用するこのkube-apiserverのポート`
# …その他のフラグは通常通り
APIサーバー間のプロキシトランスポートと認証 ソースkube-apiserverは、既存のAPIサーバークライアント認証フラグ --proxy-client-cert-fileと--proxy-client-key-fileを再利用して、ピア(宛先kube-apiserver)によって検証される自身のIDを提示します。
宛先APIサーバーは、--requestheader-client-ca-fileコマンドライン引数を使用して指定した設定に基づいてピア接続を検証します。
宛先サーバーのサービング証明書を認証するには、ソース APIサーバーに--peer-ca-fileコマンドライン引数を使用して認証局バンドルを設定する必要があります。
ピアAPIサーバー接続の設定 ピアがリクエストをプロキシするために使用するkube-apiserverのネットワークロケーションを設定するには、kube-apiserverに--peer-advertise-ipと--peer-advertise-portコマンドライン引数を使用するか、APIサーバー設定ファイルでこれらのフィールドを指定します。
これらのフラグが指定されていない場合、ピアはkube-apiserverの--advertise-addressまたは--bind-addressコマンドライン引数の値を使用します。
それらも設定されていない場合、ホストのデフォルトインターフェースが使用されます。
ピア集約ディスカバリ この機能を有効にすると、ディスカバリリクエストはデフォルトで包括的なディスカバリドキュメント(クラスター内のすべてのapiserverによって提供されるすべてのリソースをリストする)を提供するように自動的に有効になります。
ピア集約されていないディスカバリドキュメントをリクエストしたい場合は、ディスカバリリクエストに次のAcceptヘッダーを追加することでそれを示すことができます:
application/json;g=apidiscovery.k8s.io;v=v2;as=APIGroupDiscoveryList;profile=nopeer
Mixed version proxying Mixed version proxyingを有効にすると、アグリゲーションレイヤー は次の処理を行う特別なフィルターをロードします:
APIサーバーがそのAPIを提供できない場合(APIが導入される前のバージョンであるか、そのAPIサーバーでAPIが無効になっているため)、リソースリクエストがAPIサーバーに到達すると、そのAPIサーバーはリクエストされたAPIを提供できるピアAPIサーバーにリクエストを送信しようとします。
これは、ローカルサーバーが認識しないAPIグループ/バージョン/リソースを識別し、リクエストを処理できるピアAPIサーバーにそれらのリクエストをプロキシしようとすることで実現されます。 ピアAPIサーバーが応答に失敗した場合、ソース APIサーバーは503(「Service Unavailable」)エラーで応答します。 内部での動作 APIサーバーがリソースリクエストを受信すると、最初にどのAPIサーバーがリクエストされたリソースを提供できるかを確認します。
この確認は、ピア集約されていないディスカバリドキュメントを使用して行われます。
リクエストを受信したAPIサーバーから取得したピア集約されていないディスカバリドキュメントにリソースがリストされている場合(例えば、GET /api/v1/pods/some-pod)、リクエストはローカルで処理されます。
リクエスト内のリソース(例えば、GET /apis/resource.k8s.io/v1beta1/resourceclaims)が、リクエストを処理しようとしているAPIサーバー(処理APIサーバー )から取得したピア集約されていないディスカバリドキュメントに見つからない場合、おそらくresource.k8s.io/v1beta1 APIがより新しいKubernetesバージョンで導入され、処理APIサーバー がそれをサポートしていない古いバージョンを実行しているためです。
その場合、処理APIサーバー はすべてのピアAPIサーバーからピア集約されていないディスカバリドキュメントを確認して、関連するAPIグループ/バージョン/リソース(この場合はresource.k8s.io/v1beta1/resourceclaims)を提供するピアAPIサーバーを取得します。
処理APIサーバー は、リクエストされたリソースを認識している一致するピアkube-apiserverの1つにリクエストをプロキシします。
そのAPIグループ/バージョン/リソースを認識しているピアがいない場合、処理APIサーバーは自身のハンドラーチェーンにリクエストを渡し、最終的に404(「Not Found」)レスポンスを返すはずです。
処理APIサーバーがピアAPIサーバーを識別して選択したが、そのピアが応答に失敗した場合(ネットワーク接続の問題、またはリクエストの受信とコントローラーがピアの情報をコントロールプレーンに登録する間のデータ競合などの理由)、処理APIサーバーは503(「Service Unavailable」)エラーで応答します。
3.3 - コンテナ アプリケーションとランタイムの依存関係を一緒にパッケージ化するための技術
実行するそれぞれのコンテナは繰り返し使用可能です。依存関係を含めて標準化されており、どこで実行しても同じ動作が得られることを意味しています。
コンテナは基盤となるホストインフラからアプリケーションを切り離します。これにより、さまざまなクラウドやOS環境下でのデプロイが容易になります。
コンテナイメージ コンテナイメージ はすぐに実行可能なソフトウェアパッケージで、アプリケーションの実行に必要なものをすべて含んています。コードと必要なランタイム、アプリケーションとシステムのライブラリ、そして必須な設定項目のデフォルト値を含みます。
設計上、コンテナは不変で、既に実行中のコンテナのコードを変更することはできません。コンテナ化されたアプリケーションがあり変更したい場合は、変更を含んだ新しいイメージをビルドし、コンテナを再作成して、更新されたイメージから起動する必要があります。
コンテナランタイム コンテナランタイムは、コンテナの実行を担当するソフトウェアです。
Kubernetesは次の複数のコンテナランタイムをサポートします。
Docker 、containerd 、CRI-O 、
および全ての
Kubernetes CRI (Container Runtime Interface)
実装です。
次の項目 3.3.1 - イメージ コンテナイメージは、アプリケーションおよびそのすべてのソフトウェア依存関係をカプセル化したバイナリデータを表します。
コンテナイメージは、スタンドアロンで実行可能なソフトウェアバンドルで、動作するためのランタイム環境が明確に規定されているのが特徴です。
通常、アプリケーションのコンテナイメージを作成してレジストリに格納し、その後、Pod から参照します。
このページでは、コンテナイメージの概要について説明します。
備考: Kubernetesのリリース(たとえばv1.35のような最新のマイナーリリース)に対応するコンテナイメージを探している場合は、
Kubernetesのダウンロード を参照してください。
イメージ名 コンテナイメージは通常、pause、example/mycontainer、またはkube-apiserverのような名前がつけられます。
イメージには、レジストリのホスト名を含めることもできます。たとえば、fictional.registry.example/imagenameのようになります。また、同じようにポート番号を含めることもでき、その場合はfictional.registry.example:10443/imagenameのようになります。
レジストリのホスト名を指定しない場合、KubernetesはDockerパブリックレジストリ を意味しているものと見なします。
この挙動は、コンテナランタイム の設定でデフォルトのイメージレジストリを指定することで変更できます。
イメージ名の後には、タグ や ダイジェスト を追加できます(これはdockerやpodmanなどのコマンドを使う場合と同様です)。
タグは、同じ系列のイメージの異なるバージョンを識別するために使用します。
ダイジェストは、イメージの特定のバージョンに対する一意の識別子です。
また、ダイジェストはイメージの内容に基づくハッシュで構成され、変更不可能です。
タグは異なるイメージを指すように移動が可能ですが、ダイジェストは固定です。
イメージタグには、小文字および大文字のアルファベット、数字、アンダースコア(_)、ピリオド(.)、ハイフン(-)を使用できます。
タグの長さは最大128文字で、次の正規表現パターンに従う必要があります: [a-zA-Z0-9_][a-zA-Z0-9._-]{0,127}。
この仕様の詳細や検証用の正規表現については、OCI Distribution Specification を参照してください。
タグを指定しない場合、Kubernetesはlatestタグを指定したものと見なします。
イメージダイジェストは、ハッシュアルゴリズム(sha256など)とハッシュ値で構成されます。
たとえば、sha256:1ff6c18fbef2045af6b9c16bf034cc421a29027b800e4f9b68ae9b1cb3e9ae07のようになります。
ダイジェスト形式の詳細について詳しく知りたい場合は、OCI Image Specification を参照してください。
Kubernetesで使用可能なイメージ名の例は次のとおりです:
busybox — イメージ名のみで、タグやダイジェストは指定されていません。KubernetesはDockerパブリックレジストリとlatestタグを使用します。docker.io/library/busybox:latestと同等です。busybox:1.32.0 — タグ付きのイメージ名。KubernetesはDockerパブリックレジストリを使用します。docker.io/library/busybox:1.32.0と同等です。registry.k8s.io/pause:latest — カスタムレジストリとlatestタグを指定したイメージ名。registry.k8s.io/pause:3.5 — カスタムレジストリと非latestタグを指定したイメージ名。registry.k8s.io/pause@sha256:1ff6c18fbef2045af6b9c16bf034cc421a29027b800e4f9b68ae9b1cb3e9ae07 — ダイジェストを含むイメージ名。registry.k8s.io/pause:3.5@sha256:1ff6c18fbef2045af6b9c16bf034cc421a29027b800e4f9b68ae9b1cb3e9ae07 — タグとダイジェストの両方を含むイメージ名。取得時にはダイジェストのみが使用されます。イメージの更新 PodTemplateを含むDeployment 、StatefulSet 、Pod、またはその他のオブジェクトを初めて作成する際に、プルポリシーが明示的に指定されていない場合、デフォルトでそのPod内のすべてのコンテナのプルポリシーはIfNotPresentに設定されます。
このポリシーでは、対象のイメージがすでに存在する場合、kubelet はそのイメージの取得をスキップします。
イメージプルポリシー コンテナのimagePullPolicyとイメージのタグの両方が、kubelet が指定されたイメージの取得(ダウンロード)を試みる タイミング に影響します。
以下は、imagePullPolicyに設定できる値とその効果の一覧です。
IfNotPresentイメージがローカルにまだ存在しない場合にのみ取得されます。 Alwayskubeletがコンテナを起動するたびに、コンテナイメージレジストリに問い合わせ、イメージ名をイメージダイジェスト に解決します。
kubeletがそのダイジェストに完全一致するイメージをローカルにキャッシュしている場合は、そのキャッシュされたイメージを使用します。存在しない場合は、kubeletは解決されたダイジェストのイメージを取得し、そのイメージを使ってコンテナを起動します。 Neverkubeletは、イメージを取得しようとしません。何らかの理由でローカルにイメージがすでに存在する場合、kubeletはコンテナを起動しようとします。それ以外の場合、起動に失敗します。
詳細は、事前に取得されたイメージ を参照してください。 レジストリに確実にアクセスできるのであれば、基盤となるイメージプロバイダーのキャッシュセマンティクスによりimagePullPolicy: Alwaysでも効率的です。
コンテナランタイムは、イメージレイヤーがすでにノード上に存在することを認識できるため、再度ダウンロードする必要がありません。
備考: 本番環境でコンテナをデプロイする場合は、:latestタグの使用を避けるべきです。
実行中のイメージのバージョンを追跡するのが難しく、正しくロールバックすることがより困難になるためです。
代わりに、v1.42.0のような意味のあるタグやダイジェストを指定してください。
Podが常に同じバージョンのコンテナイメージを使用するようにするためには、イメージのダイジェストを指定します。<image-name>:<tag>を<image-name>@<digest>に置き換えてください(たとえば、image@sha256:45b23dee08af5e43a7fea6c4cf9c25ccf269ee113168c19722f87876677c5cb2)。
イメージタグを使用している場合、レジストリ側でそのタグが指すコードが変更されると、古いコードと新しいコードを実行するPodが混在する可能性があります。
イメージダイジェストは特定のバージョンのイメージを一意に識別するため、Kubernetesは特定のイメージ名とダイジェストが指定されたコンテナを起動するたびに同じコードを実行します。
イメージをダイジェストで指定することで、実行するコードのバージョンが固定され、レジストリ側の変更によってバージョンが混在する事態を防ぐことができます。
サードパーティ製のアドミッションコントローラー の中には、Pod(およびPodTemplate)の作成時にそれらを変更し、実行されるワークロードがタグではなくイメージのダイジェストに基づいて定義されるようにするものがあります。
レジストリでどのようなタグの変更があっても、すべてのワークロードが必ず同じコードを実行するようにしたい場合に有用かもしれません。
デフォルトのイメージプルポリシー あなた(またはコントローラー)が新しいPodをAPIサーバーに送信すると、特定の条件が満たされた場合に、クラスターはimagePullPolicyフィールドを設定します。
imagePullPolicyフィールドを省略し、かつコンテナイメージにダイジェストを指定した場合、imagePullPolicyには自動的にIfNotPresentに設定される。imagePullPolicyフィールドを省略し、コンテナイメージのタグに:latestを指定した場合、imagePullPolicyには自動的にAlwaysが設定される。imagePullPolicyフィールドを省略し、コンテナイメージのタグを指定しなかった場合、imagePullPolicyには自動的にAlwaysが設定される。imagePullPolicyフィールドを省略し、コンテナイメージのタグに:latest以外を指定した場合、imagePullPolicyには自動的にIfNotPresentが設定される。備考: コンテナのimagePullPolicyの値は、そのオブジェクトが最初に 作成 されたときに常に設定され、その後イメージのタグやダイジェストが変更されても更新されません。
たとえば、タグが:latest でない イメージを使ってDeploymentを作成した場合、後でDeploymentのイメージを:latestタグに変更しても、imagePullPolicyはAlwaysに更新 されません 。初回作成後にプルポリシーを変更したい場合は、手動で更新しなければいけません。
イメージ取得を強制する 常に強制的に取得したい場合は、以下のいずれかを実行できます:
コンテナのimagePullPolicyにAlwaysを設定する。 imagePullPolicyを省略し、使用するイメージのタグに:latestを指定する(KubernetesはPodを送信する際にポリシーをAlwaysに設定します)。imagePullPolicyと使用するイメージのタグを省略する(KubernetesはPodを送信する際にポリシーをAlwaysに設定します)。AlwaysPullImages アドミッションコントローラーを有効にする。ImagePullBackOff kubeletがコンテナランタイムを使ってPodのコンテナの作成を開始するとき、ImagePullBackOffのためにコンテナがWaiting 状態になる可能性があります。
ImagePullBackOff状態は、Kubernetesがコンテナイメージを取得できず、コンテナを開始できないことを意味します(イメージ名が無効である、imagePullSecret無しでプライベートレジストリから取得したなどの理由のため)。BackOffは、バックオフの遅延を増加させながらKubernetesがイメージを取得しようとし続けることを示します。
Kubernetesは、組み込まれた制限である300秒(5分)に達するまで、試行するごとに遅延を増加させます。
ランタイムクラスごとのイメージ取得
FEATURE STATE:
Kubernetes v1.29 [alpha](disabled by default)
Kubernetesには、PodのRuntimeClassに基づいてイメージを取得するアルファ機能のサポートが含まれています。
RuntimeClassInImageCriApiフィーチャーゲート を有効にすると、kubeletは単にイメージ名やダイジェストではなく、イメージ名とランタイムハンドラーのタプルでコンテナイメージを参照するようになります。
コンテナランタイム は、選択されたランタイムハンドラーに基づいて動作を変更する可能性があります。
ランタイムクラスに応じたイメージ取得を行う機能は、Windows Hyper-VコンテナのようなVMベースのコンテナにおいて有用です。
直列・並列イメージ取得 デフォルトでは、kubeletはイメージを直列に取得します。
言い換えれば、kubeletはイメージサービスに対して一度に1つのイメージ取得の要求しか送信しません。
他のイメージ取得の要求は、処理中の要求が完了するまで待機する必要があります。
ノードは、イメージの取得を他のノードと独立して判断します。そのため、イメージ取得を直列で実行していても、異なるノード上では同じイメージを並列で取得することが可能です。
並列イメージ取得を有効にしたい場合は、kubeletの設定 でserializeImagePullsフィールドをfalseに設定します。
serializeImagePullsをfalseにすると、イメージ取得の要求は即座にイメージサービスへ送信され、複数のイメージが同時に取得されるようになります。
並列イメージ取得を有効にする場合は、使用しているコンテナランタイムのイメージサービスが並列取得に対応していることを確認してください。
なお、kubeletは1つのPodに対して複数のイメージを並列で取得することはありません。
たとえば、1つのPodがinitコンテナとアプリケーションコンテナを持つ場合、その2つのコンテナのイメージ取得は並列化されません。
しかし、異なるPodがそれぞれ異なるイメージを使用しており、並列イメージ取得機能が有効になっている場合、kubeletはその2つの異なるPodのためにイメージを並列で取得します。
最大並列イメージ取得数 FEATURE STATE:
Kubernetes v1.32 [beta]
serializeImagePullsがfalseに設定されている場合、kubeletはデフォルトで同時に取得できるイメージ数に制限を設けません。
並列で取得できるイメージ数を制限したい場合は、kubeletの設定でmaxParallelImagePullsフィールドを指定します。
maxParallelImagePullsに n を設定すると、同時に取得できるイメージは最大で n 件となり、n 件を超えるイメージ取得は、少なくとも1件のイメージ取得が完了するまで待機する必要があります。
並列イメージ取得を有効にしている場合、同時取得数を制限することで、イメージの取得によるネットワーク帯域やディスクI/Oの過剰な消費を防ぐことができます。
maxParallelImagePullsには1以上の正の整数を指定できます。
maxParallelImagePullsを2以上に設定する場合は、serializeImagePullsをfalseに設定する必要があります。
無効なmaxParallelImagePullsの設定を行うと、kubeletは起動に失敗します。
イメージインデックスを用いたマルチアーキテクチャイメージ コンテナレジストリはバイナリイメージの提供だけでなく、コンテナイメージインデックス も提供可能です。
イメージインデックスはコンテナのアーキテクチャ固有バージョンに関する複数のイメージマニフェスト を指すことができます。
イメージには(たとえばpause、example/mycontainer、kube-apiserverなどの)名前を付け、各システムが自身のマシンアーキテクチャに適したバイナリイメージを取得できるようにする、という考え方です。
Kubernetesプロジェクトでは、通常、リリースごとに-$(ARCH)というサフィックスを含む名前でコンテナイメージを作成します。
後方互換性のために、従来の形式のサフィックス付きイメージも生成されます。
たとえば、pauseという名前のイメージは、サポートされているすべてのアーキテクチャ向けのマニフェストを含むマルチアーキテクチャ対応のイメージですが、pause-amd64は旧来の構成や、サフィックス付きのイメージ名をハードコードしているYAMLファイルとの互換性のために用意されたイメージです。
プライベートレジストリの使用 プライベートレジストリでは、イメージの検索や取得を行うために認証が必要となる場合があります。
認証情報は、以下のいくつかの方法で提供できます:
これらのオプションについて、以下で詳しく説明します。
PodでimagePullSecretsを指定する
備考: この方法がプライベートレジストリのイメージに基づいてコンテナを実行するための推奨の方法です。Kubernetesは、Podに対してコンテナイメージレジストリ用のキーを指定できます。
すべてのimagePullSecretsは、そのPodと同じNamespace 内に存在するSecretでなければなりません。
これらのSecretは、型がkubernetes.io/dockercfgまたはkubernetes.io/dockerconfigjsonである必要があります。
ノードを構成してプライベートレジストリに対して認証を行う 認証情報の具体的な設定手順は、使用するコンテナランタイムやレジストリによって異なります。
最も正確な情報については、使用しているソリューションのドキュメントを参照してください。
プライベートコンテナイメージレジストリの構成例については、イメージをプライベートレジストリから取得する を参照してください。
この例では、Docker Hubのプライベートレジストリを使用しています。
kubelet credential providerによる認証付きイメージ取得 kubeletを構成して、プラグインバイナリを呼び出し、コンテナイメージのレジストリ認証情報を動的に取得させることができます。
これは、プライベートレジストリ用の認証情報を取得するための最も堅牢かつ柔軟な方法ですが、有効化するにはkubeletレベルでの設定が必要です。
この手法は、プライベートレジストリにホストされたコンテナイメージを必要とするStatic Pod を実行する際に特に有用です。
サービスアカウント やSecret を使ってプライベートレジストリの認証情報を提供することは、Static Podの仕様では不可能です。
Static Podは、その仕様として他のAPIリソースへの参照を含めることが できない ためです。
詳細については、kubelet image credential providerを設定する を参照してください。
config.jsonの解釈 config.jsonの解釈は、元のDockerの実装とKubernetesにおける解釈で異なります。
Dockerでは、authsキーにはルートURLしか指定できませんが、Kubernetesではワイルドカード形式のURLや、プレフィックスが一致するパスも許容されます。
唯一の制約は、ワイルドカード(*)を使用する場合、各サブドメインに対して.を含める必要があるという点です。
一致するサブドメインの数は、指定されたワイルドカードパターンの数(*.)と一致している必要があります。
例:
*.kubernetes.ioは、kubernetes.ioには一致 しません が、abc.kubernetes.ioには一致します。*.*.kubernetes.ioは、abc.kubernetes.ioには一致 しません が、abc.def.kubernetes.ioには一致します。prefix.*.ioは、prefix.kubernetes.ioに一致します。*-good.kubernetes.ioは、prefix-good.kubernetes.ioに一致します。つまり、次のようなconfig.jsonは有効です:
{
"auths" : {
"my-registry.example/images" : { "auth" : "…" },
"*.my-registry.example/images" : { "auth" : "…" }
}
}
イメージ取得操作では、すべての有効なパターンに対して、認証情報がCRIコンテナランタイムに渡されます。
たとえば、次のようなコンテナイメージ名は正常にマッチします。
my-registry.example/imagesmy-registry.example/images/my-imagemy-registry.example/images/another-imagesub.my-registry.example/images/my-imageしかし、次のようなコンテナイメージ名はマッチ しません 。
a.sub.my-registry.example/images/my-imagea.b.sub.my-registry.example/images/my-imagekubeletは、見つかった各認証情報に対してイメージ取得を順番に実行します。
つまり、config.json内に異なるパスに対する複数のエントリを含めることも可能です。
{
"auths" : {
"my-registry.example/images" : {
"auth" : "…"
},
"my-registry.example/images/subpath" : {
"auth" : "…"
}
}
}
このとき、コンテナがmy-registry.example/images/subpath/my-imageというイメージを取得するよう指定している場合、kubeletは、いずれかの認証元で失敗した場合でも、両方の認証情報を使ってイメージのダウンロードを試みます。
事前に取得されたイメージ
備考: この方法は、ノードの構成を自分で制御できる場合に適しています。
クラウドプロバイダーがノードを管理し、自動的に置き換えるような環境では、信頼性のある動作は期待できません。デフォルトでは、kubeletは指定されたレジストリからそれぞれのイメージを取得しようとします。
ただし、コンテナのimagePullPolicyプロパティがIfNotPresentまたはNeverに設定されている場合は、ローカルのイメージが(それぞれ優先的に、あるいは専用で)使用されます。
レジストリ認証の代替として事前に取得されたイメージを利用したい場合、クラスターのすべてのノードが同じ事前に取得されたイメージを持っていることを確認する必要があります。
これは、特定のイメージをあらかじめロードしておくことで高速化したり、プライベートレジストリへの認証の代替手段として利用したりすることができます。
kubelet credential provider の利用と同様に、事前に取得されたイメージは、プライベートレジストリにホストされたイメージに依存するStatic Pod を起動する場合にも適しています。
備考: FEATURE STATE:
Kubernetes v1.35 [beta](enabled by default)
事前に取得されたイメージへのアクセスは、イメージ取得の認証情報の検証 に基づいて許可される場合があります。
イメージ取得の認証情報の検証を保証する FEATURE STATE:
Kubernetes v1.35 [beta](enabled by default)
クラスターでKubeletEnsureSecretPulledImagesフィーチャーゲートが有効になっている場合、Kubernetesは、取得に認証が必要なすべてのイメージに対して、たとえそのイメージがノード上にすでに存在していても、認証情報を検証します。
この検証により、Podが要求するイメージのうち、指定された認証情報で正常に取得されなかったものは、レジストリから再度取得する必要があることが保証されます。
さらに、以前に成功したイメージ取得と同じ認証情報を使用する場合には、再取得は不要で、レジストリにアクセスせずローカルで検証が行われます(該当のイメージがローカルに存在する場合)。
この動作は、kubeletの設定 におけるimagePullCredentialsVerificationPolicyフィールドによって制御されます。
この設定は、イメージがすでにノード上に存在する場合に、イメージ取得の認証情報を検証する必要があるかどうかの挙動を制御します:
NeverVerify: このフィーチャーゲートが無効な場合と同じ動作を模倣します。イメージがローカルに存在する場合、イメージ取得の認証情報は検証されません。NeverVerifyPreloadedImages: kubeletの外部で取得されたイメージは検証されませんが、それ以外のすべてのイメージについては認証情報が検証されます。これがデフォルトの動作です。NeverVerifyAllowListedImages: kubeletの外部で取得されたイメージと、kubelet設定内で指定されたpreloadedImagesVerificationAllowlistに記載されたイメージは検証されません。AlwaysVerify: すべてのイメージは、使用前に認証情報の検証が行われます。この検証は、事前に取得されたイメージ 、ノード全体のSecretを使用して取得されたイメージ、PodレベルのSecretを使用して取得されたイメージに適用されます。
備考: 認証情報がローテーションされた場合でも、以前にイメージの取得に使用された認証情報は、レジストリへアクセスすることなく検証に成功し続けます。
一方、新しい認証情報やローテーション後の認証情報を使用する場合には、イメージを再度レジストリから取得する必要があります。Docker設定を用いたSecretの作成 レジストリに対して認証を行うには、ユーザー名、レジストリのパスワード、クライアントのメールアドレス、およびレジストリのホスト名を把握しておく必要があります。
プレースホルダーを適切な値に置換したうえで、以下のコマンドを実行してください。
kubectl create secret docker-registry <name> \
= <docker-registry-server> \
= <docker-user> \
= <docker-password> \
= <docker-email>
すでにDockerの認証情報ファイルを持っている場合は、上記のコマンドを使用する代わりに、その認証情報ファイルをKubernetesのSecret としてインポートすることができます。
既存のDocker認証情報に基づいてSecretを作成する に、その設定方法が説明されています。
これは、複数のプライベートコンテナレジストリを使用している場合に特に有用です。
kubectl create secret docker-registryで作成されるSecretは、単一のプライベートレジストリにしか対応していないためです。
備考: Podは自身のNamespace内にあるイメージプルシークレットしか参照できないため、この手順はNamespaceごとに1回ずつ実行する必要があります。PodでimagePullSecretsを参照する 次に、Pod定義にimagePullSecretsセクションを追加することで、そのSecretを参照するPodを作成できます。
imagePullSecrets配列の各要素は、同じNamespace内の1つのSecretのみを参照できます。
たとえば、以下のように記述します:
cat <<EOF > pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: foo
namespace: awesomeapps
spec:
containers:
- name: foo
image: janedoe/awesomeapp:v1
imagePullSecrets:
- name: myregistrykey
EOF
cat <<EOF >> ./kustomization.yaml
resources:
- pod.yaml
EOF
この作業は、プライベートレジストリを使用する各Podに対して実施する必要があります。
ただし、ServiceAccount リソースの中でimagePullSecretsセクションを指定することで、この手順を自動化することが可能です。
詳細な手順については、ServiceAccountにImagePullSecretsを追加する を参照してください。
また、各ノードにある.docker/config.jsonと併用することもできます。
これらの認証情報はマージされて使用されます。
ユースケース プライベートレジストリを構成するにはいくつかの手段があります。
ここでは、いくつかの一般的なユースケースと推奨される解決方法を示します。
非専有(たとえば、オープンソースの)イメージだけを実行し、イメージを非公開にする必要がないクラスターの場合
パブリックレジストリのパブリックイメージを利用する。設定は必要ない。 一部のクラウドプロバイダーは、パブリックイメージを自動的にキャッシュまたはミラーリングすることで、可用性を向上させ、イメージの取得にかかる時間を短縮する。 社外には非公開にすべきだが、クラスターユーザー全員には見える必要がある専有イメージを実行しているクラスターの場合
ホスティング型のプライペートレジストリを使用する。プライベートレジストリにアクセスする必要があるノードには、手動設定が必要となる場合がある。 または、ファイアウォールの内側で内部向けのプライベートレジストリを実行し、読み取りアクセスを開放して運用する。 イメージへのアクセスを制御できるホスティング型のコンテナイメージレジストリサービスを利用する。ノードを手動で構成する場合よりも、ノードのオートスケーリングと組み合わせた方がうまく機能する。 あるいは、ノードの構成を変更するのが困難なクラスターでは、imagePullSecretsを使用する。 一部に、より厳格なアクセス制御を必要とする専有イメージを含むクラスターの場合
それぞれのテナントが独自のプライベートレジストリを必要とするマルチテナントのクラスターである場合
AlwaysPullImagesアドミッションコントローラー が有効化されていることを確認する。これが無効な場合、すべてのPodがすべてのイメージにアクセスできてしまう可能性がある。認証が必要なプライベートレジストリを運用する。 テナントごとにレジストリの認証情報を生成し、それをSecretに保存して、各テナントのNamespaceへ配布する。 テナントは、そのSecretを各NamespaceのimagePullSecretsに追加する。 複数のレジストリへのアクセスが必要な場合、レジストリごとに1つのSecretを作成することができます。
レガシーな組み込みkubelet credential provider 古いバージョンのKubernetesでは、kubeletがクラウドプロバイダーの認証情報と直接統合されていました。
これにより、イメージレジストリの認証情報を動的に取得することが可能でした。
このkubelet credential provider統合には、以下の3つの組み込み実装がありました: ACR(Azure Container Registry)、ECR(Elastic Container Registry)、GCR(Google Container Registry)です。
Kubernetesバージョン1.26以降では、このレガシーな仕組みは削除されたため、以下のいずれかの対応が必要です:
各ノードにkubelet image credential providerを構成する imagePullSecretsと少なくとも1つのSecretを使用して、イメージ取得の認証情報を指定する次の項目 3.3.2 - コンテナ環境 このページでは、コンテナ環境で利用可能なリソースについて説明します。
コンテナ環境 Kubernetesはコンテナにいくつかの重要なリソースを提供します。
イメージと1つ以上のボリュームの組み合わせのファイルシステム コンテナ自体に関する情報 クラスター内の他のオブジェクトに関する情報 コンテナ情報 コンテナの ホスト名 は、コンテナが実行されているPodの名前です。
ホスト名はhostnameコマンドまたはlibcのgethostname
Podの名前と名前空間はdownward API を通じて環境変数として利用可能です。
Pod定義からのユーザー定義の環境変数もコンテナで利用できます。
コンテナイメージで静的に指定されている環境変数も同様です。
クラスター情報 コンテナの作成時に実行されていたすべてのサービスのリストは、環境変数として使用できます。
このリストは、新しいコンテナのPodおよびKubernetesコントロールプレーンサービスと同じ名前空間のサービスに制限されます。
bar という名前のコンテナに対応する foo という名前のサービスの場合、以下の変数が定義されています。
FOO_SERVICE_HOST = <サービスが実行されているホスト>
FOO_SERVICE_PORT = <サービスが実行されているポート>
サービスは専用のIPアドレスを持ち、DNSアドオン が有効の場合、DNSを介してコンテナで利用可能です。
次の項目 3.3.3 - ランタイムクラス(Runtime Class) FEATURE STATE:
Kubernetes v1.20 [stable]
このページではRuntimeClassリソースと、runtimeセクションのメカニズムについて説明します。
RuntimeClassはコンテナランタイムの設定を選択するための機能です。そのコンテナランタイム設定はPodのコンテナを稼働させるために使われます。
RuntimeClassを使う動機 異なるPodに異なるRuntimeClassを設定することで、パフォーマンスとセキュリティのバランスをとることができます。例えば、ワークロードの一部に高レベルの情報セキュリティ保証が必要な場合、ハードウェア仮想化を使用するコンテナランタイムで実行されるようにそれらのPodをスケジュールすることを選択できます。その後、追加のオーバーヘッドを犠牲にして、代替ランタイムをさらに分離することでメリットが得られます。
RuntimeClassを使用して、コンテナランタイムは同じで設定が異なるPodを実行することもできます。
セットアップ ノード上でCRI実装を設定する。(ランタイムに依存) 対応するRuntimeClassリソースを作成する。 1. ノード上でCRI実装を設定する RuntimeClassを通じて利用可能な設定はContainer Runtime Interface (CRI)の実装依存となります。
ユーザーの環境のCRI実装の設定方法は、対応するドキュメント(下記 )を参照ください。
備考: RuntimeClassは、クラスター全体で同じ種類のノード設定であることを仮定しています。(これは全てのノードがコンテナランタイムに関して同じ方法で構成されていることを意味します)。
設定が異なるノードをサポートするには、
スケジューリング を参照してください。
RuntimeClassの設定は、RuntimeClassによって参照されるハンドラー名を持ちます。そのハンドラーは有効なDNSラベル名 でなくてはなりません。
2. 対応するRuntimeClassリソースを作成する ステップ1にて設定する各項目は、関連するハンドラー 名を持ちます。それはどの設定かを指定するものです。各ハンドラーにおいて、対応するRuntimeClassオブジェクトが作成されます。
そのRuntimeClassリソースは現時点で2つの重要なフィールドを持ちます。それはRuntimeClassの名前(metadata.name)とハンドラー(handler)です。そのオブジェクトの定義は下記のようになります。
# RuntimeClassはnode.k8s.ioというAPIグループで定義されます。
apiVersion : node.k8s.io/v1
kind : RuntimeClass
metadata :
# RuntimeClass名
# RuntimeClassはネームスペースなしのリソースです。
name : myclass
# 対応するCRI設定
handler : myconfiguration
RuntimeClassオブジェクトの名前はDNSサブドメイン名 に従う必要があります。
備考: RuntimeClassの書き込み操作(create/update/patch/delete)はクラスター管理者のみに制限されることを推奨します。
これはたいていデフォルトで有効となっています。さらなる詳細に関しては
Authorization
Overview を参照してください。
使用例 RuntimeClassがクラスターに対して設定されると、PodSpecでruntimeClassNameを指定して使用できます。
例えば
apiVersion : v1
kind : Pod
metadata :
name : mypod
spec :
runtimeClassName : myclass
# ...
これは、kubeletに対してPodを稼働させるためのRuntimeClassを使うように指示します。もし設定されたRuntimeClassが存在しない場合や、CRIが対応するハンドラーを実行できない場合、そのPodはFailedというフェーズ になります。
エラーメッセージに関しては対応するイベント を参照して下さい。
もしruntimeClassNameが指定されていない場合、デフォルトのRuntimeHandlerが使用され、これはRuntimeClassの機能が無効であるときのふるまいと同じものとなります。
CRIの設定 CRIランタイムのセットアップに関するさらなる詳細は、コンテナランタイム を参照してください。
ランタイムハンドラーは、/etc/containerd/config.tomlにあるcontainerdの設定ファイルにより設定されます。
正しいハンドラーは、そのruntimeセクションで設定されます。
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.${HANDLER_NAME}]
詳細はcontainerdの設定に関するドキュメント を参照してください。
ランタイムハンドラーは、/etc/crio/crio.confにあるCRI-Oの設定ファイルにより設定されます。
正しいハンドラーはcrio.runtime
table で設定されます。
[crio.runtime.runtimes.${HANDLER_NAME}]
runtime_path = "${PATH_TO_BINARY}"
詳細はCRI-Oの設定に関するドキュメント を参照してください。
スケジューリング FEATURE STATE:
Kubernetes v1.16 [beta]
RuntimeClassのschedulingフィールドを指定することで、設定されたRuntimeClassをサポートするノードにPodがスケジューリングされるように制限することができます。
schedulingが設定されていない場合、このRuntimeClassはすべてのノードでサポートされていると仮定されます。
特定のRuntimeClassをサポートしているノードへPodが配置されることを保証するために、各ノードはruntimeclass.scheduling.nodeSelectorフィールドによって選択される共通のラベルを持つべきです。
RuntimeClassのnodeSelectorはアドミッション機能によりPodのnodeSelectorに統合され、効率よくノードを選択します。
もし設定が衝突した場合は、Pod作成は拒否されるでしょう。
もしサポートされているノードが他のRuntimeClassのPodが稼働しないようにtaint付与されていた場合、RuntimeClassに対してtolerationsを付与することができます。
nodeSelectorと同様に、tolerationsはPodのtolerationsにアドミッション機能によって統合され、効率よく許容されたノードを選択します。
ノードの選択とtolerationsについての詳細はノード上へのPodのスケジューリング を参照してください。
Podオーバーヘッド FEATURE STATE:
Kubernetes v1.24 [stable]
Podが稼働する時に関連する オーバーヘッド リソースを指定できます。オーバーヘッドを宣言すると、クラスター(スケジューラーを含む)がPodとリソースに関する決定を行うときにオーバーヘッドを考慮することができます。
PodのオーバーヘッドはRuntimeClass内のoverheadフィールドによって定義されます。
このフィールドを使用することで、RuntimeClassを使用して稼働するPodのオーバーヘッドを指定することができ、Kubernetes内部で使用されるオーバーヘッドを確保することができます。
次の項目 3.3.4 - コンテナライフサイクルフック このページでは、kubeletにより管理されるコンテナがコンテナライフサイクルフックフレームワークを使用して、管理ライフサイクル中にイベントによって引き起こされたコードを実行する方法について説明します。
概要 Angularなどのコンポーネントライフサイクルフックを持つ多くのプログラミング言語フレームワークと同様に、Kubernetesはコンテナにライフサイクルフックを提供します。
フックにより、コンテナは管理ライフサイクル内のイベントを認識し、対応するライフサイクルフックが実行されたときにハンドラーに実装されたコードを実行できます。
コンテナフック コンテナに公開されている2つのフックがあります。
PostStart
このフックはコンテナが作成された直後に実行されます。
しかし、フックがコンテナのENTRYPOINTの前に実行されるという保証はありません。
ハンドラーにパラメーターは渡されません。
PreStop
このフックは、APIからの要求、またはliveness/startup probeの失敗、プリエンプション、リソース競合などの管理イベントが原因でコンテナが終了する直前に呼び出されます。コンテナがすでに終了状態または完了状態にある場合にはPreStopフックの呼び出しは失敗し、コンテナを停止するTERMシグナルが送信される前にフックは完了する必要があります。PreStopフックが実行される前にPodの終了猶予期間のカウントダウンが開始されるので、ハンドラーの結果に関わらず、コンテナはPodの終了猶予期間内に最終的に終了します。
ハンドラーにパラメーターは渡されません。
終了動作の詳細な説明は、Termination of Pods にあります。
フックハンドラーの実装 コンテナは、フックのハンドラーを実装して登録することでそのフックにアクセスできます。
コンテナに実装できるフックハンドラーは3種類あります。
Exec - コンテナのcgroupsと名前空間の中で、 pre-stop.shのような特定のコマンドを実行します。
コマンドによって消費されたリソースはコンテナに対してカウントされます。 HTTP - コンテナ上の特定のエンドポイントに対してHTTP要求を実行します。 Sleep - 指定された期間コンテナを一時停止します。これは、PodLifecycleSleepActionフィーチャーゲート によりデフォルトで有効になっているベータ機能です。
備考: Sleepライフサイクルフックのスリープ時間を0秒(実質的なno-op)に設定したい場合は、PodLifecycleSleepActionAllowZeroフィーチャーゲートを有効にしてください。フックハンドラーの実行 コンテナライフサイクル管理フックが呼び出されると、Kubernetes管理システムはフックアクションにしたがってハンドラーを実行します。
httpGet、tcpSocket(非推奨です )、およびsleepはkubeletプロセスによって実行され、execはコンテナの中で実行されます。
フックハンドラーの呼び出しは、コンテナを含むPodのコンテキスト内で同期しています。
これは、PostStartフックの場合、コンテナのENTRYPOINTとフックは非同期に起動することを意味します。
しかし、フックの実行に時間がかかりすぎたりハングしたりすると、コンテナはrunning状態になることができません。
PreStopフックはコンテナを停止するシグナルから非同期で実行されるのではなく、TERMシグナルが送られる前に実行を完了する必要があります。
もしPreStopフックが実行中にハングした場合、PodはTerminating状態になり、
terminationGracePeriodSecondsの時間切れで強制終了されるまで続きます。
この猶予時間は、PreStopフックが実行され正常にコンテナを停止できるまでの合計時間に適用されます。
例えばterminationGracePeriodSecondsが60で、フックの終了に55秒かかり、シグナルを受信した後にコンテナを正常に停止させるのに10秒かかる場合、コンテナは正常に停止する前に終了されてしまいます。terminationGracePeriodSecondsが、これら2つの実行にかかる合計時間(55+10)よりも短いからです。
PostStartまたはPreStopフックが失敗した場合、コンテナは強制終了します。
ユーザーはフックハンドラーをできるだけ軽量にするべきです。
ただし、コンテナを停止する前に状態を保存するなどの場合は、長時間のコマンド実行が必要なケースもあります。
フック配信保証 フックの配信は 少なくとも1回 を意図しています。これはフックがPostStartやPreStopのような任意のイベントに対して複数回呼ばれることがあることを意味します。
これを正しく処理するのはフックの実装次第です。
通常、1回の配信のみが行われます。
たとえば、HTTPフックレシーバーがダウンしていてトラフィックを受け取れない場合、再送信は試みられません。
ただし、まれに二重配信が発生することがあります。
たとえば、フックの送信中にkubeletが再起動した場合、kubeletが起動した後にフックが再送信される可能性があります。
フックハンドラーのデバッグ フックハンドラーのログは、Podのイベントには表示されません。
ハンドラーが何らかの理由で失敗した場合は、イベントをブロードキャストします。
PostStartの場合、これはFailedPostStartHookイベントで、PreStopの場合、これはFailedPreStopHookイベントです。
失敗のFailedPreStopHookイベントを自分自身で生成する場合には、lifecycle-events.yaml ファイルに対してpostStartのコマンドを"badcommand"に変更し、適用してください。
kubectl describe pod lifecycle-demoを実行した結果のイベントの出力例を以下に示します。
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 7s default-scheduler Successfully assigned default/lifecycle-demo to ip-XXX-XXX-XX-XX.us-east-2...
Normal Pulled 6s kubelet Successfully pulled image "nginx" in 229.604315ms
Normal Pulling 4s (x2 over 6s) kubelet Pulling image "nginx"
Normal Created 4s (x2 over 5s) kubelet Created container lifecycle-demo-container
Normal Started 4s (x2 over 5s) kubelet Started container lifecycle-demo-container
Warning FailedPostStartHook 4s (x2 over 5s) kubelet Exec lifecycle hook ([badcommand]) for Container "lifecycle-demo-container" in Pod "lifecycle-demo_default(30229739-9651-4e5a-9a32-a8f1688862db)" failed - error: command 'badcommand' exited with 126: , message: "OCI runtime exec failed: exec failed: container_linux.go:380: starting container process caused: exec: \"badcommand\": executable file not found in $PATH: unknown\r\n"
Normal Killing 4s (x2 over 5s) kubelet FailedPostStartHook
Normal Pulled 4s kubelet Successfully pulled image "nginx" in 215.66395ms
Warning BackOff 2s (x2 over 3s) kubelet Back-off restarting failed container
次の項目 3.3.5 - コンテナランタイムインターフェース(CRI) CRIはプラグインインターフェースで、クラスターコンポーネントを再コンパイルすることなく、kubeletがさまざまなコンテナランタイムを使用できるようにします。
kubelet がPod とそのコンテナを起動できるように、クラスター内の各ノードで動作するコンテナランタイム が必要です。
コンテナランタイムインターフェース(CRI)は kubelet とコンテナランタイム間の通信のための主要なプロトコルです。
Kubernetesコンテナランタイムインターフェース(CRI)は、ノードコンポーネント であるkubelet とコンテナランタイム の間の通信のための主要なgRPC プロトコルを定義します。
API FEATURE STATE:
Kubernetes v1.23 [stable]
kubeletは、gRPCを用いてコンテナランタイムに接続するときにクライアントとして機能します。
ランタイムおよびイメージサービスエンドポイントは、コンテナランタイムで利用できる必要があります。
これらは、--container-runtime-endpointコマンドラインフラグ を使用してkubelet内で個別に設定できます。
Kubernetes v1.26以降では、kubeletはコンテナランタイムがv1 CRI APIをサポートしていることを要求します。
コンテナランタイムがv1 APIをサポートしていない場合、kubeletはノードを登録しません。
アップグレード ノード上でKubernetesのバージョンをアップグレードすると、kubeletが再起動します。
コンテナランタイムがv1 CRI APIをサポートしていない場合、kubeletは登録に失敗し、エラーを報告します。
コンテナランタイムのアップグレードによってgRPCの再接続が必要な場合、接続を成功させるには、ランタイムがv1 CRI APIをサポートしている必要があります。
これには、コンテナランタイムが正しく設定された後、kubeletの再起動が必要になる場合があります。
次の項目
3.4 - Windows in Kubernetes 3.4.1 - KubernetesのWindowsサポート概要 Windowsアプリケーションは、多くの組織で実行されているサービスやアプリケーションの大部分を占めています。Windowsコンテナ は、プロセスとパッケージの依存関係を一つにまとめる最新の方法を提供し、DevOpsプラクティスの使用とWindowsアプリケーションのクラウドネイティブパターンの追求を容易にします。Kubernetesは事実上、標準的なコンテナオーケストレータになりました。Kubernetes 1.14のリリースでは、Kubernetesクラスター内のWindowsノードでWindowsコンテナをスケジューリングする本番環境サポートが含まれたので、Windowsアプリケーションの広大なエコシステムにおいて、Kubernetesを有効的に活用できます。WindowsベースのアプリケーションとLinuxベースのアプリケーションに投資している組織は、ワークロードを管理する個別のオーケストレーターが不要となるため、オペレーティングシステムに関係なくアプリケーション全体の運用効率が向上します。
KubernetesのWindowsコンテナ KubernetesでWindowsコンテナのオーケストレーションを有効にする方法は、既存のLinuxクラスターにWindowsノードを含めるだけです。KubernetesのPod でWindowsコンテナをスケジュールすることは、Linuxベースのコンテナをスケジュールするのと同じくらいシンプルで簡単です。
Windowsコンテナを実行するには、Kubernetesクラスターに複数のオペレーティングシステムを含める必要があります。コントロールプレーンノードはLinux、ワーカーノードはワークロードのニーズに応じてWindowsまたはLinuxで実行します。Windows Server 2019は、サポートされている唯一のWindowsオペレーティングシステムであり、Windows (kubelet、コンテナランタイム 、kube-proxyを含む)でKubernetesノード を有効にします。Windowsディストリビューションチャンネルの詳細については、Microsoftのドキュメント を参照してください。
備考: マスターコンポーネント を含むKubernetesコントロールプレーンは、Linuxで実行し続けます。WindowsのみのKubernetesクラスターを導入する計画はありません。
備考: このドキュメントでは、Windowsコンテナについて説明する場合、プロセス分離のWindowsコンテナを意味します。
Hyper-V分離 のWindowsコンテナは、将来リリースが計画されています。
サポートされている機能と制限 サポートされている機能 コンピュート APIとkubectlの観点から見ると、WindowsコンテナはLinuxベースのコンテナとほとんど同じように動作します。ただし、制限セクションで概説されている主要な機能には、いくつかの顕著な違いがあります。
オペレーティングシステムのバージョンから始めましょう。KubernetesのWindowsオペレーティングシステムのサポートについては、次の表を参照してください。単一の混成Kubernetesクラスターは、WindowsとLinuxの両方のワーカーノードを持つことができます。WindowsコンテナはWindowsノードで、LinuxコンテナはLinuxノードでスケジュールする必要があります。
Kubernetes バージョン ホストOS バージョン (Kubernetes ノード) Windows Server 1709 Windows Server 1803 Windows Server 1809/Windows Server 2019 Kubernetes v1.14 サポートされていません サポートされていません Windows Server containers Builds 17763.* と Docker EE-basic 18.09 がサポートされています
備考: すべてのWindowsユーザーがアプリのオペレーティングシステムを頻繁に更新することは望んでいません。アプリケーションのアップグレードは、クラスターに新しいノードをアップグレードまたは導入することを要求する必要があります。Kubernetesで実行されているコンテナのオペレーティングシステムをアップグレードすることを選択したユーザーには、新しいオペレーティングシステムバージョンのサポート追加時に、ガイダンスと段階的な指示を提供します。このガイダンスには、クラスターノードと共にアプリケーションをアップグレードするための推奨アップグレード手順が含まれます。Windowsノードは、現在のLinuxノードと同じように、Kubernetes
バージョンスキューポリシー (ノードからコントロールプレーンのバージョン管理)に準拠しています。
Kubernetesの主要な要素は、WindowsでもLinuxと同じように機能します。このセクションでは、主要なワークロードイネーブラーのいくつかと、それらがWindowsにどのようにマップされるかについて説明します。
Pods
Podは、Kubernetesにおける最も基本的な構成要素です。人間が作成またはデプロイするKubernetesオブジェクトモデルの中で最小かつ最もシンプルな単位です。WindowsとLinuxのコンテナを同じPodにデプロイすることはできません。Pod内のすべてのコンテナは、各ノードが特定のプラットフォームとアーキテクチャを表す単一のノードにスケジュールされます。次のPod機能、プロパティ、およびイベントがWindowsコンテナでサポートされています。:
プロセス分離とボリューム共有を備えたPodごとの単一または複数のコンテナ Podステータスフィールド ReadinessとLiveness Probe postStartとpreStopコンテナのライフサイクルイベント 環境変数またはボリュームとしてのConfigMap、 Secrets EmptyDir 名前付きパイプホストマウント リソース制限 Controllers
Kubernetesコントローラーは、Podの望ましい状態を処理します。次のワークロードコントローラーは、Windowsコンテナでサポートされています。:
ReplicaSet ReplicationController Deployments StatefulSets DaemonSet Job CronJob Services
Kubernetes Serviceは、Podの論理セットとPodにアクセスするためのポリシーを定義する抽象概念です。マイクロサービスと呼ばれることもあります。オペレーティングシステム間の接続にServiceを使用できます。WindowsでのServiceは、次のタイプ、プロパティと機能を利用できます。:
サービス環境変数 NodePort ClusterIP LoadBalancer ExternalName Headless services Pod、Controller、Serviceは、KubernetesでWindowsワークロードを管理するための重要な要素です。ただし、それだけでは、動的なクラウドネイティブ環境でWindowsワークロードの適切なライフサイクル管理を可能にするのに十分ではありません。次の機能のサポートを追加しました:
Podとコンテナのメトリクス Horizontal Pod Autoscalerサポート kubectl Exec リソースクォータ Schedulerのプリエンプション コンテナランタイム Docker EE FEATURE STATE:
Kubernetes v1.14 [stable]
Docker EE-basic 18.09+は、Kubernetesを実行しているWindows Server 2019 / 1809ノードに推奨されるコンテナランタイムです。kubeletに含まれるdockershimコードで動作します。
CRI-ContainerD FEATURE STATE:
Kubernetes v1.18 [alpha]
ContainerDはLinux上のKubernetesで動作するOCI準拠のランタイムです。Kubernetes v1.18では、Windows上でのContainerD のサポートが追加されています。Windows上でのContainerDの進捗状況はenhancements#1001 で確認できます。
注意: Kubernetes v1.18におけるWindows上でのContainerDは以下の既知の欠点があります:
ContainerDは公式リリースではWindowsをサポートしていません。すなわち、Kubernetesでのすべての開発はアクティブなContainerD開発ブランチに対して行われています。本番環境へのデプロイは常に、完全にテストされセキュリティ修正をサポートした公式リリースを利用するべきです。 ContainerDを利用した場合、Group Managed Service Accountsは実装されていません。詳細はcontainerd/cri#1276 を参照してください。 永続ストレージ Kubernetesボリューム を使用すると、データの永続性とPodボリュームの共有要件を備えた複雑なアプリケーションをKubernetesにデプロイできます。特定のストレージバックエンドまたはプロトコルに関連付けられた永続ボリュームの管理には、ボリュームのプロビジョニング/プロビジョニング解除/サイズ変更、Kubernetesノードへのボリュームのアタッチ/デタッチ、およびデータを永続化する必要があるPod内の個別のコンテナへのボリュームのマウント/マウント解除などのアクションが含まれます。特定のストレージバックエンドまたはプロトコルに対してこれらのボリューム管理アクションを実装するコードは、Kubernetesボリュームプラグイン の形式で出荷されます。次の幅広いクラスのKubernetesボリュームプラグインがWindowsでサポートされています。:
In-treeボリュームプラグイン In-treeボリュームプラグインに関連付けられたコードは、コアKubernetesコードベースの一部として提供されます。In-treeボリュームプラグインのデプロイでは、追加のスクリプトをインストールしたり、個別のコンテナ化されたプラグインコンポーネントをデプロイしたりする必要はありません。これらのプラグインは、ストレージバックエンドでのボリュームのプロビジョニング/プロビジョニング解除とサイズ変更、Kubernetesノードへのボリュームのアタッチ/アタッチ解除、Pod内の個々のコンテナへのボリュームのマウント/マウント解除を処理できます。次のIn-treeプラグインは、Windowsノードをサポートしています。:
FlexVolume Plugins FlexVolume プラグインに関連付けられたコードは、ホストに直接デプロイする必要があるout-of-treeのスクリプトまたはバイナリとして出荷されます。FlexVolumeプラグインは、Kubernetesノードとの間のボリュームのアタッチ/デタッチ、およびPod内の個々のコンテナとの間のボリュームのマウント/マウント解除を処理します。FlexVolumeプラグインに関連付けられた永続ボリュームのプロビジョニング/プロビジョニング解除は、通常FlexVolumeプラグインとは別の外部プロビジョニング担当者を通じて処理できます。次のFlexVolumeプラグイン は、Powershellスクリプトとしてホストにデプロイされ、Windowsノードをサポートします:
CSIプラグイン FEATURE STATE:
Kubernetes v1.16 [alpha]
CSI プラグインに関連付けられたコードは、通常、コンテナイメージとして配布され、DaemonSetやStatefulSetなどの標準のKubernetesコンポーネントを使用してデプロイされるout-of-treeのスクリプトおよびバイナリとして出荷されます。CSIプラグインは、ボリュームのプロビジョニング/プロビジョニング解除/サイズ変更、Kubernetesノードへのボリュームのアタッチ/ボリュームからのデタッチ、Pod内の個々のコンテナへのボリュームのマウント/マウント解除、バックアップ/スナップショットとクローニングを使用した永続データのバックアップ/リストアといった、Kubernetesの幅広いボリューム管理アクションを処理します。CSIプラグインは通常、ノードプラグイン(各ノードでDaemonSetとして実行される)とコントローラープラグインで構成されます。
CSIノードプラグイン(特に、ブロックデバイスまたは共有ファイルシステムとして公開された永続ボリュームに関連付けられているプラグイン)は、ディスクデバイスのスキャン、ファイルシステムのマウントなど、さまざまな特権操作を実行する必要があります。これらの操作は、ホストオペレーティングシステムごとに異なります。Linuxワーカーノードの場合、コンテナ化されたCSIノードプラグインは通常、特権コンテナとしてデプロイされます。Windowsワーカーノードの場合、コンテナ化されたCSIノードプラグインの特権操作は、csi-proxy を使用してサポートされます。各Windowsノードにプリインストールされている。詳細については、展開するCSIプラグインの展開ガイドを参照してください。
ネットワーキング Windowsコンテナのネットワークは、CNIプラグイン を通じて公開されます。Windowsコンテナは、ネットワークに関して仮想マシンと同様に機能します。各コンテナには、Hyper-V仮想スイッチ(vSwitch)に接続されている仮想ネットワークアダプター(vNIC)があります。Host Network Service(HNS)とHost Compute Service(HCS)は連携してコンテナを作成し、コンテナvNICをネットワークに接続します。HCSはコンテナの管理を担当するのに対し、HNSは次のようなネットワークリソースの管理を担当します。:
仮想ネットワーク(vSwitchの作成を含む) エンドポイント/vNIC 名前空間 ポリシー(パケットのカプセル化、負荷分散ルール、ACL、NATルールなど) 次のServiceタイプがサポートされています。:
NodePort ClusterIP LoadBalancer ExternalName Windowsは、L2bridge、L2tunnel、Overlay、Transparent、NATの5つの異なるネットワークドライバー/モードをサポートしています。WindowsとLinuxのワーカーノードを持つ異種クラスターでは、WindowsとLinuxの両方で互換性のあるネットワークソリューションを選択する必要があります。以下のツリー外プラグインがWindowsでサポートされており、各CNIをいつ使用するかに関する推奨事項があります。:
ネットワークドライバー 説明 コンテナパケットの変更 ネットワークプラグイン ネットワークプラグインの特性 L2bridge コンテナは外部のvSwitchに接続されます。コンテナはアンダーレイネットワークに接続されますが、物理ネットワークはコンテナのMACを上り/下りで書き換えるため、MACを学習する必要はありません。コンテナ間トラフィックは、コンテナホスト内でブリッジされます。 MACはホストのMACに書き換えられ、IPは変わりません。 win-bridge 、Azure-CNI 、Flannelホストゲートウェイは、win-bridgeを使用します。win-bridgeはL2bridgeネットワークモードを使用して、コンテナをホストのアンダーレイに接続して、最高のパフォーマンスを提供します。ノード間接続にはユーザー定義ルート(UDR)が必要です。 L2Tunnel これはl2bridgeの特殊なケースですが、Azureでのみ使用されます。すべてのパケットは、SDNポリシーが適用されている仮想化ホストに送信されます。 MACが書き換えられ、IPがアンダーレイネットワークで表示されます。 Azure-CNI Azure-CNIを使用すると、コンテナをAzure vNETと統合し、Azure Virtual Networkが提供 する一連の機能を活用できます。たとえば、Azureサービスに安全に接続するか、Azure NSGを使用します。azure-cniのいくつかの例 を参照してください。 オーバーレイ(KubernetesのWindows用のオーバーレイネットワークは アルファ 段階です) コンテナには、外部のvSwitchに接続されたvNICが付与されます。各オーバーレイネットワークは、カスタムIPプレフィックスで定義された独自のIPサブネットを取得します。オーバーレイネットワークドライバーは、VXLANを使用してカプセル化します。 外部ヘッダーでカプセル化されます。 Win-overlay 、Flannel VXLAN (win-overlayを使用)win-overlayは、仮想コンテナネットワークをホストのアンダーレイから分離する必要がある場合に使用する必要があります(セキュリティ上の理由など)。データセンター内のIPが制限されている場合に、(異なるVNIDタグを持つ)異なるオーバーレイネットワークでIPを再利用できるようにします。このオプションには、Windows Server 2019でKB4489899 が必要です。 透過的(ovn-kubernetes の特別な使用例) 外部のvSwitchが必要です。コンテナは外部のvSwitchに接続され、論理ネットワーク(論理スイッチおよびルーター)を介したPod内通信を可能にします。 パケットは、GENEVE またはSTT トンネリングを介してカプセル化され、同じホスト上にないポッドに到達します。パケットは、ovnネットワークコントローラーによって提供されるトンネルメタデータ情報を介して転送またはドロップされます。NATは南北通信のために行われます。 ovn-kubernetes ansible経由でデプロイ します。分散ACLは、Kubernetesポリシーを介して適用できます。 IPAMをサポートします。負荷分散は、kube-proxyなしで実現できます。 NATは、iptables/netshを使用せずに行われます。NAT(Kubernetesでは使用されません ) コンテナには、内部のvSwitchに接続されたvNICが付与されます。DNS/DHCPは、WinNAT と呼ばれる内部コンポーネントを使用して提供されます。 MACおよびIPはホストMAC/IPに書き換えられます。 nat 完全を期すためにここに含まれています。
上で概説したように、Flannel CNIメタプラグイン は、VXLANネットワークバックエンド (アルファサポート 、win-overlayへのデリゲート)およびホストゲートウェイネットワークバックエンド (安定したサポート、win-bridgeへのデリゲート)を介してWindows でもサポートされます。このプラグインは、参照CNIプラグイン(win-overlay、win-bridge)の1つへの委任をサポートし、WindowsのFlannelデーモン(Flanneld)と連携して、ノードのサブネットリースの自動割り当てとHNSネットワークの作成を行います。このプラグインは、独自の構成ファイル(cni.conf)を読み取り、FlannelDで生成されたsubnet.envファイルからの環境変数と統合します。次に、ネットワークプラミング用の参照CNIプラグインの1つに委任し、ノード割り当てサブネットを含む正しい構成をIPAMプラグイン(ホストローカルなど)に送信します。
Node、Pod、およびServiceオブジェクトの場合、TCP/UDPトラフィックに対して次のネットワークフローがサポートされます。:
Pod -> Pod (IP) Pod -> Pod (Name) Pod -> Service (Cluster IP) Pod -> Service (PQDN、ただし、「.」がない場合のみ) Pod -> Service (FQDN) Pod -> External (IP) Pod -> External (DNS) Node -> Pod Pod -> Node Windowsでは、次のIPAMオプションがサポートされています。
制限 コントロールプレーン Windowsは、Kubernetesアーキテクチャとコンポーネントマトリックスのワーカーノードとしてのみサポートされています。つまり、Kubernetesクラスターには常にLinuxマスターノード、0以上のLinuxワーカーノード、0以上のWindowsワーカーノードが含まれている必要があります。
コンピュート リソース管理とプロセス分離 Linux cgroupsは、Linuxのリソースを制御するPodの境界として使用されます。コンテナは、ネットワーク、プロセス、およびファイルシステムを分離するのために、その境界内に作成されます。cgroups APIを使用して、cpu/io/memoryの統計を収集できます。対照的に、Windowsはシステムネームスペースフィルターを備えたコンテナごとのジョブオブジェクトを使用して、コンテナ内のすべてのプロセスを格納し、ホストからの論理的な分離を提供します。ネームスペースフィルタリングを行わずにWindowsコンテナを実行する方法はありません。これは、ホストの環境ではシステム特権を主張できないため、Windowsでは特権コンテナを使用できないことを意味します。セキュリティアカウントマネージャー(SAM)が独立しているため、コンテナはホストからIDを引き受けることができません。
オペレーティングシステムの制限 Windowsには厳密な互換性ルールがあり、ホストOSのバージョンとコンテナのベースイメージOSのバージョンは、一致する必要があります。Windows Server 2019のコンテナオペレーティングシステムを備えたWindowsコンテナのみがサポートされます。Hyper-V分離のコンテナは、Windowsコンテナのイメージバージョンに下位互換性を持たせることは、将来のリリースで計画されています。
機能制限 TerminationGracePeriod:実装されていません 単一ファイルのマッピング:CRI-ContainerDで実装されます 終了メッセージ:CRI-ContainerDで実装されます 特権コンテナ:現在Windowsコンテナではサポートされていません HugePages:現在Windowsコンテナではサポートされていません 既存のノード問題を検出する機能はLinux専用であり、特権コンテナが必要です。一般的に、特権コンテナはサポートされていないため、これがWindowsで使用されることは想定していません。 ネームスペース共有については、すべての機能がサポートされているわけではありません(詳細については、APIセクションを参照してください) メモリ予約と処理 Windowsには、Linuxのようなメモリ不足のプロセスキラーはありません。Windowsは常に全ユーザーモードのメモリ割り当てを仮想として扱い、ページファイルは必須です。正味の効果は、WindowsはLinuxのようなメモリ不足の状態にはならず、メモリ不足(OOM)終了の影響を受ける代わりにページをディスクに処理します。メモリが過剰にプロビジョニングされ、物理メモリのすべてが使い果たされると、ページングによってパフォーマンスが低下する可能性があります。
2ステップのプロセスで、メモリ使用量を妥当な範囲内に保つことが可能です。まず、kubeletパラメーター--kubelet-reserveや--system-reserveを使用して、ノード(コンテナ外)でのメモリ使用量を明確にします。これにより、NodeAllocatable )が削減されます。ワークロードをデプロイするときは、コンテナにリソース制限をかけます(制限のみを設定するか、制限が要求と等しくなければなりません)。これにより、NodeAllocatableも差し引かれ、ノードのリソースがフルな状態になるとSchedulerがPodを追加できなくなります。
過剰なプロビジョニングを回避するためのベストプラクティスは、Windows、Docker、およびKubernetesのプロセスに対応するために、最低2GBのメモリを予約したシステムでkubeletを構成することです。
フラグの振舞いについては、次のような異なる動作をします。:
--kubelet-reserve、--system-reserve、および--eviction-hardフラグはノードの割り当て可能数を更新します--enforce-node-allocableを使用した排除は実装されていません--eviction-hardおよび--eviction-softを使用した排除は実装されていませんMemoryPressureの制約は実装されていません kubeletによって実行されるOOMを排除することはありません Windowsノードで実行されているKubeletにはメモリ制限がありません。--kubelet-reserveと--system-reserveは、ホストで実行されているkubeletまたはプロセスに制限を設定しません。これは、ホスト上のkubeletまたはプロセスが、NodeAllocatableとSchedulerの外でメモリリソース不足を引き起こす可能性があることを意味します。 ストレージ Windowsには、コンテナレイヤーをマウントして、NTFSに基づいて複製されたファイルシステムを作るためのレイヤー構造のファイルシステムドライバーがあります。コンテナ内のすべてのファイルパスは、そのコンテナの環境内だけで決められます。
ボリュームマウントは、コンテナ内のディレクトリのみを対象にすることができ、個別のファイルは対象にできません ボリュームマウントは、ファイルまたはディレクトリをホストファイルシステムに投影することはできません WindowsレジストリとSAMデータベースには常に書き込みアクセスが必要であるため、読み取り専用ファイルシステムはサポートされていません。ただし、読み取り専用ボリュームはサポートされています ボリュームのユーザーマスクと権限は使用できません。SAMはホストとコンテナ間で共有されないため、それらの間のマッピングはありません。すべての権限はコンテナの環境内で決められます その結果、次のストレージ機能はWindowsノードではサポートされません。
ボリュームサブパスのマウント。Windowsコンテナにマウントできるのはボリューム全体だけです。 シークレットのサブパスボリュームのマウント ホストマウントプロジェクション DefaultMode(UID/GID依存関係による) 読み取り専用のルートファイルシステム。マップされたボリュームは引き続き読み取り専用をサポートします ブロックデバイスマッピング 記憶媒体としてのメモリ uui/guid、ユーザーごとのLinuxファイルシステム権限などのファイルシステム機能 NFSベースのストレージ/ボリュームのサポート マウントされたボリュームの拡張(resizefs) ネットワーキング Windowsコンテナネットワーキングは、Linuxネットワーキングとはいくつかの重要な実装方法の違いがあります。Microsoft documentation for Windows Container Networking には、追加の詳細と背景があります。
Windowsホストネットワーキングサービスと仮想スイッチはネームスペースを実装して、Podまたはコンテナの必要に応じて仮想NICを作成できます。ただし、DNS、ルート、メトリックなどの多くの構成は、Linuxのような/etc/...ファイルではなく、Windowsレジストリデータベースに保存されます。コンテナのWindowsレジストリはホストのレジストリとは別であるため、ホストからコンテナへの/etc/resolv.confのマッピングなどの概念は、Linuxの場合と同じ効果をもたらしません。これらは、そのコンテナの環境で実行されるWindows APIを使用して構成する必要があります。したがって、CNIの実装は、ファイルマッピングに依存する代わりにHNSを呼び出して、ネットワークの詳細をPodまたはコンテナに渡す必要があります。
次のネットワーク機能はWindowsノードではサポートされていません
ホストネットワーキングモードはWindows Podでは使用できません ノード自体からのローカルNodePortアクセスは失敗します(他のノードまたは外部クライアントで機能) ノードからのService VIPへのアクセスは、Windows Serverの将来のリリースで利用可能になる予定です kube-proxyのオーバーレイネットワーキングサポートはアルファリリースです。さらに、KB4482887 がWindows Server 2019にインストールされている必要があります ローカルトラフィックポリシーとDSRモード l2bridge、l2tunnel、またはオーバーレイネットワークに接続されたWindowsコンテナは、IPv6スタックを介した通信をサポートしていません。これらのネットワークドライバーがIPv6アドレスを使用できるようにするために必要な機能として、優れたWindowsプラットフォームの機能があり、それに続いて、kubelet、kube-proxy、およびCNIプラグインといったKubernetesの機能があります。 win-overlay、win-bridge、およびAzure-CNIプラグインを介したICMPプロトコルを使用したアウトバウンド通信。具体的には、Windowsデータプレーン(VFP )は、ICMPパケットの置き換えをサポートしていません。これの意味は:同じネットワーク内の宛先に向けられたICMPパケット(pingを介したPod間通信など)は期待どおりに機能し、制限はありません TCP/UDPパケットは期待どおりに機能し、制限はありません リモートネットワーク(Podからping経由の外部インターネット通信など)を通過するように指示されたICMPパケットは置き換えできないため、ソースにルーティングされません。 TCP/UDPパケットは引き続き置き換えできるため、ping <destination>をcurl <destination>に置き換えることで、外部への接続をデバッグできます。 これらの機能はKubernetes v1.15で追加されました。
CNIプラグイン Windowsリファレンスネットワークプラグインのwin-bridgeとwin-overlayは、CNI仕様 v0.4.0において「CHECK」実装がないため、今のところ実装されていません。 Flannel VXLAN CNIについては、Windowsで次の制限があります。: Node-podの直接間接続は設計上不可能です。FlannelPR 1096 を使用するローカルPodでのみ可能です VNI 4096とUDPポート4789の使用に制限されています。VNIの制限は現在取り組んでおり、将来のリリースで解決される予定です(オープンソースのflannelの変更)。これらのパラメーターの詳細については、公式のFlannel VXLAN バックエンドのドキュメントをご覧ください。 DNS ClusterFirstWithHostNetは、DNSでサポートされていません。Windowsでは、FQDNとしてすべての名前を「.」で扱い、PQDNでの名前解決はスキップします。 Linuxでは、PQDNで名前解決しようとするときに使用するDNSサフィックスリストがあります。Windowsでは、1つのDNSサフィックスしかありません。これは、そのPodのNamespaceに関連付けられているDNSサフィックスです(たとえば、mydns.svc.cluster.local)。Windowsでは、そのサフィックスだけで名前解決可能なFQDNおよびServiceまたはNameでの名前解決ができます。たとえば、defaultのNamespaceで生成されたPodには、DNSサフィックスdefault.svc.cluster.local が付けられます。WindowsのPodでは、kubernetes.default.svc.cluster.local とkubernetes の両方を名前解決できますが、kubernetes.default やkubernetes.default.svc のような中間での名前解決はできません。 Windowsでは、複数のDNSリゾルバーを使用できます。これらには少し異なる動作が付属しているため、ネームクエリの解決にはResolve-DNSNameユーティリティを使用することをお勧めします。 セキュリティ Secretはノードのボリュームに平文テキストで書き込まれます(Linuxのtmpfs/in-memoryの比較として)。これはカスタマーが2つのことを行う必要があります
ファイルACLを使用してSecretファイルの場所を保護する BitLocker を使って、ボリュームレベルの暗号化を使用するRunAsUser は、現在Windowsではサポートされていません。回避策は、コンテナをパッケージ化する前にローカルアカウントを作成することです。RunAsUsername機能は、将来のリリースで追加される可能性があります。
SELinux、AppArmor、Seccomp、特性(POSIX機能)のような、Linux固有のPodセキュリティ環境の権限はサポートされていません。
さらに、既に述べたように特権付きコンテナは、Windowsにおいてサポートされていません。
API ほとんどのKubernetes APIがWindowsでも機能することに違いはありません。そのわずかな違いはOSとコンテナランタイムの違いによるものです。特定の状況では、PodやコンテナなどのワークロードAPIの一部のプロパティが、Linuxで実装されているが、Windowsでは実行できないことを前提に設計されています。
高いレベルで、これらOSのコンセプトに違いがります。:
ID - Linuxでは、Integer型として表されるuserID(UID)とgroupID(GID)を使用します。ユーザー名とグループ名は正規ではありません - それらは、UID+GIDの背後にある/etc/groupsまたは/etc/passwdの単なるエイリアスです。Windowsは、Windows Security Access Manager(SAM)データベースに格納されているより大きなバイナリセキュリティ識別子(SID)を使用します。このデータベースは、ホストとコンテナ間、またはコンテナ間で共有されません。 ファイル権限 - Windowsは、権限とUID+GIDのビットマスクではなく、SIDに基づくアクセス制御リストを使用します ファイルパス - Windowsの規則では、/ではなく\を使用します。Go IOライブラリは通常両方を受け入れ、それを機能させるだけですが、コンテナ内で解釈されるパスまたはコマンドラインを設定する場合、\が必要になる場合があります。 シグナル - Windowsのインタラクティブなアプリは終了を異なる方法で処理し、次の1つ以上を実装できます。:UIスレッドは、WM_CLOSEを含む明確に定義されたメッセージを処理します コンソールアプリは、コントロールハンドラーを使用してctrl-cまたはctrl-breakを処理します サービスは、SERVICE_CONTROL_STOP制御コードを受け入れることができるサービスコントロールハンドラー関数を登録します。 終了コードは、0が成功、0以外が失敗の場合と同じ規則に従います。特定のエラーコードは、WindowsとLinuxで異なる場合があります。ただし、Kubernetesのコンポーネント(kubelet、kube-proxy)から渡される終了コードは変更されていません。
V1.Container V1.Container.ResourceRequirements.limits.cpuおよびV1.Container.ResourceRequirements.limits.memory - Windowsは、CPU割り当てにハード制限を使用しません。代わりに、共有システムが使用されます。ミリコアに基づく既存のフィールドは、Windowsスケジューラーによって追従される相対共有にスケーリングされます。参照: kuberuntime/helpers_windows.go 、参照: resource controls in Microsoft docs Huge Pagesは、Windowsコンテナランタイムには実装されてないので、使用できません。コンテナに対して設定できないユーザー特権を主張 する必要があります。 V1.Container.ResourceRequirements.requests.cpuおよびV1.Container.ResourceRequirements.requests.memory - リクエストはノードの利用可能なリソースから差し引かれるので、ノードのオーバープロビジョニングを回避するために使用できます。ただし、過剰にプロビジョニングされたノードのリソースを保証するために使用することはできません。オペレーターが完全にプロビジョニングし過ぎないようにする場合は、ベストプラクティスとしてこれらをすべてのコンテナに適用する必要があります。 V1.Container.SecurityContext.allowPrivilegeEscalation - Windowsでは使用できません、接続されている機能はありません V1.Container.SecurityContext.Capabilities - POSIX機能はWindowsでは実装されていません V1.Container.SecurityContext.privileged - Windowsでは特権コンテナをサポートしていません V1.Container.SecurityContext.procMount - Windowsでは/procファイルシステムがありません V1.Container.SecurityContext.readOnlyRootFilesystem - Windowsでは使用できません、レジストリおよびシステムプロセスがコンテナ内で実行するには、書き込みアクセスが必要です V1.Container.SecurityContext.runAsGroup - Windowsでは使用できません、GIDのサポートもありません V1.Container.SecurityContext.runAsNonRoot - Windowsではrootユーザーが存在しません。最も近いものは、ノードに存在しないIDであるContainerAdministratorです。 V1.Container.SecurityContext.runAsUser - Windowsでは使用できません。intとしてのUIDはサポートされていません。 V1.Container.SecurityContext.seLinuxOptions - Windowsでは使用できません、SELinuxがありません V1.Container.terminationMessagePath - これは、Windowsが単一ファイルのマッピングをサポートしないという点でいくつかの制限があります。デフォルト値は/dev/termination-logであり、デフォルトではWindowsに存在しないため動作します。 V1.Pod V1.Pod.hostIPC、v1.pod.hostpid - Windowsではホストのネームスペースを共有することはできません V1.Pod.hostNetwork - ホストのネットワークを共有するためのWindows OSサポートはありません V1.Pod.dnsPolicy - ClusterFirstWithHostNet - Windowsではホストネットワーキングがサポートされていないため、サポートされていません。 V1.Pod.podSecurityContext - 以下のV1.PodSecurityContextを参照 V1.Pod.shareProcessNamespace - これはベータ版の機能であり、Windowsに実装されていないLinuxのNamespace機能に依存しています。Windowsでは、プロセスのネームスペースまたはコンテナのルートファイルシステムを共有できません。共有できるのはネットワークだけです。 V1.Pod.terminationGracePeriodSeconds - これはWindowsのDockerに完全には実装されていません。リファレンス を参照してください。今日の動作では、ENTRYPOINTプロセスにCTRL_SHUTDOWN_EVENTが送信され、Windowsではデフォルトで5秒待機し、最後に通常のWindowsシャットダウン動作を使用してすべてのプロセスをシャットダウンします。5秒のデフォルトは、実際にはWindowsレジストリーコンテナ内 にあるため、コンテナ作成時にオーバーライドできます。 V1.Pod.volumeDevices - これはベータ機能であり、Windowsには実装されていません。Windowsでは、rawブロックデバイスをPodに接続できません。 V1.Pod.volumes-EmptyDir、Secret、ConfigMap、HostPath - すべて動作し、TestGridにテストがありますV1.emptyDirVolumeSource - ノードのデフォルトのメディアはWindowsのディスクです。Windowsでは、RAMディスクが組み込まれていないため、メモリはサポートされていません。 V1.VolumeMount.mountPropagation - mount propagationは、Windowsではサポートされていません。 V1.PodSecurityContext Windowsでは、PodSecurityContextフィールドはどれも機能しません。これらは参照用にここにリストされています。
V1.PodSecurityContext.SELinuxOptions - SELinuxは、Windowsでは使用できません V1.PodSecurityContext.RunAsUser - UIDを提供しますが、Windowsでは使用できません V1.PodSecurityContext.RunAsGroup - GIDを提供しますが、Windowsでは使用できません V1.PodSecurityContext.RunAsNonRoot - Windowsにはrootユーザーがありません。最も近いものは、ノードに存在しないIDであるContainerAdministratorです。 V1.PodSecurityContext.SupplementalGroups - GIDを提供しますが、Windowsでは使用できません V1.PodSecurityContext.Sysctls - これらはLinuxのsysctlインターフェースの一部です。Windowsには同等のものはありません。 ヘルプとトラブルシューティングを学ぶ Kubernetesクラスターのトラブルシューティングの主なヘルプソースは、トラブルシューティング ページから始める必要があります。このセクションには、いくつか追加的な、Windows固有のトラブルシューティングヘルプが含まれています。ログは、Kubernetesにおけるトラブルシューティング問題の重要な要素です。他のコントリビューターからトラブルシューティングの支援を求めるときは、必ずそれらを含めてください。SIG-Windowsログ収集に関するコントリビュートガイド の指示に従ってください。
start.ps1が正常に完了したことをどのように確認できますか?
ノード上でkubelet、kube-proxy、および(ネットワーキングソリューションとしてFlannelを選択した場合)flanneldホストエージェントプロセスが実行され、実行ログが個別のPowerShellウィンドウに表示されます。これに加えて、WindowsノードがKubernetesクラスターで「Ready」として表示されているはずです。
Kubernetesノードのプロセスをサービスとしてバックグラウンドで実行するように構成できますか?
Kubeletとkube-proxyは、ネイティブのWindowsサービスとして実行するように既に構成されています、障害(例えば、プロセスのクラッシュ)が発生した場合にサービスを自動的に再起動することにより、復元性を提供します。これらのノードコンポーネントをサービスとして構成するには、2つのオプションがあります。
ネイティブWindowsサービスとして
Kubeletとkube-proxyは、sc.exeを使用してネイティブのWindowsサービスとして実行できます。
# 2つの個別のコマンドでkubeletおよびkube-proxyのサービスを作成する
sc.exe create <component_name> binPath= "<path_to_binary> --service <other_args>"
# 引数にスペースが含まれている場合は、エスケープする必要があることに注意してください。
sc.exe create kubelet binPath= "C:\kubelet.exe --service --hostname-override 'minion' <other_args>"
# サービスを開始する
Start-Service kubelet
Start-Service kube-proxy
# サービスを停止する
Stop-Service kubelet (-Force)
Stop-Service kube-proxy (-Force)
# サービスの状態を問い合わせる
Get-Service kubelet
Get-Service kube-proxy
nssm.exeの使用
また、nssm.exe などの代替サービスマネージャーを使用して、これらのプロセス(flanneld、kubelet、kube-proxy)をバックグラウンドで実行することもできます。このサンプルスクリプト を使用すると、nssm.exeを利用してkubelet、kube-proxy、flanneld.exeを登録し、Windowsサービスとしてバックグラウンドで実行できます。
register-svc .ps1 -NetworkMode <Network mode> -ManagementIP <Windows Node IP> -ClusterCIDR <Cluster subnet> -KubeDnsServiceIP <Kube-dns Service IP> -LogDir <Directory to place logs>
# NetworkMode = ネットワークソリューションとして選択されたネットワークモードl2bridge(flannel host-gw、これもデフォルト値)またはoverlay(flannel vxlan)
# ManagementIP = Windowsノードに割り当てられたIPアドレス。 ipconfigを使用してこれを見つけることができます
# ClusterCIDR = クラスターのサブネット範囲。(デフォルト値 10.244.0.0/16)
# KubeDnsServiceIP = Kubernetes DNSサービスIP(デフォルト値 10.96.0.10)
# LogDir = kubeletおよびkube-proxyログがそれぞれの出力ファイルにリダイレクトされるディレクトリ(デフォルト値 C:\k)
上記のスクリプトが適切でない場合は、次の例を使用してnssm.exeを手動で構成できます。
# flanneld.exeを登録する
nssm install flanneld C:\flannel\flanneld.exe
nssm set flanneld AppParameters --kubeconfig-file =c:\k\config --iface=<ManagementIP> --ip-masq=1 --kube-subnet-mgr=1
nssm set flanneld AppEnvironmentExtra NODE_NAME=<hostname>
nssm set flanneld AppDirectory C:\flannel
nssm start flanneld
# kubelet.exeを登録
# マイクロソフトは、mcr.microsoft.com/k8s/core/pause:1.2.0としてポーズインフラストラクチャコンテナをリリース
nssm install kubelet C:\k\kubelet.exe
nssm set kubelet AppParameters --hostname-override=<hostname> --v=6 --pod-infra-container-image=mcr.microsoft.com/k8s/core/pause: 1.2 .0 --resolv-conf="" --allow-privileged=true --enable-debugging-handlers --cluster-dns=<DNS-service -IP> --cluster-domain=cluster.local --kubeconfig=c:\k\config --hairpin-mode=promiscuous-bridge --image-pull-progress-deadline=20m --cgroups-per-qos=false --log-dir=<log directory> --logtostderr=false --enforce-node-allocatable="" --network-plugin=cni --cni-bin-dir=c:\k\cni --cni-conf-dir=c:\k\cni\config
nssm set kubelet AppDirectory C:\k
nssm start kubelet
# kube-proxy.exeを登録する (l2bridge / host-gw)
nssm install kube-proxy C:\k\kube-proxy .exe
nssm set kube-proxy AppDirectory c:\k
nssm set kube-proxy AppParameters --v=4 --proxy-mode=kernelspace --hostname-override=<hostname>--kubeconfig=c:\k\config --enable-dsr=false --log-dir=<log directory> --logtostderr=false
nssm.exe set kube-proxy AppEnvironmentExtra KUBE_NETWORK=cbr0
nssm set kube-proxy DependOnService kubelet
nssm start kube-proxy
# kube-proxy.exeを登録する (overlay / vxlan)
nssm install kube-proxy C:\k\kube-proxy .exe
nssm set kube-proxy AppDirectory c:\k
nssm set kube-proxy AppParameters --v=4 --proxy-mode=kernelspace --feature-gates="WinOverlay=true" --hostname-override=<hostname> --kubeconfig=c:\k\config --network-name=vxlan0 --source-vip=<source-vip > --enable-dsr=false --log-dir=<log directory> --logtostderr=false
nssm set kube-proxy DependOnService kubelet
nssm start kube-proxy
最初のトラブルシューティングでは、nssm.exe で次のフラグを使用して、stdoutおよびstderrを出力ファイルにリダイレクトできます。:
nssm set <Service Name> AppStdout C:\k\mysvc.log
nssm set <Service Name> AppStderr C:\k\mysvc.log
詳細については、公式のnssmの使用法 のドキュメントを参照してください。
Windows Podにネットワーク接続がありません
仮想マシンを使用している場合は、すべてのVMネットワークアダプターでMACスプーフィングが有効になっていることを確認してください。
Windows Podが外部リソースにpingできません
現在、Windows Podには、ICMPプロトコル用にプログラムされた送信ルールはありません。ただし、TCP/UDPはサポートされています。クラスター外のリソースへの接続を実証する場合は、ping <IP>に対応するcurl <IP>コマンドに置き換えてください。
それでも問題が解決しない場合は、cni.conf のネットワーク構成に値する可能性があるので、いくつかの特別な注意が必要です。この静的ファイルはいつでも編集できます。構成の更新は、新しく作成されたすべてのKubernetesリソースに適用されます。
Kubernetesのネットワーキング要件の1つ(参照Kubernetesモデル )は、内部でNATを使用せずにクラスター通信を行うためのものです。この要件を遵守するために、すべての通信にExceptionList があり、アウトバウンドNATが発生しないようにします。ただし、これは、クエリしようとしている外部IPをExceptionListから除外する必要があることも意味します。そうして初めて、Windows PodからのトラフィックがSNAT処理され、外部からの応答を受信できるようになります。この点で、cni.confのExceptionListは次のようになります。:
"ExceptionList": [
"10.244.0.0/16", # クラスターのサブネット
"10.96.0.0/12", # Serviceのサブネット
"10.127.130.0/24" # 管理 (ホスト) のサブネット
]
WindowsノードがNodePort Serviceにアクセスできません
ノード自体からのローカルNodePortアクセスは失敗します。これは既知の制限です。NodePortアクセスは、他のノードまたは外部クライアントから行えます。
コンテナのvNICとHNSエンドポイントが削除されています
この問題は、hostname-overrideパラメーターがkube-proxy に渡されない場合に発生する可能性があります。これを解決するには、ユーザーは次のようにホスト名をkube-proxyに渡す必要があります。:
C:\k\kube-proxy .exe --hostname-override=$(hostname)
flannelを使用すると、クラスターに再参加した後、ノードに問題が発生します
以前に削除されたノードがクラスターに再参加するときはいつも、flannelDは新しいPodサブネットをノードに割り当てようとします。ユーザーは、次のパスにある古いPodサブネット構成ファイルを削除する必要があります。:
Remove-Item C:\k\SourceVip.json
Remove-Item C:\k\SourceVipRequest.json
start.ps1を起動した後、flanneldが「ネットワークが作成されるのを待っています」と表示されたままになります
この調査中の問題 に関する多数の報告があります。最も可能性が高いのは、flannelネットワークの管理IPが設定されるタイミングの問題です。回避策は、単純にstart.ps1を再起動するか、次のように手動で再起動することです。:
PS C:> [Environment ]::SetEnvironmentVariable("NODE_NAME" , "<Windows_Worker_Hostname>" )
PS C:> C:\flannel\flanneld.exe --kubeconfig-file =c:\k\config --iface=<Windows_Worker_Node_IP> --ip-masq=1 --kube-subnet-mgr=1
/run/flannel/subnet.envがないため、Windows Podを起動できません
これは、Flannelが正しく起動しなかったことを示しています。 flanneld.exeの再起動を試みるか、Kubernetesマスターの/run/flannel/subnet.envからWindowsワーカーノードのC:\run\flannel\subnet.envに手動でファイルをコピーすることができます。「FLANNEL_SUBNET」行を別の番号に変更します。たとえば、ノードサブネット10.244.4.1/24が必要な場合は以下となります。:
FLANNEL_NETWORK = 10.244.0.0/16
FLANNEL_SUBNET = 10.244.4.1/24
FLANNEL_MTU = 1500
FLANNEL_IPMASQ = true
WindowsノードがService IPを使用してServiceにアクセスできない
これは、Windows上の現在のネットワークスタックの既知の制限です。ただし、Windows PodはService IPにアクセスできます。
kubeletの起動時にネットワークアダプターが見つかりません
WindowsネットワーキングスタックがKubernetesネットワーキングを動かすには、仮想アダプターが必要です。次のコマンドを実行しても結果が返されない場合(管理シェルで)、仮想ネットワークの作成(Kubeletが機能するために必要な前提条件)に失敗したことになります。:
Get-HnsNetwork | ? Name -ieq "cbr0"
Get-NetAdapter | ? Name -Like "vEthernet (Ethernet*"
ホストのネットワークアダプターが「イーサネット」ではない場合、多くの場合、start.ps1スクリプトのInterfaceName パラメーターを修正する価値があります。そうでない場合はstart-kubelet.ps1スクリプトの出力結果を調べて、仮想ネットワークの作成中にエラーがないか確認します。
Podが「Container Creating」と表示されたまま動かなくなったり、何度も再起動を繰り返します
PauseイメージがOSバージョンと互換性があることを確認してください。説明 では、OSとコンテナの両方がバージョン1803であると想定しています。それ以降のバージョンのWindowsを使用している場合は、Insiderビルドなどでは、それに応じてイメージを調整する必要があります。イメージについては、MicrosoftのDockerレジストリ を参照してください。いずれにしても、PauseイメージのDockerfileとサンプルサービスの両方で、イメージに:latestのタグが付けられていると想定しています。
Kubernetes v1.14以降、MicrosoftはPauseインフラストラクチャコンテナをmcr.microsoft.com/k8s/core/pause:1.2.0でリリースしています。
DNS名前解決が正しく機能していない
このセクション でDNSの制限を確認してください。
kubectl port-forwardが「ポート転送を実行できません:wincatが見つかりません」で失敗します
これはKubernetes 1.15、およびPauseインフラストラクチャコンテナmcr.microsoft.com/k8s/core/pause:1.2.0で実装されました。必ずこれらのバージョン以降を使用してください。
独自のPauseインフラストラクチャコンテナを構築する場合は、必ずwincat を含めてください。
Windows Serverノードがプロキシの背後にあるため、Kubernetesのインストールが失敗します
プロキシの背後にある場合は、次のPowerShell環境変数を定義する必要があります。:
[Environment ]::SetEnvironmentVariable("HTTP_PROXY" , "http://proxy.example.com:80/" , [EnvironmentVariableTarget ]::Machine)
[Environment ]::SetEnvironmentVariable("HTTPS_PROXY" , "http://proxy.example.com:443/" , [EnvironmentVariableTarget ]::Machine)
pauseコンテナとは何ですか
Kubernetes Podでは、インフラストラクチャまたは「pause」コンテナが最初に作成され、コンテナエンドポイントをホストします。インフラストラクチャやワーカーコンテナなど、同じPodに属するコンテナは、共通のネットワークネームスペースとエンドポイント(同じIPとポートスペース)を共有します。Pauseコンテナは、ネットワーク構成を失うことなくクラッシュまたは再起動するワーカーコンテナに対応するために必要です。
「pause」(インフラストラクチャ)イメージは、Microsoft Container Registry(MCR)でホストされています。docker pull mcr.microsoft.com/k8s/core/pause:1.2.0を使用してアクセスできます。詳細については、DOCKERFILE をご覧ください。
さらなる調査 これらの手順で問題が解決しない場合は、次の方法で、KubernetesのWindowsノードでWindowsコンテナを実行する際のヘルプを利用できます。:
IssueとFeatureリクエストの報告 バグのようなものがある場合、またはFeatureリクエストを行う場合は、GitHubのIssueシステム を使用してください。GitHub でIssueを開いて、SIG-Windowsに割り当てることができます。以前に報告された場合は、まずIssueリストを検索し、Issueについての経験をコメントして、追加のログを加える必要があります。SIG-Windows Slackは、チケットを作成する前に、初期サポートとトラブルシューティングのアイデアを得るための素晴らしい手段でもあります。
バグを報告する場合は、問題の再現方法に関する次のような詳細情報を含めてください。:
Kubernetesのバージョン: kubectlのバージョン 環境の詳細: クラウドプロバイダー、OSのディストリビューション、選択したネットワーキングと構成、およびDockerのバージョン 問題を再現するための詳細な手順 関連するログ /sig windowsでIssueにコメントして、Issueにsig/windowsのタグを付けて、SIG-Windowsメンバーが気付くようにします次の項目 ロードマップには多くの機能があります。高レベルの簡略リストを以下に示しますが、ロードマッププロジェクト を見て、貢献すること によってWindowsサポートを改善することをお勧めします。
Hyper-V分離 Hyper-V分離はKubernetesで以下のWindowsコンテナのユースケースを実現するために必要です。
Pod間のハイパーバイザーベースの分離により、セキュリティを強化 下位互換性により、コンテナの再構築を必要とせずにノードで新しいWindows Serverバージョンを実行 Podの特定のCPU/NUMA設定 メモリの分離と予約 既存のHyper-V分離サポートは、v1.10の試験的な機能であり、上記のCRI-ContainerD機能とRuntimeClass機能を優先して将来廃止される予定です。現在の機能を使用してHyper-V分離コンテナを作成するには、kubeletのフィーチャーゲートをHyperVContainer=trueで開始し、Podにアノテーションexperimental.windows.kubernetes.io/isolation-type=hypervを含める必要があります。実験的リリースでは、この機能はPodごとに1つのコンテナに制限されています。
apiVersion : apps/v1
kind : Deployment
metadata :
name : iis
spec :
selector :
matchLabels :
app : iis
replicas : 3
template :
metadata :
labels :
app : iis
annotations :
experimental.windows.kubernetes.io/isolation-type : hyperv
spec :
containers :
- name : iis
image : microsoft/iis
ports :
- containerPort : 80
kubeadmとクラスターAPIを使用したデプロイ Kubeadmは、ユーザーがKubernetesクラスターをデプロイするための事実上の標準になりつつあります。kubeadmのWindowsノードのサポートは進行中ですが、ガイドはすでにここ で利用可能です。Windowsノードが適切にプロビジョニングされるように、クラスターAPIにも投資しています。
その他の主な機能 グループ管理サービスアカウントのベータサポート その他のCNI その他のストレージプラグイン 3.4.2 - KubernetesでWindowsコンテナをスケジュールするためのガイド Windowsアプリケーションは、多くの組織で実行されるサービスとアプリケーションの大部分を占めます。このガイドでは、KubernetesでWindowsコンテナを構成してデプロイする手順について説明します。
目的 WindowsノードでWindowsコンテナを実行するサンプルのDeploymentを構成します (オプション)Group Managed Service Accounts(GMSA)を使用してPodのActive Directory IDを構成します 始める前に はじめに:Windowsコンテナのデプロイ WindowsコンテナをKubernetesにデプロイするには、最初にサンプルアプリケーションを作成する必要があります。以下のYAMLファイルの例では、簡単なウェブサーバーアプリケーションを作成しています。以下の内容でwin-webserver.yamlという名前のサービススペックを作成します。:
apiVersion : v1
kind : Service
metadata :
name : win-webserver
labels :
app : win-webserver
spec :
ports :
# このサービスが提供するポート
- port : 80
targetPort : 80
selector :
app : win-webserver
type : NodePort
---
apiVersion : apps/v1
kind : Deployment
metadata :
labels :
app : win-webserver
name : win-webserver
spec :
replicas : 2
selector :
matchLabels :
app : win-webserver
template :
metadata :
labels :
app : win-webserver
name : win-webserver
spec :
containers :
- name : windowswebserver
image : mcr.microsoft.com/windows/servercore:ltsc2019
command :
- powershell.exe
- -command
- "<#code used from https://gist.github.com/19WAS85/5424431#> ; $$listener = New-Object System.Net.HttpListener ; $$listener.Prefixes.Add('http://*:80/') ; $$listener.Start() ; $$callerCounts = @{} ; Write-Host('Listening at http://*:80/') ; while ($$listener.IsListening) { ;$$context = $$listener.GetContext() ;$$requestUrl = $$context.Request.Url ;$$clientIP = $$context.Request.RemoteEndPoint.Address ;$$response = $$context.Response ;Write-Host '' ;Write-Host('> {0}' -f $$requestUrl) ; ;$$count = 1 ;$$k=$$callerCounts.Get_Item($$clientIP) ;if ($$k -ne $$null) { $$count = $$k } ;$$callerCounts.Set_Item($$clientIP, $$count) ;$$ip=(Get-NetAdapter | Get-NetIpAddress); $$header='<html><body><H1>Windows Container Web Server</H1>' ;$$callerCountsString='' ;$$callerCounts.Keys | % { $$callerCountsString='<p>IP {0} callerCount {1} ' -f $$ip[1].IPAddress,$$callerCounts.Item($$_) } ;$$footer='</body></html>' ;$$content='{0}{1}{2}' -f $$header,$$callerCountsString,$$footer ;Write-Output $$content ;$$buffer = [System.Text.Encoding]::UTF8.GetBytes($$content) ;$$response.ContentLength64 = $$buffer.Length ;$$response.OutputStream.Write($$buffer, 0, $$buffer.Length) ;$$response.Close() ;$$responseStatus = $$response.StatusCode ;Write-Host('< {0}' -f $$responseStatus) } ; "
nodeSelector :
kubernetes.io/os : windows
備考: ポートマッピングもサポートされていますが、この例では簡単にするために、コンテナポート80がサービスに直接公開されています。すべてのノードが正常であることを確認します。:
Serviceをデプロイして、Podの更新を確認します。:
kubectl apply -f win-webserver.yaml
kubectl get pods -o wide -w
Serviceが正しくデプロイされると、両方のPodがReadyとして表示されます。watch状態のコマンドを終了するには、Ctrl + Cを押します。
デプロイが成功したことを確認します。検証するために行うこと:
WindowsノードのPodごとの2つのコンテナにdocker psします Linuxマスターからリストされた2つのPodにkubectl get podsします ネットワークを介したノードとPod間通信、LinuxマスターからのPod IPのポート80に向けてcurlして、ウェブサーバーの応答をチェックします docker execまたはkubectl execを使用したPod間通信、Pod間(および複数のWindowsノードがある場合はホスト間)へのpingします ServiceからPodへの通信、Linuxマスターおよび個々のPodからの仮想Service IP(kubectl get servicesで表示される)にcurlします サービスディスカバリ、Kubernetesのdefault DNS suffix と共にService名にcurlします Inbound connectivity, curl the NodePort from the Linux master or machines outside of the cluster インバウンド接続、Linuxマスターまたはクラスター外のマシンからNodePortにcurlします アウトバウンド接続、kubectl execを使用したPod内からの外部IPにcurlします
備考: 今のところ、Windowsネットワークスタックのプラットフォーム制限のため、Windowsコンテナホストは、ホストされているサービスのIPにアクセスできません。Service IPにアクセスできるのは、Windows Podだけです。可観測性 ワークロードからのログキャプチャ ログは可観測性の重要な要素です。これにより、ユーザーはワークロードの運用面に関する洞察を得ることができ、問題のトラブルシューティングの主要な要素になります。WindowsコンテナとWindowsコンテナ内のワークロードの動作はLinuxコンテナとは異なるため、ユーザーはログの収集に苦労し、運用の可視性が制限されていました。たとえば、Windowsワークロードは通常、ETW(Windowsのイベントトレース)にログを記録するか、アプリケーションイベントログにエントリをプッシュするように構成されます。MicrosoftのオープンソースツールであるLogMonitor は、Windowsコンテナ内の構成されたログソースを監視するための推奨方法です。LogMonitorは、イベントログ、ETWプロバイダー、カスタムアプリケーションログのモニタリングをサポートしており、それらをSTDOUTにパイプして、kubectl logs <pod>で使用できます。
LogMonitor GitHubページの指示に従って、バイナリと構成ファイルをすべてのコンテナにコピーして、LogMonitorがログをSTDOUTにプッシュするために必要なエントリーポイントを追加します。
構成可能なコンテナのユーザー名の使用 Kubernetes v1.16以降、Windowsコンテナは、イメージのデフォルトとは異なるユーザー名でエントリーポイントとプロセスを実行するように構成できます。これが達成される方法は、Linuxコンテナで行われる方法とは少し異なります。詳しくはこちら .
Group Managed Service AccountsによるワークロードIDの管理 Kubernetes v1.14以降、Windowsコンテナワークロードは、Group Managed Service Accounts(GMSA)を使用するように構成できます。Group Managed Service Accountsは、自動パスワード管理、簡略化されたサービスプリンシパル名(SPN)管理、および複数のサーバー間で他の管理者に管理を委任する機能を提供する特定の種類のActive Directoryアカウントです。GMSAで構成されたコンテナは、GMSAで構成されたIDを保持しながら、外部Active Directoryドメインリソースにアクセスできます。Windowsコンテナ用のGMSAの構成と使用の詳細はこちら 。
TaintsとTolerations 今日のユーザーは、LinuxとWindowsのワークロードをそれぞれのOS固有のノードで維持するために、Taintsとノードセレクターのいくつかの組み合わせを使用する必要があります。これはおそらくWindowsユーザーにのみ負担をかけます。推奨されるアプローチの概要を以下に示します。主な目標の1つは、このアプローチによって既存のLinuxワークロードの互換性が損なわれないようにすることです。
OS固有のワークロードが適切なコンテナホストに確実に到達するようにする ユーザーは、TaintsとTolerationsを使用して、Windowsコンテナを適切なホストでスケジュールできるようにすることができます。現在、すべてのKubernetesノードには次のデフォルトラベルがあります。:
kubernetes.io/os = [windows|linux] kubernetes.io/arch = [amd64|arm64|...] Podの仕様で"kubernetes.io/os": windowsのようなnodeSelectorが指定されていない場合、PodをWindowsまたはLinuxの任意のホストでスケジュールすることができます。WindowsコンテナはWindowsでのみ実行でき、LinuxコンテナはLinuxでのみ実行できるため、これは問題になる可能性があります。ベストプラクティスは、nodeSelectorを使用することです。
ただし、多くの場合、ユーザーには既存の多数のLinuxコンテナのdeployment、およびコミュニティHelmチャートのような既成構成のエコシステムやOperatorのようなプログラム的にPodを生成するケースがあることを理解しています。このような状況では、nodeSelectorsを追加するための構成変更をためらう可能性があります。代替策は、Taintsを使用することです。kubeletは登録中にTaintsを設定できるため、Windowsだけで実行する時に自動的にTaintを追加するように簡単に変更できます。
例:--register-with-taints='os=windows:NoSchedule'
すべてのWindowsノードにTaintを追加することにより、それらには何もスケジュールされません(既存のLinuxPodを含む)。Windows PodがWindowsノードでスケジュールされるためには、nodeSelectorがWindowsを選択することと、適切にマッチするTolerationが必要です。
nodeSelector :
kubernetes.io/os : windows
node.kubernetes.io/windows-build : '10.0.17763'
tolerations :
- key : "os"
operator : "Equal"
value : "windows"
effect : "NoSchedule"
同じクラスター内の複数Windowsバージョンの管理 各Podで使用されるWindows Serverのバージョンは、ノードのバージョンと一致している必要があります。
同じクラスター内で複数のWindows Serverバージョンを使用したい場合は、追加のノードラベルとnodeSelectorsを設定する必要があります。
Kubernetes 1.17では、これを簡単するために新しいラベルnode.kubernetes.io/windows-buildが自動的に追加されます。古いバージョンを実行している場合は、このラベルをWindowsノードに手動で追加することをお勧めします。
このラベルは、互換性のために一致する必要があるWindowsのメジャー、マイナー、およびビルド番号を反映しています。以下は、Windows Serverの各バージョンで現在使用されている値です。
製品番号 ビルド番号 Windows Server 2019 10.0.17763 Windows Server version 1809 10.0.17763 Windows Server version 1903 10.0.18362
RuntimeClassによる簡素化 RuntimeClass は、TaintsとTolerationsを使用するプロセスを簡略化するために使用できます。クラスター管理者は、これらのTaintsとTolerationsをカプセル化するために使用するRuntimeClassオブジェクトを作成できます。
このファイルをruntimeClasses.ymlに保存します。これには、Windows OS、アーキテクチャ、およびバージョンに適切なnodeSelectorが含まれています。 apiVersion : node.k8s.io/v1beta1
kind : RuntimeClass
metadata :
name : windows-2019
handler : 'docker'
scheduling :
nodeSelector :
kubernetes.io/os : 'windows'
kubernetes.io/arch : 'amd64'
node.kubernetes.io/windows-build : '10.0.17763'
tolerations :
- effect : NoSchedule
key : os
operator : Equal
value : "windows"
クラスター管理者として使用するkubectl create -f runtimeClasses.ymlを実行します Podの仕様に応じてruntimeClassName: windows-2019を追加します 例:
apiVersion : apps/v1
kind : Deployment
metadata :
name : iis-2019
labels :
app : iis-2019
spec :
replicas : 1
template :
metadata :
name : iis-2019
labels :
app : iis-2019
spec :
runtimeClassName : windows-2019
containers :
- name : iis
image : mcr.microsoft.com/windows/servercore/iis:windowsservercore-ltsc2019
resources :
limits :
cpu : 1
memory : 800Mi
requests :
cpu : .1
memory : 300Mi
ports :
- containerPort : 80
selector :
matchLabels :
app : iis-2019
---
apiVersion : v1
kind : Service
metadata :
name : iis
spec :
type : LoadBalancer
ports :
- protocol : TCP
port : 80
selector :
app : iis-2019
3.5 - ワークロード Kubernetesにおけるデプロイ可能な最小のオブジェクトであるPodと、高レベルな抽象化がPodの実行を助けることを理解します。
ワークロードとは、Kubernetes上で実行中のアプリケーションです。
ワークロードが1つのコンポーネントからなる場合でも、複数のコンポーネントが協調して動作する場合でも、KubernetesではそれらはPod の集合として実行されます。Kubernetesでは、Podはクラスター上で実行中のコンテナ の集合として表されます。
Podには定義されたライフサイクルがあります。たとえば、一度Podがクラスター上で実行中になると、そのPodが実行中のノード 上で深刻な障害が起こったとき、そのノード上のすべてのPodは停止してしまうことになります。Kubernetesではそのようなレベルの障害を最終的なものとして扱うため、たとえノードが後で復元したとしても、ユーザーは新しいPodを作成し直す必要があります。
しかし、生活をかなり楽にするためには、それぞれのPodを直接管理する必要はありません。ワークロードリソース を利用すれば、あなたの代わりにPodの集合の管理を行ってもらえます。これらのリソースはあなたが指定した状態に一致するようにコントローラー を設定し、正しい種類のPodが正しい数だけ実行中になることを保証してくれます。
ワークロードリソースには、次のような種類があります。
多少関連のある2種類の補助的な概念もあります。
次の項目 各リソースについて読む以外にも、以下のページでそれぞれのワークロードに関連する特定のタスクについて学ぶことができます。
アプリケーションが実行できるようになったら、インターネット上で公開したくなるかもしれません。その場合には、Service として公開したり、ウェブアプリケーションだけの場合、Ingress を使用することができます。
コードを設定から分離するKubernetesのしくみについて学ぶには、設定 を読んでください。
3.5.1 - Pod Pod は、Kubernetes内で作成・管理できるコンピューティングの最小のデプロイ可能なユニットです。
Pod (Podという名前は、たとえばクジラの群れ(pod of whales)やえんどう豆のさや(pea pod)などの表現と同じような意味です)は、1つまたは複数のコンテナ のグループであり、ストレージやネットワークの共有リソースを持ち、コンテナの実行方法に関する仕様を持っています。同じPodに含まれるリソースは、常に同じ場所で同時にスケジューリングされ、共有されたコンテキストの中で実行されます。Podはアプリケーションに特化した「論理的なホスト」をモデル化します。つまり、1つのPod内には、1つまたは複数の比較的密に結合されたアプリケーションコンテナが含まれます。クラウド外の文脈で説明すると、アプリケーションが同じ物理ホストや同じバーチャルマシンで実行されることが、クラウドアプリケーションの場合には同じ論理ホスト上で実行されることに相当します。
アプリケーションコンテナと同様に、Podでも、Podのスタートアップ時に実行されるinitコンテナ を含めることができます。また、クラスターで利用できる場合には、エフェメラルコンテナ を注入してデバッグすることもできます。
Podとは何か? 備考: KubernetesはDockerだけでなく複数の
コンテナランタイム をサポートしていますが、
Docker が最も一般的に知られたランタイムであるため、Docker由来の用語を使ってPodを説明するのが理解の助けとなります。
Podの共有コンテキストは、Dockerコンテナを隔離するのに使われているのと同じ、Linuxのnamespaces、cgroups、場合によっては他の隔離技術の集合を用いて作られます。Podのコンテキスト内では、各アプリケーションが追加の準隔離技術を適用することもあります。
Dockerの概念を使って説明すると、Podは共有の名前空間と共有ファイルシステムのボリュームを持つDockerコンテナのグループに似ています。
Podを使用する 以下は、nginx:1.14.2イメージが実行されるコンテナからなるPodの例を記載しています。
apiVersion : v1
kind : Pod
metadata :
name : nginx
spec :
containers :
- name : nginx
image : nginx:1.14.2
ports :
- containerPort : 80
上記のようなPodを作成するには、以下のコマンドを実行します:
kubectl apply -f https://k8s.io/examples/pods/simple-pod.yaml
Podは通常、直接作成されず、ワークロードリソースで作成されます。ワークロードリソースでPodを作成する方法の詳細については、Podを利用する を参照してください。
Podを管理するためのワークロードリソース 通常、たとえ単一のコンテナしか持たないシングルトンのPodだとしても、自分でPodを直接作成する必要はありません。その代わりに、Deployment やJob などのワークロードリソースを使用してPodを作成します。もしPodが状態を保持する必要がある場合は、StatefulSet リソースを使用することを検討してください。
Kubernetesクラスター内のPodは、主に次の2種類の方法で使われます。
単一のコンテナを稼働させるPod 。「1Pod1コンテナ」構成のモデルは、Kubernetesでは最も一般的なユースケースです。このケースでは、ユーザーはPodを単一のコンテナのラッパーとして考えることができます。Kubernetesはコンテナを直接管理するのではなく、Podを管理します。
協調して稼働させる必要がある複数のコンテナを稼働させるPod 。単一のPodは、密に結合してリソースを共有する必要があるような、同じ場所で稼働する複数のコンテナからなるアプリケーションをカプセル化することもできます。これらの同じ場所で稼働するコンテナ群は、単一のまとまりのあるサービスのユニットを構成します。たとえば、1つのコンテナが共有ボリュームからファイルをパブリックに配信し、別のサイドカー コンテナがそれらのファイルを更新するという構成が考えられます。Podはこれらの複数のコンテナ、ストレージリソース、一時的なネットワークIDなどを、単一のユニットとしてまとめます。
備考: 複数のコンテナを同じ場所で同時に管理するように単一のPod内にグループ化するのは、比較的高度なユースケースです。このパターンを使用するのは、コンテナが密に結合しているような特定のインスタンス内でのみにするべきです。各Podは、与えられたアプリケーションの単一のインスタンスを稼働するためのものです。もしユーザーのアプリケーションを水平にスケールさせたい場合(例: 複数インスタンスを稼働させる)、複数のPodを使うべきです。1つのPodは各インスタンスに対応しています。Kubernetesでは、これは一般的にレプリケーション と呼ばれます。レプリケーションされたPodは、通常ワークロードリソースと、それに対応するコントローラー によって、作成・管理されます。
Kubernetesがワークロードリソースとそのコントローラーを活用して、スケーラブルで自動回復するアプリケーションを実装する方法については、詳しくはPodとコントローラー を参照してください。
Podが複数のコンテナを管理する方法 Podは、まとまりの強いサービスのユニットを構成する、複数の協調する(コンテナとして実行される)プロセスをサポートするために設計されました。単一のPod内の複数のコンテナは、クラスター内の同じ物理または仮想マシン上で、自動的に同じ場所に配置・スケジューリングされます。コンテナ間では、リソースや依存関係を共有したり、お互いに通信したり、停止するときにはタイミングや方法を協調して実行できます。
たとえば、あるコンテナが共有ボリューム内のファイルを配信するウェブサーバーとして動作し、別の「サイドカー」コンテナがリモートのリソースからファイルをアップデートするような構成が考えられます。この構成を以下のダイアグラムに示します。
Podによっては、appコンテナ に加えてinitコンテナ を持っている場合があります。initコンテナはappコンテナが起動する前に実行・完了するコンテナです。
Podは、Podを構成する複数のコンテナに対して、ネットワーク とストレージ の2種類の共有リソースを提供します。
Podを利用する 通常Kubernetesでは、たとえ単一のコンテナしか持たないシングルトンのPodだとしても、個別のPodを直接作成することはめったにありません。その理由は、Podがある程度一時的で使い捨てできる存在として設計されているためです。Podが作成されると(あなたが直接作成した場合でも、コントローラー が間接的に作成した場合でも)、新しいPodはクラスター内のノード 上で実行されるようにスケジューリングされます。Podは、実行が完了するか、Podオブジェクトが削除されるか、リソース不足によって強制退去 されるか、ノードが停止するまで、そのノード上にとどまります。
備考: Pod内のコンテナの再起動とPodの再起動を混同しないでください。Podはプロセスではなく、コンテナが実行するための環境です。Podは削除されるまでは残り続けます。Podオブジェクトのためのマニフェストを作成したときは、指定したPodの名前が有効なDNSサブドメイン名 であることを確認してください。
Pod OS FEATURE STATE:
Kubernetes v1.25 [stable]
.spec.os.nameフィールドでwindowsかlinuxのいずれかを設定し、Podを実行させたいOSを指定する必要があります。Kubernetesは今のところ、この2つのOSだけサポートしています。将来的には増える可能性があります。
Kubernetes v1.35では、このフィールドに設定した値はPodのスケジューリング に影響を与えません。.spec.os.nameを設定することで、Pod OSに権限を認証することができ、バリデーションにも使用されます。kubeletが実行されているノードのOSが、指定されたPod OSと異なる場合、kubeletはPodの実行を拒否します。
Podセキュリティの標準 もこのフィールドを使用し、指定したOSと関係ないポリシーの適用を回避しています。
Podとコンテナコントローラー ワークロードリソースは、複数のPodを作成・管理するために利用できます。リソースに対応するコントローラーが、複製やロールアウトを扱い、Podの障害時には自動回復を行います。たとえば、あるノードに障害が発生した場合、コントローラーはそのノードの動作が停止したことを検知し、代わりのPodを作成します。そして、スケジューラーが代わりのPodを健全なノード上に配置します。
以下に、1つ以上のPodを管理するワークロードリソースの一例をあげます。
Podテンプレート workload リソース向けのコントローラーは、PodをPodテンプレート を元に作成し、あなたの代わりにPodを管理してくれます。
PodTemplateはPodを作成するための仕様で、Deployment 、Job 、DaemonSet などのワークロードリソースの中に含まれています。
ワークロードリソースに対応する各コントローラーは、ワークロードオブジェクト内にあるPodTemplateを使用して実際のPodを作成します。PodTemplateは、アプリを実行するために使われるワークロードリソースがどんな種類のものであれ、その目的の状態の一部を構成するものです。
以下は、単純なJobのマニフェストの一例で、1つのコンテナを実行するtemplateがあります。Pod内のコンテナはメッセージを出力した後、一時停止します。
apiVersion : batch/v1
kind : Job
metadata :
name : hello
spec :
template :
# これがPodテンプレートです
spec :
containers :
- name : hello
image : busybox:1.28
command : ['sh' , '-c' , 'echo "Hello, Kubernetes!" && sleep 3600' ]
restartPolicy : OnFailure
# Podテンプレートはここまでです
Podテンプレートを修正するか新しいPodに切り替えたとしても、すでに存在するPodには直接の影響はありません。ワークロードリソース内のPodテンプレートを変更すると、そのリソースは更新されたテンプレートを使用して代わりとなるPodを作成する必要があります。
たとえば、StatefulSetコントローラーは、各StatefulSetごとに、実行中のPodが現在のPodテンプレートに一致することを保証します。Podテンプレートを変更するためにStatefulSetを編集すると、StatefulSetは更新されたテンプレートを元にした新しいPodを作成するようになります。最終的に、すべての古いPodが新しいPodで置き換えられ、更新は完了します。
各ワークロードリソースは、Podテンプレートへの変更を処理するための独自のルールを実装しています。特にStatefulSetについて更に詳しく知りたい場合は、StatefulSetの基本チュートリアル内のアップデート戦略 を読んでください。
ノード上では、kubelet はPodテンプレートに関する詳細について監視や管理を直接行うわけではありません。こうした詳細は抽象化されています。こうした抽象化や関心の分離のおかげでシステムのセマンティクスが単純化され、既存のコードを変更せずにクラスターの動作を容易に拡張できるようになっているのです。
Podの更新と取替 前のセクションで述べたように、ワークロードリソースのPodテンプレートが変更されると、コントローラーは既存のPodを更新したりパッチを適用したりするのではなく、更新されたテンプレートに基づいて新しいPodを作成します。
KubernetesはPodを直接管理することを妨げません。実行中のPodの一部のフィールドをその場で更新することが可能です。しかし、patchreplace
Podのメタデータのほとんどは固定されたものです。たとえばnamespace、name、uidまたはcreationTimestampフィールドは変更できません。generationフィールドは特別で、現在の値を増加させる更新のみを受け付けます。
metadata.deletionTimestampが設定されている場合、metadata.finalizersリストに新しい項目を追加することはできません。
Podの更新ではspec.containers[*].image、spec.initContainers[*].image、spec.activeDeadlineSecondsまたはspec.tolerations以外のフィールドを変更してはなりません。
spec.tolerationsについては新しい項目のみを追加することができます。
spec.activeDeadlineSecondsフィールドを更新する場合、2種類の更新が可能です:
未割り当てのフィールドに正の数を設定する 現在の値から負の数でない、より小さい数に更新する リソースの共有と通信 Podは、データの共有と構成するコンテナ間での通信を可能にします。
Pod内のストレージ Podでは、共有ストレージであるボリューム の集合を指定できます。Pod内のすべてのコンテナは共有ボリュームにアクセスできるため、それら複数のコンテナでデータを共有できるようになります。また、ボリュームを利用すれば、Pod内のコンテナの1つに再起動が必要になった場合にも、Pod内の永続化データを保持し続けられるようにできます。Kubernetesの共有ストレージの実装方法とPodで利用できるようにする方法に関するさらに詳しい情報は、ストレージ を読んでください。
Podネットワーク 各Podには、各アドレスファミリーごとにユニークなIPアドレスが割り当てられます。Pod内のすべてのコンテナは、IPアドレスとネットワークポートを含むネットワーク名前空間を共有します。Podの中では(かつその場合にのみ )、そのPod内のコンテナはlocalhostを使用して他のコンテナと通信できます。Podの内部にあるコンテナがPodの外部にある エンティティと通信する場合、(ポートなどの)共有ネットワークリソースの使い方をコンテナ間で調整しなければなりません。Pod内では、コンテナはIPアドレスとポートの空間を共有するため、localhostで他のコンテナにアクセスできます。また、Pod内のコンテナは、SystemVのセマフォやPOSIXの共有メモリなど、標準のプロセス間通信を使って他のコンテナと通信することもできます。異なるPod内のコンテナは異なるIPアドレスを持つため、特別な設定をしない限り、OSレベルIPCで通信することはできません。異なるPod上で実行中のコンテナ間でやり取りをしたい場合は、IPネットワークを使用して通信できます。
Pod内のコンテナは、システムのhostnameがPodに設定したnameと同一であると考えます。ネットワークについての詳しい情報は、ネットワーク で説明しています。
コンテナの特権モード Linuxでは、Pod内のどんなコンテナも、privilegedフラグをコンテナのspecのsecurity context に設定することで、特権モード(privileged mode)を有効にできます。これは、ネットワークスタックの操作やハードウェアデバイスへのアクセスなど、オペレーティングシステムの管理者の権限が必要なコンテナの場合に役に立ちます。
WindowsHostProcessContainers機能を有効にしたクラスターの場合、Pod仕様のsecurityContextにwindowsOptions.hostProcessフラグを設定することで、Windows HostProcess Pod を作成することが可能です。これらのPod内のすべてのコンテナは、Windows HostProcessコンテナとして実行する必要があります。HostProcess Podはホスト上で直接実行され、Linuxの特権コンテナで行われるような管理作業を行うのにも使用できます。
備考: この設定を有効にするには、
コンテナランタイム が特権コンテナの概念をサポートしていなければなりません。
static Pod static Pod は、APIサーバー には管理されない、特定のノード上でkubeletデーモンによって直接管理されるPodのことです。大部分のPodはコントロールプレーン(たとえばDeployment )によって管理されますが、static Podの場合はkubeletが各static Podを直接管理します(障害時には再起動します)。
static Podは常に特定のノード上の1つのKubelet に紐付けられます。static Podの主な用途は、セルフホストのコントロールプレーンを実行すること、言い換えると、kubeletを使用して個別のコントロールプレーンコンポーネント を管理することです。
kubeletは自動的にKubernetes APIサーバー上に各static Podに対応するミラーPod の作成を試みます。つまり、ノード上で実行中のPodはAPIサーバー上でも見えるようになるけれども、APIサーバー上から制御はできないということです。
コンテナのProbe Probe はkubeletがコンテナに対して行う定期診断です。診断を実行するために、kubeletはさまざまなアクションを実行できます:
ExecAction (コンテナランタイムの助けを借りて実行)TCPSocketAction (kubeletにより直接チェック)HTTPGetAction (kubeletにより直接チェック)更に詳しく知りたい場合は、PodのライフサイクルドキュメントにあるProbe を読んでください。
次の項目 Kubernetesが共通のPod APIを他のリソース内(たとえばStatefulSet やDeployment など)にラッピングしている理由の文脈を理解するためには、Kubernetes以前から存在する以下のような既存技術について読むのが助けになります。
3.5.1.1 - Podのライフサイクル このページではPodのライフサイクルについて説明します。Podは定義されたライフサイクルに従い Pendingフェーズ から始まり、少なくとも1つのプライマリーコンテナが正常に開始した場合はRunningを経由し、次に失敗により終了したコンテナの有無に応じて、SucceededまたはFailedフェーズを経由します。
Podの実行中、kubeletはコンテナを再起動して、ある種の障害を処理できます。Pod内で、Kubernetesはさまざまなコンテナのステータス を追跡して、回復させるためのアクションを決定します。
Kubernetes APIでは、Podには仕様と実際のステータスの両方があります。Podオブジェクトのステータスは、PodのCondition のセットで構成されます。カスタムのReadiness情報 をPodのConditionデータに挿入することもできます。
Podはその生存期間に1回だけスケジューリング されます。PodがNodeにスケジュール(割り当て)されると、Podは停止または終了 するまでそのNode上で実行されます。
Podのライフタイム 個々のアプリケーションコンテナと同様に、Podは(永続的ではなく)比較的短期間の存在と捉えられます。Podが作成されると、一意のID(UID )が割り当てられ、(再起動ポリシーに従って)終了または削除されるまでNodeで実行されるようにスケジュールされます。ノード が停止した場合、そのNodeにスケジュールされたPodは、タイムアウト時間の経過後に削除 されます。
Pod自体は、自己修復しません。Podがnode にスケジュールされ、その後に失敗した場合、Podは削除されます。同様に、リソースの不足またはNodeのメンテナンスによりPodはNodeから立ち退きます。Kubernetesは、比較的使い捨てのPodインスタンスの管理作業を処理する、controller と呼ばれる上位レベルの抽象化を使用します。
特定のPod(UIDで定義)は新しいNodeに"再スケジュール"されません。代わりに、必要に応じて同じ名前で、新しいUIDを持つ同一のPodに置き換えることができます。
volume など、Podと同じ存続期間を持つものがあると言われる場合、それは(そのUIDを持つ)Podが存在する限り存在することを意味します。そのPodが何らかの理由で削除された場合、たとえ同じ代替物が作成されたとしても、関連するもの(例えばボリューム)も同様に破壊されて再作成されます。
Podの図 file puller(ファイル取得コンテナ)とWebサーバーを含むマルチコンテナのPod。コンテナ間の共有ストレージとして永続ボリュームを使用しています。
Podのフェーズ Podのstatus項目はPodStatus オブジェクトで、それはphaseのフィールドがあります。
Podのフェーズは、そのPodがライフサイクルのどの状態にあるかを、簡単かつ高レベルにまとめたものです。このフェーズはコンテナやPodの状態を包括的にまとめることを目的としたものではなく、また包括的なステートマシンでもありません。
Podの各フェーズの値と意味は厳重に守られています。ここに記載されているもの以外にphaseの値は存在しないと思ってください。
これらがphaseの取りうる値です。
値 概要 PendingPodがKubernetesクラスターによって承認されましたが、1つ以上のコンテナがセットアップされて稼働する準備ができていません。これには、スケジュールされるまでの時間と、ネットワーク経由でイメージをダウンロードするための時間などが含まれます。 RunningPodがNodeにバインドされ、すべてのコンテナが作成されました。少なくとも1つのコンテナがまだ実行されているか、開始または再起動中です。 SucceededPod内のすべてのコンテナが正常に終了し、再起動されません。 FailedPod内のすべてのコンテナが終了し、少なくとも1つのコンテナが異常終了しました。つまり、コンテナはゼロ以外のステータスで終了したか、システムによって終了されました。 Unknown何らかの理由によりPodの状態を取得できませんでした。このフェーズは通常はPodのホストとの通信エラーにより発生します。
備考: Podの削除中に、kubectlコマンドには
Terminatingが出力されることがあります。この
Terminatingステータスは、Podのフェーズではありません。Podには、正常に終了するための期間を与えられており、デフォルトは30秒です。
--forceフラグを使用して、
Podを強制的に削除する ことができます。
Nodeが停止するか、クラスターの残りの部分から切断された場合、Kubernetesは失われたNode上のすべてのPodのPhaseをFailedに設定するためのポリシーを適用します。
コンテナのステータス Pod全体のフェーズ と同様に、KubernetesはPod内の各コンテナの状態を追跡します。container lifecycle hooks を使用して、コンテナのライフサイクルの特定のポイントで実行するイベントをトリガーできます。
Podがscheduler によってNodeに割り当てられると、kubeletはcontainer runtime を使用してコンテナの作成を開始します。コンテナの状態はWaiting、RunningまたはTerminatedの3ついずれかです。
Podのコンテナの状態を確認するにはkubectl describe pod [POD_NAME]のコマンドを使用します。Pod内のコンテナごとにStateの項目として表示されます。
各状態の意味は次のとおりです。
WaitingコンテナがRunningまたはTerminatedのいずれの状態でもない場合コンテナはWaitingの状態になります。Waiting状態のコンテナは引き続きコンテナイメージレジストリからイメージを取得したりSecret を適用したりするなど必要な操作を実行します。Waiting状態のコンテナを持つPodに対してkubectlコマンドを使用すると、そのコンテナがWaitingの状態である理由の要約が表示されます。
RunningRunning状態はコンテナが問題なく実行されていることを示します。postStartフックが構成されていた場合、それはすでに実行が完了しています。Running状態のコンテナを持つPodに対してkubectlコマンドを使用すると、そのコンテナがRunning状態になった時刻が表示されます。
TerminatedTerminated状態のコンテナは実行されて、完了したときまたは何らかの理由で失敗したことを示します。Terminated状態のコンテナを持つPodに対してkubectlコマンドを使用すると、いずれにせよ理由と終了コード、コンテナの開始時刻と終了時刻が表示されます。
コンテナがTerminatedに入る前にpreStopフックがあれば実行されます。
コンテナの再起動ポリシー Podのspecには、Always、OnFailure、またはNeverのいずれかの値を持つrestartPolicyフィールドがあります。デフォルト値はAlwaysです。
restartPolicyは、Pod内のすべてのコンテナに適用されます。restartPolicyは、同じNode上のkubeletによるコンテナの再起動のみを参照します。Pod内のコンテナが終了した後、kubeletは5分を上限とする指数バックオフ遅延(10秒、20秒、40秒...)でコンテナを再起動します。コンテナが10分間実行されると、kubeletはコンテナの再起動バックオフタイマーをリセットします。
PodのCondition PodにはPodStatusがあります。それにはPodが成功したかどうかの情報を持つPodCondition の配列が含まれています。kubeletは、下記のPodConditionを管理します:
PodScheduled: PodがNodeにスケジュールされました。PodHasNetwork: (アルファ版機能; 明示的に有効 にしなければならない) Podサンドボックスが正常に作成され、ネットワークの設定が完了しました。ContainersReady: Pod内のすべてのコンテナが準備できた状態です。Initialized: すべてのInitコンテナ が正常に終了しました。Ready: Podはリクエストを処理でき、一致するすべてのサービスの負荷分散プールに追加されます。フィールド名 内容 typeこのPodの状態の名前です。 statusその状態が適用可能かどうか示します。可能な値は"True"、"False"、"Unknown"のうちのいずれかです。 lastProbeTimePod Conditionが最後に確認されたときのタイムスタンプが表示されます。 lastTransitionTime最後にPodのステータスの遷移があった際のタイムスタンプが表示されます。 reason最後の状態遷移の理由を示す、機械可読のアッパーキャメルケースのテキストです。 messageステータスの遷移に関する詳細を示す人間向けのメッセージです。
PodのReadiness FEATURE STATE:
Kubernetes v1.14 [stable]
追加のフィードバックやシグナルをPodStatus:Pod readiness に注入できるようにします。これを使用するには、PodのspecでreadinessGatesを設定して、kubeletがPodのReadinessを評価する追加の状態のリストを指定します。
ReadinessゲートはPodのstatus.conditionsフィールドの現在の状態によって決まります。KubernetesがPodのstatus.conditionsフィールドでそのような状態を発見できない場合、ステータスはデフォルトでFalseになります。
以下はその例です。
Kind : Pod
...
spec :
readinessGates :
- conditionType : "www.example.com/feature-1"
status :
conditions :
- type : Ready # これはビルトインのPodCondition
status : "False"
lastProbeTime : null
lastTransitionTime : 2018-01-01T00:00:00Z
- type : "www.example.com/feature-1" # 追加のPodCondition
status : "False"
lastProbeTime : null
lastTransitionTime : 2018-01-01T00:00:00Z
containerStatuses :
- containerID : docker://abcd...
ready : true
...
PodのConditionは、Kubernetesのlabel key format に準拠している必要があります。
PodのReadinessの状態 kubectl patchコマンドはオブジェクトステータスのパッチ適用をまだサポートしていません。Podにこれらのstatus.conditionsを設定するには、アプリケーションとoperators はPATCHアクションを使用する必要があります。Kubernetes client library を使用して、PodのReadinessのためにカスタムのPodのConditionを設定するコードを記述できます。
カスタムのPodのConditionが導入されるとPodは次の両方の条件に当てはまる場合のみ 準備できていると評価されます:
Pod内のすべてのコンテナが準備完了している。 ReadinessGatesで指定された条件が全てTrueである。Podのコンテナは準備完了ですが、少なくとも1つのカスタムのConditionが欠落しているか「False」の場合、kubeletはPodのCondition をContainersReadyに設定します。
PodのネットワークのReadiness FEATURE STATE:
Kubernetes v1.25 [alpha]
Podがノードにスケジュールされた後、kubeletによって承認され、任意のボリュームがマウントされる必要があります。これらのフェーズが完了すると、kubeletはコンテナランタイム(コンテナランタイムインターフェース(CRI) を使用)と連携して、ランタイムサンドボックスのセットアップとPodのネットワークを構成します。もしPodHasNetworkConditionフィーチャーゲート が有効になっている場合、kubeletは、Podがこの初期化の節目に到達したかどうかをPodのstatus.conditionsフィールドにあるPodHasNetwork状態を使用して報告します。
ネットワークが設定されたランタイムサンドボックスがPodにないことを検出すると、PodHasNetwork状態は、kubelet によってFalseに設定されます。これは、以下のシナリオで発生します:
Podのライフサイクルの初期で、kubeletがコンテナランタイムを使用してPodのサンドボックスのセットアップをまだ開始していないとき Podのライフサイクルの後期で、Podのサンドボックスが以下のどちらかの原因で破壊された場合:Podを退去させず、ノードが再起動する コンテナランタイムの隔離に仮想マシンを使用している場合、Podサンドボックスの仮想マシンが再起動し、新しいサンドボックスと新しいコンテナネットワーク設定を作成する必要があります ランタイムプラグインによるサンドボックスの作成とPodのネットワーク設定が正常に完了すると、kubeletによってPodHasNetwork状態がTrueに設定されます。PodHasNetwork状態がTrueに設定された後、kubeletはコンテナイメージの取得とコンテナの作成を開始することができます。
initコンテナを持つPodの場合、initコンテナが正常に完了すると(ランタイムプラグインによるサンドボックスの作成とネットワーク設定が正常に行われた後に発生)、kubeletはInitialized状態をTrueに設定します。initコンテナがないPodの場合、サンドボックスの作成およびネットワーク設定が開始する前にkubeletはInitialized状態をTrueに設定します。
コンテナのProbe Probe はkubelet により定期的に実行されるコンテナの診断です。診断を行うために、kubeletはコンテナ内でコードを実行するか、ネットワークリクエストします。
チェックのメカニズム probeを使ってコンテナをチェックする4つの異なる方法があります。
各probeは、この4つの仕組みのうち1つを正確に定義する必要があります:
execコンテナ内で特定のコマンドを実行します。コマンドがステータス0で終了した場合に診断を成功と見なします。 grpcgRPC を使ってリモートプロシージャコールを実行します。
ターゲットは、gRPC health checks を実装する必要があります。
レスポンスのstatusがSERVINGの場合に診断を成功と見なします。
gRPCはアルファ版の機能のため、GRPCContainerProbeフィーチャーゲート が
有効の場合のみ利用可能です。httpGetPodのIPアドレスに対して、指定されたポートとパスでHTTP GETのリクエストを送信します。
レスポンスのステータスコードが200以上400未満の際に診断を成功とみなします。 tcpSocketPodのIPアドレスに対して、指定されたポートでTCPチェックを行います。
そのポートが空いていれば診断を成功とみなします。
オープンしてすぐにリモートシステム(コンテナ)が接続を切断した場合、健全な状態としてカウントします。 Probeの結果 各Probe 次の3つのうちの一つの結果を持ちます:
Successコンテナの診断が成功しました。 Failureコンテナの診断が失敗しました。 Unknownコンテナの診断自体が失敗しました(何も実行する必要はなく、kubeletはさらにチェックを行います)。 Probeの種類 kubeletは3種類のProbeを実行中のコンテナで行い、また反応することができます:
livenessProbeコンテナが動いているかを示します。
livenessProbeに失敗すると、kubeletはコンテナを殺します、そしてコンテナはrestart policy に従います。
コンテナにlivenessProbeが設定されていない場合、デフォルトの状態はSuccessです。 readinessProbeコンテナがリクエスト応答する準備ができているかを示します。
readinessProbeに失敗すると、エンドポイントコントローラーにより、ServiceからそのPodのIPアドレスが削除されます。
initial delay前のデフォルトのreadinessProbeの初期値はFailureです。
コンテナにreadinessProbeが設定されていない場合、デフォルトの状態はSuccessです。 startupProbeコンテナ内のアプリケーションが起動したかどうかを示します。
startupProbeが設定された場合、完了するまでその他のすべてのProbeは無効になります。
startupProbeに失敗すると、kubeletはコンテナを殺します、そしてコンテナはrestart policy に従います。
コンテナにstartupProbeが設定されていない場合、デフォルトの状態はSuccessです。 livenessProbe、readinessProbeまたはstartupProbeを設定する方法の詳細については、Liveness Probe、Readiness ProbeおよびStartup Probeを使用する を参照してください。
livenessProbeをいつ使うべきか? FEATURE STATE:
Kubernetes v1.0 [stable]
コンテナ自体に問題が発生した場合や状態が悪くなった際にクラッシュすることができればlivenessProbeは不要です。
この場合kubeletが自動でPodのrestartPolicyに基づいたアクションを実行します。
Probeに失敗したときにコンテナを殺したり再起動させたりするには、livenessProbeを設定しrestartPolicyをAlwaysまたはOnFailureにします。
readinessProbeをいつ使うべきか? FEATURE STATE:
Kubernetes v1.0 [stable]
Probeが成功したときにのみPodにトラフィックを送信したい場合は、readinessProbeを指定します。
この場合readinessProbeはlivenessProbeと同じになる可能性がありますが、readinessProbeが存在するということは、Podがトラフィックを受けずに開始され、Probe成功が開始した後でトラフィックを受け始めることになります。
コンテナがメンテナンスのために停止できるようにするには、livenessProbeとは異なる、特定のエンドポイントを確認するreadinessProbeを指定することができます。
アプリがバックエンドサービスと厳密な依存関係にある場合、livenessProbeとreadinessProbeの両方を実装することができます。アプリ自体が健全であればlivenessProbeはパスしますが、readinessProbeはさらに、必要なバックエンドサービスが利用可能であるかどうかをチェックします。これにより、エラーメッセージでしか応答できないPodへのトラフィックの転送を避けることができます。
コンテナの起動中に大きなデータ、構成ファイル、またはマイグレーションを読み込む必要がある場合は、startupProbe を使用できます。ただし、失敗したアプリと起動データを処理中のアプリの違いを検出したい場合は、readinessProbeを使用した方が良いかもしれません。
備考: Podが削除されたときにリクエストを来ないようにするためには必ずしもreadinessProbeが必要というわけではありません。Podの削除時にはreadinessProbeが存在するかどうかに関係なくPodは自動的に自身をunreadyにします。Pod内のコンテナが停止するのを待つ間Podはunreadyのままです。startupProbeをいつ使うべきか? FEATURE STATE:
Kubernetes v1.20 [stable]
startupProbeは、サービスの開始に時間がかかるコンテナを持つPodに役立ちます。livenessProbeの間隔を長く設定するのではなく、コンテナの起動時に別のProbeを構成して、livenessProbeの間隔よりも長い時間を許可できます。
コンテナの起動時間が、initialDelaySeconds + failureThreshold x periodSecondsよりも長い場合は、livenessProbeと同じエンドポイントをチェックするためにstartupProbeを指定します。periodSecondsのデフォルトは10秒です。次に、failureThresholdをlivenessProbeのデフォルト値を変更せずにコンテナが起動できるように、十分に高い値を設定します。これによりデッドロックを防ぐことができます。
Podの終了 Podは、クラスター内のNodeで実行中のプロセスを表すため、不要になったときにそれらのプロセスを正常に終了できるようにすることが重要です(対照的なケースは、KILLシグナルで強制終了され、クリーンアップする機会がない場合)。
ユーザーは削除を要求可能であるべきで、プロセスがいつ終了するかを知ることができなければなりませんが、削除が最終的に完了することも保証できるべきです。ユーザーがPodの削除を要求すると、システムはPodが強制終了される前に意図された猶予期間を記録および追跡します。強制削除までの猶予期間がある場合、kubelet 正常な終了を試みます。
通常、コンテナランタイムは各コンテナのメインプロセスにTERMシグナルを送信します。多くのコンテナランタイムは、コンテナイメージで定義されたSTOPSIGNAL値を尊重し、TERMシグナルの代わりにこれを送信します。猶予期間が終了すると、プロセスにKILLシグナルが送信され、PodはAPI server から削除されます。プロセスの終了を待っている間にkubeletかコンテナランタイムの管理サービスが再起動されると、クラスターは元の猶予期間を含めて、最初からリトライされます。
フローの例は下のようになります。
ユーザーがデフォルトの猶予期間(30秒)でPodを削除するためにkubectlコマンドを送信する。 API server内のPodは、猶予期間を越えるとPodが「死んでいる」と見なされるように更新される。kubectl describeコマンドを使用すると、Podは「終了中」と表示される。Pod内のコンテナの1つがpreStopフック を定義している場合は、コンテナの内側で呼び出される。猶予期間が終了した後もpreStopフックがまだ実行されている場合は、一度だけ猶予期間を延長される(2秒)。
備考: preStopフックが完了するまでにより長い時間が必要な場合は、terminationGracePeriodSecondsを変更する必要があります。 kubeletはコンテナランタイムをトリガーして、コンテナ内のプロセス番号1にTERMシグナルを送信する。
備考: Pod内のすべてのコンテナが同時にTERMシグナルを受信するわけではなく、シャットダウンの順序が問題になる場合はそれぞれにpreStopフックを使用して同期することを検討する。 kubeletが正常な終了を開始すると同時に、コントロールプレーンは、終了中のPodをEndpointSlice(およびEndpoints)オブジェクトから削除します。これらのオブジェクトは、selector が設定されたService を表します。ReplicaSets とその他のワークロードリソースは、終了中のPodを有効なサービス中のReplicaSetとして扱いません。ゆっくりと終了するPodは、(サービスプロキシのような)ロードバランサーが終了猶予期間が始まる とエンドポイントからそれらのPodを削除するので、トラフィックを継続して処理できません。 猶予期間が終了すると、kubeletは強制削除を開始する。コンテナランタイムは、Pod内でまだ実行中のプロセスにSIGKILLを送信する。kubeletは、コンテナランタイムが非表示のpauseコンテナを使用している場合、そのコンテナをクリーンアップします。 kubeletは猶予期間を0(即時削除)に設定することでAPI server上のPodの削除を終了する。 API serverはPodのAPIオブジェクトを削除し、クライアントからは見えなくなります。 Podの強制削除
注意: 強制削除は、Podによっては潜在的に危険な場合があるため、慎重に実行する必要があります。デフォルトでは、すべての削除は30秒以内に正常に行われます。kubectl delete コマンドは、ユーザーがデフォルト値を上書きして独自の値を指定できるようにする --grace-period=<seconds> オプションをサポートします。
--grace-periodを0に設定した場合、PodはAPI serverから即座に強制的に削除されます。PodがNode上でまだ実行されている場合、その強制削除によりkubeletがトリガーされ、すぐにクリーンアップが開始されます。
備考: 強制削除を実行するために --grace-period=0 と共に --force というフラグを追加で指定する必要があります。強制削除が実行されると、API serverは、Podが実行されていたNode上でPodが停止されたというkubeletからの確認を待ちません。API内のPodは直ちに削除されるため、新しいPodを同じ名前で作成できるようになります。Node上では、すぐに終了するように設定されるPodは、強制終了される前にわずかな猶予期間が与えられます。
注意: 即時削除では、実行中のリソースの終了を待ちません。
リソースはクラスター上で無期限に実行し続ける可能性があります。StatefulSetのPodについては、StatefulSetからPodを削除するためのタスクのドキュメント を参照してください。
終了したPodのガベージコレクション 失敗したPodは人間またはcontroller が明示的に削除するまで存在します。
コントロールプレーンは終了状態のPod(SucceededまたはFailedのphaseを持つ)の数が設定された閾値(kube-controller-manager内のterminated-pod-gc-thresholdによって定義される)を超えたとき、それらのPodを削除します。これはPodが作成されて時間とともに終了するため、リソースリークを避けます。
次の項目 3.5.1.2 - Initコンテナ このページでは、Initコンテナの概要について説明します。
Initコンテナとは、Pod 内でアプリケーションコンテナの前に実行される特別なコンテナです。
Initコンテナには、アプリケーションコンテナのイメージに存在しないユーティリティやセットアップスクリプトを含めることができます。
Podの仕様では、アプリケーションコンテナを記述するcontainers配列と同じ階層に並べて、Initコンテナを指定できます。
Kubernetesでは、サイドカーコンテナ は、メインのアプリケーションコンテナよりも前に起動し、実行し続ける コンテナです。
このドキュメントでは、Podの初期化中に実行が完了するコンテナであるInitコンテナについて説明します。
Initコンテナを理解する Pod は、内部で実行される複数のアプリケーションコンテナを持つことができますが、アプリケーションコンテナが起動する前に実行される1つ以上のInitコンテナを持つこともできます。
Initコンテナは下記の項目をのぞいて、通常のコンテナと全く同じです:
Initコンテナは常に完了するまで稼働します。 各Initコンテナは、次のInitコンテナが稼働する前に正常に完了しなくてはなりません。 Pod内のInitコンテナが失敗した場合、kubeletは成功するまで、Initコンテナの再起動を繰り返します。
しかし、PodのrestartPolicyがNeverに設定されていて、Podの起動時にInitコンテナが失敗した場合、KubernetesはPod全体を失敗として扱います。
PodにInitコンテナを指定するためには、Podの仕様 にinitContainersフィールドをcontainer項目の配列として追加してください(アプリケーションのcontainersフィールドとそのコンテンツと同様です)。
詳細については、APIリファレンスのコンテナ を参照してください。
Initコンテナのステータスは、.status.initContainerStatusesフィールドにコンテナのステータスの配列として返されます(.status.containerStatusesと同様です)。
通常のコンテナとの違い Initコンテナは、リソース制限、ボリューム 、セキュリティ設定などのアプリケーションコンテナの全てのフィールドと機能をサポートしています。
ただし、Initコンテナのリソース要求と制限は、コンテナ間のリソース共有 に記載されているように、異なる方法で処理されます。
通常のInitコンテナ(つまり、サイドカーコンテナを除く)は、lifecycle、livenessProbe、readinessProbe、startupProbeフィールドをサポートしていません。
InitコンテナはPodの準備が完了する前に実行を完了する必要があります。
一方、サイドカーコンテナはPodのライフタイム中は常に実行され続け、一部のProbeを サポートしています 。
サイドカーコンテナの詳細については、サイドカーコンテナ を参照してください。
単一のPodに対して複数のInitコンテナを指定した場合、kubeletはそれらのInitコンテナを順次実行します。
各Initコンテナは、次のInitコンテナが実行される前に正常に終了する必要があります。
全てのInitコンテナの実行が完了すると、kubeletはPodのアプリケーションコンテナを初期化し、通常通り実行します。
サイドカーコンテナとの違い Initコンテナは、メインのアプリケーションコンテナが起動する前にタスクを実行して完了します。
サイドカーコンテナ とは異なり、Initコンテナはメインコンテナと並行して継続的に実行されることはありません。
Initコンテナは順次実行され完了します。
すべてのInitコンテナが正常に完了するまで、メインコンテナは起動しません。
Initコンテナはlifecycle、livenessProbe、readinessProbe、startupProbeをサポートしていませんが、サイドカーコンテナはこれらすべてのProbe をサポートしてライフサイクルを制御します。
Initコンテナは、メインのアプリケーションコンテナとリソース(CPU、メモリ、ネットワーク)を共有しますが、直接やり取りすることはありません。
ただし、共有ボリュームを使用してデータの交換を行うことは可能です。
Initコンテナを使用する Initコンテナはアプリケーションコンテナのイメージとは分離されているため、コンテナの起動に関連したコードにおいていくつかの利点があります:
Initコンテナには、アプリケーションイメージに含まれないセットアップ用のユーティリティやカスタムコードを含めることができます。
たとえば、セットアップ時にsed、awk、python、digなどのツールを使用するためだけに、別のイメージをFROMしてイメージを作成する必要はありません。 アプリケーションイメージをビルドする役割とデプロイする役割は、共同で単一のアプリケーションイメージをビルドする必要がないため、それぞれ独立して実施することができます。 Initコンテナは、同じPod内のアプリケーションコンテナとは異なる方法でファイルシステムにアクセスできます。
その結果、アプリケーションコンテナがアクセスできないSecret に対するアクセス権限を得ることができます。 Initコンテナはアプリケーションコンテナが開始する前に完了するまで実行されるため、Initコンテナを使用することで、特定の前提条件が満たされるまでアプリケーションコンテナの起動をブロックしたり遅らせることができます。
前提条件が満たされると、Pod内の全てのアプリケーションコンテナを並行して起動することができます。 Initコンテナは、アプリケーションコンテナイメージのセキュリティを低下させる可能性のあるユーティリティやカスタムコードを安全に実行できます。
不要なツールを分離することで、アプリケーションコンテナイメージの攻撃対象領域を制限できます。 例 Initコンテナを活用する方法について、いくつかのアイデアを次に示します:
シェルのワンライナーコマンドを使ってService が作成されるのを待機する:
for i in { 1..100} ; do sleep 1; if nslookup myservice; then exit 0; fi ; done ; exit 1
以下のようなコマンドを使って、Downward APIを介してこのPodをリモートサーバーに登録する:
curl -X POST http://$MANAGEMENT_SERVICE_HOST :$MANAGEMENT_SERVICE_PORT /register -d 'instance=$(<POD_NAME>)&ip=$(<POD_IP>)'
以下のようなコマンドを使ってアプリケーションコンテナの起動を待機する:
Gitリポジトリをボリューム にクローンする。
いくつかの値を設定ファイルに配置し、メインのアプリケーションコンテナのための設定ファイルを動的に生成するためのテンプレートツールを実行する。
例えば、そのPodのPOD_IPの値を設定ファイルに配置し、Jinjaを使ってメインのアプリケーションコンテナの設定ファイルを生成する。
Initコンテナの具体的な使用方法 下記の例は、2つのInitコンテナを含むシンプルなPodを定義しています。
1つ目のInitコンテナはmyserviceの起動を、2つ目のInitコンテナはmydbの起動をそれぞれ待ちます。
両方のInitコンテナの実行が完了すると、Podはspecセクションにあるアプリケーションコンテナを実行します。
apiVersion : v1
kind : Pod
metadata :
name : myapp-pod
labels :
app.kubernetes.io/name : MyApp
spec :
containers :
- name : myapp-container
image : busybox:1.28
command : ['sh' , '-c' , 'echo The app is running! && sleep 3600' ]
initContainers :
- name : init-myservice
image : busybox:1.28
command : ['sh' , '-c' , "until nslookup myservice.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done" ]
- name : init-mydb
image : busybox:1.28
command : ['sh' , '-c' , "until nslookup mydb.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for mydb; sleep 2; done" ]
次のコマンドを実行して、このPodを開始します:
kubectl apply -f myapp.yaml
実行結果は下記のようになります:
pod/myapp-pod created
そして次のコマンドでステータスを確認します:
kubectl get -f myapp.yaml
実行結果は下記のようになります:
NAME READY STATUS RESTARTS AGE
myapp-pod 0/1 Init:0/2 0 6m
より詳細な情報は次のコマンドで確認します:
kubectl describe -f myapp.yaml
実行結果は下記のようになります:
Name: myapp-pod
Namespace: default
[...]
Labels: app.kubernetes.io/name=MyApp
Status: Pending
[...]
Init Containers:
init-myservice:
[...]
State: Running
[...]
init-mydb:
[...]
State: Waiting
Reason: PodInitializing
Ready: False
[...]
Containers:
myapp-container:
[...]
State: Waiting
Reason: PodInitializing
Ready: False
[...]
Events:
FirstSeen LastSeen Count From SubObjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
16s 16s 1 {default-scheduler } Normal Scheduled Successfully assigned myapp-pod to 172.17.4.201
16s 16s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Pulling pulling image "busybox"
13s 13s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Pulled Successfully pulled image "busybox"
13s 13s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Created Created container init-myservice
13s 13s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Started Started container init-myservice
このPod内のInitコンテナのログを確認するためには、次のコマンドを実行します:
kubectl logs myapp-pod -c init-myservice # 1つ目のInitコンテナを調査する
kubectl logs myapp-pod -c init-mydb # 2つ目のInitコンテナを調査する
この時点で、これらのInitコンテナはmydbとmyserviceという名前のService の検出を待機しています。
これらのServiceを検出するための設定は以下の通りです:
---
apiVersion : v1
kind : Service
metadata :
name : myservice
spec :
ports :
- protocol : TCP
port : 80
targetPort : 9376
---
apiVersion : v1
kind : Service
metadata :
name : mydb
spec :
ports :
- protocol : TCP
port : 80
targetPort : 9377
mydbおよびmyserviceというServiceを作成するために、以下のコマンドを実行します:
kubectl apply -f services.yaml
実行結果は下記のようになります:
service/myservice created
service/mydb created
Initコンテナが完了し、myapp-podというPodが実行状態に移行したことを確認できます:
kubectl get -f myapp.yaml
実行結果は下記のようになります:
NAME READY STATUS RESTARTS AGE
myapp-pod 1/1 Running 0 9m
この簡単な例は、独自のinitコンテナを作成する際のヒントになるはずです。
次の項目 には、さらに詳細な使用例に関するリンクがあります。
Initコンテナのふるまいに関する詳細 Podの起動時に、kubeletはネットワークおよびストレージの準備が整うまで、Initコンテナを実行可能な状態にしません。
また、kubeletはPodのspecに定義された順番に従って、PodのInitコンテナを起動します。
各Initコンテナは次のInitコンテナが起動する前に正常に終了しなくてはなりません。
もし、あるInitコンテナがランタイムにより起動失敗した場合、もしくはエラーで終了した場合、そのPodのrestartPolicyの値に従ってリトライされます。
しかし、PodのrestartPolicyがAlwaysに設定されていた場合は、InitコンテナのrestartPolicyはOnFailureとして適用されます。
すべてのInitコンテナが成功するまで、PodはReadyになりません。
InitコンテナのポートはService配下に集約されません。
初期化中のPodはPending状態ですが、条件Initializedはfalseに設定されているはずです。
Podを再起動 するとき、またはPodが再起動されたとき、全てのInitコンテナは必ず再度実行されます。
Initコンテナのspecに対する変更は、コンテナイメージフィールドに制限されています。
Initコンテナのimageフィールドを直接変更しても、Podの再起動や再作成はトリガー されません 。
ただし、Podがまだ起動していない場合、その変更はPodの起動方法に影響を与える可能性があります。
Podテンプレート の場合、通常はInitコンテナの任意のフィールドを変更できます。
その変更の影響は、Podテンプレートがどこで使用されているかによって異なります。
Initコンテナは何度も再起動、リトライおよび再実行可能であるため、べき等(Idempotent)である必要があります。
特に、emptyDirにファイルを書き込むコードは、書き込み先のファイルがすでに存在している可能性を考慮に入れなければいけません。
Initコンテナは、アプリケーションコンテナが持つすべてのフィールドを持っています。
ただし、KubernetesではreadinessProbeの使用が禁止されています。
これは、Initコンテナでは完了とは別にreadiness状態を定義することができないためです。
この制約は、バリデーション時に強制されます。
Initコンテナが永久に失敗し続けることを防ぐために、Pod上でactiveDeadlineSecondsを使用してください。
activeDeadlineSecondsの設定はInitコンテナが実行中の時間にも適用されます。
ただし、activeDeadlineSecondsはInitコンテナが完了した後にも影響が及ぶため、アプリケーションをJobとしてデプロイする場合にのみ使用することを推奨します。
すでに正しく動作しているPodは、activeDeadlineSecondsを設定すると強制終了されます。
Pod内の各アプリケーションコンテナとInitコンテナの名前はユニークである必要があります。
他のコンテナと同じ名前を共有していた場合、バリデーションエラーが返されます。
コンテナ間のリソース共有 Initコンテナ、サイドカーコンテナ、アプリケーションコンテナの実行順序を考慮すると、リソース使用に関して以下のルールが適用されます:
すべてのInitコンテナで定義された特定のリソースの要求または制限のうち、最も高い値が実効Init要求/制限 となります。
リソース制限が指定されていない場合、これが最も高い制限であるとみなされます。 リソースに対するPodの実効要求/制限 は、以下のうち高い方になります。すべてのアプリケーションコンテナのリソース要求/制限の合計 リソースに対する実効Init要求/制限 スケジューリングは実効要求/制限に基づいて行われます。
つまり、Initコンテナは初期化のためにリソースを予約できますが、これらはPodのライフタイム中は使用されません。 Podの実効QoS tier は、Initコンテナとアプリケーションコンテナの両方に適用されるQoS(サービス品質) tierです。 クォータと制限は、実効的なPodの要求と制限に基づいて適用されます。
InitコンテナとLinux cgroups Linuxでは、Podレベルのコントロールグループ(cgroups)に対するリソース割り当ては、スケジューラーと同様に、実効的なPodの要求と制限に基づいています。
Podの再起動の理由 以下の理由によりPodは再起動し、Initコンテナの再実行を引き起こす可能性があります:
Podインフラストラクチャコンテナが再起動された場合。
これは稀なケースであり、ノードへのルートアクセス権を持つ人が実行する必要があります。 restartPolicyがAlwaysに設定されている状態でPod内のすべてのコンテナが終了し、再起動が強制され、かつInitコンテナの完了記録がガベージコレクション により失われた場合。Initコンテナイメージが変更された場合、またはガベージコレクションによりInitコンテナの完了記録が失われた場合、Podは再起動されません。
これはKubernetes v1.20以降に適用されます。
それ以前のバージョンのKubernetesを使用している場合は、使用しているバージョンのドキュメントを参照してください。
次の項目 詳しく学ぶには、以下を参照してください:
3.5.1.3 - サイドカーコンテナ FEATURE STATE:
Kubernetes v1.33 [stable](enabled by default)
サイドカーコンテナは、同じPod 内でメインのアプリケーションコンテナと共に実行されるセカンダリコンテナです。
これらのコンテナは、ロギング、モニタリング、セキュリティ、データ同期などの追加サービスや機能を提供することで、プライマリの アプリケーションコンテナ の機能を強化または拡張するために使用されます。
メインのアプリケーションコードを直接変更する必要はありません。
通常、Pod内にはアプリケーションコンテナが1つだけ含まれます。
例えば、ローカルWebサーバーを必要とするWebアプリケーションがある場合、ローカルWebサーバーがサイドカーであり、Webアプリケーション自体がアプリケーションコンテナです。
Kubernetesにおけるサイドカーコンテナ Kubernetesは、サイドカーコンテナをInitコンテナ の特殊なケースとして実装しています。
サイドカーコンテナはPod起動後も実行され続けます。
このドキュメントでは、Pod起動時にのみ実行されるコンテナを明確に指すために、通常のInitコンテナ という用語を使用します。
クラスターでSidecarContainersフィーチャーゲート が有効になっている場合(この機能はKubernetes v1.29以降デフォルトで有効です)、PodのinitContainersフィールドにリストされているコンテナに対してrestartPolicyを指定できます。
これらの再起動可能な サイドカー コンテナは、同じPod内の他のInitコンテナやメインアプリケーションコンテナから独立しています。
メインアプリケーションコンテナや他のInitコンテナに影響を与えることなく、これらを起動、停止、または再起動することができます。
また、Initコンテナやサイドカーコンテナとして定義されていない複数のコンテナでPodを実行することもできます。
これは、Pod内のコンテナがPod全体の動作に必要であるが、どのコンテナを最初に起動または停止するかを制御する必要がない場合に適しています。
また、コンテナレベルのrestartPolicyフィールドをサポートしていない古いバージョンのKubernetesをサポートする必要がある場合にも、この方法を使用できます。
アプリケーションの例 以下は、2つのコンテナを持つDeploymentの例で、そのうちの1つがサイドカーコンテナです:
apiVersion : apps/v1
kind : Deployment
metadata :
name : myapp
labels :
app : myapp
spec :
replicas : 1
selector :
matchLabels :
app : myapp
template :
metadata :
labels :
app : myapp
spec :
containers :
- name : myapp
image : alpine:latest
command : ['sh' , '-c' , 'while true; do echo "logging" >> /opt/logs.txt; sleep 1; done' ]
volumeMounts :
- name : data
mountPath : /opt
initContainers :
- name : logshipper
image : alpine:latest
restartPolicy : Always
command : ['sh' , '-c' , 'tail -F /opt/logs.txt' ]
volumeMounts :
- name : data
mountPath : /opt
volumes :
- name : data
emptyDir : {}サイドカーコンテナとPodのライフサイクル InitコンテナがrestartPolicyをAlwaysに設定して作成された場合、Podの全ライフサイクルを通じて起動し、実行され続けます。
これは、メインのアプリケーションコンテナから分離した補助的なサービスを実行する際に役立ちます。
このInitコンテナにreadinessProbeが指定されている場合、その結果はPodのready状態を判定するために使用されます。
これらのコンテナはInitコンテナとして定義されているため、通常のInitコンテナと同じ順序と順次実行の保証の恩恵を受けます。
これにより、複雑なPod初期化フローの際に、サイドカーコンテナと通常のInitコンテナを混在させることができます。
通常のInitコンテナと比較して、initContainers内で定義されたサイドカーコンテナは起動後も実行され続けます。
これは、Podの.spec.initContainers内に複数のエントリがある場合に重要です。
サイドカー形式のInitコンテナが実行状態になった後(kubeletがそのInitコンテナのstartedステータスをtrueに設定した後)、kubeletは順序付けられた.spec.initContainersリストから次のInitコンテナを起動します。
このステータスは、コンテナ内でプロセスが実行されておりStartup Probeが定義されていない場合、またはstartupProbeが成功した結果として、trueになります。
Podの終了 時には、kubeletはメインのアプリケーションコンテナが完全に停止するまで、サイドカーコンテナの終了を引き延ばします。
その後、サイドカーコンテナはPodの仕様内で定義された順序と逆の順序でシャットダウンされます。
このアプローチにより、サイドカーコンテナは、そのサービスが不要になるまで、Pod内の他のコンテナをサポートし続けることが保証されます。
サイドカーコンテナを持つJob Kubernetes形式のInitコンテナを使用してサイドカーコンテナを使用するJobを定義した場合、各Pod内のサイドカーコンテナは、メインコンテナが終了した後にJobが完了することを妨げません。
以下は、2つのコンテナを持つJobの例で、そのうちの1つがサイドカーコンテナです:
apiVersion : batch/v1
kind : Job
metadata :
name : myjob
spec :
template :
spec :
containers :
- name : myjob
image : alpine:latest
command : ['sh' , '-c' , 'echo "logging" > /opt/logs.txt' ]
volumeMounts :
- name : data
mountPath : /opt
initContainers :
- name : logshipper
image : alpine:latest
restartPolicy : Always
command : ['sh' , '-c' , 'tail -F /opt/logs.txt' ]
volumeMounts :
- name : data
mountPath : /opt
restartPolicy : Never
volumes :
- name : data
emptyDir : {}
アプリケーションコンテナとの違い サイドカーコンテナは、同じPod内で アプリケーションコンテナ と並行して実行されます。
ただし、サイドカーコンテナは主要なアプリケーションロジックを実行するのではなく、メインアプリケーションに補助的な機能を提供します。
サイドカーコンテナは独自の独立したライフサイクルを持ちます。
アプリケーションコンテナとは独立して、起動、停止、再起動できます。
これは、メインアプリケーションに影響を与えることなく、サイドカーコンテナを更新、スケール、またはメンテナンスできることを意味します。
サイドカーコンテナは、プライマリコンテナと同じネットワークおよびストレージ名前空間を共有します。
このように共存することで、密接に相互作用しリソースを共有できます。
Kubernetesの観点からは、サイドカーコンテナのグレースフルな終了はそれほど重要ではありません。
他のコンテナが、割り当てられたグレースフルな終了時間をすべて消費した場合、サイドカーコンテナはグレースフルに終了する時間を持つ前に、SIGTERMシグナルに続いてSIGKILLシグナルを受信します。
そのため、サイドカーコンテナにおいては、Pod終了時の0以外の終了コード(0は正常終了を示します)は正常なものであり、一般的に外部ツールによって無視されるべきです。
Initコンテナとの違い サイドカーコンテナはメインコンテナと並行して動作し、その機能を拡張して追加のサービスを提供します。
サイドカーコンテナは、メインのアプリケーションコンテナと同時に実行されます。
サイドカーコンテナはPodのライフサイクル全体を通じてアクティブであり、メインコンテナとは独立して起動および停止できます。
Initコンテナ とは異なり、サイドカーコンテナは、ライフサイクルを制御するためのProbe をサポートしています。
サイドカーコンテナは、メインのアプリケーションコンテナと直接やり取りできます。
これは、Initコンテナと同様に常に同じネットワークを共有し、オプションでボリューム(ファイルシステム)も共有できるためです。
Initコンテナはメインコンテナが起動する前に停止するため、InitコンテナはPod内のアプリケーションコンテナとメッセージを交換できません。
データの受け渡しは一方向です(例えば、InitコンテナがemptyDirボリューム内に情報を配置することはできます)。
サイドカーコンテナのイメージを変更してもPodは再起動されませんが、コンテナの再起動はトリガーされます。
コンテナ内でのリソース共有 Initコンテナ、サイドカーコンテナ、アプリケーションコンテナの実行順序を考慮すると、リソース使用に関して以下のルールが適用されます:
すべてのInitコンテナで定義された特定のリソース要求または制限のうち、最も高い値が実効Init要求/制限 となります。
いずれかのリソースにリソース制限が指定されていない場合、これが最も高い制限と見なされます。 リソースに対するPodの実効要求/制限 は、Podのオーバーヘッド と以下のうち高い方の合計です:すべての非Initコンテナ(アプリケーションコンテナとサイドカーコンテナ)のリソース要求/制限の合計 リソースに対する実効Init要求/制限 スケジューリングは実効要求/制限に基づいて行われます。
これは、InitコンテナがPodのライフタイム中には使用されない初期化用のリソースを予約できることを意味します。 Podの実効QoS tier のQoS(サービス品質) tierは、Initコンテナ、サイドカーコンテナ、アプリケーションコンテナすべてに対するQoS tierです。 クォータと制限は、実効Pod要求と制限に基づいて適用されます。
サイドカーコンテナとLinux cgroup Linuxでは、Podレベルのコントロールグループ(cgroup)に対するリソース割り当ては、スケジューラーと同様に、実効的なPod要求/制限に基づいて行われます。
次の項目 3.5.1.4 - エフェメラルコンテナ FEATURE STATE:
Kubernetes v1.25 [stable]
このページでは、特別な種類のコンテナであるエフェメラルコンテナの概要を説明します。エフェメラルコンテナは、トラブルシューティングなどのユーザーが開始するアクションを実行するために、すでに存在するPod 内で一時的に実行するコンテナです。エフェメラルコンテナは、アプリケーションの構築ではなく、serviceの調査のために利用します。
エフェメラルコンテナを理解する Pod は、Kubernetesのアプリケーションの基本的なビルディングブロックです。Podは破棄可能かつ置き換え可能であることが想定されているため、一度Podが作成されると新しいコンテナを追加することはできません。その代わりに、通常はDeployment を使用してPodを削除して置き換えます。
たとえば、再現困難なバグのトラブルシューティングなどのために、すでに存在するPodの状態を調査する必要が出てくることがあります。このような場合、既存のPod内でエフェメラルコンテナを実行することで、Podの状態を調査したり、任意のコマンドを実行したりできます。
エフェメラルコンテナとは何か? エフェメラルコンテナは、他のコンテナと異なり、リソースや実行が保証されず、自動的に再起動されることも決してないため、アプリケーションを構築する目的には適しません。エフェメラルコンテナは、通常のコンテナと同じContainerSpecで記述されますが、多くのフィールドに互換性がなかったり、使用できなくなっています。
エフェメラルコンテナはポートを持つことができないため、ports、livenessProbe、readinessProbeなどは使えなくなっています。 Podリソースの割り当てはイミュータブルであるため、resourcesの設定が禁止されています。 利用が許可されているフィールドの一覧については、EphemeralContainerのリファレンスドキュメント を参照してください。 エフェメラルコンテナは、直接pod.specに追加するのではなく、API内の特別なephemeralcontainersハンドラを使用して作成します。そのため、エフェメラルコンテナをkubectl editを使用して追加することはできません。
エフェメラルコンテナをPodに追加した後は、通常のコンテナのようにエフェメラルコンテナを変更または削除することはできません。
エフェメラルコンテナの用途 エフェメラルコンテナは、コンテナがクラッシュしてしまったり、コンテナイメージにデバッグ用ユーティリティが同梱されていない場合など、kubectl execでは不十分なときにインタラクティブなトラブルシューティングを行うために役立ちます。
特に、distrolessイメージ を利用すると、攻撃対象領域を減らし、バグや脆弱性を露出する可能性を減らせる最小のコンテナイメージをデプロイできるようになります。distrolessイメージにはシェルもデバッグ用のユーティリティも含まれないため、kubectl execのみを使用してdistrolessイメージのトラブルシューティングを行うのは困難です。
エフェメラルコンテナを利用する場合には、他のコンテナ内のプロセスにアクセスできるように、プロセス名前空間の共有 を有効にすると便利です。
次の項目 3.5.1.5 - Disruption このガイドは、高可用性アプリケーションを構築したいと考えており、そのために、Podに対してどのような種類のDisruptionが発生する可能性があるか理解する必要がある、アプリケーション所有者を対象としたものです。
また、クラスターのアップグレードやオートスケーリングなどのクラスターの操作を自動化したいクラスター管理者も対象にしています。
自発的なDisruptionと非自発的なDisruption Podは誰か(人やコントローラー)が破壊するか、避けることができないハードウェアまたはシステムソフトウェアエラーが発生するまで、消えることはありません。
これらの不可避なケースをアプリケーションに対する非自発的なDisruption と呼びます。
例えば:
ノードのバックエンドの物理マシンのハードウェア障害 クラスター管理者が誤ってVM(インスタンス)を削除した クラウドプロバイダーまたはハイパーバイザーの障害によってVMが消えた カーネルパニック クラスターネットワークパーティションが原因でクラスターからノードが消えた ノードのリソース不足 によるPodの退避 リソース不足を除いて、これら条件は全て、大半のユーザーにとって馴染みのあるものでしょう。
これらはKubernetesに固有のものではありません。
それ以外のケースのことを自発的なDisruption と呼びます。
これらはアプリケーションの所有者によって起こされたアクションと、クラスター管理者によって起こされたアクションの両方を含みます。
典型的なアプリケーションの所有者によるアクションには次のものがあります:
Deploymentやその他のPodを管理するコントローラーの削除 再起動を伴うDeployment内のPodのテンプレートの更新 Podの直接削除(例:アクシデントによって) クラスター管理者のアクションには、次のようなものが含まれます:
修復やアップグレードのためのノードのドレイン 。 クラスターのスケールダウンのためにクラスターからノードをドレインする(クラスター自動スケーリング について学ぶ)。 そのノードに別のものを割り当てることができるように、ノードからPodを削除する。 これらのアクションはクラスター管理者によって直接実行されるか、クラスター管理者やクラスターをホスティングしているプロバイダーによって自動的に実行される可能性があります。
クラスターに対して自発的なDisruptionの要因となるものが有効になっているかどうかについては、クラスター管理者に聞くか、クラウドプロバイダーに相談または配布文書を参照してください。
有効になっているものが何もなければ、Pod Disruption Budgetの作成はスキップすることができます。
注意: 全ての自発的なDisruptionがPod Disruption Budgetによる制約を受けるわけではありません。
例えばDeploymentやPodの削除はPod Disruption Budgetをバイパスします。Disruptionへの対応 非自発的なDisruptionを軽減する方法をいくつか紹介します:
Podは必要なリソースを要求 するようにする。 高可用性が必要な場合はアプリケーションをレプリケートする。(レプリケートされたステートレス およびステートフル アプリケーションの実行について学ぶ。) レプリケートされたアプリケーションを実行する際にさらに高い可用性を得るには、(アンチアフィニティ を使って)ラックを横断して、または(マルチゾーンクラスター を使用している場合には)ゾーンを横断してアプリケーションを分散させる。 自発的なDisruptionの頻度は様々です。
基本的なKubernetesクラスターでは、自動で発生する自発的なDisruptionはありません(ユーザーによってトリガーされたものだけです)。
しかし、クラスター管理者やホスティングプロバイダーが何か追加のサービスを実行して自発的なDisruptionが発生する可能性があります。
例えば、ノード上のソフトウェアアップデートのロールアウトは自発的なDisruptionの原因となります。
また、クラスター(ノード)自動スケーリングの実装の中には、ノードのデフラグとコンパクト化のために自発的なDisruptionを伴うものがあります。
クラスタ管理者やホスティングプロバイダーは、自発的なDisruptionがある場合、どの程度のDisruptionが予想されるかを文書化しているはずです。
Podのspecの中でPriorityClassesを使用している 場合など、特定の設定オプションによっても自発的(および非自発的)なDisruptionを引き起こす可能性があります。
Pod Disruption Budget FEATURE STATE:
Kubernetes v1.21 [stable]
Kubernetesは、自発的なDisruptionが頻繁に発生する場合でも、可用性の高いアプリケーションの運用を支援する機能を提供しています。
アプリケーションの所有者として、各アプリケーションに対してPodDisruptionBudget (PDB)を作成することができます。
PDBは、レプリカを持っているアプリケーションのうち、自発的なDisruptionによって同時にダウンするPodの数を制限します。
例えば、クォーラムベースのアプリケーションでは、実行中のレプリカの数がクォーラムに必要な数を下回らないようにする必要があります。
Webフロントエンドは、負荷に対応するレプリカの数が、全体に対して一定の割合を下回らないようにしたいかもしれません。
クラスター管理者やホスティングプロバイダーは、直接PodやDeploymentを削除するのではなく、Eviction API を呼び出す、PodDisruptionBudgetsに配慮したツールを使用すべきです。
例えば、kubectl drainサブコマンドはノードを休止中とマークします。
kubectl drainを実行すると、ツールは休止中としたノード上の全てのPodを退避しようとします。
kubectlがあなたの代わりに送信する退避要求は一時的に拒否される可能性があるため、ツールは対象のノード上の全てのPodが終了するか、設定可能なタイムアウト時間に達するまで、全ての失敗した要求を定期的に再試行します。
PDBはアプリケーションの意図したレプリカ数に対して、許容できるレプリカの数を指定します。
例えば.spec.replicas: 5を持つDeploymentは常に5つのPodを持つことが想定されます。
PDBが同時に4つまでを許容する場合、Eviction APIは1度に(2つではなく)1つのPodの自発的なDisruptionを許可します。
アプリケーションを構成するPodのグループは、アプリケーションのコントローラー(Deployment、StatefulSetなど)が使用するものと同じラベルセレクターを使用して指定されます。
"意図した"Podの数は、これらのPodを管理するワークロードリソースの.spec.replicasから計算されます。
コントロールプレーンはPodの.metadata.ownerReferencesを調べることで、所有しているワークロードリソースを見つけます。
非自発的なDisruption はPDBによって防ぐことができません;
しかし、予算にはカウントされます。
アプリケーションのローリングアップデートによって削除または利用できなくなったPodはDisruptionの予算にカウントされますが、ローリングアップグレードを実行している時は(DeploymentやStatefulSetなどの)ワークロードリソースはPDBによって制限されません。
代わりに、アプリケーションのアップデート中の障害のハンドリングは、個々のワークロードリソースに対するspecで設定されます。
ノードのドレイン中に動作がおかしくなったアプリケーションの退避をサポートするために、Unhealthy Pod Eviction Policy にAlwaysAllowを設定することを推奨します。
既定の動作は、ドレインを継続する前にアプリケーションPodがhealthy な状態になるまで待機します。
Eviction APIを使用してPodを退避した場合、PodSpec で設定したterminationGracePeriodSecondsに従って正常に終了 します。
PodDisruptionBudgetの例 node-1からnode-3まで3つのノードがあるクラスターを考えます。
クラスターにはいくつかのアプリケーションが動いています。
それらのうちの1つは3つのレプリカを持ち、最初はpod-a、pod-bそしてpod-cと名前が付いています。
もう一つ、これとは独立したPDBなしのpod-xと呼ばれるものもあります。
初期状態ではPodは次のようにレイアウトされています:
node-1 node-2 node-3 pod-a available pod-b available pod-c available pod-x available
3つのPodはすべてDeploymentの一部で、これらはまとめて1つのPDBを持ち、3つのPodのうちの少なくとも2つが常に存在していることを要求します。
例えばクラスター管理者がカーネルのバグを修正するために、再起動して新しいカーネルバージョンにしたいとします。
クラスター管理者はまず、kubectl drainコマンドを使ってnode-1をドレインしようとします。
ツールはpod-aとpod-xを退避しようとします。
これはすぐに成功します。
2つのPodは同時にterminating状態になります。
これにより、クラスターは次のような状態になります:
node-1 draining node-2 node-3 pod-a terminating pod-b available pod-c available pod-x terminating
DeploymentはPodの1つが終了中であることに気づき、pod-dという代わりのPodを作成します。
node-1はcordonされたため、別のノードに展開されます。
また、pod-xの代わりとしてpod-yも作られました。
(備考: StatefulSetの場合、pod-aはpod-0のように呼ばれ、代わりのPodが作成される前に完全に終了する必要があります。
この代わりのPodは、UIDは異なりますが、同じpod-0という名前になります。
それを除けば、本例はStatefulSetにも当てはまります。)
現在、クラスターは次のような状態になっています:
node-1 draining node-2 node-3 pod-a terminating pod-b available pod-c available pod-x terminating pod-d starting pod-y
ある時点でPodは終了し、クラスターはこのようになります:
node-1 drained node-2 node-3 pod-b available pod-c available pod-d starting pod-y
この時点で、せっかちなクラスター管理者がnode-2かnode-3をドレインしようとすると、Deploymentの利用可能なPodは2つしかなく、また、PDBによって最低2つのPodが要求されているため、drainコマンドはブロックされます。
しばらくすると、pod-dが使用可能になります。
クラスターの状態はこのようになります:
node-1 drained node-2 node-3 pod-b available pod-c available pod-d available pod-y
ここでクラスター管理者がnode-2をドレインしようとします。
drainコマンドは2つのPodをなんらかの順番で退避しようとします。
例えば最初にpod-b、次にpod-dとします。
pod-bについては退避に成功します。
しかしpod-dを退避しようとすると、Deploymentに対して利用可能なPodは1つしか残らないため、退避は拒否されます。
Deploymentはpod-bの代わりとしてpod-eを作成します。
クラスターにはpod-eをスケジューリングする十分なリソースがないため、ドレインは再びブロックされます。
クラスターは次のような状態になります:
node-1 drained node-2 node-3 no node pod-b terminating pod-c available pod-e pending pod-d available pod-y
この時点で、クラスター管理者はアップグレードを継続するためにクラスターにノードを追加する必要があります。
KubernetesがどのようにDisruptionの発生率を変化させているかについては、次のようなものから知ることができます:
いくつのレプリカをアプリケーションが必要としているか インスタンスのグレースフルシャットダウンにどれくらいの時間がかかるか 新しいインスタンスのスタートアップにどれくらいの時間がかかるか コントローラーの種類 クラスターリソースのキャパシティ Pod Disruption Condition FEATURE STATE:
Kubernetes v1.26 [beta]
備考: この機能を使用するためには、クラスターで
フィーチャーゲート PodDisruptionConditionsを有効にする必要があります。
有効にすると、専用のPod DisruptionTarget Condition が追加されます。
これはPodがDisruption によって削除されようとしていることを示すものです。
Conditionのreasonフィールドにて、追加で以下のいずれかをPodの終了の理由として示します:
PreemptionBySchedulerPodはより高い優先度を持つ新しいPodを収容するために、スケジューラーによってプリエンプトされる 予定です。
詳細についてはPodの優先度とプリエンプション を参照してください。 DeletionByTaintManagerPodが許容しないNoExecute taintによって、Podは(kube-controller-managerの中のノードライフサイクルコントローラーである)Taintマネージャーによって削除される予定です。
taint ベースの退避を参照してください。 EvictionByEvictionAPIPodはKubernetes APIを使用して退避するように マークされました。 DeletionByPodGCすでに存在しないノードに紐づいているPodのため、Podのガベージコレクション によって削除される予定です。 TerminationByKubeletnode-pressureによる退避 またはGraceful Node Shutdown のため、Podはkubeletによって終了させられました。
備考: PodのDisruptionは一時停止する場合があります。
コントロールプレーンは同じPodに対するDisruptionを継続するために再試行するかもしれませんが、保証はされていません。
その結果、DisruptionTarget ConditionはPodに付与されるかもしれませんが、実際にはPodは削除されていない可能性があります。
そのような状況の場合、しばらくすると、Pod Disruption Conditionはクリアされます。フィーチャーゲートPodDisruptionConditionsを有効にすると、Podのクリーンアップと共に、Podガベージコレクタ(PodGC)が非終了フェーズにあるPodを失敗とマークします。
(Podガベージコレクション も参照してください)。
Job(またはCronJob)を使用している場合、JobのPod失敗ポリシー の一部としてこれらのPod Disruption Conditionを使用したいと思うかもしれません。
クラスターオーナーとアプリケーションオーナーロールの分離 多くの場合、クラスター管理者とアプリケーションオーナーは、互いの情報を一部しか持たない別の役割であると考えるのが便利です。
このような責任の分離は、次のようなシナリオで意味を持つことがあります:
多くのアプリケーションチームでKubernetesクラスターを共有していて、役割の専門化が自然に行われている場合 クラスター管理を自動化するためにサードパーティのツールやサービスを使用している場合 Pod Disruption Budgetはロール間のインターフェースを提供することによって、この役割の分離をサポートします。
もしあなたの組織でこのような責任の分担がなされていない場合は、Pod Disruption Budgetを使用する必要はないかもしれません。
クラスターで破壊的なアクションを実行する方法 あなたがクラスターの管理者で、ノードやシステムソフトウェアのアップグレードなど、クラスター内のすべてのノードに対して破壊的なアクションを実行する必要がある場合、次のような選択肢があります:
アップグレードの間のダウンタイムを許容する。 もう一つの完全なレプリカクラスターにフェールオーバーする。ダウンタイムはありませんが、重複するノードと、切り替えを調整する人的労力の両方のコストがかかる可能性があります。 Disruptionに耐性のあるアプリケーションを書き、PDBを使用する。ダウンタイムはありません。 リソースの重複は最小限です。 クラスター管理をより自動化できます。 Disruptionに耐えうるアプリケーションを書くことは大変ですが、自発的なDisruptionに耐えうるようにするための作業は、非自発的なDisruptionに耐えうるために必要な作業とほぼ重複しています。 次の項目 3.5.1.6 - Pod Quality of Serviceクラス このページでは、Kubernetesにおける Quality of Service(QoS)クラス を紹介し、Pod内のコンテナに指定したリソース制約に応じて、KubernetesがどのようにPodにQoSクラスを割り当てるのかについて説明します。
Kubernetesは、ノード上で利用可能なリソースが不足した際に、どのPodを退避させるかを決定するために、このクラスを利用します。
Quality of Serviceクラス Kubernetesは、実行中のPodを分類し、各Podを特定の Quality of Service(QoS)クラス に割り当てます。
Kubernetesは、このクラスを用いてそれぞれのPodの扱い方を決定します。
分類は、Pod内のコンテナ のリソース要求 と、それらの要求とリソース制限との関連性に基づいて行われます。
これはQuality of Service (QoS)クラスと呼ばれます。
Kubernetesは、Podのコンポーネントであるコンテナのリソース要求と制限に基づいて、すべてのPodにQoSクラスを割り当てます。
QoSクラスは、ノードの圧迫 が発生しているノードからどのPodを退避させるかを決定する際に使用されます。
QoSクラスにはGuaranteed、Burstable、BestEffortがあります。
ノードのリソースが不足すると、KubernetesはまずBestEffort Podを退避し、次にBurstable、最後にGuaranteed Podを退避させます。
リソースの圧迫による退避の場合、リソース要求を超過しているPodのみが退避の候補となります。
Guaranteed GuaranteedのPodは最も厳しいリソース制限を持ち、退避される可能性が最も低いです。
制限を超過するか、ノードからプリエンプト可能なより低い優先度のPodが存在しない限り、強制終了されることはありません。
ただし、指定された制限を超えてリソースを取得することはできません。
これらのPodは、static
条件 PodがGuaranteed QoSクラスとして分類されるための条件は以下の通りです:
Pod内のすべてのコンテナが、メモリ制限とメモリ要求を持っていること。 Pod内のすべてのコンテナで、メモリ制限がメモリ要求と等しいこと。 Pod内のすべてのコンテナが、CPU制限とCPU要求を持っていること。 Pod内のすべてのコンテナで、CPU制限がCPU要求と等しいこと。 もしくは、PodがPodレベルのリソース を使用する場合は以下の通りです:
FEATURE STATE:
Kubernetes v1.34 [beta](enabled by default)
PodがPodレベルのメモリ制限とメモリ要求を持ち、それらの値が等しいこと。 PodがPodレベルのCPU制限とCPU要求を持ち、それらの値が等しいこと。 Burstable BurstableのPodは、要求に基づく下限のリソース保証を持ちますが、特定の制限は必要としません。
制限が指定されていない場合、デフォルトでノードの容量と同等の制限となり、リソースが利用可能であればPodは柔軟にリソースを増やすことができます。
ノードのリソース圧迫によるPod退避の際、これらのPodは、すべてのBestEffort Podが退避されてから退避されます。
Burstable Podには、リソース制限や要求を持たないコンテナを含めることができるため、BurstableなPodは任意の量のノードリソースを使おうとする可能性があります。
条件 以下の場合、PodはBurstable QoSクラスとして分類されます:
PodがGuaranteed QoSクラスの条件を満たさないこと。 Pod内の少なくとも1つのコンテナがメモリまたはCPUの要求または制限を持つか、PodがPodレベルのメモリまたはCPUの要求または制限を持つこと。 BestEffort BestEffort QoSクラスのPodは、他のQoSクラスのPodに明示的に割り当てられていないノードリソースを使用できます。
たとえば、kubeletで利用可能な16個のCPUコアを持つノードがあり、Guaranteed Podに4個のCPUコアを割り当てた場合、BestEffort QoSクラスのPodは、残りの12個のCPUコアのうち任意の量を使うことができます。
kubeletは、ノードがリソース圧迫を受けた場合、BestEffort Podを優先的に退避させます。
条件 Podは、GuaranteedまたはBurstableのいずれの条件も満たさない場合、BestEffort QoSクラスになります。
つまり、Pod内のどのコンテナもメモリ制限またはメモリ要求を持たず、Pod内のどのコンテナもCPU制限またはCPU要求を持たず、PodがPodレベルのメモリまたはCPUの制限または要求を持たない場合にのみ、PodはBestEffortとなります。
Pod内のコンテナは、(CPUまたはメモリ以外の)他のリソースを要求していても、BestEffortとして分類されます。
cgroup v2を使用したメモリQoS FEATURE STATE:
Kubernetes v1.22 [alpha](disabled by default)
メモリQoSは、cgroup v2のメモリコントローラーを使用して、Kubernetesでメモリリソースを保証します。
Pod内のコンテナのメモリ要求と制限は、メモリコントローラーが提供するmemory.minとmemory.highインターフェースの設定に使用されます。
memory.minがメモリ要求に設定されると、メモリリソースは予約され、カーネルによって回収されることはありません。
これが、メモリQoSがKubernetes Podのメモリ可用性を保証する仕組みです。
また、コンテナでメモリ制限が設定されている場合、システムはコンテナのメモリ使用量を制限する必要があります。
メモリQoSは、memory.highを使用してメモリ制限に近づいているワークロードの動作を抑制し、瞬間的なメモリ割り当てによってシステムが圧迫されないようにします。
メモリQoSは、QoSクラスに基づいてどの設定を適用するか決定しますが、これらは異なるメカニズムであり、どちらもQuality of Serviceに対する制御を提供します。
QoSクラスに依存しない動作 Kubernetesによって割り当てられたQoSクラスとは無関係な動作もあります。
例えば、以下が該当します:
リソース制限を超過したコンテナは、そのPod内の他のコンテナに影響を与えることなく、kubeletによって強制終了され、再起動されます。
コンテナがリソース要求を超過し、実行しているノードがリソース圧迫に直面している場合、そのコンテナが含まれるPodは退避 の候補となります。
このような場合、Pod内のすべてのコンテナが終了されます。
Kubernetesは、通常は別のノード上に、置き換えとなるPodを作成する可能性があります。
Podのリソース要求は、コンポーネントであるコンテナのリソース要求の合計に等しく、Podのリソース制限は、コンポーネントであるコンテナのリソース制限の合計に等しくなります。
kube-schedulerは、どのPodをプリエンプト するかを選択する際に、QoSクラスを考慮しません。
プリエンプションは、クラスター内に、定義したすべてのPodを実行するのに十分なリソースがない場合に発生する可能性があります。
次の項目 3.5.1.7 - Podのホスト名 このページでは、Podのホスト名を設定する方法、その設定後に起こり得る副作用、そして基盤となる仕組みについて説明します。
Podのデフォルトのホスト名 Podが作成されると、(Pod内部から観測される)そのホスト名は、Podのmetadata.nameの値から導き出されます。
ホスト名と、それに対応する完全修飾ドメイン名(FQDN)の両方が(Podの視点からは)metadata.nameの値に設定されます。
apiVersion : v1
kind : Pod
metadata :
name : busybox-1
spec :
containers :
- image : busybox:1.28
command :
- sleep
- "3600"
name : busybox
このmanifestで作成されたPodは、ホスト名と完全修飾ドメイン名(FQDN)がbusybox-1に設定されます。
Podのhostnameとsubdomainフィールド Podのspecには、オプションのhostnameフィールドがあります。
この値が設定されると、Podのmetadata.nameよりも優先され、(Pod内部から観測される)ホスト名として使われます。
例えば、spec.hostnameがmy-hostに設定されているPodは、ホスト名がmy-hostです。
また、Podのspecにはオプションのsubdomainフィールドもあり、Podが自分のNamespace内のサブドメインに属していることを示します。
もしPodのspec.hostnameが"foo"、spec.subdomainが"bar"に設定され、さらにNamespaceがmy-namespaceの場合、ホスト名はfooで、完全修飾ドメイン名(FQDN)は(Podの内部から観測される)foo.bar.my-namespace.svc.cluster-domain.exampleです。
hostnameとsubdomainの両方が設定されていると、クラスターのDNSサーバーはこれらのフィールドに基づいてA/AAAAレコードを作成します。
Podのhostnameとsubdomainフィールド を参照してください。
PodのsetHostnameAsFQDNフィールド FEATURE STATE:
Kubernetes v1.22 [stable]
Podが完全修飾ドメイン名(FQDN)を持つように設定されている場合、そのホスト名は短いホスト名です。
例えば、Podの完全修飾ドメイン名がbusybox-1.busybox-subdomain.my-namespace.svc.cluster-domain.exampleの場合、デフォルトではそのPod内でhostnameコマンドを実行するとbusybox-1が返り、hostname --fqdnコマンドを実行するとFQDNが返ります。
setHostnameAsFQDN: trueとsubdomainフィールドがPodのspecに設定されている場合、kubeletはそのPodのNamespaceに対してFQDNをホスト名として書き込みます。
この場合、hostnameとhostname --fqdnの両方がPodのFQDNを返します。
PodのFQDNは前述と同じ方法で構築されます。
つまり、Podのspec.hostname(設定されている場合)またはmetadata.nameフィールド、spec.subdomain、namespace名、そしてクラスタードメインサフィックスで構成されます。
備考: Linuxでは、kernelのhostnameフィールド(struct utsnameのnodenameフィールド)は64文字に制限されています。
Podがこの機能を有効にし、そのFQDNが64文字を超える場合、起動に失敗します。
そのPodはPendingステータスのままになり(kubectlからはContainerCreatingと表示)、"Failed to construct FQDN from Pod hostname and cluster domain"などのエラーイベントが生成されます。
つまり、このフィールドを使う場合、Podのmetadata.name(またはspec.hostname)とspec.subdomainフィールドを組み合わせた長さが64文字を超えないようにする必要があります。
PodのhostnameOverride FEATURE STATE:
Kubernetes v1.35 [beta](enabled by default)
PodのspecでhostnameOverrideに値を設定すると、kubeletは無条件にその値をPodのホスト名とFQDN両方に設定します。
hostnameOverrideフィールドには64文字の長さ制限があり、RFC 1123 で定義されているDNSのサブドメイン名の基準に従う必要があります。
例:
apiVersion : v1
kind : Pod
metadata :
name : busybox-2-busybox-example-domain
spec :
hostnameOverride : busybox-2.busybox.example.domain
containers :
- image : busybox:1.28
command :
- sleep
- "3600"
name : busybox
備考: これはPod内のホスト名にのみ影響し、クラスターのDNSサーバーにおけるPodのAレコードやAAAAレコードには影響しません。hostnameOverrideがhostnameやsubdomainフィールドと同時に設定されている場合:
備考: hostnameOverrideが設定されている場合、hostNetworkとsetHostnameAsFQDNフィールドを同時に設定することはできません。
APIサーバーは、この組み合わせで作成要求が行われた場合、明示的に拒否します。
hostnameOverrideが他のフィールド(hostname、subdomain、setHostnameAsFQDN、hostNetwork)と組み合わされた時の動作の詳細については、KEP-4762の設計詳細 の表を参照してください。
3.5.1.8 - Workload参照 FEATURE STATE:
Kubernetes v1.35 [alpha](disabled by default)
PodをWorkload オブジェクトに紐づけることで、そのPodがより大きなアプリケーションやグループに属していることを示すことができます。
これにより、スケジューラーは各Podを独立したエンティティとして扱うのではなく、グループとしての要件を考慮してスケジューリングを行います。
Workload参照の指定 GenericWorkloadspec.workloadRefフィールドを使用できます。
このフィールドは、同じ名前空間内のWorkloadリソースで定義された特定のPodグループへの紐づけを行います。
apiVersion : v1
kind : Pod
metadata :
name : worker-0
namespace : some-ns
spec :
workloadRef :
# 同じ名前空間内のWorkloadオブジェクトの名前
name : training-job-workload
# このWorkload内の特定のPodグループの名前
podGroup : workers
Podグループのレプリカ より複雑なシナリオでは、単一のPodグループを複数の独立したスケジューリング単位に複製できます。
これは、PodのworkloadRef内でpodGroupReplicaKeyフィールドを使用して実現します。
このキーはラベルとして機能し、論理的なサブグループを作成します。
たとえば、minCount: 2のPodグループがあり、4つのPodを作成する場合を考えます。
2つにpodGroupReplicaKey: "0"を、残り2つにpodGroupReplicaKey: "1"を設定すると、それぞれ2つのPodから構成される独立した2つのグループとして扱われます。
spec :
workloadRef :
name : training-job-workload
podGroup : workers
# レプリカキー"0"を持つすべてのworkerは、1つのグループとして一緒にスケジュールされます
podGroupReplicaKey : "0"
動作 workloadRefを定義すると、Podは参照先のPodグループで定義されたポリシー に応じて異なる動作をします。
参照先のグループがbasicポリシーを使用している場合、Workload参照は主にグループ化のためのラベルとして機能します。 参照先のグループがgangポリシーを使用している場合(かつGangScheduling 参照が存在しない場合 スケジューラーは、配置を決定する前にworkloadRefを検証します。
Podが、存在しないWorkloadを参照している場合、またはそのWorkload内で定義されていないPodグループを参照している場合、Podは保留状態のままになります。
存在しないWorkloadオブジェクトを作成するか、不足しているPodGroup定義を含んだWorkloadを再作成するまで、配置の対象とはみなされません。
この動作は、最終的なポリシーがbasicかgangかに関係なく、workloadRefを持つすべてのPodに適用されます。
スケジューラーはポリシーを決定するためにWorkload定義を必要とするためです。
次の項目 3.5.1.9 - ユーザー名前空間 FEATURE STATE:
Kubernetes v1.30 [beta]
このページでは、KubernetesのPodにおけるユーザー名前空間 について説明します。
ユーザー名前空間はホストのユーザーとコンテナ内プロセスが利用するユーザーを隔離するものです。
ユーザー名前空間を使うと、コンテナ内でrootとして稼働するプロセスを、ホスト側の異なる(root以外の)ユーザーとして実行することができます。
言い換えれば、ユーザー名前空間内部のリソースの操作に特権をもつプロセスは、名前空間の外側では非特権のプロセスとなっています。
ホストや他のPodに危害を及ぼす、侵害されたコンテナによる被害を軽減するために、この機能を用いることができます。
HIGH ないしは CRITICAL にレートされたいくつかの脆弱性 は、ユーザー名前空間が有効な場合には悪用できないものでした。
ユーザー名前空間は、将来の脆弱性を緩和することも期待できます。
始める前に 備考: このセクションでは、Kubernetesが必要とする機能を提供するサードパーティープロジェクトにリンクしています。これらのプロジェクトはアルファベット順に記載されていて、Kubernetesプロジェクトの作者は責任を持ちません。このリストにプロジェクトを追加するには、変更を提出する前に
content guide をお読みください。
詳細はこちら。 この機能はLinux固有であり、Linuxのファイルシステムでidmapマウントがサポートされている必要があります。
ノード上で/var/lib/kubelet/pods/(ないしはそのカスタムディレクトリとして設定した場所)でidmapマウントがサポートされている必要があります。 Podのボリュームとして使われる全てのファイルシステムがidmapマウントをサポートしている必要があります。 これは、最低でもLinux 6.3以降を利用していて、かつidmapマウントをサポートするtmpfsが必要であることを意味します。
一般的に、いくつかのKubernetesの機能はtmpfsを利用しています。
(デフォルトでは、PodがサービスアカウントトークンやSecretをマウントする時にtmpfsを使っていたりします)。
Linux 6.3でidmapマウントをサポートするポピュラーなファイルシステムはbtrfs、ext4、xfs、fat、tmpfs、overlayfsです。
さらに、コンテナランタイムとその基盤であるOCIランタイムもユーザー名前空間をサポートしている必要があります。
次のOCIランタイムではサポートが提供されています。
crun バージョン1.9以上 (推奨バージョンは1.13以上).runc バージョン1.2以上
備考: いくつかのOCIランタイムには、LinuxのPodでユーザー名前空間を利用するのに必要なサポートが含まれていません。
マネージドKubernetesを利用している場合やOCIランタイムをパッケージとしてダウンロードしてセットアップした場合には、クラスタ内のノードがユーザー名前空間をサポートしない可能性があります。Kubernetesでユーザー名前空間を利用する際、Podでこの機能を使うためにはCRIコンテナランタイム も必要です。
containerd: バージョン2.0以上ではコンテナのユーザー名前空間をサポート。 CRI-O: バージョン1.25以上でコンテナのユーザー名前空間をサポート。 ユーザー名前空間のサポート状況については、GitHubのissue で確認できます。
導入 Linuxの機能であるユーザー名前空間を用いると、コンテナのユーザーをホスト側の異なるユーザーにマップすることができます。
さらに言えば、ユーザー名前空間においてPodに付与されたケーパビリティ(capability)は、ユーザー名前空間内においてのみ有効で、外側では無効です。
Podはpod.spec.hostUsersフィールドをfalseに設定することで、ユーザー名前空間を使えるようになります。
kubeletはPodに対応する(ホストの)UID/GIDを選択した上で、同一ノードの2つ以上のPodが同じ対応関係にならないよう保証するようにしつつ、ユーザーをマップします。
pod.specにおけるrunAsUserやrunAsGroup、fsGroupなどのフィールドはコンテナ内のユーザーを指すものです。
この機能が有効化された場合、UID/GIDとして正しい値の範囲は0-65535です。
これはファイルとプロセスに対して適用されます。
(runAsUserやrunAsGroupなど)。
この範囲を超えるUID/GIDを利用するファイルはオーバーフローしたID(一般的には65534)に所属するように見えるでしょう。
(/proc/sys/kernel/overflowuidと/proc/sys/kernel/overflowgidで設定されます)。
ただし、これらのファイルは65534のユーザー/グループで稼働するプロセスであっても、編集することはできません。
rootとして動かす必要があるアプリケーションであっても、ホストにおける他のユーザー名前空間や他のリソースに対してアクセスしないものの多くは、ユーザー名前空間を有効化しても動かせますし、アプリケーションを修正しなくても問題なく動作するでしょう。
Podにおけるユーザー名前空間を理解する いくつかのコンテナランタイム(Docker Engineやcontainer、CRI-Oなど)は、デフォルトでユーザー名前空間を利用するように設定されています。
これらのランタイムとその他の既存技術を組み合わせて使うことも可能です。
(例えば、Kata ContainerはLinux名前空間の代わりにVMを利用します)。
このページの内容はLinux名前空間を隔離に使うコンテナランタイムに適用できるものです。
Podを作成する時、デフォルトでは、Podの隔離にいくつかの新しい名前空間が利用されます。
(コンテナネットワークの隔離のためのネットワーク名前空間、プロセスの見える範囲を隔離するためのPID名前空間など)。
ユーザー名前空間を利用する場合には、コンテナ内のユーザーをノードのユーザーと隔離します。
これは、コンテナがrootとしてプロセスを動かせる一方で、ホスト上では非rootユーザーとしてマップされていることを意味します。
コンテナ内部のプロセスはrootとして動作しているものと思っていることでしょう。
(したがって、aptやyumなどは問題なく動作します)。
しかし、実際には、このプロセスにホスト上での特権はありません。
これを検証するには、例えばホスト上でps auxを実行することで、コンテナのプロセスがどのユーザーを使用しているかを確認するとよいでしょう。
psが示すユーザーは、コンテナ内でidを実行した場合に示されるユーザーとは異なっているはずです。
この分離によって、ホスト上で「起こせること」を制限できます。例えばコンテナ内プロセスのホストへのエスケープを処理する場合にこの制限が有効に働きます。
コンテナはホスト上で非特権のユーザーとして動作しているため、ホスト上でできることが制限されているのです。
さらに言えば、それぞれのPodのユーザーは、ホスト上においては異なるユーザーにマップされており、UID/GIDは重複しません。
他のPodに対してできることさえも制限されているのです。
Podに付与されたケーパビリティについても、Podのユーザー名前空間に制限されており、名前空間の外部においてはほとんどが効力を持たず、いくつかのケーパビリティは外部では完全に無効です。
2つの例を挙げます:
CAP_SYS_MODULE がユーザー名前空間を使うPodに付与されている場合、Podはカーネルモジュールをロードできません。CAP_SYS_ADMIN はPodのユーザー名前空間の内部のみに制限され、名前空間の外部では無効です。コンテナブレークアウトのケースについて考えてみます。
この場合、ユーザー名前空間を使用せずにコンテナをrootで稼働させていると、ノードのroot権限が取得されます。
さらに、ケーパビリティがコンテナに付与されていた場合には、そのケーパビリティはホスト上でも有効となっています。
ユーザー名前空間を利用していれば、これらはいずれも成立しません。
ユーザー名前空間を使う場合に何が変わるのかについて詳しく知りたい場合には、man 7 user_namespacesを参照してください。
ユーザー名前空間をサポートするノードを設定する ほとんどのLinuxディストリビューションで標準的なUIDである0-65535の範囲については、kubeletはホストのファイルやプロセスがこの範囲のUIDを利用しているものとみなし、デフォルトではこれよりも上のUID/GIDの値をPodに紐付けます。
言い換えれば、0-65535の範囲のIDをPodで使うことはできません。
このアプローチにより、PodとホストのUID/GIDが重複することを防ぎます。
Podによる潜在的な任意のファイル読み出しの脆弱性であるCVE-2021-25741 のような脆弱性の影響を緩和する上で、UID/GIDの重複を防ぐことは重要です。
PodとホストのUID/GIDが重複しなければ、Podができることは限定されます。
(PodのUID/GIDはホスト上のファイル所有者やグループと一致することがないのです)。
kubeletはPodに割り当てるユーザーIDとグループIDの範囲を変更することが可能です。カスタムの範囲を設定するには、ノードが次の条件を満たす必要があります。
ユーザーkubeletがシステム上に存在していること(他のユーザー名を使うことはできません) getsubidsバイナリ(shadow-utils の一部)がインストールされており、kubeletバイナリが参照するPATHに入っていることkubeletユーザーのsubordinate UID/GID (man 5 subuidman 5 subgidこれはsubordinate UID/GIDの範囲に関する設定のみを示しており、kubeletを実行するユーザーは変更しません。
ユーザーkubeletに割り当てるsubordinate IDの範囲に関しては、いくつかの制約に従う必要があります。
subordinate UIDの起点(つまりPodのUID範囲の開始位置)が65536の倍数に設定されていて、かつ65536以上であること( 必須 )。
言い換えると、0-65535の範囲をPodのUIDとして使うことはできません。
偶発的にインセキュアな設定がなされることを防ぐために、kubeletはこの制約を強制します。
subordinate UID/GIDの個数が65536の倍数であること(必須)。
subordinate UID/GIDの個数は最低でも65536 x <最大Pod数>であること(必須)。
<最大Pod数>
はノードで稼働できるPodの数の最大値を表します。
UIDとGIDとして同じ個数を割り当てること(必須)。
他のユーザーに対して、GIDの範囲と合致しないUID範囲を指定することは問題ありません。
割り当てられたUID/GID範囲は他の割当と重複しないこと(推奨)。
subordinate UID/GIDの設定は単一行でなされること(必須)。
同一のユーザーに対して複数のUID/GID範囲を定義することはできません。
例えば、ユーザーkubeletのエントリについて、/etc/subuidと/etc/subgidに次のように定義することができます。
# フォーマットは次の通り
# name:firstID:count
# この例における意味
# - firstIDは65536 (とりうる最小の値)
# - countは110 (デフォルトの制限値) * 65536
kubelet:65536:7208960
Podセキュリティのアドミッション検証への統合 FEATURE STATE:
Kubernetes v1.29 [alpha]
ユーザー名前空間を有効化したLinuxのPodでは、KubernetesはPod Security Standards で制御されるアプリケーションの制限を緩和します。
この挙動はエンドユーザーの早期オプトインを可能にするためのUserNamespacesPodSecurityStandardsフィーチャーゲート で制御することが可能です。
このフィーチャーゲートを使う場合、クラスタ管理者はユーザー名前空間が全てのノードで有効化されていることを確実にする必要があります。
フィーチャーゲートを有効化した上でユーザー名前空間を使うPodを作成する場合、_Baseline_ないしは_Restricted_Podセキュリティ基準のセキュリティコンテキストが強制されていても、以下のフィールドによる制約がなされません。
spec.securityContext.runAsNonRootspec.containers[*].securityContext.runAsNonRootspec.initContainers[*].securityContext.runAsNonRootspec.ephemeralContainers[*].securityContext.runAsNonRootspec.securityContext.runAsUserspec.containers[*].securityContext.runAsUserspec.initContainers[*].securityContext.runAsUserspec.ephemeralContainers[*].securityContext.runAsUser制限 Podでユーザー名前空間を利用する際には、他のホスト名前空間を利用することはできません。
特にhostUsers: falseを設定している場合、次の値を設定することはできません。
hostNetwork: truehostIPC: truehostPID: true次の項目 3.5.1.10 - Downward API Podやコンテナのフィールドを実行中のコンテナに公開する方法には2つあります。 1つは環境変数で、もう1つは特殊なボリュームタイプによってファイルとして公開する方法です。 これら2つの方法をまとめてDownward APIと呼びます。
Kubernetesに過度に密結合することなく、コンテナが自分自身についての情報を持つことは有用な場合があります。
downward API を用いることで、コンテナはKubernetesのクライアントやAPIサーバーを利用せずに、自分自身やクラスターに関する情報を取得することができます。
例として、特定の既知の環境変数に一意な識別子が格納されていることを前提とする既存のアプリケーションがあるとします。
一つの可能性は、アプリケーションをラップすることですが、これは煩雑でエラーが起こりやすく、疎結合という目標に反します。
より良い選択肢は、Pod名を識別子として使用し、Pod名をその既知の環境変数に注入することです。
Kubernetesでは、実行中のコンテナにPodおよびコンテナフィールドを公開する方法が2つあります:
これらPodおよびコンテナフィールドを公開する2つの方法を総称して、downward API と呼びます。
利用可能なフィールド Kubernetes APIフィールドのうち、downward APIを通じて利用可能なものは一部のみです。
このセクションでは、利用可能なフィールドを列挙します。
利用可能なPodレベルのフィールドからの情報は、fieldRefを使用して渡すことができます。
APIレベルでは、Podのspecは常に少なくとも1つのContainer を定義します。
利用可能なコンテナレベルのフィールドからの情報は、resourceFieldRefを使用して渡すことができます。
fieldRefを通じて利用可能な情報一部のPodレベルフィールドについては、環境変数として、またはdownwardAPIボリュームを使用して、コンテナに提供することができます。
どちらのメカニズムでも利用可能なフィールドは以下の通りです:
metadata.namePodの名前 metadata.namespacePodのネームスペース metadata.uidPodの一意ID metadata.annotations['<KEY>']<KEY>という名前のPodのアノテーション の値(例: metadata.annotations['myannotation'])metadata.labels['<KEY>']<KEY>という名前のPodのラベル のテキスト値(例: metadata.labels['mylabel'])以下の情報は環境変数を通じて利用可能ですが、downwardAPIボリュームのfieldRefとしては利用できません :
spec.serviceAccountNamePodのサービスアカウント の名前 spec.nodeNamePodが実行されているノード の名前 status.hostIPPodが割り当てられているノードのプライマリIPアドレス status.hostIPsstatus.hostIPのデュアルスタック版のIPアドレスで、最初のIPアドレスは常にstatus.hostIPと同じですstatus.podIPPodのプライマリIPアドレス(通常、IPv4アドレス) status.podIPsstatus.podIPのデュアルスタック版のIPアドレスで、最初のIPアドレスは常にstatus.podIPと同じです以下の情報はdownwardAPIボリュームのfieldRefを通じて利用可能ですが、環境変数としては利用できません :
metadata.labelsPodのすべてのラベルで、label-key="escaped-label-value"形式でフォーマットされ、1行に1つのラベルが記載されます metadata.annotationsPodのすべてのアノテーションで、annotation-key="escaped-annotation-value"形式でフォーマットされ、1行に1つのアノテーションが記載されます resourceFieldRefを通じて利用可能な情報これらのコンテナレベルフィールドを使用すると、CPUやメモリなどのリソースの要求と制限 に関する情報を提供することができます。
備考: FEATURE STATE:
Kubernetes v1.35 [stable](enabled by default)
コンテナのCPUとメモリリソースは、コンテナの実行中にリサイズすることができます。
この場合、downward APIボリュームは更新されますが、環境変数はコンテナが再起動されない限り更新されません。
詳細については、コンテナに割り当てるCPUとメモリ容量を変更する を参照してください。
resource: limits.cpuコンテナのCPU制限 resource: requests.cpuコンテナのCPU要求 resource: limits.memoryコンテナのメモリ制限 resource: requests.memoryコンテナのメモリ要求 resource: limits.hugepages-*コンテナのhugepages制限 resource: requests.hugepages-*コンテナのhugepages要求 resource: limits.ephemeral-storageコンテナの一時ストレージ制限 resource: requests.ephemeral-storageコンテナの一時ストレージ要求 リソース制限のフォールバック情報 コンテナにCPUとメモリの制限が指定されておらず、downward APIを使用してその情報を公開しようとする場合、kubeletはノード割り当て可能量 の計算に基づいて、CPUとメモリの最大割り当て可能値をデフォルトで公開します。
次の項目 downwardAPIボリューム
downward APIを使用してコンテナレベルまたはPodレベルの情報を公開することを試してみることができます:
3.5.2 - Workload API FEATURE STATE:
Kubernetes v1.35 [alpha](disabled by default)
Workload APIリソースを使用すると、複数のPodで構成されるアプリケーションについて、スケジューリング要件とPodのグループ構成を記述できます。
ワークロードコントローラーはワークロードのランタイム動作を提供しますが、Workload APIはJobなどの「真の」ワークロードに対して、スケジューリング制約を提供することを目的としています。
Workloadとは Workload APIリソースは、scheduling.k8s.io/v1alpha1 APIグループ の一部です(このAPIを利用するには、クラスターで、そのAPIグループとGenericWorkloadフィーチャーゲート の両方を有効にする必要があります)。
このリソースは、複数のPodで構成されるアプリケーションのスケジューリング要件を、構造化された機械可読な形式で定義します。
Job のようなユーザー向けのワークロードは何を実行するかを定義します。
一方で、Workloadリソースは、Podのグループをどのようにスケジュールし、ライフサイクル全体を通じてその配置をどう管理するかを決定します。
APIの構造 Workloadを使用すると、Podのグループを定義し、それらにスケジューリングポリシーを適用できます。
これは、Podグループのリストとコントローラーへの参照という2つのセクションで構成されます。
Podグループ podGroupsリストは、ワークロードの個別のコンポーネントを定義します。
たとえば、機械学習ジョブにはdriverグループとworkerグループがある場合があります。
podGroupsの各エントリには以下が必要です:
PodのWorkload参照 で使用できる一意のname スケジューリングポリシー (basicまたはgang)apiVersion : scheduling.k8s.io/v1alpha1
kind : Workload
metadata :
name : training-job-workload
namespace : some-ns
spec :
controllerRef :
apiGroup : batch
kind : Job
name : training-job
podGroups :
- name : workers
policy :
gang :
# gangは4つのPodが同時に実行できる場合にのみスケジュール可能
minCount : 4
ワークロード管理オブジェクトの参照 controllerRefフィールドは、WorkloadをJob やカスタムCRDなど、アプリケーションを定義する上位のオブジェクトに紐づけます。
これは可観測性とツールの利用に役立ちます。
このデータは、Workloadのスケジューリングや管理には使用されません。
次の項目 3.5.2.1 - Podグループポリシー FEATURE STATE:
Kubernetes v1.35 [alpha](disabled by default)
Workload で定義される各Podグループは、スケジューリングポリシーを宣言する必要があります。
このポリシーは、スケジューラーがPodのグループをどのように扱うかを指定します。
ポリシータイプ 現在、APIはbasicとgangの2つのポリシータイプをサポートしています。
各グループに対して、いずれか1つのポリシーを指定する必要があります。
basicポリシー basicポリシーは、グループ内のすべてのPodを独立したエンティティとして扱い、標準的なKubernetesの動作でスケジューリングするようスケジューラーに指示します。
basicポリシーを使用する主な理由は、Workload内のPodを整理して、可観測性と管理性を向上させることです。
このポリシーは、同時起動を必要としないが、論理的に同じアプリケーションに属するWorkloadのグループに使用できます。
また、将来的に「全か無か」の配置を意味しないグループ制約を追加する余地も残されています。
gangポリシー gangポリシーは、「全か無か」のスケジューリングを強制します。
これは、一部のPodだけが起動すると、デッドロックやリソースの浪費が発生する密結合したワークロードには必須です。
これは、すべてのワーカーが同時に実行されなければ処理が進まないJob や、その他のバッチ処理に使用できます。
gangポリシーにはminCountパラメーターが必要です:
policy :
gang :
# グループが受け入れられるために、
# 同時にスケジュール可能である必要があるPodの数
minCount : 4
次の項目
3.5.3 - ワークロードリソース 3.5.3.1 - Deployment Deployment はPod とReplicaSet の宣言的なアップデート機能を提供します。
Deploymentにおいて 理想的な状態 を記述すると、Deploymentコントローラー は指定された頻度で現在の状態を理想的な状態に変更します。Deploymentを定義することによって、新しいReplicaSetを作成したり、既存のDeploymentを削除して新しいDeploymentで全てのリソースを適用できます。
備考: Deploymentによって作成されたReplicaSetを管理しないでください。ご自身のユースケースが以下の項目に含まれない場合、メインのKubernetesリポジトリーにIssueを作成することを検討してください。ユースケース 以下の項目はDeploymentの典型的なユースケースです。
Deploymentの作成 以下はDeploymentの例です。これはnginxPodのレプリカを3つ持つReplicaSetを作成します。
apiVersion : apps/v1
kind : Deployment
metadata :
name : nginx-deployment
labels :
app : nginx
spec :
replicas : 3
selector :
matchLabels :
app : nginx
template :
metadata :
labels :
app : nginx
spec :
containers :
- name : nginx
image : nginx:1.14.2
ports :
- containerPort : 80
この例では、
.metadata.nameフィールドで指定されたnginx-deploymentという名前のDeploymentが作成されます。
このDeploymentは.spec.replicasフィールドで指定された通り、3つのレプリカPodを作成します。
.spec.selectorフィールドは、Deploymentが管理するPodのラベルを定義します。ここでは、Podテンプレートにて定義されたラベル(app: nginx)を選択しています。しかし、PodTemplate自体がそのルールを満たす限り、さらに洗練された方法でセレクターを指定することができます。
備考: `.spec.selector.matchLabels`フィールドはキーバリューペアのマップです。
`matchLabels`マップにおいて、{key, value}というペアは、keyというフィールドの値が"key"で、その演算子が"In"で、値の配列が"value"のみ含むような`matchExpressions`の要素と等しくなります。
`matchLabels`と`matchExpressions`の両方が設定された場合、条件に一致するには両方とも満たす必要があります。
.spec.templateフィールドは、以下のサブフィールドを持ちます。:
Podは.metadata.labelsフィールドによって指定されたapp: nginxというラベルがつけられます。 PodTemplate、または.specフィールドは、Podがnginxという名前でDocker Hub にあるnginxのバージョン1.14.2が動くコンテナを1つ動かすことを示します。 1つのコンテナを作成し、.spec.containers[0].nameフィールドを使ってnginxという名前をつけます。 作成を始める前に、Kubernetesクラスターが稼働していることを確認してください。
上記のDeploymentを作成するためには以下のステップにしたがってください:
以下のコマンドを実行してDeploymentを作成してください。 kubectl apply -f https://k8s.io/examples/controllers/nginx-deployment.yaml
Deploymentが作成されたことを確認するために、kubectl get deploymentsを実行してください。 Deploymentがまだ作成中の場合、コマンドの実行結果は以下のとおりです。
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 0/3 0 0 1s
クラスターにてDeploymentを調査するとき、以下のフィールドが出力されます。
NAMEは、クラスター内にあるDeploymentの名前一覧です。READYは、ユーザーが使用できるアプリケーションのレプリカの数です。使用可能な数/理想的な数の形式で表示されます。UP-TO-DATEは、理想的な状態を満たすためにアップデートが完了したレプリカの数です。AVAILABLEは、ユーザーが利用可能なレプリカの数です。AGEは、アプリケーションが稼働してからの時間です。.spec.replicasフィールドの値によると、理想的なレプリカ数は3であることがわかります。
Deploymentのロールアウトステータスを確認するために、kubectl rollout status deployment.v1.apps/nginx-deploymentを実行してください。 コマンドの実行結果は以下のとおりです。
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
deployment "nginx-deployment" successfully rolled out
数秒後、再度kubectl get deploymentsを実行してください。
コマンドの実行結果は以下のとおりです。 NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 18s
Deploymentが3つ全てのレプリカを作成して、全てのレプリカが最新(Podが最新のPodテンプレートを含んでいる)になり、利用可能となっていることを確認してください。
Deploymentによって作成されたReplicaSet(rs)を確認するにはkubectl get rsを実行してください。コマンドの実行結果は以下のとおりです: NAME DESIRED CURRENT READY AGE
nginx-deployment-75675f5897 3 3 3 18s
ReplicaSetの出力には次のフィールドが表示されます:
NAMEは、名前空間内にあるReplicaSetの名前の一覧です。DESIREDは、アプリケーションの理想的な レプリカ の値です。これはDeploymentを作成したときに定義したもので、これが 理想的な状態 と呼ばれるものです。CURRENTは現在実行されているレプリカの数です。READYは、ユーザーが使用できるアプリケーションのレプリカの数です。AGEは、アプリケーションが稼働してからの時間です。ReplicaSetの名前は[Deployment名]-[ランダム文字列]という形式になることに注意してください。ランダム文字列はランダムに生成され、pod-template-hashをシードとして使用します。
各Podにラベルが自動的に付けられるのを確認するにはkubectl get pods --show-labelsを実行してください。
コマンドの実行結果は以下のとおりです: NAME READY STATUS RESTARTS AGE LABELS
nginx-deployment-75675f5897-7ci7o 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897
nginx-deployment-75675f5897-kzszj 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897
nginx-deployment-75675f5897-qqcnn 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897
作成されたReplicaSetはnginxPodを3つ作成することを保証します。
備考: Deploymentに対して適切なセレクターとPodテンプレートのラベルを設定する必要があります(このケースではapp: nginx)。
ラベルやセレクターを他のコントローラーと重複させないでください(他のDeploymentやStatefulSetを含む)。Kubernetesはユーザーがラベルを重複させることを阻止しないため、複数のコントローラーでセレクターの重複が発生すると、コントローラー間で衝突し予期せぬふるまいをすることになります。
pod-template-hashラベル
注意: このラベルを変更しないでください。pod-template-hashラベルはDeploymentコントローラーによってDeploymentが作成し適用した各ReplicaSetに対して追加されます。
このラベルはDeploymentが管理するReplicaSetが重複しないことを保証します。このラベルはReplicaSetのPodTemplateをハッシュ化することにより生成され、生成されたハッシュ値はラベル値としてReplicaSetセレクター、Podテンプレートラベル、ReplicaSetが作成した全てのPodに対して追加されます。
Deploymentの更新
備考: Deploymentのロールアウトは、DeploymentのPodテンプレート(この場合.spec.template)が変更された場合にのみトリガーされます。例えばテンプレートのラベルもしくはコンテナイメージが更新された場合です。Deploymentのスケールのような更新では、ロールアウトはトリガーされません。Deploymentを更新するには以下のステップに従ってください。
nginxのPodで、nginx:1.14.2イメージの代わりにnginx:1.16.1を使うように更新します。
kubectl set image deployment.v1.apps/nginx-deployment nginx = nginx:1.16.1
または単に次のコマンドを使用します。
kubectl set image deployment/nginx-deployment nginx = nginx:1.16.1
実行結果は以下のとおりです。
deployment.apps/nginx-deployment image updated
また、Deploymentを編集して、.spec.template.spec.containers[0].imageをnginx:1.14.2からnginx:1.16.1に変更することができます。
kubectl edit deployment.v1.apps/nginx-deployment
実行結果は以下のとおりです。
deployment.apps/nginx-deployment edited
ロールアウトのステータスを確認するには、以下のコマンドを実行してください。
kubectl rollout status deployment.v1.apps/nginx-deployment
実行結果は以下のとおりです。
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
もしくは
deployment "nginx-deployment" successfully rolled out
更新されたDeploymentのさらなる情報を取得するには、以下を確認してください。
ロールアウトが成功したあと、kubectl get deploymentsを実行してDeploymentを確認できます。
実行結果は以下のとおりです。
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 36s
Deploymentが新しいReplicaSetを作成してPodを更新させたり、新しいReplicaSetのレプリカを3にスケールアップさせたり、古いReplicaSetのレプリカを0にスケールダウンさせるのを確認するにはkubectl get rsを実行してください。
実行結果は以下のとおりです。
NAME DESIRED CURRENT READY AGE
nginx-deployment-1564180365 3 3 3 6s
nginx-deployment-2035384211 0 0 0 36s
get podsを実行させると、新しいPodのみ確認できます。
実行結果は以下のとおりです。
NAME READY STATUS RESTARTS AGE
nginx-deployment-1564180365-khku8 1/1 Running 0 14s
nginx-deployment-1564180365-nacti 1/1 Running 0 14s
nginx-deployment-1564180365-z9gth 1/1 Running 0 14s
次にPodを更新させたいときは、DeploymentのPodテンプレートを再度更新するだけです。
Deploymentは、Podが更新されている間に特定の数のPodのみ停止状態になることを保証します。デフォルトでは、目標とするPod数の少なくとも75%が稼働状態であることを保証します(25% max unavailable)。
また、DeploymentはPodが更新されている間に、目標とするPod数を特定の数まで超えてPodを稼働させることを保証します。デフォルトでは、目標とするPod数に対して最大でも125%を超えてPodを稼働させることを保証します(25% max surge)。
例えば、上記で説明したDeploymentの状態を注意深く見ると、最初に新しいPodが作成され、次に古いPodが削除されるのを確認できます。十分な数の新しいPodが稼働するまでは、Deploymentは古いPodを削除しません。また十分な数の古いPodが削除しない限り新しいPodは作成されません。少なくとも2つのPodが利用可能で、最大でもトータルで4つのPodが利用可能になっていることを保証します。
Deploymentの詳細情報を取得します。
kubectl describe deployments
実行結果は以下のとおりです。
Name: nginx-deployment
Namespace: default
CreationTimestamp: Thu, 30 Nov 2017 10:56:25 +0000
Labels: app=nginx
Annotations: deployment.kubernetes.io/revision=2
Selector: app=nginx
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.16.1
Port: 80/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-deployment-1564180365 (3/3 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 2m deployment-controller Scaled up replica set nginx-deployment-2035384211 to 3
Normal ScalingReplicaSet 24s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 1
Normal ScalingReplicaSet 22s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 2
Normal ScalingReplicaSet 22s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 2
Normal ScalingReplicaSet 19s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 1
Normal ScalingReplicaSet 19s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 3
Normal ScalingReplicaSet 14s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 0
最初にDeploymentを作成した時、ReplicaSet(nginx-deployment-2035384211)を作成してすぐにレプリカ数を3にスケールするのを確認できます。Deploymentを更新すると新しいReplicaSet(nginx-deployment-1564180365)を作成してレプリカ数を1にスケールアップし、古いReplicaSeetを2にスケールダウンさせます。これは常に最低でも2つのPodが利用可能で、かつ最大4つのPodが作成されている状態にするためです。Deploymentは同じローリングアップ戦略に従って新しいReplicaSetのスケールアップと古いReplicaSetのスケールダウンを続けます。最終的に新しいReplicaSetを3にスケールアップさせ、古いReplicaSetを0にスケールダウンさせます。
ロールオーバー (リアルタイムでの複数のPodの更新) Deploymentコントローラーにより、新しいDeploymentが観測される度にReplicaSetが作成され、理想とするレプリカ数のPodを作成します。Deploymentが更新されると、既存のReplicaSetが管理するPodのラベルが.spec.selectorにマッチするが、テンプレートが.spec.templateにマッチしない場合はスケールダウンされます。最終的に、新しいReplicaSetは.spec.replicasの値にスケールアップされ、古いReplicaSetは0にスケールダウンされます。
Deploymentのロールアウトが進行中にDeploymentを更新すると、Deploymentは更新する毎に新しいReplicaSetを作成してスケールアップさせ、以前にスケールアップしたReplicaSetのロールオーバーを行います。Deploymentは更新前のReplicaSetを古いReplicaSetのリストに追加し、スケールダウンを開始します。
例えば、5つのレプリカを持つnginx:1.14.2のDeploymentを作成し、nginx:1.14.2の3つのレプリカが作成されているときに5つのレプリカを持つnginx:1.16.1に更新します。このケースではDeploymentは作成済みのnginx:1.14.2の3つのPodをすぐに削除し、nginx:1.16.1のPodの作成を開始します。nginx:1.14.2の5つのレプリカを全て作成するのを待つことはありません。
ラベルセレクターの更新 通常、ラベルセレクターを更新することは推奨されません。事前にラベルセレクターの使い方を計画しておきましょう。いかなる場合であっても更新が必要なときは十分に注意を払い、変更時の影響範囲を把握しておきましょう。
備考: apps/v1API バージョンにおいて、Deploymentのラベルセレクターは作成後に不変となります。セレクターの追加は、Deployment Specのテンプレートラベルも新しいラベルで更新する必要があります。そうでない場合はバリデーションエラーが返されます。この変更は重複がない更新となります。これは新しいセレクターは古いセレクターを持つReplicaSetとPodを選択せず、結果として古い全てのReplicaSetがみなし子状態になり、新しいReplicaSetを作成することを意味します。 セレクターの更新により、セレクターキー内の既存の値が変更されます。これにより、セレクターの追加と同じふるまいをします。 セレクターの削除により、Deploymentのセレクターから存在している値を削除します。これはPodテンプレートのラベルに関する変更を要求しません。既存のReplicaSetはみなし子状態にならず、新しいReplicaSetは作成されませんが、削除されたラベルは既存のPodとReplicaSetでは残り続けます。 Deploymentのロールバック 例えば、クラッシュループ状態などのようにDeploymentが不安定な場合においては、Deploymentをロールバックしたくなることがあります。Deploymentの全てのロールアウト履歴は、いつでもロールバックできるようにデフォルトでシステムに保持されています(リビジョン履歴の上限は設定することで変更可能です)。
備考: Deploymentのリビジョンは、Deploymentのロールアウトがトリガーされた時に作成されます。これはDeploymentのPodテンプレート(.spec.template)が変更されたときのみ新しいリビジョンが作成されることを意味します。Deploymentのスケーリングなど、他の種類の更新においてはDeploymentのリビジョンは作成されません。これは手動もしくはオートスケーリングを同時に行うことができるようにするためです。これは過去のリビジョンにロールバックするとき、DeploymentのPodテンプレートの箇所のみロールバックされることを意味します。nginx:1.16.1の代わりにnginx:1.161というイメージに更新して、Deploymentの更新中にタイプミスをしたと仮定します。
kubectl set image deployment/nginx-deployment nginx = nginx:1.161
実行結果は以下のとおりです。
deployment.apps/nginx-deployment image updated
このロールアウトはうまくいきません。ロールアウトのステータスを見るとそれを確認できます。
kubectl rollout status deployment.v1.apps/nginx-deployment
実行結果は以下のとおりです。
Waiting for rollout to finish: 1 out of 3 new replicas have been updated...
ロールアウトのステータスの確認は、Ctrl-Cを押すことで停止できます。ロールアウトがうまく行かないときは、Deploymentのステータス を読んでさらなる情報を得てください。
古いレプリカ数(nginx-deployment-1564180365 and nginx-deployment-2035384211)が2になっていることを確認でき、新しいレプリカ数(nginx-deployment-3066724191)は1になっています。
実行結果は以下のとおりです。
NAME DESIRED CURRENT READY AGE
nginx-deployment-1564180365 3 3 3 25s
nginx-deployment-2035384211 0 0 0 36s
nginx-deployment-3066724191 1 1 0 6s
作成されたPodを確認していると、新しいReplicaSetによって作成された1つのPodはコンテナイメージのpullに失敗し続けているのがわかります。
実行結果は以下のとおりです。
NAME READY STATUS RESTARTS AGE
nginx-deployment-1564180365-70iae 1/1 Running 0 25s
nginx-deployment-1564180365-jbqqo 1/1 Running 0 25s
nginx-deployment-1564180365-hysrc 1/1 Running 0 25s
nginx-deployment-3066724191-08mng 0/1 ImagePullBackOff 0 6s
備考: Deploymentコントローラーは、この悪い状態のロールアウトを自動的に停止し、新しいReplicaSetのスケールアップを止めます。これはユーザーが指定したローリングアップデートに関するパラメーター(特に`maxUnavailable`)に依存します。デフォルトではKubernetesがこの値を25%に設定します。
Deploymentの詳細情報を取得します。
kubectl describe deployment
実行結果は以下のとおりです。
Name: nginx-deployment
Namespace: default
CreationTimestamp: Tue, 15 Mar 2016 14:48:04 -0700
Labels: app=nginx
Selector: app=nginx
Replicas: 3 desired | 1 updated | 4 total | 3 available | 1 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.161
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True ReplicaSetUpdated
OldReplicaSets: nginx-deployment-1564180365 (3/3 replicas created)
NewReplicaSet: nginx-deployment-3066724191 (1/1 replicas created)
Events:
FirstSeen LastSeen Count From SubObjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
1m 1m 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-2035384211 to 3
22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 1
22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 2
22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 2
21s 21s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 1
21s 21s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 3
13s 13s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 0
13s 13s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-3066724191 to 1
これを修正するために、Deploymentを安定した状態の過去のリビジョンに更新する必要があります。
Deploymentのロールアウト履歴の確認 ロールアウトの履歴を確認するには、以下の手順に従って下さい。
最初に、Deploymentのリビジョンを確認します。
kubectl rollout history deployment.v1.apps/nginx-deployment
実行結果は以下のとおりです。
deployments "nginx-deployment"
REVISION CHANGE-CAUSE
1 kubectl apply --filename=https://k8s.io/examples/controllers/nginx-deployment.yaml
2 kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.16.1
3 kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.161
CHANGE-CAUSEはリビジョンの作成時にDeploymentのkubernetes.io/change-causeアノテーションからリビジョンにコピーされます。以下の方法によりCHANGE-CAUSEメッセージを指定できます。
kubectl annotate deployment.v1.apps/nginx-deployment kubernetes.io/change-cause="image updated to 1.16.1"の実行によりアノテーションを追加します。リソースのマニフェストを手動で編集します。 各リビジョンの詳細を確認するためには以下のコマンドを実行してください。
kubectl rollout history deployment.v1.apps/nginx-deployment --revision= 2
実行結果は以下のとおりです。
deployments "nginx-deployment" revision 2
Labels: app=nginx
pod-template-hash=1159050644
Annotations: kubernetes.io/change-cause=kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.16.1
Containers:
nginx:
Image: nginx:1.16.1
Port: 80/TCP
QoS Tier:
cpu: BestEffort
memory: BestEffort
Environment Variables: <none>
No volumes.
過去のリビジョンにロールバックする 現在のリビジョンから過去のリビジョン(リビジョン番号2)にロールバックさせるには、以下の手順に従ってください。
現在のリビジョンから過去のリビジョンにロールバックします。
kubectl rollout undo deployment.v1.apps/nginx-deployment
実行結果は以下のとおりです。
deployment.apps/nginx-deployment rolled back
その他に、--to-revisionを指定することにより特定のリビジョンにロールバックできます。
kubectl rollout undo deployment.v1.apps/nginx-deployment --to-revision= 2
実行結果は以下のとおりです。
deployment.apps/nginx-deployment rolled back
ロールアウトに関連したコマンドのさらなる情報はkubectl rollout
Deploymentが過去の安定したリビジョンにロールバックされました。Deploymentコントローラーによって、リビジョン番号2にロールバックするDeploymentRollbackイベントが作成されたのを確認できます。
ロールバックが成功し、Deploymentが正常に稼働していることを確認するために、以下のコマンドを実行してください。
kubectl get deployment nginx-deployment
実行結果は以下のとおりです。
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 30m
Deploymentの詳細情報を取得します。
kubectl describe deployment nginx-deployment
実行結果は以下のとおりです。
Name: nginx-deployment
Namespace: default
CreationTimestamp: Sun, 02 Sep 2018 18:17:55 -0500
Labels: app=nginx
Annotations: deployment.kubernetes.io/revision=4
kubernetes.io/change-cause=kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.16.1
Selector: app=nginx
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.16.1
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-deployment-c4747d96c (3/3 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 12m deployment-controller Scaled up replica set nginx-deployment-75675f5897 to 3
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 1
Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 2
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 2
Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 1
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 3
Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 0
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-595696685f to 1
Normal DeploymentRollback 15s deployment-controller Rolled back deployment "nginx-deployment" to revision 2
Normal ScalingReplicaSet 15s deployment-controller Scaled down replica set nginx-deployment-595696685f to 0
Deploymentのスケーリング 以下のコマンドを実行させてDeploymentをスケールできます。
kubectl scale deployment.v1.apps/nginx-deployment --replicas= 10
実行結果は以下のとおりです。
deployment.apps/nginx-deployment scaled
クラスター内で水平Podオートスケーラー が有効になっていると仮定します。ここでDeploymentのオートスケーラーを設定し、稼働しているPodのCPU使用量に基づいて、稼働させたいPodのレプリカ数の最小値と最大値を設定できます。
kubectl autoscale deployment.v1.apps/nginx-deployment --min= 10 --max= 15 --cpu-percent= 80
実行結果は以下のとおりです。
deployment.apps/nginx-deployment scaled
比例スケーリング Deploymentのローリングアップデートは、同時に複数のバージョンのアプリケーションの稼働をサポートします。ユーザーやオートスケーラーがローリングアップデートをロールアウト中(更新中もしくは一時停止中)のDeploymentに対して行うと、Deploymentコントローラーはリスクを削減するために既存のアクティブなReplicaSetのレプリカのバランシングを行います。これを比例スケーリング と呼びます。
レプリカ数が10、maxSurge =3、maxUnavailable =2であるDeploymentが稼働している例です。
Deployment内で10のレプリカが稼働していることを確認します。
実行結果は以下のとおりです。
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 10 10 10 10 50s
クラスター内で、解決できない新しいイメージに更新します。
kubectl set image deployment.v1.apps/nginx-deployment nginx = nginx:sometag
実行結果は以下のとおりです。
deployment.apps/nginx-deployment image updated
イメージの更新は新しいReplicaSet nginx-deployment-1989198191へのロールアウトを開始させます。しかしロールアウトは、上述したmaxUnavailableの要求によりブロックされます。ここでロールアウトのステータスを確認します。
実行結果は以下のとおりです。
NAME DESIRED CURRENT READY AGE
nginx-deployment-1989198191 5 5 0 9s
nginx-deployment-618515232 8 8 8 1m
次にDeploymentのスケーリングをするための新しい要求が発生します。オートスケーラーはDeploymentのレプリカ数を15に増やします。Deploymentコントローラーは新しい5つのレプリカをどこに追加するか決める必要がでてきます。比例スケーリングを使用していない場合、5つのレプリカは全て新しいReplicaSetに追加されます。比例スケーリングでは、追加されるレプリカは全てのReplicaSetに分散されます。比例割合が大きいものはレプリカ数の大きいReplicaSetとなり、比例割合が低いときはレプリカ数の小さいReplicaSetとなります。残っているレプリカはもっとも大きいレプリカ数を持つReplicaSetに追加されます。レプリカ数が0のReplicaSetはスケールアップされません。
上記の例では、3つのレプリカが古いReplicaSetに追加され、2つのレプリカが新しいReplicaSetに追加されました。ロールアウトの処理では、新しいレプリカ数のPodが正常になったと仮定すると、最終的に新しいReplicaSetに全てのレプリカを移動させます。これを確認するためには以下のコマンドを実行して下さい。
実行結果は以下のとおりです。
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 15 18 7 8 7m
ロールアウトのステータスでレプリカがどのように各ReplicaSetに追加されるか確認できます。
実行結果は以下のとおりです。
NAME DESIRED CURRENT READY AGE
nginx-deployment-1989198191 7 7 0 7m
nginx-deployment-618515232 11 11 11 7m
Deployment更新の一時停止と再開 ユーザーは1つ以上の更新処理をトリガーする前に更新の一時停止と再開ができます。これにより、不必要なロールアウトを実行することなく一時停止と再開を行う間に複数の修正を反映できます。
例えば、作成直後のDeploymentを考えます。
Deploymentの詳細情報を確認します。
実行結果は以下のとおりです。
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx 3 3 3 3 1m
ロールアウトのステータスを確認します。
実行結果は以下のとおりです。
NAME DESIRED CURRENT READY AGE
nginx-2142116321 3 3 3 1m
以下のコマンドを実行して更新処理の一時停止を行います。
kubectl rollout pause deployment.v1.apps/nginx-deployment
実行結果は以下のとおりです。
deployment.apps/nginx-deployment paused
次にDeploymentのイメージを更新します。
kubectl set image deployment.v1.apps/nginx-deployment nginx = nginx:1.16.1
実行結果は以下のとおりです。
deployment.apps/nginx-deployment image updated
新しいロールアウトが開始されていないことを確認します。
kubectl rollout history deployment.v1.apps/nginx-deployment
実行結果は以下のとおりです。
deployments "nginx"
REVISION CHANGE-CAUSE
1 <none>
Deploymentの更新に成功したことを確認するためにロールアウトのステータスを確認します。
実行結果は以下のとおりです。
NAME DESIRED CURRENT READY AGE
nginx-2142116321 3 3 3 2m
更新は何度でも実行できます。例えば、Deploymentが使用するリソースを更新します。
kubectl set resources deployment.v1.apps/nginx-deployment -c= nginx --limits= cpu = 200m,memory= 512Mi
実行結果は以下のとおりです。
deployment.apps/nginx-deployment resource requirements updated
一時停止する前の初期状態では更新処理は機能しますが、Deploymentが一時停止されている間は新しい更新処理は反映されません。
最後に、Deploymentの稼働を再開させ、新しいReplicaSetが更新内容を全て反映させているのを確認します。
kubectl rollout resume deployment.v1.apps/nginx-deployment
実行結果は以下のとおりです。
deployment.apps/nginx-deployment resumed
更新処理が完了するまでロールアウトのステータスを確認します。
実行結果は以下のとおりです。
NAME DESIRED CURRENT READY AGE
nginx-2142116321 2 2 2 2m
nginx-3926361531 2 2 0 6s
nginx-3926361531 2 2 1 18s
nginx-2142116321 1 2 2 2m
nginx-2142116321 1 2 2 2m
nginx-3926361531 3 2 1 18s
nginx-3926361531 3 2 1 18s
nginx-2142116321 1 1 1 2m
nginx-3926361531 3 3 1 18s
nginx-3926361531 3 3 2 19s
nginx-2142116321 0 1 1 2m
nginx-2142116321 0 1 1 2m
nginx-2142116321 0 0 0 2m
nginx-3926361531 3 3 3 20s
最新のロールアウトのステータスを確認します。
実行結果は以下のとおりです。
NAME DESIRED CURRENT READY AGE
nginx-2142116321 0 0 0 2m
nginx-3926361531 3 3 3 28s
備考: Deploymentの稼働を再開させない限り、一時停止したDeploymentをロールバックすることはできません。Deploymentのステータス Deploymentは、そのライフサイクルの間に様々な状態に遷移します。新しいReplicaSetへのロールアウト中は進行中 になり、その後は完了 し、また失敗 にもなります。
Deploymentの更新処理 以下のタスクが実行中のとき、KubernetesはDeploymentの状態を 進行中 にします。
Deploymentが新しいReplicaSetを作成します。 Deploymentが新しいReplicaSetをスケールアップさせています。 Deploymentが古いReplicaSetをスケールダウンさせています。 新しいPodが準備中もしくは利用可能な状態になります(少なくともMinReadySeconds の間は準備中になります)。 kubectl rollout statusを実行すると、Deploymentの進行状態を確認できます。
Deploymentの更新処理の完了 Deploymentが以下の状態になったとき、KubernetesはDeploymentのステータスを 完了 にします。
Deploymentの全てのレプリカが、指定された最新のバージョンに更新されます。これは指定した更新処理が完了したことを意味します。 Deploymentの全てのレプリカが利用可能になります。 Deploymentの古いレプリカが1つも稼働していません。 kubectl rollout statusを実行して、Deploymentの更新が完了したことを確認できます。ロールアウトが正常に完了するとkubectl rollout statusの終了コードが0で返されます。
kubectl rollout status deployment.v1.apps/nginx-deployment
実行結果は以下のとおりです。
Waiting for rollout to finish: 2 of 3 updated replicas are available...
deployment "nginx-deployment" successfully rolled out
そしてkubectl rolloutの終了ステータスが0となります(成功です):
0
Deploymentの更新処理の失敗 新しいReplicaSetのデプロイが完了せず、更新処理が止まる場合があります。これは主に以下の要因によるものです。
不十分なリソースの割り当て ReadinessProbeの失敗 コンテナイメージの取得ができない 不十分なパーミッション リソースリミットのレンジ アプリケーションランタイムの設定の不備 このような状況を検知する1つの方法として、Deploymentのリソース定義でデッドラインのパラメーターを指定します(.spec.progressDeadlineSeconds.spec.progressDeadlineSecondsはDeploymentの更新が停止したことを示す前にDeploymentコントローラーが待つ秒数を示します。
以下のkubectlコマンドでリソース定義にprogressDeadlineSecondsを設定します。これはDeploymentの更新が止まってから10分後に、コントローラーが失敗を通知させるためです。
kubectl patch deployment.v1.apps/nginx-deployment -p '{"spec":{"progressDeadlineSeconds":600}}'
実行結果は以下のとおりです。
deployment.apps/nginx-deployment patched
一度デッドラインを超過すると、DeploymentコントローラーはDeploymentの.status.conditionsに以下のDeploymentConditionを追加します。
Type=Progressing Status=False Reason=ProgressDeadlineExceeded ステータスの状態に関するさらなる情報はKubernetes APIの規則 を参照してください。
備考: Kubernetesは停止状態のDeploymentに対して、ステータス状態を報告する以外のアクションを実行しません。高レベルのオーケストレーターはこれを利用して、状態に応じて行動できます。例えば、前のバージョンへのDeploymentのロールバックが挙げられます。
備考: Deploymentを停止すると、Kubernetesは指定したデッドラインを超えたかどうかチェックしません。
ロールアウトの途中でもDeploymentを安全に一時停止でき、デッドラインを超えたイベントをトリガーすることなく再開できます。設定したタイムアウトの秒数が小さかったり、一時的なエラーとして扱える他の種類のエラーが原因となり、Deploymentで一時的なエラーが出る場合があります。例えば、リソースの割り当てが不十分な場合を考えます。Deploymentの詳細情報を確認すると、以下のセクションが表示されます。
kubectl describe deployment nginx-deployment
実行結果は以下のとおりです。
<...>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True ReplicaSetUpdated
ReplicaFailure True FailedCreate
<...>
kubectl get deployment nginx-deployment -o yamlを実行すると、Deploymentのステータスは以下のようになります。
status:
availableReplicas: 2
conditions:
- lastTransitionTime: 2016-10-04T12:25:39Z
lastUpdateTime: 2016-10-04T12:25:39Z
message: Replica set "nginx-deployment-4262182780" is progressing.
reason: ReplicaSetUpdated
status: "True"
type: Progressing
- lastTransitionTime: 2016-10-04T12:25:42Z
lastUpdateTime: 2016-10-04T12:25:42Z
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
- lastTransitionTime: 2016-10-04T12:25:39Z
lastUpdateTime: 2016-10-04T12:25:39Z
message: 'Error creating: pods "nginx-deployment-4262182780-" is forbidden: exceeded quota:
object-counts, requested: pods=1, used: pods=3, limited: pods=2'
reason: FailedCreate
status: "True"
type: ReplicaFailure
observedGeneration: 3
replicas: 2
unavailableReplicas: 2
最後に、一度Deploymentの更新処理のデッドラインを越えると、KubernetesはDeploymentのステータスと進行中の状態を更新します。
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing False ProgressDeadlineExceeded
ReplicaFailure True FailedCreate
Deploymentか他のリソースコントローラーのスケールダウンを行うか、使用している名前空間内でリソースの割り当てを増やすことで、リソースの割り当て不足の問題に対処できます。割り当て条件を満たすと、DeploymentコントローラーはDeploymentのロールアウトを完了させ、Deploymentのステータスが成功状態になるのを確認できます(Status=TrueとReason=NewReplicaSetAvailable)。
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
Status=TrueのType=Availableは、Deploymentが最小可用性の状態であることを意味します。最小可用性は、Deploymentの更新戦略において指定されているパラメーターにより決定されます。Status=TrueのType=Progressingは、Deploymentのロールアウトの途中で、更新処理が進行中であるか、更新処理が完了し、必要な最小数のレプリカが利用可能であることを意味します(各TypeのReason項目を確認してください。このケースでは、Reason=NewReplicaSetAvailableはDeploymentの更新が完了したことを意味します)。
kubectl rollout statusを実行してDeploymentが更新に失敗したかどうかを確認できます。kubectl rollout statusはDeploymentが更新処理のデッドラインを超えたときに0以外の終了コードを返します。
kubectl rollout status deployment.v1.apps/nginx-deployment
実行結果は以下のとおりです。
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
error: deployment "nginx" exceeded its progress deadline
そしてkubectl rolloutの終了ステータスが1となります(エラーを示しています):
1
失敗したDeploymentの操作 更新完了したDeploymentに適用した全てのアクションは、更新失敗したDeploymentに対しても適用されます。スケールアップ、スケールダウンができ、前のリビジョンへのロールバックや、Deploymentのテンプレートに複数の更新を適用させる必要があるときは一時停止もできます。
古いリビジョンのクリーンアップポリシー Deploymentが管理する古いReplicaSetをいくつ保持するかを指定するために、.spec.revisionHistoryLimitフィールドを設定できます。この値を超えた古いReplicaSetはバックグラウンドでガーベージコレクションの対象となって削除されます。デフォルトではこの値は10です。
備考: このフィールドを明示的に0に設定すると、Deploymentの全ての履歴を削除します。従って、Deploymentはロールバックできません。カナリアパターンによるデプロイ Deploymentを使って一部のユーザーやサーバーに対してリリースのロールアウトをしたい場合、リソースの管理 に記載されているカナリアパターンに従って、リリース毎に1つずつ、複数のDeploymentを作成できます。
Deployment Specの記述 他の全てのKubernetesの設定と同様に、Deploymentは.apiVersion、.kindや.metadataフィールドを必要とします。
設定ファイルの利用に関する情報はアプリケーションのデプロイ を参照してください。コンテナの設定に関してはリソースを管理するためのkubectlの使用 を参照してください。
Deploymentオブジェクトの名前は、有効なDNSサブドメイン名 でなければなりません。
Deploymentは.specセクション
Podテンプレート .spec.templateと.spec.selectorは.specにおける必須のフィールドです。
.spec.templateはPodテンプレート です。これは.spec内でネストされていないことと、apiVersionやkindを持たないことを除いてはPod と同じスキーマとなります。
Podの必須フィールドに加えて、Deployment内のPodテンプレートでは適切なラベルと再起動ポリシーを設定しなくてはなりません。ラベルは他のコントローラーと重複しないようにしてください。ラベルについては、セレクター を参照してください。
.spec.template.spec.restartPolicyAlwaysに等しいときのみ許可されます。これはテンプレートで指定されていない場合のデフォルト値です。
レプリカ数 .spec.repliasは理想的なPodの数を指定するオプションのフィールドです。デフォルトは1です。
セレクター .spec.selectorは必須フィールドで、Deploymentによって対象とされるPodのラベルセレクター を指定します。
.spec.selectorは.spec.template.metadata.labelsと一致している必要があり、一致しない場合はAPIによって拒否されます。
apps/v1バージョンにおいて、.spec.selectorと.metadata.labelsが指定されていない場合、.spec.template.metadata.labelsの値に初期化されません。そのため.spec.selectorと.metadata.labelsを明示的に指定する必要があります。またapps/v1のDeploymentにおいて.spec.selectorは作成後に不変になります。
Deploymentのテンプレートが.spec.templateと異なる場合や、.spec.replicasの値を超えてPodが稼働している場合、Deploymentはセレクターに一致するラベルを持つPodを削除します。Podの数が理想状態より少ない場合Deploymentは.spec.templateをもとに新しいPodを作成します。
備考: Deploymentのセレクターに一致するラベルを持つPodを直接作成したり、他のDeploymentやReplicaSetやReplicationControllerによって作成するべきではありません。作成してしまうと、最初のDeploymentがラベルに一致する新しいPodを作成したとみなされます。こうなったとしても、Kubernetesは処理を止めません。セレクターが重複する複数のコントローラーを持つとき、そのコントローラーは互いに競合状態となり、正しくふるまいません。
更新戦略 .spec.strategyは古いPodから新しいPodに置き換える際の更新戦略を指定します。.spec.strategy.typeは"Recreate"もしくは"RollingUpdate"を指定できます。デフォルトは"RollingUpdate"です。
Deploymentの再作成 .spec.strategy.type==Recreateと指定されているとき、既存の全てのPodは新しいPodが作成される前に削除されます。
備考: これは更新のための作成の前にPodを停止する事を保証するだけです。Deploymentを更新する場合、古いリビジョンのPodは全てすぐに停止されます。削除に成功するまでは、新しいリビジョンのPodは作成されません。手動でPodを削除すると、ライフサイクルがReplicaSetに制御されているのですぐに置き換えが実施されます(たとえ古いPodがまだ停止中のステータスでも)。Podに"高々この程度の"保証を求めるならば
StatefulSet の使用を検討してください。
Deploymentのローリングアップデート .spec.strategy.type==RollingUpdateと指定されているとき、DeploymentはローリングアップデートによりPodを更新します。ローリングアップデートの処理をコントロールするためにmaxUnavailableとmaxSurgeを指定できます。
Max Unavailable .spec.strategy.rollingUpdate.maxUnavailableはオプションのフィールドで、更新処理において利用不可となる最大のPod数を指定します。値は絶対値(例: 5)を指定するか、理想状態のPodのパーセンテージを指定します(例: 10%)。パーセンテージを指定した場合、絶対値は小数切り捨てされて計算されます。.spec.strategy.rollingUpdate.maxSurgeが0に指定されている場合、この値を0にできません。デフォルトでは25%です。
例えば、この値が30%と指定されているとき、ローリングアップデートが開始すると古いReplicaSetはすぐに理想状態の70%にスケールダウンされます。一度新しいPodが稼働できる状態になると、古いReplicaSetはさらにスケールダウンされ、続いて新しいReplicaSetがスケールアップされます。この間、利用可能なPodの総数は理想状態のPodの少なくとも70%以上になるように保証されます。
Max Surge .spec.strategy.rollingUpdate.maxSurgeはオプションのフィールドで、理想状態のPod数を超えて作成できる最大のPod数を指定します。値は絶対値(例: 5)を指定するか、理想状態のPodのパーセンテージを指定します(例: 10%)。パーセンテージを指定した場合、絶対値は小数切り上げで計算されます。MaxUnavailableが0に指定されている場合、この値を0にできません。デフォルトでは25%です。
例えば、この値が30%と指定されているとき、ローリングアップデートが開始すると新しいReplicaSetはすぐに更新されます。このとき古いPodと新しいPodの総数は理想状態の130%を超えないように更新されます。一度古いPodが削除されると、新しいReplicaSetはさらにスケールアップされます。この間、利用可能なPodの総数は理想状態のPodに対して最大130%になるように保証されます。
Progress Deadline Seconds .spec.progressDeadlineSecondsはオプションのフィールドで、システムがDeploymentの更新に失敗 したと判断するまでに待つ秒数を指定します。更新に失敗したと判断されたとき、リソースのステータスはType=Progressing、Status=FalseかつReason=ProgressDeadlineExceededとなるのを確認できます。DeploymentコントローラーはDeploymentの更新のリトライし続けます。デフォルト値は600です。今後、自動的なロールバックが実装されたとき、更新失敗状態になるとすぐにDeploymentコントローラーがロールバックを行うようになります。
この値が指定されているとき、.spec.minReadySecondsより大きい値を指定する必要があります。
Min Ready Seconds .spec.minReadySecondsはオプションのフィールドで、新しく作成されたPodが利用可能となるために、最低どれくらいの秒数コンテナがクラッシュすることなく稼働し続ければよいかを指定するものです。デフォルトでは0です(Podは作成されるとすぐに利用可能と判断されます)。Podが利用可能と判断された場合についてさらに学ぶためにContainer Probes を参照してください。
リビジョン履歴の保持上限 Deploymentのリビジョン履歴は、Deploymentが管理するReplicaSetに保持されています。
.spec.revisionHistoryLimitはオプションのフィールドで、ロールバック可能な古いReplicaSetの数を指定します。この古いReplicaSetはetcd内のリソースを消費し、kubectl get rsの出力結果を見にくくします。Deploymentの各リビジョンの設定はReplicaSetに保持されます。このため一度古いReplicaSetが削除されると、そのリビジョンのDeploymentにロールバックすることができなくなります。デフォルトでは10もの古いReplicaSetが保持されます。しかし、この値の最適値は新しいDeploymentの更新頻度と安定性に依存します。
さらに詳しく言うと、この値を0にすると、0のレプリカを持つ古い全てのReplicaSetが削除されます。このケースでは、リビジョン履歴が完全に削除されているため新しいDeploymentのロールアウトを元に戻すことができません。
paused .spec.pausedはオプションのboolean値で、Deploymentの一時停止と再開のための値です。一時停止されているものと、そうでないものとの違いは、一時停止されているDeploymentはPodTemplateSpecのいかなる変更があってもロールアウトがトリガーされないことです。デフォルトではDeploymentは一時停止していない状態で作成されます。
3.5.3.2 - ReplicaSet ReplicaSetの目的は、どのような時でも安定したレプリカPodのセットを維持することです。これは、理想的なレプリカ数のPodが利用可能であることを保証するものとして使用されます。
ReplicaSetがどのように動くか ReplicaSetは、ReplicaSetが対象とするPodをどう特定するかを示すためのセレクターや、稼働させたいPodのレプリカ数、Podテンプレート(理想のレプリカ数の条件を満たすために作成される新しいPodのデータを指定するために用意されるもの)といったフィールドとともに定義されます。ReplicaSetは、指定された理想のレプリカ数にするためにPodの作成と削除を行うことにより、その目的を達成します。ReplicaSetが新しいPodを作成するとき、ReplicaSetはそのPodテンプレートを使用します。
ReplicaSetがそのPod群と連携するためのリンクは、Podのmetadata.ownerReferences というフィールド(現在のオブジェクトが所有されているリソースを指定する)を介して作成されます。ReplicaSetによって所持された全てのPodは、それらのownerReferencesフィールドにReplicaSetを特定する情報を保持します。このリンクを通じて、ReplicaSetは管理しているPodの状態を把握したり、その後の実行計画を立てます。
ReplicaSetは、そのセレクターを使用することにより、所有するための新しいPodを特定します。もしownerReferenceフィールドの値を持たないPodか、ownerReferenceフィールドの値が コントローラー でないPodで、そのPodがReplicaSetのセレクターとマッチした場合に、そのPodは即座にそのReplicaSetによって所有されます。
ReplicaSetを使うとき ReplicaSetはどんな時でも指定された数のPodのレプリカが稼働することを保証します。しかし、DeploymentはReplicaSetを管理する、より上位レベルの概念で、Deploymentはその他の多くの有益な機能と共に、宣言的なPodのアップデート機能を提供します。それゆえ、我々はユーザーが独自のアップデートオーケストレーションを必要としたり、アップデートを全く必要としないような場合を除いて、ReplicaSetを直接使うよりも代わりにDeploymentを使うことを推奨します。
これは、ユーザーがReplicaSetのオブジェクトを操作する必要が全く無いことを意味します。
代わりにDeploymentを使用して、specセクションにユーザーのアプリケーションを定義してください。
ReplicaSetの使用例 apiVersion : apps/v1
kind : ReplicaSet
metadata :
name : frontend
labels :
app : guestbook
tier : frontend
spec :
# ケースに応じてレプリカを修正する
replicas : 3
selector :
matchLabels :
tier : frontend
template :
metadata :
labels :
tier : frontend
spec :
containers :
- name : php-redis
image : gcr.io/google_samples/gb-frontend:v3
上記のマニフェストをfrontend.yamlファイルに保存しKubernetesクラスターに適用すると、マニフェストに定義されたReplicaSetとそれが管理するPod群を作成します。
kubectl apply -f http://k8s.io/examples/controllers/frontend.yaml
ユーザーはデプロイされた現在のReplicaSetの情報も取得できます。
そして、ユーザーが作成したfrontendリソースについての情報も取得できます。
NAME DESIRED CURRENT READY AGE
frontend 3 3 3 6s
ユーザーはまたReplicaSetの状態も確認できます。
kubectl describe rs/frontend
その結果は以下のようになります。
Name: frontend
Namespace: default
Selector: tier=frontend
Labels: app=guestbook
tier=frontend
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"apps/v1","kind":"ReplicaSet","metadata":{"annotations":{},"labels":{"app":"guestbook","tier":"frontend"},"name":"frontend",...
Replicas: 3 current / 3 desired
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: tier=frontend
Containers:
php-redis:
Image: gcr.io/google_samples/gb-frontend:v3
Port: <none>
Host Port: <none>
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 117s replicaset-controller Created pod: frontend-wtsmm
Normal SuccessfulCreate 116s replicaset-controller Created pod: frontend-b2zdv
Normal SuccessfulCreate 116s replicaset-controller Created pod: frontend-vcmts
そして最後に、ユーザーはReplicaSetによって作成されたPodもチェックできます。
表示されるPodに関する情報は以下のようになります。
NAME READY STATUS RESTARTS AGE
frontend-b2zdv 1/1 Running 0 6m36s
frontend-vcmts 1/1 Running 0 6m36s
frontend-wtsmm 1/1 Running 0 6m36s
ユーザーはまた、それらのPodのownerReferencesがfrontendReplicaSetに設定されていることも確認できます。
これを確認するためには、稼働しているPodの中のどれかのyamlファイルを取得します。
kubectl get pods frontend-b2zdv -o yaml
その表示結果は、以下のようになります。そのfrontendReplicaSetの情報がmetadataのownerReferencesフィールドにセットされています。
apiVersion : v1
kind : Pod
metadata :
creationTimestamp : "2020-02-12T07:06:16Z"
generateName : frontend-
labels :
tier : frontend
name : frontend-b2zdv
namespace : default
ownerReferences :
- apiVersion : apps/v1
blockOwnerDeletion : true
controller : true
kind : ReplicaSet
name : frontend
uid : f391f6db-bb9b-4c09-ae74-6a1f77f3d5cf
...
テンプレートなしのPodの所有 ユーザーが問題なくベアPod(Bare Pod: ここではPodテンプレート無しのPodのこと)を作成しているとき、そのベアPodがユーザーのReplicaSetの中のいずれのセレクターともマッチしないことを確認することを強く推奨します。
この理由として、ReplicaSetは、所有対象のPodがReplicaSetのテンプレートによって指定されたPodのみに限定されていないからです(ReplicaSetは前のセクションで説明した方法によって他のPodも所有できます)。
前のセクションで取り上げたfrontendReplicaSetと、下記のマニフェストのPodをみてみます。
apiVersion : v1
kind : Pod
metadata :
name : pod1
labels :
tier : frontend
spec :
containers :
- name : hello1
image : gcr.io/google-samples/hello-app:2.0
---
apiVersion : v1
kind : Pod
metadata :
name : pod2
labels :
tier : frontend
spec :
containers :
- name : hello2
image : gcr.io/google-samples/hello-app:1.0
これらのPodはownerReferencesに何のコントローラー(もしくはオブジェクト)も指定されておらず、そしてfrontendReplicaSetにマッチするセレクターをもっており、これらのPodは即座にfrontendReplicaSetによって所有されます。
このfrontendReplicaSetがデプロイされ、初期のPodレプリカがレプリカ数の要求を満たすためにセットアップされた後で、ユーザーがそのPodを作成することを考えます。
kubectl apply -f http://k8s.io/examples/pods/pod-rs.yaml
新しいPodはそのReplicaSetによって所有され、そのReplicaSetのレプリカ数が、設定された理想のレプリカ数を超えた場合すぐにそれらのPodは削除されます。
下記のコマンドでPodを取得できます。
その表示結果で、新しいPodがすでに削除済みか、削除中のステータスになっているのを確認できます。
NAME READY STATUS RESTARTS AGE
frontend-b2zdv 1/1 Running 0 10m
frontend-vcmts 1/1 Running 0 10m
frontend-wtsmm 1/1 Running 0 10m
pod1 0/1 Terminating 0 1s
pod2 0/1 Terminating 0 1s
もしユーザーがそのPodを最初に作成する場合
kubectl apply -f http://k8s.io/examples/pods/pod-rs.yaml
そしてその後にfrontendReplicaSetを作成すると、
kubectl apply -f http://k8s.io/examples/controllers/frontend.yaml
ユーザーはそのReplicaSetが作成したPodを所有し、さらにもともと存在していたPodと今回新たに作成されたPodの数が、理想のレプリカ数になるまでPodを作成するのを確認できます。
ここでまたPodの状態を取得します。
取得結果は下記のようになります。
NAME READY STATUS RESTARTS AGE
frontend-hmmj2 1/1 Running 0 9s
pod1 1/1 Running 0 36s
pod2 1/1 Running 0 36s
この方法で、ReplicaSetはテンプレートで指定されたもの以外のPodを所有することができます。
ReplicaSetのマニフェストを記述する。 他の全てのKubernetes APIオブジェクトのように、ReplicaSetはapiVersion、kindとmetadataフィールドを必要とします。
ReplicaSetでは、kindフィールドの値はReplicaSetです。
ReplicaSetオブジェクトの名前は、有効な
DNSサブドメイン名 である必要があります。
また、ReplicaSetは.spec セクション
Pod テンプレート .spec.templateはラベルを持つことが必要なPodテンプレート です。先ほど作成したfrontend.yamlの例では、tier: frontendというラベルを1つ持っています。
他のコントローラーがこのPodを所有しようとしないためにも、他のコントローラーのセレクターでラベルを上書きしないように注意してください。
テンプレートの再起動ポリシー のためのフィールドである.spec.template.spec.restartPolicyはAlwaysのみ許可されていて、そしてそれがデフォルト値です。
Pod セレクター .spec.selectorフィールドはラベルセレクター です。
先ほど 議論したように、ReplicaSetが所有するPodを指定するためにそのラベルが使用されます。
先ほどのfrontend.yamlの例では、そのセレクターは下記のようになっていました
matchLabels :
tier : frontend
そのReplicaSetにおいて、.spec.template.metadata.labelsフィールドの値はspec.selectorと一致しなくてはならず、一致しない場合はAPIによって拒否されます。
備考: 2つのReplicaSetが同じ.spec.selectorの値を設定しているが、それぞれ異なる.spec.template.metadata.labelsと.spec.template.specフィールドの値を持っていたとき、それぞれのReplicaSetはもう一方のReplicaSetによって作成されたPodを無視します。レプリカ数について ユーザーは.spec.replicasフィールドの値を設定することにより、いくつのPodを同時に稼働させるか指定できます。そのときReplicaSetはレプリカ数がこの値に達するまでPodを作成、または削除します。
もしユーザーが.spec.replicasを指定しない場合、デフォルト値として1がセットされます。
ReplicaSetを利用する ReplicaSetとPodの削除 ReplicaSetとそれが所有する全てのPod削除したいときは、kubectl deleteガベージコレクター がデフォルトで自動的に全ての依存するPodを削除します。
REST APIもしくはclient-goライブラリーを使用するとき、ユーザーは-dオプションでpropagationPolicyをBackgroundかForegroundと指定しなくてはなりません。例えば下記のように実行します。
kubectl proxy --port= 8080
curl -X DELETE 'localhost:8080/apis/apps/v1/namespaces/default/replicasets/frontend' \
'{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Foreground"}' \
"Content-Type: application/json"
ReplicaSetのみを削除する ユーザーはkubectl delete--cascade=falseオプションを付けることにより、所有するPodに影響を与えることなくReplicaSetを削除できます。
REST APIもしくはclient-goライブラリーを使用するとき、ユーザーは-dオプションでpropagationPolicyをOrphanと指定しなくてはなりません。
例えば下記のように実行します:
kubectl proxy --port= 8080
curl -X DELETE 'localhost:8080/apis/apps/v1/namespaces/default/replicasets/frontend' \
'{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Orphan"}' \
"Content-Type: application/json"
一度元のReplicaSetが削除されると、ユーザーは新しいものに置き換えるため新しいReplicaSetを作ることができます。新旧のReplicaSetの.spec.selectorの値が同じである間、新しいReplicaSetは古いReplicaSetで稼働していたPodを取り入れます。
しかし、存在するPodが新しく異なるPodテンプレートとマッチさせようとするとき、この仕組みは機能しません。
ReplicaSetはローリングアップデートを直接サポートしないため、ユーザーのコントロール下においてPodを新しいspecにアップデートしたい場合は、Deployment を使用してください。
PodをReplicaSetから分離させる ユーザーはPodのラベルを変更することにより、ReplicaSetからそのPodを削除できます。この手法はデバッグや、データ修復などのためにサービスからPodを削除したいときに使用できます。
この方法で削除されたPodは自動的に新しいものに置き換えられます。(レプリカ数は変更されないものと仮定します。)
ReplicaSetのスケーリング ReplicaSetは、ただ.spec.replicasフィールドを更新することによって簡単にスケールアップまたはスケールダウンできます。ReplicaSetコントローラーは、ラベルセレクターにマッチするような指定した数のPodが利用可能であり、操作可能であることを保証します。
スケールダウンする場合、ReplicaSetコントローラーは以下の一般的なアルゴリズムに基づき、利用可能なPodをソートし、スケールダウンするPodの優先順位を付け、削除するPodを選択します:
保留している(またはスケジュール不可な)Podが先にスケールダウンされます。 controller.kubernetes.io/pod-deletion-costアノテーションが設定されている場合、値の小さいPodが優先されます。レプリカ数の多いノード上のPodが、レプリカ数の少ないノード上のPodより優先されます。 Podの作成時間が異なる場合、より新しく作成されたPodが古いPodより優先されます(LogarithmicScaleDownフィーチャーゲート が有効の場合、作成時間は整数対数スケールでバケット化されます)。 上記条件のすべてに該当する場合は、ランダム選択となります。
Pod削除コスト FEATURE STATE:
Kubernetes v1.22 [beta]
controller.kubernetes.io/pod-deletion-cost
アノテーションはPodに設定する必要があり、範囲は[-2147483648, 2147483647]になります。同じReplicaSetに属する他のPodと比較して、Podを削除する際のコストを表しています。削除コストの低いPodは、削除コストの高いPodより優先的に削除されます。
このアノテーションを設定しないPodは暗黙的に0と設定され、負の値は許容されます。
無効な値はAPIサーバーによって拒否されます。
この機能はbeta版で、デフォルトで有効になっています。kube-apiserverとkube-controller-managerでフィーチャーゲート PodDeletionCostを設定することで無効にすることができます。
備考: これはベストエフォートで実行されているもので、Pod削除の順番を保証するものではありません。 ユーザーは、メトリック値に基づいてアノテーションを更新するなど、頻繁に更新することは避けるべきです。APIサーバー上で大量のPodの更新操作を発生させることになるためです。 使用事例 アプリケーションの異なるPodは、異なる使用レベルになる可能性があります。スケールダウンする場合、アプリケーションは使用率の低いPodを削除することを優先しています。Podを頻繁に更新することを避けるため、アプリケーションはスケールダウンする前に一度controller.kubernetes.io/pod-deletion-costを更新する必要があります(アノテーションをPod使用レベルに比例する値に設定します)。Spark DeploymentのドライバーPodのように、アプリケーション自体がスケールダウンを制御する場合も機能します。
HorizontalPodAutoscaler(HPA)のターゲットとしてのReplicaSet ReplicaSetはまた、Horizontal Pod Autoscalers (HPA) のターゲットにもなることができます。
これはつまりReplicaSetがHPAによってオートスケールされうることを意味します。
ここではHPAが、前の例で作成したReplicaSetをターゲットにする例を示します。
apiVersion : autoscaling/v1
kind : HorizontalPodAutoscaler
metadata :
name : frontend-scaler
spec :
scaleTargetRef :
kind : ReplicaSet
name : frontend
minReplicas : 3
maxReplicas : 10
targetCPUUtilizationPercentage : 50
このマニフェストをhpa-rs.yamlに保存し、Kubernetesクラスターに適用すると、レプリケートされたPodのCPU使用量にもとづいてターゲットのReplicaSetをオートスケールするHPAを作成します。
kubectl apply -f https://k8s.io/examples/controllers/hpa-rs.yaml
同様のことを行うための代替案として、kubectl autoscaleコマンドも使用できます。(こちらの方がより簡単です。)
kubectl autoscale rs frontend --max= 10 --min= 3 --cpu= 50%
ReplicaSetの代替案 Deployment (推奨) Deployment
ベアPod(Bare Pods) ユーザーがPodを直接作成するケースとは異なり、ReplicaSetはNodeの故障やカーネルのアップグレードといった破壊的なNodeのメンテナンスなど、どのような理由に限らず削除または停止されたPodを置き換えます。
このため、我々はもしユーザーのアプリケーションが単一のPodのみ必要とする場合でもReplicaSetを使用することを推奨します。プロセスのスーパーバイザーについても同様に考えると、それは単一Node上での独立したプロセスの代わりに複数のNodeにまたがった複数のPodを監視します。
ReplicaSetは、KubeletのようなNode上のいくつかのエージェントに対して、ローカルのコンテナ再起動を移譲します。
Job PodをPodそれ自身で停止させたいような場合(例えば、バッチ用のジョブなど)は、ReplicaSetの代わりにJob
DaemonSet マシンの監視やロギングなど、マシンレベルの機能を提供したい場合は、ReplicaSetの代わりにDaemonSet
ReplicationController ReplicaSetはReplicationControllers ラベルについてのユーザーガイド に書かれているように、集合ベース(set-based)のセレクター要求をサポートしていないことを除いては、同じ目的を果たし、同じようにふるまいます。
次の項目 3.5.3.3 - StatefulSet StatefulSetはステートフルなアプリケーションを管理するためのワークロードAPIです。
StatefulSetはPod のデプロイとスケーリングを管理し、それらのPodの順序と一意性を保証 します。
Deployment のように、StatefulSetは指定したコンテナのspecに基づいてPodを管理します。Deploymentとは異なり、StatefulSetは各Podにおいて管理が大変な同一性を維持します。これらのPodは同一のspecから作成されますが、それらは交換可能ではなく、リスケジュール処理をまたいで維持される永続的な識別子を持ちます。
ワークロードに永続性を持たせるためにストレージボリュームを使いたい場合は、解決策の1つとしてStatefulSetが利用できます。StatefulSet内の個々のPodは障害の影響を受けやすいですが、永続化したPodの識別子は既存のボリュームと障害によって置換された新しいPodの紐付けを簡単にします。
StatefulSetの使用 StatefulSetは下記の1つ以上の項目を要求するアプリケーションにおいて最適です。
安定した一意のネットワーク識別子 安定した永続ストレージ 規則的で安全なデプロイとスケーリング 規則的で自動化されたローリングアップデート 上記において安定とは、Podのスケジュール(または再スケジュール)をまたいでも永続的であることと同義です。
もしアプリケーションが安定したネットワーク識別子と規則的なデプロイや削除、スケーリングを全く要求しない場合、ユーザーはステートレスなレプリカのセットを提供するワークロードを使ってアプリケーションをデプロイするべきです。
Deployment やReplicaSet のようなコントローラーはこのようなステートレスな要求に対して最適です。
制限事項 提供されたPodのストレージは、要求されたstorage classにもとづいてPersistentVolume Provisioner によってプロビジョンされるか、管理者によって事前にプロビジョンされなくてはなりません。 StatefulSetの削除もしくはスケールダウンをすることにより、StatefulSetに関連したボリュームは削除されません 。 これはデータ安全性のためで、関連するStatefulSetのリソース全てを自動的に削除するよりもたいてい有効です。 StatefulSetは現在、Podのネットワークアイデンティティーに責務をもつためにHeadless Service を要求します。ユーザーはこのServiceを作成する責任があります。 StatefulSetは、StatefulSetが削除されたときにPodの停止を行うことを保証していません。StatefulSetにおいて、規則的で安全なPodの停止を行う場合、削除のために事前にそのStatefulSetの数を0にスケールダウンさせることが可能です。 デフォルト設定のPod管理ポリシー (OrderedReady)によってローリングアップデート を行う場合、修復のための手動介入 を要求するようなブロークンな状態に遷移させることが可能です。 コンポーネント 下記の例は、StatefulSetのコンポーネントのデモンストレーションとなります。
apiVersion : v1
kind : Service
metadata :
name : nginx
labels :
app : nginx
spec :
ports :
- port : 80
name : web
clusterIP : None
selector :
app : nginx
---
apiVersion : apps/v1
kind : StatefulSet
metadata :
name : web
spec :
selector :
matchLabels :
app : nginx # .spec.template.metadata.labelsの値と一致する必要があります
serviceName : "nginx"
replicas : 3 # by default is 1
template :
metadata :
labels :
app : nginx # .spec.selector.matchLabelsの値と一致する必要があります
spec :
terminationGracePeriodSeconds : 10
containers :
- name : nginx
image : registry.k8s.io/nginx-slim:0.8
ports :
- containerPort : 80
name : web
volumeMounts :
- name : www
mountPath : /usr/share/nginx/html
volumeClaimTemplates :
- metadata :
name : www
spec :
accessModes : [ "ReadWriteOnce" ]
storageClassName : "my-storage-class"
resources :
requests :
storage : 1Gi
上記の例では、
nginxという名前のHeadlessServiceは、ネットワークドメインをコントロールするために使われます。 webという名前のStatefulSetは、specで3つのnginxコンテナのレプリカを持ち、そのコンテナはそれぞれ別のPodで稼働するように設定されています。 volumeClaimTemplatesは、PersistentVolumeプロビジョナーによってプロビジョンされたPersistentVolume を使って安定したストレージを提供します。 StatefulSetの名前は有効な名前 である必要があります。
Podセレクター ユーザーは、StatefulSetの.spec.template.metadata.labelsのラベルと一致させるため、StatefulSetの.spec.selectorフィールドをセットしなくてはなりません。Kubernetes1.8以前では、.spec.selectorフィールドは省略された場合デフォルト値になります。Kubernetes1.8とそれ以降のバージョンでは、ラベルに一致するPodセレクターの指定がない場合はStatefulSetの作成時にバリデーションエラーになります。
Podアイデンティティー StatefulSetのPodは、順番を示す番号、安定したネットワークアイデンティティー、安定したストレージからなる一意なアイデンティティーを持ちます。
そのアイデンティティーはどのNode上にスケジュール(もしくは再スケジュール)されるかに関わらず、そのPodに紐付きます。
順序インデックス N個のレプリカをもったStatefulSetにおいて、StatefulSet内の各Podは、0からはじまりN-1までの整数値を順番に割り当てられ、そのStatefulSetにおいては一意となります。
安定したネットワークID StatefulSet内の各Podは、そのStatefulSet名とPodの順序番号から派生してホストネームが割り当てられます。
作成されたホストネームの形式は$(StatefulSet名)-$(順序番号)となります。先ほどの上記の例では、web-0,web-1,web-2という3つのPodが作成されます。
StatefulSetは、PodのドメインをコントロールするためにHeadless Service を使うことができます。
このHeadless Serviceによって管理されたドメインは$(Service名).$(ネームスペース).svc.cluster.local形式となり、"cluster.local"というのはそのクラスターのドメインとなります。
各Podが作成されると、Podは$(Pod名).$(管理するServiceドメイン名)に一致するDNSサブドメインを取得し、管理するServiceはStatefulSetのserviceNameで定義されます。
クラスターでのDNSの設定方法によっては、新たに起動されたPodのDNS名をすぐに検索できない場合があります。
この動作は、クラスター内の他のクライアントが、Podが作成される前にそのPodのホスト名に対するクエリーをすでに送信していた場合に発生する可能性があります。
(DNSでは通常)ネガティブキャッシュは、Podの起動後でも、少なくとも数秒間、以前に失敗したルックアップの結果が記憶され、再利用されることを意味します。
Podが作成された後、速やかにPodを検出する必要がある場合は、いくつかのオプションがあります。
DNSルックアップに依存するのではなく、Kubernetes APIに直接(例えばwatchを使って)問い合わせる。 Kubernetes DNS プロバイダーのキャッシュ時間を短縮する(これは現在30秒キャッシュされるようになっているCoreDNSのConfigMapを編集することを意味しています。)。 制限事項 セクションで言及したように、ユーザーはPodのネットワークアイデンティティーのためにHeadless Service を作成する責任があります。
ここで、クラスタードメイン、Service名、StatefulSet名の選択と、それらがStatefulSetのPodのDNS名にどう影響するかの例をあげます。
Cluster Domain Service (ns/name) StatefulSet (ns/name) StatefulSet Domain Pod DNS Pod Hostname cluster.local default/nginx default/web nginx.default.svc.cluster.local web-{0..N-1}.nginx.default.svc.cluster.local web-{0..N-1} cluster.local foo/nginx foo/web nginx.foo.svc.cluster.local web-{0..N-1}.nginx.foo.svc.cluster.local web-{0..N-1} kube.local foo/nginx foo/web nginx.foo.svc.kube.local web-{0..N-1}.nginx.foo.svc.kube.local web-{0..N-1}
備考: クラスタードメインは
その他の設定 がされない限り、
cluster.localにセットされます。
安定したストレージ StatefulSetで定義された各VolumeClaimTemplateに対して、各Podは1つのPersistentVolumeClaimを受け取ります。上記のnginxの例において、各Podはmy-storage-classというStorageClassをもち、1GiBのストレージ容量を持った単一のPersistentVolumeを受け取ります。もしStorageClassが指定されていない場合、デフォルトのStorageClassが使用されます。PodがNode上にスケジュール(もしくは再スケジュール)されたとき、そのvolumeMountsはPersistentVolume Claimに関連したPersistentVolumeをマウントします。
注意点として、PodのPersistentVolume Claimと関連したPersistentVolumeは、PodやStatefulSetが削除されたときに削除されません。
削除する場合は手動で行わなければなりません。
Podのネームラベル StatefulSet コントローラー がPodを作成したとき、Podの名前として、statefulset.kubernetes.io/pod-nameにラベルを追加します。このラベルによってユーザーはServiceにStatefulSet内の指定したPodを割り当てることができます。
デプロイとスケーリングの保証 N個のレプリカをもつStatefulSetにおいて、Podがデプロイされるとき、それらのPodは{0..N-1}の番号で順番に作成されます。 Podが削除されるとき、それらのPodは{N-1..0}の番号で降順に削除されます。 Podに対してスケーリングオプションが適用される前に、そのPodの前の順番の全てのPodがRunningかつReady状態になっていなくてはなりません。 Podが停止される前に、そのPodの番号より大きい番号を持つの全てのPodは完全にシャットダウンされていなくてはなりません。 StatefulSetはpod.Spec.TerminationGracePeriodSecondsを0に指定すべきではありません。これは不安全で、やらないことを強く推奨します。さらなる説明としては、StatefulSetのPodの強制削除 を参照してください。
上記の例のnginxが作成されたとき、3つのPodはweb-0、web-1、web-2の順番でデプロイされます。web-1はweb-0がRunningかつReady状態 になるまでは決してデプロイされないのと、同様にweb-2はweb-1がRunningかつReady状態にならないとデプロイされません。もしweb-0がweb-1がRunningかつReady状態になった後だが、web-2が起動する前に失敗した場合、web-2はweb-0の再起動が成功し、RunningかつReady状態にならないと再起動されません。
もしユーザーがreplicas=1といったようにStatefulSetにパッチをあてることにより、デプロイされたものをスケールすることになった場合、web-2は最初に停止されます。web-1はweb-2が完全にシャットダウンされ削除されるまでは、停止されません。もしweb-0が、web-2が完全に停止され削除された後だが、web-1の停止の前に失敗した場合、web-1はweb-0がRunningかつReady状態になるまでは停止されません。
Podの管理ポリシー Kubernetes1.7とそれ以降のバージョンでは、StatefulSetは.spec.podManagementPolicyフィールドを介して、Podの一意性とアイデンティティーを保証します。
OrderedReadyなPod管理 OrderedReadyなPod管理はStatefulSetにおいてデフォルトです。これはデプロイとスケーリングの保証 に記載されている項目の振る舞いを実装します。
並行なPod管理 ParallelなPod管理は、StatefulSetコントローラーに対して、他のPodが起動や停止される前にそのPodが完全に起動し準備完了になるか停止するのを待つことなく、Podが並行に起動もしくは停止するように指示します。
アップデートストラテジー Kubernetes1.7とそれ以降のバージョンにおいて、StatefulSetの.spec.updateStrategyフィールドで、コンテナの自動のローリングアップデートの設定やラベル、リソースのリクエストとリミットや、StatefulSet内のPodのアノテーションを指定できます。
OnDelete OnDeleteというアップデートストラテジーは、レガシーな(Kubernetes1.6以前)振る舞いとなります。StatefulSetの.spec.updateStrategy.typeがOnDeleteにセットされていたとき、そのStatefulSetコントローラーはStatefulSet内でPodを自動的に更新しません。StatefulSetの.spec.template項目の修正を反映した新しいPodの作成をコントローラーに支持するためには、ユーザーは手動でPodを削除しなければなりません。
RollingUpdate RollingUpdateというアップデートストラテジーは、StatefulSet内のPodに対する自動化されたローリングアップデートの機能を実装します。これは.spec.updateStrategyフィールドが未指定の場合のデフォルトのストラテジーです。StatefulSetの.spec.updateStrategy.typeがRollingUpdateにセットされたとき、そのStatefulSetコントローラーは、StatefulSet内のPodを削除し、再作成します。これはPodの停止(Podの番号の降順)と同じ順番で、一度に1つのPodを更新します。コントローラーは、その前のPodの状態がRunningかつReady状態になるまで次のPodの更新を待ちます。
パーティション RollingUpdateというアップデートストラテジーは、.spec.updateStrategy.rollingUpdate.partitionを指定することにより、パーティションに分けることができます。もしパーティションが指定されていたとき、そのパーティションの値と等しいか、大きい番号を持つPodが更新されます。パーティションの値より小さい番号を持つPodは更新されず、たとえそれらのPodが削除されたとしても、それらのPodは以前のバージョンで再作成されます。もしStatefulSetの.spec.updateStrategy.rollingUpdate.partitionが、.spec.replicasより大きい場合、.spec.templateへの更新はPodに反映されません。
多くのケースの場合、ユーザーはパーティションを使う必要はありませんが、もし一部の更新を行う場合や、カナリー版のバージョンをロールアウトする場合や、段階的ロールアウトを行う場合に最適です。
強制ロールバック デフォルトのPod管理ポリシー (OrderedReady)によるローリングアップデート を行う際、修復のために手作業が必要な状態にすることが可能です。
もしユーザーが、決してRunningかつReady状態にならないような設定になるようにPodテンプレートを更新した場合(例えば、不正なバイナリや、アプリケーションレベルの設定エラーなど)、StatefulSetはロールアウトを停止し、待機します。
この状態では、Podテンプレートを正常な状態に戻すだけでは不十分です。既知の問題 によって、StatefulSetは元の正常な状態へ戻す前に、壊れたPodがReady状態(決して起こりえない)に戻るのを待ち続けます。
そのテンプレートを戻したあと、ユーザーはまたStatefulSetが異常状態で稼働しようとしていたPodをすべて削除する必要があります。StatefulSetはその戻されたテンプレートを使ってPodの再作成を始めます。
次の項目 3.5.3.4 - DaemonSet DaemonSet は全て(またはいくつか)のNodeが単一のPodのコピーを稼働させることを保証します。Nodeがクラスターに追加されるとき、PodがNode上に追加されます。Nodeがクラスターから削除されたとき、それらのPodはガーベージコレクターにより除去されます。DaemonSetの削除により、DaemonSetが作成したPodもクリーンアップします。
DaemonSetのいくつかの典型的な使用例は以下の通りです。
クラスターのストレージデーモンを全てのNode上で稼働させる。 ログ集計デーモンを全てのNode上で稼働させる。 Nodeのモニタリングデーモンを全てのNode上で稼働させる。 シンプルなケースとして、各タイプのデーモンにおいて、全てのNodeをカバーする1つのDaemonSetが使用されるケースがあります。さらに複雑な設定では、単一のタイプのデーモン用ですが、異なるフラグや、異なるハードウェアタイプに対するメモリー、CPUリクエストを要求する複数のDaemonSetを使用するケースもあります。
DaemonSet Specの記述 DaemonSetの作成 ユーザーはYAMLファイル内でDaemonSetの設定を記述することができます。例えば、下記のdaemonset.yamlファイルではfluentd-elasticsearchというDockerイメージを稼働させるDaemonSetの設定を記述します。
apiVersion : apps/v1
kind : DaemonSet
metadata :
name : fluentd-elasticsearch
namespace : kube-system
labels :
k8s-app : fluentd-logging
spec :
selector :
matchLabels :
name : fluentd-elasticsearch
template :
metadata :
labels :
name : fluentd-elasticsearch
spec :
tolerations :
- key : node-role.kubernetes.io/master
operator : Exists
effect : NoSchedule
containers :
- name : fluentd-elasticsearch
image : quay.io/fluentd_elasticsearch/fluentd:v5.0.1
resources :
limits :
memory : 200Mi
requests :
cpu : 100m
memory : 200Mi
volumeMounts :
- name : varlog
mountPath : /var/log
- name : varlibdockercontainers
mountPath : /var/lib/docker/containers
readOnly : true
terminationGracePeriodSeconds : 30
volumes :
- name : varlog
hostPath :
path : /var/log
- name : varlibdockercontainers
hostPath :
path : /var/lib/docker/containers
YAMLファイルに基づいてDaemonSetを作成します。
kubectl apply -f https://k8s.io/examples/controllers/daemonset.yaml
必須のフィールド 他の全てのKubernetesの設定と同様に、DaemonSetはapiVersion、kindとmetadataフィールドが必須となります。設定ファイルの活用法に関する一般的な情報は、ステートレスアプリケーションの稼働 、kubectlを用いたオブジェクトの管理 といったドキュメントを参照ください。
DaemonSetオブジェクトの名前は、有効な
DNSサブドメイン名 である必要があります。
また、DaemonSetにおいて.spec
Podテンプレート .spec.templateは.spec内での必須のフィールドの1つです。
.spec.templateはPodテンプレート となります。これはフィールドがネストされていて、apiVersionやkindをもたないことを除いては、Pod のテンプレートと同じスキーマとなります。
Podに対する必須のフィールドに加えて、DaemonSet内のPodテンプレートは適切なラベルを指定しなくてはなりません(Podセレクター の項目を参照ください)。
DaemonSet内のPodテンプレートでは、RestartPolicyAlwaysを使用するか、明示的にAlwaysを設定するかのどちらかである必要があります。
Podセレクター .spec.selectorフィールドはPodセレクターとなります。これはJob の.spec.selectorと同じものです。
ユーザーは.spec.templateのラベルにマッチするPodセレクターを指定しなくてはいけません。
また、一度DaemonSetが作成されると、その.spec.selectorは変更不可能になります。Podセレクターの変更は、意図しないPodの孤立を引き起こし、ユーザーにとってやっかいなものとなります。
.spec.selectorは2つのフィールドからなるオブジェクトです。
matchLabels - ReplicationController の.spec.selectorと同じように機能します。matchExpressions - キーと、値のリストとさらにはそれらのキーとバリューに関連したオペレーターを指定することにより、より洗練された形式のセレクターを構成できます。上記の2つが指定された場合は、2つの条件をANDでどちらも満たすものを結果として返します。
spec.selectorは.spec.template.metadata.labelsとマッチしなければなりません。この2つの値がマッチしない設定をした場合、APIによってリジェクトされます。
選択したNode上でPodを稼働させる もしユーザーが.spec.template.spec.nodeSelectorを指定したとき、DaemonSetコントローラーは、そのnode selector にマッチするNode上にPodを作成します。同様に、もし.spec.template.spec.affinityを指定したとき、DaemonSetコントローラーはnode affinity にマッチするNode上にPodを作成します。
もしユーザーがどちらも指定しないとき、DaemonSetコントローラーは全てのNode上にPodを作成します。
Daemon Podがどのようにスケジューリングされるか DaemonSetは、全ての利用可能なNodeがPodのコピーを稼働させることを保証します。DaemonSetコントローラーは対象となる各Nodeに対してPodを作成し、ターゲットホストに一致するようにPodのspec.affinity.nodeAffinityフィールドを追加します。Podが作成されると、通常はデフォルトのスケジューラーが引き継ぎ、.spec.nodeNameを設定することでPodをターゲットホストにバインドします。新しいNodeに適合できない場合、デフォルトスケジューラーは新しいPodの優先度 に基づいて、既存Podのいくつかを先取り(退避)させることがあります。
ユーザーは、DaemonSetの.spec.template.spec.schedulerNameフィールドを設定することにより、DaemonSetのPodに対して異なるスケジューラーを指定することができます。
.spec.template.spec.affinity.nodeAffinityフィールド(指定された場合)で指定された元のNodeアフィニティは、DaemonSetコントローラーが対象Nodeを評価する際に考慮されますが、作成されたPod上では対象Nodeの名前と一致するNodeアフィニティに置き換わります。
nodeAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
nodeSelectorTerms :
- matchFields :
- key : metadata.name
operator : In
values :
- target-host-name
TaintとToleration DaemonSetコントローラーはDaemonSet Podに一連のToleration を自動的に追加します:
DaemonSetのPodテンプレートで定義すれば、DaemonSetのPodに独自のTolerationを追加することも可能です。
DaemonSetコントローラーはnode.kubernetes.io/unschedulable:NoScheduleのTolerationを自動的に設定するため、Kubernetesは スケジューリング不可能 としてマークされているNodeでDaemonSet Podを実行することが可能です。
クラスターのネットワーク のような重要なNodeレベルの機能をDaemonSetで提供する場合、KubernetesがDaemonSet PodをNodeが準備完了になる前に配置することは有用です。
例えば、その特別なTolerationがなければ、ネットワークプラグインがそこで実行されていないためにNodeが準備完了としてマークされず、同時にNodeがまだ準備完了でないためにそのNode上でネットワークプラグインが実行されていないというデッドロック状態に陥ってしまう可能性があるのです。
Daemon Podとのコミュニケーション DaemonSet内のPodとのコミュニケーションをする際に考えられるパターンは以下の通りです:
Push : DaemonSet内のPodは統計データベースなどの他のサービスに対して更新情報を送信するように設定されます。クライアントは持っていません。NodeIPとKnown Port : PodがNodeIPを介して疎通できるようにするため、DaemonSet内のPodはhostPortを使用できます。慣例により、クライアントはNodeIPのリストとポートを知っています。DNS : 同じPodセレクターを持つHeadlessService を作成し、endpointsリソースを使ってDaemonSetを探すか、DNSから複数のAレコードを取得します。Service : 同じPodセレクターを持つServiceを作成し、複数のうちのいずれかのNode上のDaemonに疎通させるためにそのServiceを使います。(特定のNodeにアクセスする方法はありません。)DaemonSetの更新 もしNodeラベルが変更されたとき、そのDaemonSetは直ちに新しくマッチしたNodeにPodを追加し、マッチしなくなったNodeからPodを削除します。
ユーザーはDaemonSetが作成したPodを修正可能です。しかし、Podは全てのフィールドの更新を許可していません。また、DaemonSetコントローラーは次のNode(同じ名前でも)が作成されたときにオリジナルのテンプレートを使ってPodを作成します。
ユーザーはDaemonSetを削除可能です。kubectlコマンドで--cascade=orphanを指定するとDaemonSetのPodはNode上に残り続けます。その後、同じセレクターで新しいDaemonSetを作成すると、新しいDaemonSetは既存のPodを再利用します。PodでDaemonSetを置き換える必要がある場合は、updateStrategyに従ってそれらを置き換えます。
ユーザーはDaemonSet上でローリングアップデートの実施 が可能です。
DaemonSetの代替案 Initスクリプト Node上で直接起動することにより(例: init、upstartd、systemdを使用する)、デーモンプロセスを稼働することが可能です。この方法は非常に良いですが、このようなプロセスをDaemonSetを介して起動することはいくつかの利点があります。
アプリケーションと同じ方法でデーモンの監視とログの管理ができる。 デーモンとアプリケーションで同じ設定用の言語とツール(例: Podテンプレート、kubectl)を使える。 リソースリミットを使ったコンテナ内でデーモンを稼働させることにより、デーモンとアプリケーションコンテナの分離性が高まります。ただし、これはPod内ではなく、コンテナ内でデーモンを稼働させることでも可能です。 ベアPod 特定のNode上で稼働するように指定したPodを直接作成することは可能です。しかし、DaemonSetはNodeの故障やNodeの破壊的なメンテナンスやカーネルのアップグレードなど、どのような理由に限らず、削除されたもしくは停止されたPodを置き換えます。このような理由で、ユーザーはPod単体を作成するよりもむしろDaemonSetを使うべきです。
静的Pod Kubeletによって監視されているディレクトリに対してファイルを書き込むことによって、Podを作成することが可能です。これは静的Pod と呼ばれます。DaemonSetと違い、静的Podはkubectlや他のKubernetes APIクライアントで管理できません。静的PodはApiServerに依存しておらず、クラスターの自立起動時に最適です。また、静的Podは将来的には廃止される予定です。
Deployment DaemonSetは、Podの作成し、そのPodが停止されることのないプロセスを持つことにおいてDeployment と同様です(例: webサーバー、ストレージサーバー)。
フロントエンドのようなServiceのように、どのホスト上にPodが稼働するか制御するよりも、レプリカ数をスケールアップまたはスケールダウンしたりローリングアップデートする方が重要であるような、状態をもたないServiceに対してDeploymentを使ってください。
DaemonSetがNodeレベルの機能を提供し、他のPodがその特定のNodeで正しく動作するようにする場合、Podのコピーが全てまたは特定のホスト上で常に稼働していることが重要な場合にDaemonSetを使ってください。
例えば、ネットワークプラグイン には、DaemonSetとして動作するコンポーネントが含まれていることがよくあります。DaemonSetコンポーネントは、それが動作しているNodeでクラスターネットワークが動作していることを確認します。
次の項目 3.5.3.5 - Job Jobは一つ以上のPodを作成し、指定された数のPodが正常に終了するまで、Podの実行を再試行し続けます。Podが正常に終了すると、Jobは成功したPodの数を追跡します。指定された完了数に達すると、そのタスク(つまりJob)は完了したとみなされます。Jobを削除すると、作成されたPodも一緒に削除されます。Jobを一時停止すると、再開されるまで、稼働しているPodは全部削除されます。
単純なケースを言うと、確実に一つのPodが正常に完了するまで実行されるよう、一つのJobオブジェクトを作成します。
一つ目のPodに障害が発生したり、(例えばノードのハードウェア障害またノードの再起動が原因で)削除されたりすると、Jobオブジェクトは新しいPodを作成します。
Jobで複数のPodを並列で実行することもできます。
スケジュールに沿ってJob(単一のタスクか複数タスク並列のいずれか)を実行したい場合は CronJob を参照してください。
実行例 下記にJobの定義例を記載しています。πを2000桁まで計算して出力するJobで、完了するまで約10秒かかります。
apiVersion : batch/v1
kind : Job
metadata :
name : pi
spec :
template :
spec :
containers :
- name : pi
image : perl:5.34.0
command : ["perl" , "-Mbignum=bpi" , "-wle" , "print bpi(2000)" ]
restartPolicy : Never
backoffLimit : 4
このコマンドで実行できます:
kubectl apply -f https://kubernetes.io/examples/controllers/job.yaml
実行結果はこのようになります:
job.batch/pi created
kubectlでJobの状態を確認できます:
Name: pi
Namespace: default
Selector: batch.kubernetes.io/controller-uid= c9948307-e56d-4b5d-8302-ae2d7b7da67c
Labels: batch.kubernetes.io/controller-uid= c9948307-e56d-4b5d-8302-ae2d7b7da67c
batch.kubernetes.io/job-name= pi
...
Annotations: batch.kubernetes.io/job-tracking: ""
Parallelism: 1
Completions: 1
Start Time: Mon, 02 Dec 2019 15:20:11 +0200
Completed At: Mon, 02 Dec 2019 15:21:16 +0200
Duration: 65s
Pods Statuses: 0 Running / 1 Succeeded / 0 Failed
Pod Template:
Labels: batch.kubernetes.io/controller-uid= c9948307-e56d-4b5d-8302-ae2d7b7da67c
batch.kubernetes.io/job-name= pi
Containers:
pi:
Image: perl:5.34.0
Port: <none>
Host Port: <none>
Command:
perl
-Mbignum= bpi
-wle
print bpi( 2000)
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 21s job-controller Created pod: pi-xf9p4
Normal Completed 18s job-controller Job completed
apiVersion: batch/v1
kind: Job
metadata:
annotations: batch.kubernetes.io/job-tracking: ""
...
creationTimestamp: "2022-11-10T17:53:53Z"
generation: 1
labels:
batch.kubernetes.io/controller-uid: 863452e6-270d-420e-9b94-53a54146c223
batch.kubernetes.io/job-name: pi
name: pi
namespace: default
resourceVersion: "4751"
uid: 204fb678-040b-497f-9266-35ffa8716d14
spec:
backoffLimit: 4
completionMode: NonIndexed
completions: 1
parallelism: 1
selector:
matchLabels:
batch.kubernetes.io/controller-uid: 863452e6-270d-420e-9b94-53a54146c223
suspend: false
template:
metadata:
creationTimestamp: null
labels:
batch.kubernetes.io/controller-uid: 863452e6-270d-420e-9b94-53a54146c223
batch.kubernetes.io/job-name: pi
spec:
containers:
- command:
- perl
- -Mbignum= bpi
- -wle
- print bpi( 2000)
image: perl:5.34.0
imagePullPolicy: IfNotPresent
name: pi
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Never
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
status:
active: 1
ready: 0
startTime: "2022-11-10T17:53:57Z"
uncountedTerminatedPods: {}
Jobの完了したPodを確認するには、kubectl get podsを使います。
Jobに属するPodの一覧を機械可読形式で出力するには、下記のコマンドを使います:
pods = $( kubectl get pods --selector= batch.kubernetes.io/job-name= pi --output= jsonpath = '{.items[*].metadata.name}' )
echo $pods
出力結果はこのようになります:
pi-5rwd7
ここのセレクターはJobのセレクターと同じです。--output=jsonpathオプションは、返されたリストからPodのnameフィールドを指定するための表現です。
その中の一つのPodの標準出力を確認するには:
Jobの標準出力を確認するもう一つの方法は:
出力結果はこのようになります:
3.1415926535897932384626433832795028841971693993751058209749445923078164062862089986280348253421170679821480865132823066470938446095505822317253594081284811174502841027019385211055596446229489549303819644288109756659334461284756482337867831652712019091456485669234603486104543266482133936072602491412737245870066063155881748815209209628292540917153643678925903600113305305488204665213841469519415116094330572703657595919530921861173819326117931051185480744623799627495673518857527248912279381830119491298336733624406566430860213949463952247371907021798609437027705392171762931767523846748184676694051320005681271452635608277857713427577896091736371787214684409012249534301465495853710507922796892589235420199561121290219608640344181598136297747713099605187072113499999983729780499510597317328160963185950244594553469083026425223082533446850352619311881710100031378387528865875332083814206171776691473035982534904287554687311595628638823537875937519577818577805321712268066130019278766111959092164201989380952572010654858632788659361533818279682303019520353018529689957736225994138912497217752834791315155748572424541506959508295331168617278558890750983817546374649393192550604009277016711390098488240128583616035637076601047101819429555961989467678374494482553797747268471040475346462080466842590694912933136770289891521047521620569660240580381501935112533824300355876402474964732639141992726042699227967823547816360093417216412199245863150302861829745557067498385054945885869269956909272107975093029553211653449872027559602364806654991198818347977535663698074265425278625518184175746728909777727938000816470600161452491921732172147723501414419735685481613611573525521334757418494684385233239073941433345477624168625189835694855620992192221842725502542568876717904946016534668049886272327917860857843838279679766814541009538837863609506800642251252051173929848960841284886269456042419652850222106611863067442786220391949450471237137869609563643719172874677646575739624138908658326459958133904780275901
Job spec(仕様)の書き方 他のKubernetesオブジェクト設定ファイルと同様に、JobにもapiVersion、kindまたはmetadataフィールドが必要です。
コントロールプレーンがJobのために新しいPodを作成するとき、Jobの.metadata.nameはそれらのPodに名前をつけるための基礎の一部になります。Jobの名前は有効なDNSサブドメイン名 である必要がありますが、これはPodのホスト名に予期しない結果をもたらす可能性があります。最高の互換性を得るためには、名前はDNSラベル のより限定的な規則に従うべきです。名前がDNSサブドメインの場合でも、名前は63文字以下でなければなりません。
Jobには.specセクション
Jobラベル Jobラベルのjob-nameとcontroller-uidの接頭辞はbatch.kubernetes.io/となります。
Podテンプレート .spec.templateは.specの唯一の必須フィールドです。
.spec.templateはpodテンプレート です。ネストされていることとapiVersionやkindフィールドが不要になったことを除いて、仕様の定義がPod と全く同じです。
Podの必須フィールドに加えて、Job定義ファイルにあるPodテンプレートでは、適切なラベル(podセレクター を参照)と適切な再起動ポリシーを指定する必要があります。
RestartPolicyNeverかOnFailureのみ設定可能です。
Podセレクター .spec.selectorフィールドはオプションです。ほとんどの場合はむしろ指定しないほうがよいです。
独自のPodセレクターを指定 セクションを参照してください。
Jobの並列実行 Jobで実行するのに適したタスクは主に3種類あります:
非並列Job通常、Podに障害が発生しない限り、一つのPodのみが起動されます。 Podが正常に終了すると、Jobはすぐに完了します。 固定の完了数 を持つ並列Job:.spec.completionsに0以外の正の値を指定します。Jobは全体的なタスクを表し、.spec.completions個のPodが成功すると、Jobの完了となります。 .spec.completionMode="Indexed"を利用する場合、各Podは0から.spec.completions-1までの範囲内のインデックスがアサインされます。ワークキュー を利用した並列Job:.spec.completionsの指定をしない場合、デフォルトは.spec.parallelismとなります。Pod間で調整する、または外部サービスを使う方法で、それぞれ何のタスクに着手するかを決めます。例えば、一つのPodはワークキューから最大N個のタスクを一括で取得できます。 各Podは他のPodがすべて終了したかどうか、つまりJobが完了したかどうかを単独で判断できます。 Jobに属する 任意 のPodが正常に終了すると、新しいPodは作成されません。 一つ以上のPodが正常に終了し、すべてのPodが終了すると、Jobは正常に完了します。 一つのPodが正常に終了すると、他のPodは同じタスクの作業を行ったり、出力を書き込んだりすることはできません。すべてのPodが終了プロセスに進む必要があります。 非並列 Jobの場合、.spec.completionsと.spec.parallelismの両方を未設定のままにしておくことも可能です。未設定の場合、両方がデフォルトで1になります。
完了数固定 Jobの場合、.spec.completionsを必要完了数に設定する必要があります。
.spec.parallelismを設定してもいいですし、未設定の場合、デフォルトで1になります。
ワークキュー 並列Jobの場合、.spec.completionsを未設定のままにし、.spec.parallelismを非負の整数に設定する必要があります。
各種類のJobの使用方法の詳細については、Jobパターン セクションを参照してください。
並列処理の制御 必要並列数(.spec.parallelism)は任意の非負の値に設定できます。
未設定の場合は、デフォルトで1になります。
0に設定した際には、増加するまでJobは一時停止されます。
実際の並列数(任意の瞬間に実行されているPod数)は、さまざまな理由により、必要並列数と異なる可能性があります:
完了数固定 Jobの場合、実際に並列して実行されるPodの数は、残りの完了数を超えることはありません。 .spec.parallelismの値が高い場合は無視されます。ワークキュー Jobの場合、任意のPodが成功すると、新しいPodは作成されません。ただし、残りのPodは終了まで実行し続けられます。Jobコントローラー の応答する時間がなかった場合。 Jobコントローラーが何らかの理由で(ResourceQuotaの不足、権限の不足など)、Podを作成できない場合、
実際の並列数は必要並列数より少なくなる可能性があります。 同じJobで過去に発生した過度のPod障害が原因で、Jobコントローラーは新しいPodの作成を抑制することがあります。 Podがグレースフルシャットダウンされた場合、停止するのに時間がかかります。 完了モード FEATURE STATE:
Kubernetes v1.24 [stable]
完了数固定 Job、つまり.spec.completionsの値がnullではないJobは.spec.completionModeで完了モードを指定できます:
NonIndexed(デフォルト): .spec.completions個のPodが成功した場合、Jobの完了となります。言い換えれば、各Podの完了状態は同質です。ここで要注意なのは、.spec.completionsの値がnullの場合、暗黙的にNonIndexedとして指定されることです。
Indexed: Jobに属するPodはそれぞれ、0から.spec.completions-1の範囲内の完了インデックスを取得できます。インデックスは下記の三つの方法で取得できます。
Podアノテーションbatch.kubernetes.io/job-completion-index。 Podホスト名の一部として、$(job-name)-$(index)の形式になっています。
インデックス付きJob(Indexed Job)とService を一緒に使用すると、Jobに属するPodはお互いにDNSを介して確定的ホスト名で通信できます。この設定方法の詳細はPod間通信を使用したJob を参照してください。 コンテナ化されたタスクの環境変数JOB_COMPLETION_INDEX。 各インデックスに1つずつ正常に完了したPodがあると、Jobは完了したとみなされます。このモードの使い方については、静的な処理の割り当てを使用した並列処理のためのインデックス付きJob を参照してください。
備考: めったに発生しませんが、同じインデックスに対して複数のPodが起動することがあります。(Nodeの障害、kubeletの再起動、Podの立ち退きなど)。この場合、正常に完了した最初のPodだけ完了数にカウントされ、Jobのステータスが更新されます。同じインデックスに対して実行中または完了した他のPodは、検出されるとJobコントローラーによって削除されます。Podとコンテナの障害対策 Pod内のコンテナは、その中のプロセスが0以外の終了コードで終了した、またはメモリ制限を超えたためにコンテナが強制終了されたなど、様々な理由で失敗することがあります。この場合、もし.spec.template.spec.restartPolicy = "OnFailure"と設定すると、Podはノード上に残りますが、コンテナは再実行されます。そのため、プログラムがローカルで再起動した場合の処理を行うか、.spec.template.spec.restartPolicy = "Never"と指定する必要があります。
restartPolicyの詳細についてはPodのライフサイクル を参照してください。
Podがノードからキックされた(ノードがアップグレード、再起動、削除されたなど)、または.spec.template.spec.restartPolicy = "Never"と設定されたときにPodに属するコンテナが失敗したなど、様々な理由でPod全体が故障することもあります。Podに障害が発生すると、Jobコントローラーは新しいPodを起動します。つまりアプリケーションは新しいPodで再起動された場合の処理を行う必要があります。特に、過去に実行した際に生じた一時ファイル、ロック、不完全な出力などを処理する必要があります。
デフォルトでは、それぞれのPodの失敗は.spec.backoffLimitにカウントされます。詳しくはPod失敗のバックオフポリシー をご覧ください。しかし、JobのPod失敗ポリシー を設定することで、Pod失敗の処理をカスタマイズすることができます。
.spec.parallelism = 1、.spec.completions = 1と.spec.template.spec.restartPolicy = "Never"を指定しても、同じプログラムが2回起動されることもありますので注意してください。
.spec.parallelismと.spec.completionsを両方とも2以上指定した場合、複数のPodが同時に実行される可能性があります。そのため、Podは並行処理を行えるようにする必要があります。
フィーチャーゲート のPodDisruptionConditionsとJobPodFailurePolicyの両方が有効で、.spec.podFailurePolicyフィールドが設定されている場合、Jobコントローラーは終了するPod(.metadata.deletionTimestampフィールドが設定されているPod)を、そのPodが終了する(.status.phaseがFailedまたはSucceededになる)までは失敗とはみなしません。ただし、Jobコントローラーは、終了が明らかになるとすみやかに代わりのPodを作成します。Podが終了すると、Jobコントローラーはこの終了したPodを考慮に入れて、該当のJobの.backoffLimitと.podFailurePolicyを評価します。
これらの要件のいずれかが満たされていない場合、Jobコントローラーは、そのPodが後にphase: "Succeeded"で終了する場合でも、終了するPodを即時に失敗として数えます。
Pod失敗のバックオフポリシー 設定の論理エラーなどにより、Jobが数回再試行した後に失敗状態にしたい場合があります。.spec.backoffLimitを設定すると、失敗したと判断するまでの再試行回数を指定できます。バックオフ制限はデフォルトで6に設定されています。Jobに属していて失敗したPodはJobコントローラーにより再作成され、バックオフ遅延は指数関数的に増加し(10秒、20秒、40秒…)、最大6分まで増加します。
再実行回数の算出方法は以下の2通りです:
.status.phase = "Failed"で設定されたPod数を計算します。restartPolicy = "OnFailure"と設定された場合、.status.phaseがPendingまたはRunningであるPodに属するすべてのコンテナで再試行する回数を計算します。どちらかの計算が.spec.backoffLimitに達した場合、Jobは失敗とみなされます。
JobTrackingWithFinalizers
備考: restartPolicy = "OnFailure"が設定されたJobはバックオフ制限に達すると、属するPodは全部終了されるので注意してください。これにより、Jobの実行ファイルのデバッグ作業が難しくなる可能性があります。失敗したJobからの出力が不用意に失われないように、Jobのデバッグ作業をする際はrestartPolicy = "Never"を設定するか、ロギングシステムを使用することをお勧めします。Pod失敗ポリシー FEATURE STATE:
Kubernetes v1.26 [beta]
備考: クラスターで
JobPodFailurePolicyフィーチャーゲート が有効になっている場合のみ、Jobに対してPod失敗ポリシーを設定することができます。さらにPod失敗ポリシーでPodの中断条件を検知して処理できるように、
PodDisruptionConditionsフィーチャーゲートを有効にすることが推奨されます。(
Podの中断条件 を参照してください)。どちらのフィーチャーゲートもKubernetes 1.27で利用可能です。
.spec.podFailurePolicyフィールドで定義されるPod失敗ポリシーを使用すると、コンテナの終了コードとPodの条件に基づいてクラスターがPodの失敗を処理できるようになります。
状況によっては、Podの失敗を処理するときに、Jobの.spec.backoffLimitに基づいたPod失敗のバックオフポリシー が提供する制御よりも、Podの失敗処理に対してより良い制御を求めるかもしれません。これらはいくつかの使用例です:
不要なPodの再起動を回避してワークロードの実行コストを最適化するために、Podの1つがソフトウェアバグを示す終了コードで失敗するとすぐにJobを終了させることができます。 中断が発生してもJobが完了するように、中断によって発生したPodの失敗(preemption 、APIを起点とした退避 、taint を起点とした立ち退き)を無視し、.spec.backoffLimitのリトライ回数にカウントしないようにすることができます。 上記のユースケースを満たすために、.spec.podFailurePolicyフィールドでPod失敗ポリシーを設定できます。このポリシーは、コンテナの終了コードとPodの条件に基づいてPodの失敗を処理できます。
以下は、podFailurePolicyを定義するJobのマニフェストです:
apiVersion : batch/v1
kind : Job
metadata :
name : job-pod-failure-policy-example
spec :
completions : 12
parallelism : 3
template :
spec :
restartPolicy : Never
containers :
- name : main
image : docker.io/library/bash:5
command : ["bash" ] # example command simulating a bug which triggers the FailJob action
args :
- -c
- echo "Hello world!" && sleep 5 && exit 42
backoffLimit : 6
podFailurePolicy :
rules :
- action : FailJob
onExitCodes :
containerName : main # optional
operator: In # one of : In, NotIn
values : [42 ]
- action: Ignore # one of : Ignore, FailJob, Count
onPodConditions :
- type : DisruptionTarget # indicates Pod disruption
上記の例では、Pod失敗ポリシーの最初のルールは、mainコンテナが42の終了コードで失敗した場合、そのJobを失敗とマークすることを指定しています。以下は特に mainコンテナに関するルールです:
終了コード0はコンテナが成功したことを意味します。 終了コード42はJob全体 が失敗したことを意味します。 それ以外の終了コードは、コンテナが失敗したこと、つまりPod全体が失敗したことを示します。再起動の合計回数がbackoffLimit未満であれば、Podは再作成されます。backoffLimitに達した場合、Job全体 が失敗したことになります。
備考: PodテンプレートはrestartPolicy.Neverを指定しているため、kubeletはその特定のPodのmainコンテナを再起動しません。Pod失敗ポリシーの2つ目のルールでは、DisruptionTargetという条件で失敗したPodに対してIgnoreアクションを指定することで、Podの中断が.spec.backoffLimitによるリトライの制限にカウントされないようにします。
備考: Pod失敗ポリシーまたはPod失敗のバックオフポリシーのいずれかによってJobが失敗し、そのJobが複数のPodを実行している場合、KubernetesはそのJob内の保留中または実行中のすべてのPodを終了します。これらはAPIの要件と機能です:
.spec.podFailurePolicyフィールドをJobに使いたい場合は、.spec.restartPolicyをNeverに設定してそのJobのPodテンプレートも定義する必要があります。spec.podFailurePolicy.rulesで指定したPod失敗ポリシーのルールが順番に評価されます。あるPodの失敗がルールに一致すると、残りのルールは無視されます。Pod失敗に一致するルールがない場合は、デフォルトの処理が適用されます。spec.podFailurePolicy.rules[*].onExitCodes.containerNameを指定することで、ルールを特定のコンテナに制限することができます。指定しない場合、ルールはすべてのコンテナに適用されます。指定する場合は、Pod テンプレート内のコンテナ名またはinitContainer名のいずれかに一致する必要があります。Pod失敗ポリシーがspec.podFailurePolicy.rules[*].actionにマッチしたときに実行されるアクションを指定できます。指定可能な値は以下のとおりです。FailJob: PodのJobをFailedとしてマークし、実行中の Pod をすべて終了させる必要があることを示します。Ignore: .spec.backoffLimitのカウンターは加算されず、代替のPodが作成すべきであることを示します。Count: Podがデフォルトの方法で処理されるべきであることを示します。.spec.backoffLimitのカウンターが加算されます。 備考: PodFailurePolicyを使用すると、Jobコントローラーは
FailedフェーズのPodのみにマッチします。削除タイムスタンプを持つPodで、終了フェーズ(
Failedまたは
Succeeded)にないものは、まだ終了中と見なされます。これは、終了中Podは終了フェーズに達するまで
追跡ファイナライザー を保持することを意味します。Kubernetes 1.27以降、Kubeletは削除されたPodを終了フェーズに遷移させます(参照:
Podのフェーズ )。これにより、削除されたPodはJobコントローラーによってファイナライザーが削除されます。
Jobの終了とクリーンアップ Jobが完了すると、それ以上Podは作成されませんが、通常 Podが削除されることもありません。
これらを残しておくと、完了したPodのログを確認でき、エラーや警告などの診断出力を確認できます。
またJobオブジェクトはJob完了後も残っているため、状態を確認することができます。古いJobの状態を把握した上で、削除するかどうかはユーザー次第です。Jobを削除するにはkubectl (例:kubectl delete jobs/piまたはkubectl delete -f ./job.yaml)を使います。kubectlでJobを削除する場合、Jobが作成したPodも全部削除されます。
デフォルトでは、Podが失敗しない(restartPolicy=Never)またはコンテナがエラーで終了しない(restartPolicy=OnFailure)限り、Jobは中断されることなく実行されます。.spec.backoffLimitに達するとそのJobは失敗と見なされ、実行中のPodはすべて終了します。
Jobを終了させるもう一つの方法は、活動期間を設定することです。
Jobの.spec.activeDeadlineSecondsフィールドに秒数を設定することで、活動期間を設定できます。
Podがいくつ作成されても、activeDeadlineSecondsはJobの存続する時間に適用されます。
JobがactiveDeadlineSecondsに達すると、実行中のすべてのPodは終了され、Jobの状態はtype: Failedになり、理由はreason: DeadlineExceededになります。
ここで要注意なのは、Jobの.spec.activeDeadlineSecondsは.spec.backoffLimitよりも優先されます。したがって、失敗して再試行しているPodが一つ以上持っているJobは、backoffLimitに達していなくても、activeDeadlineSecondsで指定された設定時間に達すると、追加のPodをデプロイしなくなります。
例えば:
apiVersion : batch/v1
kind : Job
metadata :
name : pi-with-timeout
spec :
backoffLimit : 5
activeDeadlineSeconds : 100
template :
spec :
containers :
- name : pi
image : perl:5.34.0
command : ["perl" , "-Mbignum=bpi" , "-wle" , "print bpi(2000)" ]
restartPolicy : Never
Job仕様と、Jobに属するPodテンプレートの仕様 は両方ともactiveDeadlineSecondsフィールドを持っているので注意してください。適切なレベルで設定していることを確認してください。
またrestartPolicyはJob自体ではなく、Podに適用されることも注意してください: Jobの状態はtype: Failedになると、自動的に再起動されることはありません。
つまり、.spec.activeDeadlineSecondsと.spec.backoffLimitによって引き起こされるJob終了メカニズムは、永久的なJob失敗につながり、手動で介入して解決する必要があります。
終了したJobの自動クリーンアップ 終了したJobは通常システムに残す必要はありません。残ったままにしておくとAPIサーバーに負担をかけることになります。Jobが上位コントローラーにより直接管理されている場合、例えばCronJobs の場合、Jobは指定された容量ベースのクリーンアップポリシーに基づき、CronJobによりクリーンアップされます。
終了したJobのTTLメカニズム FEATURE STATE:
Kubernetes v1.23 [stable]
終了したJob(状態がCompleteかFailedになったJob)を自動的にクリーンアップするもう一つの方法は
TTLコントローラー より提供されたTTLメカニズムです。.spec.ttlSecondsAfterFinishedフィールドを指定することで、終了したリソースをクリーンアップすることができます。
TTLコントローラーでJobをクリーンアップする場合、Jobはカスケード的に削除されます。つまりJobを削除する際に、Jobに属しているオブジェクト、例えばPodなども一緒に削除されます。Jobが削除される場合、Finalizerなどの、Jobのライフサイクル保証は守られることに注意してください。
例えば:
apiVersion : batch/v1
kind : Job
metadata :
name : pi-with-ttl
spec :
ttlSecondsAfterFinished : 100
template :
spec :
containers :
- name : pi
image : perl:5.34.0
command : ["perl" , "-Mbignum=bpi" , "-wle" , "print bpi(2000)" ]
restartPolicy : Never
Job pi-with-ttlは終了してからの100秒後に自動的に削除されるようになっています。
このフィールドに0を設定すると、Jobは終了後すぐに自動削除の対象になります。このフィールドに何も設定しないと、Jobが終了してもTTLコントローラーによるクリーンアップはされません。
備考: ttlSecondsAfterFinishedフィールドを設定することが推奨されます。管理されていないJob(CronJobなどの、他のワークロードAPIを経由せずに、直接作成したJob)はorphanDependentsというデフォルトの削除ポリシーがあるため、Jobが完全に削除されても、属しているPodが残ってしまうからです。
コントロールプレーン は最終的に、失敗または完了して削除されたJobに属するPodをガベージコレクション しますが、Podが残っていると、クラスターのパフォーマンスが低下することがあり、最悪の場合、この低下によりクラスターがオフラインになることがあります。
LimitRanges とリソースクォータ で、指定する名前空間が消費できるリソースの量に上限を設定することができます。
Jobパターン Jobオブジェクトは、Podの確実な並列実行をサポートするために使用されます。科学技術計算でよく見られるような、密接に通信を行う並列処理をサポートするようには設計されていません。独立だが関連性のある一連の作業項目 の並列処理をサポートします。例えば送信すべき電子メール、レンダリングすべきフレーム、トランスコードすべきファイル、スキャンすべきNoSQLデータベースのキーの範囲、などです。
複雑なシステムでは、異なる作業項目のセットが複数存在する場合があります。ここでは、ユーザーが一斉に管理したい作業項目のセットが一つだけの場合 — つまりバッチJob だけを考えます。
並列計算にはいくつかのパターンがあり、それぞれに長所と短所があります。
トレードオフの関係にあるのは:
各作業項目に1つのJobオブジェクト vs. すべての作業項目に1つのJobオブジェクト。
後者は大量の作業項目を処理する場合に適しています。
前者は大量のJobオブジェクトを管理するため、ユーザーとシステムにオーバーヘッドをかけることになります。 作成されるPod数が作業項目数と等しい、 vs. 各Podが複数の作業項目を処理する。
前者は通常、既存のコードやコンテナへの変更が少なくて済みます。
後者は上記と同じ理由で、大量の作業項目を処理する場合に適しています。 ワークキューを利用するアプローチもいくつかあります。それを使うためには、キューサービスを実行し、既存のプログラムやコンテナにワークキューを利用させるための改造を行う必要があります。
他のアプローチは既存のコンテナ型アプリケーションに適用しやすいです。 ここでは、上記のトレードオフをまとめてあり、それぞれ2~4列目に対応しています。
またパターン名のところは、例やより詳しい説明が書いてあるページへのリンクになっています。
.spec.completionsで完了数を指定する場合、Jobコントローラーより作成された各Podは同一のspec
この表は、各パターンで必要な.spec.parallelismと.spec.completionsの設定を示しています。
ここで、Wは作業項目の数を表しています。
高度な使い方 Jobの一時停止 FEATURE STATE:
Kubernetes v1.24 [stable]
Jobが作成されると、JobコントローラーはJobの要件を満たすために直ちにPodの作成を開始し、Jobが完了するまで作成し続けます。しかし、Jobの実行を一時的に中断して後で再開したい場合、または一時停止状態のJobを再開し、再開時間は後でカスタムコントローラーに判断させたい場合はあると思います。
Jobを一時停止するには、Jobの.spec.suspendフィールドをtrueに修正し、後でまた再開したい場合にはfalseに修正すればよいです。
.spec.suspendをtrueに設定してJobを作成すると、一時停止状態のままで作成されます。
一時停止状態のJobを再開すると、.status.startTimeフィールドの値は現在時刻にリセットされます。これはつまり、Jobが一時停止して再開すると、.spec.activeDeadlineSecondsタイマーは停止してリセットされることになります。
Jobを中断すると、状態がCompletedではない実行中のPodはすべてSIGTERMシグナルを受信して終了されます 。Podのグレースフル終了の猶予期間がカウントダウンされ、この期間内に、Podはこのシグナルを処理しなければなりません。場合により、その後のために処理状況を保存したり、変更を元に戻したりする処理が含まれます。この方法で終了したPodはcompletions数にカウントされません。
下記は一時停止状態のままで作成されたJobの定義例になります:
kubectl get job myjob -o yaml
apiVersion : batch/v1
kind : Job
metadata :
name : myjob
spec :
suspend : true
parallelism : 1
completions : 5
template :
spec :
...
コマンドラインを使ってJobにパッチを当てることで、Jobの一時停止状態を切り替えることもできます。
活動中のJobを一時停止する:
kubectl patch job/myjob --type= strategic --patch '{"spec":{"suspend":true}}'
一時停止中のJobを再開する:
kubectl patch job/myjob --type= strategic --patch '{"spec":{"suspend":false}}'
Jobのstatusセクションで、Jobが停止中なのか、過去に停止したことがあるかを判断できます:
kubectl get jobs/myjob -o yaml
apiVersion : batch/v1
kind : Job
# .metadata and .spec omitted
status :
conditions :
- lastProbeTime : "2021-02-05T13:14:33Z"
lastTransitionTime : "2021-02-05T13:14:33Z"
status : "True"
type : Suspended
startTime : "2021-02-05T13:13:48Z"
Jobのcondition.typeが"Suspended"で、statusが"True"になった場合、Jobは一時停止中になります。lastTransitionTimeフィールドで、どのぐらい中断されたかを判断できます。statusが"False"になった場合、Jobは一時停止状態でしたが、今は実行されていることになります。conditionが書いていない場合、Jobは一度も停止していないことになります。
Jobが一時停止して再開した場合、Eventsも作成されます:
kubectl describe jobs/myjob
Name: myjob
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 12m job-controller Created pod: myjob-hlrpl
Normal SuccessfulDelete 11m job-controller Deleted pod: myjob-hlrpl
Normal Suspended 11m job-controller Job suspended
Normal SuccessfulCreate 3s job-controller Created pod: myjob-jvb44
Normal Resumed 3s job-controller Job resumed
最後の4つのイベント、特に"Suspended"と"Resumed"のイベントは、.spec.suspendフィールドの値を切り替えた直接の結果です。この2つのイベントの間に、Podは作成されていないことがわかりますが、Jobが再開されるとすぐにPodの作成も再開されました。
可変スケジューリング命令 FEATURE STATE:
Kubernetes v1.27 [stable]
ほとんどの場合、並列Jobは、すべてのPodが同じゾーン、またはすべてのGPUモデルxかyのいずれかであるが、両方の混在ではない、などの制約付きで実行することが望ましいです。
suspend フィールドは、これらの機能を実現するための第一歩です。Suspendは、カスタムキューコントローラーがJobをいつ開始すべきかを決定することができます。しかし、Jobの一時停止が解除されると、カスタムキューコントローラーは、Job内のPodの実際の配置場所には影響を与えません。
この機能により、Jobが開始する前にスケジューリング命令を更新でき、カスタムキューコントローラーがPodの配置に影響を与えることができるようになります。同時に実際のPodからNodeへの割り当てをkube-schedulerにオフロードする能力を提供します。これは一時停止されたJobの中で、一度も一時停止解除されたことのないJobに対してのみ許可されます。
JobのPodテンプレートで更新可能なフィールドはnodeAffinity、nodeSelector、tolerations、labelsとannotations、スケジューリングゲート です。
独自のPodセレクターを指定 Jobオブジェクトを作成する際には通常、.spec.selectorを指定しません。Jobが作成された際に、システムのデフォルトロジックは、他のJobと重ならないようなセレクターの値を選択し、このフィールドに追加します。
しかし、場合によっては、この自動設定されたセレクターをオーバーライドする必要があります。そのためには、Jobの.spec.selectorを指定します。
その際には十分な注意が必要です。そのJobの他のPodと重なったラベルセレクターを指定し、無関係のPodにマッチした場合、無関係のJobのPodが削除されたり、無関係のPodが完了されてもこのJobの完了数とカウントしたり、片方または両方のJobがPodの作成または完了までの実行を拒否する可能性があります。
一意でないセレクターを選択した場合、他のコントローラー(例えばReplicationController)や属しているPodが予測できない挙動をする可能性があります。Kubernetesは.spec.selectorを間違って設定しても止めることはしません。
下記はこの機能の使用例を紹介しています。
oldと名付けたJobがすでに実行されていると仮定します。既存のPodをそのまま実行し続けてほしい一方で、作成する残りのPodには別のテンプレートを使用し、そのJobには新しい名前を付けたいとしましょう。これらのフィールドは更新できないため、Jobを直接更新できません。そのため、kubectl delete jobs/old --cascade=orphanで、属しているPodが実行されたまま 、oldJobを削除します。削除する前に、どのセレクターを使用しているかをメモしておきます:
kubectl get job old -o yaml
出力結果はこのようになります:
kind : Job
metadata :
name : old
...
spec :
selector :
matchLabels :
batch.kubernetes.io/controller-uid : a8f3d00d-c6d2-11e5-9f87-42010af00002
...
次に、newという名前で新しくJobを作成し、同じセレクターを明示的に指定します。既存のPodもbatch.kubernetes.io/controller-uid=a8f3d00d-c6d2-11e5-9f87-42010af00002ラベルが付いているので、同じくnewJobによってコントロールされます。
通常システムが自動的に生成するセレクターを使用しないため、新しいJobで manualSelector: trueを指定する必要があります。
kind : Job
metadata :
name : new
...
spec :
manualSelector : true
selector :
matchLabels :
batch.kubernetes.io/controller-uid : a8f3d00d-c6d2-11e5-9f87-42010af00002
...
新しいJobはa8f3d00d-c6d2-11e5-9f87-42010af00002ではなく、別のuidを持つことになります。manualSelector: trueを設定することで、自分は何をしているかを知っていて、またこのミスマッチを許容することをシステムに伝えます。
FinalizerによるJob追跡 FEATURE STATE:
Kubernetes v1.26 [stable]
備考: JobTrackingWithFinalizers機能が無効になっている時に作成されたJobについては、コントロールプレーンを1.26にアップグレードしても、ファイナライザーを使用してJobを追跡しません。コントロールプレーンは任意のJobに属するPodを追跡し、そのPodがAPIサーバーから削除されたかどうか認識します。そのためJobコントローラーはファイナライザーbatch.kubernetes.io/job-trackingを持つPodを作成します。コントローラーがファイナライザーを削除するのは、PodがJobステータスに反映された後なので、他のコントローラーやユーザがPodを削除することができます。
Kubernetes 1.26にアップグレードする前、またはフィーチャーゲートJobTrackingWithFinalizersが有効になる前に作成されたJobは、Podファイナライザーを使用せずに追跡されます。Jobコントローラー は、クラスターに存在するPodのみに基づいて、succeededPodとfailedPodのステータスカウンタを更新します。クラスターからPodが削除されると、コントロールプレーンはJobの進捗を見失う可能性があります。
Jobがbatch.kubernetes.io/job-trackingというアノテーションを持っているかどうかをチェックすることで、コントロールプレーンがPodファイナライザーを使ってJobを追跡しているかどうかを判断できます。Jobからこのアノテーションを手動で追加したり削除したりしてはいけません 。代わりに、JobがPodファイナライザーを使用して追跡されていることを確認するために、Jobを再作成することができます。
静的なインデックス付きJob FEATURE STATE:
Kubernetes v1.27 [beta]
.spec.parallelismと.spec.compleitionsの両方を、.spec.parallelism == .spec.compleitionsとなるように変更することで、インデックス付きJobを増減させることができます。APIサーバ のElasticIndexedJobフィーチャーゲート が無効になっている場合、.spec.compleitionsは不変です。
静的なインデックス付きJobの使用例としては、MPI、Horovod、Ray、PyTorchトレーニングジョブなど、インデックス付きJobのスケーリングを必要とするバッチワークロードがあります。
代替案 単なるPod Podが動作しているノードが再起動または故障した場合、Podは終了し、再起動されません。しかし、終了したPodを置き換えるため、Jobが新しいPodを作成します。このため、たとえアプリケーションが1つのPodしか必要としない場合でも、単なるPodではなくJobを使用することをお勧めします。
Replication Controller JobはReplication Controllers を補完するものです。
Replication Controllerは、終了することが想定されていないPod(Webサーバーなど)を管理し、Jobは終了することが想定されているPod(バッチタスクなど)を管理します。
Podのライフサイクル で説明したように、JobはRestartPolicyがOnFailureかNeverと設定されているPodにのみ 適用されます。(注意:RestartPolicyが設定されていない場合、デフォルト値はAlwaysになります)
シングルJobによるコントローラーPodの起動 もう一つのパターンは、一つのJobが一つPodを作り、そのPodがカスタムコントローラーのような役割を果たし、他のPodを作ります。これは最も柔軟性がありますが、使い始めるにはやや複雑で、Kubernetesとの統合もあまりできません。
この方法のメリットは、全処理過程でJobオブジェクトが完了する保証がありながらも、どのPodを作成し、どのように作業を割り当てるかを完全に制御できることです。
次の項目 Pods について学ぶ。Jobのさまざまな実行方法について学ぶ: 終了したJobの自動クリーンアップ のリンクから、クラスターが完了または失敗したJobをどのようにクリーンアップするかをご確認ください。JobはKubernetes REST APIの一部です。JobのAPIを理解するために、
Job オブジェクトの定義をお読みください。UNIXツールのcronと同様に、スケジュールに基づいて実行される一連のJobを定義するために使用できるCronJob 段階的な例 に基づいて、PodFailurePolicyを使用して、回復可能なPod失敗と回復不可能なPod失敗の処理を構成する方法を練習します。 3.5.3.6 - 終了したリソースのためのTTLコントローラー(TTL Controller for Finished Resources) FEATURE STATE:
Kubernetes v1.12 [alpha]
TTLコントローラーは実行を終えたリソースオブジェクトのライフタイムを制御するためのTTL (time to live) メカニズムを提供します。Job のみ扱っていて、将来的にPodやカスタムリソースなど、他のリソースの実行終了を扱えるように拡張される予定です。
α版の免責事項: この機能は現在α版の機能で、kube-apiserverとkube-controller-managerのFeature Gate のTTLAfterFinishedを有効にすることで使用可能です。
TTLコントローラー TTLコントローラーは現在Jobに対してのみサポートされています。クラスターオペレーターはこの例 のように、Jobの.spec.ttlSecondsAfterFinishedフィールドを指定することにより、終了したJob(完了したもしくは失敗した)を自動的に削除するためにこの機能を使うことができます。
TTL秒はいつでもセット可能です。下記はJobの.spec.ttlSecondsAfterFinishedフィールドのセットに関するいくつかの例です。
Jobがその終了後にいくつか時間がたった後に自動的にクリーンアップできるように、そのリソースマニフェストにこの値を指定します。 この新しい機能を適用させるために、存在していてすでに終了したリソースに対してこのフィールドをセットします。 リソース作成時に、このフィールドを動的にセットするために、管理webhookの変更 をさせます。クラスター管理者は、終了したリソースに対して、このTTLポリシーを強制するために使うことができます。 リソースが終了した後に、このフィールドを動的にセットしたり、リソースステータスやラベルなどの値に基づいて異なるTTL値を選択するために、管理webhookの変更 をさせます。 注意 TTL秒の更新 注意点として、Jobの.spec.ttlSecondsAfterFinishedフィールドといったTTL期間はリソースが作成された後、もしくは終了した後に変更できます。しかし、一度Jobが削除可能(TTLの期限が切れたとき)になると、それがたとえTTLを伸ばすような更新に対してAPIのレスポンスで成功したと返されたとしても、そのシステムはJobが稼働し続けることをもはや保証しません。
タイムスキュー(Time Skew) TTLコントローラーが、TTL値が期限切れかそうでないかを決定するためにKubernetesリソース内に保存されたタイムスタンプを使うため、この機能はクラスター内のタイムスキュー(時刻のずれ)に対してセンシティブとなります。タイムスキューは、誤った時間にTTLコントローラーに対してリソースオブジェクトのクリーンアップしてしまうことを引き起こすものです。
Kubernetesにおいてタイムスキューを避けるために、全てのNode上でNTPの稼働を必須とします(#6159 を参照してください)。クロックは常に正しいものではありませんが、Node間におけるその差はとても小さいものとなります。TTLに0でない値をセットするときにこのリスクに対して注意してください。
次の項目 3.5.3.7 - CronJob FEATURE STATE:
Kubernetes v1.8 [beta]
CronJob は繰り返しのスケジュールによってJob を作成します。
CronJob オブジェクトとは crontab (cron table)ファイルでみられる一行のようなものです。
Cron 形式で記述された指定のスケジュールの基づき、定期的にジョブが実行されます。
注意: すべてのCronJob スケジュール: 時刻はジョブが開始されたkube-controller-manager のタイムゾーンに基づいています。
コントロールプレーンがkube-controller-managerをPodもしくは素のコンテナで実行している場合、CronJobコントローラーのタイムゾーンとして、kube-controller-managerコンテナに設定されたタイムゾーンを使用します。
CronJobリソースのためのマニフェストを作成する場合、その名前が有効なDNSサブドメイン名 か確認してください。
名前は52文字を超えることはできません。これはCronJobコントローラーが自動的に、与えられたジョブ名に11文字を追加し、ジョブ名の長さは最大で63文字以内という制約があるためです。
CronJob CronJobは、バックアップの実行やメール送信のような定期的であったり頻発するタスクの作成に役立ちます。
CronJobは、クラスターがアイドル状態になりそうなときにJobをスケジューリングするなど、特定の時間に個々のタスクをスケジュールすることもできます。
例 このCronJobマニフェスト例は、毎分ごとに現在の時刻とhelloメッセージを表示します。
apiVersion : batch/v1
kind : CronJob
metadata :
name : hello
spec :
schedule : "* * * * *"
jobTemplate :
spec :
template :
spec :
containers :
- name : hello
image : busybox
command :
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy : OnFailure
(Running Automated Tasks with a CronJob ではこの例をより詳しく説明しています。).
CronJobの制限 cronジョブは一度のスケジュール実行につき、 おおよそ 1つのジョブオブジェクトを作成します。ここで おおよそ と言っているのは、ある状況下では2つのジョブが作成される、もしくは1つも作成されない場合があるためです。通常、このようなことが起こらないようになっていますが、完全に防ぐことはできません。したがって、ジョブは 冪等 であるべきです。
startingDeadlineSecondsが大きな値、もしくは設定されていない(デフォルト)、そして、concurrencyPolicyをAllowに設定している場合には、少なくとも一度、ジョブが実行されることを保証します。
最後にスケジュールされた時刻から現在までの間に、CronJobコントローラー はどれだけスケジュールが間に合わなかったのかをCronJobごとにチェックします。もし、100回以上スケジュールが失敗していると、ジョブは開始されずに、ログにエラーが記録されます。
Cannot determine if job needs to be started. Too many missed start time (> 100). Set or decrease .spec.startingDeadlineSeconds or check clock skew.
startingDeadlineSecondsフィールドが設定されると(nilではない)、最後に実行された時刻から現在までではなく、startingDeadlineSecondsの値から現在までで、どれだけジョブを逃したのかをコントローラーが数えます。 startingDeadlineSecondsが200の場合、過去200秒間にジョブが失敗した回数を記録します。
スケジュールされた時間にCronJobが作成できないと、失敗したとみなされます。たとえば、concurrencyPolicyがForbidに設定されている場合、前回のスケジュールがまだ実行中にCronJobをスケジュールしようとすると、CronJobは作成されません。
例として、CronJobが08:30:00を開始時刻として1分ごとに新しいJobをスケジュールするように設定され、startingDeadlineSecondsフィールドが設定されていない場合を想定します。CronJobコントローラーが08:29:00 から10:21:00の間にダウンしていた場合、スケジューリングを逃したジョブの数が100を超えているため、ジョブは開始されません。
このコンセプトをさらに掘り下げるために、CronJobが08:30:00から1分ごとに新しいJobを作成し、startingDeadlineSecondsが200秒に設定されている場合を想定します。CronJobコントローラーが前回の例と同じ期間(08:29:00 から10:21:00まで)にダウンしている場合でも、10:22:00時点でJobはまだ動作しています。このようなことは、過去200秒間(言い換えると、3回の失敗)に何回スケジュールが間に合わなかったをコントローラーが確認するときに発生します。これは最後にスケジュールされた時間から今までのものではありません。
CronJobはスケジュールに一致するJobの作成にのみ関与するのに対して、JobはJobが示すPod管理を担います。
次の項目 Cron表現形式 では、CronJobのscheduleフィールドのフォーマットを説明しています。
cronジョブの作成や動作の説明、CronJobマニフェストの例については、Running automated tasks with cron jobs を見てください。
3.5.3.8 - ReplicationController 水平スケーリング可能なワークロードを管理するためのレガシーAPI。 DeploymentおよびReplicaSet APIに置き換えられています。
ReplicationController は、常に指定した数のPodレプリカが実行されていることを保証します。
つまり、ReplicationControllerは、単一のPodまたは同質な複数のPodが常に稼働し、利用可能であることを保証します。
ReplicationControllerの動作 Podが多すぎる場合、ReplicationControllerは余分なPodを終了します。
Podが少なすぎる場合、ReplicationControllerはさらにPodを起動します。
手動で作成したPodとは異なり、ReplicationControllerによって管理されるPodは、障害が発生したり、削除されたり、終了されたりすると自動的に置き換えられます。
たとえば、カーネルのアップグレードなどの破壊的なメンテナンスの後には、Podはノード上で再作成されます。
このため、アプリケーションが単一のPodのみを必要とする場合でも、ReplicationControllerを使用するべきです。
ReplicationControllerはプロセススーパーバイザーに似ていますが、単一ノード上の個々のプロセスを監視する代わりに、ReplicationControllerは複数のノード上の複数のPodを監視します。
ReplicationControllerは、議論の中では「rc」と略されることが多く、kubectlコマンドのショートカットとしても使われます。
単純なケースとしては、ReplicationControllerオブジェクトを1つ作成し、Podインスタンスを1つ無期限に実行し続けることができます。
より複雑なユースケースとしては、Webサーバーなどで、複数の同一レプリカを実行することができます。
ReplicationControllerの実行例 このReplicationController設定の例では、nginx Webサーバーの3つのコピーを実行します。
apiVersion : v1
kind : ReplicationController
metadata :
name : nginx
spec :
replicas : 3
selector :
app : nginx
template :
metadata :
name : nginx
labels :
app : nginx
spec :
containers :
- name : nginx
image : nginx
ports :
- containerPort : 80
サンプルファイルをダウンロードして、次のコマンドを実行することで、サンプルジョブを実行できます:
kubectl apply -f https://k8s.io/examples/controllers/replication.yaml
出力は次のようになります:
replicationcontroller/nginx created
次のコマンドを使用して、ReplicationControllerのステータスを確認します:
kubectl describe replicationcontrollers/nginx
出力は次のようになります:
Name: nginx
Namespace: default
Selector: app=nginx
Labels: app=nginx
Annotations: <none>
Replicas: 3 current / 3 desired
Pods Status: 0 Running / 3 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx
Port: 80/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- ---- ------ -------
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-qrm3m
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-3ntk0
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-4ok8v
ここでは、3つのPodが作成されていますが、おそらくイメージを取得中であるため、まだ実行状態にはなっていません。
少し経ってから同じコマンドを実行すると、次のような出力が得られます:
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
ReplicationControllerに属するすべてのPodをプログラムで処理しやすい形式でリストするには、次のようなコマンドを使用できます:
pods = $( kubectl get pods --selector= app = nginx --output= jsonpath ={ .items..metadata.name} )
echo $pods
出力は次のようになります:
nginx-3ntk0 nginx-4ok8v nginx-qrm3m
ここで、セレクターは、ReplicationControllerのセレクター(kubectl describeの出力で確認できます)と同じで、replication.yamlでは異なる形式で記述されています。
--output=jsonpathオプションは、返されたリスト内の各Podから名前を取得する式を指定します。
ReplicationControllerマニフェストの記述 他のすべてのKubernetes設定と同様に、ReplicationControllerにはapiVersion、kind、metadataフィールドが必要です。
コントロールプレーンがReplicationControllerの新しいPodを作成する際、ReplicationControllerの.metadata.nameが、それらのPodを命名する際の基準の一部になります。
ReplicationControllerの名前は有効なDNSサブドメイン の値である必要がありますが、これはPodのホスト名に予期しない結果をもたらす可能性があります。
互換性を最大限に保つために、名前はDNSラベル に準じた、より厳格なルールに従うことをお勧めします。
設定ファイルの操作に関する一般的な情報については、オブジェクト管理 を参照してください。
また、ReplicationControllerには.specセクション
Podテンプレート .spec.templateは.specの唯一の必須フィールドです。
.spec.templateはPodテンプレート です。
Pod とまったく同じスキーマを持ちますが、ネストされている点や、apiVersionやkindを持たない点が異なります。
Podの必須フィールドに加えて、ReplicationController内のPodテンプレートは適切なラベルと適切な再起動ポリシーを指定する必要があります。
ラベルについては、他のコントローラーと重複しないようにしてください。
詳しくは、Podセレクター を参照してください。
.spec.template.spec.restartPolicyAlwaysのみが許可されており、指定されていない場合、デフォルトでAlwaysになります。
ローカルコンテナの再起動については、ReplicationControllerはKubelet などのノード上のエージェントに委任します。
ReplicationControllerのラベル ReplicationController自体もラベル(.metadata.labels)を持つことができます。
通常、これらは.spec.template.metadata.labelsと同じに設定します。
.metadata.labelsが指定されていない場合、デフォルトで.spec.template.metadata.labelsになります。
ただし、これらは異なる値に設定することが可能で、.metadata.labelsはReplicationControllerの動作には影響しません。
Podセレクター .spec.selectorフィールドはラベルセレクター です。
ReplicationControllerは、セレクターに一致するラベルを持つすべてのPodを管理します。
ReplicationController自身が作成したPodか、他の人やプロセスが作成したPodかを区別しません。
これにより、実行中のPodに影響を与えることなく、ReplicationControllerを置き換えることができます。
指定されている場合、.spec.template.metadata.labelsは.spec.selectorと等しい必要があり、そうでない場合はAPIによって拒否されます。
もし、.spec.selectorが指定されていない場合は、デフォルトで.spec.template.metadata.labelsに設定されます。
また、通常は、このセレクターに一致するラベルを持つPodを、直接、または別のReplicationControllerを通して、またはJobなどの別のコントローラーで作成しないでください。
もし作成すると、ReplicationControllerは他のPodを自身が作成したPodであるとみなしてしまいます。
Kubernetesはこのような操作を制限しません。
複数のコントローラーのセレクターが重複してしまった場合、削除を自分で管理する必要があります(下記 を参照)。
複数のレプリカ .spec.replicasを、同時に実行したいPodの数に設定することで、同時に実行すべきPodの数を指定できます。
任意の時点で実行されているPod数は、レプリカ数の増減直後や、Podの正常なシャットダウンと代替Podの早期起動が重なった場合などに、指定した数と多少異なることがあります。
.spec.replicasを指定しない場合、デフォルトは1に設定されます。
ReplicationControllerの操作 ReplicationControllerとそのPodの削除 ReplicationControllerとそのすべてのPodを削除するには、kubectl delete
REST APIまたはクライアントライブラリ を使用する場合は、明示的に手順を実行する必要があります(レプリカを0にスケール後、Pod削除を待機し、ReplicationControllerを削除する)。
ReplicationControllerのみの削除 Podに影響を与えることなく、ReplicationControllerを削除することが可能です。
kubectlを使用して、kubectl delete--cascade=orphanオプションを指定します。
REST APIまたはクライアントライブラリ を使用する場合は、ReplicationControllerオブジェクトを削除できます。
元のコントローラーが削除されたら、新しいReplicationControllerを作成して置き換えることができます。
新旧の.spec.selectorが同じである限り、新しいコントローラーは古いPodを引き継ぎます。
ただし、既存のPodを新しい異なるPodテンプレートに合わせて更新することはしません。
制御された方法でPodを新しい仕様に更新するには、ローリングアップデート を使用します。
ReplicationControllerからPodを分離する Podのラベルを変更することで、ReplicationControllerの管理対象から外すことができます。
この手法は、デバッグやデータ復旧の目的で、Podをサービスから削除するために使用できます。
この方法で削除されたPodは、自動的に置き換えられます(レプリカ数も変更されていないと仮定)。
一般的な使用パターン 再スケジューリング 前述のとおり、実行し続けたいPodが1つでも1000でも、ReplicationControllerは、ノード障害やPodの終了(たとえば、別の制御エージェントによる操作など)が発生した場合でも、指定された数のPodが存在することを保証します。
スケーリング ReplicationControllerは、手動またはオートスケーリング制御エージェントによって、replicasフィールドを更新することで、レプリカ数を増減させることができます。
ローリングアップデート ReplicationControllerは、Podを1つずつ置き換えることで、サービスへのローリングアップデートを容易にするように設計されています。
#1353 で説明されているように、推奨されるアプローチは、1つのレプリカで新しいReplicationControllerを作成し、新しいコントローラー(+1)と古いコントローラー(-1)を1つずつスケールし、古いコントローラーが0レプリカに達したら削除することです。
これにより、予期しない障害に左右されることなく、Podのセットが予測どおりに更新されます。
理想的には、ローリングアップデートコントローラーはアプリケーションの準備状態を考慮し、常に十分な数のPodが実際にサービスを提供できる状態にあることを保証します。
2つのReplicationControllerは、Podのプライマリコンテナのイメージタグなど、少なくとも1つのラベルで区別できるPodを作成する必要があります。
ローリングアップデートのきっかけになるのは、通常はイメージの更新が原因であるためです。
複数のリリーストラック ローリングアップデート中にアプリケーションの複数のリリースを実行するのに加えて、複数のリリーストラックを用いて、複数のリリースを長期間、あるいは継続的に実行することも一般的です。
トラックはラベルで区別されます。
たとえば、とあるサービスがtier in (frontend), environment in (prod)の条件を満たすラベルを持つ、すべてのPodを対象にしているとします。
このティアを構成する10個のレプリケートされたPodがあるとします。
ただし、このコンポーネントの新しいバージョンを「カナリア」リリースしたいとします。
大部分のレプリカについて、replicasを9に設定し、ラベルtier=frontend, environment=prod, track=stableを持つReplicationControllerを設定し、
カナリア用にreplicasを1に設定し、ラベルtier=frontend, environment=prod, track=canaryを持つ別のReplicationControllerを設定できます。
これで、サービスはカナリアと非カナリアの両方のPodをカバーします。
一方で、ReplicationControllerを個別に操作して、テストしたり、結果を監視したりすることもできます。
ReplicationControllerとサービスの併用 複数のReplicationControllerを単一のサービスの背後に配置して、たとえば、一部のトラフィックが古いバージョンに送られ、一部が新しいバージョンに送られるようにすることができます。
ReplicationControllerは自ら終了することはありませんが、サービスほど長く存在し続けることは想定されていません。
サービスは、複数のReplicationControllerによって制御されるPodで構成される場合があり、1つのサービスの存続期間中に多くのReplicationControllerが作成・破棄されることが想定されます(たとえば、サービスを実行するPodを更新する場合など)。
サービス自体とそのクライアントは、サービスのPodを維持しているReplicationControllerについて意識する必要はありません。
レプリケーション用のプログラムの記述 ReplicationControllerによって作成されたPodは、交換可能で意味的に同一であることを意図していますが、時間の経過とともに構成が不均一になる可能性があります。
これは、レプリケートされたステートレスなサーバーに適していることは明らかですが、ReplicationControllerは、マスター選出、シャーディング、ワーカープールアプリケーションなど可用性維持のためにも使用できます。
このようなアプリケーションでは、アンチパターンと見なされる各Podの構成の静的/1回限りのカスタマイズではなく、RabbitMQワークキュー などの動的なワーク割り当てメカニズムを使用する必要があります。
実行されるPodのカスタマイズ、たとえばリソースの垂直オートサイジング(cpuやメモリなど)は、ReplicationController自体と同様に、別のオンラインコントローラープロセスによって実行される必要があります。
ReplicationControllerの責任 ReplicationControllerは、ラベルセレクターに一致するPodが目的の数だけ存在し、それらが動作していることを保証します。
現在は、終了したPodのみがカウントから除外されます。
将来的には、readiness やシステムから利用可能なその他の情報が考慮される可能性があり、置き換えポリシーに対してより多くの制御を追加する可能性があります。
また、外部クライアントが任意の洗練された置き換えポリシーやスケールダウンポリシーを実装するために使用できるイベントを発行する予定です。
ReplicationControllerは、常にこの限定された責任のみを持ちます。
ReplicationController自身が、Readiness ProbeやLiveness Probeを実行することはありません。
オートスケーリングを実行するのではなく、(#492 で議論されているように)外部のオートスケーラーによって制御され、そのオートスケーラーがreplicasフィールドを変更することを想定しています。
ReplicationControllerにスケジューリングポリシー(たとえば、spreading )を追加することはありません。
また、制御しているPodが現在指定されているテンプレートと一致することを検証すべきではありません。
それは、オートサイジングやその他の自動化されたプロセスを妨げるためです。
同様に、完了期限、順序依存関係、設定の展開、その他の機能は別の場所に属します。
一括でのPod作成のメカニズムを分離することさえ計画しています(#170 )。
ReplicationControllerは、組み合わせ可能なビルディングブロックのプリミティブとして意図されています。
将来的には、ユーザーの利便性のために、ReplicationControllerやその他の補完的なプリミティブの上に、より高レベルのAPIやツールが構築されることを期待しています。
現在kubectlでサポートされている「マクロ」操作(run、scale)は、これの概念実証の例です。
たとえば、ReplicationController、オートスケーラー、サービス、スケジューリングポリシー、カナリアなどを管理するAsgard のようなものが想定されます。
APIオブジェクト ReplicationControllerは、Kubernetes REST APIのトップレベルリソースです。
APIオブジェクトの詳細については、以下を参照してください:
ReplicationController APIオブジェクト 。
ReplicationControllerの代替 ReplicaSet ReplicaSet集合ベースのラベルセレクター をサポートする次世代のReplicationControllerです。
主にDeployment によって、Pod作成、削除、更新を調整するメカニズムとして使用されます。
カスタムの更新オーケストレーションが必要な場合や、更新がまったく必要ない場合を除き、ReplicaSetを直接使用するのではなく、Deploymentを使用することをお勧めします。
Deployment(推奨) Deployment
ベアPod ユーザーが直接Podを作成した場合とは異なり、ReplicationControllerは、ノード障害やカーネルアップグレードなどの破壊的なノードメンテナンスなど、何らかの理由で削除または終了されたPodを置き換えます。
このため、アプリケーションが単一のPodのみを必要とする場合でも、ReplicationControllerを使用することを推奨します。
プロセススーパーバイザーと同様に考えてください。
ただし、単一ノード上の個々のプロセスではなく、複数のノード上の複数のPodを監視する点が異なります。
ReplicationControllerは、ローカルコンテナの再起動をkubeletなどのノード上のエージェントに委任します。
Job 自ら終了することが期待されるPod(つまり、バッチジョブ)には、ReplicationControllerの代わりにJob
DaemonSet マシン監視やマシンログなど、マシンレベルの機能を提供するPodには、ReplicationControllerの代わりにDaemonSet
次の項目 3.5.4 - ワークロードの管理 アプリケーションをデプロイし、Serviceを介して公開しました。次に何をすべきでしょうか?
Kubernetesには、スケーリングや更新など、アプリケーションのデプロイメントを管理するためのいくつかのツールが用意されています。
リソース構成の整理 多くのアプリケーションでは、Serviceに加えてDeploymentなどの複数のリソースを作成する必要があります。複数のリソースを管理しやすくするために、同じファイル内にまとめて記述することができます(YAMLでは---で区切ります)。例えば、以下のように定義します。
apiVersion : v1
kind : Service
metadata :
name : my-nginx-svc
labels :
app : nginx
spec :
type : LoadBalancer
ports :
- port : 80
selector :
app : nginx
---
apiVersion : apps/v1
kind : Deployment
metadata :
name : my-nginx
labels :
app : nginx
spec :
replicas : 3
selector :
matchLabels :
app : nginx
template :
metadata :
labels :
app : nginx
spec :
containers :
- name : nginx
image : nginx:1.14.2
ports :
- containerPort : 80
複数のリソースは、単一のリソースと同じ方法で作成できます。
kubectl apply -f https://k8s.io/examples/application/nginx-app.yaml
service/my-nginx-svc created
deployment.apps/my-nginx created
リソースはマニフェスト内に記述された順番で作成されます。したがって、Serviceを先に指定するのが望ましいです。これにより、DeploymentなどのコントローラーによってPodが作成される際に、スケジューラーがServiceに関連付けられたPodを適切に分散できるようになります。
また、kubectl applyは複数の-f引数を受け付けます。
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-svc.yaml \
同じマイクロサービスやアプリケーションの階層に関連するリソースは、同じファイルにまとめることが推奨されます。また、アプリケーションに関連するすべてのファイルを同じディレクトリに整理することで、管理しやすくなります。アプリケーションの各階層がDNSを使用して相互に接続される場合、スタックのすべてのコンポーネントをまとめてデプロイできます。
さらに、設定ソースとしてURLを指定することも可能です。これにより、ソース管理システム内のマニフェストから直接デプロイする際に便利です。
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx created
さらに、ConfigMapを追加するなど、追加のマニフェストを定義することも可能です。
外部ツール このセクションでは、Kubernetes上でワークロードを管理するために一般的に使用されるツールのみを紹介します。
より多くのツールの一覧については、CNCF Landscapeの
アプリケーション定義とイメージビルド を参照してください。
🛇 This item links to a third party project or product that is not part of Kubernetes itself.
More information Helm は、あらかじめ設定されたKubernetesリソースのパッケージを管理するためのツールです。これらのパッケージは Helmチャート と呼ばれます。
Kustomize は、Kubernetesのマニフェストを処理し、設定オプションを追加・削除・更新するツールです。Kustomizeは単独のバイナリとして利用できるほか、kubectlのネイティブ機能 としても利用できます。
kubectlにおける一括操作 リソースの作成だけがkubectlによる一括操作の対象ではありません。設定ファイルからリソース名を抽出し、他の操作を実行することも可能です。特に、作成したリソースを削除する際に利用できます。
kubectl delete -f https://k8s.io/examples/application/nginx-app.yaml
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
2つのリソースを対象とする場合、resource/nameの構文を使って、両方のリソースをコマンドラインで指定することができます。
kubectl delete deployments/my-nginx services/my-nginx-svc
さらに多数のリソースを扱う場合は、-lまたは--selectorを使用してラベルによるフィルタリング(ラベルクエリ)を行う方が簡単です。
kubectl delete deployment,services -l app = nginx
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
チェーン処理とフィルタリング kubectlは、受け入れるのと同じ構文でリソース名を出力するため、$()やxargsを使用して操作を連結できます。
kubectl get $( kubectl create -f docs/concepts/cluster-administration/nginx/ -o name | grep service/)
kubectl create -f docs/concepts/cluster-administration/nginx/ -o name | grep service/ | xargs -i kubectl get '{}'
出力は次のようになります。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx-svc LoadBalancer 10.0.0.208 <pending> 80/TCP 0s
上記のコマンドでは、まずdocs/concepts/cluster-administration/nginx/内のリソースを作成し、-o name出力形式を使用して作成されたリソースを出力します(各リソースをresource/nameの形式で出力します)。次にgrepを使ってServiceのみを抽出し、それをkubectl get
ローカルファイルに対する再帰的操作 特定のディレクトリ内でリソースを複数のサブディレクトリに整理している場合、--filename/-f引数とともに--recursiveまたは-Rを指定することで、サブディレクトリ内のリソースにも再帰的に操作を実行できます。
例えば、開発環境に必要なすべての マニフェスト を保持し、リソースの種類ごとに整理されたproject/k8s/developmentというディレクトリがあるとします。
project/k8s/development
├── configmap
│ └── my-configmap.yaml
├── deployment
│ └── my-deployment.yaml
└── pvc
└── my-pvc.yaml
デフォルトでは、project/k8s/developmentに対して一括操作を実行すると、ディレクトリの最上位レベルで処理が止まり、サブディレクトリ内のリソースは処理されません。そのため、以下のコマンドを使用してこのディレクトリ内のリソースを作成しようとすると、エラーが発生します。
kubectl apply -f project/k8s/development
error: you must provide one or more resources by argument or filename (.json|.yaml|.yml|stdin)
その代わりに、--filename/-f引数とともに--recursiveまたは-Rを指定してください。
kubectl apply -f project/k8s/development --recursive
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
--recursive引数は、--filename/-f引数を受け付けるすべての操作で使用できます。例えば、kubectl create、kubectl get、kubectl delete、kubectl describe、kubectl rolloutなどに適用できます。
また、--recursive引数は、複数の-f引数が指定された場合にも機能します。
kubectl apply -f project/k8s/namespaces -f project/k8s/development --recursive
namespace/development created
namespace/staging created
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
kubectlについて詳しく知りたい場合は、コマンドラインツール(kubectl) を参照してください。
アプリケーションをダウンタイムなしで更新する デプロイ済みのアプリケーションは、いずれ更新が必要になります。通常は、新しいイメージまたはイメージタグを指定することで更新を行います。kubectlには、さまざまな更新操作が用意されており、それぞれ異なるシナリオに適用できます。
アプリケーションの複数のコピーを実行し、ロールアウト を使用して新しい正常なPodへ段階的にトラフィックを移行することで、ダウンタイムなしの更新が可能です。最終的には、すべての実行中のPodが新しいソフトウェアへ更新されます。
このセクションでは、Deploymentを使用してアプリケーションを作成し、更新する方法について説明します。
例えば、nginxのバージョン1.14.2を実行しているとします。
kubectl create deployment my-nginx --image= nginx:1.14.2
deployment.apps/my-nginx created
1つのレプリカが存在することを確認します。
kubectl scale --replicas 1 deployments/my-nginx --subresource= 'scale' --type= 'merge' -p '{"spec":{"replicas": 1}}'
deployment.apps/my-nginx scaled
そして、ロールアウト時にKubernetesが一時的なレプリカをより多く追加できるようにするため、最大サージ を100%に設定します。
kubectl patch --type= 'merge' -p '{"spec":{"strategy":{"rollingUpdate":{"maxSurge": "100%" }}}}'
deployment.apps/my-nginx patched
バージョン1.16.1へ更新するには、.spec.template.spec.containers[0].imageをnginx:1.14.2からnginx:1.16.1に変更します。kubectl editを使用してマニフェストを編集します。
kubectl edit deployment/my-nginx
# 新しいコンテナイメージを使用するようにマニフェストを変更し、変更を保存
以上で完了です!Deploymentは、デプロイされたnginxアプリケーションを宣言的に更新し、バックグラウンドで段階的に処理を進めます。これにより、更新中に一定数の古いレプリカのみが停止され、新しいレプリカが必要なPod数を超えて作成されることがないように制御されます。この仕組みの詳細については、Deployment を参照してください。
ロールアウトは、DaemonSet、Deployment、StatefulSetに対して使用できます。
ロールアウトの管理 kubectl rollout
例えば、次のように実行できます。
kubectl apply -f my-deployment.yaml
# ロールアウトの完了を待機
kubectl rollout status deployment/my-deployment --timeout 10m # 10分のタイムアウト
または、次のように実行できます。
kubectl apply -f backing-stateful-component.yaml
# ロールアウトの完了を待たず、ステータスのみを確認
kubectl rollout status statefulsets/backing-stateful-component --watch= false
さらに、ロールアウトを一時停止、再開、または取り消すことも可能です。
詳細については、kubectl rollout
カナリアデプロイ 複数のラベルが必要となる別のシナリオとして、同じコンポーネントの異なるリリースや設定を区別する場合があります。
一般的な方法として、新しいアプリケーションリリース(Podテンプレート内のイメージタグで指定)を、以前のリリースと並行してカナリア デプロイすることがあります。これにより、新しいリリースが本番環境のトラフィックを受け取りつつ、完全にロールアウトする前に動作を確認できます。
例えば、trackラベルを使用して異なるリリースを区別することができます。
プライマリの安定したリリースには、trackラベルの値としてstableを設定します。
name: frontend
replicas: 3
...
labels:
app: guestbook
tier: frontend
track: stable
...
image: gb-frontend:v3
その後、trackラベルの値を異なる値(例:canary)に設定した新しいguestbook frontendのリリースを作成することで、2つのPodセットが重ならないようにすることができます。
name: frontend-canary
replicas: 1
...
labels:
app: guestbook
tier: frontend
track: canary
...
image: gb-frontend:v4
フロントエンドのServiceは、両方のレプリカセットにまたがるように、共通のラベルの部分集合(つまり、trackラベルを省略)を選択することで、トラフィックを両方のアプリケーションに振り分けることができます。
selector :
app : guestbook
tier : frontend
stableリリースとcanaryリリースのレプリカ数を調整することで、それぞれのリリースが本番トラフィックを受け取る割合(この例では、3:1)を決定できます。新しいリリースに十分な自信が持てたら、stableトラックを新しいアプリケーションリリースに更新し、canaryリリースを削除します。
アノテーションの更新 リソースにアノテーションを付与したい場合があります。
アノテーションは、ツールやライブラリなどのAPIクライアントが取得できる、識別情報ではない任意のメタデータです。
これを行うには、kubectl annotateを使用します。例えば、次のように実行できます。
kubectl annotate pods my-nginx-v4-9gw19 description = 'my frontend running nginx'
kubectl get pods my-nginx-v4-9gw19 -o yaml
apiVersion: v1
kind: pod
metadata:
annotations:
description: my frontend running nginx
...
詳細については、アノテーション およびkubectl annotate を参照してください。
アプリケーションのスケーリング アプリケーションの負荷が増減した際には、kubectlを使用してスケーリングを行うことができます。
例えば、nginxのレプリカ数を3から1に減らすには、次のように実行します。
kubectl scale deployment/my-nginx --replicas= 1
deployment.apps/my-nginx scaled
これで、Deploymentによって管理されるPodは1つだけになりました。
kubectl get pods -l app = my-nginx
NAME READY STATUS RESTARTS AGE
my-nginx-2035384211-j5fhi 1/1 Running 0 30m
システムに必要に応じてnginxのレプリカ数(1~3の範囲)を自動的に選択させるには、次のコマンドを実行します。
# これには、コンテナおよびPodのメトリクスの取得元が必要です
kubectl autoscale deployment/my-nginx --min= 1 --max= 3
horizontalpodautoscaler.autoscaling/my-nginx autoscaled
これで、nginxのレプリカ数は必要に応じて自動的にスケールアップおよびスケールダウンされます。
詳しくは、kubectl scale 、kubectl autoscale 、および水平Pod自動スケーリング のドキュメントを参照してください。
リソースのインプレース更新 作成したリソースに対して、小規模で影響の少ない更新を行う必要がある場合があります。
kubectl apply 構成ファイルのセットをソース管理下で管理すること(構成のコード化 を参照)が推奨されています。これにより、構成対象のリソースのコードとともに、構成を保守・バージョン管理することができます。その後、kubectl apply
このコマンドは、適用しようとしている設定のバージョンと、以前のバージョンを比較し、変更を適用します。指定していないプロパティに対する自動的な変更は上書きされません。
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx configured
基盤となる仕組みについて詳しく知りたい場合は、server-side apply を参照してください。
kubectl edit あるいは、kubectl edit
kubectl edit deployment/my-nginx
これは、まずリソースをgetで取得し、テキストエディターで編集した後、更新されたバージョンをapplyで適用するのと同等です。
kubectl get deployment my-nginx -o yaml > /tmp/nginx.yaml
vi /tmp/nginx.yaml
# 何らかの編集を行い、ファイルを保存
kubectl apply -f /tmp/nginx.yaml
deployment.apps/my-nginx configured
rm /tmp/nginx.yaml
これにより、より大きな変更を簡単に行うことができます。
なお、EDITORまたはKUBE_EDITOR環境変数を指定することで、使用するエディターを設定できます。
詳しくは、kubectl edit を参照してください。
kubectl patch kubectl patch
詳細については、kubectl patchを使用したAPIオブジェクトのインプレース更新 を参照してください。
破壊的な更新 場合によっては、一度初期化されると更新できないリソースのフィールドを変更する必要があることがあります。また、Deploymentによって作成された異常なPodを修正するなど、即座に再帰的な変更を行いたい場合もあります。そのようなフィールドを変更するには、replace --forceを使用します。このコマンドは、リソースを削除し再作成することで変更を適用します。この場合、元の設定ファイルを修正して適用できます。
kubectl replace -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml --force
deployment.apps/my-nginx deleted
deployment.apps/my-nginx replaced
次の項目 3.5.5 - ワークロードの自動スケーリング 自動スケーリングによって、何らかのかたちでワークロードを自動的に更新できます。これによりクラスターはリソース要求の変化に対してより弾力的かつ効率的に対応できるようになります。
Kubernetesでは、現在のリソース要求に応じてワークロードをスケールできます。
これによりクラスターはリソース要求の変化に対してより弾力的かつ効率的に対応できるようになります。
ワークロードをスケールするとき、ワークロードによって管理されるレプリカ数を増減したり、レプリカで使用可能なリソースをインプレースで調整できます。
ひとつ目のアプローチは 水平スケーリング と呼ばれ、一方でふたつ目のアプローチは 垂直スケーリング と呼ばれます。
ユースケースに応じて、ワークロードをスケールするには手動と自動の方法があります。
ワークロードを手動でスケーリングする Kubernetesはワークロードの 手動スケーリング をサポートします。
水平スケーリングはkubectl CLIを使用して行うことができます。
垂直スケーリングの場合、ワークロードのリソース定義を パッチ適用 する必要があります。
両方の戦略の例については以下をご覧ください。
ワークロードを自動でスケーリングする Kubernetesはワークロードの 自動スケーリング もサポートしており、これがこのページの焦点です。
Kubernetesにおける オートスケーリング の概念は、一連のPodを管理するオブジェクト(例えばDeployment )を自動的に更新する機能を指します。
ワークロードを水平方向にスケーリングする Kubernetesにおいて、 HorizontalPodAutoscaler (HPA)を使用してワークロードを水平方向に自動的にスケールできます。
これはKubernetes APIリソースおよびコントローラー として実装されており、CPUやメモリ使用率のような観測されたリソース使用率と一致するようにワークロードのレプリカ 数を定期的に調整します。
Deployment用のHorizontalPodAutoscalerを構成するウォークスルーチュートリアル があります。
ワークロードを垂直方向にスケーリングする FEATURE STATE:
Kubernetes v1.25 [stable]
VerticalPodAutoscaler (VPA)を使用してワークロードを垂直方向に自動的にスケールできます。
HPAと異なり、VPAはデフォルトでKubernetesに付属していませんが、GitHubで 見つかる別のプロジェクトです。
インストールすることにより、管理されたレプリカのリソースを どのように いつ スケールするのかを定義するワークロードのCustomResourceDefinitions (CRDs)を作成できるようになります。
現時点では、VPAは4つの異なるモードで動作できます:
VPAの異なるモード モード 説明 Auto現在はRecreateです。これは将来インプレースアップデートに変更される可能性があります。 RecreateVPAはPod作成時にリソースリクエストを割り当てるだけでなく、要求されたリソースが新しい推奨事項と大きく異なる場合にそれらを削除することによって既存のPod上でリソースリクエストを更新します。 InitialVPAはPod作成時にリソースリクエストを割り当て、後から変更することはありません。 OffVPAはPodのリソース要件を自動的に変更しません。推奨事項は計算され、VPAオブジェクトで検査できます。
インプレースPodの水平スケーリング FEATURE STATE:
Kubernetes v1.35 [stable](enabled by default)
Kubernetes 1.35の時点では、VPAはインプレースでのPodのリサイズをサポートしていませんが、この統合は現在作業中です。
インプレースでPodの手動リサイズをするには、コンテナリソースをインプレースでリサイズする を参照してください。
クラスターサイズに基づく自動スケーリング クラスターのサイズに基づいてスケールする必要があるワークロード(例えばcluster-dnsや他のシステムコンポーネント)の場合は、Cluster Proportional Autoscaler
Cluster Proportional Autoscalerはスケジュール可能なノード とコアの数を監視し、それに応じてターゲットワークロードのレプリカ数をスケールします。
レプリカ数を同じままにする必要がある場合、Cluster Proportional Vertical Autoscaler 現在ベータ版 でありGitHubで見つけることができます。
Cluster Proportional Autoscalerがワークロードのレプリカ数をスケールする一方で、Cluster Proportional Vertical Autoscalerはクラスター内のノードおよび/またはコアの数に基づいてワークロード(例えばDeploymentやDaemonSet)のリソース要求を調整します。
イベント駆動型自動スケーリング 例えばKubernetes Event Driven Autoscaler
(KEDA )
KEDAは例えばキューのメッセージ数などの処理するべきイベント数に基づいてワークロードをスケールするCNCF Graduatedプロジェクトです。
様々なイベントソースに合わせて選択できる幅広いアダプターが存在します。
スケジュールに基づく自動スケーリング ワークロードををスケールするためのもう一つの戦略は、例えばオフピークの時間帯にリソース消費を削減するために、スケーリング操作をスケジュールする ことです。
イベント駆動型オートスケーリングと同様に、そのような動作はKEDAをCronスケーラーCronスケーラーによりワークロードをスケールインまたはスケールアウトするためのスケジュール(およびタイムゾーン)を定義できます。
クラスターのインフラストラクチャのスケーリング ワークロードのスケーリングだけではニーズを満たすのに十分でない場合は、クラスターのインフラストラクチャ自体をスケールすることもできます。
クラスターのインフラストラクチャのスケーリングは通常ノード の追加または削除を意味します。
詳しくはNodeの自動スケーリング を読んでください。
次の項目 3.6 - Service、負荷分散とネットワーク Kubernetesにおけるネットワークの概念とリソース。
Kubernetesのネットワークモデル Kubernetesのネットワークモデルは、いくつかの要素で構成されています:
クラスター内の各Pod は、クラスター全体で一意のIPアドレスを取得します。
Podは独自のプライベートネットワーク名前空間を持ち、Pod内のすべてのコンテナで共有されます。
同じPod内の異なるコンテナで実行されているプロセスは、localhostで相互に通信できます。 Podネットワーク (クラスターネットワークとも呼ばれます)は、Pod間の通信を処理します。
これにより、以下が保証されます(意図的なネットワークセグメンテーションがない限り):
すべてのPodは、同じノード 上にあるか、異なるノード上にあるかに関わらず、他のすべてのPodと通信できます。
Podは、プロキシやアドレス変換(NAT)を使用せずに直接通信できます。
Windowsでは、このルールはホストネットワークPodには適用されません。
ノード上のエージェント(システムデーモンやkubeletなど)は、そのノード上のすべてのPodと通信できます。
Service APIは、複数のバックエンドPodによって実装されるサービスに対して、安定した(長期的な)IPアドレスまたはホスト名を提供します。
サービスを構成する個々のPodが時間とともに変化しても、このIPアドレスやホスト名は変わりません。
Kubernetesは、Serviceを構成するPodに関する情報を提供するため、EndpointSlice オブジェクトを自動的に管理します。
サービスプロキシ実装は、ServiceとEndpointSliceオブジェクトのセットを監視します。
そして、オペレーティングシステムまたはクラウドプロバイダーAPIを使用してパケットをインターセプトまたは書き換えることで、サービストラフィックをバックエンドにルーティングするようデータプレーンをプログラムします。
Gateway API(またはその前身であるIngress )を使用すると、クラスター外部のクライアントからServiceにアクセスできるようになります。
NetworkPolicy は、Pod間、またはPodと外部との間のトラフィックを制御できる組み込みのKubernetes APIです。
古いコンテナシステムでは、異なるホスト上のコンテナ同士は自動的には通信できませんでした。
そのため、コンテナ間のリンクを明示的に作成したり、コンテナポートをホストポートにマッピングして他のホストから到達可能にしたりする必要がありました。
Kubernetesではこのような作業は不要です。
Kubernetesのネットワークモデルでは、ポート割り当て、名前解決、サービスディスカバリ、負荷分散、アプリケーション設定、マイグレーションといった観点から、Podは、VMや物理ホストと同じように扱えます。
Kubernetes本体で実装されているのは、このモデルの一部のみです。
その他の部分については、KubernetesがAPIを定義し、実際の機能は外部コンポーネントが提供します。これらのコンポーネントの一部はオプションです:
Podネットワーク名前空間のセットアップは、コンテナランタイムインターフェース を実装するシステムレベルのソフトウェアによって処理されます。
Podネットワーク自体は、Podネットワーク実装 によって管理されます。
Linuxでは、ほとんどのコンテナランタイムがコンテナネットワークインターフェース(CNI) を使用してPodネットワーク実装と連携するため、これらの実装は CNIプラグイン と呼ばれることがよくあります。
Kubernetesは、kube-proxy と呼ばれるサービスプロキシのデフォルト実装を提供していますが、一部のPodネットワーク実装は、実装の他の部分とより密に統合された独自のサービスプロキシを使用します。
一般的には、NetworkPolicyもPodネットワーク実装によって実装されます(一部のシンプルなPodネットワーク実装ではNetworkPolicyを実装していない場合や、管理者がNetworkPolicyサポートなしでPodネットワークを設定する場合があります。これらの場合、APIは引き続き存在しますが、効果はありません)。
Gateway APIの実装 は多数存在し、特定のクラウド環境に特化したもの、「ベアメタル」環境に焦点を当てたもの、より汎用的なものなどがあります。
次の項目 アプリケーションをServiceに接続する チュートリアルでは、実践的な例を通じてServiceとKubernetesネットワークについて学ぶことができます。
クラスターのネットワーク では、クラスターのネットワークを設定する方法について説明し、関連する技術の概要も提供しています。
3.6.1 - Service ワークロードが複数のバックエンドに分散している場合でも、クラスター内で実行されているアプリケーションを、単一の外部向けエンドポイントの背後に公開します。
Kubernetesにおいて、Serviceとは、 クラスター内で1つ以上のPod として実行されているネットワークアプリケーションを公開する方法です。
KubernetesにおけるServiceの主要な目的の一つは、既存のアプリケーションを改修することなく、サービスディスカバリの仕組みを利用できるようにすることです。
Pod内で実行するコードは、クラウドネイティブな環境向けに設計されたものでも、コンテナ化した古いアプリケーションでも構いません。
Serviceを使用することで、その複数のPodがネットワーク上でアクセス可能になり、クライアントから通信できるようになります。
Deployment を使用してアプリケーションを実行する場合、DeploymentはPodを動的に作成、削除します。
常に、どれだけのPodが動作していて健全な状態であるかは分からず、健全なPodの名前すら分からない可能性もあります。
KubernetesのPod は、クラスターの望ましい状態に一致させるために作成、削除されます。
Podは一時的なリソースです(個々のPodに対して、信頼性が高く永続的であるとは期待すべきではありません)。
各Podは独自のIPアドレスを取得します(Kubernetesは、ネットワークプラグインがこれを保証することを期待しています)。
クラスター内の特定のDeploymentで、ある時点で実行されているPodの集合は、少し時が経過すると、異なるPodの集合になっている可能性があります。
これは、とある問題につながります。
Podの集合(「バックエンド」と呼びます)がクラスター内の他のPod(「フロントエンド」と呼びます)に機能を提供する場合、フロントエンドがワークロードのバックエンド部分を使用できるように、どのようにして接続対象のIPアドレスを発見し、追跡するのでしょうか?
ここで Service の登場です。
KubernetesにおけるService Kubernetesの一部であるService APIは、Podのグループをネットワーク経由で公開するための抽象化です。
各Serviceオブジェクトは、エンドポイントの論理的な集合(通常、これらのエンドポイントはPodです)および、Podの公開方法についてのポリシーを定義します。
例として、3つのレプリカで実行されているステートレスな画像処理バックエンドについて考えます。
これらのレプリカは互いに代替可能です—フロントエンドはどのバックエンドを使用するかを気にしません。
バックエンドを構成する実際のPodは変化する可能性がありますが、フロントエンドのクライアントはそれを意識する必要はなく、バックエンドの集合を自身で追跡すべきでもありません。
Serviceという抽象化により、この分離が可能になります。
Serviceが対象とするPodは、通常、ユーザーが定義するセレクター によって決定されます。
Serviceのエンドポイントを定義する他の方法については、セレクター なし のService を参照してください。
ワークロードがHTTPを使用する場合、Ingress を使用して、Webトラフィックがワークロードに到達する方法を制御できます。
IngressはServiceタイプではありませんが、クラスターへのエントリポイントとして機能します。
Ingressを使用すると、ルーティングルールを単一のリソースに統合できるため、クラスター内で個別に実行されている複数のワークロードコンポーネントを、単一のリスナーの背後で公開できます。
KubernetesのGateway APIは、IngressやServiceを超える追加機能を提供します。
GatewayはCustomResourceDefinition を使用して実装された拡張APIの一種であり、クラスターに追加することで、クラスター内で実行されているネットワークサービスへのアクセスを設定できます。
クラウドネイティブなサービスディスカバリ アプリケーションでサービスディスカバリにKubernetes APIを使用できる場合、APIサーバー に問い合わせて一致するEndpointSliceを取得できます。
KubernetesはService内のPodの集合が変更されるたびに、そのServiceのEndpointSliceを更新します。
ネイティブではないアプリケーションの場合、KubernetesはアプリケーションとバックエンドのPodの間にネットワークポートまたはロードバランサーを配置する方法を提供します。
いずれの場合でも、ワークロードはこれらのサービスディスカバリ の仕組みを使用して、接続先を見つけることができます。
Serviceの定義方法 Serviceはオブジェクト です(PodやConfigMapがオブジェクトであるのと同じです)。
Kubernetes APIを使用してServiceの定義を作成、表示、変更できます。
通常はkubectlのようなツールを使用して、これらのAPI呼び出しを行います。
例えば、TCPポート9376でリッスンし、app.kubernetes.io/name=MyAppというラベルが付けられたPodの集合があるとします。
そのTCPリスナーを公開するServiceを定義できます:
apiVersion : v1
kind : Service
metadata :
name : my-service
spec :
selector :
app.kubernetes.io/name : MyApp
ports :
- protocol : TCP
port : 80
targetPort : 9376
このマニフェストを適用すると、デフォルトのClusterIP Serviceタイプ で「my-service」という名前の新しいServiceが作成されます。
このServiceは、app.kubernetes.io/name: MyAppラベルを持つすべてのPodのTCPポート9376を対象とします。
KubernetesはこのServiceに対してIPアドレス(ClusterIP )を割り当てます。
このIPアドレスは仮想IPアドレスメカニズムによって使用されます。
このメカニズムの詳細については、仮想IPとServiceプロキシ を参照してください。
このServiceのコントローラーは、セレクターに一致するPodを継続的にスキャンし、ServiceのEndpointSliceの集合に対して必要に応じて更新を行います。
Serviceオブジェクト名は、有効なRFC 1035ラベル名 である必要があります。
備考: Serviceは 任意の 受信portをtargetPortにマッピングできます。
ただし、デフォルトでは、利便性のためにtargetPortはportフィールドと同じ値に設定されます。Serviceオブジェクトの緩和された命名要件 FEATURE STATE:
Kubernetes v1.34 [alpha](disabled by default)
RelaxedServiceNameValidationフィーチャーゲートは、Serviceオブジェクト名が数字で始まることを許可します。
このフィーチャーゲートが有効化されている場合、Serviceオブジェクト名は有効なRFC 1123ラベル名 である必要があります。
ポート定義 Pod内のポート定義には名前が含まれ、ServiceのtargetPort属性でこれらの名前を参照できます。
例えば、次のようにServiceのtargetPortをPodのポートにバインドできます:
apiVersion : v1
kind : Service
metadata :
name : nginx-service
spec :
selector :
app.kubernetes.io/name : proxy
ports :
- name : name-of-service-port
protocol : TCP
port : 80
targetPort : http-web-svc
---
apiVersion : v1
kind : Pod
metadata :
name : nginx
labels :
app.kubernetes.io/name : proxy
spec :
containers :
- name : nginx
image : nginx:stable
ports :
- containerPort : 80
name : http-web-svc
これは、Serviceに異なるポート番号で同じネットワークプロトコルを提供する複数のPodが混在している場合でも、単一の設定された名前を使用して機能します。
これにより、Serviceのデプロイと進化に大きな柔軟性がもたらされます。
たとえば、バックエンドソフトウェアの次のバージョンでPodが公開するポート番号を変更しても、クライアントを壊すことはありません。
ServiceのデフォルトプロトコルはTCP です。
他のサポートされているプロトコル も使用できます。
多くのServiceは複数のポートを公開する必要があるため、Kubernetesは単一のServiceに対して、複数のポート定義 をサポートしています。
各ポート定義は、同じprotocolを持つことも、異なるものを持つことも可能です。
セレクター無しのService Serviceは、セレクターを使ってKubernetes Podへのアクセスを抽象化するのが一般的です。
ただし、セレクター無しで対応するEndpointSlice オブジェクトを使用すれば、クラスター外のバックエンドなど、他の種類のバックエンドも抽象化できます。
例えば:
本番環境では外部のデータベースクラスターを使用したいが、テスト環境では独自のデータベースを使用する場合。 Serviceを別のNamespace または別のクラスター上のServiceに向けたい場合。 ワークロードをKubernetesに移行中の場合。
移行方法を評価している間は、バックエンドの一部のみをKubernetesで実行する場合。 これらのいずれのシナリオでも、Podに一致するセレクターを指定 せずに Serviceを定義できます。
例えば:
apiVersion : v1
kind : Service
metadata :
name : my-service
spec :
ports :
- name : http
protocol : TCP
port : 80
targetPort : 9376
このServiceにはセレクターが含まれないため、対応するEndpointSliceオブジェクトは自動的に作成されません。
EndpointSliceオブジェクトを手動で追加することで、実行されているネットワークアドレスとポートにServiceをマッピングできます。
例えば、次のように定義します:
apiVersion : discovery.k8s.io/v1
kind : EndpointSlice
metadata :
name : my-service-1 # 慣習で、EndpointSliceの名前にプレフィックスとしてService名を使用します
labels :
# "kubernetes.io/service-name"ラベルを設定する必要があります。
# その値はServiceの名前と一致させてください
kubernetes.io/service-name : my-service
addressType : IPv4
ports :
- name : http # 上記で定義したServiceポート名と一致させる必要があります
appProtocol : http
protocol : TCP
port : 9376
endpoints :
- addresses :
- "10.4.5.6"
- addresses :
- "10.1.2.3"
カスタムEndpointSlice Service用にEndpointSlice オブジェクトを作成する場合、EndpointSliceには任意の名前を使用できます。
ただし、名前空間内の各EndpointSliceは一意の名前である必要があります。
EndpointSliceにkubernetes.io/service-nameラベル を設定することで、EndpointSliceをServiceに関連付けられます。
備考: エンドポイントのIPは次のものであっては いけません : ループバック(IPv4の場合は127.0.0.0/8、IPv6の場合は::1/128)、またはリンクローカル(IPv4の場合は169.254.0.0/16と224.0.0.0/24、IPv6の場合はfe80::/64)。
エンドポイントIPアドレスは、他のKubernetes ServiceのClusterIPにすることはできません。
これは、kube-proxy が宛先として仮想IPをサポートしていないためです。
自身で作成するEndpointSlice、または独自のコード内で作成するEndpointSliceの場合、endpointslice.kubernetes.io/managed-by"my-domain.example/name-of-controller"のような値の使用を検討してください。
サードパーティツールを使用している場合は、ツールの名前をすべて小文字で使用し、スペースやその他の句読点をダッシュ(-)に変更してください。
kubectlのようなツールを直接使用してEndpointSliceを管理する場合は、"staff"や"cluster-admins"のような、手動で管理していることを説明する名前を使用してください。
Kubernetes自身のコントロールプレーンによって管理されるEndpointSliceを識別する予約語である"controller"の使用は避けてください。
セレクターの無いServiceへのアクセス セレクターの無いServiceへのアクセスは、セレクターがある場合と同じように機能します。
セレクターの無いServiceの例 では、トラフィックはEndpointSliceマニフェストで定義された2つのエンドポイントのいずれかにルーティングされます: ポート9376上の10.1.2.3または10.4.5.6へのTCP接続です。
備考: Kubernetes APIサーバーは、Podにマッピングされていないエンドポイントへのプロキシを許可しません。
kubectl port-forward service/<service-name> forwardedPort:servicePortのようなアクションは、Serviceにセレクターが無い場合、この制約により失敗します。
これにより、Kubernetes APIサーバーが、呼び出し元に未許可のエンドポイントへのプロキシとして使用されることを防ぐことができます。ExternalName Serviceは、セレクターを持たず、代わりにDNS名を使用するServiceの特殊なケースです。
詳細については、ExternalName セクションを参照してください。
EndpointSlice FEATURE STATE:
Kubernetes v1.21 [stable]
EndpointSlice は、Serviceの背後にあるネットワークエンドポイントのサブセット(スライス )を表すオブジェクトです。
Kubernetesクラスターは、各EndpointSliceが保持するエンドポイントの数を追跡します。
特定のServiceに紐づくエンドポイント数が多く、しきい値に達した場合、Kubernetesは新しい空のEndpointSliceを追加し、そこに新たなエンドポイント情報を保存します。
デフォルトでは、既存のすべてのEndpointSliceがそれぞれ、少なくとも100個のエンドポイントを含むと、Kubernetesは新しいEndpointSliceを作成します。
Kubernetesは、追加のエンドポイントを追加する必要性が生じるまで、新しいEndpointSliceを作成しません。
このAPIの詳細については、EndpointSlice を参照してください。
Endpoints(非推奨) FEATURE STATE:
Kubernetes v1.33 [deprecated]
EndpointSlice APIは、従来のEndpoints APIの後継です。
非推奨となったEndpoints APIには、EndpointSliceと比較していくつかの問題があります:
デュアルスタッククラスターをサポートしていません。 trafficDistribution のような新しい機能をサポートするために必要な情報が含まれていません。エンドポイントのリストが単一のオブジェクトに収まらないほど長い場合、切り捨てられます。 このため、すべてのクライアントはEndpointsではなくEndpointSlice APIを使用することをお勧めします。
容量超過のEndpoints Kubernetesでは、単一のEndpointsオブジェクトに格納できるエンドポイントの数は制限されています。
Serviceに1000個を超えるエンドポイントが存在する場合、KubernetesはEndpointsオブジェクト内のデータを切り捨てます。
Serviceは複数のEndpointSliceにリンクできるため、1000個という制限はレガシーのEndpoints APIにのみ影響します。
その場合、KubernetesはEndpointsオブジェクトに格納する最大1000個のバックエンドエンドポイントを選択し、Endpointsにendpoints.kubernetes.io/over-capacity: truncatedアノテーション を設定します。
コントロールプレーンはまた、バックエンドのPod数が1000未満に減少した場合、このアノテーションを削除します。
トラフィックは引き続きバックエンドに送信されますが、レガシーのEndpoints APIに依存するロードバランシング機構は、利用可能なバックエンドのエンドポイントのうち最大1000個にのみトラフィックを送信します。
同様に、APIの制限によって、Endpointsを手動で更新して1000個を超えるエンドポイントを持つようにすることはできません。
アプリケーションプロトコル FEATURE STATE:
Kubernetes v1.20 [stable]
appProtocolフィールドは、各Serviceポートに対してアプリケーションプロトコルを指定する方法を提供します。
これは、実装が理解するプロトコルに対して、より高度な動作を提供するためのヒントとして使用されます。
このフィールドの値は、対応するEndpointsおよびEndpointSliceオブジェクトに反映されます。
このフィールドは、標準のKubernetesラベル構文に従います。
有効な値は次のいずれかです:
プロトコル 説明 kubernetes.io/h2cRFC 7540 で説明されている平文のHTTP/2kubernetes.io/wsRFC 6455 で説明されている平文のWebSocketkubernetes.io/wssRFC 6455 で説明されているTLS上のWebSocket
マルチポートService 一部のServiceでは、複数のポートを公開する必要があります。
Kubernetesでは、単一のServiceオブジェクトに複数のポート定義を設定できます。
Serviceに複数のポートを使用する場合、曖昧さを避けるために、すべてのポートに名前を付ける必要があります。
例えば、下記のように設定します:
apiVersion : v1
kind : Service
metadata :
name : my-service
spec :
selector :
app.kubernetes.io/name : MyApp
ports :
- name : http
protocol : TCP
port : 80
targetPort : 9376
- name : https
protocol : TCP
port : 443
targetPort : 9377
備考: Kubernetesの名前 全般と同様に、ポート名は小文字の英数字と-のみを含む必要があります。
ポート名は英数字で始まり、英数字で終わる必要もあります。
例えば、123-abcやwebという名前は有効ですが、123_abcや-webは無効です。
Serviceタイプ アプリケーションの一部(例えば、フロントエンド)で、Serviceをクラスターの外部からアクセス可能な外部IPアドレスとして公開したい場合があります。
KubernetesのServiceタイプを使用すると、必要なServiceの種類を指定できます。
利用可能なtypeの値とその動作は次の通りです:
ClusterIPクラスター内部のIPでServiceを公開します。
この値を選択すると、Serviceはクラスター内からのみ到達可能になります。
これは、Serviceに対して明示的にtypeを指定しない場合に使用されるデフォルトです。
Ingress またはGateway を使用して、Serviceをパブリックインターネットに公開できます。 NodePort各ノードのIPの静的ポート(NodePort)でServiceを公開します
NodePortを利用可能にするために、Kubernetesは、type: ClusterIPのServiceを要求した場合と同じように、ClusterIPアドレスを設定します。 LoadBalancer外部のロードバランサーを使用してServiceを外部に公開します。
Kubernetesはロードバランシングコンポーネントを直接提供しないため、独自に提供するか、Kubernetesクラスターをクラウドプロバイダーと統合する必要があります。 ExternalNameServiceをexternalNameフィールドの内容(例えば、ホスト名api.foo.bar.example)にマッピングします。
このマッピングにより、クラスターのDNSサーバーがその外部ホスト名の値を持つCNAMEレコードを返すように設定されます。
いかなる種類のプロキシも設定されません。 Service APIのtypeフィールドは階層的な機能として設計されており、上位のタイプは下位のタイプの機能を含みます。
ただし、この階層的な設計には例外があります。
ロードバランサーのNodePort割り当てを無効にする ことで、LoadBalancer Serviceを定義できます。
type: ClusterIPこのデフォルトのServiceタイプでは、クラスターが予約済みのIPアドレスプールからIPアドレスが割り当てられます。
他のいくつかのServiceタイプは、ClusterIPタイプを基盤として構築されています。
.spec.clusterIPを"None"に設定したServiceを定義すると、KubernetesはIPアドレスを割り当てません。
詳細については、ヘッドレスService を参照してください。
独自のIPアドレスの選択 Service作成リクエストの一部として、独自のclusterIPアドレスを指定できます。
指定するためには、.spec.clusterIPフィールドを設定します。
例えば、再利用したい既存のDNSエントリがある場合や、特定のIPアドレス用に設定されていて再設定が困難なレガシーシステムがある場合などです。
選択するIPアドレスは、APIサーバーに設定されているservice-cluster-ip-range CIDR範囲内の有効なIPv4またはIPv6アドレスである必要があります。
無効なclusterIPアドレスの値でServiceを作成しようとすると、APIサーバーは問題が発生したことを示す422 HTTPステータスコードを返します。
Kubernetesがどのように、2つの異なるServiceが同じIPアドレスを使用しようとする際のリスクと影響を軽減するかについては、衝突の回避 を参照してください。
type: NodePorttypeフィールドをNodePortに設定すると、Kubernetesコントロールプレーンは--service-node-port-rangeフラグで指定された範囲(デフォルト: 30000-32767)からポートを割り当てます。
各ノードはそのポート(すべてのノードで同じポート番号)をServiceにプロキシします。
割り当てられたポートは、Serviceの.spec.ports[*].nodePortフィールドで確認できます。
NodePortを使用すると、独自のロードバランシングソリューションのセットアップや、Kubernetesで完全にサポートされていない環境の構成、あるいはノードのIPアドレスの直接公開さえ可能になります。
NodePortタイプのServiceの場合、Kubernetesはさらにポート(Serviceのプロトコルに合わせてTCP、UDP、またはSCTP)を割り当てます。
クラスター内のすべてのノードは、割り当てられたポートをリッスンし、Serviceに関連付けられた準備完了状態のエンドポイントの1つにトラフィックを転送するように自身を構成します。
適切なプロトコル(例: TCP)と適切なポート(そのServiceに割り当てられたポート)を使用して任意のノードに接続することで、クラスター外からtype: NodePortのServiceにアクセスできます。
独自のポート選択 特定のポート番号が必要な場合は、nodePortフィールドに値を指定できます。
コントロールプレーンはそのポートを割り当てるか、APIのトランザクションが失敗したことを報告します。
つまり、ポートの衝突を自分で処理する必要があります。
また、NodePortによる使用のために設定された範囲内の有効なポート番号を使用する必要があります。
以下は、NodePort値(この例では、30007)を指定したtype: NodePortのServiceのマニフェストの例です:
apiVersion : v1
kind : Service
metadata :
name : my-service
spec :
type : NodePort
selector :
app.kubernetes.io/name : MyApp
ports :
- port : 80
# デフォルトでは、利便性のために`targetPort`は
# `port`フィールドと同じ値に設定されます。
targetPort : 80
# オプションのフィールド
# デフォルトでは、利便性のためにKubernetesコントロールプレーンは
# 範囲(デフォルト: 30000-32767)からポートを割り当てます
nodePort : 30007
ポート衝突を避けるためのNodePort範囲の予約 NodePortサービスへのポート割り当てのポリシーは、自動割り当てと手動割り当ての両方のシナリオに適用されます。
ユーザーが特定のポートを使用するNodePortサービスを作成する場合、ターゲットポートはすでに割り当てられている別のポートと競合する可能性があります。
この問題を回避するため、NodePortサービスのポート範囲は2つの帯域に分割されています。
動的なポート割り当てはデフォルトで上位の帯域を使用し、上位の帯域が使い尽くされると下位帯域を使用することがあります。
ユーザーは、下位の帯域から割り当てることでポート衝突のリスクを低減することができます。
デフォルトのNodePortの範囲である30000-32767を使用する場合、各帯域は次のように分割されます:
静的帯域: 30000-30085 動的帯域: 30086-32767 静的帯域と動的帯域がどのように計算されるかの詳細は、NodePort Serviceへのポート割り当てにおける衝突の回避 を参照してください。
type: NodePort ServiceのカスタムIPアドレス設定NodePortサービスを提供するために特定のIPアドレスを使用するよう、クラスター内のノードを設定できます。
各ノードが複数のネットワークに接続されている場合(例: アプリケーショントラフィック用のネットワークと、ノード間およびコントロールプレーン間のトラフィック用の別のネットワーク)に、この設定が必要になることがあります。
ポートをプロキシする特定のIPアドレスを指定する場合は、kube-proxyの--nodeport-addressesフラグ、またはkube-proxy設定ファイル の同等のnodePortAddressesフィールドを特定のIPブロックに設定できます。
このフラグは、カンマ区切りのIPブロックリスト(例: 10.0.0.0/8、192.0.2.0/25)を受け取り、kube-proxyがこのノードのローカルとみなすIPアドレス範囲を指定します。
例えば、--nodeport-addresses=127.0.0.0/8フラグでkube-proxyを起動すると、kube-proxyはNodePortサービスに対してループバックインターフェースのみを選択します。
--nodeport-addressesのデフォルトは空のリストです。
これは、kube-proxyがNodePortに対して利用可能なすべてのネットワークインターフェースを考慮する必要があることを意味します。(これは以前のKubernetesリリースとも互換性があります。)
備考: このServiceは<NodeIP>:spec.ports[*].nodePortおよび.spec.clusterIP:spec.ports[*].portとして表示されます。
kube-proxyの--nodeport-addressesフラグまたはkube-proxy設定ファイルの同等のフィールドが設定されている場合、<NodeIP>はフィルタリングされたノードのIPアドレス(または複数のIPアドレスの可能性)になります。type: LoadBalancer外部ロードバランサーをサポートするクラウドプロバイダーでは、typeフィールドをLoadBalancerに設定すると、Service向けにロードバランサーがプロビジョニングされます。
実際のロードバランサーの作成は非同期で行われ、プロビジョニングされたバランサーに関する情報はServiceの.status.loadBalancerフィールドで公開されます。
たとえば、次のように設定します:
apiVersion : v1
kind : Service
metadata :
name : my-service
spec :
selector :
app.kubernetes.io/name : MyApp
ports :
- protocol : TCP
port : 80
targetPort : 9376
clusterIP : 10.0.171.239
type : LoadBalancer
status :
loadBalancer :
ingress :
- ip : 192.0.2.127
外部ロードバランサーからのトラフィックはバックエンドのPodに転送されます。
負荷分散の方法は、クラウドプロバイダーが決定します。
type: LoadBalancerのServiceを実装するために、Kubernetesは通常、まずtype: NodePortのServiceをリクエストした場合と同等の変更を行います。
その後、cloud-controller-managerコンポーネントが外部ロードバランサーを設定し、割り当てられたNodePortにトラフィックを転送します。
クラウドプロバイダーの実装でサポートされている場合、LoadBalancerタイプのServiceを設定してNodePortの割り当てを省略 できます。
一部のクラウドプロバイダーではloadBalancerIPを指定できます。
その場合、ユーザーが指定したloadBalancerIPでロードバランサーが作成されます。
loadBalancerIPフィールドが指定されていない場合、ロードバランサーは一時的なIPアドレスで設定されます。
loadBalancerIPを指定しても、クラウドプロバイダーがこの機能をサポートしていない場合、設定したloadbalancerIPフィールドは無視されます。
備考: Serviceの.spec.loadBalancerIPフィールドはKubernetes v1.24で非推奨になりました。
このフィールドは仕様が不十分で、実装によって意味が異なっていました。
また、デュアルスタックネットワーキングをサポートできません。
このフィールドは将来のAPIバージョンで削除される可能性があります。
(プロバイダー固有の)アノテーションを介してServiceのロードバランサーIPアドレスの指定をサポートするプロバイダーと統合する場合は、その方法に切り替えてください。
Kubernetesとロードバランサーの統合コードを書いている場合は、このフィールドの使用を避けてください。
ServiceではなくGateway と統合するか、同等の詳細を指定するService上の独自の(プロバイダー固有の)アノテーションを定義できます。
ノードの稼働状態がロードバランサーのトラフィックに与える影響 ロードバランサーによるヘルスチェックは現代のアプリケーションにとって重要です。
これらはロードバランサーがトラフィックをディスパッチするサーバー(仮想マシンまたはIPアドレス)を決定するために使用されます。
Kubernetes APIはKubernetesが管理するロードバランサーに対してヘルスチェックをどのように実装する必要があるかを定義していません。
代わりに、クラウドプロバイダー(および統合コードを実装する人々)によって動作が決定されます。
ロードバランサーによるヘルスチェックはServiceのexternalTrafficPolicyフィールドをサポートする文脈で広く使用されています。
混合プロトコルタイプのロードバランサー FEATURE STATE:
Kubernetes v1.26 [stable](enabled by default)
デフォルトでは、LoadBalancerタイプのServiceで複数のポートが定義されている場合、すべてのポートは同じプロトコルを持つ必要があり、そのプロトコルはクラウドプロバイダーがサポートするものでなければなりません。
フィーチャーゲートMixedProtocolLBService(v1.24以降のkube-apiserverではデフォルトで有効)により、複数のポートが定義されている場合、LoadBalancerタイプのServiceで異なるプロトコルを使用できます。
備考: ロードバランサーServiceで使用できるプロトコルのセットは、クラウドプロバイダーによって定義されます。
クラウドプロバイダーは、Kubernetes APIが強制する制限を超えた追加の制限を課す場合があります。ロードバランサーによるNodePort割り当ての無効化 FEATURE STATE:
Kubernetes v1.24 [stable]
spec.allocateLoadBalancerNodePortsフィールドをfalseに設定することで、type: LoadBalancerのServiceに対するNodePort割り当てをオプションで無効にできます。
これは、NodePortを使用せずに、トラフィックをPodに直接ルーティングするロードバランサー実装に対してのみ使用してください。
デフォルトでは、spec.allocateLoadBalancerNodePortsはtrueであり、LoadBalancerタイプのServiceは引き続きNodePortを割り当てます。
既に割り当て済みのNodePortを持つ既存のServiceに対してspec.allocateLoadBalancerNodePortsをfalseに設定しても、それらのNodePortは自動的に割り当て解除されません 。
NodePortの割り当てを解除するには、すべてのServiceポートのnodePortsエントリを明示的に削除する必要があります。
ロードバランサー実装のクラスの指定 FEATURE STATE:
Kubernetes v1.24 [stable]
typeがLoadBalancerに設定されたServiceの場合、.spec.loadBalancerClassフィールドを使用すると、クラウドプロバイダーのデフォルト以外のロードバランサー実装を使用できます。
デフォルトでは、.spec.loadBalancerClassは設定されておらず、クラスターが--cloud-providerコンポーネントフラグを使用してクラウドプロバイダーで設定されている場合、LoadBalancerタイプのServiceはクラウドプロバイダーのデフォルトロードバランサー実装を使用します。
.spec.loadBalancerClassを指定すると、指定されたクラスに一致するロードバランサー実装がServiceを監視していると想定されます。
デフォルトのロードバランサー実装(たとえば、クラウドプロバイダーが提供するもの)は、このフィールドが設定されたServiceを無視します。
spec.loadBalancerClassはLoadBalancerタイプのServiceにのみ設定できます。
一度設定すると、変更できません。
spec.loadBalancerClassの値はラベル形式の識別子である必要があり、"internal-vip"や"example.com/internal-vip"などのプレフィックスをオプションとして持つことができます。
プレフィックスのない名前はエンドユーザー向けに予約されています。
ロードバランサーのIPアドレスモード FEATURE STATE:
Kubernetes v1.32 [stable](enabled by default)
type: LoadBalancerのServiceの場合、コントローラーは.status.loadBalancer.ingress.ipModeを設定できます。
.status.loadBalancer.ingress.ipModeは、ロードバランサーIPの動作方法を指定します。
これは.status.loadBalancer.ingress.ipフィールドも指定されている場合にのみ指定できます。
.status.loadBalancer.ingress.ipModeには、「VIP」と「Proxy」の2つの値が設定できます。
デフォルト値は「VIP」で、これはトラフィックがロードバランサーのIPとポートを宛先として設定された状態でノードに配信されることを意味します。
「Proxy」に設定する場合、クラウドプロバイダーのロードバランサーがトラフィックを配信する方法に応じて、2つのケースがあります:
トラフィックがノードに配信されてからPodにDNATされる場合、宛先はノードのIPとNodePortに設定されます。 トラフィックがPodに直接配信される場合、宛先はPodのIPとポートに設定されます。 Service実装はこの情報を使用してトラフィックルーティングを調整できます。
内部ロードバランサー 混在環境では、同じ(仮想)ネットワークアドレスブロック内のServiceからトラフィックをルーティングする必要がある場合があります。
スプリットホライズンDNS環境では、エンドポイントへの外部トラフィックと内部トラフィックの両方をルーティングできるように、2つのServiceが必要です。
内部ロードバランサーを設定するには、使用しているクラウドサービスプロバイダーに応じて、次のいずれかのアノテーションをServiceに追加します:
metadata :
name : my-service
annotations :
networking.gke.io/load-balancer-type : "Internal"
metadata :
name : my-service
annotations :
service.beta.kubernetes.io/aws-load-balancer-scheme : "internal"
metadata :
name : my-service
annotations :
service.beta.kubernetes.io/azure-load-balancer-internal : "true"
metadata :
name : my-service
annotations :
service.kubernetes.io/ibm-load-balancer-cloud-provider-ip-type : "private"
metadata :
name : my-service
annotations :
service.beta.kubernetes.io/openstack-internal-load-balancer : "true"
metadata :
name : my-service
annotations :
service.beta.kubernetes.io/cce-load-balancer-internal-vpc : "true"
metadata :
annotations :
service.kubernetes.io/qcloud-loadbalancer-internal-subnetid : subnet-xxxxx
metadata :
annotations :
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-address-type : "intranet"
metadata :
name : my-service
annotations :
service.beta.kubernetes.io/oci-load-balancer-internal : true
type: ExternalNameExternalNameタイプのServiceは、my-serviceやcassandraのような典型的なセレクターではなく、ServiceをDNS名にマッピングします。
これらのServiceはspec.externalNameパラメーターで指定します。
たとえば、このServiceの定義は、prod Namespace内のmy-service Serviceをmy.database.example.comにマッピングします:
apiVersion : v1
kind : Service
metadata :
name : my-service
namespace : prod
spec :
type : ExternalName
externalName : my.database.example.com
備考: type: ExternalNameのServiceはIPv4アドレスの文字列を受け入れますが、文字列をIPアドレスとしてではなく、数字で構成されたDNS名として扱います(ただし、インターネットでは、DNSにそのような名前を設定することは許可されていません)。
IPv4アドレスに似た外部名を持つServiceはDNSサーバーによって解決されません。
ServiceをIPアドレスに直接マッピングしたい場合は、ヘッドレスService の使用を検討してください。
ホストmy-service.prod.svc.cluster.localを検索すると、クラスターのDNSサービスはmy.database.example.comを持つCNAMEレコードを返します。
my-serviceへのアクセスは他のServiceと同じように機能しますが、重要な違いは、リダイレクトがプロキシや転送を介してではなく、DNSレベルで発生することです。
後でデータベースをクラスター内に移動することにした場合、Podを起動し、適切なセレクターまたはエンドポイントを追加し、Serviceのtypeを変更できます。
注意: ExternalNameを使用すると、HTTPやHTTPSを含む一部の一般的なプロトコルで問題が発生する可能性があります。
ExternalNameを使用する場合、クラスター内のクライアントが使用するホスト名は、ExternalNameが参照する名前とは異なります。
ホスト名を使用するプロトコルの場合、この違いによりエラーや予期しないレスポンスが発生する可能性があります。
HTTPリクエストには、オリジンサーバーが認識しないHost:ヘッダーが含まれることになります。
また、TLSサーバーは、クライアントが接続したホスト名と一致する証明書を提供できなくなります。
ヘッドレスService 時には、負荷分散や単一のService IPが不要な場合があります。
この場合、ClusterIPアドレス(.spec.clusterIP)に明示的に"None"を指定することで、いわゆる ヘッドレスService を作成できます。
ヘッドレスServiceを使用すると、Kubernetesの実装に縛られることなく、他のサービスディスカバリ機構と連携できます。
ヘッドレスServiceの場合、ClusterIPは割り当てられず、kube-proxyはこれらのServiceを処理せず、プラットフォームによる負荷分散やプロキシは行われません。
ヘッドレスServiceにより、クライアントは好みのPodに直接接続できます。
ヘッドレスServiceは仮想IPアドレスとプロキシ を使用してルートやパケット転送を設定しません。
その代わりに、ヘッドレスServiceはクラスターのDNSサービス を通じて提供される内部DNSレコードを介して、個々のPodのエンドポイントIPアドレスを報告します。
ヘッドレスServiceを定義するには、.spec.typeをClusterIPに設定し(typeのデフォルトでもあります)、さらに.spec.clusterIPをNoneに設定します。
文字列値のNoneは特殊なケースであり、.spec.clusterIPフィールドを未設定のままにすることとは異なります。
DNSが自動的に設定される方法は、Serviceにセレクターが定義されているかどうかによって異なります:
セレクターありの場合 セレクターを定義するヘッドレスServiceの場合、エンドポイントコントローラーはKubernetes APIでEndpointSliceを作成し、ServiceのPodを直接指すAまたはAAAAレコード(IPv4またはIPv6アドレス)を返すようにDNS設定を変更します。
セレクターなしの場合 セレクターを定義しないヘッドレスServiceの場合、コントロールプレーンはEndpointSliceオブジェクトを作成しません。
ただし、DNSシステムは次のいずれかを検索して設定します:
type: ExternalNameExternalName以外のすべてのServiceタイプについて、Serviceの準備完了エンドポイントのすべてのIPアドレスに対するDNS A/AAAAレコードIPv4エンドポイントの場合、DNSシステムはAレコードを作成します。 IPv6エンドポイントの場合、DNSシステムはAAAAレコードを作成します。 セレクターなしでヘッドレスServiceを定義する場合、portはtargetPortと一致する必要があります。
Serviceの検出 クラスター内で実行されているクライアントに対して、Kubernetesは、環境変数とDNSという2つの主要なServiceの検出方法をサポートしています。
環境変数 Podがノード上で実行されると、kubeletはアクティブな各Serviceに対して環境変数のセットを追加します。
{SVCNAME}_SERVICE_HOSTと{SVCNAME}_SERVICE_PORT変数が追加されます。
ここで、Service名は大文字に変換され、ハイフンはアンダースコアに変換されます。
たとえば、TCPポートとして6379を公開し、ClusterIPアドレスとして10.0.0.11が割り当てられたService redis-primaryは、次の環境変数を生成します:
REDIS_PRIMARY_SERVICE_HOST = 10.0.0.11
REDIS_PRIMARY_SERVICE_PORT = 6379
REDIS_PRIMARY_PORT = tcp://10.0.0.11:6379
REDIS_PRIMARY_PORT_6379_TCP = tcp://10.0.0.11:6379
REDIS_PRIMARY_PORT_6379_TCP_PROTO = tcp
REDIS_PRIMARY_PORT_6379_TCP_PORT = 6379
REDIS_PRIMARY_PORT_6379_TCP_ADDR = 10.0.0.11
備考: PodがServiceにアクセスする必要があり、環境変数を使用してポートとClusterIPをクライアントPodに公開する場合、クライアントPodが作成される前に Serviceを作成する必要があります。
そうしないと、クライアントPodに環境変数が設定されません。
DNSのみを使用してServiceのClusterIPを検出する場合は、この順序の問題を気にする必要はありません。
Kubernetesは、Docker Engineの「レガシーコンテナリンク makeLinkVariables
DNS アドオン を使用して、KubernetesクラスターのDNSサービスを設定できます(そしてほぼ常に設定すべきです)。
CoreDNSなどのクラスター対応のDNSサーバーは、新しいServiceについてKubernetes APIを監視し、それぞれに対してDNSレコードのセットを作成します。
クラスター全体でDNSが有効になっている場合、すべてのPodはDNS名によってServiceを自動的に解決できるはずです。
たとえば、KubernetesのNamespace my-nsにmy-serviceというServiceがある場合、コントロールプレーンとDNS Serviceが連携してmy-service.my-nsのDNSレコードを作成します。
my-ns Namespace内のPodは、my-serviceの名前解決を行うことでServiceを見つけることができるはずです(my-service.my-nsも機能します)。
他のNamespace内のPodは、名前をmy-service.my-nsとして修飾する必要があります。
これらの名前は、Serviceに割り当てられたClusterIPに解決されます。
Kubernetesは、名前付きポートに対するDNS SRV(Service)レコードもサポートしています。
my-service.my-ns ServiceにプロトコルがTCPに設定されたhttpという名前のポートがある場合、_http._tcp.my-service.my-nsに対してDNS SRVクエリを実行して、httpのポート番号とIPアドレスを検出できます。
Kubernetes DNSサーバーは、ExternalName Serviceにアクセスする唯一の方法です。
ExternalNameの解決に関する詳細情報は、ServiceとPodに対するDNS を参照してください。
仮想IPアドレッシング機構 仮想IPとServiceプロキシ では、Kubernetesが仮想IPアドレスを使用してServiceを公開するために提供する機構について詳しく説明しています。
トラフィックポリシー .spec.internalTrafficPolicyおよび.spec.externalTrafficPolicyフィールドを設定して、Kubernetesが正常な("ready")バックエンドにトラフィックをルーティングする方法を制御できます。
詳細については、トラフィックポリシー を参照してください。
トラフィック分散制御 .spec.trafficDistributionフィールドは、Kubernetes Service内のトラフィックルーティングに影響を与える別の方法を提供します。
トラフィックポリシーが厳密なセマンティック保証に焦点を当てているのに対し、トラフィック分散では 優先設定 (トポロジー的に近いエンドポイントへのルーティングなど)を表現できます。
これにより、パフォーマンス、コスト、または信頼性の最適化に役立ちます。
Kubernetes 1.35では、次のフィールド値がサポートされています:
PreferSameZoneクライアントと同じゾーンにあるエンドポイントへのトラフィックルーティングの優先設定を示します。 PreferSameNodeクライアントと同じノード上にあるエンドポイントへのトラフィックルーティングの優先設定を示します。 PreferClose(非推奨)これはPreferSameZoneの旧称にあたるエイリアスであり、この名称が示す対象が明確ではないため推奨されません。 フィールドが設定されていない場合、実装はデフォルトのルーティング戦略を適用します。
詳細については、トラフィック分散 を参照してください。
スティッキーセッション 特定のクライアントからの接続が毎回同じPodに渡されるようにしたい場合、クライアントのIPアドレスに基づいてセッションアフィニティを設定できます。
詳細については、セッションアフィニティ を参照してください。
外部IP もし、1つ以上のクラスターノードに転送する外部IPが複数ある場合、Kubernetes ServiceはそれらをexternalIPsで公開できます。
外部IP(宛先IPとして)とServiceに一致するポートでネットワークトラフィックがクラスターに到達すると、Kubernetesが設定したルールとルートにより、トラフィックがそのServiceのエンドポイントの1つにルーティングされることが保証されます。
Serviceを定義する際、任意のServiceタイプ に対してexternalIPsを指定できます。
以下の例では、"my-service"という名前のServiceは、"198.51.100.32:80"(.spec.externalIPs[]と.spec.ports[].portから計算)でTCPを使用してクライアントからアクセスできます。
apiVersion : v1
kind : Service
metadata :
name : my-service
spec :
selector :
app.kubernetes.io/name : MyApp
ports :
- name : http
protocol : TCP
port : 80
targetPort : 49152
externalIPs :
- 198.51.100.32
備考: KubernetesはexternalIPsの割り当てを管理しません。
これらはクラスター管理者の責任です。APIオブジェクト ServiceはKubernetes REST APIにおいてトップレベルのリソースです。
詳細については、Service APIオブジェクト を参照してください。
次の項目 Serviceと、それがKubernetesにどのように適合するかについて、さらに学習してください:
さらなる背景情報については、以下を参照してください:
3.6.2 - Ingress
FEATURE STATE:
Kubernetes v1.19 [stable]
クラスター内のServiceに対する外部からのアクセス(主にHTTP)を管理するAPIオブジェクトです。
Ingressは負荷分散、SSL終端、名前ベースの仮想ホスティングの機能を提供します。
用語 簡単のために、このガイドでは次の用語を定義します。
ノード: Kubernetes内のワーカーマシンで、クラスターの一部です。 クラスター: Kubernetesによって管理されているコンテナ化されたアプリケーションを実行させるノードの集合です。この例や、多くのKubernetesによるデプロイでは、クラスター内のノードはインターネットに公開されていません。 エッジルーター: クラスターでファイアウォールのポリシーを強制するルーターです。クラウドプロバイダーが管理するゲートウェイや、物理的なハードウェアの一部である場合もあります。 クラスターネットワーク: 物理的または論理的な繋がりの集合で、Kubernetesのネットワークモデル によって、クラスター内でのコミュニケーションを司るものです。 Service: ラベル セレクターを使ったPodの集合を特定するKubernetes Service です。特に指定がない限り、Serviceはクラスターネットワーク内でのみ疎通可能な仮想IPを持つものとして扱われます。 Ingressとは何か Ingress はクラスター外からクラスター内Service へのHTTPとHTTPSのルートを公開します。トラフィックのルーティングはIngressリソース上で定義されるルールによって制御されます。
全てのトラフィックを単一のServiceに送る単純なIngressの例を示します。
図. Ingress
IngressはServiceに対して、外部疎通できるURL、負荷分散トラフィック、SSL/TLS終端の機能や、名前ベースの仮想ホスティングを提供するように設定できます。Ingressコントローラー は通常はロードバランサーを使用してIngressの機能を実現しますが、エッジルーターや、追加のフロントエンドを構成してトラフィックの処理を支援することもできます。
Ingressは任意のポートやプロトコルを公開しません。HTTPやHTTPS以外のServiceをインターネットに公開する場合、Service.Type=NodePort やService.Type=LoadBalancer のServiceタイプを一般的には使用します。
Ingressを使用する上での前提条件 Ingressを提供するためにはIngressコントローラー が必要です。Ingressリソースを作成するのみでは何の効果もありません。
ingress-nginx のようなIngressコントローラーのデプロイが必要な場合があります。いくつかのIngressコントローラー の中から選択してください。
理想的には、全てのIngressコントローラーはリファレンスの仕様を満たすはずです。しかし実際には、各Ingressコントローラーは微妙に異なる動作をします。
備考: Ingressコントローラーのドキュメントを確認して、選択する際の注意点について理解してください。Ingressリソース Ingressリソースの最小構成の例は以下のとおりです。
apiVersion : networking.k8s.io/v1
kind : Ingress
metadata :
name : minimal-ingress
annotations :
nginx.ingress.kubernetes.io/rewrite-target : /
spec :
ingressClassName : nginx-example
rules :
- http :
paths :
- path : /testpath
pathType : Prefix
backend :
service :
name : test
port :
number : 80
IngressにはapiVersion、kind、metadataやspecフィールドが必要です。Ingressオブジェクトの名前は、有効なDNSサブドメイン名 である必要があります。設定ファイルに関する一般的な情報は、アプリケーションのデプロイ 、コンテナの設定 、リソースの管理 を参照してください。Ingressでは、Ingressコントローラーに依存しているいくつかのオプションの設定をするためにアノテーションを一般的に使用します。例としては、rewrite-targetアノテーション などがあります。Ingressコントローラー の種類が異なれば、サポートするアノテーションも異なります。サポートされているアノテーションについて学ぶためには、使用するIngressコントローラーのドキュメントを確認してください。
Ingress Spec は、ロードバランサーやプロキシサーバーを設定するために必要な全ての情報を持っています。最も重要なものとして、外部からくる全てのリクエストに対して一致したルールのリストを含みます。IngressリソースはHTTP(S)トラフィックに対してのルールのみサポートしています。
ingressClassNameが省略された場合、デフォルトのIngressClass を定義する必要があります。
デフォルトのIngressClassを定義しなくても動作するIngressコントローラーがいくつかあります。例えば、Ingress-NGINXコントローラーはフラグ
--watch-ingress-without-classで設定できます。ただし、下記 のようにデフォルトのIngressClassを指定することを推奨します 。
Ingressのルール 各HTTPルールは以下の情報を含みます。
オプションで設定可能なホスト名。上記のリソースの例では、ホスト名が指定されていないので、そのルールは指定されたIPアドレスを経由する全てのインバウンドHTTPトラフィックに適用されます。ホスト名が指定されていると(例: foo.bar.com)、そのルールは指定されたホストに対して適用されます。 パスのリスト(例: /testpath)。各パスにはservice.nameとservice.port.nameまたはservice.port.numberで定義されるバックエンドが関連づけられます。ロードバランサーがトラフィックを関連づけられたServiceに転送するために、外部からくるリクエストのホスト名とパスが条件と一致させる必要があります。 バックエンドはServiceドキュメント に書かれているようなService名とポート名の組み合わせ、またはCRD によるカスタムリソースバックエンド です。Ingressで設定されたホスト名とパスのルールに一致するHTTP(とHTTPS)のリクエストは、リスト内のバックエンドに対して送信されます。 Ingressコントローラーでは、defaultBackendが設定されていることがあります。これはSpec内で指定されているパスに一致しないようなリクエストのためのバックエンドです。
デフォルトのバックエンド ルールが設定されていないIngressは、全てのトラフィックを単一のデフォルトのバックエンドに転送します。.spec.defaultBackendはその場合にリクエストを処理するバックエンドになります。defaultBackendは、Ingressコントローラー のオプション設定であり、Ingressリソースでは指定されていません。.spec.rulesを設定しない場合、.spec.defaultBackendの設定は必須です。defaultBackendが設定されていない場合、どのルールにもマッチしないリクエストの処理は、Ingressコントローラーに任されます(このケースをどう処理するかは、お使いのIngressコントローラーのドキュメントを参照してください)。
HTTPリクエストがIngressオブジェクトのホスト名とパスの条件に1つも一致しない時、そのトラフィックはデフォルトのバックエンドに転送されます。
リソースバックエンド ResourceバックエンドはIngressオブジェクトと同じnamespaceにある他のKubernetesリソースを指すObjectRefです。
ResourceはServiceの設定とは排他であるため、両方を指定するとバリデーションに失敗します。
Resourceバックエンドの一般的な用途は、静的なアセットが入ったオブジェクトストレージバックエンドにデータを導入することです。
apiVersion : networking.k8s.io/v1
kind : Ingress
metadata :
name : ingress-resource-backend
spec :
defaultBackend :
resource :
apiGroup : k8s.example.com
kind : StorageBucket
name : static-assets
rules :
- http :
paths :
- path : /icons
pathType : ImplementationSpecific
backend :
resource :
apiGroup : k8s.example.com
kind : StorageBucket
name : icon-assets
上記のIngressを作成した後に、次のコマンドで参照することができます。
kubectl describe ingress ingress-resource-backend
Name: ingress-resource-backend
Namespace: default
Address:
Default backend: APIGroup: k8s.example.com, Kind: StorageBucket, Name: static-assets
Rules:
Host Path Backends
---- ---- --------
*
/icons APIGroup: k8s.example.com, Kind: StorageBucket, Name: icon-assets
Annotations: <none>
Events: <none>
パスのタイプ Ingressのそれぞれのパスは対応するパスのタイプを持ちます。pathTypeが明示的に指定されていないパスはバリデーションに通りません。サポートされているパスのタイプは3種類あります。
ImplementationSpecific(実装に特有): このパスタイプでは、パスとの一致はIngressClassに依存します。Ingressの実装はこれを独立したpathTypeと扱うことも、PrefixやExactと同一のパスタイプと扱うこともできます。
Exact: 大文字小文字を区別して完全に一致するURLパスと一致します。
Prefix: /で分割されたURLと前方一致で一致します。大文字小文字は区別され、パスの要素対要素で比較されます。パス要素は/で分割されたパスの中のラベルのリストを参照します。リクエストがパス p に一致するのは、Ingressのパス p がリクエストパス p と要素単位で前方一致する場合です。
備考: パスの最後の要素がリクエストパスの最後の要素の部分文字列である場合、これは一致しません(例えば、/foo/barは/foo/bar/bazと一致しますが、/foo/barbazとは一致しません)。例 タイプ パス リクエストパス 一致するか Prefix /(全てのパス) はい Exact /foo/fooはい Exact /foo/barいいえ Exact /foo/foo/いいえ Exact /foo//fooいいえ Prefix /foo/foo, /foo/はい Prefix /foo//foo, /foo/はい Prefix /aaa/bb/aaa/bbbいいえ Prefix /aaa/bbb/aaa/bbbはい Prefix /aaa/bbb//aaa/bbbはい、末尾のスラッシュは無視 Prefix /aaa/bbb/aaa/bbb/はい、末尾のスラッシュと一致 Prefix /aaa/bbb/aaa/bbb/cccはい、パスの一部と一致 Prefix /aaa/bbb/aaa/bbbxyzいいえ、接頭辞と一致しない Prefix /, /aaa/aaa/cccはい、接頭辞/aaaと一致 Prefix /, /aaa, /aaa/bbb/aaa/bbbはい、接頭辞/aaa/bbbと一致 Prefix /, /aaa, /aaa/bbb/cccはい、接頭辞/と一致 Prefix /aaa/cccいいえ、デフォルトバックエンドを使用 Mixed /foo (Prefix), /foo (Exact)/fooはい、Exactが優先
複数のパスとの一致 リクエストがIngressの複数のパスと一致することがあります。そのような場合は、最も長くパスが一致したものが優先されます。2つのパスが同等に一致した場合は、完全一致が前方一致よりも優先されます。
ホスト名のワイルドカード ホストは正確に一致する(例えばfoo.bar.com)かワイルドカード(例えば*.foo.com)とすることができます。
正確な一致ではHTTPヘッダーのhostがhostフィールドと一致することが必要です。
ワイルドカードによる一致では、HTTPヘッダーのhostがワイルドカードルールに沿って後方一致することが必要です。
Host Hostヘッダー 一致するか *.foo.combar.foo.com共通の接尾辞により一致 *.foo.combaz.bar.foo.com一致しない。ワイルドカードは単一のDNSラベルのみを対象とする *.foo.comfoo.com一致しない。ワイルドカードは単一のDNSラベルのみを対象とする
apiVersion : networking.k8s.io/v1
kind : Ingress
metadata :
name : ingress-wildcard-host
spec :
rules :
- host : "foo.bar.com"
http :
paths :
- pathType : Prefix
path : "/bar"
backend :
service :
name : service1
port :
number : 80
- host : "*.foo.com"
http :
paths :
- pathType : Prefix
path : "/foo"
backend :
service :
name : service2
port :
number : 80
Ingress Class Ingressは異なったコントローラーで実装されうるため、しばしば異なった設定を必要とします。
各Ingressはクラス、つまりIngressClassリソースへの参照を指定する必要があります。IngressClassリソースには、このクラスを実装するコントローラーの名前などの追加設定が含まれています。
apiVersion : networking.k8s.io/v1
kind : IngressClass
metadata :
name : external-lb
spec :
controller : example.com/ingress-controller
parameters :
apiGroup : k8s.example.com
kind : IngressParameters
name : external-lb
IngressClassの.spec.parametersフィールドを使って、そのIngressClassに関連する設定を持っている別のリソースを参照することができます。
使用するパラメーターの種類は、IngressClassの.spec.controllerフィールドで指定したIngressコントローラーに依存します。
IngressClassスコープ Ingressコントローラーによっては、クラスター全体で設定したパラメーターを使用できる場合もあれば、1つのNamespaceに対してのみ設定したパラメーターを使用できる場合もあります。
IngressClassパラメーターのデフォルトのスコープは、クラスター全体です。
.spec.parametersフィールドを設定して.spec.parameters.scopeフィールドを設定しなかった場合、または.spec.parameters.scopeをClusterに設定した場合、IngressClassはクラスタースコープのリソースを参照します。
パラーメーターのkind(およびapiGroup)はクラスタースコープのAPI(カスタムリソースの場合もあり)を指し、パラメーターのnameはそのAPIの特定のクラスタースコープのリソースを特定します。
例えば:
---
apiVersion : networking.k8s.io/v1
kind : IngressClass
metadata :
name : external-lb-1
spec :
controller : example.com/ingress-controller
parameters :
# このIngressClassのパラメーターは「external-config-1」という名前の
# ClusterIngressParameter(APIグループk8s.example.net)で指定されています。この定義は、Kubernetesに
# クラスタースコープのパラメーターリソースを探すように指示しています。
scope : Cluster
apiGroup : k8s.example.net
kind : ClusterIngressParameter
name : external-config-1
FEATURE STATE:
Kubernetes v1.23 [stable]
.spec.parametersフィールドを設定して.spec.parameters.scopeフィールドをNamespaceに設定した場合、IngressClassはNamespaceスコープのリソースを参照します。また.spec.parameters内のnamespaceフィールドには、使用するパラメーターが含まれているNamespaceを設定する必要があります。
パラメーターのkind(およびapiGroup)はNamespaceスコープのAPI(例えば:ConfigMap)を指し、パラメーターのnameはnamespaceで指定したNamespace内の特定のリソースを特定します。
Namespaceスコープのパラメーターはクラスターオペレーターがワークロードに使用される設定(例えば:ロードバランサー設定、APIゲートウェイ定義)に対する制御を委譲するのに役立ちます。クラスタースコープパラメーターを使用した場合は以下のいずれかになります:
クラスターオペレーターチームは、新しい設定変更が適用されるたびに、別のチームの変更内容を承認する必要があります。 クラスターオペレーターは、アプリケーションチームがクラスタースコープのパラメーターリソースに変更を加えることができるように、RBAC のRoleやRoleBindingといった、特定のアクセス制御を定義する必要があります。 IngressClass API自体は常にクラスタースコープです。
以下はNamespaceスコープのパラメーターを参照しているIngressClassの例です:
---
apiVersion : networking.k8s.io/v1
kind : IngressClass
metadata :
name : external-lb-2
spec :
controller : example.com/ingress-controller
parameters :
# このIngressClassのパラメーターは「external-config」という名前の
# IngressParameter(APIグループk8s.example.com)で指定されています。
# このリソースは「external-configuration」というNamespaceにあります。
scope : Namespace
apiGroup : k8s.example.com
kind : IngressParameter
namespace : external-configuration
name : external-config
非推奨のアノテーション Kubernetes 1.18でIngressClassリソースとingressClassNameフィールドが追加される前は、Ingressの種別はIngressのkubernetes.io/ingress.classアノテーションにより指定されていました。
このアノテーションは正式に定義されたことはありませんが、Ingressコントローラーに広くサポートされています。
Ingressの新しいingressClassNameフィールドはこのアノテーションを置き換えるものですが、完全に等価ではありません。
アノテーションは一般にIngressを実装すべきIngressのコントローラーの名称を示していましたが、フィールドはIngressClassリソースへの参照であり、Ingressのコントローラーの名称を含む追加のIngressの設定情報を含んでいます。
デフォルトのIngressClass 特定のIngressClassをクラスターのデフォルトとしてマークすることができます。
IngressClassリソースのingressclass.kubernetes.io/is-default-classアノテーションをtrueに設定すると、ingressClassNameフィールドが指定されないIngressにはこのデフォルトIngressClassが割り当てられるようになります。
注意: 複数のIngressClassをクラスターのデフォルトに設定すると、アドミッションコントローラーはingressClassNameが指定されていない新しいIngressオブジェクトを作成できないようにします。クラスターのデフォルトIngressClassを1つ以下にすることで、これを解消することができます。Ingressコントローラーの中には、デフォルトのIngressClassを定義しなくても動作するものがあります。 例えば、Ingress-NGINXコントローラーはフラグ
--watch-ingress-without-classで設定することができます。ただし、デフォルトIngressClassを指定することを推奨します :
apiVersion : networking.k8s.io/v1
kind : IngressClass
metadata :
labels :
app.kubernetes.io/component : controller
name : nginx-example
annotations :
ingressclass.kubernetes.io/is-default-class : "true"
spec :
controller : k8s.io/ingress-nginx
Ingressのタイプ 単一ServiceのIngress Kubernetesには、単一のServiceを公開できるようにする既存の概念があります(Ingressの代替案 を参照してください)。ルールなしでデフォルトのバックエンド を指定することにより、Ingressでこれを実現することもできます。
apiVersion : networking.k8s.io/v1
kind : Ingress
metadata :
name : test-ingress
spec :
defaultBackend :
service :
name : test
port :
number : 80
kubectl apply -fを実行してIngressを作成すると、その作成したIngressの状態を確認することができます。
kubectl get ingress test-ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
test-ingress external-lb * 203.0.113.123 80 59s
203.0.113.123はIngressコントローラーによって割り当てられたIPで、作成したIngressを利用するためのものです。
備考: IngressコントローラーとロードバランサーがIPアドレス割り当てるのに1、2分ほどかかります。この間、ADDRESSの情報は<pending>となっているのを確認できます。リクエストのシンプルなルーティング ファンアウト設定では単一のIPアドレスのトラフィックを、リクエストされたHTTP URIに基づいて1つ以上のServiceに転送します。Ingressによってロードバランサーの数を少なくすることができます。例えば、以下のように設定します。
図. Ingressファンアウト
Ingressを以下のように設定します。
apiVersion : networking.k8s.io/v1
kind : Ingress
metadata :
name : simple-fanout-example
spec :
rules :
- host : foo.bar.com
http :
paths :
- path : /foo
pathType : Prefix
backend :
service :
name : service1
port :
number : 4200
- path : /bar
pathType : Prefix
backend :
service :
name : service2
port :
number : 8080
Ingressをkubectl apply -fによって作成したとき:
kubectl describe ingress simple-fanout-example
Name: simple-fanout-example
Namespace: default
Address: 178.91.123.132
Default backend: default-http-backend:80 (10.8.2.3:8080)
Rules:
Host Path Backends
---- ---- --------
foo.bar.com
/foo service1:4200 (10.8.0.90:4200)
/bar service2:8080 (10.8.0.91:8080)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ADD 22s loadbalancer-controller default/test
IngressコントローラーはService(service1、service2)が存在する限り、Ingressの条件を満たす実装固有のロードバランサーを構築します。
構築が完了すると、ADDRESSフィールドでロードバランサーのアドレスを確認できます。
名前ベースのバーチャルホスティング 名前ベースのバーチャルホストは、HTTPトラフィックを同一のIPアドレスの複数のホスト名に転送することをサポートしています。
図. Ingress名前ベースのバーチャルホスティング
以下のIngress設定は、ロードバランサーに対して、Hostヘッダー に基づいてリクエストを転送するように指示するものです。
apiVersion : networking.k8s.io/v1
kind : Ingress
metadata :
name : name-virtual-host-ingress
spec :
rules :
- host : foo.bar.com
http :
paths :
- pathType : Prefix
path : "/"
backend :
service :
name : service1
port :
number : 80
- host : bar.foo.com
http :
paths :
- pathType : Prefix
path : "/"
backend :
service :
name : service2
port :
number : 80
rules項目でのホストの設定がないIngressを作成すると、IngressコントローラーのIPアドレスに対するwebトラフィックは、要求されている名前ベースのバーチャルホストなしにマッチさせることができます。
例えば、以下のIngressはfirst.bar.comに対するトラフィックをservice1へ、second.foo.comに対するトラフィックをservice2へ、リクエストにおいてホスト名が指定されていない(リクエストヘッダーがないことを意味します)トラフィックはservice3へ転送します。
apiVersion : networking.k8s.io/v1
kind : Ingress
metadata :
name : name-virtual-host-ingress-no-third-host
spec :
rules :
- host : first.bar.com
http :
paths :
- pathType : Prefix
path : "/"
backend :
service :
name : service1
port :
number : 80
- host : second.bar.com
http :
paths :
- pathType : Prefix
path : "/"
backend :
service :
name : service2
port :
number : 80
- http :
paths :
- pathType : Prefix
path : "/"
backend :
service :
name : service3
port :
number : 80
TLS TLSの秘密鍵と証明書を含んだSecret を指定することにより、Ingressをセキュアにできます。Ingressは単一のTLSポートである443番ポートのみサポートし、IngressでTLS終端を行うことを想定しています。IngressからServiceやPodへのトラフィックは平文です。IngressのTLS設定のセクションで異なるホストを指定すると、それらのホストはSNI TLSエクステンション(IngressコントローラーがSNIをサポートしている場合)を介して指定されたホスト名に対し、同じポート上で多重化されます。TLSのSecretはtls.crtとtls.keyというキーを含む必要があり、TLSを使用するための証明書と秘密鍵を含む値となります。以下がその例です。
apiVersion : v1
kind : Secret
metadata :
name : testsecret-tls
namespace : default
data :
tls.crt : base64 encoded cert
tls.key : base64 encoded key
type : kubernetes.io/tls
IngressでこのSecretを参照すると、クライアントとロードバランサー間の通信にTLSを使用するようIngressコントローラーに指示することになります。作成したTLS Secretは、https-example.foo.comの完全修飾ドメイン名(FQDN)とも呼ばれる共通名(CN)を含む証明書から作成したものであることを確認する必要があります。
備考: デフォルトルールではTLSが機能しない可能性があることに注意してください。
これは取り得る全てのサブドメインに対する証明書を発行する必要があるからです。
そのため、tlsセクションのhostsはrulesセクションのhostと明示的に一致する必要があります。apiVersion : networking.k8s.io/v1
kind : Ingress
metadata :
name : tls-example-ingress
spec :
tls :
- hosts :
- https-example.foo.com
secretName : testsecret-tls
rules :
- host : https-example.foo.com
http :
paths :
- path : /
pathType : Prefix
backend :
service :
name : service1
port :
number : 80
備考: サポートされるTLSの機能はIngressコントローラーによって違いがあります。利用する環境でTLSがどのように動作するかを理解するためには、
nginx や、
GCE 、または他のプラットフォーム固有のIngressコントローラーのドキュメントを確認してください。
負荷分散 Ingressコントローラーは、負荷分散アルゴリズムやバックエンドの重みスキームなど、すべてのIngressに適用されるいくつかの負荷分散ポリシーの設定とともにブートストラップされます。発展した負荷分散のコンセプト(例: セッションの永続化、動的重み付けなど)はIngressによってサポートされていません。代わりに、それらの機能はService用のロードバランサーを介して利用できます。
ヘルスチェックの機能はIngressによって直接には公開されていませんが、Kubernetesにおいて、同等の機能を提供するReadiness Probe のようなコンセプトが存在することは注目に値します。コントローラーがどのようにヘルスチェックを行うかについては、コントローラーのドキュメントを参照してください(例えばnginx 、またはGCE )。
Ingressの更新 リソースを編集することで、既存のIngressに対して新しいホストを追加することができます。
kubectl describe ingress test
Name: test
Namespace: default
Address: 178.91.123.132
Default backend: default-http-backend:80 (10.8.2.3:8080)
Rules:
Host Path Backends
---- ---- --------
foo.bar.com
/foo service1:80 (10.8.0.90:80)
Annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ADD 35s loadbalancer-controller default/test
kubectl edit ingress test
このコマンドを実行すると既存の設定をYAMLフォーマットで編集するエディターが表示されます。新しいホストを追加するには、リソースを修正してください。
spec :
rules :
- host : foo.bar.com
http :
paths :
- backend :
service :
name : service1
port :
number : 80
path : /foo
pathType : Prefix
- host : bar.baz.com
http :
paths :
- backend :
service :
name : service2
port :
number : 80
path : /foo
pathType : Prefix
変更を保存した後、kubectlはAPIサーバー内のリソースを更新し、Ingressコントローラーに対してロードバランサーの再設定を指示します。
変更内容を確認してください。
kubectl describe ingress test
Name: test
Namespace: default
Address: 178.91.123.132
Default backend: default-http-backend:80 (10.8.2.3:8080)
Rules:
Host Path Backends
---- ---- --------
foo.bar.com
/foo service1:80 (10.8.0.90:80)
bar.baz.com
/foo service2:80 (10.8.0.91:80)
Annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ADD 45s loadbalancer-controller default/test
修正されたIngressのYAMLファイルに対してkubectl replace -fを実行することで、同様の結果を得られます。
アベイラビリティーゾーンをまたいだ障害について 障害のあるドメインをまたいでトラフィックを分散する手法は、クラウドプロバイダーによって異なります。詳細に関して、Ingress コントローラー のドキュメントを参照してください。
Ingressの代替案 Ingressリソースを直接含まずにサービスを公開する方法は複数あります。
次の項目 3.6.3 - サービスとアプリケーションの接続 コンテナを接続するためのKubernetesモデル 継続的に実行され、複製されたアプリケーションの準備ができたので、ネットワーク上で公開することが可能になります。
Kubernetesのネットワークのアプローチについて説明する前に、Dockerの「通常の」ネットワーク手法と比較することが重要です。
デフォルトでは、Dockerはホストプライベートネットワーキングを使用するため、コンテナは同じマシン上にある場合にのみ他のコンテナと通信できます。
Dockerコンテナがノード間で通信するには、マシンのIPアドレスにポートを割り当ててから、コンテナに転送またはプロキシする必要があります。
これは明らかに、コンテナが使用するポートを非常に慎重に調整するか、ポートを動的に割り当てる必要があることを意味します。
コンテナを提供する複数の開発者やチーム間でポートの割り当てを調整することは、規模的に大変困難であり、ユーザが制御できないクラスターレベルの問題にさらされます。
Kubernetesでは、どのホストで稼働するかに関わらず、Podが他のPodと通信できると想定しています。
すべてのPodに独自のクラスタープライベートIPアドレスを付与するため、Pod間のリンクを明示的に作成したり、コンテナポートをホストポートにマップしたりする必要はありません。
これは、Pod内のコンテナがすべてlocalhostの相互のポートに到達でき、クラスター内のすべてのPodがNATなしで相互に認識できることを意味します。
このドキュメントの残りの部分では、このようなネットワークモデルで信頼できるサービスを実行する方法について詳しく説明します。
このガイドでは、シンプルなnginxサーバーを使用して概念実証を示します。
Podをクラスターに公開する 前の例でネットワークモデルを紹介しましたが、再度ネットワークの観点に焦点を当てましょう。
nginx Podを作成し、コンテナポートの仕様を指定していることに注意してください。
apiVersion : apps/v1
kind : Deployment
metadata :
name : my-nginx
spec :
selector :
matchLabels :
run : my-nginx
replicas : 2
template :
metadata :
labels :
run : my-nginx
spec :
containers :
- name : my-nginx
image : nginx
ports :
- containerPort : 80
これにより、クラスター内のどのノードからでもアクセスできるようになります。
Podが実行されているノードを確認します:
kubectl apply -f ./run-my-nginx.yaml
kubectl get pods -l run = my-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE
my-nginx-3800858182-jr4a2 1/1 Running 0 13s 10.244.3.4 kubernetes-minion-905m
my-nginx-3800858182-kna2y 1/1 Running 0 13s 10.244.2.5 kubernetes-minion-ljyd
PodのIPを確認します:
kubectl get pods -l run = my-nginx -o yaml | grep podIP
podIP: 10.244.3.4
podIP: 10.244.2.5
クラスター内の任意のノードにSSH接続し、両方のIPにcurl接続できるはずです。
コンテナはノードでポート80を使用していない ことに注意してください。
また、Podにトラフィックをルーティングする特別なNATルールもありません。
つまり、同じcontainerPortを使用して同じノードで複数のnginx Podを実行し、IPを使用してクラスター内の他のPodやノードからそれらにアクセスできます。
Dockerと同様に、ポートは引き続きホストノードのインターフェースに公開できますが、ネットワークモデルにより、この必要性は根本的に減少します。
興味があれば、これをどのように達成するか について詳しく読むことができます。
Serviceを作成する そのため、フラットでクラスター全体のアドレス空間でnginxを実行するPodがあります。
理論的には、これらのPodと直接通信することができますが、ノードが停止するとどうなりますか?
Podはそれで死に、Deploymentは異なるIPを持つ新しいものを作成します。
これは、Serviceが解決する問題です。
Kubernetes Serviceは、クラスター内のどこかで実行されるPodの論理セットを定義する抽象化であり、すべて同じ機能を提供します。
作成されると、各Serviceには一意のIPアドレス(clusterIPとも呼ばれます)が割り当てられます。
このアドレスはServiceの有効期間に関連付けられており、Serviceが動作している間は変更されません。
Podは、Serviceと通信するように構成でき、Serviceへの通信は、ServiceのメンバーであるPodに自動的に負荷分散されることを認識できます。
2つのnginxレプリカのサービスをkubectl exposeで作成できます:
kubectl expose deployment/my-nginx
service/my-nginx exposed
これは次のyamlをkubectl apply -fすることと同等です:
apiVersion : v1
kind : Service
metadata :
name : my-nginx
labels :
run : my-nginx
spec :
ports :
- port : 80
protocol : TCP
selector :
run : my-nginx
この仕様は、run:my-nginxラベルを持つ任意のPodのTCPポート80をターゲットとするサービスを作成し、抽象化されたサービスポートでPodを公開します(targetPort:はコンテナがトラフィックを受信するポート、port:は抽象化されたServiceのポートであり、他のPodがServiceへのアクセスに使用する任意のポートにすることができます)。
サービス定義でサポートされているフィールドのリストはService APIオブジェクトを参照してください。
Serviceを確認します:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx ClusterIP 10.0.162.149 <none> 80/TCP 21s
前述のように、ServiceはPodのグループによってサポートされています。
これらのPodはエンドポイントを通じて公開されます。
Serviceのセレクターは継続的に評価され、結果はmy-nginxという名前のEndpointsオブジェクトにPOSTされます。
Podが終了すると、エンドポイントから自動的に削除され、Serviceのセレクターに一致する新しいPodが自動的にエンドポイントに追加されます。
エンドポイントを確認し、IPが最初のステップで作成されたPodと同じであることを確認します:
kubectl describe svc my-nginx
Name: my-nginx
Namespace: default
Labels: run=my-nginx
Annotations: <none>
Selector: run=my-nginx
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.0.162.149
IPs: 10.0.162.149
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.2.5:80,10.244.3.4:80
Session Affinity: None
Events: <none>
NAME ENDPOINTS AGE
my-nginx 10.244.2.5:80,10.244.3.4:80 1m
クラスター内の任意のノードから、<CLUSTER-IP>:<PORT>でnginx Serviceにcurl接続できるようになりました。
Service IPは完全に仮想的なもので、ホスト側のネットワークには接続できないことに注意してください。
この仕組みに興味がある場合は、サービスプロキシ の詳細をお読みください。
Serviceにアクセスする Kubernetesは、環境変数とDNSの2つの主要なService検索モードをサポートしています。
前者はそのまま使用でき、後者はCoreDNSクラスターアドオン を必要とします。
備考: サービス環境変数が望ましくない場合(予想されるプログラム変数と衝突する可能性がある、処理する変数が多すぎる、DNSのみを使用するなど)、
Pod仕様 で
enableServiceLinksフラグを
falseに設定することでこのモードを無効にできます。
環境変数 ノードでPodが実行されると、kubeletはアクティブな各サービスの環境変数のセットを追加します。
これにより、順序付けの問題が発生します。
理由を確認するには、実行中のnginx Podの環境を調べます(Pod名は環境によって異なります):
kubectl exec my-nginx-3800858182-jr4a2 -- printenv | grep SERVICE
KUBERNETES_SERVICE_HOST=10.0.0.1
KUBERNETES_SERVICE_PORT=443
KUBERNETES_SERVICE_PORT_HTTPS=443
サービスに言及がないことに注意してください。これは、サービスの前にレプリカを作成したためです。
これのもう1つの欠点は、スケジューラーが両方のPodを同じマシンに配置し、サービスが停止した場合にサービス全体がダウンする可能性があることです。
2つのPodを強制終了し、Deploymentがそれらを再作成するのを待つことで、これを正しい方法で実行できます。
今回は、サービスはレプリカの「前」に存在します。
これにより、スケジューラーレベルのサービスがPodに広がり(すべてのノードの容量が等しい場合)、適切な環境変数が提供されます:
kubectl scale deployment my-nginx --replicas= 0; kubectl scale deployment my-nginx --replicas= 2;
kubectl get pods -l run = my-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE
my-nginx-3800858182-e9ihh 1/1 Running 0 5s 10.244.2.7 kubernetes-minion-ljyd
my-nginx-3800858182-j4rm4 1/1 Running 0 5s 10.244.3.8 kubernetes-minion-905m
Podは強制終了されて再作成されるため、異なる名前が付いていることに気付くでしょう。
kubectl exec my-nginx-3800858182-e9ihh -- printenv | grep SERVICE
KUBERNETES_SERVICE_PORT=443
MY_NGINX_SERVICE_HOST=10.0.162.149
KUBERNETES_SERVICE_HOST=10.0.0.1
MY_NGINX_SERVICE_PORT=80
KUBERNETES_SERVICE_PORT_HTTPS=443
DNS Kubernetesは、DNS名を他のServiceに自動的に割り当てるDNSクラスターアドオンサービスを提供します。
クラスターで実行されているかどうかを確認できます:
kubectl get services kube-dns --namespace= kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.0.0.10 <none> 53/UDP,53/TCP 8m
このセクションの残りの部分は、寿命の長いIP(my-nginx)を持つServiceと、そのIPに名前を割り当てたDNSサーバーがあることを前提にしています。ここではCoreDNSクラスターアドオン(アプリケーション名: kube-dns)を使用しているため、標準的なメソッド(gethostbyname()など) を使用してクラスター内の任意のPodからServiceに通信できます。CoreDNSが起動していない場合、CoreDNS README またはInstalling CoreDNS を参照し、有効にする事ができます。curlアプリケーションを実行して、これをテストしてみましょう。
kubectl run curl --image= radial/busyboxplus:curl -i --tty --rm
Waiting for pod default/curl-131556218-9fnch to be running, status is Pending, pod ready: false
Hit enter for command prompt
次に、Enterキーを押してnslookup my-nginxを実行します:
[ root@curl-131556218-9fnch:/ ] $ nslookup my-nginx
Server: 10.0.0.10
Address 1: 10.0.0.10
Name: my-nginx
Address 1: 10.0.162.149
Serviceを安全にする これまでは、クラスター内からnginxサーバーにアクセスしただけでした。
サービスをインターネットに公開する前に、通信チャネルが安全であることを確認する必要があります。
これには、次のものが必要です:
https用の自己署名証明書(既にID証明書を持っている場合を除く) 証明書を使用するように構成されたnginxサーバー Podが証明書にアクセスできるようにするSecret これらはすべてnginx httpsの例 から取得できます。
これにはツールをインストールする必要があります。
これらをインストールしたくない場合は、後で手動の手順に従ってください。つまり:
make keys KEY = /tmp/nginx.key CERT = /tmp/nginx.crt
kubectl create secret tls nginxsecret --key /tmp/nginx.key --cert /tmp/nginx.crt
secret/nginxsecret created
NAME TYPE DATA AGE
default-token-il9rc kubernetes.io/service-account-token 1 1d
nginxsecret kubernetes.io/tls 2 1m
configmapも作成します:
kubectl create configmap nginxconfigmap --from-file= default.conf
configmap/nginxconfigmap created
NAME DATA AGE
nginxconfigmap 1 114s
以下は、(Windows上など)makeの実行で問題が発生した場合に実行する手動の手順です:
# 公開秘密鍵ペアを作成します
openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /d/tmp/nginx.key -out /d/tmp/nginx.crt -subj "/CN=my-nginx/O=my-nginx"
# キーをbase64エンコードに変換します
cat /d/tmp/nginx.crt | base64
cat /d/tmp/nginx.key | base64
前のコマンドの出力を使用して、次のようにyamlファイルを作成します。
base64でエンコードされた値はすべて1行である必要があります。
apiVersion : "v1"
kind : "Secret"
metadata :
name : "nginxsecret"
namespace : "default"
type : kubernetes.io/tls
data :
# 注意: 以下の値はご自身で base64 エンコードした証明書と鍵に置き換えてください。
nginx.crt : "REPLACE_WITH_BASE64_CERT"
nginx.key : "REPLACE_WITH_BASE64_KEY"
ファイルを使用してSecretを作成します:
kubectl apply -f nginxsecrets.yaml
kubectl get secrets
NAME TYPE DATA AGE
default-token-il9rc kubernetes.io/service-account-token 1 1d
nginxsecret kubernetes.io/tls 2 1m
次に、nginxレプリカを変更して、シークレットの証明書とServiceを使用してhttpsサーバーを起動し、両方のポート(80と443)を公開します:
apiVersion : v1
kind : Service
metadata :
name : my-nginx
labels :
run : my-nginx
spec :
type : NodePort
ports :
- port : 8080
targetPort : 80
protocol : TCP
name : http
- port : 443
protocol : TCP
name : https
selector :
run : my-nginx
---
apiVersion : apps/v1
kind : Deployment
metadata :
name : my-nginx
spec :
selector :
matchLabels :
run : my-nginx
replicas : 1
template :
metadata :
labels :
run : my-nginx
spec :
volumes :
- name : secret-volume
secret :
secretName : nginxsecret
containers :
- name : nginxhttps
image : bprashanth/nginxhttps:1.0
ports :
- containerPort : 443
- containerPort : 80
volumeMounts :
- mountPath : /etc/nginx/ssl
name : secret-volume
nginx-secure-appマニフェストに関する注目すべき点:
同じファイルにDeploymentとServiceの両方が含まれています。 nginxサーバー はポート80のHTTPトラフィックと443のHTTPSトラフィックを処理し、nginx Serviceは両方のポートを公開します。各コンテナは/etc/nginx/sslにマウントされたボリュームを介してキーにアクセスできます。
これは、nginxサーバーが起動する前に セットアップされます。 kubectl delete deployments,svc my-nginx; kubectl create -f ./nginx-secure-app.yaml
この時点で、任意のノードからnginxサーバーに到達できます。
kubectl get pods -l run = my-nginx -o custom-columns= POD_IP:.status.podIPs
POD_IP
[ map[ ip:10.244.3.5]]
node $ curl -k https://10.244.3.5
...
<h1>Welcome to nginx!</h1>
最後の手順でcurlに-kパラメーターを指定したことに注意してください。
これは、証明書の生成時にnginxを実行しているPodについて何も知らないためです。
CNameの不一致を無視するようcurlに指示する必要があります。
Serviceを作成することにより、証明書で使用されるCNameを、Service検索中にPodで使用される実際のDNS名にリンクしました。
これをPodからテストしましょう(簡単にするために同じシークレットを再利用しています。PodはServiceにアクセスするためにnginx.crtのみを必要とします):
apiVersion : apps/v1
kind : Deployment
metadata :
name : curl-deployment
spec :
selector :
matchLabels :
app : curlpod
replicas : 1
template :
metadata :
labels :
app : curlpod
spec :
volumes :
- name : secret-volume
secret :
secretName : nginxsecret
containers :
- name : curlpod
command :
- sh
- -c
- while true; do sleep 1; done
image : radial/busyboxplus:curl
volumeMounts :
- mountPath : /etc/nginx/ssl
name : secret-volume
kubectl apply -f ./curlpod.yaml
kubectl get pods -l app = curlpod
NAME READY STATUS RESTARTS AGE
curl-deployment-1515033274-1410r 1/1 Running 0 1m
kubectl exec curl-deployment-1515033274-1410r -- curl https://my-nginx --cacert /etc/nginx/ssl/tls.crt
...
<title>Welcome to nginx!</title>
...
Serviceを公開する アプリケーションの一部では、Serviceを外部IPアドレスに公開したい場合があります。
Kubernetesは、NodePortとLoadBalancerの2つの方法をサポートしています。
前のセクションで作成したServiceはすでにNodePortを使用しているため、ノードにパブリックIPがあれば、nginx HTTPSレプリカはインターネット上のトラフィックを処理する準備ができています。
kubectl get svc my-nginx -o yaml | grep nodePort -C 5
uid: 07191fb3-f61a-11e5-8ae5-42010af00002
spec:
clusterIP: 10.0.162.149
ports:
- name: http
nodePort: 31704
port: 8080
protocol: TCP
targetPort: 80
- name: https
nodePort: 32453
port: 443
protocol: TCP
targetPort: 443
selector:
run: my-nginx
kubectl get nodes -o yaml | grep ExternalIP -C 1
- address: 104.197.41.11
type: ExternalIP
allocatable:
--
- address: 23.251.152.56
type: ExternalIP
allocatable:
...
$ curl https://<EXTERNAL-IP>:<NODE-PORT> -k
...
<h1>Welcome to nginx!</h1>
クラウドロードバランサーを使用するようにサービスを再作成しましょう。
my-nginxサービスのTypeをNodePortからLoadBalancerに変更するだけです:
kubectl edit svc my-nginx
kubectl get svc my-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx LoadBalancer 10.0.162.149 xx.xxx.xxx.xxx 8080:30163/TCP 21s
curl https://<EXTERNAL-IP> -k
...
<title>Welcome to nginx!</title>
EXTERNAL-IP列のIPアドレスは、パブリックインターネットで利用可能なものです。
CLUSTER-IPは、クラスター/プライベートクラウドネットワーク内でのみ使用できます。
AWSでは、type LoadBalancerはIPではなく(長い)ホスト名を使用するELBが作成されます。
実際、標準のkubectl get svcの出力に収まるには長すぎるので、それを確認するにはkubectl describe service my-nginxを実行する必要があります。
次のようなものが表示されます:
kubectl describe service my-nginx
...
LoadBalancer Ingress: a320587ffd19711e5a37606cf4a74574-1142138393.us-east-1.elb.amazonaws.com
...
次の項目 3.6.4 - Ingressコントローラー クラスターで
Ingress を動作させるためには、
ingress controller が動作している必要があります。 少なくとも1つのIngressコントローラーを選択し、クラスター内にセットアップされていることを確認する必要があります。 このページはデプロイ可能な一般的なIngressコントローラーをリストアップします。
Ingressリソースが動作するためには、クラスターでIngressコントローラーが実行されている必要があります。
kube-controller-managerバイナリの一部として実行される他のタイプのコントローラーとは異なり、Ingressコントローラーはクラスターで自動的に起動されません。このページを使用して、クラスターに最適なIngressコントローラーの実装を選択してください。
プロジェクトとしてのKubernetesは現在、AWS 、GCE 、およびnginx のIngressコントローラーをサポート・保守しています。
追加のコントローラー 備考: このセクションでは、Kubernetesが必要とする機能を提供するサードパーティープロジェクトにリンクしています。これらのプロジェクトはアルファベット順に記載されていて、Kubernetesプロジェクトの作者は責任を持ちません。このリストにプロジェクトを追加するには、変更を提出する前に
content guide をお読みください。
詳細はこちら。 複数のIngressコントローラーの使用 Ingress Class を使用して、複数のIngressコントローラーをクラスターにデプロイすることができます。
Ingress Classリソースの.metadata.nameに注目してください。
Ingressを作成する際には、IngressオブジェクトでingressClassNameフィールドを指定するために、その名前が必要になります(IngressSpec v1 reference を参照)。
ingressClassNameは古いannotation method の代替品です。
Ingressに対してIngressClassを指定せず、クラスターにはデフォルトとして設定されたIngressClassが1つだけある場合、KubernetesはIngressにクラスターのデフォルトIngressClassを適用 します。
IngressClassのingressclass.kubernetes.io/is-default-classアノテーション"true"に設定することで、デフォルトとしてIngressClassを設定します。
理想的には、すべてのIngressコントローラーはこの仕様を満たすべきですが、いくつかのIngressコントローラーはわずかに異なる動作をします。
備考: Ingressコントローラーのドキュメントを確認して、選択する際の注意点を理解してください。次の項目 3.6.5 - Gateway API Gateway APIは動的なインフラストラクチャの展開と高度なトラフィックルーティングを提供するAPIの種類のファミリーです。
拡張可能でロール指向な、プロトコルを意識した設定メカニズムを使用して、ネットワークサービスを利用可能にします。
Gateway API は、動的なインフラストラクチャの展開と高度なトラフィックルーティングを提供するAPIの種類 を含むアドオン です。
デザイン原則 Gateway APIのデザインとアーキテクチャは次の原則から成ります:
ロール指向: Gateway APIの種類は、Kubernetesのサービスネットワークの管理に対して責任を持つ組織のロールをモデルとしています:インフラストラクチャプロバイダー: 複数の独立したクラスターをクラウドプロバイダーなどの複数のテナントに提供できるよう、インフラストラクチャを管理します。クラスターオペレーター: クラスターを管理し、通常はポリシー、ネットワークアクセス、アプリケーションのパーミッションなどに関わります。アプリケーション開発者: クラスター上で実行されるアプリケーションを管理し、通常はアプリケーションレベルの設定やService の構成に関わります。ポータビリティ: Gateway APIの仕様はカスタムリソース として定義され、多くの実装 によってサポートされています。豊富な機能: Gateway APIの種類は、ヘッダーベースのマッチング、トラフィックの重み付けといった、一般的なトラフィックルーティングのユースケースに対する機能をサポートしています。これは、Ingress ではカスタムアノテーションを使用することでのみ実現可能でした。拡張可能: GatewayはカスタムリソースをAPIのさまざまなレイヤーでリンクさせることができます。これにより、APIの構造内の適切な場所で細かなカスタマイズが可能となります。リソースモデル Gateway APIには3つの安定版のAPIの種類があります:
GatewayClass: 共通の設定を持ち、クラスを実装するコントローラーによって管理されたゲートウェイの集合を定義します。
Gateway: クラウドロードバランサーなどのトラフィックを処理するインフラストラクチャのインスタンスを定義します。
HTTPRoute: Gatewayリスナーからバックエンドのネットワークエンドポイントへのトラフィックのマッピングに関する、HTTP固有のルールを定義します。
これらのエンドポイントは多くの場合、Service で表されます。
Gateway APIは、組織のロール指向の性質をサポートするために、相互に依存関係を持つ異なるAPIの種類によって構成されます。
Gatewayオブジェクトはただ一つのGatewayClassと関連づけられます。
GatewayClassは、このクラスのGatewayを管理する責任を持つGatewayコントローラーを記述します。
HTTPRouteのような1つ以上のルートの種類がGatewayに関連づけられます。
Gatewayは、そのリスナーにアタッチされる可能性のあるルートをフィルタリングすることができ、ルートとの双方向の信頼モデルを形成します。
次の図は、3つの安定版のGateway APIの種類の関係を示しています:
GatewayClass Gatewayは、通常異なる設定を持つ、異なるコントローラーによって実装されます。
Gatewayはクラスを実装したコントローラーの名前を含むGatewayClassを参照する必要があります。
最小のGatewayClassの例:
apiVersion : gateway.networking.k8s.io/v1
kind : GatewayClass
metadata :
name : example-class
spec :
controllerName : example.com/gateway-controller
この例では、Gateway APIを実装したコントローラーは、example.com/gateway-controllerという名前のコントローラーを持つGatewayClassを管理するように構成されます。
このクラスのGatewayは実装のコントローラーによって管理されます。
このAPIの種類の完全な定義については、GatewayClass のリファレンスを参照してください。
Gateway Gatewayはトラフィックを処理するインフラストラクチャのインスタンスを記述します。
これは、Serviceのようなバックエンドに対して、フィルタリング、分散、分割などのようなトラフィック処理のために使用されるネットワークエンドポイントを定義します。
例えばGatewayは、HTTPトラフィックを受け付けるために構成された、クラウドロードバランサーやクラスター内のプロキシサーバーを表す場合があります。
最小のGatewayリソースの例:
apiVersion : gateway.networking.k8s.io/v1
kind : Gateway
metadata :
name : example-gateway
spec :
gatewayClassName : example-class
listeners :
- name : http
protocol : HTTP
port : 80
この例では、トラフィックを処理するインフラストラクチャのインスタンスは、80番ポートでHTTPトラフィックをリッスンするようにプログラムされています。
addressフィールドが指定されていないので、アドレスまたはホスト名はコントローラーの実装によってGatewayに割り当てられます。
このアドレスは、ルートで定義されたバックエンドのネットワークエンドポイントのトラフィックを処理するためのネットワークエンドポイントとして使用されます。
このAPIの種類の完全な定義については、Gateway のリファレンスを参照してください。
HTTPRoute HTTPRouteの種類は、Gatewayリスナーからバックエンドのネットワークエンドポイントに対するHTTPリクエストのルーティングの振る舞いを指定します。
Serviceバックエンドに対して、実装はバックエンドのネットワークエンドポイントをService IPまたはServiceの背後のエンドポイントとして表すことができます。
基盤となるGatewayの実装に適用される設定はHTTPRouteによって表されます。
例えば、新しいHTTPRouteを定義することにより、クラウドロードバランサーやクラスター内のプロキシサーバーの追加のトラフィックルートを構成する場合があります。
最小のHTTPRouteの例:
apiVersion : gateway.networking.k8s.io/v1
kind : HTTPRoute
metadata :
name : example-httproute
spec :
parentRefs :
- name : example-gateway
hostnames :
- "www.example.com"
rules :
- matches :
- path :
type : PathPrefix
value : /login
backendRefs :
- name : example-svc
port : 8080
この例では、Host:ヘッダーにwww.example.comが設定され、リクエストパスに/loginが指定されたHTTPトラフィックが、example-gatewayという名前のGatewayから、8080番ポート上のexample-svcという名前のServiceにルーティングされます。
このAPIの種類の完全な定義については、HTTPRoute のリファレンスを参照してください。
リクエストフロー 以下は、GatewayとHTTPRouteを使用してHTTPトラフィックをServiceにルーティングする簡単な例です:
この例では、リバースプロキシとして実装されたGatewayに対するリクエストフローは次のようになります:
クライアントはURL http://www.example.comに対するHTTPリクエストの準備を開始します。 クライアントのDNSリゾルバは宛先の名前をクエリし、Gatewayに関連づけられた1つ以上のIPアドレスとのマッピングを学習します。 クライアントはGatewayのIPアドレスにリクエストを送信します。リバースプロキシはHTTPリクエストを受信し、Host:ヘッダーを使用してGatewayとそれに関連づけられたHTTPRouteから導かれた構成にマッチさせます。 オプションで、リバースプロキシはHTTPRouteのマッチングルールに基づいて、リクエストヘッダーもしくはパスのマッチングを実行することができます。 オプションで、リバースプロキシはリクエストを変更することができます。例えば、HTTPRouteのフィルタールールに従ってヘッダーを追加または削除します。 最後に、リバースプロキシはリクエストを1つ以上のバックエンドにフォワードします。 適合性 Gateway APIは幅広い機能をカバーし、広く実装されています。
この組み合わせは、APIがどこで使われても一貫した体験を提供することを保証するために、明確な適合性の定義とテストを必要とします。
リリースチャンネル、サポートレベル、そして適合テストの実行などの詳細を理解するためには、適合性 のドキュメントを参照してください。
Ingressからの移行 Gateway APIはIngress APIの後継です。
しかし、Ingressは含まれていません。
このため、既存のIngressリソースからGateway APIリソースへの変換を1度だけ行う必要があります。
IngressリソースからGateway APIリソースへの移行の詳細に関するガイドは、Ingressの移行 を参照してください。
次の項目 Gateway APIリソースをKubernetesでネイティブに実装する代わりに、幅広い実装 によってサポートされたカスタムリソース として仕様が定義されています。
Gateway API CRDをインストール するか、選んだ実装のインストール手順に従ってください。
実装をインストールした後、Getting Started ガイドを使用してGateway APIをすぐに使い始めることができます。
備考: 選択した実装のドキュメントを必ず確認し、注意点を理解するようにしてください。すべてのGateway API種別の追加の詳細についてはAPI仕様 を参照してください。
3.6.6 - EndpointSlice FEATURE STATE:
Kubernetes v1.17 [beta]
EndpointSlice は、Kubernetesクラスター内にあるネットワークエンドポイントを追跡するための単純な手段を提供します。EndpointSliceは、よりスケーラブルでより拡張可能な、Endpointの代わりとなるものです。
動機 Endpoint APIはKubernetes内のネットワークエンドポイントを追跡する単純で直観的な手段を提供してきました。
残念ながら、KubernetesクラスターやService が大規模になり、より多くのトラフィックを処理し、より多くのバックエンドPodに送信するようになるにしたがって、Endpoint APIの限界が明らかになってきました。
最も顕著な問題の1つに、ネットワークエンドポイントの数が大きくなったときのスケーリングの問題があります。
Serviceのすべてのネットワークエンドポイントが単一のEndpointリソースに格納されていたため、リソースのサイズが非常に大きくなる場合がありました。これがKubernetesのコンポーネント(特に、マスターコントロールプレーン)の性能に悪影響を与え、結果として、Endpointに変更があるたびに、大量のネットワークトラフィックと処理が発生するようになってしまいました。EndpointSliceは、この問題を緩和するとともに、トポロジカルルーティングなどの追加機能のための拡張可能なプラットフォームを提供します。
EndpointSliceリソース Kubernetes内ではEndpointSliceにはネットワークエンドポイントの集合へのリファレンスが含まれます。
コントロールプレーンは、セレクター が指定されているKubernetes ServiceのEndpointSliceを自動的に作成します。
これらのEndpointSliceには、Serviceセレクターに一致するすべてのPodへのリファレンスが含まれています。
EndpointSliceは、プロトコル、ポート番号、およびサービス名の一意の組み合わせによってネットワークエンドポイントをグループ化します。
EndpointSliceオブジェクトの名前は有効なDNSサブドメイン名 である必要があります。
一例として、以下にexampleというKubernetes Serviceに対するサンプルのEndpointSliceリソースを示します。
apiVersion : discovery.k8s.io/v1beta1
kind : EndpointSlice
metadata :
name : example-abc
labels :
kubernetes.io/service-name : example
addressType : IPv4
ports :
- name : http
protocol : TCP
port : 80
endpoints :
- addresses :
- "10.1.2.3"
conditions :
ready : true
hostname : pod-1
topology :
kubernetes.io/hostname : node-1
topology.kubernetes.io/zone : us-west2-a
デフォルトでは、コントロールプレーンはEndpointSliceを作成・管理し、それぞれのエンドポイント数が100以下になるようにします。--max-endpoints-per-slicekube-controller-manager フラグを設定することで、最大1000個まで設定可能です。
EndpointSliceは内部トラフィックのルーティング方法に関して、kube-proxy に対する唯一のソース(source of truth)として振る舞うことができます。EndpointSliceを有効にすれば、非常に多数のエンドポイントを持つServiceに対して性能向上が得られるはずです。
アドレスの種類 EndpointSliceは次の3種類のアドレスをサポートします。
IPv4 IPv6 FQDN (Fully Qualified Domain Name、完全修飾ドメイン名) トポロジー EndpointSliceに属する各エンドポイントは、関連するトポロジーの情報を持つことができます。この情報は、エンドポイントの場所を示すために使われ、対応するNode、ゾーン、リージョンに関する情報が含まれます。
値が利用できる場合には、コントロールプレーンはEndpointSliceコントローラーに次のようなTopologyラベルを設定します。
kubernetes.io/hostname - このエンドポイントが存在するNodeの名前。topology.kubernetes.io/zone - このエンドポイントが存在するゾーン。topology.kubernetes.io/region - このエンドポイントが存在するリージョン。これらのラベルの値はスライス内の各エンドポイントと関連するリソースから継承したものです。hostnameラベルは対応するPod上のNodeNameフィールドの値を表します。zoneとregionラベルは対応するNode上の同じ名前のラベルの値を表します。
管理 ほとんどの場合、コントロールプレーン(具体的には、EndpointSlice コントローラー )は、EndpointSliceオブジェクトを作成および管理します。EndpointSliceには、サービスメッシュの実装など、他のさまざまなユースケースがあり、他のエンティティまたはコントローラーがEndpointSliceの追加セットを管理する可能性があります。
複数のエンティティが互いに干渉することなくEndpointSliceを管理できるようにするために、KubernetesはEndpointSliceを管理するエンティティを示すendpointslice.kubernetes.io/managed-byというラベル を定義します。
EndpointSliceを管理するその他のエンティティも同様に、このラベルにユニークな値を設定する必要があります。
所有権 ほとんどのユースケースでは、EndpointSliceはエンドポイントスライスオブジェクトがエンドポイントを追跡するServiceによって所有されます。
これは、各EndpointSlice上のownerリファレンスとkubernetes.io/service-nameラベルによって示されます。これにより、Serviceに属するすべてのEndpointSliceを簡単に検索できるようになっています。
EndpointSliceのミラーリング 場合によっては、アプリケーションはカスタムEndpointリソースを作成します。これらのアプリケーションがEndpointリソースとEndpointSliceリソースの両方に同時に書き込む必要がないようにするために、クラスターのコントロールプレーンは、ほとんどのEndpointリソースを対応するEndpointSliceにミラーリングします。
コントロールプレーンは、次の場合を除いて、Endpointリソースをミラーリングします。
Endpointリソースのendpointslice.kubernetes.io/skip-mirrorラベルがtrueに設定されています。 Endpointリソースがcontrol-plane.alpha.kubernetes.io/leaderアノテーションを持っています。 対応するServiceリソースが存在しません。 対応するServiceリソースには、nil以外のセレクターがあります。 個々のEndpointリソースは、複数のEndpointSliceに変換される場合があります。これは、Endpointリソースに複数のサブセットがある場合、または複数のIPファミリ(IPv4およびIPv6)を持つエンドポイントが含まれている場合に発生します。サブセットごとに最大1000個のアドレスがEndpointSliceにミラーリングされます。
EndpointSliceの分散 それぞれのEndpointSliceにはポートの集合があり、リソース内のすべてのエンドポイントに適用されます。サービスが名前付きポートを使用した場合、Podが同じ名前のポートに対して、結果的に異なるターゲットポート番号が使用されて、異なるEndpointSliceが必要になる場合があります。これはサービスの部分集合がEndpointにグループ化される場合と同様です。
コントロールプレーンはEndpointSliceをできる限り充填しようとしますが、積極的にリバランスを行うことはありません。コントローラーのロジックは極めて単純で、以下のようになっています。
既存のEndpointSliceをイテレートし、もう必要のないエンドポイントを削除し、変更があったエンドポイントを更新する。 前のステップで変更されたEndpointSliceをイテレートし、追加する必要がある新しいエンドポイントで充填する。 まだ追加するべき新しいエンドポイントが残っていた場合、これまで変更されなかったスライスに追加を試み、その後、新しいスライスを作成する。 ここで重要なのは、3番目のステップでEndpointSliceを完全に分散させることよりも、EndpointSliceの更新を制限することを優先していることです。たとえば、もし新しい追加するべきエンドポイントが10個あり、2つのEndpointSliceにそれぞれ5個の空きがあった場合、このアプローチでは2つの既存のEndpointSliceを充填する代わりに、新しいEndpointSliceが作られます。言い換えれば、1つのEndpointSliceを作成する方が複数のEndpointSliceを更新するよりも好ましいということです。
各Node上で実行されているkube-proxyはEndpointSliceを監視しており、EndpointSliceに加えられた変更はクラスター内のすべてのNodeに送信されるため、比較的コストの高い処理になります。先ほどのアプローチは、たとえ複数のEndpointSliceが充填されない結果となるとしても、すべてのNodeへ送信しなければならない変更の数を抑制することを目的としています。
現実的には、こうしたあまり理想的ではない分散が発生することは稀です。EndpointSliceコントローラーによって処理されるほとんどの変更は、既存のEndpointSliceに収まるほど十分小さくなるためです。そうでなかったとしても、すぐに新しいEndpointSliceが必要になる可能性が高いです。また、Deploymentのローリングアップデートが行われれば、自然な再充填が行われます。Podとそれに対応するエンドポイントがすべて置換されるためです。
エンドポイントの重複 EndpointSliceの変更の性質上、エンドポイントは同時に複数のEndpointSliceで表される場合があります。
これは、さまざまなEndpointSliceオブジェクトへの変更が、さまざまな時間にKubernetesクライアントのウォッチ/キャッシュに到達する可能性があるために自然に発生します。
EndpointSliceを使用する実装では、エンドポイントを複数のスライスに表示できる必要があります。
エンドポイント重複排除を実行する方法のリファレンス実装は、kube-proxyのEndpointSliceCache実装にあります。
次の項目 3.6.7 - ネットワークポリシー IPアドレスまたはポートのレベル(OSI参照モデルのレイヤー3または4)でトラフィックフローを制御したい場合、クラスター内の特定のアプリケーションにKubernetesのネットワークポリシーを使用することを検討してください。ネットワークポリシーはアプリケーション中心の構造であり、Pod がネットワークを介して多様な「エンティティ」(「Endpoint」や「Service」のようなKubernetesに含まれる特定の意味を持つ共通の用語との重複を避けるため、ここではエンティティという単語を使用します。)と通信する方法を指定できます。
Podが通信できるエンティティは以下の3つの識別子の組み合わせによって識別されます。
許可されている他のPod(例外: Podはそれ自体へのアクセスをブロックできません) 許可されている名前空間 IPブロック(例外: PodまたはノードのIPアドレスに関係なく、Podが実行されているノードとの間のトラフィックは常に許可されます。) Podベースもしくは名前空間ベースのネットワークポリシーを定義する場合、セレクター を使用してセレクターに一致するPodとの間で許可されるトラフィックを指定します。
一方でIPベースのネットワークポリシーが作成されると、IPブロック(CIDRの範囲)に基づいてポリシーが定義されます。
前提条件 ネットワークポリシーは、ネットワークプラグイン により実装されます。ネットワークポリシーを使用するには、NetworkPolicyをサポートするネットワークソリューションを使用しなければなりません。ネットワークポリシーを実装したコントローラーを使用せずにNetworkPolicyリソースを作成した場合は、何も効果はありません。
分離されたPodと分離されていないPod デフォルトでは、Podは分離されていない状態(non-isolated)となるため、すべてのソースからのトラフィックを受信します。
Podを選択するNetworkPolicyが存在すると、Podは分離されるようになります。名前空間内に特定のPodを選択するNetworkPolicyが1つでも存在すると、そのPodはいずれかのNetworkPolicyで許可されていないすべての接続を拒否するようになります。(同じ名前空間内のPodでも、どのNetworkPolicyにも選択されなかった他のPodは、引き続きすべてのトラフィックを許可します。)
ネットワークポリシーは追加式であるため、競合することはありません。複数のポリシーがPodを選択する場合、そのPodに許可されるトラフィックは、それらのポリシーのingress/egressルールの和集合で制限されます。したがって、評価の順序はポリシーの結果には影響がありません。
NetworkPolicyリソース リソースの完全な定義については、リファレンスのNetworkPolicy のセクションを参照してください。
以下は、NetworkPolicyの一例です。
apiVersion : networking.k8s.io/v1
kind : NetworkPolicy
metadata :
name : test-network-policy
namespace : default
spec :
podSelector :
matchLabels :
role : db
policyTypes :
- Ingress
- Egress
ingress :
- from :
- ipBlock :
cidr : 172.17.0.0 /16
except :
- 172.17.1.0 /24
- namespaceSelector :
matchLabels :
project : myproject
- podSelector :
matchLabels :
role : frontend
ports :
- protocol : TCP
port : 6379
egress :
- to :
- ipBlock :
cidr : 10.0.0.0 /24
ports :
- protocol : TCP
port : 5978
備考: 選択したネットワークソリューションがネットワークポリシーをサポートしていない場合には、これをクラスターのAPIサーバーにPOSTしても効果はありません。必須フィールド : 他のKubernetesの設定と同様に、NetworkPolicyにもapiVersion、kind、metadataフィールドが必須です。設定ファイルの扱い方に関する一般的な情報については、ConfigMapを使用してコンテナを構成する とオブジェクト管理 を参照してください。
spec : NetworkPolicyのspec を見ると、指定した名前空間内で特定のネットワークポリシーを定義するのに必要なすべての情報が確認できます。
podSelector : 各NetworkPolicyには、ポリシーを適用するPodのグループを選択するpodSelectorが含まれます。ポリシーの例では、ラベル"role=db"を持つPodを選択しています。podSelectorを空にすると、名前空間内のすべてのPodが選択されます。
policyTypes : 各NetworkPolicyには、policyTypesとして、Ingress、Egress、またはその両方からなるリストが含まれます。policyTypesフィールドでは、指定したポリシーがどの種類のトラフィックに適用されるかを定めます。トラフィックの種類としては、選択したPodへの内向きのトラフィック(Ingress)、選択したPodからの外向きのトラフィック(Egress)、またはその両方を指定します。policyTypesを指定しなかった場合、デフォルトで常に
Ingressが指定され、NetworkPolicyにegressルールが1つでもあればEgressも設定されます。
ingress : 各NetworkPolicyには、許可するingressルールのリストを指定できます。各ルールは、fromおよびportsセクションの両方に一致するトラフィックを許可します。ポリシーの例には1つのルールが含まれ、このルールは、3つのソースのいずれかから送信された1つのポート上のトラフィックに一致します。1つ目のソースはipBlockで、2つ目のソースはnamespaceSelectorで、3つ目のソースはpodSelectorでそれぞれ定められます。
egress : 各NetworkPolicyには、許可するegressルールのリストを指定できます。各ルールは、toおよびportsセクションの両方に一致するトラフィックを許可します。ポリシーの例には1つのルールが含まれ、このルールは、1つのポート上で10.0.0.0/24の範囲内の任意の送信先へ送られるトラフィックに一致します。
したがって、上のNetworkPolicyの例では、次のようにネットワークポリシーを適用します。
"default"名前空間内にある"role=db"のPodを、内向きと外向きのトラフィックに対して分離する(まだ分離されていない場合) (Ingressルール) "default"名前空間内の"role=db"ラベルが付いたすべてのPodのTCPの6379番ポートへの接続のうち、次の送信元からのものを許可する"default"名前空間内のラベル"role=frontend"が付いたすべてのPod ラベル"project=myproject"が付いた名前空間内のすべてのPod 172.17.0.0–172.17.0.255および172.17.2.0–172.17.255.255(言い換えれば、172.17.1.0/24の範囲を除く172.17.0.0/16)の範囲内のすべてのIPアドレス (Egressルール) "role=db"というラベルが付いた"default"名前空間内のすべてのPodからの、TCPの5978番ポート上でのCIDR 10.0.0.0/24への接続を許可する 追加の例については、ネットワークポリシーを宣言する の説明を参照してください。
toとfromのセレクターの振る舞いingressのfromセクションまたはegressのtoセクションに指定できるセレクターは4種類あります。
podSelector : NetworkPolicyと同じ名前空間内の特定のPodを選択して、ingressの送信元またはegressの送信先を許可します。
namespaceSelector : 特定の名前空間を選択して、その名前空間内のすべてのPodについて、ingressの送信元またはegressの送信先を許可します。
namespaceSelector および podSelector : 1つのtoまたはfromエントリーでnamespaceSelectorとpodSelectorの両方を指定して、特定の名前空間内の特定のPodを選択します。正しいYAMLの構文を使うように気をつけてください。このポリシーの例を以下に示します。
...
ingress :
- from :
- namespaceSelector :
matchLabels :
user : alice
podSelector :
matchLabels :
role : client
...
このポリシーには、1つのfrom要素があり、ラベルuser=aliceの付いた名前空間内にある、ラベルrole=clientの付いたPodからの接続を許可します。しかし、以下の ポリシーには注意が必要です。
...
ingress :
- from :
- namespaceSelector :
matchLabels :
user : alice
- podSelector :
matchLabels :
role : client
...
このポリシーには、from配列の中に2つの要素があります。そのため、ラベルrole=clientの付いた名前空間内にあるすべてのPodからの接続、または 、任意の名前空間内にあるラベルuser=aliceの付いたすべてのPodからの接続を許可します。
正しいルールになっているか自信がないときは、kubectl describeを使用すると、Kubernetesがどのようにポリシーを解釈したのかを確認できます。
ipBlock : 特定のIPのCIDRの範囲を選択して、ingressの送信元またはegressの送信先を許可します。PodのIPは一時的なもので予測できないため、ここにはクラスター外のIPを指定するべきです。
クラスターのingressとegressの仕組みはパケットの送信元IPや送信先IPの書き換えを必要とすることがよくあります。その場合、NetworkPolicyの処理がIPの書き換えの前後どちらで行われるのかは定義されていません。そのため、ネットワークプラグイン、クラウドプロバイダー、Serviceの実装などの組み合わせによっては、動作が異なる可能性があります。
内向きのトラフィックの場合は、実際のオリジナルの送信元IPに基づいてパケットをフィルタリングできる可能性もあれば、NetworkPolicyが対象とする「送信元IP」がLoadBalancerやPodのノードなどのIPになってしまっている可能性もあることになります。
外向きのトラフィックの場合は、クラスター外のIPに書き換えられたPodからServiceのIPへの接続は、ipBlockベースのポリシーの対象になる場合とならない場合があることになります。
デフォルトのポリシー デフォルトでは、名前空間にポリシーが存在しない場合、その名前空間内のPodの内向きと外向きのトラフィックはすべて許可されます。以下の例を利用すると、その名前空間内でのデフォルトの振る舞いを変更できます。
デフォルトですべての内向きのトラフィックを拒否する すべてのPodを選択して、そのPodへのすべての内向きのトラフィックを許可しないNetworkPolicyを作成すると、その名前空間に対する「デフォルト」の分離ポリシーを作成できます。
---
apiVersion : networking.k8s.io/v1
kind : NetworkPolicy
metadata :
name : default-deny-ingress
spec :
podSelector : {}
policyTypes :
- Ingress
このポリシーを利用すれば、他のいかなるNetworkPolicyにも選択されなかったPodでも分離されることを保証できます。このポリシーは、デフォルトの外向きの分離の振る舞いを変更しません。
デフォルトで内向きのすべてのトラフィックを許可する (たとえPodを「分離されたもの」として扱うポリシーが追加された場合でも)名前空間内のすべてのPodへのすべてのトラフィックを許可したい場合には、その名前空間内のすべてのトラフィックを明示的に許可するポリシーを作成できます。
---
apiVersion : networking.k8s.io/v1
kind : NetworkPolicy
metadata :
name : allow-all-ingress
spec :
podSelector : {}
ingress :
- {}
policyTypes :
- Ingress
デフォルトで外向きのすべてのトラフィックを拒否する すべてのPodを選択して、そのPodからのすべての外向きのトラフィックを許可しないNetworkPolicyを作成すると、その名前空間に対する「デフォルト」の外向きの分離ポリシーを作成できます。
---
apiVersion : networking.k8s.io/v1
kind : NetworkPolicy
metadata :
name : default-deny-egress
spec :
podSelector : {}
policyTypes :
- Egress
このポリシーを利用すれば、他のいかなるNetworkPolicyにも選択されなかったPodでも、外向きのトラフィックが許可されないことを保証できます。このポリシーは、デフォルトの内向きの分離の振る舞いを変更しません。
デフォルトで外向きのすべてのトラフィックを許可する (たとえPodを「分離されたもの」として扱うポリシーが追加された場合でも)名前空間内のすべてのPodからのすべてのトラフィックを許可したい場合には、その名前空間内のすべての外向きのトラフィックを明示的に許可するポリシーを作成できます。
---
apiVersion : networking.k8s.io/v1
kind : NetworkPolicy
metadata :
name : allow-all-egress
spec :
podSelector : {}
egress :
- {}
policyTypes :
- Egress
デフォルトで内向きと外向きのすべてのトラフィックを拒否する 名前空間内に以下のNetworkPolicyを作成すると、その名前空間で内向きと外向きのすべてのトラフィックを拒否する「デフォルト」のポリシーを作成できます。
---
apiVersion : networking.k8s.io/v1
kind : NetworkPolicy
metadata :
name : default-deny-all
spec :
podSelector : {}
policyTypes :
- Ingress
- Egress
このポリシーを利用すれば、他のいかなるNetworkPolicyにも選択されなかったPodでも、内向きと外向きのトラフィックが許可されないことを保証できます。
SCTPのサポート FEATURE STATE:
Kubernetes v1.19 [beta]
ベータ版の機能として、これはデフォルトで有効化されます。
クラスターレベルでSCTPを無効化するために、クラスター管理者はAPIサーバーで--feature-gates=SCTPSupport=false,…と指定して、SCTPSupportフィーチャーゲート を無効にする必要があります。
備考: SCTPプロトコルのネットワークポリシーをサポートする
CNI プラグインを使用している必要があります。
ネットワークポリシーでできないこと(少なくともまだ) Kubernetes1.20現在、ネットワークポリシーAPIに以下の機能は存在しません。
しかし、オペレーティングシステムのコンポーネント(SELinux、OpenVSwitch、IPTablesなど)、レイヤー7の技術(Ingressコントローラー、サービスメッシュ実装)、もしくはアドミッションコントローラーを使用して回避策を実装できる場合があります。
Kubernetesのネットワークセキュリティを初めて使用する場合は、ネットワークポリシーAPIを使用して以下のユーザーストーリーを(まだ)実装できないことに注意してください。これらのユーザーストーリーの一部(全てではありません)は、ネットワークポリシーAPIの将来のリリースで活発に議論されています。
クラスター内トラフィックを強制的に共通ゲートウェイを通過させる(これは、サービスメッシュもしくは他のプロキシで提供するのが最適な場合があります)。 TLS関連のもの(これにはサービスメッシュまたはIngressコントローラーを使用します)。 ノードの固有のポリシー(これらにはCIDR表記を使用できますが、Kubernetesのアイデンティティでノードを指定することはできません)。 名前空間またはサービスを名前で指定する(ただし、Podまたは名前空間をラベル で指定することができます。これは多くの場合で実行可能な回避策です)。 サードパーティによって実行される「ポリシー要求」の作成または管理 全ての名前空間もしくはPodに適用されるデフォルトのポリシー(これを実現できるサードパーティのKubernetesディストリビューションとプロジェクトがいくつか存在します)。 高度なポリシークエリと到達可能性ツール 単一のポリシー宣言でポートの範囲を指定する機能 ネットワークセキュリティイベント(例えばブロックされた接続や受け入れられた接続)をログに記録する機能 ポリシーを明示的に拒否する機能(現在、ネットワークポリシーのモデルはデフォルトで拒否されており、許可ルールを追加する機能のみが存在します)。 ループバックまたは内向きのホストトラフィックを拒否する機能(Podは現在localhostのアクセスやそれらが配置されているノードからのアクセスをブロックすることはできません)。 次の項目 3.6.8 - ServiceとPodに対するDNS ワークロードは、DNSを用いてクラスター内のServiceを探索できます。 本ページでは、その仕組みを解説します。
KubernetesはServiceとPodのDNSレコードを作成します。
IPアドレスの代わりに安定したDNS名を用いて、Serviceに接続できます。
Kubernetesは、DNSの設定に用いられるPodとServiceの情報を公開します。
kubeletがPodのDNSを設定することで、実行中のコンテナがIPアドレスではなくDNS名でServiceの名前解決を行えます。
クラスター内で定義されたServiceにはDNS名が割り当てられます。
デフォルトでは、クライアントであるPodのDNS検索リストには、そのPod自身の名前空間とクラスターのデフォルトドメインが含まれています。
サービスの名前空間 DNSクエリの結果は、クエリを発行したPodの名前空間によって異なる場合があります。
名前空間を指定しないDNSクエリは、Pod自身の名前空間に限定して解決されます。
他の名前空間にアクセスするには、DNSクエリ内で名前空間を指定する必要があります。
例えば、testという名前空間にPodが、prodという名前空間にdataというServiceがそれぞれ存在しているとします。
Podからdataというクエリを発行しても、DNS解決はPodの名前空間testに限定されるため、結果は返りません。
data.prodというクエリを発行すれば、Serviceの属する名前空間が指定されているため、Serviceを探索することができます。
DNSクエリはPodの/etc/resolv.confに基づいて展開される場合があります。
kubeletは、それぞれのPodにこのファイルを設定します。
例えば、dataというクエリは、data.test.svc.cluster.localに展開される場合があります。
クエリの展開にはsearchオプションの値が用いられます。
DNSクエリの詳細については、resolv.confのマニュアル
nameserver 10.32.0.10
search <namespace>.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
以上のように、test という名前空間に存在するPodは、data.prodやdata.prod.svc.cluster.localというクエリを正常に名前解決できます。
DNSレコード DNSレコードが作成されるオブジェクトは、以下の2つです。
Service Pod 以降のセクションでは、サポートされているDNSレコードの種類および構成について説明します。
その他の構成、名前、クエリは実装に依存し、予告なく変更される可能性があります。
最新の仕様については、Kubernetes DNS-Based Service Discovery をご覧ください。
Service A/AAAAレコード 「通常の」(ヘッドレスでない)Serviceは、my-svc.my-namespace.svc.cluster-domain.exampleという形式のDNS A(AAAA)レコードが、ServiceのIPファミリーに応じて割り当てられます。
割り当てられたAレコードは、ServiceのClusterIPへと名前解決されます。
ClusterIPのないヘッドレスService にもmy-svc.my-namespace.svc.cluster-domain.exampleの形式のDNS A(AAAA)レコードが割り当てられます。
通常のServiceとは異なり、Serviceによって選択されたすべてのPodのIPアドレスに解決されます。
クライアントは、得られたIPアドレスの集合を扱うか、標準のラウンドロビン方式で集合からIPアドレスを選択します。
SRVレコード SRVレコードは、通常のServiceもしくはヘッドレスServiceの一部である名前付きポート向けに作成されます。
それぞれの名前付きポートに対して、SRVレコードは_port-name._port-protocol.my-svc.my-namespace.svc.cluster-domain.exampleという形式です。 通常のServiceに対しては、このSRVレコードはmy-svc.my-namespace.svc.cluster-domain.exampleという形式のドメイン名とポート番号へ名前解決します。 ヘッドレスServiceに対しては、このSRVレコードは複数の結果を返します。
Serviceの背後にある各Podに対し1つずつレコードが返され、それぞれのレコードはPodのポート番号とhostname.my-svc.my-namespace.svc.cluster-domain.exampleという形式のドメイン名を含んでいます。 Pod A/AAAAレコード DNSの仕様 が実装される前のバージョンのKube-DNSでは、以下のような名前解決が行われていました。
<pod-IPv4-address>.<namespace>.pod.<cluster-domain>
例えば、IPアドレスが172.17.0.3のPodがdefaultという名前空間に存在しており、クラスターのドメイン名がcluster.localの場合、PodのDNS名は以下のとおりです。
172-17-0-3.default.pod.cluster.local
CoreDNS などの一部のクラスター実装では、以下のようなAレコードも提供されます。
<pod-ipv4-address>.<service-name>.<my-namespace>.svc.<cluster-domain.example>
例えば、IPアドレスが172.17.0.3のPodがcafeという名前空間に存在しており、PodがbaristaというServiceのエンドポイントで、クラスターのドメイン名がcluster.localの場合、Podは次のようなServiceスコープのAレコードを持ちます。
172-17-0-3.barista.cafe.svc.cluster.local
Podのhostnameとsubdomainフィールド 現在、Podが作成されたとき、Pod内部から観測されるホスト名は、Podのmetadata.nameフィールドの値です。
Podのspecでは、オプションのhostnameフィールドで別のホスト名を指定できます。
hostnameを指定すると、Podの内部から観測されるホスト名として、Podの名前よりも優先されます。
例えば、spec.hostnameフィールドが"my-host"に設定されたPodのホスト名は"my-host"です。
Podのspecはまた、オプションのsubdomainフィールドで、Podの名前空間のサブグループを指定することができます。
例えば、"my-namespace"という名前空間において、spec.hostnameが"foo"、spec.subdomainが"bar"にそれぞれ設定されているPodがあるとします。
このとき、Podのホスト名は"foo"で、Pod内部から観測される完全修飾ドメイン名(FQDN)は"foo.bar.my-namespace.svc.cluster.local"です。
Podと同じ名前空間内に、Podのサブドメインと同じ名前のヘッドレスServiceが存在する場合、クラスターのDNSサーバーは、そのPodのFQDNに対するA(AAAA)レコードを返します。
例えば、以下の設定について考えてみましょう:
apiVersion : v1
kind : Service
metadata :
name : busybox-subdomain
spec :
selector :
name : busybox
clusterIP : None
ports :
- name : foo # 単一ポートのServiceには、nameは必須ではありません
port : 1234
---
apiVersion : v1
kind : Pod
metadata :
name : busybox1
labels :
name : busybox
spec :
hostname : busybox-1
subdomain : busybox-subdomain
containers :
- image : busybox:1.28
command :
- sleep
- "3600"
name : busybox
---
apiVersion : v1
kind : Pod
metadata :
name : busybox2
labels :
name : busybox
spec :
hostname : busybox-2
subdomain : busybox-subdomain
containers :
- image : busybox:1.28
command :
- sleep
- "3600"
name : busybox
上記の設定のように、"busybox-subdomain"というServiceと、spec.subdomainに"busybox-subdomain"を指定したPodが存在するとします。
このとき、1つ目のPodは、自身のFQDNを"busybox-1.busybox-subdomain.my-namespace.svc.cluster-domain.example"と認識します。
DNSはその名前に対して、PodのIPを指し示すA(AAAA)レコードを返します。
"busybox1"と"busybox2"の両方のPodはそれぞれ自身のA(AAAA)レコードを持ちます。
EndpointSlice では、IPアドレスとともに、任意のエンドポイントアドレスに対するDNSホスト名を指定できます。
備考: Podにhostnameが設定されていない場合、そのPod名に対するhostnameベースのA(AAAA)レコードは作成されません。
hostnameを持たずにsubdomainのみを持つPodの場合、ヘッドレスService(busybox-subdomain.my-namespace.svc.cluster-domain.example)に対し、PodのIPアドレスを指すA(AAAA)レコードのみが作成されます。
なお、ServiceにpublishNotReadyAddresses=Trueが設定されている場合を除き、PodがDNSレコードに含まれるためには、Podの状態がReadyである必要があります。PodのsetHostnameAsFQDNフィールド FEATURE STATE:
Kubernetes v1.22 [stable]
PodがFQDNを持つように構成されている場合、そのホスト名は短縮されたホスト名です。
例えば、FQDNがbusybox-1.busybox-subdomain.my-namespace.svc.cluster-domain.exampleのPodがあるとします。
この場合、デフォルトではそのPod内でhostnameコマンドを実行するとbusybox-1が返され、hostname --fqdnコマンドを実行するとFQDNが返されます。
PodのspecでsetHostnameAsFQDN: trueを設定した場合、kubeletはPodのFQDNを、そのPodの名前空間におけるホスト名として書き込みます。
この場合、hostnameとhostname --fqdnの両方がPodのFQDNを返します。
備考: Linuxでは、カーネルのホスト名のフィールド(struct utsnameのnodenameフィールド)は64文字に制限されています。
Podがこの機能を有効にしていて、そのFQDNが64文字より長い場合、Podは起動に失敗します。
PodはPendingステータス(kubectlではContainerCreatingと表示)のままになり、「Failed to construct FQDN from Pod hostname and cluster domain, FQDN long-FQDN is too long (64 characters is the max, 70 characters requested)」といったエラーイベントが生成されます。
この場合のユーザー体験を向上させる1つの方法は、admission webhook controller を作成して、ユーザーがDeploymentなどのトップレベルのオブジェクトを作成するときにFQDNのサイズを制御することです。
PodのDNSポリシー DNSポリシーはPodごとに設定できます。
現在のKubernetesでは次のようなPod固有のDNSポリシーをサポートしています。
これらのポリシーはPodのspecのdnsPolicyフィールドで指定されます。
"Default": Podが実行されているノードから名前解決の設定を継承します。
詳細に関しては、関連する議論 を参照してください。
"ClusterFirst": "www.kubernetes.io"のようなクラスターのドメインのサフィックスに一致しないDNSクエリは、DNSサーバーによって上流のネームサーバーに転送されます。
クラスター管理者が追加のスタブドメインと上流のDNSサーバーを設定している場合があります。
このような場合におけるDNSクエリ処理の詳細に関しては、関連する議論 を参照してください。
"ClusterFirstWithHostNet": hostNetworkによって稼働しているPodに対しては、明示的にDNSポリシーを"ClusterFirstWithHostNet"に設定してください。
そうしない場合、hostNetworkによって稼働し、かつ"ClusterFirst"が設定されているPodは、"Default"ポリシーの挙動にフォールバックします。
"None": Kubernetes環境からDNS設定を無視することができます。
全てのDNS設定は、PodのspecのdnsConfigフィールドで指定する必要があります。
詳細は、以下のPodのDNS設定 をご覧ください。
備考: "Default"は、デフォルトのDNSポリシーではありません。
dnsPolicyが明示的に指定されていない場合、"ClusterFirst"が使用されます。下記の例では、hostNetworkフィールドがtrueのためdnsPolicyに"ClusterFirstWithHostNet"を指定したPodを示しています。
apiVersion : v1
kind : Pod
metadata :
name : busybox
namespace : default
spec :
containers :
- image : busybox:1.28
command :
- sleep
- "3600"
imagePullPolicy : IfNotPresent
name : busybox
restartPolicy : Always
hostNetwork : true
dnsPolicy : ClusterFirstWithHostNet
PodのDNS設定 FEATURE STATE:
Kubernetes v1.14 [stable]
PodのDNS設定では、Podに対するDNS設定をより細かく制御できます。
dnsConfigフィールドは任意で指定でき、どのdnsPolicyの設定でも併用できます。
ただし、PodのdnsPolicyが"None"の場合、dnsConfigフィールドの設定は必須です。
以下は、dnsConfigフィールドで指定可能なプロパティです。
nameservers: PodのDNSサーバーとして使用されるIPアドレスのリストです。
最大で3つのIPアドレスを指定できます。
PodのdnsPolicyが"None"の場合、少なくとも1つのIPアドレスを指定する必要があります。
それ以外の場合は、このプロパティは任意です。
ここで指定したサーバーは、指定されたDNSポリシーから生成されるベースのネームサーバーと結合され、重複するアドレスは削除されます。searches: Pod内のホスト名の名前解決のためのDNS検索ドメインのリストです。
このプロパティは任意です。
このプロパティを指定した場合、このリストは、選択されたDNSポリシーから生成されるベースの検索ドメイン名にマージされます。
重複するドメイン名は削除されます。
最大で32個の検索ドメインを指定できます。options: nameプロパティ(必須)とvalueプロパティ(任意)を持つオブジェクトのリストです。
このプロパティの内容は、指定されたDNSポリシーから生成されるオプションにマージされます。
重複するエントリは削除されます。以下は、カスタムDNS設定を持つPodの例です。
apiVersion : v1
kind : Pod
metadata :
namespace : default
name : dns-example
spec :
containers :
- name : test
image : nginx
dnsPolicy : "None"
dnsConfig :
nameservers :
- 192.0.2.1 # このIPアドレスは例です
searches :
- ns1.svc.cluster-domain.example
- my.dns.search.suffix
options :
- name : ndots
value : "2"
- name : edns0
上記のPodが作成されたとき、testコンテナの/etc/resolv.confファイルには以下の内容が設定されます。
nameserver 192.0.2.1
search ns1.svc.cluster-domain.example my.dns.search.suffix
options ndots:2 edns0
IPv6の設定では、検索パスとネームサーバーは次のように設定されます。
kubectl exec -it dns-example -- cat /etc/resolv.conf
このコマンドの出力は以下のようになります。
nameserver 2001:db8:30::a
search default.svc.cluster-domain.example svc.cluster-domain.example cluster-domain.example
options ndots:5
DNS検索ドメインリストの制限 FEATURE STATE:
Kubernetes 1.28 [stable]
Kubernetes自体は、DNS検索リストの要素数が32を超えたり、DNS検索ドメイン名の文字数の合計が2048を超えたりしない限り、DNS設定に制限を設けません。
この制限は、ノードのリゾルバー設定ファイル、PodのDNS設定、およびそれらがマージされたDNS設定に適用されます。
備考: 古いバージョンの一部のコンテナランタイムでは、DNS検索リストの要素数に制限がある場合があります。
コンテナランタイムによっては、DNS検索ドメインの要素数が多い場合、Podの状態がPendingのままとなることがあります。
この問題は、containerd v1.5.5以前、およびCRI-O v1.21以前で発生することが確認されています。
WindowsノードにおけるDNSの名前解決 Windowsノード上で実行されるPodでは、DNSポリシーのClusterFirstWithHostNetはサポートされていません。
Windowsでは、.を含む名前をFQDNとして扱い、FQDN解決はスキップされます。 Windowsにおいては、複数のDNSリゾルバーを利用できます。
それぞれのリゾルバーの挙動がわずかに異なるため、Resolve-DNSName Linuxには完全修飾名としての名前解決が失敗した後に使用されるDNSサフィックスリストがあります。
一方で、WindowsにはDNSサフィックスを1つしか指定できず、それはPodの名前空間に対応するDNSサフィックスです(例: mydns.svc.cluster.local)。
Windowsでは、この単一のサフィックスを用いてFQDNやService、ネットワーク名の名前解決を行えます。
例えば、defaultという名前空間で起動されたPodは、DNSサフィックスとしてdefault.svc.cluster.localが設定されます。
このPodでは、kubernetes.default.svc.cluster.localやkubernetesは名前解決できますが、部分的に修飾された名前(kubernetes.defaultやkubernetes.default.svc)は名前解決できません。 次の項目 DNS設定の管理方法に関しては、DNS Serviceの設定 を確認してください。
3.6.9 - IPv4/IPv6デュアルスタック FEATURE STATE:
Kubernetes v1.16 [alpha]
IPv4/IPv6デュアルスタックを利用すると、IPv4とIPv6のアドレスの両方をPod およびService に指定できるようになります。
KubernetesクラスターでIPv4/IPv6デュアルスタックのネットワークを有効にすれば、クラスターはIPv4とIPv6のアドレスの両方を同時に割り当てることをサポートするようになります。
サポートされている機能 KubernetesクラスターでIPv4/IPv6デュアルスタックを有効にすると、以下の機能が提供されます。
デュアルスタックのPodネットワーク(PodごとにIPv4とIPv6のアドレスが1つずつ割り当てられます) IPv4およびIPv6が有効化されたService(各Serviceは1つのアドレスファミリーでなければなりません) IPv4およびIPv6インターフェースを経由したPodのクラスター外向きの(たとえば、インターネットへの)ルーティング 前提条件 IPv4/IPv6デュアルスタックのKubernetesクラスターを利用するには、以下の前提条件を満たす必要があります。
Kubernetesのバージョンが1.16以降である プロバイダーがデュアルスタックのネットワークをサポートしている(クラウドプロバイダーなどが、ルーティング可能なIPv4/IPv6ネットワークインターフェースが搭載されたKubernetesを提供可能である) ネットワークプラグインがデュアルスタックに対応している(KubenetやCalicoなど) IPv4/IPv6デュアルスタックを有効にする IPv4/IPv6デュアルスタックを有効にするには、クラスターの関連コンポーネントでIPv6DualStackフィーチャーゲート を有効にして、デュアルスタックのクラスターネットワークの割り当てを以下のように設定します。
kube-apiserver:--feature-gates="IPv6DualStack=true"--service-cluster-ip-range=<IPv4 CIDR>,<IPv6 CIDR> kube-controller-manager:--feature-gates="IPv6DualStack=true"--cluster-cidr=<IPv4 CIDR>,<IPv6 CIDR>--service-cluster-ip-range=<IPv4 CIDR>,<IPv6 CIDR>--node-cidr-mask-size-ipv4|--node-cidr-mask-size-ipv6 デフォルトのサイズは、IPv4では/24、IPv6では/64です kubelet:--feature-gates="IPv6DualStack=true" kube-proxy:--cluster-cidr=<IPv4 CIDR>,<IPv6 CIDR>--feature-gates="IPv6DualStack=true" 備考: IPv4 CIDRの例: 10.244.0.0/16 (自分のクラスターのアドレス範囲を指定してください)
IPv6 CIDRの例: fdXY:IJKL:MNOP:15::/64 (これはフォーマットを示すための例であり、有効なアドレスではありません。詳しくはRFC 4193 を参照してください)
Service クラスターでIPv4/IPv6デュアルスタックのネットワークを有効にした場合、IPv4またはIPv6のいずれかのアドレスを持つService を作成できます。Serviceのcluster IPのアドレスファミリーは、Service上に.spec.ipFamilyフィールドを設定することで選択できます。このフィールドを設定できるのは、新しいServiceの作成時のみです。.spec.ipFamilyフィールドの指定はオプションであり、Service とIngress でIPv4とIPv6を有効にする予定がある場合にのみ使用するべきです。このフィールドの設定は、外向きのトラフィック に対する要件には含まれません。
備考: クラスターのデフォルトのアドレスファミリーは、kube-controller-managerに--service-cluster-ip-rangeフラグで設定した、最初のservice cluster IPの範囲のアドレスファミリーです。.spec.ipFamilyは、次のいずれかに設定できます。
IPv4: APIサーバーはipv4のservice-cluster-ip-rangeの範囲からIPアドレスを割り当てますIPv6: APIサーバーはipv6のservice-cluster-ip-rangeの範囲からIPアドレスを割り当てます次のServiceのspecにはipFamilyフィールドが含まれていません。Kubernetesは、最初に設定したservice-cluster-ip-rangeの範囲からこのServiceにIPアドレス(別名「cluster IP」)を割り当てます。
apiVersion : v1
kind : Service
metadata :
name : my-service
labels :
app : MyApp
spec :
selector :
app : MyApp
ports :
- protocol : TCP
port : 80
次のServiceのspecにはipFamilyフィールドが含まれています。Kubernetesは、最初に設定したservice-cluster-ip-rangeの範囲からこのServiceにIPv6のアドレス(別名「cluster IP」)を割り当てます。
apiVersion : v1
kind : Service
metadata :
name : my-service
spec :
ipFamily : IPv6
selector :
app : MyApp
ports :
- protocol : TCP
port : 80
targetPort : 9376 比較として次のServiceのspecを見ると、このServiceには最初に設定したservice-cluster-ip-rangeの範囲からIPv4のアドレス(別名「cluster IP」)が割り当てられます。
apiVersion : v1
kind : Service
metadata :
name : my-service
spec :
ipFamily : IPv4
selector :
app : MyApp
ports :
- protocol : TCP
port : 80
targetPort : 9376 Type LoadBalancer IPv6が有効になった外部ロードバランサーをサポートしているクラウドプロバイダーでは、typeフィールドにLoadBalancerを指定し、ipFamilyフィールドにIPv6を指定することにより、クラウドロードバランサーをService向けにプロビジョニングできます。
外向きのトラフィック パブリックおよび非パブリックでのルーティングが可能なIPv6アドレスのブロックを利用するためには、クラスターがベースにしているCNI プロバイダーがIPv6の転送を実装している必要があります。もし非パブリックでのルーティングが可能なIPv6アドレスを使用するPodがあり、そのPodをクラスター外の送信先(例:パブリックインターネット)に到達させたい場合、外向きのトラフィックと応答の受信のためにIPマスカレードを設定する必要があります。ip-masq-agent はデュアルスタックに対応しているため、デュアルスタックのクラスター上でのIPマスカレードにはip-masq-agentが利用できます。
既知の問題 Kubenetは、IPv4,IPv6の順番にIPを報告することを強制します(--cluster-cidr) 次の項目 3.6.10 - トポロジーを意識したルーティング Topology Aware Routing は、ネットワークトラフィックを発信元のゾーン内に留めておくのに役立つメカニズムを提供します。クラスター内のPod間で同じゾーンのトラフィックを優先することで、信頼性、パフォーマンス(ネットワークの待ち時間やスループット)の向上、またはコストの削減に役立ちます。
FEATURE STATE:
Kubernetes v1.23 [beta]
備考: Kubernetes 1.27より前には、この機能は、Topology Aware Hint として知られていました。Topology Aware Routing は、トラフィックを発信元のゾーンに維持するようにルーティング動作を調整します。場合によっては、コストを削減したり、ネットワークパフォーマンスを向上させたりすることができます。
動機 Kubernetesクラスターは、マルチゾーン環境で展開されることが多くなっています。
Topology Aware Routing は、トラフィックを発信元のゾーン内に留めておくのに役立つメカニズムを提供します。EndpointSliceコントローラーはService のendpointを計算する際に、各endpointのトポロジー(リージョンとゾーン)を考慮し、ゾーンに割り当てるためのヒントフィールドに値を入力します。kube-proxy のようなクラスターコンポーネントは、次にこれらのヒントを消費し、それらを使用してトラフィックがルーティングされる方法に影響を与えることが可能です(トポロジー的に近いendpointを優先します)。
Topology Aware Routingを有効にする
備考: Kubernetes 1.27より前には、この動作はservice.kubernetes.io/topology-aware-hintsアノテーションを使用して制御されていました。service.kubernetes.io/topology-modeアノテーションをautoに設定すると、サービスに対してTopology Aware Routingを有効にすることができます。各ゾーンに十分なendpointがある場合、個々のendpointを特定のゾーンに割り当てるために、トポロジーヒントがEndpointSliceに入力され、その結果、トラフィックは発信元の近くにルーティングされます。
最も効果的なとき この機能は、次の場合に最も効果的に動作します。
1. 受信トラフィックが均等に分散されている トラフィックの大部分が単一のゾーンから発信されている場合、トラフィックはそのゾーンに割り当てられたendpointのサブセットに過負荷を与える可能性があります。受信トラフィックが単一のゾーンから発信されることが予想される場合、この機能は推奨されません。
2. 1つのゾーンに3つ以上のendpointを持つサービス 3つのゾーンからなるクラスターでは、これは9つ以上のendpointがあることを意味します。ゾーン毎のendpointが3つ未満の場合、EndpointSliceコントローラーはendpointを均等に割り当てることができず、代わりにデフォルトのクラスター全体のルーティングアプローチに戻る可能性が高く(約50%)なります。
使い方 「Auto」ヒューリスティックは、各ゾーンに多数のendpointを比例的に割り当てようとします。このヒューリスティックは、非常に多くのendpointを持つサービスに最適です。
EndpointSliceコントローラー このヒューリスティックが有効な場合、EndpointSliceコントローラーはEndpointSliceにヒントを設定する役割を担います。コントローラーは、各ゾーンに比例した量のendpointを割り当てます。この割合は、そのゾーンで実行されているノードの割り当て可能な CPUコアを基に決定されます。
たとえば、あるゾーンに2つのCPUコアがあり、別のゾーンに1つのCPUコアしかない場合、コントローラーは2つのCPUコアを持つゾーンに2倍のendpointを割り当てます。
次の例は、ヒントが入力されたときのEndpointSliceの様子を示しています。
apiVersion : discovery.k8s.io/v1
kind : EndpointSlice
metadata :
name : example-hints
labels :
kubernetes.io/service-name : example-svc
addressType : IPv4
ports :
- name : http
protocol : TCP
port : 80
endpoints :
- addresses :
- "10.1.2.3"
conditions :
ready : true
hostname : pod-1
zone : zone-a
hints :
forZones :
- name : "zone-a"
kube-proxy kube-proxyは、EndpointSliceコントローラーによって設定されたヒントに基づいて、ルーティング先のendpointをフィルター処理します。ほとんどの場合、これはkube-proxyが同じゾーン内のendpointにトラフィックをルーティングできることを意味します。コントローラーが別のゾーンからendpointを割り当てて、ゾーン間でendpointがより均等に分散されるようにする場合があります。これにより、一部のトラフィックが他のゾーンにルーティングされます。
セーフガード 各ノードのKubernetesコントロールプレーンとkube-proxyは、Topology Aware Hintを使用する前に、いくつかのセーフガードルールを適用します。これらがチェックアウトされない場合、kube-proxyは、ゾーンに関係なく、クラスター内のどこからでもendpointを選択します。
endpointの数が不十分です: クラスター内のゾーンよりもendpointが少ない場合、コントローラーはヒントを割り当てません。
バランスの取れた割り当てを実現できません: 場合によっては、ゾーン間でendpointのバランスの取れた割り当てを実現できないことがあります。たとえば、ゾーンaがゾーンbの2倍の大きさであるが、endpointが2つしかない場合、ゾーンaに割り当てられたendpointはゾーンbの2倍のトラフィックを受信する可能性があります。この「予想される過負荷」値が各ゾーンの許容しきい値を下回ることができない場合、コントローラーはヒントを割り当てません。重要なことに、これはリアルタイムのフィードバックに基づいていません。それでも、個々のendpointが過負荷になる可能性があります。
1つ以上のノードの情報が不十分です: ノードにtopology.kubernetes.io/zoneラベルがないか、割り当て可能なCPUの値を報告していない場合、コントロールプレーンはtopology-aware endpoint hintsを設定しないため、kube-proxyはendpointをゾーンでフィルタリングしません。
1つ以上のendpointにゾーンヒントが存在しません: これが発生すると、kube-proxyはTopology Aware Hintから、またはTopology Aware Hintへの移行が進行中であると見なします。この状態のサービスに対してendpointをフィルタリングすることは危険であるため、kube-proxyはすべてのendpointを使用するようにフォールバックします。
ゾーンはヒントで表されません: kube-proxyが、実行中のゾーンをターゲットとするヒントを持つendpointを1つも見つけることができない場合、すべてのゾーンのendpointを使用することになります。これは既存のクラスターに新しいゾーンを追加するときに発生する可能性が最も高くなります。
制約事項 ServiceでexternalTrafficPolicyまたはinternalTrafficPolicyがLocalに設定されている場合、Topology Aware Hintは使用されません。同じServiceではなく、異なるServiceの同じクラスターで両方の機能を使用することができます。
このアプローチは、ゾーンのサブセットから発信されるトラフィックの割合が高いサービスではうまく機能しません。代わりに、これは着信トラフィックが各ゾーンのノードの容量にほぼ比例することを前提としています。
EndpointSliceコントローラーは、各ゾーンの比率を計算するときに、準備ができていないノードを無視します。ノードの大部分の準備ができていない場合、これは意図しない結果をもたらす可能性があります。
EndpointSliceコントローラーは、node-role.kubernetes.io/control-planeまたはnode-role.kubernetes.io/masterラベルが設定されたノードを無視します。それらのノードでワークロードが実行されている場合、これは問題になる可能性があります。
EndpointSliceコントローラーは、各ゾーンの比率を計算するデプロイ時にtoleration を考慮しません。サービスをバックアップするPodがクラスター内のノードのサブセットに制限されている場合、これは考慮されません。
これはオートスケーリングと相性が悪いかもしれません。例えば、多くのトラフィックが1つのゾーンから発信されている場合、そのゾーンに割り当てられたendpointのみがそのトラフィックを処理することになります。その結果、Horizontal Pod Autoscaler がこのイベントを拾えなくなったり、新しく追加されたPodが別のゾーンで開始されたりする可能性があります。
カスタムヒューリスティック Kubernetesは様々な方法でデブロイされ、endpointをゾーンに割り当てるための単独のヒューリスティックは、すべてのユースケースに通用するわけではありません。
この機能の主な目的は、内蔵のヒューリスティックがユースケースに合わない場合に、カスタムヒューリスティックを開発できるようにすることです。カスタムヒューリスティックを有効にするための最初のステップは、1.27リリースに含まれています。これは限定的な実装であり、関連する妥当と思われる状況をまだカバーしていない可能性があります。
次の項目 3.6.11 - ServiceのClusterIPの割り当て Kubernetesでは、Service はPodの集合上で実行しているアプリケーションを抽象的に公開する方法です。Serviceはクラスター内で仮想IPアドレス(type: ClusterIPのServiceを使用)を持つことができます。クライアントはその仮想IPアドレスを使用してServiceに接続することができます。そしてKubernetesは、そのServiceへのトラフィックを異なる背後のPod間で負荷分散します。
どのようにServiceのClusterIPが割り当てられるのか? KubernetesがServiceに仮想IPアドレスを割り当てる必要がある場合、2つの方法の内どちらかの方法で行われます:
動的割り当て クラスターのコントロールプレーンは自動的にtype: ClusterIPのServiceのために設定されたIP範囲の中から未割り当てのIPアドレスを選びます。 静的割り当て Serviceのために設定されたIP範囲の中から自身でIPアドレスを選びます。 クラスター全体を通して、ServiceのClusterIPはユニークでなければいけません。割り当て済みのClusterIPを使用してServiceを作成しようとするとエラーが返ってきます。
なぜServiceのClusterIPを予約する必要があるのか? 時には、クラスター内の他のコンポーネントやユーザーが利用できるように、Serviceをよく知られたIPアドレスで実行したい場合があります。
その最たる例がクラスターのDNS Serviceです。慣習として、一部のKubernetesインストーラーはServiceのIP範囲の10番目のIPアドレスをDNS Serviceに割り当てます。ServiceのIP範囲を10.96.0.0/16とするクラスターを構成し、DNS ServiceのIPを10.96.0.10にするとします。この場合、下記のようなServiceを作成する必要があります。
apiVersion : v1
kind : Service
metadata :
labels :
k8s-app : kube-dns
kubernetes.io/cluster-service : "true"
kubernetes.io/name : CoreDNS
name : kube-dns
namespace : kube-system
spec :
clusterIP : 10.96.0.10
ports :
- name : dns
port : 53
protocol : UDP
targetPort : 53
- name : dns-tcp
port : 53
protocol : TCP
targetPort : 53
selector :
k8s-app : kube-dns
type : ClusterIP
しかし、前述したように10.96.0.10のIPアドレスは予約されていません。他のServiceが動的割り当てよりも前に、または同時に作成された場合、このIPアドレスがそのServiceに割り当てられる可能性があります。その場合、競合エラーで失敗しDNS Serviceを作成することができません。
どのようにServiceのClusterIPの競合を回避するのか? Kubernetesで実装されているServiceへのClusterIPの割り当て戦略は、衝突リスクを軽減します。
ClusterIPの範囲は、min(max(16, cidrSize / 16), 256)という式に基づいて分割されます。最小で16、最大でも256で、その範囲内で段階的に変化する ように表されます。
動的IP割り当てはデフォルトで上位の帯域を使用し、それが使い切られると下位の範囲を使用します。これにより、ユーザーは下位の帯域を使用して静的な割り当てを行うことができ、衝突のリスクを抑えることができます。
例 例1 この例ではServiceのIPアドレスとして、10.96.0.0/24(CIDR表記法)のIPアドレスの範囲を使用します。
範囲の大きさ: 28 - 2 = 254
帯域のオフセット(開始位置): min(max(16, 256/16), 256) = min(16, 256) = 16
静的割り当ての帯域の開始: 10.96.0.1
静的割り当ての帯域の終了: 10.96.0.16
範囲の終了: 10.96.0.254
pie showData
title 10.96.0.0/24
"静的割り当て" : 16
"動的割り当て" : 238
このコンテンツを表示するには、JavaScriptを有効に する必要があります 例2 この例では、ServiceのIPアドレスとして、10.96.0.0/20(CIDR表記法)のIPアドレスの範囲を使用します。
範囲の大きさ: 212 - 2 = 4094
帯域のオフセット(開始位置): min(max(16, 4096/16), 256) = min(256, 256) = 256
静的割り当ての帯域の開始: 10.96.0.1
静的割り当ての帯域の終了: 10.96.1.0
範囲の終了: 10.96.15.254
pie showData
title 10.96.0.0/20
"静的割り当て" : 256
"動的割り当て" : 3838
このコンテンツを表示するには、JavaScriptを有効に する必要があります 例3 この例ではServiceのIPアドレスとして、10.96.0.0/16(CIDR表記法)のIPアドレスの範囲を使用します。
範囲の大きさ: 216 - 2 = 65534
帯域のオフセット(開始位置): min(max(16, 65536/16), 256) = min(4096, 256) = 256
静的割り当ての帯域の開始: 10.96.0.1
静的割り当ての帯域の終了: 10.96.1.0
範囲の終了: 10.96.255.254
pie showData
title 10.96.0.0/16
"静的割り当て" : 256
"動的割り当て" : 65278
このコンテンツを表示するには、JavaScriptを有効に する必要があります 次の項目 3.6.12 - サービス内部トラフィックポリシー FEATURE STATE:
Kubernetes v1.21 [alpha]
サービス内部トラフィックポリシー を使用すると、内部トラフィック制限により、トラフィックが発信されたノード内のエンドポイントにのみ内部トラフィックをルーティングできます。
ここでの「内部」トラフィックとは、現在のクラスターのPodから発信されたトラフィックを指します。これは、コストを削減し、パフォーマンスを向上させるのに役立ちます。
ServiceInternalTrafficPolicyの使用 ServiceInternalTrafficPolicy フィーチャーゲート を有効にすると、.spec.internalTrafficPolicyをLocalに設定して、Service 内部のみのトラフィックポリシーを有効にすることができます。
これにより、kube-proxyは、クラスター内部トラフィックにノードローカルエンドポイントのみを使用するようになります。
備考: 特定のServiceのエンドポイントがないノード上のPodの場合、Serviceに他のノードのエンドポイントがある場合でも、Serviceは(このノード上のポッドの)エンドポイントがゼロであるかのように動作します。次の例は、.spec.internalTrafficPolicyをLocalに設定した場合のServiceの様子を示しています:
apiVersion : v1
kind : Service
metadata :
name : my-service
spec :
selector :
app : MyApp
ports :
- protocol : TCP
port : 80
targetPort : 9376
internalTrafficPolicy : Local
使い方 kube-proxyは、spec.internalTrafficPolicyの設定に基づいて、ルーティング先のエンドポイントをフィルタリングします。
spec.internalTrafficPolicyがLocalであれば、ノードのローカルエンドポイントにのみルーティングできるようにします。Clusterまたは未設定であればすべてのエンドポイントにルーティングできるようにします。
ServiceInternalTrafficPolicyフィーチャーゲート が有効な場合、spec.internalTrafficPolicyのデフォルトはClusterです。
制約 ServiceでexternalTrafficPolicyがLocalに設定されている場合、サービス内部トラフィックポリシーは使用されません。同じServiceだけではなく、同じクラスター内の異なるServiceで両方の機能を使用することができます。 次の項目
3.7 - ストレージ 3.7.1 - ボリューム コンテナ内のディスク上のファイルは一時的なものであり、コンテナ内で実行する場合、重要なアプリケーションでいくつかの問題が発生します。1つの問題は、コンテナがクラッシュしたときにファイルが失われることです。kubeletはコンテナを再起動しますが、クリーンな状態です。
2番目の問題は、Podで一緒に実行されているコンテナ間でファイルを共有するときに発生します。
Kubernetesボリューム の抽象化は、これらの問題の両方を解決します。
Pod に精通していることをお勧めします。
背景 Dockerにはボリューム の概念がありますが、多少緩く、管理も不十分です。Dockerボリュームは、ディスク上または別のコンテナ内のディレクトリです。Dockerはボリュームドライバーを提供しますが、機能は多少制限されています。
Kubernetesは多くの種類のボリュームをサポートしています。
Pod は任意の数のボリュームタイプを同時に使用できます。
エフェメラルボリュームタイプにはPodの存続期間がありますが、永続ボリュームはPodの存続期間を超えて存在します。
Podが存在しなくなると、Kubernetesはエフェメラルボリュームを破棄します。ただしKubernetesは永続ボリュームを破棄しません。
特定のPod内のあらゆる種類のボリュームについて、データはコンテナの再起動後も保持されます。
コアとなるボリュームはディレクトリであり、Pod内のコンテナからアクセスできるデータが含まれている可能性があります。
ディレクトリがどのように作成されるか、それをバックアップするメディア、およびそのコンテンツは、使用する特定のボリュームタイプによって決まります。
ボリュームを使用するには、.spec.volumesでPodに提供するボリュームを指定し、.spec.containers[*].volumeMountsでそれらのボリュームをコンテナにマウントする場所を宣言します。
コンテナ内のプロセスはコンテナイメージ の初期コンテンツと、コンテナ内にマウントされたボリューム(定義されている場合)で構成されるファイルシステムビューを確認します。
プロセスは、コンテナイメージのコンテンツと最初に一致するルートファイルシステムを確認します。
そのファイルシステム階層内への書き込みは、もし許可されている場合、後続のファイルシステムアクセスを実行するときにそのプロセスが表示する内容に影響します。
ボリュームはイメージ内の指定されたパス へマウントされます。
Pod内で定義されたコンテナごとに、コンテナが使用する各ボリュームをマウントする場所を個別に指定する必要があります。
ボリュームは他のボリューム内にマウントできません(ただし、関連するメカニズムについては、subPathの使用 を参照してください)。
またボリュームには、別のボリューム内の何かへのハードリンクを含めることはできません。
ボリュームの種類 Kubernetesはいくつかのタイプのボリュームをサポートしています。
awsElasticBlockStore awsElasticBlockStoreボリュームは、Amazon Web Services(AWS)EBSボリューム をPodにマウントします。
Podを削除すると消去されるemptyDirとは異なり、EBSボリュームのコンテンツは保持されたままボリュームはアンマウントされます。
これは、EBSボリュームにデータを事前入力でき、データをPod間で共有できることを意味します。
備考: 使用する前に、aws ec2 create-volumeまたはAWSAPIを使用してEBSボリュームを作成する必要があります。awsElasticBlockStoreボリュームを使用する場合、いくつかの制限があります。
Podが実行されているノードはAWS EC2インスタンスである必要があります これらのインスタンスは、EBSボリュームと同じリージョンおよびアベイラビリティーゾーンにある必要があります EBSは、ボリュームをマウントする単一のEC2インスタンスのみをサポートします AWS EBSボリュームの作成 PodでEBSボリュームを使用する前に作成する必要があります。
aws ec2 create-volume --availability-zone= eu-west-1a --size= 10 --volume-type= gp2
ゾーンがクラスターを立ち上げたゾーンと一致していることを確認してください。サイズとEBSボリュームタイプが使用に適していることを確認してください。
AWS EBS設定例 apiVersion : v1
kind : Pod
metadata :
name : test-ebs
spec :
containers :
- image : registry.k8s.io/test-webserver
name : test-container
volumeMounts :
- mountPath : /test-ebs
name : test-volume
volumes :
- name : test-volume
# This AWS EBS volume must already exist.
awsElasticBlockStore :
volumeID : "<volume id>"
fsType : ext4
EBSボリュームがパーティション化されている場合は、オプションのフィールドpartition: "<partition number>"を指定して、マウントするパーティションを指定できます。
AWS EBS CSIの移行 FEATURE STATE:
Kubernetes v1.17 [beta]
awsElasticBlockStoreのCSIMigration機能を有効にすると、すべてのプラグイン操作が既存のツリー内プラグインからebs.csi.aws.comContainer Storage Interface(CSI)ドライバーにリダイレクトされます。
この機能を使用するには、AWS EBS CSIドライバー がクラスターにインストールされ、CSIMigrationとCSIMigrationAWSのbeta機能が有効になっている必要があります。
AWS EBS CSIの移行の完了 FEATURE STATE:
Kubernetes v1.17 [alpha]
awsElasticBlockStoreストレージプラグインがコントローラーマネージャーとkubeletによって読み込まれないようにするには、InTreePluginAWSUnregisterフラグをtrueに設定します。
azureDisk azureDiskボリュームタイプは、MicrosoftAzureデータディスク をPodにマウントします。
詳細については、azureDiskボリュームプラグイン
azureDisk CSIの移行 FEATURE STATE:
Kubernetes v1.19 [beta]
azureDiskのCSIMigration機能を有効にすると、すべてのプラグイン操作が既存のツリー内プラグインからdisk.csi.azure.comContainer Storage Interface(CSI)ドライバーにリダイレクトされます。
この機能を利用するには、クラスターにAzure Disk CSI Driver をインストールし、CSIMigrationおよびCSIMigrationAzureDisk機能を有効化する必要があります。
azureFile azureFileボリュームタイプは、Microsoft Azureファイルボリューム(SMB 2.1および3.0)をPodにマウントします。
詳細についてはazureFile volume plugin
azureFile CSIの移行 FEATURE STATE:
Kubernetes v1.21 [beta]
zureFileのCSIMigration機能を有効にすると、既存のツリー内プラグインからfile.csi.azure.comContainer Storage Interface(CSI)Driverへすべてのプラグイン操作がリダイレクトされます。
この機能を利用するには、クラスターにAzure File CSI Driver をインストールし、CSIMigrationおよびCSIMigrationAzureFileフィーチャーゲート を有効化する必要があります。
Azure File CSIドライバーは、異なるfsgroupで同じボリュームを使用することをサポートしていません。AzurefileCSIの移行が有効になっている場合、異なるfsgroupで同じボリュームを使用することはまったくサポートされません。
cephfs cephfsボリュームを使用すると、既存のCephFSボリュームをPodにマウントすることができます。
Podを取り外すと消去されるemptyDirとは異なり、cephfsボリュームは内容を保持したまま単にアンマウントされるだけです。
つまりcephfsボリュームにあらかじめデータを入れておき、そのデータをPod間で共有することができます。
cephfsボリュームは複数の書き込み元によって同時にマウントすることができます。
備考: 事前に共有をエクスポートした状態で、自分のCephサーバーを起動しておく必要があります。詳細についてはCephFSの例 を参照してください。
cinder
備考: KubernetesはOpenStackクラウドプロバイダーで構成する必要があります。cinderボリュームタイプは、PodにOpenStackのCinderのボリュームをマウントするために使用されます。
Cinderボリュームの設定例 apiVersion : v1
kind : Pod
metadata :
name : test-cinder
spec :
containers :
- image : registry.k8s.io/test-webserver
name : test-cinder-container
volumeMounts :
- mountPath : /test-cinder
name : test-volume
volumes :
- name : test-volume
# This OpenStack volume must already exist.
cinder :
volumeID : "<volume id>"
fsType : ext4
OpenStack CSIの移行 FEATURE STATE:
Kubernetes v1.21 [beta]
CinderのCSIMigration機能は、Kubernetes1.21ではデフォルトで有効になっています。
既存のツリー内プラグインからのすべてのプラグイン操作をcinder.csi.openstack.orgContainer Storage Interface(CSI) Driverへリダイレクトします。
OpenStack Cinder CSIドライバー をクラスターにインストールする必要があります。
CSIMigrationOpenStackフィーチャーゲート をfalseに設定すると、クラスターのCinder CSIマイグレーションを無効化することができます。
CSIMigrationOpenStack機能を無効にすると、ツリー内のCinderボリュームプラグインがCinderボリュームのストレージ管理のすべての側面に責任を持つようになります。
configMap ConfigMap は構成データをPodに挿入する方法を提供します。
ConfigMapに格納されたデータは、タイプconfigMapのボリュームで参照され、Podで実行されているコンテナ化されたアプリケーションによって使用されます。
ConfigMapを参照するときは、ボリューム内のConfigMapの名前を指定します。
ConfigMapの特定のエントリに使用するパスをカスタマイズできます。
次の設定は、log-config ConfigMapをconfigmap-podというPodにマウントする方法を示しています。
apiVersion : v1
kind : Pod
metadata :
name : configmap-pod
spec :
containers :
- name : test
image : busybox
volumeMounts :
- name : config-vol
mountPath : /etc/config
volumes :
- name : config-vol
configMap :
name : log-config
items :
- key : log_level
path : log_level.conf
log-configConfigMapはボリュームとしてマウントされ、そのlog_levelエントリに格納されているすべてのコンテンツは、パス/etc/config/log_level.confのPodにマウントされます。
このパスはボリュームのmountPathとlog_levelをキーとするpathから派生することに注意してください。
備考: 使用する前にConfigMap を作成する必要があります。
subPath
テキストデータはUTF-8文字エンコードを使用してファイルとして公開されます。その他の文字エンコードにはbinaryDataを使用します。
downwardAPI downwardAPIボリュームは、アプリケーションへのdownward APIデータを利用できるようになります。ディレクトリをマウントし、要求されたデータをプレーンテキストファイルに書き込みます。
備考: subPathボリュームマウントとしてdownward APIを使用するコンテナは、downward APIの更新を受け取りません。
詳細についてはdownward API example を参照してください。
emptyDir emptyDirボリュームはPodがノードに割り当てられたときに最初に作成され、そのPodがそのノードで実行されている限り存在します。
名前が示すようにemptyDirボリュームは最初は空です。
Pod内のすべてのコンテナはemptyDirボリューム内の同じファイルを読み書きできますが、そのボリュームは各コンテナで同じパスまたは異なるパスにマウントされることがあります。
何らかの理由でPodがノードから削除されると、emptyDir内のデータは永久に削除されます。
備考: コンテナがクラッシュしても、ノードからPodが削除されることはありません 。emptyDirボリューム内のデータは、コンテナのクラッシュしても安全です。emptyDirのいくつかの用途は次の通りです。
ディスクベースのマージソートなどのスクラッチスペース クラッシュからの回復のための長い計算のチェックポイント Webサーバーコンテナがデータを提供している間にコンテンツマネージャコンテナがフェッチするファイルを保持する 環境に応じて、emptyDirボリュームは、ディスクやSSD、ネットワークストレージなど、ノードをバックアップするあらゆる媒体に保存されます。
ただし、emptyDir.mediumフィールドを"Memory"に設定すると、Kubernetesは代わりにtmpfs(RAMベースのファイルシステム)をマウントします。
tmpfsは非常に高速ですが、ディスクと違ってノードのリブート時にクリアされ、書き込んだファイルはコンテナのメモリー制限にカウントされることに注意してください。
備考: SizeMemoryBackedVolumesフィーチャーゲート が有効な場合、メモリーバックアップボリュームにサイズを指定することができます。
サイズが指定されていない場合、メモリーでバックアップされたボリュームは、Linuxホストのメモリーの50%のサイズになります。
emptyDirの設定例 apiVersion : v1
kind : Pod
metadata :
name : test-pd
spec :
containers :
- image : registry.k8s.io/test-webserver
name : test-container
volumeMounts :
- mountPath : /cache
name : cache-volume
volumes :
- name : cache-volume
emptyDir : {}
fc (fibre channel) fcボリュームタイプを使用すると、既存のファイバーチャネルブロックストレージボリュームをPodにマウントできます。
targetWWNsボリューム構成のパラメーターを使用して、単一または複数のターゲットWorld Wide Name(WWN)を指定できます。
複数のWWNが指定されている場合、targetWWNは、それらのWWNがマルチパス接続からのものであると想定します。
備考: Kubernetesホストがアクセスできるように、事前にこれらのLUN(ボリューム)をターゲットWWNに割り当ててマスクするようにFCSANゾーニングを構成する必要があります。flocker (非推奨) Flocker はオープンソースのクラスター化されたコンテナデータボリュームマネージャーです。
Flockerは、さまざまなストレージバックエンドに支えられたデータボリュームの管理とオーケストレーションを提供します。
flockerボリュームを使用すると、FlockerデータセットをPodにマウントできます。
もしデータセットがまだFlockerに存在しない場合は、まずFlocker CLIかFlocker APIを使ってデータセットを作成する必要があります。
データセットがすでに存在する場合は、FlockerによってPodがスケジュールされているノードに再アタッチされます。
これは、必要に応じてPod間でデータを共有できることを意味します。
備考: 使用する前に、独自のFlockerインストールを実行する必要があります。詳細についてはFlocker example を参照してください。
gcePersistentDisk gcePersistentDiskボリュームは、Google Compute Engine (GCE)の永続ディスク (PD)をPodにマウントします。
Podを取り外すと消去されるemptyDirとは異なり、PDの内容は保持されボリュームは単にアンマウントされるだけです。これはPDにあらかじめデータを入れておくことができ、そのデータをPod間で共有できることを意味します。
備考: gcloudを使用する前に、またはGCE APIまたはUIを使用してPDを作成する必要があります。gcePersistentDiskを使用する場合、いくつかの制限があります。
Podが実行されているノードはGCE VMである必要があります これらのVMは、永続ディスクと同じGCEプロジェクトおよびゾーンに存在する必要があります GCE永続ディスクの機能の1つは、永続ディスクへの同時読み取り専用アクセスです。gcePersistentDiskボリュームを使用すると、複数のコンシューマーが永続ディスクを読み取り専用として同時にマウントできます。
これはPDにデータセットを事前入力してから、必要な数のPodから並行して提供できることを意味します。
残念ながらPDは読み取り/書き込みモードで1つのコンシューマーのみがマウントできます。同時書き込みは許可されていません。
PDが読み取り専用であるか、レプリカ数が0または1でない限り、ReplicaSetによって制御されるPodでGCE永続ディスクを使用すると失敗します。
GCE永続ディスクの作成 PodでGCE永続ディスクを使用する前に、それを作成する必要があります。
gcloud compute disks create --size= 500GB --zone= us-central1-a my-data-disk
GCE永続ディスクの設定例 apiVersion : v1
kind : Pod
metadata :
name : test-pd
spec :
containers :
- image : registry.k8s.io/test-webserver
name : test-container
volumeMounts :
- mountPath : /test-pd
name : test-volume
volumes :
- name : test-volume
# This GCE PD must already exist.
gcePersistentDisk :
pdName : my-data-disk
fsType : ext4
リージョン永続ディスク リージョン永続ディスク 機能を使用すると、同じリージョン内の2つのゾーンで使用できる永続ディスクを作成できます。
この機能を使用するには、ボリュームをPersistentVolumeとしてプロビジョニングする必要があります。Podから直接ボリュームを参照することはサポートされていません。
リージョンPD PersistentVolumeを手動でプロビジョニングする GCE PDのStorageClass を使用して動的プロビジョニングが可能です。
SPDPersistentVolumeを作成する前に、永続ディスクを作成する必要があります。
gcloud compute disks create --size= 500GB my-data-disk
--region us-central1
--replica-zones us-central1-a,us-central1-b
リージョン永続ディスクの設定例 apiVersion : v1
kind : PersistentVolume
metadata :
name : test-volume
spec :
capacity :
storage : 400Gi
accessModes :
- ReadWriteOnce
gcePersistentDisk :
pdName : my-data-disk
fsType : ext4
nodeAffinity :
required :
nodeSelectorTerms :
- matchExpressions :
# failure-domain.beta.kubernetes.io/zone should be used prior to 1.21
- key : topology.kubernetes.io/zone
operator : In
values :
- us-central1-a
- us-central1-b
GCE CSIの移行 FEATURE STATE:
Kubernetes v1.17 [beta]
GCE PDのCSIMigration機能を有効にすると、すべてのプラグイン操作が既存のツリー内プラグインからpd.csi.storage.gke.ioContainer Storage Interface (CSI) Driverにリダイレクトされるようになります。
この機能を使用するには、クラスターにGCE PD CSI Driver がインストールされ、CSIMigrationとCSIMigrationGCEのbeta機能が有効になっている必要があります。
GCE CSIの移行の完了 FEATURE STATE:
Kubernetes v1.21 [alpha]
gcePersistentDiskストレージプラグインがコントローラーマネージャーとkubeletによって読み込まれないようにするには、InTreePluginGCEUnregisterフラグをtrueに設定します。
gitRepo(非推奨) 警告: gitRepoボリュームタイプは非推奨です。gitリポジトリを使用してコンテナをプロビジョニングするには、Gitを使用してリポジトリのクローンを作成するInitContainerに
EmptyDir をマウントしてから、Podのコンテナに
EmptyDir をマウントします。
gitRepoボリュームは、ボリュームプラグインの一例です。このプラグインは空のディレクトリをマウントし、そのディレクトリにgitリポジトリをクローンしてPodで使えるようにします。
gitRepoボリュームの例を次に示します。
apiVersion : v1
kind : Pod
metadata :
name : server
spec :
containers :
- image : nginx
name : nginx
volumeMounts :
- mountPath : /mypath
name : git-volume
volumes :
- name : git-volume
gitRepo :
repository : "git@somewhere:me/my-git-repository.git"
revision : "22f1d8406d464b0c0874075539c1f2e96c253775"
glusterfs glusterfsボリュームはGlusterfs (オープンソースのネットワークファイルシステム)ボリュームをPodにマウントできるようにするものです。
Podを取り外すと消去されるemptyDirとは異なり、glusterfsボリュームの内容は保持され、単にアンマウントされるだけです。
これは、glusterfsボリュームにデータを事前に入力でき、データをPod間で共有できることを意味します。
GlusterFSは複数のライターが同時にマウントすることができます。
備考: GlusterFSを使用するためには、事前にGlusterFSのインストールを実行しておく必要があります。詳細についてはGlusterFSの例 を参照してください。
hostPath 警告: HostPathボリュームには多くのセキュリティリスクがあり、可能な場合はHostPathの使用を避けることがベストプラクティスです。HostPathボリュームを使用する必要がある場合は、必要なファイルまたはディレクトリのみにスコープを設定し、読み取り専用としてマウントする必要があります。
AdmissionPolicyによって特定のディレクトリへのHostPathアクセスを制限する場合、ポリシーを有効にするためにvolumeMountsはreadOnlyマウントを使用するように要求されなければなりません。
hostPathボリュームは、ファイルまたはディレクトリをホストノードのファイルシステムからPodにマウントします。
これはほとんどのPodに必要なものではありませんが、一部のアプリケーションには強力なエスケープハッチを提供します。
たとえばhostPathのいくつかの使用法は次のとおりです。
Dockerの内部にアクセスする必要があるコンテナを実行する場合:hostPathに/var/lib/dockerを使用します。 コンテナ内でcAdvisorを実行する場合:hostPathに/sysを指定します。 Podが実行される前に、与えられたhostPathが存在すべきかどうか、作成すべきかどうか、そして何として存在すべきかを指定できるようにします。 必須のpathプロパティに加えて、オプションでhostPathボリュームにtypeを指定することができます。
フィールドtypeでサポートされている値は次のとおりです。
値 ふるまい 空の文字列(デフォルト)は下位互換性のためです。つまり、hostPathボリュームをマウントする前にチェックは実行されません。 DirectoryOrCreate指定されたパスに何も存在しない場合、必要に応じて、権限を0755に設定し、Kubeletと同じグループと所有権を持つ空のディレクトリが作成されます。 Directory指定されたパスにディレクトリが存在する必要があります。 FileOrCreate指定されたパスに何も存在しない場合、必要に応じて、権限を0644に設定し、Kubeletと同じグループと所有権を持つ空のファイルが作成されます。 File指定されたパスにファイルが存在する必要があります。 SocketUNIXソケットは、指定されたパスに存在する必要があります。 CharDeviceキャラクターデバイスは、指定されたパスに存在する必要があります。 BlockDeviceブロックデバイスは、指定されたパスに存在する必要があります。
このタイプのボリュームを使用するときは、以下の理由のため注意してください。
HostPath は、特権的なシステム認証情報(Kubeletなど)や特権的なAPI(コンテナランタイムソケットなど)を公開する可能性があり、コンテナのエスケープやクラスターの他の部分への攻撃に利用される可能性があります。 同一構成のPod(PodTemplateから作成されたものなど)は、ノード上のファイルが異なるため、ノードごとに動作が異なる場合があります。 ホスト上に作成されたファイルやディレクトリは、rootでしか書き込みができません。特権コンテナ 内でrootとしてプロセスを実行するか、ホスト上のファイルのパーミッションを変更してhostPathボリュームに書き込みができるようにする必要があります。 hostPathの設定例 apiVersion : v1
kind : Pod
metadata :
name : test-pd
spec :
containers :
- image : registry.k8s.io/test-webserver
name : test-container
volumeMounts :
- mountPath : /test-pd
name : test-volume
volumes :
- name : test-volume
hostPath :
# directory location on host
path : /data
# this field is optional
type : Directory
注意: FileOrCreateモードでは、ファイルの親ディレクトリは作成されません。マウントされたファイルの親ディレクトリが存在しない場合、Podは起動に失敗します。
このモードが確実に機能するようにするには、
FileOrCreate構成に示すように、ディレクトリとファイルを別々にマウントしてみてください。
hostPath FileOrCreateの設定例 apiVersion : v1
kind : Pod
metadata :
name : test-webserver
spec :
containers :
- name : test-webserver
image : registry.k8s.io/test-webserver:latest
volumeMounts :
- mountPath : /var/local/aaa
name : mydir
- mountPath : /var/local/aaa/1.txt
name : myfile
volumes :
- name : mydir
hostPath :
# Ensure the file directory is created.
path : /var/local/aaa
type : DirectoryOrCreate
- name : myfile
hostPath :
path : /var/local/aaa/1.txt
type : FileOrCreate
iscsi iscsiボリュームは、既存のiSCSI(SCSI over IP)ボリュームをPodにマウントすることができます。
Podを取り外すと消去されるemptyDirとは異なり、iscsiボリュームの内容は保持され、単にアンマウントされるだけです。
つまり、iscsiボリュームにはあらかじめデータを入れておくことができ、そのデータをPod間で共有することができるのです。
備考: 使用する前に、ボリュームを作成したiSCSIサーバーを起動する必要があります。iSCSIの特徴として、複数のコンシューマーから同時に読み取り専用としてマウントできることが挙げられます。
つまり、ボリュームにあらかじめデータセットを入れておき、必要な数のPodから並行してデータを提供することができます。
残念ながら、iSCSIボリュームは1つのコンシューマによってのみ読み書きモードでマウントすることができます。
同時に書き込みを行うことはできません。
local localボリュームは、ディスク、パーティション、ディレクトリなど、マウントされたローカルストレージデバイスを表します。
ローカルボリュームは静的に作成されたPersistentVolumeとしてのみ使用できます。動的プロビジョニングはサポートされていません。
hostPathボリュームと比較して、localボリュームは手動でノードにPodをスケジューリングすることなく、耐久性と移植性に優れた方法で使用することができます。
システムはPersistentVolume上のノードアフィニティーを見ることで、ボリュームのノード制約を認識します。
ただし、localボリュームは、基盤となるノードの可用性に左右されるため、すべてのアプリケーションに適しているわけではありません。
ノードが異常になると、Podはlocalボリュームにアクセスできなくなります。
このボリュームを使用しているPodは実行できません。localボリュームを使用するアプリケーションは、基盤となるディスクの耐久性の特性に応じて、この可用性の低下と潜在的なデータ損失に耐えられる必要があります。
次の例では、localボリュームとnodeAffinityを使用したPersistentVolumeを示しています。
apiVersion : v1
kind : PersistentVolume
metadata :
name : example-pv
spec :
capacity :
storage : 100Gi
volumeMode : Filesystem
accessModes :
- ReadWriteOnce
persistentVolumeReclaimPolicy : Delete
storageClassName : local-storage
local :
path : /mnt/disks/ssd1
nodeAffinity :
required :
nodeSelectorTerms :
- matchExpressions :
- key : kubernetes.io/hostname
operator : In
values :
- example-node
ローカルボリュームを使用する場合は、PersistentVolume nodeAffinityを設定する必要があります。
KubernetesのスケジューラはPersistentVolume nodeAffinityを使用して、これらのPodを正しいノードにスケジューリングします。
PersistentVolume volumeModeを(デフォルト値の「Filesystem」ではなく)「Block」に設定して、ローカルボリュームをrawブロックデバイスとして公開できます。
ローカルボリュームを使用する場合、volumeBindingModeをWaitForFirstConsumerに設定したStorageClassを作成することをお勧めします。
詳細については、local StorageClass の例を参照してください。
ボリュームバインディングを遅延させると、PersistentVolumeClaimバインディングの決定が、ノードリソース要件、ノードセレクター、Podアフィニティ、Podアンチアフィニティなど、Podが持つ可能性のある他のノード制約も含めて評価されるようになります。
ローカルボリュームのライフサイクルの管理を改善するために、外部の静的プロビジョナーを個別に実行できます。
このプロビジョナーはまだ動的プロビジョニングをサポートしていないことに注意してください。
外部ローカルプロビジョナーの実行方法の例については、ローカルボリュームプロビジョナーユーザーガイド を参照してください。
備考: ボリュームのライフサイクルを管理するために外部の静的プロビジョナーが使用されていない場合、ローカルのPersistentVolumeは、ユーザーによる手動のクリーンアップと削除を必要とします。nfs nfsボリュームは、既存のNFS(Network File System)共有をPodにマウントすることを可能にします。Podを取り外すと消去されるemptyDirとは異なり、nfsボリュームのコンテンツは保存され、単にアンマウントされるだけです。
つまり、NFSボリュームにはあらかじめデータを入れておくことができ、そのデータをPod間で共有することができます。
NFSは複数のライターによって同時にマウントすることができます。
備考: 使用する前に、共有をエクスポートしてNFSサーバーを実行する必要があります。persistentVolumeClaim PersistentVolumeClaimボリュームはPersistentVolume をPodにマウントするために使用されます。
PersistentVolumeClaimは、ユーザが特定のクラウド環境の詳細を知らなくても、耐久性のあるストレージ(GCE永続ディスクやiSCSIボリュームなど)を「要求」するための方法です。
詳細についてはPersistentVolume を参照してください。
portworxVolume portworxVolumeは、Kubernetesとハイパーコンバージドで動作するエラスティックブロックストレージレイヤーです。
Portworx は、サーバー内のストレージをフィンガープリントを作成し、機能に応じて階層化し、複数のサーバーにまたがって容量を集約します。
Portworxは、仮想マシンまたはベアメタルのLinuxノードでゲスト内動作します。
portworxVolumeはKubernetesを通して動的に作成することができますが、事前にプロビジョニングしてPodの中で参照することもできます。
以下は、事前にプロビジョニングされたPortworxボリュームを参照するPodの例です。
apiVersion : v1
kind : Pod
metadata :
name : test-portworx-volume-pod
spec :
containers :
- image : registry.k8s.io/test-webserver
name : test-container
volumeMounts :
- mountPath : /mnt
name : pxvol
volumes :
- name : pxvol
# This Portworx volume must already exist.
portworxVolume :
volumeID : "pxvol"
fsType : "<fs-type>"
備考: Podで使用する前に、pxvolという名前の既存のPortworxVolumeがあることを確認してください。投影 投影ボリュームは、複数の既存のボリュームソースを同じディレクトリにマッピングします。
詳細については投影ボリューム を参照してください。
quobyte(非推奨) quobyteボリュームは、既存のQuobyte ボリュームをPodにマウントすることができます。
備考: 使用する前にQuobyteをセットアップして、ボリュームを作成した状態で動作させる必要があります。CSIは、Kubernetes内部でQuobyteボリュームを使用するための推奨プラグインです。
QuobyteのGitHubプロジェクトには、CSIを使用してQuobyteをデプロイするための手順 と例があります
rbd rbdボリュームはRados Block Device (RBD)ボリュームをPodにマウントすることを可能にします。
Podを取り外すと消去されるemptyDirとは異なり、rbdボリュームの内容は保存され、ボリュームはアンマウントされます。つまり、RBDボリュームにはあらかじめデータを入れておくことができ、そのデータをPod間で共有することができるのです。
備考: RBDを使用する前に、Cephのインストールが実行されている必要があります。RBDの特徴として、複数のコンシューマーから同時に読み取り専用としてマウントできることが挙げられます。
つまり、ボリュームにあらかじめデータセットを入れておき、必要な数のPodから並行して提供することができるのです。
残念ながら、RBDボリュームは1つのコンシューマーによってのみ読み書きモードでマウントすることができます。
同時に書き込みを行うことはできません。
詳細についてはRBDの例 を参照してください。
RBD CSIの移行 FEATURE STATE:
Kubernetes v1.23 [alpha]
RBDのCSIMigration機能を有効にすると、既存のツリー内プラグインからrbd.csi.ceph.comCSI ドライバーにすべてのプラグイン操作がリダイレクトされます。
この機能を使用するには、クラスターにCeph CSIドライバー をインストールし、CSIMigrationおよびcsiMigrationRBDフィーチャーゲート を有効にしておく必要があります。
備考: ストレージを管理するKubernetesクラスターオペレーターとして、RBD CSIドライバーへの移行を試みる前に完了する必要のある前提条件は次のとおりです。
Ceph CSIドライバー(rbd.csi.ceph.com)v3.5.0以降をKubernetesクラスターにインストールする必要があります。 CSIドライバーの動作に必要なパラメーターとしてclusterIDフィールドがありますが、ツリー内StorageClassにはmonitorsフィールドがあるため、Kubernetesストレージ管理者はCSI config mapでモニターハッシュ(例:#echo -n '<monitors_string>' | md5sum)に基づいたclusterIDを作成し、モニターをこのclusterID設定の下に保持しなければなりません。 また、ツリー内StorageclassのadminIdの値がadminと異なる場合、ツリー内Storageclassに記載されているadminSecretNameにadminIdパラメーター値のbase64値をパッチしなければなりませんが、それ以外はスキップすることが可能です。 secret secretボリュームは、パスワードなどの機密情報をPodに渡すために使用します。
Kubernetes APIにsecretを格納し、Kubernetesに直接結合することなくPodが使用するファイルとしてマウントすることができます。
secretボリュームはtmpfs(RAM-backed filesystem)によってバックアップされるため、不揮発性ストレージに書き込まれることはありません。
備考: 使用する前にKubernetes APIでSecretを作成する必要があります。備考: SubPathボリュームマウントとしてSecretを使用しているコンテナは、Secretの更新を受け取りません。
詳細についてはSecretの設定 を参照してください。
storageOS(非推奨) storageosボリュームを使用すると、既存のStorageOS ボリュームをPodにマウントできます。
StorageOSは、Kubernetes環境内でコンテナとして実行され、Kubernetesクラスター内の任意のノードからローカルストレージまたは接続されたストレージにアクセスできるようにします。
データを複製してノードの障害から保護することができます。シンプロビジョニングと圧縮により使用率を向上させ、コストを削減できます。
根本的にStorageOSは、コンテナにブロックストレージを提供しファイルシステムからアクセスできるようにします。
StorageOS Containerは64ビットLinuxを必要とし、追加の依存関係はありません。
無償の開発者ライセンスが利用可能です。
注意: StorageOSボリュームにアクセスする、またはプールにストレージ容量を提供する各ノードでStorageOSコンテナを実行する必要があります。
インストール手順については、
StorageOSドキュメント を参照してください。
次の例は、StorageOSを使用したPodの設定です。
apiVersion : v1
kind : Pod
metadata :
labels :
name : redis
role : master
name : test-storageos-redis
spec :
containers :
- name : master
image : kubernetes/redis:v1
env :
- name : MASTER
value : "true"
ports :
- containerPort : 6379
volumeMounts :
- mountPath : /redis-master-data
name : redis-data
volumes :
- name : redis-data
storageos :
# The `redis-vol01` volume must already exist within StorageOS in the `default` namespace.
volumeName : redis-vol01
fsType : ext4
StorageOS、動的プロビジョニング、およびPersistentVolumeClaimの詳細については、StorageOSの例 を参照してください。
vsphereVolume 備考: KubernetesvSphereクラウドプロバイダーを設定する必要があります。クラウドプロバイダーの設定については、
vSphere入門ガイド を参照してください。
vsphereVolumeは、vSphereVMDKボリュームをPodにマウントするために使用されます。
ボリュームの内容は、マウント解除されたときに保持されます。VMFSとVSANの両方のデータストアをサポートします。
備考: Podで使用する前に、次のいずれかの方法を使用してvSphereVMDKボリュームを作成する必要があります。Creating a VMDK volume 次のいずれかの方法を選択して、VMDKを作成します。
最初にESXにSSHで接続し、次に以下のコマンドを使用してVMDKを作成します。
vmkfstools -c 2G /vmfs/volumes/DatastoreName/volumes/myDisk.vmdk
次のコマンドを使用してVMDKを作成します。
vmware-vdiskmanager -c -t 0 -s 40GB -a lsilogic myDisk.vmdk
vSphere VMDKの設定例 apiVersion : v1
kind : Pod
metadata :
name : test-vmdk
spec :
containers :
- image : registry.k8s.io/test-webserver
name : test-container
volumeMounts :
- mountPath : /test-vmdk
name : test-volume
volumes :
- name : test-volume
# This VMDK volume must already exist.
vsphereVolume :
volumePath : "[DatastoreName] volumes/myDisk"
fsType : ext4
詳細についてはvSphereボリューム の例を参照してください。
vSphere CSIの移行 FEATURE STATE:
Kubernetes v1.19 [beta]
vsphereVolumeのCSIMigration機能を有効にすると、既存のツリー内プラグインからcsi.vsphere.vmware.comCSI ドライバーにすべてのプラグイン操作がリダイレクトされます。
この機能を使用するには、クラスターにvSphere CSIドライバー がインストールされ、CSIMigrationおよびCSIMigrationvSphereフィーチャーゲート が有効になっていなければなりません。
また、vSphere vCenter/ESXiのバージョンが7.0u1以上、HWのバージョンがVM version 15以上であることが条件です。
備考: 組み込みのvsphereVolumeプラグインの次のStorageClassパラメーターは、vSphere CSIドライバーでサポートされていません。
diskformathostfailurestotolerateforceprovisioningcachereservationdiskstripesobjectspacereservationiopslimitこれらのパラメーターを使用して作成された既存のボリュームはvSphere CSIドライバーに移行されますが、vSphere CSIドライバーで作成された新しいボリュームはこれらのパラメーターに従わないことに注意してください。
vSphere CSIの移行の完了 FEATURE STATE:
Kubernetes v1.19 [beta]
vsphereVolumeプラグインがコントローラーマネージャーとkubeletによって読み込まれないようにするには、InTreePluginvSphereUnregister機能フラグをtrueに設定する必要があります。すべてのワーカーノードにcsi.vsphere.vmware.comCSI ドライバーをインストールする必要があります。
Portworx CSIの移行 FEATURE STATE:
Kubernetes v1.23 [alpha]
PortworxのCSIMigration機能が追加されましたが、Kubernetes 1.23ではAlpha状態であるため、デフォルトで無効になっています。
すべてのプラグイン操作を既存のツリー内プラグインからpxd.portworx.comContainer Storage Interface(CSI)ドライバーにリダイレクトします。
Portworx CSIドライバー をクラスターにインストールする必要があります。
この機能を有効にするには、kube-controller-managerとkubeletでCSIMigrationPortworx=trueを設定します。
subPathの使用 1つのPodで複数の用途に使用するために1つのボリュームを共有すると便利な場合があります。
volumeMounts[*].subPathプロパティは、ルートではなく、参照されるボリューム内のサブパスを指定します。
次の例は、単一の共有ボリュームを使用してLAMPスタック(Linux Apache MySQL PHP)でPodを構成する方法を示しています。
このサンプルのsubPath構成は、プロダクションでの使用にはお勧めしません。
PHPアプリケーションのコードとアセットはボリュームのhtmlフォルダーにマップされ、MySQLデータベースはボリュームのmysqlフォルダーに保存されます。例えば:
apiVersion : v1
kind : Pod
metadata :
name : my-lamp-site
spec :
containers :
- name : mysql
image : mysql
env :
- name : MYSQL_ROOT_PASSWORD
value : "rootpasswd"
volumeMounts :
- mountPath : /var/lib/mysql
name : site-data
subPath : mysql
- name : php
image : php:7.0-apache
volumeMounts :
- mountPath : /var/www/html
name : site-data
subPath : html
volumes :
- name : site-data
persistentVolumeClaim :
claimName : my-lamp-site-data
拡張された環境変数でのsubPathの使用 FEATURE STATE:
Kubernetes v1.17 [stable]
subPathExprフィールドを使用して、downwart API環境変数からsubPathディレクトリ名を作成します。
subPathプロパティとsubPathExprプロパティは相互に排他的です。
この例では、PodがsubPathExprを使用して、hostPathボリューム/var/log/pods内にpod1というディレクトリを作成します。
hostPathボリュームはdownwardAPIからPod名を受け取ります。
ホストディレクトリ/var/log/pods/pod1は、コンテナ内の/logsにマウントされます。
apiVersion : v1
kind : Pod
metadata :
name : pod1
spec :
containers :
- name : container1
env :
- name : POD_NAME
valueFrom :
fieldRef :
apiVersion : v1
fieldPath : metadata.name
image : busybox
command : [ "sh" , "-c" , "while [ true ]; do echo 'Hello'; sleep 10; done | tee -a /logs/hello.txt" ]
volumeMounts :
- name : workdir1
mountPath : /logs
# The variable expansion uses round brackets (not curly brackets).
subPathExpr : $(POD_NAME)
restartPolicy : Never
volumes :
- name : workdir1
hostPath :
path : /var/log/pods
リソース emptyDirボリュームの記憶媒体(DiskやSSDなど)は、kubeletのルートディレクトリ(通常は/var/lib/kubelet)を保持するファイルシステムの媒体によって決定されます。
emptyDirまたはhostPathボリュームが消費する容量に制限はなく、コンテナ間またはPod間で隔離されることもありません。
リソース仕様を使用したスペースの要求については、リソースの管理方法 を参照してください。
ツリー外のボリュームプラグイン ツリー外ボリュームプラグインにはContainer Storage Interface (CSI)、およびFlexVolume(非推奨)があります。
これらのプラグインによりストレージベンダーは、プラグインのソースコードをKubernetesリポジトリに追加することなく、カスタムストレージプラグインを作成することができます。
以前は、すべてのボリュームプラグインが「ツリー内」にありました。
「ツリー内」のプラグインは、Kubernetesのコアバイナリとともにビルド、リンク、コンパイルされ、出荷されていました。
つまり、Kubernetesに新しいストレージシステム(ボリュームプラグイン)を追加するには、Kubernetesのコアコードリポジトリにコードをチェックインする必要があったのです。
CSIとFlexVolumeはどちらも、ボリュームプラグインをKubernetesコードベースとは独立して開発し、拡張機能としてKubernetesクラスターにデプロイ(インストール)することを可能にします。
ツリー外のボリュームプラグインの作成を検討しているストレージベンダーについては、ボリュームプラグインのFAQ を参照してください。
csi Container Storage Interface (CSI)は、コンテナオーケストレーションシステム(Kubernetesなど)の標準インターフェースを定義して、任意のストレージシステムをコンテナワークロードに公開します。
詳細についてはCSI design proposal を参照してください。
備考: CSI仕様バージョン0.2および0.3のサポートは、Kubernetes v1.13で非推奨になり、将来のリリースで削除される予定です。
備考: CSIドライバーは、すべてのKubernetesリリース間で互換性があるとは限りません。各Kubernetesリリースでサポートされているデプロイ手順と互換性マトリックスについては、特定のCSIドライバーのドキュメントを確認してください。CSI互換のボリュームドライバーがKubernetesクラスター上に展開されると、ユーザーはcsiボリュームタイプを使用して、CSIドライバーによって公開されたボリュームをアタッチまたはマウントすることができます。
csiボリュームはPodで3つの異なる方法によって使用することができます。
ストレージ管理者は、CSI永続ボリュームを構成するために次のフィールドを使用できます。
driver: 使用するボリュームドライバーの名前を指定する文字列。
この値はCSI spec で定義されたCSIドライバーがGetPluginInfoResponseで返す値に対応していなければなりません。
これはKubernetesが呼び出すCSIドライバーを識別するために使用され、CSIドライバーコンポーネントがCSIドライバーに属するPVオブジェクトを識別するために使用されます。volumeHandle: ボリュームを一意に識別する文字列。この値は、CSI spec で定義されたCSIドライバーがCreateVolumeResponseのvolume.idフィールドに返す値に対応していなければなりません。この値はCSIボリュームドライバーのすべての呼び出しで、ボリュームを参照する際にvolume_idとして渡されます。readOnly: ボリュームを読み取り専用として「ControllerPublished」(添付)するかどうかを示すオプションのブール値。デフォルトはfalseです。この値は、ControllerPublishVolumeRequestのreadonlyフィールドを介してCSIドライバーに渡されます。fsType: PVのVolumeModeがFilesystemの場合、このフィールドを使用して、ボリュームのマウントに使用する必要のあるファイルシステムを指定できます。ボリュームがフォーマットされておらず、フォーマットがサポートされている場合、この値はボリュームのフォーマットに使用されます。この値は、ControllerPublishVolumeRequest、NodeStageVolumeRequest、およびNodePublishVolumeRequestのVolumeCapabilityフィールドを介してCSIドライバーに渡されます。volumeAttributes: ボリュームの静的プロパティを指定する、文字列から文字列へのマップ。このマップは、CSI spec で定義されているように、CSIドライバーがCreateVolumeResponseのvolume.attributesフィールドで返すマップと一致しなければなりません。このマップはControllerPublishVolumeRequest,NodeStageVolumeRequest,NodePublishVolumeRequestのvolume_contextフィールドを介してCSIドライバーに渡されます。controllerPublishSecretRef: CSIControllerPublishVolumeおよびControllerUnpublishVolume呼び出しを完了するためにCSIドライバーに渡す機密情報を含むsecretオブジェクトへの参照。このフィールドはオプションで、secretが必要ない場合は空にすることができます。secretに複数のsecretが含まれている場合は、すべてのsecretが渡されます。nodeStageSecretRef: CSINodeStageVolume呼び出しを完了するために、CSIドライバーに渡す機密情報を含むsecretオブジェクトへの参照。このフィールドはオプションで、secretが必要ない場合は空にすることができます。secretに複数のsecretが含まれている場合、すべてのsecretが渡されます。nodePublishSecretRef: CSINodePublishVolume呼び出しを完了するために、CSIドライバーに渡す機密情報を含むsecretオブジェクトへの参照。このフィールドはオプションで、secretが必要ない場合は空にすることができます。secretオブジェクトが複数のsecretを含んでいる場合、すべてのsecretが渡されます。CSI rawブロックボリュームのサポート FEATURE STATE:
Kubernetes v1.18 [stable]
外部のCSIドライバーを使用するベンダーは、Kubernetesワークロードでrawブロックボリュームサポートを実装できます。
CSI固有の変更を行うことなく、通常どおり、rawブロックボリュームをサポートするPersistentVolume/PersistentVolumeClaim を設定できます。
CSIエフェメラルボリューム FEATURE STATE:
Kubernetes v1.16 [beta]
Pod仕様内でCSIボリュームを直接構成できます。この方法で指定されたボリュームは一時的なものであり、Podを再起動しても持続しません。詳細についてはエフェメラルボリューム を参照してください。
CSIドライバーの開発方法の詳細についてはkubernetes-csiドキュメント を参照してください。
ツリー内プラグインからCSIドライバーへの移行 FEATURE STATE:
Kubernetes v1.17 [beta]
CSIMigration機能を有効にすると、既存のツリー内プラグインに対する操作が、対応するCSIプラグイン(インストールおよび構成されていることが期待されます)に転送されます。
その結果、オペレーターは、ツリー内プラグインに取って代わるCSIドライバーに移行するときに、既存のストレージクラス、PersistentVolume、またはPersistentVolumeClaim(ツリー内プラグインを参照)の構成を変更する必要がありません。
サポートされている操作と機能には、プロビジョニング/削除、アタッチ/デタッチ、マウント/アンマウント、およびボリュームのサイズ変更が含まれます。
CSIMigrationをサポートし、対応するCSIドライバーが実装されているツリー内プラグインは、ボリュームのタイプ にリストされています。
flexVolume FEATURE STATE:
Kubernetes v1.23 [deprecated]
FlexVolumeは、ストレージドライバーとのインターフェースにexecベースのモデルを使用するツリー外プラグインインターフェースです。FlexVolumeドライバーのバイナリは、各ノード、場合によってはコントロールプレーンノードにも、あらかじめ定義されたボリュームプラグインパスにインストールする必要があります。
PodはflexVolumeツリー内ボリュームプラグインを通してFlexVolumeドライバーと対話します。
詳細についてはFlexVolumeのREADME を参照してください。
備考: FlexVolumeは非推奨です。ツリー外のCSIドライバーを使用することは、外部ストレージをKubernetesと統合するための推奨される方法です。
FlexVolumeドライバーのメンテナーは、CSIドライバーを実装し、FlexVolumeドライバーのユーザーをCSIに移行するのを支援する必要があります。FlexVolumeのユーザーは、同等のCSIドライバーを使用するようにワークロードを移動する必要があります。
マウントの伝播 マウントの伝播により、コンテナによってマウントされたボリュームを、同じPod内の他のコンテナ、または同じノード上の他のPodに共有できます。
ボリュームのマウント伝播は、containers[*].volumeMountsのmountPropagationフィールドによって制御されます。その値は次のとおりです。
None - このボリュームマウントは、ホストによってこのボリュームまたはそのサブディレクトリにマウントされる後続のマウントを受け取りません。同様に、コンテナによって作成されたマウントはホストに表示されません。これがデフォルトのモードです。
このモードはLinuxカーネルドキュメント で説明されているprivateマウント伝播と同じです。
HostToContainer - このボリュームマウントは、このボリュームまたはそのサブディレクトリのいずれかにマウントされる後続のすべてのマウントを受け取ります。
つまりホストがボリュームマウント内に何かをマウントすると、コンテナはそこにマウントされていることを確認します。
同様に同じボリュームに対してBidirectionalマウント伝搬を持つPodが何かをマウントすると、HostToContainerマウント伝搬を持つコンテナはそれを見ることができます。
このモードはLinuxカーネルドキュメント で説明されているrslaveマウント伝播と同じです。
Bidirectional - このボリュームマウントは、HostToContainerマウントと同じように動作します。さらに、コンテナによって作成されたすべてのボリュームマウントは、ホストと、同じボリュームを使用するすべてのPodのすべてのコンテナに伝播されます。
このモードの一般的な使用例は、FlexVolumeまたはCSIドライバーを備えたPod、またはhostPathボリュームを使用してホストに何かをマウントする必要があるPodです。
このモードはLinuxカーネルドキュメント で説明されているrsharedマウント伝播と同じです。
警告: Bidirectionalマウント伝搬は危険です。ホストオペレーティングシステムにダメージを与える可能性があるため、特権的なコンテナでのみ許可されています。
Linuxカーネルの動作に精通していることが強く推奨されます。
また、Pod内のコンテナによって作成されたボリュームマウントは、終了時にコンテナによって破棄(アンマウント)される必要があります。構成 一部のデプロイメント(CoreOS、RedHat/Centos、Ubuntu)でマウント伝播が正しく機能する前に、以下に示すように、Dockerでマウント共有を正しく構成する必要があります。
Dockerのsystemdサービスファイルを編集します。以下のようにMountFlagsを設定します。
または、MountFlags=slaveがあれば削除してください。その後、Dockerデーモンを再起動します。
sudo systemctl daemon-reload
sudo systemctl restart docker
次の項目 永続ボリュームを使用してWordPressとMySQLをデプロイする例 に従ってください。
3.7.2 - 永続ボリューム このドキュメントではKubernetesの PersistentVolume について説明します。ボリューム を一読することをおすすめします。
概要 ストレージを管理することはインスタンスを管理することとは全くの別物です。PersistentVolumeサブシステムは、ストレージが何から提供されているか、どのように消費されているかをユーザーと管理者から抽象化するAPIを提供します。これを実現するためのPersistentVolumeとPersistentVolumeClaimという2つの新しいAPIリソースを紹介します。
PersistentVolume (PV)はストレージクラス を使って管理者もしくは動的にプロビジョニングされるクラスターのストレージの一部です。これはNodeと同じようにクラスターリソースの一部です。PVはVolumeのようなボリュームプラグインですが、PVを使う個別のPodとは独立したライフサイクルを持っています。このAPIオブジェクトはNFS、iSCSIやクラウドプロバイダー固有のストレージシステムの実装の詳細を捕捉します。
PersistentVolumeClaim (PVC)はユーザーによって要求されるストレージです。これはPodと似ています。PodはNodeリソースを消費し、PVCはPVリソースを消費します。Podは特定レベルのCPUとメモリーリソースを要求することができます。クレームは特定のサイズやアクセスモード(例えば、ReadWriteOnce、ReadOnlyMany、ReadWriteManyにマウントできます。詳しくはアクセスモード を参照してください)を要求することができます。
PersistentVolumeClaimはユーザーに抽象化されたストレージリソースの消費を許可する一方、ユーザーは色々な問題に対処するためにパフォーマンスといった様々なプロパティを持ったPersistentVolumeを必要とすることは一般的なことです。クラスター管理者はユーザーに様々なボリュームがどのように実装されているかを表に出すことなく、サイズやアクセスモードだけではない色々な点で異なった、様々なPersistentVolumeを提供できる必要があります。これらのニーズに応えるために StorageClass リソースがあります。
実例を含む詳細なチュートリアル を参照して下さい。
ボリュームと要求のライフサイクル PVはクラスター内のリソースです。PVCはこれらのリソースの要求でありまた、クレームのチェックとしても機能します。PVとPVCの相互作用はこのライフサイクルに従います。
プロビジョニング PVは静的か動的どちらかでプロビジョニングされます。
静的 クラスター管理者は多数のPVを作成します。それらはクラスターのユーザーが使うことのできる実際のストレージの詳細を保持します。それらはKubernetes APIに存在し、利用できます。
動的 ユーザーのPersistentVolumeClaimが管理者の作成したいずれの静的PVにも一致しない場合、クラスターはPVC用にボリュームを動的にプロビジョニングしようとする場合があります。
このプロビジョニングはStorageClassに基づいています。PVCはストレージクラス の要求が必要であり、管理者は動的プロビジョニングを行うためにストレージクラスの作成・設定が必要です。ストレージクラスを""にしたストレージ要求は、自身の動的プロビジョニングを事実上無効にします。
ストレージクラスに基づいたストレージの動的プロビジョニングを有効化するには、クラスター管理者がDefaultStorageClassアドミッションコントローラー をAPIサーバーで有効化する必要があります。
これは例えば、DefaultStorageClassがAPIサーバーコンポーネントの--enable-admission-pluginsフラグのコンマ区切りの順序付きリストの中に含まれているかで確認できます。
APIサーバーのコマンドラインフラグの詳細についてはkube-apiserver のドキュメントを参照してください。
バインディング ユーザは、特定のサイズのストレージとアクセスモードを指定した上でPersistentVolumeClaimを作成します(動的プロビジョニングの場合は、すでに作られています)。マスター内のコントロールループは、新しく作られるPVCをウォッチして、それにマッチするPVが見つかったときに、それらを紐付けます。PVが新しいPVC用に動的プロビジョニングされた場合、コントロールループは常にPVをそのPVCに紐付けます。そうでない場合、ユーザーは常に少なくとも要求したサイズ以上のボリュームを取得しますが、ボリュームは要求されたサイズを超えている可能性があります。一度紐付けされると、どのように紐付けられたかに関係なくPersistentVolumeClaimの紐付けは排他的(決められた特定のPVとしか結びつかない状態)になります。PVCからPVへの紐付けは、PersistentVolumeとPersistentVolumeClaim間の双方向の紐付けであるClaimRefを使用した1対1のマッピングになっています。
一致するボリュームが存在しない場合、クレームはいつまでも紐付けされないままになります。一致するボリュームが利用可能になると、クレームがバインドされます。たとえば、50GiのPVがいくつもプロビジョニングされているクラスターだとしても、100Giを要求するPVCとは一致しません。100GiのPVがクラスターに追加されると、PVCを紐付けできます。
使用 Podは要求をボリュームとして使用します。クラスターは、要求を検査して紐付けられたボリュームを見つけそのボリュームをPodにマウントします。複数のアクセスモードをサポートするボリュームの場合、ユーザーはPodのボリュームとしてクレームを使う時にどのモードを希望するかを指定します。
ユーザーがクレームを取得し、そのクレームがバインドされると、バインドされたPVは必要な限りそのユーザーに属します。ユーザーはPodをスケジュールし、PodのvolumesブロックにpersistentVolumeClaimを含めることで、バインドされたクレームのPVにアクセスします。
書式の詳細はこちらを確認して下さい。
使用中のストレージオブジェクトの保護 使用中のストレージオブジェクト保護機能の目的はデータ損失を防ぐために、Podによって実際に使用されている永続ボリュームクレーム(PVC)と、PVCにバインドされている永続ボリューム(PV)がシステムから削除されないようにすることです。
備考: PVCを使用しているPodオブジェクトが存在する場合、PVCはPodによって実際に使用されています。ユーザーがPodによって実際に使用されているPVCを削除しても、そのPVCはすぐには削除されません。PVCの削除は、PVCがPodで使用されなくなるまで延期されます。また、管理者がPVCに紐付けられているPVを削除しても、PVはすぐには削除されません。PVがPVCに紐付けられなくなるまで、PVの削除は延期されます。
PVCの削除が保護されているかは、PVCのステータスがTerminatingになっていて、そしてFinalizersのリストにkubernetes.io/pvc-protectionが含まれているかで確認できます。
kubectl describe pvc hostpath
Name: hostpath
Namespace: default
StorageClass: example-hostpath
Status: Terminating
Volume:
Labels: <none>
Annotations: volume.beta.kubernetes.io/storage-class= example-hostpath
volume.beta.kubernetes.io/storage-provisioner= example.com/hostpath
Finalizers: [ kubernetes.io/pvc-protection]
同様にPVの削除が保護されているかは、PVのステータスがTerminatingになっていて、そしてFinalizersのリストにkubernetes.io/pv-protectionが含まれているかで確認できます。
kubectl describe pv task-pv-volume
Name: task-pv-volume
Labels: type = local
Annotations: <none>
Finalizers: [ kubernetes.io/pv-protection]
StorageClass: standard
Status: Terminating
Claim:
Reclaim Policy: Delete
Access Modes: RWO
Capacity: 1Gi
Message:
Source:
Type: HostPath ( bare host directory volume)
Path: /tmp/data
HostPathType:
Events: <none>
再クレーム ユーザーは、ボリュームの使用が完了したら、リソースの再クレームを許可するAPIからPVCオブジェクトを削除できます。PersistentVolumeの再クレームポリシーはそのクレームが解放された後のボリュームの処理をクラスターに指示します。現在、ボリュームは保持、リサイクル、または削除できます。
保持 Retainという再クレームポリシーはリソースを手動で再クレームすることができます。PersistentVolumeClaimが削除される時、PersistentVolumeは依然として存在はしますが、ボリュームは解放済みです。ただし、以前のクレームデータはボリューム上に残っているため、別のクレームにはまだ使用できません。管理者は次の手順でボリュームを手動で再クレームできます。
PersistentVolumeを削除します。PVが削除された後も、外部インフラストラクチャー(AWS EBS、GCE PD、Azure Disk、Cinderボリュームなど)に関連付けられたストレージアセットは依然として残ります。 ストレージアセットに関連するのデータを手動で適切にクリーンアップします。 関連するストレージアセットを手動で削除するか、同じストレージアセットを再利用したい場合、新しいストレージアセット定義と共にPersistentVolumeを作成します。 削除 Delete再クレームポリシーをサポートするボリュームプラグインの場合、削除するとPersistentVolumeオブジェクトがKubernetesから削除されるだけでなく、AWS EBS、GCE PD、Azure Disk、Cinderボリュームなどの外部インフラストラクチャーの関連ストレージアセットも削除されます。動的にプロビジョニングされたボリュームは、StorageClassの再クレームポリシー を継承します。これはデフォルトで削除です。管理者は、ユーザーの需要に応じてStorageClassを構成する必要があります。そうでない場合、PVは作成後に編集またはパッチを適用する必要があります。PersistentVolumeの再クレームポリシーの変更 を参照してください。
リサイクル
警告: Recycle再クレームポリシーは非推奨になりました。代わりに、動的プロビジョニングを使用することをおすすめします。基盤となるボリュームプラグインでサポートされている場合、Recycle再クレームポリシーはボリュームに対して基本的な削除(rm -rf /thevolume/*)を実行し、新しいクレームに対して再び利用できるようにします。
管理者はreference で説明するように、Kubernetesコントローラーマネージャーのコマンドライン引数を使用して、カスタムリサイクラーPodテンプレートを構成できます。カスタムリサイクラーPodテンプレートには、次の例に示すように、volumes仕様が含まれている必要があります。
apiVersion : v1
kind : Pod
metadata :
name : pv-recycler
namespace : default
spec :
restartPolicy : Never
volumes :
- name : vol
hostPath :
path : /any/path/it/will/be/replaced
containers :
- name : pv-recycler
image : "registry.k8s.io/busybox"
command : ["/bin/sh" , "-c" , "test -e /scrub && rm -rf /scrub/..?* /scrub/.[!.]* /scrub/* && test -z \"$(ls -A /scrub)\" || exit 1" ]
volumeMounts :
- name : vol
mountPath : /scrub
ただし、カスタムリサイクラーPodテンプレートのvolumesパート内で指定された特定のパスは、リサイクルされるボリュームの特定のパスに置き換えられます。
永続ボリュームの予約 コントロールプレーンは、永続ボリュームクレームをクラスター内の一致する永続ボリュームにバインド できます。
ただし、永続ボリュームクレームを特定の永続ボリュームにバインドする場合、それらを事前にバインドする必要があります。
永続ボリュームクレームで永続ボリュームを指定することにより、その特定の永続ボリュームと永続ボリュームクレームの間のバインディングを宣言します。
永続ボリュームが存在し、そのclaimRefフィールドで永続ボリュームクレームを予約していない場合に永続ボリュームと永続ボリュームクレームがバインドされます。
バインディングは、ノードアフィニティを含むいくつかのボリュームの一致基準に関係なく発生します。
コントロールプレーンは、依然としてストレージクラス 、アクセスモード、および要求されたストレージサイズが有効であることをチェックします。
apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : foo-pvc
namespace : foo
spec :
storageClassName : "" # 空の文字列を明示的に指定する必要があります。そうしないとデフォルトのストレージクラスが設定されてしまいます。
volumeName : foo-pv
...
この方法は、永続ボリュームへのバインド特権を保証するものではありません。
他の永続ボリュームクレームが指定した永続ボリュームを使用できる場合、最初にそのストレージボリュームを予約する必要があります。
永続ボリュームのclaimRefフィールドに関連する永続ボリュームクレームを指定して、他の永続ボリュームクレームがその永続ボリュームにバインドできないようにしてください。
apiVersion : v1
kind : PersistentVolume
metadata :
name : foo-pv
spec :
storageClassName : ""
claimRef :
name : foo-pvc
namespace : foo
...
これは、既存の永続ボリュームを再利用する場合など、claimPolicyがRetainに設定されている永続ボリュームを使用する場合に役立ちます。
永続ボリュームクレームの拡大 FEATURE STATE:
Kubernetes v1.24 [stable]
PersistentVolumeClaim(PVC)の拡大はデフォルトで有効です。次のボリュームの種類で拡大できます。
gcePersistentDisk awsElasticBlockStore Cinder glusterfs rbd Azure File Azure Disk Portworx FlexVolumes CSI そのストレージクラスのallowVolumeExpansionフィールドがtrueとなっている場合のみ、PVCを拡大できます。
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : gluster-vol-default
provisioner : kubernetes.io/glusterfs
parameters :
resturl : "http://192.168.10.100:8080"
restuser : ""
secretNamespace : ""
secretName : ""
allowVolumeExpansion : true
PVCに対してさらに大きなボリュームを要求するには、PVCオブジェクトを編集してより大きなサイズを指定します。これによりPersistentVolumeを受け持つ基盤にボリュームの拡大がトリガーされます。クレームを満たすため新しくPersistentVolumeが作成されることはありません。代わりに既存のボリュームがリサイズされます。
CSIボリュームの拡張 FEATURE STATE:
Kubernetes v1.24 [stable]
CSIボリュームの拡張のサポートはデフォルトで有効になっていますが、ボリューム拡張をサポートするにはボリューム拡張を利用できるCSIドライバーも必要です。詳細については、それぞれのCSIドライバーのドキュメントを参照してください。
ファイルシステムを含むボリュームのリサイズ ファイルシステムがXFS、Ext3、またはExt4の場合にのみ、ファイルシステムを含むボリュームのサイズを変更できます。
ボリュームにファイルシステムが含まれる場合、新しいPodがPersistentVolumeClaimでReadWriteモードを使用している場合にのみ、ファイルシステムのサイズが変更されます。ファイルシステムの拡張は、Podの起動時、もしくはPodの実行時で基盤となるファイルシステムがオンラインの拡張をサポートする場合に行われます。
FlexVolumesでは、ドライバのRequiresFSResize機能がtrueに設定されている場合、サイズを変更できます。
FlexVolumeは、Podの再起動時にサイズ変更できます。
使用中の永続ボリュームクレームのリサイズ FEATURE STATE:
Kubernetes v1.15 [beta]
備考: 使用中のPVCの拡張は、Kubernetes 1.15以降のベータ版と、1.11以降のアルファ版として利用可能です。
ExpandInUsePersistentVolume機能を有効化する必要があります。これはベータ機能のため多くのクラスターで自動的に行われます。詳細については、
フィーチャーゲート のドキュメントを参照してください。
この場合、既存のPVCを使用しているPodまたはDeploymentを削除して再作成する必要はありません。使用中のPVCは、ファイルシステムが拡張されるとすぐにPodで自動的に使用可能になります。この機能は、PodまたはDeploymentで使用されていないPVCには影響しません。拡張を完了する前に、PVCを使用するPodを作成する必要があります。
他のボリュームタイプと同様、FlexVolumeボリュームは、Podによって使用されている最中でも拡張できます。
備考: FlexVolumeのリサイズは、基盤となるドライバーがリサイズをサポートしている場合のみ可能です。
備考: EBSの拡張は時間がかかる操作です。また変更は、ボリュームごとに6時間に1回までというクォータもあります。ボリューム拡張時の障害からの復旧 基盤ストレージの拡張に失敗した際には、クラスターの管理者はPersistent Volume Claim (PVC)の状態を手動で復旧し、リサイズ要求をキャンセルします。それをしない限り、リサイズ要求は管理者の介入なしにコントローラーによって継続的に再試行されます。
PersistentVolumeClaim(PVC)にバインドされているPersistentVolume(PV)をRetain再クレームポリシーとしてマークします。 PVCを削除します。PVはRetain再クレームポリシーを持っているため、PVCを再び作成したときにいかなるデータも失うことはありません。 claimRefエントリーをPVスペックから削除して、新しいPVCがそれにバインドできるようにします。これによりPVはAvailableになります。PVより小さいサイズでPVCを再作成し、PVCのvolumeNameフィールドをPVの名前に設定します。これにより新しいPVCを既存のPVにバインドします。 PVを再クレームポリシーを復旧することを忘れずに行ってください。 永続ボリュームの種類 PersistentVolumeの種類はプラグインとして実装されます。Kubernetesは現在次のプラグインに対応しています。
永続ボリューム 各PVには、仕様とボリュームのステータスが含まれているspecとstatusが含まれています。
PersistentVolumeオブジェクトの名前は、有効な
DNSサブドメイン名 である必要があります。
apiVersion : v1
kind : PersistentVolume
metadata :
name : pv0003
spec :
capacity :
storage : 5Gi
volumeMode : Filesystem
accessModes :
- ReadWriteOnce
persistentVolumeReclaimPolicy : Recycle
storageClassName : slow
mountOptions :
- hard
- nfsvers=4.1
nfs :
path : /tmp
server : 172.17.0.2
備考: クラスター内でPersistentVolumeを使用するには、ボリュームタイプに関連するヘルパープログラムが必要な場合があります。
この例では、PersistentVolumeはNFSタイプで、NFSファイルシステムのマウントをサポートするためにヘルパープログラム/sbin/mount.nfsが必要になります。容量 通常、PVには特定のストレージ容量があります。これはPVのcapacity属性を使用して設定されます。容量によって期待される単位を理解するためには、Kubernetesのリソースモデル を参照してください。
現在、設定または要求できるのはストレージサイズのみです。将来の属性には、IOPS、スループットなどが含まれます。
ボリュームモード FEATURE STATE:
Kubernetes v1.18 [stable]
KubernetesはPersistentVolumesの2つのvolumeModesをサポートしています: FilesystemとBlockです。volumeModeは任意のAPIパラメーターです。FilesystemはvolumeModeパラメーターが省略されたときに使用されるデフォルトのモードです。
volumeMode: FilesystemであるボリュームはPodにマウント されてディレクトリになります。 ボリュームがブロックデバイスでデバイスが空の時、Kubernetesは初めてそれにマウントされる前にデバイスのファイルシステムを作成します。
volumeModeの値をBlockに設定してボリュームをRAWブロックデバイスとして使用します。volumeMode: Blockとともにボリュームを使用する例としては、Raw Block Volume Support を参照してください。
アクセスモード PersistentVolumeは、リソースプロバイダーがサポートする方法でホストにマウントできます。次の表に示すように、プロバイダーにはさまざまな機能があり、各PVのアクセスモードは、その特定のボリュームでサポートされる特定のモードに設定されます。たとえば、NFSは複数の読み取り/書き込みクライアントをサポートできますが、特定のNFSのPVはサーバー上で読み取り専用としてエクスポートされる場合があります。各PVは、その特定のPVの機能を記述する独自のアクセスモードのセットを取得します。
アクセスモードは次の通りです。
ReadWriteOnceボリュームは単一のNodeで読み取り/書き込みとしてマウントできます ReadOnlyManyボリュームは多数のNodeで読み取り専用としてマウントできます ReadWriteManyボリュームは多数のNodeで読み取り/書き込みとしてマウントできます ReadWriteOncePodボリュームは、単一のPodで読み取り/書き込みとしてマウントできます。クラスター全体で1つのPodのみがそのPVCの読み取りまたは書き込みを行えるようにする場合は、ReadWriteOncePodアクセスモードを使用します。これは、CSIボリュームとKubernetesバージョン1.22以降でのみサポートされます。 これについてはブログIntroducing Single Pod Access Mode for PersistentVolumes に詳細が記載されています。
CLIではアクセスモードは次のように略されます。
RWO - ReadWriteOnce ROX - ReadOnlyMany RWX - ReadWriteMany Important! ボリュームは、多数のモードをサポートしていても、一度に1つのアクセスモードでしかマウントできません。たとえば、GCEPersistentDiskは、単一NodeではReadWriteOnceとして、または多数のNodeではReadOnlyManyとしてマウントできますが、同時にマウントすることはできません。
ボリュームプラグイン ReadWriteOnce ReadOnlyMany ReadWriteMany AWSElasticBlockStore ✓ - - AzureFile ✓ ✓ ✓ AzureDisk ✓ - - CephFS ✓ ✓ ✓ Cinder ✓ - - CSI ドライバーに依存 ドライバーに依存 ドライバーに依存 FC ✓ ✓ - FlexVolume ✓ ✓ ドライバーに依存 Flocker ✓ - - GCEPersistentDisk ✓ ✓ - Glusterfs ✓ ✓ ✓ HostPath ✓ - - iSCSI ✓ ✓ - Quobyte ✓ ✓ ✓ NFS ✓ ✓ ✓ RBD ✓ ✓ - VsphereVolume ✓ - - (Podが連結されている場合のみ) PortworxVolume ✓ - ✓ ScaleIO ✓ ✓ - StorageOS ✓ - -
Class PVはクラスを持つことができます。これはstorageClassName属性をストレージクラス の名前に設定することで指定されます。特定のクラスのPVは、そのクラスを要求するPVCにのみバインドできます。storageClassNameにクラスがないPVは、特定のクラスを要求しないPVCにのみバインドできます。
以前volume.beta.kubernetes.io/storage-classアノテーションは、storageClassName属性の代わりに使用されていました。このアノテーションはまだ機能しています。ただし、将来のKubernetesリリースでは完全に非推奨です。
再クレームポリシー 現在の再クレームポリシーは次のとおりです。
保持 -- 手動再クレーム リサイクル -- 基本的な削除 (rm -rf /thevolume/*) 削除 -- AWS EBS、GCE PD、Azure Disk、もしくはOpenStack Cinderボリュームに関連するストレージアセットを削除 現在、NFSとHostPathのみがリサイクルをサポートしています。AWS EBS、GCE PD、Azure Disk、およびCinder volumeは削除をサポートしています。
マウントオプション Kubernetes管理者は永続ボリュームがNodeにマウントされるときの追加マウントオプションを指定できます。
備考: すべての永続ボリュームタイプがすべてのマウントオプションをサポートするわけではありません。次のボリュームタイプがマウントオプションをサポートしています。
AWSElasticBlockStore AzureDisk AzureFile CephFS Cinder (OpenStackブロックストレージ) GCEPersistentDisk Glusterfs NFS Quobyte Volumes RBD (Ceph Block Device) StorageOS VsphereVolume iSCSI マウントオプションは検証されないため、不正だった場合マウントは失敗します。
以前volume.beta.kubernetes.io/mount-optionsアノテーションがmountOptions属性の代わりに使われていました。このアノテーションはまだ機能しています。ただし、将来のKubernetesリリースでは完全に非推奨です。
ノードアフィニティ PVはノードアフィニティ を指定して、このボリュームにアクセスできるNodeを制限する制約を定義できます。PVを使用するPodは、ノードアフィニティによって選択されたNodeにのみスケジュールされます。
フェーズ ボリュームは次のフェーズのいずれかです。
利用可能 -- まだクレームに紐付いていない自由なリソース バウンド -- クレームに紐付いている リリース済み -- クレームが削除されたが、クラスターにまだクレームされている 失敗 -- 自動再クレームに失敗 CLIにはPVに紐付いているPVCの名前が表示されます。
永続ボリューム要求 各PVCにはspecとステータスが含まれます。これは、仕様とクレームのステータスです。
PersistentVolumeClaimオブジェクトの名前は、有効な
DNSサブドメイン名 である必要があります。
apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : myclaim
spec :
accessModes :
- ReadWriteOnce
volumeMode : Filesystem
resources :
requests :
storage : 8Gi
storageClassName : slow
selector :
matchLabels :
release : "stable"
matchExpressions :
- {key: environment, operator: In, values : [dev]}
アクセスモード クレームは、特定のアクセスモードでストレージを要求するときにボリュームと同じ規則を使用します。
ボリュームモード クレームは、ボリュームと同じ規則を使用して、ファイルシステムまたはブロックデバイスとしてのボリュームの消費を示します。
リソース Podと同様に、クレームは特定の量のリソースを要求できます。この場合、要求はストレージ用です。同じリソースモデル がボリュームとクレームの両方に適用されます。
セレクター クレームでは、ラベルセレクター を指定して、ボリュームセットをさらにフィルター処理できます。ラベルがセレクターに一致するボリュームのみがクレームにバインドできます。セレクターは2つのフィールドで構成できます。
matchLabels - ボリュームはこの値のラベルが必要ですmatchExpressions - キー、値のリスト、およびキーと値を関連付ける演算子を指定することによって作成された要件のリスト。有効な演算子は、In、NotIn、ExistsおよびDoesNotExistです。matchLabelsとmatchExpressionsの両方からのすべての要件はANDで結合されます。一致するには、すべてが一致する必要があります。
クラス クレームは、storageClassName属性を使用してストレージクラス の名前を指定することにより、特定のクラスを要求できます。PVCにバインドできるのは、PVCと同じstorageClassNameを持つ、要求されたクラスのPVのみです。
PVCは必ずしもクラスをリクエストする必要はありません。storageClassNameが""に設定されているPVCは、クラスのないPVを要求していると常に解釈されるため、クラスのないPVにのみバインドできます(アノテーションがないか、""に等しい1つのセット)。storageClassNameのないPVCはまったく同じではなく、DefaultStorageClassアドミッションプラグイン
アドミッションプラグインがオンになっている場合、管理者はデフォルトのStorageClassを指定できます。storageClassNameを持たないすべてのPVCは、そのデフォルトのPVにのみバインドできます。デフォルトのStorageClassの指定は、StorageClassオブジェクトでstorageclass.kubernetes.io/is-default-classアノテーションをtrueに設定することにより行われます。管理者がデフォルトを指定しない場合、クラスターは、アドミッションプラグインがオフになっているかのようにPVC作成をレスポンスします。複数のデフォルトが指定されている場合、アドミッションプラグインはすべてのPVCの作成を禁止します。 アドミッションプラグインがオフになっている場合、デフォルトのStorageClassの概念はありません。storageClassNameを持たないすべてのPVCは、クラスを持たないPVにのみバインドできます。この場合、storageClassNameを持たないPVCは、storageClassNameが""に設定されているPVCと同じように扱われます。 インストール方法によっては、インストール時にアドオンマネージャーによってデフォルトのストレージクラスがKubernetesクラスターにデプロイされる場合があります。
PVCがselectorを要求することに加えてStorageClassを指定する場合、要件はANDで一緒に結合されます。要求されたクラスのPVと要求されたラベルのみがPVCにバインドされます。
備考: 現在、selectorが空ではないPVCは、PVを動的にプロビジョニングできません。以前は、storageClassName属性の代わりにvolume.beta.kubernetes.io/storage-classアノテーションが使用されていました。このアノテーションはまだ機能しています。ただし、今後のKubernetesリリースではサポートされません。
ボリュームとしてのクレーム Podは、クレームをボリュームとして使用してストレージにアクセスします。クレームは、そのクレームを使用するPodと同じ名前空間に存在する必要があります。クラスターは、Podの名前空間でクレームを見つけ、それを使用してクレームを支援しているPersistentVolumeを取得します。次に、ボリュームがホストとPodにマウントされます。
apiVersion : v1
kind : Pod
metadata :
name : mypod
spec :
containers :
- name : myfrontend
image : nginx
volumeMounts :
- mountPath : "/var/www/html"
name : mypd
volumes :
- name : mypd
persistentVolumeClaim :
claimName : myclaim
名前空間に関する注意 PersistentVolumeバインドは排他的であり、PersistentVolumeClaimは名前空間オブジェクトであるため、"多"モード(ROX、RWX)でクレームをマウントすることは1つの名前空間内でのみ可能です。
Rawブロックボリュームのサポート FEATURE STATE:
Kubernetes v1.18 [stable]
次のボリュームプラグインは、必要に応じて動的プロビジョニングを含むrawブロックボリュームをサポートします。
AWSElasticBlockStore AzureDisk CSI FC (Fibre Channel) GCEPersistentDisk iSCSI Local volume OpenStack Cinder RBD (Ceph Block Device) VsphereVolume Rawブロックボリュームを使用した永続ボリューム apiVersion : v1
kind : PersistentVolume
metadata :
name : block-pv
spec :
capacity :
storage : 10Gi
accessModes :
- ReadWriteOnce
volumeMode : Block
persistentVolumeReclaimPolicy : Retain
fc :
targetWWNs : ["50060e801049cfd1" ]
lun : 0
readOnly : false
Rawブロックボリュームを要求する永続ボリュームクレーム apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : block-pvc
spec :
accessModes :
- ReadWriteOnce
volumeMode : Block
resources :
requests :
storage : 10Gi
コンテナにRawブロックデバイスパスを追加するPod仕様 apiVersion : v1
kind : Pod
metadata :
name : pod-with-block-volume
spec :
containers :
- name : fc-container
image : fedora:26
command : ["/bin/sh" , "-c" ]
args : [ "tail -f /dev/null" ]
volumeDevices :
- name : data
devicePath : /dev/xvda
volumes :
- name : data
persistentVolumeClaim :
claimName : block-pvc
備考: Podにrawブロックデバイスを追加する場合は、マウントパスの代わりにコンテナでデバイスパスを指定します。ブロックボリュームのバインド ユーザーがPersistentVolumeClaim specのvolumeModeフィールドを使用してrawブロックボリュームの要求を示す場合、バインディングルールは、このモードをspecの一部として考慮しなかった以前のリリースとわずかに異なります。表にリストされているのは、ユーザーと管理者がrawブロックデバイスを要求するために指定可能な組み合わせの表です。この表は、ボリュームがバインドされるか、組み合わせが与えられないかを示します。静的にプロビジョニングされたボリュームのボリュームバインディングマトリクスはこちらです。
PVボリュームモード PVCボリュームモード 結果 未定義 未定義 バインド 未定義 ブロック バインドなし 未定義 ファイルシステム バインド ブロック 未定義 バインドなし ブロック ブロック バインド ブロック ファイルシステム バインドなし ファイルシステム ファイルシステム バインド ファイルシステム ブロック バインドなし ファイルシステム 未定義 バインド
備考: アルファリリースでは、静的にプロビジョニングされたボリュームのみがサポートされます。管理者は、rawブロックデバイスを使用する場合、これらの値を考慮するように注意する必要があります。ボリュームのスナップショットとスナップショットからのボリュームの復元のサポート FEATURE STATE:
Kubernetes v1.17 [beta]
ボリュームスナップショット機能は、CSIボリュームプラグインのみをサポートするために追加されました。詳細については、ボリュームのスナップショット を参照してください。
ボリュームスナップショットのデータソースからボリュームを復元する機能を有効にするには、apiserverおよびcontroller-managerでVolumeSnapshotDataSourceフィーチャーゲートを有効にします。
ボリュームスナップショットから永続ボリュームクレームを作成する apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : restore-pvc
spec :
storageClassName : csi-hostpath-sc
dataSource :
name : new-snapshot-test
kind : VolumeSnapshot
apiGroup : snapshot.storage.k8s.io
accessModes :
- ReadWriteOnce
resources :
requests :
storage : 10Gi
ボリュームの複製 ボリュームの複製 はCSIボリュームプラグインにのみ利用可能です。
PVCデータソースからのボリューム複製機能を有効にするには、apiserverおよびcontroller-managerでVolumeSnapshotDataSourceフィーチャーゲートを有効にします。
既存のPVCからの永続ボリュームクレーム作成 apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : cloned-pvc
spec :
storageClassName : my-csi-plugin
dataSource :
name : existing-src-pvc-name
kind : PersistentVolumeClaim
accessModes :
- ReadWriteOnce
resources :
requests :
storage : 10Gi
可搬性の高い設定の作成 もし幅広いクラスターで実行され、永続ボリュームが必要となる構成テンプレートやサンプルを作成している場合は、次のパターンを使用することをお勧めします。
構成にPersistentVolumeClaimオブジェクトを含める(DeploymentやConfigMapと共に)
ユーザーが設定をインスタンス化する際にPersistentVolumeを作成する権限がない場合があるため、設定にPersistentVolumeオブジェクトを含めない。
テンプレートをインスタンス化する時にストレージクラス名を指定する選択肢をユーザーに与える
ユーザーがストレージクラス名を指定する場合、persistentVolumeClaim.storageClassName フィールドにその値を入力する。これにより、クラスターが管理者によって有効にされたストレージクラスを持っている場合、PVCは正しいストレージクラスと一致する。 ユーザーがストレージクラス名を指定しない場合、persistentVolumeClaim.storageClassNameフィールドはnilのままにする。これにより、PVはユーザーにクラスターのデフォルトストレージクラスで自動的にプロビジョニングされる。多くのクラスター環境ではデフォルトのストレージクラスがインストールされているが、管理者は独自のデフォルトストレージクラスを作成することができる。 ツールがPVCを監視し、しばらくしてもバインドされないことをユーザーに表示する。これはクラスターが動的ストレージをサポートしない(この場合ユーザーは対応するPVを作成するべき)、もしくはクラスターがストレージシステムを持っていない(この場合ユーザーはPVCを必要とする設定をデプロイできない)可能性があることを示す。
次の項目 リファレンス 3.7.3 - 投影ボリューム このドキュメントでは、Kubernetesの投影ボリューム について説明します。ボリューム に精通していることをお勧めします。
概要 ボリュームは、いくつかの既存の投影ボリュームソースを同じディレクトリにマップします。
現在、次のタイプのボリュームソースを投影できます。
すべてのソースは、Podと同じnamespaceにある必要があります。詳細はall-in-one volume デザインドキュメントを参照してください。
secret、downwardAPI、およびconfigMapを使用した構成例 apiVersion : v1
kind : Pod
metadata :
name : volume-test
spec :
containers :
- name : container-test
image : busybox
volumeMounts :
- name : all-in-one
mountPath : "/projected-volume"
readOnly : true
volumes :
- name : all-in-one
projected :
sources :
- secret :
name : mysecret
items :
- key : username
path : my-group/my-username
- downwardAPI :
items :
- path : "labels"
fieldRef :
fieldPath : metadata.labels
- path : "cpu_limit"
resourceFieldRef :
containerName : container-test
resource : limits.cpu
- configMap :
name : myconfigmap
items :
- key : config
path : my-group/my-config
構成例:デフォルト以外のアクセス許可モードが設定されたsecret apiVersion : v1
kind : Pod
metadata :
name : volume-test
spec :
containers :
- name : container-test
image : busybox
volumeMounts :
- name : all-in-one
mountPath : "/projected-volume"
readOnly : true
volumes :
- name : all-in-one
projected :
sources :
- secret :
name : mysecret
items :
- key : username
path : my-group/my-username
- secret :
name : mysecret2
items :
- key : password
path : my-group/my-password
mode : 511
各投影ボリュームソースは、specのsourcesにリストされています。パラメーターは、2つの例外を除いてほぼ同じです。
secretについて、ConfigMapの命名と一致するようにsecretNameフィールドがnameに変更されました。 defaultModeはprojectedレベルでのみ指定でき、各ボリュームソースには指定できません。ただし上に示したように、個々の投影ごとにmodeを明示的に設定できます。TokenRequestProjection機能が有効になっている場合、現在のサービスアカウントトークン を指定されたパスのPodに挿入できます。例えば:
apiVersion : v1
kind : Pod
metadata :
name : sa-token-test
spec :
containers :
- name : container-test
image : busybox
volumeMounts :
- name : token-vol
mountPath : "/service-account"
readOnly : true
serviceAccountName : default
volumes :
- name : token-vol
projected :
sources :
- serviceAccountToken :
audience : api
expirationSeconds : 3600
path : token
この例のPodには、挿入されたサービスアカウントトークンを含む投影ボリュームがあります。このトークンはPodのコンテナがKubernetes APIサーバーにアクセスするために使用できます。このaudienceフィールドにはトークンの受信対象者が含まれています。トークンの受信者は、トークンのaudienceフィールドで指定された識別子で自分自身であるかを識別します。そうでない場合はトークンを拒否します。このフィールドはオプションで、デフォルトではAPIサーバーの識別子が指定されます。
expirationSecondsはサービスアカウントトークンが有効であると予想される期間です。
デフォルトは1時間で、最低でも10分(600秒)でなければなりません。
管理者は、APIサーバーに--service-account-max-token-expirationオプションを指定することで、その最大値を制限することも可能です。
pathフィールドは、投影ボリュームのマウントポイントへの相対パスを指定します。
備考: 投影ボリュームソースを
subPathボリュームマウントとして使用しているコンテナは、それらのボリュームソースの更新を受信しません。
SecurityContextの相互作用 サービスアカウントの投影ボリューム拡張でのファイル権限処理の提案 により、正しい所有者権限が設定された投影ファイルが導入されました。
Linux 投影ボリュームがあり、PodのSecurityContextRunAsUserが設定されているLinux Podでは、投影されたファイルには、コンテナユーザーの所有権を含む正しい所有権が設定されます。
Windows 投影ボリュームを持ち、PodのSecurityContextでRunAsUsernameを設定したWindows Podでは、Windowsのユーザーアカウント管理方法により所有権が強制されません。
Windowsは、ローカルユーザーとグループアカウントをセキュリティアカウントマネージャー(SAM)と呼ばれるデータベースファイルに保存し、管理します。
各コンテナはSAMデータベースの独自のインスタンスを維持し、コンテナの実行中はホストはそのインスタンスを見ることができません。
Windowsコンテナは、OSのユーザーモード部分をホストから分離して実行するように設計されており、そのため仮想SAMデータベースを維持することになります。
そのため、ホスト上で動作するkubeletには、仮想化されたコンテナアカウントのホストファイル所有権を動的に設定する機能がありません。
ホストマシン上のファイルをコンテナと共有する場合は、C:\以外の独自のボリュームマウントに配置することをお勧めします。
デフォルトでは、投影ボリュームファイルの例に示されているように、投影されたファイルには次の所有権があります。
PS C:\> Get-Acl C:\var\run\secrets\kubernetes.io\serviceaccount\..2021_08_31_22_22_18.318230061 \ca.crt | Format-List
Path : Microsoft.PowerShell.Core\FileSystem::C:\var\run\secrets\kubernetes.io\serviceaccount\..2021_08_31_22_22_18.318230061 \ca.crt
Owner : BUILTIN\Administrators
Group : NT AUTHORITY\SYSTEM
Access : NT AUTHORITY\SYSTEM Allow FullControl
BUILTIN\Administrators Allow FullControl
BUILTIN\Users Allow ReadAndExecute, Synchronize
Audit :
Sddl : O:BAG: SYD: AI(A;ID;FA;;;SY)(A;ID;FA;;;BA)(A;ID;0x1200a9;;;BU)
これは、ContainerAdministratorのようなすべての管理者ユーザーが読み取り、書き込み、および実行アクセス権を持ち、非管理者ユーザーが読み取りおよび実行アクセス権を持つことを意味します。
備考: 一般に、コンテナにホストへのアクセスを許可することは、潜在的なセキュリティの悪用への扉を開く可能性があるため、お勧めできません。
Windows PodのSecurityContextにRunAsUserを指定して作成すると、PodはContainerCreatingで永久に固まります。したがって、Windows PodでLinux専用のRunAsUserオプションを使用しないことをお勧めします。
3.7.4 - エフェメラルボリューム このドキュメントでは、Kubernetesのエフェメラルボリューム について説明します。ボリューム 、特にPersistentVolumeClaimとPersistentVolumeに精通していることをお勧めします。
一部のアプリケーションでは追加のストレージが必要ですが、そのデータが再起動後も永続的に保存されるかどうかは気にしません。
たとえば、キャッシュサービスは多くの場合メモリサイズによって制限されており、使用頻度の低いデータを、全体的なパフォーマンスにほとんど影響を与えずに、メモリよりも低速なストレージに移動できます。
他のアプリケーションは、構成データや秘密鍵など、読み取り専用の入力データがファイルに存在することを想定しています。
エフェメラルボリューム は、これらのユースケース向けに設計されています。
ボリュームはPodの存続期間に従い、Podとともに作成および削除されるため、Podは、永続ボリュームが利用可能な場所に制限されることなく停止および再起動できます。
エフェメラルボリュームはPod仕様でインライン で指定されているため、アプリケーションの展開と管理が簡素化されます。
エフェメラルボリュームのタイプ Kubernetesは、さまざまな目的のためにいくつかの異なる種類のエフェメラルボリュームをサポートしています。
emptyDir、configMap、downwardAPI、secretはローカルエフェメラルストレージ として提供されます。
これらは、各ノードのkubeletによって管理されます。
CSIエフェメラルボリュームは、サードパーティーのCSIストレージドライバーによって提供される必要があります 。
汎用エフェメラルボリュームは、サードパーティーのCSIストレージドライバーによって提供される可能性があります が、動的プロビジョニングをサポートする他のストレージドライバーによって提供されることもあります。一部のCSIドライバーは、CSIエフェメラルボリューム用に特別に作成されており、動的プロビジョニングをサポートしていません。これらは汎用エフェメラルボリュームには使用できません。
サードパーティー製ドライバーを使用する利点は、Kubernetes自体がサポートしていない機能を提供できることです。たとえば、kubeletによって管理されるディスクとは異なるパフォーマンス特性を持つストレージや、異なるデータの挿入などです。
CSIエフェメラルボリューム FEATURE STATE:
Kubernetes v1.25 [stable]
備考: CSIエフェメラルボリュームは、CSIドライバーのサブセットによってのみサポートされます。
Kubernetes CSI
ドライバーリスト には、エフェメラルボリュームをサポートするドライバーが表示されます。
概念的には、CSIエフェメラルボリュームはconfigMap、downwardAPI、およびsecretボリュームタイプに似ています。
ストレージは各ノードでローカルに管理され、Podがノードにスケジュールされた後に他のローカルリソースと一緒に作成されます。Kubernetesには、この段階でPodを再スケジュールするという概念はもうありません。
ボリュームの作成は、失敗する可能性が低くなければなりません。さもないと、Podの起動が停止します。
特に、ストレージ容量を考慮したPodスケジューリング は、これらのボリュームではサポートされていません 。
これらは現在、Podのストレージリソースの使用制限の対象外です。これは、kubeletが管理するストレージに対してのみ強制できるものであるためです。
CSIエフェメラルストレージを使用するPodのマニフェストの例を次に示します。
kind : Pod
apiVersion : v1
metadata :
name : my-csi-app
spec :
containers :
- name : my-frontend
image : busybox:1.28
volumeMounts :
- mountPath : "/data"
name : my-csi-inline-vol
command : [ "sleep" , "1000000" ]
volumes :
- name : my-csi-inline-vol
csi :
driver : inline.storage.kubernetes.io
volumeAttributes :
foo : bar
volumeAttributesは、ドライバーによって準備されるボリュームを決定します。これらの属性は各ドライバーに固有のものであり、標準化されていません。詳細な手順については、各CSIドライバーのドキュメントを参照してください。
CSIドライバーの制限事項 CSIエフェメラルボリュームを使用すると、ユーザーはPod仕様の一部としてvolumeAttributesをCSIドライバーに直接提供できます。
通常は管理者に制限されているvolumeAttributesを許可するCSIドライバーは、インラインエフェメラルボリュームでの使用には適していません。
たとえば、通常StorageClassで定義されるパラメーターは、インラインエフェメラルボリュームを使用してユーザーに公開しないでください。
Pod仕様内でインラインボリュームとして使用できるCSIドライバーを制限する必要があるクラスター管理者は、次の方法で行うことができます。
CSIドライバー仕様のvolumeLifecycleModesからEphemeralを削除します。これにより、ドライバーをインラインエフェメラルボリュームとして使用できなくなります。 admission webhook を使用して、このドライバーの使用方法を制限します。汎用エフェメラルボリューム FEATURE STATE:
Kubernetes v1.23 [stable]
汎用エフェメラルボリュームは、プロビジョニング後に通常は空であるスクラッチデータ用のPodごとのディレクトリを提供するという意味で、emptyDirボリュームに似ています。ただし、追加の機能がある場合もあります。
ストレージは、ローカルまたはネットワークに接続できます。 ボリュームは、Podが超えることができない固定サイズを持つことができます。 ボリュームには、ドライバーとパラメーターによっては、いくつかの初期データがある場合があります。 スナップショット 、クローン作成 、サイズ変更 、ストレージ容量の追跡 などボリュームに対する一般的な操作は、ドライバーがそれらをサポートしていることを前提としてサポートされています。例:
kind : Pod
apiVersion : v1
metadata :
name : my-app
spec :
containers :
- name : my-frontend
image : busybox:1.28
volumeMounts :
- mountPath : "/scratch"
name : scratch-volume
command : [ "sleep" , "1000000" ]
volumes :
- name : scratch-volume
ephemeral :
volumeClaimTemplate :
metadata :
labels :
type : my-frontend-volume
spec :
accessModes : [ "ReadWriteOnce" ]
storageClassName : "scratch-storage-class"
resources :
requests :
storage : 1Gi
LifecycleとPersistentVolumeClaim 設計上の重要なアイデアは、ボリュームクレームのパラメーター がPodのボリュームソース内で許可されることです。
PersistentVolumeClaimのラベル、アノテーション、および一連のフィールド全体がサポートされています。
そのようなPodが作成されると、エフェメラルボリュームコントローラーは、Podと同じ名前空間に実際のPersistentVolumeClaimオブジェクトを作成し、Podが削除されたときにPersistentVolumeClaimが確実に削除されるようにします。
これにより、ボリュームバインディングおよび/またはプロビジョニングがトリガーされます。
これは、StorageClass が即時ボリュームバインディングを使用する場合、またはPodが一時的にノードにスケジュールされている場合(WaitForFirstConsumerボリュームバインディングモード)のいずれかです。
後者は、スケジューラーがPodに適したノードを自由に選択できるため、一般的なエフェメラルボリュームに推奨されます。即時バインディングでは、ボリュームが利用可能になった時点で、ボリュームにアクセスできるノードをスケジューラーが選択する必要があります。
リソースの所有権 に関して、一般的なエフェメラルストレージを持つPodは、そのエフェメラルストレージを提供するPersistentVolumeClaimの所有者です。Podが削除されると、KubernetesガベージコレクターがPVCを削除します。これにより、通常、ボリュームの削除がトリガーされます。これは、ストレージクラスのデフォルトの再利用ポリシーがボリュームを削除することであるためです。retainの再利用ポリシーを持つStorageClassを使用して、準エフェメラルなローカルストレージを作成できます。ストレージはPodよりも長く存続します。この場合、ボリュームのクリーンアップが個別に行われるようにする必要があります。
これらのPVCは存在しますが、他のPVCと同様に使用できます。特に、ボリュームのクローン作成またはスナップショットでデータソースとして参照できます。PVCオブジェクトは、ボリュームの現在のステータスも保持します。
PersistentVolumeClaimの命名 自動的に作成されたPVCの命名は決定論的です。名前はPod名とボリューム名を組み合わせたもので、途中にハイフン(-)があります。上記の例では、PVC名はmy-app-scratch-volumeになります。この決定論的な命名により、Pod名とボリューム名が分かればPVCを検索する必要がないため、PVCとの対話が容易になります。
また、決定論的な命名では、異なるPod間、およびPodと手動で作成されたPVCの間で競合が発生する可能性があります(ボリュームが"scratch"のPod"pod-a"と、名前が"pod"でボリュームが"a-scratch"の別のPodは、どちらも同じPVC名"pod-a-scratch")。
次のような競合が検出されます。Pod用に作成された場合、PVCはエフェメラルボリュームにのみ使用されます。このチェックは、所有関係に基づいています。既存のPVCは上書きまたは変更されません。ただし、適切なPVCがないとPodを起動できないため、これでは競合が解決されません。
注意: これらの競合が発生しないように、同じ名前空間内でPodとボリュームに名前を付けるときは注意してください。セキュリティ GenericEphemeralVolume機能を有効にすると、ユーザーは、PVCを直接作成する権限がなくても、Podを作成できる場合、間接的にPVCを作成できます。クラスター管理者はこれを認識している必要があります。これがセキュリティモデルに適合しない場合は、一般的なエフェメラルボリュームを持つPodなどのオブジェクトを拒否するadmission webhook を使用する必要があります。
通常のPVCの名前空間割り当て は引き続き適用されるため、ユーザーがこの新しいメカニズムの使用を許可されたとしても、他のポリシーを回避するために使用することはできません。
次の項目 kubeletによって管理されるエフェメラルボリューム ローカルエフェメラルボリューム を参照してください。
CSIエフェメラルボリューム 汎用エフェメラルボリューム 3.7.5 - VolumeAttributesClass FEATURE STATE:
Kubernetes v1.29 [alpha]
このページでは、Kubernetesのストレージクラス 、
ボリューム および永続ボリューム についてよく理解していることを前提としています。
VolumeAttributesClassは、管理者がストレージの変更可能な「クラス」を表現する方法を提供します。
異なるクラスは異なるサービス品質レベルに対応する場合があります。
Kubernetes自体は、これらのクラスが何を表すかかについては見解を持っていません。
これはアルファ機能であり、デフォルトで無効化されています。
アルファ機能であるうちにテストしたい場合は、kube-controller-managerおよびkube-apiserverでVolumeAttributesClassフィーチャーゲート を有効化する必要があります。
コマンドライン引数の--feature-gatesを使用します:
--feature-gates="...,VolumeAttributesClass=true"
VolumeAttributesClassはContainer Storage Interface をバックエンドとするストレージでのみ使用することができ、
関連するCSIドライバーがModifyVolume APIを実装している場合にのみ使用することができます
VolumeAttributesClass API 各VolumeAttributesClassにはdriverNameとparametersが含まれており、
クラスに属する永続ボリューム(PV)を動的にプロビジョニングまたは変更する際に利用されます。
VolumeAttributesClassのオブジェクト名は重要であり、ユーザーが特定のクラスを要求する方法です。
管理者はVolumeAttributesClassのオブジェクトを最初に作成する際に、クラス名や他のパラメータを設定します。
PersistentVolumeClaim内のVolumeAttributesClassのオブジェクト名は変更可能ですが、
既存のクラスのパラメータは変更できません。
apiVersion : storage.k8s.io/v1alpha1
kind : VolumeAttributesClass
metadata :
name : silver
driverName : pd.csi.storage.gke.io
parameters :
provisioned-iops : "3000"
provisioned-throughput : "50"
プロビジョナー 各VolumeAttributesClassには、PVのプロビジョニングにどのボリュームプラグインを使用するかを決定するプロビジョナが備わっています。
VolumeAttributesClassに関する機能のサポートはkubernetes-csi/external-provisioner に実装されています。
kubernetes-csi/external-provisioner に限定されることはありません。
Kubernetesによって定義された仕様にそった独立したプログラムである、外部プロビジョナを実行、指定することもできます。
外部プロビジョナの作成者は、コードの保存場所、プロビジョナの配布方法、実行方法、使用するボリュームプラグインなど、あらゆる裁量を持っています。
リサイザー 各VolumeAttributesClassには、PVの変更にどのボリュームプラグインを使用するかを決定するリサイザが備わっています。
driverNameフィールドの指定は必須です。
VolumeAttributesClassに関するボリューム変更機能のサポートはkubernetes-csi/external-resizer に実装されています。
例えば、既存のPersistentVolumeClaimがsilverという名前のVolumeAttributesClassを使用しているとします:
apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : test-pv-claim
spec :
…
volumeAttributesClassName : silver
…
新しいgoldというVolumeAttributesClassがクラスターで使用可能です:
apiVersion : storage.k8s.io/v1alpha1
kind : VolumeAttributesClass
metadata :
name : gold
driverName : pd.csi.storage.gke.io
parameters :
iops : "4000"
throughput : "60"
エンドユーザーは新しいgoldというVolumeAttributesClassを使ってPVCを更新、適用できます:
apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : test-pv-claim
spec :
…
volumeAttributesClassName : gold
…
パラメーター VolumeAttributesClassにはそれらに属するボリュームを記述するパラメータがあります。
プロビジョナまたはリサイザによって、異なるパラメータを受け取る場合があります。
例えば、パラメータiopsの値4000や、パラメータthroughputはGCE Persistent Disk固有のものです。
パラメータを省略した場合は、デフォルト値がボリュームのプロビジョニング時に使用されます。
ユーザーがパラメータを省略して異なるPVCを適用する場合、CSIドライバーの実装に応じてデフォルトのパラメータが使用されることがあります。
詳細については、関連するCSIドライバーのドキュメントを参照してください。
VolumeAttributesClassには最大512個のパラメータを定義できます。
キーと値を含むパラメータオブジェクトの合計の長さは256KiBを超過することはできません。
3.7.6 - ストレージクラス このドキュメントでは、KubernetesにおけるStorageClassの概念について説明します。ボリューム と永続ボリューム に精通していることをお勧めします。
概要 StorageClassは、管理者が提供するストレージの「クラス」を記述する方法を提供します。さまざまなクラスが、サービス品質レベル、バックアップポリシー、またはクラスター管理者によって決定された任意のポリシーにマップされる場合があります。Kubernetes自体は、クラスが何を表すかについて意見を持っていません。この概念は、他のストレージシステムでは「プロファイル」と呼ばれることがあります。
StorageClassリソース 各StorageClassには、クラスに属するPersistentVolumeを動的にプロビジョニングする必要がある場合に使用されるフィールドprovisioner、parameters、およびreclaimPolicyが含まれています。
StorageClassオブジェクトの名前は重要であり、ユーザーが特定のクラスを要求する方法です。管理者は、最初にStorageClassオブジェクトを作成するときにクラスの名前とその他のパラメーターを設定します。オブジェクトは、作成後に更新することはできません。
管理者は、バインドする特定のクラスを要求しないPVCに対してのみ、デフォルトのStorageClassを指定できます。詳細については、PersistentVolumeClaimセクション を参照してください。
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : standard
provisioner : kubernetes.io/aws-ebs
parameters :
type : gp2
reclaimPolicy : Retain
allowVolumeExpansion : true
mountOptions :
- debug
volumeBindingMode : Immediate
プロビジョナー 各StorageClassには、PVのプロビジョニングに使用するボリュームプラグインを決定するプロビジョナーがあります。このフィールドを指定する必要があります。
ここにリストされている「内部」プロビジョナー(名前には「kubernetes.io」というプレフィックスが付いており、Kubernetesと共に出荷されます)を指定することに制限はありません。Kubernetesによって定義された仕様 に従う独立したプログラムである外部プロビジョナーを実行して指定することもできます。外部プロビジョナーの作成者は、コードの保存場所、プロビジョナーの出荷方法、実行方法、使用するボリュームプラグイン(Flexを含む)などについて完全な裁量権を持っています。リポジトリkubernetes-sigs/sig-storage-lib-external-provisioner には、仕様の大部分を実装する外部プロビジョナーを作成するためのライブラリが含まれています。一部の外部プロビジョナーは、リポジトリkubernetes-sigs/sig-storage-lib-external-provisioner の下にリストされています。
たとえば、NFSは内部プロビジョナーを提供しませんが、外部プロビジョナーを使用できます。サードパーティのストレージベンダーが独自の外部プロビジョナーを提供する場合もあります。
再利用ポリシー StorageClassによって動的に作成されるPersistentVolumeには、クラスのreclaimPolicyフィールドで指定された再利用ポリシーがあり、DeleteまたはRetainのいずれかになります。StorageClassオブジェクトの作成時にreclaimPolicyが指定されていない場合、デフォルトでDeleteになります。
手動で作成され、StorageClassを介して管理されるPersistentVolumeには、作成時に割り当てられた再利用ポリシーが適用されます。
ボリューム拡張の許可 FEATURE STATE:
Kubernetes v1.11 [beta]
PersistentVolumeは、拡張可能になるように構成できます。この機能をtrueに設定すると、ユーザーは対応するPVCオブジェクトを編集してボリュームのサイズを変更できます。
次のタイプのボリュームは、基になるStorageClassのフィールドallowVolumeExpansionがtrueに設定されている場合に、ボリュームの拡張をサポートします。
Table of Volume types and the version of Kubernetes they require Volume type Required Kubernetes version gcePersistentDisk 1.11 awsElasticBlockStore 1.11 Cinder 1.11 glusterfs 1.11 rbd 1.11 Azure File 1.11 Azure Disk 1.11 Portworx 1.11 FlexVolume 1.13 CSI 1.14 (alpha), 1.16 (beta)
備考: ボリューム拡張機能を使用してボリュームを拡張することはできますが、縮小することはできません。マウントオプション StorageClassによって動的に作成されるPersistentVolumeには、クラスのmountOptionsフィールドで指定されたマウントオプションがあります。
ボリュームプラグインがマウントオプションをサポートしていないにもかかわらず、マウントオプションが指定されている場合、プロビジョニングは失敗します。マウントオプションは、クラスまたはPVのいずれでも検証されません。マウントオプションが無効な場合、PVマウントは失敗します。
ボリュームバインディングモード volumeBindingModeフィールドは、ボリュームバインディングと動的プロビジョニング が発生するタイミングを制御します。設定を解除すると、デフォルトで"Immediate"モードが使用されます。
Immediateモードは、PersistentVolumeClaimが作成されると、ボリュームバインディングと動的プロビジョニングが発生することを示します。トポロジに制約があり、クラスター内のすべてのノードからグローバルにアクセスできないストレージバックエンドの場合、PersistentVolumeはPodのスケジューリング要件を知らなくてもバインドまたはプロビジョニングされます。これにより、Podがスケジュール不能になる可能性があります。
クラスター管理者は、PersistentVolumeClaimを使用するPodが作成されるまでPersistentVolumeのバインドとプロビジョニングを遅らせるWaitForFirstConsumerモードを指定することで、この問題に対処できます。
PersistentVolumeは、Podのスケジュール制約によって指定されたトポロジに準拠して選択またはプロビジョニングされます。これらには、リソース要件 、ノードセレクター 、ポッドアフィニティとアンチアフィニティ 、およびtaints and tolerations が含まれますが、これらに限定されません。
次のプラグインは、動的プロビジョニングでWaitForFirstConsumerをサポートしています。
次のプラグインは、事前に作成されたPersistentVolumeバインディングでWaitForFirstConsumerをサポートします。
FEATURE STATE:
Kubernetes v1.17 [stable]
CSIボリューム も動的プロビジョニングと事前作成されたPVでサポートされていますが、サポートされているトポロジーキーと例を確認するには、特定のCSIドライバーのドキュメントを参照する必要があります。
備考: WaitForFirstConsumerの使用を選択した場合は、Pod仕様でnodeNameを使用してノードアフィニティを指定しないでください。この場合にnodeNameを使用すると、スケジューラはバイパスされ、PVCは保留状態のままになります。
代わりに、以下に示すように、この場合はホスト名にノードセレクターを使用できます。
apiVersion : v1
kind : Pod
metadata :
name : task-pv-pod
spec :
nodeSelector :
kubernetes.io/hostname : kube-01
volumes :
- name : task-pv-storage
persistentVolumeClaim :
claimName : task-pv-claim
containers :
- name : task-pv-container
image : nginx
ports :
- containerPort : 80
name : "http-server"
volumeMounts :
- mountPath : "/usr/share/nginx/html"
name : task-pv-storage
許可されたトポロジー クラスターオペレーターがWaitForFirstConsumerボリュームバインディングモードを指定すると、ほとんどの状況でプロビジョニングを特定のトポロジに制限する必要がなくなります。ただし、それでも必要な場合は、allowedTopologiesを指定できます。
この例は、プロビジョニングされたボリュームのトポロジを特定のゾーンに制限する方法を示しており、サポートされているプラグインのzoneおよびzonesパラメーターの代わりとして使用する必要があります。
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : standard
provisioner : kubernetes.io/gce-pd
parameters :
type : pd-standard
volumeBindingMode : WaitForFirstConsumer
allowedTopologies :
matchLabelExpressions :
- key : failure-domain.beta.kubernetes.io/zone
values :
- us-central-1a
- us-central-1b
パラメーター ストレージクラスには、ストレージクラスに属するボリュームを記述するパラメーターがあります。プロビジョナーに応じて、異なるパラメーターが受け入れられる場合があります。たとえば、パラメーターtypeの値io1とパラメーターiopsPerGBはEBSに固有です。パラメーターを省略すると、デフォルトが使用されます。
StorageClassに定義できるパラメーターは最大512個です。
キーと値を含むパラメーターオブジェクトの合計の長さは、256KiBを超えることはできません。
AWS EBS apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : slow
provisioner : kubernetes.io/aws-ebs
parameters :
type : io1
iopsPerGB : "10"
fsType : ext4
type:io1、gp2、sc1、st1。詳細については、AWSドキュメント を参照してください。デフォルト:gp2。zone(非推奨):AWS zone。zoneもzonesも指定されていない場合、ボリュームは通常、Kubernetesクラスターにノードがあるすべてのアクティブなゾーンにわたってラウンドロビン方式で処理されます。zoneパラメーターとzonesパラメーターを同時に使用することはできません。zones(非推奨):AWS zoneのコンマ区切りリスト。zoneもzonesも指定されていない場合、ボリュームは通常、Kubernetesクラスターにノードがあるすべてのアクティブなゾーンにわたってラウンドロビン方式で処理されます。zoneパラメーターとzonesパラメーターを同時に使用することはできません。iopsPerGB:io1ボリュームのみ。GiBごとの1秒あたりのI/O操作。AWSボリュームプラグインは、これを要求されたボリュームのサイズで乗算して、ボリュームのIOPSを計算し、上限を20,000IOPSに設定します(AWSでサポートされる最大値については、AWSドキュメント を参照してください)。ここでは文字列が必要です。つまり、10ではなく"10"です。fsType:kubernetesでサポートされているfsType。デフォルト:"ext4"。encrypted:EBSボリュームを暗号化するかどうかを示します。有効な値は"true"または"false"です。ここでは文字列が必要です。つまり、trueではなく"true"です。kmsKeyId:オプション。ボリュームを暗号化するときに使用するキーの完全なAmazonリソースネーム。何も指定されていなくてもencryptedがtrueの場合、AWSによってキーが生成されます。有効なARN値については、AWSドキュメントを参照してください。GCE PD apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : slow
provisioner : kubernetes.io/gce-pd
parameters :
type : pd-standard
fstype : ext4
replication-type : none
type:pd-standardまたはpd-ssd。デフォルト:pd-standardzone(非推奨):GCE zone。zoneもzonesも指定されていない場合、ボリュームは通常、Kubernetesクラスターにノードがあるすべてのアクティブなゾーンにわたってラウンドロビン方式で処理されます。zoneパラメーターとzonesパラメーターを同時に使用することはできません。zones(非推奨):GCE zoneのコンマ区切りリスト。zoneもzonesも指定されていない場合、ボリュームは通常、Kubernetesクラスターにノードがあるすべてのアクティブなゾーンにわたってラウンドロビン方式で処理されます。zoneパラメーターとzonesパラメーターを同時に使用することはできません。fstype:ext4またはxfs。デフォルト:ext4。定義されたファイルシステムタイプは、ホストオペレーティングシステムでサポートされている必要があります。replication-type:noneまたはregional-pd。デフォルト:none。replication-typeがnoneに設定されている場合、通常の(ゾーン)PDがプロビジョニングされます。
replication-typeがregional-pdに設定されている場合、Regional Persistent Disk がプロビジョニングされます。volumeBindingMode: WaitForFirstConsumerを設定することを強くお勧めします。この場合、このStorageClassを使用するPersistentVolumeClaimを使用するPodを作成すると、Regional Persistent Diskが2つのゾーンでプロビジョニングされます。1つのゾーンは、Podがスケジュールされているゾーンと同じです。もう1つのゾーンは、クラスターで使用可能なゾーンからランダムに選択されます。ディスクゾーンは、allowedTopologiesを使用してさらに制限できます。
Glusterfs(非推奨) apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : slow
provisioner : kubernetes.io/glusterfs
parameters :
resturl : "http://127.0.0.1:8081"
clusterid : "630372ccdc720a92c681fb928f27b53f"
restauthenabled : "true"
restuser : "admin"
secretNamespace : "default"
secretName : "heketi-secret"
gidMin : "40000"
gidMax : "50000"
volumetype : "replicate:3"
resturl:glusterボリュームをオンデマンドでプロビジョニングするGluster RESTサービス/HeketiサービスのURL。一般的な形式はIPaddress:Portである必要があり、これはGlusterFS動的プロビジョナーの必須パラメーターです。Heketiサービスがopenshift/kubernetesセットアップでルーティング可能なサービスとして公開されている場合、これはhttp://heketi-storage-project.cloudapps.mystorage.comのような形式になる可能性があります。ここで、fqdnは解決可能なHeketiサービスURLです。
restauthenabled:RESTサーバーへの認証を有効にするGluster RESTサービス認証ブール値。この値が"true"の場合、restuserとrestuserkeyまたはsecretNamespace+secretNameを入力する必要があります。このオプションは非推奨です。restuser、restuserkey、secretName、またはsecretNamespaceのいずれかが指定されている場合、認証が有効になります。
restuser:Gluster Trusted Poolでボリュームを作成するためのアクセス権を持つGluster RESTサービス/Heketiユーザー。
restuserkey:RESTサーバーへの認証に使用されるGluster RESTサービス/Heketiユーザーのパスワード。このパラメーターは、secretNamespace+secretNameを優先されて廃止されました。
secretNamespace、secretName:Gluster RESTサービスと通信するときに使用するユーザーパスワードを含むSecretインスタンスの識別。これらのパラメーターはオプションです。secretNamespaceとsecretNameの両方が省略された場合、空のパスワードが使用されます。提供されたシークレットには、タイプkubernetes.io/glusterfsが必要です。たとえば、次のように作成されます。
kubectl create secret generic heketi-secret \
--type="kubernetes.io/glusterfs" --from-literal=key='opensesame' \
--namespace=default
シークレットの例はglusterfs-provisioning-secret.yaml にあります。
clusterid:630372ccdc720a92c681fb928f27b53fは、ボリュームのプロビジョニング時にHeketiによって使用されるクラスターのIDです。また、クラスターIDのリストにすることもできます。これはオプションのパラメーターです。
gidMin、gidMax:StorageClassのGID範囲の最小値と最大値。この範囲内の一意の値(GID)(gidMin-gidMax)が、動的にプロビジョニングされたボリュームに使用されます。これらはオプションの値です。指定しない場合、ボリュームは、それぞれgidMinとgidMaxのデフォルトである2000から2147483647の間の値でプロビジョニングされます。
volumetype:ボリュームタイプとそのパラメーターは、このオプションの値で構成できます。ボリュームタイプが記載されていない場合、プロビジョニング担当者がボリュームタイプを決定します。
例えば、
レプリカボリューム:volumetype: replica:3ここで、'3'はレプリカ数です。 Disperse/ECボリューム:volumetype: disperse:4:2ここで、'4'はデータ、'2'は冗長数です。 ボリュームの分配:volumetype: none 利用可能なボリュームタイプと管理オプションについては、管理ガイド を参照してください。
詳細な参考情報については、Heketiの設定方法 を参照してください。
永続ボリュームが動的にプロビジョニングされると、Glusterプラグインはエンドポイントとヘッドレスサービスをgluster-dynamic-<claimname>という名前で自動的に作成します。永続ボリューム要求が削除されると、動的エンドポイントとサービスは自動的に削除されます。
NFS apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : example-nfs
provisioner : example.com/external-nfs
parameters :
server : nfs-server.example.com
path : /share
readOnly : "false"
server:サーバーは、NFSサーバーのホスト名またはIPアドレスです。path:NFSサーバーによってエクスポートされるパス。readOnly:ストレージが読み取り専用としてマウントされるかどうかを示すフラグ(デフォルトはfalse)。Kubernetesには、内部NFSプロビジョナーは含まれていません。NFS用のStorageClassを作成するには、外部プロビジョナーを使用する必要があります。
ここではいくつかの例を示します。
OpenStack Cinder apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : gold
provisioner : kubernetes.io/cinder
parameters :
availability : nova
availability:アベイラビリティゾーン。指定されていない場合、ボリュームは通常、Kubernetesクラスターにノードがあるすべてのアクティブなゾーンにわたってラウンドロビン方式で処理されます。vSphere vSphereストレージクラスのプロビジョナーには2つのタイプがあります。
インツリープロビジョナーは非推奨です 。CSIプロビジョナーの詳細については、Kubernetes vSphere CSIドライバー およびvSphereVolume CSI移行 を参照してください。
CSIプロビジョナー vSphere CSI StorageClassプロビジョナーは、Tanzu Kubernetesクラスターと連携します。例については、vSphere CSIリポジトリ を参照してください。
vCPプロビジョナー 次の例では、VMware Cloud Provider(vCP) StorageClassプロビジョナーを使用しています。
ユーザー指定のディスク形式でStorageClassを作成します。
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : fast
provisioner : kubernetes.io/vsphere-volume
parameters :
diskformat : zeroedthick
diskformat:thin、zeroedthick、eagerzeroedthick。デフォルト:"thin".
ユーザー指定のデータストアにディスクフォーマットのStorageClassを作成します。
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : fast
provisioner : kubernetes.io/vsphere-volume
parameters :
diskformat : zeroedthick
datastore : VSANDatastore
datastore:ユーザーはStorageClassでデータストアを指定することもできます。
ボリュームは、StorageClassで指定されたデータストア(この場合はVSANDatastore)に作成されます。このフィールドはオプションです。データストアが指定されていない場合、vSphere Cloud Providerの初期化に使用されるvSphere構成ファイルで指定されたデータストアにボリュームが作成されます。
kubernetes内のストレージポリシー管理
既存のvCenter SPBMポリシーを使用
vSphere for Storage Managementの最も重要な機能の1つは、ポリシーベースの管理です。Storage Policy Based Management(SPBM)は、幅広いデータサービスとストレージソリューションにわたって単一の統合コントロールプレーンを提供するストレージポリシーフレームワークです。SPBMにより、vSphere管理者は、キャパシティプランニング、差別化されたサービスレベル、キャパシティヘッドルームの管理など、事前のストレージプロビジョニングの課題を克服できます。SPBMポリシーは、storagePolicyNameパラメーターを使用してStorageClassで指定できます。
Kubernetes内でのVirtual SANポリシーのサポート
Vsphere Infrastructure(VI)管理者は、動的ボリュームプロビジョニング中にカスタムVirtual SANストレージ機能を指定できます。動的なボリュームプロビジョニング時に、パフォーマンスや可用性などのストレージ要件をストレージ機能の形で定義できるようになりました。ストレージ機能の要件はVirtual SANポリシーに変換され、永続ボリューム(仮想ディスク)の作成時にVirtual SANレイヤーにプッシュダウンされます。仮想ディスクは、要件を満たすためにVirtual SANデータストア全体に分散されます。
永続的なボリューム管理にストレージポリシーを使用する方法の詳細については、ボリュームの動的プロビジョニングのためのストレージポリシーベースの管理 を参照してください。
vSphereの例 では、Kubernetes for vSphere内で永続的なボリューム管理を試すことができます。
Ceph RBD apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : fast
provisioner : kubernetes.io/rbd
parameters :
monitors : 10.16.153.105 :6789
adminId : kube
adminSecretName : ceph-secret
adminSecretNamespace : kube-system
pool : kube
userId : kube
userSecretName : ceph-secret-user
userSecretNamespace : default
fsType : ext4
imageFormat : "2"
imageFeatures : "layering"
monitors:カンマ区切りのCephモニター。このパラメーターは必須です。
adminId:プールにイメージを作成できるCephクライアントID。デフォルトは"admin"です。
adminSecretName:adminIdのシークレット名。このパラメーターは必須です。指定されたシークレットのタイプは"kubernetes.io/rbd"である必要があります。
adminSecretNamespace:adminSecretNameの名前空間。デフォルトは"default"です。
pool:Ceph RBDプール。デフォルトは"rbd"です。
userId:RBDイメージのマッピングに使用されるCephクライアントID。デフォルトはadminIdと同じです。
userSecretName:RBDイメージをマップするためのuserIdのCephシークレットの名前。PVCと同じ名前空間に存在する必要があります。このパラメーターは必須です。提供されたシークレットのタイプは"kubernetes.io/rbd"である必要があります。たとえば、次のように作成されます。
kubectl create secret generic ceph-secret --type= "kubernetes.io/rbd" \
= key = 'QVFEQ1pMdFhPUnQrSmhBQUFYaERWNHJsZ3BsMmNjcDR6RFZST0E9PQ==' \
= kube-system
userSecretNamespace:userSecretNameの名前空間。
fsType:kubernetesでサポートされているfsType。デフォルト:"ext4"。
imageFormat:Ceph RBDイメージ形式、"1"または"2"。デフォルトは"2"です。
imageFeatures:このパラメーターはオプションであり、imageFormatを"2"に設定した場合にのみ使用する必要があります。現在サポートされている機能はlayeringのみです。デフォルトは""で、オンになっている機能はありません。
Azure Disk Azure Unmanaged Disk storage class apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : slow
provisioner : kubernetes.io/azure-disk
parameters :
skuName : Standard_LRS
location : eastus
storageAccount : azure_storage_account_name
skuName:AzureストレージアカウントのSku層。デフォルトは空です。location:Azureストレージアカウントの場所。デフォルトは空です。storageAccount:Azureストレージアカウント名。ストレージアカウントを指定する場合、それはクラスターと同じリソースグループに存在する必要があり、locationは無視されます。ストレージアカウントが指定されていない場合、クラスターと同じリソースグループに新しいストレージアカウントが作成されます。Azure Disk storage class (starting from v1.7.2) apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : slow
provisioner : kubernetes.io/azure-disk
parameters :
storageaccounttype : Standard_LRS
kind : managed
storageaccounttype:AzureストレージアカウントのSku層。デフォルトは空です。kind:可能な値は、shared、dedicated、およびmanaged(デフォルト)です。kindがsharedの場合、すべてのアンマネージドディスクは、クラスターと同じリソースグループ内のいくつかの共有ストレージアカウントに作成されます。kindがdedicatedの場合、新しい専用ストレージアカウントが、クラスターと同じリソースグループ内の新しいアンマネージドディスク用に作成されます。kindがmanagedの場合、すべてのマネージドディスクはクラスターと同じリソースグループに作成されます。resourceGroup:Azureディスクが作成されるリソースグループを指定します。これは、既存のリソースグループ名である必要があります。指定しない場合、ディスクは現在のKubernetesクラスターと同じリソースグループに配置されます。Premium VMはStandard_LRSディスクとPremium_LRSディスクの両方を接続できますが、Standard VMはStandard_LRSディスクのみを接続できます。 マネージドVMはマネージドディスクのみをアタッチでき、アンマネージドVMはアンマネージドディスクのみをアタッチできます。 Azure File apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : azurefile
provisioner : kubernetes.io/azure-file
parameters :
skuName : Standard_LRS
location : eastus
storageAccount : azure_storage_account_name
skuName:AzureストレージアカウントのSku層。デフォルトは空です。location:Azureストレージアカウントの場所。デフォルトは空です。storageAccount:Azureストレージアカウント名。デフォルトは空です。ストレージアカウントが指定されていない場合は、リソースグループに関連付けられているすべてのストレージアカウントが検索され、skuNameとlocationに一致するものが見つかります。ストレージアカウントを指定する場合は、クラスターと同じリソースグループに存在する必要があり、skuNameとlocationは無視されます。secretNamespace:Azureストレージアカウント名とキーを含むシークレットの名前空間。デフォルトはPodと同じです。secretName:Azureストレージアカウント名とキーを含むシークレットの名前。デフォルトはazure-storage-account-<accountName>-secretですreadOnly:ストレージが読み取り専用としてマウントされるかどうかを示すフラグ。デフォルトはfalseで、読み取り/書き込みマウントを意味します。この設定は、VolumeMountsのReadOnly設定にも影響します。ストレージのプロビジョニング中に、secretNameという名前のシークレットがマウント資格証明用に作成されます。クラスターでRBAC とController Roles の両方が有効になっている場合は、追加します。clusterrolesystem:controller:persistent-volume-binderに対するリソースsecretのcreateパーミッション。
マルチテナンシーコンテキストでは、secretNamespaceの値を明示的に設定することを強くお勧めします。そうしないと、ストレージアカウントの資格情報が他のユーザーに読み取られる可能性があります。
Portworx Volume apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : portworx-io-priority-high
provisioner : kubernetes.io/portworx-volume
parameters :
repl : "1"
snap_interval : "70"
priority_io : "high"
fs:配置するファイルシステム:none/xfs/ext4(デフォルト:ext4)。block_size:キロバイト単位のブロックサイズ(デフォルト:32)。repl:レプリケーション係数1..3の形式で提供される同期レプリカの数(デフォルト:1)。ここでは文字列が期待されます。つまり、1ではなく"1"です。priority_io:ボリュームがパフォーマンスの高いストレージから作成されるか、優先度の低いストレージhigh/medium/low(デフォルト:low)から作成されるかを決定します。snap_interval:スナップショットをトリガーするクロック/時間間隔(分単位)。スナップショットは、前のスナップショットとの差分に基づいて増分されます。0はスナップを無効にします(デフォルト:0)。ここでは文字列が必要です。つまり、70ではなく"70"です。aggregation_level:ボリュームが分散されるチャンクの数を指定します。0は非集約ボリュームを示します(デフォルト:0)。ここには文字列が必要です。つまり、0ではなく"0"です。ephemeral:アンマウント後にボリュームをクリーンアップするか、永続化するかを指定します。emptyDirユースケースではこの値をtrueに設定でき、Cassandraなどのデータベースのようなpersistent volumesユースケースではfalse、true/false(デフォルトはfalse)に設定する必要があります。ここでは文字列が必要です。つまり、trueではなく"true"です。Local FEATURE STATE:
Kubernetes v1.14 [stable]
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : local-storage
provisioner : kubernetes.io/no-provisioner
volumeBindingMode : WaitForFirstConsumer
ローカルボリュームは現在、動的プロビジョニングをサポートしていませんが、Podのスケジューリングまでボリュームバインドを遅らせるには、引き続きStorageClassを作成する必要があります。これは、WaitForFirstConsumerボリュームバインディングモードによって指定されます。
ボリュームバインディングを遅延させると、PersistentVolumeClaimに適切なPersistentVolumeを選択するときに、スケジューラはPodのスケジューリング制約をすべて考慮することができます。
3.7.7 - ボリュームの動的プロビジョニング(Dynamic Volume Provisioning) ボリュームの動的プロビジョニングにより、ストレージ用のボリュームをオンデマンドに作成することができます。
動的プロビジョニングなしでは、クラスター管理者はクラウドプロバイダーまたはストレージプロバイダーに対して新規のストレージ用のボリュームとPersistentVolumeオブジェクト
バックグラウンド ボリュームの動的プロビジョニングの実装はstorage.k8s.ioというAPIグループ内のStorageClassというAPIオブジェクトに基づいています。クラスター管理者はStorageClassオブジェクトを必要に応じていくつでも定義でき、各オブジェクトはボリュームをプロビジョンするVolumeプラグイン (別名プロビジョナー )と、プロビジョンされるときにプロビジョナーに渡されるパラメーターを指定します。
クラスター管理者はクラスター内で複数の種類のストレージ(同一または異なるストレージシステム)を定義し、さらには公開でき、それらのストレージはパラメーターのカスタムセットを持ちます。この仕組みにおいて、エンドユーザーはストレージがどのようにプロビジョンされるか心配する必要がなく、それでいて複数のストレージオプションから選択できることを保証します。
StorageClassに関するさらなる情報はStorage Class を参照ください。
動的プロビジョニングを有効にする 動的プロビジョニングを有効にするために、クラスター管理者はユーザーのために1つまたはそれ以上のStorageClassを事前に作成する必要があります。StorageClassオブジェクトは、動的プロビジョニングが実行されるときに、どのプロビジョナーが使用されるべきか、またどのようなパラメーターをプロビジョナーに渡すべきか定義します。StorageClassオブジェクトの名前は、有効なDNSサブドメイン名 である必要があります。
下記のマニフェストでは標準的な永続化ディスクをプロビジョンする"slow"というStorageClassを作成します。
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : slow
provisioner : kubernetes.io/gce-pd
parameters :
type : pd-standard
下記のマニフェストではSSDを使った永続化ディスクをプロビジョンする"fast"というStorageClassを作成します。
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : fast
provisioner : kubernetes.io/gce-pd
parameters :
type : pd-ssd
動的プロビジョニングの使用 ユーザーはPersistentVolumeClaimリソース内でStorageClassを含むことで、動的にプロビジョンされたStorageをリクエストできます。Kubernetes v1.6以前では、この機能はvolume.beta.kubernetes.io/storage-classアノテーションを介して使うことができました。しかしこのアノテーションはv1.9から非推奨になりました。その代わりユーザーは現在ではPersistentVolumeClaimオブジェクトのstorageClassNameを使う必要があります。このフィールドの値は、管理者によって設定されたStorageClassの名前と一致しなければなりません(下記 のセクションも参照ください)。
"fast"というStorageClassを選択するために、例としてユーザーは下記のPersistentVolumeClaimを作成します。
apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : claim1
spec :
accessModes :
- ReadWriteOnce
storageClassName : fast
resources :
requests :
storage : 30Gi
このリソースによってSSDのような永続化ディスクが自動的にプロビジョンされます。このリソースが削除された時、そのボリュームは削除されます。
デフォルトの挙動 動的プロビジョニングは、もしStorageClassが1つも指定されていないときに全てのPersistentVolumeClaimが動的にプロビジョンされるようにクラスター上で有効にできます。クラスター管理者は、下記を行うことによりこのふるまいを有効にできます。
管理者はStorageClassに対してstorageclass.kubernetes.io/is-default-classアノテーションをつけることで、デフォルトのStorageClassとしてマーキングできます。
デフォルトのStorageClassがクラスター内で存在し、かつユーザーがPersistentVolumeClaimリソースでstorageClassNameを指定しなかった場合、DefaultStorageClassという管理コントローラーはstorageClassNameフィールドの値をデフォルトのStorageClassを指し示すように自動で追加します。
注意点として、クラスター上では最大1つしかデフォルト のStorageClassが指定できず、storageClassNameを明示的に指定しないPersistentVolumeClaimは作成することもできません。
トポロジーに関する注意 マルチゾーン クラスター内では、Podは単一のリージョン内のゾーンをまたいでしか稼働できません。シングルゾーンのStorageバックエンドはPodがスケジュールされるゾーン内でプロビジョンされる必要があります。これはVolume割り当てモード を設定することにより可能となります。
3.7.8 - ボリュームのスナップショット Kubernetesでは、VolumeSnapshot はストレージシステム上のボリュームのスナップショットを表します。このドキュメントは、Kubernetes永続ボリューム に既に精通していることを前提としています。
概要 APIリソースPersistentVolumeとPersistentVolumeClaimを使用してユーザーと管理者にボリュームをプロビジョニングする方法と同様に、VolumeSnapshotContentとVolumeSnapshotAPIリソースは、ユーザーと管理者のボリュームスナップショットを作成するために提供されます。
VolumeSnapshotContentは、管理者によってプロビジョニングされたクラスター内のボリュームから取得されたスナップショットです。PersistentVolumeがクラスターリソースであるように、これはクラスターのリソースです。
VolumeSnapshotは、ユーザーによるボリュームのスナップショットの要求です。PersistentVolumeClaimに似ています。
VolumeSnapshotClassを使用すると、VolumeSnapshotに属するさまざまな属性を指定できます。これらの属性は、ストレージシステム上の同じボリュームから取得されたスナップショット間で異なる場合があるため、PersistentVolumeClaimの同じStorageClassを使用して表現することはできません。
ボリュームスナップショットは、完全に新しいボリュームを作成することなく、特定の時点でボリュームの内容をコピーするための標準化された方法をKubernetesユーザーに提供します。この機能により、たとえばデータベース管理者は、編集または削除の変更を実行する前にデータベースをバックアップできます。
この機能を使用する場合、ユーザーは次のことに注意する必要があります。
APIオブジェクトVolumeSnapshot、VolumeSnapshotContent、およびVolumeSnapshotClassはCRD であり、コアAPIの一部ではありません。 VolumeSnapshotのサポートは、CSIドライバーでのみ利用できます。VolumeSnapshotの展開プロセスの一環として、Kubernetesチームは、コントロールプレーンに展開されるスナップショットコントローラーと、CSIドライバーと共に展開されるcsi-snapshotterと呼ばれるサイドカーヘルパーコンテナを提供します。スナップショットコントローラーは、VolumeSnapshotおよびVolumeSnapshotContentオブジェクトを管理し、VolumeSnapshotContentオブジェクトの作成と削除を担当します。サイドカーcsi-snapshotterは、VolumeSnapshotContentオブジェクトを監視し、CSIエンドポイントに対してCreateSnapshotおよびDeleteSnapshot操作をトリガーします。スナップショットオブジェクトの厳密な検証を提供するvalidation Webhookサーバーもあります。これは、CSIドライバーではなく、スナップショットコントローラーおよびCRDと共にKubernetesディストリビューションによってインストールする必要があります。スナップショット機能が有効になっているすべてのKubernetesクラスターにインストールする必要があります。 CSIドライバーは、ボリュームスナップショット機能を実装している場合と実装していない場合があります。ボリュームスナップショットのサポートを提供するCSIドライバーは、csi-snapshotterを使用する可能性があります。詳細については、CSIドライバーのドキュメント を参照してください。 CRDとスナップショットコントローラーのインストールは、Kubernetesディストリビューションの責任です。 ボリュームスナップショットとボリュームスナップショットのコンテンツのライフサイクル VolumeSnapshotContentsはクラスター内のリソースです。VolumeSnapshotsは、これらのリソースに対するリクエストです。VolumeSnapshotContentsとVolumeSnapshotsの間の相互作用は、次のライフサイクルに従います。
プロビジョニングボリュームのスナップショット スナップショットをプロビジョニングするには、事前プロビジョニングと動的プロビジョニングの2つの方法があります。
事前プロビジョニング クラスター管理者は、多数のVolumeSnapshotContentsを作成します。それらは、クラスターユーザーが使用できるストレージシステム上の実際のボリュームスナップショットの詳細を保持します。それらはKubernetesAPIに存在し、消費することができます。
動的プロビジョニング 既存のスナップショットを使用する代わりに、スナップショットをPersistentVolumeClaimから動的に取得するように要求できます。VolumeSnapshotClass は、スナップショットを作成するときに使用するストレージプロバイダー固有のパラメーターを指定します。
バインディング スナップショットコントローラーは、事前プロビジョニングされたシナリオと動的にプロビジョニングされたシナリオの両方で、適切なVolumeSnapshotContentオブジェクトを使用したVolumeSnapshotオブジェクトのバインディングを処理します。バインディングは1対1のマッピングです。
事前プロビジョニングされたバインディングの場合、要求されたVolumeSnapshotContentオブジェクトが作成されるまで、VolumeSnapshotはバインドされないままになります。
スナップショットソース保護としてのPersistentVolumeClaim この保護の目的は、スナップショットがシステムから取得されている間、使用中のPersistentVolumeClaim APIオブジェクトがシステムから削除されないようにすることです(これにより、データが失われる可能性があります)。
PersistentVolumeClaimのスナップショットが作成されている間、そのPersistentVolumeClaimは使用中です。スナップショットソースとしてアクティブに使用されているPersistentVolumeClaim APIオブジェクトを削除しても、PersistentVolumeClaimオブジェクトはすぐには削除されません。代わりに、PersistentVolumeClaimオブジェクトの削除は、スナップショットがReadyToUseになるか中止されるまで延期されます。
削除 削除はVolumeSnapshotオブジェクトの削除によってトリガーされ、DeletionPolicyに従います。DeletionPolicyがDeleteの場合、基になるストレージスナップショットはVolumeSnapshotContentオブジェクトとともに削除されます。DeletionPolicyがRetainの場合、基になるスナップショットとVolumeSnapshotContentの両方が残ります。
ボリュームスナップショット 各VolumeSnapshotには、仕様とステータスが含まれています。
apiVersion : snapshot.storage.k8s.io/v1
kind : VolumeSnapshot
metadata :
name : new-snapshot-test
spec :
volumeSnapshotClassName : csi-hostpath-snapclass
source :
persistentVolumeClaimName : pvc-test
persistentVolumeClaimNameは、スナップショットのPersistentVolumeClaimデータソースの名前です。このフィールドは、スナップショットを動的にプロビジョニングするために必要です。
ボリュームスナップショットは、属性volumeSnapshotClassNameを使用してVolumeSnapshotClass の名前を指定することにより、特定のクラスを要求できます。何も設定されていない場合、利用可能な場合はデフォルトのクラスが使用されます。
事前プロビジョニングされたスナップショットの場合、次の例に示すように、スナップショットのソースとしてvolumeSnapshotContentNameを指定する必要があります。事前プロビジョニングされたスナップショットには、volumeSnapshotContentNameソースフィールドが必要です。
apiVersion : snapshot.storage.k8s.io/v1
kind : VolumeSnapshot
metadata :
name : test-snapshot
spec :
source :
volumeSnapshotContentName : test-content
ボリュームスナップショットコンテンツ 各VolumeSnapshotContentには、仕様とステータスが含まれています。動的プロビジョニングでは、スナップショット共通コントローラーがVolumeSnapshotContentオブジェクトを作成します。以下に例を示します。
apiVersion : snapshot.storage.k8s.io/v1
kind : VolumeSnapshotContent
metadata :
name : snapcontent-72d9a349-aacd-42d2-a240-d775650d2455
spec :
deletionPolicy : Delete
driver : hostpath.csi.k8s.io
source :
volumeHandle : ee0cfb94-f8d4-11e9-b2d8-0242ac110002
sourceVolumeMode : Filesystem
volumeSnapshotClassName : csi-hostpath-snapclass
volumeSnapshotRef :
name : new-snapshot-test
namespace : default
uid : 72d9a349-aacd-42d2-a240-d775650d2455
volumeHandleは、ストレージバックエンドで作成され、ボリュームの作成中にCSIドライバーによって返されるボリュームの一意の識別子です。このフィールドは、スナップショットを動的にプロビジョニングするために必要です。これは、スナップショットのボリュームソースを指定します。
事前プロビジョニングされたスナップショットの場合、(クラスター管理者として)次のようにVolumeSnapshotContentオブジェクトを作成する必要があります。
apiVersion : snapshot.storage.k8s.io/v1
kind : VolumeSnapshotContent
metadata :
name : new-snapshot-content-test
spec :
deletionPolicy : Delete
driver : hostpath.csi.k8s.io
source :
snapshotHandle : 7bdd0de3-aaeb-11e8-9aae-0242ac110002
sourceVolumeMode : Filesystem
volumeSnapshotRef :
name : new-snapshot-test
namespace : default
snapshotHandleは、ストレージバックエンドで作成されたボリュームスナップショットの一意の識別子です。このフィールドは、事前プロビジョニングされたスナップショットに必要です。このVolumeSnapshotContentが表すストレージシステムのCSIスナップショットIDを指定します。
sourceVolumeModeは、スナップショットが作成されるボリュームのモードです。sourceVolumeModeフィールドの値は、FilesystemまたはBlockのいずれかです。ソースボリュームモードが指定されていない場合、Kubernetesはスナップショットをソースボリュームのモードが不明であるかのように扱います。
volumeSnapshotRefは、対応するVolumeSnapshotの参照です。VolumeSnapshotContentが事前プロビジョニングされたスナップショットとして作成されている場合、volumeSnapshotRefで参照されるVolumeSnapshotがまだ存在しない可能性があることに注意してください。
スナップショットのボリュームモードの変換 クラスターにインストールされているVolumeSnapshotsAPIがsourceVolumeModeフィールドをサポートしている場合、APIには、権限のないユーザーがボリュームのモードを変換するのを防ぐ機能があります。
クラスターにこの機能の機能があるかどうかを確認するには、次のコマンドを実行します。
$ kubectl get crd volumesnapshotcontent -o yaml
ユーザーが既存のVolumeSnapshotからPersistentVolumeClaimを作成できるようにしたいが、ソースとは異なるボリュームモードを使用する場合は、VolumeSnapshotに対応するVolumeSnapshotContentにアノテーションsnapshot.storage.kubernetes.io/allow-volume-mode-change: "true"を追加する必要があります。
事前プロビジョニングされたスナップショットの場合、クラスター管理者がspec.sourceVolumeModeを入力する必要があります。
この機能を有効にしたVolumeSnapshotContentリソースの例は次のようになります。
apiVersion : snapshot.storage.k8s.io/v1
kind : VolumeSnapshotContent
metadata :
name : new-snapshot-content-test
annotations :
- snapshot.storage.kubernetes.io/allow-volume-mode-change : "true"
spec :
deletionPolicy : Delete
driver : hostpath.csi.k8s.io
source :
snapshotHandle : 7bdd0de3-aaeb-11e8-9aae-0242ac110002
sourceVolumeMode : Filesystem
volumeSnapshotRef :
name : new-snapshot-test
namespace : default
スナップショットからのボリュームのプロビジョニング PersistentVolumeClaimオブジェクトのdataSource フィールドを使用して、スナップショットからのデータが事前に取り込まれた新しいボリュームをプロビジョニングできます。
詳細については、ボリュームのスナップショットとスナップショットからのボリュームの復元 を参照してください。
3.7.9 - VolumeSnapshotClass このドキュメントでは、KubernetesにおけるVolumeSnapshotClassのコンセプトについて説明します。Volumeのスナップショット とストレージクラス も参照してください。
イントロダクション StorageClassはVolumeをプロビジョンするときに、ストレージの"クラス"に関する情報を記述する方法を提供します。それと同様に、VolumeSnapshotClassではVolumeSnapshotをプロビジョンするときに、ストレージの"クラス"に関する情報を記述する方法を提供します。
VolumeSnapshotClass リソース 各VolumeSnapshotClassはdriver、deletionPolicyとparametersフィールドを含み、それらは、そのクラスに属するVolumeSnapshotが動的にプロビジョンされるときに使われます。
VolumeSnapshotClassオブジェクトの名前は重要であり、それはユーザーがどのように特定のクラスをリクエストできるかを示したものです。管理者は初めてVolumeSnapshotClassオブジェクトを作成するときに、その名前と他のパラメーターをセットし、そのオブジェクトは一度作成されるとそのあと更新することができません。
管理者は、バインド対象のクラスを1つもリクエストしないようなVolumeSnapshotのために、デフォルトのVolumeSnapshotClassを指定することができます。
apiVersion : snapshot.storage.k8s.io/v1beta1
kind : VolumeSnapshotClass
metadata :
name : csi-hostpath-snapclass
driver : hostpath.csi.k8s.io
deletionPolicy : Delete
parameters :
Driver VolumeSnapshotClassは、VolumeSnapshotをプロビジョンするときに何のCSIボリュームプラグインを使うか決定するためのdriverフィールドを持っています。このフィールドは必須となります。
DeletionPolicy VolumeSnapshotClassにはdeletionPolicyがあります。これにより、バインドされている VolumeSnapshotオブジェクトが削除されるときに、VolumeSnapshotContentがどうなるかを設定することができます。VolumeSnapshotのdeletionPolicyは、RetainまたはDeleteのいずれかです。このフィールドは指定しなければなりません。
deletionPolicyがDeleteの場合、元となるストレージスナップショットは VolumeSnapshotContentオブジェクトとともに削除されます。deletionPolicyがRetainの場合、元となるスナップショットとVolumeSnapshotContentの両方が残ります。
Parameters VolumeSnapshotClassは、そのクラスに属するVolumeSnapshotを指定するパラメーターを持っています。
driverに応じて様々なパラメーターを使用できます。
3.7.10 - CSI Volume Cloning このドキュメントではKubernetesで既存のCSIボリュームの複製についてのコンセプトを説明します。このページを読む前にあらかじめボリューム についてよく理解していることが望ましいです。
イントロダクション CSI のボリューム複製機能は、ユーザーがボリューム の複製を作成することを示すdataSourceフィールドで既存のPVC を指定するためのサポートを追加します。
複製は既存のKubernetesボリュームの複製として定義され、標準のボリュームと同じように使用できます。唯一の違いは、プロビジョニング時に「新しい」空のボリュームを作成するのではなく、バックエンドデバイスが指定されたボリュームの正確な複製を作成することです。
複製の実装は、Kubernetes APIの観点からは新しいPVCの作成時に既存のPVCをdataSourceとして指定する機能を追加するだけです。ソースPVCはバインドされており、使用可能でなければなりません(使用中ではありません)。
この機能を使用する場合、ユーザーは次のことに注意する必要があります:
複製のサポート(VolumePVCDataSource)はCSIドライバーのみです。 複製のサポートは動的プロビジョニングのみです。 CSIドライバーはボリューム複製機能を実装している場合としていない場合があります。 PVCは複製先のPVCと同じ名前空間に存在する場合にのみ複製できます(複製元と複製先は同じ名前空間になければなりません)。 複製は同じストレージクラス内でのみサポートされます。宛先ボリュームは、ソースと同じストレージクラスである必要があります。 デフォルトのストレージクラスを使用でき、仕様ではstorageClassNameを省略できます。 複製は同じVolumeMode設定を使用する2つのボリューム間でのみ実行できます(ブロックモードのボリュームを要求する場合、ソースもブロックモードである必要があります)。 プロビジョニング 複製は同じ名前空間内の既存のPVCを参照するdataSourceを追加すること以外は他のPVCと同様にプロビジョニングされます。
apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : clone-of-pvc-1
namespace : myns
spec :
accessModes :
- ReadWriteOnce
storageClassName : cloning
resources :
requests :
storage : 5Gi
dataSource :
kind : PersistentVolumeClaim
name : pvc-1
備考: spec.resources.requests.storageに容量の値を指定する必要があります。指定する値は、ソースボリュームの容量と同じかそれ以上である必要があります。このyamlの作成結果は指定された複製元であるpvc-1と全く同じデータを持つclone-of-pvc-1という名前の新しいPVCです。
使い方 新しいPVCが使用可能になると、複製されたPVCは他のPVCと同じように利用されます。またこの時点で新しく作成されたPVCは独立したオブジェクトであることが期待されます。元のdataSource PVCを考慮せず個別に利用、複製、スナップショット、削除できます。これはまた複製元が新しく作成された複製にリンクされておらず、新しく作成された複製に影響を与えずに変更または削除できることを意味します。
3.7.11 - ストレージ容量 ストレージ容量は、Podが実行されるノードごとに制限があったり、大きさが異なる可能性があります。たとえば、NASがすべてのノードからはアクセスできなかったり、初めからストレージがノードローカルでしか利用できない可能性があります。
FEATURE STATE:
Kubernetes v1.19 [alpha]
このページでは、Kubernetesがストレージ容量を追跡し続ける方法と、スケジューラーがその情報を利用して、残りの未作成のボリュームのために十分なストレージ容量へアクセスできるノード上にどのようにPodをスケジューリングするかについて説明します。もしストレージ容量の追跡がなければ、スケジューラーは、ボリュームをプロビジョニングするために十分な容量のないノードを選択してしまい、スケジューリングの再試行が複数回行われてしまう恐れがあります。
ストレージ容量の追跡は、Container Storage Interface (CSI)向けにサポートされており、CSIドライバーのインストール時に有効にする必要があります 。
API この機能には、以下の2つのAPI拡張があります。
スケジューリング ストレージ容量の情報がKubernetesのスケジューラーで利用されるのは、以下のすべての条件を満たす場合です。
CSIStorageCapacityフィーチャーゲートがtrueであるPodがまだ作成されていないボリュームを使用する時 そのボリュームが、CSIドライバーを参照し、volume binding mode にWaitForFirstConsumerを使うStorageClass を使用している ドライバーに対するCSIDriverオブジェクトのStorageCapacityがtrueに設定されている その場合、スケジューラーはPodに対して、十分なストレージ容量が利用できるノードだけを考慮するようになります。このチェックは非常に単純で、ボリュームのサイズと、CSIStorageCapacityオブジェクトに一覧された容量を、ノードを含むトポロジーで比較するだけです。
volume binding modeがImmediateのボリュームの場合、ストレージドライバーはボリュームを使用するPodとは関係なく、ボリュームを作成する場所を決定します。次に、スケジューラーはボリュームが作成された後、Podをボリュームが利用できるノードにスケジューリングします。
CSI ephemeral volumes の場合、スケジューリングは常にストレージ容量を考慮せずに行われます。このような動作になっているのは、このボリュームタイプはノードローカルな特別なCSIドライバーでのみ使用され、そこでは特に大きなリソースが必要になることはない、という想定に基づいています。
再スケジューリング WaitForFirstConsumerボリュームがあるPodに対してノードが選択された場合は、その決定はまだ一時的なものです。次のステップで、CSIストレージドライバーに対して、選択されたノード上でボリュームが利用可能になることが予定されているというヒントを使用してボリュームの作成を要求します。
Kubernetesは古い容量の情報をもとにノードを選択する場合があるため、実際にはボリュームが作成できないという可能性が存在します。その場合、ノードの選択がリセットされ、KubernetesスケジューラーはPodに割り当てるノードを再び探します。
制限 ストレージ容量を追跡することで、1回目の試行でスケジューリングが成功する可能性が高くなります。しかし、スケジューラーは潜在的に古い情報に基づいて決定を行う可能性があるため、成功を保証することはできません。通常、ストレージ容量の情報が存在しないスケジューリングと同様のリトライの仕組みによって、スケジューリングの失敗に対処します。
スケジューリングが永続的に失敗する状況の1つは、Podが複数のボリュームを使用する場合で、あるトポロジーのセグメントで1つのボリュームがすでに作成された後、もう1つのボリュームのために十分な容量が残っていないような場合です。この状況から回復するには、たとえば、容量を増加させたり、すでに作成されたボリュームを削除するなどの手動での対応が必要です。この問題に自動的に対処するためには、まだ追加の作業 が必要となっています。
ストレージ容量の追跡を有効にする ストレージ容量の追跡はアルファ機能 であり、CSIStorageCapacityフィーチャーゲート とstorage.k8s.io/v1alpha1 API group を有効にした場合にのみ、有効化されます。詳細については、--feature-gatesおよび--runtime-config kube-apiserverパラメーター を参照してください。
Kubernetesクラスターがこの機能をサポートしているか簡単に確認するには、以下のコマンドを実行して、CSIStorageCapacityオブジェクトを一覧表示します。
kubectl get csistoragecapacities --all-namespaces
クラスターがCSIStorageCapacityをサポートしていれば、CSIStorageCapacityのリストが表示されるか、次のメッセージが表示されます。
No resources found
もしサポートされていなければ、代わりに次のエラーが表示されます。
error: the server doesn't have a resource type "csistoragecapacities"
クラスター内で機能を有効化することに加えて、CSIドライバーもこの機能をサポートしている必要があります。詳細については、各ドライバーのドキュメントを参照してください。
次の項目 3.7.12 - ノード固有のボリューム制限 このページでは、さまざまなクラウドプロバイダーのノードに接続できるボリュームの最大数について説明します。
通常、Google、Amazon、Microsoftなどのクラウドプロバイダーには、ノードに接続できるボリュームの数に制限があります。Kubernetesがこれらの制限を尊重することが重要です。
そうしないと、ノードでスケジュールされたPodが、ボリュームが接続されるのを待ってスタックする可能性があります。
Kubernetesのデフォルトの制限 Kubernetesスケジューラーには、ノードに接続できるボリュームの数にデフォルトの制限があります。
カスタム制限 これらの制限を変更するには、KUBE_MAX_PD_VOLS環境変数の値を設定し、スケジューラーを開始します。CSIドライバーの手順は異なる場合があります。制限をカスタマイズする方法については、CSIドライバーのドキュメントを参照してください。
デフォルトの制限よりも高い制限を設定する場合は注意してください。クラウドプロバイダーのドキュメントを参照して、設定した制限をノードが実際にサポートしていることを確認してください。
制限はクラスター全体に適用されるため、すべてのノードに影響します。
動的ボリューム制限 FEATURE STATE:
Kubernetes v1.17 [stable]
動的ボリューム制限は、次のボリュームタイプでサポートされています。
Amazon EBS Google Persistent Disk Azure Disk CSI ツリー内のボリュームプラグインによって管理されるボリュームの場合、Kubernetesはノードタイプを自動的に決定し、ノードに適切なボリュームの最大数を適用します。例えば:
3.7.13 - ボリュームヘルスモニタリング FEATURE STATE:
Kubernetes v1.21 [alpha]
CSI ボリュームヘルスモニタリングにより、CSIドライバーは、基盤となるストレージシステムから異常なボリューム状態を検出し、それらをPVC またはPod のイベントとして報告できます。
ボリュームヘルスモニタリング Kubernetes volume health monitoring は、KubernetesがContainerStorageInterface(CSI)を実装する方法の一部です。ボリュームヘルスモニタリング機能は、外部のヘルスモニターコントローラーとkubelet の2つのコンポーネントで実装されます。
CSIドライバーがコントローラー側からのボリュームヘルスモニタリング機能をサポートしている場合、CSIボリュームで異常なボリューム状態が検出されると、関連するPersistentVolumeClaim (PVC)でイベントが報告されます。
外部ヘルスモニターコントローラー も、ノード障害イベントを監視します。enable-node-watcherフラグをtrueに設定することで、ノード障害の監視を有効にできます。外部ヘルスモニターがノード障害イベントを検出すると、コントローラーは、このPVCを使用するポッドが障害ノード上にあることを示すために、PVCでイベントが報告されることを報告します。
CSIドライバーがノード側からのボリュームヘルスモニタリング機能をサポートしている場合、CSIボリュームで異常なボリューム状態が検出されると、PVCを使用するすべてのPodでイベントが報告されます。さらに、ボリュームヘルス情報はKubelet VolumeStatsメトリクスとして公開されます。新しいメトリックkubelet_volume_stats_health_status_abnormalが追加されました。このメトリックにはnamespaceとpersistentvolumeclaimの2つのラベルが含まれます。カウントは1または0です。1はボリュームが異常であることを示し、0はボリュームが正常であることを示します。詳細については、KEP を確認してください。
備考: ノード側からこの機能を使用するには、
CSIVolumeHealthfeature gate を有効にする必要があります。
次の項目 CSIドライバーのドキュメント を参照して、この機能を実装しているCSIドライバーを確認してください。
3.8 - 設定 3.8.1 - 設定のベストプラクティス このドキュメントでは、ユーザーガイド、入門マニュアル、および例を通して紹介されている設定のベストプラクティスを中心に説明します。
このドキュメントは生ものです。このリストには載っていないが他の人に役立つかもしれない何かについて考えている場合、IssueまたはPRを遠慮なく作成してください。
一般的な設定のTips 構成を定義する際には、最新の安定したAPIバージョンを指定してください。
設定ファイルは、クラスターに反映される前にバージョン管理システムに保存されるべきです。これによって、必要に応じて設定変更を迅速にロールバックできます。また、クラスターの再作成や復元時にも役立ちます。
JSONではなくYAMLを使って設定ファイルを書いてください。これらのフォーマットはほとんどすべてのシナリオで互換的に使用できますが、YAMLはよりユーザーフレンドリーになる傾向があります。
意味がある場合は常に、関連オブジェクトを単一ファイルにグループ化します。多くの場合、1つのファイルの方が管理が簡単です。例としてguestbook-all-in-one.yaml ファイルを参照してください。
多くのkubectlコマンドがディレクトリに対しても呼び出せることも覚えておきましょう。たとえば、設定ファイルのディレクトリで kubectl applyを呼び出すことができます。
不必要にデフォルト値を指定しないでください。シンプルかつ最小限の設定のほうがエラーが発生しにくくなります。
よりよいイントロスペクションのために、オブジェクトの説明をアノテーションに入れましょう。
"真っ裸"のPod に対する ReplicaSet、Deployment、およびJob 可能な限り、"真っ裸"のPod(ReplicaSet やDeployment にバインドされていないPod)は使わないでください。Nodeに障害が発生した場合、これらのPodは再スケジュールされません。
明示的にrestartPolicy: NeverJob のほうが適切な場合もあるかもしれません。
Service 対応するバックエンドワークロード(DeploymentまたはReplicaSet)の前、およびそれにアクセスする必要があるワークロードの前にService を作成します。Kubernetesがコンテナを起動すると、コンテナ起動時に実行されていたすべてのServiceを指す環境変数が提供されます。たとえば、fooという名前のServiceが存在する場合、すべてのコンテナは初期環境で次の変数を取得します。
FOO_SERVICE_HOST = <the host the Service is running on>
FOO_SERVICE_PORT = <the port the Service is running on>
これは順序付けの必要性を意味します - PodがアクセスしたいServiceはPod自身の前に作らなければならず、そうしないと環境変数は注入されません。DNSにはこの制限はありません。
(強くお勧めしますが)クラスターアドオン の1つの選択肢はDNSサーバーです。DNSサーバーは、新しいServiceについてKubernetes APIを監視し、それぞれに対して一連のDNSレコードを作成します。クラスター全体でDNSが有効になっている場合は、すべてのPodが自動的にServicesの名前解決を行えるはずです。
どうしても必要な場合以外は、PodにhostPortを指定しないでください。PodをhostPortにバインドすると、Podがスケジュールできる場所の数を制限します、それぞれの<hostIP、 hostPort、protocol>の組み合わせはユニークでなければならないからです。hostIPとprotocolを明示的に指定しないと、KubernetesはデフォルトのhostIPとして0.0.0.0を、デフォルトの protocolとしてTCPを使います。
デバッグ目的でのみポートにアクセスする必要がある場合は、apiserver proxy またはkubectl port-forward
ノード上でPodのポートを明示的に公開する必要がある場合は、hostPortに頼る前にNodePort の使用を検討してください。
hostPortの理由と同じくして、hostNetworkの使用はできるだけ避けてください。
kube-proxyのロードバランシングが不要な場合は、headless Service (ClusterIPがNone)を使用してServiceを簡単に検出できます。
ラベルの使用 { app: myapp, tier: frontend, phase: test, deployment: v3 }のように、アプリケーションまたはデプロイメントの セマンティック属性 を識別するラベル を定義して使いましょう。これらのラベルを使用して、他のリソースに適切なPodを選択できます。例えば、すべてのtier:frontendを持つPodを選択するServiceや、app:myappに属するすべてのphase:testコンポーネント、などです。このアプローチの例を知るには、ゲストブック アプリも合わせてご覧ください。セレクターからリリース固有のラベルを省略することで、Serviceを複数のDeploymentにまたがるように作成できます。 Deployment により、ダウンタイムなしで実行中のサービスを簡単に更新できます。
オブジェクトの望ましい状態はDeploymentによって記述され、その仕様への変更が 適用 されると、Deploymentコントローラーは制御された速度で実際の状態を望ましい状態に変更します。
デバッグ用にラベルを操作できます。Kubernetesコントローラー(ReplicaSetなど)とServiceはセレクターラベルを使用してPodとマッチするため、Podから関連ラベルを削除すると、コントローラーによって考慮されたり、Serviceによってトラフィックを処理されたりすることがなくなります。既存のPodのラベルを削除すると、そのコントローラーはその代わりに新しいPodを作成します。これは、「隔離」環境で以前の「ライブ」Podをデバッグするのに便利な方法です。対話的にラベルを削除または追加するには、kubectl label コンテナイメージ imagePullPolicy とイメージのタグは、kubelet が特定のイメージをpullしようとしたときに作用します。
imagePullPolicy: IfNotPresent: ローカルでイメージが見つからない場合にのみイメージをpullします。
imagePullPolicy: Always: kubeletがコンテナを起動する度に、kubeletはコンテナイメージレジストリに問い合わせて、イメージのダイジェストの名前解決を行います。もし、kubeletが同じダイジェストのコンテナイメージをローカルにキャッシュしていたら、kubeletはそのキャッシュされたイメージを利用します。そうでなければ、kubeletは解決されたダイジェストのイメージをダウンロードし、そのイメージを利用してコンテナを起動します。
imagePullPolicy のタグが省略されていて、利用してるイメージのタグが:latestの場合や省略されている場合、Alwaysが適用されます。
imagePullPolicy のタグが省略されていて、利用してるイメージのタグはあるが:latestでない場合、IfNotPresentが適用されます。
imagePullPolicy: Never: 常にローカルでイメージを探そうとします。ない場合にもイメージはpullしません。
備考: コンテナが常に同じバージョンのイメージを使用するようにするためには、そのコンテナイメージの
ダイジェスト を指定することができます。
<image-name>:<tag>を
<image-name>@<digest>で置き換えます(例:
image@sha256:45b23dee08af5e43a7fea6c4cf9c25ccf269ee113168c19722f87876677c5cb2)。このダイジェストはイメージの特定のバージョンを一意に識別するため、ダイジェスト値を変更しない限り、Kubernetesによって更新されることはありません。
備考: どのバージョンのイメージが実行されているのかを追跡するのが難しく、適切にロールバックするのが難しいため、本番環境でコンテナをデプロイするときは :latestタグを使用しないでください。
備考: ベースイメージのプロバイダーのキャッシュセマンティクスにより、imagePullPolicy:Alwaysもより効率的になります。たとえば、Dockerでは、イメージがすでに存在する場合すべてのイメージレイヤーがキャッシュされ、イメージのダウンロードが不要であるため、pullが高速になります。kubectlの使い方 kubectl apply -f <directory>を使いましょう。これを使うと、ディレクトリ内のすべての.yaml、.yml、および.jsonファイルがapplyに渡されます。
getやdeleteを行う際は、特定のオブジェクト名を指定するのではなくラベルセレクターを使いましょう。ラベルセレクター とラベルの効果的な使い方 のセクションを参照してください。
単一コンテナのDeploymentやServiceを素早く作成するなら、kubectl create deploymentやkubectl exposeを使いましょう。一例として、Serviceを利用したクラスター内のアプリケーションへのアクセス を参照してください。
3.8.2 - ConfigMap
ConfigMapは、 機密性のないデータをキーと値のペアで保存するために使用されるAPIオブジェクトです。Pod は、環境変数、コマンドライン引数、またはボリューム 内の設定ファイルとしてConfigMapを使用できます。
ConfigMapを使用すると、環境固有の設定をコンテナイメージ から分離できるため、アプリケーションを簡単に移植できるようになります。
注意: ConfigMapは機密性や暗号化を提供しません。保存したいデータが機密情報である場合は、ConfigMapの代わりに
Secret を使用するか、追加の(サードパーティー)ツールを使用してデータが非公開になるようにしてください。
動機 アプリケーションのコードとは別に設定データを設定するには、ConfigMapを使用します。
たとえば、アプリケーションを開発していて、(開発用時には)自分のコンピューター上と、(実際のトラフィックをハンドルするときは)クラウド上とで実行することを想像してみてください。あなたは、DATABASE_HOSTという名前の環境変数を使用するコードを書きます。ローカルでは、この変数をlocalhostに設定します。クラウド上では、データベースコンポーネントをクラスター内に公開するKubernetesのService を指すように設定します。
こうすることで、必要であればクラウド上で実行しているコンテナイメージを取得することで、ローカルでも完全に同じコードを使ってデバッグができるようになります。
ConfigMapは、大量のデータを保持するようには設計されていません。ConfigMapに保存されるデータは1MiBを超えることはできません。この制限を超える設定を保存する必要がある場合は、ボリュームのマウントを検討するか、別のデータベースまたはファイルサービスを使用することを検討してください。
ConfigMapオブジェクト ConfigMapは、他のオブジェクトが使うための設定を保存できるAPIオブジェクト です。ほとんどのKubernetesオブジェクトにspecセクションがあるのとは違い、ConfigMapにはdataおよびbinaryDataフィールドがあります。これらのフィールドは、キーとバリューのペアを値として受け入れます。dataフィールドとbinaryDataフィールドはどちらもオプションです。dataフィールドはUTF-8バイトシーケンスを含むように設計されていますが、binaryDataフィールドはバイナリデータを含むように設計されています。
ConfigMapの名前は、有効なDNSのサブドメイン名 でなければなりません。
dataまたはbinaryDataフィールドの各キーは、英数字、-、_、または.で構成されている必要があります。dataに格納されているキーは、binaryDataフィールドのキーと重複することはできません。
v1.19以降、ConfigMapの定義にimmutableフィールドを追加して、イミュータブルなConfigMap を作成できます。
ConfigMapとPod ConfigMapを参照して、ConfigMap内のデータを元にしてPod内のコンテナの設定をするPodのspecを書くことができます。このとき、PodとConfigMapは同じ名前空間 内に存在する必要があります。
以下に、ConfigMapの例を示します。単一の値を持つキーと、Configuration形式のデータ片のような値を持つキーがあります。
apiVersion : v1
kind : ConfigMap
metadata :
name : game-demo
data :
# プロパティーに似たキー。各キーは単純な値にマッピングされている
player_initial_lives : "3"
ui_properties_file_name : "user-interface.properties"
# ファイルに似たキー
game.properties : |
enemy.types=aliens,monsters
player.maximum-lives=5
user-interface.properties : |
color.good=purple
color.bad=yellow
allow.textmode=true
ConfigMapを利用してPod内のコンテナを設定する方法には、次の4種類があります。
コンテナ内のコマンドと引数 環境変数をコンテナに渡す 読み取り専用のボリューム内にファイルを追加し、アプリケーションがそのファイルを読み取る Kubernetes APIを使用してConfigMapを読み込むコードを書き、そのコードをPod内で実行する これらのさまざまな方法は、利用するデータをモデル化するのに役立ちます。最初の3つの方法では、kubelet がPodのコンテナを起動する時にConfigMapのデータを使用します。
4番目の方法では、ConfigMapとそのデータを読み込むためのコードを自分自身で書く必要があります。しかし、Kubernetes APIを直接使用するため、アプリケーションはConfigMapがいつ変更されても更新イベントを受信でき、変更が発生したときにすぐに反応できます。この手法では、Kubernetes APIに直接アクセスすることで、別の名前空間にあるConfigMapにもアクセスできます。
以下に、Podを設定するためにgame-demoから値を使用するPodの例を示します。
apiVersion : v1
kind : Pod
metadata :
name : configmap-demo-pod
spec :
containers :
- name : demo
image : alpine
command : ["sleep" , "3600" ]
env :
# 環境変数を定義します。
- name : PLAYER_INITIAL_LIVES # ここではConfigMap内のキーの名前とは違い
# 大文字が使われていることに着目してください。
valueFrom :
configMapKeyRef :
name : game-demo # この値を取得するConfigMap。
key : player_initial_lives # 取得するキー。
- name : UI_PROPERTIES_FILE_NAME
valueFrom :
configMapKeyRef :
name : game-demo
key : ui_properties_file_name
volumeMounts :
- name : config
mountPath : "/config"
readOnly : true
volumes :
# Podレベルでボリュームを設定し、Pod内のコンテナにマウントします。
- name : config
configMap :
# マウントしたいConfigMapの名前を指定します。
name : game-demo
# ファイルとして作成するConfigMapのキーの配列
items :
- key : "game.properties"
path : "game.properties"
- key : "user-interface.properties"
path : "user-interface.properties"
ConfigMapは1行のプロパティの値と複数行のファイルに似た形式の値を区別しません。問題となるのは、Podや他のオブジェクトによる値の使用方法です。
この例では、ボリュームを定義して、demoコンテナの内部で/configにマウントしています。これにより、ConfigMap内には4つのキーがあるにもかかわらず、2つのファイル/config/game.propertiesおよび/config/user-interface.propertiesだけが作成されます。
これは、Podの定義がvolumesセクションでitemsという配列を指定しているためです。もしitemsの配列を完全に省略すれば、ConfigMap内の各キーがキーと同じ名前のファイルになり、4つのファイルが作成されます。
ConfigMapを使う ConfigMapは、データボリュームとしてマウントできます。ConfigMapは、Podへ直接公開せずにシステムの他の部品として使うこともできます。たとえば、ConfigMapには、システムの他の一部が設定のために使用するデータを保存できます。
ConfigMapの最も一般的な使い方では、同じ名前空間にあるPod内で実行されているコンテナに設定を構成します。ConfigMapを独立して使用することもできます。
たとえば、ConfigMapに基づいて動作を調整するアドオン やオペレーター を見かけることがあるかもしれません。
ConfigMapをPodからファイルとして使う ConfigMapをPod内のボリュームで使用するには、次のようにします。
ConfigMapを作成するか、既存のConfigMapを使用します。複数のPodから同じConfigMapを参照することもできます。 Podの定義を修正して、.spec.volumes[]以下にボリュームを追加します。ボリュームに任意の名前を付け、.spec.volumes[].configMap.nameフィールドにConfigMapオブジェクトへの参照を設定します。 ConfigMapが必要な各コンテナに.spec.containers[].volumeMounts[]を追加します。.spec.containers[].volumeMounts[].readOnly = trueを指定して、.spec.containers[].volumeMounts[].mountPathには、ConfigMapのデータを表示したい未使用のディレクトリ名を指定します。 イメージまたはコマンドラインを修正して、プログラムがそのディレクトリ内のファイルを読み込むように設定します。ConfigMapのdataマップ内の各キーが、mountPath以下のファイル名になります。 以下は、ボリューム内にConfigMapをマウントするPodの例です。
apiVersion : v1
kind : Pod
metadata :
name : mypod
spec :
containers :
- name : mypod
image : redis
volumeMounts :
- name : foo
mountPath : "/etc/foo"
readOnly : true
volumes :
- name : foo
configMap :
name : myconfigmap
使用したいそれぞれのConfigMapごとに、.spec.volumes内で参照する必要があります。
Pod内に複数のコンテナが存在する場合、各コンテナにそれぞれ別のvolumeMountsのブロックが必要ですが、.spec.volumesはConfigMapごとに1つしか必要ありません。
マウントしたConfigMapの自動的な更新 ボリューム内で現在使用中のConfigMapが更新されると、射影されたキーも最終的に(eventually)更新されます。kubeletは定期的な同期のたびにマウントされたConfigMapが新しいかどうか確認します。しかし、kubeletが現在のConfigMapの値を取得するときにはローカルキャッシュを使用します。キャッシュの種類は、KubeletConfiguration構造体 の中のConfigMapAndSecretChangeDetectionStrategyフィールドで設定可能です。ConfigMapは、監視(デフォルト)、ttlベース、またはすべてのリクエストを直接APIサーバーへ単純にリダイレクトする方法のいずれかによって伝搬されます。その結果、ConfigMapが更新された瞬間から、新しいキーがPodに射影されるまでの遅延の合計は、最長でkubeletの同期期間+キャッシュの伝搬遅延になります。ここで、キャッシュの伝搬遅延は選択したキャッシュの種類に依存します(監視の伝搬遅延、キャッシュのttl、または0に等しくなります)。
環境変数として使用されるConfigMapは自動的に更新されないため、ポッドを再起動する必要があります。
イミュータブルなConfigMap FEATURE STATE:
Kubernetes v1.19 [beta]
Kubernetesのベータ版の機能である イミュータブルなSecretおよびConfigMap は、個別のSecretやConfigMapをイミュータブルに設定するオプションを提供します。ConfigMapを広範に使用している(少なくとも数万のConfigMapがPodにマウントされている)クラスターでは、データの変更を防ぐことにより、以下のような利点が得られます。
アプリケーションの停止を引き起こす可能性のある予想外の(または望まない)変更を防ぐことができる ConfigMapをイミュータブルにマークして監視を停止することにより、kube-apiserverへの負荷を大幅に削減し、クラスターの性能が向上する この機能は、ImmutableEmphemeralVolumesフィーチャーゲート によって管理されます。immutableフィールドをtrueに設定することで、イミュータブルなConfigMapを作成できます。次に例を示します。
apiVersion : v1
kind : ConfigMap
metadata :
...
data :
...
immutable : true
一度ConfigMapがイミュータブルに設定されると、この変更を元に戻したり、dataまたはbinaryDataフィールドのコンテンツを変更することはできません 。ConfigMapの削除と再作成のみ可能です。既存のPodは削除されたConfigMapのマウントポイントを保持するため、こうしたPodは再作成することをおすすめします。
次の項目 3.8.3 - Secret Secretとは、パスワードやトークン、キーなどの少量の機密データを含むオブジェクトのことです。
このような情報は、Secretを用いないとPod の定義やコンテナイメージ に直接記載することになってしまうかもしれません。
Secretを使用すれば、アプリケーションコードに機密データを含める必要がなくなります。
なぜなら、Secretは、それを使用するPodとは独立して作成することができ、
Podの作成、閲覧、編集といったワークフローの中でSecret(およびそのデータ)が漏洩する危険性が低くなるためです。
また、Kubernetesやクラスター内で動作するアプリケーションは、不揮発性ストレージに機密データを書き込まないようにするなど、Secretで追加の予防措置を取ることができます。
Secretsは、ConfigMaps に似ていますが、機密データを保持するために用います。
注意: KubernetesのSecretは、デフォルトでは、APIサーバーの基礎となるデータストア(etcd)に暗号化されずに保存されます。APIにアクセスできる人は誰でもSecretを取得または変更でき、etcdにアクセスできる人も同様です。
さらに、名前空間でPodを作成する権限を持つ人は、そのアクセスを使用して、その名前空間のあらゆるSecretを読むことができます。これには、Deploymentを作成する能力などの間接的なアクセスも含まれます。
Secretsを安全に使用するには、以下の手順を推奨します。
Secretsを安全に暗号化する Secretsのデータの読み取りを制限するRBACルール の有効化または設定 適切な場合には、RBACなどのメカニズムを使用して、どの原則が新しいSecretの作成や既存のSecretの置き換えを許可されるかを制限します。 Secretの概要 Secretを使うには、PodはSecretを参照することが必要です。
PodがSecretを使う方法は3種類あります。
KubernetesのコントロールプレーンでもSecretsは使われています。例えば、bootstrap token Secrets は、ノード登録を自動化するための仕組みです。
Secretオブジェクトの名称は正当なDNSサブドメイン名 である必要があります。
シークレットの構成ファイルを作成するときに、dataおよび/またはstringDataフィールドを指定できます。dataフィールドとstringDataフィールドはオプションです。
dataフィールドのすべてのキーの値は、base64でエンコードされた文字列である必要があります。
base64文字列への変換が望ましくない場合は、代わりにstringDataフィールドを指定することを選択できます。これは任意の文字列を値として受け入れます。
dataとstringDataのキーは、英数字、-、_、または.で構成されている必要があります。
stringDataフィールドのすべてのキーと値のペアは、内部でdataフィールドにマージされます。
キーがdataフィールドとstringDataフィールドの両方に表示される場合、stringDataフィールドで指定された値が優先されます。
Secretの種類 Secretを作成するときは、Secrettypeフィールド、または特定の同等のkubectlコマンドラインフラグ(使用可能な場合)を使用して、その型を指定できます。
Secret型は、Secret dataのプログラムによる処理を容易にするために使用されます。
Kubernetesは、いくつかの一般的な使用シナリオに対応するいくつかの組み込み型を提供します。
これらの型は、実行される検証とKubernetesが課す制約の点で異なります。
Builtin Type Usage Opaquearbitrary user-defined data kubernetes.io/service-account-tokenservice account token kubernetes.io/dockercfgserialized ~/.dockercfg file kubernetes.io/dockerconfigjsonserialized ~/.docker/config.json file kubernetes.io/basic-authcredentials for basic authentication kubernetes.io/ssh-authcredentials for SSH authentication kubernetes.io/tlsdata for a TLS client or server bootstrap.kubernetes.io/tokenbootstrap token data
Secretオブジェクトのtype値として空でない文字列を割り当てることにより、独自のSecret型を定義して使用できます。空の文字列はOpaque型として扱われます。Kubernetesは型名に制約を課しません。ただし、組み込み型の1つを使用している場合は、その型に定義されているすべての要件を満たす必要があります。
Opaque secrets Opaqueは、Secret構成ファイルから省略された場合のデフォルトのSecret型です。
kubectlを使用してSecretを作成する場合、genericサブコマンドを使用してOpaqueSecret型を示します。 たとえば、次のコマンドは、Opaque型の空のSecretを作成します。
kubectl create secret generic empty-secret
kubectl get secret empty-secret
出力は次のようになります。
NAME TYPE DATA AGE
empty-secret Opaque 0 2m6s
DATA列には、Secretに保存されているデータ項目の数が表示されます。
この場合、0は空のSecretを作成したことを意味します。
Service account token Secrets kubernetes.io/service-account-token型のSecretは、サービスアカウントを識別するトークンを格納するために使用されます。 このSecret型を使用する場合は、kubernetes.io/service-account.nameアノテーションが既存のサービスアカウント名に設定されていることを確認する必要があります。Kubernetesコントローラーは、kubernetes.io/service-account.uidアノテーションや実際のトークンコンテンツに設定されたdataフィールドのtokenキーなど、他のいくつかのフィールドに入力します。
apiVersion : v1
kind : Secret
metadata :
name : secret-sa-sample
annotations :
kubernetes.io/service-account.name : "sa-name"
type : kubernetes.io/service-account-token
data :
# You can include additional key value pairs as you do with Opaque Secrets
extra : YmFyCg==
Podを作成すると、Kubernetesはservice account Secretを自動的に作成し、このSecretを使用するようにPodを自動的に変更します。service account token Secretには、APIにアクセスするための資格情報が含まれています。
API証明の自動作成と使用は、必要に応じて無効にするか、上書きすることができます。 ただし、API Serverに安全にアクセスするだけの場合は、これが推奨されるワークフローです。
ServiceAccountの動作の詳細については、ServiceAccount のドキュメントを参照してください。
PodからServiceAccountを参照する方法については、PodautomountServiceAccountTokenフィールドとserviceAccountNameフィールドを確認することもできます。
Docker config Secrets 次のtype値のいずれかを使用して、イメージのDockerレジストリにアクセスするための資格情報を格納するSecretを作成できます。
kubernetes.io/dockercfgkubernetes.io/dockerconfigjsonkubernetes.io/dockercfg型は、Dockerコマンドラインを構成するためのレガシー形式であるシリアル化された~/.dockercfgを保存するために予約されています。
このSecret型を使用する場合は、Secretのdataフィールドに.dockercfgキーが含まれていることを確認する必要があります。このキーの値は、base64形式でエンコードされた~/.dockercfgファイルの内容です。
kubernetes.io/dockerconfigjson型は、~/.dockercfgの新しいフォーマットである~/.docker/config.jsonファイルと同じフォーマットルールに従うシリアル化されたJSONを保存するために設計されています。
このSecret型を使用する場合、Secretオブジェクトのdataフィールドには.dockerconfigjsonキーが含まれている必要があります。このキーでは、~/.docker/config.jsonファイルのコンテンツがbase64でエンコードされた文字列として提供されます。
以下は、kubernetes.io/dockercfg型のSecretの例です。
apiVersion : v1
kind : Secret
name : secret-dockercfg
type : kubernetes.io/dockercfg
data :
.dockercfg : |
"<base64 encoded ~/.dockercfg file>"
備考: base64エンコーディングを実行したくない場合は、代わりにstringDataフィールドを使用することを選択できます。マニフェストを使用してこれらの型のSecretを作成すると、APIserverは期待されるキーがdataフィールドに存在するかどうかを確認し、提供された値を有効なJSONとして解析できるかどうかを確認します。APIサーバーは、JSONが実際にDocker configファイルであるかどうかを検証しません。
Docker configファイルがない場合、またはkubectlを使用してDockerレジストリSecretを作成する場合は、次の操作を実行できます。
kubectl create secret docker-registry secret-tiger-docker \
= tiger \
= pass113 \
= tiger@acme.com \
= my-registry.example:5000
このコマンドは、kubernetes.io/dockerconfigjson型のSecretを作成します。
dataフィールドから.dockerconfigjsonコンテンツをダンプすると、その場で作成された有効なDocker configである次のJSONコンテンツを取得します。
{
"apiVersion" : "v1" ,
"data" : {
".dockerconfigjson" : "eyJhdXRocyI6eyJteS1yZWdpc3RyeTo1MDAwIjp7InVzZXJuYW1lIjoidGlnZXIiLCJwYXNzd29yZCI6InBhc3MxMTMiLCJlbWFpbCI6InRpZ2VyQGFjbWUuY29tIiwiYXV0aCI6ImRHbG5aWEk2Y0dGemN6RXhNdz09In19fQ=="
},
"kind" : "Secret" ,
"metadata" : {
"creationTimestamp" : "2021-07-01T07:30:59Z" ,
"name" : "secret-tiger-docker" ,
"namespace" : "default" ,
"resourceVersion" : "566718" ,
"uid" : "e15c1d7b-9071-4100-8681-f3a7a2ce89ca"
},
"type" : "kubernetes.io/dockerconfigjson"
}
Basic authentication Secret kubernetes.io/basic-auth型は、Basic認証に必要な認証を保存するために提供されています。このSecret型を使用する場合、Secretのdataフィールドには次の2つのキーが含まれている必要があります。
username: 認証のためのユーザー名password: 認証のためのパスワードかトークン上記の2つのキーの両方の値は、base64でエンコードされた文字列です。もちろん、Secretの作成にstringDataを使用してクリアテキストコンテンツを提供することもできます。
次のYAMLは、Basic authentication Secretの設定例です。
apiVersion : v1
kind : Secret
metadata :
name : secret-basic-auth
type : kubernetes.io/basic-auth
stringData :
username : admin
password : t0p-Secret
Basic認証Secret型は、ユーザーの便宜のためにのみ提供されています。Basic認証に使用される資格情報のOpaqueを作成できます。
ただし、組み込みのSecret型を使用すると、認証の形式を統一するのに役立ち、APIserverは必要なキーがSecret configurationで提供されているかどうかを確認します。
SSH authentication secrets 組み込みのタイプkubernetes.io/ssh-authは、SSH認証で使用されるデータを保存するために提供されています。このSecret型を使用する場合、使用するSSH認証としてdata(またはstringData)フィールドにssh-privatekeyキーと値のペアを指定する必要があります。
次のYAMLはSSH authentication Secretの設定例です:
apiVersion : v1
kind : Secret
metadata :
name : secret-ssh-auth
type : kubernetes.io/ssh-auth
data :
# the data is abbreviated in this example
ssh-privatekey : |
MIIEpQIBAAKCAQEAulqb/Y ...
SSH authentication Secret型は、ユーザーの便宜のためにのみ提供されています。
SSH認証に使用される資格情報のOpaqueを作成できます。
ただし、組み込みのSecret型を使用すると、認証の形式を統一するのに役立ち、APIserverは必要なキーがSecret configurationで提供されているかどうかを確認します。
TLS secrets Kubernetesは、TLSに通常使用される証明書とそれに関連付けられたキーを保存するための組み込みのSecret型kubernetes.io/tlsを提供します。このデータは、主にIngressリソースのTLS terminationで使用されますが、他のリソースで使用されることも、ワークロードによって直接使用されることもあります。
このSecret型を使用する場合、APIサーバーは各キーの値を実際には検証しませんが、tls.keyおよびtls.crtキーをSecret configurationのdata(またはstringData)フィールドに指定する必要があります。
次のYAMLはTLS Secretの設定例です:
apiVersion : v1
kind : Secret
metadata :
name : secret-tls
type : kubernetes.io/tls
data :
# the data is abbreviated in this example
tls.crt : |
MIIC2DCCAcCgAwIBAgIBATANBgkqh ...
tls.key : |
MIIEpgIBAAKCAQEA7yn3bRHQ5FHMQ ...
TLS Secret型は、ユーザーの便宜のために提供されています。 TLSサーバーやクライアントに使用される資格情報のOpaqueを作成できます。ただし、組み込みのSecret型を使用すると、プロジェクトでSecret形式の一貫性を確保できます。APIserverは、必要なキーがSecret configurationで提供されているかどうかを確認します。
kubectlを使用してTLS Secretを作成する場合、次の例に示すようにtlsサブコマンドを使用できます。
kubectl create secret tls my-tls-secret \
= path/to/cert/file \
= path/to/key/file
公開鍵と秘密鍵のペアは、事前に存在している必要があります。--certの公開鍵証明書は.PEMエンコード(Base64エンコードDER形式)であり、--keyの指定された秘密鍵と一致する必要があります。
秘密鍵は、一般にPEM秘密鍵形式と呼ばれる暗号化されていない形式である必要があります。どちらの場合も、PEMの最初と最後の行(たとえば、-------- BEGIN CERTIFICATE -----と------- END CERTIFICATE ----)は含まれていません 。
Bootstrap token Secrets Bootstrap token Secretは、Secretのtypeをbootstrap.kubernetes.io/tokenに明示的に指定することで作成できます。このタイプのSecretは、ノードのブートストラッププロセス中に使用されるトークン用に設計されています。よく知られているConfigMapに署名するために使用されるトークンを格納します。
Bootstrap token Secretは通常、kube-systemnamespaceで作成されbootstrap-token-<token-id>の形式で名前が付けられます。ここで<token-id>はトークンIDの6文字の文字列です。
Kubernetesマニフェストとして、Bootstrap token Secretは次のようになります。
apiVersion : v1
kind : Secret
metadata :
name : bootstrap-token-5emitj
namespace : kube-system
type : bootstrap.kubernetes.io/token
data :
auth-extra-groups : c3lzdGVtOmJvb3RzdHJhcHBlcnM6a3ViZWFkbTpkZWZhdWx0LW5vZGUtdG9rZW4=
expiration : MjAyMC0wOS0xM1QwNDozOToxMFo=
token-id : NWVtaXRq
token-secret : a3E0Z2lodnN6emduMXAwcg==
usage-bootstrap-authentication : dHJ1ZQ==
usage-bootstrap-signing : dHJ1ZQ==
Bootstrap type Secretには、dataで指定された次のキーがあります。
token_id:トークン識別子としてのランダムな6文字の文字列。必須。token-secret:実際のtoken secretとしてのランダムな16文字の文字列。必須。description:トークンの使用目的を説明する人間が読める文字列。オプション。expiration:トークンの有効期限を指定するRFC3339 を使用した絶対UTC時間。オプション。usage-bootstrap-<usage>:Bootstrap tokenの追加の使用法を示すブールフラグ。auth-extra-groups:system:bootstrappersグループに加えて認証されるグループ名のコンマ区切りのリスト。上記のYAMLは、値がすべてbase64でエンコードされた文字列であるため、分かりづらく見えるかもしれません。実際には、次のYAMLを使用して同一のSecretを作成できます。
apiVersion : v1
kind : Secret
metadata :
# Note how the Secret is named
name : bootstrap-token-5emitj
# A bootstrap token Secret usually resides in the kube-system namespace
namespace : kube-system
type : bootstrap.kubernetes.io/token
stringData :
auth-extra-groups : "system:bootstrappers:kubeadm:default-node-token"
expiration : "2020-09-13T04:39:10Z"
# This token ID is used in the name
token-id : "5emitj"
token-secret : "kq4gihvszzgn1p0r"
# This token can be used for authentication
usage-bootstrap-authentication : "true"
# and it can be used for signing
usage-bootstrap-signing : "true"
Secretの作成 Secretを作成するには、いくつかのオプションがあります。
Secretの編集 既存のSecretは次のコマンドで編集することができます。
kubectl edit secrets mysecret
デフォルトに設定されたエディターが開かれ、dataフィールドのBase64でエンコードされたSecretの値を編集することができます。
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion : v1
data :
username : YWRtaW4=
password : MWYyZDFlMmU2N2Rm
kind : Secret
metadata :
annotations :
kubectl.kubernetes.io/last-applied-configuration : { ... }
creationTimestamp : 2016-01-22T18:41:56Z
name : mysecret
namespace : default
resourceVersion : "164619"
uid : cfee02d6-c137-11e5-8d73-42010af00002
type : Opaque
Secretの使用 Podの中のコンテナがSecretを使うために、データボリュームとしてマウントしたり、環境変数 として値を参照できるようにできます。
Secretは直接Podが参照できるようにはされず、システムの別の部分に使われることもあります。
例えば、Secretはあなたに代わってシステムの他の部分が外部のシステムとやりとりするために使う機密情報を保持することもあります。
SecretをファイルとしてPodから利用する PodのボリュームとしてSecretを使うには、
Secretを作成するか既存のものを使用します。複数のPodが同一のSecretを参照することができます。 ボリュームを追加するため、Podの定義の.spec.volumes[]以下を書き換えます。ボリュームに命名し、.spec.volumes[].secret.secretNameフィールドはSecretオブジェクトの名称と同一にします。 Secretを必要とするそれぞれのコンテナに.spec.containers[].volumeMounts[]を追加します。.spec.containers[].volumeMounts[].readOnly = trueを指定して.spec.containers[].volumeMounts[].mountPathをSecretをマウントする未使用のディレクトリ名にします。 イメージやコマンドラインを変更し、プログラムがそのディレクトリを参照するようにします。連想配列dataのキーはmountPath以下のファイル名になります。 これはSecretをボリュームとしてマウントするPodの例です。
apiVersion : v1
kind : Pod
metadata :
name : mypod
spec :
containers :
- name : mypod
image : redis
volumeMounts :
- name : foo
mountPath : "/etc/foo"
readOnly : true
volumes :
- name : foo
secret :
secretName : mysecret
使用したいSecretはそれぞれ.spec.volumesの中で参照されている必要があります。
Podに複数のコンテナがある場合、それぞれのコンテナがvolumeMountsブロックを必要としますが、.spec.volumesはSecret1つあたり1つで十分です。
多くのファイルを一つのSecretにまとめることも、多くのSecretを使うことも、便利な方を採ることができます。
Secretのキーの特定のパスへの割り当て Secretのキーが割り当てられるパスを制御することができます。
それぞれのキーがターゲットとするパスは.spec.volumes[].secret.itemsフィールドによって指定できます。
apiVersion : v1
kind : Pod
metadata :
name : mypod
spec :
containers :
- name : mypod
image : redis
volumeMounts :
- name : foo
mountPath : "/etc/foo"
readOnly : true
volumes :
- name : foo
secret :
secretName : mysecret
items :
- key : username
path : my-group/my-username
次のような挙動をします。
usernameは/etc/foo/usernameの代わりに/etc/foo/my-group/my-usernameの元に格納されます。passwordは現れません。.spec.volumes[].secret.itemsが使われるときは、itemsの中で指定されたキーのみが現れます。
Secretの中の全てのキーを使用したい場合は、itemsフィールドに全て列挙する必要があります。
列挙されたキーは対応するSecretに存在する必要があり、そうでなければボリュームは生成されません。
Secretファイルのパーミッション 単一のSecretキーに対して、ファイルアクセスパーミッションビットを指定することができます。
パーミッションを指定しない場合、デフォルトで0644が使われます。
Secretボリューム全体のデフォルトモードを指定し、必要に応じてキー単位で上書きすることもできます。
例えば、次のようにしてデフォルトモードを指定できます。
apiVersion : v1
kind : Pod
metadata :
name : mypod
spec :
containers :
- name : mypod
image : redis
volumeMounts :
- name : foo
mountPath : "/etc/foo"
volumes :
- name : foo
secret :
secretName : mysecret
defaultMode : 0400
Secretは/etc/fooにマウントされ、Secretボリュームが生成する全てのファイルはパーミッション0400に設定されます。
JSONの仕様は8進数の記述に対応していないため、パーミッション0400を示す値として256を使用することに注意が必要です。
Podの定義にJSONではなくYAMLを使う場合は、パーミッションを指定するためにより自然な8進表記を使うことができます。
kubectl execを使ってPodに入るときは、期待したファイルモードを知るためにシンボリックリンクを辿る必要があることに注意してください。
例として、PodのSecretのファイルモードを確認します。
kubectl exec mypod -it sh
cd /etc/foo
ls -l
出力は次のようになります。
total 0
lrwxrwxrwx 1 root root 15 May 18 00:18 password -> ..data/password
lrwxrwxrwx 1 root root 15 May 18 00:18 username -> ..data/username
正しいファイルモードを知るためにシンボリックリンクを辿ります。
cd /etc/foo/..data
ls -l
出力は次のようになります。
total 8
-r-------- 1 root root 12 May 18 00:18 password
-r-------- 1 root root 5 May 18 00:18 username
前の例のようにマッピングを使い、ファイルごとに異なるパーミッションを指定することができます。
apiVersion : v1
kind : Pod
metadata :
name : mypod
spec :
containers :
- name : mypod
image : redis
volumeMounts :
- name : foo
mountPath : "/etc/foo"
volumes :
- name : foo
secret :
secretName : mysecret
items :
- key : username
path : my-group/my-username
mode : 0777
この例では、ファイル/etc/foo/my-group/my-usernameのパーミッションは0777になります。
JSONを使う場合は、JSONの制約により10進表記の511と記述する必要があります。
後で参照する場合、このパーミッションの値は10進表記で表示されることがあることに注意してください。
Secretの値のボリュームによる利用 Secretのボリュームがマウントされたコンテナからは、Secretのキーはファイル名として、Secretの値はBase64デコードされ、それらのファイルに格納されます。
上記の例のコンテナの中でコマンドを実行した結果を示します。
出力は次のようになります。
username
password
出力は次のようになります。
admin
出力は次のようになります。
1f2d1e2e67df
コンテナ内のプログラムはファイルからSecretの内容を読み取る責務を持ちます。
マウントされたSecretの自動更新 ボリュームとして使用されているSecretが更新されると、やがて割り当てられたキーも同様に更新されます。
kubeletは定期的な同期のたびにマウントされたSecretが新しいかどうかを確認します。
しかしながら、kubeletはSecretの現在の値の取得にローカルキャッシュを使用します。
このキャッシュはKubeletConfiguration struct 内のConfigMapAndSecretChangeDetectionStrategyフィールドによって設定可能です。
Secretはwatch(デフォルト)、TTLベース、単に全てのリクエストをAPIサーバーへリダイレクトすることのいずれかによって伝搬します。
結果として、Secretが更新された時点からPodに新しいキーが反映されるまでの遅延時間の合計は、kubeletの同期間隔 + キャッシュの伝搬遅延となります。
キャッシュの遅延は、キャッシュの種別により、それぞれwatchの伝搬遅延、キャッシュのTTL、0になります。
備考: Secretを
subPath を指定してボリュームにマウントしているコンテナには、Secretの更新が反映されません。
Secretを環境変数として使用する SecretをPodの環境変数 として使用するには、
Secretを作成するか既存のものを使います。複数のPodが同一のSecretを参照することができます。 Podの定義を変更し、Secretを使用したいコンテナごとにSecretのキーと割り当てたい環境変数を指定します。Secretキーを利用する環境変数はenv[].valueFrom.secretKeyRefにSecretの名前とキーを指定すべきです。 イメージまたはコマンドライン(もしくはその両方)を変更し、プログラムが指定した環境変数を参照するようにします。 Secretを環境変数で参照するPodの例を示します。
apiVersion : v1
kind : Pod
metadata :
name : secret-env-pod
spec :
containers :
- name : mycontainer
image : redis
env :
- name : SECRET_USERNAME
valueFrom :
secretKeyRef :
name : mysecret
key : username
- name : SECRET_PASSWORD
valueFrom :
secretKeyRef :
name : mysecret
key : password
restartPolicy : Never
環境変数からのSecretの値の利用 Secretを環境変数として利用するコンテナの内部では、Secretのキーは一般の環境変数名として現れ、値はBase64デコードされた状態で保持されます。
上記の例のコンテナの内部でコマンドを実行した結果の例を示します。
出力は次のようになります。
admin
出力は次のようになります。
1f2d1e2e67df
Immutable Secrets FEATURE STATE:
Kubernetes v1.19 [beta]
Kubernetesベータ機能ImmutableSecrets and ConfigMaps は、個々のSecretsとConfigMapsをimutableとして設定するオプションを提供します。Secret(少なくとも数万の、SecretからPodへの一意のマウント)を広範囲に使用するクラスターの場合、データの変更を防ぐことには次の利点があります。
アプリケーションの停止を引き起こす可能性のある偶発的な(または不要な)更新からユーザーを保護します imutableとしてマークされたSecretのウォッチを閉じることで、kube-apiserverの負荷を大幅に削減することができ、クラスターのパフォーマンスを向上させます。 この機能は、ImmutableEphemeralVolumesfeature gate によって制御されます。これは、v1.19以降デフォルトで有効になっています。immutableフィールドをtrueに設定することで、imutableのSecretを作成できます。例えば、
apiVersion : v1
kind : Secret
metadata :
...
data :
...
immutable : true
備考: SecretまたはConfigMapがimutableとしてマークされると、この変更を元に戻したり、dataフィールドの内容を変更したりすることはできません 。Secretを削除して再作成することしかできません。
既存のPodは、削除されたSecretへのマウントポイントを維持します。これらのPodを再作成することをお勧めします。imagePullSecretsを使用する imagePullSecretsフィールドは同一のネームスペース内のSecretの参照のリストです。
kubeletにDockerやその他のイメージレジストリのパスワードを渡すために、imagePullSecretsにそれを含むSecretを指定することができます。
kubeletはこの情報をPodのためにプライベートイメージをpullするために使います。
imagePullSecretsの詳細はPodSpec API を参照してください。
imagePullSecretを手動で指定する ImagePullSecretsの指定の方法はコンテナイメージのドキュメント に記載されています。
imagePullSecretsが自動的にアタッチされるようにする imagePullSecretsを手動で作成し、サービスアカウントから参照することができます。
サービスアカウントが指定されるまたはデフォルトでサービスアカウントが設定されたPodは、サービスアカウントが持つimagePullSecretsフィールドを得ます。
詳細な手順の説明はサービスアカウントへのImagePullSecretsの追加 を参照してください。
手動で作成されたSecretの自動的なマウント 手動で作成されたSecret(例えばGitHubアカウントへのアクセスに使うトークンを含む)はサービスアカウントを基に自動的にアタッチすることができます。
詳細な説明はPodPresetを使ったPodへの情報の注入 を参照してください。
詳細 制限事項 Secretボリュームは指定されたオブジェクト参照が実際に存在するSecretオブジェクトを指していることを保証するため検証されます。
そのため、Secretはそれを必要とするPodよりも先に作成する必要があります。
Secretリソースはnamespace に属します。
Secretは同一のnamespaceに属するPodからのみ参照することができます。
各Secretは1MiBの容量制限があります。
これはAPIサーバーやkubeletのメモリーを枯渇するような非常に大きなSecretを作成することを避けるためです。
しかしながら、小さなSecretを多数作成することも同様にメモリーを枯渇させます。
Secretに起因するメモリー使用量をより網羅的に制限することは、将来計画されています。
kubeletがPodに対してSecretを使用するとき、APIサーバーから取得されたSecretのみをサポートします。
これにはkubectlを利用して、またはレプリケーションコントローラーによって間接的に作成されたPodが含まれます。
kubeletの--manifest-urlフラグ、--configフラグ、またはREST APIにより生成されたPodは含まれません
(これらはPodを生成するための一般的な方法ではありません)。
環境変数として使われるSecretは任意と指定されていない限り、それを使用するPodよりも先に作成される必要があります。
存在しないSecretへの参照はPodの起動を妨げます。
Secretに存在しないキーへの参照(secretKeyRefフィールド)はPodの起動を妨げます。
SecretをenvFromフィールドによって環境変数へ設定する場合、環境変数の名称として不適切なキーは飛ばされます。
Podは起動することを認められます。
このとき、reasonがInvalidVariableNamesであるイベントが発生し、メッセージに飛ばされたキーのリストが含まれます。
この例では、Podは2つの不適切なキー1badkeyと2alsobadを含むdefault/mysecretを参照しています。
出力は次のようになります。
LASTSEEN FIRSTSEEN COUNT NAME KIND SUBOBJECT TYPE REASON
0s 0s 1 dapi-test-pod Pod Warning InvalidEnvironmentVariableNames kubelet, 127.0.0.1 Keys [1badkey, 2alsobad] from the EnvFrom secret default/mysecret were skipped since they are considered invalid environment variable names.
SecretとPodの相互作用 Kubernetes APIがコールされてPodが生成されるとき、参照するSecretの存在は確認されません。
Podがスケジューリングされると、kubeletはSecretの値を取得しようとします。
Secretが存在しない、または一時的にAPIサーバーへの接続が途絶えたことにより取得できない場合、kubeletは定期的にリトライします。
kubeletはPodがまだ起動できない理由に関するイベントを報告します。
Secretが取得されると、kubeletはそのボリュームを作成しマウントします。
Podのボリュームが全てマウントされるまでは、Podのコンテナは起動することはありません。
ユースケース ユースケース: コンテナの環境変数として Secretの作成
apiVersion : v1
kind : Secret
metadata :
name : mysecret
type : Opaque
data :
USER_NAME : YWRtaW4=
PASSWORD : MWYyZDFlMmU2N2Rm
kubectl apply -f mysecret.yaml
envFromを使ってSecretの全てのデータをコンテナの環境変数として定義します。
SecretのキーはPod内の環境変数の名称になります。
apiVersion : v1
kind : Pod
metadata :
name : secret-test-pod
spec :
containers :
- name : test-container
image : registry.k8s.io/busybox
command : [ "/bin/sh" , "-c" , "env" ]
envFrom :
- secretRef :
name : mysecret
restartPolicy : Never
ユースケース: SSH鍵を持つPod SSH鍵を含むSecretを作成します。
kubectl create secret generic ssh-key-secret --from-file= ssh-privatekey= /path/to/.ssh/id_rsa --from-file= ssh-publickey= /path/to/.ssh/id_rsa.pub
出力は次のようになります。
secret "ssh-key-secret" created
SSH鍵を含むsecretGeneratorフィールドを持つkustomization.yamlを作成することもできます。
注意: 自身のSSH鍵を送る前に慎重に検討してください。クラスターの他のユーザーがSecretにアクセスできる可能性があります。
Kubernetesクラスターを共有しているユーザー全員がアクセスできるようにサービスアカウントを使用し、ユーザーが安全でない状態になったらアカウントを無効化することができます。SSH鍵のSecretを参照し、ボリュームとして使用するPodを作成することができます。
apiVersion : v1
kind : Pod
metadata :
name : secret-test-pod
labels :
name : secret-test
spec :
volumes :
- name : secret-volume
secret :
secretName : ssh-key-secret
containers :
- name : ssh-test-container
image : mySshImage
volumeMounts :
- name : secret-volume
readOnly : true
mountPath : "/etc/secret-volume"
コンテナのコマンドを実行するときは、下記のパスにて鍵が利用可能です。
/etc/secret-volume/ssh-publickey
/etc/secret-volume/ssh-privatekey
コンテナはSecretのデータをSSH接続を確立するために使用することができます。
ユースケース: 本番、テスト用の認証情報を持つPod あるPodは本番の認証情報のSecretを使用し、別のPodはテスト環境の認証情報のSecretを使用する例を示します。
secretGeneratorフィールドを持つkustomization.yamlを作成するか、kubectl create secretを実行します。
kubectl create secret generic prod-db-secret --from-literal= username = produser --from-literal= password = Y4nys7f11
出力は次のようになります。
secret "prod-db-secret" created
kubectl create secret generic test-db-secret --from-literal= username = testuser --from-literal= password = iluvtests
出力は次のようになります。
secret "test-db-secret" created
備考: $、\、*、=、!のような特殊文字はシェル に解釈されるので、エスケープする必要があります。
ほとんどのシェルではパスワードをエスケープする最も簡単な方法はシングルクォート(')で囲むことです。
例えば、実際のパスワードがS!B\*d$zDsb=だとすると、実行すべきコマンドは下記のようになります。
kubectl create secret generic dev-db-secret --from-literal= username = devuser --from-literal= password = 'S!B\*d$zDsb='
--from-fileによってファイルを指定する場合は、そのパスワードに含まれる特殊文字をエスケープする必要はありません。
Podを作成します。
cat <<EOF > pod.yaml
apiVersion: v1
kind: List
items:
- kind: Pod
apiVersion: v1
metadata:
name: prod-db-client-pod
labels:
name: prod-db-client
spec:
volumes:
- name: secret-volume
secret:
secretName: prod-db-secret
containers:
- name: db-client-container
image: myClientImage
volumeMounts:
- name: secret-volume
readOnly: true
mountPath: "/etc/secret-volume"
- kind: Pod
apiVersion: v1
metadata:
name: test-db-client-pod
labels:
name: test-db-client
spec:
volumes:
- name: secret-volume
secret:
secretName: test-db-secret
containers:
- name: db-client-container
image: myClientImage
volumeMounts:
- name: secret-volume
readOnly: true
mountPath: "/etc/secret-volume"
EOF
同じkustomization.yamlにPodを追記します。
cat <<EOF >> kustomization.yaml
resources:
- pod.yaml
EOF
下記のコマンドを実行して、APIサーバーにこれらのオブジェクト群を適用します。
両方のコンテナはそれぞれのファイルシステムに下記に示すファイルを持ちます。ファイルの値はそれぞれのコンテナの環境ごとに異なります。
/etc/secret-volume/username
/etc/secret-volume/password
2つのPodの仕様の差分は1つのフィールドのみである点に留意してください。
これは共通のPodテンプレートから異なる能力を持つPodを作成することを容易にします。
2つのサービスアカウントを使用すると、ベースのPod仕様をさらに単純にすることができます。
prod-userとprod-db-secrettest-userとtest-db-secret簡略化されたPod仕様は次のようになります。
apiVersion : v1
kind : Pod
metadata :
name : prod-db-client-pod
labels :
name : prod-db-client
spec :
serviceAccount : prod-db-client
containers :
- name : db-client-container
image : myClientImage
ユースケース: Secretボリューム内のdotfile キーをドットから始めることで、データを「隠す」ことができます。
このキーはdotfileまたは「隠し」ファイルを示します。例えば、次のSecretはsecret-volumeボリュームにマウントされます。
apiVersion : v1
kind : Secret
metadata :
name : dotfile-secret
data :
.secret-file : dmFsdWUtMg0KDQo=
---
apiVersion : v1
kind : Pod
metadata :
name : secret-dotfiles-pod
spec :
volumes :
- name : secret-volume
secret :
secretName : dotfile-secret
containers :
- name : dotfile-test-container
image : registry.k8s.io/busybox
command :
- ls
- "-l"
- "/etc/secret-volume"
volumeMounts :
- name : secret-volume
readOnly : true
mountPath : "/etc/secret-volume"
このボリュームは.secret-fileという単一のファイルを含み、dotfile-test-containerはこのファイルを/etc/secret-volume/.secret-fileのパスに持ちます。
備考: ドットから始まるファイルはls -lの出力では隠されるため、ディレクトリの内容を参照するときにはls -laを使わなければなりません。ユースケース: Podの中の単一コンテナのみが参照できるSecret HTTPリクエストを扱い、複雑なビジネスロジックを処理し、メッセージにHMACによる認証コードを付与する必要のあるプログラムを考えます。
複雑なアプリケーションロジックを持つため、サーバーにリモートのファイルを読み出せる未知の脆弱性がある可能性があり、この脆弱性は攻撃者に秘密鍵を晒してしまいます。
このプログラムは2つのコンテナに含まれる2つのプロセスへと分割することができます。
フロントエンドのコンテナはユーザーとのやりとりやビジネスロジックを扱い、秘密鍵を参照することはできません。
署名コンテナは秘密鍵を参照することができて、単にフロントエンドからの署名リクエストに応答します。例えば、localhostの通信によって行います。
この分割する手法によって、攻撃者はアプリケーションサーバーを騙して任意の処理を実行させる必要があるため、ファイルの内容を読み出すより困難になります。
ベストプラクティス Secret APIを使用するクライアント Secret APIとやりとりするアプリケーションをデプロイするときには、RBAC のような認可ポリシー を使用して、アクセスを制限すべきです。
Secretは様々な種類の重要な値を保持することが多く、サービスアカウントのトークンのようにKubernetes内部や、外部のシステムで昇格できるものも多くあります。個々のアプリケーションが、Secretの能力について推論することができたとしても、同じネームスペースの別のアプリケーションがその推定を覆すこともあります。
これらの理由により、ネームスペース内のSecretに対するwatchやlistリクエストはかなり強力な能力であり、避けるべきです。Secretのリストを取得することはクライアントにネームスペース内の全てのSecretの値を調べさせることを認めるからです。クラスター内の全てのSecretに対するwatch、list権限は最も特権的な、システムレベルのコンポーネントに限って認めるべきです。
Secret APIへのアクセスが必要なアプリケーションは、必要なSecretに対するgetリクエストを発行すべきです。管理者は全てのSecretに対するアクセスは制限しつつ、アプリケーションが必要とする個々のインスタンスに対するアクセス許可 を与えることができます。
getリクエストの繰り返しに対するパフォーマンスを向上するために、クライアントはSecretを参照するリソースを設計し、それをwatchして、参照が変更されたときにSecretを再度リクエストすることができます。加えて、個々のリソースをwatchすることのできる"bulk watch" API が提案されており、将来のKubernetesリリースにて利用可能になる可能性があります。
セキュリティ特性 保護 Secretはそれを使用するPodとは独立に作成されるので、Podを作ったり、参照したり、編集したりするワークフローにおいてSecretが晒されるリスクは軽減されています。
システムは、可能であればSecretの内容をディスクに書き込まないような、Secretについて追加の考慮も行っています。
Secretはノード上のPodが必要とした場合のみ送られます。
kubeletはSecretがディスクストレージに書き込まれないよう、tmpfsに保存します。
Secretを必要とするPodが削除されると、kubeletはSecretのローカルコピーも同様に削除します。
同一のノードにいくつかのPodに対する複数のSecretが存在することもあります。
しかし、コンテナから参照できるのはPodが要求したSecretのみです。
そのため、あるPodが他のPodのためのSecretにアクセスすることはできません。
Podに複数のコンテナが含まれることもあります。しかし、Podの各コンテナはコンテナ内からSecretを参照するためにvolumeMountsによってSecretボリュームを要求する必要があります。
これはPodレベルでのセキュリティ分離 を実装するのに便利です。
ほとんどのKubernetesディストリビューションにおいては、ユーザーとAPIサーバー間やAPIサーバーからkubelet間の通信はSSL/TLSで保護されています。
そのような経路で伝送される場合、Secretは保護されています。
FEATURE STATE:
Kubernetes v1.13 [beta]
保存データの暗号化 を有効にして、Secretがetcd に平文で保存されないようにすることができます。
リスク APIサーバーでは、機密情報はetcd に保存されます。
そのため、管理者はクラスターデータの保存データの暗号化を有効にすべきです(v1.13以降が必要)。 管理者はetcdへのアクセスを管理ユーザに限定すべきです。 管理者はetcdで使用していたディスクを使用しなくなったときにはそれをワイプするか完全消去したくなるでしょう。 クラスターの中でetcdが動いている場合、管理者はetcdのピアツーピア通信がSSL/TLSを利用していることを確認すべきです。 Secretをマニフェストファイル(JSONまたはYAML)を介して設定する場合、それはBase64エンコードされた機密情報を含んでいるので、ファイルを共有したりソースリポジトリに入れることは秘密が侵害されることを意味します。Base64エンコーディングは暗号化手段では なく 、平文と同様であると判断すべきです。 アプリケーションはボリュームからSecretの値を読み取った後も、その値を保護する必要があります。例えば意図せずログに出力する、信用できない相手に送信するようなことがないようにです。 Secretを利用するPodを作成できるユーザーはSecretの値を見ることができます。たとえAPIサーバーのポリシーがユーザーにSecretの読み取りを許可していなくても、ユーザーはSecretを晒すPodを実行することができます。 現在、任意のノードでルート権限を持つ人は誰でも、kubeletに偽装することで 任意の SecretをAPIサーバーから読み取ることができます。
単一のノードのルート権限を不正に取得された場合の影響を抑えるため、実際に必要としているノードに対してのみSecretを送る機能が計画されています。 次の項目 3.8.4 - Liveness、ReadinessおよびStartup Probe Kubernetesは様々な種類のProbeがあります。
Liveness Probe コンテナの再起動を判断するためにLiveness Probeを使用します。
例えば、Liveness Probeはアプリケーションは起動しているが、処理が継続できないデッドロックを検知することができます。
コンテナがLiveness Probeを繰り返し失敗するとkubeletはコンテナを再起動します。
Liveness ProbeはReadiness Probeの成功を待ちません。Liveness Probeの実行を待つためには、initialDelaySecondsを定義するか、Startup Probe を使用してください。
Readiness Probe Readiness Probeはコンテナがトラフィックを受け入れる準備ができたかを決定します。ネットワーク接続の確立、ファイルの読み込み、キャッシュのウォームアップなどの時間のかかる初期タスクを実行するアプリケーションを待つ場合に有用です。
Readiness Probeが失敗状態を返す場合、KubernetesはそのPodをすべての一致するサービスエンドポイントから取り除きます。
Readiness Probeはコンテナのライフサイクル全体にわたって実行されます。
Startup Probe Startup Probeはコンテナ内のアプリケーションが起動されたかどうかを検証します。起動が遅いコンテナに対して起動されたかどうかチェックを取り入れるために使用され、kubeletによって起動や実行する前に終了されるのを防ぎます。
Startup Probeが設定された場合、成功するまでLiveness ProbeとReadiness Probeのチェックを無効にします。
定期的に実行されるReadiness Probeとは異なり、Startup Probeは起動時のみ実行されます。
3.8.5 - コンテナのリソース管理 Pod を指定する際に、コンテナ が必要とする各リソースの量をオプションで指定することができます。
指定する最も一般的なリソースはCPUとメモリ(RAM)ですが、他にもあります。
Pod内のコンテナのリソースrequests を指定すると、スケジューラはこの情報を使用して、どのNodeにPodを配置するかを決定します。コンテナにリソースのlimits を指定すると、kubeletはその制限を適用し、実行中のコンテナが設定した制限を超えてリソースを使用することができないようにします。また、kubeletは、少なくともそのシステムリソースのうち、requests の量を、そのコンテナが使用するために特別に確保します。
requestsとlimits Podが動作しているNodeに利用可能なリソースが十分にある場合、そのリソースのrequestsが指定するよりも多くのリソースをコンテナが使用することが許可されます
ただし、コンテナはそのリソースのlimitsを超えて使用することはできません。
たとえば、コンテナに256MiBのメモリーrequestsを設定し、そのコンテナが8GiBのメモリーを持つNodeにスケジュールされたPod内に存在し、他のPodが存在しない場合、コンテナはより多くのRAMを使用しようとする可能性があります。
そのコンテナに4GiBのメモリーlimitsを設定すると、kubelet(およびコンテナランタイム ) が制限を適用します。ランタイムは、コンテナが設定済みのリソース制限を超えて使用するのを防ぎます。例えば、コンテナ内のプロセスが、許容量を超えるメモリを消費しようとすると、システムカーネルは、メモリ不足(OOM)エラーで、割り当てを試みたプロセスを終了します。
制限は、違反が検出されるとシステムが介入するように事後的に、またはコンテナが制限を超えないようにシステムが防ぐように強制的に、実装できます。
異なるランタイムは、同じ制限を実装するために異なる方法をとることができます。
備考: コンテナが自身のメモリーlimitsを指定しているが、メモリーrequestsを指定していない場合、Kubernetesはlimitsに一致するメモリーrequestsを自動的に割り当てます。同様に、コンテナが自身のCPU limitsを指定しているが、CPU requestsを指定していない場合、Kubernetesはlimitsに一致するCPU requestsを自動的に割り当てます。リソースタイプ CPU とメモリー はいずれもリソースタイプ です。リソースタイプには基本単位があります。
CPUは計算処理を表し、Kubernetes CPUs の単位で指定されます。
メモリはバイト単位で指定されます。
Kubernetes v1.14以降を使用している場合は、huge page リソースを指定することができます。
Huge PageはLinux固有の機能であり、Nodeのカーネルはデフォルトのページサイズよりもはるかに大きいメモリブロックを割り当てます。
たとえば、デフォルトのページサイズが4KiBのシステムでは、hugepages-2Mi: 80Miというlimitsを指定できます。
コンテナが40を超える2MiBの巨大ページ(合計80 MiB)を割り当てようとすると、その割り当ては失敗します。
備考: hugepages-*リソースをオーバーコミットすることはできません。
これはmemoryやcpuリソースとは異なります。CPUとメモリーは、まとめてコンピュートリソース または単にリソース と呼ばれます。
コンピューティングリソースは、要求され、割り当てられ、消費され得る測定可能な量です。
それらはAPI resources とは異なります。
PodやServices などのAPIリソースは、Kubernetes APIサーバーを介して読み取りおよび変更できるオブジェクトです。
Podとコンテナのリソースrequestsとlimits Podの各コンテナは、次の1つ以上を指定できます。
spec.containers[].resources.limits.cpuspec.containers[].resources.limits.memoryspec.containers[].resources.limits.hugepages-<size>spec.containers[].resources.requests.cpuspec.containers[].resources.requests.memoryspec.containers[].resources.requests.hugepages-<size>requestsとlimitsはそれぞれのコンテナでのみ指定できますが、このPodリソースのrequestsとlimitsの関係性について理解すると便利です。
特定のリソースタイプのPodリソースrequests/limits は、Pod内の各コンテナに対するそのタイプのリソースrequests/limitsの合計です。
Kubernetesにおけるリソースの単位 CPUの意味 CPUリソースのlimitsとrequestsは、cpu 単位で測定されます。
Kubernetesにおける1つのCPUは、クラウドプロバイダーの1 vCPU/コア およびベアメタルのインテルプロセッサーの1 ハイパースレッド に相当します。
requestsを小数で指定することもできます。
spec.containers[].resources.requests.cpuが0.5のコンテナは、1CPUを要求するコンテナの半分のCPUが保証されます。
0.1という表現は100mという表現と同等であり、100ミリCPUと読み替えることができます。
100ミリコアという表現も、同じことを意味しています。
0.1のような小数点のあるrequestsはAPIによって100mに変換され、1mより細かい精度は許可されません。
このため、100mの形式が推奨されます。
CPUは常に相対量としてではなく、絶対量として要求されます。
0.1は、シングルコア、デュアルコア、あるいは48コアマシンのどのCPUに対してでも、同一の量を要求します。
メモリーの意味 メモリーのlimitsとrequestsはバイト単位で測定されます。
E、P、T、G、M、Kのいずれかのサフィックスを使用して、メモリーを整数または固定小数点数として表すことができます。
また、Ei、Pi、Ti、Gi、Mi、Kiのような2の累乗の値を使用することもできます。
たとえば、以下はほぼ同じ値を表しています。
128974848, 129e6, 129M, 123Mi
例を見てみましょう。
次のPodには2つのコンテナがあります。
各コンテナには、0.25cpuおよび64MiB(226 バイト)のメモリーrequestsと、0.5cpuおよび128MiBのメモリーlimitsがあります
Podには0.5cpuと128MiBのメモリーrequestsがあり、1cpuと256MiBのメモリーlimitsがあると言えます。
apiVersion : v1
kind : Pod
metadata :
name : frontend
spec :
containers :
- name : app
image : images.my-company.example/app:v4
resources :
requests :
memory : "64Mi"
cpu : "250m"
limits :
memory : "128Mi"
cpu : "500m"
- name : log-aggregator
image : images.my-company.example/log-aggregator:v6
resources :
requests :
memory : "64Mi"
cpu : "250m"
limits :
memory : "128Mi"
cpu : "500m"
リソースrequestsを含むPodがどのようにスケジュールされるか Podを作成すると、KubernetesスケジューラーはPodを実行するNodeを選択します。
各Nodeには、リソースタイプごとに最大容量があります。それは、Podに提供できるCPUとメモリの量です。
スケジューラーは、リソースタイプごとに、スケジュールされたコンテナのリソースrequestsの合計がNodeの容量より少ないことを確認します。
Node上の実際のメモリーまたはCPUリソースの使用率は非常に低いですが、容量チェックが失敗した場合、スケジューラーはNodeにPodを配置しないことに注意してください。
これにより、例えば日々のリソース要求のピーク時など、リソース利用が増加したときに、Nodeのリソース不足から保護されます。
リソースlimitsのあるPodがどのように実行されるか kubeletがPodのコンテナを開始すると、CPUとメモリーのlimitsがコンテナランタイムに渡されます。
Dockerを使用する場合:
spec.containers[].resources.requests.cpuは、潜在的に小数であるコア値に変換され、1024倍されます。
docker runコマンドの--cpu-shares
spec.containers[].resources.limits.cpuはミリコアの値に変換され、100倍されます。
結果の値は、コンテナが100ミリ秒ごとに使用できるCPU時間の合計です。
コンテナは、この間隔の間、CPU時間の占有率を超えて使用することはできません。
備考: デフォルトのクォータ期間は100ミリ秒です。
CPUクォータの最小分解能は1ミリ秒です。spec.containers[].resources.limits.memoryは整数に変換され、docker runコマンドの--memory
コンテナがメモリーlimitsを超過すると、終了する場合があります。
コンテナが再起動可能である場合、kubeletは他のタイプのランタイム障害と同様にコンテナを再起動します。
コンテナがメモリーrequestsを超過すると、Nodeのメモリーが不足するたびにそのPodが排出される可能性があります。
コンテナは、長時間にわたってCPU limitsを超えることが許可される場合と許可されない場合があります。
ただし、CPUの使用量が多すぎるために、コンテナが強制終了されることはありません。
コンテナをスケジュールできないか、リソースlimitsが原因で強制終了されているかどうかを確認するには、トラブルシューティング のセクションを参照してください。
コンピュートリソースとメモリーリソースの使用量を監視する Podのリソース使用量は、Podのステータスの一部として報告されます。
オプションの監視ツール がクラスターにおいて利用可能な場合、Podのリソース使用量はメトリクスAPI から直接、もしくは監視ツールから取得できます。
ローカルのエフェメラルストレージ FEATURE STATE:
Kubernetes v1.10 [beta]
Nodeには、ローカルに接続された書き込み可能なデバイス、または場合によってはRAMによってサポートされるローカルのエフェメラルストレージがあります。
"エフェメラル"とは、耐久性について長期的な保証がないことを意味します。
Podは、スクラッチ領域、キャッシュ、ログ用にエフェメラルなローカルストレージを使用しています。
kubeletは、ローカルのエフェメラルストレージを使用して、Podにスクラッチ領域を提供し、emptyDirボリューム をコンテナにマウントできます。
また、kubeletはこの種類のストレージを使用して、Nodeレベルのコンテナログ 、コンテナイメージ、実行中のコンテナの書き込み可能なレイヤーを保持します。
注意: Nodeに障害が発生すると、そのエフェメラルストレージ内のデータが失われる可能性があります。
アプリケーションは、ローカルのエフェメラルストレージにパフォーマンスのサービス品質保証(ディスクのIOPSなど)を期待することはできません。ベータ版の機能として、Kubernetesでは、Podが消費するローカルのエフェメラルストレージの量を追跡、予約、制限することができます。
ローカルエフェメラルストレージの設定 Kubernetesは、Node上のローカルエフェメラルストレージを構成する2つの方法をサポートしています。
この構成では、さまざまな種類のローカルのエフェメラルデータ(emptyDirボリュームや、書き込み可能なレイヤー、コンテナイメージ、ログなど)をすべて1つのファイルシステムに配置します。
kubeletを構成する最も効果的な方法は、このファイルシステムをKubernetes(kubelet)データ専用にすることです。
kubeletはNodeレベルのコンテナログ も書き込み、これらをエフェメラルなローカルストレージと同様に扱います。
kubeletは、設定されたログディレクトリ(デフォルトでは/var/log)内のファイルにログを書き出し、ローカルに保存された他のデータのベースディレクトリ(デフォルトでは/var/lib/kubelet)を持ちます。
通常、/var/lib/kubeletと/var/logはどちらもシステムルートファイルシステムにあり、kubeletはそのレイアウトを考慮して設計されています。
Nodeには、Kubernetesに使用されていない他のファイルシステムを好きなだけ持つことができます。
Node上にファイルシステムがありますが、このファイルシステムは、ログやemptyDirボリュームなど、実行中のPodの一時的なデータに使用されます。
このファイルシステムは、例えばKubernetesに関連しないシステムログなどの他のデータに使用することができ、ルートファイルシステムとすることさえ可能です。
また、kubeletはノードレベルのコンテナログ を最初のファイルシステムに書き込み、これらをエフェメラルなローカルストレージと同様に扱います。
また、別の論理ストレージデバイスでバックアップされた別のファイルシステムを使用することもできます。
この設定では、コンテナイメージレイヤーと書き込み可能なレイヤーを配置するようにkubeletに指示するディレクトリは、この2番目のファイルシステム上にあります。
最初のファイルシステムは、コンテナイメージレイヤーや書き込み可能なレイヤーを保持していません。
Nodeには、Kubernetesに使用されていない他のファイルシステムを好きなだけ持つことができます。
kubeletは、ローカルストレージの使用量を測定できます。
これは、以下の条件で提供されます。
LocalStorageCapacityIsolationフィーチャーゲート が有効になっています。(デフォルトでオンになっています。)そして、ローカルのエフェメラルストレージ用にサポートされている構成の1つを使用してNodeをセットアップします。 別の構成を使用している場合、kubeletはローカルのエフェメラルストレージにリソース制限を適用しません。
備考: kubeletは、tmpfsのemptyDirボリュームをローカルのエフェメラルストレージとしてではなく、コンテナメモリーとして追跡します。ローカルのエフェメラルストレージのrequestsとlimits設定 ローカルのエフェメラルストレージを管理するためには ephemeral-storage パラメーターを利用することができます。
Podの各コンテナは、次の1つ以上を指定できます。
spec.containers[].resources.limits.ephemeral-storagespec.containers[].resources.requests.ephemeral-storageephemeral-storageのlimitsとrequestsはバイト単位で記します。
ストレージは、次のいずれかの接尾辞を使用して、通常の整数または固定小数点数として表すことができます。
E、P、T、G、M、K。Ei、Pi、Ti、Gi、Mi、Kiの2のべき乗を使用することもできます。
たとえば、以下はほぼ同じ値を表しています。
128974848, 129e6, 129M, 123Mi
次の例では、Podに2つのコンテナがあります。
各コンテナには、2GiBのローカルのエフェメラルストレージrequestsがあります。
各コンテナには、4GiBのローカルのエフェメラルストレージlimitsがあります。
したがって、Podには4GiBのローカルのエフェメラルストレージのrequestsと、8GiBのローカルのエフェメラルストレージlimitsがあります。
apiVersion : v1
kind : Pod
metadata :
name : frontend
spec :
containers :
- name : app
image : images.my-company.example/app:v4
resources :
requests :
ephemeral-storage : "2Gi"
limits :
ephemeral-storage : "4Gi"
volumeMounts :
- name : ephemeral
mountPath : "/tmp"
- name : log-aggregator
image : images.my-company.example/log-aggregator:v6
resources :
requests :
ephemeral-storage : "2Gi"
limits :
ephemeral-storage : "4Gi"
volumeMounts :
- name : ephemeral
mountPath : "/tmp"
volumes :
- name : ephemeral
emptyDir : {}
エフェメラルストレージrequestsを含むPodのスケジュール方法 Podを作成すると、KubernetesスケジューラーはPodを実行するNodeを選択します。
各Nodeには、Podに提供できるローカルのエフェメラルストレージの上限があります。
詳細については、Node割り当て可能 を参照してください。
スケジューラーは、スケジュールされたコンテナのリソースrequestsの合計がNodeの容量より少なくなるようにします。
エフェメラルストレージの消費管理 kubeletがローカルのエフェメラルストレージをリソースとして管理している場合、kubeletはストレージの使用量を測定します
tmpfs emptyDirボリュームを除くemptyDirボリュームNodeレベルのログを保持するディレクトリ 書き込み可能なコンテナレイヤー Podが許可するよりも多くのエフェメラルストレージを使用している場合、kubeletはPodの排出をトリガーするシグナルを設定します。
コンテナレベルの分離の場合、コンテナの書き込み可能なレイヤーとログ使用量がストレージのlimitsを超えると、kubeletはPodに排出のマークを付けます。
Podレベルの分離の場合、kubeletはPod内のコンテナのlimitsを合計し、Podの全体的なストレージlimitsを計算します。
このケースでは、すべてのコンテナからのローカルのエフェメラルストレージの使用量とPodのemptyDirボリュームの合計がPod全体のストレージlimitsを超過する場合、
kubeletはPodをまた排出対象としてマークします。
注意: kubeletがローカルのエフェメラルストレージを測定していない場合、ローカルストレージのlimitsを超えるPodは、ローカルストレージのリソース制限に違反しても排出されません。
ただし、書き込み可能なコンテナレイヤー、Nodeレベルのログ、またはemptyDirボリュームのファイルシステムスペースが少なくなると、Nodeはローカルストレージが不足しているとTainttaints し、このTaintは、Taintを特に許容しないPodの排出をトリガーします。
ローカルのエフェメラルストレージについては、サポートされている設定 をご覧ください。
kubeletはPodストレージの使用状況を測定するさまざまな方法をサポートしています
kubeletは、emptyDirボリューム、コンテナログディレクトリ、書き込み可能なコンテナレイヤーをスキャンする定期的なスケジュールチェックを実行します。
スキャンは、使用されているスペースの量を測定します。
備考: このモードでは、kubeletは削除されたファイルのために、開いているファイルディスクリプタを追跡しません。
あなた(またはコンテナ)がemptyDirボリューム内にファイルを作成した後、何かがそのファイルを開き、そのファイルが開かれたままの状態でファイルを削除した場合、削除されたファイルのinodeはそのファイルを閉じるまで残りますが、kubeletはそのスペースを使用中として分類しません。
FEATURE STATE:
Kubernetes v1.15 [alpha]
プロジェクトクォータは、ファイルシステム上のストレージ使用量を管理するためのオペレーティングシステムレベルの機能です。
Kubernetesでは、プロジェクトクォータを有効にしてストレージの使用状況を監視することができます。
ノード上のemptyDirボリュームをバックアップしているファイルシステムがプロジェクトクォータをサポートしていることを確認してください。
例えば、XFSやext4fsはプロジェクトクォータを提供しています。
備考: プロジェクトクォータはストレージの使用状況を監視しますが、制限を強制するものではありません。Kubernetesでは、1048576から始まるプロジェクトIDを使用します。
使用するプロジェクトIDは/etc/projectsと/etc/projidに登録されます。
この範囲のプロジェクトIDをシステム上で別の目的で使用する場合は、それらのプロジェクトIDを/etc/projectsと/etc/projidに登録し、
Kubernetesが使用しないようにする必要があります。
クォータはディレクトリスキャンよりも高速で正確です。
ディレクトリがプロジェクトに割り当てられると、ディレクトリ配下に作成されたファイルはすべてそのプロジェクト内に作成され、カーネルはそのプロジェクト内のファイルによって使用されているブロックの数を追跡するだけです。
ファイルが作成されて削除されても、開いているファイルディスクリプタがあれば、スペースを消費し続けます。
クォータトラッキングはそのスペースを正確に記録しますが、ディレクトリスキャンは削除されたファイルが使用するストレージを見落としてしまいます。
プロジェクトクォータを使用する場合は、次のことを行う必要があります。
kubelet設定で、LocalocalStorpactionCapactionIsolationFSQuotaMonitoring=trueフィーチャーゲート を有効にします。
ルートファイルシステム(またはオプションのランタイムファイルシステム))がプロジェクトクォータを有効にしていることを確認してください。
すべてのXFSファイルシステムはプロジェクトクォータをサポートしています。
ext4ファイルシステムでは、ファイルシステムがマウントされていない間は、プロジェクトクォータ追跡機能を有効にする必要があります。
# ext4の場合、/dev/block-deviceがマウントされていません
sudo tune2fs -O project -Q prjquota /dev/block-device
ルートファイルシステム(またはオプションのランタイムファイルシステム)がプロジェクトクォータを有効にしてマウントされていることを確認してください。
XFSとext4fsの両方で、マウントオプションはprjquotaという名前になっています。
拡張リソース 拡張リソースはkubernetes.ioドメインの外で完全に修飾されたリソース名です。
これにより、クラスターオペレーターはKubernetesに組み込まれていないリソースをアドバタイズし、ユーザはそれを利用することができるようになります。
拡張リソースを使用するためには、2つのステップが必要です。
第一に、クラスターオペレーターは拡張リソースをアドバタイズする必要があります。
第二に、ユーザーはPodで拡張リソースを要求する必要があります。
拡張リソースの管理 Nodeレベルの拡張リソース Nodeレベルの拡張リソースはNodeに関連付けられています。
デバイスプラグイン管理のリソース 各Nodeにデバイスプラグインで管理されているリソースをアドバタイズする方法については、デバイスプラグイン を参照してください。
その他のリソース 新しいNodeレベルの拡張リソースをアドバタイズするには、クラスターオペレーターはAPIサーバにPATCHHTTPリクエストを送信し、クラスター内のNodeのstatus.capacityに利用可能な量を指定します。
この操作の後、ノードのstatus.capacityには新しいリソースが含まれます。
status.allocatableフィールドは、kubeletによって非同期的に新しいリソースで自動的に更新されます。
スケジューラはPodの適合性を評価する際にNodeのstatus.allocatable値を使用するため、Nodeの容量に新しいリソースを追加してから、そのNodeでリソースのスケジューリングを要求する最初のPodが現れるまでには、短い遅延が生じる可能性があることに注意してください。
例:
以下は、curlを使用して、Masterがk8s-masterであるNodek8s-node-1で5つのexample.com/fooリソースを示すHTTPリクエストを作成する方法を示す例です。
curl --header "Content-Type: application/json-patch+json" \
\
'[{"op": "add", "path": "/status/capacity/example.com~1foo", "value": "5"}]' \
備考: 上記のリクエストでは、
~1はパッチパス内の文字
/のエンコーディングです。
JSON-Patchの操作パス値は、JSON-Pointerとして解釈されます。
詳細については、
IETF RFC 6901, section 3 を参照してください。
クラスターレベルの拡張リソース クラスターレベルの拡張リソースはノードに関連付けられていません。
これらは通常、リソース消費とリソースクォータを処理するスケジューラー拡張機能によって管理されます。
スケジューラーポリシー構成 では。スケジューラー拡張機能によって扱われる拡張リソースを指定できます。
例:
次のスケジューラーポリシーの構成は、クラスターレベルの拡張リソース"example.com/foo"がスケジューラー拡張機能によって処理されることを示しています。
スケジューラーは、Podが"example.com/foo"を要求した場合にのみ、Podをスケジューラー拡張機能に送信します。 ignoredBySchedulerフィールドは、スケジューラがそのPodFitsResources述語で"example.com/foo"リソースをチェックしないことを指定します。{
"kind" : "Policy" ,
"apiVersion" : "v1" ,
"extenders" : [
{
"urlPrefix" :"<extender-endpoint>" ,
"bindVerb" : "bind" ,
"managedResources" : [
{
"name" : "example.com/foo" ,
"ignoredByScheduler" : true
}
]
}
]
}
拡張リソースの消費 ユーザーは、CPUやメモリのようにPodのスペックで拡張されたリソースを消費できます。
利用可能な量以上のリソースが同時にPodに割り当てられないように、スケジューラーがリソースアカウンティングを行います。
APIサーバーは、拡張リソースの量を整数の値で制限します。
有効な数量の例は、3、3000m、3Kiです。
無効な数量の例は、0.5、1500mです。
備考: 拡張リソースは不透明な整数リソースを置き換えます。
ユーザーは、予約済みのkubernetes.io以外のドメイン名プレフィックスを使用できます。Podで拡張リソースを消費するには、コンテナ名のspec.containers[].resources.limitsマップにキーとしてリソース名を含めます。
備考: 拡張リソースはオーバーコミットできないので、コンテナスペックにrequestsとlimitsの両方が存在する場合は等しくなければなりません。Podは、CPU、メモリ、拡張リソースを含むすべてのリソースrequestsが満たされた場合にのみスケジュールされます。
リソースrequestsが満たされない限り、PodはPENDING状態のままです。
例:
下のPodはCPUを2つ、"example.com/foo"(拡張リソース)を1つ要求しています。
apiVersion : v1
kind : Pod
metadata :
name : my-pod
spec :
containers :
- name : my-container
image : myimage
resources :
requests :
cpu : 2
example.com/foo : 1
limits :
example.com/foo : 1
トラブルシューティング failedSchedulingイベントメッセージが表示され、Podが保留中になる スケジューラーがPodが収容されるNodeを見つけられない場合、場所が見つかるまでPodはスケジュールされないままになります。
スケジューラーがPodの場所を見つけられないたびに、次のようなイベントが生成されます。
kubectl describe pod frontend | grep -A 3 Events
Events:
FirstSeen LastSeen Count From Subobject PathReason Message
36s 5s 6 {scheduler } FailedScheduling Failed for reason PodExceedsFreeCPU and possibly others
前述の例では、"frontend"という名前のPodは、Node上のCPUリソースが不足しているためにスケジューリングに失敗しています。
同様のエラーメッセージは、メモリー不足による失敗を示唆することもあります(PodExceedsFreeMemory)。
一般的に、このタイプのメッセージでPodが保留されている場合は、いくつか試すべきことがあります。
クラスターにNodeを追加します。 不要なポッドを終了して、保留中のPodのためのスペースを空けます。 PodがすべてのNodeよりも大きくないことを確認してください。
例えば、すべてのNodeがcpu: 1の容量を持っている場合、cpu: 1.1を要求するPodは決してスケジューリングされません。 Nodeの容量や割り当て量はkubectl describe nodesコマンドで調べることができる。
例えば、以下のようになる。
kubectl describe nodes e2e-test-node-pool-4lw4
Name: e2e-test-node-pool-4lw4
[ ... lines removed for clarity ...]
Capacity:
cpu: 2
memory: 7679792Ki
pods: 110
Allocatable:
cpu: 1800m
memory: 7474992Ki
pods: 110
[ ... lines removed for clarity ...]
Non-terminated Pods: (5 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits
--------- ---- ------------ ---------- --------------- -------------
kube-system fluentd-gcp-v1.38-28bv1 100m (5%) 0 (0%) 200Mi (2%) 200Mi (2%)
kube-system kube-dns-3297075139-61lj3 260m (13%) 0 (0%) 100Mi (1%) 170Mi (2%)
kube-system kube-proxy-e2e-test-... 100m (5%) 0 (0%) 0 (0%) 0 (0%)
kube-system monitoring-influxdb-grafana-v4-z1m12 200m (10%) 200m (10%) 600Mi (8%) 600Mi (8%)
kube-system node-problem-detector-v0.1-fj7m3 20m (1%) 200m (10%) 20Mi (0%) 100Mi (1%)
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
CPU Requests CPU Limits Memory Requests Memory Limits
------------ ---------- --------------- -------------
680m (34%) 400m (20%) 920Mi (12%) 1070Mi (14%)
前述の出力では、Podが1120m以上のCPUや6.23Gi以上のメモリーを要求した場合、そのPodはNodeに収まらないことがわかります。
Podsセクションを見れば、どのPodがNode上でスペースを占有しているかがわかります。
システムデーモンが利用可能なリソースの一部を使用しているため、Podに利用可能なリソースの量はNodeの容量よりも少なくなっています。
allocatableフィールドNodeStatus は、Podに利用可能なリソースの量を与えます。
詳細については、ノード割り当て可能なリソース を参照してください。
リソースクォータ 機能は、消費できるリソースの総量を制限するように設定することができます。
名前空間と組み合わせて使用すると、1つのチームがすべてのリソースを占有するのを防ぐことができます。
コンテナが終了した コンテナはリソース不足のため、終了する可能性があります。
コンテナがリソースlimitsに達したために強制終了されているかどうかを確認するには、対象のPodでkubectl describe podを呼び出します。
kubectl describe pod simmemleak-hra99
Name: simmemleak-hra99
Namespace: default
Image(s): saadali/simmemleak
Node: kubernetes-node-tf0f/10.240.216.66
Labels: name=simmemleak
Status: Running
Reason:
Message:
IP: 10.244.2.75
Replication Controllers: simmemleak (1/1 replicas created)
Containers:
simmemleak:
Image: saadali/simmemleak
Limits:
cpu: 100m
memory: 50Mi
State: Running
Started: Tue, 07 Jul 2015 12:54:41 -0700
Last Termination State: Terminated
Exit Code: 1
Started: Fri, 07 Jul 2015 12:54:30 -0700
Finished: Fri, 07 Jul 2015 12:54:33 -0700
Ready: False
Restart Count: 5
Conditions:
Type Status
Ready False
Events:
FirstSeen LastSeen Count From SubobjectPath Reason Message
Tue, 07 Jul 2015 12:53:51 -0700 Tue, 07 Jul 2015 12:53:51 -0700 1 {scheduler } scheduled Successfully assigned simmemleak-hra99 to kubernetes-node-tf0f
Tue, 07 Jul 2015 12:53:51 -0700 Tue, 07 Jul 2015 12:53:51 -0700 1 {kubelet kubernetes-node-tf0f} implicitly required container POD pulled Pod container image "registry.k8s.io/pause:0.8.0" already present on machine
Tue, 07 Jul 2015 12:53:51 -0700 Tue, 07 Jul 2015 12:53:51 -0700 1 {kubelet kubernetes-node-tf0f} implicitly required container POD created Created with docker id 6a41280f516d
Tue, 07 Jul 2015 12:53:51 -0700 Tue, 07 Jul 2015 12:53:51 -0700 1 {kubelet kubernetes-node-tf0f} implicitly required container POD started Started with docker id 6a41280f516d
Tue, 07 Jul 2015 12:53:51 -0700 Tue, 07 Jul 2015 12:53:51 -0700 1 {kubelet kubernetes-node-tf0f} spec.containers{simmemleak} created Created with docker id 87348f12526a
上記の例では、Restart Count:5はPodのsimmemleakコンテナが終了して、5回再起動したことを示しています。
-o go-template=...オプションを指定して、kubectl get podを呼び出し、以前に終了したコンテナのステータスを取得できます。
kubectl get pod -o go-template= '{{range.status.containerStatuses}}{{"Container Name: "}}{{.name}}{{"\r\nLastState: "}}{{.lastState}}{{end}}' simmemleak-hra99
Container Name: simmemleak
LastState: map[terminated:map[exitCode:137 reason:OOM Killed startedAt:2015-07-07T20:58:43Z finishedAt:2015-07-07T20:58:43Z containerID:docker://0e4095bba1feccdfe7ef9fb6ebffe972b4b14285d5acdec6f0d3ae8a22fad8b2]]
reason:OOM Killedが原因でコンテナが終了したことがわかります。OOMはメモリー不足を表します。
次の項目 3.8.6 - kubeconfigファイルを使用してクラスターアクセスを組織する kubeconfigを使用すると、クラスターに、ユーザー、名前空間、認証の仕組みに関する情報を組織できます。kubectlコマンドラインツールはkubeconfigファイルを使用してクラスターを選択するために必要な情報を見つけ、クラスターのAPIサーバーと通信します。
備考: クラスターへのアクセスを設定するために使われるファイルはkubeconfigファイル と呼ばれます。これは設定ファイルを指すために使われる一般的な方法です。kubeconfigという名前を持つファイルが存在するという意味ではありません。
警告: 信頼できるソースからのkubeconfigファイルのみを使用してください。特別に細工されたkubeconfigファイルを使用すると、悪意のあるコードの実行やファイルの公開につながる可能性があります。
信頼できないkubeconfigファイルを使用しなければならない場合は、シェルスクリプトを使用するのと同じように、まず最初に慎重に検査してください。デフォルトでは、kubectlは$HOME/.kubeディレクトリ内にあるconfigという名前のファイルを探します。KUBECONFIG環境変数を設定するか、--kubeconfig
kubeconfigファイルの作成と指定に関するステップバイステップの手順を知りたいときは、複数のクラスターへのアクセスを設定する を参照してください。
複数のクラスター、ユーザ、認証の仕組みのサポート 複数のクラスターを持っていて、ユーザーやコンポーネントがさまざまな方法で認証を行う次のような状況を考えてみます。
実行中のkubeletが証明書を使用して認証を行う可能性がある。 ユーザーがトークンを使用して認証を行う可能性がある。 管理者が個別のユーザに提供する複数の証明書を持っている可能性がある。 kubeconfigファイルを使用すると、クラスター、ユーザー、名前空間を組織化することができます。また、contextを定義することで、複数のクラスターや名前空間を素早く簡単に切り替えられます。
Context kubeconfigファイルのcontext 要素は、アクセスパラメーターを使いやすい名前でグループ化するために使われます。各contextは3つのパラメーター、cluster、namespace、userを持ちます。デフォルトでは、kubectlコマンドラインツールはクラスターとの通信にcurrent context のパラメーターを使用します。
current contextを選択するには、以下のコマンドを使用します。
kubectl config use-context
KUBECONFIG環境変数 KUBECONFIG環境変数には、kubeconfigファイルのリストを指定できます。LinuxとMacでは、リストはコロン区切りです。Windowsでは、セミコロン区切りです。KUBECONFIG環境変数は必須ではありません。KUBECONFIG環境変数が存在しない場合は、kubectlはデフォルトのkubeconfigファイルである$HOME/.kube/configを使用します。
KUBECONFIG環境変数が存在する場合は、kubectlはKUBECONFIG環境変数にリストされているファイルをマージした結果を有効な設定として使用します。
kubeconfigファイルのマージ 設定ファイルを確認するには、以下のコマンドを実行します。
上で説明したように、出力は1つのkubeconfigファイルから作られる場合も、複数のkubeconfigファイルをマージした結果となる場合もあります。
kubectlがkubeconfigファイルをマージするときに使用するルールを以下に示します。
もし--kubeconfigフラグが設定されていた場合、指定したファイルだけが使用されます。マージは行いません。このフラグに指定できるのは1つのファイルだけです。
そうでない場合、KUBECONFIG環境変数が設定されていた場合には、それをマージするべきファイルのリストとして使用します。KUBECONFIG環境変数にリストされたファイルのマージは、次のようなルールに従って行われます。
空のファイルを無視する。 デシリアライズできない内容のファイルに対してエラーを出す。 特定の値やmapのキーを設定する最初のファイルが勝つ。 値やmapのキーは決して変更しない。
例: 最初のファイルが指定したcurrent-contextを保持する。
例: 2つのファイルがred-userを指定した場合、1つ目のファイルのred-userだけを使用する。もし2つ目のファイルのred-user以下に競合しないエントリーがあったとしても、それらは破棄する。 KUBECONFIG環境変数を設定する例については、KUBECONFIG環境変数を設定する を参照してください。
それ以外の場合は、デフォルトのkubeconfigファイル$HOME/.kube/configをマージせずに使用します。
以下のチェーンで最初に見つかったものをもとにして、使用するcontextを決定する。
--contextコマンドラインフラグが存在すれば、それを使用する。マージしたkubeconrfigファイルからcurrent-contextを使用する。 この時点では、空のcontextも許容されます。
クラスターとユーザーを決定する。この時点では、contextである場合もそうでない場合もあります。以下のチェーンで最初に見つかったものをもとにして、クラスターとユーザーを決定します。この手順はユーザーとクラスターについてそれぞれ1回ずつ、合わせて2回実行されます。
もし存在すれば、コマンドラインフラグ--userまたは--clusterを使用する。 もしcontextが空でなければ、contextからユーザーまたはクラスターを取得する。 この時点では、ユーザーとクラスターは空である可能性があります。
使用する実際のクラスター情報を決定する。この時点では、クラスター情報は存在しない可能性があります。以下のチェーンで最初に見つかったものをもとにして、クラスター情報の各パーツをそれぞれを構築します。
もし存在すれば、--server、--certificate-authority、--insecure-skip-tls-verifyコマンドラインフラグを使用する。 もしマージしたkubeconfigファイルにクラスター情報の属性が存在すれば、それを使用する。 もしサーバーの場所が存在しなければ、マージは失敗する。 使用する実際のユーザー情報を決定する。クラスター情報の場合と同じルールを使用して、ユーザー情報を構築します。ただし、ユーザーごとに許可される認証方法は1つだけです。
もし存在すれば、--client-certificate、--client-key、--username、--password、--tokenコマンドラインフラグを使用する。 マージしたkubeconfigファイルのuserフィールドを使用する。 もし2つの競合する方法が存在する場合、マージは失敗する。 もし何らかの情報がまだ不足していれば、デフォルトの値を使用し、認証情報については場合によってはプロンプトを表示する。
ファイルリファレンス kubeconfigファイル内のファイルとパスのリファレンスは、kubeconfigファイルの位置からの相対パスで指定します。コマンドライン上のファイルのリファレンスは、現在のワーキングディレクトリからの相対パスです。$HOME/.kube/config内では、相対パスは相対のまま、絶対パスは絶対のまま保存されます。
プロキシ kubeconfigファイルでproxy-urlを使用すると、以下のようにクラスターごとにプロキシを使用するようにkubectlを設定することができます。
apiVersion : v1
kind : Config
clusters :
cluster :
proxy-url : http://proxy.example.org:3128
server : https://k8s.example.org/k8s/clusters/c-xxyyzz
name : development
users :
name : developer
contexts :
context :
name : development
次の項目 3.8.7 - Windowsノードにおけるリソース管理 このページでは、LinuxとWindowsにおけるリソース管理の違いについて説明します。
Linuxノードでは、cgroups がリソース管理のPodの境界として使われています。
コンテナはネットワーク、プロセス、ファイルシステムが分離された境界内に作成されます。
Linux cgroup APIを利用して、CPU、IO、メモリの統計情報を収集することができます。
対照的に、Windowsは、システム名前空間フィルターを使用してコンテナごとにジョブオブジェクト Job とは異なります。)
Windowsコンテナでは名前空間のフィルタリングを行わずに実行する方法はありません。
つまり、システム権限はホストのコンテキストでは宣言することが出来ません。
そのため、Windows上で特権コンテナは利用出来ません。
Security Account Manager(SAM)が分離されているため、コンテナはホストからの認証情報を受け取ることはできません。
メモリ管理 WindowsではLinuxのようなOut-Of-Memoryによるプロセスの終了は提供されていません。
Windowsではすべてのユーザモードでのメモリアロケーションを仮想的に取り扱います。
そのためpagefilesが必ず必要になります。
Windowsノードではプロセスのメモリオーバーコミットを行いません。
そのため、WindowsではプロセスはLinuxのようにメモリ不足状態になる事はなく、Out-Of-Memory(OOM)により終了するのではなくディスクへのページングを行います。
メモリが過剰に確保され物理メモリが使い果たされた場合に、ページングによりパフォーマンスが低下する可能性があります。
CPU管理 Windowsは様々なプロセスに割り当てるCPU時間を制限することは出来ますが、最小限のCPU時間を保証することは出来ません。
Windowsでは、kubeletプロセスの--windows-priorityclassコマンドラインフラグによるscheduling priority の設定をサポートしています。
このフラグによりkubeletプロセスは同じWindowsホスト上で動作している他のプロセスと比べて多くのCPU時間のスライスを得ることが出来ます。
許容される値とその意味に関する詳細はWindows Priority Classes を参照して下さい。
実行中のPodによりkubeletのCPUサイクルが不足しないためには、このフラグをABOVE_NORMAL_PRIORITY_CLASS以上に設定して下さい。
リソースの予約 オペレーティングシステムやコンテナランタイム、kubeletのようなKubernetesのホストプロセスによって利用されるCPUやメモリを考慮するために、kubeletの--kube-reservedや--system-reservedフラグを利用して、リソースを予約することが出来ます(また、予約する必要もあります)。
Windowsではこれらの値はノードのallocatable リソースの計算のみに利用されます。
注意: ワークロードをデプロイする時に、コンテナにメモリとCPUの制限を設定して下さい。
これにより、NodeAllocatableが減少し、クラスタ全体のスケジューラーがどのPodをどのノードに配置するかの決定に役立ちます。
制限なしでPodをスケジューリングするとWindowsノードに過剰にプロビジョニングされ、極端な場合にはノードの健全性が低下する可能性があります。
Windowsでは少なくとも2GiBのメモリを予約する事を推奨します。
どの程度、CPUを予約すればよいのか決定するには、各ノードでのPodの密度を特定し、ノードで実行されるシステムサービスのCPU利用率を監視し、ワークロードのニーズを満たす値を選択します。
3.9 - セキュリティ クラウドネイティブなワークロードをセキュアに維持するためのコンセプト
このセクションは、ワークロードをより安全に実行する方法やKubernetesクラスターのセキュリティを保つための重要な観点について学ぶのに役立ちます。
Kubernetesはクラウドネイティブアーキテクチャに基づいており、クラウドネイティブ情報セキュリティのグッドプラクティスについてのCNCF からのアドバイスを参考にしています。
クラスターとクラスター上で実行しているアプリケーションをどのように保護するかについての広い文脈を理解するためにクラウドネイティブセキュリティとKubernetes を参照してください。
Kubernetesセキュリティメカニズム KubernetesはいくつかのAPIとセキュリティコントロールを含んでいます。
Kubernetesには、情報セキュリティを管理する方法の一部を構成するポリシー を定義する方法のほか、いくつかのAPIとセキュリティコントロールが含まれています。
コントロールプレーンの保護 どのKubernetesのクラスターでも重要なセキュリティメカニズムはKubernetes APIへのアクセスコントロール です。
Kubernetesでは、コントロールプレーン内やコントロールプレーンとそのクライアント間でデータ転送中の暗号化 を提供するために、TLSを設定し使用することが求められます。また、Kubernetesコントロールプレーン内に保存されているデータに対して保存データの暗号化 を有効にすることもできます。これは、自身のワークロードのデータに対して保存データの暗号化を使用することとは別のもので、この方法もまた有効かもしれません。
Secret Secret APIは機密性が必要な設定値の基本的な保護を提供します。
ワークロードの保護 Podセキュリティ基準 を順守して、Podやコンテナが適切に独立されるようにします。必要に応じてカスタムの分離を定義するためにRuntimeClass を使用することもできます。
ネットワークポリシー を使用すると、Pod間やPodとクラスター外との通信のネットワークトラフィックを制御できます。
Podやそのコンテナ、それらで実行されるイメージに対して、予防的または検出的なコントロールを実装するために周辺のエコシステムからセキュリティコントロールを導入することができます。
監査 Kubernetesの監査ログ はクラスター内でのアクションの一連の流れを時系列で記録し、セキュリティに関連する情報を提供します。クラスターはKubernetes APIを利用するユーザーやアプリケーション、コントロールプレーン自身によって生成されるアクティビティを監査します。
クラウドプロバイダーのセキュリティ 備考: Items on this page refer to vendors external to Kubernetes. The Kubernetes project authors aren't responsible for those third-party products or projects. To add a vendor, product or project to this list, read the
content guide before submitting a change.
More information. Kubernetesクラスターを自身のハードウェアや様々クラウドプロバイダーで実行している場合、セキュリティのベストプラクティスのドキュメントを参照してください。以下に、いくつかの主要なクラウドプロバイダーのセキュリティドキュメントへのリンクを示します。
ポリシー ネットワークポリシー (ネットワークパケットフィルタリングの宣言的制御)やアドミッションポリシーの検証 (Kubernetes APIを使用し誰が何を変更できるかの宣言的な制限)などのKubernetesネイティブメカニズムを使用し、セキュリティポリシーを定義することができます。
また、Kubernetesの周辺のエコシステムによるポリシーの実装に頼ることもできます。Kubernetesはエコシステムのプロジェクトに独自のポリシー制御を実装させるための拡張メカニズムを提供します。ソースコードレビューやコンテナイメージの承認、APIアクセスコントロール、ネットワーキングなどをポリシー制御に実装することができます。
次の項目 関連するKubernetesセキュリティのトピックを学ぶためには:
背景について学ぶためには:
認定を取得するためには:
このセクションのさらなる詳細については:
3.9.1 - クラウドネイティブセキュリティの概要 この概要では、クラウドネイティブセキュリティにおけるKubernetesのセキュリティを考えるためのモデルを定義します。
警告: コンテナセキュリティモデルは、実証済の情報セキュリティポリシーではなく提案を提供します。クラウドネイティブセキュリティの4C セキュリティは階層で考えることができます。クラウドネイティブの4Cは、クラウド、クラスター、コンテナ、そしてコードです。
備考: 階層化されたアプローチは、セキュリティに対する
多層防御 のアプローチを強化します。これはソフトウェアシステムを保護するベストプラクティスとして幅広く認知されています。
クラウドネイティブセキュリティの4C クラウドネイティブセキュリティモデルの各レイヤーは次の最も外側のレイヤー上に構築します。コードレイヤーは、強固な基盤(クラウド、クラスター、コンテナ)セキュリティレイヤーから恩恵を受けます。コードレベルのセキュリティに対応しても基盤レイヤーが低い水準のセキュリティでは守ることができません。
クラウド いろいろな意味でも、クラウド(または同じ場所に設置されたサーバー、企業のデータセンター)はKubernetesクラスターのトラステッド・コンピューティング・ベース です。クラウドレイヤーが脆弱な(または脆弱な方法で構成されている)場合、この基盤の上に構築されたコンポーネントが安全であるという保証はありません。各クラウドプロバイダーは、それぞれの環境でワークロードを安全に実行させるためのセキュリティの推奨事項を作成しています。
クラウドプロバイダーのセキュリティ Kubernetesクラスターを所有しているハードウェアや様々なクラウドプロバイダー上で実行している場合、セキュリティのベストプラクティスに関するドキュメントを参考にしてください。ここでは人気のあるクラウドプロバイダーのセキュリティドキュメントの一部のリンクを紹介します。
インフラのセキュリティ Kubernetesクラスターのインフラを保護するための提案です。
Infrastructure security Kubernetesインフラに関する懸念事項 推奨事項 API Server(コントロールプレーン)へのネットワークアクセス Kubernetesコントロールプレーンへのすべてのアクセスは、インターネット上での一般公開は許されず、クラスター管理に必要なIPアドレスに制限するネットワークアクセス制御リストによって制御されます。 Nodeへのネットワークアクセス Nodeはコントロールプレーンの特定ポート のみ 接続(ネットワークアクセス制御リストを介して)を受け入れるよう設定し、NodePortとLoadBalancerタイプのKubernetesのServiceに関する接続を受け入れるよう設定する必要があります。可能であれば、それらのNodeはパブリックなインターネットに完全公開しないでください。 KubernetesからのクラウドプロバイダーAPIへのアクセス 各クラウドプロバイダーはKubernetesコントロールプレーンとNodeに異なる権限を与える必要があります。最小権限の原則 に従い、管理に必要なリソースに対してクラウドプロバイダーへのアクセスをクラスターに提供するのが最善です。Kopsドキュメント にはIAMのポリシーとロールについての情報が記載されています。 etcdへのアクセス etcd(Kubernetesのデータストア)へのアクセスはコントロールプレーンのみに制限すべきです。設定によっては、TLS経由でetcdを利用する必要があります。詳細な情報はetcdドキュメント を参照してください。 etcdの暗号化 可能な限り、保存時に全ドライブを暗号化することは良いプラクティスですが、etcdはクラスター全体(Secretを含む)の状態を保持しているため、そのディスクは特に暗号化する必要があります。
クラスター Kubernetesを保護する為には2つの懸念事項があります。
設定可能なクラスターコンポーネントの保護 クラスターで実行されるアプリケーションの保護 クラスターのコンポーネント 想定外または悪意のあるアクセスからクラスターを保護して適切なプラクティスを採用したい場合、クラスターの保護 に関するアドバイスを読み従ってください。
クラスター内のコンポーネント(アプリケーション) アプリケーションを対象にした攻撃に応じて、セキュリティの特定側面に焦点をあてたい場合があります。例:他のリソースとの連携で重要なサービス(サービスA)と、リソース枯渇攻撃に対して脆弱な別のワークロード(サービスB)が実行されている場合、サービスBのリソースを制限していないとサービスAが危険にさらされるリスクが高くなります。次の表はセキュリティの懸念事項とKubernetesで実行されるワークロードを保護するための推奨事項を示しています。
コンテナ コンテナセキュリティは本ガイドの範囲外になります。このトピックを検索するために一般的な推奨事項とリンクを以下に示します。
コンテナに関する懸念事項 推奨事項 コンテナの脆弱性スキャンとOS依存のセキュリティ イメージをビルドする手順の一部として、既知の脆弱性がないかコンテナをスキャンする必要があります。 イメージの署名と実施 コンテナイメージを署名し、コンテナの中身に関する信頼性を維持します。 特権ユーザーを許可しない コンテナの構成時に、コンテナの目的を実行するために必要最低限なOS特権を持ったユーザーをコンテナ内部に作成する方法のドキュメントを参考にしてください。
コード アプリケーションコードは、あなたが最も制御できる主要な攻撃対象のひとつです。アプリケーションコードを保護することはKubernetesのセキュリティトピックの範囲外ですが、アプリケーションコードを保護するための推奨事項を以下に示します。
コードセキュリティ Code security コードに関する懸念事項 推奨事項 TLS経由のアクセスのみ コードがTCP通信を必要とする場合は、事前にクライアントとのTLSハンドシェイクを実行してください。 いくつかの例外を除いて、全ての通信を暗号化してください。さらに一歩すすめて、サービス間のネットワークトラフィックを暗号化することはよい考えです。これは、サービスを特定した2つの証明書で通信の両端を検証する相互認証、またはmTLS して知られているプロセスを通じて実行できます。 通信ポートの範囲制限 この推奨事項は一目瞭然かもしれませんが、可能なかぎり、通信とメトリクス収集に必要不可欠なサービスのポートのみを公開します。 サードパティに依存するセキュリティ 既知の脆弱性についてアプリケーションのサードパーティ製ライブラリーを定期的にスキャンすることを推奨します。それぞれの言語は自動でこのチェックを実行するツールを持っています。 静的コード解析 ほとんどの言語ではコードのスニペットを解析して、安全でない可能性のあるコーディングを分析する方法が提供しています。可能な限り、コードベースでスキャンして、よく起こるセキュリティエラーを検出できる自動ツールを使用してチェックを実行すべきです。一部のツールはここで紹介されています。 https://owasp.org/www-community/Source_Code_Analysis_Tools 動的プロービング攻撃 よく知られているいくつかのサービス攻撃をサービスに対して試すことができる自動ツールがいくつかあります。これにはSQLインジェクション、CSRF、そしてXSSが含まれます。よく知られている動的解析ツールはOWASP Zed Attack proxy toolです。
次の項目 関連するKubernetesセキュリティについて学びます。
3.9.2 - Podセキュリティの標準 Podに対するセキュリティの設定は通常Security Context を使用して適用されます。Security ContextはPod単位での特権やアクセスコントロールの定義を実現します。
クラスターにおけるSecurity Contextの強制やポリシーベースの定義はPod Security Policy によって実現されてきました。
Pod Security Policy はクラスターレベルのリソースで、Pod定義のセキュリティに関する設定を制御します。
しかし、PodSecurityPolicyを拡張したり代替する、ポリシーを強制するための多くの方法が生まれてきました。
このページの意図は、推奨されるPodのセキュリティプロファイルを特定の実装から切り離して詳しく説明することです。
ポリシーの種別 まず、幅広いセキュリティの範囲をカバーできる、基礎となるポリシーの定義が必要です。
それらは強く制限をかけるものから自由度の高いものまでをカバーすべきです。
特権 ベースライン、デフォルト 制限 ポリシー 特権 特権ポリシーは意図的に開放されていて、完全に制限がかけられていません。この種のポリシーは通常、特権ユーザーまたは信頼されたユーザーが管理する、システムまたはインフラレベルのワークロードに対して適用されることを意図しています。
特権ポリシーは制限がないことと定義されます。gatekeeperのようにデフォルトで許可される仕組みでは、特権プロファイルはポリシーを設定せず、何も制限を適用しないことにあたります。
一方で、Pod Security Policyのようにデフォルトで拒否される仕組みでは、特権ポリシーでは全ての制限を無効化してコントロールできるようにする必要があります。
ベースライン、デフォルト ベースライン、デフォルトのプロファイルは一般的なコンテナ化されたランタイムに適用しやすく、かつ既知の特権昇格を防ぐことを意図しています。
このポリシーはクリティカルではないアプリケーションの運用者または開発者を対象にしています。
次の項目は強制、または無効化すべきです。
ベースラインポリシーの定義 項目 ポリシー ホストのプロセス Windows Podは、Windowsノードへの特権的なアクセスを可能にするHostProcess コンテナを実行する機能を提供します。ベースラインポリシーでは、ホストへの特権的なアクセスは禁止されています。HostProcess Podは、Kubernetes v1.22時点ではアルファ版の機能です。
ホストのネームスペースの共有は無効化すべきです。
制限されるフィールド
spec.securityContext.windowsOptions.hostProcessspec.containers[*].securityContext.windowsOptions.hostProcessspec.initContainers[*].securityContext.windowsOptions.hostProcessspec.ephemeralContainers[*].securityContext.windowsOptions.hostProcess認められる値
ホストのネームスペース ホストのネームスペースの共有は無効化すべきです。制限されるフィールド: 認められる値: false, Undefined/nil 特権コンテナ 特権を持つPodはほとんどのセキュリティ機構を無効化できるので、禁止すべきです。制限されるフィールド: 認められる値: false, undefined/nil ケーパビリティー デフォルト よりも多くのケーパビリティーを与えることは禁止すべきです。制限されるフィールド: 認められる値:
Undefined/nilHostPathボリューム HostPathボリュームは禁止すべきです。制限されるフィールド: 認められる値: undefined/nil ホストのポート HostPortは禁止するか、最小限の既知のリストに限定すべきです。制限されるフィールド: 認められる値: 0, undefined (または既知のリストに限定) AppArmor(任意) サポートされるホストでは、AppArmorの'runtime/default'プロファイルがデフォルトで適用されます。デフォルトのポリシーはポリシーの上書きや無効化を防ぎ、許可されたポリシーのセットを上書きできないよう制限すべきです。制限されるフィールド: 認められる値: 'runtime/default', undefined, localhost/* SELinux (任意) SELinuxのオプションをカスタムで設定することは禁止すべきです。制限されるフィールド: 認められる値: undefined/nil制限されるフィールド: 認められる値: undefined/nil /procマウントタイプ 攻撃対象を縮小するため/procのマスクを設定し、必須とすべきです。制限されるフィールド: 認められる値: undefined/nil, 'Default' Seccomp Seccompプロファイルを明示的にUnconfinedに設定することはできません。
Restricted Fields
spec.securityContext.seccompProfile.typespec.containers[*].securityContext.seccompProfile.typespec.initContainers[*].securityContext.seccompProfile.typespec.ephemeralContainers[*].securityContext.seccompProfile.typeAllowed Values
Undefined/nil RuntimeDefaultLocalhostSysctl Sysctlはセキュリティ機構を無効化したり、ホストの全てのコンテナに影響を与えたりすることが可能なので、「安全」なサブネットを除いては禁止すべきです。
コンテナまたはPodの中にsysctlがありネームスペースが分離されていて、同じノードの別のPodやプロセスから分離されている場合はsysctlは安全だと考えられます。制限されるフィールド: 認められる値:
制限 制限ポリシーはいくらかの互換性を犠牲にして、Podを強化するためのベストプラクティスを強制することを意図しています。
セキュリティ上クリティカルなアプリケーションの運用者や開発者、また信頼度の低いユーザーも対象にしています。
下記の項目を強制、無効化すべきです。
制限ポリシーの定義 項目 ポリシー デフォルトプロファイルにある項目全て Volumeタイプ HostPathボリュームの制限に加え、制限プロファイルではコアでない種類のボリュームの利用をPersistentVolumeにより定義されたものに限定します。制限されるフィールド: 認められる値: undefined/nil 特権昇格 特権昇格(ファイルモードのset-user-IDまたはset-group-IDのような方法による)は禁止すべきです。制限されるフィールド: 認められる値: false root以外での実行 コンテナはroot以外のユーザーで実行する必要があります。制限されるフィールド: 認められる値: true root以外のグループ (任意) コンテナをrootのプライマリまたは補助GIDで実行することを禁止すべきです。制限されるフィールド: 認められる値: Seccomp SeccompのRuntimeDefaultを必須とする、または特定の追加プロファイルを許可することが必要です。制限されるフィールド: 認められる値: Capabilities (v1.22+) コンテナはすべてのケイパビリティを削除する必要があり、NET_BIND_SERVICEケイパビリティを追加することだけが許可されています。
Restricted Fields
spec.containers[*].securityContext.capabilities.dropspec.initContainers[*].securityContext.capabilities.dropspec.ephemeralContainers[*].securityContext.capabilities.dropAllowed Values
Any list of capabilities that includes ALL Restricted Fields
spec.containers[*].securityContext.capabilities.addspec.initContainers[*].securityContext.capabilities.addspec.ephemeralContainers[*].securityContext.capabilities.addAllowed Values
Undefined/nil NET_BIND_SERVICE
ポリシーの実例 ポリシーの定義とポリシーの実装を切り離すことによって、ポリシーを強制する機構とは独立して、汎用的な理解や複数のクラスターにわたる共通言語とすることができます。
機構が成熟してきたら、ポリシーごとに下記に定義されます。それぞれのポリシーを強制する方法についてはここでは定義しません。
PodSecurityPolicy
FAQ 特権とデフォルトの間のプロファイルがないのはどうしてですか? ここで定義されている3つのプロファイルは最も安全(制限)から最も安全ではない(特権)まで、直線的に段階が設定されており、幅広いワークロードをカバーしています。
ベースラインを超える特権が必要な場合、その多くはアプリケーションに特化しているため、その限られた要求に対して標準的なプロファイルを提供することはできません。
これは、このような場合に必ず特権プロファイルを使用すべきだという意味ではなく、場合に応じてポリシーを定義する必要があります。
将来、他のプロファイルの必要性が明らかになった場合、SIG Authはこの方針について再考する可能性があります。
セキュリティポリシーとセキュリティコンテキストの違いは何ですか? Security Context は実行時のコンテナやPodを設定するものです。
Security ContextはPodのマニフェストの中でPodやコンテナの仕様の一部として定義され、コンテナランタイムへ渡されるパラメーターを示します。
セキュリティポリシーはコントロールプレーンの機構で、Security Contextとそれ以外も含め、特定の設定を強制するものです。
2020年2月時点では、ネイティブにサポートされているポリシー強制の機構はPod Security
Policy です。これはクラスター全体にわたってセキュリティポリシーを中央集権的に強制するものです。
セキュリティポリシーを強制する他の手段もKubernetesのエコシステムでは開発が進められています。例えばOPA
Gatekeeper があります。
WindowsのPodにはどのプロファイルを適用すればよいですか? Kubernetesでは、Linuxベースのワークロードと比べてWindowsの使用は制限や差異があります。
特に、PodのSecurityContextフィールドはWindows環境では効果がありません 。
したがって、現段階では標準化されたセキュリティポリシーは存在しません。
Windows Podに制限付きプロファイルを適用すると、実行時にPodに影響が出る場合があります。
制限付きプロファイルでは、Linux固有の制限(seccompプロファイルや特権昇格の不許可など)を適用する必要があります。
kubeletおよび/またはそのコンテナランタイムがこれらのLinux固有の値を無視した場合、Windows Podは制限付きプロファイル内で正常に動作します。
ただし、強制力がないため、Windows コンテナを使用するPodについては、ベースラインプロファイルと比較して追加の制限はありません。
HostProcess Podを作成するためのHostProcessフラグの使用は、特権的なポリシーに沿ってのみ行われるべきです。
Windows HostProcess Podの作成は、ベースラインおよび制限されたポリシーの下でブロックされているため、いかなるHostProcess Podも特権的であるとみなされるべきです。
サンドボックス化されたPodはどのように扱えばよいでしょうか? 現在のところ、Podがサンドボックス化されていると見なされるかどうかを制御できるAPI標準はありません。
サンドボックス化されたPodはサンドボックス化されたランタイム(例えばgVisorやKata Containers)の使用により特定することは可能ですが、サンドボックス化されたランタイムの標準的な定義は存在しません。
サンドボックス化されたランタイムに対して必要な保護は、それ以外に対するものとは異なります。
例えば、ワークロードがその基になるカーネルと分離されている場合、特権を制限する必要性は小さくなります。
これにより、強い権限を必要とするワークロードが隔離された状態を維持できます。
加えて、サンドボックス化されたワークロードの保護はサンドボックス化の実装に強く依存します。
したがって、全てのサンドボックス化されたワークロードに推奨される単一のポリシーは存在しません。
3.9.3 - クラウドネイティブセキュリティとKubernetes クラウドネイティブワークロードを安全に保つためのコンセプト。
Kubernetesはクラウドネイティブアーキテクチャに基づいており、クラウドネイティブ情報セキュリティのグッドプラクティスに関するアドバイスをCNCF から受けています。
このページを読み進めることで、安全なクラウドネイティブプラットフォームをデプロイするためにKubernetesがどのように設計されているかについての概要を知ることができます。
クラウドネイティブ情報セキュリティ クラウドネイティブセキュリティに関するCNCFホワイトペーパー では、さまざまな ライフサイクルフェーズ に適したセキュリティコントロールとプラクティスが定義されています。
Develop ライフサイクルフェーズ開発環境の整合性を確保します。 状況に応じて、情報セキュリティのグッドプラクティスに沿ったアプリケーションを設計します。 エンドユーザーのセキュリティをソリューション設計の一部として考慮します。 これを実現するためには、次のようなことができます:
内部の脅威であっても、攻撃対象となる範囲を最小限に抑えるゼロトラスト のようなアーキテクチャを採用します。 セキュリティの懸念を考慮したコードレビュープロセスを定義します。 システムまたはアプリケーションの 脅威モデル を作成し、信頼境界を特定します。
そのモデルを使用してリスクを特定し、それらのリスクに対処する方法を見つけるのに役立てます。 ファジング やセキュリティカオスエンジニアリング のような高度なセキュリティ自動化を組み込みます。Distribute ライフサイクルフェーズ実行するコンテナイメージのサプライチェーンのセキュリティを確保します。 クラスターとその他のコンポーネントがアプリケーションを実行するためのサプライチェーンのセキュリティを確保します。
他のコンポーネントの例としては、クラウドネイティブアプリケーションが永続性のために使用する外部データベースがあります。 これを実現するためには、次のようなことができます:
既知の脆弱性を持つコンテナイメージやその他のアーティファクトをスキャンします。 ソフトウェアのディストリビューションが、ソフトウェアのソースに対するトラストチェーンを使用して、転送中の暗号化を行うようにします。 利用可能になった更新に対応するための依存関係の更新プロセスを採用し、それに従います。 サプライチェーンを保証するために、デジタル証明書などの検証メカニズムを使用します。 セキュリティリスクを通知するためのフィードや他のメカニズムにサブスクライブします。 アーティファクトへのアクセスを制限します。
コンテナイメージをプライベートレジストリ に配置し、認証されたクライアントのみがイメージを取得できるようにします。 Deploy ライフサイクルフェーズ何をデプロイできるか、誰がデプロイできるか、どこにデプロイできるかに関する適切な制限を確保します。
コンテナイメージアーティファクトの暗号化されたアイデンティティを検証するなど、Distribute フェーズからの対策を適用できます。
Kubernetesをデプロイすると、アプリケーションのランタイム環境の基盤、つまりKubernetesクラスター(または複数のクラスター)も設定されます。
ITインフラストラクチャは、より高いレイヤーが期待するセキュリティ保証を提供する必要があります。
Runtime ライフサイクルフェーズRuntimeフェーズは、コンピューティング 、アクセス 、およびストレージ の3つの重要な領域から構成されます。
Runtime保護: アクセス Kubernetes APIはクラスターを機能させるためのものです。
このAPIを保護することは、効果的なクラスターセキュリティを提供するための鍵となります。
Kubernetesドキュメント内の他のページでは、アクセスコントロールの特定の側面を設定する方法について詳しく説明しています。
セキュリティチェックリスト には、クラスターの基本的なチェックを行うための提案が記載されています。
さらに、APIアクセスのための効果的な認証 と認可 を実装することがクラスターのセキュリティを確保することにつながります。
サービスアカウント を使用して、ワークロードとクラスターコンポーネントのセキュリティアイデンティティを提供および管理します。
KubernetesはTLSを使用してAPIトラフィックを保護します。
(ノードとコントロールプレーン間のトラフィックを含めて)TLSを使用してクラスターをデプロイし、暗号化キーを保護してください。
CertificateSigningRequests にKubernetes独自のAPIを使用する場合は、その悪用を制限するために特に注意を払ってください。
Runtime保護: コンピューティング コンテナ は、異なるアプリケーション間の分離と、それらの分離されたアプリケーションを同じホストコンピューターで実行するメカニズムの2つを提供します。
これらの2つの側面、分離と集約は、ランタイムセキュリティとのトレードオフがあり、適切なバランスを見つける必要があることを意味します。
Kubernetesは実際にコンテナを設定して実行するためにコンテナランタイム に依存しています。
Kubernetesプロジェクトは特定のコンテナランタイムを推奨しておらず、選択したランタイムが情報セキュリティの要件を満たしていることを確認する必要があります。
ランタイムでコンピューティングを保護するために、次のことができます:
アプリケーションのPodのセキュリティ標準 を強制することで、アプリケーションが必要な権限のみで実行されるようにします。
コンテナ化されたワークロードを実行するために、特別に設計されたオペレーティングシステムをノード上で実行します。
これは通常、コンテナの実行に不可欠なサービスのみを提供する読み取り専用オペレーティングシステム(イミュータブルイメージ )に基づいています。
コンテナ固有のオペレーティングシステムは、システムコンポーネントを分離し、コンテナエスケープが発生した際の攻撃対象領域を減らすのに役立ちます。
ResourceQuotas を定義して、共有リソースを公平に割り当て、Podがリソース要件を指定できるようにするためにLimitRanges などのメカニズムを使用します。
異なるノード間でワークロードを分割します。
Kubernetes自体またはエコシステムのいずれかからノードの分離 メカニズムを使用して、異なる信頼コンテキストのPodが別個のノードセットで実行されるようにします。
セキュリティ制約を提供するコンテナランタイム を使用します。
Linuxノードでは、AppArmor やseccomp などのLinuxセキュリティモジュールを使用します。
Runtime保護: ストレージ クラスターのストレージとそこで実行されるアプリケーションの保護のために、次のことができます:
クラスターを、ボリューム保存時の暗号化を提供する外部ストレージプラグインと統合します。 APIオブジェクトの保存時の暗号化 を有効にします。 バックアップを使用してデータの耐久性を保護します。
必要に応じていつでもこれらを復元できることを確認します。 クラスターノードとそれが依存するネットワークストレージ間の接続を認証します。 自分自身のアプリケーション内でデータ暗号化を実装します。 暗号化キーについては、専用のハードウェア内で生成することで、漏洩リスクに対する最善の保護を提供します。
ハードウェアセキュリティモジュール を使用すると、セキュリティキーを他の場所にコピーすることなく暗号化操作を実施できます。
ネットワークとセキュリティ ネットワークポリシー やサービスメッシュ などのネットワークセキュリティ対策の検討もまた重要です。
Kubernetesの一部のネットワークプラグインは、仮想プライベートネットワーク(VPN)オーバーレイなどの技術を使用して、クラスターネットワークの暗号化を提供します。
設計上、Kubernetesはクラスターに独自のネットワークプラグインを使用することを許可しています(マネージドKubernetesを使用している場合、クラスターを管理している個人または組織がネットワークプラグインを選択している可能性があります)。
選択したネットワークプラグインとその統合方法は、転送中の情報のセキュリティに大きな影響を与える可能性があります。
オブザーバビリティとランタイムセキュリティ Kubernetesを使用すると、追加のツールを使用してクラスターを拡張できます。
サードパーティのソリューションをセットアップすることで、アプリケーションと実行中のクラスターを監視またはトラブルシューティングするのに役立ちます。
Kubernetes自体にもいくつかの基本的なオブザーバビリティ機能が組み込まれています。
コンテナ内で実行されるコードは、ログの生成、メトリクスの公開、その他の可観測性データの提供ができます。
デプロイ時に、クラスターが適切な保護レベルを提供していることを確認する必要があります。
メトリクスダッシュボードやそれに類似するものをセットアップする場合、そのダッシュボードにデータを投入する一連のコンポーネントと、ダッシュボード自体を確認してください。
クラスターの機能が低下するようなインシデントが発生している場合でも信頼できるように、全体のチェーンが十分な回復力と整合性保護を備えて設計されていることを確認してください。
必要に応じて、(ログや監査レコードの忠実性を確保するのに役立つ)暗号化されたメジャーブートや認証された時間配分など、Kubernetes自体よりも下位のセキュリティ対策をデプロイしてください。
高い信頼性の環境のために、ログの改ざん防止と機密性を確保するために暗号化保護をデプロイしてください。
次の項目 クラウドネイティブセキュリティ Kubernetesと情報セキュリティ 3.9.4 - Podのセキュリティアドミッション FEATURE STATE:
Kubernetes v1.23 [beta]
KubernetesのPodセキュリティの標準 はPodに対して異なる分離レベルを定義します。
これらの標準によって、Podの動作をどのように制限したいかを、明確かつ一貫した方法で定義することができます。
ベータ版機能として、KubernetesはPodSecurityPolicy の後継である組み込みの Pod Security アドミッションコントローラー を提供しています。
Podセキュリティの制限は、Pod作成時に名前空間 レベルで適用されます。
備考: PodSecurityPolicy APIは非推奨であり、v1.25でKubernetesから
削除 される予定です。
PodSecurityアドミッションプラグインの有効化v1.23において、PodSecurityのフィーチャーゲート はベータ版の機能で、デフォルトで有効化されています。
v1.22において、PodSecurityのフィーチャーゲート はアルファ版の機能で、組み込みのアドミッションプラグインを使用するには、kube-apiserverで有効にする必要があります。
--feature-gates= "...,PodSecurity=true"
代替案:PodSecurityアドミッションwebhookのインストール クラスターがv1.22より古い、あるいはPodSecurity機能を有効にできないなどの理由で、ビルトインのPodSecurityアドミッションプラグインが使えない環境では、PodSecurityはアドミッションロジックはベータ版のvalidating admission webhook としても提供されています。
ビルド前のコンテナイメージ、証明書生成スクリプト、マニフェストの例は、https://git.k8s.io/pod-security-admission/webhook で入手可能です。
インストール方法:
git clone git@github.com:kubernetes/pod-security-admission.git
cd pod-security-admission/webhook
make certs
kubectl apply -k .
備考: 生成された証明書の有効期限は2年間です。有効期限が切れる前に、証明書を再生成するか、内蔵のアドミッションプラグインを使用してWebhookを削除してください。Podのセキュリティレベル Podのセキュリティアドミッションは、PodのSecurity Context とその他の関連フィールドに、Podセキュリティの標準 で定義された3つのレベル、privileged、baseline、restrictedに従って要件を設定するものです。
これらの要件の詳細については、Podセキュリティの標準 のページを参照してください。
Podの名前空間に対するセキュリティアドミッションラベル この機能を有効にするか、Webhookをインストールすると、名前空間を設定して、各名前空間でPodセキュリティに使用したいadmission controlモードを定義できます。
Kubernetesは、名前空間に使用したい定義済みのPodセキュリティの標準レベルのいずれかを適用するために設定できるラベル のセットを用意しています。
選択したラベルは、以下のように違反の可能性が検出された場合にコントロールプレーン が取るアクションを定義します。
Podのセキュリティアドミッションのモード モード 説明 enforce ポリシーに違反した場合、Podは拒否されます。 audit ポリシー違反は、監査ログ に記録されるイベントに監査アノテーションを追加するトリガーとなりますが、それ以外は許可されます。 warn ポリシーに違反した場合は、ユーザーへの警告がトリガーされますが、それ以外は許可されます。
名前空間は、任意のまたはすべてのモードを設定することができ、異なるモードに対して異なるレベルを設定することもできます。
各モードには、使用するポリシーを決定する2つのラベルがあります。
# モードごとのレベルラベルは、そのモードに適用するポリシーレベルを示す。
#
# MODEは`enforce`、`audit`、`warn`のいずれかでなければならない。
# LEVELは`privileged`、`baseline`、`restricted`のいずれかでなければならない。
pod-security.kubernetes.io/<MODE> : <LEVEL>
# オプション: モードごとのバージョンラベルは、Kubernetesのマイナーバージョンに同梱される
# バージョンにポリシーを固定するために使用できる(例えばv1.35など)。
#
# MODEは`enforce`、`audit`、`warn`のいずれかでなければならない。
# VERSIONは有効なKubernetesのマイナーバージョンか`latest`でなければならない。
pod-security.kubernetes.io/<MODE>-version : <VERSION>
名前空間ラベルでのPodセキュリティの標準の適用 で使用例を確認できます。
WorkloadのリソースとPodテンプレート Podは、Deployment やJob のようなワークロードオブジェクト を作成することによって、しばしば間接的に生成されます。
ワークロードオブジェクトは_Pod template_を定義し、ワークロードリソースのコントローラー はそのテンプレートに基づきPodを作成します。
違反の早期発見を支援するために、auditモードとwarningモードは、ワークロードリソースに適用されます。
ただし、enforceモードはワークロードリソースには適用されず 、結果としてのPodオブジェクトにのみ適用されます。
適用除外(Exemption) Podセキュリティの施行から exemptions を定義することで、特定の名前空間に関連するポリシーのために禁止されていたPodの作成を許可することができます。
Exemptionはアドミッションコントローラーの設定 で静的に設定することができます。
Exemptionは明示的に列挙する必要があります。
Exemptionを満たしたリクエストは、アドミッションコントローラーによって 無視 されます(enforce、audit、warnのすべての動作がスキップされます)。Exemptionの次元は以下の通りです。
Usernames: 認証されていない(あるいは偽装された)ユーザー名を持つユーザーからの要求は無視されます。RuntimeClassNames: Podとワークロードリソース で指定された除外ランタイムクラス名は、無視されます。Namespaces: 除外された名前空間のPodとワークロードリソース は、無視されます。注意: ほとんどのPodは、
ワークロードリソース に対応してコントローラーが作成します。つまり、エンドユーザーを適用除外にするのはPodを直接作成する場合のみで、ワークロードリソースを作成する場合は適用除外になりません。
コントローラーサービスアカウント(
system:serviceaccount:kube-system:replicaset-controllerなど)は通常、除外してはいけません。そうした場合、対応するワークロードリソースを作成できるすべてのユーザーを暗黙的に除外してしまうためです。
以下のPodフィールドに対する更新は、ポリシーチェックの対象外となります。つまり、Podの更新要求がこれらのフィールドを変更するだけであれば、Podが現在のポリシーレベルに違反していても拒否されることはありません。
すべてのメタデータの更新(seccompまたはAppArmorアノテーションへの変更を除く )seccomp.security.alpha.kubernetes.io/pod(非推奨)container.seccomp.security.alpha.kubernetes.io/*(非推奨)container.apparmor.security.beta.kubernetes.io/* .spec.activeDeadlineSecondsに対する有効な更新.spec.tolerationsに対する有効な更新次の項目 3.9.5 - サービスアカウント KubernetesのServicesAccountオブジェクトについて学びます。
このページではKubernetesのServiceAccountオブジェクトについて説明し、どのようにサービスアカウントが機能するか、使用例、制限、代替手段、追加のガイダンスとなるリソースへのリンクを紹介します。
サービスアカウントとは? サービスアカウントは、Kubernetesにおいて、Kubernetesクラスター内で固有のアイデンティティを提供する人間以外のアカウントの一種です。
アプリケーションPod、システムコンポーネント、およびクラスター内外のエンティティは、特定のServiceAccountの認証情報を使用してそのServiceAccountとして識別できます。
このアイデンティティは、APIサーバーへの認証やアイデンティティベースのセキュリティポリシーの実装など、さまざまな状況で役立ちます。
サービスアカウントは、APIサーバー内のServiceAccountオブジェクトとして存在します。
サービスアカウントには次の特性があります:
Namespaced: 各サービスアカウントはKubernetesのnamespace にバインドされます。
各namespaceは作成時にdefault ServiceAccount
Lightweight: サービスアカウントはクラスター内に存在し、Kubernetes APIで定義されています。
特定のタスクを有効にするためにサービスアカウントを素早く作成できます。
Portable: 複雑なコンテナ化されたワークロードの構成バンドルには、システムのコンポーネントのサービスアカウント定義が含まれる場合があります。
サービスアカウントの軽量性と名前空間内のアイデンティティは、構成をポータブルにします。
サービスアカウントは、クラスター内の認証された人間のユーザーであるユーザーアカウントとは異なります。
デフォルトでは、KubernetesのAPIサーバーにユーザーアカウントは存在しません。代わりに、APIサーバーはユーザーのアイデンティティを不透明なデータとして扱います。
複数の方法を使用して、ユーザーアカウントとして認証できます。
一部のKubernetesディストリビューションでは、APIサーバーでユーザーアカウントを表すカスタム拡張APIが追加されることがあります。
サービスアカウントとユーザーの比較 説明 ServiceAccount ユーザーまたはグループ ロケーション Kubernetes API (ServiceAccountオブジェクト) 外部 アクセス制御 Kubernetes RBACまたはその他の認可メカニズム Kubernetes RBACまたはその他のアイデンティティおよびアクセス管理メカニズム 使用目的 ワークロード、自動化 人間
デフォルトのサービスアカウント クラスターを作成すると、Kubernetesはクラスター内の各Namespaceに対してdefaultという名前のServiceAccountオブジェクトを自動的に作成します。
各Namespaceのdefaultサービスアカウントは、ロールベースのアクセス制御(RBAC)が有効になっている場合、Kubernetesがすべての認証されたプリンシパルに付与するデフォルトのAPI検出権限 以外の権限をデフォルトで取得しません。
Namespace内のdefault ServiceAccountオブジェクトを削除すると、コントロールプレーン が新しいServiceAccountオブジェクトを作成します。
NamespaceにPodをデプロイし、Podに手動でServiceAccountを割り当て ない場合、KubernetesはそのNamespaceのdefault ServiceAccountをPodに割り当てます。
Kubernetesサービスアカウントの使用例 一般的なガイドラインとして、次のシナリオでサービスアカウントを使用できます:
PodがKubernetes APIサーバーと通信する必要がある場合、例えば次のような場合です:Secretに保存されている機密情報への読み取り専用アクセスを提供します。 Namespaceをまたいだアクセス を許可します。例えば、example NamespaceのPodがkube-node-lease NamespaceのLeaseオブジェクトを読み取り、一覧、監視することを許可します。 Podが外部のサービスと通信する必要がある場合。例えば、ワークロードのPodには商用クラウドAPIのアイデンティティが必要であり、商用プロバイダーは適切な信頼関係の構成を許可する場合です。 imagePullSecretを使用してプライベートイメージレジストリに認証する外部サービスがKubernetes APIサーバーと通信する必要がある場合。例えば、CI/CDパイプラインの一部としてクラスターに認証する必要がある場合です。 クラスター内でサードパーティのセキュリティソフトウェアを使用する場合。さまざまなPodのServiceAccountアイデンティティを使用してこれらのPodを異なるコンテキストにグループ化します。 サービスアカウントの使用方法 Kubernetesサービスアカウントを使用するには、次の手順を実行します:
kubectlなどのKubernetesクライアントを使用してServiceAccountオブジェクトを作成するか、オブジェクトを定義するマニフェストを使用します。
RBAC などの認可メカニズムを使用してServiceAccountオブジェクトに権限を付与します。
Podの作成時にServiceAccountオブジェクトをPodに割り当てます。
外部サービスからのアイデンティティを使用している場合は、ServiceAccountトークンを取得 し、そのサービスから使用します。
詳細な手順については、PodにServiceAccountを割り当てる を参照してください。
ServiceAccountに権限を付与する 各ServiceAccountに必要な最小限の権限を付与するために、Kubernetesビルトインのロールベースのアクセス制御(RBAC) メカニズムを使用できます。
ServiceAccountにアクセスを付与するロール を作成し、そのロールをServiceAccountにバインド します。
RBACを使用すると、ServiceAccountの権限が最小限になるように定義できます。
PodがそのServiceAccountを使用している場合、そのPodは正しく機能するために必要な権限以上の権限を取得しません。
詳細な手順については、ServiceAccount権限 を参照してください。
ServiceAccountを使用したNamespace間のアクセス RBACを使用して、クラスターの異なるNamespaceにあるリソースに対して別のNamespaceのServiceAccountがアクションを実行できるようにすることができます。
例えば、dev NamespaceにサービスアカウントとPodがあり、そのPodがmaintenance Namespaceで実行されているJobを見る必要がある場合を考えてみましょう。
Jobオブジェクトをリストする権限を付与するRoleオブジェクトを作成できます。
次に、そのRoleをmaintenance NamespaceのServiceAccountオブジェクトにバインドするRoleBindingオブジェクトを作成します。
そうすることで、dev NamespaceのPodは、そのServiceAccountを使用してmaintenance NamespaceのJobオブジェクトをリストできます。
PodにServiceAccountを割り当てる ServiceAccountをPodに割り当てるには、Podの仕様にあるspec.serviceAccountNameフィールドを設定します。
Kubernetesは、そのServiceAccountの認証情報をPodに自動的に提供します。
v1.22以降では、KubernetesはTokenRequest APIを使用して有効期間が短く自動的にローテーションされる トークンを取得し、そのトークンを投影ボリューム としてPodにマウントします。
デフォルトではKubernetesは、ServiceAccountがdefault ServiceAccountか指定したカスタムServiceAccountであるかに関わらず、PodにそのServiceAccountの認証情報を提供します。
Kubernetesが指定されたServiceAccountまたはdefault ServiceAccountの認証情報を自動的に注入しないようにするには、Podの使用にあるautomountServiceAccountTokenフィールドをfalseに設定します。
1.22より前のバージョンでは、Kubernetesは有効期間の長い静的なトークンをSecretとしてPodに提供します。
ServiceAccount認証情報の手動取得 ServiceAccountを標準以外の場所にマウントするための認証情報、またはAPIサーバー以外の対象向けの認証情報が必要な場合は、次のいずれかの方法を使用します:
TokenRequest API
(推奨): 独自のアプリケーションコード から短期間のサービスアカウントトークンをリクエストします。
トークンは自動的に期限切れになり、期限切れ時にローテーションできます。
Kubernetesに対応していないレガシーアプリケーションがある場合、同じPod内のサイドカーコンテナを使用してこれらのトークンを取得し、アプリケーションワークロードで使用できるようにすることができます。トークン投影ボリューム
(推奨): Kubernetes v1.20以降では、Podの仕様を使用して、kubeletにサービスアカウントトークンを投影ボリュームとしてPodに追加するように指示します。
投影トークンは自動的に期限切れになり、kubeletはトークンが期限切れになる前にトークンをローテーションします。サービスアカウントトークンシークレット (Kubernetes v1.24からv1.26ではデフォルトで有効)
(非推奨): サービスアカウントトークンをKubernetes SecretとしてPodにマウントできます。
これらのトークンは期限切れになることも、ローテーションされることもありません。
v1.24以前のバージョンでは、サービスアカウントごとに永続的なトークンが自動的に作成されていました。
この方法は、静的で有効期間の長い認証情報に関するリスクがあるため、特に大規模な環境では推奨されなくなりました。
LegacyServiceAccountTokenNoAutoGenerationフィーチャーゲート により、Kubernetesが指定されたServiceAccountに対してこれらのトークンを自動的に作成するのを防止できました。
このフィーチャーゲートはGAステータスに昇格したため、v1.27では削除されました。
無期限のサービスアカウントトークンを手動で作成することは引き続き可能ですが、セキュリティ上の影響を考慮する必要があります。備考: Kubernetesクラスターの外部で実行されるアプリケーションの場合は、Secretに保存される有効期間の長いServiceAccountトークンの作成を検討するかもしれません。
これにより認証が可能になりますが、Kubernetesプロジェクトではこのアプローチを避けることを推奨しています。
長期間有効なBearerトークンは、一度漏洩するとトークンが悪用される可能性があるため、セキュリティリスクとなります。
代わりとなる手段を検討してください。
例えば、外部アプリケーションは、十分に保護された秘密鍵 と 証明書を使用して認証するか、独自に実装したWebhook認証 などのカスタムメカニズムを使用して認証することもできます。
また、TokenRequestを使用して外部アプリケーションのために有効期間の短いトークンを取得することもできます。
シークレットへのアクセスを制限する Kubernetesは、ServiceAccountに追加できるkubernetes.io/enforce-mountable-secretsというアノテーションを提供しています。
このアノテーションを適用すると、ServiceAccountのシークレットは指定された種類のリソースにのみマウントできるため、クラスターのセキュリティ体制が強化されます。
マニフェストを使用してServiceAccountにアノテーションを追加できます:
apiVersion : v1
kind : ServiceAccount
metadata :
annotations :
kubernetes.io/enforce-mountable-secrets : "true"
name : my-serviceaccount
namespace : my-namespace
このアノテーションが"true"に設定されている場合、Kubernetesコントロールプレーンは、このServiceAccountのSecretが特定のマウント制限の対象であることを確認します。
Pod内のボリュームとしてマウントされる各Secretの名前は、PodのServiceAccountのsecretsフィールドに表示される必要があります。 Pod内のenvFromを使用して参照される各Secretの名前は、PodのServiceAccountのsecretsフィールドに表示される必要があります。 Pod内のimagePullSecretsを使用して参照される各Secretの名前は、PodのServiceAccountのsecretsフィールドに表示される必要があります。 これらの制限を理解して適用することで、クラスター管理者はより厳格なセキュリティプロファイルを維持し、適切なリソースのみがシークレットにアクセスできるようにします。
サービスアカウント認証情報の認証 ServiceAccountは、Kubernetes APIサーバーおよび信頼関係が存在する他のシステムに対して、署名されたJSON Web Tokens (JWTs) を使用して認証を行います。
トークンの発行方法(TokenRequestを使用して時間制限付きで発行されるか、Secretを使用して従来のメカニズムで発行されるか)に応じて、ServiceAccountトークンには有効期限、オーディエンス、トークンが有効になる 時間などが含まれる場合があります。
ServiceAccountとして機能しているクライアントがKubernetes APIサーバーと通信しようとすると、クライアントはHTTPリクエストにAuthorization: Bearer <token>ヘッダーを含めます。
APIサーバーは、次のようにしてBearerトークンの有効性を確認します:
トークンの署名を確認します。 トークンが期限切れかどうかを確認します。 トークン要求内のオブジェクト参照が現在有効かどうかを確認します。 トークンが現在有効かどうかを確認します。 オーディエンス要求を確認します。 TokenRequest APIは、ServiceAccountに バインドされたトークン を生成します。
このバインディングは、そのServiceAccountとして機能しているクライアント(Podなど)のライフタイムにリンクされています。
バインドされたPodのサービスアカウントトークンのJWTスキーマとペイロードの例については、トークンボリューム投影 を参照してください。
TokenRequest APIを使用して発行されたトークンの場合、APIサーバーは、そのオブジェクトの ユニークID と一致する、ServiceAccountを使用している特定のオブジェクト参照がまだ存在するかどうかも確認します。
PodにSecretとしてマウントされているレガシートークンの場合、APIサーバーはトークンをSecretと照合します。
認証プロセスの詳細については、認証 を参照してください。
独自のコードでサービスアカウントの認証情報を認証する Kubernetesサービスアカウントの認証情報の検証が必要なサービスがある場合、次の方法を使用できます:
Kubernetesプロジェクトでは、TokenReview APIの使用を推奨しており、この方法ではSecret、ServiceAccount、Pod、NodeなどのAPIオブジェクトにバインドされたトークンが削除されると、そのトークンが無効になります。
例えば、投影されたServiceAccountトークンを含むPodを削除すると、クラスターはただちにそのトークンを無効にし、TokenReviewはただちに失敗します。
代わりにOIDC認証を使用する場合、トークンが有効期限のタイムスタンプに達するまで、クライアントはトークンを有効なものとして扱い続けます。
アプリケーションでは、受け入れるオーディエンスを常に定義し、トークンのオーディエンスがアプリケーションが期待するオーディエンスと一致するかどうかを確認する必要があります。
これにより、トークンのスコープが最小限に抑えられ、アプリケーション内でのみ使用でき、他の場所では使用できないようになります。
代替案 別のメカニズムを使用して独自のトークンを発行し、Webhookトークン認証 を使用して、独自の検証サービスを使用してBearerトークンを検証します。 Podに独自のアイデンティティを提供します。 サービスアカウントトークンを使用せずに、クラスター外部からAPIサーバーに認証します: イメージレジストリから認証情報を取得するようにkubeletを構成する .Device Pluginを使用して仮想Trusted Platform Module (TPM)にアクセスし、秘密鍵を使用した認証を許可します。 次の項目 3.9.6 - Podセキュリティポリシー 削除された機能 PodSecurityPolicyは、Kubernetes v1.21で
非推奨 となり、Kubernetes v1.25で削除されました。
PodSecurityPolicyの代わりに、次のいずれか、または両方を使用して、Podに対して同様の制限を適用できます:
移行ガイドについては、PodSecurityPolicyからビルトインのPodセキュリティアドミッションコントローラーへの移行 を参照してください。
このAPIの削除に関する詳細は、PodSecurityPolicyの非推奨: 過去・現在・未来 を参照してください。
Kubernetes v1.35を使用していない場合は、使用中のKubernetesバージョンのドキュメントを参照してください。
3.9.7 - Linuxノードのセキュリティ このページでは、Linuxオペレーティングシステムに固有のセキュリティ上の考慮事項とベストプラクティスについて説明します。
ノード上のSecretデータの保護 Linuxノードでは、メモリベースのボリューム(secretmedium: Memoryを指定したemptyDirtmpfsファイルシステムで実装されています。
スワップが設定されており、古いLinuxカーネルを使用している場合(または現在のカーネルで、Kubernetesがサポートしていない設定を使用している場合)、メモリ ベースのボリュームのデータが永続ストレージに書き込まれる可能性があります。
Linuxカーネルはバージョン6.3から公式にnoswapオプションをサポートしているため、ノードでスワップが有効になっている場合は、使用するカーネルバージョンを6.3以降にするか、バックポートによりnoswapオプションをサポートするバージョンを使用することが推奨されます。
詳細については、スワップメモリ管理 を参照してください。
3.9.8 - Windowsノードのセキュリティ このページでは、Windowsオペレーティングシステムに特有のセキュリティ上の考慮事項とベストプラクティスについて説明します。
Windowsでは、Secretデータがノードのローカルストレージに平文で書き込まれます(Linuxのtmpfs、インメモリファイルシステムとは異なります)。
クラスターオペレーターは、次の両方の追加対策を講じる必要があります:
ファイルACLを使用して、Secretのファイル配置場所を保護する。 BitLocker を使用して、ボリュームレベルの暗号化を適用する。コンテナユーザー RunAsUsername は、WindowsのPodまたはコンテナに対して、特定のユーザーとしてコンテナプロセスを実行するために指定できます。
これは、おおよそRunAsUser と同等です。
Windowsコンテナには、ContainerUserとContainerAdministratorという2つのデフォルトのユーザーアカウントが用意されています。
これら2つのユーザーアカウントの違いについては、Microsoftの Secure Windows containers ドキュメント内のContainerAdminとContainerUserのユーザーアカウントを使うタイミング に記載されています。
ローカルユーザーは、コンテナのビルドプロセス中にコンテナイメージに追加できます。
Windowsコンテナは、グループ管理サービスアカウント を利用することで、Active DirectoryのIDとして実行することもできます
Podレベルのセキュリティ分離 Linux固有のPodセキュリティコンテキスト機構(SELinux、AppArmor、Seccomp、カスタムPOSIXケーパビリティなど)は、Windowsノードではサポートされていません。
特権コンテナは、Windowsではサポートされていません 。
代わりに、WindowsではHostProcessコンテナ を使用することで、Linuxの特権コンテナが実行する多くのタスクを実行できます。
3.9.9 - Kubernetes APIへのアクセスコントロール このページではKubernetes APIへのアクセスコントロールの概要を説明します。
Kubernetes API にはkubectlやクライアントライブラリ、あるいはRESTリクエストを用いてアクセスします。
APIアクセスには、人間のユーザーとKubernetesサービスアカウント の両方が認証可能です。
リクエストがAPIに到達すると、次の図のようにいくつかの段階を経ます。
トランスポート層のセキュリティ 一般的なKubernetesクラスターでは、APIはTLSで保護された443番ポートで提供されます。
APIサーバーは証明書を提示します。
この証明書は、プライベート認証局(CA)を用いて署名することも、一般に認知されているCAと連携した公開鍵基盤に基づき署名することも可能です。
クラスターがプライベート認証局を使用している場合、接続を信頼し、傍受されていないと確信できるように、クライアント上の~/.kube/configに設定されたそのCA証明書のコピーが必要です。
クライアントは、この段階でTLSクライアント証明書を提示することができます。
認証 TLSが確立されると、HTTPリクエストは認証のステップに移行します。
これは図中のステップ1 に該当します。
クラスター作成スクリプトまたはクラスター管理者は、1つまたは複数のAuthenticatorモジュールを実行するようにAPIサーバーを設定します。
Authenticatorについては、認証 で詳しく説明されています。
認証ステップへの入力はHTTPリクエスト全体ですが、通常はヘッダとクライアント証明書の両方、またはどちらかを調べます。
認証モジュールには、クライアント証明書、パスワード、プレーントークン、ブートストラップトークン、JSON Web Tokens(サービスアカウントに使用)などがあります。
複数の認証モジュールを指定することができ、その場合、1つの認証モジュールが成功するまで、それぞれを順番に試行します。
認証できない場合、HTTPステータスコード401で拒否されます。
そうでなければ、ユーザーは特定のusernameとして認証され、そのユーザー名は後続のステップでの判断に使用できるようになります。
また、ユーザーのグループメンバーシップを提供する認証機関と、提供しない認証機関があります。
Kubernetesはアクセスコントロールの決定やリクエストログにユーザー名を使用しますが、Userオブジェクトを持たず、ユーザー名やその他のユーザーに関する情報をAPIはに保存しません。
認可 リクエストが特定のユーザーからのものであると認証された後、そのリクエストは認可される必要があります。
これは図のステップ2 に該当します。
リクエストには、リクエスト者のユーザー名、リクエストされたアクション、そのアクションによって影響を受けるオブジェクトを含める必要があります。
既存のポリシーで、ユーザーが要求されたアクションを完了するための権限を持っていると宣言されている場合、リクエストは承認されます。
例えば、Bobが以下のようなポリシーを持っている場合、彼は名前空間projectCaribou内のPodのみを読むことができます。
{
"apiVersion" : "abac.authorization.kubernetes.io/v1beta1" ,
"kind" : "Policy" ,
"spec" : {
"user" : "bob" ,
"namespace" : "projectCaribou" ,
"resource" : "pods" ,
"readonly" : true
}
}
Bobが次のようなリクエストをした場合、Bobは名前空間projectCaribouのオブジェクトを読むことが許可されているので、このリクエストは認可されます。
{
"apiVersion" : "authorization.k8s.io/v1beta1" ,
"kind" : "SubjectAccessReview" ,
"spec" : {
"resourceAttributes" : {
"namespace" : "projectCaribou" ,
"verb" : "get" ,
"group" : "unicorn.example.org" ,
"resource" : "pods"
}
}
}
Bobが名前空間projectCaribouのオブジェクトに書き込み(createまたはupdate)のリクエストをした場合、承認は拒否されます。
また、もしBobがprojectFishのような別の名前空間にあるオブジェクトを読み込む(get)リクエストをした場合も、承認は拒否されます。
Kubernetesの認可では、組織全体またはクラウドプロバイダー全体の既存のアクセスコントロールシステムと対話するために、共通のREST属性を使用する必要があります。
これらのコントロールシステムは、Kubernetes API以外のAPIとやり取りする可能性があるため、REST形式を使用することが重要です。
Kubernetesは、ABACモード、RBACモード、Webhookモードなど、複数の認可モジュールをサポートしています。
管理者はクラスターを作成する際に、APIサーバーで使用する認証モジュールを設定します。
複数の認可モジュールが設定されている場合、Kubernetesは各モジュールをチェックし、いずれかのモジュールがリクエストを認可した場合、リクエストを続行することができます。
すべてのモジュールがリクエストを拒否した場合、リクエストは拒否されます(HTTPステータスコード403)。
サポートされている認可モジュールを使用したポリシー作成の詳細を含む、Kubernetesの認可については、認可 を参照してください。
アドミッションコントロール アドミッションコントロールモジュールは、リクエストを変更したり拒否したりすることができるソフトウェアモジュールです。
認可モジュールが利用できる属性に加えて、アドミッションコントロールモジュールは、作成または修正されるオブジェクトのコンテンツにアクセスすることができます。
アドミッションコントローラーは、オブジェクトの作成、変更、削除、または接続(プロキシ)を行うリクエストに対して動作します。
アドミッションコントローラーは、単にオブジェクトを読み取るだけのリクエストには動作しません。
複数のアドミッションコントローラーが設定されている場合は、順番に呼び出されます。
これは図中のステップ3 に該当します。
認証・認可モジュールとは異なり、いずれかのアドミッションコントローラーモジュールが拒否した場合、リクエストは即座に拒否されます。
オブジェクトを拒否するだけでなく、アドミッションコントローラーは、フィールドに複雑なデフォルトを設定することもできます。
利用可能なアドミッションコントロールモジュールは、アドミッションコントローラー に記載されています。
リクエストがすべてのアドミッションコントローラーを通過すると、対応するAPIオブジェクトの検証ルーチンを使って検証され、オブジェクトストアに書き込まれます(図のステップ4 に該当します)。
監査 Kubernetesの監査は、クラスター内の一連のアクションを文書化した、セキュリティに関連する時系列の記録を提供します。
クラスターは、ユーザー、Kubernetes APIを使用するアプリケーション、およびコントロールプレーン自身によって生成されるアクティビティを監査します。
詳しくは監査 をご覧ください。
APIサーバーのIPとポート これまでの説明は、APIサーバーのセキュアポートに送信されるリクエストに適用されます(典型的なケース)。
APIサーバーは、実際には2つのポートでサービスを提供することができます。
デフォルトでは、Kubernetes APIサーバーは2つのポートでHTTPを提供します。
localhostポート:
テストとブートストラップ用で、マスターノードの他のコンポーネント(スケジューラー、コントローラーマネージャー)がAPIと通信するためのものです。 TLSは使用しません。 デフォルトポートは8080です。 デフォルトのIPはlocalhostですが、--insecure-bind-addressフラグで変更することができます。 リクエストは認証と認可のモジュールをバイパス します。 リクエストは、アドミッションコントロールモジュールによって処理されます。 ホストにアクセスする必要があるため、保護されています。 “セキュアポート”:
可能な限りこちらを使用してください。 TLSを使用します。証明書は--tls-cert-fileフラグで、鍵は--tls-private-key-fileフラグで設定します。 デフォルトポートは6443です。--secure-portフラグで変更することができます。 デフォルトのIPは、最初の非localhostのネットワークインターフェースです。--bind-addressフラグで変更することができます。 リクエストは、認証・認可モジュールによって処理されます。 リクエストは、アドミッションコントロールモジュールによって処理されます。 認証・認可モジュールが実行されます。 次の項目 認証、認可、APIアクセスコントロールに関する詳しいドキュメントはこちらをご覧ください。
以下についても知ることができます。
PodがAPIクレデンシャルを取得するためにSecrets を使用する方法について。 3.9.10 - ロールベースアクセスコントロールのグッドプラクティス クラスター運用者向けの適切なRBAC設計の原則と実践方法
Kubernetes RBAC は、クラスターユーザーやワークロードがその役割を果たすために、必要なリソースへのアクセスしかできないようにするための重要なセキュリティコントロールです。
クラスターユーザーの権限を設計する際には、クラスター管理者が特権昇格が発生しうる領域を理解し、セキュリティインシデントを引き起こすリスクを減らすことが重要です。
ここで説明するグッドプラクティスは、一般的なRBACドキュメント と併せて読むことを推奨します。
一般的なグッドプラクティス 最小特権の原則 理想的には、ユーザーやサービスには最小限の権限のみ割り当てるべきです。
権限は、その操作に明示的に必要なものだけを使用するべきです。
クラスターによって異なりますが、一般的なルールは次のとおりです:
可能であれば、namespaceレベルで権限を割り当てます。
特定のnamespace内でのみユーザーに権限を与えるため、ClusterRoleBindingsではなくRoleBindingsを使用します。 可能であれば、ワイルドカード権限を提供しないでください。特に全てのリソースへの権限を提供しないでください。
Kubernetesは拡張可能なシステムであるため、ワイルドカードアクセスを提供すると、クラスター内に現存するすべてオブジェクトタイプだけでなく、将来作成されるすべてのオブジェクトタイプにも権限が与えられてしまいます。 管理者は特に必要でない限り、cluster-adminアカウントを使用すべきではありません。
権限の低いアカウントに偽装権限 を提供することで、クラスターリソースの誤った変更を回避できます。 system:mastersグループにユーザーを追加しないでください。
このグループのメンバーであるユーザーは、すべてのRBAC権限をバイパスし、常に制限のないスーパーユーザーアクセス権限を持ちます。この権限はRoleBindingsまたはClusterRoleBindingsを削除しても取り消すことができません。
余談ですが、クラスターが認可ウェブフックを使用している場合、このグループのメンバーシップもそのウェブフックをバイパスします(そのグループのメンバーであるユーザーからのリクエストがウェブフックに送信されることはありません)特権トークンの配布を最小限に抑える 理想的には、Podには強力な権限が付与されたサービスアカウントを割り当てられるべきではありません。
(例えば、特権昇格リスク にリストされている権限)。
強力な権限が必要な場合は、次のプラクティスを検討してください:
強力なPodを実行するノードの数を制限します。
実行する任意のDaemonSetが必要であることを確認し、コンテナエスケープの影響範囲を制限するために最小限の権限で実行されるようにします。 信頼できない、または公開されたPodと強力なPodを一緒に実行しないようにする。
信頼できない、または信頼度の低いPodと一緒に実行されないようにするために、TaintsとToleration 、NodeAffinity 、またはPodAntiAffinity の使用を検討してください。
信頼性の低いPodが制限付き Podセキュリティ標準を満たしていない場合は、特に注意してください。 強化 Kubernetesは、すべてのクラスターに必要とは限らないアクセスをデフォルトで提供します。
デフォルトで提供されるRBAC権限を確認することで、セキュリティを強化する機会が得られます。
一般的に、system:アカウントに提供される権限を変更するべきではありませんが、クラスター権限を強化するためのオプションがいくつか存在します:
system:unauthenticatedグループのバインディングを確認し、可能であれば削除します。
これにより、ネットワークレベルでAPIサーバーに接続できるすべてのユーザーにアクセスが許可されます。automountServiceAccountToken: falseを設定することで、サービスアカウントトークンのデフォルトの自動マウントを回避します。
詳細については、デフォルトのサービスアカウントトークンの使用 を参照してください。
Podにこの値を設定すると、サービスアカウント設定が上書きされ、サービスアカウントトークンを必要とするワークロードは引き続きそれをマウントできます。定期的なレビュー 冗長なエントリや特権昇格の可能性がないか、定期的にKubernetes RBAC設定を確認することが不可欠です。
攻撃者が削除されたユーザーと同じ名前のユーザーアカウントを作成できる場合、特にそのユーザーに割り当てられた権限を自動的に継承できます。
Kubernetes RBAC - 特権昇格リスク Kubernetes RBAC内には、ユーザーやサービスアカウントがクラスター内で特権昇格したり、クラスター外のシステムに影響を与えたりすることができる権限がいくつかあります。
このセクションは、クラスター運用者が意図した以上のクラスターへのアクセスを誤って許可しないようにするために注意を払うべき領域を示すことを目的としています。
Secretのリスト 一般に、Secretに対するgetアクセスを許可すると、ユーザーがその内容を読むことができることは明らかです。
また、listおよびwatchアクセスも、ユーザーがSecretの内容を読むことを事実上可能にします。
例えば、Listレスポンスが返却される(例: kubectl get secrets -A -o yaml)と、そのレスポンスにはすべてのSecretの内容が含まれます。
ワークロードの作成 Namespace内でワークロード(PodやPodを管理するワークロードリソース )を作成する権限により、そのnamespace内のSecret、ConfigMap、PersistentVolumeなどのPodにマウントできる他の多くのリソースへのアクセスが暗黙的に許可されます。
さらに、Podは任意のServiceAccount として実行できるため、ワークロードを作成する権限もまた、そのnamespace内の任意のサービスアカウントのAPIアクセスレベルを暗黙的に許可します。
特権付きPodを実行できるユーザーは、そのアクセス権を使用してノードへのアクセスを取得し、さらに特権昇格させる可能性があります。
適切に安全で隔離されたPodを作成できるユーザーや他のプリンシパルを完全に信頼していない場合は、ベースライン または制限付き Podセキュリティ標準を強制する必要があります。
Podのセキュリティアドミッション や他の(サードパーティ)メカニズムを使用して、その強制を実装できます。
これらの理由から、namespaceは異なる信頼レベルやテナンシーを必要とするリソースを分離するために使用されるべきです。
最小特権 の原則に従い、最小限の権限セットを割り当てることがベストプラクティスとされていますが、namespace内の境界は弱いと考えるべきです。
永続ボリュームの作成 誰か、または何らかのアプリケーションが、任意のPersistentVolumeを作成する権限を持っている場合、そのアクセスにはhostPathボリュームの作成も含まれており、これはPodが関連づけられたノードの基盤となるホストファイルシステムにアクセスできることを意味します。
その権限を与えることはセキュリティリスクとなります。
ホストファイルシステムに制限のないアクセス権を持つコンテナが特権昇格する方法は数多くあり、これには他のコンテナからのデータの読み取りや、Kubeletなどのシステムサービスの資格情報の悪用が含まれます。
PersistentVolumeオブジェクトを作成する権限を許可するのは、次の場合に限定するべきです:
ユーザー(クラスター運用者)が、作業にこのアクセスを必要としており、かつ信頼できる場合。 自動プロビジョニングのために設定されたPersistentVolumeClaimに基づいてPersistentVolumeを作成するKubernetesコントロールコンポーネント。
これは通常、KubernetesプロバイダーまたはCSIドライバーのインストール時に設定されます。 永続ストレージへのアクセスが必要な場合、信頼できる管理者がPersistentVolumeを作成し、制約のあるユーザーはPersistentVolumeClaimを使用してそのストレージにアクセスするべきです。
ノードのproxyサブリソースへのアクセス ノードオブジェクトのプロキシサブリソースへのアクセス権を持つユーザーは、Kubelet APIに対する権限を持ち、権限を持つノード上のすべてのPodでコマンドを実行できます。
このアクセスは監査ログやアドミッションコントロールをバイパスするため、このリソースに権限を付与する際には注意が必要です。
Escalate動詞 一般的に、RBACシステムはユーザーが所有する権限以上のクラスターロールを作成できないようにします。
この例外はescalate動詞です。
RBACのドキュメント に記載されているように、この権限を持つユーザーは事実上特権昇格させることができます。
Bind動詞 escalate動詞と同様に、ユーザーにこの権限を付与すると、特権昇格に対するKubernetesビルトインの保護をバイパスし、ユーザーがすでに持っていない権限を持つロールへのバインディングを作成できるようになります。
Impersonate動詞 この動詞は、ユーザーがクラスター内の他のユーザーになりすまし、そのユーザーの権限を取得することを可能にします。
権限を付与する場合は、なりすましアカウントを介して過剰な権限を取得できないように注意する必要があります。
CSRと証明書の発行 CSR APIは、CSRに対するcreate権限とkubernetes.io/kube-apiserver-clientを署名者とするcertificatesigningrequests/approvalに対するupdate権限を持つユーザーが、クラスターに対して認証するための新しいクライアント証明書を作成できるようにします。
これらのクライアント証明書は、Kubernetesシステムコンポーネントの重複を含む任意の名前を持つことができます。
これにより、特権昇格が可能になります。
トークンリクエスト serviceaccounts/tokenに対するcreate権限を持つユーザーは、既存のサービスアカウント用のトークンを発行するためのTokenRequestsを作成できます。
アドミッションウェブフックの制御 validatingwebhookconfigurationsまたはmutatingwebhookconfigurationsを制御するユーザーは、クラスターに許可された任意のオブジェクトを読み取ることができるウェブフックを制御し、ウェブフックを変更する場合は許されたオブジェクトも変更できます。
Namespaceの変更 Namespaceオブジェクトにおいてpatch 操作を実行できるユーザーは(そのアクセス権を持つロールへのnamespace付きのRoleBindingを通じて)namespaceのラベルを変更できます。
Podのセキュリティアドミッションが使用されているクラスターでは、ユーザーは管理者が意図したより緩いポリシーをnamespaceに設定できる場合があります。
NetworkPolicyが使用されているクラスターでは、ユーザーは管理者が意図していないサービスへのアクセスを間接的に許可するラベルを設定できる場合があります。
Kubernetes RBAC - サービス拒否リスク オブジェクト作成によるサービス拒否 クラスター内のオブジェクトを作成する権限を持つユーザーは、etcd used by Kubernetes is vulnerable to OOM attack で議論されているように、オブジェクトのサイズや数に基づいてサービス拒否を引き起こすほど大きなオブジェクトを作成できる可能性があります。
これは、半信頼または信頼されていないユーザーにシステムへの限定的なアクセスが許可されている場合、特にマルチテナントクラスターに関係する可能性があります。
この問題を緩和するための1つのオプションとして、リソースクォータ を使用して作成可能なオブジェクトの量を制限することが考えられます。
次の項目 3.9.11 - Kubernetes Secretの適切な使用方法 クラスター管理者とアプリケーション開発者向けの適切なSecret管理の原則と実践方法。
Kubernetesでは、Secretは次のようなオブジェクトです。 パスワードやOAuthトークン、SSHキーのような機密の情報を保持します。
Secretは、機密情報の使用方法をより管理しやすくし、偶発的な漏洩のリスクを減らすことができます。Secretの値はbase64文字列としてエンコードされ、デフォルトでは暗号化されずに保存されますが、保存時に暗号化 するように設定することもできます。
Pod は、ボリュームマウントや環境変数など、さまざまな方法でSecretを参照できます。Secretは機密データ用に設計されており、ConfigMap は非機密データ用に設計されています。
以下の適切な使用方法は、クラスター管理者とアプリケーション開発者の両方を対象としています。
これらのガイドラインに従って、Secretオブジェクト内の機密情報のセキュリティを向上させ、Secretの効果的な管理を行ってください。
クラスター管理者 このセクションでは、クラスター管理者がクラスター内の機密情報のセキュリティを強化するために使用できる適切な方法を提供します。
データ保存時の暗号化を構成する デフォルトでは、Secretオブジェクトはetcd 内で暗号化されていない状態で保存されます。
etcd内のSecretデータを暗号化するように構成する必要があります。
手順については、機密データ保存時の暗号化 を参照してください。
Secretへの最小特権アクセスを構成する Kubernetesのロールベースアクセス制御 (RBAC) などのアクセス制御メカニズムを計画する際、Secretオブジェクトへのアクセスに関する以下のガイドラインを考慮してください。
また、RBACの適切な使用方法 の他のガイドラインにも従ってください。
コンポーネント : watchまたはlistアクセスを、最上位の特権を持つシステムレベルのコンポーネントのみに制限してください。コンポーネントの通常の動作が必要とする場合にのみ、Secretへのgetアクセスを許可してください。ユーザー : Secretへのget、watch、listアクセスを制限してください。etcdへのアクセスはクラスター管理者にのみ許可し、読み取り専用アクセスも許可してください。特定の注釈を持つSecretへのアクセスを制限するなど、より複雑なアクセス制御については、サードパーティの認証メカニズムを検討してください。
注意: Secretへのlistアクセスを暗黙的に許可すると、サブジェクトがSecretの内容を取得できるようになります。Secretを使用するPodを作成できるユーザーは、そのSecretの値も見ることができます。
クラスターのポリシーがユーザーにSecretを直接読むことを許可しない場合でも、同じユーザーがSecretを公開するPodを実行するアクセスを持つかもしれません。
このようなアクセスを持つユーザーによるSecretデータの意図的または偶発的な公開の影響を検出または制限することができます。
いくつかの推奨事項には以下があります:
短寿命のSecretを使用する 特定のイベントに対してアラートを出す監査ルールを実装する(例:単一ユーザーによる複数のSecretの同時読み取り) etcdの管理ポリシーを改善する 使用しなくなった場合には、etcdが使用する永続ストレージを削除するかシュレッダーで処理してください。
複数のetcdインスタンスがある場合、インスタンス間の通信を暗号化されたSSL/TLS通信に設定して、転送中のSecretデータを保護してください。
外部Secretへのアクセスを構成する 備考: このセクションでは、Kubernetesが必要とする機能を提供するサードパーティープロジェクトにリンクしています。これらのプロジェクトはアルファベット順に記載されていて、Kubernetesプロジェクトの作者は責任を持ちません。このリストにプロジェクトを追加するには、変更を提出する前に
content guide をお読みください。
詳細はこちら。 外部のSecretストアプロバイダーを使用して機密データをクラスターの外部に保存し、その情報にアクセスするようにPodを構成できます。
Kubernetes Secrets Store CSI Driver は、kubeletが外部ストアからSecretを取得し、データにアクセスすることを許可された特定のPodにSecretをボリュームとしてマウントするDaemonSetです。
サポートされているプロバイダーの一覧については、Secret Store CSI Driverのプロバイダー を参照してください。
開発者 このセクションでは、Kubernetesリソースの作成と展開時に機密データのセキュリティを向上させるための開発者向けの適切な使用方法を提供します。
特定のコンテナへのSecretアクセスを制限する Pod内で複数のコンテナを定義し、そのうち1つのコンテナだけがSecretへのアクセスを必要とする場合、他のコンテナがそのSecretにアクセスできないようにボリュームマウントや環境変数の設定を行ってください。
読み取り後にSecretデータを保護する アプリケーションは、環境変数やボリュームから機密情報を読み取った後も、その値を保護する必要があります。
例えば、アプリケーションは機密情報を平文でログに記録したり、信頼できない第三者に送信したりしないようにする必要があります。
Secretマニフェストの共有を避ける Secretをマニフェスト を介して設定し、秘密データをBase64でエンコードしている場合、このファイルを共有したりソースリポジトリにチェックインしたりすると、その秘密はマニフェストを読むことのできる全員に公開されます。
注意: Base64エンコードは暗号化方法ではなく、平文と同じく機密性を提供しません。3.9.12 - Kubernetes APIサーバーのバイパスリスク APIサーバーとその他のコンポーネントに関連するセキュリティアーキテクチャ情報
Kubernetes APIサーバーは、外部の関係者(ユーザーやサービス)がクラスターと対話するための主要なエントリポイントです。
この役割の一環として、APIサーバーには監査ログやアドミッションコントローラー など、いくつかの重要なセキュリティ制御が組み込まれています。
しかし、これらの制御をバイパスしてクラスターの設定やコンテンツを変更する方法があります。
このページでは、Kubernetes APIサーバーに組み込まれているセキュリティ制御をバイパスする方法について説明します。
これにより、クラスター運用者やセキュリティアーキテクトは、これらのバイパスが適切に制限されるようにできます。
Static Pod 各ノードのkubelet は、特定のディレクトリに保存されているマニフェストや、特定のURLから取得したマニフェストをクラスター内のstatic Pod
Static Podは、Kubernetes API内の他のオブジェクトへのアクセスが制限されています。
例えば、static PodにクラスターからSecretをマウントするように設定することはできません。
ただし、これらのPodは基盤となるノードからhostPathマウントを使用するなど、他のセキュリティ上機微な操作を行うことができます。
デフォルトでは、kubeletはミラーPod を作成し、static PodをKubernetes APIで参照できるようにします。
ただし、攻撃者がPod作成時に無効なNamespaceを指定した場合、Kubernetes APIで参照することはできず、影響を受けるホストにアクセスできるツールでのみ発見できます。
static Podがアドミッション制御に失敗した場合、kubeletはPodをAPIサーバーに登録しません。
ただし、Podはノード上で実行され続けます。
詳細については、kubeadm issue #1541 を参照してください。
緩和策 ノードでstatic Pod機能が必要な場合のみ、kubelet static Podマニフェスト機能を有効にします 。 ノードでstatic Pod機能を使用する場合、static PodマニフェストディレクトリまたはURLへのファイルシステムアクセスを必要なユーザーに制限します。 kubeletの設定パラメーターやファイルへのアクセスを制限し、攻撃者がstatic PodのパスやURLを設定できないようにします。 static Podのマニフェストとkubeletの設定ファイルをホストするディレクトリやwebストレージのロケーションへのすべてのアクセスを定期的に監査し、一元的にレポートします。 kubelet API kubeletは通常、クラスターのワーカーノードのTCPポート10250で公開されるHTTP APIを提供します。
APIは、使用しているKubernetesディストリビューションによっては、コントロールプレーンノードでも公開される場合があります。
APIに直接アクセスすると、ノード上で実行されているPodに関する情報や、これらのPodからのログの開示、およびノード上で実行されているすべてのコンテナ内でのコマンド実行が可能になります。
KubernetesクラスターユーザーがNodeオブジェクトのサブリソースにRBACアクセスを持つ場合、そのアクセスはkubelet APIと対話するための認可を提供します。
正確なアクセスは、kubelet認証 で詳しく説明されているように、付与されたサブリソースアクセスに依存します。
kubelet APIに直接アクセスすると、アドミッション制御の対象にならず、Kubernetesの監査ログにも記録されません。
このAPIに直接アクセスできる攻撃者は、特定のアクションを検出または防止する制御をバイパスできる可能性があります。
kubelet APIは、さまざまな方法でリクエストを認証するように構成できます。
デフォルトでは、kubeletの設定は匿名アクセスを許可します。
ほとんどのKubernetesプロバイダーは、デフォルトをwebhookおよび証明書認証を使用するように変更します。
これにより、コントロールプレーンは呼び出し元がnodes APIリソースまたはサブリソースにアクセスする権限があることを確認できます。
デフォルトの匿名アクセスでは、コントロールプレーンでこのアサーションは行われません。
緩和策 RBAC などのメカニズムを使用して、nodes APIオブジェクトのサブリソースへのアクセスを制限します。
監視サービスなど、必要な場合にのみこのアクセスを許可してください。kubeletのポートへのアクセスを制限します。
指定された信頼できるIPアドレス範囲からのアクセスのみを許可します。 kubelet認証 が、webhookまたは証明書モードに設定されていることを確認します。認証されていない「読み取り専用」Kubeletポートがクラスターで有効になっていないことを確認します。 etcd API Kubernetesクラスターは、etcdをデータストアとして使用します。
etcdサービスは、TCPポート2379でリッスンします。
アクセスが必要なクライアントは、Kubernetes APIサーバーと使用しているバックアップツールのみです。
このAPIに直接アクセスすると、クラスター内のデータの開示または変更が可能になります。
etcd APIへのアクセスは通常、クライアント証明書認証によって管理されます。
etcdが信頼する認証局によって発行された証明書は、etcd内に保存されているデータへのフルアクセスを許可します。
etcdに直接アクセスすると、Kubernetesのアドミッション制御の対象にならず、Kubernetesの監査ログにも記録されません。
APIサーバーのetcdクライアント証明書の秘密鍵を読み取る権限を持つ(または新しい信頼できるクライアント証明書を作成できる)攻撃者は、クラスターのシークレットにアクセスしたり、アクセスルールを変更したりすることで、クラスター管理者権限を取得できます。
KubernetesのRBAC特権を昇格させなくとも、etcdを変更できる攻撃者は、任意のAPIオブジェクトを取得したり、クラスター内に新しいワークロードを作成したりできます。
多くのKubernetesプロバイダーは、相互TLS(クライアントとサーバーの両方が認証のために互いの証明書を検証)を使用するようにetcdを構成します。
etcd APIには広く受け入れられた認可の実装はありませんが、機能は存在します。
認可モデルが存在しないため、etcdへのクライアントアクセス権限を持つ証明書であれば、etcdへのフルアクセスを取得できます。
通常、ヘルスチェックのみに使用されるetcdクライアント証明書も、完全な読み取りおよび書き込みアクセスを付与できます。
緩和策 etcdに信頼されている認証局は、そのサービスへの認証目的のみに使用されることを確認してください。 etcdのサーバー証明書の秘密鍵、およびAPIサーバーのクライアント証明書と秘密鍵へのアクセスを制御します。 指定された信頼できるIPアドレス範囲からのアクセスのみを許可するように、ネットワークレベルでetcdポートへのアクセスを制限することを検討してください。 コンテナランタイムソケット Kubernetesクラスターの各ノードでは、コンテナと対話するためのアクセスはコンテナランタイム(1つ以上のランタイムを構成している場合はそれらのランタイム)によって制御されます。
通常、コンテナランタイムはkubeletがアクセスできるUnixソケットを公開します。
このソケットにアクセスできる攻撃者は、新しいコンテナを起動したり、実行中のコンテナと対話したりする可能性があります。
クラスターレベルでは、このアクセスの影響は、侵害されたノードで実行されているコンテナが、他のワーカーノードやコントロールプレーンのコンポーネントへの特権昇格のために、攻撃者が使用する可能性のあるSecretやその他の機密データにアクセスできるかどうかによって異なります。
緩和策 コンテナランタイムソケットへのファイルシステムアクセスを厳密に制御してください。
可能であれば、rootユーザーにこのアクセスを制限してください。 Linuxカーネルの名前空間などのメカニズムを使用して、ノード上で実行されている他のコンポーネントからkubeletを分離します。 コンテナランタイムソケットを含むhostPathマウントhostPathマウントは読み取り専用として設定する必要があります。 ノードへのユーザーアクセスを制限し、特にノードへのスーパーユーザーアクセスを制限してください。 3.9.13 - 堅牢化ガイド - スケジューラーの設定 Kubernetesスケジューラーのセキュリティ強化に関する情報。
Kubernetesのスケジューラー は、コントロールプレーン の中のもっとも重要なコンポーネントの一つです。
このドキュメントでは、Kubernetesスケジューラーのセキュリティ体制を向上させる方法について説明します。
設定が不適切なスケジューラーは、セキュリティ上の脆弱性を引き起こす可能性があります。
このようなスケジューラーは、特定のノードをターゲットにして、そのノードおよびリソースを共有しているワークロードやアプリケーションを強制的に退避させることができます。
この設定は、脆弱性のあるオートスケーラーを標的としたYoYo攻撃 に対する防御を強化するのにも役立ちます。
kube-schedulerの設定 スケジューラーの認証/認可に関するコマンドラインオプション 認証設定を構成する際には、kube-schedulerの認証方式がkube-api-serverの認証方式と整合性を保つように設定することが重要です。
認証ヘッダーが欠落しているリクエストがあった場合、クラスター全体で認証方式を統一的に管理するために、kube-api-server経由で認証を行うようにしてください 。
authentication-kubeconfig: スケジューラーがAPIサーバーから認証設定オプションを取得できるよう、適切なkubeconfigを設定するようにしてください。この kubeconfig ファイルは、厳格なファイル権限で保護する必要があります。authentication-tolerate-lookup-failure: この設定をfalseに設定すると、スケジューラーが 常に APIサーバーから認証設定を取得するようになります。authentication-skip-lookup: この設定をfalseに設定すると、スケジューラーが 常に APIサーバーから認証設定を取得するようになります。authorization-always-allow-paths: これらのパスは、匿名アクセス権限に適したデータを返すように設定する必要があります。デフォルト値は、/healthz,/readyz,/livezです。profiling: プロファイリングエンドポイントを無効化する場合はfalseに設定してください。これらのエンドポイントはデバッグ情報を提供しますが、本番環境のクラスターでは使用すべきではありません。サービス拒否攻撃や情報漏洩のリスクがあるためです。--profiling引数は非推奨となっており、現在はKubeScheduler DebuggingConfiguration を通じて指定できます。プロファイリング機能を無効化するには、kube-schedulerの設定ファイルで enableProfilingをfalseに設定してください。requestheader-client-ca-file: この引数の使用は避けてください。スケジューラーのネットワークコマンドラインオプション bind-address: 通常、kube-schedulerは外部からアクセス可能な状態にする必要はありません。バインドアドレスをlocalhostに設定することは、セキュリティ上推奨されるベストプラクティスです。permit-address-sharing: SO_REUSEADDRによる接続共有を無効にする場合は、この設定をfalseに設定してください。SO_REUSEADDRを使用すると、TIME_WAIT状態にある終了済み接続が再利用される可能性があります。permit-port-sharing: デフォルト値はfalseです。セキュリティ上の影響を十分に理解している場合を除き、デフォルト設定をそのまま使用してください。スケジューラーのTLSコマンドラインオプション tls-cipher-suites: 常に、優先される暗号スイートのリストを明示的に指定してください。これにより、安全性の低い暗号スイートを使用した暗号化が実行されるのを防ぎます。カスタムスケジューラーのスケジュール設定 Kubernetesのスケジューリングコードをベースとしたカスタムスケジューラーを使用する場合、クラスター管理者は、queueSort、prefilter、filter、permitといった拡張ポイント を使用するプラグインの設定には注意が必要です。
これらの拡張ポイントはスケジューリングプロセスの様々な段階を制御しており、設定を誤るとkube-schedulerのクラスター内での動作に影響を及ぼす可能性があります。
重要な考慮事項 queueSort拡張ポイントを使用するプラグインは同時に1つだけ有効化できます。queueSortを使用するプラグインについては、特に慎重に検証する必要があります。prefilterまたはfilter拡張ポイントを実装するプラグインは、すべてのノードをスケジューリング不可と判定する可能性があります。これにより、新規Podのスケジューリングが完全に停止する恐れがあります。permit拡張ポイントを実装したプラグインは、Podのバインド処理を阻止または遅延させることができます。このようなプラグインは、クラスター管理者が十分に検証する必要があります。デフォルトプラグイン 以外を使用する場合、queueSort、filter、permitの各拡張ポイントを無効化することを検討してください。具体的な手順は以下の通りです。
apiVersion : kubescheduler.config.k8s.io/v1
kind : KubeSchedulerConfiguration
profiles :
- schedulerName : my-scheduler
plugins :
# Disable specific plugins for different extension points
# You can disable all plugins for an extension point using "*"
queueSort :
disabled :
- name : "*" # Disable all queueSort plugins
# - name: "PrioritySort" # Disable specific queueSort plugin
filter :
disabled :
- name : "*" # Disable all filter plugins
# - name: "NodeResourcesFit" # Disable specific filter plugin
permit :
disabled :
- name : "*" # Disables all permit plugins
# - name: "TaintToleration" # Disable specific permit plugin
これにより、my-schedulerというスケジューラープロファイルが作成されます。
Podの.specに.spec.schedulerNameの値が指定されていない場合、kube-schedulerはそのPodに対してデフォルトの設定とデフォルトプラグインを使用して動作します。
.spec.schedulerNameにmy-schedulerを指定したPodを定義すると、カスタム設定が適用されたkube-schedulerが起動します。
このカスタム設定では、queueSort、filter、permitの各拡張ポイントが無効化されています。
このKubeSchedulerConfigurationを使用し、かつカスタムスケジューラーを実行していない場合、.spec.schedulerNameにnonexistent-scheduler(またはクラスター内に存在しない任意のスケジューラー名)を指定したPodを定義しても、そのPodに関するイベントは生成されません。
ノードへのラベル付けを禁止する クラスター管理者は、クラスターユーザーがノードにラベルを付与できないように設定する必要があります。
悪意のある攻撃者がnodeSelectorを利用することで、本来配置されるべきでないノードにワークロードをスケジュールすることが可能になります。
3.9.14 - 堅牢化ガイド - 認証メカニズム Kubernetesの認証オプションとそのセキュリティ特性に関する情報。
適切な認証メカニズムの選択はクラスターのセキュリティ確保において重要です。
Kubernetesはいくつかの組み込みのメカニズムを提供しており、それぞれに長所と短所があります。
クラスターに最適な認証メカニズムを選択する際は、これらを慎重に検討する必要があります。
一般的に、有効にする認証メカニズムをできるだけ少なくすることが推奨されています。
これはユーザー管理を単純化し、不要となったクラスターへのアクセス権をユーザーが保持し続けることを防ぐためです。
重要な注意点として、Kubernetesはクラスター内に組み込みのユーザーデータベースを持っていません。
代わりに、設定された認証システムからユーザー情報を取得し、それを使用して認可の判断を行います。
そのため、ユーザーアクセスを監査するには、設定されているすべての認証ソースの認証情報を確認する必要があります。
複数のユーザーが直接Kubernetes APIにアクセスする本番環境のクラスターでは、OIDCなどの外部認証ソースを使用することが推奨されています。
以下で説明するクライアント証明書やサービスアカウントトークンなどの内部認証メカニズムは、このユースケースには適していません。
X509クライアント証明書認証 Kubernetesは、kubeletがAPIサーバーに対して認証を行う場合など、システムコンポーネントにX509クライアント証明書 認証を活用します。
このメカニズムはユーザー認証にも使用できますが、以下の制限により本番環境での使用には適さない可能性があります:
クライアント証明書は個別に無効化することができません。
証明書が漏洩した場合、有効期限が切れるまで攻撃者に使用される可能性があります。
このリスクを軽減するため、クライアント証明書を使用して作成されたユーザー認証情報には短い有効期限を設定することが推奨されます。 もし証明書を無効にする必要がある場合、認証局の鍵の再生成が必要となり、クラスターの可用性にリスクをもたらす可能性があります。 クラスター内で作成されたクライアント証明書の永続的な記録は残りません。
そのため、証明書を追跡する必要がある場合は、発行されたすべての証明書を記録しておく必要があります。 クライアント証明書認証に使用する秘密鍵はパスワードで保護することができません。
鍵を含むファイルを読み取ることができる人は誰でもそれを使用できます。 クライアント証明書認証を使用するためには、クライアントからAPIサーバーへ直接接続する必要があり、TLS終端点を介在させることができません。
これにより、ネットワークアーキテクチャが複雑になる可能性があります。 グループデータはクライアント証明書のO値に埋め込まれているため、証明書の有効期間中はユーザーのグループメンバーシップを変更することができません。 静的なトークンファイル Kubernetesではコントロールプレーンノードのディスクにある静的なトークンファイル から認証情報を読み込むことができますが、以下の理由により本番環境のサーバーではこの方法は推奨されません:
認証情報がコントロールプレーンノードのディスクに平文で保存されるため、セキュリティ上のリスクとなる可能性があります。 認証情報を変更するためには、APIサーバーのプロセスを再起動する必要があり、可用性に影響を与える可能性があります。 認証情報のローテーションを可能にするメカニズムは存在しません。
認証情報をローテーションするためには、クラスター管理者がディスク上のトークンを変更し、ユーザーに配布する必要があります。 ブルートフォース攻撃を防ぐためのロックアウトメカニズムは存在しません。 ブートストラップトークン ブートストラップトークン はノードをクラスターに参加させるために使用されます。
以下の理由により、ユーザー認証には推奨されません:
ハードコードされたグループメンバーシップを持っており、一般的な使用に適していないため、認証の目的には適していません。 ブートストラップトークンを手動で生成すると、攻撃者が推測可能な脆弱なトークンが生成される可能性があり、セキュリティ上のリスクとなります。 ブルートフォース攻撃を防ぐためのロックアウトメカニズムが存在しないため、攻撃者がトークンを推測または解読しやすくなります。 サービスアカウントシークレットトークン サービスアカウントシークレット は、クラスター内で実行されるワークロードがAPIサーバーに対して認証を行うためのオプションとして利用できます。
Kubernetes 1.23より前のバージョンではデフォルトのオプションでしたが、現在はTokenRequest APIトークンに置き換えられています。
これらのSecretはユーザー認証に使用できますが、以下の理由により一般的に不適切です:
有効期限を設定することができず、関連付けられたサービスアカウントが削除されるまで有効なままとなります。 トークンはそれらが定義されているNamespace内でSecretを読み取ることができる任意のクラスターユーザーが閲覧できます。 サービスアカウントは任意のグループに追加できないため、それらを使用する場合にRBACの管理が複雑になります。 TokenRequest APIトークン TokenRequest APIは、APIサーバーまたはサードパーティシステムへのサービス認証のために有効期間の短い認証情報を生成するために有用なツールです。
ただし、認証情報の失効方法が無いため、一般的にユーザー認証には推奨されず、ユーザーへの認証情報の安全な配布が困難です。
TokenRequestトークンをサービス認証に使用する場合、トークンが漏洩した際の影響を軽減するために、短い有効期間を設定することが推奨されます。
OpenID Connectトークン認証 Kubernetesは、OpenID Connect (OIDC) を使用した外部認証サービスとKubernetes APIとの統合をサポートしています。
Kubernetesをアイデンティティプロバイダーと統合するために使用できるソフトウェアは多岐にわたります。
しかし、KubernetesでOIDC認証を使用する際は、以下のセキュリティ強化策を考慮することが重要です:
OIDC認証をサポートするためにクラスターにインストールされたソフトウェアは、高い権限で実行されるため、一般的なワークロードから分離する必要があります。 一部のKubernetesマネージドサービスでは、使用できるOIDCプロバイダーが制限されています。 TokenRequestトークンと同様に、トークンが漏洩した際の影響を軽減するため、OIDCトークンは短い有効期間を設定する必要があります。 Webhookトークン認証 Webhookトークン認証 は、外部認証プロバイダーをKubernetesに統合するもう一つのオプションです。
この認証メカニズムを用いると、クラスター内部または外部で実行される認証サービスに対してWebhookを介して認証の判断を問い合わせることができます。
この認証メカニズムへの適合性は認証サービスに使用されるソフトウェアに依存する可能性が高く、Kubernetes特有の考慮事項があることに注意が必要です。
Webhook認証を設定するには、コントロールプレーンサーバーのファイルシステムへのアクセスが必要です。
そのため、プロバイダーが特別に利用可能にしない限り、マネージドKubernetesでは使用できません。
また、このアクセスをサポートするためにクラスターにインストールされるソフトウェアは高い権限で実行されるため、一般的なワークロードから分離する必要があります。
認証プロキシ 認証プロキシ は、外部認証システムをKubernetesに統合するもう一つのオプションです。
この認証メカニズムでは、Kubernetesは認可のために割り当てるユーザー名とグループメンバーシップを示す特定のヘッダー値が設定されたリクエストをプロキシから受け取ることを想定しています。
この認証メカニズムを使用する際には、特定の考慮事項に注意する必要があります。
まず、トラフィックの傍受やスニッフィング攻撃のリスクを軽減するため、プロキシとKubernetes APIサーバー間では安全に設定されたTLSを使用する必要があります。
これにより、プロキシとKubernetes APIサーバー間の通信の安全性が確保されます。
次に、リクエストヘッダーを改ざんできる攻撃者がKubernetesリソースへの不正アクセスを取得できる可能性があることを認識することが重要です。
そのため、ヘッダーが適切に保護され、改ざんされないようにすることが重要です。
次の項目 3.9.15 - セキュリティチェックリスト Kubernetesクラスターのセキュリティを確保するための基本的なチェックリスト。
このチェックリストは、各トピックについて、より包括的な文書へのリンクとともにガイダンスの基本的なリストを提供することを目的としています。
網羅的なものではなく、進化することを目的としています。
この文書の読み方、使い方について:
トピックの順序は、優先順位を反映したものではありません。 いくつかのチェックリスト項目は、各セクションのリストの下の段落に詳述されています。
注意: チェックリストだけでは、適切なセキュリティ体制を確立するのに十分ではありません 。
適切なセキュリティ体制には継続的な注意と改善が必要ですが、チェックリストはセキュリティ対策に向けた終わりのない旅の第一歩です。
このチェックリストの推奨事項の一部は、特定のセキュリティニーズに対して制限が厳しすぎたり、緩すぎたりする場合があります。
Kubernetesのセキュリティは「万能」ではないため、チェックリストの各項目のメリットに基づいて評価する必要があります。認証と認可 ブートストラップ後、ユーザーもコンポーネントもKubernetes APIに対してsystem:mastersとして認証しないでください。
同様に、すべてのkube-controller-managerをsystem:mastersとして実行することは避けてください。
実際には、system:mastersは管理者ユーザーとは対照的に、緊急アクセス用としてのみ使用してください。
ネットワークセキュリティ 多数のコンテナネットワークインターフェース(CNI)プラグイン は、Podが通信できるネットワークリソースを制限する機能を提供します。
これは、ルールを定義するためのNamespaceリソースを提供するネットワークポリシー を通じて最も一般的に行われます。
各Namespaceですべてのegressとingressをブロックし、すべてのPodを選択するデフォルトのネットワークポリシーは、許可リストアプローチを採用してワークロードの見落としがないようにするのに役立ちます。
すべてのCNIプラグインが転送中の暗号化を提供するわけではありません。
選択したプラグインにこの機能がない場合、代替ソリューションとして、サービスメッシュを使用してその機能を提供することができます。
コントロールプレーンのetcdデータストアには、アクセスを制限し、インターネット上で公開されないようにする制御が必要です。
さらに、安全に通信するために相互TLS(mTLS)を使用する必要があります。
この認証局はetcdに固有のものである必要があります。
Kubernetes APIサーバーへの外部インターネットアクセスは、APIが公開されないように制限する必要があります。
多くのマネージドKubernetesディストリビューションは、デフォルトでAPIサーバーを公開しているため注意してください。
その場合、要塞ホストを使用してサーバーにアクセスできます。
kubelet のAPIアクセスは制限し、公開しないようにする必要があります。
--configフラグで設定ファイルが指定されていない場合、デフォルトの認証および認可設定は過度に許可されています。
Kubernetesのホスティングにクラウドプロバイダーを使用する場合、PodからクラウドメタデータAPI169.254.169.254へのアクセスも、情報が漏洩する可能性があるため、必要でない場合は制限またはブロックする必要があります。
LoadBalancerおよびExternalIPの制限付き使用の詳細についてはCVE-2020-8554: Man in the middle using LoadBalancer or ExternalIPs およびDenyServiceExternalIPsアドミッションコントローラー を参照してください。
Podセキュリティ RBAC認証は重要ですが、Podのリソース (またはPodを管理する任意のリソース)に対する認証を行うほど細かく設定することはできません。
唯一の細分性は、リソース自体に対するAPI動詞です。
たとえばPodに対するcreateです。
追加のアドミッションがなければ、これらのリソースを作成する権限によって、クラスターのスケジューリング可能なノードへの直接的な無制限のアクセスが許可されます。
Podセキュリティ標準 は、セキュリティに関してPodSpecでフィールドを設定する方法を制限する、特権、ベースライン、制限の3つの異なるポリシーを定義します。
デフォルトで有効になっている新しいPodセキュリティ アドミッション、またはサードパーティのアドミッションWebhookを使用して、Namespaceレベルで適用できます。
削除され置き換えられたPodSecurityPolicyアドミッションとは異なり、Podセキュリティ アドミッションは、アドミッションWebhookや外部サービスと簡単に組み合わせることが可能な点に注意してください。
Podセキュリティアドミッションrestrictedポリシーは、Podセキュリティ標準 セットの中で最も制限の厳しいポリシーで、複数のモードで動作可能 です。
warn、audit、またはenforceを使用して、セキュリティのベストプラクティスに従って、最も適切なセキュリティコンテキスト を段階的に適用します。
ただし、特定のユースケースでは、事前定義されたセキュリティ標準に加えて、Podが持つ権限とアクセスを制限するために、Podのセキュリティコンテキスト を個別に調査する必要があります。
Podセキュリティ の実践的なチュートリアルについては、ブログ投稿Kubernetes 1.23: Podセキュリティがベータ版に移行 を参照してください。
メモリとCPUの制限 を設定して、Podがノードで消費できるメモリとCPUリソースを制限し、悪意のあるワークロードや侵害されたワークロードによる潜在的なDoS攻撃を防ぐ必要があります。
このようなポリシーは、アドミッションコントローラーによって適用できます。
CPU制限により使用量が制限されるため、自動スケーリング機能や効率性、つまり利用可能なCPUリソースをベストエフォートで実行することに対して、意図しない影響が生じる可能性があります。
注意: メモリ制限が要求を上回ると、ノード全体がOOM問題にさらされる可能性があります。Seccompの有効化 Seccompはセキュアコンピューティングモードの略で、バージョン2.6.12以降のLinuxカーネルの機能です。
プロセスの権限をサンドボックス化して、ユーザー空間からカーネルへの呼び出しを制限するために使用できます。
Kubernetesを使用すると、ノードに読み込まれたseccompプロファイルを、Podとコンテナに自動的に適用できます。
Seccompを使用すると、コンテナ内で利用可能なLinuxカーネルsyscall攻撃対象領域を減らすことで、ワークロードのセキュリティを向上できます。
seccompフィルターモードは、BPFを利用して、プロファイルという名前の特定のsyscallの許可または拒否リストを作成します。
Kubernetes 1.27以降、すべてのワークロードのデフォルトのseccompプロファイルとしてRuntimeDefaultの使用を有効にできます。
このトピックに関するセキュリティチュートリアル が利用可能です。
さらに、Kubernetes Security Profiles Operator は、クラスターでのseccompの管理と使用を容易にするプロジェクトです。
備考: seccompはLinuxノードでのみ使用できます。AppArmorまたはSELinuxの有効化 AppArmor AppArmor は、強制アクセス制御(MAC)を簡単に実装し、システムログを通じて監査を向上させることができるLinuxカーネルセキュリティモジュールです。
デフォルトのAppArmorプロファイルは、それをサポートするノードで強制されますが、カスタムプロファイルを構成することもできます。
seccompと同様に、AppArmorもプロファイルを通じて構成されます。
各プロファイルは、許可されていないリソースへのアクセスをブロックする強制モード(complain mode)か、違反のみを報告する苦情モード(enforce mode)で実行されます。
AppArmorプロファイルは、コンテナごとに注釈付きで適用され、プロセスが適切な権限を取得できるようにします。
SELinux SELinux も、強制アクセス制御(MAC)などのアクセス制御セキュリティポリシーをサポートするLinuxカーネルセキュリティモジュールです。
SELinuxラベルは、コンテナまたはPodにsecurityContextセクションを介して
ログと監査 Podの配置 アプリケーションPodとKubernetes APIサーバーなど、機密性の異なる層にあるPodは、別々のノードにデプロイする必要があります。
ノード分離の目的は、アプリケーションコンテナのブレイクアウトを防ぎ、より機密性の高いアプリケーションへのアクセスを直接提供して、クラスター内で簡単にピボットできるようにすることです。
Podが誤って同じノードにデプロイされるのを防ぐために、この分離を実施する必要があります。
これは、次の機能を使用して実施できます。
ノードセレクター Pod仕様の一部として、デプロイするノードを指定するキーと値のペア。
これらは、PodNodeSelector アドミッションコントローラーを使用して、Namespaceとクラスターレベルで実施できます。 PodTolerationRestriction 管理者がNamespace内で許可されたtoleration を制限できるようにするアドミッションコントローラー。
Namespace内のPodは、デフォルトおよび許可された一連のtolerationを提供するNamespaceオブジェクトアノテーションキーで指定されたtolerationのみを使用できます。 RuntimeClass RuntimeClassは、コンテナのランタイム構成を選択するための機能です。 コンテナのランタイム構成は、Podのコンテナを実行するために使用され、パフォーマンスのオーバーヘッドを犠牲にして、多少なりともホストからの分離を提供できます。
Secret Podに必要なシークレットは、ConfigMapなどの代替手段ではなく、Kubernetes Secret内に保存する必要があります。
etcd内に保存されているシークレットリソースは、保存時に暗号化 する必要があります。
シークレットを必要とするPodでは、ボリュームを介してシークレットが自動的にマウントされ、できればemptyDir.mediumオプションSecret Store CSIドライバー などのボリュームとしてサードパーティのストレージからシークレットを挿入するためにも使用できます。
PodのサービスアカウントにシークレットへのRBACアクセスを提供するよりも、これを優先的に行う必要があります。
これにより、シークレットを環境変数またはファイルとしてPodに追加できます。
環境変数メソッドは、ファイルの権限メカニズムとは異なり、ログのクラッシュダンプとLinuxの環境変数の非機密性により、漏洩が発生しやすい可能性があることに注意してください。
サービスアカウントトークンは、それらを必要としないPodにマウントしないでください。
これは、サービスアカウント内でautomountServiceAccountTokenfalseに設定して、Namespace全体に適用するか、Podに固有の設定にすることで構成できます。
Kubernetes v1.22以降では、時間制限のあるサービスアカウント認証情報にはバインドされたサービスアカウント を使用します。
イメージ コンテナイメージには、パッケージ化されたプログラムを実行するための最小限のものだけが含まれている必要があります。
できれば、プログラムとその依存関係のみで、最小限のベースからイメージを構築します。
特に、本番環境で使用するイメージには、シェルやデバッグユーティリティを含めないでください。
エフェメラル(一時的)なデバッグコンテナ をトラブルシューティングに使用できます。
DockerfileのUSER命令 を使用して、権限のないユーザーで直接起動するイメージを構築します。
セキュリティコンテキスト を使用すると、イメージマニフェストで指定されていない場合でも、runAsUserおよびrunAsGroupを使用して特定のユーザーとグループでコンテナイメージを開始できます。
ただし、イメージレイヤーのファイル権限により、イメージを変更せずに新しい権限のないユーザーでプロセスを開始することが不可能になる場合があります。
イメージタグ、特にlatestタグを使用してイメージを参照することは避けてください。
タグの背後にあるイメージはレジストリで簡単に変更できます。
イメージマニフェストに固有の完全なsha256ダイジェストを使用することをお勧めします。
このポリシーは、ImagePolicyWebhook を介して適用できます。
イメージ署名は、デプロイ時に自動的にアドミッションコントローラーで検証 して、信頼性と整合性を検証することもできます。
コンテナイメージをスキャンすると、重大な脆弱性がコンテナイメージと一緒にクラスターにデプロイされるのを防ぐことができます。
イメージスキャンは、コンテナイメージをクラスターにデプロイする前に完了する必要があり、通常はCI/CDパイプラインのデプロイプロセスの一部として行われます。
イメージスキャンの目的は、コンテナイメージ内の潜在的な脆弱性とその防止策に関する情報(共通脆弱性評価システム(CVSS) スコアなど)を取得することです。
イメージスキャンの結果をパイプラインのコンプライアンスルールと組み合わせると、適切にパッチが適用されたコンテナイメージのみが本番環境に導入されます。
アドミッションコントローラー 次のリストは、クラスターとアプリケーションのセキュリティ体制を強化するために検討できるアドミッションコントローラーをいくつか示しています。
このドキュメントの他の部分で参照される可能性のあるコントローラーも含まれています。
この最初のアドミッションコントローラーグループには、デフォルトで有効 になっているプラグインがあります。
何をしているのかよくわからない場合は、有効のままにしておいてください:
CertificateApproval承認ユーザーが証明書要求を承認する権限を持っていることを確認するために、追加の承認チェックを実行します。 CertificateSigning署名ユーザーが証明書要求に署名する権限を持っていることを確認するために、追加の承認チェックを実行します。 CertificateSubjectRestrictionsystem:mastersの「グループ」(または「組織属性」)を指定するすべての証明書リクエストを拒否します。LimitRangerLimitRange API制約を適用します。 MutatingAdmissionWebhookWebhookを介してカスタムコントローラーの使用を許可します。これらのコントローラーは、確認するリクエストを変更する場合があります。 PodSecurityPodセキュリティポリシーの代替で、デプロイされたPodのセキュリティコンテキストを制限します。 ResourceQuotaリソースの過剰使用を防ぐためにリソースクォータを適用します。 ValidatingAdmissionWebhookWebhookを介してカスタムコントローラーの使用を許可します。これらのコントローラーは、確認するリクエストを変更しません。 2番目のグループには、デフォルトでは有効になっていませんが、GAステータスであり、セキュリティ体制を向上させるために推奨されるプラグインが含まれます:
DenyServiceExternalIPsService.spec.externalIPsフィールドの新規使用をすべて拒否します。
これは、CVE-2020-8554: Man in the middle using LoadBalancer or ExternalIPs の緩和策です。NodeRestrictionkubeletの権限を、所有するPod APIリソースまたは自身を表すノードAPIリソースのみを変更するように制限します。
また、kubeletがnode-restriction.kubernetes.io/アノテーションを使用するのを防ぎます。このアノテーションは、kubeletの認証情報にアクセスできる攻撃者が、制御対象ノードへのPodの配置に影響を与えるために使用する可能性があります。 3番目のグループには、デフォルトでは有効になっていませんが、特定のユースケースで検討できるプラグインが含まれます:
AlwaysPullImagesタグ付けされたイメージの最新バージョンの使用を強制し、デプロイヤーがイメージを使用する権限を持っていることを確認します。 ImagePolicyWebhookWebhookを通じてイメージの追加制御を強制できるようにします。 次のステップ 3.9.16 - アプリケーションセキュリティチェックリスト アプリケーション開発者を対象とした、Kubernetes上でのアプリケーションセキュリティを確保するための基準となるガイドライン
このチェックリストは、開発者の観点からKubernetes上で動作するアプリケーションのセキュリティ確保に関する基本的なガイドラインを提供することを目的としています。
このリストは包括的なものではなく、時間の経過とともに発展させていくことを意図しています。
この文書の読み方と使い方について:
トピックの順序は優先度の順序を反映していません。 一部のチェックリスト項目は、各セクションのリストの下の段落で詳しく説明されています。 このチェックリストでは、開発者とはKubernetesクラスターのユーザーで、名前空間スコープのオブジェクトを操作する人を想定しています。
注意: チェックリストだけでは、優れたセキュリティ体制を構築するのに十分ではありません 。
優れたセキュリティ体制には継続的な注意と改善が必要ですが、チェックリストはセキュリティ対応という終わりのない道のりにおける最初の一歩となり得ます。
このチェックリストの一部の推奨事項は、ユーザーの特定のセキュリティニーズに対して制限が厳しすぎる場合や、逆に緩すぎる場合があります。
Kubernetesセキュリティは「万能」ではないため、チェックリスト項目の各カテゴリはそのメリットに基づいて評価する必要があります。ベースセキュリティ強化 以下のチェックリストは、Kubernetesにデプロイするほとんどのアプリケーションに適用されるベースセキュリティ強化の推奨事項を提供します。
アプリケーション設計 サービスアカウント PodレベルのsecurityContextの推奨事項 コンテナレベルのsecurityContextの推奨事項 ロールベースアクセス制御(RBAC) create 、update 、delete の権限は慎重に許可する必要があります。
patch 権限をNamespaceに対して許可すると、ユーザーが名前空間やデプロイメントのラベルを更新できるようになり 、攻撃対象領域が拡大する可能性があります。
機密性の高いワークロードについては、許可される書き込みアクションをさらに制限する推奨ValidatingAdmissionPolicyの提供を検討してください。
イメージセキュリティ ネットワークポリシー クラスターがNetworkPolicyを提供し、適用していることを確認してください。
ユーザーが異なるクラスターにデプロイするアプリケーションを作成している場合、NetworkPolicyが利用可能で適用されているとみなすことができるかどうかを確認してください。
高度なセキュリティ強化 このガイドのこのセクションでは、Kubernetes環境の構成に応じて有用となる可能性があるいくつかの高度なセキュリティ強化ポイントについて説明します。
Linuxコンテナセキュリティ Podとコンテナ用のSecurity Context を設定する。
ランタイムクラス 備考: このセクションでは、Kubernetesが必要とする機能を提供するサードパーティープロジェクトにリンクしています。これらのプロジェクトはアルファベット順に記載されていて、Kubernetesプロジェクトの作者は責任を持ちません。このリストにプロジェクトを追加するには、変更を提出する前に
content guide をお読みください。
詳細はこちら。 一部のコンテナは、クラスターのデフォルトランタイムが提供するものとは異なる分離レベルを必要とする場合があります。
runtimeClassNameをpodspecで使用して、異なるランタイムクラスを定義できます。
機密性の高いワークロードについては、gVisor などのカーネルエミュレーションツールや、kata-containers などのメカニズムを使用した仮想化分離の使用を検討してください。
高い信頼性が要求される環境では、クラスターセキュリティをさらに向上させるために機密仮想マシン の使用を検討してください。
3.10 - ポリシー 3.10.1 - Limit Range デフォルトでは、コンテナは、Kubernetesクラスター上の計算リソース の消費を制限されずに実行されます。リソースクォータを利用すれば、クラスター管理者はリソースの消費と作成を名前空間 ベースで制限することができます。名前空間内では、Podやコンテナは名前空間のリソースクォータで定義された範囲内でできるだけ多くのCPUとメモリーを消費できてしまうため、1つのPodまたはコンテナが利用可能なすべてのリソースを専有してしまう恐れがあります。LimitRangeを利用すれば、このような名前空間内での(Podやコンテナへの)リソースの割り当てを制限するポリシーを定めることができます。
LimitRange を利用すると、次のような制約を課せるようになります。
名前空間内のPodまたはコンテナごとに、計算リソースの使用量の最小値と最大値を強制する。 名前空間内のPersistentVolumeClaimごとに、ストレージリクエストの最小値と最大値を強制する。 名前空間内で、リソースのrequestとlimitの割合を強制する。 名前空間内の計算リソースのデフォルトのrequest/limitの値を設定して、実行時にコンテナに自動的に注入する。 LimitRangeを有効にする Kubernetes 1.10以降では、LimitRangeのサポートはデフォルトで有効になりました。
LimitRangeが特定の名前空間内で強制されるのは、その名前空間内にLimitRangeオブジェクトが存在する場合です。
LimitRangeオブジェクトの名前は、有効なDNSサブドメイン名 でなければなりません。
Limit Rangeの概要 管理者は、1つの名前空間に1つのLimitRangeを作成します。 ユーザーは、Pod、コンテナ、PersistentVolumeClaimのようなリソースを名前空間内に作成します。 LimitRangerアドミッションコントローラーは、計算リソース要求が設定されていないすべてのPodとコンテナに対して、デフォルト値と制限値を強制します。そして、リソースの使用量を追跡し、名前空間内に存在するすべてのLimitRangeで定義された最小値、最大値、割合を外れないことを保証します。LimitRangeの制約を破るようなリソース(Pod、コンテナ、PersistentVolumeClaim)の作成や更新を行うと、APIサーバーへのリクエストがHTTPステータスコード403 FORBIDDENで失敗し、破られた制約を説明するメッセージが返されます。 名前空間内でLimitRangeがcpuやmemoryなどの計算リソースに対して有効になっている場合、ユーザーはrequestsやlimitsに値を指定しなければなりません。指定しなかった場合、システムはPodの作成を拒否する可能性があります。 LimitRangeの検証は、Podのアドミッションステージでのみ発生し、実行中のPodでは発生しません。 以下は、LimitRangeを使用して作成できるポリシーの例です。
8GiBのRAMと16コアのCPUの容量がある2ノードのクラスター上で、名前空間内のPodに対して、CPUには100mのrequestと最大500mのlimitの制約を課し、メモリーには200Miのrequestと600Miのlimitの制約を課す。 Spec内のrequestsにcpuやmemoryを指定せずに起動したコンテナに対して、CPUにはデフォルトで150mのlimitとrequestを、メモリーにはデフォルトで300Miのrequestをそれぞれ定義する。 名前空間のlimitの合計が、Podやコンテナのlimitの合計よりも小さくなる場合、リソースの競合が起こる可能性があります。その場合、コンテナやPodは作成されません。
LimitRangeに対する競合や変更は、すでに作成済みのリソースに対しては影響しません。
次の項目 より詳しい情報は、LimitRangerの設計ドキュメント を参照してください。
制限の使用例については、以下のページを読んでください。
3.10.2 - リソースクォータ 複数のユーザーやチームが決められた数のノードを持つクラスターを共有しているとき、1つのチームが公平に使えるリソース量を超えて使用するといった問題が出てきます。
リソースクォータはこの問題に対処するための管理者向けツールです。
ResourceQuotaオブジェクトによって定義されるリソースクォータは、名前空間ごとの総リソース消費を制限するための制約を提供します。リソースクォータは同じ名前空間のクラスター内でタイプごとに作成できるオブジェクト数や、名前空間内のリソースによって消費されるコンピュートリソースの総量を制限できます。
リソースクォータは下記のように働きます。
異なる名前空間で異なるチームが存在するとき。現時点ではこれは自主的なものですが、将来的にはACLsを介してリソースクォータの設定を強制するように計画されています。 管理者は各名前空間で1つのResourceQuotaを作成します。 ユーザーが名前空間内でリソース(Pod、Serviceなど)を作成し、クォータシステムがResourceQuotaによって定義されたハードリソースリミットを超えないことを保証するために、リソースの使用量をトラッキングします。 リソースの作成や更新がクォータの制約に違反しているとき、そのリクエストはHTTPステータスコード403 FORBIDDENで失敗し、違反した制約を説明するメッセージが表示されます。 cpuやmemoryといったコンピューターリソースに対するクォータが名前空間内で有効になっているとき、ユーザーはそれらの値に対するrequestsやlimitsを設定する必要があります。設定しないとクォータシステムがPodの作成を拒否します。 ヒント: コンピュートリソースの要求を設定しないPodに対してデフォルト値を強制するために、LimitRangerアドミッションコントローラーを使用してください。この問題を解決する例はwalkthrough で参照できます。備考: cpuおよびmemoryリソースに関しては、ResourceQuotaはlimitを設定している名前空間内の全ての (新しい)Podに対して当該リソースのlimitの設定を強制します。名前空間内のcpuまたはmemoryどちらかに対してリソースクォータを適用する場合、ユーザーやクライアントは全ての新しいPodごとに、そのリソースのrequestsあるいはlimitsを指定しなければなりません 。そうでない場合、コントロールプレーンがそのPodの作成を拒否する可能性があります。その他のリソースに関して: ResourceQuotaはリソースのlimitまたはrequestを設定していないPodでも機能します。これは、名前空間内のリソースクォータにおいてエフェメラルストレージのlimitを設定している場合、エフェメラルストレージのlimit/requestsを設定していないPodでも新規作成できることを意味します。LimitRange を使うことで、リソースに対して自動的にデフォルト要求を設定することができます。 ResourceQuotaのオブジェクト名は、有効なDNSサブドメイン名 である必要があります.
名前空間とクォータを使用して作成できるポリシーの例は以下の通りです。
32GiB RAM、16コアのキャパシティーを持つクラスターで、Aチームに20GiB、10コアを割り当て、Bチームに10GiB、4コアを割り当て、将来の割り当てのために2GiB、2コアを予約しておく。 "testing"という名前空間に対して1コア、1GiB RAMの使用制限をかけ、"production"という名前空間には制限をかけない。 クラスターの総キャパシティーが、その名前空間のクォータの合計より少ない場合、リソースの競合が発生する場合があります。このとき、リソースの先着順で処理されます。
リソースの競合もクォータの変更も、作成済みのリソースには影響しません。
リソースクォータを有効にする 多くのKubernetesディストリビューションにおいてリソースクォータはデフォルトで有効になっています。APIサーバーで--enable-admission-plugins=の値にResourceQuotaが含まれるときに有効になります。
特定の名前空間にResourceQuotaがあるとき、そのリソースクォータはその名前空間に適用されます。
コンピュートリソースクォータ 特定の名前空間において、コンピュートリソース の合計に上限を設定できます。
下記のリソースタイプがサポートされています。
リソース名 説明 limits.cpu停止していない状態の全てのPodで、CPUリミットの合計がこの値を超えることができません。 limits.memory停止していない状態の全てのPodで、メモリーの合計がこの値を超えることができません。 requests.cpu停止していない状態の全てのPodで、CPUリクエストの合計がこの値を超えることができません。 requests.memory停止していない状態の全てのPodで、メモリーリクエストの合計がこの値を超えることができません。 hugepages-<size>停止していない状態の全てのPodで, 指定されたサイズのHuge Pageリクエスト数がこの値を超えることができません。 cpurequests.cpuと同じ。memoryrequests.memoryと同じ。
拡張リソースのためのリソースクォータ 上記で取り上げたリソースに加えて、Kubernetes v1.10において、拡張リソース のためのリソースクォータのサポートが追加されました。
拡張リソースに対するオーバーコミットが禁止されているのと同様に、リソースクォータで拡張リソース用にrequestsとlimitsの両方を指定しても意味がありません。現在、拡張リソースに対してはrequests.というプレフィックスのついたクォータアイテムのみ設定できます。
GPUリソースを例にすると、もしリソース名がnvidia.com/gpuで、ユーザーが名前空間内でリクエストされるGPUの上限を4に指定するとき、下記のようにリソースクォータを定義します。
requests.nvidia.com/gpu: 4さらなる詳細はクォータの確認と設定 を参照してください。
ストレージのリソースクォータ 特定の名前空間においてストレージリソース の総数に上限をかけることができます。
さらに、関連するストレージクラスに基づいて、ストレージリソースの消費量に上限をかけることもできます。
リソース名 説明 requests.storage全てのPersistentVolumeClaimにおいて、ストレージのリクエストの合計がこの値を超えないようにします。 persistentvolumeclaims特定の名前空間内で作成可能なPersistentVolumeClaim の総数。 <storage-class-name>.storageclass.storage.k8s.io/requests.storageストレージクラス名<storage-class-name>に関連する全てのPersistentVolumeClaimにおいて、ストレージリクエストの合計がこの値を超えないようにします。 <storage-class-name>.storageclass.storage.k8s.io/persistentvolumeclaimsストレージクラス名<storage-class-name>に関連する全てのPersistentVolumeClaimにおいて、特定の名前空間内で作成可能なPersistentVolumeClaim の総数。
例えば、もし管理者がgoldストレージクラスをbronzeストレージクラスと分けてリソースクォータを設定するとき、管理者はリソースクォータを下記のように指定できます。
gold.storageclass.storage.k8s.io/requests.storage: 500Gibronze.storageclass.storage.k8s.io/requests.storage: 100GiKubernetes v1.8において、ローカルのエフェメラルストレージに対するリソースクォータのサポートがα版の機能として追加されました。
リソース名 説明 requests.ephemeral-storage名前空間内の全てのPodで、ローカルのエフェメラルストレージのリクエストの合計がこの値を超えないようにします。 limits.ephemeral-storage名前空間内の全てのPodで、ローカルのエフェメラルストレージのリミットの合計がこの値を超えないようにします。 ephemeral-storagerequests.ephemeral-storageと同じ。
オブジェクト数に対するクォータ 下記のシンタックスを使用して、名前空間に紐づいた全ての標準であるリソースタイプの中の特定のリソースの総数に対するリソースクォータを設定できます。
count/<resource>.<group> コアでないグループのリソース用count/<resource> コアグループのリソース用オブジェクト数に対するクォータでユーザーが設定するリソースの例は下記の通りです。
count/persistentvolumeclaimscount/servicescount/secretscount/configmapscount/replicationcontrollerscount/deployments.appscount/replicasets.appscount/statefulsets.appscount/jobs.batchcount/cronjobs.batchカスタムリソースに対して同じシンタックスを使用できます。例えば、example.comというAPIグループ内のwidgetsというカスタムリソースのリソースクォータを設定するにはcount/widgets.example.comと記述します。
count/*リソースクォータの使用において、オブジェクトがサーバーストレージに存在するときオブジェクトはクォータの計算対象となります。このようなタイプのリソースクォータはストレージリソース浪費の防止に有効です。例えば、もしSecretが大量に存在するとき、そのSecretリソースの総数に対してリソースクォータの制限をかけたい場合です。クラスター内でSecretが大量にあると、サーバーとコントローラーの起動を妨げることになります。適切に設定されていないCronJobから保護するためにジョブのクォータを設定できます。名前空間内で大量のJobを作成するCronJobは、サービスを利用不可能にする可能性があります。
また、限定されたリソースのセットにおいて汎用オブジェクトカウントのリソースクォータを実行可能です。
下記のタイプのリソースがサポートされています。
リソース名 説明 configmaps名前空間内で存在可能なConfigMapの総数。 persistentvolumeclaims名前空間内で存在可能なPersistentVolumeClaim の総数。 pods名前空間内で存在可能な停止していないPodの総数。.status.phase in (Failed, Succeeded)がtrueのとき、Podは停止状態にあります。 replicationcontrollers名前空間内で存在可能なReplicationControllerの総数。 resourcequotas名前空間内で存在可能なResourceQuotaの総数。 services名前空間内で存在可能なServiceの総数。 services.loadbalancers名前空間内で存在可能なtype:LoadBalancerであるServiceの総数。 services.nodeports名前空間内で存在可能なtype:NodePortであるServiceの総数。 secrets名前空間内で存在可能なSecretの総数。
例えば、podsのリソースクォータはPodの総数をカウントし、特定の名前空間内で作成されたPodの総数の最大数を設定します。またユーザーが多くのPodを作成し、クラスターのPodのIPが枯渇する状況を避けるためにpodsのリソースクォータを名前空間に設定したい場合があります。
クォータのスコープについて 各リソースクォータには関連するscopeのセットを関連づけることができます。クォータは、列挙されたscopeの共通部分と一致する場合にのみリソースの使用量を計測します。
スコープがクォータに追加されると、サポートするリソースの数がスコープに関連するリソースに制限されます。許可されたセット以外のクォータ上でリソースを指定するとバリデーションエラーになります。
スコープ 説明 Terminating.spec.activeDeadlineSeconds >= 0であるPodに一致します。NotTerminating.spec.activeDeadlineSecondsがnilであるPodに一致します。BestEffortベストエフォート型のサービス品質のPodに一致します。 NotBestEffortベストエフォート型のサービス品質でないPodに一致します。 PriorityClass指定された優先度クラス と関連付いているPodに一致します。
BestEffortスコープはリソースクォータを次のリソースに対するトラッキングのみに制限します:
Terminating、NotTerminating、NotBestEffort、PriorityClassスコープは、リソースクォータを次のリソースに対するトラッキングのみに制限します:
podscpumemoryrequests.cpurequests.memorylimits.cpulimits.memory同じクォータでTerminatingとNotTerminatingの両方のスコープを指定することはできず、また同じクォータでBestEffortとNotBestEffortの両方のスコープを指定することもできないことに注意してください。
scopeSelectorはoperator フィールドにおいて下記の値をサポートしています。:
InNotInExistsDoesNotExistscopeSelectorの定義においてscopeNameに下記のいずれかの値を使用する場合、operatorにExistsを指定してください。
TerminatingNotTerminatingBestEffortNotBestEffortoperatorがInまたはNotInの場合、valuesフィールドには少なくとも1つの値が必要です。例えば以下のように記述します:
scopeSelector :
matchExpressions :
- scopeName : PriorityClass
operator : In
values :
- middle
operatorがExistsまたはDoesNotExistの場合、valuesフィールドは指定しないでください 。
PriorityClass毎のリソースクォータ FEATURE STATE:
Kubernetes v1.17 [stable]
Podは特定の優先度 で作成されます。リソースクォータのSpec内にあるscopeSelectorフィールドを使用して、Podの優先度に基づいてPodのシステムリソースの消費をコントロールできます。
リソースクォータのSpec内のscopeSelectorによってPodが選択されたときのみ、そのリソースクォータが一致し、消費されます。
リソースクォータがscopeSelectorフィールドを使用して優先度クラスに対してスコープされる場合、リソースクォータのオプジェクトは、次のリソースのみトラッキングするように制限されます:
podscpumemoryephemeral-storagelimits.cpulimits.memorylimits.ephemeral-storagerequests.cpurequests.memoryrequests.ephemeral-storageこの例ではリソースクォータのオブジェクトを作成し、特定の優先度を持つPodに一致させます。この例は下記のように動作します。
クラスター内のPodは"low"、"medium"、"high"の3つの優先度クラスのうち1つをもちます。 1つのリソースクォータのオブジェクトは優先度毎に作成されます。 下記のYAMLをquota.ymlというファイルに保存します。
apiVersion : v1
kind : List
items :
apiVersion : v1
kind : ResourceQuota
metadata :
name : pods-high
spec :
hard :
cpu : "1000"
memory : 200Gi
pods : "10"
scopeSelector :
matchExpressions :
- operator : In
scopeName : PriorityClass
values : ["high" ]
apiVersion : v1
kind : ResourceQuota
metadata :
name : pods-medium
spec :
hard :
cpu : "10"
memory : 20Gi
pods : "10"
scopeSelector :
matchExpressions :
- operator : In
scopeName : PriorityClass
values : ["medium" ]
apiVersion : v1
kind : ResourceQuota
metadata :
name : pods-low
spec :
hard :
cpu : "5"
memory : 10Gi
pods : "10"
scopeSelector :
matchExpressions :
- operator : In
scopeName : PriorityClass
values : ["low" ]
kubectl createを実行してYAMLの内容を適用します。
kubectl create -f ./quota.yml
resourcequota/pods-high created
resourcequota/pods-medium created
resourcequota/pods-low created
kubectl describe quotaを実行してUsedクォータが0であることを確認します。
Name: pods-high
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 1k
memory 0 200Gi
pods 0 10
Name: pods-low
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 5
memory 0 10Gi
pods 0 10
Name: pods-medium
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 10
memory 0 20Gi
pods 0 10
プライオリティーが"high"であるPodを作成します。下記の内容をhigh-priority-pod.ymlというファイルに保存します。
apiVersion : v1
kind : Pod
metadata :
name : high-priority
spec :
containers :
- name : high-priority
image : ubuntu
command : ["/bin/sh" ]
args : ["-c" , "while true; do echo hello; sleep 10;done" ]
resources :
requests :
memory : "10Gi"
cpu : "500m"
limits :
memory : "10Gi"
cpu : "500m"
priorityClassName : high
kubectl createでマニフェストを適用します。
kubectl create -f ./high-priority-pod.yml
pods-highという名前のプライオリティーが"high"のクォータにおける"Used"項目の値が変更され、それ以外の2つの値は変更されていないことを確認してください。
Name: pods-high
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 500m 1k
memory 10Gi 200Gi
pods 1 10
Name: pods-low
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 5
memory 0 10Gi
pods 0 10
Name: pods-medium
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 10
memory 0 20Gi
pods 0 10
リクエスト vs リミット コンピュートリソースを分配する際に、各コンテナはCPUとメモリーそれぞれのリクエストとリミット値を指定します。クォータはそれぞれの値を設定できます。
クォータにrequests.cpuやrequests.memoryの値が指定されている場合は、コンテナはそれらのリソースに対する明示的な要求を行います。同様に、クォータにlimits.cpuやlimits.memoryの値が指定されている場合は、コンテナはそれらのリソースに対する明示的な制限を行います。
クォータの確認と設定 kubectlでは、クォータの作成、更新、確認をサポートしています。
kubectl create namespace myspace
cat <<EOF > compute-resources.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
spec:
hard:
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
requests.nvidia.com/gpu: 4
EOF
kubectl create -f ./compute-resources.yaml --namespace= myspace
cat <<EOF > object-counts.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
spec:
hard:
configmaps: "10"
persistentvolumeclaims: "4"
pods: "4"
replicationcontrollers: "20"
secrets: "10"
services: "10"
services.loadbalancers: "2"
EOF
kubectl create -f ./object-counts.yaml --namespace= myspace
kubectl get quota --namespace= myspace
NAME AGE
compute-resources 30s
object-counts 32s
kubectl describe quota compute-resources --namespace= myspace
Name: compute-resources
Namespace: myspace
Resource Used Hard
-------- ---- ----
limits.cpu 0 2
limits.memory 0 2Gi
requests.cpu 0 1
requests.memory 0 1Gi
requests.nvidia.com/gpu 0 4
kubectl describe quota object-counts --namespace= myspace
Name: object-counts
Namespace: myspace
Resource Used Hard
-------- ---- ----
configmaps 0 10
persistentvolumeclaims 0 4
pods 0 4
replicationcontrollers 0 20
secrets 1 10
services 0 10
services.loadbalancers 0 2
また、kubectlはcount/<resource>.<group>というシンタックスを用いることにより、名前空間に依存した全ての主要なリソースに対するオブジェクト数のクォータをサポートしています。
kubectl create namespace myspace
kubectl create quota test --hard= count/deployments.apps= 2,count/replicasets.apps= 4,count/pods= 3,count/secrets= 4 --namespace= myspace
kubectl create deployment nginx --image= nginx --namespace= myspace --replicas= 2
kubectl describe quota --namespace= myspace
Name: test
Namespace: myspace
Resource Used Hard
-------- ---- ----
count/deployments.apps 1 2
count/pods 2 3
count/replicasets.apps 1 4
count/secrets 1 4
クォータとクラスター容量 ResourceQuotaはクラスター容量に依存しません。またユニット数の絶対値で表されます。そのためクラスターにノードを追加したことにより、各名前空間が自動的により多くのリソースを消費するような機能が提供されるわけではありません 。
下記のようなより複雑なポリシーが必要な状況があります。
複数チーム間でクラスターリソースの総量を分けあう。 各テナントが必要な時にリソース使用量を増やせるようにするが、偶発的なリソースの枯渇を防ぐために上限を設定する。 1つの名前空間に対してリソース消費の需要を検出し、ノードを追加し、クォータを増加させる。 このようなポリシーは、クォータの使用量の監視と、他のシグナルにしたがってクォータのハードの制限を調整する"コントローラー"を記述することにより、ResourceQuotaをビルディングブロックのように使用して実装できます。
リソースクォータは集約されたクラスターリソースを分割しますが、ノードに対しては何の制限も行わないことに注意して下さい。例: 複数の名前空間のPodは同一のノード上で稼働する可能性があります。
デフォルトで優先度クラスの消費を制限する 例えば"cluster-services"のように、条件に一致するクォータオブジェクトが存在する場合に限り、特定の優先度のPodを名前空間で許可することが望ましい場合があります。
このメカニズムにより、オペレーターは特定の高優先度クラスの使用を限られた数の名前空間に制限することができ、全ての名前空間でこれらの優先度クラスをデフォルトで使用することはできなくなります。
これを実施するには、kube-apiserverの--admission-control-config-fileというフラグを使い、下記の設定ファイルに対してパスを渡す必要がります。
apiVersion : apiserver.config.k8s.io/v1
kind : AdmissionConfiguration
plugins :
name : "ResourceQuota"
configuration :
apiVersion : apiserver.config.k8s.io/v1
kind : ResourceQuotaConfiguration
limitedResources :
- resource : pods
matchScopes :
- scopeName : PriorityClass
operator : In
values : ["cluster-services" ]
なお、"cluster-services"Podは、条件に一致するscopeSelectorを持つクォータオブジェクトが存在する名前空間でのみ許可されます。
scopeSelector :
matchExpressions :
- scopeName : PriorityClass
operator : In
values : ["cluster-services" ]
次の項目 3.10.3 - プロセスIDの制限と予約 FEATURE STATE:
Kubernetes v1.20 [stable]
Kubernetesでは、Pod が使用できるプロセスID(PID)数を制限することができます。また、オペレーティングシステムやデーモンによる使用のために、Podだけではなくノード ごとに割り当て可能なPID数を予約することができます。
プロセスID(PID)はノードの基本的なリソースです。他のリソース制限に達することなくタスク制限に達することは容易であり、それがホストマシンの不安定性を引き起こす可能性があります。
クラスター管理者はクラスター内で実行しているPodがホストデーモン(kubelet やkube-proxy や場合によってはコンテナランタイムなど)の実行を妨げる、PIDの枯渇を引き起こさないことを保証するメカニズムを必要とします。それに加えて、同ノード上の他のワークロードへの影響を制限するためにPod間でPIDが制限されていることも重要です。
備考: 特定のLinuxのインストール時に、オペレーティングシステムはPID制限の値を32768のような低いデフォルト値に設定することがあります。/proc/sys/kernel/pid_maxの値を上げることを検討してください。Podが使用できるPID数の制限をkubeletに設定できます。例えば、ノードのホストOSがPIDの最大値を262144に設定し、250未満のPodをホストします。この場合、各Podに1000PIDを割り当てることで、そのノードで利用可能なPIDを使い切ることを防ぐことができます。管理者がCPUやメモリのようにPIDでもオーバーコミットを行いたい場合、同様にいくつかの追加のリスクがあります。いずれにしても、単一のPodがマシン全体をダウンさせることはできません。このようなリソース制限は単純なフォーク爆弾がクラスター全体の運用に影響を与えるのを防ぐのに役立ちます。
PodごとのPID制限により、管理者はあるPodを他のPodから保護できますが、ホスト上にスケジュールされたすべてのPodがノード全体に影響を与えないことを保証するものではありません。Podごとの制限は、ノードエージェント自体をPID枯渇から保護するものでもありません。
また、Podへの割り当てとは別に、ノードのオーバーヘッドのために一定量のPIDを予約することもできます。これは、CPU、メモリ、その他のリソースをオペレーティングシステムやPodおよびコンテナ外の他の機能で使用するために予約する方法と似ています。
PID制限は、コンピュータリソース のリクエストと制限と並んで重要な機能です。ただし、指定方法は異なります。Podのリソース制限をPodの.specで定義するのではなく、kubeletの設定として制限を設定します。現在、Pod定義のPID制限はサポートされていません。
注意: これは、Podに適用される制限が、Podがスケジュールされる場所によって異なる可能性があることを意味します。簡単にするためには、すべてのノードが同じPIDリソースの制限と予約を使用するのが最も簡単です。ノードのPID制限 KubernetesはKubernetesシステムが利用するプロセスID数を予約することができます。予約を設定するために、kubeletのコマンドラインオプションで--system-reservedおよび--kube-reservedのpid=<number>パラメーターを使用します。指定された値は、システム全体およびKubernetesシステムデーモン用それぞれに、指定された数のプロセスIDが予約されることを宣言します。
PodのPID制限 KubernetesはPodで実行するプロセス数を制限することができます。特定のPodのリソース制限として設定するのではなく、ノードレベルでこの制限を指定します。各ノードは異なるPID制限を持つことができます。制限を設定するために、kubeletに--pod-max-pidsのコマンドラインパラメーターを指定するか、kubeletの構成ファイル のPodPidsLimitに設定します。
Evictionを基にしたPID Podが誤操作していたり、異常なリソースを消費している時にPodの終了を実行することをkubeletに設定できます。この機能はEvictionと呼ばれています。様々なEvictionシグナルのためにリソース不足への対処の設定 ができます。pid.availableEvictionシグナルを使用して、Podによって使用されるPIDの数の閾値を設定します。ソフトとハードのEvictionポリシーを設定できます。しかし、ハードEvictionポリシーを使用しても、PIDの数が非常に速く増加している場合、ノードはPID制限に達することで不安定な状態になる可能性があります。Evictionシグナルの値は定期的に計算されますが、この値は制限を強制するものではありません。
PIDの制限、つまりPod毎、ノード毎にハード制限を設定できます。一度制限に達すると、ワークロードは新しいPIDを取得しようとする際に失敗し始めます。これがPodの再スケジューリングにつながるかどうかは、ワークロードがこれらの失敗にどのように反応するか、PodのLiveness ProbeとReadiness Probeがどのように設定されているかに依存します。しかし、リミットが正しく設定されていれば、あるPodが誤動作している場合でも、他のPodのワークロードやシステムプロセスがPIDを使い果たすことはないと保証することができます。
次の項目 3.10.4 - ノードリソースマネージャー レイテンシーが致命的なワークロードや高スループットのワークロードをサポートするために、Kubernetesは一連のリソースマネージャーを提供します。リソースマネージャーはCPUやデバイス、メモリ(hugepages)などのリソースの特定の要件が設定されたPodのためにノードリソースの調整と最適化を目指しています。
メインのマネージャーであるトポロジーマネージャーはポリシー に沿って全体のリソース管理プロセスを調整するKubeletコンポーネントです。
個々のマネージャーの設定は下記のドキュメントで詳しく説明されてます。
3.11 - スケジューリング、プリエンプションと退避 Kubernetesにおいてスケジューリングとは、稼働させたいPodをノードにマッチさせ、kubeletが実行できるようにすることを指します。 プリエンプションは、優先度の低いPodを終了させて、より優先度の高いPodがノード上でスケジュールできるようにするプロセスです。 退避(eviction)とは、リソース不足のノードで1つ以上のPodを積極的に終了させるプロセスです。
Kubernetesにおいてスケジューリングとは、稼働させたいPod をノード にマッチさせ、kubelet が実行できるようにすることを指します。
プリエンプションは、優先度 の低いPodを終了させて、より優先度の高いPodがノード上でスケジュールできるようにするプロセスです。
退避とは、リソース不足のノードで1つ以上のPodを積極的に終了させるプロセスです。
スケジューリング Pod Disruption 3.11.1 - Kubernetesのスケジューラー Kubernetesにおいて、スケジューリング とは、Kubelet がPod を稼働させるためにNode に割り当てることを意味します。
スケジューリングの概要 スケジューラーは新規に作成されたPodで、Nodeに割り当てられていないものを監視します。スケジューラーは発見した各Podのために、稼働させるべき最適なNodeを見つけ出す責務を担っています。そのスケジューラーは下記で説明するスケジューリングの原理を考慮に入れて、NodeへのPodの割り当てを行います。
Podが特定のNodeに割り当てられる理由を理解したい場合や、カスタムスケジューラーを自身で作ろうと考えている場合、このページはスケジューリングに関して学ぶのに役立ちます。
kube-scheduler kube-scheduler はKubernetesにおけるデフォルトのスケジューラーで、コントロールプレーン の一部分として稼働します。
kube-schedulerは、もし希望するのであれば自分自身でスケジューリングのコンポーネントを実装でき、それを代わりに使用できるように設計されています。
kube-schedulerは、新規に作成された各Podや他のスケジューリングされていないPodを稼働させるために最適なNodeを選択します。
しかし、Pod内の各コンテナにはそれぞれ異なるリソースの要件があり、各Pod自体にもそれぞれ異なる要件があります。そのため、既存のNodeは特定のスケジューリング要求によってフィルターされる必要があります。
クラスター内でPodに対する割り当て要求を満たしたNodeは 割り当て可能 なNodeと呼ばれます。
もし適切なNodeが一つもない場合、スケジューラーがNodeを割り当てることができるまで、そのPodはスケジュールされずに残ります。
スケジューラーはPodに対する割り当て可能なNodeをみつけ、それらの割り当て可能なNodeにスコアをつけます。その中から最も高いスコアのNodeを選択し、Podに割り当てるためのいくつかの関数を実行します。
スケジューラーは binding と呼ばれる処理中において、APIサーバーに対して割り当てが決まったNodeの情報を通知します。
スケジューリングを決定する上で考慮が必要な要素としては、個別または複数のリソース要求や、ハードウェア/ソフトウェアのポリシー制約、affinityやanti-affinityの設定、データの局所性や、ワークロード間での干渉などが挙げられます。
kube-schedulerによるスケジューリング kube-schedulerは2ステップの操作によってPodに割り当てるNodeを選択します。
フィルタリング
スコアリング
フィルタリング ステップでは、Podに割り当て可能なNodeのセットを探します。例えばPodFitsResourcesフィルターは、Podのリソース要求を満たすのに十分なリソースをもつNodeがどれかをチェックします。このステップの後、候補のNodeのリストは、要求を満たすNodeを含みます。
たいてい、リストの要素は複数となります。もしこのリストが空の場合、そのPodはスケジュール可能な状態とはなりません。
スコアリング ステップでは、Podを割り当てるのに最も適したNodeを選択するために、スケジューラーはリストの中のNodeをランク付けします。
スケジューラーは、フィルタリングによって選ばれた各Nodeに対してスコアを付けます。このスコアはアクティブなスコア付けのルールに基づいています。
最後に、kube-schedulerは最も高いランクのNodeに対してPodを割り当てます。もし同一のスコアのNodeが複数ある場合は、kube-schedulerがランダムに1つ選択します。
スケジューラーのフィルタリングとスコアリングの動作に関する設定には2つのサポートされた手法があります。
スケジューリングポリシー は、フィルタリングのための Predicates とスコアリングのための Priorities の設定することができます。スケジューリングプロファイル は、QueueSort、 Filter、 Score、 Bind、 Reserve、 Permitやその他を含む異なるスケジューリングの段階を実装するプラグインを設定することができます。kube-schedulerを異なるプロファイルを実行するように設定することもできます。次の項目 3.11.2 - ノード上へのPodのスケジューリング Pod を特定のノード で実行するように 制限 したり、特定のノードで実行することを 優先 させたりといった制約をかけることができます。
これを実現するためにはいくつかの方法がありますが、推奨されている方法は、すべてラベルセレクター を使用して選択を容易にすることです。
多くの場合、このような制約を設定する必要はなく、スケジューラー が自動的に妥当な配置を行います(例えば、Podを複数のノードに分散させ、空きリソースが十分でないノードにPodを配置しないようにすることができます)。
しかし、例えばSSDが接続されているノードにPodが配置されるようにしたり、多くの通信を行う2つの異なるサービスのPodを同じアベイラビリティーゾーンに配置したりする等、どのノードに配置するかを制御したい状況もあります。
Kubernetesが特定のPodの配置場所を選択するために、以下の方法があります:
ノードラベル 他の多くのKubernetesオブジェクトと同様に、ノードにもラベル があります。手動でラベルを付ける ことができます。
また、Kubernetesはクラスター内のすべてのノードに対し、いくつかの標準ラベルを付けます。ノードラベルの一覧についてはよく使われるラベル、アノテーションとtaint を参照してください。
備考: これらのラベルの値はクラウドプロバイダー固有のもので、信頼性を保証できません。
例えば、kubernetes.io/hostnameの値はある環境ではノード名と同じになり、他の環境では異なる値になることがあります。ノードの分離/制限 ノードにラベルを追加することで、Podを特定のノードまたはノードグループ上でのスケジューリングの対象にすることができます。この機能を使用すると、特定のPodが一定の独立性、安全性、または規制といった属性を持ったノード上でのみ実行されるようにすることができます。
ノード分離するのにラベルを使用する場合、kubelet が修正できないラベルキーを選択してください。
これにより、侵害されたノードが自身でそれらのラベルを設定することで、スケジューラーがそのノードにワークロードをスケジュールしてしまうのを防ぐことができます。
NodeRestrictionアドミッションプラグインnode-restriction.kubernetes.io/というプレフィックスを持つラベルを設定または変更するのを防ぎます。
ラベルプレフィックスをNode分離に利用するには:
ノード認可 を使用していることと、NodeRestriction アドミッションプラグインが 有効 になっていることを確認します。node-restriction.kubernetes.io/プレフィックスを持つラベルをノードに追加し、 nodeSelector でそれらのラベルを使用します。
例えば、example.com.node-restriction.kubernetes.io/fips=trueやexample.com.node-restriction.kubernetes.io/pci-dss=trueなどです。nodeSelector nodeSelectorは、ノード選択制約の中で最もシンプルな推奨形式です。
Podのspec(仕様)にnodeSelectorフィールドを追加することで、ターゲットノードが持つべきノードラベル を指定できます。
Kubernetesは指定された各ラベルを持つノードにのみ、Podをスケジューリングします。
詳しい情報についてはPodをノードに割り当てる を参照してください。
アフィニティとアンチアフィニティ nodeSelectorはPodを特定のラベルが付与されたノードに制限する最も簡単な方法です。
アフィニティとアンチアフィニティでは、定義できる制約の種類が拡張されています。
アフィニティとアンチアフィニティのメリットは以下の通りです。
アフィニティとアンチアフィニティで使われる言語は、より表現力が豊かです。nodeSelectorは指定されたラベルを全て持つノードを選択するだけです。アフィニティとアンチアフィニティは選択ロジックをより細かく制御することができます。 ルールが柔軟 であったり優先 での指定ができたりするため、一致するノードが見つからない場合でも、スケジューラーはPodをスケジュールします。 ノード自体のラベルではなく、ノード(または他のトポロジカルドメイン)上で稼働している他のPodのラベルを使ってPodを制約することができます。これにより、ノード上にどのPodを共存させるかのルールを定義することができます。 アフィニティ機能は、2種類のアフィニティで構成されています:
ノードアフィニティ はnodeSelectorフィールドと同様に機能しますが、より表現力が豊かで、より柔軟にルールを指定することができます。Pod間アフィニティとアンチアフィニティ は、他のPodのラベルを元に、Podを制約することができます。ノードアフィニティ ノードアフィニティは概念的には、ノードのラベルによってPodがどのノードにスケジュールされるかを制限するnodeSelectorと同様です。
ノードアフィニティには2種類あります:
requiredDuringSchedulingIgnoredDuringExecution:
スケジューラーは、ルールが満たされない限り、Podをスケジュールすることができません。これはnodeSelectorと同じように機能しますが、より表現力豊かな構文になっています。preferredDuringSchedulingIgnoredDuringExecution:
スケジューラーは、対応するルールを満たすノードを探そうとします。 一致するノードが見つからなくても、スケジューラーはPodをスケジュールします。
備考: 上記の2種類にあるIgnoredDuringExecutionは、KubernetesがPodをスケジュールした後にノードラベルが変更されても、Podは実行し続けることを意味します。Podのspec(仕様)にある.spec.affinity.nodeAffinityフィールドを使用して、ノードアフィニティを指定することができます。
例えば、次のようなPodのspec(仕様)を考えてみましょう:
apiVersion : v1
kind : Pod
metadata :
name : with-node-affinity
spec :
affinity :
nodeAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
nodeSelectorTerms :
- matchExpressions :
- key : topology.kubernetes.io/zone
operator : In
values :
- antarctica-east1
- antarctica-west1
preferredDuringSchedulingIgnoredDuringExecution :
- weight : 1
preference :
matchExpressions :
- key : another-node-label-key
operator : In
values :
- another-node-label-value
containers :
- name : with-node-affinity
image : registry.k8s.io/pause:2.0この例では、以下のルールが適用されます:
ノードにはtopology.kubernetes.io/zoneをキーとするラベルが必要 で、そのラベルの値はantarctica-east1またはantarctica-west1のいずれかでなければなりません。 ノードにはキー名がanother-node-label-keyで、値がanother-node-label-valueのラベルを持つことが望ましい です。 operatorフィールドを使用して、Kubernetesがルールを解釈する際に使用できる論理演算子を指定することができます。In、NotIn、Exists、DoesNotExist、Gt、Ltが使用できます。
NotInとDoesNotExistを使って、ノードのアンチアフィニティ動作を定義することができます。また、ノードのTaint を使用して、特定のノードからPodをはじくこともできます。
備考: nodeSelectorとnodeAffinityの両方を指定した場合、両方の 条件を満たさないとPodはノードにスケジュールされません。
nodeAffinityタイプに関連付けられたnodeSelectorTerms内に、複数の条件を指定した場合、Podは指定した条件のいずれかを満たしたノードへスケジュールされます(条件はORされます)。
nodeSelectorTerms内の条件に関連付けられた1つのmatchExpressionsフィールド内に、複数の条件を指定した場合、Podは全ての条件を満たしたノードへスケジュールされます(条件はANDされます)。
詳細についてはノードアフィニティを利用してPodをノードに割り当てる を参照してください。
ノードアフィニティの重み preferredDuringSchedulingIgnoredDuringExecutionアフィニティタイプの各インスタンスに、1から100の範囲のweightを指定できます。
Podの他のスケジューリング要件をすべて満たすノードを見つけると、スケジューラーはそのノードが満たすすべての優先ルールを繰り返し実行し、対応する式のweight値を合計に加算します。
最終的な合計は、そのノードの他の優先度関数のスコアに加算されます。合計スコアが最も高いノードが、スケジューラーがPodのスケジューリングを決定する際に優先されます。
例えば、次のようなPodのspec(仕様)を考えてみましょう:
apiVersion : v1
kind : Pod
metadata :
name : with-affinity-anti-affinity
spec :
affinity :
nodeAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
nodeSelectorTerms :
- matchExpressions :
- key : kubernetes.io/os
operator : In
values :
- linux
preferredDuringSchedulingIgnoredDuringExecution :
- weight : 1
preference :
matchExpressions :
- key : label-1
operator : In
values :
- key-1
- weight : 50
preference :
matchExpressions :
- key : label-2
operator : In
values :
- key-2
containers :
- name : with-node-affinity
image : registry.k8s.io/pause:2.0preferredDuringSchedulingIgnoredDuringExecutionルールにマッチするノードとして、一つはlabel-1:key-1ラベル、もう一つはlabel-2:key-2ラベルの2つの候補がある場合、スケジューラーは各ノードのweightを考慮し、その重みとノードの他のスコアを加え、最終スコアが最も高いノードにPodをスケジューリングします。
備考: この例でKubernetesにPodを正常にスケジュールさせるには、kubernetes.io/os=linuxラベルを持つ既存のノードが必要です。スケジューリングプロファイルごとのノードアフィニティ FEATURE STATE:
Kubernetes v1.20 [beta]
複数のスケジューリングプロファイル を設定する場合、プロファイルにノードアフィニティを関連付けることができます。これは、プロファイルが特定のノード群にのみ適用される場合に便利です。スケジューラーの設定 にあるNodeAffinityプラグインargsフィールドにaddedAffinityを追加すると実現できます。例えば:
apiVersion : kubescheduler.config.k8s.io/v1
kind : KubeSchedulerConfiguration
profiles :
- schedulerName : default-scheduler
- schedulerName : foo-scheduler
pluginConfig :
- name : NodeAffinity
args :
addedAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
nodeSelectorTerms :
- matchExpressions :
- key : scheduler-profile
operator : In
values :
- foo
addedAffinityは、Podの仕様(spec)で指定されたノードアフィニティに加え、.spec.schedulerNameをfoo-schedulerに設定したすべてのPodに適用されます。つまり、Podにマッチするためには、ノードはaddedAffinityとPodの.spec.NodeAffinityを満たす必要があるのです。
addedAffinityはエンドユーザーには見えないので、その動作はエンドユーザーにとって予期しないものになる可能性があります。スケジューラープロファイル名と明確な相関関係のあるノードラベルを使用すべきです。
備考: DaemonSetのPodを作成する DaemonSetコントローラーは、スケジューリングプロファイルをサポートしていません。DaemonSetコントローラーがPodを作成すると、デフォルトのKubernetesスケジューラーがそれらのPodを配置し、DaemonSetコントローラーの
nodeAffinityルールに優先して従います。
Pod間のアフィニティとアンチアフィニティ Pod間のアフィニティとアンチアフィニティは、ノードのラベルではなく、すでにノード上で稼働しているPod のラベルに従って、Podがどのノードにスケジュールされるかを制限できます。
Xはノードや、ラック、クラウドプロバイダーのゾーンやリージョン等を表すトポロジードメインで、YはKubernetesが満たそうとするルールである場合、Pod間のアフィニティとアンチアフィニティのルールは、"XにてルールYを満たすPodがすでに稼働している場合、このPodもXで実行すべき(アンチアフィニティの場合はすべきではない)"という形式です。
これらのルール(Y)は、オプションの関連する名前空間のリストを持つラベルセレクター で表現されます。PodはKubernetesの名前空間オブジェクトであるため、Podラベルも暗黙的に名前空間を持ちます。Kubernetesが指定された名前空間でラベルを探すため、Podラベルのラベルセレクターは、名前空間を指定する必要があります。
トポロジードメイン(X)はtopologyKeyで表現され、システムがドメインを示すために使用するノードラベルのキーになります。具体例はよく知られたラベル、アノテーションとTaint を参照してください。
備考: Pod間アフィニティとアンチアフィニティはかなりの処理量を必要とするため、大規模クラスターでのスケジューリングが大幅に遅くなる可能性があります
そのため、数百台以上のノードから成るクラスターでの使用は推奨されません。
備考: Podのアンチアフィニティは、ノードに必ず一貫性の持つラベルが付与されている必要があります。
言い換えると、クラスターの全てのノードが、topologyKeyに合致する適切なラベルが必要になります。
一部、または全部のノードにtopologyKeyラベルが指定されていない場合、意図しない挙動に繋がる可能性があります。Pod間のアフィニティとアンチアフィニティの種類 ノードアフィニティ と同様に、Podアフィニティとアンチアフィニティにも下記の2種類があります:
requiredDuringSchedulingIgnoredDuringExecutionpreferredDuringSchedulingIgnoredDuringExecution例えば、requiredDuringSchedulingIgnoredDuringExecutionアフィニティを使用して、2つのサービスのPodはお互いのやり取りが多いため、同じクラウドプロバイダーゾーンに併置するようにスケジューラーに指示することができます。
同様に、preferredDuringSchedulingIgnoredDuringExecutionアンチアフィニティを使用して、あるサービスのPodを複数のクラウドプロバイダーゾーンに分散させることができます。
Pod間アフィニティを使用するには、Pod仕様(spec)のaffinity.podAffinityフィールドで指定します。Pod間アンチアフィニティを使用するには、Pod仕様(spec)のaffinity.podAntiAffinityフィールドで指定します。
Podアフィニティ使用例 次のようなPod仕様(spec)を考えてみましょう:
apiVersion : v1
kind : Pod
metadata :
name : with-pod-affinity
spec :
affinity :
podAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
- labelSelector :
matchExpressions :
- key : security
operator : In
values :
- S1
topologyKey : topology.kubernetes.io/zone
podAntiAffinity :
preferredDuringSchedulingIgnoredDuringExecution :
- weight : 100
podAffinityTerm :
labelSelector :
matchExpressions :
- key : security
operator : In
values :
- S2
topologyKey : topology.kubernetes.io/zone
containers :
- name : with-pod-affinity
image : registry.k8s.io/pause:2.0
この例では、PodアフィニティルールとPodアンチアフィニティルールを1つずつ定義しています。
Podアフィニティルールは"ハード"なrequiredDuringSchedulingIgnoredDuringExecutionを使用し、アンチアフィニティルールは"ソフト"なpreferredDuringSchedulingIgnoredDuringExecutionを使用しています。
アフィニティルールは、スケジューラーがノードにPodをスケジュールできるのは、そのノードが、security=S1ラベルを持つ1つ以上の既存のPodと同じゾーンにある場合のみであることを示しています。より正確には、現在Podラベルsecurity=S1を持つPodが1つ以上あるノードが、そのゾーン内に少なくとも1つ存在する限り、スケジューラーはtopology.kubernetes.io/zone=Vラベルを持つノードにPodを配置しなければなりません。
アンチアフィニティルールは、security=S2ラベルを持つ1つ以上のPodと同じゾーンにあるノードには、スケジューラーがPodをスケジュールしないようにすることを示しています。より正確には、PodラベルSecurity=S2を持つPodが稼働している他のノードが、同じゾーン内に存在する場合、スケジューラーはtopology.kubernetes.io/zone=Rラベルを持つノードにはPodを配置しないようにしなければなりません。
Podアフィニティとアンチアフィニティの使用例についてもっと知りたい方はデザイン案 を参照してください。
Podアフィニティとアンチアフィニティのoperatorフィールドで使用できるのは、In、NotIn、 Exists、 DoesNotExistです。
原則として、topologyKeyには任意のラベルキーが指定できますが、パフォーマンスやセキュリティの観点から、以下の例外があります:
Podアフィニティとアンチアフィニティでは、requiredDuringSchedulingIgnoredDuringExecutionとpreferredDuringSchedulingIgnoredDuringExecution内のどちらも、topologyKeyフィールドが空であることは許可されていません。 PodアンチアフィニティルールのrequiredDuringSchedulingIgnoredDuringExecutionでは、アドミッションコントローラーLimitPodHardAntiAffinityTopologyがtopologyKeyをkubernetes.io/hostnameに制限しています。アドミッションコントローラーを修正または無効化すると、トポロジーのカスタマイズができるようになります。 labelSelectorとtopologyKeyに加え、labelSelectorとtopologyKeyと同じレベルのnamespacesフィールドを使用して、labelSelectorが合致すべき名前空間のリストを任意に指定することができます。省略または空の場合、namespacesがデフォルトで、アフィニティとアンチアフィニティが定義されたPodの名前空間に設定されます。
名前空間セレクター FEATURE STATE:
Kubernetes v1.24 [stable]
namespaceSelectorを使用し、ラベルで名前空間の集合に対して検索することによって、名前空間を選択することができます。
アフィニティ項はnamespaceSelectorとnamespacesフィールドによって選択された名前空間に適用されます。
要注意なのは、空のnamespaceSelector({})はすべての名前空間にマッチし、nullまたは空のnamespacesリストとnullのnamespaceSelectorは、ルールが定義されているPodの名前空間にマッチします。
実践的なユースケース Pod間アフィニティとアンチアフィニティは、ReplicaSet、StatefulSet、Deploymentなどのより高レベルなコレクションと併せて使用するとさらに有用です。これらのルールにより、ワークロードのセットが同じ定義されたトポロジーに併置されるように設定できます。たとえば、2つの関連するPodを同じノードに配置することが好ましい場合です。
例えば、3つのノードで構成されるクラスターを想像してください。そのクラスターを使用してウェブアプリケーションを実行し、さらにインメモリーキャッシュ(Redisなど)を使用します。この例では、ウェブアプリケーションとメモリーキャッシュの間のレイテンシーは実用的な範囲の低さも想定しています。Pod間アフィニティやアンチアフィニティを使って、ウェブサーバーとキャッシュをなるべく同じ場所に配置することができます。
以下のRedisキャッシュのDeploymentの例では、各レプリカはラベルapp=storeが付与されています。podAntiAffinityルールは、app=storeラベルを持つ複数のレプリカを単一ノードに配置しないよう、スケジューラーに指示します。これにより、各キャッシュが別々のノードに作成されます。
apiVersion : apps/v1
kind : Deployment
metadata :
name : redis-cache
spec :
selector :
matchLabels :
app : store
replicas : 3
template :
metadata :
labels :
app : store
spec :
affinity :
podAntiAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
- labelSelector :
matchExpressions :
- key : app
operator : In
values :
- store
topologyKey : "kubernetes.io/hostname"
containers :
- name : redis-server
image : redis:3.2-alpine
次のウェブサーバーのDeployment例では、app=web-storeラベルが付与されたレプリカを作成します。Podアフィニティルールは、各レプリカを、app=storeラベルが付与されたPodを持つノードに配置するようスケジューラーに指示します。Podアンチアフィニティルールは、1つのノードに複数のapp=web-storeサーバーを配置しないようにスケジューラーに指示します。
apiVersion : apps/v1
kind : Deployment
metadata :
name : web-server
spec :
selector :
matchLabels :
app : web-store
replicas : 3
template :
metadata :
labels :
app : web-store
spec :
affinity :
podAntiAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
- labelSelector :
matchExpressions :
- key : app
operator : In
values :
- web-store
topologyKey : "kubernetes.io/hostname"
podAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
- labelSelector :
matchExpressions :
- key : app
operator : In
values :
- store
topologyKey : "kubernetes.io/hostname"
containers :
- name : web-app
image : nginx:1.16-alpine
上記2つのDeploymentが生成されると、以下のようなクラスター構成になり、各ウェブサーバーはキャッシュと同位置に、3つの別々のノードに配置されます。
node-1 node-2 node-3 webserver-1 webserver-2 webserver-3 cache-1 cache-2 cache-3
全体的な効果として、各キャッシュインスタンスは、同じノード上で実行している単一のクライアントによってアクセスされる可能性が高いです。この方法は、スキュー(負荷の偏り)とレイテンシーの両方を最小化することを目的としています。
Podアンチアフィニティを使用する理由は他にもあります。
この例と同様の方法で、アンチアフィニティを用いて高可用性を実現したStatefulSetの使用例はZooKeeperチュートリアル を参照してください。
nodeName nodeNameはアフィニティやnodeSelectorよりも直接的なノード選択形式になります。nodeNameはPod仕様(spec)内のフィールドです。nodeNameフィールドが空でない場合、スケジューラーはPodを考慮せずに、指定されたノードにあるkubeletがそのノードにPodを配置しようとします。nodeNameを使用すると、nodeSelectorやアフィニティおよびアンチアフィニティルールを使用するよりも優先されます。
nodeNameを使ってノードを選択する場合の制約は以下の通りです:
指定されたノードが存在しない場合、Podは実行されず、場合によっては自動的に削除されることがあります。 指定されたノードがPodを収容するためのリソースを持っていない場合、Podの起動は失敗し、OutOfmemoryやOutOfcpuなどの理由が表示されます。 クラウド環境におけるノード名は、常に予測可能で安定したものではありません。 備考: nodeNameは、カスタムスケジューラーや、設定済みのスケジューラーをバイパスする必要がある高度なユースケースで使用することを目的としています。
スケジューラーをバイパスすると、割り当てられたノードに過剰なPodの配置をしようとした場合には、Podの起動に失敗することがあります。
ノードアフィニティ または
nodeSelectorフィールドを使用すれば、スケジューラーをバイパスせずに、特定のノードにPodを割り当てることができます。
以下は、nodeNameフィールドを使用したPod仕様(spec)の例になります:
apiVersion : v1
kind : Pod
metadata :
name : nginx
spec :
containers :
- name : nginx
image : nginx
nodeName : kube-01
上記のPodはkube-01というNodeでのみ実行されます。
Podトポロジー分散制約 トポロジー分散制約 を使って、リージョン、ゾーン、ノードなどの障害ドメイン間、または定義したその他のトポロジードメイン間で、クラスター全体にどのようにPod を分散させるかを制御することができます。これにより、パフォーマンス、予想される可用性、または全体的な使用率を向上させることができます。
詳しい仕組みについては、トポロジー分散制約 を参照してください。
次の項目 3.11.3 - Podのオーバーヘッド FEATURE STATE:
Kubernetes v1.24 [stable]
PodをNode上で実行する時に、Pod自身は大量のシステムリソースを消費します。これらのリソースは、Pod内のコンテナ(群)を実行するために必要なリソースとして追加されます。Podのオーバーヘッドは、コンテナの要求と制限に加えて、Podのインフラストラクチャで消費されるリソースを計算するための機能です。
Kubernetesでは、PodのRuntimeClass に関連するオーバーヘッドに応じて、アドミッション 時にPodのオーバーヘッドが設定されます。
Podのオーバーヘッドを有効にした場合、Podのスケジューリング時にコンテナのリソース要求の合計に加えて、オーバーヘッドも考慮されます。同様に、Kubeletは、Podのcgroupのサイズ決定時およびPodの退役の順位付け時に、Podのオーバーヘッドを含めます。
Podのオーバーヘッドの有効化 クラスター全体でPodOverheadのフィーチャーゲート が有効になっていること(1.18時点ではデフォルトでオンになっています)と、overheadフィールドを定義するRuntimeClassが利用されていることを確認する必要があります。
使用例 Podのオーバーヘッド機能を使用するためには、overheadフィールドが定義されたRuntimeClassが必要です。例として、仮想マシンとゲストOSにPodあたり約120MiBを使用する仮想化コンテナランタイムで、次のようなRuntimeClassを定義できます。
apiVersion : node.k8s.io/v1
kind : RuntimeClass
metadata :
name : kata-fc
handler : kata-fc
overhead :
podFixed :
memory : "120Mi"
cpu : "250m"
kata-fcRuntimeClassハンドラーを指定して作成されたワークロードは、リソースクォータの計算や、Nodeのスケジューリング、およびPodのcgroupのサイズ決定にメモリーとCPUのオーバーヘッドが考慮されます。
次のtest-podのワークロードの例を実行するとします。
apiVersion : v1
kind : Pod
metadata :
name : test-pod
spec :
runtimeClassName : kata-fc
containers :
- name : busybox-ctr
image : busybox:1.28
stdin : true
tty : true
resources :
limits :
cpu : 500m
memory : 100Mi
- name : nginx-ctr
image : nginx
resources :
limits :
cpu : 1500m
memory : 100Mi
アドミッション時、RuntimeClassアドミッションコントローラー は、RuntimeClass内に記述されたオーバーヘッドを含むようにワークロードのPodSpecを更新します。もし既にPodSpec内にこのフィールドが定義済みの場合、そのPodは拒否されます。この例では、RuntimeClassの名前しか指定されていないため、アドミッションコントローラーはオーバーヘッドを含むようにPodを変更します。
RuntimeClassのアドミッションコントローラーの後、更新されたPodSpecを確認できます。
kubectl get pod test-pod -o jsonpath = '{.spec.overhead}'
出力は次の通りです:
map[cpu:250m memory:120Mi]
ResourceQuotaが定義されている場合、コンテナ要求の合計とオーバーヘッドフィールドがカウントされます。
kube-schedulerが新しいPodを実行すべきNodeを決定する際、スケジューラーはそのPodのオーバーヘッドと、そのPodに対するコンテナ要求の合計を考慮します。この例だと、スケジューラーは、要求とオーバーヘッドを追加し、2.25CPUと320MiBのメモリを持つNodeを探します。
PodがNodeにスケジュールされると、そのNodeのkubeletはPodのために新しいcgroup を生成します。基盤となるコンテナランタイムがコンテナを作成するのは、このPod内です。
リソースにコンテナごとの制限が定義されている場合(制限が定義されているGuaranteed QoSまたはBustrable QoS)、kubeletはそのリソース(CPUはcpu.cfs_quota_us、メモリはmemory.limit_in_bytes)に関連するPodのcgroupの上限を設定します。この上限は、コンテナの制限とPodSpecで定義されたオーバーヘッドの合計に基づきます。
CPUについては、PodがGuaranteedまたはBurstable QoSの場合、kubeletはコンテナの要求の合計とPodSpecに定義されたオーバーヘッドに基づいてcpu.shareを設定します。
次の例より、ワークロードに対するコンテナの要求を確認できます。
kubectl get pod test-pod -o jsonpath = '{.spec.containers[*].resources.limits}'
コンテナの要求の合計は、CPUは2000m、メモリーは200MiBです。
map[cpu: 500m memory:100Mi] map[cpu:1500m memory:100Mi]
Nodeで観測される値と比較してみましょう。
kubectl describe node | grep test-pod -B2
出力では、2250mのCPUと320MiBのメモリーが要求されており、Podのオーバーヘッドが含まれていることが分かります。
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
default test-pod 2250m (56%) 2250m (56%) 320Mi (1%) 320Mi (1%) 36m
Podのcgroupの制限を確認 ワークロードで実行中のNode上にある、Podのメモリーのcgroupを確認します。次に示す例では、CRI互換のコンテナランタイムのCLIを提供するNodeでcrictl
まず、特定のNodeで、Podの識別子を決定します。
# PodがスケジュールされているNodeで実行
POD_ID = " $( sudo crictl pods --name test-pod -q) "
ここから、Podのcgroupのパスが決定します。
# PodがスケジュールされているNodeで実行
sudo crictl inspectp -o= json $POD_ID | grep cgroupsPath
結果のcgroupパスにはPodのポーズ中コンテナも含まれます。Podレベルのcgroupは1つ上のディレクトリです。
"cgroupsPath": "/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/7ccf55aee35dd16aca4189c952d83487297f3cd760f1bbf09620e206e7d0c27a"
今回のケースでは、Podのcgroupパスは、kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2となります。メモリーのPodレベルのcgroupの設定を確認しましょう。
# PodがスケジュールされているNodeで実行
# また、Podに割り当てられたcgroupと同じ名前に変更
cat /sys/fs/cgroup/memory/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/memory.limit_in_bytes
予想通り320MiBです。
335544320
Observability Podのオーバヘッドが利用されているタイミングを特定し、定義されたオーバーヘッドで実行されているワークロードの安定性を観察するため、kube-state-metrics にはkube_pod_overheadというメトリクスが用意されています。この機能はv1.9のkube-state-metricsでは利用できませんが、次のリリースで期待されています。それまでは、kube-state-metricsをソースからビルドする必要があります。
次の項目 3.11.4 - Podトポロジー分散制約 トポロジー分散制約 を使用するとリージョン、ゾーン、ノードおよびその他のユーザー定義されたトポロジー領域などの障害ドメインをまたがって、クラスター内のPod がどのように分散されるかを制御できます。
これにより、高可用性と効率的なリソース活用を実現できます。
クラスターレベルの制約 をデフォルトとして設定するか、個々のワークロードに対してトポロジー分散制約を設定できます。
動機 最大20ノードのクラスターがあり、使用するレプリカ数を自動的にスケーリングするワークロード を実行したいとします。
このワークロードには、2つのPodが存在する場合もあれば、15のPodが存在する場合もあります。
Podが2つだけの場合、単一ノードの障害でワークロードがオフラインになるリスクがあるため、同じノードで両方のPodを実行したくありません。
この基本的な使用方法に加えて、高可用性とクラスターの利用率を向上させるための高度な使用方法があります。
スケールアップしてより多くのPodを実行すると、また別の懸念事項が重要になります。
5つのPodを実行する3つのノードがあるとします。
ノードは該当数のレプリカを実行するために十分なキャパシティを持っていますが、このワークロードとやり取りするクライアントは3つの異なるデータセンター(またはインフラストラクチャゾーン)に分散されています。
単一ノードの障害についての懸念は減りましたが、レイテンシーが予想よりも高く、異なるゾーン間でネットワークトラフィックを送信する際にネットワークコストがかかっていることに気づきます。
通常の運用では、各インフラストラクチャゾーンに同数のレプリカをスケジュール し、問題が発生した場合はクラスターが自己修復するようにしたいと考えるでしょう。
Podトポロジー分散制約は、このようなシナリオに対処するための手段を提供します。
topologySpreadConstraintsフィールドPod APIには、spec.topologySpreadConstraintsフィールドが含まれています。
このフィールドの使用方法は次のようになります:
---
apiVersion : v1
kind : Pod
metadata :
name : example-pod
spec :
# トポロジー分散制約を設定
topologySpreadConstraints :
- maxSkew : <integer>
minDomains : <integer> # オプション
topologyKey : <string>
whenUnsatisfiable : <string>
labelSelector : <object>
matchLabelKeys : <list> # オプション; v1.27以降ベータ
nodeAffinityPolicy : [Honor|Ignore] # オプション; v1.26以降ベータ
nodeTaintsPolicy : [Honor|Ignore] # オプション; v1.26以降ベータ
### 他のPodのフィールドはここにあります
kubectl explain Pod.spec.topologySpreadConstraintsを実行するか、PodのAPIリファレンスのscheduling セクションを参照して、このフィールドについて詳しく読むことができます。
分散制約の定義 クラスター全体の既存のPodに対して、新しいPodをどのように配置するかをkube-schedulerに指示するために、1つまたは複数のtopologySpreadConstraintsエントリを定義できます。
これらのフィールドは次の通りです:
maxSkew は、Podが不均等に分散される程度を表します。
このフィールドは必須であり、0より大きい数値を指定する必要があります。
このフィールドのセマンティクスは、whenUnsatisfiableの値によって異なります:
whenUnsatisfiable: DoNotScheduleを選択した場合、maxSkewは対象トポロジー内の一致するPodの数と、グローバル最小値 (適格ドメイン内の一致するPodの最小数、または適格ドメインの数がMinDomainsより少ない場合は0)の間で許容される最大の差を定義します。
例えば、3つのゾーンがあり、それぞれ2、2、1つの一致するPodがありMaxSkewが1に設定されている場合、グローバル最小値は1です。whenUnsatisfiable: ScheduleAnywayを選択した場合、スケジューラーはスキューの削減に役立つトポロジーを優先します。minDomains は、適格ドメインの最小数を示します。
このフィールドはオプションです。
ドメインとは、特定のトポロジーのインスタンスを指します。
適格ドメインとは、ノードセレクターに一致するノードのドメインを指します。
備考: Kubernetes v1.30以前では、
minDomainsフィールドは、
MinDomainsInPodTopologySpreadフィーチャーゲート が有効になっている場合のみ利用可能でした(v1.28以降はデフォルト)。
より古いKubernetesクラスターでは、明示的に無効になっているか、フィールドが利用できない場合があります。
minDomainsの値を指定する場合、その値は0より大きくする必要があります。
minDomainsは、whenUnsatisfiable: DoNotScheduleと組み合わせてのみ指定できます。トポロジーキーに一致する適格ドメインの数がminDomainsより少ない場合、Podトポロジー分散はグローバル最小値を0として扱い、skewの計算を行います。
グローバル最小値は、適格ドメイン内の一致するPodの最小数であり、適格ドメインの数がminDomainsより少ない場合は0になります。 トポロジーキーに一致する適格ドメインの数がminDomainsと等しいかそれ以上の場合、この値はスケジューリングに影響しません。 minDomainsを指定しない場合、制約はminDomainsが1であるかのように動作します。topologyKey はノードラベル のキーです。
このキーと同じ値を持つノードは、同じトポロジー内にあると見なされます。
トポロジー内の各インスタンス(つまり、<key, value>ペア)をドメインと呼びます。
スケジューラーは、各ドメインに均等な数のPodを配置しようとします。
また、適格ドメインはnodeAffinityPolicyとnodeTaintsPolicyの要件を満たすノードのドメインとして定義します。
whenUnsatisfiable は、Podが分散制約を満たさない場合の処理方法を示します:
DoNotSchedule(デフォルト)は、スケジューラーにスケジュールしないように指示します。ScheduleAnywayは、スケジューラーにスキューを最小化するノードを優先してスケジュールするよう指示します。labelSelector は、一致するPodを見つけるために使用されます。
このラベルセレクターに一致するPodは、対応するトポロジードメイン内のPodの数を決定するためにカウントされます。
詳細については、ラベルセレクター を参照してください。
matchLabelKeys は、分散を計算するPodを選択するためのPodラベルキーのリストです。
このキーは、Podラベルから値を検索するために使用され、これらのkey-valueラベルはlabelSelectorとAND演算され、新しいPodのために分散が計算される既存のPodのグループを選択します。
同じキーはmatchLabelKeysとlabelSelectorの両方に存在してはいけません。
labelSelectorが設定されていない場合は、matchLabelKeysを設定することはできません。
Podラベルに存在しないキーは無視されます。
nullまたは空のリストは、labelSelectorに対してのみ一致します。
matchLabelKeysを使用すると、異なるリビジョン間でpod.specを更新する必要がありません。
コントローラー/オペレーターは、異なるリビジョンに対して同じラベルキーを異なる値に設定するだけです。
スケジューラーは、matchLabelKeysに基づいて値を自動的に推定します。
例えばDeploymentを構成する場合、Deploymentコントローラーによって自動的に追加されるpod-template-hash をキーとするラベルを使用して、単一のDeployment内の異なるリビジョンを区別できます。
topologySpreadConstraints :
- maxSkew : 1
topologyKey : kubernetes.io/hostname
whenUnsatisfiable : DoNotSchedule
labelSelector :
matchLabels :
app : foo
matchLabelKeys :
- pod-template-hash
備考: matchLabelKeysフィールドは、ベータレベルのフィールドであり、1.27でデフォルトで有効になっています。
MatchLabelKeysInPodTopologySpreadフィーチャーゲート を無効にすることで無効にできます。
nodeAffinityPolicy は、Podのトポロジー分散スキューを計算する際に、PodのnodeAffinity/nodeSelectorをどのように扱うかを示します。
オプションは次の通りです:
Honor: nodeAffinity/nodeSelectorに一致するノードのみが計算に含まれます。 Ignore: nodeAffinity/nodeSelectorは無視されます。
すべてのノードが計算に含まれます。 この値がnullの場合、動作はHonorポリシーと同等です。
備考: nodeAffinityPolicyはベータレベルのフィールドであり、1.26でデフォルトで有効になっています。
NodeInclusionPolicyInPodTopologySpreadフィーチャーゲート を無効にすることで無効にできます。
nodeTaintsPolicy は、Podのトポロジー分散スキューを計算する際に、ノードのtaintをどのように扱うかを示します。
オプションは次の通りです:
Honor: taintのないノード、新しいPodがtolerationを持つtaintされたノードが含まれます。 Ignore: ノードのtaintは無視されます。
すべてのノードが含まれます。 この値がnullの場合、動作はIgnoreポリシーと同等です。
備考: nodeTaintsPolicyはベータレベルのフィールドであり、1.26でデフォルトで有効になっています。
NodeInclusionPolicyInPodTopologySpreadフィーチャーゲート を無効にすることで無効にできます。
PodにtopologySpreadConstraintsが複数定義されている場合、これらの制約は論理AND演算を使用して結合され、kube-schedulerは新しいPodに対して構成された制約をすべて満たすノードを探します。
ノードラベル トポロジー分散制約は、ノードラベルを使用して、各ノード がどのトポロジードメインに属するかを識別します。
例えば、ノードには次のようなラベルがあるかもしれません:
region : us-east-1
zone : us-east-1a
備考: 簡潔にするため、この例ではwell-known ラベルキーのtopology.kubernetes.io/zoneとtopology.kubernetes.io/regionは使用していません。
ただし、ここで使用されているregionおよびzoneといったプライベート(修飾されていない)ラベルキーよりも、これらの登録済みラベルキーが推奨されます。
異なるコンテキスト間でのプライベートラベルキーの意味について、信頼できる前提として扱うことはできません。
次のラベルを持つ4ノードのクラスターがあるとします:
NAME STATUS ROLES AGE VERSION LABELS
node1 Ready <none> 4m26s v1.16.0 node=node1,zone=zoneA
node2 Ready <none> 3m58s v1.16.0 node=node2,zone=zoneA
node3 Ready <none> 3m17s v1.16.0 node=node3,zone=zoneB
node4 Ready <none> 2m43s v1.16.0 node=node4,zone=zoneB
クラスターは論理的には以下のように表されます:
graph TB
subgraph "zoneB"
n3(Node3)
n4(Node4)
end
subgraph "zoneA"
n1(Node1)
n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4 k8s;
class zoneA,zoneB cluster;
このコンテンツを表示するには、JavaScriptを有効に する必要があります 一貫性 グループ内のすべてのPodに同じトポロジー分散制約を適用する必要があります。
通常、Deploymentなどのワークロードコントローラーを使用している場合、Podテンプレートがこれを自動的に処理します。
異なる分散制約を混在させると、KubernetesはフィールドのAPI定義に従いますが、その動作は混乱しやすくなりトラブルシューティングがより困難になる可能性があります。
トポロジードメイン(例えばクラウドプロバイダーのリージョン)内のすべてのノードに、一貫してラベルが付与されていることを保証するメカニズムが必要です。
手動でノードにラベルを付与する必要がないように、多くのクラスターはkubernetes.io/hostnameのようなwell-knownラベルを自動的に設定します。
ご自身のクラスターがこれをサポートしているかどうかを確認してください。
トポロジー分散制約の例 例: 単一のトポロジー分散制約 4ノードのクラスターがあり、foo: barというラベルの付いた3つのPodがそれぞれ node1、node2、node3に配置されているとします:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class zoneA,zoneB cluster;
このコンテンツを表示するには、JavaScriptを有効に する必要があります 新しいPodを既存のPodとゾーン全体に均等に分散したい場合は、次のようなマニフェストを使用できます:
kind : Pod
apiVersion : v1
metadata :
name : mypod
labels :
foo : bar
spec :
topologySpreadConstraints :
- maxSkew : 1
topologyKey : zone
whenUnsatisfiable : DoNotSchedule
labelSelector :
matchLabels :
foo : bar
containers :
- name : pause
image : registry.k8s.io/pause:3.1このマニフェストでは、topologyKey: zoneはzone: <任意の値>というラベルが付いたノードにのみ均等に分散が適用されることを意味します(ラベルzoneがないノードはスキップされます)。
whenUnsatisfiable: DoNotScheduleフィールドは、スケジューラーが制約を満たせない場合に、新しいPodを保留状態にするようにスケジューラーに指示します。
スケジューラーがこの新しいPodをゾーンAに配置した場合、Podの分布は[3, 1]になります。
これは実際のスキューが2(3 - 1として計算)であることを意味し、maxSkew: 1に違反します。
この例の制約とコンテキストを満たすためには、新しいPodはゾーンBのノードにのみ配置される必要があります:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
p4(mypod) --> n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
このコンテンツを表示するには、JavaScriptを有効に する必要があります または
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
p4(mypod) --> n3
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
このコンテンツを表示するには、JavaScriptを有効に する必要があります Podの仕様を調整することで、様々な要件に対応できます:
maxSkewをより大きい値(例えば2)に変更すると、新しいPodをゾーンAに配置できるようになります。topologyKeyをnodeに変更すると、ゾーン単位ではなくノード単位でPodを均等に分散させるようになります。
上記の例では、maxSkewが1のままである場合、新しいPodはnode4にのみ配置可能です。whenUnsatisfiable: DoNotScheduleをwhenUnsatisfiable: ScheduleAnywayに変更すると、新しいPodが常にスケジュール可能になります(他のスケジュールAPIが満たされていると仮定)。
ただし、一致するPodが少ないトポロジードメインに配置されることが好ましいです。
(この設定は、リソース使用率などの他の内部スケジューリング優先度と共に正規化されることに注意してください)。例: 複数のトポロジー分散制約 これは前の例に基づいています。
4ノードのクラスターがあり、foo: barというラベルの付いた3つのPodがそれぞれ node1、node2、node3に配置されているとします:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
このコンテンツを表示するには、JavaScriptを有効に する必要があります 2つのトポロジー分散制約を組み合わせて、ノードとゾーンの両方でPodの分散を制御できます:
kind : Pod
apiVersion : v1
metadata :
name : mypod
labels :
foo : bar
spec :
topologySpreadConstraints :
- maxSkew : 1
topologyKey : zone
whenUnsatisfiable : DoNotSchedule
labelSelector :
matchLabels :
foo : bar
- maxSkew : 1
topologyKey : node
whenUnsatisfiable : DoNotSchedule
labelSelector :
matchLabels :
foo : bar
containers :
- name : pause
image : registry.k8s.io/pause:3.1この場合、最初の制約に一致させるために、新しいPodはゾーンBのノードにのみ配置できます。
一方、2番目の制約に関しては、新しいPodはnode4にのみスケジュールできます。
スケジューラーは、定義されたすべての制約を満たすオプションのみを考慮するため、有効な配置はnode4のみです。
例: トポロジー分散制約の競合 複数の制約は競合する可能性があります。
2つのゾーンにまたがる3ノードのクラスターがあるとします:
graph BT
subgraph "zoneB"
p4(Pod) --> n3(Node3)
p5(Pod) --> n3
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n1
p3(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3,p4,p5 k8s;
class zoneA,zoneB cluster;
このコンテンツを表示するには、JavaScriptを有効に する必要があります この クラスターにtwo-constraints.yamlmypodがPending状態のままであることがわかります。
これは、最初の制約を満たすために、Pod mypodはゾーンBにしか配置できないのに対して、2番目の制約に関しては、Pod mypodはノードnode2にしかスケジュールできないために発生します。
2つの制約の共通部分として空集合が返され、スケジューラーはPodを配置できません。
この状況を克服するためには、maxSkewの値を増やすか、制約の1つをwhenUnsatisfiable: ScheduleAnywayに変更します。
状況によっては、バグ修正のロールアウトが進まない理由をトラブルシューティングする場合などで、既存のPodを手動で削除することもあります。
ノードアフィニティとノードセレクターとの相互作用 新しいPodにspec.nodeSelectorまたはspec.affinity.nodeAffinityが定義されている場合、スケジューラーは一致しないノードをスキュー計算からスキップします。
例: ノードアフィニティを使用したトポロジー分散制約 ゾーンAからCにまたがる5ノードクラスターがあるとします:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
このコンテンツを表示するには、JavaScriptを有効に する必要があります graph BT
subgraph "zoneC"
n5(Node5)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n5 k8s;
class zoneC cluster;
このコンテンツを表示するには、JavaScriptを有効に する必要があります そして、ゾーンCを除外する必要があることがわかっているとします。
この場合、以下のようにマニフェストを作成して、Pod mypodをゾーンCではなくゾーンBに配置することができます。
同様に、Kubernetesはspec.nodeSelectorを尊重します。
kind : Pod
apiVersion : v1
metadata :
name : mypod
labels :
foo : bar
spec :
topologySpreadConstraints :
- maxSkew : 1
topologyKey : zone
whenUnsatisfiable : DoNotSchedule
labelSelector :
matchLabels :
foo : bar
affinity :
nodeAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
nodeSelectorTerms :
- matchExpressions :
- key : zone
operator : NotIn
values :
- zoneC
containers :
- name : pause
image : registry.k8s.io/pause:3.1暗黙的な規則 ここで注目すべき暗黙的な規則がいくつかあります:
新しいPodと同じNamespaceを持つPodのみが一致する候補となります。
スケジューラーは、すべてのtopologySpreadConstraints[*].topologyKeyが同時に存在するノードのみを考慮します。
これらのtopologyKeysのいずれかが欠落しているノードはバイパスされます。
これは次のことを意味します:
これらのバイパスされたノードにあるPodはmaxSkewの計算に影響しません。
上記の例 では、ノードnode1に"zone"ラベルがない場合、2つのPodは無視され、新しいPodはゾーンAにスケジュールされます。 新しいPodがこれらのノードにスケジュールされる可能性はありません。
上記の例では、ノードnode5に誤字のある ラベルzone-typo: zoneCがある(かつzoneラベルが設定されていない)とします。
node5がクラスターに参加しても、バイパスされ、このワークロードのPodはそのノードにスケジュールされません。 新しいPodのtopologySpreadConstraints[*].labelSelectorが自身のラベルと一致しない場合に何が起こるかに注意してください。
上記の例では、新しいPodのラベルを削除しても、すでに制約が満たされているため、ゾーンBのノードに配置できます。
ただしその配置後、クラスターの不均衡の度合いは変わらず、ゾーンAにはfoo: barというラベルが付いた2つのPodがあり、ゾーンBにはfoo: barというラベルが付いた1つのPodがあります。
これが期待する動作ではない場合、ワークロードのtopologySpreadConstraints[*].labelSelectorを更新して、Podテンプレート内のラベルと一致するようにします。
クラスターレベルのデフォルト制約 クラスターにはデフォルトのトポロジー分散制約を設定することができます。
デフォルトのトポロジー分散制約は、次の場合にのみPodに適用されます:
.spec.topologySpreadConstraintsに制約が定義されていない。PodがService、ReplicaSet、StatefulSet、またはReplicationControllerに属している。 デフォルトの制約は、スケジューリングプロファイル のPodTopologySpreadプラグイン引数の一部として設定できます。
制約は、上記のAPI と同じように指定されますが、labelSelectorは空である必要があります。
Podが属するService、ReplicaSet、StatefulSet、またはReplicationControllerから計算されたセレクターが使用されます。
設定例は次のようになります:
apiVersion : kubescheduler.config.k8s.io/v1
kind : KubeSchedulerConfiguration
profiles :
- schedulerName : default-scheduler
pluginConfig :
- name : PodTopologySpread
args :
defaultConstraints :
- maxSkew : 1
topologyKey : topology.kubernetes.io/zone
whenUnsatisfiable : ScheduleAnyway
defaultingType : List
ビルトインのデフォルト制約 FEATURE STATE:
Kubernetes v1.24 [stable]
Podトポロジー分散のためのクラスターレベルのデフォルト制約を構成しない場合、kube-schedulerは次のデフォルトのトポロジー制約を指定したかのように動作します:
defaultConstraints :
- maxSkew : 3
topologyKey : "kubernetes.io/hostname"
whenUnsatisfiable : ScheduleAnyway
- maxSkew : 5
topologyKey : "topology.kubernetes.io/zone"
whenUnsatisfiable : ScheduleAnyway
また、同等の動作を提供する従来のSelectorSpreadプラグインは、デフォルトで無効になっています。
備考: PodTopologySpreadプラグインは、分散制約で指定されていないトポロジーキーを持つノードにスコアをつけません。
これにより、デフォルトのトポロジー制約を使用する場合、従来のSelectorSpreadプラグインと比較して、デフォルトの動作が異なる場合があります。
ノードにkubernetes.io/hostnameとtopology.kubernetes.io/zoneラベルの両方 が設定されることを想定していない場合、Kubernetesのデフォルトを使用する代わりに独自の制約を定義してください。
クラスターにデフォルトのPod分散制約を使用したくない場合は、PodTopologySpreadプラグイン構成のdefaultingTypeをListに設定し、defaultConstraintsを空のままにすることで、これらのデフォルトを無効にできます:
apiVersion : kubescheduler.config.k8s.io/v1
kind : KubeSchedulerConfiguration
profiles :
- schedulerName : default-scheduler
pluginConfig :
- name : PodTopologySpread
args :
defaultConstraints : []
defaultingType : List
podAffinityとpodAntiAffinityとの比較 Kubernetesでは、Pod間のアフィニティとアンチアフィニティ によって、Podがより密集させるか分散させるかといった、Podが互いにどのようにスケジュールされるかを制御できます。
podAffinityPodを引き付けます。
適切なトポロジードメインに任意の数のPodを配置できます。 podAntiAffinityPodを遠ざけます。
requiredDuringSchedulingIgnoredDuringExecutionモードに設定すると、単一のトポロジードメインには1つのPodしかスケジュールできません。
preferredDuringSchedulingIgnoredDuringExecutionモードに設定すると、この制約を強制できません。 より細かい制御を行うには、トポロジー分散制約を指定して、異なるトポロジードメインにPodを分散させることで、高可用性やコスト削減を実現できます。
またワークロードのローリングアップデートやレプリカのスムーズなスケールアウトにも役立ちます。
詳しくは、Podのトポロジー分散制約に関する機能強化提案のMotivation セクションを参照してください。
既知の制限 Podの削除後も、制約が満たされていることは保証されません。
例えば、Deploymentのスケールダウンによって、Podの分布が不均衡になる可能性があります。
Podの分布をリバランスするには、Descheduler などのツールを使用できます。
taintされたノードに一致するPodは優先されます。
Issue 80921 を参照してください。
スケジューラーは、クラスター内のすべてのゾーンやその他のトポロジードメインを事前に把握しているわけではありません。
これらはクラスター内の既存のノードから決定されます。
オートスケールされるクラスターでは、ノードプール(またはノードグループ)が0ノードにスケールされ、クラスターがスケールアップすることを期待している場合に問題が発生する可能性があります。
この場合、トポロジードメインはその中に少なくとも1つのノードが存在するまで考慮されないためです。
これを回避するためには、Podのトポロジー分散制約を認識し、全体のトポロジードメインの集合も認識しているノードオートスケーラーを使用することができます。
次の項目 3.11.5 - Podのスケジューリング準備 FEATURE STATE:
Kubernetes v1.30 [stable]
Podは1度作成されると、スケジュールの準備ができたとみなされます。Kubernetesのスケジューラーは、すべての保留中のPodを配置するためにノードを見つけることに最善を尽くします。しかし実際のケースでは、一部のPodが「必要なリソースを満たさない」状態に長期間とどまることがあります。このようなPodは、実際にはスケジューラー(およびCluster AutoScalerのようなダウンストリームのインテグレーター)を不必要に混乱させます。
Podの.spec.schedulingGatesを指定したり削除したりすることで、Podがスケジューリングの対象になるタイミングを制御できます。
PodにschedulingGatesを設定する schedulingGatesのフィールドは、文字列のリストで構成されており、各文字列はPodがスケジューリング可能とみなされる前に満たすべき条件を表します。このフィールドは、Pod作成時のみ初期化できます(クライアントによる作成時、またはアドミッション中の変更時)。作成後、個々のschedulingGateは順序不同で削除できますが、新しいschedulingGateを追加することはできません。
Pod スケジューリングゲートの図
使用例 Podがスケジューリングされる準備ができていないと示すには、次のように1つ以上のスケジューリングゲートを使って作成します。
apiVersion : v1
kind : Pod
metadata :
name : test-pod
spec :
schedulingGates :
- name : example.com/foo
- name : example.com/bar
containers :
- name : pause
image : registry.k8s.io/pause:3.6
Podの作成後、状態を確認するには以下のようにします。
出力からSchedulingGated状態であることがわかります。
NAME READY STATUS RESTARTS AGE
test-pod 0/1 SchedulingGated 0 7s
また、schedulingGatesフィールドから確認することもできます。
kubectl get pod test-pod -o jsonpath = '{.spec.schedulingGates}'
出力は以下のようになります。
[{"name":"example.com/foo"},{"name":"example.com/bar"}]
このPodがスケジューリング可能であることをスケジューラーに知らせるには、変更したマニフェストを再適用することで、schedulingGatesを完全に削除できます。
apiVersion : v1
kind : Pod
metadata :
name : test-pod
spec :
containers :
- name : pause
image : registry.k8s.io/pause:3.6
schedulingGatesが削除されているかどうかは、以下のように確認できます。
kubectl get pod test-pod -o jsonpath = '{.spec.schedulingGates}'
出力は、空であることが期待されます。そして、以下のように実行することで最新の状態を確認することができます。
kubectl get pod test-pod -o wide
test-podがCPU/メモリリソースを要求しないため、このPodのステータスは、以前のSchedulingGatedからRunningに遷移することが予想されます。
NAME READY STATUS RESTARTS AGE IP NODE
test-pod 1/1 Running 0 15s 10.0.0.4 node-2
可観測性 scheduler_pending_podsメトリックには、Podがスケジューリングされようとしているがスケジューリング不可能とされているのか、それとも明示的にスケジューリングの準備ができておらずマークされているのかを区別する新しいラベル"gated"があります。scheduler_pending_pods{queue="gated"}でメトリックの結果を確認できます。
変更可能なPodのスケジューリング命令 Podにスケジューリングゲートが設定されている間、Podのスケジューリング命令は、一定の制約のもとで変更できます。高いレベルでは、Podのスケジューリング命令を厳格にすることしかできません。言い換えると、更新された命令は、Podが以前マッチしていたノードのサブセットでしかスケジューリングできなくなります。より具体的には、Podのスケジューリング命令を更新するルールは以下のようになります。
.spec.nodeSelectorは、追加のみが許可されます。 存在しない場合は設定が許可されます。
spec.affinity.nodeAffinityは、空の場合、何でも設定できます。
NodeSelectorTermsが空の場合、設定が許可されます。 空でない場合は、matchExpressionsまたはfieldExpressionsへのNodeSelectorRequirementsの追加のみが許可され、既存のmatchExpressionsおよびfieldExpressionsへの変更は許可されません。これは、.requiredDuringSchedulingIgnoredDuringExecution.NodeSelectorTermsの項目がORで結合されるのに対し、nodeSelectorTerms[].matchExpressionsおよびnodeSelectorTerms[].fieldExpressionsの項目はANDで結合されるためです。
.preferredDuringSchedulingIgnoredDuringExecutionは、すべての更新が許可されます。これは、優先項目の権威がないため、ポリシーコントローラーがこれらの項目を検証しないためです。
次の項目 3.11.6 - TaintとToleration ノードアフィニティ Pod の属性であり、あるノード 群を引きつけます (優先条件または必須条件)。反対に taint はノードがある種のPodを排除できるようにします。
toleration はPodに適用され、一致するtaintが付与されたノードへPodがスケジューリングされることを認めるものです。ただしそのノードへ必ずスケジューリングされるとは限りません。
taintとtolerationは組になって機能し、Podが不適切なノードへスケジューリングされないことを保証します。taintはノードに一つまたは複数個付与することができます。これはそのノードがtaintを許容しないPodを受け入れるべきではないことを示します。
コンセプト ノードにtaintを付与するにはkubectl taint コマンドを使用します。
例えば、次のコマンドは
kubectl taint nodes node1 key1 = value1:NoSchedule
node1にtaintを設定します。このtaintのキーはkey1、値はvalue1、taintの効果はNoScheduleです。
これはnode1にはPodに合致するtolerationがなければスケジューリングされないことを意味します。
上記のコマンドで付与したtaintを外すには、下記のコマンドを使います。
kubectl taint nodes node1 key1 = value1:NoSchedule-
PodのtolerationはPodSpecの中に指定します。下記のtolerationはどちらも、上記のkubectl taintコマンドで追加したtaintと合致するため、どちらのtolerationが設定されたPodもnode1へスケジューリングされることができます。
tolerations :
key : "key1"
operator : "Equal"
value : "value1"
effect : "NoSchedule"
tolerations :
key : "key1"
operator : "Exists"
effect : "NoSchedule"
tolerationを設定したPodの例を示します。
apiVersion : v1
kind : Pod
metadata :
name : nginx
labels :
env : test
spec :
containers :
- name : nginx
image : nginx
imagePullPolicy : IfNotPresent
tolerations :
- key : "example-key"
operator : "Exists"
effect : "NoSchedule"
operatorのデフォルトはEqualです。
tolerationがtaintと合致するのは、keyとeffectが同一であり、さらに下記の条件のいずれかを満たす場合です。
operatorがExists(valueを指定すべきでない場合)operatorがEqualであり、かつvalueが同一である場合備考: 2つ特殊な場合があります。
空のkeyと演算子Existsは全てのkey、value、effectと一致するため、すべてのtaintと合致します。
空のeffectはkey1が一致する全てのeffectと合致します。
上記の例ではeffectにNoScheduleを指定しました。代わりに、effectにPreferNoScheduleを指定することができます。
これはNoScheduleの「ソフトな」バージョンであり、システムはtaintに対応するtolerationが設定されていないPodがノードへ配置されることを避けようとしますが、必須の条件とはしません。3つ目のeffectの値としてNoExecuteがありますが、これについては後述します。
同一のノードに複数のtaintを付与することや、同一のPodに複数のtolerationを設定することができます。
複数のtaintやtolerationが設定されている場合、Kubernetesはフィルタのように扱います。最初はノードの全てのtaintがある状態から始め、Podが対応するtolerationを持っているtaintは無視され外されていきます。無視されずに残ったtaintが効果を及ぼします。
具体的には、
effect NoScheduleのtaintが無視されず残った場合、KubernetesはそのPodをノードへスケジューリングしません。 effect NoScheduleのtaintは残らず、effect PreferNoScheduleのtaintは残った場合、Kubernetesはそのノードへのスケジューリングをしないように試みます。 effect NoExecuteのtaintが残った場合、既に稼働中のPodはそのノードから排除され、まだ稼働していないPodはスケジューリングされないようになります。 例として、下記のようなtaintが付与されたノードを考えます。
kubectl taint nodes node1 key1 = value1:NoSchedule
kubectl taint nodes node1 key1 = value1:NoExecute
kubectl taint nodes node1 key2 = value2:NoSchedule
Podには2つのtolerationが設定されています。
tolerations :
key : "key1"
operator : "Equal"
value : "value1"
effect : "NoSchedule"
key : "key1"
operator : "Equal"
value : "value1"
effect : "NoExecute"
この例では、3つ目のtaintと合致するtolerationがないため、Podはノードへはスケジューリングされません。
しかし、これらのtaintが追加された時点で、そのノードでPodが稼働していれば続けて稼働することが可能です。 これは、Podのtolerationと合致しないtaintは3つあるtaintのうちの3つ目のtaintのみであり、それがNoScheduleであるためです。
一般に、effect NoExecuteのtaintがノードに追加されると、合致するtolerationが設定されていないPodは即時にノードから排除され、合致するtolerationが設定されたPodが排除されることは決してありません。
しかし、effectNoExecuteに対するtolerationはtolerationSecondsフィールドを任意で指定することができ、これはtaintが追加された後にそのノードにPodが残る時間を示します。例えば、
tolerations :
key : "key1"
operator : "Equal"
value : "value1"
effect : "NoExecute"
tolerationSeconds : 3600
この例のPodが稼働中で、対応するtaintがノードへ追加された場合、Podはそのノードに3600秒残り、その後排除されます。仮にtaintがそれよりも前に外された場合、Podは排除されません。
ユースケースの例 taintとtolerationは、実行されるべきではないノードからPodを遠ざけたり、排除したりするための柔軟な方法です。いくつかのユースケースを示します。
専有ノード : あるノード群を特定のユーザーに専有させたい場合、そのノード群へtaintを追加し(kubectl taint nodes nodename dedicated=groupName:NoSchedule) 対応するtolerationをPodへ追加します(これを実現する最も容易な方法はカスタム
アドミッションコントローラー を書くことです)。
tolerationが設定されたPodはtaintの設定された(専有の)ノードと、クラスターにあるその他のノードの使用が認められます。もしPodが必ず専有ノードのみ を使うようにしたい場合は、taintと同様のラベルをそのノード群に設定し(例: dedicated=groupName)、アドミッションコントローラーはノードアフィニティを使ってPodがdedicated=groupNameのラベルの付いたノードへスケジューリングすることが必要であるということも設定する必要があります。
特殊なハードウェアを備えるノード : クラスターの中の少数のノードが特殊なハードウェア(例えばGPU)を備える場合、そのハードウェアを必要としないPodがスケジューリングされないようにして、後でハードウェアを必要とするPodができたときの余裕を確保したいことがあります。
これは特殊なハードウェアを持つノードにtaintを追加(例えば kubectl taint nodes nodename special=true:NoSchedule または
kubectl taint nodes nodename special=true:PreferNoSchedule)して、ハードウェアを使用するPodに対応するtolerationを追加することで可能です。
専有ノードのユースケースと同様に、tolerationを容易に適用する方法はカスタム
アドミッションコントローラー を使うことです。
例えば、特殊なハードウェアを表すために拡張リソース
を使い、ハードウェアを備えるノードに拡張リソースの名称のtaintを追加して、
拡張リソースtoleration
アドミッションコントローラーを実行することが推奨されます。ノードにはtaintが付与されているため、tolerationのないPodはスケジューリングされません。しかし拡張リソースを要求するPodを作成しようとすると、拡張リソースtoleration アドミッションコントローラーはPodに自動的に適切なtolerationを設定し、Podはハードウェアを備えるノードへスケジューリングされます。
これは特殊なハードウェアを備えたノードではそれを必要とするPodのみが稼働し、Podに対して手作業でtolerationを追加しなくて済むようにします。
taintを基にした排除 : ノードに問題が起きたときにPodごとに排除する設定を行うことができます。次のセクションにて説明します。
taintを基にした排除 FEATURE STATE:
Kubernetes v1.18 [stable]
上述したように、effect NoExecuteのtaintはノードで実行中のPodに次のような影響を与えます。
対応するtolerationのないPodは即座に除外される 対応するtolerationがあり、それにtolerationSecondsが指定されていないPodは残り続ける 対応するtolerationがあり、それにtolerationSecondsが指定されているPodは指定された間、残される Nodeコントローラーは特定の条件を満たす場合に自動的にtaintを追加します。
組み込まれているtaintは下記の通りです。
node.kubernetes.io/not-ready: ノードの準備ができていない場合。これはNodeCondition ReadyがFalseである場合に対応します。node.kubernetes.io/unreachable: ノードがノードコントローラーから到達できない場合。これはNodeConditionReadyがUnknownの場合に対応します。node.kubernetes.io/out-of-disk: ノードのディスクの空きがない場合。node.kubernetes.io/memory-pressure: ノードのメモリーが不足している場合。node.kubernetes.io/disk-pressure: ノードのディスクが不足している場合。node.kubernetes.io/network-unavailable: ノードのネットワークが利用できない場合。node.kubernetes.io/unschedulable: ノードがスケジューリングできない場合。node.cloudprovider.kubernetes.io/uninitialized: kubeletが外部のクラウド事業者により起動されたときに設定されるtaintで、このノードは利用不可能であることを示します。cloud-controller-managerによるコントローラーがこのノードを初期化した後にkubeletはこのtaintを外します。ノードから追い出すときには、ノードコントローラーまたはkubeletは関連するtaintをNoExecute効果の状態で追加します。
不具合のある状態から通常の状態へ復帰した場合は、kubeletまたはノードコントローラーは関連するtaintを外すことができます。
備考: コントロールプレーンは新しいtaintをノードに加えるレートを制限しています。
このレート制限は一度に多くのノードが到達不可能になった場合(例えばネットワークの断絶)に、退役させられるノードの数を制御します。PodにtolerationSecondsを指定することで不具合があるか応答のないノードに残る時間を指定することができます。
例えば、ローカルの状態を多数持つアプリケーションとネットワークが分断された場合を考えます。ネットワークが復旧して、Podを排除しなくて済むことを見込んで、長時間ノードから排除されないようにしたいこともあるでしょう。
この場合Podに設定するtolerationは次のようになります。
tolerations :
key : "node.kubernetes.io/unreachable"
operator : "Exists"
effect : "NoExecute"
tolerationSeconds : 6000
備考: Kubernetesはユーザーまたはコントローラーが明示的に指定しない限り、自動的にnode.kubernetes.io/not-readyとnode.kubernetes.io/unreachableに対するtolerationをtolerationSeconds=300にて設定します。
自動的に設定されるtolerationは、taintに対応する問題がノードで検知されても5分間はそのノードにPodが残されることを意味します。
DaemonSet のPodは次のtaintに対してNoExecuteのtolerationがtolerationSecondsを指定せずに設定されます。
node.kubernetes.io/unreachablenode.kubernetes.io/not-readyこれはDaemonSetのPodはこれらの問題によって排除されないことを保証します。
条件によるtaintの付与 ノードのライフサイクルコントローラーはノードの状態に応じてNoSchedule効果のtaintを付与します。
スケジューラーはノードの状態ではなく、taintを確認します。
ノードに何がスケジューリングされるかは、そのノードの状態に影響されないことを保証します。ユーザーは適切なtolerationをPodに付与することで、どの種類のノードの問題を無視するかを選ぶことができます。
DaemonSetのコントローラーは、DaemonSetが中断されるのを防ぐために自動的に次のNoScheduletolerationを全てのDaemonSetに付与します。
node.kubernetes.io/memory-pressurenode.kubernetes.io/disk-pressurenode.kubernetes.io/out-of-disk (重要なPodのみ )node.kubernetes.io/unschedulable (1.10またはそれ以降)node.kubernetes.io/network-unavailable (ホストネットワークのみ )これらのtolerationを追加することは後方互換性を保証します。DaemonSetに任意のtolerationを加えることもできます。
次の項目 3.11.7 - スケジューリングフレームワーク FEATURE STATE:
Kubernetes v1.19 [stable]
スケジューリングフレームワークはKubernetesのスケジューラーに対してプラグイン可能なアーキテクチャです。
このアーキテクチャは、既存のスケジューラーに新たに「プラグイン」としてAPI群を追加するもので、プラグインはスケジューラー内部にコンパイルされます。このAPI群により、スケジューリングの「コア」の軽量かつ保守しやすい状態に保ちながら、ほとんどのスケジューリングの機能をプラグインとして実装することができます。このフレームワークの設計に関する技術的な情報についてはこちらのスケジューリングフレームワークの設計提案 をご覧ください。
フレームワークのワークフロー スケジューリングフレームワークは、いくつかの拡張点を定義しています。スケジューラープラグインは、1つ以上の拡張点で呼び出されるように登録します。これらのプラグインの中には、スケジューリングの決定を変更できるものから、単に情報提供のみを行うだけのものなどがあります。
この1つのPodをスケジュールしようとする各動作はScheduling Cycle とBinding Cycle の2つのフェーズに分けられます。
Scheduling Cycle & Binding Cycle Scheduling CycleではPodが稼働するNodeを決定し、Binding Cycleではそれをクラスターに適用します。この2つのサイクルを合わせて「スケジューリングコンテキスト」と呼びます。
Scheduling CycleではPodに対して1つ1つが順番に実行され、Binding Cyclesでは並列に実行されます。
Podがスケジューリング不能と判断された場合や、内部エラーが発生した場合、Scheduling CycleまたはBinding Cycleを中断することができます。その際、Podはキューに戻され再試行されます。
拡張点 次の図はPodに対するスケジューリングコンテキストとスケジューリングフレームワークが公開する拡張点を示しています。この図では「Filter」がフィルタリングのための「Predicate」、「Scoring」がスコアリングのための「Priorities」機能に相当します。
1つのプラグインを複数の拡張点に登録することで、より複雑なタスクやステートフルなタスクを実行することができます。
scheduling framework extension points QueueSort これらのプラグインはスケジューリングキュー内のPodをソートするために使用されます。このプラグインは、基本的にLess(Pod1, Pod2)という関数を提供します。また、このプラグインは、1つだけ有効化できます。
PreFilter これらのプラグインは、Podに関する情報を前処理したり、クラスターやPodが満たすべき特定の条件をチェックするために使用されます。もし、PreFilterプラグインのいずれかがエラーを返した場合、Scheduling Cycleは中断されます。
Filter FilterプラグインはPodを実行できないNodeを候補から除外します。各Nodeに対して、スケジューラーは設定された順番でFilterプラグインを呼び出します。もし、いずれかのFilterプラグインが途中でそのNodeを実行不可能とした場合、残りのプラグインではそのNodeは呼び出されません。Nodeは同時に評価されることがあります。
PostFilter これらのプラグインはFilterフェーズで、Podに対して実行可能なNodeが見つからなかった場合にのみ呼び出されます。このプラグインは設定された順番で呼び出されます。もしいずれかのPostFilterプラグインが、あるNodeを「スケジュール可能(Schedulable)」と目星をつけた場合、残りのプラグインは呼び出されません。典型的なPostFilterの実装はプリエンプション方式で、他のPodを先取りして、Podをスケジューリングできるようにしようとします。
PreScore これらのプラグインは、Scoreプラグインが使用する共有可能な状態を生成する「スコアリングの事前」作業を行うために使用されます。このプラグインがエラーを返した場合、Scheduling Cycleは中断されます。
Score これらのプラグインはフィルタリングのフェーズを通過したNodeをランク付けするために使用されます。スケジューラーはそれぞれのNodeに対して、それぞれのscoringプラグインを呼び出します。スコアの最小値と最大値の範囲が明確に定義されます。NormalizeScore フェーズの後、スケジューラーは設定されたプラグインの重みに従って、全てのプラグインからNodeのスコアを足し合わせます。
NormalizeScore これらのプラグインはスケジューラーが最終的なNodeの順位を計算する前にスコアを修正するために使用されます。この拡張点に登録されたプラグインは、同じプラグインのScore の結果を使用して呼び出されます。各プラグインはScheduling Cycle毎に、1回呼び出されます。
例えば、BlinkingLightScorerというプラグインが、点滅する光の数に基づいてランク付けをするとします。
func ScoreNode (_ * v1.pod, n * v1.Node) (int , error ) {
return getBlinkingLightCount (n)
}
ただし、NodeScoreMaxに比べ、点滅をカウントした最大値の方が小さい場合があります。これを解決するために、BlinkingLightScorerも拡張点に登録する必要があります。
func NormalizeScores (scores map [string ]int ) {
highest := 0
for _, score := range scores {
highest = max (highest, score)
}
for node, score := range scores {
scores[node] = score* NodeScoreMax/ highest
}
}
NormalizeScoreプラグインが途中でエラーを返した場合、Scheduling Cycleは中断されます。
備考: 「Reserveの事前」作業を行いたいプラグインは、NormalizeScore拡張点を使用してください。Reserve Reserve拡張を実装したプラグインには、ReserveとUnreserveという2つのメソッドがあり、それぞれReserve
とUnreserveと呼ばれる2つの情報スケジューリングフェーズを返します。
実行状態を保持するプラグイン(別名「ステートフルプラグイン」)は、これらのフェーズを使用して、Podに対してNodeのリソースが予約されたり予約解除された場合に、スケジューラーから通知を受け取ります。
Reserveフェーズは、スケジューラーが実際にPodを指定されたNodeにバインドする前に発生します。このフェーズはスケジューラーがバインドが成功するのを待つ間にレースコンディションの発生を防ぐためにあります。
各ReserveプラグインのReserveメソッドは成功することも失敗することもあります。もしどこかのReserveメソッドの呼び出しが失敗すると、後続のプラグインは実行されず、Reserveフェーズは失敗したものとみなされます。全てのプラグインのReserveメソッドが成功した場合、Reserveフェーズは成功とみなされ、残りのScheduling CycleとBinding Cycleが実行されます。
Unreserveフェーズは、Reserveフェーズまたは後続のフェーズが失敗した場合に、呼び出されます。この時、全ての ReserveプラグインのUnreserveメソッドが、Reserveメソッドの呼び出された逆の順序で実行されます。このフェーズは予約されたPodに関連する状態をクリーンアップするためにあります。
注意: Unreserveメソッドの実装は冪等性を持つべきであり、この処理で問題があった場合に失敗させてはなりません。Permit Permit プラグインは、各PodのScheduling Cycleの終了時に呼び出され、候補Nodeへのバインドを阻止もしくは遅延させるために使用されます。permitプラグインは次の3つのうちどれかを実行できます。
承認(approve)
拒否(deny) Reserveプラグイン 内のUnreserveフェーズで呼び出されます。
待機(wait) (タイムアウトあり)待機(wait)は deny へ変わり、対象のPodはスケジューリングキューに戻されると共に、Reserveプラグイン のUnreserveフェーズが呼び出されます。
備考: どのプラグインも「待機中」Podリストにアクセスして、それらを承認(approve)することができますが(参考:
FrameworkHandle)、その中の予約済みPodのバインドを承認(approve)できるのはPermitプラグインだけであると予想します。承認(approve)されたPodは、
PreBind フェーズへ送られます。
PreBind これらのプラグインは、Podがバインドされる前に必要な作業を行うために使用されます。例えば、Podの実行を許可する前に、ネットワークボリュームをプロビジョニングし、Podを実行予定のNodeにマウントすることができます。
もし、いずれかのPreBindプラグインがエラーを返した場合、Podは拒否 され、スケジューリングキューに戻されます。
Bind これらのプラグインはPodをNodeにバインドするために使用されます。このプラグインは全てのPreBindプラグインの処理が完了するまで呼ばれません。それぞれのBindプラグインは設定された順序で呼び出されます。このプラグインは、与えられたPodを処理するかどうかを選択することができます。もしPodを処理することを選択した場合、残りのBindプラグインは全てスキップされます。
PostBind これは単に情報提供のための拡張点です。Post-bindプラグインはPodのバインドが成功した後に呼び出されます。これはBinding Cycleの最後であり、関連するリソースのクリーンアップに使用されます。
プラグインAPI プラグインAPIには2つの段階があります。まず、プラグインを登録し設定することです。そして、拡張点インターフェースを使用することです。このインターフェースは次のような形式をとります。
type Plugin interface {
Name () string
}
type QueueSortPlugin interface {
Plugin
Less (* v1.pod, * v1.pod) bool
}
type PreFilterPlugin interface {
Plugin
PreFilter (context.Context, * framework.CycleState, * v1.pod) error
}
// ...
プラグインの設定 スケジューラーの設定でプラグインを有効化・無効化することができます。Kubernetes v1.18以降を使用しているなら、ほとんどのスケジューリングプラグイン は使用されており、デフォルトで有効になっています。
デフォルトのプラグインに加えて、独自のスケジューリングプラグインを実装し、デフォルトのプラグインと一緒に使用することも可能です。詳しくはスケジューラープラグイン をご覧下さい。
Kubernetes v1.18以降を使用しているなら、プラグインのセットをスケジューラープロファイルとして設定し、様々な種類のワークロードに適合するように複数のプロファイルを定義することが可能です。詳しくは複数のプロファイル をご覧下さい。
3.11.8 - 動的リソース割り当て 構造化パラメーターを用いたコアのDynamic Resource Allocation:
FEATURE STATE:
Kubernetes v1.35 [stable](enabled by default)
コントロールプレーンコントローラーを用いたDynamic Resource Allocation:
FEATURE STATE:
Kubernetes v1.26 [alpha](disabled by default)
動的なリソース割り当ては、PodとPod内のコンテナ間でリソースを要求および共有するためのAPIです。
これは、汎用リソース用の永続ボリュームAPIを一般化したものです。
通常、これらのリソースはGPUなどのデバイスです。
サードパーティのリソースドライバーは、リソースの追跡と準備を行い、リソースの割り当ては 構造化パラメーター (Kubernetes 1.30で導入)を介してKubernetesによって処理されます。
さまざまな種類のリソースが、要求と初期化を定義するための任意のパラメーターをサポートします。
ドライバーが コントロールプレーンコントローラー を提供する場合、ドライバー自体がKubernetesスケジューラーと連携して割り当てを処理します。
始める前に Kubernetes v1.35には、動的リソース割り当てに関するクラスターレベルのAPIサポートが含まれていますが、明示的に有効化する必要があります 。
また、このAPIを使用して管理する特定のリソースのリソースドライバーもインストールする必要があります。
Kubernetes v1.35を実行していない場合は、そのバージョンのKubernetesのドキュメントを確認してください。
API resource.k8s.io/v1alpha3 APIグループ は次のタイプを提供します:
ResourceClaim ワークロードによって使用される、クラスター内のリソースへのアクセス要求を記述します。
たとえば、ワークロードが特定のプロパティを持つアクセラレーターデバイスを必要とする場合、その要求はこのように表現されます。
ステータススタンザは、この要求が満たされたかどうかと、どのリソースが割り当てられたかを追跡します。 ResourceClaimTemplate ResourceClaimを作成するための仕様とメタデータを定義します。
ユーザーがワークロードをデプロイするときに作成されます。
PodごとのResourceClaimは、Kubernetesによって自動的に作成および削除されます。 DeviceClass 特定のデバイスとそれらの構成に対する事前定義の選択基準が含まれています。
DeviceClassは、リソースドライバーをインストールするときにクラスター管理者によって作成されます。
ResourceClaim内でデバイスを割り当てる各要求は、正確に1つのDeviceClassを参照する必要があります。 PodSchedulingContext ResourceClaimをPodに割り当てる必要があり、それらのResourceClaimがコントロールプレーンコントローラーを使用する場合に、Podのスケジューリングを調整するために、コントロールプレーンとリソースドライバーによって内部的に使用されます。 ResourceSlice クラスター内で使用可能なリソースに関する情報を公開するために、構造化パラメーターとともに使用します。 リソースドライバーの開発者は、コントロールプレーンコントローラーを使用して割り当てを処理するか、代わりに構造化パラメーターを使用してKubernetesを介した割り当てに依存するかを決定します。
カスタムコントローラーは柔軟性が高い一方で、クラスターの自動スケーリングがノードのローカルリソースに対して確実に機能しない可能性があります。
構造化パラメーターはクラスターの自動スケーリングを可能にしますが、すべてのユースケースを満たすわけではありません。
ドライバーが構造化パラメーターを使用する場合、デバイスを選択するためのすべてのパラメーターは、Kubrnetes本体に組み込まれたResourceClaimおよびDeviceClass内で定義されます。
構成パラメーターは任意のJSONオブジェクトとして埋め込むことができます。
core/v1 PodSpecは、ResourceClaimフィールド内でPodに必要なResourceClaimを定義します。
このリスト内のエントリは、ResourceClaimまたはResourceClaimTemplateを参照します。
ResourceClaimを参照する場合、このPodSpecを使用するすべてのPod(例えば、DeploymentまたはStatefulSet内)は、同じResourceClaimインスタンスを共有します。
ResourceClaimTemplateを参照する場合、各Podには独自のインスタンスが割り当てられます。
コンテナリソースのresources.claimsリストは、コンテナがこれらのリソースインスタンスにアクセスできるかどうかを定義します。
これにより、1つ以上のコンテナ間でリソースを共有することが可能になります。
以下は、架空のリソースドライバーの例です。
このPodに対して2つのResourceClaimオブジェクトが作成され、各コンテナがそれぞれ1つにアクセスできます。
apiVersion : resource.k8s.io/v1alpha3
kind : DeviceClass
name : resource.example.com
spec :
selectors :
- cel :
expression : device.driver == "resource-driver.example.com"
---
apiVersion : resource.k8s.io/v1alpha2
kind : ResourceClaimTemplate
metadata :
name : large-black-cat-claim-template
spec :
spec :
devices :
requests :
- name : req-0
deviceClassName : resource.example.com
selectors :
- cel :
expression : |-
device.attributes["resource-driver.example.com"].color == "black" &&
device.attributes["resource-driver.example.com"].size == "large"
apiVersion : v1
kind : Pod
metadata :
name : pod-with-cats
spec :
containers :
- name : container0
image : ubuntu:20.04
command : ["sleep" , "9999" ]
resources :
claims :
- name : cat-0
- name : container1
image : ubuntu:20.04
command : ["sleep" , "9999" ]
resources :
claims :
- name : cat-1
ResourceClaim :
- name : cat-0
resourceClaimTemplateName : large-black-cat-claim-template
- name : cat-1
resourceClaimTemplateName : large-black-cat-claim-template
スケジューリング コントロールプレーンコントローラーを使用する ネイティブリソース(CPU、RAM)と拡張リソース(デバイスプラグインによって管理され、kubeletによってアドバタイズされる)とは異なり、構造化パラメーターがない場合、スケジューラーはクラスター内の使用可能な動的リソースや、特定のResourceClaimの要件を満たすためにどのように分割できるかについて知識がありません。
リソースドライバーがその責任を持ちます。
ResourceClaimはリソースが予約されると「割り当て済み」としてマークされます。
これにより、スケジューラーはResourceClaimが使用可能であるクラスター内の場所を知ることができます。
Podがスケジュールされると、スケジューラーはPodに必要なすべてのResourceClaimをチェックし、PodSchedulingオブジェクトを作成して、それらのResourceClaimに関連するリソースドライバーにスケジューラーが適していると判断したノードについて通知します。
リソースドライバーは、ドライバーのリソースが十分に残っていないノードを除外することで応答します。
スケジューラーがその情報を取得すると、ノードを1つ選択し、その選択をPodSchedulingオブジェクトに保存します。
リソースドライバーはその後、リソースがそのノードで使用できるようにResourceClaimを割り当てます。
それが完了すると、Podがスケジュールされます。
このプロセスの一環として、ResourceClaimもPodのために予約されます。
現在、ResourceClaimは単一のPodまたは無制限の数のPodによって排他的に使用できます。
重要な機能の1つは、すべてのリソースが割り当てられて、予約されない限り、Podがノードにスケジュールされないことです。
これにより、Podが1つのノードにスケジュールされ、そのノードで実行できないというシナリオが回避されます。
このような保留中のPodは、RAMやCPUなどの他のすべてのリソースもブロックするため、問題が発生します。
備考: ResourceClaimを使用するPodのスケジューリングは、追加の通信が必要となるため遅くなります。
一度に1つのPodしかスケジュールされず、ResourceClaimでPodを処理するときにAPI呼び出しをブロックすることになり、次のPodのスケジュールが遅延するため、ResourceClaimを使用しないPodにも影響する可能性があることに注意してください。構造化パラメーターを使用する ドライバーが構造化パラメーターを使用する場合、Podがリソースを必要とするたびに、スケジューラーがResourceClaimにリソースを割り当てる責任を引き継ぎます。
これは、ResourceSliceオブジェクトから使用可能なリソースの完全なリストを取得し、既存のResourceClaimに割り当てられているリソースを追跡し、これらの残存リソースから選択することによって行われます。
現時点でサポートされているリソースの種類はデバイスのみです。
デバイスインスタンスは、名前といくつかの属性とキャパシティを持ちます。
デバイスは、それらの属性とキャパシティをチェックするCEL式を通じて選択されます。
さらに、選択されたデバイスのセットを、特定の制約を満たすセットに制限することもできます。
選択されたリソースはベンダー固有の構成とともにResourceClaimのステータスに記録されるため、Podがノード上で起動しようとすると、ノード上のリソースドライバーはリソースを準備するために必要なすべての情報を持ちます。
構造化パラメーターを使用することで、スケジューラーは任意のDRAリソースドライバーと通信せずに決定を下すことができます。
またResourceClaimの割り当てに関する情報をメモリに保持し、Podをノードにバインドする際にバックエンドでこの情報をResourceClaimオブジェクトに書き込むことで、複数のPodを迅速にスケジュールすることができます。
リソースの監視 kubeletは、実行中のPodの動的リソースの検出を可能にするgRPCサービスを提供します。
gRPCエンドポイントに関する詳細については、リソース割り当てレポート を参照してください。
事前スケジュールされたPod あなた、または他のAPIクライアントが、spec.nodeNameがすでに設定されているPodを作成すると、スケジューラーはバイパスされます。
そのPodに必要なResourceClaimがまだ存在しない場合や、Podに割り当てられていない、またはPodのために予約されていない場合、kubeletはPodの実行に失敗し、それらの要件が後に満たされる可能性があるため定期的に再チェックを行います。
このような状況は、Podがスケジュールされた時点でスケジューラーに動的リソース割り当てのサポートが有効になっていなかった場合にも発生します(バージョンスキュー、構成、フィーチャーゲートなど)。
kube-controller-managerはこれを検出し、必要なResourceClaimの割り当てや予約をトリガーすることで、Podを実行可能にしようとします。
備考: これは、構造化パラメーターを使用しないリソースドライバーにのみ適用されます。ノードに割り当てられたPodは通常のリソース(RAM、CPU)をブロックし、そのPodがスタックしている間は他のPodで使用できなくなるため、スケジューラーのバイパスは避けることが望ましいです。
Podを通常のスケジューリングフローを通して特定のノード上で実行するには、目的のノードと完全に一致するノードセレクターを使用してPodを作成します:
apiVersion : v1
kind : Pod
metadata :
name : pod-with-cats
spec :
nodeSelector :
kubernetes.io/hostname : name-of-the-intended-node
...
また、アドミッション時に入力されるPodの.spec.nodeNameフィールドを解除し、代わりにノードセレクターを使用することもできます。
動的リソース割り当ての有効化 動的リソース割り当てはアルファ機能 であり、DynamicResourceAllocationフィーチャーゲート とresource.k8s.io/v1alpha3 APIグループ が有効になっている場合のみ有効になります。
詳細については、--feature-gatesおよび--runtime-configkube-apiserverパラメーター を参照してください。
kube-scheduler、kube-controller-manager、kubeletもフィーチャーゲートが必要です。
リソースドライバーがコントロールプレーンコントローラーを使用する場合、DynamicResourceAllocationに加えてDRAControlPlaneControllerフィーチャーゲートを有効化する必要があります。
Kubernetesクラスターがこの機能をサポートしているかどうかを簡単に確認するには、次のコマンドを使用してDeviceClassオブジェクトをリストします:
kubectl get deviceclasses
クラスターが動的リソース割り当てをサポートしている場合、レスポンスはDeviceClassオブジェクトのリストか、次のように表示されます:
No resources found
サポートされていない場合、代わりに次のエラーが表示されます:
error: the server doesn't have a resource type "deviceclasses"
spec.controllerフィールドが設定されているResourceClaimが作成可能な場合、コントロールプレーンコントローラーがサポートされます。
DRAControlPlaneControllerフィーチャーゲートが無効になっている場合、そのフィールドはResourceClaimを保存するときに自動的にクリアされます。
kube-schedulerのデフォルト構成では、フィーチャーゲートが有効でありv1構成APIを使用している場合にのみ「DynamicResources」プラグインが有効になります。
カスタム構成では、このプラグインを含めるように変更する必要があるかもしれません。
クラスターで機能を有効化するには、リソースドライバーもインストールする必要があります。
詳細については、ドライバーのドキュメントを参照してください。
次の項目 3.11.9 - Gangスケジューリング FEATURE STATE:
Kubernetes v1.35 [alpha](disabled by default)
Gangスケジューリングは、Podのグループを「全か無か」の原則でスケジュールすることを保証します。
クラスターがグループ全体(または、定義された最小数のPod)を収容できない場合、どのPodもノードにバインドされません。
この機能はWorkload API に依存しています。
クラスターでGenericWorkloadscheduling.k8s.io/v1alpha1 APIグループ が有効になっていることを確認してください。
動作の仕組み GangSchedulingプラグインが有効な場合、スケジューラーはWorkload 内のgang Podグループポリシー に属するPodのライフサイクルを変更します。
このプロセスは、各Podグループとそのレプリカキーごとに独立して実行されます:
スケジューラーは、以下の条件をすべて満たすまで、PodをPreEnqueueフェーズで保持します:
参照先のWorkloadオブジェクトが作成されている 参照先のPodグループがWorkload内に存在する 特定のグループに対して作成されたPodの数が、少なくともminCount以上である これらの条件がすべて満たされるまで、Podはアクティブなスケジューリングキューに入りません。
必要数が満たされると、スケジューラーはグループ内のすべてのPodの配置先を見つけようとします。
この処理中、割り当てられたすべてのPodはWaitOnPermitゲートで待機します。
なお、この機能のAlphaフェーズでは、配置先の検索は単一サイクル方式ではなく、Pod単位のスケジューリングに基づいています。
スケジューラーが少なくともminCount個のPodに対して有効な配置先を見つけた場合、それらすべてを割り当てられたノードにバインドすることを許可します。
5分間の固定タイムアウト内にグループ全体の配置先を見つけられない場合、どのPodもスケジュールされません。
代わりに、クラスターのリソースが空くのを待つため、スケジュール不可能キューに移動され、その間に他のワークロードをスケジュールできるようにします。
次の項目 3.11.10 - スケジューラーのパフォーマンスチューニング FEATURE STATE:
Kubernetes 1.14 [beta]
kube-scheduler はKubernetesのデフォルトのスケジューラーです。
クラスター内のノード上にPodを割り当てる責務があります。
クラスター内に存在するノードで、Podのスケジューリング要求を満たすものはPodに対して割り当て可能 なノードと呼ばれます。
スケジューラーはPodに対する割り当て可能なノードをみつけ、それらの割り当て可能なノードにスコアをつけます。
その中から最も高いスコアのノードを選択し、Podに割り当てるためのいくつかの関数を実行します。
スケジューラーはBinding と呼ばれる処理中において、APIサーバーに対して割り当てが決まったノードの情報を通知します。
このページでは、大規模のKubernetesクラスターにおけるパフォーマンス最適化のためのチューニングについて説明します。
大規模クラスターでは、レイテンシー(新規Podをすばやく配置)と精度(スケジューラーが不適切な配置を行うことはめったにありません)の間でスケジューリング結果を調整するスケジューラーの動作をチューニングできます。
このチューニング設定は、kube-scheduler設定のpercentageOfNodesToScoreで設定できます。
KubeSchedulerConfiguration設定は、クラスター内のノードにスケジュールするための閾値を決定します。
閾値の設定 percentageOfNodesToScoreオプションは、0から100までの数値を受け入れます。
0は、kube-schedulerがコンパイル済みのデフォルトを使用することを示す特別な値です。
percentageOfNodesToScoreに100より大きな値を設定した場合、kube-schedulerの挙動は100を設定した場合と同様となります。
この値を変更するためには、kube-schedulerの設定ファイル(これは/etc/kubernetes/config/kube-scheduler.yamlの可能性が高い)を編集し、スケジューラーを再起動します。
この変更をした後、
kubectl get pods -n kube-system | grep kube-scheduler
を実行して、kube-schedulerコンポーネントが正常であることを確認できます。
ノードへのスコア付けの閾値 スケジューリング性能を改善するため、kube-schedulerは割り当て可能なノードが十分に見つかるとノードの検索を停止できます。
大規模クラスターでは、すべてのノードを考慮する単純なアプローチと比較して時間を節約できます。
クラスター内のすべてのノードに対する十分なノード数を整数パーセンテージで指定します。
kube-schedulerは、これをノード数に変換します。
スケジューリング中に、kube-schedulerが設定されたパーセンテージを超える十分な割り当て可能なノードを見つけた場合、kube-schedulerはこれ以上割り当て可能なノードを探すのを止め、スコアリングフェーズ に進みます。
スケジューラーはどのようにノードを探索するか で処理を詳しく説明しています。
デフォルトの閾値 閾値を指定しない場合、Kubernetesは100ノードのクラスターでは50%、5000ノードのクラスターでは10%になる線形方程式を使用して数値を計算します。
自動計算の下限は5%です。
つまり、明示的にpercentageOfNodesToScoreを5未満の値を設定しない限り、クラスターの規模に関係なく、kube-schedulerは常に少なくともクラスターの5%のノードに対してスコア付けをします。
スケジューラーにクラスター内のすべてのノードに対してスコア付けをさせる場合は、percentageOfNodesToScoreの値に100を設定します。
例 percentageOfNodesToScoreの値を50%に設定する例は下記のとおりです。
apiVersion : kubescheduler.config.k8s.io/v1alpha1
kind : KubeSchedulerConfiguration
algorithmSource :
provider : DefaultProvider
...
percentageOfNodesToScore : 50
percentageOfNodesToScoreのチューニング percentageOfNodesToScoreは1から100の間の範囲である必要があり、デフォルト値はクラスターのサイズに基づいて計算されます。
また、クラスターのサイズの最小値は100ノードとハードコードされています。
備考: 割り当て可能なノードが100以下のクラスターでは、スケジューラの検索を早期に停止するのに十分な割り当て可能なノードがないため、スケジューラはすべてのノードをチェックします。
小規模クラスターでは、percentageOfNodesToScoreに低い値を設定したとしても、同様の理由で変更による影響は全くないか、ほとんどありません。
クラスターのノード数が数百以下の場合は、この設定オプションをデフォルト値のままにします。
変更してもスケジューラの性能を大幅に改善する可能性はほとんどありません。
この値を設定する際に考慮するべき重要な注意事項として、割り当て可能ノードのチェック対象のノードが少ないと、一部のノードはPodの割り当てのためにスコアリングされなくなります。
結果として、高いスコアをつけられる可能性のあるノードがスコアリングフェーズに渡されることがありません。
これにより、Podの配置が理想的なものでなくなります。
kube-schedulerが頻繁に不適切なPodの配置を行わないよう、percentageOfNodesToScoreをかなり低い値を設定することは避けるべきです。
スケジューラのスループットがアプリケーションにとって致命的で、ノードのスコアリングが重要でない場合を除いて、10%未満に設定することは避けてください。
言いかえると、割り当て可能な限り、Podは任意のノード上で稼働させるのが好ましいです。
スケジューラーはどのようにノードを探索するか このセクションでは、この機能の内部の詳細を理解したい人向けになります。
クラスター内の全てのノードに対して平等にPodの割り当ての可能性を持たせるため、スケジューラーはラウンドロビン方式でノードを探索します。
複数のノードの配列になっているイメージです。
スケジューラーはその配列の先頭から探索を開始し、percentageOfNodesToScoreによって指定された数のノードを検出するまで、割り当て可能かどうかをチェックしていきます。
次のPodでは、スケジューラーは前のPodの割り当て処理でチェックしたところから探索を再開します。
ノードが複数のゾーンに存在するとき、スケジューラーは様々なゾーンのノードを探索して、異なるゾーンのノードが割り当て可能かどうかのチェック対象になるようにします。
例えば2つのゾーンに6つのノードがある場合を考えます。
Zone 1: Node 1, Node 2, Node 3, Node 4
Zone 2: Node 5, Node 6
スケジューラーは、下記の順番でノードの割り当て可能性を評価します。
Node 1, Node 5, Node 2, Node 6, Node 3, Node 4
全てのノードのチェックを終えたら、1番目のノードに戻ってチェックをします。
Opportunistic Batchingの有効化 FEATURE STATE:
Kubernetes v1.35 [beta](enabled by default)
大規模なワークロードをスケジューリングする場合、通常、Podの定義はほぼ同一であり、スケジューラーが同じ処理を繰り返し実行する必要があります。
Opportunistic Batching 機能は、スケジューリングサイクル間でフィルタリングおよびスコアリング結果を再利用することで、スケジューリング処理を大幅に高速化します。
基本的には、この機能は次のように動作します。
スケジューラーが最初のpod-1をスケジュールし、その結果をキャッシュします。 続くpod-2,pod-3,…は、キャッシュされた結果を利用してスケジュールされます。 キャッシュは0.5秒後に期限切れとなり、その後スケジュールされるPodについて新たにキャッシュが構築されます。 注意: 同じスケジューリング制約を持つPodが連続してスケジューリングサイクルに投入される必要があります。
異なる制約を持つPodがスケジュールされる場合、既存キャッシュは使用されず、新しいキャッシュに置き換えられます。
このバッチングスケジューリングは、次の条件を満たすPodに適用されます。
Pod間のアフィニティ/アンチアフィニティを持たない トポロジースプレッド制約を持たない ResourceClaimのようなDRAを持たない ノードを専有してスケジュールされる(1ノードに複数のPodを配置するとキャッシュが無効化される) 本機能を有効化するため、スケジューラー設定では次の対応が必要です。
デフォルトのトポロジースプレッド制約 を空に設定し、無効化するDRAExtendedResource 機能ゲートを無効化するInterPodAffinityArgs のIgnorePreferredTermsOfExistingPodsをtrueに設定し、バッチング効率を向上させる注意:
既存のPodが、スケジュール対象のPodのラベルに一致するPodアフィニティ制約を使用している場合、この機能による恩恵を受けられない可能性があります。 カスタムプラグインを使用している場合、Signature拡張ポイントの実装が必要です。 これらの制約および条件は、将来のリリースで変更される可能性があります。
3.11.11 - 拡張リソースのリソースビンパッキング FEATURE STATE:
Kubernetes v1.16 [alpha]
kube-schedulerでは、優先度関数RequestedToCapacityRatioResourceAllocationを使用した、
拡張リソースを含むリソースのビンパッキングを有効化できます。優先度関数はそれぞれのニーズに応じて、kube-schedulerを微調整するために使用できます。
RequestedToCapacityRatioResourceAllocationを使用したビンパッキングの有効化Kubernetesでは、キャパシティー比率への要求に基づいたNodeのスコアリングをするために、各リソースの重みと共にリソースを指定することができます。これにより、ユーザーは適切なパラメーターを使用することで拡張リソースをビンパックすることができ、大規模クラスターにおける希少なリソースを有効活用できるようになります。優先度関数RequestedToCapacityRatioResourceAllocationの動作はRequestedToCapacityRatioArgsと呼ばれる設定オプションによって変わります。この引数はshapeとresourcesパラメーターによって構成されます。shapeパラメーターはutilizationとscoreの値に基づいて、最も要求が多い場合か最も要求が少ない場合の関数をチューニングできます。resourcesパラメーターは、スコアリングの際に考慮されるリソース名のnameと、各リソースの重みを指定するweightで構成されます。
以下は、拡張リソースintel.com/fooとintel.com/barのビンパッキングにrequestedToCapacityRatioArgumentsを設定する例になります。
apiVersion : kubescheduler.config.k8s.io/v1beta1
kind : KubeSchedulerConfiguration
profiles :
# ...
pluginConfig :
- name : RequestedToCapacityRatio
args :
shape :
- utilization : 0
score : 10
- utilization : 100
score : 0
resources :
- name : intel.com/foo
weight : 3
- name : intel.com/bar
weight : 5
スケジューラーには、kube-schedulerフラグ--config=/path/to/config/fileを使用してKubeSchedulerConfigurationのファイルを指定することで渡すことができます。
この機能はデフォルトで無効化されています
優先度関数のチューニング shapeはRequestedToCapacityRatioPriority関数の動作を指定するために使用されます。
shape :
- utilization : 0
score : 0
- utilization : 100
score : 10
上記の引数は、utilizationが0%の場合は0、utilizationが100%の場合は10というscoreをNodeに与え、ビンパッキングの動作を有効にしています。最小要求を有効にするには、次のようにスコアを反転させる必要があります。
shape :
- utilization : 0
score : 10
- utilization : 100
score : 0
resourcesはオプションパラメーターで、デフォルトでは以下の通りです。
resources :
- name : cpu
weight : 1
- name : memory
weight : 1
以下のように拡張リソースの追加に利用できます。
resources :
- name : intel.com/foo
weight : 5
- name : cpu
weight : 3
- name : memory
weight : 1
weightはオプションパラメーターで、指定されてない場合1が設定されます。また、マイナスの値は設定できません。
キャパシティ割り当てのためのNodeスコアリング このセクションは、本機能の内部詳細について理解したい方を対象としています。以下は、与えられた値に対してNodeのスコアがどのように計算されるかの例です。
要求されたリソース:
intel.com/foo : 2
memory: 256MB
cpu: 2
リソースの重み:
intel.com/foo : 5
memory: 1
cpu: 3
shapeの値 {{0, 0}, {100, 10}}
Node1のスペック:
Available:
intel.com/foo: 4
memory: 1 GB
cpu: 8
Used:
intel.com/foo: 1
memory: 256MB
cpu: 1
Nodeのスコア:
intel.com/foo = resourceScoringFunction((2+1),4)
= (100 - ((4-3)*100/4))
= (100 - 25)
= 75 # requested + used = 75% * available
= rawScoringFunction(75)
= 7 # floor(75/10)
memory = resourceScoringFunction((256+256),1024)
= (100 -((1024-512)*100/1024))
= 50 # requested + used = 50% * available
= rawScoringFunction(50)
= 5 # floor(50/10)
cpu = resourceScoringFunction((2+1),8)
= (100 -((8-3)*100/8))
= 37.5 # requested + used = 37.5% * available
= rawScoringFunction(37.5)
= 3 # floor(37.5/10)
NodeScore = ((7 * 5) + (5 * 1) + (3 * 3)) / (5 + 1 + 3)
= 5
Node2のスペック:
Available:
intel.com/foo: 8
memory: 1GB
cpu: 8
Used:
intel.com/foo: 2
memory: 512MB
cpu: 6
Nodeのスコア:
intel.com/foo = resourceScoringFunction((2+2),8)
= (100 - ((8-4)*100/8)
= (100 - 50)
= 50
= rawScoringFunction(50)
= 5
memory = resourceScoringFunction((256+512),1024)
= (100 -((1024-768)*100/1024))
= 75
= rawScoringFunction(75)
= 7
cpu = resourceScoringFunction((2+6),8)
= (100 -((8-8)*100/8))
= 100
= rawScoringFunction(100)
= 10
NodeScore = ((5 * 5) + (7 * 1) + (10 * 3)) / (5 + 1 + 3)
= 7
次の項目 3.11.12 - Podの優先度とプリエンプション FEATURE STATE:
Kubernetes v1.14 [stable]
Pod は priority (優先度)を持つことができます。
優先度は他のPodに対する相対的なPodの重要度を示します。
もしPodをスケジューリングできないときには、スケジューラーはそのPodをスケジューリングできるようにするため、優先度の低いPodをプリエンプトする(追い出す)ことを試みます。
警告: クラスターの全てのユーザーが信用されていない場合、悪意のあるユーザーが可能な範囲で最も高い優先度のPodを作成することが可能です。これは他のPodが追い出されたりスケジューリングできない状態を招きます。
管理者はResourceQuotaを使用して、ユーザーがPodを高い優先度で作成することを防ぐことができます。
詳細はデフォルトで優先度クラスの消費を制限する
を参照してください。
優先度とプリエンプションを使う方法 優先度とプリエンプションを使うには、
1つまたは複数のPriorityClass を追加します
追加したPriorityClassをpriorityClassNamepriorityClassNameをDeploymentのようなコレクションオブジェクトのPodテンプレートに追加します。
これらの手順のより詳しい情報については、この先を読み進めてください。
PriorityClass PriorityClassはnamespaceによらないオブジェクトで、優先度クラスの名称から優先度を表す整数値への対応を定義します。
PriorityClassオブジェクトのメタデータのnameフィールドにて名称を指定します。
値はvalueフィールドで指定し、必須です。
値が大きいほど、高い優先度を示します。
PriorityClassオブジェクトの名称はDNSサブドメイン名 として適切であり、かつsystem-から始まってはいけません。
PriorityClassオブジェクトは10億以下の任意の32ビットの整数値を持つことができます。これは、PriorityClassオブジェクトの値の範囲が-2147483648から1000000000までであることを意味します。
それよりも大きな値は通常はプリエンプトや追い出すべきではない重要なシステム用のPodのために予約されています。
クラスターの管理者は割り当てたい優先度に対して、PriorityClassオブジェクトを1つずつ作成すべきです。
PriorityClassは任意でフィールドglobalDefaultとdescriptionを設定可能です。
globalDefaultフィールドはpriorityClassNameが指定されないPodはこのPriorityClassを使うべきであることを示します。globalDefaultがtrueに設定されたPriorityClassはシステムで一つのみ存在可能です。globalDefaultが設定されたPriorityClassが存在しない場合は、priorityClassNameが設定されていないPodの優先度は0に設定されます。
descriptionフィールドは任意の文字列です。クラスターの利用者に対して、PriorityClassをどのような時に使うべきか示すことを意図しています。
PodPriorityと既存のクラスターに関する注意 もし既存のクラスターをこの機能がない状態でアップグレードすると、既存のPodの優先度は実質的に0になります。
globalDefaultがtrueに設定されたPriorityClassを追加しても、既存のPodの優先度は変わりません。PriorityClassのそのような値は、PriorityClassが追加された以後に作成されたPodのみに適用されます。
PriorityClassを削除した場合、削除されたPriorityClassの名前を使用する既存のPodは変更されませんが、削除されたPriorityClassの名前を使うPodをそれ以上作成することはできなくなります。
PriorityClassの例 apiVersion : scheduling.k8s.io/v1
kind : PriorityClass
metadata :
name : high-priority
value : 1000000
globalDefault : false
description : "この優先度クラスはXYZサービスのPodに対してのみ使用すべきです。"
非プリエンプトのPriorityClass FEATURE STATE:
Kubernetes v1.24 [stable]
preemptionPolicy: Neverと設定されたPodは、スケジューリングのキューにおいて他の優先度の低いPodよりも優先されますが、他のPodをプリエンプトすることはありません。
スケジューリングされるのを待つ非プリエンプトのPodは、リソースが十分に利用可能になるまでスケジューリングキューに残ります。
非プリエンプトのPodは、他のPodと同様に、スケジューラーのバックオフの対象になります。これは、スケジューラーがPodをスケジューリングしようと試みたものの失敗した場合、低い頻度で再試行するようにして、より優先度の低いPodが先にスケジューリングされることを許します。
非プリエンプトのPodは、他の優先度の高いPodにプリエンプトされる可能性はあります。
preemptionPolicyはデフォルトではPreemptLowerPriorityに設定されており、これが設定されているPodは優先度の低いPodをプリエンプトすることを許容します。これは既存のデフォルトの挙動です。
preemptionPolicyをNeverに設定すると、これが設定されたPodはプリエンプトを行わないようになります。
ユースケースの例として、データサイエンスの処理を挙げます。
ユーザーは他の処理よりも優先度を高くしたいジョブを追加できますが、そのとき既存の実行中のPodの処理結果をプリエンプトによって破棄させたくはありません。
preemptionPolicy: Neverが設定された優先度の高いジョブは、他の既にキューイングされたPodよりも先に、クラスターのリソースが「自然に」開放されたときにスケジューリングされます。
非プリエンプトのPriorityClassの例 apiVersion : scheduling.k8s.io/v1
kind : PriorityClass
metadata :
name : high-priority-nonpreempting
value : 1000000
preemptionPolicy : Never
globalDefault : false
description : "この優先度クラスは他のPodをプリエンプトさせません。"
Podの優先度 一つ以上のPriorityClassがあれば、仕様にPriorityClassを指定したPodを作成することができるようになります。優先度のアドミッションコントローラーはpriorityClassNameフィールドを使用し、優先度の整数値を設定します。PriorityClassが見つからない場合、そのPodの作成は拒否されます。
下記のYAMLは上記の例で作成したPriorityClassを使用するPodの設定の例を示します。優先度のアドミッションコントローラーは仕様を確認し、このPodの優先度は1000000であると設定します。
apiVersion : v1
kind : Pod
metadata :
name : nginx
labels :
env : test
spec :
containers :
- name : nginx
image : nginx
imagePullPolicy : IfNotPresent
priorityClassName : high-priority
スケジューリング順序におけるPodの優先度の効果 Podの優先度が有効な場合、スケジューラーは待機状態のPodをそれらの優先度順に並べ、スケジューリングキューにおいてより優先度の低いPodよりも前に来るようにします。その結果、その条件を満たしたときには優先度の高いPodは優先度の低いPodより早くスケジューリングされます。優先度の高いPodがスケジューリングできない場合は、スケジューラーは他の優先度の低いPodのスケジューリングも試みます。
プリエンプション Podが作成されると、スケジューリング待ちのキューに入り待機状態になります。スケジューラーはキューからPodを取り出し、ノードへのスケジューリングを試みます。Podに指定された条件を全て満たすノードが見つからない場合は、待機状態のPodのためにプリエンプションロジックが発動します。待機状態のPodをPと呼ぶことにしましょう。プリエンプションロジックはPよりも優先度の低いPodを一つ以上追い出せばPをスケジューリングできるようになるノードを探します。そのようなノードがあれば、優先度の低いPodはノードから追い出されます。Podが追い出された後に、Pはノードへスケジューリング可能になります。
ユーザーへ開示される情報 Pod PがノードNのPodをプリエンプトした場合、ノードNの名称がPのステータスのnominatedNodeNameフィールドに設定されます。このフィールドはスケジューラーがPod Pのために予約しているリソースの追跡を助け、ユーザーにクラスターにおけるプリエンプトに関する情報を与えます。
Pod Pは必ずしも「指名したノード」へスケジューリングされないことに注意してください。スケジューラーは、他のノードに対して処理を繰り返す前に、常に「指定したノード」に対して試行します。Podがプリエンプトされると、そのPodは終了までの猶予期間を得ます。スケジューラーがPodの終了を待つ間に他のノードが利用可能になると、スケジューラーは他のノードをPod Pのスケジューリング先にすることがあります。この結果、PodのnominatedNodeNameとnodeNameは必ずしも一致しません。また、スケジューラーがノードNのPodをプリエンプトさせた後に、Pod Pよりも優先度の高いPodが来た場合、スケジューラーはノードNをその新しい優先度の高いPodへ与えることもあります。このような場合は、スケジューラーはPod PのnominatedNodeNameを消去します。これによって、スケジューラーはPod Pが他のノードのPodをプリエンプトさせられるようにします。
プリエンプトの制限 プリエンプトされるPodの正常終了 Podがプリエンプトされると、猶予期間 が与えられます。
Podは作業を完了し、終了するために十分な時間が与えられます。仮にそうでない場合、強制終了されます。この猶予期間によって、スケジューラーがPodをプリエンプトした時刻と、待機状態のPod Pがノード Nにスケジュール可能になるまでの時刻の間に間が開きます。この間、スケジューラーは他の待機状態のPodをスケジュールしようと試みます。プリエンプトされたPodが終了したら、スケジューラーは待ち行列にあるPodをスケジューリングしようと試みます。そのため、Podがプリエンプトされる時刻と、Pがスケジュールされた時刻には間が開くことが一般的です。この間を最小にするには、優先度の低いPodの猶予期間を0または小さい値にする方法があります。
PodDisruptionBudgetは対応するが、保証されない PodDisruptionBudget (PDB)は、アプリケーションのオーナーが冗長化されたアプリケーションのPodが意図的に中断される数の上限を設定できるようにするものです。KubernetesはPodをプリエンプトする際にPDBに対応しますが、PDBはベストエフォートで考慮します。スケジューラーはプリエンプトさせたとしてもPDBに違反しないPodを探します。そのようなPodが見つからない場合でもプリエンプションは実行され、PDBに反しますが優先度の低いPodが追い出されます。
優先度の低いPodにおけるPod間のアフィニティ 次の条件が真の場合のみ、ノードはプリエンプションの候補に入ります。
「待機状態のPodよりも優先度の低いPodをノードから全て追い出したら、待機状態のPodをノードへスケジュールできるか」
備考: プリエンプションは必ずしも優先度の低いPodを全て追い出しません。
優先度の低いPodを全て追い出さなくても待機状態のPodがスケジューリングできる場合、一部のPodのみ追い出されます。
このような場合であったとしても、上記の条件は真である必要があります。偽であれば、そのノードはプリエンプションの対象とはされません。待機状態のPodが、優先度の低いPodとの間でPod間のアフィニティ を持つ場合、Pod間のアフィニティはそれらの優先度の低いPodがなければ満たされません。この場合、スケジューラーはノードのどのPodもプリエンプトしようとはせず、代わりに他のノードを探します。スケジューラーは適切なノードを探せる場合と探せない場合があります。この場合、待機状態のPodがスケジューリングされる保証はありません。
この問題に対して推奨される解決策は、優先度が同一または高いPodに対してのみPod間のアフィニティを作成することです。
複数ノードに対するプリエンプション Pod PがノードNにスケジューリングできるよう、ノードNがプリエンプションの対象となったとします。
他のノードのPodがプリエンプトされた場合のみPが実行可能になることもあります。下記に例を示します。
Pod PをノードNに配置することを検討します。 Pod QはノードNと同じゾーンにある別のノードで実行中です。 Pod Pはゾーンに対するQへのアンチアフィニティを持ちます (topologyKey: topology.kubernetes.io/zone)。 Pod Pと、ゾーン内の他のPodに対しては他のアンチアフィニティはない状態です。 Pod PをノードNへスケジューリングするには、Pod Qをプリエンプトすることが考えられますが、スケジューラーは複数ノードにわたるプリエンプションは行いません。そのため、Pod PはノードNへはスケジューリングできないとみなされます。 Pod Qがそのノードから追い出されると、Podアンチアフィニティに違反しなくなるので、Pod PはノードNへスケジューリング可能になります。
複数ノードに対するプリエンプションに関しては、十分な需要があり、合理的な性能を持つアルゴリズムを見つけられた場合に、将来的に機能追加を検討する可能性があります。
トラブルシューティング Podの優先度とプリエンプションは望まない副作用をもたらす可能性があります。
いくつかの起こりうる問題と、その対策について示します。
Podが不必要にプリエンプトされる プリエンプションは、リソースが不足している場合に優先度の高い待機状態のPodのためにクラスターの既存のPodを追い出します。
誤って高い優先度をPodに割り当てると、意図しない高い優先度のPodはクラスター内でプリエンプションを引き起こす可能性があります。Podの優先度はPodの仕様のpriorityClassNameフィールドにて指定されます。優先度を示す整数値へと変換された後、podSpecのpriorityへ設定されます。
この問題に対処するには、PodのpriorityClassNameをより低い優先度に変更するか、このフィールドを未設定にすることができます。priorityClassNameが未設定の場合、デフォルトでは優先度は0とされます。
Podがプリエンプトされたとき、プリエンプトされたPodのイベントが記録されます。
プリエンプションはPodに必要なリソースがクラスターにない場合のみ起こるべきです。
このような場合、プリエンプションはプリエンプトされるPodよりも待機状態のPodの優先度が高い場合のみ発生します。
プリエンプションは待機状態のPodがない場合や待機状態のPodがプリエンプト対象のPod以下の優先度を持つ場合には決して発生しません。そのような状況でプリエンプションが発生した場合、問題を報告してください。
Podはプリエンプトされたが、プリエンプトさせたPodがスケジューリングされない Podがプリエンプトされると、それらのPodが要求した猶予期間が与えられます。そのデフォルトは30秒です。
Podがその期間内に終了しない場合、強制終了されます。プリエンプトされたPodがなくなれば、プリエンプトさせたPodはスケジューリング可能です。
プリエンプトさせたPodがプリエンプトされたPodの終了を待っている間に、より優先度の高いPodが同じノードに対して作成されることもあります。この場合、スケジューラーはプリエンプトさせたPodの代わりに優先度の高いPodをスケジューリングします。
これは予期された挙動です。優先度の高いPodは優先度の低いPodに取って代わります。
優先度の高いPodが優先度の低いPodより先にプリエンプトされる スケジューラーは待機状態のPodが実行可能なノードを探します。ノードが見つからない場合、スケジューラーは任意のノードから優先度の低いPodを追い出し、待機状態のPodのためのリソースを確保しようとします。
仮に優先度の低いPodが動いているノードが待機状態のPodを動かすために適切ではない場合、スケジューラーは他のノードで動いているPodと比べると、優先度の高いPodが動いているノードをプリエンプションの対象に選ぶことがあります。この場合もプリエンプトされるPodはプリエンプトを起こしたPodよりも優先度が低い必要があります。
複数のノードがプリエンプションの対象にできる場合、スケジューラーは優先度が最も低いPodのあるノードを選ぼうとします。しかし、そのようなPodがPodDisruptionBudgetを持っており、プリエンプトするとPDBに反する場合はスケジューラーは優先度の高いPodのあるノードを選ぶこともあります。
複数のノードがプリエンプションの対象として利用可能で、上記の状況に当てはまらない場合、スケジューラーは優先度の最も低いノードを選択します。
Podの優先度とQoSの相互作用 Podの優先度とQoSクラス は直交する機能で、わずかに相互作用がありますが、デフォルトではQoSクラスによる優先度の設定の制約はありません。スケジューラーのプリエンプションのロジックはプリエンプションの対象を決めるときにQoSクラスは考慮しません。
プリエンプションはPodの優先度を考慮し、優先度が最も低いものを候補とします。より優先度の高いPodは優先度の低いPodを追い出すだけではプリエンプトを起こしたPodのスケジューリングに不十分な場合と、PodDisruptionBudgetにより優先度の低いPodが保護されている場合のみ対象になります。
kubeletはnode-pressureによる退避 を行うPodの順番を決めるために、優先度を利用します。QoSクラスを使用して、最も退避される可能性の高いPodの順番を推定することができます。
kubeletは追い出すPodの順位付けを次の順で行います。
枯渇したリソースを要求以上に使用しているか Podの優先度 要求に対するリソースの使用量 詳細はkubeletによるPodの退避 を参照してください。
kubeletによるリソース不足時のPodの追い出しでは、リソースの消費が要求を超えないPodは追い出されません。優先度の低いPodのリソースの利用量がその要求を超えていなければ、追い出されることはありません。より優先度が高く、要求を超えてリソースを使用しているPodが追い出されます。
次の項目 3.11.13 - ノードの圧迫による退避 ノード圧迫による退避は、kubelet がノード上のリソースを回収するためにPodを積極的に失敗させるプロセスです。
備考: FEATURE STATE:
Kubernetes v1.31 [beta](enabled by default)
分割イメージファイルシステム 機能は、containerfsファイルシステムのサポートを有効にし、いくつかの新しい退避シグナル、閾値、メトリクスを追加します。
containerfsを使用するには、Kubernetesリリース v1.35でKubeletSeparateDiskGCフィーチャーゲート を有効にする必要があります。
現在、containerfsファイルシステムのサポートを提供しているのはCRI-O(v1.29以降)のみです。
kubelet は、クラスターのノード上のメモリ、ディスク容量、ファイルシステムのinodeといったのリソースを監視します。
これらのリソースの1つ以上が特定の消費レベルに達すると、kubeletはリソースの枯渇を防ぐため、ノード上の1つ以上のPodを事前に停止してリソースを回収します。
ノードのリソース枯渇による退避中に、kubeletは選択されたPodのフェーズ をFailedに設定し、Podを終了します。
ノードのリソース枯渇による退避は、APIを起点とした退避 とは異なります。
kubeletは、設定したPodDisruptionBudget やPodのterminationGracePeriodSecondsを考慮しません。
ソフト退避の閾値 を使用する場合は、kubeletは設定されたeviction-max-pod-grace-periodを順守します。
ハード退避の閾値 を使用する場合は、kubeletは終了に0秒の猶予期間(即時シャットダウン)を使用します。
自己修復の仕組み kubeletは、エンドユーザーのPodを終了する前にノードレベルのリソースを回収 しようとします。
例えば、ディスクリソースが枯渇している場合は未使用のコンテナイメージを削除します。
失敗したPodを置き換えるワークロード 管理オブジェクト(StatefulSet やDeployment )によってPodが管理されている場合、コントロールプレーン(kube-controller-manager)は退避されたPodの代わりに新しいPodを作成します。
static Podの自己修復 リソースが圧迫しているノード上でstatic pod が実行されている場合、kubeletはそのstatic Podを退避することがあります。
static Podは常にそのノード上でPodを実行しようとするため、kubeletは代替のPodの作成を試みます。
kubeletは、代替のPodを作成する際にstatic Podの priority を考慮します。
static Podのマニフェストで低い優先度が指定され、クラスターのコントロールプレーン内で定義されたより高い優先度のPodがあります。
ノードのリソースが圧迫されている場合、kubeletはそのstatic Podのためにスペースを確保できない可能性があります。
kubeletは、ノードのリソースが圧迫されている場合でもすべてのstatic Podの実行を試行し続けます。
退避シグナルと閾値 kubeletは、退避を決定するために次のようにさまざまなパラメータを使用します:
退避シグナル 退避シグナルは、ある時点での特定リソースの状態を表します。
kubeletは退避シグナルを使用して、シグナルと退避閾値(ノード上で利用可能なリソースの最小量)を比較して退避を決定します。
kubeletは次の退避シグナルを使用します:
退避シグナル 説明 Linux専用 memory.availablememory.available := node.status.capacity[memory] - node.stats.memory.workingSetnodefs.availablenodefs.available := node.stats.fs.availablenodefs.inodesFreenodefs.inodesFree := node.stats.fs.inodesFree• imagefs.availableimagefs.available := node.stats.runtime.imagefs.availableimagefs.inodesFreeimagefs.inodesFree := node.stats.runtime.imagefs.inodesFree• containerfs.availablecontainerfs.available := node.stats.runtime.containerfs.availablecontainerfs.inodesFreecontainerfs.inodesFree := node.stats.runtime.containerfs.inodesFree• pid.availablepid.available := node.stats.rlimit.maxpid - node.stats.rlimit.curproc•
この表では、説明 列がシグナルの値の取得方法を示しています。
それぞれのシグナルは、パーセンテージまたはリテラル値をサポートします。
kubeletは、シグナルに関連付けられた総容量に対する割合を計算します。
メモリシグナル Linuxノード上では、free -mのようなツールの代わりにcgroupfsからmemory.availableの値が取得されます。
これは重要なことであり、free -mはコンテナ内で動作せず、ユーザーがNode Allocatable 機能を使用する場合、リソース不足の判断はルートノードと同様にcgroup階層のエンドユーザーPodの一部に対してローカルに行われるためです。
このスクリプト またはcgroupv2スクリプト は、kubeletがmemory.availableを計算するために実行する一連の手順を再現します。
kubeletは、圧迫下でもメモリが再利用可能であると想定しているため、inactive_file(非アクティブなLRUリスト上のファイルベースのメモリのバイト数)を計算から除外します。
Windowsノードでは、memory.availableの値は、ノードのグローバルメモリコミットレベル(GetPerformanceInfo関数CommitLimitCommitTotalCommitLimitも変更されることに注意してください。
ファイルシステムシグナル kubeletは、退避シグナル(<identifier>.inodesFreeや<identifier>.available)で使用できる3つの特定のファイルシステム識別子を認識します:
nodefs: ノードのファイルシステムであり、ローカルディスクボリューム、メモリにバックアップされていないemptyDirボリューム、ログストレージ、エフェメラルストレージなどに使用されます。
例えば、nodefsには/var/lib/kubeletが含まれます。
imagefs: コンテナランタイムがコンテナイメージ(読み取り専用レイヤー)とコンテナの書き込みレイヤーを格納するために使用できるオプションのファイルシステムです。
containerfs: コンテナランタイムが書き込み可能なレイヤーを格納するために使用できるオプションのファイルシステムです。
メインファイルシステム(nodefsを参照)と同様に、ローカルディスクボリューム、メモリにバックアップされていないemptyDirボリューム、ログストレージ、エフェメラルストレージに使用されますが、コンテナイメージは含まれません。
containerfsを使用すると、imagefsファイルシステムをコンテナイメージ(読み取り専用レイヤー)のみを格納するように分割できます。
したがって、kubeletは通常コンテナファイルシステムについて次の3つのオプションを許可します:
すべてが単一のnodefsにある場合、"rootfs"または単に"root"として参照され、専用のイメージファイルシステムはありません。
コンテナストレージ(nodefsを参照)は専用のディスクにあり、imagefs(書き込み可能レイヤーと読み取り専用レイヤー)はルートファイルシステムから分離されています。
これはよく「分割ディスク」(または「分離ディスク」)ファイルシステムと呼ばれます。
コンテナファイルシステムcontainerfs(書き込み可能レイヤーを含むnodefsと同じ)がルートにあり、コンテナイメージ(読み取り専用レイヤー)は分離されたimagefsに格納されています。
これはよく「分割イメージ」ファイルシステムと呼ばれます。
kubeletは、これらのファイルシステムを現在の構成に基づいてコンテナランタイムから直接自動検出しようとし、他のローカルノードファイルシステムを無視します。
kubeletは、他のコンテナファイルシステムやストレージ構成をサポートせず、現在イメージとコンテナに対して複数のファイルシステムをサポートしていません。
非推奨のkubeletガベージコレクション機能 一部のkubeletガベージコレクション機能は、退避に置き換えられるため非推奨となりました:
既存フラグ 理由 --maximum-dead-containers古いログがコンテナのコンテキスト外に保存されると非推奨になります --maximum-dead-containers-per-container古いログがコンテナのコンテキスト外に保存されると非推奨になります --minimum-container-ttl-duration古いログがコンテナのコンテキスト外に保存されると非推奨になります
退避閾値 kubeletは、退避の判断を行うときに使用するカスタムの退避閾値を指定できます。
ソフト退避の閾値 とハード退避の閾値 の退避閾値を構成できます。
退避閾値は[eviction-signal][operator][quantity]の形式を取ります:
eviction-signalは、使用する退避シグナル です。operatorは、<(より小さい)などの関係演算子 です。quantityは、1Giなどの退避閾値量です。
quantityの値はKubernetesで使用される数量表現と一致する必要があります。
リテラル値またはパーセンテージ(%)を使用できます。例えば、ノードの総メモリが10GiBで、利用可能なメモリが1GiB未満になった場合に退避をトリガーする場合、退避閾値をmemory.available<10%またはmemory.available<1Giのどちらかで定義できます(両方を使用することはできません)。
ソフト退避の閾値 ソフト退避閾値は、退避閾値と必須の管理者指定の猶予期間をペアにします。
kubeletは猶予期間が経過するまでポッドを退避しません。
kubeletは猶予期間を指定しない場合、起動時にエラーを返します。
ソフト退避閾値の猶予期間と、kubeletが退避中に使用する最大許容Pod終了の猶予期間を両方指定できます。
最大許容猶予期間を指定しており、かつソフト退避閾値に達した場合、kubeletは2つの猶予期間のうち短い方を使用します。
最大許容猶予期間を指定していない場合、kubeletはグレースフルな終了ではなくPodを即座に終了します。
ソフト退避閾値を構成するために次のフラグを使用できます:
eviction-soft: 指定された猶予期間を超えた場合にPodの退避をトリガーする、memory.available<1.5Giのような退避閾値のセット。eviction-soft-grace-period: Podと退避をトリガーする前にソフト退避閾値を保持する必要がある時間を定義する、memory.available=1m30sのような退避猶予期間のセット。eviction-max-pod-grace-period: ソフト退避閾値に達した場合、Podを終了する際に使用する最大許容猶予期間(秒)。ハード退避の閾値 ハード退避閾値には、猶予期間がありません。
ハード退避閾値に達した場合、kubeletはグレースフルな終了ではなく即座にポッドを終了してリソースを回収します。
eviction-hardフラグを使用して、memory.available<1Giのようなハード退避閾値のセットを構成します。
kubeletには、次のデフォルトのハード退避閾値があります:
memory.available<100Mi(Linuxノード)memory.available<500Mi(Windowsノード)nodefs.available<10%imagefs.available<15%nodefs.inodesFree<5%(Linuxノード)imagefs.inodesFree<5%(Linuxノード)これらのハード退避閾値のデフォルト値は、いずれのパラメーター値も変更されていない場合にのみ設定されます。
いずれかのパラメーター値を変更すると、他のパラメーター値はデフォルト値として継承されず、ゼロに設定されます。
カスタム値を指定するには、すべての閾値を指定する必要があります。
containerfs.availableとcontainerfs.inodesFree(Linuxノード)のデフォルトの退避閾値は次のように設定されます:
現在はcontainerfsに関連する閾値のカスタムオーバーライド設定はサポートされていないため、そのような設定を試みると警告が出ます。指定されたカスタム値はすべて無視されます。
退避の監視間隔 kubeletは、設定されたhousekeeping-intervalに基づいて退避閾値を評価しており、デフォルトでは10sです。
ノードの状態 kubeletは、猶予期間の構成とは関係なく、ハードまたはソフト退避閾値に達したためにノードが圧迫されていることを示すノードのConditions を報告します。
kubeletは、次のように退避シグナルをノードの状態にマッピングします:
ノードのCondition 退避シグナル 説明 MemoryPressurememory.availableノード上の利用可能なメモリが退避閾値に達しています DiskPressurenodefs.available, nodefs.inodesFree, imagefs.available, imagefs.inodesFree, containerfs.available, or containerfs.inodesFreeノードのルートファイルシステム、イメージファイルシステム、またはコンテナファイルシステムのいずれかの利用可能なディスク容量とinodeが退避閾値に達しています PIDPressurepid.available(Linux)ノード上で使用可能なプロセス識別子が退避閾値を下回りました
コントロールプレーンは、これらのノードの状態をテイントにもマッピング します。
kubeletは、設定された--node-status-update-frequencyに基づいてノードの状態を更新し、デフォルトでは10sです。
ノードの状態の振動 場合によっては、ノードが定義された猶予期間を超えずに、ソフト閾値の上下を振動することがあります。
これにより、報告されるノードの状態がtrueとfalseの間で頻繁に切り替わり、不適切な退避の判断をトリガーする可能性があります。
振動を防ぐために、eviction-pressure-transition-periodフラグを使用できます。
このフラグは、kubeletがノードの状態を別の状態に遷移させるまでの時間を制御します。
デフォルトの遷移期間は5mです。
ノードレベルのリソースの回収 kubeletは、エンドユーザーのPodを退避する前にのノードレベルのリソースを回収しようとします。
ノードのDiscPressure状態が報告されると、kubeletはノード上のファイルシステムに基づいてノードレベルのリソースを回収します。
imagefsまたはcontainerfsがない場合ノードにnodefsファイルシステムのみがあり、退避閾値に達した場合、kubeletは次の順序でディスク容量を解放します:
deadなPodとコンテナをガベージコレクションします。 未使用のイメージを削除します。 imagefsを使用する場合ノードにコンテナランタイムが使用するためのimagefsファイルシステムがある場合、kubeletは次のようにノードレベルのリソースを回収します:
imagefsとcontainerfsを使用する場合ノードにコンテナランタイムが使用するためのcontainerfsとimagefsファイルシステムがある場合、kubeletは次のようにノードレベルのリソースを回収します:
kubeletの退避におけるPodの選択 kubeletは、ノードレベルのリソースを回収しても退避シグナルが閾値を下回らない場合、エンドユーザーのPodを退避し始めます。
kubeletは、次のパラメータを使用してPodの退避順序を決定します:
Podのリソース使用量がリクエストを超えているかどうか Podの優先度 Podのリソース使用量がリクエストを下回っているかどうか 結果として、kubeletは次の順序でPodをランク付けして退避します:
リソース使用量がリクエストを超えているBestEffortまたはBurstablePod。
これらのPodは、その優先度に基づき、リクエストを超える使用量に応じて退避されます。
リソース使用量がリクエストを下回っているGuaranteedとBurstablePodは、その優先度に基づいて最後に退避されます。
備考: kubeletは、Podの
QoSクラス を使用して退避順序を決定しません。
メモリなどのリソースを回収する際に、QoSクラスを使用して最も退避される可能性の高いPodの順序を予測することができます。
QoSの分類はEphemeralStorageのリクエストには適用されないため、例えばノードが
DiskPressure状態にある場合、上記のシナリオは当てはまりません。
GuaranteedPodは、すべてのコンテナにリクエストとリミットが指定されており、それらが等しい場合にのみ保証されます。
これらのPodは、他のPodのリソース消費によって退避されることはありません。
(kubeletやjournaldのような)システムデーモンが、system-reservedやkube-reservedの割り当てよりも多くのリソースを消費しており、ノードにはリクエストより少ないリソースを使用しているGuaranteedまたはBurstablePodしかない場合、kubeletは他のPodへのリソース枯渇の影響を制限してノードの安定性を保つために、これらのPodのなかから退避するPodを選択する必要があります。
この場合、最も低い優先度のPodを退避するように選択します。
static Pod を実行しており、リソース圧迫による退避を回避したい場合は、そのPodに直接priorityフィールドを設定します。
Static PodはpriorityClassNameフィールドをサポートしていません。
kubeletは、inodeまたはプロセスIDの枯渇に応じてPodを退避する場合、inodeとPIDにはリクエストがないため、Podの相対的な優先度を使用して退避順序を決定します。
kubeletは、ノードが専用のimagefsまたはcontainerfsファイルシステムを持っているかどうかに基づいて、異なる方法でPodをソートします:
imagefsまたはcontainerfsがない場合(nodefsとimagefsは同じファイルシステムを使用します)nodefsが退避をトリガーした場合、kubeletはそれらの合計ディスク使用量(ローカルボリューム + すべてのコンテナのログと書き込み可能レイヤー)に基づいてPodをソートします。imagefsを使用する場合(nodefsとimagefsファイルシステムが分離されている)imagefsとcontainerfsを使用する場合(imagefsとcontainerfsは分割されています)退避による最小の回収
備考: Kubernetes v1.35以降、containerfs.availableメトリクスのカスタム値を設定することはできません。
この特定のメトリクスの構成は、構成に応じて、nodefsまたはimagefsに設定された値を自動的に反映するように設定されます。場合によっては、Podの退避によって回収されるリソースがごくわずかであることがあります。
このため、kubeletが設定された退避閾値に繰り返し達し、複数の退避をトリガーする可能性があります。
--eviction-minimum-reclaimフラグやkubeletの設定ファイル を使用して、各リソースの最小の回収量を構成できます。
kubeletがリソース不足を検知すると、指定した値に達するまでリソースを回収し続けます。
例えば、次の構成は最小回収量を設定します:
apiVersion : kubelet.config.k8s.io/v1beta1
kind : KubeletConfiguration
evictionHard :
memory.available : "500Mi"
nodefs.available : "1Gi"
imagefs.available : "100Gi"
evictionMinimumReclaim :
memory.available : "0Mi"
nodefs.available : "500Mi"
imagefs.available : "2Gi"
この例では、nodefs.availableシグナルが退避閾値に達した場合、kubeletはシグナルが1GiBに達するまでリソースを回収します。
その後は500MiBの最小量を回収し続け、利用可能なnodefsストレージが1.5GiBに達するまで続行します。
同様に、kubeletはimagefsリソースを回収し、imagefs.availableの値が102Giに達するまでリソースを回収を試みます。
これは、コンテナイメージストレージの102GiBが利用可能であることを示します。
kubeletが回収できるストレージ量が2GiB未満の場合、kubeletは何も回収しません。
eviction-minimum-reclaimのデフォルト値は、すべてのリソースに対して0です。
ノードのメモリ不足の挙動 kubeletがメモリを回収する前にノードで メモリ不足 (OOM)イベントが発生した場合、ノードはoom_killer に依存して対応します。
kubeletは、PodのQoSに基づいて各コンテナのoom_score_adj値を設定します。
サービスの品質 oom_score_adjGuaranteed-997 BestEffort1000 Burstablemin(max(2, 1000 - (1000 × memoryRequestBytes) / machineMemoryCapacityBytes), 999)
備考: またkubeletは、
system-node-critical優先度 を持つPodのコンテナに対して
oom_score_adj値を
-997に設定します。
kubeletがノードでOOMが発生する前にメモリを回収できない場合、oom_killerはそのノード上で使用しているメモリの割合に基づいてoom_scoreを計算し、次にoom_score_adjを加算して各コンテナの有効なoom_scoreを計算します。
その後、oom_killerは最も高いスコアを持つコンテナを終了します。
これは、スケジューリングリクエストに対して多くのメモリを消費する低いQoS Podのコンテナが最初に終了されることを意味します。
Podの退避とは異なり、コンテナがOOMで強制終了された場合、kubeletはrestartPolicyに基づいてコンテナを再起動できます。
グッドプラクティス 退避の構成に関するグッドプラクティスを次のセクションで説明します。
スケジュール可能なリソースと退避ポリシー 退避ポリシーを使用してkubeletを構成する場合、スケジューラーがPodのスケジュール直後にメモリ圧迫をトリガーして退避を引き起こさないようにする必要があります。
次のシナリオを考えてみましょう:
ノードのメモリキャパシティ: 10GiB オペレーターはシステムデーモン(kernel、kubeletなど)に10%のメモリ容量を予約したい オペレーターはシステムのOOMの発生を減らすために、メモリ使用率が95%に達したときにPodを退避したい この場合、kubeletは次のように起動されます:
--eviction-hard=memory.available<500Mi
--system-reserved=memory=1.5Gi
この構成では、--system-reservedフラグによりシステム用に1.5GiBのメモリが予約されます。
これは総メモリの10% + 退避閾値量です。
ノードは、Podがリクエスト以上のメモリを使用している場合や、システムが1GiB以上のメモリを使用している場合に、退避閾値に達する可能性があります。
これにより、memory.availableシグナルが500MiBを下回り、閾値がトリガーされます。
DaemonSetとノードの圧迫による退避 Podの優先度は、退避の決定において重要な要素です。
kubeletは、DaemonSetに属するPodを退避させたくない場合、そのPodのspecに適切なpriorityClassNameを指定して十分な優先度を与えることができます。
より低い、またはデフォルトの優先度を使用して、十分なリソースがある場合にのみDaemonSetのPodを実行できるようにすることも可能です。
既知の問題 リソースの圧迫に関連する既知の問題について次のセクションで説明します。
kubeletが即座にメモリ圧迫を検知しないことがある デフォルトでは、kubeletはcAdvisorを定期的にポーリングしてメモリ使用量の統計を収集します。
メモリ使用量がその間に急速に増加した場合、kubeletはMemoryPressure状態を十分な早さで検知できない可能性があり、OOMキラーが呼び出される可能性があります。
--kernel-memcg-notificationフラグにより、kubeletのmemcg通知APIを有効にして、閾値を超えたとき即座に通知を受け取ることができます。
極端な使用率を達成しようとするのではなく、合理的なオーバーコミットを目指している場合、この問題に対して実行可能な回避策は--kube-reservedおよび--system-reservedフラグを使用してシステム用のメモリを割り当てることです。
active_fileメモリは使用可能なメモリとして見なされません Linuxでは、カーネルがアクティブなLRUリスト上のファイルベースのメモリのバイト数をactive_file統計として追跡します。
kubeletは、active_fileメモリの領域を回収不可能として扱います。
一時的なローカルストレージを含むブロックベースのローカルストレージを集中的に使用するワークロードの場合、カーネルレベルのファイルおよびブロックデータのキャッシュにより、多くの直近アクセスされたキャッシュページがactive_fileとしてカウントされる可能性が高いです。
これらのカーネルブロックバッファがアクティブなLRUリストに十分に存在すると、kubeletはこれを高いリソース使用として観測し、ノードにメモリ圧迫が発生しているとしてテイントし、Podの退避をトリガーします。
より詳細については、https://github.com/kubernetes/kubernetes/issues/43916 を参照してください。
その動作を回避するためには、集中的なI/Oアクティビティを行う可能性があるコンテナに対してメモリリミットとメモリリクエストを同じ値に設定します。
そのコンテナに対して最適なメモリのリミット値を見積もるか、測定する必要があります。
次の項目 3.11.14 - APIを起点とした退避 APIを起点とした退避は、Eviction API を使用して退避オブジェクトを作成し、Podの正常終了を起動させるプロセスです。
Eviction APIを直接呼び出すか、kubectl drainコマンドのようにAPIサーバー のクライアントを使って退避を要求することが可能です。これにより、Evictionオブジェクトを作成し、APIサーバーにPodを終了させます。
APIを起点とした退避はPodDisruptionBudgetsterminationGracePeriodSeconds
APIを使用してPodのEvictionオブジェクトを作成することは、Podに対してポリシー制御されたDELETE操作
Eviction APIの実行 Kubernetes APIへアクセスしてEvictionオブジェクトを作るためにKubernetesのプログラミング言語のクライアント を使用できます。
そのためには、次の例のようなデータをPOSTすることで操作を試みることができます。
備考: policy/v1においてEvictionはv1.22以上で利用可能です。それ以前のリリースでは、policy/v1beta1を使用してください。{
"apiVersion" : "policy/v1" ,
"kind" : "Eviction" ,
"metadata" : {
"name" : "quux" ,
"namespace" : "default"
}
}
備考: v1.22で非推奨となり、policy/v1が採用されました。{
"apiVersion" : "policy/v1beta1" ,
"kind" : "Eviction" ,
"metadata" : {
"name" : "quux" ,
"namespace" : "default"
}
}
また、以下の例のようにcurlやwgetを使ってAPIにアクセスすることで、操作を試みることもできます。
curl -v -H 'Content-type: application/json' https://your-cluster-api-endpoint.example/api/v1/namespaces/default/pods/quux/eviction -d @eviction.json
APIを起点とした退避の仕組み APIを使用して退去を要求した場合、APIサーバーはアドミッションチェックを行い、以下のいずれかを返します。
200 OK:この場合、退去が許可されるとEvictionサブリソースが作成され、PodのURLにDELETEリクエストを送るのと同じように、Podが削除されます。429 Too Many Requests:PodDisruptionBudget の設定により、現在退去が許可されていないことを示します。しばらく時間を空けてみてください。また、APIのレート制限のため、このようなレスポンスが表示されることもあります。500 Internal Server Error:複数のPodDisruptionBudgetが同じPodを参照している場合など、設定に誤りがあり退去が許可されないことを示します。退去させたいPodがPodDisruptionBudgetを持つワークロードの一部でない場合、APIサーバーは常に200 OKを返して退去を許可します。
APIサーバーが退去を許可した場合、以下の流れでPodが削除されます。
APIサーバーのPodリソースの削除タイムスタンプが更新され、APIサーバーはPodリソースが終了したと見なします。またPodリソースは、設定された猶予期間が設けられます。 ローカルのPodが動作しているNodeのkubelet は、Podリソースが終了するようにマークされていることに気付き、Podの適切なシャットダウンを開始します。 kubeletがPodをシャットダウンしている間、コントロールプレーンはEndpoint オブジェクトからPodを削除します。その結果、コントローラーはPodを有効なオブジェクトと見なさないようになります。 Podの猶予期間が終了すると、kubeletはローカルPodを強制的に終了します。 kubeletはAPIサーバーにPodリソースを削除するように指示します。 APIサーバーはPodリソースを削除します。 トラブルシューティング 場合によっては、アプリケーションが壊れた状態になり、対処しない限りEviction APIが429または500レスポンスを返すだけとなることがあります。例えば、ReplicaSetがアプリケーション用のPodを作成しても、新しいPodがReady状態にならない場合などです。また、最後に退去したPodの終了猶予期間が長い場合にも、この事象が見られます。
退去が進まない場合は、以下の解決策を試してみてください。
問題を引き起こしている自動化された操作を中止または一時停止し、操作を再開する前に、スタックしているアプリケーションを調査を行ってください。 しばらく待ってから、Eviction APIを使用する代わりに、クラスターのコントロールプレーンから直接Podを削除してください。 次の項目 3.11.15 - Node Declared Features FEATURE STATE:
Kubernetes v1.35 [alpha](disabled by default)
Kubernetesノードは Declared Features を使用して、新規機能やフィーチャーゲート制御された特定の機能が利用可能かどうかを報告します。
コントロールプレーンコンポーネントは、この情報を利用してより適切な判断を行います。
kube-schedulerは、NodeDeclaredFeaturesプラグインを介して、Podが必要とする機能を明示的にサポートするノードにのみPodを配置します。
さらに、NodeDeclaredFeatureValidatorアドミッションコントローラーは、Pod更新時にノードが必要な機能を宣言しているかを検証します。
このメカニズムにより、バージョンスキューを管理でき、クラスターの安定性が向上します。
特に、クラスターのアップグレード時や、すべてのノードで同じ機能が有効になっていない可能性がある混合バージョン環境で有効です。
これは、新しいノードレベルの機能を導入するKubernetes機能開発者向けのもので、バックグラウンドで動作します。
Podをデプロイするアプリケーション開発者は、このフレームワークと直接やり取りする必要はありません。
動作の仕組み Kubeletによる機能報告: 起動時に、各ノード上のkubeletは、現在有効になっている管理対象のKubernetes機能を検出し、Nodeオブジェクトの.status.declaredFeaturesフィールドで報告します。
このフィールドには、アクティブに開発中の機能のみが含まれます。スケジューラーによるフィルタリング: デフォルトのkube-schedulerはNodeDeclaredFeaturesプラグインを使用します。
このプラグインは:PreFilterステージで、PodSpecをチェックして、Podが必要とするノード機能のセットを推測します。Filterステージで、ノードの.status.declaredFeaturesにリストされている機能が、Podに対して推測された要件を満たすかどうかをチェックします。
必要な機能を持たないノードにはPodはスケジュールされません。
カスタムスケジューラーも.status.declaredFeaturesフィールドを利用して、同様の制約を適用できます。アドミッションコントロール: nodedeclaredfeaturevalidatorアドミッションコントローラーは、バインド先のノードで宣言されていない機能を必要とするPodを拒否でき、Pod更新時の問題を防ぎます。Node Declared Featuresの有効化 Node Declared Featuresを使用するには、kube-apiserver、kube-scheduler、およびkubeletコンポーネントでNodeDeclaredFeaturesフィーチャーゲート を有効にする必要があります。
次の項目
3.12 - クラスターの管理 3.12.1 - クラスター管理の概要 このページはKubernetesクラスターの作成や管理者向けの内容です。Kubernetesのコアコンセプト についてある程度精通していることを前提とします。
クラスターのプランニング Kubernetesクラスターの計画、セットアップ、設定の例を知るには設定 のガイドを参照してください。この記事で列挙されているソリューションはディストリビューション と呼ばれます。
ガイドを選択する前に、いくつかの考慮事項を挙げます。
ユーザーのコンピューター上でKubernetesを試したいでしょうか、それとも高可用性のあるマルチノードクラスターを構築したいでしょうか?あなたのニーズにあったディストリビューションを選択してください。 もしあなたが高可用性を求める場合 、 複数ゾーンにまたがるクラスター の設定について学んでください。Google Kubernetes Engine のようなホストされているKubernetesクラスター を使用するのか、それとも自分自身でクラスターをホストするのでしょうか ?使用するクラスターはオンプレミス なのか、それともクラウド(IaaS) でしょうか?Kubernetesはハイブリッドクラスターを直接サポートしていません。その代わりユーザーは複数のクラスターをセットアップできます。 Kubernetesを 「ベアメタル」なハードウェア 上で稼働させますか?それとも仮想マシン(VMs) 上で稼働させますか? もしオンプレミスでKubernetesを構築する場合 、どのネットワークモデル が最適か検討してください。ただクラスターを稼働させたいだけ でしょうか、それともKubernetesプロジェクトのコードの開発 を行いたいでしょうか?もし後者の場合、開発が進行中のディストリビューションを選択してください。いくつかのディストリビューションはバイナリリリースのみ使用していますが、多くの選択肢があります。クラスターを稼働させるのに必要なコンポーネント についてよく理解してください。 注意: 全てのディストリビューションがアクティブにメンテナンスされている訳ではありません。最新バージョンのKubernetesでテストされたディストリビューションを選択してください。
クラスターの管理 クラスターをセキュアにする kubeletをセキュアにする オプションのクラスターサービス 3.12.2 - ノードの自動スケーリング 需要に適応し、コストを最適化するために、クラスター内のノードを自動的にプロビジョニングおよび統合します。
クラスター内でワークロードを実行するには、ノード が必要です。
クラスター内のノードは 自動スケール 可能であり、必要なキャパシティを提供しながらコストを最適化するために、動的にプロビジョニング 統合 オートスケーラー
ノードのプロビジョニング 既存のノードにスケジュールできないPodがクラスター内にある場合、それらのPodを収容するために、新しいノードをクラスターに自動的に追加—プロビジョニング —できます。
これは、例えば水平ワークロードとノードの自動スケーリングを組み合わせた 結果として、時間の経過とともにPodの数が変化する場合に特に役立ちます。
オートスケーラーは、ノードを裏で支えるクラウドプロバイダーのリソースを作成および削除することにより、ノードをプロビジョニングします。
一般的に、ノードを裏で支えるリソースは仮想マシンです。
プロビジョニングの主な目的は、すべてのPodをスケジュール可能にすることです。
この目的は、構成されたプロビジョニングの制限に達したり、特定のPodのセットと互換性のないプロビジョニング構成であったり、クラウドプロバイダーのキャパシティが不足していたりするなど、さまざまな制限によって常に達成可能ではありません。
プロビジョニング中には、追加の目的(たとえばプロビジョニングされたノードのコストを最小限に抑える、障害ドメイン間のノード数を調整するなど)を達成しようとすることがよくあります。
プロビジョニングするノードを決定する際のノードオートスケーラーへの2つの主な入力は、Podのスケジューリング制約 とオートスケーラー構成によって課されるノード制約 です。
オートスケーラーの構成には、他のノードのプロビジョニングトリガー(たとえば、設定された最小制限を下回るノードの数など)も含まれる場合があります。
備考: プロビジョニングは、以前はCluster Autoscalerで スケールアップ として知られていました。Podのスケジューリング制約 Podは、スケジュール可能なノードの種類に制限を課すためにスケジューリング制約 を表現できます。
ノードオートスケーラーは、これらの制約を考慮して、保留中のPodがプロビジョニングされたノードにスケジュールできるようにします。
最も一般的なスケジューリング制約の種類は、Podコンテナによって指定されたリソース要求です。
オートスケーラーは、プロビジョニングされたノードに要求を満たすのに十分なリソースがあることを確認します。
ただし、Podの実行開始後の実際のリソース使用量は直接考慮することはありません。
実際のワークロードのリソース使用量に基づいてノードを自動スケールするには、水平ワークロードの自動スケーリング をノードの自動スケーリングと組み合わせることができます。
その他の一般的なPodのスケジューリング制約には、ノードアフィニティ 、Pod間アフィニティ 、特定のストレージボリューム の要件などがあります。
オートスケーラー構成によって課されるノード制約 プロビジョニングされるノードの詳細(たとえばリソース量、特定ラベルの有無)は、オートスケーラーの構成によって異なります。
オートスケーラーは、事前定義されたノード構成のセットから選択するか、自動プロビジョニング を使用できます。
自動プロビジョニング ノードの自動プロビジョニングは、プロビジョニング可能なノードの詳細をユーザーが完全に構成する必要のないプロビジョニングモードです。
かわりに、オートスケーラーは、対応している保留中のPodと事前に定義された制約(たとえば、最小リソース量や特定ラベルの必要性)に基づいて、ノード構成を動的に選択します。
ノードの統合 クラスターを運用する際の主な考慮事項は、スケジュール可能なすべてのPodが実行されていることを確認しながら、可能な限りクラスターのコストを低く抑えることです。
これを達成するには、Podのリソース要求がノードのリソースをできるだけ多く利用する必要があります。
この観点から、クラスター内の全体的なノードの使用率は、クラスターのコスト効率の指標として使用できます。
備考: Podのリソース要求を正しく設定することは、ノードの使用率を最適化することと同様に、クラスター全体のコスト効率にとって重要です。
ノードの自動スケーリングを
垂直ワークロードの自動スケーリング と組み合わせることで、これを実現できます。
クラスター内のノードは自動的に 統合 され、全体的なノードの使用率とクラスターのコスト効率を改善できます。
統合は、クラスターから使用率の低いノードのセットを削除することで行われます。
必要に応じて、それらを置き換えるために別のノードセットをプロビジョニング できます。
プロビジョニングと同様に、統合の決定を下す際にはPodのリソース要求のみを考慮し、実際のリソース使用量は考慮しません。
統合の目的のために、ノード上でDeamonSetと静的Podのみが実行されている場合は、そのノードは 空 と見なされます。
統合中に空のノードを削除することは、空でないノードを削除するよりも簡単であり、オートスケーラーには空のノードを統合するために特別に設計された最適化が備わっていることがよくあります。
統合中に空でないノードを削除することは破壊的であり、そのノード上で実行されているPodが終了し、(たとえばDeploymentによって)再作成が必要になる可能性があります。
ただし、再作成されたすべてのPodは、クラスター内の既存のノードまたは統合の一環としてプロビジョニングされた代替ノードにスケジュールできる必要があります。
通常、統合の結果としてPodが保留中になることはありません。
備考: オートスケーラーは、ノードのプロビジョニングまたは統合後に再作成されたPodがどのようにスケジュールされるかを予測しますが、実際のスケジューリングを制御することはありません。
そのため、統合の実行中にまったく新しいPodが出現するなどの理由で、統合の結果として一部のPodが保留中になる可能性があります。オートスケーラー構成では、さまざまなプロパティ(たとえばクラスター内のノードの最大ライフスパン)を最適化するために、他の条件(たとえばノードが作成されてからの経過時間)によって統合をトリガーすることもできます。
統合の実行方法の詳細は、特定のオートスケーラーの構成によって異なります。
備考: 統合は、以前はCluster Autoscalerで スケールダウン として知られていました。オートスケーラー 前のセクションで説明した機能は、ノードの オートスケーラー によって提供されます。
Kubernetes APIに加えて、オートスケーラーはノードをプロビジョニングおよび統合のためにクラウドプロバイダーのAPIと対話する必要があります。
つまり、サポートされている各クラウドプロバイダーと明示的に連携する必要があります。
個々のオートスケーラーのパフォーマンスと機能のセットは、連携先のクラウドプロバイダーによって異なる場合があります。
graph TD
na[Node autoscaler]
k8s[Kubernetes]
cp[Cloud Provider]
k8s --> |get Pods/Nodes|na
na --> |drain Nodes|k8s
na --> |create/remove resources backing Nodes|cp
cp --> |get resources backing Nodes|na
classDef white_on_blue fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef blue_on_white fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class na blue_on_white;
class k8s,cp white_on_blue;
このコンテンツを表示するには、JavaScriptを有効に する必要があります オートスケーラーの実装 Cluster Autoscaler とKarpenter は、現在SIG Autoscaling がスポンサーをしている2つのノードオートスケーラーです。
クラスターユーザーの観点から、どちらのオートスケーラーも同様のノード自動スケーリング体験を提供するはずです。
どちらもスケジュールできないPodのために新しいノードをプロビジョニングし、最適に利用されなくなったノードを統合します。
さまざまなオートスケーラーがこのページで説明されているノード自動スケーリングの範囲外の機能を提供する場合もあり、それらの追加機能はオートスケーラーごとに異なる場合があります。
以下のセクションと個々のオートスケーラーにリンクされたドキュメントを参照して、どのオートスケーラーがユースケースに適しているかを判断してください。
Cluster Autoscaler Cluster Autoscalerは、事前に構成された ノードグループ にノードを追加または削除します。
ノードグループは通常、何らかのクラウドプロバイダーのリソースグループ(最も一般的なのは仮想マシングループ)にマッピングされます。
Cluster Autoscalerの1つのインスタンスで、複数のノードグループを同時に管理できます。
プロビジョニング時には、Cluster Autoscalerは保留中のPodの要求に最も適したグループにノードを追加します。
統合時には、Cluster Autoscalerは基盤となるクラウドプロバイダーのリソースグループのサイズを単に変更するのではなく、削除する特定のノードを常に選択します。
追加のコンテキスト:
Karpenter Karpenterは、クラスター運用者によって提供されるNodePool 構成に基づいてノードを自動プロビジョニングします。
Karpenterは、自動スケーリングだけでなく、ノードのライフサイクルのあらゆる側面を処理します。
これには、特定のライフタイムに達したノードの自動更新や、新しいワーカーノードイメージがリリースされたときのノードの自動アップグレードが含まれます。
Karpenterは、個々のクラウドプロバイダーリソース(最も一般的なのは個々の仮想マシン)と直接連携し、クラウドプロバイダーのリソースグループに依存しません。
追加のコンテキスト:
実装の比較 CarpenterとCluster Autoscalerの主な違い:
Cluster Autoscalerは、ノードの自動スケーリングに関連する機能のみを提供します。
Karpenterはより広範囲であり、ノードのライフサイクル全体を管理すること(たとえば、特定のライフタイムに達したノードを自動的に再作成したり、新しいバージョンに自動的にアップグレードしたりするなど)を目的とした機能も提供します。 Cluster Autoscalerは、自動プロビジョニングをサポートしておらず、プロビジョニングできるノードグループは事前に構成する必要があります。
Karpeterは、自動プロビジョニングをサポートしているため、ユーザーは均質なグループを完全に構成するのではなく、プロビジョニングされるノードの制約セットを構成するだけで済みます。 Cluster Autoscalerは、クラウドプロバイダーとの連携機能を直接提供し、Kubernetesプロジェクトの一部となっています。
Karpenterの場合、KuberentesプロジェクトはKarpenterをライブラリとして公開しており、クラウドプロバイダーはこのライブラリと連携してノードオートスケーラーを構築できます。 Cluster Autoscalerは、小規模であまり知られていないプロバイダーを含む多数のクラウドプロバイダーとの連携機能を提供します。
Karpenterと連携できるクラウドプロバイダーは、AWS やAzure など、より少数です。 ワークロードとノードの自動スケーリングを組み合わせる 水平ワークロードの自動スケーリング ノードの自動スケーリングは通常、Podに応じて機能します。
つまり、スケジュールできないPodを収容するために新しいノードをプロビジョニングし、不要になったらノードを統合します。
水平ワークロードの自動スケーリング は、ワークロードのレプリカ数を自動的に調整し、レプリカ全体で望ましい平均リソース使用率を維持します。
言い換えると、アプリケーション負荷に応じて新しいPodを自動的に作成し、負荷が減少するとPodを削除します。
ノードの自動スケーリングを水平ワークロードの自動スケーリングと組み合わせて使用することで、Podの実際の平均リソース使用率に基づいてクラスター内のノードを自動スケーリングできます。
アプリケーション負荷が増加すると、そのPodの平均使用率も増加し、ワークロードの自動スケーリングによって新しいPodが作成されます。
その後、ノードの自動スケーリングは、新しいPodを収容するために新しいノードをプロビジョニングします。
アプリケーション負荷が減少すると、ワークロードの自動スケーリングによって不要なPodが削除されます。
また、ノードの自動スケーリングによって、不要になったノードが統合されるはずです。
このパターンが正しく構成されている場合、アプリケーションは必要に応じて負荷の急増に対応するためのノードキャパシティを常に保ちますが、必要ないキャパシティに対して料金を支払う必要はありません。
垂直ワークロードの自動スケーリング ノードの自動スケーリングを使用する場合、Podのリソース要求を正しく設定することが重要です。
特定のPodの要求が低すぎると、新しいノードをプロビジョニングしても、実際にはPodの実行に役立たない可能性があります。
特定のPodの要求が高すぎると、ノードの統合を誤って妨げる可能性があります。
垂直ワークロードの自動スケーリング は、過去のリソース使用量に基づいてPodのリソース要求を自動的に調整します。
ノードの自動スケーリングと垂直ワークロードの自動スケーリングを組み合わせて使用することで、クラスター内のノードの自動スケーリング機能を維持しながら、Podのリソース要求を調整できます。
注意: ノードの自動スケーリングを使用する場合、DaemonSetのPodに対して垂直ワークロードの自動スケーリングを設定することは推奨されていません。
オートスケーラーは、使用可能なノードリソースを予測するために、新しいノード上のDaemonSetのPodの状態を予測する必要があります。
垂直ワークロードの自動スケーリングは、これらの予測の信頼性を低下させ、誤ったスケーリングの決定につながる可能性があります。このセクションでは、ノードの自動スケーリングに関連する機能を提供するコンポーネントについて説明します。
Descheduler descheduler は、カスタムポリシーに基づいてノードの統合機能を提供するコンポーネントであり、ノードとPodの最適化に関連するその他の機能(たとえば、頻繁に再起動するPodの削除)も提供します。
クラスターサイズに基づくワークロードオートスケーラー Cluster Proportional Autoscaler とCluster Proportional Vertical Autoscaler は、クラスター内のノード数に基づいて水平または垂直ワークロードの自動スケーリングを提供します。
クラスターサイズに基づく自動スケーリング で詳細を読むことができます。
次の項目 3.12.3 - 証明書 クライアント証明書認証を使用する場合、easyrsaやopenssl、cfsslを用いて、手動で証明書を生成できます。
easyrsa easyrsa を用いると、クラスターの証明書を手動で生成できます。
パッチを当てたバージョンのeasyrsa3をダウンロードして解凍し、初期化します。
curl -LO https://dl.k8s.io/easy-rsa/easy-rsa.tar.gz
tar xzf easy-rsa.tar.gz
cd easy-rsa-master/easyrsa3
./easyrsa init-pki
新しい認証局(CA)を生成します。--batchは自動モードを設定し、--req-cnはCAの新しいルート証明書の共通名(CN)を指定します。
./easyrsa --batch "--req-cn=${MASTER_IP}@`date +%s`" build-ca nopass
サーバー証明書と鍵を生成します。
引数--subject-alt-nameは、APIサーバーへのアクセスに使用できるIPおよびDNS名を設定します。
MASTER_CLUSTER_IPは通常、APIサーバーとコントローラーマネージャーコンポーネントの両方で引数--service-cluster-ip-rangeとして指定されるサービスCIDRの最初のIPです。
引数--daysは、証明書の有効期限が切れるまでの日数を設定するために使われます。
以下の例は、デフォルトのDNSドメイン名としてcluster.localを使用していることを前提とします。
./easyrsa --subject-alt-name="IP:${MASTER_IP},"\
"IP:${MASTER_CLUSTER_IP},"\
"DNS:kubernetes,"\
"DNS:kubernetes.default,"\
"DNS:kubernetes.default.svc,"\
"DNS:kubernetes.default.svc.cluster,"\
"DNS:kubernetes.default.svc.cluster.local" \
--days=10000 \
build-server-full server nopass
pki/ca.crt、pki/issued/server.crt、pki/private/server.keyをディレクトリーにコピーします。
以下のパラメーターを、APIサーバーの開始パラメーターとして追加します。
--client-ca-file=/yourdirectory/ca.crt
--tls-cert-file=/yourdirectory/server.crt
--tls-private-key-file=/yourdirectory/server.key
openssl openssl はクラスターの証明書を手動で生成できます。
2048ビットのca.keyを生成します。
openssl genrsa -out ca.key 2048
ca.keyに応じて、ca.crtを生成します。証明書の有効期間を設定するには、-daysを使用します。
openssl req -x509 -new -nodes -key ca.key -subj "/CN=${MASTER_IP}" -days 10000 -out ca.crt
2048ビットのserver.keyを生成します。
openssl genrsa -out server.key 2048
証明書署名要求(CSR)を生成するための設定ファイルを生成します。
ファイル(例: csr.conf)に保存する前に、かぎ括弧で囲まれた値(例: <MASTER_IP>)を必ず実際の値に置き換えてください。
MASTER_CLUSTER_IPの値は、前節で説明したAPIサーバーのサービスクラスターIPであることに注意してください。
以下の例は、デフォルトのDNSドメイン名としてcluster.localを使用していることを前提とします。
[ req ]
default_bits = 2048
prompt = no
default_md = sha256
req_extensions = req_ext
distinguished_name = dn
[ dn ]
C = <country>
ST = <state>
L = <city>
O = <organization>
OU = <organization unit>
CN = <MASTER_IP>
[ req_ext ]
subjectAltName = @alt_names
[ alt_names ]
DNS.1 = kubernetes
DNS.2 = kubernetes.default
DNS.3 = kubernetes.default.svc
DNS.4 = kubernetes.default.svc.cluster
DNS.5 = kubernetes.default.svc.cluster.local
IP.1 = <MASTER_IP>
IP.2 = <MASTER_CLUSTER_IP>
[ v3_ext ]
authorityKeyIdentifier=keyid,issuer:always
basicConstraints=CA:FALSE
keyUsage=keyEncipherment,dataEncipherment
extendedKeyUsage=serverAuth,clientAuth
subjectAltName=@alt_names
設定ファイルに基づいて、証明書署名要求を生成します。
openssl req -new -key server.key -out server.csr -config csr.conf
ca.key、ca.crt、server.csrを使用してサーバー証明書を生成します。
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key \
-CAcreateserial -out server.crt -days 10000 \
-extensions v3_ext -extfile csr.conf -sha256
証明書を表示します。
openssl x509 -noout -text -in ./server.crt
最後にAPIサーバーの起動パラメーターに、同様のパラメーターを追加します。
cfssl cfssl も証明書を生成するためのツールです。
以下のように、ダウンロードして解凍し、コマンドラインツールを用意します。
使用しているハードウェアアーキテクチャやcfsslのバージョンに応じて、サンプルコマンドの調整が必要な場合があります。
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl_1.5.0_linux_amd64 -o cfssl
chmod +x cfssl
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssljson_1.5.0_linux_amd64 -o cfssljson
chmod +x cfssljson
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl-certinfo_1.5.0_linux_amd64 -o cfssl-certinfo
chmod +x cfssl-certinfo
アーティファクトを保持するディレクトリーを生成し、cfsslを初期化します。
mkdir cert
cd cert
../cfssl print-defaults config > config.json
../cfssl print-defaults csr > csr.json
CAファイルを生成するためのJSON設定ファイル(例: ca-config.json)を生成します。
{
"signing": {
"default": {
"expiry": "8760h"
},
"profiles": {
"kubernetes": {
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
],
"expiry": "8760h"
}
}
}
}
CA証明書署名要求(CSR)用のJSON設定ファイル(例: ca-csr.json)を生成します。
かぎ括弧で囲まれた値は、必ず使用したい実際の値に置き換えてください。
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names":[{
"C": "<country>",
"ST": "<state>",
"L": "<city>",
"O": "<organization>",
"OU": "<organization unit>"
}]
}
CA鍵(ca-key.pem)と証明書(ca.pem)を生成します。
../cfssl gencert -initca ca-csr.json | ../cfssljson -bare ca
APIサーバーの鍵と証明書を生成するためのJSON設定ファイル(例: server-csr.json)を生成します。
かぎ括弧で囲まれた値は、必ず使用したい実際の値に置き換えてください。
MASTER_CLUSTER_IPの値は、前節で説明したAPIサーバーのサービスクラスターIPです。
以下の例は、デフォルトのDNSドメイン名としてcluster.localを使用していることを前提とします。
{
"CN": "kubernetes",
"hosts": [
"127.0.0.1",
"<MASTER_IP>",
"<MASTER_CLUSTER_IP>",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [{
"C": "<country>",
"ST": "<state>",
"L": "<city>",
"O": "<organization>",
"OU": "<organization unit>"
}]
}
APIサーバーの鍵と証明書を生成します。デフォルトでは、それぞれserver-key.pemとserver.pemというファイルに保存されます。
../cfssl gencert -ca=ca.pem -ca-key=ca-key.pem \
--config=ca-config.json -profile=kubernetes \
server-csr.json | ../cfssljson -bare server
自己署名CA証明書の配布 クライアントノードは、自己署名CA証明書を有効だと認識しないことがあります。
プロダクション用でない場合や、会社のファイアウォールの背後で実行する場合は、自己署名CA証明書をすべてのクライアントに配布し、有効な証明書のローカルリストを更新できます。
各クライアントで、以下の操作を実行します。
sudo cp ca.crt /usr/local/share/ca-certificates/kubernetes.crt
sudo update-ca-certificates
Updating certificates in /etc/ssl/certs...
1 added, 0 removed; done.
Running hooks in /etc/ca-certificates/update.d....
done.
証明書API certificates.k8s.ioAPIを用いることで、こちら のドキュメントにあるように、認証に使用するx509証明書をプロビジョニングすることができます。
3.12.4 - リソースの管理 アプリケーションをデプロイし、Serviceを介して外部に公開できました。さて、どうしますか?Kubernetesは、スケーリングや更新など、アプリケーションのデプロイを管理するための多くのツールを提供します。
我々が取り上げる機能についての詳細は設定ファイル とラベル について詳細に説明します。
リソースの設定を管理する 多くのアプリケーションではDeploymentやServiceなど複数のリソースの作成を要求します。複数のリソースの管理は、同一のファイルにひとまとめにしてグループ化すると簡単になります(YAMLファイル内で---で区切る)。
例えば:
apiVersion : v1
kind : Service
metadata :
name : my-nginx-svc
labels :
app : nginx
spec :
type : LoadBalancer
ports :
- port : 80
selector :
app : nginx
---
apiVersion : apps/v1
kind : Deployment
metadata :
name : my-nginx
labels :
app : nginx
spec :
replicas : 3
selector :
matchLabels :
app : nginx
template :
metadata :
labels :
app : nginx
spec :
containers :
- name : nginx
image : nginx:1.14.2
ports :
- containerPort : 80
複数のリソースは単一のリソースと同様の方法で作成できます。
kubectl apply -f https://k8s.io/examples/application/nginx-app.yaml
service/my-nginx-svc created
deployment.apps/my-nginx created
リソースは、ファイル内に記述されている順番通りに作成されます。そのため、Serviceを最初に指定するのが理想です。スケジューラーがServiceに関連するPodを、Deploymentなどのコントローラーによって作成されるときに確実に拡散できるようにするためです。
kubectl applyもまた、複数の-fによる引数指定を許可しています。
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-svc.yaml -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
個別のファイルに加えて、-fの引数としてディレクトリ名も指定できます:
kubectl apply -f https://k8s.io/examples/application/nginx/
kubectlは.yaml、.yml、.jsonといったサフィックスの付くファイルを読み込みます。
同じマイクロサービス、アプリケーションティアーのリソースは同一のファイルにまとめ、アプリケーションに関するファイルをグループ化するために、それらのファイルを同一のディレクトリに配備するのを推奨します。アプリケーションのティアーがDNSを通じて互いにバインドされると、アプリケーションスタックの全てのコンポーネントをひとまとめにして簡単にデプロイできます。
リソースの設定ソースとして、URLも指定できます。githubから取得した設定ファイルから直接手軽にデプロイができます:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/website/master/content/en/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx created
kubectlによる一括操作 kubectlが一括して実行できる操作はリソースの作成のみではありません。作成済みのリソースの削除などの他の操作を実行するために、設定ファイルからリソース名を取得することができます。
kubectl delete -f https://k8s.io/examples/application/nginx-app.yaml
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
2つのリソースだけを削除する場合には、コマンドラインでリソース/名前というシンタックスを使うことで簡単に指定できます。
kubectl delete deployments/my-nginx services/my-nginx-svc
さらに多くのリソースに対する操作では、リソースをラベルでフィルターするために-lや--selectorを使ってセレクター(ラベルクエリ)を指定するのが簡単です:
kubectl delete deployment,services -l app = nginx
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
kubectlは同様のシンタックスでリソース名を出力するので、$()やxargsを使ってパイプで操作するのが容易です:
kubectl get $( kubectl create -f docs/concepts/cluster-administration/nginx/ -o name | grep service)
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT( S) AGE
my-nginx-svc LoadBalancer 10.0.0.208 <pending> 80/TCP 0s
上記のコマンドで、最初にexamples/application/nginx/配下でリソースを作成し、-o nameという出力フォーマットにより、作成されたリソースの名前を表示します(各リソースをresource/nameという形式で表示)。そして"service"のみgrepし、kubectl getを使って表示させます。
あるディレクトリ内の複数のサブディレクトリをまたいでリソースを管理するような場合、--filename,-fフラグと合わせて--recursiveや-Rを指定することでサブディレクトリに対しても再帰的に操作が可能です。
例えば、開発環境用に必要な全てのマニフェスト をリソースタイプによって整理しているproject/k8s/developmentというディレクトリがあると仮定します。
project/k8s/development
├── configmap
│ └── my-configmap.yaml
├── deployment
│ └── my-deployment.yaml
└── pvc
└── my-pvc.yaml
デフォルトでは、project/k8s/developmentにおける一括操作は、どのサブディレクトリも処理せず、ディレクトリの第1階層で処理が止まります。下記のコマンドによってこのディレクトリ配下でリソースを作成しようとすると、エラーが発生します。
kubectl apply -f project/k8s/development
error: you must provide one or more resources by argument or filename ( .json|.yaml|.yml|stdin)
代わりに、下記のように--filename,-fフラグと合わせて--recursiveや-Rを指定してください:
kubectl apply -f project/k8s/development --recursive
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
--recursiveフラグはkubectl {create,get,delete,describe,rollout}などのような--filename,-fフラグを扱うどの操作でも有効です。
また、--recursiveフラグは複数の-fフラグの引数を指定しても有効です。
kubectl apply -f project/k8s/namespaces -f project/k8s/development --recursive
namespace/development created
namespace/staging created
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
kubectlについてさらに知りたい場合は、コマンドラインツール(kubectl) を参照してください。
ラベルを有効に使う これまで取り上げた例では、リソースに対して最大1つのラベルを適用してきました。リソースのセットを他のセットと区別するために、複数のラベルが必要な状況があります。
例えば、異なるアプリケーション間では、異なるappラベルを使用したり、ゲストブックの例 のようなマルチティアーのアプリケーションでは、各ティアーを区別する必要があります。frontendというティアーでは下記のラベルを持ちます。:
labels :
app : guestbook
tier : frontend
Redisマスターやスレーブでは異なるtierラベルを持ち、加えてroleラベルも持つことでしょう。:
labels :
app : guestbook
tier : backend
role : master
そして
labels :
app : guestbook
tier : backend
role : slave
ラベルを使用すると、ラベルで指定された任意の次元に沿ってリソースを分割できます。
kubectl apply -f examples/guestbook/all-in-one/guestbook-all-in-one.yaml
kubectl get pods -Lapp -Ltier -Lrole
NAME READY STATUS RESTARTS AGE APP TIER ROLE
guestbook-fe-4nlpb 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-ght6d 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-jpy62 1/1 Running 0 1m guestbook frontend <none>
guestbook-redis-master-5pg3b 1/1 Running 0 1m guestbook backend master
guestbook-redis-slave-2q2yf 1/1 Running 0 1m guestbook backend slave
guestbook-redis-slave-qgazl 1/1 Running 0 1m guestbook backend slave
my-nginx-divi2 1/1 Running 0 29m nginx <none> <none>
my-nginx-o0ef1 1/1 Running 0 29m nginx <none> <none>
kubectl get pods -lapp= guestbook,role= slave
NAME READY STATUS RESTARTS AGE
guestbook-redis-slave-2q2yf 1/1 Running 0 3m
guestbook-redis-slave-qgazl 1/1 Running 0 3m
Canary deployments カナリアデプロイ 複数のラベルが必要な他の状況として、異なるリリース間でのDeploymentや、同一コンポーネントの設定を区別することが挙げられます。よく知られたプラクティスとして、本番環境の実際のトラフィックを受け付けるようにするために、新しいリリースを完全にロールアウトする前に、新しいカナリア版 のアプリケーションを過去のリリースと合わせてデプロイする方法があります。
例えば、異なるリリースバージョンを分けるためにtrackラベルを使用できます。
主要な安定板のリリースではtrackラベルにstableという値をつけることがあるでしょう。:
name : frontend
replicas : 3
...
labels :
app : guestbook
tier : frontend
track : stable
...
image : gb-frontend:v3
そして2つの異なるPodのセットを上書きしないようにするため、trackラベルに異なる値を持つ(例: canary)ようなguestbookフロントエンドの新しいリリースを作成できます。
name : frontend-canary
replicas : 1
...
labels :
app : guestbook
tier : frontend
track : canary
...
image : gb-frontend:v4
frontend Serviceは、トラフィックを両方のアプリケーションにリダイレクトさせるために、両方のアプリケーションに共通したラベルのサブセットを選択して両方のレプリカを扱えるようにします。:
selector :
app : guestbook
tier : frontend
安定版とカナリア版リリースで本番環境の実際のトラフィックを転送する割合を決めるため、双方のレプリカ数を変更できます(このケースでは3対1)。
最新版のリリースをしても大丈夫な場合、安定版のトラックを新しいアプリケーションにして、カナリア版を削除します。
さらに具体的な例については、tutorial of deploying Ghost を参照してください。
ラベルの更新 新しいリソースを作成する前に、既存のPodと他のリソースのラベルの変更が必要な状況があります。これはkubectl labelで実行できます。
例えば、全てのnginx Podを frontendティアーとしてラベル付けするには、下記のコマンドを実行するのみです。
kubectl label pods -l app = nginx tier = fe
pod/my-nginx-2035384211-j5fhi labeled
pod/my-nginx-2035384211-u2c7e labeled
pod/my-nginx-2035384211-u3t6x labeled
これは最初に"app=nginx"というラベルのついたPodをフィルターし、そのPodに対して"tier=fe"というラベルを追加します。
ラベル付けしたPodを確認するには、下記のコマンドを実行してください。
kubectl get pods -l app = nginx -L tier
NAME READY STATUS RESTARTS AGE TIER
my-nginx-2035384211-j5fhi 1/1 Running 0 23m fe
my-nginx-2035384211-u2c7e 1/1 Running 0 23m fe
my-nginx-2035384211-u3t6x 1/1 Running 0 23m fe
このコマンドでは"app=nginx"というラベルのついた全てのPodを出力し、Podのtierという項目も表示します(-Lまたは--label-columnsで指定)。
さらなる情報は、ラベル やkubectl label を参照してください。
アノテーションの更新 リソースに対してアノテーションを割り当てたい状況があります。アノテーションは、ツール、ライブラリなどのAPIクライアントによって取得するための任意の非識別メタデータです。アノテーションの割り当てはkubectl annotateで可能です。例:
kubectl annotate pods my-nginx-v4-9gw19 description = 'my frontend running nginx'
kubectl get pods my-nginx-v4-9gw19 -o yaml
apiVersion: v1
kind: pod
metadata:
annotations:
description: my frontend running nginx
...
さらなる情報は、アノテーション や、kubectl annotate を参照してください。
アプリケーションのスケール アプリケーションの負荷が増減するとき、kubectlを使って簡単にスケールできます。例えば、nginxのレプリカを3から1に減らす場合、下記を実行します:
kubectl scale deployment/my-nginx --replicas= 1
deployment.apps/my-nginx scaled
実行すると、Deploymentによって管理されるPod数が1となります。
kubectl get pods -l app = nginx
NAME READY STATUS RESTARTS AGE
my-nginx-2035384211-j5fhi 1/1 Running 0 30m
システムに対してnginxのレプリカ数を自動で選択させるには、下記のように1から3の範囲で指定します。:
kubectl autoscale deployment/my-nginx --min= 1 --max= 3
horizontalpodautoscaler.autoscaling/my-nginx autoscaled
実行すると、nginxのレプリカは必要に応じて自動でスケールアップ、スケールダウンします。
さらなる情報は、kubectl scale 、kubectl autoscale and horizontal pod autoscaler を参照してください。
リソースの直接的アップデート 場合によっては、作成したリソースに対して処理を中断させずに更新を行う必要があります。
kubectl apply 開発者が設定するリソースをコードとして管理しバージョニングも行えるように、設定ファイルのセットをソースによって管理する方法が推奨されています。
この場合、クラスターに対して設定の変更をプッシュするためにkubectl apply
このコマンドは、リソース設定の過去のバージョンと、今適用した変更を比較し、差分に現れないプロパティーに対して上書き変更することなくクラスターに適用させます。
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx configured
注意として、前回の変更適用時からの設定の変更内容を決めるため、kubectl applyはリソースに対してアノテーションを割り当てます。変更が実施されるとkubectl applyは、1つ前の設定内容と、今回変更しようとする入力内容と、現在のリソースの設定との3つの間で変更内容の差分をとります。
現在、リソースはこのアノテーションなしで作成されました。そのため、最初のkubectl paplyの実行においては、与えられた入力と、現在のリソースの設定の2つの間の差分が取られ、フォールバックします。この最初の実行の間、リソースが作成された時にプロパティーセットの削除を検知できません。この理由により、プロパティーの削除はされません。
kubectl applyの実行後の全ての呼び出しや、kubectl replaceやkubectl editなどの設定を変更する他のコマンドではアノテーションを更新します。kubectl applyした後の全ての呼び出しにおいて3-wayの差分取得によってプロパティの検知と削除を実施します。
kubectl edit その他に、kubectl editによってリソースの更新もできます。:
kubectl edit deployment/my-nginx
このコマンドは、最初にリソースをgetし、テキストエディタでリソースを編集し、更新されたバージョンでリソースをapplyします。:
kubectl get deployment my-nginx -o yaml > /tmp/nginx.yaml
vi /tmp/nginx.yaml
# yamlファイルを編集し、ファイルを保存します。
kubectl apply -f /tmp/nginx.yaml
deployment.apps/my-nginx configured
rm /tmp/nginx.yaml
このコマンドによってより重大な変更を簡単に行えます。注意として、あなたのEDITORやKUBE_EDITORといった環境変数も指定できます。
さらなる情報は、kubectl edit を参照してください。
kubectl patch APIオブジェクトの更新にはkubectl patchを使うことができます。このコマンドはJSON patch、JSON merge patch、戦略的merge patchをサポートしています。
kubectl patchを使ったAPIオブジェクトの更新 やkubectl patch を参照してください。
破壊的なアップデート 一度初期化された後、更新できないようなリソースフィールドの更新が必要な場合や、Deploymentによって作成され、壊れている状態のPodを修正するなど、再帰的な変更を即座に行いたい場合があります。このようなフィールドを変更するため、リソースの削除と再作成を行うreplace --forceを使用してください。このケースでは、シンプルに元の設定ファイルを修正するのみです。:
kubectl replace -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml --force
deployment.apps/my-nginx deleted
deployment.apps/my-nginx replaced
サービス停止なしでアプリケーションを更新する ある時点で、前述したカナリアデプロイのシナリオにおいて、新しいイメージやイメージタグを指定することによって、デプロイされたアプリケーションを更新が必要な場合があります。kubectlではいくつかの更新操作をサポートしており、それぞれの操作が異なるシナリオに対して適用可能です。
ここでは、Deploymentを使ってアプリケーションの作成と更新についてガイドします。
まずnginxのバージョン1.14.2を稼働させていると仮定します。:
kubectl create deployment my-nginx --image= nginx:1.14.2
deployment.apps/my-nginx created
レプリカ数を3にします(新旧のリビジョンは混在します)。:
kubectl scale deployment my-nginx --current-replicas= 1 --replicas= 3
deployment.apps/my-nginx scaled
バージョン1.16.1に更新するには、上述したkubectlコマンドを使って.spec.template.spec.containers[0].imageの値をnginx:1.14.2からnginx:1.16.1に変更するだけでできます。
kubectl edit deployment/my-nginx
できました!Deploymentはデプロイされたnginxのアプリケーションを宣言的にプログレッシブに更新します。更新途中では、決まった数の古いレプリカのみダウンし、一定数の新しいレプリカが希望するPod数以上作成されても良いことを保証します。詳細について学ぶにはDeployment page を参照してください。
次の項目 3.12.5 - クラスターのネットワーク ネットワークはKubernetesにおける中心的な部分ですが、どのように動作するかを正確に理解することは難解な場合もあります。
Kubernetesには、4つの異なる対応すべきネットワークの問題があります:
高度に結合されたコンテナ間の通信: これは、Pod およびlocalhost通信によって解決されます。 Pod間の通信: 本ドキュメントの主な焦点です。 Podからサービスへの通信: これはService でカバーされています。 外部からサービスへの通信: これはService でカバーされています。 Kubernetesは、言ってしまえばアプリケーション間でマシンを共有するためのものです。通常、マシンを共有するには、2つのアプリケーションが同じポートを使用しないようにする必要があります。
複数の開発者間でのポートの調整は、大規模に行うことが非常に難しく、ユーザーが制御できないクラスターレベルの問題に直面することになります。
動的ポート割り当てはシステムに多くの複雑さをもたらします。すべてのアプリケーションはポートをフラグとして受け取らなければならない、APIサーバーは設定ブロックに動的ポート番号を挿入する方法を知っていなければならない、各サービスは互いを見つける方法を知らなければならない、などです。Kubernetesはこれに対処するのではなく、別のアプローチを取ります。
Kubernetesネットワークモデルについては、こちら を参照してください。
Kubernetesネットワークモデルの実装方法 ネットワークモデルは、各ノード上のコンテナランタイムによって実装されます。最も一般的なコンテナランタイムは、Container Network Interface (CNI)プラグインを使用して、ネットワークとセキュリティ機能を管理します。CNIプラグインは、さまざまなベンダーから多数提供されています。これらの中には、ネットワークインターフェースの追加と削除という基本的な機能のみを提供するものもあれば、他のコンテナオーケストレーションシステムとの統合、複数のCNIプラグインの実行、高度なIPAM機能など、より洗練されたソリューションを提供するものもあります。
Kubernetesがサポートするネットワークアドオンの非網羅的なリストについては、このページ を参照してください。
次の項目 ネットワークモデルの初期設計とその根拠、および将来の計画については、ネットワーク設計ドキュメント で詳細に説明されています。
3.12.6 - 可観測性(オブザーバビリティ) メトリクス、ログ、トレースを収集して、Kubernetesクラスター全体をエンドツーエンドで可視化する方法について理解しましょう。
Kubernetesにおいて、可観測性(オブザーバビリティ)とは、メトリクス、ログ、トレース(しばしば可観測性の3本柱と呼ばれる)を収集・分析し、クラスターの内部状態、パフォーマンス、健全性をより深く理解するプロセスです。
Kubernetesコントロールプレーンコンポーネントや多くのアドオンは、これらのシグナルを生成・出力します。
これらを集約・相関付けることで、クラスター全体のコントロールプレーン、アドオン、アプリケーションの統合された全体像を得ることができます。
図1は、クラスターコンポーネントが、3つの主要なシグナルタイプをどのように出力するかを示しています。
flowchart LR
A[クラスターコンポーネント] --> M[メトリクスパイプライン]
A --> L[ログパイプライン]
A --> T[トレースパイプライン]
M --> S[(ストレージと分析)]
L --> S
T --> S
S --> O[オペレーターと自動化]
このコンテンツを表示するには、JavaScriptを有効に する必要があります 図1. クラスターコンポーネントによって出力される高レベルなシグナルとそのコンシューマー。
メトリクス Kubernetesコンポーネントは、/metricsエンドポイントからPrometheus形式 でメトリクスを出力します。
以下が含まれます:
kube-controller-manager kube-proxy kube-apiserver kube-scheduler kubelet kubeletは、/metrics/cadvisor、/metrics/resource、/metrics/probesでもメトリクスを公開します。
また、kube-state-metrics などのアドオンは、Kubernetesオブジェクトのステータスを追加して、これらのコントロールプレーンシグナルを充実させます。
一般的なKubernetesメトリクスパイプラインは、これらのエンドポイントを定期的にスクレイピングし、サンプルを時系列データベースに保存します(例: Prometheus)
詳細や設定オプションについては、システムメトリクスガイド を参照してください。
図2は、一般的なKubernetesメトリクスパイプラインを示しています。
flowchart LR
C[クラスターコンポーネント] --> P[Prometheusスクレイパー]
P --> TS[(時系列ストレージ)]
TS --> D[ダッシュボードとアラート]
TS --> A[自動化されたアクション]
このコンテンツを表示するには、JavaScriptを有効に する必要があります 図2. 一般的なKubernetesメトリクスパイプラインのコンポーネント。
マルチクラスターやマルチクラウドで可視性を高めるには、分散時系列データベース(例: ThanosやCortex)とPrometheusを組み合わせて使用することができます。
メトリクススクレイパーや時系列データベースについては、一般的な可観測性ツール - メトリクスツール を参照してください。
See Also ログ ログは、アプリケーション内、Kubernetesシステムコンポーネント内、および監査ログなどのセキュリティに関連するアクティビティのイベントを時系列で記録します。
コンテナランタイムは、コンテナ化されたアプリケーションの標準出力(stdout)および標準エラー出力(stderr)ストリームからの出力をキャプチャします。
ランタイムごとに実装方法は異なりますが、kubeletとの統合は CRIログ形式 を通じて標準化されており、kubeletはこれらのログをkubectl logsで取得できるようにします。
図3a. ノードレベルのログ記録アーキテクチャ。
システムコンポーネントログは、クラスターからのイベントをキャプチャし、デバッグやトラブルシューティングに役立つことがよくあります。
これらのコンポーネントは、コンテナ内で実行されるものと実行されないものの2つに分類されます。
例えば、kube-schedulerやkube-proxyは通常コンテナ内で実行されますが、kubeletやコンテナランタイムはホスト上で直接実行されます。
systemdを使用するマシンでは、kubeletとコンテナランタイムはjournaldに書き込みます。
それ以外の場合は、/var/logディレクトリの.logファイルに書き込みます。コンテナ内で実行されるシステムコンポーネントは、デフォルトのコンテナログ記録メカニズムをバイパスして、常に/var/logの.logファイルに書き込みます。 /var/log配下に保存されるシステムコンポーネントのログやコンテナのログは、無制限に増大しないようにログローテーションが必要です。
一部のクラスタープロビジョニングスクリプトは、デフォルトでログローテーションを設定します。
自身の環境を確認し、必要に応じて調整してください。
ログファイルの保存場所、形式、設定オプションの詳細については、システムログリファレンス を参照してください。
ほとんどのクラスターは、これらのファイルをtailして中央ログストアにエントリを転送するノードレベルのログエージェント(例: Fluent BitまたはFluentd)を実行しています。
ログアーキテクチャガイダンス では、このようなパイプラインの設計、保持の適用、バックエンドへのログフローについて説明しています。
図3は、一般的なログ集約パイプラインを示しています。
flowchart LR
subgraph "ソース"
A[アプリケーション stdout / stderr]
B[コントロールプレーンログ]
C[監査記録]
end
A --> N[ノードログエージェント]
B --> N
C --> N
N --> L[中央ログストア]
L --> Q[ダッシュボード、アラート、SIEM]
このコンテンツを表示するには、JavaScriptを有効に する必要があります 図3. 一般的なKubernetesログパイプラインのコンポーネント。
ログエージェントと中央ログストアについては、一般的な可観測性ツール - ログツール を参照してください。
See Also トレース トレースは、リクエストがKubernetesコンポーネントとアプリケーション間をどのように移動するかをキャプチャし、レイテンシー、タイミング、処理間の関係を結び付けます。
トレースを収集することで、エンドツーエンドのリクエストフローを可視化し、パフォーマンスの問題を診断し、コントロールプレーン、アドオン、またはアプリケーションのボトルネックや予期しない動作を特定できます。
Kubernetes 1.35は、組み込みのgRPCエクスポーターを介して直接、またはOpenTelemetry Collectorを通じて転送することで、OpenTelemetry Protocol (OTLP)経由でスパンをエクスポートできます。
OpenTelemetry Collectorは、コンポーネントやアプリケーションからスパンを受信し、それらを処理(例: サンプリングやリダクションの適用)して、保存と分析のためにトレーシングバックエンドに転送します。
図4は、一般的な分散トレーシングパイプラインを示しています。
flowchart LR
subgraph "ソース"
A[コントロールプレーンスパン]
B[アプリケーションスパン]
end
A --> X[OTLPエクスポーター]
B --> X
X --> COL[OpenTelemetry Collector]
COL --> TS[(トレーシングバックエンド)]
TS --> V[可視化と分析]
このコンテンツを表示するには、JavaScriptを有効に する必要があります 図4. 一般的なKubernetesトレースパイプラインのコンポーネント。
トレーシングコレクターとバックエンドについては、一般的な可観測性ツール - トレーシングツール を参照してください。
See Also 備考: このセクションでは、Kubernetesが必要とする機能を提供するサードパーティープロジェクトにリンクしています。これらのプロジェクトはアルファベット順に記載されていて、Kubernetesプロジェクトの作者は責任を持ちません。このリストにプロジェクトを追加するには、変更を提出する前に
content guide をお読みください。
詳細はこちら。 注意: このセクションは、Kubernetesが必要とする可観測性機能を提供するサードパーティプロジェクトにリンクしています。
Kubernetesプロジェクトのメンテナーは、アルファベット順にリストされているこれらのプロジェクトに対して責任を負いません。
このリストにプロジェクトを追加するには、変更を提出する前にコンテンツガイド を読んでください。
Cortex は、水平スケーラブルな長期Prometheusストレージを提供します。Grafana Mimir は、マルチテナント、水平スケーラブルなPrometheus互換ストレージを提供するGrafana Labsのプロジェクトです。Prometheus は、Kubernetesコンポーネントからメトリクスをスクレイピングして保存する監視システムです。Thanos は、グローバルクエリ、ダウンサンプリング、オブジェクトストレージサポートでPrometheusを拡張します。次の項目 3.12.7 - ロギングのアーキテクチャ アプリケーションログは、アプリケーション内で何が起こっているかを理解するのに役立ちます。ログは、問題のデバッグとクラスターアクティビティの監視に特に役立ちます。最近のほとんどのアプリケーションには、何らかのロギングメカニズムがあります。同様に、コンテナエンジンはロギングをサポートするように設計されています。コンテナ化されたアプリケーションで、最も簡単で最も採用されているロギング方法は、標準出力と標準エラーストリームへの書き込みです。
ただし、コンテナエンジンまたはランタイムによって提供されるネイティブ機能は、たいていの場合、完全なロギングソリューションには十分ではありません。
たとえば、コンテナがクラッシュした場合やPodが削除された場合、またはノードが停止した場合に、アプリケーションのログにアクセスしたい場合があります。
クラスターでは、ノードやPod、またはコンテナに関係なく、ノードに個別のストレージとライフサイクルが必要です。この概念は、クラスターレベルロギング と呼ばれます。
クラスターレベルロギングのアーキテクチャでは、ログを保存、分析、およびクエリするための個別のバックエンドが必要です。Kubernetesは、ログデータ用のネイティブストレージソリューションを提供していません。代わりに、Kubernetesに統合される多くのロギングソリューションがあります。次のセクションでは、ノードでログを処理および保存する方法について説明します。
Kubernetesでの基本的なロギング この例では、1秒に1回標準出力ストリームにテキストを書き込むコンテナを利用する、Pod specificationを使います。
apiVersion : v1
kind : Pod
metadata :
name : counter
spec :
containers :
- name : count
image : busybox
args : [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done' ]
このPodを実行するには、次のコマンドを使用します:
kubectl apply -f https://k8s.io/examples/debug/counter-pod.yaml
出力は次のようになります:
ログを取得するには、以下のようにkubectl logsコマンドを使用します:
出力は次のようになります:
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
コンテナの以前のインスタンスからログを取得するために、kubectl logs --previousを使用できます。Podに複数のコンテナがある場合は、次のように-cフラグでコマンドにコンテナ名を追加することで、アクセスするコンテナのログを指定します。
kubectl logs counter -c count
詳細については、kubectl logsドキュメント
ノードレベルでのロギング
コンテナエンジンは、生成された出力を処理して、コンテナ化されたアプリケーションのstdoutとstderrストリームにリダイレクトします。たとえば、Dockerコンテナエンジンは、これら2つのストリームをロギングドライバー にリダイレクトします。ロギングドライバーは、JSON形式でファイルに書き込むようにKubernetesで設定されています。
備考: Docker JSONロギングドライバーは、各行を個別のメッセージとして扱います。Dockerロギングドライバーを使用する場合、複数行メッセージを直接サポートすることはできません。ロギングエージェントレベルあるいはそれ以上のレベルで、複数行のメッセージを処理する必要があります。デフォルトでは、コンテナが再起動すると、kubeletは1つの終了したコンテナをログとともに保持します。Podがノードから削除されると、対応する全てのコンテナが、ログとともに削除されます。
ノードレベルロギングでの重要な考慮事項は、ノードで使用可能な全てのストレージをログが消費しないように、ログローテーションを実装することです。Kubernetesはログのローテーションを担当しませんが、デプロイツールでそれに対処するソリューションを構築する必要があります。たとえば、kube-up.shスクリプトによってデプロイされたKubernetesクラスターには、1時間ごとに実行するように構成されたlogrotate
例として、configure-helper scriptkube-up.shが、どのようにGCPでCOSイメージのロギングを構築しているかについて、詳細な情報を見つけることができます。
CRIコンテナランタイム を使用する場合、kubeletはログのローテーションとログディレクトリ構造の管理を担当します。kubeletはこの情報をCRIコンテナランタイムに送信し、ランタイムはコンテナログを指定された場所に書き込みます。2つのkubeletパラメーター、container-log-max-sizeとcontainer-log-max-fileskubelet設定ファイル で使うことで、各ログファイルの最大サイズと各コンテナで許可されるファイルの最大数をそれぞれ設定できます。
基本的なロギングの例のように、kubectl logs
備考: 外部システムがローテーションを実行した場合、またはCRIコンテナランタイムが使用されている場合は、最新のログファイルの内容のみがkubectl logsで利用可能になります。例えば、10MBのファイルがある場合、logrotateによるローテーションが実行されると、2つのファイルが存在することになります: 1つはサイズが10MBのファイルで、もう1つは空のファイルです。この例では、kubectl logsは最新のログファイルの内容、つまり空のレスポンスを返します。システムコンポーネントログ システムコンポーネントには、コンテナ内で実行されるものとコンテナ内で実行されないものの2種類があります。例えば以下のとおりです。
Kubernetesスケジューラーとkube-proxyはコンテナ内で実行されます。 kubeletとコンテナランタイムはコンテナ内で実行されません。 systemdを搭載したマシンでは、kubeletとコンテナランタイムがjournaldに書き込みます。systemdが存在しない場合、kubeletとコンテナランタイムはvar/logディレクトリ内の.logファイルに書き込みます。コンテナ内のシステムコンポーネントは、デフォルトのロギングメカニズムを迂回して、常に/var/logディレクトリに書き込みます。それらはklogdevelopment docs on logging に記載されています。
コンテナログと同様に、/var/logディレクトリ内のシステムコンポーネントログはローテーションする必要があります。kube-up.shスクリプトによって生成されたKubernetesクラスターでは、これらのログは、logrotateツールによって毎日、またはサイズが100MBを超えた時にローテーションされるように設定されています。
クラスターレベルロギングのアーキテクチャ Kubernetesはクラスターレベルロギングのネイティブソリューションを提供していませんが、検討可能な一般的なアプローチがいくつかあります。ここにいくつかのオプションを示します:
全てのノードで実行されるノードレベルのロギングエージェントを使用します。 アプリケーションのPodにログインするための専用のサイドカーコンテナを含めます。 アプリケーション内からバックエンドに直接ログを送信します。 ノードロギングエージェントの使用
各ノードに ノードレベルのロギングエージェント を含めることで、クラスターレベルロギングを実装できます。ロギングエージェントは、ログを公開したり、ログをバックエンドに送信したりする専用のツールです。通常、ロギングエージェントは、そのノード上の全てのアプリケーションコンテナからのログファイルを含むディレクトリにアクセスできるコンテナです。
ロギングエージェントは全てのノードで実行する必要があるため、エージェントをDaemonSetとして実行することをおすすめします。
ノードレベルのロギングは、ノードごとに1つのエージェントのみを作成し、ノードで実行されているアプリケーションに変更を加える必要はありません。
コンテナはstdoutとstderrに書き込みますが、合意された形式はありません。ノードレベルのエージェントはこれらのログを収集し、集約のために転送します。
ロギングエージェントでサイドカーコンテナを使用する サイドカーコンテナは、次のいずれかの方法で使用できます:
サイドカーコンテナは、アプリケーションログを自身のstdoutにストリーミングします。 サイドカーコンテナは、アプリケーションコンテナからログを取得するように設定されたロギングエージェントを実行します。 ストリーミングサイドカーコンテナ
サイドカーコンテナに自身のstdoutやstderrストリームへの書き込みを行わせることで、各ノードですでに実行されているkubeletとロギングエージェントを利用できます。サイドカーコンテナは、ファイル、ソケット、またはjournaldからログを読み取ります。各サイドカーコンテナは、ログを自身のstdoutまたはstderrストリームに出力します。
このアプローチにより、stdoutまたはstderrへの書き込みのサポートが不足している場合も含め、アプリケーションのさまざまな部分からいくつかのログストリームを分離できます。ログのリダイレクトの背後にあるロジックは最小限であるため、大きなオーバーヘッドにはなりません。さらに、stdoutとstderrはkubeletによって処理されるため、kubectl logsのような組み込みツールを使用できます。
たとえば、Podは単一のコンテナを実行し、コンテナは2つの異なる形式を使用して2つの異なるログファイルに書き込みます。Podの構成ファイルは次のとおりです:
apiVersion : v1
kind : Pod
metadata :
name : counter
spec :
containers :
- name : count
image : busybox
args :
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts :
- name : varlog
mountPath : /var/log
volumes :
- name : varlog
emptyDir : {}
両方のコンポーネントをコンテナのstdoutストリームにリダイレクトできたとしても、異なる形式のログエントリを同じログストリームに書き込むことはおすすめしません。代わりに、2つのサイドカーコンテナを作成できます。各サイドカーコンテナは、共有ボリュームから特定のログファイルを追跡し、ログを自身のstdoutストリームにリダイレクトできます。
2つのサイドカーコンテナを持つPodの構成ファイルは次のとおりです:
apiVersion : v1
kind : Pod
metadata :
name : counter
spec :
containers :
- name : count
image : busybox
args :
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts :
- name : varlog
mountPath : /var/log
- name : count-log-1
image : busybox
args : [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts :
- name : varlog
mountPath : /var/log
- name : count-log-2
image : busybox
args : [/bin/sh, -c, 'tail -n+1 -f /var/log/2.log']
volumeMounts :
- name : varlog
mountPath : /var/log
volumes :
- name : varlog
emptyDir : {}
これで、このPodを実行するときに、次のコマンドを実行して、各ログストリームに個別にアクセスできます:
kubectl logs counter count-log-1
出力は次のようになります:
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
kubectl logs counter count-log-2
出力は次のようになります:
Mon Jan 1 00:00:00 UTC 2001 INFO 0
Mon Jan 1 00:00:01 UTC 2001 INFO 1
Mon Jan 1 00:00:02 UTC 2001 INFO 2
...
クラスターにインストールされているノードレベルのエージェントは、それ以上の設定を行わなくても、これらのログストリームを自動的に取得します。必要があれば、ソースコンテナに応じてログをパースするようにエージェントを構成できます。
CPUとメモリーの使用量が少ない(CPUの場合は数ミリコアのオーダー、メモリーの場合は数メガバイトのオーダー)にも関わらず、ログをファイルに書き込んでからstdoutにストリーミングすると、ディスクの使用量が2倍になる可能性があることに注意してください。単一のファイルに書き込むアプリケーションがある場合は、ストリーミングサイドカーコンテナアプローチを実装するのではなく、/dev/stdoutを宛先として設定することをおすすめします。
サイドカーコンテナを使用して、アプリケーション自体ではローテーションできないログファイルをローテーションすることもできます。このアプローチの例は、logrotateを定期的に実行する小さなコンテナです。しかし、stdoutとstderrを直接使い、ローテーションと保持のポリシーをkubeletに任せることをおすすめします。
ロギングエージェントを使用したサイドカーコンテナ
ノードレベルロギングのエージェントが、あなたの状況に必要なだけの柔軟性を備えていない場合は、アプリケーションで実行するように特別に構成した別のロギングエージェントを使用してサイドカーコンテナを作成できます。
備考: サイドカーコンテナでロギングエージェントを使用すると、大量のリソースが消費される可能性があります。さらに、これらのログはkubeletによって制御されていないため、kubectl logsを使用してこれらのログにアクセスすることができません。ロギングエージェントを使用したサイドカーコンテナを実装するために使用できる、2つの構成ファイルを次に示します。最初のファイルには、fluentdを設定するためのConfigMap
apiVersion : v1
kind : ConfigMap
metadata :
name : fluentd-config
data :
fluentd.conf : |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
2番目のファイルは、fluentdを実行しているサイドカーコンテナを持つPodを示しています。Podは、fluentdが構成データを取得できるボリュームをマウントします。
apiVersion : v1
kind : Pod
metadata :
name : counter
spec :
containers :
- name : count
image : busybox:1.28
args :
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts :
- name : varlog
mountPath : /var/log
- name : count-agent
image : registry.k8s.io/fluentd-gcp:1.30
env :
- name : FLUENTD_ARGS
value : -c /etc/fluentd-config/fluentd.conf
volumeMounts :
- name : varlog
mountPath : /var/log
- name : config-volume
mountPath : /etc/fluentd-config
volumes :
- name : varlog
emptyDir : {}
- name : config-volume
configMap :
name : fluentd-config
サンプル構成では、fluentdを任意のロギングエージェントに置き換えて、アプリケーションコンテナ内の任意のソースから読み取ることができます。
アプリケーションから直接ログを公開する
すべてのアプリケーションから直接ログを公開または送信するクラスターロギングは、Kubernetesのスコープ外です。
3.12.8 - Kubernetesコントロールプレーンコンポーネントの互換性バージョン v1.32のリリース以降、Kubernetesコントロールプレーンコンポーネントに、バージョン互換性の設定やエミュレーションのオプションを導入しました。
これにより、クラスター管理者はより細かく手順を制御できるようになり、アップグレードをより安全に行えるようにしました。
エミュレートバージョン エミュレーションオプションは、コントロールプレーンコンポーネントの--emulated-versionフラグによって設定されます。
このオプションにより、コンポーネントはKubernetesの以前のバージョンの動作(API、機能など)をエミュレートすることができます。
使用すると、利用可能な機能はエミュレートされたバージョンと一致します:
エミュレートするバージョン以降に導入されたバイナリバージョンの機能は利用できません。 エミュレートするバージョン以降に削除された機能は利用可能です。 これにより、特定のKubernetesリリースのバイナリが以前のバージョンの動作を十分な忠実度でエミュレートできるようになり、他のシステムコンポーネントとの相互運用性をエミュレートされたバージョンの観点から定義することが可能になります。
--emulated-versionはbinaryVersion以下でなければなりません。
サポートされるエミュレートバージョンの範囲については、--emulated-versionフラグのヘルプメッセージを参照してください。
3.12.9 - Kubernetesオブジェクトの状態メトリクス クラスターレベルのメトリクスを生成・公開するアドオンエージェント、kube-state-metrics。
Kubernetes API内のKubernetesオブジェクトの状態は、メトリクスとして公開することができます。
kube-state-metrics と呼ばれるアドオンエージェントは、Kubernetes APIサーバーに接続し、クラスター内の個別オブジェクトの状態から生成されたメトリクスを含むHTTPエンドポイントを公開します。
このエージェントは、ラベルやアノテーション、起動・終了時刻、ステータス、またはオブジェクトが現在置かれているフェーズなど、オブジェクトの状態に関する様々な情報を公開します。
例えば、Pod内で実行されているコンテナはkube_pod_container_infoメトリクスを作成します。
このメトリクスには、コンテナ名、それが属するPod名、Podが実行されているネームスペース 、コンテナイメージ名、イメージID、コンテナspecからのイメージ名、実行中のコンテナID、およびPod IDがラベルとして含まれています。
🛇 This item links to a third party project or product that is not part of Kubernetes itself.
More information kube-state-metricsのエンドポイントをスクレイプすることができる外部コンポーネント(例えば、Prometheusなど)を使用することで、以下のユースケースを実現できます。
例: kube-state-metricsのメトリクスを使用したクラスター状態のクエリ kube-state-metricsによって生成されるメトリクス系列は、クエリに使用できるため、クラスターに関する更なる洞察を得るのに役立ちます。
Prometheusまたは同じクエリ言語を使用する他のツールを使用している場合、以下のPromQLクエリは準備完了していないPodの数を返します:
count(kube_pod_status_ready{condition="false"}) by (namespace, pod)
例: kube-state-metricsに基づくアラート kube-state-metricsから生成されるメトリクスを使用することで、クラスター内の問題に対するアラートも可能になります。
Prometheusまたは同じアラートルール言語を使用する類似のツールを使用している場合、以下のアラートは5分以上Terminating状態にあるPodが存在する際に発火します:
groups :
name : Pod state
rules :
- alert : PodsBlockedInTerminatingState
expr : count(kube_pod_deletion_timestamp) by (namespace, pod) * count(kube_pod_status_reason{reason="NodeLost"} == 0) by (namespace, pod) > 0
for : 5m
labels :
severity : page
annotations :
summary : Pod {{$labels.namespace}}/{{$labels.pod}} blocked in Terminating state.
3.12.10 - システムログ システムコンポーネントのログは、クラスター内で起こったイベントを記録します。このログはデバッグのために非常に役立ちます。ログのverbosityを設定すると、ログをどの程度詳細に見るのかを変更できます。ログはコンポーネント内のエラーを表示する程度の荒い粒度にすることも、イベントのステップバイステップのトレース(HTTPのアクセスログ、Podの状態の変更、コントローラーの動作、スケジューラーの決定など)を表示するような細かい粒度に設定することもできます。
klog klogは、Kubernetesのログライブラリです。klog は、Kubernetesのシステムコンポーネント向けのログメッセージを生成します。
klogの設定に関する詳しい情報については、コマンドラインツールのリファレンス を参照してください。
klogネイティブ形式の例:
I1025 00:15:15.525108 1 httplog.go:79] GET /api/v1/namespaces/kube-system/pods/metrics-server-v0.3.1-57c75779f-9p8wg: (1.512ms) 200 [pod_nanny/v0.0.0 (linux/amd64) kubernetes/$Format 10.56.1.19:51756]
構造化ログ FEATURE STATE:
Kubernetes v1.19 [alpha]
警告: 構造化ログへのマイグレーションは現在進行中の作業です。このバージョンでは、すべてのログメッセージが構造化されているわけではありません。ログファイルをパースする場合、JSONではないログの行にも対処しなければなりません。
ログの形式と値のシリアライズは変更される可能性があります。
構造化ログは、ログメッセージに単一の構造を導入し、プログラムで情報の抽出ができるようにするものです。構造化ログは、僅かな労力とコストで保存・処理できます。新しいメッセージ形式は後方互換性があり、デフォルトで有効化されます。
構造化ログの形式:
<klog header> "<message>" <key1> = "<value1>" <key2>="<value2>" ...
例:
I1025 00:15:15.525108 1 controller_utils.go:116] "Pod status updated" pod = "kube-system/kubedns" status="ready"
JSONログ形式 FEATURE STATE:
Kubernetes v1.19 [alpha]
警告: JSONの出力は多数の標準のklogフラグをサポートしていません。非対応のklogフラグの一覧については、コマンドラインツールリファレンス を参照してください。
すべてのログがJSON形式で書き込むことに対応しているわけではありません(たとえば、プロセスの開始時など)。ログのパースを行おうとしている場合、JSONではないログの行に対処できるようにしてください。
フィールド名とJSONのシリアライズは変更される可能性があります。
--logging-format=jsonフラグは、ログの形式をネイティブ形式klogからJSON形式に変更します。以下は、JSONログ形式の例(pretty printしたもの)です。
{
"ts" : 1580306777.04728 ,
"v" : 4 ,
"msg" : "Pod status updated" ,
"pod" :{
"name" : "nginx-1" ,
"namespace" : "default"
},
"status" : "ready"
}
特別な意味を持つキー:
ts - Unix時間のタイムスタンプ(必須、float)v - verbosity (必須、int、デフォルトは0)err - エラー文字列 (オプション、string)msg - メッセージ (必須、string)現在サポートされているJSONフォーマットの一覧:
ログのサニタイズ FEATURE STATE:
Kubernetes v1.20 [alpha]
警告: ログのサニタイズ大きな計算のオーバーヘッドを引き起こす可能性があるため、本番環境では有効にするべきではありません。--experimental-logging-sanitizationフラグはklogのサニタイズフィルタを有効にします。有効にすると、すべてのログの引数が機密データ(パスワード、キー、トークンなど)としてタグ付けされたフィールドについて検査され、これらのフィールドのログの記録は防止されます。
現在ログのサニタイズをサポートしているコンポーネント一覧:
kube-controller-manager kube-apiserver kube-scheduler kubelet
備考: ログのサニタイズフィルターは、ユーザーのワークロードのログが機密データを漏洩するのを防げるわけではありません。ログのverbosityレベル -vフラグはログのverbosityを制御します。値を増やすとログに記録されるイベントの数が増えます。値を減らすとログに記録されるイベントの数が減ります。verbosityの設定を増やすと、ますます多くの深刻度の低いイベントをログに記録するようになります。verbosityの設定を0にすると、クリティカルなイベントだけをログに記録します。
ログの場所 システムコンポーネントには2種類あります。コンテナ内で実行されるコンポーネントと、コンテナ内で実行されないコンポーネントです。たとえば、次のようなコンポーネントがあります。
Kubernetesのスケジューラーやkube-proxyはコンテナ内で実行されます。 kubeletやDockerのようなコンテナランタイムはコンテナ内で実行されません。 systemdを使用しているマシンでは、kubeletとコンテナランタイムはjournaldに書き込みを行います。それ以外のマシンでは、/var/logディレクトリ内の.logファイルに書き込みます。コンテナ内部のシステムコンポーネントは、デフォルトのログ機構をバイパスするため、常に/var/logディレクトリ内の.logファイルに書き込みます。コンテナのログと同様に、/var/logディレクトリ内のシステムコンポーネントのログはローテートする必要があります。kube-up.shスクリプトによって作成されたKubernetesクラスターでは、ログローテーションはlogrotateツールで設定されます。logrotateツールはログを1日ごとまたはログのサイズが100MBを超えたときにローテートします。
次の項目 3.12.11 - Kubernetesシステムコンポーネントのトレース FEATURE STATE:
Kubernetes v1.27 [beta]
システムコンポーネントのトレースは、クラスター内の処理のレイテンシーと処理間の関係性を記録します。
Kubernetesコンポーネントは、gRPCエクスポーターを使用してOpenTelemetry Protocol でトレースを出力し、OpenTelemetry Collector を使用してトレースバックエンドに収集およびルーティングできます。
トレースの収集 Kubernetesコンポーネントには、OTLPのトレースをエクスポートするための組み込みgRPCエクスポーターがあり、OpenTelemetry Collectorを使用する場合と使用しない場合の両方で利用できます。
トレースの収集とCollectorの使用に関する完全なガイドについては、OpenTelemetry Collectorの使い方 を参照してください。
ただし、Kubernetesコンポーネント固有の注意点がいくつかあります。
デフォルトでは、KubernetesコンポーネントはOTLPのgRPCエクスポーターを使用して、IANA OpenTelemetryポート である4317番ポートでトレースをエクスポートします。
例えば、CollectorがKubernetesコンポーネントのサイドカーとして実行されている場合、以下のレシーバー設定でスパンを収集し、標準出力にログを出力します:
receivers :
otlp :
protocols :
grpc :
exporters :
# このエクスポーターをバックエンド用のエクスポーターに置き換えてください
exporters :
debug :
verbosity : detailed
service :
pipelines :
traces :
receivers : [otlp]
exporters : [debug]
Collectorを使用せずにバックエンドに直接トレースを出力するには、Kubernetesトレース設定ファイルのendpointフィールドに目的のトレースバックエンドアドレスを指定します。
この方法ではCollectorが不要になり、全体的な構成がシンプルになります。
認証情報を含むトレースバックエンドのヘッダー設定については、OTEL_EXPORTER_OTLP_HEADERS環境変数を使用できます。
詳細はOTLPエクスポーターの設定 を参照してください。
また、Kubernetesクラスター名、名前空間、Pod名などのトレースリソース属性の設定には、OTEL_RESOURCE_ATTRIBUTES環境変数を使用できます。
詳細はOTLP Kubernetesリソース を参照してください。
コンポーネントのトレース kube-apiserverのトレース kube-apiserverは、受信HTTPリクエスト、およびWebhook、etcd、再入リクエストへの送信リクエストに対してスパンを生成します。
kube-apiserverは送信リクエストでW3C Trace Context を伝播しますが、kube-apiserverは多くの場合パブリックエンドポイントであるため、受信リクエストに付加されたトレースコンテキストは使用しません。
kube-apiserverでのトレースの有効化 トレースを有効にするには、--tracing-config-file=<設定ファイルのパス>でkube-apiserverにトレース設定ファイルを提供します。
以下は、10000リクエストに1つの割合でスパンを記録し、デフォルトのOpenTelemetryエンドポイントを使用する設定の例です:
apiVersion : apiserver.config.k8s.io/v1
kind : TracingConfiguration
# default value
#endpoint: localhost:4317
samplingRatePerMillion : 100
TracingConfiguration構造体の詳細については、APIサーバー設定API (v1) を参照してください。
kubeletのトレース FEATURE STATE:
Kubernetes v1.34 [stable](enabled by default)
kubeletのCRIインターフェースと認証済みHTTPサーバーは、トレーススパンを生成するように計装されています。
apiserverと同様に、エンドポイントとサンプリングレートは設定可能です。
トレースコンテキストの伝播も設定されています。
親スパンのサンプリング決定は常に尊重されます。
指定されたトレース設定のサンプリングレートは、親を持たないスパンに適用されます。
エンドポイントを設定せずに有効にした場合、デフォルトのOpenTelemetry Collectorレシーバーアドレス「localhost:4317」が設定されます。
kubeletでのトレースの有効化 トレースを有効にするには、トレース設定 を適用します。
以下は、10000リクエストに1つの割合でスパンを記録し、デフォルトのOpenTelemetryエンドポイントを使用するkubelet設定のスニペット例です:
apiVersion : kubelet.config.k8s.io/v1beta1
kind : KubeletConfiguration
tracing :
# default value
#endpoint: localhost:4317
samplingRatePerMillion : 100
samplingRatePerMillionを100万(1000000)に設定すると、すべてのスパンがエクスポーターに送信されます。
Kubernetes v1.35のkubeletは、ガベージコレクション、Pod同期ルーチン、およびすべてのgRPCメソッドからスパンを収集します。
kubeletはgRPCリクエストでトレースコンテキストを伝播するため、CRI-Oやcontainerdなどのトレースインストルメンテーションをサポートするコンテナランタイムは、kubeletからのトレースコンテキストに関連付けてエクスポートされたスパンを作成できます。
結果として得られるトレースには、kubeletとコンテナランタイムのスパン間の親子リンクが含まれ、ノードの問題をデバッグする際に役立つコンテキストを提供します。
スパンのエクスポートには、システム全体の設定に応じて、ネットワークとCPU側で常に小さなパフォーマンスオーバーヘッドが発生することに注意してください。
トレースが有効なクラスターでそのような問題が発生した場合は、samplingRatePerMillionを減らすか、設定を削除してトレースを完全に無効にすることで問題を軽減してください。
安定性 トレースインストルメンテーションはまだ活発に開発中であり、さまざまな形で変更される可能性があります。
これには、スパン名、付加された属性、計測対象のエンドポイントなどが含まれます。
この機能がStableに昇格するまで、トレースインストルメンテーションの後方互換性は保証されません。
次の項目 3.12.12 - Kubernetesのプロキシ このページではKubernetesと併用されるプロキシについて説明します。
プロキシ Kubernetesを使用する際に、いくつかのプロキシを使用する場面があります。
kubectlのプロキシ :
ユーザーのデスクトップ上かPod内で稼働します ローカルホストのアドレスからKubernetes apiserverへのプロキシを行います クライアントからプロキシ間ではHTTPを使用します プロキシからapiserverへはHTTPSを使用します apiserverの場所を示します 認証用のヘッダーを追加します apiserverのプロキシ :
apiserver内で動作する踏み台となります これがなければ到達不可能であるクラスターIPへ、クラスターの外部からのユーザーを接続します apiserverのプロセス内で稼働します クライアントからプロキシ間ではHTTPSを使用します(apiserverの設定により、HTTPを使用します) プロキシからターゲット間では利用可能な情報を使用して、プロキシによって選択されたHTTPかHTTPSのいずれかを使用します Node、Pod、Serviceへ到達するのに使えます Serviceへ到達するときは負荷分散を行います kube proxy :
各ノード上で稼働します UDP、TCP、SCTPをプロキシします HTTPを解釈しません 負荷分散機能を提供します Serviceへ到達させるためのみに使用されます apiserverの前段にあるプロキシ/ロードバランサー:
実際に存在するかどうかと実装はクラスターごとに異なります(例: nginx) 全てのクライアントと、1つ以上のapiserverの間に位置します 複数のapiserverがあるときロードバランサーとして稼働します 外部サービス上で稼働するクラウドロードバランサー:
いくつかのクラウドプロバイダーによって提供されます(例: AWS ELB、Google Cloud Load Balancer) LoadBalancerというtypeのKubernetes Serviceが作成されたときに自動で作成されますたいていのクラウドロードバランサーはUDP/TCPのみサポートしています SCTPのサポートはクラウドプロバイダーのロードバランサーの実装によって異なります ロードバランサーの実装はクラウドプロバイダーによって異なります Kubernetesユーザーのほとんどは、最初の2つのタイプ以外に心配する必要はありません。クラスター管理者はそれ以外のタイプのロードバランサーを正しくセットアップすることを保証します。
リダイレクトの要求 プロキシはリダイレクトの機能を置き換えました。リダイレクトの使用は非推奨となります。
3.12.13 - アドオンのインストール 備考: このセクションでは、Kubernetesが必要とする機能を提供するサードパーティープロジェクトにリンクしています。これらのプロジェクトはアルファベット順に記載されていて、Kubernetesプロジェクトの作者は責任を持ちません。このリストにプロジェクトを追加するには、変更を提出する前に
content guide をお読みください。
詳細はこちら。 アドオンはKubernetesの機能を拡張するものです。
このページでは、利用可能なアドオンの一部の一覧と、それぞれのアドオンのインストール方法へのリンクを提供します。
この一覧は、すべてを網羅するものではありません。
ネットワークとネットワークポリシー ACI は、統合されたコンテナネットワークとネットワークセキュリティをCisco ACIを使用して提供します。Antrea は、L3またはL4で動作して、Open vSwitchをネットワークデータプレーンとして活用する、Kubernetes向けのネットワークとセキュリティサービスを提供します。
AntreaはSandboxレベルのCNCFプロジェクト です。Calico は、ネットワーキングおよびネットワークポリシーのプロバイダーです。
Calicoは柔軟なネットワーキングオプションをサポートしており、BGPの有無を含む非オーバーレイネットワークやオーバーレイネットワークなど、状況に応じて最も効率的なオプションを選択できます。
Calicoは、ホスト、Pod、および(IstioとEnvoyを使用している場合)サービスメッシュレイヤーのアプリケーションに対して、同じエンジンを使用してネットワークポリシーを適用します。Canal はFlannelとCalicoをあわせたもので、ネットワークとネットワークポリシーを提供します。Cilium は、eBPFベースのデータプレーンを備えたネットワーク、可観測性、およびセキュリティのソリューションです。
Ciliumは、ネイティブなルーティングまたはoverlay/encapsulationモードのいずれかを用いて複数のクラスターにまたがることができる、シンプルでフラットなL3ネットワークを提供します。
また、ネットワークのアドレス指定から切り離されたアイデンティティベースのセキュリティモデルを使用して、L3からL7のネットワークポリシーを適用することができます。
Ciliumはkube-proxyの代替として機能し、オプトインにて可観測性およびセキュリティ機能も追加で提供しています。
CiliumはGraduatedレベルのCNCFプロジェクト です。CNI-Genie は、KubernetesをCalico、Canal、Flannel、Weaveなど選択したCNIプラグインをシームレスに接続できるようにするプラグインです。
CNI-GenieはSandboxレベルのCNCFプロジェクト です。Contiv は、さまざまなユースケースと豊富なポリシーフレームワーク向けに設定可能なネットワーク(BGPを使用したネイティブのL3、vxlanを使用したオーバーレイ、古典的なL2、Cisco-SDN/ACI)を提供します。
Contivプロジェクトは完全にオープンソース です。
インストーラー はkubeadmとkubeadm以外の両方をベースとしたインストールオプションがあります。Contrail は、Tungsten Fabric をベースにしている、オープンソースでマルチクラウドに対応したネットワーク仮想化およびポリシー管理プラットフォームです。
ContrailおよびTungsten Fabricは、Kubernetes、OpenShift、OpenStack、Mesosなどのオーケストレーションシステムと統合されており、仮想マシン、コンテナ/Pod、ベアメタルのワークロードに隔離モードを提供します。Flannel は、Kubernetesで使用できるオーバーレイネットワークプロバイダーです。Gateway API は、SIG Network コミュニティによって管理されているオープンソースプロジェクトで、サービスネットワーキングをモデル化するための表現力豊かで拡張可能、かつロール指向のAPIを提供します。Knitter は、1つのKubernetes Podで複数のネットワークインターフェースをサポートするためのプラグインです。Multus は、すべてのCNIプラグイン(たとえば、Calico、Cilium、Contiv、Flannel)に加えて、SRIOV、DPDK、OVS-DPDK、VPPをベースとするKubernetes上のワークロードをサポートする、複数のネットワークサポートのためのマルチプラグインです。OVN-Kubernetes は、Open vSwitch(OVS)プロジェクトから生まれた仮想ネットワーク実装であるOVN(Open Virtual Network) をベースとする、Kubernetesのためのネットワークプロバイダーです。
OVN-Kubernetesは、OVSベースのロードバランサーおよびネットワークポリシーの実装を含む、Kubernetes向けのオーバーレイベースのネットワーク実装を提供します。Nodus は、OVNベースのCNIコントローラープラグインで、クラウドネイティブベースのService function chaining(SFC)を提供します。NSX-T Container Plug-in(NCP)は、VMware NSX-TとKubernetesなどのコンテナオーケストレーター間のインテグレーションを提供します。
また、NSX-Tと、Pivotal Container Service(PKS)とOpenShiftなどのコンテナベースのCaaS/PaaSプラットフォームとのインテグレーションも提供します。Nuage は、Kubernetes Podと非Kubernetes環境間で可視化とセキュリティモニタリングを使用してポリシーベースのネットワークを提供するSDNプラットフォームです。Romana は、NetworkPolicy APIもサポートするPodネットワーク向けのL3のネットワークソリューションです。Spiderpool は、Kubernetes向けのアンダーレイおよびRDMAネットワークソリューションです。
Spiderpoolは、ベアメタル、仮想マシン、パブリッククラウド環境でサポートされています。Terway は、AlibabaCloudのVPCおよびECSネットワーク製品をベースとしたCNIプラグインの一式です。
AlibabaCloud環境でネイティブVPCネットワーキングとネットワークポリシーを提供します。Weave Net は、ネットワークパーティションの両面で機能し、外部データベースを必要とせずに、ネットワークとネットワークポリシーを提供します。サービスディスカバリ 可視化と制御 Dashboard はKubernetes向けのダッシュボードを提供するウェブインターフェースです。Headlamp は、拡張可能なKubernetesのUIです。
クラスター内にデプロイすることや、デスクトップアプリケーションとして使用することができます。インフラストラクチャ 計測 レガシーなアドオン いくつかのアドオンは、廃止されたcluster/addons ディレクトリに掲載されています。
よくメンテナンスされたアドオンはここにリンクしてください。
PRを歓迎しています。
3.12.14 - 協調的リーダー選出 FEATURE STATE:
Kubernetes v1.33 [beta](disabled by default)
Kubernetes 1.35には、コントロールプレーン コンポーネントが 協調的リーダー選出 により、特定の戦略でリーダーを選択できるようにするベータ機能が含まれています。
これは、クラスターアップグレード中のKubernetesバージョンスキュー制約を満たすのに有用です。
現在、唯一の組み込まれたリーダー選択戦略はOldestEmulationVersionで、最も低いエミュレートバージョンを持つリーダーを優先し、次にバイナリバージョン、次に作成タイムスタンプの順で選択します。
協調的リーダー選出の有効化 APIサーバー を起動する際に、CoordinatedLeaderElectionフィーチャーゲート が有効になっており、coordination.k8s.io/v1beta1 APIグループも有効になっていることを確認してください。
これは、--feature-gates="CoordinatedLeaderElection=true"フラグと--runtime-config="coordination.k8s.io/v1beta1=true"フラグを設定することで実行できます。
コンポーネントの設定 CoordinatedLeaderElectionフィーチャーゲートを有効にし、かつ coordination.k8s.io/v1beta1 APIグループを有効にしている場合、互換性のあるコントロールプレーンコンポーネントは、必要に応じてLeaseCandidateおよびLease APIを自動的に使用してリーダーを選出します。
Kubernetes 1.35では、フィーチャーゲートとAPIグループが有効になっている場合、2つのコントロールプレーンコンポーネント(kube-controller-managerとkube-scheduler)が協調的リーダー選出を自動的に使用します。
3.13 - Kubernetesを拡張する Kubernetesクラスターの挙動を変えるいろいろな方法
Kubernetesは柔軟な設定が可能で、高い拡張性を持っています。
結果として、Kubernetesのプロジェクトソースコードをフォークしたり、パッチを当てて利用することは滅多にありません。
このガイドは、Kubernetesクラスターをカスタマイズするための選択肢を記載します。
管理しているKubernetesクラスターを、動作環境の要件にどのように適合させるべきかを理解したいクラスター管理者 を対象にしています。
将来の プラットフォーム開発者 、またはKubernetesプロジェクトのコントリビューター にとっても、どのような拡張のポイントやパターンが存在するのか、また、それぞれのトレードオフや制限事項を学ぶための導入として役立つでしょう。
概要 カスタマイズのアプローチには大きく分けて、フラグ、ローカル設定ファイル、またはAPIリソースの変更のみを含んだ 設定 と、稼働しているプログラムまたはサービスも含んだ 拡張 があります。このドキュメントでは、主に拡張について説明します。
設定 設定ファイル と フラグ はオンラインドキュメントのリファレンスセクションの中の、各項目に記載されています:
ホスティングされたKubernetesサービスやマネージドなKubernetesでは、フラグと設定ファイルが常に変更できるとは限りません。変更可能な場合でも、通常はクラスターの管理者のみが変更できます。また、それらは将来のKubernetesバージョンで変更される可能性があり、設定変更にはプロセスの再起動が必要になるかもしれません。これらの理由により、この方法は他の選択肢が無いときにのみ利用するべきです。
ResourceQuota 、PodSecurityPolicy 、NetworkPolicy 、そしてロールベースアクセス制御(RBAC )といった ビルトインポリシーAPI は、ビルトインのKubernetes APIです。APIは通常、ホスティングされたKubernetesサービスやマネージドなKubernetesで利用されます。これらは宣言的で、Podのような他のKubernetesリソースと同じ慣例に従っています。そのため、新しいクラスターの設定は繰り返し再利用することができ、アプリケーションと同じように管理することが可能です。さらに、安定版(stable)を利用している場合、他のKubernetes APIのような定義済みのサポートポリシー を利用することができます。これらの理由により、この方法は、適切な用途の場合、 設定ファイル や フラグ よりも好まれます。
拡張 拡張はKubernetesを拡張し、深く統合されたソフトウェアの構成要素です。
これは新しいタイプと、新しい種類のハードウェアをサポートするために利用されます。
ほとんどのクラスター管理者は、ホスティングされている、またはディストリビューションとしてのKubernetesを使っているでしょう。
結果として、ほとんどのKubernetesユーザーは既存の拡張を使えばよいため、新しい拡張を書く必要は無いと言えます。
拡張パターン Kubernetesは、クライアントのプログラムを書くことで自動化ができるようにデザインされています。
Kubernetes APIに読み書きをするどのようなプログラムも、役に立つ自動化機能を提供することができます。
自動化機能 はクラスター上、またはクラスター外で実行できます。
このドキュメントに後述のガイダンスに従うことで、高い可用性を持つ頑強な自動化機能を書くことができます。
自動化機能は通常、ホスティングされているクラスター、マネージドな環境など、どのKubernetesクラスター上でも動きます。
Kubernetes上でうまく動くクライアントプログラムを書くために、コントローラー パターンという明確なパターンがあります。
コントローラーは通常、オブジェクトの .spec を読み取り、何らかの処理をして、オブジェクトの .status を更新します。
コントローラーはKubernetesのクライアントです。Kubernetesがクライアントとして動き、外部のサービスを呼び出す場合、それは Webhook と呼ばれます。
呼び出されるサービスは Webhookバックエンド と呼ばれます。コントローラーのように、Webhookも障害点を追加します。
Webhookのモデルでは、Kubernetesは外部のサービスを呼び出します。
バイナリプラグイン モデルでは、Kubernetesはバイナリ(プログラム)を実行します。
バイナリプラグインはkubelet(例、FlexVolumeプラグイン 、ネットワークプラグイン )、またkubectlで利用されています。
下図は、それぞれの拡張ポイントが、Kubernetesのコントロールプレーンとどのように関わっているかを示しています。
拡張ポイント この図は、Kubernetesにおける拡張ポイントを示しています。
ユーザーは頻繁にkubectlを使って、Kubernetes APIとやり取りをします。Kubectlプラグイン は、kubectlのバイナリを拡張します。これは個別ユーザーのローカル環境のみに影響を及ぼすため、サイト全体にポリシーを強制することはできません。 APIサーバーは全てのリクエストを処理します。APIサーバーのいくつかの拡張ポイントは、リクエストを認可する、コンテキストに基づいてブロックする、リクエストを編集する、そして削除を処理することを可能にします。これらはAPIアクセス拡張 セクションに記載されています。 APIサーバーは様々な種類の リソース を扱います。Podのような ビルトインリソース はKubernetesプロジェクトにより定義され、変更できません。ユーザーも、自身もしくは、他のプロジェクトで定義されたリソースを追加することができます。それは カスタムリソース と呼ばれ、カスタムリソース セクションに記載されています。カスタムリソースは度々、APIアクセス拡張と一緒に使われます。 KubernetesのスケジューラーはPodをどのノードに配置するかを決定します。スケジューリングを拡張するには、いくつかの方法があります。それらはスケジューラー拡張 セクションに記載されています。 Kubernetesにおける多くの振る舞いは、APIサーバーのクライアントであるコントローラーと呼ばれるプログラムに実装されています。コントローラーは度々、カスタムリソースと共に使われます。 kubeletはサーバー上で実行され、Podが仮想サーバーのようにクラスターネットワーク上にIPを持った状態で起動することをサポートします。ネットワークプラグイン がPodのネットワーキングにおける異なる実装を適用することを可能にします。 kubeletはまた、コンテナのためにボリュームをマウント、アンマウントします。新しい種類のストレージはストレージプラグイン を通じてサポートされます。 もしあなたがどこから始めるべきかわからない場合、このフローチャートが役立つでしょう。一部のソリューションは、いくつかの種類の拡張を含んでいることを留意してください。
API拡張 ユーザー定義タイプ 新しいコントローラー、アプリケーションの設定に関するオブジェクト、また宣言型APIを定義し、それらをkubectlのようなKubernetesのツールから管理したい場合、Kubernetesにカスタムリソースを追加することを検討して下さい。
カスタムリソースはアプリケーション、ユーザー、監視データのデータストレージとしては使わないで下さい。
カスタムリソースに関するさらなる情報は、カスタムリソースコンセプトガイド を参照して下さい。
新しいAPIと自動化機能の連携 カスタムリソースAPIと制御ループの組み合わせはオペレーターパターン と呼ばれています。オペレーターパターンは、通常ステートフルな特定のアプリケーションを管理するために利用されます。これらのカスタムAPIと制御ループは、ストレージ、またはポリシーのような他のリソースを管理するためにも利用されます。
ビルトインリソースの変更 カスタムリソースを追加し、KubernetesAPIを拡張する場合、新たに追加されたリソースは常に新しいAPIグループに分類されます。既存のAPIグループを置き換えたり、変更することはできません。APIを追加することは直接、既存のAPI(例、Pod)の振る舞いに影響を与えることは無いですが、APIアクセス拡張の場合、その可能性があります。
APIアクセス拡張 リクエストがKubernetes APIサーバーに到達すると、まず最初に認証が行われ、次に認可、その後、様々なAdmission Controlの対象になります。このフローの詳細はKubernetes APIへのアクセスをコントロールする を参照して下さい。
これらの各ステップごとに拡張ポイントが用意されています。
Kubdernetesはいくつかのビルトイン認証方式をサポートしています。それは認証プロキシの後ろに配置することも可能で、認可ヘッダーを通じて(Webhookの)検証のために外部サービスにトークンを送ることもできます。全てのこれらの方法は認証ドキュメント でカバーされています。
認証 認証 は、全てのリクエストのヘッダーまたは証明書情報を、リクエストを投げたクライアントのユーザー名にマッピングします。
Kubernetesはいくつかのビルトイン認証方式と、それらが要件に合わない場合、認証Webhook を提供します。
認可 認可 は特定のユーザーがAPIリソースに対して、読み込み、書き込み、そしてその他の操作が可能かどうかを決定します。それはオブジェクト全体のレベルで機能し、任意のオブジェクトフィールドに基づいての区別は行いません。もしビルトインの認可メカニズムが要件に合わない場合、認可Webhook が、ユーザー提供のコードを呼び出し認可の決定を行うことを可能にします。
動的Admission Control リクエストが認可された後、もしそれが書き込み操作だった場合、リクエストはAdmission Control のステップを通ります。ビルトインのステップに加え、いくつかの拡張が存在します:
インフラストラクチャ拡張 ストレージプラグイン Flex Volumes は、Kubeletがバイナリプラグインを呼び出してボリュームをマウントすることにより、ユーザーはビルトインのサポートなしでボリュームタイプをマウントすることを可能にします。
デバイスプラグイン デバイスプラグイン を通じて、ノードが新たなノードのリソース(CPU、メモリなどのビルトインのものに加え)を見つけることを可能にします。
ネットワークプラグイン 他のネットワークファブリックがネットワークプラグイン を通じてサポートされます。
スケジューラー拡張 スケジューラーは特別な種類のコントローラーで、Podを監視し、Podをノードに割り当てます。デフォルトのコントローラーを完全に置き換えることもできますが、他のKubernetesのコンポーネントの利用を継続する、または複数のスケジューラー を同時に動かすこともできます。
これはかなりの大きな作業で、ほとんど全てのKubernetesユーザーはスケジューラーを変更する必要はありません。
スケジューラはWebhook もサポートしており、Webhookバックエンド(スケジューラー拡張)を通じてPodを配置するために選択されたノードをフィルタリング、優先度付けすることが可能です。
次の項目 3.13.1 - Kubernetesクラスターの拡張 Kubernetesは柔軟な設定が可能で、高い拡張性を持っています。
結果として、Kubernetesのプロジェクトソースコードをフォークしたり、パッチを当てて利用することは滅多にありません。
このガイドは、Kubernetesクラスターをカスタマイズするための選択肢を記載します。
管理しているKubernetesクラスターを、動作環境の要件にどのように適合させるべきかを理解したいクラスター管理者 を対象にしています。
将来の プラットフォーム開発者 、またはKubernetesプロジェクトのコントリビューター にとっても、どのような拡張のポイントやパターンが存在するのか、また、それぞれのトレードオフや制限事項を学ぶための導入として役立つでしょう。
概要 カスタマイズのアプローチには大きく分けて、フラグ、ローカル設定ファイル、またはAPIリソースの変更のみを含んだ コンフィグレーション と、稼働しているプログラムまたはサービスも含んだ エクステンション があります。このドキュメントでは、主にエクステンションについて説明します。
コンフィグレーション 設定ファイル と フラグ はオンラインドキュメントのリファレンスセクションの中の、各項目に記載されています:
ホスティングされたKubernetesサービスやマネージドなKubernetesでは、フラグと設定ファイルが常に変更できるとは限りません。変更可能な場合でも、通常はクラスターの管理者のみが変更できます。また、それらは将来のKubernetesバージョンで変更される可能性があり、設定変更にはプロセスの再起動が必要になるかもしれません。これらの理由により、この方法は他の選択肢が無いときにのみ利用するべきです。
ResourceQuota 、PodSecurityPolicy 、NetworkPolicy 、そしてロールベースアクセス制御(RBAC )といった ビルトインポリシーAPI は、ビルトインのKubernetes APIです。APIは通常、ホスティングされたKubernetesサービスやマネージドなKubernetesで利用されます。これらは宣言的で、Podのような他のKubernetesリソースと同じ慣例に従っています。そのため、新しいクラスターの設定は繰り返し再利用することができ、アプリケーションと同じように管理することが可能です。さらに、安定版(stable)を利用している場合、他のKubernetes APIのような定義済みのサポートポリシー を利用することができます。これらの理由により、この方法は、適切な用途の場合、 設定ファイル や フラグ よりも好まれます。
エクステンション エクステンションはKubernetesを拡張し、深く統合されたソフトウェアの構成要素です。
これは新しいタイプと、新しい種類のハードウェアをサポートするために利用されます。
ほとんどのクラスター管理者は、ホスティングされている、またはディストリビューションとしてのKubernetesを使っているでしょう。
結果として、ほとんどのKubernetesユーザーは既存のエクステンションを使えばよいため、新しいエクステンションを書く必要は無いと言えます。
エクステンションパターン Kubernetesは、クライアントのプログラムを書くことで自動化ができるようにデザインされています。
Kubernetes APIに読み書きをするどのようなプログラムも、役に立つ自動化機能を提供することができます。
自動化機能 はクラスター上、またはクラスター外で実行できます。
このドキュメントに後述のガイダンスに従うことで、高い可用性を持つ頑強な自動化機能を書くことができます。
自動化機能は通常、ホスティングされているクラスター、マネージドな環境など、どのKubernetesクラスター上でも動きます。
Kubernetes上でうまく動くクライアントプログラムを書くために、コントローラー パターンという明確なパターンがあります。
コントローラーは通常、オブジェクトの .spec を読み取り、何らかの処理をして、オブジェクトの .status を更新します。
コントローラーはKubernetesのクライアントです。Kubernetesがクライアントとして動き、外部のサービスを呼び出す場合、それは Webhook と呼ばれます。
呼び出されるサービスは Webhookバックエンド と呼ばれます。コントローラーのように、Webhookも障害点を追加します。
Webhookのモデルでは、Kubernetesは外部のサービスを呼び出します。
バイナリプラグイン モデルでは、Kubernetesはバイナリ(プログラム)を実行します。
バイナリプラグインはkubelet(例、FlexVolumeプラグイン 、ネットワークプラグイン )、またkubectlで利用されています。
下図は、それぞれの拡張ポイントが、Kubernetesのコントロールプレーンとどのように関わっているかを示しています。
拡張ポイント この図は、Kubernetesにおける拡張ポイントを示しています。
ユーザーは頻繁にkubectlを使って、Kubernetes APIとやり取りをします。Kubectlプラグイン は、kubectlのバイナリを拡張します。これは個別ユーザーのローカル環境のみに影響を及ぼすため、サイト全体にポリシーを強制することはできません。 APIサーバーは全てのリクエストを処理します。APIサーバーのいくつかの拡張ポイントは、リクエストを認可する、コンテキストに基づいてブロックする、リクエストを編集する、そして削除を処理することを可能にします。これらはAPIアクセスエクステンション セクションに記載されています。 APIサーバーは様々な種類の リソース を扱います。Podのような ビルトインリソース はKubernetesプロジェクトにより定義され、変更できません。ユーザーも、自身もしくは、他のプロジェクトで定義されたリソースを追加することができます。それは カスタムリソース と呼ばれ、カスタムリソース セクションに記載されています。カスタムリソースは度々、APIアクセスエクステンションと一緒に使われます。 KubernetesのスケジューラーはPodをどのノードに配置するかを決定します。スケジューリングを拡張するには、いくつかの方法があります。それらはスケジューラーエクステンション セクションに記載されています。 Kubernetesにおける多くの振る舞いは、APIサーバーのクライアントであるコントローラーと呼ばれるプログラムに実装されています。コントローラーは度々、カスタムリソースと共に使われます。 kubeletはサーバー上で実行され、Podが仮想サーバーのようにクラスターネットワーク上にIPを持った状態で起動することをサポートします。ネットワークプラグイン がPodのネットワーキングにおける異なる実装を適用することを可能にします。 kubeletはまた、コンテナのためにボリュームをマウント、アンマウントします。新しい種類のストレージはストレージプラグイン を通じてサポートされます。 もしあなたがどこから始めるべきかわからない場合、このフローチャートが役立つでしょう。一部のソリューションは、いくつかの種類のエクステンションを含んでいることを留意してください。
APIエクステンション ユーザー定義タイプ 新しいコントローラー、アプリケーションの設定に関するオブジェクト、また宣言型APIを定義し、それらをkubectlのようなKubernetesのツールから管理したい場合、Kubernetesにカスタムリソースを追加することを検討して下さい。
カスタムリソースはアプリケーション、ユーザー、監視データのデータストレージとしては使わないで下さい。
カスタムリソースに関するさらなる情報は、カスタムリソースコンセプトガイド を参照して下さい。
新しいAPIと自動化機能の連携 カスタムリソースAPIと制御ループの組み合わせはオペレーターパターン と呼ばれています。オペレーターパターンは、通常ステートフルな特定のアプリケーションを管理するために利用されます。これらのカスタムAPIと制御ループは、ストレージ、またはポリシーのような他のリソースを管理するためにも利用されます。
ビルトインリソースの変更 カスタムリソースを追加し、KubernetesAPIを拡張する場合、新たに追加されたリソースは常に新しいAPIグループに分類されます。既存のAPIグループを置き換えたり、変更することはできません。APIを追加することは直接、既存のAPI(例、Pod)の振る舞いに影響を与えることは無いですが、APIアクセスエクステンションの場合、その可能性があります。
APIアクセスエクステンション リクエストがKubernetes APIサーバーに到達すると、まず最初に認証が行われ、次に認可、その後、様々なAdmission Controlの対象になります。このフローの詳細はKubernetes APIへのアクセスをコントロールする を参照して下さい。
これらの各ステップごとに拡張ポイントが用意されています。
Kubdernetesはいくつかのビルトイン認証方式をサポートしています。それは認証プロキシの後ろに配置することも可能で、認可ヘッダーを通じて(Webhookの)検証のために外部サービスにトークンを送ることもできます。全てのこれらの方法は認証ドキュメント でカバーされています。
認証 認証 は、全てのリクエストのヘッダーまたは証明書情報を、リクエストを投げたクライアントのユーザー名にマッピングします。
Kubernetesはいくつかのビルトイン認証方式と、それらが要件に合わない場合、認証Webhook を提供します。
認可 認可 は特定のユーザーがAPIリソースに対して、読み込み、書き込み、そしてその他の操作が可能かどうかを決定します。それはオブジェクト全体のレベルで機能し、任意のオブジェクトフィールドに基づいての区別は行いません。もしビルトインの認可メカニズムが要件に合わない場合、認可Webhook が、ユーザー提供のコードを呼び出し認可の決定を行うことを可能にします。
動的Admission Control リクエストが認可された後、もしそれが書き込み操作だった場合、リクエストはAdmission Control のステップを通ります。ビルトインのステップに加え、いくつかのエクステンションが存在します:
インフラストラクチャエクステンション ストレージプラグイン Flex Volumes は、Kubeletがバイナリプラグインを呼び出してボリュームをマウントすることにより、ユーザーはビルトインのサポートなしでボリュームタイプをマウントすることを可能にします。
デバイスプラグイン デバイスプラグイン を通じて、ノードが新たなノードのリソース(CPU、メモリなどのビルトインのものに加え)を見つけることを可能にします。
ネットワークプラグイン 他のネットワークファブリックがネットワークプラグイン を通じてサポートされます。
スケジューラーエクステンション スケジューラーは特別な種類のコントローラーで、Podを監視し、Podをノードに割り当てます。デフォルトのコントローラーを完全に置き換えることもできますが、他のKubernetesのコンポーネントの利用を継続する、または複数のスケジューラー を同時に動かすこともできます。
これはかなりの大きな作業で、ほとんど全てのKubernetesユーザーはスケジューラーを変更する必要はありません。
スケジューラはWebhook もサポートしており、Webhookバックエンド(スケジューラーエクステンション)を通じてPodを配置するために選択されたノードをフィルタリング、優先度付けすることが可能です。
次の項目
3.13.2 - Kubernetes APIの拡張 3.13.2.1 - カスタムリソース カスタムリソース はKubernetes APIの拡張です。このページでは、いつKubernetesのクラスターにカスタムリソースを追加するべきなのか、そしていつスタンドアローンのサービスを利用するべきなのかを議論します。カスタムリソースを追加する2つの方法と、それらの選択方法について説明します。
カスタムリソース リソース は、Kubernetes API のエンドポイントで、特定のAPIオブジェクト のコレクションを保持します。例えば、ビルトインの Pods リソースは、Podオブジェクトのコレクションを包含しています。
カスタムリソース は、Kubernetes APIの拡張で、デフォルトのKubernetesインストールでは、必ずしも利用できるとは限りません。つまりそれは、特定のKubernetesインストールのカスタマイズを表します。しかし、今現在、多数のKubernetesのコア機能は、カスタムリソースを用いて作られており、Kubernetesをモジュール化しています。
カスタムリソースは、稼働しているクラスターに動的に登録され、現れたり、消えたりし、クラスター管理者はクラスター自体とは無関係にカスタムリソースを更新できます。一度、カスタムリソースがインストールされると、ユーザーはkubectl を使い、ビルトインのリソースである Pods と同じように、オブジェクトを作成、アクセスすることが可能です。
カスタムコントローラー カスタムリソースそれ自身は、単純に構造化データを格納、取り出す機能を提供します。カスタムリソースを カスタムコントローラー と組み合わせることで、カスタムリソースは真の 宣言的API を提供します。
宣言的API は、リソースのあるべき状態を 宣言 または指定することを可能にし、Kubernetesオブジェクトの現在の状態を、あるべき状態に同期し続けるように動きます。
コントローラーは、構造化データをユーザーが指定したあるべき状態と解釈し、その状態を管理し続けます。
稼働しているクラスターのライフサイクルとは無関係に、カスタムコントローラーをデプロイ、更新することが可能です。カスタムコントローラーはあらゆるリソースと連携できますが、カスタムリソースと組み合わせると特に効果を発揮します。オペレーターパターン は、カスタムリソースとカスタムコントローラーの組み合わせです。カスタムコントローラーにより、特定アプリケーションのドメイン知識を、Kubernetes APIの拡張に変換することができます。
カスタムリソースをクラスターに追加するべきか? 新しいAPIを作る場合、APIをKubernetesクラスターAPIにアグリゲート(集約)する か、もしくはAPIをスタンドアローンで動かすかを検討します。
APIアグリゲーションを使う場合: スタンドアローンAPIを使う場合: APIが宣言的 APIが宣言的 モデルに適さない 新しいリソースをkubectlを使い読み込み、書き込みしたい kubectlのサポートは必要ない新しいリソースをダッシュボードのような、Kubernetes UIで他のビルトインリソースと同じように管理したい Kubernetes UIのサポートは必要ない 新しいAPIを開発している APIを提供し、適切に機能するプログラムが既に存在している APIグループ、名前空間というような、RESTリソースパスに割り当てられた、Kubernetesのフォーマット仕様の制限を許容できる(API概要 を参照) 既に定義済みのREST APIと互換性を持っていなければならない リソースはクラスターごとか、クラスター内の名前空間に自然に分けることができる クラスター、または名前空間による分割がリソース管理に適さない。特定のリソースパスに基づいて管理したい Kubernetes APIサポート機能 を再利用したいこれらの機能は必要ない
宣言的API 宣言的APIは、通常、下記に該当します:
APIは、比較的少数の、比較的小さなオブジェクト(リソース)で構成されている オブジェクトは、アプリケーションの設定、インフラストラクチャーを定義する オブジェクトは、比較的更新頻度が低い 人は、オブジェクトの情報をよく読み書きする オブジェクトに対する主要な手続きは、CRUD(作成、読み込み、更新、削除)になる 複数オブジェクトをまたいだトランザクションは必要ない: APIは今現在の状態ではなく、あるべき状態を表現する 命令的APIは、宣言的ではありません。
APIが宣言的ではない兆候として、次のものがあります:
クライアントから"これを実行"と命令がきて、完了の返答を同期的に受け取る クライアントから"これを実行"と命令がきて、処理IDを取得する。そして処理が完了したかどうかを、処理IDを利用して別途問い合わせる リモートプロシージャコール(RPC)という言葉が飛び交っている 直接、大量のデータを格納している(例、1オブジェクトあたり数kBより大きい、または数千オブジェクトより多い) 高帯域アクセス(持続的に毎秒数十リクエスト)が必要 エンドユーザーのデータ(画像、PII、その他)を格納している、またはアプリケーションが処理する大量のデータを格納している オブジェクトに対する処理が、CRUDではない APIをオブジェクトとして簡単に表現できない 停止している処理を処理ID、もしくは処理オブジェクトで表現することを選択している ConfigMapとカスタムリソースのどちらを使うべきか? 下記のいずれかに該当する場合は、ConfigMapを使ってください:
mysql.cnf、pom.xmlのような、十分に文書化された設定ファイルフォーマットが既に存在している単一キーのConfigMapに、設定ファイルの内容の全てを格納している 設定ファイルの主な用途は、クラスター上のPodで実行されているプログラムがファイルを読み込み、それ自体を構成することである ファイルの利用者は、Kubernetes APIよりも、Pod内のファイルまたはPod内の環境変数を介して利用することを好む ファイルが更新されたときに、Deploymentなどを介してローリングアップデートを行いたい 備考: センシティブなデータには、ConfigMapに類似していますがよりセキュアな
secret を使ってください
下記のほとんどに該当する場合、カスタムリソース(CRD、またはアグリゲートAPI)を使ってください:
新しいリソースを作成、更新するために、Kubernetesのクライアントライブラリー、CLIを使いたい kubectlのトップレベルサポートが欲しい(例、kubectl get my-object object-name) 新しい自動化の仕組みを作り、新しいオブジェクトの更新をウォッチしたい、その更新を契機に他のオブジェクトのCRUDを実行したい、またはその逆を行いたい オブジェクトの更新を取り扱う、自動化の仕組みを書きたい .spec、.status、.metadataというような、Kubernetes APIの慣習を使いたいオブジェクトは、制御されたリソースコレクションの抽象化、または他のリソースのサマリーとしたい カスタムリソースを追加する Kubernetesは、クラスターへカスタムリソースを追加する2つの方法を提供しています:
CRDはシンプルで、プログラミングなしに作成可能 APIアグリゲーション は、プログラミングが必要だが、データがどのように格納され、APIバージョン間でどのように変換されるかというような、より詳細なAPIの振る舞いを制御できるKubernetesは、さまざまなユーザーのニーズを満たすためにこれら2つのオプションを提供しており、使いやすさや柔軟性が損なわれることはありません。
アグリゲートAPIは、プロキシとして機能するプライマリAPIサーバーの背後にある、下位のAPIServerです。このような配置はAPIアグリゲーション (AA)と呼ばれています。ユーザーにとっては、単にAPIサーバーが拡張されているように見えます。
CRDでは、APIサーバーの追加なしに、ユーザーが新しい種類のリソースを作成できます。CRDを使うには、APIアグリゲーションを理解する必要はありません。
どのようにインストールされたかに関わらず、新しいリソースはカスタムリソースとして参照され、ビルトインのKubernetesリソース(Podなど)とは区別されます。
CustomResourceDefinition CustomResourceDefinition APIリソースは、カスタムリソースを定義します。CRDオブジェクトを定義することで、指定した名前、スキーマで新しいカスタムリソースが作成されます。Kubernetes APIは、作成したカスタムリソースのストレージを提供、および処理します。
CRDオブジェクトの名前はDNSサブドメイン名 に従わなければなりません。
これはカスタムリソースを処理するために、独自のAPIサーバーを書くことから解放してくれますが、一般的な性質としてAPIサーバーアグリゲーション と比べると、柔軟性に欠けます。
新しいカスタムリソースをどのように登録するか、新しいリソースタイプとの連携、そしてコントローラーを使いイベントを処理する方法例について、カスタムコントローラー例 を参照してください。
APIサーバーアグリゲーション 通常、Kubernetes APIの各リソースは、RESTリクエストとオブジェクトの永続的なストレージを管理するためのコードが必要です。メインのKubernetes APIサーバーは Pod や Service のようなビルトインのリソースを処理し、またカスタムリソースもCRD を通じて同じように管理することができます。
アグリゲーションレイヤー は、独自のAPIサーバーを書き、デプロイすることで、カスタムリソースに特化した実装の提供を可能にします。メインのAPIサーバーが、処理したいカスタムリソースへのリクエストを独自のAPIサーバーに委譲することで、他のクライアントからも利用できるようにします。
カスタムリソースの追加方法を選択する CRDは簡単に使えます。アグリゲートAPIはより柔軟です。ニーズに最も合う方法を選択してください。
通常、CRDは下記の場合に適しています:
少数のフィールドしか必要ない そのリソースは社内のみで利用している、または小さいオープンソースプロジェクトの一部で利用している(商用プロダクトではない) 使いやすさの比較 CRDは、アグリゲートAPIと比べ、簡単に作れます。
CRD アグリゲートAPI プログラミングが不要で、ユーザーはCRDコントローラーとしてどの言語でも選択可能 Go言語でプログラミングし、バイナリとイメージの作成が必要 追加のサービスは不要。CRDはAPIサーバーで処理される 追加のサービス作成が必要で、障害が発生する可能性がある CRDが作成されると、継続的なサポートは無い。バグ修正は通常のKubernetesマスターのアップグレードで行われる 定期的にアップストリームからバグ修正の取り込み、リビルド、そしてアグリゲートAPIサーバーの更新が必要かもしれない 複数バージョンのAPI管理は不要。例えば、あるリソースを操作するクライアントを管理していた場合、APIのアップグレードと一緒に更新される 複数バージョンのAPIを管理しなければならない。例えば、世界中に共有されている拡張機能を開発している場合
高度な機能、柔軟性 アグリゲートAPIは、例えばストレージレイヤーのカスタマイズのような、より高度なAPI機能と他の機能のカスタマイズを可能にします。
機能 詳細 CRD アグリゲートAPI バリデーション エラーを予防し、クライアントと無関係にAPIを発達させることができるようになる。これらの機能は多数のクライアントがおり、同時に全てを更新できないときに最も効果を発揮する はい、ほとんどのバリデーションはOpenAPI v3.0 validation で、CRDに指定できる。その他のバリデーションはWebhookのバリデーション によりサポートされている はい、任意のバリデーションが可能 デフォルト設定 上記を参照 はい、OpenAPI v3.0 validation のdefaultキーワード(1.17でGA)、またはMutating Webhook を通じて可能 (ただし、この方法は古いオブジェクトをetcdから読み込む場合には動きません) はい 複数バージョニング 同じオブジェクトを、違うAPIバージョンで利用可能にする。フィールドの名前を変更するなどのAPIの変更を簡単に行うのに役立つ。クライアントのバージョンを管理する場合、重要性は下がる はい はい カスタムストレージ 異なる性能のストレージが必要な場合(例えば、キーバリューストアの代わりに時系列データベース)または、セキュリティの分離(例えば、機密情報の暗号化、その他) いいえ はい カスタムビジネスロジック オブジェクトが作成、読み込み、更新、また削除されるときに任意のチェック、アクションを実行する はい、Webhooks を利用 はい サブリソースのスケール HorizontalPodAutoscalerやPodDisruptionBudgetなどのシステムが、新しいリソースと連携できるようにする はい はい サブリソースの状態 ユーザーがspecセクションに書き込み、コントローラーがstatusセクションに書き込む際に、より詳細なアクセスコントロールができるようにする。カスタムリソースのデータ変換時にオブジェクトの世代を上げられるようにする(リソース内のspecとstatusでセクションが分離している必要がある) はい はい その他のサブリソース "logs"や"exec"のような、CRUD以外の処理の追加 いいえ はい strategic-merge-patch Content-Type: application/strategic-merge-patch+jsonで、PATCHをサポートする新しいエンドポイント。ローカル、サーバー、どちらでも更新されうるオブジェクトに有用。さらなる情報は"APIオブジェクトをkubectl patchで決まった場所で更新" を参照いいえ はい プロトコルバッファ プロトコルバッファを使用するクライアントをサポートする新しいリソース いいえ はい OpenAPIスキーマ サーバーから動的に取得できる型のOpenAPI(Swagger)スキーマはあるか、許可されたフィールドのみが設定されるようにすることで、ユーザーはフィールド名のスペルミスから保護されているか、型は強制されているか(言い換えると、「文字列」フィールドに「int」を入れさせない) はい、OpenAPI v3.0 validation スキーマがベース(1.16でGA) はい
一般的な機能 CRD、またはアグリゲートAPI、どちらを使ってカスタムリソースを作った場合でも、Kubernetesプラットフォーム外でAPIを実装するのに比べ、多数の機能が提供されます:
機能 何を実現するか CRUD 新しいエンドポイントが、HTTP、kubectlを通じて、基本的なCRUD処理をサポート Watch 新しいエンドポイントが、HTTPを通じて、KubernetesのWatch処理をサポート Discovery kubectlやダッシュボードのようなクライアントが、自動的にリソースの一覧表示、個別表示、フィールドの編集処理を提供json-patch 新しいエンドポイントがContent-Type: application/json-patch+jsonを用いたPATCHをサポート merge-patch 新しいエンドポイントがContent-Type: application/merge-patch+jsonを用いたPATCHをサポート HTTPS 新しいエンドポイントがHTTPSを利用 ビルトイン認証 拡張機能へのアクセスに認証のため、コアAPIサーバー(アグリゲーションレイヤー)を利用 ビルトイン認可 拡張機能へのアクセスにコアAPIサーバーで使われている認可メカニズムを再利用(例、RBAC) ファイナライザー 外部リソースの削除が終わるまで、拡張リソースの削除をブロック Admission Webhooks 拡張リソースの作成/更新/削除処理時に、デフォルト値の設定、バリデーションを実施 UI/CLI 表示 kubectl、ダッシュボードで拡張リソースを表示 未設定 対 空設定 クライアントは、フィールドの未設定とゼロ値を区別することができる クライアントライブラリーの生成 Kubernetesは、一般的なクライアントライブラリーと、タイプ固有のクライアントライブラリーを生成するツールを提供 ラベルとアノテーション ツールがコアリソースとカスタムリソースの編集方法を知っているオブジェクト間で、共通のメタデータを提供
カスタムリソースのインストール準備 クラスターにカスタムリソースを追加する前に、いくつか認識しておくべき事項があります。
サードパーティのコードと新しい障害点 CRDを作成しても、勝手に新しい障害点が追加されてしまうことはありませんが(たとえば、サードパーティのコードをAPIサーバーで実行することによって)、パッケージ(たとえば、Chart)またはその他のインストールバンドルには、多くの場合、CRDと新しいカスタムリソースのビジネスロジックを実装するサードパーティコードが入ったDeploymentが含まれます。
アグリゲートAPIサーバーのインストールすると、常に新しいDeploymentが付いてきます。
ストレージ カスタムリソースは、ConfigMapと同じ方法でストレージの容量を消費します。多数のカスタムリソースを作成すると、APIサーバーのストレージ容量を超えてしまうかもしれません。
アグリゲートAPIサーバーも、メインのAPIサーバーと同じストレージを利用するかもしれません。その場合、同じ問題が発生しえます。
認証、認可、そして監査 CRDでは、APIサーバーのビルトインリソースと同じ認証、認可、そして監査ロギングの仕組みを利用します。
もしRBACを使っている場合、ほとんどのRBACのロールは新しいリソースへのアクセスを許可しません。(クラスター管理者ロール、もしくはワイルドカードで作成されたロールを除く)新しいリソースには、明示的にアクセスを許可する必要があります。多くの場合、CRDおよびアグリゲートAPIには、追加するタイプの新しいロール定義がバンドルされています。
アグリゲートAPIサーバーでは、APIサーバーのビルトインリソースと同じ認証、認可、そして監査の仕組みを使う場合と使わない場合があります。
カスタムリソースへのアクセス Kubernetesのクライアントライブラリー を使い、カスタムリソースにアクセスすることが可能です。全てのクライアントライブラリーがカスタムリソースをサポートしているわけでは無いですが、Go と Python のライブラリーはサポートしています。
カスタムリソースは、下記のような方法で操作できます:
kubectlkubernetesの動的クライアント 自作のRESTクライアント Kubernetesクライアント生成ツール を使い生成したクライアント(生成は高度な作業ですが、一部のプロジェクトは、CRDまたはAAとともにクライアントを提供する場合があります)次の項目 3.13.2.2 - アグリゲーションレイヤーを使ったKubernetes APIの拡張 アグリゲーションレイヤーを使用すると、KubernetesのコアAPIで提供されている機能を超えて、追加のAPIでKubernetesを拡張できます。追加のAPIは、service-catalog のような既製のソリューション、または自分で開発したAPIのいずれかです。
アグリゲーションレイヤーは、カスタムリソース とは異なり、kube-apiserver に新しい種類のオブジェクトを認識させる方法です。
アグリゲーションレイヤー アグリゲーションレイヤーは、kube-apiserverのプロセス内で動きます。拡張リソースが登録されるまでは、アグリゲーションレイヤーは何もしません。APIを登録するには、ユーザーはKubernetes APIで使われるURLのパスを"要求"した、APIService オブジェクトを追加します。それを追加すると、アグリゲーションレイヤーはAPIパス(例、/apis/myextension.mycompany.io/v1/…)への全てのアクセスを、登録されたAPIServiceにプロキシします。
APIServiceを実装する最も一般的な方法は、クラスター内で実行されるPodで拡張APIサーバー を実行することです。クラスター内のリソース管理に拡張APIサーバーを使用している場合、拡張APIサーバー("extension-apiserver"とも呼ばれます)は通常、1つ以上のコントローラー とペアになっています。apiserver-builderライブラリは、拡張APIサーバーと関連するコントローラーの両方にスケルトンを提供します。
応答遅延 拡張APIサーバーは、kube-apiserverとの間の低遅延ネットワーキングが必要です。
kube-apiserverとの間を5秒以内に往復するためには、ディスカバリーリクエストが必要です。
拡張APIサーバーがそのレイテンシ要件を達成できない場合は、その要件を満たすように変更することを検討してください。また、kube-apiserverでEnableAggregatedDiscoveryTimeout=false フィーチャーゲート を設定することで、タイムアウト制限を無効にすることができます。この非推奨のフィーチャーゲートは将来のリリースで削除される予定です。
次の項目 3.13.3 - オペレーターパターン オペレーターはカスタムリソース を使用するKubernetesへのソフトウェア拡張です。
オペレーターは、特に制御ループ のようなKubernetesが持つ仕組みに準拠しています。
モチベーション オペレーターパターンはサービス、またはサービス群を管理している運用担当者の主な目的をキャプチャすることが目標です。
特定のアプリケーション、サービスの面倒を見ている運用担当者は、システムがどのように振る舞うべきか、どのようにデプロイをするか、何らかの問題があったときにどのように対応するかについて深い知識を持っています。
Kubernetes上でワークロードを稼働させている人は、しばしば繰り返し可能なタスクを自動化することを好みます。
オペレーターパターンは、Kubernetes自身が提供している機能を超えて、あなたがタスクを自動化するために、どのようにコードを書くかをキャプチャします。
Kubernetesにおけるオペレーター Kubernetesは自動化のために設計されています。追加の作業、設定無しに、Kubernetesのコア機能によって多数のビルトインされた自動化機能が提供されます。
ワークロードのデプロイおよび稼働を自動化するためにKubernetesを使うことができます。 さらに Kubernetesがそれをどのように行うかの自動化も可能です。
Kubernetesのオペレーターパターン コンセプトは、Kubernetesのソースコードを修正すること無く、一つ以上のカスタムリソースにカスタムコントローラー をリンクすることで、クラスターの振る舞いを拡張することを可能にします。
オペレーターはKubernetes APIのクライアントで、Custom Resource にとっての、コントローラーのように振る舞います。
オペレーターの例 オペレーターを使い自動化できるいくつかのことは、下記のようなものがあります:
必要に応じてアプリケーションをデプロイする アプリケーションの状態のバックアップを取得、リストアする アプリケーションコードの更新と同時に、例えばデータベーススキーマ、追加の設定修正など必要な変更の対応を行う Kubernetes APIをサポートしていないアプリケーションに、サービスを公開してそれらを発見する クラスターの回復力をテストするために、全て、または一部分の障害をシミュレートする 内部のリーダー選出プロセス無しに、分散アプリケーションのリーダーを選択する オペレーターをもっと詳しく見るとどのように見えるでしょうか?より詳細な例を示します:
クラスターに設定可能なSampleDBという名前のカスタムリソース オペレーターの、コントローラー部分を含むPodが実行されていることを保証するDeployment オペレーターのコードを含んだコンテナイメージ 設定されているSampleDBのリソースを見つけるために、コントロールプレーンに問い合わせるコントローラーのコード オペレーターのコアは、現実を、設定されているリソースにどのように合わせるかをAPIサーバーに伝えるコードです。もし新しいSampleDBを追加した場合、オペレーターは永続化データベースストレージを提供するためにPersistentVolumeClaimsをセットアップし、StatefulSetがSampleDBの起動と、初期設定を担うJobを走らせます もしそれを削除した場合、オペレーターはスナップショットを取り、StatefulSetとVolumeも合わせて削除されたことを確認します オペレーターは定期的なデータベースのバックアップも管理します。それぞれのSampleDBリソースについて、オペレーターはデータベースに接続可能な、バックアップを取得するPodをいつ作成するかを決定します。これらのPodはデータベース接続の詳細情報、クレデンシャルを保持するConfigMapとSecret、もしくはどちらかに依存するでしょう。 オペレーターは、管理下のリソースの堅牢な自動化を提供することを目的としているため、補助的な追加コードが必要になるかもしれません。この例では、データベースが古いバージョンで動いているかどうかを確認するコードで、その場合、アップグレードを行うJobをあなたに代わり作成します。 オペレーターのデプロイ オペレーターをデプロイする最も一般的な方法は、Custom Resource Definitionとそれに関連するコントローラーをクラスターに追加することです。
このコントローラーは通常、あなたがコンテナアプリケーションを動かすのと同じように、コントロールプレーン 外で動作します。
例えば、コントローラーをDeploymentとしてクラスター内で動かすことができます。
オペレーターを利用する 一度オペレーターをデプロイすると、そのオペレーターを使って、それ自身が使うリソースの種類を追加、変更、または削除できます。
上記の利用例に従ってオペレーターそのもののためのDeploymentをセットアップし、以下のようなコマンドを実行します:
kubectl get SampleDB # 設定したデータベースを発見します
kubectl edit SampleDB/example-database # 手動でいくつかの設定を変更します
これだけです!オペレーターが変更の適用だけでなく既存のサービスがうまく稼働し続けるように面倒を見てくれます。
自分でオペレーターを書く 必要な振る舞いを実装したオペレーターがエコシステム内に無い場合、自分で作成することができます。
次の項目 で、自分でクラウドネイティブオペレーターを作るときに利用できるライブラリやツールのリンクを見つけることができます。
オペレーター(すなわち、コントローラー)はどの言語/ランタイムでも実装でき、Kubernetes APIのクライアント として機能させることができます。
次の項目 3.13.4 - コンピュート、ストレージ、ネットワーキングの拡張機能 このセクションでは、Kubernetes自体の一部としては提供されていない、クラスターへの拡張について説明します。
これらの拡張を使用して、クラスター内のノードを強化したり、Pod同士をつなぐネットワークファブリックを提供したりすることができます。
CSI およびFlexVolume ストレージプラグイン
Container Storage Interface (CSI)プラグインは、新しい種類のボリュームをサポートするためのKubernetesの拡張方法を提供します。
これらのボリュームは、永続性のある外部ストレージにバックアップすることができます。また、一時的なストレージを提供することも、ファイルシステムのパラダイムを使用して、情報への読み取り専用のインターフェースを提供することもできます。
Kubernetesには、Kubernetes v1.23から非推奨とされている(CSIに置き換えられる)FlexVolume プラグインへのサポートも含まれています。
FlexVolumeプラグインは、Kubernetesがネイティブにサポートしていないボリュームタイプをマウントすることをユーザーに可能にします。
FlexVolumeストレージに依存するPodを実行すると、kubeletはバイナリプラグインを呼び出してボリュームをマウントします。
アーカイブされたFlexVolume デザインの提案には、このアプローチの詳細が記載されています。
Kubernetes Volume Plugin FAQ for Storage Vendors には、ストレージプラグインに関する一般的な情報が含まれています。
デバイスプラグイン
デバイスプラグインは、ノードが(cpuやmemoryなどの組み込みノードリソースに加えて)新しいNode設備を発見し、これらのカスタムなノードローカル設備を要求するPodに提供することを可能にします。
ネットワークプラグイン
ネットワークプラグインにより、Kubernetesはさまざまなネットワーキングのトポロジーや技術を扱うことができます。
動作するPodネットワークを持ち、Kubernetesネットワークモデルの他の側面をサポートするためには、Kubernetesクラスターに ネットワークプラグイン が必要です。
Kubernetes 1.35は、CNI ネットワークプラグインと互換性があります。
3.13.4.1 - ネットワークプラグイン Kubernetes 1.35は、クラスターネットワーキングのためにContainer Network Interface (CNI)プラグインをサポートしています。
クラスターと互換性があり、需要に合ったCNIプラグインを使用する必要があります。
様々なプラグイン(オープンソースあるいはクローズドソース)が幅広いKubernetesエコシステムで利用可能です。
Kubernetesネットワークモデル を実装するには、CNIプラグインが必要です。
v0.4.0 以降のCNI仕様のリリースと互換性のあるCNIプラグインを使用する必要があります。
Kubernetesプロジェクトは、v1.0.0 のCNI仕様と互換性のあるプラグインの使用を推奨しています(プラグインは複数の仕様のバージョンに対応できます)。
インストール ネットワーキングの文脈におけるコンテナランタイムは、ノード上のデーモンであり、kubelet向けのCRIサービスを提供するように設定されています。
特に、コンテナランタイムは、Kubernetesネットワークモデルを実装するために必要なCNIプラグインを読み込むように設定する必要があります。
備考: Kubernetes 1.24以前は、CNIプラグインはcni-bin-dirやnetwork-pluginといったコマンドラインパラメーターを使用してkubeletによって管理することもできました。
これらのコマンドラインパラメーターはKubernetes 1.24で削除され、CNIの管理はkubeletの範囲外となりました。
dockershimの削除に伴う問題に直面している場合は、CNIプラグイン関連のエラーのトラブルシューティング を参照してください。
コンテナランタイムがCNIプラグインをどのように管理しているかについての具体的な情報については、そのコンテナランタイムのドキュメントを参照してください。
例えば:
CNIプラグインのインストールや管理方法についての具体的な情報については、そのプラグインまたはネットワーキングプロバイダー のドキュメントを参照してください。
ネットワークプラグインの要件 ループバックCNI Kubernetesネットワークモデルを実装するためにノードにインストールされたCNIプラグインに加えて、Kubernetesはコンテナランタイムにループバックインターフェースloを提供することも要求します。
これは各サンドボックス(Podサンドボックス、VMサンドボックスなど)に使用されます。
ループバックインターフェースの実装は、CNIループバックプラグイン を再利用するか、自分で実装することで達成できます(例: CRI-Oを用いた例 )。
hostPortのサポート CNIネットワーキングプラグインはhostPortをサポートしています。
CNIプラグインチームが提供する公式のportmap プラグインを使用するか、ポートマッピング(portMapping)機能を持つ独自のプラグインを使用できます。
hostPortサポートを有効にする場合、cni-conf-dirでportMappings capabilityを指定する必要があります。
例:
{
"name" : "k8s-pod-network" ,
"cniVersion" : "0.4.0" ,
"plugins" : [
{
"type" : "calico" ,
"log_level" : "info" ,
"datastore_type" : "kubernetes" ,
"nodename" : "127.0.0.1" ,
"ipam" : {
"type" : "host-local" ,
"subnet" : "usePodCidr"
},
"policy" : {
"type" : "k8s"
},
"kubernetes" : {
"kubeconfig" : "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type" : "portmap" ,
"capabilities" : {"portMappings" : true },
"externalSetMarkChain" : "KUBE-MARK-MASQ"
}
]
}
トラフィックシェーピングのサポート これは実験的な機能です
CNIネットワーキングプラグインは、Podの入出力トラフィックシェーピングにも対応しています。
CNIプラグインチームが提供する公式のbandwidth プラグインを使用するか、帯域制御機能を持つ独自のプラグインを使用できます。
トラフィックシェーピングのサポートを有効にする場合、bandwidthプラグインをCNIの設定ファイル(デフォルトは/etc/cni/net.d)に追加し、バイナリがCNIのbinディレクトリ(デフォルトは/opt/cni/bin)に含まれていることを確認する必要があります。
{
"name" : "k8s-pod-network" ,
"cniVersion" : "0.4.0" ,
"plugins" : [
{
"type" : "calico" ,
"log_level" : "info" ,
"datastore_type" : "kubernetes" ,
"nodename" : "127.0.0.1" ,
"ipam" : {
"type" : "host-local" ,
"subnet" : "usePodCidr"
},
"policy" : {
"type" : "k8s"
},
"kubernetes" : {
"kubeconfig" : "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type" : "bandwidth" ,
"capabilities" : {"bandwidth" : true }
}
]
}
これでPodにkubernetes.io/ingress-bandwidthとkubernetes.io/egress-bandwidthのアノテーションを追加できます。
例:
apiVersion : v1
kind : Pod
metadata :
annotations :
kubernetes.io/ingress-bandwidth : 1M
kubernetes.io/egress-bandwidth : 1M
...
次の項目 4 - タスク Kubernetesドキュメントのこのセクションには、個々のタスクの実行方法を示すページが含まれています。タスクページは、通常、短い手順を実行することにより、1つのことを行う方法を示します。
タスクページを作成したい場合は、ドキュメントのPull Requestの作成 を参照してください。
4.1 - ツールのインストール Kubernetesのツールをローカルのコンピューター上にセットアップします。
kubectl Kubernetesのコマンドラインツールkubectlkubectlのリファレンスドキュメント
kubectlはさまざまなLinuxプラットフォーム、macOS、Windows上にインストールできます。
下記の中から好きなオペレーティングシステムを選んでください。
kind kindDocker とPodman のどちらかのインストールが必要です。
Quick Start に、kindの起動と実行に必要なことが書かれています。
kindのQuick Startのガイドを見る
minikube kindと同じように、minikube は、Kubernetesをローカルで実行するツールです。
minikubeはオールインワンまたはマルチノードのローカルKubernetesクラスターをパーソナルコンピューター上(Windows、macOS、Linux PCを含む)で実行することで、Kubernetesを試したり、日常的な開発作業のために利用できます。
ツールのインストールについて知りたい場合は、公式のGet Started! のガイドに従ってください。
minikubeのGet Started!のガイドを見る
minikubeが起動したら、サンプルアプリケーションの実行 を試すことができます。
kubeadm Kubernetesクラスターの作成、管理をするためにkubeadm ツールを使用することができます。
最低限実行可能でセキュアなクラスタを、ユーザーフレンドリーな方法で稼働させるために必要なアクションを実行します。
kubeadmのインストール では、kubeadmをインストールする方法を示しています。
一度インストールすれば、クラスターを作成 するために使用できます。
kubeadmのインストールガイドを見る
4.1.1 - Linux上でのkubectlのインストールおよびセットアップ 始める前に kubectlのバージョンは、クラスターのマイナーバージョンとの差分が1つ以内でなければなりません。
たとえば、クライアントがv1.35であれば、v1.34、v1.35、v1.36のコントロールプレーンと通信できます。
最新の互換性のあるバージョンのkubectlを使うことで、不測の事態を避けることができるでしょう。
Linuxへkubectlをインストールする Linuxへkubectlをインストールするには、次の方法があります:
curlを使用してLinuxへkubectlのバイナリをインストールする 次のコマンドにより、最新リリースをダウンロードしてください:
curl -LO "https://dl.k8s.io/release/ $( curl -L -s https://dl.k8s.io/release/stable.txt) /bin/linux/amd64/kubectl"
curl -LO "https://dl.k8s.io/release/ $( curl -L -s https://dl.k8s.io/release/stable.txt) /bin/linux/arm64/kubectl"
備考: 特定のバージョンをダウンロードする場合、コマンドの$(curl -L -s https://dl.k8s.io/release/stable.txt)の部分を特定のバージョンに書き換えてください。
たとえば、Linux x86-64へ1.35.0のバージョンをダウンロードするには、次のコマンドを入力します:
curl -LO https://dl.k8s.io/release/v1.35.0/bin/linux/amd64/kubectl
そして、Linux ARM64に対しては、次のコマンドを入力します:
curl -LO https://dl.k8s.io/release/v1.35.0/bin/linux/arm64/kubectl
バイナリを検証してください(オプション)
kubectlのチェックサムファイルをダウンロードします:
curl -LO "https://dl.k8s.io/release/ $( curl -L -s https://dl.k8s.io/release/stable.txt) /bin/linux/amd64/kubectl.sha256"
curl -LO "https://dl.k8s.io/release/ $( curl -L -s https://dl.k8s.io/release/stable.txt) /bin/linux/arm64/kubectl.sha256"
チェックサムファイルに対してkubectlバイナリを検証します:
echo " $( cat kubectl.sha256) kubectl" | sha256sum --check
正しければ、出力は次のようになります:
チェックに失敗すると、sha256は0以外のステータスで終了し、次のような出力を表示します:
kubectl: FAILED
sha256sum: WARNING: 1 computed checksum did NOT match
備考: 同じバージョンのバイナリとチェックサムをダウンロードしてください。kubectlをインストールしてください
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
備考: ターゲットシステムにルートアクセスを持っていない場合でも、~/.local/binディレクトリにkubectlをインストールできます:
chmod +x kubectl
mkdir -p ~/.local/bin
mv ./kubectl ~/.local/bin/kubectl
# そして ~/.local/bin を $PATH の末尾 (または先頭) に追加します
インストールしたバージョンが最新であることを確認してください:
または、バージョンの詳細を表示するために次を使用します:
kubectl version --client --output=yaml
ネイティブなパッケージマネージャーを使用してインストールする
aptのパッケージ一覧を更新し、Kubernetesのaptリポジトリを利用するのに必要なパッケージをインストールしてください:
sudo apt-get update
# apt-transport-httpsはダミーパッケージの可能性があります。その場合、そのパッケージはスキップできます
sudo apt-get install -y apt-transport-https ca-certificates curl gnupg
Kubernetesパッケージリポジトリの公開署名キーをダウンロードしてください。
すべてのリポジトリに同じ署名キーが使用されるため、URL内のバージョンは無視できます:
# `/etc/apt/keyrings`フォルダーが存在しない場合は、curlコマンドの前に作成する必要があります。下記の備考を参照してください。
# sudo mkdir -p -m 755 /etc/apt/keyrings
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.35/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
sudo chmod 644 /etc/apt/keyrings/kubernetes-apt-keyring.gpg # 特権のないAPTプログラムがこのkeyringを読めるようにします
備考: Debian 12とUbuntu 22.04より古いリリースでは、/etc/apt/keyringsフォルダーは既定では存在しないため、curlコマンドの前に作成する必要があります。適切なKubernetesのaptリポジトリを追加してください。
v1.35とは異なるKubernetesバージョンを利用したい場合は、以下のコマンドのv1.35を目的のマイナーバージョンに置き換えてください:
# これにより、/etc/apt/sources.list.d/kubernetes.listにある既存の設定が上書きされます
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.35/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo chmod 644 /etc/apt/sources.list.d/kubernetes.list # command-not-foundのようなツールが正しく動作するようにします
aptのパッケージインデックスを更新し、kubectlをインストールしてください:
sudo apt-get update
sudo apt-get install -y kubectl
Kubernetesのyumリポジトリを追加してください。
v1.35とは異なるKubernetesバージョンを利用したい場合は、以下のコマンドのv1.35を目的のマイナーバージョンに置き換えてください:
# これにより、/etc/yum.repos.d/kubernetes.repoにある既存の設定が上書きされます
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.35/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.35/rpm/repodata/repomd.xml.key
EOF
yumを使用してkubectlをインストールしてください:
sudo yum install -y kubectl
Kubernetesのzypperリポジトリを追加してください。
v1.35とは異なるKubernetesバージョンを利用したい場合は、以下のコマンドのv1.35を目的のマイナーバージョンに置き換えてください。
# これにより、/etc/zypp/repos.d/kubernetes.repoにある既存の設定が上書きされます
cat <<EOF | sudo tee /etc/zypp/repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.35/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.35/rpm/repodata/repomd.xml.key
EOF
zypperを更新し、新しいリポジトリの追加を確認してください:
このメッセージが表示されたら、't' または 'a' を押してください:
New repository or package signing key received:
Repository: Kubernetes
Key Fingerprint: 1111 2222 3333 4444 5555 6666 7777 8888 9999 AAAA
Key Name: isv:kubernetes OBS Project <isv:kubernetes@build.opensuse.org>
Key Algorithm: RSA 2048
Key Created: Thu 25 Aug 2022 01:21:11 PM -03
Key Expires: Sat 02 Nov 2024 01:21:11 PM -03 (expires in 85 days)
Rpm Name: gpg-pubkey-9a296436-6307a177
Note: Signing data enables the recipient to verify that no modifications occurred after the data
were signed. Accepting data with no, wrong or unknown signature can lead to a corrupted system
and in extreme cases even to a system compromise.
Note: A GPG pubkey is clearly identified by its fingerprint. Do not rely on the key's name. If
you are not sure whether the presented key is authentic, ask the repository provider or check
their web site. Many providers maintain a web page showing the fingerprints of the GPG keys they
are using.
Do you want to reject the key, trust temporarily, or trust always? [r/t/a/?] (r): a
zypperを使用してkubectlをインストールしてください:
sudo zypper install -y kubectl
他のパッケージマネージャーを使用してインストールする
Ubuntuまたはsnap パッケージマネージャーをサポートする別のLinuxディストリビューションを使用している場合、kubectlはsnap アプリケーションとして使用できます。
snap install kubectl --classic
kubectl version --client
LinuxでHomebrew パッケージマネージャーを使用している場合は、kubectlをインストール することが可能です。
brew install kubectl
kubectl version --client
kubectlの設定を検証する kubectlがKubernetesクラスターを探索し接続するために、kubeconfigファイル が必要です。
これは、kube-up.sh によりクラスターを作成した際や、Minikubeクラスターを正常にデプロイした際に自動生成されます。
デフォルトでは、kubectlの設定は~/.kube/configに格納されています。
クラスターの状態を取得し、kubectlが適切に設定されていることを確認してください:
URLのレスポンスが表示されている場合は、kubectlはクラスターに接続するよう正しく設定されています。
以下のようなメッセージが表示されている場合は、kubectlは正しく設定されていないか、Kubernetesクラスターに接続できていません。
The connection to the server <server-name:port> was refused - did you specify the right host or port?
たとえば、ラップトップ上(ローカル環境)でKubernetesクラスターを起動するような場合、Minikube などのツールを最初にインストールしてから、上記のコマンドを再実行する必要があります。
kubectl cluster-infoがURLレスポンスを返したにもかかわらずクラスターにアクセスできない場合は、次のコマンドで設定が正しいことを確認してください:
kubectl cluster-info dump
エラーメッセージ'No Auth Provider Found'のトラブルシューティング Kubernetes 1.26にて、kubectlは以下のクラウドプロバイダーが提供するマネージドKubernetesのビルトイン認証を削除しました。
これらのプロバイダーは、クラウド固有の認証を提供するkubectlプラグインをリリースしています。
手順については以下のプロバイダーのドキュメントを参照してください:
(この変更とは関係なく、他の理由で同じエラーメッセージが表示される可能性もあります。)
オプションのkubectlの設定とプラグイン シェルの自動補完を有効にする kubectlはBash、Zsh、Fish、PowerShellの自動補完を提供しています。
これにより、入力を大幅に削減することができます。
以下にBash、Fish、Zshの自動補完の設定手順を示します。
はじめに Bashにおけるkubectlの補完スクリプトはkubectl completion bashコマンドで生成できます。
補完スクリプトをシェル内に読み込ませることでkubectlの自動補完が有効になります。
ただし、補完スクリプトはbash-completion type _init_completionを実行することで、bash-completionがすでにインストールされていることを確認できます)。
bash-completionをインストールする bash-completionは多くのパッケージマネージャーから提供されています(こちら を参照してください)。
apt-get install bash-completionまたはyum install bash-completionなどでインストールできます。
上記のコマンドでbash-completionの主要スクリプトである/usr/share/bash-completion/bash_completionが作成されます。
パッケージマネージャーによっては、このファイルを~/.bashrcにて手動で読み込ませる必要があります。
これを調べるには、シェルをリロードしてからtype _init_completionを実行してください。
コマンドが成功していればすでに設定済みです。そうでなければ、~/.bashrcファイルに以下を追記してください:
source /usr/share/bash-completion/bash_completion
シェルをリロードし、type _init_completionを実行してbash-completionが正しくインストールされていることを検証してください。
kubectlの自動補完を有効にする Bash 次に、kubectl補完スクリプトがすべてのシェルセッションで読み込まれるように設定する必要があります。
これを行うには2つの方法があります:
echo 'source <(kubectl completion bash)' >>~/.bashrc
kubectl completion bash | sudo tee /etc/bash_completion.d/kubectl > /dev/null
sudo chmod a+r /etc/bash_completion.d/kubectl
kubectlにエイリアスを張っている場合は、エイリアスでも動作するようにシェルの補完を拡張することができます:
echo 'alias k=kubectl' >>~/.bashrc
echo 'complete -o default -F __start_kubectl k' >>~/.bashrc
備考: bash-completionは/etc/bash_completion.d内のすべての補完スクリプトを読み込みます。どちらも同様の手法です。
シェルをリロードしたあとに、kubectlの自動補完が機能するはずです。
シェルの現在のセッションでbashの自動補完を有効にするには、~/.bashrcを読み込みます:
備考: Fishに対する自動補完はkubectl 1.23以降が必要です。Fishにおけるkubectlの補完スクリプトはkubectl completion fishコマンドで生成できます。
補完スクリプトをシェル内に読み込ませることでkubectlの自動補完が有効になります。
すべてのシェルセッションで使用するには、~/.config/fish/config.fishに以下を追記してください:
kubectl completion fish | source
シェルをリロードしたあとに、kubectlの自動補完が機能するはずです。
Zshにおけるkubectlの補完スクリプトはkubectl completion zshコマンドで生成できます。
補完スクリプトをシェル内に読み込ませることでkubectlの自動補完が有効になります。
すべてのシェルセッションで使用するには、~/.zshrcに以下を追記してください:
source <( kubectl completion zsh)
kubectlにエイリアスを張っている場合でも、kubectlの自動補完は自動的に機能します。
シェルをリロードしたあとに、kubectlの自動補完が機能するはずです。
2: command not found: compdefのようなエラーが出力された場合は、以下を~/.zshrcの先頭に追記してください:
autoload -Uz compinit
compinit
kubercを設定する 詳細については、kuberc を参照してください。
kubectl convertプラグインをインストールする異なるAPIバージョン間でマニフェストを変換できる、Kubernetesコマンドラインツールkubectlのプラグインです。
これは特に、新しいKubernetesのリリースで、非推奨ではないAPIバージョンにマニフェストを移行する場合に役に立ちます。
詳細については非推奨ではないAPIへの移行 を参照してください。
次のコマンドを使用して最新リリースをダウンロードしてください:
curl -LO "https://dl.k8s.io/release/ $( curl -L -s https://dl.k8s.io/release/stable.txt) /bin/linux/amd64/kubectl-convert"
curl -LO "https://dl.k8s.io/release/ $( curl -L -s https://dl.k8s.io/release/stable.txt) /bin/linux/arm64/kubectl-convert"
バイナリを検証してください(オプション)
kubectl-convertのチェックサムファイルをダウンロードします:
curl -LO "https://dl.k8s.io/release/ $( curl -L -s https://dl.k8s.io/release/stable.txt) /bin/linux/amd64/kubectl-convert.sha256"
curl -LO "https://dl.k8s.io/release/ $( curl -L -s https://dl.k8s.io/release/stable.txt) /bin/linux/arm64/kubectl-convert.sha256"
チェックサムファイルに対してkubectl-convertバイナリを検証します:
echo " $( cat kubectl-convert.sha256) kubectl-convert" | sha256sum --check
正しければ、出力は次のようになります:
チェックに失敗すると、sha256は0以外のステータスで終了し、次のような出力を表示します:
kubectl-convert: FAILED
sha256sum: WARNING: 1 computed checksum did NOT match
備考: 同じバージョンのバイナリとチェックサムをダウンロードしてください。kubectl-convertをインストールしてください
sudo install -o root -g root -m 0755 kubectl-convert /usr/local/bin/kubectl-convert
プラグインが正常にインストールできたことを確認してください
何もエラーが表示されない場合は、プラグインが正常にインストールされたことを示しています。
プラグインのインストール後、インストールファイルを削除してください:
rm kubectl-convert kubectl-convert.sha256
次の項目 4.1.2 - macOS上でのkubectlのインストールおよびセットアップ 始める前に kubectlのバージョンは、クラスターのマイナーバージョンとの差分が1つ以内でなければなりません。
たとえば、クライアントがv1.35であれば、v1.34、v1.35、v1.36のコントロールプレーンと通信できます。
最新の互換性のあるバージョンのkubectlを使うことで、不測の事態を避けることができるでしょう。
macOSへkubectlをインストールする macOSへkubectlをインストールするには、次の方法があります:
curlを使用してmacOSへkubectlのバイナリをインストールする 最新リリースをダウンロードしてください:
curl -LO "https://dl.k8s.io/release/ $( curl -L -s https://dl.k8s.io/release/stable.txt) /bin/darwin/amd64/kubectl"
curl -LO "https://dl.k8s.io/release/ $( curl -L -s https://dl.k8s.io/release/stable.txt) /bin/darwin/arm64/kubectl"
備考: 特定のバージョンをダウンロードする場合、コマンドの$(curl -L -s https://dl.k8s.io/release/stable.txt)の部分を特定のバージョンに置き換えてください。
例えば、Intel macOSへ1.35.0のバージョンをダウンロードするには、次のコマンドを入力します:
curl -LO "https://dl.k8s.io/release/v1.35.0/bin/darwin/amd64/kubectl"
Appleシリコン上のmacOSに対しては、次を入力します:
curl -LO "https://dl.k8s.io/release/v1.35.0/bin/darwin/arm64/kubectl"
バイナリを検証してください(オプション)
kubectlのチェックサムファイルをダウンロードします:
curl -LO "https://dl.k8s.io/release/ $( curl -L -s https://dl.k8s.io/release/stable.txt) /bin/darwin/amd64/kubectl.sha256"
curl -LO "https://dl.k8s.io/release/ $( curl -L -s https://dl.k8s.io/release/stable.txt) /bin/darwin/arm64/kubectl.sha256"
チェックサムファイルに対してkubectlバイナリを検証します:
echo " $( cat kubectl.sha256) kubectl" | shasum -a 256 --check
正しければ、出力は次のようになります:
チェックに失敗すると、shasumは0以外のステータスで終了し、次のような出力を表示します:
kubectl: FAILED
shasum: WARNING: 1 computed checksum did NOT match
備考: 同じバージョンのバイナリとチェックサムをダウンロードしてください。kubectlバイナリを実行可能にしてください。
kubectlバイナリをPATHの中に移動させてください。
sudo mv ./kubectl /usr/local/bin/kubectl
sudo chown root: /usr/local/bin/kubectl
備考: /usr/local/binがPATH環境変数の中に含まれるようにしてください。インストールしたバージョンが最新であることを確認してください:
または、バージョンの詳細を表示するために次を使用します:
kubectl version --client --output=yaml
kubectlをインストールし、検証した後は、チェックサムファイルを削除してください:
Homebrewを使用してmacOSへインストールする macOSでHomebrew パッケージマネージャーを使用していれば、Homebrewでkubectlをインストールできます。
インストールコマンドを実行してください:
または
brew install kubernetes-cli
インストールしたバージョンが最新であることを確認してください:
MacPortsを使用してmacOSへインストールする macOSでMacPorts パッケージマネージャーを使用していれば、MacPortsでkubectlをインストールできます。
インストールコマンドを実行してください:
sudo port selfupdate
sudo port install kubectl
インストールしたバージョンが最新であることを確認してください:
kubectlの設定を検証する kubectlがKubernetesクラスターを探索し接続するために、kubeconfigファイル が必要です。
これは、kube-up.sh によりクラスターを作成した際や、Minikubeクラスターを正常にデプロイした際に自動生成されます。
デフォルトでは、kubectlの設定は~/.kube/configに格納されています。
クラスターの状態を取得し、kubectlが適切に設定されていることを確認してください:
URLのレスポンスが表示されている場合は、kubectlはクラスターに接続するよう正しく設定されています。
以下のようなメッセージが表示されている場合は、kubectlは正しく設定されていないか、Kubernetesクラスターに接続できていません。
The connection to the server <server-name:port> was refused - did you specify the right host or port?
たとえば、ラップトップ上(ローカル環境)でKubernetesクラスターを起動するような場合、Minikube などのツールを最初にインストールしてから、上記のコマンドを再実行する必要があります。
kubectl cluster-infoがURLレスポンスを返したにもかかわらずクラスターにアクセスできない場合は、次のコマンドで設定が正しいことを確認してください:
kubectl cluster-info dump
エラーメッセージ'No Auth Provider Found'のトラブルシューティング Kubernetes 1.26にて、kubectlは以下のクラウドプロバイダーが提供するマネージドKubernetesのビルトイン認証を削除しました。
これらのプロバイダーは、クラウド固有の認証を提供するkubectlプラグインをリリースしています。
手順については以下のプロバイダーのドキュメントを参照してください:
(この変更とは関係なく、他の理由で同じエラーメッセージが表示される可能性もあります。)
オプションのkubectlの設定とプラグイン シェルの自動補完を有効にする kubectlはBash、Zsh、Fish、PowerShellの自動補完を提供しています。
これにより、入力を大幅に削減することができます。
以下にBash、Fish、Zshの自動補完の設定手順を示します。
はじめに Bashにおけるkubectlの補完スクリプトはkubectl completion bashコマンドで生成できます。
補完スクリプトをシェル内に読み込ませることでkubectlの自動補完が有効になります。
ただし、補完スクリプトはbash-completion
警告: bash-completionにはv1とv2の2つのバージョンがあります。
v1はBash 3.2(macOSのデフォルト)用で、v2はBash 4.1以降向けです。
kubectlの補完スクリプトはbash-completionのv1とBash 3.2では正しく
動作しません 。
bash-completion v2 と
Bash 4.1以降 が必要になります。
したがって、macOSで正常にkubectlの補完を使用するには、Bash 4.1以降をインストールする必要があります(
手順 )。
以下の手順では、Bash4.1以降(Bashのバージョンが4.1またはそれより新しいことを指します)を使用することを前提とします。
Bashのアップグレード ここではBash 4.1以降の使用を前提としています。
Bashのバージョンは下記のコマンドで調べることができます:
バージョンが古い場合、Homebrewを使用してインストールもしくはアップグレードできます:
シェルをリロードし、希望するバージョンを使用していることを確認してください:
echo $BASH_VERSION $SHELL
Homebrewは通常、/usr/local/bin/bashにインストールします。
bash-completionをインストールする
備考: 前述のとおり、この手順ではBash 4.1以降であることが前提のため、bash-completion v2をインストールすることになります(これとは逆に、Bash 3.2およびbash-completion v1の場合ではkubectlの補完は動作しません)。type _init_completionを実行することで、bash-completionがすでにインストールされていることを確認できます。
ない場合は、Homebrewを使用してインストールすることができます:
brew install bash-completion@2
このコマンドの出力で示されたように、~/.bash_profileに以下を追記してください:
brew_etc = " $( brew --prefix) /etc" && [[ -r " ${ brew_etc } /profile.d/bash_completion.sh" ]] && . " ${ brew_etc } /profile.d/bash_completion.sh"
シェルをリロードし、type _init_completionを実行してbash-completion v2が正しくインストールされていることを検証してください。
kubectlの自動補完を有効にする 次に、kubectl補完スクリプトがすべてのシェルセッションで読み込まれるように設定する必要があります。
これを行うには複数の方法があります:
補完スクリプトを~/.bash_profile内で読み込ませる:
echo 'source <(kubectl completion bash)' >>~/.bash_profile
補完スクリプトを/usr/local/etc/bash_completion.dディレクトリに追加する:
kubectl completion bash >/usr/local/etc/bash_completion.d/kubectl
kubectlにエイリアスを張っている場合は、エイリアスでも動作するようにシェルの補完を拡張することができます:
echo 'alias k=kubectl' >>~/.bash_profile
echo 'complete -o default -F __start_kubectl k' >>~/.bash_profile
kubectlをHomebrewでインストールした場合(前述 の通り)、kubectlの補完スクリプトはすでに/usr/local/etc/bash_completion.d/kubectlに格納されているでしょうか。
この場合、なにも操作する必要はありません。
備考: Homebrewでインストールしたbash-completion v2はBASH_COMPLETION_COMPAT_DIRディレクトリ内のすべてのファイルを読み込むため、後者の2つの方法が機能します。どの場合でも、シェルをリロードしたあとに、kubectlの自動補完が機能するはずです。
備考: Fishに対する自動補完はkubectl 1.23以降が必要です。Fishにおけるkubectlの補完スクリプトはkubectl completion fishコマンドで生成できます。
補完スクリプトをシェル内に読み込ませることでkubectlの自動補完が有効になります。
すべてのシェルセッションで使用するには、~/.config/fish/config.fishに以下を追記してください:
kubectl completion fish | source
シェルをリロードしたあとに、kubectlの自動補完が機能するはずです。
Zshにおけるkubectlの補完スクリプトはkubectl completion zshコマンドで生成できます。
補完スクリプトをシェル内に読み込ませることでkubectlの自動補完が有効になります。
すべてのシェルセッションで使用するには、~/.zshrcに以下を追記してください:
source <( kubectl completion zsh)
kubectlにエイリアスを張っている場合でも、kubectlの自動補完は自動的に機能します。
シェルをリロードしたあとに、kubectlの自動補完が機能するはずです。
2: command not found: compdefのようなエラーが出力された場合は、以下を~/.zshrcの先頭に追記してください:
autoload -Uz compinit
compinit
kubectl convertプラグインをインストールする異なるAPIバージョン間でマニフェストを変換できる、Kubernetesコマンドラインツールkubectlのプラグインです。
これは特に、新しいKubernetesのリリースで、非推奨ではないAPIバージョンにマニフェストを移行する場合に役に立ちます。
詳細については非推奨ではないAPIへの移行 を参照してください。
次のコマンドを使用して最新リリースをダウンロードしてください:
curl -LO "https://dl.k8s.io/release/ $( curl -L -s https://dl.k8s.io/release/stable.txt) /bin/darwin/amd64/kubectl-convert"
curl -LO "https://dl.k8s.io/release/ $( curl -L -s https://dl.k8s.io/release/stable.txt) /bin/darwin/arm64/kubectl-convert"
バイナリを検証してください(オプション)
kubectl-convertのチェックサムファイルをダウンロードします:
curl -LO "https://dl.k8s.io/release/ $( curl -L -s https://dl.k8s.io/release/stable.txt) /bin/darwin/amd64/kubectl-convert.sha256"
curl -LO "https://dl.k8s.io/release/ $( curl -L -s https://dl.k8s.io/release/stable.txt) /bin/darwin/arm64/kubectl-convert.sha256"
チェックサムファイルに対してkubectl-convertバイナリを検証します:
echo " $( cat kubectl-convert.sha256) kubectl-convert" | shasum -a 256 --check
正しければ、出力は次のようになります:
チェックに失敗すると、shasumは0以外のステータスで終了し、次のような出力を表示します:
kubectl-convert: FAILED
shasum: WARNING: 1 computed checksum did NOT match
備考: 同じバージョンのバイナリとチェックサムをダウンロードしてください。kubectl-convertバイナリを実行可能にしてください。
chmod +x ./kubectl-convert
kubectl-convertバイナリをPATHの中に移動してください。
sudo mv ./kubectl-convert /usr/local/bin/kubectl-convert
sudo chown root: /usr/local/bin/kubectl-convert
備考: /usr/local/binがPATH環境変数の中に含まれるようにしてください。インストールしたバージョンが最新であることを確認してください
何もエラーが表示されない場合は、プラグインが正常にインストールされたことを示しています。
プラグインのインストール後、インストールファイルを削除してください:
rm kubectl-convert kubectl-convert.sha256
macOS上のkubectlをアンインストールする kubectlのインストール方法に応じて、次の方法を使用してください。
コマンドラインを使用してkubectlをアンインストールする システム上のkubectlバイナリの場所を特定してください:
kubectlバイナリを削除してください:
<path>を前のステップのkubectlバイナリのパスに置き換えてください。
例えばsudo rm /usr/local/bin/kubectl。
Homebrewを使用してkubectlをアンインストールする Homebrewを使用してkubectlをインストールした場合は、次のコマンドを実行してください:
次の項目 4.1.3 - Windows上でのkubectlのインストールおよびセットアップ 始める前に kubectlのバージョンは、クラスターのマイナーバージョンとの差分が1つ以内でなければなりません。
たとえば、クライアントがv1.35であれば、v1.34、v1.35、v1.36のコントロールプレーンと通信できます。
最新の互換性のあるバージョンのkubectlを使うことで、不測の事態を避けることができるでしょう。
Windowsへkubectlをインストールする Windowsへkubectlをインストールするには、次の方法があります:
curlを使用してWindowsへkubectlのバイナリをインストールする 最新の1.35のパッチリリースをダウンロードしてください:
kubectl 1.35.0 。
または、curlがインストールされていれば、次のコマンドも使用できます:
curl.exe -LO "https://dl.k8s.io/release/v1.35.0/bin/windows/amd64/kubectl.exe"
バイナリを検証してください(オプション)
kubectlのチェックサムファイルをダウンロードします:
curl.exe -LO "https://dl.k8s.io/v1.35.0/bin/windows/amd64/kubectl.exe.sha256"
チェックサムファイルに対してkubectlバイナリを検証します:
kubectlバイナリのフォルダーをPATH環境変数に追加します。
kubectlのバージョンがダウンロードしたものと同じであることを確認してください:
または、バージョンの詳細を表示するために次を使用します:
kubectl version --client --output=yaml
備考: Docker Desktop for Windows は、それ自身のバージョンの
kubectlを
PATHに追加します。
Docker Desktopをすでにインストールしている場合、Docker Desktopインストーラーによって追加された
PATHの前に追加するか、Docker Desktopの
kubectlを削除してください。
Windowsへkubectlをインストールするために、Chocolatey パッケージマネージャーやScoop コマンドラインインストーラー、winget パッケージマネージャーを使用することもできます。
choco install kubernetes-cli
winget install -e --id Kubernetes.kubectl
インストールしたバージョンが最新であることを確認してください:
ホームディレクトリへ移動してください:
# cmd.exeを使用している場合はcd %USERPROFILE%を実行してください。
cd ~
.kubeディレクトリを作成してください:
作成した.kubeディレクトリへ移動してください:
リモートのKubernetesクラスターを使うために、kubectlを設定してください:
New-Item config -type file
備考: Notepadなどの選択したテキストエディターから設定ファイルを編集してください。kubectlの設定を検証する kubectlがKubernetesクラスターを探索し接続するために、kubeconfigファイル が必要です。
これは、kube-up.sh によりクラスターを作成した際や、Minikubeクラスターを正常にデプロイした際に自動生成されます。
デフォルトでは、kubectlの設定は~/.kube/configに格納されています。
クラスターの状態を取得し、kubectlが適切に設定されていることを確認してください:
URLのレスポンスが表示されている場合は、kubectlはクラスターに接続するよう正しく設定されています。
以下のようなメッセージが表示されている場合は、kubectlは正しく設定されていないか、Kubernetesクラスターに接続できていません。
The connection to the server <server-name:port> was refused - did you specify the right host or port?
たとえば、ラップトップ上(ローカル環境)でKubernetesクラスターを起動するような場合、Minikube などのツールを最初にインストールしてから、上記のコマンドを再実行する必要があります。
kubectl cluster-infoがURLレスポンスを返したにもかかわらずクラスターにアクセスできない場合は、次のコマンドで設定が正しいことを確認してください:
kubectl cluster-info dump
エラーメッセージ'No Auth Provider Found'のトラブルシューティング Kubernetes 1.26にて、kubectlは以下のクラウドプロバイダーが提供するマネージドKubernetesのビルトイン認証を削除しました。
これらのプロバイダーは、クラウド固有の認証を提供するkubectlプラグインをリリースしています。
手順については以下のプロバイダーのドキュメントを参照してください:
(この変更とは関係なく、他の理由で同じエラーメッセージが表示される可能性もあります。)
オプションのkubectlの設定とプラグイン シェルの自動補完を有効にする kubectlはBash、Zsh、Fish、PowerShellの自動補完を提供しています。
これにより、入力を大幅に削減することができます。
以下にPowerShellの自動補完の設定手順を示します。
PowerShellにおけるkubectlの補完スクリプトはkubectl completion powershellコマンドで生成できます。
すべてのシェルセッションでこれを行うには、次の行を$PROFILEファイルに追加します。
kubectl completion powershell | Out-String | Invoke-Expression
このコマンドは、PowerShellを起動する度に自動補完のスクリプトを再生成します。
生成されたスクリプトを直接$PROFILEファイルに追加することもできます。
生成されたスクリプトを$PROFILEファイルに追加するためには、PowerShellのプロンプトで次の行を実行します:
kubectl completion powershell >> $PROFILE
シェルをリロードした後、kubectlの自動補完が機能します。
kubectl convertプラグインをインストールする異なるAPIバージョン間でマニフェストを変換できる、Kubernetesコマンドラインツールkubectlのプラグインです。
これは特に、新しいKubernetesのリリースで、非推奨ではないAPIバージョンにマニフェストを移行する場合に役に立ちます。
詳細については非推奨ではないAPIへの移行 を参照してください。
次のコマンドを使用して最新リリースをダウンロードしてください:
curl.exe -LO "https://dl.k8s.io/release/v1.35.0/bin/windows/amd64/kubectl-convert.exe"
バイナリを検証してください(オプション)。
kubectl-convertのチェックサムファイルをダウンロードします:
curl.exe -LO "https://dl.k8s.io/v1.35.0/bin/windows/amd64/kubectl-convert.exe.sha256"
チェックサムファイルに対してkubectl-convertバイナリを検証します:
kubectl-convertバイナリのフォルダーをPATH環境変数に追加します。
プラグインが正常にインストールされたことを確認してください。
何もエラーが表示されない場合は、プラグインが正常にインストールされたことを示しています。
プラグインのインストール後、インストールファイルを削除してください:
del kubectl-convert .exe
del kubectl-convert .exe.sha256
次の項目 4.2 - クラスターの管理 クラスターの管理のための一般的なタスクについて学びます。
4.2.1 - kubeadmによる管理 4.2.1.1 - Linuxワーカーノードの追加 このページでは、kubeadmクラスターにLinuxワーカーノードを追加する方法を示します。
始める前に Linuxワーカーノードの追加 新たなLinuxワーカーノードをクラスターに追加するために、以下を各マシンに対して実行してください。
SSH等の手段でマシンへ接続します。 kubeadm init実行時に出力されたコマンドを実行します。例:sudo kubeadm join --token <token> <control-plane-host>:<control-plane-port> --discovery-token-ca-cert-hash sha256:<hash>
kubeadm joinに関する追加情報
備考: <control-plane-host>:<control-plane-port>にIPv6タプルを指定するには、IPv6アドレスを角括弧で囲みます。
例: [2001:db8::101]:2073トークンが不明な場合は、コントロールプレーンノードで次のコマンドを実行すると取得できます。
# コントロールプレーンノード上で実行してください。
sudo kubeadm token list
出力は次のようになります。
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
8ewj1p.9r9hcjoqgajrj4gi 23h 2018-06-12T02:51:28Z authentication, The default bootstrap system:
signing token generated by bootstrappers:
'kubeadm init'. kubeadm:
default-node-token
デフォルトでは、トークンは24時間後に有効期限が切れます。
現在のトークンの有効期限が切れた後にクラスターにノードを参加させたい場合は、コントロールプレーンノード上で次のコマンドを実行することで、新しいトークンを生成できます。
# コントロールプレーンノード上で実行してください。
sudo kubeadm token create
このコマンドの出力は次のようになります。
新たなトークンを生成しながらkubeadm joinコマンドを出力するには、次のコマンドを使用します。
sudo kubeadm token create --print-join-command
--discovery-token-ca-cert-hashの値が不明な場合は、コントロールプレーンノード上で次のコマンドを実行することで取得できます。
# コントロールプレーンノード上で実行してください。
sudo cat /etc/kubernetes/pki/ca.crt | openssl x509 -pubkey | openssl rsa -pubin -outform der 2>/dev/null | \
's/^.* //'
出力は次のようになります。
8cb2de97839780a412b93877f8507ad6c94f73add17d5d7058e91741c9d5ec78
kubeadm joinコマンドによって以下のように出力されるはずです。
[preflight] Running pre-flight checks
... (log output of join workflow) ...
Node join complete:
* Certificate signing request sent to control-plane and response
received.
* Kubelet informed of new secure connection details.
Run 'kubectl get nodes' on control-plane to see this machine join.
数秒後、kubectl get nodesを実行すると、出力内にこのノードが表示されるはずです(kubectlコマンドは、コントロールプレーンノード等で実行してください)。
備考: クラスターのノードは、通常は順番に初期化されるため、CoreDNSのPodは全て最初のコントロールプレーンノードで実行されている可能性があります。
高可用性を実現するため、新たなノードを追加した後にはkubectl -n kube-system rollout restart deployment corednsコマンドを実行してCoreDNSのPodを再配置してください。次の項目 4.2.1.2 - cgroupドライバーの設定 このページでは、kubeadmクラスターのコンテナランタイムcgroupドライバーに合わせて、kubelet cgroupドライバーを設定する方法について説明します。
始める前に Kubernetesのコンテナランタイムの要件 を熟知している必要があります。
コンテナランタイムのcgroupドライバーの設定 コンテナランタイム ページでは、kubeadmベースのセットアップではcgroupfsドライバーではなく、systemdドライバーが推奨されると説明されています。
このページでは、デフォルトのsystemdドライバーを使用して多くの異なるコンテナランタイムをセットアップする方法についての詳細も説明されています。
kubelet cgroupドライバーの設定 kubeadmでは、kubeadm initの際にKubeletConfiguration構造体を渡すことができます。
このKubeletConfigurationには、kubeletのcgroupドライバーを制御するcgroupDriverフィールドを含めることができます。
備考: v1.22では、ユーザーがKubeletConfigurationのcgroupDriverフィールドを設定していない場合、kubeadmはデフォルトでsystemdを設定するようになりました。フィールドを明示的に設定する最小限の例です:
# kubeadm-config.yaml
kind : ClusterConfiguration
apiVersion : kubeadm.k8s.io/v1beta3
kubernetesVersion : v1.21.0
---
kind : KubeletConfiguration
apiVersion : kubelet.config.k8s.io/v1beta1
cgroupDriver : systemd
このような設定ファイルは、kubeadmコマンドに渡すことができます:
kubeadm init --config kubeadm-config.yaml
備考: Kubeadmはクラスター内の全ノードで同じKubeletConfigurationを使用します。
KubeletConfigurationはkube-system名前空間下のConfigMap オブジェクトに格納されます。
サブコマンドinit、join、upgradeを実行すると、kubeadmがKubeletConfigurationを/var/lib/kubelet/config.yaml以下にファイルとして書き込み、ローカルノードのkubeletに渡します。
cgroupfsドライバーの使用 このガイドで説明するように、cgroupfsドライバーをkubeadmと一緒に使用することは推奨されません。
cgroupfsを使い続け、kubeadm upgradeが既存のセットアップでKubeletConfiguration cgroupドライバーを変更しないようにするには、その値を明示的に指定する必要があります。
これは、将来のバージョンのkubeadmにsystemdドライバーをデフォルトで適用させたくない場合に適用されます。
値を明示する方法については、後述の「kubelet ConfigMapの修正」の項を参照してください。
cgroupfsドライバーを使用するようにコンテナランタイムを設定したい場合は、選択したコンテナランタイムのドキュメントを参照する必要があります。
systemdドライバーへの移行既存のkubeadmクラスターのcgroupドライバーをsystemdにインプレースで変更する場合は、kubeletのアップグレードと同様の手順が必要です。
これには、以下に示す両方の手順を含める必要があります。
備考: あるいは、クラスター内の古いノードをsystemdドライバーを使用する新しいノードに置き換えることも可能です。
この場合、新しいノードに参加する前に以下の最初のステップのみを実行し、古いノードを削除する前にワークロードが新しいノードに安全に移動できることを確認する必要があります。kubelet ConfigMapの修正 kubectl get cm -n kube-system | grep kubelet-configで、kubelet ConfigMapの名前を探します。kubectl edit cm kubelet-config-x.yy -n kube-systemを呼び出します(x.yyはKubernetesのバージョンに置き換えてください)。既存のcgroupDriverの値を修正するか、以下のような新しいフィールドを追加します。 このフィールドは、ConfigMapのkubelet:セクションの下に存在する必要があります。
全ノードでcgroupドライバーを更新 クラスター内の各ノードについて:
Drain the node をkubectl drain <node-name> --ignore-daemonsetsを使ってドレーンします。systemctl stop kubeletを使用して、kubeletを停止します。コンテナランタイムの停止。 コンテナランタイムのcgroupドライバーをsystemdに変更します。 var/lib/kubelet/config.yamlにcgroupDriver: systemdを設定します。コンテナランタイムの開始。 systemctl start kubeletでkubeletを起動します。Drain the node をkubectl uncordon <node-name>を使って行います。ワークロードが異なるノードでスケジュールするための十分な時間を確保するために、これらのステップを1つずつノード上で実行します。
プロセスが完了したら、すべてのノードとワークロードが健全であることを確認します。
4.2.1.3 - Windowsノードの追加 FEATURE STATE:
Kubernetes v1.18 [beta]
Kubernetesを使用してLinuxノードとWindowsノードを混在させて実行できるため、Linuxで実行するPodとWindowsで実行するPodを混在させることができます。このページでは、Windowsノードをクラスターに登録する方法を示します。
始める前に 作業するKubernetesサーバーは次のバージョン以降のものである必要があります: 1.17.
バージョンを確認するには次のコマンドを実行してください: kubectl version.
目標 Windowsノードをクラスターに登録する LinuxとWindowsのPodとServiceが相互に通信できるようにネットワークを構成する はじめに: クラスターへのWindowsノードの追加 ネットワーク構成 LinuxベースのKubernetesコントロールプレーンノードを取得したら、ネットワーキングソリューションを選択できます。このガイドでは、簡単にするためにVXLANモードでのFlannelの使用について説明します。
Flannel構成 FlannelのためにKubernetesコントロールプレーンを準備する
クラスター内のKubernetesコントロールプレーンでは、多少の準備が推奨されます。Flannelを使用する場合は、iptablesチェーンへのブリッジIPv4トラフィックを有効にすることをお勧めします。すべてのLinuxノードで次のコマンドを実行する必要があります:
sudo sysctl net.bridge.bridge-nf-call-iptables= 1
Linux用のFlannelをダウンロードして構成する
最新のFlannelマニフェストをダウンロード:
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
VNIを4096、ポートを4789に設定するために、flannelマニフェストのnet-conf.jsonセクションを変更します。次のようになります:
net-conf.json: |
{
"Network" : "10.244.0.0/16" ,
"Backend" : {
"Type" : "vxlan" ,
"VNI" : 4096 ,
"Port" : 4789
}
}
備考: Linux上のFlannelがWindows上のFlannelと相互運用するには、VNIを4096およびポート4789に設定する必要があります。これらのフィールドの説明については、
VXLANドキュメント を参照してください。
備考: L2Bridge/Host-gatewayモードを使用するには、代わりにTypeの値を"host-gw"に変更し、VNIとPortを省略します。Flannelマニフェストを適用して検証する
Flannelの構成を適用しましょう:
kubectl apply -f kube-flannel.yml
数分後、Flannel Podネットワークがデプロイされていれば、すべてのPodが実行されていることがわかります。
kubectl get pods -n kube-system
出力結果には、実行中のLinux flannel DaemonSetが含まれているはずです:
NAMESPACE NAME READY STATUS RESTARTS AGE
...
kube-system kube-flannel-ds-54954 1/1 Running 0 1m
Windows Flannelとkube-proxy DaemonSetを追加する
これで、Windows互換バージョンのFlannelおよびkube-proxyを追加できます。
互換性のあるバージョンのkube-proxyを確実に入手するには、イメージのタグを置換する必要があります。
次の例は、Kubernetes 1.35.0の使用方法を示していますが、
独自のデプロイに合わせてバージョンを調整する必要があります。
curl -L https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/kube-proxy.yml | sed 's/VERSION/v1.35.0/g' | kubectl apply -f -
kubectl apply -f https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/flannel-overlay.yml
備考: ホストゲートウェイを使用している場合は、代わりに https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/flannel-host-gw.yml を使用してください。
備考: Windowsノードでイーサネット(「Ethernet0 2」など)ではなく別のインターフェースを使用している場合は、次の行を変更する必要があります:
wins cli process run --path /k/flannel/setup.exe --args "--mode=overlay --interface=Ethernet"
flannel-host-gw.ymlまたはflannel-overlay.ymlファイルで、それに応じてインターフェースを指定します。
# 例
curl -L https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/flannel-overlay.yml | sed 's/Ethernet/Ethernet0 2/g' | kubectl apply -f -
Windowsワーカーノードの参加
備考: Windowsセクションのすべてのコードスニペットは、
Windowsワーカーノードの(管理者)権限を持つPowerShell環境で実行されます。wins、kubelet、kubeadmをインストールします。
curl.exe -LO https: //raw.githubusercontent.com/kubernetes-sigs /sig-windows -tools/master/kubeadm/scripts/PrepareNode.ps1
.\PrepareNode.ps1 -KubernetesVersion v1.35.0
kubeadmを実行してノードに参加します
コントロールプレーンホストでkubeadm initを実行したときに提供されたコマンドを使用します。
このコマンドがなくなった場合、またはトークンの有効期限が切れている場合は、kubeadm token create --print-join-command
(コントロールプレーンホスト上で)を実行して新しいトークンを生成します。
インストールの確認 次のコマンドを実行して、クラスター内のWindowsノードを表示できるようになります:
kubectl get nodes -o wide
新しいノードがNotReady状態の場合は、flannelイメージがまだダウンロード中の可能性があります。
kube-system名前空間のflannel Podを確認することで、以前と同様に進行状況を確認できます:
kubectl -n kube-system get pods -l app = flannel
flannel Podが実行されると、ノードはReady状態になり、ワークロードを処理できるようになります。
次の項目 4.2.1.4 - Linuxノードのアップグレード このページでは、kubeadmで構築したLinuxワーカーノードのアップグレード方法を示します。
始める前に
全てのノードへのシェルアクセスが可能であり、kubectlコマンドラインツールがクラスターと通信できるように設定されている必要があります。
このチュートリアルでは、コントロールプレーンのホストではないノードが少なくとも2つ存在するクラスターで実行することを推奨します。
バージョンを確認するには次のコマンドを実行してください: kubectl version.
パッケージリポジトリの変更 コミュニティ所有のパッケージリポジトリ(pkgs.k8s.io)を使用している場合、必要なKubernetesのマイナーリリースのパッケージリポジトリを有効化する必要があります。
これは、Kubernetesパッケージリポジトリの変更 ドキュメントにて説明されています。
備考: 古いパッケージリポジトリ(
apt.kubernetes.ioおよび
yum.kubernetes.io)は
2023年9月13日以降、非推奨となり凍結されています 。
pkgs.k8s.ioにてホストされている新しいリポジトリ
非推奨の古いリポジトリとその内容は、将来事前予告なく削除される可能性があります。
新しいパッケージリポジトリでは、v1.24.0以降のKubernetesバージョンのダウンロードを提供しています。
ワーカーノードのアップグレード kubeadmのアップグレード kubeadmをアップグレードします。
#「1.35.x-*」の「x」は最新のパッチバージョンに置き換えてください。
sudo apt-mark unhold kubeadm && \
&& sudo apt-get install -y kubeadm = '1.35.x-*' && \
DNFを搭載したシステムの場合:
#「1.35.x-*」の「x」は最新のパッチバージョンに置き換えてください。
sudo yum install -y kubeadm-'1.35.x-*' --disableexcludes= kubernetes
DNF5を搭載したシステムの場合:
#「1.35.x-*」の「x」は最新のパッチバージョンに置き換えてください。
sudo yum install -y kubeadm-'1.35.x-*' --setopt= disable_excludes = kubernetes
"kubeadm upgrade"の実行 ワーカーノードは、以下のコマンドによってローカルのkubeletの設定がアップグレードされます。
sudo kubeadm upgrade node
ノードのドレイン ノードをスケジュール不可としてマークし、ワークロードを退去させることで、ノードのメンテナンスの準備をします。
# このコマンドはコントロールプレーンノードで実行してください。
# <node-to-drain>は、ドレインするノード名に置き換えてください。
kubectl drain <node-to-drain> --ignore-daemonsets
kubeletとkubectlのアップグレード kubeletとkubectlをアップグレードします。
#「1.35.x-*」の「x」は最新のパッチバージョンに置き換えてください。
sudo apt-mark unhold kubelet kubectl && \
&& sudo apt-get install -y kubelet = '1.35.x-*' kubectl = '1.35.x-*' && \
DNFを搭載したシステムの場合:
#「1.35.x-*」の「x」は最新のパッチバージョンに置き換えてください。
sudo yum install -y kubelet-'1.35.x-*' kubectl-'1.35.x-*' --disableexcludes= kubernetes
DNF5を搭載したシステムの場合:
#「1.35.x-*」の「x」は最新のパッチバージョンに置き換えてください。
sudo yum install -y kubelet-'1.35.x-*' kubectl-'1.35.x-*' --setopt= disable_excludes = kubernetes
kubeletを再起動します。
sudo systemctl daemon-reload
sudo systemctl restart kubelet
ノードの隔離解除 ノードをスケジュール可能としてマークすることで、ノードをオンラインに戻します。
# このコマンドはコントロールプレーンノードで実行してください。
# <node-to-uncordon>は対象のノード名に置き換えてください。
kubectl uncordon <node-to-uncordon>
次の項目 4.2.1.5 - Windowsノードのアップグレード FEATURE STATE:
Kubernetes v1.18 [beta]
このページでは、kubeadmで作られた Windowsノードをアップグレードする方法について説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: 1.17.
バージョンを確認するには次のコマンドを実行してください: kubectl version.
ワーカーノードをアップグレード kubeadmをアップグレード Windowsノードから、kubeadmをアップグレードします。:
# 1.35.0を目的のバージョンに置き換えます
curl.exe -Lo C:\k\kubeadm.exe https: //dl.k8s.io/v1.35.0 /bin/windows/amd64/kubeadm.exe
ノードをドレインする Kubernetes APIにアクセスできるマシンから、
ノードをスケジュール不可としてマークして、ワークロードを削除することでノードのメンテナンスを準備します:
# <node-to-drain>をドレインするノードの名前に置き換えます
kubectl drain <node-to-drain> --ignore-daemonsets
このような出力結果が表示されるはずです:
node/ip-172-31-85-18 cordoned
node/ip-172-31-85-18 drained
kubeletの構成をアップグレード Windowsノードから、次のコマンドを呼び出して新しいkubelet構成を同期します:
kubeletをアップグレード Windowsノードから、kubeletをアップグレードして再起動します:
stop-service kubelet
curl.exe -Lo C:\k\kubelet.exe https: //dl.k8s.io/v1.35.0 /bin/windows/amd64/kubelet.exe
restart-service kubelet
ノードをオンライン状態に Kubernetes APIにアクセスできるマシンから、
スケジュール可能としてマークして、ノードをオンラインに戻します:
# <node-to-drain>をノードの名前に置き換えます
kubectl uncordon <node-to-drain>
kube-proxyをアップグレード Kubernetes APIにアクセスできるマシンから、次を実行します、
もう一度1.35.0を目的のバージョンに置き換えます:
curl -L https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/kube-proxy.yml | sed 's/VERSION/v1.35.0/g' | kubectl apply -f -
4.2.1.6 - kubeadmによる証明書管理 FEATURE STATE:
Kubernetes v1.15 [stable]
kubeadm で生成されたクライアント証明書は1年で失効します。
このページでは、kubeadmで証明書の更新を管理する方法について説明します。
また、kubeadmによる証明書管理に関連するタスクも説明します。
Kubernetesプロジェクトでは、最新のパッチリリースに速やかにアップグレードし、サポートされているKubernetesのマイナーリリースを実行していることを推奨しています。
この推奨事項に従うことで、セキュリティを維持できます。
始める前に KubernetesにおけるPKI証明書と要件 を熟知している必要があります。
kubeadmコマンドに対して、kubeadmの設定 ファイルを渡す方法について熟知している必要があります。
本ページではopensslコマンド(手動で証明書に署名する場合に使用)の使用方法について説明しますが、他のツールで代用することもできます。
ここで紹介する手順の一部では、管理者アクセスにsudoを使用していますが、同等のツールを使用しても構いません。
カスタム証明書の使用 デフォルトでは、kubeadmはクラスターの実行に必要なすべての証明書を生成します。
独自の証明書を提供することで、この動作をオーバーライドできます。
そのためには、--cert-dirフラグまたはkubeadmのClusterConfigurationのcertificatesDirフィールドで指定された任意のディレクトリに配置する必要があります。
デフォルトは/etc/kubernetes/pkiです。
kubeadm initを実行する前に既存の証明書と秘密鍵のペアが存在する場合、kubeadmはそれらを上書きしません。
つまり、例えば既存のCAを/etc/kubernetes/pki/ca.crtと/etc/kubernetes/pki/ca.keyにコピーすれば、kubeadmは残りの証明書に署名する際、このCAを使用できます。
暗号化アルゴリズムの選択 kubeadmでは、公開鍵や秘密鍵を作成する際に暗号化アルゴリズムを選択できます。
設定するには、kubeadmの設定ファイルにてencryptionAlgorithmフィールドを使用します。
apiVersion : kubeadm.k8s.io/v1beta4
kind : ClusterConfiguration
encryptionAlgorithm : <ALGORITHM>
<ALGORITHM>は、RSA-2048(デフォルト)、RSA-3072、RSA-4096、ECDSA-P256が選択できます。
証明書の有効期間の選択 kubeadmでは、CAおよびリーフ証明書の有効期間を選択可能です。
設定するには、kubeadmの設定ファイルにて、certificateValidityPeriod、caCertificateValidityPeriodフィールドを使用します。
apiVersion : kubeadm.k8s.io/v1beta4
kind : ClusterConfiguration
certificateValidityPeriod: 8760h # デフォルト : 365日 × 24時間 = 1年
caCertificateValidityPeriod: 87600h # デフォルト : 365日 × 24時間 * 10 = 10年
フィールドの値は、Go言語のtime.Durationの値 で許容される形式に準拠しており、サポートされている最長単位はh(時間)です。
外部CAモード また、ca.crtファイルのみを提供し、ca.keyファイルを提供しないことも可能です(これはルートCAファイルのみに有効で、他の証明書ペアには有効ではありません)。
他の証明書とkubeconfigファイルがすべて揃っている場合、kubeadmはこの状態を認識し、「外部CA」モードを有効にします。
kubeadmはディスク上のCAキーがなくても処理を進めます。
代わりに、--controllers=csrsignerを使用してController-managerをスタンドアロンで実行し、CA証明書と鍵を指定します。
外部CAモードを使用する場合、コンポーネントの資格情報を作成する方法がいくつかあります。
手動によるコンポーネント資格情報の作成 PKI証明書とその要件 には、kubeadmコンポーネントに必要な全ての資格情報を手動で作成する方法が記載されています。
本ページではopensslコマンド(手動で証明書を署名する場合に使用)の使用方法について説明しますが、他のツールを代用することもできます。
kubeadmによって生成されたCSRへの署名による資格情報の作成 kubeadmは、opensslのようなツールと外部CAを使用して手動で署名可能なCSRファイルの生成 ができます。
これらのCSRファイルには、kubeadmによってデプロイされるコンポーネントに必要な資格情報の全ての仕様が含まれます。
kubeadm phaseを使用したコンポーネント資格情報の自動作成 もしくは、kubeadm phaseコマンドを使用して、これらのプロセスを自動化することが可能です。
kubeadmコントロールプレーンノードとして外部CAを用いて構築するホストに対し、アクセスします。 外部CAのca.crtとca.keyファイルを、ノードの/etc/kubernetes/pkiへコピーします。 kubeadm initで使用する、config.yamlという一時的なkubeadmの設定ファイル を準備します。
このファイルには、ClusterConfiguration.controlPlaneEndpoint、ClusterConfiguration.certSANs、InitConfiguration.APIEndpointなど、証明書に含まれる可能性のある、クラスター全体またはホスト固有の関連情報が全て記載されていることを確認します。同じホストでkubeadm init phase kubeconfig all --config config.yamlおよびkubeadm init phase certs all --config config.yamlコマンドを実行します。
これにより、必要な全てのkubeconfigファイルと証明書が/etc/kubernetes/配下およびpkiサブディレクトリ配下に作成されます。 作成されたファイルを調べます。/etc/kubernetes/pki/ca.keyを削除し、/etc/kubernetes/super-admin.confを削除するか、安全な場所に退避します。 kubeadm joinを実行するノードでは、/etc/kubernetes/kubelet.confも削除します。
このファイルはkubeadm initが実行される最初のノードでのみ必要とされます。pki/sa.*、pki/front-proxy-ca.*、pki/etc/ca.*等のファイルは、コントロールプレーンノード間で共有されます。
kubeadm joinを実行するノードに手動で証明書を配布する か、kubeadm initの--upload-certskubeadm joinの--certificate-keyオプションを使用することでこれらを自動配布します。全てのノードにて資格情報を準備した後、これらのノードをクラスターに参加させるためにkubeadm initおよびkubeadm joinを実行します。
kubeadmは/etc/kubernetes/およびpkiサブディレクトリ配下に存在するkubeconfigと証明書を使用します。
証明書の有効期限と管理
備考: kubeadmは、外部CAによって署名された証明書を管理することができません。check-expirationサブコマンドを使うと、証明書の有効期限を確認することができます。
kubeadm certs check-expiration
このような出力になります:
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Dec 30, 2020 23:36 UTC 364d no
apiserver Dec 30, 2020 23:36 UTC 364d ca no
apiserver-etcd-client Dec 30, 2020 23:36 UTC 364d etcd-ca no
apiserver-kubelet-client Dec 30, 2020 23:36 UTC 364d ca no
controller-manager.conf Dec 30, 2020 23:36 UTC 364d no
etcd-healthcheck-client Dec 30, 2020 23:36 UTC 364d etcd-ca no
etcd-peer Dec 30, 2020 23:36 UTC 364d etcd-ca no
etcd-server Dec 30, 2020 23:36 UTC 364d etcd-ca no
front-proxy-client Dec 30, 2020 23:36 UTC 364d front-proxy-ca no
scheduler.conf Dec 30, 2020 23:36 UTC 364d no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Dec 28, 2029 23:36 UTC 9y no
etcd-ca Dec 28, 2029 23:36 UTC 9y no
front-proxy-ca Dec 28, 2029 23:36 UTC 9y no
このコマンドは、/etc/kubernetes/pkiフォルダー内のクライアント証明書と、kubeadmが使用するkubeconfigファイル(admin.conf、controller-manager.conf、scheduler.conf)に埋め込まれたクライアント証明書の有効期限/残余時間を表示します。
また、証明書が外部管理されている場合、kubeadmはユーザーに通知します。この場合、ユーザーは証明書の更新を手動または他のツールを使用して管理する必要があります。
kubeadmは/var/lib/kubelet/pki配下にあるローテーション可能な証明書でkubeletの証明書の自動更新 を構成するため、kubelet.confは上記のリストに含まれません。
期限切れのkubeletクライアント証明書を修復するには、kubeletクライアント証明書のローテーションに失敗する を参照ください。
備考: kubeadm version 1.17より前のkubeadm initで作成したノードでは、kubelet.confの内容を手動で変更しなければならないというバグ が存在します。
kubeadm initが終了したら、client-certificate-dataとclient-key-dataを置き換えて、ローテーションされたkubeletクライアント証明書を指すようにkubelet.confを更新してください。
client-certificate : /var/lib/kubelet/pki/kubelet-client-current.pem
client-key : /var/lib/kubelet/pki/kubelet-client-current.pem
証明書の自動更新 kubeadmはコントロールプレーンのアップグレード 時にすべての証明書を更新します。
この機能は、最もシンプルなユースケースに対応するために設計されています。
証明書の更新に特別な要件がなく、Kubernetesのバージョンアップを定期的に行う場合(各アップグレードの間隔が1年未満)、kubeadmは、クラスターを最新に保ち、適切なセキュリティを確保します。
証明書の更新に関してより複雑な要求がある場合は、--certificate-renewal=falseをkubeadm upgrade applyやkubeadm upgrade nodeに渡して、デフォルトの動作から外れるようにすることができます。
手動による証明書更新 適切なコマンドラインオプションを指定してkubeadm certs renewコマンドを実行すれば、いつでも証明書を手動で更新できます。
複数のコントロールプレーンによってクラスターが稼働している場合、全てのコントロールプレーンノード上でこのコマンドを実行する必要があります。
このコマンドは/etc/kubernetes/pkiに格納されているCA(またはfront-proxy-CA)の証明書と鍵を使用して更新を行います。
kubeadm certs renewは、属性(Common Name、Organization、SANなど)の信頼できるソースとして、kubeadm-config ConfigMapではなく、既存の証明書を使用します。
それでも、Kubernetesプロジェクトでは、混乱のリスクを避けるために証明書とConfigMap内の関連した値を同期したままにしておくことを推奨しています。
コマンド実行後、コントロールプレーンのPodを再起動する必要があります。
これは、現在は動的な証明書のリロードが、すべてのコンポーネントと証明書でサポートされているわけではないため、必要な作業です。
static Pod はローカルkubeletによって管理され、APIサーバーによって管理されないため、kubectlで削除および再起動することはできません。
static Podを再起動するには、一時的に/etc/kubernetes/manifests/からマニフェストファイルを削除して20秒間待ちます(KubeletConfiguration構造体 のfileCheckFrequency値を参照してください)。
マニフェストディレクトリにてマニフェストファイルが存在しなくなると、kubeletはPodを終了します。
その後ファイルを戻し、さらにfileCheckFrequency期間後に、kubeletはPodを再作成し、コンポーネントの証明書更新を完了することができます。
kubeadm certs renewは、特定の証明書を更新できます。
また、allサブコマンドを用いることで全ての証明書を更新できます。
# 複数のコントロールプレーンによってクラスターが稼働している場合、このコマンドは全てのコントロールプレーン上で実行する必要があります。
kubeadm certs renew all
管理者用の証明書のコピー(オプション) kubeadmで構築されたクラスターでは、多くの場合、kubeadmを使用したクラスターの作成 の指示に従い、admin.conf証明書が$HOME/.kube/configへコピーされます。
このようなシステムでは、admin.confを更新した後に$HOME/.kube/configの内容を更新するため、次のコマンドを実行します。
sudo cp -i /etc/kubernetes/admin.conf $HOME /.kube/config
sudo chown $( id -u) :$( id -g) $HOME /.kube/config
Kubernetes certificates APIによる証明書の更新 ここでは、Kubernetes certificates APIを使用して手動で証明書更新を実行する方法について詳しく説明します。
注意: これらは、組織の証明書インフラをkubeadmで構築されたクラスターに統合する必要があるユーザー向けの上級者向けのトピックです。
kubeadmのデフォルトの設定で満足できる場合は、代わりにkubeadmに証明書を管理させる必要があります。署名者の設定 Kubernetesの認証局は、そのままでは機能しません。
cert-manager などの外部署名者を設定するか、組み込みの署名者を使用することができます。
ビルトインサイナーはkube-controller-manager
ビルトインサイナーを有効にするには、--cluster-signing-cert-fileと--cluster-signing-key-fileフラグを渡す必要があります。
新しいクラスターを作成する場合は、kubeadm設定ファイル を使用します。
apiVersion : kubeadm.k8s.io/v1beta4
kind : ClusterConfiguration
controllerManager :
extraArgs :
- name : "cluster-signing-cert-file"
value : "/etc/kubernetes/pki/ca.crt"
- name : "cluster-signing-key-file"
value : "/etc/kubernetes/pki/ca.key"
証明書署名要求(CSR)の作成 Kubernetes APIでのCSR作成については、CertificateSigningRequestの作成 を参照ください。
外部CAによる証明書の更新 ここでは、外部認証局を利用して手動で証明書更新を行う方法について詳しく説明します。
外部CAとの連携を強化するために、kubeadmは証明書署名要求(CSR)を生成することもできます。
CSRとは、クライアント用の署名付き証明書をCAに要求することを表します。
kubeadmでは、通常ディスク上のCAによって署名される証明書をCSRとして生成することができます。しかし、CAはCSRとして生成することはできません。
証明書署名要求(CSR)による証明書の更新 証明書の更新は、新たなCSRを作成し外部CAで署名することで実施できます。
kubeadmによって生成されたCSRの署名についての詳細は、kubeadmによって生成された証明書署名要求(CSR)の署名 セクションを参照してください。
認証局(CA)のローテーション kubeadmは、CA証明書のローテーションや置換を標準ではサポートしていません。
CAの手動ローテーションや置換についての詳細は、CA証明書の手動ローテーション を参照してください。
署名付きkubeletサーバー証明書の有効化 デフォルトでは、kubeadmによって展開されるkubeletサーバー証明書は自己署名されています。
これは、metrics-server のような外部サービスからkubeletへの接続がTLSで保護されないことを意味します。
新しいkubeadmクラスター内のkubeletが適切に署名されたサーバー証明書を取得するように設定するには、kubeadm initに以下の最小限の設定を渡す必要があります。
apiVersion : kubeadm.k8s.io/v1beta4
kind : ClusterConfiguration
---
apiVersion : kubelet.config.k8s.io/v1beta1
kind : KubeletConfiguration
serverTLSBootstrap : true
すでにクラスターを作成している場合は、以下の手順で適応させる必要があります。
kube-system namespace中のkubelet-config ConfigMapを探して編集します。
このConfigMap内には、kubeletキーの値として、KubeletConfiguration に関する記述が存在します。
KubeletConfigurationの内容を編集し、serverTLSBootstrap: trueを設定します。各ノードで、/var/lib/kubelet/config.yamlにserverTLSBootstrap: trueフィールドを追加し、systemctl restart kubeletでkubeletを再起動します。 serverTLSBootstrap: trueフィールドは、certificates.k8s.io APIからkubeletのサーバー証明書をリクエストすることで、kubeletサーバー証明書のブートストラップを有効にします。
既知の制限事項の1つとして、これらのCSR(証明書署名要求)はkube-controller-managerのデフォルトの署名者によって自動的に承認されないことが挙げられます。
kubernetes.io/kubelet-serving
これらのCSRは、以下を使用して表示できます:
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-9wvgt 112s kubernetes.io/kubelet-serving system:node:worker-1 Pending
csr-lz97v 1m58s kubernetes.io/kubelet-serving system:node:control-plane-1 Pending
承認するためには、次のようにします:
kubectl certificate approve <CSR-name>
デフォルトでは、これらのサーバー証明書は1年後に失効します。
kubeadmはKubeletConfigurationフィールドのrotateCertificatesをtrueに設定します。
これは有効期限が切れる間際に、サーバー証明書のための新しいCSRセットを作成し、ローテーションを完了するために承認する必要があることを意味します。
詳しくは証明書のローテーション を参照してください。
これらのCSRを自動的に承認するためのソリューションをお探しの場合は、クラウドプロバイダーに連絡し、ノードの識別をアウトオブバンドのメカニズムで行うCSRの署名者がいるかどうか確認することをお勧めします。
備考: このセクションでは、Kubernetesが必要とする機能を提供するサードパーティープロジェクトにリンクしています。これらのプロジェクトはアルファベット順に記載されていて、Kubernetesプロジェクトの作者は責任を持ちません。このリストにプロジェクトを追加するには、変更を提出する前に
content guide をお読みください。
詳細はこちら。 サードパーティのカスタムコントローラーを使用することができます。
このようなコントローラーは、CSRのCommonNameを検証するだけでなく、要求されたIPやドメイン名も検証しなければ、安全なメカニズムとは言えません。
これにより、kubeletクライアント証明書にアクセスできる悪意のあるアクターが、任意のIPやドメイン名に対してサーバー証明書を要求するCSRを作成することを防止できます。
追加ユーザー用のkubeconfigファイルの生成 クラスターの構築中、kubeadm initはsuper-admin.conf内の証明書に署名し、Subject: O = system:masters, CN = kubernetes-super-adminを設定します。
system:mastersRBAC )、緊急用のスーパーユーザーグループです。
admin.confファイルもkubeadmによってコントロールプレーン上に作成され、Subject: O = kubeadm:cluster-admins, CN = kubernetes-adminと設定された証明書が含まれています。
kubeadm:cluster-adminsはkubeadmが属している論理的なグループです。
RBAC(kubeadmのデフォルト)をクラスターに使用している場合、kubeadm:cluster-adminsグループはcluster-admin
警告: super-admin.confおよびadmin.confファイルを共有しないでください。
代わりに、管理者として従事するユーザーに対しても最小限のアクセス権限を作成し、緊急アクセス以外の場合にはその最小限の権限の代替手段を使用します。kubeadm kubeconfig userkubeadm configuration オプションの組み合わせが可能です。
生成されたkubeconfigファイルはstdoutに書き込まれ、kubeadm kubeconfig user ... > somefile.confを使用してファイルにパイプすることができます。
--configで使用できる設定ファイルの例:
# example.yaml
apiVersion : kubeadm.k8s.io/v1beta4
kind : ClusterConfiguration
# kubeconfig内にて、対象の"cluster"として使用します。
clusterName : "kubernetes"
# kubeconfig内にて、このクラスターの"server"(IPもしくはDNS名)として使用します。
controlPlaneEndpoint : "some-dns-address:6443"
# クラスターCAの秘密鍵と証明書が、このローカルディレクトリからロードされます。
certificatesDir : "/etc/kubernetes/pki"
これらの設定が、目的の対象クラスターの設定と一致していることを確認します。
既存のクラスターの設定を表示するには、次のコマンドを使用します。
kubectl get cm kubeadm-config -n kube-system -o= jsonpath = "{.data.ClusterConfiguration}"
次の例では、appdevsグループに属する新しいユーザーjohndoeに対して24時間有効な資格情報を含むkubeconfigファイルが生成されます。
kubeadm kubeconfig user --config example.yaml --org appdevs --client-name johndoe --validity-period 24h
次の例では、1週間有効な管理者の資格情報を持つkubeconfigファイルが生成されます。
kubeadm kubeconfig user --config example.yaml --client-name admin --validity-period 168h
kubeadmによって生成された証明書署名要求(CSR)の署名 kubeadm certs generate-csrコマンドで、証明書署名要求を作成できます。
通常の証明書については、このコマンドの実行によって.csr/.keyファイルのペアが生成されます。
kubeconfigに埋め込まれた証明書については、このコマンドで.csr/.confのペアが生成されます。このペアでは、鍵は.confファイルに埋め込まれています。
CSRファイルには、CAが証明書に署名するために必要な情報が全て含まれています。
kubeadmは全ての証明書とCSRに対し、明確に定義された仕様 を適用します。
証明書のデフォルトのディレクトリは/etc/kubernetes/pkiであり、kubeconfigファイルのデフォルトのディレクトリは/etc/kubernetesです。
これらのデフォルトのディレクトリは、それぞれ--cert-dirと--kubeconfig-dirフラグで上書きできます。
kubeadm certs generate-csrにカスタムオプションを渡すには、--configフラグを使用します。
このフラグは、kubeadm initと同様に、kubeadmの設定 ファイルを受け入れます。
追加のSANやカスタムIPアドレスなどの指定については、関連の全てのkubeadmコマンドに使用するために、全て同じ設定ファイルに保存し、--configとして渡す必要があります。
備考: このガイドでは、Kubernetesのデフォルトのディレクトリである/etc/kubernetesを使用しています。このディレクトリにはスーパーユーザー権限が必要です。
このガイドに従って、書き込み可能なディレクトリを使用している場合(通常は--cert-dirと--kubeconfig-dirを指定してkubeadmを実行します)は、sudoコマンドを省略できます。
次に、作成したファイルを/etc/kubernetesディレクトリ内にコピーして、kubeadm initもしくはkubeadm joinがこれらのファイルを検出できるようにする必要があります。
CAとサービスアカウントファイルの準備 kubeadm initを実行する最初のコントロールプレーンノードでは、以下のコマンドを実行してください。
sudo kubeadm init phase certs ca
sudo kubeadm init phase certs etcd-ca
sudo kubeadm init phase certs front-proxy-ca
sudo kubeadm init phase certs sa
これにより、コントロールプレーンノードでkubeadmが必要とする、全ての自己署名CAファイル(証明書と鍵)とサービスアカウント(公開鍵と秘密鍵)が/etc/kubernetes/pkiおよび/etc/kubernetes/pki/etcdフォルダーに作成されます。
備考: 外部CAを使用する場合、同じファイルをアウトオブバンドで作成し、最初のコントロールプレーンノードの/etc/kubernetesへ手動でコピーする必要があります。
全ての証明書に署名した後、外部CAモード セクションの記載のように、ルートCAの鍵(ca.key)は削除しても構いません。
2番目以降のコントロールプレーンノード(kubeadm join --control-planeを実行します)では、上記のコマンドを実行する必要はありません。
高可用性 クラスターの構築方法に応じて、最初のコントロールプレーンノードから同じファイルを手動でコピーするか、kubeadm initの自動化された--upload-certs機能を使用する必要があります。
CSRの生成 kubeadm certs generate-csrコマンドは、kubeadmによって管理される全ての既知の証明書のCSRファイルを作成します。
コマンドの実行後、不要な.csr、.conf、または.keyファイルを手動で削除する必要があります。
kubelet.confに対する考慮事項 このセクションはコントロールプレーンノードとワーカーノードの両方に適用されます。
ca.keyファイルをコントロールプレーンから削除している場合(外部CAモード )、クラスターで実行中のkube-controller-managerはkubeletクライアント証明書への署名ができなくなります。
構成内にこれらの証明書へ署名するための外部の方法(外部署名者 など)が存在しない場合は、このガイドで説明されているように、kubelet.conf.csrに手動で署名できます。
なお、これにより、自動によるkubeletクライアント証明書のローテーション が無効になることに注意してください。
その場合は、証明書の有効期限が近づいたら、新しいkubelet.conf.csrを生成し、証明書に署名してkubelet.confに埋め込み、kubeletを再起動する必要があります。
ca.keyファイルがコントロールプレーンノード上に存在する場合、2番目以降のコントロールプレーンノードおよびワーカーノード(kubeadm join ...を実行する全てのノード)では、kubelet.conf.csrの処理をスキップできます。
これは、実行中のkube-controller-managerが新しいkubeletクライアント証明書の署名を担当するためです。
備考: kubelet.conf.csrファイルは、最初のコントロールプレーンノード(最初にkubeadm initを実行したホスト)で処理する必要があります。
これは、kubeadmがそのノードをクラスターのブートストラップ用のノードと見なすため、事前に設定されたkubelet.confが必要になるためです。コントロールプレーンノード 1番目(kubeadm init)および2番目以降(kubeadm join --control-plane)のコントロールプレーンノードで以下のコマンドを実行し、全てのCSRファイルを生成します。
sudo kubeadm certs generate-csr
外部etcdを使用する場合は、kubeadmとetcdノードに必要なCSRファイルについて理解するために、kubeadmを使用した外部etcd のガイドを参照してください。
/etc/kubernetes/pki/etcd配下にある他の.csrおよび.keyファイルは削除して構いません。
kubelet.confに対する考慮事項 の説明に基づいて、kubelet.confおよびkubelet.conf.csrファイルを保持するか削除します。
ワーカーノード kubelet.confに対する考慮事項 の説明に基づいて、オプションで以下のコマンドを実行し、kubelet.confおよびkubelet.conf.csrファイルを保持します。
sudo kubeadm certs generate-csr
あるいは、ワーカーノードの手順を完全にスキップします。
全ての証明書のCSRへ署名 備考: 外部CAを使用し、openssl用のCAのシリアル番号ファイル(.srl)が既に存在する場合は、これらのファイルをCSRを署名するkubeadmノードにコピーできます。
コピーする.srlファイルは、/etc/kubernetes/pki/ca.srl、/etc/kubernetes/pki/front-proxy-ca.srlおよび/etc/kubernetes/pki/etcd/ca.srlです。
その後、これらのファイルをCSRファイルに署名する新たなノードに移動できます。
ノード上のCAに対して.srlファイルが存在しない場合、以下のスクリプトはランダムな開始シリアル番号を持つ新規のSRLファイルを生成します。
.srlファイルの詳細については、openssl--CAserialフラグを参照してください。
CSRファイルが存在する全てのノードで、この手順を繰り返してください。
/etc/kubernetesディレクトリに次のスクリプトを作成し、そのディレクトリに移動してスクリプトを実行します。
このスクリプトは、/etc/kubernetesツリー以下に存在する全てのCSRファイルに対する証明書ファイルを生成します。
#!/bin/bash
# 日単位で証明書の有効期間を設定
DAYS = 365
# front-proxyとetcdを除いた全てのCSRファイルへ署名
find ./ -name "*.csr" | grep -v "pki/etcd" | grep -v "front-proxy" | while read -r FILE;
do
echo "* Processing ${ FILE } ..."
FILE = ${ FILE %.*} # 拡張子を取り除く
if [ -f "./pki/ca.srl" ] ; then
SERIAL_FLAG = "-CAserial ./pki/ca.srl"
else
SERIAL_FLAG = "-CAcreateserial"
fi
openssl x509 -req -days " ${ DAYS } " -CA ./pki/ca.crt -CAkey ./pki/ca.key ${ SERIAL_FLAG } \
" ${ FILE } .csr" -out " ${ FILE } .crt"
sleep 2
done
# 全てのetcdのCSRへ署名
find ./pki/etcd -name "*.csr" | while read -r FILE;
do
echo "* Processing ${ FILE } ..."
FILE = ${ FILE %.*} # 拡張子を取り除く
if [ -f "./pki/etcd/ca.srl" ] ; then
SERIAL_FLAG = -CAserial ./pki/etcd/ca.srl
else
SERIAL_FLAG = -CAcreateserial
fi
openssl x509 -req -days " ${ DAYS } " -CA ./pki/etcd/ca.crt -CAkey ./pki/etcd/ca.key ${ SERIAL_FLAG } \
" ${ FILE } .csr" -out " ${ FILE } .crt"
done
# front-proxyのCSRへ署名
echo "* Processing ./pki/front-proxy-client.csr ..."
openssl x509 -req -days " ${ DAYS } " -CA ./pki/front-proxy-ca.crt -CAkey ./pki/front-proxy-ca.key -CAcreateserial \
kubeconfigファイルへの証明書の組み込み CSRファイルが存在する全てのノードで、この手順を繰り返してください。
/etc/kubernetesディレクトリに次のスクリプトを作成し、そのディレクトリに移動してスクリプトを実行します。
このスクリプトは、前の手順でCSRファイルからkubeconfigファイル用に署名された.crtファイルを取得し、これらをkubeconfigファイルに組み込みます。
#!/bin/bash
CLUSTER = kubernetes
find ./ -name "*.conf" | while read -r FILE;
do
echo "* Processing ${ FILE } ..."
KUBECONFIG = " ${ FILE } " kubectl config set-cluster " ${ CLUSTER } " --certificate-authority ./pki/ca.crt --embed-certs
USER = $( KUBECONFIG = " ${ FILE } " kubectl config view -o jsonpath = '{.users[0].name}' )
KUBECONFIG = " ${ FILE } " kubectl config set-credentials " ${ USER } " --client-certificate " ${ FILE } .crt" --embed-certs
done
クリーンアップの実行 CSRファイルがあるすべてのノードでこの手順を実行します。
/etc/kubernetesディレクトリに次のスクリプトを作成し、そのディレクトリに移動してスクリプトを実行します。
#!/bin/bash
# CSRファイルのクリーンアップ
rm -f ./*.csr ./pki/*.csr ./pki/etcd/*.csr # 全てのCSRファイルを削除します。
# kubeconfigファイル内に既に埋め込まれているCRTファイルのクリーンアップ
rm -f ./*.crt
必要に応じて、.srlファイルを次に使用するノードへ移動させます。
必要に応じて、外部CAを使用する場合は、外部CAモード のセクションで説明されているように、/etc/kubernetes/pki/ca.keyファイルを削除します。
kubeadmノードの初期化 CSRファイルに署名し、ノードとして使用する各ホストへ証明書を配置すると、kubeadm initコマンドとkubeadm joinを使用してKubernetesクラスターを構築できます。
initとjoinの実行時、kubeadmは各ホストのローカルファイルシステムの/etc/kubernetesツリーで検出した既存の証明書、暗号化キー、およびkubeconfigファイルを使用します。
4.2.2 - dockershimからの移行 dockershimから他のコンテナランタイムに移行する際に知っておくべき情報を紹介します。
Kubernetes 1.20でdockershim deprecation が発表されてから、様々なワークロードやKubernetesインストールにどう影響するのかという質問が寄せられています。
この問題をよりよく理解するために、dockershimの削除に関するFAQ ブログが役に立つでしょう。
dockershimから代替のコンテナランタイムに移行することが推奨されます。
コンテナランタイム のセクションをチェックして、どのような選択肢があるかを確認してください。
問題が発生した場合は、必ず問題の報告 をしてください。
そうすれば、問題が適時に修正され、クラスターがdockershimの削除に対応できるようになります。
4.2.2.1 - ノードのコンテナランタイムをDocker Engineからcontainerdに変更する このタスクでは、コンテナランタイムをDockerからcontainerdに更新するために必要な手順について説明します。
これは、Kubernetes 1.23以前を使用しているクラスターオペレーターに適用されます。
また、dockershimからcontainerdへの移行を行う際の具体的なシナリオ例も含まれています。
代替のコンテナランタイムについては、このページ を参照してください。
始める前に 備考: このセクションでは、Kubernetesが必要とする機能を提供するサードパーティープロジェクトにリンクしています。これらのプロジェクトはアルファベット順に記載されていて、Kubernetesプロジェクトの作者は責任を持ちません。このリストにプロジェクトを追加するには、変更を提出する前に
content guide をお読みください。
詳細はこちら。 containerdをインストールします。
詳細についてはcontainerdのインストールドキュメント を参照してください。
特定の前提条件については、containerdガイド を参照してください。
ノードのドレイン kubectl drain <node-to-drain> --ignore-daemonsets
<node-to-drain>は、ドレイン対象のノード名に置き換えてください。
Dockerデーモンの停止 systemctl stop kubelet
systemctl disable docker.service --now
containerdのインストール containerdをインストールする手順の詳細については、ガイド を参照してください。
公式のDockerリポジトリからcontainerd.ioパッケージをインストールします。
各Linuxディストリビューション向けにDockerリポジトリを設定し、containerd.ioパッケージをインストールする手順については、Getting started with containerd を参照してください。
containerdを設定する:
sudo mkdir -p /etc/containerd
containerd config default | sudo tee /etc/containerd/config.toml
containerdを再起動する:
sudo systemctl restart containerd
PowerShellセッションを開始し、$Versionに目的のバージョンを設定します(例: $Version="1.4.3")。
その後、次のコマンドを実行します:
containerdをダウンロードする:
curl.exe -L https: //github.com/containerd/containerd/releases/download/v$Version /containerd-$Version -windows-amd64.tar.gz -o containerd-windows -amd64.tar.gz
tar.exe xvf .\containerd-windows -amd64.tar.gz
展開および設定:
Copy-Item -Path ".\bin\" -Destination " $Env:ProgramFiles \containerd" -Recurse -Force
cd $Env:ProgramFiles \containerd\
.\containerd.exe config default | Out-File config.toml -Encoding ascii
# 設定内容を確認します。セットアップによっては、以下を調整する必要があります:
# - sandbox_image(Kubernetesのpauseイメージ)
# - cniのbin_dirおよびconf_dirの場所
Get-Content config.toml
# (オプションだが、強く推奨される)containerdをWindows Defenderのスキャン対象から除外する
Add-MpPreference -ExclusionProcess " $Env:ProgramFiles \containerd\containerd.exe"
containerdを起動する:
.\containerd.exe --register-service
Start-Service containerd
containerdをコンテナランタイムとして使用するためのkubeletの設定 /var/lib/kubelet/kubeadm-flags.envファイルを編集し、フラグに--container-runtime-endpoint=unix:///run/containerd/containerd.sockを追加して、containerdランタイムを指定します。
kubeadmを使用しているユーザーは、kubeadmツールが各ホストのCRIソケットを、そのホストのノードオブジェクトにアノテーションとして保存していることに注意してください。
これを変更するには、/etc/kubernetes/admin.confファイルが存在するマシン上で次のコマンドを実行します。
kubectl edit no <node-name>
これによりテキストエディタが起動し、ノードオブジェクトを編集できます。
使用するテキストエディタを指定するには、KUBE_EDITOR環境変数を設定してください。
kubeadm.alpha.kubernetes.io/cri-socketの値を/var/run/dockershim.sockから、使用したいCRIソケットのパス(例: unix:///run/containerd/containerd.sock)に変更します。
新しいCRIソケットのパスは、原則としてunix://で始める必要がある点に注意してください。
テキストエディタで変更を保存すると、ノードオブジェクトが更新されます。
kubeletの再起動 ノードが正常であることの確認 kubectl get nodes -o wideを実行し、先ほど変更したノードのランタイムとしてcontainerdが表示されていることを確認します。
Docker Engineの削除 備考: このセクションでは、Kubernetesが必要とする機能を提供するサードパーティープロジェクトにリンクしています。これらのプロジェクトはアルファベット順に記載されていて、Kubernetesプロジェクトの作者は責任を持ちません。このリストにプロジェクトを追加するには、変更を提出する前に
content guide をお読みください。
詳細はこちら。 ノードが正常に見える場合は、Dockerを削除します。
sudo yum remove docker-ce docker-ce-cli
sudo apt-get purge docker-ce docker-ce-cli
sudo dnf remove docker-ce docker-ce-cli
sudo apt-get purge docker-ce docker-ce-cli
前述のコマンドは、ホスト上のイメージ、コンテナ、ボリューム、またはカスタマイズされた設定ファイルを削除しません。
これらを削除するには、DockerのDocker Engineのアンインストール 手順に従ってください。
注意: Docker Engineのアンインストール手順には、containerdを削除してしまうリスクがあります。コマンドの実行には十分注意してください。ノードのuncordon kubectl uncordon <node-to-uncordon>
<node-to-uncordon>は、以前にドレインしたノードの名前に置き換えてください。
4.2.2.2 - ノードで使用されているコンテナランタイムの確認 このページでは、クラスター内のノードが使用しているコンテナランタイム を確認する手順を概説しています。
クラスターの実行方法によっては、ノード用のコンテナランタイムが事前に設定されている場合と、設定する必要がある場合があります。
マネージドKubernetesサービスを使用している場合、ノードに設定されているコンテナランタイムを確認するためのベンダー固有の方法があるかもしれません。
このページで説明する方法は、kubectlの実行が許可されていればいつでも動作するはずです。
始める前に kubectlをインストールし、設定します。詳細はツールのインストール の項を参照してください。
ノードで使用されているコンテナランタイムの確認 ノードの情報を取得して表示するにはkubectlを使用します:
kubectl get nodes -o wide
出力は以下のようなものです。列CONTAINER-RUNTIMEには、ランタイムとそのバージョンが出力されます。
# For dockershim
NAME STATUS VERSION CONTAINER-RUNTIME
node-1 Ready v1.16.15 docker://19.3.1
node-2 Ready v1.16.15 docker://19.3.1
node-3 Ready v1.16.15 docker://19.3.1
# For containerd
NAME STATUS VERSION CONTAINER-RUNTIME
node-1 Ready v1.19.6 containerd://1.4.1
node-2 Ready v1.19.6 containerd://1.4.1
node-3 Ready v1.19.6 containerd://1.4.1
コンテナランタイムについては、コンテナランタイム のページで詳細を確認することができます。
4.2.2.3 - dockershim削除の影響範囲を確認する Kubernetesのdockershimコンポーネントは、DockerをKubernetesのコンテナランタイム として使用することを可能にします。
Kubernetesの組み込みコンポーネントであるdockershimはリリースv1.24で削除されました。
このページでは、あなたのクラスターがどのようにDockerをコンテナランタイムとして使用しているか、使用中のdockershimが果たす役割について詳しく説明し、dockershimの削除によって影響を受けるワークロードがあるかどうかをチェックするためのステップを示します。
自分のアプリがDockerに依存しているかどうかの確認 アプリケーションコンテナの構築にDockerを使用している場合でも、これらのコンテナを任意のコンテナランタイム上で実行することができます。このようなDockerの使用は、コンテナランタイムとしてのDockerへの依存とはみなされません。
代替のコンテナランタイムが使用されている場合、Dockerコマンドを実行しても動作しないか、予期せぬ出力が得られる可能性があります。
このように、Dockerへの依存があるかどうかを調べることができます:
特権を持つPodがDockerコマンド(docker psなど)を実行したり、Dockerサービスを再起動したり(systemctl restart docker.serviceなどのコマンド)、Docker固有のファイル(/etc/docker/daemon.jsonなど)を変更しないことを確認すること。 Dockerの設定ファイル(/etc/docker/daemon.json など)にプライベートレジストリやイメージミラーの設定がないか確認します。これらは通常、別のコンテナランタイムのために再設定する必要があります。 Kubernetesインフラストラクチャーの外側のノードで実行される以下のようなスクリプトやアプリがDockerコマンドを実行しないことを確認します。トラブルシューティングのために人間がノードにSSHで接続 ノードのスタートアップスクリプト ノードに直接インストールされた監視エージェントやセキュリティエージェント 上記のような特権的な操作を行うサードパーティツール。詳しくはMigrating telemetry and security agents from dockershim を参照してください。 dockershimの動作に間接的な依存性がないことを確認します。
これはエッジケースであり、あなたのアプリケーションに影響を与える可能性は低いです。ツールによっては、Docker固有の動作に反応するように設定されている場合があります。例えば、特定のメトリクスでアラートを上げたり、トラブルシューティングの指示の一部として特定のログメッセージを検索したりします。そのようなツールを設定している場合、移行前にテストクラスターで動作をテストしてください。 Dockerへの依存について解説 コンテナランタイム とは、Kubernetes Podを構成するコンテナを実行できるソフトウェアです。
KubernetesはPodのオーケストレーションとスケジューリングを担当し、各ノードではkubelet がコンテナランタイムインターフェースを抽象化して使用するので、互換性があればどのコンテナランタイムでも使用することができます。
初期のリリースでは、Kubernetesは1つのコンテナランタイムと互換性を提供していました: Dockerです。
その後、Kubernetesプロジェクトの歴史の中で、クラスター運用者は追加のコンテナランタイムを採用することを希望しました。
CRIはこのような柔軟性を可能にするために設計され、kubeletはCRIのサポートを開始しました。
しかし、DockerはCRI仕様が考案される前から存在していたため、Kubernetesプロジェクトはアダプタコンポーネント「dockershim」を作成しました。
dockershimアダプターは、DockerがCRI互換ランタイムであるかのように、kubeletがDockerと対話することを可能にします。
Kubernetes Containerd integration goes GA ブログ記事で紹介されています。
コンテナランタイムとしてContainerdに切り替えることで、中間マージンを排除することができます。
これまでと同じように、Containerdのようなコンテナランタイムですべてのコンテナを実行できます。
しかし今は、コンテナはコンテナランタイムで直接スケジュールするので、Dockerからは見えません。
そのため、これらのコンテナをチェックするために以前使っていたかもしれないDockerツールや派手なUIは、もはや利用できません。
docker psやdocker inspectを使用してコンテナ情報を取得することはできません。
コンテナを一覧表示できないので、ログを取得したり、コンテナを停止したり、docker execを使用してコンテナ内で何かを実行したりすることもできません。
備考: Kubernetes経由でワークロードを実行している場合、コンテナを停止する最善の方法は、コンテナランタイムを直接経由するよりもKubernetes APIを経由することです(このアドバイスはDockerだけでなく、すべてのコンテナランタイムに適用されます)。この場合でも、イメージを取得したり、docker buildコマンドを使用してビルドすることは可能です。
しかし、Dockerによってビルドまたはプルされたイメージは、コンテナランタイムとKubernetesからは見えません。
Kubernetesで使用できるようにするには、何らかのレジストリにプッシュする必要がありました。
4.2.2.4 - dockershimからテレメトリーやセキュリティエージェントを移行する Kubernetes 1.20でdockershimは非推奨になりました。
dockershimの削除に関するFAQ から、ほとんどのアプリがコンテナをホストするランタイムに直接依存しないことは既にご存知かもしれません。
しかし、コンテナのメタデータやログ、メトリクスを収集するためにDockerに依存しているテレメトリーやセキュリティエージェントはまだ多く存在します。
この文書では、これらの依存関係を検出する方法と、これらのエージェントを汎用ツールまたは代替ランタイムに移行する方法に関するリンクを集約しています。
テレメトリーとセキュリティエージェント Kubernetesクラスター上でエージェントを実行するには、いくつかの方法があります。エージェントはノード上で直接、またはDaemonSetとして実行することができます。
テレメトリーエージェントがDockerに依存する理由とは? 歴史的には、KubernetesはDockerの上に構築されていました。
Kubernetesはネットワークとスケジューリングを管理し、Dockerはコンテナをノードに配置して操作していました。
そのため、KubernetesからはPod名などのスケジューリング関連のメタデータを、Dockerからはコンテナの状態情報を取得することができます。
時が経つにつれ、コンテナを管理するためのランタイムも増えてきました。
また、多くのランタイムにまたがるコンテナ状態情報の抽出を一般化するプロジェクトやKubernetesの機能もあります。
いくつかのエージェントはDockerツールに関連しています。
エージェントはdocker psdocker topdocker logs を使えば、dockerログを購読することができます。
Dockerがコンテナランタイムとして非推奨になったため、これらのコマンドはもう使えません。
Dockerに依存するDaemonSetの特定 Podがノード上で動作しているdockerdを呼び出したい場合、Podは以下のいずれかを行う必要があります。
例: COSイメージでは、DockerはそのUnixドメインソケットを/var/run/docker.sockに公開します。
つまり、Pod仕様には/var/run/docker.sockのhostPathボリュームマウントが含まれることになります。
以下は、Dockerソケットを直接マッピングしたマウントを持つPodを探すためのシェルスクリプトのサンプルです。
このスクリプトは、Podの名前空間と名前を出力します。
grep '/var/run/docker.sock'を削除して、他のマウントを確認することもできます。
kubectl get pods --all-namespaces \
= jsonpath = '{range .items[*]}{"\n"}{.metadata.namespace}{":\t"}{.metadata.name}{":\t"}{range .spec.volumes[*]}{.hostPath.path}{", "}{end}{end}' \
\
'/var/run/docker.sock'
備考: Podがホスト上のDockerにアクセスするための代替方法があります。
例えば、フルパスの代わりに親ディレクトリ
/var/runをマウントすることができます(
この例 のように)。
上記のスクリプトは、最も一般的な使用方法のみを検出します。
ノードエージェントからDockerの依存性を検出する クラスターノードをカスタマイズし、セキュリティやテレメトリーのエージェントをノードに追加インストールする場合、エージェントのベンダーにDockerへの依存性があるかどうかを必ず確認してください。
テレメトリーとセキュリティエージェントのベンダー 様々なテレメトリーおよびセキュリティエージェントベンダーのための移行指示の作業中バージョンをGoogle doc に保管しています。
dockershimからの移行に関する最新の手順については、各ベンダーにお問い合わせください。
4.2.3 - 証明書を手動で生成する クライアント証明書認証を使用する場合、easyrsaopensslcfssl
easyrsa easyrsa はクラスターの証明書を手動で生成することができます。
パッチが適用されたバージョンのeasyrsa3をダウンロードして解凍し、初期化します。
curl -LO https://dl.k8s.io/easy-rsa/easy-rsa.tar.gz
tar xzf easy-rsa.tar.gz
cd easy-rsa-master/easyrsa3
./easyrsa init-pki
新しい認証局(CA)を生成します。
--batchで自動モードに設定します。--req-cnはCAの新しいルート証明書のコモンネーム(CN)を指定します。
./easyrsa --batch "--req-cn= ${ MASTER_IP } @`date +%s`" build-ca nopass
サーバー証明書と鍵を生成します。
引数--subject-alt-nameは、APIサーバーがアクセス可能なIPとDNS名を設定します。
MASTER_CLUSTER_IPは通常、APIサーバーとコントローラーマネージャーコンポーネントの両方で--service-cluster-ip-range引数に指定したサービスCIDRの最初のIPとなります。
引数--daysは、証明書の有効期限が切れるまでの日数を設定するために使用します。
また、以下のサンプルでは、デフォルトのDNSドメイン名としてcluster.localを使用することを想定しています。
./easyrsa --subject-alt-name= "IP: ${ MASTER_IP } ," \
"IP: ${ MASTER_CLUSTER_IP } ," \
"DNS:kubernetes," \
"DNS:kubernetes.default," \
"DNS:kubernetes.default.svc," \
"DNS:kubernetes.default.svc.cluster," \
"DNS:kubernetes.default.svc.cluster.local" \
= 10000 \
pki/ca.crt、pki/issued/server.crt、pki/private/server.keyを自分のディレクトリにコピーします。
APIサーバーのスタートパラメーターに以下のパラメーターを記入し、追加します。
--client-ca-file= /yourdirectory/ca.crt
--tls-cert-file= /yourdirectory/server.crt
--tls-private-key-file= /yourdirectory/server.key
openssl openssl は、クラスター用の証明書を手動で生成することができます。
2048bitのca.keyを生成します:
openssl genrsa -out ca.key 2048
ca.keyに従ってca.crtを生成します(-daysで証明書の有効期限を設定します):
openssl req -x509 -new -nodes -key ca.key -subj "/CN= ${ MASTER_IP } " -days 10000 -out ca.crt
2048bitでserver.keyを生成します:
openssl genrsa -out server.key 2048
証明書署名要求(CSR)を生成するための設定ファイルを作成します。
山括弧で囲まれた値(例:<MASTER_IP>)は必ず実際の値に置き換えてから、ファイル(例:csr.conf)に保存してください。MASTER_CLUSTER_IPの値は、前のサブセクションで説明したように、APIサーバーのサービスクラスターのIPであることに注意してください。また、以下のサンプルでは、デフォルトのDNSドメイン名としてcluster.localを使用することを想定しています。
[ req ]
default_bits = 2048
prompt = no
default_md = sha256
req_extensions = req_ext
distinguished_name = dn
[ dn ]
C = <country>
ST = <state>
L = <city>
O = <organization>
OU = <organization unit>
CN = <MASTER_IP>
[ req_ext ]
subjectAltName = @alt_names
[ alt_names ]
DNS.1 = kubernetes
DNS.2 = kubernetes.default
DNS.3 = kubernetes.default.svc
DNS.4 = kubernetes.default.svc.cluster
DNS.5 = kubernetes.default.svc.cluster.local
IP.1 = <MASTER_IP>
IP.2 = <MASTER_CLUSTER_IP>
[ v3_ext ]
authorityKeyIdentifier = keyid,issuer:always
basicConstraints = CA:FALSE
keyUsage = keyEncipherment,dataEncipherment
extendedKeyUsage = serverAuth,clientAuth
subjectAltName = @alt_names
設定ファイルに基づき、証明書署名要求を生成します:
openssl req -new -key server.key -out server.csr -config csr.conf
ca.key、ca.crt、server.csrを使用して、サーバー証明書を生成します:
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key \
10000 \
証明書署名要求を表示します:
openssl req -noout -text -in ./server.csr
証明書を表示します:
openssl x509 -noout -text -in ./server.crt
最後に、同じパラメーターをAPIサーバーのスタートパラメーターに追加します。
cfssl cfssl も証明書を生成するためのツールです。
以下のように、コマンドラインツールをダウンロードし、解凍して準備してください。
なお、サンプルのコマンドは、お使いのハードウェア・アーキテクチャやCFSSLのバージョンに合わせる必要があるかもしれません。
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl_1.5.0_linux_amd64 -o cfssl
chmod +x cfssl
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssljson_1.5.0_linux_amd64 -o cfssljson
chmod +x cfssljson
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl-certinfo_1.5.0_linux_amd64 -o cfssl-certinfo
chmod +x cfssl-certinfo
成果物を格納するディレクトリを作成し、cfsslを初期化します:
mkdir cert
cd cert
../cfssl print-defaults config > config.json
../cfssl print-defaults csr > csr.json
CAファイルを生成するためのJSON設定ファイル、例えばca-config.jsonを作成します:
{
"signing" : {
"default" : {
"expiry" : "8760h"
},
"profiles" : {
"kubernetes" : {
"usages" : [
"signing" ,
"key encipherment" ,
"server auth" ,
"client auth"
],
"expiry" : "8760h"
}
}
}
}
CA証明書署名要求(CSR)用のJSON設定ファイル(例:ca-csr.json)を作成します。
山括弧で囲まれた値は、必ず使用したい実際の値に置き換えてください。
{
"CN" : "kubernetes" ,
"key" : {
"algo" : "rsa" ,
"size" : 2048
},
"names" :[{
"C" : "<country>" ,
"ST" : "<state>" ,
"L" : "<city>" ,
"O" : "<organization>" ,
"OU" : "<organization unit>"
}]
}
CAキー(ca-key.pem)と証明書(ca.pem)を生成します:
../cfssl gencert -initca ca-csr.json | ../cfssljson -bare ca
APIサーバーの鍵と証明書を生成するためのJSON設定ファイル、例えばserver-csr.jsonを作成します。
山括弧内の値は、必ず使用したい実際の値に置き換えてください。
MASTER_CLUSTER_IPは、前のサブセクションで説明したように、APIサーバーのサービスクラスターのIPです。
また、以下のサンプルでは、デフォルトのDNSドメイン名としてcluster.localを使用することを想定しています。
{
"CN" : "kubernetes" ,
"hosts" : [
"127.0.0.1" ,
"<MASTER_IP>" ,
"<MASTER_CLUSTER_IP>" ,
"kubernetes" ,
"kubernetes.default" ,
"kubernetes.default.svc" ,
"kubernetes.default.svc.cluster" ,
"kubernetes.default.svc.cluster.local"
],
"key" : {
"algo" : "rsa" ,
"size" : 2048
},
"names" : [{
"C" : "<country>" ,
"ST" : "<state>" ,
"L" : "<city>" ,
"O" : "<organization>" ,
"OU" : "<organization unit>"
}]
}
APIサーバーの鍵と証明書を生成します。
デフォルトでは、それぞれserver-key.pemとserver.pemというファイルに保存されます:
../cfssl gencert -ca= ca.pem -ca-key= ca-key.pem \
= ca-config.json -profile= kubernetes \
自己署名入りCA証明書を配布する クライアントノードが自己署名入りCA証明書を有効なものとして認識できない場合があります。
非プロダクション環境、または会社のファイアウォールの内側での開発環境であれば、自己署名入りCA証明書をすべてのクライアントに配布し、有効な証明書のローカルリストを更新することができます。
各クライアントで、次の操作を実行します:
sudo cp ca.crt /usr/local/share/ca-certificates/kubernetes.crt
sudo update-ca-certificates
Updating certificates in /etc/ssl/certs...
1 added, 0 removed; done.
Running hooks in /etc/ca-certificates/update.d....
done.
証明書API 認証に使用するx509証明書のプロビジョニングにはcertificates.k8s.ioAPIを使用することができます。クラスターでのTLSの管理 に記述されています。
4.2.4 - メモリー、CPU、APIリソースの管理 4.2.4.1 - ネームスペースのデフォルトのメモリー要求と制限を設定する ネームスペースのデフォルトのメモリーリソース制限を定義して、そのネームスペース内のすべての新しいPodにメモリーリソース制限が設定されるようにします。
このページでは、ネームスペース のデフォルトのメモリー要求と制限を設定する方法を説明します。
Kubernetesクラスターはネームスペースに分割することができます。デフォルトのメモリー制限 を持つネームスペースがあり、独自のメモリー制限を指定しないコンテナでPodを作成しようとすると、コントロールプレーン はそのコンテナにデフォルトのメモリー制限を割り当てます。
Kubernetesは、このトピックで後ほど説明する特定の条件下で、デフォルトのメモリー要求を割り当てます。
始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
クラスターにネームスペースを作成するには、アクセス権が必要です。
クラスターの各ノードには、最低でも2GiBのメモリーが必要です。
ネームスペースの作成 この演習で作成したリソースがクラスターの他の部分から分離されるように、ネームスペースを作成します。
kubectl create namespace default-mem-example
LimitRangeとPodの作成 以下は、LimitRange のマニフェストの例です。このマニフェストでは、デフォルトのメモリー要求とデフォルトのメモリー制限を指定しています。
apiVersion : v1
kind : LimitRange
metadata :
name : mem-limit-range
spec :
limits :
- default :
memory : 512Mi
defaultRequest :
memory : 256Mi
type : Container
default-mem-exampleネームスペースにLimitRangeを作成します:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults.yaml --namespace= default-mem-example
default-mem-exampleネームスペースでPodを作成し、そのPod内のコンテナがメモリー要求とメモリー制限の値を独自に指定しない場合、コントロールプレーン はデフォルト値のメモリー要求256MiBとメモリー制限512MiBを適用します。
以下は、コンテナを1つ持つPodのマニフェストの例です。コンテナは、メモリー要求とメモリー制限を指定していません。
apiVersion : v1
kind : Pod
metadata :
name : default-mem-demo
spec :
containers :
- name : default-mem-demo-ctr
image : nginx
Podを作成します:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod.yaml --namespace= default-mem-example
Podの詳細情報を表示します:
kubectl get pod default-mem-demo --output= yaml --namespace= default-mem-example
この出力は、Podのコンテナのメモリー要求が256MiBで、メモリー制限が512MiBであることを示しています。
これらはLimitRangeで指定されたデフォルト値です。
containers:
- image: nginx
imagePullPolicy: Always
name: default-mem-demo-ctr
resources:
limits:
memory: 512Mi
requests:
memory: 256Mi
Podを削除します:
kubectl delete pod default-mem-demo --namespace= default-mem-example
コンテナの制限を指定し、要求を指定しない場合 以下は1つのコンテナを持つPodのマニフェストです。コンテナはメモリー制限を指定しますが、メモリー要求は指定しません。
apiVersion : v1
kind : Pod
metadata :
name : default-mem-demo-2
spec :
containers :
- name : default-mem-demo-2-ctr
image : nginx
resources :
limits :
memory : "1Gi"
Podを作成します:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod-2.yaml --namespace= default-mem-example
Podの詳細情報を表示します:
kubectl get pod default-mem-demo-2 --output= yaml --namespace= default-mem-example
この出力は、コンテナのメモリー要求がそのメモリー制限に一致するように設定されていることを示しています。
コンテナにはデフォルトのメモリー要求値である256Miが割り当てられていないことに注意してください。
resources:
limits:
memory: 1Gi
requests:
memory: 1Gi
コンテナの要求を指定し、制限を指定しない場合 1つのコンテナを持つPodのマニフェストです。コンテナはメモリー要求を指定しますが、メモリー制限は指定しません。
apiVersion : v1
kind : Pod
metadata :
name : default-mem-demo-3
spec :
containers :
- name : default-mem-demo-3-ctr
image : nginx
resources :
requests :
memory : "128Mi"
Podを作成します:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod-3.yaml --namespace= default-mem-example
Podの詳細情報を表示します:
kubectl get pod default-mem-demo-3 --output= yaml --namespace= default-mem-example
この出力は、コンテナのメモリー要求が、コンテナのマニフェストで指定された値に設定されていることを示しています。
コンテナは512MiB以下のメモリーを使用するように制限されていて、これはネームスペースのデフォルトのメモリー制限と一致します。
resources:
limits:
memory: 512Mi
requests:
memory: 128Mi
デフォルトのメモリー制限と要求の動機 ネームスペースにメモリーリソースクォータ が設定されている場合、メモリー制限のデフォルト値を設定しておくと便利です。
以下はリソースクォータがネームスペースに課す制限のうちの2つです。
ネームスペースで実行されるすべてのPodについて、Podとその各コンテナにメモリー制限を設ける必要があります(Pod内のすべてのコンテナに対してメモリー制限を指定すると、Kubernetesはそのコンテナの制限を合計することでPodレベルのメモリー制限を推測することができます)。 メモリー制限は、当該Podがスケジュールされているノードのリソース予約を適用します。ネームスペース内のすべてのPodに対して予約されるメモリーの総量は、指定された制限を超えてはなりません。 また、ネームスペース内のすべてのPodが実際に使用するメモリーの総量も、指定された制限を超えてはなりません。 LimitRangeの追加時:
コンテナを含む、そのネームスペース内のいずれかのPodが独自のメモリー制限を指定していない場合、コントロールプレーンはそのコンテナにデフォルトのメモリー制限を適用し、メモリーのResourceQuotaによって制限されているネームスペース内でPodを実行できるようにします。
クリーンアップ ネームスペースを削除します:
kubectl delete namespace default-mem-example
次の項目 クラスター管理者向け アプリケーション開発者向け 4.2.4.2 - Namespaceに対する最小および最大メモリー制約の構成 このページでは、Namespaceで実行されるコンテナが使用するメモリーの最小値と最大値を設定する方法を説明します。
LimitRange で最小値と最大値のメモリー値を指定します。
PodがLimitRangeによって課される制約を満たさない場合、そのNamespaceではPodを作成できません。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
クラスター内の各ノードには、少なくとも1GiBのメモリーが必要です。
Namespaceの作成 この演習で作成したリソースがクラスターの他の部分から分離されるように、Namespaceを作成します。
kubectl create namespace constraints-mem-example
LimitRangeとPodを作成 LimitRangeの設定ファイルです。
apiVersion : v1
kind : LimitRange
metadata :
name : mem-min-max-demo-lr
spec :
limits :
- max :
memory : 1Gi
min :
memory : 500Mi
type : Container
LimitRangeを作成します。
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints.yaml --namespace= constraints-mem-example
LimitRangeの詳細情報を表示します。
kubectl get limitrange mem-min-max-demo-lr --namespace= constraints-mem-example --output= yaml
出力されるのは、予想通りメモリー制約の最小値と最大値を示しています。
しかし、LimitRangeの設定ファイルでデフォルト値を指定していないにもかかわらず、
自動的に作成されていることに気づきます。
limits:
- default:
memory: 1Gi
defaultRequest:
memory: 1Gi
max:
memory: 1Gi
min:
memory: 500Mi
type: Container
constraints-mem-exampleNamespaceにコンテナが作成されるたびに、
Kubernetesは以下の手順を実行するようになっています。
コンテナが独自のメモリー要求と制限を指定しない場合は、デフォルトのメモリー要求と制限をコンテナに割り当てます。
コンテナに500MiB以上のメモリー要求があることを確認します。
コンテナのメモリー制限が1GiB以下であることを確認します。
以下は、1つのコンテナを持つPodの設定ファイルです。設定ファイルのコンテナ(containers)では、600MiBのメモリー要求と800MiBのメモリー制限が指定されています。これらはLimitRangeによって課される最小と最大のメモリー制約を満たしています。
apiVersion : v1
kind : Pod
metadata :
name : constraints-mem-demo
spec :
containers :
- name : constraints-mem-demo-ctr
image : nginx
resources :
limits :
memory : "800Mi"
requests :
memory : "600Mi"
Podの作成
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod.yaml --namespace= constraints-mem-example
Podのコンテナが実行されていることを確認します。
kubectl get pod constraints-mem-demo --namespace= constraints-mem-example
Podの詳細情報を見ます
kubectl get pod constraints-mem-demo --output= yaml --namespace= constraints-mem-example
出力は、コンテナが600MiBのメモリ要求と800MiBのメモリー制限になっていることを示しています。これらはLimitRangeによって課される制約を満たしています。
resources :
limits :
memory : 800Mi
requests :
memory : 600Mi
Podを消します。
kubectl delete pod constraints-mem-demo --namespace= constraints-mem-example
最大メモリ制約を超えるPodの作成の試み これは、1つのコンテナを持つPodの設定ファイルです。コンテナは800MiBのメモリー要求と1.5GiBのメモリー制限を指定しています。
apiVersion : v1
kind : Pod
metadata :
name : constraints-mem-demo-2
spec :
containers :
- name : constraints-mem-demo-2-ctr
image : nginx
resources :
limits :
memory : "1.5Gi"
requests :
memory : "800Mi"
Podを作成してみます。
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-2.yaml --namespace= constraints-mem-example
出力は、コンテナが大きすぎるメモリー制限を指定しているため、Podが作成されないことを示しています。
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-2.yaml":
pods "constraints-mem-demo-2" is forbidden: maximum memory usage per Container is 1Gi, but limit is 1536Mi.
最低限のメモリ要求を満たさないPodの作成の試み これは、1つのコンテナを持つPodの設定ファイルです。コンテナは100MiBのメモリー要求と800MiBのメモリー制限を指定しています。
apiVersion : v1
kind : Pod
metadata :
name : constraints-mem-demo-3
spec :
containers :
- name : constraints-mem-demo-3-ctr
image : nginx
resources :
limits :
memory : "800Mi"
requests :
memory : "100Mi"
Podを作成してみます。
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-3.yaml --namespace= constraints-mem-example
出力は、コンテナが小さすぎるメモリー要求を指定しているため、Podが作成されないことを示しています。
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-3.yaml":
pods "constraints-mem-demo-3" is forbidden: minimum memory usage per Container is 500Mi, but request is 100Mi.
メモリ要求や制限を指定しないPodの作成 これは、1つのコンテナを持つPodの設定ファイルです。コンテナはメモリー要求を指定しておらず、メモリー制限も指定していません。
apiVersion : v1
kind : Pod
metadata :
name : constraints-mem-demo-4
spec :
containers :
- name : constraints-mem-demo-4-ctr
image : nginx
Podを作成します。
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-4.yaml --namespace= constraints-mem-example
Podの詳細情報を見ます
kubectl get pod constraints-mem-demo-4 --namespace=constraints-mem-example --output=yaml
出力を見ると、Podのコンテナのメモリ要求は1GiB、メモリー制限は1GiBであることがわかります。
コンテナはどのようにしてこれらの値を取得したのでしょうか?
resources:
limits:
memory: 1Gi
requests:
memory: 1Gi
コンテナが独自のメモリー要求と制限を指定していなかったため、LimitRangeから与えられのです。
コンテナが独自のメモリー要求と制限を指定していなかったため、LimitRangeからデフォルトのメモリー要求と制限 が与えられたのです。
この時点で、コンテナは起動しているかもしれませんし、起動していないかもしれません。このタスクの前提条件は、ノードが少なくとも1GiBのメモリーを持っていることであることを思い出してください。それぞれのノードが1GiBのメモリーしか持っていない場合、どのノードにも1GiBのメモリー要求に対応するのに十分な割り当て可能なメモリーがありません。たまたま2GiBのメモリーを持つノードを使用しているのであれば、おそらく1GiBのメモリーリクエストに対応するのに十分なスペースを持っていることになります。
Podを削除します。
kubectl delete pod constraints-mem-demo-4 --namespace=constraints-mem-example
最小および最大メモリー制約の強制 LimitRangeによってNamespaceに課される最大および最小のメモリー制約は、Podが作成または更新されたときにのみ適用されます。LimitRangeを変更しても、以前に作成されたPodには影響しません。
最小・最大メモリー制約の動機 クラスター管理者としては、Podが使用できるメモリー量に制限を課したいと思うかもしれません。
例:
クラスター内の各ノードは2GBのメモリーを持っています。クラスター内のどのノードもその要求をサポートできないため、2GB以上のメモリーを要求するPodは受け入れたくありません。
クラスターは運用部門と開発部門で共有されています。 本番用のワークロードでは最大8GBのメモリーを消費しますが、開発用のワークロードでは512MBに制限したいとします。本番用と開発用に別々のNamespaceを作成し、それぞれのNamespaceにメモリー制限を適用します。
クリーンアップ Namespaceを削除します。
kubectl delete namespace constraints-mem-example
次の項目 クラスター管理者向け アプリケーション開発者向け
4.2.5 - ネットワークポリシープロバイダーのインストール 4.2.6 - Kubernetes APIを使用してクラスターにアクセスする このページでは、Kubernetes APIを使用してクラスターにアクセスする方法を説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
Kubernetes APIへのアクセス kubectlを使用した初回アクセス Kubernetes APIに初めてアクセスする際は、Kubernetesコマンドラインツールのkubectlを使用します。
クラスターにアクセスするには、クラスターのロケーションを知り、アクセス用の認証情報が必要です。
通常、これははじめに を進めていく中で自動的に設定されるか、他の誰かがクラスターをセットアップしてあなたに認証情報とロケーションを提供してくれます。
このコマンドで、kubectlが認識しているロケーションと認証情報を確認できます:
多くの例 でkubectlの使用方法について紹介しています。
完全なドキュメントはkubectlマニュアル にあります。
REST APIへの直接アクセス kubectlはAPIサーバーの特定と認証を扱います。
curlやwgetなどのHTTPクライアント、またはブラウザでREST APIに直接アクセスしたい場合は、APIサーバーを特定して認証する方法がいくつかあります:
kubectlをプロキシモードで実行する(推奨)。
この方法は、保存されたAPIサーバーのロケーションを使用し、自己署名証明書を使用してAPIサーバーを検証するため、推奨されます。
この方法では中間者攻撃(MITM)は不可能です。 あるいは、ロケーションと認証情報をHTTPクライアントに直接提供することもできます。
これはプロキシに混乱するクライアントコードで機能します。
中間者攻撃から保護するには、ブラウザにルート証明書をインポートする必要があります。 GoまたはPythonのクライアントライブラリを使用すると、プロキシモードでkubectlにアクセスできます。
kubectl proxyの使用 次のコマンドは、kubectlをリバースプロキシとして動作するモードで実行します。
APIサーバーの特定と認証を扱います。
次のように実行します:
kubectl proxy --port= 8080 &
詳細については、kubectl proxy を参照してください。
その後、curl、wget、またはブラウザでAPIを探索できます。次のように:
curl http://localhost:8080/api/
出力は次のとおりです:
{
"versions" : [
"v1"
],
"serverAddressByClientCIDRs" : [
{
"clientCIDR" : "0.0.0.0/0" ,
"serverAddress" : "10.0.1.149:443"
}
]
}
kubectl proxyを使用しない 認証トークンをAPIサーバーに直接渡すことで、kubectl proxyの使用を避けることが可能です。
次のように:
grep/cutアプローチを使用:
# .KUBECONFIGが複数コンテキストを含む可能性があるため、接続可能なすべてのクラスターをチェックする
kubectl config view -o jsonpath = '{"Cluster name\tServer\n"}{range .clusters[*]}{.name}{"\t"}{.cluster.server}{"\n"}{end}'
# 上記出力結果から接続したいクラスター名を選択する:
export CLUSTER_NAME = "some_server_name"
# クラスター名を参照してAPIサーバーを指定する
APISERVER = $( kubectl config view -o jsonpath = "{.clusters[?(@.name==\" $CLUSTER_NAME \")].cluster.server}" )
# デフォルトのService Accountのトークンを保持するSecretを作成する
kubectl apply -f - <<EOF
apiVersion: v1
kind: Secret
metadata:
name: default-token
annotations:
kubernetes.io/service-account.name: default
type: kubernetes.io/service-account-token
EOF
# トークンコントローラーがSecretを追加するまで待つ:
while ! kubectl describe secret default-token | grep -E '^token' >/dev/null; do
echo "waiting for token..." >&2
sleep 1
done
# トークンの値を取得する
TOKEN = $( kubectl get secret default-token -o jsonpath = '{.data.token}' | base64 --decode)
# TOKENを利用してAPIを調査する
curl -X GET $APISERVER /api --header "Authorization: Bearer $TOKEN " --insecure
出力結果は次のとおりです:
{
"kind" : "APIVersions" ,
"versions" : [
"v1"
],
"serverAddressByClientCIDRs" : [
{
"clientCIDR" : "0.0.0.0/0" ,
"serverAddress" : "10.0.1.149:443"
}
]
}
上記の例では--insecureフラグを使用しています。
これは、MITM攻撃を受ける可能性があります。
kubectlがクラスターにアクセスする際は、保存されたルート証明書とクライアント証明書を使用してサーバーにアクセスします(これらは~/.kubeディレクトリにインストールされています)。
クラスター証明書は通常自己署名されているため、HTTPクライアントにルート証明書を使用させるには特別な設定が必要な場合があります。
一部のクラスターでは、APIサーバーは認証を必要としません。
localhostで提供される場合や、ファイアウォールで保護されている場合などです。
このように、認証を必要としない構成を行うための標準的な方法はありません。
Kubernetes APIへのアクセスコントロール では、クラスター管理者としてこれを設定する方法を説明しています。
APIへのプログラムによるアクセス Kubernetesは、公式にGo 、Python 、Java 、dotnet 、JavaScript 、Haskell のクライアントライブラリをサポートしています。
Kubernetesチームではなく、それぞれのライブラリの作成者によって提供および保守されている他のクライアントライブラリもあります。
他の言語からAPIにアクセスする方法と認証方法については、クライアントライブラリ を参照してください。
Goクライアント
備考: client-goは独自のAPIオブジェクトを定義しているため、必要に応じて、メインリポジトリではなくclient-goからAPI定義をインポートしてください。
例えば、import "k8s.io/client-go/kubernetes"が正しいです。Goクライアントは、kubectl CLIと同じkubeconfigファイル を使用して、APIサーバーを特定し、認証できます。
この例 を参照してください:
package main
import (
"context"
"fmt"
"k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/tools/clientcmd"
)
func main () {
// kubeconfigのcurrent contextを使用する
// path-to-kubeconfig -- 例として /root/.kube/config
:= clientcmd.BuildConfigFromFlags ("" , "<path-to-kubeconfig>" )
// creates the clientset
:= kubernetes.NewForConfig (config)
// Podを一覧するためにAPIにアクセスする
:= clientset.CoreV1 ().Pods ("" ).List (context.TODO (), v1.ListOptions{})
fmt.Printf ("There are %d pods in the cluster\n" , len (pods.Items))
}
もしアプリケーションがクラスター内のPodとしてデプロイされているのであれば、Pod内からAPIにアクセスする を参照してください。
Pythonクライアント Pythonクライアント を使用するには、次のコマンドを実行します:
pip install kubernetes。
その他のインストールオプションについては、Pythonクライアントライブラリページ を参照してください。
Pythonクライアントは、kubectl CLIと同じkubeconfigファイル を使用して、APIサーバーを特定し、認証できます。
この例 を参照してください:
from kubernetes import client, config
config. load_kube_config()
v1= client. CoreV1Api()
print ("Listing pods with their IPs:" )
ret = v1. list_pod_for_all_namespaces(watch= False )
for i in ret. items:
print (" %s \t %s \t %s " % (i. status. pod_ip, i. metadata. namespace, i. metadata. name))
Javaクライアント Javaクライアント をインストールするには、次を実行します:
# Clone java library
git clone --recursive https://github.com/kubernetes-client/java
# Installing project artifacts, POM etc:
cd java
mvn install
サポートされているバージョンについては、https://github.com/kubernetes-client/java/releases を参照してください。
Javaクライアントは、kubectl CLIと同じkubeconfigファイル を使用して、APIサーバーを特定し、認証できます。
この例 を参照してください:
package io.kubernetes.client.examples ;
import io.kubernetes.client.ApiClient ;
import io.kubernetes.client.ApiException ;
import io.kubernetes.client.Configuration ;
import io.kubernetes.client.apis.CoreV1Api ;
import io.kubernetes.client.models.V1Pod ;
import io.kubernetes.client.models.V1PodList ;
import io.kubernetes.client.util.ClientBuilder ;
import io.kubernetes.client.util.KubeConfig ;
import java.io.FileReader ;
import java.io.IOException ;
/**
* Kubernetesクラスター外のアプリケーションからJava APIを利用する簡単な例
*
* <p>最も簡単に実行する方法: mvn exec:java
* -Dexec.mainClass="io.kubernetes.client.examples.KubeConfigFileClientExample"
*
*/
public class KubeConfigFileClientExample {
public static void main (String[] args) throws IOException, ApiException {
// KubeConfigへのファイルパス
String kubeConfigPath = "~/.kube/config" ;
// クラスター外の設定(ファイルシステム上のkubeconfig)を読み込む
ApiClient client =
ClientBuilder.kubeconfig (KubeConfig.loadKubeConfig (new FileReader(kubeConfigPath))).build ();
// 上記のクラスター内api-clientをグローバル標準api-clientに設定する
Configuration.setDefaultApiClient (client);
// the CoreV1Api loads default api-client from global configuration.
// CoreV1Apiはグローバル設定から標準のapi-clientを読み込む
CoreV1Api api = new CoreV1Api();
// CoreV1Api clientを呼び出す
V1PodList list = api.listPodForAllNamespaces (null , null , null , null , null , null , null , null , null );
System.out .println ("Listing all pods: " );
for (V1Pod item : list.getItems ()) {
System.out .println (item.getMetadata ().getName ());
}
}
dotnetクライアント dotnetクライアント を使用するには、次のコマンドを実行します: dotnet add package KubernetesClient --version 1.6.1。
その他のインストールオプションについては、dotnetクライアントライブラリページ を参照してください。
サポートされているバージョンについては、https://github.com/kubernetes-client/csharp/releases を参照してください。
dotnetクライアントは、kubectl CLIと同じkubeconfigファイル を使用して、APIサーバーを特定し、認証できます。
この例 を参照してください:
using System ;
using k8s ;
namespace simple
{
internal class PodList
{
private static void Main(string [] args)
{
var config = KubernetesClientConfiguration.BuildDefaultConfig();
IKubernetes client = new Kubernetes(config);
Console.WriteLine("Starting Request!" );
var list = client.ListNamespacedPod("default" );
foreach (var item in list.Items)
{
Console.WriteLine(item.Metadata.Name);
}
if (list.Items.Count == 0 )
{
Console.WriteLine("Empty!" );
}
}
}
}
JavaScriptクライアント JavaScriptクライアント をインストールするには、次のコマンドを実行します: npm install @kubernetes/client-node。
サポートされているバージョンについては、https://github.com/kubernetes-client/javascript/releases を参照してください。
JavaScriptクライアントは、kubectl CLIと同じkubeconfigファイル を使用して、APIサーバーを特定し、認証できます。
この例 を参照してください:
const k8s = require('@kubernetes/client-node' );
const kc = new k8s.KubeConfig();
kc.loadFromDefault();
const k8sApi = kc.makeApiClient(k8s.CoreV1Api);
k8sApi.listNamespacedPod({ namespace: 'default' }).then((res) => {
console.log(res);
});
Haskellクライアント サポートされているバージョンについては、https://github.com/kubernetes-client/haskell/releases を参照してください。
Haskellクライアント は、kubectl CLIと同じkubeconfigファイル を使用して、APIサーバーを特定し、認証できます。
この例 を参照してください:
exampleWithKubeConfig :: IO ()
exampleWithKubeConfig = do
oidcCache <- atomically $ newTVar $ Map . fromList []
(mgr, kcfg) <- mkKubeClientConfig oidcCache $ KubeConfigFile "/path/to/kubeconfig"
dispatchMime
mgr
kcfg
(CoreV1 . listPodForAllNamespaces (Accept MimeJSON ))
>>= print
次の項目 4.2.7 - フィーチャーゲートの有効化または無効化 このページでは、フィーチャーゲートを有効化また無効化して、クラスター内でKubernetesの特定の機能を制御する方法を説明します。
フィーチャーゲートを有効化することで、一般提供される前にアルファまたはベータ機能をテストおよび使用できます。
備考: 一部の安定版(GA)ゲートについては、通常はGA後の1つのマイナーリリースでのみ無効化することもできます。
ただし、その場合はクラスターがKubernetesに準拠しなくなる可能性があります。始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
以下も必要です:
備考: GA(安定版)機能は常にデフォルトで有効化されています。
通常、ゲートはアルファまたはベータ機能に対して設定します。フィーチャーゲートの成熟度を理解する フィーチャーゲートを有効化する前に、フィーチャーゲートのリファレンス で機能の成熟度レベルを確認してください:
アルファ : デフォルトでは無効化されており、バグを含む可能性があります。
テストクラスターでのみ使用してください。ベータ : デフォルトでは通常有効化されており、十分にテストされています。GA : デフォルトでは常に有効化されています。
GA後の1つのリリースまでは無効化できる場合があります。フィーチャーゲートを必要とするコンポーネントの特定 フィーチャーゲートごとに、影響を受けるKubernetesコンポーネントは異なります:
一部の機能は、複数のコンポーネント でゲートを有効化する必要があります(例: APIサーバーとコントローラーマネージャー) 他の機能は、単一のコンポーネント のみでゲートを必要とします(例: kubeletのみ) フィーチャーゲートのリファレンス は通常、各ゲートによって影響を受けるコンポーネントを示しています。
すべてのKubernetesコンポーネントは同じフィーチャーゲート定義を共有しているため、すべてのゲートがヘルプ出力に表示されますが、各コンポーネントの動作に影響を与えるのは関連するゲートのみです。
設定 クラスター初期化中 関連するコンポーネント全体でフィーチャーゲートを有効化するための構成ファイルを作成します:
apiVersion : kubeadm.k8s.io/v1beta4
kind : ClusterConfiguration
apiServer :
extraArgs :
feature-gates : "FeatureName=true"
controllerManager :
extraArgs :
feature-gates : "FeatureName=true"
scheduler :
extraArgs :
feature-gates : "FeatureName=true"
---
apiVersion : kubelet.config.k8s.io/v1beta1
kind : KubeletConfiguration
featureGates :
FeatureName : true
クラスターを初期化します:
kubeadm init --config kubeadm-config.yaml
既存のクラスター kubeadmクラスターの場合、フィーチャーゲートの設定はマニフェストファイル、構成ファイル、kubeadm設定など複数の場所で行うことができます。
/etc/kubernetes/manifests/内のコントロールプレーンコンポーネントのマニフェストを編集します:
kube-apiserver、kube-controller-manager、またはkube-schedulerの場合、コマンドにフラグを追加します:
spec :
containers :
- command :
- kube-apiserver
- --feature-gates=FeatureName=true
# ... other flags
ファイルを保存します。
Podは自動的に再起動します。
kubeletの場合、/var/lib/kubelet/config.yamlを編集します:
apiVersion : kubelet.config.k8s.io/v1beta1
kind : KubeletConfiguration
featureGates :
FeatureName : true
kubeletを再起動します:
sudo systemctl restart kubelet
kube-proxyの場合、ConfigMapを編集します:
kubectl -n kube-system edit configmap kube-proxy
設定にフィーチャーゲートを追加します:
featureGates :
FeatureName : true
DaemonSetを再起動します:
kubectl -n kube-system rollout restart daemonset kube-proxy
コマンドラインのフラグに、カンマ区切りのリストを使用します:
--feature-gates= FeatureA = true,FeatureB= false,FeatureC= true
構成ファイルをサポートするコンポーネント(kubelet、kube-proxy)の場合:
featureGates :
FeatureA : true
FeatureB : false
FeatureC : true
備考: kubeadmクラスターの場合、コントロールプレーンのコンポーネント(kube-apiserver、kube-controller-manager、kube-scheduler)は通常、/etc/kubernetes/manifests/にある静的Podマニフェスト内のコマンドラインフラグを介して構成されます。
これらのコンポーネントは--configフラグを介して構成ファイルをサポートしていますが、kubeadmは主にコマンドラインフラグを使用します。フィーチャーゲート設定の確認 設定後、フィーチャーゲートがアクティブであることを確認します。
以下の方法は、コントロールプレーンのコンポーネントが静的Podとして実行されるkubeadmクラスターに適用されます。
コントロールプレーンコンポーネントのマニフェストを確認する 静的Podマニフェストで設定されたフィーチャーゲートを表示します:
kubectl -n kube-system get pod kube-apiserver-<node-name> -o yaml | grep feature-gates
kubeletの設定を確認する kubeletのconfigzエンドポイントを使用します:
kubectl proxy --port= 8001 &
curl -sSL "http://localhost:8001/api/v1/nodes/<node-name>/proxy/configz" | grep featureGates -A 5
もしくは、ノード上で直接構成ファイルを確認します:
cat /var/lib/kubelet/config.yaml | grep -A 10 featureGates
メトリクスエンドポイントを介して確認する フィーチャーゲートのステータスは、KubernetesコンポーネントによってPrometheusスタイルのメトリクスで公開されます(利用可能なのはKubernetes 1.26以降)。
メトリクスエンドポイントをクエリして、どのフィーチャーゲートが有効になっているかを確認します:
kubectl get --raw /metrics | grep kubernetes_feature_enabled
特定のフィーチャーゲートを確認するには:
kubectl get --raw /metrics | grep kubernetes_feature_enabled | grep FeatureName
メトリクスは、有効なゲートには1、無効なゲートには0を表示します。
備考: kubeadmクラスターでは、フィーチャーゲートが構成される可能性のあるすべての関連場所を確認してください。
設定は複数のファイルと場所に分散しています。/flagzエンドポイントで確認する コンポーネントのデバッグエンドポイントにアクセスでき、ComponentFlagzフィーチャーゲートがそのコンポーネントで有効化されている場合、/flagzエンドポイントにアクセスしてコンポーネントの起動に使用されたコマンドラインフラグを検査できます。
コマンドラインフラグを使用して構成されたフィーチャーゲートは、この出力に表示されます。
/flagzエンドポイントは、Kubernetesのz-pages の一部であり、人間が読みやすい形式でコアコンポーネントのランタイムデバッグ情報を提供します。
より詳しくは、z-pagesのドキュメント を参照してください。
コンポーネント固有の要件の理解 コンポーネント固有のフィーチャーゲートの例:
APIサーバー向け : StructuredAuthenticationConfigurationのような機能は主にkube-apiserverに影響しますKubelet向け : GracefulNodeShutdownのような機能は主にkubeletに影響します複数コンポーネント : 一部の機能では、コンポーネント間の調整が必要です
注意: ある機能が複数のコンポーネントを必要とする場合、関連するすべてのコンポーネントでゲートを有効化する必要があります。
一部のコンポーネントでのみ有効化すると、予期しない動作やエラーが発生する可能性があります。フィーチャーゲートは必ず本番環境以外の環境で最初にテストしてください。
アルファ機能は予告なしに削除される可能性があります。
次の項目 4.2.8 - 拡張リソースをNodeにアドバタイズする このページでは、Nodeに対して拡張リソースを指定する方法を説明します。拡張リソースを利用すると、Kubernetesにとって未知のノードレベルのリソースをクラスター管理者がアドバタイズできるようになります。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
Nodeの名前を取得する この練習で使いたいNodeを1つ選んでください。
Nodeの1つで新しい拡張リソースをアドバタイズする Node上の新しい拡張リソースをアドバタイズするには、HTTPのPATCHリクエストをKubernetes APIサーバーに送ります。たとえば、Nodeの1つに4つのドングルが接続されているとします。以下に、4つのドングルリソースをNodeにアドバタイズするPATCHリクエストの例を示します。
PATCH /api/v1/nodes/<選択したNodeの名前>/status HTTP/1.1
Accept: application/json
Content-Type: application/json-patch+json
Host: k8s-master:8080
[
{
"op" : "add" ,
"path" : "/status/capacity/example.com~1dongle" ,
"value" : "4"
}
]
Kubernetesは、ドングルとは何かも、ドングルが何に利用できるのかを知る必要もないことに注意してください。上のPATCHリクエストは、ただNodeが4つのドングルと呼ばれるものを持っているとKubernetesに教えているだけです。
Kubernetes APIサーバーに簡単にリクエストを送れるように、プロキシを実行します。
もう1つのコマンドウィンドウを開き、HTTPのPATCHリクエストを送ります。<選択したNodeの名前>の部分は、選択したNodeの名前に置き換えてください。
curl --header "Content-Type: application/json-patch+json" \
\
'[{"op": "add", "path": "/status/capacity/example.com~1dongle", "value": "4"}]' \
備考: 上のリクエストにある
~1は、PATCHのパスにおける
/という文字をエンコーディングしたものです。JSON-Patch内のoperationのpathはJSON-Pointerとして解釈されます。詳細については、
IETF RFC 6901 のsection 3を読んでください。
出力には、Nodeがキャパシティー4のdongleを持っていることが示されます。
"capacity": {
"cpu": "2",
"memory": "2049008Ki",
"example.com/dongle": "4",
Nodeの説明を確認します。
kubectl describe node <選択したNodeの名前>
出力には、再びdongleリソースが表示されます。
Capacity :
cpu : 2
memory : 2049008Ki
example.com/dongle : 4
これで、アプリケーション開発者は特定の数のdongleをリクエストするPodを作成できるようになりました。詳しくは、拡張リソースをコンテナに割り当てる を読んでください。
議論 拡張リソースは、メモリやCPUリソースと同様のものです。たとえば、Nodeが持っている特定の量のメモリやCPUがNode上で動作している他のすべてのコンポーネントと共有されるのと同様に、Nodeが搭載している特定の数のdongleが他のすべてのコンポーネントと共有されます。そして、アプリケーション開発者が特定の量のメモリとCPUをリクエストするPodを作成できるのと同様に、Nodeが搭載している特定の数のdongleをリクエストするPodが作成できます。
拡張リソースはKubernetesには詳細を意図的に公開しないため、Kubernetesは拡張リソースの実体をまったく知りません。Kubernetesが知っているのは、Nodeが特定の数の拡張リソースを持っているということだけです。拡張リソースは整数値でアドバタイズしなければなりません。たとえば、Nodeは4つのdongleをアドバタイズできますが、4.5のdongleというのはアドバタイズできません。
Storageの例 Nodeに800GiBの特殊なディスクストレージがあるとします。この特殊なストレージの名前、たとえばexample.com/special-storageという名前の拡張リソースが作れます。そして、そのなかの一定のサイズ、たとえば100GiBのチャンクをアドバタイズできます。この場合、Nodeはexample.com/special-storageという種類のキャパシティ8のリソースを持っているとアドバタイズします。
Capacity :
...
example.com/special-storage : 8
特殊なストレージに任意のサイズのリクエストを許可したい場合、特殊なストレージを1バイトのサイズのチャンクでアドバタイズできます。その場合、example.com/special-storageという種類の800Giのリソースとしてアドバタイズします。
Capacity :
...
example.com/special-storage : 800Gi
すると、コンテナは好きなバイト数の特殊なストレージを最大800Giまでリクエストできるようになります。
クリーンアップ 以下に、dongleのアドバタイズをNodeから削除するPATCHリクエストを示します。
PATCH /api/v1/nodes/<選択したNodeの名前>/status HTTP/1.1
Accept: application/json
Content-Type: application/json-patch+json
Host: k8s-master:8080
[
{
"op": "remove",
"path": "/status/capacity/example.com~1dongle",
}
]
Kubernetes APIサーバーに簡単にリクエストを送れるように、プロキシを実行します。
もう1つのコマンドウィンドウで、HTTPのPATCHリクエストを送ります。<選択したNodeの名前>の部分は、選択したNodeの名前に置き換えてください。
curl --header "Content-Type: application/json-patch+json" \
\
'[{"op": "remove", "path": "/status/capacity/example.com~1dongle"}]' \
dongleのアドバタイズが削除されたことを検証します。
kubectl describe node <選択したNodeの名前> | grep dongle
(出力には何も表示されないはずです)
次の項目 アプリケーション開発者向け クラスター管理者向け 4.2.9 - クラスター内のDNSサービスのオートスケール このページでは、KubernetesクラスターでDNSサービスのオートスケールを有効にし、設定する方法を説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
このガイドでは、ノードがAMD64またはIntel 64のCPUアーキテクチャを使用していることを前提としています。
Kubernetes DNS が有効になっていることを確認してください。
DNS水平オートスケールがすでに有効になっているかどうかの確認 kube-system名前空間 内のクラスターのDeployment を一覧表示します:
kubectl get deployment --namespace= kube-system
出力は次のようになります:
NAME READY UP-TO-DATE AVAILABLE AGE
...
kube-dns-autoscaler 1/1 1 1 ...
...
出力に「kube-dns-autoscaler」が表示されている場合、DNS水平オートスケールはすでに有効になっています。
オートスケーリングパラメーターの調整 にスキップしても問題ありません。
DNS Deploymentの名前を取得する kube-system名前空間内のクラスターのDNS Deploymentを一覧表示します:
kubectl get deployment -l k8s-app= kube-dns --namespace= kube-system
出力は次のようになります:
NAME READY UP-TO-DATE AVAILABLE AGE
...
coredns 2/2 2 2 ...
...
DNSサービスのDeploymentが表示されない場合は、名前で検索することもできます:
kubectl get deployment --namespace= kube-system
そして、corednsまたはkube-dnsという名前のDeploymentを探します。
スケール対象は
Deployment/<your-deployment-name>
となります。
ここで、<your-deployment-name>はDNS Deploymentの名前です。
たとえば、DNS Deploymentの名前がcorednsの場合、スケール対象はDeployment/corednsになります。
備考: CoreDNSはKubernetesのデフォルトDNSサービスです。
CoreDNSは、もともとkube-dnsを使用していたクラスターでも動作できるように、k8s-app=kube-dnsというラベルを設定しています。DNS水平オートスケールを有効にする このセクションでは、新しいDeploymentを作成します。
Deployment内のPodは、cluster-proportional-autoscaler-amd64イメージに基づくコンテナを実行します。
次の内容でdns-horizontal-autoscaler.yamlという名前のファイルを作成します:
kind : ServiceAccount
apiVersion : v1
metadata :
name : kube-dns-autoscaler
namespace : kube-system
---
kind : ClusterRole
apiVersion : rbac.authorization.k8s.io/v1
metadata :
name : system:kube-dns-autoscaler
rules :
- apiGroups : ["" ]
resources : ["nodes" ]
verbs : ["list" , "watch" ]
- apiGroups : ["" ]
resources : ["replicationcontrollers/scale" ]
verbs : ["get" , "update" ]
- apiGroups : ["apps" ]
resources : ["deployments/scale" , "replicasets/scale" ]
verbs : ["get" , "update" ]
# Remove the configmaps rule once below issue is fixed:
# kubernetes-incubator/cluster-proportional-autoscaler#16
- apiGroups : ["" ]
resources : ["configmaps" ]
verbs : ["get" , "create" ]
---
kind : ClusterRoleBinding
apiVersion : rbac.authorization.k8s.io/v1
metadata :
name : system:kube-dns-autoscaler
subjects :
- kind : ServiceAccount
name : kube-dns-autoscaler
namespace : kube-system
roleRef :
kind : ClusterRole
name : system:kube-dns-autoscaler
apiGroup : rbac.authorization.k8s.io
---
apiVersion : apps/v1
kind : Deployment
metadata :
name : kube-dns-autoscaler
namespace : kube-system
labels :
k8s-app : kube-dns-autoscaler
kubernetes.io/cluster-service : "true"
spec :
selector :
matchLabels :
k8s-app : kube-dns-autoscaler
template :
metadata :
labels :
k8s-app : kube-dns-autoscaler
spec :
priorityClassName : system-cluster-critical
securityContext :
seccompProfile :
type : RuntimeDefault
supplementalGroups : [ 65534 ]
fsGroup : 65534
nodeSelector :
kubernetes.io/os : linux
containers :
- name : autoscaler
image : registry.k8s.io/cpa/cluster-proportional-autoscaler:1.8.4
resources :
requests :
cpu : "20m"
memory : "10Mi"
command :
- /cluster-proportional-autoscaler
- --namespace=kube-system
- --configmap=kube-dns-autoscaler
# Should keep target in sync with cluster/addons/dns/kube-dns.yaml.base
- --target=<SCALE_TARGET>
# When cluster is using large nodes(with more cores), "coresPerReplica" should dominate.
# If using small nodes, "nodesPerReplica" should dominate.
- --default-params={"linear":{"coresPerReplica":256,"nodesPerReplica":16,"preventSinglePointFailure":true,"includeUnschedulableNodes":true}}
- --logtostderr=true
- --v=2
tolerations :
- key : "CriticalAddonsOnly"
operator : "Exists"
serviceAccountName : kube-dns-autoscaler
ファイル内で、<SCALE_TARGET>をスケール対象に置き換えます。
設定ファイルがあるディレクトリに移動し、次のコマンドを入力してDeploymentを作成します:
kubectl apply -f dns-horizontal-autoscaler.yaml
コマンドが成功した場合の出力は次のようになります:
deployment.apps/kube-dns-autoscaler created
DNS水平オートスケールが有効になりました。
DNSオートスケーリングパラメーターを調整する kube-dns-autoscaler ConfigMap が存在することを確認します:
kubectl get configmap --namespace= kube-system
出力は次のようになります:
NAME DATA AGE
...
kube-dns-autoscaler 1 ...
...
ConfigMap内のデータを変更します:
kubectl edit configmap kube-dns-autoscaler --namespace= kube-system
次の行を探します:
linear : '{"coresPerReplica":256,"min":1,"nodesPerReplica":16}'
ニーズに応じてフィールドを変更します。
「min」フィールドは、DNSバックエンドの最小数を示します。
実際のバックエンド数は次の式を使用して計算されます:
replicas = max( ceil( cores × 1/coresPerReplica ) , ceil( nodes × 1/nodesPerReplica ) )
coresPerReplicaとnodesPerReplicaの値はどちらも浮動小数点数であることに注意してください。
クラスターで多くのコアを持つノードが使用されている場合はcoresPerReplicaが支配的になります。
クラスターでコアが少ないノードが使用されている場合はnodesPerReplicaが支配的になります。
他にもサポートされているスケーリングパターンがあります。
詳細は、cluster-proportional-autoscaler を参照してください。
DNS水平オートスケールを無効にする DNS水平オートスケールを調整するためのオプションはいくつかあります。
どのオプションを使用するかは、さまざまな条件によって異なります。
オプション1: kube-dns-autoscaler Deploymentを0レプリカにスケールダウンする このオプションはすべての状況で機能します。
次のコマンドを入力します:
kubectl scale deployment --replicas= 0 kube-dns-autoscaler --namespace= kube-system
出力は次のようになります:
deployment.apps/kube-dns-autoscaler scaled
レプリカ数がゼロであることを確認します:
kubectl get rs --namespace= kube-system
出力のDESIRED列とCURRENT列に0が表示されます:
NAME DESIRED CURRENT READY AGE
...
kube-dns-autoscaler-6b59789fc8 0 0 0 ...
...
オプション2: kube-dns-autoscaler Deploymentを削除する このオプションは、kube-dns-autoscalerが自身の管理下にある場合、つまり誰も再作成しない場合に機能します:
kubectl delete deployment kube-dns-autoscaler --namespace= kube-system
出力は次のようになります:
deployment.apps "kube-dns-autoscaler" deleted
オプション3: マスターノードからkube-dns-autoscalerマニフェストファイルを削除する このオプションは、kube-dns-autoscalerが(非推奨の)Addon Manager の管理下にあり、マスターノードへの書き込みアクセス権がある場合に機能します。
マスターノードにサインインし、対応するマニフェストファイルを削除します。
このkube-dns-autoscalerの一般的なパスは次のとおりです:
/etc/kubernetes/addons/dns-horizontal-autoscaler/dns-horizontal-autoscaler.yaml
マニフェストファイルが削除されると、Addon Managerはkube-dns-autoscaler Deploymentを削除します。
DNS水平オートスケールの仕組みを理解する cluster-proportional-autoscalerアプリケーションは、DNSサービスとは別にデプロイされます。
オートスケーラーPodは、クラスター内のノード数とコア数についてKubernetes APIサーバーをポーリングするクライアントを実行します。
現在のスケジュール可能なノードとコア、および指定されたスケーリングパラメーターに基づいて、必要なレプリカ数が計算され、DNSバックエンドに適用されます。
スケーリングパラメーターとデータポイントはConfigMapを介してオートスケーラーに提供され、最新の目的のスケーリングパラメーターで最新の状態を維持するために、ポーリング間隔ごとにパラメーターテーブルを更新します。
スケーリングパラメーターへの変更は、オートスケーラーPodを再構築または再起動することなく許可されます。
オートスケーラーは、linear とladder の2つの制御パターンをサポートするコントローラーインターフェースを提供します。
次の項目 4.2.10 - デフォルトのStorageClassを変更する このページでは、特別な要件を持たないPersistentVolumeClaimのボリュームをプロビジョニングするために使用される、デフォルトのStorage Classを変更する方法を示します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
なぜデフォルトのストレージクラスを変更するのか? インストール方法によっては、Kubernetesクラスターがデフォルトとしてマークされた既存のStorageClassと共にデプロイされる場合があります。
このデフォルトのStorageClassは、特定のストレージクラスを必要としないPersistentVolumeClaimのストレージを動的にプロビジョニングするために使用されます。
詳細はPersistentVolumeClaimのドキュメント を参照してください。
プリインストールされたデフォルトのStorageClassは、想定されるワークロードに適合しない場合があります。
たとえば、高価すぎるストレージをプロビジョニングする可能性があります。
このような場合、デフォルトのStorageClassを変更するか、ストレージの動的プロビジョニングを回避するために完全に無効にすることができます。
デフォルトのStorageClassを削除しても、機能しない場合があります。
クラスター内で実行されているアドオンマネージャーによって自動的に再作成される可能性があるためです。
アドオンマネージャーと個々のアドオンを無効にする方法の詳細については、インストールのドキュメントを参照してください。
デフォルトのStorageClassを変更する クラスター内のStorageClassをリストします:
出力は次のようになります:
NAME PROVISIONER AGE
standard ( default) kubernetes.io/gce-pd 1d
gold kubernetes.io/gce-pd 1d
デフォルトのStorageClassは(default)でマークされています。
デフォルトのStorageClassを非デフォルトとしてマークします:
デフォルトのStorageClassには、storageclass.kubernetes.io/is-default-classアノテーションがtrueに設定されています。
その他の値やアノテーションの欠如はfalseとして解釈されます。
StorageClassを非デフォルトとしてマークするには、その値をfalseに変更する必要があります:
kubectl patch storageclass standard -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'
ここで、standardは選択したStorageClassの名前です。
StorageClassをデフォルトとしてマークします:
前のステップと同様に、アノテーションstorageclass.kubernetes.io/is-default-class=trueを追加/設定する必要があります。
kubectl patch storageclass gold -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
複数のStorageClassをデフォルトとしてマークできることに注意してください。
複数のStorageClassがデフォルトとしてマークされている場合、storageClassNameが明示的に定義されていないPersistentVolumeClaimは、最も新しく作成されたデフォルトのStorageClassを使用して作成されます。
PersistentVolumeClaimが指定されたvolumeNameで作成された場合、静的ボリュームのstorageClassNameがPersistentVolumeClaimのStorageClassと一致しないと、保留状態のままになります。
選択したStorageClassがデフォルトであることを確認します:
出力は次のようになります:
NAME PROVISIONER AGE
standard kubernetes.io/gce-pd 1d
gold ( default) kubernetes.io/gce-pd 1d
次の項目 4.2.11 - クラウドコントローラーマネージャーの運用管理 FEATURE STATE:
Kubernetes v1.11 [beta]
クラウドプロバイダーはKubernetesプロジェクトとは異なるペースで開発およびリリースされるため、プロバイダー固有のコードを`cloud-controller-manager` バイナリに抽象化することでクラウドベンダーはKubernetesのコアのコードとは独立して開発が可能となりました。
cloud-controller-managerは、cloudprovider.Interface を満たす任意のクラウドプロバイダーと接続できます。下位互換性のためにKubernetesのコアプロジェクトで提供されるcloud-controller-manager はkube-controller-managerと同じクラウドライブラリを使用します。Kubernetesのコアリポジトリですでにサポートされているクラウドプロバイダーは、Kubernetesリポジトリにあるcloud-controller-managerを使用してKubernetesのコアから移行することが期待されています。
運用 要件 すべてのクラウドには動作させるためにそれぞれのクラウドプロバイダーの統合を行う独自の要件があり、kube-controller-managerを実行する場合の要件とそれほど違わないようにする必要があります。一般的な経験則として、以下のものが必要です。
クラウドの認証/認可: クラウドではAPIへのアクセスを許可するためにトークンまたはIAMルールが必要になる場合があります kubernetesの認証/認可: cloud-controller-managerは、kubernetes apiserverと通信するためにRBACルールの設定を必要とする場合があります 高可用性: kube-controller-managerのように、リーダー選出を使用したクラウドコントローラーマネージャーの高可用性のセットアップが必要になる場合があります(デフォルトでオンになっています)。 cloud-controller-managerを動かす cloud-controller-managerを正常に実行するにはクラスター構成にいくつかの変更が必要です。
kube-apiserverとkube-controller-managerは**--cloud-providerフラグを指定してはいけません**。これによりクラウドコントローラーマネージャーによって実行されるクラウド固有のループが実行されなくなります。将来このフラグは非推奨になり削除される予定です。kubeletは--cloud-provider=externalで実行する必要があります。これは作業をスケジュールする前にクラウドコントローラーマネージャーによって初期化する必要があることをkubeletが認識できるようにするためです。クラウドコントローラーマネージャーを使用するようにクラスターを設定するとクラスターの動作がいくつか変わることに注意してください。
--cloud-provider=externalを指定したkubeletは、初期化時にNoScheduleのnode.cloudprovider.kubernetes.io/uninitializedTaintを追加します。これによりノードは作業をスケジュールする前に外部のコントローラーからの2回目の初期化が必要であるとマークされます。クラウドコントローラーマネージャーが使用できない場合クラスター内の新しいノードはスケジュールできないままになることに注意してください。スケジューラーはリージョンやタイプ(高CPU、GPU、高メモリ、スポットインスタンスなど)などのノードに関するクラウド固有の情報を必要とする場合があるためこのTaintは重要です。クラスター内のノードに関するクラウド情報はローカルメタデータを使用して取得されなくなりましたが、代わりにノード情報を取得するためのすべてのAPI呼び出しはクラウドコントローラーマネージャーを経由して行われるようになります。これはセキュリティを向上させるためにkubeletでクラウドAPIへのアクセスを制限できることを意味します。大規模なクラスターではクラスター内からクラウドのほとんどすべてのAPI呼び出しを行うため、クラウドコントローラーマネージャーがレートリミットに達するかどうかを検討する必要があります。 クラウドコントローラーマネージャーは以下を実装できます。
ノードコントローラー - クラウドAPIを使用してkubernetesノードを更新し、クラウドで削除されたkubernetesノードを削除します。 サービスコントローラー - タイプLoadBalancerのサービスに対応してクラウド上のロードバランサーを操作します。 ルートコントローラー - クラウド上でネットワークルートを設定します。 Kubernetesリポジトリの外部にあるプロバイダーを実行している場合はその他の機能の実装。 例 現在Kubernetesのコアでサポートされているクラウドを使用していて、クラウドコントローラーマネージャーを利用する場合は、kubernetesのコアのクラウドコントローラーマネージャー を参照してください。
Kubernetesのコアリポジトリにないクラウドコントローラーマネージャーの場合、クラウドベンダーまたはsigリードが管理するリポジトリでプロジェクトを見つけることができます。
すでにKubernetesのコアリポジトリにあるプロバイダーの場合、クラスター内でデーモンセットとしてKubernetesリポジトリ内部のクラウドコントローラーマネージャーを実行できます。以下をガイドラインとして使用してください。
# This is an example of how to set up cloud-controller-manager as a Daemonset in your cluster.
# It assumes that your masters can run pods and has the role node-role.kubernetes.io/master
# Note that this Daemonset will not work straight out of the box for your cloud, this is
# meant to be a guideline.
---
apiVersion : v1
kind : ServiceAccount
metadata :
name : cloud-controller-manager
namespace : kube-system
---
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRoleBinding
metadata :
name : system:cloud-controller-manager
roleRef :
apiGroup : rbac.authorization.k8s.io
kind : ClusterRole
name : cluster-admin
subjects :
kind : ServiceAccount
name : cloud-controller-manager
namespace : kube-system
---
apiVersion : apps/v1
kind : DaemonSet
metadata :
labels :
k8s-app : cloud-controller-manager
name : cloud-controller-manager
namespace : kube-system
spec :
selector :
matchLabels :
k8s-app : cloud-controller-manager
template :
metadata :
labels :
k8s-app : cloud-controller-manager
spec :
serviceAccountName : cloud-controller-manager
containers :
- name : cloud-controller-manager
# for in-tree providers we use registry.k8s.io/cloud-controller-manager
# this can be replaced with any other image for out-of-tree providers
image : registry.k8s.io/cloud-controller-manager:v1.8.0
command :
- /usr/local/bin/cloud-controller-manager
- --cloud-provider=[YOUR_CLOUD_PROVIDER] # Add your own cloud provider here!
- --leader-elect=true
- --use-service-account-credentials
# these flags will vary for every cloud provider
- --allocate-node-cidrs=true
- --configure-cloud-routes=true
- --cluster-cidr=172.17.0.0/16
tolerations :
# this is required so CCM can bootstrap itself
- key : node.cloudprovider.kubernetes.io/uninitialized
value : "true"
effect : NoSchedule
# these tolerations are to have the daemonset runnable on control plane nodes
# remove them if your control plane nodes should not run pods
- key : node-role.kubernetes.io/control-plane
operator : Exists
effect : NoSchedule
- key : node-role.kubernetes.io/master
operator : Exists
effect : NoSchedule
# this is to restrict CCM to only run on master nodes
# the node selector may vary depending on your cluster setup
nodeSelector :
node-role.kubernetes.io/master : ""
制限 クラウドコントローラーマネージャーの実行にはいくつかの制限があります。これらの制限は今後のリリースで対処されますが、本番のワークロードにおいてはこれらの制限を認識することが重要です。
ボリュームのサポート ボリュームの統合にはkubeletとの調整も必要になるためクラウドコントローラーマネージャーはkube-controller-managerにあるボリュームコントローラーを実装しません。CSI(コンテナストレージインターフェース)が進化してFlexボリュームプラグインの強力なサポートが追加されるにつれ、クラウドがボリュームと完全に統合できるようクラウドコントローラーマネージャーに必要なサポートが追加されます。Kubernetesリポジトリの外部にあるCSIボリュームプラグインの詳細についてはこちら をご覧ください。
スケーラビリティ cloud-controller-managerは、クラウドプロバイダーのAPIにクエリーを送信して、すべてのノードの情報を取得します。非常に大きなクラスターの場合、リソース要件やAPIレートリミットなどのボトルネックの可能性を考慮する必要があります。
鶏と卵 クラウドコントローラーマネージャープロジェクトの目標はKubernetesのコアプロジェクトからクラウドに関する機能の開発を切り離すことです。残念ながら、Kubernetesプロジェクトの多くの面でクラウドプロバイダーの機能がKubernetesプロジェクトに緊密に結びついているという前提があります。そのため、この新しいアーキテクチャを採用するとクラウドプロバイダーの情報を要求する状況が発生する可能性がありますが、クラウドコントローラーマネージャーはクラウドプロバイダーへのリクエストが完了するまでその情報を返すことができない場合があります。
これの良い例は、KubeletのTLSブートストラップ機能です。TLSブートストラップはKubeletがすべてのアドレスタイプ(プライベート、パブリックなど)をクラウドプロバイダー(またはローカルメタデータサービス)に要求する能力を持っていると仮定していますが、クラウドコントローラーマネージャーは最初に初期化されない限りノードのアドレスタイプを設定できないためapiserverと通信するためにはkubeletにTLS証明書が必要です。
このイニシアチブが成熟するに連れ、今後のリリースでこれらの問題に対処するための変更が行われます。
次の項目 独自のクラウドコントローラーマネージャーを構築および開発するにはクラウドコントローラーマネージャーの開発 を参照してください。
4.2.12 - kubelet image credential providerの設定 FEATURE STATE:
Kubernetes v1.26 [stable]
Kubernetes v1.20以降、kubeletはexecプラグインを使用してコンテナイメージレジストリへの認証情報を動的に取得できるようになりました。
kubeletとexecプラグインは、Kubernetesのバージョン管理されたAPIを用いて標準入出力(stdin、stdout、stderr)を通じて通信します。
これらのプラグインを使用することで、kubeletはディスク上に静的な認証情報を保存する代わりに、コンテナレジストリへの認証情報を動的に要求できるようになります。
たとえば、プラグインがローカルのメタデータサーバーと通信し、kubeletが取得しようとしているイメージに対する、短期間有効な認証情報を取得することがあります。
以下のいずれかに該当する場合、この機能の利用を検討するとよいでしょう:
レジストリへの認証情報を取得するために、クラウドプロバイダーのサービスへのAPI呼び出しが必要である。 認証情報の有効期限が短く、頻繁に新しい認証情報の取得が必要である。 認証情報をディスク上やimagePullSecretsに保存することが許容されない。 このガイドでは、kubelet image credential providerプラグイン機構の設定方法について説明します。
イメージ取得用のServiceAccountトークン FEATURE STATE:
Kubernetes v1.34 [beta](enabled by default)
Kubernetes v1.33以降、kubeletは、イメージの取得を行っているPodにバインドされたサービスアカウントトークンを、credential providerプラグインに送信するように設定できます。
これにより、プラグインはそのトークンを使用して、イメージレジストリへのアクセスに必要な認証情報と交換することが可能になります。
この機能を有効化するには、kubeletでKubeletServiceAccountTokenForCredentialProvidersフィーチャーゲートを有効化し、プラグイン用のCredentialProviderConfigファイルでtokenAttributesフィールドを設定する必要があります。
tokenAttributesフィールドには、プラグインに渡されるサービスアカウントトークンに関する情報が含まれており、トークンの対象となるオーディエンスや、プラグインがPodにサービスアカウントを必要とするかどうかといった内容が指定されます。
サービスアカウントトークンによる認証情報を用いることで、次のようなユースケースに対応できます:
レジストリからイメージを取得するために、kubeletやノードに基づくアイデンティティを必要としないようにする 長期間有効なシークレットや永続的なシークレットを使用せずに、ワークロードが自身のランタイムのアイデンティティに基づいてイメージを取得できるようにする 始める前に kubelet credential providerプラグインをサポートするノードを持つKubernetesクラスターが必要です。このサポートは、Kubernetes 1.35で利用可能です。Kubernetes v1.24およびv1.25で、デフォルトで有効なベータ機能として含まれるようになりました。 サービスアカウントトークンを必要とするcredential providerプラグインを設定する場合は、Kubernetes v1.33以降を実行しているノードを持つクラスターと、kubelet上でKubeletServiceAccountTokenForCredentialProvidersフィーチャーゲートが有効になっている必要があります。 credential provider execプラグインの動作する実装。独自にプラグインを作成するか、クラウドプロバイダーが提供するものを使用できます。 作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.26.
バージョンを確認するには次のコマンドを実行してください: kubectl version.
ノードへのプラグインのインストール credential providerプラグインは、kubeletによって実行される実行可能バイナリです。
クラスター内のすべてのノードにこのプラグインバイナリが存在し、既知のディレクトリに配置されていることを確認してください。
このディレクトリは、後でkubeletのフラグを設定する際に必要です。
kubeletの設定 この機能を使用するには、kubeletに次の2つのフラグを設定する必要があります:
--image-credential-provider-config - credential providerプラグインの設定ファイルへのパス--image-credential-provider-bin-dir - credential providerプラグインのバイナリが配置されているディレクトリへのパスkubelet credential providerを設定する --image-credential-provider-configに指定された設定ファイルは、どのコンテナイメージに対してどのexecプラグインを呼び出すかを判断するためにkubeletによって読み込まれます。
以下は、ECRベースのプラグイン を使用する場合に利用される可能性がある設定ファイルの例です。
apiVersion : kubelet.config.k8s.io/v1
kind : CredentialProviderConfig
# providersは、kubeletによって有効化されるcredential provider補助プラグインのリストです。
# 単一のイメージに対して複数のプロバイダーが一致する場合、すべてのプロバイダーからの認証情報がkubeletに返されます。
# 単一のイメージに対して複数のプロバイダーが呼び出されると、結果は結合されます。
# 認証キーが重複する場合は、このリスト内で先に定義されたプロバイダーの値が使用されます。
providers :
# nameはcredential providerの名前で必須項目です。kubeletから見えるプロバイダーの実行可能ファイル名と一致している必要があります。
# 実行可能ファイルは、kubeletのbinディレクトリ(--image-credential-provider-bin-dirフラグで指定)内に存在しなければなりません。
- name : ecr-credential-provider
# matchImagesは必須の文字列リストで、イメージに対して一致判定を行い、
# このプロバイダーを呼び出すべきかどうかを判断するために使用されます。
# 指定された文字列のいずれか1つが、kubeletから要求されたイメージに一致した場合、
# プラグインが呼び出され、認証情報を提供する機会が与えられます。
# イメージには、レジストリのドメインおよびURLパスが含まれている必要があります。
#
# matchImagesの各エントリは、オプションでポートおよびパスを含むことができるパターンです。
# ドメインにはグロブを使用できますが、ポートやパスには使用できません。
# グロブは、'*.k8s.io'や'k8s.*.io'のようなサブドメインや、'k8s.*'のようなトップレベルドメインでサポートされています。
# 'app*.k8s.io'のような部分的なサブドメインの一致もサポートされています。
# 各グロブはサブドメインの1セグメントのみに一致するため、`*.io`は`*.k8s.io`には**一致しません**。
#
# イメージとmatchImageが一致すると見なされるのは、以下のすべての条件を満たす場合です:
# - 双方が同じ数のドメインパートを含み、各パートが一致していること
# - matchImagesに指定されたURLパスが、対象のイメージURLパスのプレフィックスであること
# - matchImagesにポートが含まれている場合、そのポートがイメージのポートにも一致すること
#
# matchImagesの値の例:
# - 123456789.dkr.ecr.us-east-1.amazonaws.com
# - *.azurecr.io
# - gcr.io
# - *.*.registry.io
# - registry.io:8080/path
matchImages :
- "*.dkr.ecr.*.amazonaws.com"
- "*.dkr.ecr.*.amazonaws.com.cn"
- "*.dkr.ecr-fips.*.amazonaws.com"
- "*.dkr.ecr.us-iso-east-1.c2s.ic.gov"
- "*.dkr.ecr.us-isob-east-1.sc2s.sgov.gov"
# defaultCacheDurationは、プラグインの応答にキャッシュ期間が指定されていない場合に、
# プラグインが認証情報をメモリ内でキャッシュするデフォルトの期間です。このフィールドは必須です。
defaultCacheDuration : "12h"
# exec CredentialProviderRequestの入力に必要なバージョンです。返されるCredentialProviderResponseは、
# 入力と同じエンコーディングバージョンを使用しなければなりません。現在サポートされている値は以下のとおりです:
# - credentialprovider.kubelet.k8s.io/v1
apiVersion : credentialprovider.kubelet.k8s.io/v1
# コマンドを実行する際に渡す引数です。
# +optional
# args:
# - --example-argument
# envは、プロセスに対して公開する追加の環境変数を定義します。
# これらはホストの環境変数および、client-goがプラグインに引数を渡すために使用する変数と結合されます。
# +optional
env :
- name : AWS_PROFILE
value : example_profile
# tokenAttributesは、プラグインに渡されるサービスアカウントトークンの設定です。
# このフィールドを設定することで、credential providerはイメージの取得にサービスアカウントトークンを使用するようになります。
# このフィールドが設定されているにも関わらず、`KubeletServiceAccountTokenForCredentialProviders`フィーチャーゲートが有効になっていない場合、
# kubeletは無効な設定エラーとして起動に失敗します。
# +optional
tokenAttributes :
# serviceAccountTokenAudienceは、投影されたサービスアカウントトークンの対象となるオーディエンスです。
# +required
serviceAccountTokenAudience : "<audience for the token>"
# requireServiceAccountは、プラグインがPodにサービスアカウントを必要とするかどうかを示します。
# trueに設定された場合、kubeletはPodにサービスアカウントがある場合にのみプラグインを呼び出します。
# falseに設定された場合、Podにサービスアカウントがなくてもkubeletはプラグインを呼び出し、
# CredentialProviderRequestにはトークンを含めません。これは、サービスアカウントを持たないPod
# (たとえば、Static Pod)に対してイメージを取得するためのプラグインに有用です。
# +required
requireServiceAccount : true
# requiredServiceAccountAnnotationKeysは、プラグインが対象とし、サービスアカウントに存在する必要があるアノテーションキーのリストです。
# このリストに定義されたキーは、対応するサービスアカウントから抽出され、CredentialProviderRequestの一部としてプラグインに渡されます。
# このリストに定義されたキーのいずれかがサービスアカウントに存在しない場合、kubeletはプラグインを呼び出さず、エラーを返します。
# このフィールドはオプションであり、空であっても構いません。プラグインはこのフィールドを使用して、
# 認証情報の取得に必要な追加情報を抽出したり、サービスアカウントトークンによるイメージ取得の利用を
# ワークロード側で選択可能にしたりできます。
# このフィールドが空でない場合、requireServiceAccountはtrueに設定されていなければなりません。
# このリストに定義されたキーは一意である必要があり、
# optionalServiceAccountAnnotationKeysリストに定義されたキーと重複してはいけません。
# +optional
requiredServiceAccountAnnotationKeys :
- "example.com/required-annotation-key-1"
- "example.com/required-annotation-key-2"
# optionalServiceAccountAnnotationKeysは、プラグインが対象とするアノテーションキーのリストで、
# サービスアカウントに存在していなくてもよいオプションの項目です。
# このリストに定義されたキーは、対応するサービスアカウントから抽出され、
# CredentialProviderRequestの一部としてプラグインに渡されます。
# アノテーションの存在や値の検証はプラグイン側の責任です。
# このフィールドはオプションであり、空でも構いません。
# プラグインはこのフィールドを使用して、認証情報の取得に必要な追加情報を抽出できます。
# このリストに定義されたキーは一意でなければならず、
# requiredServiceAccountAnnotationKeysリストに定義されたキーと重複してはいけません。
# +optional
optionalServiceAccountAnnotationKeys :
- "example.com/optional-annotation-key-1"
- "example.com/optional-annotation-key-2"
providersフィールドは、kubeletが使用する有効なプラグインのリストです。
各エントリには、いくつかの入力必須のフィールドがあります:
name: プラグインの名前であり、--image-credential-provider-bin-dirで指定されたディレクトリ内に存在する実行可能バイナリの名前と一致していなければなりません。matchImages: このプロバイダーを呼び出すべきかどうかを判断するために、イメージと照合するための文字列リスト。詳細は後述します。defaultCacheDuration: プラグインによってキャッシュ期間が指定されていない場合に、kubeletが認証情報をメモリ内にキャッシュするデフォルトの期間。apiVersion: kubeletとexecプラグインが通信時に使用するAPIバージョン。各credential providerには、オプションの引数や環境変数を指定することもできます。
特定のプラグインで必要となる引数や環境変数のセットについては、プラグインの実装者に確認してください。
KubeletServiceAccountTokenForCredentialProvidersフィーチャーゲートを使用し、tokenAttributesフィールドを設定してプラグインにサービスアカウントトークンを使用させる場合、以下のフィールドの設定が必須となります:
これは、サービスアカウントを持たないPod(たとえば、Static Pod)に対してイメージを取得するためのプラグインに有用です。
イメージのマッチングを設定する 各credential providerのmatchImagesフィールドは、Podが使用する特定のイメージに対してプラグインを呼び出すべきかどうかを、kubeletが判断するために使用されます。
matchImagesの各エントリはイメージパターンであり、オプションでポートやパスを含めることができます。
ドメインにはグロブを使用できますが、ポートやパスには使用できません。
グロブは、*.k8s.ioやk8s.*.ioのようなサブドメインや、k8s.*のようなトップレベルドメインで使用可能です。
app*.k8s.ioのような部分的なサブドメインの一致もサポートされています。
ただし、各グロブは1つのサブドメインセグメントにしか一致しないため、*.ioは*.k8s.ioには一致しません。
イメージ名とmatchImageエントリが一致すると見なされるのは、以下のすべての条件を満たす場合です:
両者が同じ数のドメインパートを持ち、それぞれのパートが一致していること。 イメージの一致条件として指定されたURLパスが、対象のイメージのURLパスのプレフィックスであること。 matchImagesにポートが含まれている場合、イメージのポートとも一致すること。 matchImagesパターンの値のいくつかの例:
123456789.dkr.ecr.us-east-1.amazonaws.com*.azurecr.iogcr.io*.*.registry.iofoo.registry.io:8080/path次の項目 4.2.13 - ノードのトポロジー管理ポリシーを制御する FEATURE STATE:
Kubernetes v1.18 [beta]
近年、CPUやハードウェア・アクセラレーターの組み合わせによって、レイテンシーが致命的となる実行や高いスループットを求められる並列計算をサポートするシステムが増えています。このようなシステムには、通信、科学技術計算、機械学習、金融サービス、データ分析などの分野のワークロードが含まれます。このようなハイブリッドシステムは、高い性能の環境で構成されます。
最高のパフォーマンスを引き出すために、CPUの分離やメモリーおよびデバイスの位置に関する最適化が求められます。しかしながら、Kubernetesでは、これらの最適化は分断されたコンポーネントによって処理されます。
トポロジーマネージャー はKubeletコンポーネントの1つで最適化の役割を担い、コンポーネント群を調和して機能させます。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.18.
バージョンを確認するには次のコマンドを実行してください: kubectl version.
トポロジーマネージャーはどのように機能するか トポロジーマネージャー導入前は、KubernetesにおいてCPUマネージャーやデバイスマネージャーはそれぞれ独立してリソースの割り当てを決定します。
これは、マルチソケットのシステムでは望ましくない割り当てとなり、パフォーマンスやレイテンシーが求められるアプリケーションは、この望ましくない割り当てに悩まされます。
この場合の望ましくない例として、CPUやデバイスが異なるNUMAノードに割り当てられ、それによりレイテンシー悪化を招くことが挙げられます。
トポロジーマネージャーはKubeletコンポーネントであり、信頼できる情報源として振舞います。それによって、他のKubeletコンポーネントはトポロジーに沿ったリソース割り当ての選択を行うことができます。
トポロジーマネージャーは Hint Providers と呼ばれるコンポーネントのインターフェースを提供し、トポロジー情報を送受信します。トポロジーマネージャーは、ノード単位のポリシー群を保持します。ポリシーについて以下で説明します。
トポロジーマネージャーは Hint Providers からトポロジー情報を受け取ります。トポロジー情報は、利用可能なNUMAノードと優先割り当て表示を示すビットマスクです。トポロジーマネージャーのポリシーは、提供されたヒントに対して一連の操作を行い、ポリシーに沿ってヒントをまとめて最適な結果を得ます。もし、望ましくないヒントが保存された場合、ヒントの優先フィールドがfalseに設定されます。現在のポリシーでは、最も狭い優先マスクが優先されます。
選択されたヒントはトポロジーマネージャーの一部として保存されます。設定されたポリシーにしたがい、選択されたヒントに基づいてノードがPodを許可したり、拒否することができます。
トポロジーマネージャーに保存されたヒントは、Hint Providers が使用しリソース割り当てを決定します。
トポロジーマネージャーの機能を有効にする トポロジーマネージャーをサポートするには、TopologyManager フィーチャーゲート を有効にする必要があります。Kubernetes 1.18ではデフォルトで有効です。
トポロジーマネージャーのスコープとポリシー トポロジーマネージャは現在:
全てのQoAクラスのPodを調整する Hint Providerによって提供されたトポロジーヒントから、要求されたリソースを調整する これらの条件が合致した場合、トポロジーマネージャーは要求されたリソースを調整します。
この調整をどのように実行するかカスタマイズするために、トポロジーマネージャーは2つのノブを提供します: スコープ とポリシーです。
スコープはリソースの配置を行う粒度を定義します(例:podやcontainer)。そして、ポリシーは調整を実行するための実戦略を定義します(best-effort, restricted, single-numa-node等)。
現在利用可能なスコープとポリシーの値について詳細は以下の通りです。
備考: PodのSpecにある他の要求リソースとCPUリソースを調整するために、CPUマネージャーを有効にし、適切なCPUマネージャーのポリシーがノードに設定されるべきです。
CPU管理ポリシー を参照してください。
備考: PodのSpecにある他の要求リソースとメモリー(およびhugepage)リソースを調整するために、メモリーマネージャーを有効にし、適切なメモリーマネージャーポリシーがノードに設定されるべきです。
メモリーマネージャー のドキュメントを確認してください。
トポロジーマネージャーのスコープ トポロジーマネージャーは、以下の複数の異なるスコープでリソースの調整を行う事が可能です:
いずれのオプションも、--topology-manager-scopeフラグによって、kubelet起動時に選択できます。
containerスコープ containerスコープはデフォルトで使用されます。
このスコープでは、トポロジーマネージャーは連続した複数のリソース調整を実行します。つまり、Pod内の各コンテナは、分離された配置計算がされます。言い換えると、このスコープでは、コンテナを特定のNUMAノードのセットにグループ化するという概念はありません。実際には、トポロジーマネージャーは各コンテナのNUMAノードへの配置を任意に実行します。
コンテナをグループ化するという概念は、以下のスコープで設定・実行されます。例えば、podスコープが挙げられます。
podスコープ podスコープを選択するには、コマンドラインで--topology-manager-scope=podオプションを指定してkubeletを起動します。
このスコープでは、Pod内全てのコンテナを共通のNUMAノードのセットにグループ化することができます。トポロジーマネージャーはPodをまとめて1つとして扱い、ポッド全体(全てのコンテナ)を単一のNUMAノードまたはNUMAノードの共通セットのいずれかに割り当てようとします。以下の例は、さまざまな場面でトポロジーマネージャーが実行する調整を示します:
全てのコンテナは、単一のNUMAノードに割り当てられます。 全てのコンテナは、共有されたNUMAノードのセットに割り当てられます。 Pod全体に要求される特定のリソースの総量は有効なリクエスト/リミット の式に従って計算されるため、この総量の値は以下の最大値となります。
全てのアプリケーションコンテナのリクエストの合計。 リソースに対するinitコンテナのリクエストの最大値。 podスコープとsingle-numa-nodeトポロジーマネージャーポリシーを併用することは、レイテンシーが重要なワークロードやIPCを行う高スループットのアプリケーションに対して特に有効です。両方のオプションを組み合わせることで、Pod内の全てのコンテナを単一のNUMAノードに配置できます。そのため、PodのNUMA間通信によるオーバーヘッドを排除することができます。
single-numa-nodeポリシーの場合、可能な割り当ての中に適切なNUMAノードのセットが存在する場合にのみ、Podが許可されます。上の例をもう一度考えてみましょう:
1つのNUMAノードのみを含むセット - Podが許可されます。 2つ以上のNUMAノードを含むセット - Podが拒否されます(1つのNUMAノードの代わりに、割り当てを満たすために2つ以上のNUMAノードが必要となるため)。 要約すると、トポロジーマネージャーはまずNUMAノードのセットを計算し、それをトポロジーマネージャーのポリシーと照合し、Podの拒否または許可を検証します。
トポロジーマネージャーのポリシー トポロジーマネージャーは4つの調整ポリシーをサポートします。--topology-manager-policyというKubeletフラグを通してポリシーを設定できます。
4つのサポートされるポリシーがあります:
none (デフォルト)best-effortrestrictedsingle-numa-node
備考: トポロジーマネージャーが pod スコープで設定された場合、コンテナはポリシーによって、Pod全体の要求として反映します。
したがって、Podの各コンテナは 同じ トポロジー調整と同じ結果となります。none ポリシー これはデフォルトのポリシーで、トポロジーの調整を実行しません。
best-effort ポリシー Pod内の各コンテナに対して、best-effort トポロジー管理ポリシーが設定されたkubeletは、各Hint Providerを呼び出してそれらのリソースの可用性を検出します。
トポロジーマネージャーはこの情報を使用し、そのコンテナの推奨されるNUMAノードのアフィニティーを保存します。アフィニティーが優先されない場合、トポロジーマネージャーはこれを保存し、Podをノードに許可します。
Hint Providers はこの情報を使ってリソースの割り当てを決定します。
restricted ポリシー Pod内の各コンテナに対して、restricted トポロジー管理ポリシーが設定されたkubeletは各Hint Providerを呼び出してそれらのリソースの可用性を検出します。
トポロジーマネージャーはこの情報を使用し、そのコンテナの推奨されるNUMAノードのアフィニティーを保存します。アフィニティーが優先されない場合、トポロジーマネージャーはPodをそのノードに割り当てることを拒否します。この結果、PodはPodの受付失敗となりTerminated 状態になります。
Podが一度Terminated状態になると、KubernetesスケジューラーはPodの再スケジューリングを試み ません 。Podの再デプロイをするためには、ReplicasetかDeploymenを使用してください。Topology Affinityエラーとなったpodを再デプロイするために、外部のコントロールループを実行することも可能です。
Podが許可されれば、 Hint Providers はこの情報を使ってリソースの割り当てを決定します。
single-numa-node ポリシー Pod内の各コンテナに対して、single-numa-nodeトポロジー管理ポリシーが設定されたkubeletは各Hint Prociderを呼び出してそれらのリソースの可用性を検出します。
トポロジーマネージャーはこの情報を使用し、単一のNUMAノードアフィニティが可能かどうか決定します。
可能な場合、トポロジーマネージャーは、この情報を保存し、Hint Providers はこの情報を使ってリソースの割り当てを決定します。
不可能な場合、トポロジーマネージャーは、Podをそのノードに割り当てることを拒否します。この結果、Pod は Pod の受付失敗となりTerminated状態になります。
Podが一度Terminated状態になると、KubernetesスケジューラーはPodの再スケジューリングを試みません 。Podの再デプロイをするためには、ReplicasetかDeploymentを使用してください。Topology Affinityエラーとなったpodを再デプロイするために、外部のコントロールループを実行することも可能です。
Podとトポロジー管理ポリシーの関係 以下のようなpodのSpecで定義されるコンテナを考えます:
spec :
containers :
- name : nginx
image : nginx
requestsもlimitsも定義されていないため、このPodはBestEffortQoSクラスで実行します。
spec :
containers :
- name : nginx
image : nginx
resources :
limits :
memory : "200Mi"
requests :
memory : "100Mi"
requestsがlimitsより小さい値のため、このPodはBurstableQoSクラスで実行します。
選択されたポリシーがnone以外の場合、トポロジーマネージャーは、これらのPodのSpecを考慮します。トポロジーマネージャーは、Hint Providersからトポロジーヒントを取得します。CPUマネージャーポリシーがstaticの場合、デフォルトのトポロジーヒントを返却します。これらのPodは明示的にCPUリソースを要求していないからです。
spec :
containers :
- name : nginx
image : nginx
resources :
limits :
memory : "200Mi"
cpu : "2"
example.com/device : "1"
requests :
memory : "200Mi"
cpu : "2"
example.com/device : "1"
整数値でCPUリクエストを指定されたこのPodは、requestsがlimitsが同じ値のため、GuaranteedQoSクラスで実行します。
spec :
containers :
- name : nginx
image : nginx
resources :
limits :
memory : "200Mi"
cpu : "300m"
example.com/device : "1"
requests :
memory : "200Mi"
cpu : "300m"
example.com/device : "1"
CPUの一部をリクエストで指定されたこのPodは、requestsがlimitsが同じ値のため、GuaranteedQoSクラスで実行します。
spec :
containers :
- name : nginx
image : nginx
resources :
limits :
example.com/deviceA : "1"
example.com/deviceB : "1"
requests :
example.com/deviceA : "1"
example.com/deviceB : "1"
CPUもメモリもリクエスト値がないため、このPodは BestEffort QoSクラスで実行します。
トポロジーマネージャーは、上記Podを考慮します。トポロジーマネージャーは、Hint ProvidersとなるCPUマネージャーとデバイスマネージャーに問い合わせ、トポロジーヒントを取得します。
整数値でCPU要求を指定されたGuaranteedQoSクラスのPodの場合、staticが設定されたCPUマネージャーポリシーは、排他的なCPUに関するトポロジーヒントを返却し、デバイスマネージャーは要求されたデバイスのヒントを返します。
CPUの一部を要求を指定されたGuaranteedQoSクラスのPodの場合、排他的ではないCPU要求のためstaticが設定されたCPUマネージャーポリシーはデフォルトのトポロジーヒントを返却します。デバイスマネージャーは要求されたデバイスのヒントを返します。
上記のGuaranteedQoSクラスのPodに関する2ケースでは、noneで設定されたCPUマネージャーポリシーは、デフォルトのトポロジーヒントを返却します。
BestEffortQoSクラスのPodの場合、staticが設定されたCPUマネージャーポリシーは、CPUの要求がないためデフォルトのトポロジーヒントを返却します。デバイスマネージャーは要求されたデバイスごとのヒントを返します。
トポロジーマネージャーはこの情報を使用してPodに最適なヒントを計算し保存します。保存されたヒントは Hint Providersが使用しリソースを割り当てます。
既知の制限 トポロジーマネージャーが許容するNUMAノードの最大値は8です。8より多いNUMAノードでは、可能なNUMAアフィニティを列挙しヒントを生成する際に、生成する状態数が爆発的に増加します。
スケジューラーはトポロジーを意識しません。そのため、ノードにスケジュールされた後に実行に失敗する可能性があります。
4.2.14 - ネットワークポリシーを宣言する このドキュメントでは、Pod同士の通信を制御するネットワークポリシーを定義するための、KubernetesのNetworkPolicy API を使い始める手助けをします。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.8.
バージョンを確認するには次のコマンドを実行してください: kubectl version.
ネットワークポリシーをサポートしているネットワークプロバイダーが設定済みであることを確認してください。さまざまなネットワークプロバイダーがNetworkPolicyをサポートしています。次に挙げるのは一例です。
備考: 上記のリストは製品名のアルファベット順にソートされていて、推奨順や好ましい順にソートされているわけではありません。このページの例は、Kubernetesクラスターでこれらのどのプロバイダーを使用していても有効です。nginx Deploymentを作成してService経由で公開するKubernetesのネットワークポリシーの仕組みを理解するために、まずはnginx Deploymentを作成することから始めましょう。
kubectl create deployment nginx --image=nginx
deployment.apps/nginx created
nginxという名前のService経由でDeploymentを公開します。
kubectl expose deployment nginx --port=80
service/nginx exposed
上記のコマンドを実行すると、nginx Podを持つDeploymentが作成され、そのDeploymentがnginxという名前のService経由で公開されます。nginxのPodおよびDeploymentはdefault名前空間の中にあります。
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes 10.100.0.1 <none> 443/TCP 46m
service/nginx 10.100.0.16 <none> 80/TCP 33s
NAME READY STATUS RESTARTS AGE
pod/nginx-701339712-e0qfq 1/1 Running 0 35s
もう1つのPodからアクセスしてServiceを検証する これで、新しいnginxサービスに他のPodからアクセスできるようになったはずです。default名前空間内の他のPodからnginx Serviceにアクセスするために、busyboxコンテナを起動します。
kubectl run busybox --rm -ti --image=busybox -- /bin/sh
シェルの中で、次のコマンドを実行します。
wget --spider --timeout= 1 nginx
Connecting to nginx (10.100.0.16:80)
remote file exists
nginx Serviceへのアクセスを制限するnginx Serviceへのアクセスを制限するために、access: trueというラベルが付いたPodだけがクエリできるようにします。次の内容でNetworkPolicyオブジェクトを作成してください。
apiVersion : networking.k8s.io/v1
kind : NetworkPolicy
metadata :
name : access-nginx
spec :
podSelector :
matchLabels :
app : nginx
ingress :
- from :
- podSelector :
matchLabels :
access : "true"
NetworkPolicyオブジェクトの名前は、有効なDNSサブドメイン名 でなければなりません。
備考: このNetworkPolicyには、ポリシーを適用するPodのグループを選択するためのpodSelectorが含まれています。このポリシーは、ラベルapp=nginxの付いたPodを選択していることがわかります。このラベルは、nginx Deployment内のPodに自動的に追加されたものです。空のpodSelectorは、その名前空間内のすべてのPodを選択します。Serviceにポリシーを割り当てる kubectlを使って、上記のnginx-policy.yamlファイルからNetworkPolicyを作成します。
kubectl apply -f https://k8s.io/examples/service/networking/nginx-policy.yaml
networkpolicy.networking.k8s.io/access-nginx created
accessラベルが定義されていない状態でServiceへのアクセスをテストする nginx Serviceに正しいラベルが付いていないPodからアクセスを試してみると、リクエストがタイムアウトします。
kubectl run busybox --rm -ti --image=busybox -- /bin/sh
シェルの中で、次のコマンドを実行します。
wget --spider --timeout= 1 nginx
Connecting to nginx (10.100.0.16:80)
wget: download timed out
accessラベルを定義して再テストする 正しいラベルが付いたPodを作成すると、リクエストが許可されるようになるのがわかります。
kubectl run busybox --rm -ti --labels="access=true" --image=busybox -- /bin/sh
シェルの中で、次のコマンドを実行します。
wget --spider --timeout= 1 nginx
Connecting to nginx (10.100.0.16:80)
remote file exists
4.2.15 - クラウドコントローラーマネージャーの開発
cloud-controller-managerは クラウド特有の制御ロジックを組み込むKubernetesのコントロールプレーン コンポーネントです。クラウドコントロールマネージャーは、クラスターをクラウドプロバイダーAPIとリンクし、クラスターのみで相互作用するコンポーネントからクラウドプラットフォームで相互作用するコンポーネントを分離します。
Kubernetesと基盤となるクラウドインフラストラクチャ間の相互運用ロジックを分離することで、クラウドプロバイダーはcloud-controller-managerコンポーネントにより、メインのKubernetesプロジェクトとは異なるペースで機能をリリースできるようになります。
背景 クラウドプロバイダーはKubernetesプロジェクトとは異なる速度で開発しリリースすることから、プロバイダー特有なコードをcloud-controller-managerバイナリから抽象化することで、クラウドベンダーはコアKubernetesコードから独立して発展することができます。
Kubernetesプロジェクトは、(クラウドプロバイダーの)独自実装を組み込めるGoインターフェースを備えたcloud-controller-managerのスケルトンコードを提供しています。これは、クラウドプロバイダーがKubernetesコアからパッケージをインポートすることでcloud-controller-managerを実装できることを意味します。各クラウドプロバイダーは利用可能なクラウドプロバイダーのグローバル変数を更新するためにcloudprovider.RegisterCloudProviderを呼び出し、独自のコードを登録します。
開発 Kubernetesには登録されていない独自クラウドプロバイダー Kubernetesには登録されていない独自のクラウドプロバイダーのクラウドコントローラーマネージャーを構築するには、
cloudprovider.Interface を満たす go パッケージを実装します。Kubernetesのコアにあるcloud-controller-managerのmain.go をあなたのmain.goのテンプレートとして利用します。上で述べたように、唯一の違いはインポートされるクラウドパッケージのみです。 クラウドパッケージを main.go にインポートし、パッケージに cloudprovider.RegisterCloudProviderinit ブロックがあることを確認します。 多くのクラウドプロバイダーはオープンソースとしてコントローラーマネージャーのコードを公開しています。新たにcloud-controller-managerをスクラッチから開発する際には、既存のKubernetesには登録されていない独自クラウドプロバイダーのコントローラーマネージャーを開始地点とすることができます。
Kubernetesに登録されているクラウドプロバイダー Kubernetesに登録されているクラウドプロバイダーであれば、DaemonSet を使ってあなたのクラスターで動かすことができます。詳細についてはKubernetesクラウドコントローラーマネージャー を参照してください。
4.2.16 - Kubernetes APIの有効化または無効化 このページでは、クラスターのコントロールプレーン から特定のAPIバージョンを有効化または無効化する方法について説明します。
特定のAPIバージョンは、APIサーバーのコマンドライン引数として--runtime-config=api/<version>を渡すことで有効化または無効化できます。
この引数の値はカンマ区切りのAPIバージョンのリストで、後に定義された値が前に定義された値を上書きします。
また、runtime-configコマンドライン引数は、以下の2つの特殊なキーもサポートしています:
api/all: すべての既知のAPIを表します。api/legacy: レガシーAPIのみを表します。
レガシーAPIとは、明示的に非推奨 とされたすべてのAPIを指します。例えば、v1以外のすべてのAPIバージョンを無効にするには、kube-apiserverに--runtime-config=api/all=false,api/v1=trueを渡します。
次の項目 kube-apiserverコンポーネントの完全なドキュメント を参照してください。
4.2.17 - 重要なアドオンPodに対するスケジューリングの保証 APIサーバー、スケジューラー、コントローラーマネージャーなどのKubernetesコアコンポーネントは、コントロールプレーンノード上で実行されます。
しかし、アドオンは通常のクラスターノード上で実行する必要があります。
これらのアドオンの中には、metrics-server、DNS、UIなど、クラスターが完全に機能するために重要なものがあります。
重要度の高いアドオンが退避させられ(手動で、またはアップグレードなどの他の操作の副作用として)、保留状態になった場合、クラスターは正常に動作しなくなる可能性があります(たとえば、クラスターの使用率が高く、退避させられた重要度の高いアドオンPodが空けたスペースに他の保留中のPodがスケジュールされる場合や、何らかの理由でノード上で利用可能なリソース量が変化した場合など)。
Podを重要度の高いものとして設定することは、退避を完全に防ぐことを意図しておらず、Podが永続的に利用不可能になることを防ぐだけであることに注意してください。
重要度の高いPodとして設定されたstatic Podは退避させられません。
ただし、重要度の高いPodとして設定された非static Podは常に再スケジュールされます。
重要度の高いPodとして設定する方法 Podを重要度の高いものとして設定するには、そのPodのpriorityClassNameをsystem-cluster-criticalまたはsystem-node-criticalに設定します。
system-node-criticalは、system-cluster-criticalの優先度よりもさらに高く、利用可能な優先度の中で最も高く設定されています。
4.2.18 - Kubernetes向けetcdクラスターの運用
etcdは 一貫性、高可用性を持ったキーバリューストアで、Kubernetesの全てのクラスター情報の保存場所として利用されています。
etcdをKubernetesのデータストアとして使用する場合、必ずデータのバックアップ プランを作成して下さい。
公式ドキュメント でetcdに関する詳細な情報を見つけることができます。
始める前に Kubernetesクラスターが必要で、kubectlコマンドラインツールがクラスターと通信できるように設定されている必要があります。
コントロールプレーンノード以外に少なくとも2つのノードを持つクラスターで、このガイドに従うことを推奨します。
まだクラスターを用意していない場合は、minikube を使用して作成することができます。
前提条件 etcdは、奇数のメンバーを持つクラスターとして実行します。
etcdはリーダーベースの分散システムです。リーダーが定期的に全てのフォロワーにハートビートを送信し、クラスターの安定性を維持するようにします。
リソース不足が発生しないようにします。
クラスターのパフォーマンスと安定性は、ネットワークとディスクのI/Oに敏感です。
リソース不足はハートビートのタイムアウトを引き起こし、クラスターの不安定化につながる可能性があります。
不安定なetcdは、リーダーが選出されていないことを意味します。
そのような状況では、クラスターは現在の状態に変更を加えることができません。
これは、新しいPodがスケジュールされないことを意味します。
Kubernetesクラスターの安定性には、etcdクラスターの安定性が不可欠です。
したがって、etcdクラスターは専用のマシンまたは保証されたリソース要件 を持つ隔離された環境で実行してください。
本番環境で実行するために推奨される最低限のetcdバージョンは、3.4.22以降あるいは3.5.6以降です。
リソース要件 限られたリソースでetcdを運用するのはテスト目的にのみ適しています。
本番環境へのデプロイには、高度なハードウェア構成が必要です。
本番環境へetcdをデプロイする前に、リソース要件 を確認してください。
ツール どの作業に取り組んでいるかにより、etcdctlツールまたはetcdutlツールが必要になります(両方必要になる場合もあります)。
etcdctlとetcdutlの理解 etcdctlとetcdutlはetcdクラスターと対話するために使用されるコマンドラインツールですが、それぞれ異なる目的を持っています。
etcdctl: これはネットワーク経由でetcdと対話するための主要なコマンドラインクライアントです。
キーと値の管理、クラスターの管理、ヘルスチェックなど、日常的な操作に使用されます。
etcdutl: これはetcdデータファイルに直接操作を行うための管理ユーティリティで、etcdバージョン間のデータ移行、データベースのデフラグ、スナップショットの復元、データ整合性の検証などを含みます。
ネットワーク経由の操作の場合は、etcdctlを使用すべきです。
etcdutlに関する詳細情報については、etcdリカバリのドキュメント を参照してください。
etcdクラスターの起動 このセクションでは、単一ノードおよびマルチノードetcdクラスターの起動について説明します。
単一ノードetcdクラスター 単一ノードetcdクラスターは、テスト目的でのみ使用してください。
以下を実行します:
etcd --listen-client-urls= http://$PRIVATE_IP :2379 \
= http://$PRIVATE_IP :2379
Kubernetes APIサーバーをフラグ--etcd-servers=$PRIVATE_IP:2379で起動します。
PRIVATE_IPがetcdクライアントIPに設定されていることを確認してください。
マルチノードetcdクラスター 耐久性と高可用性のために、本番環境ではマルチノードクラスターとしてetcdを実行し、定期的にバックアップを取ります。
本番環境では5つのメンバーによるクラスターが推奨されます。
詳細はFAQドキュメント を参照してください。
etcdクラスターは、静的なメンバー情報、または動的な検出によって構成されます。
クラスタリングに関する詳細は、etcdクラスタリングドキュメント を参照してください。
例として、次のクライアントURLで実行される5つのメンバーによるetcdクラスターを考えてみます。
5つのURLは、http://$IP1:2379、http://$IP2:2379、http://$IP3:2379、http://$IP4:2379、およびhttp://$IP5:2379です。Kubernetes APIサーバーを起動するには、
以下を実行します:
etcd --listen-client-urls= http://$IP1 :2379,http://$IP2 :2379,http://$IP3 :2379,http://$IP4 :2379,http://$IP5 :2379 --advertise-client-urls= http://$IP1 :2379,http://$IP2 :2379,http://$IP3 :2379,http://$IP4 :2379,http://$IP5 :2379
フラグ--etcd-servers=$IP1:2379,$IP2:2379,$IP3:2379,$IP4:2379,$IP5:2379を使ってKubernetes APIサーバーを起動します。
IP<n>変数がクライアントのIPアドレスに設定されていることを確認してください。
ロードバランサーを使用したマルチノードetcdクラスター ロードバランシングされたetcdクラスターを実行するには、次の手順に従います。
etcdクラスターを設定します。 etcdクラスターの前にロードバランサーを設定します。
例えば、ロードバランサーのアドレスを$LBとします。 フラグ--etcd-servers=$LB:2379を使ってKubernetes APIサーバーを起動します。 etcdクラスターのセキュリティ確保 etcdへのアクセスはクラスター内でのルート権限に相当するため、理想的にはAPIサーバーのみがアクセスできるようにするべきです。
データの機密性を考慮して、etcdクラスターへのアクセス権を必要とするノードのみに付与することが推奨されます。
etcdをセキュアにするためには、ファイアウォールのルールを設定するか、etcdによって提供されるセキュリティ機能を使用します。
etcdのセキュリティ機能はx509公開鍵基盤(PKI)に依存します。
この機能を使用するには、キーと証明書のペアを生成して、セキュアな通信チャンネルを確立します。
例えば、etcdメンバー間の通信をセキュアにするためにpeer.keyとpeer.certのキーペアを使用し、etcdとそのクライアント間の通信をセキュアにするためにclient.keyとclient.certを使用します。
クライアント認証用のキーペアとCAファイルを生成するには、etcdプロジェクトによって提供されているサンプルスクリプト を参照してください。
通信のセキュリティ確保 セキュアなピア通信を持つetcdを構成するためには、--peer-key-file=peer.keyおよび--peer-cert-file=peer.certフラグを指定し、URLスキーマとしてHTTPSを使用します。
同様に、セキュアなクライアント通信を持つetcdを構成するためには、--key-file=k8sclient.keyおよび--cert-file=k8sclient.certフラグを指定し、URLスキーマとしてHTTPSを使用します。
セキュアな通信を使用するクライアントコマンドの例は以下の通りです:
ETCDCTL_API=3 etcdctl --endpoints 10.2.0.9:2379 \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
member list
etcdクラスターへのアクセス制限 セキュアな通信を構成した後、TLS認証を使用して、etcdクラスターへのアクセスをKubernetes APIサーバーのみに制限します。
例えば、CA etcd.caによって信頼されるキーペアk8sclient.keyとk8sclient.certを考えてみます。
--client-cert-authとTLSを使用してetcdが構成されている場合、etcdは--trusted-ca-fileフラグで渡されたCAまたはシステムのCAを使用してクライアントからの証明書を検証します。
--client-cert-auth=trueおよび--trusted-ca-file=etcd.caフラグを指定することで、証明書k8sclient.certを持つクライアントのみにアクセスを制限します。
etcdが正しく構成されると、有効な証明書を持つクライアントのみがアクセスできます。
Kubernetes APIサーバーにアクセス権を与えるためには、--etcd-certfile=k8sclient.cert、--etcd-keyfile=k8sclient.keyおよび--etcd-cafile=ca.certフラグで構成します。
備考: etcd認証は、Kubernetesでは現在サポートされていません。障害が発生したetcdメンバーの交換 etcdクラスターは、一部のメンバーの障害を許容することで高可用性を実現します。
しかし、クラスターの全体的な状態を改善するためには、障害が発生したメンバーを直ちに交換することが重要です。
複数のメンバーに障害が発生した場合は、1つずつ交換します。
障害が発生したメンバーを交換するには、メンバーを削除し、新しいメンバーを追加するという2つのステップがあります。
etcdは内部でユニークなメンバーIDを保持していますが、人的なミスを避けるためにも各メンバーにはユニークな名前を使用することが推奨されます。
例えば、3つのメンバーのetcdクラスターを考えてみましょう。
URLがmember1=http://10.0.0.1、member2=http://10.0.0.2、そしてmember3=http://10.0.0.3だとします。
member1に障害が発生した場合、member4=http://10.0.0.4で交換します。
障害が発生したmember1のメンバーIDを取得します:
etcdctl --endpoints= http://10.0.0.2,http://10.0.0.3 member list
次のメッセージが表示されます:
8211f1d0f64f3269, started, member1, http://10.0.0.1:2380, http://10.0.0.1:2379
91bc3c398fb3c146, started, member2, http://10.0.0.2:2380, http://10.0.0.2:2379
fd422379fda50e48, started, member3, http://10.0.0.3:2380, http://10.0.0.3:2379
以下のいずれかを行います:
各Kubernetes APIサーバーが全てのetcdメンバーと通信するように構成されている場合、--etcd-serversフラグから障害が発生したメンバーを削除し、各Kubernetes APIサーバーを再起動します。 各Kubernetes APIサーバーが単一のetcdメンバーと通信している場合、障害が発生したetcdと通信しているKubernetes APIサーバーを停止します。 壊れたノード上のetcdサーバーを停止します。
Kubernetes APIサーバー以外のクライアントからetcdにトラフィックが流れている可能性があり、データディレクトリへの書き込みを防ぐためにすべてのトラフィックを停止することが望ましいです。
メンバーを削除します:
etcdctl member remove 8211f1d0f64f3269
次のメッセージが表示されます:
Removed member 8211f1d0f64f3269 from cluster
新しいメンバーを追加します:
etcdctl member add member4 --peer-urls= http://10.0.0.4:2380
次のメッセージが表示されます:
Member 2be1eb8f84b7f63e added to cluster ef37ad9dc622a7c4
IP 10.0.0.4のマシン上で新たに追加されたメンバーを起動します:
export ETCD_NAME = "member4"
export ETCD_INITIAL_CLUSTER = "member2=http://10.0.0.2:2380,member3=http://10.0.0.3:2380,member4=http://10.0.0.4:2380"
export ETCD_INITIAL_CLUSTER_STATE = existing
etcd [ flags]
以下のいずれかを行います:
各Kubernetes APIサーバーが全てのetcdメンバーと通信するように構成されている場合、--etcd-serversフラグに新たに追加されたメンバーを加え、各Kubernetes APIサーバーを再起動します。 各Kubernetes APIサーバーが単一のetcdメンバーと通信している場合、ステップ2で停止したKubernetes APIサーバーを起動します。
その後、Kubernetes APIサーバークライアントを再度構成して、停止されたKubernetes APIサーバーへのリクエストをルーティングします。
これは多くの場合、ロードバランサーを構成することで行われます。 クラスターの再構成に関する詳細については、etcd再構成ドキュメント を参照してください。
etcdクラスターのバックアップ すべてのKubernetesオブジェクトはetcdに保存されています。
定期的にetcdクラスターのデータをバックアップすることは、すべてのコントロールプレーンノードを失うなどの災害シナリオでKubernetesクラスターを復旧するために重要です。
スナップショットファイルには、すべてのKubernetesの状態と重要な情報が含まれています。
機密性の高いKubernetesデータを安全に保つために、スナップショットファイルを暗号化してください。
etcdクラスターのバックアップは、etcdのビルトインスナップショットとボリュームスナップショットの2つの方法で実現できます。
ビルトインスナップショット etcdはビルトインスナップショットをサポートしています。
スナップショットは、etcdctl snapshot saveコマンドを使用してライブメンバーから、あるいはetcdプロセスによって現在使用されていないデータディレクトリ からmember/snap/dbファイルをコピーして作成できます。
スナップショットを作成しても、メンバーのパフォーマンスに影響はありません。
以下は、$ENDPOINTによって提供されるキースペースのスナップショットをsnapshot.dbファイルに作成する例です:
ETCDCTL_API = 3 etcdctl --endpoints $ENDPOINT snapshot save snapshot.db
スナップショットを確認します:
ETCDCTL_API = 3 etcdctl --write-out= table snapshot status snapshot.db
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| fe01cf57 | 10 | 7 | 2.1 MB |
+----------+----------+------------+------------+
ボリュームスナップショット etcdがAmazon Elastic Block Storeのようなバックアップをサポートするストレージボリューム上で実行されている場合、ストレージボリュームのスナップショットを作成することによってetcdデータをバックアップします。
etcdctlオプションを使用したスナップショット etcdctlによって提供されるさまざまなオプションを使用してスナップショットを作成することもできます。例えば
はetcdctlから利用可能なさまざまなオプションを一覧表示します。
例えば、以下のようにエンドポイント、証明書、キーを指定してスナップショットを作成することができます:
ETCDCTL_API = 3 etcdctl --endpoints= https://127.0.0.1:2379 \
= <trusted-ca-file> --cert= <cert-file> --key= <key-file> \
ここで、trusted-ca-file、cert-file、key-fileはetcd Podの説明から取得できます。
etcdクラスターのスケールアウト etcdクラスターのスケールアウトは、パフォーマンスとのトレードオフで可用性を高めます。
スケーリングはクラスターのパフォーマンスや能力を高めるものではありません。
一般的なルールとして、etcdクラスターをスケールアウトまたはスケールインすることはありません。
etcdクラスターに自動スケーリンググループを設定しないでください。
公式にサポートされるどんなスケールの本番環境のKubernetesクラスターにおいても、常に静的な5つのメンバーのetcdクラスターを運用することを強く推奨します。
合理的なスケーリングは、より高い信頼性が求められる場合に、3つのメンバーで構成されるクラスターを5つのメンバーにアップグレードすることです。
既存のクラスターにメンバーを追加する方法については、etcdの再構成ドキュメント を参照してください。
etcdクラスターの復元 etcdは、major.minor バージョンのetcdプロセスから取得されたスナップショットからの復元をサポートしています。
異なるパッチバージョンのetcdからのバージョン復元もサポートされています。
復元操作は、障害が発生したクラスターのデータを回復するために用いられます。
復元操作を開始する前に、スナップショットファイルが存在している必要があります。
これは、以前のバックアップ操作からのスナップショットファイルでも、残っているデータディレクトリ からのスナップショットファイルでも構いません。
クラスターを復元する場合は、--data-dirオプションを使用して、クラスターをどのフォルダーに復元するかを指定します:
ETCDCTL_API = 3 etcdctl --data-dir <data-dir-location> snapshot restore snapshot.db
ここで、<data-dir-location>は復元プロセス中に作成されるディレクトリです。
もう一つの例としては、まずETCDCTL_API環境変数をエクスポートします:
export ETCDCTL_API = 3
etcdctl --data-dir <data-dir-location> snapshot restore snapshot.db
<data-dir-location>が以前と同じフォルダーである場合は、クラスターを復元する前にそれを削除してetcdプロセスを停止します。そうでない場合は、etcdの構成を変更し、復元後にetcdプロセスを再起動して新しいデータディレクトリを使用するようにします。
スナップショットファイルからクラスターを復元する方法と例についての詳細は、etcd災害復旧ドキュメント を参照してください。
復元されたクラスターのアクセスURLが前のクラスターと異なる場合、Kubernetes APIサーバーをそれに応じて再設定する必要があります。
この場合、--etcd-servers=$OLD_ETCD_CLUSTERのフラグの代わりに、--etcd-servers=$NEW_ETCD_CLUSTERのフラグでKubernetes APIサーバーを再起動します。
$NEW_ETCD_CLUSTERと$OLD_ETCD_CLUSTERをそれぞれのIPアドレスに置き換えてください。
etcdクラスターの前にロードバランサーを使用している場合、代わりにロードバランサーを更新する必要があるかもしれません。
etcdメンバーの過半数に永続的な障害が発生した場合、etcdクラスターは故障したと見なされます。
このシナリオでは、Kubernetesは現在の状態に対して変更を加えることができません。
スケジュールされたPodは引き続き実行されるかもしれませんが、新しいPodはスケジュールできません。
このような場合、etcdクラスターを復旧し、必要に応じてKubernetes APIサーバーを再設定して問題を修正します。
備考: クラスター内でAPIサーバーが実行されている場合、etcdのインスタンスを復元しようとしないでください。
代わりに、以下の手順に従ってetcdを復元してください:
すべての APIサーバーインスタンスを停止すべてのetcdインスタンスで状態を復元 すべてのAPIサーバーインスタンスを再起動 また、kube-scheduler、kube-controller-manager、kubeletなどのコンポーネントを再起動することもお勧めします。
これは、これらが古いデータに依存していないことを確認するためです。実際には、復元には少し時間がかかります。
復元中、重要なコンポーネントはリーダーロックを失い、自動的に再起動します。
etcdクラスターのアップグレード etcdのアップグレードに関する詳細は、etcdアップグレード のドキュメントを参照してください。
備考: アップグレードを開始する前に、まずetcdクラスターをバックアップしてください。etcdクラスターのメンテナンス etcdのメンテナンスに関する詳細は、etcdメンテナンス のドキュメントを参照してください。
🛇 This item links to a third party project or product that is not part of Kubernetes itself.
More information 備考: デフラグメンテーションはコストがかかる操作のため、できるだけ頻繁に実行しないようにしてください。
一方で、etcdメンバーがストレージのクォータを超えないようにする必要もあります。
Kubernetesプロジェクトでは、デフラグメンテーションを行う際には、etcd-defrag などのツールを使用することを推奨しています。
また、デフラグメンテーションを定期的に実行するために、KubernetesのCronJobとしてデフラグメンテーションツールを実行することもできます。
詳細はetcd-defrag-cronjob.yaml
4.2.19 - ノードを安全にドレインする このページでは、ノード を安全にドレインする方法を示します。
オプションで、定義されたPodDisruptionBudgetを考慮することも可能です。
始める前に このタスクを実行するには、以下のいずれかの前提条件を満たしている必要があります:
ノードのドレイン中にアプリケーションの高可用性を必要としない PodDisruptionBudget の概念に関する記事を読み、必要とするアプリケーションに対してPodDisruptionBudgetを設定 していることメンテナンス中もワークロードの可用性を維持するために、PodDisruptionBudget を設定できます。
ドレイン対象のノード上で動作している、または今後動作する可能性のあるアプリケーションにとって可用性が重要である場合は、まずPodDisruptionBudgetを設定 してから、このガイドに従ってください。
ノードのドレイン中に不具合のあるアプリケーションの削除を許容するため、PodDisruptionBudgetにはAlwaysAllowのUnhealthyPodEvictionPolicy を設定することが推奨されます。
デフォルトの挙動では、アプリケーションのPodが健全 になるまで、ドレインは実行されません。
kubectl drainを使ってノードをサービスから除外するノードに対してメンテナンス(例: カーネルのアップグレードやハードウェアのメンテナンスなど)を行う前に、kubectl drainを使用して、そのノード上のすべてのPodを安全に退避させることができます。
安全に退避すると、Podのコンテナが正常に終了 し、指定したPodDisruptionBudgetも尊重されます。
備考: デフォルトでは、
kubectl drainはノード上で削除不可の特定のシステム用Podを無視します。
詳細は
kubectl drain のドキュメントを参照してください。
kubectl drainが正常に終了した場合、それは(前段で述べた除外対象を除く)すべてのPodが安全に削除されたことを示します(望ましい正常終了期間および定義されたPodDisruptionBudgetは尊重されます)。
その時点で、ノードを停止しても安全です。
物理マシンの場合は電源を落とすことができ、クラウドプラットフォーム上であれば仮想マシンを削除しても差し支えありません。
備考: node.kubernetes.io/unschedulable taintを許容する新しいPodが存在する場合、それらのPodはドレイン済みのノードにスケジューリングされる可能性があります。
DaemonSet以外では、そのtaintを許容しないようにしてください。
あなた、または他のAPIユーザーがPodのnodeName
まず、ドレインしたいノードの名前を特定します。
クラスター内のすべてのノードは、次のコマンドで一覧表示できます:
次に、ノードをドレインするようにKubernetesに指示します:
kubectl drain --ignore-daemonsets <node name>
DaemonSetによって管理されているPodが存在する場合は、ノードを正常にドレインするために、kubectlに--ignore-daemonsetsを指定する必要があります。
kubectl drainサブコマンド単体では、実際にはDaemonSetのPodをノードからドレインしません:
DaemonSetコントローラー(コントロールプレーンの一部)は、欠落したPodをただちに同等の新しいPodで置き換えます。
また、DaemonSetコントローラーはスケジューリング不可のtaintを無視するPodも作成するため、ドレイン中のノード上に新しいPodが起動されることがあります。
エラーなくコマンドが完了したら、そのノードの電源を切ることができます(あるいは同等に、クラウドプラットフォーム上であれば、そのノードに対応する仮想マシンを削除することもできます)。
メンテナンス作業中にそのノードをクラスターに残しておいた場合は、作業完了後にKubernetesがそのノードへのPodのスケジューリングを再び可能にするために、次のコマンドを実行してください。
kubectl uncordon <node name>
複数ノードの並列ドレイン kubectl drainコマンドは、一度に1つのノードに対してのみ発行すべきです。
ただし、異なるノードに対して、複数のkubectl drainコマンドを異なるターミナルまたはバックグラウンドで並行で実行することは可能です。
複数のドレインコマンドが同時に実行されていても、指定したPodDisruptionBudgetは引き続き順守されます。
たとえば、3つのレプリカを持つStatefulSetがあり、そのセットに対してminAvailable: 2を指定したPodDisruptionBudgetを設定している場合、kubectl drainは、3つのレプリカのPodがすべて健全 である場合にのみ、そのStatefulSetのPodを退避させます。
このとき、複数のドレインコマンドを並行して発行した場合でも、KubernetesはPodDisruptionBudgetを順守し、任意の時点で使用不能なPodが1つ(replicas - minAvailableで計算)にとどまるように制御します。
健全 なレプリカの数が指定したバジェットを下回る原因となるようなドレイン操作はブロックされます。
Eviction API kubectl drain を使用したくないとき(外部コマンドの呼び出しを避けたい場合や、Podの退避プロセスをより細かく制御したい場合など)は、Eviction APIを用いてプログラムから退避を実行することもできます。
詳細は、APIを基点とした退避 を参照してください。
次の項目 4.2.20 - クラスターのセキュリティ このドキュメントでは、偶発的または悪意のあるアクセスからクラスターを保護するためのトピックについて説明します。
また、全体的なセキュリティに関する推奨事項を提供します。
始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
Kubernetes APIへのアクセスの制御 Kubernetesは完全にAPI駆動であるため、誰がクラスターにアクセスできるか、どのようなアクションを実行できるかを制御・制限することが第一の防御策となります。
すべてのAPIトラフィックにTLS(Transport Layer Security)を使用する Kubernetesは、クラスター内のすべてのAPI通信がデフォルトでTLSにより暗号化されていることを期待しており、大半のインストール方法では、必要な証明書を作成してクラスターコンポーネントに配布することができます。
コンポーネントやインストール方法によっては、HTTP上のローカルポートを有効にする場合があることに注意してください。管理者は、潜在的に保護されていないトラフィックを特定するために、各コンポーネントの設定に精通している必要があります。
APIの認証 クラスターのインストール時に、共通のアクセスパターンに合わせて、APIサーバーが使用する認証メカニズムを選択します。
例えば、シングルユーザーの小規模なクラスターでは、シンプルな証明書や静的なBearerトークンを使用することができます。
大規模なクラスターでは、ユーザーをグループに細分化できる既存のOIDCまたはLDAPサーバーを統合することができます。
ノード、プロキシ、スケジューラー、ボリュームプラグインなど、インフラの一部であるものも含めて、すべてのAPIクライアントを認証する必要があります。
これらのクライアントは通常、service accounts であるか、またはx509クライアント証明書を使用しており、クラスター起動時に自動的に作成されるか、クラスターインストールの一部として設定されます。
詳細については、認証 を参照してください。
APIの認可 認証されると、すべてのAPIコールは認可チェックを通過することになります。
Kubernetesには、統合されたRBAC コンポーネントが搭載されており、入力されたユーザーやグループを、ロールにまとめられたパーミッションのセットにマッチさせます。
これらのパーミッションは、動詞(get, create, delete)とリソース(pods, services, nodes)を組み合わせたもので、ネームスペース・スコープまたはクラスター・スコープに対応しています。
すぐに使えるロールのセットが提供されており、クライアントが実行したいアクションに応じて、デフォルトで適切な責任の分離を提供します。
Node とRBAC の承認者は、NodeRestriction のアドミッションプラグインと組み合わせて使用することをお勧めします。
認証の場合と同様に、小規模なクラスターにはシンプルで幅広い役割が適切かもしれません。
しかし、より多くのユーザーがクラスターに関わるようになるとチームを別の名前空間に分け、より限定的な役割を持たせることが必要になるかもしれません。
認可においては、あるオブジェクトの更新が、他の場所でどのようなアクションを起こすかを理解することが重要です。
たとえば、ユーザーは直接Podを作成することはできませんが、ユーザーに代わってPodを作成するDeploymentの作成を許可することで、間接的にそれらのPodを作成することができます。
同様に、APIからノードを削除すると、そのノードにスケジューリングされていたPodが終了し、他のノードに再作成されます。
すぐに使えるロールは、柔軟性と一般的なユースケースのバランスを表していますが、より限定的なロールは、偶発的なエスカレーションを防ぐために慎重に検討する必要があります。
すぐに使えるロールがニーズを満たさない場合は、ユースケースに合わせてロールを作成することができます。
詳しくはauthorization reference section に参照してください。
Kubeletへのアクセスの制御 Kubeletsは、ノードやコンテナの強力な制御を可能にするHTTPSエンドポイントを公開しています。
デフォルトでは、KubeletsはこのAPIへの認証されていないアクセスを許可しています。
本番環境のクラスターでは、Kubeletの認証と認可を有効にする必要があります。
詳細は、Kubelet 認証/認可 に参照してください。
ワークロードやユーザーのキャパシティーを実行時に制御 Kubernetesにおける権限付与は、意図的にハイレベルであり、リソースに対する粗いアクションに焦点を当てています。
より強力なコントロールはpolicies として存在し、それらのオブジェクトがクラスターや自身、その他のリソースにどのように作用するかをユースケースによって制限します。
クラスターのリソース使用量の制限 リソースクォータ は、ネームスペースに付与されるリソースの数や容量を制限するものです。
これは、ネームスペースが割り当てることのできるCPU、メモリー、永続的なディスクの量を制限するためによく使われますが、各ネームスペースに存在するPod、サービス、ボリュームの数を制御することもできます。
Limit ranges は、上記のリソースの一部の最大または最小サイズを制限することで、ユーザーがメモリーなどの一般的に予約されたリソースに対して不当に高いまたは低い値を要求するのを防いだり、何も指定されていない場合にデフォルトの制限を提供したりします。
コンテナが利用する特権の制御 Podの定義には、security context が含まれており、ノード上の特定の Linux ユーザー(rootなど)として実行するためのアクセス、特権的に実行するためのアクセス、ホストネットワークにアクセスするためのアクセス、その他の制御を要求することができます。
Pod security policies は、危険なセキュリティコンテキスト設定を提供できるユーザーやサービスアカウントを制限することができます。
たとえば、Podのセキュリティポリシーでは、ボリュームマウント、特にhostPathを制限することができ、これはPodの制御すべき側面です。
一般に、ほとんどのアプリケーションワークロードでは、ホストリソースへのアクセスを制限する必要があります。
ホスト情報にアクセスすることなく、ルートプロセス(uid 0)として正常に実行できます。
ただし、ルートユーザーに関連する権限を考慮して、非ルートユーザーとして実行するようにアプリケーションコンテナを記述する必要があります。
コンテナが不要なカーネルモジュールをロードしないようにします Linuxカーネルは、ハードウェアが接続されたときやファイルシステムがマウントされたときなど、特定の状況下で必要となるカーネルモジュールをディスクから自動的にロードします。
特にKubernetesでは、非特権プロセスであっても、適切なタイプのソケットを作成するだけで、特定のネットワークプロトコル関連のカーネルモジュールをロードさせることができます。これにより、管理者が使用されていないと思い込んでいるカーネルモジュールのセキュリティホールを攻撃者が利用できる可能性があります。
特定のモジュールが自動的にロードされないようにするには、そのモジュールをノードからアンインストールしたり、ルールを追加してブロックしたりします。
ほとんどのLinuxディストリビューションでは、/etc/modprobe.d/kubernetes-blacklist.confのような内容のファイルを作成することで実現できます。
# DCCPは必要性が低く、複数の深刻な脆弱性があり、保守も十分ではありません。
blacklist dccp
# SCTPはほとんどのKubernetesクラスターでは使用されておらず、また過去には脆弱性がありました。
blacklist sctp
モジュールのロードをより一般的にブロックするには、SELinuxなどのLinuxセキュリティモジュールを使って、コンテナに対する module_request権限を完全に拒否し、いかなる状況下でもカーネルがコンテナ用のモジュールをロードできないようにすることができます。
(Podは、手動でロードされたモジュールや、より高い権限を持つプロセスに代わってカーネルがロードしたモジュールを使用することはできます)。
ネットワークアクセスの制限 名前空間のネットワークポリシー により、アプリケーション作成者は、他の名前空間のPodが自分の名前空間内のPodやポートにアクセスすることを制限することができます。
サポートされているKubernetes networking providers の多くは、ネットワークポリシーを尊重するようになりました。
クォータやリミットの範囲は、ユーザーがノードポートや負荷分散サービスを要求するかどうかを制御するためにも使用でき、多くのクラスターでは、ユーザーのアプリケーションがクラスターの外で見えるかどうかを制御できます。
ノードごとのファイアウォール、クロストークを防ぐための物理的なクラスターノードの分離、高度なネットワークポリシーなど、プラグインや環境ごとにネットワークルールを制御する追加の保護機能が利用できる場合もあります。
クラウドメタデータのAPIアクセスを制限 クラウドプラットフォーム(AWS、Azure、GCEなど)では、しばしばメタデータサービスをインスタンスローカルに公開しています。
デフォルトでは、これらのAPIはインスタンス上で実行されているPodからアクセスでき、そのノードのクラウド認証情報や、kubelet認証情報などのプロビジョニングデータを含むことができます。
これらの認証情報は、クラスター内でのエスカレーションや、同じアカウントの他のクラウドサービスへのエスカレーションに使用できます。
クラウドプラットフォーム上でKubernetesを実行する場合は、インスタンスの認証情報に与えられるパーミッションを制限し、ネットワークポリシー を使用してメタデータAPIへのPodのアクセスを制限し、プロビジョニングデータを使用してシークレットを配信することは避けてください。
Podのアクセス可能ノードを制御 デフォルトでは、どのノードがPodを実行できるかについての制限はありません。
Kubernetesは、エンドユーザーが利用できるNode上へのPodのスケジューリング とTaintとToleration を提供します。
多くのクラスターでは、ワークロードを分離するためにこれらのポリシーを使用することは、作者が採用したり、ツールを使って強制したりする慣習になっています。
管理者としては、ベータ版のアドミッションプラグイン「PodNodeSelector」を使用して、ネームスペース内のPodをデフォルトまたは特定のノードセレクタを必要とするように強制することができます。
エンドユーザーがネームスペースを変更できない場合は、特定のワークロード内のすべてのPodの配置を強く制限することができます。
クラスターのコンポーネントの保護 このセクションでは、クラスターを危険から守るための一般的なパターンを説明します。
etcdへのアクセスの制限 API用のetcdバックエンドへの書き込みアクセスは、クラスター全体のrootを取得するのと同等であり、読み取りアクセスはかなり迅速にエスカレートするために使用できます。
管理者は、TLSクライアント証明書による相互認証など、APIサーバーからetcdサーバーへの強力な認証情報を常に使用すべきであり、API サーバーのみがアクセスできるファイアウォールの後ろにetcdサーバーを隔離することがしばしば推奨されます。
注意: クラスター内の他のコンポーネントが、完全なキースペースへの読み取りまたは書き込みアクセスを持つマスターetcdインスタンスへのアクセスを許可することは、クラスター管理者のアクセスを許可することと同じです。
マスター以外のコンポーネントに別のetcdインスタンスを使用するか、またはetcd ACLを使用してキースペースのサブセットへの読み取りおよび書き込みアクセスを制限することを強く推奨します。監査ログの有効 audit logger はベータ版の機能で、APIによって行われたアクションを記録し、侵害があった場合に後から分析できるようにするものです。
監査ログを有効にして、ログファイルを安全なサーバーにアーカイブすることをお勧めします。
アルファまたはベータ機能へのアクセスの制限 アルファ版およびベータ版のKubernetesの機能は活発に開発が行われており、セキュリティ上の脆弱性をもたらす制限やバグがある可能性があります。
常に、アルファ版またはベータ版の機能が提供する価値と、セキュリティ体制に起こりうるリスクを比較して評価してください。
疑問がある場合は、使用しない機能を無効にしてください。
インフラの認証情報を頻繁に交換 秘密やクレデンシャルの有効期間が短いほど、攻撃者がそのクレデンシャルを利用することは難しくなります。
証明書の有効期間を短く設定し、そのローテーションを自動化します。
発行されたトークンの利用可能期間を制御できる認証プロバイダーを使用し、可能な限り短いライフタイムを使用します。
外部統合でサービス・アカウント・トークンを使用する場合、これらのトークンを頻繁にローテーションすることを計画します。
例えば、ブートストラップ・フェーズが完了したら、ノードのセットアップに使用したブートストラップ・トークンを失効させるか、その認証を解除する必要があります。
サードパーティの統合を有効にする前に確認 Kubernetesへの多くのサードパーティの統合は、クラスターのセキュリティプロファイルを変更する可能性があります。
統合を有効にする際には、アクセスを許可する前に、拡張機能が要求するパーミッションを常に確認してください。
例えば、多くのセキュリティ統合は、事実上そのコンポーネントをクラスター管理者にしているクラスター上のすべての秘密を見るためのアクセスを要求するかもしれません。
疑問がある場合は、可能な限り単一の名前空間で機能するように統合を制限してください。
Podを作成するコンポーネントも、kube-system名前空間のような名前空間内で行うことができれば、予想外に強力になる可能性があります。これは、サービスアカウントのシークレットにアクセスしたり、サービスアカウントに寛容なpod security policies へのアクセスが許可されている場合に、昇格したパーミッションでPodが実行される可能性があるからです。
etcdにあるSecretを暗号化 一般的に、etcdデータベースにはKubernetes APIを介してアクセス可能なあらゆる情報が含まれており、クラスターの状態に対する大きな可視性を攻撃者へ与える可能性があります。
よく吟味されたバックアップおよび暗号化ソリューションを使用して、常にバックアップを暗号化し、可能な場合はフルディスク暗号化の使用を検討してください。
Kubernetesは1.7で導入された機能であるencryption at rest をサポートしており、これは1.13からはベータ版となっています。
これは、etcdのSecretリソースを暗号化し、etcdのバックアップにアクセスした人が、それらのシークレットの内容を見ることを防ぎます。
この機能は現在ベータ版ですが、バックアップが暗号化されていない場合や、攻撃者がetcdへの読み取りアクセスを得た場合に、追加の防御レベルを提供します。
セキュリティアップデートのアラートの受信と脆弱性の報告 kubernetes-announce に参加してください。
グループに参加すると、セキュリティアナウンスに関するメールを受け取ることができます。
脆弱性の報告方法については、security reporting ページを参照してください。
4.2.21 - 名前空間を使用してクラスターを共有する このページでは、名前空間 の確認、操作、削除の方法を説明します。
また、Kubernetesの名前空間を使用してクラスターを分割する方法についても説明します。
始める前に 名前空間の確認 次のコマンドを使用して、クラスター内の現在の名前空間の一覧を表示します。
NAME STATUS AGE
default Active 11d
kube-node-lease Active 11d
kube-public Active 11d
kube-system Active 11d
Kubernetesは初期状態で以下の4つの名前空間を持ちます。
default 他に名前空間が指定されていないオブジェクトに対するデフォルトの名前空間です。kube-node-lease 各ノードに関連付けられたリース オブジェクトを保持する名前空間です。
ノードのリースにより、kubeletはハートビート を送信でき、これによってコントロールプレーンはノードの障害を検知できます。kube-public この名前空間は自動的に作成され、すべてのユーザー(認証されていないユーザーを含む)が読み取り可能です。
この名前空間は、クラスター全体で一部のリソースを公開・参照可能にする必要がある場合に備えて、主にクラスター用途として予約されています。
この名前空間が公開されているのは慣習的なものであり、必須ではありません。kube-system Kubernetesシステムによって作成されるオブジェクト用の名前空間です。次のコマンドを使用して、特定の名前空間の概要を取得することもできます。
kubectl get namespaces <name>
また、次のコマンドを使用して、詳細な情報を取得することもできます。
kubectl describe namespaces <name>
Name: default
Labels: <none>
Annotations: <none>
Status: Active
No resource quota.
Resource Limits
Type Resource Min Max Default
---- -------- --- --- ---
Container cpu - - 100m
これらの詳細には、リソースクォータ(存在する場合)とリソースのLimit Rangeの両方が表示される点に留意してください。
リソースクォータは、名前空間内のリソース使用量の合計を追跡し、クラスター管理者が名前空間で消費可能なリソース使用量に対してハード 制限を定義できるようにします。
Limit Rangeは、名前空間内で1つのエンティティが消費可能なリソース量の最小値および最大値の制約を定義します。
詳細については、Admission control: Limit Range を参照してください。
名前空間は、以下の2つのフェーズのいずれかの状態になります。
Active 名前空間が使用中の状態です。Terminating 名前空間が削除中の状態であり、新しいオブジェクトを作成できません。詳細については、APIリファレンスの名前空間 を参照してください。
新しい名前空間の作成
備考: kube-というプレフィックスを持つ名前空間の作成は、Kubernetesシステム用の名前空間として予約されているため避けてください。次の内容でmy-namespace.yamlという新しいYAMLファイルを作成します。
apiVersion : v1
kind : Namespace
metadata :
name : <insert-namespace-name-here>
次に、以下を実行します。
kubectl create -f ./my-namespace.yaml
または、次のコマンドを使用して名前空間を作成できます。
kubectl create namespace <insert-namespace-name-here>
名前空間の名前は、有効なDNSラベル である必要があります。
オプションのフィールドfinalizersがあり、これにより名前空間が削除される際に、コントローラーが関連リソースをクリーンアップできるようになります。
存在しないファイナライザーを指定した場合、名前空間自体は作成されますが、ユーザーが削除しようとするとTerminating状態のまま停止する点に注意してください。
finalizersに関する詳細は、名前空間のデザインドキュメント を参照してください。
名前空間の削除 次のコマンドで名前空間を削除します。
kubectl delete namespaces <insert-some-namespace-name>
警告: このコマンドは、その名前空間配下の すべて のリソースを削除します!この削除処理は非同期で行われるため、しばらくの間、名前空間はTerminating状態として表示されます。
Kubernetesの名前空間を使用してクラスターを分割する デフォルトでは、Kubernetesクラスターはプロビジョニング時に、クラスターで使用されるデフォルトのPod、Service、Deploymentを格納するためのdefaultという名前空間を作成します。
新しく作成されたクラスターを前提とすると、次の手順で利用可能な名前空間を確認できます。
NAME STATUS AGE
default Active 13m
新しい名前空間の作成 この演習では、作業内容を格納するために、2つの追加のKubernetes名前空間を作成します。
Kubernetesクラスターを開発環境と本番環境の両方で使用している組織のシナリオを考えてみます。
開発チームは、アプリケーションのビルドおよび実行に使用しているPod、Service、Deploymentの一覧を把握できるスペースをクラスター内に維持したいと考えています。
このスペースでは、Kubernetesリソースは頻繁に作成・削除され、アジャイル開発を可能にするため、誰がリソースを変更できるか、またはできないかの制限は緩和されています。
運用チームは、本番環境で稼働するPod、Service、Deploymentの集合に対して、誰が操作できるか、またはできないかを厳密に管理するためのスペースをクラスター内に維持したいと考えています。
このような組織では、Kubernetesクラスターをdevelopmentとproductionという2つの名前空間に分割するという設計パターンを採用できます。
それでは、作業用に2つの新しい名前空間を作成してみましょう。
kubectlを使用してdevelopmentという名前空間を作成します。
kubectl create -f https://k8s.io/examples/admin/namespace-dev.json
続いて、kubectlを使用してproductionという名前空間を作成します。
kubectl create -f https://k8s.io/examples/admin/namespace-prod.json
正しく作成されたことを確認するために、クラスター内のすべての名前空間を一覧表示します。
kubectl get namespaces --show-labels
NAME STATUS AGE LABELS
default Active 32m <none>
development Active 29s name=development
production Active 23s name=production
各名前空間にPodを作成する Kubernetesの名前空間は、クラスター内におけるPod、Service、Deploymentのスコープを提供します。
ある名前空間とやり取りするユーザーは、別の名前空間の内容を見ることはできません。
これを確認するために、development名前空間に簡単なDeploymentとPodを作成してみましょう。
kubectl create deployment snowflake \
= registry.k8s.io/serve_hostname \
= development --replicas= 2
レプリカ数が2のDeploymentを作成し、ホスト名を返す基本的なコンテナを実行するsnowflakeというPodが起動されています。
kubectl get deployment -n= development
NAME READY UP-TO-DATE AVAILABLE AGE
snowflake 2/2 2 2 2m
kubectl get pods -l app = snowflake -n= development
NAME READY STATUS RESTARTS AGE
snowflake-3968820950-9dgr8 1/1 Running 0 2m
snowflake-3968820950-vgc4n 1/1 Running 0 2m
これにより、開発者は自由に作業を進めることができ、production名前空間の内容に影響を与える心配はありません。
次にproduction名前空間に切り替えて、ある名前空間のリソースが他の名前空間からは見えないことを確認します。
production名前空間には何も存在しないはずで、以下のコマンドは何も返さないはずです。
kubectl get deployment -n= production
kubectl get pods -n= production
本番環境では、cattleとして実行したいため、いくつかのcattleというPodを作成してみましょう。
kubectl create deployment cattle --image= registry.k8s.io/serve_hostname -n= production
kubectl scale deployment cattle --replicas= 5 -n= production
kubectl get deployment -n= production
NAME READY UP-TO-DATE AVAILABLE AGE
cattle 5/5 5 5 10s
kubectl get pods -l app = cattle -n= production
NAME READY STATUS RESTARTS AGE
cattle-2263376956-41xy6 1/1 Running 0 34s
cattle-2263376956-kw466 1/1 Running 0 34s
cattle-2263376956-n4v97 1/1 Running 0 34s
cattle-2263376956-p5p3i 1/1 Running 0 34s
cattle-2263376956-sxpth 1/1 Running 0 34s
この時点で、ある名前空間に作成されたリソースは、他の名前空間からは見えないことが明確になったはずです。
Kubernetesにおけるポリシーのサポートが進化するにつれて、このシナリオを拡張し、名前空間ごとに異なる認可ルールを提供する方法を紹介していく予定です。
名前空間を使用する動機の理解 1つのKubernetesクラスターは、複数のユーザー、またはユーザーグループ(本ドキュメントでは、以降これらを ユーザーコミュニティ と呼びます)の要件を満たす必要があります。
Kubernetesの 名前空間 は、異なるプロジェクト、チーム、または顧客が1つのKubernetesクラスターを共有するのに役立ちます。
これは、次の機能を提供することで実現されます。
名前 のスコープクラスターの一部に対して認可およびポリシーを関連付ける仕組み 複数の名前空間を使用することは必須ではありません。
各ユーザーコミュニティは、他のコミュニティから分離された状態で作業できることを望みます。
各ユーザーコミュニティは、次のものを独自に持ちます。
リソース(Pod、Service、ReplicationControllerなど) ポリシー(誰がそのコミュニティ内で操作を行えるか、または行えないか) 制約(そのコミュニティに許可されるクォータなど) クラスター管理者は、各ユーザーコミュニティに対して名前空間を作成できます。
名前空間は、次のためのユニークなスコープを提供します。
名前付きリソース(基本的な名前の衝突を防ぐため) 信頼されたユーザーへの管理権限の委譲 コミュニティごとのリソース消費量を制限する機能 ユースケースは次のとおりです。
クラスター管理者として、1つのクラスター上で複数のユーザーコミュニティをサポートしたい。 クラスター管理者として、クラスターの一部の管理権限を、各コミュニティ内の信頼されたユーザーに委譲したい。 クラスター管理者として、クラスターを共有する他のコミュニティへの影響を抑えるために、各コミュニティが消費できるリソース量を制限したい。 クラスター利用者として、他のユーザーコミュニティの活動から分離された上で、自分のコミュニティに関連するリソースのみを操作したい。 名前空間とDNSの理解 Service を作成すると、それに対応するDNSエントリ が作成されます。
このエントリは<service-name>.<namespace-name>.svc.cluster.localという形式です。
これは、コンテナ内で<service-name>を使用した場合、同じ名前空間内にあるServiceに名前解決されることを意味します。
これは、Development、Staging、Productionなど複数の名前空間で同一の設定を使用する際に便利です。
名前空間をまたいでServiceにアクセスしたい場合は、完全修飾ドメイン名(FQDN)を使用する必要があります。
次の項目 4.2.22 - クラスターのアップグレード このページでは、Kubernetesクラスターをアップグレードする際に従うべき手順の概要を提供します。
クラスターのアップグレード方法は、初期のデプロイ方法やその後の変更によって異なります。
大まかな手順は以下の通りです:
コントロールプレーン のアップグレードクラスター内にあるノードのアップグレード kubectl など、クライアントのアップグレード新しいKubernetesバージョンに伴うAPI変更に基づいたマニフェストやその他のリソースの調整 始める前に 既存のクラスターが必要です。このページではKubernetes 1.34からKubernetes 1.35へのアップグレードについて説明しています。現在のクラスターがKubernetes 1.34を実行していない場合は、アップグレードしようとしているKubernetesバージョンのドキュメントを確認してください。
アップグレード方法 kubeadm クラスターがkubeadmツールを使用してデプロイされた場合の詳細なアップグレード方法は、kubeadmクラスターのアップグレード を参照してください。
クラスターをアップグレードしたら、忘れずに最新バージョンのkubectlをインストール してください。
手動デプロイ
注意: これらの手順は、ネットワークおよびストレージプラグインなどのサードパーティ製拡張機能には対応していません。次の順序でコントロールプレーンを手動で更新する必要があります:
etcd(すべてのインスタンス) kube-apiserver(すべてのコントロールプレーンホスト) kube-controller-manager kube-scheduler クラウドコントローラーマネージャー(使用している場合) この時点で、最新バージョンのkubectlをインストール してください。
クラスター内の各ノードに対して、そのノードをドレイン し、1.35 kubeletを使用する新しいノードと置き換えるか、そのノードのkubeletをアップグレードして再稼働させます。
注意: kubeletをアップグレードする前にノードをドレインすることで、Podが再収容され、コンテナが再作成されるため、一部のセキュリティ問題や重要なバグの解決が必要な場合があります。その他のデプロイ クラスターデプロイメントツールのドキュメントを参照して、メンテナンスの推奨手順を確認してください。
アップグレード後のタスク クラスターのストレージAPIバージョンを切り替える クラスターの内部表現でアクティブなKubernetesリソースのためにetcdにシリアル化されるオブジェクトは、特定のAPIバージョンを使用して書き込まれます。
サポートされるAPIが変更されると、これらのオブジェクトは新しいAPIで再書き込みする必要があります。これを行わないと、最終的にはKubernetes APIサーバーによってデコードまたは使用できなくなるリソースが発生する可能性があります。
影響を受ける各オブジェクトについて、最新のサポートされるAPIを使用して取得し、最新のサポートされるAPIを使用して再書き込みします。
マニフェストの更新 新しいKubernetesバージョンへのアップグレードにより、新しいAPIが提供されることがあります。
異なるAPIバージョン間でマニフェストを変換するためにkubectl convertコマンドを使用できます。例えば:
kubectl convert -f pod.yaml --output-version v1
kubectlツールはpod.yamlの内容を、kindがPod(変更なし)で、apiVersionが改訂されたマニフェストに置き換えます。
デバイスプラグイン クラスターがデバイスプラグインを実行しており、ノードを新しいデバイスプラグインAPIバージョンを含むKubernetesリリースにアップグレードする必要がある場合、デバイスプラグインをアップグレードして両方のバージョンをサポートする必要があります。これにより、アップグレード中にデバイスの割り当てが正常に完了し続けることが保証されます。
詳細については、API互換性 およびkubeletのデバイスマネージャーAPIバージョン を参照してください。
4.2.23 - クラスターでカスケード削除を使用する このページでは、ガベージコレクション 中にクラスターで使用するカスケード削除 のタイプを指定する方法を示します。
始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
また、さまざまな種類のカスケード削除を試すために、サンプルのDeploymentを作成する 必要があります。 タイプごとにDeploymentを再作成する必要があります。
Podのオーナーリファレンスを確認する PodにownerReferencesフィールドが存在することを確認します:
kubectl get pods -l app = nginx --output= yaml
出力には、次のようにownerReferencesフィールドがあります。
apiVersion : v1
...
ownerReferences :
- apiVersion : apps/v1
blockOwnerDeletion : true
controller : true
kind : ReplicaSet
name : nginx-deployment-6b474476c4
uid : 4fdcd81c-bd5d-41f7-97af-3a3b759af9a7
...
フォアグラウンドカスケード削除を使用する デフォルトでは、Kubernetesはバックグラウンドカスケード削除 を使用して、オブジェクトの依存関係を削除します。
クラスターが動作しているKubernetesのバージョンに応じて、kubectlまたはKubernetes APIのいずれかを使用して、フォアグラウンドカスケード削除に切り替えることができます。
バージョンを確認するには次のコマンドを実行してください: kubectl version.
kubectlまたはKubernetes APIを使用して、フォアグラウンドカスケード削除を使用してオブジェクトを削除することができます。
kubectlを使用する
以下のコマンドを実行してください:
kubectl delete deployment nginx-deployment --cascade= foreground
Kubernetes APIを使用する
ローカルプロキシセッションを開始します:
kubectl proxy --port= 8080
削除のトリガーとしてcurlを使用します:
curl -X DELETE localhost:8080/apis/apps/v1/namespaces/default/deployments/nginx-deployment \
'{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Foreground"}' \
"Content-Type: application/json"
出力には、次のようにforegroundDeletionファイナライザー が含まれています。
"kind": "Deployment",
"apiVersion": "apps/v1",
"metadata": {
"name": "nginx-deployment",
"namespace": "default",
"uid": "d1ce1b02-cae8-4288-8a53-30e84d8fa505",
"resourceVersion": "1363097",
"creationTimestamp": "2021-07-08T20:24:37Z",
"deletionTimestamp": "2021-07-08T20:27:39Z",
"finalizers": [
"foregroundDeletion"
]
...
バッググラウンドカスケード削除を使用する サンプルのDeploymentを作成する 。クラスターが動作しているKubernetesのバージョンに応じて、kubectlまたはKubernetes APIのいずれかを使用してDeploymentを削除します。バージョンを確認するには次のコマンドを実行してください: kubectl version.
kubectlまたはKubernetes APIを使用して、バックグラウンドカスケード削除を使用してオブジェクトを削除できます。
Kubernetesはデフォルトでバックグラウンドカスケード削除を使用し、--cascadeフラグまたはpropagationPolicy引数なしで以下のコマンドを実行した場合も同様です。
kubectlを使用する
以下のコマンドを実行してください:
kubectl delete deployment nginx-deployment --cascade= background
Kubernetes APIを使用する
ローカルプロキシセッションを開始します:
kubectl proxy --port= 8080
削除のトリガーとしてcurlを使用します:
curl -X DELETE localhost:8080/apis/apps/v1/namespaces/default/deployments/nginx-deployment \
'{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Background"}' \
"Content-Type: application/json"
出力は、次のようになります。
"kind": "Status",
"apiVersion": "v1",
...
"status": "Success",
"details": {
"name": "nginx-deployment",
"group": "apps",
"kind": "deployments",
"uid": "cc9eefb9-2d49-4445-b1c1-d261c9396456"
}
オーナーオブジェクトの削除と従属オブジェクトの孤立 デフォルトでは、Kubernetesにオブジェクトの削除を指示すると、コントローラー は従属オブジェクトも削除します。クラスターが動作しているKubernetesのバージョンに応じて、kubectlまたはKubernetes APIを使用して、これらの従属オブジェクトをKubernetesでorphan にすることができます。
バージョンを確認するには次のコマンドを実行してください: kubectl version.
kubectlを使用する
以下のコマンドを実行してください:
kubectl delete deployment nginx-deployment --cascade= orphan
Kubernetes APIを使用する
ローカルプロキシセッションを開始します:
kubectl proxy --port= 8080
削除のトリガーとしてcurlを使用します:
curl -X DELETE localhost:8080/apis/apps/v1/namespaces/default/deployments/nginx-deployment \
'{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Orphan"}' \
"Content-Type: application/json"
出力には、次のようにfinalizersフィールドにorphanが含まれます。
"kind": "Deployment",
"apiVersion": "apps/v1",
"namespace": "default",
"uid": "6f577034-42a0-479d-be21-78018c466f1f",
"creationTimestamp": "2021-07-09T16:46:37Z",
"deletionTimestamp": "2021-07-09T16:47:08Z",
"deletionGracePeriodSeconds": 0,
"finalizers": [
"orphan"
],
...
Deploymentによって管理されているPodがまだ実行中であることを確認できます。
kubectl get pods -l app = nginx
次の項目 4.2.24 - データ暗号化にKMSプロバイダーを使用する このページでは、機密データの暗号化を有効にするために、Key Management Service(KMS)プロバイダーとプラグインを設定する方法について説明します。
Kubernetes 1.35では、KMSによる保存時暗号化はv1とv2の2つのバージョンが利用できます。
KMS v1は(Kubernetes v1.28以降で)非推奨であり、(Kubernetes v1.29以降では)デフォルトで無効化されているため、特段の理由がない限りKMS v2を使用すべきです。
KMS v2は、KMS v1よりも大幅に優れたパフォーマンス特性を提供します。
注意: このドキュメントは、KMS v2のGAな実装(および非推奨のv1の実装)について記載しています。
Kubernetes v1.29より古いコントロールプレーンコンポーネントを使用している場合は、クラスターが実行しているKubernetesのバージョンに対応するドキュメントの同等のページを確認してください。
以前のKubernetesのリリースでは、情報セキュリティに影響する可能性のある異なる挙動が存在します。始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
必要なKubernetesのバージョンは、選択したKMS APIバージョンによって異なります。
KubernetesではKMS v2の使用を推奨しています。
バージョンv1.27より前のクラスターをサポートするためにKMS API v1を選択した場合、またはKMS v1のみをサポートするレガシーKMSプラグインを使用している場合、KMS v1をサポートする全てのKubernetesバージョンが動作します。
このAPIはKubernetes v1.28時点で非推奨です。
KubernetesではこのAPIの使用を推奨していません。 バージョンを確認するには次のコマンドを実行してください: kubectl version.
KMS v1 FEATURE STATE:
Kubernetes v1.28 [deprecated]
Kubernetesバージョン1.10.0以降が必要です
バージョン1.29以降では、KMSのv1実装はデフォルトで無効になっています。
この機能を有効化するには、--feature-gates=KMSv1=trueを設定してKMS v1プロバイダーを構成してください。
クラスターはetcd v3以降を使用する必要があります
KMS v2 FEATURE STATE:
Kubernetes v1.29 [stable]
クラスターはetcd v3以降を使用する必要があります KMS暗号化とオブジェクトごとの暗号化キー KMSプロバイダーは、etcd内のデータを暗号化するためにエンベロープ暗号化方式を使用します。
データはデータ暗号化鍵(DEK)を使用して暗号化されます。
DEKは、リモートKMSで保存・管理される鍵暗号化鍵(KEK)で暗号化されます。
(非推奨の)KMSのv1実装を使用する場合、各暗号化に対して新しいDEKが生成されます。
KMS v2では、暗号化ごと に新しいDEKが生成されます: APIサーバーは 鍵導出関数 を使用して、シークレットシード(暗号鍵生成の種)とランダムデータを組み合わせて単一用途のデータ暗号化鍵を生成します。
シードは、KEKがローテーションされるたびにローテーションされます(詳細については、以下の「key_idと鍵ローテーションの理解」セクションを参照してください)。
KMSプロバイダーは、UNIXドメインソケット経由で特定のKMSプラグインと通信するためにgRPCを使用します。
KMSプラグインは、gRPCサーバーとして実装され、Kubernetesコントロールプレーンと同じホストにデプロイされ、リモートKMSとのすべての通信を担当します。
KMSプロバイダーの設定 APIサーバーでKMSプロバイダーを設定するには、暗号化設定ファイルのproviders配列にkmsタイプのプロバイダーを含め、以下のプロパティを設定してください:
KMS v1 apiVersion: KMSプロバイダーのAPIバージョン。
この値を空のままにするか、v1に設定してください。name: KMSプラグインの表示名。
一度設定すると変更できません。endpoint: gRPCサーバー(KMSプラグイン)のリッスンアドレス。
このエンドポイントはUNIXドメインソケットです。cachesize: 平文でキャッシュするデータ暗号化鍵(DEK)の数。
キャッシュする場合、DEKはKMSへの追加の呼び出しなしで使用できますが、キャッシュしない場合はKMSを呼び出して鍵を取り出す必要があります。timeout: kube-apiserverがエラーを返す前にkms-pluginの応答を待つ時間(デフォルトは3秒)。KMS v2 apiVersion: KMSプロバイダーのAPIバージョン。
これをv2に設定してください。name: KMSプラグインの表示名。
一度設定すると変更できません。endpoint: gRPCサーバー(KMSプラグイン)のリッスンアドレス。
このエンドポイントはUNIXドメインソケットです。timeout: kube-apiserverがエラーを返す前にkms-pluginの応答を待つ時間(デフォルトは3秒)。KMS v2はcachesizeプロパティをサポートしていません。
KMSを呼び出してサーバーが取り出した全てのデータ暗号化鍵(DEK)は、平文でキャッシュされます。
いったんキャッシュされたDEKは、KMSを呼び出すことなく無期限で復号に使用できます。
保存時暗号化設定の理解 を参照してください。
KMSプラグインの実装 KMSプラグインを実装するには、新しいプラグインgRPCサーバーを開発するか、クラウドプロバイダーによって既に提供されているKMSプラグインを有効にすることができます。
その後、プラグインをリモートKMSと統合し、Kubernetesコントロールプレーンにデプロイします。
クラウドプロバイダーがサポートするKMSの有効化 クラウドプロバイダー固有のKMSプラグインを有効にする手順については、お使いのクラウドプロバイダーを参照してください。
KMSプラグインgRPCサーバーの開発 Go用に利用可能なスタブファイルを使用してKMSプラグインgRPCサーバーを開発できます。
他の言語については、protoファイルを使用してgRPCサーバーコードの開発に使用できるスタブファイルを作成します。
KMS v1 KMS v2 その後、スタブファイル内の関数とデータ構造を使用してサーバーコードを開発してください。
注意事項 KMS v1 KMSプラグインバージョン: v1beta1
Versionプロシージャコールへの応答で、互換性のあるKMSプラグインはVersionResponse.versionとしてv1beta1を返す必要があります。
メッセージバージョン: v1beta1
KMSプロバイダーからのすべてのメッセージには、バージョンフィールドがv1beta1に設定されています。
プロトコル: UNIXドメインソケット(unix)
プラグインは、UNIXドメインソケットでリッスンするgRPCサーバーとして実装されます。
稼働中のプラグインは、UNIXドメインソケットでgRPC接続を待受するために、ファイルシステム上にファイルを作成する必要があります。
APIサーバー(gRPCクライアント)は、KMSプロバイダー(gRPCサーバー)とUNIXドメインソケットを通じて通信するためにエンドポイントを設定します。
unix:///@fooのように、/@から始まるエンドポイントを指定すると、抽象化したLinuxソケットを利用できます。
従来のファイルベースのソケットとは異なり、このタイプのソケットにはACLの概念がないため、使用する際は注意が必要です。
ただし、これらのソケットはLinuxネットワーク名前空間で制御されるため、ホストネットワーキングが使用されていない限りは、同じPod内のコンテナからのみアクセスできます。
KMS v2 KMSプラグインバージョン: v2
Statusリモートプロシージャコールへの応答の際、KMS v2に互換なKMSプラグインはStatusResponse.versionとしてKMS互換性バージョンを返す必要があります。
また、ステータス応答にはStatusResponse.healthzとして「ok」、StatusResponse.key_idとしてkey_id(リモートKMSのKEK ID)を含める必要があります。
Kubernetesプロジェクトでは、プラグインを安定したv2 KMS APIと互換性があるようにすることを推奨します。
Kubernetes 1.35はKMS用のv2beta1 APIもサポートしており、将来のKubernetesリリースでもそのベータバージョンのサポートが継続される可能性があります。
APIサーバーは、すべてが正常な場合は約1分ごとにStatusプロシージャコールをポーリングし、プラグインが正常でない場合は10秒ごとにポーリングします。
プラグインは、常にこの呼び出し負荷がかかることを考慮して最適化する必要があります。
暗号化
EncryptRequestプロシージャコールは、平文に加えて、ログ目的のUIDフィールドを提供します。
応答には暗号文と使用するKEKのkey_idを含める必要があり、KMSプラグインが将来のDecryptRequest呼び出しを(annotationsフィールド経由で)支援するために必要とする、任意のメタデータを含めることもできます。
プラグインは、異なる任意の平文が異なる応答(ciphertext, key_id, annotations)を与えることを保証しなければなりません(MUST)。
プラグインが空でないannotationsマップを返す場合、すべてのマップキーはexample.comのような完全修飾ドメイン名である必要があります。
annotationの使用例は{"kms.example.io/remote-kms-auditid":"<audit ID used by the remote KMS>"}です。
APIサーバーは高頻度でEncryptRequestプロシージャコールを実行しませんが、プラグインの実装では各リクエストのレイテンシーを100ミリ秒未満に保つことを目指す必要があります。
復号
DecryptRequestプロシージャコールでは、EncryptRequestから得た(ciphertext, key_id, annotations)とログ目的のUIDを提供します。
期待される通り、これはEncryptRequest呼び出しの逆です。
プラグインはkey_idが既知のものかどうかを検証しなければなりません(MUST)。
また、以前にプラグイン自身が暗号化したデータであることを確証できない限り、データの復号を試みてはいけません(MUST NOT)。
APIサーバーは、Watchキャッシュを満たすために起動時に何千ものDecryptRequestプロシージャコールを実行する可能性があります。
したがって、プラグインの実装はこれらの呼び出しを可能な限り迅速に実行する必要があり、各リクエストのレイテンシーを10ミリ秒未満に保つことを目指す必要があります。
key_idと鍵ローテーションの理解
key_idは、現在使用中のリモートKMS KEKの公開された非機密の名前です。
APIサーバーの通常の動作中にログに記録される可能性があるため、プライベートデータを含んではいけません。
プラグインの実装では、データの漏洩を避けるためにハッシュの使用が推奨されます。
KMS v2メトリクスは、/metricsエンドポイント経由で公開する前にこの値をハッシュ化するよう注意しています。
APIサーバーは、Statusプロシージャコールから返されるkey_idを信頼できるものと見なします。
したがって、この値の変更は、リモートKEKが変更されたことをAPIサーバーに通知し、古いKEKで暗号化されたデータはno-op書き込みが実行されたときに古いものとしてマークされる必要があります(以下で説明)。
EncryptRequestプロシージャコールがStatusとは異なるkey_idを返す場合、応答は破棄され、プラグインは正常でないと見なされます。
したがって、実装はStatusから返されるkey_idがEncryptRequestによって返されるものと同じであることを保証する必要があります。
さらに、プラグインはkey_idが安定しており、値間で変動しないことを確保する必要があります(つまり、リモートKEKローテーション中)。
プラグインは、以前に使用されたリモートKEKが復元された状況でも、key_idを再利用してはいけません。
プラグインがkey_id=Aを使用していて、key_id=Bに切り替え、その後key_id=Aに戻った場合、key_id=Aを報告する代わりに、プラグインはkey_id=A_001のような派生値を報告するか、key_id=Cのような新しい値を使用する必要があります。
APIサーバーは約1分ごとにStatusをポーリングするため、key_idローテーションは即座には行われません。
さらに、APIサーバーは約3分間最後の有効な状態で継続します。
したがって、ユーザーがストレージ移行に対して受動的な(つまり、待機による)アプローチを取りたい場合、リモートKEKがローテーションされた後の3 + N + M分でマイグレーションを予定する必要があります(Nはプラグインがkey_idの変更を検知するのにかかる時間、Mは設定変更が処理されることを許可するための望ましいバッファです。Mの最小値は5分が推奨されます)。
KEKローテーションを実行するためにAPIサーバーの再起動は必要ないことに注意してください。
注意: DEKで実行される書き込み数を制御できないため、Kubernetesプロジェクトでは、KEKを少なくとも90日ごとにローテーションすることを推奨します。プロトコル: UNIXドメインソケット(unix)
プラグインは、UNIXドメインソケットでリッスンするgRPCサーバーとして実装されます。
稼働中のプラグインは、UNIXドメインソケットでgRPC接続を待受するために、ファイルシステム上にファイルを作成する必要があります。
APIサーバー(gRPCクライアント)は、KMSプロバイダー(gRPCサーバー)とUNIXドメインソケットを通じて通信するためにエンドポイントを設定します。
unix:///@fooのように、/@から始まるエンドポイントを指定すると、抽象化したLinuxソケットを利用できます。
従来のファイルベースのソケットとは異なり、このタイプのソケットにはACLの概念がないため、使用する際は注意が必要です。
ただし、これらのソケットはLinuxネットワーク名前空間で制御されるため、ホストネットワーキングが使用されていない限りは、同じPod内のコンテナからのみアクセスできます。
KMSプラグインとリモートKMSの統合 KMSプラグインは、KMSがサポートする任意のプロトコルを使用してリモートKMSと通信できます。
KMSプラグインがリモートKMSとの通信に使用する認証資格情報を含むすべての設定データは、KMSプラグインによって独立して保存・管理されます。
KMSプラグインは、復号のためにKMSに送信する前に必要な追加のメタデータで暗号文をエンコードできます(KMS v2は専用のannotationsフィールドを提供することでこのプロセスを簡単にします)。
KMSプラグインのデプロイ KMSプラグインがKubernetes APIサーバーと同じホストで実行されることを確認してください。
KMSプロバイダーでデータを暗号化する データを暗号化するには:
SecretやConfigMapなどのリソースを暗号化するために、kmsプロバイダーの適切なプロパティを使用して新しいEncryptionConfigurationファイルを作成します。
CustomResourceDefinitionで定義された拡張APIを暗号化したい場合、クラスターはKubernetes v1.26以降を実行している必要があります。
kube-apiserverの--encryption-provider-configフラグを、設定ファイルの場所を指すように設定します。
--encryption-provider-config-automatic-reloadブール引数は、--encryption-provider-configで設定されたファイルがディスクの内容が変更された場合に自動的にリロード されるかどうかを決定します。
APIサーバーを再起動します。
KMS v1 apiVersion : apiserver.config.k8s.io/v1
kind : EncryptionConfiguration
resources :
- resources :
- secrets
- configmaps
- pandas.awesome.bears.example
providers :
- kms :
name : myKmsPluginFoo
endpoint : unix:///tmp/socketfile-foo.sock
cachesize : 100
timeout : 3s
- kms :
name : myKmsPluginBar
endpoint : unix:///tmp/socketfile-bar.sock
cachesize : 100
timeout : 3s
KMS v2 apiVersion : apiserver.config.k8s.io/v1
kind : EncryptionConfiguration
resources :
- resources :
- secrets
- configmaps
- pandas.awesome.bears.example
providers :
- kms :
apiVersion : v2
name : myKmsPluginFoo
endpoint : unix:///tmp/socketfile-foo.sock
timeout : 3s
- kms :
apiVersion : v2
name : myKmsPluginBar
endpoint : unix:///tmp/socketfile-bar.sock
timeout : 3s
--encryption-provider-config-automatic-reloadをtrueに設定すると、すべてのヘルスチェックが単一のヘルスチェックエンドポイントに統合されます。
個別のヘルスチェックは、KMS v1プロバイダーが使用されており、暗号化設定が自動リロードされない場合にのみ利用できます。
以下の表は、各KMSバージョンのヘルスチェックエンドポイントをまとめています:
KMS設定 自動リロードなし 自動リロードあり KMS v1のみ 個別ヘルスチェック 単一ヘルスチェック KMS v2のみ 単一ヘルスチェック 単一ヘルスチェック KMS v1とv2の両方 個別ヘルスチェック 単一ヘルスチェック KMSなし なし 単一ヘルスチェック
単一ヘルスチェックは、唯一のヘルスチェックエンドポイントが/healthz/kms-providersであることを意味します。
個別ヘルスチェックは、各KMSプラグインが暗号化設定での位置に基づいて関連するヘルスチェックエンドポイントを持つことを意味します: /healthz/kms-provider-0、/healthz/kms-provider-1など。
これらのヘルスチェックエンドポイントパスはハードコードされており、サーバーによって生成/制御されます。
個別ヘルスチェックのインデックスは、KMS暗号化設定が処理される順序に対応します。
すべてのシークレットが暗号化されていることを確認する で定義された手順が実行されるまで、providersリストは暗号化されていないデータの読み取りを許可するためにidentity: {}プロバイダーで終わる必要があります。
すべてのリソースが暗号化されたら、APIサーバーが暗号化されていないデータを受け入れることを防ぐためにidentityプロバイダーを削除する必要があります。
EncryptionConfiguration形式の詳細については、APIサーバー暗号化APIリファレンス を確認してください。
データが暗号化されていることを確認する 保存時暗号化が正しく設定されている場合、リソースは書き込み時に暗号化されます。
kube-apiserverを再起動した後、新しく作成または更新されたSecretやEncryptionConfigurationで設定されたその他のリソースタイプは、保存時に暗号化される必要があります。
確認するには、etcdctlコマンドラインプログラムを使用して機密データの内容を取得できます。
default名前空間にsecret1という新しいシークレットを作成します:
kubectl create secret generic secret1 -n default --from-literal= mykey = mydata
etcdctlコマンドラインを使用して、etcdからそのシークレットを読み取ります:
ETCDCTL_API = 3 etcdctl get /kubernetes.io/secrets/default/secret1 [ ...] | hexdump -C
ここで[...]にはetcdサーバーに接続するための追加の引数が含まれます。
保存されたシークレットがKMS v1の場合はk8s:enc:kms:v1:で始まり、KMS v2の場合はk8s:enc:kms:v2:で始まることを確認します。
これはkmsプロバイダーが結果データを暗号化したことを示します。
API経由で取得されたときに、シークレットが正しく復号されることを確認します:
kubectl describe secret secret1 -n default
Secretにはmykey: mydataが含まれている必要があります
すべてのシークレットが暗号化されていることを確認する 保存時暗号化が正しく設定されている場合、リソースは書き込み時に暗号化されます。
したがって、データが暗号化されることを確保するために、インプレースでno-op更新を実行できます。
以下のコマンドは、すべてのシークレットを読み取り、その後サーバーサイド暗号化を適用するために更新します。
競合する書き込みによるエラーが発生した場合は、コマンドを再試行してください。
大規模なクラスターの場合、名前空間によってシークレットを細分化するか、更新をスクリプト化することをお勧めします。
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
ローカル暗号化プロバイダーからKMSプロバイダーへの切り替え ローカル暗号化プロバイダーからkmsプロバイダーに切り替えて、すべてのシークレットを再暗号化するには:
以下の例に示すように、kmsプロバイダーを設定ファイルの最初のエントリとして追加します。
apiVersion : apiserver.config.k8s.io/v1
kind : EncryptionConfiguration
resources :
- resources :
- secrets
providers :
- kms :
apiVersion : v2
name : myKmsPlugin
endpoint : unix:///tmp/socketfile.sock
- aescbc :
keys :
- name : key1
secret : <BASE64エンコード済みシークレット>
すべてのkube-apiserverプロセスを再起動します。
以下のコマンドを実行して、kmsプロバイダーを使用してすべてのシークレットを強制的に再暗号化します。
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
次の項目 Kubernetes APIに永続化されたデータの暗号化をもう使用したくない場合は、既に保存時に保存されているデータの復号 を読んでください。
4.2.25 - サービスディスカバリーにCoreDNSを使用する このページでは、CoreDNSのアップグレードプロセスと、kube-dnsの代わりにCoreDNSをインストールする方法を説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.9.
バージョンを確認するには次のコマンドを実行してください: kubectl version.
CoreDNSについて CoreDNS は、KubernetesクラスターDNSとして稼働させることができる柔軟で拡張可能なDNSサーバーです。Kubernetesと同様に、CoreDNSプロジェクトはCNCF によってホストされています。
既存のデプロイでkube-dnsを置き換えるか、クラスターのデプロイとアップグレードを代行してくれるkubeadmのようなツールを使用することで、クラスターでkube-dnsの代わりにCoreDNSを使用することができます。
CoreDNSのインストール kube-dnsの手動デプロイや置き換えについては、CoreDNS website のドキュメントを参照してください。
CoreDNSへの移行 kubeadmを使用した既存のクラスターのアップグレード Kubernetesバージョン1.21でkubeadmはDNSアプリケーションとしてのkube-dnsに対するサポートを削除しました。
kubeadm v1.35に対してサポートされるクラスターDNSアプリケーションはCoreDNSのみです。
kube-dnsを使用しているクラスターをkubeadmを使用してアップグレードするときに、CoreDNSに移行することができます。
この場合、kubeadmは、kube-dns ConfigMapをベースにしてCoreDNS設定("Corefile")を生成し、スタブドメインおよび上流のネームサーバーの設定を保持します。
CoreDNSのアップグレード KubernetesのバージョンごとにkubeadmがインストールするCoreDNSのバージョンは、KubernetesにおけるCoreDNSのバージョン のページで確認することができます。
CoreDNSのみをアップグレードしたい場合や、独自のカスタムイメージを使用したい場合は、CoreDNSを手動でアップグレードすることができます。
スムーズなアップグレードのために役立つガイドラインとウォークスルー が用意されています。
クラスターをアップグレードする際には、既存のCoreDNS設定("Corefile")が保持されていることを確認してください。
kubeadmツールを使用してクラスターをアップグレードしている場合、kubeadmは既存のCoreDNSの設定を自動的に保持する処理を行うことができます。
CoreDNSのチューニング リソース使用率が問題になる場合は、CoreDNSの設定を調整すると役立つ場合があります。
詳細は、CoreDNSのスケーリングに関するドキュメント を参照してください。
次の項目 CoreDNS は、設定("Corefile")を変更することで、kube-dnsよりも多くのユースケースをサポートする構成にすることができます。
詳細はKubernetes CoreDNSプラグインのドキュメント を参照するか、CoreDNSブログ を参照してください。
4.2.26 - KubernetesクラスターでNodeLocal DNSキャッシュを使用する
FEATURE STATE:
Kubernetes v1.18 [stable]
このページでは、KubernetesのNodeLocal DNSキャッシュの機能の概要について説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
イントロダクション NodeLocal DNSキャッシュは、クラスターノード上でDNSキャッシュエージェントをDaemonSetで稼働させることで、クラスターのDNSパフォーマンスを向上させます。現在のアーキテクチャにおいて、ClusterFirstのDNSモードでのPodは、DNSクエリー用にkube-dnsのService IPに疎通します。これにより、kube-proxyによって追加されたiptablesを介してkube-dns/CoreDNSのエンドポイントへ変換されます。この新しいアーキテクチャによって、Podは同じノード上で稼働するDNSキャッシュエージェントに対して疎通し、それによってiptablesのDNATルールとコネクショントラッキングを回避します。ローカルのキャッシュエージェントはクラスターのホスト名(デフォルトではcluster.localというサフィックス)に対するキャッシュミスがあるときはkube-dnsサービスへ問い合わせます。
動機 現在のDNSアーキテクチャでは、ローカルのkube-dns/CoreDNSがないとき、DNSへの秒間クエリー数が最も高いPodは他のノードへ疎通する可能性があります。ローカルでキャッシュを持つことにより、この状況におけるレイテンシーの改善に役立ちます。
iptables DNATとコネクショントラッキングをスキップすることはconntrackの競合 を減らし、UDPでのDNSエントリーがconntrackテーブルを満杯にすることを避けるのに役立ちます。
ローカルのキャッシュエージェントからkube-dnsサービスへの接続がTCPにアップグレードされます。タイムアウトをしなくてはならないUDPエントリーと比べ、TCPのconntrackエントリーはコネクションクローズ時に削除されます(デフォルトの nf_conntrack_udp_timeout は30秒です)。
DNSクエリーをUDPからTCPにアップグレードすることで、UDPパケットの欠損や、通常30秒(10秒のタイムアウトで3回再試行する)であるDNSのタイムアウトによるテイルレイテンシーを減少させます。NodeLocalキャッシュはUDPのDNSクエリーを待ち受けるため、アプリケーションを変更する必要はありません。
DNSクエリーに対するノードレベルのメトリクスと可視性を得られます。
DNSの不在応答のキャッシュも再度有効にされ、それによりkube-dnsサービスに対するクエリー数を減らします。
アーキテクチャ図 この図はNodeLocal DNSキャッシュが有効にされた後にDNSクエリーがあったときの流れとなります。
Nodelocal DNSCacheのフロー この図は、NodeLocal DNSキャッシュがDNSクエリーをどう扱うかを表したものです。
設定
備考: NodeLocal DNSキャッシュのローカルリッスン用のIPアドレスは、クラスター内の既存のIPと衝突しないことが保証できるものであれば、どのようなアドレスでもかまいません。例えば、IPv4のリンクローカル範囲169.254.0.0/16やIPv6のユニークローカルアドレス範囲fd00::/8から、ローカルスコープのアドレスを使用することが推奨されています。この機能は、下記の手順により有効化できます。
nodelocaldns.yamlnodelocaldns.yamlという名前で保存してください。
マニフェスト内の変数を正しい値に置き換えてください。
<cluster-domain>はデフォルトで"cluster.local"です。<node-local-address> はNodeLocal DNSキャッシュ用に確保されたローカルの待ち受けIPアドレスです。
kube-proxyがIPTABLESモードで稼働中のとき:
sed -i "s/__PILLAR__LOCAL__DNS__/ $localdns /g; s/__PILLAR__DNS__DOMAIN__/ $domain /g; s/__PILLAR__DNS__SERVER__/ $kubedns /g" nodelocaldns.yaml
__PILLAR__CLUSTER__DNS__と__PILLAR__UPSTREAM__SERVERS__はnode-local-dnsというPodによって生成されます。
このモードでは、node-local-dns Podは<node-local-address>とkube-dnsのサービスIPの両方で待ち受けるため、PodはIPアドレスでもDNSレコードのルップアップができます。
kube-proxyがIPVSモードで稼働中のとき:
sed -i "s/__PILLAR__LOCAL__DNS__/ $localdns /g; s/__PILLAR__DNS__DOMAIN__/ $domain /g; s/__PILLAR__DNS__SERVER__//g; s/__PILLAR__CLUSTER__DNS__/ $kubedns /g" nodelocaldns.yaml
このモードでは、node-local-dns Podは<node-local-address>上のみで待ち受けます。node-local-dnsのインターフェースはkube-dnsのクラスターIPをバインドしません。なぜならばIPVSロードバランシング用に使われているインターフェースは既にこのアドレスを使用しているためです。
__PILLAR__UPSTREAM__SERVERS__ はnode-local-dns Podにより生成されます。
kubectl create -f nodelocaldns.yamlを実行してください。
kube-proxyをIPVSモードで使用しているとき、NodeLocal DNSキャッシュが待ち受けている<node-local-address>を使用するため、kubeletに対する--cluster-dnsフラグを修正する必要があります。IPVSモード以外のとき、--cluster-dnsフラグの値を修正する必要はありません。なぜならNodeLocal DNSキャッシュはkube-dnsのサービスIPと<node-local-address>の両方で待ち受けているためです。
一度有効にすると、クラスターの各Node上で、kube-systemという名前空間でnode-local-dns Podが、稼働します。このPodはCoreDNS をキャッシュモードで稼働させるため、異なるプラグインによって公開された全てのCoreDNSのメトリクスがNode単位で利用可能となります。
kubectl delete -f <manifest>を実行してDaemonSetを削除することによって、この機能を無効にできます。また、kubeletの設定に対して行った全ての変更をリバートすべきです。
4.2.27 - EndpointSliceの有効化 このページはKubernetesのEndpointSliceの有効化の概要を説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
概要 EndpointSliceは、KubernetesのEndpointsに対してスケーラブルで拡張可能な代替手段を提供します。Endpointsが提供する機能のベースの上に構築し、スケーラブルな方法で拡張します。Serviceが多数(100以上)のネットワークエンドポイントを持つ場合、それらは単一の大きなEndpointsリソースではなく、複数の小さなEndpointSliceに分割されます。
EndpointSliceの有効化 FEATURE STATE:
Kubernetes v1.17 [beta]
備考: EndpointSliceは、最終的には既存のEndpointsを置き換える可能性がありますが、多くのKubernetesコンポーネントはまだ既存のEndpointsに依存しています。現時点ではEndpointSliceを有効化することは、Endpointsの置き換えではなく、クラスター内のEndpointsへの追加とみなされる必要があります。EndpoitSliceはベータ版の機能です。APIとEndpointSliceコントローラー はデフォルトで有効です。kube-proxy はデフォルトでEndpointSliceではなくEndpointsを使用します。
スケーラビリティと性能向上のため、kube-proxy上でEndpointSliceProxyingフィーチャーゲート を有効にできます。この変更はデータソースをEndpointSliceに移します、これはkube-proxyとKubernetes API間のトラフィックの量を削減します。
EndpointSliceの使用 クラスター内でEndpointSliceを完全に有効にすると、各Endpointsリソースに対応するEndpointSliceリソースが表示されます。既存のEndpointsの機能をサポートすることに加えて、EndpointSliceはトポロジーなどの新しい情報を含みます。これらにより、クラスター内のネットワークエンドポイントのスケーラビリティと拡張性が大きく向上します。
次の項目 4.3 - Podとコンテナの設定 Podとコンテナの一般的な設定のタスクを行います。
4.3.1 - コンテナおよびPodへのメモリーリソースの割り当て このページでは、メモリーの 要求 と 制限 をコンテナに割り当てる方法について示します。コンテナは要求されたメモリーを確保することを保証しますが、その制限を超えるメモリーの使用は許可されません。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
クラスターの各ノードには、少なくとも300MiBのメモリーが必要になります。
このページのいくつかの手順では、クラスターにてmetrics-server サービスを実行する必要があります。すでにmetrics-serverが動作している場合、これらの手順をスキップできます。
Minikubeを動作させている場合、以下のコマンドによりmetrics-serverを有効にできます:
minikube addons enable metrics-server
metrics-serverが実行されているか、もしくはリソースメトリクスAPI (metrics.k8s.io) の別のプロバイダが実行されていることを確認するには、以下のコマンドを実行してください:
リソースメトリクスAPIが利用可能であれば、出力には metrics.k8s.io への参照が含まれます。
NAME
v1beta1.metrics.k8s.io
namespaceの作成 この練習で作成するリソースがクラスター内で分離されるよう、namespaceを作成します。
kubectl create namespace mem-example
メモリーの要求と制限を指定する コンテナにメモリーの要求を指定するには、コンテナのリソースマニフェストにresources:requestsフィールドを追記します。メモリーの制限を指定するには、resources:limitsを追記します。
この練習では、一つのコンテナをもつPodを作成します。コンテナに100MiBのメモリー要求と200MiBのメモリー制限を与えます。Podの設定ファイルは次のようになります:
apiVersion : v1
kind : Pod
metadata :
name : memory-demo
namespace : mem-example
spec :
containers :
- name : memory-demo-ctr
image : polinux/stress
resources :
limits :
memory : "200Mi"
requests :
memory : "100Mi"
command : ["stress" ]
args : ["--vm" , "1" , "--vm-bytes" , "150M" , "--vm-hang" , "1" ]
設定ファイルのargsセクションでは、コンテナ起動時の引数を与えます。"--vm-bytes", "150M"という引数では、コンテナに150MiBのメモリーを割り当てます。
Podを作成してください:
kubectl apply -f https://k8s.io/examples/pods/resource/memory-request-limit.yaml --namespace= mem-example
Podのコンテナが起動していることを検証してください:
kubectl get pod memory-demo --namespace= mem-example
Podの詳細な情報を確認してください:
kubectl get pod memory-demo --output= yaml --namespace= mem-example
この出力では、Pod内の一つのコンテナに100MiBのメモリー要求と200MiBのメモリー制限があることを示しています。
...
resources :
limits :
memory : 200Mi
requests :
memory : 100Mi
...
kubectl topを実行し、Podのメトリクスを取得してください:
kubectl top pod memory-demo --namespace= mem-example
この出力では、Podが約162,900,000バイト(約150MiB)のメモリーを使用していることを示しています。Podの100MiBの要求を超えていますが、200MiBの制限には収まっています。
NAME CPU(cores) MEMORY(bytes)
memory-demo <something> 162856960
Podを削除してください:
kubectl delete pod memory-demo --namespace= mem-example
コンテナのメモリー制限を超える ノードに利用可能なメモリーがある場合、コンテナはメモリー要求を超えることができます。しかしながら、メモリー制限を超えて使用することは許可されません。コンテナが制限を超えてメモリーを確保しようとした場合、そのコンテナは終了候補となります。コンテナが制限を超えてメモリーを消費し続ける場合、コンテナは終了されます。終了したコンテナを再起動できる場合、ほかのランタイムの失敗時と同様に、kubeletがコンテナを再起動させます。
この練習では、制限を超えてメモリーを確保しようとするPodを作成します。以下に50MiBのメモリー要求と100MiBのメモリー制限を与えたコンテナを持つ、Podの設定ファイルを示します:
apiVersion : v1
kind : Pod
metadata :
name : memory-demo-2
namespace : mem-example
spec :
containers :
- name : memory-demo-2-ctr
image : polinux/stress
resources :
requests :
memory : "50Mi"
limits :
memory : "100Mi"
command : ["stress" ]
args : ["--vm" , "1" , "--vm-bytes" , "250M" , "--vm-hang" , "1" ]
設定ファイルのargsセクションでは、コンテナに250MiBのメモリーを割り当てており、これは100MiBの制限を十分に超えています。
Podを作成してください:
kubectl apply -f https://k8s.io/examples/pods/resource/memory-request-limit-2.yaml --namespace= mem-example
Podの詳細な情報を確認してください:
kubectl get pod memory-demo-2 --namespace= mem-example
この時点で、コンテナは起動中か強制終了されているでしょう。コンテナが強制終了されるまで上記のコマンドをくり返し実行してください:
NAME READY STATUS RESTARTS AGE
memory-demo-2 0/1 OOMKilled 1 24s
コンテナステータスの詳細な情報を取得してください:
kubectl get pod memory-demo-2 --output= yaml --namespace= mem-example
この出力では、コンテナがメモリー不足 (OOM) により強制終了されたことを示しています。
lastState:
terminated:
containerID: docker://65183c1877aaec2e8427bc95609cc52677a454b56fcb24340dbd22917c23b10f
exitCode: 137
finishedAt: 2017-06-20T20:52:19Z
reason: OOMKilled
startedAt: null
この練習のコンテナはkubeletによって再起動されます。次のコマンドを数回くり返し実行し、コンテナが強制終了と再起動を続けていることを確認してください:
kubectl get pod memory-demo-2 --namespace= mem-example
この出力では、コンテナが強制終了され、再起動され、再度強制終了および再起動が続いていることを示しています:
kubectl get pod memory-demo-2 --namespace=mem-example
NAME READY STATUS RESTARTS AGE
memory-demo-2 0/1 OOMKilled 1 37s
kubectl get pod memory-demo-2 --namespace=mem-example
NAME READY STATUS RESTARTS AGE
memory-demo-2 1/1 Running 2 40s
Podの履歴について詳細な情報を確認してください:
kubectl describe pod memory-demo-2 --namespace=mem-example
この出力では、コンテナの開始とその失敗が繰り返されていることを示しています:
... Normal Created Created container with id 66a3a20aa7980e61be4922780bf9d24d1a1d8b7395c09861225b0eba1b1f8511
... Warning BackOff Back-off restarting failed container
クラスターのノードの詳細な情報を確認してください:
kubectl describe nodes
この出力には、メモリー不足の状態のためコンテナが強制終了された記録が含まれます:
Warning OOMKilling Memory cgroup out of memory: Kill process 4481 (stress) score 1994 or sacrifice child
Podを削除してください:
kubectl delete pod memory-demo-2 --namespace= mem-example
ノードよりも大きいメモリー要求を指定する メモリー要求と制限はコンテナと関連づけられていますが、Podにメモリー要求と制限が与えられていると考えるとわかりやすいでしょう。Podのメモリー要求は、Pod内のすべてのコンテナのメモリー要求の合計となります。同様に、Podのメモリー制限は、Pod内のすべてのコンテナのメモリー制限の合計となります。
Podのスケジューリングは要求に基づいています。Podはノード上で動作するうえで、そのメモリー要求に対してノードに十分利用可能なメモリーがある場合のみスケジュールされます。
この練習では、クラスター内のノードのキャパシティを超える大きさのメモリー要求を与えたPodを作成します。以下に1000GiBのメモリー要求を与えた一つのコンテナを持つ、Podの設定ファイルを示します。これは、クラスター内のノードのキャパシティを超える可能性があります。
apiVersion : v1
kind : Pod
metadata :
name : memory-demo-3
namespace : mem-example
spec :
containers :
- name : memory-demo-3-ctr
image : polinux/stress
resources :
limits :
memory : "1000Gi"
requests :
memory : "1000Gi"
command : ["stress" ]
args : ["--vm" , "1" , "--vm-bytes" , "150M" , "--vm-hang" , "1" ]
Podを作成してください:
kubectl apply -f https://k8s.io/examples/pods/resource/memory-request-limit-3.yaml --namespace= mem-example
Podの状態を確認してください:
kubectl get pod memory-demo-3 --namespace= mem-example
この出力では、Podのステータスが待機中であることを示しています。つまり、Podがどのノードに対しても実行するようスケジュールされておらず、いつまでも待機状態のままであることを表しています:
kubectl get pod memory-demo-3 --namespace=mem-example
NAME READY STATUS RESTARTS AGE
memory-demo-3 0/1 Pending 0 25s
イベントを含むPodの詳細な情報を確認してください:
kubectl describe pod memory-demo-3 --namespace= mem-example
この出力では、ノードのメモリー不足のためコンテナがスケジュールされないことを示しています:
Events:
... Reason Message
------ -------
... FailedScheduling No nodes are available that match all of the following predicates:: Insufficient memory ( 3) .
メモリーの単位 メモリーリソースはバイト単位で示されます。メモリーをE、P、T、G、M、K、Ei、Pi、Ti、Gi、Mi、Kiという接尾辞とともに、整数型または固定小数点整数で表現できます。たとえば、以下はおおよそ同じ値を表します:
128974848, 129e6, 129M , 123Mi
Podを削除してください:
kubectl delete pod memory-demo-3 --namespace= mem-example
メモリー制限を指定しない場合 コンテナのメモリー制限を指定しない場合、次のいずれかの状態となります:
コンテナのメモリー使用量に上限がない状態となります。コンテナは実行中のノードで利用可能なすべてのメモリーを使用でき、その後OOM Killerが呼び出される可能性があります。さらに、OOM killの場合、リソース制限のないコンテナは強制終了される可能性が高くなります。
メモリー制限を与えられたnamespaceでコンテナを実行されると、コンテナにはデフォルトの制限値が自動的に指定されます。クラスターの管理者はLimitRange によってメモリー制限のデフォルト値を指定できます。
メモリー要求と制限のモチベーション クラスターで動作するコンテナにメモリー要求と制限を設定することで、クラスターのノードで利用可能なメモリーリソースを効率的に使用することができます。Podのメモリー要求を低く保つことで、Podがスケジュールされやすくなります。メモリー要求よりも大きい制限を与えることで、次の2つを実現できます:
Podは利用可能なメモリーを、突発的な活動(バースト)に使用することができます。 バースト中のPodのメモリー使用量は、適切な量に制限されます。 クリーンアップ namespaceを削除してください。これにより、今回のタスクで作成したすべてのPodが削除されます:
kubectl delete namespace mem-example
次の項目 アプリケーション開発者向け クラスター管理者向け 4.3.2 - コンテナおよびPodへのCPUリソースの割り当て このページでは、CPUの request と limit をコンテナに割り当てる方法について示します。コンテナは設定された制限を超えてCPUを使用することはできません。システムにCPUの空き時間がある場合、コンテナには要求されたCPUを割り当てられます。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
タスク例を実行するには、クラスターに少なくとも利用可能な1 CPUが必要です。
このページのいくつかの手順では、クラスターにてmetrics-server サービスを実行する必要があります。すでにmetrics-serverが動作している場合、これらの手順をスキップできます。
Minikube を動作させている場合、以下のコマンドによりmetrics-serverを有効にできます:
minikube addons enable metrics-server
metrics-serverが実行されているか、もしくはリソースメトリクスAPI (metrics.k8s.io) の別のプロバイダーが実行されていることを確認するには、以下のコマンドを実行してください:
リソースメトリクスAPIが利用可能であれば、出力には metrics.k8s.io への参照が含まれます。
NAME
v1beta1.metrics.k8s.io
namespaceの作成 この練習で作成するリソースがクラスター内で分離されるよう、Namespace を作成します。
kubectl create namespace cpu-example
CPUの要求と制限を指定する コンテナにCPUの要求を指定するには、コンテナのリソースマニフェストにresources:requestsフィールドを追記します。CPUの制限を指定するには、resources:limitsを追記します。
この練習では、一つのコンテナをもつPodを作成します。コンテナに0.5 CPUの要求と1 CPUの制限を与えます。Podの設定ファイルは次のようになります:
apiVersion : v1
kind : Pod
metadata :
name : cpu-demo
namespace : cpu-example
spec :
containers :
- name : cpu-demo-ctr
image : vish/stress
resources :
limits :
cpu : "1"
requests :
cpu : "0.5"
args :
- -cpus
- "2"
設定ファイルのargsセクションでは、コンテナ起動時の引数を与えます。-cpus "2"という引数では、コンテナに2 CPUを割り当てます。
Podを作成してください:
kubectl apply -f https://k8s.io/examples/pods/resource/cpu-request-limit.yaml --namespace= cpu-example
Podのコンテナが起動していることを検証してください:
kubectl get pod cpu-demo --namespace= cpu-example
Podの詳細な情報を確認してください:
kubectl get pod cpu-demo --output= yaml --namespace= cpu-example
この出力では、Pod内の一つのコンテナに500ミリCPUの要求と1 CPUの制限があることを示しています。
resources :
limits :
cpu : "1"
requests :
cpu : 500m
kubectl topを実行し、Podのメトリクスを取得してください:
kubectl top pod cpu-demo --namespace= cpu-example
この出力では、Podが974ミリCPUを使用していることを示しています。Podの設定で指定した1 CPUの制限よりわずかに小さい値です。
NAME CPU(cores) MEMORY(bytes)
cpu-demo 974m <something>
-cpu "2"を設定することで、コンテナが2 CPU利用しようとすることを思い出してください。しかしながら、コンテナは約1 CPUしか使用することができません。コンテナが制限よりも多くのCPUリソースを利用しようとしているため、コンテナのCPUの利用が抑制されています。
備考: CPUの使用量が1.0未満である理由の可能性して、ノードに利用可能なCPUリソースが十分にないことが挙げられます。この練習における必要条件として、クラスターに少なくとも利用可能な1 CPUが必要であることを思い出してください。1 CPUのノード上でコンテナを実行させる場合、指定したコンテナのCPU制限にかかわらず、コンテナは1 CPU以上使用することはできません。CPUの単位 CPUリソースは CPU の単位で示されます。Kubernetesにおいて1つのCPUは次に等しくなります:
1 AWS vCPU 1 GCPコア 1 Azure vCore ハイパースレッディングが有効なベアメタルIntelプロセッサーの1スレッド 小数値も利用可能です。0.5 CPUを要求するコンテナには、1 CPUを要求するコンテナの半分のCPUが与えられます。mというミリを表す接尾辞も使用できます。たとえば、100m CPU、100 milliCPU、0.1 CPUはすべて同じです。1m以上の精度は指定できません。
CPUはつねに絶対量として要求され、決して相対量としては要求されません。0.1はシングルコア、デュアルコア、48コアCPUのマシンで同じ量となります。
Podを削除してください:
kubectl delete pod cpu-demo --namespace= cpu-example
ノードよりも大きいCPU要求を指定する CPU要求と制限はコンテナと関連づけられていますが、PodにCPU要求と制限が与えられていると考えるとわかりやすいでしょう。PodのCPU要求は、Pod内のすべてのコンテナのCPU要求の合計となります。同様に、PodのCPU制限は、Pod内のすべてのコンテナのCPU制限の合計となります。
Podのスケジューリングはリソースの要求量に基づいています。Podはノード上で動作するうえで、そのCPU要求に対してノードに十分利用可能なCPUリソースがある場合のみスケジュールされます。
この練習では、クラスター内のノードのキャパシティを超える大きさのCPU要求を与えたPodを作成します。以下に100 CPUの要求を与えた一つのコンテナを持つ、Podの設定ファイルを示します。これは、クラスター内のノードのキャパシティを超える可能性があります。
apiVersion : v1
kind : Pod
metadata :
name : cpu-demo-2
namespace : cpu-example
spec :
containers :
- name : cpu-demo-ctr-2
image : vish/stress
resources :
limits :
cpu : "100"
requests :
cpu : "100"
args :
- -cpus
- "2"
Podを作成してください:
kubectl apply -f https://k8s.io/examples/pods/resource/cpu-request-limit-2.yaml --namespace= cpu-example
Podの状態を確認してください:
kubectl get pod cpu-demo-2 --namespace= cpu-example
この出力では、Podのステータスが待機中であることを示しています。つまり、Podがどのノードに対しても実行するようスケジュールされておらず、いつまでも待機状態のままであることを表しています:
NAME READY STATUS RESTARTS AGE
cpu-demo-2 0/1 Pending 0 7m
イベントを含むPodの詳細な情報を確認してください:
kubectl describe pod cpu-demo-2 --namespace= cpu-example
この出力では、ノードのCPU不足のためコンテナがスケジュールされないことを示しています:
Events:
Reason Message
------ -------
FailedScheduling No nodes are available that match all of the following predicates:: Insufficient cpu (3).
Podを削除してください:
kubectl delete pod cpu-demo-2 --namespace= cpu-example
CPU制限を指定しない場合 コンテナのCPU制限を指定しない場合、次のいずれかの状態となります:
CPU要求と制限のモチベーション クラスターで動作するコンテナにCPU要求と制限を設定することで、クラスターのノードで利用可能なCPUリソースを効率的に使用することができます。PodのCPU要求を低く保つことで、Podがスケジュールされやすくなります。CPU要求よりも大きい制限を与えることで、次の2つを実現できます:
Podは利用可能なCPUリソースを、突発的な活動(バースト)に使用することができます。 バースト中のPodのCPUリソース量は、適切な量に制限されます。 クリーンアップ namespaceを削除してください:
kubectl delete namespace cpu-example
次の項目 アプリケーション開発者向け クラスター管理者向け 4.3.3 - Windows Podとコンテナに対するGMSAの設定 FEATURE STATE:
Kubernetes v1.18 [stable]
このページでは、Windowsノード上で動作するPodとコンテナに対するグループ管理サービスアカウント (GMSA)の設定方法を示します。
グループ管理サービスアカウントは特別な種類のActive Directoryアカウントで、パスワードの自動管理、簡略化されたサービスプリンシパル名(SPN)の管理、および管理を他の管理者に委任する機能を複数のサーバーに提供します。
Kubernetesでは、GMSA資格情報仕様は、Kubernetesクラスター全体をスコープとするカスタムリソースとして設定されます。
WindowsのPodおよびPod内の個々のコンテナは、他のWindowsサービスとやり取りする際に、ドメインベースの機能(例えばKerberos認証)に対してGMSAを使用するように設定できます。
始める前に Kubernetesクラスターが必要で、kubectlコマンドラインツールがクラスターと通信できるように設定されている必要があります。
クラスターにはWindowsワーカーノードを持つことが求められます。
このセクションでは、各クラスターに対して一度だけ実施する必要がある一連の初期ステップについて説明します:
GMSACredentialSpec CRDのインストール カスタムリソースタイプGMSACredentialSpecを定義するために、GMSA資格情報仕様リソースに対するCustomResourceDefinition (CRD)をクラスター上で設定する必要があります。
GMSA CRDのYAML をダウンロードし、gmsa-crd.yamlとして保存します。
次に、kubectl apply -f gmsa-crd.yamlを実行してCRDをインストールします。
GMSAユーザーを検証するためのWebhookのインストール Podまたはコンテナレベルで参照するGMSA資格情報仕様を追加および検証するために、Kubernetesクラスター上で2つのWebhookを設定する必要があります:
Mutating Webhookは、(Podの仕様から名前で指定された)GMSAへの参照を、JSON形式の完全な資格情報仕様としてPodのspecの中へ展開します。
Validating Webhookは、すべてのGMSAへの参照に対して、Podサービスアカウントによる利用が認可されているか確認します。
上記Webhookと関連するオブジェクトをインストールするためには、次の手順が必要です:
証明書と鍵のペアを作成します(Webhookコンテナがクラスターと通信できるようにするために使用されます)
上記の証明書を含むSecretをインストールします。
コアとなるWebhookロジックのためのDeploymentを作成します。
Deploymentを参照するValidating WebhookとMutating Webhookの設定を作成します。
上で述べたGMSA Webhookと関連するオブジェクトを展開、構成するためのスクリプト があります。
スクリプトは、--dry-run=serverオプションをつけることで、クラスターに対して行われる変更内容をレビューすることができます。
Webhookと関連するオプジェクトを(適切なパラメーターを渡すことで)手動で展開するためのYAMLテンプレート もあります。
Active DirectoryにGMSAとWindowsノードを構成する Windows GMSAのドキュメント に記載されている通り、Kubernetes内のPodがGMSAを使用するために設定できるようにする前に、Active Directory内に目的のGMSAを展開する必要があります。
Windows GMSAのドキュメント に記載されている通り、(Kubernetesクラスターの一部である)Windowsワーカーノードは、目的のGMSAに関連づけられたシークレット資格情報にアクセスできるように、Active Directory内で設定されている必要があります。
GMSA資格情報仕様リソースの作成 (前述の通り)GMSACredentialSpec CRDをインストールすると、GMSA資格情報仕様を含むカスタムリソースを設定できます。
GMSA資格情報仕様には、シークレットや機密データは含まれません。
それは、コンテナランタイムが目的のコンテナのGMSAをWindowsに対して記述するために使用できる情報です。
GMSA資格情報仕様は、PowerShellスクリプト のユーティリティを使用して、YAMLフォーマットで生成することができます。
以下は、GMSA資格情報仕様をJSON形式で手動で生成し、その後それをYAMLに変換する手順です:
CredentialSpecモジュール をインポートします: ipmo CredentialSpec.psm1
New-CredentialSpecを使用してJSONフォーマットの資格情報仕様を作成します。
WebApp1という名前のGMSA資格情報仕様を作成するには、New-CredentialSpec -Name WebApp1 -AccountName WebApp1 -Domain $(Get-ADDomain -Current LocalComputer)を実行します
Get-CredentialSpecを使用して、JSONファイルのパスを表示します。
credspecファイルをJSON形式からYAML形式に変換し、Kubernetesで設定可能なGMSACredentialSpecカスタムリソースにするために、必要なヘッダーフィールドであるapiVersion、kind、metadata、credspecを記述します。
次のYAML設定は、gmsa-WebApp1という名前のGMSA資格情報仕様を記述しています:
apiVersion : windows.k8s.io/v1
kind : GMSACredentialSpec
metadata :
name : gmsa-WebApp1 # これは任意の名前で構いませんが、参照時に使用されます
credspec :
ActiveDirectoryConfig :
GroupManagedServiceAccounts :
- Name : WebApp1 # GMSAアカウントのユーザー名
Scope : CONTOSO # NETBIOSドメイン名
- Name : WebApp1 # GMSAアカウントのユーザー名
Scope : contoso.com # DNSドメイン名
CmsPlugins :
- ActiveDirectory
DomainJoinConfig :
DnsName : contoso.com # DNSドメイン名
DnsTreeName : contoso.com # DNSルートドメイン名
Guid : 244818ae-87ac-4fcd-92ec-e79e5252348a # GUID
MachineAccountName : WebApp1 # GMSAアカウントのユーザー名
NetBiosName : CONTOSO # NETBIOSドメイン名
Sid : S-1-5-21-2126449477-2524075714-3094792973 # GMSAのSID
上記の資格情報仕様リソースはgmsa-Webapp1-credspec.yamlとして保存され、次のコマンドを使用してクラスターに適用されます: kubectl apply -f gmsa-Webapp1-credspec.yml
指定されたGMSA資格情報仕様上にRBACを有効にするためのクラスターロールの設定 各GMSA資格情報仕様リソースに対して、クラスターロールを定義する必要があります。
これは特定のGMSAリソース上のuse verbを、通常はサービスアカウントであるsubjectに対して認可します。
次の例は、前述のgmsa-WebApp1資格情報仕様の利用を認可するクラスターロールを示しています。
ファイルをgmsa-webapp1-role.yamlとして保存し、kubectl apply -f gmsa-webapp1-role.yamlを使用して適用します。
# credspecを読むためのロールを作成
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRole
metadata :
name : webapp1-role
rules :
apiGroups : ["windows.k8s.io" ]
resources : ["gmsacredentialspecs" ]
verbs : ["use" ]
resourceNames : ["gmsa-WebApp1" ]
指定されたGMSA credspecを使用するためのサービスアカウントへのロールの割り当て (Podに対して設定される)サービスアカウントを、上で作成したクラスターロールに結びつける必要があります。
これによって、要求されたGMSA資格情報仕様のリソースの利用をサービスアカウントに対して認可できます。
以下は、上で作成した資格情報仕様リソースgmsa-WebApp1を使うために、既定のサービスアカウントに対してクラスターロールwebapp1-roleを割り当てる方法を示しています。
apiVersion : rbac.authorization.k8s.io/v1
kind : RoleBinding
metadata :
name : allow-default-svc-account-read-on-gmsa-WebApp1
namespace : default
subjects :
kind : ServiceAccount
name : default
namespace : default
roleRef :
kind : ClusterRole
name : webapp1-role
apiGroup : rbac.authorization.k8s.io
Podのspec内で参照するGMSA資格情報仕様の設定 PodのspecのフィールドsecurityContext.windowsOptions.gmsaCredentialSpecNameは、要求されたGMSA資格情報仕様のカスタムリソースに対する参照を、Podのspec内で指定するために使用されます。
これは、Podのspec内の全てのコンテナに対して、指定されたGMSAを使用するように設定します。
gmsa-WebApp1を参照するために追加された注釈を持つPodのspecのサンプルです:
apiVersion : apps/v1
kind : Deployment
metadata :
labels :
run : with-creds
name : with-creds
namespace : default
spec :
replicas : 1
selector :
matchLabels :
run : with-creds
template :
metadata :
labels :
run : with-creds
spec :
securityContext :
windowsOptions :
gmsaCredentialSpecName : gmsa-webapp1
containers :
- image : mcr.microsoft.com/windows/servercore/iis:windowsservercore-ltsc2019
imagePullPolicy : Always
name : iis
nodeSelector :
kubernetes.io/os : windows
Podのspec内の個々のコンテナも、コンテナ毎のsecurityContext.windowsOptions.gmsaCredentialSpecNameフィールドを使用することで、要求されたGMSA credspecを指定することができます。
設定例:
apiVersion : apps/v1
kind : Deployment
metadata :
labels :
run : with-creds
name : with-creds
namespace : default
spec :
replicas : 1
selector :
matchLabels :
run : with-creds
template :
metadata :
labels :
run : with-creds
spec :
containers :
- image : mcr.microsoft.com/windows/servercore/iis:windowsservercore-ltsc2019
imagePullPolicy : Always
name : iis
securityContext :
windowsOptions :
gmsaCredentialSpecName : gmsa-Webapp1
nodeSelector :
kubernetes.io/os : windows
(上記のような)GMSAフィールドが入力されたPod specがクラスターに適用されると、次の一連のイベントが発生します:
Mutating WebhookがGMSA資格情報仕様リソースへの全ての参照を解決し、GMSA資格情報仕様の内容を展開します。
Validating Webhookは、Podに関連付けられたサービスアカウントが、指定されたGMSA資格情報仕様上のuse verbに対して認可されていることを保証します。
コンテナランタイムは、指定されたGMSA資格情報仕様で各Windowsコンテナを設定します。
それによってコンテナはGMSAのIDがActive Directory内にあることを仮定でき、そのIDを使用してドメイン内のサービスにアクセスできます。
ホスト名またはFQDNを使用してネットワーク共有に対して認証する PodからSMB共有へのホスト名やFQDNを使用した接続で問題が発生した際に、IPv4アドレスではSMB共有にアクセスすることはできる場合には、次のレジストリキーがWindowsノード上で設定されているか確認してください。
reg add "HKLM\SYSTEM\CurrentControlSet\Services\hns\State" /v EnableCompartmentNamespace /t REG_DWORD /d 1
その後、動作の変更を反映させるために、実行中のPodを再作成する必要があります。
このレジストリキーがどのように使用されるかについてのより詳細な情報は、こちら を参照してください。
トラブルシューティング 自分の環境でGMSAがうまく動作しない時に実行できるトラブルシューティングステップがあります。
まず、credspecがPodに渡されたことを確認します。
そのためには、Podのひとつにexecで入り、nltest.exe /parentdomainコマンドの出力をチェックする必要があります。
以下の例では、Podはcredspecを正しく取得できませんでした:
kubectl exec -it iis-auth -7776966999 -n5nzr powershell.exe
nltest.exe /parentdomainの結果は次のようなエラーになります:
Getting parent domain failed: Status = 1722 0x6ba RPC_S_SERVER_UNAVAILABLE
Podが正しくcredspecを取得したら、次にドメインと正しく通信できることを確認します。
まずはPodの中から、ドメインのルートを見つけるために、手短にnslookupを実行します。
これから3つのことがわかります:
PodがDCまで到達できる DCがPodに到達できる DNSが正しく動作している DNSと通信のテストをパスしたら、次にPodがドメインとセキュアチャネル通信を構築することができるか確認する必要があります。
そのためには、再びexecを使用してPodの中に入り、nltest.exe /queryコマンドを実行します。
結果は次のように出力されます:
I_NetLogonControl failed: Status = 1722 0x6ba RPC_S_SERVER_UNAVAILABLE
これは、Podがなんらかの理由で、credspec内で指定されたアカウントを使用してドメインにログオンできなかったことを示しています。
次のコマンドを実行してセキュアチャネルを修復してみてください:
nltest /sc_reset: domain.example
コマンドが成功したら、このような出力を確認することができます:
Flags: 30 HAS_IP HAS_TIMESERV
Trusted DC Name \\dc10.domain.example
Trusted DC Connection Status Status = 0 0x0 NERR_Success
The command completed successfully
もし上記によってエラーが解消された場合は、次のライフサイクルフックをPodのspecに追加することで、手順を自動化できます。
エラーが解消されなかった場合は、credspecをもう一度調べ、正しく完全であることを確認する必要があります。
image : registry.domain.example/iis-auth:1809v1
lifecycle :
postStart :
exec :
command : ["powershell.exe" ,"-command" ,"do { Restart-Service -Name netlogon } while ( $($Result = (nltest.exe /query); if ($Result -like '*0x0 NERR_Success*') {return $true} else {return $false}) -eq $false)" ]
imagePullPolicy : IfNotPresent
Podのspecに上記のlifecycleセクションを追加すると、nltest.exe /queryコマンドがエラーとならずに終了するまでnetlogonサービスを再起動するために、Podは一連のコマンドを実行します。
4.3.4 - コンテナに割り当てるCPUとメモリ容量を変更する FEATURE STATE:
Kubernetes v1.35 [stable](enabled by default)
このページはQuality of Service に馴染みのある読者を前提としています。
このページでは、稼働中のPodやコンテナを再起動することなく、コンテナに割り当てられるCPUやメモリ容量を変更(リサイズ)するための方法を示します。
Kubernetesノードは、PodのContainerに指定したrequestsに基づいてPodにリソースを割り当て、limitsに基づいてPodのリソース使用量を制限します。
稼働中のPodのリソース割当を変更するには、 InPlacePodVerticalScaling フィーチャーゲート を有効化する必要があります。
代替手法としては、Podを削除した上で、異なるリソース要求を有するPodをワークロードコントローラー に作成させることもできます。
稼働中のPodのリソースを変更するために
Containerの requests と limits はCPUおよびメモリリソースに対して 可変 なものとなっています。 Podステータスの containerStatuses における allocatedResources フィールドは、PodのContainerに割り当てられたリソースを反映します。 Podステータスの containerStatuses における resources フィールドは、稼働中Containerに設定済みの実際のリソース要求(requests)とリソース制限(limits)を反映しており、これらの値はコンテナランタイムが通知したものです。 Podステータスの resize フィールドは直前の適用待ちのリサイズ要求を示します。
このフィールドの値には次のようなものがあります。Proposed: リサイズ要求の受理を表し、リクエストが検証済みかつ記録済み
であることを示します。InProgress: リサイズ要求がノードによって受理され、Podのコンテナに対する
適用が進行中であることを示します。Deferred: リサイズ要求が現時点では通っていないことを示します。
他のPodが除去されてノードの資源が開放されたら、リサイズが承認されるかもしれません。Infeasible: ノードがリサイズ要求に対応できないことを示すシグナルです。
Podに対してノードが割り当て可能なリソースの最大値を上回るリサイズ要求がある時に
発生する可能性があります。 始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: 1.27.
バージョンを確認するには次のコマンドを実行してください: kubectl version.
クラスターのコントロールプレーンを含む全ノードでInPlacePodVerticalScaling フィーチャーゲート が有効化されている必要があります。
コンテナリサイズポリシー リサイズポリシーはPodにおけるコンテナのCPUやメモリリソースを取り扱うためのきめ細かい制御を可能にします。
例えば、アプリケーションを再起動せずにコンテナのCPUリソースのリサイズを行える場合でも、メモリのリサイズについてはアプリケーションとコンテナの再起動が必要となる場合があります。
これを実現するために、ユーザーはContainerの仕様に resizePolicy を指定できるようになっています。
以下の再起動ポリシーをCPUやメモリのリサイズの際に指定できます。
NotRequired: 稼働中のコンテナリソースをリサイズします。RestartContainer: コンテナを再起動させ、再起動時に新しいリソースを適用します。resizePolicy[*].restartPolicy が指定されない場合のデフォルトは、NotRequiredです。
備考: PodのrestartPolicyがNeverである場合、Podの全コンテナの再起動ポリシーがNotRequiredである必要があります。以下のPodの例は、ContainerのCPUのリサイズは再起動なしで実施させ、メモリのリサイズにはコンテナの再起動を要求するものです。
apiVersion : v1
kind : Pod
metadata :
name : qos-demo-5
namespace : qos-example
spec :
containers :
- name : qos-demo-ctr-5
image : nginx
resizePolicy :
- resourceName : cpu
restartPolicy : NotRequired
- resourceName : memory
restartPolicy : RestartContainer
resources :
limits :
memory : "200Mi"
cpu : "700m"
requests :
memory : "200Mi"
cpu : "700m"
備考: この例の requests ないしは limits が CPUとメモリの 両方を 変化させる場合、
メモリのリサイズが生じるので、コンテナは再起動します。リソース要求やリソース制限のあるPodを作成する リソース要求やリソース制限をPodのコンテナに指定することで、保証(Guaranteed)ないしは バースト可能(Burstable)なQuality of Service クラスのPodを作成することができます。
次のような単一のコンテナを含むPodのマニフェストを考えてみましょう。
apiVersion : v1
kind : Pod
metadata :
name : qos-demo-5
namespace : qos-example
spec :
containers :
- name : qos-demo-ctr-5
image : nginx
resources :
limits :
memory : "200Mi"
cpu : "700m"
requests :
memory : "200Mi"
cpu : "700m"
Podをqos-example Namespace に作成します。
kubectl create namespace qos-example
kubectl create -f https://k8s.io/examples/pods/qos/qos-pod-5.yaml
このPodは保証QoSクラスに区分され、700mのCPU、200Miのメモリを要求します。
Podの詳細な情報を見てみましょう。
kubectl get pod qos-demo-5 --output= yaml --namespace= qos-example
resizePolicy[*].restartPolicyの値がデフォルトのNotRequiredになっていることに気づいたでしょうか。
これはCPUとメモリがコンテナ稼働中にリサイズできることを示しています。
spec :
containers :
...
resizePolicy :
- resourceName : cpu
restartPolicy : NotRequired
- resourceName : memory
restartPolicy : NotRequired
resources :
limits :
cpu : 700m
memory : 200Mi
requests :
cpu : 700m
memory : 200Mi
...
containerStatuses :
...
name : qos-demo-ctr-5
ready : true
...
allocatedResources :
cpu : 700m
memory : 200Mi
resources :
limits :
cpu : 700m
memory : 200Mi
requests :
cpu : 700m
memory : 200Mi
restartCount : 0
started : true
...
qosClass : Guaranteed
Podのリソースを更新する 要求CPUを0.8CPUに増やしてみます。
これは手動でも指定できますし、VerticalPodAutoscaler (VPA)などを用いて自動的に検出/適用することもできます。
備考: Podのリソース要求やリソース制限を変更して希望の容量に合わせることはできますが、Pod作成時に指定したQoSクラスを変更することはできません。PodのContainerのCPU要求とCPU制限をいずれも800mに指定するパッチを当ててみます。
kubectl -n qos-example patch pod qos-demo-5 --patch '{"spec":{"containers":[{"name":"qos-demo-ctr-5", "resources":{"requests":{"cpu":"800m"}, "limits":{"cpu":"800m"}}}]}}'
Podへのパッチが当たったら、Podの詳細情報を参照してみましょう。
kubectl get pod qos-demo-5 --output= yaml --namespace= qos-example
以下のPod仕様は更新済みのCPU要求とCPU制限を反映しています。
spec :
containers :
...
resources :
limits :
cpu : 800m
memory : 200Mi
requests :
cpu : 800m
memory : 200Mi
...
containerStatuses :
...
allocatedResources :
cpu : 800m
memory : 200Mi
resources :
limits :
cpu : 800m
memory : 200Mi
requests :
cpu : 800m
memory : 200Mi
restartCount : 0
started : true
期待する新しいCPU要求を反映する形で allocatedResources の値が更新されていることを確認しておきましょう。
これはノードがCPUリソースの追加要求に対応できたことを示しています。
Containerの状態においてはCPUリソースの値が更新されており、新しいCPUリソースが適用されたことを示しています。
ContainerのrestartCountは変化しておらず、コンテナのCPUリソースがコンテナの再起動なしで変更されたことを示しています。
クリーンアップ 名前空間を削除しましょう。
kubectl delete namespace qos-example
次の項目 アプリケーション開発者向け クラスター管理者向け 4.3.5 - PodにQuality of Serviceを設定する このページでは、特定のQuality of Service (QoS)クラスをPodに割り当てるための設定方法を示します。Kubernetesは、Podのスケジューリングおよび退役を決定するためにQoSクラスを用います。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
QoSクラス KubernetesはPodの作成時に次のいずれかのQoSクラスをPodに割り当てます:
Guaranteed Burstable BestEffort namespaceの作成 この演習で作成するリソースがクラスター内で分離されるよう、namespaceを作成します。
kubectl create namespace qos-example
GuaranteedのQoSクラスを割り当てたPodを作成する PodにGuaranteedのQoSクラスを与えるには、以下が必要になります:
Pod内のすべてのコンテナにメモリーの制限と要求が与えられており、同じ値であること。 Pod内のすべてのコンテナにCPUの制限と要求が与えられており、同じ値であること。 以下に1つのコンテナをもつPodの設定ファイルを示します。コンテナには200MiBのメモリー制限とリクエストを与え、700ミリCPUの制限と要求を与えます。
apiVersion : v1
kind : Pod
metadata :
name : qos-demo
namespace : qos-example
spec :
containers :
- name : qos-demo-ctr
image : nginx
resources :
limits :
memory : "200Mi"
cpu : "700m"
requests :
memory : "200Mi"
cpu : "700m"
Podを作成してください:
kubectl apply -f https://k8s.io/examples/pods/qos/qos-pod.yaml --namespace= qos-example
Podの詳細な情報を確認してください:
kubectl get pod qos-demo --namespace= qos-example --output= yaml
この出力では、KubernetesがPodにGuaranteed QoSクラスを与えたことを示しています。Podのコンテナにメモリー制限と一致するメモリー要求があり、CPU制限と一致するCPU要求があることも確認できます。
spec :
containers :
...
resources :
limits :
cpu : 700m
memory : 200Mi
requests :
cpu : 700m
memory : 200Mi
...
status :
qosClass : Guaranteed
備考: コンテナにメモリー制限を指定し、メモリー要求を指定していない場合は、Kubernetesは自動的にメモリー制限と一致するメモリー要求を割り当てます。同様に、コンテナにCPU制限を指定し、CPU要求を指定していない場合は、Kubernetesは自動的にCPU制限と一致するCPU要求を割り当てます。Podを削除してください:
kubectl delete pod qos-demo --namespace= qos-example
BurstableのQoSクラスを割り当てたPodを作成する 次のような場合に、Burstable QoSクラスがPodに与えられます:
PodがGuaranteed QoSクラスの基準に満たない場合。 Pod内の1つ以上のコンテナがメモリーまたはCPUの要求を与えられている場合。 以下に1つのコンテナをもつPodの設定ファイルを示します。コンテナには200MiBのメモリー制限と100MiBのメモリー要求を与えます。
apiVersion : v1
kind : Pod
metadata :
name : qos-demo-2
namespace : qos-example
spec :
containers :
- name : qos-demo-2-ctr
image : nginx
resources :
limits :
memory : "200Mi"
requests :
memory : "100Mi"
Podを作成してください:
kubectl apply -f https://k8s.io/examples/pods/qos/qos-pod-2.yaml --namespace= qos-example
Podの詳細な情報を確認してください:
kubectl get pod qos-demo-2 --namespace= qos-example --output= yaml
この出力では、KubernetesがPodにBurstable QoSクラスを与えたことを示しています。
spec :
containers :
- image : nginx
imagePullPolicy : Always
name : qos-demo-2-ctr
resources :
limits :
memory : 200Mi
requests :
memory : 100Mi
...
status :
qosClass : Burstable
Podを削除してください:
kubectl delete pod qos-demo-2 --namespace= qos-example
BestEffortのQoSクラスを割り当てたPodを作成する PodにBestEffort QoSクラスを与えるには、Pod内のコンテナにはメモリーやCPUの制限や要求を指定してはなりません。
以下に1つのコンテナをもつPodの設定ファイルを示します。コンテナにはメモリーやCPUの制限や要求がありません:
apiVersion : v1
kind : Pod
metadata :
name : qos-demo-3
namespace : qos-example
spec :
containers :
- name : qos-demo-3-ctr
image : nginx
Podを作成してください:
kubectl apply -f https://k8s.io/examples/pods/qos/qos-pod-3.yaml --namespace= qos-example
Podの詳細な情報を確認してください:
kubectl get pod qos-demo-3 --namespace= qos-example --output= yaml
この出力では、KubernetesがPodにBestEffort QoSクラスを与えたことを示しています。
spec :
containers :
...
resources : {}
...
status :
qosClass : BestEffort
Podを削除してください:
kubectl delete pod qos-demo-3 --namespace= qos-example
2つのコンテナを含むPodを作成する 以下に2つのコンテナをもつPodの設定ファイルを示します。一方のコンテナは200MiBのメモリー要求を指定し、もう一方のコンテナには要求や制限を指定しません。
apiVersion : v1
kind : Pod
metadata :
name : qos-demo-4
namespace : qos-example
spec :
containers :
- name : qos-demo-4-ctr-1
image : nginx
resources :
requests :
memory : "200Mi"
- name : qos-demo-4-ctr-2
image : redis
このPodがBurstable QoSクラスの基準を満たしていることに注目してください。つまり、Guaranteed QoSクラスの基準に満たしておらず、一方のコンテナにはメモリー要求を与えられています。
Podを作成してください:
kubectl apply -f https://k8s.io/examples/pods/qos/qos-pod-4.yaml --namespace= qos-example
Podの詳細な情報を確認してください:
kubectl get pod qos-demo-4 --namespace= qos-example --output= yaml
この出力では、KubernetesがPodにBurstable QoSクラスを与えたことを示しています:
spec :
containers :
...
name : qos-demo-4-ctr-1
resources :
requests :
memory : 200Mi
...
name : qos-demo-4-ctr-2
resources : {}
...
status :
qosClass : Burstable
Podを削除してください:
kubectl delete pod qos-demo-4 --namespace= qos-example
クリーンアップ namespaceを削除してください:
kubectl delete namespace qos-example
次の項目 アプリケーション開発者向け クラスター管理者向け 4.3.6 - 拡張リソースをコンテナに割り当てる FEATURE STATE:
Kubernetes v1.35 [stable]
このページでは、拡張リソースをコンテナに割り当てる方法について説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
この練習を始める前に、Nodeに拡張リソースをアドバタイズする の練習を行ってください。これにより、Nodeの1つがドングルリソースをアドバタイズするように設定されます。
拡張リソースをPodに割り当てる 拡張リソースをリクエストするには、コンテナのマニフェストにresources:requestsフィールドを含めます。拡張リソースは、*.kubernetes.io/以外の任意のドメインで完全修飾されます。有効な拡張リソース名は、example.com/fooという形式になります。ここで、example.comはあなたの組織のドメインで、fooは記述的なリソース名で置き換えます。
1つのコンテナからなるPodの構成ファイルを示します。
apiVersion : v1
kind : Pod
metadata :
name : extended-resource-demo
spec :
containers :
- name : extended-resource-demo-ctr
image : nginx
resources :
requests :
example.com/dongle : 3
limits :
example.com/dongle : 3
構成ファイルでは、コンテナが3つのdongleをリクエストしていることがわかります。
次のコマンドでPodを作成します。
kubectl apply -f https://k8s.io/examples/pods/resource/extended-resource-pod.yaml
Podが起動したことを確認します。
kubectl get pod extended-resource-demo
Podの説明を表示します。
kubectl describe pod extended-resource-demo
dongleのリクエストが表示されます。
Limits :
example.com/dongle : 3
Requests :
example.com/dongle : 3
2つ目のPodの作成を試みる 以下に、1つのコンテナを持つPodの構成ファイルを示します。コンテナは2つのdongleをリクエストします。
apiVersion : v1
kind : Pod
metadata :
name : extended-resource-demo-2
spec :
containers :
- name : extended-resource-demo-2-ctr
image : nginx
resources :
requests :
example.com/dongle : 2
limits :
example.com/dongle : 2
Kubernetesは、2つのdongleのリクエストを満たすことができません。1つ目のPodが、利用可能な4つのdongleのうち3つを使用してしまっているためです。
Podを作成してみます。
kubectl apply -f https://k8s.io/examples/pods/resource/extended-resource-pod-2.yaml
Podの説明を表示します。
kubectl describe pod extended-resource-demo-2
出力にはPodがスケジュールできないことが示されます。2つのdongleが利用できるNodeが存在しないためです。
Conditions:
Type Status
PodScheduled False
...
Events:
...
... Warning FailedScheduling pod (extended-resource-demo-2) failed to fit in any node
fit failure summary on nodes : Insufficient example.com/dongle (1)
Podのステータスを表示します。
kubectl get pod extended-resource-demo-2
出力には、Podは作成されたものの、Nodeにスケジュールされなかったことが示されています。PodはPending状態になっています。
NAME READY STATUS RESTARTS AGE
クリーンアップ この練習で作成したPodを削除します。
kubectl delete pod extended-resource-demo
kubectl delete pod extended-resource-demo-2
次の項目 アプリケーション開発者向け クラスター管理者向け 4.3.7 - ストレージにボリュームを使用するPodを構成する このページでは、ストレージにボリュームを使用するPodを構成する方法を示します。
コンテナのファイルシステムは、コンテナが存在する間のみ存続します。
そのため、コンテナが終了して再起動すると、ファイルシステムの変更は失われます。
コンテナに依存しない、より一貫したストレージを実現するには、ボリューム を使用できます。
これは、キーバリューストア(Redisなど)やデータベースなどのステートフルアプリケーションにとって特に重要です。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
Podのボリュームを構成する この演習では、1つのコンテナを実行するPodを作成します。
今回作成するPodには、コンテナが終了して再起動した場合でもPodの寿命が続くemptyDir タイプのボリュームがあります。
これがPodの設定ファイルです:
apiVersion : v1
kind : Pod
metadata :
name : redis
spec :
containers :
- name : redis
image : redis
volumeMounts :
- name : redis-storage
mountPath : /data/redis
volumes :
- name : redis-storage
emptyDir : {}
Podを作成します:
kubectl apply -f https://k8s.io/examples/pods/storage/redis.yaml
Podのコンテナが実行されていることを確認し、Podへの変更を監視します:
kubectl get pod redis --watch
出力は次のようになります:
NAME READY STATUS RESTARTS AGE
redis 1/1 Running 0 13s
別のターミナルで、実行中のコンテナへのシェルを取得します:
kubectl exec -it redis -- /bin/bash
シェルで、/data/redisに移動し、ファイルを作成します:
root@redis:/data# cd /data/redis/
root@redis:/data/redis# echo Hello > test-file
シェルで、実行中のプロセスを一覧表示します:
root@redis:/data/redis# apt-get update
root@redis:/data/redis# apt-get install procps
root@redis:/data/redis# ps aux
出力はこのようになります:
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
redis 1 0.1 0.1 33308 3828 ? Ssl 00:46 0:00 redis-server *:6379
root 12 0.0 0.0 20228 3020 ? Ss 00:47 0:00 /bin/bash
root 15 0.0 0.0 17500 2072 ? R+ 00:48 0:00 ps aux
シェルで、Redisプロセスを終了します:
root@redis:/data/redis# kill <pid>
ここで<pid>はRedisプロセスID(PID)です。
元の端末で、Redis Podへの変更を監視します。最終的には、このようなものが表示されます:
NAME READY STATUS RESTARTS AGE
redis 1/1 Running 0 13s
redis 0/1 Completed 0 6m
redis 1/1 Running 1 6m
この時点で、コンテナは終了して再起動しました。
これは、Redis PodのrestartPolicy がAlwaysであるためです。
再起動されたコンテナへのシェルを取得します:
kubectl exec -it redis -- /bin/bash
シェルで/data/redisに移動し、test-fileがまだ存在することを確認します。
root@redis:/data/redis# cd /data/redis/
root@redis:/data/redis# ls
test-file
この演習用に作成したPodを削除します:
次の項目 4.3.8 - ストレージにProjectedボリュームを使用するようPodを設定する このページでは、projectedsecret、configMap、downwardAPIおよびserviceAccountTokenボリュームを投影できます。
備考: serviceAccountTokenはボリュームタイプではありません。始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
ProjectedボリュームをPodに設定する この課題では、ローカルファイルからユーザーネームおよびパスワードのSecret を作成します。
次に、単一のコンテナを実行するPodを作成し、projected
以下にPodの設定ファイルを示します:
apiVersion : v1
kind : Pod
metadata :
name : test-projected-volume
spec :
containers :
- name : test-projected-volume
image : busybox
args :
- sleep
- "86400"
volumeMounts :
- name : all-in-one
mountPath : "/projected-volume"
readOnly : true
volumes :
- name : all-in-one
projected :
sources :
- secret :
name : user
- secret :
name : pass
Secretを作成します:
# ユーザーネームおよびパスワードを含むファイルを作成します:
echo -n "admin" > ./username.txt
echo -n "1f2d1e2e67df" > ./password.txt
# これらのファイルからSecretを作成します:
kubectl create secret generic user --from-file= ./username.txt
kubectl create secret generic pass --from-file= ./password.txt
Podを作成します:
kubectl apply -f https://k8s.io/examples/pods/storage/projected.yaml
Pod内のコンテナが実行されていることを確認するため、Podの変更を監視します:
kubectl get --watch pod test-projected-volume
出力は次のようになります:
NAME READY STATUS RESTARTS AGE
test-projected-volume 1/1 Running 0 14s
別の端末にて、実行中のコンテナへのシェルを取得します:
kubectl exec -it test-projected-volume -- /bin/sh
シェル内にて、投影されたソースを含むprojected-volumeディレクトリが存在することを確認します:
クリーンアップ PodおよびSecretを削除します:
kubectl delete pod test-projected-volume
kubectl delete secret user pass
次の項目 4.3.9 - Podとコンテナにセキュリティコンテキストを設定する セキュリティコンテキストはPod・コンテナの特権やアクセスコントロールの設定を定義します。
セキュリティコンテキストの設定には以下のものが含まれますが、これらに限定はされません。
上記の項目は全てのセキュリティコンテキスト設定を記載しているわけではありません。
より広範囲なリストはSecurityContext を確認してください。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
Podにセキュリティコンテキストを設定する Podにセキュリティ設定を行うには、Podの設定にsecurityContextフィールドを追加してください。
securityContextフィールドはPodSecurityContext オブジェクトが入ります。
Podに設定したセキュリティ設定はPod内の全てのコンテナに適用されます。こちらはsecurityContextとemptyDirボリュームを持ったPodの設定ファイルです。
apiVersion : v1
kind : Pod
metadata :
name : security-context-demo
spec :
securityContext :
runAsUser : 1000
runAsGroup : 3000
fsGroup : 2000
supplementalGroups : [4000 ]
volumes :
- name : sec-ctx-vol
emptyDir : {}
containers :
- name : sec-ctx-demo
image : busybox:1.28
command : [ "sh" , "-c" , "sleep 1h" ]
volumeMounts :
- name : sec-ctx-vol
mountPath : /data/demo
securityContext :
allowPrivilegeEscalation : false 設定ファイルの中のrunAsUserフィールドは、Pod内のコンテナに対して全てのプロセスをユーザーID 1000で実行するように指定します。
runAsGroupフィールドはPod内のコンテナに対して全てのプロセスをプライマリーグループID 3000で実行するように指定します。このフィールドが省略されたときは、コンテナのプライマリーグループIDはroot(0)になります。runAsGroupが指定されている場合、作成されたファイルもユーザー1000とグループ3000の所有物になります。
またfsGroupも指定されているため、全てのコンテナ内のプロセスは補助グループID 2000にも含まれます。/data/demoボリュームとこのボリュームに作成されたファイルはグループID 2000になります。加えて、supplementalGroupsフィールドが指定されている場合、全てのコンテナ内のプロセスは指定されている補助グループIDにも含まれます。もしこのフィールドが指定されていない場合、空を意味します。
Podを作成してみましょう。
kubectl apply -f https://k8s.io/examples/pods/security/security-context.yaml
Podのコンテナが実行されていることを確認します。
kubectl get pod security-context-demo
実行中のコンテナでshellを取ります。
kubectl exec -it security-context-demo -- sh
shellで、実行中のプロセスの一覧を確認します。
runAsUserで指定した値である、ユーザー1000でプロセスが実行されていることが確認できます。
PID USER TIME COMMAND
1 1000 0:00 sleep 1h
6 1000 0:00 sh
...
shellで/dataに入り、ディレクトリの一覧を確認します。
fsGroupで指定した値であるグループID 2000で/data/demoディレクトリが作成されていることが確認できます。
drwxrwsrwx 2 root 2000 4096 Jun 6 20:08 demo
shellで/data/demoに入り、ファイルを作成します。
cd demo
echo hello > testfile
/data/demoディレクトリでファイルの一覧を確認します。
fsGroupで指定した値であるグループID 2000でtestfileが作成されていることが確認できます。
-rw-r--r-- 1 1000 2000 6 Jun 6 20:08 testfile
以下のコマンドを実行してください。
出力はこのようになります。
uid=1000 gid=3000 groups=2000,3000,4000
出力からrunAsGroupフィールドと同じくgidが3000になっていることが確認できるでしょう。runAsGroupが省略された場合、gidは0(root)になり、そのプロセスはグループroot(0)とグループroot(0)に必要なグループパーミッションを持つグループが所有しているファイルを操作することができるようになります。また、groupsの出力に、gidに加えて、fsGroups、supplementalGroupsフィールドで指定したグループIDも含まれていることも確認できるでしょう。
shellから抜けましょう。
コンテナイメージ内の/etc/groupから暗黙的にマージされるグループ情報 Kubernetesは、デフォルトでは、Podで定義された情報に加えて、コンテナイメージ内の/etc/groupのグループ情報をマージします。
apiVersion : v1
kind : Pod
metadata :
name : security-context-demo
spec :
securityContext :
runAsUser : 1000
runAsGroup : 3000
supplementalGroups : [4000 ]
containers :
- name : sec-ctx-demo
image : registry.k8s.io/e2e-test-images/agnhost:2.45
command : [ "sh" , "-c" , "sleep 1h" ]
securityContext :
allowPrivilegeEscalation : false
このPodはsecurity contextでrunAsUser、runAsGroup、supplementalGroupsフィールドが指定されています。しかし、コンテナ内のプロセスには、コンテナイメージ内の/etc/groupに定義されたグループIDが、補助グループとして付与されていることが確認できるでしょう。
Podを作成してみましょう。
kubectl apply -f https://k8s.io/examples/pods/security/security-context-5.yaml
Podのコンテナが実行されていることを確認します。
kubectl get pod security-context-demo
実行中のコンテナでshellを取ります。
kubectl exec -it security-context-demo -- sh
プロセスのユーザー、グループ情報を確認します。
出力はこのようになります。
uid=1000 gid=3000 groups=3000,4000,50000
groupsにグループID50000が含まれていることが確認できるでしょう。これは、ユーザー(uid=1000)がコンテナイメージで定義されており、コンテナイメージ内の/etc/groupでグループ(gid=50000)に所属しているためです。
コンテナイメージの/etc/groupの内容を確認してみましょう。
ユーザー1000がグループ50000に所属していることが確認できるでしょう。
...
user-defined-in-image:x:1000:
group-defined-in-image:x:50000:user-defined-in-image
shellから抜けましょう。
Podにfine-grained(きめ細かい) SupplementalGroups controlを設定する FEATURE STATE:
Kubernetes v1.33 [beta](enabled by default)
この機能はkubeletとkube-apiserverにSupplementalGroupsPolicy
フィーチャーゲート を設定し、Podの.spec.securityContext.supplementalGroupsPolicyフィールドを指定することで利用できます。
supplementalGroupsPolicyフィールドは、Pod内のコンテナプロセスに付与される補助グループを、どのように決定するかを定義します。有効な値は次の2つです。
Merge: /etc/groupで定義されている、コンテナのプライマリユーザーが所属するグループをマージします。指定されていない場合、このポリシーがデフォルトです。
Strict: fsGroup、supplementalGroups、runAsGroupフィールドで指定されたグループのみ補助グループに指定されます。つまり、/etc/groupで定義された、コンテナのプライマリユーザーのグループ情報はマージされません。
この機能が有効な場合、.status.containerStatuses[].user.linuxフィールドで、コンテナの最初のプロセスに付与されたユーザー、グループ情報が確認出来ます。暗黙的なグループIDが付与されているかどうかを確認するのに便利でしょう。
apiVersion : v1
kind : Pod
metadata :
name : security-context-demo
spec :
securityContext :
runAsUser : 1000
runAsGroup : 3000
supplementalGroups : [4000 ]
supplementalGroupsPolicy : Strict
containers :
- name : sec-ctx-demo
image : registry.k8s.io/e2e-test-images/agnhost:2.45
command : [ "sh" , "-c" , "sleep 1h" ]
securityContext :
allowPrivilegeEscalation : false
このPodマニフェストはsupplementalGroupsPolicy=Strictを指定しています。/etc/groupに定義されているグループ情報が、コンテナ内のプロセスの補助グループにマージされないことが確認できるでしょう。
Podを作成してみましょう。
kubectl apply -f https://k8s.io/examples/pods/security/security-context-6.yaml
Podのコンテナが実行されていることを確認します。
kubectl get pod security-context-demo
プロセスのユーザー、グループ情報を確認します。
kubectl exec -it security-context-demo -- id
出力はこのようになります。
uid=1000 gid=3000 groups=3000,4000
Podのステータスを確認します。
kubectl get pod security-context-demo -o yaml
status.containerStatuses[].user.linuxフィールドでコンテナの最初のプロセスに付与されたユーザー、グループ情報が確認出来ます。
...
status:
containerStatuses:
- name: sec-ctx-demo
user:
linux:
gid: 3000
supplementalGroups:
- 3000
- 4000
uid: 1000
...
備考: status.containerStatuses[].user.linuxフィールドで公開されているユーザー、グループ情報は、コンテナの最初のプロセスに、
最初に付与された 情報であることに注意してください。
もしそのプロセスが、自身のユーザー、グループ情報を変更できるシステムコール(例えば
setuid(2),
setgid(2),
setgroups(2)等)を実行する権限を持っている場合、プロセス自身で動的に変更が可能なためです。
つまり、実際にプロセスに付与されているユーザー、グループ情報は動的に変化します。
利用可能な実装 備考: このセクションでは、Kubernetesが必要とする機能を提供するサードパーティープロジェクトにリンクしています。これらのプロジェクトはアルファベット順に記載されていて、Kubernetesプロジェクトの作者は責任を持ちません。このリストにプロジェクトを追加するには、変更を提出する前に
content guide をお読みください。
詳細はこちら。 下記のコンテナランタイムがfine-grained(きめ細かい) SupplementalGroups controlを実装しています。
CRI実装:
ノードのステータスでこの機能が利用可能かどうか確認出来ます。
apiVersion : v1
kind : Node
...
status :
features :
supplementalGroupsPolicy : true
備考: アルファリリース(v1.31, v1.32)では、SupplementalGroupsPolicy=Strictを指定されたPodが、この機能をサポートされていないノード(.status.features.supplementalGroupsPolicy=falseなノード)にスケジュールされた場合、そのPodのSupplementalGroupsPolicyはMergeに暗黙的にフォールバックされていました。
しかし、ベータリリース(v1.33)以降は、ポリシーをより厳格に強制するため、そのようなPodの作成は、ノードによるポリシーの強制が不可能なためkubeletによって拒否されます。Podの作成が拒否された場合、下記のようなreason=SupplementalGroupsPolicyNotSupportedを持つWarningイベントが作成されます。
apiVersion : v1
kind : Event
...
type : Warning
reason : SupplementalGroupsPolicyNotSupported
message : "SupplementalGroupsPolicy=Strict is not supported in this node"
involvedObject :
apiVersion : v1
kind : Pod
...
Podのボリュームパーミッションと所有権変更ポリシーを設定する FEATURE STATE:
Kubernetes v1.23 [stable]
デフォルトでは、Kubernetesはボリュームがマウントされたときに、PodのsecurityContextで指定されたfsGroupに合わせて再帰的に各ボリュームの中の所有権とパーミッションを変更します。
大きなボリュームでは所有権の確認と変更に時間がかかり、Podの起動が遅くなります。
securityContextの中のfsGroupChangePolicyフィールドを設定することで、Kubernetesがボリュームの所有権・パーミッションの確認と変更をどう行うかを管理することができます。
fsGroupChangePolicy - fsGroupChangePolicyは、ボリュームがPod内部で公開される前に所有権とパーミッションを変更するための動作を定義します。
このフィールドはfsGroupで所有権とパーミッションを制御することができるボリュームタイプにのみ適用されます。このフィールドは以下の2つの値を取ります。
OnRootMismatch : ルートディレクトリのパーミッションと所有権がボリュームに設定したパーミッションと一致しない場合のみ、パーミッションと所有権を変更します。ボリュームの所有権とパーミッションを変更するのにかかる時間が短くなる可能性があります。Always : ボリュームがマウントされたときに必ずパーミッションと所有権を変更します。例:
securityContext :
runAsUser : 1000
runAsGroup : 3000
fsGroup : 2000
fsGroupChangePolicy : "OnRootMismatch"
CSIドライバーにボリュームパーミッションと所有権を移譲する FEATURE STATE:
Kubernetes v1.26 [stable]
VOLUME_MOUNT_GROUP NodeServiceCapabilityをサポートしているContainer Storage Interface (CSI) ドライバーをデプロイした場合、securityContextのfsGroupで指定された値に基づいてKubernetesの代わりにCSIドライバーがファイルの所有権とパーミッションの設定処理を行います。
この場合Kubernetesは所有権とパーミッションの設定を行わないためfsGroupChangePolicyは無効となり、CSIで指定されている通りドライバーはfsGroupに従ってボリュームをマウントすると考えられるため、ボリュームはfsGroupに従って読み取り・書き込み可能になります。
コンテナにセキュリティコンテキストを設定する コンテナに対してセキュリティ設定を行うには、コンテナマニフェストにsecurityContextフィールドを含めてください。securityContextフィールドにはSecurityContext オブジェクトが入ります。
コンテナに指定したセキュリティ設定は個々のコンテナに対してのみ反映され、Podレベルの設定を上書きします。コンテナの設定はPodのボリュームに対しては影響しません。
こちらは一つのコンテナを持つPodの設定ファイルです。PodもコンテナもsecurityContextフィールドを含んでいます。
apiVersion : v1
kind : Pod
metadata :
name : security-context-demo-2
spec :
securityContext :
runAsUser : 1000
containers :
- name : sec-ctx-demo-2
image : gcr.io/google-samples/node-hello:1.0
securityContext :
runAsUser : 2000
allowPrivilegeEscalation : false Podを作成します。
kubectl apply -f https://k8s.io/examples/pods/security/security-context-2.yaml
Podのコンテナが実行されていることを確認します。
kubectl get pod security-context-demo-2
実行中のコンテナでshellを取ります。
kubectl exec -it security-context-demo-2 -- sh
shellの中で、実行中のプロセスの一覧を表示します。
ユーザー2000として実行されているプロセスが表示されました。これはコンテナのrunAsUserで指定された値です。Podで指定された値である1000を上書きしています。
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
2000 1 0.0 0.0 4336 764 ? Ss 20:36 0:00 /bin/sh -c node server.js
2000 8 0.1 0.5 772124 22604 ? Sl 20:36 0:00 node server.js
...
shellから抜けます。
コンテナにケーパビリティを設定する Linuxケーパビリティ を用いると、プロセスに対してrootユーザーの全権を渡すことなく特定の権限を与えることができます。
コンテナに対してLinuxケーパビリティを追加したり削除したりするには、コンテナマニフェストのsecurityContextセクションのcapabilitiesフィールドに追加してください。
まず、capabilitiesフィールドを含まない場合どうなるかを見てみましょう。
こちらはコンテナに対してケーパビリティを渡していない設定ファイルです。
apiVersion : v1
kind : Pod
metadata :
name : security-context-demo-3
spec :
containers :
- name : sec-ctx-3
image : gcr.io/google-samples/node-hello:1.0Podを作成します。
kubectl apply -f https://k8s.io/examples/pods/security/security-context-3.yaml
Podが実行されていることを確認します。
kubectl get pod security-context-demo-3
実行中のコンテナでshellを取ります。
kubectl exec -it security-context-demo-3 -- sh
shellの中で、実行中のプロセスの一覧を表示します。
コンテナのプロセスID(PID)が出力されます。
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 4336 796 ? Ss 18:17 0:00 /bin/sh -c node server.js
root 5 0.1 0.5 772124 22700 ? Sl 18:17 0:00 node server.js
shellの中で、プロセス1のステータスを確認します。
プロセスのケーパビリティビットマップが表示されます。
...
CapPrm: 00000000a80425fb
CapEff: 00000000a80425fb
...
ケーパビリティビットマップのメモを取った後、shellから抜けます。
次に、追加のケーパビリティを除いて上と同じ設定のコンテナを実行します。
こちらは1つのコンテナを実行するPodの設定ファイルです。
CAP_NET_ADMINとCAP_SYS_TIMEケーパビリティを設定に追加しました。
apiVersion : v1
kind : Pod
metadata :
name : security-context-demo-4
spec :
containers :
- name : sec-ctx-4
image : gcr.io/google-samples/node-hello:1.0
securityContext :
capabilities :
add : ["NET_ADMIN" , "SYS_TIME" ]Podを作成します。
kubectl apply -f https://k8s.io/examples/pods/security/security-context-4.yaml
実行中のコンテナでshellを取ります。
kubectl exec -it security-context-demo-4 -- sh
shellの中で、プロセス1のケーパビリティを確認します。
プロセスのケーパビリティビットマップが表示されます。
...
CapPrm: 00000000aa0435fb
CapEff: 00000000aa0435fb
...
2つのコンテナのケーパビリティを比較します。
00000000a80425fb
00000000aa0435fb
1つ目のコンテナのケーパビリティビットマップでは、12, 25ビット目がクリアされています。2つ目のコンテナでは12, 25ビット目がセットされています。12ビット目はCAP_NET_ADMIN、25ビット目はCAP_SYS_TIMEです。
ケーパビリティの定数の定義はcapability.h を確認してください。
備考: Linuxケーパビリティの定数はCAP_XXX形式です。
ただしコンテナのマニフェストでケーパビリティを記述する際は、定数のCAP_の部分を省いてください。
例えば、CAP_SYS_TIMEを追加したい場合はケーパビリティにSYS_TIMEを追加してください。コンテナにSeccompプロフィールを設定する コンテナにSeccompプロフィールを設定するには、Pod・コンテナマニフェストのsecurityContextにseccompProfileフィールドを追加してください。
seccompProfileフィールドはSeccompProfile オブジェクトで、typeとlocalhostProfileで構成されています。
typeではRuntimeDefault、Unconfined、Localhostが有効です。
localhostProfileはtype: Localhostのときのみ指定可能です。こちらはノード上で事前に設定されたプロファイルのパスを示していて、kubeletのSeccompプロファイルの場所(--root-dirフラグで設定したもの)からの相対パスです。
こちらはノードのコンテナランタイムのデフォルトプロフィールをSeccompプロフィールとして設定した例です。
...
securityContext :
seccompProfile :
type : RuntimeDefault
こちらは<kubelet-root-dir>/seccomp/my-profiles/profile-allow.jsonで事前に設定したファイルをSeccompプロフィールに設定した例です。
...
securityContext :
seccompProfile :
type : Localhost
localhostProfile : my-profiles/profile-allow.json
コンテナにAppArmorプロフィールを設定する コンテナにAppArmorプロフィールを設定するには、securityContextセクションにappAormorProfileフィールドを含めてください。
appAormerProfileフィールドには、typeフィールドとlocalhostProfileフィールドから構成されるAppArmorProfile オブジェクトが入ります。typeフィールドの有効なオプションはRuntimeDefault(デフォルト)、Unconfined、Localhostです。
localhostProfileはtypeがLocalhostのときには必ず設定しなければなりません。この値はノードで事前に設定されたプロフィール名を示します。Podは事前にどのノードにスケジュールされるかわからないため、指定されたプロフィールはPodがスケジュールされ得る全てのノードにロードされている必要があります。カスタムプロフィールをセットアップする方法はSetting up nodes with profiles を参照してください。
注意: containers[*].securityContext.appArmorProfile.typeが明示的にRuntimeDefaultに設定されている場合は、もしノードでAppArmorが有効化されていなければ、Podの作成は許可されません。
しかし、containers[*].securityContext.appArmorProfile.typeが設定されていない場合、AppArmorが有効化されていれば、デフォルト(RuntimeDefault)が適用されます。もし、AppArmorが無効化されている場合は、Podの作成は許可されますが、コンテナにはRuntimeDefaultプロフィールの制限は適用されません。
これは、AppArmorプロフィールとして、ノードのコンテナランタイムのデフォルトプロフィールを設定する例です。
...
containers :
name : container-1
securityContext :
appArmorProfile :
type : RuntimeDefault
これは、AppArmorプロフィールとして、k8s-apparmor-example-deny-writeという名前で事前に設定されたプロフィールを設定する例です。
...
containers :
name : container-1
securityContext :
appArmorProfile :
type : Localhost
localhostProfile : k8s-apparmor-example-deny-write
より詳細な内容についてはRestrict a Container's Access to Resources with AppArmor を参照してください。
コンテナにSELinuxラベルをつける コンテナにSELinuxラベルをつけるには、Pod・コンテナマニフェストのsecurityContextセクションにseLinuxOptionsフィールドを追加してください。
seLinuxOptionsフィールドはSELinuxOptions オブジェクトが入ります。
こちらはSELinuxレベルを適用する例です。
...
securityContext :
seLinuxOptions :
level : "s0:c123,c456"
備考: SELinuxラベルを適用するには、ホストOSにSELinuxセキュリティモジュールが含まれている必要があります。効率的なSELinuxのボリューム再ラベル付け FEATURE STATE:
Kubernetes v1.28 [beta](enabled by default)
備考: Kubernetes v1.27で、ReadWriteOncePod アクセスモードを使用するボリューム(およびPersistentVolumeClaim)にのみ、この機能の限定的な機能が早期提供されています。
Alphaフィーチャーとして、SELinuxMountフィーチャーゲート を有効にすることで、以下で説明するように、他の種類のPersistentVolumeClaimにもパフォーマンス改善の範囲を広げる事ができます。
デフォルトでは、コンテナランタイムは全てのPodのボリュームの全てのファイルに再帰的にSELinuxラベルを付与します。処理速度を上げるために、Kubernetesはマウントオプションで-o context=<label>を使うことでボリュームのSELinuxラベルを即座に変更することができます。
この高速化の恩恵を受けるには、以下の全ての条件を満たす必要があります。
AlphaフィーチャーゲートのReadWriteOncePodとSELinuxMountReadWriteOncePodを有効にすること Podが適用可能なaccessModesでPersistentVolumeClaimを使うことボリュームがaccessModes: ["ReadWriteOncePod"]を持ち、フィーチャーゲートSELinuxMountReadWriteOncePodが有効であること または、ボリュームが他のアクセスモードを使用し、フィーチャーゲートSELinuxMountReadWriteOncePodとSELinuxMountの両方が有効であること Pod(またはPersistentVolumeClaimを使っている全てのコンテナ)にseLinuxOptionsが設定されていること 対応するPersistentVolumeが以下のいずれかであることレガシーのin-treeボリュームの場合、iscs、rbd、fcボリュームタイプであること または、CSI ドライバーを使用するボリュームで、そのCSIドライバーがCSIドライバーインスタンスでspec.seLinuxMount: trueを指定したときに-o contextでマウントを行うとアナウンスしていること それ以外のボリュームタイプでは、コンテナランタイムはボリュームに含まれる全てのinode(ファイルやディレクトリ)に対してSELinuxラベルを再帰的に変更します。
ボリューム内のファイルやディレクトリが増えるほど、ラベリングにかかる時間は増加します。
/procファイルシステムへのアクセスを管理するFEATURE STATE:
Kubernetes v1.33 [beta](enabled by default)
OCI runtime specificationに準拠するランタイムでは、コンテナはデフォルトで、いくつかの複数のパスはマスクされ、かつ、読み取り専用のモードで実行されます。
その結果、コンテナのマウントネームスペース内にはこれらのパスが存在し、あたかもコンテナが隔離されたホストであるかのように機能しますが、コンテナプロセスはそれらのパスに書き込むことはできません。
マスクされるパスおよび読み取り専用のパスのリストは次のとおりです。
マスクされるパス:
/proc/asound/proc/acpi/proc/kcore/proc/keys/proc/latency_stats/proc/timer_list/proc/timer_stats/proc/sched_debug/proc/scsi/sys/firmware/sys/devices/virtual/powercap読み取り専用のパス:
/proc/bus/proc/fs/proc/irq/proc/sys/proc/sysrq-trigger一部のPodでは、デフォルトでパスがマスクされるのを回避したい場合があります。このようなケースで最も一般的なのは、Kubernetesコンテナ(Pod内のコンテナ)内でコンテナを実行しようとする場合です。
securityContextのprocMountフィールドを使用すると、コンテナの/procをUnmaskedにしたり、コンテナプロセスによって読み書き可能な状態でマウントすることができます。この設定は、/proc以外の/sys/firmwareにも適用されます。
...
securityContext :
procMount : Unmasked
備考: procMountをUnmaskedに設定するには、Podの
spec.hostUsersの値が
falseである必要があります。
つまり、Unmaskedな
/procやUnmaskedな
/sysを使用したいコンテナは、
user namespace 内で動作している必要があります。
Kubernetes v1.12からv1.29までは、この要件は強制されません。
議論 PodのセキュリティコンテキストはPodのコンテナや、適用可能であればPodのボリュームに対しても適用されます。
特にfsGroupとseLinuxOptionsは以下のようにボリュームに対して適用されます。
警告: Podに対してMCSラベルを指定すると、同じラベルを持つ全てのPodがボリュームにアクセスすることができます。
Pod内の保護が必要な場合、それぞれのPodに対して一意なMCSラベルを割り当ててください。クリーンアップ Podを削除します。
kubectl delete pod security-context-demo
kubectl delete pod security-context-demo-2
kubectl delete pod security-context-demo-3
kubectl delete pod security-context-demo-4
次の項目 4.3.10 - イメージをプライベートレジストリから取得する このページでは、Secret を用いるPodを作成するためにイメージをプライベートコンテナイメージレジストリもしくはリポジトリから取得する方法について説明します。
多くのプライベートレジストリが存在しますが、このタスクではDocker Hub をレジストリの一例として使用します。
🛇 This item links to a third party project or product that is not part of Kubernetes itself.
More information 始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
この演習を行うためには、dockerコマンドラインツールと自身のDocker ID が必要です。
別のプライベートコンテナレジストリを使用している場合は、そのレジストリのコマンドラインツールとログイン情報が必要です。
Docker Hubにログインする ラップトップ(ローカル環境)上では、プライベートイメージを取得するためにレジストリに認証する必要があります。
dockerツールを使用してDocker Hubにログインしてください。詳細はDocker IDアカウント の Sign in セクションを参照してください。
プロンプトが表示されたら、Docker IDと使用したい認証情報(アクセストークンまたはDocker IDのパスワード)を入力してください。
ログインプロセスは、認証トークンを保持するconfig.jsonファイルを作成または更新します。Kubernetesがこのファイルを解釈する方法 を確認してください。
以下のようにconfig.jsonファイルを確認します:
cat ~/.docker/config.json
出力には以下のような部分が含まれています:
{
"auths" : {
"https://index.docker.io/v1/" : {
"auth" : "c3R...zE2"
}
}
}
既存の認証情報を用いるSecretを作成する Kubernetesクラスターはプライベートイメージを取得するためのレジストリとの認証にkubernetes.io/dockerconfigjsonタイプのSecretを使用します。
既にdocker loginを実行済みの場合、その認証情報をKubernetesにコピーできます:
kubectl create secret generic regcred \
= .dockerconfigjson= <path/to/.docker/config.json> \
= kubernetes.io/dockerconfigjson
新しいSecretをカスタマイズする必要がある場合(例えば、新しいSecretにNamespaceやLabelを設定する場合)は、保存する前にSecretをカスタマイズできます。
必ず以下を行ってください:
data項目の名前を.dockerconfigjsonに設定するDockerの設定ファイルをbase64エンコードし、その文字列を分割せずにdata[".dockerconfigjson"]の値として貼り付ける typeをkubernetes.io/dockerconfigjsonに設定するSecretをカスタマイズする場合のマニフェストの例:
apiVersion : v1
kind : Secret
metadata :
name : myregistrykey
namespace : awesomeapps
data :
.dockerconfigjson : UmVhbGx5IHJlYWxseSByZWVlZWVlZWVlZWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWxsbGxsbGxsbGxsbGxsbGxsbGxsbGxsbGxsbGxsbGx5eXl5eXl5eXl5eXl5eXl5eXl5eSBsbGxsbGxsbGxsbGxsbG9vb29vb29vb29vb29vb29vb29vb29vb29vb25ubm5ubm5ubm5ubm5ubm5ubm5ubm5ubmdnZ2dnZ2dnZ2dnZ2dnZ2dnZ2cgYXV0aCBrZXlzCg==
type : kubernetes.io/dockerconfigjson
error: no objects passed to createをエラーメッセージとして受け取った場合、base64エンコードされた文字列が無効である可能性があります。
Secret "myregistrykey" is invalid: data[.dockerconfigjson]: invalid value ...をエラーメッセージとして受け取った場合は、data内のbase64エンコードされた文字列は正常にデコードされたものの、.docker/config.jsonファイルとして読み込むことができなかったことを意味します。
コマンドライン上で認証情報を入力してSecretを作成する このSecretをregcredという名前で作成します:
kubectl create secret docker-registry regcred --docker-server= <your-registry-server> --docker-username= <your-name> --docker-password= <your-pword> --docker-email= <your-email>
ここでは:
<your-registry-server>は、プライベートDockerレジストリのFQDN(完全修飾ドメイン名)です。
Docker Hubを使用する場合は、https://index.docker.io/v1/を設定して下さい。<your-name>は、Dockerのユーザー名です。<your-pword>は、Dockerのパスワードです。<your-email>は、Dockerのメールアドレスです。Dockerレジストリの認証情報がSecretとしてregcredという名前でクラスターに正常に設定されました。
備考: コマンドラインで認証情報を入力すると、認証情報が保護されていない状態でシェルの履歴に保存される可能性があり、またkubectl実行中はPCの他のユーザーがそれらの認証情報を閲覧できる可能性があります。regcredSecretを確認する作成したregcredSecretの内容を理解するために、まずYAML形式でSecretを表示します:
kubectl get secret regcred --output= yaml
出力は以下のようになります:
apiVersion : v1
kind : Secret
metadata :
...
name : regcred
...
data :
.dockerconfigjson : eyJodHRwczovL2luZGV4L ... J0QUl6RTIifX0=
type : kubernetes.io/dockerconfigjson
.dockerconfigjsonフィールドの値は、Docker認証情報をbase64でエンコードしたものです。
.dockerconfigjsonフィールドの内容を理解するために、認証情報のデータを読解可能な形式に変換します:
kubectl get secret regcred --output= "jsonpath={.data.\.dockerconfigjson}" | base64 --decode
出力は以下のようになります:
{"auths" :{"your.private.registry.example.com" :{"username" :"janedoe" ,"password" :"xxxxxxxxxxx" ,"email" :"jdoe@example.com" ,"auth" :"c3R...zE2" }}}
authフィールドの内容を理解するために、base64エンコードされたデータを読解可能な形式に変換します:
echo "c3R...zE2" | base64 --decode
出力はユーザー名とパスワードが:で連結された以下のような形式になります:
janedoe:xxxxxxxxxxx
Secretのdataには、ローカルの~/.docker/config.jsonファイルと同様の認証トークンが含まれていることが分かります。
クラスターにregcredという名前のSecretとしてDockerの認証情報が正常に設定されました。
作成したSecretを利用するPodを作成する 以下はregcredという名前のDockerの認証情報へのアクセスが必要なPodのマニフェストの例です:
apiVersion : v1
kind : Pod
metadata :
name : private-reg
spec :
containers :
- name : private-reg-container
image : <your-private-image>
imagePullSecrets :
- name : regcred
上記のファイルをあなたのコンピューターにダウンロードします:
curl -L -o my-private-reg-pod.yaml https://k8s.io/examples/pods/private-reg-pod.yaml
my-private-reg-pod.yamlファイル内の<your-private-image>を、以下のようなプライベートレジストリのイメージのパスに置き換えてください:
your.private.registry.example.com/janedoe/jdoe-private:v1
プライベートレジストリからイメージを取得するために、Kubernetesは認証情報を必要とします。
設定ファイル内のimagePullSecretsフィールドは、Kubernetesがregcredという名前のSecretから認証情報を取得することを指定します。
以下のようにして作成したSecretを使用するPodを作成し、Podが実行されていることを確認します:
kubectl apply -f my-private-reg-pod.yaml
kubectl get pod private-reg
備考: イメージプルシークレットをPod(またはDeployment、あるいはPodテンプレートを使用するその他のオブジェクト)で使用するには、適切なSecretが正しいNamespaceに存在することを確認する必要があります。
使用するNamespaceは、Podを定義したNamespaceと同一である必要があります。また、PodのステータスがImagePullBackOffになり起動に失敗した場合は、Podのイベントを確認してください:
kubectl describe pod private-reg
もしFailedToRetrieveImagePullSecretという理由を持つイベントが表示された場合は、Kubernetesが指定された名前のSecret(この例ではregcred)を見つけることができないことを示します。
指定したSecretが存在し、その名前が正しく記載されていることを確認してください。
Events:
... Reason ... Message
------ -------
... FailedToRetrieveImagePullSecret ... Unable to retrieve some image pull secrets ( <regcred>) ; attempting to pull the image may not succeed.
複数のレジストリ上のイメージを利用する 1つのPodは複数のコンテナを持つことができ、各コンテナのイメージは異なるレジストリから取得できます。
1つのPodで複数のimagePullSecretsを使用でき、それぞれに複数の認証情報を含めることができます。
レジストリに一致する各認証情報を使用してイメージの取得が試行されます。
レジストリに一致する認証情報がない場合、認証なしで、またはカスタムランタイム固有の設定を使用してイメージの取得が試行されます。
次の項目 4.3.11 - Liveness Probe、Readiness ProbeおよびStartup Probeを使用する このページでは、Liveness Probe、Readiness ProbeおよびStartup Probeの使用方法について説明します。
kubelet は、Liveness Probeを使用して、コンテナをいつ再起動するかを認識します。
例えば、アプリケーション自体は起動しているが、処理を継続することができないデッドロック状態を検知することができます。
このような状態のコンテナを再起動することで、バグがある場合でもアプリケーションの可用性を高めることができます。
kubeletは、Readiness Probeを使用して、コンテナがトラフィックを受け入れられる状態であるかを認識します。
Podが準備ができていると見なされるのは、Pod内の全てのコンテナの準備が整ったときです。
一例として、このシグナルはServiceのバックエンドとして使用されるPodを制御するときに使用されます。
Podの準備ができていない場合、そのPodはServiceのロードバランシングから切り離されます。
kubeletは、Startup Probeを使用して、コンテナアプリケーションの起動が完了したかを認識します。
Startup Probeを使用している場合、Startup Probeが成功するまでは、Liveness Probeと
Readiness Probeによるチェックを無効にし、これらがアプリケーションの起動に干渉しないようにします。
例えば、これを起動が遅いコンテナの起動チェックとして使用することで、起動する前にkubeletによって
強制終了されることを防ぐことができます。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
コマンド実行によるLiveness Probeを定義する 長期間実行されているアプリケーションの多くは、再起動されるまで回復できないような異常な状態になることがあります。
Kubernetesはこのような状況を検知し、回復するためのLiveness Probeを提供します。
この演習では、registry.k8s.io/busyboxイメージのコンテナを起動するPodを作成します。
Podの構成ファイルは次の通りです。
apiVersion : v1
kind : Pod
metadata :
labels :
test : liveness
name : liveness-exec
spec :
containers :
- name : liveness
image : registry.k8s.io/busybox
args :
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600
livenessProbe :
exec :
command :
- cat
- /tmp/healthy
initialDelaySeconds : 5
periodSeconds : 5
この構成ファイルでは、Podは一つのContainerを起動します。
periodSecondsフィールドは、kubeletがLiveness Probeを5秒おきに行うように指定しています。
initialDelaySecondsフィールドは、kubeletが最初のProbeを実行する前に5秒間待機するように指示しています。
Probeの動作としては、kubeletはcat /tmp/healthyを対象のコンテナ内で実行します。
このコマンドが成功し、リターンコード0が返ると、kubeletはコンテナが問題なく動いていると判断します。
リターンコードとして0以外の値が返ると、kubeletはコンテナを終了し、再起動を行います。
このコンテナは、起動すると次のコマンドを実行します:
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600"
コンテナが起動してから初めの30秒間は/tmp/healthyファイルがコンテナ内に存在します。
そのため初めの30秒間はcat /tmp/healthyコマンドは成功し、正常なリターンコードが返ります。
その後30秒が経過すると、cat /tmp/healthyコマンドは異常なリターンコードを返します。
このPodを起動してください:
kubectl apply -f https://k8s.io/examples/pods/probe/exec-liveness.yaml
30秒間以内に、Podのイベントを確認します。
kubectl describe pod liveness-exec
この出力結果は、Liveness Probeがまだ失敗していないことを示しています。
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
24s 24s 1 {default-scheduler } Normal Scheduled Successfully assigned liveness-exec to worker0
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Pulling pulling image "registry.k8s.io/busybox"
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Pulled Successfully pulled image "registry.k8s.io/busybox"
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Created Created container with docker id 86849c15382e; Security:[seccomp=unconfined]
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Started Started container with docker id 86849c15382e
35秒後に、Podのイベントをもう一度確認します:
kubectl describe pod liveness-exec
出力結果の最後に、Liveness Probeが失敗していることを示すメッセージが表示されます。これによりコンテナは強制終了し、再作成されました。
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
37s 37s 1 {default-scheduler } Normal Scheduled Successfully assigned liveness-exec to worker0
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Pulling pulling image "registry.k8s.io/busybox"
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Pulled Successfully pulled image "registry.k8s.io/busybox"
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Created Created container with docker id 86849c15382e; Security:[seccomp=unconfined]
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Started Started container with docker id 86849c15382e
2s 2s 1 {kubelet worker0} spec.containers{liveness} Warning Unhealthy Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
さらに30秒後、コンテナが再起動していることを確認します:
kubectl get pod liveness-exec
出力結果から、RESTARTSがインクリメントされていることを確認します:
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 1 1m
HTTPリクエストによるLiveness Probeを定義する 別の種類のLiveness Probeでは、HTTP GETリクエストを使用します。
次の構成ファイルは、registry.k8s.io/e2e-test-images/agnhostイメージを使用したコンテナを起動するPodを作成します。
apiVersion : v1
kind : Pod
metadata :
labels :
test : liveness
name : liveness-http
spec :
containers :
- name : liveness
image : registry.k8s.io/e2e-test-images/agnhost:2.40
args :
- liveness
livenessProbe :
httpGet :
path : /healthz
port : 8080
httpHeaders :
- name : Custom-Header
value : Awesome
initialDelaySeconds : 3
periodSeconds : 3
この構成ファイルでは、Podは一つのContainerを起動します。
periodSecondsフィールドは、kubeletがLiveness Probeを3秒おきに行うように指定しています。
initialDelaySecondsフィールドは、kubeletが最初のProbeを実行する前に3秒間待機するように指示しています。
Probeの動作としては、kubeletは8080ポートをリッスンしているコンテナ内のサーバーに対してHTTP GETリクエストを送ります。
サーバー内の/healthzパスに対するハンドラーが正常なリターンコードを応答した場合、
kubeletはコンテナが問題なく動いていると判断します。
異常なリターンコードを応答すると、kubeletはコンテナを終了し、再起動を行います。
200以上400未満のコードは成功とみなされ、その他のコードは失敗とみなされます。
server.go
にてサーバーのソースコードを確認することができます。
コンテナが生きている初めの10秒間は、/healthzハンドラーが200ステータスを返します。
その後、ハンドラーは500ステータスを返します。
http.HandleFunc ("/healthz" , func (w http.ResponseWriter, r * http.Request) {
duration := time.Now ().Sub (started)
if duration.Seconds () > 10 {
w.WriteHeader (500 )
w.Write ([]byte (fmt.Sprintf ("error: %v" , duration.Seconds ())))
} else {
w.WriteHeader (200 )
w.Write ([]byte ("ok" ))
}
})
kubeletは、コンテナが起動してから3秒後からヘルスチェックを行います。
そのため、初めのいくつかのヘルスチェックは成功します。しかし、10秒経過するとヘルスチェックは失敗し、kubeletはコンテナを終了し、再起動します。
HTTPリクエストのチェックによるLiveness Probeを試すには、以下のようにPodを作成します:
kubectl apply -f https://k8s.io/examples/pods/probe/http-liveness.yaml
10秒後、Podのイベントを表示して、Liveness Probeが失敗し、コンテナが再起動されていることを確認します。
kubectl describe pod liveness-http
v1.13以前(v1.13を含む)のリリースにおいては、Podが起動しているノードに環境変数http_proxy
(または HTTP_PROXY)が設定されている場合、HTTPリクエストのLiveness Probeは設定されたプロキシを使用します。
v1.13より後のリリースにおいては、ローカルHTTPプロキシ環境変数の設定はHTTPリクエストのLiveness Probeに影響しません。
TCPによるLiveness Probeを定義する 3つ目のLiveness ProbeはTCPソケットを使用するタイプです。
この構成においては、kubeletは指定したコンテナのソケットを開くことを試みます。
コネクションが確立できる場合はコンテナを正常とみなし、失敗する場合は異常とみなします。
apiVersion : v1
kind : Pod
metadata :
name : goproxy
labels :
app : goproxy
spec :
containers :
- name : goproxy
image : registry.k8s.io/goproxy:0.1
ports :
- containerPort : 8080
readinessProbe :
tcpSocket :
port : 8080
initialDelaySeconds : 5
periodSeconds : 10
livenessProbe :
tcpSocket :
port : 8080
initialDelaySeconds : 15
periodSeconds : 20
見ての通り、TCPによるチェックの構成はHTTPによるチェックと非常に似ています。
この例では、Readiness ProbeとLiveness Probeを両方使用しています。
kubeletは、コンテナが起動してから5秒後に最初のReadiness Probeを開始します。
これはgoproxyコンテナの8080ポートに対して接続を試みます。
このProbeが成功すると、Podは準備ができていると通知されます。kubeletはこのチェックを10秒ごとに行います。
この構成では、Readiness Probeに加えてLiveness Probeが含まれています。
kubeletは、コンテナが起動してから15秒後に最初のLiveness Probeを実行します。
Readiness Probeと同様に、これはgoproxyコンテナの8080ポートに対して接続を試みます。
Liveness Probeが失敗した場合、コンテナは再起動されます。
TCPのチェックによるLiveness Probeを試すには、以下のようにPodを作成します:
kubectl apply -f https://k8s.io/examples/pods/probe/tcp-liveness-readiness.yaml
15秒後、Podのイベントを表示し、Liveness Probeが行われていることを確認します:
kubectl describe pod goproxy
名前付きポートを使用する HTTPまたはTCPによるProbeにおいて、ContainerPort
で定義した名前付きポートを使用することができます。
ports :
name : liveness-port
containerPort : 8080
livenessProbe :
httpGet :
path : /healthz
port : liveness-port
Startup Probeを使用して、起動の遅いコンテナを保護する 場合によっては、最初の初期化において追加の起動時間が必要になるようなレガシーアプリケーションを扱う必要があります。
そのような場合、デッドロックに対する迅速な反応を損なうことなくLiveness Probeのパラメーターを設定することは難しい場合があります。
これに対する解決策の一つは、Liveness Probeと同じ構成のコマンドを用いるか、HTTPまたはTCPによるチェックを使用したStartup Probeをセットアップすることです。
その際、failureThreshold * periodSecondsで計算される時間を、起動時間として想定される最も遅いケースをカバーできる十分な長さに設定します。
上記の例は、次のようになります:
ports :
name : liveness-port
containerPort : 8080
livenessProbe :
httpGet :
path : /healthz
port : liveness-port
failureThreshold : 1
periodSeconds : 10
startupProbe :
httpGet :
path : /healthz
port : liveness-port
failureThreshold : 30
periodSeconds : 10
Startup Probeにより、アプリケーションは起動が完了するまでに最大5分間の猶予(30 * 10 = 300秒)が与えられます。
Startup Probeに一度成功すると、その後はLiveness Probeが引き継ぎ、コンテナのデッドロックに対して迅速に反応します。
Startup Probeが成功しない場合、コンテナは300秒後に終了し、その後はPodのrestartPolicyに従います。
Readiness Probeを定義する アプリケーションは一時的にトラフィックを処理できないことが起こり得ます。
例えば、アプリケーションは起動時に大きなデータまたは構成ファイルを読み込む必要がある場合や、起動後に外部サービスに依存している場合があります。
このような場合、アプリケーション自体を終了させたくはありませんが、このアプリケーションに対してリクエストも送信したくないと思います。
Kubernetesは、これらの状況を検知して緩和するための機能としてReadiness Probeを提供します。
これにより、準備ができていないことを報告するコンテナを含むPodは、KubernetesのServiceを通してトラフィックを受信しないようになります。
備考: Readiness Probeは、コンテナの全てのライフサイクルにおいて実行されます。Readiness ProbeはLiveness Probeと同様に構成します。
唯一の違いはreadinessProbeフィールドをlivenessProbeフィールドの代わりに利用することだけです。
readinessProbe :
exec :
command :
- cat
- /tmp/healthy
initialDelaySeconds : 5
periodSeconds : 5
HTTPおよびTCPによるReadiness Probeの構成もLiveness Probeと同じです。
Readiness ProbeとLiveness Probeは同じコンテナで同時に使用できます。
両方使用することで、準備できていないコンテナへのトラフィックが到達しないようにし、コンテナが失敗したときに再起動することができます。
Probe には、
Liveness ProbeおよびReadiness Probeのチェック動作をより正確に制御するために使用できるフィールドがあります:
initialDelaySeconds: コンテナが起動してから、Liveness ProbeまたはReadiness Probeが開始されるまでの秒数。デフォルトは0秒。最小値は0。periodSeconds: Probeが実行される頻度(秒数)。デフォルトは10秒。最小値は1。
コンテナが起動してから準備が整うまでの間、periodSecondsで指定した間隔とは異なるタイミングでReadiness Probeが実行される場合があります。
これは、Podをより早く準備完了の状態に移行させるためです。timeoutSeconds: Probeがタイムアウトになるまでの秒数。デフォルトは1秒。最小値は1。successThreshold: 一度Probeが失敗した後、次のProbeが成功したとみなされるための最小連続成功数。
デフォルトは1。Liveness ProbeおよびStartup Probeには1を設定する必要があります。最小値は1。failureThreshold: Probeが失敗した場合、KubernetesはfailureThresholdに設定した回数までProbeを試行します。
Liveness Probeにおいて、試行回数に到達することはコンテナを再起動することを意味します。
Readiness Probeの場合は、Podが準備できていない状態として通知されます。デフォルトは3。最小値は1。HTTPによるProbe
には、httpGetにて設定できる追加のフィールドがあります:
host: 接続先ホスト名。デフォルトはPod IP。おそらくはこのフィールドの代わりにhttpHeaders内の"Host"を代わりに使用することになります。scheme: ホストへの接続で使用するスキーマ(HTTP または HTTPS)。デフォルトは HTTP。path: HTTPサーバーへアクセスする際のパスhttpHeaders: リクエスト内のカスタムヘッダー。HTTPでは重複したヘッダーが許可されています。port: コンテナにアクセスする際のポートの名前または番号。ポート番号の場合、1から65535の範囲内である必要があります。HTTPによるProbeの場合、kubeletは指定したパスとポートに対するHTTPリクエストを送ることでチェックを行います。
httpGetのオプションであるhostフィールドでアドレスが上書きされない限り、kubeletはPodのIPアドレスに対してProbeを送ります。
schemeフィールドにHTTPSがセットされている場合、kubeletは証明書の検証を行わずにHTTPSリクエストを送ります。
ほとんどのシナリオにおいては、hostフィールドを使用する必要はありません。次のシナリオは使用する場合の一例です。
仮にコンテナが127.0.0.1をリッスンしており、かつPodのhostNetworkフィールドがtrueだとします。
その場合においては、httpGetフィールド内のhostには127.0.0.1をセットする必要があります。
より一般的なケースにおいてPodが仮想ホストに依存している場合は、おそらくhostフィールドではなく、httpHeadersフィールド内のHostヘッダーを使用する必要があります。
TCPによるProbeの場合、kubeletはPodの中ではなく、ノードに対してコネクションを確立するProbeを実行します。
kubeletはServiceの名前を解決できないため、hostパラメーター内でServiceの名前を使用することはできません。
次の項目 また、次のAPIリファレンスも参考にしてください:
4.3.12 - Podをノードに割り当てる このページでは、KubernetesのPodをKubernetesクラスター上の特定のノードに割り当てる方法を説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
ラベルをノードに追加する クラスター内のノード のリストをラベル付きで表示します。
kubectl get nodes --show-labels
出力は次のようになります。
NAME STATUS ROLES AGE VERSION LABELS
worker0 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname= worker0
worker1 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname= worker1
worker2 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname= worker2
ノードの1つを選択して、ラベルを追加します。
kubectl label nodes <your-node-name> disktype = ssd
ここで、<your-node-name>は選択したノードの名前です。
選択したノードにdisktype=ssdラベルがあることを確認します。
kubectl get nodes --show-labels
出力は次のようになります。
NAME STATUS ROLES AGE VERSION LABELS
worker0 Ready <none> 1d v1.13.0 ...,disktype= ssd,kubernetes.io/hostname= worker0
worker1 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname= worker1
worker2 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname= worker2
上の出力を見ると、worker0にdisktype=ssdというラベルがあることがわかります。
選択したノードにスケジューリングされるPodを作成する 以下のPodの構成ファイルには、nodeSelectorにdisktype: ssdを持つPodが書かれています。これにより、Podはdisktype: ssdというラベルを持っているノードにスケジューリングされるようになります。
apiVersion : v1
kind : Pod
metadata :
name : nginx
labels :
env : test
spec :
containers :
- name : nginx
image : nginx
imagePullPolicy : IfNotPresent
nodeSelector :
disktype : ssd
構成ファイルを使用して、選択したノードにスケジューリングされるPodを作成します。
kubectl apply -f https://k8s.io/examples/pods/pod-nginx.yaml
Podが選択したノード上で実行されているをことを確認します。
kubectl get pods --output= wide
出力は次のようになります。
NAME READY STATUS RESTARTS AGE IP NODE
nginx 1/1 Running 0 13s 10.200.0.4 worker0
特定のノードにスケジューリングされるPodを作成する nodeNameという設定を使用して、Podを特定のノードにスケジューリングすることもできます。
apiVersion : v1
kind : Pod
metadata :
name : nginx
spec :
nodeName : foo-node # 特定のノードにPodをスケジューリングする
containers :
- name : nginx
image : nginx
imagePullPolicy : IfNotPresent
構成ファイルを使用して、foo-nodeにだけスケジューリングされるPodを作成します。
次の項目 4.3.13 - Node Affinityを利用してPodをノードに割り当てる このページでは、Node Affinityを利用して、PodをKubernetesクラスター内の特定のノードに割り当てる方法を説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.10.
バージョンを確認するには次のコマンドを実行してください: kubectl version.
ノードにラベルを追加する クラスター内のノードを一覧表示して、ラベルを確認します。
kubectl get nodes --show-labels
出力は次のようになります。
NAME STATUS ROLES AGE VERSION LABELS
worker0 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname= worker0
worker1 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname= worker1
worker2 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname= worker2
ノードを選択して、ラベルを追加します。
kubectl label nodes <your-node-name> disktype = ssd
ここで、<your-node-name>は選択したノードの名前で置換します。
選択したノードにdisktype=ssdラベルがあることを確認します。
kubectl get nodes --show-labels
出力は次のようになります。
NAME STATUS ROLES AGE VERSION LABELS
worker0 Ready <none> 1d v1.13.0 ...,disktype=ssd,kubernetes.io/hostname=worker0
worker1 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker1
worker2 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker2
この出力を見ると、worker0ノードにdisktype=ssdというラベルが追加されたことがわかります。
required node affinityを使用してPodをスケジューリングする 以下に示すマニフェストには、requiredDuringSchedulingIgnoredDuringExecutionにdisktype: ssdというnode affinityを使用したPodが書かれています。このように書くと、Podはdisktype=ssdというラベルを持つノードにだけスケジューリングされるようになります。
apiVersion : v1
kind : Pod
metadata :
name : nginx
spec :
affinity :
nodeAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
nodeSelectorTerms :
- matchExpressions :
- key : disktype
operator : In
values :
- ssd
containers :
- name : nginx
image : nginx
imagePullPolicy : IfNotPresent
マニフェストを適用して、選択したノード上にスケジューリングされるPodを作成します。
kubectl apply -f https://k8s.io/examples/pods/pod-nginx-required-affinity.yaml
Podが選択したノード上で実行されていることを確認します。
kubectl get pods --output= wide
出力は次のようになります。
NAME READY STATUS RESTARTS AGE IP NODE
nginx 1/1 Running 0 13s 10.200.0.4 worker0
preferred node affinityを使用してPodをスケジューリングする 以下に示すマニフェストには、preferredDuringSchedulingIgnoredDuringExecutionにdisktype: ssdというnode affinityを使用したPodが書かれています。このように書くと、Podはdisktype=ssdというラベルを持つノードに優先的にスケジューリングされるようになります。
apiVersion : v1
kind : Pod
metadata :
name : nginx
spec :
affinity :
nodeAffinity :
preferredDuringSchedulingIgnoredDuringExecution :
- weight : 1
preference :
matchExpressions :
- key : disktype
operator : In
values :
- ssd
containers :
- name : nginx
image : nginx
imagePullPolicy : IfNotPresent
マニフェストを適用して、選択したノード上にスケジューリングされるPodを作成します。
kubectl apply -f https://k8s.io/examples/pods/pod-nginx-preferred-affinity.yaml
Podが選択したノード上で実行されていることを確認します。
kubectl get pods --output= wide
出力は次のようになります。
NAME READY STATUS RESTARTS AGE IP NODE
nginx 1/1 Running 0 13s 10.200.0.4 worker0
次の項目 Node Affinity についてさらに学ぶ。
4.3.14 - Pod初期化の設定 このページでは、アプリケーションコンテナが実行される前に、Initコンテナを使用してPodを初期化する方法を示します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
Initコンテナを持つPodを作成する この演習では、アプリケーションコンテナが1つ、Initコンテナが1つのPodを作成します。
Initコンテナはアプリケーションコンテナが実行される前に完了します。
Podの設定ファイルは次の通りです:
apiVersion : v1
kind : Pod
metadata :
name : init-demo
spec :
containers :
- name : nginx
image : nginx
ports :
- containerPort : 80
volumeMounts :
- name : workdir
mountPath : /usr/share/nginx/html
# These containers are run during pod initialization
initContainers :
- name : install
image : busybox
command :
- wget
- "-O"
- "/work-dir/index.html"
- http://kubernetes.io
volumeMounts :
- name : workdir
mountPath : "/work-dir"
dnsPolicy : Default
volumes :
- name : workdir
emptyDir : {}
設定ファイルを確認すると、PodはInitコンテナとアプリケーションコンテナが共有するボリュームを持っています。
Initコンテナは共有ボリュームを/work-dirにマウントし、アプリケーションコンテナは共有ボリュームを/usr/share/nginx/htmlにマウントします。
Initコンテナは以下のコマンドを実行してから終了します:
wget -O /work-dir/index.html http://info.cern.ch
Initコンテナは、nginxサーバーのルートディレクトリのindex.htmlファイルに書き込むことに注意してください。
Podを作成します:
kubectl apply -f https://k8s.io/examples/pods/init-containers.yaml
nginxコンテナが実行中であることを確認します:
kubectl get pod init-demo
次の出力はnginxコンテナが実行中であることを示します:
NAME READY STATUS RESTARTS AGE
init-demo 1/1 Running 0 1m
init-demo Podで実行中のnginxコンテナのシェルを取得します:
kubectl exec -it init-demo -- /bin/bash
シェルで、nginxサーバーにGETリクエストを送信します:
root@nginx:~# apt-get update
root@nginx:~# apt-get install curl
root@nginx:~# curl localhost
出力は、Initコンテナが書き込んだウェブページをnginxが提供していることを示します:
<html ><head ></head ><body ><header >
<title >http://info.cern.ch</title >
</header >
<h1 >http://info.cern.ch - home of the first website</h1 >
...
<li ><a href = "http://info.cern.ch/hypertext/WWW/TheProject.html" >Browse the first website</a ></li >
...
次の項目 4.3.15 - コンテナライフサイクルイベントへのハンドラー紐付け このページでは、コンテナのライフサイクルイベントにハンドラーを紐付けする方法を説明します。KubernetesはpostStartとpreStopイベントをサポートしています。Kubernetesはコンテナの起動直後にpostStartイベントを送信し、コンテナの終了直前にpreStopイベントを送信します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
postStartハンドラーとpreStopハンドラーを定義する この課題では、1つのコンテナを持つPodを作成します。コンテナには、postStartイベントとpreStopイベントのハンドラーがあります。
これがPodの設定ファイルです:
apiVersion : v1
kind : Pod
metadata :
name : lifecycle-demo
spec :
containers :
- name : lifecycle-demo-container
image : nginx
lifecycle :
postStart :
exec :
command : ["/bin/sh" , "-c" , "echo Hello from the postStart handler > /usr/share/message" ]
preStop :
exec :
command : ["/usr/sbin/nginx" ,"-s" ,"quit" ]
設定ファイルでは、postStartコマンドがmessageファイルをコンテナの/usr/shareディレクトリに書き込むことがわかります。preStopコマンドはnginxを適切にシャットダウンします。これは、障害のためにコンテナが終了している場合に役立ちます。
Podを作成します:
kubectl apply -f https://k8s.io/examples/pods/lifecycle-events.yaml
Pod内のコンテナが実行されていることを確認します:
kubectl get pod lifecycle-demo
Pod内で実行されているコンテナでシェルを実行します:
kubectl exec -it lifecycle-demo -- /bin/bash
シェルで、postStartハンドラーがmessageファイルを作成したことを確認します:
root@lifecycle-demo:/# cat /usr/share/message
出力は、postStartハンドラーによって書き込まれたテキストを示しています。
Hello from the postStart handler
議論 コンテナが作成された直後にKubernetesはpostStartイベントを送信します。
ただし、コンテナのエントリーポイントが呼び出される前にpostStartハンドラーが呼び出されるという保証はありません。postStartハンドラーはコンテナのコードに対して非同期的に実行されますが、postStartハンドラーが完了するまでコンテナのKubernetesによる管理はブロックされます。postStartハンドラーが完了するまで、コンテナのステータスはRUNNINGに設定されません。
Kubernetesはコンテナが終了する直前にpreStopイベントを送信します。
コンテナのKubernetesによる管理は、Podの猶予期間が終了しない限り、preStopハンドラーが完了するまでブロックされます。詳細はPodのライフサイクル を参照してください。
備考: Kubernetesは、Podが
終了 したときにのみpreStopイベントを送信します。
これは、Podが
完了 したときにpreStopフックが呼び出されないことを意味します。
この制限は
issue #55087 で追跡されています。
次の項目 参照 4.3.16 - Podを構成してConfigMapを使用する ConfigMapを使用すると、設定をイメージのコンテンツから切り離して、コンテナ化されたアプリケーションの移植性を維持できます。このページでは、ConfigMapを作成し、ConfigMapに保存されているデータを使用してPodを構成する一連の使用例を示します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
ConfigMapを作成する kubectl create configmapまたはkustomization.yamlのConfigMap generatorを使用すると、ConfigMapを作成できます。kubectlがkustomization.yamlをサポートをしているのは1.14からである点に注意してください。
kubectl create configmapを使用してConfigMapを作成する kubectl create configmapを使用してConfigMapをディレクトリ 、ファイル 、またはリテラル値 から作成します:
kubectl create configmap <map-name> <data-source>
<map-name>の部分はConfigMapに割り当てる名前で、<data-source>はデータを取得するディレクトリ、ファイル、またはリテラル値です。ConfigMapの名前は有効なDNSサブドメイン名 である必要があります。
ファイルをベースにConfigMapを作成する場合、<data-source> のキーはデフォルトでファイル名になり、値はデフォルトでファイルの中身になります。
kubectl describekubectl get
ディレクトリからConfigMapを作成する kubectl create configmapを使用すると、同一ディレクトリ内にある複数のファイルから1つのConfigMapを作成できます。ディレクトリをベースにConfigMapを作成する場合、kubectlはディレクトリ内でベース名が有効なキーであるファイルを識別し、それらのファイルを新たなConfigMapにパッケージ化します。ディレクトリ内にある通常のファイルでないものは無視されます(例: サブディレクトリ、シンボリックリンク、デバイス、パイプなど)。
例えば:
# ローカルディレクトリを作成します
mkdir -p configure-pod-container/configmap/
# `configure-pod-container/configmap/`ディレクトリにサンプルファイルをダウンロードします
wget https://kubernetes.io/examples/configmap/game.properties -O configure-pod-container/configmap/game.properties
wget https://kubernetes.io/examples/configmap/ui.properties -O configure-pod-container/configmap/ui.properties
# ConfigMapを作成します
kubectl create configmap game-config --from-file= configure-pod-container/configmap/
上記のコマンドは各ファイルをパッケージ化します。この場合、configure-pod-container/configmap/ ディレクトリのgame.properties と ui.propertiesをgame-config ConfigMapにパッケージ化します。 以下のコマンドを使用すると、ConfigMapの詳細を表示できます:
kubectl describe configmaps game-config
出力結果は以下のようになります:
Name: game-config
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
game.properties:
----
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
ui.properties:
----
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
configure-pod-container/configmap/ ディレクトリのgame.properties と ui.properties ファイルはConfigMapのdataセクションに表示されます。
kubectl get configmaps game-config -o yaml
出力結果は以下のようになります:
apiVersion : v1
kind : ConfigMap
metadata :
creationTimestamp : 2016-02-18T18:52:05Z
name : game-config
namespace : default
resourceVersion : "516"
uid : b4952dc3-d670-11e5-8cd0-68f728db1985
data :
game.properties : |
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
ui.properties : |
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
ファイルからConfigMapを作成する kubectl create configmapを使用して、個別のファイルまたは複数のファイルからConfigMapを作成できます。
例えば、
kubectl create configmap game-config-2 --from-file= configure-pod-container/configmap/game.properties
は、以下のConfigMapを生成します:
kubectl describe configmaps game-config-2
出力結果は以下のようになります:
Name: game-config-2
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
game.properties:
----
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
--from-file引数を複数回渡し、ConfigMapを複数のデータソースから作成できます。
kubectl create configmap game-config-2 --from-file= configure-pod-container/configmap/game.properties --from-file= configure-pod-container/configmap/ui.properties
以下のコマンドを使用すると、ConfigMapgame-config-2の詳細を表示できます:
kubectl describe configmaps game-config-2
出力結果は以下のようになります:
Name: game-config-2
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
game.properties:
----
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
ui.properties:
----
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
--from-env-fileオプションを利用してConfigMapをenv-fileから作成します。例えば:
# Env-filesは環境編集のリストを含んでいます。
# 以下のシンタックスルールが適用されます:
# envファイルの各行はVAR=VALの形式である必要がある。
# #で始まる行 (例えばコメント)は無視される。
# 空の行は無視される。
# クオーテーションマークは特別な扱いは処理をしない(例えばConfigMapの値の一部になる).
# `configure-pod-container/configmap/`ディレクトリにサンプルファイルをダウンロードします
wget https://kubernetes.io/examples/configmap/game-env-file.properties -O configure-pod-container/configmap/game-env-file.properties
# env-file `game-env-file.properties`は以下のようになります
cat configure-pod-container/configmap/game-env-file.properties
enemies = aliens
lives = 3
allowed = "true"
# このコメントと上記の空の行は無視されます
kubectl create configmap game-config-env-file \
= configure-pod-container/configmap/game-env-file.properties
は、以下のConfigMapを生成します:
kubectl get configmap game-config-env-file -o yaml
出力結果は以下のようになります:
apiVersion : v1
kind : ConfigMap
metadata :
creationTimestamp : 2017-12-27T18:36:28Z
name : game-config-env-file
namespace : default
resourceVersion : "809965"
uid : d9d1ca5b-eb34-11e7-887b-42010a8002b8
data :
allowed : '"true"'
enemies : aliens
lives : "3"
注意: --from-env-fileを複数回渡してConfigMapを複数のデータソースから作成する場合、最後のenv-fileのみが使用されます。--from-env-fileを複数回渡す場合の挙動は以下のように示されます:
# `configure-pod-container/configmap/`ディレクトリにサンブルファイルをダウンロードします
wget https://kubernetes.io/examples/configmap/ui-env-file.properties -O configure-pod-container/configmap/ui-env-file.properties
# ConfigMapを作成します
kubectl create configmap config-multi-env-files \
= configure-pod-container/configmap/game-env-file.properties \
= configure-pod-container/configmap/ui-env-file.properties
は、以下のConfigMapを生成します:
kubectl get configmap config-multi-env-files -o yaml
出力結果は以下のようになります:
apiVersion : v1
kind : ConfigMap
metadata :
creationTimestamp : 2017-12-27T18:38:34Z
name : config-multi-env-files
namespace : default
resourceVersion : "810136"
uid : 252c4572-eb35-11e7-887b-42010a8002b8
data :
color : purple
how : fairlyNice
textmode : "true"
ファイルからConfigMap作成する場合は使用するキーを定義する --from-file引数を使用する場合、ConfigMapのdata セクションでキーにファイル名以外を定義できます:
kubectl create configmap game-config-3 --from-file= <my-key-name>= <path-to-file>
<my-key-name>の部分はConfigMapで使うキー、<path-to-file> はキーで表示したいデータソースファイルの場所です。
例えば:
kubectl create configmap game-config-3 --from-file= game-special-key= configure-pod-container/configmap/game.properties
は、以下のConfigMapを生成します:
kubectl get configmaps game-config-3 -o yaml
出力結果は以下のようになります:
apiVersion : v1
kind : ConfigMap
metadata :
creationTimestamp : 2016-02-18T18:54:22Z
name : game-config-3
namespace : default
resourceVersion : "530"
uid : 05f8da22-d671-11e5-8cd0-68f728db1985
data :
game-special-key : |
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
リテラル値からConfigMapを作成する --from-literal引数を指定してkubectl create configmapを使用すると、コマンドラインからリテラル値を定義できます:
kubectl create configmap special-config --from-literal= special.how= very --from-literal= special.type= charm
複数のキーバリューペアを渡せます。CLIに提供された各ペアは、ConfigMapのdataセクションで別のエントリーとして表示されます。
kubectl get configmaps special-config -o yaml
出力結果は以下のようになります:
apiVersion : v1
kind : ConfigMap
metadata :
creationTimestamp : 2016-02-18T19:14:38Z
name : special-config
namespace : default
resourceVersion : "651"
uid : dadce046-d673-11e5-8cd0-68f728db1985
data :
special.how : very
special.type : charm
ジェネレーターからConfigMapを作成する kubectlはkustomization.yamlを1.14からサポートしています。
ジェネレーターからConfigMapを作成して適用すると、APIサーバー上でオブジェクトを作成できます。ジェネレーターはディレクトリ内のkustomization.yamlで指定する必要があリます。
ファイルからConfigMapを生成する 例えば、ファイルconfigure-pod-container/configmap/game.propertiesからConfigMapを生成するには、
# ConfigMapGeneratorを含むkustomization.yamlファイルを作成する
cat <<EOF >./kustomization.yaml
configMapGenerator:
- name: game-config-4
files:
- configure-pod-container/configmap/game.properties
EOF
ConfigMapを作成するためにkustomizationディレクトリを適用します。
kubectl apply -k .
configmap/game-config-4-m9dm2f92bt created
ConfigMapが作成されたことを以下のようにチェックできます:
kubectl get configmap
NAME DATA AGE
game-config-4-m9dm2f92bt 1 37s
kubectl describe configmaps/game-config-4-m9dm2f92bt
Name: game-config-4-m9dm2f92bt
Namespace: default
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{ "apiVersion" :"v1" ,"data" :{ "game.properties" :"enemies=aliens\nlives=3\nenemies.cheat=true\nenemies.cheat.level=noGoodRotten\nsecret.code.p...
Data
====
game.properties:
----
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
Events: <none>
生成されたConfigMapの名前は、コンテンツをハッシュ化したサフィックスを持つことに注意してください。これにより、コンテンツが変更されるたびに新しいConfigMapが生成されます。
ファイルからConfigMapを生成する場合に使用するキーを定義する ConfigMapジェネレーターで使用するキーはファイルの名前以外を定義できます。
例えば、ファイルconfigure-pod-container/configmap/game.propertiesからキーgame-special-keyを持つConfigMapを作成する場合
# ConfigMapGeneratorを含むkustomization.yamlファイルを作成する
cat <<EOF >./kustomization.yaml
configMapGenerator:
- name: game-config-5
files:
- game-special-key=configure-pod-container/configmap/game.properties
EOF
kustomizationディレクトリを適用してConfigMapを作成します。
kubectl apply -k .
configmap/game-config-5-m67dt67794 created
リテラルからConfigMapを作成する リテラルspecial.type=charmとspecial.how=veryからConfigMapを作成する場合は、
以下のようにkustomization.yamlのConfigMapジェネレーターで指定できます。
# ConfigMapGeneratorを含むkustomization.yamlファイルを作成します
cat <<EOF >./kustomization.yaml
configMapGenerator:
- name: special-config-2
literals:
- special.how=very
- special.type=charm
EOF
kustomizationディレクトリを適用してConfigMapを作成します。
kubectl apply -k .
configmap/special-config-2-c92b5mmcf2 created
ConfigMapデータを使用してコンテナ環境変数を定義する 単一のConfigMapのデータを使用してコンテナ環境変数を定義する ConfigMapに環境変数をキーバリューペアとして定義します:
kubectl create configmap special-config --from-literal= special.how= very
ConfigMapに定義された値special.howをPod specificationの環境変数SPECIAL_LEVEL_KEYに割り当てます。
apiVersion : v1
kind : Pod
metadata :
name : dapi-test-pod
spec :
containers :
- name : test-container
image : registry.k8s.io/busybox
command : [ "/bin/sh" , "-c" , "env" ]
env :
# 環境変数を定義します
- name : SPECIAL_LEVEL_KEY
valueFrom :
configMapKeyRef :
# SPECIAL_LEVEL_KEYに割り当てる値をConfigMapが保持します
name : special-config
# 値に紐付けるキーを指定します
key : special.how
restartPolicy : Never
Podを作成します:
kubectl create -f https://kubernetes.io/examples/pods/pod-single-configmap-env-variable.yaml
すると、Podの出力結果に環境変数SPECIAL_LEVEL_KEY=veryが含まれています。
複数のConfigMapのデータを使用してコンテナ環境変数を定義する kubectl create -f https://kubernetes.io/examples/configmap/configmaps.yaml
kubectl create -f https://kubernetes.io/examples/pods/pod-multiple-configmap-env-variable.yaml
すると、Podの出力結果に環境変数SPECIAL_LEVEL_KEY=very and LOG_LEVEL=INFOが含まれています。
ConfigMapの全てのキーバリューペアをコンテナ環境変数として構成する
備考: この機能はKubernetes v1.6以降で利用可能です。kubectl create -f https://kubernetes.io/examples/configmap/configmap-multikeys.yaml
envFromを利用して全てのConfigMapのデータをコンテナ環境変数として定義します。ConfigMapからのキーがPodの環境変数名になります。apiVersion : v1
kind : Pod
metadata :
name : dapi-test-pod
spec :
containers :
- name : test-container
image : registry.k8s.io/busybox
command : [ "/bin/sh" , "-c" , "env" ]
envFrom :
- configMapRef :
name : special-config
restartPolicy : Never
Podを作成します:
kubectl create -f https://kubernetes.io/examples/pods/pod-configmap-envFrom.yaml
すると、Podの出力結果は環境変数SPECIAL_LEVEL=veryとSPECIAL_TYPE=charmが含まれています。
PodのコマンドでConfigMapに定義した環境変数を使用する ConfigMapに環境変数を定義し、Pod specificationのcommand セクションで$(VAR_NAME)Kubernetes置換構文を介して使用できます。
例えば以下のPod specificationは
apiVersion : v1
kind : Pod
metadata :
name : dapi-test-pod
spec :
containers :
- name : test-container
image : registry.k8s.io/busybox
command : [ "/bin/echo" , "$(SPECIAL_LEVEL_KEY) $(SPECIAL_TYPE_KEY)" ]
env :
- name : SPECIAL_LEVEL_KEY
valueFrom :
configMapKeyRef :
name : special-config
key : SPECIAL_LEVEL
- name : SPECIAL_TYPE_KEY
valueFrom :
configMapKeyRef :
name : special-config
key : SPECIAL_TYPE
restartPolicy : Never
以下コマンドの実行で作成され、
kubectl create -f https://kubernetes.io/examples/pods/pod-configmap-env-var-valueFrom.yaml
test-containerコンテナで以下の出力結果を表示します:
kubectl logs dapi-test-pod
ボリュームにConfigMapデータを追加する ファイルからConfigMapを作成する で説明したように、--from-fileを使用してConfigMapを作成する場合は、ファイル名がConfigMapのdataセクションに保存されるキーになり、ファイルのコンテンツがキーの値になります。
このセクションの例は以下に示されているspecial-configと名付けれたConfigMapについて言及したものです。
apiVersion : v1
kind : ConfigMap
metadata :
name : special-config
namespace : default
data :
SPECIAL_LEVEL : very
SPECIAL_TYPE : charm
ConfigMapを作成します:
kubectl create -f https://kubernetes.io/examples/configmap/configmap-multikeys.yaml
ConfigMapに保存されているデータをボリュームに入力する ConfigMap名をPod specificationのvolumesセクション配下に追加します。
これによりConfigMapデータがvolumeMounts.mountPathで指定されたディレクトリに追加されます (このケースでは、/etc/configに)。commandセクションはConfigMapのキーに合致したディレクトリファイルを名前別でリスト表示します。
apiVersion : v1
kind : Pod
metadata :
name : dapi-test-pod
spec :
containers :
- name : test-container
image : registry.k8s.io/busybox
command : [ "/bin/sh" , "-c" , "ls /etc/config/" ]
volumeMounts :
- name : config-volume
mountPath : /etc/config
volumes :
- name : config-volume
configMap :
# コンテナに追加するファイルを含むConfigMapの名前を提供する
name : special-config
restartPolicy : Never
Podを作成します:
kubectl create -f https://kubernetes.io/examples/pods/pod-configmap-volume.yaml
Podが稼働していると、ls /etc/config/は以下の出力結果を表示します:
SPECIAL_LEVEL
SPECIAL_TYPE
注意: /etc/config/ディレクトリに何かファイルがある場合、それらは削除されます。
備考: テキストデータはUTF-8文字エンコーディングを使用しているファイルとして公開されます。他の文字エンコーディングを使用する場合は、バイナリデータを使用してください。ConfigMapデータをボリュームの特定のパスに追加する pathフィールドを利用して特定のConfigMapのアイテム向けに希望のファイルパスを指定します。
このケースではSPECIAL_LEVELアイテムが/etc/config/keysのconfig-volumeボリュームにマウントされます。
apiVersion : v1
kind : Pod
metadata :
name : dapi-test-pod
spec :
containers :
- name : test-container
image : registry.k8s.io/busybox
command : [ "/bin/sh" ,"-c" ,"cat /etc/config/keys" ]
volumeMounts :
- name : config-volume
mountPath : /etc/config
volumes :
- name : config-volume
configMap :
name : special-config
items :
- key : SPECIAL_LEVEL
path : keys
restartPolicy : Never
Podを作成します:
kubectl create -f https://kubernetes.io/examples/pods/pod-configmap-volume-specific-key.yaml
Podが稼働していると、 cat /etc/config/keysは以下の出力結果を表示します:
注意: 先ほどのように、/etc/config/ ディレクトリのこれまでのファイルは全て削除されますキーを特定のパスとファイルアクセス許可に投影する キーをファイル単位で特定のパスとアクセス許可に投影できます。Secret のユーザーガイドで構文が解説されています。
マウントされたConfigMapは自動的に更新される ボリュームで使用されているConfigMapが更新されている場合、投影されているキーも同じく結果的に更新されます。kubeletは定期的な同期ごとにマウントされているConfigMapが更新されているかチェックします。しかし、これはローカルのttlを基にしたキャッシュでConfigMapの現在の値を取得しています。その結果、新しいキーがPodに投影されてからConfigMapに更新されるまでのトータルの遅延はkubeletで、kubeletの同期期間(デフォルトで1分) + ConfigMapキャッシュのttl(デフォルトで1分)の長さになる可能性があります。Podのアノテーションを1つ更新すると即時のリフレッシュをトリガーできます。
備考: ConfigMapを
subPath ボリュームとして利用するコンテナはConfigMapの更新を受け取りません。
ConfigMapとPodsを理解する ConfigMap APIリソースは構成情報をキーバリューペアとして保存します。データはPodで利用したり、コントローラーなどのシステムコンポーネントに提供できます。ConfigMapはSecret に似ていますが、機密情報を含まない文字列を含まない操作する手段を提供します。ユーザーとシステムコンポーネントはどちらも構成情報をConfigMapに保存できます。
備考: ConfigMapはプロパティーファイルを参照するべきであり、置き換えるべきではありません。ConfigMapをLinuxの
/etcディレクトリとそのコンテンツのように捉えましょう。例えば、
Kubernetes Volume をConfigMapから作成した場合、ConfigMapのデータアイテムはボリューム内で個別のファイルとして表示されます。
ConfigMapのdataフィールドは構成情報を含みます。下記の例のように、シンプルに個別のプロパティーを--from-literalで定義、または複雑に構成ファイルまたはJSON blobsを--from-fileで定義できます。
apiVersion : v1
kind : ConfigMap
metadata :
creationTimestamp : 2016-02-18T19:14:38Z
name : example-config
namespace : default
data :
# --from-literalを使用してシンプルにプロパティーを定義する例
example.property.1 : hello
example.property.2 : world
# --from-fileを使用して複雑にプロパティーを定義する例
example.property.file : |-
property.1=value-1
property.2=value-2
property.3=value-3
制限事項 ConfigMapはPod specificationを参照させる前に作成する必要があります(ConfigMapを"optional"として設定しない限り)。存在しないConfigMapを参照させた場合、Podは起動しません。同様にConfigMapに存在しないキーを参照させた場合も、Podは起動しません。
ConfigMapでenvFromを使用して環境変数を定義した場合、無効と判断されたキーはスキップされます。Podは起動されますが、無効な名前はイベントログに(InvalidVariableNames)と記録されます。ログメッセージはスキップされたキーごとにリスト表示されます。例えば:
出力結果は以下のようになります:
LASTSEEN FIRSTSEEN COUNT NAME KIND SUBOBJECT TYPE REASON SOURCE MESSAGE
0s 0s 1 dapi-test-pod Pod Warning InvalidEnvironmentVariableNames {kubelet, 127.0.0.1} Keys [1badkey, 2alsobad] from the EnvFrom configMap default/myconfig were skipped since they are considered invalid environment variable names.
ConfigMapは特定のNamespace に属します。ConfigMapは同じ名前空間に属するPodからのみ参照できます。
static pods はKubeletがサポートしていないため、ConfigMapに使用できません。
次の項目 4.3.17 - Pod内のコンテナ間でプロセス名前空間を共有する FEATURE STATE:
Kubernetes v1.17 [stable]
このページでは、プロセス名前空間を共有するPodを構成する方法を示します。
プロセス名前空間の共有が有効になっている場合、コンテナ内のプロセスは、そのPod内の他のすべてのコンテナに表示されます。
この機能を使用して、ログハンドラーサイドカーコンテナなどの協調コンテナを構成したり、シェルなどのデバッグユーティリティを含まないコンテナイメージをトラブルシューティングしたりできます。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.10.
バージョンを確認するには次のコマンドを実行してください: kubectl version.
Podを構成する プロセス名前空間の共有は、v1.PodSpecのshareProcessNamespaceフィールドを使用して有効にします。
例:
apiVersion : v1
kind : Pod
metadata :
name : nginx
spec :
shareProcessNamespace : true
containers :
- name : nginx
image : nginx
- name : shell
image : busybox
securityContext :
capabilities :
add :
- SYS_PTRACE
stdin : true
tty : true
クラスターにPod nginxを作成します:
kubectl apply -f https://k8s.io/examples/pods/share-process-namespace.yaml
shellコンテナにアタッチしてpsを実行します:
kubectl exec -it nginx -c shell -- /bin/sh
コマンドプロンプトが表示されない場合は、Enterキーを押してみてください。
/ # ps ax
PID USER TIME COMMAND
1 root 0:00 /pause
8 root 0:00 nginx: master process nginx -g daemon off;
14 101 0:00 nginx: worker process
15 root 0:00 sh
21 root 0:00 ps ax
他のコンテナのプロセスにシグナルを送ることができます。
たとえば、ワーカープロセスを再起動するには、SIGHUPをnginxに送信します。
この操作にはSYS_PTRACE機能が必要です。
/ # kill -HUP 8
/ # ps ax
PID USER TIME COMMAND
1 root 0:00 /pause
8 root 0:00 nginx: master process nginx -g daemon off;
15 root 0:00 sh
22 101 0:00 nginx: worker process
23 root 0:00 ps ax
/proc/$pid/rootリンクを使用して別のコンテナイメージにアクセスすることもできます。
/ # head /proc/8/root/etc/nginx/nginx.conf
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
プロセス名前空間の共有について理解する Podは多くのリソースを共有するため、プロセスの名前空間も共有することになります。
ただし、一部のコンテナイメージは他のコンテナから分離されることが期待されるため、これらの違いを理解することが重要です:
コンテナプロセスは PID 1ではなくなります。
一部のコンテナイメージは、PID 1なしで起動することを拒否し(たとえば、systemdを使用するコンテナ)、kill -HUP 1などのコマンドを実行してコンテナプロセスにシグナルを送信します。
共有プロセス名前空間を持つPodでは、kill -HUP 1はPodサンドボックスにシグナルを送ります。(上の例では/pause)
プロセスはPod内の他のコンテナに表示されます。
これには、引数または環境変数として渡されたパスワードなど、/procに表示されるすべての情報が含まれます。
これらは、通常のUnixアクセス許可によってのみ保護されます。
コンテナファイルシステムは、/proc/$pid/rootリンクを介してPod内の他のコンテナに表示されます。
これによりデバッグが容易になりますが、ファイルシステム内の秘密情報はファイルシステムのアクセス許可によってのみ保護されることも意味します。
4.3.18 - static Podを作成する Static Pod とは、APIサーバー が監視せず、特定のノード上のkubeletデーモンによって直接管理されるPodです。コントロールプレーンに管理されるPod(たとえばDeployment など)とは異なり、kubeletがそれぞれのstatic Podを監視(および障害時には再起動)します。
Static Podは、常に特定のノード上の1つのKubelet に紐付けられます。
kubeletは、各static Podに対して、自動的にKubernetes APIサーバー上にミラーPod の作成を試みます。つまり、ノード上で実行中のPodはAPIサーバーから検出されますが、APIサーバー自身から制御されることはないということです。
備考: 複数ノードからなるKubernetesクラスターを実行していて、Podをすべてのノード上で実行するためにstatic Podを使用している場合、おそらくstatic Podの代わりに
DaemonSet を使用するべきでしょう。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
このページの説明では、Podを実行するためにDocker を使用しており、ノード上のOSがFedoraであることを前提としています。他のディストリビューションやKubernetesのインストール方法によっては、操作が異なる場合があります。
static Podを作成する static Podは、ファイルシステム上でホストされた設定ファイル またはウェブ上でホストされた設定ファイル を使用して設定できます。
ファイルシステム上でホストされたstatic Podマニフェスト マニフェストは、JSONまたはYAML形式の標準のPod定義で、特定のディレクトリに置きます。kubeletの設定ファイル の中で、staticPodPath: <ディレクトリの場所>というフィールドを使用すると、kubeletがこのディレクトリを定期的にスキャンして、YAML/JSONファイルが作成/削除されるたびに、static Podの作成/削除が行われるようになります。指定したディレクトリをスキャンする際、kubeletはドットから始まる名前のファイルを無視することに注意してください。
例として、単純なウェブサーバーをstatic Podとして実行する方法を示します。
static Podを実行したいノードを選択します。この例では、my-node1です。
ディレクトリを選び(ここでは/etc/kubelet.dとします)、ここにウェブサーバーのPodの定義を置きます。たとえば、/etc/kubelet.d/static-web.yamlに置きます。
# このコマンドは、kubeletが実行中のノード上で実行してください
mkdir /etc/kubelet.d/
cat <<EOF >/etc/kubelet.d/static-web.yaml
apiVersion: v1
kind: Pod
metadata:
name: static-web
labels:
role: myrole
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
EOF
ノード上のkubeletがこのディレクトリを使用するようにするために、--pod-manifest-path=/etc/kubelet.d/引数を付けてkubeletを実行するように設定します。Fedoraの場合、次の行が含まれるように/etc/kubernetes/kubeletを編集します。
KUBELET_ARGS="--cluster-dns=10.254.0.10 --cluster-domain=kube.local --pod-manifest-path=/etc/kubelet.d/"
あるいは、kubeletの設定ファイル に、staticPodPath: <ディレクトリの場所>フィールドを追加することでも設定できます。
kubeletを再起動します。Fedoraの場合、次のコマンドを実行します。
# このコマンドは、kubeletが実行中のノード上で実行してください
systemctl restart kubelet
ウェブ上でホストされたstatic Podマニフェスト kubeletは、--manifest-url=<URL>引数で指定されたファイルを定期的にダウンロードし、Podの定義が含まれたJSON/YAMLファイルとして解釈します。kubeletは、ファイルシステム上でホストされたマニフェスト での動作方法と同じように、定期的にマニフェストを再取得します。static Podのリスト中に変更が見つかると、kubeletがその変更を適用します。
このアプローチを採用する場合、次のように設定します。
YAMLファイルを作成し、kubeletにファイルのURLを渡せるようにするために、ウェブサーバー上に保存する。
apiVersion : v1
kind : Pod
metadata :
name : static-web
labels :
role : myrole
spec :
containers :
- name : web
image : nginx
ports :
- name : web
containerPort : 80
protocol : TCP
選択したノード上のkubeletを--manifest-url=<manifest-url>を使用して実行することで、このウェブ上のマニフェストを使用するように設定する。Fedoraの場合、/etc/kubernetes/kubeletに次の行が含まれるように編集します。
KUBELET_ARGS="--cluster-dns=10.254.0.10 --cluster-domain=kube.local --manifest-url=<マニフェストのURL"
kubeletを再起動する。Fedoraの場合、次のコマンドを実行します。
# このコマンドは、kubeletが実行中のノード上で実行してください
systemctl restart kubelet
static Podの動作を観察する kubeletが起動すると、定義されたすべてのstatic Podを起動します。ここまででstatic Podを設定してkubeletを再起動したため、すでに新しいstatic Podが実行中になっているはずです。
次のコマンドを(ノード上で)実行することで、(static Podを含む)実行中のコンテナを確認できます。
# このコマンドは、kubeletが実行中のノード上で実行してください
docker ps
出力は次のようになります。
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f6d05272b57e nginx:latest "nginx" 8 minutes ago Up 8 minutes k8s_web.6f802af4_static-web-fk-node1_default_67e24ed9466ba55986d120c867395f3c_378e5f3c
APIサーバー上では、ミラーPodを確認できます。
NAME READY STATUS RESTARTS AGE
static-web-my-node1 1/1 Running 0 2m
備考: kubeletにAPIサーバー上のミラーPodを作成する権限があることを確認してください。もし権限がない場合、APIサーバーによって作成のリクエストが拒否されてしまいます。詳しくは、
PodSecurityPolicy を参照してください。
static Podに付けたラベル はミラーPodに伝搬します。ミラーPodに付けたラベルは、通常のPodと同じようにセレクター などから利用できます。
もしkubectlを使用してAPIサーバーからミラーPodを削除しようとしても、kubeletはstatic Podを削除しません 。
kubectl delete pod static-web-my-node1
pod "static-web-my-node1" deleted
Podはまだ実行中であることがわかります。
NAME READY STATUS RESTARTS AGE
static-web-my-node1 1/1 Running 0 12s
kubeletが実行中のノードに戻り、Dockerコンテナを手動で停止してみることができます。しばらくすると、kubeletが変化に気づき、Podを自動的に再起動することがわかります。
# このコマンドは、kubeletが実行中のノード上で実行してください
docker stop f6d05272b57e # 実際のコンテナIDと置き換えてください
sleep 20
docker ps
CONTAINER ID IMAGE COMMAND CREATED ...
5b920cbaf8b1 nginx:latest "nginx -g 'daemon of 2 seconds ago ...
static Podの動的な追加と削除 実行中のkubeletは設定ディレクトリ(この例では/etc/kubelet.d)の変更を定期的にスキャンし、このディレクトリ内にファイルが追加/削除されると、Podの追加/削除を行います。
# This assumes you are using filesystem-hosted static Pod configuration
# このコマンドは、kubeletが実行中のノード上で実行してください
#
mv /etc/kubernetes/manifests/static-web.yaml /tmp
sleep 20
docker ps
# You see that no nginx container is running
mv /tmp/static-web.yaml /etc/kubernetes/manifests/
sleep 20
docker ps
CONTAINER ID IMAGE COMMAND CREATED ...
e7a62e3427f1 nginx:latest "nginx -g 'daemon of 27 seconds ago
4.3.19 - PodSecurityPolicyからビルトインのPodセキュリティアドミッションコントローラーに移行する このページはPodSecurityPolicyからビルトインのPodセキュリティアドミッションコントローラーに移行するための手順について説明します。
この手順は、auditモードやwarnモードとdry-runを組み合わせて用いることで効率的に実施できますが、Podを変更するPSPを利用している場合には難しいものになるかも知れません。
始める前に 作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.22.
バージョンを確認するには次のコマンドを実行してください: kubectl version.
Kubernetesバージョン1.35以外が稼働している場合には、実際に走っているKubernetesのバージョンのドキュメントに切り替えて読んだほうが良いかもしれません。
このページはPod Security Admission の基本コンセプトに馴染みのある方を対象にしています。
アプローチの全体像 PodSecurityPolicyをPod Security Admissionに移行する場合、とりうる戦略は複数存在します。
以下のステップは、実運用環境の停止やセキュリティギャップが生じるリスクを最小化することを目標とする場合の、1つの移行手順の例です。
Pod Security Admissionがあなたのユースケースに適合するかどうかを判断する Namespaceの権限をレビューする PodSecurityPolicyをシンプルにして標準化する Namespaceを更新する適切なPodのセキュリティ水準を特定する Podのセキュリティ水準を検証する Podのセキュリティ水準を強制する PodSecurityPolicyをバイパスする Namespaceの作成プロセスをレビューする PodSecurityPolicyを無効化する 0. Pod Security Admissionが正しい選択かどうかを判断する Pod Security Admissionは、複数のセキュリティ水準の標準的な集合をクラスター全体にわたって提供するもので、そのまま使うだけで最も一般的なセキュリティ要求を満たせるように設計されました。
しかし、PodSecurityPolicyよりも柔軟性に乏しい作りとなっています。
特に、以下の機能はPodSecurityPolicyではサポートされているものの、Pod Security Admissionではサポートされていません。
デフォルトのsecurity constraintsの設定 - Pod Security AdmissionはValidating Admission Controllerであるため、Podを検証する前にPodを変更しません。
あなたがPSPにおけるdefault security constraintsに依存している場合、ワークロードを修正したり、Mutating Admission Webhook を使ったりして、Pod Securityの制約を満たせるような変更を実施することが必要です。
詳細は、後で述べるPodSecurityPolicyをシンプルにして標準化する を参照してください。ポリシー定義のきめ細やかな制御 - Pod Security Admissionは3つのセキュリティ水準 のみをサポートします。
特定の制約条件についてさらなる制御が必要な場合には、ポリシーを強制するためにValidating Admission Webhook を使う必要があります。sub-namespaceの粒度のポリシー - PodSecurityPolicyは、個々のNamespace内部で異なるサービスアカウントやユーザーに対する異なるポリシーの紐付けが可能です。
この手法にはいくつもの落とし穴があるため推奨されませんが、どうしてもこの性質が必要な場合は、サードパーティーのWebhookをPSPの代わりに利用する必要があるでしょう。
ただし、Pod Security Admissionで静的な適用除外設定 をしており、特定のユーザーやRuntimeClass を完全に適用除外とする必要がある場合には、サードパーティーWebhookは必要ないかもしれません。あなたの全ての要求を満たせない場合であっても、Pod Security Admissionは他のポリシー強制メカニズムに対する 補完的な 仕組みとなるよう設計されており、他のアドミッションWebhookと併用する場合にも有益なフォールバック機構を提供します。
1. Namespaceの権限をレビューする Pod Security AdmissionはNamespaceのラベル で制御します。
これはNamespaceを更新(もしくは作成やパッチ)できる人物が、同じNamespaceのPodセキュリティ標準を修正できることを意味しており、強固な制限ポリシーを迂回するために利用される可能性があります。
ここから先に進む前に、信頼済みの特権的なユーザーのみがNamespaceに関する権限を有することを確実にしておきましょう。
2. PodSecurityPolicyをシンプルにして標準化する この節では、Podを変更するPodSecurityPolicyの定義を減らしていき、Podセキュリティ標準のスコープ外のオプションを除去します。
ポリシーの修正前に、編集対象のオリジナルのPodSecurityPolicyについて、オフラインコピーを作成しておくことを推奨します。
複製したPSPの名前には異なる文字を追加しておくべきです。
(例えば名前の先頭に0を追加するなど)。
この段階ではKubernetesに新しいポリシーは作成しないでください。
ポリシーの作成については、この後の更新したポリシーをロールアウトする で説明します。
2.a Podの変更のみを行うフィールドを排除する あるPodSecurityPolicyがPodを変更する場合、最後にPodSecurityPolicyをオフにした時点で、あなたのPodのセキュリティ水準の要件に適合しないPodが残ってしまう可能性があります。
こうした問題を回避するために、PSPを無効化する前に、PSPによるPodの変更処理を排除しておく必要があります。
残念なことに、PSPはPodを変更する設定項目(mutating field)とPodの検証を行う設定項目(validating field)をきれいに分離できていないため、簡単に移行できるわけではありません。
手始めに、Podの検証処理を損なわないような形で、Pod変更のみを行う設定項目を除去することができます。
PSPでPodの変更のみを行うフィールドは次のとおりです。
(PodSecurityPolicyとPodセキュリティ標準の対応関係 にも一覧があります)。
.spec.defaultAllowPrivilegeEscalation.spec.runtimeClass.defaultRuntimeClassName.metadata.annotations['seccomp.security.alpha.kubernetes.io/defaultProfileName'].metadata.annotations['apparmor.security.beta.kubernetes.io/defaultProfileName'].spec.defaultAddCapabilities - 技術的にはPodを変更する設定とPodを検証する設定を兼ねているため、Podを変更せずに同じ検証処理を行える.spec.allowedCapabilitiesにマージすべきです。注意: これらのフィールドを除去することにより、必須のフィールドが設定されないワークロードが生じて、問題が発生する可能性があります。
更新したポリシーをロールアウトする を参照して変更を安全にロールアウトするための方法を確認することをお勧めします。
2.b. Podセキュリティ標準が対応できないオプションを排除する PodSecurityPolicyにはPodセキュリティ標準でカバーできない設定項目があります。
このようなオプションを強制する必要がある場合、(この記事のスコープ外の話題ですが)、Pod Security AdmissionをアドミッションWebhook で補強する必要があるでしょう。
まず、Podセキュリティ標準がカバーしない、純粋にPodの検証のみを行う設定項目は除去できます。
この条件に該当するフィールドは以下のとおりです。
(PodSecurityPolicyとPodセキュリティ標準の対応関係 には"no opinion"と表記されています)。
.spec.allowedHostPaths.spec.allowedFlexVolumes.spec.allowedCSIDrivers.spec.forbiddenSysctls.spec.runtimeClass以下のようなPOSIX/UNIXグループの制御に関するフィールドも除去できます。
注意: いずれかのフィールドが
MustRunAs戦略を使っている場合、Podを変更している可能性があります!
これらのフィールドを除去することで、必須のグループ設定がなされていないワークロードが生じ、問題が発生する可能性があります。
更新したポリシーをロールアウトする を参照して、変更を安全にロールアウトするための方法を確認することをお勧めします。
.spec.runAsGroup.spec.supplementalGroups.spec.fsGroupその他のPod変更に関わるフィールドはPodセキュリティ標準を正確にサポートするためには必要なものであるため、ケースバイケースでの取り扱いが求められるでしょう。
.spec.requiredDropCapabilities - Restrictedプロフィールでdrop ALLするために必要です。.spec.seLinux - (MustRunAsルールがある場合のみPodを変更)Baseline/RestrictedでSELinux関連の要件を強制するために必要です。.spec.runAsUser - (RunAsAnyルールがある場合にはPodを変更しない)RestrictedプロフィールでRunAsNonRootを強制するために必要です。.spec.allowPrivilegeEscalation - (falseの場合にはPodを変更)Restrictedプロフィールで必要です。2.c. 更新したPSPをロールアウトする ここからは、クラスターに対して更新したポリシーをロールアウトしていきます。
必須のフィールドが設定されないワークロードを発生させるような変更設定を除去した上で、注意深く進めてください。
更新する個別のPodSecurityPolicyについては
オリジナルのPSPが適用されている稼働中のPodを特定してください。
kubernetes.io/pspアノテーションを使うとよいでしょう。
例えば、kubectlを次のように実行します。
PSP_NAME = "original" #確認したいPSPの名称を入力します
kubectl get pods --all-namespaces -o jsonpath = "{range .items[?(@.metadata.annotations.kubernetes\.io\/psp==' $PSP_NAME ')]}{.metadata.namespace} {.metadata.name}{'\n'}{end}"
オリジナルのPod specと稼働中のPodを比較して、PodSecurityPolicyがPodを変更したのかどうかを判定してください。
ワークロードリソース が作成したPodについては、Pod specをコントローラーリソースのPodTemplateと比較するとよいでしょう。
変更箇所を特定したら、オリジナルのPodないしはPodTemplateが期待する設定内容となるように更新する必要があります。
レビューが必要なフィールドは以下のとおりです。
.metadata.annotations['container.apparmor.security.beta.kubernetes.io/*'] (* をコンテナ名で置き換えてください).spec.runtimeClassName.spec.securityContext.fsGroup.spec.securityContext.seccompProfile.spec.securityContext.seLinuxOptions.spec.securityContext.supplementalGroups.spec.containers[*]ないしは.spec.initContainers[*]配下のコンテナのspecについては次の通り:.securityContext.allowPrivilegeEscalation.securityContext.capabilities.add.securityContext.capabilities.drop.securityContext.readOnlyRootFilesystem.securityContext.runAsGroup.securityContext.runAsNonRoot.securityContext.runAsUser.securityContext.seccompProfile.securityContext.seLinuxOptions新しくPodSecurityPolicyを作成してください。
任意のRoleないしはClusterRoleに全てのPSPをuseする権限を付与すれば、新しいPSPが使われるようになる代わりに、既存のPod変更型のPSPは使われなくなります。
認可メカニズムを更新し、新しいPSPへのアクセス権限を付与してください。
これはRBACの更新を意味しており、オリジナルのPSPに対してuse権限があるRoleやClusterRoleを更新し、新しいPSPに対するuse権限を追加付与することにほかなりません。
設定を検証しましょう。
多少の猶予期間を設けて、手順1のコマンドに戻り、まだオリジナルのPSPを使っているPodがあるかどうかを見極めましょう。
新規のポリシーのロールアウト後、ポリシーの検証前にPodの再作成が必要となることに注意してください。
(オプション)オリジナルのPSPがすでに使われていないことがはっきりしたら、削除しておいてもよいでしょう。
3. Namespaceを更新する 以下の手順はクラスターの全てのNamespaceで実施する必要があります。
この手順に示されている$NAMESPACE変数を使ったコマンドは、更新対象のNamespaceを参照するものです。
3.a. 適切なPodのセキュリティ水準を特定する Podセキュリティ標準(Pod Security Standards, PSS) のレビューを始めます。
PSSには3つの異なるセキュリティ水準があることに慣れておきましょう。
NamespaceにおけるPodのセキュリティ水準を決定する方法はいくつかあります。
Namespaceのセキュリティ要求を満たすように決める - 対象のNamespaceで求められるアクセスレベルについて熟知しているのであれば、新しいクラスターに対して実施するのと同様のやり方で、Namespaceの要件に基づいた適切なアクセス水準を選べるはずです。既存のPodSecurityPolicyに基づいて決める - PodSecurityPolicyとPodセキュリティ標準の対応関係 のレファレンスを用いることで、それぞれのPSPをPodセキュリティ標準の各セキュリティ水準に対応させることができます。
PSPがPodセキュリティ標準に対応しない場合は、あえて制限の多いレベルにするか、それともPSPと同等程度に許容的なセキュリティ水準に留めておくか、あなたが決定する必要があるかも知れません。既存のPodを見て決める - 下記のPodのセキュリティ水準を検証する の手順を用いると、BaselineおよびRestrictedレベルの両方について、既存のワークロードに対して十分許容的なものかどうかをテストした上で、妥当で最小特権なセキュリティ水準を選択することが可能です。
注意: 上述の選択肢2と3は 既存の Podに基づいて実施するものであるため、現時点で稼働していないワークロードを取りこぼす可能性があります。
例えば、CronJobやレプリカ数0のワークロード、ロールアウトされていないその他のワークロードなどがこうしたものに該当します。3.b. Podのセキュリティ水準を検証する Namespaceに対するPodのセキュリティ水準を選択したら(ないしは複数検討したら)、まずはテストにかけてみると良いでしょう(Privilegedレベルを用いる場合にはこのステップを省略できます)。
Podセキュリティにはプロファイルの安全なロールアウトを支援するいくつかのツールがあります。
まず紹介するのは、ポリシーのdry-runです。
新たなポリシーを実際に適用せずに、適用予定のポリシーに対してNamespaceで現在稼働しているPodを評価することができます。
# $LEVELはdry-run対象のセキュリティ水準。"baseline"か"restricted"のいずれかの値をとる。
kubectl label --dry-run= server --overwrite ns $NAMESPACE pod-security.kubernetes.io/enforce= $LEVEL
このコマンドは、 現存する Podがセキュリティ水準の要求に適合しなかった場合、警告を返します。
次の選択肢であるauditモードは、稼働していないワークロードを捕捉する上で有用です。
auditモードは(enforcingモードとは対象的に)、Podがポリシーを侵害した場合、その実行を禁止せずに監査ログに記録するため、いくらかの猶予期間の後でログをレビューすることができます。
warningモードはこれと同じような動作をしますが、ユーザーに対して即座に警告を返します。
Namespaceの監査レベルは次のコマンドで設定できます。
kubectl label --overwrite ns $NAMESPACE pod-security.kubernetes.io/audit= $LEVEL
上記いずれかのアプローチが予期せぬポリシー侵害をもたらす場合、侵害的なワークロードがポリシー要求を充足するように更新するか、NamespaceのPodのセキュリティ水準を引き下げる必要があります。
3.c. Podのセキュリティ水準を強制する 選択済みのセキュリティ水準をNamespaceに対して安全に強制できることの確証がもてたら、セキュリティ水準を強制するためにNamespaceを更新します。
kubectl label --overwrite ns $NAMESPACE pod-security.kubernetes.io/enforce= $LEVEL
3.d. PodSecurityPolicyを迂回する ここまでくれば、
特権PSP
をNamespaceの全てのServiceAccountに紐づけて、NamespaceレベルでPodSecurityPolicyを迂回できます。
kubectl apply -f privileged-psp.yaml
kubectl create clusterrole privileged-psp --verb use --resource podsecuritypolicies.policy --resource-name privileged
# Namespace単位での無効化
kubectl create -n $NAMESPACE rolebinding disable-psp --clusterrole privileged-psp --group system:serviceaccounts:$NAMESPACE
特権PSPはPodを変更しません。
PSPのアドミッションコントローラーはPodを変更しないPSPを優先的に利用するため、PodがPodSecurityPolicyによって変更されたり制限されたりしないことが保証できます。
このようにNamespace単位でPodSecurityPolicyを無効化することの利点としては、問題が発生した際にRoleBindingを削除するだけで変更を簡単にロールバックできることです。
もちろん、既存のPodSecurityPolicyが残っていることは確認しておきましょう。
# PodSecurityPolicyの無効化を一旦やめる
kubectl delete -n $NAMESPACE rolebinding disable-psp
4. Namespace作成プロセスをレビューする この時点で、Pod Security Admissionを強制するための既存Namespaceの更新が完了しています。
新たなNamespaceに対して適切なPodセキュリティプロファイルを確実に適用できるよう、新規にNamespaceを作るための手順とポリシーについても必ず更新しておくべきです。
ラベルのないNamespaceに対するデフォルトの強制、監査、警告レベルを適用するために、Pod Securityアドミッションコントローラーを静的に定義することもできます。
詳しくはアドミッションコントローラーを設定する を読んでください。
5. PodSecurityPolicyを無効化する PodSecurityPolicyを無効化する準備が整いました。
これを実施するには、APIサーバーのアドミッションコントローラー設定を修正する必要があります。
(アドミッションコントローラーを無効化する方法 )
PodSecurityPolicyアドミッションコントローラーが無効化されていることを確認するには、PodSecurityPolicyへのアクセス権限を有しないユーザーになりすましたアクセスや、APIサーバーのログを検証するなどといった、手動のテストを実施するとよいでしょう。
また、APIサーバーの起動時のログには、ロード済みのアドミッションコントローラーの一覧が表示されます。
I0218 00:59:44.903329 13 plugins.go:158] Loaded 16 mutating admission controller(s) successfully in the following order: NamespaceLifecycle,LimitRanger,ServiceAccount,NodeRestriction,TaintNodesByCondition,Priority,DefaultTolerationSeconds,ExtendedResourceToleration,PersistentVolumeLabel,DefaultStorageClass,StorageObjectInUseProtection,RuntimeClass,DefaultIngressClass,MutatingAdmissionWebhook.
I0218 00:59:44.903350 13 plugins.go:161] Loaded 14 validating admission controller(s) successfully in the following order: LimitRanger,ServiceAccount,PodSecurity,Priority,PersistentVolumeClaimResize,RuntimeClass,CertificateApproval,CertificateSigning,CertificateSubjectRestriction,DenyServiceExternalIPs,ValidatingAdmissionWebhook,ResourceQuota.
(Validating Admission Controllerの中に)PodSecurityが確認できるはずです。
また、いずれの行もPodSecurityPolicyを含まないはずです。
PSPアドミッションコントローラーを無効化したら、(また、ロールバックが必要ないと判断するのに十分な時間が経過したら)、PodSecurityPolicyと関連するRoleやClusterRole、ClusterRoleBindingを削除してもよいでしょう。
(他の無関係な権限付与に使われていないことを確認しておいてください)。
4.4 - 監視、ログ、デバッグ クラスターのトラブルシューティングや、コンテナ化したアプリケーションのデバッグのために、監視とログをセットアップします。
時には物事がうまくいかないこともあります。このガイドは、それらを正すことを目的としています。
2つのセクションから構成されています:
アプリケーションのデバッグ - Kubernetesにコードをデプロイしていて、なぜ動かないのか不思議に思っているユーザーに便利です。クラスターのデバッグ - クラスター管理者やKubernetesクラスターに不満がある人に有用です。また、使用しているリリース の既知の問題を確認する必要があります。
ヘルプを受けます もしあなたの問題が上記のどのガイドでも解決されない場合は、Kubernetesコミュニティから助けを得るための様々な方法があります。
ご質問 本サイトのドキュメントは、様々な疑問に対する答えを提供するために構成されています。
コンセプト では、Kubernetesのアーキテクチャと各コンポーネントの動作について説明し、セットアップ では、使い始めるための実用的な手順を提供しています。
タスク は、よく使われるタスクの実行方法を示し、 チュートリアル は、実世界の業界特有、またはエンドツーエンドの開発シナリオ、より包括的なウォークスルーとなります。
リファレンス セクションでは、Kubernetes API やkubectl
ヘルプ!私の質問はカバーされていません!今すぐ助けてください! Stack Overflow コミュニティの誰かがすでに同じような質問をしている可能性があり、あなたの問題を解決できるかもしれません。
KubernetesチームもKubernetesタグが付けられた投稿 を監視しています。
もし役立つ既存の質問がない場合は、新しく質問する 前に、あなたの質問がStack Overflowのトピックに沿ったものであることを確認し 、新しく質問する方法 のガイダンスに目を通してください!
Slack Kubernetesコミュニティの多くの人々は、Kubernetes Slackの#kubernetes-usersチャンネルに集まっています。
Slackは登録が必要です。招待をリクエストする ことができ、登録は誰でも可能です。
お気軽にお越しいただき、何でも質問してください。
登録が完了したら、WebブラウザまたはSlackの専用アプリからKubernetes organization in Slack にアクセスします。
登録が完了したら、増え続けるチャンネルリストを見て、興味のある様々なテーマについて調べてみましょう。
たとえば、Kubernetesの初心者は、#kubernetes-novice#kubernetes-contributors
また、多くの国別/言語別チャンネルがあります。これらのチャンネルに参加すれば、地域特有のサポートや情報を得ることができます。
フォーラム Kubernetesの公式フォーラムへの参加は大歓迎ですdiscuss.kubernetes.io 。
バグと機能の要望 バグらしきものを発見した場合、または機能要望を出したい場合、GitHub課題追跡システム をご利用ください。
課題を提出する前に、既存の課題を検索して、あなたの課題が解決されているかどうかを確認してください。
バグを報告する場合は、そのバグを再現するための詳細な情報を含めてください。
Kubernetes のバージョン: kubectl version クラウドプロバイダー、OSディストリビューション、ネットワーク構成、コンテナランタイムバージョン 問題を再現するための手順 4.4.1 - アプリケーションのトラブルシューティング コンテナ化されたアプリケーションの一般的な問題をデバッグします。
このドキュメントには、コンテナ化されたアプリケーションの問題を解決するための、一連のリソースが記載されています。Kubernetesリソース(Pod、Service、StatefulSetなど)に関する一般的な問題や、コンテナ終了メッセージを理解するためのアドバイス、実行中のコンテナをデバッグする方法などが網羅されています。
4.4.1.1 - Podのデバッグ このガイドは、Kubernetesにデプロイされ、正しく動作しないアプリケーションをユーザーがデバッグするためのものです。
これは、自分のクラスターをデバッグしたい人のためのガイドでは ありません 。
そのためには、debug-cluster を確認する必要があります。
問題の診断 トラブルシューティングの最初のステップは切り分けです。何が問題なのでしょうか?
Podなのか、レプリケーションコントローラーなのか、それともサービスなのか?
Podのデバッグ デバッグの第一歩は、Podを見てみることです。
以下のコマンドで、Podの現在の状態や最近のイベントを確認します。
kubectl describe pods ${ POD_NAME }
Pod内のコンテナの状態を見てください。
すべてRunningですか? 最近、再起動がありましたか?
Podの状態に応じてデバッグを続けます。
PodがPendingのまま PodがPendingで止まっている場合、それはノードにスケジュールできないことを意味します。
一般に、これはある種のリソースが不十分で、スケジューリングできないことが原因です。
上のkubectl describe ...コマンドの出力を見てください。
なぜあなたのPodをスケジュールできないのか、スケジューラーからのメッセージがあるはずです。
理由は以下の通りです。
リソースが不足しています。 クラスターのCPUまたはメモリーを使い果たしている可能性があります。Podを削除するか、リソースの要求値を調整するか、クラスターに新しいノードを追加する必要があります。詳しくはCompute Resources document を参照してください。
あなたが使用しているのはhostPortです。 PodをhostPortにバインドすると、そのPodがスケジュールできる場所が限定されます。ほとんどの場合、hostPortは不要なので、Serviceオブジェクトを使ってPodを公開するようにしてください。もしhostPort が必要な場合は、Kubernetesクラスターのノード数だけPodをスケジュールすることができます。
Podがwaitingのまま PodがWaiting状態で止まっている場合、ワーカーノードにスケジュールされていますが、そのノード上で実行することができません。この場合も、kubectl describe ...の情報が参考になるはずです。Waiting状態のPodの最も一般的な原因は、コンテナイメージのプルに失敗することです。
確認すべきことは3つあります。
イメージの名前が正しいかどうか確認してください。 イメージをレジストリにプッシュしましたか? あなたのマシンで手動でdocker pull <image>を実行し、イメージをプルできるかどうか確認してください。 Podがクラッシュするなどの不健全な状態 Podがスケジュールされると、実行中のPodのデバッグ で説明されている方法がデバッグに利用できるようになります。
Podが期待する通りに動きません Podが期待した動作をしない場合、ポッドの記述(ローカルマシンの mypod.yaml ファイルなど)に誤りがあり、Pod作成時にその誤りが黙って無視された可能性があります。Pod記述のセクションのネストが正しくないか、キー名が間違って入力されていることがよくあり、そのようなとき、そのキーは無視されます。たとえば、commandのスペルをcommndと間違えた場合、Podは作成されますが、あなたが意図したコマンドラインは使用されません。
まずPodを削除して、--validate オプションを付けて再度作成してみてください。
例えば、kubectl apply --validate -f mypod.yamlと実行します。
commandのスペルをcommndに間違えると、以下のようなエラーになります。
I0805 10:43:25.129850 46757 schema.go:126] unknown field: commnd
I0805 10:43:25.129973 46757 schema.go:129] this may be a false alarm, see https://github.com/kubernetes/kubernetes/issues/6842
pods/mypod
次に確認することは、apiserver上のPodが、作成しようとしたPod(例えば、ローカルマシンのyamlファイル)と一致しているかどうかです。
例えば、kubectl get pods/mypod -o yaml > mypod-on-apiserver.yaml を実行して、元のポッドの説明であるmypod.yamlとapiserverから戻ってきたmypod-on-apiserver.yamlを手動で比較してみてください。
通常、"apiserver" バージョンには、元のバージョンにはない行がいくつかあります。これは予想されることです。
しかし、もし元のバージョンにある行がapiserverバージョンにない場合、これはあなたのPod specに問題があることを示している可能性があります。
レプリケーションコントローラーのデバッグ レプリケーションコントローラーはかなり単純なものです。
彼らはPodを作ることができるか、できないか、どちらかです。
もしPodを作成できないのであれば、上記の説明 を参照して、Podをデバッグしてください。
また、kubectl describe rc ${CONTROLLER_NAME}を使用すると、レプリケーションコントローラーに関連するイベントを確認することができます。
Serviceのデバッグ Serviceは、Podの集合全体でロードバランシングを提供します。
Serviceが正しく動作しない原因には、いくつかの一般的な問題があります。
以下の手順は、Serviceの問題をデバッグするのに役立つはずです。
まず、Serviceに対応するEndpointが存在することを確認します。
全てのServiceオブジェクトに対して、apiserverは endpoints リソースを利用できるようにします。
このリソースは次のようにして見ることができます。
kubectl get endpoints ${ SERVICE_NAME }
EndpointがServiceのメンバーとして想定されるPod数と一致していることを確認してください。
例えば、3つのレプリカを持つnginxコンテナ用のServiceであれば、ServiceのEndpointには3つの異なるIPアドレスが表示されるはずです。
Serviceに対応するEndpointがありません Endpointが見つからない場合は、Serviceが使用しているラベルを使用してPodをリストアップしてみてください。
ラベルがあるところにServiceがあると想像してください。
...
spec :
- selector :
name : nginx
type : frontend
セレクタに一致するPodを一覧表示するには、次のコマンドを使用します。
kubectl get pods --selector= name = nginx,type= frontend
リストがServiceを提供する予定のPodと一致することを確認します。
PodのcontainerPortがServiceのtargetPortと一致することを確認します。
ネットワークトラフィックが転送されません 詳しくはServiceのデバッグ を参照してください。
次の項目 上記のいずれの方法でも問題が解決しない場合は、以下の手順に従ってください。
Serviceのデバッグに関するドキュメント で、Serviceが実行されていること、Endpointsがあること、Podsが実際にサービスを提供していること、DNSが機能していること、IPtablesルールがインストールされていること、kube-proxyが誤作動を起こしていないようなことを確認してください。
トラブルシューティングドキュメント に詳細が記載されています。
4.4.1.2 - Serviceのデバッグ 新規にKubernetesをインストールした環境でかなり頻繁に発生する問題は、Serviceが適切に機能しないというものです。Deployment(または他のワークロードコントローラー)を通じてPodを実行し、サービスを作成したにもかかわらず、アクセスしようとしても応答がありません。何が問題になっているのかを理解するのに、このドキュメントがきっと役立つでしょう。
Pod内でコマンドを実行する ここでの多くのステップでは、クラスターで実行されているPodが見ているものを確認する必要があります。これを行う最も簡単な方法は、インタラクティブなalpineのPodを実行することです。
kubectl run -it --rm --restart=Never alpine --image=alpine sh
備考: コマンドプロンプトが表示されない場合は、Enterキーを押してみてください。使用したい実行中のPodがすでにある場合は、以下のようにしてそのPod内でコマンドを実行できます。
kubectl exec <POD-NAME> -c <CONTAINER-NAME> -- <COMMAND>
セットアップ このドキュメントのウォークスルーのために、いくつかのPodを実行しましょう。おそらくあなた自身のServiceをデバッグしているため、あなた自身の詳細に置き換えることもできますし、これに沿って2番目のデータポイントを取得することもできます。
kubectl create deployment hostnames --image= registry.k8s.io/serve_hostname
deployment.apps/hostnames created
kubectlコマンドは作成、変更されたリソースのタイプと名前を出力するため、この後のコマンドで使用することもできます。
Deploymentを3つのレプリカにスケールさせてみましょう。
kubectl scale deployment hostnames --replicas= 3
deployment.apps/hostnames scaled
これは、次のYAMLでDeploymentを開始した場合と同じです。
apiVersion : apps/v1
kind : Deployment
metadata :
name : hostnames
labels :
app : hostnames
spec :
selector :
matchLabels :
app : hostnames
replicas : 3
template :
metadata :
labels :
app : hostnames
spec :
containers :
- name : hostnames
image : registry.k8s.io/serve_hostname
"app"ラベルはkubectl create deploymentによって、Deploymentの名前に自動的にセットされます。
Podが実行されていることを確認できます。
kubectl get pods -l app = hostnames
NAME READY STATUS RESTARTS AGE
hostnames-632524106-bbpiw 1/1 Running 0 2m
hostnames-632524106-ly40y 1/1 Running 0 2m
hostnames-632524106-tlaok 1/1 Running 0 2m
Podが機能していることも確認できます。Pod IP アドレスリストを取得し、直接テストできます。
kubectl get pods -l app = hostnames \
= '{{range .items}}{{.status.podIP}}{{"\n"}}{{end}}'
10.244.0.5
10.244.0.6
10.244.0.7
このウォークスルーに使用されるサンプルコンテナは、ポート9376でHTTPを介して独自のホスト名を提供するだけですが、独自のアプリをデバッグする場合は、Podがリッスンしているポート番号を使用する必要があります。
Pod内から実行します。
for ep in 10.244.0.5:9376 10.244.0.6:9376 10.244.0.7:9376; do
wget -qO- $ep
done
次のように表示されます。
hostnames-632524106-bbpiw
hostnames-632524106-ly40y
hostnames-632524106-tlaok
この時点で期待通りの応答が得られない場合、Podが正常でないか、想定しているポートでリッスンしていない可能性があります。なにが起きているかを確認するためにkubectl logsが役立ちます。Podに直接に入りデバッグする場合はkubectl execが必要になります。
これまでにすべての計画が完了していると想定すると、Serviceが機能しない理由を調査することができます。
Serviceは存在するか? 賢明な読者は、Serviceをまだ実際に作成していないことにお気付きかと思いますが、これは意図的です。これは時々忘れられるステップであり、最初に確認すべきことです。
存在しないServiceにアクセスしようとするとどうなるでしょうか?このServiceを名前で利用する別のPodがあると仮定すると、次のような結果が得られます。
Resolving hostnames (hostnames)... failed: Name or service not known.
wget: unable to resolve host address 'hostnames'
最初に確認するのは、そのServiceが実際に存在するかどうかです。
kubectl get svc hostnames
No resources found.
Error from server (NotFound): services "hostnames" not found
Serviceを作成しましょう。前と同様に、これはウォークスルー用です。ご自身のServiceの詳細を使用することもできます。
kubectl expose deployment hostnames --port= 80 --target-port= 9376
service/hostnames exposed
そして、念のため内容を確認します。
kubectl get svc hostnames
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hostnames ClusterIP 10.0.1.175 <none> 80/TCP 5s
これで、Serviceが存在することがわかりました。
前と同様に、これは次のようなYAMLでServiceを開始した場合と同じです。
apiVersion : v1
kind : Service
metadata :
name : hostnames
spec :
selector :
app : hostnames
ports :
- name : default
protocol : TCP
port : 80
targetPort : 9376
構成の全範囲をハイライトするため、ここで作成したServiceはPodとは異なるポート番号を使用します。多くの実際のServiceでは、これらのポートは同じになる場合があります。
サービスはDNS名によって機能しているか? クライアントがサービスを使用する最も一般的な方法の1つは、DNS名を使用することです。同じNamespaceのPodから次のコマンドを実行してください。
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: hostnames
Address 1: 10.0.1.175 hostnames.default.svc.cluster.local
これが失敗した場合、おそらくPodとServiceが異なるNamespaceにあるため、ネームスペースで修飾された名前を試してください。(Podの中からもう一度)
nslookup hostnames.default
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: hostnames.default
Address 1: 10.0.1.175 hostnames.default.svc.cluster.local
これが機能する場合、クロスネームスペース名を使用するようにアプリケーションを調整するか、同じNamespaceでアプリとServiceを実行する必要があります。これでも失敗する場合は、完全修飾名を試してください。
nslookup hostnames.default.svc.cluster.local
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: hostnames.default.svc.cluster.local
Address 1: 10.0.1.175 hostnames.default.svc.cluster.local
ここでのサフィックス"default.svc.cluster.local"に注意してください。"default"は、操作しているNamespaceです。"svc"は、これがServiceであることを示します。"cluster.local"はクラスタードメインであり、あなたのクラスターでは異なる場合があります。
クラスター内のノードからも試すこともできます。
備考: 10.0.0.10はクラスターのDNSサービスのIPであり、あなたのクラスターでは異なるかもしれません。nslookup hostnames.default.svc.cluster.local 10.0.0.10
Server: 10.0.0.10
Address: 10.0.0.10#53
Name: hostnames.default.svc.cluster.local
Address: 10.0.1.175
完全修飾名では検索できるのに、相対名ではできない場合、Podの/etc/resolv.confファイルが正しいことを確認する必要があります。Pod内から実行します。
次のように表示されます。
nameserver 10.0.0.10
search default.svc.cluster.local svc.cluster.local cluster.local example.com
options ndots:5
nameserver行はクラスターのDNS Serviceを示さなければなりません。これは、--cluster-dnsフラグでkubeletに渡されます。
search行には、Service名を見つけるための適切なサフィックスを含める必要があります。この場合、ローカルのNamespaceでServiceを見つけるためのサフィックス(default.svc.cluster.local)、すべてのNamespacesでServiceを見つけるためのサフィックス(svc.cluster.local)、およびクラスターのサフィックス(cluster.local)です。インストール方法によっては、その後に追加のレコードがある場合があります(合計6つまで)。クラスターのサフィックスは、--cluster-domainフラグを使用してkubeletに渡されます。このドキュメントではそれが"cluster.local"であると仮定していますが、あなたのクラスターでは異なる場合があります。その場合は、上記のすべてのコマンドでクラスターのサフィックスを変更する必要があります。
options行では、DNSクライアントライブラリーが検索パスをまったく考慮しないようにndotsを十分に高く設定する必要があります。Kubernetesはデフォルトでこれを5に設定します。これは、生成されるすべてのDNS名をカバーするのに十分な大きさです。
DNS名で機能するServiceはあるか? 上記がまだ失敗する場合、DNSルックアップがServiceに対して機能していません。一歩離れて、他の何が機能していないかを確認しましょう。KubernetesマスターのServiceは常に機能するはずです。Pod内から実行します。
nslookup kubernetes.default
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes.default
Address 1: 10.0.0.1 kubernetes.default.svc.cluster.local
これが失敗する場合は、このドキュメントのkube-proxy セクションを参照するか、このドキュメントの先頭に戻って最初からやり直してください。ただし、あなた自身のServiceをデバッグするのではなく、DNSサービスをデバッグします。
ServiceはIPでは機能するか? DNSサービスが正しく動作できると仮定すると、次にテストするのはIPによってServiceが動作しているかどうかです。上述のkubectl getで確認できるIPに、クラスター内のPodからアクセスします。
for i in $( seq 1 3) ; do
wget -qO- 10.0.1.175:80
done
次のように表示されます。
hostnames-0uton
hostnames-bvc05
hostnames-yp2kp
Serviceが機能している場合は、正しい応答が得られるはずです。そうでない場合、おかしい可能性のあるものがいくつかあるため、続けましょう。
Serviceは正しく定義されているか? 馬鹿げているように聞こえるかもしれませんが、Serviceが正しく定義されPodのポートとマッチすることを二度、三度と確認すべきです。Serviceを読み返して確認しましょう。
kubectl get service hostnames -o json
{
"kind" : "Service" ,
"apiVersion" : "v1" ,
"metadata" : {
"name" : "hostnames" ,
"namespace" : "default" ,
"uid" : "428c8b6c-24bc-11e5-936d-42010af0a9bc" ,
"resourceVersion" : "347189" ,
"creationTimestamp" : "2015-07-07T15:24:29Z" ,
"labels" : {
"app" : "hostnames"
}
},
"spec" : {
"ports" : [
{
"name" : "default" ,
"protocol" : "TCP" ,
"port" : 80 ,
"targetPort" : 9376 ,
"nodePort" : 0
}
],
"selector" : {
"app" : "hostnames"
},
"clusterIP" : "10.0.1.175" ,
"type" : "ClusterIP" ,
"sessionAffinity" : "None"
},
"status" : {
"loadBalancer" : {}
}
}
アクセスしようとしているServiceポートはspec.ports[]のリストのなかに定義されていますか? targetPortはPodに対して適切ですか(いくつかのPodはServiceとは異なるポートを使用します)?targetPortを数値で定義しようとしている場合、それは数値(9376)、文字列"9376"のどちらですか?targetPortを名前で定義しようとしている場合、Podは同じ名前でポートを公開していますか?ポートのprotocolはPodに適切ですか? ServiceにEndpointsがあるか? ここまで来たということは、Serviceは正しく定義され、DNSによって名前解決できることが確認できているでしょう。ここでは、実行したPodがServiceによって実際に選択されていることを確認しましょう。
以前に、Podが実行されていることを確認しました。再確認しましょう。
kubectl get pods -l app = hostnames
NAME READY STATUS RESTARTS AGE
hostnames-632524106-bbpiw 1/1 Running 0 1h
hostnames-632524106-ly40y 1/1 Running 0 1h
hostnames-632524106-tlaok 1/1 Running 0 1h
-l app=hostnames引数はラベルセレクターで、ちょうど私たちのServiceに定義されているものと同じです。
"AGE"列は、これらのPodが約1時間前のものであることを示しており、それらが正常に実行され、クラッシュしていないことを意味します。
"RESTARTS"列は、これらのポッドが頻繁にクラッシュしたり、再起動されていないことを示しています。頻繁に再起動すると、断続的な接続性の問題が発生する可能性があります。再起動回数が多い場合は、ポッドをデバッグする を参照してください。
Kubernetesシステム内には、すべてのServiceのセレクターを評価し、結果をEndpointsオブジェクトに保存するコントロールループがあります。
kubectl get endpoints hostnames
NAME ENDPOINTS
hostnames 10.244.0.5:9376,10.244.0.6:9376,10.244.0.7:9376
これにより、EndpointsコントローラーがServiceの正しいPodを見つけていることを確認できます。ENDPOINTS列が<none>の場合、Serviceのspec.selectorフィールドが実際にPodのmetadata.labels値を選択していることを確認する必要があります。よくある間違いは、タイプミスやその他のエラー、たとえばDeployment作成にもkubectl runが使われた1.18以前のバージョンのように、Serviceがapp=hostnamesを選択しているのにDeploymentがrun=hostnamesを指定していることです。
Podは機能しているか? この時点で、Serviceが存在し、Podを選択していることがわかります。このウォークスルーの最初に、Pod自体を確認しました。Podが実際に機能していることを確認しましょう。Serviceメカニズムをバイパスして、上記EndpointsにリストされているPodに直接アクセスすることができます。
備考: これらのコマンドは、Serviceポート(80)ではなく、Podポート(9376)を使用します。Pod内から実行します。
for ep in 10.244.0.5:9376 10.244.0.6:9376 10.244.0.7:9376; do
wget -qO- $ep
done
次のように表示されます。
hostnames-632524106-bbpiw
hostnames-632524106-ly40y
hostnames-632524106-tlaok
Endpointsリスト内の各Podは、それぞれの自身のホスト名を返すはずです。そうならない(または、あなた自身のPodの正しい振る舞いにならない)場合は、そこで何が起こっているのかを調査する必要があります。
kube-proxyは機能しているか? ここに到達したのなら、Serviceは実行され、Endpointsがあり、Podが実際にサービスを提供しています。この時点で、Serviceのプロキシメカニズム全体が疑わしいです。ひとつひとつ確認しましょう。
Serviceのデフォルト実装、およびほとんどのクラスターで使用されるものは、kube-proxyです。kube-proxyはそれぞれのノードで実行され、Serviceの抽象化を提供するための小さなメカニズムセットの1つを構成するプログラムです。クラスターがkube-proxyを使用しない場合、以下のセクションは適用されず、使用しているServiceの実装を調査する必要があります。
kube-proxyは実行されているか? kube-proxyがノード上で実行されていることを確認しましょう。ノードで実行されていれば、以下のような結果が得られるはずです。
ps auxw | grep kube-proxy
root 4194 0.4 0.1 101864 17696 ? Sl Jul04 25:43 /usr/local/bin/kube-proxy --master=https://kubernetes-master --kubeconfig=/var/lib/kube-proxy/kubeconfig --v=2
次に、マスターとの接続など、明らかな失敗をしていないことを確認します。これを行うには、ログを確認する必要があります。ログへのアクセス方法は、ノードのOSに依存します。一部のOSでは/var/log/kube-proxy.logのようなファイルですが、他のOSではjournalctlを使用してログにアクセスします。次のように表示されます。
I1027 22:14:53.995134 5063 server.go:200] Running in resource-only container "/kube-proxy"
I1027 22:14:53.998163 5063 server.go:247] Using iptables Proxier.
I1027 22:14:53.999055 5063 server.go:255] Tearing down userspace rules. Errors here are acceptable.
I1027 22:14:54.038140 5063 proxier.go:352] Setting endpoints for "kube-system/kube-dns:dns-tcp" to [10.244.1.3:53]
I1027 22:14:54.038164 5063 proxier.go:352] Setting endpoints for "kube-system/kube-dns:dns" to [10.244.1.3:53]
I1027 22:14:54.038209 5063 proxier.go:352] Setting endpoints for "default/kubernetes:https" to [10.240.0.2:443]
I1027 22:14:54.038238 5063 proxier.go:429] Not syncing iptables until Services and Endpoints have been received from master
I1027 22:14:54.040048 5063 proxier.go:294] Adding new service "default/kubernetes:https" at 10.0.0.1:443/TCP
I1027 22:14:54.040154 5063 proxier.go:294] Adding new service "kube-system/kube-dns:dns" at 10.0.0.10:53/UDP
I1027 22:14:54.040223 5063 proxier.go:294] Adding new service "kube-system/kube-dns:dns-tcp" at 10.0.0.10:53/TCP
マスターに接続できないことに関するエラーメッセージが表示された場合、ノードの設定とインストール手順をダブルチェックする必要があります。
kube-proxyが正しく実行できない理由の可能性の1つは、必須のconntrackバイナリが見つからないことです。これは、例えばKubernetesをスクラッチからインストールするなど、クラスターのインストール方法に依存して、一部のLinuxシステムで発生する場合があります。これが該当する場合は、conntrackパッケージを手動でインストール(例: Ubuntuではsudo apt install conntrack)する必要があり、その後に再試行する必要があります。
kube-proxyは、いくつかのモードのいずれかで実行できます。上記のログのUsing iptables Proxierという行は、kube-proxyが「iptables」モードで実行されていることを示しています。最も一般的な他のモードは「ipvs」です。古い「ユーザースペース」モードは、主にこれらに置き換えられました。
Iptables mode 「iptables」モードでは、ノードに次のようなものが表示されます。
iptables-save | grep hostnames
-A KUBE-SEP-57KPRZ3JQVENLNBR -s 10.244.3.6/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-57KPRZ3JQVENLNBR -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.3.6:9376
-A KUBE-SEP-WNBA2IHDGP2BOBGZ -s 10.244.1.7/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-WNBA2IHDGP2BOBGZ -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.1.7:9376
-A KUBE-SEP-X3P2623AGDH6CDF3 -s 10.244.2.3/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-X3P2623AGDH6CDF3 -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.2.3:9376
-A KUBE-SERVICES -d 10.0.1.175/32 -p tcp -m comment --comment "default/hostnames: cluster IP" -m tcp --dport 80 -j KUBE-SVC-NWV5X2332I4OT4T3
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-WNBA2IHDGP2BOBGZ
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-X3P2623AGDH6CDF3
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -j KUBE-SEP-57KPRZ3JQVENLNBR
各サービスのポートごとに、KUBE-SERVICESに1つのルールと1つのKUBE-SVC- <hash>チェーンが必要です。Podエンドポイントごとに、そのKUBE-SVC- <hash>に少数のルールがあり、少数のルールが含まれる1つのKUBE-SEP- <hash>チェーンがあるはずです。正確なルールは、正確な構成(NodePortとLoadBalancerを含む)に基づいて異なります。
IPVS mode 「ipvs」モードでは、ノードに次のようなものが表示されます。
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
...
TCP 10.0.1.175:80 rr
-> 10.244.0.5:9376 Masq 1 0 0
-> 10.244.0.6:9376 Masq 1 0 0
-> 10.244.0.7:9376 Masq 1 0 0
...
各Serviceの各ポートに加えて、NodePort、External IP、およびLoad Balancer IPに対して、kube-proxyは仮想サーバーを作成します。Pod endpointごとに、対応する実サーバーが作成されます。この例では、サービスhostnames(10.0.1.175:80)は3つのendpoints(10.244.0.5:9376、10.244.0.6:9376、10.244.0.7:9376)を持っています。
IPVSプロキシは、各Serviceアドレス(Cluster IP、External IP、NodePort IP、Load Balancer IPなど)毎の仮想サーバーと、Serviceのエンドポイントが存在する場合に対応する実サーバーを作成します。この例では、hostnames Service(10.0.1.175:80)は3つのエンドポイント(10.244.0.5:9376、10.244.0.6:9376、10.244.0.7:9376)を持ち、上と似た結果が得られるはずです。
Userspace mode まれに、「userspace」モードを使用している場合があります。
ノードから実行します。
iptables-save | grep hostnames
-A KUBE-PORTALS-CONTAINER -d 10.0.1.175/32 -p tcp -m comment --comment "default/hostnames:default" -m tcp --dport 80 -j REDIRECT --to-ports 48577
-A KUBE-PORTALS-HOST -d 10.0.1.175/32 -p tcp -m comment --comment "default/hostnames:default" -m tcp --dport 80 -j DNAT --to-destination 10.240.115.247:48577
サービスの各ポートには2つのルールが必要です(この例では1つだけ)-「KUBE-PORTALS-CONTAINER」と「KUBE-PORTALS-HOST」です。
「userspace」モードを使用する必要はほとんどないので、ここでこれ以上時間を費やすことはありません。
kube-proxyはプロキシしているか? 上記のいずれかが発生したと想定して、いずれかのノードからIPでサービスにアクセスをしています。
hostnames-632524106-bbpiw
もしこれが失敗し、あなたがuserspaceプロキシを使用している場合、プロキシへの直接アクセスを試してみてください。もしiptablesプロキシを使用している場合、このセクションはスキップしてください。
上記のiptables-saveの出力を振り返り、kube-proxyがServiceに使用しているポート番号を抽出します。上記の例では"48577"です。このポートに接続してください。
hostnames-632524106-tlaok
もしまだ失敗する場合は、kube-proxyログで次のような特定の行を探してください。
Setting endpoints for default/hostnames:default to [10.244.0.5:9376 10.244.0.6:9376 10.244.0.7:9376]
これらが表示されない場合は、-vフラグを4に設定してkube-proxyを再起動してから、再度ログを確認してください。
エッジケース: PodがService IP経由で自身に到達できない これはありそうに聞こえないかもしれませんが、実際には起こり、動作するはずです。これはネットワークが"hairpin"トラフィック用に適切に設定されていない場合、通常はkube-proxyがiptablesモードで実行され、Podがブリッジネットワークに接続されている場合に発生します。Kubeletはhairpin-modeフラグ を公開します。これにより、Serviceのエンドポイントが自身のServiceのVIPにアクセスしようとした場合に、自身への負荷分散を可能にします。hairpin-modeフラグはhairpin-vethまたはpromiscuous-bridgeに設定する必要があります。
この問題をトラブルシューティングする一般的な手順は次のとおりです。
hairpin-modeがhairpin-vethまたはpromiscuous-bridgeに設定されていることを確認します。次のような表示がされるはずです。この例では、hairpin-modeはpromiscuous-bridgeに設定されています。root 3392 1.1 0.8 186804 65208 ? Sl 00:51 11:11 /usr/local/bin/kubelet --enable-debugging-handlers=true --config=/etc/kubernetes/manifests --allow-privileged=True --v=4 --cluster-dns=10.0.0.10 --cluster-domain=cluster.local --configure-cbr0=true --cgroup-root=/ --system-cgroups=/system --hairpin-mode=promiscuous-bridge --runtime-cgroups=/docker-daemon --kubelet-cgroups=/kubelet --babysit-daemons=true --max-pods=110 --serialize-image-pulls=false --outofdisk-transition-frequency=0
実際に使われているhairpin-modeを確認します。これを行うには、kubeletログを確認する必要があります。ログへのアクセス方法は、ノードのOSによって異なります。一部のOSでは/var/log/kubelet.logなどのファイルですが、他のOSではjournalctlを使用してログにアクセスします。互換性のために、実際に使われているhairpin-modeが--hairpin-modeフラグと一致しない場合があることに注意してください。kubelet.logにキーワードhairpinを含むログ行があるかどうかを確認してください。実際に使われているhairpin-modeを示す以下のようなログ行があるはずです。 I0629 00:51:43.648698 3252 kubelet.go:380] Hairpin mode set to "promiscuous-bridge"
実際に使われているhairpin-modeがhairpin-vethの場合、Kubeletにノードの/sysで操作する権限があることを確認します。すべてが正常に機能している場合、次のようなものが表示されます。 for intf in /sys/devices/virtual/net/cbr0/brif/*; do cat $intf /hairpin_mode; done
1
1
1
1
実際に使われているhairpin-modeがpromiscuous-bridgeの場合、Kubeletにノード上のLinuxブリッジを操作する権限があることを確認してください。cbr0ブリッジが使用され適切に構成されている場合、以下が表示されます。
ifconfig cbr0 |grep PROMISC
UP BROADCAST RUNNING PROMISC MULTICAST MTU:1460 Metric:1
上記のいずれも解決しない場合、助けを求めてください。 助けを求める ここまでたどり着いたということは、とてもおかしなことが起こっています。Serviceは実行中で、Endpointsがあり、Podは実際にサービスを提供しています。DNSは動作していて、kube-proxyも誤動作していないようです。それでも、あなたのServiceは機能していません。おそらく私たちにお知らせ頂いた方がよいでしょう。調査をお手伝いします!
Slack 、Forum またはGitHub でお問い合わせください。
次の項目 詳細については、トラブルシューティングドキュメント をご覧ください。
4.4.1.3 - Pod障害の原因を特定する このページでは、コンテナ終了メッセージの読み書き方法を説明します。
終了メッセージは、致命的なイベントに関する情報を、ダッシュボードや監視ソフトウェアなどのツールで簡単に取得して表示できる場所にコンテナが書き込むための手段を提供します。 ほとんどの場合、終了メッセージに入力した情報も一般的なKubernetesログ に書き込まれるはずです。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
終了メッセージの書き込みと読み取り この課題では、1つのコンテナを実行するPodを作成します。
設定ファイルには、コンテナの開始時に実行されるコマンドを指定します。
apiVersion : v1
kind : Pod
metadata :
name : termination-demo
spec :
containers :
- name : termination-demo-container
image : debian
command : ["/bin/sh" ]
args : ["-c" , "sleep 10 && echo Sleep expired > /dev/termination-log" ]
YAML設定ファイルに基づいてPodを作成します:
kubectl apply -f https://k8s.io/examples/debug/termination.yaml
YAMLファイルのcommandフィールドとargsフィールドで、コンテナが10秒間スリープしてから/dev/termination-logファイルに「Sleep expired」と書いているのがわかります。コンテナが「Sleep expired」メッセージを書き込んだ後、コンテナは終了します。
Podに関する情報を表示します:
kubectl get pod termination-demo
Podが実行されなくなるまで、上記のコマンドを繰り返します。
Podに関する詳細情報を表示します:
kubectl get pod termination-demo --output=yaml
出力には「Sleep expired」メッセージが含まれています:
apiVersion: v1
kind: Pod
...
lastState:
terminated:
containerID: ...
exitCode: 0
finishedAt: ...
message: |
Sleep expired
...
Goテンプレートを使用して、終了メッセージのみが含まれるように出力をフィルタリングします:
kubectl get pod termination-demo -o go-template="{{range .status.containerStatuses}}{{.lastState.terminated.message}}{{end}}"
終了メッセージのカスタマイズ Kubernetesは、コンテナのterminationMessagePathフィールドで指定されている終了メッセージファイルから終了メッセージを取得します。デフォルト値は/dev/termination-logです。このフィールドをカスタマイズすることで、Kubernetesに別のファイルを使うように指示できます。Kubernetesは指定されたファイルの内容を使用して、成功と失敗の両方についてコンテナのステータスメッセージを入力します。
終了メッセージはアサーションエラーメッセージのように、最終状態を簡潔に示します。kubeletは4096バイトより長いメッセージは切り詰めます。全コンテナの合計メッセージの長さの上限は12キビバイトです。デフォルトの終了メッセージのパスは/dev/termination-logです。Pod起動後に終了メッセージのパスを設定することはできません。
次の例では、コンテナはKubernetesが取得するために終了メッセージを/tmp/my-logに書き込みます:
apiVersion : v1
kind : Pod
metadata :
name : msg-path-demo
spec :
containers :
- name : msg-path-demo-container
image : debian
terminationMessagePath : "/tmp/my-log"
さらに、ユーザーは追加のカスタマイズをするためにContainerのterminationMessagePolicyフィールドを設定できます。このフィールドのデフォルト値はFileです。これは、終了メッセージが終了メッセージファイルからのみ取得されることを意味します。terminationMessagePolicyをFallbackToLogsOnErrorに設定することで、終了メッセージファイルが空でコンテナがエラーで終了した場合に、コンテナログ出力の最後のチャンクを使用するようにKubernetesに指示できます。ログ出力は、2048バイトまたは80行のどちらか小さい方に制限されています。
次の項目 4.4.1.4 - StatefulSetのデバッグ このタスクでは、StatefulSetをデバッグする方法を説明します。
始める前に Kubernetesクラスターが必要です。また、kubectlコマンドラインツールがクラスターと通信するように設定されている必要があります。 調べたいStatefulSetを実行しておきましょう。 StatefulSetのデバッグ StatefulSetに属し、ラベルapp=myappが設定されているすべてのPodを一覧表示するには、以下のコマンドを利用できます。
kubectl get pods -l app = myapp
Podが長期間UnknownまたはTerminatingの状態になっていることがわかった場合は、それらを処理する方法についてStatefulSetの削除 タスクを参照してください。
Podのデバッグ ガイドを使用して、StatefulSet内の個々のPodをデバッグできます。
次の項目 Initコンテナのデバッグ の詳細
4.4.1.5 - Initコンテナのデバッグ このページでは、Initコンテナの実行に関連する問題を調査する方法を説明します。以下のコマンドラインの例では、Podを<pod-name>、Initコンテナを<init-container-1>および<init-container-2>として参照しています。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
Initコンテナのステータスを確認する Podのステータスを表示します:
kubectl get pod <pod-name>
たとえば、Init:1/2というステータスは、2つのInitコンテナのうちの1つが正常に完了したことを示します。
NAME READY STATUS RESTARTS AGE
<pod-name> 0/1 Init:1/2 0 7s
ステータス値とその意味の例については、Podのステータスを理解する を参照してください。
Initコンテナの詳細を取得する Initコンテナの実行に関する詳細情報を表示します:
kubectl describe pod <pod-name>
たとえば、2つのInitコンテナを持つPodでは、次のように表示されます:
Init Containers:
<init-container-1>:
Container ID: ...
...
State: Terminated
Reason: Completed
Exit Code: 0
Started: ...
Finished: ...
Ready: True
Restart Count: 0
...
<init-container-2>:
Container ID: ...
...
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: Error
Exit Code: 1
Started: ...
Finished: ...
Ready: False
Restart Count: 3
...
また、Pod Specのstatus.initContainerStatusesフィールドを読むことでプログラムでInitコンテナのステータスにアクセスすることもできます。:
kubectl get pod nginx --template '{{.status.initContainerStatuses}}'
このコマンドは生のJSONで上記と同じ情報を返します。
Initコンテナのログにアクセスする ログにアクセスするには、Initコンテナ名とPod名を渡します。
kubectl logs <pod-name> -c <init-container-2>
シェルスクリプトを実行するInitコンテナは、実行時にコマンドを出力します。たとえば、スクリプトの始めにset -xを実行することでBashで同じことができます。
Podのステータスを理解する Init:で始まるPodステータスはInitコンテナの実行ステータスを要約します。以下の表は、Initコンテナのデバッグ中に表示される可能性のあるステータス値の例をいくつか示しています。
ステータス 意味 Init:N/MPodはM個のInitコンテナを持ち、これまでにN個完了しました。 Init:ErrorInitコンテナが実行に失敗しました。 Init:CrashLoopBackOffInitコンテナが繰り返し失敗しました。 PendingPodはまだInitコンテナの実行を開始していません。 PodInitializing or RunningPodはすでにInitコンテナの実行を終了しています。
4.4.1.6 - 実行中のPodのデバッグ このページでは、ノード上で動作している(またはクラッシュしている)Podをデバッグする方法について説明します。
始める前に あなたのPod は既にスケジュールされ、実行されているはずです。Podがまだ実行されていない場合は、アプリケーションのトラブルシューティング から始めてください。
いくつかの高度なデバッグ手順では、Podがどのノードで動作しているかを知り、そのノードでコマンドを実行するためのシェルアクセス権を持っていることが必要です。kubectlを使用する標準的なデバッグ手順の実行には、そのようなアクセスは必要ではありません。
kubectl describe podを使ってpodの詳細を取得この例では、先ほどの例と同様に、Deploymentを使用して2つのpodを作成します。
apiVersion : apps/v1
kind : Deployment
metadata :
name : nginx-deployment
spec :
selector :
matchLabels :
app : nginx
replicas : 2
template :
metadata :
labels :
app : nginx
spec :
containers :
- name : nginx
image : nginx
resources :
limits :
memory : "128Mi"
cpu : "500m"
ports :
- containerPort : 80
以下のコマンドを実行して、Deploymentを作成します:
kubectl apply -f https://k8s.io/examples/application/nginx-with-request.yaml
deployment.apps/nginx-deployment created
以下のコマンドでPodの状態を確認します:
NAME READY STATUS RESTARTS AGE
nginx-deployment-1006230814-6winp 1/1 Running 0 11s
nginx-deployment-1006230814-fmgu3 1/1 Running 0 11s
kubectl describe podを使うと、これらのPodについてより多くの情報を得ることができます。
例えば:
kubectl describe pod nginx-deployment-1006230814-6winp
Name: nginx-deployment-1006230814-6winp
Namespace: default
Node: kubernetes-node-wul5/10.240.0.9
Start Time: Thu, 24 Mar 2016 01:39:49 +0000
Labels: app=nginx,pod-template-hash=1006230814
Annotations: kubernetes.io/created-by={"kind":"SerializedReference","apiVersion":"v1","reference":{"kind":"ReplicaSet","namespace":"default","name":"nginx-deployment-1956810328","uid":"14e607e7-8ba1-11e7-b5cb-fa16" ...
Status: Running
IP: 10.244.0.6
Controllers: ReplicaSet/nginx-deployment-1006230814
Containers:
nginx:
Container ID: docker://90315cc9f513c724e9957a4788d3e625a078de84750f244a40f97ae355eb1149
Image: nginx
Image ID: docker://6f62f48c4e55d700cf3eb1b5e33fa051802986b77b874cc351cce539e5163707
Port: 80/TCP
QoS Tier:
cpu: Guaranteed
memory: Guaranteed
Limits:
cpu: 500m
memory: 128Mi
Requests:
memory: 128Mi
cpu: 500m
State: Running
Started: Thu, 24 Mar 2016 01:39:51 +0000
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-5kdvl (ro)
Conditions:
Type Status
Initialized True
Ready True
PodScheduled True
Volumes:
default-token-4bcbi:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-4bcbi
Optional: false
QoS Class: Guaranteed
Node-Selectors: <none>
Tolerations: <none>
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
54s 54s 1 {default-scheduler } Normal Scheduled Successfully assigned nginx-deployment-1006230814-6winp to kubernetes-node-wul5
54s 54s 1 {kubelet kubernetes-node-wul5} spec.containers{nginx} Normal Pulling pulling image "nginx"
53s 53s 1 {kubelet kubernetes-node-wul5} spec.containers{nginx} Normal Pulled Successfully pulled image "nginx"
53s 53s 1 {kubelet kubernetes-node-wul5} spec.containers{nginx} Normal Created Created container with docker id 90315cc9f513
53s 53s 1 {kubelet kubernetes-node-wul5} spec.containers{nginx} Normal Started Started container with docker id 90315cc9f513
ここでは、コンテナ(複数可)とPodに関する構成情報(ラベル、リソース要件など)や、コンテナ(複数可)とPodに関するステータス情報(状態、準備状況、再起動回数、イベントなど)を確認できます。
コンテナの状態は、Waiting(待機中)、Running(実行中)、Terminated(終了)のいずれかです。状態に応じて、追加の情報が提供されます。ここでは、Running状態のコンテナについて、コンテナがいつ開始されたかが表示されています。
Readyは、コンテナが最後のReadiness Probeに合格したかどうかを示す。(この場合、コンテナにはReadiness Probeが設定されていません。Readiness Probeが設定されていない場合、コンテナは準備が完了した状態であるとみなされます)。
Restart Countは、コンテナが何回再起動されたかを示します。この情報は、再起動ポリシーが「always」に設定されているコンテナのクラッシュループを検出するのに役立ちます。
現在、Podに関連する条件は、二値のReady条件のみです。これは、Podがリクエストに対応可能であり、マッチングするすべてのサービスのロードバランシングプールに追加されるべきであることを示します。
最後に、Podに関連する最近のイベントのログが表示されます。このシステムでは、複数の同一イベントを圧縮して、最初に見られた時刻と最後に見られた時刻、そして見られた回数を示します。"From"はイベントを記録しているコンポーネントを示し、"SubobjectPath"はどのオブジェクト(例: Pod内のコンテナ)が参照されているかを示し、"Reason"と "Message"は何が起こったかを示しています。
例: Pending Podsのデバッグ イベントを使って検出できる一般的なシナリオは、どのノードにも収まらないPodを作成した場合です。例えば、Podがどのノードでも空いている以上のリソースを要求したり、どのノードにもマッチしないラベルセレクターを指定したりする場合です。例えば、各(仮想)マシンが1つのCPUを持つ4ノードのクラスター上で、(2つではなく)5つのレプリカを持ち、500ではなく600ミリコアを要求する前のDeploymentを作成したとします。この場合、Podの1つがスケジュールできなくなります。(なお、各ノードではfluentdやskydnsなどのクラスターアドオンPodが動作しているため、もし1000ミリコアを要求した場合、どのPodもスケジュールできなくなります)
NAME READY STATUS RESTARTS AGE
nginx-deployment-1006230814-6winp 1/1 Running 0 7m
nginx-deployment-1006230814-fmgu3 1/1 Running 0 7m
nginx-deployment-1370807587-6ekbw 1/1 Running 0 1m
nginx-deployment-1370807587-fg172 0/1 Pending 0 1m
nginx-deployment-1370807587-fz9sd 0/1 Pending 0 1m
nginx-deployment-1370807587-fz9sdのPodが実行されていない理由を調べるには、保留中のPodに対してkubectl describe podを使用し、そのイベントを見てみましょう
kubectl describe pod nginx-deployment-1370807587-fz9sd
Name: nginx-deployment-1370807587-fz9sd
Namespace: default
Node: /
Labels: app=nginx,pod-template-hash=1370807587
Status: Pending
IP:
Controllers: ReplicaSet/nginx-deployment-1370807587
Containers:
nginx:
Image: nginx
Port: 80/TCP
QoS Tier:
memory: Guaranteed
cpu: Guaranteed
Limits:
cpu: 1
memory: 128Mi
Requests:
cpu: 1
memory: 128Mi
Environment Variables:
Volumes:
default-token-4bcbi:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-4bcbi
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
1m 48s 7 {default-scheduler } Warning FailedScheduling pod (nginx-deployment-1370807587-fz9sd) failed to fit in any node
fit failure on node (kubernetes-node-6ta5): Node didn't have enough resource: CPU, requested: 1000, used: 1420, capacity: 2000
fit failure on node (kubernetes-node-wul5): Node didn't have enough resource: CPU, requested: 1000, used: 1100, capacity: 2000
ここでは、理由 FailedScheduling (およびその他の理由)でPodのスケジュールに失敗したという、スケジューラーによって生成されたイベントを見ることができます。このメッセージは、どのノードでもPodに十分なリソースがなかったことを示しています。
この状況を修正するには、kubectl scaleを使用して、4つ以下のレプリカを指定するようにDeploymentを更新します。(あるいは、1つのPodを保留にしたままにしておいても害はありません。)
kubectl describe podの最後に出てきたようなイベントは、etcdに永続化され、クラスターで何が起こっているかについての高レベルの情報を提供します。
すべてのイベントをリストアップするには、次のようにします:
しかし、イベントは名前空間に所属することを忘れてはいけません。つまり、名前空間で管理されているオブジェクトのイベントに興味がある場合(例: 名前空間 my-namespaceのPods で何が起こったか)、コマンドに名前空間を明示的に指定する必要があります。
kubectl get events --namespace= my-namespace
すべての名前空間からのイベントを見るには、--all-namespaces 引数を使用できます。
kubectl describe podに加えて、(kubectl get pod で提供される以上の)Podに関する追加情報を得るためのもう一つの方法は、-o yaml出力形式フラグを kubectl get podに渡すことです。これにより、kubectl describe podよりもさらに多くの情報、つまりシステムが持っているPodに関するすべての情報をYAML形式で得ることができます。ここでは、アノテーション(Kubernetesのシステムコンポーネントが内部的に使用している、ラベル制限のないキーバリューのメタデータ)、再起動ポリシー、ポート、ボリュームなどが表示されます。
kubectl get pod nginx-deployment-1006230814-6winp -o yaml
apiVersion : v1
kind : Pod
metadata :
annotations :
kubernetes.io/created-by : |
{"kind":"SerializedReference","apiVersion":"v1","reference":{"kind":"ReplicaSet","namespace":"default","name":"nginx-deployment-1006230814","uid":"4c84c175-f161-11e5-9a78-42010af00005","apiVersion":"extensions","resourceVersion":"133434"}}
creationTimestamp : 2016-03-24T01:39:50Z
generateName : nginx-deployment-1006230814-
labels :
app : nginx
pod-template-hash : "1006230814"
name : nginx-deployment-1006230814-6winp
namespace : default
resourceVersion : "133447"
uid : 4c879808-f161-11e5-9a78-42010af00005
spec :
containers :
- image : nginx
imagePullPolicy : Always
name : nginx
ports :
- containerPort : 80
protocol : TCP
resources :
limits :
cpu : 500m
memory : 128Mi
requests :
cpu : 500m
memory : 128Mi
terminationMessagePath : /dev/termination-log
volumeMounts :
- mountPath : /var/run/secrets/kubernetes.io/serviceaccount
name : default-token-4bcbi
readOnly : true
dnsPolicy : ClusterFirst
nodeName : kubernetes-node-wul5
restartPolicy : Always
securityContext : {}
serviceAccount : default
serviceAccountName : default
terminationGracePeriodSeconds : 30
volumes :
- name : default-token-4bcbi
secret :
secretName : default-token-4bcbi
status :
conditions :
- lastProbeTime : null
lastTransitionTime : 2016-03-24T01:39:51Z
status : "True"
type : Ready
containerStatuses :
- containerID : docker://90315cc9f513c724e9957a4788d3e625a078de84750f244a40f97ae355eb1149
image : nginx
imageID : docker://6f62f48c4e55d700cf3eb1b5e33fa051802986b77b874cc351cce539e5163707
lastState : {}
name : nginx
ready : true
restartCount : 0
state :
running :
startedAt : 2016-03-24T01:39:51Z
hostIP : 10.240.0.9
phase : Running
podIP : 10.244.0.6
startTime : 2016-03-24T01:39:49Z
例: ダウン/到達不可能なノードのデバッグ 例えば、ノード上で動作しているPodのおかしな挙動に気付いたり、Podがノード上でスケジュールされない原因を探ったりと、デバッグ時にノードのステータスを見ることが有用な場合があります。Podと同様に、kubectl describe nodeやkubectl get node -o yamlを使ってノードの詳細情報を取得することができます。例えば、ノードがダウンした場合(ネットワークから切断された、またはkubeletが死んで再起動しないなど)に表示される内容は以下の通りです。ノードがNotReadyであることを示すイベントに注目してください。また、Podが実行されなくなっていることにも注目してください(NotReady状態が5分続くと、Podは退避されます)。
NAME STATUS ROLES AGE VERSION
kubernetes-node-861h NotReady <none> 1h v1.13.0
kubernetes-node-bols Ready <none> 1h v1.13.0
kubernetes-node-st6x Ready <none> 1h v1.13.0
kubernetes-node-unaj Ready <none> 1h v1.13.0
kubectl describe node kubernetes-node-861h
Name: kubernetes-node-861h
Role
Labels: kubernetes.io/arch=amd64
kubernetes.io/os=linux
kubernetes.io/hostname=kubernetes-node-861h
Annotations: node.alpha.kubernetes.io/ttl=0
volumes.kubernetes.io/controller-managed-attach-detach=true
Taints: <none>
CreationTimestamp: Mon, 04 Sep 2017 17:13:23 +0800
Phase:
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
OutOfDisk Unknown Fri, 08 Sep 2017 16:04:28 +0800 Fri, 08 Sep 2017 16:20:58 +0800 NodeStatusUnknown Kubelet stopped posting node status.
MemoryPressure Unknown Fri, 08 Sep 2017 16:04:28 +0800 Fri, 08 Sep 2017 16:20:58 +0800 NodeStatusUnknown Kubelet stopped posting node status.
DiskPressure Unknown Fri, 08 Sep 2017 16:04:28 +0800 Fri, 08 Sep 2017 16:20:58 +0800 NodeStatusUnknown Kubelet stopped posting node status.
Ready Unknown Fri, 08 Sep 2017 16:04:28 +0800 Fri, 08 Sep 2017 16:20:58 +0800 NodeStatusUnknown Kubelet stopped posting node status.
Addresses: 10.240.115.55,104.197.0.26
Capacity:
cpu: 2
hugePages: 0
memory: 4046788Ki
pods: 110
Allocatable:
cpu: 1500m
hugePages: 0
memory: 1479263Ki
pods: 110
System Info:
Machine ID: 8e025a21a4254e11b028584d9d8b12c4
System UUID: 349075D1-D169-4F25-9F2A-E886850C47E3
Boot ID: 5cd18b37-c5bd-4658-94e0-e436d3f110e0
Kernel Version: 4.4.0-31-generic
OS Image: Debian GNU/Linux 8 (jessie)
Operating System: linux
Architecture: amd64
Container Runtime Version: docker://1.12.5
Kubelet Version: v1.6.9+a3d1dfa6f4335
Kube-Proxy Version: v1.6.9+a3d1dfa6f4335
ExternalID: 15233045891481496305
Non-terminated Pods: (9 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits
--------- ---- ------------ ---------- --------------- -------------
......
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
CPU Requests CPU Limits Memory Requests Memory Limits
------------ ---------- --------------- -------------
900m (60%) 2200m (146%) 1009286400 (66%) 5681286400 (375%)
Events: <none>
kubectl get node kubernetes-node-861h -o yaml
apiVersion : v1
kind : Node
metadata :
creationTimestamp : 2015-07-10T21:32:29Z
labels :
kubernetes.io/hostname : kubernetes-node-861h
name : kubernetes-node-861h
resourceVersion : "757"
uid : 2a69374e-274b-11e5-a234-42010af0d969
spec :
externalID : "15233045891481496305"
podCIDR : 10.244.0.0 /24
providerID : gce://striped-torus-760/us-central1-b/kubernetes-node-861h
status :
addresses :
- address : 10.240.115.55
type : InternalIP
- address : 104.197.0.26
type : ExternalIP
capacity :
cpu : "1"
memory : 3800808Ki
pods : "100"
conditions :
- lastHeartbeatTime : 2015-07-10T21:34:32Z
lastTransitionTime : 2015-07-10T21:35:15Z
reason : Kubelet stopped posting node status.
status : Unknown
type : Ready
nodeInfo :
bootID : 4e316776 -b40d-4f78-a4ea-ab0d73390897
containerRuntimeVersion : docker://Unknown
kernelVersion : 3.16.0-0. bpo.4-amd64
kubeProxyVersion : v0.21.1-185-gffc5a86098dc01
kubeletVersion : v0.21.1-185-gffc5a86098dc01
machineID : ""
osImage : Debian GNU/Linux 7 (wheezy)
systemUUID : ABE5F6B4-D44B-108B-C46A-24CCE16C8B6E
Podログを調べます まず、影響を受けるコンテナのログを見ます。
kubectl logs ${ POD_NAME } ${ CONTAINER_NAME }
コンテナが以前にクラッシュしたことがある場合、次のコマンドで以前のコンテナのクラッシュログにアクセスすることができます:
kubectl logs --previous ${ POD_NAME } ${ CONTAINER_NAME }
container execによるデバッグ もしcontainer image がデバッグユーティリティを含んでいれば、LinuxやWindows OSのベースイメージからビルドしたイメージのように、kubectl execで特定のコンテナ内でコマンドを実行することが可能です:
kubectl exec ${ POD_NAME } -c ${ CONTAINER_NAME } -- ${ CMD } ${ ARG1 } ${ ARG2 } ... ${ ARGN }
備考: -c ${CONTAINER_NAME}は省略可能です。コンテナを1つだけ含むPodの場合は省略できます。例として、実行中のCassandra Podからログを見るには、次のように実行します。
kubectl exec cassandra -- cat /var/log/cassandra/system.log
例えばkubectl execの-iと-t引数を使って、端末に接続されたシェルを実行することができます:
kubectl exec -it cassandra -- sh
詳しくは、実行中のコンテナへのシェルを取得する を参照してください。
エフェメラルコンテナによるデバッグ FEATURE STATE:
Kubernetes v1.25 [stable]
エフェメラルコンテナ は、コンテナがクラッシュしたり、コンテナイメージにデバッグユーティリティが含まれていないなどの理由でkubectl execが不十分な場合に、対話的にトラブルシューティングを行うのに便利です(ディストロレスイメージ の場合など)。
エフェメラルコンテナを使用したデバッグ例 実行中のPodにエフェメラルコンテナを追加するには、kubectl debugコマンドを使用することができます。
まず、サンプル用のPodを作成します:
kubectl run ephemeral-demo --image= registry.k8s.io/pause:3.1 --restart= Never
このセクションの例では、デバッグユーティリティが含まれていないpauseコンテナイメージを使用していますが、この方法はすべてのコンテナイメージで動作します。
もし、kubectl execを使用してシェルを作成しようとすると、このコンテナイメージにはシェルが存在しないため、エラーが表示されます。
kubectl exec -it ephemeral-demo -- sh
OCI runtime exec failed: exec failed: container_linux.go:346: starting container process caused "exec: \"sh\": executable file not found in $PATH": unknown
代わりに、kubectl debugを使ってデバッグ用のコンテナを追加することができます。
引数に-i/--interactiveを指定すると、kubectlは自動的にエフェメラルコンテナのコンソールにアタッチされます。
kubectl debug -it ephemeral-demo --image= busybox:1.28 --target= ephemeral-demo
Defaulting debug container name to debugger-8xzrl.
If you don't see a command prompt, try pressing enter.
/ #
このコマンドは新しいbusyboxコンテナを追加し、それにアタッチします。--targetパラメーターは、他のコンテナのプロセス名前空間をターゲットにします。これはkubectl runが作成するPodでプロセス名前空間の共有 を有効にしないため、指定する必要があります。
備考: --targetパラメーターは
Container Runtime でサポートされている必要があります。サポートされていない場合、エフェメラルコンテナは起動されないか、
psが他のコンテナ内のプロセスを表示しないように孤立したプロセス名前空間を使用して起動されます。
新しく作成されたエフェメラルコンテナの状態はkubectl describeを使って見ることができます:
kubectl describe pod ephemeral-demo
...
Ephemeral Containers:
debugger-8xzrl:
Container ID: docker://b888f9adfd15bd5739fefaa39e1df4dd3c617b9902082b1cfdc29c4028ffb2eb
Image: busybox
Image ID: docker-pullable://busybox@sha256:1828edd60c5efd34b2bf5dd3282ec0cc04d47b2ff9caa0b6d4f07a21d1c08084
Port: <none>
Host Port: <none>
State: Running
Started: Wed, 12 Feb 2020 14:25:42 +0100
Ready: False
Restart Count: 0
Environment: <none>
Mounts: <none>
...
終了したらkubectl deleteを使ってPodを削除してください:
kubectl delete pod ephemeral-demo
Podのコピーを使ったデバッグ Podの設定オプションによって、特定の状況でのトラブルシューティングが困難になることがあります。
例えば、コンテナイメージにシェルが含まれていない場合、またはアプリケーションが起動時にクラッシュした場合は、kubectl execを実行してトラブルシューティングを行うことができません。
このような状況では、kubectl debugを使用してデバッグを支援するために設定値を変更したPodのコピーを作ることができます。
新しいコンテナを追加しながらPodをコピーします 新しいコンテナを追加することは、アプリケーションは動作しているが期待通りの動作をせず、トラブルシューティングユーティリティをPodに追加したい場合に便利です。
例えば、アプリケーションのコンテナイメージはbusybox上にビルドされているが、busyboxに含まれていないデバッグユーティリティが必要な場合があります。このシナリオはkubectl runを使ってシミュレーションすることができます。
kubectl run myapp --image= busybox:1.28 --restart= Never -- sleep 1d
このコマンドを実行すると、myappのコピーにmyapp-debugという名前が付き、デバッグ用の新しいUbuntuコンテナが追加されます。
kubectl debug myapp -it --image= ubuntu --share-processes --copy-to= myapp-debug
Defaulting debug container name to debugger-w7xmf.
If you don't see a command prompt, try pressing enter.
root@myapp-debug:/#
備考: kubectl debugは--containerフラグでコンテナ名を選択しない場合、自動的にコンテナ名を生成します。
iフラグを指定すると、デフォルトでkubectl debugが新しいコンテナにアタッチされます。これを防ぐには、--attach=falseを指定します。セッションが切断された場合は、kubectl attachを使用して再接続することができます。
--share-processesを指定すると、このPod内のコンテナが、Pod内の他のコンテナのプロセスを参照することができます。この仕組みについて詳しくは、Pod内のコンテナ間でプロセス名前空間を共有する を参照してください。
デバッグが終わったら、Podの後始末をするのを忘れないでください。
kubectl delete pod myapp myapp-debug
Podのコマンドを変更しながらコピーします 例えば、デバッグフラグを追加する場合や、アプリケーションがクラッシュしている場合などでは、コンテナのコマンドを変更すると便利なことがあります。
アプリケーションのクラッシュをシミュレートするには、kubectl runを使用して、すぐに終了するコンテナを作成します:
kubectl run --image=busybox:1.28 myapp -- false
kubectl describe pod myappを使用すると、このコンテナがクラッシュしていることがわかります:
Containers:
myapp:
Image: busybox
...
Args:
false
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: Error
Exit Code: 1
kubectl debugを使うと、コマンドをインタラクティブシェルに変更したこのPodのコピーを作成することができます。
kubectl debug myapp -it --copy-to=myapp-debug --container=myapp -- sh
If you don't see a command prompt, try pressing enter.
/ #
これで、ファイルシステムのパスのチェックやコンテナコマンドの手動実行などのタスクを実行するために使用できる対話型シェルが完成しました。
備考: 特定のコンテナのコマンドを変更するには、そのコンテナ名を--containerで指定する必要があります。そうしなければ、指定したコマンドを実行するための新しいコンテナを、kubectl debugが代わりに作成します。
-iフラグは、デフォルトでkubectl debugがコンテナにアタッチされるようにします。これを防ぐには、--attach=falseを指定します。セッションが切断された場合は、kubectl attachを使用して再接続することができます。
デバッグが終わったら、Podの後始末をするのを忘れないでください:
kubectl delete pod myapp myapp-debug
コンテナイメージを変更してPodをコピーします 状況によっては、動作不良のPodを通常のプロダクション用のコンテナイメージから、デバッグビルドや追加ユーティリティを含むイメージに変更したい場合があります。
例として、kubectl runを使用してPodを作成します:
kubectl run myapp --image=busybox:1.28 --restart=Never -- sleep 1d
ここで、kubectl debugを使用してコピーを作成し、そのコンテナイメージをubuntuに変更します:
kubectl debug myapp --copy-to=myapp-debug --set-image=*=ubuntu
--set-imageの構文は、kubectl set imageと同じcontainer_name=imageの構文を使用します。*=ubuntuは、全てのコンテナのイメージをubuntuに変更することを意味します。
デバッグが終わったら、Podの後始末をするのを忘れないでください:
kubectl delete pod myapp myapp-debug
ノード上のシェルによるデバッグ いずれの方法でもうまくいかない場合は、Podが動作しているノードを探し出し、ホストの名前空間で動作するデバッグ用のPodを作成します。
ノード上でkubectl debugを使って対話型のシェルを作成するには、以下を実行します:
kubectl debug node/mynode -it --image= ubuntu
Creating debugging pod node-debugger-mynode-pdx84 with container debugger on node mynode.
If you don't see a command prompt, try pressing enter.
root@ek8s:/#
ノードでデバッグセッションを作成する場合、以下の点に注意してください:
kubectl debugはノードの名前に基づいて新しいPodの名前を自動的に生成します。ノードのルートファイルシステムは/hostにマウントされます。 コンテナはホストのIPC、Network、PIDネームスペースで実行されますが、特権は付与されません。そのため、ホスト上のプロセス情報の参照や、chroot /hostの実行に失敗する場合があります。 特権が必要な場合は手動でPodを作成するか、--profile=sysadminを使用してください。 デバッグが終わったら、Podの後始末をするのを忘れないでください:
kubectl delete pod node-debugger-mynode-pdx84
デバッグプロファイルを使用したPodやNodeのデバッグ kubectl debugでノードやPodをデバッグする場合、デバッグ用のPod、エフェメラルコンテナ、またはコピーされたPodにデバッグプロファイルを適用できます。
デバッグプロファイルを適用することで、securityContext など特定のプロパティが設定され、
さまざまなシナリオに適応できるようになります。
デバッグプロファイルにはスタティックプロファイルとカスタムプロファイルの2種類があります。
スタティックプロファイルの適用 スタティックプロファイルは事前に定義されたプロパティの組み合わせで構成され、--profileフラグを使用して適用できます。
使用可能なスタティックプロファイルは以下の通りです:
備考: もし--profileを指定しない場合、デフォルトでlegacyプロファイルが使用されます。
legacyプロファイルは将来的に廃止される予定であるため、generalプロファイルなどの他のプロファイルを使用することを推奨します。例えば、myappという名前のPodを作成し、デバッグを行います:
kubectl run myapp --image= busybox:1.28 --restart= Never -- sleep 1d
エフェメラルコンテナを使用して、Podをデバッグします。
エフェメラルコンテナに特権が必要な場合は、sysadminプロファイルを使用できます:
kubectl debug -it myapp --image= busybox:1.28 --target= myapp --profile= sysadmin
Targeting container "myapp". If you don't see processes from this container it may be because the container runtime doesn't support this feature.
Defaulting debug container name to debugger-6kg4x.
If you don't see a command prompt, try pressing enter.
/ #
コンテナで次のコマンドを実行して、エフェメラルコンテナプロセスのケーパビリティを確認します:
/ # grep Cap /proc/$$/status
...
CapPrm: 000001ffffffffff
CapEff: 000001ffffffffff
...
この結果は、sysadminプロファイルを適用したことで、エフェメラルコンテナプロセスに特権が付与されていることを示しています。
詳細はコンテナにケーパビリティを設定する を参照してください。
エフェメラルコンテナが特権コンテナであることは、次のコマンドからも確認できます:
kubectl get pod myapp -o jsonpath = '{.spec.ephemeralContainers[0].securityContext}'
{"privileged":true}
確認が終わったらPodを削除します:
カスタムプロファイルの適用 FEATURE STATE:
Kubernetes v1.32 [stable]
デバッグに使用するコンテナのspecをYAMLまたはJSON形式でカスタムプロファイルとして定義し、--customフラグを使用して適用できます。
備考: カスタムプロファイルはコンテナのspecの変更のみをサポートしていますが、name, image, command, lifecycle
および volumeDevicesフィールドの変更は許可されません。
また、Podのspecの変更もサポートされていません。例えば、myappという名前のPodを作成します:
kubectl run myapp --image= busybox:1.28 --restart= Never -- sleep 1d
YAMLまたはJSON形式でカスタムプロファイルを作成します。
ここでは、custom-profile.yamlという名前のYAML形式のファイルを作成します:
env :
name : ENV_VAR_1
value : value_1
name : ENV_VAR_2
value : value_2
securityContext :
capabilities :
add :
- NET_ADMIN
- SYS_TIME
次のコマンドを実行することで、エフェメラルコンテナにカスタムプロファイルを適用し、Podをデバッグします:
kubectl debug -it myapp --image= busybox:1.28 --target= myapp --profile= general --custom= custom-profile.yaml
Podにカスタムプロファイルが適用された状態のエフェメラルコンテナが追加されたことを確認できます:
kubectl get pod myapp -o jsonpath = '{.spec.ephemeralContainers[0].env}'
[{"name":"ENV_VAR_1","value":"value_1"},{"name":"ENV_VAR_2","value":"value_2"}]
kubectl get pod myapp -o jsonpath = '{.spec.ephemeralContainers[0].securityContext}'
{"capabilities":{"add":["NET_ADMIN","SYS_TIME"]}}
確認が終わったらPodを削除します:
4.4.1.7 - 実行中のコンテナへのシェルを取得する このページはkubectl execを使用して実行中のコンテナへのシェルを取得する方法を説明します。
始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
コンテナへのシェルの取得 このエクササイズでは、1つのコンテナを持つPodを作成します。
コンテナはnginxのイメージを実行します。以下がそのPodの設定ファイルです:
apiVersion : v1
kind : Pod
metadata :
name : shell-demo
spec :
volumes :
- name : shared-data
emptyDir : {}
containers :
- name : nginx
image : nginx
volumeMounts :
- name : shared-data
mountPath : /usr/share/nginx/html
Podを作成します:
kubectl apply -f https://k8s.io/examples/application/shell-demo.yaml
コンテナが実行中であることを確認します:
kubectl get pod shell-demo
実行中のコンテナへのシェルを取得します:
kubectl exec --stdin --tty shell-demo -- /bin/bash
備考: ダブルダッシュ(--)のセパレーターは、コマンドに渡す引数とkubectlの引数を分離します。シェル内で、ルートディレクトリーのファイル一覧を表示します:
# このコマンドをコンテナ内で実行します
ls /
シェル内で、他のコマンドを試しましょう。以下がいくつかの例です:
# これらのサンプルコマンドをコンテナ内で実行することができます
ls /
cat /proc/mounts
cat /proc/1/maps
apt-get update
apt-get install -y tcpdump
tcpdump
apt-get install -y lsof
lsof
apt-get install -y procps
ps aux
ps aux | grep nginx
nginxのルートページへの書き込み Podの設定ファイルを再度確認します。PodはemptyDirボリュームを持ち、
コンテナは/usr/share/nginx/htmlボリュームをマウントします。
シェル内で、/usr/share/nginx/htmlディレクトリにindex.htmlを作成します。
# このコマンドをコンテナ内で実行します
echo 'Hello shell demo' > /usr/share/nginx/html/index.html
シェル内で、nginxサーバーにGETリクエストを送信します:
# これらのコマンドをコンテナ内のシェルで実行します
apt-get update
apt-get install curl
curl http://localhost/
出力にindex.htmlファイルに書き込んだ文字列が表示されます:
Hello shell demo
シェルを終了する場合、exitを入力します。
コンテナ内での各コマンドの実行 シェルではない通常のコマンドウインドウ内で、実行中のコンテナの環境変数の一覧を表示します:
kubectl exec shell-demo -- env
他のコマンドを試します。以下がいくつかの例です:
kubectl exec shell-demo -- ps aux
kubectl exec shell-demo -- ls /
kubectl exec shell-demo -- cat /proc/1/mounts
Podが1つ以上のコンテナを持つ場合にシェルを開く Podが1つ以上のコンテナを持つ場合、--containerか-cを使用して、kubectl execコマンド内でコンテナを指定します。
例えば、my-podという名前のPodがあり、そのPodが main-app と helper-app という2つのコンテナを持つとします。
以下のコマンドは main-app のコンテナへのシェルを開きます。
kubectl exec -i -t my-pod --container main-app -- /bin/bash
備考: ショートオプションの-iと-tは、ロングオプションの--stdinと--ttyと同様です。次の項目 4.4.2 - クラスターのトラブルシューティング 一般的なクラスターの問題をデバッグします。
このドキュメントはクラスターのトラブルシューティングに関するもので、あなたが経験している問題の根本原因として、アプリケーションをすでに除外していることを前提としています。
アプリケーションのデバッグのコツは、アプリケーションのトラブルシューティングガイド をご覧ください。
また、トラブルシューティングドキュメント にも詳しい情報があります。
kubectl のトラブルシューティングについては、kubectlのトラブルシューティング を参照してください。
クラスターのリストアップ クラスターで最初にデバッグするのは、ノードがすべて正しく登録されているかどうかです。
以下を実行します。
そして、期待するノードがすべて存在し、それらがすべて Ready 状態であることを確認します。
クラスター全体の健全性に関する詳細な情報を得るには、以下を実行します。
kubectl cluster-info dump
例: ダウンあるいは到達不能なノードのデバッグ デバッグを行う際、ノードの状態を見ることが有用なことがあります。
たとえば、そのノード上で動作しているPodが奇妙な挙動を示している場合や、なぜPodがそのノードにスケジュールされないのかを知りたい場合などです。
Podと同様に、kubectl describe nodeやkubectl get node -o yamlを使用してノードに関する詳細情報を取得できます。
例えば、ノードがダウンしている(ネットワークから切断されている、またはkubeletが停止して再起動しないなど)場合に見られる状況は以下の通りです。
ノードがNotReadyであることを示すイベントに注意し、また、Podが動作していないことにも注意してください(NotReady状態が5分間続くとPodは追い出されます)。
NAME STATUS ROLES AGE VERSION
kube-worker-1 NotReady <none> 1h v1.23.3
kubernetes-node-bols Ready <none> 1h v1.23.3
kubernetes-node-st6x Ready <none> 1h v1.23.3
kubernetes-node-unaj Ready <none> 1h v1.23.3
kubectl describe node kube-worker-1
Name: kube-worker-1
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=kube-worker-1
kubernetes.io/os=linux
Annotations: kubeadm.alpha.kubernetes.io/cri-socket: /run/containerd/containerd.sock
node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Thu, 17 Feb 2022 16:46:30 -0500
Taints: node.kubernetes.io/unreachable:NoExecute
node.kubernetes.io/unreachable:NoSchedule
Unschedulable: false
Lease:
HolderIdentity: kube-worker-1
AcquireTime: <unset>
RenewTime: Thu, 17 Feb 2022 17:13:09 -0500
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
NetworkUnavailable False Thu, 17 Feb 2022 17:09:13 -0500 Thu, 17 Feb 2022 17:09:13 -0500 WeaveIsUp Weave pod has set this
MemoryPressure Unknown Thu, 17 Feb 2022 17:12:40 -0500 Thu, 17 Feb 2022 17:13:52 -0500 NodeStatusUnknown Kubelet stopped posting node status.
DiskPressure Unknown Thu, 17 Feb 2022 17:12:40 -0500 Thu, 17 Feb 2022 17:13:52 -0500 NodeStatusUnknown Kubelet stopped posting node status.
PIDPressure Unknown Thu, 17 Feb 2022 17:12:40 -0500 Thu, 17 Feb 2022 17:13:52 -0500 NodeStatusUnknown Kubelet stopped posting node status.
Ready Unknown Thu, 17 Feb 2022 17:12:40 -0500 Thu, 17 Feb 2022 17:13:52 -0500 NodeStatusUnknown Kubelet stopped posting node status.
Addresses:
InternalIP: 192.168.0.113
Hostname: kube-worker-1
Capacity:
cpu: 2
ephemeral-storage: 15372232Ki
hugepages-2Mi: 0
memory: 2025188Ki
pods: 110
Allocatable:
cpu: 2
ephemeral-storage: 14167048988
hugepages-2Mi: 0
memory: 1922788Ki
pods: 110
System Info:
Machine ID: 9384e2927f544209b5d7b67474bbf92b
System UUID: aa829ca9-73d7-064d-9019-df07404ad448
Boot ID: 5a295a03-aaca-4340-af20-1327fa5dab5c
Kernel Version: 5.13.0-28-generic
OS Image: Ubuntu 21.10
Operating System: linux
Architecture: amd64
Container Runtime Version: containerd://1.5.9
Kubelet Version: v1.23.3
Kube-Proxy Version: v1.23.3
Non-terminated Pods: (4 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
default nginx-deployment-67d4bdd6f5-cx2nz 500m (25%) 500m (25%) 128Mi (6%) 128Mi (6%) 23m
default nginx-deployment-67d4bdd6f5-w6kd7 500m (25%) 500m (25%) 128Mi (6%) 128Mi (6%) 23m
kube-system kube-proxy-dnxbz 0 (0%) 0 (0%) 0 (0%) 0 (0%) 28m
kube-system weave-net-gjxxp 100m (5%) 0 (0%) 200Mi (10%) 0 (0%) 28m
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 1100m (55%) 1 (50%)
memory 456Mi (24%) 256Mi (13%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events:
...
kubectl get node kube-worker-1 -o yaml
apiVersion : v1
kind : Node
metadata :
annotations :
kubeadm.alpha.kubernetes.io/cri-socket : /run/containerd/containerd.sock
node.alpha.kubernetes.io/ttl : "0"
volumes.kubernetes.io/controller-managed-attach-detach : "true"
creationTimestamp : "2022-02-17T21:46:30Z"
labels :
beta.kubernetes.io/arch : amd64
beta.kubernetes.io/os : linux
kubernetes.io/arch : amd64
kubernetes.io/hostname : kube-worker-1
kubernetes.io/os : linux
name : kube-worker-1
resourceVersion : "4026"
uid : 98efe7cb-2978-4a0b-842a-1a7bf12c05f8
spec : {}
status :
addresses :
- address : 192.168.0.113
type : InternalIP
- address : kube-worker-1
type : Hostname
allocatable :
cpu : "2"
ephemeral-storage : "14167048988"
hugepages-2Mi : "0"
memory : 1922788Ki
pods : "110"
capacity :
cpu : "2"
ephemeral-storage : 15372232Ki
hugepages-2Mi : "0"
memory : 2025188Ki
pods : "110"
conditions :
- lastHeartbeatTime : "2022-02-17T22:20:32Z"
lastTransitionTime : "2022-02-17T22:20:32Z"
message : Weave pod has set this
reason : WeaveIsUp
status : "False"
type : NetworkUnavailable
- lastHeartbeatTime : "2022-02-17T22:20:15Z"
lastTransitionTime : "2022-02-17T22:13:25Z"
message : kubelet has sufficient memory available
reason : KubeletHasSufficientMemory
status : "False"
type : MemoryPressure
- lastHeartbeatTime : "2022-02-17T22:20:15Z"
lastTransitionTime : "2022-02-17T22:13:25Z"
message : kubelet has no disk pressure
reason : KubeletHasNoDiskPressure
status : "False"
type : DiskPressure
- lastHeartbeatTime : "2022-02-17T22:20:15Z"
lastTransitionTime : "2022-02-17T22:13:25Z"
message : kubelet has sufficient PID available
reason : KubeletHasSufficientPID
status : "False"
type : PIDPressure
- lastHeartbeatTime : "2022-02-17T22:20:15Z"
lastTransitionTime : "2022-02-17T22:15:15Z"
message : kubelet is posting ready status. AppArmor enabled
reason : KubeletReady
status : "True"
type : Ready
daemonEndpoints :
kubeletEndpoint :
Port : 10250
nodeInfo :
architecture : amd64
bootID : 22333234 -7a6b-44d4-9ce1-67e31dc7e369
containerRuntimeVersion : containerd://1.5.9
kernelVersion : 5.13.0-28 -generic
kubeProxyVersion : v1.23.3
kubeletVersion : v1.23.3
machineID : 9384e2927f544209b5d7b67474bbf92b
operatingSystem : linux
osImage : Ubuntu 21.10
systemUUID : aa829ca9-73d7-064d-9019-df07404ad448
ログの確認 今のところ、クラスターをより深く掘り下げるには、関連するマシンにログインする必要があります。
以下は、関連するログファイルの場所です。
(systemdベースのシステムでは、代わりにjournalctlを使う必要があるかもしれないことに注意してください)
コントロールプレーンノード /var/log/kube-apiserver.log - APIの提供を担当するAPIサーバーのログ/var/log/kube-scheduler.log - スケジューリング決定責任者であるスケジューラーのログ/var/log/kube-controller-manager.log - スケジューリングを除く、ほとんどのKubernetes組み込みのコントローラー を実行するコンポーネントのログ(スケジューリングはkube-schedulerが担当します)ワーカーノード /var/log/kubelet.log - ノード上でコンテナの実行を担当するKubeletのログ/var/log/kube-proxy.log - サービスのロードバランシングを担うKube Proxyのログクラスター障害モードの一般的な概要 これは、問題が発生する可能性のある事柄と、問題を軽減するためにクラスターのセットアップを調整する方法の不完全なリストです。
根本的な原因 VMのシャットダウン クラスター内、またはクラスターとユーザー間のネットワークパーティション Kubernetesソフトウェアのクラッシュ データの損失や永続的ストレージ(GCE PDやAWS EBSボリュームなど)の使用不能 Kubernetesソフトウェアやアプリケーションソフトウェアの設定ミスなど、オペレーターのミス 具体的なシナリオ apiserver VMのシャットダウンまたはapiserverのクラッシュその結果新しいPod、サービス、レプリケーションコントローラーの停止、更新、起動ができない Kubernetes APIに依存していない限り、既存のPodやサービスは正常に動作し続けるはずです apiserverのバックアップストレージが失われたその結果apiserverが立ち上がらない kubeletは到達できなくなりますが、同じPodを実行し、同じサービスのプロキシを提供し続けます apiserverを再起動する前に、手動でapiserverの状態を回復または再現する必要がある サポートサービス(ノードコントローラー、レプリケーションコントローラーマネージャー、スケジューラーなど)VMのシャットダウンまたはクラッシュ現在、これらはapiserverとコロケーションしており、使用できない場合はapiserverと同様の影響があります 将来的には、これらも複製されるようになり、同じ場所に配置されない可能性があります 独自の永続的な状態を持っていない 個別ノード(VMまたは物理マシン)のシャットダウン ネットワークパーティションその結果パーティションAはパーティションBのノードがダウンしていると考え、パーティションBはapiserverがダウンしていると考えています。(マスターVMがパーティションAで終了したと仮定) Kubeletソフトウェア障害その結果クラッシュしたkubeletがノード上で新しいPodを起動できない kubeletがPodを削除するかどうか ノードが不健全と判定される レプリケーションコントローラーが別の場所で新しいPodを起動する クラスターオペレーターエラーその結果PodやServiceなどの損失 apiserverのバックエンドストレージの紛失 ユーザーがAPIを読めなくなる その他 軽減策 対処法: IaaSプロバイダーの自動VM再起動機能をIaaS VMに使用する
異常: Apiserver VMのシャットダウンまたはApiserverのクラッシュ 異常: サポートサービスのVMシャットダウンまたはクラッシュ 対処法: IaaSプロバイダーの信頼できるストレージ(GCE PDやAWS EBSボリュームなど)をapiserver+etcdを使用するVMに使用する
異常: Apiserverのバックエンドストレージが失われる 対処法: 高可用性 構成を使用します
異常: コントロールプレーンノードのシャットダウンまたはコントロールプレーンコンポーネント(スケジューラー、APIサーバー、コントローラーマネージャー)のクラッシュ1つ以上のノードまたはコンポーネントの同時故障に耐えることができる 異常: APIサーバーのバックアップストレージ(etcdのデータディレクトリーなど)が消失 対処法: apiserver PDs/EBS-volumesを定期的にスナップショットする
異常: Apiserverのバックエンドストレージが失われる 異常: 操作ミスが発生する場合がある 異常: Kubernetesのソフトウェアに障害が発生する場合がある 対処法:レプリケーションコントローラーとServiceをPodの前に使用する
異常: ノードのシャットダウン 異常: Kubeletソフトウェア障害 対処法: 予期せぬ再起動に耐えられるように設計されたアプリケーション(コンテナ)
異常: ノードのシャットダウン 異常: Kubeletソフトウェア障害 次の項目 4.4.2.1 - kubectlのトラブルシューティング このドキュメントは、kubectl 関連の問題の調査と診断に関するものです。
kubectlへのアクセスやクラスターへの接続で問題に直面した場合、このドキュメントではさまざまな一般的なシナリオや考えられる解決策を概説し、問題の特定と対処するのに役立ちます。
始める前に Kubernetesクラスターが必要です。 kubectlもインストールする必要があります。ツールのインストール を参照してください。kubectlセットアップを検証する kubectlがローカルマシンに正しくインストールされ、構成されていることを確認してください。
kubectlバージョンが最新であり、クラスターと互換性があることを確認してください。
kubectlバージョンを確認します:
以下のような出力が表示されます:
Client Version: version.Info{Major:"1", Minor:"27", GitVersion:"v1.27.4",GitCommit:"fa3d7990104d7c1f16943a67f11b154b71f6a132", GitTreeState:"clean",BuildDate:"2023-07-19T12:20:54Z", GoVersion:"go1.20.6", Compiler:"gc", Platform:"linux/amd64"}
Kustomize Version: v5.0.1
Server Version: version.Info{Major:"1", Minor:"27", GitVersion:"v1.27.3",GitCommit:"25b4e43193bcda6c7328a6d147b1fb73a33f1598", GitTreeState:"clean",BuildDate:"2023-06-14T09:47:40Z", GoVersion:"go1.20.5", Compiler:"gc", Platform:"linux/amd64"}
Server VersionではなくUnable to connect to the server: dial tcp <server-ip>:8443: i/o timeoutと表示された場合、クラスターとのkubectl接続のトラブルシューティングを行う必要があります。
kubectlのインストールについての公式ドキュメント に従ってkubectlがインストールされていること、環境変数$PATHが適切に設定されていることを確認してください。
kubeconfigを確認する kubectlがKubernetesクラスターに接続するためにはkubeconfigファイルが必要です。
kubeconfigファイルは通常~/.kube/configディレクトリに配置されています。
有効なkubeconfigファイルがあることを確認してください。
kubeconfigファイルがない場合、Kubernetes管理者から入手するか、Kubernetesコントロールプレーンの/etc/kubernetes/admin.confディレクトリからコピーすることができます。
Kubernetesクラスターをクラウドプラットフォームにデプロイし、kubeconfigファイルを紛失した場合は、クラウドプロバイダーのツールを使用してファイルを再生成できます。
kubeconfigファイルの再生成については、クラウドプロバイダーのドキュメントを参照してください。
環境変数$KUBECONFIGが正しく設定されていることを確認してください。
環境変数$KUBECONFIGを設定するか、kubectlで--kubeconfigパラメーターを使用して、kubeconfigファイルのディレクトリを指定できます。
VPNの接続性を確認する Kubernetesクラスターにアクセスするために仮想プライベートネットワーク(VPN)を使用している場合は、VPN接続がアクティブで安定していることを確認してください。
しばしば、VPNの切断がクラスターへの接続の問題につながることがあります。
VPNに再接続して、クラスターに再度アクセスしてみてください。
認証と認可 トークンベースの認証を使用していて、kubectlが認証トークンや認証サーバーのアドレスに関するエラーを返している場合は、Kubernetesの認証トークンと認証サーバーのアドレスが正しく設定されていることを確認してください。
kubectlが認可に関するエラーを返している場合は、有効なユーザー資格情報を使用していることを確認してください。
また、リクエストしたリソースにアクセスする権限があることを確認してください。
コンテキストを検証する Kubernetesは複数のクラスターとコンテキスト をサポートしています。
クラスターとやり取りするために正しいコンテキストを使用していることを確認してください。
使用可能なコンテキストの一覧を表示します:
kubectl config get-contexts
適切なコンテキストに切り替えます:
kubectl config use-context <context-name>
APIサーバーとロードバランサー kube-apiserver サーバーは、Kubernetesクラスターの中心的なコンポーネントです。
APIサーバーや、APIサーバーの前段にあるロードバランサーに到達できない、または応答しない場合、クラスターとのやり取りができません。
APIサーバーのホストに到達可能かどうかを確認するためにpingコマンドを使用します。
クラスターネットワークの接続性とファイアウォールを確認してください。
クラウドプロバイダーを使用してクラスターをデプロイしている場合は、クラスターのAPIサーバーに対して、クラウドプロバイダーのヘルスチェックのステータスを確認してください。
(使用している場合)ロードバランサーのステータスを確認し、ロードバランサーが正常であり、APIサーバーにトラフィックを転送していることを確認してください。
TLSの問題 追加ツールが必要です - base64およびopensslバージョン3.0以上。 KubernetesのAPIサーバーは、デフォルトではHTTPSリクエストのみを処理します。
TLSの問題は、証明書の有効期限切れやトラストチェーンの有効性など、さまざまな原因で発生する可能性があります。
TLS証明書は、~/.kube/configディレクトリにあるkubeconfigファイルに含まれています。
certificate-authority属性にはCA証明書が、client-certificate属性にはクライアント証明書が含まれています。
これらの証明書の有効期限を確認します:
kubectl config view --flatten --output 'jsonpath={.clusters[0].cluster.certificate-authority-data}' | base64 -d | openssl x509 -noout -dates
出力:
notBefore=Feb 13 05:57:47 2024 GMT
notAfter=Feb 10 06:02:47 2034 GMT
kubectl config view --flatten --output 'jsonpath={.users[0].user.client-certificate-data}' | base64 -d | openssl x509 -noout -dates
出力:
notBefore=Feb 13 05:57:47 2024 GMT
notAfter=Feb 12 06:02:50 2025 GMT
kubectlヘルパーを検証する 一部のkubectl認証ヘルパーは、Kubernetesクラスターへの容易なアクセスを提供します。
そのようなヘルパーを使用して接続性の問題が発生している場合は、必要な構成がまだ存在していることを確認してください。
認証の詳細についてはkubectl構成を確認します:
以前にヘルパーツール(kubectl-oidc-loginなど)を使用していた場合は、そのツールがまだインストールされ正しく構成されていることを確認してください。
4.4.2.2 - リソースメトリクスパイプライン Kubernetesでは、コンテナのCPU使用率やメモリ使用率といったリソース使用量のメトリクスが、メトリクスAPIを通じて提供されています。これらのメトリクスは、ユーザーがkubectl topコマンドで直接アクセスするか、クラスター内のコントローラー(例えばHorizontal Pod Autoscaler)が判断するためにアクセスすることができます。
メトリクスAPI メトリクスAPIを使用すると、指定したノードやPodが現在使用しているリソース量を取得することができます。
このAPIはメトリックの値を保存しないので、例えば10分前に指定されたノードが使用したリソース量を取得することはできません。
メトリクスAPIは他のAPIと何ら変わりはありません。
他のKubernetes APIと同じエンドポイントを経由して、/apis/metrics.k8s.io/パスの下で発見できます。 同じセキュリティ、スケーラビリティ、信頼性の保証を提供します。 メトリクスAPIはk8s.io/metrics リポジトリで定義されています。
メトリクスAPIについての詳しい情報はそちらをご覧ください。
備考: メトリクスAPIを使用するには、クラスター内にメトリクスサーバーが配置されている必要があります。そうでない場合は利用できません。リソース使用量の測定 CPU CPUは、一定期間の平均使用量をCPU cores という単位で報告されます。
この値は、カーネルが提供する累積CPUカウンターの比率を取得することで得られます(LinuxとWindowsの両カーネルで)。
kubeletは、比率計算のためのウィンドウを選択します。
メモリ メモリは、測定値が収集された時点のワーキングセットとして、バイト単位で報告されます。
理想的な世界では、「ワーキングセット」は、メモリ不足で解放できない使用中のメモリ量です。
しかし、ワーキングセットの計算はホストOSによって異なり、一般に推定値を生成するために経験則を多用しています。
Kubernetesはスワップをサポートしていないため、すべての匿名(非ファイルバックアップ)メモリが含まれます。
ホストOSは常にそのようなページを再請求することができないため、メトリックには通常、一部のキャッシュされた(ファイルバックされた)メモリも含まれます。
メトリクスサーバー メトリクスサーバー は、クラスター全体のリソース使用量データのアグリゲーターです。
デフォルトでは、kube-up.shスクリプトで作成されたクラスターにDeploymentオブジェクトとしてデプロイされます。
別のKubernetesセットアップ機構を使用する場合は、提供されるdeployment components.yaml ファイルを使用してデプロイすることができます。
メトリクスサーバーは、Summary APIからメトリクスを収集します。
各ノードのKubelet からKubernetes aggregator 経由でメインAPIサーバーに登録されるようになっています。
メトリクスサーバーについては、Design proposals で詳しく解説しています。
Summary APIソース Kubelet は、ノード、ボリューム、Pod、コンテナレベルの統計情報を収集し、Summary API で省略して消費者が読めるようにするものです。
1.23以前は、これらのリソースは主にcAdvisor から収集されていました。しかし、1.23ではPodAndContainerStatsFromCRIフィーチャーゲートの導入により、コンテナとPodレベルの統計情報をCRI実装で収集することができます。
注意: これはCRI実装によるサポートも必要です(containerd >= 1.6.0, CRI-O >= 1.23.0)。
4.4.2.3 - リソース監視のためのツール アプリケーションを拡張し、信頼性の高いサービスを提供するために、デプロイ時にアプリケーションがどのように動作するかを理解する必要があります。
コンテナ、Pod 、Service 、クラスター全体の特性を調べることにより、Kubernetesクラスターのアプリケーションパフォーマンスを調査することができます。
Kubernetesは、これらの各レベルでアプリケーションのリソース使用に関する詳細な情報を提供します。
この情報により、アプリケーションのパフォーマンスを評価し、ボトルネックを取り除くことで全体のパフォーマンスを向上させることができます。
Kubernetesでは、アプリケーションの監視は1つの監視ソリューションに依存することはありません。
新しいクラスターでは、リソースメトリクス またはフルメトリクス パイプラインを使用してモニタリング統計を収集することができます。
リソースメトリクスパイプライン リソースメトリックパイプラインは、Horizontal Pod Autoscaler コントローラーなどのクラスターコンポーネントや、kubectl topユーティリティに関連する限定的なメトリックセットを提供します。
これらのメトリクスは軽量、短期、インメモリーのmetrics-server によって収集され、metrics.k8s.io APIを通じて公開されます。
metrics-serverはクラスター上のすべてのノードを検出し
各ノードのkubelet にCPUとメモリーの使用量を問い合わせます。
kubeletはKubernetesマスターとノードの橋渡し役として、マシン上で動作するPodやコンテナを管理する。
kubeletは各Podを構成するコンテナに変換し、コンテナランタイムインターフェースを介してコンテナランタイムから個々のコンテナ使用統計情報を取得します。この情報は、レガシーDocker統合のための統合cAdvisorから取得されます。
そして、集約されたPodリソース使用統計情報を、metrics-server Resource Metrics APIを通じて公開します。
このAPIは、kubeletの認証済みおよび読み取り専用ポート上の /metrics/resource/v1beta1 で提供されます。
フルメトリクスパイプライン フルメトリクスパイプラインは、より豊富なメトリクスにアクセスすることができます。
Kubernetesは、Horizontal Pod Autoscalerなどのメカニズムを使用して、現在の状態に基づいてクラスターを自動的にスケールまたは適応させることによって、これらのメトリクスに対応することができます。
モニタリングパイプラインは、kubeletからメトリクスを取得し、custom.metrics.k8s.io または external.metrics.k8s.io APIを実装してアダプタ経由でKubernetesにそれらを公開します。
CNCFプロジェクトのPrometheus は、Kubernetes、ノード、Prometheus自身をネイティブに監視することができます。
CNCFに属さない完全なメトリクスパイプラインのプロジェクトは、Kubernetesのドキュメントの範囲外です。
次の項目 以下のような追加のデバッグツールについて学びます:
4.4.2.4 - ノードの健全性を監視します Node Problem Detector は、ノードの健全性を監視し、報告するためのデーモンです。
Node Problem DetectorはDaemonSetとして、あるいはスタンドアロンデーモンとして実行することができます。
Node Problem Detectorは様々なデーモンからノードの問題に関する情報を収集し、これらの状態をNodeCondition およびEvent としてAPIサーバーにレポートします。
Node Problem Detectorのインストール方法と使用方法については、Node Problem Detectorプロジェクトドキュメント を参照してください。
始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
制限事項 Node Problem Detectorは、ファイルベースのカーネルログのみをサポートします。
journaldのようなログツールはサポートされていません。
Node Problem Detectorは、カーネルの問題を報告するためにカーネルログフォーマットを使用します。
カーネルログフォーマットを拡張する方法については、Add support for another log format を参照してください。
ノード問題検出の有効化 クラウドプロバイダーによっては、Node Problem DetectorをAddon として有効にしている場合があります。
また、kubectlを使ってNode Problem Detectorを有効にするか、Addon podを作成することで有効にできます。
kubectlを使用してNode Problem Detectorを有効化します kubectlはNode Problem Detectorを最も柔軟に管理することができます。
デフォルトの設定を上書きして自分の環境に合わせたり、カスタマイズしたノードの問題を検出したりすることができます。
例えば:
node-problem-detector.yamlのようなNode Problem Detectorの設定を作成します:
apiVersion : apps/v1
kind : DaemonSet
metadata :
name : node-problem-detector-v0.1
namespace : kube-system
labels :
k8s-app : node-problem-detector
version : v0.1
kubernetes.io/cluster-service : "true"
spec :
selector :
matchLabels :
k8s-app : node-problem-detector
version : v0.1
kubernetes.io/cluster-service : "true"
template :
metadata :
labels :
k8s-app : node-problem-detector
version : v0.1
kubernetes.io/cluster-service : "true"
spec :
hostNetwork : true
containers :
- name : node-problem-detector
image : registry.k8s.io/node-problem-detector:v0.1
securityContext :
privileged : true
resources :
limits :
cpu : "200m"
memory : "100Mi"
requests :
cpu : "20m"
memory : "20Mi"
volumeMounts :
- name : log
mountPath : /log
readOnly : true
volumes :
- name : log
hostPath :
path : /var/log/
備考: システムログのディレクトリが、お使いのOSのディストリビューションに合っていることを確認する必要があります。Node Problem Detectorをkubectlで起動します。
kubectl apply -f https://k8s.io/examples/debug/node-problem-detector.yaml
Addon podを使用してNode Problem Detectorを有効化します カスタムのクラスターブートストラップソリューションを使用していて、デフォルトの設定を上書きする必要がない場合は、Addon Podを利用してデプロイをさらに自動化できます。
node-problem-detector.yamlを作成し、制御プレーンノードのAddon Podのディレクトリ/etc/kubernetes/addons/node-problem-detectorに設定を保存します。
コンフィギュレーションを上書きします Node Problem Detectorの Dockerイメージをビルドする際に、default configuration が埋め込まれます。
ConfigMap
config/ にある設定ファイルを変更します
ConfigMap node-problem-detector-configを作成します。
kubectl create configmap node-problem-detector-config --from-file= config/
node-problem-detector.yamlを変更して、ConfigMapを使用するようにします。
apiVersion : apps/v1
kind : DaemonSet
metadata :
name : node-problem-detector-v0.1
namespace : kube-system
labels :
k8s-app : node-problem-detector
version : v0.1
kubernetes.io/cluster-service : "true"
spec :
selector :
matchLabels :
k8s-app : node-problem-detector
version : v0.1
kubernetes.io/cluster-service : "true"
template :
metadata :
labels :
k8s-app : node-problem-detector
version : v0.1
kubernetes.io/cluster-service : "true"
spec :
hostNetwork : true
containers :
- name : node-problem-detector
image : registry.k8s.io/node-problem-detector:v0.1
securityContext :
privileged : true
resources :
limits :
cpu : "200m"
memory : "100Mi"
requests :
cpu : "20m"
memory : "20Mi"
volumeMounts :
- name : log
mountPath : /log
readOnly : true
- name : config # Overwrite the config/ directory with ConfigMap volume
mountPath : /config
readOnly : true
volumes :
- name : log
hostPath :
path : /var/log/
- name : config # Define ConfigMap volume
configMap :
name : node-problem-detector-config新しい設定ファイルでNode Problem Detectorを再作成します。
# If you have a node-problem-detector running, delete before recreating
kubectl delete -f https://k8s.io/examples/debug/node-problem-detector.yaml
kubectl apply -f https://k8s.io/examples/debug/node-problem-detector-configmap.yaml
備考: この方法は kubectl で起動された Node Problem Detector にのみ適用されます。ノード問題検出装置がクラスターアドオンとして実行されている場合、設定の上書きはサポートされていません。
Addon Managerは、ConfigMapをサポートしていません。
Kernel Monitor Kernel Monitor はNode Problem Detectorでサポートされるシステムログ監視デーモンです。
Kernel Monitor はカーネルログを監視し、事前に定義されたルールに従って既知のカーネル問題を検出します。
Kernel Monitor はconfig/kernel-monitor.json
新しいNodeConditionsの追加 新しいNodeConditionをサポートするには、例えばconfig/kernel-monitor.jsonのconditionsフィールド内に条件定義を作成します。
{
"type" : "NodeConditionType" ,
"reason" : "CamelCaseDefaultNodeConditionReason" ,
"message" : "arbitrary default node condition message"
}
新たな問題の発見 新しい問題を検出するために、config/kernel-monitor.jsonのrulesフィールドを新しいルール定義で拡張することができます。
{
"type" : "temporary/permanent" ,
"condition" : "NodeConditionOfPermanentIssue" ,
"reason" : "CamelCaseShortReason" ,
"message" : "regexp matching the issue in the kernel log"
}
カーネルログデバイスのパスの設定 ご使用のオペレーティングシステム(OS)ディストリビューションのカーネルログパスをご確認ください。
Linuxカーネルのログデバイス は通常/dev/kmsgとして表示されます。
しかし、OSのディストリビューションによって、ログパスの位置は異なります。
config/kernel-monitor.jsonのlogフィールドは、コンテナ内のログパスを表します。
logフィールドは、Node Problem Detectorで見たデバイスパスと一致するように設定することができます。
Kernel monitorはTranslator
推奨・制限事項 ノードの健全性を監視するために、クラスターでNode Problem Detectorを実行することが推奨されます。
Node Problem Detectorを実行する場合、各ノードで余分なリソースのオーバーヘッドが発生することが予想されます。
通常これは問題ありません。
カーネルログは比較的ゆっくりと成長します。 Node Problem Detector にはリソース制限が設定されています。 高負荷時であっても、リソースの使用は許容範囲内です。 詳細はNode Problem Detectorベンチマーク結果 を参照してください。
4.4.2.5 - crictlによるKubernetesノードのデバッグ FEATURE STATE:
Kubernetes v1.11 [stable]
crictlはCRI互換のコンテナランタイム用のコマンドラインインターフェースです。
これを使って、Kubernetesノード上のコンテナランタイムやアプリケーションの検査やデバッグを行うことができます。
crictlとそのソースコードはcri-tools リポジトリにホストされています。
始める前に crictlにはCRIランタイムを搭載したLinuxが必要です。
crictlのインストール cri-toolsのリリースページ から、いくつかの異なるアーキテクチャ用の圧縮アーカイブcrictlをダウンロードできます。
お使いのKubernetesのバージョンに対応するバージョンをダウンロードしてください。
それを解凍してシステムパス上の/usr/local/bin/などの場所に移動します。
一般的な使い方 crictlコマンドにはいくつかのサブコマンドとランタイムフラグがあります。
詳細はcrictl helpまたはcrictl <subcommand> helpを参照してください。
crictlはデフォルトではunix:///var/run/dockershim.sockに接続します。
他のランタイムの場合は、複数の異なる方法でエンドポイントを設定することができます:
フラグ--runtime-endpointと--image-endpointの設定により 環境変数CONTAINER_RUNTIME_ENDPOINTとIMAGE_SERVICE_ENDPOINTの設定により 設定ファイル--config=/etc/crictl.yamlでエンドポイントの設定により また、サーバーに接続する際のタイムアウト値を指定したり、デバッグを有効/無効にしたりすることもできます。
これには、設定ファイルでtimeoutやdebugを指定するか、--timeoutや--debugのコマンドラインフラグを使用します。
現在の設定を表示または編集するには、/etc/crictl.yamlの内容を表示または編集します。
cat /etc/crictl.yaml
runtime-endpoint: unix:///var/run/dockershim.sock
image-endpoint: unix:///var/run/dockershim.sock
timeout: 10
debug: true
crictlコマンドの例 以下の例では、いくつかのcrictlコマンドとその出力例を示しています。
警告: 実行中のKubernetesクラスターにcrictlを使ってポッドのサンドボックスやコンテナを作成しても、Kubeletは最終的にそれらを削除します。crictl は汎用のワークフローツールではなく、デバッグに便利なツールです。podsの一覧 すべてのポッドをリストアップ:
出力はこのようになります:
POD ID CREATED STATE NAME NAMESPACE ATTEMPT
926f1b5a1d33a About a minute ago Ready sh-84d7dcf559-4r2gq default 0
4dccb216c4adb About a minute ago Ready nginx-65899c769f-wv2gp default 0
a86316e96fa89 17 hours ago Ready kube-proxy-gblk4 kube-system 0
919630b8f81f1 17 hours ago Ready nvidia-device-plugin-zgbbv kube-system 0
Podを名前でリストアップします:
crictl pods --name nginx-65899c769f-wv2gp
出力はこのようになります:
POD ID CREATED STATE NAME NAMESPACE ATTEMPT
4dccb216c4adb 2 minutes ago Ready nginx-65899c769f-wv2gp default 0
Podをラベルでリストアップします:
crictl pods --label run = nginx
出力はこのようになります:
POD ID CREATED STATE NAME NAMESPACE ATTEMPT
4dccb216c4adb 2 minutes ago Ready nginx-65899c769f-wv2gp default 0
イメージの一覧 すべてのイメージをリストアップします:
出力はこのようになります:
IMAGE TAG IMAGE ID SIZE
busybox latest 8c811b4aec35f 1.15MB
k8s-gcrio.azureedge.net/hyperkube-amd64 v1.10.3 e179bbfe5d238 665MB
k8s-gcrio.azureedge.net/pause-amd64 3.1 da86e6ba6ca19 742kB
nginx latest cd5239a0906a6 109MB
イメージをリポジトリでリストアップします:
出力はこのようになります:
IMAGE TAG IMAGE ID SIZE
nginx latest cd5239a0906a6 109MB
イメージのIDのみをリストアップします:
出力はこのようになります:
sha256:8c811b4aec35f259572d0f79207bc0678df4c736eeec50bc9fec37ed936a472a
sha256:e179bbfe5d238de6069f3b03fccbecc3fb4f2019af741bfff1233c4d7b2970c5
sha256:da86e6ba6ca197bf6bc5e9d900febd906b133eaa4750e6bed647b0fbe50ed43e
sha256:cd5239a0906a6ccf0562354852fae04bc5b52d72a2aff9a871ddb6bd57553569
List containers すべてのコンテナをリストアップします:
出力はこのようになります:
CONTAINER ID IMAGE CREATED STATE NAME ATTEMPT
1f73f2d81bf98 busybox@sha256:141c253bc4c3fd0a201d32dc1f493bcf3fff003b6df416dea4f41046e0f37d47 7 minutes ago Running sh 1
9c5951df22c78 busybox@sha256:141c253bc4c3fd0a201d32dc1f493bcf3fff003b6df416dea4f41046e0f37d47 8 minutes ago Exited sh 0
87d3992f84f74 nginx@sha256:d0a8828cccb73397acb0073bf34f4d7d8aa315263f1e7806bf8c55d8ac139d5f 8 minutes ago Running nginx 0
1941fb4da154f k8s-gcrio.azureedge.net/hyperkube-amd64@sha256:00d814b1f7763f4ab5be80c58e98140dfc69df107f253d7fdd714b30a714260a 18 hours ago Running kube-proxy 0
ランニングコンテナをリストアップします:
crictl ps
出力はこのようになります:
CONTAINER ID IMAGE CREATED STATE NAME ATTEMPT
1f73f2d81bf98 busybox@sha256:141c253bc4c3fd0a201d32dc1f493bcf3fff003b6df416dea4f41046e0f37d47 6 minutes ago Running sh 1
87d3992f84f74 nginx@sha256:d0a8828cccb73397acb0073bf34f4d7d8aa315263f1e7806bf8c55d8ac139d5f 7 minutes ago Running nginx 0
1941fb4da154f k8s-gcrio.azureedge.net/hyperkube-amd64@sha256:00d814b1f7763f4ab5be80c58e98140dfc69df107f253d7fdd714b30a714260a 17 hours ago Running kube-proxy 0
実行中のコンテナでコマンドの実行 crictl exec -i -t 1f73f2d81bf98 ls
出力はこのようになります:
bin dev etc home proc root sys tmp usr var
コンテナログの取得 すべてのコンテナログを取得します:
crictl logs 87d3992f84f74
出力はこのようになります:
10.240.0.96 - - [06/Jun/2018:02:45:49 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.47.0" "-"
10.240.0.96 - - [06/Jun/2018:02:45:50 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.47.0" "-"
10.240.0.96 - - [06/Jun/2018:02:45:51 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.47.0" "-"
最新のN行のログのみを取得します:
crictl logs --tail= 1 87d3992f84f74
出力はこのようになります:
10.240.0.96 - - [06/Jun/2018:02:45:51 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.47.0" "-"
Podサンドボックスの実行 crictlを使ってPodサンドボックスを実行することは、コンテナのランタイムをデバッグするのに便利です。
稼働中のKubernetesクラスターでは、サンドボックスは最終的にKubeletによって停止され、削除されます。
以下のようなJSONファイルを作成します:
{
"metadata" : {
"name" : "nginx-sandbox" ,
"namespace" : "default" ,
"attempt" : 1 ,
"uid" : "hdishd83djaidwnduwk28bcsb"
},
"logDirectory" : "/tmp" ,
"linux" : {
}
}
JSONを適用してサンドボックスを実行するには、crictl runpコマンドを使用します:
crictl runp pod-config.json
サンドボックスのIDが返されます。
コンテナの作成 コンテナの作成にcrictlを使うと、コンテナのランタイムをデバッグするのに便利です。
稼働中のKubernetesクラスターでは、サンドボックスは最終的にKubeletによって停止され、削除されます。
busyboxイメージをプルします:
crictl pull busybox
Image is up to date for busybox@sha256:141c253bc4c3fd0a201d32dc1f493bcf3fff003b6df416dea4f41046e0f37d47
Podとコンテナのコンフィグを作成します:
Pod config :
{
"metadata": {
"name": "nginx-sandbox" ,
"namespace": "default" ,
"attempt": 1 ,
"uid": "hdishd83djaidwnduwk28bcsb"
},
"log_directory": "/tmp" ,
"linux": {
}
Container config :
{
"metadata": {
"name": "busybox"
},
"image" :{
"image": "busybox"
},
"command": [
"top"
],
"log_path" :"busybox.log" ,
"linux": {
}
先に作成されたPodのID、コンテナの設定ファイル、Podの設定ファイルを渡して、コンテナを作成します。コンテナのIDが返されます。
crictl create f84dd361f8dc51518ed291fbadd6db537b0496536c1d2d6c05ff943ce8c9a54f container-config.json pod-config.json
すべてのコンテナをリストアップし、新しく作成されたコンテナの状態がCreatedに設定されていることを確認します:
出力はこのようになります:
CONTAINER ID IMAGE CREATED STATE NAME ATTEMPT
3e025dd50a72d busybox 32 seconds ago Created busybox 0
コンテナの起動 コンテナを起動するには、そのコンテナのIDをcrictl startに渡します:
crictl start 3e025dd50a72d956c4f14881fbb5b1080c9275674e95fb67f965f6478a957d60
出力はこのようになります:
3e025dd50a72d956c4f14881fbb5b1080c9275674e95fb67f965f6478a957d60
コンテナの状態が「Running」に設定されていることを確認します:
出力はこのようになります:
CONTAINER ID IMAGE CREATED STATE NAME ATTEMPT
3e025dd50a72d busybox About a minute ago Running busybox 0
詳しくはkubernetes-sigs/cri-tools をご覧ください。
docker cliからcrictlへのマッピング 以下のマッピング表の正確なバージョンは、docker cli v1.40とcrictl v1.19.0のものです。
この一覧はすべてを網羅しているわけではないことに注意してください。
たとえば、docker cliの実験的なコマンドは含まれていません。
備考: CRICTLの出力形式はDocker CLIと似ていますが、いくつかのCLIでは列が欠けています。デバッグ情報の取得 mapping from docker cli to crictl - retrieve debugging information docker cli crictl 説明 サポートされていない機能 attachattach実行中のコンテナにアタッチ --detach-keys, --sig-proxyexecexec実行中のコンテナでコマンドの実行 --privileged, --user, --detach-keysimagesimagesイメージのリストアップ infoinfoシステム全体の情報の表示 inspectinspect, inspectiコンテナ、イメージ、タスクの低レベルの情報を返します logslogsコンテナのログを取得します --detailspspsコンテナのリストアップ statsstatsコンテナのリソース使用状況をライブで表示 Column: NET/BLOCK I/O, PIDs versionversionランタイム(Docker、ContainerD、その他)のバージョン情報を表示します
変更を行います mapping from docker cli to crictl - perform changes docker cli crictl 説明 サポートされていない機能 createcreate新しいコンテナを作成します killstop (timeout = 0)1つ以上の実行中のコンテナを停止します --signalpullpullレジストリーからイメージやリポジトリをプルします --all-tags, --disable-content-trustrmrm1つまたは複数のコンテナを削除します rmirmi1つまたは複数のイメージを削除します runrun新しいコンテナでコマンドを実行 startstart停止した1つまたは複数のコンテナを起動 --detach-keysstopstop実行中の1つまたは複数のコンテナの停止 updateupdate1つまたは複数のコンテナの構成を更新 --restart、--blkio-weightとその他
crictlでのみ対応 mapping from docker cli to crictl - supported only in crictl crictl 説明 imagefsinfoイメージファイルシステムの情報を返します inspectp1つまたは複数のPodの状態を表示します port-forwardローカルポートをPodに転送します runp新しいPodを実行します rmp1つまたは複数のPodを削除します stopp稼働中の1つまたは複数のPodを停止します
4.4.2.6 - Kubectlを用いたKubernetesノードのデバッグ このページでは、Kubernetesクラスター上で動作しているノード をkubectl debugコマンドを使用してデバッグする方法について説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: 1.2.
バージョンを確認するには次のコマンドを実行してください: kubectl version.
Podを作成し、それらの新しいPodを任意のノードに割り当てる権限が必要です。
また、ホストのファイルシステムにアクセスするPodを作成する権限も必要です。
kubectl debug nodeを用いてノードをデバッグするkubectl debug nodeコマンドを使用して、トラブルシューティングしたいノードにPodをデプロイします。
このコマンドは、SSH接続を使用してノードにアクセスできないシナリオで役に立ちます。
Podが作成されると、そのPodはノード上で対話型シェルを開きます。
mynodeという名前のノード上で対話型シェルを作成するには、次のように実行します。
kubectl debug node/mynode -it --image= ubuntu
mynodeという名前のノード上に、コンテナデバッガーを持つデバッグの用Pod、node-debugger-mynode-pdx84を作成します。
コマンドプロンプトが表示されない場合は、エンターキーを押してみてください。
root@mynode:/#
デバッグコマンドは、情報を収集し、問題をトラブルシューティングするのに役立ちます。
使用する可能性のあるコマンドには、ip、ifconfig、nc、ping、psなどがあります。
また、mtr、tcpdump、curlなどの他のツールもそれぞれのパッケージマネージャーからインストールすることができます。
備考: デバッグコマンドは、デバッグ用のPodが使用しているイメージに基づいて異なる場合があり、これらのコマンドをインストールする必要があるかもしれません。デバッグ用のPodは、Pod内の/hostにマウントされたノードのルートファイルシステムにアクセスできます。
kubeletをファイルシステムのネームスペースで実行している場合、デバッグ用のPodはそのネームスペースのルートを見ることになり、ノード全体のルートではありません。
典型的なLinuxノードの場合、関連するログを見つけるために以下のパスを確認できます。
/host/var/log/kubelet.logノード上でコンテナを実行する責任があるkubeletからのログです。 /host/var/log/kube-proxy.logサービスのエンドポイントへのトラフィックを指示する責任があるkube-proxyからのログです。 /host/var/log/containerd.logノード上で実行されているcontainerdプロセスからのログです。 /host/var/log/syslogシステムに関する一般的なメッセージや情報です。 /host/var/log/kern.logカーネルログです。 ノード上でデバッグセッションを作成する際には、以下の点を考慮してください。
kubectl debugは、新しいPodの名前をノードの名前に基づいて自動的に生成します。ノードのルートファイルシステムは/hostにマウントされます。 コンテナはホストのIPC、ネットワーク、PID Namespaceで実行されますが、Podは特権を持っていません。
これは、一部のプロセス情報の読み取りが失敗する可能性があることを意味します。
その情報へのアクセスはスーパーユーザーに制限されているためです。
例えば、chroot /hostは失敗します。
特権Podが必要な場合は、手動で作成するか、--profile=sysadminを使用してください。 デバッグ用のPodにデバッグプロファイル を適用することで、securityContext などの特定のプロパティを設定できます。 クリーンアップ デバッグ用のPodの使用が終了したら、それを削除してください。
NAME READY STATUS RESTARTS AGE
node-debugger-mynode-pdx84 0/1 Completed 0 8m1s
# Podの名前は適宜変更してください
kubectl delete pod node-debugger-mynode-pdx84 --now
pod "node-debugger-mynode-pdx84" deleted
備考: ノードがダウンしている場合(ネットワークから切断されている、kubeletが停止して再起動しないなど)、
kubectl debug nodeコマンドは機能しません。
その場合は、
ダウンあるいは到達不能なノードのデバッグ を確認してください。
4.4.2.7 - WindowsデバッグTips ノードレベルのトラブルシューティング Podが"Container Creating"と表示されたまま動かなくなったり、何度も再起動を繰り返します
pauseイメージがWindows OSのバージョンと互換性があることを確認してください。
最新/推奨のpauseイメージや詳細情報については、Pauseコンテナ を参照してください。
備考: コンテナランタイムとしてcontainerdを使用している場合、pauseイメージはconfig.toml設定ファイルのplugins.plugins.cri.sandbox_imageフィールドで指定されます。PodがErrImgPullまたはImagePullBackOffのステータスを表示します
Podが互換性 のあるWindowsノードにスケジュールされていることを確認してください。
Podに対して互換性のあるノードを指定する方法の詳細については、このガイド を参照してください。
ネットワークのトラブルシューティング Windows Podがネットワークに接続できません
仮想マシンを使用している場合は、すべてのVMのネットワークアダプターでMACスプーフィングが有効 になっていることを確認してください。
Windows Podから外部リソースにpingできません
Windows Podには、ICMPプロトコル用にプログラムされたアウトバウンドルールはありません。ただし、TCP/UDPはサポートされています。
クラスター外のリソースへの接続を実証する場合は、ping <IP>を対応するcurl <IP>コマンドに置き換えてください。
それでも問題が解決しない場合は、cni.conf のネットワーク設定に問題がある可能性が高いです。
この静的ファイルはいつでも編集できます。
設定の更新は、新しく作成されたすべてのKubernetesリソースに適用されます。
Kubernetesのネットワーク要件の1つ(Kubernetesモデル を参照)は、内部でNATせずにクラスター通信が行われることです。
この要件を満たすために、アウトバウンドのNATを発生させたくないすべての通信のためのExceptionList があります。
ただしこれは、クエリしようとしている外部IPをExceptionListから除外する必要があることも意味します。
そうして初めて、Windows Podからのトラフィックが正しくSNATされ、外部からの応答を受信できるようになります。
この点について、cni.confのExceptionListは次のようになります:
"ExceptionList": [
"10.244.0.0/16", # クラスターのサブネット
"10.96.0.0/12", # Serviceのサブネット
"10.127.130.0/24" # 管理(ホスト)のサブネット
]
WindowsノードがNodePortタイプのServiceにアクセスできません
ノード自身からのローカルNodePortへのアクセスは失敗します。
これは既知の制限です。
NodePortへのアクセスは、他のノードや外部のクライアントからは動作します。
コンテナのvNICとHNSエンドポイントが削除されています
この問題はhostname-overrideパラメーターがkube-proxy
に渡されていない場合に発生する可能性があります。
これを解決するためには、ユーザーは次のようにkube-proxyにホスト名を渡す必要があります:
C:\k\kube-proxy .exe --hostname-override=$(hostname)
WindowsノードがService IPを使用してサービスにアクセスできません
これはWindows上のネットワークスタックの既知の制限です。
ただし、Windows PodはService IPにアクセスできます。
kubeletの起動時にネットワークアダプターが見つかりません
Windowsのネットワーキングスタックでは、Kubernetesネットワーキングが動作するために仮想アダプターが必要です。
(管理者シェルで)次のコマンドを実行しても結果が返されない場合、kubeletが動作するために必要な前提条件である仮想ネットワークの作成に失敗しています。
Get-HnsNetwork | ? Name -ieq "cbr0"
Get-NetAdapter | ? Name -Like "vEthernet (Ethernet*"
ホストのネットワークアダプターが"Ethernet"ではない場合、start.ps1スクリプトのInterfaceName パラメーターを修正することが有益です。
それ以外の場合は、start-kubelet.ps1スクリプトの出力結果を参照して、仮想ネットワークの作成中にエラーが発生していないか確認します。
DNS名前解決が正しく動作しません
このセクション のWindowsにおけるDNSの制限について確認してください。
kubectl port-forwardが"unable to do port forwarding: wincat not found"で失敗します
これは、pauseインフラコンテナmcr.microsoft.com/oss/kubernetes/pause:3.6にwincat.exeを含める形で、Kubernetes 1.15にて実装されました。
必ずサポートされたKubernetesのバージョンを使用してください。
独自のpauseインフラコンテナをビルドしたい場合は、必ずwincat を含めるようにしてください。
Windows Serverノードがプロキシの背後にあるため、Kubernetesのインストールに失敗しています
プロキシの背後にある場合は、次のPowerShell環境変数が定義されている必要があります:
[Environment ]::SetEnvironmentVariable("HTTP_PROXY" , "http://proxy.example.com:80/" , [EnvironmentVariableTarget ]::Machine)
[Environment ]::SetEnvironmentVariable("HTTPS_PROXY" , "http://proxy.example.com:443/" , [EnvironmentVariableTarget ]::Machine)
Flannelのトラブルシューティング Flannelを使用すると、クラスターに再参加した後にノードに問題が発生します
以前に削除したノードがクラスターに再参加すると、flanneldはノードに新しいPodサブネットを割り当てようとします。
ユーザーは、次のパスにある古いPodサブネットの設定ファイルを削除する必要があります:
Remove-Item C:\k\SourceVip.json
Remove-Item C:\k\SourceVipRequest.json
Flanneldが"Waiting for the Network to be created"と表示されたままになります
このIssue に関する多数の報告があります;
最も可能性が高いのは、flannelネットワークの管理IPが設定されるタイミングの問題です。
回避策は、start.ps1を再度実行するか、次のように手動で再起動することです:
[Environment ]::SetEnvironmentVariable("NODE_NAME" , "<Windows_Worker_Hostname>" )
C:\flannel\flanneld.exe --kubeconfig-file =c:\k\config --iface=<Windows_Worker_Node_IP> --ip-masq=1 --kube-subnet-mgr=1
/run/flannel/subnet.envが見つからないためにWindows Podが起動しません
これはFlannelが正常に起動できなかったことを示しています。
flanneld.exeを再起動するか、Kubernetesマスター上の/run/flannel/subnet.envをWindowsワーカーノード上のC:\run\flannel\subnet.envに手動でコピーして、FLANNEL_SUBNET行を異なる数値に変更します。
例えば、ノードのサブネットを10.244.4.1/24としたい場合は次のようにします:
FLANNEL_NETWORK = 10.244.0.0/16
FLANNEL_SUBNET = 10.244.4.1/24
FLANNEL_MTU = 1500
FLANNEL_IPMASQ = true
さらなる調査 これらの手順で問題が解決しない場合は、下記からKubernetesのWindowsノード上でWindowsコンテナを実行するためのヘルプを得ることができます:
4.4.2.8 - テレプレゼンスを使用したローカルでのサービス開発・デバッグ Kubernetesアプリケーションは通常、複数の独立したサービスから構成され、それぞれが独自のコンテナで動作しています。これらのサービスをリモートのKubernetesクラスター上で開発・デバッグするには、実行中のコンテナへのシェルを取得 してリモートシェル内でツールを実行しなければならず面倒な場合があります。
telepresenceは、リモートKubernetesクラスターにサービスをプロキシしながら、ローカルでサービスを開発・デバッグするプロセスを容易にするためのツールです。
telepresence を使用すると、デバッガーやIDEなどのカスタムツールをローカルサービスで使用でき、ConfigMapやsecret、リモートクラスター上で動作しているサービスへのフルアクセスをサービスに提供します。
このドキュメントでは、リモートクラスター上で動作しているサービスをローカルで開発・デバッグするためにtelepresenceを使用する方法を説明します。
始める前に Kubernetesクラスターがインストールされていること クラスターと通信するために kubectl が設定されていること telepresence がインストールされていることリモートクラスター上でシェルの取得 ターミナルを開いて、引数なしでtelepresenceを実行すると、telepresenceシェルが表示されます。
このシェルはローカルで動作し、ローカルのファイルシステムに完全にアクセスすることができます。
このtelepresenceシェルは様々な方法で使用することができます。
例えば、ラップトップでシェルスクリプトを書いて、それをシェルから直接リアルタイムで実行することができます。これはリモートシェルでもできますが、好みのコードエディターが使えないかもしれませんし、コンテナが終了するとスクリプトは削除されます。
終了してシェルを閉じるにはexitと入力してください。
既存サービスの開発・デバッグ Kubernetes上でアプリケーションを開発する場合、通常は1つのサービスをプログラミングまたはデバッグすることになります。
そのサービスは、テストやデバッグのために他のサービスへのアクセスを必要とする場合があります。
継続的なデプロイメントパイプラインを使用することも一つの選択肢ですが、最速のデプロイメントパイプラインでさえ、プログラムやデバッグサイクルに遅延が発生します。
既存のデプロイメントとtelepresenceプロキシを交換するには、--swap-deployment オプションを使用します。
スワップすることで、ローカルでサービスを実行し、リモートのKubernetesクラスターに接続することができます。
リモートクラスター内のサービスは、ローカルで実行されているインスタンスにアクセスできるようになりました。
telepresenceを「--swap-deployment」で実行するには、次のように入力します。
telepresence --swap-deployment $DEPLOYMENT_NAME
ここで、$DEPLOYMENT_NAMEは既存のDeploymentの名前です。
このコマンドを実行すると、シェルが起動します。そのシェルで、サービスを起動します。
そして、ローカルでソースコードの編集を行い、保存すると、すぐに変更が反映されるのを確認できます。
また、デバッガーやその他のローカルな開発ツールでサービスを実行することもできます。
次の項目 もしハンズオンのチュートリアルに興味があるなら、Google Kubernetes Engine上でGuestbookアプリケーションをローカルに開発する手順を説明したこちらのチュートリアル をチェックしてみてください。
telepresenceには、状況に応じてnumerous proxying options があります。
さらに詳しい情報は、telepresence website をご覧ください。
4.4.2.9 - 監査 Kubernetesの監査はクラスター内の一連の行動を記録するセキュリティに関連した時系列の記録を提供します。
クラスターはユーザー、Kubernetes APIを使用するアプリケーション、
およびコントロールプレーン自体によって生成されたアクティビティなどを監査します。
監査により、クラスター管理者は以下の質問に答えることができます:
何が起きたのか? いつ起こったのか? 誰がそれを始めたのか? 何のために起こったのか? それはどこで観察されたのか? それはどこから始まったのか? それはどこへ向かっていたのか? 監査記録のライフサイクルはkube-apiserver コンポーネントの中で始まります。
各リクエストの実行の各段階で、監査イベントが生成されます。
ポリシーに従って前処理され、バックエンドに書き込まれます。 ポリシーが何を記録するかを決定し、
バックエンドがその記録を永続化します。現在のバックエンドの実装はログファイルやWebhookなどがあります。
各リクエストは関連する stage で記録されます。
定義されたステージは以下の通りです:
RequestReceived - 監査ハンドラーがリクエストを受信すると同時に生成されるイベントのステージ。
つまり、ハンドラーチェーンに委譲される前に生成されるイベントのステージです。ResponseStarted - レスポンスヘッダーが送信された後、レスポンスボディが送信される前のステージです。
このステージは長時間実行されるリクエスト(watchなど)でのみ発生します。ResponseComplete - レスポンスボディの送信が完了して、それ以上のバイトは送信されません。Panic - パニックが起きたときに発生するイベント。監査ログ機能は、リクエストごとに監査に必要なコンテキストが保存されるため、APIサーバーのメモリー消費量が増加します。
メモリーの消費量は、監査ログ機能の設定によって異なります。
監査ポリシー 監査ポリシーはどのようなイベントを記録し、どのようなデータを含むべきかについてのルールを定義します。
監査ポリシーのオブジェクト構造は、audit.k8s.io API group
イベントが処理されると、そのイベントは順番にルールのリストと比較されます。
最初のマッチングルールは、イベントの監査レベルを設定します。
定義されている監査レベルは:
None - ルールに一致するイベントを記録しません。Metadata - リクエストのメタデータ(リクエストしたユーザー、タイムスタンプ、リソース、動作など)を記録しますが、リクエストやレスポンスのボディは記録しません。Request - ログイベントのメタデータとリクエストボディは表示されますが、レスポンスボディは表示されません。
これは非リソースリクエストには適用されません。RequestResponse - イベントのメタデータ、リクエストとレスポンスのボディを記録しますが、
非リソースリクエストには適用されません。audit-policy-fileフラグを使って、ポリシーを記述したファイルを kube-apiserverに渡すことができます。
このフラグが省略された場合イベントは記録されません。
監査ポリシーファイルでは、rulesフィールドが必ず指定されることに注意してください。
ルールがない(0)ポリシーは不当なものとして扱われます。
以下は監査ポリシーファイルの例です:
apiVersion : audit.k8s.io/v1 # This is required.
kind : Policy
# Don't generate audit events for all requests in RequestReceived stage.
omitStages :
- "RequestReceived"
rules :
# Log pod changes at RequestResponse level
- level : RequestResponse
resources :
- group : ""
# Resource "pods" doesn't match requests to any subresource of pods,
# which is consistent with the RBAC policy.
resources : ["pods" ]
# Log "pods/log", "pods/status" at Metadata level
- level : Metadata
resources :
- group : ""
resources : ["pods/log" , "pods/status" ]
# Don't log requests to a configmap called "controller-leader"
- level : None
resources :
- group : ""
resources : ["configmaps" ]
resourceNames : ["controller-leader" ]
# Don't log watch requests by the "system:kube-proxy" on endpoints or services
- level : None
users : ["system:kube-proxy" ]
verbs : ["watch" ]
resources :
- group : "" # core API group
resources : ["endpoints" , "services" ]
# Don't log authenticated requests to certain non-resource URL paths.
- level : None
userGroups : ["system:authenticated" ]
nonResourceURLs :
- "/api*" # Wildcard matching.
- "/version"
# Log the request body of configmap changes in kube-system.
- level : Request
resources :
- group : "" # core API group
resources : ["configmaps" ]
# This rule only applies to resources in the "kube-system" namespace.
# The empty string "" can be used to select non-namespaced resources.
namespaces : ["kube-system" ]
# Log configmap and secret changes in all other namespaces at the Metadata level.
- level : Metadata
resources :
- group : "" # core API group
resources : ["secrets" , "configmaps" ]
# Log all other resources in core and extensions at the Request level.
- level : Request
resources :
- group : "" # core API group
- group : "extensions" # Version of group should NOT be included.
# A catch-all rule to log all other requests at the Metadata level.
- level : Metadata
# Long-running requests like watches that fall under this rule will not
# generate an audit event in RequestReceived.
omitStages :
- "RequestReceived"
最小限の監査ポリシーファイルを使用して、すべてのリクエストを Metadataレベルで記録することができます。
# Log all requests at the Metadata level.
apiVersion : audit.k8s.io/v1
kind : Policy
rules :
level : Metadata
独自の監査プロファイルを作成する場合は、Google Container-Optimized OSの監査プロファイルを出発点として使用できます。
監査ポリシーファイルを生成するconfigure-helper.sh スクリプトを確認することができます。
スクリプトを直接見ることで、監査ポリシーファイルのほとんどを見ることができます。
また、定義されているフィールドの詳細については、Policy` configuration reference を参照できます。
監査バックエンド 監査バックエンドは監査イベントを外部ストレージに永続化します。
kube-apiserverには2つのバックエンドが用意されています。
イベントをファイルシステムに書き込むログバックエンド 外部のHTTP APIにイベントを送信するWebhookバックエンド いずれの場合も、監査イベントはKubernetes APIaudit.k8s.io API group
備考: パッチの場合、リクエストボディはパッチ操作を含むJSON配列であり、適切なKubernetes APIオブジェクトを含むJSONオブジェクトではありません。
例えば、以下のリクエストボディは/apis/batch/v1/namespaces/some-namespace/jobs/some-job-nameに対する有効なパッチリクエストです。
[
{
"op" : "replace" ,
"path" : "/spec/parallelism" ,
"value" : 0
},
{
"op" : "remove" ,
"path" : "/spec/template/spec/containers/0/terminationMessagePolicy"
}
]
ログバックエンド ログバックエンドは監査イベントをJSONlines 形式のファイルに書き込みます。
以下の kube-apiserver フラグを使ってログ監査バックエンドを設定できます。
--audit-log-path は、ログバックエンドが監査イベントを書き込む際に使用するログファイルのパスを指定します。
このフラグを指定しないと、ログバックエンドは無効になります。- は標準出力を意味します。--audit-log-maxage は、古い監査ログファイルを保持する最大日数を定義します。audit-log-maxbackupは、保持する監査ログファイルの最大数を定義します。--audit-log-maxsize は、監査ログファイルがローテーションされるまでの最大サイズをメガバイト単位で定義します。クラスターのコントロールプレーンでkube-apiserverをPodとして動作させている場合は、監査記録が永久化されるように、ポリシーファイルとログファイルの場所にhostPathをマウントすることを忘れないでください。
例えば:
- --audit-policy-file=/etc/kubernetes/audit-policy.yaml
- --audit-log-path=/var/log/kubernetes/audit/audit.log
それからボリュームをマウントします:
...
volumeMounts :
- mountPath : /etc/kubernetes/audit-policy.yaml
name : audit
readOnly : true
- mountPath : /var/log/audit.log
name : audit-log
readOnly : false
最後にhostPathを設定します:
...
volumes :
name : audit
hostPath :
path : /etc/kubernetes/audit-policy.yaml
type : File
name : audit-log
hostPath :
path : /var/log/audit.log
type : FileOrCreate
Webhookバックエンド Webhook監査バックエンドは、監査イベントをリモートのWeb APIに送信しますが、
これは認証手段を含むKubernetes APIの形式であると想定されます。
Webhook監査バックエンドを設定するには、以下のkube-apiserverフラグを使用します。
--audit-webhook-config-file は、Webhookの設定ファイルのパスを指定します。
webhookの設定は、事実上特化したkubeconfig です。--audit-webhook-initial-backoff は、最初に失敗したリクエストの後、再試行するまでに待つ時間を指定します。
それ以降のリクエストは、指数関数的なバックオフで再試行されます。Webhookの設定ファイルは、kubeconfig形式でサービスのリモートアドレスと接続に使用する認証情報を指定します。
イベントバッチ ログバックエンドとwebhookバックエンドの両方がバッチ処理をサポートしています。
webhookを例に、利用可能なフラグの一覧を示します。
ログバックエンドで同じフラグを取得するには、フラグ名のwebhookをlogに置き換えてください。
デフォルトでは、バッチングはwebhookでは有効で、logでは無効です。
同様に、デフォルトではスロットリングは webhook で有効で、logでは無効です。
--audit-webhook-mode は、バッファリング戦略を定義します。以下のいずれかとなります。batch - イベントをバッファリングして、非同期にバッチ処理します。これがデフォルトです。blocking - 個々のイベントを処理する際に、APIサーバーの応答をブロックします。blocking-strict - blockingと同じですが、RequestReceivedステージでの監査ログに失敗した場合は RequestReceivedステージで監査ログに失敗すると、kube-apiserverへのリクエスト全体が失敗します。以下のフラグは batch モードでのみ使用されます:
--audit-webhook-batch-buffer-sizeは、バッチ処理を行う前にバッファリングするイベントの数を定義します。
入力イベントの割合がバッファをオーバーフローすると、イベントはドロップされます。--audit-webhook-batch-max-sizeは、1つのバッチに入れるイベントの最大数を定義します。--audit-webhook-batch-max-waitは、キュー内のイベントを無条件にバッチ処理するまでの最大待機時間を定義します。--audit-webhook-batch-throttle-qpsは、1秒あたりに生成されるバッチの最大平均数を定義します。--audit-webhook-batch-throttle-burstは、許可された QPS が低い場合に、同じ瞬間に生成されるバッチの最大数を定義します。パラメーターチューニング パラメーターは、APIサーバーの負荷に合わせて設定してください。
例えば、kube-apiserverが毎秒100件のリクエストを受け取り、それぞれのリクエストがResponseStartedとResponseCompleteの段階でのみ監査されるとします。毎秒≅200の監査イベントが発生すると考えてください。
1つのバッチに最大100個のイベントがあるの場合、スロットリングレベルを少なくとも2クエリ/秒に設定する必要があります。
バックエンドがイベントを書き込むのに最大で5秒かかる場合、5秒分のイベントを保持するようにバッファーサイズを設定する必要があります。
10バッチ、または1000イベントとなります。
しかし、ほとんどの場合デフォルトのパラメーターで十分であり、手動で設定する必要はありません。
kube-apiserverが公開している以下のPrometheusメトリクスや、ログを見て監査サブシステムの状態を監視することができます。
apiserver_audit_event_totalメトリックには、エクスポートされた監査イベントの合計数が含まれます。apiserver_audit_error_totalメトリックには、エクスポート中にエラーが発生してドロップされたイベントの総数が含まれます。ログエントリー・トランケーション logバックエンドとwebhookバックエンドは、ログに記録されるイベントのサイズを制限することをサポートしています。
例として、logバックエンドで利用可能なフラグの一覧を以下に示します
audit-log-truncate-enabledイベントとバッチの切り捨てを有効にするかどうかです。audit-log-truncate-max-batch-sizeバックエンドに送信されるバッチのバイト単位の最大サイズ。audit-log-truncate-max-event-sizeバックエンドに送信される監査イベントのバイト単位の最大サイズです。デフォルトでは、webhookとlogの両方で切り捨ては無効になっていますが、クラスター管理者は audit-log-truncate-enabledまたはaudit-webhook-truncate-enabledを設定して、この機能を有効にする必要があります。
次の項目 4.5 - Kubernetesオブジェクトの管理 Kubernetes APIと対話するための宣言型および命令型のパラダイム。
4.6 - Secretの管理 Secretを使用した機密設定データの管理
4.6.1 - kubectlを使用してSecretを管理する kubectlコマンドラインを使用してSecretを作成する
始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
Secretを作成する SecretはデータベースにアクセスするためにPodが必要とするユーザー資格情報を含めることができます。
たとえば、データベース接続文字列はユーザー名とパスワードで構成されます。
ユーザー名はローカルマシンの./username.txtに、パスワードは./password.txtに保存します。
echo -n 'admin' > ./username.txt
echo -n '1f2d1e2e67df' > ./password.txt
上記の2つのコマンドの-nフラグは、生成されたファイルにテキスト末尾の余分な改行文字が含まれないようにします。
kubectlがファイルを読み取り、内容をbase64文字列にエンコードすると、余分な改行文字もエンコードされるため、これは重要です。
kubectl create secretコマンドはこれらのファイルをSecretにパッケージ化し、APIサーバー上にオブジェクトを作成します。
kubectl create secret generic db-user-pass \
= ./username.txt \
= ./password.txt
出力は次のようになります:
secret/db-user-pass created
ファイル名がデフォルトのキー名になります。オプションで--from-file=[key=]sourceを使用してキー名を設定できます。たとえば:
kubectl create secret generic db-user-pass \
= username = ./username.txt \
= password = ./password.txt
--from-fileに指定したファイルに含まれるパスワードの特殊文字をエスケープする必要はありません。
また、--from-literal=<key>=<value>タグを使用してSecretデータを提供することもできます。
このタグは、複数のキーと値のペアを提供するために複数回指定することができます。
$、\、*、=、!などの特殊文字はシェル によって解釈されるため、エスケープを必要とすることに注意してください。
ほとんどのシェルでは、パスワードをエスケープする最も簡単な方法は、シングルクォート(')で囲むことです。
たとえば、実際のパスワードがS!B\*d$zDsb=の場合、次のようにコマンドを実行します:
kubectl create secret generic db-user-pass \
= username = admin \
= password = 'S!B\*d$zDsb='
Secretを検証する Secretが作成されたことを確認できます:
出力は次のようになります:
NAME TYPE DATA AGE
db-user-pass Opaque 2 51s
Secretの説明を参照できます:
kubectl describe secrets/db-user-pass
出力は次のようになります:
Name: db-user-pass
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password: 12 bytes
username: 5 bytes
kubectl getとkubectl describeコマンドはデフォルトではSecretの内容を表示しません。
これは、Secretが不用意に他人にさらされたり、ターミナルログに保存されたりしないようにするためです。
Secretをデコードする 先ほど作成したSecretの内容を見るには、以下のコマンドを実行します:
kubectl get secret db-user-pass -o jsonpath = '{.data}'
出力は次のようになります:
{"password" :"MWYyZDFlMmU2N2Rm" ,"username" :"YWRtaW4=" }
passwordのデータをデコードします:
echo 'MWYyZDFlMmU2N2Rm' | base64 --decode
出力は次のようになります:
1f2d1e2e67df
クリーンアップ 作成したSecretを削除するには次のコマンドを実行します:
kubectl delete secret db-user-pass
次の項目 4.6.2 - 設定ファイルを使用してSecretを管理する リソース設定ファイルを使用してSecretを作成する
始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
設定ファイルを作成する あらかじめYAMLまたはJSON形式でSecretのマニフェストを作成したうえで、オブジェクトを作成することができます。
Secret リソースには、dataとstringDataの2つのマップが含まれています。
dataフィールドは任意のデータを格納するのに使用され、base64でエンコードされます。
stringDataフィールドは利便性のために用意されており、Secretデータをエンコードされていない文字列として提供することができます。
dataとstringDataのキーは、英数字、-、_、.で構成されている必要があります。
たとえば、dataフィールドを使用して2つの文字列をSecretに格納するには、次のように文字列をbase64に変換します:
出力は次のようになります:
YWRtaW4=
echo -n '1f2d1e2e67df' | base64
出力は次のようになります:
MWYyZDFlMmU2N2Rm
以下のようなSecret設定ファイルを記述します:
apiVersion : v1
kind : Secret
metadata :
name : mysecret
type : Opaque
data :
username : YWRtaW4=
password : MWYyZDFlMmU2N2Rm
なお、Secretオブジェクトの名前は、有効なDNSサブドメイン名 である必要があります。
備考: SecretデータのシリアライズされたJSONおよびYAMLの値は、base64文字列としてエンコードされます。
文字列中の改行は不正で、含まれていてはなりません。
Darwin/macOSでbase64ユーティリティーを使用する場合、長い行を分割するために-bオプションを使用するのは避けるべきです。
逆に、Linux ユーザーは、base64 コマンドにオプション-w 0を追加するか、-wオプションが利用できない場合には、パイプラインbase64 | tr -d '\n'を追加する必要があります 。特定のシナリオでは、代わりにstringDataフィールドを使用できます。
このフィールドでは、base64エンコードされていない文字列を直接Secretに入れることができ、Secretの作成時や更新時には、その文字列がエンコードされます。
たとえば、設定ファイルを保存するためにSecretを使用しているアプリケーションをデプロイする際に、デプロイプロセス中に設定ファイルの一部を入力したい場合などが考えられます。
たとえば、次のような設定ファイルを使用しているアプリケーションの場合:
apiUrl : "https://my.api.com/api/v1"
username : "<user>"
password : "<password>"
次のような定義でSecretに格納できます:
apiVersion : v1
kind : Secret
metadata :
name : mysecret
type : Opaque
stringData :
config.yaml : |
apiUrl: "https://my.api.com/api/v1"
username: <user>
password: <password>
Secretを作成する kubectl apply
kubectl apply -f ./secret.yaml
出力は次のようになります:
secret/mysecret created
Secretを確認する stringDataフィールドは、書き込み専用の便利なフィールドです。Secretを取得する際には決して出力されません。たとえば、次のようなコマンドを実行した場合:
kubectl get secret mysecret -o yaml
出力は次のようになります:
apiVersion : v1
data :
config.yaml : YXBpVXJsOiAiaHR0cHM6Ly9teS5hcGkuY29tL2FwaS92MSIKdXNlcm5hbWU6IHt7dXNlcm5hbWV9fQpwYXNzd29yZDoge3twYXNzd29yZH19
kind : Secret
metadata :
creationTimestamp : 2018-11-15T20:40:59Z
name : mysecret
namespace : default
resourceVersion : "7225"
uid : c280ad2e-e916-11e8-98f2-025000000001
type : Opaque
kubectl getとkubectl describeコマンドはデフォルトではSecretの内容を表示しません。
これは、Secretが不用意に他人にさらされたり、ターミナルログに保存されたりしないようにするためです。
エンコードされたデータの実際の内容を確認するには、Secretのデコード を参照してください。
usernameなどのフィールドがdataとstringDataの両方に指定されている場合は、stringDataの値が使われます。
たとえば、以下のようなSecretの定義の場合:
apiVersion : v1
kind : Secret
metadata :
name : mysecret
type : Opaque
data :
username : YWRtaW4=
stringData :
username : administrator
結果は以下の通りです:
apiVersion : v1
data :
username : YWRtaW5pc3RyYXRvcg==
kind : Secret
metadata :
creationTimestamp : 2018-11-15T20:46:46Z
name : mysecret
namespace : default
resourceVersion : "7579"
uid : 91460ecb-e917-11e8-98f2-025000000001
type : Opaque
YWRtaW5pc3RyYXRvcg==をデコードするとadministratorとなります。
クリーンアップ 作成したSecretを削除するには次のコマンドを実行します:
kubectl delete secret mysecret
次の項目 4.6.3 - Kustomizeを使用してSecretを管理する kustomization.yamlを使用してSecretを作成する
Kubernetes v1.14以降、kubectlはKustomizeを使ったオブジェクト管理 をサポートしています。
KustomizeはSecretやConfigMapを作成するためのリソースジェネレーターを提供します。
Kustomizeジェネレーターは、ディレクトリ内のkustomization.yamlファイルで指定します。
Secretを生成したら、kubectl applyでAPIサーバー上にSecretを作成します。
始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
Kustomizationファイルを作成する kustomization.yamlファイルの中でsecretGeneratorを定義し、他の既存のファイルを参照することで、Secretを生成することができます。
たとえば、以下のkustomizationファイルは./username.txtと./password.txtを参照しています。
secretGenerator :
name : db-user-pass
files :
- username.txt
- password.txt
また、kustomization.yamlファイルの中でリテラルを指定してsecretGeneratorを定義することもできます。
たとえば、以下のkustomization.yamlファイルにはusernameとpasswordの2つのリテラルが含まれています。
secretGenerator :
name : db-user-pass
literals :
- username=admin
- password=1f2d1e2e67df
また、kustomization.yamlファイルに.envファイルを用意してsecretGeneratorを定義することもできます。
たとえば、以下のkustomization.yamlファイルは、.env.secretファイルからデータを取り込みます。
secretGenerator :
name : db-user-pass
envs :
- .env.secret
なお、いずれの場合も、値をbase64エンコードする必要はありません。
Secretを作成する kustomization.yamlを含むディレクトリを適用して、Secretを作成します。
出力は次のようになります:
secret/db-user-pass-96mffmfh4k created
なお、Secretを生成する際には、データをハッシュ化し、そのハッシュ値を付加することでSecret名を生成します。
これにより、データが変更されるたびに、新しいSecretが生成されます。
作成したSecretを確認する Secretが作成されたことを確認できます:
出力は次のようになります:
NAME TYPE DATA AGE
db-user-pass-96mffmfh4k Opaque 2 51s
Secretの説明を参照できます:
kubectl describe secrets/db-user-pass-96mffmfh4k
出力は次のようになります:
Name: db-user-pass-96mffmfh4k
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password.txt: 12 bytes
username.txt: 5 bytes
kubectl getとkubectl describeコマンドはデフォルトではSecretの内容を表示しません。
これは、Secretが不用意に他人にさらされたり、ターミナルログに保存されたりしないようにするためです。
エンコードされたデータの実際の内容を確認するには、Secretのデコード を参照してください。
クリーンアップ 作成したSecretを削除するには次のコマンドを実行します:
kubectl delete secret db-user-pass-96mffmfh4k
次の項目 4.7 - アプリケーションへのデータ注入 ワークロードを実行するPodの構成とその他のデータを指定します。
4.7.1 - コンテナにコマンドと引数を定義する このページでは、Pod でコンテナを実行するときにコマンドと引数を定義する方法を説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
Podの作成時にコマンドと引数を定義する Podを作成するときに、Pod内で実行するコンテナのコマンドと引数を定義できます。コマンドを定義するには、設定ファイルにcommandフィールドを記述します。コマンドの引数を定義するには、設定ファイルにargsフィールドを記述します。定義したコマンドと引数はPodの作成後に変更することはできません。
設定ファイルで定義したコマンドと引数は、コンテナイメージが提供するデフォルトのコマンドと引数を上書きします。引数を定義し、コマンドを定義しなかった場合、デフォルトのコマンドと新しい引数が使用されます。
備考: commandフィールドは、いくつかのコンテナランタイムではエントリポイントに相当します。この演習では、1つのコンテナを実行するPodを作成します。Podの設定ファイルには、コマンドと2つの引数を定義します。
apiVersion : v1
kind : Pod
metadata :
name : command-demo
labels :
purpose : demonstrate-command
spec :
containers :
- name : command-demo-container
image : debian
command : ["printenv" ]
args : ["HOSTNAME" , "KUBERNETES_PORT" ]
restartPolicy : OnFailure
YAMLの設定ファイルに基づいてPodを作成
kubectl apply -f https://k8s.io/examples/pods/commands.yaml
実行中のPodをリストアップ
出力は、command-demo Podで実行されたコンテナが完了したことを示します。
コンテナ内で実行されたコマンドの出力を確認するためにPodのログを見る
kubectl logs command-demo
出力は、HOSTNAMEとKUBERNETES_PORT環境変数の値を示します。
command-demo
tcp://10.3.240.1:443
環境変数を使って引数を定義する 前述の例では、文字列を指定して引数を直接定義しました。文字列を直接指定する代わりに、環境変数を使用して引数を定義することもできます。
env :
name : MESSAGE
value : "hello world"
command : ["/bin/echo" ]
args : ["$(MESSAGE)" ]
つまり、ConfigMap やSecret など、環境変数を定義するために利用可能な技術のどれを使っても、Podの引数を定義できるということです。
備考: 環境変数は"$(VAR)"という括弧で囲まれて表示されます。これは、commandやargsフィールドで変数を展開するために必要です。シェルでコマンドを実行する シェルでコマンドを実行する必要がある場合もあります。例えば、コマンドが複数のコマンドをパイプでつないだものであったり、シェルスクリプトであったりします。コマンドをシェルで実行するには、次のように記述します。
command: [ "/bin/sh" ]
args: [ "-c" , "while true; do echo hello; sleep 10;done" ]
次の項目 4.7.2 - コンテナの環境変数の定義 このページでは、Kubernetes Podでコンテナの環境変数を定義する方法を説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
コンテナの環境変数を定義する Podを作成するとき、そのPodで実行するコンテナに環境変数を設定することができます。環境変数を設定するには、設定ファイルに env または envFrom フィールドを含めます。
この演習では、1つのコンテナを実行するPodを作成します。Podの設定ファイルには、名前 DEMO_GREETING、値 "Hello from the environment"を持つ環境変数が定義されています。Podの設定マニフェストを以下に示します:
apiVersion : v1
kind : Pod
metadata :
name : envar-demo
labels :
purpose : demonstrate-envars
spec :
containers :
- name : envar-demo-container
image : gcr.io/google-samples/node-hello:1.0
env :
- name : DEMO_GREETING
value : "Hello from the environment"
- name : DEMO_FAREWELL
value : "Such a sweet sorrow"
マニフェストに基づいてPodを作成します:
kubectl apply -f https://k8s.io/examples/pods/inject/envars.yaml
実行中のPodを一覧表示します:
kubectl get pods -l purpose = demonstrate-envars
出力は以下のようになります:
NAME READY STATUS RESTARTS AGE
envar-demo 1/1 Running 0 9s
Podで実行しているコンテナのシェルを取得します:
kubectl exec -it envar-demo -- /bin/bash
シェルでprintenvコマンドを実行すると、環境変数の一覧が表示されます。
# コンテナ内のシェルで以下のコマンドを実行します
printenv
出力は以下のようになります:
NODE_VERSION=4.4.2
EXAMPLE_SERVICE_PORT_8080_TCP_ADDR=10.3.245.237
HOSTNAME=envar-demo
...
DEMO_GREETING=Hello from the environment
DEMO_FAREWELL=Such a sweet sorrow
シェルを終了するには、exitと入力します。
備考: envまたはenvFromフィールドを使用して設定された環境変数は、コンテナイメージで指定された環境変数を上書きします。
備考: 環境変数は互いに参照することができますが、順序が重要です。同じコンテキストで定義されている他の変数を使用する場合は、その変数をリストの後に配置する必要があります。同様に、循環参照は避けてください。設定の中で環境変数を使用する Podの設定で定義した環境変数は、Podのコンテナに設定したコマンドや引数など、設定の他の場所で使用することができます。以下の設定例では、環境変数GREETING、HONORORIFIC、NAMEにそれぞれ Warm greetings to、The Most Honorable、Kubernetesを設定しています。これらの環境変数は、env-print-demoコンテナに渡されるCLI引数で使われます。
apiVersion : v1
kind : Pod
metadata :
name : print-greeting
spec :
containers :
- name : env-print-demo
image : bash
env :
- name : GREETING
value : "Warm greetings to"
- name : HONORIFIC
value : "The Most Honorable"
- name : NAME
value : "Kubernetes"
command : ["echo" ]
args : ["$(GREETING) $(HONORIFIC) $(NAME)" ]
作成されると、コンテナ上でecho Warm greetings to The Most Honorable Kubernetesというコマンドが実行されます。
次の項目 4.7.3 - 依存関係のある環境変数の定義 このページでは、KubernetesのPod内のコンテナに対して、依存関係のある環境変数を定義する方法について説明します。
始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
コンテナに依存関係のある環境変数を定義する Podを作成する際に、そのPod内で実行されるコンテナに対して依存関係のある環境変数を設定できます。
依存関係のある環境変数を設定するには、設定ファイル内のenvのvalueに$(VAR_NAME)を使用します。
このチュートリアルでは、1つのコンテナを実行するPodを作成します。
このPodの設定ファイルでは、一般的な使い方に基づいて依存関係のある環境変数が定義されています。
以下がPodの設定マニフェストです。
apiVersion : v1
kind : Pod
metadata :
name : dependent-envars-demo
spec :
containers :
- name : dependent-envars-demo
args :
- while true; do echo -en '\n'; printf UNCHANGED_REFERENCE=$UNCHANGED_REFERENCE'\n'; printf SERVICE_ADDRESS=$SERVICE_ADDRESS'\n';printf ESCAPED_REFERENCE=$ESCAPED_REFERENCE'\n'; sleep 30; done;
command :
- sh
- -c
image : busybox:1.28
env :
- name : SERVICE_PORT
value : "80"
- name : SERVICE_IP
value : "172.17.0.1"
- name : UNCHANGED_REFERENCE
value : "$(PROTOCOL)://$(SERVICE_IP):$(SERVICE_PORT)"
- name : PROTOCOL
value : "https"
- name : SERVICE_ADDRESS
value : "$(PROTOCOL)://$(SERVICE_IP):$(SERVICE_PORT)"
- name : ESCAPED_REFERENCE
value : "$$(PROTOCOL)://$(SERVICE_IP):$(SERVICE_PORT)"
このマニフェストに基づいてPodを作成します:
kubectl apply -f https://k8s.io/examples/pods/inject/dependent-envars.yaml
pod/dependent-envars-demo created
実行中のPodを一覧表示します:
kubectl get pods dependent-envars-demo
NAME READY STATUS RESTARTS AGE
dependent-envars-demo 1/1 Running 0 9s
Pod内で実行中のコンテナのログを確認します:
kubectl logs pod/dependent-envars-demo
UNCHANGED_REFERENCE=$(PROTOCOL)://172.17.0.1:80
SERVICE_ADDRESS=https://172.17.0.1:80
ESCAPED_REFERENCE=$(PROTOCOL)://172.17.0.1:80
上記のとおり、SERVICE_ADDRESSには正しい依存関係の参照を定義しており、UNCHANGED_REFERENCEには誤った依存関係の参照が、ESCAPED_REFERENCEには依存関係の参照をスキップする表現が使われています。
参照される環境変数がすでに定義されている場合、その参照は正しく解決されます。
たとえば、SERVICE_ADDRESSの場合がそれに該当します。
envリスト内の順序が重要であることに注意してください。
環境変数は、リスト内で後に記述されているだけでは「定義済み」と見なされません。
このため、上記の例ではUNCHANGED_REFERENCEが$(PROTOCOL)を解決できません。
環境変数が未定義であるか、いくつかの変数しか含まれていない場合、その未定義の環境変数はUNCHANGED_REFERENCEのように通常の文字列として扱われます。
一般に、誤って解釈された環境変数があっても、コンテナの起動が妨げられることはないことに注意してください。
$(VAR_NAME)構文は、$を2つ重ねて$$(VAR_NAME)のように記述することでエスケープできます。
エスケープされた参照は、参照される変数が定義されているかどうかに関係なく展開されることはありません。
これは、上記のESCAPED_REFERENCEの例からも確認できます。
次の項目 4.7.4 - 環境変数によりコンテナにPod情報を共有する このページでは、Podが内部で実行しているコンテナに自身の情報を共有する方法を説明します。環境変数ではPodのフィールドとコンテナのフィールドを共有することができます。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
Downward API Podとコンテナのフィールドを実行中のコンテナに共有する方法は2つあります:
これら2つの方法を合わせて、Podとコンテナフィールドを共有する方法をDownward API と呼びます。
Podフィールドを環境変数の値として使用する この演習では、1つのコンテナを持つPodを作成します。Podの設定ファイルは次のとおりです:
apiVersion : v1
kind : Pod
metadata :
name : dapi-envars-fieldref
spec :
containers :
- name : test-container
image : registry.k8s.io/busybox
command : [ "sh" , "-c" ]
args :
- while true; do
echo -en '\n';
printenv MY_NODE_NAME MY_POD_NAME MY_POD_NAMESPACE;
printenv MY_POD_IP MY_POD_SERVICE_ACCOUNT;
sleep 10;
done;
env :
- name : MY_NODE_NAME
valueFrom :
fieldRef :
fieldPath : spec.nodeName
- name : MY_POD_NAME
valueFrom :
fieldRef :
fieldPath : metadata.name
- name : MY_POD_NAMESPACE
valueFrom :
fieldRef :
fieldPath : metadata.namespace
- name : MY_POD_IP
valueFrom :
fieldRef :
fieldPath : status.podIP
- name : MY_POD_SERVICE_ACCOUNT
valueFrom :
fieldRef :
fieldPath : spec.serviceAccountName
restartPolicy : Never
設定ファイルには、5つの環境変数があります。envフィールドはEnvVars の配列です。配列の最初の要素では、環境変数MY_NODE_NAMEの値をPodのspec.nodeNameフィールドから取得することを指定します。同様に、他の環境変数もPodのフィールドから名前を取得します。
備考: この例のフィールドはPodのフィールドです。これらはPod内のコンテナのフィールドではありません。Podを作成します:
kubectl apply -f https://k8s.io/examples/pods/inject/dapi-envars-pod.yaml
Podのコンテナが実行されていることを確認します:
コンテナのログを表示します:
kubectl logs dapi-envars-fieldref
出力には、選択した環境変数の値が表示されます:
minikube
dapi-envars-fieldref
default
172.17.0.4
default
これらの値がログにある理由を確認するには、設定ファイルのcommandおよびargsフィールドを確認してください。コンテナが起動すると、5つの環境変数の値が標準出力に書き込まれます。これを10秒ごとに繰り返します。
次に、Podで実行しているコンテナへのシェルを取得します:
kubectl exec -it dapi-envars-fieldref -- sh
シェルで環境変数を表示します:
出力は、特定の環境変数にPodフィールドの値が割り当てられていることを示しています:
MY_POD_SERVICE_ACCOUNT=default
...
MY_POD_NAMESPACE=default
MY_POD_IP=172.17.0.4
...
MY_NODE_NAME=minikube
...
MY_POD_NAME=dapi-envars-fieldref
コンテナフィールドを環境変数の値として使用する 前の演習では、環境変数の値としてPodフィールドを使用しました。次の演習では、環境変数の値としてコンテナフィールドを使用します。これは、1つのコンテナを持つPodの設定ファイルです:
apiVersion : v1
kind : Pod
metadata :
name : dapi-envars-resourcefieldref
spec :
containers :
- name : test-container
image : registry.k8s.io/busybox:1.24
command : [ "sh" , "-c" ]
args :
- while true; do
echo -en '\n';
printenv MY_CPU_REQUEST MY_CPU_LIMIT;
printenv MY_MEM_REQUEST MY_MEM_LIMIT;
sleep 10;
done;
resources :
requests :
memory : "32Mi"
cpu : "125m"
limits :
memory : "64Mi"
cpu : "250m"
env :
- name : MY_CPU_REQUEST
valueFrom :
resourceFieldRef :
containerName : test-container
resource : requests.cpu
- name : MY_CPU_LIMIT
valueFrom :
resourceFieldRef :
containerName : test-container
resource : limits.cpu
- name : MY_MEM_REQUEST
valueFrom :
resourceFieldRef :
containerName : test-container
resource : requests.memory
- name : MY_MEM_LIMIT
valueFrom :
resourceFieldRef :
containerName : test-container
resource : limits.memory
restartPolicy : Never
設定ファイルには、4つの環境変数があります。envフィールドはEnvVars の配列です。配列の最初の要素では、環境変数MY_CPU_REQUESTの値をtest-containerという名前のコンテナのrequests.cpuフィールドから取得することを指定します。同様に、他の環境変数もコンテナのフィールドから値を取得します。
Podを作成します:
kubectl apply -f https://k8s.io/examples/pods/inject/dapi-envars-container.yaml
Podのコンテナが実行されていることを確認します:
コンテナのログを表示します:
kubectl logs dapi-envars-resourcefieldref
出力には、選択した環境変数の値が表示されます:
1
1
33554432
67108864
次の項目 4.7.5 - Secretsで安全にクレデンシャルを配布する このページでは、パスワードや暗号化キーなどの機密データをPodに安全に注入する方法を紹介します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.6.
バージョンを確認するには次のコマンドを実行してください: kubectl version.
機密データをbase64でエンコードする ユーザー名my-appとパスワード39528$vdg7Jbの2つの機密データが必要だとします。
まず、base64エンコーディングツールを使って、ユーザ名とパスワードをbase64表現に変換します。
ここでは、手軽に入手できるbase64プログラムを使った例を紹介します:
echo -n 'my-app' | base64
echo -n '39528$vdg7Jb' | base64
出力結果によると、ユーザ名のbase64表現はbXktYXBwで、パスワードのbase64表現はMzk1MjgkdmRnN0piです。
注意: OSから信頼されているローカルツールを使用することで、外部ツールのセキュリティリスクを低減することができます。Secretを作成する 以下はユーザー名とパスワードを保持するSecretを作成するために使用できる設定ファイルです:
apiVersion : v1
kind : Secret
metadata :
name : test-secret
data :
username : bXktYXBw
password : Mzk1MjgkdmRnN0pi
Secret を作成する
kubectl apply -f https://k8s.io/examples/pods/inject/secret.yaml
Secretの情報を取得する
kubectl get secret test-secret
出力:
NAME TYPE DATA AGE
test-secret Opaque 2 1m
Secretの詳細な情報を取得する:
kubectl describe secret test-secret
出力:
Name: test-secret
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password: 13 bytes
username: 7 bytes
kubectlでSecretを作成する base64エンコードの手順を省略したい場合は、kubectl create secretコマンドで同じSecretを作成することができます。
例えば:
kubectl create secret generic test-secret --from-literal= 'username=my-app' --from-literal= 'password=39528$vdg7Jb'
先ほどの詳細なアプローチでは 各ステップを明示的に実行し、何が起こっているかを示していますが、kubectl create secretの方が便利です。
Volumeにある機密情報をアクセスするPodを作成する これはPodの作成に使用できる設定ファイルです。
apiVersion : v1
kind : Pod
metadata :
name : secret-test-pod
spec :
containers :
- name : test-container
image : nginx
volumeMounts :
# name must match the volume name below
- name : secret-volume
mountPath : /etc/secret-volume
# The secret data is exposed to Containers in the Pod through a Volume.
volumes :
- name : secret-volume
secret :
secretName : test-secret
Podを作成する:
kubectl apply -f https://k8s.io/examples/pods/inject/secret-pod.yaml
PodのSTATUSがRunningであるのを確認する:
kubectl get pod secret-test-pod
出力:
NAME READY STATUS RESTARTS AGE
secret-test-pod 1/1 Running 0 42m
Podの中にあるコンテナにシェルを実行する
kubectl exec -i -t secret-test-pod -- /bin/bash
機密データは /etc/secret-volume にマウントされたボリュームを介してコンテナに公開されます。
ディレクトリ /etc/secret-volume 中のファイルの一覧を確認する:
# Run this in the shell inside the container
ls /etc/secret-volume
passwordとusername 2つのファイル名が出力される:
password username
username と password ファイルの中身を表示する:
# Run this in the shell inside the container
echo " $( cat /etc/secret-volume/username ) "
echo " $( cat /etc/secret-volume/password ) "
出力:
my-app
39528$vdg7Jb
Secretでコンテナの環境変数を定義する 単一のSecretでコンテナの環境変数を定義する Secretの中でkey-valueペアで環境変数を定義する:
kubectl create secret generic backend-user --from-literal= backend-username= 'backend-admin'
Secretで定義されたbackend-usernameの値をPodの環境変数SECRET_USERNAMEに割り当てます。
apiVersion : v1
kind : Pod
metadata :
name : env-single-secret
spec :
containers :
- name : envars-test-container
image : nginx
env :
- name : SECRET_USERNAME
valueFrom :
secretKeyRef :
name : backend-user
key : backend-username
Podを作成する:
kubectl create -f https://k8s.io/examples/pods/inject/pod-single-secret-env-variable.yaml
コンテナの環境変数SECRET_USERNAMEの中身を表示する:
kubectl exec -i -t env-single-secret -- /bin/sh -c 'echo $SECRET_USERNAME'
出力:
backend-admin
複数のSecretからコンテナの環境変数を定義する Secretのすべてのkey-valueペアを環境変数として設定する
備考: この機能は Kubernetes v1.6 以降から利用可能複数のkey-valueペアを含むSecretを作成する
kubectl create secret generic test-secret --from-literal= username = 'my-app' --from-literal= password = '39528$vdg7Jb'
envFromを使用してSecretのすべてのデータをコンテナの環境変数として定義します。SecretのキーがPodの環境変数名になります。
apiVersion : v1
kind : Pod
metadata :
name : envfrom-secret
spec :
containers :
- name : envars-test-container
image : nginx
envFrom :
- secretRef :
name : test-secret
Podを作成する:
kubectl create -f https://k8s.io/examples/pods/inject/pod-secret-envFrom.yaml
usernameとpasswordコンテナの環境変数を表示する
kubectl exec -i -t envfrom-secret -- /bin/sh -c 'echo "username: $username\npassword: $password\n"'
出力:
username: my-app
password: 39528$vdg7Jb
参考文献 次の項目 4.8 - アプリケーションの実行 ステートレスアプリケーションとステートフルアプリケーションの両方を実行および管理します。
4.8.1 - Deploymentを使用してステートレスアプリケーションを実行する このページでは、Kubernetes Deploymentオブジェクトを使用してアプリケーションを実行する方法を説明します。
目標 nginx deploymentを作成します。 kubectlを使ってdeploymentに関する情報を一覧表示します。 deploymentを更新します。 始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.9.
バージョンを確認するには次のコマンドを実行してください: kubectl version.
nginx deploymentの作成と探検 Kubernetes Deploymentオブジェクトを作成することでアプリケーションを実行できます。また、YAMLファイルでDeploymentを記述できます。例えば、このYAMLファイルはnginx:1.14.2 Dockerイメージを実行するデプロイメントを記述しています:
apiVersion : apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind : Deployment
metadata :
name : nginx-deployment
spec :
selector :
matchLabels :
app : nginx
replicas : 2 # tells deployment to run 2 pods matching the template
template :
metadata :
labels :
app : nginx
spec :
containers :
- name : nginx
image : nginx:1.14.2
ports :
- containerPort : 80
YAMLファイルに基づいてDeploymentを作成します:
kubectl apply -f https://k8s.io/examples/application/deployment.yaml
Deploymentに関する情報を表示します:
kubectl describe deployment nginx-deployment
出力はこのようになります:
Name: nginx-deployment
Namespace: default
CreationTimestamp: Tue, 30 Aug 2016 18:11:37 -0700
Labels: app=nginx
Annotations: deployment.kubernetes.io/revision=1
Selector: app=nginx
Replicas: 2 desired | 2 updated | 2 total | 2 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 1 max unavailable, 1 max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.14.2
Port: 80/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-deployment-1771418926 (2/2 replicas created)
No events.
Deploymentによって作成されたPodを一覧表示します:
kubectl get pods -l app=nginx
出力はこのようになります:
NAME READY STATUS RESTARTS AGE
nginx-deployment-1771418926-7o5ns 1/1 Running 0 16h
nginx-deployment-1771418926-r18az 1/1 Running 0 16h
Podに関する情報を表示します:
kubectl describe pod <pod-name>
ここで<pod-name>はPodの1つの名前を指定します。
Deploymentの更新 新しいYAMLファイルを適用してDeploymentを更新できます。このYAMLファイルは、Deploymentを更新してnginx 1.16.1を使用するように指定しています。
apiVersion : apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind : Deployment
metadata :
name : nginx-deployment
spec :
selector :
matchLabels :
app : nginx
replicas : 2
template :
metadata :
labels :
app : nginx
spec :
containers :
- name : nginx
image : nginx:1.16.1 # Update the version of nginx from 1.14.2 to 1.16.1
ports :
- containerPort : 80
新しいYAMLファイルを適用します:
kubectl apply -f https://k8s.io/examples/application/deployment-update.yaml
Deploymentが新しい名前でPodを作成し、古いPodを削除するのを監視します:
kubectl get pods -l app=nginx
レプリカ数を増やすことによるアプリケーションのスケール 新しいYAMLファイルを適用することで、Deployment内のPodの数を増やすことができます。このYAMLファイルはreplicasを4に設定します。これはDeploymentが4つのPodを持つべきであることを指定します:
apiVersion : apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind : Deployment
metadata :
name : nginx-deployment
spec :
selector :
matchLabels :
app : nginx
replicas : 4 # Update the replicas from 2 to 4
template :
metadata :
labels :
app : nginx
spec :
containers :
- name : nginx
image : nginx:1.16.1
ports :
- containerPort : 80
新しいYAMLファイルを適用します:
kubectl apply -f https://k8s.io/examples/application/deployment-scale.yaml
Deploymentに4つのPodがあることを確認します:
kubectl get pods -l app=nginx
出力はこのようになります:
NAME READY STATUS RESTARTS AGE
nginx-deployment-148880595-4zdqq 1/1 Running 0 25s
nginx-deployment-148880595-6zgi1 1/1 Running 0 25s
nginx-deployment-148880595-fxcez 1/1 Running 0 2m
nginx-deployment-148880595-rwovn 1/1 Running 0 2m
Deploymentの削除 Deploymentを名前を指定して削除します:
kubectl delete deployment nginx-deployment
ReplicationControllers -- 昔のやり方 複製アプリケーションを作成するための好ましい方法はDeploymentを使用することです。そして、DeploymentはReplicaSetを使用します。 DeploymentとReplicaSetがKubernetesに追加される前は、ReplicationController を使用して複製アプリケーションを構成していました。
次の項目 4.8.2 - 単一レプリカのステートフルアプリケーションを実行する このページでは、PersistentVolumeとDeploymentを使用して、Kubernetesで単一レプリカのステートフルアプリケーションを実行する方法を説明します。アプリケーションはMySQLです。
目標 自身の環境のディスクを参照するPersistentVolumeを作成します。 MySQLのDeploymentを作成します。 MySQLをDNS名でクラスター内の他のPodに公開します。 始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
ここで使用されているPersistentVolumeClaims の要件を満たすには、デフォルトのStorageClass を使用して動的PersistentVolumeプロビジョナーを作成するか、PersistentVolumesを静的にプロビジョニングする 必要があります。
MySQLをデプロイする Kubernetes Deploymentを作成し、PersistentVolumeClaimを使用して既存のPersistentVolumeに接続することで、ステートフルアプリケーションを実行できます。
たとえば、以下のYAMLファイルはMySQLを実行し、PersistentVolumeClaimを参照するDeploymentを記述しています。
このファイルは/var/lib/mysqlのボリュームマウントを定義してから、20Gのボリュームを要求するPersistentVolumeClaimを作成します。
この要求は、要件を満たす既存のボリューム、または動的プロビジョナーによって満たされます。
注:パスワードはYAMLファイル内に定義されており、これは安全ではありません。安全な解決策についてはKubernetes Secret を参照してください 。
apiVersion : v1
kind : Service
metadata :
name : mysql
spec :
ports :
- port : 3306
selector :
app : mysql
clusterIP : None
---
apiVersion : apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind : Deployment
metadata :
name : mysql
spec :
selector :
matchLabels :
app : mysql
strategy :
type : Recreate
template :
metadata :
labels :
app : mysql
spec :
containers :
- image : mysql:9
name : mysql
env :
# Use secret in real usage
- name : MYSQL_ROOT_PASSWORD
value : password
ports :
- containerPort : 3306
name : mysql
volumeMounts :
- name : mysql-persistent-storage
mountPath : /var/lib/mysql
volumes :
- name : mysql-persistent-storage
persistentVolumeClaim :
claimName : mysql-pv-claim
kind : PersistentVolume
apiVersion : v1
metadata :
name : mysql-pv-volume
labels :
type : local
spec :
storageClassName : manual
capacity :
storage : 20Gi
accessModes :
- ReadWriteOnce
hostPath :
path : "/mnt/data"
---
apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : mysql-pv-claim
spec :
storageClassName : manual
accessModes :
- ReadWriteOnce
resources :
requests :
storage : 20Gi
YAMLファイルに記述されたPVとPVCをデプロイします。
kubectl create -f https://k8s.io/examples/application/mysql/mysql-pv.yaml
YAMLファイルの内容をデプロイします。
kubectl create -f https://k8s.io/examples/application/mysql/mysql-deployment.yaml
作成したDeploymentの情報を表示します。
kubectl describe deployment mysql
Name: mysql
Namespace: default
CreationTimestamp: Tue, 01 Nov 2016 11:18:45 -0700
Labels: app=mysql
Annotations: deployment.kubernetes.io/revision=1
Selector: app=mysql
Replicas: 1 desired | 1 updated | 1 total | 0 available | 1 unavailable
StrategyType: Recreate
MinReadySeconds: 0
Pod Template:
Labels: app=mysql
Containers:
mysql:
Image: mysql:9
Port: 3306/TCP
Environment:
MYSQL_ROOT_PASSWORD: password
Mounts:
/var/lib/mysql from mysql-persistent-storage (rw)
Volumes:
mysql-persistent-storage:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: mysql-pv-claim
ReadOnly: false
Conditions:
Type Status Reason
---- ------ ------
Available False MinimumReplicasUnavailable
Progressing True ReplicaSetUpdated
OldReplicaSets: <none>
NewReplicaSet: mysql-63082529 (1/1 replicas created)
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
33s 33s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set mysql-63082529 to 1
Deploymentによって作成されたPodを一覧表示します。
kubectl get pods -l app=mysql
NAME READY STATUS RESTARTS AGE
mysql-63082529-2z3ki 1/1 Running 0 3m
PersistentVolumeClaimを確認します。
kubectl describe pvc mysql-pv-claim
Name: mysql-pv-claim
Namespace: default
StorageClass:
Status: Bound
Volume: mysql-pv-volume
Labels: <none>
Annotations: pv.kubernetes.io/bind-completed=yes
pv.kubernetes.io/bound-by-controller=yes
Capacity: 20Gi
Access Modes: RWO
Events: <none>
MySQLインスタンスにアクセスする 前述のYAMLファイルは、クラスター内の他のPodがデータベースにアクセスできるようにするServiceを作成します。
ServiceのオプションでclusterIP: Noneを指定すると、ServiceのDNS名がPodのIPアドレスに直接解決されます。
このオプションは、ServiceのバックエンドのPodが1つのみであり、Podの数を増やす予定がない場合に適しています。
MySQLクライアントを実行してサーバーに接続します。
kubectl run -it --rm --image=mysql:9 --restart=Never mysql-client -- mysql -h mysql -ppassword
このコマンドは、クラスター内にMySQLクライアントを実行する新しいPodを作成し、Serviceを通じてMySQLサーバーに接続します。
接続できれば、ステートフルなMySQLデータベースが稼働していることが確認できます。
Waiting for pod default/mysql-client-274442439-zyp6i to be running, status is Pending, pod ready: false
If you don't see a command prompt, try pressing enter.
mysql>
アップデート イメージまたはDeploymentの他の部分は、kubectl applyコマンドを使用して通常どおりに更新できます。
ステートフルアプリケーションに固有のいくつかの注意事項を以下に記載します。
アプリケーションをスケールしないでください。このセットアップは単一レプリカのアプリケーション専用です。
下層にあるPersistentVolumeは1つのPodにしかマウントできません。
クラスター化されたステートフルアプリケーションについては、StatefulSetのドキュメント を参照してください。 Deploymentを定義するYAMLファイルではstrategy: type: Recreateを使用して下さい。
この設定はKubernetesにローリングアップデートを使用 しない ように指示します。
同時に複数のPodを実行することはできないため、ローリングアップデートは使用できません。
Recreate戦略は、更新された設定で新しいPodを作成する前に、最初のPodを停止します。 Deploymentの削除 名前を指定してデプロイしたオブジェクトを削除します。
kubectl delete deployment,svc mysql
kubectl delete pvc mysql-pv-claim
kubectl delete pv mysql-pv-volume
PersistentVolumeを手動でプロビジョニングした場合は、PersistentVolumeを手動で削除し、また、下層にあるリソースも解放する必要があります。
動的プロビジョニング機能を使用した場合は、PersistentVolumeClaimを削除すれば、自動的にPersistentVolumeも削除されます。
一部の動的プロビジョナー(EBSやPDなど)は、PersistentVolumeを削除すると同時に下層にあるリソースも解放します。
次の項目 4.8.3 - レプリカを持つステートフルアプリケーションを実行する このページでは、StatefulSet
コントローラーを使用して、レプリカを持つステートフルアプリケーションを実行する方法を説明します。
ここでの例は、非同期レプリケーションを行う複数のスレーブを持つ、単一マスターのMySQLです。
この例は本番環境向けの構成ではない ことに注意してください。
具体的には、MySQLの設定が安全ではないデフォルトのままとなっています。
これはKubernetesでステートフルアプリケーションを実行するための一般的なパターンに焦点を当てるためです。
始める前に 目標 StatefulSetコントローラーを使用して、レプリカを持つMySQLトポロジーをデプロイします。 MySQLクライアントトラフィックを送信します。 ダウンタイムに対する耐性を観察します。 StatefulSetをスケールアップおよびスケールダウンします。 MySQLをデプロイする このMySQLのデプロイの例は、1つのConfigMap、2つのService、および1つのStatefulSetから構成されます。
ConfigMap 次のYAML設定ファイルからConfigMapを作成します。
kubectl apply -f https://k8s.io/examples/application/mysql/mysql-configmap.yaml
apiVersion : v1
kind : ConfigMap
metadata :
name : mysql
labels :
app : mysql
app.kubernetes.io/name : mysql
data :
primary.cnf : |
# Apply this config only on the primary.
[mysqld]
log-bin
replica.cnf : |
# Apply this config only on replicas.
[mysqld]
super-read-only
このConfigMapは、MySQLマスターとスレーブの設定を独立して制御するために、
それぞれのmy.cnfを上書きする内容を提供します。
この場合、マスターはスレーブにレプリケーションログを提供するようにし、
スレーブはレプリケーション以外の書き込みを拒否するようにします。
ConfigMap自体に特別なことはありませんが、ConfigMapの各部分は異なるPodに適用されます。
各Podは、StatefulSetコントローラーから提供される情報に基づいて、
初期化時にConfigMapのどの部分を見るかを決定します。
Services 以下のYAML設定ファイルからServiceを作成します。
kubectl apply -f https://k8s.io/examples/application/mysql/mysql-services.yaml
# Headless service for stable DNS entries of StatefulSet members.
apiVersion : v1
kind : Service
metadata :
name : mysql
labels :
app : mysql
spec :
ports :
- name : mysql
port : 3306
clusterIP : None
selector :
app : mysql
---
# Client service for connecting to any MySQL instance for reads.
# For writes, you must instead connect to the master: mysql-0.mysql.
apiVersion : v1
kind : Service
metadata :
name : mysql-read
labels :
app : mysql
spec :
ports :
- name : mysql
port : 3306
selector :
app : mysql
ヘッドレスサービスは、StatefulSetコントローラーが
StatefulSetの一部であるPodごとに作成するDNSエントリーのベースエントリーを提供します。
この例ではヘッドレスサービスの名前はmysqlなので、同じKubernetesクラスターの
同じ名前空間内の他のPodは、<pod-name>.mysqlを名前解決することでPodにアクセスできます。
mysql-readと呼ばれるクライアントサービスは、独自のクラスターIPを持つ通常のServiceであり、
Ready状態のすべてのMySQL Podに接続を分散します。
Serviceのエンドポイントには、MySQLマスターとすべてのスレーブが含まれる可能性があります。
読み込みクエリーのみが、負荷分散されるクライアントサービスを使用できることに注意してください。
MySQLマスターは1つしかいないため、クライアントが書き込みを実行するためには、
(ヘッドレスサービス内のDNSエントリーを介して)MySQLのマスターPodに直接接続する必要があります。
StatefulSet 最後に、次のYAML設定ファイルからStatefulSetを作成します。
kubectl apply -f https://k8s.io/examples/application/mysql/mysql-statefulset.yaml
apiVersion : apps/v1
kind : StatefulSet
metadata :
name : mysql
spec :
selector :
matchLabels :
app : mysql
serviceName : mysql
replicas : 3
template :
metadata :
labels :
app : mysql
spec :
initContainers :
- name : init-mysql
image : mysql:5.7
command :
- bash
- "-c"
- |
set -ex
# Generate mysql server-id from pod ordinal index.
[[ $HOSTNAME =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
echo [mysqld] > /mnt/conf.d/server-id.cnf
# Add an offset to avoid reserved server-id=0 value.
echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf
# Copy appropriate conf.d files from config-map to emptyDir.
if [[ $ordinal -eq 0 ]]; then
cp /mnt/config-map/master.cnf /mnt/conf.d/
else
cp /mnt/config-map/slave.cnf /mnt/conf.d/
fi
volumeMounts :
- name : conf
mountPath : /mnt/conf.d
- name : config-map
mountPath : /mnt/config-map
- name : clone-mysql
image : gcr.io/google-samples/xtrabackup:1.0
command :
- bash
- "-c"
- |
set -ex
# Skip the clone if data already exists.
[[ -d /var/lib/mysql/mysql ]] && exit 0
# Skip the clone on master (ordinal index 0).
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
[[ $ordinal -eq 0 ]] && exit 0
# Clone data from previous peer.
ncat --recv-only mysql-$(($ordinal-1)).mysql 3307 | xbstream -x -C /var/lib/mysql
# Prepare the backup.
xtrabackup --prepare --target-dir=/var/lib/mysql
volumeMounts :
- name : data
mountPath : /var/lib/mysql
subPath : mysql
- name : conf
mountPath : /etc/mysql/conf.d
containers :
- name : mysql
image : mysql:5.7
env :
- name : MYSQL_ALLOW_EMPTY_PASSWORD
value : "1"
ports :
- name : mysql
containerPort : 3306
volumeMounts :
- name : data
mountPath : /var/lib/mysql
subPath : mysql
- name : conf
mountPath : /etc/mysql/conf.d
resources :
requests :
cpu : 500m
memory : 1Gi
livenessProbe :
exec :
command : ["mysqladmin" , "ping" ]
initialDelaySeconds : 30
periodSeconds : 10
timeoutSeconds : 5
readinessProbe :
exec :
# Check we can execute queries over TCP (skip-networking is off).
command : ["mysql" , "-h" , "127.0.0.1" , "-e" , "SELECT 1" ]
initialDelaySeconds : 5
periodSeconds : 2
timeoutSeconds : 1
- name : xtrabackup
image : gcr.io/google-samples/xtrabackup:1.0
ports :
- name : xtrabackup
containerPort : 3307
command :
- bash
- "-c"
- |
set -ex
cd /var/lib/mysql
# Determine binlog position of cloned data, if any.
if [[ -f xtrabackup_slave_info && "x$(<xtrabackup_slave_info)" != "x" ]]; then
# XtraBackup already generated a partial "CHANGE MASTER TO" query
# because we're cloning from an existing slave. (Need to remove the tailing semicolon!)
cat xtrabackup_slave_info | sed -E 's/;$//g' > change_master_to.sql.in
# Ignore xtrabackup_binlog_info in this case (it's useless).
rm -f xtrabackup_slave_info xtrabackup_binlog_info
elif [[ -f xtrabackup_binlog_info ]]; then
# We're cloning directly from master. Parse binlog position.
[[ `cat xtrabackup_binlog_info` =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1
rm -f xtrabackup_binlog_info xtrabackup_slave_info
echo "CHANGE MASTER TO MASTER_LOG_FILE='${BASH_REMATCH[1]}',\
MASTER_LOG_POS=${BASH_REMATCH[2]}" > change_master_to.sql.in
fi
# Check if we need to complete a clone by starting replication.
if [[ -f change_master_to.sql.in ]]; then
echo "Waiting for mysqld to be ready (accepting connections)"
until mysql -h 127.0.0.1 -e "SELECT 1"; do sleep 1; done
echo "Initializing replication from clone position"
mysql -h 127.0.0.1 \
-e "$(<change_master_to.sql.in), \
MASTER_HOST='mysql-0.mysql', \
MASTER_USER='root', \
MASTER_PASSWORD='', \
MASTER_CONNECT_RETRY=10; \
START SLAVE;" || exit 1
# In case of container restart, attempt this at-most-once.
mv change_master_to.sql.in change_master_to.sql.orig
fi
# Start a server to send backups when requested by peers.
exec ncat --listen --keep-open --send-only --max-conns=1 3307 -c \
"xtrabackup --backup --slave-info --stream=xbstream --host=127.0.0.1 --user=root"
volumeMounts :
- name : data
mountPath : /var/lib/mysql
subPath : mysql
- name : conf
mountPath : /etc/mysql/conf.d
resources :
requests :
cpu : 100m
memory : 100Mi
volumes :
- name : conf
emptyDir : {}
- name : config-map
configMap :
name : mysql
volumeClaimTemplates :
- metadata :
name : data
spec :
accessModes : ["ReadWriteOnce" ]
resources :
requests :
storage : 10Gi
次のコマンドを実行して起動の進行状況を確認できます。
kubectl get pods -l app = mysql --watch
しばらくすると、3つのPodすべてがRunning状態になるはずです。
NAME READY STATUS RESTARTS AGE
mysql-0 2/2 Running 0 2m
mysql-1 2/2 Running 0 1m
mysql-2 2/2 Running 0 1m
Ctrl+C を押してウォッチをキャンセルします。
起動が進行しない場合は、始める前に で説明されているように、
PersistentVolumeの動的プロビジョニング機能が有効になっていることを確認してください。
このマニフェストでは、StatefulSetの一部としてステートフルなPodを管理するためにさまざまな手法を使用しています。
次のセクションでは、これらの手法のいくつかに焦点を当て、StatefulSetがPodを作成するときに何が起こるかを説明します。
ステートフルなPodの初期化を理解する StatefulSetコントローラーは、序数インデックスの順にPodを一度に1つずつ起動します。
各PodがReady状態を報告するまで待機してから、その次のPodの起動が開始されます。
さらに、コントローラーは各Podに <statefulset-name>-<ordinal-index>という形式の一意で不変の名前を割り当てます。
この例の場合、Podの名前はmysql-0、mysql-1、そしてmysql-2となります。
上記のStatefulSetマニフェスト内のPodテンプレートは、これらのプロパティーを利用して、
MySQLレプリケーションの起動を順序正しく実行します。
構成を生成する Podスペック内のコンテナを起動する前に、Podは最初に
初期化コンテナ を定義された順序で実行します。
最初の初期化コンテナはinit-mysqlという名前で、序数インデックスに基づいて特別なMySQL設定ファイルを生成します。
スクリプトは、hostnameコマンドによって返されるPod名の末尾から抽出することによって、自身の序数インデックスを特定します。
それから、序数を(予約された値を避けるために数値オフセット付きで)MySQLのconf.dディレクトリーのserver-id.cnfというファイルに保存します。
これは、StatefulSetコントローラーによって提供される一意で不変のIDを、同じ特性を必要とするMySQLサーバーIDの領域に変換します。
さらに、init-mysqlコンテナ内のスクリプトは、master.cnfまたはslave.cnfのいずれかを、
ConfigMapから内容をconf.dにコピーすることによって適用します。
このトポロジー例は単一のMySQLマスターと任意の数のスレーブで構成されているため、
スクリプトは単に序数の0がマスターになるように、それ以外のすべてがスレーブになるように割り当てます。
StatefulSetコントローラーによる
デプロイ順序の保証 と組み合わせると、
スレーブが作成される前にMySQLマスターがReady状態になるため、スレーブはレプリケーションを開始できます。
既存データをクローンする 一般に、新しいPodがセットにスレーブとして参加するときは、
MySQLマスターにはすでにデータがあるかもしれないと想定する必要があります。
また、レプリケーションログが期間の先頭まで全て揃っていない場合も想定する必要があります。
これらの控えめな仮定は、実行中のStatefulSetのサイズを初期サイズに固定するのではなく、
時間の経過とともにスケールアップまたはスケールダウンできるようにするために重要です。
2番目の初期化コンテナはclone-mysqlという名前で、スレーブPodが空のPersistentVolumeで最初に起動したときに、
クローン操作を実行します。
つまり、実行中の別のPodから既存のデータをすべてコピーするので、
そのローカル状態はマスターからレプリケーションを開始するのに十分な一貫性があります。
MySQL自体はこれを行うためのメカニズムを提供していないため、この例ではPercona XtraBackupという人気のあるオープンソースツールを使用しています。
クローンの実行中は、ソースとなるMySQLサーバーのパフォーマンスが低下する可能性があります。
MySQLマスターへの影響を最小限に抑えるために、スクリプトは各Podに序数インデックスが自分より1低いPodからクローンするように指示します。
StatefulSetコントローラーは、N+1のPodを開始する前には必ずNのPodがReady状態であることを保証するので、この方法が機能します。
レプリケーションを開始する 初期化コンテナが正常に完了すると、通常のコンテナが実行されます。
MySQLのPodは実際にmysqldサーバーを実行するmysqlコンテナと、
サイドカー
として機能するxtrabackupコンテナから成ります。
xtrabackupサイドカーはクローンされたデータファイルを見て、
スレーブ上でMySQLレプリケーションを初期化する必要があるかどうかを決定します。
もし必要がある場合、mysqldが準備できるのを待ってから、
XtraBackupクローンファイルから抽出されたレプリケーションパラメーターでCHANGE MASTER TOとSTART SLAVEコマンドを実行します。
スレーブがレプリケーションを開始すると、スレーブはMySQLマスターを記憶し、
サーバーが再起動した場合または接続が停止した場合に、自動的に再接続します。
また、スレーブはその不変のDNS名(mysql-0.mysql)でマスターを探すため、
再スケジュールされたために新しいPod IPを取得したとしても、自動的にマスターを見つけます。
最後に、レプリケーションを開始した後、xtrabackupコンテナはデータのクローンを要求する他のPodからの接続を待ち受けます。
StatefulSetがスケールアップした場合や、次のPodがPersistentVolumeClaimを失ってクローンをやり直す必要がある場合に備えて、
このサーバーは無期限に起動したままになります。
クライアントトラフィックを送信する テストクエリーをMySQLマスター(ホスト名 mysql-0.mysql)に送信するには、
mysql:5.7イメージを使って一時的なコンテナを実行し、mysqlクライアントバイナリを実行します。
kubectl run mysql-client --image= mysql:5.7 -i --rm --restart= Never --\
<<EOF
CREATE DATABASE test;
CREATE TABLE test.messages (message VARCHAR(250));
INSERT INTO test.messages VALUES ('hello');
EOF
Ready状態を報告したいずれかのサーバーにテストクエリーを送信するには、ホスト名mysql-readを使用します。
kubectl run mysql-client --image= mysql:5.7 -i -t --rm --restart= Never --\
"SELECT * FROM test.messages"
次のような出力が得られるはずです。
Waiting for pod default/mysql-client to be running, status is Pending, pod ready: false
+---------+
| message |
+---------+
| hello |
+---------+
pod "mysql-client" deleted
mysql-readサービスがサーバー間で接続を分散させることを実証するために、
ループでSELECT @@server_idを実行することができます。
kubectl run mysql-client-loop --image= mysql:5.7 -i -t --rm --restart= Never --\
"while sleep 1; do mysql -h mysql-read -e 'SELECT @@server_id,NOW()'; done"
接続の試行ごとに異なるエンドポイントが選択される可能性があるため、
報告される@@server_idはランダムに変更されるはずです。
+-------------+---------------------+
| @@server_id | NOW() |
+-------------+---------------------+
| 100 | 2006-01-02 15:04:05 |
+-------------+---------------------+
+-------------+---------------------+
| @@server_id | NOW() |
+-------------+---------------------+
| 102 | 2006-01-02 15:04:06 |
+-------------+---------------------+
+-------------+---------------------+
| @@server_id | NOW() |
+-------------+---------------------+
| 101 | 2006-01-02 15:04:07 |
+-------------+---------------------+
ループを止めたいときはCtrl+C を押すことができますが、別のウィンドウで実行したままにしておくことで、
次の手順の効果を確認できます。
PodとNodeのダウンタイムをシミュレーションする 単一のサーバーではなくスレーブのプールから読み取りを行うことによって可用性が高まっていることを実証するため、
Podを強制的にReadyではない状態にする間、上記のSELECT @@server_idループを実行したままにしてください。
Readiness Probeを壊す mysqlコンテナに対する
readiness probe
は、mysql -h 127.0.0.1 -e 'SELECT 1'コマンドを実行することで、サーバーが起動していてクエリーが実行できることを確認します。
このreadiness probeを失敗させる1つの方法は、そのコマンドを壊すことです。
kubectl exec mysql-2 -c mysql -- mv /usr/bin/mysql /usr/bin/mysql.off
ここでは、mysql-2 Podの実際のコンテナのファイルシステムにアクセスし、
mysqlコマンドの名前を変更してreadiness probeがコマンドを見つけられないようにしています。
数秒後、Podはそのコンテナの1つがReadyではないと報告するはずです。以下を実行して確認できます。
READY列の1/2を見てください。
NAME READY STATUS RESTARTS AGE
mysql-2 1/2 Running 0 3m
この時点で、SELECT @@server_idループは実行され続け、しかしもう102が報告されないことが確認できるはずです。
init-mysqlスクリプトがserver-idを100+$ordinalとして定義したことを思い出して下さい。
そのため、サーバーID102はPodのmysql-2に対応します。
それではPodを修復しましょう。すると数秒後にループ出力に再び現れるはずです。
kubectl exec mysql-2 -c mysql -- mv /usr/bin/mysql.off /usr/bin/mysql
Podを削除する StatefulSetは、Podが削除された場合にPodを再作成します。
これはReplicaSetがステートレスなPodに対して行うのと同様です。
kubectl delete pod mysql-2
StatefulSetコントローラーはmysql-2 Podがもう存在しないことに気付き、
同じ名前で同じPersistentVolumeClaimにリンクされた新しいPodを作成します。
サーバーID102がしばらくの間ループ出力から消えて、また元に戻るのが確認できるはずです。
ノードをdrainする Kubernetesクラスターに複数のノードがある場合は、
drain を発行して
ノードのダウンタイム(例えばノードのアップグレード時など)をシミュレートできます。
まず、あるMySQL Podがどのノード上にいるかを確認します。
kubectl get pod mysql-2 -o wide
ノード名が最後の列に表示されるはずです。
NAME READY STATUS RESTARTS AGE IP NODE
mysql-2 2/2 Running 0 15m 10.244.5.27 kubernetes-minion-group-9l2t
その後、次のコマンドを実行してノードをdrainします。
これにより、新しいPodがそのノードにスケジュールされないようにcordonされ、そして既存のPodは強制退去されます。
<node-name>は前のステップで確認したノードの名前に置き換えてください。
この操作はノード上の他のアプリケーションに影響を与える可能性があるため、
テストクラスターでのみこの操作を実行 するのが最善です。
kubectl drain <node-name> --force --delete-local-data --ignore-daemonsets
Podが別のノードに再スケジュールされる様子を確認しましょう。
kubectl get pod mysql-2 -o wide --watch
次のような出力が見られるはずです。
NAME READY STATUS RESTARTS AGE IP NODE
mysql-2 2/2 Terminating 0 15m 10.244.1.56 kubernetes-minion-group-9l2t
[...]
mysql-2 0/2 Pending 0 0s <none> kubernetes-minion-group-fjlm
mysql-2 0/2 Init:0/2 0 0s <none> kubernetes-minion-group-fjlm
mysql-2 0/2 Init:1/2 0 20s 10.244.5.32 kubernetes-minion-group-fjlm
mysql-2 0/2 PodInitializing 0 21s 10.244.5.32 kubernetes-minion-group-fjlm
mysql-2 1/2 Running 0 22s 10.244.5.32 kubernetes-minion-group-fjlm
mysql-2 2/2 Running 0 30s 10.244.5.32 kubernetes-minion-group-fjlm
また、サーバーID102がSELECT @@server_idループの出力からしばらくの消えて、
そして戻ることが確認できるはずです。
それでは、ノードをuncordonして正常な状態に戻しましょう。
kubectl uncordon <node-name>
スレーブの数をスケーリングする MySQLレプリケーションでは、スレーブを追加することで読み取りクエリーのキャパシティーをスケールできます。
StatefulSetを使用している場合、単一のコマンドでこれを実行できます。
kubectl scale statefulset mysql --replicas= 5
次のコマンドを実行して、新しいPodが起動してくるのを確認します。
kubectl get pods -l app = mysql --watch
新しいPodが起動すると、サーバーID103と104がSELECT @@server_idループの出力に現れます。
また、これらの新しいサーバーが、これらのサーバーが存在する前に追加したデータを持っていることを確認することもできます。
kubectl run mysql-client --image= mysql:5.7 -i -t --rm --restart= Never --\
"SELECT * FROM test.messages"
Waiting for pod default/mysql-client to be running, status is Pending, pod ready: false
+---------+
| message |
+---------+
| hello |
+---------+
pod "mysql-client" deleted
元の状態へのスケールダウンもシームレスに可能です。
kubectl scale statefulset mysql --replicas= 3
ただし、スケールアップすると新しいPersistentVolumeClaimが自動的に作成されますが、
スケールダウンしてもこれらのPVCは自動的には削除されないことに注意して下さい。
このため、初期化されたPVCをそのまま置いておいくことで再スケールアップを速くしたり、
PVを削除する前にデータを抽出するといった選択が可能になります。
次のコマンドを実行してこのことを確認できます。
kubectl get pvc -l app = mysql
StatefulSetを3にスケールダウンしたにもかかわらず、5つのPVCすべてがまだ存在しています。
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
data-mysql-0 Bound pvc-8acbf5dc-b103-11e6-93fa-42010a800002 10Gi RWO 20m
data-mysql-1 Bound pvc-8ad39820-b103-11e6-93fa-42010a800002 10Gi RWO 20m
data-mysql-2 Bound pvc-8ad69a6d-b103-11e6-93fa-42010a800002 10Gi RWO 20m
data-mysql-3 Bound pvc-50043c45-b1c5-11e6-93fa-42010a800002 10Gi RWO 2m
data-mysql-4 Bound pvc-500a9957-b1c5-11e6-93fa-42010a800002 10Gi RWO 2m
余分なPVCを再利用するつもりがないのであれば、削除することができます。
kubectl delete pvc data-mysql-3
kubectl delete pvc data-mysql-4
クリーンアップ SELECT @@server_idループを実行している端末でCtrl+C を押すか、
別の端末から次のコマンドを実行して、ループをキャンセルします。
kubectl delete pod mysql-client-loop --now
StatefulSetを削除します。これによってPodの終了も開始されます。
kubectl delete statefulset mysql
Podが消えたことを確認します。
Podが終了処理が完了するのには少し時間がかかるかもしれません。
kubectl get pods -l app = mysql
上記のコマンドから以下の出力が戻れば、Podが終了したことがわかります。
No resources found.
ConfigMap、Services、およびPersistentVolumeClaimを削除します。
kubectl delete configmap,service,pvc -l app = mysql
PersistentVolumeを手動でプロビジョニングした場合は、それらを手動で削除し、
また、下層にあるリソースも解放する必要があります。
動的プロビジョニング機能を使用した場合は、PersistentVolumeClaimを削除すれば、自動的にPersistentVolumeも削除されます。
一部の動的プロビジョナー(EBSやPDなど)は、PersistentVolumeを削除すると同時に下層にあるリソースも解放します。
次の項目 4.8.4 - StatefulSetのスケール このタスクは、StatefulSetをスケールする方法を示します。StatefulSetをスケーリングするとは、レプリカの数を増減することです。
始める前に StatefulSetはKubernetesバージョン1.5以降でのみ利用可能です。
Kubernetesのバージョンを確認するには、kubectl versionを実行してください。
すべてのステートフルアプリケーションがうまくスケールできるわけではありません。StatefulSetがスケールするかどうかわからない場合は、StatefulSetの概念 またはStatefulSetのチュートリアル を参照してください。
ステートフルアプリケーションクラスターが完全に健全であると確信できる場合にのみ、スケーリングを実行してください。
StatefulSetのスケール kubectlを使用したStatefulSetのスケール まず、スケールしたいStatefulSetを見つけます。
kubectl get statefulsets <stateful-set-name>
StatefulSetのレプリカ数を変更します:
kubectl scale statefulsets <stateful-set-name> --replicas= <new-replicas>
StatefulSetのインプレースアップデート コマンドライン上でレプリカ数を変更する代わりに、StatefulSetにインプレースアップデート が可能です。
StatefulSetが最初に kubectl applyで作成されたのなら、StatefulSetマニフェストの.spec.replicasを更新してから、kubectl applyを実行します:
kubectl apply -f <stateful-set-file-updated>
そうでなければ、kubectl editでそのフィールドを編集してください:
kubectl edit statefulsets <stateful-set-name>
あるいはkubectl patchを使ってください:
kubectl patch statefulsets <stateful-set-name> -p '{"spec":{"replicas":<new-replicas>}}'
トラブルシューティング スケールダウンがうまくいかない 管理するステートフルPodのいずれかが異常である場合、StatefulSetをスケールダウンすることはできません。それらのステートフルPodが実行され準備ができた後にのみ、スケールダウンが行われます。
spec.replicas > 1の場合、Kubernetesは不健康なPodの理由を判断できません。それは、永続的な障害または一時的な障害の結果である可能性があります。一時的な障害は、アップグレードまたはメンテナンスに必要な再起動によって発生する可能性があります。
永続的な障害が原因でPodが正常でない場合、障害を修正せずにスケーリングすると、StatefulSetメンバーシップが正しく機能するために必要な特定の最小レプリカ数を下回る状態になる可能性があります。これにより、StatefulSetが利用できなくなる可能性があります。
一時的な障害によってPodが正常でなくなり、Podが再び使用可能になる可能性がある場合は、一時的なエラーがスケールアップまたはスケールダウン操作の妨げになる可能性があります。一部の分散データベースでは、ノードが同時に参加および脱退するときに問題があります。このような場合は、アプリケーションレベルでスケーリング操作を考えることをお勧めします。また、ステートフルアプリケーションクラスターが完全に健全であることが確実な場合にのみスケーリングを実行してください。
次の項目 4.8.5 - StatefulSetの削除 このタスクでは、StatefulSet を削除する方法を説明します。
始める前に このタスクは、クラスター上で、StatefulSetで表現されるアプリケーションが実行されていることを前提としています。 StatefulSetの削除 Kubernetesで他のリソースを削除するのと同じ方法でStatefulSetを削除することができます。つまり、kubectl deleteコマンドを使い、StatefulSetをファイルまたは名前で指定します。
kubectl delete -f <file.yaml>
kubectl delete statefulsets <statefulset-name>
StatefulSet自体が削除された後で、関連するヘッドレスサービスを個別に削除する必要があるかもしれません。
kubectl delete service <service-name>
kubectlを使ってStatefulSetを削除すると0にスケールダウンされ、すべてのPodが削除されます。PodではなくStatefulSetだけを削除したい場合は、--cascade=orphanを使用してください。
kubectl delete -f <file.yaml> --cascade= orphan
--cascade=orphanをkubectl deleteに渡すことで、StatefulSetオブジェクト自身が削除された後でも、StatefulSetによって管理されていたPodは残ります。Podにapp.kubernetes.io/name=MyAppというラベルが付いている場合は、次のようにして削除できます:
kubectl delete pods -l app.kubernetes.io/name= MyApp
永続ボリューム StatefulSet内のPodを削除しても、関連付けられているボリュームは削除されません。これは、削除する前にボリュームからデータをコピーする機会があることを保証するためです。Podが終了した後にPVCを削除すると、ストレージクラスと再利用ポリシーによっては、背後にある永続ボリュームの削除がトリガーされることがあります。決してクレーム削除後にボリュームにアクセスできると想定しないでください。
備考: データを損失する可能性があるため、PVCを削除するときは注意してください。StatefulSetの完全削除 関連付けられたPodを含むStatefulSet内のすべてのものを単純に削除するには、次のような一連のコマンドを実行します:
grace = $( kubectl get pods <stateful-set-pod> --template '{{.spec.terminationGracePeriodSeconds}}' )
kubectl delete statefulset -l app.kubernetes.io/name= MyApp
sleep $grace
kubectl delete pvc -l app.kubernetes.io/name= MyApp
上の例では、Podはapp.kubernetes.io/name=MyAppというラベルを持っています。必要に応じてご利用のラベルに置き換えてください。
StatefulSet Podの強制削除 StatefulSet内の一部のPodが長期間TerminatingまたはUnknown状態のままになっていることが判明した場合は、手動でapiserverからPodを強制的に削除する必要があります。これは潜在的に危険な作業です。詳細はStatefulSet Podの強制削除 を参照してください。
次の項目 StatefulSet Podの強制削除 の詳細。
4.8.6 - StatefulSet Podの強制削除 このページでは、StatefulSetの一部であるPodを削除する方法と、削除する際に考慮すべき事項について説明します。
始める前に これはかなり高度なタスクであり、StatefulSetに固有のいくつかの特性に反する可能性があります。 先に進む前に、以下に列挙されている考慮事項をよく理解してください。 StatefulSetに関する考慮事項 StatefulSetの通常の操作では、StatefulSet Podを強制的に削除する必要はまったく ありません。StatefulSetコントローラーは、StatefulSetのメンバーの作成、スケール、削除を行います。それは序数0からN-1までの指定された数のPodが生きていて準備ができていることを保証しようとします。StatefulSetは、クラスター内で実行されている特定のIDを持つ最大1つのPodがいつでも存在することを保証します。これは、StatefulSetによって提供される最大1つの セマンティクスと呼ばれます。
手動による強制削除は、StatefulSetに固有の最大1つのセマンティクスに違反する可能性があるため、慎重に行う必要があります。StatefulSetを使用して、安定したネットワークIDと安定した記憶域を必要とする分散型およびクラスター型アプリケーションを実行できます。これらのアプリケーションは、固定IDを持つ固定数のメンバーのアンサンブルに依存する構成を持つことがよくあります。同じIDを持つ複数のメンバーを持つことは悲惨なことになり、データの損失につながる可能性があります(例:定足数ベースのシステムでのスプリットブレインシナリオ)。
Podの削除 次のコマンドで正常なPod削除を実行できます:
kubectl delete pods <pod>
上記がグレースフルターミネーションにつながるためには、pod.Spec.TerminationGracePeriodSecondsに0を指定してはいけません 。pod.Spec.TerminationGracePeriodSecondsを0秒に設定することは安全ではなく、StatefulSet Podには強くお勧めできません。グレースフル削除は安全で、kubeletがapiserverから名前を削除する前にPodが適切にシャットダウンする ことを保証します。
Kubernetes(バージョン1.5以降)は、Nodeにアクセスできないという理由だけでPodを削除しません。到達不能なNodeで実行されているPodは、タイムアウト の後にTerminatingまたはUnknown状態になります。到達不能なNode上のPodをユーザーが適切に削除しようとすると、Podはこれらの状態に入ることもあります。そのような状態のPodをapiserverから削除することができる唯一の方法は以下の通りです:
(ユーザーまたはNode Controller によって)Nodeオブジェクトが削除されます。 応答していないNodeのkubeletが応答を開始し、Podを終了してapiserverからエントリーを削除します。 ユーザーによりPodを強制削除します。 推奨されるベストプラクティスは、1番目または2番目のアプローチを使用することです。Nodeが死んでいることが確認された(例えば、ネットワークから恒久的に切断された、電源が切られたなど)場合、Nodeオブジェクトを削除します。Nodeがネットワークパーティションに苦しんでいる場合は、これを解決するか、解決するのを待ちます。パーティションが回復すると、kubeletはPodの削除を完了し、apiserverでその名前を解放します。
通常、PodがNode上で実行されなくなるか、管理者によってそのNodeが削除されると、システムは削除を完了します。あなたはPodを強制的に削除することでこれを無効にすることができます。
強制削除 強制削除はPodが終了したことをkubeletから確認するまで待ちません 。強制削除がPodの削除に成功したかどうかに関係なく、apiserverから名前をすぐに解放します。これにより、StatefulSetコントローラーは、同じIDを持つ交換Podを作成できます。これは、まだ実行中のPodの複製につながる可能性があり、そのPodがまだStatefulSetの他のメンバーと通信できる場合、StatefulSetが保証するように設計されている最大1つのセマンティクスに違反します。
StatefulSetのPodを強制的に削除するということは、問題のPodがStatefulSet内の他のPodと再び接触することはなく、代わりのPodを作成するために名前が安全に解放されることを意味します。
バージョン1.5以上のkubectlを使用してPodを強制的に削除する場合は、次の手順を実行します:
kubectl delete pods <pod> --grace-period= 0 --force
バージョン1.4以下のkubectlを使用している場合、--forceオプションを省略する必要があります:
kubectl delete pods <pod> --grace-period= 0
これらのコマンドを実行した後でもPodがUnknown状態のままになっている場合は、次のコマンドを使用してPodをクラスターから削除します:
kubectl patch pod <pod> -p '{"metadata":{"finalizers":null}}'
StatefulSet Podの強制削除は、常に慎重に、関連するリスクを完全に把握して実行してください。
次の項目 StatefulSetのデバッグ の詳細
4.8.7 - 水平Pod自動スケーリング Kubernetesでは、 HorizontalPodAutoscaler は自動的にワークロードリソース(Deployment やStatefulSet など)を更新し、ワークロードを自動的にスケーリングして需要に合わせることを目指します。
水平スケーリングとは、負荷の増加に対応するために、より多くのPod をデプロイすることを意味します。これは、Kubernetesの場合、既に稼働しているワークロードのPodに対して、より多くのリソース(例:メモリーやCPU)を割り当てることを意味する 垂直 スケーリングとは異なります。
負荷が減少し、Podの数が設定された最小値より多い場合、HorizontalPodAutoscalerはワークロードリソース(Deployment、StatefulSet、または他の類似のリソース)に対してスケールダウンするよう指示します。
水平Pod自動スケーリングは、スケーリングできないオブジェクト(例:DaemonSet )には適用されません。
HorizontalPodAutoscalerは、Kubernetes APIリソースとコントローラー として実装されています。リソースはコントローラーの動作を決定します。Kubernetesコントロールプレーン 内で稼働している水平Pod自動スケーリングコントローラーは、平均CPU利用率、平均メモリー利用率、または指定した任意のカスタムメトリクスなどの観測メトリクスに合わせて、ターゲット(例:Deployment)の理想的なスケールを定期的に調整します。
水平Pod自動スケーリングの使用例のウォークスルー があります。
HorizontalPodAutoscalerの仕組みは? graph BT
hpa[Horizontal Pod Autoscaler] --> scale[Scale]
subgraph rc[Deployment]
scale
end
scale -.-> pod1[Pod 1]
scale -.-> pod2[Pod 2]
scale -.-> pod3[Pod N]
classDef hpa fill:#D5A6BD,stroke:#1E1E1D,stroke-width:1px,color:#1E1E1D;
classDef rc fill:#F9CB9C,stroke:#1E1E1D,stroke-width:1px,color:#1E1E1D;
classDef scale fill:#B6D7A8,stroke:#1E1E1D,stroke-width:1px,color:#1E1E1D;
classDef pod fill:#9FC5E8,stroke:#1E1E1D,stroke-width:1px,color:#1E1E1D;
class hpa hpa;
class rc rc;
class scale scale;
class pod1,pod2,pod3 pod
このコンテンツを表示するには、JavaScriptを有効に する必要があります 図1. HorizontalPodAutoscalerはDeploymentとそのReplicaSetのスケールを制御します。
Kubernetesは水平Pod自動スケーリングを断続的に動作する制御ループとして実装しています(これは連続的なプロセスではありません)。その間隔はkube-controller-manager--horizontal-pod-autoscaler-sync-periodパラメーターで設定します(デフォルトの間隔は15秒です)。
各期間中に1回、コントローラーマネージャーはHorizontalPodAutoscalerの定義のそれぞれに指定されたメトリクスに対するリソース使用率を照会します。コントローラーマネージャーはscaleTargetRefによって定義されたターゲットリソースを見つけ、ターゲットリソースの.spec.selectorラベルに基づいてPodを選択し、リソースメトリクスAPI(Podごとのリソースメトリクスの場合)またはカスタムメトリクスAPI(他のすべてのメトリクスの場合)からメトリクスを取得します。
Podごとのリソースメトリクス(CPUなど)の場合、コントローラーはHorizontalPodAutoscalerによってターゲットとされた各PodのリソースメトリクスAPIからメトリクスを取得します。その後、使用率の目標値が設定されている場合、コントローラーは各Pod内のコンテナの同等のリソース要求 に対する割合として使用率を算出します。生の値の目標値が設定されている場合、生のメトリクス値が直接使用されます。次に、コントローラーはすべてのターゲットとなるPod間で使用率または生の値(指定されたターゲットのタイプによります)の平均を取り、理想のレプリカ数でスケールするために使用される比率を生成します。
Podのコンテナの一部に関連するリソース要求が設定されていない場合、PodのCPU利用率は定義されず、オートスケーラーはそのメトリクスに対して何も行動を起こしません。オートスケーリングアルゴリズムの動作についての詳細は、以下のアルゴリズムの詳細 をご覧ください。
Podごとのカスタムメトリクスについては、コントローラーはPodごとのリソースメトリクスと同様に機能しますが、使用率の値ではなく生の値で動作します。
オブジェクトメトリクスと外部メトリクスについては、問題となるオブジェクトを表す単一のメトリクスが取得されます。このメトリクスは目標値と比較され、上記のような比率を生成します。autoscaling/v2 APIバージョンでは、比較を行う前にこの値をPodの数で割ることもできます。
HorizontalPodAutoscalerを使用する一般的な目的は、集約API (metrics.k8s.io、custom.metrics.k8s.io、またはexternal.metrics.k8s.io)からメトリクスを取得するように設定することです。metrics.k8s.io APIは通常、別途起動する必要があるMetrics Serverというアドオンによって提供されます。リソースメトリクスについての詳細は、Metrics Server をご覧ください。
メトリクスAPIのサポート は、これらの異なるAPIの安定性の保証とサポート状況を説明します。
HorizontalPodAutoscalerコントローラーは、スケーリングをサポートするワークロードリソース(DeploymentやStatefulSetなど)にアクセスします。これらのリソースはそれぞれscaleというサブリソースを持っており、これはレプリカの数を動的に設定し、各々の現在の状態を調べることができるインターフェースを提供します。Kubernetes APIのサブリソースに関する一般的な情報については、Kubernetes API Concepts をご覧ください。
アルゴリズムの詳細 最も基本的な観点から言えば、HorizontalPodAutoscalerコントローラーは、理想のメトリクス値と現在のメトリクス値との間の比率で動作します:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
たとえば、現在のメトリクス値が200mで、理想の値が100mの場合、レプリカの数は倍増します。なぜなら、200.0 / 100.0 == 2.0だからです。現在の値が50mの場合、レプリカの数は半分になります。なぜなら、50.0 / 100.0 == 0.5だからです。コントロールプレーンは、比率が十分に1.0に近い場合(全体的に設定可能な許容範囲内、デフォルトでは0.1)には、任意のスケーリング操作をスキップします。
targetAverageValueまたはtargetAverageUtilizationが指定されている場合、currentMetricValueは、HorizontalPodAutoscalerのスケールターゲット内のすべてのPodで指定されたメトリクスの平均を取ることで計算されます。
許容範囲を確認し、最終的な値を決定する前に、コントロールプレーンは、メトリクスが欠けていないか、また何個のPodがReady
特定のPodがメトリクスを欠いている場合、それは後で検討するために取っておかれます。メトリクスが欠けているPodは、最終的なスケーリング量の調整に使用されます。
CPUに基づいてスケーリングする場合、任意のPodがまだReadyになっていない(まだ初期化中か、おそらくunhealthy)、または PodがReadyになる前の最新のメトリクスポイントがある場合、そのPodも取り置かれます。
技術的な制約により、HorizontalPodAutoscalerコントローラーは特定のCPUメトリクスを取り置くかどうかを判断する際に、Podが初めてReadyになる時間を正確に決定することができません。その代わり、Podが起動してから設定可能な短い時間内にReadyに遷移した場合、それを「まだReadyになっていない」とみなします。この値は、--horizontal-pod-autoscaler-initial-readiness-delayフラグで設定し、デフォルトは30秒です。Podが一度Readyになると、起動してから設定可能な長い時間内に発生した場合、それが最初のReadyへの遷移だとみなします。この値は、--horizontal-pod-autoscaler-cpu-initialization-periodフラグで設定し、デフォルトは5分です。
次に、上記で取り置かれたり破棄されたりしていない残りのPodを使用して、currentMetricValue / desiredMetricValueの基本スケール比率が計算されます。
メトリクスが欠けていた場合、コントロールプレーンは平均値をより保守的に再計算し、スケールダウンの場合はそのPodが理想の値の100%を消費していたと仮定し、スケールアップの場合は0%を消費していたと仮定します。これにより、潜在的なスケールの大きさが抑制されます。
さらに、まだReadyになっていないPodが存在し、欠けているメトリクスやまだReadyになっていないPodを考慮せずにワークロードがスケールアップした場合、コントローラーは保守的にまだReadyになっていないPodが理想のメトリクスの0%を消費していると仮定し、スケールアップの大きさをさらに抑制します。
まだReadyになっていないPodと欠けているメトリクスを考慮に入れた後、コントローラーは使用率の比率を再計算します。新しい比率がスケールの方向を逆転させるか、許容範囲内である場合、コントローラーはスケーリング操作を行いません。その他の場合、新しい比率がPodの数の変更を決定するために使用されます。
新しい使用率の比率が使用されたときであっても、平均使用率の元の値は、まだReadyになっていないPodや欠けているメトリクスを考慮せずに、HorizontalPodAutoscalerのステータスを通じて報告されることに注意してください。
HorizontalPodAutoscalerに複数のメトリクスが指定されている場合、この計算は各メトリクスに対して行われ、その後、理想のレプリカ数の最大値が選択されます。これらのメトリクスのいずれかを理想のレプリカ数に変換できない場合(例えば、メトリクスAPIからのメトリクスの取得エラーが原因)、そして取得可能なメトリクスがスケールダウンを提案する場合、スケーリングはスキップされます。これは、1つ以上のメトリクスが現在の値よりも大きなdesiredReplicasを示す場合でも、HPAはまだスケーリングアップ可能であることを意味します。
最後に、HPAがターゲットを減らす直前に、減らす台数の推奨値が記録されます。コントローラーは、設定可能な時間内のすべての推奨値を考慮し、その時間内で最も高い推奨値を選択します。この値は、--horizontal-pod-autoscaler-downscale-stabilizationフラグを使用して設定でき、デフォルトは5分です。これは、スケールダウンが徐々に行われ、急速に変動するメトリクス値の影響を滑らかにすることを意味します。
APIオブジェクト Horizontal Pod Autoscalerは、Kubernetesのautoscaling APIグループのAPIリソースです。現行の安定バージョンは、メモリーおよびカスタムメトリクスに対するスケーリングのサポートを含むautoscaling/v2 APIバージョンに見つけることができます。autoscaling/v2で導入された新たなフィールドは、autoscaling/v1で作業する際にアノテーションとして保持されます。
HorizontalPodAutoscaler APIオブジェクトを作成するときは、指定された名前が有効なDNSサブドメイン名 であることを確認してください。APIオブジェクトについての詳細は、HorizontalPodAutoscaler Object で見つけることができます。
ワークロードスケールの安定性 HorizontalPodAutoscalerを使用してレプリカ群のスケールを管理する際、評価されるメトリクスの動的な性質により、レプリカの数が頻繁に変動する可能性があります。これは、スラッシング または フラッピング と呼ばれることがあります。これは、サイバネティクス における ヒステリシス の概念に似ています。
ローリングアップデート中の自動スケーリング Kubernetesでは、Deploymentに対してローリングアップデートを行うことができます。その場合、Deploymentが基礎となるReplicaSetを管理します。Deploymentに自動スケーリングを設定すると、HorizontalPodAutoscalerを単一のDeploymentに結びつけます。HorizontalPodAutoscalerはDeploymentのreplicasフィールドを管理します。Deploymentコントローラーは、ロールアウト時およびその後も適切な数になるように、基礎となるReplicaSetのreplicasを設定する責任があります。
自動スケールされたレプリカ数を持つStatefulSetのローリングアップデートを実行する場合、StatefulSetは直接そのPodのセットを管理します(ReplicaSetのような中間リソースは存在しません)。
リソースメトリクスのサポート HPAの任意のターゲットは、スケーリングターゲット内のPodのリソース使用状況に基づいてスケールすることができます。Podの仕様を定義する際には、cpuやmemoryなどのリソース要求を指定する必要があります。これはリソースの使用状況を決定するために使用され、HPAコントローラーがターゲットをスケールアップまたはスケールダウンするために使用されます。リソース使用状況に基づくスケーリングを使用するには、以下のようなメトリクスソースを指定します:
type : Resource
resource :
name : cpu
target :
type : Utilization
averageUtilization : 60
このメトリクスを使用すると、HPAコントローラーはスケーリングターゲット内のPodの平均使用率を60%に保ちます。使用率は、Podの要求したリソースに対する現在のリソース使用量の比率です。使用率がどのように計算され、平均化されるかの詳細については、アルゴリズム を参照してください。
備考: 全てのコンテナのリソース使用量が合算されるため、全体のPodの利用率は個々のコンテナのリソース使用量を正確に反映しないかもしれません。これにより、単一のコンテナが高い使用率で稼働していても、全体のPodの使用率が依然として許容範囲内であるため、HPAがスケールアウトしない状況が生じる可能性があります。コンテナリソースメトリクス FEATURE STATE:
Kubernetes v1.27 [beta]
HorizontalPodAutoscaler APIは、コンテナメトリクスソースもサポートしています。これは、ターゲットリソースをスケールするために、HPAが一連のPod内の個々のコンテナのリソース使用状況を追跡できるようにするものです。これにより、特定のPodで最も重要なコンテナのスケーリング閾値を設定することができます。例えば、Webアプリケーションとロギングサイドカーがある場合、サイドカーのコンテナとそのリソース使用を無視して、Webアプリケーションのリソース使用に基づいてスケーリングすることができます。
ターゲットリソースを新しいPodの仕様に修正し、異なるコンテナのセットを持つようにした場合、新たに追加されたコンテナもスケーリングに使用されるべきであれば、HPAの仕様も修正すべきです。メトリクスソースで指定されたコンテナが存在しないか、または一部のPodのみに存在する場合、それらのPodは無視され、推奨が再計算されます。計算に関する詳細は、アルゴリズム を参照してください。コンテナリソースを自動スケーリングに使用するためには、以下のようにメトリクスソースを定義します:
type : ContainerResource
containerResource :
name : cpu
container : application
target :
type : Utilization
averageUtilization : 60
上記の例では、HPAコントローラーはターゲットをスケールし、すべてのPodのapplicationコンテナ内のCPUの平均使用率が60%になるようにします。
備考: HorizontalPodAutoscalerが追跡しているコンテナの名前を変更する場合、特定の順序でその変更を行うことで、変更が適用されている間も、スケーリングが利用可能で有効なままであることが保証されます。コンテナを定義するリソース(Deploymentなど)を更新する前に、関連するHPAを更新して新旧のコンテナ名を両方追跡するようにします。これにより、HPAはアップデートプロセス全体でスケーリングの推奨を計算することができます。
コンテナ名の変更をワークロードリソースにロールアウトしたら、HPAの仕様から古いコンテナ名を削除して片付けます。
カスタムメトリクスでのスケーリング FEATURE STATE:
Kubernetes v1.23 [stable]
(以前のautoscaling/v2beta2 APIバージョンでは、これをベータ機能として提供していました)
autoscaling/v2 APIバージョンを使用することで、HorizontalPodAutoscalerをカスタムメトリクス(KubernetesまたはKubernetesのコンポーネントに組み込まれていない)に基づいてスケールするように設定することができます。その後、HorizontalPodAutoscalerコントローラーはこれらのカスタムメトリクスをKubernetes APIからクエリします。
要件については、メトリクスAPIのサポート を参照してください。
複数メトリクスでのスケーリング FEATURE STATE:
Kubernetes v1.23 [stable]
(以前のautoscaling/v2beta2 APIバージョンでは、これをベータ機能として提供していました)
autoscaling/v2 APIバージョンを使用することで、HorizontalPodAutoscalerがスケールするための複数のメトリクスを指定することができます。その後、HorizontalPodAutoscalerコントローラーは各メトリクスを評価し、そのメトリクスに基づいた新しいスケールを提案します。HorizontalPodAutoscalerは、各メトリクスで推奨される最大のスケールを取得し、そのサイズにワークロードを設定します(ただし、これが設定した全体の最大値を超えていないことが前提です)。
メトリクスAPIのサポート デフォルトでは、HorizontalPodAutoscalerコントローラーは一連のAPIからメトリクスを取得します。これらのAPIにアクセスするためには、クラスター管理者が以下を確認する必要があります:
API集約レイヤー が有効になっていること。
対応するAPIが登録されていること:
リソースメトリクスの場合、これは一般的にmetrics-server によって提供されるmetrics.k8s.io APIです。クラスターの追加機能として起動することができます。
カスタムメトリクスの場合、これはcustom.metrics.k8s.io APIです。これはメトリクスソリューションベンダーが提供する「アダプター」APIサーバーによって提供されます。利用可能なKubernetesメトリクスアダプターがあるかどうかは、メトリクスパイプラインで確認してください。
外部メトリクスの場合、これはexternal.metrics.k8s.io APIです。これは上記のカスタムメトリクスアダプターによって提供される可能性があります。
これらの異なるメトリクスパスとその違いについての詳細は、HPA V2 、custom.metrics.k8s.io 、およびexternal.metrics.k8s.io の関連デザイン提案をご覧ください。
これらの使用方法の例については、カスタムメトリクスの使用方法 と外部メトリクスの使用方法 をご覧ください。
設定可能なスケーリング動作 FEATURE STATE:
Kubernetes v1.23 [stable]
(以前のautoscaling/v2beta2 APIバージョンでは、これをベータ機能として提供していました)
v2 HorizontalPodAutoscaler APIを使用する場合、behaviorフィールド(APIリファレンス を参照)を使用して、スケールアップとスケールダウンの振る舞いを個別に設定することができます。これらの振る舞いは、behaviorフィールドの下でscaleUpおよび/またはscaleDownを設定することにより指定します。
スケーリングターゲットのレプリカ数のフラッピング を防ぐための 安定化ウィンドウ を指定することができます。また、スケーリングポリシーにより、スケーリング中のレプリカの変化率を制御することもできます。
スケーリングポリシー 1つ以上のスケーリングポリシーをspecのbehaviorセクションで指定することができます。複数のポリシーが指定された場合、デフォルトで最も多くの変更を許可するポリシーが選択されます。次の例は、スケールダウンする際のこの振る舞いを示しています:
behavior :
scaleDown :
policies :
- type : Pods
value : 4
periodSeconds : 60
- type : Percent
value : 10
periodSeconds : 60
periodSecondsは、ポリシーが真でなければならない過去の時間を示します。最初のポリシー(Pods )では、1分間で最大4つのレプリカをスケールダウンできます。2つ目のポリシー(Percent )では、1分間で現在のレプリカの最大10%をスケールダウンできます。
デフォルトでは、最も多くの変更を許可するポリシーが選択されるため、2つ目のポリシーはPodのレプリカの数が40を超える場合にのみ使用されます。40レプリカ以下の場合、最初のポリシーが適用されます。例えば、レプリカが80あり、ターゲットを10レプリカにスケールダウンしなければならない場合、最初のステップでは8レプリカが減少します。次のイテレーションでは、レプリカの数が72で、ポッドの10%は7.2ですが、数値は8に切り上げられます。オートスケーラーコントローラーの各ループで、変更するべきPodの数は現在のレプリカの数に基づいて再計算されます。レプリカの数が40以下になると、最初のポリシー(Pods )が適用され、一度に4つのレプリカが減少します。
ポリシーの選択は、スケーリング方向のselectPolicyフィールドを指定することで変更できます。この値をMinに設定すると、レプリカ数の最小変化を許可するポリシーが選択されます。この値をDisabledに設定すると、その方向へのスケーリングが完全に無効になります。
安定化ウィンドウ 安定化ウィンドウは、スケーリングに使用されるメトリクスが常に変動する場合のレプリカ数のフラッピング を制限するために使用されます。自動スケーリングアルゴリズムは、このウィンドウを使用して以前の望ましい状態を推測し、ワークロードスケールへの望ましくない変更を避けます。
例えば、次の例のスニペットでは、scaleDownに対して安定化ウィンドウが指定されています。
behavior :
scaleDown :
stabilizationWindowSeconds : 300
メトリクスがターゲットをスケールダウンすべきであることを示すと、アルゴリズムは以前に計算された望ましい状態を探し、指定された間隔から最高値を使用します。上記の例では、過去5分間のすべての望ましい状態が考慮されます。
これは移動最大値を近似し、スケーリングアルゴリズムが頻繁にPodを削除して、わずかな時間後に同等のPodの再作成をトリガーするのを防ぎます。
デフォルトの動作 カスタムスケーリングを使用するためには、全てのフィールドを指定する必要はありません。カスタマイズが必要な値のみを指定することができます。これらのカスタム値はデフォルト値とマージされます。デフォルト値はHPAアルゴリズムの既存の動作と一致します。
behavior :
scaleDown :
stabilizationWindowSeconds : 300
policies :
- type : Percent
value : 100
periodSeconds : 15
scaleUp :
stabilizationWindowSeconds : 0
policies :
- type : Percent
value : 100
periodSeconds : 15
- type : Pods
value : 4
periodSeconds : 15
selectPolicy : Max
スケールダウンの場合、安定化ウィンドウは300秒(--horizontal-pod-autoscaler-downscale-stabilizationフラグが指定されている場合はその値)です。スケールダウンのための単一のポリシーがあり、現在稼働しているレプリカの100%を削除することが許可されています。これは、スケーリングターゲットが最小許容レプリカ数まで縮小されることを意味します。スケールアップの場合、安定化ウィンドウはありません。メトリクスがターゲットをスケールアップするべきであることを示すと、ターゲットはすぐにスケールアップされます。2つのポリシーがあり、HPAが安定状態に達するまで、最大で15秒ごとに4つのポッドまたは現在稼働しているレプリカの100%が追加されます。
例: ダウンスケール安定化ウィンドウの変更 1分間のカスタムダウンスケール安定化ウィンドウを提供するには、HPAに以下の動作を追加します:
behavior :
scaleDown :
stabilizationWindowSeconds : 60
例: スケールダウン率の制限 HPAによるPodの除去率を毎分10%に制限するには、HPAに以下の動作を追加します:
behavior :
scaleDown :
policies :
- type : Percent
value : 10
periodSeconds : 60
1分あたりに削除されるPodが5つを超えないようにするために、固定サイズ5の2番目のスケールダウンポリシーを追加し、selectPolicyを最小に設定することができます。selectPolicyをMinに設定すると、オートスケーラーは最少数のPodに影響を与えるポリシーを選択します:
behavior :
scaleDown :
policies :
- type : Percent
value : 10
periodSeconds : 60
- type : Pods
value : 5
periodSeconds : 60
selectPolicy : Min
例: スケールダウンの無効化 selectPolicyの値がDisabledの場合、指定された方向のスケーリングをオフにします。したがって、スケールダウンを防ぐには、次のようなポリシーが使われます:
behavior :
scaleDown :
selectPolicy : Disabled
kubectlにおけるHorizontalPodAutoscalerのサポート HorizontalPodAutoscalerは、他のすべてのAPIリソースと同様にkubectlによって標準的にサポートされています。kubectl createコマンドを使用して新しいオートスケーラーを作成することができます。kubectl get hpaを使用してオートスケーラーを一覧表示したり、kubectl describe hpaを使用して詳細な説明を取得したりできます。最後に、kubectl delete hpaを使用してオートスケーラーを削除することができます。
さらに、HorizontalPodAutoscalerオブジェクトを作成するための特別なkubectl autoscaleコマンドがあります。例えば、kubectl autoscale rs foo --min=2 --max=5 --cpu-percent=80を実行すると、ReplicaSet fooのオートスケーラーが作成され、ターゲットのCPU使用率が80%に設定され、レプリカ数は2から5の間になります。
暗黙のメンテナンスモードの非活性化 HPAの設定自体を変更することなく、ターゲットのHPAを暗黙的に非活性化することができます。ターゲットの理想のレプリカ数が0に設定され、HPAの最小レプリカ数が0より大きい場合、HPAはターゲットの調整を停止します(そして、自身のScalingActive条件をfalseに設定します)。これは、ターゲットの理想のレプリカ数またはHPAの最小レプリカ数を手動で調整して再活性化するまで続きます。
DeploymentとStatefulSetを水平自動スケーリングへ移行する HPAが有効になっている場合、Deploymentおよび/またはStatefulSetのspec.replicasの値をそのマニフェスト から削除することが推奨されます。これを行わない場合、たとえばkubectl apply -f deployment.yamlを介してそのオブジェクトに変更が適用されるたびに、これはKubernetesに現在のPodの数をspec.replicasキーの値にスケールするよう指示します。これは望ましくない場合があり、HPAがアクティブなときに問題になる可能性があります。
spec.replicasの削除は、このキーのデフォルト値が1であるため(参照: Deploymentのレプリカ数 )、一度だけPod数が低下する可能性があることに注意してください。更新時に、1つを除くすべてのPodが終了手順を開始します。その後の任意のDeploymentアプリケーションは通常どおり動作し、望む通りのローリングアップデート設定を尊重します。Deploymentをどのように変更しているかによって、以下の2つの方法から1つを選択することでこの低下を回避することができます:
kubectl apply edit-last-applied deployment/<deployment_name>エディターでspec.replicasを削除します。保存してエディターを終了すると、kubectlが更新を適用します。このステップではPod数に変更はありません。 これでマニフェストからspec.replicasを削除できます。ソースコード管理を使用している場合は、変更をコミットするか、更新の追跡方法に適したソースコードの改訂に関するその他の手順を行います。 ここからはkubectl apply -f deployment.yamlを実行できます。 次の項目 クラスターでオートスケーリングを設定する場合、Cluster Autoscaler のようなクラスターレベルのオートスケーラーを実行することも検討してみてください。
HorizontalPodAutoscalerに関する詳細情報:
4.8.8 - Horizontal Pod Autoscalerウォークスルー Horizontal Pod Autoscalerは、Deployment、ReplicaSetまたはStatefulSetといったレプリケーションコントローラー内のPodの数を、観測されたCPU使用率(もしくはベータサポートの、アプリケーションによって提供されるその他のメトリクス)に基づいて自動的にスケールさせます。
このドキュメントはphp-apacheサーバーに対しHorizontal Pod Autoscalerを有効化するという例に沿ってウォークスルーで説明していきます。Horizontal Pod Autoscalerの動作についてのより詳細な情報を知りたい場合は、Horizontal Pod Autoscalerユーザーガイド をご覧ください。
始める前に この例ではバージョン1.2以上の動作するKubernetesクラスターおよびkubectlが必要です。
Metrics API を介してメトリクスを提供するために、Metrics server によるモニタリングがクラスター内にデプロイされている必要があります。
Horizontal Pod Autoscalerはメトリクスを収集するためにこのAPIを利用します。metrics-serverをデプロイする方法を知りたい場合はmetrics-server ドキュメント をご覧ください。
Horizontal Pod Autoscalerで複数のリソースメトリクスを利用するためには、バージョン1.6以上のKubernetesクラスターおよびkubectlが必要です。カスタムメトリクスを使えるようにするためには、あなたのクラスターがカスタムメトリクスAPIを提供するAPIサーバーと通信できる必要があります。
最後に、Kubernetesオブジェクトと関係のないメトリクスを使うにはバージョン1.10以上のKubernetesクラスターおよびkubectlが必要で、さらにあなたのクラスターが外部メトリクスAPIを提供するAPIサーバーと通信できる必要があります。
詳細についてはHorizontal Pod Autoscaler user guide をご覧ください。
php-apacheの起動と公開 Horizontal Pod Autoscalerのデモンストレーションのために、php-apacheイメージをもとにしたカスタムのDockerイメージを使います。
このDockerfileは下記のようになっています。
FROM php:5-apache
COPY index.php /var/www/html/index.php
RUN chmod a+rx index.php
これはCPU負荷の高い演算を行うindex.phpを定義しています。
<? php
$x = 0.0001 ;
for ($i = 0 ; $i <= 1000000 ; $i ++ ) {
$x += sqrt($x );
}
echo "OK!" ;
?>
まず最初に、イメージを動かすDeploymentを起動し、Serviceとして公開しましょう。
下記の設定を使います。
apiVersion : apps/v1
kind : Deployment
metadata :
name : php-apache
spec :
selector :
matchLabels :
run : php-apache
template :
metadata :
labels :
run : php-apache
spec :
containers :
- name : php-apache
image : registry.k8s.io/hpa-example
ports :
- containerPort : 80
resources :
limits :
cpu : 500m
requests :
cpu : 200m
---
apiVersion : v1
kind : Service
metadata :
name : php-apache
labels :
run : php-apache
spec :
ports :
- port : 80
selector :
run : php-apache
以下のコマンドを実行してください。
kubectl apply -f https://k8s.io/examples/application/php-apache.yaml
deployment.apps/php-apache created
service/php-apache created
Horizontal Pod Autoscalerを作成する サーバーが起動したら、kubectl autoscale を使ってautoscalerを作成しましょう。以下のコマンドで、最初のステップで作成したphp-apache deploymentによって制御されるPodレプリカ数を1から10の間に維持するHorizontal Pod Autoscalerを作成します。
簡単に言うと、HPAは(Deploymentを通じて)レプリカ数を増減させ、すべてのPodにおける平均CPU使用率を50%(それぞれのPodはkubectl runで200 milli-coresを要求しているため、平均CPU使用率100 milli-coresを意味します)に保とうとします。
このアルゴリズムについての詳細はこちら をご覧ください。
kubectl autoscale deployment php-apache --cpu-percent= 50 --min= 1 --max= 10
horizontalpodautoscaler.autoscaling/php-apache autoscaled
以下を実行して現在のAutoscalerの状況を確認できます。
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 0% / 50% 1 10 1 18s
現在はサーバーにリクエストを送っていないため、CPU使用率が0%になっていることに注意してください(TARGETカラムは対応するDeploymentによって制御される全てのPodの平均値を示しています。)。
負荷の増加 Autoscalerがどのように負荷の増加に反応するか見てみましょう。
コンテナを作成し、クエリの無限ループをphp-apacheサーバーに送ってみます(これは別のターミナルで実行してください)。
kubectl run -i --tty load-generator --rm --image= busybox --restart= Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
数分以内に、下記を実行することでCPU負荷が高まっていることを確認できます。
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 305% / 50% 1 10 1 3m
ここでは、CPU使用率はrequestの305%にまで高まっています。
結果として、Deploymentはレプリカ数7にリサイズされました。
kubectl get deployment php-apache
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 7/7 7 7 19m
備考: レプリカ数が安定するまでは数分かかることがあります。負荷量は何らかの方法で制御されているわけではないので、最終的なレプリカ数はこの例とは異なる場合があります。負荷の停止 ユーザー負荷を止めてこの例を終わらせましょう。
私たちがbusyboxイメージを使って作成したコンテナ内のターミナルで、<Ctrl> + Cを入力して負荷生成を終了させます。
そして結果の状態を確認します(数分後)。
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 0% / 50% 1 10 1 11m
kubectl get deployment php-apache
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 1/1 1 1 27m
ここでCPU使用率は0に下がり、HPAによってオートスケールされたレプリカ数は1に戻ります。
備考: レプリカのオートスケールには数分かかることがあります。複数のメトリクスやカスタムメトリクスを基にオートスケーリングする autoscaling/v2beta2 APIバージョンと使うと、php-apache Deploymentをオートスケーリングする際に使う追加のメトリクスを導入することが出来ます。
まず、autoscaling/v2beta2内のHorizontalPodAutoscalerのYAMLファイルを入手します。
kubectl get hpa.v2beta2.autoscaling -o yaml > /tmp/hpa-v2.yaml
/tmp/hpa-v2.yamlファイルをエディタで開くと、以下のようなYAMLファイルが見えるはずです。
apiVersion : autoscaling/v2beta2
kind : HorizontalPodAutoscaler
metadata :
name : php-apache
spec :
scaleTargetRef :
apiVersion : apps/v1
kind : Deployment
name : php-apache
minReplicas : 1
maxReplicas : 10
metrics :
- type : Resource
resource :
name : cpu
target :
type : Utilization
averageUtilization : 50
status :
observedGeneration : 1
lastScaleTime : <some-time>
currentReplicas : 1
desiredReplicas : 1
currentMetrics :
- type : Resource
resource :
name : cpu
current :
averageUtilization : 0
averageValue : 0
targetCPUUtilizationPercentageフィールドはmetricsと呼ばれる配列に置換されています。
CPU使用率メトリクスは、Podコンテナで定められたリソースの割合として表されるため、リソースメトリクス です。CPU以外のリソースメトリクスを指定することもできます。デフォルトでは、他にメモリだけがリソースメトリクスとしてサポートされています。これらのリソースはクラスター間で名前が変わることはなく、そしてmetrics.k8s.io APIが利用可能である限り常に利用可能です。
さらにtarget.typeにおいてUtilizationの代わりにAverageValueを使い、target.averageUtilizationフィールドの代わりに対応するtarget.averageValueフィールドを設定することで、リソースメトリクスをrequest値に対する割合に代わり、直接的な値に設定することも可能です。
PodメトリクスとObjectメトリクスという2つの異なる種類のメトリクスが存在し、どちらもカスタムメトリクス とみなされます。これらのメトリクスはクラスター特有の名前を持ち、利用するにはより発展的なクラスター監視設定が必要となります。
これらの代替メトリクスタイプのうち、最初のものがPodメトリクス です。これらのメトリクスはPodを説明し、Podを渡って平均され、レプリカ数を決定するためにターゲット値と比較されます。
これらはほとんどリソースメトリクス同様に機能しますが、targetの種類としてはAverageValueのみ をサポートしている点が異なります。
Podメトリクスはmetricブロックを使って以下のように指定されます。
type : Pods
pods :
metric :
name : packets-per-second
target :
type : AverageValue
averageValue : 1k
2つ目のメトリクスタイプはObjectメトリクス です。これらのメトリクスはPodを説明するかわりに、同一Namespace内の異なったオブジェクトを説明します。このメトリクスはオブジェクトから取得される必要はありません。単に説明するだけです。Objectメトリクスはtargetの種類としてValueとAverageValueをサポートします。Valueでは、ターゲットはAPIから返ってきたメトリクスと直接比較されます。AverageValueでは、カスタムメトリクスAPIから返ってきた値はターゲットと比較される前にPodの数で除算されます。以下の例はrequests-per-secondメトリクスのYAML表現です。
type : Object
object :
metric :
name : requests-per-second
describedObject :
apiVersion : networking.k8s.io/v1beta1
kind : Ingress
name : main-route
target :
type : Value
value : 2k
もしこのようなmetricブロックを複数提供した場合、HorizontalPodAutoscalerはこれらのメトリクスを順番に処理します。
HorizontalPodAutoscalerはそれぞれのメトリクスについて推奨レプリカ数を算出し、その中で最も多いレプリカ数を採用します。
例えば、もしあなたがネットワークトラフィックについてのメトリクスを収集する監視システムを持っているなら、kubectl editを使って指定を次のように更新することができます。
apiVersion : autoscaling/v2beta2
kind : HorizontalPodAutoscaler
metadata :
name : php-apache
spec :
scaleTargetRef :
apiVersion : apps/v1
kind : Deployment
name : php-apache
minReplicas : 1
maxReplicas : 10
metrics :
- type : Resource
resource :
name : cpu
target :
type : Utilization
averageUtilization : 50
- type : Pods
pods :
metric :
name : packets-per-second
target :
type : AverageValue
averageValue : 1k
- type : Object
object :
metric :
name : requests-per-second
describedObject :
apiVersion : networking.k8s.io/v1beta1
kind : Ingress
name : main-route
target :
type : Value
value : 10k
status :
observedGeneration : 1
lastScaleTime : <some-time>
currentReplicas : 1
desiredReplicas : 1
currentMetrics :
- type : Resource
resource :
name : cpu
current :
averageUtilization : 0
averageValue : 0
- type : Object
object :
metric :
name : requests-per-second
describedObject :
apiVersion : networking.k8s.io/v1beta1
kind : Ingress
name : main-route
current :
value : 10k
この時、HorizontalPodAutoscalerはそれぞれのPodがCPU requestの50%を使い、1秒当たり1000パケットを送信し、そしてmain-route
Ingressの裏にあるすべてのPodが合計で1秒当たり10000パケットを送信する状態を保持しようとします。
より詳細なメトリクスをもとにオートスケーリングする 多くのメトリクスパイプラインは、名前もしくは labels と呼ばれる追加の記述子の組み合わせによって説明することができます。全てのリソースメトリクス以外のメトリクスタイプ(Pod、Object、そして下で説明されている外部メトリクス)において、メトリクスパイプラインに渡す追加のラベルセレクターを指定することができます。例えば、もしあなたがhttp_requestsメトリクスをverbラベルとともに収集しているなら、下記のmetricブロックを指定してGETリクエストにのみ基づいてスケールさせることができます。
type : Object
object :
metric :
name : http_requests
selector : {matchLabels : {verb : GET}}
このセレクターは完全なKubernetesラベルセレクターと同じ文法を利用します。もし名前とセレクターが複数の系列に一致した場合、この監視パイプラインはどのようにして複数の系列を一つの値にまとめるかを決定します。このセレクターは付加的なもので、ターゲットオブジェクト(Podsタイプの場合は対象Pod、Objectタイプの場合は説明されるオブジェクト)ではない オブジェクトを説明するメトリクスを選択することは出来ません。
Kubernetesオブジェクトと関係ないメトリクスに基づいたオートスケーリング Kubernetes上で動いているアプリケーションを、Kubernetes Namespaceと直接的な関係がないサービスを説明するメトリクスのような、Kubernetesクラスター内のオブジェクトと明確な関係が無いメトリクスを基にオートスケールする必要があるかもしれません。Kubernetes 1.10以降では、このようなユースケースを外部メトリクス によって解決できます。
外部メトリクスを使うにはあなたの監視システムについての知識が必要となります。この設定はカスタムメトリクスを使うときのものに似ています。外部メトリクスを使うとあなたの監視システムのあらゆる利用可能なメトリクスに基づいてクラスターをオートスケールできるようになります。上記のようにmetricブロックでnameとselectorを設定し、ObjectのかわりにExternalメトリクスタイプを使います。
もし複数の時系列がmetricSelectorにより一致した場合は、それらの値の合計がHorizontalPodAutoscalerに使われます。
外部メトリクスはValueとAverageValueの両方のターゲットタイプをサポートしています。これらの機能はObjectタイプを利用するときとまったく同じです。
例えばもしあなたのアプリケーションがホストされたキューサービスからのタスクを処理している場合、あなたは下記のセクションをHorizontalPodAutoscalerマニフェストに追記し、未処理のタスク30個あたり1つのワーカーを必要とすることを指定します。
- type : External
external :
metric :
name : queue_messages_ready
selector : "queue=worker_tasks"
target :
type : AverageValue
averageValue : 30
可能なら、クラスター管理者がカスタムメトリクスAPIを保護することを簡単にするため、外部メトリクスのかわりにカスタムメトリクスを用いることが望ましいです。外部メトリクスAPIは潜在的に全てのメトリクスへのアクセスを許可するため、クラスター管理者はこれを公開する際には注意が必要です。
付録: Horizontal Pod Autoscaler status conditions autoscaling/v2beta2形式のHorizontalPodAutoscalerを使っている場合は、KubernetesによるHorizontalPodAutoscaler上のstatus conditions セットを見ることができます。status conditionsはHorizontalPodAutoscalerがスケール可能かどうか、そして現時点でそれが何らかの方法で制限されているかどうかを示しています。
このconditionsはstatus.conditionsフィールドに現れます。HorizontalPodAutoscalerに影響しているconditionsを確認するために、kubectl describe hpaを利用できます。
kubectl describe hpa cm-test
Name: cm-test
Namespace: prom
Labels: <none>
Annotations: <none>
CreationTimestamp: Fri, 16 Jun 2017 18:09:22 +0000
Reference: ReplicationController/cm-test
Metrics: ( current / target )
"http_requests" on pods: 66m / 500m
Min replicas: 1
Max replicas: 4
ReplicationController pods: 1 current / 1 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale the last scale time was sufficiently old as to warrant a new scale
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from pods metric http_requests
ScalingLimited False DesiredWithinRange the desired replica count is within the acceptable range
Events:
このHorizontalPodAutoscalerにおいて、いくつかの正常な状態のconditionsを見ることができます。まず最初に、AbleToScaleは、HPAがスケール状況を取得し、更新させることが出来るかどうかだけでなく、何らかのbackoffに関連した状況がスケーリングを妨げていないかを示しています。2番目に、ScalingActiveは、HPAが有効化されているかどうか(例えば、レプリカ数のターゲットがゼロでないこと)や、望ましいスケールを算出できるかどうかを示します。もしこれがFalseの場合、大体はメトリクスの取得において問題があることを示しています。最後に、一番最後の状況であるScalingLimitedは、HorizontalPodAutoscalerの最大値や最小値によって望ましいスケールがキャップされていることを示しています。この指標を見てHorizontalPodAutoscaler上の最大・最小レプリカ数制限を増やす、もしくは減らす検討ができます。
付録: 数量 全てのHorizontalPodAutoscalerおよびメトリクスAPIにおけるメトリクスはquantity として知られる特殊な整数表記によって指定されます。例えば、10500mという数量は10進数表記で10.5と書くことができます。メトリクスAPIは可能であれば接尾辞を用いない整数を返し、そうでない場合は基本的にミリ単位での数量を返します。これはメトリクス値が1と1500mの間で、もしくは10進法表記で書かれた場合は1と1.5の間で変動するということを意味します。
付録: その他の起きうるシナリオ Autoscalerを宣言的に作成する kubectl autoscaleコマンドを使って命令的にHorizontalPodAutoscalerを作るかわりに、下記のファイルを使って宣言的に作成することができます。
apiVersion : autoscaling/v1
kind : HorizontalPodAutoscaler
metadata :
name : php-apache
namespace : default
spec :
scaleTargetRef :
apiVersion : apps/v1
kind : Deployment
name : php-apache
minReplicas : 1
maxReplicas : 10
targetCPUUtilizationPercentage : 50
下記のコマンドを実行してAutoscalerを作成します。
kubectl create -f https://k8s.io/examples/application/hpa/php-apache.yaml
horizontalpodautoscaler.autoscaling/php-apache created
4.8.9 - アプリケーションにDisruption Budget指定する FEATURE STATE:
Kubernetes v1.21 [stable]
このページでは、アプリケーションで同時に発生するDisruptionの数を制限する方法を説明します。
これによりクラスター管理者は、クラスターのノードを管理しながら、高い可用性を実現できます。
始める前に 作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.21.
バージョンを確認するには次のコマンドを実行してください: kubectl version.
PodDisruptionBudgetを使用してアプリケーションを保護する PodDisruptionBudget(PDB)で保護したいアプリケーションを特定します。 アプリケーションがDisruptionにどのように反応するかを検討します。 PDB定義をYAMLファイルとして作成します。 YAMLファイルからPDBオブジェクトを作成します。 保護するアプリケーションを特定する ビルトインのKubernetesコントローラーのいずれかによって指定されたアプリケーションを保護する場合の最も一般的なユースケースは次の通りです:
Deployment ReplicationController ReplicaSet StatefulSet このケースでは、コントーラーの.spec.selectorをメモし、同じセレクターをPDBの.spec.selectorに設定します。
バージョン1.15以降では、PDBはscale subresource が有効になっているカスタムコントローラーをサポートします。
上記のコントローラーのいずれかによって制御されていないPodや、任意のPodグループでPDBを使用することもできますが、任意のワークロードと任意のセレクター で説明されているように、いくつかの制限があります。
アプリケーションがDisruptionにどのように反応するかを検討する 自発的なDisruptionによって短期間に同時に停止できるインスタンス数を決定してください。
ステートレスフロントエンド:留意事項: サービス提供能力を10%以上低下させない。解決策: 例えば、minAvailable 90%のPDBを使用する。 単一インスタンスのステートフルアプリケーション:留意事項: 相談なしにこのアプリケーションを終了しない。可能な解決策1: PDBを使用せず、偶発的なダウンタイムを許容する。 可能な解決策2: maxUnavailable=0のPDBを設定する。
クラスター管理者が終了する前に、あなたに相談する必要があることを(Kubernetesの外部で)理解する。
クラスター管理者から連絡があれば、ダウンタイムに備え、Disruptionの準備ができたことを示すためにPDBを削除する。
その後、PDBを再作成する。 Consul、ZooKeeper、etcdのような複数インスタンスのステートフルアプリケーション:留意事項: インスタンス数をクォーラム以下に減らない、さもなければ書き込みが失敗する。可能な解決策1: maxUnavailableを1に設定する(アプリケーションの規模が変化する場合に機能する)。 可能な解決策2: minAvailableをクォーラムサイズ(スケールが5の場合は3)に設定する(一度により多くのDisruptionを許可する)。 再起動可能なバッチジョブ:留意事項: 自発的なDisruptionの場合にジョブが完了する必要がある。可能な解決策: PDBを作成しない。
Jobコントローラーが代替Podを作成する。 パーセンテージを指定する場合の丸めロジック minAvailableまたはmaxUnavailableの値は整数またはパーセンテージで表すことができます。
整数を指定すると、Podの数を表します。
インスタンスのminAvailableを10に設定すると、Disruptionの間も常に10個のPodが利用可能である必要があります。 パーセンテージを表現する文字列(例. "50%")によってパーセンテージを指定すると、Podの合計パーセンテージを表します。
例えば、インスタンスのminAvailableを"50%"に設定すると、Disruptionの間に少なくとも50%のPodが利用可能である必要があります。 パーセンテージを指定すると、Podの数には正確にマッピングされない場合があります。
例えば、7個のPodがありminAvailableが"50%"に設定されている場合、利用可能である必要があるPodの数が3個か4個かはすぐにはわかりません。
Kubernetesは最も近い整数に切り上げるため、このケースでは4個のPodが利用可能である必要があります。
パーセンテージとしてmaxUnavailableの値を指定すると、KubernetesはDisruptionされるPodの数を切り上げます。
その結果、定義されたmaxUnavailableのパーセンテージを超えるDisruptionが発生する可能性があります。
この挙動を制御するコード を確認できます。
PodDisruptionBudgetを定義する PodDisruptionBudgetには3つのフィールドがあります:
.spec.selectorラベルセレクターは、適用されるPodのセットを指定します。
このフィールドは必須です。.spec.minAvailableは、退避されたPodがない場合であっても、退避後もそのセットで利用可能である必要があるPodの数を記述します。
minAvailableは絶対数またはパーセンテージのいずれかを指定できます。.spec.maxUnavailable(Kubernetes 1.7以上で利用可能)は、退避後にそのセットで利用できないことを許容するPodの数を記述します。
絶対数またはパーセンテージのいずれかを指定できます。
備考: policy/v1beta1およびpolicy/v1 APIのPodDisruptionBudgetにおいて、空のセレクターの挙動は異なります。
policy/v1beta1では空のセレクターは0個のPodにマッチしますが、policy/v1では空のセレクターはNamespace内のすべてのPodにマッチします。単一のPodDisruptionBudgetには、maxUnavailableとminAvailableのいずれか1つだけを指定できます。
maxUnavailableは、コントローラーによって管理されているPodについてのみ、退避を制御するために使用できます。
以下の例において"理想的なレプリカ数"は、PodDisruptionBudgetによって選択されるPodを管理しているコントローラーのscaleです。
例1: minAvailableが5に設定されている場合、PodDisruptionBudgetのselectorによって選択されたPodの中で、少なくとも5つ以上の健全 なPodが残る限り、退避が許可されます。
例2: minAvailableが30%に設定されている場合、少なくとも理想的なレプリカ数の30%が健全である限り、退避が許可されます。
例3: maxUnavailableが5に設定されている場合、理想的なレプリカの総数のうち、不健全なレプリカが最大5つである限り、退避が許可されます。
例4: maxUnavailableが30%に設定されている場合、不健全なレプリカ数が、最も近い整数に切り上げられた理想的なレプリカの総数の30%を超えない限り、退避が許可されます。
理想的なレプリカの総数が1の場合、その単一のレプリカも退避可能となり、実質的な利用不可率が100%になります。
通常の用途では、単一のバジェットはコントローラーによって管理されるPodのコレクション(例えば、単一のReplicaSetまたはStatefulSet内のPod)に使用されます。
備考: Disruption Budgetは、指定された数/パーセンテージのPodが常に利用可能であることを保証しません。
例えば、コレクションに属するPodをホストしているノードが、バジェットで指定された最小サイズに達しているときに障害を起こすと、コレクション内の利用可能なPodの数が指定されたサイズを下回る可能性があります。
バジェットは、あくまで自発的な退避に対する保護を提供するものであり、すべての可用性を失う原因を防ぐことはできません。maxUnavailableを0%または0に設定するか、minAvailableを100%またはレプリカ数に設定すると、自発的な退避を一切要求しません。
この設定をReplicaSetのようなワークロードオブジェクトに適用すると、それらのPodが実行されているノードを正常にドレインできなくなります。
退避できないPodが実行されているノードをドレインしようしても、ドレインは完了しません。
これはPodDisruptionBudgetの仕様上、正しい挙動です。
以下にPodDisruptionBudgetの例を示します。
これらの例は、ラベルapp: zookeeperを持つPodに一致します。
minAvailableを使用した例:
apiVersion : policy/v1
kind : PodDisruptionBudget
metadata :
name : zk-pdb
spec :
minAvailable : 2
selector :
matchLabels :
app : zookeeper
maxUnavailableを使用した例:
apiVersion : policy/v1
kind : PodDisruptionBudget
metadata :
name : zk-pdb
spec :
maxUnavailable : 1
selector :
matchLabels :
app : zookeeper
例えば、上記のzk-pdbオブジェクトがサイズ3のStatefulSetのPodを選択する場合、どちらの仕様もまったく同じ意味を持ちます。
maxUnavailableの使用が推奨されており、これは対応するコントローラーのレプリカ数の変更に自動的に対応するためです。
PDBオブジェクトを作成する kubectlを使用してPDBオブジェクトを作成または更新できます。
kubectl apply -f mypdb.yaml
PDBのステータスを確認する kubectlを使用してPDBが作成されたことを確認します。
Namespace内にapp: zookeeperに一致するPodがないと仮定すると、次のようになります:
kubectl get poddisruptionbudgets
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
zk-pdb 2 N/A 0 7s
一致するPod(例えば3つ)があれば、次のように表示されます:
kubectl get poddisruptionbudgets
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
zk-pdb 2 N/A 1 7s
ALLOWED DISRUPTIONSの値がゼロ以外である場合、DisruptionコントローラーはPodを確認し、一致するPodをカウントし、PDBのステータスを更新しています。
PDBのステータスについての詳細情報を取得するには、次のコマンドを使用します:
kubectl get poddisruptionbudgets zk-pdb -o yaml
apiVersion : policy/v1
kind : PodDisruptionBudget
metadata :
annotations :
creationTimestamp : "2020-03-04T04:22:56Z"
generation : 1
name : zk-pdb
status :
currentHealthy : 3
desiredHealthy : 2
disruptionsAllowed : 1
expectedPods : 3
observedGeneration : 1
Podの健全性 現在の実装では、type="Ready"かつstatus="True"の.status.conditions項目を持つPodが健全なPodと見なされます。
これらのPodは、PDBステータスの.status.currentHealthyフィールドで追跡されます。
不健全なPodの退避ポリシー FEATURE STATE:
Kubernetes v1.31 [stable](enabled by default)
アプリケーションを保護するPodDisruptionBudgetは、健全なPodの退避を許可しないことで、.status.currentHealthyのPod数が.status.desiredHealthyで指定された数を下回らないようにします。
.spec.unhealthyPodEvictionPolicyを使用すると、不健全なPodを退避する基準を定義できます。
ポリシーが指定されていない場合のデフォルトの動作は、IfHealthyBudgetポリシーに準じます。
ポリシー:
IfHealthyBudgetPodが実行中(.status.phase="Running")であるがまだ健全ではない場合、保護されたアプリケーションが中断されていない(.status.currentHealthyが少なくとも.status.desiredHealthyと等しい)場合にのみ退避できます。 このポリシーによって、すでに中断されているアプリケーションで実行中のPodが健全になる可能性が最も高くなります。
これは、PDBによって保護されている異常なアプリケーションによってノードのドレインがブロックされる悪影響をもたらします。
具体的には、(バグや設定ミスによって)PodがCrashLoopBackOff状態にあるアプリケーション、またはReady条件を正しく報告できないPodがあるアプリケーションが該当します。
AlwaysAllowPodが実行中(.status.phase="Running")であるがまだ健全ではないPodは、中断されているとみなされ、PDBの基準が満たされているかどうかに関係なく退避されます。 これは、中断されたアプリケーションで実行中のPodが健全にならない可能性があることを意味します。
このポリシーによって、クラスター管理者はPDBによって保護されている異常なアプリケーションを簡単に退避できます。
具体的には、(バグや設定ミスによって)PodがCrashLoopBackOff状態にあるアプリケーション、またはReady条件を正しく報告できないPodがあるアプリケーションが該当します。
備考: Pending、Succeeded、またはFailedフェーズのPodは常に退避対象と見なされます。任意のワークロードと任意のセレクター ビルトインのワークロードリソース(Deployment、ReplicaSet、StatefulSet、ReplicationController)、またはscaleサブリソース を実装したカスタムリソース でのみPDBを使用し、PDBセレクターがPodを所有するリソースのセレクターと完全に一致する場合は、このセクションをスキップできます。
他のリソースや"オペレーター"に制御されるPodまたはベアPodにおいてもPDBを使用することができますが、次の制限があります:
.spec.minAvailableのみ使用でき、.spec.maxUnavailableは使用できません.spec.minAvailableは整数値のみ使用でき、パーセンテージは使用できませんKubernetesはサポートされている所有リソースがない場合にPodの合計数を導き出せないため、他の可用性構成を使用することはできません。
セレクターを使用して、ワークロードリソースに属するPodのサブセットまたはスーパーセットを選択できます。
退避APIは、複数のPDBにカバーされるPodの退避を許可しないため、ほとんどのユーザーはセレクターの重複を避けるべきです。
重複するPDBの合理的な使用方法の1つは、Podが1つのPDBから別のPDBに移行している場合です。
4.8.10 - PodからKubernetes APIにアクセスする このガイドでは、Pod内からKubernetes APIにアクセスする方法を示します。
始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
Pod内からAPIへのアクセス Podの中からAPIにアクセスする時、APIサーバーの場所の検出と認証は、外部クライアントの場合とは若干異なります。
PodからKubernetes APIを使用する最も簡単な方法は、公式のクライアントライブラリ を使用することです。
これらのライブラリは自動的にAPIサーバーを検出して認証できます。
公式クライアントライブラリの使用 Podの中からKubernetes APIに接続する推奨された方法として次のものがあります:
いずれの場合も、APIサーバーと安全に通信するために、Podのサービスアカウントの資格情報が使用されます。
REST APIによる直接アクセス コンテナは、Pod内での実行中に環境変数KUBERNETES_SERVICE_HOSTとKUBERNETES_SERVICE_PORT_HTTPSを取得することで、Kubernetes APIサーバーのHTTPSのURLを作成することができます。
APIサーバーのクラスター内アドレスは、PodがローカルAPIサーバーのDNS名としてkubernetes.default.svcを参照できるように、default Namespaceのkubernetesという名前のServiceにも公開されます。
備考: Kubernetesは、APIサーバーがホスト名kubernetes.default.svcに対する有効な証明書を持っていることを保証しません。
しかし、コントロールプレーンは$KUBERNETES_SERVICE_HOSTによって表されるホスト名またはIPアドレスに対する有効な証明書を提示することが期待されます 。APIサーバーに対して認証を行う推奨された方法は、サービスアカウント の資格情報を使用することです。
既定では、Podはサービスアカウントと関連づけられており、そのサービスアカウントに対する資格情報(トークン)が、そのPod内の各コンテナのファイルシステムツリーの/var/run/secrets/kubernetes.io/serviceaccount/token内に配置されます。
利用可能であれば、証明書バンドルが各コンテナのファイルシステムツリーの/var/run/secrets/kubernetes.io/serviceaccount/ca.crtに配置され、APIサーバーが提供する証明書を検証するために使用されます。
最後に、NamespaceスコープのAPIの操作に対して使用される既定のNamespaceは、各コンテナの/var/run/secrets/kubernetes.io/serviceaccount/namespaceにあるファイルに記載されます。
kubectl proxyの使用 公式のクライアントライブラリを使用せずにAPIを呼び出したい場合は、Pod内の新しいサイドカーコンテナのコマンド としてkubectl proxyを実行することができます。
こうすることで、kubectl proxyがAPIを認証してPodのlocalhostインターフェースに公開するため、Pod内の他のコンテナが直接使用することができます。
プロキシを使用しない方法 認証トークンを直接APIサーバーに渡すことで、kubectl proxyの使用を避けることも可能です。
内部の証明書によって接続を保護します。
# 内部のAPIサーバーのホスト名の指定
APISERVER = https://kubernetes.default.svc
# ServiceAccountトークンのパス
SERVICEACCOUNT = /var/run/secrets/kubernetes.io/serviceaccount
# PodのNamespaceの読み込み
NAMESPACE = $( cat ${ SERVICEACCOUNT } /namespace)
# ServiceAccountのBearerトークンを取得
TOKEN = $( cat ${ SERVICEACCOUNT } /token)
# 内部の認証局(CA)の参照
CACERT = ${ SERVICEACCOUNT } /ca.crt
# トークンを用いてAPIの探索
curl --cacert ${ CACERT } --header "Authorization: Bearer ${ TOKEN } " -X GET ${ APISERVER } /api
次のような出力になります:
{
"kind" : "APIVersions" ,
"versions" : ["v1" ],
"serverAddressByClientCIDRs" : [
{
"clientCIDR" : "0.0.0.0/0" ,
"serverAddress" : "10.0.1.149:443"
}
]
}
4.9 - Jobの実行 並列処理を使用してJobを実行します。
4.9.1 - CronJobを使用して自動化タスクを実行する CronJobは、Kubernetes v1.21で一般利用(GA)に昇格しました。古いバージョンのKubernetesを使用している場合、正確な情報を参照できるように、使用しているバージョンのKubernetesのドキュメントを参照してください。古いKubernetesのバージョンでは、batch/v1 CronJob APIはサポートされていません。
CronJob を使用すると、Job を時間ベースのスケジュールで実行できるようになります。この自動化されたJobは、LinuxまたはUNIXシステム上のCron のように実行されます。
CronJobは、バックアップやメールの送信など、定期的なタスクや繰り返しのタスクを作成する時に便利です。CronJobはそれぞれのタスクを、たとえばアクティビティが少ない期間など、特定の時間にスケジューリングすることもできます。
CronJobには制限と特性があります。たとえば、特定の状況下では、1つのCronJobが複数のJobを作成する可能性があるため、Jobは冪等性を持つようにしなければいけません。
制限に関する詳しい情報については、CronJob を参照してください。
始める前に CronJobを作成する CronJobには設定ファイルが必要です。次の例のCronJobの.specは、現在の時刻とhelloというメッセージを1分ごとに表示します。
apiVersion : batch/v1
kind : CronJob
metadata :
name : hello
spec :
schedule : "* * * * *"
jobTemplate :
spec :
template :
spec :
containers :
- name : hello
image : busybox
command :
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy : OnFailure
次のコマンドで例のCronJobを実行します。
kubectl create -f https://k8s.io/examples/application/job/cronjob.yaml
出力は次のようになります。
cronjob.batch/hello created
CronJobを作成したら、次のコマンドで状態を取得します。
kubectl get cronjob hello
出力は次のようになります。
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 0 <none> 10s
コマンドの結果からわかるように、CronJobはまだスケジュールされておらず、まだ何のJobも実行していません。約1分以内にJobが作成されるのを見てみましょう。
出力は次のようになります。
NAME COMPLETIONS DURATION AGE
hello-4111706356 0/1 0s
hello-4111706356 0/1 0s 0s
hello-4111706356 1/1 5s 5s
"hello"CronJobによってスケジュールされたJobが1つ実行中になっていることがわかります。Jobを見るのをやめて、再度CronJobを表示して、Jobがスケジュールされたことを確認してみます。
kubectl get cronjob hello
出力は次のようになります。
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 0 50s 75s
CronJobhelloが、LAST SCHEDULEで指定された時間にJobを正しくスケジュールしたことが確認できるはずです。現在、activeなJobの数は0です。つまり、Jobは完了または失敗したことがわかります。
それでは、最後にスケジュールされたJobの作成と、Podの1つの標準出力を表示してみましょう。
備考: Jobの名前とPodの名前は異なります。# "hello-4111706356" の部分は、あなたのシステム上のJobの名前に置き換えてください。
pods = $( kubectl get pods --selector= job-name= hello-4111706356 --output= jsonpath ={ .items[ *] .metadata.name} )
Podのログを表示します。
出力は次のようになります。
Fri Feb 22 11:02:09 UTC 2019
Hello from the Kubernetes cluster
CronJobの削除 CronJobが必要なくなったときは、kubectl delete cronjob <cronjob name>で削除します。
kubectl delete cronjob hello
CronJobを削除すると、すべてのJobと、そのJobが作成したPodが削除され、追加のJobの作成が停止されます。Jobの削除について詳しく知りたい場合は、ガベージコレクション を読んでください。
CronJobのspecを書く すべてのKubernetesの設定と同じように、CronJobにもapiVersion、kind、metadataのフィールドが必要です。設定ファイルの扱い方についての一般的な情報については、アプリケーションのデプロイ とkubectlを使用してリソースを管理する を読んでください。
CronJobの設定には、.specセクション
備考: CronJobの特にspecへのすべての修正は、それ以降の実行にのみ適用されます。Schedule .spec.scheduleは、.specには必須のフィールドです。0 * * * *や@hourlyなどのCron 形式の文字列を取り、Jobの作成と実行のスケジュール時間を指定します。
フォーマットにはVixie cronのステップ値(step value)も指定できます。FreeBSDのマニュアル では次のように説明されています。
ステップ値は範囲指定と組み合わせて使用できます。範囲の後ろに/<number>を付けると、範囲全体で指定したnumberの値ごとにスキップすることを意味します。たとえば、0-23/2をhoursフィールドに指定すると、2時間毎にコマンド実行を指定することになります(V7標準では代わりに0,2,4,6,8,10,12,14,16,18,20,22と指定する必要があります)。ステップはアスタリスクの後ろにつけることもできます。そのため、「2時間毎に実行」したい場合は、単純に*/2と指定できます。
備考: スケジュール内の疑問符?はアスタリスク*と同じ意味を持ちます。つまり、与えられたフィールドには任意の値が使えるという意味になります。Job Template .spec.jobTemplateはJobのテンプレートであり、必須です。Job と完全に同一のスキーマを持ちますが、フィールドがネストされている点と、apiVersionとkindが存在しない点だけが異なります。Jobの.specを書くための情報については、JobのSpecを書く を参照してください。
Starting Deadline .spec.startingDeadlineSecondsフィールドはオプションです。何かの理由でスケジュールに間に合わなかった場合に適用される、Jobの開始のデッドライン(締め切り)を秒数で指定します。デッドラインを過ぎると、CronJobはJobを開始しません。この場合にデッドラインに間に合わなかったJobは、失敗したJobとしてカウントされます。もしこのフィールドが指定されなかった場合、Jobはデッドラインを持ちません。
.spec.startingDeadlineSecondsフィールドがnull以外に設定された場合、CronJobコントローラーはJobの作成が期待される時間と現在時刻との間の時間を計測します。もしその差が制限よりも大きかった場合、その実行はスキップされます。
たとえば、この値が200に設定された場合、実際のスケジュールの最大200秒後までに作成されるJobだけが許可されます。
Concurrency Policy .spec.concurrencyPolicyフィールドもオプションです。このフィールドは、このCronJobで作成されたJobの並列実行をどのように扱うかを指定します。specには以下のconcurrency policyのいずれかを指定します。
Allow (デフォルト): CronJobがJobを並列に実行することを許可します。Forbid: CronJobの並列実行を禁止します。もし新しいJobの実行時に過去のJobがまだ完了していなかった場合、CronJobは新しいJobの実行をスキップします。Replace: もし新しいJobの実行の時間になっても過去のJobの実行が完了していなかった場合、CronJobは現在の実行中のJobを新しいJobで置換します。concurrency policyは、同じCronJobが作成したJobにのみ適用されます。もし複数のCronJobがある場合、それぞれのJobの並列実行は常に許可されます。
Suspend .spec.suspendフィールドもオプションです。このフィールドをtrueに設定すると、すべての後続の実行がサスペンド(一時停止)されます。この設定はすでに実行開始したJobには適用されません。デフォルトはfalseです。
注意: スケジュールされた時間中にサスペンドされた実行は、見逃されたJob(missed job)としてカウントされます。
starting deadline が設定されていない既存のCronJob
.spec.suspendが
trueから
falseに変更されると、見逃されたJobは即座にスケジュールされます。
Job History Limit .spec.successfulJobsHistoryLimitと.spec.failedJobsHistoryLimitフィールドはオプションです。これらのフィールドには、完了したJobと失敗したJobをいくつ保持するかを指定します。デフォルトでは、それぞれ3と1に設定されます。リミットを0に設定すると、対応する種類のJobを実行完了後に何も保持しなくなります。
4.9.2 - 静的な処理の割り当てを使用した並列処理のためのインデックス付きJob FEATURE STATE:
Kubernetes v1.21 [alpha]
この例では、複数の並列ワーカープロセスを使用するKubernetesのJobを実行します。各ワーカーは、それぞれが自分のPod内で実行される異なるコンテナです。Podはコントロールプレーンが自動的に設定するインデックス値 を持ち、この値を利用することで、各Podは処理するタスク全体のどの部分を処理するのかを特定できます。
Podのインデックスは、アノテーション 内のbatch.kubernetes.io/job-completion-indexを整数値の文字列表現として利用できます。コンテナ化されたタスクプロセスがこのインデックスを取得できるようにするために、このアノテーションの値はdownward API の仕組みを利用することで公開できます。利便性のために、コントロールプレーンは自動的にdownward APIを設定して、JOB_COMPLETION_INDEX環境変数にインデックスを公開します。
以下に、この例で実行するステップの概要を示します。
completionのインデックスを使用してJobのマニフェストを定義する 。downward APIはPodのインデックスのアノテーションを環境変数またはファイルとしてコンテナに渡してくれます。そのマニフェストに基づいてインデックス付き(Indexed)のJobを開始する 。始める前に あらかじめ基本的な非並列のJob の使用に慣れている必要があります。
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.21.
バージョンを確認するには次のコマンドを実行してください: kubectl version.
インデックス付きJobを作成できるようにするには、APIサーバー とコントローラーマネージャー 上でIndexedJobフィーチャーゲート を有効にしていることを確認してください。
アプローチを選択する ワーカープログラムから処理アイテムにアクセスするには、いくつかの選択肢があります。
JOB_COMPLETION_INDEX環境変数を読み込む。Jobコントローラー は、この変数をcompletion indexを含むアノテーションに自動的にリンクします。completion indexを含むファイルを読み込む。 プログラムを修正できない場合、プログラムをスクリプトでラップし、上のいずれかの方法でインデックスを読み取り、プログラムが入力として使用できるものに変換する。 この例では、3番目のオプションを選択肢して、rev ユーティリティを実行したいと考えているとしましょう。このプログラムはファイルを引数として受け取り、内容を逆さまに表示します。
revツールはbusybox
これは単なる例であるため、各Podはごく簡単な処理(短い文字列を逆にする)をするだけです。現実のワークロードでは、たとえば、シーンデータをもとに60秒の動画を生成するというようなタスクを記述したJobを作成するかもしれません。ビデオレンダリングJobの各処理アイテムは、ビデオクリップの特定のフレームのレンダリングを行うものになるでしょう。その場合、インデックス付きの完了が意味するのは、クリップの最初からフレームをカウントすることで、Job内の各Podがレンダリングと公開をするのがどのフレームであるかがわかるということです。
インデックス付きJobを定義する 以下は、completion modeとしてIndexedを使用するJobのマニフェストの例です。
apiVersion : batch/v1
kind : Job
metadata :
name : 'indexed-job'
spec :
completions : 5
parallelism : 3
completionMode : Indexed
template :
spec :
restartPolicy : Never
initContainers :
- name : 'input'
image : 'docker.io/library/bash'
command :
- "bash"
- "-c"
- |
items=(foo bar baz qux xyz)
echo ${items[$JOB_COMPLETION_INDEX]} > /input/data.txt
volumeMounts :
- mountPath : /input
name : input
containers :
- name : 'worker'
image : 'docker.io/library/busybox'
command :
- "rev"
- "/input/data.txt"
volumeMounts :
- mountPath : /input
name : input
volumes :
- name : input
emptyDir : {}
上記の例では、Jobコントローラーがすべてのコンテナに設定する組み込みのJOB_COMPLETION_INDEX環境変数を使っています。initコンテナ がインデックスを静的な値にマッピングし、その値をファイルに書き込み、ファイルをemptyDir volume を介してワーカーを実行しているコンテナと共有します。オプションとして、インデックスとコンテナに公開するためにdownward APIを使用して独自の環境変数を定義する こともできます。環境変数やファイルとして設定したConfigMap から値のリストを読み込むという選択肢もあります。
他には、以下の例のように、直接downward APIを使用してアノテーションの値をボリュームファイルとして渡す こともできます。
apiVersion : batch/v1
kind : Job
metadata :
name : 'indexed-job'
spec :
completions : 5
parallelism : 3
completionMode : Indexed
template :
spec :
restartPolicy : Never
containers :
- name : 'worker'
image : 'docker.io/library/busybox'
command :
- "rev"
- "/input/data.txt"
volumeMounts :
- mountPath : /input
name : input
volumes :
- name : input
downwardAPI :
items :
- path : "data.txt"
fieldRef :
fieldPath : metadata.annotations['batch.kubernetes.io/job-completion-index']Jobを実行する 次のコマンドでJobを実行します。
# このコマンドでは1番目のアプローチを使っています ($JOB_COMPLETION_INDEX に依存しています)
kubectl apply -f https://kubernetes.io/examples/application/job/indexed-job.yaml
このJobを作成したら、コントロールプレーンは指定した各インデックスごとに一連のPodを作成します。.spec.parallelismの値が同時に実行できるPodの数を決定し、.spec.completionsの値がJobが作成するPodの合計数を決定します。
.spec.parallelismは.spec.completionsより小さいため、コントロールプレーンは別のPodを開始する前に最初のPodの一部が完了するまで待機します。
Jobを作成したら、少し待ってから進行状況を確認します。
kubectl describe jobs/indexed-job
出力は次のようになります。
Name: indexed-job
Namespace: default
Selector: controller-uid=bf865e04-0b67-483b-9a90-74cfc4c3e756
Labels: controller-uid=bf865e04-0b67-483b-9a90-74cfc4c3e756
job-name=indexed-job
Annotations: <none>
Parallelism: 3
Completions: 5
Start Time: Thu, 11 Mar 2021 15:47:34 +0000
Pods Statuses: 2 Running / 3 Succeeded / 0 Failed
Completed Indexes: 0-2
Pod Template:
Labels: controller-uid=bf865e04-0b67-483b-9a90-74cfc4c3e756
job-name=indexed-job
Init Containers:
input:
Image: docker.io/library/bash
Port: <none>
Host Port: <none>
Command:
bash
-c
items=(foo bar baz qux xyz)
echo ${items[$JOB_COMPLETION_INDEX]} > /input/data.txt
Environment: <none>
Mounts:
/input from input (rw)
Containers:
worker:
Image: docker.io/library/busybox
Port: <none>
Host Port: <none>
Command:
rev
/input/data.txt
Environment: <none>
Mounts:
/input from input (rw)
Volumes:
input:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit: <unset>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 4s job-controller Created pod: indexed-job-njkjj
Normal SuccessfulCreate 4s job-controller Created pod: indexed-job-9kd4h
Normal SuccessfulCreate 4s job-controller Created pod: indexed-job-qjwsz
Normal SuccessfulCreate 1s job-controller Created pod: indexed-job-fdhq5
Normal SuccessfulCreate 1s job-controller Created pod: indexed-job-ncslj
この例では、各インデックスごとにカスタムの値を使用してJobを実行します。次のコマンドでPodの1つの出力を確認できます。
kubectl logs indexed-job-fdhq5 # これを対象のJobのPodの名前に一致するように変更してください。
出力は次のようになります。
xuq
4.10 - クラスター内アプリケーションへのアクセス クラスター内アプリケーションへアクセスできるようにするために、ロードバランシングやポートフォワーディングの設定、ファイアウォールやDNS設定のセットアップを行います。
4.10.1 - Web UI (Dashboard) ダッシュボードは、WebベースのKubernetesユーザーインターフェースです。
ダッシュボードを使用して、コンテナ化されたアプリケーションをKubernetesクラスターにデプロイしたり、
コンテナ化されたアプリケーションをトラブルシューティングしたり、クラスターリソースを管理したりすることができます。
ダッシュボードを使用して、クラスター上で実行されているアプリケーションの概要を把握したり、
個々のKubernetesリソース(Deployments、Jobs、DaemonSetsなど)を作成または修正したりすることができます。
たとえば、Deploymentのスケール、ローリングアップデートの開始、Podの再起動、
デプロイウィザードを使用した新しいアプリケーションのデプロイなどが可能です。
ダッシュボードでは、クラスター内のKubernetesリソースの状態や、発生した可能性のあるエラーに関する情報も提供されます。
ダッシュボードUIのデプロイ
備考: Kubernetes Dashboardは現在、Helmベースのインストールのみをサポートしています。
これは、すべての依存関係をより高速かつ適切に制御できるためです。ダッシュボードUIはデフォルトではデプロイされていません。デプロイするには、以下のコマンドを実行します:
# kubernetes-dashboardリポジトリを追加
helm repo add kubernetes-dashboard https://kubernetes.github.io/dashboard/
# "kubernetes-dashboard"という名前のHelm Releaseをkubernetes-dashboardチャートを使用してデプロイ
helm upgrade --install kubernetes-dashboard kubernetes-dashboard/kubernetes-dashboard --create-namespace --namespace kubernetes-dashboard
ダッシュボードUIへのアクセス クラスターデータを保護するために、ダッシュボードはデフォルトで最小限のRBAC構成でデプロイします。
現在、ダッシュボードはBearer Tokenによるログインのみをサポートしています。
このデモ用のトークンを作成するには、
サンプルユーザーの作成 ガイドに従ってください。
警告: チュートリアルで作成されたサンプルユーザーには管理者権限が与えられ、教育目的のみに使用されます。コマンドラインプロキシ 以下のコマンドを実行することで、kubectlコマンドラインツールを使ってダッシュボードにアクセスすることができます:
kubectl -n kubernetes-dashboard port-forward svc/kubernetes-dashboard-kong-proxy 8443:443
kubectlは、ダッシュボードをhttps://localhost:8443 で利用可能にします。
UIはコマンドを実行しているマシンから のみ アクセスできます。オプションについてはkubectl port-forward --helpを参照してください。
備考: Kubeconfigの認証方法は、外部IDプロバイダーやx509証明書ベースの認証には対応していません。ウェルカムビュー 空のクラスターでダッシュボードにアクセスすると、ウェルカムページが表示されます。
このページには、このドキュメントへのリンクと、最初のアプリケーションをデプロイするためのボタンが含まれています。
さらに、クラスターのkube-system名前空間 でデフォルトで実行されているシステムアプリケーション、たとえばダッシュボード自体を見ることができます。
コンテナ化されたアプリケーションのデプロイ ダッシュボードを使用すると、簡単なウィザードでコンテナ化されたアプリケーションをDeploymentとオプションのServiceとして作成してデプロイすることができます。
アプリケーションの詳細を手動で指定するか、アプリケーションの設定を含むYAMLまたはJSONファイルをアップロードすることができます。
任意のページの右上にあるCREATE ボタンをクリックして開始します。
アプリケーションの詳細の指定 デプロイウィザードでは、以下の情報を入力する必要があります:
App name (必須): アプリケーションの名前です。
その名前のlabel は、デプロイされるDeploymentとServiceに追加されます。
アプリケーション名は、選択したKubernetes名前空間 内で一意である必要があります。
小文字で始まり、小文字または数字で終わり、小文字、数字、ダッシュ(-)のみを含む必要があります。文字数は24文字に制限されています。先頭と末尾のスペースは無視されます。
Container image (必須): 任意のレジストリ上の公開Dockerコンテナイメージ 、またはプライベートイメージ(一般的にはGoogle Container RegistryやDocker Hub上でホストされている)のURLです。
コンテナイメージの指定はコロンで終わらせる必要があります。
クラスター全体で必要な数のPodを維持するために、Deployment が作成されます。
Service (任意): アプリケーションのいくつかの部分(たとえばフロントエンド)では、
Service をクラスター外の外部、おそらくパブリックIPアドレス(外部サービス)に公開したいと思うかもしれません。
備考: 外部サービスの場合は、そのために1つ以上のポートを開放する必要があるでしょう。クラスター内部からしか見えないその他のサービスは、内部サービスと呼ばれます。
サービスの種類にかかわらず、サービスを作成し、コンテナがポート(受信)をリッスンする場合は、
2つのポートを指定する必要があります。
サービスは、ポート(受信)をコンテナから見たターゲットポートにマッピングして作成されます。
このサービスは、デプロイされたPodにルーティングされます。サポートされるプロトコルはTCPとUDPです。
このサービスの内部DNS名は、上記のアプリケーション名として指定した値になります。
必要に応じて、高度なオプション セクションを展開して、より多くの設定を指定することができます:
Description : ここで入力したテキストは、
アノテーション としてDeploymentに追加され、アプリケーションの詳細に表示されます。
Labels : アプリケーションに使用するデフォルトのラベル は、アプリケーション名とバージョンです。
リリース、環境、ティア、パーティション、リリーストラックなど、Deployment、Service(存在する場合)、Podに適用する追加のラベルを指定できます。
例:
release=1.0
tier=frontend
environment=pod
track=stable
Namespace : Kubernetesは、同じ物理クラスターを基盤とする複数の仮想クラスターをサポートしています。
これらの仮想クラスターは名前空間 と呼ばれます。
これにより、リソースを論理的に名前のついたグループに分割することができます。
ダッシュボードでは、利用可能なすべての名前空間がドロップダウンリストに表示され、新しい名前空間を作成することができます。
名前空間名には、最大63文字の英数字とダッシュ(-)を含めることができますが、大文字を含めることはできません。
名前空間名は数字だけで構成されるべきではありません。
名前が10などの数値として設定されている場合、Podはデフォルトの名前空間に配置されます。
名前空間の作成に成功した場合は、デフォルトで選択されます。
作成に失敗した場合は、最初の名前空間が選択されます。
Image Pull Secret :
指定されたDockerコンテナイメージが非公開の場合、
pull secret の認証情報が必要になる場合があります。
ダッシュボードでは、利用可能なすべてのSecretがドロップダウンリストに表示され、新しいSecretを作成できます。
Secret名は DNSドメイン名の構文に従う必要があります。たとえば、new.image-pull.secretです。
Secretの内容はbase64エンコードされ、.dockercfg
イメージプルシークレットの作成に成功した場合は、デフォルトで選択されています。作成に失敗した場合は、シークレットは適用されません。
CPU requirement (cores)と Memory requirement (MiB) :
コンテナの最小リソース制限 を指定することができます。デフォルトでは、PodはCPUとメモリの制限がない状態で実行されます。
Run command とRun command arguments :
デフォルトでは、コンテナは指定されたDockerイメージのデフォルトのentrypointコマンド を実行します。
コマンドのオプションと引数を使ってデフォルトを上書きすることができます。
Run as privileged : この設定は、特権コンテナ 内のプロセスが、ホスト上でrootとして実行されているプロセスと同等であるかどうかを決定します。特権コンテナは、
ネットワークスタックの操作やデバイスへのアクセスなどの機能を利用できます。
Environment variables : Kubernetesは環境変数 を介してServiceを公開しています。
環境変数を作成したり、環境変数の値を使ってコマンドに引数を渡したりすることができます。
環境変数の値はServiceを見つけるためにアプリケーションで利用できます。
値は$(VAR_NAME)構文を使用して他の変数を参照できます。
YAMLまたはJSONファイルのアップロード Kubernetesは宣言的な設定をサポートしています。
このスタイルでは、すべての設定は Kubernetes API リソーススキーマを使用してYAMLまたは JSON設定ファイルに格納されます。
デプロイウィザードでアプリケーションの詳細を指定する代わりに、
YAMLまたはJSONファイルでアプリケーションを定義し、ダッシュボードを使用してファイルをアップロードできます。
ダッシュボードの使用 以下のセクションでは、Kubernetes Dashboard UIのビュー、それらが提供するものとその使用方法について説明します。
ナビゲーション クラスターにKubernetesオブジェクトが定義されている場合、ダッシュボードではそれらのオブジェクトが初期表示されます。
デフォルトでは default 名前空間のオブジェクトのみが表示されますが、これはナビゲーションメニューにある名前空間セレクターで変更できます。
ダッシュボードにはほとんどのKubernetesオブジェクトの種類が表示され、いくつかのメニューカテゴリーにグループ化されています。
管理者の概要 クラスターと名前空間の管理者向けに、ダッシュボードにはノード、名前空間、永続ボリュームが一覧表示され、それらの詳細ビューが用意されています。
ノードリストビューには、すべてのノードにわたって集計されたCPUとメモリーのメトリクスが表示されます。
詳細ビューには、ノードのメトリクス、仕様、ステータス、割り当てられたリソース、イベント、ノード上で実行されているPodが表示されます。
ワークロード 選択した名前空間で実行されているすべてのアプリケーションを表示します。
このビューでは、アプリケーションがワークロードの種類(例:Deployment、ReplicaSet、StatefulSetなど)ごとに一覧表示され、各ワークロードの種類を個別に表示することができます。
リストには、ReplicaSetの準備ができたPodの数やPodの現在のメモリ使用量など、ワークロードに関する実用的な情報がまとめられています。
ワークロードの詳細ビューには、ステータスや仕様情報、オブジェクト間の表面関係が表示されます。
たとえば、ReplicaSetが制御しているPodや、新しいReplicaSet、DeploymentのためのHorizontal Pod Autoscalerなどです。
Service 外部の世界にサービスを公開し、クラスター内でサービスを発見できるようにするKubernetesリソースを表示します。
そのため、ServiceとIngressのビューには、それらが対象とするPod、クラスター接続の内部エンドポイント、外部ユーザーの外部エンドポイントが表示されます。
ストレージ ストレージビューには、アプリケーションがデータを保存するために使用するPersistentVolumeClaimリソースが表示されます。
ConfigMapとSecret クラスターで実行されているアプリケーションのライブ設定に使用されているすべてのKubernetesリソースを表示します。
このビューでは、設定オブジェクトの編集と管理が可能で、デフォルトで非表示になっているSecretを表示します。
ログビューアー Podのリストと詳細ページは、ダッシュボードに組み込まれたログビューアーにリンクしています。
このビューアーでは、単一のPodに属するコンテナからログをドリルダウンすることができます。
次の項目 詳細についてはKubernetes Dashboardプロジェクトページ をご覧ください。
4.10.2 - 複数のクラスターへのアクセスを設定する ここでは、設定ファイルを使って複数のクラスターにアクセスする方法を紹介します。クラスター、ユーザー、コンテキストの情報を一つ以上の設定ファイルにまとめることで、kubectl config use-contextのコマンドを使ってクラスターを素早く切り替えることができます。
備考: クラスターへのアクセスを設定するファイルを、kubeconfig ファイルと呼ぶことがあります。これは設定ファイルの一般的な呼び方です。kubeconfigという名前のファイルが存在するわけではありません。始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
kubectl がインストールされているか確認するため、kubectl version --clientを実行してください。kubectlのバージョンは、クラスターのAPIサーバーの1つのマイナーバージョン内 である必要があります。
クラスター、ユーザー、コンテキストを設定する 例として、開発用のクラスターが一つ、実験用のクラスターが一つ、計二つのクラスターが存在する場合を考えます。developmentと呼ばれる開発用のクラスター内では、フロントエンドの開発者はfrontendというnamespace内で、ストレージの開発者はstorageというnamespace内で作業をします。scratchと呼ばれる実験用のクラスター内では、開発者はデフォルトのnamespaceで作業をするか、状況に応じて追加のnamespaceを作成します。開発用のクラスターは証明書を通しての認証を必要とします。実験用のクラスターはユーザーネームとパスワードを通しての認証を必要とします。
config-exerciseというディレクトリを作成してください。config-exerciseディレクトリ内に、以下を含むconfig-demoというファイルを作成してください:
apiVersion: v1
kind: Config
preferences: {}
clusters:
- cluster:
name: development
- cluster:
name: scratch
users:
- name: developer
- name: experimenter
contexts:
- context:
name: dev-frontend
- context:
name: dev-storage
- context:
name: exp-scratch
設定ファイルには、クラスター、ユーザー、コンテキストの情報が含まれています。上記のconfig-demo設定ファイルには、二つのクラスター、二人のユーザー、三つのコンテキストの情報が含まれています。
config-exerciseディレクトリに移動してください。クラスター情報を設定ファイルに追加するために、以下のコマンドを実行してください:
kubectl config --kubeconfig= config-demo set-cluster development --server= https://1.2.3.4 --certificate-authority= fake-ca-file
kubectl config --kubeconfig= config-demo set-cluster scratch --server= https://5.6.7.8 --insecure-skip-tls-verify
ユーザー情報を設定ファイルに追加してください:
kubectl config --kubeconfig= config-demo set-credentials developer --client-certificate= fake-cert-file --client-key= fake-key-seefile
kubectl config --kubeconfig= config-demo set-credentials experimenter --username= exp --password= some-password
備考: kubectl --kubeconfig=config-demo config unset users.<name>を実行すると、ユーザーを削除することができます。
kubectl --kubeconfig=config-demo config unset clusters.<name>を実行すると、クラスターを除去することができます。
kubectl --kubeconfig=config-demo config unset contexts.<name>を実行すると、コンテキスト情報を除去することができます。コンテキスト情報を設定ファイルに追加してください:
kubectl config --kubeconfig= config-demo set-context dev-frontend --cluster= development --namespace= frontend --user= developer
kubectl config --kubeconfig= config-demo set-context dev-storage --cluster= development --namespace= storage --user= developer
kubectl config --kubeconfig= config-demo set-context exp-scratch --cluster= scratch --namespace= default --user= experimenter
追加した情報を確認するために、config-demoファイルを開いてください。config-demoファイルを開く代わりに、config viewのコマンドを使うこともできます。
kubectl config --kubeconfig= config-demo view
出力には、二つのクラスター、二人のユーザー、三つのコンテキストが表示されます:
apiVersion: v1
clusters:
- cluster:
certificate-authority: fake-ca-file
server: https://1.2.3.4
name: development
- cluster:
insecure-skip-tls-verify: true
server: https://5.6.7.8
name: scratch
contexts:
- context:
cluster: development
namespace: frontend
user: developer
name: dev-frontend
- context:
cluster: development
namespace: storage
user: developer
name: dev-storage
- context:
cluster: scratch
namespace: default
user: experimenter
name: exp-scratch
current-context: ""
kind: Config
preferences: {}
users:
- name: developer
user:
client-certificate: fake-cert-file
client-key: fake-key-file
- name: experimenter
user:
password: some-password
username: exp
上記のfake-ca-file、fake-cert-file、fake-key-fileは、証明書ファイルの実際のパスのプレースホルダーです。環境内にある証明書ファイルの実際のパスに変更してください。
証明書ファイルのパスの代わりにbase64にエンコードされたデータを使用したい場合は、キーに-dataの接尾辞を加えてください。例えば、certificate-authority-data、client-certificate-data、client-key-dataとできます。
それぞれのコンテキストは、クラスター、ユーザー、namespaceの三つ組からなっています。例えば、dev-frontendは、developerユーザーの認証情報を使ってdevelopmentクラスターのfrontendnamespaceへのアクセスを意味しています。
現在のコンテキストを設定してください:
kubectl config --kubeconfig= config-demo use-context dev-frontend
これ以降実行されるkubectlコマンドは、dev-frontendに設定されたクラスターとnamespaceに適用されます。また、dev-frontendに設定されたユーザーの認証情報を使用します。
現在のコンテキストの設定情報のみを確認するには、--minifyフラグを使用してください。
kubectl config --kubeconfig= config-demo view --minify
出力には、dev-frontendの設定情報が表示されます:
apiVersion: v1
clusters:
- cluster:
certificate-authority: fake-ca-file
server: https://1.2.3.4
name: development
contexts:
- context:
cluster: development
namespace: frontend
user: developer
name: dev-frontend
current-context: dev-frontend
kind: Config
preferences: {}
users:
- name: developer
user:
client-certificate: fake-cert-file
client-key: fake-key-file
今度は、実験用のクラスター内でしばらく作業する場合を考えます。
現在のコンテキストをexp-scratchに切り替えてください:
kubectl config --kubeconfig= config-demo use-context exp-scratch
これ以降実行されるkubectlコマンドは、scratchクラスター内のデフォルトnamespaceに適用されます。また、exp-scratchに設定されたユーザーの認証情報を使用します。
新しく切り替えたexp-scratchの設定を確認してください。
kubectl config --kubeconfig= config-demo view --minify
最後に、developmentクラスター内のstoragenamespaceでしばらく作業する場合を考えます。
現在のコンテキストをdev-storageに切り替えてください:
kubectl config --kubeconfig= config-demo use-context dev-storage
新しく切り替えたdev-storageの設定を確認してください。
kubectl config --kubeconfig= config-demo view --minify
二つ目の設定ファイルを作成する config-exerciseディレクトリ内に、以下を含むconfig-demo-2というファイルを作成してください:
apiVersion: v1
kind: Config
preferences: {}
contexts:
- context:
cluster: development
namespace: ramp
user: developer
name: dev-ramp-up
上記の設定ファイルは、dev-ramp-upというコンテキストを表します。
KUBECONFIG環境変数を設定する KUBECONFIGという環境変数が存在するかを確認してください。もし存在する場合は、後で復元できるようにバックアップしてください。例えば:
Linux export KUBECONFIG_SAVED = $KUBECONFIG
Windows PowerShell $Env :KUBECONFIG_SAVED= $ENV :KUBECONFIG
KUBECONFIG環境変数は、設定ファイルのパスのリストです。リスト内のパスはLinuxとMacではコロンで区切られ、Windowsではセミコロンで区切られます。KUBECONFIG環境変数が存在する場合は、リスト内の設定ファイルの内容を確認してください。
一時的にKUBECONFIG環境変数に以下の二つのパスを追加してください。例えば:
Linux export KUBECONFIG = $KUBECONFIG :config-demo:config-demo-2
Windows PowerShell $Env :KUBECONFIG=( "config-demo;config-demo-2" )
config-exerciseディレクトリ内から、以下のコマンドを実行してください:
出力には、KUBECONFIG環境変数に含まれる全てのファイルの情報がまとめて表示されます。config-demo-2ファイルに設定されたdev-ramp-upの情報と、config-demoに設定された三つのコンテキストの情報がまとめてあることに注目してください:
contexts:
- context:
cluster: development
namespace: frontend
user: developer
name: dev-frontend
- context:
cluster: development
namespace: ramp
user: developer
name: dev-ramp-up
- context:
cluster: development
namespace: storage
user: developer
name: dev-storage
- context:
cluster: scratch
namespace: default
user: experimenter
name: exp-scratch
kubeconfigファイルに関するさらなる情報を参照するには、kubeconfigファイルを使ってクラスターへのアクセスを管理する を参照してください。
$HOME/.kubeディレクトリの内容を確認する 既にクラスターを所持していて、kubectlを使ってクラスターを操作できる場合は、$HOME/.kubeディレクトリ内にconfigというファイルが存在する可能性が高いです。
$HOME/.kubeに移動して、そこに存在するファイルを確認してください。configという設定ファイルが存在するはずです。他の設定ファイルも存在する可能性があります。全てのファイルの中身を確認してください。
$HOME/.kube/configをKUBECONFIG環境変数に追加する もし$HOME/.kube/configファイルが存在していて、既にKUBECONFIG環境変数に追加されていない場合は、KUBECONFIG環境変数に追加してください。例えば:
Linux export KUBECONFIG = $KUBECONFIG :$HOME /.kube/config
Windows Powershell $Env :KUBECONFIG= " $Env :KUBECONFIG; $HOME /.kube/config"
KUBECONFIG環境変数内のファイルからまとめられた設定情報を確認してください。config-exerciseディレクトリ内から、以下のコマンドを実行してください:
クリーンアップ KUBECONFIG環境変数を元に戻してください。例えば:
Linux: export KUBECONFIG = $KUBECONFIG_SAVED
Windows PowerShell $Env :KUBECONFIG= $ENV :KUBECONFIG_SAVED
次の項目 4.10.3 - クラスター内のアプリケーションにアクセスするためにポートフォワーディングを使用する このページでは、kubectl port-forwardを使用して、Kubernetesクラスター内で実行中のMongoDBサーバーに接続する方法について説明します。
この種の接続は、データベースのデバッグに役立ちます。
始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.10.バージョンを確認するには次のコマンドを実行してください: kubectl version.
MongoDB Shell をインストールする。MongoDBのDeploymentとServiceを作成する MongoDBを実行するDeploymentを作成する:
kubectl apply -f https://k8s.io/examples/application/mongodb/mongo-deployment.yaml
正常にコマンドが実行されると、Deploymentが作成されたことを示す出力が表示されます:
deployment.apps/mongo created
Podのステータスを表示して、準備完了であることを確認します:
出力には作成されたPodが表示されます:
NAME READY STATUS RESTARTS AGE
mongo-75f59d57f4-4nd6q 1/1 Running 0 2m4s
Deploymentのステータスを表示します:
出力には、Deploymentが作成されたことが表示されます:
NAME READY UP-TO-DATE AVAILABLE AGE
mongo 1/1 1 1 2m21s
Deploymentは自動的にReplicaSetを管理します。
ReplicaSetのステータスを表示するには、次のコマンドを使用します:
出力には、ReplicaSetが作成されたことが表示されます:
NAME DESIRED CURRENT READY AGE
mongo-75f59d57f4 1 1 1 3m12s
ネットワーク上にMongoDBを公開するためのServiceを作成します:
kubectl apply -f https://k8s.io/examples/application/mongodb/mongo-service.yaml
正常にコマンドが実行されると、Serviceが作成されたことを示す出力が表示されます:
service/mongo created
Serviceが作成されたことを確認します:
kubectl get service mongo
出力には、Serviceが作成されたことが表示されます:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mongo ClusterIP 10.96.41.183 <none> 27017/TCP 11s
MongoDBサーバーがPod内で実行中であり、27017番ポートでリッスンしていることを確認します:
# mongo-75f59d57f4-4nd6qをPod名に置き換えてください
kubectl get pod mongo-75f59d57f4-4nd6q --template= '{{(index (index .spec.containers 0).ports 0).containerPort}}{{"\n"}}'
出力には、そのPod内のMongoDBのポートが表示されます:
27017
27017は、MongoDBの公式なTCPポートです。
ローカルポートをPodのポートにフォワードする kubectl port-forwardでは、Pod名などのリソース名を指定して、ポートフォワードの対象となるPodを選択できます。
# mongo-75f59d57f4-4nd6qを実際のPod名に置き換えてください
kubectl port-forward mongo-75f59d57f4-4nd6q 28015:27017
これは、次のコマンドと同じ意味になります。
kubectl port-forward pods/mongo-75f59d57f4-4nd6q 28015:27017
または、
kubectl port-forward deployment/mongo 28015:27017
または、
kubectl port-forward replicaset/mongo-75f59d57f4 28015:27017
または、
kubectl port-forward service/mongo 28015:27017
上記のいずれのコマンドも有効です。出力は次のようになります:
Forwarding from 127.0.0.1:28015 -> 27017
Forwarding from [::1]:28015 -> 27017
備考: kubectl port-forwardは終了せずに待機状態のままとなります。演習を続けるには、別のターミナルを開く必要があります。MongoDBのコマンドラインインターフェースを起動します:
MongoDBのコマンドラインプロンプトで、pingコマンドを入力します:
db.runCommand( { ping: 1 } )
pingリクエストが成功すると、次のような結果が返されます:
{ ok: 1 }
オプションで kubectl にローカルポートを自動割り当てさせる 特定のローカルポートを指定する必要がない場合は、kubectlにローカルポートの割り当てを任せることができます。
これにより、ローカルポートの競合を管理する必要がなくなり、構文もやや簡潔になります:
kubectl port-forward deployment/mongo :27017
kubectlツールは、使用されていないローカルポート番号を見つけて割り当てます(他のアプリケーションで使用されている可能性があるため、低いポート番号は避けられます)。
出力は次のようになります:
Forwarding from 127.0.0.1:63753 -> 27017
Forwarding from [::1]:63753 -> 27017
解説 ローカルの28015番ポートへの接続は、MongoDBサーバーを実行しているPodの27017番ポートにフォワードされます。
この接続が確立されていれば、ローカルのワークステーションから、Pod内で実行中のデータベースのデバッグを行うことができます。
備考: kubectl port-forwardはTCPポートのみに対応しています。
UDPプロトコルのサポートについては、
Issue 47862 で追跡されています。
次の項目 kubectl port-forward について詳しくは、こちらを参照してください。
4.10.4 - Serviceを利用したクラスター内のアプリケーションへのアクセス ここでは、クラスター内で稼働しているアプリケーションに外部からアクセスするために、KubernetesのServiceオブジェクトを作成する方法を紹介します。
例として、2つのインスタンスから成るアプリケーションへのロードバランシングを扱います。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
目標 2つのHello Worldアプリケーションを稼働させる。 Nodeのポートを公開するServiceオブジェクトを作成する。 稼働しているアプリケーションにアクセスするためにServiceオブジェクトを使用する。 2つのPodから成るアプリケーションのServiceを作成 アプリケーションDeploymentの設定ファイルは以下の通りです:
apiVersion : apps/v1
kind : Deployment
metadata :
name : hello-world
spec :
selector :
matchLabels :
run : load-balancer-example
replicas : 2
template :
metadata :
labels :
run : load-balancer-example
spec :
containers :
- name : hello-world
image : gcr.io/google-samples/node-hello:1.0
ports :
- containerPort : 8080
protocol : TCP
クラスターでHello Worldアプリケーションを稼働させます:
上記のファイルを使用し、アプリケーションのDeploymentを作成します:
kubectl apply -f https://k8s.io/examples/service/access/hello-application.yaml
このコマンドはDeployment オブジェクトとそれに紐付くReplicaSet オブジェクトを作成します。ReplicaSetは、Hello Worldアプリケーションが稼働している2つのPod から構成されます。
Deploymentの情報を表示します:
kubectl get deployments hello-world
kubectl describe deployments hello-world
ReplicaSetオブジェクトの情報を表示します:
kubectl get replicasets
kubectl describe replicasets
Deploymentを公開するServiceオブジェクトを作成します:
kubectl expose deployment hello-world --type= NodePort --name= example-service
Serviceに関する情報を表示します:
kubectl describe services example-service
出力例は以下の通りです:
Name: example-service
Namespace: default
Labels: run = load-balancer-example
Annotations: <none>
Selector: run = load-balancer-example
Type: NodePort
IP: 10.32.0.16
Port: <unset> 8080/TCP
TargetPort: 8080/TCP
NodePort: <unset> 31496/TCP
Endpoints: 10.200.1.4:8080,10.200.2.5:8080
Session Affinity: None
Events: <none>
NodePortの値を記録しておきます。上記の例では、31496です。
Hello Worldアプリーションが稼働しているPodを表示します:
kubectl get pods --selector= "run=load-balancer-example" --output= wide
出力例は以下の通りです:
NAME READY STATUS ... IP NODE
hello-world-2895499144-bsbk5 1/1 Running ... 10.200.1.4 worker1
hello-world-2895499144-m1pwt 1/1 Running ... 10.200.2.5 worker2
Hello World podが稼働するNodeのうち、いずれか1つのパブリックIPアドレスを確認します。
確認方法は、使用している環境により異なります。
例として、Minikubeの場合はkubectl cluster-info、Google Compute Engineの場合はgcloud compute instances listによって確認できます。
選択したノード上で、NodePortの値でのTCP通信を許可するファイヤーウォールを作成します。
NodePortの値が31568の場合、31568番のポートを利用したTCP通信を許可するファイヤーウォールを作成します。
クラウドプロバイダーによって設定方法が異なります。
Hello World applicationにアクセスするために、Nodeのアドレスとポート番号を使用します:
curl http://<public-node-ip>:<node-port>
ここで <public-node-ip> はNodeのパブリックIPアドレス、
<node-port> はNodePort Serviceのポート番号の値を表しています。
リクエストが成功すると、下記のメッセージが表示されます:
service configuration fileの利用 kubectl exposeコマンドの代わりに、
service configuration file
を使用してServiceを作成することもできます。
クリーンアップ Serviceを削除するには、以下のコマンドを実行します:
kubectl delete services example-service
Hello Worldアプリケーションが稼働しているDeployment、ReplicaSet、Podを削除するには、以下のコマンドを実行します:
kubectl delete deployment hello-world
次の項目 詳細は
serviceを利用してアプリケーションと接続する
を確認してください。
4.10.5 - Serviceを使用してフロントエンドをバックエンドに接続する このタスクでは、フロントエンドとバックエンドのマイクロサービスを作成する方法を示します。
バックエンドのマイクロサービスは挨拶です。
フロントエンドとバックエンドは、Kubernetes Service オブジェクトを使用して接続されます。
目標 Deployment オブジェクトを使用してマイクロサービスを作成および実行します。フロントエンドを経由してトラフィックをバックエンドにルーティングします。 Serviceオブジェクトを使用して、フロントエンドアプリケーションをバックエンドアプリケーションに接続します。 始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
このタスクではServiceで外部ロードバランサー を使用しますが、外部ロードバランサーの使用がサポートされている環境である必要があります。
ご使用の環境がこれをサポートしていない場合は、代わりにタイプNodePort のServiceを使用できます。
Deploymentを使用したバックエンドの作成 バックエンドは、単純な挨拶マイクロサービスです。
バックエンドのDeploymentの構成ファイルは次のとおりです:
apiVersion : apps/v1
kind : Deployment
metadata :
name : hello
spec :
selector :
matchLabels :
app : hello
tier : backend
track : stable
replicas : 7
template :
metadata :
labels :
app : hello
tier : backend
track : stable
spec :
containers :
- name : hello
image : "gcr.io/google-samples/hello-go-gke:1.0"
ports :
- name : http
containerPort : 80
バックエンドのDeploymentを作成します:
kubectl apply -f https://k8s.io/examples/service/access/hello.yaml
バックエンドのDeploymentに関する情報を表示します:
kubectl describe deployment hello
出力はこのようになります:
Name: hello
Namespace: default
CreationTimestamp: Mon, 24 Oct 2016 14:21:02 -0700
Labels: app=hello
tier=backend
track=stable
Annotations: deployment.kubernetes.io/revision=1
Selector: app=hello,tier=backend,track=stable
Replicas: 7 desired | 7 updated | 7 total | 7 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 1 max unavailable, 1 max surge
Pod Template:
Labels: app=hello
tier=backend
track=stable
Containers:
hello:
Image: "gcr.io/google-samples/hello-go-gke:1.0"
Port: 80/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: hello-3621623197 (7/7 replicas created)
Events:
...
バックエンドServiceオブジェクトの作成 フロントエンドをバックエンドに接続する鍵は、バックエンドServiceです。
Serviceは、バックエンドマイクロサービスに常に到達できるように、永続的なIPアドレスとDNS名のエントリを作成します。
Serviceはセレクター を使用して、トラフィックをルーティングするPodを見つけます。
まず、Service構成ファイルを調べます:
kind : Service
apiVersion : v1
metadata :
name : hello
spec :
selector :
app : hello
tier : backend
ports :
- protocol : TCP
port : 80
targetPort : http
設定ファイルで、Serviceがapp:helloおよびtier:backendというラベルを持つPodにトラフィックをルーティングしていることがわかります。
hello Serviceを作成します:
kubectl apply -f https://k8s.io/examples/service/access/hello-service.yaml
この時点で、バックエンドのDeploymentが実行され、そちらにトラフィックをルーティングできるServiceがあります。
フロントエンドの作成 バックエンドができたので、バックエンドに接続するフロントエンドを作成できます。
フロントエンドは、バックエンドServiceに指定されたDNS名を使用して、バックエンドワーカーPodに接続します。
DNS名はhelloです。これは、前のサービス設定ファイルのnameフィールドの値です。
フロントエンドDeploymentのPodは、helloバックエンドServiceを見つけるように構成されたnginxイメージを実行します。
これはnginx設定ファイルです:
upstream hello {
server hello;
}
server {
listen 80;
location / {
proxy_pass http://hello;
}
}
バックエンドと同様に、フロントエンドにはDeploymentとServiceがあります。
Serviceの設定にはtype:LoadBalancerがあります。これは、Serviceがクラウドプロバイダーのデフォルトのロードバランサーを使用することを意味します。
apiVersion : v1
kind : Service
metadata :
name : frontend
spec :
selector :
app : hello
tier : frontend
ports :
- protocol : "TCP"
port : 80
targetPort : 80
type : LoadBalancer
---
apiVersion : apps/v1
kind : Deployment
metadata :
name : frontend
spec :
selector :
matchLabels :
app : hello
tier : frontend
track : stable
replicas : 1
template :
metadata :
labels :
app : hello
tier : frontend
track : stable
spec :
containers :
- name : nginx
image : "gcr.io/google-samples/hello-frontend:1.0"
lifecycle :
preStop :
exec :
command : ["/usr/sbin/nginx" ,"-s" ,"quit" ]
フロントエンドのDeploymentとServiceを作成します:
kubectl apply -f https://k8s.io/examples/service/access/frontend.yaml
出力結果から両方のリソースが作成されたことを確認します:
deployment.apps/frontend created
service/frontend created
備考: nginxの構成は、
コンテナイメージ に焼き付けられます。
これを行うためのより良い方法は、
ConfigMap を使用して、構成をより簡単に変更できるようにすることです。
フロントエンドServiceと対話 LoadBalancerタイプのServiceを作成したら、このコマンドを使用して外部IPを見つけることができます:
kubectl get service frontend --watch
これによりfrontend Serviceの設定が表示され、変更が監視されます。
最初、外部IPは<pending>としてリストされます:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
frontend LoadBalancer 10.51.252.116 <pending> 80/TCP 10s
ただし、外部IPがプロビジョニングされるとすぐに、EXTERNAL-IPという見出しの下に新しいIPが含まれるように構成が更新されます:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
frontend LoadBalancer 10.51.252.116 XXX.XXX.XXX.XXX 80/TCP 1m
このIPを使用して、クラスターの外部からfrontend Serviceとやり取りできるようになりました。
フロントエンドを介するトラフィック送信 フロントエンドとバックエンドが接続されました。
フロントエンドServiceの外部IPに対してcurlコマンドを使用して、エンドポイントにアクセスできます。
curl http://${ EXTERNAL_IP } # これを前に見たEXTERNAL-IPに置き換えます
出力には、バックエンドによって生成されたメッセージが表示されます:
クリーンアップ Serviceを削除するには、このコマンドを入力してください:
kubectl delete services frontend hello
バックエンドとフロントエンドアプリケーションを実行しているDeploymentとReplicaSetとPodを削除するために、このコマンドを入力してください:
kubectl delete deployment frontend hello
次の項目 4.10.6 - 外部ロードバランサーを作成する このページでは、外部ロードバランサーを作成する方法について説明します。
Service を作成する際に、クラウドロードバランサーを自動的に作成するオプションがあります。
これにより、外部からアクセス可能なIPアドレスが割り当てられ、そのIPからのトラフィックがクラスター内のノード上の正しいポートへと送信されます。
ただし、クラスターが対応する環境で実行されており、適切なクラウドロードバランサープロバイダーのパッケージが構成されている必要があります 。
Serviceの代わりに、Ingress を使用することもできます。
詳細については、Ingress のドキュメントを参照してください。
始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
クラスターは、外部ロードバランサーの構成をサポートするクラウド環境、またはそれに相当する他の環境上で実行されている必要があります。
Serviceを作成する マニフェストからServiceを作成する 外部ロードバランサーを作成するには、Serviceのマニフェストに次の行を追加します:
マニフェストは次のようになります:
apiVersion : v1
kind : Service
metadata :
name : example-service
spec :
selector :
app : example
ports :
- port : 8765
targetPort : 9376
type : LoadBalancer
kubectlを使用してServiceを作成する 代わりに、kubectl exposeコマンドとその--type=LoadBalancerフラグを使用してServiceを作成することも可能です:
kubectl expose deployment example --port= 8765 --target-port= 9376 \
= example-service --type= LoadBalancer
このコマンドは、参照されているリソース(上記の例ではexampleという名前のDeployment )と同じセレクターを使用して、新しいServiceを作成します。
オプションのフラグを含む詳細については、kubectl exposeのリファレンス
IPアドレスの確認 kubectlを使用してサービスの情報を取得することで、そのサービスに割り当てられたIPアドレスを確認できます:
kubectl describe services example-service
このコマンドの出力は次のようになります:
Name: example-service
Namespace: default
Labels: app=example
Annotations: <none>
Selector: app=example
Type: LoadBalancer
IP Families: <none>
IP: 10.3.22.96
IPs: 10.3.22.96
LoadBalancer Ingress: 192.0.2.89
Port: <unset> 8765/TCP
TargetPort: 9376/TCP
NodePort: <unset> 30593/TCP
Endpoints: 172.17.0.3:9376
Session Affinity: None
External Traffic Policy: Cluster
Events: <none>
ロードバランサーのIPアドレスは、LoadBalancer Ingressの横に表示されます。
備考: Minikube上でサービスを実行している場合は、割り当てられたIPアドレスとポートを、次のコマンドで確認できます:
minikube service example-service --url
クライアントの送信元IPアドレスを保持する デフォルトでは、ターゲットコンテナから見える送信元IPは、クライアントの元の送信元IPアドレスではありません 。
クライアントIPの保持を有効にするには、Serviceの.spec内で次のフィールドを設定する必要があります:
.spec.externalTrafficPolicy - このServiceが外部トラフィックをノードローカルのエンドポイントにルーティングするか、クラスター全体のエンドポイントにルーティングするかを指定します。指定可能な値はCluster(デフォルト)とLocalの2つです。Clusterを指定するとクライアントの送信元IPは隠蔽され、他のノードへの2回目のホップが発生する可能性がありますが、全体的な負荷分散は良好になります。Localを指定するとクライアントの送信元IPが保持され、LoadBalancer型およびNodePort型Serviceにおいて2回目のホップを回避できますが、トラフィックの分散が偏るリスクがあります。.spec.healthCheckNodePort - サービスのヘルスチェック用ノードポート(数値のポート番号)を指定します。healthCheckNodePortを指定しない場合、サービスコントローラーがクラスターのNodePortレンジから自動的にポートを割り当てます。
このポートレンジは、APIサーバーのコマンドラインオプション--service-node-port-rangeで設定できます。ServiceのtypeがLoadBalancerで、externalTrafficPolicyがLocalに設定されている場合に限り、指定したhealthCheckNodePortの値が使用されます。ServiceのマニフェストでexternalTrafficPolicyをLocalに設定することで、この機能が有効になります。
たとえば、次のように指定します:
apiVersion : v1
kind : Service
metadata :
name : example-service
spec :
selector :
app : example
ports :
- port : 8765
targetPort : 9376
externalTrafficPolicy : Local
type : LoadBalancer
送信元IPアドレスを保持する際の注意点と制限事項 一部のクラウドプロバイダーが提供するロードバランサーサービスでは、各ターゲットに対して異なる重みを設定することができません。
各ターゲットがノードへのトラフィック送信において等しく重み付けされているため、外部トラフィックは異なるPod間で均等に負荷分散されません。外部ロードバランサーは、ターゲットとして使用される各ノード上のPod数を認識していません。
NumServicePods << NumNodesまたはNumServicePods >> NumNodesの場合、重み付けがなくても、かなり均等に近い分散が見られます。
Pod間の内部トラフィックは、すべてのPodに対して等しい確率で、ClusterIPサービスと同様の動作をするはずです。
ロードバランサーのガベージコレクション FEATURE STATE:
Kubernetes v1.17 [stable]
通常、LoadBalancer型Serviceが削除されると、それに関連付けられたクラウドプロバイダー上のロードバランサーリソースも速やかにクリーンアップされるはずです。
しかし、Serviceの削除後に関連するクラウドリソースが孤立状態になるさまざまなコーナーケースが知られています。
これを防ぐために、「Service LoadBalancerのFinalizer保護」が導入されました。
Finalizerを使用することで、対応するロードバランサーリソースが削除されるまでは、Serviceリソース自体も削除されなくなります。
具体的には、typeがLoadBalancerであるServiceには、service.kubernetes.io/load-balancer-cleanupという名前のFinalizerがサービスコントローラーによって付与されます。
このFinalizerは、ロードバランサーリソースがクリーンアップされるまで削除されません。
これにより、たとえばサービスコントローラーがクラッシュするようなコーナーケースにおいても、ロードバランサーリソースが取り残されるのを防ぐことができます。
外部ロードバランサープロバイダー この機能のデータパスは、Kubernetesクラスター外部のロードバランサーによって提供されることに注意が必要です。
ServiceのtypeがLoadBalancerに設定されている場合、Kubernetesはクラスター内のPodに対してはtypeがClusterIPに相当する機能を提供し、さらに(Kubernetesの外部にある)ロードバランサーに、該当するPodをホストしているノードの情報を登録することで、この機能を拡張します。
Kubernetesのコントロールプレーンは、外部ロードバランサーの作成、必要に応じたヘルスチェックやパケットフィルタリングルールの設定を自動で行います。
クラウドプロバイダーによってロードバランサーのIPアドレスが割り当てられると、コントロールプレーンはその外部IPアドレスを取得し、Serviceオブジェクトに反映します。
次の項目 4.10.7 - クラスターで実行されているすべてのコンテナイメージを一覧表示する このページでは、kubectlを使用して、クラスターで実行されているPodのすべてのコンテナイメージを一覧表示する方法を説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
この演習では、kubectlを使用してクラスターで実行されているすべてのPodを取得し、出力をフォーマットしてそれぞれのコンテナの一覧を取得します。
すべての名前空間のコンテナイメージを一覧表示する kubectl get pods --all-namespacesを使用して、すべての名前空間のPodを取得します-o jsonpath={.. image}を使用して、コンテナイメージ名のリストのみが含まれるように出力をフォーマットします。これは、返されたjsonのimageフィールドを再帰的に解析します。tr、sort、uniqなどの標準ツールを使用して出力をフォーマットします。trを使用してスペースを改行に置換します。sortを使用して結果を並べ替えます。uniqを使用してイメージ数を集計します。kubectl get pods --all-namespaces -o jsonpath = "{..image}" |\
'[[:space:]]' '\n' |\
\
上記のコマンドは、返されるすべてのアイテムについて、imageという名前のすべてのフィールドを再帰的に返します。
別の方法として、Pod内のimageフィールドへの絶対パスを使用することができます。これにより、フィールド名が繰り返されている場合でも正しいフィールドが取得されます。多くのフィールドは与えられたアイテム内でnameと呼ばれます:
kubectl get pods --all-namespaces -o jsonpath = "{.items[*].spec.containers[*].image}"
jsonpathは次のように解釈されます:
.items[*]: 各戻り値.spec: 仕様の取得.containers[*]: 各コンテナ.image: イメージの取得
備考: 例えばkubectl get pod nginxのように名前を指定して単一のPodを取得する場合、アイテムのリストではなく単一のPodが返されるので、パスの.items[*]部分は省略してください。Podごとにコンテナイメージを一覧表示する rangeを使用して要素を個別に繰り返し処理することにより、フォーマットをさらに制御できます。
kubectl get pods --all-namespaces -o jsonpath = '{range .items[*]}{"\n"}{.metadata.name}{":\t"}{range .spec.containers[*]}{.image}{", "}{end}{end}' |\
Podのラベルを使用してコンテナイメージ一覧をフィルタリングする 特定のラベルに一致するPodのみを対象とするには、-lフラグを使用します。以下は、app=nginxに一致するラベルを持つPodのみに一致します。
kubectl get pods --all-namespaces -o jsonpath = "{..image}" -l app = nginx
Podの名前空間でコンテナイメージ一覧をフィルタリングする 特定の名前空間のPodのみを対象とするには、namespaceフラグを使用します。以下はkube-system名前空間のPodのみに一致します。
kubectl get pods --namespace kube-system -o jsonpath = "{..image}"
jsonpathの代わりにgo-templateを使用してコンテナイメージを一覧表示する jsonpathの代わりに、kubectlはgo-templates を使用した出力のフォーマットをサポートしています:
kubectl get pods --all-namespaces -o go-template --template= "{{range .items}}{{range .spec.containers}}{{.image}} {{end}}{{end}}"
次の項目 参照 4.10.8 - Minikube上でNGINX Ingressコントローラーを使用してIngressをセットアップする Ingress とは、クラスター内のServiceに外部からのアクセスを許可するルールを定義するAPIオブジェクトです。Ingressコントローラー はIngress内に設定されたルールを満たすように動作します。
このページでは、簡単なIngressをセットアップして、HTTPのURIに応じてwebまたはweb2というServiceにリクエストをルーティングする方法を説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
Minikubeクラスターを作成する Launch Terminal をクリックします。
(オプション) Minikubeをローカル環境にインストールした場合は、次のコマンドを実行します。
Ingressコントローラーを有効化する NGINX Ingressコントローラーを有効にするために、次のコマンドを実行します。
minikube addons enable ingress
NGINX Ingressコントローラーが起動したことを確認します。
kubectl get pods -n kube-system
備考: このコマンドの実行には数分かかる場合があります。
出力は次のようになります。
NAME READY STATUS RESTARTS AGE
default-http-backend-59868b7dd6-xb8tq 1/1 Running 0 1m
kube-addon-manager-minikube 1/1 Running 0 3m
kube-dns-6dcb57bcc8-n4xd4 3/3 Running 0 2m
kubernetes-dashboard-5498ccf677-b8p5h 1/1 Running 0 2m
nginx-ingress-controller-5984b97644-rnkrg 1/1 Running 0 1m
storage-provisioner 1/1 Running 0 2m
Hello Worldアプリをデプロイする 次のコマンドを実行して、Deploymentを作成します。
kubectl create deployment web --image= gcr.io/google-samples/hello-app:1.0
出力は次のようになります。
deployment.apps/web created
Deploymentを公開します。
kubectl expose deployment web --type= NodePort --port= 8080
出力は次のようになります。
Serviceが作成され、NodePort上で利用できるようになったことを確認します。
出力は次のようになります。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT( S) AGE
web NodePort 10.104.133.249 <none> 8080:31637/TCP 12m
NodePort経由でServiceを訪問します。
minikube service web --url
出力は次のようになります。
出力は次のようになります。
Hello, world!
Version: 1.0.0
Hostname: web-55b8c6998d-8k564
これで、MinikubeのIPアドレスとNodePort経由で、サンプルアプリにアクセスできるようになりました。次のステップでは、Ingressリソースを使用してアプリにアクセスできるように設定します。
Ingressリソースを作成する 以下に示すファイルは、hello-world.info経由で送られたトラフィックをServiceに送信するIngressリソースです。
以下の内容でexample-ingress.yamlを作成します。
apiVersion : networking.k8s.io/v1
kind : Ingress
metadata :
name : example-ingress
spec :
ingressClassName : nginx
rules :
- host : hello-world.info
http :
paths :
- path : /
pathType : Prefix
backend :
service :
name : web
port :
number : 8080 次のコマンドを実行して、Ingressリソースを作成します。
kubectl apply -f https://kubernetes.io/examples/service/networking/example-ingress.yaml
出力は次のようになります。
ingress.networking.k8s.io/example-ingress created
次のコマンドで、IPアドレスが設定されていることを確認します。
備考: このコマンドの実行には数分かかる場合があります。
NAME CLASS HOSTS ADDRESS PORTS AGE
example-ingress <none> hello-world.info 172.17.0.15 80 38s
次の行を/etc/hostsファイルの最後に書きます。
備考: Minikubeをローカル環境で実行している場合、`minikube ip`コマンドを使用すると外部のIPが取得できます。Ingressのリスト内に表示されるIPアドレスは、内部のIPになるはずです。
172.17.0.15 hello-world.info
この設定により、リクエストがhello-world.infoからMinikubeに送信されるようになります。
Ingressコントローラーがトラフィックを制御していることを確認します。
出力は次のようになります。
Hello, world!
Version: 1.0.0
Hostname: web-55b8c6998d-8k564
備考: Minikubeをローカル環境で実行している場合、ブラウザからhello-world.infoにアクセスできます。
2番目のDeploymentを作成する 次のコマンドを実行して、v2のDeploymentを作成します。
kubectl create deployment web2 --image= gcr.io/google-samples/hello-app:2.0
出力は次のようになります。
deployment.apps/web2 created
Deploymentを公開します。
kubectl expose deployment web2 --port= 8080 --type= NodePort
出力は次のようになります。
Ingressを編集する 既存のexample-ingress.yamlを編集して、以下の行を追加します。
- path : /v2
pathType : Prefix
backend :
service :
name : web2
port :
number : 8080
次のコマンドで変更を適用します。
kubectl apply -f example-ingress.yaml
出力は次のようになります。
ingress.networking/example-ingress configured
Ingressを試す Hello Worldアプリの1番目のバージョンにアクセスします。
出力は次のようになります。
Hello, world!
Version: 1.0.0
Hostname: web-55b8c6998d-8k564
Hello Worldアプリの2番目のバージョンにアクセスします。
出力は次のようになります。
Hello, world!
Version: 2.0.0
Hostname: web2-75cd47646f-t8cjk
備考: Minikubeをローカル環境で実行している場合、ブラウザからhello-world.infoおよびhello-world.info/v2にアクセスできます。
次の項目 4.10.9 - 共有ボリュームを使用して同じPod内のコンテナ間で通信する このページでは、ボリュームを使用して、同じPodで実行されている2つのコンテナ間で通信する方法を示します。
コンテナ間でプロセス名前空間を共有する ことにより、プロセスが通信できるようにする方法も参照してください。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
2つのコンテナを実行するPodの作成 この演習では、2つのコンテナを実行するPodを作成します。
2つのコンテナは、通信に使用できるボリュームを共有します。
これがPodの設定ファイルです:
apiVersion : v1
kind : Pod
metadata :
name : two-containers
spec :
restartPolicy : Never
volumes :
- name : shared-data
emptyDir : {}
containers :
- name : nginx-container
image : nginx
volumeMounts :
- name : shared-data
mountPath : /usr/share/nginx/html
- name : debian-container
image : debian
volumeMounts :
- name : shared-data
mountPath : /pod-data
command : ["/bin/sh" ]
args : ["-c" , "echo Hello from the debian container > /pod-data/index.html" ]
設定ファイルで、Podにshared-dataという名前のボリュームがあることがわかります。
設定ファイルにリストされている最初のコンテナは、nginxサーバーを実行します。
共有ボリュームのマウントパスは/usr/share/nginx/htmlです。
2番目のコンテナはdebianイメージをベースとしており、/pod-dataのマウントパスを持っています。
2番目のコンテナは次のコマンドを実行してから終了します。
echo Hello from the debian container > /pod-data/index.html
2番目のコンテナがnginxサーバーのルートディレクトリにindex.htmlファイルを書き込むことに注意してください。
Podと2つのコンテナを作成します:
kubectl apply -f https://k8s.io/examples/pods/two-container-pod.yaml
Podとコンテナに関する情報を表示します:
kubectl get pod two-containers --output=yaml
こちらは出力の一部です:
apiVersion: v1
kind: Pod
metadata:
...
name: two-containers
namespace: default
...
spec:
...
containerStatuses:
- containerID: docker://c1d8abd1 ...
image: debian
...
lastState:
terminated:
...
name: debian-container
...
- containerID: docker://96c1ff2c5bb ...
image: nginx
...
name: nginx-container
...
state:
running:
...
debianコンテナが終了し、nginxコンテナがまだ実行されていることがわかります。
nginxコンテナへのシェルを取得します:
kubectl exec -it two-containers -c nginx-container -- /bin/bash
シェルで、nginxが実行されていることを確認します:
root@two-containers:/# apt-get update
root@two-containers:/# apt-get install curl procps
root@two-containers:/# ps aux
出力はこのようになります:
USER PID ... STAT START TIME COMMAND
root 1 ... Ss 21:12 0:00 nginx: master process nginx -g daemon off;
debianコンテナがnginxルートディレクトリにindex.htmlファイルを作成したことを思い出してください。
curlを使用して、GETリクエストをnginxサーバーに送信します:
root@two-containers:/# curl localhost
出力は、nginxがdebianコンテナによって書かれたWebページを提供することを示しています:
Hello from the debian container
議論 Podが複数のコンテナを持つことができる主な理由は、プライマリアプリケーションを支援するヘルパーアプリケーションをサポートするためです。
ヘルパーアプリケーションの典型的な例は、データプラー、データプッシャー、およびプロキシです。
多くの場合、ヘルパーアプリケーションとプライマリアプリケーションは互いに通信する必要があります。
通常、これは、この演習に示すように共有ファイルシステムを介して、またはループバックネットワークインターフェースであるlocalhostを介して行われます。
このパターンの例は、新しい更新のためにGitリポジトリをポーリングするヘルパープログラムを伴うWebサーバーです。
この演習のボリュームは、コンテナがポッドの寿命中に通信する方法を提供します。
Podを削除して再作成すると、共有ボリュームに保存されているデータはすべて失われます。
次の項目 4.10.10 - クラスターのDNSを設定する Kubernetesは、DNSクラスターアドオンを提供しており、サポートされているほとんどの環境ではデフォルトで有効になっています。
Kubernetesバージョン1.11以降では、CoreDNSが推奨されており、kubeadmでデフォルトでインストールされます。
KubernetesクラスターでCoreDNSを構成する方法の詳細については、DNSサービスのカスタマイズ を参照してください。
kube-dnsを使用してKubernetes DNSを利用する方法の例については、Kubernetes DNSサンプルプラグイン を参照してください。
4.10.11 - クラスター内で実行されているサービスへのアクセス このページでは、Kubernetesクラスター内で実行されているサービスに接続する方法を説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
クラスター内で実行されているサービスへのアクセス Kubernetesでノード 、Pod 、そしてService は、それぞれの独自のIPアドレスを持ちます。
多くの場合、クラスター内のノードIP、Pod IP、そして一部のService IPはルーティングされないため、デスクトップマシンなどのクラスター外のマシンからは到達できません。
接続方法 クラスター外からノード、PodそしてServiceに接続するためには、いくつかのオプションがあります。
パブリックIPを介してServiceにアクセスする。クラスター外からServiceに到達できるようにNodePortまたはLoadBalancerタイプのServiceを使用します。
詳細はService およびkubectl expose のドキュメントを参照してください。 クラスターの環境によって、Serviceが社内ネットワークのみに公開される場合もあれば、インターネットに公開される場合もあります。
公開するServiceが安全かどうかを検討してください。
そのServiceは独自の認証機能を備えていますか? PodはServiceの背後に配置します。
デバッグなどの目的で、複数のレプリカの中から特定のPodにアクセスするためには、そのPodにユニークなラベルを付与し、そのラベルを選択する新しいServiceを作成します。 ほとんどの場合、アプリケーション開発者がnodeIPを使用してノードに直接アクセスする必要はありません。 Proxy Verbを使用してService、ノード、Podにアクセスする。リモートのServiceにアクセスする前に、APIサーバーによる認証および認可が行われます。
Serviceをインターネットに公開するほど安全ではない場合や、ノードIP上のポートにアクセスしたい場合、またはデバッグ目的で使用します。 プロキシは、一部のWebアプリケーションで問題を引き起こす可能性があります。 HTTP/HTTPSのみで動作します。 詳細はこちら を参照してください。 クラスター内のノードまたはPodからアクセスする。Podを起動し、kubectl exec を使用してそのPodのシェルに接続します。
そのシェルから、ほかのノード、Pod、Serviceに接続できます。 一部のクラスターは、ノードへのSSHアクセスを許可する場合があります。
その場合、そこからクラスターのServiceにアクセスできる可能性があります。
ただし、これは標準的な方法ではなく、クラスターによっては動作しないことがあります。
ブラウザやほかのツールがインストールされていない場合もあります。
クラスターDNSが動作しないこともあります。 組み込みServiceの検出 通常、kube-systemによってクラスター内で起動されるServiceがいくつか存在します。
これらは、kubectl cluster-infoコマンドを通して一覧表示ができます。
出力は次のとおりです。
Kubernetes master is running at https://192.0.2.1
elasticsearch-logging is running at https://192.0.2.1/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy
kibana-logging is running at https://192.0.2.1/api/v1/namespaces/kube-system/services/kibana-logging/proxy
kube-dns is running at https://192.0.2.1/api/v1/namespaces/kube-system/services/kube-dns/proxy
grafana is running at https://192.0.2.1/api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
heapster is running at https://192.0.2.1/api/v1/namespaces/kube-system/services/monitoring-heapster/proxy
これは、各Serviceにアクセスするためのproxy-verb URLを示しています。
たとえば、このクラスターでは(Elasticsearchを使用した)クラスター単位のログ収集が有効で、適切な認証情報を渡すことで、https://192.0.2.1/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/からアクセスできます。
または、たとえば次のようにkubectl proxyを介してhttp://localhost:8080/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/からアクセスすることも可能です。
APIサーバーのプロキシURLを手動で構築する方法 前述のとおり、ServiceのプロキシURLを取得するにはkubectl cluster-infoコマンドを使用します。
Serviceのエンドポイント、サフィックス、パラメータを含むプロキシURLを作成するには、次の形式でServiceのプロキシURLに追記します。
http://kubernetes_master_address/api/v1/namespaces/namespace_name/services/[https:]service_name[:port_name]/proxy
ポートに名前を指定していない場合、URLにport_name を指定する必要はありません。
また、名前付きポート、名前なしポートのいずれの場合でも、port_name の代わりにポート番号を使用することもできます。
デフォルトでは、APIサーバーはHTTPを使用してServiceにプロキシします。
HTTPSを使用する場合は、Service名の前にhttps:を付与します。
http://<kubernetes_master_address>/api/v1/namespaces/<namespace_name>/services/<service_name>/proxy
URLの<service_name>部分では、次の形式がサポートされています。
<service_name> - HTTPを使用して、デフォルトまたは名前なしのポートにプロキシします<service_name>:<port_name> - HTTPを使用して、指定したポート名またはポート番号にプロキシしますhttps:<service_name>: - httpsを使用して、デフォルトまたは名前なしのポートにプロキシします(末尾のコロンに注意してください)https:<service_name>:<port_name> - httpsを使用して、指定したポート名またはポート番号にプロキシします例 Elasticsearchサービスのエンドポイント_search?q=user:kimchyにアクセスするには、次のURLを使用します。
http://192.0.2.1/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/_search?q=user:kimchy
Elasticsearchクラスターのヘルス情報_cluster/health?pretty=trueにアクセスするには、次のURLを使用します。
https://192.0.2.1/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/_cluster/health?pretty=true
ヘルス情報は次のような内容です。
{
"cluster_name" : "kubernetes_logging" ,
"status" : "yellow" ,
"timed_out" : false ,
"number_of_nodes" : 1 ,
"number_of_data_nodes" : 1 ,
"active_primary_shards" : 5 ,
"active_shards" : 5 ,
"relocating_shards" : 0 ,
"initializing_shards" : 0 ,
"unassigned_shards" : 5
}
https を経由してElasticsearchサービスのヘルス情報_cluster/health?pretty=trueにアクセスするには、次のURLを使用します。
https://192.0.2.1/api/v1/namespaces/kube-system/services/https:elasticsearch-logging:/proxy/_cluster/health?pretty=true
クラスター内で実行されているサービスにWebブラウザからアクセスする ブラウザのアドレスバーにAPIサーバーのプロキシURLを直接入力してアクセスできる場合があります。ただし、以下の点に注意してください。
Webブラウザのアドレスバーは通常トークンを送信できないため、Basic認証(パスワード)を使用する必要があります。
APIサーバーはBasic認証を受け付けるように設定できますが、クラスターがその設定になっていない場合もあります。 一部のWebアプリケーションは正しく動作しないことがあります。特に、プロキシのパスプレフィックスを考慮せずにURLを生成するクライアントサイドJavaScriptを使用している場合です。 4.11 - Kubernetesを拡張する 作業環境の要求にKubernetesクラスターを適応させるための高度な方法を理解します。
4.11.1 - 複数のスケジューラーを設定する Kubernetesにはこちら で説明されているデフォルトのスケジューラーが付属します。
もしデフォルトのスケジューラーがあなたの要求を満たさない場合、独自にスケジューラーを実装できます。
さらに、デフォルトのスケジューラーと一緒に複数のスケジューラーを同時に実行し、どのPodにどのスケジューラーを使うかKubernetesに指示できます。
具体例を見ながらKubernetesで複数のスケジューラーを実行する方法を学びましょう。
スケジューラーの実装方法の詳細は本ドキュメントの範囲外です。
標準的な例としてKubernetesのソースディレクトリのpkg/scheduler にあるkube-schedulerの実装が参照できます。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
スケジューラーをパッケージ化する スケジューラーのバイナリをコンテナイメージとしてパッケージ化します。
例として、デフォルトのスケジューラー(kube-scheduler)を2つ目のスケジューラーとして使用します。
GitHubからKubernetesのソースコード をクローンし、ビルドします。
git clone https://github.com/kubernetes/kubernetes.git
cd kubernetes
make
kube-schedulerバイナリを含むコンテナイメージを作成します。
そのためのDockerfileは次のとおりです:
FROM busybox
ADD ./_output/local/bin/linux/amd64/kube-scheduler /usr/local/bin/kube-scheduler
これをDockerfileとして保存し、イメージをビルドしてレジストリにプッシュします。
次の例ではGoogle Container Registry (GCR) を使用します。
詳細はGCRのドキュメント から確認できます。
代わりにDocker Hub を使用することもできます。
Docker Hubの詳細はドキュメント から確認できます。
docker build -t gcr.io/my-gcp-project/my-kube-scheduler:1.0 . # The image name and the repository
gcloud docker -- push gcr.io/my-gcp-project/my-kube-scheduler:1.0 # used in here is just an example
スケジューラー用のKubernetes Deploymentを定義する スケジューラーをコンテナイメージとして用意できたら、それ用のPodの設定を作成してクラスター上で動かします。
この例では、直接Podをクラスターに作成する代わりに、Deployment を使用します。
Deployment はReplicaSet を管理し、そのReplicaSetがPodを管理することで、スケジューラーを障害に対して堅牢にします。
my-scheduler.yamlとして保存するDeploymentの設定を示します:
apiVersion : v1
kind : ServiceAccount
metadata :
name : my-scheduler
namespace : kube-system
---
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRoleBinding
metadata :
name : my-scheduler-as-kube-scheduler
subjects :
kind : ServiceAccount
name : my-scheduler
namespace : kube-system
roleRef :
kind : ClusterRole
name : system:kube-scheduler
apiGroup : rbac.authorization.k8s.io
---
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRoleBinding
metadata :
name : my-scheduler-as-volume-scheduler
subjects :
kind : ServiceAccount
name : my-scheduler
namespace : kube-system
roleRef :
kind : ClusterRole
name : system:volume-scheduler
apiGroup : rbac.authorization.k8s.io
---
apiVersion : rbac.authorization.k8s.io/v1
kind : RoleBinding
metadata :
name : my-scheduler-extension-apiserver-authentication-reader
namespace : kube-system
roleRef :
kind : Role
name : extension-apiserver-authentication-reader
apiGroup : rbac.authorization.k8s.io
subjects :
kind : ServiceAccount
name : my-scheduler
namespace : kube-system
---
apiVersion : v1
kind : ConfigMap
metadata :
name : my-scheduler-config
namespace : kube-system
data :
my-scheduler-config.yaml : |
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: my-scheduler
leaderElection:
leaderElect: false
---
apiVersion : apps/v1
kind : Deployment
metadata :
labels :
component : scheduler
tier : control-plane
name : my-scheduler
namespace : kube-system
spec :
selector :
matchLabels :
component : scheduler
tier : control-plane
replicas : 1
template :
metadata :
labels :
component : scheduler
tier : control-plane
version : second
spec :
serviceAccountName : my-scheduler
containers :
- command :
- /usr/local/bin/kube-scheduler
- --config=/etc/kubernetes/my-scheduler/my-scheduler-config.yaml
image : gcr.io/my-gcp-project/my-kube-scheduler:1.0
livenessProbe :
httpGet :
path : /healthz
port : 10259
scheme : HTTPS
initialDelaySeconds : 15
name : kube-second-scheduler
readinessProbe :
httpGet :
path : /healthz
port : 10259
scheme : HTTPS
resources :
requests :
cpu : '0.1'
securityContext :
privileged : false
volumeMounts :
- name : config-volume
mountPath : /etc/kubernetes/my-scheduler
hostNetwork : false
hostPID : false
volumes :
- name : config-volume
configMap :
name : my-scheduler-config
上に示したマニフェストでは、KubeSchedulerConfiguration を使用してあなたのスケジューラー実装の振る舞いを変更できます。
この設定ファイルはkube-schedulerの初期化時に--configオプションから渡されます。
この設定ファイルはmy-scheduler-config ConfigMapに格納されており、my-scheduler DeploymentのPodはmy-scheduler-config ConfigMapをボリュームとしてマウントします。
前述のスケジューラー設定において、あなたのスケジューラー実装はKubeSchedulerProfile を使って表現されます。
備考: 特定のPodをどのスケジューラーが処理するかを指定するには、PodTemplateやPodのマニフェストにあるspec.schedulerNameフィールドをKubeSchedulerProfileのschedulerNameフィールドに一致させます。
クラスターで動作させるすべてのスケジューラーの名前は一意的である必要があります。また、専用のサービスアカウントmy-schedulerを作成してsystem:kube-scheduler ClusterRoleに紐づけを行い、スケジューラーにkube-schedulerと同じ権限を付与している点に注意します。
その他のコマンドライン引数の詳細はkube-schedulerのドキュメント から、その他の変更可能なkube-schedulerの設定はスケジューラー設定のリファレンス から確認できます。
クラスターで2つ目のスケジューラーを実行する 2つ目のスケジューラーをクラスター上で動かすには、前述のDeploymentをKubernetesクラスターに作成します:
kubectl create -f my-scheduler.yaml
スケジューラーのPodが実行中であることを確認します:
kubectl get pods --namespace= kube-system
NAME READY STATUS RESTARTS AGE
....
my-scheduler-lnf4s-4744f 1/1 Running 0 2m
...
このリストにはデフォルトのkube-schedulerのPodに加えて、my-schedulerのPodが「Running」になっているはずです。
リーダー選出を有効にする リーダー選出を有効にして複数のスケジューラーを実行するには、次の対応が必要です:
YAMLファイルにあるmy-scheduler-config ConfigMap内のKubeSchedulerConfigurationの次のフィールドを更新します:
leaderElection.leaderElectをtrueに設定しますleaderElection.resourceNamespaceを<lock-object-namespace>に設定しますleaderElection.resourceNameを<lock-object-name>に設定します
備考: ロックオブジェクトはコントロールプレーンが自動的に作成しますが、使用するNamespaceはあらかじめ存在している必要があります。
kube-system Namespaceを使うこともできます。クラスターでRBACが有効になっている場合、system:kube-scheduler ClusterRoleを更新し、endpointsとleasesリソースに適用されるルールのresourceNamesにスケジューラー名を追加します。
例を示します:
kubectl edit clusterrole system:kube-scheduler
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRole
metadata :
annotations :
rbac.authorization.kubernetes.io/autoupdate : "true"
labels :
kubernetes.io/bootstrapping : rbac-defaults
name : system:kube-scheduler
rules :
- apiGroups :
- coordination.k8s.io
resources :
- leases
verbs :
- create
- apiGroups :
- coordination.k8s.io
resourceNames :
- kube-scheduler
- my-scheduler
resources :
- leases
verbs :
- get
- update
- apiGroups :
- ""
resourceNames :
- kube-scheduler
- my-scheduler
resources :
- endpoints
verbs :
- delete
- get
- patch
- update
Podにスケジューラーを指定する 2つ目のスケジューラーが動作している状態で、Podをいくつか作成し、デフォルトのスケジューラーまたは新しいスケジューラーのどちらで配置するか指定します。
あるPodを特定のスケジューラーで配置するには、Podのspecにスケジューラー名を指定します。
3つの例を確認しましょう。
スケジューラー名を指定しないPodの設定
apiVersion : v1
kind : Pod
metadata :
name : no -annotation
labels :
name : multischeduler-example
spec :
containers :
- name : pod-with-no-annotation-container
image : registry.k8s.io/pause:3.8スケジューラー名が指定されていない場合、Podは自動的にdefault-schedulerによって配置されます。
このファイルをpod1.yamlとして保存し、Kubernetesクラスターに投入します。
kubectl create -f pod1.yaml
default-schedulerを指定するPodの設定
apiVersion : v1
kind : Pod
metadata :
name : annotation-default-scheduler
labels :
name : multischeduler-example
spec :
schedulerName : default-scheduler
containers :
- name : pod-with-default-annotation-container
image : registry.k8s.io/pause:3.8
使用するスケジューラーはspec.schedulerNameの値にスケジューラー名を与えることで指定します。
この場合、デフォルトのスケジューラーであるdefault-schedulerを指定します。
このファイルをpod2.yamlとして保存し、Kubernetesクラスターに投入します。
kubectl create -f pod2.yaml
my-schedulerを指定するPodの設定
apiVersion : v1
kind : Pod
metadata :
name : annotation-second-scheduler
labels :
name : multischeduler-example
spec :
schedulerName : my-scheduler
containers :
- name : pod-with-second-annotation-container
image : registry.k8s.io/pause:3.8
この場合、前述の手順でデプロイしたmy-schedulerを使用してPodを配置することを指定します。
spec.schedulerNameの値はKubeSchedulerProfileのschedulerNameフィールドに設定した名前と一致する必要があります。
このファイルをpod3.yamlとして保存し、クラスターに投入します。
kubectl create -f pod3.yaml
3つのPodがすべて実行中であることを確認します。
Podが目的のスケジューラーによって配置されたことを確認する わかりやすさのため、前述の例ではPodが実際に指定したスケジューラーによって配置されたことを確認していません。
確認したい場合はPodとDeploymentの設定の適用順序を変えてみてください。
もしPodの設定をすべて先に適用し、その後にスケジューラーのDeploymentを適用した場合、annotation-second-scheduler Podは「Pending」のままになり、他の2つのPodが先に配置されることを確認できます。
その後にスケジューラーのDeploymentを適用して新しいスケジューラーが動作すると、annotation-second-scheduler Podも配置されます。
あるいは、イベントログの「Scheduled」の項目を見ることで、どのPodがどのスケジューラーによって配置されたかを確認できます。
クラスターのメインのスケジューラーについては、独自のスケジューラー設定 を適用することや、関連するコントロールプレーンノードにある静的Podのマニフェストを変更し独自のコンテナイメージを使うことができます。
4.12 - TLS Transport Layer Security(TLS)を使用して、クラスター内のトラフィックを保護する方法について理解します。
4.12.1 - Kubeletの証明書のローテーションを設定する このページでは、kubeletの証明書のローテーションを設定する方法を説明します。
FEATURE STATE:
Kubernetes v1.8 [beta]
始める前に Kubernetesはバージョン1.8.0以降である必要があります。 概要 kubeletは、Kubernetes APIへの認証のために証明書を使用します。デフォルトでは、証明書は1年間の有効期限付きで発行されるため、頻繁に更新する必要はありません。
Kubernetes 1.8にはベータ機能のkubelet certificate rotation が含まれているため、現在の証明書の有効期限が近づいたときに自動的に新しい鍵を生成して、Kubernetes APIに新しい証明書をリクエストできます。新しい証明書が利用できるようになると、Kubernetes APIへの接続の認証に利用されます。
クライアント証明書のローテーションを有効にする kubeletプロセスは--rotate-certificatesという引数を受け付けます。この引数によって、現在使用している証明書の有効期限が近づいたときに、kubeletが自動的に新しい証明書をリクエストするかどうかを制御できます。証明書のローテーションはベータ機能であるため、--feature-gates=RotateKubeletClientCertificate=trueを使用してフィーチャーフラグを有効にする必要もあります。
kube-controller-managerプロセスは、--experimental-cluster-signing-durationという引数を受け付け、この引数で証明書が発行される期間を制御できます。
証明書のローテーションの設定を理解する kubeletが起動すると、ブートストラップが設定されている場合(--bootstrap-kubeconfigフラグを使用した場合)、初期証明書を使用してKubernetes APIに接続して、証明書署名リクエスト(certificate signing request、CSR)を発行します。証明書署名リクエストのステータスは、次のコマンドで表示できます。
ノード上のkubeletから発行された証明書署名リクエストは、初めはPending状態です。証明書署名リクエストが特定の条件を満たすと、コントローラーマネージャーに自動的に承認され、Approved状態になります。次に、コントローラーマネージャーは--experimental-cluster-signing-durationパラメーターで指定された有効期限で発行された証明書に署名を行い、署名された証明書が証明書署名リクエストに添付されます。
kubeletは署名された証明書をKubernetes APIから取得し、ディスク上の--cert-dirで指定された場所に書き込みます。その後、kubeletは新しい証明書を使用してKubernetes APIに接続するようになります。
署名された証明書の有効期限が近づくと、kubeletはKubernetes APIを使用して新しい証明書署名リクエストを自動的に発行します。再び、コントローラーマネージャーは証明書のリクエストを自動的に承認し、署名された証明書を証明書署名リクエストに添付します。kubeletは新しい署名された証明書をKubernetes APIから取得してディスクに書き込みます。その後、kubeletは既存のコネクションを更新して、新しい証明書でKubernetes APIに再接続します。
4.13 - クラスターデーモンの管理 ローリングアップデートの実行など、DaemonSetを管理するための一般的なタスクを実行します。
4.13.1 - 基本的なDaemonSetを構築する このページでは、Kubernetesクラスターの全てのノード上でPodを実行する、基本的なDaemonSet を構築する方法について示します。
ホストからファイルをマウントし、Initコンテナ を使用してその内容をログに記録して、pauseコンテナを利用するという単純なユースケースを取り上げます。
始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
DaemonSetの動作を示すために、少なくとも2つのノード(1つのコントロールプレーンと1つのワーカーノード)を持つKubernetesクラスターを用意します。
DaemonSetの定義 このタスクでは、Podのコピーが全てのノード上でスケジュールされるようにする、基本的なDaemonSetが作成されます。
PodはInitコンテナを使用してホストから/etc/machine-idの内容を読み込んでログに記録し、メインのコンテナはPodを実行し続けるpauseコンテナとなります。
apiVersion : apps/v1
kind : DaemonSet
metadata :
name : example-daemonset
spec :
selector :
matchLabels :
app.kubernetes.io/name : example
template :
metadata :
labels :
app.kubernetes.io/name : example
spec :
containers :
- name : pause
image : registry.k8s.io/pause
initContainers :
- name : log-machine-id
image : busybox:1.37
command : ['sh' , '-c' , 'cat /etc/machine-id > /var/log/machine-id.log' ]
volumeMounts :
- name : machine-id
mountPath : /etc/machine-id
readOnly : true
- name : log-dir
mountPath : /var/log
volumes :
- name : machine-id
hostPath :
path : /etc/machine-id
type : File
- name : log-dir
hostPath :
path : /var/log
(YAML)マニフェストに基づいたDaemonSetを作成します:
kubectl apply -f https://k8s.io/examples/application/basic-daemonset.yaml
適用すると、DaemonSetがクラスター内の全てのノードでPodを実行していることを確認できます:
出力には、以下のようにノード毎に1つのPodが一覧表示されます:
NAME READY STATUS RESTARTS AGE IP NODE
example-daemonset-xxxxx 1/1 Running 0 5m x.x.x.x node-1
example-daemonset-yyyyy 1/1 Running 0 5m x.x.x.x node-2
ホストからマウントされたログディレクトリをチェックすることで、ログに記録された/etc/machine-idファイルの内容を調べることができます:
kubectl exec <pod-name> -- cat /var/log/machine-id.log
<pod-name>は1つのPodの名前です。
クリーンアップ DaemonSetを削除するためには、次のコマンドを実行します:
kubectl delete --cascade= foreground --ignore-not-found --now daemonsets/example-daemonset
この単純なDaemonSetの例では、Initコンテナやホストパスボリュームなどの主要なコンポーネントを紹介しており、より高度なユースケースに応じて拡張することができます。
詳細についてはDaemonSet を参照してください。
次の項目 4.13.2 - DaemonSet上でローリングアップデートを実施する このページでは、DaemonSet上でローリングアップデートを行う方法について説明します。
始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
DaemonSetのアップデート戦略 DaemonSetには2種類のアップデート戦略があります:
OnDelete: OnDeleteアップデート戦略では、DaemonSetのテンプレートを更新した後、古いDaemonSetのPodを手動で削除した時のみ 、新しいDaemonSetのPodが作成されます。
これはKubernetesのバージョン1.5またはそれ以前のDaemonSetと同じ挙動です。RollingUpdate: これは既定のアップデート戦略です。
RollingUpdateアップデート戦略では、DaemonSetのテンプレートを更新した後、古いDaemonSetのPodが削除され、制御された方法で自動的に新しいDaemonSetのPodが作成されます。
アップデートのプロセス全体を通して、各ノード上で稼働するDaemonSetのPodは最大で1つだけです。ローリングアップデートの実施 DaemonSetに対してローリングアップデートの機能を有効にするには、.spec.updateStrategy.typeをRollingUpdateに設定する必要があります。
.spec.updateStrategy.rollingUpdate.maxUnavailable.spec.minReadySeconds.spec.updateStrategy.rollingUpdate.maxSurge
RollingUpdateアップデート戦略によるDaemonSetの作成このYAMLファイルでは、アップデート戦略としてRollingUpdateが指定されたDaemonSetを定義しています。
apiVersion : apps/v1
kind : DaemonSet
metadata :
name : fluentd-elasticsearch
namespace : kube-system
labels :
k8s-app : fluentd-logging
spec :
selector :
matchLabels :
name : fluentd-elasticsearch
updateStrategy :
type : RollingUpdate
rollingUpdate :
maxUnavailable : 1
template :
metadata :
labels :
name : fluentd-elasticsearch
spec :
tolerations :
# これらのTolerationはコントロールプレーンノード上でDaemonSetを実行できるようにするためのものです
# コントロールプレーンノードでPodを実行すべきではない場合は、これらを削除してください
- key : node-role.kubernetes.io/control-plane
operator : Exists
effect : NoSchedule
- key : node-role.kubernetes.io/master
operator : Exists
effect : NoSchedule
containers :
- name : fluentd-elasticsearch
image : quay.io/fluentd_elasticsearch/fluentd:v5.0.1
volumeMounts :
- name : varlog
mountPath : /var/log
- name : varlibdockercontainers
mountPath : /var/lib/docker/containers
readOnly : true
terminationGracePeriodSeconds : 30
volumes :
- name : varlog
hostPath :
path : /var/log
- name : varlibdockercontainers
hostPath :
path : /var/lib/docker/containers
DaemonSetのマニフェストのアップデート戦略を検証した後、DaemonSetを作成します:
kubectl create -f https://k8s.io/examples/controllers/fluentd-daemonset.yaml
あるいは、kubectl applyを使用してDaemonSetを更新する予定がある場合は、kubectl applyを使用して同じDaemonSetを作成してください。
kubectl apply -f https://k8s.io/examples/controllers/fluentd-daemonset.yaml
DaemonSetのRollingUpdateアップデート戦略の確認 DaemonSetのアップデート戦略を確認し、RollingUpdateが設定されているようにします:
kubectl get ds/fluentd-elasticsearch -o go-template= '{{.spec.updateStrategy.type}}{{"\n"}}' -n kube-system
システムにDaemonSetが作成されていない場合は、代わりに次のコマンドによってDaemonSetのマニフェストを確認します:
kubectl apply -f https://k8s.io/examples/controllers/fluentd-daemonset.yaml --dry-run= client -o go-template= '{{.spec.updateStrategy.type}}{{"\n"}}'
どちらのコマンドも、出力は次のようになります:
RollingUpdate
出力がRollingUpdate以外の場合は、DaemonSetオブジェクトまたはマニフェストを見直して、修正してください。
DaemonSetテンプレートの更新 RollingUpdateのDaemonSetの.spec.templateに対して任意の更新が行われると、ローリングアップデートがトリガーされます。
新しいYAMLファイルを適用してDaemonSetを更新しましょう。
これにはいくつかの異なるkubectlコマンドを使用することができます。
apiVersion : apps/v1
kind : DaemonSet
metadata :
name : fluentd-elasticsearch
namespace : kube-system
labels :
k8s-app : fluentd-logging
spec :
selector :
matchLabels :
name : fluentd-elasticsearch
updateStrategy :
type : RollingUpdate
rollingUpdate :
maxUnavailable : 1
template :
metadata :
labels :
name : fluentd-elasticsearch
spec :
tolerations :
# これらのTolerationはコントロールプレーンノード上でDaemonSetを実行できるようにするためのものです
# コントロールプレーンノードでPodを実行すべきではない場合は、これらを削除してください
- key : node-role.kubernetes.io/control-plane
operator : Exists
effect : NoSchedule
- key : node-role.kubernetes.io/master
operator : Exists
effect : NoSchedule
containers :
- name : fluentd-elasticsearch
image : quay.io/fluentd_elasticsearch/fluentd:v5.0.1
resources :
limits :
memory : 200Mi
requests :
cpu : 100m
memory : 200Mi
volumeMounts :
- name : varlog
mountPath : /var/log
- name : varlibdockercontainers
mountPath : /var/lib/docker/containers
readOnly : true
terminationGracePeriodSeconds : 30
volumes :
- name : varlog
hostPath :
path : /var/log
- name : varlibdockercontainers
hostPath :
path : /var/lib/docker/containers
宣言型コマンド 設定ファイル を使用してDaemonSetを更新する場合は、kubectl applyを使用します:
kubectl apply -f https://k8s.io/examples/controllers/fluentd-daemonset-update.yaml
命令型コマンド 命令型コマンド を使用してDaemonSetを更新する場合は、kubectl editを使用します:
kubectl edit ds/fluentd-elasticsearch -n kube-system
コンテナイメージのみのアップデート DaemonSetのテンプレート内のコンテナイメージ、つまり.spec.template.spec.containers[*].imageのみを更新したい場合、kubectl set imageを使用します:
kubectl set image ds/fluentd-elasticsearch fluentd-elasticsearch= quay.io/fluentd_elasticsearch/fluentd:v2.6.0 -n kube-system
ローリングアップデートのステータスの監視 最後に、最新のDaemonSetの、ローリングアップデートのロールアウトステータスを監視します:
kubectl rollout status ds/fluentd-elasticsearch -n kube-system
ロールアウトが完了すると、次のような出力となります:
daemonset "fluentd-elasticsearch" successfully rolled out
トラブルシューティング DaemonSetのローリングアップデートがスタックする 時々、DaemonSetのローリングアップデートがスタックする場合があります。
これにはいくつかの原因が考えられます:
いくつかのノードのリソース不足 1つ以上のノードで新しいDaemonSetのPodをスケジュールすることができず、ロールアウトがスタックしています。
これはノードのリソース不足 の可能性があります。
この事象が起きた場合は、kubectl get nodesの出力と次の出力を比較して、DaemonSetのPodがスケジュールされていないノードを見つけます:
kubectl get pods -l name = fluentd-elasticsearch -o wide -n kube-system
そのようなノードを見つけたら、新しいDaemonSetのPodのための空きを作るために、ノードからDaemonSet以外のいくつかのPodを削除します。
備考: コントローラーによって制御されていないPodや、レプリケートされていないPodを削除すると、これはサービスの中断が発生する原因となります。
これはまた、
PodDisruptionBudget についても考慮しません。
壊れたロールアウト 例えばコンテナがクラッシュを繰り返したり、(しばしばtypoによって)コンテナイメージが存在しないといった理由で最新のDaemonSetのテンプレートの更新が壊れた場合、DaemonSetのロールアウトは進みません。
これを修正するためには、DaemonSetのテンプレートを再度更新します。
新しいロールアウトは、前の不健全なロールアウトによってブロックされません。
クロックスキュー DaemonSet内で.spec.minReadySecondsが指定されると、マスターとノードの間のクロックスキューによって、DaemonSetがロールアウトの進捗を正しく認識できなくなる場合があります。
クリーンアップ NamespaceからDaemonSetを削除します:
kubectl delete ds fluentd-elasticsearch -n kube-system
次の項目 4.13.3 - DaemonSet上でロールバックを実施する このページでは、DaemonSet 上でロールバックを行う方法について説明します。
始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: 1.7.
バージョンを確認するには次のコマンドを実行してください: kubectl version.
DaemonSet上でローリングアップデートを実施する 方法については既に知っているものとします。
DaemonSet上のロールバックの実施 ステップ1: ロールバック先のDaemonSetのリビジョンを見つける 最新のリビジョンにロールバックしたい場合は、このステップを省略できます。
DaemonSetの全てのリビジョンを列挙します:
kubectl rollout history daemonset <daemonset-name>
これはDaemonSetのリビジョンのリストを返します:
daemonsets "<daemonset-name>"
REVISION CHANGE-CAUSE
1 ...
2 ...
...
変更理由は作成時にDaemonSetのアノテーションkubernetes.io/change-causeからコピーされます。
実行したコマンドをchange-causeアノテーションに記録するために、kubectl内で--record=trueを指定することができます。 特定のリビジョンの詳細を見るためには次を実行します:
kubectl rollout history daemonset <daemonset-name> --revision= 1
これは、そのリビジョンの詳細を返します:
daemonsets "<daemonset-name>" with revision #1
Pod Template:
Labels: foo=bar
Containers:
app:
Image: ...
Port: ...
Environment: ...
Mounts: ...
Volumes: ...
ステップ2: 特定のリビジョンにロールバックする # ステップ1で得たリビジョン番号を--to-revisionで指定します。
kubectl rollout undo daemonset <daemonset-name> --to-revision= <revision>
成功すると、コマンドは次を返します:
daemonset "<daemonset-name>" rolled back
備考: --to-revisionフラグが指定されない場合は、kubectlは最新のリビジョンを取得します。ステップ3: DaemonSetのロールバックの進行状況を監視する kubectl rollout undo daemonsetは、サーバーに対してDaemonSetのロールバックを開始するよう指示します。
実際のロールバックはクラスターのコントロールプレーン 内で非同期に実行されます。
ロールバックの進行状況を監視するためには次を実行します:
kubectl rollout status ds/<daemonset-name>
ロールバックが完了すると、次のような出力が得られます:
daemonset "<daemonset-name>" successfully rolled out
DaemonSetのリビジョンを理解する 前のkubectl rollout historyのステップでは、DaemonSetのリビジョンのリストを取得しました。
各リビジョンは、ControllerRevisionという名前のリソースに格納されています。
各リビジョンに何が格納されているか確認するためには、DaemonSetのリビジョンの生のリソースを探します:
kubectl get controllerrevision -l <daemonset-selector-key>= <daemonset-selector-value>
これはControllerRevisionsのリストを返します:
NAME CONTROLLER REVISION AGE
<daemonset-name>-<revision-hash> DaemonSet/<daemonset-name> 1 1h
<daemonset-name>-<revision-hash> DaemonSet/<daemonset-name> 2 1h
各ControllerRevisionはアノテーションとDaemonSetのリビジョンのテンプレートを格納します。
kubectl rollout undoは特定のControllerRevisionを受け取り、DaemonSetのテンプレートを、ControllerRevision内に保管されたテンプレートに置き換えます。
kubectl rollout undoはDaemonSetのテンプレートを、kubectl editやkubectl applyのような他のコマンドによって、以前のリビジョンに更新することに相当します。
備考: DaemonSetのリビジョンはロールフォワードのみとなります。
これはつまり、ロールバックが完了すると、ControllerRevisionのリビジョン番号(.revisionフィールド)が繰り上がります。
例えば、システムにリビジョン1と2があってリビジョン2からリビジョン1にロールバックすると、.revision: 1のControllerRevisionは.revision: 3になります。トラブルシューティング 4.13.4 - 特定のノード上でのみPodを実行する このページでは、DaemonSet の一部として、特定のノード 上でのみPod を実行する方法を説明します。
始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
特定のノードでのみPodを実行する DaemonSet を実行したいが、そのデーモンPodをローカルのソリッドステートドライブ(SSD)ストレージを備えたノードでのみ実行する必要があるとします。
例えば、Podがノードにキャッシュサービスを提供し、低遅延のローカルストレージが利用可能な場合にのみキャッシュが有用である場合などです。
ステップ1: ノードにラベルを追加する SSDを持つノードにssd=trueというラベルを追加します。
kubectl label nodes example-node-1 example-node-2 ssd = true
ステップ2: マニフェストを作成する SSDのラベルが付けられたノード 上にのみデーモンPodを配置するDaemonSet を作成してみましょう。
次に、nodeSelectorを使用して、DaemonSetがssdラベルに"true"が設定されたノード上でのみPodを実行するようにします。
apiVersion : apps/v1
kind : DaemonSet
metadata :
name : ssd-driver
labels :
app : nginx
spec :
selector :
matchLabels :
app : ssd-driver-pod
template :
metadata :
labels :
app : ssd-driver-pod
spec :
nodeSelector :
ssd : "true"
containers :
- name : example-container
image : example-imageステップ3: DaemonSetを作成する kubectl createまたはkubectl applyを使用してマニフェストからDaemonSetを作成します。
別のノードにssd=trueというラベルを付けてみましょう。
kubectl label nodes example-node-3 ssd = true
ノードにラベルを付けると、それによってコントロールプレーン(正確にはDaemonSetコントローラー)がトリガーされ、そのノード上で新しいデーモンPodが実行されます。
出力は次のようになります:
NAME READY STATUS RESTARTS AGE IP NODE
<daemonset-name><some-hash-01> 1/1 Running 0 13s ..... example-node-1
<daemonset-name><some-hash-02> 1/1 Running 0 13s ..... example-node-2
<daemonset-name><some-hash-03> 1/1 Running 0 5s ..... example-node-3
4.14 - ネットワーク クラスターのネットワークの設定方法を学びます。
4.14.1 - HostAliasesを使用してPodの/etc/hostsにエントリーを追加する Podの/etc/hostsファイルにエントリーを追加すると、DNSやその他の選択肢を利用できない場合に、Podレベルでホスト名の名前解決を上書きできるようになります。このようなカスタムエントリーは、PodSpecのHostAliasesフィールドに追加できます。
HostAliasesを使用せずにファイルを修正することはおすすめできません。このファイルはkubeletが管理しており、Podの作成や再起動時に上書きされる可能性があるためです。
デフォルトのhostsファイルの内容 Nginx Podを実行すると、Pod IPが割り当てられます。
kubectl run nginx --image nginx
pod/nginx created
Pod IPを確認します。
kubectl get pods --output= wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx 1/1 Running 0 13s 10.200.0.4 worker0
hostsファイルの内容は次のようになります。
kubectl exec nginx -- cat /etc/hosts
# Kubernetes-managed hosts file.
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
fe00::0 ip6-mcastprefix
fe00::1 ip6-allnodes
fe00::2 ip6-allrouters
10.200.0.4 nginx
デフォルトでは、hostsファイルには、localhostやPod自身のホスト名などのIPv4とIPv6のボイラープレートだけが含まれています。
追加エントリーをhostAliasesに追加する デフォルトのボイラープレートに加えて、hostsファイルに追加エントリーを追加できます。たとえば、foo.localとbar.localを127.0.0.1に、foo.remoteとbar.remoteを10.1.2.3にそれぞれ解決するためには、PodのHostAliasesを.spec.hostAliases以下に設定します。
apiVersion : v1
kind : Pod
metadata :
name : hostaliases-pod
spec :
restartPolicy : Never
hostAliases :
- ip : "127.0.0.1"
hostnames :
- "foo.local"
- "bar.local"
- ip : "10.1.2.3"
hostnames :
- "foo.remote"
- "bar.remote"
containers :
- name : cat-hosts
image : busybox
command :
- cat
args :
- "/etc/hosts"
この設定を使用したPodを開始するには、次のコマンドを実行します。
kubectl apply -f https://k8s.io/examples/service/networking/hostaliases-pod.yaml
pod/hostaliases-pod created
Podの詳細情報を表示して、IPv4アドレスと状態を確認します。
kubectl get pod --output= wide
NAME READY STATUS RESTARTS AGE IP NODE
hostaliases-pod 0/1 Completed 0 6s 10.200.0.5 worker0
hostsファイルの内容は次のようになります。
kubectl logs hostaliases-pod
# Kubernetes-managed hosts file.
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
fe00::0 ip6-mcastprefix
fe00::1 ip6-allnodes
fe00::2 ip6-allrouters
10.200.0.5 hostaliases-pod
# Entries added by HostAliases.
127.0.0.1 foo.local bar.local
10.1.2.3 foo.remote bar.remote
ファイルの最後に追加エントリーが指定されています。
kubeletがhostsファイルを管理するのはなぜですか? kubeletがPodの各コンテナのhostsファイルを管理する のは、コンテナ起動後にDockerがファイルを編集する のを防ぐためです。
注意: コンテナ内部でhostsファイルを手動で変更するのは控えてください。
hostsファイルを手動で変更すると、コンテナが終了したときに変更が失われてしまいます。
4.14.2 - IPv4/IPv6デュアルスタックの検証 このドキュメントでは、IPv4/IPv6デュアルスタックが有効化されたKubernetesクラスターを検証する方法について共有します。
始める前に プロバイダーがデュアルスタックのネットワークをサポートしていること (クラウドプロバイダーか、ルーティングできるIPv4/IPv6ネットワークインターフェースを持つKubernetesノードが提供できること) (KubenetやCalicoなど)デュアルスタックをサポートするネットワークプラグイン デュアルスタックを有効化 したクラスター作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.20.
バージョンを確認するには次のコマンドを実行してください: kubectl version.
アドレスの検証 ノードアドレスの検証 各デュアルスタックのノードは、1つのIPv4ブロックと1つのIPv6ブロックを割り当てる必要があります。IPv4/IPv6のPodアドレスの範囲が設定されていることを検証するには、次のコマンドを実行します。例の中のノード名は、自分のクラスターの有効なデュアルスタックのノードの名前に置換してください。この例では、ノードの名前はk8s-linuxpool1-34450317-0になっています。
kubectl get nodes k8s-linuxpool1-34450317-0 -o go-template --template= '{{range .spec.podCIDRs}}{{printf "%s\n" .}}{{end}}'
10.244.1.0/24
2001:db8::/64
IPv4ブロックとIPv6ブロックがそれぞれ1つずつ割り当てられているはずです。
ノードが検出されたIPv4とIPv6のインターフェースを持っていることを検証します。ノード名は自分のクラスター内の有効なノード名に置換してください。この例では、ノード名はk8s-linuxpool1-34450317-0になっています。
kubectl get nodes k8s-linuxpool1-34450317-0 -o go-template --template= '{{range .status.addresses}}{{printf "%s: %s\n" .type .address}}{{end}}'
Hostname: k8s-linuxpool1-34450317-0
InternalIP: 10.0.0.5
InternalIP: 2001:db8:10::5
Podアドレスの検証 PodにIPv4とIPv6のアドレスが割り当てられていることを検証します。Podの名前は自分のクラスター内の有効なPodの名前と置換してください。この例では、Podの名前はpod01になっています。
kubectl get pods pod01 -o go-template --template= '{{range .status.podIPs}}{{printf "%s\n" .ip}}{{end}}'
10.244.1.4
2001:db8::4
Downward APIを使用して、status.podIPsのfieldPath経由でPod IPを検証することもできます。次のスニペットは、Pod IPをMY_POD_IPSという名前の環境変数経由でコンテナ内に公開する方法を示しています。
env:
- name: MY_POD_IPS
valueFrom:
fieldRef:
fieldPath: status.podIPs
次のコマンドを実行すると、MY_POD_IPS環境変数の値をコンテナ内から表示できます。値はカンマ区切りのリストであり、PodのIPv4とIPv6のアドレスに対応しています。
kubectl exec -it pod01 -- set | grep MY_POD_IPS
MY_POD_IPS=10.244.1.4,2001:db8::4
PodのIPアドレスは、コンテナ内の/etc/hostsにも書き込まれます。次のコマンドは、デュアルスタックのPod上で/etc/hostsに対してcatコマンドを実行します。出力を見ると、Pod用のIPv4およびIPv6のIPアドレスの両方が確認できます。
kubectl exec -it pod01 -- cat /etc/hosts
# Kubernetes-managed hosts file.
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
fe00::0 ip6-mcastprefix
fe00::1 ip6-allnodes
fe00::2 ip6-allrouters
10.244.1.4 pod01
2001:db8::4 pod01
Serviceの検証 .spec.isFamilyPolicyを明示的に定義していない、以下のようなServiceを作成してみます。Kubernetesは最初に設定したservice-cluster-ip-rangeの範囲からServiceにcluster IPを割り当てて、.spec.ipFamilyPolicyをSingleStackに設定します。
apiVersion : v1
kind : Service
metadata :
name : my-service
labels :
app : MyApp
spec :
selector :
app : MyApp
ports :
- protocol : TCP
port : 80
kubectlを使ってServiceのYAMLを表示します。
kubectl get svc my-service -o yaml
Serviceの.spec.ipFamilyPolicyはSingleStackに設定され、.spec.clusterIPにはkube-controller-manager上の--service-cluster-ip-rangeフラグで最初に設定した範囲から1つのIPv4アドレスが設定されているのがわかります。
apiVersion : v1
kind : Service
metadata :
name : my-service
namespace : default
spec :
clusterIP : 10.0.217.164
clusterIPs :
- 10.0.217.164
ipFamilies :
- IPv4
ipFamilyPolicy : SingleStack
ports :
- port : 80
protocol : TCP
targetPort : 9376
selector :
app : MyApp
sessionAffinity : None
type : ClusterIP
status :
loadBalancer : {}
.spec.ipFamilies内の配列の1番目の要素にIPv6を明示的に指定した、次のようなServiceを作成してみます。Kubernetesはservice-cluster-ip-rangeで設定したIPv6の範囲からcluster IPを割り当てて、.spec.ipFamilyPolicyをSingleStackに設定します。
apiVersion : v1
kind : Service
metadata :
name : my-service
labels :
app : MyApp
spec :
ipFamilies :
- IPv6
selector :
app : MyApp
ports :
- protocol : TCP
port : 80
kubectlを使ってServiceのYAMLを表示します。
kubectl get svc my-service -o yaml
Serviceの.spec.ipFamilyPolicyはSingleStackに設定され、.spec.clusterIPには、kube-controller-manager上の--service-cluster-ip-rangeフラグで指定された最初の設定範囲から1つのIPv6アドレスが設定されているのがわかります。
apiVersion : v1
kind : Service
metadata :
labels :
app : MyApp
name : my-service
spec :
clusterIP : 2001 :db8:fd00::5118
clusterIPs :
- 2001 :db8:fd00::5118
ipFamilies :
- IPv6
ipFamilyPolicy : SingleStack
ports :
- port : 80
protocol : TCP
targetPort : 80
selector :
app : MyApp
sessionAffinity : None
type : ClusterIP
status :
loadBalancer : {}
.spec.ipFamiliePolicyにPreferDualStackを明示的に指定した、次のようなServiceを作成してみます。Kubernetesは(クラスターでデュアルスタックを有効化しているため)IPv4およびIPv6のアドレスの両方を割り当て、.spec.ClusterIPsのリストから、.spec.ipFamilies配列の最初の要素のアドレスファミリーに基づいた.spec.ClusterIPを設定します。
apiVersion : v1
kind : Service
metadata :
name : my-service
labels :
app : MyApp
spec :
ipFamilyPolicy : PreferDualStack
selector :
app : MyApp
ports :
- protocol : TCP
port : 80
備考: kubectl get svcコマンドは、CLUSTER-IPフィールドにプライマリーのIPだけしか表示しません。
kubectl get svc -l app = MyApp
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT( S) AGE
my-service ClusterIP 10.0.216.242 <none> 80/TCP 5s
kubectl describeを使用して、ServiceがIPv4およびIPv6アドレスのブロックからcluster IPを割り当てられていることを検証します。その後、ServiceにIPアドレスとポートを使用してアクセスできることを検証することもできます。
kubectl describe svc -l app = MyApp
Name: my-service
Namespace: default
Labels: app=MyApp
Annotations: <none>
Selector: app=MyApp
Type: ClusterIP
IP Family Policy: PreferDualStack
IP Families: IPv4,IPv6
IP: 10.0.216.242
10.0.216.242,2001:db8:fd00::af55
Port: <unset> 80/TCP
TargetPort: 9376/TCP
Endpoints: <none>
Session Affinity: None
Events: <none>
デュアルスタックのLoadBalancer Serviceを作成する クラウドプロバイダーがIPv6を有効化した外部ロードバランサーのプロビジョニングをサポートする場合、.spec.ipFamilyPolicyにPreferDualStackを指定し、.spec.ipFamiliesの最初の要素をIPv6にして、typeフィールドにLoadBalancerを指定したServiceを作成できます。
apiVersion : v1
kind : Service
metadata :
name : my-service
labels :
app : MyApp
spec :
ipFamilyPolicy : PreferDualStack
ipFamilies :
- IPv6
type : LoadBalancer
selector :
app : MyApp
ports :
- protocol : TCP
port : 80
Serviceを確認します。
kubectl get svc -l app = MyApp
ServiceがIPv6アドレスブロックからCLUSTER-IPのアドレスとEXTERNAL-IPを割り当てられていることを検証します。その後、IPとポートを用いたServiceへのアクセスを検証することもできます。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT( S) AGE
my-service LoadBalancer 2001:db8:fd00::7ebc 2603:1030:805::5 80:30790/TCP 35s
4.14.3 - Service IPの範囲を拡張する FEATURE STATE:
Kubernetes v1.33 [stable](enabled by default)
このドキュメントはクラスターに割り当てられている既存のService IPの範囲を拡張する方法を説明します。
始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
作業するKubernetesサーバーは次のバージョン以降のものである必要があります: v1.29.
バージョンを確認するには次のコマンドを実行してください: kubectl version.
API APIサーバーでMultiCIDRServiceAllocatorフィーチャーゲート を有効にし、networking.k8s.io/v1beta1APIグループをアクティブにしているKubernetesクラスターは、kubernetesという名前の特別なServiceCIDRオブジェクトを作成します。このオブジェクトには、APIサーバーのコマンドライン引数--service-cluster-ip-rangeの値に基づいたIPアドレス範囲が指定されます。
NAME CIDRS AGE
kubernetes 10.96.0.0/28 17d
APIサーバーのエンドポイントをPodに公開するkubernetesという特別なServiceは、デフォルトのServiceCIDRの範囲の最初のIPアドレスを算出し、そのIPアドレスをCluster IPとして使用します。
kubectl get service kubernetes
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 17d
この例では、デフォルトのServiceはClusterIPとして10.96.0.1を使用しており、対応するIPAddressオブジェクトがあります。
kubectl get ipaddress 10.96.0.1
NAME PARENTREF
10.96.0.1 services/default/kubernetes
ServiceCIDRはファイナライザー によって保護されており、ServiceのClusterIPが孤立することを防ぎます。ファイナライザーが削除されるのは、既存の全IPAddressを含む別のサブネットがある場合またはサブネットに属するIPAddressがない場合のみです。
Serviceに使用できるIPアドレスの個数を拡張する ユーザーはServiceに使用できるアドレスの個数を増やしたい場合がありますが、従来はServiceの範囲を拡張することは破壊的な操作であり、データ損失につながる可能性もありました。この新しい機能を使用することで、ユーザーは新しいServiceCIDRを追加するだけで使用可能なアドレスを増やすことができます。
新しいServiceCIDRを追加する Service用として10.96.0.0/28の範囲が設定されたクラスターでは、2^(32-28) - 2 = 14個のIPアドレスしか使用できません。kubernetes.defaultServiceは常に作成されるため、この例では最大13個しかServiceを作れません。
for i in $( seq 1 13) ; do kubectl create service clusterip "test- $i " --tcp 80 -o json | jq -r .spec.clusterIP; done
10.96.0.11
10.96.0.5
10.96.0.12
10.96.0.13
10.96.0.14
10.96.0.2
10.96.0.3
10.96.0.4
10.96.0.6
10.96.0.7
10.96.0.8
10.96.0.9
error: failed to create ClusterIP service: Internal error occurred: failed to allocate a serviceIP: range is full
IPアドレス範囲を拡張または追加する新しいServiceCIDRを作成することで、Serviceに使用できるIPアドレスの個数を増やせます。
cat <EOF | kubectl apply -f -
apiVersion: networking.k8s.io/v1beta1
kind: ServiceCIDR
metadata:
name: newcidr1
spec:
cidrs:
- 10.96.0.0/24
EOF
servicecidr.networking.k8s.io/newcidr1 created
これにより、新しいServiceを作成できるようになり、新しい範囲からClusterIPが割り当てられます。
for i in $( seq 13 16) ; do kubectl create service clusterip "test- $i " --tcp 80 -o json | jq -r .spec.clusterIP; done
10.96.0.48
10.96.0.200
10.96.0.121
10.96.0.144
ServiceCIDRの削除 あるServiceCIDRに依存しているIPAddressが存在する場合、そのServiceCIDRは削除できません。
kubectl delete servicecidr newcidr1
servicecidr.networking.k8s.io "newcidr1" deleted
KubernetesはServiceCIDRのファイナライザーを使ってこの依存関係を追跡します。
kubectl get servicecidr newcidr1 -o yaml
apiVersion : networking.k8s.io/v1beta1
kind : ServiceCIDR
metadata :
creationTimestamp : "2023-10-12T15:11:07Z"
deletionGracePeriodSeconds : 0
deletionTimestamp : "2023-10-12T15:12:45Z"
finalizers :
- networking.k8s.io/service-cidr-finalizer
name : newcidr1
resourceVersion : "1133"
uid : 5ffd8afe-c78f-4e60-ae76-cec448a8af40
spec :
cidrs :
- 10.96.0.0 /24
status :
conditions :
- lastTransitionTime : "2023-10-12T15:12:45Z"
message : There are still IPAddresses referencing the ServiceCIDR, please remove
them or create a new ServiceCIDR
reason : OrphanIPAddress
status : "False"
type : Ready
ServiceCIDRの削除を止めているIPAddressを含むServiceを削除すると
for i in $( seq 13 16) ; do kubectl delete service "test- $i " ; done
service "test-13" deleted
service "test-14" deleted
service "test-15" deleted
service "test-16" deleted
コントロールプレーンがそれを検知します。そしてコントロールプレーンはファイナライザを削除し、削除が保留されているServiceCIDRが実際に削除されるようにします。
kubectl get servicecidr newcidr1
Error from server (NotFound): servicecidrs.networking.k8s.io "newcidr1" not found
4.15 - GPUのスケジューリング クラスター内のノードのリソースとしてGPUを設定してスケジューリングします
FEATURE STATE:
Kubernetes v1.10 [beta]
Kubernetesには、複数ノードに搭載されたAMDおよびNVIDIAのGPU(graphical processing unit)を管理するための実験的な サポートが含まれています。
このページでは、異なるバージョンのKubernetesを横断してGPUを使用する方法と、現時点での制限について説明します。
デバイスプラグインを使用する Kubernetesでは、GPUなどの特別なハードウェアの機能にPodがアクセスできるようにするために、デバイスプラグイン が実装されています。
管理者として、ノード上に対応するハードウェアベンダーのGPUドライバーをインストールして、以下のような対応するGPUベンダーのデバイスプラグインを実行する必要があります。
上記の条件を満たしていれば、Kubernetesはamd.com/gpuまたはnvidia.com/gpuをスケジュール可能なリソースとして公開します。
これらのGPUをコンテナから使用するには、cpuやmemoryをリクエストするのと同じように<vendor>.com/gpuというリソースをリクエストするだけです。ただし、GPUを使用するときにはリソースのリクエストの指定方法にいくつか制限があります。
GPUはlimitsセクションでのみ指定されることが想定されている。この制限は、次のことを意味します。Kubernetesはデフォルトでlimitの値をrequestの値として使用するため、GPUのrequestsを省略してlimitsを指定できる。 GPUをlimitsとrequestsの両方で指定できるが、これら2つの値は等しくなければならない。 GPUのlimitsを省略してrequestsだけを指定することはできない。 コンテナ(およびPod)はGPUを共有しない。GPUのオーバーコミットは起こらない。 各コンテナは1つ以上のGPUをリクエストできる。1つのGPUの一部だけをリクエストすることはできない。 以下に例を示します。
apiVersion : v1
kind : Pod
metadata :
name : cuda-vector-add
spec :
restartPolicy : OnFailure
containers :
- name : cuda-vector-add
# https://github.com/kubernetes/kubernetes/blob/v1.7.11/test/images/nvidia-cuda/Dockerfile
image : "registry.k8s.io/cuda-vector-add:v0.1"
resources :
limits :
nvidia.com/gpu : 1 # 1 GPUをリクエストしています
AMDのGPUデバイスプラグインをデプロイする AMD公式のGPUデバイスプラグイン には以下の要件があります。
Kubernetesのノードに、AMDのGPUのLinuxドライバーがあらかじめインストール済みでなければならない。 クラスターが起動して上記の要件が満たされれば、以下のコマンドを実行することでAMDのデバイスプラグインをデプロイできます。
kubectl create -f https://raw.githubusercontent.com/RadeonOpenCompute/k8s-device-plugin/v1.10/k8s-ds-amdgpu-dp.yaml
このサードパーティーのデバイスプラグインに関する問題は、RadeonOpenCompute/k8s-device-plugin で報告できます。
NVIDIAのGPUデバイスプラグインをデプロイする 現在、NVIDIAのGPU向けのデバイスプラグインの実装は2種類あります。
NVIDIA公式のGPUデバイスプラグイン NVIDIA公式のGPUデバイスプラグイン には以下の要件があります。
Kubernetesのノードに、NVIDIAのドライバーがあらかじめインストール済みでなければならない。 Kubernetesのノードに、nvidia-docker 2.0 があらかじめインストール済みでなければならない。 KubeletはコンテナランタイムにDockerを使用しなければならない。 runcの代わりにDockerのデフォルトランタイム として、nvidia-container-runtimeを設定しなければならない。 NVIDIAのドライバーのバージョンが次の条件を満たさなければならない ~= 384.81。 クラスターが起動して上記の要件が満たされれば、以下のコマンドを実行することでNVIDIAのデバイスプラグインがデプロイできます。
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/1.0.0-beta4/nvidia-device-plugin.yml
このサードパーティーのデバイスプラグインに関する問題は、NVIDIA/k8s-device-plugin で報告できます。
GCEで使用されるNVIDIAのGPUデバイスプラグイン GCEで使用されるNVIDIAのGPUデバイスプラグイン は、nvidia-dockerを必要としないため、KubernetesのContainer Runtime Interface(CRI)と互換性のある任意のコンテナランタイムで動作するはずです。このデバイスプラグインはContainer-Optimized OS でテストされていて、1.9以降ではUbuntu向けの実験的なコードも含まれています。
以下のコマンドを実行すると、NVIDIAのドライバーとデバイスプラグインをインストールできます。
# NVIDIAドライバーをContainer-Optimized OSにインストールする
kubectl create -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/stable/daemonset.yaml
# NVIDIAドライバーをUbuntuにインストールする(実験的)
kubectl create -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/stable/nvidia-driver-installer/ubuntu/daemonset.yaml
# デバイスプラグインをインストールする
kubectl create -f https://raw.githubusercontent.com/kubernetes/kubernetes/release-1.14/cluster/addons/device-plugins/nvidia-gpu/daemonset.yaml
このサードパーティーのデバイスプラグインの使用やデプロイに関する問題は、GoogleCloudPlatform/container-engine-accelerators で報告できます。
Googleは、GKE上でNVIDIAのGPUを使用するための手順 も公開しています。
異なる種類のGPUを搭載するクラスター クラスター上の別のノードに異なる種類のGPUが搭載されている場合、NodeラベルとNodeセレクター を使用することで、Podを適切なノードにスケジューリングできます。
以下に例を示します。
# アクセラレーターを搭載したノードにラベルを付けます。
kubectl label nodes <node-with-k80> accelerator = nvidia-tesla-k80
kubectl label nodes <node-with-p100> accelerator = nvidia-tesla-p100
自動的なNodeラベルの付加 AMDのGPUデバイスを使用している場合、Node Labeller をデプロイできます。Node Labellerはコントローラー の1種で、GPUデバイスのプロパティを持つノードに自動的にラベルを付けてくれます。
現在は、このコントローラーは以下のプロパティに基づいてラベルを追加できます。
デバイスID(-device-id) VRAMのサイズ(-vram) SIMDの数(-simd-count) Compute Unitの数(-cu-count) ファームウェアとフィーチャーのバージョン(-firmware) 2文字の頭字語で表されたGPUファミリー(-family)SI - Southern Islands CI - Sea Islands KV - Kaveri VI - Volcanic Islands CZ - Carrizo AI - Arctic Islands RV - Raven kubectl describe node cluster-node-23
Name: cluster-node-23
Roles: <none>
Labels: beta.amd.com/gpu.cu-count.64=1
beta.amd.com/gpu.device-id.6860=1
beta.amd.com/gpu.family.AI=1
beta.amd.com/gpu.simd-count.256=1
beta.amd.com/gpu.vram.16G=1
beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/hostname=cluster-node-23
Annotations: kubeadm.alpha.kubernetes.io/cri-socket: /var/run/dockershim.sock
node.alpha.kubernetes.io/ttl: 0
…
Node Labellerを使用すると、GPUの種類をPodのspec内で指定できます。
apiVersion : v1
kind : Pod
metadata :
name : cuda-vector-add
spec :
restartPolicy : OnFailure
containers :
- name : cuda-vector-add
# https://github.com/kubernetes/kubernetes/blob/v1.7.11/test/images/nvidia-cuda/Dockerfile
image : "registry.k8s.io/cuda-vector-add:v0.1"
resources :
limits :
nvidia.com/gpu : 1
nodeSelector :
accelerator : nvidia-tesla-p100 # または nvidia-tesla-k80 など
これにより、指定した種類のGPUを搭載したノードにPodがスケジューリングされることを保証できます。
4.16 - huge pageを管理する クラスター内のスケジュール可能なリソースとしてhuge pageの設定と管理を行います。
FEATURE STATE:
Kubernetes v1.35 [stable]
Kubernetesでは、事前割り当てされたhuge pageをPod内のアプリケーションに割り当てたり利用したりすることをサポートしています。このページでは、ユーザーがhuge pageを利用できるようにする方法について説明します。
始める前に Kubernetesのノードがhuge pageのキャパシティを報告するためには、ノード上でhuge pageを事前割り当てしておく必要があります。1つのノードでは複数のサイズのhuge pageが事前割り当てできます。 ノードは、すべてのhuge pageリソースを、スケジュール可能なリソースとして自動的に探索・報告してくれます。
API huge pageはコンテナレベルのリソース要求でhugepages-<size>という名前のリソースを指定することで利用できます。ここで、<size>は、特定のノード上でサポートされている整数値を使った最も小さなバイナリ表記です。たとえば、ノードが2048KiBと1048576KiBのページサイズをサポートしている場合、ノードはスケジュール可能なリソースとして、hugepages-2Miとhugepages-1Giの2つのリソースを公開します。CPUやメモリとは違い、huge pageはオーバーコミットをサポートしません。huge pageリソースをリクエストするときには、メモリやCPUリソースを同時にリクエストしなければならないことに注意してください。
1つのPodのspec内に書くことで、Podから複数のサイズのhuge pageを利用することもできます。その場合、すべてのボリュームマウントでmedium: HugePages-<hugepagesize>という表記を使う必要があります。
apiVersion : v1
kind : Pod
metadata :
name : huge-pages-example
spec :
containers :
- name : example
image : fedora:latest
command :
- sleep
- inf
volumeMounts :
- mountPath : /hugepages-2Mi
name : hugepage-2mi
- mountPath : /hugepages-1Gi
name : hugepage-1gi
resources :
limits :
hugepages-2Mi : 100Mi
hugepages-1Gi : 2Gi
memory : 100Mi
requests :
memory : 100Mi
volumes :
- name : hugepage-2mi
emptyDir :
medium : HugePages-2Mi
- name : hugepage-1gi
emptyDir :
medium : HugePages-1Gi
Podで1種類のサイズのhuge pageをリクエストするときだけは、medium: HugePagesという表記を使うこともできます。
apiVersion : v1
kind : Pod
metadata :
name : huge-pages-example
spec :
containers :
- name : example
image : fedora:latest
command :
- sleep
- inf
volumeMounts :
- mountPath : /hugepages
name : hugepage
resources :
limits :
hugepages-2Mi : 100Mi
memory : 100Mi
requests :
memory : 100Mi
volumes :
- name : hugepage
emptyDir :
medium : HugePages
huge pageのrequestsはlimitsと等しくなければなりません。limitsを指定した場合にはこれがデフォルトですが、requestsを指定しなかった場合にはデフォルトではありません。 huge pageはコンテナのスコープで隔離されるため、各コンテナにはそれぞれのcgroupサンドボックスの中でcontainer specでリクエストされた通りのlimitが設定されます。 huge pageベースのEmptyDirボリュームは、Podがリクエストしたよりも大きなサイズのページメモリーを使用できません。 shmget()にSHM_HUGETLBを指定して取得したhuge pageを使用するアプリケーションは、/proc/sys/vm/hugetlb_shm_groupに一致する補助グループ(supplemental group)を使用して実行する必要があります。namespace内のhuge pageの使用量は、ResourceQuotaに対してcpuやmemoryのような他の計算リソースと同じようにhugepages-<size>というトークンを使用することで制御できます。 複数のサイズのhuge pageのサポートはフィーチャーゲートによる設定が必要です。kubelet とkube-apiserver 上で、HugePageStorageMediumSizeフィーチャーゲート を使用すると有効にできます(--feature-gates=HugePageStorageMediumSize=true)。 5 - チュートリアル 本セクションにはチュートリアルが含まれています。チュートリアルでは、単一のタスク よりも大きな目標を達成する方法を示します。通常、チュートリアルにはいくつかのセクションがあり、各セクションには一連のステップがあります。各チュートリアルを進める前に、後で参照できるように標準化された用語集 ページをブックマークしておくことをお勧めします。
基本 設定 ステートレスアプリケーション ステートフルアプリケーション サービス セキュリティ 次の項目 チュートリアルのページタイプについての情報は、Content Page Types を参照してください。
5.1 - Hello Minikube このチュートリアルでは、minikubeを使用して、Kubernetes上でサンプルアプリケーションを動かす方法を紹介します。
このチュートリアルはNGINXを利用してすべての要求をエコーバックするコンテナイメージを提供します。
目標 minikubeへのサンプルアプリケーションのデプロイ アプリケーションの実行 アプリケーションログの確認 始める前に このチュートリアルは、minikubeがセットアップ済みであることを前提としています。
インストール手順はminikube start の Step 1 を参照してください。
備考: Step 1, Installation の手順のみ実行してください。それ以降の手順はこのページで説明します。また、kubectlをインストールする必要があります。
インストール手順はツールのインストール を参照してください。
minikubeクラスターの作成 ダッシュボードを開く Kubernetesダッシュボードを開きます。これには二通りの方法があります:
新しい ターミナルを開き、次のコマンドを実行します:
# 新しいターミナルを起動し、以下を実行したままにします
minikube dashboard
minikube startを実行したターミナルに戻ります。
備考: dashboardコマンドは、ダッシュボードアドオンを有効にし、デフォルトのWebブラウザーでプロキシを開きます。
ダッシュボード上で、DeploymentやServiceなどのKubernetesリソースを作成できます。
ターミナルから直接ブラウザーを起動させずに、WebダッシュボードのURLを取得する方法については、「URLをコピー&ペースト」タブを参照してください。
デフォルトでは、ダッシュボードはKubernetesの仮想ネットワーク内部からのみアクセス可能です。
dashboardコマンドは、Kubernetes仮想ネットワークの外部からダッシュボードにアクセス可能にするための一時的なプロキシを作成します。
プロキシを停止するには、Ctrl+Cを実行してプロセスを終了します。
dashboardコマンドが終了した後も、ダッシュボードはKubernetesクラスター内で実行を続けます。
再度dashboardコマンドを実行すれば、新しい別のプロキシを作成してダッシュボードにアクセスできます。
minikubeが自動的にWebブラウザーを開くことを望まない場合、dashboardサブコマンドを--urlフラグと共に実行します。
minikubeは、お好みのブラウザーで開くことができるURLを出力します。
新しい ターミナルを開き、次のコマンドを実行します:
# 新しいターミナルを起動し、以下を実行したままにします
minikube dashboard --url
URLをコピー&ペーストし、ブラウザーで開きます。
minikube startを実行したターミナルに戻ります。
Deploymentの作成 KubernetesのPod Deployment
kubectl createコマンドを使用してPodを管理するDeploymentを作成してください。Podは提供されたDockerイメージを元にコンテナを実行します。
# Webサーバーを含むテストコンテナイメージを実行する
kubectl create deployment hello-node --image= registry.k8s.io/e2e-test-images/agnhost:2.53 -- /agnhost netexec --http-port= 8080
Deploymentを確認します:
出力は下記のようになります:
NAME READY UP-TO-DATE AVAILABLE AGE
hello-node 1/1 1 1 1m
(Podが利用可能になるまで時間がかかる場合があります。"0/1"と表示された場合は、数秒後にもう一度確認してみてください。)
Podを確認します:
出力は下記のようになります:
NAME READY STATUS RESTARTS AGE
hello-node-5f76cf6ccf-br9b5 1/1 Running 0 1m
クラスターイベントを確認します:
kubectlで設定を確認します:
Podで実行されているコンテナのアプリケーションログを確認します(Podの名前はkubectl get podsで取得したものに置き換えてください)。
備考: kubectl logsコマンドの引数hello-node-5f76cf6ccf-br9b5は、kubectl get podsコマンドで取得したPodの名前に置き換えてください。kubectl logs hello-node-5f76cf6ccf-br9b5
出力は下記のようになります:
I0911 09:19:26.677397 1 log.go:195] Started HTTP server on port 8080
I0911 09:19:26.677586 1 log.go:195] Started UDP server on port 8081
Serviceの作成 通常、PodはKubernetesクラスター内部のIPアドレスからのみアクセスすることができます。hello-nodeコンテナをKubernetesの仮想ネットワークの外部からアクセスするためには、KubernetesのService
警告: agnhostコンテナには/shellエンドポイントがあり、デバッグには便利ですが、インターネットに公開するのは危険です。
インターネットに接続されたクラスターや、プロダクション環境のクラスターで実行しないでください。kubectl exposeコマンドを使用してPodをインターネットに公開します:
kubectl expose deployment hello-node --type= LoadBalancer --port= 8080
--type=LoadBalancerフラグはServiceをクラスター外部に公開したいことを示しています。
テストイメージ内のアプリケーションコードはTCPの8080番ポートのみを待ち受けます。
kubectl exposeで8080番ポート以外を公開した場合、クライアントはそのポートに接続できません。
作成したServiceを確認します:
出力は下記のようになります:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hello-node LoadBalancer 10.108.144.78 <pending> 8080:30369/TCP 21s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 23m
ロードバランサーをサポートするクラウドプロバイダーでは、Serviceにアクセスするための外部IPアドレスが提供されます。
minikubeでは、LoadBalancerタイプはminikube serviceコマンドを使用した接続可能なServiceを作成します。
次のコマンドを実行します:
minikube service hello-node
アプリケーションとその応答が表示されるブラウザーウィンドウが開きます。
アドオンの有効化 minikubeはビルトインのアドオン があり、有効化、無効化、あるいはローカルのKubernetes環境に公開することができます。
サポートされているアドオンをリストアップします:
出力は下記のようになります:
addon-manager: enabled
dashboard: enabled
default-storageclass: enabled
efk: disabled
freshpod: disabled
gvisor: disabled
helm-tiller: disabled
ingress: disabled
ingress-dns: disabled
logviewer: disabled
metrics-server: disabled
nvidia-driver-installer: disabled
nvidia-gpu-device-plugin: disabled
registry: disabled
registry-creds: disabled
storage-provisioner: enabled
storage-provisioner-gluster: disabled
ここでは例としてmetrics-serverのアドオンを有効化します:
minikube addons enable metrics-server
出力は下記のようになります:
The 'metrics-server' addon is enabled
作成されたPodとサービスを確認します:
kubectl get pod,svc -n kube-system
出力:
NAME READY STATUS RESTARTS AGE
pod/coredns-5644d7b6d9-mh9ll 1/1 Running 0 34m
pod/coredns-5644d7b6d9-pqd2t 1/1 Running 0 34m
pod/metrics-server-67fb648c5 1/1 Running 0 26s
pod/etcd-minikube 1/1 Running 0 34m
pod/influxdb-grafana-b29w8 2/2 Running 0 26s
pod/kube-addon-manager-minikube 1/1 Running 0 34m
pod/kube-apiserver-minikube 1/1 Running 0 34m
pod/kube-controller-manager-minikube 1/1 Running 0 34m
pod/kube-proxy-rnlps 1/1 Running 0 34m
pod/kube-scheduler-minikube 1/1 Running 0 34m
pod/storage-provisioner 1/1 Running 0 34m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/metrics-server ClusterIP 10.96.241.45 <none> 80/TCP 26s
service/kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP 34m
service/monitoring-grafana NodePort 10.99.24.54 <none> 80:30002/TCP 26s
service/monitoring-influxdb ClusterIP 10.111.169.94 <none> 8083/TCP,8086/TCP 26s
metrics-serverの出力を確認します:
出力は下記のようになります:
NAME CPU(cores) MEMORY(bytes)
hello-node-ccf4b9788-4jn97 1m 6Mi
次のメッセージが表示された場合は、しばらく待ってから再度実行してください:
error: Metrics API not available
metrics-serverを無効化します:
minikube addons disable metrics-server
出力は下記のようになります:
metrics-server was successfully disabled
クリーンアップ クラスターに作成したリソースをクリーンアップします:
kubectl delete service hello-node
kubectl delete deployment hello-node
minikubeクラスターを停止します
(オプション)minikubeのVMを削除します:
Kubernetesの学習で再度minikubeを使用したい場合、minikubeのVMを削除する必要はありません。
まとめ このページでは、minikubeクラスターを立ち上げて実行するための基本的な部分を説明しました。
これでアプリケーションをデプロイする準備が整いました。
次の項目 5.2 - Kubernetesの基本を学ぶ Kubernetesの基本 このチュートリアルでは、Kubernetesクラスターオーケストレーションシステムの基本について学びます。各モジュールには、Kubernetesの主な機能と概念に関する背景情報と、一緒に進めるためのチュートリアルが含まれています。
このチュートリアルでは、以下のことを学ぶことができます:
コンテナ化されたアプリケーションをクラスターにデプロイ Deploymentのスケーリング 新しいソフトウェアのバージョンでコンテナ化されたアプリケーションをアップデート コンテナ化されたアプリケーションのデバッグ Kubernetesはどんなことができるの? モダンなWebサービスでは、ユーザはアプリケーションが24時間365日利用可能であることを期待しており、開発者はそれらのアプリケーションの新しいバージョンを1日に数回デプロイすることを期待しています。コンテナ化は、パッケージソフトウェアがこれらの目標を達成するのを助け、アプリケーションをダウンタイムなしでリリース、アップデートできるようにします。Kubernetesを使用すると、コンテナ化されたアプリケーションをいつでもどこでも好きなときに実行できるようになり、それらが機能するために必要なリソースとツールを見つけやすくなります。Kubernetesは、コンテナオーケストレーションにおけるGoogleのこれまでの経験と、コミュニティから得られた最善のアイデアを組み合わせて設計された、プロダクションレディなオープンソースプラットフォームです。
5.2.1 - クラスターの作成 5.2.1.1 - Minikubeを使ったクラスターの作成 Kubernetesクラスターとは何かを学ぶ。
Minikubeとは何かを学ぶ。
Kubernetesクラスターを起動する。
目標 Kubernetesクラスターとは何かを学ぶ Minikubeとは何かを学ぶ Kubernetesクラスターをローカルで動かす Kubernetesクラスター Kubernetesは、単一のユニットとして機能するように接続された、可用性の高いコンピューターのクラスターをまとめあげます。 Kubernetesの抽象化により、コンテナ化されたアプリケーションを個々のマシンに特に結び付けることなくクラスターにデプロイできます。この新しいデプロイモデルを利用するには、アプリケーションを個々のホストから切り離す方法でアプリケーションをパッケージ化(つまり、コンテナ化)する必要があります。コンテナ化されたアプリケーションは、アプリケーションがホストに深く統合されたパッケージとして特定のマシンに直接インストールされていた従来のデプロイモデルよりも柔軟で、より迅速に利用可能です。Kubernetesはより効率的な方法で、クラスター全体のアプリケーションコンテナの配布とスケジューリングを自動化します。 Kubernetesはオープンソースのプラットフォームであり、プロダクションレディです。
Kubernetesクラスターは以下の2種類のリソースで構成されています:
コントロールプレーン がクラスターを管理するノード がアプリケーションを動かすワーカーとなるKubernetesは、コンピュータークラスター内およびコンピュータークラスター間でのアプリケーションコンテナの配置(スケジューリング)および実行を調整する、プロダクショングレードのオープンソースプラットフォームです。
コントロールプレーンはクラスターの管理を担当します。 コントロールプレーンは、アプリケーションのスケジューリング、望ましい状態の維持、アプリケーションのスケーリング、新しい更新のロールアウトなど、クラスター内のすべての動作をまとめあげます。
ノードは、Kubernetesクラスターのワーカーマシンとして機能するVMまたは物理マシンです。 各ノードにはKubeletがあり、これはノードを管理し、Kubernetesコントロールプレーンと通信するためのエージェントです。ノードにはcontainerd や CRI-O などのコンテナ操作を処理するためのツールもあるはずです。プロダクションのトラフィックを処理するKubernetesクラスターには、最低3つのノードが必要です。これは、1ノードがダウンすると、etcd メンバーとコントロールプレーンのインスタンスの両方を同時に失うリスクがあり、冗長性が損なわれてしまうからです。このリスクを軽減するには、コントロールプレーンノードを複数構成することで対応できます。
コントロールプレーンは実行中のアプリケーションをホストするために使用されるノードとクラスターを管理します。
Kubernetesにアプリケーションをデプロイするときは、コントロールプレーンにアプリケーションコンテナを起動するように指示します。コントロールプレーンはコンテナがクラスターのノードで実行されるようにスケジュールします。ノードは、コントロールプレーンが公開しているKubernetes API を使用してコントロールプレーンと通信します。 エンドユーザーは、Kubernetes APIを直接使用して対話することもできます。
Kubernetesクラスターは、物理マシンまたは仮想マシンのどちらにも配置できます。Kubernetes開発を始めるためにMinikubeを使うことができます。Minikubeは、ローカルマシン上にVMを作成し、1つのノードのみを含む単純なクラスターをデプロイする軽量なKubernetes実装です。Minikubeは、Linux、macOS、およびWindowsシステムで利用可能です。Minikube CLIは、起動、停止、ステータス、削除など、クラスターを操作するための基本的なブートストラップ操作を提供します。
Kubernetesが何であるかがわかったので、Hello Minikube に行き、最初のクラスターを動かしましょう!
5.2.2 - アプリケーションのデプロイ 5.2.2.1 - Deploymentを作成するためにkubectlを使う 目標 アプリケーションのデプロイについて学ぶ。 kubectlを使って、Kubernetes上にはじめてのアプリケーションをデプロイする。 KubernetesのDeployment Deploymentは、アプリケーションのインスタンスを作成および更新する責務があります。
備考: このチュートリアルでは、AMD64アーキテクチャを必要とするコンテナを使用します。
異なるCPUアーキテクチャのコンピューターでminikubeを使用する場合は、AMD64をエミュレートできるドライバーでminikubeを使用してみてください。
例えば、Docker Desktopドライバーはこれが可能です。実行中のKubernetesクラスター を入手すると、その上にコンテナ化アプリケーションをデプロイすることができます。
そのためには、KubernetesのDeployment の設定を作成します。
DeploymentはKubernetesにあなたのアプリケーションのインスタンスを作成し、更新する方法を指示します。
Deploymentを作成すると、KubernetesコントロールプレーンはDeployment内に含まれるアプリケーションインスタンスをクラスター内の個々のノードで実行するようにスケジュールします。
アプリケーションインスタンスが作成されると、Kubernetes Deploymentコントローラーは、それらのインスタンスを継続的に監視します。
インスタンスをホストしているノードが停止、削除された場合、Deploymentコントローラーはそのインスタンスをクラスター内の別のノード上のインスタンスと置き換えます。
これは、マシンの故障やメンテナンスに対処するためのセルフヒーリングの仕組みを提供しています。
オーケストレーションが登場する前の世界では、インストールスクリプトを使用してアプリケーションを起動することはよくありましたが、マシン障害が発生した場合に復旧する事はできませんでした。
アプリケーションのインスタンスを作成し、それらをノード間で実行し続けることで、Kubernetes Deploymentはアプリケーションの管理に根本的に異なるアプローチを提供します。
Kubernetes上にはじめてのアプリケーションをデプロイする Kubernetesにデプロイするには、アプリケーションをサポートされているコンテナ形式のいずれかにパッケージ化する必要があります。
Kubernetesのコマンドラインインターフェースであるkubectl を使用して、Deploymentを作成、管理できます。
kubectlはKubernetes APIを使用してクラスターと対話します。
このモジュールでは、Kubernetesクラスターでアプリケーションを実行するDeploymentを作成するために必要な、最も一般的なkubectlコマンドについて学びます。
Deploymentを作成するときは、アプリケーションのコンテナイメージと実行するレプリカの数を指定する必要があります。
Deploymentを更新することで、あとでその情報を変更できます。
ブートキャンプのModule 5 とModule 6 では、Deploymentをどのようにスケール、更新できるかについて説明します。
最初のDeploymentには、NGINXを使用して全てのリクエストをエコーバックする、Dockerコンテナにパッケージ化されたhello-nodeアプリケーションを使用します。
(まだhello-nodeアプリケーションを作成して、コンテナを使用してデプロイしていない場合、Hello Minikube tutorial の通りにやってみましょう。)
kubectlもインストールされている必要があります。
インストールが必要な場合は、ツールのインストール からインストールしてください。
Deploymentが何であるかがわかったので、最初のアプリケーションをデプロイしましょう!
kubectlの基本 kubectlコマンドの一般的な書式はkubectl action resourceです。
これは指定された resource (node、deploymentなど)に対して指定された action (create、describe、deleteなど)を実行します。
指定可能なパラメーターに関する追加情報を取得するために、サブコマンドの後に--helpを使うこともできます(例:kubectl get nodes --help)。
kubectl versionコマンドを実行して、kubectlがクラスターと通信できるように設定されていることを確認してください。
kubectlがインストールされていて、クライアントとサーバーの両方のバージョンを確認できることを確認してください。
クラスター内のノードを表示するには、kubectl get nodesコマンドを実行します。
利用可能なノードが表示されます。
後で、KubernetesはNodeの利用可能なリソースに基づいてアプリケーションをデプロイする場所を選択します。
アプリケーションをデプロイする 最初のアプリケーションをkubectl create deploymentコマンドでKubernetesにデプロイしてみましょう。
デプロイ名とアプリケーションイメージの場所を指定する必要があります(Docker Hub外でホストされているイメージはリポジトリの完全なURLを含める必要があります)。
kubectl create deployment kubernetes-bootcamp --image= gcr.io/google-samples/kubernetes-bootcamp:v1
素晴らしい!Deploymentを作成して、最初のアプリケーションをデプロイしました。
これによっていくつかのことが実行されました。
アプリケーションのインスタンスを実行可能な適切なノードを探しました(利用可能なノードは1つしかない)。 アプリケーションをそのノードで実行するためのスケジュールを行いました。 必要な場合にインスタンスを新しいノードで再スケジュールするような設定を行いました。 Deploymentの一覧を得るにはkubectl get deploymentsコマンドを使います。
アプリケーションの単一のインスタンスを実行しているDeploymentが1つあることが分かります。
インスタンスはノード上のコンテナ内で実行されています。
アプリケーションを見る Kubernetes内部で動作しているPod は、プライベートに隔離されたネットワーク上で動作しています。
デフォルトでは、同じKubernetesクラスター内の他のPodやServiceからは見えますが、そのネットワークの外からは見えません。
kubectlを使用する場合、アプリケーションと通信するためにAPIエンドポイントを通じてやりとりしています。
アプリケーションをKubernetesクラスターの外部に公開するための他のオプションについては、後ほどModule 4 で説明します。
また、これは基本的なチュートリアルであるため、ここではPodとは何かについては詳しく説明しません。
kubectl proxyコマンドによって、通信をクラスター全体のプライベートネットワークに転送するプロキシを作成することができます。
プロキシはcontrol-Cキーを押すことで終了させることができ、実行中は何も出力されません。
プロキシを実行するにはもう一つターミナルウィンドウを開く必要があります。
ホスト(端末)とKubernetesクラスター間の接続ができました。
プロキシによって端末からAPIへの直接アクセスが可能となります。
プロキシエンドポイントを通してホストされている全てのAPIを確認することができます。
例えば、curlコマンドを使って、APIを通じて直接バージョンを調べることができます。
curl http://localhost:8001/version
備考: ポート8001にアクセスできない場合は、上で起動したkube proxyがもう一つのターミナルで実行されていることを確認してください。APIサーバーはPod名に基づいて各Pod用のエンドポイントを自動的に作成し、プロキシからもアクセスできるようにします。
まずPod名を取得する必要があるので、環境変数POD_NAMEに格納しておきます。
export POD_NAME = $( kubectl get pods -o go-template --template '{{range .items}}{{.metadata.name}}{{"\n"}}{{end}}' )
echo Name of the Pod: $POD_NAME
以下を実行することで、プロキシされたAPIを通してPodにアクセスすることができます。
curl http://localhost:8001/api/v1/namespaces/default/pods/$POD_NAME :8080/proxy/
プロキシを使わずに新しいDeploymentにアクセスするには、Module 4 で説明するServiceが必要です。
次の項目
5.2.3 - アプリケーションの探索 5.2.3.1 - Podとノードについて 目標 KubernetesのPodについて学ぶ Kubernetesのノードについて学ぶ デプロイされたアプリケーションのトラブルシューティング Kubernetes Pod モジュール2 でDeploymentを作成したときに、KubernetesはアプリケーションインスタンスをホストするためのPodを作成しました。Podは、1つ以上のアプリケーションコンテナ(Dockerなど)のグループとそれらのコンテナの共有リソースを表すKubernetesの抽象概念です。 Podには以下のものが含まれます:
共有ストレージ(ボリューム) ネットワーキング(クラスターに固有のIPアドレス) コンテナのイメージバージョンや使用するポートなどの、各コンテナをどう動かすかに関する情報 Podは、アプリケーション固有の「論理ホスト」をモデル化し、比較的密接に結合されたさまざまなアプリケーションコンテナを含むことができます。 たとえば、Podには、Node.jsアプリケーションを含むコンテナと、Node.js Webサーバによって公開されるデータを供給する別のコンテナの両方を含めることができます。Pod内のコンテナはIPアドレスとポートスペースを共有し、常に同じ場所に配置され、同じスケジュールに入れられ、同じノード上の共有コンテキストで実行されます。
Podは、Kubernetesプラットフォームの原子単位です。 Kubernetes上にDeploymentを作成すると、そのDeploymentはその中にコンテナを持つPodを作成します(コンテナを直接作成するのではなく)。 各Podは、スケジュールされているノードに関連付けられており、終了(再起動ポリシーに従って)または削除されるまでそこに残ります。 ノードに障害が発生した場合、同じPodがクラスター内の他の使用可能なノードにスケジュールされます。
Podは1つ以上のアプリケーションコンテナ(Dockerなど)のグループであり、共有ストレージ(ボリューム)、IPアドレス、それらの実行方法に関する情報が含まれています。
ノード Podは常にノード 上で動作します。ノードはKubernetesではワーカーマシンであり、クラスターによって仮想、物理マシンのどちらであってもかまいません。各ノードはマスターによって管理されます。ノードは複数のPodを持つことができ、Kubernetesマスターはクラスター内のノード間でPodのスケジュールを自動的に処理します。マスターの自動スケジューリングは各ノードで利用可能なリソースを考慮に入れます。
すべてのKubernetesノードでは少なくとも以下のものが動作します。
Kubelet: Kubernetesマスターとノード間の通信を担当するプロセス。マシン上で実行されているPodとコンテナを管理します。 レジストリからコンテナイメージを取得し、コンテナを解凍し、アプリケーションを実行することを担当する、Dockerのようなコンテナランタイム。 コンテナ同士が密接に結合され、ディスクなどのリソースを共有する必要がある場合は、コンテナを1つのPodにまとめてスケジュールする必要があります。
kubectlを使ったトラブルシューティング モジュール2 では、kubectlのコマンドラインインターフェースを使用しました。モジュール3でもこれを使用して、デプロイされたアプリケーションとその環境に関する情報を入手します。最も一般的な操作は、次のkubectlコマンドで実行できます。
kubectl get - リソースの一覧を表示kubectl describe - 単一リソースに関する詳細情報を表示kubectl logs - 単一Pod上の単一コンテナ内のログを表示kubectl exec - 単一Pod上の単一コンテナ内でコマンドを実行これらのコマンドを使用して、アプリケーションがいつデプロイされたか、それらの現在の状況、実行中の場所、および構成を確認することができます。
クラスターのコンポーネントとコマンドラインの詳細についてわかったので、次にデプロイしたアプリケーションを探索してみましょう。
ノードはKubernetesではワーカーマシンであり、クラスターに応じてVMまたは物理マシンになります。 複数のPodを1つのノードで実行できます。
5.2.4 - アプリケーションの公開 5.2.4.1 - Serviceを使ったアプリケーションの公開 目標 KubernetesにおけるServiceについて理解する ラベルとLabelSelectorオブジェクトがServiceにどう関係しているかを理解する Serviceを使って、Kubernetesクラスターの外にアプリケーションを公開する Kubernetes Serviceの概要 Kubernetes Podの寿命は永続的ではありません。実際、Pod にはライフサイクル があります。ワーカーのノードが停止すると、そのノードで実行されているPodも失われます。そうなると、ReplicaSet は、新しいPodを作成してアプリケーションを実行し続けるために、クラスターを動的に目的の状態に戻すことができます。別の例として、3つのレプリカを持つ画像処理バックエンドを考えます。それらのレプリカは交換可能です。フロントエンドシステムはバックエンドのレプリカを気にしたり、Podが失われて再作成されたとしても配慮すべきではありません。ただし、Kubernetesクラスター内の各Podは、同じノード上のPodであっても一意のIPアドレスを持っているため、アプリケーションが機能し続けるように、Pod間の変更を自動的に調整する方法が必要です。
KubernetesのServiceは、Podの論理セットと、それらにアクセスするためのポリシーを定義する抽象概念です。Serviceによって、依存Pod間の疎結合が可能になります。Serviceは、すべてのKubernetesオブジェクトのように、YAML(推奨) またはJSONを使って定義されます。Serviceが対象とするPodのセットは通常、LabelSelector によって決定されます(なぜ仕様にセレクタを含めずにServiceが必要になるのかについては下記を参照してください)。
各Podには固有のIPアドレスがありますが、それらのIPは、Serviceなしではクラスターの外部に公開されません。Serviceによって、アプリケーションはトラフィックを受信できるようになります。ServiceSpecでtypeを指定することで、Serviceをさまざまな方法で公開することができます。
ClusterIP (既定値) - クラスター内の内部IPでServiceを公開します。この型では、Serviceはクラスター内からのみ到達可能になります。NodePort - NATを使用して、クラスター内の選択された各ノードの同じポートにServiceを公開します。<NodeIP>:<NodePort>を使用してクラスターの外部からServiceにアクセスできるようにします。これはClusterIPのスーパーセットです。LoadBalancer - 現在のクラウドに外部ロードバランサを作成し(サポートされている場合)、Serviceに固定の外部IPを割り当てます。これはNodePortのスーパーセットです。ExternalName - 仕様のexternalNameで指定した名前のCNAMEレコードを返すことによって、任意の名前を使ってServiceを公開します。プロキシは使用されません。このタイプはv1.7以上のkube-dnsを必要とします。さまざまな種類のServiceに関する詳細情報はUsing Source IP tutorialにあります。アプリケーションとServiceの接続 も参照してください。
加えて、Serviceには、仕様にselectorを定義しないというユースケースがいくつかあります。selectorを指定せずに作成したServiceについて、対応するEndpointsオブジェクトは作成されません。これによって、ユーザーは手動でServiceを特定のエンドポイントにマッピングできます。セレクタがない可能性があるもう1つの可能性は、type:ExternalNameを厳密に使用していることです。
まとめ Podを外部トラフィックに公開する 複数のPod間でトラフィックを負荷分散する ラベルを使う Kubernetes Serviceは、Podの論理セットを定義し、それらのPodに対する外部トラフィックの公開、負荷分散、およびサービス検出を可能にする抽象化層です。
Serviceは、一連のPodにトラフィックをルーティングします。Serviceは、アプリケーションに影響を与えることなく、KubernetesでPodが死んだり複製したりすることを可能にする抽象概念です。(アプリケーションのフロントエンドおよびバックエンドコンポーネントなどの)依存Pod間の検出とルーティングは、Kubernetes Serviceによって処理されます。
Serviceは、ラベルとセレクタを使用して一連のPodを照合します。これは、Kubernetes内のオブジェクトに対する論理操作を可能にするグループ化のプリミティブです。ラベルはオブジェクトに付けられたkey/valueのペアであり、さまざまな方法で使用できます。
開発、テスト、および本番用のオブジェクトを指定する バージョンタグを埋め込む タグを使用してオブジェクトを分類する ラベルは、作成時またはそれ以降にオブジェクトにアタッチでき、いつでも変更可能です。Serviceを使用してアプリケーションを公開し、いくつかのラベルを適用してみましょう。
5.2.5 - アプリケーションのスケーリング 5.2.5.1 - アプリケーションの複数インスタンスを実行 目標 kubectlを使用してアプリケーションをスケールする アプリケーションのスケーリング 前回のモジュールでは、Deployment を作成し、それをService 経由で公開しました。該当のDeploymentでは、アプリケーションを実行するためのPodを1つだけ作成しました。トラフィックが増加した場合、ユーザーの需要に対応するためにアプリケーションをスケールする必要があります。
スケーリング は、Deploymentのレプリカの数を変更することによって実現可能です。
kubectl create deploymentコマンドの--replicasパラメーターを使用することで、最初から複数のインスタンスを含むDeploymentを作成できます。
Deploymentをスケールアウトすると、新しいPodが作成され、使用可能なリソースを持つノードにスケジュールされます。スケールすると、Podの数が増えて新たな望ましい状態になります。KubernetesはPodのオートスケーリング もサポートしていますが、このチュートリアルでは範囲外です。スケーリングを0に設定することも可能で、指定された配置のすべてのPodを終了させます。
アプリケーションの複数インスタンスを実行するには、それらすべてにトラフィックを分散する方法が必要になります。Serviceには、公開されたDeploymentのすべてのPodにネットワークトラフィックを分散する統合ロードバランサがあります。Serviceは、エンドポイントを使用して実行中のPodを継続的に監視し、トラフィックが使用可能なPodにのみ送信されるようにします。
スケーリングは、Deploymentのレプリカの数を変更することによって実現可能です。
アプリケーションの複数のインスタンスを実行すると、ダウンタイムなしでローリングアップデートを実行できます。それについては、次のモジュールで学習します。それでは、オンラインのターミナルを使って、アプリケーションをデプロイしてみましょう。
5.2.6 - アプリケーションのアップデート 5.2.6.1 - ローリングアップデートの実行 目標 kubectlを使ってローリングアップデートを実行する アプリケーションのアップデート ユーザーはアプリケーションが常に利用可能であることを期待し、開発者はそれらの新しいバージョンを1日に数回デプロイすることが期待されます。Kubernetesでは、アプリケーションのアップデートをローリングアップデートで行います。ローリングアップデート では、Podインスタンスを新しいインスタンスで段階的にアップデートすることで、ダウンタイムなしでDeploymentをアップデートできます。新しいPodは、利用可能なリソースを持つノードにスケジュールされます。
前回のモジュールでは、複数のインスタンスを実行するようにアプリケーションをデプロイしました。これは、アプリケーションの可用性に影響を与えずにアップデートを行うための要件です。デフォルトでは、アップデート中に使用できなくなる可能性があるPodの最大数と作成できる新しいPodの最大数は1です。どちらのオプションも、Podの数または全体数に対する割合(%)のいずれかに設定できます。Kubernetesでは、アップデートはバージョン管理されており、Deploymentにおけるアップデートは以前の(stable)バージョンに戻すことができます。
ローリングアップデートでは、Podを新しいインスタンスで段階的にアップデートすることで、ダウンタイムなしDeploymentをアップデートできます。
アプリケーションのスケーリングと同様に、Deploymentがパブリックに公開されている場合、Serviceはアップデート中に利用可能なPodのみにトラフィックを負荷分散します。 利用可能なPodは、アプリケーションのユーザーが利用できるインスタンスです。
ローリングアップデートでは、次の操作が可能です。
コンテナイメージのアップデートを介した、ある環境から別の環境へのアプリケーションの昇格 以前のバージョンへのロールバック ダウンタイムなしでのアプリケーションのCI/CD Deploymentがパブリックに公開されている場合、Serviceはアップデート中に利用可能なPodにのみトラフィックを負荷分散します。
次の対話型チュートリアルでは、アプリケーションを新しいバージョンにアップデートし、ロールバックも実行します。
5.3 - 設定 5.3.1 - ConfigMapを使ったRedisの設定 本ページでは、ConfigMapを使ったコンテナの設定 に基づき、ConfigMapを使ってRedisの設定を行う実践的な例を提供します。
目標 以下の要素を含むkustomization.yamlファイルを作成する:ConfigMapGenerator ConfigMapを使ったPodリソースの設定 kubectl apply -k ./コマンドにてディレクトリ全体を適用する設定が正しく反映されていることを確認する 始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
実践例: ConfigMapを使ったRedisの設定 以下の手順に従って、ConfigMapに保存されているデータを使用してRedisキャッシュを設定できます。
最初に、redis-configファイルからConfigMapを含むkustomization.yamlを作成します:
maxmemory 2mb
maxmemory-policy allkeys-lru
curl -OL https://k8s.io/examples/pods/config/redis-config
cat <<EOF >./kustomization.yaml
configMapGenerator:
- name: example-redis-config
files:
- redis-config
EOF
Podリソースの設定をkustomization.yamlに入れます:
apiVersion : v1
kind : Pod
metadata :
name : redis
spec :
containers :
- name : redis
image : kubernetes/redis:v1
env :
- name : MASTER
value : "true"
ports :
- containerPort : 6379
resources :
limits :
cpu : "0.1"
volumeMounts :
- mountPath : /redis-master-data
name : data
- mountPath : /redis-master
name : config
volumes :
- name : data
emptyDir : {}
- name : config
configMap :
name : example-redis-config
items :
- key : redis-config
path : redis.conf
curl -OL https://raw.githubusercontent.com/kubernetes/website/master/content/en/examples/pods/config/redis-pod.yaml
cat <<EOF >>./kustomization.yaml
resources:
- redis-pod.yaml
EOF
kustomizationディレクトリを反映して、ConfigMapオブジェクトとPodオブジェクトの両方を作成します:
作成されたオブジェクトを確認します
> kubectl get -k .
NAME DATA AGE
configmap/example-redis-config-dgh9dg555m 1 52s
NAME READY STATUS RESTARTS AGE
pod/redis 1/1 Running 0 52s
この例では、設定ファイルのボリュームは/redis-masterにマウントされています。
pathを使ってredis-configキーをredis.confという名前のファイルに追加します。
したがって、redisコンフィグのファイルパスは/redis-master/redis.confです。
ここが、コンテナイメージがredisマスターの設定ファイルを探す場所です。
kubectl execを使ってPodに入り、redis-cliツールを実行して設定が正しく適用されたことを確認してください:
kubectl exec -it pod/redis -- redis-cli
127.0.0.1:6379> CONFIG GET maxmemory
1) "maxmemory"
2) "2097152"
127.0.0.1:6379> CONFIG GET maxmemory-policy
1) "maxmemory-policy"
2) "allkeys-lru"
作成したPodを削除します:
次の項目
5.4 - ステートレスアプリケーション 5.4.1 - クラスター内のアプリケーションにアクセスするために外部IPアドレスを公開する このページでは、外部IPアドレスを公開するKubernetesのServiceオブジェクトを作成する方法を示します。
始める前に kubectl をインストールしてください。
Kubernetesクラスターを作成する際に、Google Kubernetes EngineやAmazon Web Servicesのようなクラウドプロバイダーを使用します。このチュートリアルでは、クラウドプロバイダーを必要とする外部ロードバランサー を作成します。
Kubernetes APIサーバーと通信するために、kubectlを設定してください。手順については、各クラウドプロバイダーのドキュメントを参照してください。
目標 5つのインスタンスで実際のアプリケーションを起動します。 外部IPアドレスを公開するServiceオブジェクトを作成します。 起動中のアプリケーションにアクセスするためにServiceオブジェクトを使用します。 5つのPodで起動しているアプリケーションへのServiceの作成 クラスターにてHello Worldアプリケーションを実行してください。 apiVersion : apps/v1
kind : Deployment
metadata :
labels :
app.kubernetes.io/name : load-balancer-example
name : hello-world
spec :
replicas : 5
selector :
matchLabels :
app.kubernetes.io/name : load-balancer-example
template :
metadata :
labels :
app.kubernetes.io/name : load-balancer-example
spec :
containers :
- image : gcr.io/google-samples/node-hello:1.0
name : hello-world
ports :
- containerPort : 8080
kubectl apply -f https://k8s.io/examples/service/load-balancer-example.yaml
上記のコマンドにより、 Deployment を作成し、ReplicaSet を関連づけます。ReplicaSetには5つのPod があり、それぞれHello Worldアプリケーションが起動しています。
Deploymentに関する情報を表示します:
kubectl get deployments hello-world
kubectl describe deployments hello-world
ReplicaSetオブジェクトに関する情報を表示します:
kubectl get replicasets
kubectl describe replicasets
Deploymentを公開するServiceオブジェクトを作成します。
kubectl expose deployment hello-world --type=LoadBalancer --name=my-service
Serviceに関する情報を表示します:
kubectl get services my-service
出力は次のようになります:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-service LoadBalancer 10.3.245.137 104.198.205.71 8080/TCP 54s
備考: `type=LoadBalancer`のServiceは外部のクラウドプロバイダーによってサポートされており、ここでは扱いません。詳細は[こちらのページ](/ja/docs/concepts/services-networking/service/#loadbalancer)を参照してください。
備考: 外部IPアドレスが\<pending\>と表示されている場合は、しばらく待ってから同じコマンドを実行してください。
Serviceに関する詳細な情報を表示します:
kubectl describe services my-service
出力は次のようになります:
Name: my-service
Namespace: default
Labels: app.kubernetes.io/name=load-balancer-example
Annotations: <none>
Selector: app.kubernetes.io/name=load-balancer-example
Type: LoadBalancer
IP: 10.3.245.137
LoadBalancer Ingress: 104.198.205.71
Port: <unset> 8080/TCP
NodePort: <unset> 32377/TCP
Endpoints: 10.0.0.6:8080,10.0.1.6:8080,10.0.1.7:8080 + 2 more...
Session Affinity: None
Events: <none>
Serviceによって公開された外部IPアドレス(LoadBalancer Ingress)を記録しておいてください。
この例では、外部IPアドレスは104.198.205.71です。
また、PortおよびNodePortの値も控えてください。
この例では、Portは8080、NodePortは32377です。
先ほどの出力にて、Serviceにはいくつかのエンドポイントがあることを確認できます: 10.0.0.6:8080、
10.0.1.6:8080、10.0.1.7:8080、その他2つです。
これらはHello Worldアプリケーションが動作しているPodの内部IPアドレスです。
これらのPodのアドレスを確認するには、次のコマンドを実行します:
kubectl get pods --output=wide
出力は次のようになります:
NAME ... IP NODE
hello-world-2895499144-1jaz9 ... 10.0.1.6 gke-cluster-1-default-pool-e0b8d269-1afc
hello-world-2895499144-2e5uh ... 10.0.1.8 gke-cluster-1-default-pool-e0b8d269-1afc
hello-world-2895499144-9m4h1 ... 10.0.0.6 gke-cluster-1-default-pool-e0b8d269-5v7a
hello-world-2895499144-o4z13 ... 10.0.1.7 gke-cluster-1-default-pool-e0b8d269-1afc
hello-world-2895499144-segjf ... 10.0.2.5 gke-cluster-1-default-pool-e0b8d269-cpuc
Hello Worldアプリケーションにアクセスするために、外部IPアドレス(LoadBalancer Ingress)を使用します:
curl http://<external-ip>:<port>
ここで、<external-ip>はServiceの外部IPアドレス(LoadBalancer Ingress)で、
<port>はServiceの詳細出力におけるPortです。minikubeを使用している場合、minikube service my-serviceを実行することでHello Worldアプリケーションをブラウザで自動的に
開かれます。
正常なリクエストに対するレスポンスは、helloメッセージです:
Hello Kubernetes!
クリーンアップ Serviceを削除する場合、次のコマンドを実行します:
kubectl delete services my-service
Deployment、ReplicaSet、およびHello Worldアプリケーションが動作しているPodを削除する場合、次のコマンドを実行します:
kubectl delete deployment hello-world
次の項目 connecting applications with services にて詳細を学ぶことができます。
5.4.2 - 例: Redisを使用したPHPのゲストブックアプリケーションのデプロイ このチュートリアルでは、KubernetesとDocker を使用した、シンプルなマルチティアのウェブアプリケーションのビルドとデプロイの方法を紹介します。この例は、以下のコンポーネントから構成されています。
目標 Redisのマスターを起動する。 Redisのスレーブを起動する。 ゲストブックのフロントエンドを起動する。 フロントエンドのServiceを公開して表示を確認する。 クリーンアップする。 始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
Redisのマスターを起動する ゲストブックアプリケーションでは、データを保存するためにRedisを使用します。ゲストブックはRedisのマスターインスタンスにデータを書き込み、複数のRedisのスレーブインスタンスからデータを読み込みます。
RedisのマスターのDeploymentを作成する 以下のマニフェストファイルは、シングルレプリカのRedisのマスターPodを実行するDeploymentコントローラーを指定しています。
apiVersion : apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind : Deployment
metadata :
name : redis-master
labels :
app : redis
spec :
selector :
matchLabels :
app : redis
role : master
tier : backend
replicas : 1
template :
metadata :
labels :
app : redis
role : master
tier : backend
spec :
containers :
- name : master
image: registry.k8s.io/redis:e2e # or just image : redis
resources :
requests :
cpu : 100m
memory : 100Mi
ports :
- containerPort : 6379
マニフェストファイルをダウンロードしたディレクトリ内で、ターミナルウィンドウを起動します。
redis-master-deployment.yamlファイルから、RedisのマスターのDeploymentを適用します。
kubectl apply -f https://k8s.io/examples/application/guestbook/redis-master-deployment.yaml
Podのリストを問い合わせて、RedisのマスターのPodが実行中になっていることを確認します。
結果は次のようになるはずです。
NAME READY STATUS RESTARTS AGE
redis-master-1068406935-3lswp 1/1 Running 0 28s
次のコマンドを実行して、RedisのマスターのPodからログを表示します。
備考: POD-NAMEの部分を実際のPodの名前に書き換えてください。RedisのマスターのServiceを作成する ゲストブックアプリケーションは、データを書き込むためにRedisのマスターと通信する必要があります。そのためには、Service を適用して、トラフィックをRedisのマスターのPodへプロキシしなければなりません。Serviceは、Podにアクセスするためのポリシーを指定します。
apiVersion : v1
kind : Service
metadata :
name : redis-master
labels :
app : redis
role : master
tier : backend
spec :
ports :
- port : 6379
targetPort : 6379
selector :
app : redis
role : master
tier : backend
次のredis-master-service.yamlから、RedisのマスターのServiceを適用します。
kubectl apply -f https://k8s.io/examples/application/guestbook/redis-master-service.yaml
Serviceのリストを問い合わせて、RedisのマスターのServiceが実行中になっていることを確認します。
The response should be similar to this:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT( S) AGE
kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 1m
redis-master ClusterIP 10.0.0.151 <none> 6379/TCP 8s
備考: このマニフェストファイルは、redis-masterという名前のServiceを、前に定義したラベルにマッチする一連のラベル付きで作成します。これにより、ServiceはネットワークトラフィックをRedisのマスターのPodへとルーティングできるようになります。Redisのスレーブを起動する Redisのマスターは1つのPodですが、レプリカのRedisのスレーブを追加することで、トラフィックの需要を満たすための高い可用性を持たせることができます。
RedisのスレーブのDeploymentを作成する Deploymentはマニフェストファイル内に書かれた設定に基づいてスケールします。ここでは、Deploymentオブジェクトは2つのレプリカを指定しています。
もし1つもレプリカが実行されていなければ、このDeploymentは2つのレプリカをコンテナクラスター上で起動します。逆に、もしすでに2つ以上のレプリカが実行されていれば、実行中のレプリカが2つになるようにスケールダウンします。
apiVersion : apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind : Deployment
metadata :
name : redis-slave
labels :
app : redis
spec :
selector :
matchLabels :
app : redis
role : slave
tier : backend
replicas : 2
template :
metadata :
labels :
app : redis
role : slave
tier : backend
spec :
containers :
- name : slave
image : gcr.io/google_samples/gb-redisslave:v3
resources :
requests :
cpu : 100m
memory : 100Mi
env :
- name : GET_HOSTS_FROM
value : dns
# Using `GET_HOSTS_FROM=dns` requires your cluster to
# provide a dns service. As of Kubernetes 1.3, DNS is a built-in
# service launched automatically. However, if the cluster you are using
# does not have a built-in DNS service, you can instead
# access an environment variable to find the master
# service's host. To do so, comment out the 'value: dns' line above, and
# uncomment the line below:
# value: env
ports :
- containerPort : 6379
redis-slave-deployment.yamlファイルから、RedisのスレーブのDeploymentを適用します。
kubectl apply -f https://k8s.io/examples/application/guestbook/redis-slave-deployment.yaml
Podのリストを問い合わせて、RedisのスレーブのPodが実行中になっていることを確認します。
結果は次のようになるはずです。
NAME READY STATUS RESTARTS AGE
redis-master-1068406935-3lswp 1/1 Running 0 1m
redis-slave-2005841000-fpvqc 0/1 ContainerCreating 0 6s
redis-slave-2005841000-phfv9 0/1 ContainerCreating 0 6s
RedisのスレーブのServiceを作成する ゲストブックアプリケーションは、データを読み込むためにRedisのスレーブと通信する必要があります。Redisのスレーブが発見できるようにするためには、Serviceをセットアップする必要があります。Serviceは一連のPodに対する透過的なロードバランシングを提供します。
apiVersion : v1
kind : Service
metadata :
name : redis-slave
labels :
app : redis
role : slave
tier : backend
spec :
ports :
- port : 6379
selector :
app : redis
role : slave
tier : backend
次のredis-slave-service.yamlファイルから、RedisのスレーブのServiceを適用します。
kubectl apply -f https://k8s.io/examples/application/guestbook/redis-slave-service.yaml
Serviceのリストを問い合わせて、RedisのスレーブのServiceが実行中になっていることを確認します。
結果は次のようになるはずです。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 2m
redis-master ClusterIP 10.0.0.151 <none> 6379/TCP 1m
redis-slave ClusterIP 10.0.0.223 <none> 6379/TCP 6s
ゲストブックのフロントエンドをセットアップして公開する ゲストブックアプリケーションには、HTTPリクエストをサーブするPHPで書かれたウェブフロントエンドがあります。このアプリケーションは、書き込みリクエストに対してはredis-master Serviceに、読み込みリクエストに対してはredis-slave Serviceに接続するように設定されています。
ゲストブックのフロントエンドのDeploymentを作成する apiVersion : apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind : Deployment
metadata :
name : frontend
labels :
app : guestbook
spec :
selector :
matchLabels :
app : guestbook
tier : frontend
replicas : 3
template :
metadata :
labels :
app : guestbook
tier : frontend
spec :
containers :
- name : php-redis
image : gcr.io/google-samples/gb-frontend:v4
resources :
requests :
cpu : 100m
memory : 100Mi
env :
- name : GET_HOSTS_FROM
value : dns
# Using `GET_HOSTS_FROM=dns` requires your cluster to
# provide a dns service. As of Kubernetes 1.3, DNS is a built-in
# service launched automatically. However, if the cluster you are using
# does not have a built-in DNS service, you can instead
# access an environment variable to find the master
# service's host. To do so, comment out the 'value: dns' line above, and
# uncomment the line below:
# value: env
ports :
- containerPort : 80
frontend-deployment.yamlファイルから、フロントエンドのDeploymentを適用します。
kubectl apply -f https://k8s.io/examples/application/guestbook/frontend-deployment.yaml
Podのリストを問い合わせて、3つのフロントエンドのレプリカが実行中になっていることを確認します。
kubectl get pods -l app = guestbook -l tier = frontend
結果は次のようになるはずです。
NAME READY STATUS RESTARTS AGE
frontend-3823415956-dsvc5 1/1 Running 0 54s
frontend-3823415956-k22zn 1/1 Running 0 54s
frontend-3823415956-w9gbt 1/1 Running 0 54s
フロントエンドのServiceを作成する 適用したredis-slaveおよびredis-master Serviceは、コンテナクラスター内部からのみアクセス可能です。これは、デフォルトのServiceのtypeがClusterIP であるためです。ClusterIPは、Serviceが指している一連のPodに対して1つのIPアドレスを提供します。このIPアドレスはクラスター内部からのみアクセスできます。
もしゲストの人にゲストブックにアクセスしてほしいのなら、フロントエンドServiceを外部から見えるように設定しなければなりません。そうすれば、クライアントはコンテナクラスターの外部からServiceにリクエストを送れるようになります。Minikubeでは、ServiceをNodePortでのみ公開できます。
備考: 一部のクラウドプロバイダーでは、Google Compute EngineやGoogle Kubernetes Engineなど、外部のロードバランサーをサポートしているものがあります。もしクラウドプロバイダーがロードバランサーをサポートしていて、それを使用したい場合は、type: NodePortという行を単に削除またはコメントアウトして、type: LoadBalancerのコメントアウトを外せば使用できます。apiVersion : v1
kind : Service
metadata :
name : frontend
labels :
app : guestbook
tier : frontend
spec :
# comment or delete the following line if you want to use a LoadBalancer
type : NodePort
# if your cluster supports it, uncomment the following to automatically create
# an external load-balanced IP for the frontend service.
# type: LoadBalancer
ports :
- port : 80
selector :
app : guestbook
tier : frontend
frontend-service.yamlファイルから、フロントエンドのServiceを提供します。
kubectl apply -f https://k8s.io/examples/application/guestbook/frontend-service.yaml
Serviceのリストを問い合わせて、フロントエンドのServiceが実行中であることを確認します。
結果は次のようになるはずです。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
frontend NodePort 10.0.0.112 <none> 80:31323/TCP 6s
kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 4m
redis-master ClusterIP 10.0.0.151 <none> 6379/TCP 2m
redis-slave ClusterIP 10.0.0.223 <none> 6379/TCP 1m
フロントエンドのServiceをNodePort経由で表示する このアプリケーションをMinikubeやローカルのクラスターにデプロイした場合、ゲストブックを表示するためのIPアドレスを見つける必要があります。
次のコマンドを実行すると、フロントエンドServiceに対するIPアドレスを取得できます。
minikube service frontend --url
結果は次のようになるはずです。
http://192.168.99.100:31323
IPアドレスをコピーして、ブラウザー上でページを読み込み、ゲストブックを表示しましょう。
フロントエンドのServiceをLoadBalancer経由で表示する もしfrontend-service.yamlマニフェストをtype: LoadBalancerでデプロイした場合、ゲストブックを表示するためのIPアドレスを見つける必要があります。
次のコマンドを実行すると、フロントエンドServiceに対するIPアドレスを取得できます。
kubectl get service frontend
結果は次のようになるはずです。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
frontend ClusterIP 10.51.242.136 109.197.92.229 80:32372/TCP 1m
外部IPアドレス(EXTERNAL-IP)をコピーして、ブラウザー上でページを読み込み、ゲストブックを表示しましょう。
ウェブフロントエンドをスケールする サーバーがDeploymentコントローラーを使用するServiceとして定義されているため、スケールアップやスケールダウンは簡単です。
次のコマンドを実行すると、フロントエンドのPodの数をスケールアップできます。
kubectl scale deployment frontend --replicas= 5
Podのリストを問い合わせて、実行中のフロントエンドのPodの数を確認します。
結果は次のようになるはずです。
NAME READY STATUS RESTARTS AGE
frontend-3823415956-70qj5 1/1 Running 0 5s
frontend-3823415956-dsvc5 1/1 Running 0 54m
frontend-3823415956-k22zn 1/1 Running 0 54m
frontend-3823415956-w9gbt 1/1 Running 0 54m
frontend-3823415956-x2pld 1/1 Running 0 5s
redis-master-1068406935-3lswp 1/1 Running 0 56m
redis-slave-2005841000-fpvqc 1/1 Running 0 55m
redis-slave-2005841000-phfv9 1/1 Running 0 55m
次のコマンドを実行すると、フロントエンドのPodの数をスケールダウンできます。
kubectl scale deployment frontend --replicas= 2
Podのリストを問い合わせて、実行中のフロントエンドのPodの数を確認します。
結果は次のようになるはずです。
NAME READY STATUS RESTARTS AGE
frontend-3823415956-k22zn 1/1 Running 0 1h
frontend-3823415956-w9gbt 1/1 Running 0 1h
redis-master-1068406935-3lswp 1/1 Running 0 1h
redis-slave-2005841000-fpvqc 1/1 Running 0 1h
redis-slave-2005841000-phfv9 1/1 Running 0 1h
クリーンアップ DeploymentとServiceを削除すると、実行中のPodも削除されます。ラベルを使用すると、複数のリソースを1つのコマンドで削除できます。
次のコマンドを実行すると、すべてのPod、Deployment、Serviceが削除されます。
kubectl delete deployment -l app = redis
kubectl delete service -l app = redis
kubectl delete deployment -l app = guestbook
kubectl delete service -l app = guestbook
結果は次のようになるはずです。
deployment.apps "redis-master" deleted
deployment.apps "redis-slave" deleted
service "redis-master" deleted
service "redis-slave" deleted
deployment.apps "frontend" deleted
service "frontend" deleted
Podのリストを問い合わせて、実行中のPodが存在しないことを確認します。
結果は次のようになるはずです。
No resources found.
次の項目 5.4.3 - 例: PHP / Redisを使用したゲストブックの例にロギングとメトリクスを追加する このチュートリアルは、Redisを使用したPHPのゲストブック のチュートリアルを前提に作られています。Elasticが開発したログ、メトリクス、ネットワークデータを転送するオープンソースの軽量データシッパーであるBeats を、ゲストブックと同じKubernetesクラスターにデプロイします。BeatsはElasticsearchに対してデータの収集、分析、インデックス作成を行うため、結果の運用情報をKibana上で表示・分析できるようになります。この例は、以下のコンポーネントから構成されます。
目標 Redisを使用したPHPのゲストブックを起動する。 kube-state-metricsをインストールする。 KubernetesのSecretを作成する。 Beatsをデプロイする。 ログとメトリクスのダッシュボードを表示する。 始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
追加で以下の作業が必要です。
Redisを使用したPHPのゲストブックを起動する このチュートリアルは、Redisを使用したPHPのゲストブック のチュートリアルを前提に作られています。もしゲストブックアプリケーションが実行中なら、そのアプリケーションを監視できます。もしまだ実行中のアプリケーションがなければ、ゲストブックのデプロイの手順を行い、クリーンアップ のステップは実行しないでください。ゲストブックが起動したら、このページに戻ってきてください。
Cluster role bindingを追加する クラスターレベルのrole binding を作成して、kube-state-metricsとBeatsをクラスターレベルで(kube-system内に)デプロイできるようにします。
kubectl create clusterrolebinding cluster-admin-binding \
= cluster-admin --user= <k8sのプロバイダーアカウントと紐付いたあなたのメールアドレス>
kube-state-metricsをインストールする Kubernetesのkube-state-metrics
kube-state-metricsが起動しているか確認する kubectl get pods --namespace= kube-system | grep kube-state
必要に応じてkube-state-metricsをインストールする git clone https://github.com/kubernetes/kube-state-metrics.git kube-state-metrics
kubectl apply -f kube-state-metrics/examples/standard
kubectl get pods --namespace= kube-system | grep kube-state-metrics
kube-state-metricsがRunningかつreadyの状態になっていることを確認します。
kubectl get pods -n kube-system -l app.kubernetes.io/name= kube-state-metrics
結果は次のようになります。
NAME READY STATUS RESTARTS AGE
kube-state-metrics-89d656bf8-vdthm 1/1 Running 0 21s
GitHubリポジトリのElasticの例をクローンする git clone https://github.com/elastic/examples.git
これ以降のコマンドはexamples/beats-k8s-send-anywhereディレクトリ内のファイルを参照するため、カレントディレクトリを変更します。
cd examples/beats-k8s-send-anywhere
KubernetesのSecretを作成する KubernetesのSecret とは、パスワード、トークン、または鍵などの小さなサイズの機密データを含んだオブジェクトのことです。このような機密情報はPodのspecやイメージの中に置くことも不可能ではありませんが、Secretオブジェクトの中に置くことで、情報の使用方法を適切に制御したり、誤って公開してしまうリスクを減らすことができます。
備考: ここでは2種類の手順を紹介します。1つはセルフマネージド な(自分のサーバーで実行中またはElastic Helm Chartを使用して構築された)ElasticsearchおよびKibanaのためのもので、もう1つはマネージドサービス のElastic CloudのElasticsearch Serviceのための別の手順です。このチュートリアルで使う種類のElasticsearchおよびKibanaのシステムのためのSecretだけを作成してください。
セルフマネージド Elastic Cloud上のElasticsearch Serviceに接続する場合は、マネージドサービス タブに切り替えてください。
クレデンシャルを設定する セルフマネージドのElasticsearchとKibanaへ接続する場合、KubernetesのSecretを作成するために編集するべきファイルは4つあります(セルフマネージドとは、事実上Elastic Cloud以外で実行されているElasticsearch Serviceを指します)。ファイルは次の4つです。
ELASTICSEARCH_HOSTS ELASTICSEARCH_PASSWORD ELASTICSEARCH_USERNAME KIBANA_HOST これらのファイルにElasticsearchクラスターとKibanaホストの情報を設定してください。ここでは例をいくつか示します(こちらの設定
ELASTICSEARCH_HOSTSElastic Elasticsearch Helm Chartで作成したnodeGroupの場合。
[ "http://elasticsearch-master.default.svc.cluster.local:9200" ]
Mac上で単一のElasticsearchノードが実行されており、BeatsがDocker for Macで実行中の場合。
[ "http://host.docker.internal:9200" ]
2ノードのElasticsearchがVM上または物理ハードウェア上で実行中の場合。
[ "http://host1.example.com:9200" , "http://host2.example.com:9200" ]
ELASTICSEARCH_HOSTSを編集します。
ELASTICSEARCH_PASSWORDパスワードだけを書きます。空白、クォート、<>などの文字は書かないでください。
<yoursecretpassword>
ELASTICSEARCH_PASSWORDを編集します。
vi ELASTICSEARCH_PASSWORD
ELASTICSEARCH_USERNAMEユーザー名だけを書きます。空白、クォート、<>などの文字は書かないでください。
<Elasticsearchに追加するユーザー名>
ELASTICSEARCH_USERNAMEを編集します。
vi ELASTICSEARCH_USERNAME
KIBANA_HOSTElastic Kibana Helm Chartで作成したKibanaインスタンスが実行中の場合。defaultというサブドメインは、default Namespaceを指します。もしHelm Chartを別のNamespaceにデプロイした場合、サブドメインは異なります。
"kibana-kibana.default.svc.cluster.local:5601"
Mac上でKibanaインスタンスが実行中で、BeatsがDocker for Macで実行中の場合。
"host.docker.internal:5601"
2つのElasticsearchノードが、VMまたは物理ハードウェア上で実行中の場合。
KIBANA_HOSTを編集します。
KubernetesのSecretを作成する 次のコマンドを実行すると、KubernetesのシステムレベルのNamespace(kube-system)に、たった今編集したファイルを元にSecretが作成されます。
kubectl create secret generic dynamic-logging \
--from-file=./ELASTICSEARCH_HOSTS \
--from-file=./ELASTICSEARCH_PASSWORD \
--from-file=./ELASTICSEARCH_USERNAME \
--from-file=./KIBANA_HOST \
--namespace=kube-system
マネージドサービス このタブは、Elastic Cloud上のElasticsearch Serviceの場合のみ必要です。もしセルフマネージドのElasticsearchとKibanaのDeployment向けにSecretをすでに作成した場合、Beatsをデプロイする に進んでください。
クレデンシャルを設定する Elastic Cloud上のマネージドElasticsearch Serviceに接続する場合、KubernetesのSecretを作成するために編集する必要があるのは、次の2つのファイルです。
ELASTIC_CLOUD_AUTH ELASTIC_CLOUD_ID Deploymentを作成するときに、Elasticsearch Serviceのコンソールから提供された情報を設定してください。以下に例を示します。
ELASTIC_CLOUD_ID devk8s:ABC123def456ghi789jkl123mno456pqr789stu123vwx456yza789bcd012efg345hijj678klm901nop345zEwOTJjMTc5YWQ0YzQ5OThlN2U5MjAwYTg4NTIzZQ==
ELASTIC_CLOUD_AUTH ユーザー名、コロン(:)、パスワードだけを書きます。空白やクォートは書かないでください。
elastic:VFxJJf9Tjwer90wnfTghsn8w
必要なファイルを編集する vi ELASTIC_CLOUD_ID
vi ELASTIC_CLOUD_AUTH
KubernetesのSecretを作成する 次のコマンドを実行すると、KubernetesのシステムレベルのNamespace(kube-system)に、たった今編集したファイルを元にSecretが作成されます。
kubectl create secret generic dynamic-logging \
--from-file=./ELASTIC_CLOUD_ID \
--from-file=./ELASTIC_CLOUD_AUTH \
--namespace=kube-system
Beatsをデプロイする マニフェストファイルはBeatごとに提供されます。これらのマニフェストファイルは、上で作成したSecretを使用して、BeatsをElasticsearchおよびKibanaサーバーに接続するように設定します。
Filebeatについて Filebeatは、Kubernetesのノードと、ノード上で実行している各Pod内のコンテナから、ログを収集します。FilebeatはDaemonSet としてデプロイされます。FilebeatはKubernetesクラスター上で実行されているアプリケーションを自動検出することもできます。起動時にFilebeatは既存のコンテナをスキャンし、それらに対して適切な設定を立ち上げ、その後、新しいstart/stopイベントを監視します。
Filebeatが、ゲストブックアプリケーションでデプロイしたRedisコンテナからRedisのログを特定・解析できるように自動検出を設定する例を示します。この設定はfilebeat-kubernetes.yamlファイル内にあります。
- condition.contains :
kubernetes.labels.app : redis
config :
- module : redis
log :
input :
type : docker
containers.ids :
- ${data.kubernetes.container.id}
slowlog :
enabled : true
var.hosts : ["${data.host}:${data.port}" ]
この設定により、Filebeatは、appラベルにredisという文字列が含まれるコンテナを検出したときにredis Filebeatモジュールを適用するようになります。redisモジュールには、input typeとしてdockerを使用することで(このRedisコンテナの標準出力のストリームと関連付けられた、Kubernetesノード上のファイルを読み取ることで)コンテナからlogストリームを収集する機能があります。さらに、このモジュールには、コンテナのメタデータとして提供された適切なPodのホストとポートと接続することにより、Redisのslowlogエントリーを収集する機能もあります。
Filebeatをデプロイする kubectl create -f filebeat-kubernetes.yaml
検証する kubectl get pods -n kube-system -l k8s-app= filebeat-dynamic
Metricbeatについて Metricbeatの自動検出はFilebeatと同じ方法で設定します。以下にMetricbeatにおけるRedisコンテナの自動検出の設定を示します。この設定はmetricbeat-kubernetes.yamlファイル内にあります。
- condition.equals :
kubernetes.labels.tier : backend
config :
- module : redis
metricsets : ["info" , "keyspace" ]
period : 10s
# Redis hosts
hosts : ["${data.host}:${data.port}" ]
この設定により、Metricbeatは、tierラベルにbackendという文字列が含まれるコンテナを検出したときにredis Metricbeatモジュールを適用するようになります。redisモジュールには、コンテナのメタデータとして提供された適切なPodのホストとポートと接続することにより、コンテナからinfoおよびkeyspaceメトリクスを収集する機能があります。
Metricbeatをデプロイする kubectl create -f metricbeat-kubernetes.yaml
検証する kubectl get pods -n kube-system -l k8s-app= metricbeat
Packetbeatについて Packetbeatの設定は、FilebeatやMetricbeatとは異なります。コンテナのラベルに対するパターンマッチを指定する代わりに、関連するプロトコルとポート番号に基づいた設定を書きます。以下に示すのは、ポート番号のサブセットです。
備考: サービスを標準ポート以外で実行している場合、そのポート番号をfilebeat.yaml内の適切なtypeに追加し、PacketbeatのDaemonSetを削除・再作成してください。packetbeat.interfaces.device : any
packetbeat.protocols :
type : dns
ports : [53 ]
include_authorities : true
include_additionals : true
type : http
ports : [80 , 8000 , 8080 , 9200 ]
type : mysql
ports : [3306 ]
type : redis
ports : [6379 ]
packetbeat.flows :
timeout : 30s
period : 10s
Packetbeatをデプロイする kubectl create -f packetbeat-kubernetes.yaml
検証する kubectl get pods -n kube-system -l k8s-app= packetbeat-dynamic
Kibanaで表示する ブラウザでKibanaを開き、Dashboard アプリケーションを開きます。検索バーでKubernetesと入力して、KubernetesのためのMetricbeatダッシュボードを開きます。このダッシュボードでは、NodeやDeploymentなどの状態のレポートが表示されます。
DashboardページでPacketbeatと検索し、Packetbeat overviewを表示します。
同様に、ApacheおよびRedisのためのDashboardを表示します。それぞれに対してログとメトリクスのDashboardが表示されます。Apache Metricbeat dashboardには何も表示されていないはずです。Apache Filebeat dashboardを表示して、ページの最下部までスクロールしてApacheのエラーログを確認します。ログを読むと、Apacheのメトリクスが表示されない理由が分かります。
Metricbeatを有効にしてApacheのメトリクスを取得するには、mod-status設定ファイルを含んだConfigMapを追加してゲストブックを再デプロイすることで、server-statusを有効にします。
Deploymentをスケールして新しいPodが監視されるのを確認する 存在するDeploymentを一覧します。
出力は次のようになります。
NAME READY UP-TO-DATE AVAILABLE AGE
frontend 3/3 3 3 3h27m
redis-master 1/1 1 1 3h27m
redis-slave 2/2 2 2 3h27m
frontendのPodを2つにスケールダウンします。
kubectl scale --replicas= 2 deployment/frontend
出力は次のようになります。
deployment.extensions/frontend scaled
frontendのPodを再び3つにスケールアップします。
kubectl scale --replicas= 3 deployment/frontend
Kibana上で変更を表示する スクリーンショットを確認し、指定されたフィルターを追加して、ビューにカラムを追加します。赤い枠の右下を見ると、ScalingReplicaSetというエントリーが確認できます。そこからリストを上に見てゆくと、イメージのpull、ボリュームのマウント、Podのスタートなどのイベントが確認できます。
クリーンアップ DeploymentとServiceを削除すると、実行中のすべてのPodも削除されます。ラベルを使って複数のリソースを1つのコマンドで削除します。
次のコマンドを実行して、すべてのPod、Deployment、Serviceを削除します。
kubectl delete deployment -l app = redis
kubectl delete service -l app = redis
kubectl delete deployment -l app = guestbook
kubectl delete service -l app = guestbook
kubectl delete -f filebeat-kubernetes.yaml
kubectl delete -f metricbeat-kubernetes.yaml
kubectl delete -f packetbeat-kubernetes.yaml
kubectl delete secret dynamic-logging -n kube-system
Podの一覧を問い合わせて、実行中のPodがなくなったことを確認します。
結果は次のようになるはずです。
No resources found.
次の項目
5.5 - セキュリティ 5.5.1 - クラスターレベルでのPodセキュリティの標準の適用
Note このチュートリアルは、新しいクラスターにのみ適用されます。Podセキュリティアドミッション(PSA)は、ベータへ進み 、v1.23以降でデフォルトで有効になっています。
Podセキュリティアドミッションは、Podが作成される際に、Podセキュリティの標準 の適用の認可を制御するものです。
このチュートリアルでは、クラスター内の全ての名前空間に標準設定を適用することで、クラスターレベルでbaseline Podセキュリティの標準を強制する方法を示します。
Podセキュリティの標準を特定の名前空間に適用するには、名前空間レベルでのPodセキュリティの標準の適用 を参照してください。
v1.35以外のKubernetesバージョンを実行している場合は、そのバージョンのドキュメントを確認してください。
始める前に ワークステーションに以下をインストールしてください:
このチュートリアルでは、完全な制御下にあるKubernetesクラスターの何を設定できるかをデモンストレーションします。
コントロールプレーンを設定できない管理されたクラスターのPodセキュリティアドミッションに対しての設定方法を知りたいのであれば、名前空間レベルでのPodセキュリティの標準の適用 を参照してください。
適用する正しいPodセキュリティの標準の選択 Podのセキュリティアドミッション は、以下のモードでビルトインのPodセキュリティの標準 の適用を促します: enforce、audit、warn。
設定に最適なPodセキュリティの標準を選択するにあたって助けになる情報を収集するために、以下を行ってください:
Podセキュリティの標準を適用していないクラスターを作成します:
kind create cluster --name psa-wo-cluster-pss
出力は次のようになります:
Creating cluster "psa-wo-cluster-pss" ...
✓ Ensuring node image (kindest/node:v1.35.0) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
Set kubectl context to "kind-psa-wo-cluster-pss"
You can now use your cluster with:
kubectl cluster-info --context kind-psa-wo-cluster-pss
Thanks for using kind! 😊
kubectl contextを新しいクラスターにセットします:
kubectl cluster-info --context kind-psa-wo-cluster-pss
出力は次のようになります:
Kubernetes control plane is running at https://127.0.0.1:61350
CoreDNS is running at https://127.0.0.1:61350/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
クラスター内の名前空間の一覧を取得します:
出力は次のようになります:
NAME STATUS AGE
default Active 9m30s
kube-node-lease Active 9m32s
kube-public Active 9m32s
kube-system Active 9m32s
local-path-storage Active 9m26s
異なるPodセキュリティの標準が適用されたときに何が起きるかを理解するために、-dry-run=serverを使います:
privileged
kubectl label --dry-run= server --overwrite ns --all \
= privileged
出力は次のようになります:
namespace/default labeled
namespace/kube-node-lease labeled
namespace/kube-public labeled
namespace/kube-system labeled
namespace/local-path-storage labeled
baseline
kubectl label --dry-run= server --overwrite ns --all \
= baseline
出力は次のようになります:
namespace/default labeled
namespace/kube-node-lease labeled
namespace/kube-public labeled
Warning: existing pods in namespace "kube-system" violate the new PodSecurity enforce level "baseline:latest"
Warning: etcd-psa-wo-cluster-pss-control-plane (and 3 other pods): host namespaces, hostPath volumes
Warning: kindnet-vzj42: non-default capabilities, host namespaces, hostPath volumes
Warning: kube-proxy-m6hwf: host namespaces, hostPath volumes, privileged
namespace/kube-system labeled
namespace/local-path-storage labeled
restricted
kubectl label --dry-run= server --overwrite ns --all \
= restricted
出力は次のようになります:
namespace/default labeled
namespace/kube-node-lease labeled
namespace/kube-public labeled
Warning: existing pods in namespace "kube-system" violate the new PodSecurity enforce level "restricted:latest"
Warning: coredns-7bb9c7b568-hsptc (and 1 other pod): unrestricted capabilities, runAsNonRoot != true, seccompProfile
Warning: etcd-psa-wo-cluster-pss-control-plane (and 3 other pods): host namespaces, hostPath volumes, allowPrivilegeEscalation != false, unrestricted capabilities, restricted volume types, runAsNonRoot != true
Warning: kindnet-vzj42: non-default capabilities, host namespaces, hostPath volumes, allowPrivilegeEscalation != false, unrestricted capabilities, restricted volume types, runAsNonRoot != true, seccompProfile
Warning: kube-proxy-m6hwf: host namespaces, hostPath volumes, privileged, allowPrivilegeEscalation != false, unrestricted capabilities, restricted volume types, runAsNonRoot != true, seccompProfile
namespace/kube-system labeled
Warning: existing pods in namespace "local-path-storage" violate the new PodSecurity enforce level "restricted:latest"
Warning: local-path-provisioner-d6d9f7ffc-lw9lh: allowPrivilegeEscalation != false, unrestricted capabilities, runAsNonRoot != true, seccompProfile
namespace/local-path-storage labeled
この出力から、privileged Podセキュリティの標準を適用すると、名前空間のどれにも警告が示されないことに気付くでしょう。
これに対し、baselineとrestrictの標準ではどちらも、とりわけkube-system名前空間に対して警告が示されています。
モード、バージョン、標準のセット このセクションでは、latestバージョンに以下のPodセキュリティの標準を適用します:
enforceモードでbaseline標準。warnおよびauditモードでrestricted標準。baseline Podセキュリティの標準は、免除リストを短く保てて、かつ既知の特権昇格を防ぐような、利便性のある中庸を提供します。
加えて、kube-system内の失敗からPodを守るために、適用されるPodセキュリティの標準の対象から名前空間を免除します。
環境にPodセキュリティアドミッションを実装する際には、以下の点を考慮してください:
クラスターに適用されるリスク状況に基づくと、restrictedのようにより厳格なPodセキュリティの標準のほうが、より良い選択肢かもしれません。
kube-system名前空間の免除は、Podがその名前空間でprivilegedとして実行するのを許容することになります。
実世界で使うにあたっては、以下の最小権限の原則に従ってkube-systemへのアクセスを制限する厳格なRBACポリシーを適用することを、Kubernetesプロジェクトは強く推奨します。
上記の標準を実装するには、次のようにします:
目的のPodセキュリティの標準を実装するために、Podセキュリティアドミッションコントローラーで利用可能な設定ファイルを作成します:
mkdir -p /tmp/pss
cat <<EOF > /tmp/pss/cluster-level-pss.yaml
apiVersion: apiserver.config.k8s.io/v1
kind: AdmissionConfiguration
plugins:
- name: PodSecurity
configuration:
apiVersion: pod-security.admission.config.k8s.io/v1
kind: PodSecurityConfiguration
defaults:
enforce: "baseline"
enforce-version: "latest"
audit: "restricted"
audit-version: "latest"
warn: "restricted"
warn-version: "latest"
exemptions:
usernames: []
runtimeClasses: []
namespaces: [kube-system]
EOF
備考: pod-security.admission.config.k8s.io/v1設定はv1.25+での対応です。
v1.23とv1.24では
v1beta1 を使用してください。
v1.22では
v1alpha1 を使用してください。
クラスターの作成中にこのファイルを取り込むAPIサーバーを設定します:
cat <<EOF > /tmp/pss/cluster-config.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
kubeadmConfigPatches:
- |
kind: ClusterConfiguration
apiServer:
extraArgs:
admission-control-config-file: /etc/config/cluster-level-pss.yaml
extraVolumes:
- name: accf
hostPath: /etc/config
mountPath: /etc/config
readOnly: false
pathType: "DirectoryOrCreate"
extraMounts:
- hostPath: /tmp/pss
containerPath: /etc/config
# optional: if set, the mount is read-only.
# default false
readOnly: false
# optional: if set, the mount needs SELinux relabeling.
# default false
selinuxRelabel: false
# optional: set propagation mode (None, HostToContainer or Bidirectional)
# see https://kubernetes.io/docs/concepts/storage/volumes/#mount-propagation
# default None
propagation: None
EOF
備考: macOSでDocker Desktopとkind を利用している場合は、Preferences > Resources > File Sharing のメニュー項目からShared Directoryとして/tmpを追加できます。目的のPodセキュリティの標準を適用するために、Podセキュリティアドミッションを使うクラスターを作成します:
kind create cluster --name psa-with-cluster-pss --config /tmp/pss/cluster-config.yaml
出力は次のようになります:
Creating cluster "psa-with-cluster-pss" ...
✓ Ensuring node image (kindest/node:v1.35.0) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
Set kubectl context to "kind-psa-with-cluster-pss"
You can now use your cluster with:
kubectl cluster-info --context kind-psa-with-cluster-pss
Have a question, bug, or feature request? Let us know! https://kind.sigs.k8s.io/#community 🙂
kubectlをこのクラスターに向けます:
kubectl cluster-info --context kind-psa-with-cluster-pss
出力は次のようになります:
Kubernetes control plane is running at https://127.0.0.1:63855
CoreDNS is running at https://127.0.0.1:63855/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
デフォルトの名前空間にPodを作成します:
kubectl apply -f https://k8s.io/examples/security/example-baseline-pod.yaml
Podは正常に開始されますが、出力には警告が含まれます:
Warning: would violate PodSecurity "restricted:latest": allowPrivilegeEscalation != false (container "nginx" must set securityContext.allowPrivilegeEscalation=false), unrestricted capabilities (container "nginx" must set securityContext.capabilities.drop=["ALL"]), runAsNonRoot != true (pod or container "nginx" must set securityContext.runAsNonRoot=true), seccompProfile (pod or container "nginx" must set securityContext.seccompProfile.type to "RuntimeDefault" or "Localhost")
pod/nginx created
後片付け では、上記で作成したクラスターを、以下のコマンドを実行して削除します:
kind delete cluster --name psa-with-cluster-pss
kind delete cluster --name psa-wo-cluster-pss
次の項目 5.5.2 - 名前空間レベルでのPodセキュリティの標準の適用
Note このチュートリアルは、新しいクラスターにのみ適用されます。Podセキュリティアドミッション(PSA)は、ベータへ進み 、v1.23以降でデフォルトで有効になっています。
Podセキュリティアドミッションは、Podが作成される際に、Podセキュリティの標準 の適用の認可を制御するものです。
このチュートリアルでは、一度に1つの名前空間でbaseline Podセキュリティ標準を強制します。
Podセキュリティの標準を複数の名前空間に一度にクラスターレベルで適用することもできます。やり方についてはクラスターレベルでのPodセキュリティの標準の適用 を参照してください。
始める前に ワークステーションに以下をインストールしてください:
クラスターの作成 以下のようにKinDクラスターを作成します。
kind create cluster --name psa-ns-level
出力は次のようになります:
Creating cluster "psa-ns-level" ...
✓ Ensuring node image (kindest/node:v1.35.0) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
Set kubectl context to "kind-psa-ns-level"
You can now use your cluster with:
kubectl cluster-info --context kind-psa-ns-level
Not sure what to do next? 😅 Check out https://kind.sigs.k8s.io/docs/user/quick-start/
kubectl のコンテキストを新しいクラスターにセットします:
kubectl cluster-info --context kind-psa-ns-level
出力は次のようになります:
Kubernetes control plane is running at https://127.0.0.1:50996
CoreDNS is running at https://127.0.0.1:50996/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
名前空間の作成 exampleと呼ぶ新しい名前空間を作成します:
kubectl create ns example
出力は次のようになります:
namespace/example created
名前空間へのPodセキュリティの標準チェックの有効化 ビルトインのPod Security Admissionでサポートされているラベルを使って、この名前空間のPodセキュリティの標準を有効にします。
このステップでは、baseline Podセキュリティの標準の最新バージョンに合わないPodについて警告するチェックを設定します。
kubectl label --overwrite ns example \
= baseline \
= latest
ラベルを使って、任意の名前空間に対して複数のPodセキュリティの標準チェックを設定できます。
以下のコマンドは、baseline Podセキュリティの標準をenforce(強制)としますが、restricted Podセキュリティの標準には最新バージョンに準じてwarn(警告)およびaudit(監査)とします(デフォルト値)。
kubectl label --overwrite ns example \
= baseline \
= latest \
= restricted \
= latest \
= restricted \
= latest
Podセキュリティの標準の強制の実証 example名前空間内にbaseline Podを作成します:
kubectl apply -n example -f https://k8s.io/examples/security/example-baseline-pod.yaml
Podは正常に起動しますが、出力には警告が含まれています。例えば:
Warning: would violate PodSecurity "restricted:latest": allowPrivilegeEscalation != false (container "nginx" must set securityContext.allowPrivilegeEscalation=false), unrestricted capabilities (container "nginx" must set securityContext.capabilities.drop=["ALL"]), runAsNonRoot != true (pod or container "nginx" must set securityContext.runAsNonRoot=true), seccompProfile (pod or container "nginx" must set securityContext.seccompProfile.type to "RuntimeDefault" or "Localhost")
pod/nginx created
default名前空間内にbaseline Podを作成します:
kubectl apply -n default -f https://k8s.io/examples/security/example-baseline-pod.yaml
出力は次のようになります:
pod/nginx created
example名前空間にだけ、Podセキュリティの標準のenforceと警告の設定が適用されました。
default名前空間内では、警告なしに同じPodを作成できました。
後片付け では、上記で作成したクラスターを、以下のコマンドを実行して削除します:
kind delete cluster --name psa-ns-level
次の項目 5.5.3 - AppArmorを使用してコンテナのリソースへのアクセスを制限する FEATURE STATE:
Kubernetes v1.31 [stable](enabled by default)
このページでは、ノードでAppArmorプロファイルを読み込み、それらのプロファイルをPodに適用する方法を説明します。
AppArmorを使用してPodを制限するKubernetesの仕組みについて詳しく知りたい場合は、PodとコンテナのためのLinuxカーネルのセキュリティ制約 をご覧ください。
目標 プロファイルをノードに読み込む方法の例を見る Pod上でプロファイルを強制する方法を学ぶ プロファイルが読み込まれたかを確認する方法を学ぶ プロファイルに違反した場合に何が起こるのかを見る プロファイルが読み込めなかった場合に何が起こるのかを見る 始める前に AppArmorはカーネルモジュールおよびKubernetesのオプション機能です。
そのため、先に進む前にノード上でAppArmorがサポートされていることを確認してください:
AppArmorカーネルモジュールが有効であること。
LinuxカーネルがAppArmorプロファイルを強制するためには、AppArmorカーネルモジュールのインストールと有効化が必須です。
UbuntuやSUSEなどのディストリビューションではデフォルトで有効化されますが、他の多くのディストリビューションでのサポートはオプションです。
モジュールが有効になっているかどうかを確認するためには、/sys/module/apparmor/parameters/enabledファイルを確認します:
cat /sys/module/apparmor/parameters/enabled
Y
Kubeletは、AppArmorが明示的に設定されたPodを受け入れる前にホスト上でAppArmorが有効になっているかどうかを検証します。
コンテナランタイムがAppArmorをサポートしていること。
Kubernetesがサポートするcontainerd やCRI-O などのすべての一般的なコンテナランタイムは、AppArmorをサポートしています。
関連するランタイムのドキュメントを参照して、クラスターがAppArmorを利用するための要求を満たしているかどうかを検証してください。
プロファイルが読み込まれていること。
AppArmorがPodに適用されるのは、各コンテナが実行するAppArmorプロファイルを指定したときです。
もし指定されたプロファイルがまだカーネルに読み込まれていなければ、KubeletはPodを拒否します。
どのプロファイルがノードに読み込まれているのかを確かめるには、/sys/kernel/security/apparmor/profilesを確認します。
例えば:
ssh gke-test-default-pool-239f5d02-gyn2 "sudo cat /sys/kernel/security/apparmor/profiles | sort"
apparmor-test-deny-write (enforce)
apparmor-test-audit-write (enforce)
docker-default (enforce)
k8s-nginx (enforce)
ノード上でのプロファイルの読み込みの詳細については、プロファイルを使用したノードのセットアップ を参照してください。
Podをセキュアにする
備考: Kubernetes v1.30より前では、AppArmorはアノテーションを通じて指定されていました。
この非推奨となったAPIに関するドキュメントを表示するには、ドキュメントのバージョンセレクターを使用してください。AppArmorプロファイルは、Podレベルまたはコンテナレベルで指定することができます。
コンテナのAppArmorプロファイルは、Podのプロファイルよりも優先されます。
securityContext :
appArmorProfile :
type : <profile_type>
ここで、<profile_type>には次の値のうち1つを指定します:
RuntimeDefault: ランタイムのデフォルトのプロファイルを適用します。Localhost: ホストに読み込まれたプロファイルを適用します(下記を参照してください)。unconfined: AppArmorなしで実行します。AppArmorプロファイルAPIの詳細については、AppArmorによる制限の指定 を参照してください。
プロファイルが適用されたかどうかを確認するには、proc attrを調べることでコンテナのルートプロセスが正しいプロファイルで実行されているかどうかを確認します:
kubectl exec <pod_name> -- cat /proc/1/attr/current
出力は以下のようになるはずです:
cri-containerd.apparmor.d (enforce)
例 この例は、クラスターがすでにAppArmorのサポート付きでセットアップ済みであることを前提としています。
まず、使用したいプロファイルをノード上に読み込む必要があります。
このプロファイルは、すべてのファイル書き込みを拒否します:
#include <tunables/global>
profile k8s-apparmor-example-deny-write flags=(attach_disconnected) {
#include <abstractions/base>
file,
# Deny all file writes.
deny /** w,
}
Podがどのノードにスケジュールされるかは予測できないため、プロファイルはすべてのノードに読み込ませる必要があります。
この例では、単純にSSHを使ってプロファイルをインストールしますが、プロファイルを使用したノードのセットアップ では、他のアプローチについて議論しています。
# この例では、ノード名がホスト名と一致し、SSHで到達可能であることを前提としています。
NODES =( $( kubectl get node -o jsonpath = '{.items[*].status.addresses[?(.type == "Hostname")].address}' ) )
for NODE in ${ NODES [*]} ; do ssh $NODE 'sudo apparmor_parser -q <<EOF
#include <tunables/global>
profile k8s-apparmor-example-deny-write flags=(attach_disconnected) {
#include <abstractions/base>
file,
# Deny all file writes.
deny /** w,
}
EOF'
done
次に、deny-writeプロファイルを使用した単純な"Hello AppArmor" Podを実行します。
apiVersion : v1
kind : Pod
metadata :
name : hello-apparmor
spec :
securityContext :
appArmorProfile :
type : Localhost
localhostProfile : k8s-apparmor-example-deny-write
containers :
- name : hello
image : busybox:1.28
command : [ "sh" , "-c" , "echo 'Hello AppArmor!' && sleep 1h" ]
kubectl create -f hello-apparmor.yaml
/proc/1/attr/currentを確認することで、コンテナがこのプロファイルで実際に実行されていることを検証できます:
kubectl exec hello-apparmor -- cat /proc/1/attr/current
出力は以下のようになるはずです:
k8s-apparmor-example-deny-write (enforce)
最後に、ファイルへの書き込みを行おうとすることで、プロファイルに違反すると何が起こるか見てみましょう:
kubectl exec hello-apparmor -- touch /tmp/test
touch: /tmp/test: Permission denied
error: error executing remote command: command terminated with non-zero exit code: Error executing in Docker Container: 1
まとめとして、読み込まれていないプロファイルを指定しようとするとどうなるのか見てみましょう:
kubectl create -f /dev/stdin <<EOF
apiVersion: v1
kind: Pod
metadata:
name: hello-apparmor-2
spec:
securityContext:
appArmorProfile:
type: Localhost
localhostProfile: k8s-apparmor-example-allow-write
containers:
- name: hello
image: busybox:1.28
command: [ "sh", "-c", "echo 'Hello AppArmor!' && sleep 1h" ]
EOF
pod/hello-apparmor-2 created
Podは正常に作成されましたが、さらに調査すると、PodがPendingで止まっていることがわかります:
kubectl describe pod hello-apparmor-2
Name: hello-apparmor-2
Namespace: default
Node: gke-test-default-pool-239f5d02-x1kf/10.128.0.27
Start Time: Tue, 30 Aug 2016 17:58:56 -0700
Labels: <none>
Annotations: container.apparmor.security.beta.kubernetes.io/hello=localhost/k8s-apparmor-example-allow-write
Status: Pending
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 10s default-scheduler Successfully assigned default/hello-apparmor to gke-test-default-pool-239f5d02-x1kf
Normal Pulled 8s kubelet Successfully pulled image "busybox:1.28" in 370.157088ms (370.172701ms including waiting)
Normal Pulling 7s (x2 over 9s) kubelet Pulling image "busybox:1.28"
Warning Failed 7s (x2 over 8s) kubelet Error: failed to get container spec opts: failed to generate apparmor spec opts: apparmor profile not found k8s-apparmor-example-allow-write
Normal Pulled 7s kubelet Successfully pulled image "busybox:1.28" in 90.980331ms (91.005869ms including waiting)
イベントにはエラーメッセージとその理由が表示されます。
具体的な文言はランタイムによって異なります:
Warning Failed 7s (x2 over 8s) kubelet Error: failed to get container spec opts: failed to generate apparmor spec opts: apparmor profile not found
管理 プロファイルを使用したノードのセットアップ Kubernetes 1.35は、AppArmorプロファイルをノードに読み込むネイティブの仕組みは提供していません。
プロファイルは、カスタムインフラストラクチャーやKubernetes Security Profiles Operator などのツールを通じて読み込むことができます。
スケジューラーはどのプロファイルがどのノードに読み込まれているのかがわからないため、すべてのプロファイルがすべてのノードに読み込まれていなければなりません。
もう1つのアプローチとしては、各プロファイル(あるいはプロファイルのクラス)ごとにノードラベルを追加し、ノードセレクター を用いてPodが必要なプロファイルを読み込んだノードで実行されるようにする方法もあります。
Profilesの作成 AppArmorプロファイルを正しく指定するのはやっかいな作業です。
幸い、その作業を補助するツールがいくつかあります:
aa-genprofおよびaa-logprofは、アプリケーションの動作とログを監視し、実行されるアクションを許可することで、プロファイルのルールを生成します。
詳しい説明については、AppArmor documentation を参照してください。bane は、Docker向けのAppArmorプロファイル・ジェネレーターです。簡略化されたプロファイル言語を使用しています。AppArmorに関する問題をデバッグするには、システムログを確認して、特に何が拒否されたのかを確認できます。
AppArmorのログはdmesgにverboseメッセージを送り、エラーは通常システムログまたはjournalctlで確認できます。
詳しい情報は、AppArmor failures で提供されています。
AppArmorによる制限の指定
注意: Kubernetes v1.30より前では、AppArmorはアノテーションを通じて指定されていました。
この非推奨となったAPIに関するドキュメントを表示するには、ドキュメントのバージョンセレクターを使用してください。セキュリティコンテキスト内のAppArmorプロファイル appArmorProfileは、コンテナのsecurityContextまたはPodのsecurityContextのいずれかで指定できます。
プロファイルがPodレベルで設定されている場合、Pod内のすべてのコンテナ(initコンテナ、サイドカーコンテナ、およびエフェメラルコンテナを含む)のデフォルトのプロファイルとして使用されます。
Podとコンテナの両方でAppArmorプロファイルが設定されている場合は、コンテナのプロファイルが使用されます。
AppArmorプロファイルには2つのフィールドがあります:
type (必須) - 適用されるAppArmorプロファイルの種類を示します。
有効なオプションは以下の通りです:
Localhostノードに事前に読み込まれているプロファイル(localhostProfileで指定します)。 RuntimeDefaultコンテナランタイムのデフォルトのプロファイル。 UnconfinedAppArmorによる制限を適用しません。 localhostProfile - ノード上に読み込まれている、使用すべきプロファイルの名前。
このプロファイルは、ノード上であらかじめ設定されている必要があります。
このオプションは、typeがLocalhostの場合にのみ指定する必要があります。
次の項目 追加のリソースとしては以下のものがあります:
5.5.4 - seccompを使用してコンテナのシステムコールを制限する FEATURE STATE:
Kubernetes v1.19 [stable]
seccomp(SECure COMPuting mode)はLinuxカーネル2.6.12以降の機能です。
この機能を用いると、ユーザー空間からカーネルに対して発行できるシステムコールを制限することで、プロセス権限のサンドボックスを構築することができます。
Kubernetesでは、ノード 上で読み込んだseccompプロファイルをPodやコンテナに対して自動で適用することができます。
あなたのワークロードが必要とする権限を特定するのは、実際には難しい作業になるかもしれません。
このチュートリアルでは、ローカルのKubernetesクラスターでseccompプロファイルを読み込むための方法を説明し、seccompプロファイルのPodへの適用方法について学んだ上で、コンテナプロセスに対して必要な権限のみを付与するためのseccompプロファイルを作成する方法を概観していきます。
目標 ノードでseccompプロファイルを読み込む方法を学ぶ。 seccompプロファイルをコンテナに適用する方法を学ぶ。 コンテナプロセスが生成するシステムコールの監査出力を確認する。 seccompプロファイルが指定されない場合の挙動を確認する。 seccompプロファイルの違反を確認する。 きめ細やかなseccompプロファイルの作成方法を学ぶ。 コンテナランタイムの標準seccompプロファイルを適用する方法を学ぶ。 始める前に このチュートリアルのステップを完了するためには、kind とkubectl をインストールしておく必要があります。
このチュートリアルで利用するコマンドは、Docker をコンテナランタイムとして利用していることを前提としています。
(kindが作成するクラスターは内部的に異なるコンテナランタイムを利用する可能性があります)。
Podman を使うこともできますが、チュートリアルを完了するためには、所定の手順 に従う必要があります。
このチュートリアルでは、現時点(v1.25以降)でのベータ機能を利用する設定例をいくつか示しますが、その他の例についてはGAなseccomp関連機能を用いています。
利用するKubernetesバージョンを対象としたクラスターの正しい設定 がなされていることを確認してください。
チュートリアル内では、サンプルをダウンロードするためにcurlを利用します。
この手順については、ほかの好きなツールを用いて実施してもかまいません。
備考: securityContextにprivileged: trueが設定されているContainerに対しては、seccompプロファイルを適用することができません。
特権コンテナは常にUnconfinedな状態で動作します。サンプルのseccompプロファイルをダウンロードする プロファイルの内容については後で解説しますので、まずはクラスターで読み込むためのseccompプロファイルをprofiles/ディレクトリ内にダウンロードしましょう。
{
"defaultAction" : "SCMP_ACT_LOG"
}
{
"defaultAction" : "SCMP_ACT_ERRNO"
}
{
"defaultAction" : "SCMP_ACT_ERRNO" ,
"architectures" : [
"SCMP_ARCH_X86_64" ,
"SCMP_ARCH_X86" ,
"SCMP_ARCH_X32"
],
"syscalls" : [
{
"names" : [
"accept4" ,
"epoll_wait" ,
"pselect6" ,
"futex" ,
"madvise" ,
"epoll_ctl" ,
"getsockname" ,
"setsockopt" ,
"vfork" ,
"mmap" ,
"read" ,
"write" ,
"close" ,
"arch_prctl" ,
"sched_getaffinity" ,
"munmap" ,
"brk" ,
"rt_sigaction" ,
"rt_sigprocmask" ,
"sigaltstack" ,
"gettid" ,
"clone" ,
"bind" ,
"socket" ,
"openat" ,
"readlinkat" ,
"exit_group" ,
"epoll_create1" ,
"listen" ,
"rt_sigreturn" ,
"sched_yield" ,
"clock_gettime" ,
"connect" ,
"dup2" ,
"epoll_pwait" ,
"execve" ,
"exit" ,
"fcntl" ,
"getpid" ,
"getuid" ,
"ioctl" ,
"mprotect" ,
"nanosleep" ,
"open" ,
"poll" ,
"recvfrom" ,
"sendto" ,
"set_tid_address" ,
"setitimer" ,
"writev" ,
"fstatfs" ,
"getdents64" ,
"pipe2" ,
"getrlimit"
],
"action" : "SCMP_ACT_ALLOW"
}
]
} 次のコマンドを実行してください:
mkdir ./profiles
curl -L -o profiles/audit.json https://k8s.io/examples/pods/security/seccomp/profiles/audit.json
curl -L -o profiles/violation.json https://k8s.io/examples/pods/security/seccomp/profiles/violation.json
curl -L -o profiles/fine-grained.json https://k8s.io/examples/pods/security/seccomp/profiles/fine-grained.json
ls profiles
最終的に3つのプロファイルが確認できるはずです:
audit.json fine-grained.json violation.json
kindでローカルKubernetesクラスターを構築する 手軽な方法として、kind を利用することで、seccompプロファイルを読み込んだ単一ノードクラスターを構築できます。
kindはKubernetesをDocker内で稼働させるため、クラスターの各ノードはコンテナとなります。
これにより、ノード上にファイルを展開するのと同じように、各コンテナのファイルシステムに対してファイルをマウントすることが可能です。
apiVersion : kind.x-k8s.io/v1alpha4
kind : Cluster
nodes :
role : control-plane
extraMounts :
- hostPath : "./profiles"
containerPath : "/var/lib/kubelet/seccomp/profiles" kindの設定サンプルをダウンロードして、kind.yamlの名前で保存してください:
curl -L -O https://k8s.io/examples/pods/security/seccomp/kind.yaml
ノードのコンテナイメージを設定する際には、特定のKubernetesバージョンを指定することもできます。
この設定方法の詳細については、kindのドキュメント内の、ノード の項目を参照してください。
このチュートリアルではKubernetes v1.35を使用することを前提とします。
ベータ機能として、Unconfinedにフォールバックするのではなく、コンテナランタイム がデフォルトで推奨するプロファイルを利用するようにKubernetesを設定することもできます。
この機能を試したい場合、これ以降の手順に進む前に、全ワークロードに対する標準seccompプロファイルとしてRuntimeDefaultを使用する を参照してください。
kindの設定ファイルを設置したら、kindクラスターを作成します:
kind create cluster --config= kind.yaml
Kubernetesクラスターが準備できたら、単一ノードクラスターが稼働しているDockerコンテナを特定してください:
kind-control-planeという名前のコンテナが稼働していることが確認できるはずです。
出力は次のようになるでしょう:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6a96207fed4b kindest/node:v1.18.2 "/usr/local/bin/entr…" 27 seconds ago Up 24 seconds 127.0.0.1:42223->6443/tcp kind-control-plane
このコンテナのファイルシステムを観察すると、profiles/ディレクトリがkubeletのデフォルトのseccompパスとして正しく読み込まれていることを確認できるはずです。
Pod内でコマンドを実行するためにdocker execを使います:
# 6a96207fed4bを"docker ps"で確認したコンテナIDに変更してください。
docker exec -it 6a96207fed4b ls /var/lib/kubelet/seccomp/profiles
audit.json fine-grained.json violation.json
kind内で稼働しているkubeletがseccompプロファイルを利用可能であることを確認しました。
コンテナランタイムの標準seccompプロファイルを利用してPodを作成する ほとんどのコンテナランタイムは、許可・拒否の対象とする標準的なシステムコールの集合を提供しています。
PodやContainerのセキュリティコンテキストでseccompタイプをRuntimeDefaultに設定すると、コンテナランタイムが提供するデフォルトのプロファイルをワークロードに適用することができます。
備考: seccompDefaultの
設定 を有効化している場合、他にseccompプロファイルを定義しなくても、Podは
RuntimeDefault seccompプロファイルを使用します。
seccompDefaultが無効の場合のデフォルトは
Unconfinedです。
Pod内の全てのContainerに対してRuntimeDefault seccompプロファイルを要求するマニフェストは次のようなものです:
apiVersion : v1
kind : Pod
metadata :
name : default-pod
labels :
app : default-pod
spec :
securityContext :
seccompProfile :
type : RuntimeDefault
containers :
- name : test-container
image : hashicorp/http-echo:1.0
args :
- "-text=just made some more syscalls!"
securityContext :
allowPrivilegeEscalation : false このPodを作成してみます:
kubectl apply -f https://k8s.io/examples/pods/security/seccomp/ga/default-pod.yaml
kubectl get pod default-pod
Podが正常に起動できていることを確認できるはずです:
NAME READY STATUS RESTARTS AGE
default-pod 1/1 Running 0 20s
次のセクションに進む前に、Podを削除します:
kubectl delete pod default-pod --wait --now
システムコール監査のためのseccompプロファイルを利用してPodを作成する 最初に、新しいPodにプロセスの全システムコールを記録するためのaudit.jsonプロファイルを適用します。
このPodのためのマニフェストは次の通りです:
apiVersion : v1
kind : Pod
metadata :
name : audit-pod
labels :
app : audit-pod
spec :
securityContext :
seccompProfile :
type : Localhost
localhostProfile : profiles/audit.json
containers :
- name : test-container
image : hashicorp/http-echo:1.0
args :
- "-text=just made some syscalls!"
securityContext :
allowPrivilegeEscalation : false 備考: 過去のバージョンのKubernetesでは、
アノテーション を用いてseccompの挙動を制御することができました。
Kubernetes 1.35におけるseccompの設定では
.spec.securityContextフィールドのみをサポートしており、このチュートリアルではKubernetes 1.35における手順を解説しています。
クラスター内にPodを作成します:
kubectl apply -f https://k8s.io/examples/pods/security/seccomp/ga/audit-pod.yaml
このプロファイルは、いかなるシステムコールも制限しないため、Podは正常に起動するはずです。
kubectl get pod audit-pod
NAME READY STATUS RESTARTS AGE
audit-pod 1/1 Running 0 30s
このコンテナが公開するエンドポイントとやりとりするために、kindのコントロールプレーンコンテナの内部からこのエンドポイントにアクセスできるように、NodePort Service を作成します。
kubectl expose pod audit-pod --type NodePort --port 5678
どのポートがノード上のServiceに割り当てられたのかを確認しましょう。
kubectl get service audit-pod
次のような出力が得られます:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
audit-pod NodePort 10.111.36.142 <none> 5678:32373/TCP 72s
ここまで来れば、kindのコントロールプレーンコンテナの内部からエンドポイントに対して、Serviceが公開するポートを通じてcurlで接続することができます。
docker execを使って、コントロールプレーンコンテナに属するコンテナの中からcurlを実行しましょう:
# 6a96207fed4bと32373を、それぞれ"docker ps"で確認したコンテナIDとポート番号に変更してください。
docker exec -it 6a96207fed4b curl localhost:32373
just made some syscalls!
プロセスが実行されていることは確認できましたが、実際にどんなシステムコールが発行されているのでしょうか?
このPodはローカルクラスターで稼働しているため、発行されたシステムコールを/var/log/syslogで確認することができるはずです。
新しいターミナルを開いて、http-echoが発行するシステムコールをtailしてみましょう:
# あなたのマシンのログは"/var/log/syslog"以外の場所にあるかもしれません。
tail -f /var/log/syslog | grep 'http-echo'
すでにhttp-echoが発行したいくつかのシステムコールのログが見えているはずです。
コントロールプレーンコンテナ内から再度curlを実行すると、新たにログに追記された内容が出力されます。
例えば、次のような出力が得られるでしょう:
Jul 6 15:37:40 my-machine kernel: [369128.669452] audit: type=1326 audit(1594067860.484:14536): auid=4294967295 uid=0 gid=0 ses=4294967295 pid=29064 comm="http-echo" exe="/http-echo" sig=0 arch=c000003e syscall=51 compat=0 ip=0x46fe1f code=0x7ffc0000
Jul 6 15:37:40 my-machine kernel: [369128.669453] audit: type=1326 audit(1594067860.484:14537): auid=4294967295 uid=0 gid=0 ses=4294967295 pid=29064 comm="http-echo" exe="/http-echo" sig=0 arch=c000003e syscall=54 compat=0 ip=0x46fdba code=0x7ffc0000
Jul 6 15:37:40 my-machine kernel: [369128.669455] audit: type=1326 audit(1594067860.484:14538): auid=4294967295 uid=0 gid=0 ses=4294967295 pid=29064 comm="http-echo" exe="/http-echo" sig=0 arch=c000003e syscall=202 compat=0 ip=0x455e53 code=0x7ffc0000
Jul 6 15:37:40 my-machine kernel: [369128.669456] audit: type=1326 audit(1594067860.484:14539): auid=4294967295 uid=0 gid=0 ses=4294967295 pid=29064 comm="http-echo" exe="/http-echo" sig=0 arch=c000003e syscall=288 compat=0 ip=0x46fdba code=0x7ffc0000
Jul 6 15:37:40 my-machine kernel: [369128.669517] audit: type=1326 audit(1594067860.484:14540): auid=4294967295 uid=0 gid=0 ses=4294967295 pid=29064 comm="http-echo" exe="/http-echo" sig=0 arch=c000003e syscall=0 compat=0 ip=0x46fd44 code=0x7ffc0000
Jul 6 15:37:40 my-machine kernel: [369128.669519] audit: type=1326 audit(1594067860.484:14541): auid=4294967295 uid=0 gid=0 ses=4294967295 pid=29064 comm="http-echo" exe="/http-echo" sig=0 arch=c000003e syscall=270 compat=0 ip=0x4559b1 code=0x7ffc0000
Jul 6 15:38:40 my-machine kernel: [369188.671648] audit: type=1326 audit(1594067920.488:14559): auid=4294967295 uid=0 gid=0 ses=4294967295 pid=29064 comm="http-echo" exe="/http-echo" sig=0 arch=c000003e syscall=270 compat=0 ip=0x4559b1 code=0x7ffc0000
Jul 6 15:38:40 my-machine kernel: [369188.671726] audit: type=1326 audit(1594067920.488:14560): auid=4294967295 uid=0 gid=0 ses=4294967295 pid=29064 comm="http-echo" exe="/http-echo" sig=0 arch=c000003e syscall=202 compat=0 ip=0x455e53 code=0x7ffc0000
各行のsyscall=エントリに着目することで、http-echoプロセスが必要とするシステムコールを理解していくことができるでしょう。
このプロセスが利用する全てのシステムコールを網羅するものではないかもしれませんが、このコンテナのseccompプロファイルを作成する上での基礎とすることは可能です。
次のセクションに進む前にServiceとPodを削除します:
kubectl delete service audit-pod --wait
kubectl delete pod audit-pod --wait --now
違反が発生するseccompプロファイルでPodを作成する デモとして、いかなるシステムコールも許可しないseccompプロファイルをPodに適用してみましょう。
マニフェストは次の通りです:
apiVersion : v1
kind : Pod
metadata :
name : violation-pod
labels :
app : violation-pod
spec :
securityContext :
seccompProfile :
type : Localhost
localhostProfile : profiles/violation.json
containers :
- name : test-container
image : hashicorp/http-echo:1.0
args :
- "-text=just made some syscalls!"
securityContext :
allowPrivilegeEscalation : false クラスターにPodを作成してみます:
kubectl apply -f https://k8s.io/examples/pods/security/seccomp/ga/violation-pod.yaml
Podを作成しても問題が発生します。
Podの状態を確認すると、起動に失敗していることが確認できるはずです。
kubectl get pod violation-pod
NAME READY STATUS RESTARTS AGE
violation-pod 0/1 CrashLoopBackOff 1 6s
直前の事例で見てきたように、http-echoプロセスは多くのシステムコールを必要とします。
ここでは"defaultAction": "SCMP_ACT_ERRNO"が設定されているため、あらゆるシステムコールに対してseccompがエラーを発生させました。
この構成はとてもセキュアですが、有意義な処理は何もできないことを意味します。
私たちが実際にやりたいのは、ワークロードが必要とする権限のみを付与することです。
次のセクションに進む前にPodを削除します。
kubectl delete pod violation-pod --wait --now
必要なシステムコールのみを許可するseccompプロファイルを用いてPodを作成する fine-grained.jsonプロファイルの内容を見れば、最初の例で"defaultAction":"SCMP_ACT_LOG"を設定していた際に、ログに表示されたシステムコールが含まれていることに気づくでしょう。
今回のプロファイルでも"defaultAction": "SCMP_ACT_ERRNO"を設定しているものの、"action": "SCMP_ACT_ALLOW"ブロックで明示的に一連のシステムコールを許可しています。
理想的な状況下であれば、コンテナが正常に稼働することに加え、syslogへのメッセージ送信を見ることはなくなるでしょう。
この事例のマニフェストは次の通りです:
apiVersion : v1
kind : Pod
metadata :
name : fine-pod
labels :
app : fine-pod
spec :
securityContext :
seccompProfile :
type : Localhost
localhostProfile : profiles/fine-grained.json
containers :
- name : test-container
image : hashicorp/http-echo:1.0
args :
- "-text=just made some syscalls!"
securityContext :
allowPrivilegeEscalation : false クラスター内にPodを作成します:
kubectl apply -f https://k8s.io/examples/pods/security/seccomp/ga/fine-pod.yaml
Podは正常に起動しているはずです:
NAME READY STATUS RESTARTS AGE
fine-pod 1/1 Running 0 30s
新しいターミナルを開いて、http-echoからのシステムコールに関するログエントリをtailで監視しましょう:
# あなたのマシンのログは"/var/log/syslog"以外の場所にあるかもしれません。
tail -f /var/log/syslog | grep 'http-echo'
次のPodをNodePort Serviceで公開します:
kubectl expose pod fine-pod --type NodePort --port 5678
ノード上のServiceに割り当てられたポートを確認します:
kubectl get service fine-pod
出力は次のようになるでしょう:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
fine-pod NodePort 10.111.36.142 <none> 5678:32373/TCP 72s
kindのコントロールプレーンコンテナの内部から、curlを用いてエンドポイントにアクセスします:
# 6a96207fed4bと32373を、それぞれ"docker ps"で確認したコンテナIDとポート番号に変更してください。
docker exec -it 6a96207fed4b curl localhost:32373
just made some syscalls!
syslogには何も出力されないはずです。
なぜなら、このプロファイルは必要なシステムコールを全て許可しており、一覧にないシステムコールが呼び出された時にのみエラーを発生させるように構成しているためです。
これはセキュリティの観点からすると理想的なシチュエーションといえますが、seccompプロファイルを作成するためのプログラムの解析には多少の労力が必要です。
多くの労力を割かなくてもこれに近いセキュリティが得られるシンプルな手法があったなら、きっと素晴らしいものになるでしょう。
次のセクションに進む前にServiceとPodを削除します:
kubectl delete service fine-pod --wait
kubectl delete pod fine-pod --wait --now
全ワークロードに対する標準seccompプロファイルとしてRuntimeDefaultを使用する FEATURE STATE:
Kubernetes v1.27 [stable]
標準seccompプロファイルを指定するためには、この機能を利用したい全てのノードで--seccomp-defaultコマンドラインフラグ を用いてkubeletを起動する必要があります。
この機能を有効化すると、kubeletはコンテナランタイムが定義するRuntimeDefaultのseccompプロファイルをデフォルトで使用するようになり、Unconfinedモード(seccomp無効化)になることはありません。
コンテナランタイムが用意する標準プロファイルは、ワークロードの機能性を維持しつつ、強力な標準セキュリティルールの一式を用意することを目指しています。
標準のプロファイルはコンテナランタイムやリリースバージョンによって異なる可能性があります。
例えば、CRI-Oとcontainerdの標準プロファイルを比較してみるとよいでしょう。
備考: この機能を有効化しても、PodやContainerなどの
securityContext.seccompProfileフィールドは変更されず、非推奨のアノテーションがワークロードに追加されることもありません。
したがって、ユーザーはワークロードの設定を変更せずにロールバックすることが可能です。
crictl inspectのようなツールを使うことで、コンテナがどのseccompプロファイルを利用しているのかを確認できます。
いくつかのワークロードでは、他のワークロードよりもシステムコール制限を少なくすることが必要な場合があります。
つまり、RuntimeDefaultを適用する場合、こうしたワークロードの実行が失敗する可能性があります。
このような障害を緩和するために、次のような対策を講じることができます:
ワークロードを明示的にUnconfinedとして稼働させる。 SeccompDefault機能をノードで無効化する。
また、機能を無効化したノードに対してワークロードが配置されていることを確認しておく。ワークロードを対象とするカスタムseccompプロファイルを作成する。 実運用環境に近いクラスターに対してこの機能を展開する場合、クラスター全体に対して変更をロールアウトする前に、一部ノードのみを対象にしてこのフィーチャーゲートを有効化し、ワークロードが実行できることを検証しておくことをお勧めします。
クラスターに対してとりうるアップグレード・ダウングレード戦略について更に詳細な情報を知りたい場合は、関連するKubernetes Enhancement Proposal (KEP)であるEnable seccomp by default を参照してください。
Kubernetes 1.35では、specで特定のseccompプロファイルを指定していないPodに対して、デフォルトで適用するseccompプロファイルを設定することができます。
ただし、この標準seccompプロファイルを利用する場合、対象とする全ノードでこの機能を有効化しておく必要があります。
稼働中のKubernetes 1.35クラスターでこの機能を有効化する場合、kubeletに--seccomp-defaultコマンドラインフラグを付与して起動するか、Kubernetesの設定ファイル でこの機能を有効化する必要があります。
このフィーチャーゲートをkind で有効化する場合、kindが最低限必要なKubernetesバージョンを満たしていて、かつkindの設定ファイル でSeccompDefaultを有効化してください:
kind : Cluster
apiVersion : kind.x-k8s.io/v1alpha4
nodes :
- role : control-plane
image : kindest/node:v1.28.0@sha256:9f3ff58f19dcf1a0611d11e8ac989fdb30a28f40f236f59f0bea31fb956ccf5c
kubeadmConfigPatches :
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
seccomp-default: "true"
- role : worker
image : kindest/node:v1.28.0@sha256:9f3ff58f19dcf1a0611d11e8ac989fdb30a28f40f236f59f0bea31fb956ccf5c
kubeadmConfigPatches :
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
seccomp-default: "true"
クラスターの準備ができたら、Podを実行します:
kubectl run --rm -it --restart= Never --image= alpine alpine -- sh
このコマンドで標準のseccompプロファイルを紐付けられるはずです。
この結果を確認するには、docker exec経由でcrictl inspectを実行することで、kindワーカー上のコンテナを確認します:
docker exec -it kind-worker bash -c \
'crictl inspect $(crictl ps --name=alpine -q) | jq .info.runtimeSpec.linux.seccomp'
{
"defaultAction" : "SCMP_ACT_ERRNO" ,
"architectures" : ["SCMP_ARCH_X86_64" , "SCMP_ARCH_X86" , "SCMP_ARCH_X32" ],
"syscalls" : [
{
"names" : ["..." ]
}
]
}
次の項目 Linuxのseccompについて更に学びたい場合は、次の記事を参考にすると良いでしょう:
5.6 - ステートフルアプリケーション 5.6.1 - StatefulSetの基本 このチュートリアルでは、StatefulSet を使用したアプリケーションを管理するための基本を説明します。StatefulSetのPodを作成、削除、スケール、そして更新する方法について紹介します。
始める前に このチュートリアルを始める前に、以下のKubernetesの概念について理解しておく必要があります。
備考: このチュートリアルでは、クラスターがPersistentVolumeの動的なプロビジョニングが行われるように設定されていることを前提としています。クラスターがそのように設定されていない場合、チュートリアルを始める前に1GiBのボリュームを2つ手動でプロビジョニングする必要があります。目標 StatefulSetはステートフルアプリケーションや分散システムで使用するために存在します。しかし、Kubernetes上のステートフルアプリケーションや分散システムは、広範で複雑なトピックです。StatefulSetの基本的な機能を示すという目的のため、また、ステートフルアプリケーションを分散システムと混同しないようにするために、ここでは、Statefulsetを使用する単純なウェブアプリケーションのデプロイを行います。
このチュートリアルを終えると、以下のことが理解できるようになります。
StatefulSetの作成方法 StatefulSetがどのようにPodを管理するのか StatefulSetの削除方法 StatefulSetのスケール方法 StatefulSetが管理するPodの更新方法 StatefulSetを作成する はじめに、以下の例を使ってStatefulSetを作成しましょう。これは、コンセプトのStatefulSet のページで使ったものと同じような例です。nginxというheadless Service を作成し、webというStatefulSet内のPodのIPアドレスを公開します。
apiVersion : v1
kind : Service
metadata :
name : nginx
labels :
app : nginx
spec :
ports :
- port : 80
name : web
clusterIP : None
selector :
app : nginx
---
apiVersion : apps/v1
kind : StatefulSet
metadata :
name : web
spec :
serviceName : "nginx"
replicas : 2
selector :
matchLabels :
app : nginx
template :
metadata :
labels :
app : nginx
spec :
containers :
- name : nginx
image : registry.k8s.io/nginx-slim:0.8
ports :
- containerPort : 80
name : web
volumeMounts :
- name : www
mountPath : /usr/share/nginx/html
volumeClaimTemplates :
- metadata :
name : www
spec :
accessModes : [ "ReadWriteOnce" ]
resources :
requests :
storage : 1Gi
上の例をダウンロードして、web.yamlという名前で保存します。
ここでは、ターミナルウィンドウを2つ使う必要があります。1つ目のターミナルでは、kubectl get
kubectl get pods -w -l app = nginx
2つ目のターミナルでは、kubectl applyweb.yamlに定義されたheadless ServiceとStatefulSetを作成します。
kubectl apply -f web.yaml
service/nginx created
statefulset.apps/web created
上のコマンドを実行すると、2つのPodが作成され、それぞれのPodでNGINX ウェブサーバーが実行されます。nginxServiceを取得してみましょう。
kubectl get service nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx ClusterIP None <none> 80/TCP 12s
そして、webStatefulSetを取得して、2つのリソースの作成が成功したことも確認します。
kubectl get statefulset web
NAME DESIRED CURRENT AGE
web 2 1 20s
順序付きPodの作成 n 個のレプリカを持つStatefulSetは、Podをデプロイするとき、1つずつ順番に作成し、 {0..n-1} という順序付けを行います。1つ目のターミナルでkubectl getコマンドの出力を確認しましょう。最終的に、以下の例のような出力が表示されるはずです。
kubectl get pods -w -l app = nginx
NAME READY STATUS RESTARTS AGE
web-0 0/1 Pending 0 0s
web-0 0/1 Pending 0 0s
web-0 0/1 ContainerCreating 0 0s
web-0 1/1 Running 0 19s
web-1 0/1 Pending 0 0s
web-1 0/1 Pending 0 0s
web-1 0/1 ContainerCreating 0 0s
web-1 1/1 Running 0 18s
web-0Podが Running (Pod Phase を参照)かつ Ready (Pod Conditions のtypeを参照)の状態になるまでは、web-1Podが起動していないことに注目してください。
StatefulSet内のPod StatefulSet内のPodは、ユニークな順序インデックスと安定したネットワーク識別子を持ちます。
Podの順序インデックスを確かめる StatefulSetのPodを取得します。
kubectl get pods -l app = nginx
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 1m
web-1 1/1 Running 0 1m
StatefulSet のコンセプトで説明したように、StatefulSet内のPodは安定したユニークな識別子を持ちます。この識別子は、StatefulSetコントローラー によって各Podに割り当てられる、ユニークな順序インデックスに基づいて付けられます。Podの名前は、<statefulsetの名前>-<順序インデックス>という形式です。webStatefulSetは2つのレプリカを持つため、web-0とweb-1という2つのPodを作成します。
安定したネットワーク識別子の使用 各Podは、順序インデックスに基づいた安定したホスト名を持ちます。kubectl exechostnameコマンドを実行してみましょう。
for i in 0 1; do kubectl exec "web- $i " -- sh -c 'hostname' ; done
web-0
web-1
kubectl rundnsutilsパッケージのnslookupコマンドを提供するコンテナを実行します。Podのホスト名に対してnslookupを実行すると、クラスター内のDNSアドレスが確認できます。
kubectl run -i --tty --image busybox:1.28 dns-test --restart= Never --rm
これにより、新しいシェルが起動します。新しいシェルで、次のコマンドを実行します。
# このコマンドは、dns-testコンテナのシェルで実行してください
nslookup web-0.nginx
出力は次のようになります。
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-0.nginx
Address 1: 10.244.1.6
nslookup web-1.nginx
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-1.nginx
Address 1: 10.244.2.6
(コンテナのシェルを終了するために、exitコマンドを実行してください。)
headless serviceのCNAMEは、SRVレコードを指しています(1つのレコードがRunningかつReadyのPodに対応します)。SRVレコードは、PodのIPアドレスを含むAレコードを指します。
1つ目のターミナルで、StatefulSetのPodを監視します。
kubectl get pod -w -l app = nginx
2つ目のターミナルで、kubectl delete
kubectl delete pod -l app = nginx
pod "web-0" deleted
pod "web-1" deleted
StatefulSetがPodを再起動して、2つのPodがRunningかつReadyの状態に移行するのを待ちます。
kubectl get pod -w -l app = nginx
NAME READY STATUS RESTARTS AGE
web-0 0/1 ContainerCreating 0 0s
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 2s
web-1 0/1 Pending 0 0s
web-1 0/1 Pending 0 0s
web-1 0/1 ContainerCreating 0 0s
web-1 1/1 Running 0 34s
kubectl execとkubectl runコマンドを使用して、Podのホスト名とクラスター内DNSエントリーを確認します。まず、Podのホスト名を見てみましょう。
for i in 0 1; do kubectl exec web-$i -- sh -c 'hostname' ; done
web-0
web-1
その後、次のコマンドを実行します。
kubectl run -i --tty --image busybox:1.28 dns-test --restart= Never --rm
これにより、新しいシェルが起動します。新しいシェルで、次のコマンドを実行します。
# このコマンドは、dns-testコンテナのシェルで実行してください
nslookup web-0.nginx
出力は次のようになります。
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-0.nginx
Address 1: 10.244.1.7
nslookup web-1.nginx
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-1.nginx
Address 1: 10.244.2.8
(コンテナのシェルを終了するために、exitコマンドを実行してください。)
Podの順序インデックス、ホスト名、SRVレコード、そしてAレコード名は変化していませんが、Podに紐付けられたIPアドレスは変化する可能性があります。このチュートリアルで使用しているクラスターでは、IPアドレスは変わりました。このようなことがあるため、他のアプリケーションがStatefulSet内のPodに接続するときには、IPアドレスで指定しないことが重要です。
StatefulSetの有効なメンバーを探して接続する必要がある場合は、headless ServiceのCNAME(nginx.default.svc.cluster.local)をクエリしなければなりません。CNAMEに紐付けられたSRVレコードには、StatefulSet内のRunningかつReadyなPodだけが含まれます。
アプリケーションがlivenessとreadinessをテストするコネクションのロジックをすでに実装している場合、PodのSRVレコード(web-0.nginx.default.svc.cluster.local、web-1.nginx.default.svc.cluster.local)をPodが安定しているものとして使用できます。PodがRunning and Readyな状態に移行すれば、アプリケーションはPodのアドレスを発見できるようになります。
安定したストレージへの書き込み web-0およびweb-1のためのPersistentVolumeClaimを取得しましょう。
kubectl get pvc -l app = nginx
出力は次のようになります。
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
www-web-0 Bound pvc-15c268c7-b507-11e6-932f-42010a800002 1Gi RWO 48s
www-web-1 Bound pvc-15c79307-b507-11e6-932f-42010a800002 1Gi RWO 48s
StatefulSetコントローラーは、2つのPersistentVolume にバインドされた2つのPersistentVolumeClaim を作成しています。
このチュートリアルで使用しているクラスターでは、PersistentVolumeの動的なプロビジョニングが設定されているため、PersistentVolumeが自動的に作成されてバインドされています。
デフォルトでは、NGINXウェブサーバーは/usr/share/nginx/html/index.htmlに置かれたindexファイルを配信します。StatefulSetのspec内のvolumeMountsフィールドによって、/usr/share/nginx/htmlディレクトリがPersistentVolume上にあることが保証されます。
Podのホスト名をindex.htmlファイルに書き込むことで、NGINXウェブサーバーがホスト名を配信することを検証しましょう。
for i in 0 1; do kubectl exec "web- $i " -- sh -c 'echo "$(hostname)" > /usr/share/nginx/html/index.html' ; done
for i in 0 1; do kubectl exec -i -t "web- $i " -- curl http://localhost/; done
web-0
web-1
備考: 上記のcurlコマンドに対して代わりに403 Forbidden というレスポンスが返ってくる場合、volumeMountsでマウントしたディレクトリのパーミッションを修正する必要があります(これは、hostPathボリュームを使用したときに起こるバグ が原因です)。この問題に対処するには、上のcurlコマンドを再実行する前に、次のコマンドを実行します。
for i in 0 1; do kubectl exec web-$i -- chmod 755 /usr/share/nginx/html; done
1つ目のターミナルで、StatefulSetのPodを監視します。
kubectl get pod -w -l app = nginx
2つ目のターミナルで、StatefulSetのすべてのPodを削除します。
kubectl delete pod -l app = nginx
pod "web-0" deleted
pod "web-1" deleted
1つ目のターミナルでkubectl getコマンドの出力を確認して、すべてのPodがRunningかつReadyの状態に変わるまで待ちます。
kubectl get pod -w -l app = nginx
NAME READY STATUS RESTARTS AGE
web-0 0/1 ContainerCreating 0 0s
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 2s
web-1 0/1 Pending 0 0s
web-1 0/1 Pending 0 0s
web-1 0/1 ContainerCreating 0 0s
web-1 1/1 Running 0 34s
ウェブサーバーがホスト名を配信し続けていることを確認します。
for i in 0 1; do kubectl exec -i -t "web-$i" -- curl http://localhost/; done
web-0
web-1
もしweb-0およびweb-1が再スケジュールされたとしても、Podは同じホスト名を配信し続けます。これは、PodのPersistentVolumeClaimに紐付けられたPersistentVolumeが、PodのvolumeMountsに再マウントされるためです。web-0とweb-1がどんなノードにスケジュールされたとしても、PodのPersistentVolumeは適切なマウントポイントにマウントされます。
StatefulSetをスケールする StatefulSetのスケールとは、レプリカ数を増減することを意味します。これは、replicasフィールドを更新することによって実現できます。StatefulSetのスケールには、kubectl scalekubectl patch
スケールアップ 1つ目のターミナルで、StatefulSet内のPodを監視します。
kubectl get pods -w -l app = nginx
2つ目のターミナルで、kubectl scaleを使って、レプリカ数を5にスケールします。
kubectl scale sts web --replicas= 5
statefulset.apps/web scaled
1つ目のターミナルのkubectl getコマンドの出力を確認して、3つの追加のPodがRunningかつReadyの状態に変わるまで待ちます。
kubectl get pods -w -l app = nginx
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 2h
web-1 1/1 Running 0 2h
NAME READY STATUS RESTARTS AGE
web-2 0/1 Pending 0 0s
web-2 0/1 Pending 0 0s
web-2 0/1 ContainerCreating 0 0s
web-2 1/1 Running 0 19s
web-3 0/1 Pending 0 0s
web-3 0/1 Pending 0 0s
web-3 0/1 ContainerCreating 0 0s
web-3 1/1 Running 0 18s
web-4 0/1 Pending 0 0s
web-4 0/1 Pending 0 0s
web-4 0/1 ContainerCreating 0 0s
web-4 1/1 Running 0 19s
StatefulSetコントローラーはレプリカ数をスケールします。
StatefulSetを作成する で説明したように、StatefulSetコントローラーは各Podを順序インデックスに従って1つずつ作成し、次のPodを起動する前に、1つ前のPodがRunningかつReadyの状態になるまで待ちます。
スケールダウン 1つ目のターミナルで、StatefulSetのPodを監視します。
kubectl get pods -w -l app = nginx
2つ目のターミナルで、kubectl patchコマンドを使用して、StatefulSetを3つのレプリカにスケールダウンします。
kubectl patch sts web -p '{"spec":{"replicas":3}}'
statefulset.apps/web patched
web-4およびweb-3がTerminatingの状態になるまで待ちます。
kubectl get pods -w -l app = nginx
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 3h
web-1 1/1 Running 0 3h
web-2 1/1 Running 0 55s
web-3 1/1 Running 0 36s
web-4 0/1 ContainerCreating 0 18s
NAME READY STATUS RESTARTS AGE
web-4 1/1 Running 0 19s
web-4 1/1 Terminating 0 24s
web-4 1/1 Terminating 0 24s
web-3 1/1 Terminating 0 42s
web-3 1/1 Terminating 0 42s
順序付きPodを削除する コントローラーは、順序インデックスの逆順に1度に1つのPodを削除し、次のPodを削除する前には、各Podが完全にシャットダウンするまで待機しています。
StatefulSetのPersistentVolumeClaimを取得しましょう。
kubectl get pvc -l app = nginx
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
www-web-0 Bound pvc-15c268c7-b507-11e6-932f-42010a800002 1Gi RWO 13h
www-web-1 Bound pvc-15c79307-b507-11e6-932f-42010a800002 1Gi RWO 13h
www-web-2 Bound pvc-e1125b27-b508-11e6-932f-42010a800002 1Gi RWO 13h
www-web-3 Bound pvc-e1176df6-b508-11e6-932f-42010a800002 1Gi RWO 13h
www-web-4 Bound pvc-e11bb5f8-b508-11e6-932f-42010a800002 1Gi RWO 13h
まだ、5つのPersistentVolumeClaimと5つのPersistentVolumeが残っています。安定したストレージへの書き込み を読むと、StatefulSetのPodが削除されても、StatefulSetのPodにマウントされたPersistentVolumeは削除されないと書かれています。このことは、StatefulSetのスケールダウンによってPodが削除された場合にも当てはまります。
StatefulSetsを更新する Kubernetes 1.7以降では、StatefulSetコントローラーは自動アップデートをサポートしています。使われる戦略は、StatefulSet APIオブジェクトのspec.updateStrategyフィールドによって決まります。この機能はコンテナイメージのアップグレード、リソースのrequestsやlimits、ラベル、StatefulSet内のPodのアノテーションの更新時に利用できます。有効なアップデートの戦略は、RollingUpdateとOnDeleteの2種類です。
RollingUpdateは、StatefulSetのデフォルトのアップデート戦略です。
RollingUpdate RollingUpdateアップデート戦略は、StatefulSetの保証を尊重しながら、順序インデックスの逆順にStatefulSet内のすべてのPodをアップデートします。
webStatefulSetにpatchを当てて、RollingUpdateアップデート戦略を適用しましょう。
kubectl patch statefulset web -p '{"spec":{"updateStrategy":{"type":"RollingUpdate"}}}'
statefulset.apps/web patched
1つ目のターミナルで、webStatefulSetに再度patchを当てて、コンテナイメージを変更します。
kubectl patch statefulset web --type= 'json' -p= '[{"op": "replace", "path": "/spec/template/spec/containers/0/image", "value":"gcr.io/google_containers/nginx-slim:0.8"}]'
statefulset.apps/web patched
2つ目のターミナルで、StatefulSet内のPodを監視します。
kubectl get pod -l app = nginx -w
出力は次のようになります。
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 7m
web-1 1/1 Running 0 7m
web-2 1/1 Running 0 8m
web-2 1/1 Terminating 0 8m
web-2 1/1 Terminating 0 8m
web-2 0/1 Terminating 0 8m
web-2 0/1 Terminating 0 8m
web-2 0/1 Terminating 0 8m
web-2 0/1 Terminating 0 8m
web-2 0/1 Pending 0 0s
web-2 0/1 Pending 0 0s
web-2 0/1 ContainerCreating 0 0s
web-2 1/1 Running 0 19s
web-1 1/1 Terminating 0 8m
web-1 0/1 Terminating 0 8m
web-1 0/1 Terminating 0 8m
web-1 0/1 Terminating 0 8m
web-1 0/1 Pending 0 0s
web-1 0/1 Pending 0 0s
web-1 0/1 ContainerCreating 0 0s
web-1 1/1 Running 0 6s
web-0 1/1 Terminating 0 7m
web-0 1/1 Terminating 0 7m
web-0 0/1 Terminating 0 7m
web-0 0/1 Terminating 0 7m
web-0 0/1 Terminating 0 7m
web-0 0/1 Terminating 0 7m
web-0 0/1 Pending 0 0s
web-0 0/1 Pending 0 0s
web-0 0/1 ContainerCreating 0 0s
web-0 1/1 Running 0 10s
StatefulSet内のPodは、順序インデックスの逆順に更新されました。StatefulSetコントローラーは各Podを終了させ、次のPodを更新する前に、新しいPodがRunningかつReadyの状態に変わるまで待機します。ここで、StatefulSetコントローラーは順序インデックスの前のPodがRunningかつReadyの状態になるまで次のPodの更新を始めず、現在の状態へのアップデートに失敗したPodがあった場合、そのPodをリストアすることに注意してください。
すでにアップデートを受け取ったPodは、アップデートされたバージョンにリストアされます。まだアップデートを受け取っていないPodは、前のバージョンにリストアされます。このような方法により、もし途中で失敗が起こっても、コントローラーはアプリケーションが健全な状態を保ち続けられるようにし、更新が一貫したものになるようにします。
Podを取得して、コンテナイメージを確認してみましょう。
for p in 0 1 2; do kubectl get pod "web- $p " --template '{{range $i, $c := .spec.containers}}{{$c.image}}{{end}}' ; echo; done
registry.k8s.io/nginx-slim:0.8
registry.k8s.io/nginx-slim:0.8
registry.k8s.io/nginx-slim:0.8
現在、StatefulSet内のすべてのPodは、前のコンテナイメージを実行しています。
備考: kubectl rollout status sts/<name>を使って、StatefulSetへのローリングアップデートの状態を確認することもできます。ステージングアップデート RollingUpdateアップデート戦略にpartitionパラメーターを使用すると、StatefulSetへのアップデートをステージングすることができます。ステージングアップデートを利用すれば、StatefulSet内のすべてのPodを現在のバージョンにしたまま、StatefulSetの.spec.templateを変更することが可能になります。
webStatefulSetにpatchを当てて、updateStrategyフィールドにpartitionを追加しましょう。
kubectl patch statefulset web -p '{"spec":{"updateStrategy":{"type":"RollingUpdate","rollingUpdate":{"partition":3}}}}'
statefulset.apps/web patched
StatefulSetに再度patchを当てて、コンテナイメージを変更します。
kubectl patch statefulset web --type= 'json' -p= '[{"op": "replace", "path": "/spec/template/spec/containers/0/image", "value":"registry.k8s.io/nginx-slim:0.7"}]'
statefulset.apps/web patched
StatefulSet内のPodを削除します。
pod "web-2" deleted
PodがRunningかつReadyになるまで待ちます。
kubectl get pod -l app = nginx -w
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 4m
web-1 1/1 Running 0 4m
web-2 0/1 ContainerCreating 0 11s
web-2 1/1 Running 0 18s
Podのコンテナイメージを取得します。
kubectl get pod web-2 --template '{{range $i, $c := .spec.containers}}{{$c.image}}{{end}}'
registry.k8s.io/nginx-slim:0.8
アップデート戦略がRollingUpdateであっても、StatefulSetが元のコンテナを持つPodをリストアしたことがわかります。これは、Podの順序インデックスがupdateStrategyで指定したpartitionより小さいためです。
カナリア版をロールアウトする ステージングアップデート のときに指定したpartitionを小さくすることで、変更をテストするためのカナリア版をロールアウトできます。
StatefulSetにpatchを当てて、partitionを小さくします。
kubectl patch statefulset web -p '{"spec":{"updateStrategy":{"type":"RollingUpdate","rollingUpdate":{"partition":2}}}}'
statefulset.apps/web patched
web-2がRunningかつReadyの状態になるまで待ちます。
kubectl get pod -l app = nginx -w
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 4m
web-1 1/1 Running 0 4m
web-2 0/1 ContainerCreating 0 11s
web-2 1/1 Running 0 18s
Podのコンテナを取得します。
kubectl get pod web-2 --template '{{range $i, $c := .spec.containers}}{{$c.image}}{{end}}'
registry.k8s.io/nginx-slim:0.7
partitionを変更すると、StatefulSetコントローラーはPodを自動的に更新します。Podの順序インデックスがpartition以上の値であるためです。
web-1Podを削除します。
pod "web-1" deleted
web-1PodがRunningかつReadyになるまで待ちます。
kubectl get pod -l app = nginx -w
出力は次のようになります。
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 6m
web-1 0/1 Terminating 0 6m
web-2 1/1 Running 0 2m
web-1 0/1 Terminating 0 6m
web-1 0/1 Terminating 0 6m
web-1 0/1 Terminating 0 6m
web-1 0/1 Pending 0 0s
web-1 0/1 Pending 0 0s
web-1 0/1 ContainerCreating 0 0s
web-1 1/1 Running 0 18s
web-1Podのコンテナイメージを取得します。
kubectl get pod web-1 --template '{{range $i, $c := .spec.containers}}{{$c.image}}{{end}}'
registry.k8s.io/nginx-slim:0.8
Podの順序インデックスがpartitionよりも小さいため、web-1は元の設定のコンテナイメージにリストアされました。partitionを指定すると、StatefulSetの.spec.templateが更新されたときに、順序インデックスがそれ以上の値を持つすべてのPodがアップデートされます。partitionよりも小さな順序インデックスを持つPodが削除されたり終了されたりすると、元の設定のPodにリストアされます。
フェーズロールアウト カナリア版 をロールアウトするのと同じような方法でパーティションされたローリングアップデートを使用すると、フェーズロールアウト(例: 線形、幾何級数的、指数関数的ロールアウト)を実行できます。フェーズロールアウトを実行するには、コントローラーがアップデートを途中で止めてほしい順序インデックスをpartitionに設定します。
現在、partitionは2に設定されています。partitionを0に設定します。
kubectl patch statefulset web -p '{"spec":{"updateStrategy":{"type":"RollingUpdate","rollingUpdate":{"partition":0}}}}'
statefulset.apps/web patched
StatefulSet内のすべてのPodがRunningかつReadyの状態になるまで待ちます。
kubectl get pod -l app = nginx -w
出力は次のようになります。
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 3m
web-1 0/1 ContainerCreating 0 11s
web-2 1/1 Running 0 2m
web-1 1/1 Running 0 18s
web-0 1/1 Terminating 0 3m
web-0 1/1 Terminating 0 3m
web-0 0/1 Terminating 0 3m
web-0 0/1 Terminating 0 3m
web-0 0/1 Terminating 0 3m
web-0 0/1 Terminating 0 3m
web-0 0/1 Pending 0 0s
web-0 0/1 Pending 0 0s
web-0 0/1 ContainerCreating 0 0s
web-0 1/1 Running 0 3s
StatefulSet内のPodのコンテナイメージの詳細を取得します。
for p in 0 1 2; do kubectl get pod "web- $p " --template '{{range $i, $c := .spec.containers}}{{$c.image}}{{end}}' ; echo; done
registry.k8s.io/nginx-slim:0.7
registry.k8s.io/nginx-slim:0.7
registry.k8s.io/nginx-slim:0.7
partitionを0に移動することで、StatefulSetがアップデート処理を続けられるようにできます。
OnDelete OnDeleteアップデート戦略は、(1.6以前の)レガシーな動作を実装しています。このアップデート戦略を選択すると、StatefulSetの.spec.templateフィールドへ変更を加えても、StatefulSetコントローラーが自動的にPodを更新しなくなります。この戦略を選択するには、.spec.template.updateStrategy.typeにOnDeleteを設定します。
StatefulSetを削除する StatefulSetは、非カスケードな削除とカスケードな削除の両方をサポートしています。非カスケードな削除では、StatefulSetが削除されても、StatefulSet内のPodは削除されません。カスケードな削除では、StatefulSetとPodが一緒に削除されます。
非カスケードな削除 1つ目のターミナルで、StatefulSet内のPodを監視します
kubectl get pods -w -l app=nginx
kubectl delete--cascade=orphanパラメーターをコマンドに与えてください。このパラメーターは、Kubernetesに対して、StatefulSetだけを削除して配下のPodは削除しないように指示します。
kubectl delete statefulset web --cascade= orphan
statefulset.apps "web" deleted
Podを取得して、ステータスを確認します。
kubectl get pods -l app = nginx
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 6m
web-1 1/1 Running 0 7m
web-2 1/1 Running 0 5m
webが削除されても、すべてのPodはまだRunningかつReadyの状態のままです。web-0を削除します。
pod "web-0" deleted
StatefulSetのPodを取得します。
kubectl get pods -l app = nginx
NAME READY STATUS RESTARTS AGE
web-1 1/1 Running 0 10m
web-2 1/1 Running 0 7m
webStatefulSetはすでに削除されているため、web-0は再起動しません。
1つ目のターミナルで、StatefulSetのPodを監視します。
kubectl get pods -w -l app = nginx
2つ目のターミナルで、StatefulSetを再作成します。もしnginxServiceを削除しなかった場合(この場合は削除するべきではありませんでした)、Serviceがすでに存在することを示すエラーが表示されます。
kubectl apply -f web.yaml
statefulset.apps/web created
service/nginx unchanged
このエラーは無視してください。このメッセージは、すでに存在する nginx というheadless Serviceを作成しようと試みたということを示しているだけです。
1つ目のターミナルで、kubectl getコマンドの出力を確認します。
kubectl get pods -w -l app = nginx
NAME READY STATUS RESTARTS AGE
web-1 1/1 Running 0 16m
web-2 1/1 Running 0 2m
NAME READY STATUS RESTARTS AGE
web-0 0/1 Pending 0 0s
web-0 0/1 Pending 0 0s
web-0 0/1 ContainerCreating 0 0s
web-0 1/1 Running 0 18s
web-2 1/1 Terminating 0 3m
web-2 0/1 Terminating 0 3m
web-2 0/1 Terminating 0 3m
web-2 0/1 Terminating 0 3m
webStatefulSetが再作成されると、最初にweb-0を再実行します。web-1はすでにRunningかつReadyの状態であるため、web-0がRunningかつReadyの状態に移行すると、StatefulSetは単純にこのPodを選びます。StatefulSetをreplicasを2にして再作成したため、一度web-0が再作成されて、web-1がすでにRunningかつReadyの状態であることが判明したら、web-2は停止されます。
Podのウェブサーバーが配信しているindex.htmlファイルのコンテンツをもう一度見てみましょう。
for i in 0 1; do kubectl exec -i -t "web- $i " -- curl http://localhost/; done
web-0
web-1
たとえStatefulSetとweb-0Podの両方が削除されても、Podは最初にindex.htmlファイルに書き込んだホスト名をまだ配信しています。これは、StatefulSetがPodに紐付けられたPersistentVolumeを削除しないためです。StatefulSetを再作成してweb-0を再実行すると、元のPersistentVolumeが再マウントされます。
カスケードな削除 1つ目のターミナルで、StatefulSet内のPodを監視します。
kubectl get pods -w -l app = nginx
2つ目のターミナルで、StatefulSetをもう一度削除します。今回は、--cascade=orphanパラメーターを省略します。
kubectl delete statefulset web
statefulset.apps "web" deleted
1つ目のターミナルで実行しているkubectl getコマンドの出力を確認し、すべてのPodがTerminatingの状態に変わるまで待ちます。
kubectl get pods -w -l app = nginx
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 11m
web-1 1/1 Running 0 27m
NAME READY STATUS RESTARTS AGE
web-0 1/1 Terminating 0 12m
web-1 1/1 Terminating 0 29m
web-0 0/1 Terminating 0 12m
web-0 0/1 Terminating 0 12m
web-0 0/1 Terminating 0 12m
web-1 0/1 Terminating 0 29m
web-1 0/1 Terminating 0 29m
web-1 0/1 Terminating 0 29m
スケールダウン のセクションで見たように、順序インデックスの逆順に従って、Podは一度に1つずつ終了します。StatefulSetコントローラーは、次のPodを終了する前に、前のPodが完全に終了するまで待ちます。
備考: カスケードな削除ではStatefulSetがPodとともに削除されますが、StatefulSetと紐付けられたheadless Serviceは削除されません。そのため、nginxServiceは手動で削除する必要があります。kubectl delete service nginx
service "nginx" deleted
さらにもう一度、StatefulSetとheadless Serviceを再作成します。
kubectl apply -f web.yaml
service/nginx created
statefulset.apps/web created
StatefulSet上のすべてのPodがRunningかつReadyの状態に変わったら、Pod上のindex.htmlファイルのコンテンツを取得します。
for i in 0 1; do kubectl exec -i -t "web- $i " -- curl http://localhost/; done
web-0
web-1
StatefulSetを完全に削除して、すべてのPodが削除されたとしても、PersistentVolumeがマウントされたPodが再生成されて、web-0とweb-1はホスト名の配信を続けます。
最後に、webStatefulSetを削除します。
kubectl delete service nginx
service "nginx" deleted
そして、nginxServiceも削除します。
kubectl delete statefulset web
statefulset "web" deleted
Pod管理ポリシー 分散システムによっては、StatefulSetの順序の保証が不必要であったり望ましくない場合もあります。こうしたシステムでは、一意性と同一性だけが求められます。この問題に対処するために、Kubernetes 1.7でStatefulSet APIオブジェクトに.spec.podManagementPolicyが導入されました。
OrderedReadyのPod管理 OrderedReadyのPod管理はStatefulSetのデフォルトの設定です。StatefulSetコントローラーに対して、これまでに紹介したような順序の保証を尊重するように指示します。
ParallelのPod管理 ParallelのPod管理では、StatefulSetコントローラーに対して、PodがRunningかつReadyの状態や完全に停止するまで待たないように指示し、すべてのPodを並列に起動または停止させるようにします。
apiVersion : v1
kind : Service
metadata :
name : nginx
labels :
app : nginx
spec :
ports :
- port : 80
name : web
clusterIP : None
selector :
app : nginx
---
apiVersion : apps/v1
kind : StatefulSet
metadata :
name : web
spec :
serviceName : "nginx"
podManagementPolicy : "Parallel"
replicas : 2
selector :
matchLabels :
app : nginx
template :
metadata :
labels :
app : nginx
spec :
containers :
- name : nginx
image : registry.k8s.io/nginx-slim:0.8
ports :
- containerPort : 80
name : web
volumeMounts :
- name : www
mountPath : /usr/share/nginx/html
volumeClaimTemplates :
- metadata :
name : www
spec :
accessModes : [ "ReadWriteOnce" ]
resources :
requests :
storage : 1Gi
上の例をダウンロードして、web-parallel.yamlという名前でファイルに保存してください。
このマニフェストは、.spec.podManagementPolicyがParallelに設定されている以外は、前にダウンロードしたwebStatefulSetと同一です。
1つ目のターミナルで、StatefulSet内のPodを監視します。
kubectl get pod -l app = nginx -w
2つ目のターミナルで、マニフェスト内のStatefulSetとServiceを作成します。
kubectl apply -f web-parallel.yaml
service/nginx created
statefulset.apps/web created
1つ目のターミナルで実行したkubectl getコマンドの出力を確認します。
kubectl get pod -l app = nginx -w
NAME READY STATUS RESTARTS AGE
web-0 0/1 Pending 0 0s
web-0 0/1 Pending 0 0s
web-1 0/1 Pending 0 0s
web-1 0/1 Pending 0 0s
web-0 0/1 ContainerCreating 0 0s
web-1 0/1 ContainerCreating 0 0s
web-0 1/1 Running 0 10s
web-1 1/1 Running 0 10s
StatefulSetコントローラーはweb-0とweb-1を同時に起動しています。
2つ目のターミナルで、StatefulSetをスケールしてみます。
kubectl scale statefulset/web --replicas= 4
statefulset.apps/web scaled
kubectl getコマンドを実行しているターミナルの出力を確認します。
web-3 0/1 Pending 0 0s
web-3 0/1 Pending 0 0s
web-3 0/1 Pending 0 7s
web-3 0/1 ContainerCreating 0 7s
web-2 1/1 Running 0 10s
web-3 1/1 Running 0 26s
StatefulSetが2つのPodを実行し、1つ目のPodがRunningかつReadyの状態になるのを待たずに2つ目のPodを実行しているのがわかります。
クリーンアップ 2つのターミナルが開かれているはずなので、クリーンアップの一部としてkubectlコマンドを実行する準備ができています。
kubectl delete sts web
# stsは、statefulsetの略です。
kubectl getを監視すると、Podが削除されていく様子を確認できます。
kubectl get pod -l app = nginx -w
web-3 1/1 Terminating 0 9m
web-2 1/1 Terminating 0 9m
web-3 1/1 Terminating 0 9m
web-2 1/1 Terminating 0 9m
web-1 1/1 Terminating 0 44m
web-0 1/1 Terminating 0 44m
web-0 0/1 Terminating 0 44m
web-3 0/1 Terminating 0 9m
web-2 0/1 Terminating 0 9m
web-1 0/1 Terminating 0 44m
web-0 0/1 Terminating 0 44m
web-2 0/1 Terminating 0 9m
web-2 0/1 Terminating 0 9m
web-2 0/1 Terminating 0 9m
web-1 0/1 Terminating 0 44m
web-1 0/1 Terminating 0 44m
web-1 0/1 Terminating 0 44m
web-0 0/1 Terminating 0 44m
web-0 0/1 Terminating 0 44m
web-0 0/1 Terminating 0 44m
web-3 0/1 Terminating 0 9m
web-3 0/1 Terminating 0 9m
web-3 0/1 Terminating 0 9m
削除の間、StatefulSetはすべてのPodを並列に削除し、順序インデックスが1つ前のPodが停止するのを待つことはありません。
kubectl getコマンドを実行しているターミナルを閉じて、nginxServiceを削除します。
備考: このチュートリアルで使用したPersistentVolumeのための永続ストレージも削除する必要があります。
すべてのストレージが再利用できるようにするために、環境、ストレージの設定、プロビジョニング方法に基づいて必要な手順に従ってください。
5.6.2 - 例: Persistent Volumeを使用したWordpressとMySQLをデプロイする このチュートリアルでは、WordPressのサイトとMySQLデータベースをMinikubeを使ってデプロイする方法を紹介します。2つのアプリケーションとも、データを保存するためにPersistentVolumeとPersistentVolumeClaimを使用します。
PersistentVolume (PV)とは、管理者が手動でプロビジョニングを行うか、StorageClass を使ってKubernetesによって動的にプロビジョニングされた、クラスター内のストレージの一部です。PersistentVolumeClaim (PVC)は、PVによって満たすことができる、ユーザーによるストレージへのリクエストのことです。PersistentVolumeとPersistentVolumeClaimは、Podのライフサイクルからは独立していて、Podの再起動、Podの再スケジューリング、さらにはPodの削除が行われたとしても、その中のデータは削除されずに残ります。
警告: シングルインスタンスのWordPressとMySQLのPodを使用しているため、ここで行うデプロイは本番のユースケースには適しません。WordPressを本番環境にデプロイするときは、
WordPress Helm Chart を使用することを検討してください。
備考: このチュートリアルで提供されるファイルは、GAとなっているDeployment APIを使用しているため、Kubernetesバージョン1.9以降のためのものになっています。もしこのチュートリアルを古いバージョンのKubernetesで使いたい場合は、APIのバージョンを適切にアップデートするか、このチュートリアルの古いバージョンを参照してください。目標 PersistentVolumeClaimとPersistentVolumeを作成する 以下を含むkustomization.yamlを作成するSecret generator MySQLリソースの設定 WordPressリソースの設定 kustomizationディレクトリをkubectl apply -k ./で適用する クリーンアップする 始める前に
Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
このページで示された例は、
kubectl 1.14以降で動作します。
以下の設定ファイルをダウンロードします。
mysql-deployment.yaml
wordpress-deployment.yaml
PersistentVolumeClaimとPersistentVolumeを作成する MySQLとWordpressはそれぞれ、データを保存するためのPersistentVolumeを必要とします。各PersistentVolumeClaimはデプロイの段階で作成されます。
多くのクラスター環境では、デフォルトのStorageClassがインストールされています。StorageClassがPersistentVolumeClaim中で指定されていなかった場合、クラスターのデフォルトのStorageClassが代わりに使われます。
PersistentVolumeClaimが作成されるとき、StorageClassの設定に基づいてPersistentVolumeが動的にプロビジョニングされます。
警告: ローカルのクラスターでは、デフォルトのStorageClassにはhostPathプロビジョナーが使われます。hostPathボリュームは開発およびテストにのみ適しています。hostPathボリュームでは、データはPodがスケジュールされたノード上の/tmp内に保存されます。そのため、もしPodが死んだり、クラスター上の他のノードにスケジュールされたり、ノードが再起動すると、データは失われます。
備考: hostPathプロビジョナーを使用する必要があるクラスターを立ち上げたい場合は、--enable-hostpath-provisionerフラグを controller-manager コンポーネントで設定する必要があります。備考: Google Kubernetes Engine上で動作するKubernetesクラスターを使っている場合は、
このガイド に従ってください。
kustomization.yamlを作成する Secret generatorを追加する Secret とは、パスワードやキーのような機密性の高いデータ片を保存するためのオブジェクトです。バージョン1.14からは、kubectlがkustomizationファイルを使用したKubernetesオブジェクトの管理をサポートしています。kustomization.yaml内のgeneratorによってSecretを作成することができます。
以下のコマンドを実行して、kustomization.yamlの中にSecret generatorを追加します。YOUR_PASSWORDの部分を使いたいパスワードに置換してください。
cat <<EOF >./kustomization.yaml
secretGenerator:
- name: mysql-pass
literals:
- password=YOUR_PASSWORD
EOF
MySQLとWordPressのためのリソースの設定を追加する 以下のマニフェストには、シングルインスタンスのMySQLのDeploymentが書かれています。MySQLコンテナはPersistentVolumeを/var/lib/mysqlにマウントします。MYSQL_ROOT_PASSWORD環境変数には、Secretから得られたデータベースのパスワードが設定されます。
apiVersion : v1
kind : Service
metadata :
name : wordpress-mysql
labels :
app : wordpress
spec :
ports :
- port : 3306
selector :
app : wordpress
tier : mysql
clusterIP : None
---
apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : mysql-pv-claim
labels :
app : wordpress
spec :
accessModes :
- ReadWriteOnce
resources :
requests :
storage : 20Gi
---
apiVersion : apps/v1
kind : Deployment
metadata :
name : wordpress-mysql
labels :
app : wordpress
spec :
selector :
matchLabels :
app : wordpress
tier : mysql
strategy :
type : Recreate
template :
metadata :
labels :
app : wordpress
tier : mysql
spec :
containers :
- image : mysql:8.0
name : mysql
env :
- name : MYSQL_ROOT_PASSWORD
valueFrom :
secretKeyRef :
name : mysql-pass
key : password
- name : MYSQL_DATABASE
value : wordpress
- name : MYSQL_USER
value : wordpress
- name : MYSQL_PASSWORD
valueFrom :
secretKeyRef :
name : mysql-pass
key : password
ports :
- containerPort : 3306
name : mysql
volumeMounts :
- name : mysql-persistent-storage
mountPath : /var/lib/mysql
volumes :
- name : mysql-persistent-storage
persistentVolumeClaim :
claimName : mysql-pv-claim
以下のマニフェストには、シングルインスタンスのWordPressのDeploymentが書かれています。WordPressコンテナはPersistentVolumeをウェブサイトのデータファイルのために/var/www/htmlにマウントします。WORDPRESS_DB_HOST環境変数に上で定義したMySQLのServiceの名前を設定すると、WordPressはServiceによってデータベースにアクセスします。WORDPRESS_DB_PASSWORD環境変数には、kustomizeが生成したSecretから得たデータベースのパスワードが設定されます。
apiVersion : v1
kind : Service
metadata :
name : wordpress
labels :
app : wordpress
spec :
ports :
- port : 80
selector :
app : wordpress
tier : frontend
type : LoadBalancer
---
apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : wp-pv-claim
labels :
app : wordpress
spec :
accessModes :
- ReadWriteOnce
resources :
requests :
storage : 20Gi
---
apiVersion : apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind : Deployment
metadata :
name : wordpress
labels :
app : wordpress
spec :
selector :
matchLabels :
app : wordpress
tier : frontend
strategy :
type : Recreate
template :
metadata :
labels :
app : wordpress
tier : frontend
spec :
containers :
- image : wordpress:4.8-apache
name : wordpress
env :
- name : WORDPRESS_DB_HOST
value : wordpress-mysql
- name : WORDPRESS_DB_PASSWORD
valueFrom :
secretKeyRef :
name : mysql-pass
key : password
ports :
- containerPort : 80
name : wordpress
volumeMounts :
- name : wordpress-persistent-storage
mountPath : /var/www/html
volumes :
- name : wordpress-persistent-storage
persistentVolumeClaim :
claimName : wp-pv-claim
MySQLのDeploymentの設定ファイルをダウンロードします。
curl -LO https://k8s.io/examples/application/wordpress/mysql-deployment.yaml
WordPressの設定ファイルをダウンロードします。
curl -LO https://k8s.io/examples/application/wordpress/wordpress-deployment.yaml
これらをkustomization.yamlファイルに追加します。
cat <<EOF >>./kustomization.yaml
resources:
- mysql-deployment.yaml
- wordpress-deployment.yaml
EOF
適用と確認 kustomization.yamlには、WordPressのサイトとMySQLデータベースのためのすべてのリソースが含まれています。次のコマンドでこのディレクトリを適用できます。
これで、すべてのオブジェクトが存在していることを確認できます。
次のコマンドを実行して、Secretが存在していることを確認します。
結果は次のようになるはずです。
NAME TYPE DATA AGE
mysql-pass-c57bb4t7mf Opaque 1 9s
次のコマンドを実行して、PersistentVolumeが動的にプロビジョニングされていることを確認します。
備考: PVがプロビジョニングされてバインドされるまでに、最大で数分かかる場合があります。
結果は次のようになるはずです。
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mysql-pv-claim Bound pvc-8cbd7b2e-4044-11e9-b2bb-42010a800002 20Gi RWO standard 77s
wp-pv-claim Bound pvc-8cd0df54-4044-11e9-b2bb-42010a800002 20Gi RWO standard 77s
次のコマンドを実行して、Podが実行中であることを確認します。
備考: PodのStatusが`Running`の状態になる前に、最大で数分かかる場合があります。
結果は次のようになるはずです。
NAME READY STATUS RESTARTS AGE
wordpress-mysql-1894417608-x5dzt 1/1 Running 0 40s
次のコマンドを実行して、Serviceが実行中であることを確認します。
kubectl get services wordpress
結果は次のようになるはずです。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
wordpress LoadBalancer 10.0.0.89 <pending> 80:32406/TCP 4m
備考: MinikubeではServiceを`NodePort`経由でしか公開できません。EXTERNAL-IPは常にpendingのままになります。
次のコマンドを実行して、WordPress ServiceのIPアドレスを取得します。
minikube service wordpress --url
結果は次のようになるはずです。
http://1.2.3.4:32406
IPアドレスをコピーして、ブラウザーで読み込み、サイトを表示しましょう。
WordPressによりセットアップされた次のスクリーンショットのようなページが表示されるはずです。
警告: WordPressのインストールをこのページのまま放置してはいけません。もしほかのユーザーがこのページを見つけた場合、その人はインスタンス上にウェブサイトをセットアップして、悪意のあるコンテンツの配信に利用できてしまいます。クリーンアップ 次のコマンドを実行して、Secret、Deployment、Service、およびPersistentVolumeClaimを削除します。
次の項目 5.6.3 - 例: StatefulSetを使用したCassandraのデプロイ このチュートリアルでは、Apache Cassandra をKubernetes上で実行する方法を紹介します。
データベースの一種であるCassandraには、データの耐久性(アプリケーションの 状態 )を提供するために永続ストレージが必要です。
この例では、カスタムのCassandraのseed providerにより、Cassandraクラスターに参加した新しいCassandraインスタンスを検出できるようにします。
StatefulSet を利用すると、ステートフルなアプリケーションをKubernetesクラスターにデプロイするのが簡単になります。
このチュートリアルで使われている機能のより詳しい情報は、StatefulSet を参照してください。
備考: CassandraとKubernetesは、ともにクラスターのメンバーを表すために ノード という用語を使用しています。このチュートリアルでは、StatefulSetに属するPodはCassandraのノードであり、Cassandraクラスター( ring と呼ばれます)のメンバーでもあります。これらのPodがKubernetesクラスター内で実行されるとき、Kubernetesのコントロールプレーンは、PodをKubernetesのNode 上にスケジュールします。
Cassandraノードが開始すると、 シードリスト を使ってring上の他のノードの検出が始まります。
このチュートリアルでは、Kubernetesクラスター内に現れた新しいCassandra Podを検出するカスタムのCassandraのseed providerをデプロイします。
目標 Cassandraのheadless Service を作成して検証する。 StatefulSet を使用してCassandra ringを作成する。StatefulSetを検証する。 StatefulSetを編集する。 StatefulSetとPod を削除する。 始める前に Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
このチュートリアルを完了するには、Pod 、Service 、StatefulSet の基本についてすでに知っている必要があります。
Minikubeのセットアップに関する追加の設定手順 注意: Minikube は、デフォルトでは1024MiBのメモリと1CPUに設定されます。
デフォルトのリソース設定で起動したMinikubeでは、このチュートリアルの実行中にリソース不足のエラーが発生してしまいます。このエラーを回避するためにはMinikubeを次の設定で起動してください:
minikube start --memory 5120 --cpus= 4
Cassandraのheadless Serviceを作成する Kubernetesでは、Service は同じタスクを実行するPod の集合を表します。
以下のServiceは、Cassandra Podとクラスター内のクライアント間のDNSルックアップに使われます:
apiVersion : v1
kind : Service
metadata :
labels :
app : cassandra
name : cassandra
spec :
clusterIP : None
ports :
- port : 9042
selector :
app : cassandra
cassandra-service.yamlファイルから、Cassandra StatefulSetのすべてのメンバーをトラッキングするServiceを作成します。
kubectl apply -f https://k8s.io/examples/application/cassandra/cassandra-service.yaml
検証 (オプション) Cassandra Serviceを取得します。
kubectl get svc cassandra
結果は次のようになります。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
cassandra ClusterIP None <none> 9042/TCP 45s
cassandraという名前のServiceが表示されない場合、作成に失敗しています。よくある問題のトラブルシューティングについては、Serviceのデバッグ を読んでください。
StatefulSetを使ってCassandra ringを作成する 以下に示すStatefulSetマニフェストは、3つのPodからなるCassandra ringを作成します。
備考: この例ではMinikubeのデフォルトのプロビジョナーを使用しています。
クラウドを使用している場合、StatefulSetを更新してください。apiVersion : apps/v1
kind : StatefulSet
metadata :
name : cassandra
labels :
app : cassandra
spec :
serviceName : cassandra
replicas : 3
selector :
matchLabels :
app : cassandra
template :
metadata :
labels :
app : cassandra
spec :
terminationGracePeriodSeconds : 500
containers :
- name : cassandra
image : gcr.io/google-samples/cassandra:v13
imagePullPolicy : Always
ports :
- containerPort : 7000
name : intra-node
- containerPort : 7001
name : tls-intra-node
- containerPort : 7199
name : jmx
- containerPort : 9042
name : cql
resources :
limits :
cpu : "500m"
memory : 1Gi
requests :
cpu : "500m"
memory : 1Gi
securityContext :
capabilities :
add :
- IPC_LOCK
lifecycle :
preStop :
exec :
command :
- /bin/sh
- -c
- nodetool drain
env :
- name : MAX_HEAP_SIZE
value : 512M
- name : HEAP_NEWSIZE
value : 100M
- name : CASSANDRA_SEEDS
value : "cassandra-0.cassandra.default.svc.cluster.local"
- name : CASSANDRA_CLUSTER_NAME
value : "K8Demo"
- name : CASSANDRA_DC
value : "DC1-K8Demo"
- name : CASSANDRA_RACK
value : "Rack1-K8Demo"
- name : POD_IP
valueFrom :
fieldRef :
fieldPath : status.podIP
readinessProbe :
exec :
command :
- /bin/bash
- -c
- /ready-probe.sh
initialDelaySeconds : 15
timeoutSeconds : 5
# These volume mounts are persistent. They are like inline claims,
# but not exactly because the names need to match exactly one of
# the stateful pod volumes.
volumeMounts :
- name : cassandra-data
mountPath : /cassandra_data
# These are converted to volume claims by the controller
# and mounted at the paths mentioned above.
# do not use these in production until ssd GCEPersistentDisk or other ssd pd
volumeClaimTemplates :
- metadata :
name : cassandra-data
spec :
accessModes : [ "ReadWriteOnce" ]
storageClassName : fast
resources :
requests :
storage : 1Gi
---
kind : StorageClass
apiVersion : storage.k8s.io/v1
metadata :
name : fast
provisioner : k8s.io/minikube-hostpath
parameters :
type : pd-ssd
cassandra-statefulset.yamlファイルから、CassandraのStatefulSetを作成します:
# cassandra-statefulset.yaml を編集せずにapplyできる場合は、このコマンドを使用してください
kubectl apply -f https://k8s.io/examples/application/cassandra/cassandra-statefulset.yaml
クラスターに合わせてcassandra-statefulset.yamlを編集する必要がある場合、 https://k8s.io/examples/application/cassandra/cassandra-statefulset.yaml をダウンロードして、修正したバージョンを保存したフォルダからマニフェストを適用してください。
# cassandra-statefulset.yaml をローカルで編集する必要がある場合、このコマンドを使用してください
kubectl apply -f cassandra-statefulset.yaml
CassandraのStatefulSetを検証する CassandraのStatefulSetを取得します
kubectl get statefulset cassandra
結果は次のようになるはずです:
NAME DESIRED CURRENT AGE
cassandra 3 0 13s
StatefulSetリソースがPodを順番にデプロイします。
Podを取得して順序付きの作成ステータスを確認します
kubectl get pods -l= "app=cassandra"
結果は次のようになるはずです:
NAME READY STATUS RESTARTS AGE
cassandra-0 1/1 Running 0 1m
cassandra-1 0/1 ContainerCreating 0 8s
3つすべてのPodのデプロイには数分かかる場合があります。デプロイが完了すると、同じコマンドは次のような結果を返します:
NAME READY STATUS RESTARTS AGE
cassandra-0 1/1 Running 0 10m
cassandra-1 1/1 Running 0 9m
cassandra-2 1/1 Running 0 8m
1番目のPodの中でCassandraのnodetool を実行して、ringのステータスを表示します。
kubectl exec -it cassandra-0 -- nodetool status
結果は次のようになるはずです:
Datacenter: DC1-K8Demo
======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 172.17.0.5 83.57 KiB 32 74.0% e2dd09e6-d9d3-477e-96c5-45094c08db0f Rack1-K8Demo
UN 172.17.0.4 101.04 KiB 32 58.8% f89d6835-3a42-4419-92b3-0e62cae1479c Rack1-K8Demo
UN 172.17.0.6 84.74 KiB 32 67.1% a6a1e8c2-3dc5-4417-b1a0-26507af2aaad Rack1-K8Demo
CassandraのStatefulSetを変更する kubectl editを使うと、CassandraのStatefulSetのサイズを変更できます。
次のコマンドを実行します。
kubectl edit statefulset cassandra
このコマンドを実行すると、ターミナルでエディタが起動します。変更が必要な行はreplicasフィールドです。
以下の例は、StatefulSetファイルの抜粋です:
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion : apps/v1
kind : StatefulSet
metadata :
creationTimestamp : 2016-08-13T18:40:58Z
generation : 1
labels :
app : cassandra
name : cassandra
namespace : default
resourceVersion : "323"
uid : 7a219483-6185-11e6-a910-42010a8a0fc0
spec :
replicas : 3
レプリカ数を4に変更し、マニフェストを保存します。
これで、StatefulSetが4つのPodを実行するようにスケールされました。
CassandraのStatefulSetを取得して、変更を確かめます:
kubectl get statefulset cassandra
結果は次のようになるはずです:
NAME DESIRED CURRENT AGE
cassandra 4 4 36m
クリーンアップ StatefulSetを削除したりスケールダウンしても、StatefulSetに関係するボリュームは削除されません。
StatefulSetに関連するすべてのリソースを自動的に破棄するよりも、データの方がより貴重であるため、安全のためにこのような設定になっています。
警告: ストレージクラスやreclaimポリシーによっては、PersistentVolumeClaim を削除すると、関連するボリュームも削除される可能性があります。PersistentVolumeClaimの削除後にもデータにアクセスできるとは決して想定しないでください。次のコマンドを実行して(単一のコマンドにまとめています)、CassandraのStatefulSetに含まれるすべてのリソースを削除します:
grace = $( kubectl get pod cassandra-0 -o= jsonpath = '{.spec.terminationGracePeriodSeconds}' ) \
&& kubectl delete statefulset -l app = cassandra \
&& echo "Sleeping ${ grace } seconds" 1>&2 \
&& sleep $grace \
&& kubectl delete persistentvolumeclaim -l app = cassandra
次のコマンドを実行して、CassandraをセットアップしたServiceを削除します:
kubectl delete service -l app = cassandra
Cassandraコンテナの環境変数 このチュートリアルのPodでは、Googleのコンテナレジストリ のgcr.io/google-samples/cassandra:v13debian-base をベースにしており、OpenJDK 8が含まれています。
このイメージには、Apache Debianリポジトリの標準のCassandraインストールが含まれます。
環境変数を利用すると、cassandra.yamlに挿入された値を変更できます。
環境変数 デフォルト値 CASSANDRA_CLUSTER_NAME'Test Cluster'CASSANDRA_NUM_TOKENS32CASSANDRA_RPC_ADDRESS0.0.0.0
次の項目 5.6.4 - 分散システムコーディネーターZooKeeperの実行 このチュートリアルでは、StatefulSet 、PodDisruptionBudgets 、Podアンチアフィニティ を使って、Kubernetes上でのApache Zookeeper の実行をデモンストレーションします。
始める前に このチュートリアルを始める前に、以下のKubernetesの概念について理解しておく必要があります。
少なくとも4つのノードのクラスターが必要で、各ノードは少なくとも2つのCPUと4GiBのメモリが必須です。このチュートリアルでは、クラスターのノードをcordonおよびdrainします。
つまり、クラスターがそのノードの全てのPodを終了して退去させ、ノードが一時的にスケジュールできなくなる、ということです。
このチュートリアル専用のクラスターを使うか、起こした破壊がほかのテナントに干渉しない確証を得ることをお勧めします。
このチュートリアルでは、クラスターがPersistentVolumeの動的なプロビジョニングが行われるように設定されていることを前提としています。
クラスターがそのように設定されていない場合、チュートリアルを始める前に20GiBのボリュームを3つ、手動でプロビジョニングする必要があります。
目標 このチュートリアルを終えると、以下の知識を得られます。
StatefulSetを使ってZooKeeperアンサンブルをデプロイする方法。 アンサンブルを一貫して設定する方法。 ZooKeeperサーバーのデプロイをアンサンブルに広げる方法。 計画されたメンテナンス中もサービスが利用可能であることを保証するためにPodDisruptionBudgetsを使う方法。 ZooKeeper Apache ZooKeeper は、分散アプリケーションのための、分散型オープンソースコーディネーションサービスです。
ZooKeeperでは、データの読み書き、および更新の監視ができます。
データは階層化されてファイルシステム内に編成され、アンサンブル(ZooKeeperサーバーのセット)内の全てのZooKeeperサーバーに複製されます。
データへの全ての操作はアトミックかつ逐次的に一貫性を持ちます。
ZooKeeperは、アンサンブル内の全てのサーバー間でステートマシンを複製するためにZab 合意プロトコルを使ってこれを保証します。
アンサンブルはリーダーを選出するのにZabプロトコルを使い、選出が完了するまでデータを書き出しません。
完了すると、アンサンブルは複製するのにZabを使い、書き込みが承認されてクライアントに可視化されるより前に、全ての書き込みをクォーラムに複製することを保証します。
重み付けされたクォーラムでなければ、クォーラムは現在のリーダーを含むアンサンブルの過半数を占めるコンポーネントです。
例えばアンサンブルが3つのサーバーを持つ時、リーダーとそれ以外のもう1つのサーバーを含むコンポーネントが、クォーラムを構成します。
アンサンブルがクォーラムに達しない場合、アンサンブルはデータを書き出せません。
ZooKeeperサーバー群はそれらの全てのステートマシンをメモリに保持し、それぞれの変化をストレージメディア上の永続的なWAL(Write Ahead Log)に書き出します。
サーバーがクラッシュした時には、WALをリプレーすることで以前のステートに回復できます。
WALを際限のない増加から防ぐために、ZooKeeperサーバーは、メモリステートにあるものをストレージメディアに定期的にスナップショットします。
これらのスナップショットはメモリに直接読み込むことができ、スナップショットより前の全てのWALエントリは破棄され得ます。
ZooKeeperアンサンブルの作成 以下のマニフェストはHeadless Service 、Service 、PodDisruptionBudget 、StatefulSet を含んでいます。
apiVersion : v1
kind : Service
metadata :
name : zk-hs
labels :
app : zk
spec :
ports :
- port : 2888
name : server
- port : 3888
name : leader-election
clusterIP : None
selector :
app : zk
---
apiVersion : v1
kind : Service
metadata :
name : zk-cs
labels :
app : zk
spec :
ports :
- port : 2181
name : client
selector :
app : zk
---
apiVersion : policy/v1
kind : PodDisruptionBudget
metadata :
name : zk-pdb
spec :
selector :
matchLabels :
app : zk
maxUnavailable : 1
---
apiVersion : apps/v1
kind : StatefulSet
metadata :
name : zk
spec :
selector :
matchLabels :
app : zk
serviceName : zk-hs
replicas : 3
updateStrategy :
type : RollingUpdate
podManagementPolicy : OrderedReady
template :
metadata :
labels :
app : zk
spec :
affinity :
podAntiAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
- labelSelector :
matchExpressions :
- key : "app"
operator : In
values :
- zk
topologyKey : "kubernetes.io/hostname"
containers :
- name : kubernetes-zookeeper
imagePullPolicy : Always
image : "registry.k8s.io/kubernetes-zookeeper:1.0-3.4.10"
resources :
requests :
memory : "1Gi"
cpu : "0.5"
ports :
- containerPort : 2181
name : client
- containerPort : 2888
name : server
- containerPort : 3888
name : leader-election
command :
- sh
- -c
- "start-zookeeper \
--servers=3 \
--data_dir=/var/lib/zookeeper/data \
--data_log_dir=/var/lib/zookeeper/data/log \
--conf_dir=/opt/zookeeper/conf \
--client_port=2181 \
--election_port=3888 \
--server_port=2888 \
--tick_time=2000 \
--init_limit=10 \
--sync_limit=5 \
--heap=512M \
--max_client_cnxns=60 \
--snap_retain_count=3 \
--purge_interval=12 \
--max_session_timeout=40000 \
--min_session_timeout=4000 \
--log_level=INFO"
readinessProbe :
exec :
command :
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds : 10
timeoutSeconds : 5
livenessProbe :
exec :
command :
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds : 10
timeoutSeconds : 5
volumeMounts :
- name : datadir
mountPath : /var/lib/zookeeper
securityContext :
runAsUser : 1000
fsGroup : 1000
volumeClaimTemplates :
- metadata :
name : datadir
spec :
accessModes : [ "ReadWriteOnce" ]
resources :
requests :
storage : 10Gi
ターミナルを開き、マニフェストを作成するために
kubectl apply
kubectl apply -f https://k8s.io/examples/application/zookeeper/zookeeper.yaml
これはzk-hs Headless Service、zk-cs Service、zk-pdb PodDisruptionBudget、 zk StatefulSetを作成します。
service/zk-hs created
service/zk-cs created
poddisruptionbudget.policy/zk-pdb created
statefulset.apps/zk created
StatefulSetのPodを作成するStatefulSetコントローラーを監視するため、kubectl get
kubectl get pods -w -l app = zk
zk-2 PodがRunningおよびReadyになったら、CTRL-Cでkubectlを終了してください。
NAME READY STATUS RESTARTS AGE
zk-0 0/1 Pending 0 0s
zk-0 0/1 Pending 0 0s
zk-0 0/1 ContainerCreating 0 0s
zk-0 0/1 Running 0 19s
zk-0 1/1 Running 0 40s
zk-1 0/1 Pending 0 0s
zk-1 0/1 Pending 0 0s
zk-1 0/1 ContainerCreating 0 0s
zk-1 0/1 Running 0 18s
zk-1 1/1 Running 0 40s
zk-2 0/1 Pending 0 0s
zk-2 0/1 Pending 0 0s
zk-2 0/1 ContainerCreating 0 0s
zk-2 0/1 Running 0 19s
zk-2 1/1 Running 0 40s
StatefulSetコントローラーが3つのPodを作成し、各PodはZooKeeper サーバー付きのコンテナを持ちます。
リーダーの選出のファシリテート 匿名のネットワークにおいてリーダー選出を終了するアルゴリズムがないので、Zabはリーダー選出のための明示的なメンバーシップ設定を要します。
アンサンブルの各サーバーはユニーク識別子を持つ必要があり、全てのサーバーは識別子のグローバルセットを知っている必要があり、各識別子はネットワークアドレスと関連付けられている必要があります。
zk StatefulSetのPodのホスト名を取得するためにkubectl exec
for i in 0 1 2; do kubectl exec zk-$i -- hostname; done
StatefulSetコントローラーは各Podに、その順序インデックスに基づくユニークなホスト名を提供します。
ホスト名は<statefulset名>-<順序インデックス>という形をとります。
zk StatefulSetのreplicasフィールドが3にセットされているので、このセットのコントローラーは、ホスト名にそれぞれzk-0、zk-1、zk-2が付いた3つのPodを作成します。
zk-0
zk-1
zk-2
ZooKeeperアンサンブルのサーバーは、ユニーク識別子として自然数を使い、それぞれのサーバーの識別子をサーバーのデータディレクトリ内のmyidというファイルに格納します。
各サーバーのmyidファイルの内容を調べるには、以下のコマンドを使います。
for i in 0 1 2; do echo "myid zk- $i " ;kubectl exec zk-$i -- cat /var/lib/zookeeper/data/myid; done
識別子が自然数で順序インデックスは正の整数なので、順序に1を加算することで識別子を生成できます。
myid zk-0
1
myid zk-1
2
myid zk-2
3
zk StatefulSet内の各Podの完全修飾ドメイン名(FQDN)を取得するには、以下のコマンドを使います。
for i in 0 1 2; do kubectl exec zk-$i -- hostname -f; done
zk-hs Serviceは、全Podのためのドメインzk-hs.default.svc.cluster.localを作成します。
zk-0.zk-hs.default.svc.cluster.local
zk-1.zk-hs.default.svc.cluster.local
zk-2.zk-hs.default.svc.cluster.local
Kubernetes DNS のAレコードは、FQDNをPodのIPアドレスに解決します。
KubernetesがPodを再スケジュールした場合、AレコードはPodの新しいIPアドレスに更新されますが、Aレコードの名前は変更されません。
ZooKeeperはそのアプリケーション設定をzoo.cfgという名前のファイルに格納します。
zk-0 Pod内のzoo.cfgファイルの内容を見るには、kubectl execを使います。
kubectl exec zk-0 -- cat /opt/zookeeper/conf/zoo.cfg
ファイル末尾にあるserver.1、server.2、server.3のプロパティの、1、2、3はZooKeeperサーバーのmyidファイル内の識別子に対応します。
これらはzk StatefulSet内のPodのFQDNにセットされます。
clientPort=2181
dataDir=/var/lib/zookeeper/data
dataLogDir=/var/lib/zookeeper/log
tickTime=2000
initLimit=10
syncLimit=2000
maxClientCnxns=60
minSessionTimeout= 4000
maxSessionTimeout= 40000
autopurge.snapRetainCount=3
autopurge.purgeInterval=0
server.1=zk-0.zk-hs.default.svc.cluster.local:2888:3888
server.2=zk-1.zk-hs.default.svc.cluster.local:2888:3888
server.3=zk-2.zk-hs.default.svc.cluster.local:2888:3888
合意形成 合意(consensus)プロトコルは、各参加者の識別子がユニークであることを要件としています。
Zabプロトコル内で同じユニーク識別子を主張する2つの参加者はないものとします。
これは、システム内のプロセスが、どのプロセスがどのデータをコミットしたかを同意できるようにするために必須です。
2つのPodが同じ順序値で起動されたなら、2つのZooKeeperサーバーはどちらもそれら自身を同じサーバーとして認識してしまうでしょう。
kubectl get pods -w -l app = zk
NAME READY STATUS RESTARTS AGE
zk-0 0/1 Pending 0 0s
zk-0 0/1 Pending 0 0s
zk-0 0/1 ContainerCreating 0 0s
zk-0 0/1 Running 0 19s
zk-0 1/1 Running 0 40s
zk-1 0/1 Pending 0 0s
zk-1 0/1 Pending 0 0s
zk-1 0/1 ContainerCreating 0 0s
zk-1 0/1 Running 0 18s
zk-1 1/1 Running 0 40s
zk-2 0/1 Pending 0 0s
zk-2 0/1 Pending 0 0s
zk-2 0/1 ContainerCreating 0 0s
zk-2 0/1 Running 0 19s
zk-2 1/1 Running 0 40s
各PodのAレコードは、PodがReadyになった時に記入されます。そのため、ZooKeeperサーバー群のFQDNはある1つのエンドポイント、すなわちmyidファイルで設定された識別子を主張するユニークなZooKeeperサーバーに解決されます。
zk-0.zk-hs.default.svc.cluster.local
zk-1.zk-hs.default.svc.cluster.local
zk-2.zk-hs.default.svc.cluster.local
これは、ZooKeeperのzoo.cfgファイル内のserversプロパティが正しく設定されたアンサンブルを表していることを保証します。
server.1=zk-0.zk-hs.default.svc.cluster.local:2888:3888
server.2=zk-1.zk-hs.default.svc.cluster.local:2888:3888
server.3=zk-2.zk-hs.default.svc.cluster.local:2888:3888
サーバーが値のコミットを試みるためにZabプロトコルを使う時、(リーダー選出が成功していて、少なくともPodのうちの2つがRunningおよびReadyならば)それぞれのサーバーは双方の合意をとって値をコミット、あるいは、(もし双方の状態が合わなければ)それを行うことに失敗します。
あるサーバーが別のサーバーを代行して書き込みを承認する状態は発生しません。
アンサンブルの健全性テスト 最も基本的な健全性テストは、データを1つのZooKeeperサーバーに書き込み、そのデータを別のサーバーで読み取ることです。
以下のコマンドは、worldをアンサンブル内のzk-0 Podのパス/helloに書き込むのに、zkCli.shスクリプトを実行します。
kubectl exec zk-0 -- zkCli.sh create /hello world
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
Created /hello
zk-1 Podからデータを取得するには、以下のコマンドを使います。
kubectl exec zk-1 -- zkCli.sh get /hello
zk-0に作成したデータは、アンサンブル内の全てのサーバーで利用できます。
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
world
cZxid = 0x100000002
ctime = Thu Dec 08 15:13:30 UTC 2016
mZxid = 0x100000002
mtime = Thu Dec 08 15:13:30 UTC 2016
pZxid = 0x100000002
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 5
numChildren = 0
永続的なストレージの提供 ZooKeeperの概要 のセクションで言及したように、
ZooKeeperは全てのエントリを永続的なWALにコミットし、定期的にメモリ状態のスナップショットをストレージメディアに書き出します。
永続性を提供するためにWALを使用するのは、複製されたステートマシンを立てるために合意プロトコルを使うアプリケーションでよくあるテクニックです。
zk StatefulSetを削除するために、kubectl delete
kubectl delete statefulset zk
statefulset.apps "zk" deleted
StatefulSet内のPodの終了を観察します。
kubectl get pods -w -l app = zk
zk-0が完全に終了したら、CTRL-Cでkubectlを終了します。
zk-2 1/1 Terminating 0 9m
zk-0 1/1 Terminating 0 11m
zk-1 1/1 Terminating 0 10m
zk-2 0/1 Terminating 0 9m
zk-2 0/1 Terminating 0 9m
zk-2 0/1 Terminating 0 9m
zk-1 0/1 Terminating 0 10m
zk-1 0/1 Terminating 0 10m
zk-1 0/1 Terminating 0 10m
zk-0 0/1 Terminating 0 11m
zk-0 0/1 Terminating 0 11m
zk-0 0/1 Terminating 0 11m
zookeeper.yamlのマニフェストを再適用します。
kubectl apply -f https://k8s.io/examples/application/zookeeper/zookeeper.yaml
これはzk StatefulSetオブジェクトを作成しますが、マニフェストのその他のAPIオブジェクトはすでに存在しているので変更されません。
StatefulSetコントローラーがStatefulSetのPodを再作成するのを見てみます。
kubectl get pods -w -l app = zk
zk-2 PodがRunningおよびReadyになったら、CTRL-Cでkubectlを終了します。
NAME READY STATUS RESTARTS AGE
zk-0 0/1 Pending 0 0s
zk-0 0/1 Pending 0 0s
zk-0 0/1 ContainerCreating 0 0s
zk-0 0/1 Running 0 19s
zk-0 1/1 Running 0 40s
zk-1 0/1 Pending 0 0s
zk-1 0/1 Pending 0 0s
zk-1 0/1 ContainerCreating 0 0s
zk-1 0/1 Running 0 18s
zk-1 1/1 Running 0 40s
zk-2 0/1 Pending 0 0s
zk-2 0/1 Pending 0 0s
zk-2 0/1 ContainerCreating 0 0s
zk-2 0/1 Running 0 19s
zk-2 1/1 Running 0 40s
健全性テスト で入力した値をzk-2 Podから取得するには、以下のコマンドを使います。
kubectl exec zk-2 zkCli.sh get /hello
zk StatefulSet内の全てのPodを終了して再作成したにもかかわらず、アンサンブルは元の値をなおも供給します。
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
world
cZxid = 0x100000002
ctime = Thu Dec 08 15:13:30 UTC 2016
mZxid = 0x100000002
mtime = Thu Dec 08 15:13:30 UTC 2016
pZxid = 0x100000002
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 5
numChildren = 0
zk StatefulSetのspecのvolumeClaimTemplatesフィールドは、各PodにプロビジョニングされるPersistentVolumeを指定します。
volumeClaimTemplates :
- metadata :
name : datadir
annotations :
volume.alpha.kubernetes.io/storage-class : anything
spec :
accessModes : [ "ReadWriteOnce" ]
resources :
requests :
storage : 20Gi
StatefulSetコントローラーは、StatefulSet内の各PodのためにPersistentVolumeClaimを生成します。
StatefulSetのPersistentVolumeClaimsを取得するために、以下のコマンドを使います。
kubectl get pvc -l app = zk
StatefulSetがそのPodを再作成した時、StatefulSetはPodのPersistentVolumeを再マウントします。
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
datadir-zk-0 Bound pvc-bed742cd-bcb1-11e6-994f-42010a800002 20Gi RWO 1h
datadir-zk-1 Bound pvc-bedd27d2-bcb1-11e6-994f-42010a800002 20Gi RWO 1h
datadir-zk-2 Bound pvc-bee0817e-bcb1-11e6-994f-42010a800002 20Gi RWO 1h
StatefulSetのコンテナtemplateのvolumeMountsセクションは、ZooKeeperサーバーのデータディレクトリにあるPersistentVolumeをマウントします。
volumeMounts :
name : datadir
mountPath : /var/lib/zookeeper
zk StatefulSet内のPodが(再)スケジュールされると、ZooKeeperサーバーのデータディレクトリにマウントされた同じPersistentVolumeを常に得ます。
Podが再スケジュールされたとしても、全ての書き込みはZooKeeperサーバーのWALおよび全スナップショットに行われ、永続性は残ります。
一貫性のある設定の保証 リーダーの選出のファシリテート および合意形成 のセクションで記したように、ZooKeeperのアンサンブル内のサーバー群は、リーダーを選出しクォーラムを形成するための一貫性のある設定を必要とします。
また、プロトコルがネットワーク越しで正しく動作するために、Zabプロトコルの一貫性のある設定も必要です。
この例では、設定を直接マニフェストに埋め込むことで一貫性のある設定を達成します。
zk StatefulSetを取得しましょう。
kubectl get sts zk -o yaml
…
command:
- sh
- -c
- "start-zookeeper \
--servers=3 \
--data_dir=/var/lib/zookeeper/data \
--data_log_dir=/var/lib/zookeeper/data/log \
--conf_dir=/opt/zookeeper/conf \
--client_port=2181 \
--election_port=3888 \
--server_port=2888 \
--tick_time=2000 \
--init_limit=10 \
--sync_limit=5 \
--heap=512M \
--max_client_cnxns=60 \
--snap_retain_count=3 \
--purge_interval=12 \
--max_session_timeout=40000 \
--min_session_timeout=4000 \
--log_level=INFO"
…
このcommandでは、ZooKeeperサーバーを開始するためにコマンドラインパラメータで設定を渡しています。
設定をアンサンブルへ渡すのには環境変数を使うこともできます。
ログの設定 zkGenConfig.shスクリプトで生成されたファイルの1つは、ZooKeeperのログを制御します。
ZooKeeperはLog4j を使い、デフォルトではログの設定に基づいて、ログ設定に時間およびサイズベースでのローリングファイルアペンダー(ログのローテーション)を使用します。
zk StatefulSet内のPodの1つからログ設定を取得するには、以下のコマンドを使います。
kubectl exec zk-0 cat /usr/etc/zookeeper/log4j.properties
以下のログ設定は、ZooKeeperにログの全てを標準出力ファイルストリームに書き出す処理をさせます。
zookeeper.root.logger=CONSOLE
zookeeper.console.threshold=INFO
log4j.rootLogger=${zookeeper.root.logger}
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.Threshold=${zookeeper.console.threshold}
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
これはログコンテナ内のログを安全にとるための、最もシンプルと思われる方法です。
アプリケーションはログを標準出力に書き出し、Kubernetesがログのローテーションを処理してくれます。
Kubernetesは、標準出力と標準エラー出力に書き出されるアプリケーションのログがローカルストレージメディアを使い尽くさないことを保証する、健全維持ポリシーも実装しています。
Podの1つから末尾20行を取得するために、kubectl logs
kubectl logs zk-0 --tail 20
kubectl logsを利用するか、Kubernetes Dashboardから、標準出力または標準エラーに書き出されたアプリケーションログを参照できます。
2016-12-06 19:34:16,236 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@827] - Processing ruok command from /127.0.0.1:52740
2016-12-06 19:34:16,237 [myid:1] - INFO [Thread-1136:NIOServerCnxn@1008] - Closed socket connection for client /127.0.0.1:52740 (no session established for client)
2016-12-06 19:34:26,155 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@192] - Accepted socket connection from /127.0.0.1:52749
2016-12-06 19:34:26,155 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@827] - Processing ruok command from /127.0.0.1:52749
2016-12-06 19:34:26,156 [myid:1] - INFO [Thread-1137:NIOServerCnxn@1008] - Closed socket connection for client /127.0.0.1:52749 (no session established for client)
2016-12-06 19:34:26,222 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@192] - Accepted socket connection from /127.0.0.1:52750
2016-12-06 19:34:26,222 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@827] - Processing ruok command from /127.0.0.1:52750
2016-12-06 19:34:26,226 [myid:1] - INFO [Thread-1138:NIOServerCnxn@1008] - Closed socket connection for client /127.0.0.1:52750 (no session established for client)
2016-12-06 19:34:36,151 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@192] - Accepted socket connection from /127.0.0.1:52760
2016-12-06 19:34:36,152 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@827] - Processing ruok command from /127.0.0.1:52760
2016-12-06 19:34:36,152 [myid:1] - INFO [Thread-1139:NIOServerCnxn@1008] - Closed socket connection for client /127.0.0.1:52760 (no session established for client)
2016-12-06 19:34:36,230 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@192] - Accepted socket connection from /127.0.0.1:52761
2016-12-06 19:34:36,231 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@827] - Processing ruok command from /127.0.0.1:52761
2016-12-06 19:34:36,231 [myid:1] - INFO [Thread-1140:NIOServerCnxn@1008] - Closed socket connection for client /127.0.0.1:52761 (no session established for client)
2016-12-06 19:34:46,149 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@192] - Accepted socket connection from /127.0.0.1:52767
2016-12-06 19:34:46,149 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@827] - Processing ruok command from /127.0.0.1:52767
2016-12-06 19:34:46,149 [myid:1] - INFO [Thread-1141:NIOServerCnxn@1008] - Closed socket connection for client /127.0.0.1:52767 (no session established for client)
2016-12-06 19:34:46,230 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@192] - Accepted socket connection from /127.0.0.1:52768
2016-12-06 19:34:46,230 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@827] - Processing ruok command from /127.0.0.1:52768
2016-12-06 19:34:46,230 [myid:1] - INFO [Thread-1142:NIOServerCnxn@1008] - Closed socket connection for client /127.0.0.1:52768 (no session established for client)
Kubernetesは多くのログソリューションを統合しています。
クラスターおよびアプリケーションに最も適合するログソリューションを選べます。
クラスターレベルのロギングとアグリゲーションとして、ログをローテートおよび輸送するためのサイドカーコンテナ をデプロイすることを検討してください。
非特権ユーザーの設定 コンテナ内で特権ユーザーとしての実行をアプリケーションに許可するベストプラクティスは、議論の的です。
アプリケーションが非特権ユーザーとして動作することを組織で必須としているなら、エントリポイントがそのユーザーとして実行できるユーザーを制御するセキュリティコンテキスト を利用できます。
zk StatefulSetのPod templateは、SecurityContextを含んでいます。
securityContext :
runAsUser : 1000
fsGroup : 1000
Podのコンテナ内で、UID 1000はzookeeperユーザーに、GID 1000はzookeeperグループにそれぞれ相当します。
zk-0 PodからのZooKeeperプロセス情報を取得してみましょう。
kubectl exec zk-0 -- ps -elf
securityContextオブジェクトのrunAsUserフィールドが1000にセットされているとおり、ZooKeeperプロセスは、rootとして実行される代わりにzookeeperユーザーとして実行されています。
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S zookeep+ 1 0 0 80 0 - 1127 - 20:46 ? 00:00:00 sh -c zkGenConfig.sh && zkServer.sh start-foreground
0 S zookeep+ 27 1 0 80 0 - 1155556 - 20:46 ? 00:00:19 /usr/lib/jvm/java-8-openjdk-amd64/bin/java -Dzookeeper.log.dir=/var/log/zookeeper -Dzookeeper.root.logger=INFO,CONSOLE -cp /usr/bin/../build/classes:/usr/bin/../build/lib/*.jar:/usr/bin/../share/zookeeper/zookeeper-3.4.9.jar:/usr/bin/../share/zookeeper/slf4j-log4j12-1.6.1.jar:/usr/bin/../share/zookeeper/slf4j-api-1.6.1.jar:/usr/bin/../share/zookeeper/netty-3.10.5.Final.jar:/usr/bin/../share/zookeeper/log4j-1.2.16.jar:/usr/bin/../share/zookeeper/jline-0.9.94.jar:/usr/bin/../src/java/lib/*.jar:/usr/bin/../etc/zookeeper: -Xmx2G -Xms2G -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.local.only=false org.apache.zookeeper.server.quorum.QuorumPeerMain /usr/bin/../etc/zookeeper/zoo.cfg
デフォルトでは、PodのPersistentVolumeがZooKeeperサーバーのデータディレクトリにマウントされている時、rootユーザーのみがそこにアクセス可能です。
この設定はZooKeeperのプロセスがそのWALに書き込んだりスナップショットに格納したりするのを妨げることになります。
zk-0 PodのZooKeeperデータディレクトリのファイルパーミッションを取得するには、以下のコマンドを使います。
kubectl exec -ti zk-0 -- ls -ld /var/lib/zookeeper/data
securityContextオブジェクトのfsGroupフィールドが1000にセットされているので、PodのPersistentVolumeの所有権はzookeeperグループにセットされ、ZooKeeperのプロセスがそのデータを読み書きできるようになります。
drwxr-sr-x 3 zookeeper zookeeper 4096 Dec 5 20:45 /var/lib/zookeeper/data
ZooKeeperプロセスの管理 ZooKeeperドキュメント では、「You will want to have a supervisory process that manages each of your ZooKeeper server processes (JVM).(各ZooKeeperサーバープロセス(JVM)を管理する監督プロセスを持ちたくなります)」と述べています。
分散型システム内で失敗したプロセスを再起動するのにwatchdog(監督プロセス)を使うのは、典型的パターンです。
アプリケーションをKubernetesにデプロイする時には、監督プロセスのような外部ユーティリティを使うよりもむしろ、アプリケーションのwatchdogとしてKubernetesを使うべきです。
アンサンブルのアップデート zk StatefulSetはRollingUpdateアップデート戦略を使うように設定されています。
サーバーに割り当てられるcpusの数を更新するのに、kubectl patchを利用できます。
kubectl patch sts zk --type= 'json' -p= '[{"op": "replace", "path": "/spec/template/spec/containers/0/resources/requests/cpu", "value":"0.3"}]'
statefulset.apps/zk patched
更新の状況を見るには、kubectl rollout statusを使います。
kubectl rollout status sts/zk
waiting for statefulset rolling update to complete 0 pods at revision zk-5db4499664...
Waiting for 1 pods to be ready...
Waiting for 1 pods to be ready...
waiting for statefulset rolling update to complete 1 pods at revision zk-5db4499664...
Waiting for 1 pods to be ready...
Waiting for 1 pods to be ready...
waiting for statefulset rolling update to complete 2 pods at revision zk-5db4499664...
Waiting for 1 pods to be ready...
Waiting for 1 pods to be ready...
statefulset rolling update complete 3 pods at revision zk-5db4499664...
これはPod群を終了し、逆の順番で1つずつそれらを新しい設定で再作成します。
これはクォーラムがローリングアップデート中に維持されることを保証します。
履歴や過去の設定を見るには、kubectl rollout historyコマンドを使います。
kubectl rollout history sts/zk
出力は次のようになります:
statefulsets "zk"
REVISION
1
2
変更をロールバックするには、kubectl rollout undoコマンドを使います。
kubectl rollout undo sts/zk
出力は次のようになります:
statefulset.apps/zk rolled back
プロセスの失敗の取り扱い 再起動ポリシー は、Pod内のコンテナのエントリポイントへのプロセスの失敗をKubernetesがどのように取り扱うかを制御します。
StatefulSet内のPodにおいて唯一妥当なRestartPolicyはAlwaysで、これはデフォルト値です。
ステートフルなアプリケーションでは、このデフォルトポリシーの上書きは絶対にすべきではありません 。
zk-0 Pod内で実行されているZooKeeperサーバーのプロセスツリーを調査するには、以下のコマンドを使います。
kubectl exec zk-0 -- ps -ef
コンテナのエントリポイントとして使われるコマンドはPID 1、エントリポイントの子であるZooKeeperプロセスはPID 27となっています。
UID PID PPID C STIME TTY TIME CMD
zookeep+ 1 0 0 15:03 ? 00:00:00 sh -c zkGenConfig.sh && zkServer.sh start-foreground
zookeep+ 27 1 0 15:03 ? 00:00:03 /usr/lib/jvm/java-8-openjdk-amd64/bin/java -Dzookeeper.log.dir=/var/log/zookeeper -Dzookeeper.root.logger=INFO,CONSOLE -cp /usr/bin/../build/classes:/usr/bin/../build/lib/*.jar:/usr/bin/../share/zookeeper/zookeeper-3.4.9.jar:/usr/bin/../share/zookeeper/slf4j-log4j12-1.6.1.jar:/usr/bin/../share/zookeeper/slf4j-api-1.6.1.jar:/usr/bin/../share/zookeeper/netty-3.10.5.Final.jar:/usr/bin/../share/zookeeper/log4j-1.2.16.jar:/usr/bin/../share/zookeeper/jline-0.9.94.jar:/usr/bin/../src/java/lib/*.jar:/usr/bin/../etc/zookeeper: -Xmx2G -Xms2G -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.local.only=false org.apache.zookeeper.server.quorum.QuorumPeerMain /usr/bin/../etc/zookeeper/zoo.cfg
別のターミナルで、以下のコマンドを使ってzk StatefulSet内のPodを見てみます。
kubectl get pod -w -l app = zk
別のターミナルで、以下のコマンドを使ってPod zk-0内のZooKeeperプロセスを終了します。
kubectl exec zk-0 -- pkill java
ZooKeeperプロセスの終了は、その親プロセスの終了を引き起こします。
コンテナのRestartPolicyはAlwaysなので、親プロセスが再起動(restart)されます。
NAME READY STATUS RESTARTS AGE
zk-0 1/1 Running 0 21m
zk-1 1/1 Running 0 20m
zk-2 1/1 Running 0 19m
NAME READY STATUS RESTARTS AGE
zk-0 0/1 Error 0 29m
zk-0 0/1 Running 1 29m
zk-0 1/1 Running 1 29m
アプリケーションが、そのビジネスロジックを実装するプロセスを立ち上げるのにスクリプト(zkServer.shなど)を使っている場合、スクリプトは子プロセスとともに終了する必要があります。
これは、Kubernetesがアプリケーションのコンテナを、そのビジネスロジックを実装しているプロセスが失敗した時に再起動することを保証します。
生存性(liveness)テスト 失敗したプロセスを再起動するための設定をアプリケーションに施すのは、分散型システムの健全さを保つのに十分ではありません。
システムのプロセスが生きていることもあれば無反応なこともあり、あるいはそうでなく不健全という状況もあります。
アプリケーションのプロセスが不健全で再起動すべきであることをKubernetesに通知するには、liveness probeを使うのがよいでしょう。
zk StatefulSetのPod templateでliveness probeを指定します。
livenessProbe :
exec :
command :
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds : 15
timeoutSeconds : 5
プローブはサーバーの健全さをテストするのに、ZooKeeperのruok 4文字コマンドを使うbashスクリプトを呼び出します。
OK=$(echo ruok | nc 127.0.0.1 $1)
if [ "$OK" == "imok" ]; then
exit 0
else
exit 1
fi
ターミナルウィンドウで、zk StatefulSet内のPodを見るのに以下のコマンドを使います。
kubectl get pod -w -l app = zk
別のウィンドウで、Pod zk-0のファイルシステムからzookeeper-readyスクリプトを削除するために以下のコマンドを使います。
kubectl exec zk-0 -- rm /opt/zookeeper/bin/zookeeper-ready
ZooKeeperプロセスの失敗のためにliveness probeを使う時、アンサンブル内の不健全なプロセスが再起動されることを保証するために、Kubernetesは自動的にプロセスを再起動します。
kubectl get pod -w -l app = zk
NAME READY STATUS RESTARTS AGE
zk-0 1/1 Running 0 1h
zk-1 1/1 Running 0 1h
zk-2 1/1 Running 0 1h
NAME READY STATUS RESTARTS AGE
zk-0 0/1 Running 0 1h
zk-0 0/1 Running 1 1h
zk-0 1/1 Running 1 1h
準備性(readiness)テスト 準備性は生存性と同じではありません。
プロセスが生きているのであれば、スケジュールされ健全です。
プロセスの準備ができたら、入力を処理できます。
生存性はなくてはならないものですが、準備性の状態には十分ではありません。
プロセスは生きてはいるが準備はできていない時、特に初期化および終了の間がそのケースに相当します。
readiness probeを指定するとKubernetesは、準備性チェックに合格するまで、アプリケーションのプロセスがネットワークトラフィックを受け取らないことを保証します。
ZooKeeperサーバーにとって、健全性は準備性を意味します。
そのため、zookeeper.yamlマニフェストからのreadiness probeは、liveness probeと同一です。
readinessProbe :
exec :
command :
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds : 15
timeoutSeconds : 5
liveness probeとreadiness probeが同一だとしても、両方を指定することが重要です。
これは、ZooKeeperアンサンブル内の健全なサーバーだけがネットワークトラフィックを受け取ることを保証します。
ノードの失敗の許容 ZooKeeperはデータの変更を正しくコミットするのにサーバーのクォーラムを必要とします。
3つのサーバーのアンサンブルにおいては、書き込みの成功のために2つのサーバーは健全でなければなりません。
クォーラムベースのシステムにおいて、可用性を保証するために、メンバーは障害ドメインにデプロイされます。
個々のマシンの損失による障害を避けるためのベストプラクティスは、同じマシン上でアプリケーションの複数のインスタンスがコロケート(同じ場所に配置)されないようにすることです。
デフォルトでKubernetesは、同じノードのStatefulSetにPodをコロケートします。
3つのサーバーアンサンブルを作成していたとして、2つのサーバーが同じノードにあり、そのノードが障害を起こした場合、ZooKeeperサービスのクライアントは、少なくともPodの1つが再スケジュールされるまで障害に見舞われることになります。
クリティカルシステムのプロセスがノードの失敗イベントで再スケジュールできるよう、追加のキャパシティを常にプロビジョンしておくべきです。
そうしておけば、障害は単にKubernetesのスケジューラーがZooKeeperのサーバーの1つを再スケジュールするまでの辛抱です。
ただし、ダウンタイムなしでノードの障害への耐性をサービスに持たせたいなら、podAntiAffinityをセットすべきです。
zk StatefulSet内のPodのノードを取得するには、以下のコマンドを使います。
for i in 0 1 2; do kubectl get pod zk-$i --template {{ .spec.nodeName}} ; echo "" ; done
zk StatefulSet内の全てのPodは、別々のノードにデプロイされます。
kubernetes-node-cxpk
kubernetes-node-a5aq
kubernetes-node-2g2d
これはzk StatefulSet内のPodにPodAntiAffinityの指定があるからです。
affinity :
podAntiAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
- labelSelector :
matchExpressions :
- key : "app"
operator : In
values :
- zk
topologyKey : "kubernetes.io/hostname"
requiredDuringSchedulingIgnoredDuringExecutionフィールドは、topologyKeyで定義されたドメイン内でappラベルの値がzkの2つのPodが絶対にコロケートすべきでないことを、Kubernetes Schedulerに指示します。
topologyKeyのkubernetes.io/hostnameは、ドメインが固有ノードであることを示しています。
異なるルール、ラベル、セレクターを使って、物理・ネットワーク・電源といった障害ドメイン全体に広がるアンサンブルにこのテクニックを広げることができます。
メンテナンス時の存続 このセクションでは、ノードをcordon(スケジュール不可化)およびdorain(解放)します。もし共有クラスターでこのチュートリアルを試しているのであれば、これがほかのテナントに有害な影響を及ぼさないことを確認してください。
前のセクションでは、計画外のノード障害に備えてどのようにPodをノード全体に広げるかを示しましたが、計画されたメンテナンスのため引き起こされる一時的なノード障害に対して計画する必要もあります。
クラスター内のノードを取得するために、以下のコマンドを使います。
このチュートリアルでは、4つのノードのあるクラスターを仮定しています。
クラスターが4つよりも多くある場合には、4つのノード以外全てをcordonするためにkubectl cordon
zk-pdbのPodDisruptionBudgetを取得するために、以下のコマンドを使います。
max-unavailableフィールドは、zk StatefulSetの最大で1つのPodがいつでも利用できなくなる可能性があるということを、Kubernetesに指示します。
NAME MIN-AVAILABLE MAX-UNAVAILABLE ALLOWED-DISRUPTIONS AGE
zk-pdb N/A 1 1
1つ目のターミナルで、zk StatefulSet内のPodを見るのに以下のコマンドを使います。
kubectl get pods -w -l app = zk
次に別のターミナルで、Podが現在スケジュールされているノードを取得するために、以下のコマンドを使います。
for i in 0 1 2; do kubectl get pod zk-$i --template {{ .spec.nodeName}} ; echo "" ; done
出力は次のようになります:
kubernetes-node-pb41
kubernetes-node-ixsl
kubernetes-node-i4c4
zk-0 Podがスケジュールされているノードをcordonおよびdrainするには、kubectl drain
kubectl drain $( kubectl get pod zk-0 --template {{ .spec.nodeName}} ) --ignore-daemonsets --force --delete-emptydir-data
出力は次のようになります:
node "kubernetes-node-pb41" cordoned
WARNING: Deleting pods not managed by ReplicationController, ReplicaSet, Job, or DaemonSet: fluentd-cloud-logging-kubernetes-node-pb41, kube-proxy-kubernetes-node-pb41; Ignoring DaemonSet-managed pods: node-problem-detector-v0.1-o5elz
pod "zk-0" deleted
node "kubernetes-node-pb41" drained
クラスターに4つのノードがあるので、kubectl drainは成功し、zk-0が別のノードに再スケジュールされます。
NAME READY STATUS RESTARTS AGE
zk-0 1/1 Running 2 1h
zk-1 1/1 Running 0 1h
zk-2 1/1 Running 0 1h
NAME READY STATUS RESTARTS AGE
zk-0 1/1 Terminating 2 2h
zk-0 0/1 Terminating 2 2h
zk-0 0/1 Terminating 2 2h
zk-0 0/1 Terminating 2 2h
zk-0 0/1 Pending 0 0s
zk-0 0/1 Pending 0 0s
zk-0 0/1 ContainerCreating 0 0s
zk-0 0/1 Running 0 51s
zk-0 1/1 Running 0 1m
最初のターミナルでStatefulSetのPodを見守り、zk-1がスケジュールされたノードをdrainします。
kubectl drain $( kubectl get pod zk-1 --template {{ .spec.nodeName}} ) --ignore-daemonsets --force --delete-emptydir-data
出力は次のようになります:
"kubernetes-node-ixsl" cordoned
WARNING: Deleting pods not managed by ReplicationController, ReplicaSet, Job, or DaemonSet: fluentd-cloud-logging-kubernetes-node-ixsl, kube-proxy-kubernetes-node-ixsl; Ignoring DaemonSet-managed pods: node-problem-detector-v0.1-voc74
pod "zk-1" deleted
node "kubernetes-node-ixsl" drained
zk StatefulSetがPodのコロケーションを抑止するPodAntiAffinityルールを含んでいるので、zk-1 Podはスケジュールされず、またスケジュール可能なのは2つのノードだけなので、PodはPendingの状態のままになっています。
kubectl get pods -w -l app = zk
出力は次のようになります:
NAME READY STATUS RESTARTS AGE
zk-0 1/1 Running 2 1h
zk-1 1/1 Running 0 1h
zk-2 1/1 Running 0 1h
NAME READY STATUS RESTARTS AGE
zk-0 1/1 Terminating 2 2h
zk-0 0/1 Terminating 2 2h
zk-0 0/1 Terminating 2 2h
zk-0 0/1 Terminating 2 2h
zk-0 0/1 Pending 0 0s
zk-0 0/1 Pending 0 0s
zk-0 0/1 ContainerCreating 0 0s
zk-0 0/1 Running 0 51s
zk-0 1/1 Running 0 1m
zk-1 1/1 Terminating 0 2h
zk-1 0/1 Terminating 0 2h
zk-1 0/1 Terminating 0 2h
zk-1 0/1 Terminating 0 2h
zk-1 0/1 Pending 0 0s
zk-1 0/1 Pending 0 0s
StatefulSetのPodを見続け、zk-2がスケジュールされているノードをdrainします。
kubectl drain $( kubectl get pod zk-2 --template {{ .spec.nodeName}} ) --ignore-daemonsets --force --delete-emptydir-data
出力は次のようになります:
node "kubernetes-node-i4c4" cordoned
WARNING: Deleting pods not managed by ReplicationController, ReplicaSet, Job, or DaemonSet: fluentd-cloud-logging-kubernetes-node-i4c4, kube-proxy-kubernetes-node-i4c4; Ignoring DaemonSet-managed pods: node-problem-detector-v0.1-dyrog
WARNING: Ignoring DaemonSet-managed pods: node-problem-detector-v0.1-dyrog; Deleting pods not managed by ReplicationController, ReplicaSet, Job, or DaemonSet: fluentd-cloud-logging-kubernetes-node-i4c4, kube-proxy-kubernetes-node-i4c4
There are pending pods when an error occurred: Cannot evict pod as it would violate the pod's disruption budget.
pod/zk-2
kubectlを終了するためにCTRL-Cを押します。
zk-2を退去させるとzk-budget違反になってしまうので、3つ目のノードはdrainできません。ただし、ノードはcordonされたままとなります。
健全性テスト中に入力した値をzk-0から取得するには、zkCli.shを使います。
kubectl exec zk-0 zkCli.sh get /hello
PodDisruptionBudgetが遵守されているので、サービスはまだ利用可能です。
WatchedEvent state:SyncConnected type:None path:null
world
cZxid = 0x200000002
ctime = Wed Dec 07 00:08:59 UTC 2016
mZxid = 0x200000002
mtime = Wed Dec 07 00:08:59 UTC 2016
pZxid = 0x200000002
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 5
numChildren = 0
最初のノードをuncordon(スケジュール可能化)するには、kubectl uncordon
kubectl uncordon kubernetes-node-pb41
出力は次のようになります:
node "kubernetes-node-pb41" uncordoned
zk-1はこのノードで再スケジュールされます。zk-1がRunningおよびReadyになるまで待ちます。
kubectl get pods -w -l app = zk
出力は次のようになります:
NAME READY STATUS RESTARTS AGE
zk-0 1/1 Running 2 1h
zk-1 1/1 Running 0 1h
zk-2 1/1 Running 0 1h
NAME READY STATUS RESTARTS AGE
zk-0 1/1 Terminating 2 2h
zk-0 0/1 Terminating 2 2h
zk-0 0/1 Terminating 2 2h
zk-0 0/1 Terminating 2 2h
zk-0 0/1 Pending 0 0s
zk-0 0/1 Pending 0 0s
zk-0 0/1 ContainerCreating 0 0s
zk-0 0/1 Running 0 51s
zk-0 1/1 Running 0 1m
zk-1 1/1 Terminating 0 2h
zk-1 0/1 Terminating 0 2h
zk-1 0/1 Terminating 0 2h
zk-1 0/1 Terminating 0 2h
zk-1 0/1 Pending 0 0s
zk-1 0/1 Pending 0 0s
zk-1 0/1 Pending 0 12m
zk-1 0/1 ContainerCreating 0 12m
zk-1 0/1 Running 0 13m
zk-1 1/1 Running 0 13m
試しにzk-2がスケジュールされているノードをdrainしてみます。
kubectl drain $( kubectl get pod zk-2 --template {{ .spec.nodeName}} ) --ignore-daemonsets --force --delete-emptydir-data
出力は次のようになります:
node "kubernetes-node-i4c4" already cordoned
WARNING: Deleting pods not managed by ReplicationController, ReplicaSet, Job, or DaemonSet: fluentd-cloud-logging-kubernetes-node-i4c4, kube-proxy-kubernetes-node-i4c4; Ignoring DaemonSet-managed pods: node-problem-detector-v0.1-dyrog
pod "heapster-v1.2.0-2604621511-wht1r" deleted
pod "zk-2" deleted
node "kubernetes-node-i4c4" drained
今度はkubectl drainは成功しました。
zk-2の再スケジュールができるように、2つ目のノードをuncordonします。
kubectl uncordon kubernetes-node-ixsl
出力は次のようになります:
node "kubernetes-node-ixsl" uncordoned
サービスがメンテナンス中も利用可能なままであることを保証するために、PodDisruptionBudgetsとあわせてkubectl drainを利用できます。
メンテナンスでノードがオフラインになる前にノードをcordonして、Podを退去させるのにdrainが使われている場合、Disruption Budget(停止状態の予算)を表すサービスは遵守すべきバジェットを持ちます。
クリティカルサービスでは、Podをすぐに再スケジュールできるよう、追加のキャパティを常に割り当てておくべきです。
クリーンアップ クラスターの全てのノードをuncordonするために、kubectl uncordonを実行してください。 このチュートリアルで使ったPersistentVolumeの永続的なストレージメディアを削除する必要があります。
全てのストレージが回収されたことを確実とするために、お使いの環境、ストレージ設定、プロビジョニング方法に基いて必要な手順に従ってください。
5.7 - Service 5.7.1 - アプリケーションをServiceに接続する コンテナに接続するためのKubernetesモデル さて、継続的に実行され、複製されたアプリケーションができたので、これをネットワーク上に公開できます。
Kubernetesは、Podがどのホストに配置されているかにかかわらず、ほかのPodと通信できることを引き受けます。
Kubernetesは各Podにそれぞれ固有のクラスタープライベートなIPアドレスを付与するので、Pod間のリンクや、コンテナのポートとホストのポートのマップを明示的に作成する必要はありません。
これは、Pod内のコンテナは全てlocalhost上でお互いのポートに到達でき、クラスター内の全てのPodはNATなしに互いを見られるということを意味します。このドキュメントの残りの部分では、このようなネットワークモデルの上で信頼性のあるServiceを実行する方法について、詳しく述べていきます。
このチュートリアルでは概念のデモンストレーションのために、シンプルなnginx Webサーバーを例として使います。
Podをクラスターへ公開 これは前出の例でも行いましたが、もう一度やってみて、ネットワークからの観点に着目してみましょう。
nginx Podを作成し、コンテナのポート指定も記載します:
apiVersion : apps/v1
kind : Deployment
metadata :
name : my-nginx
spec :
selector :
matchLabels :
run : my-nginx
replicas : 2
template :
metadata :
labels :
run : my-nginx
spec :
containers :
- name : my-nginx
image : nginx
ports :
- containerPort : 80
この設定で、あなたのクラスターにはどのノードからもアクセス可能になります。Podを実行中のノードを確認してみましょう:
kubectl apply -f ./run-my-nginx.yaml
kubectl get pods -l run = my-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE
my-nginx-3800858182-jr4a2 1/1 Running 0 13s 10.244.3.4 kubernetes-minion-905m
my-nginx-3800858182-kna2y 1/1 Running 0 13s 10.244.2.5 kubernetes-minion-ljyd
PodのIPアドレスを確認します:
kubectl get pods -l run = my-nginx -o custom-columns= POD_IP:.status.podIPs
POD_IP
[ map[ ip:10.244.3.4]]
[ map[ ip:10.244.2.5]]
あなたのクラスター内のどのノードにもsshで入ることができて、双方のIPアドレスに対して問い合わせるためにcurlのようなツールを使えるようにしておくのがよいでしょう。
各コンテナはノード上でポート80を使っておらず 、トラフィックをPodに流すための特別なNATルールもなんら存在しないことに注意してください。
つまり、全て同じcontainerPortを使った同じノード上で複数のnginx Podを実行でき、Serviceに割り当てられたIPアドレスを使って、クラスター内のほかのどのPodあるいはノードからもそれらにアクセスできます。
背後にあるPodにフォワードするためにホストNode上の特定のポートを充てたいというのであれば、それも可能です。とはいえ、ネットワークモデルではそのようなことをする必要がありません。
興味があれば、さらなる詳細について
Kubernetesネットワークモデル
を読んでください。
Serviceの作成 さて、フラットなクラスター全体のアドレス空間内でnginxを実行中のPodが得られました。
理論的にはこれらのPodと直接対話することは可能ですが、ノードが死んでしまった時には何が起きるでしょうか?
ノードと一緒にPodは死に、Deploymentが新しいPodを異なるIPアドレスで作成します。
これがServiceが解決する問題です。
KubernetesのServiceは、全て同じ機能を提供する、クラスター内のどこかで実行するPodの論理的な集合を定義した抽象物です。
作成時に各Serviceは固有のIPアドレス(clusterIPとも呼ばれます)を割り当てられます。
このアドレスはServiceのライフスパンと結び付けられており、Serviceが生きている間は変わりません。
PodはServiceと対話できるよう設定され、Serviceのメンバーである複数のPodへ自動的に負荷分散されたServiceへ通信する方法を知っています。
kubectl exposeを使って、2つのnginxレプリカのためのServiceを作成できます:
kubectl expose deployment/my-nginx
service/my-nginx exposed
これはkubectl apply -fを以下のyamlに対して実行するのと同じです:
apiVersion : v1
kind : Service
metadata :
name : my-nginx
labels :
run : my-nginx
spec :
ports :
- port : 80
protocol : TCP
selector :
run : my-nginx
この指定は、run: my-nginxラベルの付いた任意のPod上のTCPポート80を宛先とし、それを抽象化されたServiceポート(targetPortはコンテナがトラフィックを許可するポート、portは抽象化されたServiceポートで、ほかのPodがServiceにアクセスするのに使う任意のポートです)で公開するServiceを作成します。
Service定義内でサポートされているフィールドのリストを見るには、Service APIオブジェクトを参照してください。
Serviceを確認してみましょう:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx ClusterIP 10.0.162.149 <none> 80/TCP 21s
前述したとおり、ServiceはPodのグループに支えられています。
これらのPodはEndpointSlices を通して公開されています。
Serviceのセレクターは継続的に評価され、その結果はServiceに接続されているEndpointSliceにlabels を使って「投稿(POST)」されます。
Podが死ぬと、エンドポイントとして含まれていたEndpointSliceからそのPodは自動的に削除されます。
Serviceのセレクターにマッチする新しいPodが、Serviceのために自動的にEndpointSliceに追加されます。
エンドポイントを確認し、IPアドレスが最初のステップで作成したPodと同じであることに注目してください:
kubectl describe svc my-nginx
Name: my-nginx
Namespace: default
Labels: run=my-nginx
Annotations: <none>
Selector: run=my-nginx
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.0.162.149
IPs: 10.0.162.149
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.2.5:80,10.244.3.4:80
Session Affinity: None
Events: <none>
kubectl get endpointslices -l kubernetes.io/service-name= my-nginx
NAME ADDRESSTYPE PORTS ENDPOINTS AGE
my-nginx-7vzhx IPv4 80 10.244.2.5,10.244.3.4 21s
今や、あなたのクラスター内のどのノードからもnginx Serviceに<CLUSTER-IP>:<PORT>でcurlを使用してアクセスできるはずです。Service IPは完全に仮想であり、物理的なケーブルで接続されるものではありません。どのように動作しているのか興味があれば、さらなる詳細についてサービスプロキシ を読んでください。
Serviceへのアクセス KubernetesはServiceを探す2つの主要なモードとして、環境変数とDNSをサポートしています。
前者はすぐに動かせるのに対し、後者はCoreDNSクラスターアドオン が必要です。
備考: もしServiceの環境変数が望ましくないなら(想定しているプログラムの環境変数と競合する可能性がある、処理する変数が多すぎる、DNSだけ使いたい、など)、
pod spec で
enableServiceLinksのフラグを
falseにすることで、このモードを無効化できます。
環境変数 PodをNode上で実行する時、kubeletはアクティブなServiceのそれぞれに環境変数のセットを追加します。
これは順序問題を生みます。なぜそうなるかの理由を見るために、実行中のnginx Podの環境を調査してみましょう(Podの名前は環境によって異なります):
kubectl exec my-nginx-3800858182-jr4a2 -- printenv | grep SERVICE
KUBERNETES_SERVICE_HOST=10.0.0.1
KUBERNETES_SERVICE_PORT=443
KUBERNETES_SERVICE_PORT_HTTPS=443
Serviceについて何も言及がないことに注意してください。
これは、Serviceの前にレプリカを作成したからです。
このようにすることでの不利益のもう1つは、スケジューラーが同一のマシンに両方のPodを置く可能性があることです(もしそのマシンが死ぬと全Serviceがダウンしてしまいます)。
2つのPodを殺し、Deploymentがそれらを再作成するのを待つことで、これを正しいやり方にできます。
今回は、レプリカの前に Serviceが存在します。
これにより、正しい環境変数だけでなく、(全てのノードで等量のキャパシティを持つ場合)Podに広がった、スケジューラーレベルのServiceが得られます:
kubectl scale deployment my-nginx --replicas= 0; kubectl scale deployment my-nginx --replicas= 2;
kubectl get pods -l run = my-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE
my-nginx-3800858182-e9ihh 1/1 Running 0 5s 10.244.2.7 kubernetes-minion-ljyd
my-nginx-3800858182-j4rm4 1/1 Running 0 5s 10.244.3.8 kubernetes-minion-905m
Podが、いったん殺されて再作成された後、異なる名前を持ったことに気付いたでしょうか。
kubectl exec my-nginx-3800858182-e9ihh -- printenv | grep SERVICE
KUBERNETES_SERVICE_PORT=443
MY_NGINX_SERVICE_HOST=10.0.162.149
KUBERNETES_SERVICE_HOST=10.0.0.1
MY_NGINX_SERVICE_PORT=80
KUBERNETES_SERVICE_PORT_HTTPS=443
DNS Kubernetesは、DNS名をほかのServiceに自動的に割り当てる、DNSクラスターアドオンServiceを提供しています。
クラスター上でそれを実行しているならば、確認できます:
kubectl get services kube-dns --namespace= kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.0.0.10 <none> 53/UDP,53/TCP 8m
本セクションの以降では、長寿命のIPアドレス(my-nginx)を持つServiceと、そのIPアドレスに名前を割り当てているDNSサーバーがあることを想定しています。
ここではCoreDNSクラスターアドオン(アプリケーション名kube-dns)を使い、標準的な手法(例えばgethostbyname())を使ってクラスター内の任意のPodからServiceと対話してみます。
CoreDNSが動作していない時には、
CoreDNS README
やCoreDNSのインストール を参照して有効化してください。
テストするために、別のcurlアプリケーションを実行してみましょう:
kubectl run curl --image= radial/busyboxplus:curl -i --tty
Waiting for pod default/curl-131556218-9fnch to be running, status is Pending, pod ready: false
Hit enter for command prompt
次にenterを押し、nslookup my-nginxを実行します:
[ root@curl-131556218-9fnch:/ ] $ nslookup my-nginx
Server: 10.0.0.10
Address 1: 10.0.0.10
Name: my-nginx
Address 1: 10.0.162.149
Serviceのセキュア化 これまではクラスター内からnginxサーバーだけにアクセスしてきました。
Serviceをインターネットに公開する前に、通信経路がセキュアかどうかを確かめたいところです。
そのためには次のようなものが必要です:
https用の自己署名証明書(まだ本人証明を用意していない場合) 証明書を使うよう設定されたnginxサーバー 証明書をPodからアクセスできるようにするSecret これら全てはnginx https example から取得できます。
go環境とmakeツールのインストールが必要です
(もしこれらをインストールしたくないときには、後述の手動手順に従ってください)。簡潔には:
make keys KEY = /tmp/nginx.key CERT = /tmp/nginx.crt
kubectl create secret tls nginxsecret --key /tmp/nginx.key --cert /tmp/nginx.crt
secret/nginxsecret created
NAME TYPE DATA AGE
nginxsecret kubernetes.io/tls 2 1m
configmapも同様:
kubectl create configmap nginxconfigmap --from-file= default.conf
configmap/nginxconfigmap created
NAME DATA AGE
nginxconfigmap 1 114s
以下に示すのは、makeを実行したときに問題が発生する場合(例えばWindowsなど)の手動手順です:
# 公開鍵と秘密鍵のペアを作成する
openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /d/tmp/nginx.key -out /d/tmp/nginx.crt -subj "/CN=my-nginx/O=my-nginx"
# 鍵をbase64エンコーディングに変換する
cat /d/tmp/nginx.crt | base64
cat /d/tmp/nginx.key | base64
以下のようなyamlファイルを作成するために、前のコマンドからの出力を使います。
base64エンコードされた値は、全て1行で記述する必要があります。
apiVersion : "v1"
kind : "Secret"
metadata :
name : "nginxsecret"
namespace : "default"
type : kubernetes.io/tls
data :
# 注意: 以下の値はご自身で base64 エンコードした証明書と鍵に置き換えてください。
tls.crt : "REPLACE_WITH_BASE64_CERT"
tls.key : "REPLACE_WITH_BASE64_KEY"
では、このファイルを使ってSecretを作成します:
kubectl apply -f nginxsecrets.yaml
kubectl get secrets
NAME TYPE DATA AGE
nginxsecret kubernetes.io/tls 2 1m
Secretにある証明書を使ってhttpsサーバーを開始するために、nginxレプリカを変更します。また、Serviceは(80および443の)両方のポートを公開するようにします:
apiVersion : v1
kind : Service
metadata :
name : my-nginx
labels :
run : my-nginx
spec :
type : NodePort
ports :
- port : 8080
targetPort : 80
protocol : TCP
name : http
- port : 443
protocol : TCP
name : https
selector :
run : my-nginx
---
apiVersion : apps/v1
kind : Deployment
metadata :
name : my-nginx
spec :
selector :
matchLabels :
run : my-nginx
replicas : 1
template :
metadata :
labels :
run : my-nginx
spec :
volumes :
- name : secret-volume
secret :
secretName : nginxsecret
containers :
- name : nginxhttps
image : bprashanth/nginxhttps:1.0
ports :
- containerPort : 443
- containerPort : 80
volumeMounts :
- mountPath : /etc/nginx/ssl
name : secret-volume
nginx-secure-appマニフェストの注目すべきポイント:
DeploymentとServiceの指定の両方が同じファイルに含まれています。 nginxサーバー は、ポート80でHTTPトラフィック、ポート443でHTTPSトラフィックをサービスし、nginx Serviceは両方のポートを公開します。各コンテナは、/etc/nginx/sslにマウントされたボリューム経由で鍵にアクセスできます。
これはnginxサーバーが開始する前 にセットアップされます。 kubectl delete deployments,svc my-nginx; kubectl create -f ./nginx-secure-app.yaml
この時点で、任意のノードからnginxサーバーに到達できます。
kubectl get pods -l run = my-nginx -o custom-columns= POD_IP:.status.podIPs
POD_IP
[ map[ ip:10.244.3.5]]
node $ curl -k https://10.244.3.5
...
<h1>Welcome to nginx!</h1>
最後の手順でcurlに-kパラメーターを与えていることに注意してください。
これは、証明書の生成時点ではnginxを実行中のPodについて何もわからないので、curlにCNameのミスマッチを無視するよう指示する必要があるからです。
Serviceを作成することで、証明書で使われているCNameと、PodがServiceルックアップ時に使う実際のDNS名とがリンクされます。
Podからこれをテストしてみましょう(単純化のため同じSecretが再利用されるので、ServiceにアクセスするのにPodが必要なのはnginx.crtだけです):
apiVersion : apps/v1
kind : Deployment
metadata :
name : curl-deployment
spec :
selector :
matchLabels :
app : curlpod
replicas : 1
template :
metadata :
labels :
app : curlpod
spec :
volumes :
- name : secret-volume
secret :
secretName : nginxsecret
containers :
- name : curlpod
command :
- sh
- -c
- while true; do sleep 1; done
image : radial/busyboxplus:curl
volumeMounts :
- mountPath : /etc/nginx/ssl
name : secret-volume
kubectl apply -f ./curlpod.yaml
kubectl get pods -l app = curlpod
NAME READY STATUS RESTARTS AGE
curl-deployment-1515033274-1410r 1/1 Running 0 1m
kubectl exec curl-deployment-1515033274-1410r -- curl https://my-nginx --cacert /etc/nginx/ssl/tls.crt
...
<title>Welcome to nginx!</title>
...
Serviceの公開 アプリケーションのいくつかの部分においては、Serviceを外部IPアドレスで公開したいと思うかもしれません。
Kubernetesはこれに対して2つのやり方をサポートしています: NodePortとLoadBalancerです。
前のセクションで作成したServiceではすでにNodePortを使っていたので、ノードにパブリックIPアドレスがあれば、nginx HTTPSレプリカもトラフィックをインターネットでサービスする準備がすでに整っています。
kubectl get svc my-nginx -o yaml | grep nodePort -C 5
uid: 07191fb3-f61a-11e5-8ae5-42010af00002
spec:
clusterIP: 10.0.162.149
ports:
- name: http
nodePort: 31704
port: 8080
protocol: TCP
targetPort: 80
- name: https
nodePort: 32453
port: 443
protocol: TCP
targetPort: 443
selector:
run: my-nginx
kubectl get nodes -o yaml | grep ExternalIP -C 1
- address: 104.197.41.11
type: ExternalIP
allocatable:
--
- address: 23.251.152.56
type: ExternalIP
allocatable:
...
$ curl https://<EXTERNAL-IP>:<NODE-PORT> -k
...
<h1>Welcome to nginx!</h1>
では、クラウドロードバランサーを使うために、Serviceを再作成してみましょう。
my-nginxのTypeをNodePortからLoadBalancerに変更してください:
kubectl edit svc my-nginx
kubectl get svc my-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx LoadBalancer 10.0.162.149 xx.xxx.xxx.xxx 8080:30163/TCP 21s
curl https://<EXTERNAL-IP> -k
...
<title>Welcome to nginx!</title>
EXTERNAL-IP列のIPアドレスが、パブリックインターネットで利用可能なものになっています。
CLUSTER-IPはクラスター/プライベートクラウドネットワーク内でのみ利用可能なものです。
AWSにおいては、LoadBalancerタイプは、IPアドレスではなく(長い)ホスト名を使うELBを作成することに注意してください。
これは標準のkubectl get svcの出力に合わせるには長すぎ、実際それを見るにはkubectl describe service my-nginxを使う必要があります。
これは以下のような見た目になります:
kubectl describe service my-nginx
...
LoadBalancer Ingress: a320587ffd19711e5a37606cf4a74574-1142138393.us-east-1.elb.amazonaws.com
...
次の項目 5.7.2 - 送信元IPを使用する Kubernetesクラスター内で実行されているアプリケーションは、Serviceという抽象化を経由して、他のアプリケーションや外の世界との発見や通信を行います。このドキュメントでは、異なる種類のServiceに送られたパケットの送信元IPに何が起こるのか、そして必要に応じてこの振る舞いを切り替える方法について説明します。
始める前に 用語 このドキュメントでは、以下の用語を使用します。
NAT ネットワークアドレス変換(network address translation) 送信元NAT パケットの送信元のIPを置換します。このページでは、通常ノードのIPアドレスを置換することを意味します。 送信先NAT パケットの送信先のIPを置換します。このページでは、通常Pod のIPアドレスを置換することを意味します。 VIP Kubernetes内のすべてのService などに割り当てられる仮想IPアドレス(virtual IP address)です。 kube-proxy すべてのノード上でServiceのVIPを管理するネットワークデーモンです。 前提条件 Kubernetesクラスターが必要、かつそのクラスターと通信するためにkubectlコマンドラインツールが設定されている必要があります。
このチュートリアルは、コントロールプレーンのホストとして動作していない少なくとも2つのノードを持つクラスターで実行することをおすすめします。
まだクラスターがない場合、minikube を使って作成するか、
以下のいずれかのKubernetesプレイグラウンドも使用できます:
以下の例では、HTTPヘッダー経由で受け取ったリクエストの送信元IPをエコーバックする、小さなnginxウェブサーバーを使用します。次のコマンドでウェブサーバーを作成できます。
kubectl create deployment source-ip-app --image= registry.k8s.io/echoserver:1.10
出力は次のようになります。
deployment.apps/source-ip-app created
目標 単純なアプリケーションを様々な種類のService経由で公開する それぞれの種類のServiceがどのように送信元IPのNATを扱うかを理解する 送信元IPを保持することに関わるトレードオフを理解する Type=ClusterIPを使用したServiceでの送信元IPkube-proxyがiptablesモード (デフォルト)で実行されている場合、クラスター内部からClusterIPに送られたパケットに送信元のNATが行われることは決してありません。kube-proxyが実行されているノード上でhttp://localhost:10249/proxyModeにリクエストを送って、kube-proxyのモードを問い合わせてみましょう。
出力は次のようになります。
NAME STATUS ROLES AGE VERSION
kubernetes-node-6jst Ready <none> 2h v1.13.0
kubernetes-node-cx31 Ready <none> 2h v1.13.0
kubernetes-node-jj1t Ready <none> 2h v1.13.0
これらのノードの1つでproxyモードを取得します(kube-proxyはポート10249をlistenしています)。
# このコマンドは、問い合わせを行いたいノード上のシェルで実行してください。
curl http://localhost:10249/proxyMode
出力は次のようになります。
iptables
source IPアプリのServiceを作成することで、送信元IPが保持されているかテストできます。
kubectl expose deployment source-ip-app --name= clusterip --port= 80 --target-port= 8080
出力は次のようになります。
service/clusterip exposed
kubectl get svc clusterip
出力は次のようになります。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
clusterip ClusterIP 10.0.170.92 <none> 80/TCP 51s
そして、同じクラスター上のPodからClusterIPにアクセスします。
kubectl run busybox -it --image= busybox --restart= Never --rm
出力は次のようになります。
Waiting for pod default/busybox to be running, status is Pending, pod ready: false
If you don't see a command prompt, try pressing enter.
これで、Podの内部でコマンドが実行できます。
# このコマンドは、"kubectl run" のターミナルの内部で実行してください
ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
3: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1460 qdisc noqueue
link/ether 0a:58:0a:f4:03:08 brd ff:ff:ff:ff:ff:ff
inet 10.244.3.8/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::188a:84ff:feb0:26a5/64 scope link
valid_lft forever preferred_lft forever
そして、wgetを使用してローカルのウェブサーバーに問い合わせます。
# "10.0.170.92" の部分をService名が"clusterip"のIPv4アドレスに置き換えてください
wget -qO - 10.0.170.92
CLIENT VALUES:
client_address=10.244.3.8
command=GET
...
client_addressは常にクライアントのPodのIPアドレスになります。これは、クライアントのPodとサーバーのPodが同じノード内にあっても異なるノードにあっても変わりません。
Type=NodePortを使用したServiceでの送信元IPType=NodePortNodePort Serviceを作ることでテストできます。
kubectl expose deployment source-ip-app --name= nodeport --port= 80 --target-port= 8080 --type= NodePort
出力は次のようになります。
service/nodeport exposed
NODEPORT = $( kubectl get -o jsonpath = "{.spec.ports[0].nodePort}" services nodeport)
NODES = $( kubectl get nodes -o jsonpath = '{ $.items[*].status.addresses[?(@.type=="InternalIP")].address }' )
クラウドプロバイダーで実行する場合、上に示したnodes:nodeportに対してファイアウォールのルールを作成する必要があるかもしれません。それでは、上で割り当てたノードポート経由で、クラスターの外部からServiceにアクセスしてみましょう。
for node in $NODES ; do curl -s $node :$NODEPORT | grep -i client_address; done
出力は次のようになります。
client_address=10.180.1.1
client_address=10.240.0.5
client_address=10.240.0.3
これらは正しいクライアントIPではなく、クラスターのinternal IPであることがわかります。ここでは、次のようなことが起こっています。
クライアントがパケットをnode2:nodePortに送信する node2は、パケット内の送信元IPアドレスを自ノードのIPアドレスに置換する(SNAT)node2は、パケット内の送信先IPアドレスをPodのIPアドレスに置換するパケットはnode1にルーティングされ、endpointにルーティングされる Podからの応答がnode2にルーティングされて戻ってくる Podからの応答がクライアントに送り返される 図で表すと次のようになります。
graph LR;
client(client)-->node2[Node 2];
node2-->client;
node2-. SNAT .->node1[Node 1];
node1-. SNAT .->node2;
node1-->endpoint(Endpoint);
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
class node1,node2,endpoint k8s;
class client plain;
このコンテンツを表示するには、JavaScriptを有効に する必要があります クライアントのIPが失われることを回避するために、Kubernetesにはクライアントの送信元IPを保持する 機能があります。service.spec.externalTrafficPolicyの値をLocalに設定すると、kube-proxyはローカルに存在するエンドポイントへのプロキシリクエストだけをプロキシし、他のノードへはトラフィックを転送しなくなります。このアプローチでは、オリジナルの送信元IPアドレスが保持されます。ローカルにエンドポイントが存在しない場合には、そのノードに送信されたパケットは損失します。そのため、エンドポイントに到達するパケットに適用する可能性のあるパケット処理ルールでは、送信元IPが正しいことを信頼できます。
次のようにしてservice.spec.externalTrafficPolicyフィールドを設定します。
kubectl patch svc nodeport -p '{"spec":{"externalTrafficPolicy":"Local"}}'
出力は次のようになります。
service/nodeport patched
そして、再度テストしてみます。
for node in $NODES ; do curl --connect-timeout 1 -s $node :$NODEPORT | grep -i client_address; done
出力は次のようになります。
client_address=198.51.100.79
今度は、正しい クライアントIPが含まれる応答が1つだけ得られました。これは、エンドポイントのPodが実行されているノードから来たものです。
ここでは、次のようなことが起こっています。
クライアントがパケットをエンドポイントが存在しないnode2:nodePortに送信する パケットが損失する クライアントがパケットをエンドポイントが存在する node1:nodePortに送信する node1は、正しい送信元IPを持つパケットをエンドポイントにルーティングする 図で表すと次のようになります。
graph TD;
client --> node1[Node 1];
client(client) --x node2[Node 2];
node1 --> endpoint(endpoint);
endpoint --> node1;
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
class node1,node2,endpoint k8s;
class client plain;
このコンテンツを表示するには、JavaScriptを有効に する必要があります Type=LoadBalancerを使用したServiceでの送信元IPType=LoadBalancerReady状態にあるすべてのスケジュール可能なKubernetesのNodeは、ロードバランサーからのトラフィックを受付可能であるためです。そのため、エンドポイントが存在しないノードにパケットが到達した場合、システムはエンドポイントが存在する ノードにパケットをプロシキーします。このとき、(前のセクションで説明したように)パケットの送信元IPがノードのIPに置換されます。
ロードバランサー経由でsource-ip-appを公開することで、これをテストできます。
kubectl expose deployment source-ip-app --name= loadbalancer --port= 80 --target-port= 8080 --type= LoadBalancer
出力は次のようになります。
service/loadbalancer exposed
ServiceのIPアドレスを表示します。
kubectl get svc loadbalancer
出力は次のようになります。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
loadbalancer LoadBalancer 10.0.65.118 203.0.113.140 80/TCP 5m
次に、Serviceのexternal-ipにリクエストを送信します。
出力は次のようになります。
CLIENT VALUES:
client_address=10.240.0.5
...
しかし、Google Kubernetes EngineやGCE上で実行している場合、同じservice.spec.externalTrafficPolicyフィールドをLocalに設定すると、ロードバランサーからのトラフィックを受け付け可能なノードのリストから、Serviceエンドポイントが存在しない ノードが強制的に削除されます。この動作は、ヘルスチェックを意図的に失敗させることによって実現されています。
図で表すと次のようになります。
アノテーションを設定することで動作をテストできます。
kubectl patch svc loadbalancer -p '{"spec":{"externalTrafficPolicy":"Local"}}'
Kubernetesにより割り当てられたservice.spec.healthCheckNodePortフィールドをすぐに確認します。
kubectl get svc loadbalancer -o yaml | grep -i healthCheckNodePort
出力は次のようになります。
healthCheckNodePort : 32122
service.spec.healthCheckNodePortフィールドは、/healthzでhealth checkを配信しているすべてのノード上のポートを指しています。次のコマンドでテストできます。
kubectl get pod -o wide -l run = source-ip-app
出力は次のようになります。
NAME READY STATUS RESTARTS AGE IP NODE
source-ip-app-826191075-qehz4 1/1 Running 0 20h 10.180.1.136 kubernetes-node-6jst
curlを使用して、さまざまなノード上の/healthzエンドポイントからデータを取得します。
# このコマンドは選んだノードのローカル上で実行してください
curl localhost:32122/healthz
1 Service Endpoints found
ノードが異なると、得られる結果も異なる可能性があります。
# このコマンドは、選んだノード上でローカルに実行してください
curl localhost:32122/healthz
No Service Endpoints Found
コントロールプレーン 上で実行中のコントローラーは、クラウドのロードバランサーを割り当てる責任があります。同じコントローラーは、各ノード上のポートやパスを指すHTTPのヘルスチェックも割り当てます。エンドポイントが存在しない2つのノードがヘルスチェックに失敗するまで約10秒待った後、curlを使用してロードバランサーのIPv4アドレスに問い合わせます。
出力は次のようになります。
CLIENT VALUES:
client_address=198.51.100.79
...
クロスプラットフォームのサポート Type=LoadBalancerを使用したServiceで送信元IPを保持する機能を提供しているのは一部のクラウドプロバイダだけです。実行しているクラウドプロバイダによっては、以下のように異なる方法でリクエストを満たす場合があります。
クライアントとのコネクションをプロキシが終端し、ノードやエンドポイントとの接続には新しいコネクションが開かれる。このような場合、送信元IPは常にクラウドのロードバランサーのものになり、クライアントのIPにはなりません。
クライアントからロードバランサーのVIPに送信されたリクエストが、中間のプロキシではなく、クライアントの送信元IPとともにノードまで到達するようなパケット転送が使用される。
1つめのカテゴリーのロードバランサーの場合、真のクライアントIPと通信するために、 HTTPのForwarded ヘッダーやX-FORWARDED-FOR ヘッダー、proxy protocol などの、ロードバランサーとバックエンドの間で合意されたプロトコルを使用する必要があります。2つ目のカテゴリーのロードバランサーの場合、Serviceのservice.spec.healthCheckNodePortフィールドに保存されたポートを指すHTTPのヘルスチェックを作成することで、上記の機能を活用できます。
クリーンアップ Serviceを削除します。
kubectl delete svc -l app = source-ip-app
Deployment、ReplicaSet、Podを削除します。
kubectl delete deployment source-ip-app
次の項目 5.7.3 - Podとそのエンドポイントの終了動作を探る アプリケーションをServiceに接続する で概略を示したステップに従ってアプリケーションをServiceに接続すると、ネットワーク上で公開され、継続的に実行されて、複製されたアプリケーションが得られます。
このチュートリアルでは、Podを終了する流れを見て、gracefulな(猶予のある)接続ドレインを実装する手法を模索するための手助けをします。
Podの終了手続きとそのエンドポイント アップグレードやスケールダウンのために、Podを終了しなければならない場面はままあります。
アプリケーションの可用性を高めるために、適切なアクティブ接続ドレインを実装することは重要でしょう。
このチュートリアルでは概念のデモンストレーションのために、シンプルなnginx Webサーバーを例として、対応するエンドポイントの状態に関連したPodの終了および削除の流れを説明します。
エンドポイント終了の流れの例 以下は、Podの終了 ドキュメントに記載されている流れの例です。
1つのnginxレプリカを含むDeployment(純粋にデモンストレーション目的です)とServiceがあるとします:
apiVersion : apps/v1
kind : Deployment
metadata :
name : nginx-deployment
labels :
app : nginx
spec :
replicas : 1
selector :
matchLabels :
app : nginx
template :
metadata :
labels :
app : nginx
spec :
terminationGracePeriodSeconds : 120 # 非常に長い猶予期間
containers :
- name : nginx
image : nginx:latest
ports :
- containerPort : 80
lifecycle :
preStop :
exec :
# 実際の活動終了はterminationGracePeriodSecondsまでかかる可能性がある。
# この例においては、少なくともterminationGracePeriodSecondsの間は待機し、
# 120秒経過すると、コンテナは強制的に終了される。
# この間ずっとnginxはリクエストを処理し続けていることに注意。
command : [
"/bin/sh" , "-c" , "sleep 180"
]
apiVersion : apps/v1
kind : Deployment
metadata :
name : nginx-deployment
labels :
app : nginx
spec :
replicas : 1
selector :
matchLabels :
app : nginx
template :
metadata :
labels :
app : nginx
spec :
terminationGracePeriodSeconds : 120 # 非常に長い猶予期間
containers :
- name : nginx
image : nginx:latest
ports :
- containerPort : 80
lifecycle :
preStop :
exec :
# 実際の活動終了はterminationGracePeriodSecondsまでかかる可能性がある。
# この例においては、少なくともterminationGracePeriodSecondsの間は待機し、
# 120秒経過すると、コンテナは強制終了される。
# この間ずっとnginxはリクエストを処理し続けていることに注意。
command : [
"/bin/sh" , "-c" , "sleep 180"
]
---
apiVersion : v1
kind : Service
metadata :
name : nginx-service
spec :
selector :
app : nginx
ports :
- protocol : TCP
port : 80
targetPort : 80
PodとServiceが実行中になったら、関連付けられたEndpointSliceの名前を得られます:
kubectl get endpointslice
この出力は以下のようなものになります:
NAME ADDRESSTYPE PORTS ENDPOINTS AGE
nginx-service-6tjbr IPv4 80 10.12.1.199,10.12.1.201 22m
状態からわかるように、1つのエンドポイントが登録されていることが確認できます:
kubectl get endpointslices -o json -l kubernetes.io/service-name= nginx-service
この出力は以下のようなものになります:
{
"addressType": "IPv4",
"apiVersion": "discovery.k8s.io/v1",
"endpoints": [
{
"addresses": [
"10.12.1.201"
],
"conditions": {
"ready": true,
"serving": true,
"terminating": false
では、Podを終了し、そのPodがgracefulな終了期間設定を守って終了されていることを確認してみましょう:
kubectl delete pod nginx-deployment-7768647bf9-b4b9s
全Podについて調べます:
この出力は以下のようなものになります:
NAME READY STATUS RESTARTS AGE
nginx-deployment-7768647bf9-b4b9s 1/1 Terminating 0 4m1s
nginx-deployment-7768647bf9-rkxlw 1/1 Running 0 8s
新しいPodがスケジュールされたことを見てとれます。
新しいPodのために新しいエンドポイントが作成される間、古いエンドポイントは終了中の状態のまま残っています:
kubectl get endpointslice -o json nginx-service-6tjbr
この出力は以下のようなものになります:
{
"addressType": "IPv4",
"apiVersion": "discovery.k8s.io/v1",
"endpoints": [
{
"addresses": [
"10.12.1.201"
],
"conditions": {
"ready": false,
"serving": true,
"terminating": true
},
"nodeName": "gke-main-default-pool-dca1511c-d17b",
"targetRef": {
"kind": "Pod",
"name": "nginx-deployment-7768647bf9-b4b9s",
"namespace": "default",
"uid": "66fa831c-7eb2-407f-bd2c-f96dfe841478"
},
"zone": "us-central1-c"
},
{
"addresses": [
"10.12.1.202"
],
"conditions": {
"ready": true,
"serving": true,
"terminating": false
},
"nodeName": "gke-main-default-pool-dca1511c-d17b",
"targetRef": {
"kind": "Pod",
"name": "nginx-deployment-7768647bf9-rkxlw",
"namespace": "default",
"uid": "722b1cbe-dcd7-4ed4-8928-4a4d0e2bbe35"
},
"zone": "us-central1-c"
これを使うと、終了中のアプリケーションがその状態について、接続ドレイン機能の実装目的でクライアント(ロードバランサーなど)と通信する、ということが可能です。
これらのクライアントではエンドポイントの終了を検出し、そのための特別なロジックを実装できます。
Kubernetesでは、終了中のエンドポイントのready状態は全てfalseにセットされます。
これは後方互換性のために必要な措置で、既存のロードバランサーは通常のトラフィックにはそれを使用しません。
Podの終了時にトラフィックのドレインが必要な場合、実際に準備できているかはserving状態として調べられます。
Podが削除される時には、古いエンドポイントも削除されます。
次の項目 6 - リファレンス 本セクションには、Kubernetesのドキュメントのリファレンスが含まれています。
APIリファレンス 公式にサポートされているクライアントライブラリ プログラミング言語からKubernetesのAPIを呼ぶためには、クライアントライブラリ を使うことができます。公式にサポートしているクライアントライブラリ:
CLIリファレンス kubectl - コマンドの実行やKubernetesクラスターの管理に使う主要なCLIツールです。kubeadm - セキュアなKubernetesクラスターを簡単にプロビジョニングするためのCLIツールです。コンポーネントリファレンス kubelet - 各ノード上で動作する最も重要なノードエージェントです。kubeletは一通りのPodSpecを受け取り、コンテナが実行中で正常であることを確認します。
kube-apiserver - Pod、Service、Replication Controller等、APIオブジェクトのデータを検証・設定するREST APIサーバーです。
kube-controller-manager - Kubernetesに同梱された、コアのコントロールループを埋め込むデーモンです。
kube-proxy - 単純なTCP/UDPストリームのフォワーディングや、一連のバックエンド間でTCP/UDPのラウンドロビンでのフォワーディングを実行できます。
kube-scheduler - 可用性、パフォーマンス、およびキャパシティを管理するスケジューラーです。
コントロールプレーンとワーカーノードで開いておくべきポートとプロトコル の一覧
設定APIリファレンス このセクションでは、Kubernetesのコンポーネントやツールを設定するのに使われている「未公開」のAPIのドキュメントをまとめています。
クラスターを使ったり管理したりするユーザーやオペレーターにとって必要不可欠ではありますが、これらのAPIの大半はRESTful方式のAPIサーバーでは提供されません。
kubeadmの設定APIリファレンス 設計のドキュメント Kubernetesの機能に関する設計ドキュメントのアーカイブです。Kubernetesアーキテクチャ とKubernetesデザイン概要 から読み始めると良いでしょう。
6.1 - 標準化用語集 6.2 - KubeletチェックポイントAPI FEATURE STATE:
Kubernetes v1.25 [alpha]
コンテナのチェックポイントは実行中のコンテナのステートフルコピーを作成するための機能です。
コンテナのステートフルコピーがあると、デバックや類似の目的のために別のコンピューターに移動させることができます。
チェックポイントコンテナデータを復元可能なコンピューターに移動させる場合、その復元したコンテナは、チェックポイントが作成された正確に同じ地点で実行が再開されます。
保存したデータを検査することも可能です。
ただし、検査を行うための適したツールを保持している必要があります。
コンテナのチェックポイントを作成することで、セキュリティ影響が発生する場合があります。
通常、チェックポイントはチェックポイントされたコンテナ内のすべてのプロセスのすべてのメモリーページを含んでいます。
メモリー内で使用された全てがローカルディスク上で利用できるようになることを意味しています。
これはすべてのプライベートデータを含んでおり、もしかしたら暗号化に使用した鍵も含まれているかもしれません。
基礎となるCRI実装(そのノード上のコンテナランタイム)は、rootユーザーのみがアクセス可能なチェックポイントアーカイブを作成するべきです。
チェックポイントアーカイブが他のシステムに転送された場合、全てのメモリーページがチェックポイントアーカイブのオーナーによって読み取れるようになることを覚えておくことが重要です。
操作方法 post 指定したコンテナのチェックポイント指定したPodから指定したコンテナのチェックポイントを作成するようにkubeletに指示します。
kubeletチェックポイントインターフェースへのアクセスの制御方法についての詳細な情報は、Kubelet authentication/authorization reference を参照してください。
kubeletは基礎となるCRI 実装にチェックポイントをリクエストします。
チェックポイントリクエストでは、kubeletがcheckpoint-<podFullName>-<containerName>-<timestamp>.tarのようなチェックポイントアーカイブの名前を指定します。
併せて、(--root-dirで定義される)rootディレクトリ配下のcheckpointsディレクトリに、チェックポイントアーカイブを保存することをリクエストします。
デフォルトは/var/lib/kubelet/checkpointsです。
チェックポイントアーカイブは tar フォーマットであり、tar
HTTPリクエスト POST /checkpoint/{namespace}/{pod}/{container}
パラメーター namespace (パス内 ): string, 必須項目
Namespace pod (パス内 ): string, 必須項目
Pod container (パス内 ): string, 必須項目
コンテナ timeout (クエリ内 ): integer
チェックポイントの作成が終了するまで待機する秒単位のタイムアウト。
ゼロまたはタイムアウトが指定されていない場合、デフォルトはCRI タイムアウトの値が使用されます。
チェックポイント作成時間はコンテナの使用メモリーに直接依存します。
コンテナの使用メモリーが多いほど、対応するチェックポイントを作成するために必要な時間が長くなります。
レスポンス 200: OK
401: Unauthorized
404: Not Found (ContainerCheckpointフィーチャーゲートが無効の場合)
404: Not Found (指定したnamespaceやpod、containerが見つからない場合)
500: Internal Server Error (CRI実装でチェックポイント中にエラーが発生した場合(詳細はエラーメッセージを参照))
500: Internal Server Error (CRI実装がチェックポイントCRI APIを実装していない場合(詳細はエラーメッセージを参照))
6.3 - 認証 このページでは、認証の概要について説明します。
Kubernetesにおけるユーザー すべてのKubernetesクラスターには、2種類のユーザーがあります。Kubernetesによって管理されるサービスアカウントと、通常のユーザーです。
クラスターから独立したサービスは通常のユーザーを以下の方法で管理することを想定されています。
秘密鍵を配布する管理者 KeystoneやGoogle Accountsのようなユーザーストア ユーザー名とパスワードのリストを持つファイル これを考慮すると、 Kubernetesは通常のユーザーアカウントを表すオブジェクトを持ちません。 APIコールを介して、通常のユーザーをクラスターに追加することはできません。
APIコールを介して通常のユーザーを追加できませんが、クラスターの認証局(CA)に署名された有効な証明書で表すユーザーは認証済みと判断されます。この構成では、Kubernetesは証明書の‘subject’内にある一般的な名前フィールド(例えば、“/CN=bob”)からユーザー名を特定します。そこから、ロールベースアクセス制御(RBAC)サブシステムは、ユーザーがあるリソースにおける特定の操作を実行するために認証済みかどうか特定します。詳細は、 証明書要求 内の通常のユーザーの題目を参照してください。
対照的に、サービスアカウントはKubernetes APIによって管理されるユーザーです。サービスアカウントは特定の名前空間にバインドされており、APIサーバーによって自動的に作成されるか、APIコールによって手動で作成されます。サービスアカウントは、Secretsとして保存された資格情報の集合に紐付けられています。これをPodにマウントすることで、クラスター内のプロセスがKubernetes APIと通信できるようにします。
APIリクエストは、通常のユーザーかサービスアカウントに紐付けられているか、匿名リクエスト として扱われます。つまり、ワークステーションでkubectlを入力する人間のユーザーから、ノード上のkubeletsやコントロールプレーンのメンバーまで、クラスター内外の全てのプロセスは、APIサーバーへのリクエストを行う際に認証を行うか匿名ユーザーとして扱われる必要があります。
認証戦略 Kubernetesは、クライアント証明書、Bearerトークン、認証プロキシ、HTTP Basic認証を使い、認証プラグインを通してAPIリクエストを認証します。APIサーバーにHTTPリクエストが送信されると、プラグインは以下の属性をリクエストに関連付けようとします。
ユーザー名: エンドユーザーを識別する文字列です。一般的にな値は、kube-adminやjane@example.comです。 UID: エンドユーザーを識別する文字列であり、ユーザー名よりも一貫性と一意性を持たせようとするものです。 グループ: 各要素がユーザーの役割を示すような意味を持つ文字列の集合です。system:mastersやdevops-teamといった値が一般的です。 追加フィールド: 認証者が有用と思われる追加情報を保持する文字列のリストに対する、文字列のマップです。 すべての値は認証システムに対して非透過であり、認可機能 が解釈した場合にのみ意味を持ちます。
一度に複数の認証方法を有効にすることができます。通常は、以下のように少なくとも2つの方法を使用するべきです。
サービスアカウント用のサービスアカウントトークン ユーザー認証のための、少なくとも1つの他の方法 複数の認証モジュールが有効化されている場合、リクエストの認証に成功した最初のモジュールが、評価が簡略化します。APIサーバーは、認証の実行順序を保証しません。
system:authenticatedグループには、すべての認証済みユーザーのグループのリストが含まれます。
他の認証プロトコル(LDAP、SAML、Kerberos、X509スキームなど)との統合は、認証プロキシ や認証Webhook を使用して実施できます。
X509クライアント証明書 クライアント証明書認証は、APIサーバーに--client-ca-file=SOMEFILEオプションを渡すことで有効になります。参照されるファイルには、APIサーバーに提示されたクライアント証明書を検証するために使用する1つ以上の認証局が含まれている必要があります。クライアント証明書が提示され、検証された場合、サブジェクトのCommon Nameがリクエストのユーザー名として使用されます。Kubernetes1.4時点では、クライアント証明書は、証明書のOrganizationフィールドを使用して、ユーザーのグループメンバーシップを示すこともできます。あるユーザーに対して複数のグループメンバーシップを含めるには、証明書に複数のOrganizationフィールドを含めます。
例えば、証明書署名要求を生成するために、opensslコマンドラインツールを使用します。
openssl req -new -key jbeda.pem -out jbeda-csr.pem -subj "/CN=jbeda/O=app1/O=app2"
これにより、"app1"と"app2"の2つのグループに属するユーザー名"jbeda"の証明書署名要求が作成されます。
クライアント証明書の生成方法については、証明書の管理 を参照してください。
静的なトークンファイル コマンドラインで--token-auth-file=SOMEFILEオプションを指定すると、APIサーバーはファイルからBearerトークンを読み込みます。現在のところ、トークンの有効期限は無く、APIサーバーを再起動しない限りトークンのリストを変更することはできません。
トークンファイルは、トークン、ユーザー名、ユーザーUIDの少なくとも3つの列を持つcsvファイルで、その後にオプションでグループ名が付きます。
備考: 複数のグループがある場合はダブルクォートで囲む必要があります。
token,user,uid,"group1,group2,group3"
リクエストにBearerトークンを含める HTTPクライアントからBearerトークン認証を利用する場合、APIサーバーはBearer THETOKENという値を持つAuthorizationヘッダーを待ち受けます。Bearerトークンは、HTTPのエンコーディングとクォート機能を利用してHTTPヘッダーの値に入れることができる文字列でなければなりません。例えば、Bearerトークンが31ada4fd-adec-460c-809a-9e56ceb75269であれば、HTTPのヘッダを以下のようにします。
Authorization: Bearer 31ada4fd-adec-460c-809a-9e56ceb75269
ブートストラップトークン FEATURE STATE:
Kubernetes v1.18 [stable]
新しいクラスターの効率的なブートストラップを可能にするために、Kubernetesにはブートストラップトークン と呼ばれる動的に管理されたBearerトークンタイプが含まれています。これらのトークンは、kube-system名前空間にSecretsとして格納され、動的に管理したり作成したりすることができます。コントローラーマネージャーには、TokenCleanerコントローラーが含まれており、ブートストラップトークンの有効期限が切れると削除します。
トークンの形式は[a-z0-9]{6}.[a-z0-9]{16}です。最初のコンポーネントはトークンIDであり、第2のコンポーネントはToken Secretです。以下のように、トークンをHTTPヘッダーに指定します。
Authorization: Bearer 781292.db7bc3a58fc5f07e
APIサーバーの--enable-bootstrap-token-authフラグで、Bootstrap Token Authenticatorを有効にする必要があります。TokenCleanerコントローラーを有効にするには、コントローラーマネージャーの--controllersフラグを使います。--controllers=*,tokencleanerのようにして行います。クラスターをブートストラップするためにkubeadmを使用している場合は、kubeadmがこれを代行してくれます。
認証機能はsystem:bootstrap:<Token ID>という名前で認証します。これはsystem:bootstrappersグループに含まれます。名前とグループは意図的に制限されており、ユーザーがブートストラップ後にこれらのトークンを使わないようにしています。ユーザー名とグループは、クラスターのブートストラップをサポートする適切な認可ポリシーを作成するために使用され、kubeadmによって使用されます。
ブートストラップトークンの認証機能やコントローラーについての詳細な説明、kubeadmでこれらのトークンを管理する方法については、ブートストラップトークン を参照してください。
サービスアカウントトークン サービスアカウントは、自動的に有効化される認証機能で、署名されたBearerトークンを使ってリクエストを検証します。このプラグインは、オプションとして2つのフラグを取ります。
--service-account-key-file: Bearerトークンに署名するためのPEMエンコードされた鍵を含むファイルです。指定しない場合は、APIサーバーのTLS秘密鍵が使われます。--service-account-lookup: 有効にすると、APIから削除されたトークンは取り消されます。サービスアカウントは通常、APIサーバーによって自動的に作成され、ServiceAccountAdmission Controller を介してクラスター内のPodに関連付けられます。Bearerトークンは、Podのよく知られた場所にマウントされ、これによりクラスター内のプロセスがAPIサーバー通信できるようになります。アカウントはPodSpecのserviceAccountNameフィールドを使って、明示的にPodに関連付けることができます。
備考: 自動で行われるため、通常serviceAccountNameは省略します。apiVersion : apps/v1 # このapiVersionは、Kubernetes1.9時点で適切です
kind : Deployment
metadata :
name : nginx-deployment
namespace : default
spec :
replicas : 3
template :
metadata :
# ...
spec :
serviceAccountName : bob-the-bot
containers :
- name : nginx
image : nginx:1.14.2
サービスアカウントのBearerトークンは、クラスター外で使用するために完全に有効であり、Kubernetes APIと通信したい長期的なジョブのアイデンティティを作成するために使用することができます。サービスアカウントを手動で作成するには、単にkubectl create serviceaccount (NAME)コマンドを使用します。これにより、現在の名前空間にサービスアカウントと関連するSecretが作成されます。
kubectl create serviceaccount jenkins
serviceaccount "jenkins" created
以下のように、関連するSecretを確認できます。
kubectl get serviceaccounts jenkins -o yaml
apiVersion : v1
kind : ServiceAccount
metadata :
# ...
secrets :
name : jenkins-token-1yvwg
作成されたSecretは、APIサーバーのパブリック認証局と署名されたJSON Web Token(JWT)を保持します。
kubectl get secret jenkins-token-1yvwg -o yaml
apiVersion : v1
data :
ca.crt : (base64でエンコードされたAPIサーバーの認証局)
namespace : ZGVmYXVsdA==
token : (base64でエンコードされたBearerトークン)
kind : Secret
metadata :
# ...
type : kubernetes.io/service-account-token
備考: Secretは常にbase64でエンコードされるため、これらの値もbase64でエンコードされています。署名されたJWTは、与えられたサービスアカウントとして認証するためのBearerトークンとして使用できます。トークンをリクエストに含める方法については、リクエストにBearerトークンを含める を参照してください。通常、これらのSecretはAPIサーバーへのクラスター内アクセス用にPodにマウントされますが、クラスター外からも使用することができます。
サービスアカウントは、ユーザー名system:serviceaccount:(NAMESPACE):(SERVICEACCOUNT)で認証され、グループsystem:serviceaccountsとsystem:serviceaccounts:(NAMESPACE)に割り当てられます。
警告: サービスアカウントトークンはSecretに保持されているため、Secretにアクセスできるユーザーは誰でもサービスアカウントとして認証することができます。サービスアカウントに権限を付与したり、Secretの読み取り機能を付与したりする際には注意が必要です。
OpenID Connectトークン OpenID Connect は、Azure Active Directory、Salesforce、Googleなど、いくつかのOAuth2プロバイダーでサポートされているOAuth2の一種です。
このプロトコルのOAuth2の主な拡張機能は、ID Token と呼ばれる、アクセストークンとアクセストークンと一緒に返される追加フィールドです。
このトークンは、ユーザーの電子メールなどのよく知られたフィールドを持つJSON Web Token(JWT)であり、サーバーによって署名されています。トークンをリクエストに含める方法については、リクエストにBearerトークンを含める を参照してください。
IDプロバイダーにログインします IDプロバイダーは、access_token、id_token、refresh_tokenを提供します kubectlを使う場合は、--tokenフラグでid_tokenを使うか、kubeconfigに直接追加してくださいkubectlは、id_tokenをAuthorizationと呼ばれるヘッダーでAPIサーバーに送りますAPIサーバーは、設定で指定された証明書と照合することで、JWT署名が有効であることを確認します id_tokenの有効期限が切れていないことを確認しますユーザーが認可されていることを確認します 認可されると、APIサーバーはkubectlにレスポンスを返します kubectlはユーザーにフィードバックを提供します自分が誰であるかを確認するために必要なデータはすべてid_tokenの中にあるので、KubernetesはIDプロバイダーと通信する必要がありません。すべてのリクエストがステートレスであるモデルでは、これは非常に認証のためのスケーラブルなソリューションを提供します。一方で、以下のようにいくつか課題があります。
Kubernetesには、認証プロセスを起動するための"Webインターフェース"がありません。クレデンシャルを収集するためのブラウザやインターフェースがないため、まずIDプロバイダに認証を行う必要があります。 id_tokenは、取り消すことができません。これは証明書のようなもので、有効期限が短い(数分のみ)必要があるので、数分ごとに新しいトークンを取得しなければならないのは非常に面倒です。Kubernetesダッシュボードへの認証において、kubectl proxyコマンドやid_tokenを注入するリバースプロキシを使う以外に、簡単な方法はありません。 APIサーバーの設定 プラグインを有効にするには、APIサーバーで以下のフラグを設定します。
パラメーター 説明 例 必須か --oidc-issuer-urlAPIサーバーが公開署名鍵を発見できるようにするプロバイダーのURLです。 https://スキームを使用するURLのみが受け入れられます。これは通常、"https://accounts.google.com"や"https://login.salesforce.com"のようにパスを持たないプロバイダのディスカバリーURLです。このURLは、.well-known/openid-configurationの下のレベルを指す必要があります。 ディスカバリーURLがhttps://accounts.google.com/.well-known/openid-configurationである場合、値はhttps://accounts.google.comとします。 はい --oidc-client-idすべてのトークンが発行されなければならないクライアントIDです。 kubernetes はい --oidc-username-claimユーザー名として使用するJWTのクレームを指定します。デフォルトではsubが使用されますが、これはエンドユーザーの一意の識別子であることが期待されます。管理者はプロバイダーに応じてemailやnameなどの他のクレームを選択することができます。ただし、他のプラグインとの名前の衝突を防ぐために、email以外のクレームには、プレフィックスとして発行者のURLが付けられます。 sub いいえ --oidc-username-prefix既存の名前(system:ユーザーなど)との衝突を防ぐために、ユーザー名の前にプレフィックスを付加します。例えばoidc:という値は、oidc:jane.doeのようなユーザー名を生成します。このフラグが指定されておらず、--oidc-username-claimがemail以外の値である場合、プレフィックスのデフォルトは(Issuer URL)#で、(Issuer URL)は--oidc-issuer-urlの値です。すべてのプレフィックスを無効にするためには、-という値を使用できます。 oidc:いいえ --oidc-groups-claimユーザーのグループとして使用するJWTのクレームです。クレームがある場合は、文字列の配列である必要があります。 groups いいえ --oidc-groups-prefix既存の名前(system:グループなど)との衝突を防ぐために、グループ名の前にプレフィックスを付加します。例えばoidc:という値は、oidc:engineeringやoidc:infraのようなグループ名を生成します。 oidc:いいえ --oidc-required-claimIDトークンの中の必須クレームを記述するkey=valueのペアです。設定されている場合、クレームが一致する値でIDトークンに存在することが検証されます。このフラグを繰り返して複数のクレームを指定します。 claim=valueいいえ --oidc-ca-fileIDプロバイダーのWeb証明書に署名した認証局の証明書へのパスです。デフォルトはホストのルート認証局が指定されます。 /etc/kubernetes/ssl/kc-ca.pemいいえ
重要なのは、APIサーバーはOAuth2クライアントではなく、ある単一の発行者を信頼するようにしか設定できないことです。これにより、サードパーティーに発行されたクレデンシャルを信頼せずに、Googleのようなパブリックプロバイダーを使用することができます。複数のOAuthクライアントを利用したい管理者は、azpクレームをサポートしているプロバイダや、あるクライアントが別のクライアントに代わってトークンを発行できるような仕組みを検討する必要があります。
KubernetesはOpenID Connect IDプロバイダーを提供していません。既存のパブリックなOpenID Connect IDプロバイダー(Googleやその他 など)を使用できます。もしくは、CoreOS dex 、Keycloak 、CloudFoundryUAA 、Tremolo SecurityのOpenUnison など、独自のIDプロバイダーを実行することもできます。
IDプロバイダーがKubernetesと連携するためには、以下のことが必要です。
すべてではないが、[OpenID Connect Discovery](https://openid.net/specs/openid-connect-discovery-1_0.html )をサポートしていること 廃れていない暗号を用いたTLSで実行されていること 認証局が署名した証明書を持っていること(認証局が商用ではない場合や、自己署名の場合も可) 上述の要件#3、認証局署名付き証明書を必要とすることについて、注意事項があります。GoogleやMicrosoftなどのクラウドプロバイダーではなく、独自のIDプロバイダーをデプロイする場合は、たとえ自己署名されていても、CAフラグがTRUEに設定されている証明書によって署名されたIDプロバイダーのWebサーバー証明書を持っていなければなりません。これは、Go言語のTLSクライアント実装が、証明書検証に関する標準に対して非常に厳格であるためです。認証局をお持ちでない場合は、CoreOSチームのこのスクリプト を使用して、シンプルな認証局と署名付きの証明書と鍵のペアを作成することができます。
または、この類似のスクリプト を使って、より寿命が長く、よりキーサイズの大きいSHA256証明書を生成できます。
特定のシステム用のセットアップ手順は、以下を参照してください。
kubectlの使用 選択肢1 - OIDC認証機能 最初の選択肢は、kubectlのoidc認証機能を利用することです。これはすべてのリクエストのBearerトークンとしてid_tokenを設定し、有効期限が切れるとトークンを更新します。プロバイダーにログインした後、kubectlを使ってid_token、refresh_token、client_id、client_secretを追加してプラグインを設定します。
リフレッシュトークンのレスポンスの一部としてid_tokenを返さないプロバイダーは、このプラグインではサポートされていないので、以下の"選択肢2"を使用してください。
kubectl config set-credentials USER_NAME \
= oidc \
= idp-issuer-url=( issuer url ) \
= client-id=( your client id ) \
= client-secret=( your client secret ) \
= refresh-token=( your refresh token ) \
= idp-certificate-authority=( path to your ca certificate ) \
= id-token=( your id_token )
例として、IDプロバイダーに認証した後に以下のコマンドを実行します。
kubectl config set-credentials mmosley \
= oidc \
= idp-issuer-url= https://oidcidp.tremolo.lan:8443/auth/idp/OidcIdP \
= client-id= kubernetes \
= client-secret= 1db158f6-177d-4d9c-8a8b-d36869918ec5 \
= refresh-token= q1bKLFOyUiosTfawzA93TzZIDzH2TNa2SMm0zEiPKTUwME6BkEo6Sql5yUWVBSWpKUGphaWpxSVAfekBOZbBhaEW+VlFUeVRGcluyVF5JT4+haZmPsluFoFu5XkpXk5BXqHega4GAXlF+ma+vmYpFcHe5eZR+slBFpZKtQA= \
= idp-certificate-authority= /root/ca.pem \
= id-token= eyJraWQiOiJDTj1vaWRjaWRwLnRyZW1vbG8ubGFuLCBPVT1EZW1vLCBPPVRybWVvbG8gU2VjdXJpdHksIEw9QXJsaW5ndG9uLCBTVD1WaXJnaW5pYSwgQz1VUy1DTj1rdWJlLWNhLTEyMDIxNDc5MjEwMzYwNzMyMTUyIiwiYWxnIjoiUlMyNTYifQ.eyJpc3MiOiJodHRwczovL29pZGNpZHAudHJlbW9sby5sYW46ODQ0My9hdXRoL2lkcC9PaWRjSWRQIiwiYXVkIjoia3ViZXJuZXRlcyIsImV4cCI6MTQ4MzU0OTUxMSwianRpIjoiMm96US15TXdFcHV4WDlHZUhQdy1hZyIsImlhdCI6MTQ4MzU0OTQ1MSwibmJmIjoxNDgzNTQ5MzMxLCJzdWIiOiI0YWViMzdiYS1iNjQ1LTQ4ZmQtYWIzMC0xYTAxZWU0MWUyMTgifQ.w6p4J_6qQ1HzTG9nrEOrubxIMb9K5hzcMPxc9IxPx2K4xO9l-oFiUw93daH3m5pluP6K7eOE6txBuRVfEcpJSwlelsOsW8gb8VJcnzMS9EnZpeA0tW_p-mnkFc3VcfyXuhe5R3G7aa5d8uHv70yJ9Y3-UhjiN9EhpMdfPAoEB9fYKKkJRzF7utTTIPGrSaSU6d2pcpfYKaxIwePzEkT4DfcQthoZdy9ucNvvLoi1DIC-UocFD8HLs8LYKEqSxQvOcvnThbObJ9af71EwmuE21fO5KzMW20KtAeget1gnldOosPtz1G5EwvaQ401-RPQzPGMVBld0_zMCAwZttJ4knw
これは以下のような構成になります。
users :
name : mmosley
user :
auth-provider :
config :
client-id : kubernetes
client-secret : 1db158f6-177d-4d9c-8a8b-d36869918ec5
id-token : eyJraWQiOiJDTj1vaWRjaWRwLnRyZW1vbG8ubGFuLCBPVT1EZW1vLCBPPVRybWVvbG8gU2VjdXJpdHksIEw9QXJsaW5ndG9uLCBTVD1WaXJnaW5pYSwgQz1VUy1DTj1rdWJlLWNhLTEyMDIxNDc5MjEwMzYwNzMyMTUyIiwiYWxnIjoiUlMyNTYifQ.eyJpc3MiOiJodHRwczovL29pZGNpZHAudHJlbW9sby5sYW46ODQ0My9hdXRoL2lkcC9PaWRjSWRQIiwiYXVkIjoia3ViZXJuZXRlcyIsImV4cCI6MTQ4MzU0OTUxMSwianRpIjoiMm96US15TXdFcHV4WDlHZUhQdy1hZyIsImlhdCI6MTQ4MzU0OTQ1MSwibmJmIjoxNDgzNTQ5MzMxLCJzdWIiOiI0YWViMzdiYS1iNjQ1LTQ4ZmQtYWIzMC0xYTAxZWU0MWUyMTgifQ.w6p4J_6qQ1HzTG9nrEOrubxIMb9K5hzcMPxc9IxPx2K4xO9l-oFiUw93daH3m5pluP6K7eOE6txBuRVfEcpJSwlelsOsW8gb8VJcnzMS9EnZpeA0tW_p-mnkFc3VcfyXuhe5R3G7aa5d8uHv70yJ9Y3-UhjiN9EhpMdfPAoEB9fYKKkJRzF7utTTIPGrSaSU6d2pcpfYKaxIwePzEkT4DfcQthoZdy9ucNvvLoi1DIC-UocFD8HLs8LYKEqSxQvOcvnThbObJ9af71EwmuE21fO5KzMW20KtAeget1gnldOosPtz1G5EwvaQ401-RPQzPGMVBld0_zMCAwZttJ4knw
idp-certificate-authority : /root/ca.pem
idp-issuer-url : https://oidcidp.tremolo.lan:8443/auth/idp/OidcIdP
refresh-token : q1bKLFOyUiosTfawzA93TzZIDzH2TNa2SMm0zEiPKTUwME6BkEo6Sql5yUWVBSWpKUGphaWpxSVAfekBOZbBhaEW+VlFUeVRGcluyVF5JT4+haZmPsluFoFu5XkpXk5BXq
name : oidc
id_tokenの有効期限が切れると、kubectlはrefresh_tokenとclient_secretを用いてid_tokenの更新しようとします。refresh_tokenとid_tokenの新しい値は、.kube/configに格納されます。
選択肢2 - --tokenオプションの使用 kubectlコマンドでは、--tokenオプションを使ってトークンを渡すことができる。以下のように、このオプションにid_tokenをコピーして貼り付けるだけです。
kubectl --token= eyJhbGciOiJSUzI1NiJ9.eyJpc3MiOiJodHRwczovL21sYi50cmVtb2xvLmxhbjo4MDQzL2F1dGgvaWRwL29pZGMiLCJhdWQiOiJrdWJlcm5ldGVzIiwiZXhwIjoxNDc0NTk2NjY5LCJqdGkiOiI2RDUzNXoxUEpFNjJOR3QxaWVyYm9RIiwiaWF0IjoxNDc0NTk2MzY5LCJuYmYiOjE0NzQ1OTYyNDksInN1YiI6Im13aW5kdSIsInVzZXJfcm9sZSI6WyJ1c2VycyIsIm5ldy1uYW1lc3BhY2Utdmlld2VyIl0sImVtYWlsIjoibXdpbmR1QG5vbW9yZWplZGkuY29tIn0.f2As579n9VNoaKzoF-dOQGmXkFKf1FMyNV0-va_B63jn-_n9LGSCca_6IVMP8pO-Zb4KvRqGyTP0r3HkHxYy5c81AnIh8ijarruczl-TK_yF5akjSTHFZD-0gRzlevBDiH8Q79NAr-ky0P4iIXS8lY9Vnjch5MF74Zx0c3alKJHJUnnpjIACByfF2SCaYzbWFMUNat-K1PaUk5-ujMBG7yYnr95xD-63n8CO8teGUAAEMx6zRjzfhnhbzX-ajwZLGwGUBT4WqjMs70-6a7_8gZmLZb2az1cZynkFRj2BaCkVT3A2RrjeEwZEtGXlMqKJ1_I2ulrOVsYx01_yD35-rw get nodes
Webhookトークン認証 Webhook認証は、Bearerトークンを検証するためのフックです。
--authentication-token-webhook-config-file: リモートのWebhookサービスへのアクセス方法を記述した設定ファイルです--authentication-token-webhook-cache-ttl: 認証をキャッシュする時間を決定します。デフォルトは2分です設定ファイルは、kubeconfig のファイル形式を使用します。
ファイル内で、clustersはリモートサービスを、usersはAPIサーバーのWebhookを指します。例えば、以下のようになります。
# Kubernetes APIのバージョン
apiVersion : v1
# APIオブジェクトの種類
kind : Config
# clustersは、リモートサービスを指します。
clusters :
- name : name-of-remote-authn-service
cluster :
certificate-authority : /path/to/ca.pem # リモートサービスを検証するためのCA
server : https://authn.example.com/authenticate # クエリするリモートサービスのURL。'https'を使用する必要があります。
# usersは、APIサーバーのWebhook設定を指します。
users :
- name : name-of-api-server
user :
client-certificate : /path/to/cert.pem # Webhookプラグインを使うための証明書
client-key : /path/to/key.pem # 証明書に合致する鍵
# kubeconfigファイルにはコンテキストが必要です。APIサーバー用のものを用意してください。
current-context : webhook
contexts :
context :
cluster : name-of-remote-authn-service
user : name-of-api-sever
name : webhook
クライアントが上記 のようにBearerトークンを使用してAPIサーバーとの認証を試みた場合、認証Webhookはトークンを含むJSONでシリアライズされたauthentication.k8s.io/v1beta1 TokenReviewオブジェクトをリモートサービスにPOSTします。Kubernetesはそのようなヘッダーが不足しているリクエストを作成しようとはしません。
Webhook APIオブジェクトは、他のKubernetes APIオブジェクトと同じように、Versioning Compatibility Rule に従うことに注意してください。実装者は、ベータオブジェクトで保証される互換性が緩いことに注意し、正しいデシリアライゼーションが使用されるようにリクエストの"apiVersion"フィールドを確認する必要があります。さらにAPIサーバーは、API拡張グループauthentication.k8s.io/v1beta1を有効にしなければなりません(--runtime config=authentication.k8s.io/v1beta1=true)。
POSTボディは、以下の形式になります。
{
"apiVersion" : "authentication.k8s.io/v1beta1" ,
"kind" : "TokenReview" ,
"spec" : {
"token" : "(Bearerトークン)"
}
}
リモートサービスはログインの成功を示すために、リクエストのstatusフィールドを埋めることが期待されます。レスポンスボディのspecフィールドは無視され、省略することができます。Bearerトークンの検証に成功すると、以下のようにBearerトークンが返されます。
{
"apiVersion" : "authentication.k8s.io/v1beta1" ,
"kind" : "TokenReview" ,
"status" : {
"authenticated" : true ,
"user" : {
"username" : "janedoe@example.com" ,
"uid" : "42" ,
"groups" : [
"developers" ,
"qa"
],
"extra" : {
"extrafield1" : [
"extravalue1" ,
"extravalue2"
]
}
}
}
}
リクエストに失敗した場合は、以下のように返されます。
{
"apiVersion" : "authentication.k8s.io/v1beta1" ,
"kind" : "TokenReview" ,
"status" : {
"authenticated" : false
}
}
HTTPステータスコードは、追加のエラーコンテキストを提供するために使うことができます。
認証プロキシ APIサーバーは、X-Remote-Userのようにリクエストヘッダの値からユーザーを識別するように設定することができます。
これは、リクエストヘッダの値を設定する認証プロキシと組み合わせて使用するために設計です。
--requestheader-username-headers: 必須であり、大文字小文字を区別しません。ユーザーのIDをチェックするためのヘッダー名を順番に指定します。値を含む最初のヘッダーが、ユーザー名として使われます。--requestheader-group-headers: バージョン1.6以降で任意であり、大文字小文字を区別しません。"X-Remote-Group"を推奨します。ユーザーのグループをチェックするためのヘッダー名を順番に指定します。指定されたヘッダーの全ての値が、グループ名として使われます。--requestheader-extra-headers-prefix バージョン1.6以降で任意であり、大文字小文字を区別しません。"X-Remote-Extra-"を推奨します。ユーザーに関する追加情報を判断するために検索するヘッダーのプレフィックスです。通常、設定された認可プラグインによって使用されます。指定されたプレフィックスのいずれかで始まるヘッダーは、プレフィックスが削除されます。ヘッダー名の残りの部分は小文字化されパーセントデコーディング されて追加のキーとなり、ヘッダーの値が追加の値となります。例えば、このような設定を行います。
--requestheader-username-headers=X-Remote-User
--requestheader-group-headers=X-Remote-Group
--requestheader-extra-headers-prefix=X-Remote-Extra-
以下のようなリクエストを考えます。
GET / HTTP / 1.1
X-Remote-User: fido
X-Remote-Group: dogs
X-Remote-Group: dachshunds
X-Remote-Extra-Acme.com%2Fproject: some-project
X-Remote-Extra-Scopes: openid
X-Remote-Extra-Scopes: profile
このリクエストは、このユーザー情報を取得します。
name : fido
groups :
extra :
acme.com/project :
- some-project
scopes :
- openid
- profile
ヘッダーのスプーフィングを防ぐため、認証プロキシはリクエストヘッダーがチェックされる前に、指定された認証局に対する検証のために有効なクライアント証明書をAPIサーバーへ提示する必要があります。
--requestheader-client-ca-file: 必須です。PEMエンコードされた証明書バンドルです。有効なクライアント証明書を提示し、リクエストヘッダーでユーザー名がチェックされる前に、指定されたファイル内の認証局に対して検証する必要があります。--requestheader-allowed-names: 任意です。Common Name(CN)の値のリストです。設定されている場合、リクエストヘッダーでユーザー名がチェックされる前に、指定されたリストのCNを持つ有効なクライアント証明書を提示する必要があります。空の場合は、任意のCNが許可されます。匿名リクエスト この機能を有効にすると、他の設定された認証方法で拒否されなかったリクエストは匿名リクエストとして扱われ、 system:anonymousというユーザー名とsystem:unauthenticatedというグループが与えられます。
例えば、トークン認証が設定されており、匿名アクセスが有効になっているサーバー上で、無効なBearerトークンを提供するリクエストは401 Unauthorizedエラーを受け取ります。Bearerトークンを提供しないリクエストは匿名リクエストとして扱われます。
バージョン1.5.1から1.5.xでは、匿名アクセスはデフォルトでは無効になっており、APIサーバーに --anonymous-auth=trueオプションを渡すことで有効にすることができます。
バージョン1.6以降では、AlwaysAllow以外の認証モードが使用されている場合、匿名アクセスがデフォルトで有効であり、--anonymous-auth=falseオプションをAPIサーバーに渡すことで無効にできます。
1.6以降、ABACおよびRBAC認可機能は、system:anonymousユーザーまたはsystem:unauthenticatedグループの明示的な認証を必要とするようになったため、*ユーザーまたは*グループへのアクセスを許可する従来のポリシールールには匿名ユーザーは含まれません。
ユーザーの偽装 ユーザーは偽装ヘッダーを使って別のユーザーとして振る舞うことができます。これにより、リクエストが認証したユーザー情報を手動で上書きすることが可能です。例えば、管理者はこの機能を使って一時的に別のユーザーに偽装、リクエストが拒否されたかどうかを確認することで認可ポリシーをデバッグすることができます。
偽装リクエストは最初にリクエスト中のユーザーとして認証を行い、次に偽装ユーザー情報に切り替えます。
ユーザーは、認証情報と偽装ヘッダーを使ってAPIコールを行います。 APIサーバーはユーザーを認証します。 APIサーバーは、認証されたユーザーが偽装した権限を持っていることを確認します。 リクエストされたユーザー情報は、偽装した値に置き換えられます。 リクエストが評価され、認可は偽装されたユーザー情報に基づいて実行されます。 偽装リクエストを実行する際には、以下のHTTPヘッダを使用することができます。
Impersonate-User: ユーザー名を指定します。このユーザーとして振る舞います。Impersonate-Group: グループ名を指定します。このグループとして振る舞います。複数回指定して複数のグループを設定することができます。任意であり、"Impersonate-User"が必要です。Impersonate-Extra-( extra name ): 追加フィールドをユーザーに関連付けるために使用される動的なヘッダーです。任意であり、"Impersonate-User"が必要です。一貫して保存されるためには、( extra name )は小文字である必要があり、HTTPヘッダーラベルで使用可能な文字 以外の文字は、UTF-8であり、パーセントエンコーディング されている必要があります.以下が、ヘッダーの例です。
Impersonate-User: jane.doe@example.com
Impersonate-Group: developers
Impersonate-Group: admins
Impersonate-Extra-dn: cn=jane,ou=engineers,dc=example,dc=com
Impersonate-Extra-acme.com%2Fproject: some-project
Impersonate-Extra-scopes: view
Impersonate-Extra-scopes: development
kubectlを使う場合は、--asフラグにImpersonate-Userヘッダーを、--as-groupフラグにImpersonate-Groupヘッダーを設定します。
Error from server (Forbidden): User "clark" cannot get nodes at the cluster scope. (get nodes mynode)
--asフラグと--as-groupフラグを設定します。
kubectl drain mynode --as= superman --as-group= system:masters
node/mynode cordoned
node/mynode drained
ユーザー、グループ、または追加フィールドを偽装するために、偽装ユーザーは偽装される属性の種類("user"、"group"など)に対して、"偽装した"操作を行う能力を持っている必要があります。RBAC認可プラグインが有効なクラスターの場合、以下のClusterRoleは、ユーザーとグループの偽装ヘッダーを設定するために必要なルールを網羅しています。
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRole
metadata :
name : impersonator
rules :
apiGroups : ["" ]
resources : ["users" , "groups" , "serviceaccounts" ]
verbs : ["impersonate" ]
追加フィールドは、"userextras"リソースのサブリソースとして評価されます。ユーザーが追加フィールド"scopes"に偽装ヘッダーを使用できるようにするには、ユーザーに以下のようなロールを付与する必要があります。
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRole
metadata :
name : scopes-impersonator
rules :
# "Impersonate-Extra-scopes"ヘッダーを設定できます。
apiGroups : ["authentication.k8s.io" ]
resources : ["userextras/scopes" ]
verbs : ["impersonate" ]
偽装ヘッダーの値は、リソースが取り得るresourceNamesの集合を制限することで、管理することもできます。
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRole
metadata :
name : limited-impersonator
rules :
# "jane.doe@example.com"というユーザーを偽装できます。
apiGroups : ["" ]
resources : ["users" ]
verbs : ["impersonate" ]
resourceNames : ["jane.doe@example.com" ]
# "developers"と"admins"というグループを偽装できます。
apiGroups : ["" ]
resources : ["groups" ]
verbs : ["impersonate" ]
resourceNames : ["developers" ,"admins" ]
# "view"と"development"を値に持つ"scopes"という追加フィールドを偽装できます。
apiGroups : ["authentication.k8s.io" ]
resources : ["userextras/scopes" ]
verbs : ["impersonate" ]
resourceNames : ["view" , "development" ]
client-goクレデンシャルプラグイン FEATURE STATE:
Kubernetes v1.11 [beta]
k8s.io/client-goと、それを使用するkubectlやkubeletのようなツールは、外部コマンドを実行してユーザーの認証情報を受け取ることができます。
この機能はk8s.io/client-goがネイティブにサポートしていない認証プロトコル(LDAP、Kerberos、OAuth2、SAMLなど)とクライアントサイドで統合するためのものです。プラグインはプロトコル固有のロジックを実装し、使用する不透明なクレデンシャルを返します。ほとんどすべてのクレデンシャルプラグインのユースケースでは、クライアントプラグインが生成するクレデンシャルフォーマットを解釈するために、Webhookトークン認証 をサポートするサーバーサイドコンポーネントが必要です。
使用例 ある組織は、LDAPクレデンシャルをユーザー固有の署名済みトークンと交換する外部サービスを実行すると仮定します。このサービスは、トークンを検証するためにWebhookトークン認証 リクエストに応答することもできます。ユーザーはワークステーションにクレデンシャルプラグインをインストールする必要があります。
以下のようにして、APIに対して認証を行います。
ユーザーはkubectlコマンドを発行します。 クレデンシャルプラグインは、LDAPクレデンシャルの入力をユーザーに要求し、クレデンシャルを外部サービスとトークンと交換します。 クレデンシャルプラグインはトークンをclient-goに返します。これはAPIサーバーに対するBearerトークンとして使用されます。 APIサーバーは、Webhookトークン認証 を使用して、TokenReviewを外部サービスに送信します。 外部サービスはトークンの署名を検証し、ユーザーのユーザー名とグループを返します。 設定 クレデンシャルプラグインの設定は、userフィールドの一部としてkubectlの設定ファイル で行います。
apiVersion : v1
kind : Config
users :
name : my-user
user :
exec :
# 実行するコマンドです。必須です。
command : "example-client-go-exec-plugin"
# ExecCredentialsリソースをデコードする際に使用するAPIのバージョン。必須です。
#
# プラグインが返すAPIのバージョンは、ここに記載されているバージョンと一致しなければなりません
#
# 複数のバージョンをサポートするツール(client.authentication.k8s.io/v1alpha1など)と統合するには、
# 環境変数を設定するか、execプラグインが期待するバージョンを示す引数をツールに渡します。
apiVersion : "client.authentication.k8s.io/v1beta1"
# プラグインを実行する際に設定する環境変数です。任意です。
env :
- name : "FOO"
value : "bar"
# プラグインを実行する際に渡す引数です。任意です。
args :
- "arg1"
- "arg2"
clusters :
name : my-cluster
cluster :
server : "https://172.17.4.100:6443"
certificate-authority : "/etc/kubernetes/ca.pem"
contexts :
name : my-cluster
context :
cluster : my-cluster
user : my-user
current-context : my-cluster
相対的なコマンドパスは、設定ファイルのディレクトリーからの相対的なものとして解釈されます。KUBECONFIGが/home/jane/kubeconfigに設定されていて、execコマンドが./bin/example-client-go-exec-pluginの場合、バイナリ/home/jane/bin/example-client-go-exec-pluginが実行されます。
- name : my-user
user :
exec :
# kubeconfigのディレクトリーへの相対パス
command : "./bin/example-client-go-exec-plugin"
apiVersion : "client.authentication.k8s.io/v1beta1"
入出力フォーマット 実行されたコマンドはExecCredentialオブジェクトをstdoutに出力します。k8s.io/client-goはstatusで返された認証情報を用いて、Kubernetes APIに対して認証を行ういます。
対話的なセッションから実行する場合、stdinはプラグインに直接公開されます。プラグインはTTYチェック を使って、対話的にユーザーにプロンプトを出すことが適切かどうかを判断する必要があります。
Bearerトークンのクレデンシャルを使用するために、プラグインはExecCredentialのステータスにトークンを返します。
{
"apiVersion" : "client.authentication.k8s.io/v1beta1" ,
"kind" : "ExecCredential" ,
"status" : {
"token" : "my-bearer-token"
}
}
あるいは、PEMエンコードされたクライアント証明書と鍵を返して、TLSクライアント認証を使用することもできます。
プラグインが後続の呼び出しで異なる証明書と鍵を返すと、k8s.io/client-goはサーバーとの既存の接続を閉じて、新しいTLSハンドシェイクを強制します
指定された場合、clientKeyDataとclientCertificateData両方が存在しなければなりません。
clientCertificateDataには、サーバーに送信するための中間証明書を含めることができます。
{
"apiVersion" : "client.authentication.k8s.io/v1beta1" ,
"kind" : "ExecCredential" ,
"status" : {
"clientCertificateData" : "-----BEGIN CERTIFICATE-----\n...\n-----END CERTIFICATE-----" ,
"clientKeyData" : "-----BEGIN RSA PRIVATE KEY-----\n...\n-----END RSA PRIVATE KEY-----"
}
}
オプションで、レスポンスにはRFC3339のタイムスタンプとしてフォーマットされたクレデンシャルの有効期限を含めることができます。有効期限の有無には、以下のような影響あります。
有効期限が含まれている場合、BearerトークンとTLSクレデンシャルは有効期限に達するまで、またはサーバーがHTTPステータスコード401で応答したとき、またはプロセスが終了するまでキャッシュされます。 有効期限が省略された場合、BearerトークンとTLSクレデンシャルはサーバーがHTTPステータスコード401で応答したとき、またはプロセスが終了するまでキャッシュされます。 {
"apiVersion" : "client.authentication.k8s.io/v1beta1" ,
"kind" : "ExecCredential" ,
"status" : {
"token" : "my-bearer-token" ,
"expirationTimestamp" : "2018-03-05T17:30:20-08:00"
}
}
6.4 - API概要 このセクションでは、Kubernetes APIのリファレンス情報を提供します。
REST APIはKubernetesの基本的な構造です。
すべての操作とコンポーネント間の通信、および外部ユーザーのコマンドは、REST API呼び出しでありAPIサーバーが処理します。
その結果、Kubernetesプラットフォーム内のすべてのものは、APIオブジェクトとして扱われ、API に対応するエントリーがあります。
Kubernetes APIリファレンス は、Kubernetesバージョンv1.35のAPI一覧を提供します。
一般的な背景情報を知るには、The Kubernetes API 、
Controlling Access to the Kubernetes API を読んでください。
それらはKubernetes APIサーバーがクライアントを認証する方法とリクエストを認可する方法を説明します。
APIバージョニング JSONとProtobufなどのシリアル化スキーマの変更については同じガイドラインに従います。
以下の説明は、両方のフォーマットをカバーしています。
APIのバージョニングとソフトウェアのバージョニングは間接的に関係しています。
API and release versioning proposal は、APIバージョニングとソフトウェアバージョニングの関係を説明しています。
APIのバージョンが異なると、安定性やサポートのレベルも異なります。
各レベルの基準については、API Changes documentation で詳しく説明しています。
各レベルの概要は以下の通りです:
APIグループ API groups で、KubernetesのAPIを簡単に拡張することができます。
APIグループは、RESTパスとシリアル化されたオブジェクトのapiVersionフィールドで指定されます。
KubernetesにはいくつかのAPIグループがあります:
core (legacy とも呼ばれる)グループは、RESTパス /api/v1 にあります。
コアグループは apiVersion フィールドの一部としては指定されません。
例えば、apiVersion: v1 のように。名前付きのグループは、RESTパス /apis/$GROUP_NAME/$VERSION にあり、以下のように使用します。
apiVersion: $GROUP_NAME/$VERSIONを使用します(例:apiVersion: batch/v1)。
サポートされているAPIグループの完全なリストは以下にあります。
Kubernetes API reference 。 APIグループの有効化と無効化 一部のリソースやAPIグループはデフォルトで有効になっています。
APIサーバー上で--runtime-configを設定することで、有効にしたり無効にしたりすることができます。
またruntime-configフラグには、APIサーバーのランタイム構成を記述したコンマ区切りの<key>[=<value>]ペアを指定します。
もし=<value>の部分が省略された場合には、=trueが指定されたものとして扱われます。
例えば:
batch/v1を無効するには、--runtime-config=batch/v1=falseを設定するbatch/v2alpha1を有効するには、--runtime-config=batch/v2alpha1を設定する
備考: グループやリソースを有効または無効にした場合、
APIサーバーとコントローラーマネージャーを再起動して、--runtime-configの変更を反映させる必要があります。永続化 Kubernetesはシリアライズされた状態を、APIリソースとしてetcd に書き込んで保存します。
次の項目 6.4.1 - Kubernetes非推奨ポリシー このドキュメントではシステムのさまざまな側面に関する非推奨ポリシーについて詳しく説明します。
Kubernetesは多くのコンポーネントと多くのコントリビュータを持つ大規模なシステムです。
このようなソフトウェアでは、機能セットは時間の経過とともに自然に進化し、時には機能を削除する必要がある場合があります。
これにはAPI、フラグ、または機能全体が含まれることもあります。
既存のユーザーへの影響を避けるため、Kubernetesは削除される予定のシステムの側面については非推奨ポリシーに従っています。
API KubernetesはAPI駆動型のシステムであるため、問題領域の理解の進化を反映して時間の経過とともに進化してきました。
Kubernetes APIは実際は「APIグループ」と呼ばれる一連のAPIであり、各APIグループは個別にバージョン管理されています。
APIバージョン は主に3つのトラックに分類され、それぞれに異なる非推奨ポリシーがあります:
例 トラック v1 GA (一般提供、安定版) v1beta1 Beta (プレリリース) v1alpha1 Alpha (実験的)
Kubernetesの特定のリリースでは任意の数のAPIグループと任意の数のそれぞれのバージョンをサポートすることができます。
次のルールはAPIの要素の非推奨を管理します。これには以下が含まれます:
RESTリソース (別名 APIオブジェクト) RESTリソースのフィールド RESTリソースのアノテーション、"beta"アノテーションは含まれますが"alpha"アノテーションは含まれません 列挙された値や定数値 コンポーネントの設定構造 これらのルールは、masterまたはリリースブランチへの任意のコミット間ではなく、公式リリース間に適用されます。
ルール #1: APIの要素はAPIグループのバージョンをインクリメントすることでもに削除することができます。
APIの要素が特定バージョンのAPIグループに追加されると、
トラックに関係なくそのバージョンから削除されたり、
大幅に挙動が変更されることはありません。
備考: 歴史的な理由により、「core」(グループ名なし)と「extensions」という2つの「monolithic」APIグループがあります。
リソースはこれらのレガシーなAPIグループからより特定のドメインに特化したAPIグループに段階的に移行されます。ルール #2: APIオブジェクトはいくつかのバージョンに存在しないRESTリソース全体を除き、
任意のリリース内のAPIバージョン間で情報を失うことなくラウンドトリップできる必要があります
例えば、あるオブジェクトがv1として書き込まれその後v2として読み取られv1に変換された場合、
結果として得られるv1リソースは元のリソースと同一である必要があります。
v2における表現はv1とは異なるかもしれませんが、システムは両方向にそれらを変換する方法を知っています。
さらに、v2で追加された新しいフィールドはv1にラウンドトリップできる必要があります。
つまりv1では同等のフィールドを追加するかアノテーションとして表現する必要があるかもしれません。
ルール #3: 特定のトラックのAPIバージョンは安定性の低いAPIバージョンを優先して非推奨になることはありません。
GA APIバージョンは、betaおよびalpha APIバージョンに置き換えることができます。 Beta APIバージョンは以前のbetaおよびalpha APIバージョンに置き換えることはできますが、GA APIバージョンに置き換えることはできません 。 Alpha APIバージョンは以前のalpha APIバージョンに置き換えることはできますが、GAまたはbeta APIバージョンに置き換えることはできません。 ルール #4a: APIの有効期間はAPIの安定性レベルによって決まります
GA APIバージョンは非推奨としてマークされることがありますが、Kubernetesのメジャーバージョン内で削除されることはありません。 Beta APIバージョンは導入後9ヶ月または3つのマイナーリリース(いずれか長い方)以内に非推奨にされ、
非推奨後9ヶ月または3つのマイナーリリース(いずれか長い方)以内に提供されなくなります。 Alpha APIバージョンは事前の非推奨通知なしにリリースから削除される場合があります。 これによりbeta APIバージョンのサポートは 最大2つのリリースのバージョンの差異 をカバーし、
APIが不安定なbetaバージョンで停滞し、beta APIのサポートが終了したときに本番稼働が中断されることはありません。
備考: GA APIを削除するKubernetesのメジャーバージョン改訂の計画は現在ありません。備考: #52185 が解決されるまで、
ストレージに永続化されているAPIバージョンは削除されません。
これらのバージョンのAPIエンドポイントの提供は無効にできます(このドキュメントの非推奨タイムラインに従います)が、
APIサーバーはストレージから以前永続化されたデータをデコード/変換できる機能を維持する必要があります。
ルール #4b: 特定のグループの「優先」APIバージョンと「ストレージバージョン」は、
新しいバージョンと以前のバージョンの両方をサポートするリリースが行われるまで更新されない場合があります。
ユーザーはKubernetesの新しいリリースにアップグレードした後、
(新しいバージョンでのみ利用可能な機能を明示的に使用していない限り)
何も新しいAPIバージョンに変換することなく、また破損が発生することなく、
以前のリリースにロールバックできる必要があります。
これはオブジェクトの保存された表現において特に顕著です。
これらはすべて例を挙げて説明するのが最も適切です。新しいAPIグループを導入する
Kubernetesリリース、バージョンXを想像してください。
新しいKubernetesリリースは約4ヶ月ごと(1年に3回)に行われます。
以下の表は一連の後続リリースでサポートされるAPIバージョンを示しています。
リリース APIバージョン 優先/ストレージバージョン ノート X v1alpha1 v1alpha1 X+1 v1alpha2 v1alpha2 v1alpha1は削除され、リリースノートに"action required"と記載されます X+2 v1beta1 v1beta1 v1alpha2は削除され、リリースノートに"action required"と記載されます X+3 v1beta2, v1beta1 (非推奨) v1beta1 v1beta1は非推奨になり、リリースノートに"action required"と記載されます X+4 v1beta2, v1beta1 (deprecated) v1beta2 X+5 v1, v1beta1 (非推奨), v1beta2 (非推奨) v1beta2 v1beta2は非推奨になり、リリースノートに"action required"と記載されます X+6 v1, v1beta2 (非推奨) v1 v1beta1は削除され、リリースノートに"action required"と記載されます X+7 v1, v1beta2 (非推奨) v1 X+8 v2alpha1, v1 v1 v1beta2は削除され、リリースノートに"action required"と記載されます X+9 v2alpha2, v1 v1 v2alpha1は削除され、リリースノートに"action required"と記載されます X+10 v2beta1, v1 v1 v2alpha2は削除され、リリースノートに"action required"と記載されます X+11 v2beta2, v2beta1 (非推奨), v1 v1 v2beta1は非推奨になり、リリースノートに"action required"と記載されます X+12 v2, v2beta2 (非推奨), v2beta1 (非推奨), v1 (非推奨) v1 v2beta2は非推奨になり、リリースノートに"action required"と記載されます v1 is deprecated in favor of v2, but will not be removed v1はv2に置き換えられますが、削除はされません X+13 v2, v2beta1 (非推奨), v2beta2 (非推奨), v1 (非推奨) v2 X+14 v2, v2beta2 (非推奨), v1 (非推奨) v2 v2beta1は削除され、リリースノートに"action required"と記載されます X+15 v2, v1 (非推奨) v2 v2beta2は削除され、リリースノートに"action required"と記載されます
REST resources (別名APIオブジェクト) 上記のタイムラインではAPI v1に存在し、非推奨化される必要があるWidgetという仮想のRESTリソースを考えてみましょう。
私たちはリリースX+1と同期して非推奨をドキュメント化とアナウンス を行います。
WidgetリソースはAPIバージョンv1(非推奨)にはまだ存在しますがv2alpha1には存在しません。
WidgetリソースはX+8までのリリースに引き続き存在して機能します。
API v1が期限切れになるX+9でのみ、Widgetリソースは存在しなくなり、その動作が削除されます。
Kubernetes v1.19以降は、非推奨のREST APIエンドポイントへのAPIリクエストを行うと、以下のようになります:
APIレスポンスにおいてWarningヘッダー(RFC7234, Section 5.5 で定義)を返します。
リクエストに対して記録された監査イベント に"k8s.io/deprecated":"true"というアノテーションを追加します。
kube-apiserverプロセスでapiserver_requested_deprecated_apisゲージメトリクスに1を設定します。
このメトリクスにはapiserver_request_totalメトリクスに結合することができる group、version、resource、subresourceラベルと、APIが提供されなくなるKubernetesリリースを表すremoved_releaseがあります。
次のPrometheusクエリはv1.22で削除される非推奨APIへのリクエストに関する情報を返します:
apiserver_requested_deprecated_apis {removed_release = "1.22 "} * on ( group ,version ,resource ,subresource ) group_right () apiserver_request_total
RESTリソースのフィールド すべてのRESTリソースと同様に、API v1に存在していた個々のフィールドはAPI v1が削除されるまで存在して機能する必要があります。
リソース全体と異なり、v2 APIはフィールドをラウンドトリップできる限り、異なる表現を選択することができます。
例えば非推奨になった「magnitude」という名前のv1フィールドは、API v2では「deprecatedMagnitude」という名前になる可能性があります。
最終的にv1が削除されると、v2から非推奨のフィールドも削除することができます。
列挙された値や定数値 すべてのRESTリソースとそのフィールドと同様にAPI v1でサポートされていた定数値はAPI v0が削除されるまで存在して機能する必要があります。
コンポーネント設定の構造 コンポーネント設定はRESTリソースと同様にバージョン付けされて管理されています。
今後の取り組み 時間の経過とともに、Kubernetesはよりきめ細かいAPIバージョンを導入し、これらのルールは必要に応じて調整されます。
フラグまたはCLIの非推奨化 Kubernetesシステムは複数の異なるプログラムが連携して構成されています。
KubernetesリリースではこれらのプログラムのフラグやCLIコマンド(総称して「CLI要素」)が削除されることがしばしばあります。
個々のプログラムは、非推奨ポリシーが若干異なる、ユーザー向けプログラムと管理者向けプログラムの2つの主要グループに分類されます。
フラグに明示的に接頭辞が付けられていないか、「alpha」または「beta」としてドキュメント化されない限り、そのフラグはGAとみなされます。
CLI要素は事実上システムに対するAPIの一部ですが、REST APIと同じ方法ではバージョン管理されておらず、非推奨のルールは次のようになっています:
ルール #5a: ユーザー向けのコンポーネントのCLI要素(例: kubectl)は
非推奨がアナウンスされてから以下の期間は機能しなければなりません:
GA: 12ヶ月または2リリース(いずれか長い方) Beta: 3ヶ月または1リリース(いずれか長い方) Alpha: 0リリース ルール #5b: 管理者向けのコンポーネントのCLI要素(例: kubelet)は
非推奨がアナウンスされてから以下の期間は機能しなければなりません:
GA: 6ヶ月または1リリース(いずれか長い方) Beta: 3ヶ月または1リリース(いずれか長い方) Alpha: 0リリース ルール #5c: コマンドラインインターフェース(CLI)の要素は
より不安定なCLI要素の代わりに廃止されることはありません
APIに関するルール#3と同様、コマンドラインインターフェースの要素が代替実装にリプレイスされる、
例えば既存の要素名の変更やコマンドライン引数の代わりにファイルから取得した設定を使用するように切り替える場合、
推奨される代替案は同じかそれ以上の安定性レベルでなければなりません。
ルール #6: 非推奨のCLI要素は使用時に警告を表示しなければなりません(オプションで無効化可能)
機能や動作の非推奨化 時には、KubernetesリリースではAPIやCLIによって制御されないシステムの機能や動作を非推奨にする必要があります。
その場合、非推奨に関するルールは以下の通りです:
ルール #7: 非推奨となる動作はアナウンスされてから最低1年間は機能しなければなりません。
機能や動作が、変更を取り込む作業が必要な代替実装に置き換えられる場合、
可能な限り移行を簡素化する努力が必要です。
代替実装がKubernetes organizationの管理下にある場合、以下のルールが適用されます:
ルール #8: 安定性の低い代替実装を優先して、動作の機能を非推奨にしてはなりません
例えば、一般提供されている機能がBeta版にリプレイスために非推奨にされることはありません。
ただし、Kubernetesプロジェクトは同じ成熟度に達する前であっても、ユーザーが代替実装を採用して移行することを推奨しています。
これは、機能の新しいユースケースを検討したり、リプレイスについての早期フィードバックを得るために特に重要です。
代替実装は、外部のツールや製品である場合があります。
例えば、機能がkubeletからKubernetesプロジェクト管理外のコンテナランタイムに移行することがあります。
このような場合、ルールを適用することはできませんが、コンポーネントの成熟度を損なわない移行方法を確保するための努力が必要です。
コンテナランタイムを例に挙げると、一般的なコンテナランタイムが、リプレイスする動作を実装しながら同等の安定性を提供するバージョンを持つように取り組む必要があるかもしれません。
機能と動作の非推奨ルールは、システムに対するすべての変更がこのポリシーによって管理されることを意味するものではありません。
これらのルールはKubernetes上で実行されているアプリケーションの正確性やKubernetesクラスターの管理に影響する、また完全に削除されるものにのみ適用されます。
上記のルールの例外は フィーチャーゲート です。
フィーチャーゲートはユーザーが実験的な機能を有効/無効にできるようにするキー=バリューのペアです。
フィーチャーゲートは機能の開発ライフサイクルをカバーすることを目的としており、
長期的なAPIを目的としたものではありません。
そのため、機能がGAになるが削除された後は、非推奨となり削除されることが期待されます。
機能が段階を踏むにつれて、関連するフィーチャーゲートも進化します。
機能のライフサイクルと対応するフィーチャーゲートの関係は以下の通りです:
Alpha: フィーチャーゲートはデフォルトで無効化されており、ユーザーによって有効化できます。 Beta: フィーチャーゲートはデフォルトで有効化されており、ユーザーによって無効化できます。 GA: フィーチャーゲートは非推奨となり("非推奨" を参照)動作しなくなります。 GA、非推奨期間終了後: フィーチャーゲートは削除され、呼び出しは受け付けられなくなります。 非推奨 機能はGA前のライフサイクルのどの時点でも削除できます。
GA前に機能が削除されると、それに関連するフィーチャーゲートも非推奨になります。
動作しないフィーチャーゲートを無効化するために呼び出そうとすると、
サイレントに実行される可能性あるサポートされていないシナリオを避けるため呼び出しは失敗します。
場合によっては、GA前の機能を削除にかなりの時間がかかることがあります。
フィーチャーゲートは、関連する機能が完全に削除されるまで機能し続け、
その時点でフィーチャーゲート自体が非推奨になる可能性があります。
GAされた機能のフィーチャーゲートの削除にも時間がかかる場合、
フィーチャーゲートが機能に影響を与えず、エラーも引き起こさない場合、
フィーチャーゲートへの呼び出しは動作し続けることがあります。
ユーザーによって無効化されることを意図した機能には、関連するフィーチャーゲートで
その機能を無効化するためにメカニズムが含まれている必要があります。
フィーチャーゲートのバージョニングは、前述のコンポーネントとは異なるため、
非推奨に関するルールは次のとおりです:
ルール #9:
フィーチャーゲートは、対応する機能が次のようにライフサイクルステージを移行する際に非推奨にする必要があります。
フィーチャーゲートは以下の期間は機能しなければなりません:
Beta機能からGA: 6ヶ月または2リリース(どちらか長い方) Beta機能からEOL: 3ヶ月または1リリース(どちらか長い方) Alpha機能からEOL: 0リリース ルール #10: 非推奨となったフィーチャーゲートは使用時に警告を返す必要があります。
フィーチャーゲートが非推奨になる場合には、リリースノートと対応するCLIヘルプの両方にドキュメント化される必要があります。
警告とドキュメントの両方には、フィーチャーゲートが動作しないかどうかを明記する必要があります。
メトリクスの非推奨化 Kubernetesコントロールプレーンの各コンポーネントはメトリクス(通常は/metricsエンドポイント)を公開しており、
通常はクラスター管理者によって収集されます。
すべてのメトリクスが同じというわけではありません。一部のメトリクスは一般的にSLIとして使用されたり、
SLOを決定するために使用されるため、より重要な役割を持つ傾向があります。
他のメトリクスは、事実上実験的なものであるか、主にKubernetesの開発プロセスで使用されます。
そのため、メトリクスは3つの安定性クラス(ALPHA、BETA、STABLE)に分類され、
Kubernetesリリース間のメトリクスの削除に影響します。
これらのクラスは、メトリクスの重要性に基づいて決定されます。
メトリクスの非推奨と削除に関するルールは次のとおりです:
ルール #11a: メトリクスは、対応する安定性クラスに応じて、以下の期間は機能しなければなりません:
STABLE: 4リリースまたは12ヶ月(いずれか長い方) BETA: 2リリースまたは8ヶ月(いずれか長い方) ALPHA: 0リリース ルール #11b: メトリクスは、非推奨がアナウンスされた後も、以下の期間は機能しなければなりません:
STABLE: 3リリースまたは9ヶ月(いずれか長い方) BETA: 1リリースまたは4ヶ月(いずれか長い方) ALPHA: 0リリース 非推奨となったメトリクスの説明テキストには、先頭に非推奨を通知する文字列「(Deprecated from x.y)」が付けられ、
メトリクスの登録時に警告ログが出力されます。
非推奨でない安定版のメトリクスと同様に、非推奨となったメトリクスも自動的にメトリクスエンドポイントに登録されるため、表示されます。
後続のリリース(メトリクスのdeprecatedVersionが current_kubernetes_version - 3 に等しい場合)で、
非推奨となったメトリクスは 非表示 になります。
非推奨となったメトリクス とは異なり --show-hidden-metrics-for-version=)を使用して明示的に有効化することができます。
これによりクラスター管理者は、以前の非推奨の警告に対応できなかった場合でも、
非推奨となったメトリクスから適切に移行するための回避策を取ることができます。
非表示のメトリクスは、1リリース後に削除される必要があります。
例外 想定し得るすべての状況を網羅するポリシーはありません。
このポリシーは生きたドキュメントであり、時間の経過とともに改善されます。
実際には、このポリシーにうまく適合しない状況や、このポリシーが重大な障害となる状況が発生する可能性があります。
そのような状況では、特定のケースに対して最適な解決策を見つけるためにSIGやプロジェクトリーダーと協議するべきであり、
Kubernetesが可能な限りユーザーに影響を与えない安定したシステムであることを常に念頭に置いておくべきです。
例外は、関連するすべてのリリースノートで常にアナウンスされます。
6.5 - RBAC認可を使用する Role Based Access Control(RBAC)は、組織内の個々のユーザーのRoleをベースに、コンピューターまたはネットワークリソースへのアクセスを制御する方法です。
RBAC認可はAPIグループ rbac.authorization.k8s.ioを使用して認可の決定を行い、Kubernetes APIを介して動的にポリシーを構成できるようにします。
RBACを有効にするには、以下の例のようにAPI server の--authorization-mode フラグをコンマ区切りのRBACを含むリストでスタートします。
kube-apiserver --authorization-mode= Example,RBAC --other-options --more-options
APIオブジェクト RBAC APIは4種類のKubernetesオブジェクト(Role 、 ClusterRole 、 RoleBinding そして ClusterRoleBinding )を宣言します。他のKubernetesオブジェクトのようにkubectlのようなツールを使って、オブジェクトを記述 、または変更できます。
注意: これらのオブジェクトは設計上、アクセス制限を課します。学んできたように変更を行っている場合、
特権エスカレーション防止とブートストラップ
を参照し、これらの制限がどのようにいつかの変更を防止するのかを理解しましょう。
RoleとClusterRole RBACの Role または ClusterRole には、一連の権限を表すルールが含まれて言います。
権限は完全な追加方式です(「deny」のルールはありません)。
Roleは常に特定のnamespace で権限を設定します。
つまり、Roleを作成する時は、Roleが属するNamespaceを指定する必要があります。
対照的にClusterRoleは、Namespaceに属さないリソースです。Kubernetesオブジェクトは常にNamespaceに属するか、属さないかのいずれかである必要があり、リソースは異なる名前(RoleとClusterRole)を持っています。つまり、両方であることは不可能です。
ClusterRolesにはいくつかの用途があります。ClusterRoleを利用して、以下のことができます。
Namespaceに属するリソースに対する権限を定義し、個々のNamespace内で付与する Namespaceに属するリソースに対する権限を定義し、すべてのNamespaceにわたって付与する クラスター単位でスコープされているリソースに対するアクセス許可を定義する NamespaceでRoleを定義する場合は、Roleを使用します。クラスター全体でRoleを定義する場合は、ClusterRoleを使用します
Roleの例 以下はNamespace「default」にあるRoleの例で、
Pod への読み取りアクセス権の付与に使用できます。
apiVersion : rbac.authorization.k8s.io/v1
kind : Role
metadata :
namespace : default
name : pod-reader
rules :
apiGroups : ["" ] # "" はコアのAPIグループを示します
resources : ["pods" ]
verbs : ["get" , "watch" , "list" ]
ClusterRoleの例 ClusterRoleを使用してRoleと同じ権限を付与できます。
ClusterRolesはクラスター単位でスコープされているため、以下へのアクセスの許可もできます。
クラスター単位でスコープされているリソースに(node など) 非リソースエンドポイントに(/healthzなど) すべてのNamespaceに渡ってNamespaceに属するリソースに(Podなど)。
例えば、ClusterRoleを使用して特定のユーザーにkubectl get pods --all-namespacesの実行を許可できます。 以下は特定のNamespace、またはすべてのNamespace(バインド 方法によります)でsecrets への読み取りアクセス権を付与するClusterRoleの例です。
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRole
metadata :
# 「namespace」はClusterRolesがNamespaceに属していないため、省略されています
name : secret-reader
rules :
apiGroups : ["" ]
#
# HTTPレベルでの、Secretにアクセスするリソースの名前
# オブジェクトは"secrets"
resources : ["secrets" ]
verbs : ["get" , "watch" , "list" ]
RoleまたはClusterRoleオブジェクトの名前は有効な
パスセグメント名 である必要があります。
RoleBindingとClusterRoleBinding RoleBindingはRoleで定義された権限をユーザーまたはユーザのセットに付与します。
RoleBindingはsubjects (ユーザー、グループ、サービスアカウント)のリストと、付与されるRoleへの参照を保持します。
RoleBindingは特定のNamespace内の権限を付与しますが、ClusterRoleBindingはクラスター全体にアクセスする権限を付与します。
RoleBindingは、同じNamespace内の任意のRoleを参照できます。
または、RoleBindingはClusterRoleを参照し、そのClusterRoleをRoleBindingのNamespaceにバインドできます。
ClusterRoleをクラスター内のすべてのNamespaceにバインドする場合は、ClusterRoleBindingを使用します。
RoleBindingまたはClusterRoleBindingオブジェクトは有効な
パスセグメント名 である必要があります。
RoleBindingの例 以下はNamespace「default」内でユーザー「jane」に「pod-reader」のRoleを付与するRoleBindingの例です。
これにより、「jane」にNamespace「default」のポッドの読み取り許可されます。
apiVersion : rbac.authorization.k8s.io/v1
# このRoleBindingは「jane」にNamespace「default」のポッドの読み取りを許可する
# そのNamespaceでRole「pod-reader」を既に持っている必要があります。
kind : RoleBinding
metadata :
name : read-pods
namespace : default
subjects :
# 一つ以上の「subject」を指定する必要があります
kind : User
name : jane # 「name」は大文字と小文字が区別されます
apiGroup : rbac.authorization.k8s.io
roleRef :
# 「roleRef」はRole/ClusterRoleへのバインドを指定します
kind : Role #RoleまたはClusterRoleである必要があります
name : pod-reader # これはバインドしたいRole名またはClusterRole名とマッチする必要があります
apiGroup : rbac.authorization.k8s.io
RoleBindingはClusterRoleを参照し、ClusterRoleで定義されている権限をRoleBinding内のNamespaceのリソースに権限付与もできます。この種類の参照を利用すると、クラスター全体で共通のRoleのセットを定義して、それらを複数のNamespace内での再利用できます。
例えば、以下のRoleBindingがClusterRoleを参照している場合でも、
「dave」(大文字と小文字が区別されるsubject)はRoleBindingのNamespace(メタデータ内)が「development」のため、Namespace「development」のSecretsのみの読み取りができます。
apiVersion : rbac.authorization.k8s.io/v1
# このRoleBindingは「dave」にNamespace「development」のSecretsの読み取りを許可する
# ClusterRole「secret-reader」を既に持っている必要があります。
kind : RoleBinding
metadata :
name : read-secrets
#
# RoleBindingのNamespaceが、どこの権限が付与されるかを決定する。
# これはNamespace「development」内の権限のみ付与する。
namespace : development
subjects :
kind : User
name : dave # nameは大文字、小文字を区別する
apiGroup : rbac.authorization.k8s.io
roleRef :
kind : ClusterRole
name : secret-reader
apiGroup : rbac.authorization.k8s.io
ClusterRoleBindingの例 クラスター全体に権限を付与するには、ClusterRoleBindingを使用できます。
以下のClusterRoleBindingはグループ「manager」のすべてのユーザーに
Secretsの読み取りを許可します。
apiVersion : rbac.authorization.k8s.io/v1
# このClusterRoleBindingはグループ「manager」のすべてのユーザーに任意のNamespaceのSecretsの読み取りを許可します。
kind : ClusterRoleBinding
metadata :
name : read-secrets-global
subjects :
kind : Group
name : manager # nameは大文字、小文字を区別します
apiGroup : rbac.authorization.k8s.io
roleRef :
kind : ClusterRole
name : secret-reader
apiGroup : rbac.authorization.k8s.io
Bindingを作成後は、それが参照するRoleまたはClusterRoleを変更できません。
BindingのroleRefを変更しようとすると、バリデーションエラーが発生します。BindingのroleRefを変更する場合は、Bindingのオブジェクトを削除して、代わりのオブジェクトを作成する必要があります。
この制限には2つの理由があります。
roleRefをイミュータブルにすることで、誰かに既存のオブジェクトに対するupdate権限を付与します。それにより、subjectsに付与されたRoleの変更ができなくても、subjectsのリストを管理できるようになります。異なるRoleへのBindingは根本的に異なるBindingです。
roleRefを変更するためにBindingの削除/再作成を要求することによって、(すべての既存のsubjectsを確認せずに、roleRefだけを誤って変更できるようにするのとは対照的に)Binding内のsubjectsのリストのすべてが意図された新しいRoleが付与されることを担保します。 kubectl auth reconcile コマンドラインユーティリティーはRBACオブジェクトを含んだマニフェストファイルを作成または更新します。また、それらが参照しているRoleへの変更を要求されると、Bindingオブジェクトの削除と再作成を取り扱います。
詳細はcommand usage and examples を確認してください。
リソースを参照する KubernetesのAPIでは、ほとんどのリソースはPodであればpodsのように、オブジェクト名の文字列表現を使用して表されます。RBACは、関連するAPIエンドポイントのURLに表示されるものとまったく同じ名前を使用するリソースを参照します。
一部のKubernetes APIには、Podのログなどの
subresource が含まれます。Podのログのリクエストは次のようになります。
GET /api/v1/namespaces/{namespace}/pods/{name}/log
この場合、pods はPodリソースのNamespaceに属するリソースであり、logはpodsのサブリソースです。これをRBACRoleで表すには、スラッシュ(/)を使用してリソースとサブリソースを区切ります。サブジェクトへのpodsの読み込みと各Podのlogサブリソースへのアクセスを許可するには、次のように記述します。
apiVersion : rbac.authorization.k8s.io/v1
kind : Role
metadata :
namespace : default
name : pod-and-pod-logs-reader
rules :
apiGroups : ["" ]
resources : ["pods" , "pods/log" ]
verbs : ["get" , "list" ]
resourceNamesリストを通じて、特定のリクエストのリソースを名前で参照することもできます。
指定すると、リクエストをリソースの個々のインスタンスに制限できます。
以下は対象をgetまたはmy-configmapと名付けられた
ConfigMap をupdateのみに制限する例です。
apiVersion : rbac.authorization.k8s.io/v1
kind : Role
metadata :
namespace : default
name : configmap-updater
rules :
apiGroups : ["" ]
#
# HTTPレベルでの、ConfigMapにアクセスするリソースの名前
# オブジェクトは"configmaps"
resources : ["configmaps" ]
resourceNames : ["my-configmap" ]
verbs : ["update" , "get" ]
備考: resourceNamesでcreateまたはdeletecollectionのリクエストを制限することはできません。この制限はcreateの場合、認証時にオブジェクト名がわからないためです。集約ClusterRole 複数のClusterRoleを一つのClusterRoleに 集約 できます。
クラスターコントロールプレーンの一部として実行されるコントローラーは、aggregationRuleセットを持つClusterRoleオブジェクトを監視します。aggregationRuleはコントローラーが、このオブジェクトのrulesフィールドに結合する必要のある他のClusterRoleオブジェクトを一致させるために使用するラベルselector を定義します。
以下に、集約されたClusterRoleの例を示します。
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRole
metadata :
name : monitoring
aggregationRule :
clusterRoleSelectors :
- matchLabels :
rbac.example.com/aggregate-to-monitoring : "true"
rules : [] # コントロールプレーンは自動的にルールを入力します
既存の集約されたClusterRoleのラベルセレクターと一致する新しいClusterRoleを作成すると、その変更をトリガーに、集約されたClusterRoleに新しいルールが追加されます。
rbac.example.com/aggregate-to-monitoring: trueラベルが付けられた別のClusterRoleを作成して、ClusterRole「monitoring」にルールを追加する例を以下に示します。
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRole
metadata :
name : monitoring-endpointslices
labels :
rbac.example.com/aggregate-to-monitoring : "true"
# ClusterRole「monitoring-endpointslices」を作成すると、
# 以下のルールがClusterRole「monitoring」に追加されます
rules :
apiGroups : ["" ]
resources : ["services" , "pods" ]
verbs : ["get" , "list" , "watch" ]
apiGroups : ["discovery.k8s.io" ]
resources : ["endpointslices" ]
verbs : ["get" , "list" , "watch" ]
デフォルトのユーザー向けRole はClusterRoleの集約を使用します。これによりクラスター管理者として、 デフォルトroleを拡張するため、CustomResourceDefinitions または集約されたAPIサーバーなどによって提供されたルールをカスタムリソースに含めることができます。
例えば、次のClusterRoleでは、「admin」と「edit」のデフォルトのRoleでCronTabという名前のカスタムリソースを管理できますが、「view」のRoleではCronTabリソースに対して読み取りアクションのみを実行できます。CronTabオブジェクトは、APIサーバーから見たURLで"crontabs"と名前が付けられていると想定できます。
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRole
metadata :
name : aggregate-cron-tabs-edit
labels :
# デフォルトRoleの「admin」と「edit」にこれらの権限を追加する。
rbac.authorization.k8s.io/aggregate-to-admin : "true"
rbac.authorization.k8s.io/aggregate-to-edit : "true"
rules :
apiGroups : ["stable.example.com" ]
resources : ["crontabs" ]
verbs : ["get" , "list" , "watch" , "create" , "update" , "patch" , "delete" ]
---
kind : ClusterRole
apiVersion : rbac.authorization.k8s.io/v1
metadata :
name : aggregate-cron-tabs-view
labels :
# デフォルトRoleの「view」にこれらの権限を追加します。
rbac.authorization.k8s.io/aggregate-to-view : "true"
rules :
apiGroups : ["stable.example.com" ]
resources : ["crontabs" ]
verbs : ["get" , "list" , "watch" ]
Roleの例 次の例は、RoleオブジェクトまたはClusterRoleオブジェクトからの抜粋であり、rulesセクションのみを示しています。
"pods"の読み取りを許可する
API Group 。
rules :
apiGroups : ["" ]
#
# HTTPレベルでの、Podにアクセスするリソースの名前
# オブジェクトは"pods"
resources : ["pods" ]
verbs : ["get" , "list" , "watch" ]
APIグループ" extensions "と " apps " の両方で、Deploymentsへの読み取り/書き込みを許可します。
(HTTPレベルでURLのリソース部分に"deployments"を持つオブジェクトで)
rules :
apiGroups : ["extensions" , "apps" ]
#
# HTTPレベルでの、Deploymentにアクセスするリソースの名前
# オブジェクトは"deployments"
resources : ["deployments" ]
verbs : ["get" , "list" , "watch" , "create" , "update" , "patch" , "delete" ]
コアAPIグループのPodの読み取り、および"batch"または"extensions"APIグループのJobリソースの読み取りまたは書き込みを許可します。
rules :
apiGroups : ["" ]
#
# HTTPレベルでの、Podにアクセスするリソースの名前
# オブジェクトは"pods"
resources : ["pods" ]
verbs : ["get" , "list" , "watch" ]
apiGroups : ["batch" , "extensions" ]
#
# HTTPレベルでの、Jobにアクセスするリソースの名前
# オブジェクトは"jobs"
resources : ["jobs" ]
verbs : ["get" , "list" , "watch" , "create" , "update" , "patch" , "delete" ]
「my-config」という名前のConfigMapの読み取りを許可します(
単一のNamespace内の単一のConfigMapに制限するRoleBinding)
rules :
apiGroups : ["" ]
#
# HTTPレベルでの、ConfigMapにアクセスするリソースの名前
# オブジェクトは"configmaps"
resources : ["configmaps" ]
resourceNames : ["my-config" ]
verbs : ["get" ]
コアグループ内のリソース "nodes"の読み取りを許可します(Nodeはクラスタースコープであり、ClusterRoleBindingが効果的であるため、ClusterRoleにバインドされている必要があります)。
rules :
apiGroups : ["" ]
#
# HTTPレベルでの、Nodeにアクセスするリソースの名前
# オブジェクトは"nodes"
resources : ["nodes" ]
verbs : ["get" , "list" , "watch" ]
非リソースエンドポイント / healthzおよびすべてのサブパス(ClusterRoleBindingが効果的であるため、ClusterRoleにバインドされている必要があります)のGETおよびPOSTリクエストを許可します。
rules :
nonResourceURLs : ["/healthz" , "/healthz/*" ] # nonResourceURLの「*」はサフィックスグロブマッチです
verbs : ["get" , "post" ]
subjectsを参照する RoleBindingまたはClusterRoleBindingは、Roleをsubjectsにバインドします。subjectsはグループ、ユーザー、またはServiceAccounts にすることができます。
Kubernetesはユーザー名を文字列として表します。
これらは次のようにできます。「alice」などの単純な名前。「bob@example.com」のような電子メール形式の名前。または文字列として表される数値のユーザーID。 認証が必要な形式のユーザー名を生成するように認証モジュール を構成するかどうかは、クラスター管理者が決定します。
注意: プレフィックスsystem:はKubernetesシステムで使用するために予約されているため、誤ってsystem:で始まる名前のユーザーまたはグループが存在しないようにする必要があります。
この特別なプレフィックスを除いて、RBAC承認システムでは、ユーザー名の形式は問いません。Kubernetesでは、Authenticatorモジュールがグループ情報を提供します。
ユーザーと同様に、グループは文字列として表され、その文字列には、プレフィックスsystem:が予約されていることを除いて、フォーマット要件はありません。
ServiceAccount の名前はプレフィックスsystem:serviceaccount:が付いており、名前のプレフィックスsystem:serviceaccounts:が付いているグループに属しています。
備考: system:serviceaccount: (単数)は、サービスアカウントのユーザー名のプレフィックスです。system:serviceaccounts:(複数)は、サービスアカウントグループのプレフィックスです。RoleBindingの例 次の例はRoleBinding、subjectsセクションのみを示す抜粋です。
alice@example.comという名前のユーザーの場合。
subjects :
kind : User
name : "alice@example.com"
apiGroup : rbac.authorization.k8s.io
frontend-adminsという名前のグループの場合。
subjects :
kind : Group
name : "frontend-admins"
apiGroup : rbac.authorization.k8s.io
Namespace「kube-system」のデフォルトのサービスアカウントの場合。
subjects :
kind : ServiceAccount
name : default
namespace : kube-system
Namespace「qa」の全てのサービスアカウントの場合。
subjects :
kind : Group
name : system:serviceaccounts:qa
apiGroup : rbac.authorization.k8s.io
任意のNamespaceの全てのサービスアカウントの場合。
subjects :
kind : Group
name : system:serviceaccounts
apiGroup : rbac.authorization.k8s.io
すべての認証済みユーザーの場合。
subjects :
kind : Group
name : system:authenticated
apiGroup : rbac.authorization.k8s.io
認証されていないすべてのユーザーの場合。
subjects :
kind : Group
name : system:unauthenticated
apiGroup : rbac.authorization.k8s.io
すべてのユーザーの場合。
subjects :
kind : Group
name : system:authenticated
apiGroup : rbac.authorization.k8s.io
kind : Group
name : system:unauthenticated
apiGroup : rbac.authorization.k8s.io
デフォルトRoleとClusterRoleBinding APIサーバーは、デフォルトのClusterRoleオブジェクトとClusterRoleBindingオブジェクトのセットを作成します。
これらの多くにはプレフィックスsystem:が付いています。これは、リソースがクラスターコントロールプレーンによって直接管理されることを示しています。
デフォルトのすべてのClusterRoleおよびClusterRoleBindingには、ラベルkubernetes.io/bootstrapping=rbac-defaultsが付いています。
注意: プレフィックスとしてsystem:を含む名前で、ClusterRolesおよびClusterRoleBindingsを変更する場合は注意してください。
これらのリソースを変更すると、クラスターが機能しなくなる可能性があります。自動調整 起動するたびに、APIサーバーはデフォルトのClusterRoleを不足している権限で更新し、
デフォルトのClusterRoleBindingを不足しているsubjectsで更新します。
これにより、誤った変更をクラスターが修復できるようになり、新しいKubernetesリリースで権限とsubjectsが変更されても、
RoleとRoleBindingを最新の状態に保つことができます。
この調整を無効化するにはrbac.authorization.kubernetes.io/autoupdateをデフォルトのClusterRoleまたはRoleBindingのアノテーションをfalseに設定します。
デフォルトの権限と subjectsがないと、クラスターが機能しなくなる可能性があることに注意してください。
RBAC authorizerが有効な場合、自動調整はデフォルトで有効になっています。
APIディスカバリーRole デフォルトのRoleBindingでは、認証されていないユーザーと認証されたユーザーが、パブリックアクセスが安全であると見なされるAPI情報(CustomResourceDefinitionを含む)の読み取りを認可しています。匿名の非認証アクセスを無効にするには、APIサーバー構成に--anonymous-auth=false 追加します。
kubectlの実行によってこれらのRoleの構成を表示するには。
kubectl get clusterroles system:discovery -o yaml
備考: ClusterRoleを編集すると、変更が
自動調整 によるAPIサーバーの再起動時に上書きされます。この上書きを回避するにはRoleを手動で編集しないか、自動調整を無効にします。
Kubernetes RBAC APIディスカバリーRole デフォルトのClusterRole デフォルトのClusterRoleBinding 説明 system:basic-user system:authenticated groupユーザーに、自身に関する基本情報への読み取り専用アクセスを許可します。v1.14より前は、このRoleはデフォルトでsystem:unauthenticated にもバインドされていました。 system:discovery system:authenticated groupAPIレベルのディスカバリーとネゴシエーションに必要なAPIディスカバリーエンドポイントへの読み取り専用アクセスを許可します。v1.14より前は、このRoleはデフォルトでsystem:unauthenticated にもバインドされていました。 system:public-info-viewer system:authenticated and system:unauthenticated groupsクラスターに関する機密情報以外への読み取り専用アクセスを許可します。Kubernetes v1.14で導入されました。
ユーザー向けRole 一部のデフォルトClusterRolesにはプレフィックスsystem:が付いていません。これらは、ユーザー向けのroleを想定しています。それらは、スーパーユーザのRole(cluster-admin)、ClusterRoleBindingsを使用してクラスター全体に付与されることを意図しているRole、そしてRoleBindings(admin, edit, view)を使用して、特定のNamespace内に付与されることを意図しているRoleを含んでいます。
ユーザー向けのClusterRolesはClusterRoleの集約 を使用して、管理者がこれらのClusterRolesにカスタムリソースのルールを含めることができるようにします。ルールをadmin、edit、またはview Roleに追加するには、次のラベルの一つ以上でClusterRoleを作成します。
metadata :
labels :
rbac.authorization.k8s.io/aggregate-to-admin : "true"
rbac.authorization.k8s.io/aggregate-to-edit : "true"
rbac.authorization.k8s.io/aggregate-to-view : "true"
デフォルトのClusterRole デフォルトのClusterRoleBinding 説明 cluster-admin system:masters groupスーパーユーザーが任意のリソースで任意のアクションを実行できるようにします。
ClusterRoleBinding で使用すると、クラスター内およびすべてのNamespace内のすべてのリソースを完全に制御できます。
RoleBinding で使用すると、Namespace自体を含む、RoleBindingのNamespace内のすべてのリソースを完全に制御できます。 admin None RoleBinding を使用してNamespace内で付与することを想定した、管理者アクセスを許可します。
RoleBinding で使用した場合、Namespace内にRoleとRoleBindingを作成する機能を含め、Namespaceのほとんどのリソースへの読み取り/書き込みアクセスを許可します。
このRoleは、リソースクォータまたはNamespace自体への書き込みアクセスを許可しません。edit None Namespace内のほとんどのオブジェクトへの読み取り/書き込みアクセスを許可します。このRoleは、RoleまたはRoleBindingの表示または変更を許可しません。
ただし、このRoleでは、Secretsにアクセスして、Namespace内の任意のServiceAccountとしてPodsを実行できるため、Namespace内の任意のServiceAccountのAPIアクセスレベルを取得するために使用できます。
view None Namespace内のほとんどのオブジェクトを表示するための読み取り専用アクセスを許可します。
RoleまたはRoleBindingは表示できません。Secretsの内容を読み取るとNamespaceのServiceAccountのクレデンシャルにアクセスできるため、このRoleではSecretsの表示は許可されません。これにより、Namespace内の任意のServiceAccountとしてAPIアクセスが許可されます(特権昇格の形式)。
コアコンポーネントのRole デフォルトのClusterRole デフォルトのClusterRoleBinding 説明 system:kube-scheduler system:kube-scheduler userscheduler コンポーネントが必要とするリソースへのアクセスを許可します。system:volume-scheduler system:kube-scheduler userkube-scheduleコンポーネントが必要とするリソースへのアクセスを許可します。 system:kube-controller-manager system:kube-controller-manager usercontroller manager コンポーネントが必要とするリソースへのアクセスを許可します。
個々のコントローラーに必要な権限については、組み込みコントローラーのRoleで詳しく説明しています 。system:node None すべてのsecretへの読み取りアクセス、すべてのポッドステータスオブジェクトへの書き込みアクセスなど、 kubeletが必要とするリソースへのアクセスを許可します。system:node Roleの代わりにNode authorizer と NodeRestriction admission plugin を使用し、それらで実行するようにスケジュールされたPodに基づいてkubeletへのAPIアクセスを許可する必要があります。
system:node のRoleは、V1.8より前のバージョンからアップグレードしたKubernetesクラスターとの互換性のためだけに存在します。
system:node-proxier system:kube-proxy userkube-proxy コンポーネントが必要とするリソースへのアクセスを許可します。
他のコンポーネントのRole デフォルトのClusterRole デフォルトのClusterRoleBinding 説明 system:auth-delegator None 委任された認証と認可のチェックを許可します。
これは一般に、認証と認可を統合するためにアドオンAPIサーバーで使用されます。 system:heapster None Heapster コンポーネントのRole(非推奨)。system:kube-aggregator None kube-aggregator コンポーネントのRole。system:kube-dns kube-system Namespaceのサービスアカウントkube-dnskube-dns コンポーネントのRole。system:kubelet-api-admin None kubelet APIへのフルアクセスを許可します。 system:node-bootstrapper None kubelet TLS bootstrapping の実行に必要なリソースへのアクセスを許可します。system:node-problem-detector None node-problem-detector コンポーネントのRole。system:persistent-volume-provisioner None ほとんどのdynamic volume provisioners が必要とするリソースへのアクセスを許可します。
組み込みコントローラーのRole Kubernetes controller manager は、Kubernetesコントロールプレーンに組み込まれているcontrollers を実行します。
--use-service-account-credentialsを指定して呼び出すと、kube-controller-manager個別のサービスアカウントを使用して各コントローラーを起動します。
組み込みコントローラーごとに、プレフィックスsystem:controller:付きの対応するRoleが存在します。
コントローラーマネージャーが--use-service-account-credentialsで開始されていない場合、コントローラーマネージャーは、関連するすべてのRoleを付与する必要がある自身のクレデンシャルを使用して、すべてのコントロールループを実行します。
これらのRoleは次のとおりです。
system:controller:attachdetach-controllersystem:controller:certificate-controllersystem:controller:clusterrole-aggregation-controllersystem:controller:cronjob-controllersystem:controller:daemon-set-controllersystem:controller:deployment-controllersystem:controller:disruption-controllersystem:controller:endpoint-controllersystem:controller:expand-controllersystem:controller:generic-garbage-collectorsystem:controller:horizontal-pod-autoscalersystem:controller:job-controllersystem:controller:namespace-controllersystem:controller:node-controllersystem:controller:persistent-volume-bindersystem:controller:pod-garbage-collectorsystem:controller:pv-protection-controllersystem:controller:pvc-protection-controllersystem:controller:replicaset-controllersystem:controller:replication-controllersystem:controller:resourcequota-controllersystem:controller:root-ca-cert-publishersystem:controller:route-controllersystem:controller:service-account-controllersystem:controller:service-controllersystem:controller:statefulset-controllersystem:controller:ttl-controller特権昇格の防止とブートストラップ RBAC APIは、RoleまたはRoleBindingを編集することにより、ユーザーが特権を昇格するのを防ぎます。
これはAPIレベルで適用されるため、RBAC authorizerが使用されていない場合でも適用されます。
Roleの作成または更新に関する制限 次の項目1つ以上が当てはまる場合にのみ、Roleを作成/更新できます。
変更対象のオブジェクトと同じスコープで、Roleに含まれるすべての権限を既に持っている(ClusterRoleの場合はクラスター全体。Roleの場合は、同じNamespace内またはクラスター全体)。 rbac.authorization.k8s.ioAPIグループの rolesまたはclusterrolesリソースで escalate verbを実行する明示的な権限が付与されている。たとえば、 user-1にクラスター全体でSecretsを一覧表示する権限がない場合、それらにその権限を含むClusterRoleを作成できません。
ユーザーがRoleを作成/更新できるようにするには、以下のいずれかを実施します。
必要に応じて、RoleオブジェクトまたはClusterRoleオブジェクトを作成/更新できるRoleを付与する。 作成/更新するRoleに特定の権限を含む権限を付与する。暗黙的に、これらの権限を付与することにより(自分自身が付与されていない権限でRoleまたはClusterRoleを作成または変更しようとすると、APIリクエストは禁止されます)。 または、rbac.authorization.k8s.ioAPIグループの rolesまたは clusterrolesリソースで escalate verbを実行する権限を与えることにより、 Roleまたは ClusterRoleで権限を指定することを明示的に許可する RoleBindingの作成または更新に関する制限 参照されるRoleに含まれるすべての権限を(RoleBindingと同じスコープで)すでに持っている場合、
または 参照されたRoleでbind verbを実行する認可されている場合のみ、RoleBindingを作成/更新できます。
たとえば、 user-1にクラスター全体でSecretsを一覧表示する権限がない場合、ClusterRoleBindingを作成してもRoleにその権限を付与できません。
ユーザーがRoleBindingを作成/更新できるようにするには、以下のいずれかを実施します。
必要に応じて、RoleBindingまたはClusterRoleBindingオブジェクトを作成/更新できるようにする役割を付与する。 特定の役割をバインドするために必要なアクセス許可を付与する。暗黙的に、Roleに含まれる権限を付与することによって。 明示的に、特定のRole(またはClusterRole)で bind verbを実行する許可を与えることによって。 たとえば、このClusterRoleとRoleBindingを使用すると、 user-1は他のユーザーにNamespace user-1-namespaceの admin、 edit、および viewRoleを付与します。
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRole
metadata :
name : role-grantor
rules :
apiGroups : ["rbac.authorization.k8s.io" ]
resources : ["rolebindings" ]
verbs : ["create" ]
apiGroups : ["rbac.authorization.k8s.io" ]
resources : ["clusterroles" ]
verbs : ["bind" ]
resourceNames : ["admin" ,"edit" ,"view" ]
---
apiVersion : rbac.authorization.k8s.io/v1
kind : RoleBinding
metadata :
name : role-grantor-binding
namespace : user-1-namespace
roleRef :
apiGroup : rbac.authorization.k8s.io
kind : ClusterRole
name : role-grantor
subjects :
apiGroup : rbac.authorization.k8s.io
kind : User
name : user-1
最初のRoleとRoleBindingをブートストラップするときは、最初のユーザーがまだ持っていない権限を付与する必要があります。
初期RoleとRoleBindingをブートストラップするには、以下のいずれかを実施します。
「system:masters」グループのクレデンシャルを使用します。このグループは、デフォルトのBindingによって「cluster-admin」スーパーユーザーRoleにバインドされています。 APIサーバーが安全でないポート(--insecure-port)を有効にして実行されている場合、そのポートを介してのAPI呼び出しもできます。これにより、認証や認可が実行されません。 コマンドラインユーティリティー kubectl create role以下に、単一のNamespace内で権限を定義するRoleオブジェクトをいくつか例として作成します。
ユーザーがポッドで get、 watch、および listを実行できるように「pod-reader」という名前のRoleを作成します。
kubectl create role pod-reader --verb= get --verb= list --verb= watch --resource= pods
resourceNamesを指定して、「pod-reader」という名前のRoleを作成します。
kubectl create role pod-reader --verb= get --resource= pods --resource-name= readablepod --resource-name= anotherpod
apiGroupsを指定して「foo」という名前のRoleを作成します。
kubectl create role foo --verb= get,list,watch --resource= replicasets.apps
サブリソースの権限を持つ「foo」という名前のRoleを作成します。
Create a Role named "foo" with subresource permissions:
kubectl create role foo --verb= get,list,watch --resource= pods,pods/status
特定の名前のリソースを取得/更新する権限を持つ「my-component-lease-holder」という名前のRoleを作成します。
kubectl create role my-component-lease-holder --verb= get,list,watch,update --resource= lease --resource-name= my-component
kubectl create clusterrole以下にClusterRoleをいくつか例として作成します。
ユーザーがポッドに対してget、 watch、および listを実行できるようにする「pod-reader」という名前のClusterRoleを作成します。
kubectl create clusterrole pod-reader --verb= get,list,watch --resource= pods
resourceNamesを指定して、「pod-reader」という名前のClusterRoleを作成します。
kubectl create clusterrole pod-reader --verb= get --resource= pods --resource-name= readablepod --resource-name= anotherpod
apiGroupsを指定して「foo」という名前のClusterRoleを作成します。
kubectl create clusterrole foo --verb= get,list,watch --resource= replicasets.apps
サブリソースの権限を持つ「foo」という名前のClusterRoleを作成します。
kubectl create clusterrole foo --verb= get,list,watch --resource= pods,pods/status
nonResourceURLを指定して「foo」という名前のClusterRoleを作成します。
kubectl create clusterrole "foo" --verb= get --non-resource-url= /logs/*
aggregationRuleを指定して、「monitoring」という名前のClusterRoleを作成します。
kubectl create clusterrole monitoring --aggregation-rule= "rbac.example.com/aggregate-to-monitoring=true"
kubectl create rolebinding以下に、特定のNamespace内でRoleまたはClusterRoleをいくつか例として付与します。
Namespace「acme」内で、「admin」ClusterRoleの権限を「bob」という名前のユーザーに付与します。
kubectl create rolebinding bob-admin-binding --clusterrole= admin --user= bob --namespace= acme
Namespace「acme」内で、ClusterRole「view」へのアクセス許可を「myapp」というNamespace「acme」のサービスアカウントに付与します。
kubectl create rolebinding myapp-view-binding --clusterrole= view --serviceaccount= acme:myapp --namespace= acme
Namespace「acme」内で、ClusterRole「view」へのアクセス許可を「myapp」というNamespace「myappnamespace」のサービスアカウントに付与します。
kubectl create rolebinding myappnamespace-myapp-view-binding --clusterrole= view --serviceaccount= myappnamespace:myapp --namespace= acme
kubectl create clusterrolebinding以下に、クラスター全体(すべてのNamespace)にClusterRoleをいくつか例として付与します。
クラスター全体で、ClusterRole「cluster-admin」へのアクセス許可を「root」という名前のユーザーに付与します。
kubectl create clusterrolebinding root-cluster-admin-binding --clusterrole= cluster-admin --user= root
クラスター全体で、ClusterRole「system:node-proxier」へのアクセス許可を「system:kube-proxy」という名前のユーザーに付与します。
kubectl create clusterrolebinding kube-proxy-binding --clusterrole= system:node-proxier --user= system:kube-proxy
クラスター全体で、ClusterRole「view」へのアクセス許可を、Namespace「acme」の「myapp」という名前のサービスアカウントに付与します。
kubectl create clusterrolebinding myapp-view-binding --clusterrole= view --serviceaccount= acme:myapp
kubectl auth reconcileマニフェストファイルから rbac.authorization.k8s.io/v1APIオブジェクトを作成または更新します。
欠落しているオブジェクトが作成され、必要に応じて、Namespaceに属するオブジェクト用にオブジェクトを含むNamespaceが作成されます。
既存のRoleが更新され、入力オブジェクトに権限が含まれるようになります。
--remove-extra-permissionsが指定されている場合は、余分な権限を削除します。
既存のBindingが更新され、入力オブジェクトにsubjectsが含まれるようになります。
--remove-extra-subjectsが指定されている場合は、余分な件名を削除します。
以下、例として。
RBACオブジェクトのマニフェストファイルをテストとして適用し、行われる変更を表示します。
kubectl auth reconcile -f my-rbac-rules.yaml --dry-run=client
RBACオブジェクトのマニフェストファイルを適用し、(Role内の)追加のアクセス許可と(Binding内の)追加のsubjectsを保持します。
kubectl auth reconcile -f my-rbac-rules.yaml
RBACオブジェクトのマニフェストファイルを適用し、(Role内の)余分なアクセス許可と(Binding内の)余分なsubjectsを削除します。
ServiceAccount権限 デフォルトのRBACポリシーは、コントロールプレーンコンポーネント、ノード、
およびコントローラーをスコープとして権限を付与しますが、 Namespacekube-system外のサービスアカウントにはno permissions で付与します
(すべての認証されたユーザーに与えられたディスカバリー権限に関わらず)。
これにより、必要に応じて特定のServiceAccountに特定のRoleを付与できます。
きめ細かいRoleBindingはセキュリティを強化しますが、管理にはより多くの労力が必要です。
より広範な権限は、不必要な(そして潜在的にエスカレートする)APIアクセスをServiceAccountsに与える可能性がありますが、管理が簡単です。
アプローチを最も安全なものから最も安全でないものの順に並べると、次のとおりです。
アプリケーション固有のサービスアカウントにRoleを付与する(ベストプラクティス)
これには、アプリケーションがpodのspec、そして作成するサービスアカウント(API、アプリケーションマニフェスト、 kubectl create serviceaccountなどを介して)でserviceAccountNameを指定する必要があります。
たとえば、「my-namespace」内の読み取り専用権限を「my-sa」サービスアカウントに付与します。
kubectl create rolebinding my-sa-view \
= view \
= my-namespace:my-sa \
= my-namespace
あるNamespaceのサービスアカウント「default」にRoleを付与します
アプリケーションが serviceAccountNameを指定しない場合、サービスアカウント「default」を使用します。
備考: サービスアカウント「default」に付与された権限は、serviceAccountNameを指定しないNamespace内のすべてのポッドで利用できます。たとえば、「my-namespace」内の読み取り専用権限をサービスアカウント「default」に付与します。
kubectl create rolebinding default-view \
= view \
= my-namespace:default \
= my-namespace
多くのアドオン は、
Namespacekube-systemのサービスアカウント「default」として実行されます。
これらのアドオンをスーパーユーザーアクセスでの実行を許可するには、Namespacekube-systemのサービスアカウント「default」のcluster-admin権限を付与します。
注意: これを有効にすると、 Namespace`kube-systemにクラスターのAPIへのスーパーユーザーアクセス許可するSecretsが含まれます。
kubectl create clusterrolebinding add-on-cluster-admin \
= cluster-admin \
= kube-system:default
Namespace内のすべてのサービスアカウントにRoleを付与します
Namespace内のすべてのアプリケーションにRoleを持たせたい場合は、使用するサービスアカウントに関係なく、
そのNamespaceのサービスアカウントグループにRoleを付与できます。
たとえば、「my-namespace」内の読み取り専用アクセス許可を、そのNamespace内のすべてのサービスアカウントに付与します。
kubectl create rolebinding serviceaccounts-view \
= view \
= system:serviceaccounts:my-namespace \
= my-namespace
クラスター全体のすべてのサービスアカウントに制限されたRoleを付与します(お勧めしません)
Namespaceごとのアクセス許可を管理したくない場合は、すべてのサービスアカウントにクラスター全体の役割を付与できます。
たとえば、クラスター内のすべてのサービスアカウントに、すべてのNamespaceで読み取り専用のアクセス許可を付与します。
kubectl create clusterrolebinding serviceaccounts-view \
= view \
= system:serviceaccounts
クラスター全体のすべてのサービスアカウントへのスーパーユーザーアクセスを許可します。(強くお勧めしません)
権限の分割をまったく考慮しない場合は、すべてのサービスアカウントにスーパーユーザーアクセスを許可できます。
警告: これにより、すべてのアプリケーションにクラスターへのフルアクセスが許可され、Secretsの読み取りアクセス権(または任意のポッドを作成する機能)を持つユーザーに、クラスターへのフルアクセスが許可されます。
kubectl create clusterrolebinding serviceaccounts-cluster-admin \
= cluster-admin \
= system:serviceaccounts
ABACからアップグレードする 以前は古いバージョンのKubernetesを実行していたクラスターは、すべてのサービスアカウントに完全なAPIアクセスを許可するなど、permissiveなABACポリシーを使用することがよくありました。
デフォルトのRBACポリシーは、コントロールプレーンコンポーネント、ノード、
およびコントローラーをスコープとして権限を付与しますが、 Namespacekube-system外のサービスアカウントにはno permissions で付与します
(すべての認証されたユーザーに与えられたディスカバリー権限に関わらず)。
これははるかに安全ですが、API権限を自動的に受け取ることを期待している既存のワークロードを混乱させる可能性があります。
この移行を管理するための2つのアプローチは次のとおりです。
並行認可 RBACとABACの両方のauthorizerを実行し、legacy ABAC policy を含むポリシーファイルを指定します。
--authorization-mode=...,RBAC,ABAC --authorization-policy-file=mypolicy.json
最初のコマンドラインオプションを詳細に説明すると、Nodeなどの以前のauthorizerが
要求を拒否すると、RBAC authorizerはAPI要求を認可しようとします。 RBACの場合
また、そのAPI要求を拒否すると、ABAC authorizerが実行されます。これにより、すべてのリクエストが
RBACまたはABACポリシーのいずれか で許可されます。
RBACコンポーネントのログレベルが5以上でkube-apiserverを実行した場合(--vmodule = rbac * = 5または --v = 5)、APIサーバーログでRBACの拒否を確認できます(プレフィックスは「RBAC」)。
その情報を使用して、どのRoleをどのユーザー、グループ、またはサービスアカウントに付与する必要があるかを判断できます。
サービスアカウントに付与されたRole を取得し、
ワークロードがサーバーログにRBACの拒否メッセージがない状態で実行されている場合は、ABAC authorizerを削除できます。
Permissive RBAC権限 RBACRoleBindingを使用して、permissive ABACポリシーを複製できます。
警告: 次のポリシーでは、すべて のサービスアカウントがクラスター管理者としてふるまうことを許可しています。
コンテナで実行されているアプリケーションは、サービスアカウントのクレデンシャルを自動的に受け取ります。
secretsの表示や権限の変更など、APIに対して任意のアクションを実行できます。
これは推奨されるポリシーではありません。
kubectl create clusterrolebinding permissive-binding \
= cluster-admin \
= admin \
= kubelet \
= system:serviceaccounts
RBACの使用に移行後、クラスターが情報セキュリティのニーズを確実に満たすように、アクセスコントロールを調整する必要があります。
6.6 - ネットワーキングのリファレンス このセクションでは、Kubernetesネットワーキングの詳細を提供します。
6.6.1 - ポートとプロトコル パブリッククラウドにおける仮想ネットワークや、物理ネットワークファイアウォールを持つオンプレミスのデータセンターのような、ネットワークの境界が厳格な環境でKubernetesを実行する場合、Kubernetesのコンポーネントが使用するポートやプロトコルを認識しておくと便利です。
コントロールプレーン プロトコル 通信の向き ポート範囲 目的 使用者 TCP Inbound 6443 Kubernetes API server 全て TCP Inbound 2379-2380 etcd server client API kube-apiserver, etcd TCP Inbound 10250 Kubelet API 自身, コントロールプレーン TCP Inbound 10259 kube-scheduler 自身 TCP Inbound 10257 kube-controller-manager 自身
etcdポートはコントロールプレーンノードに含まれていますが、独自のetcdクラスターを外部またはカスタムポートでホストすることもできます。
ワーカーノード プロトコル 通信の向き ポート範囲 目的 使用者 TCP Inbound 10250 Kubelet API 自身, コントロールプレーン TCP Inbound 30000-32767 NodePort Services† 全て
† NodePort Services のデフォルトのポート範囲。
すべてのデフォルトのポート番号が書き換え可能です。
カスタムポートを使用する場合、ここに記載されているデフォルトではなく、それらのポートを開く必要があります。
よくある例としては、API Serverのポートを443に変更することがあります。
または、デフォルトポートをそのままにし、API Serverを443でリッスンしているロードバランサーの後ろに置き、APIサーバのデフォルトポートにリクエストをルーティングする方法もあります。
6.7 - セットアップツールのリファレンス 6.7.1 - Kubeadm kubeadm initやkubeadm joinなどのコマンドを提供するツールで、Kubernetesクラスターを構築する上でのベストプラクティスを反映した「近道」を提供するものとして開発されました。
kubeadmは実用最小限のクラスターをセットアップするための処理を実行します。設計上、kubeadmはブートストラップのみを行い、マシンのプロビジョニングは行いません。同様に、Kubernetesダッシュボード、モニタリングソリューション、クラウド向けのアドオンなど、あれば便利でもなくても支障のない各種アドオンのインストールも範囲外です。
その代わりに、高度な特定用途向けのツールはkubeadmをベースに構築されることが期待されています。理想的には、すべてのデプロイのベースとしてkubeadmを使用することで、適合テストに通るクラスターを簡単に作れるようになります。
インストール方法 kubeadmをインストールするには、インストールガイド を参照してください。
次の項目
6.7.1.1 - Kubeadm Generated 6.7.1.1.1 - kubeadmが使用するイメージの一覧を出力します。
設定ファイルはイメージやイメージリポジトリをカスタマイズする際に使用されます。
概要 kubeadmが使用するイメージの一覧を出力します。
設定ファイルはイメージやイメージリポジトリをカスタマイズする際に使用されます。
kubeadm config images list [flags]
オプション --allow-missing-template-keys デフォルト値: true trueならば、テンプレートの中にフィールドやマップキーが見つからない場合に、テンプレート内のエラーを無視します。golangまたはjsonpathを出力フォーマットとした場合にのみ適用されます。
--config string kubeadmの設定ファイルのパス。
-o, --experimental-output string デフォルト値: "text" 出力フォーマット。次のいずれか: text|json|yaml|go-template|go-template-file|template|templatefile|jsonpath|jsonpath-as-json|jsonpath-file.
--feature-gates string 様々な機能に対するフィーチャーゲートを記述するkey=valueペアのセット。オプション:
-h, --help listのヘルプ
--image-repository string デフォルト値: "registry.k8s.io" コントロールプレーンのイメージをプルするコンテナレジストリを選択します。
--kubernetes-version string デフォルト値: "stable-1" コントロールプレーンの特定のKubernetesバージョンを選択します。
--show-managed-fields trueならば、JSONまたはYAMLフォーマットでmanagedFieldsを省略せずにオブジェクトを出力します。
親コマンドから継承されたオプション --kubeconfig string デフォルト値: "/etc/kubernetes/admin.conf" クラスターと通信する時に使用するkubeconfigファイル。フラグが設定されていない場合は、標準的な場所の中から既存のkubeconfigファイルが検索されます。
--rootfs string [実験的]'実際の'ホストのルートファイルシステムのパス。
6.7.1.1.2 - kubeadmによって使用されるイメージをプルします。
概要 kubeadmによって使用されるイメージをプルします。
kubeadm config images pull [flags]
オプション --config string kubeadmの設定ファイルのパス。
--cri-socket string 接続するCRIソケットへのパス。空の場合、kubeadmはこの値を自動検出しようとします。このオプションは、複数のCRIがインストールされているか、標準ではないCRIソケットがある場合のみ使用してください。
--feature-gates string 様々な機能に対するフィーチャーゲートを記述するkey=valueペアのセット。オプション:
-h, --help pullのヘルプ
--image-repository string デフォルト値: "registry.k8s.io" コントロールプレーンのイメージをプルするコンテナレジストリを選択します。
--kubernetes-version string デフォルト値: "stable-1" コントロールプレーンの特定のKubernetesバージョンを選択します。
親コマンドから継承されたオプション --kubeconfig string デフォルト値: "/etc/kubernetes/admin.conf" クラスターと通信する時に使用するkubeconfigファイル。フラグが設定されていない場合は、標準的な場所の中から既存のkubeconfigファイルが検索されます。
--rootfs string [実験的]'実際の'ホストのルートファイルシステムのパス。
6.7.1.1.3 - ファイルから古いバージョンのAPIタイプのkubeadmの設定を読み込み、新しいバージョンの同等の設定オブジェクトを出力します。
概要 このコマンドは、古いバージョンの設定オブジェクトを、サポートされている最新のバージョンに変換します。
これはクラスターを何も触ることなく、CLIツール内に閉じています。
kubeadmのこのバージョンでは、次のAPIバージョンがサポートされています:
さらに、kubeadmはバージョン"kubeadm.k8s.io/v1beta3"の設定しか出力できませんが、両方の種類を読むことができます。
このため、どのバージョンを--old-configパラメーターに渡したとしても、APIオブジェクトは読み込まれ、デシリアライズ、デフォルト化、変換、検証、再シリアライズされて、標準出力または--new-configで指定されたファイルに出力されます。
言い換えると、このコマンドの出力は、そのファイルを"kubeadm init"に渡した時にkubeadmが実際に内部で読むものとなります。
kubeadm config migrate [flags]
オプション --allow-experimental-api 実験的な未リリースのAPIへの移行を許可します。
-h, --help migrateのヘルプ
--new-config string 新しいAPIバージョンを使用して得られた同等の内容のkubeadm設定ファイルのパス。この設定はオプションで、指定しない場合は標準出力に出力されます。
--old-config string 古いAPIバージョンを使用している、変換対象のkubeadm設定ファイルのパス。このフラグは必須です。
親コマンドから継承されたオプション --kubeconfig string デフォルト値: "/etc/kubernetes/admin.conf" クラスターと通信する時に使用するkubeconfigファイル。フラグが設定されていない場合は、標準的な場所の中から既存のkubeconfigファイルが検索されます。
--rootfs string [実験的]'実際の'ホストのルートファイルシステムのパス。
6.7.1.1.4 - 設定を出力します。
概要 このコマンドは、指定されたサブコマンドに対する設定を出力します。
詳細については次を参照してください: https://pkg.go.dev/k8s.io/kubernetes/cmd/kubeadm/app/apis/kubeadm#section-directories
kubeadm config print [flags]
オプション 親コマンドから継承されたオプション --kubeconfig string デフォルト値: "/etc/kubernetes/admin.conf" クラスターと通信する時に使用するkubeconfigファイル。フラグが設定されていない場合は、標準的な場所の中から既存のkubeconfigファイルが検索されます。
--rootfs string [実験的]'実際の'ホストのルートファイルシステムのパス。
6.7.1.1.5 - kubeadm initで使用できるデフォルトのInitConfigurationを出力します。
概要 このコマンドは、'kubeadm init'で使用されるデフォルトのInitConfigurationオブジェクトを出力します。
Bootstrap Tokenフィールドのような機密性が高い値は、実際にトークンを生成する計算は実行しませんが、検証をパスするために"abcdef.0123456789abcdef"のようなプレースホルダーの値に置き換えられることに注意してください。
kubeadm config print init-defaults [flags]
オプション --component-configs strings デフォルト値を出力するコンポーネントの設定APIオブジェクトのカンマ区切りのリスト。利用可能な値: [KubeProxyConfiguration KubeletConfiguration]。このフラグが設定されていない場合は、どのコンポーネントの設定も出力されません。
-h, --help init-defaultsのヘルプ
親コマンドから継承されたオプション --kubeconfig string デフォルト値: "/etc/kubernetes/admin.conf" クラスターと通信する時に使用するkubeconfigファイル。フラグが設定されていない場合は、標準的な場所の中から既存のkubeconfigファイルが検索されます。
--rootfs string [実験的]'実際の'ホストのルートファイルシステムのパス。
6.7.1.1.6 - kubeadm joinで使用できるデフォルトのJoinConfigurationを出力します。
概要 このコマンドはkubeadm joinで使用されるデフォルトのJoinConfigurationオブジェクトを出力します
Bootstrap Tokenフィールドのような機密性が高い値は、実際にトークンを生成する計算は実行しませんが、検証をパスするために"abcdef.0123456789abcdef"のようなプレースホルダーの値に置き換えられることに注意してください。
kubeadm config print join-defaults [flags]
オプション -h, --help join-defaultsのヘルプ
親コマンドから継承されたオプション --kubeconfig string デフォルト値: "/etc/kubernetes/admin.conf" クラスターと通信する時に使用するkubeconfigファイル。フラグが設定されていない場合は、標準的な場所の中から既存のkubeconfigファイルが検索されます。
--rootfs string [実験的]'実際の'ホストのルートファイルシステムのパス。
6.7.1.1.7 - kubeadm設定APIを含むファイルを読み込み、検証に問題があれば報告します。
概要 このコマンドはkubeadm設定APIファイルを検証して、警告やエラーがあれば報告します。
エラーが無い場合は終了ステータスはゼロ、それ以外の場合はゼロ以外の値となります。
不明なAPIフィールドのようなデータ変換できない問題については、エラーが発生します。
不明なAPIバージョンや不正な値を持つフィールドについてもエラーとなります。
入力ファイルの内容によっては、その他のエラーや警告が報告されることもあります。
このバージョンのkubeadmでは、次のAPIバージョンがサポートされています:
kubeadm config validate [flags]
オプション --allow-experimental-api 実験的な未リリースのAPIの検証を許可する。
--config string kubeadm設定ファイルへのパス。
-h, --help validateのヘルプ
親コマンドから継承されたオプション --kubeconfig string デフォルト値: "/etc/kubernetes/admin.conf" クラスターと通信する時に使用するkubeconfigファイル。フラグが設定されていない場合は、標準的な場所の中から既存のkubeconfigファイルが検索されます。
--rootfs string [実験的]'実際の'ホストのルートファイルシステムのパス。
6.7.1.2 - kubeadm config kubeadm initの実行中、kubeadmはクラスターに対して、kube-system名前空間内のkubeadm-configという名前のConfigMapにClusterConfigurationオブジェクトをアップロードします。
この設定はkubeadm join、kubeadm resetおよびkubeadm upgradeの実行中に読み込まれます。
kubeadm config printによって、kubeadmがkubeadm initやkubeadm joinで使用する、デフォルトの静的な設定を表示することができます。
備考: コマンドの出力は一例として提供されるものです。
自身のセットアップに合わせるためには、コマンドの出力を手動で編集する必要があります。
不明確なフィールドは削除してください。
kubeadmは実行時にホストを調べ、そのフィールドにデフォルト値を設定しようとします。initとjoinのより詳細な情報については、設定ファイルを使ったkubeadm initの利用 、または設定ファイルを使ったkubeadm joinの利用 を参照してください。
kubeadmの設定APIの使用法に関するより詳細な情報については、kubeadm APIを使ったコンポーネントのカスタマイズ を参照してください。
非推奨のAPIバージョンを含んだ古い設定ファイルを、サポートされた新しいAPIバージョンに変換する際には、kubeadm config migrateコマンドを使用することができます。
設定ファイルを検証するためには、kubeadm config validateを使用することができます。
kubeadmが必要とするイメージを表示、取得するために、kbueadm config images listやkubeadm config images pullを使用することができます。
kubeadm config print 設定を出力します。
概要 このコマンドは、指定されたサブコマンドに対する設定を出力します。
詳細については次を参照してください: https://pkg.go.dev/k8s.io/kubernetes/cmd/kubeadm/app/apis/kubeadm#section-directories
kubeadm config print [flags]
オプション 親コマンドから継承されたオプション --kubeconfig string デフォルト値: "/etc/kubernetes/admin.conf" クラスターと通信する時に使用するkubeconfigファイル。フラグが設定されていない場合は、標準的な場所の中から既存のkubeconfigファイルが検索されます。
--rootfs string [実験的]'実際の'ホストのルートファイルシステムのパス。
kubeadm config print init-defaults kubeadm initで使用できるデフォルトのInitConfigurationを出力します。
概要 このコマンドは、'kubeadm init'で使用されるデフォルトのInitConfigurationオブジェクトを出力します。
Bootstrap Tokenフィールドのような機密性が高い値は、実際にトークンを生成する計算は実行しませんが、検証をパスするために"abcdef.0123456789abcdef"のようなプレースホルダーの値に置き換えられることに注意してください。
kubeadm config print init-defaults [flags]
オプション --component-configs strings デフォルト値を出力するコンポーネントの設定APIオブジェクトのカンマ区切りのリスト。利用可能な値: [KubeProxyConfiguration KubeletConfiguration]。このフラグが設定されていない場合は、どのコンポーネントの設定も出力されません。
-h, --help init-defaultsのヘルプ
親コマンドから継承されたオプション --kubeconfig string デフォルト値: "/etc/kubernetes/admin.conf" クラスターと通信する時に使用するkubeconfigファイル。フラグが設定されていない場合は、標準的な場所の中から既存のkubeconfigファイルが検索されます。
--rootfs string [実験的]'実際の'ホストのルートファイルシステムのパス。
kubeadm config print join-defaults kubeadm joinで使用できるデフォルトのJoinConfigurationを出力します。
概要 このコマンドはkubeadm joinで使用されるデフォルトのJoinConfigurationオブジェクトを出力します
Bootstrap Tokenフィールドのような機密性が高い値は、実際にトークンを生成する計算は実行しませんが、検証をパスするために"abcdef.0123456789abcdef"のようなプレースホルダーの値に置き換えられることに注意してください。
kubeadm config print join-defaults [flags]
オプション -h, --help join-defaultsのヘルプ
親コマンドから継承されたオプション --kubeconfig string デフォルト値: "/etc/kubernetes/admin.conf" クラスターと通信する時に使用するkubeconfigファイル。フラグが設定されていない場合は、標準的な場所の中から既存のkubeconfigファイルが検索されます。
--rootfs string [実験的]'実際の'ホストのルートファイルシステムのパス。
kubeadm config migrate ファイルから古いバージョンのAPIタイプのkubeadmの設定を読み込み、新しいバージョンの同等の設定オブジェクトを出力します。
概要 このコマンドは、古いバージョンの設定オブジェクトを、サポートされている最新のバージョンに変換します。
これはクラスターを何も触ることなく、CLIツール内に閉じています。
kubeadmのこのバージョンでは、次のAPIバージョンがサポートされています:
さらに、kubeadmはバージョン"kubeadm.k8s.io/v1beta3"の設定しか出力できませんが、両方の種類を読むことができます。
このため、どのバージョンを--old-configパラメーターに渡したとしても、APIオブジェクトは読み込まれ、デシリアライズ、デフォルト化、変換、検証、再シリアライズされて、標準出力または--new-configで指定されたファイルに出力されます。
言い換えると、このコマンドの出力は、そのファイルを"kubeadm init"に渡した時にkubeadmが実際に内部で読むものとなります。
kubeadm config migrate [flags]
オプション --allow-experimental-api 実験的な未リリースのAPIへの移行を許可します。
-h, --help migrateのヘルプ
--new-config string 新しいAPIバージョンを使用して得られた同等の内容のkubeadm設定ファイルのパス。この設定はオプションで、指定しない場合は標準出力に出力されます。
--old-config string 古いAPIバージョンを使用している、変換対象のkubeadm設定ファイルのパス。このフラグは必須です。
親コマンドから継承されたオプション --kubeconfig string デフォルト値: "/etc/kubernetes/admin.conf" クラスターと通信する時に使用するkubeconfigファイル。フラグが設定されていない場合は、標準的な場所の中から既存のkubeconfigファイルが検索されます。
--rootfs string [実験的]'実際の'ホストのルートファイルシステムのパス。
kubeadm config validate kubeadm設定APIを含むファイルを読み込み、検証に問題があれば報告します。
概要 このコマンドはkubeadm設定APIファイルを検証して、警告やエラーがあれば報告します。
エラーが無い場合は終了ステータスはゼロ、それ以外の場合はゼロ以外の値となります。
不明なAPIフィールドのようなデータ変換できない問題については、エラーが発生します。
不明なAPIバージョンや不正な値を持つフィールドについてもエラーとなります。
入力ファイルの内容によっては、その他のエラーや警告が報告されることもあります。
このバージョンのkubeadmでは、次のAPIバージョンがサポートされています:
kubeadm config validate [flags]
オプション --allow-experimental-api 実験的な未リリースのAPIの検証を許可する。
--config string kubeadm設定ファイルへのパス。
-h, --help validateのヘルプ
親コマンドから継承されたオプション --kubeconfig string デフォルト値: "/etc/kubernetes/admin.conf" クラスターと通信する時に使用するkubeconfigファイル。フラグが設定されていない場合は、標準的な場所の中から既存のkubeconfigファイルが検索されます。
--rootfs string [実験的]'実際の'ホストのルートファイルシステムのパス。
kubeadm config images list kubeadmが使用するイメージの一覧を出力します。
設定ファイルはイメージやイメージリポジトリをカスタマイズする際に使用されます。
概要 kubeadmが使用するイメージの一覧を出力します。
設定ファイルはイメージやイメージリポジトリをカスタマイズする際に使用されます。
kubeadm config images list [flags]
オプション --allow-missing-template-keys デフォルト値: true trueならば、テンプレートの中にフィールドやマップキーが見つからない場合に、テンプレート内のエラーを無視します。golangまたはjsonpathを出力フォーマットとした場合にのみ適用されます。
--config string kubeadmの設定ファイルのパス。
-o, --experimental-output string デフォルト値: "text" 出力フォーマット。次のいずれか: text|json|yaml|go-template|go-template-file|template|templatefile|jsonpath|jsonpath-as-json|jsonpath-file.
--feature-gates string 様々な機能に対するフィーチャーゲートを記述するkey=valueペアのセット。オプション:
-h, --help listのヘルプ
--image-repository string デフォルト値: "registry.k8s.io" コントロールプレーンのイメージをプルするコンテナレジストリを選択します。
--kubernetes-version string デフォルト値: "stable-1" コントロールプレーンの特定のKubernetesバージョンを選択します。
--show-managed-fields trueならば、JSONまたはYAMLフォーマットでmanagedFieldsを省略せずにオブジェクトを出力します。
親コマンドから継承されたオプション --kubeconfig string デフォルト値: "/etc/kubernetes/admin.conf" クラスターと通信する時に使用するkubeconfigファイル。フラグが設定されていない場合は、標準的な場所の中から既存のkubeconfigファイルが検索されます。
--rootfs string [実験的]'実際の'ホストのルートファイルシステムのパス。
kubeadm config images pull kubeadmによって使用されるイメージをプルします。
概要 kubeadmによって使用されるイメージをプルします。
kubeadm config images pull [flags]
オプション --config string kubeadmの設定ファイルのパス。
--cri-socket string 接続するCRIソケットへのパス。空の場合、kubeadmはこの値を自動検出しようとします。このオプションは、複数のCRIがインストールされているか、標準ではないCRIソケットがある場合のみ使用してください。
--feature-gates string 様々な機能に対するフィーチャーゲートを記述するkey=valueペアのセット。オプション:
-h, --help pullのヘルプ
--image-repository string デフォルト値: "registry.k8s.io" コントロールプレーンのイメージをプルするコンテナレジストリを選択します。
--kubernetes-version string デフォルト値: "stable-1" コントロールプレーンの特定のKubernetesバージョンを選択します。
親コマンドから継承されたオプション --kubeconfig string デフォルト値: "/etc/kubernetes/admin.conf" クラスターと通信する時に使用するkubeconfigファイル。フラグが設定されていない場合は、標準的な場所の中から既存のkubeconfigファイルが検索されます。
--rootfs string [実験的]'実際の'ホストのルートファイルシステムのパス。
次の項目 6.8 - コマンドラインツール(kubectl) Kubernetesが提供する、 kubernetes APIを使用してKubernetesクラスターのコントロールプレーン と通信するためのコマンドラインツールです。
このツールの名前は、kubectl です。
kubectlコマンドラインツールを使うと、Kubernetesクラスターを制御できます。環境設定のために、kubectlは、$HOME/.kubeディレクトリにあるconfigという名前のファイルを探します。他のkubeconfig ファイルは、KUBECONFIG環境変数を設定するか、--kubeconfig
この概要では、kubectlの構文を扱い、コマンド操作を説明し、一般的な例を示します。サポートされているすべてのフラグやサブコマンドを含め、各コマンドの詳細については、kubectl リファレンスドキュメントを参照してください。
インストール方法については、kubectlのインストールおよびセットアップ をご覧ください。クイックガイドは、チートシート をご覧ください。dockerコマンドラインツールに慣れている方は、kubectl for Docker Users
構文 ターミナルウィンドウからkubectlコマンドを実行するには、以下の構文を使用します。
kubectl [ command] [ TYPE] [ NAME] [ flags]
ここで、command、TYPE、NAME、flagsは、以下を表します。
command: 1つ以上のリソースに対して実行したい操作を指定します。例えば、create、get、describe、deleteです。
TYPE: リソースタイプ を指定します。リソースタイプは大文字と小文字を区別せず、単数形や複数形、省略形を指定できます。例えば、以下のコマンドは同じ出力を生成します。
kubectl get pod pod1
kubectl get pods pod1
kubectl get po pod1
NAME: リソースの名前を指定します。名前は大文字と小文字を区別します。kubectl get podsのように名前が省略された場合は、すべてのリソースの詳細が表示されます。
複数のリソースに対して操作を行う場合は、各リソースをタイプと名前で指定するか、1つまたは複数のファイルを指定することができます。
flags: オプションのフラグを指定します。例えば、-sまたは--serverフラグを使って、Kubernetes APIサーバーのアドレスやポートを指定できます。
注意: コマンドラインから指定したフラグは、デフォルト値および対応する任意の環境変数を上書きします。ヘルプが必要な場合は、ターミナルウィンドウからkubectl helpを実行してください。
クラスター内認証と名前空間のオーバーライド デフォルトでは、kubectlは最初にPod内で動作しているか、つまりクラスター内で動作しているかどうかを判断します。まず、KUBERNETES_SERVICE_HOSTとKUBERNETES_SERVICE_PORTの環境変数を確認し、サービスアカウントのトークンファイルが/var/run/secrets/kubernetes.io/serviceaccount/tokenに存在するかどうかを確認します。3つともクラスター内で見つかった場合、クラスター内認証とみなされます。
後方互換性を保つため、クラスター内認証時にPOD_NAMESPACE環境変数が設定されている場合には、サービスアカウントトークンのデフォルトの名前空間が上書きされます。名前空間のデフォルトに依存しているすべてのマニフェストやツールは、この影響を受けます。
POD_NAMESPACE環境変数
POD_NAMESPACE環境変数が設定されている場合、名前空間に属するリソースのCLI操作は、デフォルトで環境変数の値になります。例えば、変数にseattleが設定されている場合、kubectl get podsは、seattle名前空間のPodを返します。これは、Podが名前空間に属するリソースであり、コマンドで名前空間が指定されていないためです。kubectl api-resourcesの出力を見て、リソースが名前空間に属するかどうかを判断してください。
明示的に--namespace <value>を使用すると、この動作は上書きされます。
kubectlによるServiceAccountトークンの処理方法
以下の条件がすべて成立した場合、
/var/run/secrets/kubernetes.io/serviceaccount/tokenにマウントされたKubernetesサービスアカウントのトークンファイルがあるKUBERNETES_SERVICE_HOST環境変数が設定されているKUBERNETES_SERVICE_PORT環境変数が設定されているkubectlコマンドラインで名前空間を明示的に指定しない kubectlはクラスター内で実行されているとみなして、そのServiceAccountの名前空間(これはPodの名前空間と同じです)を検索し、その名前空間に対して機能します。これは、クラスターの外の動作とは異なります。kubectlがクラスターの外で実行され、名前空間を指定しない場合、kubectlコマンドは、クライアント構成の現在のコンテキストに設定されている名前空間に対して動作します。kubectlのデフォルトの名前空間を変更するには、次のコマンドを使用できます。
kubectl config set-context --current --namespace= <namespace-name>
操作 以下の表に、kubectlのすべての操作の簡単な説明と一般的な構文を示します。
操作 構文 説明 alphakubectl alpha SUBCOMMAND [flags]アルファ機能に該当する利用可能なコマンドを一覧表示します。これらの機能は、デフォルトではKubernetesクラスターで有効になっていません。 annotatekubectl annotate (-f FILENAME | TYPE NAME | TYPE/NAME) KEY_1=VAL_1 ... KEY_N=VAL_N [--overwrite] [--all] [--resource-version=version] [flags]1つ以上のリソースのアノテーションを、追加または更新します。 api-resourceskubectl api-resources [flags]利用可能なAPIリソースを一覧表示します。 api-versionskubectl api-versions [flags]利用可能なAPIバージョンを一覧表示します。 applykubectl apply -f FILENAME [flags]ファイルまたは標準出力から、リソースの設定変更を適用します。 attachkubectl attach POD -c CONTAINER [-i] [-t] [flags]実行中のコンテナにアタッチして、出力ストリームを表示するか、コンテナ(標準入力)と対話します。 authkubectl auth [flags] [options]認可を検査します。 autoscalekubectl autoscale (-f FILENAME | TYPE NAME | TYPE/NAME) [--min=MINPODS] --max=MAXPODS [--cpu-percent=CPU] [flags]ReplicationControllerで管理されているPodのセットを、自動的にスケールします。 certificatekubectl certificate SUBCOMMAND [options]証明書のリソースを変更します。 cluster-infokubectl cluster-info [flags]クラスター内のマスターとサービスに関するエンドポイント情報を表示します。 completionkubectl completion SHELL [options]指定されたシェル(bashまたはzsh)のシェル補完コードを出力します。 configkubectl config SUBCOMMAND [flags]kubeconfigファイルを変更します。詳細は、個々のサブコマンドを参照してください。 convertkubectl convert -f FILENAME [options]異なるAPIバージョン間で設定ファイルを変換します。YAMLとJSONに対応しています。 cordonkubectl cordon NODE [options]Nodeをスケジュール不可に設定します。 cpkubectl cp <file-spec-src> <file-spec-dest> [options]コンテナとの間でファイルやディレクトリをコピーします。 createkubectl create -f FILENAME [flags]ファイルまたは標準出力から、1つ以上のリソースを作成します。 deletekubectl delete (-f FILENAME | TYPE [NAME | /NAME | -l label | --all]) [flags]ファイル、標準出力、またはラベルセレクター、リソースセレクター、リソースを指定して、リソースを削除します。 describekubectl describe (-f FILENAME | TYPE [NAME_PREFIX | /NAME | -l label]) [flags]1つ以上のリソースの詳細な状態を表示します。 diffkubectl diff -f FILENAME [flags]ファイルまたは標準出力と、現在の設定との差分を表示します。 drainkubectl drain NODE [options]メンテナンスの準備のためにNodeをdrainします。 editkubectl edit (-f FILENAME | TYPE NAME | TYPE/NAME) [flags]デファルトのエディタを使い、サーバー上の1つ以上のリソースリソースの定義を編集し、更新します。 eventskubectl eventsイベントを一覧表示します。 execkubectl exec POD [-c CONTAINER] [-i] [-t] [flags] [-- COMMAND [args...]]Pod内のコンテナに対して、コマンドを実行します。 explainkubectl explain [--recursive=false] [flags]様々なリソースのドキュメントを取得します。例えば、Pod、Node、Serviceなどです。 exposekubectl expose (-f FILENAME | TYPE NAME | TYPE/NAME) [--port=port] [--protocol=TCP|UDP] [--target-port=number-or-name] [--name=name] [--external-ip=external-ip-of-service] [--type=type] [flags]ReplicationController、Service、Podを、新しいKubernetesサービスとして公開します。 getkubectl get (-f FILENAME | TYPE [NAME | /NAME | -l label]) [--watch] [--sort-by=FIELD] [[-o | --output]=OUTPUT_FORMAT] [flags]1つ以上のリソースを表示します。 kustomizekubectl kustomize <dir> [flags] [options]kustomization.yamlファイル内の指示から生成されたAPIリソースのセットを一覧表示します。引数はファイルを含むディレクトリのPath,またはリポジトリルートに対して同じ場所を示すパスサフィックス付きのgitリポジトリのURLを指定しなければなりません。 labelkubectl label (-f FILENAME | TYPE NAME | TYPE/NAME) KEY_1=VAL_1 ... KEY_N=VAL_N [--overwrite] [--all] [--resource-version=version] [flags]1つ以上のリソースのラベルを、追加または更新します。 logskubectl logs POD [-c CONTAINER] [--follow] [flags]Pod内のコンテナのログを表示します。 optionskubectl optionsすべてのコマンドに適用されるグローバルコマンドラインオプションを一覧表示します。 patchkubectl patch (-f FILENAME | TYPE NAME | TYPE/NAME) --patch PATCH [flags]Strategic Merge Patchの処理を使用して、リソースの1つ以上のフィールドを更新します。 pluginkubectl plugin [flags] [options]プラグインと対話するためのユーティリティを提供します。 port-forwardkubectl port-forward POD [LOCAL_PORT:]REMOTE_PORT [...[LOCAL_PORT_N:]REMOTE_PORT_N] [flags]1つ以上のローカルポートを、Podに転送します。 proxykubectl proxy [--port=PORT] [--www=static-dir] [--www-prefix=prefix] [--api-prefix=prefix] [flags]Kubernetes APIサーバーへのプロキシを実行します。 replacekubectl replace -f FILENAMEファイルや標準出力から、リソースを置き換えます。 rolloutkubectl rollout SUBCOMMAND [options]リソースのロールアウトを管理します。有効なリソースには、Deployment、DaemonSetとStatefulSetが含まれます。 runkubectl run NAME --image=image [--env="key=value"] [--port=port] [--dry-run=server|client|none] [--overrides=inline-json] [flags]指定したイメージを、クラスター上で実行します。 scalekubectl scale (-f FILENAME | TYPE NAME | TYPE/NAME) --replicas=COUNT [--resource-version=version] [--current-replicas=count] [flags]指定したReplicationControllerのサイズを更新します。 setkubectl set SUBCOMMAND [options]アプリケーションリソースを設定します。 taintkubectl taint NODE NAME KEY_1=VAL_1:TAINT_EFFECT_1 ... KEY_N=VAL_N:TAINT_EFFECT_N [options]1つ以上のNodeのtaintを更新します。 topkubectl top [flags] [options]リソース(CPU/メモリー/ストレージ)の使用量を表示します。 uncordonkubectl uncordon NODE [options]Nodeをスケジュール可に設定します。 versionkubectl version [--client] [flags]クライアントとサーバーで実行中のKubernetesのバージョンを表示します。 waitkubectl wait ([-f FILENAME] | resource.group/resource.name | resource.group [(-l label | --all)]) [--for=delete|--for condition=available] [options]実験中の機能: 1つ以上のリソースが特定の状態になるまで待ちます。
コマンド操作について詳しく知りたい場合は、kubectl リファレンスドキュメントを参照してください。
リソースタイプ 以下の表に、サポートされているすべてのリソースと、省略されたエイリアスの一覧を示します。
(この出力はkubectl api-resourcesから取得でき、Kubernetes 1.25.0時点で正確でした。)
リソース名 短縮名 APIバージョン 名前空間に属するか リソースの種類 bindingsv1 true Binding componentstatusescsv1 false ComponentStatus configmapscmv1 true ConfigMap endpointsepv1 true Endpoints eventsevv1 true Event limitrangeslimitsv1 true LimitRange namespacesnsv1 false Namespace nodesnov1 false Node persistentvolumeclaimspvcv1 true PersistentVolumeClaim persistentvolumespvv1 false PersistentVolume podspov1 true Pod podtemplatesv1 true PodTemplate replicationcontrollersrcv1 true ReplicationController resourcequotasquotav1 true ResourceQuota secretsv1 true Secret serviceaccountssav1 true ServiceAccount servicessvcv1 true Service mutatingwebhookconfigurationsadmissionregistration.k8s.io/v1 false MutatingWebhookConfiguration validatingwebhookconfigurationsadmissionregistration.k8s.io/v1 false ValidatingWebhookConfiguration customresourcedefinitionscrd,crdsapiextensions.k8s.io/v1 false CustomResourceDefinition apiservicesapiregistration.k8s.io/v1 false APIService controllerrevisionsapps/v1 true ControllerRevision daemonsetsdsapps/v1 true DaemonSet deploymentsdeployapps/v1 true Deployment replicasetsrsapps/v1 true ReplicaSet statefulsetsstsapps/v1 true StatefulSet tokenreviewsauthentication.k8s.io/v1 false TokenReview localsubjectaccessreviewsauthorization.k8s.io/v1 true LocalSubjectAccessReview selfsubjectaccessreviewsauthorization.k8s.io/v1 false SelfSubjectAccessReview selfsubjectrulesreviewsauthorization.k8s.io/v1 false SelfSubjectRulesReview subjectaccessreviewsauthorization.k8s.io/v1 false SubjectAccessReview horizontalpodautoscalershpaautoscaling/v2 true HorizontalPodAutoscaler cronjobscjbatch/v1 true CronJob jobsbatch/v1 true Job certificatesigningrequestscsrcertificates.k8s.io/v1 false CertificateSigningRequest leasescoordination.k8s.io/v1 true Lease endpointslicesdiscovery.k8s.io/v1 true EndpointSlice eventsevevents.k8s.io/v1 true Event flowschemasflowcontrol.apiserver.k8s.io/v1beta2 false FlowSchema prioritylevelconfigurationsflowcontrol.apiserver.k8s.io/v1beta2 false PriorityLevelConfiguration ingressclassesnetworking.k8s.io/v1 false IngressClass ingressesingnetworking.k8s.io/v1 true Ingress networkpoliciesnetpolnetworking.k8s.io/v1 true NetworkPolicy runtimeclassesnode.k8s.io/v1 false RuntimeClass poddisruptionbudgetspdbpolicy/v1 true PodDisruptionBudget podsecuritypoliciespsppolicy/v1beta1 false PodSecurityPolicy clusterrolebindingsrbac.authorization.k8s.io/v1 false ClusterRoleBinding clusterrolesrbac.authorization.k8s.io/v1 false ClusterRole rolebindingsrbac.authorization.k8s.io/v1 true RoleBinding rolesrbac.authorization.k8s.io/v1 true Role priorityclassespcscheduling.k8s.io/v1 false PriorityClass csidriversstorage.k8s.io/v1 false CSIDriver csinodesstorage.k8s.io/v1 false CSINode csistoragecapacitiesstorage.k8s.io/v1 true CSIStorageCapacity storageclassesscstorage.k8s.io/v1 false StorageClass volumeattachmentsstorage.k8s.io/v1 false VolumeAttachment
出力オプション ある特定のコマンドの出力に対してフォーマットやソートを行う方法については、以下の節を参照してください。どのコマンドが様々な出力オプションをサポートしているかについては、kubectl リファレンスドキュメントをご覧ください。
出力のフォーマット すべてのkubectlコマンドのデフォルトの出力フォーマットは、人間が読みやすいプレーンテキスト形式です。特定のフォーマットで、詳細をターミナルウィンドウに出力するには、サポートされているkubectlコマンドに-oまたは--outputフラグのいずれかを追加します。
構文 kubectl [ command] [ TYPE] [ NAME] -o <output_format>
kubectlの操作に応じて、以下の出力フォーマットがサポートされています。
出力フォーマット 説明 -o custom-columns=<spec>カスタムカラム のコンマ区切りのリストを使用して、テーブルを表示します。-o custom-columns-file=<filename><filename>ファイル内のカスタムカラム のテンプレートを使用して、テーブルを表示します。-o jsonJSON形式のAPIオブジェクトを出力します。 -o jsonpath=<template>jsonpath 式で定義されたフィールドを表示します。-o jsonpath-file=<filename><filename>ファイル内のjsonpath 式で定義されたフィールドを表示します。-o nameリソース名のみを表示します。 -o wide追加情報を含めて、プレーンテキスト形式で出力します。Podの場合は、Node名が含まれます。 -o yamlYAML形式のAPIオブジェクトを出力します。
例 この例において、以下のコマンドは1つのPodの詳細を、YAML形式のオブジェクトとして出力します。
kubectl get pod web-pod-13je7 -o yaml
各コマンドでサポートされている出力フォーマットの詳細については、kubectl リファレンスドキュメントを参照してください。
カスタムカラム カスタムカラムを定義して、必要な詳細のみをテーブルに出力するには、custom-columnsオプションを使います。カスタムカラムをインラインで定義するか、-o custom-columns=<spec>または-o custom-columns-file=<filename>のようにテンプレートファイルを使用するかを選択できます。
例 インラインで定義する例は、以下の通りです。
kubectl get pods <pod-name> -o custom-columns= NAME:.metadata.name,RSRC:.metadata.resourceVersion
テンプレートファイルを使用して定義する例は、以下の通りです。
kubectl get pods <pod-name> -o custom-columns-file= template.txt
ここで、template.txtには以下の内容が含まれます。
NAME RSRC
metadata.name metadata.resourceVersion
どちらのコマンドを実行した場合でも、以下の結果を得ます。
NAME RSRC
submit-queue 610995
サーバーサイドカラム kubectlは、サーバーからオブジェクトに関する特定のカラム情報を受け取ることをサポートしています。
つまり、与えられた任意のリソースについて、サーバーはそのリソースに関連する列や行を返し、クライアントが表示できるようにします。
これにより、サーバーが表示の詳細をカプセル化することで、同一クラスターに対して使用されているクライアント間で、一貫した人間が読みやすい出力が可能です。
この機能は、デフォルトで有効になっています。無効にするには、kubectl getコマンドに--server-print=falseフラグを追加します。
例 Podの状態に関する情報を表示するには、以下のようなコマンドを使用します。
kubectl get pods <pod-name> --server-print= false
以下のように出力されます。
NAME AGE
pod-name 1m
オブジェクトリストのソート ターミナルウィンドウで、オブジェクトをソートされたリストに出力するには、サポートされているkubectlコマンドに--sort-byフラグを追加します。--sort-byフラグで任意の数値フィールドや文字列フィールドを指定することで、オブジェクトをソートします。フィールドの指定には、jsonpath 式を使用します。
構文 kubectl [ command] [ TYPE] [ NAME] --sort-by= <jsonpath_exp>
例 名前でソートしたPodのリストを表示するには、以下のように実行します。
kubectl get pods --sort-by= .metadata.name
例: 一般的な操作 よく使われるkubectlの操作に慣れるために、以下の例を使用してください。
kubectl apply - ファイルや標準出力から、リソースの適用や更新を行います。
# example-service.yaml内の定義を使用して、Serviceを作成します。
kubectl apply -f example-service.yaml
# example-controller.yaml内の定義を使用して、ReplicationControllerを作成します。
kubectl apply -f example-controller.yaml
# <directory>ディレクトリ内の、任意の.yaml、.yml、.jsonファイルで定義されているオブジェクトを作成します。
kubectl apply -f <directory>
kubectl get - 1つ以上のリソースの一覧を表示します。
# すべてのPodの一覧をプレーンテキスト形式で表示します。
kubectl get pods
# すべてのPodの一覧を、ノード名などの追加情報を含めて、プレーンテキスト形式で表示します。
kubectl get pods -o wide
# 指定した名前のReplicationControllerの一覧をプレーンテキスト形式で表示します。'replicationcontroller'リソースタイプを短縮して、エイリアス'rc'で置き換えることもできます。
kubectl get replicationcontroller <rc-name>
# すべてのReplicationControllerとServiceの一覧をまとめてプレーンテキスト形式で表示します。
kubectl get rc,services
# すべてのDaemonSetの一覧をプレーンテキスト形式で表示します。
kubectl get ds
# server01ノードで実行中のPodの一覧をプレーンテキスト形式で表示します。
kubectl get pods --field-selector= spec.nodeName= server01
kubectl describe - 1つ以上のリソースの詳細な状態を、デフォルトでは初期化されないものも含めて表示します。
# Node <node-name>の詳細を表示します。
kubectl describe nodes <node-name>
# Pod <pod-name>の詳細を表示します。
kubectl describe pods/<pod-name>
# ReplicationController <rc-name>が管理しているすべてのPodの詳細を表示します。
# ReplicationControllerによって作成された任意のPodには、ReplicationControllerの名前がプレフィックスとして付与されます。
kubectl describe pods <rc-name>
# すべてのPodの詳細を表示します。
kubectl describe pods
備考: kubectl getコマンドは通常、同じリソースタイプの1つ以上のリソースを取得するために使用します。豊富なフラグが用意されており、例えば-oや--outputフラグを使って、出力フォーマットをカスタマイズできます。-wや--watchフラグを指定することで、特定のオブジェクトの更新を監視できます。kubectl describeコマンドは、指定されたリソースに関する多くの側面を説明することに重点を置いています。ユーザーに対してビューを構築するために、APIサーバーへ複数のAPIコールを呼び出すことができます。例えば、kubectl describe nodeコマンドは、Nodeに関する情報だけでなく、その上で動いているPodやNodeで生成されたイベントなどをまとめて表示します。kubectl delete - ファイル、標準出力、または指定したラベルセレクター、名前、リソースセレクター、リソースを指定して、リソースを削除します。
# pod.yamlファイルで指定されたタイプと名前を用いて、Podを削除します。
kubectl delete -f pod.yaml
# '<label-key>=<label-value>'というラベルを持つPodとServiceをすべて削除します。
kubectl delete pods,services -l <label-key>= <label-value>
# 初期化されていないPodを含む、すべてのPodを削除します。
kubectl delete pods --all
kubectl exec - Pod内のコンテナに対してコマンドを実行します。
# Pod <pod-name>から、'date'を実行している時の出力を取得します。デフォルトでは、最初のコンテナから出力されます。
kubectl exec <pod-name> -- date
# Pod <pod-name>のコンテナ <container-name>から、'date'を実行している時の出力を取得します。
kubectl exec <pod-name> -c <container-name> -- date
# インタラクティブな TTY を取得し、Pod <pod-name>から/bin/bashを実行します。デフォルトでは、最初のコンテナから出力されます。
kubectl exec -ti <pod-name> -- /bin/bash
kubectl logs - Pod内のコンテナのログを表示します。
# Pod <pod-name>のログのスナップショットを返します。
kubectl logs <pod-name>
# Pod <pod-name>から、ログのストリーミングを開始します。Linuxの'tail -f'コマンドと似ています。
kubectl logs -f <pod-name>
kubectl diff - 提案されたクラスターに対する更新の差分を表示します。
# pod.jsonに含まれるリソースの差分を表示します。
kubectl diff -f pod.json
# 標準出力から読み込んだファイルの差分を表示します。
cat service.yaml | kubectl diff -f -
例: プラグインの作成と使用 kubectlプラグインの書き方や使い方に慣れるために、以下の例を使用してください。
# 任意の言語でシンプルなプラグインを作成し、生成される実行可能なファイルに
# プレフィックス"kubectl-"で始まる名前を付けます。
cat ./kubectl-hello
#!/bin/sh
# このプラグインは、"hello world"という単語を表示します。
echo "hello world"
プラグインを書いたら、実行可能にします。
chmod a+x ./kubectl-hello
# さらに、PATH内の場所に移動させます。
sudo mv ./kubectl-hello /usr/local/bin
sudo chown root:root /usr/local/bin
# これでkubectlプラグインを作成し、"インストール"できました。
# 通常のコマンドのようにkubectlから呼び出すことで、プラグインを使用できます。
kubectl hello
hello world
# 配置したPATHのフォルダから削除することで、プラグインを"アンインストール"できます。
sudo rm /usr/local/bin/kubectl-hello
kubectlで利用可能なプラグインをすべて表示するには、kubectl plugin listサブコマンドを使用してください。
出力は以下のようになります。
The following kubectl-compatible plugins are available:
/usr/local/bin/kubectl-hello
/usr/local/bin/kubectl-foo
/usr/local/bin/kubectl-bar
kubectl plugin listコマンドは、実行不可能なプラグインや、他のプラグインの影に隠れてしまっているプラグインなどについて、警告することもできます。例えば、以下のようになります。
sudo chmod -x /usr/local/bin/kubectl-foo # 実行権限を削除します。
kubectl plugin list
The following kubectl-compatible plugins are available:
/usr/local/bin/kubectl-hello
/usr/local/bin/kubectl-foo
- warning: /usr/local/bin/kubectl-foo identified as a plugin, but it is not executable
/usr/local/bin/kubectl-bar
error: one plugin warning was found
プラグインは、既存のkubectlコマンドの上に、より複雑な機能を構築するための手段であると考えることができます。
次の例では、下記の内容を含んだkubectl-whoamiが既に作成済であることを前提としています。
#!/bin/bash
# このプラグインは、`kubectl config`コマンドを使って
# 現在選択されているコンテキストに基づいて、現在のユーザーに関する情報を提供します。
kubectl config view --template= '{{ range .contexts }}{{ if eq .name "' $( kubectl config current-context) '" }}Current user: {{ printf "%s\n" .context.user }}{{ end }}{{ end }}'
上記のコマンドを実行すると、KUBECONFIGファイル内のカレントコンテキストのユーザーを含んだ出力を得られます。
# ファイルを実行可能にします。
sudo chmod +x ./kubectl-whoami
# さらに、ファイルをPATHに移動します。
sudo mv ./kubectl-whoami /usr/local/bin
kubectl whoami
Current user: plugins-user
次の項目 6.8.1 - kubectlチートシート このページには、一般的によく使われるkubectlコマンドとフラグのリストが含まれています。
Kubectlコマンドの補完 BASH source <( kubectl completion bash) # 現在のbashシェルにコマンド補完を設定するには、最初にbash-completionパッケージをインストールする必要があります。
echo "source <(kubectl completion bash)" >> ~/.bashrc # bashシェルでのコマンド補完を永続化するために.bashrcに追記します。
また、エイリアスを使用している場合にもkubectlコマンドを補完できます。
alias k = kubectl
complete -F __start_kubectl k
ZSH source <( kubectl completion zsh) # 現在のzshシェルにコマンド補完を設定します
echo "[[ $commands [kubectl] ]] && source <(kubectl completion zsh)" >> ~/.zshrc # zshシェルでのコマンド補完を永続化するために.zshrcに追記します。
Kubectlコンテキストの設定 kubectlがどのKubernetesクラスターと通信するかを設定します。
設定ファイル詳細についてはkubeconfigを使用した複数クラスターとの認証 をご覧ください。
kubectl config view # マージされたkubeconfigの設定を表示します。
# 複数のkubeconfigファイルを同時に読み込む場合はこのように記述します。
KUBECONFIG = ~/.kube/config:~/.kube/kubconfig2
kubectl config view
# e2eユーザのパスワードを取得します。
kubectl config view -o jsonpath = '{.users[?(@.name == "e2e")].user.password}'
kubectl config view -o jsonpath = '{.users[].name}' # 最初のユーザー名を表示します
kubectl config view -o jsonpath = '{.users[*].name}' # ユーザー名のリストを表示します
kubectl config get-contexts # コンテキストのリストを表示します
kubectl config current-context # 現在のコンテキストを表示します
kubectl config use-context my-cluster-name # デフォルトのコンテキストをmy-cluster-nameに設定します
# basic認証をサポートする新たなユーザーをkubeconfigに追加します
kubectl config set-credentials kubeuser/foo.kubernetes.com --username= kubeuser --password= kubepassword
# 現在のコンテキストでkubectlのサブコマンドの名前空間を永続的に変更します
kubectl config set-context --current --namespace= ggckad-s2
# 特定のユーザー名と名前空間を使用してコンテキストを設定します
kubectl config set-context gce --user= cluster-admin --namespace= foo \
&& kubectl config use-context gce
kubectl config unset users.foo # ユーザーfooを削除します
Kubectl Apply applyはKubernetesリソースを定義するファイルを通じてアプリケーションを管理します。kubectl applyを実行して、クラスター内のリソースを作成および更新します。これは、本番環境でKubernetesアプリケーションを管理する推奨方法です。
詳しくはKubectl Book をご覧ください。
Objectの作成 Kubernetesのマニフェストファイルは、JSONまたはYAMLで定義できます。ファイル拡張子として、.yamlや.yml、.jsonが使えます。
kubectl apply -f ./my-manifest.yaml # リソースを作成します
kubectl apply -f ./my1.yaml -f ./my2.yaml # 複数のファイルからリソースを作成します
kubectl apply -f ./dir # dirディレクトリ内のすべてのマニフェストファイルからリソースを作成します
kubectl apply -f https://git.io/vPieo # urlで公開されているファイルからリソースを作成します
kubectl create deployment nginx --image= nginx # 単一のnginx Deploymentを作成します
kubectl explain pods # Podマニフェストのドキュメントを取得します
# 標準入力から複数のYAMLオブジェクトを作成します
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: busybox-sleep
spec:
containers:
- name: busybox
image: busybox
args:
- sleep
- "1000000"
---
apiVersion: v1
kind: Pod
metadata:
name: busybox-sleep-less
spec:
containers:
- name: busybox
image: busybox
args:
- sleep
- "1000"
EOF
# いくつかの鍵を含むSecretを作成します
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
password: $(echo -n "s33msi4" | base64 -w0)
username: $(echo -n "jane" | base64 -w0)
EOF
リソースの検索と閲覧 # Getコマンドで基本的な情報を確認します
kubectl get services # 現在の名前空間上にあるすべてのサービスのリストを表示します
kubectl get pods --all-namespaces # すべての名前空間上にあるすべてのPodのリストを表示します
kubectl get pods -o wide # 現在の名前空間上にあるすべてのPodについてより詳細なリストを表示します
kubectl get deployment my-dep # 特定のDeploymentを表示します
kubectl get pods # 現在の名前空間上にあるすべてのPodのリストを表示します
kubectl get pod my-pod -o yaml # PodのYAMLを表示します
# Describeコマンドで詳細な情報を確認します
kubectl describe nodes my-node
kubectl describe pods my-pod
# 名前順にソートしたServiceのリストを表示します
kubectl get services --sort-by= .metadata.name
# Restartカウント順にPodのリストを表示します
kubectl get pods --sort-by= '.status.containerStatuses[0].restartCount'
# capacity順にソートしたPersistentVolumeのリストを表示します
kubectl get pv --sort-by= .spec.capacity.storage
# app=cassandraラベルのついたすべてのPodのversionラベルを表示します
kubectl get pods --selector= app = cassandra -o \
jsonpath = '{.items[*].metadata.labels.version}'
# 'ca.crt'のようなピリオドが含まれるキーの値を取得します
kubectl get configmap myconfig \
jsonpath = '{.data.ca\.crt}'
# すべてのワーカーノードを取得します(セレクターを使用して、
# 「node-role.kubernetes.io/master」という名前のラベルを持つ結果を除外します)
kubectl get node --selector= '!node-role.kubernetes.io/master'
# 現在の名前空間でrunning状態のPodのリストを表示します
kubectl get pods --field-selector= status.phase= Running
# すべてのノードのExternal IPのリストを表示します
kubectl get nodes -o jsonpath = '{.items[*].status.addresses[?(@.type=="ExternalIP")].address}'
# 特定のRCに属するPodの名前のリストを表示します
# `jq`コマンドは複雑なjsonpathを変換する場合に便利であり、https://stedolan.github.io/jq/で見つけることが可能です
sel = ${ $( kubectl get rc my-rc --output= json | jq -j '.spec.selector | to_entries | .[] | "\(.key)=\(.value),"' ) %?}
echo $( kubectl get pods --selector= $sel --output= jsonpath ={ .items..metadata.name} )
# すべてのPod(またはラベル付けをサポートする他のKubernetesオブジェクト)のラベルのリストを表示します
kubectl get pods --show-labels
# どのノードがready状態か確認します
JSONPATH = '{range .items[*]}{@.metadata.name}:{range @.status.conditions[*]}{@.type}={@.status};{end}{end}' \
&& kubectl get nodes -o jsonpath = " $JSONPATH " | grep "Ready=True"
# Podで現在使用中のSecretをすべて表示します
kubectl get pods -o json | jq '.items[].spec.containers[].env[]?.valueFrom.secretKeyRef.name' | grep -v null | sort | uniq
# すべてのPodのInitContainerのコンテナIDのリストを表示します
# initContainerの削除を回避しながら、停止したコンテナを削除するときに役立つでしょう
kubectl get pods --all-namespaces -o jsonpath = '{range .items[*].status.initContainerStatuses[*]}{.containerID}{"\n"}{end}' | cut -d/ -f3
# タイムスタンプでソートされたEventのリストを表示します
kubectl get events --sort-by= .metadata.creationTimestamp
# クラスターの現在の状態を、マニフェストが適用された場合のクラスターの状態と比較します。
kubectl diff -f ./my-manifest.yaml
# Nodeから返されるすべてのキーをピリオド区切りの階層表記で生成します。
# 複雑にネストされたJSON構造をもつキーを指定したい時に便利です
kubectl get nodes -o json | jq -c 'paths|join(".")'
# Pod等から返されるすべてのキーをピリオド区切り階層表記で生成します。
kubectl get pods -o json | jq -c 'paths|join(".")'
リソースのアップデート kubectl set image deployment/frontend www = image:v2 # frontend Deploymentのwwwコンテナイメージをv2にローリングアップデートします
kubectl rollout history deployment/frontend # frontend Deploymentの改訂履歴を確認します
kubectl rollout undo deployment/frontend # 1つ前のDeploymentにロールバックします
kubectl rollout undo deployment/frontend --to-revision= 2 # 特定のバージョンにロールバックします
kubectl rollout status -w deployment/frontend # frontend Deploymentのローリングアップデートを状態をwatchします
kubectl rollout restart deployment/frontend # frontend Deployment を再起動します
cat pod.json | kubectl replace -f - # 標準入力から渡されたJSONに基づいてPodを置き換えます
# リソースを強制的に削除してから再生成し、置き換えます。サービスの停止が発生します
kubectl replace --force -f ./pod.json
# ReplicaSetリソースで作られたnginxについてServiceを作成します。これは、ポート80で提供され、コンテナへはポート8000で接続します
kubectl expose rc nginx --port= 80 --target-port= 8000
# 単一コンテナのPodイメージのバージョン(タグ)をv4に更新します
kubectl get pod mypod -o yaml | sed 's/\(image: myimage\):.*$/\1:v4/' | kubectl replace -f -
kubectl label pods my-pod new-label= awesome # ラベルを追加します
kubectl annotate pods my-pod icon-url= http://goo.gl/XXBTWq # アノテーションを追加します
kubectl autoscale deployment foo --min= 2 --max= 10 # "foo" Deploymentのオートスケーリングを行います
リソースへのパッチ適用 # ノードを部分的に更新します
kubectl patch node k8s-node-1 -p '{"spec":{"unschedulable":true}}'
# コンテナのイメージを更新します。spec.containers[*].nameはマージキーであるため必須です
kubectl patch pod valid-pod -p '{"spec":{"containers":[{"name":"kubernetes-serve-hostname","image":"new image"}]}}'
# ポテンシャル配列を含むJSONパッチを使用して、コンテナのイメージを更新します
kubectl patch pod valid-pod --type= 'json' -p= '[{"op": "replace", "path": "/spec/containers/0/image", "value":"new image"}]'
# ポテンシャル配列のJSONパッチを使用してDeploymentのlivenessProbeを無効にします
kubectl patch deployment valid-deployment --type json -p= '[{"op": "remove", "path": "/spec/template/spec/containers/0/livenessProbe"}]'
# ポテンシャル配列に新たな要素を追加します
kubectl patch sa default --type= 'json' -p= '[{"op": "add", "path": "/secrets/1", "value": {"name": "whatever" } }]'
リソースの編集 任意のエディターでAPIリソースを編集します。
kubectl edit svc/docker-registry # docker-registryという名前のサービスを編集します
KUBE_EDITOR = "nano" kubectl edit svc/docker-registry # エディターを指定します
リソースのスケーリング kubectl scale --replicas= 3 rs/foo # 「foo」という名前のレプリカセットを3にスケーリングします
kubectl scale --replicas= 3 -f foo.yaml # 「foo.yaml」で指定されたリソースを3にスケーリングします
kubectl scale --current-replicas= 2 --replicas= 3 deployment/mysql # mysqlと名付けられたdeploymentの現在のサイズが2であれば、mysqlを3にスケーリングします
kubectl scale --replicas= 5 rc/foo rc/bar rc/baz # 複数のReplication controllerをスケーリングします
リソースの削除 kubectl delete -f ./pod.json # pod.jsonで指定されたタイプと名前を使用してPodを削除します
kubectl delete pod,service baz foo # 「baz」と「foo」の名前を持つPodとServiceを削除します
kubectl delete pods,services -l name = myLabel # name=myLabelラベルを持つのPodとServiceを削除します
kubectl -n my-ns delete pod,svc --all # 名前空間my-ns内のすべてのPodとServiceを削除します
# awkコマンドのpattern1またはpattern2に一致するすべてのPodを削除します。
kubectl get pods -n mynamespace --no-headers= true | awk '/pattern1|pattern2/{print $1}' | xargs kubectl delete -n mynamespace pod
実行中のポッドとの対話処理 kubectl logs my-pod # Podのログをダンプします(標準出力)
kubectl logs -l name = myLabel # name=myLabelラベルの持つPodのログをダンプします(標準出力)
kubectl logs my-pod --previous # 以前に存在したコンテナのPodログをダンプします(標準出力)
kubectl logs my-pod -c my-container # 複数コンテナがあるPodで、特定のコンテナのログをダンプします(標準出力)
kubectl logs -l name = myLabel -c my-container # name=mylabelラベルを持つPodのログをダンプします(標準出力)
kubectl logs my-pod -c my-container --previous # 複数コンテナがあるPodで、以前に作成した特定のコンテナのログをダンプします(標準出力)
kubectl logs -f my-pod # Podのログをストリームで確認します(標準出力)
kubectl logs -f my-pod -c my-container # 複数のコンテナがあるPodで、特定のコンテナのログをストリームで確認します(標準出力)
kubectl logs -f -l name = myLabel --all-containers # name-myLabelラベルを持つすべてのコンテナのログをストリームで確認します(標準出力)
kubectl run -i --tty busybox --image= busybox -- sh # Podをインタラクティブシェルとして実行します
kubectl run nginx --image= nginx -n
mynamespace # 特定の名前空間でnginx Podを実行します
kubectl run nginx --image= nginx # nginx Podを実行し、マニフェストファイルをpod.yamlという名前で書き込みます
--dry-run= client -o yaml > pod.yaml
kubectl attach my-pod -i # 実行中のコンテナに接続します
kubectl port-forward my-pod 5000:6000 # ローカルマシンのポート5000を、my-podのポート6000に転送します
kubectl exec my-pod -- ls / # 既存のPodでコマンドを実行(単一コンテナの場合)
kubectl exec my-pod -c my-container -- ls / # 既存のPodでコマンドを実行(複数コンテナがある場合)
kubectl top pod POD_NAME --containers # 特定のPodとそのコンテナのメトリクスを表示します
ノードおよびクラスターとの対話処理 kubectl cordon my-node # my-nodeをスケジューリング不能に設定します
kubectl drain my-node # メンテナンスの準備としてmy-nodeで動作中のPodを空にします
kubectl uncordon my-node # my-nodeをスケジューリング可能に設定します
kubectl top node my-node # 特定のノードのメトリクスを表示します
kubectl cluster-info # Kubernetesクラスターのマスターとサービスのアドレスを表示します
kubectl cluster-info dump # 現在のクラスター状態を標準出力にダンプします
kubectl cluster-info dump --output-directory= /path/to/cluster-state # 現在のクラスター状態を/path/to/cluster-stateにダンプします
# special-userキーとNoScheduleエフェクトを持つTaintがすでに存在する場合、その値は指定されたとおりに置き換えられます
kubectl taint nodes foo dedicated = special-user:NoSchedule
リソースタイプ サポートされているすべてのリソースタイプを、それらがAPI group かNamespaced 、Kind に関わらずその短縮名をリストします。
APIリソースを探索するためのその他の操作:
kubectl api-resources --namespaced= true # 名前空間付きのすべてのリソースを表示します
kubectl api-resources --namespaced= false # 名前空間のないすべてのリソースを表示します
kubectl api-resources -o name # すべてのリソースを単純な出力(リソース名のみ)で表示します
kubectl api-resources -o wide # すべてのリソースを拡張された形(別名 "wide")で表示します
kubectl api-resources --verbs= list,get # "list"および"get"操作をサポートするすべてのリソースを表示します
kubectl api-resources --api-group= extensions # "extensions" APIグループのすべてのリソースを表示します
出力のフォーマット 特定の形式で端末ウィンドウに詳細を出力するには、サポートされているkubectlコマンドに-o(または--output)フラグを追加します。
出力フォーマット 説明 -o=custom-columns=<spec>コンマ区切りされたカスタムカラムのリストを指定してテーブルを表示します -o=custom-columns-file=<filename><filename>ファイル内のカスタムカラムテンプレートを使用してテーブルを表示します-o=jsonJSON形式のAPIオブジェクトを出力します -o=jsonpath=<template>jsonpath 式で定義されたフィールドを出力します-o=jsonpath-file=<filename><filename>ファイル内のjsonpath 式で定義されたフィールドを出力します-o=nameリソース名のみを出力し、それ以外は何も出力しません。 -o=wide追加の情報を含むプレーンテキスト形式で出力します。Podの場合、Node名が含まれます。 -o=yamlYAML形式のAPIオブジェクトを出力します
-o=custom-columnsを使用したサンプル:
# クラスター内で実行中のすべてのイメージ名を表示する
kubectl get pods -A -o= custom-columns= 'DATA:spec.containers[*].image'
# "registry.k8s.io/coredns:1.6.2"を除いたすべてのイメージ名を表示する
kubectl get pods -A -o= custom-columns= 'DATA:spec.containers[?(@.image!="registry.k8s.io/coredns:1.6.2")].image'
# 名前に関係なくmetadata以下のすべてのフィールドを表示する
kubectl get pods -A -o= custom-columns= 'DATA:metadata.*'
kubectlに関するより多くのサンプルはカスタムカラムのリファレンス を参照してください。
Kubectlのログレベルとデバッグ kubectlのログレベルは、レベルを表す整数が後に続く-vまたは--vフラグで制御されます。一般的なKubernetesのログ記録規則と関連するログレベルについて、こちら で説明します。
ログレベル 説明 --v=0これは、クラスターオペレーターにログレベルが0であることを"常に"見えるようにするために役立ちます --v=1ログレベルが必要ない場合に、妥当なデフォルトのログレベルです --v=2サービスに関する重要な定常状態情報と、システムの重要な変更に関連する可能性がある重要なログメッセージを表示します。 これは、ほとんどのシステムで推奨されるデフォルトのログレベルです。 --v=3変更に関するより詳細なログレベルを表示します --v=4デバックにむいたログレベルで表示します --v=6要求されたリソースを表示します --v=7HTTPリクエストのヘッダを表示します --v=8HTTPリクエストのコンテンツを表示します --v=9HTTPリクエストのコンテンツをtruncationなしで表示します
次の項目 6.8.2 - kubectl Synopsis kubectlは、Kubernetesクラスターマネージャーを制御するコマンドラインツールです。
詳細は以下をご覧ください:
https://kubernetes.io/ja/docs/reference/kubectl/
kubectl [flags]
Options --as string この操作を実行する際に偽装するユーザー名を指定します。ユーザーには、通常のユーザーまたは名前空間内のサービスアカウントを指定できます。
--as-group strings この操作で偽装するグループを指定します。複数のグループを指定する場合は、このフラグを繰り返し使用できます。
--as-uid string この操作で偽装するUIDを指定します。
--cache-dir string Default: "$HOME/.kube/cache" デフォルトのキャッシュディレクトリ
--certificate-authority string 証明書の検証に使用する証明機関の証明書ファイルへのパス
--client-certificate string TLSで使用するクライアント証明書ファイルへのパス
--client-key string TLSで使用するクライアントキーのファイルへのパス
--cluster string 使用するkubeconfigのクラスター名
--context string 使用するkubeconfigのコンテキスト名
--disable-compression trueにすると、サーバーへのすべてのリクエストに対するレスポンス圧縮を無効にします
-h, --help kubectlのヘルプを表示します
--insecure-skip-tls-verify trueにすると、サーバー証明書の有効性を検証しません。この設定により、HTTPS接続の安全性は損なわれます
--kubeconfig string CLIリクエストで使用するkubeconfigファイルのパス
--kuberc string 設定に使用するkubercファイルへのパス。この機能は、KUBECTL_KUBERC=false、またはKUBERC=offの環境変数を設定し、エクスポートすることで無効化できます。
--match-server-version クライアントバージョンとサーバーバージョンが一致することを要求します
-n, --namespace string このCLIリクエストの名前空間スコープ(指定されている場合)
--password string APIサーバーへのBasic認証に使用するパスワード
--profile string Default: "none" 取得対象のプロファイル名(none|cpu|heap|goroutine|threadcreate|block|mutex)のいずれか
--profile-output string Default: "profile.pprof" プロファイルの出力先ファイル名
--request-timeout string Default: "0" 単一のサーバーリクエストに対して待機する最大時間。0以外の値には時間単位(例: 1s、2m、3h)を含める必要があります。0を指定した場合はタイムアウトしません。
-s, --server string Kubernetes APIサーバーのアドレスとポート
--storage-driver-buffer-duration duration Default: 1m0s ストレージドライバーへの書き込みはこの期間バッファリングされ、メモリ以外のバックエンドへは単一トランザクションとしてコミットされます
--storage-driver-db string Default: "cadvisor" データベース名
--storage-driver-host string Default: "localhost:8086" データベースのホスト名とポート(host:port)
--storage-driver-password string Default: "root" データベースのパスワード
--storage-driver-secure データベースとの接続でセキュア接続を使用します
--storage-driver-table string Default: "stats" テーブル名
--storage-driver-user string Default: "root" データベースのユーザー名
--tls-server-name string サーバー証明書の検証に使用するサーバー名。指定しない場合は、接続先のホスト名が使用されます
--token string APIサーバーへの認証に使用するBearerトークン
--user string 使用するkubeconfigのユーザー名
--username string APIサーバーへのBasic認証に使用するユーザー名
--version version[=true] --versionまたは--version=rawを指定すると、バージョン情報を表示して終了します。--version=vX.Y.Z...の形式で指定すると、出力されるバージョンを設定できます
--warnings-as-errors サーバーから受信した警告をエラーとして扱い、非ゼロの終了コードで終了します
See Also 6.8.3 - JSONPathのサポート kubectlはJSONPathのテンプレートをサポートしています。
JSONPathのテンプレートは、波括弧{}によって囲まれたJSONPathの式によって構成されています。
kubectlでは、JSONPathの式を使うことで、JSONオブジェクトの特定のフィールドをフィルターしたり、出力のフォーマットを変更することができます。
本来のJSONPathのテンプレートの構文に加え、以下の機能と構文が使えます:
JSONPathの式の内部でテキストをクォートするために、ダブルクォーテーションを使用します。 リストを反復するために、range、endオペレーターを使用します。 リストを末尾側から参照するために、負の数のインデックスを使用します。負の数のインデックスはリストを「周回」せず、-index + listLength >= 0が満たされる限りにおいて有効になります。 以下のようなJSONの入力が与えられたとします。
{
"kind" : "List" ,
"items" :[
{
"kind" :"None" ,
"metadata" :{"name" :"127.0.0.1" },
"status" :{
"capacity" :{"cpu" :"4" },
"addresses" :[{"type" : "LegacyHostIP" , "address" :"127.0.0.1" }]
}
},
{
"kind" :"None" ,
"metadata" :{"name" :"127.0.0.2" },
"status" :{
"capacity" :{"cpu" :"8" },
"addresses" :[
{"type" : "LegacyHostIP" , "address" :"127.0.0.2" },
{"type" : "another" , "address" :"127.0.0.3" }
]
}
}
],
"users" :[
{
"name" : "myself" ,
"user" : {}
},
{
"name" : "e2e" ,
"user" : {"username" : "admin" , "password" : "secret" }
}
]
}
機能 説明 例 結果 textプレーンテキスト kind is {.kind}kind is List@現在のオブジェクト {@}入力した値と同じ値 . or []子要素 {.kind}, {['kind']} or {['name\.type']}List..子孫要素を再帰的に探す {..name}127.0.0.1 127.0.0.2 myself e2e*ワイルドカード。すべてのオブジェクトを取得する {.items[*].metadata.name}[127.0.0.1 127.0.0.2][start:end:step]添字 {.users[0].name}myself[,]和集合 {.items[*]['metadata.name', 'status.capacity']}127.0.0.1 127.0.0.2 map[cpu:4] map[cpu:8]?()フィルター {.users[?(@.name=="e2e")].user.password}secretrange, endリストの反復 {range .items[*]}[{.metadata.name}, {.status.capacity}] {end}[127.0.0.1, map[cpu:4]] [127.0.0.2, map[cpu:8]]''解釈済みの文字列をクォートする {range .items[*]}{.metadata.name}{'\t'}{end}127.0.0.1 127.0.0.2
kubectlとJSONPathの式を使った例:
kubectl get pods -o json
kubectl get pods -o= jsonpath = '{@}'
kubectl get pods -o= jsonpath = '{.items[0]}'
kubectl get pods -o= jsonpath = '{.items[0].metadata.name}'
kubectl get pods -o= jsonpath = "{.items[*]['metadata.name', 'status.capacity']}"
kubectl get pods -o= jsonpath = '{range .items[*]}{.metadata.name}{"\t"}{.status.startTime}{"\n"}{end}'
備考: Windowsでは、空白が含まれるJSONPathのテンプレートをクォートする場合は(上記のようにシングルクォーテーションを使うのではなく)、ダブルクォーテーションを使わなければなりません。
また、テンプレート内のリテラルをクォートする際には、シングルクォーテーションか、エスケープされたダブルクォーテーションを使わなければなりません。例えば:
kubectl get pods -o=jsonpath="{range .items[*]}{.metadata.name}{'\t'}{.status.startTime}{'\n'}{end}"
kubectl get pods -o=jsonpath="{range .items[*]}{.metadata.name}{\" \t\"}{.status.startTime}{\" \n\"}{end}"
備考: JSONPathの正規表現はサポートされていません。正規表現を利用した検索を行いたい場合は、jqのようなツールを使ってください。
# kubectlはJSONpathの出力として正規表現をサポートしていないので、以下のコマンドは動作しない
kubectl get pods -o jsonpath = '{.items[?(@.metadata.name=~/^test$/)].metadata.name}'
# 上のコマンドに期待される結果が欲しい場合、以下のコマンドを使うとよい
kubectl get pods -o json | jq -r '.items[] | select(.metadata.name | test("test-")).metadata.name'
6.8.4 - kubectlの使用規則 kubectlの推奨される使用規則です。
再利用可能なスクリプトでのkubectlの使用 スクリプトでの安定した出力のために:
-o name, -o json, -o yaml, -o go-template, -o jsonpath などの機械指向の出力形式のいずれかを必要します。バージョンを完全に指定します。例えば、jobs.v1.batch/myjobのようにします。これにより、kubectlが時間とともに変化する可能性のあるデフォルトのバージョンを使用しないようにします。 コンテキストや設定、その他の暗黙的な状態に頼ってはいけません。 ベストプラクティス kubectl runkubectl runがインフラのコード化を満たすために:
イメージにバージョン固有のタグを付けて、そのタグを新しいバージョンに移さない。例えば、:latestではなく、:v1234、v1.2.3、r03062016-1-4を使用してください(詳細は、Best Practices for Configuration を参照してください)。 パラメーターが多用されているイメージをスクリプトでチェックします。 kubectl run フラグでは表現できない機能を、ソースコントロールでチェックした設定ファイルに切り替えます。dry-run=client フラグを使用すると、実際に送信することなく、クラスターに送信されるオブジェクトを確認することができます。
備考: すべての
kubectl runジェネレーターは非推奨です。ジェネレーターの
リスト とその使用方法については、Kubernetes v1.17のドキュメントを参照してください。
Generators kubectl create --dry-run=client -o yamlというkubectlコマンドで以下のリソースを生成することができます。
clusterrole: ClusterRoleを作成します。clusterrolebinding: 特定のClusterRoleに対するClusterRoleBindingを作成します。configmap: ローカルファイル、ディレクトリ、またはリテラル値からConfigMapを作成します。cronjob: 指定された名前のCronJobを作成します。deployment: 指定された名前でDeploymentを作成します。job: 指定された名前でJobを作成します。namespace: 指定された名前でNamespaceを作成します。poddisruptionbudget: 指定された名前でPodDisruptionBudgetを作成します。priorityclass: 指定された名前でPriorityClassを作成します。quota: 指定された名前でQuotaを作成します。role: 1つのルールでRoleを作成します。rolebinding: 特定のロールやClusterRoleに対するRoleBindingを作成します。secret: 指定されたサブコマンドを使用してSecretを作成します。service: 指定されたサブコマンドを使用してServiceを作成します。ServiceAccount: 指定された名前でServiceAccountを作成します。kubectl applyリソースの作成や更新には kubectl apply を使用できます。kubectl applyを使ったリソースの更新については、Kubectl Book を参照してください。
6.9 - コマンドラインツールのリファレンス 6.9.2 - Kubelet 認証/認可 概要 kubeletのHTTPSエンドポイントは、さまざまな感度のデータへのアクセスを提供するAPIを公開し、
ノードとコンテナ内のさまざまなレベルの権限でタスクを実行できるようにします。
このドキュメントでは、kubeletのHTTPSエンドポイントへのアクセスを認証および承認する方法について説明します。
Kubelet 認証 デフォルトでは、他の構成済み認証方法によって拒否されないkubeletのHTTPSエンドポイントへのリクエストは
匿名リクエストとして扱われ、ユーザー名はsystem:anonymous、
グループはsystem:unauthenticatedになります。
匿名アクセスを無効にし、認証されていないリクエストに対して401 Unauthorized応答を送信するには:
--anonymous-auth=falseフラグでkubeletを開始します。kubeletのHTTPSエンドポイントに対するX509クライアント証明書認証を有効にするには:
--client-ca-fileフラグでkubeletを起動し、クライアント証明書を確認するためのCAバンドルを提供します。--kubelet-client-certificateおよび--kubelet-client-keyフラグを使用してapiserverを起動します。詳細については、apiserver認証ドキュメント を参照してください。 APIベアラートークン(サービスアカウントトークンを含む)を使用して、kubeletのHTTPSエンドポイントへの認証を行うには:
APIサーバーでauthentication.k8s.io/v1beta1グループが有効になっていることを確認します。 --authentication-token-webhookおよび--kubeconfigフラグを使用してkubeletを開始します。kubeletは、構成済みのAPIサーバーで TokenReview APIを呼び出して、ベアラートークンからユーザー情報を判別します。 Kubelet 承認 認証に成功した要求(匿名要求を含む)はすべて許可されます。デフォルトの認可モードは、すべての要求を許可するAlwaysAllowです。
kubelet APIへのアクセスを細分化するのは、次のような多くの理由が考えられます:
匿名認証は有効になっていますが、匿名ユーザーがkubeletのAPIを呼び出す機能は制限する必要があります。 ベアラートークン認証は有効になっていますが、kubeletのAPIを呼び出す任意のAPIユーザー(サービスアカウントなど)の機能を制限する必要があります。 クライアント証明書の認証は有効になっていますが、構成されたCAによって署名されたクライアント証明書の一部のみがkubeletのAPIの使用を許可されている必要があります。 kubeletのAPIへのアクセスを細分化するには、APIサーバーに承認を委任します:
APIサーバーでauthorization.k8s.io/v1beta1 APIグループが有効になっていることを確認します。 --authorization-mode=Webhookと--kubeconfigフラグでkubeletを開始します。kubeletは、構成されたAPIサーバーでSubjectAccessReview APIを呼び出して、各リクエストが承認されているかどうかを判断します。 kubeletは、apiserverと同じリクエスト属性 アプローチを使用してAPIリクエストを承認します。
動詞は、受けとったリクエストのHTTP動詞から決定されます:
HTTP動詞 要求 動詞 POST create GET, HEAD get PUT update PATCH patch DELETE delete
リソースとサブリソースは、受けとったリクエストのパスから決定されます:
Kubelet API リソース サブリソース /stats/* nodes stats /metrics/* nodes metrics /logs/* nodes log /spec/* nodes spec all others nodes proxy
名前空間とAPIグループの属性は常に空の文字列であり、
リソース名は常にkubeletのNode APIオブジェクトの名前です。
このモードで実行する場合は、apiserverに渡される--kubelet-client-certificateフラグと--kubelet-client-key
フラグで識別されるユーザーが次の属性に対して許可されていることを確認します:
verb=*, resource=nodes, subresource=proxy verb=*, resource=nodes, subresource=stats verb=*, resource=nodes, subresource=log verb=*, resource=nodes, subresource=spec verb=*, resource=nodes, subresource=metrics
6.10 - Scheduling 6.10.1 - スケジューラーの設定 FEATURE STATE:
Kubernetes v1.19 [beta]
設定ファイルを作成し、そのパスをコマンドライン引数として渡すことでkube-schedulerの振る舞いをカスタマイズすることができます。
スケジューリングプロファイルは、kube-scheduler でスケジューリングの異なるステージを設定することができます。
各ステージは、拡張点に公開されています。プラグインをそれらの拡張点に1つ以上実装することで、スケジューリングの振る舞いを変更できます。
KubeSchedulerConfiguration(v1beta2v1beta3kube-scheduler --config <filename>を実行することで、スケジューリングプロファイルを指定することができます。
最小限の設定は次の通りです。
apiVersion : kubescheduler.config.k8s.io/v1beta2
kind : KubeSchedulerConfiguration
clientConnection :
kubeconfig : /etc/srv/kubernetes/kube-scheduler/kubeconfig
プロファイル スケジューリングプロファイルは、kube-scheduler でスケジューリングの異なるステージを設定することができます。
各ステージは拡張点 に公開されています。
プラグイン をそれらの拡張点に1つ以上実装することで、スケジューリングの振る舞いを変更できます。
単一のkube-schedulerインスタンスで複数のプロファイル を実行するように設定することも可能です。
拡張点 スケジューリングは一連のステージで行われ、以下の拡張点に公開されています。
queueSort: これらのプラグインは、スケジューリングキューにあるpending状態のPodをソートするための順序付け関数を提供します。同時に有効化できるプラグインは1つだけです。preFilter: これらのプラグインは、フィルタリングをする前にPodやクラスターの情報のチェックや前処理のために使用されます。これらのプラグインは、設定された順序で呼び出されます。filter: これらのプラグインは、スケジューリングポリシーにおけるPredicatesに相当するもので、Podの実行不可能なNodeをフィルターするために使用されます。もし全てのNodeがフィルターされてしまった場合、Podはunschedulableとしてマークされます。postFilter:これらのプラグインは、Podの実行可能なNodeが見つからなかった場合、設定された順序で呼び出されます。もしpostFilterプラグインのいずれかが、Podを スケジュール可能 とマークした場合、残りのpostFilterプラグインは呼び出されません。preScore: これは、スコアリング前の作業を行う際に使用できる情報提供のための拡張点です。score: これらのプラグインはフィルタリングフェーズを通過してきたそれぞれのNodeに対してスコア付けを行います。その後スケジューラーは、最も高い重み付きスコアの合計を持つノードを選択します。reserve: これは、指定されたPodのためにリソースが予約された際に、プラグインに通知する、情報提供のための拡張点です。また、プラグインはReserve中に失敗した際、またはReserveの後に呼び出されるUnreserveも実装しています。permit: これらのプラグインではPodのバインディングを拒む、または遅延させることができます。preBind: これらのプラグインは、Podがバインドされる前に必要な処理を実行できます。bind: これらのプラグインはPodをNodeにバインドします。bindプラグインは順番に呼び出され、1つのプラグインがバインドを完了すると、残りのプラグインはスキップされます。bindプラグインは少なくとも1つは必要です。postBind: これは、Podがバインドされた後に呼び出される情報提供のための拡張点です。multiPoint: このフィールドは設定のみ可能で、プラグインが適用されるすべての拡張点に対して同時に有効化または無効化することができます。次の例のように、それぞれの拡張点に対して、特定のデフォルトプラグイン を無効化、または自作のプラグインを有効化することができます。
apiVersion : kubescheduler.config.k8s.io/v1beta2
kind : KubeSchedulerConfiguration
profiles :
- plugins :
score :
disabled :
- name : PodTopologySpread
enabled :
- name : MyCustomPluginA
weight : 2
- name : MyCustomPluginB
weight : 1
disabled配列のnameフィールドに*を使用することで、その拡張点の全てのデフォルトプラグインを無効化できます。また、必要に応じてプラグインの順序を入れ替える場合にも使用されます。
Scheduling plugins 以下のプラグインはデフォルトで有効化されており、1つ以上の拡張点に実装されています。
また、コンポーネント設定のAPIにより、以下のプラグインを有効にすることができます。
デフォルトでは有効になっていません。
複数のプロファイル kube-schedulerは複数のプロファイルを実行するように設定することができます。
各プロファイルは関連するスケジューラー名を持ち、その拡張点 に異なるプラグインを設定することが可能です。
以下のサンプル設定では、スケジューラーは2つのプロファイルで実行されます。1つはデフォルトプラグインで、もう1つはすべてのスコアリングプラグインを無効にしたものです。
apiVersion : kubescheduler.config.k8s.io/v1beta2
kind : KubeSchedulerConfiguration
profiles :
- schedulerName : default-scheduler
- schedulerName : no -scoring-scheduler
plugins :
preScore :
disabled :
- name : '*'
score :
disabled :
- name : '*'
特定のプロファイルに従ってスケジュールさせたいPodは、その.spec.schedulerNameに、対応するスケジューラー名を含めることができます。
デフォルトでは、スケジューラー名default-schedulerとしてプロファイルが生成されます。
このプロファイルは、上記のデフォルトプラグインを含みます。複数のプロファイルを宣言する場合は、それぞれユニークなスケジューラー名にする必要があります。
もしPodがスケジューラー名を指定しない場合、kube-apiserverはdefault-schedulerを設定します。
従って、これらのPodをスケジュールするために、このスケジューラー名を持つプロファイルが存在する必要があります。
備考: Podのスケジューリングイベントには、ReportingControllerとして.spec.schedulerNameが設定されています。
リーダー選出のイベントには、リスト先頭のプロファイルのスケジューラー名が使用されます。
備考: すべてのプロファイルは、queueSort拡張点で同じプラグインを使用し、同じ設定パラメーターを持つ必要があります (該当する場合)。これは、pending状態のPodキューがスケジューラーに1つしかないためです。複数の拡張点に適用されるプラグイン kubescheduler.config.k8s.io/v1beta3からは、プロファイル設定にmultiPointというフィールドが追加され、複数の拡張点でプラグインを簡単に有効・無効化できるようになりました。
multiPoint設定の目的は、カスタムプロファイルを使用する際に、ユーザーや管理者が必要とする設定を簡素化することです。
MyPluginというプラグインがあり、preScore、score、preFilter、filter拡張点を実装しているとします。
すべての利用可能な拡張点でMyPluginを有効化するためには、プロファイル設定は次のようにします。
apiVersion : kubescheduler.config.k8s.io/v1beta3
kind : KubeSchedulerConfiguration
profiles :
- schedulerName : multipoint-scheduler
plugins :
multiPoint :
enabled :
- name : MyPlugin
これは以下のように、MyPluginを手動ですべての拡張ポイントに対して有効にすることと同じです。
apiVersion : kubescheduler.config.k8s.io/v1beta3
kind : KubeSchedulerConfiguration
profiles :
- schedulerName : non-multipoint-scheduler
plugins :
preScore :
enabled :
- name : MyPlugin
score :
enabled :
- name : MyPlugin
preFilter :
enabled :
- name : MyPlugin
filter :
enabled :
- name : MyPlugin
multiPointを使用する利点の一つは、将来的にMyPluginが別の拡張点を実装した場合に、multiPoint設定が自動的に新しい拡張点に対しても有効化されることです。
特定の拡張点は、その拡張点のdisabledフィールドを使用して、MultiPointの展開から除外することができます。
これは、デフォルトのプラグインを無効にしたり、デフォルト以外のプラグインを無効にしたり、ワイルドカード('*')を使ってすべてのプラグインを無効にしたりする場合に有効です。
ScoreとPreScoreを無効にするためには、次の例のようにします。
apiVersion : kubescheduler.config.k8s.io/v1beta3
kind : KubeSchedulerConfiguration
profiles :
- schedulerName : non-multipoint-scheduler
plugins :
multiPoint :
enabled :
- name : 'MyPlugin'
preScore :
disabled :
- name : '*'
score :
disabled :
- name : '*'
v1beta3では、MultiPointを通じて、内部的に全てのデフォルトプラグイン が有効化されています。
しかしながら、デフォルト値(並び順やスコアの重みなど)を柔軟に設定し直せるように、個別の拡張点は用意されています。
例えば、2つのスコアプラグインDefaultScore1とDefaultScore2に、重み1が設定されているとします。
その場合、次のように重さを変更し、並べ替えることができます。
apiVersion : kubescheduler.config.k8s.io/v1beta3
kind : KubeSchedulerConfiguration
profiles :
- schedulerName : multipoint-scheduler
plugins :
score :
enabled :
- name : 'DefaultScore2'
weight : 5
この例では、MultiPointはデフォルトプラグインであるため、明示的にプラグイン名を指定する必要はありません。
そして、Scoreに指定されているプラグインはDefaultScore2のみです。
これは、特定の拡張点を通じて設定されたプラグインは、常にMultiPointプラグインよりも優先されるためです。つまり、この設定例では、結果的に2つのプラグインを両方指定することなく、並び替えが行えます。
MultiPointプラグインを設定する際の一般的な優先順位は、以下の通りです。
特定の拡張点が最初に実行され、その設定は他の場所で設定されたものよりも優先される MultiPointを使用して、手動で設定したプラグインとその設定内容デフォルトプラグインとそのデフォルト設定 上記の優先順位を示すために、次の例はこれらのプラグインをベースにします。
プラグイン 拡張点 DefaultQueueSortQueueSortCustomQueueSortQueueSortDefaultPlugin1Score, FilterDefaultPlugin2ScoreCustomPlugin1Score, FilterCustomPlugin2Score, Filter
これらのプラグインの有効な設定例は次の通りです。
apiVersion : kubescheduler.config.k8s.io/v1beta3
kind : KubeSchedulerConfiguration
profiles :
- schedulerName : multipoint-scheduler
plugins :
multiPoint :
enabled :
- name : 'CustomQueueSort'
- name : 'CustomPlugin1'
weight : 3
- name : 'CustomPlugin2'
disabled :
- name : 'DefaultQueueSort'
filter :
disabled :
- name : 'DefaultPlugin1'
score :
enabled :
- name : 'DefaultPlugin2'
なお、特定の拡張点にMultiPointプラグインを再宣言しても、エラーにはなりません。
特定の拡張点が優先されるため、再宣言は無視されます(ログは記録されます)。
このサンプルは、ほとんどのコンフィグを一箇所にまとめるだけでなく、いくつかの工夫をしています。
カスタムのqueueSortプラグインを有効にし、デフォルトのプラグインを無効にする。 CustomPlugin1とCustomPlugin2を有効にし、この拡張点のプラグイン内で、最初に実行されるようにする。filter拡張点でのみ、DefaultPlugin1を無効にする。score拡張点でDefaultPlugin2が最初に実行されるように並べ替える(カスタムプラグインより先に)。v1beta3以前のバージョンで、multiPointがない場合、上記の設定例は、次のものと同等になります。
apiVersion : kubescheduler.config.k8s.io/v1beta2
kind : KubeSchedulerConfiguration
profiles :
- schedulerName : multipoint-scheduler
plugins :
# デフォルトQueueSortプラグインを無効化
queueSort :
enabled :
- name : 'CustomQueueSort'
disabled :
- name : 'DefaultQueueSort'
# カスタムFilterプラグインを有効化
filter :
enabled :
- name : 'CustomPlugin1'
- name : 'CustomPlugin2'
- name : 'DefaultPlugin2'
disabled :
- name : 'DefaultPlugin1'
# カスタムScoreプラグインを有効化し、実行順を並べ替える
score :
enabled :
- name : 'DefaultPlugin2'
weight : 1
- name : 'DefaultPlugin1'
weight : 3
これは複雑な例ですが、MultiPoint設定の柔軟性と、拡張点を設定する既存の方法とのシームレスな統合を実証しています。
スケジューラー設定の移行
v1beta2のバージョンの設定では、新しいNodeResourcesFitプラグインをスコア拡張点で使用できます。
この新しい拡張機能は、NodeResourcesLeastAllocated、NodeResourcesMostAllocated、 RequestedToCapacityRatioプラグインの機能を組み合わせたものです。
例えば、以前はNodeResourcesMostAllocatedプラグインを使っていたなら、代わりにNodeResourcesFitプラグインを使用し(デフォルトで有効)、pluginConfigに次のようなscoreStrategy`を追加することになるでしょう。
apiVersion : kubescheduler.config.k8s.io/v1beta2
kind : KubeSchedulerConfiguration
profiles :
pluginConfig :
- args :
scoringStrategy :
resources :
- name : cpu
weight : 1
type : MostAllocated
name : NodeResourcesFit
スケジューラープラグインのNodeLabelは廃止されました。代わりにNodeAffinity
スケジューラープラグインのServiceAffinityは廃止されました。代わりにInterPodAffinity
スケジューラープラグインのNodePreferAvoidPodsは廃止されました。代わりにNode taints を使用することで同様の振る舞いを実現できます。
v1beta2で有効化されたプラグインは、そのプラグインのデフォルトの設定より優先されます。
スケジューラーのヘルスとメトリクスのバインドアドレスに設定されているhostやportが無効な場合、バリデーションに失敗します。
デフォルトで3つのプラグインの重みが増加しました。InterPodAffinity:1から2NodeAffinity:1から2TaintToleration:1から3 次の項目 6.10.2 - スケジューリングポリシー バージョンv1.23より前のKubernetesでは、スケジューリングポリシーを使用して、predicates とpriorities の処理を指定することができました。例えば、kube-scheduler --policy-config-file <filename>またはkube-scheduler --policy-configmap <ConfigMap>を実行すると、スケジューリングポリシーを設定することが可能です。
このスケジューリングポリシーは、バージョンv1.23以降のKubernetesではサポートされていません。関連するフラグである、policy-config-file、policy-configmap、policy-configmap-namespace、use-legacy-policy-configも同様にサポートされていません。
代わりに、スケジューラー設定 を使用してください。
次の項目 6.11 - 他のツール Kubernetesには、Kubernetesシステムの操作に役立ついくつかの組み込みツールが含まれています。
crictl crictlCRI と互換性のあるコンテナランタイムに使用可能な、調査・デバッグ用のためのコマンドラインツールです。
Dashboard Dashboard
Headlamp Headlamp
Headlampを用いて以下のことを行います。
最新の扱いやすいGUIを用いたクラスター管理及びトラブルシューティング クラスター内へのデプロイおよびデスクトップアプリケーションへの対応 プラグインシステムによる拡張性 ユーザーの権限に応じて動的に適用されるRBACベースのアクセス制御 Helm 🛇 This item links to a third party project or product that is not part of Kubernetes itself.
More information HelmHelm Charts を管理するためのツールです。
Helmを用いて以下のことを行います。
Kubernetes chartsとしてパッケージ化された人気のあるソフトウェアの検索と利用 Kubernetes chartsとして所有するアプリケーションを共有すること Kubernetesアプリケーションの再現性のあるビルドの作成 Kubernetesマニフェストファイルの効率的な管理 Helmパッケージのリリース管理 Kompose Kompose
Komposeを用いて以下のことを行います。
Docker ComposeファイルのKubernetesオブジェクトへの変換 ローカルのDocker開発からKubernetesを経由したアプリケーション管理への移行 v1またはv2のDocker Compose用yamlファイルならびに分散されたアプリケーションバンドル の変換 Kui Kuikubectlコマンドラインリクエストを受け取り、結果をグラフィックと共に返答するツールです。
ASCIIテーブルの代わりに、Kuiはソート可能なテーブルを備えたGUIレンダリングを提供します。
Kuiを用いて以下のことを行います。
コピーペーストすることなく、自動生成された冗長なリソース名を直接クリックして確認 Kui上でkubectlを実行可能で、時折kubectl本体よりも早いパフォーマンスを発揮 Job をクエリし、実行結果をウォーターフォール図としてレンダリングタブ形式のUIを使って、クラスター内の様々なリソースをクリックして確認 Minikube minikube
7 - Kubernetesに貢献する Kubernetesに貢献する方法はたくさんあります。
新機能の設計に取り組むこともできますし、既存のコードにドキュメントを追加することも、ブログ で記事を書くこともできます。
それだけではありません。新機能を実装したり、バグを修正したりすることもできます。
貢献者コミュニティへの参加を支援することも、既存の貢献者をサポートすることもできます。
様々な方法でプロジェクトに貢献することができるため、Kubernetesは https://k8s.dev/ という専用のウェブサイトを作成しました。
Kubernetesへの貢献についてもっと学ぶために、参照することができます。
もし この ドキュメントへの貢献について特に学びたい場合は、Kubernetesドキュメントへの貢献 を参照してください。
また、Kubernetesへの貢献については、CNCF のページ を参照することもできます。
7.1 - Kubernetesのドキュメントに貢献する このウェブサイトはKubernetes SIG Docs が管理しています。
Kubernetesプロジェクトは初心者でも経験者でも、全てのコントリビューターからの改善を歓迎しています!
Kubernetesドキュメントコントリビューターは
既存のコンテンツを改善します 新しいコンテンツを作成します ドキュメントを翻訳します Kubernetesリリースサイクルの一部としてドキュメントを管理・公開します はじめに どなたでも、問題を説明するissueや、ドキュメントの改善を求めるissueを作成し、kubernetes/website GitHubリポジトリgit とGitHub を基本的に使いこなせる必要があります。
ドキュメンテーションに関わるには:
CNCFのContributor License Agreement にサインしてください。 ドキュメンテーションのリポジトリ と、ウェブサイトの静的サイトジェネレーター に慣れ親しんでください。プルリクエストのオープン と変更レビュー の基本的なプロセスを理解していることを確認してください。flowchart TB
subgraph third[プルリクエストのオープン]
direction TB
U[ ] -.-
Q[コンテンツを改善する] --- N[コンテンツを作成する]
N --- O[ドキュメントを翻訳する]
O --- P[k8sリリースサイクルの
このコンテンツを表示するには、JavaScriptを有効に する必要があります
図1は新たなコントリビューターのためのロードマップを概説しています。サインアップやレビューのステップのいくつか、またはその全てに従えばよいです。これで、プルリクエストのオープンの下にリストされているいくつかの貢献目標を達成するためのプルリクエストを開く準備が整いました。また、質問はいつでも歓迎です!
一部のタスクでは、Kubernetes organizationで、より多くの信頼とアクセス権限が必要です。
役割と権限についての詳細は、SIG Docsへの参加 を参照してください。
はじめての貢献 あらかじめいくつかのステップを見直すことで、最初の貢献に備えることができます。図2はそれらのステップの概説で、詳細は次のとおりです。
flowchart LR
subgraph second[はじめての貢献]
direction TB
S[ ] -.-
G[K8sメンバーからの
このコンテンツを表示するには、JavaScriptを有効に する必要があります
貢献時の支援の受け方 はじめて貢献を行うのは大変なことかもしれません。新規コントリビューターのためのアンバサダー は、最初の数回の貢献を行う手助けをしてくれます。Kubernetes Slack で、特に#sig-docsチャンネルを用いて連絡を取ることができます。また毎月第一火曜日に行われる新規コントリビューターのための歓迎会 もあります。ここで新規コントリビューターのアンバサダーと交流し、質問に答えてもらうことができます。
訳注: 日本語ローカライゼーションに関しては、Slackのkubernetes-docs-jaチャンネルを利用してください。
次のステップ SIG Docsに参加する SIG Docs はKubernetesのドキュメントとウェブサイトを公開・管理するコントリビューターのグループです。SIG Docsに参加することはKubernetesコントリビューター(機能開発でもそれ以外でも)にとってKubernetesプロジェクトに大きな影響を与える素晴らしい方法の一つです。
SIG Docsは複数の方法でコミュニケーションをとっています。
その他の貢献方法 7.2 - コンテンツの改善を提案する Kubernetesのドキュメントに何か問題を見つけたり、新しいコンテンツに関してアイデアを思い付いたときは、issueを作ってください。必要なものは、GitHubアカウント とウェブブラウザーだけです。
Kubernetesのドキュメント上の新しい作業は、ほとんどの場合、GitHubのissueから始まります。Kubernetesのコントリビューターは、必要に応じてレビュー、分類、タグ付けを行います。次に、あなたやKubernetesコミュニティの他のメンバーが、そのissueを解決するための変更を加えるpull requestを開きます。
issueを作る 既存のコンテンツに対して改善を提案したい場合や、間違いを発見した場合は、issueを作ってください。
ページの右側のサイドバーにあるドキュメントのissueを作成 ボタンをクリックします。GitHubのissueページにリダイレクトし、一部のヘッダーが自動的に挿入されます。 問題や改善の提案について書きます。できる限り多くの詳細情報を提供するようにしてください。 Submit new issue ボタンをクリックします。送信後、定期的にissueを確認するか、GitHubの通知を設定してください。レビュアや他のコミュニティメンバーが、issueに対して作業を行うために、あなたに何か質問をするかもしれません。
新しいコンテンツの提案 新しいコンテンツに関するアイデアがあるものの、どの場所に追加すればわからないときでも、issueを作ることができます。次のいずれかを選択して行ってください。
コンテンツが追加されるべきだと思う既存のページを選択し、ドキュメントのissueを作成 ボタンをクリックする。 GitHub に移動し、直接issueを作る。よいissueを作るには issueを作るときは、以下のことを心に留めてください。
明確なissueの説明を書く。不足している点、古くなっている点、誤っている点、改善が必要な点など、どの点がそうであるか明確に書く。 issueがユーザーに与える具体的な影響を説明する。 合理的な作業単位になるように、特定のissueのスコープを制限する。スコープの大きな問題については、小さな複数のissueに分割する。たとえば、"Fix the security docs"(セキュリティのドキュメントを修正する)というのはスコープが大きすぎますが、"Add details to the 'Restricting network access' topic"(トピック「ネットワークアクセスの制限」に詳細情報を追加する)であれば十分に作業可能な大きさです。 すでにあるissueを検索し、関連または同様のissueがないかどうか確認する。 新しいissueがほかのissueやpull requestと関係する場合は、完全なURLを参照するか、issueやpull requestの数字の前に#の文字を付けて参照する。例えば、Introduced by #987654のように書きます。 行動規範 に従って、仲間のコントリビューターに敬意を払いましょう。たとえば、"The docs are terrible"(このドキュメントは最悪だ)のようなコメントは、役に立つ敬意のあるフィードバックではありません。7.3 - 新しいコンテンツの貢献 このセクションでは、新しいコンテンツの貢献を行う前に知っておくべき情報を説明します。
flowchart LR
subgraph second[始める前に]
direction TB
S[ ] -.-
A[CNCF CLAに署名] --> B[Gitブランチを選択]
B --> C[言語ごとにPR]
C --> F[コントリビューターのための
このコンテンツを表示するには、JavaScriptを有効に する必要があります 図 - 新しいコンテンツ提供の貢献方法
上記の図は新しいコンテンツを申請する前に知っておくべき情報を示しています。
詳細については以下で説明します。
貢献の基本 KubernetesのドキュメントはMarkdownで書き、KubernetesのウェブサイトはHugo を使ってビルドします。 Kubernetesのドキュメントは、MarkdownのスタイルとしてCommonMark を使用しています。 ソースはGitHub にあります。Kubernetesのドキュメントは/content/en/docs/にあります。リファレンスドキュメントの一部は、update-imported-docs/ディレクトリ内のスクリプトから自動的に生成されます。 Page content types にHugoによるドキュメントのコンテンツの見え方を記述しています。Kubernetesのドキュメントに貢献するのにDocsy shortcode やカスタムのHugo shortcode が使えます。 標準のHugoのshortcodeに加えて、多数のカスタムのHugo shortcode を使用してコンテンツの見え方をコントロールしています。 ドキュメントのソースは/content/内にある複数の言語で利用できます。各言語はそれぞれISO 639-1標準 で定義された2文字のコードの名前のフォルダを持ちます。たとえば、英語のドキュメントのソースは/content/en/docs/内に置かれています。 複数言語でのドキュメントへの貢献や新しい翻訳の開始に関する情報については、Kubernetesのドキュメントを翻訳する を参照してください。 始める前に CNCF CLAに署名する すべてのKubernetesのコントリビューターは、コントリビューターガイド を読み、Contributor License Agreement(コントリビューターライセンス契約、CLA)への署名 を必ず行わなければなりません 。
CLAへの署名が完了していないコントリビューターからのpull requestは、自動化されたテストで失敗します。名前とメールアドレスはgit configコマンドで表示されるものに一致し、gitの名前とメールアドレスはCNCF CLAで使われたものに一致しなければなりません。
どのGitブランチを使用するかを選ぶ pull requestをオープンするときは、どのブランチをベースにして作業するかをあらかじめ知っておく必要があります。
シナリオ ブランチ 現在のリリースに対する既存または新しい英語のコンテンツ main機能変更のリリースに対するコンテンツ 機能変更が含まれるメジャーおよびマイナーバージョンに対応する、dev-<version>というパターンのブランチを使います。たとえば、機能変更がv1.36に含まれる場合、ドキュメントの変更はdev-1.36ブランチに追加します。 他の言語内のコンテンツ(翻訳) 各翻訳対象の言語のルールに従います。詳しい情報は、翻訳のブランチ戦略 を読んでください。
それでも選ぶべきブランチがわからないときは、Slack上の#sig-docsチャンネルで質問してください。
備考: すでにpull requestを作成していて、ベースブランチが間違っていたことに気づいた場合は、作成者であるあなただけがベースブランチを変更できます。言語ごとのPR pull requestはPRごとに1つの言語に限定してください。複数の言語に同一の変更を行う必要がある場合は、言語ごとに別々のPRを作成してください。
コントリビューターのためのツール kubernetes/websiteリポジトリ内のdoc contributors tools ディレクトリには、コントリビューターとしての旅を楽にしてくれるツールがあります。
7.4 - 変更のレビュー このセクションでは、コンテンツのレビュー方法について説明します。
7.4.1 - Pull Requestのレビュー ドキュメントのPull Requestは誰でもレビューすることができます。Kubernetesのwebsiteリポジトリでpull requests のセクションに移動し、open状態のPull Requestを確認してください。
ドキュメントのPull Requestのレビューは、Kubernetesコミュニティに自分を知ってもらうためのよい方法の1つです。コードベースについて学んだり、他のコントリビューターとの信頼関係を築く助けともなるはずです。
レビューを行う前には、以下のことを理解しておくとよいでしょう。
はじめる前に レビューを始める前に、以下のことを心に留めてください。
CNCFの行動規範 を読み、いかなる時にも行動規範にしたがって行動するようにする。礼儀正しく、思いやりを持ち、助け合う気持ちを持つ。 変更点だけでなく、PRのポジティブな側面についてもコメントする。 相手の気持ちに共感して、自分のレビューが相手にどのように受け取られるのかをよく意識する。 相手の善意を前提として、疑問点を明確にする質問をする。 経験を積んだコントリビューターの場合、コンテンツに大幅な変更が必要な作業を行う新規のコントリビューターとペアを組んで取り組むことを考える。 レビューのプロセス 一般に、コンテンツや文体に対するPull Requestは、英語でレビューを行います。図1は、レビュープロセスについて手順の概要を示しています。 各ステップの詳細は次のとおりです。
(訳注:SIG Docs jaでは、日本語でも対応しています。日本語の翻訳に対するレビューは、日本語でも構いません。ただし、Pull Requestの作成者や他のコントリビューターが必ずしも日本語を理解できるとは限りませんので、注意して発言してください。)
flowchart LR
subgraph fourth[レビューの開始]
direction TB
S[ ] -.-
M[コメントを追加] --> N[変更の確認]
N --> O[Commentを選択]
end
subgraph third[PRの選択]
direction TB
T[ ] -.-
J[説明とコメントを読む]--> K[Netlifyプレビューで
このコンテンツを表示するには、JavaScriptを有効に する必要があります 図1. レビュープロセスの手順
https://github.com/kubernetes/website/pulls に移動します。Kubernetesのウェブサイトとドキュメントに対するopen状態のPull Request一覧が表示されます。
open状態のPRに、以下に示すラベルを1つ以上使って絞り込みます。
cncf-cla: yes (推奨): CLAにサインしていないコントリビューターが提出したPRはマージできません。詳しい情報は、CLAの署名 を読んでください。language/en (推奨): 英語のPRだけに絞り込みます。size/<size>: 特定の大きさのPRだけに絞り込みます。レビューを始めたばかりの人は、小さなPRから始めてください。さらに、PRがwork in progressとしてマークされていないことも確認してください。work in progressラベルの付いたPRは、まだレビューの準備ができていない状態です。
レビューするPRを選んだら、以下のことを行い、変更点について理解します。
PRの説明を読み、行われた変更について理解し、関連するissueがあればそれも読みます。 他のレビュアのコメントがあれば読みます。 Files changed タブをクリックし、変更されたファイルと行を確認します。Conversation タブの下にあるPRのbuild checkセクションまでスクロールし、Netlifyのプレビュービルドで変更点をプレビューします。これはスクリーンショットです(これは、GitHubのデスクトップサイトを見せています。タブレットやスマートフォンデバイスでレビューしている場合は、GitHubウェブのUIは少し異なります):deploy/netlify 行のDetails リンクをクリックします。Files changed タブに移動してレビューを始めます。
コメントしたい場合は行の横の+マークをクリックします。
その行に関するコメントを書き、Add single comment (1つのコメントだけを残したい場合)またはStart a review (複数のコメントを行いたい場合)のいずれかをクリックします。
コメントをすべて書いたら、ページ上部のReview changes をクリックします。ここでは、レビューの要約を追加できます(コントリビューターにポジティブなコメントも書きましょう!)。常に「Comment」を使用してください。
レビューの終了時、「Request changes」ボタンをクリックしないでください。さらに変更される前にマージされるのをブロックしたい場合、「/hold」コメントを残すことができます。Holdを設定する理由を説明し、必要に応じて、自分や他のレビューアがHoldを解除できる条件を指定してください。 レビューの終了時、「Approve」ボタンをクリックしないでください。大抵の場合、「/approve」コメントを残すことが推奨されます。 レビューのチェックリスト レビューするときは、最初に以下の点を確認してみてください。
言語と文法 言語や文法に明らかな間違いはないですか? もっとよい言い方はないですか?作成者が変更している箇所の用語や文法に注目してください。作成者がページ全体の変更を目的として明確にしていない限り、そのページのすべての問題を修正する義務はありません。 既存のページを変更するPRである場合、変更されている箇所に注目してレビューしてください。その変更されたコンテンツは、技術的および編集の正確性についてレビューしてください。PRの作成者が対処しようとしている内容と直接関係のない間違いを見つけた場合、それは別のIssueとして扱うべきです(既存のIssueが無いことを確認してください)。 コンテンツを移動 するPull Requestに注意してください。作成者がページの名前を変更したり、2つのページを結合したりする場合、通常、私たち(Kubernetes SIG Docs)は、その移動されたコンテンツ内で見つけられるすべての文法やスペルの間違いを修正することを作成者に要求することを避けています。 もっと簡単な単語に置き換えられる複雑な単語や古い単語はありませんか? 使われている単語や専門用語や言い回しで差別的ではない別の言葉に置き換えられるものはありませんか? 言葉選びや大文字の使い方はstyle guide に従っていますか? もっと短くしたり単純な文に書き換えられる長い文はありませんか? 箇条書きやテーブルでもっとわかりやすく表現できる長いパラグラフはありませんか? コンテンツ 同様のコンテンツがKubernetesのサイト上のどこかに存在しませんか? コンテンツが外部サイト、特定のベンダー、オープンソースではないドキュメントなどに過剰にリンクを張っていませんか? ウェブサイト PRはページ名、slug/alias、アンカーリンクの変更や削除をしていますか? その場合、このPRの変更の結果、リンク切れは発生しませんか? ページ名を変更してslugはそのままにするなど、他の選択肢はありませんか? PRは新しいページを作成するものですか? その場合、次の点に注意してください。 Netlifyのプレビューで変更は確認できますか? 特にリスト、コードブロック、テーブル、備考、画像などに注意してください。 その他 些細な編集 に注意してください。些細な編集だと思われる変更を見つけた場合は、そのポリシーを指摘してください (それが本当に改善である場合は、変更を受け入れても問題ありません)。空白の修正を行っている作成者には、PRの最初のコミットでそれを行い、その後に他の変更を加えるよう促してください。これにより、マージとレビューの両方が容易になります。特に、大量の空白文字の整理と共に1回のコミットで発生する些細な変更に注意してください(もしそれを見つけたら、作成者に修正を促してください)。 レビュアーが誤字や不適切な空白など、PRの本質でない小さな問題を発見した場合は、コメントの先頭にnit:を付けてください。これにより、作成者はこのフィードバックが重要でないことを知ることができます。
Pull Requestの承認を検討する際、残りのすべてのフィードバックがnitとしてマークされていれば、残っていたとしてもPRをマージできます。その場合、残っているnitに関するIssueをオープンすると役立つことがよくあります。その新しいIssueをGood First Issue としてマークするための条件を満たすことができるかどうか検討してください。それができたら、これらは良い情報源になります。
7.4.2 - approverとreviewer向けのレビュー SIG DocsのReviewer(レビュアー) とApprover(承認者) は、変更をレビューする時にいくつか追加の作業を行います。
毎週、docsのメンバーの特定のapproverのボランティアは、pull requestのトリアージとレビューを担当します。この担当者は、その週の「PR Wrangler(PRの世話人)」と呼ばれます。詳しい情報は、PR Wrangler scheduler を参照してください。PR Wranglerになるには、週次のSIG Docsミーティングに参加し、ボランティアをします。もしその週にスケジュールされていなくても、活発なレビューが行われていないpull request(PR)をレビューすることは問題ありません。
このローテーションに加えて、変更されたファイルのオーナーに基づいて、botがPRにreviewerとapproverを割り当てます。
PRをレビューする KubernetesのドキュメントはKubernetesコードレビュープロセス に従います。
pull requestのレビュー に書かれているすべてのことが適用されますが、ReviewerとApproverはそれに加えて次のことも行います。
必要に応じて、/assign Prowコマンドを使用して、特定のreviewerにPRを割り当てます。これは、コードのコントリビューターからの技術的なレビューが必要な場合には特に重要です。
備考: 技術的なレビューを行える人物を知るには、Markdownファイル上部にあるfront-matterのreviewersフィールドを確認してください。PRがコンテンツ およびスタイル のガイドに従っていることを確認してください。従っていない場合は、作者にガイドの該当箇所へのリンクを示してください。
PRの作者に変更を提案できるときは、GitHubのRequest Changes (変更をリクエスト)オプションを利用してください。
提案したことが反映されたら、/approveや/lgtmコマンドを使用して、GitHubのレビューステータスを変更してください。
他の作者のPRにコミットを追加する PRにコメントを残すのは助けになりますが、まれに他の作者のPRに代わりにコミットを追加する必要がある場合があります。
あなたが明示的に作者から頼まれたり、長い間放置されたPRを蘇らせるような場合でない限り、他の作者のPRを「乗っ取る」ようなことはしないでください。短期的に見ればそのほうが短時間で終わるかもしれませんが、そのようなことをするとその人が貢献するチャンスを奪ってしまうことになります。
あなたが取る方法は、編集する必要のあるファイルがすでにPRのスコープに入っているか、あるいはPRがまだ触れていないファイルであるかによって変わります。
以下のいずれかが当てはまる場合、他の作者のPRにあなたがコミットを追加することはできません。
PRの作者が自分のブランチを直接https://github.com/kubernetes/website/ リポジトリにpushした場合。この場合、pushアクセス権限を持つreviewerしか他のユーザーのPRにコミットを追加することはできません。
備考: 次回PRを作成するとき、自分のブランチを自分のforkに対してpushするように作者に促してください。PRの作者が明示的にapproverからの編集を禁止している場合。
レビュー向けのProwコマンド Prow は、pull request(PR)に対してジョブを実行するKubernetesベースのCI/CDシステムです。Prowは、Kubernetes organization全体でチャットボットスタイルのコマンドを利用してGitHub actionsを扱えるようにします。たとえば、ラベルの追加と削除 、issueのクローズ、approverの割り当てなどが行なえます。Prowコマンドは、GitHubのコメントに/<command-name>という形式で入力します。
reviewerとapproverが最もよく使うprowコマンドには、以下のようなものがあります。
Prow commands for reviewing Prowコマンド Roleの制限 説明 /lgtmOrganizationメンバー PRのレビューが完了し、変更に納得したことを知らせる。 /approveApprover PRをマージすることを承認する。 /assign誰でも PRのレビューまたは承認するひとを割り当てる。 /closeOrganizationメンバー issueまたはPRをクローズする。 /hold誰でも do-not-merge/holdラベルを追加して、自動的にマージできないPRであることを示す。/hold cancel誰でも do-not-merge/holdラベルを削除する。
PRで利用できるすべてのコマンドを確認するには、Prowコマンドリファレンス を参照してください。
issueのトリアージとカテゴリー分類 一般に、SIG DocsはKubernetes issue triage のプロセスに従い、同じラベルを使用しています。
このGitHub issueのフィルター は、トリアージが必要な可能性があるissueを表示します。
issueをトリアージする issueを検証する
issueがドキュメントのウェブサイトに関係するものであることを確かめる。質問に答えたりリソースの場所を報告者に教えることですぐに閉じられるissueもあります。詳しくは、サポートリクエストまたはコードのバグレポート のセクションを読んでください。 issueにメリットがあるかどうか評価します。 issueに行動を取るのに十分な詳細情報がない場合や、テンプレートが十分埋められていない場合は、triage/needs-informationラベルを追加します。 lifecycle/staleとtriage/needs-informationの両方のラベルがあるときは、issueをクローズします。優先度(priority)ラベルを追加する(issueトリアージガイドライン は、priorityラベルについて詳しく定義しています。)
issueのラベル ラベル 説明 priority/critical-urgent今すぐに作業する。 priority/important-soon3ヶ月以内に取り組む。 priority/important-longterm6ヶ月以内に取り組む。 priority/backlog無期限に延期可能。リソースに余裕がある時に取り組む。 priority/awaiting-more-evidenceよいissueの可能性があるissueを見失わないようにするためのプレースホルダー。 helpまたはgood first issueKubernetesまたはSIG Docsでほとんど経験がない人に適したissue。より詳しい情報は、Help WantedとGood First Issueラベル を読んでください。
あなたの裁量で、issueのオーナーシップを取り、issueに対するPRを提出してください(簡単なissueや、自分がすでに行った作業に関連するissueである場合は特に)。
issueのトリアージについて質問があるときは、Slackの#sig-docsかkubernetes-sig-docs mailing list で質問してください。
issueラベルの追加と削除 ラベルを追加するには、以下のいずれかの形式でコメントします。
/<label-to-add>(たとえば、/good-first-issue)/<label-category> <label-to-add>(たとえば、/triage needs-informationや/language ja)ラベルを削除するには、以下のいずれかの形式でコメントします。
/remove-<label-to-remove>(たとえば、/remove-help)/remove-<label-category> <label-to-remove>(たとえば、/remove-triage needs-information)いずれの場合でも、ラベルは既存のものでなければなりません。存在しないラベルを追加しようとした場合、コマンドは無視されます。
すべてのラベル一覧は、websiteリポジトリのラベルセクション で確認できます。
SIG Docsですべてのラベルが使われているわけではありません。
issueのライフサイクルに関するラベル issueは一般にオープン後に短期間でクローズされます。しかし、オープンされたものの非アクティブになるissueもあります。逆に、90日以上オープンのままにしておく必要があるissueもあります。
issueのライブラリに関するラベル ラベル 説明 lifecycle/stale90日間活動がない場合、issueは自動的にstaleとラベル付けされます。/remove-lifecycle staleコマンドを使って手動でlifecycleをリバートしない限り、issueは自動的にクローズされます。 lifecycle/frozenこのラベルが付けられたissueは、90日間活動がなくてもstaleになりません。priority/important-longtermラベルを付けたissueなど、90日以上オープンにしておく必要があるissueには、このラベルを手動で追加します。
特別な種類のissueに対処する SIG Docsでは、対処方法をドキュメントに書いても良いくらい頻繁に、以下のような種類のissueに出会います。
重複したissue 1つの問題に対して1つ以上のissueがオープンしている場合、1つのissueに統合します。あなたはどちらのissueをオープンにしておくか(あるいは新しいissueを作成するか)を決断して、すべての関連する情報を移動し、関連するすべてのissueにリンクしなければなりません。最後に、同じ問題について書かれたすべての他のissueにtriage/duplicateラベルを付けて、それらをクローズします。作業対象のissueを1つだけにすることで、混乱を減らし、同じ問題に対して作業が重複することを避けられます。
リンク切れに関するissue リンク切れのissueがAPIまたはkubectlのドキュメントにあるものは、問題が完全に理解されるまでは/priority critical-urgentを割り当ててください。その他のすべてのリンク切れに関するissueには、手動で修正が必要であるため、/priority important-longtermを付けます。
ブログに関するissue Kubernetesブログ のエントリは時間が経つと情報が古くなるものだと考えています。そのため、ブログのエントリは1年以内のものだけをメンテナンスします。1年以上前のブログエントリに関するissueは修正せずにクローズします。
PRをクローズするときに送信するメッセージの一部として、記事の更新とメンテナンス へのリンクを含めて案内しても構いません。
関連する正当な理由がある場合には、例外を設けても問題ありません。
サポートリクエストまたはコードのバグレポート 一部のドキュメントのissueは、実際には元になっているコードの問題や、何か(たとえば、チュートリアル)がうまく動かないときにサポートをリクエストするものです。ドキュメントに関係のない問題は、kind/supportラベルを付け、サポートチャンネル(SlackやStack Overflowなど)へ報告者を導くコメントをして、もし関連があれば機能のバグに対するissueを報告するリポジトリ(kubernetes/kubernetesは始めるのに最適な場所です)を教えて、クローズします。
サポートリクエストに対する返答の例を示します。(リクエストを行うときは英語で行うことが想定されるため、英文とその日本語訳を記載しています)
This issue sounds more like a request for support and less
like an issue specifically for docs. I encourage you to bring
your question to the `#kubernetes-users` channel in
[Kubernetes slack](https://slack.k8s.io/). You can also search
resources like
[Stack Overflow](https://stackoverflow.com/questions/tagged/kubernetes)
for answers to similar questions.
You can also open issues for Kubernetes functionality in
https://github.com/kubernetes/kubernetes.
If this is a documentation issue, please re-open this issue.
このissueは特定のドキュメントに関するissueではなく、サポートリクエストのようです。
Kubernetesに関する質問については、[Kubernetes slack](https://slack.k8s.io/)の
`#kubernetes-users`チャンネルに投稿することをおすすめします。同様の質問に対する回答を
[Stack Overflow](https://stackoverflow.com/questions/tagged/kubernetes)などの
リソースで検索することもできます。
Kubernetesの機能に関するissueについては、https://github.com/kubernetes/kubernetes
でissueを作成できます。
もしこれがドキュメントに関するissueの場合、このissueを再びオープンしてください。
コードのバグに対する返答の例を示します。
This sounds more like an issue with the code than an issue with
the documentation. Please open an issue at
https://github.com/kubernetes/kubernetes/issues.
If this is a documentation issue, please re-open this issue.
こちらのissueは、ドキュメントではなくコードに関係するissueのようです。
https://github.com/kubernetes/kubernetes/issues でissueを作成してください。
もしこれがドキュメントに関するissueの場合、このissueを再びオープンしてください。
スカッシュを行う approverとして、pull request(PR)をレビューするときに、次のような場合があります。
コントリビューターにコミットをスカッシュするように伝えます。 コントリビューターの代わりにコミットをスカッシュします。 コントリビューターにまだスカッシュしないように伝えます。 スカッシュができないようにします。 コントリビューターにスカッシュを行うように伝える : 新しいコントリビューターは、pull request(PR)でコミットをスカッシュする必要があることを知らない場合があります。このような場合は、スカッシュするように案内し、役立つ情報へのリンクを表示し、必要であればサポートを手配できることを伝えます。以下は役立つリンクの例です。
コントリビューターの代わりにコミットをスカッシュする : コントリビューターがコミットのスカッシュに困っている場合やPRをマージするまでに時間的に制約がある場合は、代わりにスカッシュを行うことができます。
kubernetes/websiteリポジトリはpull requestマージのためスカッシュを許可するように設定 されています。
単純にSquash commit ボタンを選択します。 PRの中でコントリビューターがメンテナーによるPR管理を有効にしている場合、メンテナーはコミットをスカッシュし、その結果をフォークに反映させることができます。スカッシュする前に、最新の変更を保存してPRにプッシュするように伝えます。スカッシュ後は、スカッシュされたコミットをローカルクローンにプルするように伝えます。 GitHubにコミットをスカッシュさせるには、TideやGitHubがスカッシュを行うラベルを使うか、PRをマージするときにSquash commit ボタンをクリックします。 コントリビューターにスカッシュを避けるように伝える
もし1つのコミットが不具合や望ましくない変更を含み、最後のコミットでそのエラーを元に戻している場合は、コミットをスカッシュしないでください。GitHubのPRの「Files changed」タブやNetlifyのプレビューでは問題がないように見えても、このPRをマージすると他の人に対してリベースやマージのコンフリクトを発生させる可能性があります。他のコントリビューターにリスクを与えないように適切に介入してください。 決してスカッシュしないようにする
翻訳を開始する場合や、新しいバージョンのドキュメントをリリースする場合など、ユーザーのフォークではないブランチをマージするときは、決してコミットをスカッシュしないでください 。
これらのファイルについてはコミット履歴を保持する必要があるため、スカッシュしないことが重要です。 7.5 - Kubernetesのドキュメントを翻訳する このページでは、Kubernetesドキュメントにおける日本語翻訳の方針について説明します。
ドキュメントを日本語に翻訳するまでの流れ 翻訳を行うための基本的な流れについて説明します。不明点がある場合はKubernetes公式Slack の#kubernetes-docs-jaチャンネルにてお気軽にご質問ください。
前提知識 翻訳作業は全てGitHubのIssue によって管理されています。翻訳作業を行いたい場合は、Issueの一覧をまず最初にご確認ください。
また、Kubernetes傘下のリポジトリではCLAと呼ばれる同意書に署名しないと、Pull Requestをマージすることができません。詳しくは英語のドキュメント や、Qiitaに有志の方が書いてくださった日本語のまとめ をご覧ください。
翻訳を始めるまで 翻訳を希望するページのIssueが存在しない場合 こちらのサンプル に従う形でIssueを作成する自分自身を翻訳作業に割り当てたい場合は、Issueのメッセージまたはコメントに/assignと書く 新規ページを翻訳する場合 のステップに進む不明点がある場合はKubernetes公式Slack の#kubernetes-docs-jaチャンネルにてお気軽にご質問ください。
翻訳を希望するページのIssueが存在する場合 自分自身を翻訳作業に割り当てるために、Issueのコメントに/assignと書く 新規ページを翻訳する場合 のステップに進むPull Requestを送るまで 新規ページを翻訳する場合の手順 kubernetes/websiteリポジトリをフォークするmainから任意の名前でブランチを作成するcontent/enのディレクトリから必要なファイルをcontent/jaにコピーし、翻訳するmainブランチに向けてPull Requestを作成する既存のページの誤字脱字や古い記述を修正する場合の手順 kubernetes/websiteリポジトリをフォークするmainから任意の名前でブランチを作成するcontent/jaのディレクトリから必要なファイルを編集するmainブランチに向けてPull Requestを作成する翻訳スタイルガイド 基本方針 本文を、敬体(ですます調)で統一特に、「〜になります」「〜となります」という表現は「〜です」の方が適切な場合が多いため注意 句読点は「、」と「。」を使用 漢字、ひらがな、カタカナは全角で表記 数字とアルファベットは半角で表記 記号類は感嘆符「!」と疑問符「?」のみ全角、それ以外は半角で表記 英単語と日本語の間に半角スペースは不要例: Kubernetesクラスター カッコ()の前後にも半角スペースは不要 バッククォート`で囲まれた英単語と、その前後の英単語の間には半角スペースが必要例: これは`default` ServiceAccountです(前は詰めて後ろは空ける) 日本語文では、文章の途中で改行を行わない。句点「。」もしくは行末のコロン:で改行する コロン:の後には、半角スペースを入れる メタデータのreviewersの項目は削除する 本ドキュメント内のページへのリンクは、日本語ページが存在していても、URLに/jaの追加は不要(HTMLへの変換時に自動判別されるようになったため)既存の日本語ページで/jaが記載されている場合は、ページの最新化の際に削除する 各セクションの見出しを翻訳した場合は、その後ろに{#見出しID}の形式でアンカーリンクを設定する例: ## リファレンス {#reference} 見出しIDは、英語ページでの見出しのパーマリンクを確認して、URLの#以降を使用する ブログ記事については、次のことに留意する 用語の表記 Kubernetesのリソース名や技術用語などは、原則としてそのままの表記を使用します。
例えば、PodやService、Deploymentなどは翻訳せずにそのまま表記してください。
ただし、ノード(Node)に関してはKubernetesとしてのNodeリソース(例: kind: Nodeやkubectl get nodes、Nodeコントローラーなど)を指していないのであれば、「ノード」と表記してください。
またこれらの単語は、複数形ではなく単数形を用います。
例えば、原文に"pods"と表記されている場合でも、日本語訳では"Pod"と表記してください。
特定の用語がKubernetes固有の技術用語であるかどうかについて迷った時は、次の判断フローを参考にしてください。
APIリソースの一覧 または標準化用語集 に対象の用語が掲載されている場合は、掲載されている用語で表記します。その他のKubernetesに関連する用語については、固有名詞と判断できるものは原則アルファベットで表記します。 新しく用語を日本語として翻訳する際は、レビュアーやローカライゼーションチームに意見を聞いてください。 ローカライゼーションチームは、あなたのコメントを歓迎します!
頻出表記(日本語) よくある表記 あるべき形 〜ので、〜から、〜だから 〜のため 、〜ため (あいうえお。) (あいうえお)。 〇,〇,〇 〇、〇、〇(※列挙はすべて読点で統一)
長音の有無 カタカナ語に長音を付与するかどうかは、以下の原則に従ってください。
-er、-or、-ar、-cy、-gyで終わる単語は長音を付与する例: 「クラスター」「セレクター」「サイドカー」「ポリシー」「トポロジー」 -ear、-eer、-re、-ty、-dy、-ryで終わる単語は長音を付与しない例: 「クリア」「エンジニア」「アーキテクチャ」「セキュリティ」「スタディ」「ディレクトリ」 ただし、「コンテナ」は例外的に長音を付与しないこととします。
この原則を作成するにあたって、mozilla-japan/translation Editorial Guideline#カタカナ語の表記 を参考にしました。
その他の表記 その他の表記については、以下の表を参考にしてください。
英語 日本語 interface インターフェース proxy プロキシ quota クォータ stacked 積層
cron jobの訳し方に関して 混同を避けるため、cron jobはcronジョブと訳し、CronJobはリソース名としてそのまま表記します。
cron「の」ジョブは、「の」が続く事による解釈の難から基本的にはつけないものとします。
その他基本方針など カタカナ語の多用を避けるため、和語や漢語でも自然に表せる場合はそちらを優先する例: ターゲット→対象 ただし、カタカナで定着している用語はその限りではない 意訳と直訳で迷った場合は「直訳」で訳す 訳で難しい・わからないと感じたらSlackの#kubernetes-docs-jaで相談する できることを挙手制で、できないときは早めに報告 アップストリームのコントリビューター SIG Docsでは、英語のソースに対するアップストリームへのコントリビュートや誤りの訂正 を歓迎しています。
7.6 - SIG Docsへの参加 SIG Docsは、Kubernetesプロジェクト内の
special interest groups の1つであり、
Kubernetes全体のドキュメントの作成、更新、および保守に重点を置いています。
SIGの詳細については、SIG DocsのGithubリポジトリ を参照してください。
SIG Docsは、すべての寄稿者からのコンテンツとレビューを歓迎します。
誰でもPull Request(PR)を開くことができ、コンテンツに関するissueを提出したり、進行中のPull Requestにコメントしたりできます。
あなたは、member や、
reviewer 、
approver になることもできます。
これらの役割にはより多くのアクセスが必要であり、変更を承認およびコミットするための特定の責任が伴います。
Kubernetesコミュニティ内でメンバーシップがどのように機能するかについての詳細は、
community-membership
をご覧ください。
このドキュメントの残りの部分では、kubernetesの中で最も広く公開されている
Kubernetesのウェブサイトとドキュメントの管理を担当しているSIG Docsの中で、これらの役割がどのように機能するのかを概説します。
SIG Docs chairperson SIG Docsを含む各SIGは、議長として機能する1人以上のSIGメンバーを選択します。
これらは、SIGDocsとKubernetes organizationの他の部分との連絡先です。
それらには、Kubernetesプロジェクト全体の構造と、SIG Docsがその中でどのように機能するかについての広範な知識が必要です。
現在のchairpersonのリストについては、
Leadership
を参照してください。
SIG Docs teamsと自動化 SIG Docsの自動化は、GitHub teamsとOWNERSファイルの2つの異なるメカニズムに依存しています。
GitHub teams GitHubには、二つのSIG Docs
teams
カテゴリがあります:
@sig-docs-{language}-ownersは承認者かつリードです。@sig-docs-{language}-reviews はレビュアーです。それぞれをGitHubコメントの@nameで参照して、そのグループの全員とコミュニケーションできます。
ProwチームとGitHub teamsが完全に一致せずに重複する場合があります。
問題の割り当て、Pull Request、およびPR承認のサポートのために、自動化ではOWNERSファイルからの情報を使用します。
OWNERSファイルとfront-matter Kubernetesプロジェクトは、GitHubのissueとPull Requestに関連する自動化のためにprowと呼ばれる自動化ツールを使用します。
Kubernetes Webサイトリポジトリ
は、2つのprowプラグイン を使用します:
これらの2つのプラグインはkubernetes.websiteのGithubリポジトリのトップレベルにある
OWNERS ファイルと、
OWNERS_ALIASES ファイルを使用して、
リポジトリ内でのprowの動作を制御します。
OWNERSファイルには、SIG Docsのレビュー担当者および承認者であるユーザーのリストが含まれています。
OWNERSファイルはサブディレクトリに存在することもでき、そのサブディレクトリとその子孫のファイルのレビュー担当者または承認者として機能できるユーザーを上書きできます。
一般的なOWNERSファイルの詳細については、
OWNERS を参照してください。
さらに、個々のMarkdownファイルは、個々のGitHubユーザー名またはGitHubグループを一覧表示することにより、そのfront-matterでレビュー担当者と承認者を一覧表示できます。
OWNERSファイルとMarkdownファイルのfront-matterの組み合わせにより、PRの技術的および編集上のレビューを誰に依頼するかについてPRの所有者が自動化システムから得るアドバイスが決まります。
マージの仕組み Pull Requestがコンテンツの公開に使用されるブランチにマージされると、そのコンテンツは https://kubernetes.io に公開されます。
公開されたコンテンツの品質を高くするために、Pull RequestのマージはSIG Docsの承認者に限定しています。仕組みは次のとおりです。
Pull Requestにlgtmラベルとapproveラベルの両方があり、holdラベルがなく、すべてのテストに合格すると、Pull Requestは自動的にマージされます。 Kubernetes organizationのメンバーとSIG Docsの承認者はコメントを追加して、特定のPull Requestが自動的にマージされないようにすることができます(/holdコメントを追加するか、/lgtmコメントを保留します)。 Kubernetesメンバーは誰でも、/lgtmコメントを追加することでlgtmラベルを追加できます。 /approveコメントを追加してPull Requestをマージできるのは、SIG Docsの承認者だけです。一部の承認者は、PR Wrangler やSIG Docsのchairperson など、追加の特定の役割も実行します。次の項目 Kubernetesドキュメントへの貢献の詳細については、以下を参照してください:
7.6.1 - ロールと責任 誰もがKubernetesに貢献することができます。
SIG Docs へのコントリビューションが増えると、コミュニティ内で異なるレベルのメンバーシップに申請することができます。
これらの役割により、コミュニティ内でより多くの責任を担うことができます。
各役割にはより多くの時間とコミットメントが必要です。
役割は以下の通りです:
Anyone: Kubernetesドキュメントへの定期的なコントリビューター Member: Issueの割り当てとトリアージができ、Pull Requestに対する非公式なレビューができる Reviewer: ドキュメントのPull Requestのレビューをリードし、変更の品質を保証する Approver: ドキュメントのレビューをリードし、変更をマージできる Anyone GitHubのアカウントを持っている人なら誰もがKubernetesに貢献することができます。
SIG Docs はすべての新たなコントリビューターを歓迎します。
誰もが以下のことをできます:
CLA に署名 した後は、誰もが以下のことをできます:
既存のコンテンツを改善するためのPull Requestを開く、新しいコンテンツを追加する、ブログ記事やケーススタディを書く 図表やグラフィックアセット、埋め込み可能なスクリーンキャストやビデオを作成する 詳細については、新しいコンテンツの貢献 を参照してください。
Member Memberは、kubernetes/websiteに複数のPull Requestを作成した人です。
MemberはKubernetes GitHub organization の一員です。
Memberは以下のことをできます:
Anyone に列挙されているすべてのことを行う
/lgtmコメントを使用して、Pull RequestにLGTM (looks good to me)ラベルを追加する
備考: /lgtmを使用すると、自動化がトリガーされます。
非公式に承認したい場合は、"LGTM"とコメントするだけでも大丈夫です!/holdコメントを使用して、Pull Requestのマージをブロックする
/assignコメントを使用して、Pull RequestにReviewerを割り当てる
Pull Requestに非公式なレビューを提供する
自動化を使用してIssueをトリアージし、分類する
新機能をドキュメント化する
Memberになる 少なくとも5つの実質的なPull Requestを作成し、その他の要件 を満たした後に以下のようにしてMemberになることができます:
2人のReviewer またはApprover にあなたのメンバーシップをスポンサー してもらいます。
Slackの#sig-docsチャンネル やSIG Docsのメーリングリスト でスポンサーを依頼してください。
備考: 個別のSIG Docsメンバーに直接メールやSlackのダイレクトメッセージを送らないでください。
また申請する前にスポンサーを依頼する必要があります。kubernetes/orgOrganization Membership Request のissueテンプレートを使用してください。
スポンサーにGitHub Issueのことを知らせます。以下の方法があります:
Issue内でGitHubユーザー名に言及する(@<GitHub-username>)
Slackやメールを使ってIssueのリンクを送る
スポンサーは+1の投票でリクエストを承認します。
スポンサーがリクエストを承認すると、Kubernetes GitHubの管理者があなたをメンバーとして追加します。
おめでとうございます!
メンバーシップリクエストが承認されない場合はフィードバックを受け取ります。
フィードバックに対応した後、再度申請してください。
メールアカウントでKubernetes GitHub organizationの招待を受け入れます。
備考: GitHubはアカウントのデフォルトメールアドレスに招待を送信します。Reviewer ReviewerはオープンなPull Requestのレビューを担当します。
Memberのフィードバックとは異なり、PRを作成した人はReviewerのフィードバックに対応する必要があります。
Reviewerは@kubernetes/sig-docs-{language}-reviews GitHubチームのメンバーです。
Reviewerは以下のことをできます:
Anyone およびMember に列挙されているすべてのことを行う
Pull Requestをレビューし、拘束力のあるフィードバックを提供する
備考: 拘束力のないフィードバックを提供する場合、コメントの前に"Optionally: "などのフレーズを付けてください。コード内のユーザー向けの文字列を編集する
コードコメントを改善する
SIG DocsのReviewer、あるいは特定の領域に関するドキュメントのReviewerになることができます。
Pull RequestへのReviewerの割り当て 自動化により、すべてのPull RequestにReviewerが割り当てられます。
特定の人物にレビューを依頼するには、/assign [@_github_handle]とコメントします。
割り当てられたReviewerがPRにコメントしていない場合、他のReviewerが代わりにレビューできます。
また、必要に応じて技術的なReviewerを割り当てることもできます。
/lgtmの使用LGTMは"Looks good to me"の略で、Pull Requestが技術的に正確でマージの準備が整っていることを示します。
すべてのPRには、マージするためにReviewerからの/lgtmコメントとApproverからの/approveコメントが必要です。
Reviewerからの/lgtmコメントは拘束力があり、自動化によりlgtmラベルが追加されます。
Reviewerになる 要件 を満たすと、SIG DocsのReviewerになることができます。他のSIGのReviewerは、SIG DocsでのReviewerステータスを別途申請する必要があります。
申請方法は以下の通りです:
kubernetes/websiteリポジトリのOWNERS_ALIASES ファイルのセクションに、GitHubユーザー名を追加するPull Requestを開きます。
備考: どこに追加すればよいかわからない場合は、sig-docs-en-reviewsに追加してください。
訳注: sig-docs-en-reviewsは英語版のReviewerチームです。日本語ローカライゼーションのReviewerチームに参加する場合は、sig-docs-ja-reviewsに追加してください。
PRを1人以上のSIG Docs Approverに割り当てます(ユーザー名はsig-docs-{language}-ownersに記載されています)。
承認されると、SIG Docsのリードが適切なGitHubチームに追加します。
追加されると、k8s-ci-robot が新しいPull RequestのReviewerとしてあなたを割り当て、提案します。
Approver ApproverはPull Requestをレビューし、マージするために承認します。
Approverは@kubernetes/sig-docs-{language}-owners GitHubチームのメンバーです。
Approverは以下のことをできます:
Anyone 、Member 、およびReviewer に列挙されているすべてのことを行う/approveコメントを使用してPull Requestを承認およびマージすることで、コントリビューターのコンテンツを公開するスタイルガイドの改善を提案する ドキュメントテストの改善を提案する Kubernetesのウェブサイトや他のツールの改善を提案する PRに既に/lgtmが付いている場合、またはApprover自身が/lgtmコメントを付けた場合、PRは自動的にマージされます。
SIG DocsのApproverは、追加の技術的なレビューが不要な変更にのみ/lgtmを付けるべきです。
Pull Requestの承認 ApproverとSIG DocsのリードだけがPull Requestをwebsiteリポジトリにマージすることができます。
これには一定の責任が伴います。
Approverは/approveコマンドを使用して、PRをリポジトリにマージできます。
警告: 不注意なマージはサイトを壊す可能性があるため、マージする際には慎重に行ってください。提案された変更がドキュメントコンテンツガイド に準拠していることを確認してください。
もし疑問がある場合や何か不明な点がある場合は、遠慮なく追加のレビューを依頼してください。
PRを/approveする前に、Netlifyのテストに通っていることを確認してください。
承認する前に、PRのNetlifyのページプレビューをクリックして内容が正しいことを確認してください。
週ごとのローテーションであるPR Wranglerローテーションスケジュール に参加してください。SIG DocsはすべてのApproverにこのローテーションへの参加を期待しています。詳細についてはPR wranglers を参照してください。
Approverになる 要件 を満たすと、SIG DocsのApproverになることができます。
他のSIGのApproverは、SIG DocsでのApproverステータスを別途申請する必要があります。
申請方法は以下の通りです:
kubernetes/websiteリポジトリのOWNERS_ALIASES ファイルのセクションに、自分自身を追加するPull Requestを開きます。
備考: どこに追加すればよいかわからない場合は、`sig-docs-en-owners`に追加してください。
訳注: `sig-docs-en-owners`は英語版のApproverチームです。
日本語ローカライゼーションのApproverチームに参加する場合は、`sig-docs-ja-owners`に追加してください。
PRを1人以上の現在のSIG Docs Approversに割り当てます。
承認されると、SIG Docsのリードが適切なGitHubチームに追加します。
追加されると、k8s-ci-robot が新しいPull RequestのReviewerとしてあなたを割り当て、提案します。
次の項目 7.7 - ドキュメントスタイルの概要 このセクション内のトピックでは、文章のスタイル、コンテンツの形式や構成、特にKubernetesのドキュメント特有のHugoカスタマイズの使用方法に関するガイダンスを提供します。
7.7.1 - ドキュメントコンテンツガイド このページでは、Kubernetesのドキュメント上のコンテンツのガイドラインを説明します。
許可されるコンテンツに関して疑問がある場合は、Kubernetes Slack の#sig-docsチャンネルに参加して質問してください!
Kubernetes Slackには、https://slack.k8s.io/ から参加登録ができます。
Kubernetesドキュメントの新しいコンテンツの作成に関する情報については、スタイルガイド に従ってください。
概要 ドキュメントを含むKubernetesのウェブサイトのソースは、kubernetes/website リポジトリに置かれています。
Kubernetesの主要なドキュメントはkubernetes/website/content/<language_code>/docsフォルダに置かれており、これらはKubernetesプロジェクト を対象としています。
許可されるコンテンツ Kubernetesのドキュメントにサードパーティーのコンテンツを掲載することが許されるのは、次の場合のみです。
コンテンツがKubernetesプロジェクト内のソフトウェアのドキュメントとなる場合 コンテンツがプロジェクト外のソフトウェアのドキュメントとなるが、Kubernetesを機能させるために必要である場合 コンテンツがkubernetes.ioの正規のコンテンツであるか、他の場所の正規のコンテンツへのリンクである場合 サードパーティーのコンテンツ Kubernetesのドキュメントには、Kubernetesプロジェクト(kubernetes およびkubernetes-sigs GitHub organizationsに存在するプロジェクト)の適用例が含まれています。
Kubernetesプロジェクト内のアクティブなコンテンツへのリンクは常に許可されます。
Kubernetesを機能させるためには、一部サードパーティーのコンテンツが必要です。たとえば、コンテナランタイム(containerd、CRI-O、Docker)、ネットワークポリシー (CNI plugin)、Ingressコントローラー 、ロギング などです。
ドキュメント内で、Kubernetesプロジェクト外のサードパーティーのオープンソースソフトウェア(OSS)にリンクすることができるのは、Kubernetesを機能させるために必要な場合のみです。
情報源が重複するコンテンツ 可能な限り、Kubernetesのドキュメントは正規の情報源にリンクするようにし、情報源が重複してしまうようなホスティングは行いません。
情報源が重複したコンテンツは、メンテナンスするために2倍の労力(あるいはそれ以上!)が必要になり、より早く情報が古くなってしまいます。
その他の情報 許可されるコンテンツに関して疑問がある場合は、Kubernetes Slack の#sig-docsチャンネルに参加して質問してください!
次の項目 7.7.2 - コンテンツの構造化 このサイトではHugoを使用しています。Hugoでは、コンテンツの構造化 がコアコンセプトとなっています。
備考: Hugoのヒント: コンテンツの編集を始めるときは、hugo server --navigateToChangedコマンドを使用してHugoを実行してください。ページの一覧 ページの順序 ドキュメントのサイドメニューやページブラウザーなどでは、Hugoのデフォルトのソート順序を使用して一覧を作成しています。デフォルトでは、weight(1から開始)、日付(最新のものが1番目)、最後にリンクのタイトルの順でソートされます。
そのため、特定のページやセッションを上に移動したい場合には、ページのフロントマター内のweightを設定します。
title : My Page
weight : 10
備考: ページのweightについては、1、2、3…などの値を使用せず、10、20、30…のように一定の間隔を空けた方が賢明です。こうすることで、後で別のページを間に挿入できるようになります。さらに、同じディレクトリ(セクション)内の各ページのweightは、重複しないようにする必要があります。これにより、特にローカライズされたコンテンツでは、コンテンツが常に正しく整列されるようになります。ドキュメントのメインメニュー ドキュメントのメインメニューは、docs/以下に置かれたセクションのコンテンツファイル_index.mdのフロントマター内にmain_menuフラグが設定されたものから生成されます。
リンクのタイトルは、ページのlinkTitleから取得されることに注意してください。そのため、ページのタイトルとは異なるリンクテキストにしたい場合、コンテンツファイル内の値を以下のように設定します。
main_menu : true
title : ページタイトル
linkTitle : リンク内で使われるタイトル
備考: 上記の設定は言語ごとに行う必要があります。メニュー上にセクションが表示されないときは、Hugoからセクションとして認識されていないためである可能性が高いです。セクションフォルダー内に_index.mdコンテンツファイルを作成してください。ドキュメントのサイドメニュー ドキュメントのサイドバーメニューは、docs/以下の現在のセクションツリー から生成されます。
セクションと、そのセクション内のページがすべて表示されます。
特定のセクションやページをリストに表示したくない場合、フロントマター内のtoc_hideフラグをtrueに設定してください。
コンテンツが存在するセクションに移動すると、特定のセクションまたはページ(例:index.md)が表示されます。それ以外の場合、そのセクションの最初のページが表示されます。
ドキュメントのブラウザー ドキュメントのホームページのページブラウザーは、docsセクション直下のすべてのセクションとページを使用して生成されています。
特定のセクションやページを表示したくない場合、フロントマターのtoc_hideフラグをtrueに設定してください。
メインメニュー 右上のメニュー(およびフッター)にあるサイトリンクは、page-lookupの機能を使用して実装されています。これにより、ページが実際に存在することを保証しています。そのため、たとえばcase-studiesのセクションが特定の言語のサイトに存在しない場合、メニューにはケーススタディのリンクが表示されません。
Page Bundle スタンドアローンのコンテンツページ(Markdownファイル)に加えて、Hugoでは、Page Bundles がサポートされています。
Page Bundleの1つの例は、カスタムのHugo Shortcode です。これは、leaf bundleであると見做されます。ディレクトリ内のすべてのファイルは、index.mdを含めてバンドルの一部となります。これには、ページからの相対リンク、処理可能な画像なども含まれます。
en/docs/home/contribute/includes
├── example1.md
├── example2.md
├── index.md
└── podtemplate.json
もう1つのPage Bundleがよく使われる例は、includesバンドルです。フロントマターにheadless: trueを設定すると、自分自身のURLを持たなくなり、他のページ内でのみ使用されるようになります。
en/includes
├── default-storage-class-prereqs.md
├── index.md
├── partner-script.js
├── partner-style.css
├── task-tutorial-prereqs.md
├── user-guide-content-moved.md
└── user-guide-migration-notice.md
バンドル内のファイルに関して、いくつか重要な注意点があります。
翻訳されたバンドルに対しては、コンテンツ以外の見つからなかったファイルは上位の言語から継承されます。これにより重複が回避できます。 バンドル内のすべてのファイルは、HugoがResourcesと呼ぶファイルになり、フロントマター(YAMLファイルなど)をサポートしていない場合であっても、言語ごとにパラメーターやタイトルなどのメタデータを提供できます。詳しくは、Page Resourcesメタデータ を参照してください。 Resourceの.RelPermalinkから取得した値は、ページからの相対的なものとなっています。詳しくは、Permalinks を参照してください。スタイル このサイトのスタイルシートのSASS のソースは、assets/sassに置かれていて、Hugoによって自動的にビルドされます。
次の項目 7.7.3 - カスタムHugoショートコード このページではKubernetesのマークダウンドキュメント内で使用できるHugoショートコードについて説明します。
ショートコードについての詳細はHugoのドキュメント を読んでください。
機能の状態 このサイトのマークダウンページ(.mdファイル)内では、説明されている機能のバージョンや状態を表示するためにショートコードを使用することができます。
機能の状態のデモ 最新のKubernetesバージョンで機能をstableとして表示するためのデモスニペットを次に示します。
{{< feature-state state="stable" >}}
これは次の様に表示されます:
FEATURE STATE:
Kubernetes v1.35 [stable]
stateの値として妥当な値は次のいずれかです:
alpha beta deprecated stable 機能の状態コード 表示されるKubernetesのバージョンのデフォルトはそのページのデフォルトまたはサイトのデフォルトです。
for_k8s_versionパラメーターを渡すことにより、機能の状態バージョンを変更することができます。
例えば:
{{< feature-state for_k8s_version="v1.10" state="beta" >}}
これは次の様に表示されます:
FEATURE STATE:
Kubernetes v1.10 [beta]
用語集 用語集に関連するショートコードとして、glossary_tooltipとglossary_definitionの二つがあります。
コンテンツを自動的に更新し、用語集 へのリンクを付与する挿入を使用して、用語を参照することができます。
用語がマウスオーバーされると、用語集の内容がツールチップとして表示されます。
また、用語はリンクとして表示されます。
ツールチップの挿入と同様に、用語集の定義も再利用することができます。
用語集の用語データはglossaryディレクトリ に、それぞれの用語のファイルとして保存されています。
用語集のデモ 例えば、マークダウン内でツールチップ付きのcluster を表示するには、次の挿入を使用します:
{{< glossary_tooltip text="cluster" term_id="cluster" >}}
用語集の定義はこのようにします:
{{< glossary_definition prepend="A cluster is" term_id="cluster" length="short" >}}
これは次の様に表示されます:
A cluster is コンテナ化されたアプリケーションを実行する、ノード と呼ばれるワーカーマシンの集合です。すべてのクラスターには少なくとも1つのワーカーノードがあります。
完全な用語定義を挿入することもできます:
{{< glossary_definition term_id="cluster" length="all" >}}
これは次の様に表示されます:
コンテナ化されたアプリケーションを実行する、ノード と呼ばれるワーカーマシンの集合です。すべてのクラスターには少なくとも1つのワーカーノードがあります。
ワーカーノードは、アプリケーションのコンポーネントであるPodをホストします。マスターノードは、クラスター内のワーカーノードとPodを管理します。複数のマスターノードを使用して、クラスターにフェイルオーバーと高可用性を提供します。
ワーカーノードは、アプリケーションワークロードのコンポーネントであるPod をホストします。コントロールプレーン は、クラスター内のワーカーノードとPodを管理します。本番環境では、コントロールプレーンは複数のコンピューターを使用し、クラスターは複数のノードを使用し、耐障害性や高可用性を提供します。
APIリファレンスへのリンク api-referenceショートコードを使用することで、Kubernetes APIリファレンスへのリンクを作成することができます。
例えば、
Pod への参照方法は次の通りです:
{{< api-reference page="workload-resources/pod-v1" >}}
pageパラメーターの値はAPIリファレンスページのURLの末尾です。
anchorパラメーターを指定することでページ内の特定の場所へリンクすることもできます。
例えば、
PodSpec や
environment-variables へのリンクは次の様に書きます:
{{< api-reference page="workload-resources/pod-v1" anchor="PodSpec" >}}
{{< api-reference page="workload-resources/pod-v1" anchor="environment-variables" >}}
textパラメーターを指定することでリンクテキストを変更することもできます。
例えば、
Environment Variables へのリンクは次の様に書きます:
{{< api-reference page="workload-resources/pod-v1" anchor="environment-variables" text="Environment Variable" >}}
テーブルキャプション テーブルキャプションを追加することで、表をスクリーンリーダーにとってよりアクセスしやすいものにする事ができます。
表へキャプション を追加するには、表をtableショートコードで囲い、captionパラメーターにキャプションを指定します。
備考: テーブルキャプションはスクリーンリーダーからは読むことができますが、標準的なHTMLでは読むことができません。例えば、次の様に書きます:
{{ < table caption= "Configuration parameters" > }}
Parameter | Description | Default
:---------|:------------|:-------
`timeout` | The timeout for requests | `30s`
`logLevel` | The log level for log output | `INFO`
{{ < / table > }}
これは次の様に表示されます:
Configuration parameters Parameter Description Default timeoutThe timeout for requests 30slogLevelThe log level for log output INFO
この表に対するHTMLを検査すると、次の要素が<table>要素のすぐ次にあるのを見ることができるでしょう:
<caption style = "display: none;" >Configuration parameters</caption >
タブ このサイトのマークダウンページ(.mdファイル)内では、あるソリューションに対する複数のフレーバーを表示するためのタブセットを追加することができます。
tabsショートコードはこれらのパラメーターを受けとります:
name: タブに表示される名前codelang: 内側のtabショートコードにこれを指定した場合、Hugoはハイライトに使用するコード言語を知ることができます。include: タブ内で挿入するファイル。Hugo leaf bundle 内にタブがある場合そのファイル(HugoがサポートしているどのMIMEタイプでも良い)はそのbundle自身によって探されます。
もしそうでない場合、そのコンテントページは現在のページから相対的に探されます。
includeを使う場合、ショートコードの内部コンテンツはなく、自己終了構文を使用する必要があることに注意してください。
例えば、{{< tab name="Content File #1" include="example1" />}}の様にします。
codelangを指定するか、ファイル名から言語が特定される必要があります。
非コンテンツファイルはデフォルトでコードが強調表示されます。もし内部コンテンツがマークダウンの場合、タブの周りに%デリミターを使用する必要があります。
例えば、{{% tab name="Tab 1" %}}This is **markdown**{{% /tab %}}の様にします。 タブセット内で、上記で説明したバリエーションを組み合わせることができます。 タブショートコードの例を次に示します。
備考: tabs定義内のname はコンテンツページ内でユニークである必要があります。タブのデモ: コードハイライト {{ < tabs name= "tab_with_code" > }}
{{ {< tab name= "Tab 1" codelang= "bash" > }}
echo "これはタブ1です。"
{{ < / tab > }}
{{ < tab name= "Tab 2" codelang= "go" > }}
println "これはタブ2です。"
{{ < / tab > }} }
{{ < / tabs > }}
これは次の様に表示されます:
タブのデモ: インラインマークダウンとHTML {{ < tabs name= "tab_with_md" > }}
{{ % tab name= "Markdown" % }}
これは**なにがしかのマークダウン**です。
{{ < note > }}
ショートコードを含むこともできます。
{{ < / note > }}
{{ % / tab % }}
{{ < tab name= "HTML" > }}
<div >
<h3 >プレーンHTML</h3 >
<p >これはなにがしかの<i >プレーン</i >HTMLです。</p >
</div >
{{ < / tab > }}
{{ < / tabs > }}
これは次の様に表示されます。
これはなにがしかのマークダウン です。
備考: ショートコードを含むこともできます。
プレーンHTML これはなにがしかのプレーン HTMLです。
タブのデモ: ファイルの読み込み {{ < tabs name= "tab_with_file_include" > }}
{{ < tab name= "Content File #1" include= "example1" /> }}
{{ < tab name= "Content File #2" include= "example2" /> }}
{{ < tab name= "JSON File" include= "podtemplate" /> }}
{{ < / tabs > }}
これは次の様に表示されます:
これは挿入 leaf bundle内のコンテンツファイルの例 です。
備考: 挿入されたコンテンツファイル内でもショートコードを使用することができます。
これは挿入 leaf bundle内のコンテンツファイルのもう一つの例 です
{
"apiVersion" : "v1" ,
"kind" : "PodTemplate" ,
"metadata" : {
"name" : "nginx"
},
"template" : {
"metadata" : {
"labels" : {
"name" : "nginx"
},
"generateName" : "nginx-"
},
"spec" : {
"containers" : [{
"name" : "nginx" ,
"image" : "dockerfile/nginx" ,
"ports" : [{"containerPort" : 80 }]
}]
}
}
}
サードパーティーコンテンツマーカー Kubernetesの実行にはサードパーティーのソフトウェアが必要です。
例えば、名前解決を行うためにはクラスターにDNSサーバー を追加する必要があります。
私たちがサードパーティーソフトウェアにリンクするときや言及するときは、コンテンツガイド に従い、サードパーティーのものに印をつけます。
これらのショートコードを使用すると、それらを使用しているドキュメントページに免責事項が追加されます。
リスト サードパーティーのリストには、
{{% thirdparty-content %}}
をすべてのアイテムを含むセクションのヘッダーのすぐ下に追加します。
アイテム ほとんどのアイテムがプロジェクト内ソフトウェア(例えばKubernetes自体やDescheduler コンポーネント)を参照している場合、違う形を使用することができます。
次のショートコードをアイテムの前か、特定のアイテムのヘッダーのすぐ下に追加します:
{{% thirdparty-content single="true" %}}
バージョン文字列 ドキュメント内でバージョン文字列を生成して挿入するために、いくつかのバージョンショートコードから選んで使用することができます。
それぞれのバージョンショートコードはサイトの設定ファイル(hugo.toml)から取得したバージョンパラメーターの値を使用してバージョン文字列を表示します。
最もよく使われる二つのバージョンパラメーターはlatestとversionです。
{{< param "version" >}}{{< param "version" >}}ショートコードはサイトのversionパラメーターに設定されたKubernetesドキュメントの現在のバージョンを生成します。
paramショートコードはサイトパラメーターの名前の一つを受けとり、この場合はversionを渡しています。
備考: 以前にリリースされたドキュメントではlatestとversionの値は同じではありません。
新しいバージョンがリリースされると、latestはインクリメントされ、versionは変更されません。
例えば、以前にリリースされたドキュメントはversionをv1.19として表示し、latestをv1.20として表示します。これは次の様に表示されます:
v1.35
{{< latest-version >}}{{< latest-version >}}ショートコードはサイトのlatestパラメーターの値を返します。
サイトのlatestパラメーターは新しいドキュメントのバージョンがリリースされた時に更新されます。
このパラメーターは必ずしもversionの値と一致しません。
これは次の様に表示されます:
v1.35
{{< latest-semver >}}{{< latest-semver >}}ショートコードはlatestから"v"接頭辞を取り除いた値を生成します。
これは次の様に表示されます。
1.35
{{< version-check >}}{{< version-check >}}ショートコードはページにmin-kubernetes-server-versionパラメーターがあるかどうか確認し、versionと比較するために使用します。
これは次の様に表示されます:
バージョンを確認するには次のコマンドを実行してください: kubectl version.
{{< latest-release-notes >}}{{< latest-release-notes >}}ショートコードはlatestからバージョン文字列を生成し、"v"接頭辞を取り除きます。
このショートコードはバージョン文字列に対応したリリースノートCHANGELOGページのURLを表示します。
これは次の様に表示されます:
https://git.k8s.io/kubernetes/CHANGELOG/CHANGELOG-1.35.md
次の項目