日志架构
应用日志可以让你了解应用内部的运行状况。日志对调试问题和监控集群活动非常有用。 大部分现代化应用都有某种日志记录机制。同样地,容器引擎也被设计成支持日志记录。 针对容器化应用,最简单且最广泛采用的日志记录方式就是写入标准输出和标准错误流。
但是,由容器引擎或运行时提供的原生功能通常不足以构成完整的日志记录方案。
例如,如果发生容器崩溃、Pod 被逐出或节点宕机等情况,你可能想访问应用日志。
在集群中,日志应该具有独立的存储,并且其生命周期与节点、Pod 或容器的生命周期相独立。 这个概念叫集群级的日志。
集群级日志架构需要一个独立的后端用来存储、分析和查询日志。 Kubernetes 并不为日志数据提供原生的存储解决方案。 相反,有很多现成的日志方案可以集成到 Kubernetes 中。 下面各节描述如何在节点上处理和存储日志。
Pod 和容器日志
Kubernetes 从正在运行的 Pod 中捕捉每个容器的日志。
此示例使用带有一个容器的 Pod 的清单,该容器每秒将文本写入标准输出一次。
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
要运行此 Pod,请执行以下命令:
kubectl apply -f https://k8s.io/examples/debug/counter-pod.yaml
输出为:
pod/counter created
要获取这些日志,请执行以下 kubectl logs 命令:
kubectl logs counter
输出类似于:
0: Fri Apr 1 11:42:23 UTC 2022
1: Fri Apr 1 11:42:24 UTC 2022
2: Fri Apr 1 11:42:25 UTC 2022
你可以使用 kubectl logs --previous 从容器的先前实例中检索日志。
如果你的 Pod 有多个容器,请如下通过将容器名称追加到该命令并使用 -c
标志来指定要访问哪个容器的日志:
kubectl logs counter -c count
容器日志流
特性状态:
Kubernetes v1.32 [alpha](默认禁用)作为一种 Alpha 特性,kubelet 可以将容器产生的两个标准流的日志分开:
标准输出和
标准错误输出。
要使用此行为,你必须启用 PodLogsQuerySplitStreams
特性门控。
启用该特性门控后,Kubernetes 1.36 允许通过 Pod API 直接访问这些日志流。
你可以通过指定流名称(Stdout 或 Stderr)使用 stream 查询字符串来获取特定的流。
你必须具有读取该 Pod 的 log 子资源的权限。
要演示此特性,你可以创建一个定期向标准输出和标准错误流中写入文本的 Pod。
apiVersion: v1
kind: Pod
metadata:
name: counter-err
spec:
containers:
- name: count
image: busybox:1.28
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; echo "$i: err" >&2 ; i=$((i+1)); sleep 1; done']
要运行此 Pod,使用以下命令:
kubectl apply -f https://k8s.io/examples/debug/counter-pod-err.yaml
要仅获取 stderr 日志流,你可以运行以下命令:
kubectl get --raw "/api/v1/namespaces/default/pods/counter-err/log?stream=Stderr"
详见 kubectl logs 文档。
节点的容器日志处理方式
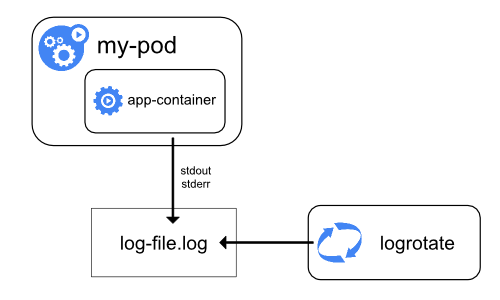
容器运行时对写入到容器化应用程序的 stdout 和 stderr 流的所有输出进行处理和转发。
不同的容器运行时以不同的方式实现这一点;不过它们与 kubelet 的集成都被标准化为 CRI 日志格式。
默认情况下,如果容器重新启动,kubelet 会保留一个终止的容器及其日志。 如果一个 Pod 被逐出节点,所对应的所有容器及其日志也会被逐出。
kubelet 通过 Kubernetes API 的特殊功能将日志提供给客户端访问。
访问这个日志的常用方法是运行 kubectl logs。
日志轮换
特性状态:
Kubernetes v1.21 [stable]kubelet 负责轮换容器日志并管理日志目录结构。 kubelet(使用 CRI)将此信息发送到容器运行时,而运行时则将容器日志写到给定位置。
你可以使用 kubelet 配置文件配置两个
kubelet 配置选项、
containerLogMaxSize (默认 10Mi)和 containerLogMaxFiles(默认 5)。
这些设置分别允许你分别配置每个日志文件大小的最大值和每个容器允许的最大文件数。
为了在工作负载生成的日志量较大的集群中执行高效的日志轮换,kubelet
还提供了一种机制,基于可以执行多少并发日志轮换以及监控和轮换日志所需要的间隔来调整日志的轮换方式。
你可以使用 kubelet 配置文件
配置两个 kubelet 配置选项:
containerLogMaxWorkers 和 containerLogMonitorInterval。
当类似于基本日志示例一样运行 kubectl logs 时,
节点上的 kubelet 会处理请求并直接从日志文件读取。kubelet 将返回该日志文件的内容。
说明:
只有最新的日志文件的内容可以通过 kubectl logs 获得。
例如,如果 Pod 写入 40 MiB 的日志,并且 kubelet 在 10 MiB 之后轮换日志,
则运行 kubectl logs 将最多返回 10 MiB 的数据。
系统组件日志
系统组件有两种类型:通常在容器中运行的组件和直接参与容器运行的组件。例如:
- kubelet 和容器运行时不在容器中运行。kubelet 运行你的容器 (一起按 Pod 分组)
- Kubernetes 调度器、控制器管理器和 API 服务器在 Pod 中运行
(通常是静态 Pod。
etcd 组件在控制平面中运行,最常见的也是作为静态 Pod。
如果你的集群使用 kube-proxy,则通常将其作为
DaemonSet运行。
日志位置
kubelet 和容器运行时写入日志的方式取决于节点使用的操作系统:
在使用 systemd 的 Linux 节点上,kubelet 和容器运行时默认写入 journald。
你要使用 journalctl 来阅读 systemd 日志;例如:journalctl -u kubelet。
如果 systemd 不存在,kubelet 和容器运行时将写入到 /var/log 目录中的 .log 文件。
如果你想将日志写入其他地方,你可以通过辅助工具 kube-log-runner 间接运行 kubelet,
并使用该工具将 kubelet 日志重定向到你所选择的目录。
默认情况下,kubelet 指示你的容器运行时将日志写入 /var/log/pods 中的目录。
有关 kube-log-runner 的更多信息,请阅读系统日志。
默认情况下,kubelet 将日志写入目录 C:\var\logs 中的文件(注意这不是 C:\var\log)。
尽管 C:\var\log 是这些日志的 Kubernetes 默认位置,
但一些集群部署工具会将 Windows 节点设置为将日志放到 C:\var\log\kubelet。
如果你想将日志写入其他地方,你可以通过辅助工具 kube-log-runner 间接运行 kubelet,
并使用该工具将 kubelet 日志重定向到你所选择的目录。
但是,kubelet 默认指示你的容器运行时在目录 C:\var\log\pods 中写入日志。
有关 kube-log-runner 的更多信息,请阅读系统日志。
对于在 Pod 中运行的 Kubernetes 集群组件,其日志会写入 /var/log 目录中的文件,
相当于绕过默认的日志机制(组件不会写入 systemd 日志)。
你可以使用 Kubernetes 的存储机制将持久存储映射到运行该组件的容器中。
kubelet 允许将 Pod 日志目录从默认的 /var/log/pods 更改为自定义路径。
可以通过在 kubelet 的配置文件中配置 podLogsDir 参数来进行此调整。
注意:
需要注意的是,默认位置 /var/log/pods 已使用很长一段时间,并且某些进程可能会隐式使用此路径。
因此,更改此参数必须谨慎,并自行承担风险。
另一个需要留意的问题是 kubelet 支持日志写入位置与 /var 位于同一磁盘上。
否则,如果日志位于与 /var 不同的文件系统上,kubelet
将不会跟踪该文件系统的使用情况。如果文件系统已满,则可能会出现问题。
有关 etcd 及其日志的详细信息,请查阅 etcd 文档。 同样,你可以使用 Kubernetes 的存储机制将持久存储映射到运行该组件的容器中。
说明:
如果你部署 Kubernetes 集群组件(例如调度器)以将日志记录到从父节点共享的卷中, 则需要考虑并确保这些日志被轮换。Kubernetes 不管理这种日志轮换。
你的操作系统可能会自动实现一些日志轮换。例如,如果你将目录 /var/log 共享到一个组件的静态 Pod 中,
则节点级日志轮换会将该目录中的文件视同为 Kubernetes 之外的组件所写入的文件。
一些部署工具会考虑日志轮换并将其自动化;而其他一些工具会将此留给你来处理。
集群级日志架构
虽然 Kubernetes 没有为集群级日志记录提供原生的解决方案,但你可以考虑几种常见的方法。 以下是一些选项:
- 使用在每个节点上运行的节点级日志记录代理。
- 在应用程序的 Pod 中,包含专门记录日志的边车(Sidecar)容器。
- 将日志直接从应用程序中推送到日志记录后端。
使用节点级日志代理
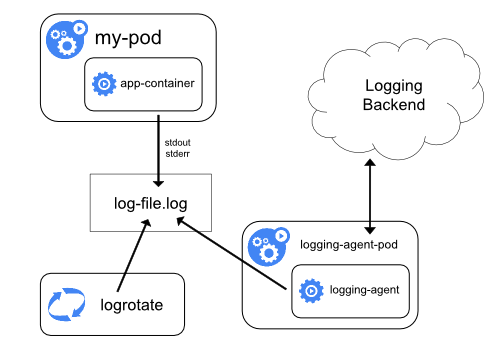
你可以通过在每个节点上使用节点级的日志记录代理来实现集群级日志记录。 日志记录代理是一种用于暴露日志或将日志推送到后端的专用工具。 通常,日志记录代理程序是一个容器,它可以访问包含该节点上所有应用程序容器的日志文件的目录。
由于日志记录代理必须在每个节点上运行,推荐以 DaemonSet 的形式运行该代理。
节点级日志在每个节点上仅创建一个代理,不需要对节点上的应用做修改。
容器向标准输出和标准错误输出写出数据,但在格式上并不统一。 节点级代理收集这些日志并将其进行转发以完成汇总。
使用边车容器运行日志代理
你可以通过以下方式之一使用边车(Sidecar)容器:
- 边车容器将应用程序日志传送到自己的标准输出。
- 边车容器运行一个日志代理,配置该日志代理以便从应用容器收集日志。
传输数据流的边车容器
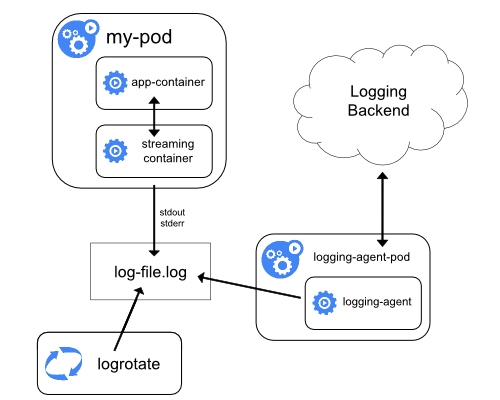
利用边车容器,写入到自己的 stdout 和 stderr 传输流,
你就可以利用每个节点上的 kubelet 和日志代理来处理日志。
边车容器从文件、套接字或 journald 读取日志。
每个边车容器向自己的 stdout 和 stderr 流中输出日志。
这种方法允许你将日志流从应用程序的不同部分分离开,其中一些可能缺乏对写入
stdout 或 stderr 的支持。重定向日志背后的逻辑是最小的,因此它的开销不大。
另外,因为 stdout 和 stderr 由 kubelet 处理,所以你可以使用内置的工具 kubectl logs。
例如,某 Pod 中运行一个容器,且该容器使用两个不同的格式写入到两个不同的日志文件。 下面是这个 Pod 的清单:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
不建议在同一个日志流中写入不同格式的日志条目,即使你成功地将其重定向到容器的 stdout 流。
相反,你可以创建两个边车容器。每个边车容器可以从共享卷跟踪特定的日志文件,
并将文件内容重定向到各自的 stdout 流。
下面是运行两个边车容器的 Pod 的清单:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
现在当你运行这个 Pod 时,你可以运行如下命令分别访问每个日志流:
kubectl logs counter count-log-1
输出类似于:
0: Fri Apr 1 11:42:26 UTC 2022
1: Fri Apr 1 11:42:27 UTC 2022
2: Fri Apr 1 11:42:28 UTC 2022
...
kubectl logs counter count-log-2
输出类似于:
Fri Apr 1 11:42:29 UTC 2022 INFO 0
Fri Apr 1 11:42:30 UTC 2022 INFO 0
Fri Apr 1 11:42:31 UTC 2022 INFO 0
...
如果你在集群中安装了节点级代理,由代理自动获取上述日志流,而无需任何进一步的配置。 如果你愿意,你可以将代理配置为根据源容器解析日志行。
即使对于 CPU 和内存使用率较低的 Pod(CPU 为几毫核,内存为几兆字节),将日志写入一个文件,
将这些日志流写到 stdout 也有可能使节点所需的存储量翻倍。
如果你有一个写入特定文件的应用程序,则建议将 /dev/stdout 设置为目标文件,而不是采用流式边车容器方法。
边车容器还可用于轮换应用程序本身无法轮换的日志文件。
这种方法的一个例子是定期运行 logrotate 的小容器。
但是,直接使用 stdout 和 stderr 更直接,而将轮换和保留策略留给 kubelet。
集群中安装的节点级代理会自动获取这些日志流,而无需进一步配置。 如果你愿意,你也可以配置代理程序来解析源容器的日志行。
注意,尽管 CPU 和内存使用率都很低(以多个 CPU 毫核指标排序或者按内存的兆字节排序),
向文件写日志然后输出到 stdout 流仍然会成倍地增加磁盘使用率。
如果你的应用向单一文件写日志,通常最好设置 /dev/stdout 作为目标路径,
而不是使用流式的边车容器方式。
如果应用程序本身不能轮换日志文件,则可以通过边车容器实现。
这种方式的一个例子是运行一个小的、定期轮换日志的容器。
然而,还是推荐直接使用 stdout 和 stderr,将日志的轮换和保留策略交给 kubelet。
具有日志代理功能的边车容器
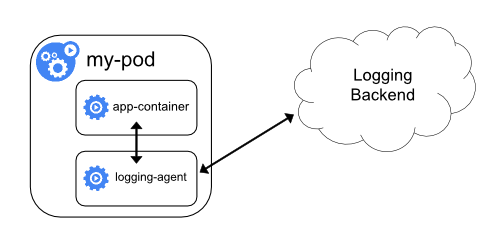
如果节点级日志记录代理程序对于你的场景来说不够灵活, 你可以创建一个带有单独日志记录代理的边车容器,将代理程序专门配置为与你的应用程序一起运行。
说明:
在边车容器中使用日志代理会带来严重的资源损耗。
此外,你不能使用 kubectl logs 访问日志,因为日志并没有被 kubelet 管理。
下面是两个配置文件,可以用来实现一个带日志代理的边车容器。 第一个文件包含用来配置 fluentd 的 ConfigMap。
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
说明:
你可以将此示例配置中的 fluentd 替换为其他日志代理,从应用容器内的其他来源读取数据。
第二个清单描述了一个运行 fluentd 边车容器的 Pod。 该 Pod 挂载一个卷,fluentd 可以从这个卷上拣选其配置数据。
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: registry.k8s.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
从应用中直接暴露日志目录
从各个应用中直接暴露和推送日志数据的集群日志机制已超出 Kubernetes 的范围。
接下来
- 阅读有关 Kubernetes 系统日志的信息
- 进一步了解追踪 Kubernetes 系统组件
- 了解当 Pod 失效时如何定制 Kubernetes 记录的终止消息