To wielostronicowy widok tej sekcji do wydrukowania. Kliknij aby wydrukować.
Dokumentacja
- 1: Kubernetes — Dokumentacja
- 2: Od czego zacząć
- 3: Pojęcia
- 3.1: Przegląd
- 3.1.1: Składniki Kubernetesa
- 3.1.2: Objekty w Kubernetesie
- 3.1.2.1: Nazwy i identyfikatory objektów
- 3.1.2.2: Etykiety i selektory
- 3.1.2.3: Przestrzenie nazw (ang. Namespaces)
- 3.1.2.4: Adnotatcje
- 3.1.2.5: Selektory pól
- 3.1.2.6: Zalecane etykiety
- 3.1.3: API Kubernetesa
- 3.2: Architektura klastra
- 3.3: Kontenery
- 3.4: Workload
- 3.4.1: Pod
- 3.4.2: Zarządzanie Workloadem
- 3.5: Usługi, równoważenie obciążenia i sieci w Kubernetesie
- 3.6: Przechowywanie danych
- 3.7: Konfiguracja
- 3.8: Bezpieczeństwo
- 3.9: Polityki
- 3.10: Harmonogramowanie, pierszeństwo i eksmisja
- 3.11: Administracja klastrem
- 3.12: Windows w Kubernetesie
- 3.13: Rozszerzanie Kubernetesa
- 4: Zadania
- 5: Samouczki
- 5.1: Hello Minikube
- 5.2: Naucz się podstaw Kubernetesa
- 5.2.1: Tworzenie klastra
- 5.2.2: Instalowanie aplikacji
- 5.2.3: Poznawanie aplikacji
- 5.2.3.1: Pody i Węzły
- 5.2.4: Udostępnianie aplikacji
- 5.2.5: Skalowanie aplikacji
- 5.2.6: Aktualizowanie aplikacji
- 5.2.6.1: Aktualizacje Rolling Update
- 6: Materiały źródłowe
- 6.1: Słownik
- 7: Współtwórz dokumentację K8s
- 7.1: Współtworzenie dokumentacji Kubernetes
- 7.2: Zgłaszanie propozycji poprawy treści
- 7.3: Współtworzenie nowych treści
- 7.4: Przeglądanie zmian
- 7.5: Tłumaczenie i adaptacja językowa dokumentacji Kubernetes
- 7.6: Współpraca z SIG Docs
- 7.7: Aktualizacja materiałów źródłowych
- 7.7.1: Wkład w kod źródłowy Kubernetesa
- 7.7.2: Generowanie materiałów źródłowych dla polecenia kubectl
- 7.7.3: Generowanie materiałów źródłowych dla metryk
- 7.7.4: Generowanie materiałów źródłowych dla komponentów i narzedzi Kubernetesa
- 7.7.5:
- 7.8: Styl dokumentacji
- 7.8.1: Typy treści
- 7.9: Zaawansowana współpraca
- 7.10: Przeglądanie statystyki strony
- 7.11: Tłumaczenie dokumentacji na język polski
1 - Kubernetes — Dokumentacja
1.1 - Dostępne wersje dokumentacji
Ten serwis zawiera dokumentację do bieżącej i czterech poprzednich wersji Kubernetesa.
Dostępność dokumentacji obejmującej konkretną wersję Kubernetesa nie oznacza automatycznie, że dana wersja Kubernetesa jest ciągle aktywnie wspierana. Zajrzyj do dokumentu Support period, aby dowiedzieć się, do kiedy objęte wsparciem są poszczególne wersje Kubernetesa.
2 - Od czego zacząć
Ten rozdział poświęcony jest różnym metodom konfiguracji i uruchomienia Kubernetesa. Instalując Kubernetesa, przy wyborze platformy kieruj się: łatwością w utrzymaniu, spełnianymi wymogami bezpieczeństwa, poziomem sterowania, dostępnością zasobów oraz doświadczeniem wymaganym do zarządzania klastrem.
Możesz pobrać Kubernetesa, aby zainstalować klaster na lokalnym komputerze, w chmurze czy w prywatnym centrum obliczeniowym.
Niektóre komponenty Kubernetesa, na przykład `kube-apiserver czy kube-proxy mogą być uruchamiane jako kontenery wewnątrz samego klastra.
Zalecamy uruchamianie komponentów Kubernetesa jako kontenery zawsze, kiedy jest to możliwe i na zarządzanie nimi przez samego Kubernetesa. Do tej kategorii nie należą komponenty odpowiedzialne za uruchamianie kontenerów, w szczególności - kubelet.
Jeśli nie chcesz zarządzać klastrem Kubernetesa samodzielnie, możesz wybrać serwis zarządzany przez zewnętrznego dostawcę, wybierając na przykład spośród certyfikowanych platform. Dostępne są także inne standardowe i specjalizowane rozwiązania dla różnych środowisk chmurowych bądź bazujące bezpośrednio na sprzęcie fizycznym.
Środowisko do nauki
Do nauki Kubernetesa wykorzystaj narzędzia wspierane przez społeczność Kubernetesa lub inne narzędzia dostępne w ekosystemie, aby uruchomić klaster Kubernetesa na swoim komputerze lokalnym. Zapoznaj się ze stroną Środowisko edukacyjne.
Środowisko produkcyjne
Wybierając rozwiązanie dla środowiska produkcyjnego musisz zdecydować, którymi poziomami zarządzania klastrem (abstrakcjami) chcesz zajmować się sam, a które będą realizowane po stronie zewnętrznego operatora.
Do instalacji klastra Kubernetesa zarządzanego samodzielnie oficjalnym narzędziem jest kubeadm.
Co dalej?
- Pobierz Kubernetesa
- Pobierz i zainstaluj narzędzia, w tym
kubectl - Wybierz środowisko uruchomieniowe dla kontenerów w nowym klastrze
- Naucz się najlepszych praktyk przy konfigurowaniu klastra
Kubernetes zaprojektowano w ten sposób, że warstwa sterowania wymaga do działania systemu Linux. W ramach klastra aplikacje mogą być uruchamiane na systemie Linux i innych, w tym Windows.
- Naucz się, jak zbudować klaster z węzłami Windows
3 - Pojęcia
Rozdział dotyczący pojęć ma za zadanie pomóc w zrozumieniu poszczególnych składowych systemu oraz obiektów abstrakcyjnych, których Kubernetes używa do reprezentacji klastra, a także posłużyć do lepszego poznania działania całego systemu.
3.1 - Przegląd
Na tej stronie znajdziesz ogólne informacje o Kubernetesie.
Nazwa Kubernetes pochodzi z języka greckiego i oznacza sternika albo pilota. Skrót K8s powstał poprzez zastąpienie ośmiu liter pomiędzy "K" i "s". Google otworzyło projekt Kubernetes publicznie w 2014. Kubernetes korzysta z piętnastoletniego doświadczenia Google w uruchamianiu wielkoskalowych serwisów i łączy je z najlepszymi pomysłami i praktykami wypracowanymi przez społeczność.
Do czego potrzebujesz Kubernetesa i jakie są jego możliwości
Kontenery są dobrą metodą na opakowywanie i uruchamianie aplikacji. W środowisku produkcyjnym musisz zarządzać kontenerami, w których działają aplikacje i pilnować, aby nie było żadnych przerw w ich dostępności. Przykładowo, kiedy jeden z kontenerów przestaje działać, musi zostać wymieniony. Nie byłoby prościej, aby takimi działaniami zajmował się jakiś system?
I tu właśnie przychodzi z pomocą Kubernetes! Kubernetes zapewnia środowisko do uruchamiania systemów rozproszonych o wysokiej niezawodności. Kubernetes obsługuje skalowanie aplikacji, przełączanie w sytuacjach awaryjnych, różne scenariusze wdrożeń itp. Przykładowo, Kubernetes w łatwy sposób może zarządzać wdrożeniem nowej wersji oprogramowania zgodnie z metodyką canary deployments.
Kubernetes zapewnia:
- Detekcję nowych serwisów i balansowanie ruchu Kubernetes może udostępnić kontener używając nazwy DNS lub swojego własnego adresu IP. Jeśli ruch przychodzący do kontenera jest duży, Kubernetes może balansować obciążenie i przekierować ruch sieciowy, aby zapewnić stabilność całej instalacji.
- Zarządzanie obsługą składowania danych Kubernetes umożliwia automatyczne montowanie systemów składowania danych dowolnego typu - lokalnych, od dostawców chmurowych i innych.
- Automatyczne wdrożenia i wycofywanie zmian Możesz opisać oczekiwany stan instalacji za pomocą Kubernetesa, który zajmie się doprowadzeniem w sposób kontrolowany stanu faktycznego do stanu oczekiwanego. Przykładowo, przy pomocy Kubernetesa możesz zautomatyzować proces tworzenia nowych kontenerów na potrzeby swojego wdrożenia, usuwania istniejących i przejęcia zasobów przez nowe kontenery.
- Automatyczne zarządzanie dostępnymi zasobami Twoim zadaniem jest dostarczenie klastra maszyn, które Kubernetes może wykorzystać do uruchamiania zadań w kontenerach. Określasz zapotrzebowanie na moc procesora i pamięć RAM dla każdego z kontenerów. Kubernetes rozmieszcza kontenery na maszynach w taki sposób, aby jak najlepiej wykorzystać dostarczone zasoby.
- Samoczynne naprawianie Kubernetes restartuje kontenery, które przestały działać, wymienia je na nowe, wymusza wyłączenie kontenerów, które nie odpowiadają na określone zapytania o stan i nie rozgłasza powiadomień o ich dostępności tak długo, dopóki nie są gotowe do działania.
- Zarządzanie informacjami poufnymi i konfiguracją Kubernetes pozwala składować i zarządzać informacjami poufnymi, takimi jak hasła, tokeny OAuth czy klucze SSH. Informacje poufne i zawierające konfigurację aplikacji mogą być dostarczane i zmieniane bez konieczności ponownego budowania obrazu kontenerów i bez ujawniania poufnych danych w ogólnej konfiguracji oprogramowania.
- Wykonywanie wsadowe Oprócz usług Kubernetes może zarządzać zadaniami wsadowymi i obciążeniami CI, automatycznie wymieniając kontenery, które ulegną awarii.
- Skalowanie poziome Skaluj swoją aplikację w górę i w dół za pomocą prostego polecenia, poprzez interfejs użytkownika lub automatycznie na podstawie zużycia CPU.
- Podwójny stos IPv4/IPv6 Przydzielanie adresów IPv4 i IPv6 do podów i usług.
- Możliwość rozbudowy Dodawaj funkcje do swojego klastra Kubernetesa bez konieczności zmiany kodu źródłowego w głównym repozytorium.
Czym Kubernetes nie jest
Kubernetes nie jest tradycyjnym, zawierającym wszystko systemem PaaS (Platform as a Service). Ponieważ Kubernetes działa w warstwie kontenerów, a nie sprzętu, posiada różne funkcjonalności ogólnego zastosowania, wspólne dla innych rozwiązań PaaS, takie jak: instalacje (deployments), skalowanie i balansowanie ruchu, umożliwiając użytkownikom integrację rozwiązań służących do logowania, monitoringu i ostrzegania. Co ważne, Kubernetes nie jest monolitem i domyślnie dostępne rozwiązania są opcjonalne i działają jako wtyczki. Kubernetes dostarcza elementy, z których może być zbudowana platforma deweloperska, ale pozostawia użytkownikowi wybór i elastyczność tam, gdzie jest to ważne.
Kubernetes:
- Nie ogranicza typów aplikacji, które są obsługiwane. Celem Kubernetesa jest możliwość obsługi bardzo różnorodnego typu zadań, włączając w to aplikacje bezstanowe (stateless), aplikacje ze stanem (stateful) i ogólne przetwarzanie danych. Jeśli jakaś aplikacja może działać w kontenerze, będzie doskonale sobie radzić w środowisku Kubernetesa.
- Nie oferuje wdrażania aplikacji wprost z kodu źródłowego i nie buduje aplikacji. Procesy Continuous Integration, Delivery, and Deployment (CI/CD) są zależne od kultury pracy organizacji, jej preferencji oraz wymagań technicznych.
- Nie dostarcza serwisów z warstwy aplikacyjnej, takich jak warstwy pośrednie middleware (np. broker wiadomości), środowiska analizy danych (np. Spark), bazy danych (np. MySQL), cache ani klastrowych systemów składowania danych (np. Ceph) jako usług wbudowanych. Te składniki mogą być uruchamiane na klastrze Kubernetes i udostępniane innym aplikacjom przez przenośne rozwiązania, takie jak Open Service Broker.
- Nie wymusza użycia konkretnych systemów zbierania logów, monitorowania ani ostrzegania. Niektóre z tych rozwiązań są udostępnione jako przykłady. Dostępne są też mechanizmy do gromadzenia i eksportowania różnych metryk.
- Nie dostarcza, ani nie wymusza języka/systemu używanego do konfiguracji (np. Jsonnet). Udostępnia API typu deklaratywnego, z którego można korzystać za pomocą różnych metod wykorzystujących deklaratywne specyfikacje.
- Nie zapewnia, ani nie wykorzystuje żadnego ogólnego systemu do zarządzania konfiguracją, utrzymaniem i samo-naprawianiem maszyn.
- Co więcej, nie jest zwykłym systemem planowania (orchestration). W rzeczywistości, eliminuje konieczność orkiestracji. Zgodnie z definicją techniczną, orkiestracja to wykonywanie określonego ciągu zadań: najpierw A, potem B i następnie C. Dla kontrastu, Kubernetes składa się z wielu niezależnych, możliwych do złożenia procesów sterujących, których zadaniem jest doprowadzenie stanu faktycznego do stanu oczekiwanego. Nie ma znaczenia, w jaki sposób przechodzi się od A do C. Nie ma konieczności scentralizowanego zarządzania. Dzięki temu otrzymujemy system, który jest potężniejszy, bardziej odporny i niezawodny i dający więcej możliwości rozbudowy.
Trochę historii
Aby zrozumieć, dlaczego Kubernetes stał się taki przydatny, cofnijmy sie trochę w czasie.

Era wdrożeń tradycyjnych:
Na początku aplikacje uruchamiane były na fizycznych serwerach. Nie było możliwości separowania zasobów poszczególnych aplikacji, co prowadziło do problemów z alokacją zasobów. Przykładowo, kiedy wiele aplikacji jest uruchomionych na jednym fizycznym serwerze, część tych aplikacji może zużyć większość dostępnych zasobów, powodując spowolnienie działania innych. Rozwiązaniem tego problemu mogło być uruchamianie każdej aplikacji na osobnej maszynie. Niestety, takie podejście ograniczało skalowanie, ponieważ większość zasobów nie była w pełni wykorzystywana, a utrzymanie wielu fizycznych maszyn było kosztowne.
Era wdrożeń w środowiskach wirtualnych:
Jako rozwiązanie zaproponowano wirtualizację, która umożliwia uruchamianie wielu maszyn wirtualnych (VM) na jednym procesorze fizycznego serwera. Wirtualizacja pozwala izolować aplikacje pomiędzy maszynami wirtualnymi, zwiększając w ten sposób bezpieczeństwo, jako że informacje związane z jedną aplikacją nie są w łatwy sposób dostępne dla pozostałych.
Wirtualizacja pozwala lepiej wykorzystywać zasoby fizycznego serwera i lepiej skalować, ponieważ aplikacje mogą być łatwo dodawane oraz aktualizowane, pozwala ograniczyć koszty sprzętu oraz ma wiele innych zalet. Za pomocą wirtualizacji można udostępnić wybrane zasoby fizyczne jako klaster maszyn wirtualnych "wielokrotnego użytku".
Każda maszyna wirtualna jest pełną maszyną zawierającą własny system operacyjny pracujący na zwirtualizowanej warstwie sprzętowej.
Era wdrożeń w kontenerach:
Kontenery działają w sposób zbliżony do maszyn wirtualnych, ale mają mniejszy stopnień wzajemnej izolacji, współdzieląc ten sam system operacyjny. Kontenery określane są mianem "lekkich". Podobnie, jak maszyna wirtualna, kontener posiada własny system plików, udział w zasobach procesora, pamięć, przestrzeń procesów itd. Ponieważ kontenery są definiowane rozłącznie od leżących poniżej warstw infrastruktury, mogą być łatwiej przenoszone pomiędzy chmurami i różnymi dystrybucjami systemu operacyjnego.
Kontenery zyskały popularność ze względu na swoje zalety, takie jak:
- Szybkość i elastyczność w tworzeniu i instalacji aplikacji: obraz kontenera buduje się łatwiej niż obraz VM.
- Ułatwienie ciągłego rozwoju, integracji oraz wdrażania aplikacji ( Continuous development, integration, and deployment): obrazy kontenerów mogą być budowane w sposób wiarygodny i częsty. W razie potrzeby, przywrócenie poprzedniej wersji aplikacji jest stosunkowo łatwie (ponieważ obrazy są niezmienne).
- Rozdzielenie zadań Dev i Ops: obrazy kontenerów powstają w fazie build/release, a nie w trakcie procesu instalacji, oddzielając w ten sposób aplikacje od infrastruktury.
- Obserwowalność obejmuje nie tylko informacje i metryki z poziomu systemu operacyjnego, ale także poprawność działania samej aplikacji i inne sygnały.
- Spójność środowiska na etapach rozwoju oprogramowania, testowania i działania w trybie produkcyjnym: działa w ten sam sposób na laptopie i w chmurze.
- Możliwość przenoszenia pomiędzy systemami operacyjnymi i platformami chmurowymi: Ubuntu, RHEL, CoreOS, prywatnymi centrami danych, największymi dostawcami usług chmurowych czy gdziekolwiek indziej.
- Zarządzanie, które w centrum uwagi ma aplikacje: Poziom abstrakcji przeniesiony jest z warstwy systemu operacyjnego działającego na maszynie wirtualnej na poziom działania aplikacji, która działa na systemie operacyjnym używając zasobów logicznych.
- Luźno powiązane, rozproszone i elastyczne "swobodne" mikro serwisy: Aplikacje podzielone są na mniejsze, niezależne komponenty, które mogą być dynamicznie uruchamiane i zarządzane - nie jest to monolityczny system działający na jednej, dużej maszynie dedykowanej na wyłączność.
- Izolacja zasobów: wydajność aplikacji możliwa do przewidzenia
- Wykorzystanie zasobów: wysoka wydajność i upakowanie.
Co dalej?
- Poczytaj o komponentach Kubernetesa
- Poczytaj o API Kubernetesa
- Poczytaj o kubectl: podstawowym narzędziu CLI dla Kubernetesa
- Poczytaj o architekturze klastra
- Jesteś gotowy zacząć pracę?
3.1.1 - Składniki Kubernetesa
Ta strona zawiera wysokopoziomy przegląd niezbędnych komponentów, które tworzą klaster Kubernetesa.

Komponenty klastra Kubernetesa
Składniki Kubernetesa
Klaster Kubernetesa składa się z warstwy sterowania oraz jednego lub więcej węzłów roboczych. Oto krótki przegląd głównych komponentów:
Części składowe warstwy sterowania
Zarządzanie ogólnym stanem klastra:
- kube-apiserver
- Podstawowy komponent udostępniający interfejs API Kubernetesa przez HTTP.
- etcd
- Stabilna i wysoko dostępna baza danych typu klucz-wartość, wykorzystywana do przechowywania stanu całego klastra Kubernetesa.
- kube-scheduler
- Wyszukuje Pody, które nie zostały jeszcze przypisane do węzła, i przydziela każdy Pod do odpowiedniego węzła.
- kube-controller-manager
- Uruchamia kontrolery realizujące logikę działania API Kubernetesa.
- cloud-controller-manager (opcjonalne)
- Zapewnia integrację klastra Kubernetesa z infrastrukturą dostarczaną przez zewnętrznych dostawców chmurowych.
Składniki węzłów
Działa na każdym węźle klastra, odpowiada za utrzymanie aktywnych podów oraz zapewnienie środowiska uruchomieniowego Kubernetesa:
- kubelet
- Odpowiada za nadzorowanie, czy pody oraz ich kontenery są uruchomione i działają zgodnie z oczekiwaniami.
- kube-proxy (opcjonalne)
- Utrzymuje reguły sieciowe na węzłach w celu obsługi komunikacji z usługami (ang. Service).
- Środowisko uruchomieniowe kontenerów
- Oprogramowanie odpowiedzialne za uruchamianie kontenerów. Przeczytaj Środowiska uruchomieniowe kontenerów, aby dowiedzieć się więcej.
Klaster może wymagać dodatkowego oprogramowania na każdym węźle; możesz na przykład uruchomić systemd na węzłach z systemem Linux do monitorowania i zarządzania lokalnymi usługami.
Dodatki (Addons)
Dodatki rozszerzają funkcjonalność Kubernetesa. Oto kilka ważnych przykładów:
- DNS
- Umożliwia rozpoznawanie nazw DNS dla usług i komponentów działających w całym klastrze.
- Web UI (Dashboard)
- Umożliwia zarządzanie klastrem Kubernetesa poprzez webowy interfejs.
- Monitorowanie zasobów kontenera
- Służy do monitorowania zasobów kontenerów poprzez gromadzenie i zapisywanie danych o ich wydajności.
- Logowanie na poziomie klastra
- Umożliwia zbieranie i przechowywanie logów z kontenerów w centralnym systemie logowania dostępnym na poziomie całego klastra.
Elastyczność architektury
Dzięki elastycznej architekturze Kubernetesa można dostosować sposób wdrażania i zarządzania poszczególnymi komponentami do konkretnych wymagań - od prostych klastrów deweloperskich po złożone systemy produkcyjne na dużą skalę.
Szczegółowe informacje o każdym komponencie oraz różnych sposobach konfiguracji architektury klastra znajdziesz na stronie Architektura klastra.
3.1.2 - Objekty w Kubernetesie
Ta strona wyjaśnia, jak obiekty Kubernetesa są reprezentowane w
API Kubernetesa oraz jak można je wyrazić w formacie .yaml.
Czym są obiekty Kubernetesa
Obiekty Kubernetesa to trwałe byty w systemie Kubernetes. Kubernetes wykorzystuje te byty do reprezentowania stanu klastra. Konkretne zastosowania to m.in.:
- Jakie aplikacje kontenerowe są uruchomione (i na których węzłach)
- Zasoby dostępne dla tych aplikacji
- Polityki dotyczące zachowania tych aplikacji, takie jak polityki restartu, aktualizacje i tolerancja na błędy
Obiekt Kubernetesa to "zapis zamiaru" - gdy go utworzysz, Kubernetes będzie stale pilnować, aby taki obiekt faktycznie istniał. Tworząc obiekt, efektywnie informujesz Kubernetesa, jak ma wyglądać workload klastra; to jest pożądany stan twojego klastra.
Aby pracować z obiektami Kubernetesa-czy to w celu ich tworzenia, modyfikacji, czy
usuwania—musisz użyć API Kubernetesa. Na przykład, kiedy używasz
interfejsu wiersza poleceń kubectl, CLI wykonuje dla ciebie niezbędne wywołania
do API Kubernetesa. Możesz także używać API Kubernetesa bezpośrednio w swoich własnych
programach, korzystając z jednej z bibliotek klienckich.
Specyfikacja i status obiektu
Prawie każdy obiekt Kubernetesa zawiera dwa zagnieżdżone pola obiektowe,
które zarządzają konfiguracją obiektu: obiekt
spec i obiekt status. W przypadku obiektów, które mają
spec, musisz go ustawić podczas tworzenia obiektu,
dostarczając opis cech, jakie chcesz, aby zasób posiadał: jego pożądany stan.
Status opisuje aktualny stan obiektu, dostarczany i
aktualizowany przez system Kubernetes i jego komponenty. Kubernetes
warstwa sterowania stale
i aktywnie zarządza rzeczywistym stanem
każdego obiektu, aby dopasować go do pożądanego stanu, który dostarczyłeś.
Na przykład: w Kubernetesie, Deployment jest obiektem, który
może reprezentować aplikację działającą na twoim klastrze.
Kiedy tworzysz Deployment, możesz ustawić spec Deploymentu, aby
określić, że chcesz, aby uruchomione były trzy repliki
aplikacji. System Kubernetes odczytuje spec Deploymentu i uruchamia
trzy instancje twojej pożądanej aplikacji—aktualizując status,
aby dopasować go do twojego spec. Jeśli któraś z instancji
ulegnie awarii (czyli zmieni się status), Kubernetes zareaguje na różnicę
między spec a status - w tym przypadku, uruchamiając nową instancję.
Aby uzyskać więcej informacji na temat specyfikacji obiektu, statusu i metadanych, zobacz Kubernetes API Conventions.
Opis obiektu w Kubernetesie
Kiedy tworzysz obiekt w Kubernetesie, musisz dostarczyć specyfikację obiektu,
która opisuje jego pożądany stan, a także podstawowe informacje o obiekcie (takie
jak nazwa). Gdy używasz API Kubernetesa do tworzenia obiektu (bezpośrednio lub za
pośrednictwem kubectl), żądanie API musi zawierać te informacje w formacie JSON
w treści żądania. Najczęściej dostarczasz informacje do kubectl w pliku znanym
jako manifest. Zgodnie z konwencją, manifesty są w formacie YAML (możesz
również użyć formatu JSON). Narzędzia takie jak kubectl konwertują informacje z
manifestu na JSON lub inny obsługiwany format serializacji podczas wysyłania żądania API przez HTTP.
Oto przykład manifestu pokazujący wymagane pola oraz specyfikację obiektu dla Deployment w Kubernetesie:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2 # tells deployment to run 2 pods matching the template
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Jednym ze sposobów utworzenia Deploymentu przy użyciu pliku manifestu, takiego jak powyżej,
jest użycie polecenia kubectl apply
w interfejsie wiersza poleceń kubectl, przekazując plik .yaml jako argument. Oto przykład:
kubectl apply -f https://k8s.io/examples/application/deployment.yaml
Wynik jest podobny do tego:
deployment.apps/nginx-deployment created
Wymagane pola
W manifeście (pliku YAML lub JSON) dla obiektu Kubernetesa, który chcesz utworzyć, musisz ustawić wartości dla następujących pól:
apiVersion- Której wersji API Kubernetesa używasz do utworzenia tego obiektukind- Jakiego rodzaju obiekt chcesz utworzyćmetadata- Dane pomagające jednoznacznie zidentyfikować obiekt, w tym łańcuch znakówname,UIDoraz opcjonalnienamespace.spec- Jaki stan jest pożądany dla obiektu
Dokładny format obiektu spec jest inny dla każdego obiektu Kubernetesa i zawiera zagnieżdżone
pola specyficzne dla tego obiektu. Kubernetes API Reference
może pomóc ci znaleźć format spec dla wszystkich obiektów, które możesz utworzyć przy użyciu Kubernetesa.
Na przykład, zobacz pole spec
w odniesieniu do API Poda. Dla
każdego Poda, pole .spec określa pod i jego pożądany stan (taki jak nazwa obrazu
kontenera dla każdego kontenera w ramach tego poda). Innym
przykładem specyfikacji obiektu jest pole spec
dla
API StatefulSet. Dla StatefulSet, pole .spec określa StatefulSet i
jego pożądany stan. W ramach .spec dla StatefulSet znajduje się
szablon dla obiektów Pod. Ten
szablon opisuje Pody, które kontroler StatefulSet utworzy w celu spełnienia
specyfikacji StatefulSet. Różne rodzaje obiektów mogą
również mieć różne .status; ponownie, strony referencyjne API
szczegółowo opisują strukturę tego pola .status i jego zawartość dla każdego rodzaju obiektu.
Zobacz Najlepsze Praktyki Konfiguracji aby uzyskać dodatkowe informacje na temat pisania plików konfiguracyjnych YAML.
Walidacja pól po stronie serwera
Począwszy od wersji Kubernetesa v1.25, serwer API oferuje
walidację pól po
stronie serwera, która wykrywa nierozpoznane lub zduplikowane pola w
obiekcie. Zapewnia ona całą funkcjonalność kubectl --validate po stronie serwera.
Narzędzie kubectl używa flagi --validate do ustawiania poziomu walidacji pól. Akceptuje
wartości ignore, warn oraz strict, a także akceptuje wartości true (równoważne strict) i
false (równoważne ignore). Domyślne ustawienie walidacji dla kubectl to --validate=true.
Strict : Ścisła walidacja pól,
błędy w przypadku niepowodzenia walidacji
Warn : Walidacja pola jest przeprowadzana, ale błędy są
zgłaszane jako ostrzeżenia zamiast powodować niepowodzenie żądania.
Ignore : Nie jest wykonywana
żadna walidacja pola po stronie serwera
Kiedy kubectl nie może połączyć się z serwerem API, który obsługuje walidację pól,
przełączy się na użycie walidacji po stronie klienta. Kubernetes 1.27 i nowsze wersje zawsze
oferują walidację pól; starsze wydania Kubernetesa mogą tego nie robić. Jeśli twój
klaster jest starszy niż v1.27, sprawdź dokumentację dla swojej wersji Kubernetesa.
Co dalej?
Jeśli dopiero zaczynasz swoją przygodę z Kubernetesem, przeczytaj więcej na temat:
- Pody, które są najważniejszymi podstawowymi obiektami Kubernetesa.
- Obiekty Deployment.
- Kontrolery w Kubernetesie.
- kubectl i kubectl commands.
Zarządzanie obiektami Kubernetesa
wyjaśnia, jak używać kubectl do zarządzania obiektami. Możesz
potrzebować zainstalować kubectl, jeśli jeszcze go nie masz.
Aby dowiedzieć się więcej ogólnie o API Kubernetesa, odwiedź:
Aby dowiedzieć się więcej o obiektach w Kubernetesie, przeczytaj inne strony w tej sekcji:
3.1.2.1 - Nazwy i identyfikatory objektów
Każdy obiekt w Twoim klastrze ma Nazwę, która jest unikalna dla tego typu zasobu. Każdy obiekt Kubernetesa posiada również UID, który jest unikalny w całym Twoim klastrze.
Na przykład, w jednym namespace można mieć tylko jeden Pod o nazwie myapp-1234, ale można mieć jeden Pod i jeden Deployment, które są nazwane myapp-1234.
Dla nieunikalnych atrybutów dostarczonych przez użytkownika, Kubernetes udostępnia etykiety oraz adnotacje.
Nazwy
Ciąg znaków dostarczony przez klienta, który odnosi się do obiektu w adresie URL
zasobu, na przykład /api/v1/pods/some-name.
W danym momencie tylko jeden obiekt danego typu może mieć określoną nazwę. Jednak po usunięciu tego obiektu można utworzyć nowy o tej samej nazwie.
Nazwy muszą być unikalne we wszystkich wersjach API dla tego samego zasobu.
Kubernetes jednoznacznie identyfikuje obiekty przy użyciu kombinacji czterech atrybutów:
- **Grupa API (ang. API group) ** (np.
apps) - Rodzaj zasobu (ang. resource type) (np.
deployments) - **Przestrzeń nazw (ang. namespace) ** (dla zasobów z przestrzeniami nazw)
- Nazwa (ang. name)
Choć do tego samego zasobu można dostać się przez różne wersje API (takie jak v1 lub v1beta1), wersje te są tylko odmiennymi reprezentacjami tego samego obiektu źródłowego. Ponieważ wersja API nie wchodzi w skład klucza jednoznacznie identyfikującego obiekt, nie można utworzyć w tej samej przestrzeni nazw dwóch obiektów o identycznej nazwie i typie zasobu, różniących się jedynie wersją API.
Informacja:
W przypadkach, gdy obiekty reprezentują fizyczną jednostkę, jak Node reprezentujący fizycznego hosta, jeśli host jest odtworzony pod tą samą nazwą bez usuwania i ponownego tworzenia Node, Kubernetes traktuje nowy host jako stary, co może prowadzić do niespójności.Serwer może wygenerować nazwę, gdy zamiast name w żądaniu utworzenia zasobu podano generateName.
Gdy używane jest generateName, podana wartość służy jako prefiks nazwy, do którego serwer dodaje
wygenerowany sufiks. Nawet jeśli nazwa jest generowana, może wystąpić konflikt z istniejącymi nazwami, co
skutkuje odpowiedzią HTTP 409. W Kubernetes v1.31 i nowszych wersjach jest to znacznie mniej
prawdopodobne, ponieważ serwer podejmuje do 8 prób wygenerowania unikalnej nazwy przed zwróceniem odpowiedzi HTTP 409.
Poniżej znajdują się cztery typy często używanych ograniczeń nazw dla zasobów.
Nazwy subdomen DNS
Większość typów zasobów wymaga nazwy, która może być używana jako nazwa poddomeny DNS, zgodnie z definicją w RFC 1123. Oznacza to, że nazwa musi:
- zawierać nie więcej niż 253 znaki
- zawierać tylko małe litery alfanumeryczne, '-' lub '.'
- zaczynać się od znaku alfanumerycznego
- kończyć się znakiem alfanumerycznym
Nazwy etykiet zgodnie z RFC 1123
Niektóre typy zasobów wymagają, aby ich nazwy były zgodne ze standardem etykiet DNS, jak zdefiniowano w RFC 1123. Oznacza to, że nazwa musi:
- zawierać maksymalnie 63 znaków
- zawierać tylko małe litery alfanumeryczne lub '-'
- zaczynać się od litery alfabetu
- kończyć się znakiem alfanumerycznym
Informacja:
Gdy bramka funkcjiRelaxedServiceNameValidation jest włączona,
nazwy obiektów usługi (ang. Service) mogą rozpoczynać się od cyfry.Nazwy etykiet zgodne z RFC 1035
Niektóre typy zasobów wymagają, aby ich nazwy spełniały standardy etykiet DNS zgodnie z definicją w RFC 1035. Oznacza to, że nazwa musi:
- zawierać maksymalnie 63 znaków
- zawierać tylko małe litery alfanumeryczne lub '-'
- zaczynać się od litery alfabetu
- kończyć się znakiem alfanumerycznym
Informacja:
Chociaż RFC 1123 technicznie pozwala, aby etykiety zaczynały się od cyfr, obecna implementacja Kubernetesa wymaga, aby zarówno etykiety (ang. label) zgodne z RFC 1035, jak i RFC 1123 zaczynały się od znaku alfabetycznego. Wyjątkiem jest sytuacja, gdy dla obiektów typu Service jest włączona brama funkcjiRelaxedServiceNameValidation, co pozwala na to, aby nazwy usług zaczynały się od cyfr.Nazwy segmentów ścieżki
Niektóre typy zasobów wymagają, aby ich nazwy mogły być bezpiecznie kodowane jako segment ścieżki. Innymi słowy, nazwa nie może być "." ani ".." oraz nie może zawierać "/" ani "%".
Oto przykładowy manifest dla Poda o nazwie nginx-demo.
apiVersion: v1
kind: Pod
metadata:
name: nginx-demo
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Informacja:
Niektóre typy zasobów mają dodatkowe ograniczenia dotyczące ich nazw.UIDy
Unikalny identyfikator obiektu generowany automatycznie przez system Kubernetes.
Każdy obiekt utworzony w trakcie całego cyklu życia klastra Kubernetesa posiada unikalny UID. Jego celem jest rozróżnianie historycznych wystąpień podobnych jednostek.
UID-y Kubernetesa to uniwersalne unikalne identyfikatory (znane również jako UUID). UUID są ustandaryzowane jako ISO/IEC 9834-8 oraz jako ITU-T X.667.
Co dalej?
- Przeczytaj o etykietach i adnotacjach w Kubernetesie.
- Zobacz Identyfikatory i nazwy w Kubernetesie.
3.1.2.2 - Etykiety i selektory
Etykiety to pary klucz/wartość, które są dołączane do obiektów takich jak Pody. Etykiety służą do określania identyfikacyjnych atrybutów obiektów, które są istotne i ważne dla użytkowników, ale bezpośrednio nie wpływają na semantykę głównego systemu. Etykiety mogą być używane do organizowania i wybierania podzbiorów obiektów. Etykiety mogą być dołączane do obiektów w momencie ich tworzenia, a następnie mogą być dodawane i modyfikowane w dowolnym momencie. Każdy obiekt może mieć zdefiniowany zestaw etykiet w postaci par klucz/wartość. Każdy klucz musi być unikalny dla konkretnego obiektu.
"metadata": {
"labels": {
"key1" : "value1",
"key2" : "value2"
}
}
Etykiety umożliwiają wydajne zapytania i obserwacje, co czyni je idealnym rozwiązaniem do użycia w interfejsach użytkownika (UI) i interfejsach wiersza poleceń (CLI). Informacje nieidentyfikujące powinny być rejestrowane przy użyciu adnotacji.
Motywacja
Etykiety umożliwiają użytkownikom odwzorowanie własnych struktur organizacyjnych na obiekty systemowe w sposób luźno powiązany, bez konieczności przechowywania tych odwzorowań przez klientów.
Rozmieszczanie usług i przetwarzanie wsadowe to często byty wielowymiarowe (np. wiele partycji lub wdrożeń, wiele ścieżek wydania, wiele poziomów, wiele mikrousług na poziom). Zarządzanie często wymaga operacji przekrojowych, co łamie enkapsulację ściśle hierarchicznych reprezentacji, zwłaszcza sztywnych hierarchii określanych przez infrastrukturę, a nie przez użytkowników.
Przykłady etykiet:
"release" : "stable","release" : "canary""environment" : "dev","environment" : "qa","environment" : "production""tier" : "frontend","tier" : "backend","tier" : "cache""partition" : "customerA","partition" : "customerB""track" : "daily","track" : "weekly"
Oto przykłady zalecanych etykiet ; możesz swobodnie opracowywać własne konwencje. Pamiętaj, że klucz etykiety musi być unikalny dla danego obiektu.
Składnia i zestaw znaków
Etykiety to pary klucz/wartość. Prawidłowe klucze etykiet mają dwa segmenty: opcjonalny
prefiks i nazwę, oddzielone ukośnikiem (/). Segment nazwy jest
wymagany i musi mieć maksymalnie 63 znaki, zaczynając i kończąc się znakiem
alfanumerycznym ([a-z0-9A-Z]), z myślnikami (-), podkreśleniami (_),
kropkami (.) i znakami alfanumerycznymi pomiędzy. Prefiks jest opcjonalny. Jeśli
jest podany, prefiks musi być subdomeną DNS: serią etykiet DNS oddzielonych
kropkami (.), o długości nieprzekraczającej łącznie 253 znaków, zakończoną ukośnikiem (/).
Jeśli prefiks zostanie pominięty, uważa się, że klucz etykiety jest prywatny dla użytkownika.
Zautomatyzowane komponenty systemowe (np. kube-scheduler,
kube-controller-manager, kube-apiserver, kubectl lub inne zewnętrzne
automatyzacje), które dodają etykiety do obiektów końcowego użytkownika, muszą określać prefiks.
Prefiksy kubernetes.io/ i k8s.io/ są
zarezerwowane dla podstawowych komponentów Kubernetesa.
Prawidłowa wartość etykiety:
- musi mieć 63 znaki lub mniej (może być puste),
- o ile ciąg nie jest pusty, musi zaczynać się i kończyć znakiem alfanumerycznym (
[a-z0-9A-Z]), - może zawierać myślniki (
-), podkreślenia (_), kropki (.) oraz znaki alfanumeryczne pomiędzy.
Na przykład, oto manifest dla Poda, który ma dwie
etykiety environment: production oraz app: nginx:
apiVersion: v1
kind: Pod
metadata:
name: label-demo
labels:
environment: production
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Selektory etykiet
W przeciwieństwie do nazw i identyfikatorów UID, etykiety nie zapewniają unikalności. To oznacza, że wiele obiektów może mieć te same etykiety.
Za pomocą selektora etykiet klient/użytkownik może zidentyfikować zestaw obiektów. Selektor etykiet jest podstawowym mechanizmem grupującym w Kubernetesie.
API obecnie obsługuje dwa typy selektorów: oparte na równości i
oparte na zbiorach. Selektor etykiet może składać się z wielu wymagań, które
są oddzielone przecinkami. W przypadku wielu wymagań, wszystkie muszą być
spełnione, więc separator przecinka działa jako logiczny operator AND (&&).
Interpretacja pustych lub niepodanych selektorów zależy od kontekstu. Każdy typ API, który je wykorzystuje, powinien jasno udokumentować ich dopuszczalność i sposób działania.
Informacja:
Dla niektórych typów API, takich jak ReplicaSets, selektory etykiet dwóch instancji nie mogą się nakładać w obrębie jednej przestrzeni nazw, ponieważ kontroler może to uznać za sprzeczne polecenia i nie będzie w stanie określić, ile replik powinno być obecnych.Uwaga:
Zarówno dla warunków opartych na równości, jak i warunków opartych na zbiorach nie istnieje operator logiczny OR (||).
Upewnij się, że twoje instrukcje filtrujące są odpowiednio skonstruowane.Wymóg oparty na równości
Wymagania oparte na równości lub nierówności umożliwiają filtrowanie
według kluczy i wartości etykiet. Pasujące obiekty muszą spełniać wszystkie
określone ograniczenia etykiet, chociaż mogą mieć również dodatkowe etykiety.
Dopuszczalne są trzy rodzaje operatorów: =,==,!=. Pierwsze dwa reprezentują
równość (i są synonimami), podczas gdy ostatni reprezentuje nierówność. Na przykład:
environment = production
tier != frontend
Poprzedni wybiera wszystkie zasoby, których klucz jest równy environment, a wartość równa się
production. Drugi wybiera wszystkie zasoby, których klucz jest równy tier, a wartość różni się od
frontend, oraz wszystkie zasoby bez etykiet z kluczem tier. Można filtrować zasoby w
production wyłączając frontend przy użyciu operatora przecinka: environment=production,tier!=frontend
Jednym ze scenariuszy użycia dla wymagań etykiet opartych na równości jest
specyfikacja kryteriów wyboru węzła przez Pody. Na przykład, poniższy przykładowy Pod wybiera
węzły, na których etykieta accelerator istnieje i jest ustawiona na nvidia-tesla-p100.
apiVersion: v1
kind: Pod
metadata:
name: cuda-test
spec:
containers:
- name: cuda-test
image: "registry.k8s.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
accelerator: nvidia-tesla-p100
Wymagania oparte na zbiorach
Wymagania dotyczące etykiet bazujących na zbiorach (Set-based)
umożliwiają filtrowanie kluczy według zbioru wartości. Obsługiwane są trzy rodzaje
operatorów: in, notin oraz exists (tylko identyfikator klucza). Na przykład:
environment in (production, qa)
tier notin (frontend, backend)
partition
!partition
- Pierwszy przykład wybiera wszystkie zasoby z kluczem
równym
environmenti wartością równąproductionlubqa. - Drugi przykład wybiera wszystkie zasoby z kluczem równym
tieri wartościami innymi niżfrontendibackend, oraz wszystkie zasoby bez etykiet z kluczemtier. - Trzeci przykład wybiera wszystkie zasoby zawierające
etykietę z kluczem
partition; wartości nie są sprawdzane. - Czwarty przykład wybiera wszystkie zasoby bez
etykiety z kluczem
partition; wartości nie są sprawdzane.
Podobnie separator przecinka działa jako operator AND.
Filtrowanie zasobów z kluczem partition (bez względu na wartość) i z
environment innym niż qa można osiągnąć używając
partition,environment notin (qa). Selekcja etykiet oparta na zbiorach
jest ogólną formą równości, ponieważ environment=production
jest równoważne environment in (production); podobnie dla != i notin.
Wymagania oparte na zbiorach mogą być mieszane z wymaganiami opartymi na
równości. Na przykład: partition in (customerA, customerB),environment!=qa.
API
Filtrowanie LIST i WATCH
Dla operacji list i watch można określić selektory etykiet, aby filtrować zestawy zwracanych obiektów; filtr określasz za pomocą parametru zapytania. (Aby dowiedzieć się więcej o mechanizmie watch w Kubernetesie, przeczytaj o wydajnym wykrywaniu zmian ). Oba wymagania są dozwolone (przedstawione tutaj tak, jak mogą się pojawić w ciągu zapytania URL):
- wymagania oparte na równości:
?labelSelector=environment%3Dproduction,tier%3Dfrontend - _wymagania oparte na zbiorach:
?labelSelector=environment+in+%28production%2Cqa%29%2Ctier+in+%28frontend%29
Oba style selektorów etykiet mogą być używane do wylistowania lub obserwacji zasobów za pomocą klienta
REST. Na przykład, kierując się na apiserver z kubectl i używając selekcji opartej na równości, można napisać:
kubectl get pods -l environment=production,tier=frontend
lub używając wymagań opartych na zbiorach:
kubectl get pods -l 'environment in (production),tier in (frontend)'
Jak już wspomniano, wymagania oparte na zbiorach są bardziej wyraziste. Na przykład mogą implementować operator LUB na wartościach:
kubectl get pods -l 'environment in (production, qa)'
lub ograniczenie dopasowywania negatywnego za pomocą operatora notin:
kubectl get pods -l 'environment,environment notin (frontend)'
Ustaw referencje w obiektach API
Niektóre obiekty Kubernetesa, takie jak
services i replicationcontrollers,
również używają selektorów etykiet do
określania zbiorów innych zasobów, takich jak pods.
Usługa i Kontroler Replikacji
Zestaw podów, na które skierowana jest usługa (service), jest określany za pomocą selektora
etykiet. Podobnie, populacja podów, którą powinien zarządzać kontroler
replikacji (replicationcontroller), jest również określana za pomocą selektora etykiet.
Selektory etykiet dla obu obiektów są definiowane w plikach json lub
yaml za pomocą map, i obsługiwane są tylko selektory wymagań oparte na równości:
"selector": {
"component" : "redis",
}
lub
selector:
component: redis
Ten selektor (odpowiednio w formacie json lub yaml)
jest równoważny z component=redis lub component in (redis).
Zasoby, które obsługują wymagania oparte na zbiorach
Nowsze zasoby, takie jak Job,
Deployment,
ReplicaSet
oraz DaemonSet,
obsługują również wymagania oparte na zbiorach.
selector:
matchLabels:
component: redis
matchExpressions:
- { key: tier, operator: In, values: [cache] }
- { key: environment, operator: NotIn, values: [dev] }
matchLabels to mapa par {klucz,wartość}. Pojedyncza para {klucz,wartość} w
mapie matchLabels jest równoważna elementowi matchExpressions, którego pole
key to "klucz", operator to "In", a tablica values zawiera wyłącznie "wartość". matchExpressions
to lista wymagań selektora podów. Prawidłowe operatory to In,
NotIn, Exists i DoesNotExist. Zbiór wartości musi być niepusty w przypadku In i
NotIn. Wszystkie wymagania zarówno z matchLabels, jak i matchExpressions są
łączone za pomocą operatora AND - muszą być wszystkie spełnione, aby dopasowanie było możliwe.
Wybieranie zestawów węzłów
Jednym z przypadków użycia wybierania w oparciu o etykiety jest ograniczenie zestawu węzłów, na które można umieścić pod. Więcej informacji można znaleźć w dokumentacji na temat wyboru węzła.
Skuteczne wykorzystywanie etykiet
Możesz zastosować pojedynczą etykietę do dowolnych zasobów, ale nie zawsze jest to najlepsza praktyka. Istnieje wiele scenariuszy, w których należy użyć wielu etykiet, aby odróżnić zestawy zasobów od siebie nawzajem.
Na przykład różne aplikacje mogą używać różnych wartości dla etykiety app, ale
aplikacja wielowarstwowa, taka jak przykład książki gości,
będzie dodatkowo musiała rozróżniać każdą warstwę.
W poniższych przykładach użyto etykiety app, żeby uprościć ręczne
zapytania i pracę z CLI. Natomiast app.kubernetes.io/name trzyma się oficjalnych konwencji
Kubernetesa i lepiej sprawdza się w narzędziach oraz automatyzacji.
Frontend mógłby nosić następujące etykiety:
labels:
app: guestbook
app.kubernetes.io/name: guestbook
tier: frontend
podczas gdy instancje master i replica Redis miałyby różne etykiety
tier, a być może nawet dodatkową etykietę role:
labels:
app: guestbook
app.kubernetes.io/name: guestbook
tier: backend
role: master
i
labels:
app: guestbook
app.kubernetes.io/name: guestbook
tier: backend
role: replica
Etykiety umożliwiają sortowanie i filtrowanie zasobów według dowolnego wymiaru określonego przez etykietę:
kubectl apply -f examples/guestbook/all-in-one/guestbook-all-in-one.yaml
kubectl get pods -Lapp -Ltier -Lrole
NAME READY STATUS RESTARTS AGE APP TIER ROLE
guestbook-fe-4nlpb 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-ght6d 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-jpy62 1/1 Running 0 1m guestbook frontend <none>
guestbook-redis-master-5pg3b 1/1 Running 0 1m guestbook backend master
guestbook-redis-replica-2q2yf 1/1 Running 0 1m guestbook backend replica
guestbook-redis-replica-qgazl 1/1 Running 0 1m guestbook backend replica
my-nginx-divi2 1/1 Running 0 29m nginx <none> <none>
my-nginx-o0ef1 1/1 Running 0 29m nginx <none> <none>
kubectl get pods -lapp=guestbook,role=replica
NAME READY STATUS RESTARTS AGE
guestbook-redis-replica-2q2yf 1/1 Running 0 3m
guestbook-redis-replica-qgazl 1/1 Running 0 3m
Aktualizacja etykiet
Czasami możesz chcieć zmienić etykiety istniejących podów i innych zasobów przed
utworzeniem nowych zasobów. Można to zrobić za pomocą kubectl label. Na
przykład, jeśli chcesz oznaczyć wszystkie swoje pody NGINX jako warstwę frontendową, wykonaj:
kubectl label pods -l app=nginx tier=fe
pod/my-nginx-2035384211-j5fhi labeled
pod/my-nginx-2035384211-u2c7e labeled
pod/my-nginx-2035384211-u3t6x labeled
Najpierw filtruje wszystkie pody z etykietą "app=nginx", a następnie nadaje im etykietę "tier=fe". Aby zobaczyć pody, które zostały oznaczone etykietą, uruchom:
kubectl get pods -l app=nginx -L tier
NAME READY STATUS RESTARTS AGE TIER
my-nginx-2035384211-j5fhi 1/1 Running 0 23m fe
my-nginx-2035384211-u2c7e 1/1 Running 0 23m fe
my-nginx-2035384211-u3t6x 1/1 Running 0 23m fe
To wyświetla wszystkie pody z etykietą "app=nginx", z dodatkową kolumną
etykiet reprezentującą warstwę podów (określoną za pomocą -L lub --label-columns).
Aby uzyskać więcej informacji, zobacz kubectl label.
Co dalej?
- Dowiedz się, jak dodać etykietę do węzła
- Zobacz Well-known labels, Annotations and Taints
- Zobacz Zalecane etykiety
- Enforce Pod Security Standards with Namespace Labels
- Przeczytaj blog Writing a Controller for Pod Labels
3.1.2.3 - Przestrzenie nazw (ang. Namespaces)
W Kubernetesie przestrzenie nazw zapewniają mechanizm izolowania grup zasobów w ramach jednego klastra. Nazwy zasobów muszą być unikalne w obrębie danej przestrzeni nazw, ale nie muszą być unikalne w całym klastrze. Zakres oparty na przestrzeniach nazw dotyczy tylko obiektów (np. Deploymentów, Service'ów, itp.), a nie dla obiektów dotyczących całego klastra (np. StorageClass, Nodes, PersistentVolumes, itp.).
Kiedy używać wielu przestrzeni nazw
Przestrzenie nazw są przeznaczone do użycia w środowiskach z wieloma użytkownikami rozproszonymi w różnych zespołach lub projektach. Dla klastrów z użytkownikami w ilości od kilku do kilkunastu nie powinieneś potrzebować tworzyć ani myśleć o przestrzeniach nazw. Zacznij używać przestrzeni nazw, gdy potrzebujesz funkcji, które one oferują.
Namespace'y zapewniają zakres dla nazw. Nazwy zasobów muszą być unikalne w obrębie jednego namespace'u, ale nie muszą być unikalne w różnych namespace'ach. Namespace'y nie mogą być zagnieżdżane w sobie wzajemnie, a każdy zasób Kubernetesa może znajdować się tylko w jednym namespace'ie.
Namespacey są sposobem na podział zasobów klastra pomiędzy wielu użytkowników (przez resource quotas).
Nie ma potrzeby używania wielu przestrzeni nazw do oddzielania nieznacznie różniących się zasobów, takich jak różne wersje tego samego oprogramowania: zamiast tego wykorzystaj etykiety, aby rozróżnić zasoby w obrębie jednej przestrzeni nazw.
Informacja:
Dla klastra produkcyjnego, rozważ nie używanie przestrzeni nazwdefault. Zamiast tego stwórz inne przestrzenie nazw i używaj ich.Początkowe przestrzenie nazw
Kubernetes rozpoczyna z czterema początkowymi przestrzeniami nazw:
default : Kubernetes zawiera tę przestrzeń nazw, aby umożliwić rozpoczęcie
korzystania z nowego klastra bez konieczności wcześniejszego tworzenia przestrzeni nazw.
kube-node-lease : Ta przestrzeń nazw przechowuje obiekty Lease powiązane z każdym węzłem. Pozwalają one kubeletowi
na wysyłanie sygnałów życia (ang. heartbeats), dzięki czemu warstwa sterowania może wykryć awarię węzła.
kube-public : Ta przestrzeń nazw jest możliwa do odczytu przez wszystkich klientów (w tym tych, którzy nie są uwierzytelnieni). Ta przestrzeń nazw jest głównie zarezerwowana do
użytku klastra, na wypadek gdyby niektóre zasoby miały być widoczne i czytelne publicznie w całym klastrze. Publiczny aspekt tej przestrzeni nazw jest jedynie konwencją, a nie wymogiem.
kube-system : Przestrzeń nazw dla
obiektów tworzonych przez system Kubernetesa.
Praca z przestrzeniami nazw
Tworzenie i usuwanie przestrzeni nazw zostało opisane w dokumentacji Przewodnika Administratora dotyczącej przestrzeni nazw.
Informacja:
Unikaj tworzenia przestrzeni nazw z prefiksemkube-, ponieważ jest on zarezerwowany dla przestrzeni nazw systemu Kubernetes.Przeglądanie przestrzeni nazw
Możesz wyświetlić listę bieżących przestrzeni nazw w klastrze za pomocą:
kubectl get namespace
NAME STATUS AGE
default Active 1d
kube-node-lease Active 1d
kube-public Active 1d
kube-system Active 1d
Ustawianie przestrzeni nazw dla żądania
Aby ustawić przestrzeń nazw dla bieżącego żądania, użyj flagi --namespace.
Na przykład:
kubectl run nginx --image=nginx --namespace=<insert-namespace-name-here>
kubectl get pods --namespace=<insert-namespace-name-here>
Ustawianie preferencji przestrzeni nazw
Możesz na stałe zapisać przestrzeń nazw dla wszystkich kolejnych poleceń kubectl w tym kontekście.
kubectl config set-context --current --namespace=<insert-namespace-name-here>
# Validate it
kubectl config view --minify | grep namespace:
Przestrzenie nazw i DNS
Kiedy tworzysz Service, tworzy on
odpowiadający mu rekord DNS.
Ten wpis ma postać <service-name>.<namespace-name>.svc.cluster.local, co oznacza,
że jeśli kontener używa tylko <service-name>, odwołuje się on do usługi lokalnej
dla danego namespace'a. Jest to przydatne do używania tej samej konfiguracji w
wielu namespace'ach, takich jak Development, Staging i Production. Jeśli chcesz uzyskać dostęp
do zasobów między namespace'ami, musisz użyć w pełni kwalifikowanej nazwy domeny (FQDN).
W związku z tym, wszystkie nazwy przestrzeni nazw muszą być zgodne z etykietami DNS RFC 1123.
Ostrzeżenie:
Poprzez tworzenie przestrzeni nazw o takiej samej nazwie jak publiczne domeny najwyższego poziomu, usługi w tych przestrzeniach nazw mogą mieć krótkie nazwy DNS, które pokrywają się z publicznymi rekordami DNS. Zapytania DNS wykonywane przez workloady z dowolnej przestrzeni nazw, bez kończącej kropki, będą przekierowane do tych usług, mając pierwszeństwo przed publicznym wpisem DNS.
Aby temu zapobiec, ogranicz uprawnienia do tworzenia przestrzeni nazw dla zaufanych użytkowników. Jeśli to konieczne, możesz dodatkowo skonfigurować zewnętrzne mechanizmy kontroli bezpieczeństwa, takie jak admission webhooks, aby zablokować tworzenie jakiejkolwiek przestrzeni nazw o nazwie z listy domen najwyższego poziomu (ang. TLD - Top-Level Domain).
Nie wszystkie obiekty znajdują się w przestrzeni nazw.
Większość zasobów Kubernetesa (np. pody, usługi, deploymenty i inne) znajduje się w jakiś przestrzeniach nazw. Jednak zasoby przestrzeni nazw nie są same w sobie w przestrzeni nazw. Zasoby niskiego poziomu, takie jak Node i PersistentVolume, nie znajdują się w żadnej przestrzeni nazw.
Aby zobaczyć, które zasoby Kubernetesa znajdują się w przestrzeni nazw, a które nie:
# In a namespace
kubectl api-resources --namespaced=true
# Not in a namespace
kubectl api-resources --namespaced=false
Automatyczne etykietowanie
Kubernetes 1.22 [stable]Warstwa sterowania Kubernetesa ustawia niezmienną
etykietę kubernetes.io/metadata.name na
wszystkich przestrzeniach nazw. Wartością etykiety jest nazwa przestrzeni nazw.
Co dalej?
- Dowiedz się więcej o tworzeniu przestrzeni nazw.
- Dowiedz się więcej o usuwaniu przestrzeni nazw.
3.1.2.4 - Adnotatcje
Możesz używać Kubernetesowych adnotacji do dołączania dodatkowych (czyli takich, które nie są wykorzystywane przy identyfikacji) metadanych do obiektów. Narzędzia i biblioteki mogą odczytywać te metadane.
Dołączanie metadanych do obiektów
Możesz używać etykiet (ang. labels) lub adnotacji (ang. annotations), aby dołączać metadane do obiektów Kubernetesa. Etykiety pomagają w wybieraniu obiektów i wyszukiwaniu ich zbiorów na podstawie określonych warunków. Z kolei adnotacje nie są używane do identyfikacji ani selekcji obiektów. Metadane w adnotacjach mogą mieć dowolny rozmiar i strukturę - mogą być małe lub duże, uporządkowane lub nie, i zawierać znaki niedozwolone w etykietach. Dopuszczalne jest jednoczesne użycie etykiet i adnotacji w tym samym obiekcie.
Adnotacje, podobnie jak etykiety, są mapami klucz/wartość:
"metadata": {
"annotations": {
"key1" : "value1",
"key2" : "value2"
}
}
Informacja:
Klucze i wartości w mapie muszą być ciągami znaków. Innymi słowy, nie można używać wartości numerycznych, logicznych, list ani innych typów ani dla kluczy, ani dla wartości.Oto przykłady informacji, które mogą być zapisane w adnotacjach:
Pola zarządzane przez warstwę konfiguracji deklaratywnej. Dołączanie tych pól jako adnotacji odróżnia je od wartości domyślnych ustawianych przez klientów lub serwery, oraz od pól generowanych automatycznie i pól ustawianych przez systemy automatycznego skalowania lub automatycznego dopasowywania rozmiaru.
Informacje dotyczące kompilacji, wersji lub obrazów, takie jak znaczniki czasu, identyfikatory wersji, gałąź git, numery PR, skróty obrazów i adres rejestru.
Referencje do zewnętrznych źródeł danych takich jak logi, metryki monitorujące, wyniki analiz czy dane audytowe.
Informacje o bibliotece klienckiej lub narzędziu, które mogą być wykorzystane do debugowania - na przykład nazwa, wersja i dane o kompilacji.
Informacje o pochodzeniu użytkownika, narzędzia lub systemu, takie jak adresy URL powiązanych obiektów z innych komponentów ekosystemu.
Metadane wykorzystywane przez proste narzędzia do wdrażania zmian (rollout), takie jak zapis stanu konfiguracji lub punktów kontrolnych służących do śledzenia postępu wdrożenia.
Numery telefonów lub pagerów osób odpowiedzialnych, lub wpisy do katalogu określające, gdzie można znaleźć te informacje, takie jak strona internetowa zespołu.
Instrukcje od użytkownika końcowego kierowane do implementacji, mające na celu zmianę zachowania systemu lub uruchomienie niestandardowych funkcji.
Zamiast używać adnotacji, można przechowywać tego typu informacje w zewnętrznej bazie danych lub katalogu, ale to znacznie utrudniłoby tworzenie wspólnych bibliotek klienckich i narzędzi do wdrażania, zarządzania, introspekcji i tym podobnych działań.
Składnia i zestaw znaków
Adnotacje są parami klucz/wartość. Prawidłowe klucze adnotacji mają dwa segmenty: opcjonalny prefiks oraz nazwę, oddzielone ukośnikiem (/). Segment nazwy jest wymagany i musi mieć maksymalnie 63 znaki, zaczynać się i kończyć znakiem alfanumerycznym ([a-z0-9A-Z]) oraz może zawierać myślniki (-), podkreślenia (_), kropki (.) i znaki alfanumeryczne pomiędzy nimi. Prefiks jest opcjonalny. Jeśli zostanie określony, prefiks musi być subdomeną DNS: serią etykiet DNS oddzielonych kropkami (.), nie dłuższą w sumie niż 253 znaki, zakończoną ukośnikiem (/).
Jeśli prefiks jest pominięty, zakłada się, że klucz adnotacji należy wyłącznie do użytkownika. Zautomatyzowane komponenty systemowe (np. kube-scheduler, kube-controller-manager, kube-apiserver, kubectl lub inna automatyzacja firm trzecich), które dodają adnotacje do obiektów końcowego użytkownika, muszą określić prefiks.
Prefiksy kubernetes.io/ i k8s.io/ są zarezerwowane dla podstawowych komponentów Kubernetesa.
Prawidłowe wartości adnotacji nie mają ograniczeń dotyczących zestawu znaków - w przeciwieństwie do wartości etykiet, wartości adnotacji mogą zawierać dowolny ciąg znaków, w tym znaki specjalne, spacje oraz dane strukturalne, takie jak JSON czy YAML. Jeśli planujesz przechowywać dane binarne (takie jak CBOR), projekt Kubernetes zaleca ich kodowanie za pomocą base64. Jednak całkowity rozmiar wszystkich adnotacji na jednym obiekcie (łączna wielkość kluczy i wartości) nie może przekraczać 256 KiB.
Na przykład, oto manifest dla Poda, który posiada adnotację imageregistry: https://hub.docker.com/ :
apiVersion: v1
kind: Pod
metadata:
name: annotations-demo
annotations:
imageregistry: "https://hub.docker.com/"
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Co dalej?
- Dowiedz się więcej o Etykietach i Selektorach.
- Znajdź Typowe etykiety, Adnotacje i Tainty (ang. Taints)
3.1.2.5 - Selektory pól
Selektory pól (Field selectors) pozwalają na wybór obiektów Kubernetesa na podstawie wartości jednego lub kilku pól zasobów. Oto kilka przykładów zapytań z użyciem selektora pól:
metadata.name=my-servicemetadata.namespace!=defaultstatus.phase=Pending
Polecenie kubectl wybiera wszystkie Pody, dla których wartość pola status.phase to Running:
kubectl get pods --field-selector status.phase=Running
Informacja:
Selektory pól to zasadniczo filtry zasobów. Domyślnie nie stosuje się żadnych selektorów/filtrów, co oznacza, że wszystkie zasoby określonego typu są wybierane. Dzięki temu zapytaniakubectl kubectl get pods i kubectl get pods --field-selector "" są równoważne.Obsługiwane pola
Obsługiwane selektory pól różnią się w zależności od typu zasobu Kubernetesa. Wszystkie typy zasobów obsługują pola metadata.name oraz metadata.namespace. Użycie nieobsługiwanych selektorów pól skutkuje błędem. Na przykład:
kubectl get ingress --field-selector foo.bar=baz
Error from server (BadRequest): Unable to find "ingresses" that match label selector "", field selector "foo.bar=baz": "foo.bar" is not a known field selector: only "metadata.name", "metadata.namespace"
Lista obsługiwanych pól
| Rodzaj | Pola |
|---|---|
| Pod | spec.nodeNamespec.restartPolicyspec.schedulerNamespec.serviceAccountNamespec.hostNetworkstatus.phasestatus.podIPstatus.podIPsstatus.nominatedNodeName |
| Event | involvedObject.kindinvolvedObject.namespaceinvolvedObject.nameinvolvedObject.uidinvolvedObject.apiVersioninvolvedObject.resourceVersioninvolvedObject.fieldPathreasonreportingComponentsourcetype |
| Secret | type |
| Service | spec.clusterIPspec.type |
| Namespace | status.phase |
| ReplicaSet | status.replicas |
| ReplicationController | status.replicas |
| Job | status.successful |
| Node | spec.unschedulable |
| CertificateSigningRequest | spec.signerName |
Pola zasobów niestandardowych
Wszystkie niestandardowe typy zasobów obsługują pola metadata.name oraz metadata.namespace.
Dodatkowo, pole spec.versions[*].selectableFields w CustomResourceDefinition określa,
które inne pola w zasobie niestandardowym mogą być używane w selektorach pól. Zobacz
selectable fields for custom resources aby uzyskać więcej informacji o tym, jak używać selektorów pól z CustomResourceDefinitions.
Obsługiwane operatory
Możesz używać operatorów =, == i != z selektorami pól (= and == oznaczają to samo). Na przykład ta komenda kubectl wybiera wszystkie usługi Kubernetesa, które nie znajdują się w przestrzeni nazw default:
kubectl get services --all-namespaces --field-selector metadata.namespace!=default
Informacja:
Operatory dla zbiorów (Set-based operators ) (in, notin, exists) nie są obsługiwane dla selektorów pól.Złożone selektory
Podobnie jak etykieta i inne selektory, selektory pól mogą być łączone w postaci listy rozdzielanej przecinkami. To polecenie kubectl wybiera wszystkie Pody, dla których status.phase nie jest równe Running, a pole spec.restartPolicy jest równe Always:
kubectl get pods --field-selector=status.phase!=Running,spec.restartPolicy=Always
Wiele typów zasobów
Możesz używać selektorów pól w różnych typach zasobów. To polecenie kubectl wybiera wszystkie obiekty typu Statefulset i Service, które nie znajdują się w przestrzeni nazw default:
kubectl get statefulsets,services --all-namespaces --field-selector metadata.namespace!=default
3.1.2.6 - Zalecane etykiety
Możesz wizualizować i zarządzać obiektami Kubernetesa za pomocą większej liczby narzędzi niż tylko kubectl i dashboard. Wspólny zestaw etykiet umożliwia narzędziom współpracę, opisując obiekty w ujednolicony sposób, który wszystkie narzędzia mogą zrozumieć.
Poza wsparciem dla narzędzi, rekomendowane etykiety opisują aplikacje tak, aby można było je łatwo wyszukiwać za pomocą zapytań.
Metadane są zorganizowane wokół pojęcia aplikacji. Kubernetes nie jest platformą typu PaaS i nie posiada ani nie wymusza formalnej definicji aplikacji. Zamiast tego aplikacje mają charakter nieformalny i są opisywane za pomocą metadanych. Definicja tego, co wchodzi w skład aplikacji, jest dość luźna.
Informacja:
Są to zalecane etykiety. Ułatwiają zarządzanie aplikacjami, ale nie są wymagane do działania podstawowych narzędzi.Współdzielone etykiety i adnotacje mają prefiks: app.kubernetes.io.
Etykiety bez prefiksu są traktowane jako prywatne. Dzięki temu prefiksowi
etykiety współdzielone nie kolidują z etykietami definiowanymi przez użytkownika.
Etykiety
Aby w pełni wykorzystać zalety etykiet, warto dodawać je do każdego obiektu w systemie.
| Klucz | Opis | Przykład | Typ |
|---|---|---|---|
app.kubernetes.io/name | Nazwa aplikacji | mysql | string |
app.kubernetes.io/instance | Unikalna nazwa identyfikująca instancję aplikacji | mysql-abcxyz | string |
app.kubernetes.io/version | Aktualna wersja aplikacji (np. SemVer 1.0, hash rewizji, itp.) | 5.7.21 | ciąg znaków |
app.kubernetes.io/component | Komponent w ramach architektury | baza danych | string |
app.kubernetes.io/part-of | Nazwa nadrzędnej aplikacji, do której należy ten element | wordpress | string |
app.kubernetes.io/managed-by | Narzędzie używane do zarządzania operacjami aplikacji | Helm | string |
Aby zilustrować działanie tych etykiet, rozważ następujący obiekt StatefulSet:
# This is an excerpt
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: mysql-abcxyz
app.kubernetes.io/version: "5.7.21"
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
app.kubernetes.io/managed-by: Helm
Aplikacje i instancje aplikacji
Aplikacja może być zainstalowana jeden lub więcej razy w klastrze Kubernetesa, a w niektórych przypadkach w tej samej przestrzeni nazw. Na przykład WordPress może być zainstalowany więcej niż raz, gdzie różne strony internetowe to różne instalacje WordPressa.
Nazwa aplikacji i nazwa instancji są rejestrowane oddzielnie. Na
przykład, WordPress ma app.kubernetes.io/name o wartości wordpress,
natomiast nazwa instancji jest reprezentowana jako
app.kubernetes.io/instance z wartością wordpress-abcxyz. Umożliwia to identyfikację
aplikacji oraz jej instancji. Każda instancja aplikacji musi mieć unikalną nazwę.
Przykłady
Aby zilustrować różne sposoby wykorzystania tych etykiet, poniższe przykłady mają różny stopień złożoności.
Prosta usługa bezstanowa (ang. Stateless Service)
Rozważmy przypadek prostego serwisu bezstanowego wdrożonego przy użyciu obiektów Deployment i Service. Poniższe dwa fragmenty przedstawiają, jak etykiety mogą być używane w najprostszej formie.
Deployment jest używany do nadzorowania podów uruchamiających samą aplikację.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: myservice
app.kubernetes.io/instance: myservice-abcxyz
...
Service służy do udostępniania aplikacji.
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: myservice
app.kubernetes.io/instance: myservice-abcxyz
...
Aplikacja webowa z bazą danych
Rozważmy nieco bardziej skomplikowaną aplikację: aplikację webową (WordPress) korzystającą z bazy danych (MySQL), zainstalowaną za pomocą Helm. Poniższe fragmenty ilustrują początek obiektów użytych do wdrożenia tej aplikacji.
Początek następującego Deployment jest używany dla WordPressa:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: wordpress
app.kubernetes.io/instance: wordpress-abcxyz
app.kubernetes.io/version: "4.9.4"
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/component: server
app.kubernetes.io/part-of: wordpress
...
Service jest używany do udostępniania WordPressa:
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: wordpress
app.kubernetes.io/instance: wordpress-abcxyz
app.kubernetes.io/version: "4.9.4"
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/component: server
app.kubernetes.io/part-of: wordpress
...
MySQL jest udostępniany jako StatefulSet z metadanymi zarówno dla niego, jak i dla nadrzędnej aplikacji, do której należy:
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: mysql-abcxyz
app.kubernetes.io/version: "5.7.21"
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
...
Serwis jest używany do udostępniania MySQL jako część WordPressa:
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: mysql-abcxyz
app.kubernetes.io/version: "5.7.21"
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
...
W StatefulSet i Service dla MySQL zawarte są informacje zarówno o MySQL, jak i o WordPressie, czyli nadrzędnej aplikacji.
3.1.3 - API Kubernetesa
Sercem warstwy sterowania Kubernetesa jest serwer API. Serwer udostępnia API poprzez HTTP, umożliwiając wzajemną komunikację pomiędzy użytkownikami, częściami składowymi klastra i komponentami zewnętrznymi.
API Kubernetesa pozwala na sprawdzanie i zmianę stanu obiektów (przykładowo: pody, Namespaces, ConfigMaps, Events).
Większość operacji może zostać wykonana poprzez interfejs linii komend (CLI) kubectl lub inne programy, takie jak kubeadm, które używają API. Możesz też korzystać z API bezpośrednio przez wywołania typu REST. Jeśli piszesz aplikację używającą API Kubernetesa, warto rozważyć użycie jednej z bibliotek klienckich.
Każdy klaster Kubernetesa publikuje specyfikację dostępnych interfejsów API. Dostępne
są dwa mechanizmy udostępniania tych specyfikacji, które
umożliwiają automatyczną integrację i interoperacyjność z narzędziami zewnętrznymi.
Na przykład narzędzie kubectl pobiera i buforuje specyfikację API w celu
umożliwienia autouzupełniania wiersza poleceń i innych funkcji. Te dwa mechanizmy to:
Discovery API dostarcza informacji o interfejsach API Kubernetesa: nazwach API, zasobach, wersjach i obsługiwanych operacjach. W Kubernetesie ten termin ma szczególne znaczenie, ponieważ to odrębny interfejs od OpenAPI i jest traktowany jako osobna część systemu. Jest to zwięzłe podsumowanie dostępnych zasobów i nie obejmuje szczegółowych definicji schematów. Szczegółowe informacje o strukturze zasobów można znaleźć w dokumencie OpenAPI.
Kubernetes OpenAPI Document dostarcza (pełne) schematy OpenAPI v2.0 i 3.0 dla wszystkich endpointów API Kubernetesa. OpenAPI v3 to zalecany sposób uzyskiwania dostępu do specyfikacji API, ponieważ zapewnia pełniejszy i dokładniejszy obraz. Zawiera wszystkie ścieżki API oraz komplet danych wejściowych i wyjściowych dla każdej operacji na wszystkich endpointach. Specyfikacja obejmuje także wszystkie rozszerzenia wspierane przez klaster. Jest to pełna definicja API, która znacząco przewyższa pod względem szczegółowości dane z Discovery API.
Discovery API
Kubernetes przez Discovery API udostępnia pełną listę obsługiwanych grup API, ich wersji oraz zasobów. Dla każdego zasobu można uzyskać następujące dane:
- Nazwa
- Klaster lub zasięg w przestrzeni nazw
- URL endpointu oraz obsługiwane metody HTTP
- Alternatywne nazwy
- Grupa, wersja, typ
API jest dostępne zarówno w formie zagregowanej, jak i niezagregowanej. W trybie zagregowanym Discovery API udostępnia dwa endpointy, natomiast w trybie niezagregowanym jest to oddzielny endpoint dla każdej wersji grupy.
Zagregowane Discovery API
Kubernetes v1.30 [stable](domyślnie włączone)Kubernetes zapewnia stabilne wsparcie dla zagregowanego
Discovery API, publikując wszystkie zasoby obsługiwane przez klaster za
pośrednictwem dwóch endpointów (/api i /apis).
Korzystanie z tych endpointów znacząco ogranicza liczbę zapytań
potrzebnych do pobrania danych z klastra. Dostęp do tych danych
uzyskuje się, wysyłając żądanie na odpowiedni endpoint z
nagłówkiem Accept, który wskazuje na zagregowany zasób Discovery:
Accept: application/json;v=v2;g=apidiscovery.k8s.io;as=APIGroupDiscoveryList.
W przypadku braku nagłówka Accept wskazującego
typ zasobu, zapytania do endpointów /api i
/apis zwracają domyślnie dane w formacie niezagregowanym.
Discovery document znajduje się w oficjalnym repozytorium GitHub Kubernetesa. Może on służyć jako odniesienie do podstawowego zestawu zasobów dostępnych w Kubernetesie, gdy nie masz możliwości wykonania zapytania do rzeczywistego klastra.
Endpoint obsługuje także mechanizm ETag oraz możliwość przesyłania danych w formacie protobuf.
Niezagregowane Discovery API
W przypadku braku agregacji Discovery API, dane udostępniane są w strukturze wielopoziomowej, w której główne endpointy publikują informacje prowadzące do podrzędnych dokumentów.
Wszystkie wersje grup API dostępnych w klastrze są udostępniane pod endpointami /api i /apis. Oto przykład:
{
"kind": "APIGroupList",
"apiVersion": "v1",
"groups": [
{
"name": "apiregistration.k8s.io",
"versions": [
{
"groupVersion": "apiregistration.k8s.io/v1",
"version": "v1"
}
],
"preferredVersion": {
"groupVersion": "apiregistration.k8s.io/v1",
"version": "v1"
}
},
{
"name": "apps",
"versions": [
{
"groupVersion": "apps/v1",
"version": "v1"
}
],
"preferredVersion": {
"groupVersion": "apps/v1",
"version": "v1"
}
},
...
}
Żeby pobrać informacje o zasobach dostępnych w konkretnej
wersji API, trzeba wysłać osobne zapytanie pod
/apis/<group>/<version> - np. /apis/rbac.authorization.k8s.io/v1alpha1. Ten
endpoint zawiera listę typów zasobów w danej grupie. Używa go
polecenie kubectl, żeby dowiedzieć się, jakie zasoby są dostępne w klastrze.
Interfejs OpenAPI
Pełną specyfikację API udokumentowano za pomocą OpenAPI.
Kubernetes obsługuje zarówno OpenAPI 2.0, jak i 3.0. Wersja
3 jest preferowana, ponieważ umożliwia
dokładniejszy i kompletny opis zasobów (bez utraty
informacji). W OpenAPI 2 niektóre pola, np. default,
nullable, oneOf, są pomijane z powodu ograniczeń formatu.
OpenAPI V2
Serwer API Kubernetesa udostępnia specyfikację
OpenAPI poprzez ścieżkę /openapi/v2. Aby wybrać
format odpowiedzi, użyj nagłówków żądania zgodnie z tabelą:
| Nagłówek | Dopuszczalne wartości | Uwagi |
|---|---|---|
Accept-Encoding | gzip | pominięcie tego nagłówka jest dozwolone |
Accept | application/com.github.proto-openapi.spec.v2@v1.0+protobuf | głównie do celu komunikacji wewnątrz klastra |
application/json | domyślne | |
* | udostępnia application/json |
Ostrzeżenie:
Reguły walidacyjne publikowane w ramach schematów OpenAPI mogą być niekompletne – i zazwyczaj nie zawierają wszystkich warunków. Dodatkowa walidacja realizowana jest przez serwer API. Aby uzyskać pełną i precyzyjną weryfikację, zaleca się użycie poleceniakubectl apply --dry-run=server, które uruchamia wszystkie
mechanizmy walidacji, również te wykonujące się podczas przyjmowania zasobów do klastra (ang. admission checks).OpenAPI V3
Kubernetes v1.27 [stable](domyślnie włączone)Kubernetes publikuje własne API zgodnie ze specyfikacją OpenAPI v3.
Pod adresem /openapi/v3 można znaleźć listę wszystkich
dostępnych grup/wersji. Zwracane wartości są dostępne tylko w formacie
JSON. Grupy/wersje opisane są następującym schematem:
{
"paths": {
...,
"api/v1": {
"serverRelativeURL": "/openapi/v3/api/v1?hash=CC0E9BFD992D8C59AEC98A1E2336F899E8318D3CF4C68944C3DEC640AF5AB52D864AC50DAA8D145B3494F75FA3CFF939FCBDDA431DAD3CA79738B297795818CF"
},
"apis/admissionregistration.k8s.io/v1": {
"serverRelativeURL": "/openapi/v3/apis/admissionregistration.k8s.io/v1?hash=E19CC93A116982CE5422FC42B590A8AFAD92CDE9AE4D59B5CAAD568F083AD07946E6CB5817531680BCE6E215C16973CD39003B0425F3477CFD854E89A9DB6597"
},
....
}
}
Względne adresy URL wskazują na niezmieniające się opisy OpenAPI, aby umożliwić
trzymanie cache po stronie klienta. Serwer API zwraca
również odpowiednie nagłówki HTTP dla cache (Expires ustawione na 1 rok wprzód,
Cache-Control jako immutable). Wysłanie zapytania do
nieaktualnego URL spowoduje przekierowanie przez serwer API do wersji najnowszej.
Serwer API Kubernetesa udostępnia specyfikację
OpenAPI v3 pod adresem /openapi/v3/apis/<group>/<version>?hash=<hash>,
zgodnie z podziałem na grupy i wersje.
Tabela poniżej podaje dopuszczalne wartości nagłówków żądania.
| Nagłówek | Dopuszczalne wartości | Uwagi |
|---|---|---|
Accept-Encoding | gzip | pominięcie tego nagłówka jest dozwolone |
Accept | application/com.github.proto-openapi.spec.v3@v1.0+protobuf | głównie do celu komunikacji wewnątrz klastra |
application/json | domyślne | |
* | udostępnia application/json |
W pakiecie k8s.io/client-go/openapi3
znajduje się implementacja w Golang do pobierania OpenAPI V3.
Kubernetes 1.36 publikuje OpenAPI w wersji 2.0 i 3.0; nie ma planów wsparcia wersji 3.1 w najbliższej przyszłości.
Serializacja Protobuf
Kubernetes implementuje alternatywny format serializacji oparty na Protobuf, który jest głównie przeznaczony do komunikacji w obrębie klastra. Aby uzyskać więcej informacji na temat tego formatu, zobacz Kubernetes Protobuf serialization propozycję projektową oraz pliki Interface Definition Language (IDL) dla każdego schematu znajdujące się w pakietach Go, które definiują obiekty API.
Przechowywanie stanu
Kubernetes przechowuje serializowany stan swoich obiektów w etcd.
Grupy i wersje API
Aby ułatwić usuwanie poszczególnych pól lub restrukturyzację reprezentacji
zasobów, Kubernetes obsługuje równocześnie wiele wersji API, każde poprzez osobną
ścieżkę API, na przykład: /api/v1 lub /apis/rbac.authorization.k8s.io/v1alpha1.
Rozdział wersji wprowadzony jest na poziomie całego API, a nie na poziomach poszczególnych zasobów lub pól, aby być pewnym, że API odzwierciedla w sposób przejrzysty i spójny zasoby systemowe i ich zachowania oraz pozwala na kontrolowany dostęp do tych API, które są w fazie wycofywania lub fazie eksperymentalnej.
Aby ułatwić rozbudowę API Kubernetes, wprowadziliśmy grupy API, które mogą być włączane i wyłączane.
Zasoby API są rozróżniane poprzez przynależność do grupy API, typ zasobu, przestrzeń nazw (namespace, o ile ma zastosowanie) oraz nazwę. Serwer API może przeprowadzać konwersję między różnymi wersjami API w sposób niewidoczny dla użytkownika: wszystkie te różne wersje reprezentują w rzeczywistości ten sam zasób. Serwer API może udostępniać te same dane poprzez kilka różnych wersji API.
Załóżmy przykładowo, że istnieją dwie wersje v1 i v1beta1 tego
samego zasobu. Obiekt utworzony przez wersję v1beta1 może być
odczytany, zaktualizowany i skasowany zarówno przez wersję v1beta1,
jak i v1, do czasu aż wersja v1beta1 będzie przestarzała i
usunięta. Wtedy możesz dalej korzystać i modyfikować obiekt poprzez wersję v1.
Zmiany w API
Z naszego doświadczenia wynika, że każdy system, który odniósł sukces, musi się nieustająco rozwijać w miarę zmieniających się potrzeb. Dlatego Kubernetes został tak zaprojektowany, aby API mogło się zmieniać i rozrastać. Projekt Kubernetes dąży do tego, aby nie wprowadzać zmian niezgodnych z istniejącymi aplikacjami klienckimi i utrzymywać zgodność przez wystarczająco długi czas, aby inne projekty zdążyły się dostosować do zmian.
W ogólności, nowe zasoby i pola definiujące zasoby API są dodawane stosunkowo często. Usuwanie zasobów lub pól jest regulowane przez API deprecation policy.
Po osiągnięciu przez API statusu ogólnej dostępności (general availability - GA), oznaczanej
zazwyczaj jako wersja API v1, bardzo zależy nam na utrzymaniu jej zgodności w kolejnych wydaniach.
Dodatkowo, Kubernetes zachowuje kompatybilność z danymi zapisanymi za pomocą wersji beta. Gdy dana
funkcja osiąga stabilność (GA), dane te mogą być automatycznie konwertowane i dostępne w docelowej wersji API.
Jeśli korzystasz z wersji beta API, musisz przejść na kolejną wersję beta lub stabilną, gdy dana wersja zostanie wycofana. Najlepszy moment na migrację to okres wycofywania wersji beta - wtedy obiekty są dostępne równocześnie w obu wersjach API. Po zakończeniu tego okresu wersja beta przestaje być obsługiwana i konieczne jest użycie wersji docelowej.
Informacja:
Mimo, że Kubernetes stara się także zachować zgodność dla API w wersji alpha, zdarzają się przypadki, kiedy nie jest to możliwe. Jeśli korzystasz z API w wersji alfa, przed aktualizacją klastra do nowej wersji zalecamy sprawdzenie w informacjach o wydaniu, czy nie nastąpiła jakaś zmiana w tej części API. Może się okazać, że API uległo niekompatybilnym zmianom, co wymaga usunięcia wszystkich istniejących obiektów alfa przed wykonaniem aktualizacji.Zajrzyj do API versions reference po szczegółowe definicje różnych poziomów wersji API.
Rozbudowa API
API Kubernetesa można rozszerzać na dwa sposoby:
- Definicje zasobów własnych (custom resources) pozwalają deklaratywnie określać, jak serwer API powinien dostarczać wybrane przez Ciebie zasoby API.
- Można także rozszerzać API Kubernetesa implementując warstwę agregacji.
Co dalej?
- Naucz się, jak rozbudowywać API Kubernetesa poprzez dodawanie własnych CustomResourceDefinition.
- Controlling Access To The Kubernetes API opisuje sposoby, jakimi klaster zarządza dostępem do API.
- Punkty dostępowe API (endpoints), typy zasobów i przykłady zamieszczono w API Reference.
- Aby dowiedzieć się, jaki rodzaj zmian można określić jako zgodne i jak zmieniać API, zajrzyj do API changes.
3.2 - Architektura klastra
Klaster Kubernetesa składa się z warstwy sterowania oraz zestawu maszyn roboczych, zwanych węzłami, które uruchamiają konteneryzowane aplikacje. Każdy klaster potrzebuje co najmniej jednego węzła roboczego, aby obsługiwać Pody.
Węzeł roboczy hostuje Pody, które są komponentami workload aplikacji. Warstwa sterowania zarządza węzłami roboczymi oraz Podami w klastrze. W środowiskach produkcyjnych, warstwa sterowania zazwyczaj działa na wielu komputerach, a klaster zazwyczaj działa na wielu węzłach, zapewniając odporność na awarie i wysoką dostępność.
Ten dokument opisuje różne komponenty, które musisz posiadać, aby mieć kompletny i działający klaster Kubernetesa.

Rysunek 1. Komponenty klastra Kubernetesa.
About this architecture
Diagram na Rysunku 1 przedstawia przykładową referencyjną architekturę klastra Kubernetesa. Rzeczywisty rozkład komponentów może różnić się w zależności od specyficznych konfiguracji klastra i wymagań.
Na schemacie każdy węzeł uruchamia komponent kube-proxy.
Potrzebujesz komponentu sieciowego proxy na każdym węźle, aby
zapewnić, że API Service i
związane z nim zachowania są dostępne w sieci klastra. Niektóre wtyczki
sieciowe jednak dostarczają własne, zewnętrzne implementacje proxy. Kiedy
korzystasz z tego rodzaju wtyczki sieciowej, węzeł nie musi uruchamiać kube-proxy.
Komponenty warstwy sterowania
Komponenty warstwy sterowania podejmują globalne decyzje dotyczące klastra (na
przykład harmonogramowanie), a także wykrywają i reagują na zdarzenia klastra (na
przykład uruchamianie nowego poda gdy nie
zgadza się liczba replik Deploymentu.
Elementy warstwy sterowania mogą być uruchamiane na dowolnej maszynie w klastrze. Jednakże, dla uproszczenia, skrypty instalacyjne zazwyczaj uruchamiają wszystkie elementy warstwy sterowania na tej samej maszynie i nie uruchamiają kontenerów użytkownika na tej maszynie. Zobacz Tworzenie klastrów o wysokiej dostępności za pomocą kubeadm dla przykładowej konfiguracji warstwy sterowania, która działa na wielu maszynach.
kube-apiserver
Serwer API jest składnikiem warstwy sterowania Kubernetesa, który udostępnia API. Server API służy jako front-end warstwy sterowania Kubernetesa.
Podstawową implementacją serwera API Kubernetesa jest kube-apiserver. kube-apiserver został zaprojektowany w taki sposób, aby móc skalować się horyzontalnie — to oznacza, że zwiększa swoją wydajność poprzez dodawanie kolejnych instancji. Można uruchomić kilka instancji kube-apiserver i rozkładać między nimi ruch od klientów.
etcd
Magazyn typu klucz-wartość (key/value store), zapewniający spójność i wysoką dostępność, używany do przechowywania wszystkich danych o klastrze Kubernetesa.
Jeśli Twój klaster Kubernetesa używa etcd do przechowywania swoich danych, upewnij się, że masz opracowany plan tworzenia kopii zapasowych tych danych.
Szczegółowe informacje na temat etcd można znaleźć w oficjalnej dokumentacji.
kube-scheduler
Składnik warstwy sterowania, który śledzi tworzenie nowych podów i przypisuje im węzły, na których powinny zostać uruchomione.
Przy podejmowaniu decyzji o wyborze węzła brane pod uwagę są wymagania indywidualne i zbiorcze odnośnie zasobów, ograniczenia wynikające z polityk sprzętu i oprogramowania, wymagania affinity i anty-affinity, lokalizacja danych, zależności między zadaniami i wymagania czasowe.
kube-controller-manager
Składnik warstwy sterowania odpowiedzialny za uruchamianie kontrolerów.
Z poziomu podziału logicznego, każdy kontroler jest oddzielnym procesem, ale w celu zmniejszenia złożoności, wszystkie kontrolery są skompilowane do jednego programu binarnego i uruchamiane jako jeden proces.
Istnieje wiele różnych typów kontrolerów. Niektóre z nich to:
- Kontroler węzłów (ang. Node controller): Odpowiada za zauważanie i reagowanie, gdy węzły przestają działać.
- Kontroler zadania (ang. Job controller): Monitoruje obiekty zadania (Job), które reprezentują jednorazowe zadania, a następnie tworzy Pody, aby wykonały te zadania do końca.
- Kontroler EndpointSlice: Uzupełnia obiekty EndpointSlice (aby zapewnić połączenie między Services a Pods).
- Kontroler ServiceAccount: Tworzenie domyślnych obiektów ServiceAccount dla nowych przestrzeni nazw.
Powyższa lista nie jest wyczerpującą.
cloud-controller-manager
Element składowy warstwy sterowania Kubernetesa, który zarządza usługami realizowanymi po stronie chmur obliczeniowych. Cloud controller manager umożliwia połączenie Twojego klastra z API operatora usług chmurowych i rozdziela składniki operujące na platformie chmurowej od tych, które dotyczą wyłącznie samego klastra.Manager 'cloud-controller' uruchamia tylko kontrolery specyficzne dla dostawcy chmury. Jeśli uruchamiasz Kubernetesa w swojej siedzibie lub w środowisku do nauki na swoim komputerze osobistym, klaster nie posiada managera 'cloud-controller'.
Podobnie jak kube-controller-manager, cloud-controller-manager łączy kilka logicznie niezależnych pętli kontrolnych w jedną binarkę, którą uruchamiasz jako pojedynczy proces. Możesz go skalować horyzontalnie (uruchamiając więcej niż jedną kopię), aby poprawić wydajność lub pomóc w tolerowaniu awarii.
Następujące kontrolery mogą mieć zależności od dostawcy chmury:
- Kontroler węzłów (ang. Node controller): Do sprawdzania dostawcy chmury w celu ustalenia, czy węzeł został usunięty w chmurze po tym, jak przestaje odpowiadać.
- Kontroler tras (ang. Route controller): Do konfiguracji tras w podstawowej infrastrukturze chmurowej.
- Kontroler usługi (ang. Service controller): Do tworzenia, aktualizowania i usuwania load balancerów dostawcy chmury.
Komponenty węzła
Komponenty węzła działają na każdym węźle, utrzymując działające pody i zapewniając środowisko wykonawcze Kubernetesa.
kubelet
Agent, który działa na każdym węźle klastra. Odpowiada za uruchamianie kontenerów w ramach poda.
kubelet korzysta z dostarczanych (różnymi metodami) PodSpecs i gwarantuje, że kontenery opisane przez te PodSpecs są uruchomione i działają poprawnie. Kubelet nie zarządza kontenerami, które nie zostały utworzone przez Kubernetesa.
kube-proxy (opcjonalne)
kube-proxy to proxy sieciowe, które uruchomione jest na każdym węźle klastra i uczestniczy w tworzeniu serwisu.
kube-proxy utrzymuje reguły sieciowe na węźle. Dzięki tym regułom sieci na zewnątrz i wewnątrz klastra mogą komunikować się z podami.
kube-proxy używa warstwy filtrowania pakietów dostarczanych przez system operacyjny, o ile taka jest dostępna. W przeciwnym przypadku, kube-proxy samo zajmuje sie przekazywaniem ruchu sieciowego.
Jeśli używasz wtyczki sieciowej, która samodzielnie implementuje przekazywanie pakietów dla Usług i zapewnia równoważne działanie do kube-proxy, to nie musisz uruchamiać kube-proxy na węzłach w swoim klastrze.Środowisko uruchomieniowe kontenera
Podstawowy komponent umożliwiający efektywne uruchamianie kontenerów w Kubernetesie. Odpowiada za zarządzanie uruchamianiem i cyklem życia kontenerów w środowisku Kubernetes.
Kubernetes obsługuje różne container runtimes: containerd, CRI-O oraz każdą implementację zgodną z Kubernetes CRI (Container Runtime Interface).
Dodatki
Dodatki (ang. Addons) wykorzystują zasoby Kubernetesa
(DaemonSet, Deployment,
itp.) do wdrażania funkcji klastra. Ponieważ zapewniają one
funkcje na poziomie klastra, zasoby te należą do przestrzeni nazw kube-system.
Wybrane dodatki są opisane poniżej; aby uzyskać rozszerzoną listę dostępnych dodatków, zobacz Dodatki.
DNS
Podczas gdy inne dodatki nie są ściśle wymagane, wszystkie klastry Kubernetes powinny mieć DNS klastra, ponieważ wiele elementów na nim polega.
Cluster DNS to serwer DNS, będący uzupełnieniem dla innych serwerów DNS w Twoim środowisku, który obsługuje rekordy DNS dla usług Kubernetes.
Kontenery uruchamiane przez Kubernetesa automatycznie uwzględniają ten serwer DNS w swoich wyszukiwaniach DNS.
Interfejs Web UI (Dashboard)
Dashboard to uniwersalny interfejs internetowy dla klastrów Kubernetesa. Umożliwia użytkownikom zarządzanie i rozwiązywanie problemów z aplikacjami działającymi w klastrze, a także samym klastrem.
Monitorowanie zasobów kontenerów
Monitorowanie Zasobów Kontenera rejestruje ogólne metryki dotyczące kontenerów w centralnej bazie danych i udostępnia interfejs użytkownika do przeglądania tych danych.
Rejestrowanie na poziomie klastra
Mechanizm logowania na poziomie klastra jest odpowiedzialny za zapisywanie logów z kontenerów w centralnym magazynie logów z interfejsem do przeszukiwania/przeglądania.
Wtyczki sieciowe
Wtyczki sieciowe są komponentami oprogramowania, które implementują specyfikację interfejsu sieciowego kontenera (CNI). Są odpowiedzialne za przydzielanie adresów IP do podów i umożliwianie im komunikacji między sobą w klastrze.
Warianty architektury
Podczas gdy podstawowe komponenty Kubernetesa pozostają niezmienne, sposób ich wdrażania i zarządzania może się różnić. Zrozumienie tych wariacji jest kluczowe dla projektowania i utrzymania klastrów Kubernetesa, które spełniają określone potrzeby operacyjne.
Opcje wdrażania warstwy sterowania
Komponenty warstwy sterowania mogą być wdrażane na kilka sposobów:
Tradycyjna implementacja: : Komponenty warstwy sterowania działają bezpośrednio na dedykowanych maszynach lub maszynach wirtualnych (VM), często zarządzane jako usługi systemd.
Statyczne Pody: : Komponenty warstwy sterowania są wdrażane jako statyczne Pody, zarządzane przez kubelet na określonych węzłach. Jest to powszechne podejście stosowane przez narzędzia takie jak kubeadm.
Samodzielnie hostowane : Warstwa sterowania działa jako Pody wewnątrz samego klastra Kubernetes, zarządzane przez Deploymenty i StatefulSety lub inne obiekty Kubernetesa.
Zarządzane usługi Kubernetesa: Dostawcy usług chmurowych zazwyczaj ukrywają warstwę kontrolną, zarządzając jej elementami w ramach swoich usług.
Rozważania dotyczące umieszczania workloadów
Umiejscowienie workloadów, w tym komponentów warstwy sterowania, może różnić się w zależności od wielkości klastra, wymagań dotyczących wydajności i polityk operacyjnych:
- W mniejszych klastrach lub klastrach deweloperskich, komponenty warstwy sterowania i workloady użytkowników mogą działać na tych samych węzłach.
- Większe klastry produkcyjne często dedykują określone węzły dla komponentów warstwy sterowania, oddzielając je od workloadów użytkowników.
- Niektóre organizacje uruchamiają krytyczne dodatki lub narzędzia monitorujące na węzłach warstwy sterowania.
Narzędzia do zarządzania klastrem
Narzędzia takie jak kubeadm, kops i Kubespray oferują różne podejścia do wdrażania i zarządzania klastrami, z których każde ma własną metodę rozmieszczenia i zarządzania komponentami.
Dostosowywanie i rozszerzalność
Architektura Kubernetesa pozwala na szeroką konfigurację:
- Niestandardowe schedulery mogą być wdrażane do pracy wraz z domyślnym schedulerem Kubernetesa lub aby całkowicie go zastąpić.
- Serwery API mogą być rozszerzane za pomocą CustomResourceDefinitions i agregacji API.
- Dostawcy chmury mogą mocno integrować się z Kubernetesem używając
cloud-controller-manager.
Elastyczność architektury Kubernetesa umożliwia organizacjom dostosowanie ich klastrów do specyficznych potrzeb, balansując czynniki takie jak złożoność operacyjna, wydajność i narzut na zarządzanie.
Co dalej?
Dowiedz się więcej na temat:
- Węzły i ich komunikacja z warstwą sterowania.
- Kontrolery Kubernetesa.
- Mechanizm usuwania zbędnych obiektów (ang. Garbage collection).
- kube-scheduler, czyli domyślny scheduler dla Kubernetesa.
- Oficjalna dokumentacja Etcd.
- Wiele środowisk uruchomieniowych kontenerów w Kubernetesie.
- Integracja z dostawcami chmury za pomocą cloud-controller-manager.
- Polecenia kubectl.
3.3 - Kontenery
Ta strona omawia kontenery i obrazy kontenerów, a także ich zastosowanie w utrzymaniu systemów i tworzeniu rozwiązań.
Słowo kontener (ang. container) jest wieloznacznym pojęciem. Zawsze, gdy go używasz, sprawdź, czy Twoi odbiorcy stosują tę samą definicję.
Każdy uruchamiany kontener jest powtarzalny; standaryzacja wynikająca z uwzględnienia zależności oznacza, że uzyskujesz to samo zachowanie, gdziekolwiek go uruchomisz.
Kontenery oddzielają aplikacje od infrastruktury hosta. To ułatwia wdrażanie w różnych środowiskach chmurowych lub systemach operacyjnych.
Każdy węzeł w klastrze Kubernetesa uruchamia kontenery, które tworzą Pody przypisane do tego węzła. Kontenery należące do jednego Poda są uruchamiane razem na tym samym węźle w ramach wspólnego harmonogramu.
Obrazy kontenerów
Obraz kontenera to gotowy do uruchomienia pakiet oprogramowania zawierający wszystko, co jest potrzebne do uruchomienia aplikacji: kod i wszelkie wymagane środowiska uruchomieniowe, biblioteki aplikacji i systemowe, oraz wartości domyślne dla wszelkich niezbędnych ustawień.
Kontenery są przeznaczone do bycia bezstanowymi i niezmiennymi: nie powinieneś zmieniać kodu kontenera, który już działa. Jeśli masz aplikację konteneryzowaną i chcesz dokonać zmian, właściwym procesem jest zbudowanie nowego obrazu zawierającego zmiany, a następnie odtworzenie kontenera w celu uruchomienia go z zaktualizowanego obrazu.
Środowiska uruchomieniowe kontenerów
Podstawowy komponent umożliwiający efektywne uruchamianie kontenerów w Kubernetesie. Odpowiada za zarządzanie uruchamianiem i cyklem życia kontenerów w środowisku Kubernetes.
Kubernetes obsługuje różne container runtimes: containerd, CRI-O oraz każdą implementację zgodną z Kubernetes CRI (Container Runtime Interface).
Zazwyczaj możesz pozwolić swojemu klastrowi na wybranie domyślnego środowiska uruchomieniowego kontenera dla Poda. Jeśli musisz używać więcej niż jednego środowiska uruchomieniowego kontenera w swoim klastrze, możesz określić RuntimeClass dla Poda, aby upewnić się, że Kubernetes uruchamia te kontenery przy użyciu konkretnego środowiska uruchomieniowego kontenera.
Możesz również użyć RuntimeClass, aby uruchamiać różne Pody z tym samym środowiskiem uruchomieniowym kontenera, ale z różnymi ustawieniami.
3.4 - Workload
Workload to ogólne określenie aplikacji działającej na Kubernetesie. Niezależnie od tego, czy Twój workload jest pojedynczym komponentem, czy kilkoma współpracującymi ze sobą, na Kubernetesie uruchamiasz go wewnątrz zestawu podów. Pod reprezentuje zbiór składający się z jednego lub więcej uruchomionych kontenerów na Twoim klastrze.
Pody mają zdefiniowany cykl życia. Na przykład, gdy Pod działa w twoim klastrze, krytyczna awaria na węźle, na którym ten Pod działa, oznacza, że wszystkie Pody na tym węźle przestają działać. Kubernetes traktuje ten typ awarii jako ostateczny: przywrócenie działania wymaga utworzenia nowego Poda, nawet jeśli węzeł później zostanie przywrócony do pełnej sprawności.
Jednak, aby znacznie ułatwić sobie życie, nie musisz zarządzać każdym Podem bezpośrednio. Zamiast tego, możesz użyć obiektów dedykowanych do obsługi workload-ów, które zarządzają zestawem Podów w Twoim imieniu. Te zasoby konfigurują kontrolery, które zapewniają, że odpowiednia liczba Podów działa, zgodnie z tym, co zdefiniowałeś.
Kubernetes udostępnia kilka wbudowanych typów obiektów przeznaczonych do obsługi workload-ów:
- Deployment i ReplicaSet (zastępując przestarzały zasób ReplicationController). Deployment jest odpowiedni do zarządzania bezstanowym workloadem aplikacji w klastrze, gdzie każdy Pod w Deployment jest wymienny i może być zastąpiony, jeśli to konieczne.
- StatefulSet pozwala na uruchomienie jednego lub więcej powiązanych Podów, które przechowują stan i potrafią go odtwarzać. Na przykład, jeśli Twój workload zapisuje dane w sposób trwały, możesz uruchomić StatefulSet, który wiąże każdy Pod z PersistentVolume. Twój kod, działający w ramach Podów dla tego StatefulSet, może replikować dane do innych Podów w tym samym StatefulSet, aby poprawić ogólną odporność na awarie.
- DaemonSet definiuje Pody, które zapewniają funkcje lokalne dla węzłów. Za każdym razem, gdy dodajesz węzeł do swojego klastra, który pasuje do specyfikacji w DaemonSet, warstwa sterowania zleca uruchomienie Poda dla tego DaemonSet na nowym węźle. Każdy Pod w DaemonSet wykonuje zadanie podobne do demona systemowego na klasycznym serwerze Unix / POSIX. DaemonSet może być fundamentalny dla działania twojego klastra, na przykład jako wtyczka do uruchamiania infrastuktury sieciowej klastra, może pomóc w zarządzaniu węzłem, lub może zapewniać opcjonalne funkcje, które ulepszają platformę kontenerową.
- Job i CronJob oferują różne sposoby definiowania zadań, które uruchamiają się do zakończenia, a następnie zatrzymują. Możesz użyć Job, aby zdefiniować zadanie, które uruchamia się do zakończenia, tylko raz. Możesz użyć CronJob, aby uruchomić to samo zadanie (Job) wielokrotnie według harmonogramu.
W szerszym ekosystemie Kubernetesa można znaleźć definicje zadań od firm trzecich, które zapewniają dodatkowe zachowania. Korzystając z Custom Resource Definition, można dodać definicję zadania od firmy trzeciej, jeśli chcesz uzyskać określone działanie, które nie jest częścią podstawowej wersji Kubernetesa. Na przykład, jeśli chcesz uruchomić grupę Podów dla swojej aplikacji, ale zatrzymać pracę, jeśli wszystkie Pody nie są dostępne (może dla jakiegoś zadania wysokoprzepustowego rozproszonego), to można zaimplementować lub zainstalować rozszerzenie, które oferuje tę funkcję.
Rozmieszczanie workloadów
Kubernetes v1.35 [alpha](domyślnie wyłączone)Podczas gdy standardowe zasoby workloadów (takie jak Deploymenty czy Joby) zarządzają cyklem życia Podów, w niektórych przypadkach możesz mieć złożone wymagania dotyczące harmonogramowania, w których grupy Podów muszą być traktowane jako jedna całość.
Za pomocą Workload API można definiować
PodGroupTemplates, które grupują Pody i umożliwiają zastosowanie wobec nich zaawansowanych mechanizmów
harmonogramowania, takich jak gang scheduling.
W trakcie działania systemu kontrolery generują z tych szablonów obiekty
PodGroup, natomiast każdy Pod wskazuje swoją grupę PodGroup
poprzez pole spec.schedulingGroup. Jest to szczególnie przydatne dla workloadów związanych z
przetwarzaniem wsadowym i uczeniem maszynowym, gdzie wymagane jest rozmieszczenie "wszystko albo nic".
Co dalej?
Oprócz przeczytania informacji o każdym rodzaju API do zarządzania workloadami, możesz dowiedzieć się, jak wykonywać konkretne zadania:
- Uruchom aplikację bezstanową za pomocą Deployment
- Uruchom aplikację stanową jako pojedynczą instancję lub jako zestaw zreplikowany
- Uruchamianie zadań automatycznych za pomocą CronJob
Aby dowiedzieć się więcej o mechanizmach Kubernetesa służących do oddzielania kodu od konfiguracji, odwiedź Konfiguracja.
Istnieją dwie wspomagające koncepcje, które dostarczają informacji o tym, jak Kubernetes zarządza Podami dla aplikacji:
- Mechanizm usuwania zbędnych obiektów (ang. Garbage collection) porządkuje obiekty z klastra po usunięciu ich zasobu właściciela.
- Kontroler czasu życia po zakończeniu (time-to-live after finished) usuwa zadania (Jobs) po upływie określonego czasu od ich zakończenia.
Gdy Twoja aplikacja jest uruchomiona, możesz chcieć udostępnić ją w internecie jako Service lub, tylko dla aplikacji webowych, używając Ingress.
3.4.1 - Pod
Pod jest najmniejszą jednostką obliczeniową, którą można utworzyć i zarządzać nią w Kubernetesie.
Pod (w języku angielskim: jak w odniesieniu do grupy wielorybów lub strąka grochu) to grupa jednego lub więcej kontenerów, z współdzielonymi zasobami pamięci i sieci, oraz specyfikacją dotyczącą sposobu uruchamiania kontenerów. Wszystkie komponenty Poda są uruchamiane razem, współdzielą ten sam kontekst i są planowane do uruchomienia na tym samym węźle. Pod modeluje specyficznego dla aplikacji "logicznego hosta": zawiera jeden lub więcej kontenerów aplikacji, które są stosunkowo ściśle ze sobą powiązane. W kontekstach niechmurowych, aplikacje wykonane na tej samej maszynie fizycznej lub wirtualnej są analogiczne do aplikacji chmurowych wykonanych na tym samym logicznym hoście.
Oprócz kontenerów aplikacyjnych, Pod może zawierać kontenery inicjalizujące uruchamiane podczas startu Pod. Możesz również wstrzyknąć kontenery efemeryczne do debugowania działającego Poda.
Czym jest Pod?
Informacja:
Musisz zainstalować środowisko uruchomieniowe kontenerów na każdym węźle w klastrze, aby mogły tam działać Pody.Wspólny kontekst Poda to zestaw przestrzeni nazw Linux, cgroups i potencjalnie innych aspektów izolacji - te same elementy, które izolują kontener (ang. container). W obrębie kontekstu Poda, poszczególne aplikacje mogą mieć dodatkowo zastosowane dalsze sub-izolacje.
Pod jest podobny do zestawu kontenerów z współdzielonymi przestrzeniami nazw i współdzielonymi woluminami systemu plików.
Pody w klastrze Kubernetesa są używane na dwa główne sposoby:
Pody, które uruchamiają pojedynczy kontener. Model "jeden-kontener-na-Poda" jest najczęstszym przypadkiem użycia; w tym przypadku możesz myśleć o Podzie jako o obudowie wokół pojedynczego kontenera; Kubernetes zarządza Podami, zamiast zarządzać kontenerami bezpośrednio.
Pody, które uruchamiają wiele kontenerów, które muszą współdziałać. Pod może zawierać aplikację składającą się z wielu współlokalizowanych kontenerów, które są ściśle powiązane i muszą współdzielić zasoby. Te współlokalizowane kontenery tworzą jedną spójną jednostkę.
Grupowanie wielu współlokalizowanych i współzarządzanych kontenerów w jednym Podzie jest stosunkowo zaawansowanym przypadkiem użycia. Ten wzorzec powinieneś używać tylko w określonych przypadkach, gdy twoje kontenery są ściśle powiązane.
Nie musisz uruchamiać wielu kontenerów, aby zapewnić replikację (dla odporności lub pojemności); jeśli potrzebujesz wielu replik, zobacz zarządzanie workloadami.
Używanie Podów
Poniżej znajduje się przykład Poda, który składa się z kontenera uruchamiającego obraz nginx:1.14.2.
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Aby utworzyć Pod pokazany powyżej, uruchom następujące polecenie:
kubectl apply -f https://k8s.io/examples/pods/simple-pod.yaml
Pody zazwyczaj nie są tworzone bezpośrednio tylko przy użyciu specjalnych zadań (workload). Zobacz Praca z Podami aby uzyskać więcej informacji na temat tego, jak Pody są używane z zasobami workload.
Zasoby workload do zarządzania podami
Zazwyczaj nie musisz tworzyć Podów bezpośrednio, nawet pojedynczych Podów. Zamiast tego, twórz je używając zasobów workload, takich jak Deployment lub Job. Jeśli Twoje Pody muszą śledzić stan, rozważ użycie zasobu StatefulSet.
Każdy Pod ma na celu uruchomienie pojedynczej instancji danej aplikacji. Jeśli chcesz skalować swoją aplikację horyzontalnie (aby zapewnić więcej zasobów ogółem poprzez uruchomienie większej liczby instancji), powinieneś użyć wielu Podów, jednego dla każdej instancji. W Kubernetesie, operację tę zazwyczaj określa się mianem replikacji. Replikowane Pody są zazwyczaj tworzone i zarządzane jako grupa przez zasób workload i jego kontroler.
Zobacz Pody i kontrolery, aby uzyskać więcej informacji na temat tego, jak Kubernetes wykorzystuje zasoby workload oraz ich kontrolery do implementacji skalowania aplikacji i automatycznego naprawiania.
Pody natywnie zapewniają dwa rodzaje zasobów współdzielonych dla ich składowych kontenerów: sieć i przechowywanie.
Praca z Podami
Rzadko będziesz tworzyć indywidualne Pody bezpośrednio w Kubernetesie - nawet pojedyncze Pody. Dzieje się tak, ponieważ Pody są zaprojektowane jako stosunkowo efemeryczne, jednorazowe obiekty. Kiedy Pod zostaje utworzony (bezpośrednio przez Ciebie lub pośrednio przez kontroller), nowy Pod jest planowany do uruchomienia na węźle w Twoim klastrze. Pod pozostaje na tym węźle, dopóki nie zakończy wykonywania, obiekt Poda nie zostanie usunięty, Pod nie zostanie usunięty z powodu braku zasobów lub węzeł ulegnie awarii.
Informacja:
Restartowanie kontenera w Podzie nie powinno być mylone z restartowaniem Poda. Pod nie jest procesem, ale środowiskiem do uruchamiania kontenera(-ów). Pod trwa, dopóki nie zostanie usunięty.Nazwa Poda musi być prawidłową wartością poddomeny DNS, ale może to powodować nieoczekiwane skutki w odniesieniu do jego nazwy hosta. Dla najlepszej kompatybilności, nazwa powinna spełniać bardziej restrykcyjne zasady dla etykiety DNS.
System operacyjny Poda
Kubernetes v1.25 [stable]Powinieneś ustawić pole .spec.os.name na windows lub linux, aby wskazać system
operacyjny, na którym chcesz uruchomić swojego Poda. Są to jedyne obsługiwane systemy
operacyjne przez Kubernetesa w chwili obecnej. W przyszłości lista ta może zostać rozszerzona.
W Kubernetesie v1.36, wartość .spec.os.name nie wpływa na to, w jaki
sposób kube-scheduler
wybiera węzeł do uruchomienia Poda. W każdym klastrze, w którym istnieje więcej niż jeden
system operacyjny dla działających węzłów, powinieneś poprawnie ustawić etykietę
kubernetes.io/os na każdym węźle
i zdefiniować Pody z nodeSelector opartym na etykiecie systemu operacyjnego.
Kube-scheduler przypisuje Pody do węzłów na podstawie określonych kryteriów, ale nie zawsze
gwarantuje wybór węzła z właściwym systemem operacyjnym dla uruchamianych kontenerów.
Standardy bezpieczeństwa Pod również używają tego
pola, aby uniknąć wymuszania polityk, które nie mają zastosowania dla danego systemu operacyjnego.
Pody i kontrolery
Możesz użyć zasobów workload do tworzenia i zarządzania wieloma Podami. Kontroler dla zasobu obsługuje replikację, wdrażanie oraz automatyczne naprawianie w przypadku awarii Poda. Na przykład, jeśli węzeł ulegnie awarii, kontroler zauważa, że Pody na tym węźle przestały działać i tworzy zastępczego Poda. Scheduler umieszcza zastępczego Poda na zdrowym węźle.
Oto kilka przykładów zasobów workload, które zarządzają Podami:
- Deployment
- StatefulSet - komponent Kubernetesa służący do zarządzania aplikacjami stateful. StatefulSet zapewnia zachowanie kolejności i spójności danych w ramach aplikacji, co jest kluczowe dla usług wymagających takiego funkcjonowania. StatefulSet śledzi, które identyfikatory Podów są skojarzone z określonymi zasobami pamięci masowej i w jakiej kolejności powinny być tworzone oraz usuwane.
- DaemonSet
Definiowanie grupy harmonogramowania (scheduling group)
Kubernetes v1.35 [alpha](domyślnie wyłączone)Standardowo Kubernetes uruchamia (ang. schedule) każdy Pod osobno. W przypadku niektórych silnie sprzężonych aplikacji konieczne jest jednoczesne zaplanowanie całej grupy Podów, aby mogły działać poprawnie.
Możesz powiązać Pod z PodGroup za pomocą pola scheduling group
(
spec.schedulingGroup). Informuje to kube-scheduler, że dany Pod należy do określonej grupy, co
pozwala na stosowanie skoordynowanych decyzji dotyczących rozmieszczenia na poziomie całej grupy.
Szablony Poda
Kontrolery zasobów workload tworzą Pody z szablonu poda i zarządzają tymi Podami w Twoim imieniu.
PodTemplates to specyfikacje do tworzenia Podów, które są uwzględniane w zasobach workload, takich jak Deployments, Jobs i DaemonSets.
Każdy kontroler dla zasobu workload używa PodTemplate wewnątrz obiektu
workload do tworzenia rzeczywistych Podów. PodTemplate jest częścią pożądanego
stanu dowolnego zasobu workload, którego użyłeś do uruchomienia swojej aplikacji.
Gdy tworzysz Pod, możesz uwzględnić zmienne środowiskowe w szablonie Poda dla kontenerów, które działają w Podzie.
Poniższy przykład to manifest dla prostego zadania (Job) z szablonem (template), który
uruchamia jeden kontener. Kontener w tym Podzie wyświetla komunikat, a następnie się zatrzymuje.
apiVersion: batch/v1
kind: Job
metadata:
name: hello
spec:
template:
# This is the pod template
spec:
containers:
- name: hello
image: busybox:1.28
command: ['sh', '-c', 'echo "Hello, Kubernetes!" && sleep 3600']
restartPolicy: OnFailure
# The pod template ends here
Modyfikacja szablonu poda lub przejście na nowy szablon poda nie ma bezpośredniego wpływu na już istniejące Pody. Jeśli zmienisz szablon poda dla zasobu workload, ten zasób musi utworzyć nowe, zamienne Pody, które korzystają ze zaktualizowanego szablonu.
Na przykład kontroler StatefulSet zapewnia, że uruchomione Pody odpowiadają bieżącemu szablonowi Poda dla każdego obiektu StatefulSet. Jeśli edytujesz StatefulSet, aby zmienić jego szablon, StatefulSet zaczyna tworzyć nowe Pody na podstawie zaktualizowanego szablonu. Ostatecznie, wszystkie stare Pody zostają zastąpione nowymi Podami, a aktualizacja jest zakończona.
Każdy zasób workload implementuje własne zasady dotyczące obsługi zmian w szablonie Pod. Jeśli chcesz dowiedzieć się więcej o StatefulSet, zapoznaj się z strategią aktualizacji w samouczku podstawy StatefulSet.
Na poziomie węzłów kubelet nie kontroluje bezpośrednio szczegółów dotyczących szablonów Podów ani ich aktualizacji – są one zarządzane na wyższym poziomie abstrakcji. Taka separacja upraszcza działanie systemu i pozwala na rozszerzanie funkcjonalności klastra bez ingerencji w istniejący kod.
Aktualizacja i wymiana Poda
Jak wspomniano w poprzedniej sekcji, gdy szablon Poda dla zasobu workload zostaje zmieniony, kontroler tworzy nowe Pody na podstawie zaktualizowanego szablonu zamiast aktualizować lub łatać istniejące Pody.
Kubernetes nie uniemożliwia bezpośredniego zarządzania Podami.
Możliwe jest aktualizowanie niektórych pól działającego Poda, na
miejscu. Jednak operacje aktualizacji Poda, takie jak
patch, oraz
replace
mają pewne ograniczenia:
Większość metadanych o Podzie jest niezmienna. Na przykład, nie można zmienić pól
namespace,name,uidanicreationTimestamp.Jeśli parametr
metadata.deletionTimestampjest ustawiony, nie można dodać nowego wpisu do listymetadata.finalizers.Aktualizacje Podów nie mogą zmieniać pól innych niż
spec.containers[*].image,spec.initContainers[*].image,spec.activeDeadlineSeconds,spec.terminationGracePeriodSeconds,spec.tolerationslubspec.schedulingGates. Dlaspec.tolerationsmożna jedynie dodawać nowe wpisy.Podczas aktualizacji pola
spec.activeDeadlineSecondsdozwolone są dwa typy aktualizacji:- ustawienie nieprzypisanego pola na liczbę dodatnią;
- aktualizacja pola z liczby dodatniej do mniejszej, nieujemnej liczby.
Podzasoby Poda
Powyższe zasady aktualizacji dotyczą standardowych zmian w Podach, jednak niektóre pola Poda mogą być aktualizowane za pomocą podzasobów.
- Zmiana rozmiaru: Podzasób
resizeumożliwia aktualizację zasobów kontenera (spec.containers [*].resources). Szczegółowe informacje znajdują się w sekcji Zmiana rozmiaru zasobów kontenera. - Kontenery efemeryczne: Podzasób
ephemeralContainersumożliwia dodanie do Poda kontenera efemerycznego. Aby uzyskać więcej szczegółów zobacz Kontenery efemeryczne. - Status: Podzasób
statusumożliwia aktualizację statusu poda. Zazwyczaj jest to używane tylko przez Kubelet i kontrolery systemowe. - Przypisanie Poda do węzła: Podzasób
bindingumożliwia ustawieniespec.nodeNamepoda za pomocą żądania typuBinding. Zazwyczaj jest to używane tylko przez kube-scheduler.
Generacja poda
- Pole
metadata.generationjest unikatowe. Zostanie automatycznie ustawione przez system w taki sposób, że nowe pody będą miały ustawioną wartośćmetadata.generationna 1, a każda aktualizacja pól zmiennych w specyfikacji poda zwiększymetadata.generationo 1.
Kubernetes v1.35 [stable](domyślnie włączone)- Pole
observedGenerationznajduje się w sekcjistatusobiektu typu Pod. Kubelet aktualizujestatus.observedGeneration, aby odzwierciedlało ono numer generacji (metadata.generation) poda w chwili raportowania jego statusu. Dzięki temu możliwe jest powiązanie aktualnego stanu poda z wersją jego specyfikacji.
Informacja:
Polestatus.observedGeneration jest zarządzane przez kubelet i zewnętrzne kontrolery nie powinny modyfikować tego pola.Różne pola statusu mogą być powiązane z metadata.generation bieżącej pętli synchronizacji lub z
metadata.generation poprzedniej pętli synchronizacji. Kluczowa różnica polega na tym, czy zmiana w spec
jest bezpośrednio odzwierciedlona w status, czy jest pośrednim wynikiem działającego procesu.
Bezpośrednie aktualizacje statusu
Dla pól statusu, gdzie przydzielona specyfikacja jest odzwierciedlona bezpośrednio, observedGeneration
będzie powiązane z bieżącym metadata.generation (Generacja N).
To zachowanie dotyczy:
- Statusu zmiany przydzielonych zasobów: Status operacji zmiany rozmiaru zasobu.
- Przydzielonych zasobów: Zasoby przydzielone do Poda po zmianie rozmiaru.
- Kontenerów efemerycznych: Gdy nowy tymczasowy kontener zostaje dodany i znajduje się w stanie
Waiting.
Pośrednie aktualizacje statusu
Dla pól statusu, które są pośrednim wynikiem wykonania specyfikacji, pole observedGeneration
będzie powiązane z wartością z metadata.generation z poprzedniej pętli synchronizacji (Generacja N-1).
To zachowanie dotyczy:
- Obrazu Kontenera: pole
ContainerStatus.ImageIDodzwierciedla obraz z poprzedniej generacji do momentu pobrania nowego obrazu i zaktualizowania kontenera. - Rzeczywiście używanych zasobów: Podczas trwającej zmiany rozmiaru, faktycznie wykorzystywane zasoby nadal odpowiadają żądaniu z poprzedniej generacji.
- Stanu kontenera: Podczas trwającej zmiany rozmiaru z wymaganą polityką restartu, stan kontenera odzwierciedla żądanie z poprzedniej generacji.
- activeDeadlineSeconds i terminationGracePeriodSeconds oraz deletionTimestamp: Zmiany w statusie poda wynikające z tych pól odnoszą się do specyfikacji z poprzedniej generacji.
Udostępnianie zasobów i komunikacja
Pody umożliwiają udostępnianie danych i komunikację pomiędzy swoimi składowymi kontenerami.
Pamięć masowa w Podach
Pod może określić zestaw współdzielonych zasobów pamięci masowej (woluminów). Wszystkie kontenery w Podzie mają dostęp do tych woluminów, co umożliwia im współdzielenie danych. Woluminy pozwalają również na utrzymanie danych w Podzie, nawet jeśli jeden z jego kontenerów wymaga ponownego uruchomienia. Zobacz sekcję Storage, aby dowiedzieć się więcej o tym, jak Kubernetes implementuje współdzieloną pamięć masową i udostępnia ją Podom.
Sieci Poda
Każdy Pod ma przypisany unikalny adres IP dla każdej rodziny adresów. Każdy kontener
w Podzie dzieli przestrzeń nazw sieci, w tym adres IP i porty
sieciowe. Wewnątrz Poda (i tylko wtedy) kontenery, które należą do Poda
mogą komunikować się ze sobą za pomocą localhost. Kiedy kontenery w Podzie
komunikują się z jednostkami poza Podem, muszą koordynować sposób
korzystania ze wspólnych zasobów sieciowych (takich jak porty). W ramach Poda,
kontenery dzielą adres IP i przestrzeń portów, i mogą znaleźć się nawzajem za
pośrednictwem localhost. Kontenery w Podzie mogą również komunikować się
między sobą za pomocą standardowych komunikatów międzyprocesowych, takich
jak semafory SystemV lub współdzielona pamięć POSIX. Kontenery w różnych
Podach mają różne adresy IP i nie mogą komunikować się poprzez IPC na poziomie systemu
operacyjnego bez specjalnej konfiguracji. Kontenery, które chcą
nawiązać interakcję z kontenerem działającym w innym Podzie, mogą używać sieci IP do komunikacji.
Kontenery w ramach Pod mają tę samą nazwę hosta systemowego, co
skonfigurowane name dla Pod. Więcej na ten temat znajduje się w sekcji
sieci.
Ustawienia zabezpieczeń Poda
Aby ustawić ograniczenia bezpieczeństwa na Podach i kontenerach, używasz pola securityContext w specyfikacji Poda.
To pole umożliwia szczegółową kontrolę nad tym, co może robić Pod lub poszczególne kontenery. Więcej
informacji znajdziesz w sekcji Zaawansowana konfiguracja Podów.
W ramach podstawowej konfiguracji bezpieczeństwa należy zapewnić zgodność ze standardem bezpieczeństwa podów Baseline oraz uruchamiać kontenery jako użytkownik niebędący rootem. Możliwe jest skonfigurowanie podstawowych kontekstów bezpieczeństwa:
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo
spec:
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- name: sec-ctx-demo
image: busybox
command: ["sh", "-c", "sleep 1h"]
W celu skonfigurowania zaawansowanych ustawień bezpieczeństwa, takich jak capabilities, profile seccomp czy inne szczegółowe opcje, zobacz rozdział koncepcje bezpieczeństwa.
- Aby dowiedzieć się o ograniczeniach bezpieczeństwa na poziomie jądra, które można użyć, zobacz Ograniczenia bezpieczeństwa jądra Linux dla Podów i kontenerów.
- Aby dowiedzieć się więcej na temat kontekstu bezpieczeństwa Poda, zobacz Konfigurowanie kontekstu bezpieczeństwa dla Poda lub kontenera.
Żądania i limity zasobów
Podczas definiowania Poda możesz opcjonalnie określić, ile każdego zasobu potrzebuje kontener. Najczęściej określane zasoby to CPU (procesor) i pamięć (RAM).
Gdy określisz żądanie zasobu dla kontenerów w Podzie, harmonogram Kubernetesa (kube-scheduler) wykorzystuje te informacje do decyzji, na którym węźle umieścić Pod. Gdy określisz limit zasobu dla kontenera, kubelet egzekwuje te limity, aby uruchomiony kontener nie mógł używać więcej danego zasobu niż ustawiony limit.
Limity CPU są egzekwowane przez dławienie CPU. Gdy kontener zbliża się do swojego limitu CPU, jądro systemu ogranicza jego dostęp do procesora. Limity pamięci są egzekwowane przez jądro systemu za pomocą zabijania procesów (OOM kills), gdy kontener przekroczy swój limit.
Informacja:
Ustawianie limitów CPU wiąże się z kompromisem. Limity CPU pomagają zapobiegać problemom związanym z tzw. "noisy neighbor", gdzie jedno zadanie ogranicza zasoby innych zadań na tym samym węźle. Jest to szczególnie ważne w środowiskach wielodostępnych. Jednak limity CPU mogą powodować dławienie nawet wtedy, gdy na węźle jest dostępna wolna moc obliczeniowa CPU, co może pogorszyć wydajność zadań wrażliwych na opóźnienia. Decyzja o ustawieniu limitów CPU zależy od Twojego środowiska, charakterystyki obciążenia i wymagań dotyczących izolacji.Szczegółowe informacje na temat jednostek zasobów, sposobu egzekwowania oraz przykłady konfiguracji można znaleźć w Zarządzanie zasobami podów i kontenerów.
Statyczne Pody
Statyczne Pody są zarządzane bezpośrednio przez demona kubelet na określonym węźle, bez nadzoru przez serwer API. Podczas gdy większość Podów jest zarządzana przez warstwę sterowania (na przykład przez Deployment), w przypadku statycznych Podów to kubelet bezpośrednio nadzoruje każdy statyczny Pod (i restartuje go, jeśli ulegnie awarii).
Statyczne Pody są zawsze powiązane z jednym komponentem Kubelet na konkretnym węźle. Głównym zastosowaniem statycznych Podów jest uruchamianie samodzielnie hostowanej warstwy sterowania: innymi słowy, użycie kubeleta do nadzorowania poszczególnych komponentów warstwy sterowania.
Więcej informacji znajdziesz w przewodniku Tworzenie statycznych Podów.
Pody z wieloma kontenerami
Pody są zaprojektowane do obsługi wielu współpracujących procesów (jako kontenery), które tworzą spójną jednostkę usługi. Kontenery w Podzie są automatycznie współlokowane i współharmonogramowane na tej samej fizycznej lub wirtualnej maszynie w klastrze. Kontenery mogą współdzielić zasoby i zależności, komunikować się ze sobą oraz koordynować, kiedy i jak są zakończane.
Pody w klastrze Kubernetesa są używane na dwa główne sposoby:
- Pody, które uruchamiają pojedynczy kontener. Model "jeden-kontener-na-Poda" jest najczęstszym przypadkiem użycia; w tym przypadku możesz myśleć o Podzie jako o obudowie wokół pojedynczego kontenera; Kubernetes zarządza Podami, zamiast zarządzać kontenerami bezpośrednio.
- Pody, które uruchamiają wiele kontenerów, które muszą współpracować. Pod może zawierać aplikację składającą się z wielu współlokalizowanych kontenerów, które są ściśle powiązane i muszą współdzielić zasoby. Te współlokalizowane kontenery tworzą jedną spójną jednostkę usługi - na przykład, jeden kontener udostępniający dane przechowywane we współdzielonym wolumenie publicznym, podczas gdy osobny kontener sidecar odświeża lub aktualizuje te pliki. Pod łączy te kontenery, zasoby pamięci, oraz efemeryczną tożsamość sieciową razem jako jedną jednostkę.
Na przykład, możesz mieć kontener, który działa jako serwer webowy dla plików we współdzielonym wolumenie oraz oddzielny kontener pomocniczy (ang. sidecar container), który aktualizuje te pliki z zewnętrznego źródła, jak pokazano na poniższym diagramie:

Niektóre Pody mają kontenery inicjujące oraz kontenery aplikacji. Domyślnie, kontenery inicjujące uruchamiają się i kończą przed startem kontenerów aplikacji.
Możesz również mieć kontenery pomocnicze, które świadczą usługi pomocnicze dla głównej aplikacji w Podzie.
Kubernetes v1.33 [stable](domyślnie włączone)Domyślnie włączona bramka funkcji SidecarContainers
feature gate pozwala na określenie
restartPolicy: Always dla kontenerów inicjalizacyjnych. Ustawienie
polityki restartu Always zapewnia, że kontenery, dla których ją ustawisz, są
traktowane jako sidecar i są utrzymywane w działaniu przez cały czas życia
Poda. Kontenery, które określisz jako kontenery sidecar, uruchamiają się przed
główną aplikacją w Podzie i pozostają uruchomione do momentu, gdy Pod zostanie zamknięty.
Kontenerowe sondy (ang. Container probes)
Sonda (ang. probe) to diagnostyka wykonywana okresowo przez kubelet na kontenerze. Aby przeprowadzić diagnostykę, kubelet może wywoływać różne akcje:
ExecAction(wykonywane za pomocą środowiska uruchomieniowego kontenera)TCPSocketAction(sprawdzane bezpośrednio przez kubelet)HTTPGetAction(sprawdzane bezpośrednio przez kubelet)
Możesz przeczytać więcej o sondach w dokumentacji dotyczącej cyklu życia Podów.
Co dalej?
- Dowiedz się więcej o cyklu życia Poda.
- Przeczytaj o PodDisruptionBudget i dowiedz się, jak możesz go używać do zarządzania dostępnością aplikacji podczas zakłóceń.
- Pod jest zasobem najwyższego poziomu w REST API Kubernetesa. Definicja obiektu Pod opisuje szczegółowo ten obiekt.
- Toolkit systemu rozproszonego: Wzorce dla kontenerów złożonych wyjaśnia typowe układy dla Podów z więcej niż jednym kontenerem.
- Przeczytaj o ograniczeniach topologii Podów
- Przeczytaj Zaawansowaną Konfigurację Podów, aby
szczegółowo poznać ten temat. Ta strona obejmuje aspekty konfiguracji Podów wykraczające poza podstawy, w tym:
- PriorityClasses
- RuntimeClasses
- zaawansowane metody konfigurowania planowania uruchamiania Podów (ang. scheduling): czyli sposobu, w jaki Kubernetes wybiera węzeł dla Poda.
Aby zrozumieć kontekst, dlaczego Kubernetes opakowuje wspólne API Poda w inne zasoby (takie jak StatefulSets lub Deployments), możesz przeczytać o wcześniejszych rozwiązaniach, w tym:
3.4.2 - Zarządzanie Workloadem
Kubernetes udostępnia kilka wbudowanych interfejsów API do deklaratywnego zarządzania Twoim workloadem oraz jego komponentami.
Twoje aplikacje działają jako kontenery wewnątrz Podów; jednakże zarządzanie pojedynczymi Podami wiąże się z dużym wysiłkiem. Na przykład, jeśli jeden Pod ulegnie awarii, prawdopodobnie będziesz chciał uruchomić nowy Pod, aby go zastąpić. Kubernetes może to zrobić za Ciebie.
Używasz API Kubernetesa aby utworzyć obiekt zadania (workload), który reprezentuje wyższy poziom abstrakcji niż Pod, a następnie warstwa sterowania Kubernetesa automatycznie zarządza obiektami Pod w Twoim imieniu, na podstawie specyfikacji zdefiniowanego przez Ciebie obiektu tego workloadu.
Wbudowane interfejsy API do zarządzania workloadami to:
Deployment (oraz pośrednio ReplicaSet), to najczęstszy sposób uruchamiania aplikacji w klastrze. Deployment jest odpowiedni do zarządzania aplikacją bezstanową w klastrze, gdzie każdy Pod w Deployment jest wymienny i może być zastąpiony w razie potrzeby. (Deploymenty zastępują przestarzałe ReplicationController API).
StatefulSet pozwala na zarządzanie jednym lub wieloma Podami – wszystkie uruchamiają ten sam kod aplikacji – gdzie Pody opierają się na posiadaniu unikalnej tożsamości. Jest to inne niż w przypadku Deployment, gdzie oczekuje się, że Pody są wymienne. Najczęstszym zastosowaniem StatefulSet jest możliwość powiązania jego Podów z ich trwałą pamięcią masową. Na przykład, można uruchomić StatefulSet, który kojarzy każdy Pod z PersistentVolume. Jeśli jeden z Podów w StatefulSet ulegnie awarii, Kubernetes tworzy zastępczy Pod, który jest połączony z tym samym PersistentVolume.
DaemonSet definiuje Pody, które zapewniają funkcje lokalne dla określonego węzła; na przykład sterownik, który umożliwia kontenerom na tym węźle dostęp do systemu przechowywania danych. DaemonSet jest wykorzystywany w sytuacjach, gdy sterownik lub inna usługa na poziomie węzła musi działać na konkretnym węźle. Każdy Pod w DaemonSet pełni rolę podobną do demona systemowego na klasycznym serwerze Unix / POSIX. DaemonSet może być kluczowy dla działania twojego klastra, na przykład jako wtyczka, która pozwala temu węzłowi uzyskać dostęp do sieci klastrowej, może pomóc w zarządzaniu węzłem albo zapewnia mniej istotne funkcje, które wzbogacają używaną platformę kontenerową. Możesz uruchamiać DaemonSety (i ich pody) na każdym węźle w twoim klastrze, lub tylko na podzbiorze (na przykład instalując sterownik GPU tylko na węzłach, które mają zainstalowany GPU).
Możesz użyć Job i/lub
CronJob do zdefiniowania zadań, które
działają do momentu ukończenia, a następnie się zatrzymują. Job reprezentuje
jednorazowe zadanie, podczas gdy każdy CronJob powtarza się zgodnie z harmonogramem.
Inne tematy w tej sekcji:
3.5 - Usługi, równoważenie obciążenia i sieci w Kubernetesie
Model sieciowy Kubernetesa
Model sieci Kubernetesa składa się z kilku części:
Każdy pod otrzymuje swój własny unikalny adres IP w całym klastrze.
- Pod ma swoją własną, prywatną przestrzeń nazw sieci, która jest
współdzielona przez wszystkie kontenery w ramach tego
poda. Procesy działające w różnych kontenerach w tym samym
podzie mogą komunikować się ze sobą za pośrednictwem
localhost.
- Pod ma swoją własną, prywatną przestrzeń nazw sieci, która jest
współdzielona przez wszystkie kontenery w ramach tego
poda. Procesy działające w różnych kontenerach w tym samym
podzie mogą komunikować się ze sobą za pośrednictwem
Sieć podów (znana również jako sieć klastra) obsługuje komunikację między podami. Zapewnia, że (z zastrzeżeniem celowego segmentowania sieci):
Wszystkie pody mogą komunikować się ze wszystkimi innymi podami, niezależnie od tego, czy znajdują się na tym samym węźle, czy na różnych węzłach. Pody mogą komunikować się ze sobą bezpośrednio, bez użycia proxy ani translacji adresów (NAT).
W systemie Windows ta reguła nie dotyczy podów z siecią hosta.
Agenci na węźle (takie jak demony systemowe czy kubelet) mogą komunikować się ze wszystkimi podami na tym węźle.
Obiekt API Service pozwala na udostępnienie stabilnego (długoterminowego) adresu IP lub nazwy hosta dla usługi zrealizowanej przez jeden lub więcej backendowych podów, gdzie poszczególne pody składające się na usługę mogą zmieniać się w czasie.
Kubernetes automatycznie zarządza obiektami EndpointSlice aby dostarczać informacje o Podach obsługujących daną usługę.
Implementacja proxy serwisu monitoruje zestaw obiektów Service i EndpointSlice, a także konfiguruje warstwę danych w celu kierowania ruchu serwisowego do jego backendów, używając API systemu operacyjnego lub dostawcy chmury do przechwytywania lub przepisania pakietów.
Obiekt API Gateway (lub jego poprzednik, Ingress ) umożliwia udostępnienie usług klientom znajdującym się poza klastrem.
- Prostszy, ale mniej konfigurowalny mechanizm dostępu do klastra (Ingress) jest
dostępny za pośrednictwem API usług (Service) z wykorzystaniem opcji
type: LoadBalancer, pod warunkiem korzystania z obsługiwanego dostawcy chmury (Cloud Provider).
- Prostszy, ale mniej konfigurowalny mechanizm dostępu do klastra (Ingress) jest
dostępny za pośrednictwem API usług (Service) z wykorzystaniem opcji
NetworkPolicy to wbudowane API Kubernetesa, które pozwala na kontrolowanie ruchu pomiędzy podami, lub pomiędzy podami a światem zewnętrznym.
W starszych systemach kontenerowych nie było automatycznej łączności pomiędzy kontenerami na różnych hostach, więc często konieczne było jawne tworzenie połączeń między kontenerami lub mapowanie portów kontenerów na porty hostów, aby były osiągalne przez kontenery na innych hostach. W Kubernetesie nie jest to potrzebne; model Kubernetesa polega na tym, że pody mogą być traktowane podobnie jak maszyny wirtualne lub fizyczne hosty z perspektyw alokacji portów, nazewnictwa, wykrywania usług, równoważenia obciążenia, konfiguracji aplikacji i migracji.
Tylko kilka części tego modelu jest implementowanych przez Kubernetesa samodzielnie. Dla pozostałych części Kubernetes definiuje API, ale odpowiadającą funkcjonalność zapewniają zewnętrzne komponenty, z których niektóre są opcjonalne:
Konfiguracja przestrzeni nazw sieci poda jest obsługiwana przez oprogramowanie systemowe implementujące Interfejs Uruchomieniowy Kontenera (ang. Container Runtime Interface).
Sama sieć podów jest zarządzana przez implementację sieci podów. W systemie Linux, większość środowisk uruchomieniowych kontenerów używa Container Networking Interface (CNI) do interakcji z implementacją sieci podów, dlatego te implementacje często nazywane są wtyczkami CNI.
Kubernetes dostarcza domyślną implementację proxy usług, nazywaną kube-proxy, ale niektóre implementacje sieciowe poda używają zamiast tego własnego proxy usług, które jest ściślej zintegrowane z resztą implementacji.
NetworkPolicy jest zazwyczaj również implementowane przez implementację sieci poda. (Niektóre prostsze implementacje sieci poda nie implementują NetworkPolicy, lub administrator może zdecydować się na skonfigurowanie sieci poda bez wsparcia dla NetworkPolicy. W takich przypadkach API będzie nadal obecne, ale nie będzie miało żadnego efektu.)
Istnieje wiele implementacji Gateway API, z których niektóre są specyficzne dla określonych środowisk chmurowych, inne bardziej skupione na środowiskach "bare metal", a jeszcze inne bardziej ogólne.
Co dalej?
Samouczek Łączenie aplikacji z usługami pozwala na naukę o Usługach i sieciach Kubernetesa poprzez praktyczne przykłady.
Dokumentacja Sieci Klastra wyjaśnia, jak skonfigurować sieć dla twojego klastra, a także dostarcza przegląd użytych technologii.
Więcej o konkretnych zagadnieniach sieciowych:
- Service - udostępnia aplikację za pomocą jednego punktu końcowego (endpoint), widocznego na zewnątrz
- Ingress - routing HTTP/HTTPS oparty na protokole, wykorzystujący URI, nazwy hostów i ścieżki
- Gateway API - dynamiczne udostępnianie infrastruktury i zaawansowane kierowanie ruchem
- Polityki sieciowe (ang. Network Policies) - kontrola przepływu ruchu na poziomie adresu IP lub portu (warstwa 3 lub 4 modelu OSI)
- DNS dla usług i podów - odkrywanie usług wewnątrz klastra za pomocą DNS
3.6 - Przechowywanie danych
3.7 - Konfiguracja
3.8 - Bezpieczeństwo
Ta sekcja dokumentacji Kubernetesa ma na celu pomoc w nauce bezpiecznego uruchamiania workloadów oraz zapoznanie z podstawowymi aspektami utrzymania bezpieczeństwa klastra Kubernetes.
Kubernetes opiera się na architekturze cloud-native i korzysta z porad CNCF dotyczących dobrych praktyk w zakresie bezpieczeństwa informacji cloud-native.
Przeczytaj Cloud Native Security and Kubernetes, aby zrozumieć szerszy kontekst zabezpieczania klastrów i uruchamianych na nich aplikacji.
Mechanizmy bezpieczeństwa Kubernetesa
Kubernetes zawiera kilka interfejsów API i mechanizmów bezpieczeństwa, a także sposoby na definiowanie polityk (ang. policies), które mogą stanowić część tego, jak zarządzasz bezpieczeństwem informacji.
Ochrona warstwy sterowania
Kluczowym mechanizmem bezpieczeństwa dla każdego klastra Kubernetes jest kontrolowanie dostępu do API Kubernetesa.
Kubernetes oczekuje, że skonfigurujesz i użyjesz TLS do zapewnienia szyfrowania przesyłanych danych w obrębie warstwy sterowania oraz pomiędzy warstwą sterowania a jej klientami. Możesz także włączyć szyfrowanie danych spoczynkowych dla danych przechowywanych w obrębie warstwy sterowania Kubernetesa; Nie należy mylić tego z szyfrowaniem danych w stanie spoczynku dla własnych workloadów, co również może być dobrą praktyką.
Sekrety (ang. Secret)
Obiekt API Secret zapewnia podstawową ochronę dla wartości konfiguracyjnych, które wymagają poufności.
Ochrona workloadów
Egzekwowanie standardów bezpieczeństwa poda zapewnia, że Pody i ich kontenery są odpowiednio izolowane. Możesz również użyć RuntimeClasses do zdefiniowania niestandardowej izolacji, jeśli tego potrzebujesz.
Polityki sieciowe pozwalają kontrolować ruch sieciowy pomiędzy Podami lub pomiędzy Podami a siecią poza klastrem.
Możesz wdrażać mechanizmy zabezpieczeń z szerszego ekosystemu, aby wprowadzać środki zapobiegawcze lub detekcyjne wokół Podów, ich kontenerów oraz obrazów, które w nich działają.
Kontrola przychodzących żądań
Kontrolery przychodzących żądań (Admission controllers ) to wtyczki, które przechwytują żądania do API Kubernetesa i mogą weryfikować lub modyfikować te żądania w oparciu o konkretne pola w żądaniu. Przemyślane projektowanie tych kontrolerów pomaga unikać niezamierzonych zakłóceń, szczególnie gdy API Kubernetesa zmienia się wraz z aktualizacjami. Aby dowiedzieć się więcej, zobacz Dobre Praktyki dla Admission Webhooks.
Audytowanie
Dziennik audytu Kubernetesa audit logging dostarcza istotnego z punktu widzenia bezpieczeństwa, chronologicznego zbioru zapisów dokumentujących sekwencję działań w klastrze. Klastr audytuje aktywności generowane przez użytkowników, przez aplikacje korzystające z API Kubernetesa oraz przez samą warstwę sterowania.
Zabezpieczenia dostawcy chmury
Jeśli uruchamiasz klaster Kubernetes na własnym sprzęcie lub sprzęcie dostawcy chmury, zapoznaj się z dokumentacją dotyczącą najlepszych praktyk w zakresie bezpieczeństwa. Oto linki do dokumentacji bezpieczeństwa niektórych popularnych dostawców chmury:
| Dostawca IaaS | Link |
|---|---|
| Alibaba Cloud | https://www.alibabacloud.com/trust-center |
| Amazon Web Services | https://aws.amazon.com/security |
| Google Cloud Platform | https://cloud.google.com/security |
| Huawei Cloud | https://www.huaweicloud.com/intl/en-us/securecenter/overallsafety |
| IBM Cloud | https://www.ibm.com/cloud/security |
| Microsoft Azure | https://docs.microsoft.com/en-us/azure/security/azure-security |
| Oracle Cloud Infrastructure | https://www.oracle.com/security |
| Tencent Cloud | https://www.tencentcloud.com/solutions/data-security-and-information-protection |
| VMware vSphere | https://www.vmware.com/solutions/security/hardening-guides |
Polityki
Możesz definiować zasady bezpieczeństwa, używając mechanizmów natywnych dla Kubernetesa, takich jak NetworkPolicy (deklaratywna kontrola nad filtrowaniem pakietów sieciowych) lub ValidatingAdmissionPolicy (deklaratywne ograniczenia dotyczące tego, jakie zmiany ktoś może wprowadzać za pomocą API Kubernetesa).
Możesz również polegać na implementacjach polityk z szerszego ekosystemu wokół Kubernetesa. Kubernetes zapewnia mechanizmy rozszerzeń, aby umożliwić projektom ekosystemowym wdrażanie własnych kontroli polityk dotyczących przeglądu kodu źródłowego, zatwierdzania obrazów kontenerów, kontroli dostępu do API, sieci i innych.
Aby uzyskać więcej informacji na temat mechanizmów polityki i Kubernetesa, przeczytaj Polityki.
Co dalej?
Dowiedz się więcej na temat powiązanych zagadnień bezpieczeństwa Kubernetesa:
- Zabezpieczanie klastra
- Znane podatności w Kubernetesie (i linki do dalszych informacji)
- Szyfrowanie danych podczas przesyłania dla warstwy sterowania
- Szyfrowanie danych w spoczynku
- Kontrola dostępu do API Kubernetesa
- Zasady sieciowe dla Podów
- Sekrety w Kubernetesie
- Standardy bezpieczeństwa podów
- Klasy środowisk uruchomieniowych
Poznaj kontekst:
Zdobądź certyfikat:
- Certyfikacja Certified Kubernetes Security Specialist oraz oficjalny kurs szkoleniowy.
Przeczytaj więcej w tej sekcji:
3.9 - Polityki
Polityki Kubernetesa to ustawienia kontrolujące inne konfiguracje lub sposób działania aplikacji w trakcie ich działania. Kubernetes oferuje różne formy polityk, opisane poniżej:
Stosowanie polityk za pomocą obiektów API
Niektóre obiekty API spełniają rolę polityk. Oto kilka przykładów:
- NetworkPolicies mogą być używane do ograniczania ruchu przychodzącego i wychodzącego dla workload.
- LimitRanges zarządzają ograniczeniami alokacji zasobów w różnych typach obiektów.
- ResourceQuotas ogranicza zużycie zasobów dla namespace.
Stosowanie polityk za pomocą kontrolerów dopuszczania (ang. Admission Controllers)
Kontroler dopuszczania (ang. Admission Controller - admission controller
) działa na serwerze API i może weryfikować lub modyfikować żądania API. Niektóre takie
kontrolery działają w celu zastosowania polityk. Na przykład kontroler
AlwaysPullImages modyfikuje nowy Pod, aby ustawić politykę pobierania obrazów na Always.
Kubernetes ma kilka wbudowanych kontrolerów dostępu, które można konfigurować za pomocą flagi --enable-admission-plugins serwera API.
Szczegóły dotyczące kontrolerów dopuszczania są udokumentowane w dedykowanej sekcji:
Stosowanie polityk używając ValidatingAdmissionPolicy
Polityki walidacji przyjmowania (ang. Validating admission policies) umożliwiają wykonywanie konfigurowalnych kontroli walidacji na serwerze API przy użyciu wspólnego języka wyrażeń (CEL). Na przykład, ValidatingAdmissionPolicy może być używana do zakazania użycia tagu obrazu latest.
Polityka ValidatingAdmissionPolicy działa na żądaniach API i może być używana do blokowania, audytowania oraz ostrzegania użytkowników o niezgodnych konfiguracjach.
Szczegóły dotyczące API ValidatingAdmissionPolicy, wraz z przykładami, są udokumentowane w dedykowanej sekcji:
Stosowanie polityk przy użyciu dynamicznej kontroli dostępu
Dynamiczne kontrolery dostępu (lub webhooki dostępu) działają poza serwerem API jako oddzielne aplikacje, które rejestrują się do odbierania żądań webhooków w celu przeprowadzania weryfikacji lub modyfikacji żądań API.
Dynamiczne kontrolery dopuszczeń mogą być używane do stosowania polityk na żądaniach API i uruchamiania innych procesów opartych na politykach. Dynamiczny kontroler dopuszczeń może przeprowadzać skomplikowane kontrole, w tym te, które wymagają pobierania innych zasobów klastra i danych zewnętrznych. Na przykład, kontrola weryfikacji obrazu może wyszukiwać dane z rejestrów OCI, aby zatwierdzić podpisy i atestacje obrazów kontenerów.
Szczegóły dotyczące dynamicznej kontroli dostępu są udokumentowane w dedykowanej sekcji:
Implementacje
Dynamiczne kontrolery dopuszczeń (Admission Controllers), które działają jako elastyczne silniki polityki, są rozwijane w ekosystemie Kubernetesa:
Stosowanie zasad za pomocą konfiguracji Kubelet
Kubernetes pozwala na konfigurowanie Kubelet na każdym węźle roboczym. Niektóre konfiguracje Kubelet działają jako polityki:
- Limity i rezerwacje identyfikatorów procesów są używane do ograniczania i rezerwacji dostępnych PID-ów.
- Menedżery zasobów węzła mogą zarządzać zasobami obliczeniowymi, pamięci oraz urządzeniami dla workloadów krytycznych pod względem opóźnień i o wysokiej przepustowości.
3.10 - Harmonogramowanie, pierszeństwo i eksmisja
W Kubernetesie, planowanie odnosi się do zapewnienia, że Pody są dopasowane do Węzłów, aby kubelet mógł je uruchomić. Pierszeństwo (ang. preemption) to proces zakończania Podów z niższym Priorytetem po to, aby Pody z wyższym Priorytetem mogły być zaplanowane na Węzłach. Eksmisja (ang. eviction) to proces zakończania jednego lub więcej Podów na Węzłach.
Harmonogramowanie
- Scheduler Kubernetesa
- Przypisywanie Podów do Węzłów
- Narzut na utrzymanie poda (ang. Pod overhead)
- Reguły rozmieszczenia Podów w klastrze
- Reguły wykluczania i dopuszczania podów
- Scheduling Framework
- Dynamiczne przydzielanie zasobów
- Tuning wydajności schedulera
- Pakowanie zasobów (Bin Packing) dla niestandardowych zasobów klastra
- Gotowość do planowania Podów
- Planowanie Podów w ramach PodGroup
- Planowanie grupowe (ang. Gang Scheduling)
- Planowanie uwzględniające topologię
- Wywłaszczenie uwzględniające obciążenie (ang. Workload)
- Descheduler
- Deklarowane funkcje węzłów
Zakłócenia w działaniu Podów
Zakłócenie działania Poda to proces, w ramach którego Pody na węzłach są zakończone dobrowolnie lub mimowolnie.
Dobrowolne zakłócenia są inicjowane celowo przez właścicieli aplikacji lub administratorów klastra. Mimowolne zakłócenia są niezamierzone i mogą być spowodowane nieuniknionymi problemami, takimi jak wyczerpanie zasobów na węzłach, lub przypadkowymi usunięciami.
3.11 - Administracja klastrem
Rozdział dotyczący administracji klastrem jest przeznaczony dla każdego, kto tworzy lub zarządza klastrem Kubernetesa. Zakłada się pewną znajomość podstawowych pojęć Kubernetesa.
Planowanie klastra
Zobacz przewodniki w Od czego zacząć zawierające przykłady planowania, konfiguracji i uruchamiania klastrów Kubernetes. Rozwiązania wymienione w tym artykule nazywane są dystrybucjami.
Informacja:
Nie wszystkie dystrybucje są aktywnie utrzymywane. Wybierz dystrybucje, które zostały przetestowane z aktualną wersją Kubernetesa.Rozważ:
- Czy chcesz wypróbować Kubernetesa na swoim komputerze, czy może chcesz zbudować klaster o wysokiej dostępności, złożony z wielu węzłów? Wybierz dystrybucję najlepiej dostosowaną do Twoich potrzeb.
- Czy będziesz korzystać z hostowanego klastra Kubernetesa, takiego jak Google Kubernetes Engine, czy też hostować własny klaster?
- Czy Twój klaster będzie w lokalnym centrum obliczeniowym (on-premises), czy w chmurze (IaaS)? Kubernetes nie obsługuje bezpośrednio klastrów hybrydowych. Zamiast tego, możesz skonfigurować wiele klastrów.
- Jeśli konfigurujesz Kubernetesa lokalnie, zastanów się, który model sieciowy pasuje najlepiej.
- Czy będziesz uruchamiać Kubernetesa na sprzęcie typu "bare metal" czy na maszynach wirtualnych (VM)?
- Czy chcesz uruchomić klaster, czy raczej zamierzasz prowadzić aktywny rozwój kodu projektu Kubernetes? Jeśli to drugie, wybierz dystrybucję aktywnie rozwijaną. Niektóre dystrybucje używają tylko wydań binarnych, ale oferują większą różnorodność wyboru.
- Zapoznaj się z komponentami potrzebnymi do uruchomienia klastra.
Zarządzanie klastrem
Dowiedz się, jak zarządzać węzłami.
- Przeczytaj o automatycznym skalowaniu węzłów.
Dowiedz się, jak skonfigurować i zarządzać przydziałem zasobów dla współdzielonych klastrów.
Zabezpieczanie klastra
Generowanie Certyfikatów opisuje kroki generowania certyfikatów z użyciem różnych zestawów narzędzi.
Środowisko Kontenerów Kubernetesa opisuje środowisko dla zarządzanych przez Kubelet kontenerów na węźle Kubernetesa.
Kontrola dostępu do API Kubernetesa opisuje, jak Kubernetes implementuje kontrolę dostępu do swojego API.
Uwierzytelnianie wyjaśnia uwierzytelnianie w Kubernetesie, w tym różne opcje uwierzytelniania.
Autoryzacja jest oddzielona od uwierzytelniania i kontroluje, w jaki sposób obsługiwane są wywołania HTTP.
Korzystanie z kontrolerów dopuszczania (Admission Controllers) opisuje wtyczki, które przechwytują żądania do serwera API Kubernetesa po uwierzytelnieniu i autoryzacji.
Dokument Dobre Praktyki dla Admission Webhooks opisuje zalecane podejście i ważne aspekty, które należy uwzględnić przy tworzeniu webhooków modyfikujących oraz wehbooków walidujących w Kubernetesie.
Używanie Sysctls w klastrach Kubernetesa opisuje administratorowi, jak używać narzędzia wiersza polecenia
sysctldo ustawiania parametrów jądra.Audyt opisuje, jak współpracować z logami audytowymi Kubernetesa.
Zabezpieczanie kubeleta
Opcjonalne usługi klastra
Integracja DNS opisuje, jak rozwiązać nazwę DNS bezpośrednio do usługi Kubernetesa.
Logowanie i monitorowanie aktywności klastra wyjaśnia, jak działa logowanie w Kubernetesie i jak je zaimplementować.
3.12 - Windows w Kubernetesie
Kubernetes obsługuje węzły robocze działające zarówno na systemie Linux, jak i Microsoft Windows.
CNCF i jej macierzysta organizacja Linux Foundation przyjmują neutralne podejście do kompatybilności w kontekście dostawców. Możliwe jest dołączenie swojego serwera Windows jako węzeł roboczy do klastra Kubernetes.
Możesz zainstalować i skonfigurować kubectl na Windows niezależnie od tego, jakiego systemu operacyjnego używasz w ramach swojego klastra.
Jeśli używasz węzłów Windows, możesz przeczytać:
- Sieci w Windows
- Windows storage w Kubernetesie
- Zarządzanie zasobami dla węzłów Windows
- Konfiguracja RunAsUserName dla Podów Windows i kontenerów
- Utwórz Windows HostProcess Pod
- Konfigurowanie grupowych zarządzanych kont Usług dla Podów i kontenerów Windows
- Bezpieczeństwo dla węzłów Windows
- Wskazówki dotyczące debugowania w systemie Windows
- Przewodnik dotyczący harmonogramowania kontenerów Windows w Kubernetesie
lub, aby uzyskać przegląd, przeczytaj:
3.13 - Rozszerzanie Kubernetesa
Kubernetes jest wysoce konfigurowalny i rozbudowywalny. W rezultacie rzadko istnieje potrzeba robienia forka lub przesyłania poprawek do kodu projektu.
Ten przewodnik opisuje opcje dostosowywania klastra Kubernetesa. Jest skierowany do operatorów klastrów, którzy chcą zrozumieć, jak dostosować swój klaster Kubernetesa do potrzeb środowiska pracy. Programiści, którzy są potencjalnymi Deweloperami Platformy lub Współtwórcami projektu Kubernetes również uznają go za przydatny jako wprowadzenie do istniejących punktów rozszerzeń i wzorców oraz ich kompromisów i ograniczeń.
Podejścia do dostosowywania można ogólnie podzielić na konfigurację, która obejmuje tylko zmiany argumentów wiersza poleceń, lokalnych plików konfiguracyjnych lub zasobów API; oraz rozszerzenia, które obejmują uruchamianie dodatkowych programów, dodatkowych usług sieciowych lub obu. Ten dokument dotyczy przede wszystkim rozszerzeń.
Konfiguracja
Pliki konfiguracyjne i argumenty poleceń są udokumentowane w sekcji Materiały źródłowe (ang. Reference) dokumentacji online, z osobną stroną dla każdego pliku binarnego:
Argumenty poleceń i pliki konfiguracyjne mogą nie zawsze być możliwe do zmiany w hostowanej usłudze Kubernetesa lub w dystrybucji z zarządzaną instalacją. Kiedy są możliwe do zmiany, zazwyczaj mogą być zmieniane tylko przez operatora klastra. Dodatkowo, mogą ulegać zmianom w przyszłych wersjach Kubernetesa, a ich ustawienie może wymagać ponownego uruchomienia procesów. Z tych powodów należy je używać tylko wtedy, gdy nie ma innych opcji.
Wbudowane interfejsy API polityk, takie jak ResourceQuota, NetworkPolicy i Role-based Access Control ( RBAC), to natywne API Kubernetesa umożliwiające deklaratywną konfigurację polityk. Interfejsy API są zazwyczaj użyteczne nawet w przypadku hostowanych usług Kubernetesa i zarządzanych instalacji Kubernetesa. Wbudowane interfejsy API polityk przestrzegają tych samych konwencji co inne zasoby Kubernetesa, takie jak Pody. Gdy korzystasz z API polityk, które są stabilne, masz zapewnione określone wsparcie, zgodnie z ogólną polityką wsparcia API Kubernetesa. Z tych powodów interfejsy API polityk są zalecane zamiast plików konfiguracyjnych i argumentów poleceń, tam gdzie to możliwe.
Rozszerzenia
Rozszerzenia to komponenty oprogramowania, które rozszerzają i głęboko integrują się z Kubernetesem. Dostosowują go do obsługi nowych typów i nowych rodzajów sprzętu.
Wielu administratorów klastra korzysta z hostowanej lub dystrybucyjnej instancji Kubernetesa. Te klastry mają zainstalowane rozszerzenia. W rezultacie, większość użytkowników Kubernetesa nie będzie musiała instalować rozszerzeń, a jeszcze mniej użytkowników będzie musiało tworzyć nowe.
Wzorce rozszerzeń
Kubernetes jest zaprojektowany tak, aby można go było zautomatyzować poprzez pisanie programów klienckich. Każdy program, który odczytuje i/lub zapisuje do API Kubernetesa, może zapewnić użyteczną automatyzację. Automatyzacja może działać zarówno na klastrze, jak i poza nim. Postępując zgodnie z wytycznymi zawartymi w tym dokumencie, możesz napisać wysoce dostępną i solidną automatyzację. Automatyzacja generalnie działa z dowolnym klastrem Kubernetesa, w tym klastrami hostowanymi i zarządzanymi instalacjami.
Istnieje specyficzny wzorzec pisania programów klienckich, które dobrze
współpracują z Kubernetesem, zwany wzorcem
kontrolera. Kontrolery zazwyczaj odczytują .spec obiektu,
ewentualnie wykonują pewne czynności, a następnie aktualizują .status obiektu.
Kontroler jest klientem API Kubernetesa. Gdy Kubernetes działa jako klient i wywołuje zdalną usługę, nazywa to webhookiem. Zdalna usługa nazywana jest backendem webhooka. Podobnie jak w przypadku niestandardowych kontrolerów, webhooki stanowią dodatkowy potencjalny punkt awarii.
Informacja:
Poza Kubernetesen, termin "webhook" zazwyczaj odnosi się do mechanizmu asynchronicznych powiadomień, gdzie wywołanie webhooka służy jako jednostronne powiadomienie do innego systemu lub komponentu. W ekosystemie Kubernetesa, nawet synchroniczne wywołania HTTP są często opisywane jako "webhooki".W modelu webhook Kubernetes wykonuje żądanie sieciowe do zdalnej usługi. W alternatywnym modelu binarnej wtyczki, Kubernetes wykonuje program binarny. Wtyczki binarne są używane przez kubelet (na przykład, wtyczki magazynu CSI i wtyczki sieciowe CNI), oraz przez kubectl (zobacz Rozszerz kubectl za pomocą wtyczek).
Punkty rozszerzeń
Ten diagram pokazuje punkty rozszerzeń w klastrze Kubernetesa oraz klientów, którzy uzyskują do niego dostęp.
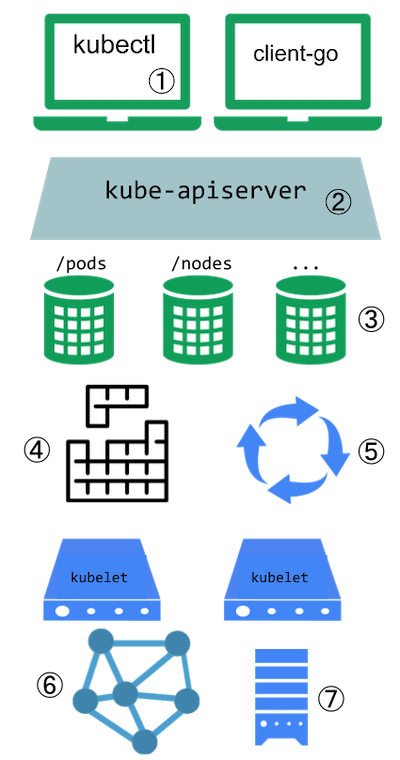
Punkty rozszerzeń Kubernetesa
Klucz do rysunku
Użytkownicy często wchodzą w interakcję z API Kubernetesa za pomocą
kubectl. Wtyczki dostosowują zachowanie klientów. Istnieją ogólne rozszerzenia, które mogą być stosowane do różnych klientów, a także specyficzne sposoby rozszerzaniakubectl.Serwer API obsługuje wszystkie żądania. Kilka typów punktów rozszerzeń w serwerze API umożliwia uwierzytelnianie żądań, blokowanie ich na podstawie ich treści, edytowanie treści oraz obsługę usuwania. Są one opisane w sekcji Rozszerzenia dostępu do API.
Serwer API obsługuje różne rodzaje zasobów. Wbudowane rodzaje zasobów, takie jak
pods, są definiowane przez projekt Kubernetesa i nie mogą być modyfikowane. Przeczytaj Rozszerzenia API, aby dowiedzieć się więcej o rozszerzaniu API Kubernetesa.Scheduler Kubernetesa decyduje, na których węzłach umieścić pody. Istnieje kilka sposobów na rozszerzenie harmonogramowania, które są opisane w sekcji Rozszerzenia harmonogramowania.
Duża część zachowań Kubernetesa jest realizowana przez programy zwane kontrolerami, które są klientami serwera API. Kontrolery są często używane w połączeniu z niestandardowymi zasobami. Przeczytaj łączenie nowych API z automatyzacją oraz Zmiana wbudowanych zasobów, aby dowiedzieć się więcej.
Kubelet działa na serwerach (węzłach) i pomaga podom wyglądać jak wirtualne serwery z własnymi adresami IP w sieci klastra. Wtyczki sieciowe umożliwiają różne implementacje sieciowania podów.
Możesz użyć Pluginów Urządzeń, aby zintegrować niestandardowy sprzęt lub inne specjalne lokalne dla węzła funkcje i udostępnić je Podom działającym w Twoim klastrze. Kubelet zawiera wsparcie dla pracy z pluginami urządzeń.
Kubelet również montuje i odmontowuje volume dla podów i ich kontenerów. Możesz użyć wtyczek magazynowania, aby dodać obsługę nowych rodzajów magazynu (ang. storage) i innych typów wolumenów.
Schemat przepływu wyboru punktu rozszerzenia
Jeśli nie jesteś pewien, od czego zacząć, ten schemat blokowy może pomóc. Zwróć uwagę, że niektóre rozwiązania mogą obejmować kilka typów rozszerzeń.

Przewodnik do wyboru metody rozszerzenia
Rozszerzenia klienta
Wtyczki do kubectl to oddzielne pliki binarne, które dodają lub zastępują działanie określonych poleceń. Narzędzie kubectl
może również integrować się z wtyczkami uwierzytelniania.
Te rozszerzenia wpływają tylko na lokalne środowisko danego użytkownika, dlatego nie mogą wymuszać polityk dla całego serwisu.
Jeśli chcesz rozszerzyć narzędzie kubectl, przeczytaj Rozszerzanie kubectl za pomocą wtyczek.
Rozszerzenia API
Definicje zasobów niestandardowych (ang. custom resource)
Rozważ dodanie Custom Resource do Kubernetesa, jeśli chcesz zdefiniować
nowe kontrolery, obiekty konfiguracji aplikacji lub inne deklaratywne
interfejsy API i zarządzać nimi za pomocą narzędzi Kubernetesa, takich jak kubectl.
Aby dowiedzieć się więcej o zasobach niestandardowych, zapoznaj się z przewodnikiem po zasobach niestandardowych.
Warstwa agregacji API
Możesz użyć warstwy agregacji API Kubernetesa, aby zintegrować API Kubernetesa z dodatkowymi usługami, takimi jak metryki.
Łączenie nowych interfejsów API z automatyzacją
Kombinacja niestandardowego API zasobu i pętli sterowania nazywana jest wzorcem controllers. Jeśli Twój kontroler zastępuje ludzkiego operatora wdrażającego infrastrukturę na podstawie pożądanego stanu, kontroler może również podążać za wzorcem operatora. Wzorzec operatora jest używany do zarządzania specyficznymi aplikacjami; zazwyczaj są to aplikacje, które utrzymują stan i wymagają uwagi w sposobie zarządzania nimi.
Możesz także tworzyć własne niestandardowe interfejsy API i pętle sterujące, które zarządzają innymi zasobami, takimi jak storage, lub definiować polityki (takie jak ograniczenia kontroli dostępu).
Zmiana wbudowanych zasobów
Kiedy rozszerzasz API Kubernetesa poprzez dodanie zasobów niestandardowych, dodane zasoby zawsze trafiają do nowych grup API. Nie możesz zastąpić ani zmienić istniejących grup API. Dodanie API nie pozwala bezpośrednio wpłynąć na zachowanie istniejących API (takich jak Pody), podczas gdy Rozszerzenia Dostępu do API mogą to zrobić.
Rozszerzenia dostępu do API
Gdy żądanie trafia do serwera API Kubernetesa, najpierw jest uwierzytelniane, następnie autoryzowane, i podlega różnym typom kontroli dostępu (niektóre żądania nie są uwierzytelniane i podlegają specjalnemu przetwarzaniu). Zobacz Kontrolowanie dostępu do API Kubernetesa aby dowiedzieć się więcej o tym procesie.
Każdy z kroków w przepływie uwierzytelniania / autoryzacji Kubernetesa oferuje punkty rozszerzeń.
Uwierzytelnianie
Uwierzytelnianie mapuje nagłówki lub certyfikaty we wszystkich żądaniach do nazwy użytkownika dla klienta składającego żądanie.
Kubernetes ma kilka wbudowanych metod uwierzytelniania, które obsługuje. Może również
działać za proxy uwierzytelniającym, a także może wysyłać token z nagłówka Authorization: do
zdalnej usługi w celu weryfikacji (przez authentication webhook
), jeśli te metody nie spełniają Twoich potrzeb.
Autoryzacja
Authorization określa, czy konkretni użytkownicy mogą odczytywać, zapisywać i wykonywać inne operacje na zasobach API. Działa na poziomie całych zasobów -- nie rozróżnia na podstawie dowolnych pól obiektu.
Jeśli wbudowane opcje autoryzacji nie spełniają Twoich potrzeb, webhook autoryzacji umożliwia wywołanie niestandardowego kodu, który podejmuje decyzję autoryzacyjną.
Dynamiczne sterowanie dostępem
Po autoryzacji żądania, jeśli jest to operacja zapisu, przechodzi również przez kroki Kontroli Przyjęć (ang. Admission Control). Oprócz wbudowanych kroków, istnieje kilka rozszerzeń:
- Webhook polityki obrazów ogranicza, jakie obrazy mogą być uruchamiane w kontenerach.
- Aby podejmować dowolne decyzje dotyczące kontroli dostępu, można użyć ogólnego webhooka dopuszczenia (ang. Admission webhook). Webhooki dopuszczenia mogą odrzucać żądania tworzenia lub aktualizacji. Niektóre webhooki modyfikują dane przychodzącego żądania, zanim zostaną one dalej obsłużone przez Kubernetesa.
Rozszerzenia infrastruktury
Wtyczki urządzeń
Device plugins pozwalają węzłowi na odkrywanie nowych zasobów Węzła (oprócz wbudowanych, takich jak CPU i pamięć) za pomocą Device Plugin.
Wtyczki magazynowe (ang. Storage plugins)
Wtyczki Container Storage Interface (CSI) dostarczają sposób na rozszerzenie Kubernetesa o wsparcie dla nowych rodzajów wolumenów. Wolumeny mogą być obsługiwane przez trwałe zewnętrzne magazyny danych, dostarczać pamięć ulotną lub oferować interfejs tylko do odczytu do informacji z wykorzystaniem paradygmatu systemu plików.
Kubernetes zawiera również wsparcie dla wtyczek FlexVolume, które są przestarzałe od wersji Kubernetes v1.23 (na rzecz CSI).
Wtyczki FlexVolume umożliwiają użytkownikom podłączanie typów woluminów, które nie są natywnie obsługiwane przez Kubernetesa. Kiedy uruchamiasz Pod, który polega na magazynie FlexVolume, kubelet wywołuje wtyczkę binarną, aby zamontować wolumin. Zarchiwizowany FlexVolume projekt wstępny zawiera więcej szczegółów na temat tego podejścia.
FAQ dotyczące Wtyczki Wolumenów Kubernetesa dla Dostawców Pamięci zawiera ogólne informacje na temat wtyczek do pamięci.
Wtyczki sieciowe
Twój klaster Kubernetesa potrzebuje wtyczki sieciowej, aby mieć działającą sieć Podów i wspierać inne aspekty modelu sieciowego Kubernetesa.
Wtyczki sieciowe pozwalają Kubernetesowi na współpracę z różnymi topologiami i technologiami sieciowymi.
Wtyczki dostawcy poświadczeń obrazu dla Kubeleta
Kubernetes v1.26 [stable]Wtyczki mogą komunikować się z zewnętrznymi usługami lub korzystać z lokalnych plików w celu uzyskania poświadczeń. W ten sposób kubelet nie musi mieć statycznych poświadczeń dla każdego rejestru i może obsługiwać różne metody i protokoły uwierzytelniania.
Aby uzyskać szczegóły dotyczące konfiguracji wtyczki, zobacz Konfigurowanie dostawcy poświadczeń obrazu kubelet.
Rozszerzenia harmonogramowania
Scheduler to specjalny typ kontrolera, który obserwuje pody i przypisuje pody do węzłów. Domyślny scheduler może być całkowicie zastąpiony, przy jednoczesnym dalszym korzystaniu z innych komponentów Kubernetesa, lub wielokrotne schedulery mogą działać jednocześnie.
Jest to duże przedsięwzięcie i prawie wszyscy użytkownicy Kubernetesa stwierdzają, że nie muszą modyfikować schedulera.
Możesz kontrolować, które wtyczki planowania są aktywne, lub kojarzyć zestawy wtyczek z różnymi nazwanymi profilami schedulera. Możesz również napisać własną wtyczkę, która integruje się z jednym lub więcej punktami rozszerzeń kube-schedulera.
Wreszcie, wbudowany komponent kube-scheduler obsługuje
webhook,
który pozwala zdalnemu backendowi HTTP (rozszerzenie schedulera) na
filtrowanie i/lub priorytetyzowanie węzłów, które kube-scheduler wybiera dla poda.
Informacja:
Za pomocą webhooka rozszerzającego harmonogram można wpływać jedynie na filtrowanie węzłów i priorytetyzację węzłów; inne punkty rozszerzenia nie są dostępne poprzez integrację webhooków.Co dalej?
- Dowiedz się więcej o rozszerzeniach infrastruktury
- Wtyczki Urządzeń
- Wtyczki sieciowe
- Wtyczki do przechowywania CSI storage plugins
- Dowiedz się więcej o wtyczkach kubectl
- Dowiedz się więcej o zasobach niestandardowych (ang. Custom Resources)
- Dowiedz się więcej o serwerach API rozszerzeń
- Dowiedz się więcej o dynamicznym kontrolowaniu dostępu
- Dowiedz się więcej o wzorcu Operatora
3.13.1 - Rozszerzanie API Kubernetesa
Niestandardowe zasoby Kubernetesa (ang. Custom Resources) stanowią rozszerzenie API. Kubernetes udostępnia dwie metody ich integracji z klastrem:
- Mechanizm CustomResourceDefinition (CRD) pozwala deklaratywnie zdefiniować nowe niestandardowe API z grupą API, rodzajem i schematem, który określisz. Warstwa sterowania Kubernetesa obsługuje i zarządza przechowywaniem twojego niestandardowego zasobu. CRD pozwalają tworzyć nowe typy zasobów dla twojego klastra bez pisania i uruchamiania niestandardowego serwera API.
- Warstwa agregacji znajduje się za głównym serwerem API, który działa jako proxy. To rozwiązanie nazywa się Agregacją API (AA), które umożliwia dostarczanie implementacji dla własnych niestandardowych zasobów poprzez napisanie i wdrożenie własnego serwera API. Główny serwer API deleguje żądania do twojego serwera API, udostępniając je wszystkim jego klientom.
3.13.2 - Rozszerzenia obliczeniowe, przechowywania danych i sieciowe
Ta sekcja obejmuje rozszerzenia do Twojego klastra, które nie są częścią samego Kubernetesa. Możesz użyć tych rozszerzeń, aby ulepszyć węzły w Twoim klastrze lub zapewnić sieć łączącą Pody.
Wtyczki pamięci masowej CSI i FlexVolume
Wtyczki Container Storage Interface (CSI) dostarczają sposób na rozszerzenie Kubernetesa o wsparcie dla nowych rodzajów wolumenów. Wolumeny mogą być wspierane przez trwałe zewnętrzne systemy przechowywania, mogą dostarczać pamięć ulotną, lub mogą oferować interfejs tylko do odczytu dla informacji przy użyciu paradygmatu systemu plików.
Kubernetes zawiera również wsparcie dla wtyczek FlexVolume, które są przestarzałe od Kubernetesa v1.23 (na rzecz CSI).
Wtyczki FlexVolume pozwalają użytkownikom montować typy woluminów, które nie są natywnie obsługiwane przez Kubernetesa. Gdy uruchamiasz Pod, który polega na przechowywaniu FlexVolume, "kubelet" wywołuje binarną wtyczkę, aby zamontować wolumin. Zarchiwizowany FlexVolume dokument projektowy zawiera więcej szczegółów na temat tego podejścia.
FAQ dotyczące wtyczek wolumenów Kubernetesa dla dostawców pamięci masowej zawiera ogólne informacje na temat wtyczek pamięci masowej.
Wtyczki urządzeń umożliwiają węzłowi odkrywanie nowych funkcji węzła (dodatkowo do wbudowanych zasobów węzła, takich jak
cpuimemory), oraz udostępniają te niestandardowe funkcje lokalne węzła dla Podów, które ich żądają.Wtyczki sieciowe (ang. network plugins) umożliwiają Kubernetesowi obsługę różnych topologii i technologii sieciowych. Aby klaster Kubernetesa miał działającą sieć Podów i wspierał różne elementy modelu sieciowego Kubernetesa, konieczne jest zainstalowanie odpowiedniej wtyczki sieciowej.
Kubernetes 1.36 jest kompatybilny z wtyczkami sieciowymi CNI.
4 - Zadania
W tej części dokumentacji Kubernetesa znajdują się opisy sposobu realizacji różnych zadań. Przedstawione są one zazwyczaj jako krótka sekwencja kilku kroków związanych z pojedynczym zadaniem.
Jeśli chciałbyś stworzyć nową stronę poświęconą jakiemuś zadaniu, przeczytaj Jak przygotować propozycję zmian (PR).
5 - Samouczki
W tym rozdziale dokumentacji Kubernetes znajdziesz różne samouczki. Dzięki nim dowiesz się, jak osiągnąć złożone cele, które przekraczają wielkość pojedynczego zadania. Typowy samouczek podzielony jest na kilka części, z których każda zawiera sekwencję odpowiednich kroków. Przed zapoznaniem się z samouczkami warto stworzyć zakładkę do słownika, aby móc się później do niego na bieżąco odwoływać.
Podstawy
- Podstawy Kubernetesa (PL) to interaktywny samouczek, który pomoże zrozumieć system Kubernetes i wypróbować jego podstawowe możliwości.
- Introduction to Kubernetes (edX)
- Hello Minikube (PL)
Konfiguracja
Tworzenie Podów
Aplikacje bezstanowe (Stateless Applications)
- Exposing an External IP Address to Access an Application in a Cluster
- Example: Deploying PHP Guestbook application with Redis
Aplikacje stanowe (Stateful Applications)
- StatefulSet Basics
- Example: WordPress and MySQL with Persistent Volumes
- Example: Deploying Cassandra with Stateful Sets
- Running ZooKeeper, A CP Distributed System
Serwisy
Bezpieczeństwo
- Apply Pod Security Standards at Cluster level
- Apply Pod Security Standards at Namespace level
- Restrict a Container's Access to Resources with AppArmor
- Seccomp
Zarządzanie Klastrem
- Configuring Swap Memory on Kubernetes Nodes
- Running Kubelet in Standalone Mode
- Install Drivers and Allocate Devices with DRA
Co dalej?
Jeśli chciałbyś napisać nowy samouczek, odwiedź Content Page Types, gdzie znajdziesz dodatkowe informacje o tym typie strony.
5.1 - Hello Minikube
Ten samouczek pokaże, jak uruchomić przykładową aplikację na Kubernetesie przy użyciu minikube. W tym samouczku wykorzystamy obraz kontenera, który korzysta z NGINX, aby wyświetlić z powrotem wszystkie przychodzące zapytania.
Cele
- Skonfiguruj przykładową aplikację do uruchomienia w minikube.
- Uruchom aplikację.
- Przejrzyj jej logi.
Zanim zaczniesz
Ten tutorial zakłada, że masz już skonfigurowane narzędzie minikube. Instrukcje instalacji
znajdziesz w Kroku 1 dokumentacji minikube start.
Informacja:
Wykonaj tylko instrukcje zawarte w kroku 1, Instalacja. Reszta jest opisana na tej stronie.Dodatkowo wymagane jest zainstalowanie kubectl. Szczegółowe instrukcje
instalacji dostępne są w sekcji Install tools.
Utwórz klaster minikube
minikube start
Sprawdź status klastra minikube.
Sprawdź status klastra minikube, aby upewnić się, że wszystkie jego komponenty są uruchomione.
minikube status
Wynik z powyższego polecenia powinien pokazywać wszystkie komponenty jako działające (ang. Running) lub skonfigurowane (ang. Configured), jak pokazano w poniższym przykładzie:
minikube
type: Control Plane
host: Running
kubelet: Running
apiserver: Running
kubeconfig: Configured
Otwórz Dashboard
Otwórz dashboard Kubernetesa. Można to zrobić na dwa sposoby:
Otwórz nowy terminal i uruchom:
# Uruchom nową sesję terminala i pozostaw ją aktywną.
minikube dashboard
Teraz wróć do terminala, w którym uruchomiłeś minikube start.
Informacja:
Polecenie dashboard uruchamia dodatek panelu i otwiera proxy w domyślnej
przeglądarce. W panelu można tworzyć różne obiekty Kubernetesa, takie jak Deployment czy Serwis.
Aby dowiedzieć się, jak uniknąć bezpośredniego uruchamiania przeglądarki z terminala i uzyskać URL do pulpitu nawigacyjnego w sieci, zapoznaj się z kartą "Kopiuj i wklej URL".
Panel jest domyślnie dostępny jedynie z wewnętrznej sieci Kubernetesa. Polecenie
dashboard tworzy tymczasowe proxy, które udostępnia panel także poza tą wewnętrzną sieć.
Aby zatrzymać proxy, wciśnij Ctrl+C i zakończ proces. Panel ciągle
działa na klastrze Kubernetesa, nawet po przerwaniu działania proxy. Aby dostać się
ponownie do panelu, trzeba stworzyć kolejne proxy poleceniem dashboard.
Jeśli nie chcesz, aby minikube automatycznie otwierał przeglądarkę internetową, uruchom podkomendę dashboard z flagą --url. minikube wyświetli adres URL, który możesz otworzyć w preferowanej przeglądarce.
Otwórz nowy terminal i uruchom:
# Uruchom nową sesję terminala i pozostaw ją aktywną.
minikube dashboard --url
Teraz możesz użyć tego URL-a i wrócić do terminala, w którym uruchomiłeś minikube start.
Stwórz Deployment
Pod w Kubernetesie to grupa jednego lub wielu kontenerów połączonych ze sobą na potrzeby administrowania i dostępu sieci. W tym samouczku Pod zawiera tylko jeden kontener. Deployment w Kubernetesie monitoruje stan twojego Poda i restartuje należące do niego kontenery, jeśli z jakichś powodów przestaną działać. Użycie Deploymentu to rekomendowana metoda zarządzania tworzeniem i skalowaniem Podów.
Użyj polecenia
kubectl createdo stworzenia Deploymentu, który będzie zarządzał Podem. Pod uruchamia kontener wykorzystując podany obraz Dockera.# Uruchom testowy obraz kontenera zawierający serwer WWW kubectl create deployment hello-node --image=registry.k8s.io/e2e-test-images/agnhost:2.53 -- /agnhost netexec --http-port=8080Sprawdź stan Deploymentu:
kubectl get deploymentsWynik powinien wyglądać podobnie do:
NAME READY UP-TO-DATE AVAILABLE AGE hello-node 1/1 1 1 1m(Może minąć trochę czasu, zanim pod stanie się dostępny. Jeśli widzisz "0/1", spróbuj ponownie za kilka sekund.)
Sprawdź stan Poda:
kubectl get podsWynik powinien wyglądać podobnie do:
NAME READY STATUS RESTARTS AGE hello-node-5f76cf6ccf-br9b5 1/1 Running 0 1mObejrzyj zdarzenia na klastrze:
kubectl get eventsSprawdź konfigurację
kubectl:kubectl config viewPobierz logi aplikacji z kontenera działającego w podzie (użyj nazwy poda zwróconej przez polecenie
kubectl get pods).Informacja:
Zastąphello-node-5f76cf6ccf-br9b5w poleceniukubectl logsnazwą poda z wyniku poleceniakubectl get pods.kubectl logs hello-node-5f76cf6ccf-br9b5Wynik powinien wyglądać podobnie do:
I0911 09:19:26.677397 1 log.go:195] Started HTTP server on port 8080 I0911 09:19:26.677586 1 log.go:195] Started UDP server on port 8081
Stwórz Serwis
Domyślnie Pod jest dostępny tylko poprzez swój wewnętrzny adres IP
wewnątrz klastra Kubernetes. Aby kontener hello-node był
osiągalny spoza wirtualnej sieci Kubernetesa, musisz najpierw udostępnić
Pod jako Serwis Kubernetes.
Ostrzeżenie:
Kontener agnhost udostępnia endpoint /shell, który jest przydatny do debugowania, ale niebezpieczny w przypadku wystawienia w publicznym internecie. Nie uruchamiaj go na klastrze dostępnym z internetu ani w środowisku produkcyjnym.Udostępnij Pod w Internecie przy pomocy polecenia
kubectl expose:kubectl expose deployment hello-node --type=LoadBalancer --port=8080Opcja
--type=LoadBalancerwskazuje, że chcesz udostępnić swój Serwis na zewnątrz klastra.Aplikacja, która jest umieszczona w obrazie kontenera, nasłuchuje jedynie na porcie TCP 8080. Jeśli użyłeś
kubectl exposedo wystawienia innego portu, aplikacje klienckie mogą nie móc się podłączyć do tamtego innego portu.Sprawdź Serwis, który właśnie utworzyłeś:
kubectl get servicesWynik powinien wyglądać podobnie do:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE hello-node LoadBalancer 10.108.144.78 <pending> 8080:30369/TCP 21s kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 23mU dostawców usług chmurowych, którzy obsługują load balancers, zostanie przydzielony zewnętrzny adres IP na potrzeby serwisu. W minikube, serwis typu
LoadBalancermożna udostępnić poprzez polecenieminikube service.Uruchom poniższe polecenie:
minikube service hello-nodeOtworzy sie okno przeglądarki obsługującej twoją aplikację i wyświetli odpowiedź tej aplikacji.
Włącz dodatki
Narzędzie minikube dysponuje zestawem wbudowanych dodatków, które mogą być włączane, wyłączane i otwierane w lokalnym środowisku Kubernetes.
Lista aktualnie obsługiwanych dodatków:
minikube addons listWynik powinien wyglądać podobnie do:
addon-manager: enabled dashboard: enabled default-storageclass: enabled efk: disabled freshpod: disabled gvisor: disabled helm-tiller: disabled ingress: disabled ingress-dns: disabled logviewer: disabled metrics-server: disabled nvidia-driver-installer: disabled nvidia-gpu-device-plugin: disabled registry: disabled registry-creds: disabled storage-provisioner: enabled storage-provisioner-gluster: disabledWłącz dodatek, na przykład
metrics-server:minikube addons enable metrics-serverWynik powinien wyglądać podobnie do:
The 'metrics-server' addon is enabledSprawdź Pody i Serwisy, który właśnie stworzyłeś:
kubectl get pod,svc -n kube-systemWynik powinien wyglądać podobnie do:
NAME READY STATUS RESTARTS AGE pod/coredns-5644d7b6d9-mh9ll 1/1 Running 0 34m pod/coredns-5644d7b6d9-pqd2t 1/1 Running 0 34m pod/metrics-server-67fb648c5 1/1 Running 0 26s pod/etcd-minikube 1/1 Running 0 34m pod/influxdb-grafana-b29w8 2/2 Running 0 26s pod/kube-addon-manager-minikube 1/1 Running 0 34m pod/kube-apiserver-minikube 1/1 Running 0 34m pod/kube-controller-manager-minikube 1/1 Running 0 34m pod/kube-proxy-rnlps 1/1 Running 0 34m pod/kube-scheduler-minikube 1/1 Running 0 34m pod/storage-provisioner 1/1 Running 0 34m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/metrics-server ClusterIP 10.96.241.45 <none> 80/TCP 26s service/kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP 34m service/monitoring-grafana NodePort 10.99.24.54 <none> 80:30002/TCP 26s service/monitoring-influxdb ClusterIP 10.111.169.94 <none> 8083/TCP,8086/TCP 26sSprawdź wynik z
metrics-server:kubectl top podsWynik powinien wyglądać podobnie do:
NAME CPU(cores) MEMORY(bytes) hello-node-ccf4b9788-4jn97 1m 6MiJeśli zobaczysz następującą wiadomość, poczekaj i spróbuj ponownie:
error: Metrics API not availableWyłącz dodatek
metrics-server:minikube addons disable metrics-serverWynik powinien wyglądać podobnie do:
metrics-server was successfully disabled
Porządkujemy po sobie
Teraz jest czas na wyczyszczenie zasobów, które utworzyłeś w klastrze:
kubectl delete service hello-node
kubectl delete deployment hello-node
Zatrzymaj wirtualną maszynę Minikube (VM):
minikube stop
(Opcjonalnie) Skasuj Minikube VM:
# Optional
minikube delete
Jeżeli planujesz ponownie używać minikube do dalszej nauki Kubernetesa, nie musisz go usuwać.
Wniosek
Ta strona obejmowała podstawowe aspekty dotyczące uruchomienia klastra minikube. Teraz jesteś gotowy do wdrażania aplikacji.
Co dalej?
- Samouczek Jak użyć kubectl do tworzenia Deploymentu.
- Dowiedz się więcej o obiektach typu Deployment.
- Dowiedz się więcej o instalowaniu aplikacji.
- Dowiedz się więcej o obiektach typu Serwis.
5.2 - Naucz się podstaw Kubernetesa
Cele
Ten samouczek poprowadzi Cię przez podstawy systemu zarządzania zadaniami na klastrze Kubernetesa. W każdym module znajdziesz najważniejsze informacje o głównych pojęciach i funkcjonalnościach Kubernetesa. Dzięki samouczkom nauczysz się zarządzać prostym klasterem i skonteneryzowanymi aplikacjami uruchamianymi na tym klastrze.
Nauczysz się, jak:
- Zainstalować skonteneryzowaną aplikację na klastrze.
- Wyskalować tę instalację.
- Zaktualizować aplikację do nowej wersji.
- Rozwiązywać problemy z aplikacją.
Co Kubernetes może dla Ciebie zrobić?
Użytkownicy oczekują od współczesnych serwisów internetowych dostępności non-stop, a deweloperzy chcą móc instalować nowe wersje swoich serwisów kilka razy dziennie. Używając kontenerów można przygotowywać oprogramowanie w taki sposób, aby mogło być instalowane i aktualizowane nie powodując żadnych przestojów. Kubernetes pomaga uruchamiać te aplikacje w kontenerach tam, gdzie chcesz i kiedy chcesz i znajdować niezbędne zasoby i narzędzia wymagane do ich pracy. Kubernetes może działać w środowiskach produkcyjnych, jest otwartym oprogramowaniem zaprojektowanym z wykorzystaniem nagromadzonego przez Google doświadczenia w zarządzaniu kontenerami, w połączeniu z najcenniejszymi ideami społeczności.
Podstawy Kubernetesa - Moduły






Co dalej?
- Więcej informacji na temat klastrów ćwiczeniowych oraz sposobu uruchamiania własnego klastra znajdziesz na stronie Środowisko edukacyjne.
- Samouczek Jak użyć Minikube do stworzenia klastra
5.2.1 - Tworzenie klastra
Poznaj klaster Kubernetesa i naucz się, jak stworzyć jego prostą wersję przy pomocy Minikube.
5.2.1.1 - Jak użyć Minikube do stworzenia klastra
Cele
- Dowiedz się, czym jest klaster Kubernetesa.
- Dowiedz się, czym jest Minikube.
- Uruchom klaster Kubernetesa.
Zanim zaczniesz
Ten samouczek zakłada, że masz już zainstalowany minikube. Aby dowiedzieć się więcej
o instrukcji instalacji zobacz minikube start.
Informacja:
Wykonaj tylko instrukcje zawarte w kroku 1: Instalacja. Reszta jest omówiona w tym przewodniku.Musisz również zainstalować kubectl. Zobacz
Instalacja narzędzi po instrukcje dotyczące instalacji.
Polecenia w tym poradniku są napisane w składni zgodnej ze standardem POSIX, którą
obsługują domyślne powłoki w Linuxie i macOS (np. bash, zsh, sh). Jeśli
używasz Windowsa, potrzebujesz powłoki zgodnej z POSIX, np. WSL
Windows Subsystem for Linux (WSL) lub
Git Bash, żeby
uruchomić je w takiej formie. Polecenia z export, $() i podobnymi
elementami nie zadziałają w PowerShellu ani w zwykłym wierszu polecenia.
Klastry Kubernetesa
Zadaniem Kubernetesa jest zarządzanie klastrem komputerów o wysokiej dostępności, działającego jako jedna całość. Kubernetes, poprzez swój system obiektów abstrakcyjnych, umożliwia uruchamianie aplikacji w kontenerach bez przypisywania ich do konkretnej maszyny. Aby móc korzystać z tego nowego modelu instalacji, aplikacje muszą być przygotowane w taki sposób, aby były niezależne od konkretnego serwera: muszą być skonteneryzowane. Aplikacje w kontenerach są bardziej elastyczne przy instalacji, niż to miało miejsce w poprzednich modelach, kiedy aplikacje były instalowane bezpośrednio na konkretne maszyny jako pakiety ściśle powiązane z tą maszyną. Kubernetes automatyzuje dystrybucję i zlecanie uruchamiania aplikacji na klastrze w bardziej efektywny sposób. Kubernetes jest platformą otwartego oprogramowania, gotowym do pracy w środowiskach produkcyjnych.
Klaster Kubernetesa składa się z dwóch rodzajów zasobów:
- Warstwa sterowania koordynuje działanie klastra
- Na węzłach (nodes) uruchamiane są aplikacje
Diagram klastra

Warstwa sterowania odpowiada za zarządzanie klastrem. Warstwa sterowania koordynuje wszystkie działania klastra, takie jak zlecanie uruchomienia aplikacji, utrzymywanie pożądanego stanu aplikacji, skalowanie aplikacji i instalowanie nowych wersji.
Węzeł to maszyna wirtualna (VM) lub fizyczny serwer, który jest maszyną roboczą w klastrze Kubernetesa. Na każdym węźle działa Kubelet, agent zarządzający tym węzłem i komunikujący się z warstwą sterowania Kubernetesa. Węzeł zawiera także narzędzia do obsługi kontenerów, takie jak containerd lub CRI-O. Klaster Kubernetesa w środowisku produkcyjnym powinien składać się minimum z trzech węzłów, ponieważ w przypadku awarii jednego węzła traci się zarówno element etcd, jak i warstwy sterowania przy jednoczesnym zachowaniu minimalnej nadmiarowości (redundancy). Dodanie kolejnych węzłów warstwy sterowania może temu zapobiec.
Kiedy instalujesz aplikację na Kubernetesie, zlecasz warstwie sterowania uruchomienie kontenera z aplikacją. Warstwa sterowania zleca uruchomienie kontenera na węzłach klastra. Komponenty działające na poziomie węzła, takie jak kubelet, komunikują się z warstwą sterowania przy użyciu API Kubernetesa, udostępnianego poprzez warstwę sterowania. Użytkownicy końcowi mogą korzystać bezpośrednio z API Kubernetesa do komunikacji z klastrem.
Klaster Kubernetesa może być zainstalowany zarówno na fizycznych, jak i na maszynach wirtualnych. Aby wypróbować Kubernetesa, można też wykorzystać Minikube. Minikube to "lekka" implementacja Kubernetesa, która tworzy VM na maszynie lokalnej i instaluje prosty klaster składający się tylko z jednego węzła. Minikube jest dostępny na systemy Linux, macOS i Windows. Narzędzie linii poleceń Minikube obsługuje podstawowe operacje na klastrze, takie jak start, stop, prezentacja informacji jego stanie i usunięcie klastra.
Utwórz klaster minikube
Aby uruchomić klaster minikube:
minikube start
Aby zweryfikować status klastra:
minikube status
Aby uzyskać pełne wprowadzenie, w tym wdrożenie Twojej pierwszej aplikacji i eksplorację dashboardu Kubernetes, zapoznaj się z samouczkiem Hello Minikube.
Co dalej?
- Samouczek Wdrażanie aplikacji.
- Dowiedz się więcej o architekturze klastra.
5.2.2 - Instalowanie aplikacji
5.2.2.1 - Jak użyć kubectl do tworzenia Deploymentu
Cele
- Poznaj sposób wdrażania aplikacji.
- Wdróż swoją pierwszą aplikację na Kubernetesie za pomocą narzędzia kubectl.
Zanim zaczniesz
Polecenia w tym poradniku są napisane w składni zgodnej ze standardem POSIX, którą
obsługują domyślne powłoki w Linuxie i macOS (np. bash, zsh, sh). Jeśli
używasz Windowsa, potrzebujesz powłoki zgodnej z POSIX, np. WSL
Windows Subsystem for Linux (WSL) lub
Git Bash, żeby
uruchomić je w takiej formie. Polecenia z export, $() i podobnymi
elementami nie zadziałają w PowerShellu ani w zwykłym wierszu polecenia.
Deploymenty w Kubernetesie
Informacja:
Ten samouczek wykorzystuje kontener wymagający architektury AMD64. Jeśli używasz minikube na komputerze z inną architekturą CPU, możesz spróbować użyć minikube z sterownikiem, który potrafi emulować AMD64. Na przykład potrafi to zrobić sterownik Docker Desktop.Mając działający klaster Kubernetesa, można na nim zacząć instalować aplikacje. W tym celu należy utworzyć Deployment. Deployment informuje Kubernetesa, jak tworzyć i aktualizować instancje Twojej aplikacji. Po stworzeniu Deploymentu, warstwa sterowania Kubernetesa zleca uruchomienie tej aplikacji na indywidualnych węzłach klastra.
Po utworzeniu instancji aplikacji, kontroler Deploymentu Kubernetesa na bieżąco monitoruje te instancje. Jeśli węzeł, na którym działała jedna z instancji ulegnie awarii lub zostanie usunięty, kontroler Deploymentu zamieni tę instancję z instancją na innym węźle klastra. W ten sposób działa samonaprawiający się mechanizm, który reaguje na awarie lub wyłączenia maszyn w klastrze.
W czasach przed wprowadzeniem takiej automatyzacji, skrypty instalacyjne używane były zazwyczaj do uruchomienia aplikacji, ale nie radziły sobie z awariami maszyn. Poprzez połączenie procesu instalacji i kontroli nad działaniem aplikacji na węzłach, Deployment Kubernetesa oferuje fundamentalnie różne podejście do zarządzania aplikacjami.
Instalacja pierwszej aplikacji w Kubernetesie

Do tworzenia i zarządzaniem Deploymentem służy polecenie linii komend, kubectl. Kubectl używa API Kubernetesa do komunikacji z klasterem. W tym module nauczysz się najczęściej używanych poleceń kubectl niezbędnych do stworzenia Deploymentu, który uruchomi Twoje aplikacje na klastrze Kubernetesa.
Tworząc Deployment musisz określić obraz kontenera oraz liczbę replik, które mają być uruchomione. Te ustawienia możesz zmieniać później, aktualizując Deployment. Moduł 5 oraz Moduł 6 omawiają skalowanie i aktualizowanie Deploymentów.
Na potrzeby pierwszej instalacji użyjesz aplikacji hello-node zapakowaną w kontener Docker-a, która korzysta z NGINXa i powtarza wszystkie wysłane do niej zapytania. (Jeśli jeszcze nie próbowałeś stworzyć aplikacji hello-node i uruchomić za pomocą kontenerów, możesz spróbować teraz, kierując się instrukcjami samouczka samouczku Hello Minikube.)
Musisz mieć zainstalowane narzędzie kubectl. Jeśli potrzebujesz go zainstalować, odwiedź install tools.
Skoro wiesz już, czym są Deploymenty, przeprowadźmy wdrożenie pierwszej aplikacji!
Podstawy kubectl
Typowy format polecenia kubectl to: kubectl akcja zasób.
Wykonuje określoną akcję (jak create, describe lub delete) na określonym
zasobie (jak node lub deployment). Możesz użyć --help po poleceniu, aby uzyskać dodatkowe
informacje o możliwych parametrach (na przykład: kubectl get nodes --help).
Sprawdź, czy kubectl jest skonfigurowany do komunikacji z twoim klastrem, uruchamiając polecenie kubectl version.
Sprawdź, czy kubectl jest zainstalowane oraz czy możesz zobaczyć zarówno wersję klienta, jak i serwera.
Aby wyświetlić węzły w klastrze, uruchom polecenie kubectl get nodes.
Zobaczysz dostępne węzły. Kubernetes wybierze, gdzie wdrożyć naszą aplikację, w oparciu o dostępne zasoby węzła.
Wdrażanie aplikacji
Uruchommy naszą pierwszą aplikację na Kubernetesie, używając polecenia
kubectl create deployment. Musimy podać nazwę wdrożenia oraz lokalizację obrazu
aplikacji (w tym pełny adres URL repozytorium dla obrazów hostowanych poza Docker Hub).
kubectl create deployment kubernetes-bootcamp --image=gcr.io/google-samples/kubernetes-bootcamp:v1
Świetnie! Właśnie wdrożyłeś swoją pierwszą aplikację, tworząc Deployment. Kubernetes wykonał dla Ciebie kilka rzeczy:
- wyszukał odpowiedni węzeł, na którym można uruchomić instancję aplikacji (mamy dostępny tylko 1 węzeł)
- zaplanował uruchomienie aplikacji na tym węźle
- skonfigurował klaster tak, aby w razie potrzeby ponownie uruchomić instancję na nowym węźle
Aby wyświetlić listę swoich wdrożeń, użyj polecenia kubectl get deployments:
kubectl get deployments
Widzimy, że jest jeden Deployment uruchamiający pojedynczą instancję Twojej aplikacji. Instancja działa wewnątrz kontenera na Twoim węźle.
Zobacz aplikację
Pody działające wewnątrz Kubernetesa
działają na prywatnej, izolowanej sieci. Domyślnie są one widoczne z innych
podów i usług w ramach tego samego klastra Kubernetesa, ale nie poza tą
siecią. Kiedy używamy kubectl, komunikujemy się z aplikacją za pośrednictwem API.
Później, w Module 4, omówimy
inne opcje dotyczące sposobów udostępniania Twojej aplikacji poza klastrem
Kubernetesa. Ponieważ jest to tylko podstawowy samouczek, to nie wyjaśniamy
tutaj szczegółowo, czym są Pody, bo będzie to omówione w późniejszych tematach.
Polecenie kubectl proxy może utworzyć proxy, które przekaże komunikację do
ogólnoklastrowej, prywatnej sieci. Proxy można zakończyć poprzez
naciśnięcie control-C - podczas działania nie wyświetla ono żadnych komunikatów.
Musisz otworzyć drugie okno terminala, aby uruchomić proxy.
kubectl proxy
Mamy teraz połączenie pomiędzy naszym hostem (terminalem) a klastrem Kubernetesa. Proxy umożliwia bezpośredni dostęp do API z tych terminali.
Możesz zobaczyć wszystkie te interfejsy API hostowane przez punkt końcowy serwera proxy.
Na przykład możemy bezpośrednio zapytać o wersję za pomocą polecenia curl:
curl http://localhost:8001/version
Informacja:
Jeśli port 8001 jest niedostępny, upewnij się, żekubectl proxy, który uruchomiłeś wyżej, działa w drugim terminalu.Serwer API automatycznie utworzy punkt końcowy dla każdego poda, bazując na nazwie poda, który jest również dostępny przez serwer proxy.
Najpierw musimy uzyskać nazwę Poda i zapisać ją w zmiennej środowiskowej POD_NAME.
export POD_NAME=$(kubectl get pods -o go-template --template '{{range .items}}{{.metadata.name}}{{"\n"}}{{end}}')
echo Name of the Pod: $POD_NAME
Możesz uzyskać dostęp do Poda za pośrednictwem API z proxy, uruchamiając:
curl http://localhost:8001/api/v1/namespaces/default/pods/$POD_NAME:8080/proxy/
Aby nowy Deployment był dostępny bez użycia proxy, wymagane jest utworzenie obiektu usługi (ang. Service), co zostanie wyjaśnione w Module 4.
Co dalej?
- Samouczek Pody i Węzły.
- Dowiedz się więcej o Deploymentach.
5.2.3 - Poznawanie aplikacji
5.2.3.1 - Pody i Węzły
Cele
- Zrozumieć, jak działają Pody Kubernetesa.
- Zrozumieć, jak działają węzły Kubernetesa.
- Nauczyć się rozwiązywać problemy z aplikacjami.
Zanim zaczniesz
Polecenia w tym poradniku są napisane w składni zgodnej ze standardem POSIX, którą
obsługują domyślne powłoki w Linuxie i macOS (np. bash, zsh, sh). Jeśli
używasz Windowsa, potrzebujesz powłoki zgodnej z POSIX, np. WSL
Windows Subsystem for Linux (WSL) lub
Git Bash, żeby
uruchomić je w takiej formie. Polecenia z export, $() i podobnymi
elementami nie zadziałają w PowerShellu ani w zwykłym wierszu polecenia.
Pody Kubernetesa
Po stworzeniu Deploymentu w Module 2, Kubernetes stworzył Pod, który "przechowuje" instancję Twojej aplikacji. Pod jest obiektem abstrakcyjnym Kubernetesa, który reprezentuje grupę jednego bądź wielu kontenerów (jak np. Docker) wraz ze wspólnymi zasobami dla tych kontenerów. Zasobami mogą być:
- Współdzielona przestrzeń dyskowa, np. Volumes
- Zasoby sieciowe, takie jak unikatowy adres IP klastra
- Informacje służące do uruchamiania każdego z kontenerów ⏤ wersja obrazu dla kontenera lub numery portów, które mają być użyte
Pod tworzy model specyficznego dla aplikacji "wirtualnego serwera" i może zawierać różne kontenery aplikacji, które są relatywnie blisko powiązane. Przykładowo, pod może zawierać zarówno kontener z Twoją aplikacją w Node.js, jak i inny kontener dostarczający dane, które mają być opublikowane przez serwer Node.js. Kontenery wewnątrz poda współdzielą adres IP i przestrzeń portów, zawsze są uruchamiane wspólnie w tej samej lokalizacji i współdzielą kontekst wykonawczy na tym samym węźle.
Pody są niepodzielnymi jednostkami na platformie Kubernetes. W trakcie tworzenia Deploymentu na Kubernetesa, Deployment tworzy Pody zawierające kontenery (w odróżnieniu od tworzenia kontenerów bezpośrednio). Każdy Pod związany jest z węzłem, na którym zostało zlecone jego uruchomienie i pozostaje tam aż do jego wyłączenia (zgodnie z polityką restartowania) lub skasowania. W przypadku awarii węzła, identyczny pod jest skierowany do uruchomienia na innym węźle klastra.
Schemat ogólny podów

Węzły
Pod jest uruchamiany na węźle (Node). Węzeł jest maszyną roboczą, fizyczną lub wirtualną, w zależności od klastra. Każdy z węzłów jest zarządzany przez warstwę sterowania (Control Plane). Węzeł może zawierać wiele podów. Warstwa sterowania Kubernetesa automatycznie zleca uruchomienie podów na różnych węzłach w ramach klastra. Automatyczne zlecanie uruchomienia bierze pod uwagę zasoby dostępne na każdym z węzłów.
Na każdym węźle Kubernetesa działają co najmniej:
Kubelet, proces odpowiedzialny za komunikację pomiędzy warstwą sterowania Kubernetesa i węzłami; zarządza podami i kontenerami działającymi na maszynie.
Proces wykonawczy kontenera (np. Docker), który zajmuje się pobraniem obrazu dla kontenera z repozytorium, rozpakowaniem kontenera i uruchomieniem aplikacji.
Schemat węzła

Rozwiązywanie problemów przy pomocy kubectl
W module Module 2 używałeś narzędzia Kubectl. W module 3 będziemy go nadal używać, aby wydobyć informacje na temat zainstalowanych aplikacji i środowiska, w jakim działają. Najczęstsze operacje przeprowadzane są przy pomocy następujących poleceń kubectl:
kubectl get- wyświetl informacje o zasobachkubectl describe- pokaż szczegółowe informacje na temat konkretnego zasobukubectl logs- wyświetl logi z kontenera w danym podziekubectl exec- wykonaj komendę wewnątrz kontenera w danym podzie
Korzystaj z tych poleceń, aby sprawdzić, kiedy aplikacja została zainstalowana, jaki jest jej aktualny status, gdzie jest uruchomiona i w jakiej konfiguracji.
Kiedy już wiemy więcej na temat części składowych klastra i podstawowych poleceń, przyjrzyjmy się naszej aplikacji.
Sprawdzanie konfiguracji aplikacji
Sprawdźmy, czy aplikacja, którą wdrożyliśmy w poprzednim scenariuszu, działa.
Użyjemy polecenia kubectl get i poszukamy istniejących Podów:
kubectl get pods
Jeśli żadne pody nie działają, poczekaj kilka sekund i ponownie wylistuj pody. Możesz kontynuować, gdy zobaczysz działający jeden pod.
Następnie, aby zobaczyć, jakie kontenery znajdują się w tym Podzie i jakie obrazy
są używane do budowy tych kontenerów, uruchamiamy polecenie kubectl describe pods:
kubectl describe pods
Widzimy tutaj szczegóły dotyczące kontenera Pod: adres IP, używane porty oraz listę zdarzeń związanych z cyklem życia Poda.
Wyjście komendy describe jest obszerne i obejmuje niektóre pojęcia, których jeszcze nie
omawialiśmy, ale nie martw się tym, bo staną się one zrozumiałe przed końcem tego bootcampu.
Informacja:
Komendadescribe może być używana do uzyskania szczegółowych informacji o większości
obiektów Kubernetesa, w tym o Węzłach, Podach i Deploymentach. Wyjście komendy
describe jest zaprojektowane tak, aby było czytelne dla ludzi, a nie do wykorzystania w skryptach.Pokazywanie aplikacji w terminalu
Pamiętaj, że Pody działają w izolowanej, prywatnej sieci - więc musimy
przepuścić do nich dostęp, aby móc je debugować i wchodzić z nimi w interakcję. Aby
to zrobić, użyjemy polecenia kubectl proxy, aby uruchomić proxy w
drugim terminalu. Otwórz nowe okno terminala, a w tym nowym terminalu uruchom:
kubectl proxy
Teraz ponownie uzyskamy nazwę Poda i zapytamy ten pod bezpośrednio przez
proxy. Aby uzyskać nazwę Poda i zapisać ją w zmiennej środowiskowej POD_NAME:
export POD_NAME="$(kubectl get pods -o go-template --template '{{range .items}}{{.metadata.name}}{{"\n"}}{{end}}')"
echo Name of the Pod: $POD_NAME
Aby zobaczyć wyniki działania naszej aplikacji, wykonaj polecenie curl:
curl http://localhost:8001/api/v1/namespaces/default/pods/$POD_NAME:8080/proxy/
URL jest ścieżką do API Poda.
Informacja:
Nie musimy określać nazwy kontenera, ponieważ wewnątrz poda mamy tylko jeden kontener.Wykonywanie polecenia w kontenerze
Możemy wykonywać polecenia bezpośrednio na kontenerze po
uruchomieniu i działaniu Poda. Do tego celu używamy podpolecenia exec i
używamy nazwy Poda jako parametru. Wymieńmy zmienne środowiskowe:
kubectl exec "$POD_NAME" -- env
Warto ponownie wspomnieć, że nazwa samego kontenera może zostać pominięta, ponieważ w Podzie mamy tylko jeden kontener.
Następnie rozpocznijmy sesję bash w kontenerze Pod:
kubectl exec -ti $POD_NAME -- bash
Mamy teraz otwartą konsolę na kontenerze, w którym uruchamiamy naszą
aplikację NodeJS. Kod źródłowy aplikacji znajduje się w pliku server.js:
cat server.js
Możesz sprawdzić, czy aplikacja działa, wykonując polecenie curl:
curl http://localhost:8080
Informacja:
Użyliśmy tutajlocalhost, ponieważ wykonaliśmy polecenie wewnątrz Podu
NodeJS. Jeśli nie możesz połączyć się z localhost:8080, upewnij się, że uruchomiłeś
polecenie kubectl exec i wykonujesz polecenie z wnętrza Podu.Aby zamknąć połączenie z kontenerem, wpisz exit.
Co dalej?
5.2.4 - Udostępnianie aplikacji
5.2.4.1 - Jak używać Service do udostępniania aplikacji
Cele
- Dowiedz się, czym jest Service w Kubernetesie.
- Zrozum, jak etykiety (labels) i selektory (selectors) są powiązane z Service.
- Wystaw aplikację na zewnątrz klastra Kubernetesa.
Zanim zaczniesz
Polecenia w tym poradniku są napisane w składni zgodnej ze standardem POSIX, którą
obsługują domyślne powłoki w Linuxie i macOS (np. bash, zsh, sh). Jeśli
używasz Windowsa, potrzebujesz powłoki zgodnej z POSIX, np. WSL
Windows Subsystem for Linux (WSL) lub
Git Bash, żeby
uruchomić je w takiej formie. Polecenia z export, $() i podobnymi
elementami nie zadziałają w PowerShellu ani w zwykłym wierszu polecenia.
Kubernetes Services - przegląd
Pody Kubernetesa są nietrwałe. Pody mają swój cykl życia. Jeśli węzeł roboczy ulegnie awarii, tracone są wszystkie pody działające na węźle. Replicaset będzie próbował automatycznie doprowadzić klaster z powrotem do pożądanego stanu tworząc nowe pody i w ten sposób zapewnić działanie aplikacji. Innym przykładem może być system na back-endzie przetwarzania obrazów posiadający 3 repliki. Każda z tych replik jest wymienna - system front-endu nie powinien musieć pilnować replik back-endu ani tego, czy któryś z podów przestał działać i został odtworzony na nowo. Nie należy jednak zapominać o tym, że każdy Pod w klastrze Kubernetesa ma swój unikatowy adres IP, nawet pody w obrębie tego samego węzła, zatem powinna istnieć metoda automatycznego uzgadniania zmian pomiędzy podami, aby aplikacja mogła dalej funkcjonować.
Serwis (ang. Service) w Kubernetesie
jest abstrakcyjnym obiektem, która definiuje logiczny zbiór podów oraz politykę dostępu
do nich. Serwisy pozwalają na swobodne łączenie zależnych podów. Serwis jest
zdefiniowany w YAMLu lub w JSONie - tak, jak wszystkie obiekty Kubernetesa. Zbiór podów, które
obsługuje Serwis, jest zazwyczaj określany przez LabelSelector (poniżej opisane
jest, w jakich przypadkach możesz potrzebować zdefiniować Serwis bez specyfikowania selektora).
Mimo, że każdy pod ma swój unikatowy adres IP, te adresy nie są dostępne poza klastrem, o ile nie
zostaną wystawione za pomocą Serwisu. Serwis umożliwia aplikacji przyjmować ruch przychodzący.
Serwisy mogą być wystawiane na zewnątrz na kilka różnych sposobów, poprzez określenie typu w ServiceSpec:
ClusterIP (domyślnie) - Wystawia serwis poprzez wewnętrzny adres IP w klastrze. W ten sposób serwis jest dostępny tylko wewnątrz klastra.
NodePort - Wystawia serwis na tym samym porcie na każdym z wybranych węzłów klastra przy pomocy NAT. W ten sposób serwis jest dostępny z zewnątrz klastra poprzez
NodeIP:NodePort. Nadzbiór ClusterIP.LoadBalancer - Tworzy zewnętrzny load balancer u bieżącego dostawcy usług chmurowych (o ile jest taka możliwość) i przypisuje serwisowi stały, zewnętrzny adres IP. Nadzbiór NodePort.
ExternalName - Przypisuje Service do
externalName(np.foo.bar.example.com), zwracając rekordCNAMEwraz z zawartością. W tym przypadku nie jest wykorzystywany proces przekierowania ruchu metodą proxy. Ta metoda wymagakube-dnsw wersji v1.7 lub wyższej lub CoreDNS w wersji 0.0.8 lub wyższej.
Więcej informacji na temat różnych typów serwisów znajduje się w samouczku Używanie adresu źródłowego (Source IP). Warto też zapoznać się z Łączeniem Aplikacji z Serwisami.
W pewnych przypadkach w serwisie nie specyfikuje się selector.
Serwis, który został stworzony bez pola selector, nie utworzy
odpowiedniego obiektu Endpoints. W ten sposób użytkownik ma możliwość ręcznego
przyporządkowania serwisu do konkretnych endpoints. Inny przypadek,
kiedy nie używa się selektora, ma miejsce, kiedy stosujemy type: ExternalName.
Sewisy i Etykiety (Labels)
Serwis kieruje przychodzący ruch do grupy Podów. Serwisy są obiektami abstrakcyjnymi, dzięki czemu Pody, które z jakichś powodów przestały działać i zostały zastąpione przez Kubernetesa nowymi instancjami, nie wpłyną ujemnie na działanie twoich aplikacji. Detekcją nowych podów i kierowaniem ruchu pomiędzy zależnymi podami (takimi, jak składowe front-end i back-end w aplikacji) zajmują się Serwisy Kubernetesa.
Serwis znajduje zestaw odpowiednich Podów przy pomocy etykiet i selektorów, podstawowych jednostek grupujących, które umożliwiają operacje logiczne na obiektach Kubernetesa. Etykiety to pary klucz/wartość przypisane do obiektów. Mogą być używane na różne sposoby:
- Dzielić obiekty na deweloperskie, testowe i produkcyjne
- Osadzać znaczniki (tags) określające wersje
- Klasyfikować obiekty przy użyciu znaczników

Obiekty mogą być oznaczane etykietami w momencie tworzenia lub później. Etykiety mogą być zmienianie w dowolnej chwili. Udostępnijmy teraz naszą aplikację przy użyciu Serwisu i oznaczmy ją odpowiednimi etykietami.
Krok 1: Tworzenie nowej Usługi
Sprawdźmy, czy nasza aplikacja działa. Użyjemy
polecenia kubectl get i sprawdzimy istniejące Pody:
kubectl get pods
Jeśli żadne Pody nie działają, oznacza to, że obiekty z poprzednich samouczków zostały usunięte. W takim przypadku wróć i odtwórz wdrożenie z samouczka Używanie kubectl do tworzenia Deploymentu. Proszę poczekać kilka sekund i ponownie wylistować Pody. Możesz kontynuować, gdy zobaczysz działający jeden Pod.
Następnie wymieńmy aktualne usługi z naszego klastra:
kubectl get services
Aby utworzyć nową usługę i udostępnić ją dla ruchu zewnętrznego, użyjemy polecenia expose z parametrem --type=NodePort:
kubectl expose deployment/kubernetes-bootcamp --type="NodePort" --port 8080
Mamy teraz działającą usługę o nazwie kubernetes-bootcamp. Tutaj widzimy, że usługa otrzymała unikalny cluster-IP, wewnętrzny port oraz zewnętrzny-IP (IP węzła).
Aby dowiedzieć się, który port został otwarty zewnętrznie (dla type: NodePort
usługi), uruchomimy komendę describe service:
kubectl describe services/kubernetes-bootcamp
Utwórz zmienną środowiskową o nazwie
NODE_PORT, która ma wartość przypisanego portu węzła:
export NODE_PORT="$(kubectl get services/kubernetes-bootcamp -o go-template='{{(index .spec.ports 0).nodePort}}')"
echo "NODE_PORT=$NODE_PORT"
Teraz możemy przetestować, czy aplikacja jest wystawiona poza
klaster, używając curl, adresu IP węzła i zewnętrznie wystawionego portu:
curl http://"$(minikube ip):$NODE_PORT"
Informacja:
Jeśli używasz minikube z Docker Desktop jako sterownik kontenerów, potrzebny jest tunel minikube. Dzieje się tak, ponieważ kontenery wewnątrz Docker Desktop są izolowane od twojego komputera głównego.
W osobnym oknie terminala wykonaj:
minikube service kubernetes-bootcamp --url
Wyjście wygląda następująco:
http://127.0.0.1:51082
! Because you are using a Docker driver on darwin, the terminal needs to be open to run it.
Następnie użyj podanego URL-a, aby uzyskać dostęp do aplikacji:
curl 127.0.0.1:51082
Otrzymaliśmy odpowiedź od serwera. Usługa jest wystawiona.
Krok 2: Używanie etykiet
Deployment automatycznie utworzył etykietę dla naszego Poda. Za pomocą
komendy describe deployment możesz zobaczyć nazwę (klucz) tej etykiety:
kubectl describe deployment
Użyjmy tej etykiety, aby zapytać o naszą listę Podów. Skorzystamy z
polecenia kubectl get pods z parametrem -l, a następnie wartościami etykiet:
kubectl get pods -l app=kubernetes-bootcamp
Możesz zrobić to samo, aby wyświetlić istniejące Usługi:
kubectl get services -l app=kubernetes-bootcamp
Pobierz nazwę Pod i zapisz ją w zmiennej środowiskowej POD_NAME:
export POD_NAME="$(kubectl get pods -o go-template --template '{{range .items}}{{.metadata.name}}{{"\n"}}{{end}}')"
echo "Name of the Pod: $POD_NAME"
Aby zastosować nową etykietę, używamy komendy label, po
której następuje typ obiektu, nazwa obiektu i nowa etykieta:
kubectl label pods "$POD_NAME" version=v1
To zastosuje nową etykietę do naszego poda (przypięliśmy wersję
aplikacji do poda), a możemy to sprawdzić za pomocą polecenia describe pod:
kubectl describe pods "$POD_NAME"
Widzimy tutaj, że etykieta jest teraz przypisana do naszego Poda. Możemy teraz zapytać o listę podów, używając nowej etykiety:
kubectl get pods -l version=v1
I widzimy Pod.
Krok 3: Usuwanie usługi
Aby usunąć Usługi, można użyć polecenia
delete service. Etykiety mogą być również używane tutaj:
kubectl delete service -l app=kubernetes-bootcamp
Potwierdź, że Usługa została usunięta:
kubectl get services
To potwierdza, że nasza usługa została usunięta. Aby upewnić się, że trasa nie
jest już wystawiona, możesz użyć curl na wcześniej wystawionym adresie IP i porcie:
curl http://"$(minikube ip):$NODE_PORT"
To dowodzi, że aplikacja nie jest już dostępna z zewnątrz klastra.
Możesz potwierdzić, że aplikacja nadal działa za pomocą curl z wnętrza poda:
kubectl exec -ti $POD_NAME -- curl http://localhost:8080
Widzimy tutaj, że aplikacja jest uruchomiona. Dzieje się tak, ponieważ aplikacją zarządza Deployment. Aby wyłączyć aplikację, należy również usunąć Deployment.
Co dalej?
Samouczek Uruchamianie wielu instancji aplikacji.
Dowiedz się więcej o Usłudze.
5.2.5 - Skalowanie aplikacji
5.2.5.1 - Uruchamianie wielu instancji aplikacji
Cele
- Ręczne skalowanie istniejącej aplikacji za pomocą narzędzia kubectl.
Zanim zaczniesz
Polecenia w tym poradniku są napisane w składni zgodnej ze standardem POSIX, którą
obsługują domyślne powłoki w Linuxie i macOS (np. bash, zsh, sh). Jeśli
używasz Windowsa, potrzebujesz powłoki zgodnej z POSIX, np. WSL
Windows Subsystem for Linux (WSL) lub
Git Bash, żeby
uruchomić je w takiej formie. Polecenia z export, $() i podobnymi
elementami nie zadziałają w PowerShellu ani w zwykłym wierszu polecenia.
Skalowanie aplikacji
Poprzednio stworzyliśmy Deployment i udostępniliśmy go publicznie korzystając z Service. Deployment utworzył tylko jeden Pod, w którym uruchomiona jest nasza aplikacja. Wraz ze wzrostem ruchu, będziemy musieli wyskalować aplikację, aby była w stanie obsłużyć zwiększone zapotrzebowanie użytkowników.
Jeśli nie pracowałeś z wcześniejszymi sekcjami, zacznij od sekcji Jak użyć Minikube do stworzenia klastra.
Skalowanie polega na zmianie liczby replik w Deploymencie.
Informacja:
Jeśli próbujesz to zrobić po
poprzedniej sekcji,
mogłeś usunąć utworzoną usługę lub utworzyłeś usługę
typu NodePort. W tej sekcji zakłada się, że dla
wdrożenia kubernetes-bootcamp utworzono usługę o typie: LoadBalancer.
Jeśli nie usunąłeś usługi utworzonej w
poprzedniej sekcji,
najpierw usuń ją, a następnie uruchom następujące
polecenie, aby utworzyć nową z ustawionym typem na LoadBalancer:
kubectl expose deployment/kubernetes-bootcamp --type="LoadBalancer" --port 8080
Ogólnie o skalowaniu


Kiedy zwiększamy skalę Deploymentu, uruchomienie nowych Podów jest zlecane na Węzłach, które posiadają odpowiednio dużo zasobów. Operacja skalowania zwiększy liczbę Podów do oczekiwanej wartości. W Kubernetesie możliwe jest również autoskalowanie Podów, ale jest ono poza zakresem niniejszego samouczka. Istnieje także możliwość skalowania do zera - w ten sposób zatrzymane zostaną wszystkie Pody należące do konkretnego Deploymentu.
Kiedy działa jednocześnie wiele instancji jednej aplikacji, należy odpowiednio rozłożyć ruch pomiędzy każdą z nich. Serwisy posiadają zintegrowany load-balancer, który dystrybuuje ruch na wszystkie Pody w Deployment wystawionym na zewnątrz. Serwis prowadzi ciągły monitoring Podów poprzez ich punkty dostępowe (endpoints), aby zapewnić, że ruch kierowany jest tylko do tych Podów, które są faktycznie dostępne.
Kiedy aplikacja ma uruchomioną więcej niż jedną instancję, można prowadzić ciągłe aktualizacje (Rolling updates) bez przerw w działaniu aplikacji. O tym będzie mowa w następnej sekcji.
Skalowanie Deploymentu
Aby wyświetlić listę swoich Deploymentów, użyj komendy get deployments:
kubectl get deployments
Wynik powinien wyglądać podobnie do:
NAME READY UP-TO-DATE AVAILABLE AGE
kubernetes-bootcamp 1/1 1 1 11m
Powinniśmy mieć 1 Pod. Jeśli nie, uruchom polecenie ponownie. To pokazuje:
- NAME wyświetla nazwy Deploymentów w klastrze.
- READY pokazuje stosunek replik bieżących (ang. CURRENT) do oczekiwanych (ang. DESIRED).
- UP-TO-DATE wyświetla liczbę replik zaktualizowanych w celu osiągnięcia pożądanego stanu.
- AVAILABLE pokazuje, ile replik aplikacji jest dostępnych dla użytkowników.
- AGE pokazuje, jak długo aplikacja jest uruchomiona.
Aby zobaczyć ReplicaSet utworzony przez Deployment, uruchom:
kubectl get rs
Zauważ, że nazwa ReplicaSet jest zawsze sformatowana jako
Dwie istotne kolumny tego wyniku to:
- DESIRED pokazuje żądaną liczbę replik aplikacji, którą określasz podczas tworzenia Deploymentu. Jest to pożądany stan.
- CURRENT pokazuje, ile replik obecnie działa.
Następnie skalujemy Deployment do 4 replik. Użyjemy polecenia
kubectl scale, po którym podajemy typ Deployment, nazwę i pożądaną liczbę instancji:
kubectl scale deployments/kubernetes-bootcamp --replicas=4
Aby ponownie wyświetlić listę swoich Deploymentów, użyj get deployments:
kubectl get deployments
Zmiana została zastosowana i mamy 4 dostępne instancje aplikacji. Następnie sprawdźmy, czy liczba Podów uległa zmianie:
kubectl get pods -o wide
Obecnie są 4 Pody, z różnymi adresami IP. Zmiana została zarejestrowana
w dzienniku zdarzeń Deploymentu. Aby to sprawdzić, użyj komendy describe:
kubectl describe deployments/kubernetes-bootcamp
Możesz również zauważyć w wyniku tego polecenia, że obecnie istnieją 4 repliki.
Równoważenie obciążenia
Sprawdźmy, czy usługa równoważy obciążenie ruchem. Aby dowiedzieć się, jaki jest wystawiony adres
IP i port, możemy użyć opcji describe service, jak nauczyliśmy się w poprzedniej części samouczka:
kubectl describe services/kubernetes-bootcamp
Utwórz zmienną środowiskową o nazwie NODE_PORT, która ma wartość jako port węzła:
export NODE_PORT="$(kubectl get services/kubernetes-bootcamp -o go-template='{{(index .spec.ports 0).nodePort}}')"
echo NODE_PORT=$NODE_PORT
Następnie wykonamy polecenie curl na wystawiony adres IP i port. Wykonaj to polecenie wielokrotnie:
curl http://"$(minikube ip):$NODE_PORT"
Za każdym razem trafiamy na inny Pod z każdym żądaniem. To pokazuje, że równoważenie obciążenia działa.
Wynik powinien wyglądać podobnie do:
Hello Kubernetes bootcamp! | Running on: kubernetes-bootcamp-644c5687f4-wp67j | v=1
Hello Kubernetes bootcamp! | Running on: kubernetes-bootcamp-644c5687f4-hs9dj | v=1
Hello Kubernetes bootcamp! | Running on: kubernetes-bootcamp-644c5687f4-4hjvf | v=1
Hello Kubernetes bootcamp! | Running on: kubernetes-bootcamp-644c5687f4-wp67j | v=1
Hello Kubernetes bootcamp! | Running on: kubernetes-bootcamp-644c5687f4-4hjvf | v=1
Informacja:
Jeśli używasz minikube z Docker Desktop jako sterownika kontenerów, potrzebny jest tunel minikube. Wynika to z faktu, że kontenery w Docker Desktop są izolowane od Twojego hosta.
W osobnym oknie terminala, wykonaj:
minikube service kubernetes-bootcamp --url
Wynik wygląda następująco:
http://127.0.0.1:51082
! Because you are using a Docker driver on darwin, the terminal needs to be open to run it.
Następnie użyj podany URL, aby uzyskać dostęp do aplikacji:
curl 127.0.0.1:51082
Zmniejsz Skalę
Aby zmniejszyć skalowalność Deployment do 2 replik, ponownie uruchom komendę scale:
kubectl scale deployments/kubernetes-bootcamp --replicas=2
Wyświetl listę Deploymentów, aby sprawdzić, czy zmiana została zastosowana, za pomocą komendy get deployments:
kubectl get deployments
Liczba replik zmniejszyła się do 2. Wyświetl listę liczby Podów za pomocą get pods:
kubectl get pods -o wide
To potwierdza, że 2 Pody zostały zakończone.
Co dalej?
Samouczek Aktualizacje Rolling Update.
Dowiedz się więcej o ReplicaSet.
Dowiedz się więcej o Autoskalowaniu.
5.2.6 - Aktualizowanie aplikacji
5.2.6.1 - Aktualizacje Rolling Update
Cele
Wykonaj aktualizację Rolling Update używając kubectl.
Zanim zaczniesz
Polecenia w tym poradniku są napisane w składni zgodnej ze standardem POSIX, którą
obsługują domyślne powłoki w Linuxie i macOS (np. bash, zsh, sh). Jeśli
używasz Windowsa, potrzebujesz powłoki zgodnej z POSIX, np. WSL
Windows Subsystem for Linux (WSL) lub
Git Bash, żeby
uruchomić je w takiej formie. Polecenia z export, $() i podobnymi
elementami nie zadziałają w PowerShellu ani w zwykłym wierszu polecenia.
Aktualizowanie aplikacji
Użytkownicy oczekują, że aplikacje są dostępne non-stop, a deweloperzy chcieliby móc wprowadzać nowe wersje nawet kilka razy dziennie. W Kubernetesie jest to możliwe dzięki mechanizmowi płynnych aktualizacji (rolling updates). Rolling updates pozwala prowadzić aktualizację w ramach Deploymentu bez przerw w jego działaniu. Odbywa się to dzięki krokowemu zastępowaniu kolejnych Podów. Nowe Pody uruchamiane są na Węzłach, które posiadają wystarczające zasoby, a Kubernetes czeka, aż uruchomią się nowe Pody, zanim usunie stare.
W poprzednim module wyskalowaliśmy aplikację aby była uruchomiona na wielu instancjach. To niezbędny wymóg, aby móc prowadzić aktualizacje bez wpływu na dostępność aplikacji. Domyślnie, maksymalna liczba Podów, które mogą być niedostępne w trakcie aktualizacji oraz Podów, które mogą być tworzone, wynosi jeden. Obydwie opcje mogą być zdefiniowane w wartościach bezwzględnych lub procentowych (ogólnej liczby Podów). W Kubernetesie, każda aktualizacja ma nadany numer wersji i każdy Deployment może być wycofany do wersji poprzedniej (stabilnej).
Ogólnie o Rolling updates




Podczas płynnych aktualizacji (ang. rolling update) utrzymywana jest dostępność aplikacji przez kierowanie ruchu wyłącznie do Podów obsługujących żądania. Rolling update umożliwia następujące działania:
- Promocję aplikacji z jednego środowiska do innego (poprzez aktualizację obrazu kontenera)
- Wycofywanie się do poprzedniej wersji
- Continuous Integration oraz Continuous Delivery aplikacji bez przerw w jej działaniu
W ramach tego interaktywnego samouczka zaktualizujemy aplikację do nowej wersji, a następnie wycofamy tę aktualizację.
Zaktualizuj wersję aplikacji
Aby wyświetlić listę swoich Deploymentów, uruchom komendę get deployments:
kubectl get deployments
Aby wyświetlić listę uruchomionych Podów, użyj komendy get pods:
kubectl get pods
Aby zobaczyć bieżącą wersję obrazu aplikacji,
uruchom komendę describe pods i poszukaj pola Image:
kubectl describe pods
Aby zaktualizować obraz aplikacji do wersji 2, użyj komendy
set image, podając nazwę Deploymentu oraz nową wersję obrazu:
kubectl set image deployments/kubernetes-bootcamp kubernetes-bootcamp=docker.io/jocatalin/kubernetes-bootcamp:v2
Polecenie zainicjowało rolling update Deploymentu, aktualizując obraz
aplikacji. Sprawdź status nowych Podów i zobacz, jak
postępuje wyłączanie poprzednich wersji używając polecenia get pods:
kubectl get pods
Zweryfikuj aktualizację
Najpierw sprawdź, czy usługa działa, ponieważ mogłeś ją usunąć w
poprzednim kroku samouczka, uruchom
describe services/kubernetes-bootcamp. Jeśli jej brakuje, możesz ją ponownie utworzyć za pomocą:
kubectl expose deployment/kubernetes-bootcamp --type="NodePort" --port 8080
Utwórz zmienną środowiskową o nazwie NODE_PORT,
która będzie miała wartość przypisanego portu Węzła:
export NODE_PORT="$(kubectl get services/kubernetes-bootcamp -o go-template='{{(index .spec.ports 0).nodePort}}')"
echo "NODE_PORT=$NODE_PORT"
Następnie wykonaj polecenie curl na udostępniony adres IP i port:
curl http://"$(minikube ip):$NODE_PORT"
Z każdym uruchomieniem polecenia curl, trafisz na inny Pod. Zwróć
uwagę, że obecnie wszystkie Pody działają na najnowszej wersji (v2).
Możesz również potwierdzić aktualizację, uruchamiając komendę rollout status:
kubectl rollout status deployments/kubernetes-bootcamp
Aby wyświetlić bieżącą wersję obrazu aplikacji, uruchom komendę describe pods:
kubectl describe pods
W polu Image sprawdź, czy
używasz najnowszej wersji obrazu (v2).
Cofnięcie aktualizacji
Wykonajmy kolejną aktualizację i spróbujmy wdrożyć obraz oznaczony tagiem v10:
kubectl set image deployments/kubernetes-bootcamp kubernetes-bootcamp=gcr.io/google-samples/kubernetes-bootcamp:v10
Użyj get deployments, aby zobaczyć status Deploymentu:
kubectl get deployments
Zauważ, że w jest za mało Podów działających poprawnie.
Uruchom komendę get pods, aby wyświetlić listę wszystkich Podów:
kubectl get pods
Zauważ, że niektóre z podów mają status ImagePullBackOff.
Aby uzyskać więcej informacji na temat problemu, uruchom komendę describe pods:
kubectl describe pods
W sekcji Events dla podów, zauważ, że
wersja obrazu v10 nie istniała w repozytorium.
Aby wycofać wdrożenie do ostatniej
działającej wersji, użyj komendy rollout undo:
kubectl rollout undo deployments/kubernetes-bootcamp
Polecenie rollout undo przywraca Deployment do poprzedniego znanego
stanu (v2 obrazu). Aktualizacje są wersjonowane i
można je cofać do dowolnego wcześniej znanego stanu Deploymentu.
Użyj polecenia get pods, aby ponownie wyświetlić listę Podów:
kubectl get pods
Aby sprawdzić obraz wdrożony na działających Podach, użyj polecenia describe pods:
kubectl describe pods
Deployment ponownie używa stabilnej wersji
aplikacji (v2). Wycofanie zakończyło się pomyślnie.
Pamiętaj o oczyszczeniu lokalnego klastra.
kubectl delete deployments/kubernetes-bootcamp services/kubernetes-bootcamp
Co dalej?
- Dowiedz się więcej o Deploymentach.
6 - Materiały źródłowe
Tutaj znajdziesz dokumentację źródłową Kubernetesa.
Dokumentacja API
Glossary - Pełna, zestandaryzowana lista terminologii Kubernetesa
Using The Kubernetes API - ogólne informacje na temat API Kubernetesa
API access control - szczegóły dotyczące kontroli dostępu do API Kubernetesa
Oficjalnie wspierane biblioteki klienckie
Aby wywołać Kubernetes API z wybranego języka programowania, możesz skorzystać z bibliotek klienckich. Oficjalnie wspierane biblioteki to:
- Kubernetes Go client library
- Kubernetes Python client library
- Kubernetes Java client library
- Kubernetes JavaScript client library
- Kubernetes C# client library
- Kubernetes Haskell client library
Polecenia tekstowe (CLI)
- kubectl - Główne narzędzie tekstowe (linii poleceń) do zarządzania klastrem Kubernetes.
- JSONPath - Podręcznik składni wyrażeń JSONPath dla kubectl.
- kubeadm - Narzędzie tekstowe do łatwego budowania klastra Kubernetes spełniającego niezbędne wymogi bezpieczeństwa.
Komponenty
kubelet - Główny agent działający na każdym węźle. Kubelet pobiera zestaw definicji PodSpecs i gwarantuje, że opisane przez nie kontenery poprawnie działają.
kube-apiserver - REST API, które sprawdza poprawność i konfiguruje obiekty API, takie jak pody, serwisy czy kontrolery replikacji.
kube-controller-manager - Proces wykonujący główne pętle sterowania Kubernetesa.
kube-proxy - Przekazuje bezpośrednio dane przepływające w transmisji TCP/UDP lub dystrybuuje ruch TCP/UDP zgodnie ze schematem round-robin pomiędzy usługi back-endu.
kube-scheduler - Scheduler odpowiada za dostępność, wydajność i zasoby.
Spis portów i protokołów, które muszą być otwarte dla warstwy sterowania i na węzłach roboczych.
API konfiguracji
W tej części zebrano "niepublikowane" API, które służą do konfiguracji komponentów Kubernetesa lub innych narzędzi. Choć większość tych API nie jest udostępniane przez serwer API w trybie RESTful, są one niezbędne dla użytkowników i administratorów w korzystaniu i zarządzaniu klastrem.
- kubeconfig (v1)
- kuberc (v1alpha1) i kuberc (v1beta1)
- kube-apiserver admission (v1)
- kube-apiserver configuration (v1alpha1), kube-apiserver configuration (v1beta1) i kube-apiserver configuration (v1)
- kube-apiserver event rate limit (v1alpha1)
- kubelet configuration (v1alpha1), kubelet configuration (v1beta1) i kubelet configuration (v1)
- kubelet credential providers (v1)
- kube-scheduler configuration (v1)
- kube-controller-manager configuration (v1alpha1)
- kube-proxy configuration (v1alpha1)
audit.k8s.io/v1API- Client authentication API (v1beta1) i Client authentication API (v1)
- WebhookAdmission configuration (v1)
- ImagePolicy API (v1alpha1)
API konfiguracji dla kubeadm
Zewnętrzne API
Istnieją API, które zostały zdefiniowane w ramach projektu Kubernetes, ale nie zostały zaimplementowane przez główny projekt:
Dokumentacja projektowa
Archiwum dokumentacji projektowej różnych funkcjonalności Kubernetes. Warto zacząć od Kubernetes Architecture oraz Kubernetes Design Overview.
Kodowanie
Narzędzia takie jak kubectl mogą współpracować z różnymi formatami / kodowaniami. Obejmują one:
- CBOR, używany w sieci, ale nie dostępny jako format wyjściowy dla kubectl
- Zobacz kodowanie zasobów CBOR
- JSON, dostępny jako format wyjściowy
kubectli używany również na warstwie HTTP - KYAML, dialekt YAML używany w Kubernetesie
- KYAML jest w istocie formatem wyjściowym; wszędzie tam, gdzie do Kubernetesa można przekazać KYAML, można również użyć dowolnego innego poprawnego wejścia w formacie YAML.
- YAML, dostępny jako format wyjściowy
kubectli również używany na warstwie HTTP
Kubernetes ma również własne kodowanie protobuf, które jest używane wyłącznie w ramach komunikatów HTTP.
Narzędzie kubectl obsługuje inne formaty wyjściowe, takie jak custom columns; patrz
formaty wyjściowe w dokumentacji referencyjnej kubectl.
6.1 - Słownik
7 - Współtwórz dokumentację K8s
Istnieje wiele sposobów, aby wnieść wkład do Kubernetes. Możesz pracować nad projektami nowych funkcji, możesz dokumentować kod, który już mamy, możesz pisać do naszych blogów. Jest więcej: możesz implementować te nowe funkcje lub naprawiać błędy. Możesz pomóc ludziom dołączyć do naszej społeczności współtwórców lub wspierać istniejących współtwórców.
We wszystkich tych sposobach, aby mieć wpływ na projekt, my - Kubernetes - stworzyliśmy dedykowaną stronę internetową: https://k8s.dev/. Możesz tam przejść, aby dowiedzieć się więcej o wnoszeniu wkładu do Kubernetes.
Jeśli chcesz dowiedzieć się, jak wnosić wkład do dokumentacji lub innych części tej strony, przeczytaj Wnoszenie wkładu do dokumentacji Kubernetes. Jeśli chcesz pomóc przy oficjalnych blogach Kubernetesa, przeczytaj Wnoszenie wkładu do blogów Kubernetesa.
Możesz również przeczytać CNCF stronę o wnoszeniu wkładu do Kubernetes.
7.1 - Współtworzenie dokumentacji Kubernetes
Ta strona jest utrzymywana przez Kubernetes SIG Docs. Projekt Kubernetes chętnie przyjmie pomoc od wszystkich współtwórców, zarówno nowych, jak i doświadczonych!
Współtwórcy dokumentacji Kubernetesa:
- Ulepszają istniejącą treść
- Tworzą nowe treści
- Tłumaczą dokumentację
- Zarządzają i publikują części dokumentacji cyklu wydawniczego Kubernetesa
Zespół blogowy, będący częścią SIG Docs, pomaga zarządzać oficjalnymi blogami. Aby dowiedzieć się więcej, przeczytaj jak współtworzyć blogi Kubernetesa.
Informacja:
Aby dowiedzieć się więcej o kontrybucji w Kubernetesach, zobacz ogólną dokumentację współtwórców.Rozpoczęcie pracy
Każdy może otworzyć zgłoszenie dotyczące
dokumentacji lub wnieść zmianę za pomocą pull request
(PR) w repozytorium kubernetes/website na GitHubie.
Musisz umieć
sprawnie korzystać z
git i GitHub,
aby efektywnie pracować w społeczności Kubernetesa.
Aby zaangażować się w tworzenie dokumentacji:
- Podpisz umowę licencyjną współtwórcy CNCF.
- Zapoznaj się z repozytorium dokumentacji oraz generatorem statycznych stron witryny.
- Upewnij się, że rozumiesz podstawowe procesy otwierania pull requesta i przeglądania zmian.
flowchart TB subgraph third[Otwórz PR] direction TB U[ ] -.- Q[Popraw treść] --- N[Utwórz treść] N --- O[Tłumacz dokumentację] O --- P[Zarządzaj/publikuj części dokumentówRysunek 1. Jak zacząć jako nowy współtwórca.
w cyklu wydania K8s] end subgraph second[Przegląd] direction TB T[ ] -.- D[Przejrzyj repozytorium
kubernetes/website] --- E[Sprawdź generator
stron statycznych Hugo] E --- F[Zrozum podstawowe
komendy GitHub] F --- G[Przejrzyj otwarte PR
i procesy przeglądu zmian] end subgraph first[Rejestracja] direction TB S[ ] -.- B[Podpisz umowę o
licencję wniesienia
wkładu CNCF] --- C[Dołącz do kanału
Slack sig-docs] C --- V[Dołącz do listy
mailowej kubernetes-sig-docs] V --- M[Uczestnicz w cotygodniowych
spotkaniach sig-docs
lub spotkaniach na Slacku] end A([fa:fa-user Nowy
Współtwórca]) --> first A --> second A --> third A --> H[Pytaj!!!] classDef grey fill:#dddddd,stroke:#ffffff,stroke-width:px,color:#000000, font-size:15px; classDef white fill:#ffffff,stroke:#000,stroke-width:px,color:#000,font-weight:bold classDef spacewhite fill:#ffffff,stroke:#fff,stroke-width:0px,color:#000 class A,B,C,D,E,F,G,H,M,Q,N,O,P,V grey class S,T,U spacewhite class first,second,third white
Rysunek 1 przedstawia plan działania dla nowych współtwórców. Możesz
podążać za niektórymi lub wszystkimi krokami dotyczącymi Sign up i
Review. Teraz możesz otwierać PR spełniające Twoje cele kontrybucji -
niektóre z nich znajdziesz w sekcji Open PR. Jak zawsze, pytania są mile widziane!
Niektóre zadania wymagają większego zaufania i większego dostępu w organizacji Kubernetes. Zobacz Udział w SIG Docs po więcej szczegółów na temat ról i uprawnień.
Twoja pierwsza kontrybucja
Aby przygotować się do twojej pierwszej kontrybucji, warto wcześniej przeanalizować kilka kroków. Rysunek 2 przedstawia ich schemat, a szczegółowe informacje znajdują się poniżej.
flowchart LR
subgraph second[Pierwszy wkład]
direction TB
S[ ] -.-
G[Przeglądaj PR od innych
członków K8s] -->
A[Sprawdź listę zgłoszeń
kubernetes/website
dobre na pierwszy PR] --> B[Otwórz PR!!]
end
subgraph first[Zalecane przygotowanie]
direction TB
T[ ] -.-
D[Przeczytaj współtworzenie nowych treści] -->E[Przeczytaj przewodniki
po treści K8s i stylach]
E --> F[Poznaj typy treści
stron Hugo
i shortcode'y]
end
first ----> second
classDef grey fill:#dddddd,stroke:#ffffff,stroke-width:px,color:#000000, font-size:15px;
classDef white fill:#ffffff,stroke:#000,stroke-width:px,color:#000,font-weight:bold
classDef spacewhite fill:#ffffff,stroke:#fff,stroke-width:0px,color:#000
class A,B,D,E,F,G grey
class S,T spacewhite
class first,second white
Rysunek 2. Przygotowanie do twojej pierwszej kontrybucji.- Przeczytaj Współtworzenie nowych treści, aby dowiedzieć się o różnych sposobach, w jakie możesz wnieść wkład.
- Sprawdź listę problemów
kubernetes/website, aby znaleźć problemy, które są dobrymi punktami wyjścia. - Otwórz pull request używając GitHub do istniejącej dokumentacji i dowiedz się więcej o zgłaszaniu problemów na GitHub.
- Przeglądaj pull requesty od innych członków społeczności Kubernetesa pod kątem dokładności i języka.
- Przeczytaj przewodnik treści i przewodniki stylu dla Kubernetesa, aby móc zostawiać merytoryczne komentarze.
- Dowiedz się więcej o typach treści stron i shortcode`ach Hugo.
Uzyskiwanie pomocy przy współtworzeniu
Rozpoczęcie współpracy nad projektem może być wyzwaniem.
Ambasadorzy Nowych Współtwórców pomogą Ci
przejść przez pierwsze kroki. Możesz skontaktować się z nimi na
Kubernetes Slack, najlepiej na kanale #sig-docs. Istnieje również rozmowa powitalna dla nowych współtwórców,
która
odbywa się w pierwszy wtorek każdego miesiąca. Możesz tu
wchodzić w interakcje z Ambasadorami Nowych Współtwórców i uzyskać odpowiedzi na swoje pytania.
Zaangażuj się w SIG Docs.
SIG Docs to grupa współtwórców, którzy publikują i utrzymują dokumentację Kubernetesa oraz stronę internetową. Zaangażowanie się w SIG Docs to doskonały sposób dla współtwórców Kubernetes (rozwój funkcji lub inne) na wywarcie dużego wpływu na projekt Kubernetesa.
SIG Dokumentacja komunikuje się za pomocą różnych metod:
- Dołącz do
#sig-docsna Slacku Kubernetes. I nie zapomnij się przedstawić! - Dołącz do listy mailingowej
kubernetes-sig-docs, gdzie odbywają się szersze dyskusje i zapisywane są oficjalne decyzje. - Dołącz do spotkania wideo SIG Docs odbywającego się
co dwa tygodnie. Spotkania są zawsze ogłaszane na
#sig-docsi dodawane do kalendarza spotkań społeczności Kubernetes. Będziesz musiał pobrać klienta Zoom lub zadzwonić z telefonu. - Dołącz do asynchronicznego spotkania SIG Docs na Slacku w tygodniach, kiedy
spotkanie wideo na Zoomie na żywo się nie odbywa. Spotkania są zawsze ogłaszane na
#sig-docs. Możesz wnieść swój wkład w dowolny z wątków do 24 godzin po ogłoszeniu spotkania.
Inne sposoby wnoszenia wkładu
- Odwiedź stronę społeczności Kubernetesa. Skorzystaj z Twittera lub Stack Overflow, dowiedz się o lokalnych spotkaniach i wydarzeniach Kubernetesa i nie tylko.
- Przeczytaj ściągawkę współtwórcy, aby zaangażować się w rozwój funkcji Kubernetesa.
- Odwiedź stronę dla współtwórców, aby dowiedzieć się więcej o współtwórcach Kubernetesa oraz dodatkowych zasobach dla współtwórców.
- Dowiedz się, jak współtworzyć oficjalne blogi
- Prześlij studium przypadku
Następne kroki.
Naucz się pracować z lokalną kopią repozytorium.
Zredaguj funkcje w wydaniu.
Weź udział w SIG Docs i zostań członkiem lub recenzentem.
Rozpocznij lub pomóż w lokalizacji.
7.2 - Zgłaszanie propozycji poprawy treści
Jeśli zauważysz problem z dokumentacją Kubernetesa lub masz pomysł na nową treść, otwórz zgłoszenie. Wszystko, czego potrzebujesz, to konto GitHub i przeglądarka internetowa.
W większości przypadków nowa praca nad dokumentacją Kubernetesa rozpoczyna się od zgłoszenia na GitHubie. Współtwórcy Kubernetesa następnie przeglądają, kategoryzują i tagują zgłoszenia. Następnie Ty lub inny członek społeczności Kubernetesa otwiera pull requesta z poprawkami rozwiązującymi problem.
Otwarcie zgłoszenia
Jeśli chcesz zasugerować ulepszenia do istniejącej treści lub zauważysz błąd, otwórz zgłoszenie.
- Kliknij link Create an issue na prawym pasku bocznym. Przekieruje Cię to na stronę z problemem w GitHub wstępnie wypełnioną kilkoma nagłówkami.
- Opisz problem lub sugestię poprawy. Podaj jak najwięcej szczegółów.
- Kliknij Submit new issue.
Po przesłaniu, od czasu do czasu sprawdzaj swoje zgłoszenie lub włącz powiadomienia GitHub. Recenzenci i inni członkowie społeczności mogą zadawać pytania, zanim będą mogli podjąć działania w sprawie Twojego zgłoszenia.
Sugestia nowej treści
Jeśli masz pomysł na nowe treści, ale nie jesteś pewien, gdzie powinny się one znaleźć, możesz nadal utworzyć zgłoszenie. Wykonaj jeden z kroków:
- Wybierz istniejącą stronę w sekcji, do której Twoim zdaniem należy treść, i kliknij Create an issue.
- Przejdź do GitHub i utwórz zgłoszenie bezpośrednio.
Jak tworzyć świetne zgłoszenia
Pamiętaj o następujących rzeczach przy zgłaszaniu problemu:
- Podaj jasny opis problemu. Opisz, co konkretnie jest brakujące, nieaktualne, błędne lub wymaga poprawy.
- Wyjaśnij, jaki konkretny wpływ ma ten problem na użytkowników.
- W przypadku problemów o dużym zakresie, podziel je na mniejsze zagadnienia, aby łatwiej było nad nimi pracować. Na przykład, "Napraw dokumentację dotyczącą bezpieczeństwa" jest zbyt ogólne, ale "Dodaj szczegóły do tematu 'Ograniczanie dostępu do sieci'" jest na tyle precyzyjne, by można było podjąć działanie.
- Przeszukaj istniejące zgłoszenia, aby sprawdzić, czy jest coś związanego lub podobnego do nowego zgłoszenia.
- Jeśli nowe zgłoszenie dotyczy innego zgłoszenia lub pull requesta,
odwołaj się do niego poprzez podanie pełnego adresu URL lub numeru zgłoszenia lub pull
requesta poprzedzonego znakiem
#. Na przykład:Introduced by #987654. - Przestrzegaj Kodeksu postępowania. Szanuj innych współtwórców. Na przykład, "Dokumentacja jest okropna" nie jest ani pomocną ani uprzejmą opinią.
7.3 - Współtworzenie nowych treści
Ta sekcja zawiera informacje, które powinieneś znać przed dodaniem nowej treści.
Istnieją również dedykowane strony dotyczące pisania studiów przypadków oraz artykułów na bloga.
Proces tworzenia nowej treści
flowchart LR
subgraph second[Zanim zaczniesz]
direction TB
S[ ] -.-
A[Podpisz CNCF CLA] --> B[Wybierz gałąź Git]
B --> C[Jeden język na PR]
C --> F[Sprawdź
narzędzia dla współtwórców]
end
subgraph first[Podstawy współtworzenia]
direction TB
T[ ] -.-
D[Pisz dokumentację w Markdown
i buduj stronę za pomocą Hugo] --- E[Kod źródłowy w GitHub]
E --- G[Folder '/content/../docs' zawiera dokumentację
w wielu językach]
G --- H[Zapoznaj się z typami stron
i shortcode'ami w Hugo]
end
first ----> second
classDef grey fill:#dddddd,stroke:#ffffff,stroke-width:px,color:#000000, font-size:15px;
classDef white fill:#ffffff,stroke:#000,stroke-width:px,color:#000,font-weight:bold
classDef spacewhite fill:#ffffff,stroke:#fff,stroke-width:0px,color:#000
class A,B,C,D,E,F,G,H grey
class S,T spacewhite
class first,second white
Rysunek - Przygotowanie nowej treści
Powyższy rysunek przedstawia informacje, które powinieneś znać przed przesłaniem nowej treści. Szczegóły znajdują się poniżej.
Podstawy kontrybucji
- Napisz dokumentację Kubernetesa w formacie Markdown i zbuduj stronę Kubernetesa za pomocą Hugo.
- Dokumentacja Kubernetesa używa CommonMark jako swojej wersji Markdown.
- Źródło znajduje się na GitHub.
Dokumentację Kubernetesa można znaleźć w
/content/en/docs/. Część dokumentacji referencyjnej jest automatycznie generowana ze skryptów w kataloguupdate-imported-docs/. - Typy zawartości strony opisują sposób prezentacji treści dokumentacji w Hugo.
- Możesz użyć kodów Docsy lub niestandardowych skrótów Hugo, aby wspierać dokumentację Kubernetes.
- Oprócz standardowych kodów Hugo, w naszej dokumentacji używamy wielu niestandardowych kodów Hugo, aby kontrolować prezentację treści.
- Dokumentacja jest dostępna w wielu językach w katalogu
/content/. Każdy język ma własny folder z dwuliterowym kodem określonym przez standard ISO 639-1 . Na przykład, źródło dokumentacji angielskiej jest przechowywane w/content/en/docs/. - Aby uzyskać więcej informacji na temat wnoszenia wkładu do dokumentacji w wielu językach lub rozpoczęcia nowego tłumaczenia, zobacz Lokalizowanie.
Zanim zaczniesz
Podpisz CNCF CLA
Wszyscy współtwórcy Kubernetesa muszą przeczytać Przewodnik dla Współtwórców i podpisać Umowę Licencyjną Współtwórcy (CLA) .
Pull requesty od autorów, którzy nie podpisali umowy CLA, nie
przechodzą testów automatycznych. Imię i adres e-mail, które podasz,
muszą zgadzać się z tymi ustawionymi w twoim git config, a twoje
imię i adres e-mail w git muszą być takie same jak te używane dla CNCF CLA.
Wybierz gałąź w Git
Podczas otwierania pull requesta musisz wiedzieć z góry, na której gałęzi oprzeć swoją pracę.
| Scenariusz | Gałąź |
|---|---|
| Istniejąca lub nowa treść w języku angielskim dla bieżącego wydania | main |
| Treść dla wydania zmiany funkcji | Gałąź, która odpowiada głównej i mniejszej wersji, w której znajduje się zmiana funkcji, używając wzorca dev-<version>. Na przykład, jeśli funkcja zmienia się w wydaniu v1.37, należy dodać zmiany w dokumentacji do gałęzi dev-1.37. |
| Treść w innych językach (lokalizacje) | Użyj konwencji danej lokalizacji. Zobacz Strategia rozgałęzień lokalizacji po więcej informacji. |
Jeśli nadal nie masz pewności, którą gałąź wybrać, zapytaj na #sig-docs na Slacku.
Informacja:
Jeśli już zgłosiłeś swoj pull request i wiesz, że była to niepoprawna gałąź bazowa, możesz ją zmienić (ty i tylko ty, zgłaszający).Języki na PR
Ogranicz żądania pull request do jednego języka na PR. Jeśli musisz wprowadzić identyczną zmianę w tym samym fragmencie kodu w wielu językach, otwórz osobne PR dla każdego języka.
Narzędzia dla współtwórców
Katalog narzędzi dla współtwórców dokumentacji
w repozytorium
kubernetes/website zawiera narzędzia, wspierające proces współtworzenia dokumentacji.
Co dalej?
- Przeczytaj jak zgłaszać artykuły na bloga.
7.3.1 - Dokumentowanie funkcji nowego wydania
Każda główna wersja Kubernetesa wprowadza nowe funkcje, które wymagają dokumentacji. Nowe wersje przynoszą również aktualizacje do istniejących funkcji i dokumentacji (na przykład awansowanie funkcji z wersji alpha do beta).
Zazwyczaj SIG odpowiedzialny za funkcję przesyła szkic dokumentacji
funkcji jako pull request do odpowiedniego gałęzi rozwojowej w repozytorium
kubernetes/website, a ktoś z zespołu SIG Docs dostarcza uwagi redakcyjne
lub edytuje szkic bezpośrednio. Ta sekcja opisuje konwencje dotyczące
rozgałęzień (ang. branching) oraz proces stosowany podczas wydania przez obie grupy.
Więcej o publikowaniu nowych funkcji na blogu przeczytasz w sekcji komunikaty po wydaniu.
Dla współtwórców dokumentacji
Ogólnie rzecz biorąc, współtwórcy dokumentacji nie piszą treści od podstaw na potrzeby wydania. Zamiast tego współpracują z SIG tworzącym nową funkcję, aby dopracować szkic dokumentacji i przygotować go do wydania.
Po wybraniu fukncji do udokumentowania lub wsparcia, zapytaj o nią na kanale
Slack #sig-docs, podczas cotygodniowego spotkania SIG Docs lub bezpośrednio w
zgłoszeniu PR wystawionym przez SIG odpowiedzialny za funkcje. Jeśli otrzymasz
zgodę, możesz edytować PR za pomocą jednej z technik opisanych w
Wprowadź zmiany do PR innej osoby.
Dowiedz się o nadchodzących funkcjach
Aby dowiedzieć się o nadchodzących funkcjach, weź udział w cotygodniowym spotkaniu SIG Release (zobacz stronę społeczności w celu uzyskania informacji o nadchodzących spotkaniach) i monitoruj dokumentację dotyczącą wydania w repozytorium kubernetes/sig-release. Każde wydanie ma podkatalog w katalogu /sig-release/tree/master/releases/. Podkatalog zawiera harmonogram wydania, szkic notatek do wydania oraz dokument z listą każdej osoby w zespole wydania.
Harmonogram wersji zawiera linki do wszystkich innych dokumentów, spotkań, protokołów spotkań i kamieni milowych związanych z wydaniem. Zawiera również informacje o celach i harmonogramie wydania oraz wszelkich specjalnych procesach wdrożonych dla tego wydania. Pod koniec dokumentu zdefiniowano kilka terminów związanych z wydaniem.
Ten dokument zawiera również link do Arkusza śledzenia funkcji, który jest oficjalnym sposobem na poznanie wszystkich nowych funkcji planowanych do wprowadzenia w wydaniu.
Dokumentacja zespołu odpowiadającego za kolejne wydanie zawiera listę osób do przypisanych do różnych ról. Jeśli nie jest jasne, do kogo się zwrócić w sprawie konkretnej funkcji lub pytania, które masz, możesz skorzystać z jednego z dwóch rozwiązań: weź udział w spotkaniu zespołu, aby zadać swoje pytanie, lub skontaktuj się z liderem wydania, aby mógł Cię odpowiednio skierować.
Szkic notatek z wydania to dobre miejsce, aby dowiedzieć się o specyficznych funkcjach, zmianach, przestarzałych elementach i innych kwestiach dotyczących wydania. Ponieważ treść nie jest ostateczna aż do późnego etapu, warto zachować ostrożność.
Arkusz śledzenia funkcji
Arkusz śledzenia funkcji dla danej wersji Kubernetesa wymienia każdą funkcję, która jest planowana do wydania. Każdy element zawiera nazwę funkcji, link do głównego problemu na GitHubie, poziom stabilności (Alpha, Beta lub Stable), SIG i osobę odpowiedzialną za jej wdrożenie, czy wymaga dokumentacji, projekt notatki o wydaniu dla funkcji oraz czy została zintegrowana. Pamiętaj o następujących zasadach:
- Funkcje w wersji Beta i Stable są zazwyczaj priorytetowane wyżej w dokumentacji niż funkcje w wersji Alfa.
- Trudno jest przetestować (a tym samym udokumentować) funkcję, która nie została zmergowana, lub przynajmniej jest uważana za kompletną w swoim PR.
- Określenie, czy funkcja wymaga dokumentacji, jest procesem manualnym. Nawet jeśli funkcja nie jest oznaczona jako wymagająca dokumentacji, może być konieczne jej udokumentowanie.
Dla developerów lub innych członków SIG
Ta sekcja zawiera informacje dla członków innych SIG Kubernetesów dokumentujących nowe funkcje na potrzeby wydania.
Jeśli jesteś członkiem SIG, który rozwija nową funkcję dla
Kubernetesa, musisz współpracować z SIG Docs, aby mieć pewność, że
Twoja funkcja zostanie udokumentowana na czas przed wydaniem.
Sprawdź arkusz śledzenia funkcji
lub sprawdź kanał Slack
Kubernetes #sig-release, aby zweryfikować szczegóły harmonogramu i terminy.
Otwórz tymczasowy PR
- Otwórz szkic pull requestu do gałęzi
dev-1.37w repozytoriumkubernetes/website, z małym commitem, który później zmienisz. Aby utworzyć szkic pull requestu, użyj rozwijanego menu Create Pull Request i wybierz Create Draft Pull Request, następnie kliknij Draft Pull Request. - Edytuj opis pull requesta, aby zawierał linki do PR-ów w kubernetes/kubernetes oraz zgłoszeń w kubernetes/enhancements.
- Zostaw komentarz w powiązanym zgłoszeniu w tym repozytorium kubernetes/enhancements z linkiem do PR, aby powiadomić osobę zajmującą się dokumentacją tej wersji, że dokumentacja dotycząca funkcji jest w przygotowaniu i powinna być śledzona w tym wydaniu.
Jeśli Twoja funkcjonalność nie wymaga żadnych zmian w dokumentacji, upewnij się, że zespół
sig-release o tym wie, wspominając o tym na kanale Slack #sig-release. Jeśli funkcjonalność wymaga
dokumentacji, ale PR nie został utworzony, funkcjonalność może zostać usunięta z kamienia milowego.
PR gotowy do przeglądu
Kiedy będziesz gotowy, wypełnij swój tymczasowy PR dokumentacją funkcji i zmień stan PR z roboczego na ready for review. Aby oznaczyć pull request jako gotowy do przeglądu, przejdź do pola scalania (ang. merge box) i kliknij Ready for review.
Najlepiej jak potrafisz opisz swoją funkcję i sposób jej użycia. Jeśli
potrzebujesz pomocy w strukturyzacji swojej dokumentacji, zapytaj na kanale Slack #sig-docs.
Gdy ukończysz swój materiał, osoba odpowiedzialna za dokumentację przypisana do Twojej funkcji go przegląda. Aby zapewnić dokładność techniczną, treść może również wymagać przeglądu technicznego przez odpowiednie SIG-i. Skorzystaj z ich sugestii, aby dopracować treść do stanu gotowego do wydania.
Jeśli twoja funkcja wymaga dokumentacji, a pierwsza wersja treści nie zostanie dostarczona, funkcja może zostać usunięta z kamienia milowego.
Bramki funkcji (ang. feature gates)
Jeśli Twoja funkcja jest funkcją Alfa lub Beta i jest włączana warunkowo
bramką funkcji (ang. feature gate), potrzebujesz dla niej pliku bramki
funkcji wewnątrz content/en/docs/reference/command-line-tools-reference/feature-gates/.
Nazwa pliku powinna być nazwą bramki funkcji z sufiksem .md.
Możesz spojrzeć na inne pliki już znajdujące się w tym samym katalogu, aby
uzyskać wskazówkę, jak powinien wyglądać Twój plik. Zwykle wystarczy jeden
akapit; dla dłuższych wyjaśnień dodaj dokumentację w innym miejscu i dodaj do niej link.
Aby upewnić się, że twój feature gate pojawi się w tabeli Alpha/Beta Feature gates, dodaj następujące informacje do sekcji front matter w pliku Markdown z opisem:
stages:
- stage: <alpha/beta/stable/deprecated> # Specify the development stage of the feature gate
defaultValue: <true or false> # Set to true if enabled by default, false otherwise
fromVersion: <Version> # Version from which the feature gate is available
toVersion: <Version> # (Optional) The version until which the feature gate is available
W przypadku nowych bramek funkcji wymagany jest również osobny opis
bramki funkcji; utwórz nowy plik Markdown w
content/en/docs/reference/command-line-tools-reference/feature-gates/ (użyj innych plików jako szablonu).
Gdy zmieniasz bramkę funkcji z domyślnie wyłączonej na domyślnie włączoną,
może być konieczne zmienienie również innej
dokumentacji (nie tylko listy bramek funkcji). Uważaj na zwroty takie jak „Pole
exampleSetting jest polem beta i jest domyślnie
wyłączone. Możesz je włączyć, włączając bramkę funkcji ProcessExampleThings.”
Jeśli Twoja funkcja osiągnęła status GA lub została oznaczona jako
przestarzała, dodaj dodatkowy wpis stage w ramach bloku stages w pliku opisu. Upewnij się,
że etapy Alpha i Beta pozostają nienaruszone. Ten krok przenosi bramkę
funkcji z Feature gates for Alpha/Beta
do
Feature gates for graduated or deprecated features.
Na przykład:
stages:
- stage: alpha
defaultValue: false
fromVersion: "1.12"
toVersion: "1.12"
- stage: beta
defaultValue: true
fromVersion: "1.13"
# Added a `toVersion` to the previous stage.
toVersion: "1.18"
# Added 'stable' stage block to existing stages.
- stage: stable
defaultValue: true
fromVersion: "1.19"
toVersion: "1.27"Ostatecznie Kubernetes przestanie w ogóle uwzględniać bramę funkcji.
Aby zasygnalizować usunięcie bramy funkcji, uwzględnij removed: true w
przedniej części odpowiedniego pliku opisu. Wprowadzenie tej zmiany
oznacza, że informacje o bramie funkcji przenoszą się z
Skróty funkcji dla ukończonych lub przestarzałych funkcji do dedykowanej
strony
zatytułowanej Skróty funkcji (usunięte),
łącznie z jej opisem.
Wszystkie PR-y zostały zrecenzowane i są gotowe do scalenia
Jeśli Twój PR nie został jeszcze scalony z gałęzią dev-1.37
przed terminem wydania, współpracuj z osobą odpowiedzialną za dokumentację i zarządzającą wydaniem,
aby dodać go przed terminem. Jeśli Twoja funkcja potrzebuje dokumentacji, a
dokumentacja nie jest gotowa, funkcja może zostać usunięta z bieżącego planu (milestone).
7.4 - Przeglądanie zmian
W tej sekcji opisano, jak dokonać przeglądu treści.
7.5 - Tłumaczenie i adaptacja językowa dokumentacji Kubernetes
Ta strona pokazuje, jak zlokalizować dokumentację na inny język.
Kontrybucja do istniejącej lokalizacji
Możesz pomóc w dodaniu lub poprawieniu treści istniejącej lokalizacji. W Kubernetes Slack, możesz znaleźć kanał dla każdej lokalizacji. Istnieje również ogólny kanal Slack dla lokalizacji dokumentacji SIG, gdzie możesz się przywitać.
Informacja:
Aby uzyskać dodatkowe szczegóły dotyczące kontrybucji do konkretnej lokalizacji, poszukaj zlokalizowanej wersji tej strony.Znajdź swój dwuliterowy kod języka
Najpierw zapoznaj się ze standardem ISO 639-1
w
celu znalezienia dwuliterowego kodu języka dla
lokalizacji. Na przykład dwuliterowy kod dla języka polskiego to pl.
Niektóre języki używają małej wersji kodu kraju, jak
zdefiniowano w ISO-3166, wraz z ich kodami językowymi. Na
przykład kod języka portugalskiego (brazylijskiego) to pt-br.
Zrób fork i clone na repozytorium
Najpierw, utwórz własny fork repozytorium kubernetes/website.
Następnie, sklonuj swój fork i przejdź do niego za pomocą cd:
git clone https://github.com/<nazwa-użytkownika>/website
cd website
Katalog zawartości witryny zawiera podkatalogi dla każdego języka.
Lokalizacja, przy której chcesz pomóc, znajduje się w content/<kod-dwuliterowy>.
Zaproponuj zmiany
Stwórz lub zaktualizuj wybraną przez Ciebie zlokalizowaną stronę na podstawie oryginału w języku angielskim. Zobacz zlokalizuj treść po więcej szczegółów.
Jeśli zauważysz błąd techniczny lub inny problem z dokumentacją źródłową (angielską), najpierw powinieneś naprawić dokumentację źródłową, a następnie powtórzyć równoważną poprawkę, aktualizując lokalizację, nad którą pracujesz.
Limituj zmiany w pull requestach do jednej lokalizacji. Przeglądanie pull requestów, które zmieniają zawartość w wielu lokalizacjach, jest problematyczne.
Postępuj zgodnie z Sugestie dotyczące ulepszenia treści, aby zaproponować zmiany w tej lokalizacji. Proces jest podobny do proponowania zmian w oryginalnej (angielskiej) treści.
Rozpocznij nową lokalizację
Jeśli chcesz, aby dokumentacja Kubernetes została przetłumaczona na nowy język, oto co musisz zrobić:
Ponieważ współtwórcy nie mogą zatwierdzać własnych pull request, potrzebujesz co najmniej dwóch współtwórców, aby rozpocząć lokalizację.
Wszystkie zespoły zajmujące się lokalizacją muszą być samowystarczalne. Strona internetowa Kubernetes chętnie udostępni Twoje prace, ale to do Ciebie należy ich przetłumaczenie oraz aktualizowanie istniejących zlokalizowanych treści.
Będziesz musiał znać dwuliterowy kod językowy dla swojego języka.
Zapoznaj się z standardem ISO 639-1,
aby znaleźć dwuliterowy kod językowy dla
swojej lokalizacji. Na przykład dwuliterowy kod dla języka polskiego to pl.
Jeśli język, dla którego zaczynasz lokalizację, jest używany w różnych
miejscach z istotnymi różnicami między wariantami, może mieć sens
połączenie małej litery kodu kraju ISO-3166 z dwuliterowym kodem językowym. Na
przykład, brazylijska odmiana języka portugalskiego jest lokalizowana jako pt-br.
Gdy rozpoczynasz nową lokalizację, musisz przetłumaczyć całą minimalnie wymaganą zawartość, zanim projekt Kubernetesa będzie mógł opublikować zmiany na stronie internetowej.
SIG Docs może pomóc Ci pracować na osobnej gałęzi, abyś mógł stopniowo dążyć do osiągnięcia tego celu.
Znajdź społeczność
Daj znać zespołowi Kubernetes SIG Docs, jeśli jesteś zainteresowany tworzeniem lokalizacji! Dołącz do kanłu Slack SIG Docs oraz kanłu Slack SIG Docs Localizations. Inne zespoły zajmujące się lokalizacją chętnie pomogą Ci zacząć i odpowiedzą na Twoje pytania.
Proszę również rozważyć udział w spotkaniu podgrupy lokalizacyjnej SIG Docs. Misją podgrupy lokalizacyjnej SIG Docs jest współpraca z zespołami lokalizacyjnymi SIG Docs w celu współpracy nad definiowaniem i dokumentowaniem procesów tworzenia zlokalizowanych przewodników wkładu. Ponadto, podgrupa lokalizacyjna SIG Docs poszukuje możliwości tworzenia i udostępniania wspólnych narzędzi wśród zespołów lokalizacyjnych oraz identyfikuje nowe wymagania dla zespołu kierowniczego SIG Docs. Jeśli masz pytania dotyczące tego spotkania, zapytaj na kanale Slack SIG Docs Localizations.
Możesz również utworzyć kanał Slack dla swojej lokalizacji w repozytorium
kubernetes/community. Przykład dodawania kanału Slack znajdziesz w PR dla
dodawania kanału dla perskiego.
Dołącz do organizacji Kubernetesa na GitHubie
Kiedy otworzysz PR lokalizacyjny, możesz zostać członkiem
organizacji Kubernetesa na GitHubie. Każda osoba w zespole musi
utworzyć własne Żądanie Członkostwa w Organizacji
w repozytorium kubernetes/org.
Dodaj swój zespół lokalizacyjny w GitHub
Następnie dodaj swój zespół lokalizacyjny Kubernetesa do
sig-docs/teams.yaml.
Aby uzyskać przykład dodawania zespołu lokalizacyjnego, zobacz PR
dodający hiszpański zespół lokalizacyjny.
Członkowie @kubernetes/sig-docs-**-owners mogą zatwierdzać PRy, które zmieniają zawartość
w (i tylko w) twoim katalogu lokalizacyjnym: /content/**/. Dla
każdej lokalizacji, zespół @kubernetes/sig-docs-**-reviews automatyzuje
przypisywanie recenzji dla nowych PRów. Członkowie @kubernetes/website-maintainers mogą
tworzyć nowe gałęzie lokalizacyjne, aby koordynować wysiłki tłumaczeniowe.
Członkowie @kubernetes/website-milestone-maintainers mogą używać
komendy Prow /milestone, aby przypisać kamień milowy do problemów lub PRów.
Skonfiguruj przepływ pracy
Następnie dodaj etykietę GitHub dla swojej lokalizacji w
repozytorium kubernetes/test-infra. Etykieta pozwala
filtrować zgłoszenia i pull requesty dla Twojego konkretnego języka.
Aby uzyskać przykład dodawania etykiety, zobacz PR dotyczący dodawania etykiety języka włoskiego.
Modyfikacja konfiguracji witryny
Strona internetowa Kubernetesa wykorzystuje Hugo jako swoją strukturę
sieciową. Konfiguracja Hugo dla strony internetowej znajduje się w pliku hugo.toml.
Trzeba
będzie zmodyfikować hugo.toml, aby obsługiwać nową lokalizację.
Dodaj blok konfiguracyjny dla nowego języka do hugo.toml pod istniejącym blokiem
[languages]. Blok dla języka niemieckiego wygląda na przykład tak:
[languages.de]
title = "Kubernetes"
languageName = "Deutsch (German)"
weight = 5
contentDir = "content/de"
languagedirection = "ltr"
[languages.de.params]
time_format_blog = "02.01.2006"
language_alternatives = ["en"]
description = "Produktionsreife Container-Orchestrierung"
languageNameLatinScript = "Deutsch"
Pasek wyboru języka wyświetla wartość dla languageName.
Przypisz "nazwa języka w ojczystym piśmie i języku (angielska nazwa
języka w łacińskim piśmie)" do languageName. Na przykład,
languageName = "한국어 (Korean)" lub languageName = "Deutsch (German)".
languageNameLatinScript można użyć do uzyskania nazwy języka w
alfabecie łacińskim i użycia jej w motywie. Przypisz "nazwa języka w
alfabecie łacińskim" do languageNameLatinScript. Na przykład,
languageNameLatinScript ="Korean" lub languageNameLatinScript = "Deutsch".
Parametr weight określa kolejność języków na pasku wyboru języka. Niższa
wartość weight ma pierwszeństwo, co skutkuje tym, że język pojawia się jako pierwszy.
Przy przypisywaniu parametru weight ważne jest, aby zbadać
istniejący blok języków i dostosować ich wartości, aby zapewnić, że są w
uporządkowanej kolejności względem wszystkich języków, w tym każdego nowo dodanego języka.
Aby uzyskać więcej informacji na temat wsparcia wielojęzycznego Hugo, zobacz Multilingual mode.
Dodaj nowy katalog lokalizacyjny
Dodaj podkatalog specyficzny dla języka do folderu
content w
repozytorium. Na przykład dwuliterowy kod dla języka niemieckiego to de:
mkdir content/de
Musisz również utworzyć katalog wewnątrz i18n
dla zlokalizowanych ciągów
; spójrz na istniejące lokalizacje jako przykład.
Na przykład, dla języka niemieckiego, ciągi znaków znajdują się w pliku i18n/de/de.toml.
Zlokalizuj kodeks postępowania społeczności
Otwórz PR w repozytorium cncf/foundation,
aby
dodać kodeks postępowania w swoim języku.
Skonfiguruj pliki OWNERS
Aby ustawić role każdego użytkownika wnoszącego wkład do
lokalizacji, utwórz plik OWNERS w podkatalogu specyficznym dla języka za pomocą:
- reviewers: Lista zespołów Kubernetesa z rolami recenzentów, w tym przypadku,
- zespół
sig-docs-**-reviewsutworzony w Dodaj swój zespół lokalizacyjny w GitHub. - approvers: Lista zespołów Kubernetesa z rolami aprobatowymi, w tym przypadku,
- zespół
sig-docs-**-ownersutworzony w Dodaj swój zespół lokalizacyjny w GitHub. - labels: Lista etykiet GitHub, które zostaną automatycznie zastosowane do PR, w tym przypadku etykieta językowa utworzona w Konfiguracja przepływu pracy.
Więcej informacji na temat pliku OWNERS można znaleźć na
stronie go.k8s.io/owners.
Plik Spanish OWNERS
z kodem języka es wygląda następująco:
# See the OWNERS docs at https://go.k8s.io/owners
# This is the localization project for Spanish.
# Teams and members are visible at https://github.com/orgs/kubernetes/teams.
reviewers:
- sig-docs-es-reviews
approvers:
- sig-docs-es-owners
labels:
- area/localization
- language/es
Po dodaniu pliku OWNERS specyficznego dla danego języka, zaktualizuj
główny plik OWNERS_ALIASES
z nowymi zespołami
Kubernetesa dla lokalizacji, sig-docs-**-owners i sig-docs-**-reviews.
Dla każdego zespołu dodaj listę użytkowników GitHub, o której mowa w Dodaj swój zespół lokalizacyjny w GitHub, w porządku alfabetycznym.
--- a/OWNERS_ALIASES
+++ b/OWNERS_ALIASES
@@ -48,6 +48,14 @@ aliases:
- stewart-yu
- xiangpengzhao
- zhangxiaoyu-zidif
+ sig-docs-es-owners: # Admins for Spanish content
+ - alexbrand
+ - raelga
+ sig-docs-es-reviews: # PR reviews for Spanish content
+ - alexbrand
+ - electrocucaracha
+ - glo-pena
+ - raelga
sig-docs-fr-owners: # Admins for French content
- perriea
- remyleone
Otwórz pull request
Następnie, otwórz pull request
(PR), aby dodać lokalizację do repozytorium
kubernetes/website. PR musi zawierać całą
wymaganą minimalną zawartość, zanim może zostać zatwierdzony.
Aby uzyskać przykład dodawania nowej lokalizacji, zobacz PR umożliwiający dokumentację w języku francuskim.
Dodaj zlokalizowany plik README
Aby poprowadzić innych współtwórców lokalizacji, dodaj nowy
plik README-**.md
na najwyższym poziomie kubernetes/website,
gdzie ** to dwuliterowy kod
języka. Na przykład, niemiecki plik README nosiłby nazwę README-de.md.
Prowadź współtwórców lokalizacji w zlokalizowanym pliku README-**.md.
Zawieraj te same informacje, które znajdują się w README.md, a także:
- Punkt kontaktowy dla projektu lokalizacyjnego
- Wszelkie informacje specyficzne dla lokalizacji
Po utworzeniu zlokalizowanego pliku README, dodaj link do tego
pliku z głównego angielskiego README.md i dołącz informacje
kontaktowe w języku angielskim. Możesz podać ID GitHub, adres e-mail,
kanał Slack, lub inną metodę kontaktu. Musisz
również podać link do zlokalizowanego Kodeksu Postępowania Społeczności.
Uruchom swoje nowe lokalizacje
Gdy lokalizacja spełnia wymagania dotyczące przepływu pracy i minimalnej wymaganej zawartości, SIG Docs wykonuje następujące czynności:
- Umożliwia wybór języka na stronie internetowej.
- Publikuje dostępność lokalizacji poprzez kanały Cloud Native Computing Foundation(CNCF), w tym blog Kubernetesa.
Zlokalizuj treść
Lokalizowanie całej dokumentacji Kubernetes to ogromne zadanie. Można zacząć od małych kroków i z czasem się rozwijać.
Minimalna wymagana zawartość
W minimalnym zakresie wszystkie lokalizacje muszą zawierać:
| Opis | URL |
|---|---|
| Strona główna | Wszystkie adresy URL nagłówków i podnagłówków |
| Konfiguracja | Wszystkie adresy URL nagłówków i podnagłówków |
| Samouczki | Podstawy Kubernetesa, Witaj Minikube |
| Ciągi znaków strony | Wszystkie ciągi znaków strony w nowym zlokalizowanym pliku TOML |
| Wydania | Wszystkie URL-e nagłówków i podnagłówków |
Przetłumaczone dokumenty muszą znajdować się we własnym podkatalogu content/**/, ale
powinny podążać tą samą ścieżką URL co źródła dla języka angielskiego. Na przykład, aby
przygotować samouczek Podstawy Kubernetesa do tłumaczenia na
język niemiecki, utwórz podkatalog w katalogu content/de/ i skopiuj angielskie źródło lub katalog:
mkdir -p content/de/docs/tutorials
cp -ra content/en/docs/tutorials/kubernetes-basics/ content/de/docs/tutorials/
Narzędzia tłumaczeniowe mogą przyspieszyć proces tłumaczenia. Na przykład, niektórzy edytorzy oferują wtyczki do szybkiego tłumaczenia tekstu.
Uwaga:
Tłumaczenia generowane maszynowo nie są wystarczające same w sobie. Lokalizacja wymaga rozbudowanej recenzji ludzkiej, aby spełnić minimalne standardy jakości.Aby zapewnić dokładność gramatyczną i znaczeniową, członkowie Twojego zespołu ds. lokalizacji powinni dokładnie przejrzeć wszystkie tłumaczenia generowane maszynowo przed publikacją.
Lokalizuj obrazy SVG
Projekt Kubernetes zaleca używanie obrazów wektorowych (SVG), gdy to możliwe, ponieważ zespołowi zajmującemu się lokalizacją znacznie łatwiej jest je edytować. Jeśli znajdziesz obraz rastrowy (ang. a raster image), który wymaga lokalizacji, rozważ najpierw przerysowanie wersji angielskiej jako obrazu wektorowego, a następnie dokonanie lokalizacji.
Kiedy tłumaczysz tekst w obrazach SVG (Scalable Vector Graphics), należy przestrzegać pewnych wytycznych, aby zapewnić dokładność i zachować spójność między wersjami językowymi. Obrazy SVG są powszechnie używane w dokumentacji Kubernetesa do ilustrowania koncepcji, przepływów pracy i diagramów.
Identyfikacja tekstu do przetłumaczenia: Zacznij od zidentyfikowania elementów tekstowych wewnątrz obrazu SVG, które wymagają tłumaczenia. Elementy te zazwyczaj obejmują etykiety, podpisy, adnotacje lub jakikolwiek tekst przekazujący informacje.
Edycja plików SVG: Pliki SVG opierają się na XML, co oznacza, że można je edytować za pomocą edytora tekstu. Jednak warto zauważyć, że większość obrazów w dokumentacji Kubernetes konwertuje już tekst na krzywe w celu uniknięcia problemów z kompatybilnością czcionek. W takich przypadkach zaleca się użycie specjalistycznego oprogramowania do edycji SVG, takiego jak Inkscape, aby edytować, otworzyć plik SVG i zlokalizować elementy tekstowe wymagające tłumaczenia.
Tłumaczenie tekstu: Zamień oryginalny tekst na przetłumaczoną wersję w wybranym języku. Upewnij się, że przetłumaczony tekst dokładnie oddaje zamierzone znaczenie i mieści się w dostępnej przestrzeni obrazu. Rodzina czcionek Open Sans powinna być używana przy pracy z językami, które korzystają z alfabetu łacińskiego. Możesz pobrać krój pisma Open Sans stąd: Open Sans Typeface.
Konwersja tekstu na krzywe: Jak już wspomniano, aby rozwiązać problemy z kompatybilnością czcionek, zaleca się konwersję przetłumaczonego tekstu na krzywe lub ścieżki. Konwersja tekstu na krzywe zapewnia, że końcowy obraz wyświetla przetłumaczony tekst poprawnie, nawet jeśli system użytkownika nie posiada dokładnie tej samej czcionki użytej w oryginalnym pliku SVG.
Przeglądanie i testowanie: Po dokonaniu niezbędnych tłumaczeń i konwersji tekstu na krzywe, zapisz i przejrzyj zaktualizowany obraz SVG, aby upewnić się, że tekst jest prawidłowo wyświetlany i wyrównany. Sprawdź Podglądaj swoje zmiany lokalnie.
Pliki źródłowe
Localizacje muszą być oparte na angielskich plikach z konkretnego wydania wybranego przez zespół lokalizacyjny. Każdy zespół lokalizacyjny może zdecydować, które wydanie będzie celem, określane poniżej jako docelowa wersja.
Aby znaleźć pliki źródłowe dla docelowej wersji:
Przejdź do repozytorium strony internetowej Kubernetes pod adresem https://github.com/kubernetes/website.
Wybierz gałąź dla swojej docelowej wersji z poniższej tabeli:
| Wersja docelowa | Gałąź |
|---|---|
| Najnowsza wersja | main |
| Poprzednia wersja | release-1.35 |
| Następna wersja | dev-1.37 |
Gałąź main zawiera treści dla bieżącego wydania
v1.36. Zespół wydawniczy tworzy gałąź
release-1.36 przed następnym wydaniem: v1.37.
Ciągi znaków strony (ang. site strings) w i18n
Lokalizacje muszą zawierać treści
i18n/en/en.toml w
nowym pliku specyficznym dla danego języka.
Na przykład używając języka niemieckiego: i18n/de/de.toml.
Dodaj nowy katalog lokalizacyjny i plik
do i18n/. Na przykład, z niemieckim (de):
mkdir -p i18n/de
cp i18n/en/en.toml i18n/de/de.toml
Przejrzyj komentarze na początku pliku, aby dostosować je do swojego lokalnego języka, a następnie przetłumacz wartość każdego ciągu. Na przykład, oto niemiecki tekst zastępczy dla formularza wyszukiwania:
[ui_search]
other = "Suchen"
Lokalizacja ciągów tekstowych witryny pozwala dostosować tekst i funkcje w całej witrynie: na przykład prawny tekst dotyczący praw autorskich w stopce na każdej stronie.
Przewodnik lokalizacyjny specyficzny dla języka
Jako zespół lokalizacyjny, możesz sformalizować najlepsze praktyki, które stosuje twój zespół, tworząc przewodnik lokalizacyjny specyficzny dla danego języka.
Na przykład, zapoznaj się z Koreańskiego przedownika lokalizacji, który zawiera treści na następujące tematy:
- Kadencja sprintów i wydania
- Strategia gałęzi
- Przepływ pracy zgłoszenia pull request
- Przewodnik stylu
- Słownik terminów zlokalizowanych i niezlokalizowanych
- Konwencje Markdown
- Terminologia obiektów API Kubernetesa
Spotkania Zoom specyficzne dla języka
Jeśli projekt lokalizacyjny wymaga osobnego terminu spotkania, skontaktuj się z współprzewodniczącym SIG Docs lub liderem technicznym, aby utworzyć nowe cykliczne spotkanie w Zoomie i zaproszenie do kalendarza. Jest to potrzebne tylko wtedy, gdy zespół jest wystarczająco duży, aby utrzymać i potrzebować osobnego spotkania.
Zgodnie z polityką CNCF, zespoły lokalizacyjne muszą przesyłać swoje spotkania na playlistę YouTube SIG Docs. Współprzewodniczący SIG Docs lub Tech Lead mogą pomóc w tym procesie, dopóki SIG Docs go nie zautomatyzuje.
Strategia gałęzi
Ponieważ projekty lokalizacyjne są wysoko współpracującymi przedsięwzięciami, zachęcamy zespoły do pracy we wspólnych gałęziach lokalizacyjnych - zwłaszcza na początku, kiedy lokalizacja nie jest jeszcze aktywna.
Aby współpracować nad gałęzią lokalizacyjną:
Członek zespołu @kubernetes/website-maintainers otwiera gałąź lokalizacyjną z gałęzi źródłowej na https://github.com/kubernetes/website.
Twój zespół zatwierdzający dołączył do zespołu
@kubernetes/website-maintainers, gdy dodałeś swój zespół ds. lokalizacji do repozytoriumkubernetes/org.Zalecamy następujący schemat nazywania gałęzi:
dev-<wersja źródłowa>-<kod języka>.<kamień milowy zespołu>Na przykład, osoba zatwierdzająca w niemieckim zespole lokalizacyjnym otwiera gałąź lokalizacyjną
dev-1.12-de.1bezpośrednio w repozytoriumkubernetes/website, bazując na gałęzi źródłowej dla Kubernetes v1.12.Indywidualni współtwórcy otwierają gałęzie z funkcjami w oparciu o gałąź lokalizacyjną.
Na przykład, niemiecki współtwórca otwiera pull request z zmianami do
kubernetes:dev-1.12-de.1zusername:local-branch-name.Osoby zatwierdzające przeglądają i scalają gałęzie funkcji z gałęzią lokalizacji.
Okresowo, zatwierdzający łączy gałąź lokalizacyjną z jej gałęzią źródłową, otwierając i zatwierdzając nowy pull request. Upewnij się, że scaliłeś commity przed zatwierdzeniem pull request.
Powtarzaj kroki od 1 do 4 według potrzeb, aż lokalizacja zostanie
ukończona. Na przykład, kolejne niemieckie
gałęzie lokalizacyjne to: dev-1.12-de.2, dev-1.12-de.3, itd.
Zespoły muszą scalić zlokalizowane treści do tej samej gałęzi, z której pochodziła treść. Na przykład:
- Gałąź lokalizacji pochodząca z
mainmusi zostać scalona zmain. - Gałąź lokalizacyjna pochodząca z
release-1.35musi być scalona zrelease-1.35.
Informacja:
Jeśli Twoja gałąź lokalizacyjna została utworzona z gałęzimain, ale
nie została scalona z main przed utworzeniem nowej gałęzi wydania
release-1.36, scal ją zarówno z main, jak i z nową gałęzią
wydania release-1.36. Aby scalić swoją gałąź lokalizacyjną z
nową gałęzią wydania release-1.36, musisz przełączyć gałąź
(ang. upstream branch) dla swojej gałęzi lokalizacyjnej na release-1.36.Na początku każdego kamienia milowego zespołu warto otworzyć zgłoszenie porównujące zmiany w upstream pomiędzy poprzednią gałęzią lokalizacyjną a obecną gałęzią lokalizacyjną. Istnieją dwa skrypty do porównywania zmian upstream.
upstream_changes.pyjest przydatne do sprawdzania zmian wprowadzonych do konkretnego pliku. Idiff_l10n_branches.pyjest przydatny do tworzenia listy nieaktualnych plików dla konkretnej gałęzi lokalizacyjnej.
Podczas gdy tylko zatwierdzający mogą otworzyć nową gałąź lokalizacyjną i scalać pull requesty, każdy może otworzyć pull request dla nowej gałęzi lokalizacyjnej. Nie są wymagane żadne specjalne uprawnienia.
Aby uzyskać więcej informacji na temat pracy z forków lub bezpośrednio z repozytorium, zobacz "fork and clone the repo".
Kontrybucje do projektu głównego
SIG Docs chętnie przyjmuje nową treść oraz korekty w angielskiej wersji źródłowej.
7.6 - Współpraca z SIG Docs
SIG Docs jest jedną z special interest group w ramach projektu Kubernetes, skoncentrowaną na pisaniu, aktualizowaniu i utrzymywaniu dokumentacji dla całego Kubernetesa. Zobacz SIG Docs z repozytorium społeczności na GitHubie aby uzyskać więcej informacji o SIG.
SIG Docs zaprasza do współpracy nad treścią i recenzjami wszystkich współtwórców. Każdy może otworzyć pull request (PR) i każdy jest mile widziany do zgłaszania problemów dotyczących treści lub komentowania pull requestów w trakcie ich realizacji.
Możesz również zostać członkiem, recenzentem lub zatwierdzającym. Te role wymagają większego dostępu i wiążą się z pewnymi obowiązkami w zakresie zatwierdzania i wprowadzania zmian. Zobacz community-membership, aby uzyskać więcej informacji na temat tego, jak działa członkostwo w społeczności Kubernetesa.
Reszta tego dokumentu przedstawia unikalne sposoby, w jakie te role funkcjonują w ramach SIG Docs, które odpowiada za utrzymanie jednego z najbardziej widocznych publicznie aspektów Kubernetesa -- strony internetowej i dokumentacji Kubernetes.
SIG Docs przewodniczący
Każda SIG, w tym SIG Docs, wybiera jednego lub więcej członków SIG do pełnienia roli przewodniczących. Są oni punktami kontaktowymi pomiędzy SIG Docs a innymi częściami organizacji Kubernetesa. Wymagają szerokiej wiedzy na temat struktury projektu Kubernetes jako całości oraz tego, jak SIG Docs działa w jej ramach. Zobacz Kierownictwo z aktualną listą przewodniczących.
Zespoły i automatyzacja SIG Docs
Automatyzacja w SIG Docs opiera się na dwóch różnych mechanizmach: zespołach GitHub i plikach OWNERS.
Zespoły GitHub
Istnieją dwie kategorie zespołów SIG Docs na GitHubie:
@sig-docs-{language}-ownerssą zatwierdzającymi i liderami@sig-docs-{language}-reviewssą recenzentami
Każdy z nich może być przywoływany za pomocą @nazwa w
komentarzach na GitHubie, aby komunikować się z wszystkimi w tej grupie.
Czasami zespoły Prow i GitHub nakładają się na siebie, ale nie
dokładnie pasują. W celu przypisywania problemów, pull requestów i
wsparcia zatwierdzeń PR, automatyzacja korzysta z informacji z plików OWNERS.
pliki OWNERS i front-matter
Projekt Kubernetesa wykorzystuje narzędzie automatyzacji o nazwie prow do automatyzacji związanej z problemami i pull requestami w GitHub. Repozytorium strony internetowej Kubernetesa używa dwóch wtyczek prow:
- blunderbuss
- approve
Te dwie wtyczki używają plików
OWNERS i
OWNERS_ALIASES w
głównym katalogu repozytorium kubernetes/website na
GitHubie, aby kontrolować jak prow działa w ramach tego repozytorium.
Plik OWNERS zawiera listę osób, które są recenzentami i zatwierdzającymi SIG Docs. Pliki OWNERS mogą również istnieć w podkatalogach i mogą nadpisywać osoby, które mogą działać jako recenzent lub zatwierdzający dla plików w tym podkatalogu i jego potomnych. Więcej informacji na temat plików OWNERS można znaleźć w OWNERS.
Ponadto, pojedynczy plik Markdown może wymieniać osoby przeglądające i zatwierdzające w swojej sekcji front-matter, albo poprzez wymienienie indywidualnych nazw użytkowników GitHub, albo grup GitHub.
Połączenie plików OWNERS i danych front-matter w plikach Markdown determinuje porady, jakie właściciele PR otrzymują od zautomatyzowanych systemów, dotyczące tego, kogo poprosić o techniczny i redakcyjny przegląd ich PR.
Jak działa scalanie (ang. merging)
Kiedy pull request zostanie scalony z gałęzią używaną do publikowania treści, ta treść jest publikowana na https://kubernetes.io. Aby zapewnić wysoką jakość naszych publikowanych treści, ograniczamy scalanie pull requestów do zatwierdzających SIG Docs. Oto jak to działa.
- Gdy pull request ma zarówno etykiety
lgtm, jak iapprove, nie ma etykiethold, i wszystkie testy przechodzą pomyślnie, pull request łączy się automatycznie. - Członkowie organizacji Kubernetesa i zatwierdzający z SIG Docs mogą
dodawać komentarze w celu wstrzymania automatycznemu scaleniu danego pull
requesta (poprzez dodanie komentarza
/holdlub wstrzymanie komentarza/lgtm). - Każdy członek Kubernetesa może dodać etykietę
lgtm, dodając komentarz/lgtm. - Tylko zatwierdzający SIG Docs mogą scalić pull request dodając
komentarz
/approve. Niektórzy zatwierdzający pełnią również dodatkowe specyficzne role, takie jak PR Wrangler lub przewodniczący SIG Docs.
Co dalej?
Aby dowiedzieć się więcej o uczestnictwie w SIG Docs, zobacz:
Więcej informacji na temat wnoszenia wkładu w dokumentację Kubernetesa można znaleźć w:
7.7 - Aktualizacja materiałów źródłowych
Tematy w tej sekcji opisują, jak aktualizować (czyli ponownie wygenerować) materiały źródłowe (ang. reference documentation) Kubernetesa.
Aby zbudować materiały źródłowe, zapoznaj się z następującym przewodnikiem:
7.7.1 - Wkład w kod źródłowy Kubernetesa
Ta strona pokazuje, jak wnieść wkład do projektu kubernetes/kubernetes. Możesz
naprawiać błędy znalezione w dokumentacji API Kubernetesa lub w treściach dla
komponentów Kubernetesa, takich jak kubeadm, kube-apiserver i kube-controller-manager.
Jeśli zamiast tego chcesz wygenerować ponownie materiały źródłowe dla API Kubernetesa lub
komponentów kube-* z kodu źródłowego, zapoznaj się z następującymi instrukcjami:
- Generowanie materiałów źródłowych dla API Kubernetesa
- Generowanie materiałów źródłowych dla komponentów i narzędzi Kubernetesa
Zanim zaczniesz
Musisz mieć zainstalowane następujące narzędzia:
Twoja zmienna środowiskowa
GOPATHmusi być ustawiona, a lokalizacjaetcdmusi znajdować się w zmiennej środowiskowejPATH.Musisz wiedzieć, jak utworzyć pull requesta do repozytorium GitHub. Zwykle obejmuje to utworzenie forka tego repozytorium. Aby uzyskać więcej informacji, zobacz Tworzenie pull requesta oraz Standardowy proces fork i pull request w GitHub.
Ogólny zarys
Materiały źródłowe dla API Kubernetesa oraz komponentów kube-*, takich jak
kube-apiserver, kube-controller-manager, są automatycznie generowane z kodu
źródłowego w głównym repozytorium Kubernetes.
Kiedy zauważysz błędy w wygenerowanej dokumentacji, możesz rozważyć stworzenie poprawki, aby naprawić je w projekcie źródłowym.
Sklonuj repozytorium Kubernetesa
Jeśli nie posiadasz jeszcze repozytorium kubernetes/kubernetes, pobierz je teraz:
mkdir $GOPATH/src
cd $GOPATH/src
go get github.com/kubernetes/kubernetes
Określ katalog bazowy swojej kopii repozytorium
kubernetes/kubernetes. Na przykład, jeśli
wykonywano wcześniejszy krok w celu pobrania tego repozytorium, to
twój katalog bazowy to $GOPATH/src/github.com/kubernetes/kubernetes.
Pozostałe kroki odnoszą się do twojego katalogu bazowego jako <k8s-base>.
Określ katalog główny swojego klonu repozytorium
kubernetes-sigs/reference-docs. Na
przykład, jeśli wykonałeś wcześniejszy krok, aby pobrać repozytorium, twój
katalog główny to $GOPATH/src/github.com/kubernetes-sigs/reference-docs.
Pozostałe kroki odnoszą się do twojego katalogu głównego jako <rdocs-base>.
Edytowanie kodu źródłowego Kubernetesa
Dokumentacja materiałów źródłowych API Kubernetesa jest automatycznie generowana z specyfikacji OpenAPI, która jest tworzona na podstawie kodu źródłowego Kubernetesa. Jeśli chcesz zmienić dokumentację materiałów źródłowych API, pierwszym krokiem jest zmiana w kodzie źródłowym Kubernetesa.
Dokumentacja dla komponentów kube-* jest także generowana z
oryginalnego kodu źródłowego. Musisz zmienić kod związany z
komponentem, który chcesz naprawić, aby naprawić generowaną dokumentację.
Wprowadź zmiany do kodu źródłowego w repozytorium głównym
Informacja:
Poniższe kroki są przykładowe, nie stanowią ogólnej procedury. Szczegóły w Twojej sytuacji będą się różnić.Oto przykład edytowania komentarza w kodzie źródłowym Kubernetesa.
W swoim lokalnym repozytorium kubernetes/kubernetes, przełącz się na domyślną gałąź i upewnij się, że jest aktualna:
cd <k8s-base>
git checkout master
git pull https://github.com/kubernetes/kubernetes master
Przypuśćmy, że ten plik źródłowy w tej domyślnej gałęzi zawiera literówkę "atmost":
kubernetes/kubernetes/staging/src/k8s.io/api/apps/v1/types.go
W swoim lokalnym środowisku otwórz plik types.go i zmień "atmost" na "at most".
Zweryfikuj, czy zmieniłeś plik:
git status
Wynik pokazuje, że znajdujesz się na gałęzi
głównej, a plik źródłowy types.go został zmodyfikowany:
On branch master
...
modified: staging/src/k8s.io/api/apps/v1/types.go
Zatwierdź swój edytowany plik
Uruchom git add i git commit, aby zatwierdzić zmiany, które do tej pory wprowadziłeś. W
kolejnym kroku wykonasz drugi commit. Ważne jest, aby utrzymać zmiany rozdzielone na dwa commity.
Generowanie specyfikacji OpenAPI i powiązanych plików
Przejdź do <k8s-base> i uruchom te skrypty:
./hack/update-codegen.sh
./hack/update-openapi-spec.sh
Uruchom git status, aby zobaczyć, co zostało wygenerowane.
On branch master
...
modified: api/openapi-spec/swagger.json
modified: api/openapi-spec/v3/apis__apps__v1_openapi.json
modified: pkg/generated/openapi/zz_generated.openapi.go
modified: staging/src/k8s.io/api/apps/v1/generated.proto
modified: staging/src/k8s.io/api/apps/v1/types_swagger_doc_generated.go
Sprawdź zawartość pliku api/openapi-spec/swagger.json, aby upewnić
się, że literówka została poprawiona. Na przykład, możesz uruchomić
git diff -a api/openapi-spec/swagger.json. Jest to ważne, ponieważ
swagger.json jest wejściem do drugiego etapu procesu generowania materiałów źródłowych.
Uruchom git add i git commit, aby zatwierdzić swoje zmiany. Teraz masz dwa commity: jeden, który
zawiera edytowany plik types.go, oraz drugi, który zawiera wygenerowaną specyfikację
OpenAPI i powiązane pliki. Zachowaj te dwa commity oddzielnie. To znaczy, nie łącz tych commitów.
Prześlij swoje zmiany jako pull request do gałęzi master w repozytorium kubernetes/kubernetes. Monitoruj swój pull request (PR) i odpowiadaj na uwagi recenzentów w miarę potrzeby. Kontynuuj monitorowanie swojego PR, aż zostanie ono scalone.
PR 57758 jest przykładem pull requesta, który naprawia literówkę w kodzie źródłowym Kubernetesa.
Informacja:
Określenie właściwego pliku źródłowego do zmiany może być skomplikowane. W podanym przykładzie, główny plik źródłowy znajduje się w katalogustaging w repozytorium kubernetes/kubernetes. Jednak w Twojej
sytuacji katalog staging może nie być właściwym miejscem do jego
znalezienia. Aby uzyskać wskazówki, sprawdź pliki README w
repozytorium kubernetes/kubernetes
oraz w powiązanych repozytoriach, takich jak
kubernetes/apiserver.Zrób cherry pick swojego commita do gałęzi wydania
W poprzednim rozdziale edytowałeś plik w głównej gałęzi (master branch) i uruchomiłeś skrypty, aby wygenerować specyfikację OpenAPI oraz powiązane pliki. Następnie przesłałeś swoje zmiany w PR (ang. pull request) do głównej gałęzi repozytorium kubernetes/kubernetes. Teraz załóżmy, że chcesz wprowadzić swoją zmianę także do gałęzi wydania (release branch). Na przykład, załóżmy, że główna gałąź jest używana do opracowywania wersji Kubernetesa 1.36, a Ty chcesz wprowadzić swoją zmianę również do gałęzi release-1.35.
Przypomnij sobie, że twój pull request zawiera dwa commity: jeden dla edycji types.go i jeden dla
plików wygenerowanych przez skrypty. Następnym krokiem jest zaproponowanie cherry pick twojego
pierwszego commita do gałęzi release-1.35. Chodzi o to, aby cherry pickować commit,
który edytował types.go, ale nie commit, który zawiera wyniki uruchomienia skryptów. Instrukcje
znajdziesz w Propose a Cherry Pick.
Informacja:
Propozycja cherry pick wymaga posiadania uprawnienia do ustawienia etykiety i kamienia milowego w swoim PR (ang. pull request). Jeśli nie masz tych uprawnień, będziesz musiał współpracować z kimś, kto może ustawić etykietę i kamień milowy za Ciebie.Kiedy masz w toku swój pull request dla zastosowania cherry picka ze swoim jednym commitem do gałęzi release-1.35, kolejnym krokiem jest uruchomienie tych skryptów w gałęzi release-1.35 w swoim lokalnym środowisku.
./hack/update-codegen.sh
./hack/update-openapi-spec.sh
Teraz dodaj commit do swojego pull requesta związanego z cherry pickiem, który zawiera niedawno wygenerowaną specyfikację OpenAPI i powiązane pliki. Monitoruj swojego pull requesta, aż zostanie scalony z gałęzią release-1.35.
W tym momencie zarówno gałąź master, jak i gałąź release-1.35 mają zaktualizowany plik
types.go oraz zestaw wygenerowanych plików, które odzwierciedlają zmiany wprowadzone do types.go. Należy zauważyć, że
wygenerowana specyfikacja OpenAPI i inne wygenerowane pliki w gałęzi release-1.35 niekoniecznie są
takie same jak wygenerowane pliki w gałęzi master. Wygenerowane pliki w gałęzi release-1.35
zawierają elementy API wyłącznie z Kubernetesa 1.35. Wygenerowane pliki w gałęzi master mogą
zawierać elementy API, które nie znajdują się w 1.35, ale są w trakcie rozwoju dla 1.36.
Generowanie opublikowanych materiałów źródłowych
Poprzednia sekcja pokazała, jak edytować plik
źródłowy, a następnie generować kilka plików, w tym
api/openapi-spec/swagger.json w repozytorium
kubernetes/kubernetes. Plik swagger.json to plik definicji
OpenAPI używany do generowania materiałów źródłowych API.
Jesteś teraz gotowy do zapoznania się z przewodnikiem generowania materiałów źródłowych dla API Kubernetesa , aby wygenerować opublikowane materiały źródłowe API Kubernetesa.
Co dalej?
7.7.2 - Generowanie materiałów źródłowych dla polecenia kubectl
Ta strona pokazuje, jak wygenerować materiały źródłowe polecenia kubectl.
Informacja:
Ten temat pokazuje, jak wygenerować materiały źródłowe dla poleceń kubectl takich jak kubectl apply i kubectl taint. Ten temat nie pokazuje, jak wygenerować stronę materiałów źródłowych opcji kubectl. Aby uzyskać instrukcje dotyczące generowania strony materiałów źródłowych opcji kubectl, zobacz Generowanie stron materiałów źródłowych dla komponentów i narzędzi Kubernetesa.Zanim zaczniesz
Wymagania:
Potrzebujesz maszyny z systemem operacyjnym Linux lub macOS.
Musisz mieć zainstalowane następujące narzędzia:
Twoja zmienna środowiskowa
PATHmusi zawierać wymagane narzędzia do budowania, takie jak binariaGoipython.Musisz wiedzieć, jak utworzyć pull requesta do repozytorium na GitHubie. Wymaga to utworzenia własnego forka repozytorium. Aby uzyskać więcej informacji, zobacz Praca z lokalnej kopii.
Skonfiguruj lokalne repozytoria
Utwórz lokalną przestrzeń roboczą i ustaw swoje GOPATH:
mkdir -p $HOME/<workspace>
export GOPATH=$HOME/<workspace>
Utwórz lokalną kopię następujących repozytoriów:
go get -u github.com/spf13/pflag
go get -u github.com/spf13/cobra
go get -u gopkg.in/yaml.v2
go get -u github.com/kubernetes-sigs/reference-docs
Jeśli nie masz jeszcze repozytorium kubernetes/website, pobierz je teraz:
git clone https://github.com/<your-username>/website $GOPATH/src/github.com/<your-username>/website
Zrób klon repozytorium kubernetes/kubernetes jako k8s.io/kubernetes:
git clone https://github.com/kubernetes/kubernetes $GOPATH/src/k8s.io/kubernetes
Usuń pakiet spf13 z $GOPATH/src/k8s.io/kubernetes/vendor/github.com:
rm -rf $GOPATH/src/k8s.io/kubernetes/vendor/github.com/spf13
Repozytorium kubernetes/kubernetes dostarcza kod źródłowy kubectl oraz kustomize.
Określ katalog bazowy twojej kopii repozytorium kubernetes/kubernetes. Na przykład, jeśli postępowałeś zgodnie z poprzednim krokiem, aby pobrać repozytorium, twój katalog bazowy to
$GOPATH/src/k8s.io/kubernetes. Kolejne kroki odwołują się do twojego katalogu bazowego jako<k8s-base>.Określ katalog bazowy klonu Twojego repozytorium kubernetes/website. Na przykład, jeśli wykonałeś poprzedni krok, aby pobrać repozytorium, Twoim katalogiem bazowym jest
$GOPATH/src/github.com/<your-username>/website. Kolejne kroki odnoszą się do Twojego katalogu bazowego jako<web-base>.Określ katalog główny dla Twojej kopii repozytorium kubernetes-sigs/reference-docs. Na przykład, jeśli postępowałeś zgodnie z poprzednim krokiem, aby uzyskać repozytorium, Twoim katalogiem głównym będzie
$GOPATH/src/github.com/kubernetes-sigs/reference-docs. Dalsze kroki odnoszą się do Twojego katalogu głównego jako<rdocs-base>.
W swoim lokalnym repozytorium k8s.io/kubernetes przejdź do interesującej Cię gałęzi i upewnij się, że jest ona aktualna. Na przykład, jeśli chcesz wygenerować dokumentację dla Kubernetesa 1.35.0, możesz użyć tych poleceń:
cd <k8s-base>
git checkout v1.35.0
git pull https://github.com/kubernetes/kubernetes 1.35.0
Jeśli nie musisz edytować kodu źródłowego kubectl, postępuj zgodnie z
instrukcjami dotyczącymi Ustawiania zmiennych kompilacji.
Edytowanie kodu źródłowego kubectl
Materiały źródłowe polecenia kubectl są automatycznie generowana z kodu źródłowego kubectl. Jeśli chcesz zmienić materiały źródłowe, pierwszym krokiem jest zmiana jednego lub więcej komentarzy w kodzie źródłowym kubectl. Wprowadź zmianę w swoim lokalnym repozytorium kubernetes/kubernetes, a następnie zgłoś pull requesta do gałęzi master na github.com/kubernetes/kubernetes.
PR 56673 jest przykładem pull requesta, który poprawia literówkę w kodzie źródłowym kubectl.
Monitoruj swój pull request (PR) i odpowiadaj na komentarze recenzentów. Kontynuuj monitorowanie swojego PR, aż zostanie scalony z docelową gałęzią w repozytorium kubernetes/kubernetes.
Zrób cherry pick do gałęzi wydania
Twoja zmiana znajduje się teraz w głównej gałęzi, która jest używana do rozwoju następnego wydania Kubernetesa. Jeśli chcesz, aby twoja zmiana pojawiła się w wersji dokumentacji Kubernetesa, która została już wydana, musisz zaproponować włączenie twojej zmiany do gałęzi wydania.
Na przykład, załóżmy, że gałąź master jest używana do rozwijania Kubernetes 1.36 i chcesz przenieść swoją zmianę do gałęzi release-1.35. Aby uzyskać instrukcje, jak to zrobić, zobacz Proponowanie Cherry Pick.
Monitoruj swój cherry pick pull request, aż zostanie scalone z gałęzią wydania.
Informacja:
Proponowanie cherry pick wymaga posiadania uprawnień do ustawiania etykiety oraz kamienia milowego w swoim pull requeście. Jeśli nie posiadasz tych uprawnień, będziesz musiał współpracować z kimś, kto może ustawić etykietę i kamień milowy za Ciebie.Ustaw zmienne budowania
Przejdź do <rdocs-base>. W swoim wierszu poleceń ustaw następujące zmienne środowiskowe.
- Ustaw
K8S_ROOTna<k8s-base>. - Ustaw
K8S_WEBROOTna<web-base>. - Ustaw
K8S_RELEASEna wersję dokumentacji, którą chcesz zbudować. Na przykład, jeśli chcesz zbudować dokumentację dla Kubernetesa 1.35, ustawK8S_RELEASEna 1.35.
Na przykład:
export K8S_WEBROOT=$GOPATH/src/github.com/<your-username>/website
export K8S_ROOT=$GOPATH/src/k8s.io/kubernetes
export K8S_RELEASE=1.35
Tworzenie katalogu wersjonowanego
Uruchomienie budowania (ang. build target) createversiondirs tworzy katalog z
wersjonowaniem i kopiuje pliki konfiguracyjne kubectl dotyczące materiałów źródłowych do tego
katalogu. Nazwa katalogu z wersjonowaniem jest zgodna z wzorcem v<major>_<minor>.
W katalogu <rdocs-base>, uruchom następujący cel budowania:
cd <rdocs-base>
make createversiondirs
Sprawdź tag wydania w k8s.io/kubernetes
W swoim lokalnym repozytorium <k8s-base>, przejdź do gałęzi, która zawiera
wersję Kubernetesa, którą chcesz udokumentować. Na przykład, jeśli chcesz
wygenerować dokumentację dla Kubernetesa 1.35.0, przejdź do tagu v1.35.
Upewnij się, że Twoja lokalna gałąź jest aktualna.
cd <k8s-base>
git checkout v1.35.0
git pull https://github.com/kubernetes/kubernetes v1.35.0
Uruchom kod generowania dokumentacji
W lokalnym katalogu <rdocs-base>, uruchom cel budowania (ang. build target) copycli. Komenda działa z uprawnieniami root:
cd <rdocs-base>
make copycli
Polecenie copycli czyści tymczasowy katalog kompilacji, generuje pliki poleceń kubectl i
kopiuje zbiorczą stronę HTML materiałów źródłowych poleceń kubectl oraz zasoby do <web-base>.
Zlokalizuj wygenerowane pliki
Zweryfikuj, czy te dwa pliki zostały wygenerowane:
[ -e "<rdocs-base>/gen-kubectldocs/generators/build/index.html" ] && echo "index.html built" || echo "no index.html"
[ -e "<rdocs-base>/gen-kubectldocs/generators/build/navData.js" ] && echo "navData.js built" || echo "no navData.js"
Zlokalizuj skopiowane pliki
Zweryfikuj, czy wszystkie wygenerowane pliki zostały skopiowane do Twojego <web-base>:
cd <web-base>
git status
Wynik powinien zawierać zmodyfikowane pliki:
static/docs/reference/generated/kubectl/kubectl-commands.html
static/docs/reference/generated/kubectl/navData.js
Wynik może również zawierać:
static/docs/reference/generated/kubectl/scroll.js
static/docs/reference/generated/kubectl/stylesheet.css
static/docs/reference/generated/kubectl/tabvisibility.js
static/docs/reference/generated/kubectl/node_modules/bootstrap/dist/css/bootstrap.min.css
static/docs/reference/generated/kubectl/node_modules/highlight.js/styles/default.css
static/docs/reference/generated/kubectl/node_modules/jquery.scrollto/jquery.scrollTo.min.js
static/docs/reference/generated/kubectl/node_modules/jquery/dist/jquery.min.js
static/docs/reference/generated/kubectl/node_modules/font-awesome/css/font-awesome.min.css
Lokalne testowanie dokumentacji
Zbuduj dokumentację Kubernetes w lokalnym <web-base>.
cd <web-base>
git submodule update --init --recursive --depth 1 # if not already done
make container-serve
Zobacz podgląd lokalny.
Dodaj i zatwierdź zmiany w kubernetes/website
Uruchom git add i git commit, aby zatwierdzić pliki.
Utwórz pull requesta
Utwórz pull requesta do repozytorium kubernetes/website.
Monitoruj swój pull request i odpowiadaj na komentarze z przeglądu.
Kontynuuj monitorowanie swojego pull requesta aż do momentu jego włączenia do głównej gałęzi kodu.
Kilka minut po włączeniu twojego pull requesta, zaktualizowane tematy materiałów źródłowych będą widoczne w opublikowanej dokumentacji.
Co dalej?
7.7.3 - Generowanie materiałów źródłowych dla metryk
Ta strona demonstruje generowanie materiałów źródłowych dotyczących metryk.
Zanim zaczniesz
Wymagania:
Potrzebujesz maszyny z systemem operacyjnym Linux lub macOS.
Musisz mieć zainstalowane następujące narzędzia:
Twoja zmienna środowiskowa
PATHmusi zawierać wymagane narzędzia do budowania, takie jak binariaGoipython.Musisz wiedzieć, jak utworzyć pull requesta do repozytorium na GitHubie. Wymaga to utworzenia własnego forka repozytorium. Aby uzyskać więcej informacji, zobacz Praca z lokalnej kopii.
Sklonuj repozytorium Kubernetesa
Generowanie metryk odbywa się w repozytorium Kubernetesa. Aby sklonować repozytorium, przejdź do katalogu, w którym chcesz, aby klon istniał.
Następnie wykonaj następujące polecenie:
git clone https://www.github.com/kubernetes/kubernetes
To tworzy folder kubernetes w bieżącym katalogu roboczym.
Generowanie metryk
W sklonowanym repozytorium Kubernetesa
zlokalizuj katalog test/instrumentation/documentation.
Dokumentacja metryk jest generowana w tym katalogu.
Przy każdej wersji dodawane są nowe metryki. Po uruchomieniu skryptu generatora dokumentacji metryk, skopiuj dokumentację metryk na stronę internetową Kubernetesa i opublikuj zaktualizowaną dokumentację metryk.
Aby wygenerować najnowsze metryki, upewnij się, że znajdujesz się w katalogu głównym sklonowanego katalogu Kubernetesa. Następnie wykonaj następujące polecenie:
./test/instrumentation/update-documentation.sh
Aby sprawdzić zmiany, wykonaj:
git status
Wynik jest podobny do:
./test/instrumentation/documentation/documentation.md
./test/instrumentation/documentation/documentation-list.yaml
Skopiuj wygenerowany plik dokumentacji metryk do repozytorium strony internetowej Kubernetesa
Ustaw zmienną środowiskową głównego katalogu strony Kubernetesa.
Wykonaj następujące polecenie, aby ustawić główny katalog witryny:
export WEBSITE_ROOT=<path to website root>Skopiuj wygenerowany plik metryk do repozytorium witryny Kubernetesa.
cp ./test/instrumentation/documentation/documentation.md "${WEBSITE_ROOT}/content/en/docs/reference/instrumentation/metrics.md"Informacja:
Jeśli pojawi się błąd, sprawdź, czy masz uprawnienia do skopiowania pliku. Możesz użyćchown, aby zmienić własność pliku na swojego użytkownika.
Utwórz pull requesta
Aby utworzyć pull request, postępuj zgodnie z instrukcjami w Otwarcie pull requesta.
Co dalej?
7.7.4 - Generowanie materiałów źródłowych dla komponentów i narzedzi Kubernetesa
Ta strona pokazuje, jak zbudować strony materiałów źródłowych komponentów i narzędzi Kubernetesa.
Zanim zaczniesz
Rozpocznij od sekcji wymagania wstępne w przewodniku "szybki start materiałów źródłowych"
Postępuj zgodnie z Szybki start, aby wygenerować strony materiałów źródłowych dla komponentów i narzędzi Kubernetesa.
Co dalej?
7.7.5 -
Wymagania:
Potrzebujesz maszyny z systemem operacyjnym Linux lub macOS.
Musisz mieć zainstalowane następujące narzędzia:
Twoja zmienna środowiskowa
PATHmusi zawierać wymagane narzędzia do budowania, takie jak binariaGoipython.Musisz wiedzieć, jak utworzyć pull requesta do repozytorium na GitHubie. Wymaga to utworzenia własnego forka repozytorium. Aby uzyskać więcej informacji, zobacz Praca z lokalnej kopii.
7.8 - Styl dokumentacji
Tematy w tej sekcji zawierają wskazówki dotyczące stylu pisania, formatowania treści i organizacji, a także korzystania ze specyficznych dostosowań Hugo dla dokumentacji Kubernetesa.
7.8.1 - Typy treści
Dokumentacja Kubernetesa obejmuje kilka typów treści stron:
- Pojęcia i koncepcje (ang. Concept)
- Zadanie (ang. Task)
- Samouczek (ang. Tutorial)
- Materiały źródłowe (ang. Reference)
Jako wskazówkę dotyczącą struktury i stylu pisania poszczególnych typów stron możesz wykorzystać framework dokumentacyjny Diátaxis.
Sekcje treści
Każdy typ strony zawiera szereg sekcji zdefiniowanych przez
komentarze Markdown i nagłówki HTML. Możesz dodać nagłówki
do swojej strony za pomocą kodu heading. Komentarze i
nagłówki pomagają utrzymać odpowiednią strukturę strony dla danego typu.
Przykłady komentarzy w Markdown definiujących sekcje strony:
<!-- overview -->
<!-- body -->
Aby utworzyć typowe nagłówki na swoich
stronach, użyj kodu heading z nazwą nagłówka.
Przykłady nazw nagłówków:
- whatsnext - co dalej
- prerequisites - wymagania wstępne
- objectives - cele
- cleanup - sprzątanie
- synopsis - streszczenie
- seealso - zobacz także
- options - opcje
Na przykład, aby utworzyć nagłówek whatsnext, dodaj kod nagłówka z nazwą "whatsnext":
## {{% heading "whatsnext" %}}
Możesz zadeklarować nagłówek prerequisites w następujący sposób:
## {{% heading "prerequisites" %}}
Kod heading oczekuje jednego parametru typu
string. Ten parametr nagłówka odpowiada prefiksowi zmiennej
w plikach i18n/<lang>/<lang>.toml. Na przykład:
i18n/en/en.toml:
[whatsnext_heading]
other = "What's next"
i18n/ko/ko.toml:
[whatsnext_heading]
other = "다음 내용"
Typy zawartości
Każdy typ zawartości nieformalnie definiuje swoją oczekiwaną strukturę strony. Twórz zawartość strony, korzystając z sugerowanych sekcji strony.
Pojęcie (ang. Concept)
Strona z pojęciami wyjaśnia określony aspekt Kubernetesa. Na przykład, strona koncepcyjna może opisywać obiekt Deployment w Kubernetesie i wyjaśniać jego rolę jako aplikacji po wdrożeniu, skalowaniu i aktualizacji. Zazwyczaj strony koncepcyjne nie zawierają instrukcji krok po kroku, lecz odsyłają do zadań lub samouczków.
Aby napisać nową stronę z pojęciem, utwórz plik Markdown w
podkatalogu katalogu /content/en/docs/concepts, z następującymi sekcjami:
Strony koncepcyjne są podzielone na trzy sekcje:
| Sekcja strony |
|---|
| overview - przegląd |
| body - treść |
| whatsnext - co dalej |
Sekcje overview i body pojawiają się jako komentarze na stronie z
koncepcjami. Możesz dodać sekcję whatsnext do swojej strony za pomocą kodu heading.
Wypełnij każdą sekcję treścią. Postępuj zgodnie z tymi wytycznymi:
- Organizuj treści za pomocą nagłówków H2 i H3.
- Dla
overview, ustaw kontekst tematu za pomocą pojedynczego akapitu. - Dla
bodywyjaśnij koncepcję. - Dla
whatsnext, podaj wypunktowaną listę tematów (maksymalnie 5), aby dowiedzieć się więcej o koncepcji.
Strona adnotacje jest opublikowanym przykładem strony koncepcyjnej.
Zadanie (ang. Task)
Strony opisujące wykonywanie zadań zawierają minimum wyjaśnień, ale zwykle podają odnośniki do dokumentacji objaśniającej pojęcia i szerszy kontekst danego tematu.
Aby napisać nową stronę zadania, utwórz plik Markdown w
podkatalogu katalogu /content/en/docs/tasks, z następującymi sekcjami:
| Sekcja strony |
|---|
| overview - przegląd |
| prerequisites - wymagania wstępne |
| steps - kroki |
| discussion - dyskusja |
| whatsnext - co dalej |
Sekcje overview, steps i discussion pojawiają się jako komentarze
na stronie zadania. Możesz dodać sekcje
prerequisites i whatsnext do swojej strony za pomocą kodu heading.
Każdą sekcję uzupełnij treścią. Użyj następujących wytycznych:
- Użyj nagłówków poziomu H2 lub niższego (z dwoma wiodącymi
znakami
#). Sekcje są automatycznie tytułowane przez szablon. - Dla
overview, użyj akapitu, aby ustawić kontekst dla całego tematu. Krótko wyjaśnij, dlaczego czytelnik miałby chcieć wykonać to zadanie - czyli opisz motywację lub przypadek użycia - aby mógł ocenić, czy strona jest dla niego istotna, zanim zacznie czytać kolejne kroki. - Dla
prerequisitesużywaj list punktowanych, kiedy to możliwe. Zaczynaj dodawać dodatkowe wymagania wstępne poniżejinclude. Domyślne wymagania wstępne obejmują działający klaster Kubernetesa. - Dla
stepsużywaj numerowanych list i skup się bezpośrednio na zadaniu. Jeśli wykonanie kroku wymaga dodatkowego wyjaśnienia, skieruj czytelnika do odpowiedniej strony, zamiast duplikować treść w instrukcji. - Do omówienia użyj standardowej treści, aby rozwinąć
informacje zawarte w sekcji
steps. - Dla
whatsnext, podaj listę punktowaną z maksymalnie 5 tematami, które mogą zainteresować czytelnika jako kolejne tematy do przeczytania.
Przykład opublikowanego tematu zadania to Korzystanie z proxy HTTP do uzyskania dostępu do API Kubernetesa.
Samouczek (ang. Tutorial)
Strona samouczka pokazuje, jak osiągnąć cel, który jest bardziej złożony niż pojedyncze zadanie. Zazwyczaj strona samouczka składa się z kilku sekcji, z których każda zawiera sekwencję kroków. Na przykład samouczek może przeprowadzać użytkownika przez przykładowy kod ilustrujący określoną funkcję Kubernetesa. Samouczki mogą zawierać ogólne wyjaśnienia, ale powinny odsyłać do powiązanych tematów koncepcyjnych w celu dogłębnego omówienia zagadnienia.
Aby napisać nową stronę samouczka, utwórz plik Markdown w
podkatalogu katalogu /content/en/docs/tutorials, z następującymi sekcjami:
| Sekcja strony |
|---|
| overview - przegląd |
| prerequisites - wymagania wstępne |
| objectives - cele |
| lessoncontent - treść lekcji |
| cleanup - sprzątanie |
| whatsnext - co dalej |
Sekcje overview, objectives i lessoncontent pojawiają się
jako komentarze na stronie samouczka. Możesz dodać sekcje
prerequisites, cleanup i whatsnext do swojej strony za pomocą kodu heading.
Każdą sekcję uzupełnij treścią. Użyj następujących wytycznych:
- Użyj nagłówków poziomu H2 lub niższego (z dwoma wiodącymi
znakami
#). Sekcje są automatycznie tytułowane przez szablon. - Dla
overviewużyj akapitu, aby ustawić kontekst dla całego tematu. - W przypadku
prerequisitesużywaj, jeśli to możliwe, list punktowanych. Dodaj dodatkowe wymagania wstępne poniżej tych domyślnie uwzględnionych. - Dla
objectives, używaj list wypunktowanych. - Dla
lessoncontent, użyj mieszanki list numerowanych i treści narracyjnej w zależności od potrzeb. - W przypadku
cleanup, użyj numerowanych list, aby opisać kroki niezbędne do posprzątania stanu klastra po zakończeniu zadania. - Dla
whatsnext, podaj listę punktowaną z maksymalnie 5 tematami, które mogą zainteresować czytelnika jako kolejne tematy do przeczytania.
Przykładem opublikowanego tematu samouczka jest Uruchamianie aplikacji bezstanowej przy użyciu Deployment.
Materiały źródłowe (ang. Reference)
Każde narzędzie Kubernetesa ma swoją stronę materiałów źródłowych (ang. reference page), gdzie można znaleźć jego opis i listę dostępnych opcji. Dokumentacja ta jest generowana przez skrypty, które automatycznie pobierają informacje z poleceń narzędzia.
Strona z odniesieniem do narzędzia ma kilka możliwych sekcji:
| Sekcja strony |
|---|
| streszczenie |
| opcje |
| opcje z nadrzędnych poleceń |
| przykłady |
| zobacz także |
Przykłady opublikowanych stron referencyjnych narzędzi to:
Co dalej?
- Dowiedz się więcej o Przewodniku stylu
- Dowiedz się więcej o Przewodniku treści
- Dowiedz się więcej o organizacji treści
7.9 - Zaawansowana współpraca
Ta strona zakłada, że rozumiesz, jak tworzyć nowe treści i recenzować pracę innych, i jesteś gotów nauczyć się więcej sposobów, jak wnosić wkład. Musisz umieć używać klienta wiersza poleceń Git jak rownież inne narzędzia do wykonania niektórych z tych zadań.
Zaproponuj ulepszenia
Członkowie SIG Docs mogą proponować usprawnienia.
Po tym, jak przez jakiś czas będziesz wnosić wkład do dokumentacji Kubernetesa,
możesz mieć pomysły na ulepszenie Przewodnika Stylu,
Przewodnika Treści,
narzędzi wykorzystywanych do tworzenia dokumentacji, stylu strony internetowej,
procesów przeglądania i scalania pull requestów, lub innych aspektów dokumentacji. Dla
maksymalnej przejrzystości, tego rodzaju propozycje muszą być omówione podczas
spotkania SIG Docs lub na liście mailingowej kubernetes-sig-docs.
Dodatkowo, może pomóc posiadanie kontekstu
dotyczącego obecnego sposobu działania i przyczyn podejmowania
wcześniejszych decyzji, zanim zaproponujesz radykalne zmiany. Najszybszym sposobem
uzyskania odpowiedzi na pytania dotyczące obecnego działania dokumentacji jest
zadanie ich na kanale #sig-docs na Slacku kubernetes.slack.com
Po odbyciu dyskusji i osiągnięciu porozumienia przez SIG w sprawie pożądanego wyniku, możesz pracować nad proponowanymi zmianami w sposób najbardziej odpowiedni. Na przykład, aktualizacja wytycznych stylu lub funkcjonalności strony internetowej może wymagać otwarcia pull requesta, podczas gdy zmiana związana z testowaniem dokumentacji może wymagać współpracy z sig-testing.
Koordynowanie dokumentacji do wydania Kubernetes
Zatwierdzający SIG Docs mogą koordynować dokumentację dla wydania Kubernetesa.
Każde wydanie Kubernetesa jest koordynowane przez zespół osób uczestniczących w sig-release (ang. Special Interest Group - SIG). Inni członkowie zespołu wydania dla danego wydania to ogólny lider wydania, a także przedstawiciele sig-testing i innych. Aby dowiedzieć się więcej o procesach wydania Kubernetesa, odwiedź https://github.com/kubernetes/sig-release.
Przedstawiciel SIG Docs dla danego wydania koordynuje następujące zadania:
- Monitoruje arkusz śledzący funkcje w poszukiwaniu nowych lub zmienionych funkcji mających wpływ na dokumentację. Jeśli dokumentacja dla danej funkcji nie będzie gotowa na wydanie, funkcja może nie zostać dopuszczona do wydania.
- Uczestniczy regularnie w spotkaniach sig-release i przekazuje aktualizacje dotyczące statusu dokumentacji dla wydania.
- Przegląda i poprawia dokumentację funkcji napisaną przez SIG odpowiedzialny za wdrożenie tej funkcji.
- Scala pull requesty związane z wydaniem i utrzymuje gałąź Git na potrzeby wydania.
- Mentoruje innych współtwórców SIG Docs, którzy chcą nauczyć się, jak pełnić tę rolę w przyszłości. Jest to znane jako "shadowing".
- Publikuje zmiany w dokumentacji związane z wydaniem, gdy artefakty wydania zostaną opublikowane.
Koordynowanie wydania to zazwyczaj zobowiązanie na 3-4 miesiące, a obowiązek ten jest rotacyjnie przejmowany przez zatwierdzających SIG Docs.
Pomoganie jako Ambasador Nowego Współtwórcy
Zatwierdzający SIG Docs mogą pełnić rolę Ambasadorów dla Nowych Współtwórców.
Ambasadorzy Nowych Współtwórców witają nowych współtwórców w SIG-Docs, proponują PR-y nowym współtwórcom i mentoruują nowych współtwórców podczas składania przez nich pierwszych kilku PR-ów.
Obowiązki Ambasadorów Nowych Współtwórców obejmują:
- Monitorowanie kanału Slack #sig-docs w poszukiwaniu pytań od nowych współtwórców.
- Współprace z osobami zajmującymi się obsługą PR w celu zidentyfikowania dobrych pierwszych problemów dla nowych współtwórców.
- Mentoring nowych współtwórców w trakcie ich pierwszych kilku PR-ów do repozytorium dokumentacji.
- Pomoc nowym współtwórcom w tworzeniu bardziej złożonych PR, które są im potrzebne, aby stać się członkami Kubernetesa.
- Sponsorowanie współtwórców w ich drodze do zostania członkami Kubernetes.
- Prowadzenie comiesięcznego spotkania w celu pomocy i mentorowania nowych współtwórców.
Obecni Ambasadorzy Nowych Współtwórców są ogłaszani na każdym spotkaniu SIG-Docs oraz w kanale Kubernetes #sig-docs.
Sponsoruj nowego współtwórcę
Recenzenci SIG Docs mogą sponsorować nowych współtwórców.
Po pomyślnym przesłaniu 5 merytorycznych pull requestów do jednego lub więcej repozytoriów Kubernetesa, nowy współtwórca może ubiegać się o członkostwo w organizacji Kubernetes. Członkostwo współtwórcy musi być poparte przez dwóch sponsorów, którzy są już recenzentami.
Nowi współtwórcy dokumentacji mogą ubiegać się o sponsorów, pytając na kanale #sig-docs w instancji Kubernetes na Slacku lub na liście mailingowej SIG Docs. Jeśli jesteś pewny pracy wnioskodawcy, możesz dobrowolnie go sponsorować. Gdy złożą swoje podanie o członkostwo, odpowiedz na aplikację z "+1" i dołącz szczegóły, dlaczego uważasz, że wnioskodawca jest odpowiednią osobą do członkostwa w organizacji Kubernetes.
Pełnij rolę współprzewodniczącego SIG
Członkowie SIG Docs mogą pełnić funkcję współprzewodniczącego SIG Docs.
Wymagania wstępne
Członek zespołu Kubernetesa musi spełniać następujące wymagania, aby zostać współprzewodniczącym:
- Rozumieć przepływy pracy i narzędzi SIG Docs: git, Hugo, lokalizacja, podprojekt bloga
- Rozumieć, w jaki sposób inne Kubernetes SIG i repozytoria wpływają na przepływ pracy SIG Docs, w tym: zespoły w k/org, proces w k/community, wtyczki w k/test-infra, oraz rolę SIG Architecture. Ponadto, rozumieć, jak działa proces wydawania dokumentacji Kubernetes.
- Być zatwierdzonym przez społeczność SIG Docs bezpośrednio lub poprzez konsensus bierny.
- Poświać co najmniej 5 godzin tygodniowo (a często więcej) na pełnienie roli przez minimum 6 miesięcy
Odpowiedzialności
Rola współprzewodniczącego jest rolą usługową: współprzewodniczący buduje potencjał współpracowników, zajmuje się procesami i polityką, organizuje i prowadzi spotkania, planuje "PR wranglers", promuje dokumentację w społeczności Kubernetesa, dba o to, aby dokumentacja odnosiła sukcesy w cyklach wydawniczych Kubernetes oraz utrzymuje SIG Docs skupione na efektywnych priorytetach.
Obowiązki obejmują:
- Koncentrowanie działań SIG Docs na tym, by dzięki świetnej dokumentacji zwiększać komfort i satysfakcję programistów.
- Bycie przykładem w przestrzeganiu kodeksu postępowania społeczności i dbanie, by inni członkowie SIG również się do niego stosowali.
- Douczanie się i ustalanie najlepszych praktyk dla SIG, aktualizując wytyczne dotyczące wkładu
- Planowanie i prowadzenie spotkań SIG: cotygodniowe aktualizacje statusu, kwartalne sesje retrospekcyjne/planistyczne oraz inne według potrzeby
- Planowanie i realizacja sprintów dokumentacyjnych podczas wydarzeń KubeCon i innych konferencji
- Rekrutowanie i działanie jako rzecznik SIG Docs w imieniu CNCF i jego platynowych partnerów, w tym Google, Oracle, Azure, IBM i Huawei.
- Utrzymywanie płynnego działania SIG
Prowadzenie efektywnych spotkań
Aby zaplanować i przeprowadzać efektywne spotkania, te wytyczne pokazują, co robić, jak to robić i dlaczego.
Przestrzegaj kodeksu postępowania społeczności:
- Zapewnij, że dyskusje są pełne szacunku i otwartości, z użyciem odpowiedniego, włączającego języka.
Ustaw klarowną agendę:
- Ustal jasny harmonogram tematów
- Opublikuj agendę z wyprzedzeniem
W przypadku cotygodniowych spotkań, skopiuj i wklej notatki z poprzedniego tygodnia do sekcji "Past meetings" w notatkach.
Współpracuj nad dokładnymi notatkami:
- Zapisz dyskusję z zebrania
- Rozważ delegowanie roli osoby prowadzącej notatki
Przypisz zadania jasno i precyzyjnie:
- Zarejestruj zadanie do wykonania, osobę do niego przypisaną oraz przewidywaną datę ukończenia.
Moderuj w razie potrzeby:
- Jeśli dyskusja odbiega od agendy, skieruj uczestników z powrotem na bieżący temat
- Zrób miejsce na różne style dyskusji, jednocześnie skupiając się na temacie rozmowy i szanując czas uczestników.
Szanuj czas ludzi:
Rozpoczynaj i kończ spotkania o czasie.
Używaj Zoom efektywnie:
- Zapoznaj się z wytycznymi Zoom dla Kubernetesa
- Zgłoś rolę hosta po zalogowaniu się, wprowadzając klucz hosta
Nagrywanie spotkań na Zoomie
Kiedy będziesz gotowy do rozpoczęcia nagrywania, kliknij Zapisz w chmurze.
Gdy będziesz gotowy, aby zatrzymać nagrywanie, kliknij Stop.
Film przesyła się automatycznie na YouTube.
Zakończenie roli współprzewodniczącego SIG (Emeritus)
7.10 - Przeglądanie statystyki strony
Ta strona zawiera informacje o dashboardzie analitycznym kubernetes.io.
Ten dashboard został zbudowany przy użyciu Google Looker Studio i pokazuje informacje zebrane na kubernetes.io przy użyciu Google Analytics 4 od sierpnia 2022 roku.
Korzystanie z dashboardu
Domyślnie dashboard pokazuje wszystkie zebrane analizy z ostatnich 30 dni. Użyj selektora dat, aby zobaczyć dane z innego zakresu dat. Inne opcje filtrowania pozwalają na przeglądanie danych w oparciu o lokalizację użytkownika, urządzenie używane do dostępu do witryny, tłumaczenie używanych dokumentów i więcej.
Jeśli zauważysz problem z tym dashboardem lub chcesz zgłosić jakieś usprawnienia, proszę otwórz zgłoszenie.
7.11 - Tłumaczenie dokumentacji na język polski
Na tej stronie znajdziesz wskazówki i wytyczne przydatne przy tłumaczeniu dokumentacji Kubernetesa na język polski.
Dokumentem nadrzędnym jest angielski opis stylu dokumentacji.
Wskazówki ogólne
Staramy się, aby styl tłumaczenia był jak najbardziej naturalny. W przypadku dokumentacji technicznej może być to trudne zadanie, szczególnie gdy chcemy utrzymać precyzję tłumaczenia. Zależy nam na unikaniu sytuacji, kiedy tekst zaczyna sprawiać wrażenie przetłumaczonego maszynowo.
Pamiętajmy też, że oficjalna wykładnia zawsze znajduje się w tekście angielskim. Polskie tłumaczenie ma ułatwić pierwsze kroki osobom, które zaczynają swoją przygodę z Kubernetesem.
Wytyczne szczegółowe
Odmiana terminu Kubernetes
Kubernetes jest nazwą własną, liczba pojedyncza, rodzaj męski. Odmieniamy: Kubernetesa, Kubernetesem itp. W uzasadnionych przypadkach można stosować też "system Kubernetes".
Odmiana terminów Pod, Deployment
Odmieniamy zgodnie z ogólnymi zasadami - poda, deploymentu itp.
Ujednolicony słownik
W sieci dostępne są słowniki terminów informatycznych. Poniższa tabela zawiera słowa specyficzne dla Kubernetesa i inne często używane wyrażenia.
| Termin angielski | Tłumaczenie |
|---|---|
| container | kontener |
| control plane | warstwa sterowania |
| Deployment | Deployment |
| horizontal scaling | skalowanie horyzontalne |
| Pod | Pod |
| rolling update | aktualizacje stopniowe |
| volume | volume (opcjonalnie: wolumin) |
| worker node | węzeł roboczy |