スケジューリング、プリエンプションと退避
Kubernetesにおいてスケジューリングとは、稼働させたいPodをノードにマッチさせ、kubeletが実行できるようにすることを指します。 プリエンプションは、優先度の低いPodを終了させて、より優先度の高いPodがノード上でスケジュールできるようにするプロセスです。 退避(eviction)とは、リソース不足のノードで1つ以上のPodを積極的に終了させるプロセスです。
Kubernetesにおいてスケジューリングとは、稼働させたいPodをノードにマッチさせ、kubeletが実行できるようにすることを指します。
プリエンプションは、優先度の低いPodを終了させて、より優先度の高いPodがノード上でスケジュールできるようにするプロセスです。
退避とは、リソース不足のノードで1つ以上のPodを積極的に終了させるプロセスです。
スケジューリング
Pod Disruption
1 - Kubernetesのスケジューラー
Kubernetesにおいて、スケジューリング とは、KubeletがPodを稼働させるためにNodeに割り当てることを意味します。
スケジューリングの概要
スケジューラーは新規に作成されたPodで、Nodeに割り当てられていないものを監視します。スケジューラーは発見した各Podのために、稼働させるべき最適なNodeを見つけ出す責務を担っています。そのスケジューラーは下記で説明するスケジューリングの原理を考慮に入れて、NodeへのPodの割り当てを行います。
Podが特定のNodeに割り当てられる理由を理解したい場合や、カスタムスケジューラーを自身で作ろうと考えている場合、このページはスケジューリングに関して学ぶのに役立ちます。
kube-scheduler
kube-schedulerはKubernetesにおけるデフォルトのスケジューラーで、コントロールプレーンの一部分として稼働します。
kube-schedulerは、もし希望するのであれば自分自身でスケジューリングのコンポーネントを実装でき、それを代わりに使用できるように設計されています。
kube-schedulerは、新規に作成された各Podや他のスケジューリングされていないPodを稼働させるために最適なNodeを選択します。
しかし、Pod内の各コンテナにはそれぞれ異なるリソースの要件があり、各Pod自体にもそれぞれ異なる要件があります。そのため、既存のNodeは特定のスケジューリング要求によってフィルターされる必要があります。
クラスター内でPodに対する割り当て要求を満たしたNodeは 割り当て可能 なNodeと呼ばれます。
もし適切なNodeが一つもない場合、スケジューラーがNodeを割り当てることができるまで、そのPodはスケジュールされずに残ります。
スケジューラーはPodに対する割り当て可能なNodeをみつけ、それらの割り当て可能なNodeにスコアをつけます。その中から最も高いスコアのNodeを選択し、Podに割り当てるためのいくつかの関数を実行します。
スケジューラーは binding と呼ばれる処理中において、APIサーバーに対して割り当てが決まったNodeの情報を通知します。
スケジューリングを決定する上で考慮が必要な要素としては、個別または複数のリソース要求や、ハードウェア/ソフトウェアのポリシー制約、affinityやanti-affinityの設定、データの局所性や、ワークロード間での干渉などが挙げられます。
kube-schedulerによるスケジューリング
kube-schedulerは2ステップの操作によってPodに割り当てるNodeを選択します。
フィルタリング
スコアリング
フィルタリング ステップでは、Podに割り当て可能なNodeのセットを探します。例えばPodFitsResourcesフィルターは、Podのリソース要求を満たすのに十分なリソースをもつNodeがどれかをチェックします。このステップの後、候補のNodeのリストは、要求を満たすNodeを含みます。
たいてい、リストの要素は複数となります。もしこのリストが空の場合、そのPodはスケジュール可能な状態とはなりません。
スコアリング ステップでは、Podを割り当てるのに最も適したNodeを選択するために、スケジューラーはリストの中のNodeをランク付けします。
スケジューラーは、フィルタリングによって選ばれた各Nodeに対してスコアを付けます。このスコアはアクティブなスコア付けのルールに基づいています。
最後に、kube-schedulerは最も高いランクのNodeに対してPodを割り当てます。もし同一のスコアのNodeが複数ある場合は、kube-schedulerがランダムに1つ選択します。
スケジューラーのフィルタリングとスコアリングの動作に関する設定には2つのサポートされた手法があります。
- スケジューリングポリシー は、フィルタリングのための Predicates とスコアリングのための Priorities の設定することができます。
- スケジューリングプロファイルは、
QueueSort、 Filter、 Score、 Bind、 Reserve、 Permitやその他を含む異なるスケジューリングの段階を実装するプラグインを設定することができます。kube-schedulerを異なるプロファイルを実行するように設定することもできます。
次の項目
2 - ノード上へのPodのスケジューリング
Podを特定のノードで実行するように 制限 したり、特定のノードで実行することを 優先 させたりといった制約をかけることができます。
これを実現するためにはいくつかの方法がありますが、推奨されている方法は、すべてラベルセレクターを使用して選択を容易にすることです。
多くの場合、このような制約を設定する必要はなく、スケジューラーが自動的に妥当な配置を行います(例えば、Podを複数のノードに分散させ、空きリソースが十分でないノードにPodを配置しないようにすることができます)。
しかし、例えばSSDが接続されているノードにPodが配置されるようにしたり、多くの通信を行う2つの異なるサービスのPodを同じアベイラビリティーゾーンに配置したりする等、どのノードに配置するかを制御したい状況もあります。
Kubernetesが特定のPodの配置場所を選択するために、以下の方法があります:
ノードラベル
他の多くのKubernetesオブジェクトと同様に、ノードにもラベルがあります。手動でラベルを付けることができます。
また、Kubernetesはクラスター内のすべてのノードに対し、いくつかの標準ラベルを付けます。ノードラベルの一覧についてはよく使われるラベル、アノテーションとtaintを参照してください。
備考:
これらのラベルの値はクラウドプロバイダー固有のもので、信頼性を保証できません。
例えば、kubernetes.io/hostnameの値はある環境ではノード名と同じになり、他の環境では異なる値になることがあります。ノードの分離/制限
ノードにラベルを追加することで、Podを特定のノードまたはノードグループ上でのスケジューリングの対象にすることができます。この機能を使用すると、特定のPodが一定の独立性、安全性、または規制といった属性を持ったノード上でのみ実行されるようにすることができます。
ノード分離するのにラベルを使用する場合、kubeletが修正できないラベルキーを選択してください。
これにより、侵害されたノードが自身でそれらのラベルを設定することで、スケジューラーがそのノードにワークロードをスケジュールしてしまうのを防ぐことができます。
NodeRestrictionアドミッションプラグインは、kubeletがnode-restriction.kubernetes.io/というプレフィックスを持つラベルを設定または変更するのを防ぎます。
ラベルプレフィックスをNode分離に利用するには:
- ノード認可を使用していることと、
NodeRestriction アドミッションプラグインが 有効 になっていることを確認します。 node-restriction.kubernetes.io/プレフィックスを持つラベルをノードに追加し、 nodeSelectorでそれらのラベルを使用します。
例えば、example.com.node-restriction.kubernetes.io/fips=trueやexample.com.node-restriction.kubernetes.io/pci-dss=trueなどです。
nodeSelector
nodeSelectorは、ノード選択制約の中で最もシンプルな推奨形式です。
Podのspec(仕様)にnodeSelectorフィールドを追加することで、ターゲットノードが持つべきノードラベルを指定できます。
Kubernetesは指定された各ラベルを持つノードにのみ、Podをスケジューリングします。
詳しい情報についてはPodをノードに割り当てるを参照してください。
アフィニティとアンチアフィニティ
nodeSelectorはPodを特定のラベルが付与されたノードに制限する最も簡単な方法です。
アフィニティとアンチアフィニティでは、定義できる制約の種類が拡張されています。
アフィニティとアンチアフィニティのメリットは以下の通りです。
- アフィニティとアンチアフィニティで使われる言語は、より表現力が豊かです。
nodeSelectorは指定されたラベルを全て持つノードを選択するだけです。アフィニティとアンチアフィニティは選択ロジックをより細かく制御することができます。 - ルールが柔軟であったり優先での指定ができたりするため、一致するノードが見つからない場合でも、スケジューラーはPodをスケジュールします。
- ノード自体のラベルではなく、ノード(または他のトポロジカルドメイン)上で稼働している他のPodのラベルを使ってPodを制約することができます。これにより、ノード上にどのPodを共存させるかのルールを定義することができます。
アフィニティ機能は、2種類のアフィニティで構成されています:
- ノードアフィニティは
nodeSelectorフィールドと同様に機能しますが、より表現力が豊かで、より柔軟にルールを指定することができます。 - Pod間アフィニティとアンチアフィニティは、他のPodのラベルを元に、Podを制約することができます。
ノードアフィニティ
ノードアフィニティは概念的には、ノードのラベルによってPodがどのノードにスケジュールされるかを制限するnodeSelectorと同様です。
ノードアフィニティには2種類あります:
requiredDuringSchedulingIgnoredDuringExecution:
スケジューラーは、ルールが満たされない限り、Podをスケジュールすることができません。これはnodeSelectorと同じように機能しますが、より表現力豊かな構文になっています。preferredDuringSchedulingIgnoredDuringExecution:
スケジューラーは、対応するルールを満たすノードを探そうとします。 一致するノードが見つからなくても、スケジューラーはPodをスケジュールします。
備考:
上記の2種類にあるIgnoredDuringExecutionは、KubernetesがPodをスケジュールした後にノードラベルが変更されても、Podは実行し続けることを意味します。Podのspec(仕様)にある.spec.affinity.nodeAffinityフィールドを使用して、ノードアフィニティを指定することができます。
例えば、次のようなPodのspec(仕様)を考えてみましょう:
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- antarctica-east1
- antarctica-west1
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: registry.k8s.io/pause:2.0
この例では、以下のルールが適用されます:
- ノードには
topology.kubernetes.io/zoneをキーとするラベルが必要で、そのラベルの値はantarctica-east1またはantarctica-west1のいずれかでなければなりません。 - ノードにはキー名が
another-node-label-keyで、値がanother-node-label-valueのラベルを持つことが望ましいです。
operatorフィールドを使用して、Kubernetesがルールを解釈する際に使用できる論理演算子を指定することができます。In、NotIn、Exists、DoesNotExist、Gt、Ltが使用できます。
NotInとDoesNotExistを使って、ノードのアンチアフィニティ動作を定義することができます。また、ノードのTaintを使用して、特定のノードからPodをはじくこともできます。
備考:
nodeSelectorとnodeAffinityの両方を指定した場合、両方の条件を満たさないとPodはノードにスケジュールされません。
nodeAffinityタイプに関連付けられたnodeSelectorTerms内に、複数の条件を指定した場合、Podは指定した条件のいずれかを満たしたノードへスケジュールされます(条件はORされます)。
nodeSelectorTerms内の条件に関連付けられた1つのmatchExpressionsフィールド内に、複数の条件を指定した場合、Podは全ての条件を満たしたノードへスケジュールされます(条件はANDされます)。
詳細についてはノードアフィニティを利用してPodをノードに割り当てるを参照してください。
ノードアフィニティの重み
preferredDuringSchedulingIgnoredDuringExecutionアフィニティタイプの各インスタンスに、1から100の範囲のweightを指定できます。
Podの他のスケジューリング要件をすべて満たすノードを見つけると、スケジューラーはそのノードが満たすすべての優先ルールを繰り返し実行し、対応する式のweight値を合計に加算します。
最終的な合計は、そのノードの他の優先度関数のスコアに加算されます。合計スコアが最も高いノードが、スケジューラーがPodのスケジューリングを決定する際に優先されます。
例えば、次のようなPodのspec(仕様)を考えてみましょう:
apiVersion: v1
kind: Pod
metadata:
name: with-affinity-anti-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: label-1
operator: In
values:
- key-1
- weight: 50
preference:
matchExpressions:
- key: label-2
operator: In
values:
- key-2
containers:
- name: with-node-affinity
image: registry.k8s.io/pause:2.0
preferredDuringSchedulingIgnoredDuringExecutionルールにマッチするノードとして、一つはlabel-1:key-1ラベル、もう一つはlabel-2:key-2ラベルの2つの候補がある場合、スケジューラーは各ノードのweightを考慮し、その重みとノードの他のスコアを加え、最終スコアが最も高いノードにPodをスケジューリングします。
備考:
この例でKubernetesにPodを正常にスケジュールさせるには、kubernetes.io/os=linuxラベルを持つ既存のノードが必要です。スケジューリングプロファイルごとのノードアフィニティ
FEATURE STATE:
Kubernetes v1.20 [beta]
複数のスケジューリングプロファイルを設定する場合、プロファイルにノードアフィニティを関連付けることができます。これは、プロファイルが特定のノード群にのみ適用される場合に便利です。スケジューラーの設定にあるNodeAffinityプラグインのargsフィールドにaddedAffinityを追加すると実現できます。例えば:
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
- schedulerName: foo-scheduler
pluginConfig:
- name: NodeAffinity
args:
addedAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: scheduler-profile
operator: In
values:
- foo
addedAffinityは、Podの仕様(spec)で指定されたノードアフィニティに加え、.spec.schedulerNameをfoo-schedulerに設定したすべてのPodに適用されます。つまり、Podにマッチするためには、ノードはaddedAffinityとPodの.spec.NodeAffinityを満たす必要があるのです。
addedAffinityはエンドユーザーには見えないので、その動作はエンドユーザーにとって予期しないものになる可能性があります。スケジューラープロファイル名と明確な相関関係のあるノードラベルを使用すべきです。
備考:
DaemonSetのPodを作成するDaemonSetコントローラーは、スケジューリングプロファイルをサポートしていません。DaemonSetコントローラーがPodを作成すると、デフォルトのKubernetesスケジューラーがそれらのPodを配置し、DaemonSetコントローラーの
nodeAffinityルールに優先して従います。
Pod間のアフィニティとアンチアフィニティ
Pod間のアフィニティとアンチアフィニティは、ノードのラベルではなく、すでにノード上で稼働しているPodのラベルに従って、Podがどのノードにスケジュールされるかを制限できます。
Xはノードや、ラック、クラウドプロバイダーのゾーンやリージョン等を表すトポロジードメインで、YはKubernetesが満たそうとするルールである場合、Pod間のアフィニティとアンチアフィニティのルールは、"XにてルールYを満たすPodがすでに稼働している場合、このPodもXで実行すべき(アンチアフィニティの場合はすべきではない)"という形式です。
これらのルール(Y)は、オプションの関連する名前空間のリストを持つラベルセレクターで表現されます。PodはKubernetesの名前空間オブジェクトであるため、Podラベルも暗黙的に名前空間を持ちます。Kubernetesが指定された名前空間でラベルを探すため、Podラベルのラベルセレクターは、名前空間を指定する必要があります。
トポロジードメイン(X)はtopologyKeyで表現され、システムがドメインを示すために使用するノードラベルのキーになります。具体例はよく知られたラベル、アノテーションとTaintを参照してください。
備考:
Pod間アフィニティとアンチアフィニティはかなりの処理量を必要とするため、大規模クラスターでのスケジューリングが大幅に遅くなる可能性があります
そのため、数百台以上のノードから成るクラスターでの使用は推奨されません。備考:
Podのアンチアフィニティは、ノードに必ず一貫性の持つラベルが付与されている必要があります。
言い換えると、クラスターの全てのノードが、topologyKeyに合致する適切なラベルが必要になります。
一部、または全部のノードにtopologyKeyラベルが指定されていない場合、意図しない挙動に繋がる可能性があります。Pod間のアフィニティとアンチアフィニティの種類
ノードアフィニティと同様に、Podアフィニティとアンチアフィニティにも下記の2種類があります:
requiredDuringSchedulingIgnoredDuringExecutionpreferredDuringSchedulingIgnoredDuringExecution
例えば、requiredDuringSchedulingIgnoredDuringExecutionアフィニティを使用して、2つのサービスのPodはお互いのやり取りが多いため、同じクラウドプロバイダーゾーンに併置するようにスケジューラーに指示することができます。
同様に、preferredDuringSchedulingIgnoredDuringExecutionアンチアフィニティを使用して、あるサービスのPodを複数のクラウドプロバイダーゾーンに分散させることができます。
Pod間アフィニティを使用するには、Pod仕様(spec)のaffinity.podAffinityフィールドで指定します。Pod間アンチアフィニティを使用するには、Pod仕様(spec)のaffinity.podAntiAffinityフィールドで指定します。
Podアフィニティ使用例
次のようなPod仕様(spec)を考えてみましょう:
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: topology.kubernetes.io/zone
containers:
- name: with-pod-affinity
image: registry.k8s.io/pause:2.0
この例では、PodアフィニティルールとPodアンチアフィニティルールを1つずつ定義しています。
Podアフィニティルールは"ハード"なrequiredDuringSchedulingIgnoredDuringExecutionを使用し、アンチアフィニティルールは"ソフト"なpreferredDuringSchedulingIgnoredDuringExecutionを使用しています。
アフィニティルールは、スケジューラーがノードにPodをスケジュールできるのは、そのノードが、security=S1ラベルを持つ1つ以上の既存のPodと同じゾーンにある場合のみであることを示しています。より正確には、現在Podラベルsecurity=S1を持つPodが1つ以上あるノードが、そのゾーン内に少なくとも1つ存在する限り、スケジューラーはtopology.kubernetes.io/zone=Vラベルを持つノードにPodを配置しなければなりません。
アンチアフィニティルールは、security=S2ラベルを持つ1つ以上のPodと同じゾーンにあるノードには、スケジューラーがPodをスケジュールしないようにすることを示しています。より正確には、PodラベルSecurity=S2を持つPodが稼働している他のノードが、同じゾーン内に存在する場合、スケジューラーはtopology.kubernetes.io/zone=Rラベルを持つノードにはPodを配置しないようにしなければなりません。
Podアフィニティとアンチアフィニティの使用例についてもっと知りたい方はデザイン案を参照してください。
Podアフィニティとアンチアフィニティのoperatorフィールドで使用できるのは、In、NotIn、 Exists、 DoesNotExistです。
原則として、topologyKeyには任意のラベルキーが指定できますが、パフォーマンスやセキュリティの観点から、以下の例外があります:
- Podアフィニティとアンチアフィニティでは、
requiredDuringSchedulingIgnoredDuringExecutionとpreferredDuringSchedulingIgnoredDuringExecution内のどちらも、topologyKeyフィールドが空であることは許可されていません。 - Podアンチアフィニティルールの
requiredDuringSchedulingIgnoredDuringExecutionでは、アドミッションコントローラーLimitPodHardAntiAffinityTopologyがtopologyKeyをkubernetes.io/hostnameに制限しています。アドミッションコントローラーを修正または無効化すると、トポロジーのカスタマイズができるようになります。
labelSelectorとtopologyKeyに加え、labelSelectorとtopologyKeyと同じレベルのnamespacesフィールドを使用して、labelSelectorが合致すべき名前空間のリストを任意に指定することができます。省略または空の場合、namespacesがデフォルトで、アフィニティとアンチアフィニティが定義されたPodの名前空間に設定されます。
名前空間セレクター
FEATURE STATE:
Kubernetes v1.24 [stable]
namespaceSelectorを使用し、ラベルで名前空間の集合に対して検索することによって、名前空間を選択することができます。
アフィニティ項はnamespaceSelectorとnamespacesフィールドによって選択された名前空間に適用されます。
要注意なのは、空のnamespaceSelector({})はすべての名前空間にマッチし、nullまたは空のnamespacesリストとnullのnamespaceSelectorは、ルールが定義されているPodの名前空間にマッチします。
実践的なユースケース
Pod間アフィニティとアンチアフィニティは、ReplicaSet、StatefulSet、Deploymentなどのより高レベルなコレクションと併せて使用するとさらに有用です。これらのルールにより、ワークロードのセットが同じ定義されたトポロジーに併置されるように設定できます。たとえば、2つの関連するPodを同じノードに配置することが好ましい場合です。
例えば、3つのノードで構成されるクラスターを想像してください。そのクラスターを使用してウェブアプリケーションを実行し、さらにインメモリーキャッシュ(Redisなど)を使用します。この例では、ウェブアプリケーションとメモリーキャッシュの間のレイテンシーは実用的な範囲の低さも想定しています。Pod間アフィニティやアンチアフィニティを使って、ウェブサーバーとキャッシュをなるべく同じ場所に配置することができます。
以下のRedisキャッシュのDeploymentの例では、各レプリカはラベルapp=storeが付与されています。podAntiAffinityルールは、app=storeラベルを持つ複数のレプリカを単一ノードに配置しないよう、スケジューラーに指示します。これにより、各キャッシュが別々のノードに作成されます。
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-cache
spec:
selector:
matchLabels:
app: store
replicas: 3
template:
metadata:
labels:
app: store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: redis-server
image: redis:3.2-alpine
次のウェブサーバーのDeployment例では、app=web-storeラベルが付与されたレプリカを作成します。Podアフィニティルールは、各レプリカを、app=storeラベルが付与されたPodを持つノードに配置するようスケジューラーに指示します。Podアンチアフィニティルールは、1つのノードに複数のapp=web-storeサーバーを配置しないようにスケジューラーに指示します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-server
spec:
selector:
matchLabels:
app: web-store
replicas: 3
template:
metadata:
labels:
app: web-store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web-store
topologyKey: "kubernetes.io/hostname"
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: web-app
image: nginx:1.16-alpine
上記2つのDeploymentが生成されると、以下のようなクラスター構成になり、各ウェブサーバーはキャッシュと同位置に、3つの別々のノードに配置されます。
| node-1 | node-2 | node-3 |
|---|
| webserver-1 | webserver-2 | webserver-3 |
| cache-1 | cache-2 | cache-3 |
全体的な効果として、各キャッシュインスタンスは、同じノード上で実行している単一のクライアントによってアクセスされる可能性が高いです。この方法は、スキュー(負荷の偏り)とレイテンシーの両方を最小化することを目的としています。
Podアンチアフィニティを使用する理由は他にもあります。
この例と同様の方法で、アンチアフィニティを用いて高可用性を実現したStatefulSetの使用例はZooKeeperチュートリアルを参照してください。
nodeName
nodeNameはアフィニティやnodeSelectorよりも直接的なノード選択形式になります。nodeNameはPod仕様(spec)内のフィールドです。nodeNameフィールドが空でない場合、スケジューラーはPodを考慮せずに、指定されたノードにあるkubeletがそのノードにPodを配置しようとします。nodeNameを使用すると、nodeSelectorやアフィニティおよびアンチアフィニティルールを使用するよりも優先されます。
nodeNameを使ってノードを選択する場合の制約は以下の通りです:
- 指定されたノードが存在しない場合、Podは実行されず、場合によっては自動的に削除されることがあります。
- 指定されたノードがPodを収容するためのリソースを持っていない場合、Podの起動は失敗し、OutOfmemoryやOutOfcpuなどの理由が表示されます。
- クラウド環境におけるノード名は、常に予測可能で安定したものではありません。
備考:
nodeNameは、カスタムスケジューラーや、設定済みのスケジューラーをバイパスする必要がある高度なユースケースで使用することを目的としています。
スケジューラーをバイパスすると、割り当てられたノードに過剰なPodの配置をしようとした場合には、Podの起動に失敗することがあります。
ノードアフィニティまたは
nodeSelectorフィールドを使用すれば、スケジューラーをバイパスせずに、特定のノードにPodを割り当てることができます。
以下は、nodeNameフィールドを使用したPod仕様(spec)の例になります:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
nodeName: kube-01
上記のPodはkube-01というNodeでのみ実行されます。
Podトポロジー分散制約
トポロジー分散制約 を使って、リージョン、ゾーン、ノードなどの障害ドメイン間、または定義したその他のトポロジードメイン間で、クラスター全体にどのようにPodを分散させるかを制御することができます。これにより、パフォーマンス、予想される可用性、または全体的な使用率を向上させることができます。
詳しい仕組みについては、トポロジー分散制約を参照してください。
次の項目
3 - Podのオーバーヘッド
FEATURE STATE:
Kubernetes v1.24 [stable]
PodをNode上で実行する時に、Pod自身は大量のシステムリソースを消費します。これらのリソースは、Pod内のコンテナ(群)を実行するために必要なリソースとして追加されます。Podのオーバーヘッドは、コンテナの要求と制限に加えて、Podのインフラストラクチャで消費されるリソースを計算するための機能です。
Kubernetesでは、PodのRuntimeClassに関連するオーバーヘッドに応じて、アドミッション時にPodのオーバーヘッドが設定されます。
Podのオーバーヘッドを有効にした場合、Podのスケジューリング時にコンテナのリソース要求の合計に加えて、オーバーヘッドも考慮されます。同様に、Kubeletは、Podのcgroupのサイズ決定時およびPodの退役の順位付け時に、Podのオーバーヘッドを含めます。
Podのオーバーヘッドの有効化
クラスター全体でPodOverheadのフィーチャーゲートが有効になっていること(1.18時点ではデフォルトでオンになっています)と、overheadフィールドを定義するRuntimeClassが利用されていることを確認する必要があります。
使用例
Podのオーバーヘッド機能を使用するためには、overheadフィールドが定義されたRuntimeClassが必要です。例として、仮想マシンとゲストOSにPodあたり約120MiBを使用する仮想化コンテナランタイムで、次のようなRuntimeClassを定義できます。
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
name: kata-fc
handler: kata-fc
overhead:
podFixed:
memory: "120Mi"
cpu: "250m"
kata-fcRuntimeClassハンドラーを指定して作成されたワークロードは、リソースクォータの計算や、Nodeのスケジューリング、およびPodのcgroupのサイズ決定にメモリーとCPUのオーバーヘッドが考慮されます。
次のtest-podのワークロードの例を実行するとします。
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
runtimeClassName: kata-fc
containers:
- name: busybox-ctr
image: busybox:1.28
stdin: true
tty: true
resources:
limits:
cpu: 500m
memory: 100Mi
- name: nginx-ctr
image: nginx
resources:
limits:
cpu: 1500m
memory: 100Mi
アドミッション時、RuntimeClassアドミッションコントローラーは、RuntimeClass内に記述されたオーバーヘッドを含むようにワークロードのPodSpecを更新します。もし既にPodSpec内にこのフィールドが定義済みの場合、そのPodは拒否されます。この例では、RuntimeClassの名前しか指定されていないため、アドミッションコントローラーはオーバーヘッドを含むようにPodを変更します。
RuntimeClassのアドミッションコントローラーの後、更新されたPodSpecを確認できます。
kubectl get pod test-pod -o jsonpath='{.spec.overhead}'
出力は次の通りです:
map[cpu:250m memory:120Mi]
ResourceQuotaが定義されている場合、コンテナ要求の合計とオーバーヘッドフィールドがカウントされます。
kube-schedulerが新しいPodを実行すべきNodeを決定する際、スケジューラーはそのPodのオーバーヘッドと、そのPodに対するコンテナ要求の合計を考慮します。この例だと、スケジューラーは、要求とオーバーヘッドを追加し、2.25CPUと320MiBのメモリを持つNodeを探します。
PodがNodeにスケジュールされると、そのNodeのkubeletはPodのために新しいcgroupを生成します。基盤となるコンテナランタイムがコンテナを作成するのは、このPod内です。
リソースにコンテナごとの制限が定義されている場合(制限が定義されているGuaranteed QoSまたはBustrable QoS)、kubeletはそのリソース(CPUはcpu.cfs_quota_us、メモリはmemory.limit_in_bytes)に関連するPodのcgroupの上限を設定します。この上限は、コンテナの制限とPodSpecで定義されたオーバーヘッドの合計に基づきます。
CPUについては、PodがGuaranteedまたはBurstable QoSの場合、kubeletはコンテナの要求の合計とPodSpecに定義されたオーバーヘッドに基づいてcpu.shareを設定します。
次の例より、ワークロードに対するコンテナの要求を確認できます。
kubectl get pod test-pod -o jsonpath='{.spec.containers[*].resources.limits}'
コンテナの要求の合計は、CPUは2000m、メモリーは200MiBです。
map[cpu: 500m memory:100Mi] map[cpu:1500m memory:100Mi]
Nodeで観測される値と比較してみましょう。
kubectl describe node | grep test-pod -B2
出力では、2250mのCPUと320MiBのメモリーが要求されており、Podのオーバーヘッドが含まれていることが分かります。
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
default test-pod 2250m (56%) 2250m (56%) 320Mi (1%) 320Mi (1%) 36m
Podのcgroupの制限を確認
ワークロードで実行中のNode上にある、Podのメモリーのcgroupを確認します。次に示す例では、CRI互換のコンテナランタイムのCLIを提供するNodeでcrictlを使用しています。これはPodのオーバーヘッドの動作を示すための高度な例であり、ユーザーがNode上で直接cgroupsを確認する必要はありません。
まず、特定のNodeで、Podの識別子を決定します。
# PodがスケジュールされているNodeで実行
POD_ID="$(sudo crictl pods --name test-pod -q)"
ここから、Podのcgroupのパスが決定します。
# PodがスケジュールされているNodeで実行
sudo crictl inspectp -o=json $POD_ID | grep cgroupsPath
結果のcgroupパスにはPodのポーズ中コンテナも含まれます。Podレベルのcgroupは1つ上のディレクトリです。
"cgroupsPath": "/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/7ccf55aee35dd16aca4189c952d83487297f3cd760f1bbf09620e206e7d0c27a"
今回のケースでは、Podのcgroupパスは、kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2となります。メモリーのPodレベルのcgroupの設定を確認しましょう。
# PodがスケジュールされているNodeで実行
# また、Podに割り当てられたcgroupと同じ名前に変更
cat /sys/fs/cgroup/memory/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/memory.limit_in_bytes
予想通り320MiBです。
335544320
Observability
Podのオーバヘッドが利用されているタイミングを特定し、定義されたオーバーヘッドで実行されているワークロードの安定性を観察するため、kube-state-metricsにはkube_pod_overheadというメトリクスが用意されています。この機能はv1.9のkube-state-metricsでは利用できませんが、次のリリースで期待されています。それまでは、kube-state-metricsをソースからビルドする必要があります。
次の項目
4 - Podトポロジー分散制約
トポロジー分散制約 を使用するとリージョン、ゾーン、ノードおよびその他のユーザー定義されたトポロジー領域などの障害ドメインをまたがって、クラスター内のPodがどのように分散されるかを制御できます。
これにより、高可用性と効率的なリソース活用を実現できます。
クラスターレベルの制約をデフォルトとして設定するか、個々のワークロードに対してトポロジー分散制約を設定できます。
動機
最大20ノードのクラスターがあり、使用するレプリカ数を自動的にスケーリングするワークロードを実行したいとします。
このワークロードには、2つのPodが存在する場合もあれば、15のPodが存在する場合もあります。
Podが2つだけの場合、単一ノードの障害でワークロードがオフラインになるリスクがあるため、同じノードで両方のPodを実行したくありません。
この基本的な使用方法に加えて、高可用性とクラスターの利用率を向上させるための高度な使用方法があります。
スケールアップしてより多くのPodを実行すると、また別の懸念事項が重要になります。
5つのPodを実行する3つのノードがあるとします。
ノードは該当数のレプリカを実行するために十分なキャパシティを持っていますが、このワークロードとやり取りするクライアントは3つの異なるデータセンター(またはインフラストラクチャゾーン)に分散されています。
単一ノードの障害についての懸念は減りましたが、レイテンシーが予想よりも高く、異なるゾーン間でネットワークトラフィックを送信する際にネットワークコストがかかっていることに気づきます。
通常の運用では、各インフラストラクチャゾーンに同数のレプリカをスケジュールし、問題が発生した場合はクラスターが自己修復するようにしたいと考えるでしょう。
Podトポロジー分散制約は、このようなシナリオに対処するための手段を提供します。
topologySpreadConstraintsフィールド
Pod APIには、spec.topologySpreadConstraintsフィールドが含まれています。
このフィールドの使用方法は次のようになります:
---
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# トポロジー分散制約を設定
topologySpreadConstraints:
- maxSkew: <integer>
minDomains: <integer> # オプション
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
matchLabelKeys: <list> # オプション; v1.27以降ベータ
nodeAffinityPolicy: [Honor|Ignore] # オプション; v1.26以降ベータ
nodeTaintsPolicy: [Honor|Ignore] # オプション; v1.26以降ベータ
### 他のPodのフィールドはここにあります
kubectl explain Pod.spec.topologySpreadConstraintsを実行するか、PodのAPIリファレンスのschedulingセクションを参照して、このフィールドについて詳しく読むことができます。
分散制約の定義
クラスター全体の既存のPodに対して、新しいPodをどのように配置するかをkube-schedulerに指示するために、1つまたは複数のtopologySpreadConstraintsエントリを定義できます。
これらのフィールドは次の通りです:
maxSkewは、Podが不均等に分散される程度を表します。
このフィールドは必須であり、0より大きい数値を指定する必要があります。
このフィールドのセマンティクスは、whenUnsatisfiableの値によって異なります:
whenUnsatisfiable: DoNotScheduleを選択した場合、maxSkewは対象トポロジー内の一致するPodの数と、グローバル最小値(適格ドメイン内の一致するPodの最小数、または適格ドメインの数がMinDomainsより少ない場合は0)の間で許容される最大の差を定義します。
例えば、3つのゾーンがあり、それぞれ2、2、1つの一致するPodがありMaxSkewが1に設定されている場合、グローバル最小値は1です。whenUnsatisfiable: ScheduleAnywayを選択した場合、スケジューラーはスキューの削減に役立つトポロジーを優先します。
minDomainsは、適格ドメインの最小数を示します。
このフィールドはオプションです。
ドメインとは、特定のトポロジーのインスタンスを指します。
適格ドメインとは、ノードセレクターに一致するノードのドメインを指します。
備考:
Kubernetes v1.30以前では、
minDomainsフィールドは、
MinDomainsInPodTopologySpreadフィーチャーゲートが有効になっている場合のみ利用可能でした(v1.28以降はデフォルト)。
より古いKubernetesクラスターでは、明示的に無効になっているか、フィールドが利用できない場合があります。
minDomainsの値を指定する場合、その値は0より大きくする必要があります。
minDomainsは、whenUnsatisfiable: DoNotScheduleと組み合わせてのみ指定できます。- トポロジーキーに一致する適格ドメインの数が
minDomainsより少ない場合、Podトポロジー分散はグローバル最小値を0として扱い、skewの計算を行います。
グローバル最小値は、適格ドメイン内の一致するPodの最小数であり、適格ドメインの数がminDomainsより少ない場合は0になります。 - トポロジーキーに一致する適格ドメインの数が
minDomainsと等しいかそれ以上の場合、この値はスケジューリングに影響しません。 minDomainsを指定しない場合、制約はminDomainsが1であるかのように動作します。
topologyKeyはノードラベルのキーです。
このキーと同じ値を持つノードは、同じトポロジー内にあると見なされます。
トポロジー内の各インスタンス(つまり、<key, value>ペア)をドメインと呼びます。
スケジューラーは、各ドメインに均等な数のPodを配置しようとします。
また、適格ドメインはnodeAffinityPolicyとnodeTaintsPolicyの要件を満たすノードのドメインとして定義します。
whenUnsatisfiableは、Podが分散制約を満たさない場合の処理方法を示します:
DoNotSchedule(デフォルト)は、スケジューラーにスケジュールしないように指示します。ScheduleAnywayは、スケジューラーにスキューを最小化するノードを優先してスケジュールするよう指示します。
labelSelectorは、一致するPodを見つけるために使用されます。
このラベルセレクターに一致するPodは、対応するトポロジードメイン内のPodの数を決定するためにカウントされます。
詳細については、ラベルセレクターを参照してください。
matchLabelKeysは、分散を計算するPodを選択するためのPodラベルキーのリストです。
このキーは、Podラベルから値を検索するために使用され、これらのkey-valueラベルはlabelSelectorとAND演算され、新しいPodのために分散が計算される既存のPodのグループを選択します。
同じキーはmatchLabelKeysとlabelSelectorの両方に存在してはいけません。
labelSelectorが設定されていない場合は、matchLabelKeysを設定することはできません。
Podラベルに存在しないキーは無視されます。
nullまたは空のリストは、labelSelectorに対してのみ一致します。
matchLabelKeysを使用すると、異なるリビジョン間でpod.specを更新する必要がありません。
コントローラー/オペレーターは、異なるリビジョンに対して同じラベルキーを異なる値に設定するだけです。
スケジューラーは、matchLabelKeysに基づいて値を自動的に推定します。
例えばDeploymentを構成する場合、Deploymentコントローラーによって自動的に追加されるpod-template-hashをキーとするラベルを使用して、単一のDeployment内の異なるリビジョンを区別できます。
topologySpreadConstraints:
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: foo
matchLabelKeys:
- pod-template-hash
備考:
matchLabelKeysフィールドは、ベータレベルのフィールドであり、1.27でデフォルトで有効になっています。
MatchLabelKeysInPodTopologySpreadフィーチャーゲートを無効にすることで無効にできます。
nodeAffinityPolicyは、Podのトポロジー分散スキューを計算する際に、PodのnodeAffinity/nodeSelectorをどのように扱うかを示します。
オプションは次の通りです:
- Honor: nodeAffinity/nodeSelectorに一致するノードのみが計算に含まれます。
- Ignore: nodeAffinity/nodeSelectorは無視されます。
すべてのノードが計算に含まれます。
この値がnullの場合、動作はHonorポリシーと同等です。
備考:
nodeAffinityPolicyはベータレベルのフィールドであり、1.26でデフォルトで有効になっています。
NodeInclusionPolicyInPodTopologySpreadフィーチャーゲートを無効にすることで無効にできます。
nodeTaintsPolicyは、Podのトポロジー分散スキューを計算する際に、ノードのtaintをどのように扱うかを示します。
オプションは次の通りです:
- Honor: taintのないノード、新しいPodがtolerationを持つtaintされたノードが含まれます。
- Ignore: ノードのtaintは無視されます。
すべてのノードが含まれます。
この値がnullの場合、動作はIgnoreポリシーと同等です。
備考:
nodeTaintsPolicyはベータレベルのフィールドであり、1.26でデフォルトで有効になっています。
NodeInclusionPolicyInPodTopologySpreadフィーチャーゲートを無効にすることで無効にできます。
PodにtopologySpreadConstraintsが複数定義されている場合、これらの制約は論理AND演算を使用して結合され、kube-schedulerは新しいPodに対して構成された制約をすべて満たすノードを探します。
ノードラベル
トポロジー分散制約は、ノードラベルを使用して、各ノードがどのトポロジードメインに属するかを識別します。
例えば、ノードには次のようなラベルがあるかもしれません:
region: us-east-1
zone: us-east-1a
備考:
簡潔にするため、この例ではwell-knownラベルキーのtopology.kubernetes.io/zoneとtopology.kubernetes.io/regionは使用していません。
ただし、ここで使用されているregionおよびzoneといったプライベート(修飾されていない)ラベルキーよりも、これらの登録済みラベルキーが推奨されます。
異なるコンテキスト間でのプライベートラベルキーの意味について、信頼できる前提として扱うことはできません。
次のラベルを持つ4ノードのクラスターがあるとします:
NAME STATUS ROLES AGE VERSION LABELS
node1 Ready <none> 4m26s v1.16.0 node=node1,zone=zoneA
node2 Ready <none> 3m58s v1.16.0 node=node2,zone=zoneA
node3 Ready <none> 3m17s v1.16.0 node=node3,zone=zoneB
node4 Ready <none> 2m43s v1.16.0 node=node4,zone=zoneB
クラスターは論理的には以下のように表されます:
graph TB
subgraph "zoneB"
n3(Node3)
n4(Node4)
end
subgraph "zoneA"
n1(Node1)
n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4 k8s;
class zoneA,zoneB cluster;
一貫性
グループ内のすべてのPodに同じトポロジー分散制約を適用する必要があります。
通常、Deploymentなどのワークロードコントローラーを使用している場合、Podテンプレートがこれを自動的に処理します。
異なる分散制約を混在させると、KubernetesはフィールドのAPI定義に従いますが、その動作は混乱しやすくなりトラブルシューティングがより困難になる可能性があります。
トポロジードメイン(例えばクラウドプロバイダーのリージョン)内のすべてのノードに、一貫してラベルが付与されていることを保証するメカニズムが必要です。
手動でノードにラベルを付与する必要がないように、多くのクラスターはkubernetes.io/hostnameのようなwell-knownラベルを自動的に設定します。
ご自身のクラスターがこれをサポートしているかどうかを確認してください。
トポロジー分散制約の例
例: 単一のトポロジー分散制約
4ノードのクラスターがあり、foo: barというラベルの付いた3つのPodがそれぞれ node1、node2、node3に配置されているとします:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class zoneA,zoneB cluster;
新しいPodを既存のPodとゾーン全体に均等に分散したい場合は、次のようなマニフェストを使用できます:
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- name: pause
image: registry.k8s.io/pause:3.1
このマニフェストでは、topologyKey: zoneはzone: <任意の値>というラベルが付いたノードにのみ均等に分散が適用されることを意味します(ラベルzoneがないノードはスキップされます)。
whenUnsatisfiable: DoNotScheduleフィールドは、スケジューラーが制約を満たせない場合に、新しいPodを保留状態にするようにスケジューラーに指示します。
スケジューラーがこの新しいPodをゾーンAに配置した場合、Podの分布は[3, 1]になります。
これは実際のスキューが2(3 - 1として計算)であることを意味し、maxSkew: 1に違反します。
この例の制約とコンテキストを満たすためには、新しいPodはゾーンBのノードにのみ配置される必要があります:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
p4(mypod) --> n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
または
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
p4(mypod) --> n3
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
Podの仕様を調整することで、様々な要件に対応できます:
maxSkewをより大きい値(例えば2)に変更すると、新しいPodをゾーンAに配置できるようになります。topologyKeyをnodeに変更すると、ゾーン単位ではなくノード単位でPodを均等に分散させるようになります。
上記の例では、maxSkewが1のままである場合、新しいPodはnode4にのみ配置可能です。whenUnsatisfiable: DoNotScheduleをwhenUnsatisfiable: ScheduleAnywayに変更すると、新しいPodが常にスケジュール可能になります(他のスケジュールAPIが満たされていると仮定)。
ただし、一致するPodが少ないトポロジードメインに配置されることが好ましいです。
(この設定は、リソース使用率などの他の内部スケジューリング優先度と共に正規化されることに注意してください)。
例: 複数のトポロジー分散制約
これは前の例に基づいています。
4ノードのクラスターがあり、foo: barというラベルの付いた3つのPodがそれぞれ node1、node2、node3に配置されているとします:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
2つのトポロジー分散制約を組み合わせて、ノードとゾーンの両方でPodの分散を制御できます:
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
- maxSkew: 1
topologyKey: node
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- name: pause
image: registry.k8s.io/pause:3.1
この場合、最初の制約に一致させるために、新しいPodはゾーンBのノードにのみ配置できます。
一方、2番目の制約に関しては、新しいPodはnode4にのみスケジュールできます。
スケジューラーは、定義されたすべての制約を満たすオプションのみを考慮するため、有効な配置はnode4のみです。
例: トポロジー分散制約の競合
複数の制約は競合する可能性があります。
2つのゾーンにまたがる3ノードのクラスターがあるとします:
graph BT
subgraph "zoneB"
p4(Pod) --> n3(Node3)
p5(Pod) --> n3
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n1
p3(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3,p4,p5 k8s;
class zoneA,zoneB cluster;
このクラスターにtwo-constraints.yaml(前の例のマニフェスト)を適用すると、Pod mypodがPending状態のままであることがわかります。
これは、最初の制約を満たすために、Pod mypodはゾーンBにしか配置できないのに対して、2番目の制約に関しては、Pod mypodはノードnode2にしかスケジュールできないために発生します。
2つの制約の共通部分として空集合が返され、スケジューラーはPodを配置できません。
この状況を克服するためには、maxSkewの値を増やすか、制約の1つをwhenUnsatisfiable: ScheduleAnywayに変更します。
状況によっては、バグ修正のロールアウトが進まない理由をトラブルシューティングする場合などで、既存のPodを手動で削除することもあります。
ノードアフィニティとノードセレクターとの相互作用
新しいPodにspec.nodeSelectorまたはspec.affinity.nodeAffinityが定義されている場合、スケジューラーは一致しないノードをスキュー計算からスキップします。
例: ノードアフィニティを使用したトポロジー分散制約
ゾーンAからCにまたがる5ノードクラスターがあるとします:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
graph BT
subgraph "zoneC"
n5(Node5)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n5 k8s;
class zoneC cluster;
そして、ゾーンCを除外する必要があることがわかっているとします。
この場合、以下のようにマニフェストを作成して、Pod mypodをゾーンCではなくゾーンBに配置することができます。
同様に、Kubernetesはspec.nodeSelectorを尊重します。
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: zone
operator: NotIn
values:
- zoneC
containers:
- name: pause
image: registry.k8s.io/pause:3.1
暗黙的な規則
ここで注目すべき暗黙的な規則がいくつかあります:
新しいPodと同じNamespaceを持つPodのみが一致する候補となります。
スケジューラーは、すべてのtopologySpreadConstraints[*].topologyKeyが同時に存在するノードのみを考慮します。
これらのtopologyKeysのいずれかが欠落しているノードはバイパスされます。
これは次のことを意味します:
- これらのバイパスされたノードにあるPodは
maxSkewの計算に影響しません。
上記の例では、ノードnode1に"zone"ラベルがない場合、2つのPodは無視され、新しいPodはゾーンAにスケジュールされます。 - 新しいPodがこれらのノードにスケジュールされる可能性はありません。
上記の例では、ノード
node5に誤字のあるラベルzone-typo: zoneCがある(かつzoneラベルが設定されていない)とします。
node5がクラスターに参加しても、バイパスされ、このワークロードのPodはそのノードにスケジュールされません。
新しいPodのtopologySpreadConstraints[*].labelSelectorが自身のラベルと一致しない場合に何が起こるかに注意してください。
上記の例では、新しいPodのラベルを削除しても、すでに制約が満たされているため、ゾーンBのノードに配置できます。
ただしその配置後、クラスターの不均衡の度合いは変わらず、ゾーンAにはfoo: barというラベルが付いた2つのPodがあり、ゾーンBにはfoo: barというラベルが付いた1つのPodがあります。
これが期待する動作ではない場合、ワークロードのtopologySpreadConstraints[*].labelSelectorを更新して、Podテンプレート内のラベルと一致するようにします。
クラスターレベルのデフォルト制約
クラスターにはデフォルトのトポロジー分散制約を設定することができます。
デフォルトのトポロジー分散制約は、次の場合にのみPodに適用されます:
.spec.topologySpreadConstraintsに制約が定義されていない。- PodがService、ReplicaSet、StatefulSet、またはReplicationControllerに属している。
デフォルトの制約は、スケジューリングプロファイルのPodTopologySpreadプラグイン引数の一部として設定できます。
制約は、上記のAPIと同じように指定されますが、labelSelectorは空である必要があります。
Podが属するService、ReplicaSet、StatefulSet、またはReplicationControllerから計算されたセレクターが使用されます。
設定例は次のようになります:
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
defaultingType: List
ビルトインのデフォルト制約
FEATURE STATE:
Kubernetes v1.24 [stable]
Podトポロジー分散のためのクラスターレベルのデフォルト制約を構成しない場合、kube-schedulerは次のデフォルトのトポロジー制約を指定したかのように動作します:
defaultConstraints:
- maxSkew: 3
topologyKey: "kubernetes.io/hostname"
whenUnsatisfiable: ScheduleAnyway
- maxSkew: 5
topologyKey: "topology.kubernetes.io/zone"
whenUnsatisfiable: ScheduleAnyway
また、同等の動作を提供する従来のSelectorSpreadプラグインは、デフォルトで無効になっています。
備考:
PodTopologySpreadプラグインは、分散制約で指定されていないトポロジーキーを持つノードにスコアをつけません。
これにより、デフォルトのトポロジー制約を使用する場合、従来のSelectorSpreadプラグインと比較して、デフォルトの動作が異なる場合があります。
ノードにkubernetes.io/hostnameとtopology.kubernetes.io/zoneラベルの両方が設定されることを想定していない場合、Kubernetesのデフォルトを使用する代わりに独自の制約を定義してください。
クラスターにデフォルトのPod分散制約を使用したくない場合は、PodTopologySpreadプラグイン構成のdefaultingTypeをListに設定し、defaultConstraintsを空のままにすることで、これらのデフォルトを無効にできます:
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints: []
defaultingType: List
podAffinityとpodAntiAffinityとの比較
Kubernetesでは、Pod間のアフィニティとアンチアフィニティによって、Podがより密集させるか分散させるかといった、Podが互いにどのようにスケジュールされるかを制御できます。
podAffinity- Podを引き付けます。
適切なトポロジードメインに任意の数のPodを配置できます。
podAntiAffinity- Podを遠ざけます。
requiredDuringSchedulingIgnoredDuringExecutionモードに設定すると、単一のトポロジードメインには1つのPodしかスケジュールできません。
preferredDuringSchedulingIgnoredDuringExecutionモードに設定すると、この制約を強制できません。
より細かい制御を行うには、トポロジー分散制約を指定して、異なるトポロジードメインにPodを分散させることで、高可用性やコスト削減を実現できます。
またワークロードのローリングアップデートやレプリカのスムーズなスケールアウトにも役立ちます。
詳しくは、Podのトポロジー分散制約に関する機能強化提案のMotivationセクションを参照してください。
既知の制限
Podの削除後も、制約が満たされていることは保証されません。
例えば、Deploymentのスケールダウンによって、Podの分布が不均衡になる可能性があります。
Podの分布をリバランスするには、Deschedulerなどのツールを使用できます。
taintされたノードに一致するPodは優先されます。
Issue 80921を参照してください。
スケジューラーは、クラスター内のすべてのゾーンやその他のトポロジードメインを事前に把握しているわけではありません。
これらはクラスター内の既存のノードから決定されます。
オートスケールされるクラスターでは、ノードプール(またはノードグループ)が0ノードにスケールされ、クラスターがスケールアップすることを期待している場合に問題が発生する可能性があります。
この場合、トポロジードメインはその中に少なくとも1つのノードが存在するまで考慮されないためです。
これを回避するためには、Podのトポロジー分散制約を認識し、全体のトポロジードメインの集合も認識しているノードオートスケーラーを使用することができます。
次の項目
5 - Podのスケジューリング準備
FEATURE STATE:
Kubernetes v1.30 [stable]
Podは1度作成されると、スケジュールの準備ができたとみなされます。Kubernetesのスケジューラーは、すべての保留中のPodを配置するためにノードを見つけることに最善を尽くします。しかし実際のケースでは、一部のPodが「必要なリソースを満たさない」状態に長期間とどまることがあります。このようなPodは、実際にはスケジューラー(およびCluster AutoScalerのようなダウンストリームのインテグレーター)を不必要に混乱させます。
Podの.spec.schedulingGatesを指定したり削除したりすることで、Podがスケジューリングの対象になるタイミングを制御できます。
PodにschedulingGatesを設定する
schedulingGatesのフィールドは、文字列のリストで構成されており、各文字列はPodがスケジューリング可能とみなされる前に満たすべき条件を表します。このフィールドは、Pod作成時のみ初期化できます(クライアントによる作成時、またはアドミッション中の変更時)。作成後、個々のschedulingGateは順序不同で削除できますが、新しいschedulingGateを追加することはできません。

Pod スケジューリングゲートの図
使用例
Podがスケジューリングされる準備ができていないと示すには、次のように1つ以上のスケジューリングゲートを使って作成します。
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
schedulingGates:
- name: example.com/foo
- name: example.com/bar
containers:
- name: pause
image: registry.k8s.io/pause:3.6
Podの作成後、状態を確認するには以下のようにします。
出力からSchedulingGated状態であることがわかります。
NAME READY STATUS RESTARTS AGE
test-pod 0/1 SchedulingGated 0 7s
また、schedulingGatesフィールドから確認することもできます。
kubectl get pod test-pod -o jsonpath='{.spec.schedulingGates}'
出力は以下のようになります。
[{"name":"example.com/foo"},{"name":"example.com/bar"}]
このPodがスケジューリング可能であることをスケジューラーに知らせるには、変更したマニフェストを再適用することで、schedulingGatesを完全に削除できます。
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- name: pause
image: registry.k8s.io/pause:3.6
schedulingGatesが削除されているかどうかは、以下のように確認できます。
kubectl get pod test-pod -o jsonpath='{.spec.schedulingGates}'
出力は、空であることが期待されます。そして、以下のように実行することで最新の状態を確認することができます。
kubectl get pod test-pod -o wide
test-podがCPU/メモリリソースを要求しないため、このPodのステータスは、以前のSchedulingGatedからRunningに遷移することが予想されます。
NAME READY STATUS RESTARTS AGE IP NODE
test-pod 1/1 Running 0 15s 10.0.0.4 node-2
可観測性
scheduler_pending_podsメトリックには、Podがスケジューリングされようとしているがスケジューリング不可能とされているのか、それとも明示的にスケジューリングの準備ができておらずマークされているのかを区別する新しいラベル"gated"があります。scheduler_pending_pods{queue="gated"}でメトリックの結果を確認できます。
変更可能なPodのスケジューリング命令
Podにスケジューリングゲートが設定されている間、Podのスケジューリング命令は、一定の制約のもとで変更できます。高いレベルでは、Podのスケジューリング命令を厳格にすることしかできません。言い換えると、更新された命令は、Podが以前マッチしていたノードのサブセットでしかスケジューリングできなくなります。より具体的には、Podのスケジューリング命令を更新するルールは以下のようになります。
.spec.nodeSelectorは、追加のみが許可されます。 存在しない場合は設定が許可されます。
spec.affinity.nodeAffinityは、空の場合、何でも設定できます。
NodeSelectorTermsが空の場合、設定が許可されます。 空でない場合は、matchExpressionsまたはfieldExpressionsへのNodeSelectorRequirementsの追加のみが許可され、既存のmatchExpressionsおよびfieldExpressionsへの変更は許可されません。これは、.requiredDuringSchedulingIgnoredDuringExecution.NodeSelectorTermsの項目がORで結合されるのに対し、nodeSelectorTerms[].matchExpressionsおよびnodeSelectorTerms[].fieldExpressionsの項目はANDで結合されるためです。
.preferredDuringSchedulingIgnoredDuringExecutionは、すべての更新が許可されます。これは、優先項目の権威がないため、ポリシーコントローラーがこれらの項目を検証しないためです。
次の項目
6 - TaintとToleration
ノードアフィニティは
Podの属性であり、あるノード群を引きつけます(優先条件または必須条件)。反対に taint はノードがある種のPodを排除できるようにします。
toleration はPodに適用され、一致するtaintが付与されたノードへPodがスケジューリングされることを認めるものです。ただしそのノードへ必ずスケジューリングされるとは限りません。
taintとtolerationは組になって機能し、Podが不適切なノードへスケジューリングされないことを保証します。taintはノードに一つまたは複数個付与することができます。これはそのノードがtaintを許容しないPodを受け入れるべきではないことを示します。
コンセプト
ノードにtaintを付与するにはkubectl taintコマンドを使用します。
例えば、次のコマンドは
kubectl taint nodes node1 key1=value1:NoSchedule
node1にtaintを設定します。このtaintのキーはkey1、値はvalue1、taintの効果はNoScheduleです。
これはnode1にはPodに合致するtolerationがなければスケジューリングされないことを意味します。
上記のコマンドで付与したtaintを外すには、下記のコマンドを使います。
kubectl taint nodes node1 key1=value1:NoSchedule-
PodのtolerationはPodSpecの中に指定します。下記のtolerationはどちらも、上記のkubectl taintコマンドで追加したtaintと合致するため、どちらのtolerationが設定されたPodもnode1へスケジューリングされることができます。
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
tolerations:
- key: "key1"
operator: "Exists"
effect: "NoSchedule"
tolerationを設定したPodの例を示します。
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "example-key"
operator: "Exists"
effect: "NoSchedule"
operatorのデフォルトはEqualです。
tolerationがtaintと合致するのは、keyとeffectが同一であり、さらに下記の条件のいずれかを満たす場合です。
operatorがExists(valueを指定すべきでない場合)operatorがEqualであり、かつvalueが同一である場合
備考:
2つ特殊な場合があります。
空のkeyと演算子Existsは全てのkey、value、effectと一致するため、すべてのtaintと合致します。
空のeffectはkey1が一致する全てのeffectと合致します。
上記の例ではeffectにNoScheduleを指定しました。代わりに、effectにPreferNoScheduleを指定することができます。
これはNoScheduleの「ソフトな」バージョンであり、システムはtaintに対応するtolerationが設定されていないPodがノードへ配置されることを避けようとしますが、必須の条件とはしません。3つ目のeffectの値としてNoExecuteがありますが、これについては後述します。
同一のノードに複数のtaintを付与することや、同一のPodに複数のtolerationを設定することができます。
複数のtaintやtolerationが設定されている場合、Kubernetesはフィルタのように扱います。最初はノードの全てのtaintがある状態から始め、Podが対応するtolerationを持っているtaintは無視され外されていきます。無視されずに残ったtaintが効果を及ぼします。
具体的には、
- effect
NoScheduleのtaintが無視されず残った場合、KubernetesはそのPodをノードへスケジューリングしません。 - effect
NoScheduleのtaintは残らず、effect PreferNoScheduleのtaintは残った場合、Kubernetesはそのノードへのスケジューリングをしないように試みます。 - effect
NoExecuteのtaintが残った場合、既に稼働中のPodはそのノードから排除され、まだ稼働していないPodはスケジューリングされないようになります。
例として、下記のようなtaintが付与されたノードを考えます。
kubectl taint nodes node1 key1=value1:NoSchedule
kubectl taint nodes node1 key1=value1:NoExecute
kubectl taint nodes node1 key2=value2:NoSchedule
Podには2つのtolerationが設定されています。
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
この例では、3つ目のtaintと合致するtolerationがないため、Podはノードへはスケジューリングされません。
しかし、これらのtaintが追加された時点で、そのノードでPodが稼働していれば続けて稼働することが可能です。 これは、Podのtolerationと合致しないtaintは3つあるtaintのうちの3つ目のtaintのみであり、それがNoScheduleであるためです。
一般に、effect NoExecuteのtaintがノードに追加されると、合致するtolerationが設定されていないPodは即時にノードから排除され、合致するtolerationが設定されたPodが排除されることは決してありません。
しかし、effectNoExecuteに対するtolerationはtolerationSecondsフィールドを任意で指定することができ、これはtaintが追加された後にそのノードにPodが残る時間を示します。例えば、
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600
この例のPodが稼働中で、対応するtaintがノードへ追加された場合、Podはそのノードに3600秒残り、その後排除されます。仮にtaintがそれよりも前に外された場合、Podは排除されません。
ユースケースの例
taintとtolerationは、実行されるべきではないノードからPodを遠ざけたり、排除したりするための柔軟な方法です。いくつかのユースケースを示します。
専有ノード: あるノード群を特定のユーザーに専有させたい場合、そのノード群へtaintを追加し(kubectl taint nodes nodename dedicated=groupName:NoSchedule) 対応するtolerationをPodへ追加します(これを実現する最も容易な方法はカスタム
アドミッションコントローラーを書くことです)。
tolerationが設定されたPodはtaintの設定された(専有の)ノードと、クラスターにあるその他のノードの使用が認められます。もしPodが必ず専有ノードのみを使うようにしたい場合は、taintと同様のラベルをそのノード群に設定し(例: dedicated=groupName)、アドミッションコントローラーはノードアフィニティを使ってPodがdedicated=groupNameのラベルの付いたノードへスケジューリングすることが必要であるということも設定する必要があります。
特殊なハードウェアを備えるノード: クラスターの中の少数のノードが特殊なハードウェア(例えばGPU)を備える場合、そのハードウェアを必要としないPodがスケジューリングされないようにして、後でハードウェアを必要とするPodができたときの余裕を確保したいことがあります。
これは特殊なハードウェアを持つノードにtaintを追加(例えば kubectl taint nodes nodename special=true:NoSchedule または
kubectl taint nodes nodename special=true:PreferNoSchedule)して、ハードウェアを使用するPodに対応するtolerationを追加することで可能です。
専有ノードのユースケースと同様に、tolerationを容易に適用する方法はカスタム
アドミッションコントローラーを使うことです。
例えば、特殊なハードウェアを表すために拡張リソース
を使い、ハードウェアを備えるノードに拡張リソースの名称のtaintを追加して、
拡張リソースtoleration
アドミッションコントローラーを実行することが推奨されます。ノードにはtaintが付与されているため、tolerationのないPodはスケジューリングされません。しかし拡張リソースを要求するPodを作成しようとすると、拡張リソースtoleration アドミッションコントローラーはPodに自動的に適切なtolerationを設定し、Podはハードウェアを備えるノードへスケジューリングされます。
これは特殊なハードウェアを備えたノードではそれを必要とするPodのみが稼働し、Podに対して手作業でtolerationを追加しなくて済むようにします。
taintを基にした排除: ノードに問題が起きたときにPodごとに排除する設定を行うことができます。次のセクションにて説明します。
taintを基にした排除
FEATURE STATE:
Kubernetes v1.18 [stable]
上述したように、effect NoExecuteのtaintはノードで実行中のPodに次のような影響を与えます。
- 対応するtolerationのないPodは即座に除外される
- 対応するtolerationがあり、それに
tolerationSecondsが指定されていないPodは残り続ける - 対応するtolerationがあり、それに
tolerationSecondsが指定されているPodは指定された間、残される
Nodeコントローラーは特定の条件を満たす場合に自動的にtaintを追加します。
組み込まれているtaintは下記の通りです。
node.kubernetes.io/not-ready: ノードの準備ができていない場合。これはNodeCondition ReadyがFalseである場合に対応します。node.kubernetes.io/unreachable: ノードがノードコントローラーから到達できない場合。これはNodeConditionReadyがUnknownの場合に対応します。node.kubernetes.io/out-of-disk: ノードのディスクの空きがない場合。node.kubernetes.io/memory-pressure: ノードのメモリーが不足している場合。node.kubernetes.io/disk-pressure: ノードのディスクが不足している場合。node.kubernetes.io/network-unavailable: ノードのネットワークが利用できない場合。node.kubernetes.io/unschedulable: ノードがスケジューリングできない場合。node.cloudprovider.kubernetes.io/uninitialized: kubeletが外部のクラウド事業者により起動されたときに設定されるtaintで、このノードは利用不可能であることを示します。cloud-controller-managerによるコントローラーがこのノードを初期化した後にkubeletはこのtaintを外します。
ノードから追い出すときには、ノードコントローラーまたはkubeletは関連するtaintをNoExecute効果の状態で追加します。
不具合のある状態から通常の状態へ復帰した場合は、kubeletまたはノードコントローラーは関連するtaintを外すことができます。
備考:
コントロールプレーンは新しいtaintをノードに加えるレートを制限しています。
このレート制限は一度に多くのノードが到達不可能になった場合(例えばネットワークの断絶)に、退役させられるノードの数を制御します。PodにtolerationSecondsを指定することで不具合があるか応答のないノードに残る時間を指定することができます。
例えば、ローカルの状態を多数持つアプリケーションとネットワークが分断された場合を考えます。ネットワークが復旧して、Podを排除しなくて済むことを見込んで、長時間ノードから排除されないようにしたいこともあるでしょう。
この場合Podに設定するtolerationは次のようになります。
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 6000
備考:
Kubernetesはユーザーまたはコントローラーが明示的に指定しない限り、自動的にnode.kubernetes.io/not-readyとnode.kubernetes.io/unreachableに対するtolerationをtolerationSeconds=300にて設定します。
自動的に設定されるtolerationは、taintに対応する問題がノードで検知されても5分間はそのノードにPodが残されることを意味します。
DaemonSetのPodは次のtaintに対してNoExecuteのtolerationがtolerationSecondsを指定せずに設定されます。
node.kubernetes.io/unreachablenode.kubernetes.io/not-ready
これはDaemonSetのPodはこれらの問題によって排除されないことを保証します。
条件によるtaintの付与
ノードのライフサイクルコントローラーはノードの状態に応じてNoSchedule効果のtaintを付与します。
スケジューラーはノードの状態ではなく、taintを確認します。
ノードに何がスケジューリングされるかは、そのノードの状態に影響されないことを保証します。ユーザーは適切なtolerationをPodに付与することで、どの種類のノードの問題を無視するかを選ぶことができます。
DaemonSetのコントローラーは、DaemonSetが中断されるのを防ぐために自動的に次のNoScheduletolerationを全てのDaemonSetに付与します。
node.kubernetes.io/memory-pressurenode.kubernetes.io/disk-pressurenode.kubernetes.io/out-of-disk (重要なPodのみ)node.kubernetes.io/unschedulable (1.10またはそれ以降)node.kubernetes.io/network-unavailable (ホストネットワークのみ)
これらのtolerationを追加することは後方互換性を保証します。DaemonSetに任意のtolerationを加えることもできます。
次の項目
7 - スケジューリングフレームワーク
FEATURE STATE:
Kubernetes v1.19 [stable]
スケジューリングフレームワークはKubernetesのスケジューラーに対してプラグイン可能なアーキテクチャです。
このアーキテクチャは、既存のスケジューラーに新たに「プラグイン」としてAPI群を追加するもので、プラグインはスケジューラー内部にコンパイルされます。このAPI群により、スケジューリングの「コア」の軽量かつ保守しやすい状態に保ちながら、ほとんどのスケジューリングの機能をプラグインとして実装することができます。このフレームワークの設計に関する技術的な情報についてはこちらのスケジューリングフレームワークの設計提案をご覧ください。
フレームワークのワークフロー
スケジューリングフレームワークは、いくつかの拡張点を定義しています。スケジューラープラグインは、1つ以上の拡張点で呼び出されるように登録します。これらのプラグインの中には、スケジューリングの決定を変更できるものから、単に情報提供のみを行うだけのものなどがあります。
この1つのPodをスケジュールしようとする各動作はScheduling CycleとBinding Cycleの2つのフェーズに分けられます。
Scheduling Cycle & Binding Cycle
Scheduling CycleではPodが稼働するNodeを決定し、Binding Cycleではそれをクラスターに適用します。この2つのサイクルを合わせて「スケジューリングコンテキスト」と呼びます。
Scheduling CycleではPodに対して1つ1つが順番に実行され、Binding Cyclesでは並列に実行されます。
Podがスケジューリング不能と判断された場合や、内部エラーが発生した場合、Scheduling CycleまたはBinding Cycleを中断することができます。その際、Podはキューに戻され再試行されます。
拡張点
次の図はPodに対するスケジューリングコンテキストとスケジューリングフレームワークが公開する拡張点を示しています。この図では「Filter」がフィルタリングのための「Predicate」、「Scoring」がスコアリングのための「Priorities」機能に相当します。
1つのプラグインを複数の拡張点に登録することで、より複雑なタスクやステートフルなタスクを実行することができます。
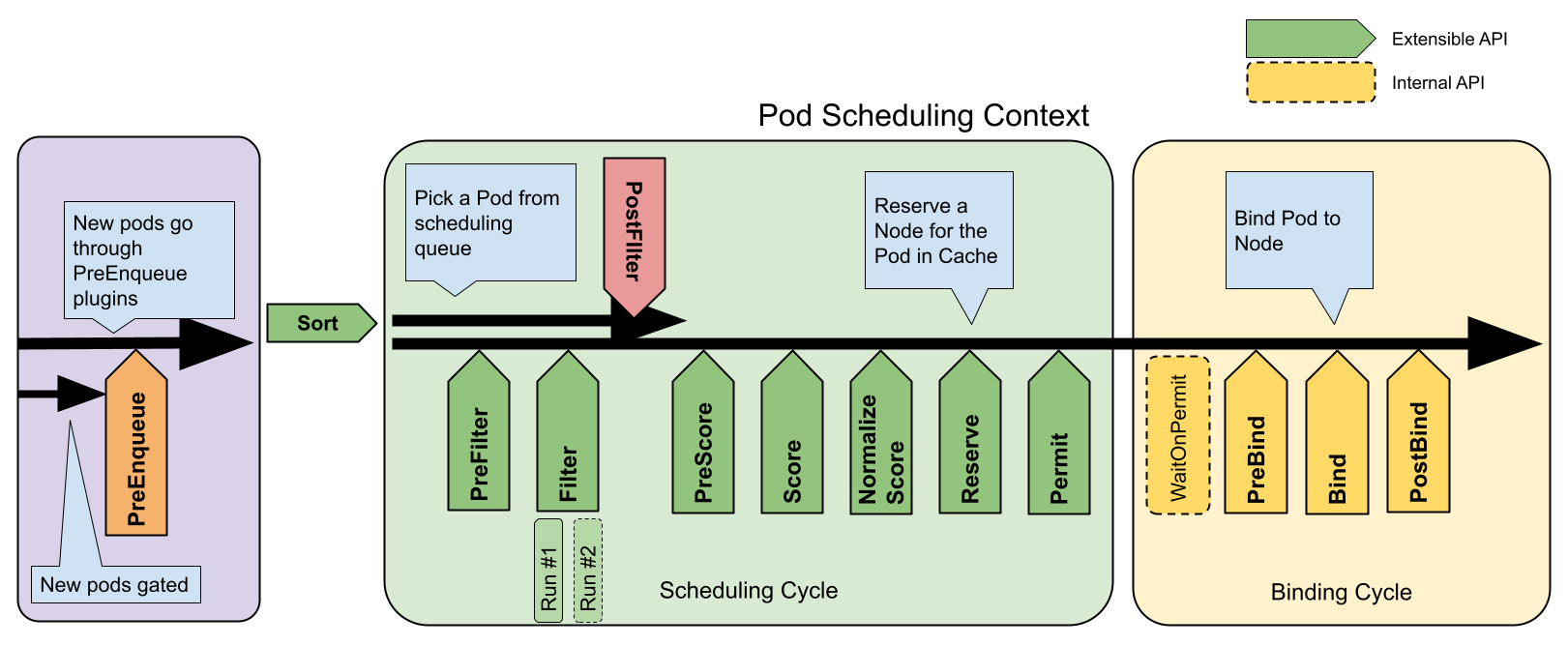
scheduling framework extension points
QueueSort
これらのプラグインはスケジューリングキュー内のPodをソートするために使用されます。このプラグインは、基本的にLess(Pod1, Pod2)という関数を提供します。また、このプラグインは、1つだけ有効化できます。
PreFilter
これらのプラグインは、Podに関する情報を前処理したり、クラスターやPodが満たすべき特定の条件をチェックするために使用されます。もし、PreFilterプラグインのいずれかがエラーを返した場合、Scheduling Cycleは中断されます。
Filter
FilterプラグインはPodを実行できないNodeを候補から除外します。各Nodeに対して、スケジューラーは設定された順番でFilterプラグインを呼び出します。もし、いずれかのFilterプラグインが途中でそのNodeを実行不可能とした場合、残りのプラグインではそのNodeは呼び出されません。Nodeは同時に評価されることがあります。
PostFilter
これらのプラグインはFilterフェーズで、Podに対して実行可能なNodeが見つからなかった場合にのみ呼び出されます。このプラグインは設定された順番で呼び出されます。もしいずれかのPostFilterプラグインが、あるNodeを「スケジュール可能(Schedulable)」と目星をつけた場合、残りのプラグインは呼び出されません。典型的なPostFilterの実装はプリエンプション方式で、他のPodを先取りして、Podをスケジューリングできるようにしようとします。
PreScore
これらのプラグインは、Scoreプラグインが使用する共有可能な状態を生成する「スコアリングの事前」作業を行うために使用されます。このプラグインがエラーを返した場合、Scheduling Cycleは中断されます。
Score
これらのプラグインはフィルタリングのフェーズを通過したNodeをランク付けするために使用されます。スケジューラーはそれぞれのNodeに対して、それぞれのscoringプラグインを呼び出します。スコアの最小値と最大値の範囲が明確に定義されます。NormalizeScoreフェーズの後、スケジューラーは設定されたプラグインの重みに従って、全てのプラグインからNodeのスコアを足し合わせます。
NormalizeScore
これらのプラグインはスケジューラーが最終的なNodeの順位を計算する前にスコアを修正するために使用されます。この拡張点に登録されたプラグインは、同じプラグインのScoreの結果を使用して呼び出されます。各プラグインはScheduling Cycle毎に、1回呼び出されます。
例えば、BlinkingLightScorerというプラグインが、点滅する光の数に基づいてランク付けをするとします。
func ScoreNode(_ *v1.pod, n *v1.Node) (int, error) {
return getBlinkingLightCount(n)
}
ただし、NodeScoreMaxに比べ、点滅をカウントした最大値の方が小さい場合があります。これを解決するために、BlinkingLightScorerも拡張点に登録する必要があります。
func NormalizeScores(scores map[string]int) {
highest := 0
for _, score := range scores {
highest = max(highest, score)
}
for node, score := range scores {
scores[node] = score*NodeScoreMax/highest
}
}
NormalizeScoreプラグインが途中でエラーを返した場合、Scheduling Cycleは中断されます。
備考:
「Reserveの事前」作業を行いたいプラグインは、NormalizeScore拡張点を使用してください。Reserve
Reserve拡張を実装したプラグインには、ReserveとUnreserveという2つのメソッドがあり、それぞれReserve
とUnreserveと呼ばれる2つの情報スケジューリングフェーズを返します。
実行状態を保持するプラグイン(別名「ステートフルプラグイン」)は、これらのフェーズを使用して、Podに対してNodeのリソースが予約されたり予約解除された場合に、スケジューラーから通知を受け取ります。
Reserveフェーズは、スケジューラーが実際にPodを指定されたNodeにバインドする前に発生します。このフェーズはスケジューラーがバインドが成功するのを待つ間にレースコンディションの発生を防ぐためにあります。
各ReserveプラグインのReserveメソッドは成功することも失敗することもあります。もしどこかのReserveメソッドの呼び出しが失敗すると、後続のプラグインは実行されず、Reserveフェーズは失敗したものとみなされます。全てのプラグインのReserveメソッドが成功した場合、Reserveフェーズは成功とみなされ、残りのScheduling CycleとBinding Cycleが実行されます。
Unreserveフェーズは、Reserveフェーズまたは後続のフェーズが失敗した場合に、呼び出されます。この時、全てのReserveプラグインのUnreserveメソッドが、Reserveメソッドの呼び出された逆の順序で実行されます。このフェーズは予約されたPodに関連する状態をクリーンアップするためにあります。
注意:
Unreserveメソッドの実装は冪等性を持つべきであり、この処理で問題があった場合に失敗させてはなりません。Permit
Permit プラグインは、各PodのScheduling Cycleの終了時に呼び出され、候補Nodeへのバインドを阻止もしくは遅延させるために使用されます。permitプラグインは次の3つのうちどれかを実行できます。
承認(approve)
全てのPermitプラグインから承認(approve)されたPodは、バインド処理へ送られます。
拒否(deny)
もしどれか1つのPermitプラグインがPodを拒否(deny)した場合、そのPodはスケジューリングキューに戻されます。
これはReserveプラグイン内のUnreserveフェーズで呼び出されます。
待機(wait) (タイムアウトあり)
もしPermitプラグインが「待機(wait)」を返した場合、そのPodは内部の「待機中」Podリストに保持され、このPodに対するBinding Cycleは開始されるものの、承認(approve)されるまで直接ブロックされます。もしタイムアウトが発生した場合、この待機(wait)はdenyへ変わり、対象のPodはスケジューリングキューに戻されると共に、ReserveプラグインのUnreserveフェーズが呼び出されます。
備考:
どのプラグインも「待機中」Podリストにアクセスして、それらを承認(approve)することができますが(参考:
FrameworkHandle)、その中の予約済みPodのバインドを承認(approve)できるのはPermitプラグインだけであると予想します。承認(approve)されたPodは、
PreBindフェーズへ送られます。
PreBind
これらのプラグインは、Podがバインドされる前に必要な作業を行うために使用されます。例えば、Podの実行を許可する前に、ネットワークボリュームをプロビジョニングし、Podを実行予定のNodeにマウントすることができます。
もし、いずれかのPreBindプラグインがエラーを返した場合、Podは拒否され、スケジューリングキューに戻されます。
Bind
これらのプラグインはPodをNodeにバインドするために使用されます。このプラグインは全てのPreBindプラグインの処理が完了するまで呼ばれません。それぞれのBindプラグインは設定された順序で呼び出されます。このプラグインは、与えられたPodを処理するかどうかを選択することができます。もしPodを処理することを選択した場合、残りのBindプラグインは全てスキップされます。
PostBind
これは単に情報提供のための拡張点です。Post-bindプラグインはPodのバインドが成功した後に呼び出されます。これはBinding Cycleの最後であり、関連するリソースのクリーンアップに使用されます。
プラグインAPI
プラグインAPIには2つの段階があります。まず、プラグインを登録し設定することです。そして、拡張点インターフェースを使用することです。このインターフェースは次のような形式をとります。
type Plugin interface {
Name() string
}
type QueueSortPlugin interface {
Plugin
Less(*v1.pod, *v1.pod) bool
}
type PreFilterPlugin interface {
Plugin
PreFilter(context.Context, *framework.CycleState, *v1.pod) error
}
// ...
プラグインの設定
スケジューラーの設定でプラグインを有効化・無効化することができます。Kubernetes v1.18以降を使用しているなら、ほとんどのスケジューリングプラグインは使用されており、デフォルトで有効になっています。
デフォルトのプラグインに加えて、独自のスケジューリングプラグインを実装し、デフォルトのプラグインと一緒に使用することも可能です。詳しくはスケジューラープラグインをご覧下さい。
Kubernetes v1.18以降を使用しているなら、プラグインのセットをスケジューラープロファイルとして設定し、様々な種類のワークロードに適合するように複数のプロファイルを定義することが可能です。詳しくは複数のプロファイルをご覧下さい。
8 - 動的リソース割り当て
構造化パラメーターを用いたコアのDynamic Resource Allocation:
FEATURE STATE:
Kubernetes v1.35 [stable](enabled by default)
コントロールプレーンコントローラーを用いたDynamic Resource Allocation:
FEATURE STATE:
Kubernetes v1.26 [alpha](disabled by default)
動的なリソース割り当ては、PodとPod内のコンテナ間でリソースを要求および共有するためのAPIです。
これは、汎用リソース用の永続ボリュームAPIを一般化したものです。
通常、これらのリソースはGPUなどのデバイスです。
サードパーティのリソースドライバーは、リソースの追跡と準備を行い、リソースの割り当ては 構造化パラメーター (Kubernetes 1.30で導入)を介してKubernetesによって処理されます。
さまざまな種類のリソースが、要求と初期化を定義するための任意のパラメーターをサポートします。
ドライバーが コントロールプレーンコントローラー を提供する場合、ドライバー自体がKubernetesスケジューラーと連携して割り当てを処理します。
始める前に
Kubernetes v1.35には、動的リソース割り当てに関するクラスターレベルのAPIサポートが含まれていますが、明示的に有効化する必要があります。
また、このAPIを使用して管理する特定のリソースのリソースドライバーもインストールする必要があります。
Kubernetes v1.35を実行していない場合は、そのバージョンのKubernetesのドキュメントを確認してください。
API
resource.k8s.io/v1alpha3 APIグループ は次のタイプを提供します:
- ResourceClaim
- ワークロードによって使用される、クラスター内のリソースへのアクセス要求を記述します。
たとえば、ワークロードが特定のプロパティを持つアクセラレーターデバイスを必要とする場合、その要求はこのように表現されます。
ステータススタンザは、この要求が満たされたかどうかと、どのリソースが割り当てられたかを追跡します。
- ResourceClaimTemplate
- ResourceClaimを作成するための仕様とメタデータを定義します。
ユーザーがワークロードをデプロイするときに作成されます。
PodごとのResourceClaimは、Kubernetesによって自動的に作成および削除されます。
- DeviceClass
- 特定のデバイスとそれらの構成に対する事前定義の選択基準が含まれています。
DeviceClassは、リソースドライバーをインストールするときにクラスター管理者によって作成されます。
ResourceClaim内でデバイスを割り当てる各要求は、正確に1つのDeviceClassを参照する必要があります。
- PodSchedulingContext
- ResourceClaimをPodに割り当てる必要があり、それらのResourceClaimがコントロールプレーンコントローラーを使用する場合に、Podのスケジューリングを調整するために、コントロールプレーンとリソースドライバーによって内部的に使用されます。
- ResourceSlice
- クラスター内で使用可能なリソースに関する情報を公開するために、構造化パラメーターとともに使用します。
リソースドライバーの開発者は、コントロールプレーンコントローラーを使用して割り当てを処理するか、代わりに構造化パラメーターを使用してKubernetesを介した割り当てに依存するかを決定します。
カスタムコントローラーは柔軟性が高い一方で、クラスターの自動スケーリングがノードのローカルリソースに対して確実に機能しない可能性があります。
構造化パラメーターはクラスターの自動スケーリングを可能にしますが、すべてのユースケースを満たすわけではありません。
ドライバーが構造化パラメーターを使用する場合、デバイスを選択するためのすべてのパラメーターは、Kubrnetes本体に組み込まれたResourceClaimおよびDeviceClass内で定義されます。
構成パラメーターは任意のJSONオブジェクトとして埋め込むことができます。
core/v1 PodSpecは、ResourceClaimフィールド内でPodに必要なResourceClaimを定義します。
このリスト内のエントリは、ResourceClaimまたはResourceClaimTemplateを参照します。
ResourceClaimを参照する場合、このPodSpecを使用するすべてのPod(例えば、DeploymentまたはStatefulSet内)は、同じResourceClaimインスタンスを共有します。
ResourceClaimTemplateを参照する場合、各Podには独自のインスタンスが割り当てられます。
コンテナリソースのresources.claimsリストは、コンテナがこれらのリソースインスタンスにアクセスできるかどうかを定義します。
これにより、1つ以上のコンテナ間でリソースを共有することが可能になります。
以下は、架空のリソースドライバーの例です。
このPodに対して2つのResourceClaimオブジェクトが作成され、各コンテナがそれぞれ1つにアクセスできます。
apiVersion: resource.k8s.io/v1alpha3
kind: DeviceClass
name: resource.example.com
spec:
selectors:
- cel:
expression: device.driver == "resource-driver.example.com"
---
apiVersion: resource.k8s.io/v1alpha2
kind: ResourceClaimTemplate
metadata:
name: large-black-cat-claim-template
spec:
spec:
devices:
requests:
- name: req-0
deviceClassName: resource.example.com
selectors:
- cel:
expression: |-
device.attributes["resource-driver.example.com"].color == "black" &&
device.attributes["resource-driver.example.com"].size == "large"
–--
apiVersion: v1
kind: Pod
metadata:
name: pod-with-cats
spec:
containers:
- name: container0
image: ubuntu:20.04
command: ["sleep", "9999"]
resources:
claims:
- name: cat-0
- name: container1
image: ubuntu:20.04
command: ["sleep", "9999"]
resources:
claims:
- name: cat-1
ResourceClaim:
- name: cat-0
resourceClaimTemplateName: large-black-cat-claim-template
- name: cat-1
resourceClaimTemplateName: large-black-cat-claim-template
スケジューリング
コントロールプレーンコントローラーを使用する
ネイティブリソース(CPU、RAM)と拡張リソース(デバイスプラグインによって管理され、kubeletによってアドバタイズされる)とは異なり、構造化パラメーターがない場合、スケジューラーはクラスター内の使用可能な動的リソースや、特定のResourceClaimの要件を満たすためにどのように分割できるかについて知識がありません。
リソースドライバーがその責任を持ちます。
ResourceClaimはリソースが予約されると「割り当て済み」としてマークされます。
これにより、スケジューラーはResourceClaimが使用可能であるクラスター内の場所を知ることができます。
Podがスケジュールされると、スケジューラーはPodに必要なすべてのResourceClaimをチェックし、PodSchedulingオブジェクトを作成して、それらのResourceClaimに関連するリソースドライバーにスケジューラーが適していると判断したノードについて通知します。
リソースドライバーは、ドライバーのリソースが十分に残っていないノードを除外することで応答します。
スケジューラーがその情報を取得すると、ノードを1つ選択し、その選択をPodSchedulingオブジェクトに保存します。
リソースドライバーはその後、リソースがそのノードで使用できるようにResourceClaimを割り当てます。
それが完了すると、Podがスケジュールされます。
このプロセスの一環として、ResourceClaimもPodのために予約されます。
現在、ResourceClaimは単一のPodまたは無制限の数のPodによって排他的に使用できます。
重要な機能の1つは、すべてのリソースが割り当てられて、予約されない限り、Podがノードにスケジュールされないことです。
これにより、Podが1つのノードにスケジュールされ、そのノードで実行できないというシナリオが回避されます。
このような保留中のPodは、RAMやCPUなどの他のすべてのリソースもブロックするため、問題が発生します。
備考:
ResourceClaimを使用するPodのスケジューリングは、追加の通信が必要となるため遅くなります。
一度に1つのPodしかスケジュールされず、ResourceClaimでPodを処理するときにAPI呼び出しをブロックすることになり、次のPodのスケジュールが遅延するため、ResourceClaimを使用しないPodにも影響する可能性があることに注意してください。構造化パラメーターを使用する
ドライバーが構造化パラメーターを使用する場合、Podがリソースを必要とするたびに、スケジューラーがResourceClaimにリソースを割り当てる責任を引き継ぎます。
これは、ResourceSliceオブジェクトから使用可能なリソースの完全なリストを取得し、既存のResourceClaimに割り当てられているリソースを追跡し、これらの残存リソースから選択することによって行われます。
現時点でサポートされているリソースの種類はデバイスのみです。
デバイスインスタンスは、名前といくつかの属性とキャパシティを持ちます。
デバイスは、それらの属性とキャパシティをチェックするCEL式を通じて選択されます。
さらに、選択されたデバイスのセットを、特定の制約を満たすセットに制限することもできます。
選択されたリソースはベンダー固有の構成とともにResourceClaimのステータスに記録されるため、Podがノード上で起動しようとすると、ノード上のリソースドライバーはリソースを準備するために必要なすべての情報を持ちます。
構造化パラメーターを使用することで、スケジューラーは任意のDRAリソースドライバーと通信せずに決定を下すことができます。
またResourceClaimの割り当てに関する情報をメモリに保持し、Podをノードにバインドする際にバックエンドでこの情報をResourceClaimオブジェクトに書き込むことで、複数のPodを迅速にスケジュールすることができます。
リソースの監視
kubeletは、実行中のPodの動的リソースの検出を可能にするgRPCサービスを提供します。
gRPCエンドポイントに関する詳細については、リソース割り当てレポートを参照してください。
事前スケジュールされたPod
あなた、または他のAPIクライアントが、spec.nodeNameがすでに設定されているPodを作成すると、スケジューラーはバイパスされます。
そのPodに必要なResourceClaimがまだ存在しない場合や、Podに割り当てられていない、またはPodのために予約されていない場合、kubeletはPodの実行に失敗し、それらの要件が後に満たされる可能性があるため定期的に再チェックを行います。
このような状況は、Podがスケジュールされた時点でスケジューラーに動的リソース割り当てのサポートが有効になっていなかった場合にも発生します(バージョンスキュー、構成、フィーチャーゲートなど)。
kube-controller-managerはこれを検出し、必要なResourceClaimの割り当てや予約をトリガーすることで、Podを実行可能にしようとします。
備考:
これは、構造化パラメーターを使用しないリソースドライバーにのみ適用されます。ノードに割り当てられたPodは通常のリソース(RAM、CPU)をブロックし、そのPodがスタックしている間は他のPodで使用できなくなるため、スケジューラーのバイパスは避けることが望ましいです。
Podを通常のスケジューリングフローを通して特定のノード上で実行するには、目的のノードと完全に一致するノードセレクターを使用してPodを作成します:
apiVersion: v1
kind: Pod
metadata:
name: pod-with-cats
spec:
nodeSelector:
kubernetes.io/hostname: name-of-the-intended-node
...
また、アドミッション時に入力されるPodの.spec.nodeNameフィールドを解除し、代わりにノードセレクターを使用することもできます。
動的リソース割り当ての有効化
動的リソース割り当てはアルファ機能であり、DynamicResourceAllocationフィーチャーゲートとresource.k8s.io/v1alpha3 APIグループが有効になっている場合のみ有効になります。
詳細については、--feature-gatesおよび--runtime-configkube-apiserverパラメーターを参照してください。
kube-scheduler、kube-controller-manager、kubeletもフィーチャーゲートが必要です。
リソースドライバーがコントロールプレーンコントローラーを使用する場合、DynamicResourceAllocationに加えてDRAControlPlaneControllerフィーチャーゲートを有効化する必要があります。
Kubernetesクラスターがこの機能をサポートしているかどうかを簡単に確認するには、次のコマンドを使用してDeviceClassオブジェクトをリストします:
kubectl get deviceclasses
クラスターが動的リソース割り当てをサポートしている場合、レスポンスはDeviceClassオブジェクトのリストか、次のように表示されます:
No resources found
サポートされていない場合、代わりに次のエラーが表示されます:
error: the server doesn't have a resource type "deviceclasses"
spec.controllerフィールドが設定されているResourceClaimが作成可能な場合、コントロールプレーンコントローラーがサポートされます。
DRAControlPlaneControllerフィーチャーゲートが無効になっている場合、そのフィールドはResourceClaimを保存するときに自動的にクリアされます。
kube-schedulerのデフォルト構成では、フィーチャーゲートが有効でありv1構成APIを使用している場合にのみ「DynamicResources」プラグインが有効になります。
カスタム構成では、このプラグインを含めるように変更する必要があるかもしれません。
クラスターで機能を有効化するには、リソースドライバーもインストールする必要があります。
詳細については、ドライバーのドキュメントを参照してください。
次の項目
9 - Gangスケジューリング
FEATURE STATE:
Kubernetes v1.35 [alpha](disabled by default)
Gangスケジューリングは、Podのグループを「全か無か」の原則でスケジュールすることを保証します。
クラスターがグループ全体(または、定義された最小数のPod)を収容できない場合、どのPodもノードにバインドされません。
この機能はWorkload APIに依存しています。
クラスターでGenericWorkloadフィーチャーゲートとscheduling.k8s.io/v1alpha1 APIグループが有効になっていることを確認してください。
動作の仕組み
GangSchedulingプラグインが有効な場合、スケジューラーはWorkload内のgang Podグループポリシーに属するPodのライフサイクルを変更します。
このプロセスは、各Podグループとそのレプリカキーごとに独立して実行されます:
スケジューラーは、以下の条件をすべて満たすまで、PodをPreEnqueueフェーズで保持します:
- 参照先のWorkloadオブジェクトが作成されている
- 参照先のPodグループがWorkload内に存在する
- 特定のグループに対して作成されたPodの数が、少なくとも
minCount以上である
これらの条件がすべて満たされるまで、Podはアクティブなスケジューリングキューに入りません。
必要数が満たされると、スケジューラーはグループ内のすべてのPodの配置先を見つけようとします。
この処理中、割り当てられたすべてのPodはWaitOnPermitゲートで待機します。
なお、この機能のAlphaフェーズでは、配置先の検索は単一サイクル方式ではなく、Pod単位のスケジューリングに基づいています。
スケジューラーが少なくともminCount個のPodに対して有効な配置先を見つけた場合、それらすべてを割り当てられたノードにバインドすることを許可します。
5分間の固定タイムアウト内にグループ全体の配置先を見つけられない場合、どのPodもスケジュールされません。
代わりに、クラスターのリソースが空くのを待つため、スケジュール不可能キューに移動され、その間に他のワークロードをスケジュールできるようにします。
次の項目
10 - スケジューラーのパフォーマンスチューニング
FEATURE STATE:
Kubernetes 1.14 [beta]
kube-schedulerはKubernetesのデフォルトのスケジューラーです。
クラスター内のノード上にPodを割り当てる責務があります。
クラスター内に存在するノードで、Podのスケジューリング要求を満たすものはPodに対して割り当て可能なノードと呼ばれます。
スケジューラーはPodに対する割り当て可能なノードをみつけ、それらの割り当て可能なノードにスコアをつけます。
その中から最も高いスコアのノードを選択し、Podに割り当てるためのいくつかの関数を実行します。
スケジューラーはBindingと呼ばれる処理中において、APIサーバーに対して割り当てが決まったノードの情報を通知します。
このページでは、大規模のKubernetesクラスターにおけるパフォーマンス最適化のためのチューニングについて説明します。
大規模クラスターでは、レイテンシー(新規Podをすばやく配置)と精度(スケジューラーが不適切な配置を行うことはめったにありません)の間でスケジューリング結果を調整するスケジューラーの動作をチューニングできます。
このチューニング設定は、kube-scheduler設定のpercentageOfNodesToScoreで設定できます。
KubeSchedulerConfiguration設定は、クラスター内のノードにスケジュールするための閾値を決定します。
閾値の設定
percentageOfNodesToScoreオプションは、0から100までの数値を受け入れます。
0は、kube-schedulerがコンパイル済みのデフォルトを使用することを示す特別な値です。
percentageOfNodesToScoreに100より大きな値を設定した場合、kube-schedulerの挙動は100を設定した場合と同様となります。
この値を変更するためには、kube-schedulerの設定ファイル(これは/etc/kubernetes/config/kube-scheduler.yamlの可能性が高い)を編集し、スケジューラーを再起動します。
この変更をした後、
kubectl get pods -n kube-system | grep kube-scheduler
を実行して、kube-schedulerコンポーネントが正常であることを確認できます。
ノードへのスコア付けの閾値
スケジューリング性能を改善するため、kube-schedulerは割り当て可能なノードが十分に見つかるとノードの検索を停止できます。
大規模クラスターでは、すべてのノードを考慮する単純なアプローチと比較して時間を節約できます。
クラスター内のすべてのノードに対する十分なノード数を整数パーセンテージで指定します。
kube-schedulerは、これをノード数に変換します。
スケジューリング中に、kube-schedulerが設定されたパーセンテージを超える十分な割り当て可能なノードを見つけた場合、kube-schedulerはこれ以上割り当て可能なノードを探すのを止め、スコアリングフェーズに進みます。
スケジューラーはどのようにノードを探索するかで処理を詳しく説明しています。
デフォルトの閾値
閾値を指定しない場合、Kubernetesは100ノードのクラスターでは50%、5000ノードのクラスターでは10%になる線形方程式を使用して数値を計算します。
自動計算の下限は5%です。
つまり、明示的にpercentageOfNodesToScoreを5未満の値を設定しない限り、クラスターの規模に関係なく、kube-schedulerは常に少なくともクラスターの5%のノードに対してスコア付けをします。
スケジューラーにクラスター内のすべてのノードに対してスコア付けをさせる場合は、percentageOfNodesToScoreの値に100を設定します。
例
percentageOfNodesToScoreの値を50%に設定する例は下記のとおりです。
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
algorithmSource:
provider: DefaultProvider
...
percentageOfNodesToScore: 50
percentageOfNodesToScoreのチューニング
percentageOfNodesToScoreは1から100の間の範囲である必要があり、デフォルト値はクラスターのサイズに基づいて計算されます。
また、クラスターのサイズの最小値は100ノードとハードコードされています。
備考:
割り当て可能なノードが100以下のクラスターでは、スケジューラの検索を早期に停止するのに十分な割り当て可能なノードがないため、スケジューラはすべてのノードをチェックします。
小規模クラスターでは、percentageOfNodesToScoreに低い値を設定したとしても、同様の理由で変更による影響は全くないか、ほとんどありません。
クラスターのノード数が数百以下の場合は、この設定オプションをデフォルト値のままにします。
変更してもスケジューラの性能を大幅に改善する可能性はほとんどありません。
この値を設定する際に考慮するべき重要な注意事項として、割り当て可能ノードのチェック対象のノードが少ないと、一部のノードはPodの割り当てのためにスコアリングされなくなります。
結果として、高いスコアをつけられる可能性のあるノードがスコアリングフェーズに渡されることがありません。
これにより、Podの配置が理想的なものでなくなります。
kube-schedulerが頻繁に不適切なPodの配置を行わないよう、percentageOfNodesToScoreをかなり低い値を設定することは避けるべきです。
スケジューラのスループットがアプリケーションにとって致命的で、ノードのスコアリングが重要でない場合を除いて、10%未満に設定することは避けてください。
言いかえると、割り当て可能な限り、Podは任意のノード上で稼働させるのが好ましいです。
スケジューラーはどのようにノードを探索するか
このセクションでは、この機能の内部の詳細を理解したい人向けになります。
クラスター内の全てのノードに対して平等にPodの割り当ての可能性を持たせるため、スケジューラーはラウンドロビン方式でノードを探索します。
複数のノードの配列になっているイメージです。
スケジューラーはその配列の先頭から探索を開始し、percentageOfNodesToScoreによって指定された数のノードを検出するまで、割り当て可能かどうかをチェックしていきます。
次のPodでは、スケジューラーは前のPodの割り当て処理でチェックしたところから探索を再開します。
ノードが複数のゾーンに存在するとき、スケジューラーは様々なゾーンのノードを探索して、異なるゾーンのノードが割り当て可能かどうかのチェック対象になるようにします。
例えば2つのゾーンに6つのノードがある場合を考えます。
Zone 1: Node 1, Node 2, Node 3, Node 4
Zone 2: Node 5, Node 6
スケジューラーは、下記の順番でノードの割り当て可能性を評価します。
Node 1, Node 5, Node 2, Node 6, Node 3, Node 4
全てのノードのチェックを終えたら、1番目のノードに戻ってチェックをします。
Opportunistic Batchingの有効化
FEATURE STATE:
Kubernetes v1.35 [beta](enabled by default)
大規模なワークロードをスケジューリングする場合、通常、Podの定義はほぼ同一であり、スケジューラーが同じ処理を繰り返し実行する必要があります。
Opportunistic Batching機能は、スケジューリングサイクル間でフィルタリングおよびスコアリング結果を再利用することで、スケジューリング処理を大幅に高速化します。
基本的には、この機能は次のように動作します。
- スケジューラーが最初の
pod-1をスケジュールし、その結果をキャッシュします。 - 続く
pod-2,pod-3,…は、キャッシュされた結果を利用してスケジュールされます。 - キャッシュは0.5秒後に期限切れとなり、その後スケジュールされるPodについて新たにキャッシュが構築されます。
注意: 同じスケジューリング制約を持つPodが連続してスケジューリングサイクルに投入される必要があります。
異なる制約を持つPodがスケジュールされる場合、既存キャッシュは使用されず、新しいキャッシュに置き換えられます。
このバッチングスケジューリングは、次の条件を満たすPodに適用されます。
- Pod間のアフィニティ/アンチアフィニティを持たない
- トポロジースプレッド制約を持たない
- ResourceClaimのようなDRAを持たない
- ノードを専有してスケジュールされる(1ノードに複数のPodを配置するとキャッシュが無効化される)
本機能を有効化するため、スケジューラー設定では次の対応が必要です。
- デフォルトのトポロジースプレッド制約を空に設定し、無効化する
- DRAExtendedResource機能ゲートを無効化する
- InterPodAffinityArgsの
IgnorePreferredTermsOfExistingPodsをtrueに設定し、バッチング効率を向上させる
注意:
- 既存のPodが、スケジュール対象のPodのラベルに一致するPodアフィニティ制約を使用している場合、この機能による恩恵を受けられない可能性があります。
- カスタムプラグインを使用している場合、Signature拡張ポイントの実装が必要です。
これらの制約および条件は、将来のリリースで変更される可能性があります。
11 - 拡張リソースのリソースビンパッキング
FEATURE STATE:
Kubernetes v1.16 [alpha]
kube-schedulerでは、優先度関数RequestedToCapacityRatioResourceAllocationを使用した、
拡張リソースを含むリソースのビンパッキングを有効化できます。優先度関数はそれぞれのニーズに応じて、kube-schedulerを微調整するために使用できます。
RequestedToCapacityRatioResourceAllocationを使用したビンパッキングの有効化
Kubernetesでは、キャパシティー比率への要求に基づいたNodeのスコアリングをするために、各リソースの重みと共にリソースを指定することができます。これにより、ユーザーは適切なパラメーターを使用することで拡張リソースをビンパックすることができ、大規模クラスターにおける希少なリソースを有効活用できるようになります。優先度関数RequestedToCapacityRatioResourceAllocationの動作はRequestedToCapacityRatioArgsと呼ばれる設定オプションによって変わります。この引数はshapeとresourcesパラメーターによって構成されます。shapeパラメーターはutilizationとscoreの値に基づいて、最も要求が多い場合か最も要求が少ない場合の関数をチューニングできます。resourcesパラメーターは、スコアリングの際に考慮されるリソース名のnameと、各リソースの重みを指定するweightで構成されます。
以下は、拡張リソースintel.com/fooとintel.com/barのビンパッキングにrequestedToCapacityRatioArgumentsを設定する例になります。
apiVersion: kubescheduler.config.k8s.io/v1beta1
kind: KubeSchedulerConfiguration
profiles:
# ...
pluginConfig:
- name: RequestedToCapacityRatio
args:
shape:
- utilization: 0
score: 10
- utilization: 100
score: 0
resources:
- name: intel.com/foo
weight: 3
- name: intel.com/bar
weight: 5
スケジューラーには、kube-schedulerフラグ--config=/path/to/config/fileを使用してKubeSchedulerConfigurationのファイルを指定することで渡すことができます。
この機能はデフォルトで無効化されています
優先度関数のチューニング
shapeはRequestedToCapacityRatioPriority関数の動作を指定するために使用されます。
shape:
- utilization: 0
score: 0
- utilization: 100
score: 10
上記の引数は、utilizationが0%の場合は0、utilizationが100%の場合は10というscoreをNodeに与え、ビンパッキングの動作を有効にしています。最小要求を有効にするには、次のようにスコアを反転させる必要があります。
shape:
- utilization: 0
score: 10
- utilization: 100
score: 0
resourcesはオプションパラメーターで、デフォルトでは以下の通りです。
resources:
- name: cpu
weight: 1
- name: memory
weight: 1
以下のように拡張リソースの追加に利用できます。
resources:
- name: intel.com/foo
weight: 5
- name: cpu
weight: 3
- name: memory
weight: 1
weightはオプションパラメーターで、指定されてない場合1が設定されます。また、マイナスの値は設定できません。
キャパシティ割り当てのためのNodeスコアリング
このセクションは、本機能の内部詳細について理解したい方を対象としています。以下は、与えられた値に対してNodeのスコアがどのように計算されるかの例です。
要求されたリソース:
intel.com/foo : 2
memory: 256MB
cpu: 2
リソースの重み:
intel.com/foo : 5
memory: 1
cpu: 3
shapeの値 {{0, 0}, {100, 10}}
Node1のスペック:
Available:
intel.com/foo: 4
memory: 1 GB
cpu: 8
Used:
intel.com/foo: 1
memory: 256MB
cpu: 1
Nodeのスコア:
intel.com/foo = resourceScoringFunction((2+1),4)
= (100 - ((4-3)*100/4))
= (100 - 25)
= 75 # requested + used = 75% * available
= rawScoringFunction(75)
= 7 # floor(75/10)
memory = resourceScoringFunction((256+256),1024)
= (100 -((1024-512)*100/1024))
= 50 # requested + used = 50% * available
= rawScoringFunction(50)
= 5 # floor(50/10)
cpu = resourceScoringFunction((2+1),8)
= (100 -((8-3)*100/8))
= 37.5 # requested + used = 37.5% * available
= rawScoringFunction(37.5)
= 3 # floor(37.5/10)
NodeScore = ((7 * 5) + (5 * 1) + (3 * 3)) / (5 + 1 + 3)
= 5
Node2のスペック:
Available:
intel.com/foo: 8
memory: 1GB
cpu: 8
Used:
intel.com/foo: 2
memory: 512MB
cpu: 6
Nodeのスコア:
intel.com/foo = resourceScoringFunction((2+2),8)
= (100 - ((8-4)*100/8)
= (100 - 50)
= 50
= rawScoringFunction(50)
= 5
memory = resourceScoringFunction((256+512),1024)
= (100 -((1024-768)*100/1024))
= 75
= rawScoringFunction(75)
= 7
cpu = resourceScoringFunction((2+6),8)
= (100 -((8-8)*100/8))
= 100
= rawScoringFunction(100)
= 10
NodeScore = ((5 * 5) + (7 * 1) + (10 * 3)) / (5 + 1 + 3)
= 7
次の項目
12 - Podの優先度とプリエンプション
FEATURE STATE:
Kubernetes v1.14 [stable]
Podは priority(優先度)を持つことができます。
優先度は他のPodに対する相対的なPodの重要度を示します。
もしPodをスケジューリングできないときには、スケジューラーはそのPodをスケジューリングできるようにするため、優先度の低いPodをプリエンプトする(追い出す)ことを試みます。
警告:
クラスターの全てのユーザーが信用されていない場合、悪意のあるユーザーが可能な範囲で最も高い優先度のPodを作成することが可能です。これは他のPodが追い出されたりスケジューリングできない状態を招きます。
管理者はResourceQuotaを使用して、ユーザーがPodを高い優先度で作成することを防ぐことができます。
詳細はデフォルトで優先度クラスの消費を制限する
を参照してください。
優先度とプリエンプションを使う方法
優先度とプリエンプションを使うには、
1つまたは複数のPriorityClassを追加します
追加したPriorityClassをpriorityClassNameに設定したPodを作成します。
もちろんPodを直接作る必要はありません。
一般的にはpriorityClassNameをDeploymentのようなコレクションオブジェクトのPodテンプレートに追加します。
これらの手順のより詳しい情報については、この先を読み進めてください。
PriorityClass
PriorityClassはnamespaceによらないオブジェクトで、優先度クラスの名称から優先度を表す整数値への対応を定義します。
PriorityClassオブジェクトのメタデータのnameフィールドにて名称を指定します。
値はvalueフィールドで指定し、必須です。
値が大きいほど、高い優先度を示します。
PriorityClassオブジェクトの名称はDNSサブドメイン名として適切であり、かつsystem-から始まってはいけません。
PriorityClassオブジェクトは10億以下の任意の32ビットの整数値を持つことができます。これは、PriorityClassオブジェクトの値の範囲が-2147483648から1000000000までであることを意味します。
それよりも大きな値は通常はプリエンプトや追い出すべきではない重要なシステム用のPodのために予約されています。
クラスターの管理者は割り当てたい優先度に対して、PriorityClassオブジェクトを1つずつ作成すべきです。
PriorityClassは任意でフィールドglobalDefaultとdescriptionを設定可能です。
globalDefaultフィールドはpriorityClassNameが指定されないPodはこのPriorityClassを使うべきであることを示します。globalDefaultがtrueに設定されたPriorityClassはシステムで一つのみ存在可能です。globalDefaultが設定されたPriorityClassが存在しない場合は、priorityClassNameが設定されていないPodの優先度は0に設定されます。
descriptionフィールドは任意の文字列です。クラスターの利用者に対して、PriorityClassをどのような時に使うべきか示すことを意図しています。
PodPriorityと既存のクラスターに関する注意
もし既存のクラスターをこの機能がない状態でアップグレードすると、既存のPodの優先度は実質的に0になります。
globalDefaultがtrueに設定されたPriorityClassを追加しても、既存のPodの優先度は変わりません。PriorityClassのそのような値は、PriorityClassが追加された以後に作成されたPodのみに適用されます。
PriorityClassを削除した場合、削除されたPriorityClassの名前を使用する既存のPodは変更されませんが、削除されたPriorityClassの名前を使うPodをそれ以上作成することはできなくなります。
PriorityClassの例
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "この優先度クラスはXYZサービスのPodに対してのみ使用すべきです。"
非プリエンプトのPriorityClass
FEATURE STATE:
Kubernetes v1.24 [stable]
preemptionPolicy: Neverと設定されたPodは、スケジューリングのキューにおいて他の優先度の低いPodよりも優先されますが、他のPodをプリエンプトすることはありません。
スケジューリングされるのを待つ非プリエンプトのPodは、リソースが十分に利用可能になるまでスケジューリングキューに残ります。
非プリエンプトのPodは、他のPodと同様に、スケジューラーのバックオフの対象になります。これは、スケジューラーがPodをスケジューリングしようと試みたものの失敗した場合、低い頻度で再試行するようにして、より優先度の低いPodが先にスケジューリングされることを許します。
非プリエンプトのPodは、他の優先度の高いPodにプリエンプトされる可能性はあります。
preemptionPolicyはデフォルトではPreemptLowerPriorityに設定されており、これが設定されているPodは優先度の低いPodをプリエンプトすることを許容します。これは既存のデフォルトの挙動です。
preemptionPolicyをNeverに設定すると、これが設定されたPodはプリエンプトを行わないようになります。
ユースケースの例として、データサイエンスの処理を挙げます。
ユーザーは他の処理よりも優先度を高くしたいジョブを追加できますが、そのとき既存の実行中のPodの処理結果をプリエンプトによって破棄させたくはありません。
preemptionPolicy: Neverが設定された優先度の高いジョブは、他の既にキューイングされたPodよりも先に、クラスターのリソースが「自然に」開放されたときにスケジューリングされます。
非プリエンプトのPriorityClassの例
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority-nonpreempting
value: 1000000
preemptionPolicy: Never
globalDefault: false
description: "この優先度クラスは他のPodをプリエンプトさせません。"
Podの優先度
一つ以上のPriorityClassがあれば、仕様にPriorityClassを指定したPodを作成することができるようになります。優先度のアドミッションコントローラーはpriorityClassNameフィールドを使用し、優先度の整数値を設定します。PriorityClassが見つからない場合、そのPodの作成は拒否されます。
下記のYAMLは上記の例で作成したPriorityClassを使用するPodの設定の例を示します。優先度のアドミッションコントローラーは仕様を確認し、このPodの優先度は1000000であると設定します。
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
スケジューリング順序におけるPodの優先度の効果
Podの優先度が有効な場合、スケジューラーは待機状態のPodをそれらの優先度順に並べ、スケジューリングキューにおいてより優先度の低いPodよりも前に来るようにします。その結果、その条件を満たしたときには優先度の高いPodは優先度の低いPodより早くスケジューリングされます。優先度の高いPodがスケジューリングできない場合は、スケジューラーは他の優先度の低いPodのスケジューリングも試みます。
プリエンプション
Podが作成されると、スケジューリング待ちのキューに入り待機状態になります。スケジューラーはキューからPodを取り出し、ノードへのスケジューリングを試みます。Podに指定された条件を全て満たすノードが見つからない場合は、待機状態のPodのためにプリエンプションロジックが発動します。待機状態のPodをPと呼ぶことにしましょう。プリエンプションロジックはPよりも優先度の低いPodを一つ以上追い出せばPをスケジューリングできるようになるノードを探します。そのようなノードがあれば、優先度の低いPodはノードから追い出されます。Podが追い出された後に、Pはノードへスケジューリング可能になります。
ユーザーへ開示される情報
Pod PがノードNのPodをプリエンプトした場合、ノードNの名称がPのステータスのnominatedNodeNameフィールドに設定されます。このフィールドはスケジューラーがPod Pのために予約しているリソースの追跡を助け、ユーザーにクラスターにおけるプリエンプトに関する情報を与えます。
Pod Pは必ずしも「指名したノード」へスケジューリングされないことに注意してください。スケジューラーは、他のノードに対して処理を繰り返す前に、常に「指定したノード」に対して試行します。Podがプリエンプトされると、そのPodは終了までの猶予期間を得ます。スケジューラーがPodの終了を待つ間に他のノードが利用可能になると、スケジューラーは他のノードをPod Pのスケジューリング先にすることがあります。この結果、PodのnominatedNodeNameとnodeNameは必ずしも一致しません。また、スケジューラーがノードNのPodをプリエンプトさせた後に、Pod Pよりも優先度の高いPodが来た場合、スケジューラーはノードNをその新しい優先度の高いPodへ与えることもあります。このような場合は、スケジューラーはPod PのnominatedNodeNameを消去します。これによって、スケジューラーはPod Pが他のノードのPodをプリエンプトさせられるようにします。
プリエンプトの制限
プリエンプトされるPodの正常終了
Podがプリエンプトされると、猶予期間が与えられます。
Podは作業を完了し、終了するために十分な時間が与えられます。仮にそうでない場合、強制終了されます。この猶予期間によって、スケジューラーがPodをプリエンプトした時刻と、待機状態のPod Pがノード Nにスケジュール可能になるまでの時刻の間に間が開きます。この間、スケジューラーは他の待機状態のPodをスケジュールしようと試みます。プリエンプトされたPodが終了したら、スケジューラーは待ち行列にあるPodをスケジューリングしようと試みます。そのため、Podがプリエンプトされる時刻と、Pがスケジュールされた時刻には間が開くことが一般的です。この間を最小にするには、優先度の低いPodの猶予期間を0または小さい値にする方法があります。
PodDisruptionBudgetは対応するが、保証されない
PodDisruptionBudget (PDB)は、アプリケーションのオーナーが冗長化されたアプリケーションのPodが意図的に中断される数の上限を設定できるようにするものです。KubernetesはPodをプリエンプトする際にPDBに対応しますが、PDBはベストエフォートで考慮します。スケジューラーはプリエンプトさせたとしてもPDBに違反しないPodを探します。そのようなPodが見つからない場合でもプリエンプションは実行され、PDBに反しますが優先度の低いPodが追い出されます。
優先度の低いPodにおけるPod間のアフィニティ
次の条件が真の場合のみ、ノードはプリエンプションの候補に入ります。
「待機状態のPodよりも優先度の低いPodをノードから全て追い出したら、待機状態のPodをノードへスケジュールできるか」
備考:
プリエンプションは必ずしも優先度の低いPodを全て追い出しません。
優先度の低いPodを全て追い出さなくても待機状態のPodがスケジューリングできる場合、一部のPodのみ追い出されます。
このような場合であったとしても、上記の条件は真である必要があります。偽であれば、そのノードはプリエンプションの対象とはされません。待機状態のPodが、優先度の低いPodとの間でPod間のアフィニティを持つ場合、Pod間のアフィニティはそれらの優先度の低いPodがなければ満たされません。この場合、スケジューラーはノードのどのPodもプリエンプトしようとはせず、代わりに他のノードを探します。スケジューラーは適切なノードを探せる場合と探せない場合があります。この場合、待機状態のPodがスケジューリングされる保証はありません。
この問題に対して推奨される解決策は、優先度が同一または高いPodに対してのみPod間のアフィニティを作成することです。
複数ノードに対するプリエンプション
Pod PがノードNにスケジューリングできるよう、ノードNがプリエンプションの対象となったとします。
他のノードのPodがプリエンプトされた場合のみPが実行可能になることもあります。下記に例を示します。
- Pod PをノードNに配置することを検討します。
- Pod QはノードNと同じゾーンにある別のノードで実行中です。
- Pod Pはゾーンに対するQへのアンチアフィニティを持ちます (
topologyKey: topology.kubernetes.io/zone)。 - Pod Pと、ゾーン内の他のPodに対しては他のアンチアフィニティはない状態です。
- Pod PをノードNへスケジューリングするには、Pod Qをプリエンプトすることが考えられますが、スケジューラーは複数ノードにわたるプリエンプションは行いません。そのため、Pod PはノードNへはスケジューリングできないとみなされます。
Pod Qがそのノードから追い出されると、Podアンチアフィニティに違反しなくなるので、Pod PはノードNへスケジューリング可能になります。
複数ノードに対するプリエンプションに関しては、十分な需要があり、合理的な性能を持つアルゴリズムを見つけられた場合に、将来的に機能追加を検討する可能性があります。
トラブルシューティング
Podの優先度とプリエンプションは望まない副作用をもたらす可能性があります。
いくつかの起こりうる問題と、その対策について示します。
Podが不必要にプリエンプトされる
プリエンプションは、リソースが不足している場合に優先度の高い待機状態のPodのためにクラスターの既存のPodを追い出します。
誤って高い優先度をPodに割り当てると、意図しない高い優先度のPodはクラスター内でプリエンプションを引き起こす可能性があります。Podの優先度はPodの仕様のpriorityClassNameフィールドにて指定されます。優先度を示す整数値へと変換された後、podSpecのpriorityへ設定されます。
この問題に対処するには、PodのpriorityClassNameをより低い優先度に変更するか、このフィールドを未設定にすることができます。priorityClassNameが未設定の場合、デフォルトでは優先度は0とされます。
Podがプリエンプトされたとき、プリエンプトされたPodのイベントが記録されます。
プリエンプションはPodに必要なリソースがクラスターにない場合のみ起こるべきです。
このような場合、プリエンプションはプリエンプトされるPodよりも待機状態のPodの優先度が高い場合のみ発生します。
プリエンプションは待機状態のPodがない場合や待機状態のPodがプリエンプト対象のPod以下の優先度を持つ場合には決して発生しません。そのような状況でプリエンプションが発生した場合、問題を報告してください。
Podはプリエンプトされたが、プリエンプトさせたPodがスケジューリングされない
Podがプリエンプトされると、それらのPodが要求した猶予期間が与えられます。そのデフォルトは30秒です。
Podがその期間内に終了しない場合、強制終了されます。プリエンプトされたPodがなくなれば、プリエンプトさせたPodはスケジューリング可能です。
プリエンプトさせたPodがプリエンプトされたPodの終了を待っている間に、より優先度の高いPodが同じノードに対して作成されることもあります。この場合、スケジューラーはプリエンプトさせたPodの代わりに優先度の高いPodをスケジューリングします。
これは予期された挙動です。優先度の高いPodは優先度の低いPodに取って代わります。
優先度の高いPodが優先度の低いPodより先にプリエンプトされる
スケジューラーは待機状態のPodが実行可能なノードを探します。ノードが見つからない場合、スケジューラーは任意のノードから優先度の低いPodを追い出し、待機状態のPodのためのリソースを確保しようとします。
仮に優先度の低いPodが動いているノードが待機状態のPodを動かすために適切ではない場合、スケジューラーは他のノードで動いているPodと比べると、優先度の高いPodが動いているノードをプリエンプションの対象に選ぶことがあります。この場合もプリエンプトされるPodはプリエンプトを起こしたPodよりも優先度が低い必要があります。
複数のノードがプリエンプションの対象にできる場合、スケジューラーは優先度が最も低いPodのあるノードを選ぼうとします。しかし、そのようなPodがPodDisruptionBudgetを持っており、プリエンプトするとPDBに反する場合はスケジューラーは優先度の高いPodのあるノードを選ぶこともあります。
複数のノードがプリエンプションの対象として利用可能で、上記の状況に当てはまらない場合、スケジューラーは優先度の最も低いノードを選択します。
Podの優先度とQoSの相互作用
Podの優先度とQoSクラスは直交する機能で、わずかに相互作用がありますが、デフォルトではQoSクラスによる優先度の設定の制約はありません。スケジューラーのプリエンプションのロジックはプリエンプションの対象を決めるときにQoSクラスは考慮しません。
プリエンプションはPodの優先度を考慮し、優先度が最も低いものを候補とします。より優先度の高いPodは優先度の低いPodを追い出すだけではプリエンプトを起こしたPodのスケジューリングに不十分な場合と、PodDisruptionBudgetにより優先度の低いPodが保護されている場合のみ対象になります。
kubeletはnode-pressureによる退避を行うPodの順番を決めるために、優先度を利用します。QoSクラスを使用して、最も退避される可能性の高いPodの順番を推定することができます。
kubeletは追い出すPodの順位付けを次の順で行います。
- 枯渇したリソースを要求以上に使用しているか
- Podの優先度
- 要求に対するリソースの使用量
詳細はkubeletによるPodの退避を参照してください。
kubeletによるリソース不足時のPodの追い出しでは、リソースの消費が要求を超えないPodは追い出されません。優先度の低いPodのリソースの利用量がその要求を超えていなければ、追い出されることはありません。より優先度が高く、要求を超えてリソースを使用しているPodが追い出されます。
次の項目
13 - ノードの圧迫による退避
ノード圧迫による退避は、kubeletがノード上のリソースを回収するためにPodを積極的に失敗させるプロセスです。
備考:
FEATURE STATE:
Kubernetes v1.31 [beta](enabled by default)
分割イメージファイルシステム 機能は、containerfsファイルシステムのサポートを有効にし、いくつかの新しい退避シグナル、閾値、メトリクスを追加します。
containerfsを使用するには、Kubernetesリリース v1.35でKubeletSeparateDiskGCフィーチャーゲートを有効にする必要があります。
現在、containerfsファイルシステムのサポートを提供しているのはCRI-O(v1.29以降)のみです。
kubeletは、クラスターのノード上のメモリ、ディスク容量、ファイルシステムのinodeといったのリソースを監視します。
これらのリソースの1つ以上が特定の消費レベルに達すると、kubeletはリソースの枯渇を防ぐため、ノード上の1つ以上のPodを事前に停止してリソースを回収します。
ノードのリソース枯渇による退避中に、kubeletは選択されたPodのフェーズをFailedに設定し、Podを終了します。
ノードのリソース枯渇による退避は、APIを起点とした退避とは異なります。
kubeletは、設定したPodDisruptionBudgetやPodのterminationGracePeriodSecondsを考慮しません。
ソフト退避の閾値を使用する場合は、kubeletは設定されたeviction-max-pod-grace-periodを順守します。
ハード退避の閾値を使用する場合は、kubeletは終了に0秒の猶予期間(即時シャットダウン)を使用します。
自己修復の仕組み
kubeletは、エンドユーザーのPodを終了する前にノードレベルのリソースを回収しようとします。
例えば、ディスクリソースが枯渇している場合は未使用のコンテナイメージを削除します。
失敗したPodを置き換えるワークロード管理オブジェクト(StatefulSetやDeployment)によってPodが管理されている場合、コントロールプレーン(kube-controller-manager)は退避されたPodの代わりに新しいPodを作成します。
static Podの自己修復
リソースが圧迫しているノード上でstatic podが実行されている場合、kubeletはそのstatic Podを退避することがあります。
static Podは常にそのノード上でPodを実行しようとするため、kubeletは代替のPodの作成を試みます。
kubeletは、代替のPodを作成する際にstatic Podの priority を考慮します。
static Podのマニフェストで低い優先度が指定され、クラスターのコントロールプレーン内で定義されたより高い優先度のPodがあります。
ノードのリソースが圧迫されている場合、kubeletはそのstatic Podのためにスペースを確保できない可能性があります。
kubeletは、ノードのリソースが圧迫されている場合でもすべてのstatic Podの実行を試行し続けます。
退避シグナルと閾値
kubeletは、退避を決定するために次のようにさまざまなパラメータを使用します:
退避シグナル
退避シグナルは、ある時点での特定リソースの状態を表します。
kubeletは退避シグナルを使用して、シグナルと退避閾値(ノード上で利用可能なリソースの最小量)を比較して退避を決定します。
kubeletは次の退避シグナルを使用します:
| 退避シグナル | 説明 | Linux専用 |
|---|
memory.available | memory.available := node.status.capacity[memory] - node.stats.memory.workingSet | |
nodefs.available | nodefs.available := node.stats.fs.available | |
nodefs.inodesFree | nodefs.inodesFree := node.stats.fs.inodesFree | • |
imagefs.available | imagefs.available := node.stats.runtime.imagefs.available | |
imagefs.inodesFree | imagefs.inodesFree := node.stats.runtime.imagefs.inodesFree | • |
containerfs.available | containerfs.available := node.stats.runtime.containerfs.available | |
containerfs.inodesFree | containerfs.inodesFree := node.stats.runtime.containerfs.inodesFree | • |
pid.available | pid.available := node.stats.rlimit.maxpid - node.stats.rlimit.curproc | • |
この表では、説明列がシグナルの値の取得方法を示しています。
それぞれのシグナルは、パーセンテージまたはリテラル値をサポートします。
kubeletは、シグナルに関連付けられた総容量に対する割合を計算します。
メモリシグナル
Linuxノード上では、free -mのようなツールの代わりにcgroupfsからmemory.availableの値が取得されます。
これは重要なことであり、free -mはコンテナ内で動作せず、ユーザーがNode Allocatable機能を使用する場合、リソース不足の判断はルートノードと同様にcgroup階層のエンドユーザーPodの一部に対してローカルに行われるためです。
このスクリプトまたはcgroupv2スクリプトは、kubeletがmemory.availableを計算するために実行する一連の手順を再現します。
kubeletは、圧迫下でもメモリが再利用可能であると想定しているため、inactive_file(非アクティブなLRUリスト上のファイルベースのメモリのバイト数)を計算から除外します。
Windowsノードでは、memory.availableの値は、ノードのグローバルメモリコミットレベル(GetPerformanceInfo関数システムコールによって参照)から、ノードのCommitLimitからノードのグローバルCommitTotalを減算することによって導出されます。
ノードのページファイルサイズが変更されると、CommitLimitも変更されることに注意してください。
ファイルシステムシグナル
kubeletは、退避シグナル(<identifier>.inodesFreeや<identifier>.available)で使用できる3つの特定のファイルシステム識別子を認識します:
nodefs: ノードのファイルシステムであり、ローカルディスクボリューム、メモリにバックアップされていないemptyDirボリューム、ログストレージ、エフェメラルストレージなどに使用されます。
例えば、nodefsには/var/lib/kubeletが含まれます。
imagefs: コンテナランタイムがコンテナイメージ(読み取り専用レイヤー)とコンテナの書き込みレイヤーを格納するために使用できるオプションのファイルシステムです。
containerfs: コンテナランタイムが書き込み可能なレイヤーを格納するために使用できるオプションのファイルシステムです。
メインファイルシステム(nodefsを参照)と同様に、ローカルディスクボリューム、メモリにバックアップされていないemptyDirボリューム、ログストレージ、エフェメラルストレージに使用されますが、コンテナイメージは含まれません。
containerfsを使用すると、imagefsファイルシステムをコンテナイメージ(読み取り専用レイヤー)のみを格納するように分割できます。
したがって、kubeletは通常コンテナファイルシステムについて次の3つのオプションを許可します:
すべてが単一のnodefsにある場合、"rootfs"または単に"root"として参照され、専用のイメージファイルシステムはありません。
コンテナストレージ(nodefsを参照)は専用のディスクにあり、imagefs(書き込み可能レイヤーと読み取り専用レイヤー)はルートファイルシステムから分離されています。
これはよく「分割ディスク」(または「分離ディスク」)ファイルシステムと呼ばれます。
コンテナファイルシステムcontainerfs(書き込み可能レイヤーを含むnodefsと同じ)がルートにあり、コンテナイメージ(読み取り専用レイヤー)は分離されたimagefsに格納されています。
これはよく「分割イメージ」ファイルシステムと呼ばれます。
kubeletは、これらのファイルシステムを現在の構成に基づいてコンテナランタイムから直接自動検出しようとし、他のローカルノードファイルシステムを無視します。
kubeletは、他のコンテナファイルシステムやストレージ構成をサポートせず、現在イメージとコンテナに対して複数のファイルシステムをサポートしていません。
非推奨のkubeletガベージコレクション機能
一部のkubeletガベージコレクション機能は、退避に置き換えられるため非推奨となりました:
| 既存フラグ | 理由 |
|---|
--maximum-dead-containers | 古いログがコンテナのコンテキスト外に保存されると非推奨になります |
--maximum-dead-containers-per-container | 古いログがコンテナのコンテキスト外に保存されると非推奨になります |
--minimum-container-ttl-duration | 古いログがコンテナのコンテキスト外に保存されると非推奨になります |
退避閾値
kubeletは、退避の判断を行うときに使用するカスタムの退避閾値を指定できます。
ソフト退避の閾値とハード退避の閾値の退避閾値を構成できます。
退避閾値は[eviction-signal][operator][quantity]の形式を取ります:
eviction-signalは、使用する退避シグナルです。operatorは、<(より小さい)などの関係演算子です。quantityは、1Giなどの退避閾値量です。
quantityの値はKubernetesで使用される数量表現と一致する必要があります。
リテラル値またはパーセンテージ(%)を使用できます。
例えば、ノードの総メモリが10GiBで、利用可能なメモリが1GiB未満になった場合に退避をトリガーする場合、退避閾値をmemory.available<10%またはmemory.available<1Giのどちらかで定義できます(両方を使用することはできません)。
ソフト退避の閾値
ソフト退避閾値は、退避閾値と必須の管理者指定の猶予期間をペアにします。
kubeletは猶予期間が経過するまでポッドを退避しません。
kubeletは猶予期間を指定しない場合、起動時にエラーを返します。
ソフト退避閾値の猶予期間と、kubeletが退避中に使用する最大許容Pod終了の猶予期間を両方指定できます。
最大許容猶予期間を指定しており、かつソフト退避閾値に達した場合、kubeletは2つの猶予期間のうち短い方を使用します。
最大許容猶予期間を指定していない場合、kubeletはグレースフルな終了ではなくPodを即座に終了します。
ソフト退避閾値を構成するために次のフラグを使用できます:
eviction-soft: 指定された猶予期間を超えた場合にPodの退避をトリガーする、memory.available<1.5Giのような退避閾値のセット。eviction-soft-grace-period: Podと退避をトリガーする前にソフト退避閾値を保持する必要がある時間を定義する、memory.available=1m30sのような退避猶予期間のセット。eviction-max-pod-grace-period: ソフト退避閾値に達した場合、Podを終了する際に使用する最大許容猶予期間(秒)。
ハード退避の閾値
ハード退避閾値には、猶予期間がありません。
ハード退避閾値に達した場合、kubeletはグレースフルな終了ではなく即座にポッドを終了してリソースを回収します。
eviction-hardフラグを使用して、memory.available<1Giのようなハード退避閾値のセットを構成します。
kubeletには、次のデフォルトのハード退避閾値があります:
memory.available<100Mi(Linuxノード)memory.available<500Mi(Windowsノード)nodefs.available<10%imagefs.available<15%nodefs.inodesFree<5%(Linuxノード)imagefs.inodesFree<5%(Linuxノード)
これらのハード退避閾値のデフォルト値は、いずれのパラメーター値も変更されていない場合にのみ設定されます。
いずれかのパラメーター値を変更すると、他のパラメーター値はデフォルト値として継承されず、ゼロに設定されます。
カスタム値を指定するには、すべての閾値を指定する必要があります。
containerfs.availableとcontainerfs.inodesFree(Linuxノード)のデフォルトの退避閾値は次のように設定されます:
現在はcontainerfsに関連する閾値のカスタムオーバーライド設定はサポートされていないため、そのような設定を試みると警告が出ます。指定されたカスタム値はすべて無視されます。
退避の監視間隔
kubeletは、設定されたhousekeeping-intervalに基づいて退避閾値を評価しており、デフォルトでは10sです。
ノードの状態
kubeletは、猶予期間の構成とは関係なく、ハードまたはソフト退避閾値に達したためにノードが圧迫されていることを示すノードのConditionsを報告します。
kubeletは、次のように退避シグナルをノードの状態にマッピングします:
| ノードのCondition | 退避シグナル | 説明 |
|---|
MemoryPressure | memory.available | ノード上の利用可能なメモリが退避閾値に達しています |
DiskPressure | nodefs.available, nodefs.inodesFree, imagefs.available, imagefs.inodesFree, containerfs.available, or containerfs.inodesFree | ノードのルートファイルシステム、イメージファイルシステム、またはコンテナファイルシステムのいずれかの利用可能なディスク容量とinodeが退避閾値に達しています |
PIDPressure | pid.available | (Linux)ノード上で使用可能なプロセス識別子が退避閾値を下回りました |
コントロールプレーンは、これらのノードの状態をテイントにもマッピングします。
kubeletは、設定された--node-status-update-frequencyに基づいてノードの状態を更新し、デフォルトでは10sです。
ノードの状態の振動
場合によっては、ノードが定義された猶予期間を超えずに、ソフト閾値の上下を振動することがあります。
これにより、報告されるノードの状態がtrueとfalseの間で頻繁に切り替わり、不適切な退避の判断をトリガーする可能性があります。
振動を防ぐために、eviction-pressure-transition-periodフラグを使用できます。
このフラグは、kubeletがノードの状態を別の状態に遷移させるまでの時間を制御します。
デフォルトの遷移期間は5mです。
ノードレベルのリソースの回収
kubeletは、エンドユーザーのPodを退避する前にのノードレベルのリソースを回収しようとします。
ノードのDiscPressure状態が報告されると、kubeletはノード上のファイルシステムに基づいてノードレベルのリソースを回収します。
imagefsまたはcontainerfsがない場合
ノードにnodefsファイルシステムのみがあり、退避閾値に達した場合、kubeletは次の順序でディスク容量を解放します:
- deadなPodとコンテナをガベージコレクションします。
- 未使用のイメージを削除します。
imagefsを使用する場合
ノードにコンテナランタイムが使用するためのimagefsファイルシステムがある場合、kubeletは次のようにノードレベルのリソースを回収します:
imagefsとcontainerfsを使用する場合
ノードにコンテナランタイムが使用するためのcontainerfsとimagefsファイルシステムがある場合、kubeletは次のようにノードレベルのリソースを回収します:
kubeletの退避におけるPodの選択
kubeletは、ノードレベルのリソースを回収しても退避シグナルが閾値を下回らない場合、エンドユーザーのPodを退避し始めます。
kubeletは、次のパラメータを使用してPodの退避順序を決定します:
- Podのリソース使用量がリクエストを超えているかどうか
- Podの優先度
- Podのリソース使用量がリクエストを下回っているかどうか
結果として、kubeletは次の順序でPodをランク付けして退避します:
リソース使用量がリクエストを超えているBestEffortまたはBurstablePod。
これらのPodは、その優先度に基づき、リクエストを超える使用量に応じて退避されます。
リソース使用量がリクエストを下回っているGuaranteedとBurstablePodは、その優先度に基づいて最後に退避されます。
備考:
kubeletは、Podの
QoSクラスを使用して退避順序を決定しません。
メモリなどのリソースを回収する際に、QoSクラスを使用して最も退避される可能性の高いPodの順序を予測することができます。
QoSの分類はEphemeralStorageのリクエストには適用されないため、例えばノードが
DiskPressure状態にある場合、上記のシナリオは当てはまりません。
GuaranteedPodは、すべてのコンテナにリクエストとリミットが指定されており、それらが等しい場合にのみ保証されます。
これらのPodは、他のPodのリソース消費によって退避されることはありません。
(kubeletやjournaldのような)システムデーモンが、system-reservedやkube-reservedの割り当てよりも多くのリソースを消費しており、ノードにはリクエストより少ないリソースを使用しているGuaranteedまたはBurstablePodしかない場合、kubeletは他のPodへのリソース枯渇の影響を制限してノードの安定性を保つために、これらのPodのなかから退避するPodを選択する必要があります。
この場合、最も低い優先度のPodを退避するように選択します。
static Podを実行しており、リソース圧迫による退避を回避したい場合は、そのPodに直接priorityフィールドを設定します。
Static PodはpriorityClassNameフィールドをサポートしていません。
kubeletは、inodeまたはプロセスIDの枯渇に応じてPodを退避する場合、inodeとPIDにはリクエストがないため、Podの相対的な優先度を使用して退避順序を決定します。
kubeletは、ノードが専用のimagefsまたはcontainerfsファイルシステムを持っているかどうかに基づいて、異なる方法でPodをソートします:
imagefsまたはcontainerfsがない場合(nodefsとimagefsは同じファイルシステムを使用します)
nodefsが退避をトリガーした場合、kubeletはそれらの合計ディスク使用量(ローカルボリューム + すべてのコンテナのログと書き込み可能レイヤー)に基づいてPodをソートします。
imagefsを使用する場合(nodefsとimagefsファイルシステムが分離されている)
imagefsとcontainerfsを使用する場合(imagefsとcontainerfsは分割されています)
退避による最小の回収
備考:
Kubernetes v1.35以降、containerfs.availableメトリクスのカスタム値を設定することはできません。
この特定のメトリクスの構成は、構成に応じて、nodefsまたはimagefsに設定された値を自動的に反映するように設定されます。場合によっては、Podの退避によって回収されるリソースがごくわずかであることがあります。
このため、kubeletが設定された退避閾値に繰り返し達し、複数の退避をトリガーする可能性があります。
--eviction-minimum-reclaimフラグやkubeletの設定ファイルを使用して、各リソースの最小の回収量を構成できます。
kubeletがリソース不足を検知すると、指定した値に達するまでリソースを回収し続けます。
例えば、次の構成は最小回収量を設定します:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
evictionHard:
memory.available: "500Mi"
nodefs.available: "1Gi"
imagefs.available: "100Gi"
evictionMinimumReclaim:
memory.available: "0Mi"
nodefs.available: "500Mi"
imagefs.available: "2Gi"
この例では、nodefs.availableシグナルが退避閾値に達した場合、kubeletはシグナルが1GiBに達するまでリソースを回収します。
その後は500MiBの最小量を回収し続け、利用可能なnodefsストレージが1.5GiBに達するまで続行します。
同様に、kubeletはimagefsリソースを回収し、imagefs.availableの値が102Giに達するまでリソースを回収を試みます。
これは、コンテナイメージストレージの102GiBが利用可能であることを示します。
kubeletが回収できるストレージ量が2GiB未満の場合、kubeletは何も回収しません。
eviction-minimum-reclaimのデフォルト値は、すべてのリソースに対して0です。
ノードのメモリ不足の挙動
kubeletがメモリを回収する前にノードで メモリ不足 (OOM)イベントが発生した場合、ノードはoom_killerに依存して対応します。
kubeletは、PodのQoSに基づいて各コンテナのoom_score_adj値を設定します。
| サービスの品質 | oom_score_adj |
|---|
Guaranteed | -997 |
BestEffort | 1000 |
Burstable | min(max(2, 1000 - (1000 × memoryRequestBytes) / machineMemoryCapacityBytes), 999) |
備考:
またkubeletは、
system-node-critical優先度を持つPodのコンテナに対して
oom_score_adj値を
-997に設定します。
kubeletがノードでOOMが発生する前にメモリを回収できない場合、oom_killerはそのノード上で使用しているメモリの割合に基づいてoom_scoreを計算し、次にoom_score_adjを加算して各コンテナの有効なoom_scoreを計算します。
その後、oom_killerは最も高いスコアを持つコンテナを終了します。
これは、スケジューリングリクエストに対して多くのメモリを消費する低いQoS Podのコンテナが最初に終了されることを意味します。
Podの退避とは異なり、コンテナがOOMで強制終了された場合、kubeletはrestartPolicyに基づいてコンテナを再起動できます。
グッドプラクティス
退避の構成に関するグッドプラクティスを次のセクションで説明します。
スケジュール可能なリソースと退避ポリシー
退避ポリシーを使用してkubeletを構成する場合、スケジューラーがPodのスケジュール直後にメモリ圧迫をトリガーして退避を引き起こさないようにする必要があります。
次のシナリオを考えてみましょう:
- ノードのメモリキャパシティ: 10GiB
- オペレーターはシステムデーモン(kernel、
kubeletなど)に10%のメモリ容量を予約したい - オペレーターはシステムのOOMの発生を減らすために、メモリ使用率が95%に達したときにPodを退避したい
この場合、kubeletは次のように起動されます:
--eviction-hard=memory.available<500Mi
--system-reserved=memory=1.5Gi
この構成では、--system-reservedフラグによりシステム用に1.5GiBのメモリが予約されます。
これは総メモリの10% + 退避閾値量です。
ノードは、Podがリクエスト以上のメモリを使用している場合や、システムが1GiB以上のメモリを使用している場合に、退避閾値に達する可能性があります。
これにより、memory.availableシグナルが500MiBを下回り、閾値がトリガーされます。
DaemonSetとノードの圧迫による退避
Podの優先度は、退避の決定において重要な要素です。
kubeletは、DaemonSetに属するPodを退避させたくない場合、そのPodのspecに適切なpriorityClassNameを指定して十分な優先度を与えることができます。
より低い、またはデフォルトの優先度を使用して、十分なリソースがある場合にのみDaemonSetのPodを実行できるようにすることも可能です。
既知の問題
リソースの圧迫に関連する既知の問題について次のセクションで説明します。
kubeletが即座にメモリ圧迫を検知しないことがある
デフォルトでは、kubeletはcAdvisorを定期的にポーリングしてメモリ使用量の統計を収集します。
メモリ使用量がその間に急速に増加した場合、kubeletはMemoryPressure状態を十分な早さで検知できない可能性があり、OOMキラーが呼び出される可能性があります。
--kernel-memcg-notificationフラグにより、kubeletのmemcg通知APIを有効にして、閾値を超えたとき即座に通知を受け取ることができます。
極端な使用率を達成しようとするのではなく、合理的なオーバーコミットを目指している場合、この問題に対して実行可能な回避策は--kube-reservedおよび--system-reservedフラグを使用してシステム用のメモリを割り当てることです。
active_fileメモリは使用可能なメモリとして見なされません
Linuxでは、カーネルがアクティブなLRUリスト上のファイルベースのメモリのバイト数をactive_file統計として追跡します。
kubeletは、active_fileメモリの領域を回収不可能として扱います。
一時的なローカルストレージを含むブロックベースのローカルストレージを集中的に使用するワークロードの場合、カーネルレベルのファイルおよびブロックデータのキャッシュにより、多くの直近アクセスされたキャッシュページがactive_fileとしてカウントされる可能性が高いです。
これらのカーネルブロックバッファがアクティブなLRUリストに十分に存在すると、kubeletはこれを高いリソース使用として観測し、ノードにメモリ圧迫が発生しているとしてテイントし、Podの退避をトリガーします。
より詳細については、https://github.com/kubernetes/kubernetes/issues/43916を参照してください。
その動作を回避するためには、集中的なI/Oアクティビティを行う可能性があるコンテナに対してメモリリミットとメモリリクエストを同じ値に設定します。
そのコンテナに対して最適なメモリのリミット値を見積もるか、測定する必要があります。
次の項目
14 - APIを起点とした退避
APIを起点とした退避は、Eviction APIを使用して退避オブジェクトを作成し、Podの正常終了を起動させるプロセスです。
Eviction APIを直接呼び出すか、kubectl drainコマンドのようにAPIサーバーのクライアントを使って退避を要求することが可能です。これにより、Evictionオブジェクトを作成し、APIサーバーにPodを終了させます。
APIを起点とした退避はPodDisruptionBudgetsとterminationGracePeriodSecondsの設定を優先します。
APIを使用してPodのEvictionオブジェクトを作成することは、Podに対してポリシー制御されたDELETE操作を実行することに似ています。
Eviction APIの実行
Kubernetes APIへアクセスしてEvictionオブジェクトを作るためにKubernetesのプログラミング言語のクライアントを使用できます。
そのためには、次の例のようなデータをPOSTすることで操作を試みることができます。
備考:
policy/v1においてEvictionはv1.22以上で利用可能です。それ以前のリリースでは、policy/v1beta1を使用してください。{
"apiVersion": "policy/v1",
"kind": "Eviction",
"metadata": {
"name": "quux",
"namespace": "default"
}
}
備考:
v1.22で非推奨となり、policy/v1が採用されました。{
"apiVersion": "policy/v1beta1",
"kind": "Eviction",
"metadata": {
"name": "quux",
"namespace": "default"
}
}
また、以下の例のようにcurlやwgetを使ってAPIにアクセスすることで、操作を試みることもできます。
curl -v -H 'Content-type: application/json' https://your-cluster-api-endpoint.example/api/v1/namespaces/default/pods/quux/eviction -d @eviction.json
APIを起点とした退避の仕組み
APIを使用して退去を要求した場合、APIサーバーはアドミッションチェックを行い、以下のいずれかを返します。
200 OK:この場合、退去が許可されるとEvictionサブリソースが作成され、PodのURLにDELETEリクエストを送るのと同じように、Podが削除されます。429 Too Many Requests:PodDisruptionBudgetの設定により、現在退去が許可されていないことを示します。しばらく時間を空けてみてください。また、APIのレート制限のため、このようなレスポンスが表示されることもあります。500 Internal Server Error:複数のPodDisruptionBudgetが同じPodを参照している場合など、設定に誤りがあり退去が許可されないことを示します。
退去させたいPodがPodDisruptionBudgetを持つワークロードの一部でない場合、APIサーバーは常に200 OKを返して退去を許可します。
APIサーバーが退去を許可した場合、以下の流れでPodが削除されます。
- APIサーバーの
Podリソースの削除タイムスタンプが更新され、APIサーバーはPodリソースが終了したと見なします。またPodリソースは、設定された猶予期間が設けられます。 - ローカルのPodが動作しているNodeのkubeletは、
Podリソースが終了するようにマークされていることに気付き、Podの適切なシャットダウンを開始します。 - kubeletがPodをシャットダウンしている間、コントロールプレーンはEndpointオブジェクトからPodを削除します。その結果、コントローラーはPodを有効なオブジェクトと見なさないようになります。
- Podの猶予期間が終了すると、kubeletはローカルPodを強制的に終了します。
- kubeletはAPIサーバーに
Podリソースを削除するように指示します。 - APIサーバーは
Podリソースを削除します。
トラブルシューティング
場合によっては、アプリケーションが壊れた状態になり、対処しない限りEviction APIが429または500レスポンスを返すだけとなることがあります。例えば、ReplicaSetがアプリケーション用のPodを作成しても、新しいPodがReady状態にならない場合などです。また、最後に退去したPodの終了猶予期間が長い場合にも、この事象が見られます。
退去が進まない場合は、以下の解決策を試してみてください。
- 問題を引き起こしている自動化された操作を中止または一時停止し、操作を再開する前に、スタックしているアプリケーションを調査を行ってください。
- しばらく待ってから、Eviction APIを使用する代わりに、クラスターのコントロールプレーンから直接Podを削除してください。
次の項目
15 - Node Declared Features
FEATURE STATE:
Kubernetes v1.35 [alpha](disabled by default)
Kubernetesノードは Declared Features を使用して、新規機能やフィーチャーゲート制御された特定の機能が利用可能かどうかを報告します。
コントロールプレーンコンポーネントは、この情報を利用してより適切な判断を行います。
kube-schedulerは、NodeDeclaredFeaturesプラグインを介して、Podが必要とする機能を明示的にサポートするノードにのみPodを配置します。
さらに、NodeDeclaredFeatureValidatorアドミッションコントローラーは、Pod更新時にノードが必要な機能を宣言しているかを検証します。
このメカニズムにより、バージョンスキューを管理でき、クラスターの安定性が向上します。
特に、クラスターのアップグレード時や、すべてのノードで同じ機能が有効になっていない可能性がある混合バージョン環境で有効です。
これは、新しいノードレベルの機能を導入するKubernetes機能開発者向けのもので、バックグラウンドで動作します。
Podをデプロイするアプリケーション開発者は、このフレームワークと直接やり取りする必要はありません。
動作の仕組み
- Kubeletによる機能報告: 起動時に、各ノード上のkubeletは、現在有効になっている管理対象のKubernetes機能を検出し、Nodeオブジェクトの
.status.declaredFeaturesフィールドで報告します。
このフィールドには、アクティブに開発中の機能のみが含まれます。 - スケジューラーによるフィルタリング: デフォルトのkube-schedulerは
NodeDeclaredFeaturesプラグインを使用します。
このプラグインは:PreFilterステージで、PodSpecをチェックして、Podが必要とするノード機能のセットを推測します。Filterステージで、ノードの.status.declaredFeaturesにリストされている機能が、Podに対して推測された要件を満たすかどうかをチェックします。
必要な機能を持たないノードにはPodはスケジュールされません。
カスタムスケジューラーも.status.declaredFeaturesフィールドを利用して、同様の制約を適用できます。
- アドミッションコントロール:
nodedeclaredfeaturevalidatorアドミッションコントローラーは、バインド先のノードで宣言されていない機能を必要とするPodを拒否でき、Pod更新時の問題を防ぎます。
Node Declared Featuresの有効化
Node Declared Featuresを使用するには、kube-apiserver、kube-scheduler、およびkubeletコンポーネントでNodeDeclaredFeaturesフィーチャーゲートを有効にする必要があります。
次の項目