로깅 아키텍처
애플리케이션 로그는 애플리케이션 내부에서 발생하는 상황을 이해하는 데 도움이 된다. 로그는 문제를 디버깅하고 클러스터 활동을 모니터링하는 데 특히 유용하다. 대부분의 최신 애플리케이션에는 일종의 로깅 메커니즘이 있다. 마찬가지로, 컨테이너 엔진들도 로깅을 지원하도록 설계되었다. 컨테이너화된 애플리케이션에 가장 쉽고 가장 널리 사용되는 로깅 방법은 표준 출력과 표준 오류 스트림에 작성하는 것이다.
그러나, 일반적으로 컨테이너 엔진이나 런타임에서 제공하는 기본 기능은 완전한 로깅 솔루션으로 충분하지 않다.
예를 들어, 컨테이너가 크래시되거나, 파드가 축출되거나, 노드가 종료된 경우에 애플리케이션의 로그에 접근하고 싶을 것이다.
클러스터에서 로그는 노드, 파드 또는 컨테이너와는 독립적으로 별도의 스토리지와 라이프사이클을 가져야 한다. 이 개념을 클러스터-레벨 로깅이라고 한다.
클러스터-레벨 로깅 아키텍처는 로그를 저장, 분석, 쿼리하기 위해서는 별도의 백엔드가 필요하다. 쿠버네티스가 로그 데이터를 위한 네이티브 스토리지 솔루션을 제공하지는 않지만, 쿠버네티스에 통합될 수 있는 기존의 로깅 솔루션이 많이 있다. 아래 내용은 노드에서 로그를 어떻게 처리하고 관리하는지 설명한다.
파드와 컨테이너 로그
쿠버네티스는 실행중인 파드의 컨테이너에서 출력하는 로그를 감시한다.
아래 예시는, 초당 한 번씩 표준 출력에 텍스트를 기록하는
컨테이너를 포함하는 파드 매니페스트를 사용한다.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
이 파드를 실행하려면, 다음의 명령을 사용한다.
kubectl apply -f https://k8s.io/examples/debug/counter-pod.yaml
출력은 다음과 같다.
pod/counter created
로그를 가져오려면, 다음과 같이 kubectl logs 명령을 사용한다.
kubectl logs counter
출력은 다음과 같다.
0: Fri Apr 1 11:42:23 UTC 2022
1: Fri Apr 1 11:42:24 UTC 2022
2: Fri Apr 1 11:42:25 UTC 2022
kubectl logs --previous 를 사용해서 컨테이너의 이전 인스턴스에 대한 로그를 검색할 수 있다.
파드에 여러 컨테이너가 있는 경우, 다음과 같이 명령에 -c 플래그와 컨테이너 이름을 추가하여
접근하려는 컨테이너 로그를 지정해야 한다.
kubectl logs counter -c countS
컨테이너 로그 스트림
기능 상태:
Kubernetes v1.32 [alpha](disabled by default)알파 기능으로, kubelet은 컨테이너에서 생성된 두 개의 표준 스트림 로그를
분리할 수 있다. 표준 출력
과 표준 오류.
이 기능을 사용하려면, PodLogsQuerySplitStreams
기능 게이트를 활성화해야 한다.
이 기능 게이트가 활성화 되면, 쿠버네티스 1.36 는 파드 API를 통해
이러한 로그 스트림에 직접 액세스할 수 있도록 허용한다. stream 쿼리 문자열으로 스트림 이름 (Stdout 또는 Stderr)을
지정하여 특정 스트림을 가져올 수 있다. 해당 파드의 log 하위 리소스를 읽을 수 있는 권한이 있어야 한다.
이 기능을 시연하려면, 표준 출력과 오류 스트림에 주기적으로 텍스트를 쓰는 파드를 만들 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: counter-err
spec:
containers:
- name: count
image: busybox:1.28
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; echo "$i: err" >&2 ; i=$((i+1)); sleep 1; done']
이 파드를 실행하기 위해서, 아래 명령어를 사용한다.
kubectl apply -f https://k8s.io/examples/debug/counter-pod-err.yaml
표준 오류 로그 스트림만 가져오려면 다음을 실행한다.
kubectl get --raw "/api/v1/namespaces/default/pods/counter-err/log?stream=Stderr"
자세한 내용은 kubectl logs 문서
을 확인한다.
노드가 컨테이너 로그를 처리하는 방법
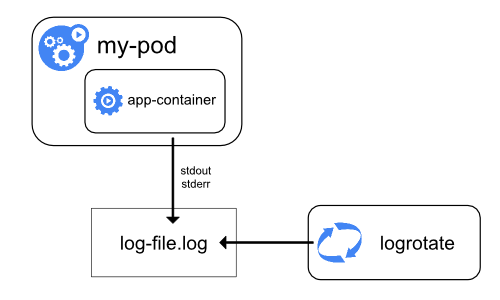
컨테이너화된 애플리케이션의 표준 출력(stdout) 및 표준 오류(stderr) 스트림에 의해
생성된 모든 출력은 컨테이너 런타임이 처리하고 리디렉션 시킨다.
다양한 컨테이너 런타임들은 이를 각자 다른 방법으로 구현하였지만, kubelet과의
호환성은 CRI 로깅 포맷 으로 표준화되어 있다.
기본적으로 컨테이너가 재시작하는 경우, kubelet은 종료된 컨테이너 하나를 로그와 함께 유지한다. 파드가 노드에서 축출되면, 해당하는 모든 컨테이너와 로그가 함께 축출된다.
kubelet은 쿠버네티스의 특정 API를 통해 사용자들에게 로그를 제공한다.
일반적으로 이 기능에 kubectl logs를 통해 접근할 수 있다.
로그 로테이션
기능 상태:
Kubernetes v1.21 [stable]kubelet은 컨테이너 로그를 로테이트하고 로깅 디렉터리 구조를 관리하는 역할을 수행한다. kubelet은 이 정보를 컨테이너 런타임으로 전송하고 (CRI를 사용), 런타임은 지정된 위치에 컨테이너 로그를 기록한다.
kubelet 설정 파일을 사용하여
두 개의 kubelet 파라미터
containerLogMaxSize(기본값 10Mi)와 containerLogMaxFiles(기본값 5)를 구성할 수 있다.
이러한 설정을 통해 각 로그 파일의 최대 크기와
각 컨테이너에 허용되는 최대 파일 수를 각각 구성할 수 있다.
워크로드로 인해 생성되는 로그 볼륨이 큰 클러스터에서 효율적인 로그 로테이션을 수행하기 위해
kubelet은 동시에 수행할 수 있는 로그 로테이션 수와 필요에 따라
로그를 모니터링하고 로테이션하는 간격을 고려하여
로그 로테이션 방식을 조정하는 메커니즘도 제공한다.
kubelet 구성 파일을 사용하여
두 가지 kubelet 구성 설정
containerLogMaxWorkers와 containerLogMonitorInterval을 구성할 수 있다.
로깅 기본 예제에서와 같이 kubectl logs를
실행하면, 노드의 kubelet이 요청을 처리하고
로그 파일에서 직접 읽는다. kubelet은 로그 파일의 내용을 반환한다.
참고:
kubectl logs를 통해서는 최신 로그만 확인할 수 있다.
예를 들어, 파드가 40MiB 크기의 로그를 기록했고 kubelet이 10MiB 마다 로그를 로테이트하는 경우
kubectl logs는 최근의 10MiB 데이터만 반환한다.
시스템 컴포넌트 로그
시스템 컴포넌트에는 두 가지 유형이 있는데, 컨테이너에서 실행되는 것과 실행 중인 컨테이너와 관련된 것이다. 예를 들면,
- kubelet과 컨테이너 런타임은 컨테이너에서 실행되지 않는다. kubelet이 컨테이너(파드와 그룹화된)를 실행시킨다.
- 쿠버네티스의 스케줄러, 컨트롤러 매니저, API 서버는
파드(일반적으로 스태틱 파드)로 실행된다.
etcd는 컨트롤 플레인에서 실행되며, 대부분의 경우 역시 스태틱 파드로써 실행된다.
클러스터가 kube-proxy를 사용하는 경우는
데몬셋(DaemonSet)으로써 실행된다.
로그의 위치
kubelet과 컨테이너 런타임이 로그를 기록하는 방법은, 노드의 운영체제에 따라 다르다.
systemd를 사용하는 리눅스 노드에서는 kubelet과 컨테이너 런타임은 기본적으로 로그를 journald에 작성한다.
journalctl을 사용하여 systemd 저널을 확인할 수 있다. 예를 들어,
journalctl -u kubelet.
systemd를 사용하지 않는 시스템에서, kubelet과 컨테이너 런타임은 로그를 /var/log 디렉터리의
.log 파일에 작성한다. 다른 경로에 로그를 기록하려면 kube-log-runner라는 도우미 도구를 통해
간접적으로 kubelet을 실행하고, 해당 도구를 사용하여
kubelet의 로그를 지정한 디렉토리로 리디렉션할 수 있다.
기본적으로, kubelet은 항상 컨테이너 런타임으로 하여금
/var/log/pods 아래에 로그를 기록하도록 지시한다.
kube-log-runner에 대한 자세한 정보는 시스템 로그를 확인한다.
kubelet은 기본적으로 C:\var\logs 아래에 로그를 기록한다
(C:\var\log가 아님에 주의한다).
C:\var\log 경로가 쿠버네티스에 설정된 기본값이지만,
몇몇 클러스터 배포 도구들은 윈도우 노드의 로그 경로로 C:\var\log\kubelet를 사용하기도 한다.
다른 경로에 로그를 기록하고 싶은 경우에는, kube-log-runner를 통해
간접적으로 kubelet을 실행하여
kubelet의 로그를 지정한 디렉토리로 리디렉션할 수 있다.
그러나, kubelet은 항상 컨테이너 런타임으로 하여금
C:\var\log\pods 아래에 로그를 기록하도록 지시한다.
kube-log-runner에 대한 자세한 정보는 시스템 로그를 확인한다.
파드에서 실행되는 쿠버네티스 컴포넌트의 경우, 기본 로깅 메커니즘을 따르지 않고
/var/log 아래에 로그를 기록한다 (해당 컴포넌트들은
systemd의 journal에 로그를 기록하지 않는다). 쿠버네티스의 저장 메커니즘을 사용하여,
컴포넌트를 실행하는 컨테이너에 영구적으로 사용 가능한 저장 공간을 연결할 수 있다.
Kubelet 파드 로그 디렉터리를 기본 /var/log/pods에서 사용자 지정 경로로
변경할 수 있도록 한다. kubelet 설정 파일에서 podLogsDir 매개변수를 설정하여
이러한 조정을 수행할 수 있다.
주의:
기본 위치인 /var/log/pods은 오랫동안 사용되어 왔으며
특정 프로세스가 이 경로를 암묵적으로 의존하고 있을 수 있다는 점은 유의해야 한다.
따라서, 이 매개변수를 변경할 때는 신중하게 접근해야 하며, 모든 책임은 사용자에게 있다.
또 다른 주의 사항은 kubelet이 /var와 동일한 디스크에 있는 위치를
지원한다는 것이다. 그렇지 않으면, 로그가 /var와 다른 파일 시스템에 있는 경우,
kubelet이 해당 파일 시스템의 사용량을 추적하지 않아 파일 시스템이 가득차면
문제가 발생할 수 있다.
etcd와 etcd의 로그를 기록하는 방식에 대한 자세한 정보는 etcd 공식 문서를 확인한다. 다시 언급하자면, 쿠버네티스의 저장 메커니즘을 사용하여 컴포넌트를 실행하는 컨테이너에 영구적으로 사용 가능한 저장 공간을 연결할 수 있다.
참고:
쿠버네티스 클러스터 컴포넌트(예: 스케줄러)를 배포하여 상위 노드에서 공유된 볼륨에 로그를 기록하는 경우, 해당 로그들이 로테이트되는지 확인하고 관리해야 한다. 쿠버네티스는 로그 로테이션을 관리하지 않는다.
운영체제에서 일부 로그 로테이션을 자동으로 구현할 수 있다. 예를 들어,
컴포넌트를 실행하는 스태틱 파드에 /var/log 디렉토리를 공유하는 경우 노드-레벨의
로그 로테이션은 해당 디렉터리의 파일을 쿠버네티스 외부의
다른 컴포넌트들이 기록한 파일과 동일하게 취급한다.
몇몇 배포 도구는 로그 로테이션을 고려하여 자동화하지만, 나머지 도구들은 이를 사용자의 책임으로 둔다.
클러스터-레벨 로깅 아키텍처
쿠버네티스는 클러스터-레벨 로깅을 위한 네이티브 솔루션을 제공하지 않지만, 몇 가지 일반적인 접근 방법을 고려할 수 있다. 다음에 몇 가지 옵션이 있다.
- 모든 노드에서 실행되는 노드-레벨 로깅 에이전트를 사용한다.
- 애플리케이션 파드에 로깅을 위한 전용 사이드카 컨테이너를 포함한다.
- 애플리케이션 내에서 로그를 백엔드로 직접 푸시한다.
노드 로깅 에이전트 사용
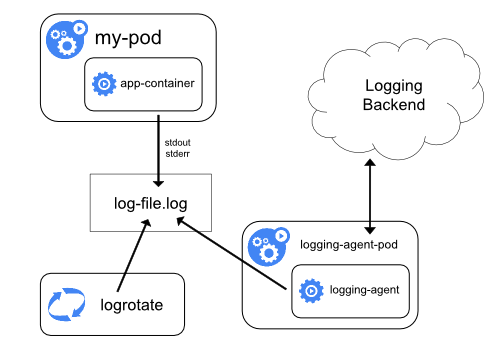
각 노드에 노드-레벨 로깅 에이전트 를 포함시켜 클러스터-레벨 로깅을 구현할 수 있다. 로깅 에이전트는 로그를 노출하거나 로그를 백엔드로 푸시하는 전용 도구이다. 일반적으로, 로깅 에이전트는 해당 노드의 모든 애플리케이션 컨테이너에서 로그 파일이 있는 디렉터리에 접근할 수 있는 컨테이너이다.
로깅 에이전트는 모든 노드에서 실행되어야 하므로, 에이전트를
DaemonSet(데몬셋) 으로 실행하는 것이 좋다.
노드-레벨 로깅은 노드별 하나의 에이전트만 생성하며, 노드에서 실행되는 애플리케이션에 대한 변경은 필요로 하지 않는다.
컨테이너는 로그를 표준 출력과 표준 오류로 출력하며, 합의된 형식은 없다. 노드-레벨 에이전트는 이러한 로그를 수집하고 취합을 위해 전달한다.
로깅 에이전트와 함께 사이드카 컨테이너 사용
다음 중 한 가지 방법으로 사이드카 컨테이너를 사용할 수 있다.
- 사이드카 컨테이너는 애플리케이션 로그를 자체
stdout으로 스트리밍한다. - 사이드카 컨테이너는 로깅 에이전트를 실행하며, 애플리케이션 컨테이너에서 로그를 가져오도록 구성한다.
사이드카 컨테이너 스트리밍
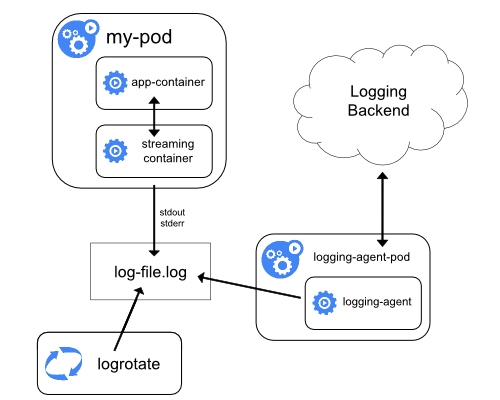
사이드카 컨테이너가 자체 stdout 및 stderr 스트림으로
기록하도록 하면, 각 노드에서 이미 실행 중인 kubelet과 로깅 에이전트를
활용할 수 있다. 사이드카 컨테이너는 파일, 소켓 또는 journald에서 로그를 읽는다.
각 사이드카 컨테이너는 자체 stdout 또는 stderr 스트림에 로그를 출력한다.
이 방법을 사용하면 애플리케이션의 다른 부분에서 여러 로그 스트림을
분리할 수 있고, 이 중 일부는 stdout 또는 stderr 으로 로그를 남기는 기능을
지원하지 않을 수 있다. 로그 리디렉션 로직은
최소화되어 있기 때문에, 심각한 오버헤드가 아니다. 또한,
stdout 및 stderr 가 kubelet에서 처리되므로, kubectl logs 와 같은
빌트인 도구를 사용할 수 있다.
예를 들어, 파드는 단일 컨테이너를 실행하고 컨테이너가 서로 다른 두 가지 형식을 사용하여 서로 다른 두 개의 로그 파일에 기록한다. 다음은 파드에 대한 매니페스트이다.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
두 컴포넌트를 컨테이너의 stdout 스트림으로 리디렉션한 경우에도, 동일한 로그
스트림에 서로 다른 형식의 로그 항목을 작성하는 것은
추천하지 않는다. 대신, 두 개의 사이드카 컨테이너를 생성할 수 있다. 각 사이드카
컨테이너는 공유 볼륨에서 특정 로그 파일을 테일(tail)한 다음 해당 로그를
자체 stdout 스트림으로 리디렉션할 수 있다.
다음은 사이드카 컨테이너가 두 개인 파드에 대한 매니페스트이다.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
이제 이 파드를 실행하면, 다음의 명령을 실행하여 각 로그 스트림에 개별적으로 접근할 수 있다.
kubectl logs counter count-log-1
출력은 다음과 같다.
0: Fri Apr 1 11:42:26 UTC 2022
1: Fri Apr 1 11:42:27 UTC 2022
2: Fri Apr 1 11:42:28 UTC 2022
...
kubectl logs counter count-log-2
출력은 다음과 같다.
Fri Apr 1 11:42:29 UTC 2022 INFO 0
Fri Apr 1 11:42:30 UTC 2022 INFO 0
Fri Apr 1 11:42:31 UTC 2022 INFO 0
...
클러스터에 노드-레벨 에이전트를 설치했다면, 에이전트는 추가적인 설정 없이도 자동으로 해당 로그 스트림을 선택한다. 원한다면, 소스 컨테이너에 따라 로그 라인을 파싱(parse)하도록 에이전트를 구성할 수도 있다.
CPU 및 메모리 사용량이 낮은(몇 밀리코어 수준의 CPU와 몇 메가바이트 수준의 메모리 요청) 파드라고 할지라도,
로그를 파일에 기록한 다음 stdout 으로 스트리밍하는 것은
노드가 필요로 하는 스토리지 양을 두 배로 늘릴 수 있다.
단일 파일에 로그를 기록하는 애플리케이션이 있는 경우,
일반적으로 스트리밍 사이드카 컨테이너 방식을 구현하는 대신
/dev/stdout 을 대상으로 설정하는 것을 추천한다.
사이드카 컨테이너를 사용하여
애플리케이션 자체에서 로테이션할 수 없는 로그 파일을 로테이션할 수도 있다.
이 방법의 예시는 정기적으로 logrotate 를 실행하는 작은 컨테이너를 두는 것이다.
그러나, stdout 및 stderr 을 직접 사용하고 로테이션과
유지 정책을 kubelet에 두는 것이 더욱 직관적이다.
로깅 에이전트가 있는 사이드카 컨테이너
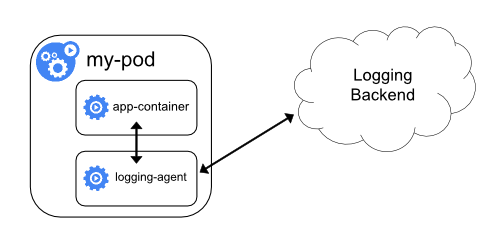
노드-레벨 로깅 에이전트가 상황에 맞게 충분히 유연하지 않은 경우, 애플리케이션과 함께 실행하도록 특별히 구성된 별도의 로깅 에이전트를 사용하여 사이드카 컨테이너를 생성할 수 있다.
참고:
사이드카 컨테이너에서 로깅 에이전트를 사용하면 상당한 리소스가 소모될 수 있다. 게다가, 이러한 로그는 kubelet에 의해 제어되지 않기 때문에kubectl logs 를 사용하여 해당 로그에
접근할 수 없다.아래는 로깅 에이전트가 포함된 사이드카 컨테이너를 구현하는 데 사용할 수 있는 두 가지 매니페스트이다.
첫 번째 매니페스트는 fluentd를 구성하는
컨피그맵(ConfigMap)이 포함되어 있다.
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
참고:
예제 매니페스트에서, 꼭 fluentd가 아니더라도, 애플리케이션 컨테이너 내의 모든 소스에서 로그를 읽어올 수 있는 다른 로깅 에이전트를 사용할 수 있다.두 번째 매니페스트는 fluentd가 실행되는 사이드카 컨테이너가 있는 파드를 설명한다. 파드는 fluentd가 구성 데이터를 가져올 수 있는 볼륨을 마운트한다.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: registry.k8s.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
애플리케이션에서 직접 로그 노출
애플리케이션에서 직접 로그를 노출하거나 푸시하는 클러스터-로깅은 쿠버네티스의 범위를 벗어난다.
다음 내용
- 쿠버네티스 시스템 로그 살펴보기.
- 쿠버네티스 시스템 컴포넌트에 대한 추적(trace) 살펴보기.
- 파드가 실패했을 때 쿠버네티스가 어떻게 로그를 남기는지에 대해, 종료 메시지를 사용자가 정의하는 방법 살펴보기.