控制节点上的拓扑管理策略
特性状态:
Kubernetes v1.27 [stable]越来越多的系统利用 CPU 和硬件加速器的组合来支持要求低延迟的任务和高吞吐量的并行计算。 这类负载包括电信、科学计算、机器学习、金融服务和数据分析等。 此类混合系统需要有高性能环境支持。
为了获得最佳性能,需要进行与 CPU 隔离、内存和设备局部性有关的优化。 但是,在 Kubernetes 中,这些优化由各自独立的组件集合来处理。
拓扑管理器(Topology Manager) 是一个 kubelet 组件,旨在协调负责这些优化的一组组件。
准备开始
你必须拥有一个 Kubernetes 的集群,且必须配置 kubectl 命令行工具让其与你的集群通信。 建议运行本教程的集群至少有两个节点,且这两个节点不能作为控制平面主机。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 v1.18.要获知版本信息,请输入 kubectl version.
拓扑管理器如何工作
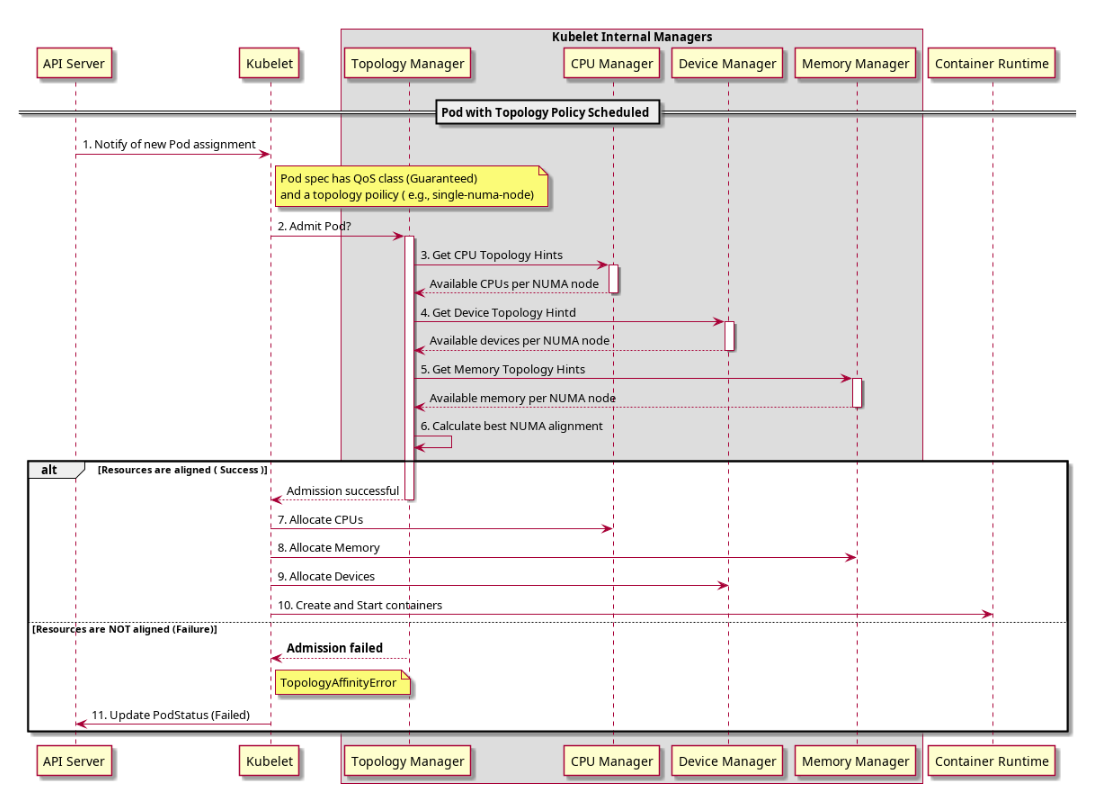
在引入拓扑管理器之前,Kubernetes 中的 CPU 和设备管理器相互独立地做出资源分配决策。 这可能会导致在多处理系统上出现不符合期望的资源分配情况;由于这些与期望相左的分配,对性能或延迟敏感的应用将受到影响。 这里的不符合期望意指,例如,CPU 和设备是从不同的 NUMA 节点分配的,因此会导致额外的延迟。
拓扑管理器是一个 kubelet 组件,扮演信息源的角色,以便其他 kubelet 组件可以做出与拓扑结构相对应的资源分配决定。
拓扑管理器为组件提供了一个称为 建议提供者(Hint Provider) 的接口,以发送和接收拓扑信息。 拓扑管理器具有一组节点级策略,具体说明如下。
拓扑管理器从建议提供者接收拓扑信息,作为表示可用的 NUMA 节点和首选分配指示的位掩码。 拓扑管理器策略对所提供的建议执行一组操作,并根据策略对提示进行约减以得到最优解。 如果存储了与预期不符的建议,则该建议的优选字段将被设置为 false。 在当前策略中,首选是最窄的优选掩码。 所选建议将被存储为拓扑管理器的一部分。 取决于所配置的策略,所选建议可用来决定节点接受或拒绝 Pod。 之后,建议会被存储在拓扑管理器中,供建议提供者在作资源分配决策时使用。
该流程可见于下图:
Windows 支持
特性状态:
Kubernetes v1.32 [alpha](默认禁用)拓扑管理器支持可以通过使用 WindowsCPUAndMemoryAffinity 特性门控在 Windows 上启用,
并且需要容器运行时的支持。
拓扑管理器作用域和策略
拓扑管理器目前:
- 对所有 QoS 类的 Pod 执行对齐操作。
- 针对建议提供者所提供的拓扑建议,对请求的资源进行对齐。
如果满足这些条件,则拓扑管理器将对齐请求的资源。
为了定制如何进行对齐,拓扑管理器提供了两个不同的选项:scope 和 policy。
scope 定义了你希望的资源对齐粒度,例如是在 pod 还是 container 层级上对齐。
policy 定义了对齐时实际使用的策略,例如 best-effort、restricted 和 single-numa-node。
可以在下文找到现今可用的各种 scopes 和 policies 的具体信息。
说明:
为了将 Pod 规约中的 CPU 资源与其他请求资源对齐,需要启用 CPU 管理器并在节点上配置适当的 CPU 管理器策略。 参见控制节点上的 CPU 管理策略。
说明:
为了将 Pod 规约中的内存(和 hugepages)资源与所请求的其他资源对齐,需要启用内存管理器, 并且在节点配置适当的内存管理器策略。 查看内存管理器文档。
拓扑管理器作用域
拓扑管理器可以在以下不同的作用域内进行资源对齐:
container(默认)pod
在 kubelet 启动时,你可以通过在
kubelet 配置文件中设置
topologyManagerScope 来选择其中任一选项。
container 作用域
默认使用的是 container 作用域。
你也可以在 kubelet 配置文件中明确将
topologyManagerScope 设置为 container。
在该作用域内,拓扑管理器依次进行一系列的资源对齐, 也就是,对(Pod 中的)每一个容器计算单独的对齐。 换句话说,在该特定的作用域内,没有根据特定的 NUMA 节点集来把容器分组的概念。 实际上,拓扑管理器会把单个容器任意地对齐到 NUMA 节点上。
容器分组的概念是在以下的作用域内特别实现的,也就是 pod 作用域。
pod 作用域
要选择 pod 作用域,在 kubelet 配置文件中将
topologyManagerScope 设置为 pod。
此作用域允许把一个 Pod 里的所有容器作为一个分组,分配到一个共同的 NUMA 节点集。 也就是,拓扑管理器会把一个 Pod 当成一个整体, 并且尝试把整个 Pod(所有容器)分配到单一的 NUMA 节点或者一个共同的 NUMA 节点集。 以下的例子说明了拓扑管理器在不同的场景下使用的对齐方式:
- 所有容器可以被分配到一个单一的 NUMA 节点,实际上也是这样分配的;
- 所有容器可以被分配到一个共享的 NUMA 节点集,实际上也是这样分配的。
整个 Pod 所请求的某种资源总量是根据 有效 request/limit 公式来计算的,因此,对某一种资源而言,该总量等于以下数值中的最大值:
- 所有应用容器请求之和;
- 初始容器请求的最大值。
pod 作用域与 single-numa-node 拓扑管理器策略一起使用,
对于延时敏感的工作负载,或者对于进行 IPC 的高吞吐量应用程序,都是特别有价值的。
把这两个选项组合起来,你可以把一个 Pod 里的所有容器都放到单一的 NUMA 节点,
使得该 Pod 消除了 NUMA 之间的通信开销。
在 single-numa-node 策略下,只有当可能的分配方案中存在合适的 NUMA 节点集时,Pod 才会被接受。
重新考虑上述的例子:
- 节点集只包含单个 NUMA 节点时,Pod 就会被接受,
- 然而,节点集包含多个 NUMA 节点时,Pod 就会被拒绝 (因为满足该分配方案需要两个或以上的 NUMA 节点,而不是单个 NUMA 节点)。
简要地说,拓扑管理器首先计算出 NUMA 节点集,然后使用拓扑管理器策略来测试该集合, 从而决定拒绝或者接受 Pod。
拓扑管理器策略
拓扑管理器支持四种分配策略。
你可以通过 kubelet 标志 --topology-manager-policy 设置策略。
所支持的策略有四种:
none(默认)best-effortrestrictedsingle-numa-node
说明:
如果拓扑管理器配置使用 pod 作用域, 那么在策略评估一个容器时,该容器反映的是整个 Pod 的要求, 所以该 Pod 里的每个容器都会应用相同的拓扑对齐决策。
none 策略
这是默认策略,不执行任何拓扑对齐。
best-effort 策略
对于 Pod 中的每个容器,具有 best-effort 拓扑管理策略的
kubelet 将调用每个建议提供者以确定资源可用性。
使用此信息,拓扑管理器存储该容器的首选 NUMA 节点亲和性。
如果亲和性不是首选,则拓扑管理器将存储该亲和性,并且无论如何都将 Pod 接纳到该节点。
之后建议提供者可以在进行资源分配决策时使用这个信息。
restricted 策略
对于 Pod 中的每个容器,配置了 restricted 拓扑管理策略的 kubelet
调用每个建议提供者以确定其资源可用性。
使用此信息,拓扑管理器存储该容器的首选 NUMA 节点亲和性。
如果亲和性不是首选,则拓扑管理器将从节点中拒绝此 Pod。
这将导致 Pod 进入 Terminated 状态,且 Pod 无法被节点接受。
一旦 Pod 处于 Terminated 状态,Kubernetes 调度器将不会尝试重新调度该 Pod。
建议使用 ReplicaSet 或者 Deployment 来触发重新部署 Pod。
还可以通过实现外部控制环,以触发重新部署具有 Topology Affinity 错误的 Pod。
如果 Pod 被允许运行在某节点,则建议提供者可以在做出资源分配决定时使用此信息。
single-numa-node 策略
对于 Pod 中的每个容器,配置了 single-numa-node 拓扑管理策略的
kubelet 调用每个建议提供者以确定其资源可用性。
使用此信息,拓扑管理器确定是否支持单 NUMA 节点亲和性。
如果支持,则拓扑管理器将存储此信息,然后建议提供者可以在做出资源分配决定时使用此信息。
如果不支持,则拓扑管理器将拒绝 Pod 运行于该节点。
这将导致 Pod 处于 Terminated 状态,且 Pod 无法被节点接受。
一旦 Pod 处于 Terminated 状态,Kubernetes 调度器将不会尝试重新调度该 Pod。
建议使用多副本的 Deployment 来触发重新部署 Pod。
还可以通过实现外部控制环,以触发重新部署具有 Topology Affinity 错误的 Pod。
拓扑管理器策略选项
对拓扑管理器策略选项的支持需要启用 TopologyManagerPolicyOptions
特性门控(默认启用)。
你可以使用以下特性门控根据成熟度级别打开和关闭这些选项组:
TopologyManagerPolicyBetaOptions默认启用。启用以显示 Beta 级别选项。TopologyManagerPolicyAlphaOptions默认禁用。启用以显示 Alpha 级别选项。
你仍然需要使用 TopologyManagerPolicyOptions kubelet 选项来启用每个选项。
prefer-closest-numa-nodes
自 Kubernetes 1.32 起,prefer-closest-numa-nodes 选项进入 GA 阶段。
在 Kubernetes 1.36 中,只要启用了
TopologyManagerPolicyOptions 特性门控,
此策略选项默认可见。
拓扑管理器默认不会感知 NUMA 距离,并且在做出 Pod 准入决策时不会考虑这些距离。 这种限制出现在多插槽以及单插槽多 NUMA 系统中,如果拓扑管理器决定将资源对齐到不相邻的 NUMA 节点上, 可能导致执行延迟敏感和高吞吐的应用出现明显的性能下降。
如果你指定 prefer-closest-numa-nodes 策略选项,则在做出准入决策时 best-effort 和 restricted
策略将偏向于彼此之间距离较短的一组 NUMA 节点。
你可以通过将 prefer-closest-numa-nodes=true 添加到拓扑管理器策略选项来启用此选项。
默认情况下,如果没有此选项,拓扑管理器会在单个 NUMA 节点或(在需要多个 NUMA 节点时)最小数量的 NUMA 节点上对齐资源。
max-allowable-numa-nodes
自 Kubernetes 1.35 起,max-allowable-numa-nodes 选项进入一般可用(GA)阶段。
在 Kubernetes 1.36 中,只要启用了 TopologyManagerPolicyOptions
特性门控,
此策略选项默认可见。
Pod 被准入的时间与物理机上的 NUMA 节点数量相关。 默认情况下,Kubernetes 不会在检测到有 8 个以上 NUMA 节点的任何(Kubernetes)节点上运行启用拓扑管理器的 kubelet。
说明:
如果你选择 max-allowable-numa-nodes 策略选项,则可以允许在有 8 个以上 NUMA 节点的节点上启用拓扑管理器。
Kubernetes 项目对在有 8 个以上 NUMA 节点的(Kubernetes)节点上使用拓扑管理器的影响只有有限的数据。
由于缺少数据,所以不推荐在 Kubernetes 1.36 上使用此策略选项,你需自行承担风险。
你可以通过将 max-allowable-numa-nodes=<integer>
添加到拓扑管理器策略选项来启用此选项,其中整数值必须大于 8。
默认值为 8,这将保留现有的限制。
设置 max-allowable-numa-nodes 的值本身不会影响 Pod 准入的延时,
但将 Pod 绑定到有多个 NUMA 节点的(Kubernetes)节点确实会产生影响。
Kubernetes 后续潜在的改进可能会提高 Pod 准入性能,并降低随着 NUMA 节点数量增加而产生的高延迟。
Pod 与拓扑管理器策略的交互
考虑以下 Pod 清单中的容器:
spec:
containers:
- name: nginx
image: nginx
该 Pod 以 BestEffort QoS 类运行,因为没有指定资源
requests 或 limits。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
由于 requests 数少于 limits,因此该 Pod 以 Burstable QoS 类运行。
如果选择的策略是 none 以外的任何其他策略,拓扑管理器都会评估这些 Pod 的规范。
拓扑管理器会咨询建议提供者,获得拓扑建议。
若策略为 static,则 CPU 管理器策略会返回默认的拓扑建议,因为这些 Pod
并没有显式地请求 CPU 资源。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
此 Pod 独立使用 CPU 请求量,以 Guaranteed QoS 类运行,因为其
requests 值等于 limits 值。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "300m"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "300m"
example.com/device: "1"
此 Pod 和其他资源共享 CPU 请求量,以 Guaranteed QoS 类运行,因为其
requests 值等于 limits 值。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
example.com/deviceA: "1"
example.com/deviceB: "1"
requests:
example.com/deviceA: "1"
example.com/deviceB: "1"
因为未指定 CPU 和内存请求,所以 Pod 以 BestEffort QoS 类运行。
拓扑管理器将考虑以上 Pod。拓扑管理器将咨询建议提供者即 CPU 和设备管理器,以获取 Pod 的拓扑提示。
对于独立使用 CPU 请求量的 Guaranteed Pod,static CPU 管理器策略将返回独占 CPU 相关的拓扑提示,
而设备管理器将返回有关所请求设备的提示。
对于与其他资源 CPU 共享请求量的 Guaranteed Pod,static CPU
管理器策略将返回默认的拓扑提示,因为没有独享的 CPU 请求;
而设备管理器则针对所请求的设备返回有关提示。
在上述两种 Guaranteed Pod 的情况中,none CPU 管理器策略会返回默认的拓扑提示。
对于 BestEffort Pod,由于没有 CPU 请求,static CPU 管理器策略将发送默认拓扑提示,
而设备管理器将为每个请求的设备发送提示。
基于此信息,拓扑管理器计算出 Pod 的最佳提示并存储此信息, 提示提供者在进行资源分配时将使用此信息。
已知的局限性
- 拓扑管理器所能处理的最大 NUMA 节点个数是 8。若 NUMA 节点数超过 8,
枚举可能的 NUMA 亲和性并为之生成提示时会发生状态爆炸。
更多选项参见
max-allowable-numa-nodes(Beta)。 - 调度器无法感知拓扑,所以有可能一个 Pod 被调度到一个节点之后,会因为拓扑管理器的缘故在该节点上启动失败。
接下来
- 了解 Pod 级资源管理器。