可观测性
理解如何通过收集 指标(metrics)、日志(logs) 和 链路(traces) 来获得对 Kubernetes 集群的端到端可观测性。
在 Kubernetes 中,可观测性是通过收集和分析指标、日志和链路(通常被称为可观测性的三大支柱), 以便更好地了解集群的内部状态、性能和健康情况的过程。
Kubernetes 控制平面组件以及许多插件都会生成并发出这些信号。 通过聚合这些信号并在其间建立关联,你可以获得整个集群中控制平面、插件和应用程序的统一视图。
图 1 概述了集群组件如何发出三种主要信号类型。
flowchart LR
A[集群组件] --> M[指标流水线]
A --> L[日志流水线]
A --> T[链路流水线]
M --> S[(存储和分析)]
L --> S
T --> S
S --> O[操作员和自动化组件]
图 1. 集群组件发出的大致信号及其消费者。
指标
Kubernetes 组件在其 /metrics 端点以 Prometheus 格式
发出指标;这些组件包括:
- kube-controller-manager
- kube-proxy
- kube-apiserver
- kube-scheduler
- kubelet
kubelet 还在 /metrics/cadvisor、/metrics/resource
和 /metrics/probes 端点公开指标。
像 kube-state-metrics
这样的插件会用 Kubernetes 对象状态丰富这些控制平面信号。
典型的 Kubernetes 指标流水线会定期抓取这些端点, 并将样本存储在时序数据库中(例如使用 Prometheus)。
有关详细信息和配置选项,请参阅系统指标指南。
图 2 概述了一个常见的 Kubernetes 指标流水线。
flowchart LR
C[集群组件] --> P[Prometheus 抓取器]
P --> TS[(时序存储)]
TS --> D[仪表板和告警]
TS --> A[自动化操作]
图 2. 典型 Kubernetes 指标流水线的组件。
对于多集群或多云可观测性,分布式时序数据库(例如 Thanos 或 Cortex) 可以补充 Prometheus。
有关指标抓取器和时间序列数据库的信息, 请参阅常见可观测性工具 - 指标工具。
另请参见
日志
日志为应用程序、Kubernetes 系统组件的内部事件,以及与安全相关的活动(例如审计日志)提供按时序排列的记录。
容器运行时从标准输出(stdout)和标准错误(stderr)流捕获容器化应用程序的输出。
虽然运行时以不同方式实现此功能,但它们与 kubelet 的集成通过 CRI 日志格式标准化,
kubelet 通过 kubectl logs 使这些日志可被访问。
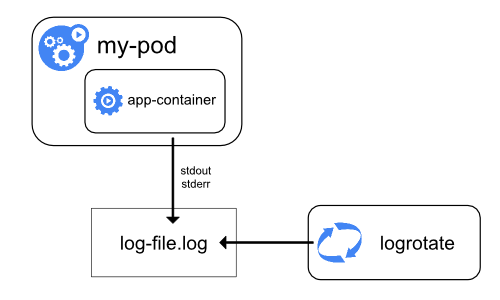
图 3a. 节点级日志记录架构。
系统组件日志捕获来自集群的事件,通常对调试和故障排查很有用。
这些组件可以分类为两种不同方式:在容器中运行的组件和不在容器中运行的组件。
例如,kube-scheduler 和 kube-proxy 通常在容器中运行,
而 kubelet 和容器运行时直接在主机上运行。
- 在安装了
systemd的机器上,kubelet 和容器运行时写入 journald。 否则,它们写入/var/log目录中的.log文件。 - 在容器内运行的系统组件始终写入
/var/log中的.log文件, 绕过默认的容器日志记录机制。
存储在 /var/log 下的系统组件和容器日志需要进行日志轮转以防止不受控制的增长。
某些集群配置脚本默认安装日志轮转;请检查你的环境并根据需要进行调整。
有关位置、格式和配置选项的详细信息,请参阅系统日志参考。
大多数集群运行一个节点级日志记录代理(例如 Fluent Bit 或 Fluentd), 该代理尾部跟踪这些日志文件并将日志条目转发到某集中式日志存储。 日志记录架构指南 解释了如何设计此类流水线、如何实施保留策略以及如何将日志流传输到后端。
图 3 概述了一个常见的日志聚合流水线。
flowchart LR
subgraph Sources
A[应用程序stdout/stderr]
B[控制平面日志]
C[审计记录]
end
A --> N[节点日志代理]
B --> N
C --> N
N --> L[集中式日志存储]
L --> Q[仪表板、告警、SIEM]
图 3. 典型 Kubernetes 日志流水线的组件。
有关日志记录代理和集中式日志存储的信息,请参阅常见可观测性工具 - 日志工具。
另请参见
链路
链路数据记录请求如何在 Kubernetes 组件和应用程序之间移动, 将操作之间的延迟、时序和关系联系起来。 通过收集链路数据,你可以将端到端的请求流可视化、诊断性能问题, 并发现控制平面、插件或应用程序中的瓶颈或意外交互。
Kubernetes 1.35 可以通过 OpenTelemetry 协议 (OTLP)导出跨度(span)数据,既可以直接通过内置的 gRPC 导出器导出, 也可以通过 OpenTelemetry Collector 转发它们。
OpenTelemetry Collector 从组件和应用程序接收跨度数据, 处理它们(例如通过执行某些采样或编辑动作), 并将它们转发到链路后端进行存储和分析。
图 4 概述了一个典型的分布式链路流水线。
flowchart LR
subgraph Sources
A[控制平面跨度]
B[应用程序跨度]
end
A --> X[OTLP 导出器]
B --> X
X --> COL[OpenTelemetry Collector]
COL --> TS[(链路后端)]
TS --> V[可视化和分析]
图 4. 典型 Kubernetes 链路流水线的组件。
有关链路收集器和后端的信息,请参阅常见可观测性工具 - 链路工具。
另请参见
常见可观测性工具
说明: 本部分链接到提供 Kubernetes 所需功能的第三方项目。Kubernetes 项目作者不负责这些项目。此页面遵循CNCF 网站指南,按字母顺序列出项目。要将项目添加到此列表中,请在提交更改之前阅读内容指南。
注意:本节包含指向提供 Kubernetes 所需可观测性能力的第三方项目的链接。 Kubernetes 项目作者不对这些项目负责,这些项目按字母顺序列出。 要将项目添加到此列表,请在提交更改之前阅读内容指南。
指标工具
- Cortex 提供水平可扩展的长期 Prometheus 存储。
- Grafana Mimir 是一个 Grafana Labs 项目, 提供多租户、水平可扩展的 Prometheus 兼容存储。
- Prometheus 是从 Kubernetes 组件抓取和存储指标的监控系统。
- Thanos 使用全局查询、下采样和对象存储支持扩展 Prometheus。
日志工具
- Elasticsearch 提供分布式日志索引和搜索。
- Fluent Bit 以低资源占用收集并转发容器和节点日志。
- Fluentd 将日志路由和转换到多个目标。
- Grafana Loki 以 Prometheus 启发的基于标签的格式存储日志。
- OpenSearch 提供与 Elasticsearch API 兼容的开源日志索引和搜索。
链路工具
- Grafana Tempo 提供可扩展、低成本的分布式链路存储。
- Jaeger 捕获并可视化微服务的分布式链路。
- OpenTelemetry Collector 接收、处理和导出包括链路在内的遥测数据。
- Zipkin 提供分布式链路收集和可视化。
接下来
- 了解如何使用 metrics-server 收集资源使用指标
- 探索日志记录任务和教程
- 阅读监控和链路任务指南
- 查看系统指标指南以了解组件端点和稳定性
- 查看常见可观测性工具部分以了解经过验证的第三方选项
最后修改 October 28, 2025 at 5:50 PM PST: [zh-cn] sync observability.md (3742109927)