O Kubernetes é altamente configurável e extensível. Como resultado, raramente existe a necessidade de criar um fork ou submeter alterações de código para o projeto Kubernetes.
Este guia descreve as opções para personalizar um cluster do Kubernetes. Este guia tem como público-alvo os operadores de clusters que desejam entender melhor como adaptar seus clusters às necessidades do seu ambiente de trabalho. Desenvolvedores que desejam tornar-se Desenvolvedores de Plataforma ou Contribuidores do Projeto Kubernetes também irão beneficiar-se deste guia como uma introdução aos pontos de extensão e padrões existentes, e suas contrapartidas e limitações.
As abordagens de personalização podem ser divididas nos grandes grupos de configuração, que envolve somente a modificação de argumentos de linha de comando, arquivos locais de configuração, ou recursos da API; e extensões, que envolve executar programas adicionais, serviços de rede adicionais, ou ambos. Este documento cobre primariamente as extensões.
Configuração
Arquivos de configuração e argumentos de comando estão documentados na seção de Referência da documentação online, com uma página para cada binário:
Argumentos de comando e arquivos de configuração podem não ser sempre alteráveis em um serviço hospedado do Kubernetes ou uma distribuição com instalação gerenciada. Quando são alteráveis, geralmente são alteráveis somente pelo operador do cluster. Além disso, são suscetíveis a mudanças em versões futuras do Kubernetes, e modificá-los pode requerer a reinicialização de processos. Por essas razões, devem ser utilizados somente quando não houver outras opções.
APIs de política embutidas, como ResourceQuota, NetworkPolicy e Role-based Access Control (RBAC), são APIs embutidas do Kubernetes que fornecem configurações declarativas de políticas. APIs são tipicamente utilizáveis mesmo nos serviços hospedados do Kubernetes e com instalações gerenciadas do Kubernetes. As APIs de política embutidas seguem as mesmas convenções de outros recursos do Kubernetes, como os Pods. Quando você utiliza uma API de políticas que é estável, você se beneficia de uma política definida de suporte como outras APIs do Kubernetes. Por essas razões, as APIs de política são recomendadas antes de arquivos de configuração e de argumentos de comando quando adequadas.
Extensões
Extensões são componentes de software que estendem e integram profundamente com o Kubernetes. Elas adaptam o Kubernetes para suportar novos tipos e novos modelos de hardware.
Muitos administradores de cluster utilizam uma instância hospedada ou de distribuição do Kubernetes. Esses clusters vêm com extensões pré-instaladas. Como resultado, a maioria dos usuários do Kubernetes não precisa instalar extensões e ainda menos usuários precisarão criar novas extensões.
Padrões de extensão
O Kubernetes é projetado para ser automatizado através de programas cliente. Qualquer programa que lê e/ou escreve através da API do Kubernetes pode fornecer automação útil. Uma automação pode executar no cluster ou fora dele. Seguindo as orientações neste documento, você pode escrever automações altamente disponíveis e robustas. Automações geralmente funcionam em quaisquer clusters do Kubernetes, incluindo clusters hospedados e instalações gerenciadas.
Há um padrão específico para a escrita de programas cliente que funcionam bem
com o Kubernetes, denominado padrão controlador.
Controladores tipicamente leem o campo .spec de um objeto, possivelmente executam
ações, e então atualizam o campo .status do objeto.
Um controlador é um cliente da API do Kubernetes. Quando o Kubernetes é o cliente e faz uma chamada para um serviço remoto, o Kubernetes chama isso de um webhook. O serviço remoto é chamado de backend de webhook. Assim como controladores personalizados, os webhooks adicionam um ponto de falha.
Nota:
Fora do Kubernetes, o termo "webhook" tipicamente se refere a um mecanismo para notificações assíncronas, onde a chamada do webhook serve como uma notificação de mão única para outro sistema ou componente. No ecossistema Kubernetes, mesmo chamadas HTTP síncronas são frequentemente descritas como "webhooks".No modelo webhook, o Kubernetes faz uma requisição de rede a um serviço remoto. Com o modelo alternativo de Plugin binário, o Kubernetes executa um binário (programa). Plugins binários são utilizados pelo kubelet (por exemplo, plugins de armazenamento CSI e plugins de rede CNI), e pelo kubectl (veja Estendendo o kubectl com plugins).
Pontos de extensão
Este diagrama mostra os pontos de extensão em um cluster do Kubernetes e os clientes que o acessam.
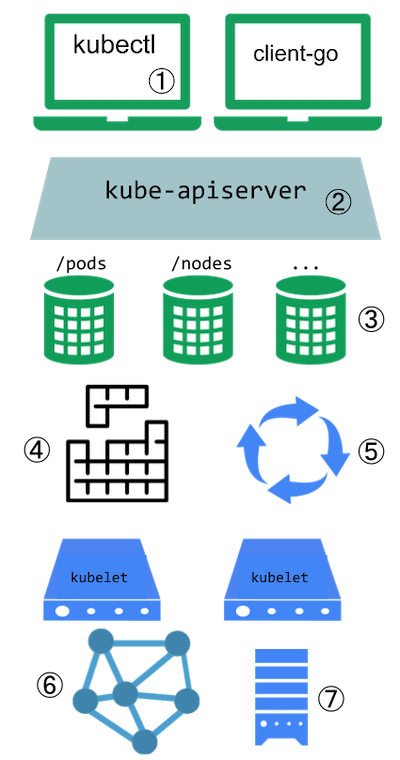
Pontos de extensão do Kubernetes
Legenda da figura
Os usuários interagem com frequência com a API do Kubernetes utilizando o
kubectl. Plugins personalizam o comportamento dos clientes. Existem extensões genéricas que podem ser aplicadas a diferentes clientes, bem como formas específicas de estender okubectl.O servidor da API manipula todas as requisições. Diversos tipos de pontos de extensão no servidor da API permitem autenticar requisições ou bloqueá-las baseada no seu conteúdo, editar o conteúdo de uma requisição, e manipular a remoção de objetos. Estes pontos de extensão estão descritos na seção Extensões de Acesso de API.
O servidor da API serve diversos tipos de recursos. Tipos de recurso embutidos, como Pods, são definidos pelo projeto Kubernetes e não podem ser modificados. Consulte Extensões de API para saber mais sobre estender a API do Kubernetes.
O alocador do Kubernetes decide em qual nó alocar Pods. Há diversas formas de estender a alocação e tais formas estão descritas na seção de Extensões de Alocação.
Muito do comportamento do Kubernetes é implementado por programas chamados controladores, que são clientes do servidor da API. Controladores são frequentemente usados em conjunto com recursos personalizados. Consulte combinando novas APIs com automação e modificando recursos embutidos para saber mais.
O kubelet roda em servidores (nós) e auxilia Pods a parecerem como servidores virtuais com seus próprios IPs na rede do cluster. Plugins de Rede permitem diferentes implementações de redes de Pod.
Você pode utilizar Plugins de Dispositivo para integrar hardware personalizado ou outras instalações locais ao nó e torná-los disponíveis aos Pods rodando no seu cluster. O kubelet inclui suporte para trabalhar com estes plugins de dispositivo.
O kubelet também monta e desmonta volumes em Pods e seus contêineres. Você pode utilizar Plugins de Armazenamento para adicionar suporte a novos tipos de armazenamento e outros tipos de volume.
Fluxograma de escolha dos pontos de extensão
Se você não tem certeza de onde começar, este fluxograma pode auxiliar. Note que algumas soluções podem envolver vários tipos de extensões.

Fluxograma guia para seleção de uma abordagem de extensão
Extensões de cliente
Plugins para o kubectl são binários que adicionam ou substituem funcionalidade
em comandos específicos. A ferramenta kubectl também pode integrar com os
plugins de credenciais.
Essas extensões afetam somente o ambiente local de um usuário, e portanto não podem
garantir políticas para vários dispositivos.
Se você deseja estender a ferramenta kubectl, leia Estenda o kubectl com plugins.
Extensões de API
Definições de recursos personalizados
Considere adicionar um Recurso Personalizado ao Kubernetes se você deseja definir
novos controladores, objetos de configuração da aplicação ou outras APIs declarativas,
e gerenciá-los utilizando ferramentas do Kubernetes, como o kubectl.
Para mais informações sobre Recursos Personalizados, veja o guia de conceito Recursos Personalizados.
Camada de agregação da API
Você pode utilizar a Camada de Agregação da API do Kubernetes para integrar a API do Kubernetes com serviços adicionais, como um serviço de métricas.
Combinando novas APIs com automação
Uma combinação de uma API de recurso personalizado e um ciclo de controle é chamado de padrão controlador. Se o seu controlador toma o lugar de um operador humano na instalação de infraestrutura baseada em um estado desejado, então o controlador pode também estar seguindo o padrão operador. O padrão operador é usado para gerenciar aplicações específicas; normalmente, essas são aplicações que mantém estado e requerem cuidado em como são gerenciadas.
Você pode também criar suas próprias APIs e ciclos de controle personalizados que gerenciam outros recursos, como armazenamento, ou para definir políticas (como uma restrição de controle de acesso).
Modificando recursos embutidos
Quando você estende a API do Kubernetes adicionando recursos personalizados, os recursos adicionados sempre caem em um novo grupo de API. Você não pode substituir ou modificar grupos de API existentes. Adicionar uma nova API não permite a você diretamente alterar o comportamento de uma API existente (como Pods), enquanto Extensões de Acesso de API permitem.
Extensões de Acesso de API
Quando uma requisição chega ao servidor da API do Kubernetes, ela é primeiro autenticada, depois é autorizada, e então é submetida a vários tipos de controle de admissão (algumas requisições não são autenticadas e recebem tratamento especial). Consulte a página Controlando Acesso à API do Kubernetes para mais informações sobre esse fluxo.
Cada uma das etapas no fluxo de autenticação/autorização do Kubernetes oferece pontos de extensão.
Autenticação
A Autenticação transforma cabeçalhos ou certificados em todas as requisições em um nome de usuário para o cliente efetuando a requisição.
O Kubernetes suporta diversas formas diferentes de autenticação embutida. Ele pode
ainda estar situado atrás de um proxy de autenticação, e pode enviar um token de
um cabeçalho Authorization: para um serviço remoto para verificação (um
webhook de autenticação)
se as formas embutidas não atenderem às suas necessidades.
Autorização
A Autorização determina se usuários específicos podem ler, escrever, e fazer outras operações em recursos da API. Ela funciona no nível de recursos completos -- e não discrimina baseado em campos arbitrários de um objeto.
Se as opções de autorização embutidas não atenderem às suas necessidades, um webhook de autorização permite efetuar uma chamada para um código personalizado que faça uma decisão de autorização.
Controle de admissão dinâmico
Após uma requisição ser autorizada, quando se tratar de uma operação de escrita, ela também passará pelas etapas de Controle de Admissão. Além das etapas embutidas, há várias extensões:
- O Webhook de Política de Imagens restringe quais imagens podem ser executadas em contêineres.
- Para tomar decisões arbitrárias de controle de admissão, um Webhook de Admissão geral pode ser utilizado. Webhooks de admissão podem rejeitar criações ou atualizações. Alguns webhooks de admissão modificam os dados requisição efetuada antes que ela seja manipulada pelo Kubernetes.
Extensões de infraestrutura
Plugins de dispositivo
Plugins de dispositivo permitem a um nó descobrir novos recursos Node (além dos preexistentes, como cpu e memória) através de um Plugin de Dispositivo.
Plugins de armazenamento
Os plugins de Interface de Armazenamento de Contêiner (Container Storage Interface, ou CSI) fornecem uma maneira de estender o Kubernetes com suporte a novos tipos de volumes. Os volumes podem ser suportados por um sistema de armazenamento externo durável, fornecer armazenamento efêmero, ou oferecer uma interface somente-leitura a informações utilizando um paradigma de sistema de arquivos.
O Kubernetes também inclui suporte aos plugins FlexVolume, que estão descontinuados desde a versão 1.23 (em favor do CSI).
Os plugins FlexVolume permitem aos usuários montar tipos de volumes que não são suportados nativamente pelo Kubernetes. Quando você executa um Pod que depende de armazenamento FlexVolume, o kubelet chama um plugin binário que monta o volume. A proposta de projeto arquivada do FlexVolume tem mais detalhes desta abordagem.
A seção de Perguntas Frequentes sobre Volumes do Kubernetes para Fornecedores de Armazenamento inclui informações gerais de plugins de armazenamento.
Plugins de rede
O seu cluster do Kubernetes precisa de um plugin de rede para que a rede de Pods funcione e para suportar outros aspectos do modelo de rede do Kubernetes.
Plugins de Rede permitem que o Kubernetes funcione com diferentes topologias e tecnologias de rede.
Plugins de credenciais de imagem do kubelet
Kubernetes v1.26 [stable]Os plugins conseguem comunicar-se com serviços externos ou utilizar arquivos locais para obter credenciais. Dessa maneira, o kubelet não precisa ter credenciais estáticas para cada registro de imagens e pode suportar diversos métodos e protocolos de autenticação.
Para detalhes de configuração de plugins, consulte Configurar um fornecedor de credenciais de imagem do kubelet.
Extensões de alocação
O alocador é um tipo especial de controlador que observa Pods, e os atribui aos nós. O alocador padrão pode ser totalmente substituído, enquanto outros componentes do Kubernetes permanecem em uso, ou múltiplos alocadores podem rodar simultaneamente.
Este é um compromisso significativo e a maior parte dos usuários do Kubernetes percebem que não precisam modificar o alocador.
Você pode controlar quais plugins de alocação estão ativos ou associar conjuntos de plugins com diferentes perfis do alocador nomeados. Você pode também escrever seu próprio plugin que integra com um ou mais dos pontos de extensão do kube-scheduler.
Por fim, o componente embutido kube-scheduler suporta um
webhook
que permite a um backend HTTP remoto (extensão do alocador) filtrar e/ou
priorizar os nós que o kube-scheduler escolhe para um Pod.
Nota:
Você pode afetar somente a filtragem e a priorização de nós com um webhook de extensão do alocador; outros pontos de extensão não estão disponíveis através da integração de webhook.Próximos passos
- Aprenda mais sobre as extensões de infraestrutura
- Aprenda sobre plugins do kubectl
- Aprenda mais sobre Recursos Personalizados
- Aprenda mais sobre Servidores de API de extensão
- Aprenda sobre Controle de admissão dinâmico
- Aprenda sobre o Padrão Operador