CGroup v1 CPU 份额(shares)到 v2 CPU 权重(weight)的新转换
我很高兴地宣布,已实现从 CGroup v1 CPU 份额(shares)到 CGroup v2 CPU 权重(weight)的改进转换公式。 这一增强解决了在支持 CGroup v2 的系统上运行 Kubernetes 工作负载时的 CPU 优先级分配关键问题。
背景
Kubernetes 最初设计时考虑的是 CGroup v1, 其中 CPU 份额 是根据容器的 CPU 请求使用以下公式得出的:
请注意,此公式中的值 1024 是 CGroup v1 中 cpu.shares 的默认值,与毫核无关。
例如,请求 1 CPU(1000m)的容器将获得 (cpu.shares = 1000 \times 1024 / 1000 = 1024),
而请求 100m 的容器将获得 (cpu.shares = 100 \times 1024 / 1000 = 102)。
一段时间后,CGroup v1 开始被其后继者 CGroup v2 取代。 在 CGroup v2 中,CPU 份额(范围从 2 到 262144,或从 2¹ 到 2¹⁸)的概念被 CPU 权重(范围从 [1, 10000],即 10⁰ 到 10⁴)取代。
随着向 CGroup v2 的过渡,
KEP-2254
引入了一个转换公式,将 CGroup v1 CPU 份额 映射到 CGroup v2 CPU 权重。
转换公式定义为:cpu.weight = (1 + ((cpu.shares - 2) * 9999) / 262142)
此公式将 [2¹, 2¹⁸] 范围的值线性映射到 [10⁰, 10⁴]。

虽然这种方法很简单,但线性映射带来了一些重大问题,影响了性能和配置粒度。
之前转换公式的问题
当前转换公式产生两个主要问题:
1. 相对于非 Kubernetes 工作负载的优先级降低
在 CGroup v1 中,CPU 份额 的默认值是 1024,
这意味着请求 1 CPU 的容器与 Kubernetes 范围之外的系统进程具有相同的优先级。
然而,在 CGroup v2 中,默认 CPU 权重 是 100,
但当前公式将 1 CPU(1000m)仅转换为 ≈39 权重——不到默认值的 40%。
示例:
- 请求 1 CPU(1000m)的容器
- CGroup v1:
cpu.shares = 1024(等于默认值) - CGroup v2(当前):
cpu.weight = 39(远低于默认值 100)
这意味着在迁移到 CGroup v2 后, Kubernetes(或 OCI)工作负载相对于非 Kubernetes 进程会实际上降低其 CPU 优先级。 对于有许多系统守护进程在 Kubernetes 范围之外运行并期望 Kubernetes 工作负载具有优先级的设置来说, 问题可能很严重,尤其是在资源匮乏的情况下。
2. 无法管理的粒度
当前公式为较小的 CPU 请求产生非常低的值, 限制了在容器内创建子 CGroup 以进行细粒度资源分配的能力(这可能在未来会更容易实现, 请参阅 KEP #5474 了解更多)。
示例:
- 请求 100m CPU 的容器
- CGroup v1:
cpu.shares = 102 - CGroup v2(当前):
cpu.weight = 4(对于子 CGroup 配置太低)
使用 CGroup v1,请求 100m CPU 导致 102 个 CPU 份额 是可控的, 因为可以在主容器内创建子 CGroup,为不同组的进程分配细粒度的 CPU 优先级。 然而,使用 CGroup v2,拥有 4 个份额 很难在子 CGroup 之间分配,因为粒度不够。
随着计划允许非特权容器的可写 CGroup, 这一点变得更加重要。
新转换公式
描述
新公式更复杂,但在 CGroup v1 CPU 份额和 CGroup v2 CPU 权重之间映射方面做得更好:
这个想法是,这是一个二次函数,需要经过以下值:
- (2, 1):两个范围的最小值。
- (1024, 100):两个范围的默认值。
- (262144, 10000):两个范围的最大值。
从视觉上看,新函数如下所示:
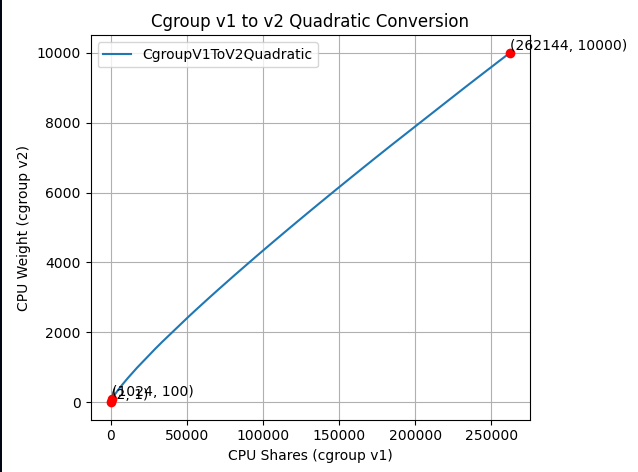
如果你放大重要部分:
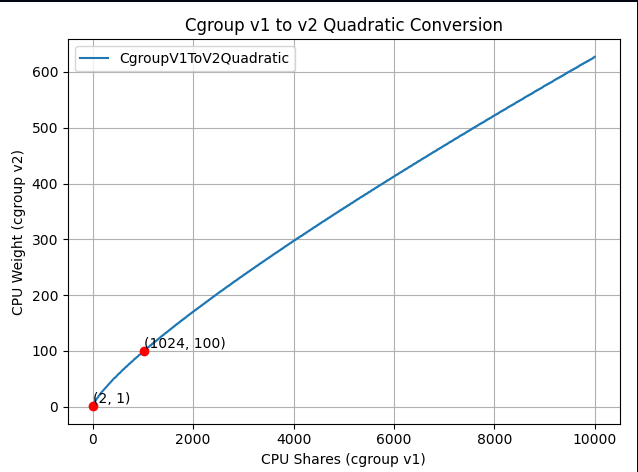
新公式“接近线性”,但经过精心设计,以一种巧妙的方式映射范围,使上述三个重要点经过。
它如何解决问题
- 更好的优先级对齐:
- 请求 1 CPU(1000m)的容器现在将获得
cpu.weight = 102。此值接近 CGroup v2 的默认值 100。 这恢复了 Kubernetes 工作负载与系统进程之间预期的优先级关系。
- 请求 1 CPU(1000m)的容器现在将获得
- 改进的粒度:
- 请求 100m CPU 的容器将获得
cpu.weight = 17(请参阅此处)。 能够在容器内实现更好的细粒度资源分配。
- 请求 100m CPU 的容器将获得
采用和集成
此更改在 OCI 层实现。换句话说,这不是在 Kubernetes 本身中实现的; 因此,新转换公式的采用完全取决于 OCI 运行时的采用。
例如:
对现有部署的影响
**重要提示:**如果用户依赖旧的线性转换公式,某些使用者可能会受到影响。 直接根据先前公式计算预期 CPU weight 值的应用程序或监控工具可能需要更新以适应新的二次转换。 这尤其与以下相关:
- 预测 CPU 权重 值的自定义资源管理工具。
- 验证或期望特定权重的监控系统。
- 以编程方式设置或验证 CPU 权重的应用程序。
另请注意,将转换从 cpu.weight 反向转换回 milliCPU 并不总是能得到完全相同的原始值。
有两个信息丢失来源:milliCPU 到 cpu.shares 的转换涉及整数截断(例如 100m 变成 102 份额,而不是 102.4),
更重要的是,份额到权重映射是多对一的(例如,milliCPU 值 90 到 109 都映射到 cpu.weight = 17)。
需要精确 CPU 请求值的工具应该直接从 pod spec 读取,而不是从 CGroup 参数派生。
Kubernetes 项目建议在升级 OCI 运行时之前在非生产环境中测试新转换公式, 以确保与现有工具的兼容性。
我可以了解更多吗?
对于对此增强感兴趣的人:
- Kubernetes GitHub Issue #131216 - 详细的技术分析和示例,包括选择上述公式的讨论和推理。
- KEP-2254: CGroup v2 - Kubernetes 中原始的 CGroup v2 实现。
- Kubernetes CGroup 文档 - 当前的资源管理指南。
我如何参与?
对于有兴趣参与 Kubernetes 节点级功能的人,请加入 Kubernetes 节点特别兴趣小组。 我们始终欢迎新的贡献者和对资源管理挑战的不同观点。