Arquitetura de Log
Os logs de aplicativos e sistemas podem ajudá-lo a entender o que está acontecendo dentro do seu cluster. Os logs são particularmente úteis para depurar problemas e monitorar a atividade do cluster. A maioria das aplicações modernas possui algum tipo de mecanismo de logs; como tal, a maioria dos mecanismos de contêineres também é projetada para suportar algum tipo de log. O método de log mais fácil e abrangente para aplicações em contêiner é gravar nos fluxos de saída e erro padrão.
No entanto, a funcionalidade nativa fornecida por um mecanismo de contêiner ou tempo de execução geralmente não é suficiente para uma solução completa de log. Por exemplo, se um contêiner travar, um pod for despejado ou um nó morrer, geralmente você ainda desejará acessar os logs do aplicativo. Dessa forma, os logs devem ter armazenamento e ciclo de vida separados, independentemente de nós, pods ou contêineres. Este conceito é chamado cluster-level-logging. O log no nível de cluster requer um back-end separado para armazenar, analisar e consultar logs. O kubernetes não fornece uma solução de armazenamento nativa para dados de log, mas você pode integrar muitas soluções de log existentes no cluster do Kubernetes.
As arquiteturas de log no nível de cluster são descritas no pressuposto de que um back-end de log esteja presente dentro ou fora do cluster. Se você não estiver interessado em ter o log no nível do cluster, ainda poderá encontrar a descrição de como os logs são armazenados e manipulados no nó para serem úteis.
Log básico no Kubernetes
Nesta seção, você pode ver um exemplo de log básico no Kubernetes que gera dados para o fluxo de saída padrão (standard output stream). Esta demostração usa uma especificação de pod com um contêiner que grava algum texto na saída padrão uma vez por segundo.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
Para executar este pod, use o seguinte comando:
kubectl apply -f https://k8s.io/examples/debug/counter-pod.yaml
A saída será:
pod/counter created
Para buscar os logs, use o comando kubectl logs, da seguinte maneira:
kubectl logs counter
A saída será:
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
Você pode usar kubectl logs para recuperar logs de uma instanciação anterior de um contêiner com o sinalizador --previous, caso o contêiner tenha falhado. Se o seu pod tiver vários contêineres, você deverá especificar quais logs do contêiner você deseja acessar anexando um nome de contêiner ao comando. Veja a documentação do kubectl logs para mais destalhes.
Logs no nível do Nó
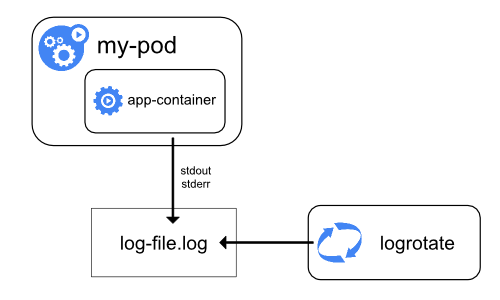
Tudo o que um aplicativo em contêiner grava no stdout e stderr é tratado e redirecionado para algum lugar por dentro do mecanismo de contêiner. Por exemplo, o mecanismo de contêiner do Docker redireciona esses dois fluxos para um driver de log, configurado no Kubernetes para gravar em um arquivo no formato json.
Nota:
O driver de log json do Docker trata cada linha como uma mensagem separada. Ao usar o driver de log do Docker, não há suporte direto para mensagens de várias linhas. Você precisa lidar com mensagens de várias linhas no nível do agente de log ou superior.Por padrão, se um contêiner reiniciar, o kubelet manterá um contêiner terminado com seus logs. Se um pod for despejado do nó, todos os contêineres correspondentes também serão despejados, juntamente com seus logs.
Uma consideração importante no log no nível do nó está implementado a rotação de log, para que os logs não consumam todo o armazenamento disponível no nó. Atualmente, o Kubernentes não é responsável pela rotação de logs, mas uma ferramenta de deployment deve configurar uma solução para resolver isso.
Por exemplo, nos clusters do Kubernetes, implementados pelo script kube-up.sh, existe uma ferramenta logrotate configurada para executar a cada hora. Você pode configurar um tempo de execução do contêiner para girar os logs do aplicativo automaticamente, por exemplo, usando o log-opt do Docker.
No script kube-up.sh, a última abordagem é usada para imagem COS no GCP, e a anterior é usada em qualquer outro ambiente. Nos dois casos por padrão, a rotação é configurada para ocorrer quando o arquivo de log exceder 10MB.
Como exemplo, você pode encontrar informações detalhadas sobre como o kube-up.sh define o log da imagem COS no GCP no script correspondente.
Quando você executa kubectl logs como no exemplo de log básico acima, o kubelet no nó lida com a solicitação e lê diretamente do arquivo de log, retornando o conteúdo na resposta.
Nota:
Atualmente, se algum sistema externo executou a rotação, apenas o conteúdo do arquivo de log mais recente estará disponível através dekubectl logs. Por exemplo, se houver um arquivo de 10MB, o logrotate executa a rotação e existem dois arquivos, um com 10MB de tamanho e um vazio, o kubectl logs retornará uma resposta vazia.Logs de componentes do sistema
Existem dois tipos de componentes do sistema: aqueles que são executados em um contêiner e aqueles que não são executados em um contêiner. Por exemplo:
- O scheduler Kubernetes e o kube-proxy são executados em um contêiner.
- O tempo de execução do kubelet e do contêiner, por exemplo, Docker, não é executado em contêineres.
Nas máquinas com systemd, o tempo de execução do kubelet e do contêiner é gravado no journald. Se systemd não estiver presente, eles gravam em arquivos .log no diretório /var/log.
Os componentes do sistema dentro dos contêineres sempre gravam no diretório /var/log, ignorando o mecanismo de log padrão. Eles usam a biblioteca de logs klog. Você pode encontrar as convenções para a gravidade do log desses componentes nos documentos de desenvolvimento sobre log.
Da mesma forma que os logs de contêiner, os logs de componentes do sistema no diretório /var/log devem ser rotacionados. Nos clusters do Kubernetes criados pelo script kube-up.sh, esses logs são configurados para serem rotacionados pela ferramenta logrotate diariamente ou quando o tamanho exceder 100MB.
Arquiteturas de log no nível de cluster
Embora o Kubernetes não forneça uma solução nativa para o log em nível de cluster, há várias abordagens comuns que você pode considerar. Aqui estão algumas opções:
- Use um agente de log no nível do nó que seja executado em todos os nós.
- Inclua um contêiner sidecar dedicado para efetuar logging em um pod de aplicativo.
- Envie logs diretamente para um back-end de dentro de um aplicativo.
Usando um agente de log de nó
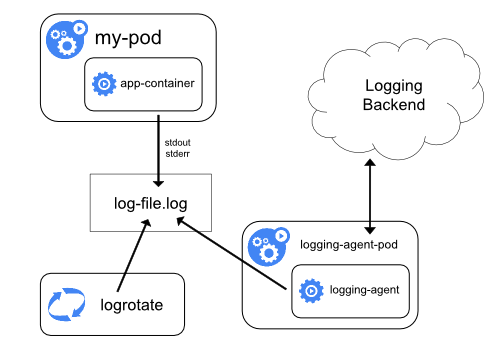
Você pode implementar o log em nível de cluster incluindo um agente de log em nível de nó em cada nó. O agente de log é uma ferramenta dedicada que expõe logs ou envia logs para um back-end. Geralmente, o agente de log é um contêiner que tem acesso a um diretório com arquivos de log de todos os contêineres de aplicativos nesse nó.
Como o agente de log deve ser executado em todos os nós, é comum implementá-lo como uma réplica do DaemonSet, um pod de manifesto ou um processo nativo dedicado no nó. No entanto, as duas últimas abordagens são obsoletas e altamente desencorajadas.
O uso de um agente de log no nível do nó é a abordagem mais comum e incentivada para um cluster Kubernetes, porque ele cria apenas um agente por nó e não requer alterações nos aplicativos em execução no nó. No entanto, o log no nível do nó funciona apenas para a saída padrão dos aplicativos e o erro padrão.
O Kubernetes não especifica um agente de log, mas dois agentes de log opcionais são fornecidos com a versão Kubernetes: Stackdriver Logging para uso com o Google Cloud Platform e Elasticsearch. Você pode encontrar mais informações e instruções nos documentos dedicados. Ambos usam fluentd com configuração customizada como um agente no nó.
Usando um contêiner sidecar com o agente de log
Você pode usar um contêiner sidecar de uma das seguintes maneiras:
- O contêiner sidecar transmite os logs do aplicativo para seu próprio
stdout. - O contêiner sidecar executa um agente de log, configurado para selecionar logs de um contêiner de aplicativo.
Streaming sidecar conteiner
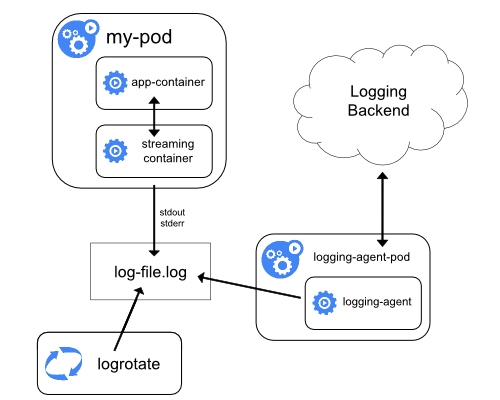
Fazendo com que seus contêineres de sidecar fluam para seus próprios stdout e stderr, você pode tirar proveito do kubelet e do agente de log que já executam em cada nó. Os contêineres sidecar lêem logs de um arquivo, socket ou journald. Cada contêiner sidecar individual imprime o log em seu próprio stdout ou stderr stream.
Essa abordagem permite separar vários fluxos de logs de diferentes partes do seu aplicativo, algumas das quais podem não ter suporte para gravar em stdout ou stderr. A lógica por trás do redirecionamento de logs é mínima, portanto dificilmente representa uma sobrecarga significativa. Além disso, como stdout e stderr são manipulados pelo kubelet, você pode usar ferramentas internas como o kubectl logs.
Considere o seguinte exemplo. Um pod executa um único contêiner e grava em dois arquivos de log diferentes, usando dois formatos diferentes. Aqui está um arquivo de configuração para o Pod:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Seria uma bagunça ter entradas de log de diferentes formatos no mesmo fluxo de logs, mesmo se você conseguisse redirecionar os dois componentes para o fluxo stdout do contêiner. Em vez disso, você pode introduzir dois contêineres sidecar. Cada contêiner sidecar pode direcionar um arquivo de log específico de um volume compartilhado e depois redirecionar os logs para seu próprio fluxo stdout.
Aqui está um arquivo de configuração para um pod que possui dois contêineres sidecar:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Agora, quando você executa este pod, é possível acessar cada fluxo de log separadamente, executando os seguintes comandos:
kubectl logs counter count-log-1
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
kubectl logs counter count-log-2
Mon Jan 1 00:00:00 UTC 2001 INFO 0
Mon Jan 1 00:00:01 UTC 2001 INFO 1
Mon Jan 1 00:00:02 UTC 2001 INFO 2
...
O agente no nível do nó instalado em seu cluster coleta esses fluxos de logs automaticamente sem nenhuma configuração adicional. Se desejar, você pode configurar o agente para analisar as linhas de log, dependendo do contêiner de origem.
Observe que, apesar do baixo uso da CPU e da memória (ordem de alguns milicores por CPU e ordem de vários megabytes de memória), gravar logs em um arquivo e depois transmiti-los para o stdout pode duplicar o uso do disco. Se você tem um aplicativo que grava em um único arquivo, geralmente é melhor definir /dev/stdout como destino, em vez de implementar a abordagem de contêiner de transmissão no sidecar.
Os contêineres sidecar também podem ser usados para rotacionar arquivos de log que não podem ser rotacionados pelo próprio aplicativo. Um exemplo dessa abordagem é um pequeno contêiner executando logrotate periodicamente.
No entanto, é recomendável usar o stdout e o stderr diretamente e deixar as políticas de rotação e retenção no kubelet.
Contêiner sidecar com um agente de log
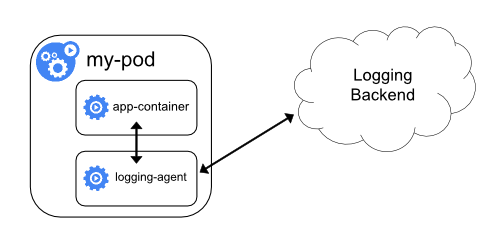
Se o agente de log no nível do nó não for flexível o suficiente para sua situação, você poderá criar um contêiner secundário com um agente de log separado que você configurou especificamente para executar com seu aplicativo.
Nota:
O uso de um agente de log em um contêiner sidecar pode levar a um consumo significativo de recursos. Além disso, você não poderá acessar esses logs usando o comandokubectl logs, porque eles não são controlados pelo kubelet.Como exemplo, você pode usar o Stackdriver, que usa fluentd como um agente de log. Aqui estão dois arquivos de configuração que você pode usar para implementar essa abordagem. O primeiro arquivo contém um ConfigMap para configurar o fluentd.
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
Nota:
A configuração do fluentd está além do escopo deste artigo. Para obter informações sobre como configurar o fluentd, consulte a documentação oficial do fluentd.O segundo arquivo descreve um pod que possui um contêiner sidecar rodando fluentemente. O pod monta um volume onde o fluentd pode coletar seus dados de configuração.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: registry.k8s.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
Depois de algum tempo, você pode encontrar mensagens de log na interface do Stackdriver.
Lembre-se de que este é apenas um exemplo e você pode realmente substituir o fluentd por qualquer agente de log, lendo de qualquer fonte dentro de um contêiner de aplicativo.
Expondo logs diretamente do aplicativo
Você pode implementar o log no nível do cluster, expondo ou enviando logs diretamente de todos os aplicativos; no entanto, a implementação desse mecanismo de log está fora do escopo do Kubernetes.