Administração de Cluster
Detalhes de baixo nível relevantes para criar ou administrar um cluster Kubernetes.
A visão geral da administração do cluster é para qualquer pessoa que crie ou administre um cluster do Kubernetes.
É pressuposto alguma familiaridade com os conceitos principais do Kubernetes.
Planejando um cluster
Consulte os guias em Configuração para exemplos de como planejar, instalar e configurar clusters Kubernetes. As soluções listadas neste artigo são chamadas de distros.
Nota:
Nem todas as distros são mantidas ativamente. Escolha distros que foram testadas com uma versão recente do Kubernetes.Antes de escolher um guia, aqui estão algumas considerações:
- Você quer experimentar o Kubernetes em seu computador ou deseja criar um cluster de vários nós com alta disponibilidade? Escolha as distros mais adequadas ás suas necessidades.
- Você vai usar um cluster Kubernetes gerenciado , como o Google Kubernetes Engine, ou vai hospedar seu próprio cluster?
- Seu cluster será local, ou na nuvem (IaaS)? O Kubernetes não oferece suporte direto a clusters híbridos. Em vez disso, você pode configurar vários clusters.
- Se você estiver configurando o Kubernetes local, leve em consideração qual modelo de rede se encaixa melhor.
- Você vai executar o Kubernetes em um hardware bare metal ou em máquinas virtuais? (VMs)?
- Você deseja apenas executar um cluster ou espera participar ativamente do desenvolvimento do código do projeto Kubernetes? Se for a segunda opção,
escolha uma distro desenvolvida ativamente. Algumas distros usam apenas versão binária, mas oferecem uma maior variedade de opções.
- Familiarize-se com os componentes necessários para executar um cluster.
Gerenciando um cluster
Protegendo um cluster
Protegendo o kubelet
Serviços Opcionais para o Cluster
1 - Desligamentos de Nó
Em um cluster Kubernetes, um nó
pode ser desligado de forma planejada e controlada ou inesperadamente devido a razões como
uma queda de energia ou algo externo. Um desligamento de nó pode levar a falhas na
carga de trabalho se o nó não for drenado antes do desligamento. Um desligamento de nó
pode ser controlado ou não controlado.
Desligamento controlado de nó
O kubelet tenta detectar o desligamento do sistema do nó e encerra os Pods em execução no nó.
O Kubelet garante que os Pods sigam o
processo normal de encerramento de Pod
durante o desligamento do nó. Durante o desligamento do nó, o kubelet não aceita novos
Pods (mesmo que esses Pods já estejam vinculados ao nó).
Habilitando o desligamento controlado de nó
ESTADO DA FUNCIONALIDADE:
Kubernetes v1.21 [beta](habilitado por padrão)
No Linux, a funcionalidade de desligamento controlado de nó é controlada com o feature gate
GracefulNodeShutdown que está habilitado por padrão na versão 1.21.
Nota:
A funcionalidade de desligamento controlado de nó depende do systemd, pois aproveita os
bloqueios inibidores do systemd para
atrasar o desligamento do nó por uma determinada duração.
ESTADO DA FUNCIONALIDADE:
Kubernetes v1.34 [beta](habilitado por padrão)
No Windows, a funcionalidade de desligamento controlado de nó é controlada com o feature gate
WindowsGracefulNodeShutdown que foi introduzido na versão 1.32 como uma funcionalidade alfa. No Kubernetes 1.34 a funcionalidade está em Beta
e está habilitada por padrão.
Nota:
A funcionalidade de desligamento controlado de nó no Windows depende do kubelet sendo executado como um serviço do Windows,
ele terá então um
manipulador de controle de serviço registrado
para atrasar o evento de pré-desligamento por uma determinada duração.
O desligamento controlado de nó no Windows não pode ser cancelado.
Se o kubelet não estiver sendo executado como um serviço do Windows, ele não será capaz de definir e monitorar
o evento Preshutdown,
o nó terá que passar pelo procedimento de Desligamento Não Controlado de Nó mencionado acima.
No caso em que a funcionalidade de desligamento controlado de nó no Windows está habilitada, mas o kubelet não está
sendo executado como um serviço do Windows, o kubelet continuará em execução em vez de falhar. No entanto,
ele registrará um erro indicando que precisa ser executado como um serviço do Windows.
Configurando o desligamento controlado de nó
Observe que, por padrão, ambas as opções de configuração descritas abaixo,
shutdownGracePeriod e shutdownGracePeriodCriticalPods, são definidas como zero,
portanto não ativando a funcionalidade de desligamento controlado de nó.
Para ativar a funcionalidade, ambas as opções devem ser configuradas adequadamente e
definidas com valores diferentes de zero.
Uma vez que o kubelet é notificado sobre um desligamento de nó, ele define uma condição NotReady no
Node, com o reason definido como "node is shutting down". O kube-scheduler respeita esta condição
e não aloca nenhum Pod no nó afetado; espera-se que outros agendadores de terceiros
sigam a mesma lógica. Isso significa que novos Pods não serão alocados naquele nó
e, portanto, nenhum será iniciado.
O kubelet também rejeita Pods durante a fase PodAdmission se um
desligamento de nó em andamento for detectado, de modo que mesmo Pods com uma
tolerância para
node.kubernetes.io/not-ready:NoSchedule não sejam iniciados lá.
Quando o kubelet está definindo essa condição em seu Nó via API,
o kubelet também começa a encerrar quaisquer Pods que estejam em execução localmente.
Durante um desligamento controlado, o kubelet encerra os Pods em duas fases:
- Encerra Pods regulares em execução no nó.
- Encerra Pods críticos
em execução no nó.
A funcionalidade de desligamento controlado de nó é configurada com duas
opções do KubeletConfiguration:
shutdownGracePeriod:
Especifica a duração total que o nó deve atrasar o desligamento. Esta é a duração
total de tolerância para o encerramento de Pods tanto para Pods regulares quanto para
Pods críticos.
shutdownGracePeriodCriticalPods:
Especifica a duração utilizada para encerrar
Pods críticos
durante um desligamento de nó. Este valor deve ser menor que shutdownGracePeriod.
Nota:
Existem casos em que o encerramento do Nó foi cancelado pelo sistema (ou talvez manualmente
por um administrador). Em qualquer uma dessas situações, o Nó retornará ao estado Ready.
No entanto, os Pods que já iniciaram o processo de encerramento não serão restaurados pelo kubelet
e precisarão ser reagendados.Por exemplo, se shutdownGracePeriod=30s e
shutdownGracePeriodCriticalPods=10s, o kubelet atrasará o desligamento do nó em
30 segundos. Durante o desligamento, os primeiros 20 (30-10) segundos serão reservados
para encerrar gradualmente os Pods normais, e os últimos 10 segundos serão
reservados para encerrar Pods críticos.
Nota:
Quando os Pods foram removidos durante o desligamento controlado do nó, eles são marcados como desligados.
Executar kubectl get pods mostra o status dos Pods removidos como Terminated.
E kubectl describe pod indica que o Pod foi removido devido ao desligamento do nó:
Reason: Terminated
Message: Pod was terminated in response to imminent node shutdown.
Desligamento controlado de nó baseado em prioridade de Pod
ESTADO DA FUNCIONALIDADE:
Kubernetes v1.24 [beta](habilitado por padrão)
Para fornecer mais flexibilidade durante o desligamento controlado de nó em relação à ordenação
de Pods durante o desligamento, o desligamento controlado de nó respeita a PriorityClass para
Pods, desde que você tenha habilitado esta funcionalidade em seu cluster. A funcionalidade
permite que administradores de cluster definam explicitamente a ordenação de Pods
durante o desligamento controlado de nó com base em
classes de prioridade.
A funcionalidade de Desligamento Controlado de Nó, conforme descrita
acima, desliga Pods em duas fases, Pods não críticos, seguidos por Pods
críticos. Se flexibilidade adicional for necessária para definir explicitamente a ordenação de
Pods durante o desligamento de uma forma mais granular, o desligamento
controlado baseado em prioridade de Pod pode ser usado.
Quando o desligamento controlado de nó respeita as prioridades de Pod, isso torna possível fazer
o desligamento controlado de nó em múltiplas fases, cada fase desligando uma
classe de prioridade específica de Pods. O kubelet pode ser configurado com as fases exatas
e o tempo de desligamento por fase.
Assumindo as seguintes
classes de prioridade
personalizadas de Pod em um cluster,
| Nome da classe de prioridade do Pod | Valor da classe de prioridade do Pod |
|---|
custom-class-a | 100000 |
custom-class-b | 10000 |
custom-class-c | 1000 |
regular/unset | 0 |
Dentro da configuração do kubelet
as configurações para shutdownGracePeriodByPodPriority poderiam ser assim:
| Valor da classe de prioridade do Pod | Período de desligamento |
|---|
| 100000 | 10 segundos |
| 10000 | 180 segundos |
| 1000 | 120 segundos |
| 0 | 60 segundos |
A configuração YAML correspondente do kubelet seria:
shutdownGracePeriodByPodPriority:
- priority: 100000
shutdownGracePeriodSeconds: 10
- priority: 10000
shutdownGracePeriodSeconds: 180
- priority: 1000
shutdownGracePeriodSeconds: 120
- priority: 0
shutdownGracePeriodSeconds: 60
A tabela acima implica que qualquer Pod com valor de priority >= 100000 terá
apenas 10 segundos para desligar, qualquer Pod com valor >= 10000 e < 100000 terá 180
segundos para desligar, qualquer Pod com valor >= 1000 e < 10000 terá 120 segundos para desligar.
Finalmente, todos os outros Pods terão 60 segundos para desligar.
Não é necessário especificar valores correspondentes a todas as classes. Por
exemplo, você poderia usar estas configurações:
| Valor da classe de prioridade do Pod | Período de desligamento |
|---|
| 100000 | 300 segundos |
| 1000 | 120 segundos |
| 0 | 60 segundos |
No caso acima, os Pods com custom-class-b irão para o mesmo grupo
que custom-class-c para o desligamento.
Se não houver Pods em um intervalo específico, então o kubelet não espera
por Pods naquele intervalo de prioridade. Em vez disso, o kubelet pula imediatamente para o
próximo intervalo de valor de classe de prioridade.
Se esta funcionalidade estiver habilitada e nenhuma configuração for fornecida, então nenhuma ação de
ordenação será realizada.
Usar esta funcionalidade requer habilitar o
feature gate
GracefulNodeShutdownBasedOnPodPriority e definir ShutdownGracePeriodByPodPriority na
configuração do kubelet
para a configuração desejada contendo os valores de classe de prioridade do Pod e
seus respectivos períodos de desligamento.
Nota:
A capacidade de levar em conta a prioridade do Pod durante o desligamento controlado de nó foi introduzida
como uma funcionalidade Alfa no Kubernetes v1.23. No Kubernetes 1.35
a funcionalidade está em Beta e está habilitada por padrão.As métricas graceful_shutdown_start_time_seconds e graceful_shutdown_end_time_seconds
são emitidas sob o subsistema do kubelet para monitorar os desligamentos de nó.
Tratamento de desligamento não controlado de nó
ESTADO DA FUNCIONALIDADE:
Kubernetes v1.28 [stable](habilitado por padrão)
Uma ação de desligamento de nó pode não ser detectada pelo Gerenciador de Desligamento de Nó do kubelet,
seja porque o comando não aciona o mecanismo de bloqueios inibidores usado pelo
kubelet ou devido a um erro do usuário, ou seja, o ShutdownGracePeriod e
ShutdownGracePeriodCriticalPods não estão configurados adequadamente. Por favor, consulte a
seção acima Desligamento Controlado de Nó para mais detalhes.
Quando um nó é desligado mas não detectado pelo Gerenciador de Desligamento de Nó do kubelet, os Pods
que fazem parte de um StatefulSet
ficarão presos no status de encerramento no nó desligado e não podem se mover para um novo nó em execução.
Isso ocorre porque o kubelet no nó desligado não está disponível para excluir os Pods, então
o StatefulSet não pode criar um novo Pod com o mesmo nome. Se houver volumes usados pelos Pods,
os VolumeAttachments não serão excluídos do nó desligado original, então os volumes
usados por esses Pods não podem ser anexados a um novo nó em execução. Como resultado, a
aplicação em execução no StatefulSet não pode funcionar adequadamente. Se o nó
desligado original voltar, os Pods serão excluídos pelo kubelet e novos Pods serão
criados em um nó diferente em execução. Se o nó desligado original não voltar,
esses Pods ficarão presos no status de encerramento no nó desligado para sempre.
Para mitigar a situação acima, um usuário pode adicionar manualmente um taint node.kubernetes.io/out-of-service
com efeito NoExecute ou NoSchedule a um Nó marcando-o como fora de serviço.
Se um Nó for marcado como fora de serviço com este taint, os Pods no nó serão excluídos forçadamente
se não houver tolerâncias correspondentes nele e as operações de desanexação de volume para os Pods encerrando no
nó acontecerão imediatamente. Isso permite que os Pods no nó fora de serviço se recuperem rapidamente
em um nó diferente.
Durante um desligamento não controlado, os Pods são encerrados em duas fases:
- Excluir forçadamente os Pods que não possuem tolerâncias
out-of-service correspondentes. - Executar imediatamente a operação de desanexação de volume para tais Pods.
Nota:
- Antes de adicionar um taint
node.kubernetes.io/out-of-service, deve ser verificado
que o nó já está em estado de desligamento ou desligado (não no meio de uma reinicialização). - O usuário é obrigado a remover manualmente o taint out-of-service depois que os Pods forem
movidos para um novo nó e o usuário tiver verificado que o nó desligado foi
recuperado, já que o usuário foi quem originalmente adicionou o taint.
Desanexação forçada de armazenamento por tempo limite
Em qualquer situação em que a exclusão de um Pod não tenha sido bem-sucedida por 6 minutos, o kubernetes irá
desanexar forçadamente os volumes sendo desmontados se o nó não estiver íntegro naquele instante. Qualquer
carga de trabalho ainda em execução no nó que usa um volume desanexado forçadamente causará uma
violação da
especificação CSI,
que afirma que ControllerUnpublishVolume "deve ser chamado após todas as
NodeUnstageVolume e NodeUnpublishVolume no volume serem chamadas e bem-sucedidas".
Em tais circunstâncias, os volumes no nó em questão podem encontrar corrupção de dados.
O comportamento de desanexação forçada de armazenamento é opcional; os usuários podem optar por usar a funcionalidade de "Desligamento
não controlado de nó" em vez disso.
A desanexação forçada de armazenamento por tempo limite pode ser desabilitada definindo o campo de configuração
disable-force-detach-on-timeout no kube-controller-manager. Desabilitar a funcionalidade de desanexação forçada por tempo limite significa
que um volume que está hospedado em um nó que não está íntegro por mais de 6 minutos não terá
seu VolumeAttachment
associado excluído.
Após esta configuração ter sido aplicada, Pods não íntegros ainda anexados a volumes devem ser recuperados
através do procedimento de Desligamento Não Controlado de Nó mencionado acima.
Próximos passos
Saiba mais sobre o seguinte:
2 - Visão Geral da Administração de Cluster
A visão geral da administração de cluster é para qualquer um criando ou administrando um cluster Kubernetes. Assume-se que você tenha alguma familiaridade com os conceitos centrais do Kubernetes.
Planejando um cluster
Veja os guias em Setup para exemplos de como planejar, iniciar e configurar clusters Kubernetes. As soluções listadas neste artigo são chamadas distros.
Antes de escolher um guia, aqui estão algumas considerações.
Você quer experimentar o Kubernetes no seu computador, ou você quer construir um cluster de alta disponibilidade e multi-nós? Escolha as distros mais adequadas às suas necessidades.
Se você esta projetando para alta-disponibilidade, saiba mais sobre configuração clusters em múltiplas zonas.
Você usará um cluster Kubernetes hospedado, como Google Kubernetes Engine, ou hospedará seu próprio cluster?
Seu cluster será on-premises, ou in the cloud (IaaS)? Kubernetes não suporta diretamente clusters híbridos. Em vez disso, você pode configurar vários clusters.
Se você estiver configurando um Kubernetes on-premisess, considere qual modelo de rede melhor se adequa.
Você estará executando o Kubernetes em hardware "bare metal" ou em máquinas virtuais (VMs)?
Você quer apenas rodar um cluster, ou você espera fazer desenvolvimento ativo do código de projeto do Kubernetes? Se for a segunda opção, escolha uma distro mais ativa. Algumas distros fornecem apenas binários, mas oferecem uma maior variedade de opções.
Familiarize-se com os componentes necessários para rodar um cluster.
Nota: Nem todas as distros são ativamente mantidas. Escolha as distros que foram testadas com uma versão recente do Kubernetes.
Gerenciando um cluster
Gerenciando um cluster descreve vários tópicos relacionados ao ciclo de vida de um cluster: criando um novo cluster, atualizando o nó mestre e os nós de trabalho do cluster, executando manutenção de nó (por exemplo, atualizações de kernel) e atualizando a versão da API do Kubernetes de um cluster em execução.
Aprender como gerenciar um nó.
Aprender como configurar e gerenciar o recurso de quota para um cluster compartilhado.
Protegendo um cluster
Protegendo o kubelet
Serviços Opcionais do Cluster
3 - Certificates
Ao usar um client para autenticação de certificado, você pode gerar certificados
manualmente através easyrsa, openssl ou cfssl.
easyrsa
easyrsa pode gerar manualmente certificados para o seu cluster.
Baixe, descompacte e inicialize a versão corrigida do easyrsa3.
curl -LO https://dl.k8s.io/easy-rsa/easy-rsa.tar.gz
tar xzf easy-rsa.tar.gz
cd easy-rsa-master/easyrsa3
./easyrsa init-pki
Gerar o CA. (--batch set automatic mode. --req-cn default CN to use.)
./easyrsa --batch "--req-cn=${MASTER_IP}@`date +%s`" build-ca nopass
Gere o certificado e a chave do servidor.
O argumento --subject-alt-name define os possíveis IPs e nomes (DNS) que o servidor de API usará para ser acessado. O MASTER_CLUSTER_IP é geralmente o primeiro IP do serviço CIDR que é especificado como argumento em --service-cluster-ip-range para o servidor de API e o componente gerenciador do controlador. O argumento --days é usado para definir o número de dias após o qual o certificado expira.
O exemplo abaixo também assume que você está usando cluster.local como DNS de domínio padrão
./easyrsa --subject-alt-name="IP:${MASTER_IP},"\
"IP:${MASTER_CLUSTER_IP},"\
"DNS:kubernetes,"\
"DNS:kubernetes.default,"\
"DNS:kubernetes.default.svc,"\
"DNS:kubernetes.default.svc.cluster,"\
"DNS:kubernetes.default.svc.cluster.local" \
--days=10000 \
build-server-full server nopass
Copie pki/ca.crt, pki/issued/server.crt, e pki/private/server.key para o seu diretório.
Preencha e adicione os seguintes parâmetros aos parâmetros de inicialização do servidor de API:
--client-ca-file=/yourdirectory/ca.crt
--tls-cert-file=/yourdirectory/server.crt
--tls-private-key-file=/yourdirectory/server.key
openssl
openssl pode gerar manualmente certificados para o seu cluster.
Gere um ca.key com 2048bit:
openssl genrsa -out ca.key 2048
De acordo com o ca.key, gere um ca.crt (use -days para definir o tempo efetivo do certificado):
openssl req -x509 -new -nodes -key ca.key -subj "/CN=${MASTER_IP}" -days 10000 -out ca.crt
Gere um server.key com 2048bit:
openssl genrsa -out server.key 2048
Crie um arquivo de configuração para gerar uma solicitação de assinatura de certificado (CSR - Certificate Signing Request). Certifique-se de substituir os valores marcados com colchetes angulares (por exemplo, <MASTER_IP>) com valores reais antes de salvá-lo em um arquivo (por exemplo, csr.conf). Note que o valor para o MASTER_CLUSTER_IP é o IP do cluster de serviços para o Servidor de API, conforme descrito na subseção anterior. O exemplo abaixo também assume que você está usando cluster.local como DNS de domínio padrão
[ req ]
default_bits = 2048
prompt = no
default_md = sha256
req_extensions = req_ext
distinguished_name = dn
[ dn ]
C = <country>
ST = <state>
L = <city>
O = <organization>
OU = <organization unit>
CN = <MASTER_IP>
[ req_ext ]
subjectAltName = @alt_names
[ alt_names ]
DNS.1 = kubernetes
DNS.2 = kubernetes.default
DNS.3 = kubernetes.default.svc
DNS.4 = kubernetes.default.svc.cluster
DNS.5 = kubernetes.default.svc.cluster.local
IP.1 = <MASTER_IP>
IP.2 = <MASTER_CLUSTER_IP>
[ v3_ext ]
authorityKeyIdentifier=keyid,issuer:always
basicConstraints=CA:FALSE
keyUsage=keyEncipherment,dataEncipherment
extendedKeyUsage=serverAuth,clientAuth
subjectAltName=@alt_names
Gere a solicitação de assinatura de certificado com base no arquivo de configuração:
openssl req -new -key server.key -out server.csr -config csr.conf
Gere o certificado do servidor usando o ca.key, ca.crt e server.csr:
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key \
-CAcreateserial -out server.crt -days 10000 \
-extensions v3_ext -extfile csr.conf -sha256
Veja o certificado:
openssl x509 -noout -text -in ./server.crt
Por fim, adicione os mesmos parâmetros nos parâmetros iniciais do Servidor de API.
cfssl
cfssl é outra ferramenta para geração de certificados.
Baixe, descompacte e prepare as ferramentas de linha de comando, conforme mostrado abaixo. Observe que você pode precisar adaptar os comandos de exemplo abaixo com base na arquitetura do hardware e versão cfssl que você está usando.
curl -L https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 -o cfssl
chmod +x cfssl
curl -L https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 -o cfssljson
chmod +x cfssljson
curl -L https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 -o cfssl-certinfo
chmod +x cfssl-certinfo
Crie um diretório para conter os artefatos e inicializar o cfssl:
mkdir cert
cd cert
../cfssl print-defaults config > config.json
../cfssl print-defaults csr > csr.json
Crie um arquivo de configuração JSON para gerar o arquivo CA, por exemplo, ca-config.json:
{
"signing": {
"default": {
"expiry": "8760h"
},
"profiles": {
"kubernetes": {
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
],
"expiry": "8760h"
}
}
}
}
Crie um arquivo de configuração JSON para o CA - solicitação de assinatura de certificado (CSR - Certificate Signing Request), por exemplo, ca-csr.json. Certifique-se de substituir os valores marcados com colchetes angulares por valores reais que você deseja usar.
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names":[{
"C": "<country>",
"ST": "<state>",
"L": "<city>",
"O": "<organization>",
"OU": "<organization unit>"
}]
}
Gere a chave CA (ca-key.pem) e o certificado (ca.pem):
../cfssl gencert -initca ca-csr.json | ../cfssljson -bare ca
Crie um arquivo de configuração JSON para gerar chaves e certificados para o Servidor de API, por exemplo, server-csr.json. Certifique-se de substituir os valores entre colchetes angulares por valores reais que você deseja usar. O MASTER_CLUSTER_IP é o IP do serviço do cluster para o servidor da API, conforme descrito na subseção anterior. O exemplo abaixo também assume que você está usando cluster.local como DNS de domínio padrão
{
"CN": "kubernetes",
"hosts": [
"127.0.0.1",
"<MASTER_IP>",
"<MASTER_CLUSTER_IP>",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [{
"C": "<country>",
"ST": "<state>",
"L": "<city>",
"O": "<organization>",
"OU": "<organization unit>"
}]
}
Gere a chave e o certificado para o Servidor de API, que são, por padrão, salvos nos arquivos server-key.pem e server.pem respectivamente:
../cfssl gencert -ca=ca.pem -ca-key=ca-key.pem \
--config=ca-config.json -profile=kubernetes \
server-csr.json | ../cfssljson -bare server
Distribuindo Certificado CA auto assinado
Um nó cliente pode se recusar a reconhecer o certificado CA self-signed como válido.
Para uma implementação de não produção ou para uma instalação que roda atrás de um firewall, você pode distribuir certificados auto-assinados para todos os clientes e atualizar a lista de certificados válidos.
Em cada cliente, execute as seguintes operações:
sudo cp ca.crt /usr/local/share/ca-certificates/kubernetes.crt
sudo update-ca-certificates
Updating certificates in /etc/ssl/certs...
1 added, 0 removed; done.
Running hooks in /etc/ca-certificates/update.d....
done.
API de certificados
Você pode usar a API certificates.k8s.io para provisionar
certificados x509 a serem usados para autenticação conforme documentado
aqui.
4 - Conectividade do Cluster
Conectividade é uma parte central do Kubernetes, mas pode ser desafiador
entender exatamente como é o seu funcionamento esperado. Existem 4 problemas
distintos em conectividade que devem ser tratados:
- Comunicações contêiner-para-contêiner altamente acopladas: Isso é resolvido
por Pods e comunicações através do
localhost. - Comunicações pod-para-pod: Esse é o foco primário desse documento.
- Comunicações pod-para-serviço (service): Isso é tratado em Services.
- Comunicações Externas-para-serviços: Isso é tratado em services.
Kubernetes é basicamente o compartilhamento de máquinas entre aplicações. Tradicionalmente,
compartilhar máquinas requer a garantia de que duas aplicações não tentem utilizar
as mesmas portas. Coordenar a alocação de portas entre múltiplos desenvolvedores é
muito dificil de fazer em escala e expõe os usuários a problemas em nível do cluster e
fora de seu controle.
A alocação dinâmica de portas traz uma série de complicações para o sistema - toda
aplicação deve obter suas portas através de flags de configuração, os servidores de API
devem saber como inserir números dinämicos de portas nos blocos de configuração, serviços
precisam saber como buscar um ao outro, etc. Ao invés de lidar com isso, o Kubernetes
faz de uma maneira diferente.
O modelo de conectividade e rede do Kubernetes
Todo Pod obtém seu próprio endereço IP. Isso significa que vocë não precisa
criar links explícitos entre os Pods e vocë quase nunca terá que lidar com o
mapeamento de portas de contêineres para portas do host. Isso cria um modelo simples,
retro-compatível onde os Pods podem ser tratados muito mais como VMs ou hosts
físicos da perspectiva de alocação de portas, nomes, descobrimento de serviços
(service discovery), balanceamento de carga, configuração de aplicações e migrações.
O Kubernetes impõe os seguintes requisitos fundamentais para qualquer implementação de
rede (exceto qualquer política de segmentação intencional):
- pods em um nó podem se comunicar com todos os pods em todos os nós sem usar NAT.
- agentes em um nó (por exemplo o kubelet ou um serviço local) podem se comunicar com
todos os Pods naquele nó.
Nota: Para as plataformas que suportam Pods executando na rede do host (como o Linux):
- pods alocados na rede do host de um nó podem se comunicar com todos os pods
em todos os nós sem NAT.
Esse modelo não só é menos complexo, mas é principalmente compatível com o
desejo do Kubernetes de permitir a portabilidade com baixo esforço de aplicações
de VMs para contêineres. Se a sua aplicação executava anteriormente em uma VM, sua VM
possuía um IP e podia se comunicar com outras VMs no seu projeto. Esse é o mesmo
modelo básico.
Os endereços de IP no Kubernetes existem no escopo do Pod - contêineres em um Pod
compartilham o mesmo network namespace - incluíndo seu endereço de IP e MAC.
Isso significa que contêineres que compõem um Pod podem se comunicar entre eles
através do endereço localhost e respectivas portas. Isso também significa que
contêineres em um mesmo Pod devem coordenar a alocação e uso de portas, o que não
difere do modelo de processos rodando dentro de uma mesma VM. Isso é chamado de
modelo "IP-por-pod".
Como isso é implementado é um detalhe do agente de execução de contêiner em uso.
É possível solicitar uma porta no nó que será encaminhada para seu Pod (chamado
de portas do host), mas isso é uma operação muito específica. Como esse encaminhamento
é implementado é um detalhe do agente de execução do contêiner. O Pod mesmo
desconhece a existência ou não de portas do host.
Como implementar o modelo de conectividade do Kubernetes
Existe um número de formas de implementar esse modelo de conectividade. Esse
documento não é um estudo exaustivo desses vários métodos, mas pode servir como
uma introdução de várias tecnologias e serve como um ponto de início.
A conectividade no Kubernetes é fornecida através de plugins de
CNIs
As seguintes opções estão organizadas alfabeticamente e não implicam preferência por
qualquer solução.
Nota: Esta seção contém links para projetos de terceiros que fornecem a funcionalidade exigida pelo Kubernetes. Os autores do projeto Kubernetes não são responsáveis por esses projetos. Esta página obedece as
diretrizes de conteúdo do site CNCF, listando os itens em ordem alfabética. Para adicionar um projeto a esta lista, leia o
guia de conteúdo antes de enviar sua alteração.
Antrea
O projeto Antrea é uma solução de
conectividade para Kubernetes que pretende ser nativa. Ela utiliza o Open vSwitch
na camada de conectividade de dados. O Open vSwitch é um switch virtual de alta
performance e programável que suporta Linux e Windows. O Open vSwitch permite
ao Antrea implementar políticas de rede do Kubernetes (NetworkPolicies) de
uma forma muito performática e eficiente.
Graças à característica programável do Open vSwitch, o Antrea consegue implementar
uma série de funcionalidades de rede e segurança.
AWS VPC CNI para Kubernetes
O AWS VPC CNI oferece conectividade
com o AWS Virtual Private Cloud (VPC) para clusters Kubernetes. Esse plugin oferece
alta performance e disponibilidade e baixa latência. Adicionalmente, usuários podem
aplicar as melhores práticas de conectividade e segurança existentes no AWS VPC
para a construção de clusters Kubernetes. Isso inclui possibilidade de usar o
VPC flow logs, políticas de roteamento da VPC e grupos de segurança para isolamento
de tráfego.
O uso desse plugin permite aos Pods no Kubernetes ter o mesmo endereço de IP dentro do
pod como se eles estivessem dentro da rede do VPC. O CNI (Container Network Interface)
aloca um Elastic Networking Interface (ENI) para cada nó do Kubernetes e usa uma
faixa de endereços IP secundário de cada ENI para os Pods no nó. O CNI inclui
controles para pré alocação dos ENIs e endereços IP para um início mais rápido dos
pods e permite clusters com até 2,000 nós.
Adicionalmente, esse CNI pode ser utilizado junto com o Calico
para a criação de políticas de rede (NetworkPolicies). O projeto AWS VPC CNI
tem código fonte aberto com a documentação no Github.
Azure CNI para o Kubernetes
Azure CNI é um
plugin de código fonte aberto
que integra os Pods do Kubernetes com uma rede virtual da Azure (também conhecida como VNet)
provendo performance de rede similar à de máquinas virtuais no ambiente. Os Pods
podem se comunicar com outras VNets e com ambientes on-premises com o uso de
funcionalidades da Azure, e também podem ter clientes com origem dessas redes.
Os Pods podem acessar serviços da Azure, como armazenamento e SQL, que são
protegidos por Service Endpoints e Private Link. Você pode utilizar as políticas
de segurança e roteamento para filtrar o tráfico do Pod. O plugin associa IPs da VNet
para os Pods utilizando um pool de IPs secundário pré-configurado na interface de rede
do nó Kubernetes.
O Azure CNI está disponível nativamente no Azure Kubernetes Service (AKS).
Calico
Calico é uma solução de conectividade e
segurança para contêineres, máquinas virtuais e serviços nativos em hosts. O
Calico suporta múltiplas camadas de conectividade/dados, como por exemplo:
uma camada Linux eBPF nativa, uma camada de conectividade baseada em conceitos
padrão do Linux e uma camada baseada no HNS do Windows. O calico provê uma
camada completa de conectividade e rede, mas também pode ser usado em conjunto com
CNIs de provedores de nuvem
para permitir a criação de políticas de rede.
Cilium
Cilium é um software de código fonte aberto
para prover conectividade e segurança entre contêineres de aplicação. O Cilium
pode lidar com tráfego na camada de aplicação (ex. HTTP) e pode forçar políticas
de rede nas camadas L3-L7 usando um modelo de segurança baseado em identidade e
desacoplado do endereçamento de redes, podendo inclusive ser utilizado com outros
plugins CNI.
Flannel
Flannel é uma camada muito simples
de conectividade que satisfaz os requisitos do Kubernetes. Muitas pessoas
reportaram sucesso em utilizar o Flannel com o Kubernetes.
Google Compute Engine (GCE)
Para os scripts de configuração do Google Compute Engine, roteamento
avançado é usado para associar
para cada VM uma sub-rede (o padrão é /24 - 254 IPs). Qualquer tráfico direcionado
para aquela sub-rede será roteado diretamente para a VM pela rede do GCE. Isso é
adicional ao IP principal associado à VM, que é mascarado para o acesso à Internet.
Uma brige Linux (chamada cbr0) é configurada para existir naquela sub-rede, e é
configurada no docker através da opção --bridge.
O Docker é iniciado com:
DOCKER_OPTS="--bridge=cbr0 --iptables=false --ip-masq=false"
Essa bridge é criada pelo Kubelet (controlada pela opção --network-plugin=kubenet)
de acordo com a informação .spec.podCIDR do Nó.
O Docker irá agora alocar IPs do bloco cbr-cidr. Contêineres podem alcançar
outros contêineres e nós através da interface cbr0. Esses IPs são todos roteáveis
dentro da rede do projeto do GCE.
O GCE mesmo não sabe nada sobre esses IPs, então não irá mascará-los quando tentarem
se comunicar com a internet. Para permitir isso uma regra de IPTables é utilizada para
mascarar o tráfego para IPs fora da rede do projeto do GCE (no exemplo abaixo, 10.0.0.0/8):
iptables -t nat -A POSTROUTING ! -d 10.0.0.0/8 -o eth0 -j MASQUERADE
Por fim, o encaminhamento de IP deve ser habilitado no Kernel de forma a processar
os pacotes vindos dos contêineres:
sysctl net.ipv4.ip_forward=1
O resultado disso tudo é que Pods agora podem alcançar outros Pods e podem também
se comunicar com a Internet.
Kube-router
Kube-router é uma solução construída
que visa prover alta performance e simplicidade operacional. Kube-router provê um
proxy de serviços baseado no LVS/IPVS,
uma solução de comunicação pod-para-pod baseada em encaminhamento de pacotes Linux e sem camadas
adicionais, e funcionalidade de políticas de redes baseadas no IPTables/IPSet.
Redes L2 e bridges Linux
Se você tem uma rede L2 "burra", como um switch em um ambiente "bare-metal",
você deve conseguir fazer algo similar ao ambiente GCE explicado acima.
Note que essas instruções foram testadas casualmente - parece funcionar, mas
não foi propriamente testado. Se você conseguir usar essa técnica e aperfeiçoar
o processo, por favor nos avise!!
Siga a parte "With Linux Bridge devices" desse
tutorial super bacana do
Lars Kellogg-Stedman.
Multus (Plugin multi redes)
Multus é um plugin Multi CNI para
suportar a funcionalidade multi redes do Kubernetes usando objetos baseados em CRDs.
Multus suporta todos os plugins referência (ex. Flannel,
DHCP,
Macvlan)
que implementam a especificação de CNI e plugins de terceiros
(ex. Calico, Weave,
Cilium, Contiv).
Adicionalmente, Multus suporta cargas de trabalho no Kubernetes que necessitem de funcionalidades como
SRIOV, DPDK,
OVS-DPDK & VPP.
OVN (Open Virtual Networking)
OVN é uma solução de virtualização de redes de código aberto desenvolvido pela
comunidade Open vSwitch. Permite a criação de switches lógicos, roteadores lógicos,
listas de acesso, balanceadores de carga e mais, para construir diferences topologias
de redes virtuais. Esse projeto possui um plugin específico para o Kubernetes e a
documentação em ovn-kubernetes.
Próximos passos
Design inicial do modelo de conectividade do Kubernetes e alguns planos futuros
estão descritos com maiores detalhes no
documento de design de redes.
5 - Arquitetura de Log
Os logs de aplicativos e sistemas podem ajudá-lo a entender o que está acontecendo dentro do seu cluster. Os logs são particularmente úteis para depurar problemas e monitorar a atividade do cluster. A maioria das aplicações modernas possui algum tipo de mecanismo de logs; como tal, a maioria dos mecanismos de contêineres também é projetada para suportar algum tipo de log. O método de log mais fácil e abrangente para aplicações em contêiner é gravar nos fluxos de saída e erro padrão.
No entanto, a funcionalidade nativa fornecida por um mecanismo de contêiner ou tempo de execução geralmente não é suficiente para uma solução completa de log. Por exemplo, se um contêiner travar, um pod for despejado ou um nó morrer, geralmente você ainda desejará acessar os logs do aplicativo. Dessa forma, os logs devem ter armazenamento e ciclo de vida separados, independentemente de nós, pods ou contêineres. Este conceito é chamado cluster-level-logging. O log no nível de cluster requer um back-end separado para armazenar, analisar e consultar logs. O kubernetes não fornece uma solução de armazenamento nativa para dados de log, mas você pode integrar muitas soluções de log existentes no cluster do Kubernetes.
As arquiteturas de log no nível de cluster são descritas no pressuposto de que um back-end de log esteja presente dentro ou fora do cluster. Se você não estiver interessado em ter o log no nível do cluster, ainda poderá encontrar a descrição de como os logs são armazenados e manipulados no nó para serem úteis.
Log básico no Kubernentes
Nesta seção, você pode ver um exemplo de log básico no Kubernetes que gera dados para o fluxo de saída padrão(standard output stream). Esta demostração usa uma especificação de pod com um contêiner que grava algum texto na saída padrão uma vez por segundo.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
Para executar este pod, use o seguinte comando:
kubectl apply -f https://k8s.io/examples/debug/counter-pod.yaml
A saída será:
pod/counter created
Para buscar os logs, use o comando kubectl logs, da seguinte maneira:
A saída será:
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
Você pode usar kubectl logs para recuperar logs de uma instanciação anterior de um contêiner com o sinalizador --previous, caso o contêiner tenha falhado. Se o seu pod tiver vários contêineres, você deverá especificar quais logs do contêiner você deseja acessar anexando um nome de contêiner ao comando. Veja a documentação do kubectl logs para mais destalhes.
Logs no nível do Nó
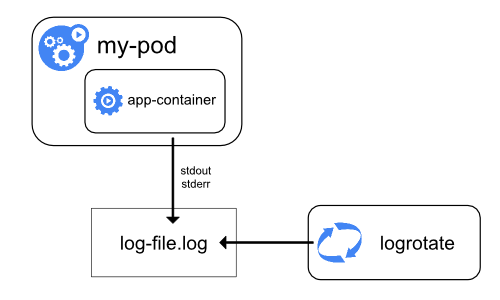
Tudo o que um aplicativo em contêiner grava no stdout e stderr é tratado e redirecionado para algum lugar por dentro do mecanismo de contêiner. Por exemplo, o mecanismo de contêiner do Docker redireciona esses dois fluxos para um driver de log, configurado no Kubernetes para gravar em um arquivo no formato json.
Nota:
O driver de log json do Docker trata cada linha como uma mensagem separada. Ao usar o driver de log do Docker, não há suporte direto para mensagens de várias linhas. Você precisa lidar com mensagens de várias linhas no nível do agente de log ou superior.Por padrão, se um contêiner reiniciar, o kubelet manterá um contêiner terminado com seus logs. Se um pod for despejado do nó, todos os contêineres correspondentes também serão despejados, juntamente com seus logs.
Uma consideração importante no log no nível do nó está implementado a rotação de log, para que os logs não consumam todo o armazenamento disponível no nó. Atualmente, o Kubernentes não é responsável pela rotação de logs, mas uma ferramenta de deployment deve configurar uma solução para resolver isso.
Por exemplo, nos clusters do Kubernetes, implementados pelo script kube-up.sh, existe uma ferramenta logrotate configurada para executar a cada hora. Você pode configurar um tempo de execução do contêiner para girar os logs do aplicativo automaticamente, por exemplo, usando o log-opt do Docker.
No script kube-up.sh, a última abordagem é usada para imagem COS no GCP, e a anterior é usada em qualquer outro ambiente. Nos dois casos por padrão, a rotação é configurada para ocorrer quando o arquivo de log exceder 10MB.
Como exemplo, você pode encontrar informações detalhadas sobre como o kube-up.sh define o log da imagem COS no GCP no script correspondente.
Quando você executa kubectl logs como no exemplo de log básico acima, o kubelet no nó lida com a solicitação e lê diretamente do arquivo de log, retornando o conteúdo na resposta.
Nota:
Atualmente, se algum sistema externo executou a rotação, apenas o conteúdo do arquivo de log mais recente estará disponível através de kubectl logs. Por exemplo, se houver um arquivo de 10MB, o logrotate executa a rotação e existem dois arquivos, um com 10MB de tamanho e um vazio, o kubectl logs retornará uma resposta vazia.Logs de componentes do sistema
Existem dois tipos de componentes do sistema: aqueles que são executados em um contêiner e aqueles que não são executados em um contêiner. Por exemplo:
- O scheduler Kubernetes e o kube-proxy são executados em um contêiner.
- O tempo de execução do kubelet e do contêiner, por exemplo, Docker, não é executado em contêineres.
Nas máquinas com systemd, o tempo de execução do kubelet e do contêiner é gravado no journald. Se systemd não estiver presente, eles gravam em arquivos .log no diretório /var/log.
Os componentes do sistema dentro dos contêineres sempre gravam no diretório /var/log, ignorando o mecanismo de log padrão. Eles usam a biblioteca de logs klog. Você pode encontrar as convenções para a gravidade do log desses componentes nos documentos de desenvolvimento sobre log.
Da mesma forma que os logs de contêiner, os logs de componentes do sistema no diretório /var/log devem ser rotacionados. Nos clusters do Kubernetes criados pelo script kube-up.sh, esses logs são configurados para serem rotacionados pela ferramenta logrotate diariamente ou quando o tamanho exceder 100MB.
Arquiteturas de log no nível de cluster
Embora o Kubernetes não forneça uma solução nativa para o log em nível de cluster, há várias abordagens comuns que você pode considerar. Aqui estão algumas opções:
- Use um agente de log no nível do nó que seja executado em todos os nós.
- Inclua um contêiner sidecar dedicado para efetuar logging em um pod de aplicativo.
- Envie logs diretamente para um back-end de dentro de um aplicativo.
Usando um agente de log de nó
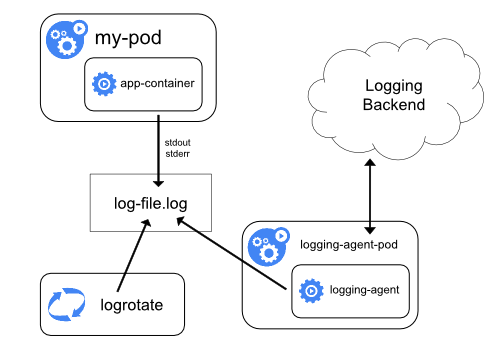
Você pode implementar o log em nível de cluster incluindo um agente de log em nível de nó em cada nó. O agente de log é uma ferramenta dedicada que expõe logs ou envia logs para um back-end. Geralmente, o agente de log é um contêiner que tem acesso a um diretório com arquivos de log de todos os contêineres de aplicativos nesse nó.
Como o agente de log deve ser executado em todos os nós, é comum implementá-lo como uma réplica do DaemonSet, um pod de manifesto ou um processo nativo dedicado no nó. No entanto, as duas últimas abordagens são obsoletas e altamente desencorajadas.
O uso de um agente de log no nível do nó é a abordagem mais comum e incentivada para um cluster Kubernetes, porque ele cria apenas um agente por nó e não requer alterações nos aplicativos em execução no nó. No entanto, o log no nível do nó funciona apenas para a saída padrão dos aplicativos e o erro padrão.
O Kubernetes não especifica um agente de log, mas dois agentes de log opcionais são fornecidos com a versão Kubernetes: Stackdriver Logging para uso com o Google Cloud Platform e Elasticsearch. Você pode encontrar mais informações e instruções nos documentos dedicados. Ambos usam fluentd com configuração customizada como um agente no nó.
Você pode usar um contêiner sidecar de uma das seguintes maneiras:
- O contêiner sidecar transmite os logs do aplicativo para seu próprio
stdout. - O contêiner sidecar executa um agente de log, configurado para selecionar logs de um contêiner de aplicativo.
Streaming sidecar conteiner
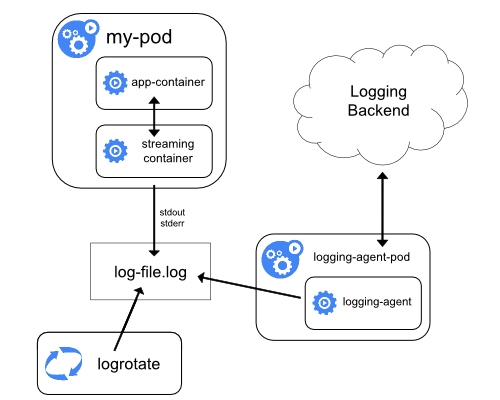
Fazendo com que seus contêineres de sidecar fluam para seus próprios stdout e stderr, você pode tirar proveito do kubelet e do agente de log que já executam em cada nó. Os contêineres sidecar lêem logs de um arquivo, socket ou journald. Cada contêiner sidecar individual imprime o log em seu próprio stdout ou stderr stream.
Essa abordagem permite separar vários fluxos de logs de diferentes partes do seu aplicativo, algumas das quais podem não ter suporte para gravar em stdout ou stderr. A lógica por trás do redirecionamento de logs é mínima, portanto dificilmente representa uma sobrecarga significativa. Além disso, como stdout e stderr são manipulados pelo kubelet, você pode usar ferramentas internas como o kubectl logs.
Considere o seguinte exemplo. Um pod executa um único contêiner e grava em dois arquivos de log diferentes, usando dois formatos diferentes. Aqui está um arquivo de configuração para o Pod:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Seria uma bagunça ter entradas de log de diferentes formatos no mesmo fluxo de logs, mesmo se você conseguisse redirecionar os dois componentes para o fluxo stdout do contêiner. Em vez disso, você pode introduzir dois contêineres sidecar. Cada contêiner sidecar pode direcionar um arquivo de log específico de um volume compartilhado e depois redirecionar os logs para seu próprio fluxo stdout.
Aqui está um arquivo de configuração para um pod que possui dois contêineres sidecar:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Agora, quando você executa este pod, é possível acessar cada fluxo de log separadamente, executando os seguintes comandos:
kubectl logs counter count-log-1
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
kubectl logs counter count-log-2
Mon Jan 1 00:00:00 UTC 2001 INFO 0
Mon Jan 1 00:00:01 UTC 2001 INFO 1
Mon Jan 1 00:00:02 UTC 2001 INFO 2
...
O agente no nível do nó instalado em seu cluster coleta esses fluxos de logs automaticamente sem nenhuma configuração adicional. Se desejar, você pode configurar o agente para analisar as linhas de log, dependendo do contêiner de origem.
Observe que, apesar do baixo uso da CPU e da memória (ordem de alguns milicores por CPU e ordem de vários megabytes de memória), gravar logs em um arquivo e depois transmiti-los para o stdout pode duplicar o uso do disco. Se você tem um aplicativo que grava em um único arquivo, geralmente é melhor definir /dev/stdout como destino, em vez de implementar a abordagem de contêiner de transmissão no sidecar.
Os contêineres sidecar também podem ser usados para rotacionar arquivos de log que não podem ser rotacionados pelo próprio aplicativo. Um exemplo dessa abordagem é um pequeno contêiner executando logrotate periodicamente.
No entanto, é recomendável usar o stdout e o stderr diretamente e deixar as políticas de rotação e retenção no kubelet.
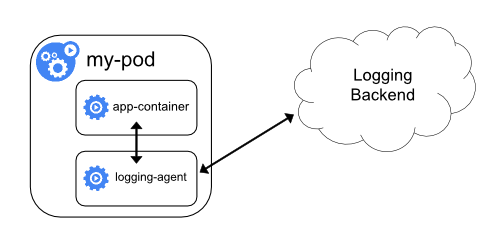
Se o agente de log no nível do nó não for flexível o suficiente para sua situação, você poderá criar um contêiner secundário com um agente de log separado que você configurou especificamente para executar com seu aplicativo.
Nota:
O uso de um agente de log em um contêiner sidecar pode levar a um consumo significativo de recursos. Além disso, você não poderá acessar esses logs usando o comando kubectl logs, porque eles não são controlados pelo kubelet.Como exemplo, você pode usar o Stackdriver, que usa fluentd como um agente de log. Aqui estão dois arquivos de configuração que você pode usar para implementar essa abordagem. O primeiro arquivo contém um ConfigMap para configurar o fluentd.
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
Nota:
A configuração do fluentd está além do escopo deste artigo. Para obter informações sobre como configurar o fluentd, consulte a
documentação oficial do fluentd.
O segundo arquivo descreve um pod que possui um contêiner sidecar rodando fluentemente.
O pod monta um volume onde o fluentd pode coletar seus dados de configuração.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: registry.k8s.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
Depois de algum tempo, você pode encontrar mensagens de log na interface do Stackdriver.
Lembre-se de que este é apenas um exemplo e você pode realmente substituir o fluentd por qualquer agente de log, lendo de qualquer fonte dentro de um contêiner de aplicativo.
Expondo logs diretamente do aplicativo
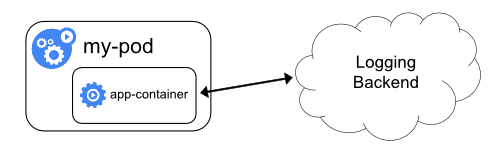
Você pode implementar o log no nível do cluster, expondo ou enviando logs diretamente de todos os aplicativos; no entanto, a implementação desse mecanismo de log está fora do escopo do Kubernetes.
6 - Logs de Sistema
Logs de componentes do sistema armazenam eventos que acontecem no cluster, sendo muito úteis para depuração. Seus níveis de detalhe podem ser ajustados para mais ou para menos. Podendo se ater, por exemplo, a mostrar apenas os erros que ocorrem no componente, ou chegando a mostrar cada passo de um evento. (Como acessos HTTP, mudanças no estado dos pods, ações dos controllers, ou decisões do scheduler).
Klog
Klog é a biblioteca de logs do Kubernetes. Responsável por gerar as mensagens de log para os componentes do sistema.
Para mais informações acerca da sua configuração, veja a documentação da ferramenta de linha de comando.
Um exemplo do formato padrão dos logs da biblioteca:
I1025 00:15:15.525108 1 httplog.go:79] GET /api/v1/namespaces/kube-system/pods/metrics-server-v0.3.1-57c75779f-9p8wg: (1.512ms) 200 [pod_nanny/v0.0.0 (linux/amd64) kubernetes/$Format 10.56.1.19:51756]
Logs Estruturados
ESTADO DA FUNCIONALIDADE:
Kubernetes v1.19 [alpha]
Aviso:
A migração pro formato de logs estruturados é um processo em andamento. Nem todos os logs estão dessa forma na versão atual. Sendo assim, para realizar o processamento de arquivos de log, você também precisa lidar com logs não estruturados.
A formatação e serialização dos logs ainda estão sujeitas a alterações.
A estruturação dos logs trás uma estrutura uniforme para as mensagens de log, permitindo a extração programática de informações. Logs estruturados podem ser armazenados e processados com menos esforço e custo. Esse formato é totalmente retrocompatível e é habilitado por padrão.
Formato dos logs estruturados:
<klog header> "<message>" <key1>="<value1>" <key2>="<value2>" ...
Exemplo:
I1025 00:15:15.525108 1 controller_utils.go:116] "Pod status updated" pod="kube-system/kubedns" status="ready"
ESTADO DA FUNCIONALIDADE:
Kubernetes v1.19 [alpha]
Aviso:
Algumas opções da biblioteca klog ainda não funcionam com os logs em formato JSON. Para ver uma lista completa de quais são estas, veja a documentação da ferramenta de linha de comando.
Nem todos os logs estarão garantidamente em formato JSON (como por exemplo durante o início de processos). Sendo assim, se você pretende realizar o processamento dos logs, seu código deverá saber tratar também linhas que não são JSON.
O nome dos campos e a serialização JSON ainda estão sujeitos a mudanças.
A opção --logging-format=json muda o formato dos logs, do formato padrão da klog para JSON. Abaixo segue um exemplo de um log em formato JSON (identado):
{
"ts": 1580306777.04728,
"v": 4,
"msg": "Pod status updated",
"pod":{
"name": "nginx-1",
"namespace": "default"
},
"status": "ready"
}
Chaves com significados especiais:
ts - Data e hora no formato Unix (obrigatório, float)v - Nível de detalhe (obrigatório, int, padrão 0)err - Mensagem de erro (opcional, string)msg - Mensagem (obrigatório, string)
Lista dos componentes que suportam o formato JSON atualmente:
Limpeza dos Logs
ESTADO DA FUNCIONALIDADE:
Kubernetes v1.20 [alpha]
Aviso:
A funcionalidade de limpeza dos logs pode causar impactos significativos na performance, sendo portanto contraindicada em produção.A opção --experimental-logging-sanitization habilita o filtro de limpeza dos logs.
Quando habilitado, esse filtro inspeciona todos os argumentos dos logs, procurando por campos contendo dados sensíveis (como senhas, chaves e tokens). Tais campos não serão expostos nas mensagens de log.
Lista dos componentes que suportam a limpeza de logs atualmente:
Nota:
O filtro de limpeza dos logs não impede a exposição de dados sensíveis nos logs das aplicações em execução.Nível de detalhe dos logs
A opção -v controla o nível de detalhe dos logs. Um valor maior aumenta o número de eventos registrados, começando a registrar também os eventos menos importantes. Similarmente, um valor menor restringe os logs apenas aos eventos mais importantes. O valor padrão 0 registra apenas eventos críticos.
Localização dos Logs
Existem dois tipos de componentes do sistema: aqueles que são executados em um contêiner e aqueles que não são. Por exemplo:
Em máquinas com systemd, o kubelet e os agentes de execução gravam os logs no journald.
Em outros casos, eles escrevem os logs em arquivos .log no diretório /var/log.
Já os componentes executados dentro de contêineres, sempre irão escrever os logs em arquivos .log
no diretório /var/log, ignorando o mecanismo padrão de log.
De forma similar aos logs de contêiner, os logs de componentes do sistema no diretório /var/log devem ser rotacionados.
Nos clusters Kubernetes criados com o script kube-up.sh, a rotação dos logs é configurada pela ferramenta logrotate. Essa ferramenta rotaciona os logs diariamente
ou quando o tamanho do arquivo excede 100MB.
Próximos passos
7 - Configurando o Garbage Collection do kubelet
O Garbage collection(Coleta de lixo) é uma função útil do kubelet que limpa imagens e contêineres não utilizados. O kubelet executará o garbage collection para contêineres a cada minuto e para imagens a cada cinco minutos.
Ferramentas externas de garbage collection não são recomendadas, pois podem potencialmente interromper o comportamento do kubelet removendo os contêineres que existem.
Coleta de imagens
O Kubernetes gerencia o ciclo de vida de todas as imagens através do imageManager, com a cooperação do cadvisor.
A política para o garbage collection de imagens leva dois fatores em consideração:
HighThresholdPercent e LowThresholdPercent. Uso do disco acima do limite acionará o garbage collection. O garbage collection excluirá as imagens que foram menos usadas recentemente até que o nível fique abaixo do limite.
Coleta de contêiner
A política para o garbage collection de contêineres considera três variáveis definidas pelo usuário. MinAge é a idade mínima em que um contêiner pode ser coletado. MaxPerPodContainer é o número máximo de contêineres mortos que todo par de pod (UID, container name) pode ter. MaxContainers é o número máximo de contêineres mortos totais. Essas variáveis podem ser desabilitadas individualmente, definindo MinAge como zero e definindo MaxPerPodContainer e MaxContainers respectivamente para menor que zero.
O Kubelet atuará em contêineres não identificados, excluídos ou fora dos limites definidos pelos sinalizadores mencionados. Os contêineres mais antigos geralmente serão removidos primeiro. MaxPerPodContainer e MaxContainer podem potencialmente conflitar entre si em situações em que a retenção do número máximo de contêineres por pod (MaxPerPodContainer) estaria fora do intervalo permitido de contêineres globais mortos (MaxContainers). O MaxPerPodContainer seria ajustado nesta situação: O pior cenário seria fazer o downgrade do MaxPerPodContainer para 1 e remover os contêineres mais antigos. Além disso, os contêineres pertencentes a pods que foram excluídos são removidos assim que se tornem mais antigos que MinAge.
Os contêineres que não são gerenciados pelo kubelet não estão sujeitos ao garbage collection de contêiner.
Configurações do usuário
Os usuários podem ajustar os seguintes limites para ajustar o garbage collection da imagem com os seguintes sinalizadores do kubelet:
image-gh-high-threshold, a porcentagem de uso de disco que aciona o garbage collection da imagem. O padrão é 85%.image-gc-low-threshold, a porcentagem de uso de disco com o qual o garbage collection da imagem tenta liberar. O padrão é 80%.
Também permitimos que os usuários personalizem a política do garbagem collection através dos seguintes sinalizadores do kubelet:
minimum-container-ttl-duration, idade mínima para um contêiner finalizado antes de ser colectado. O padrão é 0 minuto, o que significa que todo contêiner finalizado será coletado como lixo.maximum-dead-containers-per-container, número máximo de instâncias antigas a serem retidas por contêiner. O padrão é 1.maximum-dead-containers, número máximo de instâncias antigas de contêineres para retenção global. O padrão é -1, o que significa que não há limite global.
Os contêineres podem ser potencialmente coletados como lixo antes que sua utilidade expire. Esses contêineres podem conter logs e outros dados que podem ser úteis para solucionar problemas. Um valor suficientemente grande para maximum-dead-containers-per-container é altamente recomendado para permitir que pelo menos 1 contêiner morto seja retido por contêiner esperado. Um valor maior para maximum-dead-containers também é recomendados por um motivo semelhante.
Consulte esta issue para obter mais detalhes.
Descontinuado
Alguns recursos do Garbage Collection neste documento serão substituídos pelo kubelet eviction no futuro.
Incluindo:
| Flag Existente | Nova Flag | Fundamentação |
|---|
--image-gc-high-threshold | --eviction-hard ou --eviction-soft | os sinais existentes de despejo podem acionar o garbage collection da imagem |
--image-gc-low-threshold | --eviction-minimum-reclaim | recuperações de despejo atinge o mesmo comportamento |
--maximum-dead-containers | | descontinuado quando os logs antigos forem armazenados fora do contexto do contêiner |
--maximum-dead-containers-per-container | | descontinuado quando os logs antigos forem armazenados fora do contexto do contêiner |
--minimum-container-ttl-duration | | descontinuado quando os logs antigos forem armazenados fora do contexto do contêiner |
--low-diskspace-threshold-mb | --eviction-hard ou eviction-soft | O despejo generaliza os limites do disco para outros recursos |
--outofdisk-transition-frequency | --eviction-pressure-transition-period | O despejo generaliza a transição da pressão do disco para outros recursos |
Próximos passos
Consulte Configurando a Manipulação de Recursos Insuficientes para mais detalhes.
8 - Métricas para Componentes do Sistema Kubernetes
Métricas dos componentes do sistema podem dar uma visão melhor do que acontece internamente. Métricas são particularmente úteis para construir dashboards e alertas.
Componentes do Kubernetes emitem métricas no formato Prometheus. Esse formato é um texto simples estruturado, projetado para que pessoas e máquinas possam lê-lo.
Métricas no Kubernetes
Na maioria dos casos, as métricas estão disponíveis no endpoint /metrics do servidor HTTP. Para componentes que não expõem o endpoint por padrão, ele pode ser ativado usando a flag --bind-address.
Exemplos desses componentes:
Em um ambiente de produção, você pode querer configurar o Servidor Prometheus ou algum outro coletor de métricas e disponibilizá-las em algum tipo de banco de dados de séries temporais.
Observe que o kubelet também expõe métricas nos endpoints /metrics/cadvisor, /metrics/resource e /metrics/probes. Essas métricas não possuem o mesmo ciclo de vida.
Se o seu cluster usa RBAC, ler as métricas requer autorização por meio de um usuário, grupo ou ServiceAccount com um ClusterRole que conceda o acesso ao /metrics.
Por exemplo:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- nonResourceURLs:
- "/metrics"
verbs:
- get
Ciclo de vida da métrica
Métrica alfa → Métrica beta → Métrica estável → Métrica ultrapassada → Métrica oculta → Métrica excluída
A métrica alfa não tem garantias de estabilidade. Essas métricas podem ser modificadas ou deletadas a qualquer momento.
Métricas beta seguem um contrato de API menos rígido do que suas contrapartes estáveis. Nenhum rótulo pode ser removido de métricas beta durante sua vida útil, no entanto, rótulos podem ser adicionados enquanto a métrica estiver no estágio beta.
Métricas estáveis possuem a garantia de que não serão alteradas. Isso significa:
- Uma métrica estável sem uma assinatura ultrapassada não será deletada ou renomeada
- O tipo de uma métrica estável não será modificado
As métricas ultrapassadas estão programadas para exclusão, mas ainda estão disponíveis para uso.
Essas métricas incluem uma anotação sobre a versão em que se tornarão ultrapassadas.
Por exemplo:
Antes de se tornar ultrapassado
# HELP some_counter isso conta coisas
# TYPE some_counter contador
some_counter 0
Depois de se tornar ultrapassado
# HELP some_counter (obsoleto desde 1.15.0) isso conta coisas
# TYPE some_counter contador
some_counter 0
Métricas ocultas não são mais publicadas para extração, mas ainda estão disponíveis para uso.
Uma métrica ultrapassada se torna uma métrica oculta após um período de tempo, com base em seu nível de estabilidade:
- Métricas ESTÁVEIS se tornam ocultas após um mínimo de 3 versões ou 9 meses, o que for mais longo.
- Métricas BETA se tornam ocultas após um mínimo de 1 versão ou 4 meses, o que for mais longo.
- Métricas ALFA podem ser ocultadas ou removidas na mesma versão em que são ultrapassadas.
Para usar uma métrica oculta, você deve habilitá-la. Para mais detalhes, consulte a seção mostrar métricas ocultas.
Métricas excluídas não estão mais disponíveis e não podem mais ser usadas.
Mostrar métricas ocultas
Como descrito anteriormente, administradores podem habilitar métricas ocultas por meio de uma flag de linha de comando em um binário específico. Isso pode ser usado como uma saída de emergência para os administradores caso percam a migração das métricas ultrapassadas na última versão.
A flag show-hidden-metrics-for-version usa uma versão para a qual você deseja mostrar métricas ultrapassadas nessa versão. A versão é expressada como x.y, onde x é a versão principal e y a versão secundária. A versão de patch não é necessária mesmo que uma métrica possa ser descontinuada em uma versão de patch, o motivo é que a política de descontinuação de métricas é executada na versão secundária.
A flag só pode usar a versão secundária anterior como seu valor. Se você quiser mostrar todas as métricas ocultas na versão anterior, pode definir a flag show-hidden-metrics-for-version para a versão anterior. Usar uma versão muito antiga não é permitido porque viola a política de descontinuação de métricas.
Por exemplo, vamos supor que a métrica A seja descontinuada na versão 1.29. A versão na qual a métrica A se torna oculta depende de seu nível de estabilidade:
- Se a métrica
A for ALFA, ela poderá ser ocultada na versão 1.29. - Se a métrica
A for BETA, ela será ocultada na versão 1.30 no mínimo. Se você estiver atualizando para a versão 1.30 e ainda precisar de A, você deve usar a opção de linha de comando --show-hidden-metrics-for-version=1.29. - Se a métrica
A for ESTÁVEL, ela será ocultada na versão 1.32 no mínimo. Se você estiver atualizando para a versão 1.32 e ainda precisar de A, você deve usar a opção de linha de comando --show-hidden-metrics-for-version=1.31.
Métricas de componentes
Métricas do kube-controller-manager
As métricas do controller manager fornecem informações importantes sobre o desempenho e a integridade do controller manager.
Essas métricas incluem métricas comuns do agente de execução da linguagem Go, tais como a quantidade de go_routine e métricas específicas do controller, como latência de requisições etcd ou latência da API dos provedores de serviços de nuvem (AWS, GCE, OpenStack), que podem ser usadas para medir a integridade de um cluster.
A partir do Kubernetes 1.7, métricas detalhadas de provedores de serviços de nuvem estão disponíveis para operações de armazenamento para o GCE, AWS, Vsphere e OpenStack.
Essas métricas podem ser usadas para monitorar a integridade das operações de volumes persistentes.
Por exemplo, para o GCE as seguintes métricas são chamadas:
cloudprovider_gce_api_request_duration_seconds { request = "instance_list"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_insert"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_delete"}
cloudprovider_gce_api_request_duration_seconds { request = "attach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "detach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "list_disk"}
Métricas do kube-scheduler
ESTADO DA FUNCIONALIDADE:
Kubernetes v1.21 [beta]
O scheduler expõe métricas opcionais que reportam os recursos solicitados e os limites desejados de todos os pods em execução. Essas métricas podem ser usadas para criar dashboards de planejamento de capacidade, avaliar os limites de agendamentos atuais ou históricos, identificar rapidamente cargas de trabalho que não podem ser agendadas devido à falta de recursos e comparar o uso atual com a solicitação do pod.
O kube-scheduler identifica as requisições de recursos e limites configurado para cada Pod; quando uma requisição ou limite é diferente de zero o kube-scheduler relata uma série temporal de métricas. Essa série temporal é etiquetada por:
- namespace
- nome do pod
- o nó onde o pod está agendado ou uma string vazia caso ainda não esteja agendado
- prioridade
- o scheduler atribuído para esse pod
- o nome do recurso (por exemplo,
cpu) - a unidade do recurso, se conhecida (por exemplo,
cores)
Uma vez que o pod alcança um estado de conclusão (sua restartPolicy está como Never ou OnFailure e está na fase Succeeded ou Failed, ou foi deletado e todos os contêineres têm um estado de terminado), a série não é mais relatada já que o scheduler agora está livre para agendar a execução de outros pods. As duas métricas são chamadas de kube_pod_resource_request e kube_pod_resource_limit.
As métricas são expostas no endpoint HTTP /metrics/resources. Elas requerem
autorização para o endpoint /metrics/resources, geralmente concedida por uma
ClusterRole com o verbo get para a URL não-recurso /metrics/resources.
No Kubernetes 1.21 você deve usar a opção
--show-hidden-metrics-for-version=1.20 para expor essas métricas de estabilidade alfa.
ESTADO DA FUNCIONALIDADE:
Kubernetes v1.34 [beta]
Como uma funcionalidade beta, o Kubernetes permite que você configure o kubelet para coletar informações de
Pressure Stall Information
(PSI) do kernel Linux para uso de CPU, memória e I/O.
As informações são coletadas no nível de nó, Pod e contêiner.
As métricas são expostas no endpoint /metrics/cadvisor com os seguintes nomes:
container_pressure_cpu_stalled_seconds_total
container_pressure_cpu_waiting_seconds_total
container_pressure_memory_stalled_seconds_total
container_pressure_memory_waiting_seconds_total
container_pressure_io_stalled_seconds_total
container_pressure_io_waiting_seconds_total
Esta funcionalidade está habilitada por padrão, ao definir o feature gate KubeletPSI. As informações também são expostas na
API Summary.
Você pode aprender como interpretar as métricas PSI em Entender Métricas PSI.
Requisitos
Pressure Stall Information requer:
Desativando métricas
Você pode desativar explicitamente as métricas via linha de comando utilizando a flag --disabled-metrics. Isso pode ser desejado se, por exemplo, uma métrica estiver causando um problema de desempenho. A entrada é uma lista de métricas desabilitadas (ou seja, --disabled-metrics=metric1,metric2).
Aplicação de cardinalidade de métrica
As métricas com dimensões sem limites podem causar problemas de memória nos componentes que elas instrumentam. Para limitar a utilização de recursos você pode usar a opção de linha de comando --allow-label-value para dinamicamente configurar uma lista de valores de label permitidos para uma métrica.
No estágio alfa, a flag pode receber apenas uma série de mapeamentos como lista de permissões de labels para uma métrica.
Cada mapeamento tem o formato <metric_name>,<label_name>=<allowed_labels> onde <allowed_labels> é uma lista separada por vírgulas de nomes aceitáveis para a label.
O formato geral se parece com:
--allow-metric-labels <metric_name>,<label_name>='<allow_value1>, <allow_value2>...', <metric_name2>,<label_name>='<allow_value1>, <allow_value2>...', ...
Por exemplo:
--allow-metric-labels number_count_metric,odd_number='1,3,5', number_count_metric,even_number='2,4,6', date_gauge_metric,weekend='Saturday,Sunday'
Além de especificar isso pela CLI, isso também pode ser feito dentro de um arquivo de configuração. Você
pode especificar o caminho para esse arquivo de configuração usando o argumento de linha de comando
--allow-metric-labels-manifest para um componente. Aqui está um exemplo do conteúdo desse arquivo de configuração:
"metric1,label2": "v1,v2,v3"
"metric2,label1": "v1,v2,v3"
Além disso, a meta-métrica cardinality_enforcement_unexpected_categorizations_total registra a
contagem de categorizações inesperadas durante a aplicação de cardinalidade, isto é, sempre que um valor de rótulo
é encontrado que não é permitido em relação às restrições da lista de permissões.
Próximos passos
9 - Proxies no Kubernetes
Esta página descreve o uso de proxies com Kubernetes.
Proxies
Existem vários tipos diferentes de proxies que você pode encontrar usando Kubernetes:
- O kubectl proxy:
Quando o kubectl proxy é utilizado ocorre o seguinte:
- executa na máquina do usuário ou em um pod
- redireciona/encapsula conexões direcionadas ao localhost para o servidor de API
- a comunicação entre o cliente e o o proxy usa HTTP
- a comunicação entre o proxy e o servidor de API usa HTTPS
- o proxy localiza o servidor de API do cluster
- o proxy adiciona os cabeçalhos de comunicação.
O apiserver proxy:
- é um bastion server, construído no servidor de API
- conecta um usuário fora do cluster com os IPs do cluster que não podem ser acessados de outra forma
- executa dentro do processo do servidor de API
- cliente para proxy usa HTTPS (ou HTTP se o servidor de API for configurado)
- proxy para o destino pode usar HTTP ou HTTPS conforme escolhido pelo proxy usando as informações disponíveis
- pode ser usado para acessar um Nó, Pod ou serviço
- faz balanceamento de carga quando usado para acessar um Service.
O kube proxy:
- executa em todos os Nós
- atua como proxy para UDP, TCP e SCTP
- não aceita HTTP
- provém balanceamento de carga
- apenas é usado para acessar serviços.
Um Proxy/Balanceador de carga na frente de servidores de API(s):
- a existência e a implementação de tal elemento varia de cluster para cluster, por exemplo nginx
- fica entre todos os clientes e um ou mais serviços
- atua como balanceador de carga se existe mais de um servidor de API.
Balanceadores de carga da nuvem em serviços externos:
- são fornecidos por algum provedor de nuvem (e.x AWS ELB, Google Cloud Load Balancer)
- são criados automaticamente quando o serviço de Kubernetes tem o tipo
LoadBalancer - geralmente suportam apenas UDP/TCP
- O suporte ao SCTP fica por conta da implementação do balanceador de carga da provedora de nuvem
- a implementação varia de acordo com o provedor de cloud.
Os usuários de Kubernetes geralmente não precisam se preocupar com outras coisas além dos dois primeiros tipos. O
administrador do cluster tipicamente garante que os últimos tipos serão configurados corretamente.
Redirecionamento de requisições
Os proxies substituíram as capacidades de redirecionamento. O redirecionamento foi depreciado.
10 - Rastreamentos para Componentes do Sistema Kubernetes
ESTADO DA FUNCIONALIDADE:
Kubernetes v1.27 [beta]
Os rastreamentos de componentes do sistema registram a latência e os relacionamentos entre as operações no cluster.
Os componentes do Kubernetes emitem rastreamentos usando o
OpenTelemetry Protocol
com o exportador gRPC e podem ser coletados e roteados para backends de rastreamento usando um
OpenTelemetry Collector.
Coleta de Rastreamento
Os componentes do Kubernetes possuem exportadores gRPC embutidos para OTLP para exportar rastreamentos,
seja com um OpenTelemetry Collector, ou sem um OpenTelemetry Collector.
Para um guia completo sobre coleta de rastreamentos e uso do coletor, consulte
Getting Started with the OpenTelemetry Collector.
No entanto, existem algumas coisas a serem observadas que são específicas dos componentes do Kubernetes.
Por padrão, os componentes do Kubernetes exportam rastreamentos usando o exportador grpc para OTLP na
porta IANA do OpenTelemetry, 4317.
Como exemplo, se o coletor estiver sendo executado como um sidecar de um componente do Kubernetes,
a seguinte configuração de receptor coletará spans e os registrará na saída padrão:
receivers:
otlp:
protocols:
grpc:
exporters:
# Substitua este exportador pelo exportador do seu backend
exporters:
debug:
verbosity: detailed
service:
pipelines:
traces:
receivers: [otlp]
exporters: [debug]
Para emitir rastreamentos diretamente para um backend sem utilizar um coletor,
especifique o campo endpoint no arquivo de configuração de rastreamento do Kubernetes com o endereço do backend de rastreamento desejado.
Este método elimina a necessidade de um coletor e simplifica a estrutura geral.
Para configuração de cabeçalhos do backend de rastreamento, incluindo detalhes de autenticação, variáveis de ambiente podem ser usadas com OTEL_EXPORTER_OTLP_HEADERS,
consulte OTLP Exporter Configuration.
Além disso, para configuração de atributos de recurso de rastreamento, como nome do cluster Kubernetes, namespace, nome do Pod, etc.,
variáveis de ambiente também podem ser usadas com OTEL_RESOURCE_ATTRIBUTES, consulte OTLP Kubernetes Resource.
Rastreamentos de componentes
Rastreamentos do kube-apiserver
O kube-apiserver gera spans para requisições HTTP de entrada e para requisições de saída
para webhooks, etcd e requisições reentrantes. Ele propaga o
W3C Trace Context com requisições de saída,
mas não faz uso do contexto de rastreamento anexado às requisições de entrada,
pois o kube-apiserver frequentemente é um endpoint público.
Habilitando rastreamento no kube-apiserver
Para habilitar o rastreamento, forneça ao kube-apiserver um arquivo de configuração de rastreamento
com --tracing-config-file=<caminho-para-config>. Este é um exemplo de configuração que registra
spans para 1 em 10000 requisições e usa o endpoint padrão do OpenTelemetry:
apiVersion: apiserver.config.k8s.io/v1
kind: TracingConfiguration
# valor padrão
#endpoint: localhost:4317
samplingRatePerMillion: 100
Para mais informações sobre a estrutura TracingConfiguration, consulte
API server config API (v1).
Rastreamentos do kubelet
ESTADO DA FUNCIONALIDADE:
Kubernetes v1.34 [stable](habilitado por padrão)
A interface CRI do kubelet e os servidores http autenticados são instrumentados para gerar
spans de rastreamento. Assim como no apiserver, o endpoint e a taxa de amostragem são configuráveis.
A propagação do contexto de rastreamento também é configurada. A decisão de amostragem de um span raiz é sempre respeitada.
Uma taxa de amostragem de configuração de rastreamento fornecida será aplicada a spans sem um span raiz.
Habilitado sem um endpoint configurado, o endereço padrão do receptor do OpenTelemetry Collector de "localhost:4317" é definido.
Habilitando rastreamento no kubelet
Para habilitar o rastreamento, aplique a configuração de rastreamento.
Este é um trecho de exemplo de uma configuração do kubelet que registra spans para 1 em 10000 requisições e usa o endpoint padrão do OpenTelemetry:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
tracing:
# valor padrão
#endpoint: localhost:4317
samplingRatePerMillion: 100
Se o samplingRatePerMillion estiver definido como um milhão (1000000), então cada
span será enviado para o exportador.
O kubelet no Kubernetes v1.35 coleta spans da
coleta de lixo, rotina de sincronização de pods, bem como de cada método gRPC.
O kubelet propaga o contexto de rastreamento com requisições gRPC para que
agentes de execução de contêiner com instrumentação de rastreamento, como CRI-O e containerd,
possam associar seus spans exportados ao contexto de rastreamento do kubelet.
Os rastreamentos resultantes terão vínculos hierárquicos entre os spans do kubelet e
do agente de execução de contêiner, fornecendo contexto útil ao depurar problemas
do nó.
Observe que a exportação de spans sempre vem com uma pequena sobrecarga de desempenho
no lado de rede e CPU, dependendo da configuração geral do
sistema. Se houver algum problema desse tipo em um cluster que está sendo executado com
rastreamento habilitado, então mitigue o problema reduzindo o
samplingRatePerMillion ou desabilitando completamente o rastreamento removendo a
configuração.
Estabilidade
A instrumentação de rastreamento ainda está em desenvolvimento ativo e pode mudar
de várias maneiras. Isso inclui nomes de span, atributos anexados,
endpoints instrumentados, etc. Até que esta funcionalidade se torne estável,
não há garantias de retrocompatibilidade para a instrumentação de rastreamento.
Próximos passos
11 - Instalando Complementos
Nota: Esta seção contém links para projetos de terceiros que fornecem a funcionalidade exigida pelo Kubernetes. Os autores do projeto Kubernetes não são responsáveis por esses projetos. Esta página obedece as
diretrizes de conteúdo do site CNCF, listando os itens em ordem alfabética. Para adicionar um projeto a esta lista, leia o
guia de conteúdo antes de enviar sua alteração.
Complementos estendem as funcionalidades do Kubernetes.
Esta página lista alguns dos complementos disponíveis e links com suas respectivas instruções de instalação.
Rede e Política de Rede
- ACI fornece rede integrada de contêineres e segurança de rede com a Cisco ACI.
- Antrea opera nas camadas 3 e 4 do modelo de rede OSI para fornecer serviços de rede e de segurança para o Kubernetes, aproveitando o Open vSwitch como camada de dados de rede.
- Calico é um provedor de serviços de rede e de políticas de rede. Este complemento suporta um conjunto flexível de opções de rede, de modo a permitir a escolha da opção mais eficiente para um dado caso de uso, incluindo redes overlay (sobrepostas) e não-overlay, com ou sem o uso do protocolo BGP. Calico usa o mesmo mecanismo para aplicar políticas de rede a hosts, pods, e aplicações na camada de service mesh (quando Istio e Envoy estão instalados).
- Canal une Flannel e Calico, fornecendo rede e política de rede.
- Cilium é um plug-in de rede de camada 3 e de políticas de rede que pode aplicar políticas HTTP/API/camada 7 de forma transparente. Tanto o modo de roteamento quanto o de sobreposição/encapsulamento são suportados. Este plug-in também consegue operar no topo de outros plug-ins CNI.
- CNI-Genie permite que o Kubernetes se conecte facilmente a uma variedade de plug-ins CNI, como Calico, Canal, Flannel, Romana ou Weave.
- Contiv oferece serviços de rede configuráveis para diferentes casos de uso (camada 3 nativa usando BGP, overlay (sobreposição) usando vxlan, camada 2 clássica e Cisco-SDN/ACI) e também um framework rico de políticas de rede. O projeto Contiv é totalmente open source. O instalador fornece opções de instalação com ou sem kubeadm.
- Contrail é uma plataforma open source baseada no Tungsten Fabric que oferece virtualização de rede multi-nuvem e gerenciamento de políticas de rede. O Contrail e o Tungsten Fabric são integrados a sistemas de orquestração de contêineres, como Kubernetes, OpenShift, OpenStack e Mesos, e fornecem modos de isolamento para cargas de trabalho executando em máquinas virtuais, contêineres/pods e servidores físicos.
- Flannel é um provedor de redes overlay (sobrepostas) que pode ser usado com o Kubernetes.
- Knitter é um plug-in para suporte de múltiplas interfaces de rede em Pods do Kubernetes.
- Multus é um plugin para suporte a várias interfaces de rede em Pods no Kubernetes. Este plug-in pode agir como um "meta-plug-in", ou um plug-in CNI que se comunica com múltiplos outros plug-ins CNI (por exemplo, Calico, Cilium, Contiv, Flannel), além das cargas de trabalho baseadas em SRIOV, DPDK, OVS-DPDK e VPP no Kubernetes.
- NSX-T Container Plug-in (NCP) fornece integração entre o VMware NSX-T e sistemas de orquestração de contêineres como o Kubernetes. Além disso, oferece também integração entre o NSX-T e as plataformas CaaS/PaaS baseadas em contêiner, como o Pivotal Container Service (PKS) e o OpenShift.
- Nuage é uma plataforma de rede definida por software que fornece serviços de rede baseados em políticas entre os Pods do Kubernetes e os ambientes não-Kubernetes, com visibilidade e monitoramento de segurança.
- OVN-Kubernetes é um provedor de rede para o Kubernetes baseado no OVN (Open Virtual Network), uma implementação de redes virtuais que surgiu através do projeto Open vSwitch (OVS). O OVN-Kubernetes fornece uma implementação de rede baseada em overlay (sobreposição) para o Kubernetes, incluindo uma implementação baseada em OVS para serviços de balanceamento de carga e políticas de rede.
- OVN4NFV-K8S-Plugin é um plug-in controlador CNI baseado no OVN (Open Virtual Network) que fornece serviços de rede cloud native, como Service Function Chaining (SFC), redes overlay (sobrepostas) OVN múltiplas, criação dinâmica de subredes, criação dinâmica de redes virtuais, provedor de rede VLAN e provedor de rede direto, e é plugável a outros plug-ins multi-rede. Ideal para cargas de trabalho que utilizam computação de borda cloud native em redes multi-cluster.
- Romana é uma solução de rede de camada 3 para redes de pods que também suporta a API NetworkPolicy. Detalhes da instalação do complemento Kubeadm disponíveis aqui.
- Weave Net fornece rede e política de rede, funciona em ambos os lados de uma partição de rede e não requer um banco de dados externo.
Descoberta de Serviço
- CoreDNS é um servidor DNS flexível e extensível que pode ser instalado como o serviço de DNS dentro do cluster para ser utilizado por pods.
Visualização & Controle
- Dashboard é uma interface web para gestão do Kubernetes.
Infraestrutura
- KubeVirt é um complemento para executar máquinas virtuais no Kubernetes. É geralmente executado em clusters em máquina física.
Complementos Legados
Existem vários outros complementos documentados no diretório cluster/addons que não são mais utilizados.
Projetos bem mantidos devem ser listados aqui. PRs são bem-vindos!
12 - Prioridade e imparcialidade da API
ESTADO DA FUNCIONALIDADE:
Kubernetes v1.20 [beta]
Controlar o comportamento do servidor da API Kubernetes em uma situação de sobrecarga
é uma tarefa chave para administradores de cluster. O kube-apiserver tem alguns controles disponíveis
(ou seja, as flags --max-requests-inflight e --max-mutating-requests-inflight)
para limitar a quantidade de trabalho pendente que será aceito,
evitando que uma grande quantidade de solicitações de entrada sobrecarreguem, e
potencialmente travando o servidor da API, mas essas flags não são suficientes para garantir
que as solicitações mais importantes cheguem em um período de alto tráfego.
O recurso de prioridade e imparcialidade da API (do inglês API Priority and Fairness, APF) é uma alternativa que melhora
as limitações mencionadas acima. A APF classifica
e isola os pedidos de uma forma mais refinada. Também introduz
uma quantidade limitada de filas, para que nenhuma solicitação seja rejeitada nos casos
de sobrecargas muito breves. As solicitações são despachadas das filas usando uma
técnica de filas justa para que, por exemplo, um
controller não precise
negar as outras requisições (mesmo no mesmo nível de prioridade).
Esse recurso foi projetado para funcionar bem com controladores padrão, que
usam informantes e reagem a falhas de solicitações da API com exponencial
back-off, e outros clientes que também funcionam desta forma.
Cuidado:
Solicitações classificadas como "de longa duração" — principalmente watches — não são
sujeitas ao filtro da prioridade e imparcialidade da API. Isso também é verdade para
a flag --max-requests-inflight sem o recurso da APF ativado.Ativando/Desativando a prioridade e imparcialidade da API
O recurso de prioridade e imparcialidade da API é controlado por um feature gate
e está habilitado por padrão. Veja Portões de Recurso
para uma explicação geral dos portões de recursos e como habilitar e
desativá-los. O nome da porta de recurso para APF é
"APIPriorityAndFairness". Este recurso também envolve um API Group com: (a) um
Versão v1alpha1, desabilitada por padrão, e (b) v1beta1 e
Versões v1beta2, habilitadas por padrão. Você pode desativar o feature gate
e versões beta do grupo de APIs adicionando a seguinte
flag para sua invocação kube-apiserver:
kube-apiserver \
--feature-gates=APIPriorityAndFairness=false \
--runtime-config=flowcontrol.apiserver.k8s.io/v1beta1=false,flowcontrol.apiserver.k8s.io/v1beta2=false \
# …and other flags as usual
Como alternativa, você pode habilitar a versão v1alpha1 do grupo de APIs
com --runtime-config=flowcontrol.apiserver.k8s.io/v1alpha1=true.
A flag --enable-priority-and-fairness=false desabilitará o
recurso de prioridade e imparcialidade da API, mesmo que outras flags o tenha ativado.
Conceitos
Existem vários recursos distintos envolvidos na APF.
As solicitações recebidas são classificadas por atributos da solicitação usando
FlowSchemas e atribuídos a níveis de prioridade. Os níveis de prioridade adicionam um grau de
isolamento mantendo limites de simultaneidade separados, para que as solicitações atribuídas
a diferentes níveis de prioridade não travem outros. Dentro de um nível de prioridade,
um algoritmo de fair queuing impede que solicitações de diferentes flows fiquem sem energia
entre si, e permite que os pedidos sejam enfileirados para evitar que um alto tráfego
cause falhas nas solicitações quando a carga média é aceitavelmente baixa.
Níveis de prioridade
Sem o APF ativado, a simultaneidade geral no servidor de API é limitada pelo
kube-apiserver as flags --max-requests-inflight e
--max-mutating-requests-inflight. Com o APF ativado, os limites de simultaneidade
definidos por esses sinalizadores são somados e, em seguida, a soma é dividida entre um
conjunto configurável de níveis de prioridade. Cada solicitação recebida é atribuída a um
nível de prioridade único, e cada nível de prioridade só despachará tantos
solicitações simultâneas conforme sua configuração permite.
A configuração padrão, por exemplo, inclui níveis de prioridade separados para
solicitações de eleição de líder, solicitações de controladores integrados e solicitações de
Pods. Isso significa que um pod mal-comportado que inunda o servidor da API com
solicitações não podem impedir a eleição do líder ou ações dos controladores integrados
de ter sucesso.
Enfileiramento
Mesmo dentro de um nível de prioridade pode haver um grande número de fontes distintas de
tráfego. Em uma situação de sobrecarga, é importante evitar um fluxo de
pedidos de outros serviços (em particular, no caso relativamente comum de um
único cliente buggy inundando o kube-apiserver com solicitações, esse cliente buggy
idealmente não teria muito impacto em outros clientes). Isto é
tratadas pelo uso de um algoritmo de fair queuing para processar solicitações que são atribuídas
ao mesmo nível de prioridade. Cada solicitação é atribuída a um flow, identificado pelo
nome do FlowSchema correspondente mais um flow distincter — que
é o usuário solicitante, o namespace do recurso de destino ou nada — e o
sistema tenta dar peso aproximadamente igual a solicitações em diferentes
fluxos do mesmo nível de prioridade.
Para habilitar o tratamento distinto de instâncias distintas, os controladores que
muitas instâncias devem ser autenticadas com nomes de usuário distintos
Depois de classificar uma solicitação em um fluxo, a APF
pode então atribuir a solicitação a uma fila. Esta atribuição usa
uma técnica conhecida como shuffle sharding, que faz uso relativamente eficiente de
filas para isolar fluxos de baixa intensidade de fluxos de alta intensidade.
Os detalhes do algoritmo de enfileiramento são ajustáveis para cada nível de prioridade e
permitem que os administradores troquem o uso de memória, justiça (a propriedade que
fluxos independentes irão progredir quando o tráfego total exceder a capacidade),
tolerância para tráfego e a latência adicionada induzida pelo enfileiramento.
Solicitações de isenção
Alguns pedidos são considerados suficientemente importantes para que não estejam sujeitos a
qualquer uma das limitações impostas por este recurso. Estas isenções impedem uma
configuração de controle de fluxo mal configurada de desabilitar totalmente um servidor da API.
Recursos
A API de controle de fluxo envolve dois tipos de recursos.
PriorityLevelConfigurations
define as classes de isolamento disponíveis, a parte da concorrência disponível
que cada um pode tratar e permite o ajuste fino do comportamento das filas.
FlowSchemas
são usados para classificar solicitações de entrada individuais, correspondendo cada uma a um
único PriorityLevelConfiguration. Há também uma versão v1alpha1
do mesmo grupo de APIs e tem os mesmos tipos com a mesma sintaxe e
semântica.
PriorityLevelConfiguration
Um PriorityLevelConfiguration representa uma única classe de isolamento. Cada
PriorityLevelConfiguration tem um limite independente no número de solicitações de pendências
e limitações no número de solicitações enfileiradas.
Os limites de simultaneidade para PriorityLevelConfigurations não são especificados no número absoluto
de solicitações, mas sim em "compartilhamentos de simultaneidade". A simultaneidade limite total
para o servidor da API é distribuído entre os PriorityLevelConfigurations existentes
em proporção com esses compartilhamentos. Isso permite um
administrador de cluster aumentar ou diminuir a quantidade total de tráfego para um
servidor reiniciando kube-apiserver com um valor diferente para
--max-requests-inflight (ou --max-mutating-requests-inflight), e todos os
PriorityLevelConfigurations verá sua simultaneidade máxima permitida aumentar (ou
abaixar) pela mesma proporção.
Cuidado:
Com o recurso prioridade e imparcialidade ativado, o limite total de simultaneidade para
o servidor é definido como a soma de --max-requests-inflight e
--max-mutating-requests-inflight. Já não há distinção
entre solicitações mutantes e não mutantes; se você quiser tratá-las
separadamente para um determinado recurso, faça FlowSchemas separados que correspondam ao
verbos mutantes e não mutantes, respectivamente.Quando o volume de solicitações de entrada atribuídas a um único
PriorityLevelConfiguration é maior do que o permitido por seu nível de simultaneidade, o
O campo type de sua especificação determina o que acontecerá com solicitações extras.
Um tipo de 'Reject' significa que o excesso de tráfego será imediatamente rejeitado com
um erro HTTP 429 (Too Many Requests). Um tipo de Queue significa que as solicitações
acima do limite será enfileirado, com as técnicas de
shuffle sharding e fair queuing usadas
para equilibrar o progresso entre os fluxos de solicitação.
A configuração de enfileiramento permite ajustar o algoritmo de fair queuing para um
nível de prioridade. Os detalhes do algoritmo podem ser lidos no
proposta de melhoria, mas resumindo:
Aumentar as 'filas' reduz a taxa de colisões entre diferentes fluxos,
o custo do aumento do uso de memória. Um valor de 1 aqui efetivamente desabilita a
lógica de fair queuing, mas ainda permite que as solicitações sejam enfileiradas.
Aumentar o queueLengthLimit permite que tráfegos maiores sejam
sustentados sem deixar de lado nenhum pedido, ao custo de aumento
latência e uso de memória.
Alterar handSize permite ajustar a probabilidade de colisões entre
fluxos diferentes e a simultaneidade geral disponível para um único fluxo em um
situação de sobrecarga.
Nota:
Um 'handSize' maior torna menos provável que dois fluxos individuais colidam
(e, portanto, um bloqueie a solicitação do outro), mas é mais provável que
um pequeno número de fluxos pode dominar o apiserver. Um handSize maior também
aumenta potencialmente a quantidade de latência que um único fluxo de alto tráfego
pode causar. O número máximo de solicitações enfileiradas possíveis de um
fluxo único é handSize * queueLengthLimit.
A seguir está uma tabela mostrando uma coleção interessante de configurações do
shuffle sharding, mostrando para cada uma a probabilidade de que um
determinado rato (fluxo de baixa intensidade) é esmagado pelos elefantes (fluxo de alta intensidade) para
uma coleção ilustrativa de números de elefantes. Veja
https://play.golang.org/p/Gi0PLgVHiUg , que calcula esta tabela.
Example Shuffle Sharding Configurations| HandSize | Filas | 1 elefante | 4 elefantes | 16 elefantes |
|---|
| 12 | 32 | 4.428838398950118e-09 | 0.11431348830099144 | 0.9935089607656024 |
| 10 | 32 | 1.550093439632541e-08 | 0.0626479840223545 | 0.9753101519027554 |
| 10 | 64 | 6.601827268370426e-12 | 0.00045571320990370776 | 0.49999929150089345 |
| 9 | 64 | 3.6310049976037345e-11 | 0.00045501212304112273 | 0.4282314876454858 |
| 8 | 64 | 2.25929199850899e-10 | 0.0004886697053040446 | 0.35935114681123076 |
| 8 | 128 | 6.994461389026097e-13 | 3.4055790161620863e-06 | 0.02746173137155063 |
| 7 | 128 | 1.0579122850901972e-11 | 6.960839379258192e-06 | 0.02406157386340147 |
| 7 | 256 | 7.597695465552631e-14 | 6.728547142019406e-08 | 0.0006709661542533682 |
| 6 | 256 | 2.7134626662687968e-12 | 2.9516464018476436e-07 | 0.0008895654642000348 |
| 6 | 512 | 4.116062922897309e-14 | 4.982983350480894e-09 | 2.26025764343413e-05 |
| 6 | 1024 | 6.337324016514285e-16 | 8.09060164312957e-11 | 4.517408062903668e-07 |
FlowSchema
Um FlowSchema corresponde a algumas solicitações de entrada e as atribui a um
nível de prioridade. Cada solicitação de entrada é testada em relação a cada
FlowSchema, por sua vez, começando com aqueles com valores numericamente mais baixos ---
que consideramos ser o logicamente mais alto --- matchingPrecedence e
trabalhando adiante. A primeira correspondência ganha.
Cuidado:
Somente o primeiro FlowSchema correspondente para uma determinada solicitação é importante. Se vários
FlowSchemas correspondem a uma única solicitação de entrada, ela será atribuída com base na
com o maior em matchingPrecedence. Se vários FlowSchemas com igual
matchingPrecedence corresponde ao mesmo pedido, aquele com menor
name lexicográfico vencerá, mas é melhor não confiar nisso e, em vez disso,
certifique-se de que dois FlowSchemas não tenham o mesmo matchingPrecedence.Um FlowSchema corresponde a uma determinada solicitação se pelo menos uma de suas regras
são correspondidas. Uma regra corresponde se pelo menos um de seus assuntos e pelo menos
uma de suas resourceRules ou nonResourceRules (dependendo se a
solicitação de entrada é para um recurso ou URL de não-recurso) corresponde à solicitação.
Para o campo name em assuntos, e os campos verbs, apiGroups, resources,
namespaces e nonResourceURLs de regras de recursos e não recursos,
o wildcard * pode ser especificado para corresponder a todos os valores do campo fornecido,
efetivamente removendo-o de consideração.
O distinguisherMethod.type de um FlowSchema determina como as solicitações correspondentes a esse
esquema será separado em fluxos. Pode ser
ou ByUser, caso em que um usuário solicitante não poderá ser bloqueado por outros,
ou ByNamespace, caso em que solicitações de recursos
em um namespace não será capaz de privar os pedidos de recursos em outros
namespaces de capacidade, ou pode estar em branco (ou distinguisherMethod pode ser
omitido inteiramente), caso em que todas as solicitações correspondidas por este FlowSchema serão
considerados parte de um único fluxo. A escolha correta para um determinado FlowSchema
depende do recurso e do seu ambiente específico.
Padrões
Cada kube-apiserver mantém dois tipos de objetos de configuração APF:
obrigatória e sugerida.
Objetos de configuração obrigatórios
Os quatro objetos de configuração obrigatórios refletem no
comportamento do guardrail embutido. Este é o comportamento que os servidores tinham antes
desses objetos existirem e, quando esses objetos existem, suas especificações refletem
esse comportamento. Os quatro objetos obrigatórios são os seguintes.
O nível de prioridade obrigatório exempt é usado para solicitações que são
não sujeito a controle de fluxo: eles sempre serão despachados
imediatamente. O FlowSchema obrigatório exempt classifica todos
solicitações do grupo system:masters para este nível de prioridade.
Você pode definir outros FlowSchemas que direcionam outras solicitações
a este nível de prioridade, se apropriado.
O nível de prioridade obrigatório catch-all é usado em combinação com
o FlowSchema catch-all obrigatório para garantir que todas as solicitações
recebam algum tipo de classificação. Normalmente você não deve confiar
nesta configuração catch-all, e deve criar seu próprio FlowSchema catch-all
e PriorityLevelConfiguration (ou use o
nível de prioridade global-default que é instalado por padrão) como
apropriado. Como não se espera que seja usado normalmente, o
o nível de prioridade obrigatório catch-all tem uma simultaneidade muito pequena
compartilha e não enfileira solicitações.
Objetos de configuração sugeridos
Os FlowSchemas e PriorityLevelConfigurations sugeridos constituem uma
configuração padrão razoável. Você pode modificá-los e/ou criar
objetos de configuração adicionais, se desejar. Se o seu cluster tiver a
probabilidade de experimentar carga pesada, então você deve considerar qual
configuração funcionará melhor.
A configuração sugerida agrupa as solicitações em seis níveis de prioridade:
O nível de prioridade node-high é para atualizações de integridade dos nós.
O nível de prioridade system é para solicitações não relacionadas à integridade do
grupo system:nodes, ou seja, Kubelets, que deve ser capaz de contatar
o servidor de API para que as cargas de trabalho possam ser agendadas
eles.
O nível de prioridade leader-election é para solicitações de eleição de líder de
controladores embutidos (em particular, solicitações para endpoints, configmaps,
ou leases vindo do system:kube-controller-manager ou
usuários system:kube-scheduler e contas de serviço no namespace kube-system).
Estes são importantes para isolar de outro tráfego porque as falhas
na eleição do líder fazem com que seus controladores falhem e reiniciem, o que por sua vez
causa tráfego mais caro à medida que os novos controladores sincronizam seus informantes.
O nível de prioridade workload-high é para outras solicitações de controladores built-in.
O nível de prioridade workload-low é para solicitações de qualquer outra conta de serviço,
que normalmente incluirá todas as solicitações de controladores em execução
Pods.
O nível de prioridade global-default trata de todos os outros tráfegos, por exemplo,
comandos kubectl interativos executados por usuários não privilegiados.
Os FlowSchemas sugeridos servem para direcionar as solicitações para os
níveis de prioridade acima, e não são enumerados aqui.
Manutenção dos Objetos de Configuração Obrigatórios e Sugeridos
Cada kube-apiserver mantém independentemente os requisitos obrigatórios e
objetos de configuração sugeridos, usando comportamento inicial e periódico.
Assim, em uma situação com uma mistura de servidores de diferentes versões
pode haver thrashing desde que servidores diferentes tenham
opiniões sobre o conteúdo adequado desses objetos.
Para os objetos de configuração obrigatórios, a manutenção consiste em
garantir que o objeto existe e, se existir, tem a especificação adequada.
O servidor se recusa a permitir uma criação ou atualização com uma especificação que é
inconsistente com o comportamento do guarda-corpo do servidor.
A manutenção de objetos de configuração sugeridos é projetada para permitir
que suas especificações sejam substituídas. A exclusão, por outro lado, não é
respeitada: a manutenção restaurará o objeto. Se você não quer um
objeto de configuração sugerido, então você precisa mantê-lo por perto, mas defina
sua especificação para ter consequências mínimas. Manutenção de objetos
sugeridos também é projetada para suportar a migração automática quando uma nova
versão do kube-apiserver é lançada, embora potencialmente com
thrashing enquanto há uma população mista de servidores.
A manutenção de um objeto de configuração sugerido consiste em cria-lo
--- com a especificação sugerida pelo servidor --- se o objeto não
existir. OTOH, se o objeto já existir, o comportamento de manutenção
depende se os kube-apiservers ou os usuários controlam o
objeto. No primeiro caso, o servidor garante que a especificação do objeto
é o que o servidor sugere; no último caso, a especificação é deixada
sozinho.
A questão de quem controla o objeto é respondida primeiro olhando
para uma anotação com a chave apf.kubernetes.io/autoupdate-spec. Se
existe tal anotação e seu valor é true então o
kube-apiservers controlam o objeto. Se houver tal anotação
e seu valor for false, os usuários controlarão o objeto. Se
nenhuma dessas condições é satisfeita entaão a metadata.generation do
objeto é consultado. Se for 1, o kube-apiservers controla
o objeto. Caso contrário, os usuários controlam o objeto. Essas regras foram
introduzido na versão 1.22 e sua consideração de
metadata.generation é para migrar do mais simples
comportamento anterior. Usuários que desejam controlar um objeto de configuração sugerido
deve definir sua anotação apf.kubernetes.io/autoupdate-spec
para 'falso'.
A manutenção de um objeto de configuração obrigatório ou sugerido também
inclui garantir que ele tenha uma anotação apf.kubernetes.io/autoupdate-spec
que reflete com precisão se os kube-apiservers
controlam o objeto.
A manutenção também inclui a exclusão de objetos que não são obrigatórios
nem sugeridos, mas são anotados
apf.kubernetes.io/autoupdate-spec=true.
Isenção de simultaneidade da verificação de integridade
A configuração sugerida não dá nenhum tratamento especial a checagem de saúde das requisições
verifique solicitações em kube-apiservers de seus kubelets locais --- que
tendem a usar a porta segura, mas não fornecem credenciais. Com o
configuração sugerida, essas solicitações são atribuídas ao global-default
FlowSchema e o nível de prioridade "global-default" correspondente,
onde outro tráfego pode bloqueá-los.
Se você adicionar o seguinte FlowSchema adicional, isso isenta aquelas
solicitações de limitação de taxa.
Cuidado:
Fazer essa alteração também permite que qualquer parte hostil envie
solicitações de verificação de integridade que correspondam a este FlowSchema, em qualquer volume.
Se você tiver um filtro de tráfego da Web ou outro mecanismo de segurança externa semelhante
para proteger o servidor de API do seu cluster do trafego geral de internet,
você pode configurar regras para bloquear qualquer solicitação de verificação de integridade
que se originam de fora do seu cluster.apiVersion: flowcontrol.apiserver.k8s.io/v1beta3
kind: FlowSchema
metadata:
name: health-for-strangers
spec:
matchingPrecedence: 1000
priorityLevelConfiguration:
name: exempt
rules:
- nonResourceRules:
- nonResourceURLs:
- "/healthz"
- "/livez"
- "/readyz"
verbs:
- "*"
subjects:
- kind: Group
group:
name: system:unauthenticated
Diagnóstico
Cada resposta HTTP de um servidor da API com o recurso de prioridade e justiça
ativado tem dois cabeçalhos extras: X-Kubernetes-PF-FlowSchema-UID e
X-Kubernetes-PF-PriorityLevel-UID, observando o esquema de fluxo que corresponde à solicitação
e o nível de prioridade ao qual foi atribuído, respectivamente. Os nomes dos objetos da API
não são incluídos nesses cabeçalhos caso o usuário solicitante não
tenha permissão para visualizá-los, então ao depurar você pode usar um comando como
kubectl get flowschemas -o custom-columns="uid:{metadata.uid},name:{metadata.name}"
kubectl get prioritylevelconfigurations -o custom-columns="uid:{metadata.uid},name:{metadata.name}"
para obter um mapeamento de UIDs de nomes para FlowSchemas e
PriorityLevelConfigurations.
Observabilidade
Metricas
Nota:
Nas versões do Kubernetes anteriores à v1.20, as labels flow_schema e
priority_level foram nomeados de forma inconsistente como flowSchema e priorityLevel,
respectivamente. Se você estiver executando versões do Kubernetes v1.19 ou anteriores, você
deve consultar a documentação da sua versão.Quando você ativa o APF, o kube-apiserver
exporta métricas adicionais. Monitorá-los pode ajudá-lo a determinar se a sua
configuração está limitando indevidamente o tráfego importante, ou encontrar
cargas de trabalho mal comportadas que podem estar prejudicando a integridade do sistema.
apiserver_flowcontrol_rejected_requests_total é um vetor de contador
(cumulativo desde o início do servidor) de solicitações que foram rejeitadas,
dividido pelos rótulos flow_schema (indicando aquele que
correspondeu ao pedido), priority_level (indicando aquele para o qual
a solicitação foi atribuída) e reason. A label reason pode
ter um dos seguintes valores:
queue-full, indicando que muitos pedidos já foram enfileirados,concurrency-limit, indicando que o
PriorityLevelConfiguration está configurado para rejeitar em vez de
enfileirar solicitações em excesso outime-out, indicando que a solicitação ainda estava na fila
quando seu limite de tempo de fila expirou.
apiserver_flowcontrol_dispatched_requests_total é um vetor contador
(cumulativo desde o início do servidor) de solicitações que começaram
executando, dividido pelos rótulos flow_schema (indicando o
um que corresponda à solicitação) e priority_level (indicando o
aquele ao qual o pedido foi atribuído).
apiserver_current_inqueue_requests é um vetor de medidor de
limites máximos do número de solicitações enfileiradas, agrupadas por uma
label chamado request_kind cujo valor é mutating ou readOnly.
Essas marcas d'água altas descrevem o maior número visto em uma
segunda janela concluída recentemente. Estes complementam o mais antigo
vetor medidor apiserver_current_inflight_requests que contém o
marca d'água alta da última janela de número de solicitações sendo ativamente
servido.
apiserver_flowcontrol_read_vs_write_request_count_samples é um
vetor de histograma de observações do número atual de
solicitações, divididas pelos rótulos phase (que assume o
valores waiting e executing) e request_kind (que assume
os valores mutating e readOnly). As observações são feitas
periodicamente a uma taxa elevada.
apiserver_flowcontrol_read_vs_write_request_count_watermarks é um
vetor de histograma de marcas d'água altas ou baixas do número de
solicitações divididas pelos rótulos phase (que assume o
valores waiting e executing) e request_kind (que assume
os valores mutating e readOnly); o rótulo mark assume
valores high e low. As marcas d'água são acumuladas ao longo de
janelas delimitadas pelos tempos em que uma observação foi adicionada a
apiserver_flowcontrol_read_vs_write_request_count_samples. Esses
marcas d'água mostram o intervalo de valores que ocorreram entre as amostras.
apiserver_flowcontrol_current_inqueue_requests é um vetor de medidor
mantendo o número instantâneo de solicitações enfileiradas (não em execução),
dividido pelos rótulos priority_level e flow_schema.
apiserver_flowcontrol_current_executing_requests é um vetor de medidor
segurando o número instantâneo de execução (não esperando em uma
queue), divididas pelos rótulos priority_level e
flow_schema.
apiserver_flowcontrol_request_concurrency_in_use é um vetor de medidor
ocupando o número instantâneo de assentos ocupados, diferenciados pelas
labels priority_level e flow_schema.
apiserver_flowcontrol_priority_level_request_count_samples é um
vetor de histograma de observações do número atual de
solicitações divididas pelas labels phase (que assume o
valores waiting e executing) e priority_level. Cada
histograma obtém observações feitas periodicamente, até a última
atividade do tipo relevante. As observações são feitas em nota alta.
apiserver_flowcontrol_priority_level_request_count_watermarks é um
vetor de histograma de marcas d'água altas ou baixas do número de
solicitações divididas pelas labels phase (que assume o
valores waiting e executing) e priority_level; a label
mark assume valores high e low. As marcas da água são
acumulada em janelas delimitadas pelos tempos em que uma observação
foi adicionado a
apiserver_flowcontrol_priority_level_request_count_samples. Esses
marcas d'água mostram o intervalo de valores que ocorreram entre as amostras.
apiserver_flowcontrol_request_queue_length_after_enqueue é um
vetor de histograma de comprimentos de fila para as filas, dividido pelas
labels priority_level e flow_schema, conforme mostrado pelas
solicitações enfileiradas. Cada solicitação enfileirada contribui com uma
amostra para seu histograma, relatando o comprimento da fila imediatamente
depois que o pedido foi adicionado. Observe que isso produz diferentes
estatísticas do que uma pesquisa imparcial faria.
Nota:
Um valor discrepante em um histograma aqui significa que é provável que um único fluxo
(ou seja, solicitações de um usuário ou de um namespace, dependendo da
configuração) está inundando o servidor de API e sendo limitado. Por contraste,
se o histograma de um nível de prioridade mostrar que todas as filas para essa prioridade
são mais longos do que os de outros níveis de prioridade, pode ser apropriado
aumentar os compartilhamentos de simultaneidade desse PriorityLevelConfiguration.apiserver_flowcontrol_request_concurrency_limit é um vetor de medidor
mantendo o limite de simultaneidade calculado (com base no limite total de simultaneidade do servidor da API
e na simultaneidade de PriorityLevelConfigurations share), divididos pela label priority_level.
apiserver_flowcontrol_request_wait_duration_seconds é um vetor de histograma
de quanto tempo as solicitações ficaram na fila, divididas pelas labels
flow_schema (indicando qual corresponde à solicitação),
priority_level (indicando aquele para o qual o pedido foi
atribuído) e execute (indicando se a solicitação foi iniciada
executando).
Nota:
Como cada FlowSchema sempre atribui solicitações a um único
PriorityLevelConfiguration, você pode adicionar os histogramas para todos os
FlowSchemas para um nível de prioridade para obter o histograma efetivo para
solicitações atribuídas a esse nível de prioridade.apiserver_flowcontrol_request_execution_seconds é um vetor de histograma
de quanto tempo as solicitações levaram para realmente serem executadas, divididas pelas
labels flow_schema (indicando qual corresponde à solicitação)
e priority_level (indicando aquele para o qual o pedido foi
atribuído).
Debug endpoints
Quando você ativa A APF, o kube-apiserver
serve os seguintes caminhos adicionais em suas portas HTTP[S].
/debug/api_priority_and_fairness/dump_priority_levels - uma lista de
todos os níveis de prioridade e o estado atual de cada um. Você pode buscar assim:
kubectl get --raw /debug/api_priority_and_fairness/dump_priority_levels
A saída é parecido com isto:
PriorityLevelName, ActiveQueues, IsIdle, IsQuiescing, WaitingRequests, ExecutingRequests,
workload-low, 0, true, false, 0, 0,
global-default, 0, true, false, 0, 0,
exempt, <none>, <none>, <none>, <none>, <none>,
catch-all, 0, true, false, 0, 0,
system, 0, true, false, 0, 0,
leader-election, 0, true, false, 0, 0,
workload-high, 0, true, false, 0, 0,
/debug/api_priority_and_fairness/dump_queues - uma listagem de todas as
filas e seu estado atual. Você pode buscar assim:
kubectl get --raw /debug/api_priority_and_fairness/dump_queues
A saída é parecido com isto:
PriorityLevelName, Index, PendingRequests, ExecutingRequests, VirtualStart,
workload-high, 0, 0, 0, 0.0000,
workload-high, 1, 0, 0, 0.0000,
workload-high, 2, 0, 0, 0.0000,
...
leader-election, 14, 0, 0, 0.0000,
leader-election, 15, 0, 0, 0.0000,
/debug/api_priority_and_fairness/dump_requests - uma lista de todos os pedidos
que estão atualmente esperando em uma fila. Você pode buscar assim:
kubectl get --raw /debug/api_priority_and_fairness/dump_requests
A saída é parecido com isto:
PriorityLevelName, FlowSchemaName, QueueIndex, RequestIndexInQueue, FlowDistingsher, ArriveTime,
exempt, <none>, <none>, <none>, <none>, <none>,
system, system-nodes, 12, 0, system:node:127.0.0.1, 2020-07-23T15:26:57.179170694Z,
Além das solicitações enfileiradas, a saída inclui uma linha fantasma
para cada nível de prioridade isento de limitação.
Você pode obter uma lista mais detalhada com um comando como este:
kubectl get --raw '/debug/api_priority_and_fairness/dump_requests?includeRequestDetails=1'
A saída é parecido com isto:
PriorityLevelName, FlowSchemaName, QueueIndex, RequestIndexInQueue, FlowDistingsher, ArriveTime, UserName, Verb, APIPath, Namespace, Name, APIVersion, Resource, SubResource,
system, system-nodes, 12, 0, system:node:127.0.0.1, 2020-07-23T15:31:03.583823404Z, system:node:127.0.0.1, create, /api/v1/namespaces/scaletest/configmaps,
system, system-nodes, 12, 1, system:node:127.0.0.1, 2020-07-23T15:31:03.594555947Z, system:node:127.0.0.1, create, /api/v1/namespaces/scaletest/configmaps,
Próximos passos
Para obter informações básicas sobre detalhes de design para prioridade e justiça da API, consulte
a proposta de aprimoramento.
Você pode fazer sugestões e solicitações de recursos por meio do SIG API Machinery
ou do canal do slack.