Bagian konsep ini membantu kamu belajar tentang bagian-bagian sistem serta abstraksi
yang digunakan Kubernetes untuk merepresentasikan klaster kamu, serta membantu
kamu belajar lebih dalam bagaimana cara kerja Kubernetes.
Ikhtisar
Untuk menggunakan Kubernetes, kamu menggunakan objek-objek Kubernetes API untuk merepresentasikan
state yang diinginkan: apa yang aplikasi atau workload lain yang ingin kamu
jalankan, image kontainer yang digunakan, jaringan atau resource disk apa yang ingin
kamu sediakan, dan lain sebagainya. Kamu membuat state yang diinginkan dengan cara membuat
objek dengan menggunakan API Kubernetes, dan biasanya menggunakan command-line interface, yaitu kubectl.
Kamu juga dapat secara langsung berinteraksi dengan klaster untuk membuat atau mengubah
state yang kamu inginkan.
Setelah kamu membuat state yang kamu inginkan, Control Plane Kubernetes
menggunakan Pod Lifecycle Event Generator (PLEG) untuk mengubah
state yang ada saat ini supaya sama dengan state yang diinginkan.
Untuk melakukan hal tersebut, Kubernetes melakukan berbagai task secara otomatis,
misalnya dengan mekanisme start atau stop kontainer, melakukan scale replika dari
suatu aplikasi, dan lain sebagainya. Control Plane Kubernetes terdiri dari sekumpulan
process yang dijalankan di klaster:
Kubernetes Master terdiri dari tiga buah process yang dijalankan pada sebuah node di klaster kamu, node ini disebut sebagai master, yang terdiri kube-apiserver, kube-controller-manager dan kube-scheduler.
Setiap node non-master pada klaster kamu menjalankan dua buah process:
kubelet, yang menjadi perantara komunikasi dengan master.
kube-proxy, sebuah proxy yang merupakan representasi jaringan yang ada pada setiap node.
Objek Kubernetes
Kubernetes memiliki beberapa abstraksi yang merepresentasikan state dari sistem kamu:
apa yang aplikasi atau workload lain yang ingin kamu jalankan, jaringan atau resource disk apa yang ingin
kamu sediakan, serta beberapa informasi lain terkait apa yang sedang klaster kamu lakukan.
Abstraksi ini direpresentasikan oleh objek yang tersedia di API Kubernetes;
lihat ikhtisar objek-objek Kubernetes
untuk penjelasan yang lebih mendetail.
Sebagai tambahan, Kubernetes memiliki beberapa abstraksi yang lebih tinggi yang disebut kontroler.
Kontroler merupakan objek mendasar dengan fungsi tambahan, contoh dari kontroler ini adalah:
Berbagai bagian Control Plane Kubernetes, seperti master dan process-process kubelet,
mengatur bagaimana Kubernetes berkomunikasi dengan klaster kamu. Control Plane
menjaga seluruh record dari objek Kubernetes serta terus menjalankan
iterasi untuk melakukan manajemen state objek. Control Plane akan memberikan respon
apabila terdapat perubahan pada klaster kamu dan mengubah state saat ini agar sesuai
dengan state yang diinginkan.
Contohnya, ketika kamu menggunakan API Kubernetes untuk membuat sebuah Deployment,
kamu memberikan sebuah state baru yang harus dipenuhi oleh sistem. Control Plane
kemudian akan mencatat objek apa saja yang dibuat, serta menjalankan instruksi yang kamu berikan
dengan cara melakukan start aplikasi dan melakukan scheduling aplikasi tersebut
pada node, dengan kata lain mengubah state saat ini agar sesuai dengan state yang diinginkan.
Master
Master Kubernetes bertanggung jawab untuk memelihara state yang diinginkan pada klaster kamu.
Ketika kamu berinteraksi dengan Kubernetes, misalnya saja menggunakan perangkat kubectl,
kamu berkomunikasi dengan master klaster Kubernetes kamu.
Node di dalam klaster Kubernetes adalah mesin (mesin virtual maupun fisik) yang
menjalankan aplikasi kamu. Master mengontrol setiap node; kamu akan jarang berinteraksi
dengan node secara langsung.
Jika kamu ingin menulis halaman konsep, perhatikan
cara penggunaan template pada laman
untuk informasi mengenai konsep tipe halaman dan template konsep.
1 - Ikhtisar
1.1 - Apa itu Kubernetes?
Kubernetes merupakan platform open-source yang digunakan untuk melakukan manajemen workloads aplikasi yang dikontainerisasi, serta menyediakan konfigurasi dan otomatisasi secara deklaratif. Kubernetes berada di dalam ekosistem yang besar dan berkembang cepat. Service, support, dan perkakas Kubernetes tersedia secara meluas. Kubernetes merupakan platform open-source yang digunakan untuk melakukan manajemen workloads aplikasi yang dikontainerisasi, serta menyediakan konfigurasi dan otomatisasi secara deklaratif. Kubernetes berada di dalam ekosistem yang besar dan berkembang cepat. Service, support, dan perkakas Kubernetes tersedia secara meluas.
Laman ini merupakan ikhtisar Kubernetes.
Kubernetes merupakan platform open-source yang digunakan untuk melakukan
manajemen workloads aplikasi yang dikontainerisasi, serta menyediakan
konfigurasi dan otomatisasi secara deklaratif. Kubernetes berada di dalam ekosistem
yang besar dan berkembang cepat. Service, support, dan perkakas
Kubernetes tersedia secara meluas.
Mengapa Kubernetes dan hal apa saja yang dapat dilakukan oleh Kubernetes?
Kubernetes memiliki sejumlah fitur yang dapat dijabarkan sebagai berikut:
platform kontainer
platform microservices
platform cloud yang tidak mudah dipindahkan
Kubernetes menyediakan manajemen environment yang berpusat pada kontainer.
Kubernetes melakukan orkestrasi terhadap computing, networking,
dan inftrastruktur penyimpanan. Fitur inilah yang kemudian membuat konsep Platform as a Service (PaaS)
menjadi lebih sederhana dilengkapi dengan fleksibilitas yang dimiliki oleh Infrastructure as a Service (IaaS).
Lalu apa yang menyebabkan Kubernetes disebut sebagai sebuah platform?
Meskipun Kubernetes menyediakan banyak fungsionalitas, selalu ada keadaan dimana
hal tersebut membutuhkan fitur baru. Workflow spesifik yang terkait dengan
proses pengembangan aplikasi dapat ditambahkan pada streamline untuk meningkatkan
produktivitas developer. Orkestrasi ad-hoc yang dapat diterima biasanya membutuhkan desain
otomatisasi yang kokoh agar bersifat scalable. Hal inilah yang membuat
Kubernetes juga didesain sebagai platform untuk membangun ekosistem komponen dan
perkakas untuk memudahkan proses deployment, scale, dan juga manajemen
aplikasi.
Labels memudahkan pengguna mengkategorisasikan resources yang mereka miliki
sesuai dengan kebutuhan. Annotations memungkinkan pengguna untuk menambahkan informasi
tambahan pada resource yang dimiliki.
Selain itu, Kubernetes control plane dibuat berdasarkan
API yang tersedia bagi pengguna dan developer. Pengguna
dapat mengimplementasikan kontroler sesuai dengan kebutuhan mereka, contohnya adalah
schedulers,
dengan API kustom yang mereka miliki, kontroler kustom ini kemudian dapat digunakan
pada command-line
tool generik yang ada.
Desain
inilah yang memungkinkan beberapa sistem lain untuk dapat dibangun di atas Kubernetes.
Lalu hal apakah yang tidak termasuk di dalam Kubernetes?
Kubernetes bukanlah sebuah PaaS (Platform as a
Service) yang biasanya. Meskipun Kubernetes dijalankan pada tingkatan kontainer
dan bukan pada tingkatan perangkat keras, Kubernetes menyediakan beberapa fitur
yang biasanya disediakan oleh Paas, seperti deployment, scaling,
load balancing, logging, dan monitoring. Akan tetapi,
Kubernetes bukanlah sistem monolitik, melainkan suatu sistem yang bersifat sebagai
bulding block dan pluggable yang dapat digunakan untuk membangun sebuah
platform yang dibutuhkan oleh developer dengan tetap mengutamakan konsep fleksibilitas.
Kubernetes:
Tidak melakukan limitasi terhadap aplikasi yang di-support. Kubernetes bertujuan
untuk mendukung berbagai variasi workloads, termasuk
stateless, stateful, dan data-processing. Jika sebuah
aplikasi dapat dijalankan di atas kontainer, maka aplikasi tersebut juga dapat
dijalankan di atas Kubernetes.
Tidak menyediakan mekanisme untuk melakukan deploy kode sumber
maupun mekanisme build sebuah aplikasi. Continuous Integration, Delivery, and Deployment
(CI/CD) workflows ditentukan oleh preferensi serta kebutuhan teknis organisasi.
Tidak menyediakan application-level services, seperti middleware
(e.g., message buses), data-processing frameworks (for example,
Spark), databases (e.g., mysql), caches, maupun cluster storage systems (e.g.,
Ceph) sebagai suatu built-in services. Komponen tersebut dapat dijalankan di atas Kubernetes, dan/atau
dapat diakses oleh aplikasi yang dijalankan di atas Kubernetes melalui sebuah mekanisme tidak mudah dipindahkan
misalnya saja Open Service Broker.
Tidak membatasi penyedia layanan logging, monitoring, maupun alerting yang digunakan.
Kubernetes menyediakan proof of concept dan mekanisme integrasi yang dapat digunakan
untuk mengumpulkan serta mengekspor metriks yang ada.
Tidak menyediakan atau mengharuskan penggunaan configuration language/system (e.g.,
jsonnet). Kubernetes menyediakan suatu API deklaratif
yang dapat digunakan oleh berbagai jenis spesifikasi deklaratif.
Tidak menyediakan atau mengadaptasi sebuah konfigurasi, maintenance, manajemen, atau
self-healing mesin dengan spesifikasi khusus.
Sebagai tambahan, Kubernetes bukanlah sebuah sitem orkestrasi biasa. Bahkan pada kenyataannya,
Kubernetes menghilangkan kebutuhan untuk melakukan orkestrasi. Definisi teknis dari
orkestrasi merupakan eksekusi dari sebuah workflow yang sudah didefinisikan sebelumnya: pertama kerjakan A, kemudian B,
dan terakhir C. Sebaliknya, Kubernetes disusun oleh seperangkat
proses kontrol yang dapat idekomposisi yang selalu menjalankan state yang ada
saat ini hingga sesuai dengan state yang dinginkan.
Kita tidak perlu peduli proses apa saja yang perlu dilakukan untuk melakukan A hingga C.
Mekanisme kontrol yang tersentralisasi juga tidak dibutuhkan. Dengan demikian, sistem yang
dihasilkan lebih mudah digunakan lebih kokoh, serta lebih extensible.
Mengapa kontainer?
Mencari alasan kenapa kita harus menggunakan kontainer?
Cara Lama untuk melakukan mekanisme deploy suatu aplikasi
adalah dengan cara instalasi aplikasi tersebut pada sebuah mesin
dengan menggunakan package manager yang dimiliki oleh sistem operasi
mesin tersebut. Hal ini menciptakan suatu ketergantungan antara executables,
konfigurasi, serta ketergantungan lain yang dibutuhkan aplikasi dengan sistem operasi
yang digunakan oleh mesin. Untuk mengatasi hal ini, tentunya bisa saja kita melakukan
mekanisme build suatu image VM yang immutable untuk mendapatkan
mekanisme rollouts dan rollback yang dapat diprediksi.
Meskipun demikian, VM masih dianggap "berat" dan tidak tidak mudah dipindahkan.
Cara Baru adalah dengan melakukan mekanisme deploy kontainer pada tingkatan
virtualisasi di level sistem operasi (OS) bukan pada tingkatan virtualisasi perangkat keras.
Kontainer ini berada dalam lingkungan yang terisolasi satu sama lain serta terisolasi dengan
mesin dimana kontainer ini berada. Kontainer ini memiliki filesystems masing-masing.
Selain itu, setiap kontainer tidak dapat "melihat" process yang sedang dijalankan di
kontainer lain. Selain itu resource komputasi yang digunakan oleh kontainer
ini juga dapat dibatasi. Kontainer juga dapat dengan lebih mudah di-build jika
dibandingkan dengan VM, karena kontainer tidak bergantung pada filesystem
yang dimiliki mesin, serta dengan mudah dapat didistribusikan.
Karena kontainer ukurannya kecil dan lebih cepat, sebuah aplikasi dapat dibangun di setiap
image kontainer. Mekanisme pemetaan satu-satu antara kontainer dan aplikasi
inilah yang membuka keuntungan secara meyeluruh yang dapat diberikan oleh kontainer.
Dengan menggunakan kontainer, image kontainer dapat dibuat diwaktu rilis aplikasi.
Pembuatan image ini memungkinkan aplikasi secara konsisten dirilis pada
environmentdevelopment maupun production. Selain itu,
kontainer juga memiliki transparasi yang lebih tinggi dibandingkan dengan VM. Maksudnya,
infrastruktur punya tugas untuk mengatur lifecycle seluruh process yang ada di dalam kontainer. Ini bukanlah lagi tugas sebuah supervisor process yang tersembunyi di dalam kontainer.
Secara garis besar, penggunaan kontainer memiliki keuntungan sebagai berikut:
Mekanisme pembuatan aplikasi serta proses deployment yang lebih efektif:
Kontainer dapat meningkatkan kemudahan dan efisiensi jika dibandingkan dengan penggunaan VM.
Continuous development, integration, and deployment:
Digunakan untuk melakukan proses build dan deploy yang sering dilakukan
serta kemudahan mekanisme rollback karena image yang ada sifatnya immutable.
Pemisahan kepentingan antara Dev dan Ops:
Pembuatan image container dilakukan pada saat rilis dan bukan pada saat deploy
mengurangi ketergantungan aplikasi dan infrastruktur.
Observabilitas
Tidak hanya informasi dan metriks pada level OS, tapi juga kesehatan aplikasi dan signal lain.
Konsistensi environment pada masa pengembangan , testing, dan production:
Memiliki perilaku yang sama baik ketika dijalankan di mesin lokal maupun penyedia layanan cloud.
Portabilitas antar penyedia layanan cloud maupun distribusi OS:
Dapat dijalankan pada Ubuntu, RHEL, CoreOS, on-prem, Google Kubernetes Engine, dan dimanapun.
Manajemen yang bersifat Aplikasi sentris:
Meningkatkan level abstraksi dari proses menjalankan OS pada perangkat keras virtual
ke proses menjalankan aplikasi pada sebuah OS dengan menggunakan resource logis.
Mikroservis yang renggang (loosely coupled), terdistribusi, elastis, dan terliberasi:
Aplikasi dapat dipecah menjadi komponen yang lebih kecil yang independen dan dapat
di-deploy dan diatur secara dinamis -- bukan sebuah sistem monolitik yang dijalankan pada
sebuah mesin yang hanya punya satu tujuan.
Isolasi resource:
Performa aplikasi yang bisa diprediksi.
Utilisasi resource:
Efisiensi yang tinggi
Apakah arti Kubernetes? K8s?
Nama Kubernetes berasal dari Bahasa Yunani, yang berarti juru mudi atau
pilot, dan merupakan asal kata gubernur dan
cybernetic. K8s
merupakan sebuah singkatan yang didapat dengan mengganti 8 huruf "ubernete" dengan
"8".
Sebuah klaster Kubernetes terdiri dari komponen yang merepresentasikan bidang kontrol dan sepasang mesin yaitu nodes.
Dokumen ini merupakan ikhtisar yang mencakup berbagai komponen
yang dibutuhkan agar klaster Kubernetes dapat berjalan secara fungsional.
Komponen Master
Komponen master menyediakan control plane bagi klaster.
Komponen ini berperan dalam proses pengambilan secara global
pada klaster (contohnya, mekanisme schedule), serta berperan dalam proses
deteksi serta pemberian respons terhadap events yang berlangsung di dalam klaster
(contohnya, penjadwalan pod baru apabila jumlah replika yang ada pada
replication controller tidak terpenuhi).
Komponen master dapat dijalankan di mesin manapun yang ada di klaster. Meski begitu,
untuk memudahkan proses yang ada, script inisiasi awal yang dijalankan
biasanya memulai komponen master pada mesin yang sama, serta tidak menjalankan
kontainer bagi pengguna di mesin ini. Contoh konfigurasi multi-master VM
dapat dilihat di modul [Membangun Klaster HA] (/docs/admin/high-availability/).
kube-apiserver
Komponen control plane yang mengekspos API Kubernetes. Merupakan front-end dari control plane Kubernetes.
Komponen ini didesain agar dapat diskalakan secara horizontal. Lihat Membangun Klaster HA.
etcd
Penyimpanan key value konsisten yang digunakan sebagai penyimpanan data klaster Kubernetes.
Selalu perhatikan mekanisme untuk mem-backup data etcd pada klaster Kubernetes kamu. Untuk informasi lebih lanjut tentang etcd, lihat dokumentasi etcd.
kube-scheduler
Komponen control plane yang bertugas mengamati Pod baru yang belum ditempatkan di node manapun dan kemudian memilihkan Node di mana Pod baru tersebut akan dijalankan.
Faktor-faktor yang dipertimbangkan untuk keputusan penjadwalan termasuk: kebutuhan sumber daya secara individual dan kolektif, batasan perangkat keras/perangkat lunak/peraturan, spesifikasi afinitas dan nonafinitas, lokalisasi data, interferensi antar beban kerja dan tenggat waktu.
kube-controller-manager
Komponen control plane yang menjalankan pengontrol.
Secara logis, setiap pengontrol adalah sebuah proses yang berbeda, tetapi untuk mengurangi kompleksitas, kesemuanya dikompilasi menjadi sebuah biner (binary) yang dijalankan sebagai satu proses.
Kontroler-kontroler ini meliputi:
Kontroler Node : Bertanggung jawab untuk mengamati dan memberikan
respons apabila jumlah node berkurang.
Kontroler Replikasi : Bertanggung jawab untuk menjaga jumlah pod agar
jumlahnya sesuai dengan kebutuhan setiap objek kontroler replikasi yang ada di sistem.
Kontroler Endpoints : Menginisiasi objek Endpoints
(yang merupakan gabungan Pods dan Services).
Kontroler Service Account & Token: Membuat akun dan
akses token API standar untuk setiap namespaces yang dibuat.
cloud-controller-manager
Cloud-controller-manager merupakan kontroler yang berinteraksi dengan penyedia layanan cloud.
Kontroler ini merupakat fitur alfa yang diperkenalkan pada Kubernetes versi 1.6.
Cloud-controller-manager hanya menjalankan iterasi kontroler cloud-provider-specific .
Kamu harus menonaktifkan iterasi kontroler ini pada kube-controller-manager.
Kamu dapat menonaktifka iterasi kontroler ini dengan mengubah nilai argumen --cloud-provider dengan external
ketika menginisiasi kube-controller-manager.
Adanya cloud-controller-manager memungkinkan kode yang dimiliki oleh penyedia layanan cloud
dan kode yang ada pada Kubernetes saling tidak bergantung selama masa development.
Pada versi sebelumnya, Kubernetes bergantung pada fungsionalitas spesifik yang disediakan oleh
penyedia layanan cloud. Di masa mendatang, kode yang secara spesifik dimiliki oleh
penyedia layanan cloud akan dipelihara oleh penyedia layanan cloud itu sendiri,
kode ini selanjutnya akan dihubungkan dengan cloud-controller-manager ketika Kubernetes dijalankan.
Kontroler berikut ini memiliki keterkaitan dengan penyedia layanan cloud:
Kontroler Node : Melakukan pengecekan pada penyedia layanan cloud ketika menentukan apakah sebuah node telah dihapus pada cloud apabila node tersebut berhenti memberikan respons.
Kontroler Route : Melakukan pengaturan awal route yang ada pada penyedia layanan cloud
Kontroler Service : Untuk membuat, memperbaharui, menghapus load balancer yang disediakan oleh penyedia layanan cloud
Kontroler Volume : Untuk membuat, meng-attach, dan melakukan mount volume serta melakukan inetraksi dengan penyedia layanan cloud untuk melakukan orkestrasi volume
Komponen Node
Komponen ini ada pada setiap node, fungsinya adalah melakukan pemeliharaan terhadap pod serta menyediakan environment runtime bagi Kubernetes.
kubelet
Agen yang dijalankan pada setiap node di klaster yang bertugas untuk memastikan kontainer dijalankan di dalam Pod.
kube-proxy
kube-proxy membantu abstraksi service Kubernetes melakukan tugasnya. Hal ini terjadi dengan cara memelihara aturan-aturan jaringan (network rules) serta meneruskan koneksi yang ditujukan pada suatu host.
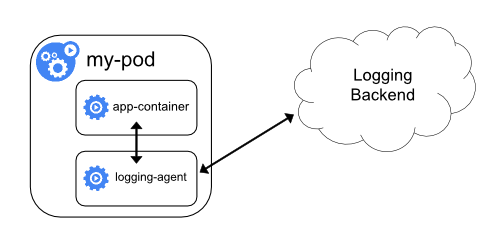
Addons merupakan pod dan service yang mengimplementasikan fitur-fitur yang diperlukan klaster.
Beberapa addons akan dijelaskan selanjutnya.
DNS
Meskipun tidak semua addons dibutuhkan, semua klaster Kubernetes hendaknya
memiliki DNS klaster. Komponen ini penting karena banyak dibutuhkan oleh komponen
lainnya.
Klaster DNS adalah server DNS, selain beberapa server DNS lain yang sudah ada di
environment kamu, yang berfungsi sebagai catatan DNS bagi Kubernetes services
Kontainer yang dimulai oleh kubernetes secara otomatis akan memasukkan server DNS ini
ke dalam mekanisme pencarian DNS yang dimilikinya.
Web UI (Dasbor)
Dasbor adalah antar muka berbasis web multifungsi yang ada pada klaster Kubernetes.
Dasbor ini memungkinkan user melakukan manajemen dan troubleshooting klaster maupun
aplikasi yang ada pada klaster itu sendiri.
Container Resource Monitoring
Container Resource Monitoring mencatat metrik time-series yang diperoleh
dari kontainer ke dalam basis data serta menyediakan antar muka yang dapat digunakan
untuk melakukan pencarian data yang dibutuhkan.
Cluster-level Logging
Cluster-level logging bertanggung jawab mencatat log kontainer pada
penyimpanan log terpusat dengan antar muka yang dapat digunakan untuk melakukan
pencarian.
1.3 - API Kubernetes
API Kubernetes membuatmu dapat melakukan query dan memanipulasi keadaan objek dalam Kubernetes. Inti dari bidang kontrol Kubernetes adalah server API dan HTTP API yang diekspos. Pengguna, berbagai bagian klastermu, dan komponen eksternal semuanya berkomunikasi satu sama lain melalui server API.
Secara keseluruhan standar yang digunakan untuk API dijelaskan di dalam dokumentasi API standar.
Endpoints API, resource types serta contoh penggunaan dijelaskan di dalam API Reference.
API Kubernetes juga berperan sebagai skema konfigurasi yang deklaratif di dalam sistem.. Sementara itu, kubectl merupakan command-line yang dapat digunakan untuk membuat, menmperbaharui, menghapus, dan mendapatkan obyek API.
Kubernetes menyimpan bentuk terserialisasi dari obyek API yang dimilikinya di dalam etcd.
Kubernetes sendiri dibagi menjadi beberapa komponen yang saling dapat saling interaksi melalui API.
Perubahan API
Berdasarkan pengalaman kami, semua sistem yang berhasil memerlukan kebutuhan
untuk terus tumbuh dan berkembang seiring dengan bertambahnya kebutuhan
yang ada. Dengan demikian, kami berekspektasi bahwa API akan selalu berubah seiring dengan bertambahnya kebutuhan yang ada.
Meski begitu, perubahan yang ada akan selalu kompatibel dengan implementasi sebelumnya, untuk jangka waktu tertentu.
Secara umum, penambahan pada sebuah resource API atau field resource bisa sering terjadi.. Penghapusan resource API atau suatu field, di sisi lain,
diharapkan untuk dapat memenuhi kaidah deprecation API.
Hal-hal apa saja yang perlu diperhatikan untuk menjamin kompatibilitas API
secara rinci dibahas di dalam dokumentasi perubahan API.
Swagger and OpenAPI Definition
Detail mengenai API didokumentasikan dengan menggunakan OpenAPI.
Semenjak Kubernetes versi 1.10, Kubernetes menghadirkan spesifikasi OpenAPI melalui endpoint/openapi/v2.
Format request dapat diterapkan dengan cara menambahkan header HTTP:
Header
Opsi
Accept
application/json, application/com.github.proto-openapi.spec.v2@v1.0+protobuf (content-type standar yang digunakan adalah application/json untuk */*)
Accept-Encoding
gzip
Sebelum versi 1.14, terdapat 4 buah endpoint yang menyediakan spesifikasi OpenAPI
dalam format berbeda yang dapat digunakan (/swagger.json, /swagger-2.0.0.json, /swagger-2.0.0.pb-v1, /swagger-2.0.0.pb-v1.gz).
Endpoint ini bersifat deprecated dan akan dihapus pada Kubernetes versi 1.14.
Kubernetes juga menyediakan alternatif mekanisme serialisasi lain,
yaitu dengan menggunakan Protobuf, yang secara umum digunakan untuk mekanisme komunikasi
intra-klaster, hal ini didokumentasikan di dalam proposal desain
serta berkas IDL sebagai bentuk spesifikasi skema berada dalam package Go
Sebelum Kubernetes versi 1.14, apiserver Kubernetes juga mengekspos API
yang dapat digunakan untuk mendapatkan spesifikasi Swagger v1.2 pada endpoint/swaggerapi.
Endpoint ini akan sudah bersifat deprecated dan akan dihapus pada
Kubernetes versi 1.14.
Pemberian Versi pada API
Untuk memudahkan restrukturisasi field dan resource yang ada,
Kubernetes menyediakan beberapa versi API yang berada pada path yang berbeda,
misalnya /api/v1 atau /apis/extensions/v1beta1.
Kita dapat memilih versi yang akan digunakan pada tingkatan API
dan bukan pada tingkatan field atau resource untuk memastikan
API yang digunakan memperlihatkan gambaran yang jelas serta konsisten
mengenai resoure dan sifat sistem yang ada.
Perhatikan bahwa pemberian versi pada API dan pemberian versi pada API dan perangkat lunak memiliki keterkaitan secara tak langsung.
Proposal API and release
versioning memberikan deskripsi keterkaitan antara
pemberian versi pada API dan pemberian versi pada perangkat lunak.
API dengan versi yang berbeda menunjukan tingkatan kestabilan dan ketersediaan yang diberikan pada versi tersebut.
Kriteria untuk setiap tingkatan dideskripsikan secara lebih detail di dalam
dokumentasi perubahan API. They are summarized here:
Tingkatan Alpha:
Nama dari versi ini mengandung string alpha (misalnya, v1alpha1).
Bisa jadi terdapat bug. Secara default fitur ini tidak diekspos.
Ketersediaan untuk fitur yang ada bisa saja dihilangkan pada suatu waktu tanpa pemberitahuan sebelumnya.
API yang ada mungkin saja berubah tanpa memperhatikan kompatibilitas dengan versi perangkat lunak sebelumnya.
Hanya direkomendasikan untuk klaster yang digunakan untuk tujuan testing.
Tingkatan Beta:
Nama dari versi ini mengandung string beta (misalnya v2beta3).
Kode yang ada sudah melalui mekanisme testing yang cukup baik. Menggunakan fitur ini dianggap cukup aman. Fitur ini diekspos secara default.
Ketersediaan untuk fitur secara menyeluruh tidak akan dihapus, meskipun begitu detail untuk suatu fitur bisa saja berubah.
Skema dan/atau semantik dari suatu obyek mungkin saja berubah tanpa memerhatikan kompatibilitas pada rilis beta selanjutnya.
Jika hal ini terjadi, kami akan menyediakan suatu instruksi untuk melakukan migrasi di versi rilis selanjutnya. hal ini bisa saja terdiri dari penghapusan, pengubahan, ataupun pembuatan
obyek API. Proses pengubahan mungkin saja membutuhkan pemikiran yang matang. Dampak proses ini bisa saja menyebabkan downtime aplikasi yang bergantung pada fitur ini.
Disarankan hanya untuk digunakan untuk penggunaan yang untuk penggunaan yang tidak berdampak langsung pada bisnis kamu.
Kami mohon untuk mencoba versi beta yang kami sediakan dan berikan masukan terhadap fitur yang kamu pakai! Apabila fitur tersebut sudah tidak lagi berada di dalam tingkatan beta perubahan yang kami buat terhadap fitur tersebut bisa jadi tidak lagi dapat digunakan
Tingkatan stabil:
Nama dari versi ini mengandung string vX dimana X merupakan bilangan bulat.
Fitur yang ada pada tingkatan ini akan selalu muncul di rilis berikutnya.
API groups
Untuk memudahkan proses ekstensi suatu API Kubernetes, kami mengimplementasikan API groups.
API group ini dispesifikasikan di dalam pathREST serta di dalam fieldapiVersion dari sebuah obyek yang sudah diserialisasi.
Saat ini, terdapat beberapa API groups yang digunakan:
Kelompok core, seringkali disebut sebagai legacy group, berada pada pathREST/api/v1 serta menggunakan apiVersion: v1.
Named groups berada pada pathREST/apis/$GROUP_NAME/$VERSION, serta menggunakan apiVersion: $GROUP_NAME/$VERSION
(misalnya apiVersion: batch/v1). Daftar menyeluruh mengenai apa saja API groups dapat dilihat di Kubernetes API reference.
Ekstensi API dengan custom resources dapat dilakukan melalui dua buah path:
CustomResourceDefinition
digunakan jika memerlukan seluruh set semantik Kubernetes API, pengguna boleh implementasi apiserver sendiri dengan menggunakan aggregator.
Pengguna yang membutuhkan seperangkat semantik API Kubernetes API dapat mengimplementasikan apiserver mereka sendiri.
dengan menggunakan aggregator
untuk membuat integrasi dengan klien menjadi lebih mudah.
Mengaktifkan API groups
Beberapa resources dan API groups sudah diaktifkan secara default.
Resource dan API groups ini dapat diaktifkan dan dinonaktifkan dengan mengatur penanda --runtime-config
pada apiserver. --runtime-config menerima nilai yang dipisahkan oleh koma. Sebagai contoh: untuk menonaktifkan batch/v1, tetapkan
--runtime-config=batch/v1=false, untuk mengaktifkan batch/v2alpha1, tetapkan --runtime-config=batch/v2alpha1.
Penanda menerima nilai yang dipisahkan oleh pasangan key=value yang mendeskripsikan konfigurasi runtime pada apiserver.
PENTING: Melakukan proses mengaktifkan atau menonaktifkan groups atau resources
membutuhkan mekanisme restartapiserver dan controller-manager
agar apiserver dapat menerima perubahan --runtime-config.
Mengaktifkan resources di dalam groups
DaemonSets, Deployments, HorizontalPodAutoscalers,
Ingresses, Jobs, dan ReplicaSets diaktifkan secara default.
Ekstensi lain dapat diaktifkan penanda --runtime-config pada apiserver. Penanda --runtime-config menerima nilai yang dipisahkan oleh koma.
Sebagai contoh untuk menonaktifkan deployments dan ingress, tetapkan.
--runtime-config=extensions/v1beta1/deployments=false,extensions/v1beta1/ingresses=false
1.4 - Menggunakan Objek-Objek Kubernetes
Objek-objek Kubernetes adalah entitas yang tetap dalam sistem Kubernetes. Kubernetes menggunakan entitas tersebut untuk merepresentasikan keadaan dari klastermu. Pelajari tentang objek model Kubernetes dan bagaimana menggunakan objek tersebut.
1.4.1 - Memahami Konsep Objek-Objek yang ada pada Kubernetes
Laman ini menjelaskan bagaimana objek-objek Kubernetes direpresentasikan di dalam API Kubernetes,
dan bagaimana kamu dapat merepresentasikannya di dalam format .yaml.
Memahami Konsep Objek-Objek yang Ada pada Kubernetes
Objek-objek Kubernetes adalah entitas persisten di dalam sistem Kubernetes.
Kubernetes menggunakan entitas ini untuk merepresentasikan state yang ada pada
klaster kamu. Secara spesifik, hal itu dapat dideskripsikan sebagai:
Aplikasi-aplikasi kontainer apa sajakah yang sedang dijalankan (serta pada node apa aplikasi tersebut dijalankan)
Resource yang tersedia untuk aplikasi tersebut
Policy yang mengatur bagaimana aplikasi tersebut dijalankan, misalnya restart, upgrade, dan fault-tolerance.
Objek Kubernetes merupakan sebuah "record of intent"--yang mana sekali kamu membuat suatu objek,
sistem Kubernetes akan bekerja secara konsisten untuk menjamin
bahwa objek tersebut akan selalu ada. Dengan membuat sebuah objek, secara tak langsung kamu
memberikan informasi pada sistem Kubernetes mengenai perilaku apakah yang kamu inginkan pada workload klaster yang kamu miliki;
dengan kata lain ini merupakan definisi state klaster yang kamu inginkan.
Untuk menggunakan objek-objek Kubernetes--baik membuat, mengubah, atau menghapus objek-objek tersebut--kamu
harus menggunakan API Kubernetes.
Ketika kamu menggunakan perintah kubectl, perintah ini akan melakukan API call untuk perintah
yang kamu berikan. Kamu juga dapat menggunakan API Kubernetes secara langsung pada program yang kamu miliki
menggunakan salah satu library klien yang disediakan.
Spec dan Status Objek
Setiap objek Kubernetes memiliki field berantai yang mengatur konfigurasi sebuah objek:
spec dan status. Spec, merupakan field yang harus kamu sediakan, field ini mendeskripsikan
state yang kamu inginkan untuk objek tersebut--karakteristik dari objek yang kamu miliki.
Status mendeskripsikan state yang sebenarnya dari sebuah objek, dan hal ini disediakan dan selalu diubah oleh
sistem Kubernetes. Setiap saat, Control Plane Kubernetes selalu memantau apakah state aktual sudah sesuai dengan
state yang diinginkan.
Sebagai contoh, Deployment merupakan sebuah objek yang merepresentasikan sebuah aplikasi yang dijalankan di klaster kamu.
Ketika kamu membuat sebuah Deployment, kamu bisa saja memberikan spec bagi Deployment untuk memberikan spesifikasi
berapa banyak replica yang kamu inginkan. Sistem Kubernetes kemudian akan membaca konfigurasi yang kamu berikan
dan mengaktifkan tiga buah instans untuk aplikasi yang kamu inginkan--mengubah status yang ada saat ini agar sesuai dengan apa yang kamu inginkan.
Jika terjadi kegagalan dalam instans yang dibuat, sistem Kubernetes akan memberikan respons bahwa terdapat perbedaan antara spec dan status serta
melakukan penyesuaian dengan cara memberikan instans pengganti.
Informasi lebih lanjut mengenai spec objek, status, dan metadata dapat kamu baca di Konvensi API Kubernetes.
Mendeskripsikan Objek Kubernetes
Ketika kamu membuat sebuah objek di Kubernetes, kamu harus menyediakan spec objek yang
mendeskripsikan state yang diinginkan, serta beberapa informasi tentang objek tersebut (seperti nama).
Ketika kamu menggunakan API Kubernetes untuk membuat objek tersebut (baik secara langsung atau menggunakan perintah
kubectl), request API yang dibuat harus mencakup informasi seperti request body dalam format JSON.
Apabila kamu memberikan informasi dalam bentuk .yaml ketika menggunakan perintah kubectl maka kubectl
akan mengubah informasi yang kamu berikan ke dalam format JSON ketika melakukan request API.
Berikut merupakan contoh file.yaml yang menunjukkan field dan spec objek untuk Deployment:
apiVersion:apps/v1# for versions before 1.9.0 use apps/v1beta2kind:Deploymentmetadata:name:nginx-deploymentspec:selector:matchLabels:app:nginxreplicas:2# tells deployment to run 2 pods matching the templatetemplate:metadata:labels:app:nginxspec:containers:- name:nginximage:nginx:1.7.9ports:- containerPort:80
Salah satu cara untuk membuat Deployment menggunakan file.yaml
seperti yang dijabarkan di atas adalah dengan menggunakan perintah
kubectl apply
pada command-line interfacekubectl kamu menerapkan file.yaml sebagai sebuah argumen.
Berikut merupakan contoh penggunaannya:
Keluaran yang digunakan kurang lebih akan ditampilkan sebagai berikut:
deployment.apps/nginx-deployment created
Field-Field yang dibutuhkan
Pada file.yaml untuk objek Kubernetes yang ingin kamu buat, kamu perlu
menyediakan value untuk field-field berikut:
apiVersion - Version API Kubernetes mana yang kamu gunakan untuk membuat objek tersebut
kind - Objek apakah yang ingin kamu buat
metadata - Data yang dapat kamu gunakan untuk melakukan identifikasi objek termasuk name dalam betuk string, UID, dan namespace yang bersifat opsional
Kamu juga harus menyediakan fieldspec. Format spesifik dari spec sebuah objek akan berbeda bergantung
pada objek apakah yang ingin kamu buat, serta mengandung field berantai yang spesifik bagi objek tersebut.
Referensi API Kubernetes memberikan penjelasan
lebih lanjut mengenai format spec untuk semua objek Kubernetes yang dapat kamu buat. Misalnya saja format spec
untuk Pod dapat kamu temukan di sini,
dan format spec untuk Deployment dapat ditemukan
di sini.
Selanjutnya
Pelajari lebih lanjut mengenai dasar-dasar penting bagi objek Kubernetes, seperti Pod.
1.4.2 - Pengaturan Objek Kubernetes
Perangkat kubectl mendukung beberapa cara untuk membuat dan mengatur objek-objek Kubernetes.
Laman ini menggambarkan berbagai macam metodenya. Baca Kubectl gitbook
untuk penjelasan pengaturan objek dengan Kubectl secara detail.
Metode pengaturan
Peringatan:
Sebuah objek Kubernetes hanya boleh diatur dengan menggunakan satu metode saja. Mengkombinasikan
beberapa metode untuk objek yang sama dapat menghasilkan perilaku yang tidak diinginkan.
Metode pengaturan
Dijalankan pada
Environment yang disarankan
Jumlah penulis yang didukung
Tingkat kesulitan mempelajari
Perintah imperatif
Objek live
Proyek pengembangan (dev)
1+
Terendah
Konfigurasi objek imperatif
Berkas individu
Proyek produksi (prod)
1
Sedang
Konfigurasi objek deklaratif
Direktori berkas
Proyek produksi (prod)
1+
Tertinggi
Perintah imperatif
Ketika menggunakan perintah-perintah imperatif, seorang pengguna menjalankan operasi secara langsung
pada objek-objek live dalam sebuah klaster. Pengguna menjalankan operasi tersebut melalui
argumen atau flag pada perintah kubectl.
Ini merupakan cara yang paling mudah untuk memulai atau menjalankan tugas "sekali jalan" pada sebuah klaster.
Karena metode ini dijalankan secara langsung pada objek live, tidak ada history yang menjelaskan konfigurasi-konfigurasi terkait sebelumnya.
Contoh
Menjalankan sebuah instans Container nginx dengan membuat suatu objek Deployment:
kubectl run nginx --image nginx
Melakukan hal yang sama menggunakan sintaks yang berbeda:
kubectl create deployment nginx --image nginx
Kelebihan dan kekurangan
Beberapa kelebihan metode ini dibandingkan metode konfigurasi objek:
Sederhana, mudah dipelajari dan diingat.
Hanya memerlukan satu langkah untuk membuat perubahan pada klaster.
Beberapa kekurangan metode ini dibandingkan metode konfigurasi objek:
Tidak terintegrasi dengan proses peninjauan (review) perubahan.
Tidak menyediakan jejak audit yang terkait dengan perubahan.
Tidak menyediakan sumber record kecuali dari apa yang live terlihat.
Tidak menyediakan templat untuk membuat objek-objek baru.
Konfigurasi objek imperatif
Pada konfigurasi objek imperatif, perintah kubectl menetapkan jenis operasi
(create, replace, etc.), flag-flag pilihan dan minimal satu nama berkas.
Berkas ini harus berisi definisi lengkap dari objek tersebut
dalam bentuk YAML atau JSON.
Lihat referensi API
untuk info lebih detail mengenai definisi objek.
Peringatan:
Perintah imperatif replace menggantikan spek yang sudah ada dengan spek yang baru,
membuang semua perubahan terhadap objek tersebut yang tidak didefinisikan pada berkas konfigurasi.
Metode ini sebaiknya tidak dilakukan pada tipe sumber daya yang spek-nya diperbarui
secara independen di luar berkas konfigurasi. Service dengan tipe LoadBalancer, sebagai contoh,
memiliki fieldexternalIPs yang diperbarui secara independen di luar konfigurasi, dilakukan
oleh klaster.
Contoh
Membuat objek yang didefinisikan pada sebuah berkas konfigurasi:
kubectl create -f nginx.yaml
Menghapus objek-objek yang didefinisikan pada dua berkas konfigurasi:
kubectl delete -f nginx.yaml -f redis.yaml
Memperbarui objek yang didefinisikan pada sebuah berkas konfigurasi dengan
menimpa konfigurasi live:
kubectl replace -f nginx.yaml
Kelebihan dan kekurangan
Beberapa kelebihan dibandingkan metode perintah imperatif:
Konfigurasi objek dapat disimpan pada suatu sistem kontrol kode seperti Git.
Konfigurasi objek dapat diintegrasikan dengan proses-proses, misalnya peninjauan (review) perubahan sebelum push dan jejak audit.
Konfigurasi objek dapat menyediakan templat untuk membuat objek-objek baru.
Beberapa kekurangan dibandingkan metode perintah imperatif:
Konfigurasi objek memerlukan pemahaman yang mendasar soal skema objek.
Konfigurasi objek memerlukan langkah tambahan untuk menulis berkas YAML.
Beberapa kelebihan dibandingkan metode konfigurasi objek deklaratif:
Konfigurasi objek imperatif memiliki perilaku yang lebih sederhana dan mudah dimengerti.
Sejak Kubernetes versi 1.5, konfigurasi objek imperatif sudah lebih stabil.
Beberapa kekurangan dibandingkan metode konfigurasi objek deklaratif:
Konfigurasi objek imperatif bekerja dengan baik untuk berkas-berkas, namun tidak untuk direktori.
Pembaruan untuk objek-objek live harus diterapkan pada berkas-berkas konfigurasi, jika tidak, hasil perubahan akan hilang pada penggantian berikutnya.
Konfigurasi objek deklaratif
Ketika menggunakan konfigurasi objek deklaratif, seorang pengguna beroperasi pada berkas-berkas
konfigurasi objek yang disimpan secara lokal, namun pengguna tidak mendefinisikan operasi
yang akan dilakukan pada berkas-berkas tersebut. Operasi create, update, dan delete
akan dideteksi secara otomatis per-objek dengan kubectl. Hal ini memungkinkan penerapan
melalui direktori, dimana operasi yang berbeda mungkin diperlukan untuk objek-objek yang berbeda.
Catatan:
Konfigurasi objek deklaratif mempertahankan perubahan yang dibuat oleh penulis lainnya, bahkan
jika perubahan tidak digabungkan (merge) kembali pada berkas konfigurasi objek. Hal ini
bisa terjadi dengan menggunakan operasi API patch supaya hanya perbedaannya saja yang ditulis,
daripada menggunakan operasi API replace untuk menggantikan seluruh konfigurasi objek.
Contoh
Melakukan pemrosesan pada semua berkas konfigurasi objek di direktori configs, dan melakukan
create atau patch untuk objek-objek live. Kamu dapat terlebih dahulu melakukan diff untuk
melihat perubahan-perubahan apa saja yang akan dilakukan, dan kemudian terapkan:
Beberapa kelebihan dibandingkan konfigurasi objek imperatif:
Perubahan-perubahan yang dilakukan secara langsung pada objek-objek live akan dipertahankan, bahkan jika perubahan tersebut tidak digabungkan kembali pada berkas-berkas konfigurasi.
Konfigurasi objek deklaratif memiliki dukungan yang lebih baik dalam mengoperasikan direktori dan secara otomatis mendeteksi tipe operasi (create, patch, delete) per-objek.
Beberapa kekurangan dibandingkan konfigurasi objek imperatif:
Konfigurasi objek deklaratif lebih sulit untuk di-debug dan hasilnya lebih sulit dimengerti untuk perilaku yang tidak diinginkan.
Pembaruan sebagian menggunakan diff menghasilkan operasi merge dan patch yang rumit.
Seluruh objek di dalam REST API Kubernetes secara jelas ditandai dengan nama dan UID.
Apabila pengguna ingin memberikan atribut tidak unik, Kubernetes menyediakan label dan anotasi.
Bacalah dokumentasi desain penanda agar kamu dapat memahami lebih lanjut sintaks yang digunakan untuk Nama dan UID.
Nama
String yang dihasilkan oleh klien yang mengacu pada sebuah objek dalam suatu URL resource, seperti /api/v1/pods/some-name.
Sebuah objek dengan kind yang sama tidak boleh memiliki nama yang sama pada suatu waktu tertentu. Meskipun begitu, apabila kamu menghapus sebuah objek, kamu membuat sebuah objek baru (yang memiliki kind yang sama) dengan nama yang sama dengan objek yang kamu hapus sebelumnya.
Berdasarkan ketentuan, nama dari resources Kubernetes memiliki panjang maksimum 253 karakter yang terdiri dari karakter alfanumerik huruf kecil, -, dan ., tetapi resources tertentu punya lebih banyak batasan yang spesifik
UID
String yang dihasilkan oleh sistem Kubernetes untuk mengidentifikasi objek secara unik.
Setiap objek yang ada pada klaster Kubernetes memiliki UID yang unik. Hal ini dilakukan untuk membedakan keberadaan historis suatu entitas dengan kind dan nama yang serupa.
1.4.4 - Namespace
Kubernetes mendukung banyak klaster virtual di dalam satu klaster fisik. Klaster virtual tersebut disebut dengan namespace.
Kapan menggunakan banyak Namespace
Namespace dibuat untuk digunakan di environment dengan banyak pengguna yang berada di dalam banyak tim ataupun proyek. Untuk sebuah klaster dengan beberapa pengguna saja, kamu tidak harus membuat ataupun memikirkan tentang namespace. Mulai gunakan namespace saat kamu membutuhkan fitur dari namespace itu sendiri.
Namespace menyediakan ruang untuk nama objek. Nama dari resource atau objek harus berbeda di dalam sebuah namespace, tetapi boleh sama jika berbeda namespace. Namespace tidak bisa dibuat di dalam namespace lain dan setiap resource atau objek Kubernetes hanya dapat berada di dalam satu namespace.
Namespace merupakan cara yang digunakan untuk memisahkan resource klaster untuk beberapa pengguna (dengan resource quota).
Dalam versi Kubernetes yang akan datang, objek di dalam satu namespace akan mempunyai access control policies yang sama secara default.
Tidak perlu menggunakan banyak namespace hanya untuk memisahkan sedikit perbedaan pada resource, seperti perbedaan versi dari perangkat lunak yang sama: gunakan label untuk membedakan resource di dalam namespace yang sama.
Kamu dapat melihat daftar namespace di dalam klaster menggunakan:
kubectl get namespace
NAME STATUS AGE
default Active 1d
kube-system Active 1d
kube-public Active 1d
Kubernetes berjalan dengan tiga namespace awal:
default, namespace default untuk objek yang dibuat tanpa mencantumkan namespace pada spesifikasinya.
kube-system, namespace yang digunakan untuk objek yang dibuat oleh sistem Kubernetes.
kube-public, namespace ini dibuat secara otomatis dan dapat diakses oleh semua pengguna (termasuk yang tidak diautentikasi). Namespace ini disediakan untuk penggunaan klaster, jika beberapa resouce harus terlihat dan dapat dibaca secara publik di seluruh klaster. Aspek publik dari namespace ini hanya sebuah konvensi, bukan persyaratan.
Mengkonfigurasi namespace untuk request
Untuk mengkonfigurasi sementara request untuk menggunakan namespace tertentu, gunakan --namespaceflag.
Sebagai contoh:
kubectl --namespace=<insert-namespace-name-here> run nginx --image=nginx
kubectl --namespace=<insert-namespace-name-here> get pods
Mengkonfigurasi preferensi namespace
Kamu dapat menyimpan konfigurasi namespace untuk semua perintah kubectl dengan perintah:
Saat kamu membuat sebuah Service, Kubernetes membuat Entri DNS untuk service tersebut. Entri DNS ini berformat <service-name>.<namespace-name>.svc.cluster.local, yang berarti jika sebuah kontainer hanya menggunakan <service-name>, kontainer tersebut akan berkomunikasi dengan service yang berada di dalam satu namespace. Ini berguna untuk menggunakan konfigurasi yang sama di beberapa namespace seperti Development, Staging, dan Production. Jika kamu ingin berkomunikasi antar namespace, kamu harus menggunakan seluruh fully qualified domain name (FQDN).
Tidak semua objek di dalam Namespace
Kebanyakan resource di Kubernetes (contohnya pod, service, replication controller, dan yang lain) ada di dalam namespace. Namun resource namespace sendiri tidak berada di dalam namespace. Dan low-level resource seperti node dan persistentVolume tidak berada di namespace manapun.
Untuk melihat resource di dalam kubernetes yang berada di dalam namespace ataupun tidak:
# Di dalam namespacekubectl api-resources --namespaced=true# Tidak di dalam namespacekubectl api-resources --namespaced=false
1.4.5 - Label dan Selektor
Label merupakan pasangan key/value yang melekat pada objek-objek, misalnya pada Pod.
Label digunakan untuk menentukan atribut identitas dari objek agar memiliki arti dan relevan bagi para pengguna, namun tidak secara langsung memiliki makna terhadap sistem inti.
Label dapat digunakan untuk mengatur dan memilih sebagian dari banyak objek. Label-label dapat ditempelkan ke objek-objek pada saat dibuatnya objek-objek tersebut dan kemudian ditambahkan atau diubah kapan saja setelahnya.
Setiap objek dapat memiliki satu set label key/value. Setiap Key harus unik untuk objek tersebut.
Label memungkinkan untuk menjalankan kueri dan pengamatan dengan efisien, serta ideal untuk digunakan pada UI dan CLI. Informasi yang tidak digunakan untuk identifikasi sebaiknya menggunakan anotasi.
Motivasi
Label memungkinkan pengguna untuk memetakan struktur organisasi mereka ke dalam objek-objek sistem yang tidak terikat secara erat, tanpa harus mewajibkan klien untuk menyimpan pemetaan tersebut.
Service deployments dan batch processing pipelines sering menjadi entitas yang berdimensi ganda (contohnya partisi berganda atau deployment, jalur rilis berganda, tingkatan berganda, micro-services berganda per tingkatan). Manajemen seringkali membutuhkan operasi lintas tim, yang menyebabkan putusnya enkapsulasi dari representasi hierarki yang ketat, khususnya pada hierarki-hierarki kaku yang justru ditentukan oleh infrastruktur, bukan oleh pengguna.
Ini hanya contoh label yang biasa digunakan; kamu bebas mengembangkan caramu sendiri. Perlu diingat bahwa Key dari label harus unik untuk objek tersebut.
Sintaksis dan set karakter
Label merupakan pasangan key/value. Key-key dari Label yang valid memiliki dua segmen: sebuah prefiks dan nama yang opsional, yang dipisahkan oleh garis miring (/). Segmen nama wajib diisi dan tidak boleh lebih dari 63, dimulai dan diakhiri dengan karakter alfanumerik ([a-z0-9A-Z]) dengan tanda pisah (-), garis bawah (_), titik (.), dan alfanumerik di antaranya. Sedangkan prefiks bersifat opsional. Jika ditentukan, prefiks harus berupa subdomain DNS: rangkaian label DNS yang dipisahkan oleh titik (.), dengan total tidak lebih dari 253 karakter, yang diikuti oleh garis miring (/).
Jika prefiks dihilangkan, Key dari label diasumsikan privat bagi pengguna. Komponen sistem otomatis (contoh kube-scheduler, kube-controller-manager, kube-apiserver, kubectl, atau otomasi pihak ketiga lainnya) yang akan menambah label ke objek-objek milik pengguna akhir harus menentukan prefiks.
Prefiks kubernetes.io/ dan k8s.io/ dikhususkan untuk komponen inti Kubernetes.
Nilai label yang valid tidak boleh lebih dari 63 karakter dan harus kosong atau diawali dan diakhiri dengan karakter alfanumerik ([a-z0-9A-Z]) dengan tanda pisah (-), garis bawah (_), titik (.), dan alfanumerik di antaranya.
Contoh di bawah ini merupakan berkas konfigurasi untuk Pod yang memiliki dua label environment: production dan app: nginx :
Tidak seperti nama dan UID, label tidak memberikan keunikan. Secara umum, kami memperkirakan bahwa banyak objek yang akan memiliki label yang sama.
Menggunakan sebuah label selector, klien/pengguna dapat mengidentifikasi suatu kumpulan objek. Selektor label merupakan alat/cara pengelompokan utama pada Kubernetes.
Saat ini API mendukung dua jenis selektor: equality-based dan set-based.
Sebuah selektor label dapat dibuat dari kondisi berganda yang dipisahkan oleh koma. Pada kasus kondisi berganda, semua kondisi harus dipenuhi sehingga separator koma dapat bertindak sebagai operator logika AND (&&).
Makna dari selektor yang kosong atau tidak diisi tergantung dari konteks, dan tipe API yang menggunakan selektor harus mendokumentasikan keabsahan dan arti dari selektor yang kosong tersebut.
Catatan:
Untuk beberapa tipe API, seperti ReplicaSet, selektor label untuk dua objek tidak boleh tumpang tindih dengan Namespace, jika tidak maka controller akan melihatnya sebagai instruksi yang menyebabkan konflik dan akan gagal menentukan berapa banyak replika yang seharusnya tersedia.
Perhatian:
Untuk kedua kondisi equality-based dan set-based tidak ada logika operator OR (||). Pastikan struktur pernyataan filter kamu ikut disesuaikan.
Kondisi Equality-based
Kondisi Equality-based atau inequality-based memungkinkan untuk melakukan filter dengan menggunakan key dan value dari label. Objek yang cocok harus memenuhi semua batasan label yang telah ditentukan, meskipun mereka dapat memiliki label tambahan lainnya.
Terdapat tiga jenis operator yang didukung yaitu =,==,!=. Dua operator pertama menyatakan kesamaan (keduanya hanyalah sinonim), sementara operator terakhir menyatakan ketidaksamaan. Contoh:
environment = production
tier != frontend
Kondisi pertama akan memilih semua sumber daya dengan keyenvironment dan nilai keyproduction.
Kondisi berikutnya akan memilih semua sumber daya dengan keytier dan nilai key selain frontend, dan semua sumber daya yang tidak memiliki label dengan keytier.
Kamu juga dapat memfilter sumber daya dalam production selain frontend dengan menggunakan operator koma: environment=production,tier!=frontend
Salah satu skenario penggunaan label dengan kondisi equality-based yaitu untuk kriteria pemilihan Node untuk Pod-Pod. Sebagai contoh, Pod percontohan di bawah ini akan memilih Node dengan label "accelerator=nvidia-tesla-p100".
Kondisi label Set-based memungkinkan memfilter key terhadap suatu kumpulan nilai. Terdapat tiga jenis operator yang didukung, yaitu: in,notin, dan exists (hanya key-nya saja). Contoh:
environment in (production, qa)
tier notin (frontend, backend)
partition
!partition
Contoh pertama akan memilih semua sumber daya dengan keyenvironment dan nilai production atau qa.
Contoh kedua akan memilih semua sumber daya dengan keytier dan nilai selain frontend dan backend, serta semua sumber daya yang tidak memiliki label dengan keytier.
Contoh ketiga akan memilih semua sumber daya yang memiliki key dari labelpartition; nilainya tidak diperiksa.
Sedangkan contoh keempat akan memilih semua sumber daya yang tidak memiliki label dengan keypartition; nilainya tidak diperiksa.
Secara serupa, operator koma bertindak sebagai operator AND. Sehingga penyaringan sumber daya dengan keypartition (tidak peduli nilai dari key) dan environment yang tidak sama dengan qa dapat dicapai dengan partition,environment notin (qa).
Selektor label set-based merupakan bentuk umum persamaan karena environment=production sama dengan environment in (production); demikian pula != dan notin.
Kondisi Set-based dapat digabungkan dengan kondisi equality-based. Contoh: partition in (customerA, customerB),environment!=qa.
API
Penyaringan LIST dan WATCH
Operasi LIST dan WATCH dapat menentukan selektor label untuk memfilter suatu kumpulan objek yang didapat dengan menggunakan parameter kueri. Kedua jenis kondisi diperbolehkan (ditampilkan sebagai berikut, sama seperti saat tampil pada string kueri di URL):
Kondisi equality-based: ?labelSelector=environment%3Dproduction,tier%3Dfrontend
Kondisi set-based: ?labelSelector=environment+in+%28production%2Cqa%29%2Ctier+in+%28frontend%29
Kedua jenis selektor label dapat digunakan untuk menampilkan (list) dan mengamati (watch) sumber daya melalui klien REST. Contohnya, menargetkan apiserver dengan kubectl dan menggunakan equality-based kamu dapat menuliskan:
kubectl get pods -l environment=production,tier=frontend
atau menggunakan kondisi set-based:
kubectl get pods -l 'environment in (production),tier in (frontend)'
Seperti yang telah disebutkan sebelumnya, kondisi set-based lebih ekspresif. Sebagai contoh, mereka dapat digunakan untuk mengimplementasi operator OR pada nilai:
kubectl get pods -l 'environment in (production, qa)'
atau membatasi pencocokan negatif dengan operator notin:
kubectl get pods -l 'environment,environment notin (frontend)'
Mengatur referensi pada objek API
Pada beberapa objek Kubernetes, seperti Service dan ReplicationController, juga menggunakan selektor label untuk menentukan kumpulan dari sumber daya lain, seperti Pod.
Service dan ReplicationController
Kumpulan Pod yang ditargetkan oleh sebuah service ditentukan dengan selektor label. Demikian pula kumpulan Pod yang harus ditangani oleh replicationcontroller juga ditentukan dengan selektor label.
Selektor label untuk kedua objek tersebut ditentukan dalam berkas json atau yaml menggunakan maps, dan hanya mendukung kondisi equality-based:
"selector":{"component":"redis",}
atau
selector:component:redis
selektor ini (baik dalam bentuk json atau yaml) sama dengan component=redis atau component in (redis).
matchLabels merupakan pemetaan dari pasangan {key,value}. Sebuah {key,value} pada pemetaan matchLabels adalah sama dengan elemen dari matchExpressions, yang nilai key nya adalah "key", dengan operator "In", dan arrayvalues hanya berisi "value". matchExpressions merupakan daftar kondisi untuk selektor Pod. Operator yang valid termasuk In, NotIn, Exists, dan DoesNotExist. Kumpulan nilai ini tidak boleh kosong pada kasus In dan NotIn. Semua kondisi, baik dari matchLabels dan matchExpressions di-AND secara sekaligus -- mereka harus memenuhi semua kondisi agar cocok.
Memilih kumpulan Node
Salah satu contoh penggunaan pemilihan dengan menggunakan label yaitu untuk membatasi suatu kumpulan Node tertentu yang dapat digunakan oleh Pod.
Lihat dokumentasi pada pemilihan Node untuk informasi lebih lanjut.
1.4.6 - Anotasi
Kamu dapat menggunakan fitur anotasi dari Kubernetes untuk menempelkan sembarang
metadata tanpa identitas pada suatu objek. Klien, seperti perangkat dan library,
dapat memperoleh metadata tersebut.
Mengaitkan metadata pada objek
Kamu dapat menggunakan label maupun anotasi untuk menempelkan metadata pada suatu
objek Kubernetes. Label dapat digunakan untuk memilih objek dan mencari sekumpulan
objek yang memenuhi kondisi tertentu. Sebaliknya, anotasi tidak digunakan untuk
mengenali atau memilih objek. Metadata dalam sebuah anotasi bisa berukuran kecil atau besar,
terstruktur atau tidak terstruktur, dan dapat berisikan karakter-karakter yang tidak
diperbolehkan oleh label.
Anotasi, seperti label, merupakan pemetaan key/value:
Berikut merupakan beberapa contoh informasi yang dapat dicatat dengan menggunakan anotasi:
Field-field yang dikelola secara deklaratif oleh layer konfigurasi. Menempelkan
field-field tersebut sebagai anotasi membedakan mereka dari nilai default yang
ditetapkan oleh klien ataupun server, dari field-field yang otomatis di-generate, serta
dari field-field yang ditetapkan oleh sistem auto-sizing atau auto-scaling.
Informasi mengenai build, rilis, atau image, seperti timestamp, rilis ID, git branch,
nomor PR, hash suatu image, dan alamat registri.
Penanda untuk logging, monitoring, analytics, ataupun repositori audit.
Informasi mengenai library klien atau perangkat yang dapat digunakan untuk debugging:
misalnya, informasi nama, versi, dan build.
Informasi yang berhubungan dengan pengguna atau perangkat/sistem, seperti URL objek yang terkait
dengan komponen dari ekosistem lain.
Metadata untuk perangkat rollout yang ringan (lightweight): contohnya, untuk
konfigurasi atau penanda (checkpoint).
Nomor telepon atau pager dari orang yang bertanggung jawab, atau entri direktori
yang berisi informasi lebih lanjut, seperti website sebuah tim.
Arahan dari pengguna (end-user) untuk melakukan implementasi, perubahan perilaku,
ataupun untuk interaksi dengan fitur-fitur non-standar.
Tanpa menggunakan anotasi, kamu dapat saja menyimpan informasi-informasi dengan tipe
di atas pada suatu basis data atau direktori eksternal, namun hal ini sangat mempersulit
pembuatan library klien dan perangkat yang bisa digunakan sama-sama (shared) untuk melakukan
deploy, pengelolaan, introspeksi, dan semacamnya.
Sintaksis dan sekumpulan karakter
Anotasi merupakan key/value pair. Key dari sebuah anotasi yang valid memiliki dua segmen: segmen prefiks yang opsional dan segmen nama, dipisahkan
oleh sebuah garis miring (/). Segmen nama bersifat wajib dan harus terdiri dari 63 karakter atau kurang, dimulai dan diakhiri dengan karakter alfanumerik ([a-z0-9A-Z]) dengan tanda minus (-), garis bawah (_), titik (.), dan alfanumerik di tengahnya. Jika terdapat prefiks,
prefiks haruslah berupa subdomain DNS: urutan dari label DNS yang dipisahkan oleh titik (.), totalnya tidak melebihi 253 karakter,
diikuti dengan garis miring (/).
Jika tidak terdapat prefiks, maka key dari anotasi diasumsikan hanya bisa dilihat oleh pengguna (privat). Komponen sistem otomasi
(seperti kube-scheduler, kube-controller-manager, kube-apiserver, kubectl, ataupun otomasi pihak ketiga) yang menambahkan anotasi
pada objek-objek pengguna harus memiliki sebuah prefiks.
Prefiks kubernetes.io/ dan k8s.io/ merupakan reservasi dari komponen inti Kubernetes.
Selektor field memungkinkan kamu untuk memilih (select) resource Kubernetes berdasarkan
nilai dari satu atau banyak field resource. Di bawah ini merupakan contoh dari beberapa query selektor field:
metadata.name=my-service
metadata.namespace!=default
status.phase=Pending
Perintah kubectl di bawah ini memilih semua Pod dengan fieldstatus.phase yang bernilai
Running:
kubectl get pods --field-selector status.phase=Running
Catatan:
Pada dasarnya, selektor field merupakan filter dari resource. Secara default, tidak ada selektor/filter apapun yang diterapkan. Artinya,
semua resource dengan tipe apapun akan terpilih. Akibatnya, query dengan perintah kubectl di bawah ini akan memberikan hasil yang sama:
kubectl get pods
kubectl get pods --field-selector ""
Field yang didukung
Selektor-selektor field yang didukung oleh Kubernetes bervariasi tergantung dari tipe resource. Semua tipe resource mendukung fieldmetadata.name dan metadata.namespace. Jika kamu menggunakan selektor field yang tidak didukung, maka akan terjadi error. Contohnya:
kubectl get ingress --field-selector foo.bar=baz
Error from server (BadRequest): Unable to find "ingresses" that match label selector "", field selector "foo.bar=baz": "foo.bar" is not a known field selector: only "metadata.name", "metadata.namespace"
Operator yang didukung
Kamu dapat menggunakan operator =, ==, dan != pada selektor field (= dan == punya arti yang sama). Sebagai contoh, perintah kubectl ini
memilih semua Kubernetes Service yang tidak terdapat pada namespacedefault:
kubectl get services --field-selector metadata.namespace!=default
Selektor berantai
Seperti halnya label dan selektor-selektor lainnya, kamu dapat membuat selektor field berantai
(chained) dengan list yang dipisahkan oleh koma. Perintah kubectl di bawah ini memilih semua Pod dengan status.phase tidak sama dengan
Running dan fieldspec.restartPolicy sama dengan Always:
kubectl get pods --field-selector=status.phase!=Running,spec.restartPolicy=Always
Resource dengan beberapa tipe
Kamu dapat menggunakan selektor-selektor field dengan beberapa tipe resource sekaligus. Perintah kubectl di bawah ini memilih semua Statefulset
dan Service yang tidak terdapat pada namespacedefault:
kubectl get statefulsets,services --all-namespaces --field-selector metadata.namespace!=default
1.4.8 - Label yang Disarankan
Kamu dapat melakukan visualisasi dan mengatur objek Kubernetes dengan lebih banyak tools
dibandingkan dengan perintah kubectl dan dasbor. Sekumpulan label mengizinkan tools
untuk bekerja dengan interoperabilitas, mendeskripsikan objek dengan cara yang umum yang dapat
dipahami semua tools.
Sebagai tambahan bagi tooling tambahan, label yang disarankan ini mendeskripsikan
aplikasi sehingga informasi yang ada diapat di-query.
Metadata ini diorganisasi berbasis konsep dari sebuah aplikasi. Kubernetes bukan merupakan
sebuah platform sebagai sebuah service (platform as a service/PaaS) dan tidak
mewajibkan sebuah gagasan formal dari sebuah aplikasi.
Sebagai gantinya, aplikasi merupakan suatu hal informal yang dideskripsikan melalui metadata.
Definisi yang dimiliki oleh sebuah aplikasi merupakan sebuah hal yang cukup longgar.
Catatan:
Berikut merupakan label yang disarankan. Label ini mempermudah
proses manajemen aplikasi tetapi tidak dibutuhkan untuk tooling utama apa pun.
Label yang digunakan secara umum serta anotasi memiliki prefiks yang serupa: app.kubernetes.io. Label
tanpa sebuah prefiks bersifat privat khusus pengguna saja. Prefiks yang digunakan secara umum tadi
menjamin bahwa label tadi tidak akan mengganggu label custom yang diberikan oleh pengguna.
Label
Untuk mendapatkan keuntungan menyeluruh dari penggunaan label ini,
label harus digunakan pada seluruh objek sumber daya.
Key
Deskripsi
Contoh
Tipe
app.kubernetes.io/name
Nama aplikasi
mysql
string
app.kubernetes.io/instance
Nama unik yang bersifat sebagai pengidentifikasi dari sebuah instans aplikasi
wordpress-abcxzy
string
app.kubernetes.io/version
Versi saat ini dari aplikasi (misalnya sebuah versi semantik, hash revisi, etc.)
5.7.21
string
app.kubernetes.io/component
Komponen yang ada pada arsitektur
database
string
app.kubernetes.io/part-of
Nama dari komponen lebih tinggi dari aplikasi yang mencakup bagian ini
wordpress
string
app.kubernetes.io/managed-by
Alat yang digunakan untuk mengatur operasi pada aplikasi
helm
string
Untuk memberikan ilustrasi dari penggunaan label, bayangkan sebuah objek StatefulSet yang didefinisikan sebagai berikut:
Sebuah aplikasi dapat diinstal sekali atau beberapa kali di dalam klaster Kubernetes dan,
pada beberapa kasus, di dalam sebuah namespace yang sama. Misalnya, wordpress dapat
diinstal lebih dari satu kali dimana situs web yang berbeda merupakan hasil instalasi yang berbeda.
Nama dari sebuah aplikasi dan nama instans akan dicatat secara terpisah. Sebagai contoh,
WordPress memiliki wordpress sebagai nilai dari app.kubernetes.io/name dimana
nama instans yang digunakan adalah wordpress-abcxzy yang merupakan nilai dari app.kubernetes.io/instance.
Hal ini memungkinkan aplikasi dan instans aplikasi untuk dapat diidentifikasi. Setiap instans dari aplikasi
haruslah memiliki nama yang unik.
Contoh
Untuk memberikan ilustrasi dengan cara yang berbeda pada penggunaan label, contoh di bawah ini
memiliki tingkat kompleksitas yang cukup beragam.
Sebuah Aplikasi Stateless Sederhana
Bayangkan sebuah kasus dimana sebuah aplikasi stateless di-deploy
menggunakan Deployment dan Service. Di bawah ini merupakan
contoh kutipan yang merepresentasikan bagaimana
label dapat digunakan secara sederhana.
Deployment digunakan untuk memastikan Pod dijalankan untuk aplikasi itu sendiri.
Bayangkan sebuah aplikasi yang lebih kompleks: sebuah aplikasi web (WordPress)
yang menggunakan basis data (MySQL), yang diinstal menggunakan Helm.
Kutipan berikut merepresentasikan objek yang di-deploy untuk aplikasi ini.
Berikut merupakan konfigurasi Deployment yang digunakan untuk WordPress:
Dengan StatefulSet MySQL dan Service kamu dapat mengetahui informasi yang ada pada MySQL dan Wordpress.
2 - Arsitektur Kubernetes
2.1 - Node
Node merupakan sebuah mesin worker di dalam Kubernetes, yang sebelumnya dinamakan minion.
Sebuah node bisa berupa VM ataupun mesin fisik, tergantung dari klaster-nya.
Masing-masing node berisi beberapa servis yang berguna untuk menjalankan banyak pod dan diatur oleh komponen-komponen yang dimiliki oleh master.
Servis-servis di dalam sebuah node terdiri dari runtime kontainer, kubelet dan kube-proxy.
Untuk lebih detail, lihat dokumentasi desain arsitektur pada Node Kubernetes.
Status Node
Sebuah status node berisikan informasi sebagai berikut:
Masing-masing bagian dijelaskan secara rinci di bawah ini.
Addresses
Penggunaan field-field ini bergantung pada penyedia layanan cloud ataupun konfigurasi bare metal yang kamu punya.
HostName: Merupakan hostname yang dilaporkan oleh kernel node. Dapat diganti melalui parameter --hostname-override pada kubelet.
ExternalIP: Biasanya merupakan alamat IP pada node yang punya route eksternal (bisa diakses dari luar klaster).
InternalIP: Biasanya merupakan alamat IP pada node yang hanya punya route di dalam klaster.
Condition
Fieldconditions menjelaskan tentang status dari semua node yang sedang berjalan (Running).
Kondisi Node
Penjelasan
OutOfDisk
True jika node sudah tidak punya cukup kapasitas disk untuk menjalankan pod baru, False jika sebaliknya
Ready
True jika node sehat (healthy) dan siap untuk menerima pod, False jika node tidak lagi sehat (unhealthy) dan tidak siap menerima pod, serta Unknown jika kontroler node tidak menerima pesan di dalam node-monitor-grace-period (standarnya 40 detik)
MemoryPressure
True jika memori pada node terkena tekanan (pressure) -- maksudnya, jika kapasitas memori node sudah di titik rendah; False untuk sebaliknya
PIDPressure
True jika process-process mengalami tekanan (pressure) -- maksudnya, jika node menjalankan terlalu banyak process; False untuk sebaliknya
DiskPressure
True jika ukuran disk mengalami tekanan (pressure) -- maksudnya, jika kapasitas disk sudah di titik rendah; False untuk sebaliknya
NetworkUnavailable
True jika jaringan untuk node tidak dikonfigurasi dengan benar, False untuk sebaliknya
Condition pada node direpresentasikan oleh suatu obyek JSON. Sebagai contoh, respon berikut ini menggambarkan node yang sedang sehat (healthy).
"conditions":[{"type":"Ready","status":"True"}]
Jika status untuk Ready condition bernilai Unknown atau False untuk waktu yang lebih dari pod-eviction-timeout, tergantung bagaimana kube-controller-manager dikonfigurasi, semua pod yang dijalankan pada node tersebut akan dihilangkan oleh Kontroler Node.
Durasi eviction timeout yang standar adalah lima menit.
Pada kasus tertentu ketika node terputus jaringannya, apiserver tidak dapat berkomunikasi dengan kubelet yang ada pada node.
Keputusan untuk menghilangkan pod tidak dapat diberitahukan pada kubelet, sampai komunikasi dengan apiserver terhubung kembali.
Sementara itu, pod-pod akan terus berjalan pada node yang sudah terputus, walaupun mendapati schedule untuk dihilangkan.
Pada versi Kubernetes sebelum 1.5, kontroler node dapat menghilangkan dengan paksa (force delete) pod-pod yang terputus dari apiserver.
Namun, pada versi 1.5 dan seterusnya, kontroler node tidak menghilangkan pod dengan paksa, sampai ada konfirmasi bahwa pod tersebut sudah berhenti jalan di dalam klaster.
Pada kasus dimana Kubernetes tidak bisa menarik kesimpulan bahwa ada node yang telah meninggalkan klaster, admin klaster mungkin perlu untuk menghilangkan node secara manual.
Menghilangkan obyek node dari Kubernetes akan membuat semua pod yang berjalan pada node tersebut dihilangkan oleh apiserver, dan membebaskan nama-namanya agar bisa digunakan kembali.
Pada versi 1.12, fitur TaintNodesByCondition telah dipromosikan ke beta, sehingga kontroler lifecycle node secara otomatis membuat taints yang merepresentasikan conditions.
Akibatnya, scheduler menghiraukan conditions ketika mempertimbangkan sebuah Node; scheduler akan melihat pada taints sebuah Node dan tolerations sebuah Pod.
Sekarang, para pengguna dapat memilih antara model scheduling yang lama dan model scheduling yang lebih fleksibel.
Pada model yang lama, sebuah pod tidak memiliki tolerations apapun sampai mendapat giliran schedule. Namun, pod dapat dijalankan pada Node tertentu, dimana pod melakukan toleransi terhadap taints yang dimiliki oleh Node tersebut.
Perhatian:
Mengaktifkan fitur ini menambahkan delay sedikit antara waktu saat suatu condition terlihat dan saat suatu taint dibuat. Delay ini biasanya kurang dari satu detik, tapi dapat menambahkan jumlah yang telah berhasil mendapat schedule, namun ditolak oleh kubelet untuk dijalankan.
Capacity
Menjelaskan tentang resource-resource yang ada pada node: CPU, memori, dan jumlah pod secara maksimal yang dapat dijalankan pada suatu node.
Info
Informasi secara umum pada suatu node, seperti versi kernel, versi Kubernetes (versi kubelet dan kube-proxy), versi Docker (jika digunakan), nama OS.
Informasi ini dikumpulkan oleh Kubelet di dalam node.
Manajemen
Tidak seperti pod dan service, sebuah node tidaklah dibuat dan dikonfigurasi oleh Kubernetes: tapi node dibuat di luar klaster oleh penyedia layanan cloud, seperti Google Compute Engine, atau pool mesin fisik ataupun virtual (VM) yang kamu punya.
Jadi ketika Kubernetes membuat sebuah node, obyek yang merepresentasikan node tersebut akan dibuat.
Setelah pembuatan, Kubernetes memeriksa apakah node tersebut valid atau tidak.
Contohnya, jika kamu mencoba untuk membuat node dari konten berikut:
Kubernetes membuat sebuah obyek node secara internal (representasinya), dan melakukan validasi terhadap node. Validasi dilakukan dengan memeriksa kondisi kesehatan node (health checking), berdasarkan fieldmetadata.name. Jika node valid -- terjadi saat semua servis yang diperlukan sudah jalan -- maka node diperbolehkan untuk menjalankan sebuah pod.
Namun jika tidak valid, node tersebut akan dihiraukan untuk aktivitas apapun yang berhubungan dengan klaster, sampai telah menjadi valid.
Catatan:
Kubernetes tetap menyimpan obyek untuk node yang tidak valid, dan terus memeriksa apakah node telah menjadi valid atau belum.
Kamu harus secara eksplisit menghilangkan obyek Node tersebut untuk menghilangkan proses ini.
Saat ini, ada tiga komponen yang berinteraksi dengan antarmuka node di Kubernetes: kontroler node, kubelet, dan kubectl.
Kontroler Node
Kontroler node adalah komponen master Kubernetes yang berfungsi untuk mengatur berbagai aspek dari node.
Kontroler node memiliki berbagai peran (role) dalam sebuah lifecycle node.
Pertama, menetapkan blok CIDR pada node tersebut saat registrasi (jika CIDR assignment diaktifkan).
Kedua, terus memperbarui daftar internal node di dalam kontroler node, sesuai dengan daftar mesin yang tersedia di dalam penyedia layanan cloud.
Ketika berjalan di dalam environment cloud, kapanpun saat sebuah node tidak lagi sehat (unhealthy), kontroler node bertanya pada penyedia cloud, apakah VM untuk node tersebut masihkah tersedia atau tidak.
Jika sudah tidak tersedia, kontroler node menghilangkan node tersebut dari daftar node.
Ketiga, melakukan monitor terhadap kondisi kesehatan (health) node.
Kontroler node bertanggung jawab untuk mengubah status NodeReady condition pada NodeStatus menjadi ConditionUnknown, ketika sebuah node terputus jaringannya (kontroler node tidak lagi mendapat heartbeat karena suatu hal, contohnya karena node tidak hidup), dan saat kemudian melakukan eviction terhadap semua pod yang ada pada node tersebut (melalui terminasi halus -- graceful) jika node masih terus terputus. (Timeout standar adalah 40 detik untuk mulai melaporkan ConditionUnknown dan 5 menit setelah itu untuk mulai melakukan eviction terhadap pod.)
Kontroler node memeriksa state masing-masing node untuk durasi yang ditentukan oleh argumen --node-monitor-period.
Pada versi Kubernetes sebelum 1.13, NodeStatus adalah heartbeat yang diberikan oleh node.
Setelah versi 1.13, fitur node lease diperkenalkan sebagai fitur alpha (fitur gate NodeLease,
KEP-0009).
Ketika fitur node lease diaktifasi, setiap node terhubung dengan obyek Lease di dalam namespacekube-node-lease yang terus diperbarui secara berkala.
Kemudian, NodeStatus dan node lease keduanya dijadikan sebagai heartbeat dari node.
Semua node lease diperbarui sesering mungkin, sedangkan NodeStatus dilaporkan dari node untuk master hanya ketika ada perubahan atau telah melewati periode waktu tertentu (default-nya 1 menit, lebih lama daripada default timeout node-node yang terputus jaringannya).
Karena node lease jauh lebih ringan daripada NodeStatus, fitur ini membuat heartbeat dari node jauh lebih murah secara signifikan dari sudut pandang skalabilitas dan performa.
Di Kubernetes 1.4, kami telah memperbarui logic dari kontroler node supaya lebih baik dalam menangani kasus saat banyak sekali node yang tidak bisa terhubung dengan master (contohnya, karena master punya masalah jaringan).
Mulai dari 1.4, kontroler node melihat state dari semua node di dalam klaster, saat memutuskan untuk melakukan eviction pada pod.
Pada kasus kebanyakan, kontroler node membatasi rate eviction menjadi --node-eviction-rate (default-nya 0.1) per detik.
Artinya, kontroler node tidak akan melakukan eviction pada pod lebih dari 1 node per 10 detik.
Perlakuan eviction pada node berubah ketika sebuah node menjadi tidak sehat (unhealthy) di dalam suatu zona availability.
Kontroler node memeriksa berapa persentase node di dalam zona tersebut yang tidak sehat (saat NodeReady condition menjadi ConditionUnknown atau ConditionFalse) pada saat yang bersamaan.
Jika persentase node yang tidak sehat bernilai --unhealthy-zone-threshold (default-nya 0.55), maka rate eviction berkurang: untuk ukuran klaster yang kecil (saat jumlahnya lebih kecil atau sama dengan jumlah node --large-cluster-size-threshold - default-nya 50), maka eviction akan berhenti dilakukan.
Jika masih besar jumlahnya, rate eviction dikurangi menjadi --secondary-node-eviction-rate (default-nya 0.01) per detik.
Alasan kenapa hal ini diimplementasi untuk setiap zona availability adalah karena satu zona bisa saja terputus dari master, saat yang lainnya masih terhubung.
Jika klaster tidak menjangkau banyak zona availability yang disediakan oleh penyedia cloud, maka hanya ada satu zona (untuk semua node di dalam klaster).
Alasan utama untuk menyebarkan node pada banyak zona availability adalah supaya workload dapat dipindahkan ke zona sehat (healthy) saat suatu zona mati secara menyeluruh.
Kemudian, jika semua node di dalam suatu zona menjadi tidak sehat (unhealthy), maka kontroler node melakukan eviction pada rate normal --node-eviction-rate.
Kasus khusus, ketika seluruh zona tidak ada satupun sehat (tidak ada node yang sehat satupun di dalam klaster).
Pada kasus ini, kontroler node berasumsi ada masalah pada jaringan master, dan menghentikan semua eviction sampai jaringan terhubung kembali.
Mulai dari Kubernetes 1.6, kontroler node juga bertanggung jawab untuk melakukan eviction pada pod-pod yang berjalan di atas node dengan taintsNoExecute, ketika pod-pod tersebut sudah tidak lagi tolerate terhadap taints.
Sebagai tambahan, hal ini di-nonaktifkan secara default pada fitur alpha, kontroler node bertanggung jawab untuk menambahkan taints yang berhubungan dengan masalah pada node, seperti terputus atau NotReady.
Lihat dokumentasi ini untuk bahasan detail tentang taintsNoExecute dan fitur alpha.
Mulai dari versi 1.8, kontroler node bisa diatur untuk bertanggung jawab pada pembuatan taints yang merepresentasikan node condition.
Ini merupakan fitur alpha untuk versi 1.8.
Self-Registration untuk Node
Ketika argumen --register-node pada kubelet bernilai true (default-nya), kubelet akan berusaha untuk registrasi dirinya melalui API server.
Ini merupakan pattern yang disukai, digunakan oleh kebanyakan distros.
Kubelet memulai registrasi diri (self-registration) dengan opsi-opsi berikut:
--kubeconfig - Path berisi kredensial-kredensial yang digunakan untuk registrasi diri pada apiserver.
--cloud-provider - Cara berbicara pada sebuah penyedia layanan cloud, baca tentang metadata-nya.
--register-node - Registrasi secara otomatis pada API server.
--register-with-taints - Registrasi node dengan daftar taints (dipisahkan oleh koma <key>=<value>:<effect>). No-op jika register-node bernilai false.
--node-ip - Alamat IP dari node dimana kubelet berjalan.
--node-labels - Label-label untuk ditambahkan saat melakukan registrasi untuk node di dalam klaster (lihat label yang dibatasi secara paksa oleh NodeRestriction admission plugin untuk 1.13+).
--node-status-update-frequency - Menentukan seberapa sering kubelet melaporkan status pada master.
Seorang admin klaster dapat membuat dan memodifikasi obyek node.
Jika admin ingin untuk membuat obyek node secara manual, atur argument --register-node=false pada kubelet.
Admin dapat memodifikasi resource-resource node (terlepas dari --register-node).
Modifikasi terdiri dari pengaturan label pada node dan membuat node tidak dapat di-schedule.
Label-label pada node digunakan oleh selector node untuk mengatur proses schedule untuk pod, misalnya, membatasi sebuah pod hanya boleh dijalankan pada node-node tertentu.
Menandai sebuah node untuk tidak dapat di-schedule mencegah pod baru untuk tidak di-schedule pada node, tanpa mempengaruhi pod-pod yang sudah berjalan pada node tersebut.
Ini berguna sebagai langkah persiapan untuk melakukan reboote pada node.
Sebagai contoh, untuk menandai sebuah node untuk tidak dapat di-schedule, jalankan perintah berikut:
kubectl cordon $NODENAME
Catatan:
Pod-pod yang dibuat oleh suatu kontroler DaemonSet menghiraukan scheduler Kubernetes dan mengabaikan tanda unschedulable pada node.
Hal ini mengasumsikan bahwa daemons dimiliki oleh mesin, walaupun telah dilakukan drain pada aplikasi, saat melakukan persaiapan reboot.
Kapasitas Node
Kapasitas node (jumlah CPU dan memori) adalah bagian dari obyek node.
Pada umumnya, node-node melakukan registrasi diri dan melaporkan kapasitasnya saat obyek node dibuat.
Jika kamu melakukan administrasi node manual, maka kamu perlu mengatur kapasitas node saat menambahkan node baru.
Scheduler Kubernetes memastikan kalau ada resource yang cukup untuk menjalankan semua pod di dalam sebuah node.
Kubernetes memeriksa jumlah semua request untuk kontainer pada sebuah node tidak lebih besar daripada kapasitas node.
Hal ini termasuk semua kontainer yang dijalankan oleh kubelet. Namun, ini tidak termasuk kontainer-kontainer yang dijalankan secara langsung oleh runtime kontainer ataupun process yang ada di luar kontainer.
Node adalah tingkatan tertinggi dari resource di dalam Kubernetes REST API.
Penjelasan lebih detail tentang obyek API dapat dilihat pada: Obyek Node API.
2.2 - Komunikasi antara Control Plane dan Node
Dokumen ini menjelaskan tentang jalur-jalur komunikasi di antara klaster Kubernetes dan control plane yang sebenarnya hanya berhubungan dengan apiserver saja.
Kenapa ada dokumen ini? Supaya kamu, para pengguna Kubernetes, punya gambaran bagaimana mengatur instalasi untuk memperketat konfigurasi jaringan di dalam klaster.
Hal ini cukup penting, karena klaster bisa saja berjalan pada jaringan tak terpercaya (untrusted network), ataupun melalui alamat-alamat IP publik pada penyedia cloud.
Node Menuju Control Plane
Kubernetes memiliki sebuah pola API "hub-and-spoke". Semua penggunaan API dari Node (atau Pod dimana Pod-Pod tersebut dijalankan) akan diterminasi pada apiserver (tidak ada satu komponen control plane apa pun yang didesain untuk diekspos pada servis remote).
Apiserver dikonfigurasi untuk mendengarkan koneksi aman remote yang pada umumnya terdapat pada porta HTTPS (443) dengan satu atau lebih bentuk autentikasi klien yang dipasang.
Sebaiknya, satu atau beberapa metode otorisasi juga dipasang, terutama jika kamu memperbolehkan permintaan anonim (anonymous request) ataupun service account token.
Jika diperlukan, Pod-Pod dapat terhubung pada apiserver secara aman dengan menggunakan ServiceAccount.
Dengan ini, Kubernetes memasukkan public root certificate dan bearer token yang valid ke dalam Pod, secara otomatis saat Pod mulai dijalankan.
Kubernetes Service (di dalam semua Namespace) diatur dengan sebuah alamat IP virtual. Semua yang mengakses alamat IP ini akan dialihkan (melalui kube-proxy) menuju endpoint HTTPS dari apiserver.
Komponen-komponen juga melakukan koneksi pada apiserver klaster melalui porta yang aman.
Akibatnya, untuk konfigurasi yang umum dan standar, semua koneksi dari klaster (node-node dan pod-pod yang berjalan di atas node tersebut) menujucontrol planesudah terhubung dengan aman.
Dan juga, klaster dancontrol planebisa terhubung melalui jaringan publik dan/atau yang tak terpercaya (untrusted).
Control Plane menuju Node
Ada dua jalur komunikasi utama dari control plane (apiserver) menuju klaster. Pertama, dari apiserver ke proses kubelet yang berjalan pada setiap Node di dalam klaster. Kedua, dari apiserver ke setiap Node, Pod, ataupun Service melalui fungsi proksi pada apiserver
Apiserver menuju kubelet
Koneksi dari apiserver menuju kubelet bertujuan untuk:
Melihat log dari pod-pod.
Masuk ke dalam pod-pod yang sedang berjalan (attach).
Menyediakan fungsi port-forward dari kubelet.
Semua koneksi ini diterminasi pada endpoint HTTPS dari kubelet.
Secara default, apiserver tidak melakukan verifikasi serving certificate dari kubelet, yang membuat koneksi terekspos pada serangan man-in-the-middle, dan juga tidak aman untuk terhubung melalui jaringan tak terpercaya (untrusted) dan/atau publik.
Untuk melakukan verifikasi koneksi ini, berikan root certificate pada apiserver melalui tanda --kubelet-certificate-authority, sehingga apiserver dapat memverifikasi serving certificate dari kubelet.
Cara lainnya, gunakan tunnel SSH antara apiserver dan kubelet jika diperlukan, untuk menghindari komunikasi melalui jaringan tak terpercaya (untrusted) atau publik.
Secara default, koneksi apiserver menuju node, pod atau service hanyalah melalui HTTP polos (plain), sehingga tidak ada autentikasi maupun enkripsi.
Koneksi tersebut bisa diamankan melalui HTTPS dengan menambahkan https: pada URL API dengan nama dari node, pod, atau service.
Namun, koneksi tidak tervalidasi dengan certificate yang disediakan oleh endpoint HTTPS maupun kredensial client, sehingga walaupun koneksi sudah terenkripsi, tidak ada yang menjamin integritasnya.
Koneksi ini tidak aman untuk dilalui pada jaringan publik dan/atau tak terpercaya untrusted.
Tunnel SSH
Kubernetes menyediakan tunnel SSH untuk mengamankan jalur komunikasi control plane -> Klaster.
Dengan ini, apiserver menginisiasi sebuah tunnel SSH untuk setiap node di dalam klaster (terhubung ke server SSH di port 22) dan membuat semua trafik menuju kubelet, node, pod, atau service dilewatkan melalui tunnel tesebut.
Tunnel ini memastikan trafik tidak terekspos keluar jaringan dimana node-node berada.
Tunnel SSH saat ini sudah usang (deprecated), jadi sebaiknya jangan digunakan, kecuali kamu tahu pasti apa yang kamu lakukan.
Sebuah desain baru untuk mengganti kanal komunikasi ini sedang disiapkan.
2.3 - Controller
Dalam bidang robotika dan otomatisasi, control loop atau kontrol tertutup adalah
lingkaran tertutup yang mengatur keadaan suatu sistem.
Berikut adalah salah satu contoh kontrol tertutup: termostat di sebuah ruangan.
Ketika kamu mengatur suhunya, itu mengisyaratkan ke termostat
tentang keadaan yang kamu inginkan. Sedangkan suhu kamar yang sebenarnya
adalah keadaan saat ini. Termostat berfungsi untuk membawa keadaan saat ini
mendekati ke keadaan yang diinginkan, dengan menghidupkan atau mematikan
perangkat.
Di Kubernetes, controller adalah kontrol tertutup yang mengawasi keadaan klaster
klaster kamu, lalu membuat atau meminta
perubahan jika diperlukan. Setiap controller mencoba untuk memindahkan status
klaster saat ini mendekati keadaan yang diinginkan.
Di Kubernetes, pengontrol adalah kontrol tertutup yang mengawasi kondisi klaster, lalu membuat atau meminta perubahan jika diperlukan. Setiap pengontrol mencoba untuk memindahkan status klaster saat ini lebih dekat ke kondisi yang diinginkan.
Pola controller
Sebuah controller melacak sekurang-kurangnya satu jenis sumber daya dari
Kubernetes.
objek-objek ini
memiliki spec field yang merepresentasikan keadaan yang diinginkan. Satu atau
lebih controller untuk resource tersebut bertanggung jawab untuk membuat
keadaan sekarang mendekati keadaan yang diinginkan.
Controller mungkin saja melakukan tindakan itu sendiri; namun secara umum, di
Kubernetes, controller akan mengirim pesan ke
API server yang
mempunyai efek samping yang bermanfaat. Kamu bisa melihat contoh-contoh
di bawah ini.
Kontrol melalui server API
ControllerJob adalah contoh dari controller
bawaan dari Kubernetes. Controller bawaan tersebut mengelola status melalui
interaksi dengan server API dari suatu klaster.
Job adalah sumber daya dalam Kubernetes yang menjalankan a
Pod, atau mungkin beberapa Pod sekaligus,
untuk melakukan sebuah pekerjaan dan kemudian berhenti.
(Setelah dijadwalkan, objek Pod
akan menjadi bagian dari keadaan yang diinginkan oleh kubelet).
Ketika controller job melihat tugas baru, maka controller itu memastikan bahwa,
di suatu tempat pada klaster kamu, kubelet dalam sekumpulan Node menjalankan
Pod-Pod dengan jumlah yang benar untuk menyelesaikan pekerjaan. Controller job
tidak menjalankan sejumlah Pod atau kontainer apa pun untuk dirinya sendiri.
Namun, controller job mengisyaratkan kepada server API untuk membuat atau
menghapus Pod. Komponen-komponen lain dalam
control plane
bekerja berdasarkan informasi baru (adakah Pod-Pod baru untuk menjadwalkan dan
menjalankan pekerjan), dan pada akhirnya pekerjaan itu selesai.
Setelah kamu membuat Job baru, status yang diharapkan adalah bagaimana
pekerjaan itu bisa selesai. Controller job membuat status pekerjaan saat ini
agar mendekati dengan keadaan yang kamu inginkan: membuat Pod yang melakukan
pekerjaan yang kamu inginkan untuk Job tersebut, sehingga Job hampir
terselesaikan.
Controller juga memperbarui objek yang mengkonfigurasinya. Misalnya: setelah
pekerjaan dilakukan untuk Job tersebut, controller job memperbarui objek Job
dengan menandainya Finished.
(Ini hampir sama dengan bagaimana beberapa termostat mematikan lampu untuk
mengindikasikan bahwa kamar kamu sekarang sudah berada pada suhu yang kamu
inginkan).
Kontrol Langsung
Berbeda dengan sebuah Job, beberapa dari controller perlu melakukan perubahan
sesuatu di luar dari klaster kamu.
Sebagai contoh, jika kamu menggunakan kontrol tertutup untuk memastikan apakah
cukup Node
dalam klaster kamu, maka controller memerlukan sesuatu di luar klaster saat ini
untuk mengatur Node-Node baru apabila dibutuhkan.
controller yang berinteraksi dengan keadaan eksternal dapat menemukan keadaan
yang diinginkannya melalui server API, dan kemudian berkomunikasi langsung
dengan sistem eksternal untuk membawa keadaan saat ini mendekat keadaan yang
diinginkan.
(Sebenarnya ada sebuah controller yang melakukan penskalaan node secara
horizontal dalam klaster kamu.
Status sekarang berbanding status yang diinginkan
Kubernetes mengambil pandangan sistem secara cloud-native, dan mampu menangani
perubahan yang konstan.
Klaster kamu dapat mengalami perubahan kapan saja pada saat pekerjaan sedang
berlangsung dan kontrol tertutup secara otomatis memperbaiki setiap kegagalan.
Hal ini berarti bahwa, secara potensi, klaster kamu tidak akan pernah mencapai
kondisi stabil.
Selama controller dari klaster kamu berjalan dan mampu membuat perubahan yang
bermanfaat, tidak masalah apabila keadaan keseluruhan stabil atau tidak.
Perancangan
Sebagai prinsip dasar perancangan, Kubernetes menggunakan banyak controller yang
masing-masing mengelola aspek tertentu dari keadaan klaster. Yang paling umum,
kontrol tertutup tertentu menggunakan salah satu jenis sumber daya
sebagai suatu keadaan yang diinginkan, dan memiliki jenis sumber daya yang
berbeda untuk dikelola dalam rangka membuat keadaan yang diinginkan terjadi.
Sangat penting untuk memiliki beberapa controller sederhana daripada hanya satu
controller saja, dimana satu kumpulan monolitik kontrol tertutup saling
berkaitan satu sama lain. Karena controller bisa saja gagal, sehingga Kubernetes
dirancang untuk memungkinkan hal tersebut.
Misalnya: controller pekerjaan melacak objek pekerjaan (untuk menemukan
adanya pekerjaan baru) dan objek Pod (untuk menjalankan pekerjaan tersebut dan
kemudian melihat lagi ketika pekerjaan itu sudah selesai). Dalam hal ini yang
lain membuat pekerjaan, sedangkan controller pekerjaan membuat Pod-Pod.
Catatan:
Ada kemungkinan beberapa controller membuat atau memperbarui jenis objek yang
sama. Namun di belakang layar, controller Kubernetes memastikan bahwa mereka
hanya memperhatikan sumbr daya yang terkait dengan sumber daya yang mereka
kendalikan.
Misalnya, kamu dapat memiliki Deployment dan Job; dimana keduanya akan membuat
Pod. Controller Job tidak akan menghapus Pod yang dibuat oleh Deployment kamu,
karena ada informasi (labels)
yang dapat oleh controller untuk membedakan Pod-Pod tersebut.
Berbagai cara menjalankan beberapa controller
Kubernetes hadir dengan seperangkat controller bawaan yang berjalan di dalam
kube-controller-manager. Beberapa controller
bawaan memberikan perilaku inti yang sangat penting.
Controller Deployment dan controller Job adalah contoh dari controller yang
hadir sebagai bagian dari Kubernetes itu sendiri (controller "bawaan").
Kubernetes memungkinkan kamu menjalankan control plane yang tangguh, sehingga
jika ada controller bawaan yang gagal, maka bagian lain dari control plane akan
mengambil alih pekerjaan.
Kamu juga dapat menemukan pengontrol yang berjalan di luar control plane, untuk
mengembangkan lebih jauh Kubernetes. Atau, jika mau, kamu bisa membuat
controller baru sendiri. Kamu dapat menjalankan controller kamu sendiri sebagai
satu kumpulan dari beberapa Pod, atau bisa juga sebagai bagian eksternal dari
Kubernetes. Manakah yang paling sesuai akan tergantung pada apa yang controller
khusus itu lakukan.
Apabila kamu ingin membuat controller sendiri, silakan lihat pola perluasan dalam memperluas Kubernetes.
2.4 - Konsep-konsep di balik Controller Manager
Konsep Cloud Controller Manager/CCM (jangan tertukar dengan program biner kube-controller-manager) awalnya dibuat untuk memungkinkan kode vendor cloud spesifik dan kode inti Kubernetes untuk berkembang secara independen satu sama lainnya. CCM berjalan bersama dengan komponen Master lainnya seperti Kubernetes Controller Manager, API Server, dan Scheduler. CCM juga dapat dijalankan sebagai Kubernetes Addon (tambahan fungsi terhadap Kubernetes), yang akan berjalan di atas klaster Kubernetes.
Desain CCM didasarkan pada mekanisme plugin yang memungkinkan penyedia layanan cloud untuk berintegrasi dengan Kubernetes dengan mudah dengan menggunakan plugin. Sudah ada rencana untuk pengenalan penyedia layanan cloud baru pada Kubernetes, dan memindahkan penyedia layanan cloud yang sudah ada dari model yang lama ke model CCM.
Dokumen ini mendiskusikan konsep di balik CCM dan mendetail fungsi-fungsinya.
Berikut adalah arsitektur sebuah klaster Kubernetes tanpa CCM:
Desain
Pada diagram sebelumnya, Kubernetes dan penyedia layanan cloud diintegrasikan melalui beberapa komponen berbeda:
Kubelet
Kubernetes Controller Manager
Kubernetes API server
CCM menggabungkan semua logika yang bergantung pada cloud dari dalam tiga komponen tersebut ke dalam sebuah titik integrasi dengan cloud. Arsitektur baru di dalam model CCM adalah sebagai berikut:
Komponen-komponen CCM
CCM memisahkan beberapa fungsi Kubernetes Controller Manager (KCM) dan menjalankannya sebagai proses yang berbeda. Secara spesifik, CCM memisahkan pengendali-pengendali (controller) di dalam KCM yang bergantung terhadap penyedia layanan cloud. KCM memiliki beberapa komponen pengendali yang bergantung pada cloud sebagai berikut:
Node Controller
Volume Controller
Route Controller
Service Controller
Pada versi 1.9, CCM menjalankan pengendali-pengendali dari daftar sebelumnya sebagai berikut:
Node Controller
Route Controller
Service Controller
Catatan:
Volume Controller secara sengaja tidak dipilih sebagai bagian dari CCM. Hal ini adalah karena kerumitan untuk melakukannya, dan mempertimbangkan usaha-usaha yang sedang berlangsung untuk memisahkan logika volume yang spesifik vendor dari KCM, sehingga diputuskan bahwa Volume Contoller tidak akan dipisahkan dari KCM ke CCM.
Rencana awal untuk mendukung volume menggunakan CCM adalah dengan menggunakan FlexVolume untuk mendukung penambahan volume secara pluggable. Namun, ada sebuah usaha lain yang diberi nama Container Storage Interface (CSI) yang sedang berlangsung untuk menggantikan FlexVolume.
Mempertimbangkan dinamika tersebut, kami memutuskan untuk mengambil tindakan sementara hingga CSI siap digunakan.
Fungsi-fungsi CCM
Fungsi-fungsi CCM diwarisi oleh komponen-komponen Kubernetes yang bergantung pada penyedia layanan cloud. Bagian ini disusun berdasarkan komponen-komponen tersebut.
1. Kubernetes Controller Manager
Kebanyakan fungsi CCM diturunkan dari KCM. Seperti yang telah disebutkan pada bagian sebelumnya, CCM menjalankan komponen-komponen pengendali sebagai berikut:
Node Controller
Route Controller
Service Controller
Node Controller
Node Controller bertugas untuk menyiapkan sebuah node dengan cara mengambil informasi node-node yang berjalan di dalam klaster dari penyedia layanan cloud. Node Controller melakukan fungsi-fungsi berikut:
Menyiapkan sebuah node dengan memberi label zone/region yang spesifik pada cloud.
Menyiapkan sebuah node dengan informasi instance yang spesifik cloud , misalnya tipe dan ukurannya.
Mendapatkan alamat jaringan dan hostname milik node tersebut.
Dalam hal sebuah node menjadi tidak responsif, memeriksa cloud untuk melihat apakah node tersebut telah dihapus dari cloud. Juga, menghapus objek Node tersebut dari klaster Kubernetes, jika node tersebut telah dihapus dari cloud.
Route Controller
Route Controller bertugas mengkonfigurasi rute jaringan di dalam cloud secara sesuai agar Container pada node-node yang berbeda di dalam klaster Kubernetes dapat berkomunikasi satu sama lain. Route Controller hanya berlaku untuk klaster yang berjalan pada Google Compute Engine (GCE) di penyedia layanan cloud GCP.
Service Controller
Service Controller bertugas memantau terjadinya operasi create, update, dan delete pada Service. Berdasarkan keadaan terkini Service-service pada klaster Kubernetes, Service Controller mengkonfigurasi load balancer spesifik cloud (seperti ELB, Google LB, atau Oracle Cloud Infrastructure LB) agar sesuai dengan keadaan Service-service pada klaster Kubernetes. Sebagai tambahan, Service Controller juga memastikan bahwa service backend (target dari load balancer yang bersangkutan) dari load balancer cloud tersebut berada dalam kondisi terkini.
2. Kubelet
Node Controller berisi fungsi Kubelet yang bergantung pada cloud. Sebelum CCM, Kubelet bertugas untuk menyiapkan node dengan informasi spesifik cloud seperti alamat IP, label zone/region, dan tipe instance. Setelah diperkenalkannya CCM, tugas tersebut telah dipindahkan dari Kubelet ke dalam CCM.
Pada model baru ini, Kubelet menyiapkan sebuah node tanpa informasi spesifik cloud. Namun, Kubelet menambahkan sebuah Taint pada node yang baru dibuat yang menjadikan node tersebut tidak dapat dijadwalkan (sehingga tidak ada Pod yang dapat dijadwalkan ke node tersebut) hingga CCM menyiapkan node tersebut dengan informasi spesifik cloud. Setelah itu, Kubelet menghapus Taint tersebut.
Mekanisme Plugin
CCM menggunakan interface Go untuk memungkinkan implementasi dari cloud apapun untuk ditambahkan. Secara spesifik, CCM menggunakan CloudProvider Interface yang didefinisikan di sini
Implementasi dari empat kontroler-kontroler yang disorot di atas, dan beberapa kerangka kerja, bersama dengan CloudProvider Interface, akan tetap berada pada kode inti Kubernetes. Implementasi spesifik penyedia layanan cloud akan dibuat di luar kode inti dan menggunakan CloudProvider Interface yang didefinisikan di kode inti.
Bagian ini memerinci akses yang dibutuhkan oleh CCM terhadap berbagai objek API untuk melakukan tugas-tugasnya.
Akses untuk Node Controller
Node Controller hanya berinteraksi dengan objek-objek Node. Node Controller membutuhkan akses penuh untuk operasi get, list, create, update, patch, watch, dan delete terhadap objek-objek Node.
v1/Node:
Get
List
Create
Update
Patch
Watch
Delete
Akses untuk Route Controller
Route Controller memantau pembuatan objek Node dan mengkonfigurasi rute jaringan secara sesuai. Route Controller membutuhkan akses untuk operasi get terhadap objek-objek Node.
v1/Node:
Get
Akses untuk Service Controller
Service Controller memantau terjadinya operasi create, update dan delete, kemudian mengkonfigurasi Endpoint untuk Service-service tersebut secara sesuai.
Untuk mengakses Service-service, Service Controller membutuhkan akses untuk operasi list dan watch. Untuk memperbarui Service-service, dibutuhkan akses untuk operasi patch dan update.
Untuk menyiapkan Endpoint bagi untuk Service-service, dibutuhkan akses untuk operasi create, list, get, watch, dan update.
v1/Service:
List
Get
Watch
Patch
Update
Akses Lainnya
Implementasi dari inti CCM membutuhkan akses untuk membuat Event, dan untuk memastikan operasi yang aman, dibutuhkan akses untuk membuat ServiceAccount.
v1/Event:
Create
Patch
Update
v1/ServiceAccount:
Create
Detail RBAC dari ClusterRole untuk CCM adalah sebagai berikut:
Petunjuk lengkap untuk mengkonfigurasi dan menjalankan CCM disediakan di sini.
2.5 - Tentang cgroup v2
Pada Linux, control groups
berfungsi untuk membatasi resources yang dialokasikan ke setiap program yang sedang berjalan.
Kubelet dan container runtime perlu berinteraksi dengan cgroups untuk menerapkan resource management pada pod dan kontainer yang mencakup pengalokasian kebutuhan CPU/Memori dan workloads dalam sebuah container.
Terdapat dua versi cgroups dalam Linux: cgroup v1 dan cgroup v2. Cgroup v2 adalah generasi baru dari cgroup API.
Apa itu cgroup v2?
FEATURE STATE:Kubernetes v1.25 [stable]
cgroup v2 adalah versi lanjutan dari Linux cgroup API. cgroup v2 menyediakan unified control system dan kemampuan resource management yang lebih baik.
cgroup v2 menawarkan beberapa peningkatan dibandingkan cgroup v1, seperti berikut:
Manajemen alokasi resource dan pengisolasian antar resources yang lebih baik
Perhitungan yang lebih terpadu untuk berbagai jenis pengalokasian memori (memori jaringan, memori kernel, dll)
Menghitung perubahan resource yang tidak langsung seperti respon cache pada sebuah halaman
Beberapa fitur-fitur Kubernetes secara eksklusif menggunakan cgroup v2 untuk resource management dan isolation yang lebih baik. Sebagai contoh, fitur MemoryQoS meningkatkan memori QoS dan mengandalkan cgroup v2 primitif.
Penggunaan cgroup v2
Cara yang direkomendasikan untuk menggunakan cgroup v2 adalah dengan menggunakan Linux Distribution yang menggunakan cgroup v2 secara default.
Untuk list Distribusi Linux yang menggunakan cgroup v2, bisa dilihat di cgroup v2 documentation
Container Optimized OS (since M97)
Ubuntu (since 21.10, 22.04+ recommended)
Debian GNU/Linux (since Debian 11 bullseye)
Fedora (since 31)
Arch Linux (since April 2021)
RHEL and RHEL-like distributions (since 9)
Untuk memeriksa apakah distribusi Linux yang anda gunakan menggunakan cgroup v2, lihat dokumentasi distribusi linux anda gunakan atau ikuti petunjuk pada Mengidentifikasi versi cgroup pada Linux.
Anda juga dapat mengaktifkan cgroup v2 secara manual pada distribusi Linux dengan memodifikasi argumen kernel cmdline boot. Jika distribusi Linux anda menggunakan GRUB, tambahkan systemd.unified_cgroup_hierarchy=1 pada variabel GRUB_CMDLINE_LINUX dalam /etc/default/grub, diikuti dengan menjalankan sudo update-grub. Namun, cara yang direkomendasikan adalah dengan menggunakan distribusi Linux yang telah mengaktifkan cgroup v2 secara default.
Migrasi ke cgroup v2
Untuk migrasi ke cgroup v2, pastikan Anda telah memenuhi requirements yang dibutuhkan, kemudian upgrade versi kernel yang telah mengaktifkan cgroup v2 secara default.
Kubelet secara otomatis akan mendeteksi bahwa OS yang digunakan berjalan pada cgroup v2 dan bekerja sebagaimana mestinya tanpa memerlukan konfigurasi tambahan.
Seharusnya tidak ada perubahan yang terlihat atau dirasakan pada user experience ketika beralih menggunakan cgroup v2, kecuali pengguna mengakses cgroup file system secara langsung, baik itu pada node atau dari dalam container.
cgroup v2 menggunakan API yang berbeda dari cgroup v1, jadi ketika terdapat aplikasi yang secara langsung mengakses cgroup file system, aplikasi tersebut perlu diupdate ke versi terbaru yang kompatibel dengan cgroup v2. Sebagai contoh:
Beberapa agen monitoring dan security dari third-party, mungkin bergantung pada cgroup filesystem. Perbarui agen-agen ini ke versi yang mendukung cgroup v2.
Jika Anda menjalankan cAdvisor sebagai stand-alone
DaemonSet untuk memonitor pods dan containers, perbarui ke versi v0.43.0 atau setelahnya.
Jika Anda men-deploy aplikasi Java, disarankan untuk menggunakan versi yang kompatibel dengan cgroup v2 secara keseluruhan:
Jika Anda menggunakan package uber-go/automaxprocs, pastikan versi yang Anda gunakan adalah v1.5.1 atau setelahnya.
Mengidentifikasi versi cgroup pada Linux
Versi cgroup bergantung pada distribusi Linux yang digunakan dan versi cgroup yang dikonfigurasi pada OS secara default. Untuk memastikan versi cgroup yang digunakan pada distribusi Linux, jalankan command stat -fc %T /sys/fs/cgroup/ pada Linux node:
Kontainer adalah teknologi untuk mengemas kode (yang telah dikompilasi) menjadi
suatu aplikasi beserta dengan dependensi-dependensi yang dibutuhkannya pada saat
dijalankan. Setiap kontainer yang Anda jalankan dapat diulang; standardisasi
dengan menyertakan dependensinya berarti Anda akan mendapatkan perilaku yang
sama di mana pun Anda menjalankannya.
Kontainer memisahkan aplikasi dari infrastruktur host yang ada dibawahnya. Hal
ini membuat penyebaran lebih mudah di lingkungan cloud atau OS yang berbeda.
Image-Image Kontainer
Kontainer image meruapakan paket perangkat lunak
yang siap dijalankan, mengandung semua yang diperlukan untuk menjalankan
sebuah aplikasi: kode dan setiap runtime yang dibutuhkan, library dari
aplikasi dan sistem, dan nilai default untuk penganturan yang penting.
Secara desain, kontainer tidak bisa berubah: Anda tidak dapat mengubah kode
dalam kontainer yang sedang berjalan. Jika Anda memiliki aplikasi yang
terkontainerisasi dan ingin melakukan perubahan, maka Anda perlu membuat
kontainer baru dengan menyertakan perubahannya, kemudian membuat ulang kontainer
dengan memulai dari image yang sudah diubah.
Kamu membuat Docker image dan mengunduhnya ke sebuah registri sebelum digunakan di dalam Kubernetes Pod.
Properti image dari sebuah Container mendukung sintaksis yang sama seperti perintah docker, termasuk registri privat dan tag.
Memperbarui Image
Kebijakan pull default adalah IfNotPresent yang membuat Kubelet tidak
lagi mengunduh (pull) sebuah image jika sudah ada terlebih dahulu. Jika kamu ingin agar
selalu diunduh, kamu bisa melakukan salah satu dari berikut:
mengatur imagePullPolicy dari Container menjadi Always.
buang imagePullPolicy dan gunakan :latesttag untuk image yang digunakan.
Harap diingat kamu sebaiknya hindari penggunaan tag:latest, lihat panduan konfigurasi untuk informasi lebih lanjut.
Membuat Image Multi-arsitektur dengan Manifest
Docker CLI saat ini mendukung perintah docker manifest dengan anak perintah create, annotate, dan push. Perintah-perintah ini dapat digunakan
untuk membuat (build) dan mengunggah (push) manifes. Kamu dapat menggunakan perintah docker manifest inspect untuk membaca manifes.
Perintah-perintah ini bergantung pada Docker CLI, dan diimplementasi hanya di sisi CLI. Kamu harus mengubah $HOME/.docker/config.json dan mengatur keyexperimental untuk mengaktifkan
atau cukup dengan mengatur DOCKER_CLI_EXPERIMENTAL variabel environment menjadi enabled ketika memanggil perintah-perintah CLI.
Catatan:
Gunakan Docker 18.06 ke atas, versi-versi di bawahnya memiliki bug ataupun tidak mendukung perintah eksperimental. Contohnya https://github.com/docker/cli/issues/1135 yang menyebabkan masalah di bawah containerd.
Kalau kamu terkena masalah ketika mengunggah manifes-manifes yang rusak, cukup bersihkan manifes-manifes yang lama di $HOME/.docker/manifests untuk memulai dari awal.
Untuk Kubernetes, kami biasanya menggunakan image-image dengan sufiks -$(ARCH). Untuk kompatibilitas (backward compatibility), lakukan generate image-image yang lama dengan sufiks. Idenya adalah men-generate, misalnya pause image yang memiliki manifes untuk semua arsitektur dan misalnya pause-amd64 yang punya kompatibilitas terhadap konfigurasi-konfigurasi lama atau berkas-berkas YAML yang bisa saja punya image-image bersufiks yang di-hardcode.
Menggunakan Registri Privat (Private Registry)
Biasanya kita memerlukan key untuk membaca image-image yang tersedia pada suatu registri privat.
Kredensial ini dapat disediakan melalui beberapa cara:
Menggunakan Google Container Registry
per-klaster
konfigurasi secara otomatis pada Google Compute Engine atau Google Kubernetes Engine
semua Pod dapat membaca registri privat yang ada di dalam proyek
Menggunakan Amazon Elastic Container Registry (ECR)
menggunakan IAM role dan policy untuk mengontrol akses ke repositori ECR
secara otomatis refresh kredensial login ECR
Menggunakan Oracle Cloud Infrastructure Registry (OCIR)
menggunakan IAM role dan policy untuk mengontrol akses ke repositori OCIR
Menggunakan Azure Container Registry (ACR)
Menggunakan IBM Cloud Container Registry
menggunakan IAM role dan policy untuk memberikan akses ke IBM Cloud Container Registry
Konfigurasi Node untuk otentikasi registri privat
semua Pod dapat membaca registri privat manapun
memerlukan konfigurasi Node oleh admin klaster
Pra-unduh image
semua Pod dapat menggunakan image apapun yang di-cached di dalam sebuah Node
memerlukan akses root ke dalam semua Node untuk pengaturannya
Mengatur ImagePullSecrets dalam sebuah Pod
hanya Pod-Pod yang menyediakan key sendiri yang dapat mengakses registri privat
Masing-masing opsi dijelaskan lebih lanjut di bawah ini.
Menggunakan Google Container Registry
Kubernetes memiliki dukungan native untuk Google Container
Registry (GCR), ketika dijalankan pada
Google Compute Engine (GCE). Jika kamu menjalankan klaster pada GCE atau Google Kubernetes Engine,
cukup gunakan nama panjang image (misalnya gcr.io/my_project/image:tag).
Semua Pod di dalam klaster akan memiliki akses baca image di registri ini.
Kubelet akan melakukan otentikasi GCR menggunakan service account yang dimiliki
instance Google. Service acccount pada instance akan memiliki sebuah https://www.googleapis.com/auth/devstorage.read_only,
sehingga dapat mengunduh dari GCR di proyek yang sama, tapi tidak untuk unggah.
Cukup gunakan nama panjang image (misalnya ACCOUNT.dkr.ecr.REGION.amazonaws.com/imagename:tag) di dalam definisi Pod.
Semua pengguna klaster yang dapat membuat Pod akan bisa menjalankan Pod yang dapat menggunakan
image-image di dalam registri ECR.
Kubelet akan mengambil dan secara periodik memperbarui kredensial ECR, yang memerlukan permission sebagai berikut:
ecr:GetAuthorizationToken
ecr:BatchCheckLayerAvailability
ecr:GetDownloadUrlForLayer
ecr:GetRepositoryPolicy
ecr:DescribeRepositories
ecr:ListImages
ecr:BatchGetImage
Persyaratan:
Kamu harus menggunakan versi kubelet v1.2.0 atau lebih (misal jalankan /usr/bin/kubelet --version=true).
Jika Node yang kamu miliki ada di region A dan registri kamu ada di region yang berbeda misalnya B, kamu perlu versi v1.3.0 atau lebih.
ECR harus tersedia di region kamu.
Cara troubleshoot:
Verifikasi semua persyaratan di atas.
Dapatkan kredensial $REGION (misalnya us-west-2) pada workstation kamu. Lakukan SSH ke dalam host dan jalankan Docker secara manual menggunakan kredensial tersebut. Apakah berhasil?
Tambahkan verbositas level log kubelet paling tidak 3 dan periksa log kubelet (misal journalctl -u kubelet) di baris-baris yang seperti ini:
aws_credentials.go:109] unable to get ECR credentials from cache, checking ECR API
aws_credentials.go:116] Got ECR credentials from ECR API for <AWS account ID for ECR>.dkr.ecr.<AWS region>.amazonaws.com
Menggunakan Azure Container Registry (ACR)
Ketika menggunakan Azure Container Registry
kamu dapat melakukan otentikasi menggunakan pengguna admin maupun sebuah service principal.
Untuk keduanya, otentikasi dilakukan melalui proses otentikasi Docker standar. Instruksi-instruksi ini
menggunakan perangkat azure-cli.
Kamu pertama perlu membuat sebuah registri dan men-generate kredensial, dokumentasi yang lengkap tentang hal ini
dapat dilihat pada dokumentasi Azure container registry.
Setelah kamu membuat registri, kamu akan menggunakan kredensial berikut untuk login:
DOCKER_USER : service principal, atau pengguna admin
DOCKER_PASSWORD: kata sandi dari service principal, atau kata sandi dari pengguna admin
IBM Cloud Container Registry menyediakan sebuah registri image privat yang multi-tenant, dapat kamu gunakan untuk menyimpan dan membagikan image-image secara aman. Secara default, image-image di dalam registri privat kamu akan dipindai (scan) oleh Vulnerability Advisor terintegrasi untuk deteksi isu
keamanan dan kerentanan (vulnerability) yang berpotensi. Para pengguna di dalam akun IBM Cloud kamu dapat mengakses image, atau kamu dapat menggunakan IAM
role dan policy untuk memberikan akses ke namespace di IBM Cloud Container Registry.
Konfigurasi Node untuk Otentikasi ke sebuah Registri Privat
Catatan:
Jika kamu jalan di Google Kubernetes Engine, akan ada .dockercfg pada setiap Node dengan kredensial untuk Google Container Registry. Kamu tidak bisa menggunakan cara ini.
Catatan:
Jika kamu jalan di AWS EC2 dan menggunakan EC2 Container Registry (ECR), kubelet pada setiap Node akan dapat
mengatur dan memperbarui kredensial login ECR. Kamu tidak bisa menggunakan cara ini.
Catatan:
Cara ini cocok jika kamu dapat mengontrol konfigurasi Node. Cara ini tidak akan bekerja dengan baik pada GCE,
dan penyedia layanan cloud lainnya yang tidak melakukan penggantian Node secara otomatis.
Catatan:
Kubernetes pada saat ini hanya mendukung bagian auths dan HttpHeaders dari konfigurasi docker. Hal ini berarti bantuan kredensial (credHelpers atau credsStore) tidak didukung.
Docker menyimpan key untuk registri privat pada $HOME/.dockercfg atau berkas $HOME/.docker/config.json. Jika kamu menempatkan berkas yang sama
pada daftar jalur pencarian (search path) berikut, kubelet menggunakannya sebagai penyedia kredensial saat mengunduh image.
{--root-dir:-/var/lib/kubelet}/config.json
{cwd of kubelet}/config.json
${HOME}/.docker/config.json
/.docker/config.json
{--root-dir:-/var/lib/kubelet}/.dockercfg
{cwd of kubelet}/.dockercfg
${HOME}/.dockercfg
/.dockercfg
Catatan:
Kamu mungkin harus mengatur HOME=/root secara eksplisit pada berkas environment kamu untuk kubelet.
Berikut langkah-langkah yang direkomendasikan untuk mengkonfigurasi Node kamu supaya bisa menggunakan registri privat.
Pada contoh ini, coba jalankan pada desktop/laptop kamu:
Jalankan docker login [server] untuk setiap set kredensial yang ingin kamu gunakan. Ini akan memperbarui $HOME/.docker/config.json.
Lihat $HOME/.docker/config.json menggunakan editor untuk memastikan sudah berisi kredensial yang ingin kamu gunakan.
Dapatkan daftar Node, contohnya:
jika kamu ingin mendapatkan nama: nodes=$(kubectl get nodes -o jsonpath='{range.items[*].metadata}{.name} {end}')
jika kamu ingin mendapatkan IP: nodes=$(kubectl get nodes -o jsonpath='{range .items[*].status.addresses[?(@.type=="ExternalIP")]}{.address} {end}')
Salin .docker/config.json yang ada di lokal kamu pada salah satu jalur pencarian di atas.
contohnya: for n in $nodes; do scp ~/.docker/config.json root@$n:/var/lib/kubelet/config.json; done
Verifikasi dengana membuat sebuah Pod yanag menggunakan image privat, contohnya:
Fri, 26 Jun 2015 15:36:13 -0700 Fri, 26 Jun 2015 15:39:13 -0700 19 {kubelet node-i2hq} spec.containers{uses-private-image} failed Failed to pull image "user/privaterepo:v1": Error: image user/privaterepo:v1 not found
Kamu harus memastikan semua Node di dalam klaster memiliki .docker/config.json yang sama. Jika tidak, Pod-Pod
akan jalan pada beberapa Node saja dan gagal di Node lainnya. Contohnya, jika kamu menggunakan Node autoscaling, maka
setiap templat instance perlu untuk mempunyai .docker/config.json atau mount sebuah penyimpanan yang berisi berkas tersebut.
Semua Pod memiliki akses baca (read) untuk image-image di registri privat manapun ketika
key registri privat ditambahkan pada .docker/config.json.
Image Pra-unduh
Catatan:
Jika kamu jalan di Google Kubernetes Engine, maka akan ada .dockercfg pada setiap Node dengan kredensial untuk Google Container Registry. Kamu dapat menggunakan cara ini.
Catatan:
Cara ini cocok jika kamu dapat mengontrol konfigurasi Node. Cara ini tidak akan
bisa berjalan dengan baik pada GCE, dan penyedia cloud lainnya yang tidak menggantikan
Node secara otomatis.
Secara default, kubelet akan mencoba untuk mengunduh setiap image dari registri yang dispesifikasikan.
Hanya saja, jika properti imagePullPolicy diatur menjadi IfNotPresent atau Never, maka
sebuah image lokal digunakan.
Jika kamu ingin memanfaatkan image pra-unduh sebagai pengganti untuk otentikasi registri,
kamu harus memastikan semua Node di dalam klaster memiliki image pra-unduh yang sama.
Cara ini bisa digunakan untuk memuat image tertentu untuk kecepatan atau sebagai alternatif untuk otentikasi untuk sebuah registri privat.
Semua Pod akan mendapatkan akses baca ke image pra-unduh manapun.
Tentukan ImagePullSecrets pada sebuah Pod
Catatan:
Cara ini merupakan cara yang direkomendasikan saat ini untuk Google Kubernetes Engine, GCE, dan penyedia cloud lainnya yang
secara otomatis dapat membuat Node.
Kubernetes mendukung penentuan key registri pada sebuah Pod.
Membuat sebuah Secret dengan Docker Config
Jalankan perintah berikut, ganti nilai huruf besar dengan yang tepat:
Jika kamu sudah memiliki berkas kredensial Docker, daripada menggunakan perintah di atas,
kamu dapat mengimpor berkas kredensial sebagai Kubernetes Secret.
Membuat sebuah Secret berbasiskan pada kredensial Docker yang sudah ada menjelaskan bagaimana mengatur ini.
Cara ini berguna khususnya jika kamu menggunakan beberapa registri kontainer privat,
perintah kubectl create secret docker-registry akan membuat sebuah Secret yang akan
hanya bekerja menggunakan satu registri privat.
Catatan:
Pod-Pod hanya dapat mengacu pada imagePullSecrets di dalam namespace,
sehingga proses ini perlu untuk diselesaikan satu kali setiap namespace.
Mengacu pada imagePullSecrets di dalam sebuah Pod
Sekarang, kamu dapat membuat Pod yang mengacu pada Secret dengan menambahkan bagian imagePullSecrets
untuk sebuah definisi Pod.
Kamu dapat menggunakan cara ini bersama .docker/config.json pada setiap Node. Kredensial-kredensial
akan dapat di-merged. Cara ini akan dapat bekerja pada Google Kubernetes Engine.
Kasus-Kasus Penggunaan (Use Case)
Ada beberapa solusi untuk konfigurasi registri privat. Berikut beberapa kasus penggunaan
dan solusi yang disarankan.
Klaster yang hanya menjalankan image non-proprietary (misalnya open-source). Tidak perlu unutuk menyembunyikan image.
Gunakan image publik pada Docker hub.
Tidak ada konfigurasi yang diperlukan.
Pada GCE/Google Kubernetes Engine, sebuah mirror lokal digunakan secara otomatis untuk meningkatkan kecepatan dan ketersediaan.
Klaster yang menjalankan image proprietary yang seharusnya disembunyikan dari luar perusahaan, tetapi bisa terlihat oleh pengguna klaster.
Jalankan sebuah registri privat dimana otorisasi diperlukan.
Men-generate kredensial registri uuntuk setiap tenant, masukkan ke dalam secret uuntuk setiap namespace tenant.
Tenant menambahkan secret pada imagePullSecrets uuntuk setiap namespace.
Jika kamu memiliki akses pada beberapa registri, kamu dapat membuat satu secret untuk setiap registri.
Kubelet akan melakukan mergeimagePullSecrets manapun menjadi sebuah virtual .docker/config.json.
3.3 - Kontainer Environment
Laman ini menjelaskan berbagai resource yang tersedia di dalam Kontainer pada suatu environment.
Environment Kontainer
Environment Kontainer pada Kubernetes menyediakan beberapa resource penting yang tersedia di dalam Kontainer:
Sebuah Filesystem, yang merupakan kombinasi antara image dan satu atau banyak volumes.
Informasi tentang Kontainer tersebut.
Informasi tentang objek-objek lain di dalam klaster.
Informasi tentang Kontainer
Hostname sebuah Kontainer merupakan nama dari Pod dimana Kontainer dijalankan.
Informasi ini tersedia melalui perintah hostname atau panggilan (function call)
gethostname pada libc.
Nama Pod dan namespace tersedia sebagai variabel environment melalui API downward.
Variabel environment yang ditulis pengguna dalam Pod definition juga tersedia di dalam Kontainer,
seperti halnya variabel environment yang ditentukan secara statis di dalam image Docker.
Informasi tentang Klaster
Daftar semua Service yang dijalankan ketika suatu Kontainer dibuat, tersedia di dalam Kontainer tersebut sebagai variabel environment.
Variabel-variabel environment tersebut sesuai dengan sintaksis links dari Docker.
Untuk suatu Service bernama foo yang terkait dengan Kontainer bernama bar,
variabel-variabel di bawah ini tersedia:
FOO_SERVICE_HOST=<host dimana service dijalankan>
FOO_SERVICE_PORT=<port dimana service dijalankan>
Semua Service memiliki alamat-alamat IP yang bisa didapatkan di dalam Kontainer melalui DNS,
jika addon DNS diaktifkan.
Laman ini menjelaskan tentang resource RuntimeClass dan proses pemilihan runtime.
Peringatan:
RuntimeClass memiliki breaking change untuk pembaruan ke beta pada v1.14. Jika kamu menggunakan
RuntimeClass sebelum v1.14, lihat Memperbarui RuntimeClass dari Alpha ke Beta.
Runtime Class
RuntimeClass merupakan sebuah fitur untuk memilih konfigurasi runtime kontainer. Konfigurasi
tersebut digunakan untuk menjalankan kontainer-kontainer milik suatu Pod.
Persiapan
Pastikan gerbang fitur (feature gate) RuntimeClass sudah aktif (secara default sudah aktif).
Lihat Gerbang Fitur untuk lebih
jelasnya soal pengaktifan gerbang fitur.
Gerbang fitur RuntimeClass ini harus aktif pada semua apiserver dan kubelet.
Lakukan konfigurasi pada implementasi CRI untuk setiap node (tergantung runtime yang dipilih)
Buat resource RuntimeClass yang terkait
1. Lakukan konfigurasi pada implementasi CRI untuk setiap node
Pilihan konfigurasi yang tersedia melalui RuntimeClass tergantung pada implementasi
Container Runtime Interface (CRI). Lihat bagian (di bawah ini)
soal bagaimana melakukan konfigurasi untuk implementasi CRI yang kamu miliki.
Catatan:
Untuk saat ini, RuntimeClass berasumsi bahwa semua node di dalam klaster punya
konfigurasi yang sama (homogen). Jika ada node yang punya konfigurasi berbeda dari
yang lain (heterogen), maka perbedaan ini harus diatur secara independen di luar RuntimeClass
melalui fitur scheduling (lihat Menempatkan Pod pada Node).
Seluruh konfigurasi memiliki nama handler yang terkait, dijadikan referensi oleh RuntimeClass.
Nama handler harus berupa valid label 1123 DNS (alfanumerik + karakter -).
2. Buat resourceRuntimeClass yang terkait
Masing-masing konfigurasi pada langkah no.1 punya nama handler yang merepresentasikan
konfigurasi-konfigurasi tersebut. Untuk masing-masing handler, buatlah sebuah objek RuntimeClass terkait.
Resource RuntimeClass saat ini hanya memiliki 2 field yang penting: nama RuntimeClass tersebut
(metadata.name) dan handler (handler). Definisi objek tersebut terlihat seperti ini:
apiVersion:node.k8s.io/v1beta1 # RuntimeClass didefinisikan pada grup API node.k8s.iokind:RuntimeClassmetadata:name:myclass # Nama dari RuntimeClass yang nantinya akan dijadikan referensi# RuntimeClass merupakan resource tanpa namespacehandler:myconfiguration # Nama dari konfigurasi CRI terkait
Catatan:
Sangat disarankan untuk hanya memperbolehkan admin klaster melakukan operasi
write pada RuntimeClass. Biasanya ini sudah jadi default. Lihat Ikhtisar
Autorisasi untuk penjelasan lebih jauh.
Penggunaan
Ketika RuntimeClass sudah dikonfigurasi pada klaster, penggunaannya sangatlah mudah.
Kamu bisa tentukan runtimeClassName di dalam spec sebuah Pod, sebagai contoh:
Kubelet akan mendapat instruksi untuk menggunakan RuntimeClass dengan nama yang sudah ditentukan tersebut
untuk menjalankan Pod ini. Jika RuntimeClass dengan nama tersebut tidak ditemukan, atau CRI tidak dapat
menjalankan handler yang terkait, maka Pod akan memasuki tahapFailed.
Lihat event untuk mengetahui pesan error yang terkait.
Jika tidak ada runtimeClassName yang ditentukan di dalam Pod, maka RuntimeHandler yang default akan digunakan.
Untuk kasus ini, perilaku klaster akan seperti saat fitur RuntimeClass dinonaktifkan.
Konfigurasi CRI
Lihat instalasi CRI untuk lebih detail mengenai pengaturan runtime CRI.
dockershim
Built-in dockershim CRI yang dimiliki Kubernetes tidak mendukung handler runtime.
Fitur Beta pada RuntimeClass memiliki perubahan sebagai berikut:
Grup API resourcenode.k8s.io dan runtimeclasses.node.k8s.io telah dimigrasi ke suatu
API built-in dari CustomResourceDefinition.
Atribut spec telah disederhakan pada definisi RuntimeClass (tidak ada lagi yang namanya
RuntimeClassSpec).
FieldruntimeHandler telah berubah nama menjadi handler.
Fieldhandler sekarang bersifat wajib untuk semua versi API. Artinya, fieldruntimeHandler
pada API Alpha juga bersifat wajib.
Fieldhandler haruslah berupa label DNS valid (RFC 1123),
yang artinya tidak bisa berisi karakter . (pada semua versi). Handler valid harus sesuai dengan
regular expression ini: ^[a-z0-9]([-a-z0-9]*[a-z0-9])?$.
Tindakan yang diperlukan: Tindakan-tindaka berikut ini diperlukan untuk melakukan
pembaruan fitur RuntimeClass dari versi alpha ke versi beta:
Resource RuntimeClass harus dibuat ulang setelah diperbarui ke v.1.14, dan
CRD runtimeclasses.node.k8s.io harus dihapus secara manual:
Fitur Alpha pada RuntimeClass akan menjadi tidak valid, jika runtimeHandler tidak ditentukan atau
kosong atau menggunakan karakter . pada handler. Ini harus dimigrasi ke handler dengan
konfigurasi yang valid (lihat petunjuk di atas).
3.5 - Lifecyle Hook pada Kontainer
Laman ini menjelaskan bagaimana semua Kontainer yang diatur kubelet menggunakan framework lifecycle hook
untuk menjalankan kode yang di-trigger oleh event selama lifecycle berlangsung.
Ikhtisar
Kubernetes menyediakan hook untuk lifecycle Kontainer. Hal ini sejalan dengan framework bahasa
pemrograman pada umumnya yang memiliki hook untuk lifecycle komponen, seperti Angular contohnya.
Hook tersebut digunakan Kontainer untuk selalu siap menerima event selama lifecycle dan
menjalankan kode yang diimplementasi pada suatu handler, ketika hook lifecycle terkait telah dieksekusi.
Jenis-jenis hook pada Kontainer
Ada dua jenis hook yang diekspos pada Kontainer:
PostStart
Hook ini dijalankan segera setelah suatu kontainer dibuat.
Hanya saja, tidak ada jaminan bahwa hook akan tereksekusi sebelum ENTRYPOINT dari kontainer.
Tidak ada parameter yang diberikan pada handler.
PreStop
Hook ini akan dipanggil sesaat sebelum kontainer dimatikan, karena suatu request API atau event pengaturan,
contohnya kegagalan pada liveness probe, preemption, perebutan resource, dan lainnya.
Sebuah panggilan untuk hookPreStop akan gagal jika kontainer tersebut telah ada pada state terminate atau complete.
Hal ini bersifat blocking, yang artinya panggilan bersifat sinkron (synchronous), harus menunggu eksekusi selesai, sebelum melakukan panggilan
untuk menghapus kontainer tersebut.
Tidak ada parameter yang diberikan pada handler.
Penjelasan yang lebih rinci tentang proses terminasi dapat dilihat pada Terminasi Pod.
Implementasi handler untuk hook
Kontainer dapat mengakses sebuah hook melalui implementasi dan registrasi sebuah handler untuk hook tersebut.
Ada dua jenis handler untuk hook yang dapat diimplementasikan untuk Kontainer:
Exec - Mengeksekusi sebuah perintah tertentu, contohnya pre-stop.sh, di dalam cgroups dan namespace suatu Kontainer. Resource yang dikonsumsi oleh perintah tersebut dianggap sebagai bagian dari Kontainer.
HTTP - Mengeksekusi sebuah request HTTP untuk endpoint tertentu pada Kontainer tersebut.
Eksekusi handler untuk hook
Ketika manajemen hook untuk suatu lifecycle Kontainer dipanggil, sistem manajemen internal pada Kubernetes
akan mengeksekusi handler di dalam Kontainer yang terdaftar untuk hook tersebut.
Panggilan handler untuk hook semuanya bersifat synchronous di dalam konteks Pod yang
memiliki Kontainer tersebut. Artinya, untuk hookPostStart, Kontainer ENTRYPOINT
dan hook dieksekusi secara asyncrhonous. Akan tetapi, jika hook mengambil waktu terlalu lama,
atau hang, Kontainer tersebut tidak bisa sampai ke staterunning.
Perilaku ini mirip dengan yang terjadi pada hookPreStop.
Jika hook terlalu lama atau hang saat dieksekusi, Pod tersebut tetap ada pada stateTerminating
dan akan dimatikan setelah terminationGracePeriodSeconds Pod selesai.
Jika sebuah hookPostStart atau PreStop gagal dieksekusi, Kontainer akan dimatikan.
Para pengguna sangat disarankan membuat handler untuk hook seringan mungkin (lightweight).
Biar bagaimanapun, ada beberapa kasus yang memang membutuhkan waktu lama untuk mengeksekusi
suatu perintah, misalnya saat proses penyimpanan state sebelum Kontainer dimatikan.
Jaminan pengiriman hook
Proses pengiriman hook akan dilakukan paling tidak satu kali.
Artinya suatu hook boleh dipanggil beberapa kali untuk event yang sama,
seperti dalam PostStart atauPreStop.
Namun begitu, implementasi hook masing-masing harus memastikan bagaimana
menangani kasus ini dengan benar.
Pada umumnya, hanya terjadi satu proses pengiriman.
Jika misalnya sebuah penerima HTTP hook mati atau tidak bisa menerima trafik,
maka tidak ada usaha untuk mengirimkan kembali.
Namun demikian, bisa saja terjadi dua kali proses pengiriman untuk kasus tertentu.
Contohnya, jika kubelet restart saat di tengah proses pengiriman hook,
hook tersebut akan dikirimkan kembali saat kubelet sudah hidup kembali.
Melakukan debughandler untuk hook
Log untuk suatu handler hook tidak terekspos pada event Pod.
Jika handler gagal dieksekusi untuk alasan tertentu, handler akan melakukan broadcast sebuah event.
Untuk PostStart, akan dilakukan broadcast eventFailedPostStartHook,
dan untuk PreStop, akan dilakukan broadcast eventFailedPreStopHook.
Kamu dapat melihat event-event ini dengan menjalankan perintah kubectl describe pod <pod_name>.
Berikut merupakan contoh keluaran event-event setelah perintah tersebut dijalankan.
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
1m 1m 1 {default-scheduler } Normal Scheduled Successfully assigned test-1730497541-cq1d2 to gke-test-cluster-default-pool-a07e5d30-siqd
1m 1m 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Pulling pulling image "test:1.0"
1m 1m 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Created Created container with docker id 5c6a256a2567; Security:[seccomp=unconfined]
1m 1m 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Pulled Successfully pulled image "test:1.0"
1m 1m 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Started Started container with docker id 5c6a256a2567
38s 38s 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Killing Killing container with docker id 5c6a256a2567: PostStart handler: Error executing in Docker Container: 1
37s 37s 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Killing Killing container with docker id 8df9fdfd7054: PostStart handler: Error executing in Docker Container: 1
38s 37s 2 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} Warning FailedSync Error syncing pod, skipping: failed to "StartContainer" for "main" with RunContainerError: "PostStart handler: Error executing in Docker Container: 1"
1m 22s 2 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Warning FailedPostStartHook
Halaman ini menyajikan ikhtisar dari Pod, objek terkecil yang dapat di deploy di dalam objek model Kubernetes.
Memahami Pod
Sebuah Pod adalah unit dasar di Kubernetes--unit terkecil dan paling sederhana di dalam objek model Kubernetes yang dapat dibuat dan di deploy. Sebuah Pod merepresentasikan suatu proses yang berjalan di dalam klaster.
Pod membungkus sebuah kontainer (atau, di beberapa kasus, beberapa kontainer), sumber penyimpanan, alamat jaringan IP yang unik, dan opsi yang mengatur bagaimana kontainer harus dijalankan. Pod merupakan representasi dari unit deployment: sebuah instance aplikasi di dalam Kubernetes, yang mungkin terdiri dari satu kontainer atau sekumpulan kontainer yang berbagi resource.
Docker adalah salah satu kontainer runtime yang paling umum digunakan di Kubernetes Pod, tetapi Pod mendukung kontainer runtime lainnya.
Pod di Kubernetes klaster dapat digunakan dengan dua cara:
Pod menjalankan satu kontainer. Model satu kontainer per Pod adalah model yang umum digunakan di Kubernetes; kamu dapat membayangkan sebuah Pod sebagai pembungkus kontainer tersebut, dan Kubernetes tidak mengelola kontainer secara langsung tetapi mengelola Pod tersebut.
Pod menjalankan beberapa kontainer yang perlu berjalan bersamaan. Sebuah Pod dapat membungkus sebuah aplikasi yang terdiri dari beberapa kontainer yang perlu berbagi resource. Kontainer yang ditempatkan di dalam satu Pod ini membentuk sebuah layanan. Sebuah kontainer menyajikan berkas dari sumber penyimpanan ke publik, sedangkan kontainer sidecar yang lain melakukan pembaharuan terhadap berkas tersebut. Pod membungkus semua kontainer dan resource penyimpanan sebagai satu kesatuan yang dapat dikelola.
Kubernetes Blog menyediakan beberapa informasi tambahan terkait penggunaan Pod. Informasi selengkapnya, kunjungi:
Setiap Pod dimaksudkan untuk menjalankan satu instance aplikasi. Jika kamu ingin mengembangkan aplikasi secara horizontal (contoh, banyak instance sekaligus), kamu dapat menggunakan banyak Pod, satu untuk setiap instance. Di Kubernetes, konsep ini umumnya disebut dengan replikasi. Pod yang direplikasi biasanya dibuat dan dikelola sebagai grup oleh objek abstraksi yang disebut kontroler. Lihat Pod dan Kontroler untuk informasi selengkapnya.
Bagaimana Pod mengelola beberapa Kontainer
Pod didesain untuk mendukung banyak proses (sebagai kontainer) yang membentuk sebuah layanan. Kontainer di dalam sebuah Pod akan otomatis ditempatkan bersama di dalam satu mesin fisik atau mesin virtual di dalam klaster. Kontainer tersebut dapat berbagi resource dan dependensi, berkomunikasi satu sama lain, dan berkoordinasi kapan dan bagaimana mereka diterminasi.
Perhatikan bahwa mengelompokan kontainer di dalam satu Pod merupakan kasus lanjutan. Kamu dapat menggunakan pola ini hanya dalam kasus tertentu. Sebagai contoh, kamu memiliki kontainer yang bertindak sebagai web server yang menyajikan berkas dari resource penyimpanan bersama, dan kontainer sidecar melakukan pembaharuan terhadap berkas tersebut dari sumber lain, seperti dalam diagram Pod berikut:
Pod diagram
Pod menyediakan dua jenis resource sebagai penyusun dari kontainer: jaringan dan penyimpanan.
Jaringan
Setiap Pod diberikan sebuah alamat IP unik. Setiap kontainer di dalam Pod berbagi network namespace, termasuk alamat IP dan port jaringan. Setiap kontainer di dalam Pod dapat berkomunikasi satu sama lain menggunakan localhost. Saat para kontainer di dalam Pod berkomunikasi dengan entitas lain di luar Pod, mereka harus berkoordinasi satu sama lain bagaimana mereka menggunakan resource jaringan (seperti Port).
Penyimpanan
Pod dapat menentukan penyimpanan bersama yaitu volumes. Semua kontainer di dalam Pod dapat mengakses volumes ini, mengizinkan kontainer untuk berbagi data. Volumes juga memungkinkan data di Pod untuk bertahan jika salah satu kontainer perlu melakukan proses restart. Lihat Volumes untuk informasi lebih lanjut bagaimana Kubernetes mengimplementasikan penyimpanan di dalam Pod.
Bekerja dengan Pod
Kamu akan jarang membuat Pod secara langsung di Kubernetes. Ini karena Pod dirancang sebagai entitas sesaat. Saat Pod dibuat (baik oleh kamu, atau secara tidak langsung oleh kontroler), Pod ditempatkan dan dijalankan di sebuah Node di dalam klaster. Pod akan tetap di Node tersebut sampai proses dihentikan, Objek Pod dihapus, Pod dihentikan karena kekurangan resource, atau Node tersebut berhenti berjalan.
Catatan:
Tidak perlu bingung untuk membedakan antara menjalankan ulang sebuah kontainer di dalam Pod dan menjalankan ulang Pod. Pod itu sendiri tidak berjalan, tetapi Pod adalah environment kontainer itu berjalan dan akan tetap ada sampai dihapus.
Pod tidak melakukan mekanisme penyembuhan diri sendiri. Jika Pod ditempatkan disebuah Node yang gagal, atau proses penempatan Pod itu sendiri gagal, Pod akan dihapus; demikian juga, Pod tidak akan bertahan jika Node tersebut kehabisan resource atau sedang dalam tahap pemeliharaan. Kubernetes menggunakan abstraksi yang disebut kontroler, yang menangani dan mengelola Pod. Jadi, meskipun Pod dapat dipakai secara langsung di Kubernetes, kontroler merupakan cara umum yang digunakan untuk mengelola Pod. Lihat Pod dan kontroler untuk informasi lebih lanjut bagaimana Kubernetes menggunakan kontroler untuk mengimpelentasikan mekanisme penyembuhan diri sendiri dan replikasi pada Pod.
Pod dan Kontroler
Kontroler dapat membuat dan mengelola banyak Pod untuk kamu, menangani replikasi dan menyediakan kemampuan penyembuhan diri sendiri pada lingkup klaster. Sebagai contoh, jika sebuah Node gagal, kontroler akan otomatis mengganti Pod tersebut dengan menempatkan Pod yang identik di Node yang lain.
Beberapa contoh kontroler yang berisi satu atau lebih Pod meliputi:
Secara umum, kontroler menggunakan templat Pod yang kamu sediakan untuk membuat Pod.
Templat Pod
Templat Pod adalah spesifikasi dari Pod yang termasuk di dalam objek lain seperti
Replication Controllers, Jobs, dan DaemonSets. Kontroler menggunakan templat Pod untuk membuat Pod.
Contoh di bawah merupakan manifestasi sederhana untuk Pod yang berisi kontainer yang membuat sebuah pesan.
Perubahan yang terjadi pada templat atau berganti ke templat yang baru tidak memiliki efek langsung pada Pod yang sudah dibuat. Pod yang dibuat oleh replication controller dapat diperbarui secara langsung.
Pod adalah unit komputasi terkecil yang bisa di-deploy dan dibuat serta dikelola dalam Kubernetes.
Apa Itu Pod?
Sebuah Pod (seperti pod pada paus atau kacang polong) adalah sebuah kelompok yang
terdiri dari satu atau lebih kontainer
(misalnya kontainer Docker), dengan ruang penyimpanan ataupun jaringan yang dipakai bersama,
dan sebuah spesifikasi mengenai bagaimana menjalankan kontainer. Isi dari Pod akan
selalu diletakkan dan dijadwalkan bersama, serta berjalan dalam konteks yang sama.
Sebuah Pod memodelkan "logical host" yang spesifik terhadap aplikasi. Ini mengandung
lebih dari satu kontainer aplikasi yang secara relatif saling terhubung erat. Sebelum
masa kontainer, menjalankan aplikasi dalam mesin fisik atau virtual berarti
menjalankan dalam logical host yang sama.
Walaupun Kubernetes mendukung lebih banyak runtime kontainer selain Docker,
namun Docker adalah yang paling umum diketahui dan ini membantu dalam menjelaskan
Pod dengan istilah pada Docker.
Konteks bersama dalam sebuah Pod adalah kumpulan Linux namespace, cgroup dan
kemungkinan segi isolasi lain, hal yang sama yang mengisolasi kontainer Docker.
Dalam sebuah konteks pada Pod, setiap aplikasi bisa menerapkan sub-isolasi lebih lanjut.
Semua kontainer dalam suatu Pod akan berbagi alamat IP dan port yang sama,
dan bisa saling berkomunikasi melalui localhost. Komunikasi tersebut mengunakan
standar inter-process communications (IPC) seperti SystemV semaphores
atau POSIX shared memory. Kontainer pada Pod yang berbeda memiliki alamat IP
yang berbeda dan tidak dapat berkomunikasi menggunakan IPC tanpa
pengaturan khusus. Kontainer ini
biasa berkomunikasi dengan yang lain menggunakan alamat IP setiap Pod.
Aplikasi dalam suatu Pod juga memiliki akses ke ruang penyimpanan bersama,
yang didefinisikan sebagai bagian dari Pod dan dibuat bisa diikatkan ke masing-masing
filesystem pada aplikasi.
Dalam istilah konsep Docker, sebuah Pod dimodelkan sebagai
gabungan dari kontainer Docker yang berbagi namespace dan ruang penyimpanan filesystem.
Layaknya aplikasi dengan kontainer, Pod dianggap sebagai entitas yang relatif tidak kekal
(tidak bertahan lama). Seperti yang didiskusikan dalam
siklus hidup Pod, Pod dibuat, diberikan
ID unik (UID), dan dijadwalkan pada suatu mesin dan akan tetap disana hingga dihentikan
(bergantung pada aturan restart) atau dihapus. Jika mesin
mati, maka semua Pod pada mesin tersebut akan dijadwalkan untuk dihapus, namun setelah
suatu batas waktu. Suatu Pod tertentu (sesuai dengan ID unik) tidak akan dijadwalkan ulang
ke mesin baru, namun akan digantikan oleh Pod yang identik, bahkan jika dibutuhkan bisa
dengan nama yang sama, tapi dengan ID unik yang baru
(baca replication controller
untuk info lebih lanjut)
Ketika sesuatu dikatakan memiliki umur yang sama dengan Pod, misalnya saja ruang penyimpanan,
maka itu berarti akan tetap ada selama Pod tersebut masih ada. Jika Pod dihapus dengan
alasan apapun, sekalipun Pod pengganti yang identik telah dibuat, semua yang berhubungan
(misalnya ruang penyimpanan) akan dihapus dan dibuat ulang.
Pod diagram
Sebuah Pod dengan banyak kontainer, yaitu File Puller dan Web Server yang menggunakan
ruang penyimpanan persisten untuk berbagi ruang penyimpanan bersama antara kontainer.
Motivasi suatu Pods
Pengelolaan
Pod adalah suatu model dari pola beberapa proses yang bekerja sama dan membentuk
suatu unit layanan yang kohesif. Menyederhanakan proses melakukan deploy dan
pengelolaan aplikasi dengan menyediakan abstraksi tingkat yang lebih tinggi
daripada konstituen aplikasinya. Pod melayani sebagai unit dari deployment,
penskalaan horizontal, dan replikasi. Colocation (co-scheduling), berbagi nasib
(misalnya dimatikan), replikasi terkoordinasi, berbagi sumber daya dan
pengelolaan ketergantungan akan ditangani otomatis untuk kontainer dalam suatu Pod.
Berbagi sumber daya dan komunikasi
Pod memungkinkan berbagi data dan komunikasi diantara konstituennya.
Semua aplikasi dalam suatu Pod menggunakan namespace jaringan yang sama
(alamat IP dan port yang sama), dan menjadikan bisa saling mencari dan berkomunikasi
dengan menggunakan localhost. Oleh karena itu, aplikasi dalam Pod harus
berkoordinasi mengenai penggunaan port. Setiap Pod memiliki alamat IP
dalam satu jaringan bersama yang bisa berkomunikasi dengan komputer lain
dan Pod lain dalam jaringan yang sama.
Kontainer dalam suatu Pod melihat hostname sistem sebagai sesuatu yang sama
dengan konfigurasi name pada Pod. Informasi lebih lanjut terdapat dibagian
jaringan.
Sebagai tambahan dalam mendefinisikan kontainer aplikasi yang berjalan dalam Pod,
Pod memberikan sepaket sistem penyimpanan bersama. Sistem penyimpanan memungkinkan
data untuk bertahan saat kontainer dijalankan ulang dan dibagikan kepada semua
aplikasi dalam Pod tersebut.
Penggunaan Pod
Pod dapat digunakan untuk menjalankan beberapa aplikasi yang terintegrasi
secara vertikal (misalnya LAMP), namun motivasi utamanya adalah untuk mendukung
berlokasi bersama, mengelola program pembantu, diantaranya adalah:
sistem pengelolaan konten, pemuat berkas dan data, manajer cache lokal, dll.
catatan dan checkpoint cadangan, kompresi, rotasi, dll.
pengamat perubahan data, pengintip catatan, adapter pencatatan dan pemantauan,
penerbit peristiwa, dll.
proksi, jembatan dan adaptor.
pengontrol, manajer, konfigurasi dan pembaharu.
Secara umum, masing-masing Pod tidak dimaksudkan untuk menjalankan beberapa
aplikasi yang sama.
Kenapa tidak menjalankan banyak program dalam satu kontainer (Docker)?
Transparansi. Membuat kontainer dalam suatu Pod menjadi terlihat dari infrastruktur,
memungkinkan infrastruktur menyediakan servis ke kontainer tersebut, misalnya saja
pengelolaan proses dan pemantauan sumber daya. Ini memfasilitasi sejumlah
kenyamanan untuk pengguna.
Pemisahan ketergantungan perangkat lunak. Setiap kontainer mungkin memiliki
versi, dibuat dan dijalankan ulang secara independen. Kubernetes mungkin mendukung
pembaharuan secara langsung terhadap suatu kontainer, suatu saat nanti.
Mudah digunakan. Penguna tidak diharuskan menjalankan manajer prosesnya sendiri,
khawatir dengan sinyal dan propagasi exit-code, dan lain sebagainya.
Efisiensi. Karena infrastruktur memegang lebih banyak tanggung jawab, kontainer
bisa lebih ringan.
Kenapa tidak mendukung penjadwalan kontainer berdasarkan affinity?
Cara itu bisa menyediakan lokasi yang sama, namun tidak memberikan banyak
keuntungan dari Pod, misalnya saja berbagi sumber daya, IPC, jaminan berbagi nasib
dan kemudahan manajemen.
Ketahanan suatu Pod (atau kekurangan)
Pod tidak dimaksudkan untuk diperlakukan sebagai entitas yang tahan lama.
Mereka tidak akan bertahan dengan kegagalan penjadwalan, kegagalan mesin,
atau eviction (pengusiran), misalnya karena kurangnya sumber daya atau dalam suatu
kasus mesin sedang dalam pemeliharaan.
Secara umum, pengguna tidak seharusnya butuh membuat Pod secara langsung. Mereka
seharusnya selalu menggunakan pengontrol, sekalipun untuk yang tunggal, misalnya,
Deployment. Pengontrol
menyediakan penyembuhan diri dengan ruang lingkup kelompok, begitu juga dengan
pengelolaan replikasi dan penluncuran.
Pengontrol seperti StatefulSet
bisa memberikan dukungan terhadap Pod yang stateful.
Penggunaan API kolektif sebagai user-facing primitive utama adalah hal yang
relatif umum diantara sistem penjadwalan klaster, seperti
Pod diekspose sebagai primitive untuk memfasilitasi hal berikut:
penjadwalan dan pengontrol sifat pluggability
mendukung operasi pada level Pod tanpa perlu melakukan proksi melalui API pengontrol
pemisahan antara umur suatu Pod dan pengontrol, seperti misalnya bootstrapping.
pemisahan antara pengontrol dan servis, pengontrol endpoint hanya memperhatikan Pod
komposisi yang bersih antara fungsionalitas dilevel Kubelet dan klaster. Kubelet
secara efektif adalah pengontrol Pod.
aplikasi dengan ketersediaan tinggi, yang akan mengharapkan Pod akan digantikan
sebelum dihentikan dan tentu saja sebelum dihapus, seperti dalam kasus penggusuran
yang direncanakan atau pengambilan gambar.
Penghentian Pod
Karena Pod merepresentasikan proses yang berjalan pada mesin didalam klaster, sangat
penting untuk memperbolehkan proses ini berhenti secara normal ketika sudah tidak
dibutuhkan (dibandingkan dengan dihentikan paksa dengan sinyal KILL dan tidak memiliki
waktu untuk dibersihkan). Pengguna seharusnya dapat meminta untuk menghapus dan tahu
proses penghentiannya, serta dapat memastikan penghentian berjalan sempurna. Ketika
pengguna meminta menghapus Pod, sistem akan mencatat masa tenggang untuk penghentian
secara normal sebelum Pod dipaksa untuk dihentikan, dan sinyal TERM akan dikirim ke
proses utama dalam setiap kontainer. Setelah masa tenggang terlewati, sinyal KILL
akan dikirim ke setiap proses dan Pod akan dihapus dari API server. Jika Kubelet
atau kontainer manajer dijalankan ulang ketika menunggu suatu proses dihentikan,
penghentian tersebut akan diulang dengan mengembalikan masa tenggang senilai semula.
Contohnya sebagai berikut:
Pengguna mengirim perintah untuk menghapus Pod, dengan masa tenggang (30 detik)
Pod dalam API server akan diperbarui dengan waktu dimana Pod dianggap "mati"
bersama dengan masa tenggang.
Pod ditampilkan dalam status "Terminating" ketika tercantum dalam perintah klien
(bersamaan dengan poin 3) Ketika Kubelet melihat Pod sudah ditandai sebagai
"Terminating" karena waktu pada poin 2 sudah diatur, ini memulai proses penghentian Pod
Jika salah satu kontainer pada Pod memiliki
preStop hook,
maka akan dipanggil di dalam kontainer. Jika preStophook masih berjalan
setelah masa tenggang habis, langkah 2 akan dipanggil dengan tambahan masa tenggang
yang sedikit, 2 detik.
Semua kontainer akan diberikan sinyal TERM. Sebagai catatan, tidak semua kontainer
akan menerima sinyal TERM dalam waktu yang sama dan mungkin butuh waktu untuk
menjalankan preStophook jika bergantung pada urutan penghentiannya.
(bersamaan dengan poin 3) Pod akan dihapus dari daftar endpoint untuk servis dan
tidak lagi dianggap sebagai bagian dari Pod yang berjalan dalam replication controllers.
Pod yang dihentikan, secara perlahan tidak akan melayani permintaan karena load balancer
(seperti servis proksi) menghapus mereka dari daftar rotasi.
Ketika masa tenggang sudah lewat, semua proses yang masih berjalan dalam Pod
akan dihentikan dengan sinyal SIGKILL.
Kubelet akan selesai menghapus Pod dalam API server dengan mengatur masa tenggang
menjadi 0 (langsung menghapus). Pod akan menghilang dari API dan tidak lagi terlihat
oleh klien.
Secara default, semua penghapusan akan berjalan normal selama 30 detik. Perintah
kubectl delete mendukung opsi --grace-period=<waktu dalam detik> yang akan
memperbolehkan pengguna untuk menimpa nilai awal dan memberikan nilai sesuai keinginan
pengguna. Nilai 0 akan membuat Pod
dihapus paksa.
Kamu harus memberikan opsi tambahan --force bersamaan dengan --grace-period=0
untuk melakukan penghapusan paksa.
Penghapusan paksa sebuah Pod
Penghapusan paksa dari sebuah Pod didefinisikan sebagai penghapusan Pod dari state
klaster dan etcd secara langsung. Ketika penghapusan paksa dilakukan, API server tidak
akan menunggu konfirmasi dari kubelet bahwa Pod sudah dihentikan pada mesin ia berjalan.
Ini menghapus Pod secara langsung dari API, sehingga Pod baru bisa dibuat dengan nama
yang sama. Dalam mesin, Pod yang dihentikan paksa akan tetap diberikan sedikit masa
tenggang sebelum dihentikan paksa.
Penghentian paksa dapat menyebabkan hal berbahaya pada beberapa Pod dan seharusnya
dilakukan dengan perhatian lebih. Dalam kasus StatefulSet Pods, silakan melihat
dokumentasi untuk penghentian Pod dari StatefulSet.
Hak istimewa untuk kontainer pada Pod
Setiap kontainer dalam Pod dapat mengaktifkan hak istimewa (mode privileged), dengan menggunakan tanda
privileged pada konteks keamanan
pada spesifikasi kontainer. Ini akan berguna untuk kontainer yang ingin menggunakan
kapabilitas Linux seperti memanipulasi jaringan dan mengakses perangkat. Proses dalam
kontainer mendapatkan hak istimewa yang hampir sama dengan proses di luar kontainer.
Dengan hak istimerwa, seharusnya lebih mudah untuk menulis pada jaringan dan plugin
ruang penyimpanan sebagai Pod berbeda yang tidak perlu dikompilasi ke dalam kubelet.
Catatan:
Runtime kontainer kamu harus mendukung konsep hak istimewa kontainer untuk membuat
pengaturan ini menjadi relevan.
API Object
Pod adalah sumber daya tingkat tinggi dalam Kubernetes REST API.
Definisi Objek Pod API menjelaskan mengenai objek secara lengkap.
4.1.3 - Siklus Hidup Pod
Halaman ini menjelaskan siklus hidup sebuah Pod
Fase Pod
Fieldstatus dari sebuah Pod merupakan sebuah objek PodStatus, yang memiliki sebuah fieldphase.
Fase dari sebuah Pod adalah sesuatu yang sederhana, ringkasan yang lebih tinggi tentang Pod dalam siklus hidupnya. Fase ini tidak ditujukan sebagai sebuah kesimpulan yang luas dari observasi suatu kontainer atau state suatu Pod, serta tidak ditujukan sebagai state machine yang luas.
Jumlah dan arti dari nilai-nilai fase Pod dijaga ketat. Selain yang ada dalam dokumentasi ini, tidak perlu berasumsi mengenai Pod telah diberikan nilai phase.
Berikut adalah nilai yang mungkin diberikan untuk suatu phase:
Nilai
Deskripsi
Pending
Pod telah disetujui oleh sistem Kubernetes, tapi ada satu atau lebih image kontainer yang belum terbuat. Ini termasuk saat sebelum dijadwalkan dan juga saat mengunduh image melalui jaringan, yang mungkin butuh beberapa waktu.
Running
Pod telah terikat ke suatu node, dan semua kontainer telah terbuat. Setidaknya ada 1 kontainer yang masih berjalan, atau dalam proses memulai atau restart.
Succeeded
Semua kontainer di dalam Pod sudah berhasil dihentikan, dan tidak akan dilakukan restart.
Failed
Semua kontainer dalan suatu Pod telah dihentikan, dan setidaknya ada satu kontainer yang terhenti karena kegagalan. Itu merupakan kontainer yang keluar dengan kode status bukan 0 atau dihentikan oleh sistem.
Unknown
State suatu Pod tidak dapat diperoleh karena suatu alasan, biasanya karena kesalahan dalam komunikasi dengan host yang digunakan Pod tersebut.
Kondisi Pod
Suatu Pod memiliki sebuah PodStatus, yang merupakan array dari PodConditions yang telah atau belum dilewati oleh Pod. Setiap elemen dari array PodConditions mungkin memiliki enam field berikut:
FieldlastProbeTime memberikan nilai timestamp yang menandakan kapan terakhir kali kondisi kondisi Pod diperiksa.
FieldlastTransitionTime memberikan nilai timestamp yang menandakan kapan terakhir kali Pod berubah status ke status lain.
Fieldmessage adalah pesan yang bisa dibaca manusia yang mengidikasikan detail dari suatu transisi.
Fieldreason adalah suatu alasan yang unik, satu kata, ditulis secara CamelCase untuk kondisi transisi terakhir.
Fieldstatus adalah sebuah kata dengan kemungkinan nilainya berupa "True", "False", dan "Unknown".
Fieldtype adalah sebuah kata yang memiliki kemungkinan nilai sebagai berikut:
PodScheduled: Pod telah dijadwalkan masuk ke node;
Ready: Pod sudah mampu menerima request masuk dan seharusnya sudah ditambahkan ke daftar pembagian beban kerja untuk servis yang sama;
Unschedulable: scheduler belum dapat menjadwalkan Pod saat ini, sebagai contoh karena kekurangan resources atau ada batasan-batasan lain.
ContainersReady: Semua kontainer di dalam Pod telah siap.
Pemeriksaan Kontainer
Sebuah Probe adalah sebuah diagnosa yang dilakukan secara berkala oleh kubelet dalam suatu kontainer. Untuk melakukan diagnosa, kubelet memanggil sebuah Handler yang diimplementasikan oleh kontainer. Ada 3 tipe Handler yang tersedia, yaitu:
ExecAction: Mengeksekusi perintah tertentu di dalam kontainer. Diagnosa dikatakan berhasil jika perintah selesai dengan kode status 0.
TCPSocketAction: Melakukan pengecekan TCP terhadap alamat IP kontainer dengan port tertentu. Diagnosa dikatakan berhasil jika port tersebut terbuka.
HTTPGetAction: Melakukan sebuah request HTTP Get terhadap alamat IP kontainer dengan port dan path tertentu. Diagnosa dikatakan berhasil jika responnya memiliki kode status lebih besar atau sama dengan 200 dan kurang dari 400.
Setiap pemeriksaan akan menghasilkan salah satu dari tiga hasil berikut:
Success: Kontainer berhasil melakukan diagnosa.
Failure: Kontainer gagal melakukan diagnosa.
Unknown: Gagal melakukan diagnosa, sehingga tidak ada aksi yang harus dilakukan.
Kubelet dapat secara optimal melakukan dan bereaksi terhadap dua jenis pemeriksaan yang sedang berjalan pada kontainer, yaitu:
livenessProbe: Ini menunjukkan apakah kontainer sedang berjalan. Jika tidak berhasil melakukan pemeriksaan terhadap liveness dari kontainer, maka kubelet akan mematikan kontainer, dan kontainer akan mengikuti aturan dari restart policy. Jika kontainer tidak menyediakan pemeriksaan terhadap liveness, maka nilai dari state adalah Success.
readinessProbe: Ini menunjukan apakah kontainer sudah siap melayani request. Jika tidak berhasil melakukan pemeriksaan terhadap kesiapan dari kontainer, maka endpoints controller akan menghapus alamat IP Pod dari daftar semua endpoint untuk servis yang sama dengan Pod. Nilai awal state sebelum jeda awal adalah Failure. Jika kontainer tidak menyediakan pemeriksaan terhadap readiness, maka nilai awal state adalah Success.
Kapan sebaiknya menggunakan pemeriksaan terhadap liveness atau readiness?
Jika proses dalam kontainer mungkin gagal yang dikarenakan menghadapi suatu masalah
atau menjadi tidak sehat, maka pemeriksaan terhadap liveness tidak diperlukan.
Kubelet akan secara otomatis melakukan aksi yang tepat mengikuti restartPolicy dari Pod.
Jika kamu ingin kontainer bisa dimatikan dan dijalankan ulang ketika gagal melakukan
pemeriksaan, maka tentukan pemeriksaan liveness dan tentukan nilai restartPolicy sebagai Always atau OnFailure.
Jika kamu ingin mulai mengirim traffic ke Pod hanya ketika pemeriksaan berhasil,
maka tentukan pemeriksaan readiness. Dalam kasus ini, pemeriksaan readiness mungkin
akan sama dengan pemeriksaan liveness, tapi keberadaan pemeriksaan readiness dalam
spec berarti Pod akan tetap dijalankan tanpa menerima traffic apapun dan akan
mulai menerima traffic ketika pemeriksaan yang dilakukan mulai berhasil.
Jika kontainermu dibutuhkan untuk tetap berjalan ketika loading data yang besar,
file konfigurasi, atau melakukan migrasi ketika startup, maka tentukanlah pemeriksaan readiness.
Jika kamu ingin kontainermu dalam mematikan dirinya sendiri, kamu dapat menentukan
suatu pemeriksaan readiness yang melakukan pengecekan terhadap endpoint untuk readiness.
endpoint tersebut berbeda dengan endpoint untuk pengecekan liveness.
Perlu dicatat, jika kamu hanya ingin bisa menutup request ketika Pod sedang dihapus
maka kamu tidak perlu menggunakan pemeriksaan readiness. Dalam penghapusan, Pod akan
secara otomatis mengubah state dirinya menjadi unready tanpa peduli apakah terdapat
pemeriksaan readiness atau tidak. Pod tetap ada pada state unready selama menunggu
kontainer dalam Pod berhenti.
Untuk informasi lebih mendalam mengenai status Pod dan kontainer, silakan lihat
PodStatus
dan
ContainerStatus.
Mohon diperhatikan, informasi tentang status Pod bergantung pada
ContainerState.
State Kontainer
Ketika Pod sudah ditempatkan pada suatu node oleh scheduler, kubelet mulai membuat kontainer menggunakan runtime kontainer.
Ada tiga kemungkinan state untuk suatu kontainer, yaitu Waiting, Running, dan Terminated.
Untuk mengecek state suatu kontainer, kamu bisa menggunakan perintah kubectl describe pod [NAMA_POD].
State akan ditampilkan untuk masing-masing kontainer dalam Pod tersebut.
Waiting: Merupakan state default dari kontainer. Jika state kontainer bukan Running atau Terminated, berarti dalam Wating state.
Suatu kontainer dalam Waiting state akan tetap menjalan operasi-operasi yang dibutuhkan, misalnya mengunduh images, mengaplikasikan Secrets, dsb.
Bersamaan dengan state ini, sebuah pesan dan alasan tentang state akan ditampilkan untuk memberi informasi lebih.
...State:WaitingReason:ErrImagePull...
Running: Menandakan kontainer telah berjalan tanpa masalah. Setelah kontainer masuk ke state Running, jika terdapat hookpostStart maka akan dijalankan. State ini juga menampilkan waktu ketika kontainer masuk ke state Running.
...State:RunningStarted:Wed, 30 Jan 2019 16:46:38 +0530...
Terminated: Menandakan kontainer telah menyelesaikan "tugasnya". Kontainer akan menjadi state ini ketika telah menyelesaikan eksekusi atau terjadi kesalahan. Terlepas dari itu, sebuah alasan dan exit code akan ditampilkan, bersama dengan waktu kontainer mulai dijalankan dan waktu berhenti. Sebelum kontainer masuk ke state Terminated, jika terdapat preStophook maka akan dijalankan.
...State:TerminatedReason:CompletedExit Code:0Started:Wed, 30 Jan 2019 11:45:26 +0530Finished:Wed, 30 Jan 2019 11:45:26 +0530...
Pod readiness gate
FEATURE STATE:Kubernetes v1.14 [stable]
Dalam rangka menambahkan ekstensibilitas terhadap kesiapan Pod dengan menggunakan
injeksi umpan balik tambahan atau sinyal ke dalam PodStatus,
Kubernetes 1.11 memperkenalkan sebuah fitur bernama Pod ready++.
Kamu dapat menggunakan field baru ReadinessGate dalam sebuah PodSpec untuk
menunjukan kondisi tambahan yang akan dievaluasi untuk kesiapan Pod. Jika Kubernetes
tidak dapat menemukan kondisi pada fieldstatus.conditions dalam suatu Pod,
maka statusnya akan secara otomatis menjadi False. Berikut adalah contoh pemakaiannya:
Kind:Pod...spec:readinessGates:- conditionType:"www.example.com/feature-1"status:conditions:- type:Ready # ini adalah PodCondition yang telah tersediastatus:"False"lastProbeTime:nulllastTransitionTime:2018-01-01T00:00:00Z- type:"www.example.com/feature-1"# sebuah PodCondition tambahanstatus:"False"lastProbeTime:nulllastTransitionTime:2018-01-01T00:00:00ZcontainerStatuses:- containerID:docker://abcd...ready:true...
Kondisi Pod yang baru harus memenuhi format label pada Kubernetes.
Sejak perintah kubectl patch belum mendukung perubahan status objek, kondisi Pod yang baru harus mengubah melalui aksi PATCH dengan menggunakan
salah satu dari KubeClient libraries.
Dengan diperkenalkannya kondisi Pod yang baru, sebuah Pod akan dianggap siap hanya jika memenuhi dua syarat berikut:
Semua kontainer dalam Pod telah siap.
Semua kontainer yang diatur dalam ReadinessGates bernilai "True".
Untuk memfasilitasi perubahan tersebut terhadap evaluasi kesiapan Pod, dibuatkan sebuah kondisi Pod baru yaitu ContainerReady,
untuk dapat menangani kondisi Pod Ready yang sudah ada.
Dalam K8s 1.12, fitur tersebut sudah diaktifkan dari awal.
Aturan Menjalankan Ulang
Sebuah PodSpec memiliki fieldrestartPolicy dengan kemungkinan nilai berupa Always, OnFailure, dan Never.
Nilai awalnya berupa Always. restartPolicy akan berlaku untuk semua kontainer dalam Pod.
Kontainer yang mati dan dijalankan ulang oleh kubelet akan dijalankan ulang dengan jeda waktu yang ekponensial (10s, 20s, 40s, ...)
dengan batas atas senilai lima menit. Jeda waktu ini akan diatur ulang setelah sukses berjalan selama 10 menit.
Sesuai dengan diskusi pada dokumen Pod,
setelah masuk ke suatu node, sebuah Pod tidak akan pindah ke node lain.
Umur Pod
Secara umum, Pod tidak hilang sampai ada yang menghapusnya. Ini mungkin dihapus oleh orang atau pengontrol.
Satu pengecualian untuk aturan ini adalah Pod dengan phase bernilai Succeeded atau Failed untuk waktu
beberapa lama yang akan berakhir dan secara otomatis akan dihapus.
(diatur dalam terminated-pod-gc-threshold pada master)
Tiga tipe pengontrol yang tersedia yaitu:
Menggunakan sebuah Job untuk Pod yang diharapkan akan berakhir,
sebagai contoh, penghitungan dalam jumlah banyak. Jobs hanyak cocok untuk Pod dengan restartPolicy yang
bernilai OnFailure atau Never.
Menggunakan sebuah ReplicationController,
ReplicaSet, atau
Deployment untuk Pod yang tidak diharapkan untuk berakhir,
sebagai contoh, web servers. ReplicationControllers hanya cocok digunakan pada Pod dengan restartPolicy
yang bernilai Always.
Menggunakan sebuah DaemonSet untuk Pod yang akan berjalan
hanya satu untuk setiap mesin, karena menyediakan servis yang spesifik untuk suatu mesin.
Ketiga tipe pengontrol ini memiliki sebuah PodTemplate. Direkomdasikan untuk membuat
pengontrol yang sesuai dan membiarkan ini membuat Pod, daripada membuat Pod sendiri secara langsung.
Karena Pod itu sendiri tidak tahan terhadap gagalnya suatu mesin, namun pengontrol tahan.
Jika node mati atau sambungannya terputus dari klaster, Kubernetes mengatur
phase dari semua Pod pada node yang mati untuk menjadi Failed.
Contoh
Contoh Liveness Probe tingkat lanjut
Liveness probe dieksekusi oleh kubelet, jadi semua permintaan akan dilakukan
di dalam namespace jaringan kubelet.
apiVersion:v1kind:Podmetadata:labels:test:livenessname:liveness-httpspec:containers:- args:- livenessimage:registry.k8s.io/e2e-test-images/agnhost:2.40livenessProbe:httpGet:# ketika "host" tidak ditentukan, "PodIP" akan digunakan# host: my-host# ketika "scheme" tidak ditentukan, _scheme_ "HTTP" akan digunakan. Hanya "HTTP" and "HTTPS" yang diperbolehkan# scheme: HTTPSpath:/healthzport:8080httpHeaders:- name:X-Custom-Headervalue:AwesomeinitialDelaySeconds:15timeoutSeconds:1name:liveness
Contoh State
Pod sedang berjalan dan memiliki sebuah kontainer. Kontainer berhenti dengan sukses.
Mencatat event penyelesaian.
Jika nilai restartPolicy adalah:
Always: Jalankan ulang kontainer; nilai phase Pod akan tetap Running.
OnFailure: nilai phase Pod akan berubah menjadi Succeeded.
Never: nilai phase Pod akan berubah menjadi Succeeded.
Pod sedang berjalan dan memiliki sebuah kontainer. Kontainer berhenti dengan kegagalan.
Mencatat event kegagalan.
Jika nilai restartPolicy adalah:
Always: Jalankan ulang kontainer, nilai phase Pod akan tetap Running.
OnFailure: Jalankan ulang kontainer, nilai phase Pod akan tetap Running.
Never: nilai phase Pod akan menjadi Failed.
Pod sedang berjalan dan memiliki dua kontainer. Kontainer pertama berhenti dengan kegagalan.
Mencatat event kegagalan.
Jika nilai restartPolicy adalah:
Always: Jalankan ulang kontainer, nilai phase Pod akan tetap Running.
OnFailure: Jalankan ulang kontainer, nilai phase Pod akan tetap Running.
Never: Tidak akan menjalankan ulang kontainer, nilai phase Pod akan tetap Running.
Jika kontainer pertama tidak berjalan dan kontainer kedua berhenti:
Mencatat event kegagalan.
Jika nilai restartPolicy adalah:
Always: Jalankan ulang kontainer, nilai phase Pod akan tetap Running.
OnFailure: Jalankan ulang kontainer, nilai phase Pod akan tetap Running.
Never: nilai phase Pod akan menjadi Failed.
Pod sedang berjalan dan memiliki satu kontainer. Kontainer berhenti karena kehabisan memory.
Kontainer diberhentikan dengan kegagalan.
Mencatat kejadian kehabisan memory (OOM)
Jika nilai restartPolicy adalah:
Always: Jalankan ulang kontainer, nilai phase Pod akan tetap Running.
OnFailure: Jalankan ulang kontainer, nilai phase Pod akan tetap Running.
Never: Mencatat kejadian kegagalan, nilai phase Pod akan menjadi Failed.
Pod sedang berjalan dan sebuah disk mati.
Menghentikan semua kontainer.
Mencatat kejadian yang sesuai.
Nilai phase Pod menjadi Failed.
Jika berjalan menggunakan pengontrol, maka Pod akan dibuat ulang di tempat lain.
Pod sedang berjalan, dan node mengalami segmented out.
Node pengontrol menunggu sampai suatu batas waktu.
Node pengontrol mengisi nilai phase Pod menjadi Failed.
Jika berjalan menggunakan pengontrol, maka Pod akan dibuat ulang di tempat lain.
Halaman ini menyediakan ikhtisar untuk Init Container, yaitu Container khusus yang dijalankan sebelum Container aplikasi dan berisi skrip peralatan atau setup yang tidak tersedia di dalam image dari Container aplikasi.
Fitur ini telah keluar dari trek Beta sejak versi 1.6. Init Container dapat dispesifikasikan di dalam PodSpec bersama dengan arraycontainers aplikasi. Nilai anotasi beta akan tetap diperhitungkan dan akan menimpa nilai pada PodSpec, tetapi telah ditandai sebagai kedaluarsa pada versi 1.6 dan 1.7. Pada versi 1.8, anotasi beta tidak didukung lagi dan harus diganti menjadi nilai pada PodSpec.
Memahami Init Container
Sebuah Pod dapat memiliki beberapa Container yang berjalan di dalamnya, dan dapat juga memiliki satu atau lebih Init Container, yang akan berjalan sebelum Container aplikasi dijalankan.
Init Container sama saja seperti Container biasa, kecuali:
Mereka selalu berjalan hingga selesai.
Setiap Init Container harus selesai secara sukses sebelum Init Container berikutnya dijalankan.
Jika sebuah Init Container tidak selesai secara sukses untuk sebuah Pod, Kubernetes akan mengulang kembali Pod tersebut secara terus menerus hingga Init Container selesai secara sukses. Tetapi, jika Pod tersebut memiliki nilai restartPolicy berupa Never, Pod tersebut tidak akan diulang kembali.
Untuk menspesifikasikan sebuah Container sebagai Init Container, tambahkan kolom initContainers pada PodSpec sebagai sebuah array JSON yang berisi objek dengan tipe Container, berdampingan dengan array containers aplikasi.
Status-status dari Init Container dikembalikan di kolom .status.initContainerStatuses sebagai sebuah array dari status-status Container (mirip seperti kolom status.containerStatuses)
Perbedaan dengan Container biasa
Init Container mendukung semua kolom dan fitur dari Container aplikasi, termasuk konfigurasi limit sumber daya, volume, dan keamanan. Tetapi, request dan limit sumber daya dari sebuah Init Container ditangani dengan cara yang sedikit berbeda, yang didokumentasikan di bagian Sumber Daya di bawah. Juga, Init Container tidak mendukung readiness probe karena mereka harus berjalan hingga selesai sebelum Pod dapat siap.
Jika beberapa Init Container dispesifikasikan untuk sebuah Pod, Container-container tersebut akan dijalankan satu per satu secara berurutan. Setiap Init Container harus selesai secara sukses sebelum yang berikutnya dapat berjalan.
Saat semua Init Container telah berjalan hingga selesai, Kubernetes akan menginisialisasi Pod dan menjalankan Container aplikasi seperti biasa.
Apa kegunaan Init Container?
Karena Init Container memiliki image yang berbeda dengan Container aplikasi, mereka memiliki beberapa kelebihan untuk kode yang berhubungan dengan dimulainya Init Container:
Mereka dapat berisi dan menjalankan skrip peralatan yang tidak diinginkan untuk berada di dalam image Container aplikasi karena alasan keamanan.
Mereka dapat berisi skrip peralatan atau setup yang tidak tersedia di dalam image aplikasi. Misalnya, kita tidak perlu membuat image dengan instruksi FROM dari image lainnya hanya untuk menggunakan peralatan seperti sed, awk, python, atau dig pada saat setup.
Peran builder atau deployer dari image dapat bekerja secara independen tanpa harus digabung untuk membuat satu image aplikasi.
Mereka menggunakan namespace Linux, sehingga mereka dapat memiliki sudut pandang filesystem yang berbeda dengan Container aplikasi. Oleh karenanya, mereka dapat diberikan akses terhadap Secret yang tidak boleh diakses oleh Container aplikasi.
Mereka berjalan hingga selesai sebelum Container aplikasi manapun dimulai, sedangkan Container aplikasi dijalankan secara paralel, sehingga Init Container menyediakan cara yang mudah untuk menunda dijalankannya Container aplikasi hingga ketentuan-ketentuan yang diinginkan dipenuhi.
Contoh-contoh
Berikut beberapa contoh kasus penggunaan Init Container:
Menunggu sebuah Service untuk dibuat dengan perintah shell seperti:
for i in {1..100}; do sleep 1; if nslookup myservice; then exit 0; fi; done; exit 1
Mendaftarkan suatu Pod ke sebuah peladen terpisah dari downward API dengan perintah seperti:
`curl -X POST http://$MANAGEMENT_SERVICE_HOST:$MANAGEMENT_SERVICE_PORT/register -d 'instance=$(<POD_NAME>)&ip=$(<POD_IP>)'`
Menunggu beberapa waktu sebelum menjalankan Container aplikasi dengan perintah seperti sleep 60.
Mengklon sebuah git repository ke dalam sebuah volume.
Menaruh nilai-nilai tertentu ke dalam sebuah file konfigurasi dan menjalankan peralatan template untuk membuat file konfigurasi secara dinamis untuk Container aplikasi utama. Misalnya, untuk menaruh nilai POD_IP ke dalam sebuah konfigurasi dan membuat konfigurasi aplikasi utama menggunakan Jinja.
File YAML untuk Kubernetes 1.5 berikut menguraikan sebuah Pod sederhana yang memiliki dua buah Init Container.
Pod pertama menunggu myservice dan yang kedua menunggu mydb. Saat kedua Init Container tersebut sudah selesai, Podnya akan dijalankan.
apiVersion:v1kind:Podmetadata:name:myapp-podlabels:app:myappannotations:pod.beta.kubernetes.io/init-containers:'[
{
"name": "init-myservice",
"image": "busybox:1.28",
"command": ['sh', '-c', "until nslookup myservice.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done"]},{"name": "init-mydb","image": "busybox:1.28","command": ['sh','-c',"until nslookup mydb.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for mydb; sleep 2; done"]}]'
spec:
containers:
- name: myapp-container
image: busybox:1.28
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
Ada sintaksis baru pada Kubernetes 1.6, walaupun sintaksis anotasi yang lama tetap akan bekerja untuk versi 1.6 dan 1.7. Sintaksis yang baru harus digunakan untuk versi 1.8 ke atas. Deklarasi Init Container dipindahkan ke dalam spec:
apiVersion:v1kind:Podmetadata:name:myapp-podlabels:app:myappspec:containers:- name:myapp-containerimage:busybox:1.28command:['sh','-c','echo The app is running! && sleep 3600']initContainers:- name:init-myserviceimage:busybox:1.28command:['sh','-c','until nslookup myservice; do echo waiting for myservice; sleep 2; done;']- name:init-mydbimage:busybox:1.28command:['sh','-c','until nslookup mydb; do echo waiting for mydb; sleep 2; done;']
Sintaksis versi 1.5 tetap akan bekerja pada versi 1.6 dan 1.7, tetapi kami menyarankan untuk menggunakan sintaksis versi 1.6. Pada Kubernetes 1.6, Init Container dijadikan sebagai sebuah kolom di dalam API Kubernetes. Anotasi beta tetap akan diperhitungkan pada versi 1.6 dan 1.7, tetapi tidak didukung lagi pada versi 1.8 ke atas.
File YAML di bawah menguraikan Service mydb dan myservice.
Saat kita menjalankan Service mydb dan myservice, kita dapat melihat Init Container telah selesai dan myapp-pod pun dibuat:
kubectl apply -f services.yaml
service/myservice created
service/mydb created
kubectl get -f myapp.yaml
NAME READY STATUS RESTARTS AGE
myapp-pod 1/1 Running 0 9m
Contoh ini sangat sederhana, tetapi dapat memberikan sedikit petunjuk bagi kamu untuk membuat Init Container sendiri.
Perilaku mendetail
Saat dimulainya sebuah Pod, Init Container dijalankan secara berurutan, setelah jaringan dan volume telah diinisialisasi. Setiap Init Container harus selesai dan keluar secara berhasil sebelum yang berikutnya dijalankan. Jika ada Init Container yang gagal dijalankan atau keluar secara gagal, dia akan diulang kembali sesuai dengan restartPolicy yang dimiliki Pod. Tetapi, jika restartPolicy Pod disetel dengan nilai Always, Init Container akan menggunakan strategi RestartPolicyOnFailure.
Sebuah Pod tidak dapat masuk ke status Ready hingga semua Init Container berhasil selesai. Port di sebuah Init Container tidak diagregasikan di dalam sebuah Service. Sebuah Pod yang sedang diinisalisasikan akan masuk ke dalam status Pending, tetapi akan memiliki kondisi Initialized yang disetel menjadi true.
Jika sebuah Pod diulang kembali, semua Init Container harus dijalankan kembali.
Perubahan pada spesifikasi Init Container dibatasi hanya pada kolom image pada Init Container. Mengganti kolom image sebuah Init Container sama dengan mengulang kembali Pod tersebut.
Karena Init Container dapat diulang kembali, dicoba ulang, atau dijalankan ulang, Init Container sebaiknya bersifat idempotent. Khususnya, kode yang menulis ke dalam file pada EmptyDir sebaiknya dipersiapkan untuk menangani kemungkinan jika file keluaran yang diharapkan sudah ada di dalam EmptyDir tersebut.
Init Container memiliki semua kolom yang dimiliki oleh Container aplikasi. Tetapi, Kubernetes melarang penggunaan readinessProbe karena Init Container tidak dapat mendefinisikan/menggunakan readiness probe setelah selesai/keluar secara berhasil. Hal ini dipaksakan saat proses validasi.
Gunakan activeDeadlineSeconds pada Pod dan livenessProbe pada Container untuk mencegah Init Container gagal terus menerus. Nilai activeDeadlineSeconds berlaku juga terhadap Init Container.
Nama setiap Container aplikasi dan Init Container pada sebuah Pod haruslah unik; Kesalahan validasi akan terjadi jika ada Container atau Init Container yang memiliki nama yang sama.
API untuk sidecar containers
FEATURE STATE:Kubernetes v1.28 [alpha]
Mulai dari Kubernetes 1.28 dalam mode alpha, terdapat fitur yang disebut SidecarContainers yang memungkinkan Anda untuk menentukan restartPolicy untuk kontainer init yang independen dari Pod dan kontainer init lainnya. [Probes] (/docs/concepts/workloads/pods/pod-lifecycle/#types-of-probe) juga dapat ditambahkan untuk mengendalikan siklus hidup mereka.
Jika sebuah kontainer init dibuat dengan restartPolicy yang diatur sebagai Always, maka kontainer ini akan mulai dan tetap berjalan selama seluruh masa hidup Pod, yang berguna untuk menjalankan layanan pendukung yang terpisah dari kontainer aplikasi utama.
Jika sebuah readinessProbe ditentukan untuk kontainer init ini, hasilnya akan digunakan untuk menentukan status siap dari Pod.
Karena kontainer-kontainer ini didefinisikan sebagai kontainer init, mereka mendapatkan manfaat dari urutan dan jaminan berurutan yang sama seperti kontainer init lainnya, yang memungkinkan mereka dicampur dengan kontainer init lainnya dalam aliran inisialisasi Pod yang kompleks.
Dibandingkan dengan kontainer init reguler, kontainer init tipe sidecar terus berjalan, dan kontainer init berikutnya dapat mulai menjalankan saat kubelet telah menetapkan status kontainer started menjadi benar untuk kontainer init tipe sidecar. Status tersebut menjadi benar karena ada proses yang berjalan dalam kontainer dan tidak ada probe awal yang ditentukan, atau sebagai hasil dari keberhasilan startupProbe.
Fitur ini dapat digunakan untuk mengimplementasikan pola kontainer sidecar dengan lebih tangguh, karena kubelet selalu akan me-restart kontainer sidecar jika kontainer tersebut gagal.
Berikut adalah contoh Deployment dengan dua kontainer, salah satunya adalah sidecar:
Fitur ini juga berguna untuk menjalankan Job dengan sidecar, karena kontainer sidecar tidak akan mencegah Job untuk menyelesaikan tugasnya setelah kontainer utama selesai.
Berikut adalah contoh sebuah Job dengan dua kontainer, salah satunya adalah sidecar:
Karena eksekusi Init Container yang berurutan, aturan-aturan untuk sumber daya berlaku sebagai berikut:
Yang tertinggi antara request atau limit sumber daya yang didefinisikan pada semua Init Container adalah request/limit inisialisasi yang berlaku.
request/limit sumber daya Pod yang berlaku adalah yang paling besar diantara:
Jumah request/limit semua Container aplikasi untuk suatu sumber daya.
request/limit inisialisasi yang berlaku untuk suatu sumber daya.
Penjadwalan dilakukan berdasarkan request/limit (Pod) yang berlaku, yang berarti bahwa Init Container dapat mengambil sumber daya inisialisasi yang tidak digunakan selama umur Pod tersebut.
Tingkat QoS yang berlaku milik Pod adalah sama dengan tingkat QoS untuk Init Container dan Container aplikasi.
ResourceQuota dan limitedResources diberlakukan berdasarkan request dan limit Pod yang berlaku.
Cgroup pada tingat Pod didasarkan pada request dan limit Pod yang berlaku, sama dengan scheduler.
Alasan Pod diulang kembali
Pod dapat diulang kembali, yang berakibat pada diulangnya eksekusi Init Container, diakibatkan oleh beberapa alasan berikut:
Seorang pengguna memperbarui PodSpec, mengakibatkan image Init Container berubah. Perubahan apapun pada image Init Container akan mengulang kembali Pod tersebut. Perubahan pada image Container aplikasi hanya mengulang kembali Container aplikasi yang bersangkutan.
Infrastruktur Container Pod diulang kembali. Hal ini jarang terjadi, dan hanya dapat dilakukan oleh seseorang yang memiliki akses root pada node yang bersangkutan.
Semua Container di dalam Pod diterminasi, dengan nilai restartPolicy yang disetel sebagai Always, memaksa pengulangan kembali, dan catatan selesainya Init Container telah hilang karena garbage collection.
Dukungan dan kompatibilitas
Sebuah klaster dengan versi Apiserver 1.6.0 ke atas mendukung Init Container melalui kolom .spec.initContainers. Versi-versi sebelumnya mendukung Init Container melalui anotasi alpha atau beta. Kolom .spec.initContainers juga diduplikasikan dalam bentuk anotasi alpha dan beta agar Kubelet versi 1.3.0 ke atas dapat menjalankan Init Container, dan agar Apiserver versi 1.6 dapat dengan aman dikembalikan ke versi 1.5.x tanpa kehilangan fungsionalitas Pod-pod yang telah dibuat sebelumnya.
Pada Apiserver dan Kubelet versi 1.8.0 ke atas, dukungan untuk anotasi alpha dan beta telah dihapus, sehingga dibutuhkan konversi (manual) dari anotasi yang telah kedaluwarsa tersebut ke dalam bentuk kolom .spec.initContainers.
Kamu dapat menggunakan batasan perseberan topologi (topology spread constraints)
untuk mengatur bagaimana Pod akan disebarkan
pada klaster yang ditetapkan sebagai failure-domains, seperti wilayah, zona, Node dan domain
topologi yang ditentukan oleh pengguna. Ini akan membantu untuk mencapai ketersediaan yang tinggi
dan juga penggunaan sumber daya yang efisien.
Batasan persebaran topologi bergantung dengan label pada Node untuk menentukan
domain topologi yang memenuhi untuk semua Node. Misalnya saja, sebuah Node bisa memiliki
label sebagai berikut: node=node1,zone=us-east-1a,region=us-east-1
Misalkan kamu memiliki klaster dengan 4 Node dengan label sebagai berikut:
NAME STATUS ROLES AGE VERSION LABELS
node1 Ready <none> 4m26s v1.16.0 node=node1,zone=zoneA
node2 Ready <none> 3m58s v1.16.0 node=node2,zone=zoneA
node3 Ready <none> 3m17s v1.16.0 node=node3,zone=zoneB
node4 Ready <none> 2m43s v1.16.0 node=node4,zone=zoneB
Maka klaster tersebut secara logika akan dilihat sebagai berikut:
Tanpa harus memberi label secara manual, kamu dapat menggunakan [label ternama]
(/docs/reference/kubernetes-api/labels-annotations-taints/) yang terbuat dan terkumpulkan
secara otomatis pada kebanyakan klaster.
Batasan Persebaran untuk Pod
API
Fieldpod.spec.topologySpreadConstraints diperkenalkan pada versi 1.16 sebagai berikut:
Kamu dapat mendefinisikan satu atau lebih topologySpreadConstraint untuk menginstruksikan
kube-scheduler mengenai cara peletakan tiap Pod baru dengan menggunakan kondisi Pod yang
sudah ada dalam klaster kamu. Field yang ada adalah:
maxSkew menentukan batasan yang menandakan Pod tidak tersebar secara merata.
Ini merupakan nilai maksimal dari selisih jumlah Pod yang sama untuk setiap 2 domain topologi
yang sama. Nilai ini harus lebih dari 0.
topologyKey adalah kunci dari label Node. Jika terdapat dua Node memiliki label dengan
kunci ini dan memiliki nilai yang identik untuk label tersebut, maka penjadwal akan menganggap
kedua Noode dalam topologi yang sama. Penjadwal akan mencoba untuk menyeimbangkan jumlah Pod
dalam setiap domain topologi.
whenUnsatisfiable mengindikasikan cara menangani Pod yang tidak memenuhi batasan persebaran:
DoNotSchedule (default) memberitahukan penjadwal untuk tidak menjadwalkan Pod tersebut.
ScheduleAnyway memberitahukan penjadwal untuk tetap menjadwalkan Pod namun tetap menjaga ketidakseimbangan Node sekecil mungkin.
labelSelector digunakan untuk mencari Pod yang sesuai. Pod dengan label yang sama dengan ini akan dihitung untuk menentukan jumlah Pod dalam domain topologi yang sesuai. Silakan baca Label dan Selector untuk lebih detailnya.
Kamu juga bisa membaca lebih detail mengenai field ini dengan menjalankan perintah
kubectl explain Pod.spec.topologySpreadConstraints.
Contoh: Satu TopologySpreadConstraint
Misalkan kamu memiliki klaster dengan 4 Node dimana 3 Pod berlabel foo:bar terdapat pada node1,
node2 dan node3 (P merepresentasikan Pod):
+---------------+---------------+
| zoneA | zoneB |
+-------+-------+-------+-------+
| node1 | node2 | node3 | node4 |
+-------+-------+-------+-------+
| P | P | P | |
+-------+-------+-------+-------+
Jika kita ingin Pod baru akan disebar secara merata berdasarkan Pod yang telah ada pada semua zona,
maka spec bernilai sebagai berikut:
topologyKey: zone berarti persebaran merata hanya akan digunakan pada Node dengan pasangan label
"zone: ". whenUnsatisfiable: DoNotSchedule memberitahukan penjadwal untuk membiarkan
tetap ditunda jika Pod yang baru tidak memenuhi batasan yang diterapkan.
Jika penjadwal menempatkan Pod baru pada "zoneA", persebaran Pod akan menjadi [3, 1], menjadikan
ketidakseimbangan menjadi bernilai 2 (3 - 1), yang mana akan melanggar batasan maxSkew: 1.
Dalam contoh ini, Pod baru hanya dapat ditempatkan pada "zoneB":
+---------------+---------------+ +---------------+---------------+
| zoneA | zoneB | | zoneA | zoneB |
+-------+-------+-------+-------+ +-------+-------+-------+-------+
| node1 | node2 | node3 | node4 | OR | node1 | node2 | node3 | node4 |
+-------+-------+-------+-------+ +-------+-------+-------+-------+
| P | P | P | P | | P | P | P P | |
+-------+-------+-------+-------+ +-------+-------+-------+-------+
Kamu dapat mengatur spesifikasi Pod untuk memenuhi beberapa persyaratan berikut:
Ubah nilai maxSkew menjadi lebih besar, misal "2", sehingga Pod baru dapat ditempatkan pada "zoneA".
Ubah nilai topologyKey menjadi "node" agar Pod disebarkan secara merata pada semua Node, bukan zona. Pada contoh di atas, jika maxSkew tetap bernilai "1", maka Pod baru hanya akan ditempatkan pada "node4".
Ubah nilai whenUnsatisfiable: DoNotSchedule menjadi whenUnsatisfiable: ScheduleAnyway untuk
menjamin agar semua Pod baru akan tetap dijadwalkan (misalkan saja API penjadwalan lain tetap
terpenuhi). Namun, ini lebih suka ditempatkan pada domain topologi yang memiliki lebih sedikit
Pod yang sesuai. (Harap diperhatikan bahwa preferensi ini digabungkan bersama dengan prioritas
penjadwalan internal yang lain, seperti rasio penggunaan sumber daya, dan lain sebagainya.)
Contoh: Beberapa TopologySpreadConstraint
Ini dibuat berdasarkan contoh sebelumnya. Misalkan kamu memiliki klaster dengan 4 Node dengan
3 Pod berlabel foo:bar yang ditempatkan pada node1, node2 dan node3. (P merepresentasikan Pod):
+---------------+---------------+
| zoneA | zoneB |
+-------+-------+-------+-------+
| node1 | node2 | node3 | node4 |
+-------+-------+-------+-------+
| P | P | P | |
+-------+-------+-------+-------+
Kamu dapat menggunakan 2 TopologySpreadConstraint untuk mengatur persebaran Pod pada zona dan Node:
Dalam contoh ini, untuk memenuhi batasan pertama, Pod yang baru hanya akan ditempatkan pada "zoneB",
sedangkan untuk batasan kedua, Pod yang baru hanya akan ditempatkan pada "node4". Maka hasil dari
2 batasan ini akan digunakan (AND), sehingga opsi untuk menempatkan Pod hanya pada "node4".
Beberapa batasan dapat berujung pada konflik. Misalnya saja kamu memiliki klaster dengan 3 Node
pada 2 zona berbeda:
+---------------+-------+
| zoneA | zoneB |
+-------+-------+-------+
| node1 | node2 | node3 |
+-------+-------+-------+
| P P | P | P P |
+-------+-------+-------+
Jika kamu menerapkan "two-constraints.yaml" pada klaster ini, kamu akan mendapatkan "mypod" tetap
dalam kondisi Pending. Ini dikarenakan oleh: untuk memenuhi batasan pertama, "mypod" hanya dapat
ditempatkan pada "zoneB", sedangkan untuk batasan kedua, "mypod" hanya dapat ditempatkan pada
"node2". Tidak ada hasil penggabungan dari "zoneB" dan "node2".
Untuk mengatasi situasi ini, kamu bisa menambahkan nilai maxSkew atau mengubah salah satu dari
batasan untuk menggunakan whenUnsatisfiable: ScheduleAnyway.
Konvensi
Ada beberapa konvensi implisit yang perlu diperhatikan di sini:
Hanya Pod dengan Namespace yang sama dengan Pod baru yang bisa menjadi kandidat yang cocok.
Node tanpa memiliki topologySpreadConstraints[*].topologyKey akan dilewatkan. Ini berarti:
Pod yang ditempatkan pada Node tersebut tidak berpengaruh pada perhitungan maxSkew. Dalam contoh di atas, misalkan "node1" tidak memiliki label "zone", maka kedua Pod tidak diperhitungkan dan menyebabkan Pod yang baru akan dijadwalkan masuk ke "zoneA".
Pod yang baru tidak memiliki kesempatan untuk dijadwalkan ke Node tersebut, pada contoh di atas, misalkan terdapat "node5" dengan label {zone-typo: zoneC} bergabung dalam klaster, Node ini akan dilewatkan karena tidak memiliki label dengan kunci "zone".
Harap diperhatikan mengenai hal yang terjadi jika nilai topologySpreadConstraints[*].labelSelector pada Pod yang baru tidak sesuai dengan labelnya.
Pada contoh di atas, jika kita menghapus label pada Pod yang baru, maka Pod akan tetap ditempatkan
pada "zoneB" karena batasan yang ada masih terpenuhi. Namun, setelah ditempatkan, nilai
ketidakseimbangan pada klaster masih tetap tidak berubah, zoneA tetap memiliki 2 Pod dengan label
{foo:bar} dan zoneB memiliki 1 Pod dengan label {foo:bar}. Jadi jika ini tidak yang kamu harapkan,
kami menyarankan nilai dari topologySpreadConstraints[*].labelSelector disamakan dengan labelnya.
Jika Pod yang baru memiliki spec.nodeSelector atau spec.affinity.nodeAffinity, Node yang tidak
sesuai dengan nilai tersebut akan dilewatkan.
Misalkan kamu memiliki klaster dengan 5 Node dari zoneA sampai zoneC:
dan kamu mengetahui bahwa "zoneC" harus tidak diperhitungkan. Dalam kasus ini, kamu dapat membuat
berkas yaml seperti di bawah, jadi "mypod" akan ditempatkan pada "zoneB", bukan "zoneC".
Demikian juga spec.nodeSelector akan digunakan.
Ini memungkinkan untuk mengatur batasan persebaran topologi bawaan untuk klaster.
Batasan persebaran topologi bawaan akan digunakan pada Pod jika dan hanya jika:
Hal ini tidak mendefinisikan batasan apapun pada .spec.topologySpreadConstraints.
Hal ini milik sebuah Service, ReplicationController, ReplicaSet atau StatefulSet.
Batasan bawaan akan diatur sebagai bagian dari argumen pada pluginPodTopologySpread
di dalam sebuah profil penjadwalan.
Batasan dispesifikasikan dengan API yang sama dengan di atas, kecuali bagian labelSelector
harus kosong. selector akan dihitung dari Service, ReplicationController, ReplicaSet atau
StatefulSet yang dimiliki oleh Pod tersebut.
Nilai yang dihasilkan oleh batasan penjadwalan bawaan mungkin akan konflik dengan
nilai yang dihasilkan oleh
DefaultPodTopologySpread plugin.
Direkomendasikan untuk kamu menonaktifkan plugin ini dalam profil penjadwalan ketika
menggunakan batasan default untuk PodTopologySpread.
Perbandingan dengan PodAffinity/PodAntiAffinity
Di Kubernetes, arahan yang terkait dengan "Afinitas" mengontrol bagaimana Pod dijadwalkan -
lebih terkumpul atau lebih tersebar.
Untuk PodAffinity, kamu dapat mencoba mengumpulkan beberapa Pod ke dalam suatu
domain topologi yang memenuhi syarat.
Untuk PodAntiAffinity, hanya satu Pod yang dalam dijadwalkan pada sebuah domain topologi.
Fitur "EvenPodsSpread" memberikan opsi fleksibilas untuk mendistribusikan Pod secara merata
pada domain topologi yang berbeda, untuk meraih ketersediaan yang tinggi atau menghemat biaya.
Ini juga dapat membantu saat perbaruan bergilir dan menaikan jumlah replika dengan lancar.
Silakan baca motivasi untuk lebih detail.
Limitasi yang diketahui
Pada versi 1.18, dimana fitur ini masih Beta, beberapa limitasi yang sudah diketahui:
Pengurangan jumlah Deployment akan membuat ketidakseimbangan pada persebaran Pod.
Pod yang cocok pada tainted Node akan dihargai. Lihat Issue 80921
4.1.6 - Pod Preset
Halaman ini menyajikan gambaran umum tentang PodPreset, yang merupakan objek untuk memasukkan informasi tertentu ke dalam Pod pada saat waktu penciptaan. Informasi dapat berupa secret, volume, volume mount, dan variabel environment.
Memahami Pod Preset
Sebuah Pod Preset adalah sebuah resource API untuk memasukkan kebutuhan runtime tambahan ke dalam sebuah Pod pada saat waktu penciptaan. Kamu akan menggunakan label selector untuk menunjuk Pod dimana Pod Preset diterapkan.
Menggunakan sebuah Pod Preset memungkinkan pembuat templat pod untuk tidak menyediakan secara eksplisit semua informasi untuk setiap pod. Dengan demikian, pembuat templat pod yang mengkonsumsi sebuah service spesifik tidak perlu tahu semua detail-detail tentang service tersebut.
Kubernetes menyediakan sebuah admission controller (PodPreset) dimana, ketika diaktifkan, PodPreset diterapkan kepada permintaan penciptaan Pod yang akan datang. Ketika sebuah penciptaan Pod terjadi, sistem melakukan hal-hal berikut:
Mengambil semua PodPreset yang tersedia untuk digunakan.
Cek jika label selector dari salah satu PodPreset cocok dengan label pada pod yang sedang diciptakan.
Usaha untuk menggabungkan berbagai resource didefinisikan oleh PodPreset ke dalam Pod yang sedang diciptakan.
Ketika terjadi galat, lempar sebuah event yang mendokumentasikan galat penggabungan dalam pod, dan membuat pod tanpa salah satu resource dari PodPreset.
Anotasikan hasil spesifikasi Pod yang telah dimodifikasi untuk menunjukkan bahwa Pod telah dimodifikasi oleh sebuah PodPreset. Anotasi berupa podpreset.admission.kubernetes.io/podpreset-<nama pod-preset>: "<versi resource>".
Tiap Pod akan bisa dipasangkan oleh nol atau lebih PodPreset; dan tiap PodPreset bisa diterapkan ke nol atau lebih Pod. Ketika sebuah PodPreset diterapkan ke satu atau lebih Pod, Kubernetes memodifikasi Pod Spec. Untuk perubahan terhadap Env,EnvFrom, dan VolumeMount, Kubernetes memodifikasi spesifikasi kontainer untuk semua kontainer di dalam Pod; Untuk perubahan terhadap Volume, Kubernetes memodifikasi Pod Spec.
Catatan:
Sebuah Pod Preset mampu memodifikasi kolom .spec.containers pada sebuah Pod Spec jika sesuai. Tidak ada definisi resource dari Pod Preset yang akan diterapkan kepada kolom initContainer.
Menonaktifkan Pod Preset untuk sebuah Pod Spesifik
Mungkin akan ada keadaan dimana kamu menginginkan sebuah Pod tidak bisa diubah oleh sebuah mutasi PodPreset. Pada kasus ini, kamu bisa menambahkan sebuah anotasi pada Pod Spec dalam bentuk: podpreset.admission.kubernetes.io/exclude: "true".
Mengaktifkan Pod Preset
Dalam rangka untuk menggunakan Pod Preset di dalam klaster kamu, kamu harus memastikan hal berikut:
Kamu telah mengaktifkan tipe API settings.k8s.io/v1alpha1/podpreset. Sebagai contoh, ini bisa dilakukan dengan menambahkan settings.k8s.io/v1alpha1=true di dalam opsi --runtime-config untuk API server. Dalam minikube tambahkan argumen berikut --extra-config=apiserver.runtime-config=settings.k8s.io/v1alpha1=true saat menginisialisasi klaster.
Kamu telah mengaktifkan admission controller dari PodPreset. Salah satu cara untuk melakukannya adalah dengan menambahkan PodPreset di dalam nilai opsi --enable-admission-plugins yang dispesifikasikan untuk API server. Dalam minikube tambahkan argumen berikut
Petunjuk ini ditujukan pada pemilik aplikasi yang meninginkan aplikasinya memiliki ketersediaan yang tinggi, sehingga butuh untuk mengerti jenis-jenis Disrupsi yang dapat terjadi pada Pod-pod.
Petunjuk ini juga ditujukan pada administrator klaster yang ingin melakukan berbagai tindakan otomasi pada klaster, seperti pembaruan dan autoscaling klaster.
Disrupsi yang Disengaja dan Tidak Disengaja
Pod-pod tidak akan terhapus sampai sesuatu (orang ataupun pengendali) menghancurkan mereka atau ada kesalahan perangkat keras maupun perangkat lunak yang tidak dapat dihindari.
Kita menyebut kasus-kasus yang tidak dapat dihindari sebagai disrupsi yang tidak disengaja terhadap aplikasi. Beberapa contohnya adalah sebagai berikut:
Kesalahan perangkat keras pada mesin yang menjalankan Node
Administrator klaster menghapus virtual machine secara tidak sengaja
Kesalahan pada penyedia layanan cloud yang mengakibatkan terhapusnya virtual machine
Sebuah kernel panic
Node menghilang dari klaster karena partisi jaringan klaster
Dengan pengecualian pada kondisi kehabisan sumber daya, kondisi-kondisi tersebut pada umumnya diketahui oleh kebanyakan pengguna karena kondisi-kondisi tersebut tidak spesifik pada Kubernetes saja.
Kita menyebut kasus-kasus lainnya sebagai disrupsi yang disengaja. Hal ini termasuk tindakan yang dilakukan oleh pemilik aplikasi atau yang dilakukan oleh administrator klaster. Pemilik aplikasi umumnya melakukan hal-hal berikut:
Menghapus Deployment atau pengendali yang mengatur Pod
Memperbarui templat Pod yang menyebabkan pengulangan kembali/restart
Menghapus Pod secara langsung
Administrator klaster umumnya melakukan hal-hal berikut:
Melakukan drain terhadap sebuah node dari klaster untuk memperkecil ukuran klaster (untuk lebih lanjutnya, pelajari Autoscaling klaster).
Menghapus sebuah Pod dari node untuk memuat Pod lain ke node tersebut.
Tindakan-tindakan tersebut dapat dilakukan secara langsung oleh administrator klaster, atau oleh alat otomasi yang dijalankan oleh administrator klaster, atau oleh penyedia layanan Kubernetes kamu.
Tanyakan administrator klaster atau penyedia layanan cloud kamu, atau lihatlah dokumentasi penyedia layanan Kubernetes kamu untuk mengetahui bila ada sumber-sumber yang berpotensi mengakibatkan disrupsi yang disengaja yang ada pada klastermu. Jika tidak ada, kamu bisa melewatkan pembuatan PodDisruptionBudget
Perhatian:
Tidak semua disrupsi yang disengaja dibatasi oleh Pod Disruption Budget. Contohnya, menghapus Deployment atau Pod dapat mengabaikan PodDisruptionBudget.
Mengatasi Disrupsi
Berikut beberapa cara untuk mengatasi disrupsi yang tidak disengaja:
Replikasikan aplikasimu jika membutuhkan ketersediaan yang tinggi. (Pelajari tentang menjalankan aplikasi
stateless dan stateful).
Untuk mencapai ketersediaan yang bahkan lebih tinggi lagi saat mereplikasikan aplikasi, sebarkanlah Pod-pod kamu di rak-rak pada data center (menggunakan anti-affinity) atau di seluruh zona (jika kamu menggunakan klaster pada beberapa zona).
Frekuensi disrupsi yang disengaja dapat berubah-ubah. Pada klaster Kubernetes yang dasar, tidak ada disrupsi yang disengaja sama sekali. Tetapi, administrator klaster atau penyedia layanan Kubernetes kamu mungkin saja menjalankan beberapa servis tambahan yang dapat mengakibatkan disrupsi yang disengaja. Misalnya, memperbarui perangkat lunak pada node yang dapat mengakibatkan disrupsi yang disengaja. Selain itu, beberapa implementasi autoscaling klaster (atau node) dapat mengakibatkan disrupsi yang disengaja untuk merapikan dan memadatkan node-node pada klaster.
Administrator klaster atau penyedia layanan Kubernetes kamu perlu mendokumentasikan tingkatan disrupsi yang disengaja, jika ada disrupsi yang telah diperkirakan.
Kubernetes menawarkan fitur-fitur untuk membantu menjalankan aplikasi-aplikasi dengan ketersediaan tinggi bersamaan dengan seringnya disrupsi yang disengaja, fitur-fitur tersebut dinamai Disruption Budget.
Bagaimana cara kerja Disruption Budget
Pemilik aplikasi dapat membuat objek PodDisruptionBudget (PDB) untuk setiap aplikasi. Sebuah PDB membatasi jumlah Pod yang boleh mati secara bersamaan pada aplikasi yang direplikasi dikarenakan disrupsi yang disengaja.
Misalnya, sebuah aplikasi yang bekerja secara quorum mau memastikan bahwa jumlah replika yang berjalan tidak jatuh ke bawah yang dibutuhkan untuk membentuk sebuah quorum. Contoh lainnya, sebuah front-end web mungkin perlu memastikan bahwa jumlah replika yang melayani trafik tidak pernah turun ke total persentase yang telah ditentukan.
Administrator klaster dan penyedia layanan Kubernetes sebaiknya menggunakan alat-alat yang menghormati PDB dengan cara berkomunikasi dengan Eviction API dari pada menghapus Pod atau Deployment secara langsung. Contohnya adalah perintah kubectl drain dan skrip pembaruan Kubernetes-on-GCE (cluster/gce/upgrade.sh)
Saat seorang administrator klaster ingin melakukan drain terhadap sebuah node, ia akan menggunakan perintah kubectl drain. Alat tersebut mencoba untuk "mengusir" semua Pod di node tersebut. Permintaan untuk mengusir Pod tersebut mungkin ditolak untuk sementara, dan alat tersebut akan mencoba ulang permintaannya secara periodik hingga semua Pod dihapus, atau hingga batas waktu yang ditentukan telah dicapai.
Sebua PDB merinci jumlah replika yang dapat ditoleransi oleh sebuah aplikasi, relatif terhadap berapa banyak yang seharusnya dimiliki oleh aplikasi tersebut. Sebagai contoh, sebuah Deployment yang memiliki rincian .spec.replicas :5 diharapkan memiliki 5 Pod pada satu waktu. Jika PDB aplikasi tersebut mengizinkan ada 4 replika pada satu waktu, maka Eviction API akan mengizinkan disrupsi yag disengaja sebanyak satu, tapi tidak mengizinkan dua, pada satu waktu.
Sebuah kelompok Pod yang mewakili aplikasi dispesifikasikan menggunakan sebuah label selector yang sama dengan yang digunakan oleh pengatur aplikasi tersebut (Deployment, StatefulSet, dsb.)
Jumlah Pod yang "diharapkan" dihitung dari .spec.replicas dari pengendali Pod tersebut. Pengendali dari sebuah Pod dapat ditemukan di spesifikasi .metadata.ownerReferences objek Pod yang bersangkutan.
Pod yang dihapus atau tidak tersetia dikarenakan pembaruan bertahap juga dihitung terhadap bujet PDB, tetapi pengendali (seperti Deployment dan StatefulSet) tidak dibatasi oleh PDB ketika melakukan pembaruan bertahap; Penanganan kerusakan saat pembaruan aplikasi dikonfigurasikan pada spesifikasi pengendali. (Pelajari tentang memperbarui sebuah Deployment.)
Saat sebuah Pod diusir menggunakan eviction API, Pod tersebut akan dihapus secara graceful (lihat terminationGracePeriodSeconds pada PodSpec.))
Contoh PDB
Kita ambil contoh sebuah klaster dengan 3 node, node-1 hingga node-3.
Klaster tersebut menjalankan beberapa aplikasi. Salah satu dari aplikasi tersebut awalnya memiliki 3 replika, yang akan kita namai Pod-a, Pod-b, dan Pod-c. Sebuah Pod lain yang tidak bersangkutan dan tidak memiliki PDB, dinamai Pod-x juga terlihat. Awalnya, Pod-pod tersebut berada pada node-node sebagai berikut:
node-1
node-2
node-3
Pod-a available
Pod-b available
Pod-c available
Pod-x available
3 Pod Pod-a hingga Pod-c adalah bagian dari sebuah Deployment, dan mereka secara kolektif memiliki sebuah PDB yang mengharuskan ada setidaknya 2 dari 3 Pod untuk tersedia sepanjang waktu.
Sebagai contoh, asumsikan administrator klaster ingin me-reboot ke dalam versi kernel baru untuk memperbaiki kesalahan di dalam kernel lama. Administator klaster pertama-tama mencoba untuk melakukan drain terhadap node-1 menggunakan perintah kubectl drain. Perintah tersebut mencoba untuk mengusir Pod-a dan Pod-x. Hal ini langsung berhasil. Kedua Pod tersebut masuk ke dalam kondisi terminating secara bersamaan. Hal ini mengubah kondisi klaster menjadi sebagai berikut:
node-1 draining
node-2
node-3
Pod-a terminating
Pod-b available
Pod-c available
Pod-x terminating
Deployment tersebut melihat bahwa salah satu Pod berada dalam kondisi terminating, sehingga Deployment mencoba untuk membuat penggantinya, Pod-d. Sejak node-1 ditutup (karena perintah kubectl-drain), Pod-d masuk ke node lainnya. Sesuatu juga membuat Pod-y sebagai pengganti Pod-x
(Catatan: untuk sebuah StatefulSet, Pod-a, akan dinamai dengan Pod-1, harus diterminasi hingga selesai sebelum penggantinya, yang juga dinamai Pod-1 tetapi memiliki UID yang berbeda, akan dibuat. Selain hal ini, seluruh contoh ini juga berlaku untuk StatefulSet.)
Sekarang, klaster berada pada kondisi berikut:
node-1 draining
node-2
node-3
Pod-a terminating
Pod-b available
Pod-c available
Pod-x terminating
Pod-d starting
Pod-y
Pada satu waktu, Pod-pod yang diusir pun selesai diterminasi, dan kondisi klaster menjadi seperti berikut:
node-1 drained
node-2
node-3
Pod-b available
Pod-c available
Pod-d starting
Pod-y
Pada titik ini, jika seorang administrator klaster yang tidak sabar mencoba untuk melakukan drain terhadap node-2 atau node-3, perintah untuk melakukan drain terhadap node tersebut akan terhalang, karena hanya ada 2 Pod yang tersedia, dan PDB-nya membutuhkan setidaknya ada 2 Pod tersedia. Setelah beberapa waktu, Pod-d menjadi tersedia.
Kondisi klaster menjadi seperti berikut:
node-1 drained
node-2
node-3
Pod-b available
Pod-c available
Pod-d available
Pod-y
Sekarang, administrator klaster mencoba untuk melakukan drain terhadap node-2. Perintah drain tersebut akan mencoba mengusir Pod-pod tersebut secara berurutan (tidak bersamaan), misalnya Pod-b yang pertama dan diikuti dengan Pod-d. Perintah tersebut akan berhasil mengusir Pod-b. Tetapi, pada saat ia mencoba untuk mengusir Pod-d, hal tersebut akan ditolak karena hal tersebut akan mengakibatkan hanya satu Pod yang tersedia untuk Deployment yang bersangkutan.
Deployment tersebut membuat pengganti Pod-b yang dinamai Pod-e.
Karena tidak ada sumber daya klaster yang cukup untuk mengalokasikan Pod-e, proses drain akan kembali terhalang.
Klaster mungkin berada pada kondisi berikut:
node-1 drained
node-2
node-3
no node
Pod-b available
Pod-c available
Pod-e pending
Pod-d available
Pod-y
Pada titik ini, administrator klaster mesti menambah sebuah node untuk klaster agar bisa melanjutkan pembaruan klaster.
Kamu dapat melihat bagaimana frekuensi disrupsi dapat berubah-ubah pada Kubernetes, tergantung pada:
Berapa banyak replika yang dibutuhkan sebuah aplikasi
Berapa lama waktu yang dibutuhkan untuk mematikan sebuah Pod secara graceful
Berapa lama waktu yang dibutuhkan untuk memulai sebuah Pod
Tipe pengendali
Kapasitas sumber daya klaster
Memisahkan Peran Pemilik Klaster dan Pemilik Aplikasi
Seringkali akan bermanfaat untuk berpikir Administrator Klaster dan Pemilik Aplikasi sebagai peran yang terpisah dan dengan pengetahuan yang terbatas satu sama lainnya. Pemisahan ini dapat dimengerti dalam beberapa skenario berikut:
Saat ada banyak tim aplikasi yang berbagi pakai sebuah klaster Kubernetes, dan ada pembagian peran yang spesifik
Saat alat atau servis pihak ketiga digunakan untuk melakukan otomasi manajemen klaster.
PDB mendukung pemisahan peran ini dengan cara menyediakan antarmuka bagi peran-peran tersebut.
Jika kamu tidak memiliki pemisahan peran seperti ini pada organisasimu, kamu mungkin tidak membutuhkan PDB.
Bagaimana cara melakukan Tindakan Disruptif terhadap Klaster
Jika kamu adalah Administrator Klaster, maka kamu mesti melakukan tindakan disruptif pada setiap node di klastermu, seperti melakukan pembaruan perangkat lunak pada node, berikut beberapa opsinya:
Menerima downtime pada saat pembaruan node
Melakukan failover ke replika lengkap klaster lain.
Tanpa downtime, tetapi mungkin lebih mahal, baik ongkos duplikasi node-node dan tenaga yang dibutuhkan untuk melakukan failover.
Membuat aplikasi yang toleran terhadap disrupsi, dan gunakan PDB.
Tanpa downtime.
Duplikasi sumber daya yang minimal.
Mengizinkan lebih banyak otomasi administrasi klaster.
Membuat aplikasi yang toleran terhadap disrupsi agak rumit, tetapi usaha yang dilakukan untuk menoleransi disrupsi yang disengaja kebanyakan beririsan dengan usaha untuk mendukung autoscaling dan menoleransi disrupsi yang tidak disengaja.
Halaman ini memberikan gambaran umum tentang kontainer sementara: satu jenis
kontainer khusus yang berjalan sementara pada Pod
yang sudah ada untuk melakukan tindakan yang diinisiasi oleh pengguna seperti
dalam pemecahan masalah. Kamu menggunakan kontainer sementara untuk memeriksa
layanan bukan untuk membangun aplikasi.
Peringatan:
Kontainer sementara masih berada dalam fase alpha dan tidak cocok untuk
klaster produksi. Kamu harus mengharapkan adanya suatu fitur yang tidak akan
berfungsi dalam beberapa situasi tertentu, seperti saat menargetkan namespace
dari suatu kontainer. Sesuai dengan Kubernetes
Deprecation Policy, fitur alpha
ini dapat berubah secara signifikan di masa depan atau akan dihapus seluruhnya.
Memahami Kontainer Sementara
Pod adalah blok pembangun
fundamental dalam aplikasi Kubernetes. Karena Pod diharapkan digunakan hanya
sekali dan dapat diganti, sehingga kamu tidak dapat menambahkan kontainer ke
dalam Pod setelah Pod tersebut dibuat. Sebaliknya, kamu biasanya menghapus dan
mengganti beberapa Pod dengan cara yang terkontrol melalui
Deployment.
Namun, kadang-kadang perlu juga untuk memeriksa keadaan Pod yang telah ada,
sebagai contoh untuk memecahkan masalah bug yang sulit direproduksi. Dalam
kasus ini, kamu dapat menjalankan sebuah kontainer sementara di dalam suatu Pod
yang sudah ada untuk memeriksa statusnya dan menjalankannya segala macam
perintah.
Apa itu Kontainer Sementara?
Kontainer sementara berbeda dengan kontainer lainnya karena tidak memiliki
jaminan sumber daya maupun akan eksekusi, dan mereka tidak akan pernah secara
otomatis melakukan restart, jadi mereka tidak sesuai untuk membangun aplikasi.
Kontainer sementara dideskripsikan dengan menggunakan ContainerSpec yang sama
dengan kontainer biasa, tetapi banyak bagian yang tidak kompatibel dan tidak
diperbolehkan untuk kontainer sementara.
Kontainer sementara mungkin tidak memiliki port, sehingga bagian seperti
port, livenessProbe, readinessProbe tidak diperbolehkan.
Alokasi sumber daya untuk Pod tidak dapat diubah, sehingga pengaturan
sumber daya tidak diperbolehkan.
Kontainer sementara dibuat dengan menggunakan handler khusus
EphemeralContainers dalam API tanpa menambahkannya langsung ke pod.spec,
sehingga tidak memungkinan untuk menambahkan kontainer sementara dengan
menggunakan kubectl edit.
Seperti dengan kontainer biasa, kamu tidak dapat mengubah atau menghapus
kontainer sementara setelah kamu memasukkannya ke dalam sebuah Pod.
Penggunaan Kontainer Sementara
Kontainer sementara berguna untuk pemecahan masalah secara interaktif pada saat
kubectl exec tidak mencukupi karena sebuah kontainer telah hancur atau
kontainer image tidak memiliki utilitas untuk debugging.
Khususnya, untuk images_distroless
memungkinkan kamu untuk menyebarkan kontainer image minimal yang mengurangi
surface attack dan paparan bug dan vulnerability. Karena
image distroless tidak mempunyai sebuah shell atau utilitas debugging apa
pun, sehingga sulit untuk memecahkan masalah image distroless dengan
menggunakan kubectl exec saja.
Saat menggunakan kontainer sementara, akan sangat membantu untuk mengaktifkan
process namespace sharing
sehingga kamu dapat melihat proses pada kontainer lain.
Contoh
Catatan:
Contoh-contoh pada bagian ini membutuhkan EphemeralContainersfeature
gate untuk
diaktifkan, dan membutuhkan Kubernetes klien dan server versi v1.16 atau
yang lebih baru.
Contoh-contoh pada bagian ini menunjukkan bagaimana kontainer sementara muncul
dalam API. Kamu biasanya dapat menggunakan plugin kubectl untuk mengatasi
masalah untuk mengotomatiskan langkah-langkah ini.
Kontainer sementara dibuat menggunakan subresourceephemeralcontainers
Pod, yang dapat didemonstrasikan menggunakan kubectl --raw. Pertama-tama
deskripsikan kontainer sementara untuk ditambahkan dalam daftar
EphemeralContainers:
Kamu dapat mengakses kontainer sementara yang baru menggunakan
kubectl attach:
kubectl attach -it example-pod -c debugger
Jika proses berbagi namespace diaktifkan, kamu dapat melihat proses dari semua
kontainer dalam Pod tersebut. Misalnya, setelah mengakses, kamu jalankan
ps di kontainer debugger:
# Jalankan ini pada _shell_ dalam _debugger_ dari kontainer sementaraps auxww
Hasilnya akan seperti ini:
PID USER TIME COMMAND
1 root 0:00 /pause
6 root 0:00 nginx: master process nginx -g daemon off;
11 101 0:00 nginx: worker process
12 101 0:00 nginx: worker process
13 101 0:00 nginx: worker process
14 101 0:00 nginx: worker process
15 101 0:00 nginx: worker process
16 101 0:00 nginx: worker process
17 101 0:00 nginx: worker process
18 101 0:00 nginx: worker process
19 root 0:00 /pause
24 root 0:00 sh
29 root 0:00 ps auxww
4.1.9 - Kelas Kualitas Layanan Pod
Halaman ini memperkenalkan Kelas QoS (Kelas Kualitas Layanan) Pod di Kubernetes, dan menjelaskan bagaimana Kubernetes menetapkan kelas QoS untuk setiap Pod sebagai konsekuensi dari batasan sumber daya yang Anda tentukan untuk Kontainer di Pod tersebut. Kubernetes mengandalkan klasifikasi ini untuk membuat keputusan tentang Pod mana yang akan diusir ketika tidak ada cukup sumber daya yang tersedia di Node.
Kelas kualitas layanan
Kubernetes mengklasifikasikan Pod yang Anda jalankan dan mengalokasikan setiap Pod ke dalam kelas QoS tertentu. Kubernetes menggunakan klasifikasi tersebut untuk memengaruhi cara penanganan Pod yang berbeda. Kubernetes melakukan klasifikasi ini berdasarkan resource requests dari Kontainer di Pod tersebut, beserta bagaimana permintaan tersebut terkait dengan batasan sumber daya. Ini dikenal sebagai kelas QoS. Kubernetes menetapkan sebuah kelas QoS pada setiap Pod berdasarkan permintaan sumber daya dan batasan Kontainer komponennya. Kelas QoS digunakan oleh Kubernetes untuk memutuskan Pod mana yang akan dikeluarkan dari Node yang mengalami Node Pressure. Kelas QoS yang mungkin adalah Guaranteed, Burstable, dan BestEffort. Ketika Node kehabisan sumber daya, Kubernetes akan terlebih dahulu mengeluarkan Pod BestEffort yang berjalan pada Node tersebut, diikuti oleh Pod Burstable dan terakhir Pod Guaranteed. Ketika pengeluaran ini disebabkan oleh tekanan sumber daya, hanya Pod yang melebihi permintaan sumber daya yang menjadi kandidat untuk pengeluaran.
Guaranteed
Pod yang Guaranteed memiliki batasan sumber daya yang paling ketat dan paling kecil kemungkinannya untuk menghadapi pengusiran dari Node. Pod tersebut dijamin tidak akan dimatikan hingga melampaui batasnya atau tidak ada Pod dengan prioritas lebih rendah yang dapat didahului dari Node. Pod tersebut tidak boleh memperoleh sumber daya di luar batas yang ditentukan. Pod ini juga dapat menggunakan CPU eksklusif menggunakan kebijakan manajemen CPU statis.
Kriteria
Agar Pod diberi kelas QoS Guaranteed:
Setiap Kontainer di Pod harus memiliki batas memori dan permintaan memori.
Untuk setiap Kontainer di Pod, batas memori harus sama dengan permintaan memori.
Setiap Kontainer di Pod harus memiliki batas CPU dan permintaan CPU.
Untuk setiap Kontainer di Pod, batas CPU harus sama dengan permintaan CPU.
Burstable
Pod yang Burstable memiliki beberapa jaminan batas bawah sumber daya berdasarkan permintaan, tetapi tidak memerlukan batasan tertentu. Jika batasan tidak ditentukan, maka batas tersebut akan ditetapkan secara default ke batas yang setara dengan kapasitas Node, yang memungkinkan Pod untuk secara fleksibel meningkatkan sumber dayanya jika sumber daya tersedia. Jika terjadi pengusiran Pod karena tekanan sumber daya Node, Pod ini akan diusir hanya setelah semua Pod BestEffort diusir. Karena Pod Burstable dapat menyertakan Kontainer yang tidak memiliki batasan atau permintaan sumber daya, Pod yang Burstable dapat mencoba menggunakan sumber daya Node dalam jumlah berapa pun.
Kriteria
Pod diberi kelas QoS Burstable jika:
Pod tidak memenuhi kriteria untuk kelas QoS Guaranteed.
Setidaknya satu Kontainer di Pod memiliki permintaan atau batasan memori atau CPU.
BestEffort
Pod dalam kelas QoS BestEffort dapat menggunakan sumber daya Node yang tidak secara khusus ditetapkan ke Pod dalam kelas QoS lainnya. Misalnya, jika Anda memiliki Node dengan 16 inti CPU yang tersedia untuk kubelet, dan Anda menetapkan 4 inti CPU ke Pod Guaranteed, maka Pod dalam kelas QoS BestEffort dapat mencoba menggunakan sejumlah dari 12 inti CPU yang tersisa.
Kubelet lebih memilih mengusir Pod BestEffort jika Node mengalami tekanan sumber daya.
Kriteria
Pod memiliki kelas QoS BestEffort jika tidak memenuhi kriteria untuk Guaranteed atau Burstable. Dengan kata lain, sebuah Pod adalah BestEffort hanya jika tidak ada Kontainer dalam Pod yang memiliki batas memori atau permintaan memori, dan tidak ada Kontainer dalam Pod yang memiliki batas CPU atau permintaan CPU.
Kontainer dalam Pod dapat meminta sumber daya lain (bukan CPU atau memori) dan masih diklasifikasikan sebagai BestEffort.
Memori QoS dengan cgroup v2
FEATURE STATE:Kubernetes v1.22 [alpha](disabled by default)
Memori QoS menggunakan pengontrol memori cgroup v2 untuk menjamin sumber daya memori di Kubernetes. Permintaan memori dan batasan Kontainer di pod digunakan untuk menyetel antarmuka tertentu memory.min dan memory.high yang disediakan oleh pengontrol memori. Saat memory.min disetel ke permintaan memori, sumber daya memori dicadangkan dan tidak pernah diambil kembali oleh kernel; beginilah cara memori QoS memastikan ketersediaan memori untuk pod Kubernetes. Dan jika batasan memori disetel di Kontainer, ini berarti sistem perlu membatasi penggunaan memori Kontainer; memori QoS menggunakan memory.high untuk membatasi beban kerja yang mendekati batas memorinya, memastikan bahwa sistem tidak kewalahan oleh alokasi memori yang terjadi secara tiba-tiba.
Memori QoS bergantung pada kelas QoS untuk menentukan setelan mana yang akan diterapkan; namun, ini adalah mekanisme berbeda yang keduanya menyediakan kontrol atas kualitas layanan.
Beberapa perilaku independen dari kelas QoS
Perilaku tertentu independen dari kelas QoS yang ditetapkan oleh Kubernetes. Misalnya:
Setiap Kontainer yang melampaui batas sumber daya akan dihentikan dan dimulai ulang oleh kubelet tanpa memengaruhi Kontainer lain dalam Pod tersebut.
Jika Kontainer melampaui permintaan sumber dayanya dan Node yang dijalankannya menghadapi tekanan sumber daya, Pod yang menjadi tempatnya menjadi kandidat untuk pengusiran. Jika ini terjadi, semua Kontainer dalam Pod akan dihentikan. Kubernetes dapat membuat Pod pengganti, biasanya pada Node yang berbeda.
Permintaan sumber daya Pod sama dengan jumlah permintaan sumber daya dari Kontainer komponennya, dan batas sumber daya Pod sama dengan jumlah batas sumber daya dari Kontainer komponennya.
kube-scheduler tidak mempertimbangkan kelas QoS saat memilih Pod mana yang akan didahulukan. Pendahuluan dapat terjadi saat klaster tidak memiliki cukup sumber daya untuk menjalankan semua Pod yang Anda tentukan.
Halaman ini menjelaskan bagaimana Namespace pengguna digunakan dalam pod Kubernetes. Namespace pengguna
mengisolasi pengguna yang berjalan di dalam kontainer dari pengguna
yang berada di host.
Proses yang berjalan sebagai root dalam kontainer dapat berjalan sebagai pengguna lain (non-root)
di host; dengan kata lain, proses tersebut memiliki hak istimewa penuh untuk operasi
di dalam Namespace pengguna, tetapi tidak memiliki hak istimewa untuk operasi di luar
Namespace.
Kamu dapat menggunakan fitur ini untuk mengurangi kerusakan yang dapat ditimbulkan oleh kontainer yang disusupi terhadap
host atau pod lain dalam node yang sama. Terdapat beberapa kerentanan
keamanan yang dinilai HIGH atau CRITICAL yang tidak
dapat dieksploitasi saat Namespace pengguna aktif. Namespace pengguna diharapkan juga akan
memitigasi beberapa kerentanan di masa mendatang.
Sebelum kamu memulai
Catatan: Bagian ini tertaut ke proyek-proyek pihak ketiga yang menyediakan fungsionalitas yang dibutuhkan oleh Kubernetes. Pencipta proyek Kubernetes tidak bertanggung jawab atas proyek-proyek tersebut. Laman ini mengikuti pedoman website CNCF dengan membuat daftar proyek menurut abjad. Untuk menambakan proyek ke dalam daftar ini, bacalah panduan sebelum mengirimkan perubahan.
Ini adalah fitur khusus Linux dan dukungan diperlukan di Linux untuk pemasangan idmap pada
sistem berkas yang digunakan. Artinya:
Pada node, sistem berkas yang kamu gunakan untuk /var/lib/kubelet/pods/, atau
direktori khusus yang kamu konfigurasikan untuk ini, memerlukan dukungan pemasangan idmap.
Semua sistem berkas yang digunakan dalam volume pod harus mendukung pemasangan idmap.
Dalam praktiknya, ini berarti kamu memerlukan setidaknya Linux 6.3, karena tmpfs mulai mendukung
pemasangan idmap pada versi tersebut. Ini biasanya diperlukan karena beberapa fitur Kubernetes
menggunakan tmpfs (token akun layanan yang dipasang secara default menggunakan
tmpfs, Secrets menggunakan tmpfs, dll.)
Beberapa sistem berkas populer yang mendukung pemasangan idmap di Linux 6.3 adalah: btrfs,
ext4, xfs, fat, tmpfs, overlayfs.
Selain itu, runtime kontainer dan runtime OCI yang mendasarinya harus mendukung
namespace pengguna. Runtime OCI berikut menawarkan dukungan:
crun versi 1.9 atau lebih tinggi (disarankan versi 1.13+).
Beberapa runtime OCI tidak menyertakan dukungan yang diperlukan untuk menggunakan namespace pengguna di
pod Linux. Jika kamu menggunakan Kubernetes terkelola, atau telah mengunduhnya dari paket
dan mengaturnya sendiri, ada kemungkinan node di klaster kamu menggunakan runtime yang tidak
menyertakan dukungan ini.
Untuk menggunakan namespace pengguna dengan Kubernetes, kamu juga perlu menggunakan CRI
container runtime
untuk menggunakan fitur ini dengan pod Kubernetes:
containerd: versi 2.0 (dan yang lebih baru) mendukung namespace pengguna untuk kontainer.
CRI-O: versi 1.25 (dan yang lebih baru) mendukung namespace pengguna untuk kontainer.
Kamu dapat melihat status dukungan namespace pengguna di cri-dockerd yang dilacak dalam issue
di GitHub.
Pengenalan
Namespace pengguna adalah fitur Linux yang memungkinkan pemetaan pengguna di dalam kontainer ke
pengguna lain di host. Lebih lanjut, kapabilitas yang diberikan kepada pod di
namespace pengguna hanya valid di dalam namespace tersebut dan tidak berlaku di luarnya.
Sebuah pod dapat memilih untuk menggunakan namespace pengguna dengan menyetel kolom pod.spec.hostUsers
ke false.
Kubelet akan memilih UID/GID host tempat pod dipetakan, dan akan melakukannya dengan cara
untuk menjamin bahwa tidak ada dua pod pada node yang sama yang menggunakan pemetaan yang sama.
Kolom runAsUser, runAsGroup, fsGroup, dll. di pod.spec selalu
merujuk ke pengguna di dalam kontainer. Pengguna ini akan digunakan untuk pemasangan volume
(ditentukan dalam pod.spec.volumes) dan oleh karena itu UID/GID host tidak akan
berpengaruh pada penulisan/pembacaan dari volume yang dapat dipasang oleh pod. Dengan kata lain,
inodes yang dibuat/dibaca dalam volume yang dipasang oleh pod akan sama seperti jika
pod tidak menggunakan namespace pengguna.
Dengan cara ini, sebuah pod dapat dengan mudah mengaktifkan dan menonaktifkan namespace pengguna (tanpa memengaruhi
kepemilikan berkas volumenya) dan juga dapat berbagi volume dengan pod tanpa namespace
pengguna hanya dengan mengatur pengguna yang sesuai di dalam kontainer
(RunAsUser, RunAsGroup, fsGroup, dll.). Ini berlaku untuk semua volume yang dapat dipasang oleh pod,
termasuk hostPath (jika pod diizinkan untuk memasang volume hostPath).
Secara default, UID/GID yang valid saat fitur ini diaktifkan adalah rentang 0-65535. Hal ini berlaku untuk berkas dan proses (runAsUser, runAsGroup, dll.).
Berkas yang menggunakan UID/GID di luar rentang ini akan dianggap sebagai milik
ID overflow, biasanya 65534 (dikonfigurasi dalam /proc/sys/kernel/overflowuid dan
/proc/sys/kernel/overflowgid). Namun, berkas
tersebut tidak dapat dimodifikasi, bahkan dengan menjalankannya sebagai pengguna/grup 65534.
Jika rentang 0-65535 diperluas dengan tombol konfigurasi, batasan
yang disebutkan di atas berlaku untuk rentang yang diperluas tersebut.
Sebagian besar aplikasi yang perlu dijalankan sebagai root tetapi tidak mengakses namespace atau sumber daya host lain,
seharusnya tetap berjalan dengan baik tanpa perlu perubahan apa pun
jika namespace pengguna diaktifkan.
Memahami namespace pengguna untuk pod
Beberapa runtime kontainer dengan konfigurasi default-nya (seperti Docker Engine,
containerd, CRI-O) menggunakan namespace Linux untuk isolasi. Teknologi lain juga tersedia
dan dapat digunakan dengan runtime tersebut (misalnya, Kata Containers menggunakan VM, bukan namespace
Linux). Halaman ini berlaku untuk runtime kontainer yang menggunakan namespace Linux
untuk isolasi.
Saat membuat pod, secara default, beberapa namespace baru digunakan untuk isolasi:
namespace jaringan untuk mengisolasi jaringan kontainer, namespace PID untuk
mengisolasi tampilan proses, dll. Jika namespace pengguna digunakan, ini akan
mengisolasi pengguna di kontainer dari pengguna di node.
Ini berarti kontainer dapat dijalankan sebagai root dan dipetakan ke pengguna non-root di
host. Di dalam kontainer, proses akan mengira dirinya berjalan sebagai root (dan
oleh karena itu, alat seperti apt, yum, dll. berfungsi dengan baik), padahal kenyataannya proses tersebut
tidak memiliki hak istimewa di host. Kamu dapat memverifikasi hal ini, misalnya, jika kamu
memeriksa pengguna mana yang dijalankan oleh proses kontainer dengan menjalankan ps aux dari
host. Pengguna yang ditampilkan ps tidak sama dengan pengguna yang kamu lihat jika kamu
mengeksekusi perintah id di dalam kontainer.
Abstraksi ini membatasi apa yang dapat terjadi, misalnya, jika kontainer berhasil
keluar ke host. Mengingat kontainer berjalan sebagai pengguna tanpa hak istimewa
di host, maka apa yang dapat dilakukannya terhadap host menjadi terbatas.
Lebih lanjut, karena pengguna di setiap pod akan dipetakan ke pengguna
berbeda yang tidak tumpang tindih di host, maka apa yang dapat mereka lakukan terhadap pod lain juga terbatas.
Kemampuan yang diberikan kepada pod juga terbatas pada namespace pengguna pod dan
sebagian besar tidak valid di luarnya, beberapa bahkan sepenuhnya batal. Berikut dua contoh:
CAP_SYS_MODULE tidak berpengaruh jika diberikan kepada pod menggunakan
namespace pengguna, pod tersebut tidak dapat memuat modul kernel.
CAP_SYS_ADMIN terbatas pada namespace pengguna pod dan tidak valid di luarnya.
Tanpa menggunakan namespace pengguna, kontainer yang berjalan sebagai root, dalam kasus
breakout kontainer, memiliki hak akses root pada node tersebut. Dan jika beberapa kemampuan diberikan kepada kontainer, kemampuan tersebut juga valid pada host. Semua hal ini
tidak berlaku ketika kita menggunakan namespace pengguna.
Jika kamu ingin mengetahui detail lebih lanjut tentang perubahan apa saja yang terjadi ketika namespace pengguna digunakan, lihat man 7 user_namespaces.
Siapkan node untuk mendukung namespace pengguna
Secara default, kubelet menetapkan UID/GID pod di atas rentang 0-65535, berdasarkan
asumsi bahwa berkas dan proses host menggunakan UID/GID dalam rentang
ini, yang merupakan standar untuk sebagian besar distribusi Linux. Pendekatan ini mencegah
tumpang tindih antara UID/GID host dan pod.
Menghindari tumpang tindih ini penting untuk mengurangi dampak kerentanan seperti
CVE-2021-25741, di mana pod berpotensi membaca berkas
sembarangan di host. Jika UID/GID pod dan host tidak tumpang tindih,
apa yang dapat dilakukan pod akan terbatas: UID/GID pod tidak akan cocok dengan
pemilik/grup berkas host.
Kubelet dapat menggunakan rentang khusus untuk ID pengguna dan ID grup untuk pod. Untuk
mengonfigurasi rentang khusus, node harus memiliki:
Pengguna kubelet di sistem (kamu tidak dapat menggunakan nama pengguna lain di sini)
Biner getsubids terpasang (bagian dari shadow-utils) dan
di PATH untuk biner kubelet.
Pengaturan ini hanya mengumpulkan konfigurasi rentang UID/GID dan tidak mengubah
pengguna yang menjalankan kubelet.
Kamu harus mengikuti beberapa batasan untuk rentang ID subordinat yang kamu tetapkan
kepada pengguna kubelet:
ID pengguna subordinat, yang memulai rentang UID untuk Pod, harus merupakan kelipatan
65536 dan juga harus lebih besar dari atau sama dengan 65536. Dengan kata lain,
kamu tidak dapat menggunakan ID apa pun dari rentang 0-65535 untuk Pod; kubelet
memaksakan batasan ini untuk mempersulit pembuatan konfigurasi
yang tidak aman secara tidak sengaja.
Jumlah ID subordinat harus kelipatan 65536.
Jumlah ID subordinat harus minimal 65536 x <maxPods> di mana <maxPods>
adalah jumlah maksimum pod yang dapat berjalan pada node tersebut.
Kamu harus menetapkan rentang yang sama untuk ID pengguna dan ID grup. Tidak masalah
jika pengguna lain memiliki rentang ID pengguna yang tidak sesuai dengan rentang ID grup.
Tidak ada rentang yang ditetapkan yang boleh tumpang tindih dengan penugasan lainnya.
Konfigurasi subordinat harus hanya satu baris. Dengan kata lain, kamu tidak dapat
memiliki beberapa rentang.
Misalnya, kamu dapat mendefinisikan /etc/subuid dan /etc/subgid agar keduanya memiliki
entri berikut untuk pengguna kubelet:
# Formatnya adalah
# name:firstID:count of IDs
# di mana
# - firstID adalah 65536 (nilai minimum yang dimungkinkan)
# - count of IDs adalah 110 * 65536
# (110 adalah batas _default_ untuk jumlah pod pada node)
kubelet:65536:7208960
Jumlah ID untuk setiap Pod
Mulai Kubernetes v1.33, jumlah ID untuk setiap Pod dapat diatur di
KubeletConfiguration.
Nilai idsPerPod (uint32) harus kelipatan 65536.
Nilai default-nya adalah 65536.
Nilai ini hanya berlaku untuk kontainer yang dibuat setelah kubelet dimulai dengan
KubeletConfiguration ini.
Kontainer yang sedang berjalan tidak terpengaruh oleh konfigurasi ini.
Di Kubernetes sebelum v1.33, jumlah ID untuk setiap Pod dikodekan secara permanen ke
65536.
Integrasi dengan pemeriksaan penerimaan keamanan Pod
FEATURE STATE:Kubernetes v1.29 [alpha]
Untuk Pod Linux yang mengaktifkan namespace pengguna, Kubernetes melonggarkan penerapan
Standar Keamanan Pod secara terkendali.
Perilaku ini dapat dikendalikan oleh feature
gateUserNamespacesPodSecurityStandards, yang memungkinkan pengguna akhir untuk memilih lebih awal. Admin harus memastikan bahwa namespace pengguna diaktifkan oleh semua node
di dalam klaster jika menggunakan feature gate.
Jika kamu mengaktifkan feature gate terkait dan membuat Pod yang menggunakan namespace pengguna, kolom-kolom berikut tidak akan dibatasi bahkan dalam konteks yang menerapkan standar keamanan pod
Baseline atau Restricted. Perilaku ini tidak
menimbulkan masalah keamanan karena root di dalam Pod dengan namespace pengguna
sebenarnya merujuk ke pengguna di dalam kontainer, yang tidak pernah dipetakan ke
pengguna istimewa di host. Berikut daftar kolom yang bukan diperiksa untuk Pod dalam
kondisi tersebut:
Saat menggunakan namespace pengguna untuk pod, penggunaan namespace host lain tidak diperbolehkan. Khususnya, jika kamu menetapkan hostUsers: false, kamu tidak
diizinkan untuk menetapkan salah satu dari:
hostNetwork: true
hostIPC: true
hostPID: true
Tidak ada kontainer yang dapat menggunakan volumeDevices (volume blok mentah, seperti /dev/sda).
Ini mencakup semua array kontainer dalam spesifikasi pod:
containers
initContainers
ephemeralContainers
Metrik dan Observabilitas
Kubelet mengekspor dua metrik Prometheus khusus untuk namespace pengguna:
started_user_namespaced_pods_total: penghitung yang melacak jumlah pod namespace pengguna yang dicoba dibuat.
started_user_namespaced_pods_errors_total: penghitung yang melacak jumlah kesalahan saat membuat pod namespace pengguna.
Tujuan dari ReplicaSet adalah untuk memelihara himpunan stabil dari replika Pod yang sedang berjalan pada satu waktu tertentu. Maka dari itu, ReplicaSet seringkali digunakan untuk menjamin ketersediaan dari beberapa Pod identik dalam jumlah tertentu.
Cara kerja ReplicaSet
Sebuah ReplicaSet didefinisikan dengan beberapa field termasuk selektor yang menentukan bagaimana mengidentifikasi Pod yang dapat diakuisisi, jumlah replika yang mengindikasi berapa jumlah Pod yang harus dikelola, dan sebuah templat pod yang menentukan data dari berbagai Pod baru yang harus dibuat untuk memenuhi kriteria jumlah replika. Sebuah ReplicaSet selanjutnya akan memenuhi tujuannya dengan membuat dan menghapus Pod sesuai dengan kebutuhan untuk mencapai jumlah yang diinginkan. Ketika ReplicaSet butuh untuk membuat Pod baru, templat Pod akan digunakan.
Tautan dari sebuah ReplicaSet terhadap Pod yang dimiliki adalah melalui fieldmetadata.ownerReferences pada Pod, yang menentukan sumber daya yang dimiliki oleh objek saat ini. Semua Pod yang diakuisisi oleh sebuah ReplicaSet masing-masing memiliki informasi yang mengidentifikasi ReplicaSet dalam field ownerReferences. Melalui tautan ini ReplicaSet dapat mengetahui keadaan dari Pod yang sedang dikelola dan melakukan perencanaan yang sesuai.
Sebuah ReplicaSet mengidentifikasi Pod baru untuk diakuisisi menggunakan selektornya. Jika terdapat sebuah Pod yang tidak memiliki OwnerReference atau OwnerReference yang dimiliki bukanlah sebuah Controller dan sesuai dengan selektor dari ReplicaSet, maka Pod akan langsung diakuisisi oleh ReplicaSet tersebut.
Kapan menggunakan ReplicaSet
Sebuah ReplicaSet memastikan replika-replika pod dalam jumlah yang ditentukan berjalan pada satu waktu tertentu. Namun demikian, sebuah Deployment adalah konsep dengan tingkatan yang lebih tinggi yang mengatur ReplicaSet dan mengubah Pod secara deklaratif serta berbagai fitur bermanfaat lainnya. Maka dari itu, kami merekomendasikan untuk menggunakan Deployment alih-alih menggunakan ReplicaSet secara langsung, kecuali jika kamu membutuhkan orkestrasi pembaruan yang khusus atau tidak membutuhkan pembaruan sama sekali.
Hal ini berarti kamu boleh jadi tidak akan membutuhkan manipulasi objek ReplicaSet: Gunakan Deployment dan definisikan aplikasi kamu pada bagian spec.
apiVersion:apps/v1kind:ReplicaSetmetadata:name:frontendlabels:app:guestbooktier:frontendspec:# modify replicas according to your casereplicas:3selector:matchLabels:tier:frontendtemplate:metadata:labels:tier:frontendspec:containers:- name:php-redisimage:gcr.io/google_samples/gb-frontend:v3
Menyimpan manifest ini dalam frontend.yaml dan mengirimkannya ke klaster Kubernetes akan membuat ReplicaSet yang telah didefinisikan beserta dengan Pod yang dikelola.
Selanjutnya kamu bisa mendapatkan ReplicaSet yang sedang di-deploy:
kubectl get rs
Dan melihat frontend yang telah dibuat:
NAME DESIRED CURRENT READY AGE
frontend 333 6s
Kamu juga dapat memeriksa kondisi dari ReplicaSet:
kubectl describe rs/frontend
Dan kamu akan melihat keluaran yang serupa dengan:
Name: frontend
Namespace: default
Selector: tier=frontend,tier in (frontend)Labels: app=guestbook
tier=frontend
Annotations: <none>
Replicas: 3 current / 3 desired
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=guestbook
tier=frontend
Containers:
php-redis:
Image: gcr.io/google_samples/gb-frontend:v3
Port: 80/TCP
Requests:
cpu: 100m
memory: 100Mi
Environment:
GET_HOSTS_FROM: dns
Mounts: <none>
Volumes: <none>
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
1m 1m 1{replicaset-controller } Normal SuccessfulCreate Created pod: frontend-qhloh
1m 1m 1{replicaset-controller } Normal SuccessfulCreate Created pod: frontend-dnjpy
1m 1m 1{replicaset-controller } Normal SuccessfulCreate Created pod: frontend-9si5l
Terakhir, kamu dapat memeriksa Pod yang dibawa:
kubectl get Pods
Kamu akan melihat informasi Pod yang serupa dengan:
NAME READY STATUS RESTARTS AGE
frontend-9si5l 1/1 Running 0 1m
frontend-dnjpy 1/1 Running 0 1m
frontend-qhloh 1/1 Running 0 1m
Kamu juga dapat memastikan bahwa referensi pemilik dari pod-pod ini telah disesuaikan terhadap ReplicaSet frontend.
Untuk melakukannya, yaml dari Pod yang sedang berjalan bisa didapatkan dengan:
kubectl get pods frontend-9si5l -o yaml
Keluarannya akan terlihat serupa dengan contoh berikut ini, dengan informasi ReplicaSet frontend yang ditentukan pada field ownerReferences pada bagian metadata:
Walaupun kamu bisa membuat Pod biasa tanpa masalah, sangat direkomendasikan untuk memastikan Pod tersebut tidak memiliki label yang sama dengan selektor dari salah satu ReplicaSet yang kamu miliki. Hal in disebabkan sebuah ReplicaSet tidak dibatasi untuk memilki Pod sesuai dengan templatnya -- ReplicaSet dapat mengakuisisi Pod lain dengan cara yang telah dijelaskan pada bagian sebelumnya.
Mengambil contoh ReplicaSet frontend sebelumnya, dan Pod yang ditentukan pada manifest berikut:
Karena Pod tersebut tidak memiliki Controller (atau objek lain) sebagai referensi pemilik yang sesuai dengan selektor dari ReplicaSet frontend, Pod tersebut akan langsung diakuisisi oleh ReplicaSet.
Misalkan kamu membuat Pod tersebut setelah ReplicaSet frontend telah di-deploy dan telah mengkonfigurasi replika Pod awal untuk memenuhi kebutuhan jumlah replika:
Kamu akan melihat bahwa ReplicaSet telah mengakuisisi Pod dan hanya membuat Pod yang baru sesuai dengan spec yang ditentukan hingga jumlah dari Pod yang baru dan yang orisinil sesuai dengan jumlah yang diinginkan. Dengan memperoleh Pod:
kubectl get Pods
Akan diperlihatkan pada keluarannya:
NAME READY STATUS RESTARTS AGE
frontend-pxj4r 1/1 Running 0 5s
pod1 1/1 Running 0 13s
pod2 1/1 Running 0 13s
Dengan cara ini, sebuah ReplicaSet dapat memiliki himpunan berbagai Pod yang tidak homogen.
Menulis manifest ReplicaSet
Seperti objek API Kubernetes lainnya, sebuah ReplicaSet membutuhkan fieldapiVersion, kind, dan metadata. Untuk ReplicaSet, nilai dari kind yang memungkinkan hanyalah ReplicaSet. Pada Kubernetes 1.9 versi API apps/v1 pada kind ReplicaSet adalah versi saat ini dan diaktifkan secara default. Versi API apps/v1beta2 telah dideprekasi. Lihat baris-baris awal pada contoh frontend.yaml untuk petunjuk.
.spec.template adalah sebuah templat pod yang juga dibutuhkan untuk mempunyai label. Pada contoh frontend.yaml kita memiliki satu label: tier: frontend.
Hati-hati agar tidak tumpang tindih dengan selektor dari controller lain, agar mereka tidak mencoba untuk mengadopsi Pod ini.
Untuk fieldrestart policy dari templat, .spec.template.spec.restartPolicy, nilai yang diperbolehkan hanyalah Always, yang merupakan nilai default.
Selektor Pod
Field.spec.selector adalah sebuah selektor labe. Seperti yang telah dibahas sebelumnya, field ini adalah label yang digunakan untuk mengidentifikasi Pod yang memungkinkan untuk diakuisisi. Pada contoh frontend.yaml, selektornya adalah:
matchLabels:
tier: frontend
Pada ReplicaSet, .spec.template.metadata.labels harus memiliki nilai yang sama dengan spec.selector, atau akan ditolak oleh API.
Catatan:
Untuk 2 ReplicaSet dengan nilai .spec.selector yang sama tetapi memiliki nilai yang berbeda pada field.spec.template.metadata.labels dan .spec.template.spec, setiap ReplicaSet akan mengabaikan Pod yang dibuat oleh ReplicaSet lain.
Replika
Kamu dapat menentukan jumlah Pod yang seharusnya berjalan secara konkuren dengan mengatur nilai dari .spec.replicas. ReplicaSet akan membuat/menghapus Pod-nya hingga jumlahnya sesuai dengan field ini.
Jika nilai .spec.replicas tidak ditentukan maka akan diatur ke nilai default 1.
Menggunakan ReplicaSet
Menghapus ReplicaSet dan Pod-nya
Untuk menghapus sebuah ReplicaSet beserta dengan Pod-nya, gunakan kubectl delete. Garbage collector secara otomatis akan menghapus semua Pod dependen secara default.
Ketika menggunakan REST API atau libraryclient-go, kamu harus mengatur nilai propagationPolicy menjadi Background atau Foreground pada opsi -d.
Sebagai contoh:
Kamu dapat menghapus ReplicaSet tanpa memengaruhi Pod-nya menggunakan kubectl delete dengan menggunakan opsi --cascade=false.
Ketika menggunakan REST API atau libraryclient-go, kamu harus mengatur nilai propagationPolicy menjadi Orphan.
Sebagai contoh:
Ketika ReplicaSet yang asli telah dihapus, kamu dapat membuat ReplicaSet baru untuk menggantikannya. Selama field.spec.selector yang lama dan baru memilki nilai yang sama, maka ReplicaSet baru akan mengadopsi Pod lama namun tidak serta merta membuat Pod yang sudah ada sama dan sesuai dengan templat Pod yang baru.
Untuk memperbarui Pod dengan spec baru dapat menggunakan Deployment karena ReplicaSet tidak mendukung pembaruan secara langsung.
Mengisolasi Pod dari ReplicaSet
Kamu dapat menghapus Pod dari ReplicaSet dengan mengubah nilai labelnya. Cara ini dapat digunakan untuk menghapus Pod dari servis untuk keperluan debugging, data recovery, dan lainnya. Pod yang dihapus dengan cara ini akan digantikan seecara otomatis (dengan asumsi jumlah replika juga tidak berubah).
Mengatur jumlah Pod pada ReplicaSet
Jumlah Pod pada ReplicaSet dapat diatur dengan mengubah nilai dari field.spec.replicas. Pengatur ReplicaSet akan memastikan Pod dengan jumlah yang telah ditentukan dan dengan nilai selektor yang sama sedang dalam keadaan berjalan.
Pengaturan jumlah Pod pada ReplicaSet menggunakan Horizontal Pod Autoscaler
Pengaturan jumlah Pod pada ReplicaSet juga dapat dilakukan mengunakan Horizontal Pod Autoscalers (HPA). Berikut adalah contoh HPA terhadap ReplicaSet yang telah dibuat pada contoh sebelumnya.
Menyimpan manifest ini dalam hpa-rs.yaml dan mengirimkannya ke klaster Kubernetes akan membuat HPA tersebut yang akan mengatur jumlah Pod pada ReplicaSet yang telah didefinisikan bergantung terhadap penggunaan CPU dari Pod yang direplikasi.
Opsi lainnya adalah dengan menggunakan perintah kubectl autoscale untuk tujuan yang sama.
kubectl autoscale rs frontend --max=10
Alternatif selain ReplicaSet
Deployment (direkomendasikan)
Deployment adalah sebuah objek yang bisa memiliki ReplicaSet dan memperbarui ReplicaSet dan Pod-nya melalui rolling update deklaratif dan server-side.
Walaupun ReplicaSet dapat digunakan secara independen, seringkali ReplicaSet digunakan oleh Deployments sebagai mekanisme untuk mengorkestrasi pembuatan, penghapusan dan pembaruan Pod. Ketika kamu menggunakan Deployments kamu tidak perlu khawatir akan pengaturan dari ReplicaSet yang dibuat. Deployments memiliki dan mengatur ReplicaSet-nya sendiri.
Maka dari itu penggunaan Deployments direkomendasikan jika kamu menginginkan ReplicaSet.
Pod sederhana
Tidak seperti pada kasus ketika pengguna secara langsung membuat Pod, ReplicaSet akan menggantikan Pod yang dihapus atau diterminasi dengan alasan apapun, seperti pada kasus dimana terjadi kegagalan node atau pemeliharaan node yang disruptif, seperti pada kasus upgrade kernel. Karena alasan ini kami merekomendasikan kamu untuk menggunakan ReplicaSet walaupun jika aplikasimu membutuhkan hanya satu Pod. Hal ini mirip dengan pengawas proses, hanya saja pada kasus ini mengawasi banyak Pod pada berbagai node alih-alih berbagai proses individu pada sebuah node. ReplicaSet mendelegasikan proses pengulangan kembali dari kontainer lokal kepada agen yang terdapat di node (sebagai contoh, Kubelet atau Docker).
Job
Gunakan Job alih-alih ReplicaSet untuk Pod yang diharapkan untuk diterminasi secara sendirinya.
DaemonSet
Gunakan DaemonSet alih-alih ReplicaSet untuk Pod yang menyediakan fungsi pada level mesin, seperti monitoring mesin atau logging mesin. Pod ini memiliki waktu hidup yang bergantung terhadap waktu hidup mesin: Pod perlu untuk berjalan pada mesin sebelum Pod lain dijalankan, dan aman untuk diterminasi ketika mesin siap untuk di-reboot atau dimatikan.
ReplicationController
ReplicaSet adalah suksesor dari ReplicationControllers. Keduanya memenuhi tujuan yang sama dan memiliki perilaku yang serupa, kecuali bahwa ReplicationController tidak mendukung kebutuhan selektor set-based seperti yang dijelaskan pada panduan penggunaan label. Pada kasus tersebut, ReplicaSet lebih direkomendasikan dibandingkan ReplicationController.
4.2.2 - ReplicationController
Catatan:
Deployment yang mengonfigurasi ReplicaSet sekarang menjadi cara yang direkomendasikan untuk melakukan replikasi.
Sebuah ReplicationController memastikan bahwa terdapat sejumlah Pod yang sedang berjalan dalam suatu waktu tertentu. Dengan kata lain, ReplicationController memastikan bahwa sebuah Pod atau sebuah kumpulan Pod yang homogen selalu berjalan dan tersedia.
Bagaimana ReplicationController Bekerja
Jika terdapat terlalu banyak Pod, maka ReplicationController akan membatasi dan mematikan Pod-Pod yang berlebih. Jika terdapat terlalu sedikit, maka ReplicationController akan memulai dan menjalankan Pod-Pod baru lainnya. Tidak seperti Pod yang dibuat secara manual, Pod-Pod yang diatur oleh sebuah ReplicationController akan secara otomatis diganti jika mereka gagal, dihapus, ataupun dimatikan.
Sebagai contoh, Pod-Pod yang kamu miliki akan dibuat ulang dalam sebuah Node setelah terjadi proses pemeliharaan seperti pembaruan kernel. Untuk alasan ini, maka kamu sebaiknya memiliki sebuah ReplicationController bahkan ketika aplikasimu hanya membutuhkan satu buah Pod saja. Sebuah ReplicationController memiliki kemiripan dengan sebuah pengawas proses, tetapi alih-alih mengawasi sebuah proses individu pada sebuah Node, ReplicationController banyak Pod yang terdapat pada beberapa Node.
ReplicationController seringkali disingkat sebagai "rc" dalam diskusi, dan sebagai shortcut dalam perintah kubectl.
Sebuah contoh sederhana adalah membuat sebuah objek ReplicationController untuk menjalankan sebuah instance Pod secara berkelanjutan. Contoh pemakaian lainnya adalah untuk menjalankan beberapa replika identik dari sebuah servis yang direplikasi, seperti peladen web.
Menjalankan Sebuah Contoh ReplicationController
Contoh ReplicationController ini mengonfigurasi tiga salinan dari peladen web nginx.
Periksa status dari ReplicationController menggunakan perintah ini:
kubectl describe replicationcontrollers/nginx
Name: nginx
Namespace: default
Selector: app=nginx
Labels: app=nginx
Annotations: <none>
Replicas: 3 current / 3 desired
Pods Status: 0 Running / 3 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx
Port: 80/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- ---- ------ -------
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-qrm3m
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-3ntk0
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-4ok8v
Tiga Pod telah dibuat namun belum ada yang berjalan, kemungkinan karena image yang sedang di-pull.
Beberapa waktu kemudian, perintah yang sama akan menunjukkan:
Untuk melihat semua Pod yang dibuat oleh ReplicationController dalam bentuk yang lebih mudah dibaca mesin, kamu dapat menggunakan perintah seperti ini:
pods=$(kubectl get pods --selector=app=nginx --output=jsonpath={.items..metadata.name})echo$pods
nginx-3ntk0 nginx-4ok8v nginx-qrm3m
Pada perintah di atas, selektor yang dimaksud adalah selektor yang sama dengan yang terdapat pada ReplicationController (yang dapat dilihat pada keluaran kubectl describe), dan dalam bentuk yang berbeda dengan yang terdapat pada replication.yaml. Opsi --output=jsonpath menentukan perintah untuh mendapatkan hanya nama dari setiap Pod yang ada pada daftar hasil.
Menulis Spesifikasi ReplicationController
Seperti semua konfigurasi Kubernetes lainnya, sebuah ReplicationController membutuhkan fieldapiVersion, kind, dan metadata.
Untuk informasi umum mengenai berkas konfigurasi, kamu dapat melihat pengaturan objek.
Sebuah ReplicationController juga membutuhkan bagian .spec.
Templat Pod
.spec.template adalah satu-satunya field yang diwajibkan pada .spec.
.spec.template adalah sebuah templat Pod. Ia memiliki skema yang sama persis dengan sebuah Pod, namun dapat berbentuk nested dan tidak memiliki fieldapiVersion ataupun kind.
Selain field-field yang diwajibkan untuk sebuah Pod, templat Pod pada ReplicationController harus menentukan label dan kebijakan pengulangan kembali yang tepat. Untuk label, pastikan untuk tidak tumpang tindih dengan kontroler lain. Lihat selektor pod.
Untuk pengulangan kembali dari sebuah kontainer lokal, ReplicationController mendelegasikannya ke agen pada Node, contohnya Kubelet atau Docker.
Label pada ReplicationController
ReplicationController itu sendiri dapat memiliki label (.metadata.labels). Biasanya, kamu akan mengaturnya untuk memiliki nilai yang sama dengan .spec.template.metadata.labels; jika .metadata.labels tidak ditentukan maka akan menggunakan nilai bawaan yaitu .spec.template.metadata.labels. Namun begitu, kedua label ini diperbolehkan untuk memiliki nilai yang berbeda, dan .metadata.labels tidak akan memengaruhi perilaku dari ReplicationController.
Selektor Pod
Field.spec.selector adalah sebuah selektor label. Sebuah ReplicationController mengatur semua Pod dengan label yang sesuai dengan nilai selektor tersebut. Ia tidak membedakan antara Pod yang ia buat atau hapus atau Pod yang dibuat atau dihapus oleh orang atau proses lain. Hal ini memungkinkan ReplicationController untuk digantikan tanpa memengaruhi Pod-Pod yang sedang berjalan.
Jika ditentukan, .spec.template.metadata.labels harus memiliki nilai yang sama dengan .spec.selector, atau akan ditolak oleh API. Jika .spec.selector tidak ditentukan, maka akan menggunakan nilai bawaan yaitu .spec.template.metadata.labels.
Selain itu, kamu juga sebaiknya tidak membuat Pod dengan label yang cocok dengan selektor ini, baik secara langsung, dengan menggunakan ReplicationController lain, ataupun menggunakan kontroler lain seperti Job. Jika kamu melakukannya, ReplicationController akan menganggap bahwa ia telah membuat Pod-Pod lainnya. Kubernetes tidak akan menghentikan kamu untuk melakukan aksi ini.
Jika kamu pada akhirnya memiliki beberapa kontroler dengan selektor-selektor yang tumpang tindih, kamu harus mengatur penghapusannya sendiri (lihat di bawah).
Beberapa Replika
Kamu dapat menentukan jumlah Pod yang seharusnya berjalan secara bersamaan dengan mengatur nilai .spec.replicas dengan jumlah Pod yang kamu inginkan untuk berjalan secara bersamaan. Jumlah yang berjalan dalam satu satuan waktu dapat lebih tinggi ataupun lebih rendah, seperti jika replika-replika tersebut melewati proses penambahan atau pengurangan, atau jika sebuah Pod melalui proses graceful shutdown, dan penggantinya telah dijalankan terlebih dahulu.
Jika kamu tidak menentukan nilai dari .spec.replicas, maka akan digunakan nilai bawaan 1.
Bekerja dengan ReplicationController
Menghapus Sebuah ReplicationController dan Pod-nya
Untuk menghapus sebuah ReplicationController dan Pod-Pod yang berhubungan dengannya, gunakan perintah kubectl delete. Kubectl akan mengatur ReplicationController ke nol dan menunggunya untuk menghapus setiap Pod sebelum menghapus ReplicationController itu sendiri. Jika perintah kubectl ini terhenti, maka dapat diulang kembali.
Ketika menggunakan REST API atau library klien go, maka kamu perlu melakukan langkah-langkahnya secara eksplisit (mengatur replika-replika ke 0, menunggu penghapusan Pod, dan barulah menghapus ReplicationController).
Menghapus Hanya ReplicationController
Kamu dapat menghapus ReplicationController tanpa memengaruhi Pod-Pod yang berhubungan dengannya.
Dengan menggunakan kubectl, tentukan opsi --cascade=false ke kubectl delete.
Ketika menggunakan REST API atau library klien go, cukup hapus objek ReplicationController.
Ketika ReplicationController yang asli telah dihapus, kamu dapat membuat ReplicationController yang baru sebagai penggantinya. Selama .spec.selector yang lama dan baru memiliki nilai yang sama, maka ReplicationController baru akan mengadopsi Pod-Pod yang lama.
Walaupun begitu, ia tidak akan melakukan usaha apapun untuk membuat Pod-Pod yang telah ada sebelumnya untuk sesuai dengan templat Pod yang baru dan berbeda.
Untuk memperbarui Pod-Pod ke spesifikasi yang baru dengan cara yang terkontrol, gunakan pembaruan bergulir.
Mengisolasi Pod dari ReplicationController
Pod-Pod dapat dihapus dari kumpulan target sebuah ReplicationController dengan mengganti nilai dari labelnya. Teknik ini dapat digunakan untuk mencopot Pod-Pod dari servis untuk keperluan pengawakutuan (debugging), pemulihan data, dan lainnya. Pod-Pod yang dicopot dengan cara ini dapat digantikan secara otomatis (dengan asumsi bahwa jumlah replika juga tidak berubah).
Pola penggunaan umum
Penjadwalan ulang
Seperti yang telah disebutkan sebelumnya, baik kamu memiliki hanya 1 Pod untuk tetap dijalankan, ataupun 1000, ReplicationController akan memastikan tersedianya jumlah Pod yang telat ditentukan, bahkan ketika terjadi kegagalan Node atau terminasi Pod (sebagai contoh karena adanya tindakan dari agen kontrol lain).
Penskalaan
ReplicationController memudahkan penskalaan jumlah replika, baik meningkatkan ataupun mengurangi, secara manual ataupun dengan agen kontrol penskalaan otomatis, dengan hanya mengubah nilai dari fieldreplicas.
Pembaruan bergulir
ReplicationController didesain untuk memfasilitasi pembaruan bergulir untuk sebuah servis dengan mengganti Pod-Pod satu per satu.
Seperti yang telah dijelaskan di #1353, pendekatan yang direkomendasikan adalah dengan membuat ReplicationController baru dengan 1 replika, skala kontroler yang baru (+1) atau yang lama (-1) satu per satu, dan kemudian hapus kontroler lama setelah menyentuh angka 0 replika. Hal ini memungkinkan pembaruan dilakukan dengan dapat diprediksi terlepas dari adanya kegagalan yang tak terduga.
Idealnya, kontroler pembaruan bergulir akan memperhitungkan kesiapan dari aplikasi, dan memastikan cukupnya jumlah Pod yang secara produktif meladen kapanpun.
Dua ReplicationController diharuskan untuk memiliki setidaknya satu label yang berbeda, seperti tagimage dari kontainer utama dari Pod, karena pembaruan bergulir biasanya dilakukan karena adanya pembaruan image.
Selain menjalankan beberapa rilis dari sebuah aplikasi ketika proses pembaruan bergulir sedang berjalan, adalah hal yang awam untuk menjalankan beberapa rilis untuk suatu periode waktu tertentu, atau bahkan secara kontinu, menggunakan operasi rilis majemuk. Operasi-operasi ini akan dibedakan menggunakan label.
Sebagai contoh, sebuah servis dapat menyasar semua Pod dengan tier in (frontend), environment in (prod). Anggap kamu memiliki 10 Pod tiruan yang membangun tier ini tetapi kamu ingin bisa menggunakan 'canary' terhadap versi baru dari komponen ini. Kamu dapat mengatur sebuah ReplicationController dengan nilai replicas 9 untuk replika-replikanya, dengan label tier=frontend, environment=prod, track=stable, dan ReplicationController lainnya dengan nilai replicas 1 untuk canary, dengan label tier=frontend, environment=prod, track=canary. Sekarang servis sudah mencakup baik canary maupun Pod-Pod yang bukan canary. Kamu juga dapat mencoba-coba ReplicationController secara terpisah untuk melakukan pengujian, mengamati hasilnya, dan lainnya.
Menggunakan ReplicationController dengan Service
Beberapa ReplicationController dapat berada di belakang sebuah Service, sedemikian sehingga, sebagai contoh, sebagian traffic dapat ditujukan ke versi lama, dan sebagian lainnya ke versi yang baru.
Sebuah ReplicationController tidak akan berhenti dengan sendirinya, namun ia tidak diekspektasikan untuk berjalan selama Service-Service yang ada. Service dapat terdiri dari berbagai Pod yang dikontrol beberapa ReplicationController, dan terdapat kemungkinan bahwa beberapa ReplicationController untuk dibuat dan dimatikan dalam jangka waktu hidup Service (contohnya adalah untuk melakukan pembaruan Pod-Pod yang menjalankan Service). Baik Service itu sendiri dan kliennya harus tetap dalam keadaan tidak mempunyai pengetahuan terhadap ReplicationController yang memelihara Pod-Pod dari Service tersebut.
Menulis program untuk Replikasi
Pod-Pod yang dibuat oleh ReplicationController ditujukan untuk dapat sepadan dan memiliki semantik yang identik, walaupun konfigurasi mereka dapat berbeda seiring keberjalanan waktunya. Ini adalah contoh yang cocok untuk peladen stateless, namun ReplicationController juga dapat digunakan untuk memelihara ketersediaan dari aplikasi-aplikasi yang master-elected, sharded, worker-pool. Aplikasi-aplikasi seperti itu sebaiknya menggunakan mekanisme penetapan kerja yang dinamis, seperti antrian kerja RabbitMQ, berlainan dengan pengubahan statis/satu kali dari konfigurasi setiap Pod, yang dipandang sebagai sebuah anti-pattern. Pengubahan apapun yang dilakukan terhadap Pod, seperti auto-sizing vertikal dari sumber daya (misalnya cpu atau memori), sebaiknya dilakukan oleh proses kontroller luring lainnya, dan bukan oleh ReplicationController itu sendiri.
Tanggung Jawab ReplicationController
ReplicationController hanya memastikan ketersediaan dari sejumlah Pod yang cocok dengan selektor label dan berjalan dengan baik. Saat ini, hanya Pod yang diterminasi yang dijadikan pengecualian dari penghitungan. Kedepannya, kesiapan dan informasi yang ada lainnya dari sistem dapat menjadi pertimbangan, kami dapat meningkatkan kontrol terhadap kebijakan penggantian, dan kami berencana untuk menginformasikan kejadian (event) yang dapat digunakan klien eksternal untuk implementasi penggantian yang sesuai dan/atau kebijakan pengurangan.
ReplicationController akan selalu dibatasi terhadap tanggung jawab spesifik ini. Ia tidak akan melakukan probe kesiapan atau keaktifan. Daripada melakukan auto-scaling, ia ditujukan untuk dikontrol oleh auto-scaler eksternal (seperti yang didiskusikan pada #492), yang akan mengganti fieldreplicas. Kami tidak akan menambahkan kebijakan penjadwalan (contohnya spreading) untuk ReplicationController. Ia juga tidak seharusnya melakukan verifikasi terhadap Pod-Pod yang sedang dikontrol yang cocok dengan spesifikasi templat saat ini, karena hal itu dapat menghambat auto-sizing dan proses otomatis lainnya. Demikian pula batas waktu penyelesaian, pengurutan dependencies, ekspansi konfigurasi, dan fitur-fitur lain yang seharusnya berada di komponen lain. Kami juga bahkan berencana untuk mengeluarkan mekanisme pembuatan Pod secara serentak (#170).
ReplicationController ditujukan untuk menjadi primitif komponen yang dapat dibangun untuk berbagai kebutuhan. Kami menargetkan API dengan tingkatan yang lebih tinggi dan/atau perkakas-perkakas untuk dibangun di atasnya dan primitif tambahan lainnya untuk kenyamanan pengguna kedepannya. Operasi-operasi makro yang sudah didukung oleh kubectl (run, scale, rolling-update) adalah contoh proof-of-concept dari konsep ini. Sebagai contohnya, kita dapat menganggap sesuatu seperti Asgard yang mengatur beberapa ReplicationController, auto-scaler, servis, kebijakan penjadwalan, canary, dan yang lainnya.
Objek API
ReplicationController adalah sebuah sumber daya top-level pada REST API Kubernetes. Detil dari objek API dapat ditemukan di: objek API ReplicationController.
Alternatif untuk ReplicationController
ReplicaSet
ReplicaSet adalah kelanjutan dari ReplicationController yang mendukung selektor selektor label set-based yang baru. Umumnya digunakan oleh Deployment sebagai mekanisme untuk mengorkestrasi pembuatan, penghapusan, dan pembaruan Pod.
Perhatikan bahwa kami merekomendasikan untuk menggunakan Deployment sebagai ganti dari menggunakan ReplicaSet secara langsung, kecuali jika kamu membutuhkan orkestrasi pembaruan khusus atau tidak membutuhkan pembaruan sama sekali.
Deployment (Direkomendasikan)
Deployment adalah objek API tingkat tinggi yang memperbarui ReplicaSet dan Pod-Pod di bawahnya yang mirip dengan cara kerja kubectl rolling-update. Deployment direkomendasikan jika kamu menginginkan fungsionalitas dari pembaruan bergulir ini, karena tidak seperti kubectl rolling-update, Deployment memiliki sifat deklaratif, server-side, dan memiliki beberapa fitur tambahan lainnya.
Pod sederhana
Tidak seperti pada kasus ketika pengguna secara langsung membuat Pod, ReplicationController menggantikan Pod-Pod yang dihapus atau dimatikan untuk alasan apapun, seperti pada kasus kegagalan Node atau pemeliharaan Node yang disruptif, seperti pembaruan kernel. Untuk alasan ini, kami merekomendasikan kamu untuk menggunakan ReplicationController bahkan ketika aplikasimu hanya membutuhkan satu Pod saja. Anggap hal ini mirip dengan pengawas proses, hanya pada kasus ini mengawasi banyak Pod yang terdapat pada berbagai Node dan bukan proses-proses tunggal pada satu Node. ReplicationController mendelegasikan pengulangan kontainer lokal ke agen yang terdapat dalam Node (contohnya Kubelet atau Docker).
Job
Gunakan Job sebagai ganti ReplicationController untuk Pod-Pod yang diharapkan diterminasi dengan sendirinya (seperti batch jobs).
DaemonSet
Gunakan DaemonSet sebagai ganti ReplicationController untuk Pod-Pod yang menyediakan fungsi pada level mesin, seperti pengamatan mesin atau pencatatan mesin. Pod-Pod ini memiliki waktu hidup yang bergantung dengan waktu hidup mesin: Pod butuh untuk dijalankan di mesin sebelum Pod-Pod lainnya dimulai, dan aman untuk diterminasi ketika mesin sudah siap untuk dinyalakan ulang atau dimatikan.
Deployment menyediakan pembaruan Pods dan
ReplicaSets secara deklaratif.
Kamu mendeskripsikan sebuah state yang diinginkan dalam Deployment, kemudian Deployment Pengontrol mengubah state sekarang menjadi seperti pada deskripsi secara bertahap. Kamu dapat mendefinisikan Deployment untuk membuat ReplicaSets baru atau untuk menghapus Deployment yang sudah ada dan mengadopsi semua resourcenya untuk Deployment baru.
Catatan:
Jangan mengganti ReplicaSets milik Deployment. Pertimbangkan untuk membuat isu pada repositori utama Kubernetes jika kasusmu tidak diatasi semua kasus di bawah.
Penggunaan
Berikut adalah penggunaan yang umum pada Deployment:
Mendeklarasikan state baru dari Pods dengan membarui PodTemplateSpec milik Deployment. ReplicaSet baru akan dibuat dan Deployment mengatur perpindahan Pod secara teratur dari ReplicaSet lama ke ReplicaSet baru. Tiap ReplicaSet baru akan mengganti revisi Deployment.
Deployment baru akan dibuat dengan nama nginx-deployment, tertulis pada kolom .metadata.name.
Deployment membuat tiga Pod yang direplikasi, ditandai dengan kolom replicas.
Kolom selector mendefinisikan bagaimana Deployment menemukan Pod yang diatur.
Dalam kasus ini, kamu hanya perlu memilih sebuah label yang didefinisikan pada templat Pod (app: nginx).
Namun, aturan pemilihan yang lebih canggih mungkin dilakukan asal templat Pod-nya memenuhi aturan.
Catatan:
Kolom `matchLabels` berbentuk pasangan {key,value}. Sebuah {key,value} dalam _map_ `matchLabels` ekuivalen dengan
elemen pada `matchExpressions`, yang mana kolom key adalah "key", operator adalah "In", dan larik values hanya berisi "value".
Semua prasyarat dari `matchLabels` maupun `matchExpressions` harus dipenuhi agar dapat dicocokkan.
Kolom template berisi sub kolom berikut:
Pod dilabeli app: nginx dengan kolom labels.
Spesifikasi templat Pod atau kolom .template.spec menandakan bahwa Pod mennjalankan satu kontainer nginx,
yang menjalankan image nginxDocker Hub dengan versi 1.7.9.
Membuat satu kontainer bernama nginx sesuai kolom name.
Ikuti langkah-langkah berikut untuk membuat Deployment di atas:
Sebelum memulai, pastikan klaster Kubernetes sedang menyala dan bekerja.
Buat Deployment dengan menjalankan perintah berikut:
Catatan:
Kamu dapat menambahkan argument `--record` untuk menulis perintah yang dijalankan pada anotasi sumber daya `kubernetes.io/change-cause`. Ini berguna untuk pemeriksaan di masa depan.
Contohnya yaitu untuk melihat perintah yang dijalankan pada tiap revisi Deployment.
Jalankan kubectl get deployments untuk mengecek apakah Deployment telah dibuat. Jika Deployment masih sedang pembuatan, keluaran akan tampil seperti berikut:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3000 1s
Ketika kamu memeriksa Deployments pada klastermu, kolom berikut akan tampil:
* `NAME` menampilkan daftar nama Deployment pada klaster.
* `DESIRED` menampilkan jumlah replika aplikasi yang diinginkan sesuai yang didefinisikan saat pembuatan Deployment. Ini adalah _state_ yang diinginkan.
* `CURRENT` menampilkan berapa jumlah replika yang sedang berjalan.
* `UP-TO-DATE` menampilkan jumlah replika yang diperbarui agar sesuai state yang diinginkan.
* `AVAILABLE` menampilkan jumlah replika aplikasi yang dapat diakses pengguna.
* `AGE` menampilkan lama waktu aplikasi telah berjalan.
Perhatikan bahwa jumlah replika yang diinginkan adalah tiga sesuai kolom .spec.replicas.
Untuk melihat status rilis Deployment, jalankan kubectl rollout status deployment.v1.apps/nginx-deployment. Keluaran akan tampil seperti berikut:
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
deployment "nginx-deployment" successfully rolled out
Jalankan kubectl get deployments lagi beberapa saat kemudian. Keluaran akan tampil seperti berikut:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3333 18s
Perhatikan bahwa Deployment telah membuat ketiga replika dan semua replika sudah merupakan yang terbaru (mereka mengandung pembaruan terakhir templat Pod) dan dapat diakses.
Untuk melihat ReplicaSet (rs) yang dibuat Deployment, jalankan kubectl get rs. Keluaran akan tampil seperti berikut:
NAME DESIRED CURRENT READY AGE
nginx-deployment-75675f5897 333 18s
Perhatikan bahwa nama ReplicaSet selalu dalam format [NAMA-DEPLOYMENT]-[KATA-ACAK]. Kata acak dibangkitkan secara acak dan menggunakan pod-template-hash sebagai benih.
Untuk melihat label yang dibangkitkan secara otomatis untuk tiap Pod, jalankan kubectl get pods --show-labels. Perintah akan menghasilkan keluaran berikut:
NAME READY STATUS RESTARTS AGE LABELS
nginx-deployment-75675f5897-7ci7o 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897
nginx-deployment-75675f5897-kzszj 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897
nginx-deployment-75675f5897-qqcnn 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897
ReplicaSet yang dibuat menjamin bahwa ada tiga Pod nginx.
Catatan:
Kamu harus memasukkan selektor dan label templat Pod yang benar pada Deployment (dalam kasus ini, app: nginx).
Jangan membuat label atau selektor yang beririsan dengan kontroler lain (termasuk Deployment dan StatefulSet lainnya). Kubernetes tidak akan mencegah adanya label yang beririsan.
Namun, jika beberapa kontroler memiliki selektor yang beririsan, kontroler itu mungkin akan konflik dan berjalan dengan tidak semestinya.
Label pod-template-hash
Catatan:
Jangan ubah label ini.
Label pod-template-hash ditambahkan oleh Deployment kontroler pada tiap ReplicaSet yang dibuat atau diadopsi Deployment.
Label ini menjamin anak-anak ReplicaSet milik Deployment tidak tumpang tindih. Dia dibangkitkan dengan melakukan hash pada PodTemplate milik ReplicaSet dan memakainya sebagai label untuk ditambahkan ke selektor ReplicaSet, label templat Pod, dan Pod apapun yang ReplicaSet miliki.
Membarui Deployment
Catatan:
Rilis Deployment hanya dapat dipicu oleh perubahan templat Pod Deployment (yaitu, .spec.template), contohnya perubahan kolom label atau image container. Yang lain, seperti replika, tidak akan memicu rilis.
Ikuti langkah-langkah berikut untuk membarui Deployment:
Ganti Pod nginx menjadi image nginx:1.9.1 dari image nginx:1.7.9.
kubectl --record deployment.apps/nginx-deployment set image deployment.v1.apps/nginx-deployment nginx=nginx:1.9.1
Keluaran akan tampil seperti berikut:
deployment.apps/nginx-deployment image updated
Alternatif lainnya, kamu dapat edit Deployment dan mengganti .spec.template.spec.containers[0].image dari nginx:1.7.9 ke nginx:1.9.1:
kubectl edit deployment.v1.apps/nginx-deployment
Keluaran akan tampil seperti berikut:
deployment.apps/nginx-deployment edited
Untuk melihat status rilis, jalankan:
kubectl rollout status deployment.v1.apps/nginx-deployment
Keluaran akan tampil seperti berikut:
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
atau
deployment "nginx-deployment" successfully rolled out
Untuk menampilkan detail lain dari Deployment yang terbaru:
Setelah rilis sukses, kamu dapat melihat Deployment dengan menjalankan kubectl get deployments.
Keluaran akan tampil seperti berikut:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 3 3 3 36s
Jalankan kubectl get rs to see that the Deployment updated the Pods dengan membuat ReplicaSet baru dan
menggandakannya menjadi 3 replika, sembari menghapus ReplicaSet menjadi 0 replika.
kubectl get rs
Keluaran akan tampil seperti berikut:
NAME DESIRED CURRENT READY AGE
nginx-deployment-1564180365 3 3 3 6s
nginx-deployment-2035384211 0 0 0 36s
Menjalankan get pods sekarang hanya akan menampilkan Pod baru:
kubectl get pods
Keluaran akan tampil seperti berikut:
NAME READY STATUS RESTARTS AGE
nginx-deployment-1564180365-khku8 1/1 Running 0 14s
nginx-deployment-1564180365-nacti 1/1 Running 0 14s
nginx-deployment-1564180365-z9gth 1/1 Running 0 14s
Selanjutnya ketika ingin membarui Pod, kamu hanya perlu mengganti templat Pod Deployment lagi.
Deployment memastikan hanya ada beberapa Pod yang mati saat pembaruan berlangsung. Umumnya,
dia memastikan paling sedikit ada 75% jumlah Pod yang diinginkan menyala (25% maksimal tidak dapat diakses).
Deployment juga memastikan hanya ada beberapa Pod yang dibuat melebihi jumlah Pod yang diinginkan.
Umumnya, dia memastikan paling banyak ada 125% jumlah Pod yang diinginkan menyala (25% tambahan maksimal).
Misalnya, jika kamu lihat Deployment diatas lebih jauh, kamu akan melihat bahwa pertama-tama dia membuat Pod baru,
kemudian menghapus beberapa Pod lama, dan membuat yang baru. Dia tidak akan menghapus Pod lama sampai ada cukup
Pod baru menyala, dan pula tidak membuat Pod baru sampai ada cukup Pod lama telah mati.
Dia memastikan paling sedikit 2 Pod menyala dan paling banyak total 4 Pod menyala.
Melihat detil Deployment:
kubectl describe deployments
Keluaran akan tampil seperti berikut:
Name: nginx-deployment
Namespace: default
CreationTimestamp: Thu, 30 Nov 2017 10:56:25 +0000
Labels: app=nginx
Annotations: deployment.kubernetes.io/revision=2
Selector: app=nginx
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.9.1
Port: 80/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-deployment-1564180365 (3/3 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 2m deployment-controller Scaled up replica set nginx-deployment-2035384211 to 3
Normal ScalingReplicaSet 24s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 1
Normal ScalingReplicaSet 22s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 2
Normal ScalingReplicaSet 22s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 2
Normal ScalingReplicaSet 19s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 1
Normal ScalingReplicaSet 19s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 3
Normal ScalingReplicaSet 14s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 0
Disini bisa dilihat ketika pertama Deployment dibuat, dia membuat ReplicaSet (nginx-deployment-2035384211)
dan langsung menggandakannya menjadi 3 replika. Saat Deployment diperbarui, dia membuat ReplicaSet baru
(nginx-deployment-1564180365) dan menambah 1 replika kemudian mengecilkan ReplicaSet lama menjadi 2,
sehingga paling sedikit 2 Pod menyala dan paling banyak 4 Pod dibuat setiap saat. Dia kemudian lanjut menaik-turunkan
ReplicaSet baru dan ReplicaSet lama, dengan strategi pembaruan rolling yang sama.
Terakhir, kamu akan dapat 3 replika di ReplicaSet baru telah menyala, dan ReplicaSet lama akan hilang (berisi 0).
Perpanjangan (alias banyak pembaruan secara langsung)
Setiap kali Deployment baru is teramati oleh Deployment kontroler, ReplicaSet dibuat untuk membangkitkan Pod sesuai keinginan.
Jika Deployment diperbarui, ReplicaSet yang terkait Pod dengan label .spec.selector yang cocok,
namun kolom .spec.template pada templat tidak cocok akan dihapus. Kemudian, ReplicaSet baru akan
digandakan sebanyak .spec.replicas dan semua ReplicaSet lama dihapus.
Jika kamu mengubah Deployment saat rilis sedang berjalan, Deployment akan membuat ReplicaSet baru
tiap perubahan dan memulai penggandaan. Lalu, dia akan mengganti ReplicaSet yang dibuat sebelumnya
-- mereka ditambahkan ke dalam daftar ReplicaSet lama dan akan mulai dihapus.
Contohnya, ketika kamu membuat Deployment untuk membangkitkan 5 replika nginx:1.7.9,
kemudian membarui Deployment dengan versi nginx:1.9.1 ketika ada 3 replika nginx:1.7.9 yang dibuat.
Dalam kasus ini, Deployment akan segera menghapus 3 replika Pod nginx:1.7.9 yang telah dibuat, dan mulai membuat
Pod nginx:1.9.1. Dia tidak akan menunggu kelima replika nginx:1.7.9 selesai baru menjalankan perubahan.
Mengubah selektor label
Umumnya, sekali dibuat, selektor label tidak boleh diubah. Sehingga disarankan untuk direncanakan dengan hati-hati sebelumnya.
Bagaimanapun, jika kamu perlu mengganti selektor label, lakukan dengan seksama dan pastikan kamu tahu segala konsekuensinya.
Catatan:
Pada versi API apps/v1, selektor label Deployment tidak bisa diubah ketika selesai dibuat.
Penambahan selektor mensyaratkan label templat Pod di spek Deployment untuk diganti dengan label baru juga.
Jika tidak, galat validasi akan muncul. Perubahan haruslah tidak tumpang-tindih, dengan kata lain selektor baru tidak mencakup ReplicaSet dan Pod yang dibuat dengan selektor lama. Sehingga, semua ReplicaSet lama akan menggantung sedangkan ReplicaSet baru tetap dibuat.
Pengubahan selektor mengubah nilai pada kunci selektor -- menghasilkan perilaku yang sama dengan penambahan.
Penghapusan selektor menghilangkan kunci yang ada pada selektor Deployment -- tidak mensyaratkan perubahan apapun pada label templat Pod.
ReplicaSet yang ada tidak menggantung dan ReplicaSet baru tidak dibuat.
Tapi perhatikan bahwa label yang dihapus masih ada pada Pod dan ReplicaSet masing-masing.
Membalikkan Deployment
Kadang, kamu mau membalikkan Deployment; misalnya, saat Deployment tidak stabil, seperti crash looping.
Umumnya, semua riwayat rilis Deployment disimpan oleh sistem sehingga kamu dapat kembali kapanpun kamu mau
(kamu dapat mengubahnya dengan mengubah batas riwayat revisi).
Catatan:
Revisi Deployment dibuat saat rilis Deployment dipicu. Ini berarti revisi baru dibuat jika dan hanya jika
templat Pod Deployment (.spec.template) berubah, misalnya jika kamu membarui label atau image kontainer pada templat.
Pembaruan lain, seperti penggantian skala Deployment, tidak membuat revisi Deployment, jadi kamu dapat memfasilitasi
penggantian skala secara manual atau otomatis secara simultan. Artinya saat kamu membalikkan ke versi sebelumnya,
hanya bagian templat Pod Deployment yang dibalikkan.
Misal kamu membuat saltik saat mengganti Deployment, dengan memberi nama image dengan nginx:1.91 alih-alih nginx:1.9.1:
kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.91 --record=true
Keluaran akan tampil seperti berikut:
deployment.apps/nginx-deployment image updated
Rilis akan tersendat. Kamu dapat memeriksanya dengan melihat status rilis:
kubectl rollout status deployment.v1.apps/nginx-deployment
Keluaran akan tampil seperti berikut:
Waiting for rollout to finish: 1 out of 3 new replicas have been updated...
Tekan Ctrl-C untuk menghentikan pemeriksaan status rilis di atas. Untuk info lebih lanjut
tentang rilis tersendat, baca disini.
Kamu lihat bahwa jumlah replika lama (nginx-deployment-1564180365 dan nginx-deployment-2035384211) adalah 2, dan replika baru (nginx-deployment-3066724191) adalah 1.
kubectl get rs
Keluaran akan tampil seperti berikut:
NAME DESIRED CURRENT READY AGE
nginx-deployment-1564180365 3 3 3 25s
nginx-deployment-2035384211 0 0 0 36s
nginx-deployment-3066724191 1 1 0 6s
Lihat pada Pod yang dibuat. Akan ada 1 Pod dibuat dari ReplicaSet baru tersendat loop(?) ketika penarikan image.
kubectl get pods
Keluaran akan tampil seperti berikut:
NAME READY STATUS RESTARTS AGE
nginx-deployment-1564180365-70iae 1/1 Running 0 25s
nginx-deployment-1564180365-jbqqo 1/1 Running 0 25s
nginx-deployment-1564180365-hysrc 1/1 Running 0 25s
nginx-deployment-3066724191-08mng 0/1 ImagePullBackOff 0 6s
Catatan:
Controller Deployment menghentikan rilis yang buruk secara otomatis dan juga berhenti meningkatkan ReplicaSet baru.
Ini tergantung pada parameter rollingUpdate (secara khusus `maxUnavailable`) yang dimasukkan.
Kubernetes umumnya mengatur jumlahnya menjadi 25%.
Tampilkan deskripsi Deployment:
kubectl describe deployment
Keluaran akan tampil seperti berikut:
Name: nginx-deployment
Namespace: default
CreationTimestamp: Tue, 15 Mar 2016 14:48:04 -0700
Labels: app=nginx
Selector: app=nginx
Replicas: 3 desired | 1 updated | 4 total | 3 available | 1 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.91
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True ReplicaSetUpdated
OldReplicaSets: nginx-deployment-1564180365 (3/3 replicas created)
NewReplicaSet: nginx-deployment-3066724191 (1/1 replicas created)
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
1m 1m 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-2035384211 to 3
22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 1
22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 2
22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 2
21s 21s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 1
21s 21s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 3
13s 13s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 0
13s 13s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-3066724191 to 1
Untuk memperbaikinya, kamu harus kembali ke revisi Deployment yang sebelumnya stabil.
Mengecek Riwayat Rilis Deployment
Ikuti langkah-langkah berikut untuk mengecek riwayat rilis:
Pertama, cek revisi Deployment sekarang:
kubectl rollout history deployment.v1.apps/nginx-deployment
Untuk detil lebih lanjut perintah terkait rilis, baca rilis kubectl.
Deployment sekarang dikembalikan ke revisi stabil sebelumnya. Seperti terlihat, ada event DeploymentRollback
yang dibentuk oleh kontroler Deployment untuk pembalikan ke revisi 2.
Cek apakah rilis telah sukses dan Deployment berjalan seharusnya, jalankan:
kubectl get deployment nginx-deployment
Keluaran akan tampil seperti berikut:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 3 3 3 30m
Tampilkan deskripsi Deployment:
kubectl describe deployment nginx-deployment
Keluaran akan tampil seperti berikut:
Name: nginx-deployment
Namespace: default
CreationTimestamp: Sun, 02 Sep 2018 18:17:55 -0500
Labels: app=nginx
Annotations: deployment.kubernetes.io/revision=4
kubernetes.io/change-cause=kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.9.1 --record=true
Selector: app=nginx
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.9.1
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-deployment-c4747d96c (3/3 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 12m deployment-controller Scaled up replica set nginx-deployment-75675f5897 to 3
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 1
Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 2
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 2
Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 1
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 3
Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 0
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-595696685f to 1
Normal DeploymentRollback 15s deployment-controller Rolled back deployment "nginx-deployment" to revision 2
Normal ScalingReplicaSet 15s deployment-controller Scaled down replica set nginx-deployment-595696685f to 0
Mengatur Skala Deployment
Kamu dapat mengatur skala Deployment dengan perintah berikut:
Dengan asumsi horizontal Pod autoscaling dalam klaster dinyalakan,
kamu dapat mengatur autoscaler untuk Deployment-mu dan memilih jumlah minimal dan maksimal Pod yang mau dijalankan berdasarkan penggunaan CPU
dari Pod.
Deployment RollingUpdate mendukung beberapa versi aplikasi berjalan secara bersamaan. Ketika kamu atau autoscaler
mengubah skala Deployment RollingUpdate yang ada di tengah rilis (yang sedang berjalan maupun terjeda),
kontroler Deployment menyeimbangkan replika tambahan dalam ReplicaSet aktif (ReplicaSet dengan Pod) untuk mencegah resiko.
Ini disebut pengaturan skala proporsional.
Sebagai contoh, kamu menjalankan Deployment dengan 10 replika, maxSurge=3, dan maxUnavailable=2.
Pastikan ada 10 replica di Deployment-mu yang berjalan.
kubectl get deploy
Keluaran akan tampil seperti berikut:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 10 10 10 10 50s
Ganti ke image baru yang kebetulan tidak bisa ditemukan dari dalam klaster.
kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:sometag
Keluaran akan tampil seperti berikut:
deployment.apps/nginx-deployment image updated
Penggantian image akan memulai rilis baru dengan ReplicaSet nginx-deployment-1989198191, namun dicegah karena
persyaratan maxUnavailable yang disebut di atas. Cek status rilis:
kubectl get rs
Keluaran akan tampil seperti berikut:
NAME DESIRED CURRENT READY AGE
nginx-deployment-1989198191 5 5 0 9s
nginx-deployment-618515232 8 8 8 1m
Kemudian, permintaan peningkatan untuk Deployment akan masuk. Autoscaler menambah replika Deployment
menjadi 15. Controller Deployment perlu menentukan dimana 5 replika ini ditambahkan. Jika kamu memakai
pengaturan skala proporsional, kelima replika akan ditambahkan ke ReplicaSet baru. Dengan pengaturan skala proporsional,
kamu menyebarkan replika tambahan ke semua ReplicaSet. Proporsi terbesar ada pada ReplicaSet dengan
replika terbanyak dan proporsi yang lebih kecil untuk replika dengan ReplicaSet yang lebih sedikit.
Sisanya akan diberikan ReplicaSet dengan replika terbanyak. ReplicaSet tanpa replika tidak akan ditingkatkan.
Dalam kasus kita di atas, 3 replika ditambahkan ke ReplicaSet lama dan 2 replika ditambahkan ke ReplicaSet baru.
Proses rilis akan segera memindahkan semua ReplicaSet baru, dengan asumsi semua replika dalam kondisi sehat.
Untuk memastikannya, jalankan:
kubectl get deploy
Keluaran akan tampil seperti berikut:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 15 18 7 8 7m
Status rilis mengkonfirmasi bagaimana replika ditambahkan ke tiap ReplicaSet.
kubectl get rs
Keluaran akan tampil seperti berikut:
NAME DESIRED CURRENT READY AGE
nginx-deployment-1989198191 7 7 0 7m
nginx-deployment-618515232 11 11 11 7m
Menjeda dan Melanjutkan Deployment
Kamu dapat menjeda Deployment sebelum memicu satu atau lebih pembaruan kemudian meneruskannya.
Hal ini memungkinkanmu menerapkan beberapa perbaikan selama selang jeda tanpa melakukan rilis yang tidak perlu.
Sebagai contoh, Deployment yang baru dibuat:
Lihat detil Deployment:
kubectl get deploy
Keluaran akan tampil seperti berikut:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx 3 3 3 3 1m
Lihat status rilis:
kubectl get rs
Keluaran akan tampil seperti berikut:
NAME DESIRED CURRENT READY AGE
nginx-2142116321 3 3 3 1m
The state awal Deployment sebelum jeda akan melanjutkan fungsinya, tapi perubahan
Deployment tidak akan berefek apapun selama Deployment masih terjeda.
Kemudian, mulai kembali Deployment dan perhatikan ReplicaSet baru akan muncul dengan semua perubahan baru:
Deployment menurunkan kapasitas ReplicaSet yang lebih lama.
Pod baru menjadi siap atau dapat diakses (siap selama setidaknya MinReadySeconds).
Kamu dapat mengawasi perkembangan Deployment dengan kubectl rollout status.
Deployment Selesai
Kubernetes menandai Deployment sebagai complete saat memiliki karakteristik berikut:
Semua replika terkait Deployment telah diperbarui ke versi terbaru yang dispecify, artinya semua pembaruan yang kamu inginkan telah selesai.
Semua replika terkait Deployment dapat diakses.
Tidak ada replika lama untuk Deployment yang berjalan.
Kamu dapat mengecek apakah Deployment telah selesai dengan kubectl rollout status.
Jika rilis selesai, kubectl rollout status akan mengembalikan nilai balik nol.
kubectl rollout status deployment.v1.apps/nginx-deployment
Keluaran akan tampil seperti berikut:
Waiting for rollout to finish: 2 of 3 updated replicas are available...
deployment "nginx-deployment" successfully rolled out
$ echo $?
0
Deployment Gagal
Deployment-mu bisa saja terhenti saat mencoba deploy ReplicaSet terbaru tanpa pernah selesai.
Ini dapat terjadi karena faktor berikut:
Kuota tidak mencukupi
Kegagalan pengecekan kesiapan
Galat saat mengunduh image
Tidak memiliki ijin
Limit ranges
Konfigurasi runtime aplikasi yang salah
Salah satu cara untuk mendeteksi kondisi ini adalah untuk menjelaskan parameter tenggat pada spesifikasi Deployment:
(.spec.progressDeadlineSeconds). .spec.progressDeadlineSeconds menyatakan
lama kontroler Deployment menunggu sebelum mengindikasikan (pada status Deployment) bahwa kemajuan Deployment
tersendat dalam detik.
Perintah kubectl berikut menetapkan spek dengan progressDeadlineSeconds untuk membuat kontroler
melaporkan kemajuan Deployment yang sedikit setelah 10 menit:
Kubernetes tidak melakukan apapun pada Deployment yang tersendat selain melaporkannya sebagai Reason=ProgressDeadlineExceeded.
Orkestrator yang lebih tinggi dapat memanfaatkannya untuk melakukan tindak lanjut. Misalnya, mengembalikan Deployment ke versi sebelumnya.
Catatan:
Jika Deployment terjeda, Kubernetes tidak akan mengecek kemajuan pada selang itu.
Kamu dapat menjeda Deployment di tengah rilis dan melanjutkannya dengan aman tanpa memicu kondisi saat tenggat telah lewat.
Kamu dapat mengalami galat sejenak pada Deployment disebabkan timeout yang dipasang terlalu kecil atau
hal-hal lain yang terjadi sementara. Misalnya, kamu punya kuota yang tidak mencukupi. Jika kamu mendeskripsikan Deployment
kamu akan menjumpai pada bagian ini:
kubectl describe deployment nginx-deployment
Keluaran akan tampil seperti berikut:
<...>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True ReplicaSetUpdated
ReplicaFailure True FailedCreate
<...>
Jika kamu menjalankan kubectl get deployment nginx-deployment -o yaml, Deployment status akan muncul seperti berikut:
Begitu tenggat kemajuan Deployment terlewat, Kubernetes membarui status dan alasan untuk kondisi Progressing:
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing False ProgressDeadlineExceeded
ReplicaFailure True FailedCreate
Kamu dapat menangani isu keterbatasan kuota dengan menurunkan jumlah Deployment, bisa dengan menghapus kontrolers
yang sedang berjalan, atau dengan meningkatkan kuota pada namespace. Jika kuota tersedia, kemudian kontroler Deployment
akan dapat menyelesaikan rilis Deployment. Kamu akan melihat bahwa status Deployment berubah menjadi kondisi sukses (Status=True dan Reason=NewReplicaSetAvailable).
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
Type=Available dengan Status=True artinya Deployment-mu punya ketersediaan minimum. Ketersediaan minimum diatur
oleh parameter yang dibuat pada strategi deployment. Type=Progressing dengan Status=True berarti Deployment
sedang dalam rilis dan masih berjalan atau sudah selesai berjalan dan jumlah minimum replika tersedia
(lihat bagian Alasan untuk kondisi tertentu - dalam kasus ini Reason=NewReplicaSetAvailable berarti Deployment telah selesai).
Kamu dapat mengecek apakah Deployment gagal berkembang dengan perintah kubectl rollout status. kubectl rollout status
mengembalikan nilai selain nol jika Deployment telah melewati tenggat kemajuan.
kubectl rollout status deployment.v1.apps/nginx-deployment
Keluaran akan tampil seperti berikut:
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
error: deployment "nginx" exceeded its progress deadline
$ echo $?
1
Menindak Deployment yang gagal
Semua aksi yang dapat diterapkan pada Deployment yang selesai berjalan juga pada Deployment gagal. Kamu dapat menaik/turunkan replika, membalikkan ke versi sebelumnya, atau menjedanya jika kamu perlu menerapkan beberapa perbaikan pada templat Pod Deployment.
Kebijakan Pembersihan
Kamu dapat mengisi kolom .spec.revisionHistoryLimit di Deployment untuk menentukan banyak ReplicaSet
pada Deployment yang ingin dipertahankan. Sisanya akan di garbage-collected di balik layar. Umumnya, nilai kolom berisi 10.
Catatan:
Mengisi secara eksplisit dengan nilai 0 akan membuat pembersihan semua riwayat rilis Deployment
sehingga Deployment tidak akan dapat dikembalikan.
Deployment Canary
Jika kamu ingin merilis ke sebagian pengguna atau server menggunakan Deployment,
kamu dapat membuat beberapa Deployment, satu tiap rilis, dengan mengikuti pola canary yang didesripsikan pada
mengelola sumber daya.
Menulis Spesifikasi Deployment
Sebagaimana konfigurasi Kubernetes lainnya, Deployment memerlukan kolom apiVersion, kind, dan metadata.
Untuk informasi umum tentang penggunaan berkas konfigurasi, lihat dokumen deploy aplikasi,
mengatur kontainer, dan memakai kubectl untuk mengatur sumber daya.
Dalam .spec hanya ada kolom .spec.template dan .spec.selector yang wajib diisi.
.spec.template adalah templat Pod. Dia memiliki skema yang sama dengan Pod. Bedanya dia bersarang dan tidak punya apiVersion atau kind.
Selain kolom wajib untuk Pod, templat Pod pada Deployment harus menentukan label dan aturan menjalankan ulang yang tepat.
Untuk label, pastikaan tidak bertumpang tindih dengan kontroler lainnya. Lihat selektor).
.spec.replicas adalah kolom opsional yang mengatur jumlah Pod yang diinginkan. Setelan bawaannya berisi 1.
Selektor
.spec.selector adalah kolom wajib yang mengatur selektor label
untuk Pod yang dituju oleh Deployment ini.
.spec.selector harus sesuai .spec.template.metadata.labels, atau akan ditolak oleh API.
Di versi API apps/v1, .spec.selector dan .metadata.labels tidak berisi .spec.template.metadata.labels jika tidak disetel.
Jadi mereka harus disetel secara eksplisit. Perhatikan juga .spec.selector tidak dapat diubah setelah Deployment dibuat pada apps/v1.
Deployment dapat mematikan Pod yang labelnya cocok dengan selektor jika templatnya berbeda
dari .spec.template atau total jumlah Pod melebihi .spec.replicas. Dia akan membuat Pod baru
dengan .spec.template jika jumlah Pod kurang dari yang diinginkan.
Catatan:
Kamu sebaiknya tidak membuat Pod lain yang labelnya cocok dengan selektor ini, baik secara langsung,
melalui Deployment lain, atau membuat kontroler lain seperti ReplicaSet atau ReplicationController.
Kalau kamu melakukannya, Deployment pertama akan mengira dia yang membuat Pod-pod ini.
Kubernetes tidak akan mencegahmu melakukannya.
Jika kamu punya beberapa kontroler dengan selektor bertindihan, mereka akan saling bertikai
dan tidak akan berjalan semestinya.
Strategi
.spec.strategy mengatur strategi yang dipakai untuk mengganti Pod lama dengan yang baru.
.spec.strategy.type dapat berisi "Recreate" atau "RollingUpdate". Nilai bawaannya adalah "RollingUpdate".
Membuat Ulang Deployment
Semua Pod yang ada dimatikan sebelum yang baru dibuat ketika nilai .spec.strategy.type==Recreate.
Membarui Deployment secara Bergulir
Deployment membarui Pod secara bergulir
saat .spec.strategy.type==RollingUpdate. Kamu dapat menentukan maxUnavailable dan maxSurge untuk mengatur
proses pembaruan bergulir.
Ketidaktersediaan Maksimum
.spec.strategy.rollingUpdate.maxUnavailable adalah kolom opsional yang mengatur jumlah Pod maksimal
yang tidak tersedia selama proses pembaruan. Nilainya bisa berupa angka mutlak (contohnya 5)
atau persentase dari Pod yang diinginkan (contohnya 10%). Angka mutlak dihitung berdasarkan persentase
dengan pembulatan ke bawah. Nilai tidak bisa nol jika .spec.strategy.rollingUpdate.maxSurge juga nol.
Nilai bawaannya yaitu 25%.
Sebagai contoh, ketika nilai berisi 30%, ReplicaSet lama dapat segera diperkecil menjadi 70% dari Pod
yang diinginkan saat pembaruan bergulir dimulai. Seketika Pod baru siap, ReplicaSet lama dapat lebih diperkecil lagi,
diikuti dengan pembesaran ReplicaSet, menjamin total jumlah Pod yang siap kapanpun ketika pembaruan
paling sedikit 70% dari Pod yang diinginkan.
Kelebihan Maksimum
.spec.strategy.rollingUpdate.maxSurge adalah kolom opsional yang mengatur jumlah Pod maksimal yang
dapat dibuat melebihi jumlah Pod yang diinginkan. Nilainya bisa berupa angka mutlak (contohnya 5) atau persentase
dari Pod yang diinginkan (contohnya 10%). Nilai tidak bisa nol jika MaxUnavailable juga nol. Angka mutlak
dihitung berdasarkan persentase dengan pembulatan ke bawah. Nilai bawaannya yaitu 25%.
Sebagai contoh, ketika nilai berisi 30%, ReplicaSet baru dapat segera diperbesar saat pembaruan bergulir dimulai,
sehingga total jumlah Pod yang baru dan lama tidak melebihi 130% dari Pod yang diinginkan.
Saat Pod lama dimatikan, ReplicaSet baru dapat lebih diperbesar lagi, menjamin total jumlah Pod yang siap
kapanpun ketika pembaruan paling banyak 130% dari Pod yang diinginkan.
Tenggat Kemajuan dalam Detik
.spec.progressDeadlineSeconds adalah kolom opsional yang mengatur lama tunggu dalam dalam detik untuk Deployment-mu berjalan
sebelum sistem melaporkan lagi bahwa Deployment gagal - ditunjukkan dengan kondisi Type=Progressing, Status=False,
dan Reason=ProgressDeadlineExceeded pada status sumber daya. Controller Deployment akan tetap mencoba ulang Deployment.
Nantinya begitu pengembalian otomatis diimplementasikan, kontroler Deployment akan membalikkan Deployment segera
saat dia menjumpai kondisi tersebut.
Jika ditentukan, kolom ini harus lebih besar dari .spec.minReadySeconds.
Lama Minimum untuk Siap dalam Detik
.spec.minReadySeconds adalah kolom opsional yang mengatur lama minimal sebuah Pod yang baru dibuat
seharusnya siap tanpa ada kontainer yang rusak, untuk dianggap tersedia, dalam detik.
Nilai bawaannya yaitu 0 (Pod akan dianggap tersedia segera ketika siap). Untuk mempelajari lebih lanjut
kapan Pod dianggap siap, lihat Pemeriksaan Kontainer.
Kembali Ke
Kolom .spec.rollbackTo telah ditinggalkan pada versi API extensions/v1beta1 dan apps/v1beta1, dan sudah tidak didukung mulai versi API apps/v1beta2.
Sebagai gantinya, disarankan untuk menggunakan kubectl rollout undo sebagaimana diperkenalkan dalam Kembali ke Revisi Sebelumnya.
Batas Riwayat Revisi
Riwayat revisi Deployment disimpan dalam ReplicaSet yang dia kendalikan.
.spec.revisionHistoryLimit adalah kolom opsional yang mengatur jumlah ReplicaSet lama yang dipertahankan
untuk memungkinkan pengembalian. ReplicaSet lama ini mengambil sumber daya dari etcd dan memunculkan keluaran
dari kubectl get rs. Konfigurasi tiap revisi Deployment disimpan pada ReplicaSet-nya; sehingga, begitu ReplicaSet lama dihapus,
kamu tidak mampu lagi membalikkan revisi Deployment-nya. Umumnya, 10 ReplicaSet lama akan dipertahankan,
namun nilai idealnya tergantung pada frekuensi dan stabilitas Deployment-deployment baru.
Lebih spesifik, mengisi kolom dengan nol berarti semua ReplicaSet lama dengan 0 replika akan dibersihkan.
Dalam kasus ini, rilis Deployment baru tidak dapat dibalikkan, sebab riwayat revisinya telah dibersihkan.
Terjeda
.spec.paused adalah kolom boolean opsional untuk menjeda dan melanjutkan Deployment. Perbedaan antara Deployment yang terjeda
dan yang tidak hanyalah perubahan apapun pada PodTemplateSpec Deployment terjeda tidak akan memicu rilis baru selama masih terjeda.
Deployment umumnya tidak terjeda saat dibuat.
Alternatif untuk Deployment
kubectl rolling update
kubectl rolling update membarui Pod dan ReplicationController
dengan cara yang serupa. Namun, Deployments lebih disarankan karena deklaratif, berjalan di sisi server, dan punya fitur tambahan,
seperti pembalikkan ke revisi manapun sebelumnya bahkan setelah pembaruan rolling selesais.
4.2.4 - StatefulSet
StatefulSet merupakan salah satu objek API workload yang digunakan untuk aplikasi stateful.
Catatan:
StatefulSet merupakan fitur stabil (GA) sejak versi 1.9.
Melakukan proses manajemen deployment dan scaling dari sebuah set Pods, serta menjamin mekanisme ordering dan keunikan dari Pod ini.
Seperti halnya Deployment, sebuah StatefulSet akan melakukan proses manajemen Pod yang didasarkan pada spec container identik. Meskipun begitu tidak seperti sebuah Deployment, sebuah StatefulSet akan menjamin identitas setiap Pod yang ada. Pod ini akan dibuat berdasarkan spec yang sama, tetapi tidak dapat digantikan satu sama lainnya: setiap Pod memiliki identifier persisten yang akan di-maintain meskipun pod tersebut di (re)schedule.
Sebuah StatefulSet beroperasi dengan pola yang sama dengan Kontroler lainnya. Kamu dapat mendefinisikan state yang diinginkan pada objek StatefulSet, dan kontroler StatefulSet akan membuat update yang dibutuhkan dari state saat ini.
Menggunakan StatefulSet
StatefulSet akan sangat bermanfaat apabila digunakan untuk aplikasi
yang membutuhkan salah satu atau beberapa fungsi berikut.
Memiliki identitas jaringan unik yang stabil.
Penyimpanan persisten yang stabil.
Mekanisme scaling dan deployment yang graceful tertara berdasarkan urutan.
Mekanisme rolling update yang otomatis berdasarkan urutan.
Stabil dalam poin-poin di atas memiliki arti yang sama dengan persisten pada
Pod saat dilakukan (re)scheduling. Jika suatu aplikasi tidak membutuhkan
identitas yang stabil atau deployment yang memiliki urutan, penghapusan, atau
mekanisme scaling, kamu harus melakukan deploy aplikasi dengan controller yang menyediakan
replika stateless. Controller seperti Deployment atau
ReplicaSet akan lebih sesuai dengan kebutuhan kamu.
Keterbatasan
StatefulSet merupakan sumber daya beta sebelum 1.9 dan tidak tersedia
pada Kubernetes rilis sebelum versi 1.5.
Penyimpanan untuk sebuah Pod harus terlebih dahulu di-provision dengan menggunakan sebuah Provisioner PersistentVolume berdasarkan storage class yang dispesifikasikan, atau sudah ditentukan sebelumnya oleh administrator.
Menghapus dan/atau scaling sebuah StatefulSet tidak akan menghapus volume yang berkaitan dengan StatefulSet tersebut. Hal ini dilakukan untuk menjamin data yang disimpan, yang secara umum dinilai lebih berhaga dibandingkan dengan mekanisme penghapusan data secara otomatis pada sumber daya terkait.
StatefulSet saat ini membutuhkan sebuah Headless Service yang nantinya akan bertanggung jawab terhadap pada identitas jaringan pada Pod. Kamulah yang bertanggung jawab untuk membuat Service tersebut.
StatefulSet tidak menjamin terminasi Pod ketika sebuah StatefulSet dihapus. Untuk mendapatkan terminasi Pod yang terurut dan graceful pada StatefulSet, kita dapat melakukan scale down Pod ke 0 sebelum penghapusan.
Contoh di bawah ini akna menunjukkan komponen-komponen penyusun StatefulSet.
Sebuah Service Headless, dengan nama nginx, digunakan untuk mengontrol domain jaringan.
StatefulSet, dengan nama web, memiliki Spek yang mengindikasikan terdapat 3 replika Container yang akan dihidupkan pada Pod yang unik.
FieldvolumeClaimTemplates akan menyediakan penyimpanan stabil menggunakan PersistentVolume yang di-provision oleh sebuah Provisioner PersistentVolume.
apiVersion:v1kind:Servicemetadata:name:nginxlabels:app:nginxspec:ports:- port:80name:webclusterIP:Noneselector:app:nginx---apiVersion:apps/v1kind:StatefulSetmetadata:name:webspec:selector:matchLabels:app:nginx# harus sesuai dengan .spec.template.metadata.labelsserviceName:"nginx"replicas:3# nilai default-nya adalah 1template:metadata:labels:app:nginx# harus sesuai dengan .spec.selector.matchLabelsspec:terminationGracePeriodSeconds:10containers:- name:nginximage:registry.k8s.io/nginx-slim:0.8ports:- containerPort:80name:webvolumeMounts:- name:wwwmountPath:/usr/share/nginx/htmlvolumeClaimTemplates:- metadata:name:wwwspec:accessModes:["ReadWriteOnce"]storageClassName:"my-storage-class"resources:requests:storage:1Gi
Selector Pod
Kamu harus menspesifikasikan field.spec.selector dari sebuah StatefulSet untuk menyesuaikan dengan label yang ada pada .spec.template.metadata.labels. Sebelum Kubernetes 1.8, field.spec.selector dapat diabaikan. Sejak versi 1.8 dan versi selanjutnya, apabila tidak terdapat selector Pod yang sesuai maka akan menghasilkan eror pada validasi pembuatan StatefulSet.
Identitas Pod
Pod pada StatefulSet memiliki identitas unik yang tersusun berdasarkan skala ordinal, sebuah
identitas jaringan yang stabil, serta penyimpanan yang stabil. Identitas yang ada pada Pod
ini akan tetap melekat, meskipun Pod tersebut dilakukan (re)schedule pada Node yang berbeda.
Indeks Ordinal
Untuk sebuah StatefulSet dengan N buah replika, setiap Pod di dalam StatefulSet akan
diberi nama pada suatu indeks ordinal tertentu, dari 0 hingga N-1, yang unik pada Set ini.
ID Jaringan yang Stabil
Setiap Pod di dalam StatefulSet memiliki hostname diturunkan dari nama SatetulSet tersebut
serta ordinal Pod tersebut. Pola pada hostname yang terbentuk adalah
$(statefulset name)-$(ordinal). Contoh di atas akan menghasilkan tiga Pod
dengan nama web-0,web-1,web-2.
Sebuah StatefulSet dapat menggunakan sebuah Service Headless
untuk mengontrol domain dari Pod yang ada. Domain yang diatur oleh Service ini memiliki format:
$(service name).$(namespace).svc.cluster.local, dimana "cluster.local" merupakan
domain klaster.
Seiring dibuatnya setiap Pod, Pod tersebut akan memiliki subdomain DNS-nya sendiri, yang memiliki format:
$(podname).$(governing service domain), dimana Service yang mengatur didefinisikan oleh
fieldserviceName pada StatefulSet.
Seperti sudah disebutkan di dalam bagian keterbatasan, kamulah yang bertanggung jawab
untuk membuat Service Headless
yang bertanggung jawab terhadap identitas jaringan pada Pod.
Di sini terdapat beberapa contoh penggunaan Domain Klaster, nama Service,
nama StatefulSet, dan bagaimana hal tersebut berdampak pada nama DNS dari Pod StatefulSet.
Kubernetes membuat sebuah PersistentVolume untuk setiap
VolumeClaimTemplate. Pada contoh nginx di atas, setiap Pod akan menerima sebuah PersistentVolume
dengan StorageClass my-storage-class dan penyimpanan senilai 1 GiB yang sudah di-provisioning. Jika tidak ada StorageClass
yang dispesifikasikan, maka StorageClass default akan digunakan. Ketika sebuah Pod dilakukan (re)schedule
pada sebuah Node, volumeMounts akan me-mount PersistentVolumes yang terkait dengan
PersistentVolume Claim-nya. Perhatikan bahwa, PersistentVolume yang terkait dengan
PersistentVolumeClaim dari Pod tidak akan dihapus ketika Pod, atau StatefulSet dihapus.
Penghapusan ini harus dilakukan secara manual.
Label Pod Name
Ketika sebuah controller StatefulSet membuat sebuah Pod, controller ini akan menambahkan label, statefulset.kubernetes.io/pod-name,
yang akan diaktifkan pada nama Pod. Label ini akan mengizinkan kamu untuk meng-attach sebuah Service pada Pod spesifik tertentu.
di StatefulSet.
Jaminan Deployment dan Mekanisme Scaling
Untuk sebuah StatefulSet dengan N buah replika, ketika Pod di-deploy, Pod tersebut akan dibuat secara berurutan dengan urutan nilai {0..N-1}.
Ketika Pod dihapus, Pod tersebut akan dihentikan dengan urutan terbalik, yaitu {N-1..0}.
Sebelum operasi scaling diaplikasikan pada sebuah Pod, semua Pod sebelum Pod tersebut haruslah sudah dalam status Running dan Ready.
Sebelum sebuah Pod dihentikan, semua Pod setelah Pod tersebut haruslah sudah terlebih dahulu dihentikan.
StatefulSet tidak boleh menspesifikasikan nilai dari pod.Spec.TerminationGracePeriodSeconds menjadi 0. Hal ini tidaklah aman dan tidak disarankan. Untuk penjelasan lebih lanjut, silakan lihat penghapusan paksa Pod pada StatefulSet.
Ketika contoh nginx di atas dibuat, tiga Pod akan di-deploy dengan urutan
web-0, web-1, web-2. web-1 tidak akan di-deploy sebelum web-0 berada dalam status
Running dan Ready, dan web-2 tidak akan di-deploy sebelum
web-1 berada dalam status Running dan Ready. Jika web-0 gagal, setelah web-1 berada dalam status Running and Ready,
tapi sebelum web-2 dibuat, maka web-2 tidak akan dibuat hingga web-0 sukses dibuat ulang dan
berada dalam status Running dan Ready.
Jika seorang pengguna akan melakukan mekanisme scale pada contoh di atas dengan cara melakukan patch,
pada StatefulSet sehingga replicas=1, maka web-2 akan dihentikan terlebih dahulu.
web-1 tidak akan dihentikan hingga web-2 benar-benar berhenti dan dihapus.
Jika web-0 gagal setelah web-2 diterminasi dan berada dalam status mati,
tetapi sebelum web-1 dihentikan, maka web-1 tidak akan dihentikan hingga
web-0 berada dalam status Running dan Ready.
Kebijakan Manajemen Pod
Pada Kubernetes versi 1.7 dan setelahnya, StatefulSet mengizinkan kamu untuk
melakukan mekanisme urutan tadi menjadi lebih fleksibel dengan tetap
menjamin keunikan dan identitas yang ada melalui field.spec.podManagementPolicy.
Manajemen OrderedReady pada Pod
Manajemen OrderedReady pada Pod merupakan nilai default dari StatefulSet.
Hal ini akan mengimplementasikan perilaku yang dijelaskan di atas.
Manajemen Pod secara Paralel
Manajemen Pod secara paralel akan menyebabkan kontroler StatefulSet untuk
memulai atau menghentikan semua Pod yang ada secara paralel, dan tidak
menunggu Pod berada dalam status Running dan Ready atau sudah dihentikan secara menyeluruh
sebelum me-launch atau menghentikan Pod yang lain. Opsi ini hanya akan memengaruhi operasi
scaling. Operasi pembaruan tidak akan terpengaruh.
Strategi Update
Pada Kubernetes versi 1.7 dan setelahnya, field.spec.updateStrategy pada StatefulSet
memungkinkan-mu untuk melakukan konfigurasi dan menonaktifkan otomatisasi
rolling updates untuk container, label, resource request/limits, dan
annotation pada Pod yang ada di dalam sebuah StatefulSet.
Mekanisme Strategi Update On Delete
Mekanisme strategi update OnDelete mengimplementasikan perilaku legasi (versi 1.6 dan sebelumnya).
Ketika sebuah field.spec.updateStrategy.type pada StatefulSet diubah menjadi OnDelete
maka kontroler StatefulSet tidak akan secara otomatis melakukan update
pada Pod yang ada di dalam StatefulSet tersebut. Pengguna haruslah secara manual
melakukan penghapusan Pod agar kontroler membuat Pod baru yang mengandung modifikasi
yang dibuat pada field.spec.template StatefulSet.
Mekanisme Strategi Update Rolling Updates
Mekanisme strategi update RollingUpdate mengimplementasikan otomatisasi rolling update
untuk Pod yang ada pada StatefulSet. Strategi inilah yang diterapkan ketika .spec.updateStrategy tidak dispesifikasikan.
Ketika field.spec.updateStrategy.type diubah nilainya menjadi RollingUpdate, maka
kontroler StatefulSet akan menghapus dan membuat setiap Pod di dalam StatefulSet. Kemudian
hal ini akan diterapkan dengan urutan yang sama dengan mekanisme terminasi Pod (dari nilai ordinal terbesar ke terkecil),
yang kemudian akan melakukan update Pod satu per satu. Mekanisme ini akan memastikan sebuah Pod yang di-update
berada dalam status Running dan Ready sebelum meng-update Pod dengan nilai ordinal lebih rendah.
Mekanisme Strategi Update dengan Partisi
Mekanisme strategi update RollingUpdate dapat dipartisi, dengan cara menspesifikasikan nilai
dari .spec.updateStrategy.rollingUpdate.partition. Jika nilai dari field ini dispesifikasikan,
maka semua Pod dengan nilai ordinal yang lebih besar atau sama dengan nilai partisi akan diupdate ketika
nilai .spec.template pada StatefulSet diubah. Semua Pod dengan nilai ordinal yang lebih kecil
dari partisi tidak akan diupdate, dan, bahkan setelah Pod tersebut dihapus, Pod ini akan digantikan
dengan Pod versi sebelumnya. Jika nilai .spec.updateStrategy.rollingUpdate.partition lebih besar dari
nilai .spec.replicas, update pada .spec.template tidak akan dipropagasi pada Pod-Pod-nya.
Pada sebagian besar kasus, kamu tidak akan perlu menggunakan partisi, tapi hal tersebut
akan sangat berguna apabila kamu ingin mekakukan mekanisme update canary.
Mekanisme Strategi Update yang Dipaksa (Forced Rollback)
Ketika menggunakan strategi update Rolling Updates dengan nilai default
Kebijakan Manajemen Pod (OrderedReady),
hal ini memungkinkan adanya kondisi broken yang membutuhkan intervensi secara manual
agar kondisi ini dapat diperbaiki.
Jika kamu melakukan update pada template Pod untuk konfigurasi
yang tidak pernah berada dalam status Running dan Ready (sebagai contohnya, apabila terdapat kode binary yang buruk atau error pada konfigurasi di level aplikasi),
maka StatefulSet akan menghentikan proses rollout dan berada dalam status wait.
Dalam kondisi ini, maka templat Pod tidak akan diubah secara otomatis pada konfigurasi sebelumnya
Hal ini terjadi karena adanya isu,
StatefulSet akan tetap berada dalam kondisi wait untuk menunggu Pod yang bermasalah untuk menjadi Ready
(yang tidak akan terjadi) dan sebelum StatefulSet ini berusaha untuk melakukan revert pada konfigurasi sebelumnya.
Setelah melakukan mekanisme revert templat, kamu juga harus menghapus semua Pod di dalam
StatefulSet tersebut yang telah berusaha untuk menggunakan konfigurasi yang broken.
StatefulSet akan mulai membuat Pod dengan templat konfigurasi yang sudah di-revert.
DaemonSet memastikan semua atau sebagian Node memiliki salinan sebuah Pod.
Ketika Node baru ditambahkan ke klaster, Pod ditambahkan ke Node tersebut.
Ketika Node dihapus dari klaster, Pod akan dibersihkan oleh garbage collector.
Menghapus DaemonSet akan menghapus semua Pod yang ia buat.
Beberapa penggunaan umum DaemonSet, yaitu:
menjalankan daemon penyimpanan di klaster, seperti glusterd, ceph, di
setiap Node.
menjalankan daemon pengumpulan log di semua Node, seperti fluentd atau
logstash.
Dalam kasus sederhana, satu DaemonSet, mencakup semua Node, akan digunakan untuk
setiap jenis daemon. Pengaturan yang lebih rumit bisa saja menggunakan lebih
dari satu DaemonSet untuk satu jenis daemon, tapi dengan flag dan/atau
permintaan cpu/memori yang berbeda untuk jenis hardware yang berbeda.
Menulis Spek DaemonSet
Buat DaemonSet
Kamu bisa definisikan DaemonSet dalam berkas YAML. Contohnya, berkas
daemonset.yaml di bawah mendefinisikan DaemonSet yang menjalankan image Docker
fluentd-elasticsearch:
.spec.template adalah salah satu field wajib di dalam .spec.
.spec.template adalah sebuah templat Pod. Skemanya benar-benar sama dengan Pod, kecuali bagian bahwa ia bersarang/nested dan tidak memiliki apiVersion atau kind.
Selain field wajib untuk Pod, templat Pod di DaemonSet harus
menspesifikasikan label yang sesuai (lihat selektor Pod).
Templat Pod di DaemonSet harus memiliki RestartPolicy
yang bernilai Always, atau tidak dispesifikasikan, sehingga default menjadi Always.
DaemonSet dengan nilai Always membuat Pod akan selalu di-restart saat kontainer
keluar/berhenti atau terjadi crash.
Selektor Pod
Field.spec.selector adalah selektor Pod. Cara kerjanya sama dengan .spec.selector pada Job.
Pada Kubernetes 1.8, kamu harus menspesifikasikan selektor Pod yang cocok dengan label pada .spec.template.
Selektor Pod tidak akan lagi diberi nilai default ketika dibiarkan kosong. Nilai default selektor tidak
cocok dengan kubectl apply. Juga, sesudah DaemonSet dibuat, .spec.selector tidak dapat diubah.
Mengubah selektor Pod dapat menyebabkan Pod orphan yang tidak disengaja, dan membingungkan pengguna.
matchExpressions - bisa digunakan untuk membuat selektor yang lebih canggih
dengan mendefinisikan key, daftar value dan operator yang menyatakan
hubungan antara key dan value.
Ketika keduanya dispesifikasikan hasilnya diperoleh dari operasi AND.
Jika .spec.selector dispesifikasikan, nilainya harus cocok dengan .spec.template.metadata.labels. Konfigurasi yang tidak cocok akan ditolak oleh API.
Selain itu kamu tidak seharusnya membuat Pod apapun yang labelnya cocok dengan
selektor tersebut, entah secara langsung, via DaemonSet lain, atau via workload resource lain seperti ReplicaSet.
Jika kamu coba buat, Pengontrol DaemonSet akan
berpikir bahwa Pod tersebut dibuat olehnya. Kubernetes tidak akan menghentikan
kamu melakukannya. Contoh kasus di mana kamu mungkin melakukan ini dengan
membuat Pod dengan nilai yang berbeda di sebuah Node untuk testing.
Menjalankan Pod di Sebagian Node
Jika kamu menspesifikasikan .spec.template.spec.nodeSelector, maka controller DaemonSet akan
membuat Pod pada Node yang cocok dengan selektor
Node. Demikian juga, jika kamu menspesifikasikan .spec.template.spec.affinity,
maka controller DaemonSet akan membuat Pod pada Node yang cocok dengan Node affinity.
Jika kamu tidak menspesifikasikan sama sekali, maka controller DaemonSet akan
membuat Pod pada semua Node.
Bagaimana Pod Daemon Dijadwalkan
Dijadwalkan oleh default scheduler
FEATURE STATE:Kubernetes 1.17 [stable]
DaemonSet memastikan bahwa semua Node yang memenuhi syarat menjalankan salinan
Pod. Normalnya, Node yang menjalankan Pod dipilih oleh scheduler Kubernetes.
Namun, Pod DaemonSet dibuat dan dijadwalkan oleh controller DaemonSet. Hal ini
mendatangkan masalah-masalah berikut:
Inkonsistensi perilaku Pod: Pod normal yang menunggu dijadwalkan akan dibuat
dalam keadaan Pending, tapi Pod DaemonSet tidak seperti itu. Ini
membingungkan untuk pengguna.
Pod preemption
ditangani oleh default scheduler. Ketika preemption dinyalakan,
controller DaemonSet akan membuat keputusan penjadwalan tanpa
memperhitungkan prioritas Pod dan preemption.
ScheduleDaemonSetPods mengizinkan kamu untuk menjadwalkan DaemonSet
menggunakan default scheduler daripada controller DaemonSet, dengan
menambahkan syarat NodeAffinity pada Pod DaemonSet daripada syarat
.spec.nodeName. Kemudian, default scheduler digunakan untuk mengikat Pod ke
host target. Jika afinitas Node dari Pod DaemonSet sudah ada, maka ini
akan diganti. Controller DaemonSet hanya akan melakukan operasi-operasi ini
ketika membuat atau mengubah Pod DaemonSet, dan tidak ada perubahan yang terjadi
pada spec.template DaemonSet.
Sebagai tambahan, tolerationnode.kubernetes.io/unschedulable:NoSchedule
ditambahkan secara otomatis pada Pod DaemonSet. Default scheduler akan
mengabaikan Node unschedulable ketika menjadwalkan Pod DaemonSet.
Taint dan Toleration
Meskipun Pod Daemon menghormati
taint dan toleration,
toleration berikut ini akan otomatis ditambahkan ke Pod DaemonSet sesuai
dengan fitur yang bersangkutan.
Toleration Key
Effect
Versi
Deskripsi
node.kubernetes.io/not-ready
NoExecute
1.13+
Pod DaemonSet tidak akan menjadi evicted ketika ada masalah Node seperti partisi jaringan.
node.kubernetes.io/unreachable
NoExecute
1.13+
Pod DaemonSet tidak akan menjadi evicted ketika ada masalah Node seperti partisi jaringan.
node.kubernetes.io/disk-pressure
NoSchedule
1.8+
node.kubernetes.io/memory-pressure
NoSchedule
1.8+
node.kubernetes.io/unschedulable
NoSchedule
1.12+
Pod DaemonSet mentoleransi atribut unschedulabledefault scheduler.
node.kubernetes.io/network-unavailable
NoSchedule
1.12+
Pod DaemonSet yang menggunakan jaringan host mentoleransi atribut network-unavailabledefault scheduler.
Berkomunikasi dengan Pod Daemon
Beberapa pola yang mungkin digunakan untuk berkomunikasi dengan Pod dalam DaemonSet, yaitu:
Push: Pod dalam DaemonSet diatur untuk mengirim pembaruan status ke servis lain,
contohnya stats database. Pod ini tidak memiliki klien.
IP Node dan Konvensi Port: Pod dalam DaemonSet dapat menggunakan hostPort, sehingga Pod dapat diakses menggunakan IP Node. Klien tahu daftar IP Node dengan suatu cara, dan tahu port berdasarkan konvensi.
DNS: Buat headless service dengan Pod selektor yang sama,
dan temukan DaemonSet menggunakan resourceendpoints atau mengambil beberapa A record dari DNS.
Service: Buat Servis dengan Pod selektor yang sama, dan gunakan Servis untuk mengakses daemon pada
Node random. (Tidak ada cara mengakses spesifik Node)
Melakukan Pembaruan DaemonSet
Jika label Node berubah, DaemonSet akan menambahkan Pod ke Node cocok yang baru dan menghapus Pod dari
Node tidak cocok yang baru.
Kamu bisa mengubah Pod yang dibuat DaemonSet. Namun, Pod tidak membolehkan perubahan semua field.
Perlu diingat, controller DaemonSet akan menggunakan templat yang asli di waktu selanjutnya
Node baru (bahkan dengan nama yang sama) dibuat.
Kamu bisa menghapus DaemonSet. Jika kamu spesifikasikan --cascade=false dengan kubectl, maka
Pod akan dibiarkan pada Node. Jika kamu pada waktu kemudian membuat DaemonSet baru dengan selektor
yang sama, DaemonSet yang baru akan mengadopsi Pod yang sudah ada. Jika ada Pod yang perlu diganti,
DaemonSet akan mengganti sesuai dengan updateStrategy.
Kamu mungkin menjalankan proses daemon dengan cara menjalankan mereka langsung pada Node (e.g.
menggunakan init, upstartd, atau systemd). Tidak ada salahnya seperti itu. Namun, ada beberapa
keuntungan menjalankan proses daemon via DaemonSet.
Kemampuan memantau dan mengatur log daemon dengan cara yang sama dengan aplikasi.
Bahasa dan alat Konfigurasi yang sama (e.g. Templat Pod, kubectl) untuk daemon dan aplikasi.
Menjalankan daemon dalam kontainer dengan batasan resource meningkatkan isolasi antar daemon dari
kontainer aplikasi. Namun, hal ini juga bisa didapat dengan menjalankan daemon dalam kontainer tapi
tanpa Pod (e.g. dijalankan langsung via Docker).
Pod Polosan
Dimungkinkan untuk membuat Pod langsung dengan menspesifikasikan Node mana untuk dijalankan. Namun,
DaemonSet akan menggantikan Pod yang untuk suatu alasan dihapus atau dihentikan, seperti pada saat
kerusakan Node atau pemeliharaan Node yang mengganggu seperti pembaruan kernel. Oleh karena itu, kamu
perlu menggunakan DaemonSet daripada membuat Pod satu per satu.
Pod Statis
Dimungkinkan untuk membuat Pod dengan menulis sebuah berkas ke direktori tertentu yang di-watch oleh Kubelet.
Pod ini disebut dengan istilah Pod statis.
Berbeda dengan DaemonSet, Pod statis tidak dapat dikelola menggunakan kubectl atau klien API Kubernetes
yang lain. Pod statis tidak bergantung kepada apiserver, membuat Pod statis berguna pada kasus-kasus
bootstrapping klaster.
Deployment
DaemonSet mirip dengan Deployment sebab mereka
sama-sama membuat Pod, dan Pod yang mereka buat punya proses yang seharusnya tidak berhenti (e.g. peladen web,
peladen penyimpanan)
Gunakan Deployment untuk layanan stateless, seperti frontend, di mana proses scaling naik
dan turun jumlah replika dan rolling update lebih penting daripada mengatur secara tepat di
host mana Pod berjalan. Gunakan DaemonSet ketika penting untuk satu salinan Pod
selalu berjalan di semua atau sebagian host, dan ketika Pod perlu berjalan
sebelum Pod lainnya.
4.2.6 - Garbage Collection
Peran daripada garbage collector Kubernetes adalah untuk menghapus objek tertentu yang sebelumnya mempunyai pemilik, tetapi tidak lagi mempunyai pemilik.
Pemilik dan dependen
Beberapa objek Kubernetes adalah pemilik dari objek lainnya. Sebagai contoh, sebuah ReplicaSet adalah pemilik dari sekumpulan Pod. Objek-objek yang dimiliki disebut dependen dari objek pemilik. Setiap objek dependen memiliki sebuah kolom metadata.ownerReferences yang menunjuk ke objek pemilik.
Terkadang, Kubernetes menentukan nilai dari ownerReference secara otomatis. Sebagai contoh, ketika kamu membuat sebuah ReplicaSet, Kubernetes secara otomatis akan menentukan tiap kolom ownerReference dari tiap Pod di dalam ReplicaSet. Pada versi 1.8, Kubernetes secara otomatis menentukan nilai dari ownerReference untuk objek yang diciptakan atau diadopsi oleh ReplicationController, ReplicaSet, StatefulSet, DaemonSet, Deployment, Job dan CronJob.
Kamu juga bisa menspesifikasikan hubungan antara pemilik dan dependen dengan cara menentukan kolom ownerReference secara manual.
Berikut adalah berkas untuk sebuah ReplicaSet yang memiliki tiga Pod:
Referensi pemilik lintas namespace tidak diperbolehkan oleh desain. Artinya:
Dependen dengan cakupan namespace hanya bisa menspesifikasikan pemilik jika berada di namespace yang sama, dan pemilik memiliki cakupan klaster.
Dependen dengan cakupan klaster hanya bisa menspesifikasikan pemilik yang memiliki cakupan klaster, tetapi tidak berlaku untuk pemilik yang memiliki cakupan klaster.
Ketika kamu menghapus sebuah objek, kamu bisa menspesifikasi apakah dependen objek tersebut juga dihapus secara otomatis. Menghapus dependen secara otomatis disebut cascading deletion. Cascading deletion memiliki dua mode: background dan foreground.
Foreground cascading deletion
Pada foreground cascading deletion, pertama objek utama akan memasuki keadaan "deletion in progress". Pada saat keadaan "deletion in progress", kondisi-kondisi berikut bernilai benar:
Objek masih terlihat via REST API
deletionTimestamp objek telah ditentukan
metadata.finalizers objek memiliki nilai foregroundDeletion.
Ketika dalam keadaan "deletion in progress", garbage collector menghapus dependen dari objek. Ketika garbage collector telah menghapus semua "blocking" dependen (objek dengan ownerReference.blockOwnerDeleteion=true), garbage collector menghapus objek pemilik.
Jika kolom ownerReferences sebuah objek ditentukan oleh sebuah controller (seperti Deployment atau Replicaset), blockOwnerDeletion akan ditentukan secara otomatis dan kamu tidak perlu memodifikasi kolom ini secara manual.
Background cascading deletion
Pada background cascading deletion, Kubernetes segera menghapus objek pemilik dan garbage collector kemudian menghapus dependen pada background.
Mengatur kebijakan cascading deletion
Untuk mengatur kebijakan cascading deletion, tambahkan kolom propagationPolicy pada argumen deleteOptions ketika menghapus sebuah Object. Nilai yang dapat digunakan adalah "Orphan", "Foreground", atau "Background".
Sebelum Kubernetes 1.9, kebijakan default dari garbage collection untuk banyak resource controller adalah orphan. Ini meliputi ReplicationController, ReplicaSet, StatefulSet, DaemonSet, dan Deployment. Untuk jenis pada kelompok versi extensions/v1beta1, apps/v1beta1, dan apps/v1beta2, kecuali kamu menspesifikasikan dengan cara lain, objek dependen adalah orphan secara default. Pada Kubernetes 1.9, untuk semua jenis pada kelompok versi apps/v1, objek dependen dihapus secara default.
Berikut sebuah contoh yang menghapus dependen di background:
kubectl juga mendukung cascading deletion. Untuk menghapus dependen secara otomatis dengan menggunakan kubectl, Ubah nilai --cascade menjadi true. Untuk orphan yang dependen, ubah nilai --cascade menjadi false. Nilai default untuk --cascade adalah true.
Berikut adalah contoh yang membuat dependen ReplicaSet menjadi orphan:
Sebelum versi 1.7, ketika menggunakan cascading delete dengan Deployment, kamu harus menggunakan propagationPolicy: Foreground untuk menghapus tidak hanya ReplicaSet yang telah diciptakan, tetapi juga Pod yang mereka miliki. Jika tipe propagationPolicy tidak digunakan, hanya ReplicaSet yag akan dihapus, dan Pod akan menjadi orphan. Lihat kubeadm/#149 untuk informasi lebih lanjut.
4.2.7 - Pengendali TTL untuk Sumber Daya yang Telah Selesai Digunakan
FEATURE STATE:Kubernetes v1.12 [alpha]
Pengendali TTL menyediakan mekanisme TTL yang membatasi umur dari suatu
objek sumber daya yang telah selesai digunakan. Pengendali TTL untuk saat ini hanya menangani
Jobs,
dan nantinya bisa saja digunakan untuk sumber daya lain yang telah selesai digunakan
misalnya saja Pod atau sumber daya khusus (custom resource) lainnya.
Peringatan Fitur Alpha: fitur ini tergolong datam fitur alpha dan dapat diaktifkan dengan
feature gateTTLAfterFinished.
Pengendali TTL
Pengendali TTL untuk saat ini hanya mendukung Job. Sebuah operator klaster
dapat menggunakan fitur ini untuk membersihkan Job yang telah dieksekusi (baik
Complete atau Failed) secara otomatis dengan menentukan field.spec.ttlSecondsAfterFinished pada Job, seperti yang tertera di
contoh.
Pengendali TTL akan berasumsi bahwa sebuah sumber daya dapat dihapus apabila
TTL dari sumber daya tersebut telah habis. Proses dihapusnya sumber daya ini
dilakukan secara berantai, dimana sumber daya lain yang
berkaitan akan ikut terhapus. Perhatikan bahwa ketika sebuah sumber daya dihapus,
siklus hidup yang ada akan menjaga bahwa finalizer akan tetap dijalankan sebagaimana mestinya.
Waktu TTL dalam detik dapat diatur kapan pun. Terdapat beberapa contoh untuk mengaktifkan field.spec.ttlSecondsAfterFinished pada suatu Job:
Spesifikasikan field ini pada manifest sumber daya, sehingga Job akan
dihapus secara otomatis beberapa saat setelah selesai dieksekusi.
Aktifkan field ini pada sumber daya yang sudah selesai dieksekusi untuk
menerapkan fitur ini.
Gunakan sebuah
mengubah (mutating) _admission)
untuk mengaktifkan field ini secara dinamis pada saat pembuatan sumber daya.
Administrator klaster dapat menggunakan hal ini untuk menjamin kebijakan (policy) TTL pada
sumber daya yang telah selesai digunakan.
Gunakan sebuah
mengubah (mutating) _admission
untuk mengaktifkan field ini secara dinamis setelah sumber daya
selesai digunakan dan TTL didefinisikan sesuai dengan status, label, atau hal lain
yang diinginkan.
Peringatan
Mengubah TTL Detik
Perhatikan bahwa periode TTL, yaitu field.spec.ttlSecondsAfterFinished pada Job,
dapat dimodifikasi baik setelah sumber daya dibuat atau setelah selesai digunakan.
Meskipun begitu, setelah Job dapat dihapus (TTL sudah habis), sistem tidak akan
menjamin Job tersebut akan tetap ada, meskipun nilai TTL berhasil diubah.
Time Skew
Karena pengendali TTL menggunakan cap waktu (timestamp) yang disimpan di sumber daya
Kubernetes untuk menentukan apakah TTL sudah habis atau belum, fitur ini tidak sensitif
terhadap time skew yang ada pada klaster dan bisa saja menghapus objek pada waktu yang salah
bagi objek tersebut akibat adanya time skew.
Pada Kubernetes, NTP haruslah dilakukan pada semua node untuk mecegah adanya time skew
(lihat #6159).
Clock tidak akan selalu tepat, meskipun begitu perbedaan yang ada haruslah diminimalisasi.
Perhatikan bahwa hal ini dapat terjadi apabila TTL diaktifkan dengan nilai selain 0.
Sebuah Job membuat satu atau beberapa Pod dan menjamin bahwa jumlah Pod yang telah dispesifikasikan sebelumnya
berhasil dijalankan. Pada saat Pod telah dihentikan, Job akan menandainya sebagai Job yang sudah berhasil dijalankan.
Ketika jumlah sukses yang dispesifikasikan sebelumnya sudah terpenuhi, maka Job tersebut dianggap selesai.
Menghapus sebuah Job akan menghapus semua Pod yang dibuat oleh Job tersebut.
Sebuah kasus sederhana yang dapat diberikan adalah membuat sebuah objek Job untuk menjamin
sebuah Pod dijalankan hingga selesai. Objek Job ini akan membuat sebuah Pod baru apabila
Pod pertama gagal atau dihapus (salah satu contohnya adalah akibat adanya kegagalan pada
perangkat keras atau terjadinya reboot pada Node).
Kamu juga dapat menggunakan Job untuk menjalankan beberapa Pod secara paralel.
Menjalankan Contoh Job
Berikut merupakan contoh konfigurasi Job. Job ini melakukan komputasi π hingga
digit ke 2000 kemudian memberikan hasilnya sebagai keluaran. Job tersebut memerlukan
waktu 10 detik untuk dapat diselesaikan.
Untuk melihat Pod yang sudah selesai dari sebuah Job, kamu dapat menggunakan perintah kubectl get pods.
Untuk menampilkan semua Pod yang merupakan bagian dari suatu Job di mesin kamu dalam bentuk
yang mudah dipahami, kamu dapat menggunakan perintah berikut ini:
pods=$(kubectl get pods --selector=job-name=pi --output=jsonpath='{.items[*].metadata.name}')echo$pods
pi-aiw0a
Disini, selektor yang ada merupakan selektor yang sama dengan yang ada pada Job.
Opsi --output=jsonpath menspesifikasikan bahwa ekspresi yang hanya
menampilkan nama dari setiap Pod pada list yang dikembalikan.
Untuk melihat keluaran standar dari salah satu pod:
Field.spec.template merupakan satu-satunya field wajib pada .spec.
Field.spec.template merupakan sebuah templat Pod. Field ini memiliki skema yang sama dengan yang ada pada Pod,
kecuali field ini bersifat nested dan tidak memiliki fieldapiVersion atau fieldkind.
Sebagai tambahan dari field wajib pada sebuah Job, sebuah tempat pod pada Job
haruslah menspesifikasikan label yang sesuai (perhatikan selektor pod)
dan sebuah mekanisme restart yang sesuai.
Hanya sebuah RestartPolicy yang sesuai dengan Never atau OnFailure yang bersifat valid.
Selektor Pod
Field.spec.selector bersifat opsional. Dan dalam sebagian besar kasus, kamu tidak perlu memberikan
spesifikasi untuk hal ini. Perhatikan bagian menspesifikasikan selektor Pod kamu sendiri.
Job Paralel
Terdapat tiga jenis utama dari task yang sesuai untuk dijalankan sebagai sebuah Job:
Job non-paralel
secara umum, hanya sebuah Pod yang dimulai, kecuali jika Pod tersebut gagal.
Job akan dianggap sudah selesai dikerjakan apabila Pod dari Job tersebut sudah selesai dijalankan dan mengalami terminasi dengan status sukses.
Job paralel dengan jumlah nilai penyelesaian tetap:
berikan spesifikasi pada .spec.completions dengan nilai non-negatif.
Job yang ada merupakan representasi dari task yang dikerjakan, dan akan dianggap selesai apabila terdapat lebih dari satu Pod yang sukses untuk setiap nilai yang ada dalam jangkauan 1 hingga .spec.completions.
belum diimplementasikan saat ini: Setiap Pod diberikan nilai indeks yang berbeda di dalam jangkauan 1 hingga .spec.completions.
Job paralel dengan sebuah work queue:
jangan berikan spesifikasi pada .spec.completions, nilai default-nya merupakan .spec.parallelism.
Pod yang ada haruslah dapat berkoordinasi satu sama lain atau dengan Service eksternal lain untuk menentukan apa yang setiap Pod tadi perlu lakukan. Sebagai contohnya, sebuah Pod bisa saja melakukan fetch job batch hingga N kali pada work queue
setiap Pod secara independen mampu menentukan apakah Pod lainnya telah menyelesaikan tugasnya dengan baik atau belum, dengan kata lain suatu Job telah dikatakan selesai
ketika Pod mana pun dari sebuah Job berhenti dalam keadaan sukses, maka tidak ada Pod lain yang akan dibuat untuk Job tersebut.
apabila salah satu Pod sudah dihentikan sekali dalam keadaan sukses, maka Job akan ditandai sebagai sukses.
apabila sebuah Pod sudah dihentikan dalam keadaan sukses, tidak boleh ada Pod lain yang mengerjakan task tersebut. Dengan kata lain, semua Pod tersebut haruslah dalam keadaan akan dihentikan.
Untuk sebuah Job yang non-paralel, kamu tidak perlu menspesifikasikan field.spec.completions dan .spec.parallelism. Ketika kedua field tersebut
dalam keadaan tidak dispesifikasikan, maka nilai defult-nya akan diubah menjadi 1.
Untuk sebuah Job dengan jumlah nilai penyelesaian tetap, kamu harus memberikan spesifikasi nilai
dari .spec.completions dengan nilai yang diinginkan. Kamu dapat menspesifikasikan .spec.parallelism,
atau jika kamu tidak melakukannya nilai dari field ini akan memiliki nilai default 1.
Untuk sebuah Job work queue, kamu harus meninggalkan spesifikasi field.spec.completions menjadi kosong, serta
memberikan nilai pada .spec.parallelism menjadi sebuah bilangan bulat non negatif.
Untuk informasi lebih lanjut mengenai bagaimana menggunakan Job dengan jenis yang berbeda, kamu
dapat melihat bagian pola job.
Mengendalikan Paralelisme
Paralelisme yang diminta (.spec.parallelism) dapat diaktifkan dengan cara
memberikan nilai bilangan bulat non-negatif. Jika tidak dispesifikasikan maka nilainya akan
secara default yaitu 1. Jika dispesifikasikan sebagai 0, maka Job akan secara otomatis dihentikan sementara
hingga nilainya dinaikkan.
Paralelisme yang sebenarnya (jumlah Pod yang dijalankan pada satu waktu tertentu)
bisa saja lebih atau kurang dari nilai yang diharapkan karena adanya alasan berikut:
Untuk Job fixed completion count, nilai sebenarnya dari jumlah Pod yang dijalankan secara paralel tidak akan melebihi jumlah completion yang tersisa. Nilai yang lebih tinggi dari .spec.parallelism secara efektif, akan diabaikan.
Untuk Job work queue, tidak akan ada Pod yang dimulai setelah ada Pod yang berhasil -- meskipun begitu, sisa Pod yang ada akan diizinkan untuk menyelesaikan tugasnya.
Jika sebuah Pengontrol Job tidak memiliki waktu untuk memberikan reaksi.
Jika sebuah controller Job gagal membuat Pod dengan alasan apa pun (kurangnya ResourceQuota, kurangnya permission, dkk.),
maka bisa saja terdapat lebih sedikit Pod dari yang diminta.
Jika controller Job melakukan throttle pembuatan Pod karena terdapat gagalnya pembuatan Pod yang berlebihan sebelumnya pada Job yang sama.
Ketika sebuah Pod dihentikan secara graceful, maka Pod tersebut akan membutuhkan waktu untuk berhenti.
Mengatasi Kegagalan Pod dan Container
Sebuah Container pada sebuah Pod bisa saja mengalami kegagalan karena berbagai alasan
yang berbeda, misalnya saja karena proses yang ada di dalamnya berakhir dengan exit code
yang tidak sama dengan nol, atau Container yang ada di-kill karena menyalahi batasan memori, dkk.
Jika hal ini terjadi, dan .spec.template.spec.restartPolicy = "OnFailure", maka Pod
akan tetap ada di dalam node, tetapi Container tersebut akan dijalankan kembali. Dengan demikian,
program kamu harus dapat mengatasi kasus dimana program tersebut di-restart secara lokal, atau jika
tidak maka spesifikasikan .spec.template.spec.restartPolicy = "Never". Perhatikan
lifecycle pod untuk informasi lebih lanjut mengenai restartPolicy.
Sebuah Pod juga dapat gagal secara menyeluruh, untuk beberapa alasan yang mungkin, misalnya saja,
ketika Pod tersebut dipindahkan dari Node (ketika Node diperbarui, di-restart, dihapus, dsb.), atau
jika sebuah Container dalam Pod gagal dan .spec.template.spec.restartPolicy = "Never". Ketika
sebuah Pod gagal, maka controller Job akan membuat sebuah Pod baru. Ini berarti aplikasi kamu haruslah
bisa mengatasi kasus dimana aplikasimu dimulai pada Pod yang baru. Secara khusus apabila aplikasi kamu
berurusan dengan berkas temporer, locks, keluaran yang tak lengkap dan hal-hal terkait dengan
program yang dijalankan sebelumnya.
Perhatikan bahwa bahakan apabila kamu menspesifikasikan .spec.parallelism = 1 dan .spec.completions = 1 dan
.spec.template.spec.restartPolicy = "Never", program yang sama bisa saja tetap dijalankan lebih dari sekali.
Jika kamu menspesifikasikan .spec.parallelism dan .spec.completions dengan nilai yang lebih besar dari 1,
maka bisa saja terdapat keadaan dimana terdapat beberapa Pod yang dijalankan pada waktu yang sama.
Dengan demikian, Pod kamu haruslah fleksibel terhadap adanya konkurensi.
Mekanisme Kebijakan Backoff apabila Terjadi Kegagalan
Terdapat situasi dimana kamu ingin membuat suatu Job gagal
setelah dijalankan mekanisme retry beberapa kali akibat adanya kesalahan pada konfigurasi
dsb. Untuk melakukan hal tersebut, spesifikasikan .spec.backoffLimit dengan nilai retry yang diinginkan
sebelum menerjemahkan Job dalam keadaan gagal. Secara default, nilai dari field tersebut adalah 6.
Pod yang gagal dijalankan dan terkait dengan suatu Job tertentu akan dibuat kembali oleh
controller Job dengan delayback-off eksponensial (10 detik, 20 detik, 40 detik ...)
yang dibatasi pada 6 menit. Penghitungan back-off akan diulang jika tidak terdapat Pod baru yang gagal
sebelum siklus pengecekan status Job selanjutnya.
Catatan:
Isu #54870 masih ada untuk versi Kubernetes sebelum 1.12.
Catatan:
Jika Job yang kamu miliki memiliki restartPolicy = "OnFailure", perhatikan bahwa Container kamu yang menjalankan
Job tersebut akan dihentikan ketika limit back-off telah dicapai. Hal ini akan membuat proses debugging semakin sulit.
Dengan demikian, kami memberikan saran untuk menspesifikasikan restartPolicy = "Never" ketika melakukan
proses debugging atau menggunakan mekanisme logging untuk menjamin keluaran
dari Job yang gagal agar tidak terus menerus hilang.
Terminasi dan Clean Up Job
Ketika sebuah Job selesai dijalankan, tidak akan ada lagi Pod yang dibuat,
meskipun begitu Pod yang ada juga tidak akan dihapus. Dengan demikian kamu masih bisa mengakses log
yang ada dari Pod yang sudah dalam status complete untuk mengecek apabila terjadi eror, warning, atau hal-hal
yang dapat digunakan untuk proses pelaporan dan identifikasi. Objek Job itu sendiri akan tetap ada,
sehingga kamu tetap bisa melihat statusnya. Penghapusan objek akan diserahkan sepenuhnya pada pengguna
apabila Job tidak lagi digunakan. Penghapusan Job dengan perintah kubectl (misalnya, kubectl delete jobs/pi atau kubectl delete -f ./job.yaml).
Ketika kamu menghapus Job menggunakan perintah kubectl, semua Pod yang terkait dengan Job tersebut akan ikut dihapus.
Secara default, sebuah Job akan dijalankan tanpa adanya interupsi kecuali terdapat Pod yang gagal, (restartPolicy=Never) atau terdapat
Container yang dihentikan dalam kondisi error (restartPolicy=OnFailure), suatu keadaan dimana Job akan dijalankan dengan mekanisme
yang dijelaskan di atas berdasarkan pada .spec.backoffLimit.
Apabila .spec.backoffLimit telah mencapai limit, maka Job akan ditandai sebagai gagal dan Pod yang saat ini sedang dijalankan juga akan dihentikan.
Cara lain untuk menghentikan sebuah Job adalah dengan mengatur deadline aktif.
Untuk melakukannya kamu dapat menspesifikasikan field.spec.activeDeadlineSeconds
dari sebuah Job dengan suatu angka dalam satuan detik. FieldactiveDeadlineSeconds
diterapkan pada durasi dari sebuah Job, tidak peduli seberapa banyak Pod yang dibuat.
Setelah sebuah Job mencapai limit activeDeadlineSeconds, semua Pod yang dijalankan akan dihentikan
dan status dari Job tersebut akan berubah menjadi type: Failed dengan reason: DeadlineExceeded.
Perhatikan bahwa field.spec.activeDeadlineSeconds pada Job memiliki tingkat
presedensi di atas .spec.backoffLimit. Dengan demikian, sebuah Job
yang sedang mencoba melakukan restart pada suatu Pod-nya tidak akan melakukan
pembuatan Pod yang baru apabila Job tersebut telah mencapai limit yang didefinisikan pada
activeDeadlineSeconds, bahkan apabila nilai dari backoffLimit belum tercapai.
Perhatikan bahwa baik spek Job dan spek templat Pod di dalam Job memiliki fieldactiveDeadlineSeconds.
Pastikan kamu telah menspesifikasikan nilai tersebut pada level yang dibutuhkan.
Mekanisme Clean Up Otomatis pada Job yang Sudah Selesai
Job yang sudah selesai biasanya tidak lagi dibutuhkan di dalam sistem. Tetap menjaga keberadaan
objek-objek tersebut di dalam sistem akan memberikan tekanan tambahan pada API server. Jika sebuah Job
yang diatur secara langsung oleh controller dengan level yang lebih tinggi, seperti
CronJob, maka Job ini dapat
di-clean up oleh CronJob berdasarkan policy berbasis kapasitas yang dispesifikasikan.
Mekanisme TTL untuk Job yang Telah Selesai Dijalankan
FEATURE STATE:Kubernetes v1.12 [alpha]
Salah satu cara untuk melakukan clean up Job yang telah selesai dijalankan
(baik dengan status Complete atau Failed) secara otomatis adalah dengan
menerapkan mekanisme TTL yang disediakan oleh
controller TTL untuk
sumber daya yang telah selesai digunakan, dengan cara menspesifikasikan
field.spec.ttlSecondsAfterFinished dari Job tersebut.
Ketika controller TTL melakukan proses clean up pada Job,
maka controller tersebut akan menghapus objek-objek terkait seperti Pod, serta Job itu sendiri.
Perhatikan bahwa ketika suatu Job dihapus, maka lifecycle-nya akan menjamin, mekanisme
finalizer yang ada akan tetap dihargai.
Job pi-with-ttl akan dihapus secara otomatis, dalam jangka waktu 100
detik setelah Job tersebut selesai dijalankan.
Jika field ini dispesifikasikan sebagai 0, maka Job akan secara otomatis dihapus
segera setelah Job tersebut selesai dijalankan. Jika field tersebut tidak dispesifikasikan,
maka Job ini tidak akan dihapus oleh controller TTL setelah Job ini selesai dijalankan.
Perhatikan bahwa mekanisme TTL ini merupakan fitur alpha, dengan gerbang fitur TTLAfterFinished.
Untuk informasi lebih lanjut, kamu dapat membaca dokumentasi untuk
controller TTL untuk
sumber daya yang telah selesai dijalankan.
Pola Job
Sebuah objek Job dapat digunakan untuk mendukung eksekusi paralel yang dapat diandalkan pada Pod.
Objek Job tidak di-desain untuk mendukung proses paralel bersifat closely-communicating,
seperti yang secara umum ditemukan dalam komputasi ilmiah. Meskipun begitu objek ini mendukung
set work item yang independen namun saling terkait satu sama lainnya. Ini termasuk surel yang harus dikirim,
frame yang harus di-render, berkas yang harus di-transcoded, jangkauan key yang ada
di dalam basis data NoSQL, dsb.
Pada suatu sistem yang kompleks, terdapat beberapa set work item yang berbeda.
Di sini, kami hanya mempertimbangkan work item yang ingin digunakan oleh pengguna
untuk melakukan manajemen secara bersamaan — sebuah batch job.
Terdapat beberapa perbedaan pola pada komputasi paralel,
setiap pola memiliki kelebihan dan kekurangannya masing-masing. Kekurangan dan kelebihan ini
dijabarkan sebagai berikut:
Satu objek Job untuk setiap work item, atau sebuah Job untuk semua work item. Pilihan kedua akan lebih baik apabila digunakan untuk jumlah work item yang lebih besar.
Sementara itu, pilihan pertama akan mengakibatkan overhead bagi pengguna dan juga sistem
untuk mengaur jumlah objek Job yang cukup banyak.
Jumlah Pod yang dibuat sesuai dengan jumlah work item atau setiap Pod dapat memproses beberapa work item sekaligus.
Pilihan pertama secara umum memerlukan modifikasi lebih sedikit untuk kode dan Container yang suda ada. Pilihan kedua
akan lebih baik jika digunakan untuk jumlah work item yang lebih banyak, untuk alasan yang sama dengan poin sebelumnya.
Beberapa pendekatan menggunakan prinsip work queue. Hal ini membutuhkan sebuah service queue yang dijalankan,
serta modifikasi untuk program atau Container yang sudah ada untuk mengizinkannya menggunakan working queue.
Pendekatan lain akan lebih mudah untuk digunakan bagi aplikasi yang sudah ada.
Tradeoff yang dirangkum di sini, dengan kolom 2 dan 4 berkaitan dengan tradeoff yang dijelaskan di atas.
Nama dari pola yang ada juga terkait dengan contoh dan deskripsi lebih lanjut.
Ketika kamu menspesifikasikan completion dengan .spec.completions, setiap Pod yang dibuat oleh controller Job
memiliki spec yang identik. Artinya
semua Pod untuk sebuah task akan memiliki perintah yang sama serta image, volume, serta variabel environment yang (hampir) sama.
Pola ini merupakan salah satu cara berbeda yang diterapkan untuk mengatur Pod agar dapat bekerja untuk hal yang berbeda-beda.
Tabel ini menunjukkan pengaturan yang dibutuhkan untuk .spec.parallelism dan .spec.completions bagi setiap pola.
Disini, W merupakan jumlah dari work item.
Secara umum, ketika kamu membuat sebuah objek Job, kamu
tidak menspesifikasikan .spec.selector. Sistem akan memberikan nilai
default pada field ini ketika Job dibuat. Sistem akan memilih nilai dari selektor yang ada
dan memastikan nilainya tidak akan beririsan dengan Job lainnya.
Meskipun demikian, pada beberapa kasus, kamu bisa saja memiliki kebutuhan untuk meng-override
nilai dari selektor ini. Untuk melakukannya, kamu dapat menspesifikasikan .spec.selector
dari Job.
Berhati-hatilah ketika kamu melakukan proses ini. Jika kamu menspesifikasikan sebuah label
selektor yang tidak unik pada Pod yang ada di dalam Job tersebut, serta sesuai dengan Pod yang tidak
terkait dengan Job tadi, maka Pod dari Job yang tidak terkait dengan Job tadi akna dihapus, atau Job ini
akan menghitung completion dari Pod lain sebagai tolak ukur suksesnya Job tersebut, atau bisa saja salah satu
atau kedua Job tidak dapat membuat Pod baru yang digunakan untuk menyelesaikan Job tersebut.
Jika selektor yang tidak unik dipilih, maka controller lain (misalnya ReplicationController) dan Pod
yang ada di dalamnya bisa saja memiliki perilaku yang tidak dapat diprediksi. Kubernetes tidak akan
mencegah kemungkinan terjadinya hal ini ketika kamu menspesifikasikan nilai .spec.selector.
Berikut merupakan contoh skenario dimana kamu ingin menggunakan fitur ini.
Misalnya saja Job dengan nama old sudah dijalankan.
Dan kamu ingin Pod yang sudah dijalankan untuk tetap berada pada state tersebut,
tapi kamu juga ingin Pod selanjutnya yang dibuat untuk menggunakan templat Pod yang berbeda dan agar
Job tersebut memiliki nama yang berbeda. Kamu tidak dapat mengubah Job karena field ini
merupakan nilai yang tidak bisa diubah. Dengan demikian, kamu menghapus Job old
tetapi tetap membiarkan Pod yang ada untuk jalan, menggunakan perintah kubectl delete jobs/old --cascade=false.
Sebelum menghapus Job tadi, kamu mencatat selektor yang digunakan oleh Job tadi:
Kemudian kamu membuat sebuah Job baru dengan nama new
dan kamu secara eksplisit menspesifikasikan selektor yang sama.
Karena Pod dengan selektor yang sama memiliki label controller-uid=a8f3d00d-c6d2-11e5-9f87-42010af00002,
maka Pod-Pod lama tadi dikendalikan juga oleh Job new.
Kamu harus menspesifikasikan manualSelector: true pada Job yang baru
karena kamu tidak menggunakan selektor yang diberikan secara default oleh sistem.
Job yang baru tadi kemudian akan memiliki uid yang berbeda dari a8f3d00d-c6d2-11e5-9f87-42010af00002. Pengaturan
manualSelector: true memberikan perintah pada sistem bahwa kamu mengetahui apa yang kamu lakukan
dan untuk mengizikan ketidaksesuaian ini untuk terjadi.
Alternatif
Pod Polosan
Ketika node dimana Pod dijalankan berada dalam kondisi reboot atau gagal, Pod tadi akan dihentikan
dan tidak akan di-restart. Meskipun demikian, sebuah Job akan membuat Pod baru yang menggantikan
Pod lama yang dihentikan. Untuk alasan inilah, kami memberikan rekomendasi agar kamu menggunakan sebuah Job dibandingkan dengan
Pod yang biasa, bahkan jika aplikasi yang kamu gunakan hanya memerlukan sebuah Pod.
Replication Controller
Job merupakan komplemen dari Replication Controller.
Sebuah Replication Controller mengatur Pod yang diharapkan untuk tidak dihentikan (misalnya, web server), dan sebuah Job
mengatur Pod yang diharapkan untuk berhenti (misalnya, batch task).
Seperti yang sudah dibahas pada Lifecycle Pod, Jobhanya pantas
digunakan untuk Pod dengan RestartPolicy yang sama dengan OnFailure atau Never.
(Perhatikan bahwa: Jika RestartPolicy tidak dispesifikasikan, nilai defaultnya adalah Always.)
Job Tunggal akan menginisiasi Kontroller Pod
Pola lain yang mungkin diterapkan adalah untuk sebuah Job tunggal untuk membuat
sebuah Pod yang kemudian akan membuat Pod lainnya, bersifat selayaknya controller kustom
bagi Pod tersebut. Hal ini mengizinkan fleksibilitas optimal, tetapi cukup kompleks untuk digunakan
dan memiliki integrasi terbatas dengan Kubernetes.
Salah satu contoh dari pola ini adalah sebuah Job yang akan menginisiasi sebuah Pod
yang menjalankan script yang kemudian akan
menjalankan controller master Spark (kamu dapat melihatnya di contoh Spark),
yang menjalankan driver Spark, dan kemudian melakukan mekanisme clean up.
Keuntungan dari pendekatan ini adalah proses keseluruhan yang memiliki jaminan completion
dari sebuah Job, tetapi kontrol secara mutlak atas Pod yang dibuat serta tugas yang diberikan pada Pod tersebut.
CronJob
Kamu dapat menggunakan CronJob untuk membuat Job yang akan
dijalankan pada waktu/tanggal yang spesifik, mirip dengan perangkat lunak cron yang ada pada Unix.
4.2.9 - CronJob
Suatu CronJob menciptakan Job yang dijadwalkan berdasarkan waktu tertentu.
Satu objek CronJob sepadan dengan satu baris pada filecrontab (cron table). CronJob tersebut menjalankan suatu pekerjaan secara berkala
pada waktu tertentu, dituliskan dalam format Cron.
Catatan:
Seluruh waktu schedule: pada CronJob mengikuti zona waktu dari master di mana Job diinisiasi.
Suatu cron job menciptakan kurang lebih satu objek Job setiap penjadwalan. Istilah yang digunakan adalah "kurang lebih" karena
terdapat beberapa kasus yang menyebabkan dua Job terbuat, atau tidak ada Job sama sekali yang terbuat. Kemungkinan-kemungkinan
seperti itu memang diusahakan untuk tidak sering terjadi, tapi tidak ada jaminan kemungkinan-kemungkinan tersebut tidak akan pernah terjadi.
Oleh karena itu, Job sudah sepantasnya memiliki sifat idempoten.
Jika pengaturan startingDeadlineSeconds menggunakan nilai yang besar atau tidak diatur (menggunakan nilai default)
dan jika pengaturan concurrencyPolicy dijadikan Allow, Job yang terbuat akan dijalankan paling tidak satu kali.
CronJob controller memeriksa berapa banyak jadwal yang terlewatkan sejak waktu terakhir eksekusi hingga saat ini. Jika terdapat lebih dari 100 jadwal yang terlewat, maka CronJob controller tidak memulai Job dan mencatat kesalahan:
Cannot determine if job needs to be started. Too many missed start time (> 100). Set or decrease .spec.startingDeadlineSeconds or check clock skew.
Perlu diingat bahwa jika pengaturan startingDeadlineSeconds memiliki suatu nilai (bukan nil), CronJob controller akan menghitung berapa banyak Job yang terlewatkan dari sejak startingDeadlineSeconds hingga sekarang dan bukan sejak waktu terakhir eksekusi. Misalnya: Jika startingDeadlineSeconds memiliki nilai 200, CronJob controller akan menghitung berapa banyak Job yang terlewatkan dalam 200 detik terakhir.
Suatu CronJob dianggap terlewat jika ia gagal diciptakan pada waktu yang semestinya. Misalnya: Jika pengaturan concurrencyPolicy dijadikan Forbid
dan suatu CronJob dicoba dijadwalkan saat masih ada penjadwalan sebelumnya yang masih berjalan, maka ia akan dianggap terlewat.
Contoh: Suatu CronJob akan menjadwalkan Job baru tiap satu menit dimulai sejak 08:30:00, dan startingDeadlineSeconds tidak diatur.
Jika CronJob controller tidak aktif dari 08:29:00 sampai 10:21:00, Job tidak akan dijalankan karena jumlah Job yang terlewat
sudah lebih dari 100.
Sebagai ilustrasi lebih lanjut, misalkan suatu CronJob diatur untuk menjadwalkan Job baru setiap satu menit dimulai sejak 08:30:00,
dan startingDeadlineSeconds memiliki nilai 200. Jika CronJob controller tidak aktif seperti pada contoh sebelumnya (08:29:00 sampai 10:21:00),
Job akan tetap dijalankan pada 10:22:00. Hal ini terjadi karena CronJob controller memeriksa banyaknya jadwal yang terlewatkan pada 200 detik terakhir
(dalam kasus ini: 3 jadwal terlewat), dan bukan dari sejak waktu eksekusi terakhir.
CronJob hanya bertanggung-jawab untuk menciptakan Job yang sesuai dengan jadwalnya sendiri,
dan Job tersebut bertanggung jawab terhadap pengelolaan Pod yang direpresentasikan olehnya.
5 - Services, Load Balancing, dan Jaringan
5.1 - Service
Pod pada Kubernetes bersifat mortal.
Artinya apabila pod-pod tersebut dibuat dan kemudian mati, pod-pod tersebut
tidak akan dihidupkan kembali. ReplicaSets secara
khusus bertugas membuat dan menghapus Pod secara dinamis (misalnya, pada proses scaling out atau scaling in).
Meskipun setiap Pod memiliki alamat IP-nya masing-masing, kamu tidak dapat mengandalkan alamat IP
yang diberikan pada pod-pod tersebut, karena alamat IP yang diberikan tidak stabil.
Hal ini kemudian menimbulkan pertanyaan baru: apabila sebuah sekumpulan Pod (yang selanjutnya kita sebut backend)
menyediakan service bagi sebuah sekumpulan Pod lain (yang selanjutnya kita sebut frontend) di dalam
klaster Kubernetes, bagaimana cara frontend menemukan backend mana yang digunakan?
Inilah alasan kenapa Service ada.
Sebuah Service pada Kubernetes adalah sebuah abstraksi yang memberikan definisi
set logis yang terdiri beberapa Pod serta policy bagaimana cara kamu mengakses sekumpulan Pod tadi - seringkali disebut sebagai microservices.
Set Pod yang dirujuk oleh suatu Service (biasanya) ditentukan oleh sebuah Label Selector
(lihat penjelasan di bawah untuk mengetahui alasan kenapa kamu mungkin saja membutuhkan Service tanpa
sebuah selector).
Sebagai contoh, misalnya terdapat sebuah backend yang menyediakan fungsionalitas image-processing
yang memiliki 3 buah replica. Replica-replica tadi sifatnya sepadan - dengan kata lain frontend
tidak peduli backend manakah yang digunakan. Meskipun Pod penyusun sekumpulan backend bisa berubah,
frontend tidak perlu peduli bagaimana proses ini dijalankan atau menyimpan list dari backend-backend
yang ada saat itu. Service memiliki tujuan untuk decouple mekanisme ini.
Untuk aplikasi yang dijalankan di atas Kubernetes, Kubernetes menyediakan API endpoint sederhana
yang terus diubah apabila state sebuah sekumpulan Pod di dalam suatu Service berubah. Untuk
aplikasi non-native, Kubernetes menyediakan bridge yang berbasis virtual-IP bagi Service
yang diarahkan pada Podbackend.
Mendefinisikan sebuah Service
Sebuah Service di Kubernetes adalah sebuah objek REST, layaknya sebuah Pod. Seperti semua
objek REST, definisi Service dapat dikirim dengan method POST pada apiserver untuk membuat
sebuah instans baru. Sebagai contoh, misalnya saja kamu memiliki satu sekumpulan Pod yang mengekspos port
9376 dan memiliki label"app=MyApp".
Spesifikasi ini akan ditranslasikan sebagai sebuah objek Service baru dengan nama "my-service"
dengan target port 9376 pada setiap Pod yang memiliki label"app=MyApp". Service ini
juga akan memiliki alamat IP tersendiri (yang terkadang disebut sebagai "cluster IP"), yang nantinya
akan digunakan oleh service proxy (lihat di bagian bawah). Selector pada Service akan selalu dievaluasi
dan hasilnya akan kembali dikirim dengan menggunakan method POST ke objek Endpoints
yang juga disebut "my-service".
Perhatikan bahwa sebuah Service dapat melakukan pemetaan setiap incoming port pada targetPort
mana pun. Secara default, fieldtargetPort akan memiliki value yang sama dengan value dari fieldport.
Hal menarik lainnya adalah value dari targetPort bisa saja berupa string yang merujuk pada nama
dari port yang didefinisikan pada Podbackend. Nomor port yang diberikan pada port dengan nama
tadi bisa saja memiliki nilai yang berbeda di setiap Podbackend. Hal ini memberikan fleksibilitas
pada saat kamu melakukan deploy atau melakukan perubahan terhadap Service. Misalnya saja suatu saat
kamu ingin mengubah nomor port yang ada pada Podbackend pada rilis selanjutnya tanpa menyebabkan
permasalahan pada sisi klien.
Secara default, protokol yang digunakan pada service adalah TCP, tapi kamu bisa saja menggunakan
protokol yang tersedia. Karena banyak Service memiliki kebutuhan untuk
mengekspos lebih dari sebuah port, Kubernetes menawarkan definisi multipleport pada sebuah objek
Service. Setiap definisi port dapat memiliki protokol yang berbeda.
Service tanpa selector
Secara umum, Service memberikan abstraksi mekanisme yang dilakukan untuk mengakses Pod, tapi
mereka juga melakukan abstraksi bagi backend lainnya. Misalnya saja:
Kamu ingin memiliki sebuah basis data eksternal di environmentproduction tapi pada tahap test,
kamu ingin menggunakan basis datamu sendiri.
Kamu ingin merujuk service kamu pada service lainnya yang berada pada
Namespace yang berbeda atau bahkan klaster yang berbeda.
Kamu melakukan migrasi workloads ke Kubernetes dan beberapa backend yang kamu miliki masih
berada di luar klaster Kubernetes.
Berdasarkan skenario-skenario di atas, kamu dapat membuat sebuah Service tanpa selector:
Karena Service ini tidak memiliki selector, objek Endpoints bagi Service ini tidak akan dibuat.
Dengan demikian, kamu bisa membuat Endpoints yang kamu inginkan:
Perhatikan bahwa alamat IP yang kamu buat untuk Endpoints tidak boleh berupa
loopback (127.0.0.0/8), link-local (169.254.0.0/16), atau link-local multicast (224.0.0.0/24).
Alamat IP tersebut juga tidak boleh berupa cluster IP dari Service Kubernetes lainnya,
karena kube-proxy belum menyediakan dukungan IP virtual sebagai destination.
Cara mengakses suatu Service tanpa selector sama saja dengan mengakses suatu Service
dengan selector. Trafik yang ada akan di-route ke Endpoints yang dispesifikasikan oleh
pengguna (dalam contoh kali ini adalah 1.2.3.4:9376).
Sebuah ExternalNameService merupakan kasus spesial dari Service
dimana Service tidak memiliki selector dan menggunakan penamaan DNS. Untuk
informasi lebih lanjut silahkan baca bagian ExternalName.
IP Virtual dan proxyService
Setiap node di klaster Kubernetes menjalankan kube-proxy. kube-proxy
bertanggung jawab terhadap implementasi IP virtual bagi Services dengan tipe
selain ExternalName.
Pada Kubernetes versi v1.0, Services adalah "layer 4" (TCP/UDP pada IP), proxy
yang digunakan murni berada pada userspace. Pada Kubernetes v1.1, API Ingress
ditambahkan untuk merepresentasikan "layer 7"(HTTP), proxyiptables juga ditambahkan
dan menjadi mode operasi default sejak Kubernetes v1.2. Pada Kubernetes v1.8.0-beta.0,
proxyipvs juga ditambahkan.
Mode Proxy: userspace
Pada mode ini, kube-proxy mengamati master Kubernetes apabila terjadi penambahan
atau penghapusan objek Service dan Endpoints. Untuk setiap Service, kube-proxy
akan membuka sebuah port (yang dipilih secara acak) pada node lokal. Koneksi
pada "proxy port" ini akan dihubungkan pada salah satu Podbackend dari Service
(yang tercatat pada Endpoints). Podbackend yang akan digunakan akan diputuskan berdasarkan
SessionAffinity pada Service. Langkah terakhir yang dilakukan oleh kube-proxy
adalah melakukan instalasi rulesiptables yang akan mengarahkan trafik yang ada pada
clusterIP (IP virtual) dan port dari Service serta melakukan redirect trafik ke proxy
yang memproksikan Podbackend. Secara default, mekanisme routing yang dipakai adalah
round robin.
Mode Proxy: iptables
Pada mode ini, kube-proxy mengamati master Kubernetes apabila terjadi penambahan
atau penghapusan objek Service dan Endpoints. Untuk setiap Service,
kube-proxy akan melakukan instalasi rulesiptables yang akan mengarahkan
trafik ke clusterIP (IP virtual) dan port dari Service. Untuk setiap objek Endpoints,
kube-proxy akan melakukan instalasi rulesiptables yang akan memilih satu buah Podbackend. Secara default, pemilihan backend ini dilakukan secara acak.
Tentu saja, iptables yang digunakan tidak boleh melakukan switching
antara userspace dan kernelspace, mekanisme ini harus lebih kokoh dan lebih cepat
dibandingkan dengan userspaceproxy. Meskipun begitu, berbeda dengan mekanisme
proxyuserspace, proxyiptables tidak bisa secara langsung menjalankan mekanisme
retry ke Pod lain apabila Pod yang sudah dipilih sebelumnya tidak memberikan respons,
dengan kata lain hal ini akan sangat bergantung pada
readiness probes.
Mode Proxy: ipvs
FEATURE STATE:Kubernetes v1.9 [beta]
Pada mode ini, kube-proxy mengamati Services dan Endpoints, kemudian memanggil
interfacenetlink untuk membuat rulesipvs yang sesuai serta melakukan sinkronisasi
rulesipvs dengan Services dan Endpoints Kubernetes secara periodik, untuk memastikan
status ipvs konsisten dengan apa yang diharapkan. Ketika sebuah Services diakses,
trafik yang ada akan diarahkan ke salah satu Podbackend.
Sama halnya dengan iptables, ipvs juga berdasarkan pada fungsi hooknetfilter,
bedanya adalah ipvs menggunakan struktur data hash table dan bekerja di kernelspace.
Dengan kata lain ipvs melakukan redirect trafik dengan lebih cepat dan dengan performa yang lebih
baik ketika melakukan sinkronisasi rulesproxy. Selain itu, ipvs juga menyediakan
lebih banyak opsi algoritma load balancing:
rr: round-robin
lc: least connection
dh: destination hashing
sh: source hashing
sed: shortest expected delay
nq: never queue
Catatan:
Mode ipvs menggunakan moduleIPVSkernel yang diinstal pada node
sebelum kube-proxy dijalankan. Ketika kube-proxy dijalankan dengan mode proxyipvs,
kube-proxy akan melakukan proses validasi, apakah moduleIPVS sudah diinstal di node,
jika module tersebut belum diinstal, maka kube-proxy akan menggunakan mode iptables.
Dari sekian model proxy yang ada, trafik inbound apa pun yang ada diterima oleh IP:Port pada Service
akan dilanjutkan melalui proxy pada backend yang sesuai, dan klien tidak perlu mengetahui
apa informasi mendetail soal Kubernetes, Service, atau Pod. afinitas session (session affinity) berbasis
Client-IP dapat dipilih dengan cara menerapkan nilai "ClientIP" pada service.spec.sessionAffinity
(nilai default untuk hal ini adalah "None"), kamu juga dapat mengatur nilai maximum sessiontimeout yang ada dengan mengatur opsi service.spec.sessionAffinityConfig.clientIP.timeoutSeconds jika
sebelumnya kamu sudah menerapkan nilai "ClusterIP" pada service.spec.sessionAffinity
(nilai default untuk opsi ini adalah "10800").
Multi-Port Services
Banyak Services dengan kebutuhan untuk mengekspos lebih dari satu port.
Untuk kebutuhan inilah, Kubernetes mendukung multipleportdefinitions pada objek Service.
Ketika menggunakan multipleport, kamu harus memberikan nama pada setiap port yang didefinisikan,
sehingga Endpoint yang dibentuk tidak ambigu. Contoh:
Perhatikan bahwa penamaan port hanya boleh terdiri dari karakter alphanumericlowercase
dan -, serta harus dimulai dan diakhiri dengan karakter alphanumeric, misalnya saja 123-abc dan web
merupakan penamaan yang valid, tapi 123_abc dan -web bukan merupakan penamaan yang valid.
Memilih sendiri alamat IP yang kamu inginkan
Kamu dapat memberikan spesifikasi alamat cluster IP yang kamu inginkan
sebagai bagian dari request pembuatan objek Service. Untuk melakukan hal ini,
kamu harus mengisi fields.spec.clusterIP field. Contoh penggunaannya adalah sebagai berikut,
misalnya saja kamu sudah memiliki entry DNS yang ingin kamu gunakan kembali,
atau sebuah sistem legacy yang sudah diatur pada alamat IP spesifik
dan sulit untuk diubah. Alamat IP yang ingin digunakan pengguna haruslah merupakan alamat IP
yang valid dan berada di dalam rangeCIDRservice-cluster-ip-range yang dispesifikasikan di dalam
penanda yang diberikan apiserver. Jika value yang diberikan tidak valid, apiserver akan
mengembalikan responsecode HTTP 422 yang mengindikasikan value yang diberikan tidak valid.
Mengapa tidak menggunakan DNS round-robin?
Pertanyaan yang selalu muncul adalah kenapa kita menggunakan IP virtual dan bukan
DNS round-robin standar? Terdapat beberapa alasan dibalik semua itu:
Terdapat sejarah panjang dimana library DNS tidak mengikuti TTL DNS dan
melakukan caching hasil dari lookup yang dilakukan.
Banyak aplikasi yang melakukan lookup DNS hanya sekali dan kemudian melakukan cache hasil yang diperoleh.
Bahkan apabila aplikasi dan library melakukan resolusi ulang yang proper, load dari setiap
klien yang melakukan resolusi ulang DNS akan sulit untuk di manage.
Kami berusaha untuk mengurangi ketertarikan pengguna untuk melakukan yang mungkin akan menyusahkan pengguna.
Dengan demikian, apabila terdapat justifikasi yang cukup kuat, kami mungkin saja memberikan implementasi
alternatif yang ada.
Discovering services
Kubernetes mendukung 2 buah mode primer untuk melakukan Service - variabel environment dan DNS.
Variabel Environment
Ketika sebuah Pod dijalankan pada node, kubelet menambahkan seperangkat variabel environment
untuk setiap Service yang aktif. Environment yang didukung adalah Docker links compatible variabel (perhatikan
makeLinkVariables)
dan variabel {SVCNAME}_SERVICE_HOST dan {SVCNAME}_SERVICE_PORT, dinama nama Service akan diubah
menjadi huruf kapital dan tanda minus akan diubah menjadi underscore.
Sebagai contoh, Service"redis-master" yang mengekspos port TCP 6379 serta alamatcluster IP10.0.0.11 akan memiliki environment sebagai berikut:
Hal ini merupakan kebutuhan yang urutannya harus diperhatikan - Service apa pun yang
akan diakses oleh sebuah Pod harus dibuat sebelum Pod tersebut dibuat,
jika tidak variabel environment tidak akan diinisiasi.
Meskipun begitu, DNS tidak memiliki keterbatasan ini.
DNS
Salah satu add-on opsional
(meskipun sangat dianjurkan) adalah server DNS. Server DNS bertugas untuk mengamati apakah
terdapat objek Service baru yang dibuat dan kemudian bertugas menyediakan DNS baru untuk
Service tersebut. Jika DNS ini diaktifkan untuk seluruh klaster, maka semua Pod akan secara otomatis
dapat melakukan resolusi DNS.
Sebagai contoh, apabila kamu memiliki sebuah Service dengan nama "my-service" pada Namespace"my-ns", maka record DNS "my-service.my-ns" akan dibuat. Pod yang berada di dalam
Namespace"my-ns" dapat langsung melakukan lookup dengan hanya menggunakan "my-service".
Sedangkan Pod yang berada di luar Namespacemy-ns" harus menggunakan "my-service.my-ns".
Hasil dari resolusi ini menrupakan cluster IP.
Kubernetes juga menyediakan record DNS SRV (service) untuk named ports. Jika
Service"my-service.my-ns" memiliki port dengan nama "http" dengan protokol TCP,
kamu dapat melakukan query DNS SRV untuk "_http._tcp.my-service.my-ns" untuk mengetahui
nomor port yang digunakan oleh http.
Server DNS Kubernetes adalah satu-satunya cara untuk mengakses
Service dengan tipe ExternalName. Informasi lebih lanjut tersedia di
DNS Pods dan Services.
Serviceheadless
Terkadang kamu tidak membutuhkan mekanisme load-balancing dan sebuah single IP Sevice.
Dalam kasus ini, kamu dapat membuat "headless"Service dengan cara memberikan spesifikasi
None pada cluster IP (.spec.clusterIP).
Opsi ini memungkinkan pengguna mengurangi ketergantungan terhadap sistem Kubernetes
dengan cara memberikan kebebasan untuk mekanisme service discovery. Aplikasi akan
tetap membutuhkan mekanisme self-registration dan adapter service discovery
lain yang dapat digunakan berdasarkan API ini.
Untuk Service"headless" alokasi cluster IP tidak dilakukan dan kube-proxy
tidak me-manageService-Service, serta tidak terdapat mekanisme load balancing
yang dilakukan. Bagaimana konfigurasi otomatis bagi DNS dilakukan bergantung pada
apakah Service tersebut memiliki selector yang dispesifikasikan.
Dengan selector
Untuk Service"headless" dengan selector, kontroler Endpoints akan membuat suatu
recordEndpoints di API, serta melakukan modifikasi konfigurasi DNS untuk mengembalikan
A records (alamat) yang merujuk secara langsung pada Podbackend.
Tanpa selector
Untuk Service"headless" tanpa selector, kontroler Endpoints
tidak akan membuat recordEnpoints. Meskipun demikian,
sistem DNS tetap melakukan konfigurasi salah satu dari:
record untuk semua Endpoints yang memiliki nama Service yang sama, untuk
tipe lainnya.
Mekanisme publishService - jenis-jenis Service
Untuk beberapa bagian dari aplikasi yang kamu miliki (misalnya saja, frontend),
bisa saja kamu memiliki kebutuhan untuk mengekspos Service yang kamu miliki
ke alamat IP eksternal (di luar klaster Kubernetes).
ServiceTypes yang ada pada Kubernetes memungkinkan kamu untuk menentukan
jenis Service apakah yang kamu butuhkan. Secara default, jenis Service
yang diberikan adalah ClusterIP.
Value dan perilaku dari tipe Service dijelaskan sebagai berikut:
ClusterIP: Mengekspos Service ke range alamat IP di dalam klaster. Apabila kamu memilih value ini
Service yang kamu miliki hanya dapat diakses secara internal. tipe ini adalah
defaultvalue dari ServiceType.
NodePort: Mengekspos Service pada setiap IP node pada port statis
atau port yang sama. Sebuah ServiceClusterIP, yang mana ServiceNodePort akan di-route
, dibuat secara otomatis. Kamu dapat mengakses Service dengan tipe ini,
dari luar klaster melalui <NodeIP>:<NodePort>.
LoadBalancer: Mengekspos Service secara eksternal dengan menggunakan LoadBalancer
yang disediakan oleh penyedia layanan cloud. Service dengan tipe NodePort dan ClusterIP,
dimana trafik akan di-route, akan dibuat secara otomatis.
ExternalName: Melakukan pemetaan Service ke konten
dari fieldexternalName (misalnya: foo.bar.example.com), dengan cara mengembalikan
catatan CNAME beserta value-nya. Tidak ada metode proxy apa pun yang diaktifkan. Mekanisme ini
setidaknya membutuhkan kube-dns versi 1.7.
Type NodePort
Jika kamu menerapkan valueNodePort pada fieldtype, master Kubernetes akan mengalokasikan
port dari range yang dispesifikasikan oleh penanda --service-node-port-range (secara default, 30000-32767)
dan setiap Node akan memproksikan port tersebut (setiap Node akan memiliki nomor port yang sama) ke Service
yang kamu miliki. Port tersebut akan dilaporkan pada field.spec.ports[*].nodePort di Service kamu.
Jika kamu ingin memberikan spesifikasi IP tertentu untuk melakukan poxy pada port.
kamu dapat mengatur penanda --nodeport-addresses pada kube-proxy untuk range alamat IP
tertentu (mekanisme ini didukung sejak v1.10). Sebuah daftar yang dipisahkan koma (misalnya, 10.0.0.0/8, 1.2.3.4/32)
digunakan untuk mem-filter alamat IP lokal ke node ini. Misalnya saja kamu memulai kube-proxy dengan penanda
--nodeport-addresses=127.0.0.0/8, maka kube-proxy hanya akan memilih interfaceloopback untuk Service dengan tipe
NodePort. Penanda --nodeport-addresses memiliki nilai default kosong ([]), yang artinya akan memilih semua interface yang ada
dan sesuai dengan perilaku NodePortdefault.
Jika kamu menginginkan nomor port yang berbeda, kamu dapat memberikan spesifikasi
value dari fieldnodePort, dan sistem yang ada akan mengalokasikan port tersebut untuk kamu,
jika port tersebut belum digunakan (perhatikan bahwa jika kamu menggunakan teknik ini, kamu perlu
mempertimbangkan collision yang mungkin terjadi dan bagaimana cara mengatasi hal tersebut)
atau transaksi API yang dilakukan akan gagal.
Hal ini memberikan kebebasan bagi pengembang untuk memilih load balancer yang akan digunakan, terutama apabila
load balancer yang ingin digunakan belum didukung sepenuhnya oleh Kubernetes.
Perhatikan bahwa Service dapat diakses baik dengan menggunakan <NodeIP>:spec.ports[*].nodePort
atau .spec.clusterIP:spec.ports[*].port. (Jika penanda --nodeport-addresses diterapkan, dapat di-filter dengan salah satu atau lebih NodeIP.)
Type LoadBalancer
Pada penyedia layanan cloud yang menyediakan pilihan load balancer eksternal, pengaturan fieldtype
ke LoadBalancer akan secara otomatis melakukan proses provisionload balancer untuk Service yang kamu buat.
Informasi mengenai load balancer yang dibuat akan ditampilkan pada field.status.loadBalancer
pada Service kamu. Contohnya:
Trafik dari load balancer eksternal akan diarahkan pada Podbackend, meskipun mekanisme
bagaimana hal ini dilakukan bergantung pada penyedia layanan cloud. Beberapa penyedia layanan
cloud mengizinkan konfigurasi untuk valueloadBalancerIP. Dalam kasus tersebut, load balancer akan dibuat
dengan loadbalancerIP yang dispesifikasikan. Jika value dari loadBalancerIP tidak dispesifikasikan.
sebuah IP sementara akan diberikan pada loadBalancer. Jika loadBalancerIP dispesifikasikan,
tetapi penyedia layanan cloud tidak mendukung hal ini, maka field yang ada akan diabaikan.
Catatan Khusus untuk Azure: Untuk spesifikasi loadBalancerIP publik yang didefinisikan oleh pengguna,
sebuah alamat IP statis publik akan disediakan terlebih dahulu, dan alamat IP tersebut harus berada di
resource group dari resource yang secara otomatis dibuat oleh klaster. Misalnya saja, MC_myResourceGroup_myAKSCluster_eastus.
Berikan spesifikasi alamat IP sebagai loadBalancerIP. Pastikan kamu sudah melakukan update pada
securityGroupName pada file konfigurasi penyedia layanan cloud.
Untuk informasi lebih lanjut mengenai permission untuk CreatingLoadBalancerFailed kamu dapat membaca troubleshooting untuk
Penggunaan alamat IP statis pada load balancer Azure Kubernetes Service (AKS) atau
CreatingLoadBalancerFailed pada klaster AKS dengan advanced networking.
Catatan:
Dukungan untuk SCTP load balancer dari penyedia layanan cloud bergantung pada
implementasi load balancer yang disediakan oleh penyedia layanan cloud tersebut.
Jika SCTP tidak didukung oleh load balancer penyedia layanan publik maka request pembuatan Service
akan tetap diterima, meskipun proses pembuatan load balancer itu sendiri gagal.
Load balancer internal
Di dalam environment, terkadang terdapat kebutuhan untuk melakukan route trafik antar
Service yang berada di dalam satu VPC.
Di dalam environmentsplit-horizon DNS kamu akan membutuhkan dua service yang mampu
melakukan mekanisme route trafik eskternal maupun internal ke endpoints yang kamu miliki.
Hal ini dapat diraih dengan cara menambahkan anotasi berikut untuk service yang disediakan oleh
penyedia layanan cloud.
Gunakan cloud.google.com/load-balancer-type: "internal" untuk master dengan versi 1.7.0 to 1.7.3.
Untuk informasi lebih lanjut, dilahkan baca dokumentasi.
Dukungan parsial untuk SSL bagi klaster yang dijalankan di AWS mulai diterapkan,
mulai versi 1.3 terdapat 3 anotasi yang dapat ditambahkan pada Service dengan tipe
LoadBalancer:
Anotasi pertama memberikan spesifikasi ARN dari sertifikat yang akan digunakan.
Sertifikat yang digunakan bisa saja berasal dari third party yang diunggah ke IAM atau
sertifikat yang dibuat secara langsung dengan menggunakan sertifikat manajer AWS.
Anotasi kedua memberikan spesifikasi bagi protokol yang digunakan oleh Pod untuk saling berkomunikasi.
Untuk HTTPS dan SSL, ELB membutuhkan Pod untuk melakukan autentikasi terhadap dirinya sendiri melalui
koneksi yang dienkripsi.
Protokol HTTP dan HTTPS akan memilih mekanisme proxy di tingkatan ke-7:
ELB akan melakukan terminasi koneksi dengan pengguna, melakukan proses parsingheaders, serta
memasukkan value bagi headerX-Forwarded-For dengan alamat IP pengguna (Pod hanya dapat melihat
alamat IP dari ELB pada akhir koneksi yang diberikan) ketika melakukan forwarding suatu request.
Protokol TCP dan SSL akan memilih mekanisme proxy pada tingkatan 4: ELB akan melakukan forwarding trafik
tanpa melakukan modifikasi headers.
Pada environment campuran dimana beberapa port diamankan sementara port lainnya dalam kondisi tidak dienkripsi,
anotasi-anotasi berikut dapat digunakan:
Pada contoh di atas, jika Service memiliki 3 buah port, yaitu: 80, 443, dan
8443, maka 443 adan 8443 akan menggunakan sertifikat SSL, tetapi 80 hanya akan
di-proxy menggunakan protokol HTTP.
Mulai versi 1.9, Service juga dapat menggunakan predefinedpolicy
untuk HTTPS atau listener SSL. Untuk melihat policy apa saja yang dapat digunakan, kamu dapat menjalankan perintah awscli:
Sejak versi 1.3.0, penggunaan anotasi berlaku untuk semua port yang diproksi oleh ELB
dan tidak dapat diatur sebaliknya.
Akses Log ELB pada AWS
Terdapat beberapa anotasi yang digunakan untuk melakukan manajemen
akses log untuk ELB pada AWS.
Anotasi service.beta.kubernetes.io/aws-load-balancer-access-log-enabled
mengatur akses log mana sajakah yang diaktifkan.
Anotasi service.beta.kubernetes.io/aws-load-balancer-access-log-emit-interval
mengatur interval (dalam menit) publikasi akses log. Kamu dapat memberikan spesifikasi interval
diantara range 5-60 menit.
Anotasi service.beta.kubernetes.io/aws-load-balancer-access-log-s3-bucket-name
mengatur nama bucket Amazon S3 dimana akses logload balancer disimpan.
Anotasi service.beta.kubernetes.io/aws-load-balancer-access-log-s3-bucket-prefix
memberikan spesifikasi hierarki logis yang kamu buat untuk bucket Amazon S3 yang kamu buat.
metadata:name:my-serviceannotations:service.beta.kubernetes.io/aws-load-balancer-access-log-enabled:"true"# Specifies whether access logs are enabled for the load balancerservice.beta.kubernetes.io/aws-load-balancer-access-log-emit-interval:"60"# The interval for publishing the access logs. You can specify an interval of either 5 or 60 (minutes).service.beta.kubernetes.io/aws-load-balancer-access-log-s3-bucket-name:"my-bucket"# The name of the Amazon S3 bucket where the access logs are storedservice.beta.kubernetes.io/aws-load-balancer-access-log-s3-bucket-prefix:"my-bucket-prefix/prod"# The logical hierarchy you created for your Amazon S3 bucket, for example _my-bucket-prefix/prod_
Mekanisme Draining Koneksi pada AWS
Mekanisme draining untuk ELB klasik dapat dilakukan dengan menggunakan anotasi
service.beta.kubernetes.io/aws-load-balancer-connection-draining-enabled serta mengatur
value-nya menjadi "true". Anotasi
service.beta.kubernetes.io/aws-load-balancer-connection-draining-timeout juga
dapat digunakan untuk mengatur maximum time (dalam detik), untuk menjaga koneksi yang ada
agar selalu terbuka sebelum melakukan deregisteringinstance.
Terdapat beberapa anotasi lain yang dapat digunakan untuk mengatur ELB klasik
sebagaimana dijelaskan seperti di bawah ini:
metadata:name:my-serviceannotations:service.beta.kubernetes.io/aws-load-balancer-connection-idle-timeout:"60"# The time, in seconds, that the connection is allowed to be idle (no data has been sent over the connection) before it is closed by the load balancerservice.beta.kubernetes.io/aws-load-balancer-cross-zone-load-balancing-enabled:"true"# Specifies whether cross-zone load balancing is enabled for the load balancerservice.beta.kubernetes.io/aws-load-balancer-additional-resource-tags:"environment=prod,owner=devops"# A comma-separated list of key-value pairs which will be recorded as# additional tags in the ELB.service.beta.kubernetes.io/aws-load-balancer-healthcheck-healthy-threshold:""# The number of successive successful health checks required for a backend to# be considered healthy for traffic. Defaults to 2, must be between 2 and 10service.beta.kubernetes.io/aws-load-balancer-healthcheck-unhealthy-threshold:"3"# The number of unsuccessful health checks required for a backend to be# considered unhealthy for traffic. Defaults to 6, must be between 2 and 10service.beta.kubernetes.io/aws-load-balancer-healthcheck-interval:"20"# The approximate interval, in seconds, between health checks of an# individual instance. Defaults to 10, must be between 5 and 300service.beta.kubernetes.io/aws-load-balancer-healthcheck-timeout:"5"# The amount of time, in seconds, during which no response means a failed# health check. This value must be less than the service.beta.kubernetes.io/aws-load-balancer-healthcheck-interval# value. Defaults to 5, must be between 2 and 60service.beta.kubernetes.io/aws-load-balancer-extra-security-groups:"sg-53fae93f,sg-42efd82e"# A list of additional security groups to be added to ELB
Dukungan Network Load Balancer (NLB) pada AWS [alpha]
Peringatan:
Ini merupakan tingkatan alpha dan tidak direkomendasikan untuk digunakan pada environmentproduction.
Sejak versi 1.9.0, Kubernetes mendukung Network Load Balancer (NLB). Untuk
menggunakan NLB pada AWS, gunakan anotasi service.beta.kubernetes.io/aws-load-balancer-type
dan atur value-nya dengan nlb.
Tidak seperti ELB klasik, NLB, melakukan forwarding IP klien melalui node.
Jika field.spec.externalTrafficPolicy diatur value-nya menjadi Cluster, maka
alamat IP klien tidak akan diteruskan pada Pod.
Dengan mengatur value dari field.spec.externalTrafficPolicy ke Local,
alamat IP klien akan diteruskan ke Pod, tapi hal ini bisa menyebabkan distribusi trafik
yang tidak merata. Node yang tidak memiliki Pod untuk Service dengan tipe LoadBalancer
akan menyebabkan kegagalan health checkNLB Target pada tahapan auto-assigned.spec.healthCheckNodePort
dan tidak akan menerima trafik apa pun.
Untuk menghasilkan distribusi trafik yang merata, kamu dapat menggunakan
DaemonSet atau melakukan spesifikasi
pod anti-affinity
agar Pod tidak di-assign ke node yang sama.
Agar trafik klien berhasil mencapai instances dibelakang ELB,
security group dari node akan diberikan rules IP sebagai berikut:
Rule
Protokol
Port
IpRange(s)
Deskripsi IpRange
Health Check
TCP
NodePort(s) (.spec.healthCheckNodePort for .spec.externalTrafficPolicy = Local)
VPC CIDR
kubernetes.io/rule/nlb/health=<loadBalancerName>
Client Traffic
TCP
NodePort(s)
.spec.loadBalancerSourceRanges (defaults to 0.0.0.0/0)
kubernetes.io/rule/nlb/client=<loadBalancerName>
MTU Discovery
ICMP
3,4
.spec.loadBalancerSourceRanges (defaults to 0.0.0.0/0)
kubernetes.io/rule/nlb/mtu=<loadBalancerName>
Perhatikan bahwa jika .spec.loadBalancerSourceRanges tidak dispesifikasikan,
Kubernetes akan mengizinkan trafik dari 0.0.0.0/0 ke Node Security Group.
Jika node memiliki akses publik, maka kamu harus memperhatikan tersebut karena trafik yang tidak berasal
dari NLB juga dapat mengakses semua instance di security group tersebut.
Untuk membatasi klien IP mana yang dapat mengakses NLB,
kamu harus memberikan spesifikasi loadBalancerSourceRanges.
spec:loadBalancerSourceRanges:- "143.231.0.0/16"
Catatan:
NLB hanya dapat digunakan dengan beberapa kelas instance tertentu baca dokumentasi AWS
untuk mengetahui lebih lanjut intance apa saja yang didukung.
Tipe ExternalName
Service dengan tipe ExternalName melakukan pemetaan antara Service dan DNS, dan bukan
ke selector seperti my-service atau cassandra. Kamu memberikan spesifikasi spec.externalName
pada Service tersebut.
Definisi Service ini, sebagai contoh, melaukan pemetaan
Servicemy-service pada namespaceprod ke DNS my.database.example.com:
ExternalName menerima alamat IPv4 dalam bentuk string,
tapi karena DNS tersusun atas angka dan bukan sebagai alamat IP.
ExternalName yang menyerupai alamat IPv4 tidak bisa di-resolve oleh CoreDNS
atau ingress-nginx karena ExternalName memang ditujukan bagi penamaan canonical DNS.
Untuk melakukan hardcode alamat IP, kamu dapat menggunakan headlessService sebagai alternatif.
Ketika melakukan pencarian hostmy-service.prod.svc.cluster.local,
servis DNS klaster akan mengembalikan recordCNAME dengan valuemy.database.example.com.
Mekanisme akses pada my-service bekerja dengan cara yang sama dengan
Service pada umumnya, perbedaan yang krusial untuk hal ini adalah mekanisme redirection
terjadi pada tingkatan DNS dan bukan melalui proxy forward. Apabila kamu berniat memindahkan basis data
yang kamu pakai ke dalam klaster, kamu hanya perlu mengganti instans basis data kamu dan menjalankannya
di dalam Pod, menambahkan selector atau endpoint yang sesuai, serta mengupah type dari
Service yang kamu gunakan.
Jika terdapat sebuah alamat IP eksternal yang melakukan mekanisme route ke satu atau lebih node yang ada di klaster, Service Kubernetes dapat diekspos
dengan menggunakan externalIP. Trafik yang diarahkan ke klaster dengan IP eksternal
(sebagai destinasi IP), pada portService akan di-route ke salah satu endpointService.
Value dari externalIP tidak diatur oleh Kubernetes dan merupakan tanggung jawab
dari administrator klaster.
Pada ServiceSpec, kamu dapat memberikan spesifikasi externalIP dan ServiceTypes.
Pada contoh di bawah ini. "my-service" dapat diakses oleh klien pada "198.51.100.32:80" (externalIP:port).
Penggunaan proxyuserspace untuk VIP dapat digunakan untuk skala kecil hingga menengah,
meski begitu hal ini tidak scalable untuk klaster yang sangat besar dan memiliki ribuan Service.
Perhatikan Desain proposal orisinil untuk portal untuk informasi
lebih lanjut.
Penggunaan proxyuserspace menghilangkan source-IP dari packet yang mengakses
sebuah Service. Hal ini membuat mekanisme firewall menjadi sulit untuk diterapkan.
Proxyiptables tidak menghilangkan source IP yang berasal dari dalam klaster,
meski begitu, hal ini masih berimbas pada klien yang berasal dari Service dengan tipe
load-balancer atau node-port.
Field tipe didesain sebagai fungsionalitas yang berantai - setiap tingkatan
menambahkan tambahan pada tingkatansebelumnya. Hal ini tidak selalu berlaku bagi
semua penyedia layanan cloud (misalnya saja Google Compute Engine tidak perlu
melakukan alokasi NodePort untuk membuat LoadBalancer bekerja sebagaimana mestinya,
hal ini berbeda dengan AWS yang memerlukan hal ini, setidaknya untuk API yang mereka miliki
saat ini).
Pengerjaan lebih lanjut
Di masa mendatang, kami berencana untuk membuat policyproxy menjadi lebih
bervariasi dan bukan hanya round robin, misalnya saja master-elected atau sharded.
Kami juga berharap bahwa beberapa Service bisa saja memiliki load balancer yang sebenarnya,
suatu kasus dimana VIP akan secara langsung mengantarkan paket.
Kami ingin meningkatkan dukungan lebih lanjut untuk Service dengan tingkatan Service L7(HTTP).
Kami ingin memiliki mode ingress yang lebih fleksibel untuk Service yang
mencakup mode ClusterIP, NodePort, dan LoadBalancer dan banyak lagi.
Detail mendalam mengenai IP virtual
Informasi sebelumnya sudah cukup bagi sebagian orang yang hanya ingin menggunakan
Service. Meskipun begitu, terdapat banyak hal yang sebenarnya terjadi dan akan
sangat bermanfaat untuk dipelajari lebih lanjut.
Menghindari collison
Salah satu filosofi Kubernetes adalah pengguna tidak mungkin menghadapi situasi
dimana apa yang mereka mengalami kegagalan tanpa adanya alasan yang jelas. Dalam kasus ini,
kita akan coba memahami lebih lanjut mengenai network port - pengguna tidak seharusnya memilih
nomor port jika hal itu memungkinkan terjadinya collision dengan pengguna lainnya. Hal ini
merupakan mekanisme isolasi kegagalan.
Agar pengguna dapat menentukan nomor port bagi Service mereka, kita harus
memastikan bahwa tidak ada dua Service yang mengalami collision. Kita melakukan
hal tersebut dengan cara melakukan alokasi alamat IP pada setiap Service.
Untuk memastikan setiap Service memiliki alamat IP yang unik, sebuah allocator
internal akan secara atomik melakukan pemetaan alokasi global di dalam etcd ketika
membuat sebuah Service baru. Pemetaan objek harus tersedia pada registryService
dimana Service akan diberikan sebuah IP, jika tidak, proses pembuatan Service akan gagal
dan sebuah pesan akan memberikan informasi bahwa alamat IP tidak dapat dialokasikan.
Sebuah backgroudcontroller bertanggung jawab terhadap mekanisme pemetaan tersebut (migrasi
dari versi Kubernetes yang digunakan dalam memory locking) sekaligus melakukan pengecekan
terhadap assignment yang tidak valid yang terjadi akibat intervensi administrator dan melakukan
penghapusan daftar IP yang dialokasikan tapi tidak digunakan oleh Service mana pun.
IP dan VIP
Tidak seperti alamat IP Pod, yang akan di route ke destinasi yang "pasti",
IP Service tidak mengarahkan request hanya pada satu host. Sebagai gantinya,
kita mneggunakan iptables (logika pemrosesan paket pada Linux) untuk melakukan definisi
alamat IP virtual yang secara transparan akan diarahkan sesuai kebutuhan. Ketika klien
dihubungkan pada VIP, trafik yang ada akan secara otomatis dialihkan pada endpoint yang sesuai.
Variabel environment dan DNS untuk Service terdiri dalam bentuk VIP dan port.
Kami mendukung tiga jenis mode proxy - userspace, iptables, dan ipvs yang memiliki
perbedaan cara kerja satu sama lainnya.
Userspace
Sebagai contoh, anggaplah kita memiliki aplikasi image processing seperti yang sudah
disebutkan di atas. Ketika Servicebackend dibuat, master Kubernetes akan mengalokasikan
sebuah alamat IP virtual, misalnya 10.0.0.1. Dengan asumsi port dari Service tersebut adalah 1234,
maka Service tersebut akan diamati oleh semua instancekube-proxy yang ada di klaster.
Ketika sebuah proxy mendapati sebuah Service baru, proxy tersebut akan membuka sebuah portacak, menyediakan iptables yang mengarahkan VIP pada port yang baru saja dibuat, dan mulai
koneksi pada port tersebut.
Ketika sebuah klien terhubung ke VIP dan terdapat rulesiptables
yang diterapkan, paket akan diarahkan ke port dari proxyService itu sendiri.
ProxyService akan memilih sebuah backend, dan mulai melakukan mekanisme proxy
trafik dari klien ke backend.
Dengan demikian, pemilik Service dapat memilih port mana pun yang dia inginkan
tanpa adanya kemungkinan terjadinya collision. Klien dapat dengan mudah mengakses IP dan port,
tanpa harus mengetahui Pod mana yang sebenarnya diakses.
Iptables
Kembali, bayangkan apabila kita memiliki aplikasi image processing seperti yang sudah
disebutkan di atas. Ketika Servicebackend dibuat, master Kubernetes akan mengalokasikan
sebuah alamat IP virtual, misalnya 10.0.0.1. Dengan asumsi port dari Service tersebut adalah 1234,
maka Service tersebut akan diamati oleh semua instancekube-proxy yang ada di klaster.
Ketika sebuah proxy mendapati sebuah Service baru, proxy tersebut akan melakukan instalasi
serangkaian rulesiptables yang akan melakukan redirect VIP ke rules tiap Service. Rules
untuk tiap Service ini terkait dengan rules tiap Endpoints yang mengarahkan (destinasi NAT)
ke backend.
Ketika sebuah klien terhubung ke VIP dan terdapat _rules _iptables
yang diterapkan. Sebuah backend akan dipilih (hal ini dapat dilakukan berdasarkan session affinity
maupun secara acak) dan paket-paket yang ada akan diarahkan ke backend. Tidak seperti mekanisme
yang terjadi di userspace, paket-paket yang ada tidak pernah disalin ke userspace, kube-proxy
tidak harus aktif untuk menjamin kerja VIP, serta IP klien juga tidak perlu diubah.
Tahapan yang dijalankan sama dengan tahapan yang dijalankan ketika trafik masuk melalui sebuah node-port
atau load-balancer, meskipun pada dua kasus di atas klien IP tidak akan mengalami perubahan.
Ipvs
Operasi iptables berlangsung secara lambat pada klaster dengan skala besar (lebih dari 10.000 Service).
IPVS didesain untuk mekanisme load balance dan berbasis pada hash tables yang berada di dalam kernel.
Dengan demikian kita dapat mendapatkan performa yang konsisten pada jumlah Service yang cukup besar dengan
menggunakan kube-proxy berbasis ipvs. Sementara itu, kube-proxy berbasis ipvs memiliki algoritma
load balance yang lebih bervariasi (misalnya saja least conns, locality, weighted, persistence).
Objek API
Service merupakan resourcetop-level pada API Kubernetes.
Penjelasan lebih lanjut mengenai objek API dapat ditemukan pada:
objek API Service.
Protokol yang didukung
TCP
FEATURE STATE:Kubernetes v1.0 [stable]
Kamu dapat menggunakan TCP untuk Service dengan type apa pun, dan protokol ini merupakan
protokol default yang digunakan.
UDP
FEATURE STATE:Kubernetes v1.0 [stable]
Kamu dapat menggunakan UDP untuk sebagian besar Service.
Untuk Service dengan type=LoadBalancer, dukungan terhadap UDP
bergantung pada penyedia layanan cloud yang kamu gunakan.
HTTP
FEATURE STATE:Kubernetes v1.1 [stable]
Apabila penyedia layanan cloud yang kamu gunakan mendukung, kamu dapat menggunakan
Service dengan typeLoadBalancer untuk melakukan mekanisme reverseproxy
bagi HTTP/HTTPS, dan melakukan forwarding ke Endpoints dari _Service.
Catatan:
Kamu juga dapat menggunakan Ingress sebagai salah satu
alternatif penggunaan Service untuk HTTP/HTTPS.
Protokol PROXY
FEATURE STATE:Kubernetes v1.1 [stable]
Apabila penyedia layanan cloud yang kamu gunakan mendukung, (misalnya saja, AWS),
Service dengan typeLoadBalancer untuk melakukan konfigurasi load balancer
di luar Kubernetes sendiri, serta akan melakukan forwarding koneksi yang memiliki prefiks
protokol PROXY.
Load balancer akan melakukan serangkaian inisiasi octet yang memberikan
deskripsi koneksi yang datang, dengan bentuk yang menyerupai:
PROXY TCP4 192.0.2.202 10.0.42.7 12345 7\r\n
yang kemudian diikuti data dari klien.
SCTP
FEATURE STATE:Kubernetes v1.12 [alpha]
Kubernetes memberikan dukungan bagi SCTP sebagai value dari definition yang ada pada
Service, Endpoints, NetworkPolicy dan Pod sebagai fitur alpha. Untuk mengaktifkan fitur ini,
administrator klaster harus mengaktifkan feature gateSCTPSupport pada apiserver, contohnya
“--feature-gates=SCTPSupport=true,...”. Ketika fature gate ini diaktifkan, pengguna dapat
memberikan value SCTP pada fieldprotocolService, Endpoints, NetworkPolicy dan Pod.
Kubernetes kemudian akan melakukan pengaturan agar jaringan yang digunakan agar jaringan tersebut menggunakan SCTP,
seperti halnya Kubernetes mengatur jaringan agar menggunakan TCP.
Perhatian
Dukungan untuk asoasiasi multihomed SCTP
Dukungan untuk asosiasi multihomed SCTP membutuhkan plugin CNI yang dapat memberikan
pengalokasian multiple interface serta alamat IP pada sebuah Pod.
NAT untuk asosiasi multihomed SCTP membutuhkan logika khusus pada modul kernel terkait.
Service dengan type=LoadBalancer
Sebuah Service dengan typeLoadBalancer dan protokol SCTP dapat dibuat
hanya jika implementasi load balancer penyedia layanan cloud menyediakan dukungan
bagi protokol SCTP. Apabila hal ini tidak terpenuhi, maka request pembuatan Servixe ini akan ditolak.
Load balancer yang disediakan oleh penyedia layanan cloud yang ada saat ini (Azure, AWS, CloudStack, GCE, OpenStack) tidak mendukung SCTP.
Windows
SCTP tidak didukung pada node berbasis Windows.
Kube-proxyuserspace
Kube-proxy tidak mendukung manajemen asosiasi SCTP ketika hal ini dilakukan pada mode
userspace
Topologi Service memungkinkan Service untuk
merutekan lalu lintas jaringan berdasarkan topologi Node dalam klaster. Misalnya, suatu
layanan dapat menentukan lalu lintas jaringan yang lebih diutamakan untuk dirutekan ke
beberapa endpoint yang berada pada Node yang sama dengan klien, atau pada
availability zone yang sama.
Pengantar
Secara bawaan lalu lintas jaringan yang dikirim ke ClusterIP atau NodePort dari Service
dapat dialihkan ke alamat backend untuk Service tersebut. Sejak Kubernetes 1.7
dimungkinkan untuk merutekan lalu lintas jaringan "eksternal" ke Pod yang berjalan di
Node yang menerima lalu lintas jaringan, tetapi fitur ini tidak didukung untuk ClusterIP dari
Service, dan topologi yang lebih kompleks — seperti rute zonasi —
belum memungkinkan. Fitur topologi Service mengatasi kekurangan ini dengan
mengizinkan pembuat layanan untuk mendefinisikan kebijakan dalam merutekan lalu lintas jaringan
berdasarkan label Node untuk Node-Node asal dan tujuan.
Dengan menggunakan label Node yang sesuai antara asal dan tujuan, operator dapat
menunjuk kelompok Node mana yang "lebih dekat" dan mana yang "lebih jauh" antara satu sama lain,
dengan menggunakan metrik apa pun yang masuk akal untuk memenuhi persyaratan
dari operator itu. Untuk sebagian besar operator di publik cloud, misalnya, ada
preferensi untuk menjaga layanan lalu lintas jaringan dalam zona yang sama, karena lalu lintas jaringan
antar zona memiliki biaya yang dibebankan, sementara lalu lintas jaringan
dalam zona yang sama tidak ada biaya. Kebutuhan umum lainnya termasuk kemampuan untuk merutekan
lalu lintas jaringan ke Pod lokal yang dikelola oleh sebuah DaemonSet, atau menjaga lalu lintas jaringan ke
Node yang terhubung ke top-of-rack switch yang sama untuk mendapatkan
latensi yang terendah.
Menggunakan Topologi Service
Jika klaster kamu mengaktifkan topologi Service kamu dapat mengontrol rute lalu lintas jaringan Service
dengan mengatur bagian topologyKeys pada spesifikasi Service. Bagian ini
adalah daftar urutan label-label Node yang akan digunakan untuk mengurutkan endpoint
saat mengakses Service ini. Lalu lintas jaringan akan diarahkan ke Node yang nilai
label pertamanya cocok dengan nilai dari Node asal untuk label yang sama. Jika
tidak ada backend untuk Service pada Node yang sesuai, maka label kedua akan
dipertimbangkan, dan seterusnya, sampai tidak ada label yang tersisa.
Jika tidak ditemukan kecocokan, lalu lintas jaringan akan ditolak, sama seperti jika tidak ada
sama sekali backend untuk Service tersebut. Artinya, endpoint dipilih
berdasarkan kunci topologi yang pertama yang tersedia pada backend. Jika dalam
bagian ini ditentukan dan semua entri tidak memiliki backend yang sesuai dengan
topologi klien, maka Service tidak memiliki backend untuk klien dan koneksi harus
digagalkan. Nilai khusus "*" dapat digunakan untuk mengartikan "topologi
apa saja". Nilai catch-all ini, jika digunakan, maka hanya sebagai
nilai terakhir dalam daftar.
Jika topologyKeys tidak ditentukan atau kosong, tidak ada batasan topologi
yang akan diterapkan.
Seandainya sebuah klaster dengan Node yang dilabeli dengan nama host ,
nama zona, dan nama wilayah mereka, maka kamu dapat mengatur nilai
topologyKeys dari sebuah Service untuk mengarahkan lalu lintas jaringan seperti berikut ini.
Hanya ke endpoint dalam Node yang sama, gagal jika tidak ada endpoint pada Node: ["kubernetes.io/hostname"].
Lebih memilih ke endpoint dalam Node yang sama, jika tidak ditemukan maka ke endpoint pada zona yang sama, diikuti oleh wilayah yang sama, dan selain itu akan gagal: ["kubernetes.io/hostname ", "topology.kubernetes.io/zone", "topology.kubernetes.io/region"]. Ini mungkin berguna, misalnya, dalam kasus di mana lokalitas data sangatlah penting.
Lebih memilih ke endpoint dalam zona yang sama, tetapi memilih endpoint mana saja yang tersedia apabila tidak ada yang tersedia dalam zona ini: ["topology.kubernetes.io/zone ","*"].
Batasan
Topologi Service tidak kompatibel dengan externalTrafficPolicy=Local, dan karena itu Service tidak dapat menggunakan kedua fitur ini sekaligus. Dimungkinkan untuk menggunakan kedua fitur pada klaster yang sama untuk Service yang berbeda, bukan untuk Service yang sama.
Untuk saat ini kunci topologi yang valid hanya terbatas pada kubernetes.io/hostname, topology.kubernetes.io/zone, dan topology.kubernetes.io/region, tetapi akan digeneralisasikan ke label Node yang lain di masa depan.
Kunci topologi harus merupakan kunci label yang valid dan paling banyak hanya 16 kunci yang dapat ditentukan.
Nilai catch-all, "*", harus menjadi nilai terakhir pada kunci topologi, jika nilai itu digunakan.
Contoh
Berikut ini adalah contoh umum penggunaan fitur topologi Service.
Hanya pada endpoint pada Node lokal
Service yang hanya merutekan ke endpoint pada Node lokal. Jika tidak ada endpoint pada Node, lalu lintas jaringan akan dihentikan:
Hanya untuk endpoint pada zona atau wilayah yang sama
Service yang lebih memilih endpoint dalam zona yang sama daripada wilayah yang sama. Jika tidak ada endpoint pada keduanya, maka lalu lintas jaringan akan dihentikan.
Lebih memilih endpoint pada Node lokal, zona yang sama, dan kemudian wilayah yang sama
Service yang lebih memilih endpoint pada Node lokal, zona yang sama, dan kemudian baru wilayah yang sama,
namun jika tetap tidak ditemukan maka akan memilih endpoint diseluruh klaster.
EndpointSlice menyediakan sebuah cara yang mudah untuk melacak endpoint jaringan dalam sebuah
klaster Kubernetes. EndpointSlice memberikan alternatif yang lebih scalable dan lebih dapat diperluas dibandingkan dengan Endpoints.
Motivasi
Endpoints API telah menyediakan sebuah cara yang mudah dan sederhana untuk
melacak endpoint jaringan pada Kubernetes. Sayangnya, seiring dengan besarnya klaster Kubernetes
dan Service, batasan-batasan yang dimiliki API tersebut semakin terlihat.
Terutama, hal tersebut termasuk kendala-kendala mengenai proses scalingendpoint jaringan
dalam jumlah yang besar.
Karena semua endpoint jaringan untuk sebuah Service disimpan dalam satu sumber daya
Endpoints, sumber daya tersebut dapat menjadi cukup besar. Hal itu dapat mempengaruhi kinerja
dari komponen-komponen Kubernetes (terutama master control plane) dan menyebabkan
lalu lintas jaringan dan pemrosesan yang cukup besar ketika Endpoints berubah.
EndpointSlice membantu kamu menghindari masalah-masalah tersebut dan juga menyediakan platform
yang dapat diperluas untuk fitur-fitur tambahan seperti topological routing.
Sumber daya EndpointSlice
Pada Kubernetes, sebuah EndpointSlice memiliki referensi-referensi terhadap sekumpulan endpoint
jaringan. Controller EndpointSlice secara otomatis membuat EndpointSlice
untuk sebuah Service Kubernetes ketika sebuah selektor dituliskan. EndpointSlice tersebut akan memiliki
referensi-referensi menuju Pod manapun yang cocok dengan selektor pada Service tersebut. EndpointSlice mengelompokkan
endpoint jaringan berdasarkan kombinasi Service dan Port yang unik.
Nama dari sebuah objek EndpointSlice haruslah berupa
nama subdomain DNS yang sah.
Sebagai contoh, berikut merupakan sampel sumber daya EndpointSlice untuk sebuah Service Kubernetes
yang bernama example.
Secara bawaan, setiap EndpointSlice yang dikelola oleh controller EndpointSlice tidak akan memiliki
lebih dari 100 endpoint. Di bawah skala tersebut, EndpointSlice akan memetakan 1:1
dengan Endpoints dan Service dan akan memiliki kinerja yang sama.
EndpointSlice dapat bertindak sebagai sumber kebenaran untuk kube-proxy sebagai acuan mengenai
bagaimana cara untuk merutekan lalu lintas jaringan internal. Ketika diaktifkan, EndpointSlice semestinya memberikan peningkatan
kinerja untuk Service yang memiliki Endpoints dalam jumlah besar.
Tipe-tipe Alamat
EndpointSlice mendukung tiga tipe alamat:
IPv4
IPv6
FQDN (Fully Qualified Domain Name)
Topologi
Setiap endpoint pada EndpointSlice dapat memiliki informasi topologi yang relevan.
Hal ini digunakan untuk mengindikasikan di mana endpoint berada, berisi informasi mengenai
Node yang bersangkutan, zona, dan wilayah. Ketika nilai-nilai tersebut tersedia,
label-label Topology berikut akan ditambahkan oleh controller EndpointSlice:
kubernetes.io/hostname - Nama dari Node tempat endpoint berada.
topology.kubernetes.io/zone - Zona tempat endpoint berada.
topology.kubernetes.io/region - Region tempat endpoint berada.
Nilai-nilai dari label-label berikut berasal dari sumber daya yang diasosiasikan dengan tiap
endpoint pada sebuah slice. Label hostname merepresentasikan nilai dari kolom NodeName
pada Pod yang bersangkutan. Label zona dan wilayah merepresentasikan nilai
dari label-label dengan nama yang sama pada Node yang bersangkutan.
Pengelolaan
Secara bawaan, EndpointSlice dibuat dan dikelola oleh controller
EndpointSlice. Ada berbagai macam kasus lain untuk EndpointSlice, seperti
implementasi service mesh, yang memungkinkan adanya entitas atau controller lain
yang dapat mengelola beberapa EndpointSlice sekaligus. Untuk memastikan beberapa entitas dapat
mengelola EndpointSlice tanpa mengganggu satu sama lain, sebuah
label endpointslice.kubernetes.io/managed-by digunakan untuk mengindikasikan entitas
yang mengelola sebuah EndpointSlice. Controller EndpointSlice akan menambahkan
endpointslice-controller.k8s.io sebagai nilai dari label tersebut pada seluruh
EndpointSlice yang dikelolanya. Entitas lain yang mengelola EndpointSlice juga diharuskan untuk
menambahkan nilai yang unik untuk label tersebut.
Kepemilikan
Pada kebanyakan kasus, EndpointSlice akan dimiliki oleh Service yang diikutinya. Hal ini diindikasikan dengan referensi pemilik pada tiap EndpointSlice dan
juga label kubernetes.io/service-name yang memudahkan pencarian seluruh
EndpointSlice yang dimiliki oleh sebuah Service.
Controller EndpointSlice
Controller EndpointSlice mengamati Service dan Pod untuk memastikan EndpointSlice
yang bersangkutan berada dalam kondisi terkini. Controller EndpointSlice akan mengelola EndpointSlice untuk
setiap Service yang memiliki selektor. Ini akan merepresentasikan IP dari Pod
yang cocok dengan selektor dari Service tersebut.
Ukuran EndpointSlice
Secara bawaan, jumlah endpoint yang dapat dimiliki tiap EndpointSlice dibatasi sebanyak 100 endpoint. Kamu dapat
mengaturnya melalui opsi --max-endpoints-per-slicekube-controller-manager sampai dengan
jumlah maksimum sebanyak 1000 endpoint.
Distribusi EndpointSlice
Tiap EndpointSlice memiliki sekumpulan port yang berlaku untuk seluruh endpoint dalam sebuah sumber daya. Ketika nama port digunakan untuk sebuah Service, Pod mungkin mendapatkan
nomor target port yang berbeda-beda untuk nama port yang sama, sehingga membutuhkan
EndpointSlice yang berbeda. Hal ini mirip dengan logika mengenai bagaimana subset dikelompokkan
dengan Endpoints.
Controller EndpointSlice akan mencoba untuk mengisi EndpointSlice sebanyak mungkin, tetapi tidak
secara aktif melakukan rebalance terhadap EndpointSlice tersebut. Logika dari controller cukup sederhana:
Melakukan iterasi terhadap EndpointSlice yang sudah ada, menghapus endpoint yang sudah tidak lagi
dibutuhkan dan memperbarui endpoint yang sesuai yang mungkin telah berubah.
Melakukan iterasi terhadap EndpointSlice yang sudah dimodifikasi pada langkah pertama dan
mengisinya dengan endpoint baru yang dibutuhkan.
Jika masih tersisa endpoint baru untuk ditambahkan, mencoba untuk menambahkannya pada
slice yang tidak berubah sebelumnya dan/atau membuat slice yang baru.
Terlebih penting, langkah ketiga memprioritaskan untuk membatasi pembaruan EndpointSlice terhadap
distribusi dari EndpointSlice yang benar-benar penuh. Sebagai contoh, jika ada 10
endpoint baru untuk ditambahkan dan ada 2 EndpointSlice yang masing-masing memiliki ruang untuk 5 endpoint baru,
pendekatan ini akan membuat sebuah EndpointSlice baru daripada mengisi 2
EndpointSlice yang sudah ada. Dengan kata lain, pembuatan sebuah EndpointSlice
lebih diutamakan daripada pembaruan beberapa EndpointSlice.
Dengan kube-proxy yang berjalan pada tiap Node dan mengamati EndpointSlice, setiap perubahan
pada sebuah EndpointSlice menjadi sangat mahal karena hal tersebut akan dikirimkan ke
setiap Node dalam klaster. Pendekatan ini ditujukan untuk membatasi jumlah
perubahan yang perlu dikirimkan ke setiap Node, meskipun hal tersebut berdampak pada banyaknya
EndpointSlice yang tidak penuh.
Pada praktiknya, distribusi yang kurang ideal seperti ini akan jarang ditemukan. Kebanyakan perubahan yang diproses oleh controller EndpointSlice akan cukup kecil untuk dapat masuk pada
EndpointSlice yang sudah ada, dan jika tidak, cepat atau lambat sebuah EndpointSlice baru
akan segera dibutuhkan. Pembaruan bertahap (rolling update) dari Deployment juga menyediakan sebuah proses
pengemasan ulang EndpointSlice yang natural seiring dengan digantikannya seluruh Pod dan endpoint yang
bersangkutan.
Laman ini menyediakan ikhtisar dari dukungan DNS oleh Kubernetes.
Pendahuluan
Kubernetes DNS melakukan scheduling DNS Pod dan Service yang ada pada klaster, serta
melakukan konfigurasi kubelet untuk memberikan informasi bagi setiap Container
untuk menggunakan DNS Service IP untuk melakukan resolusi DNS.
Apa Sajakah yang Mendapatkan Nama DNS?
Setiap Service yang didefinisikan di dalam klaster (termasuk server DNS itu sendiri)
memiliki nama DNS. Secara default, sebuah list pencarian DNS pada Pod klien
akan mencantumkan namespace Pod itu sendiri serta domain default klaster. Hal ini dapat diilustrasikan
dengan contoh berikut:
Asumsikan sebuah Service dengan nama foo pada Kubernetes dengan namespacebar.
Sebuah Pod yang dijalankan di namespacebar dapat melakukan resolusi
terhadap Service ini dengan melakukan query DNS
untuk foo. Sebuah Pod yang dijalankan pada namespace quux dapat melakukan
resolusi Service ini dengan melakukan query DNS untuk foo.bar.
Bagian di bawah ini akan menampilkan detail tipe rekaman serta layout yang didukung.
Layout atau nama query lain yang dapat digunakan dianggap sebagai detail implementasi
yang bisa saja berubah tanpa adanya pemberitahuan sebelumnya. Untuk informasi spesifikasi
terbaru kamu dapat membaca Service Discovery pada Kubernetes berbasis DNS.
Service
A record
Service "Normal" (bukan headless) akan diberikan sebuah A record untuk sebuah nama dalam bentuk
my-svc.my-namespace.svc.cluster-domain.example. Inilah yang kemudian digunakan untuk melakukan
resolusi IP klaster dari Service tersebut.
Service "Headless" (tanpa IP klaster) juga memiliki sebuah A record DNS dengan format
my-svc.my-namespace.svc.cluster-domain.example. Tidak seperti halnya Service normal,
DNS ini akan melakukan resolusi pada serangkauan IP dari Pod yang dipilih oleh Service tadi.
Klien diharapkan untuk mengkonsumsi serangkaian IP ini atau cara lain yang digunakan adalah pemilihan
menggunakan penjadwalan Round-Robin dari set yang ada.
SRV record
SRV record dibuat untuk port bernama yang merupakan bagian dari Service normal maupun Headless
Services.
Untuk setiap port bernama, SRV record akan memiliki format
_my-port-name._my-port-protocol.my-svc.my-namespace.svc.cluster-domain.example.
Untuk sebuah Service normal, ini akan melakukan resolusi pada nomor port dan
nama domain: my-svc.my-namespace.svc.cluster-domain.example.
Untuk Service headless, ini akan melakukan resolusi pada serangkaian Pod yang merupakan backend dari Service
tersebut yang memiliki format: auto-generated-name.my-svc.my-namespace.svc.cluster-domain.example.
Pod
Hostname Pod dan Field Subdomain
Saat ini ketika sebuah Pod dibuat, hostname-nya adalah nilai dari metadata.name.
Spek Pod memiliki field opsional hostname, yang dapat digunakan untuk menspesifikasikan
hostname Pod. Ketika dispesifikasikan, maka nama ini akan didahulukan di atas nama Pod .
Misalnya, sebuah Pod dengan hostname yang diberikan nilai "my-host", maka hostname Pod tersebut akan menjadi "my-host".
Spek Pod juga memiliki field opsional subdomain yang dapat digunakan untuk menspesifikasikan
subdomain Pod tersebut. Misalnya saja sebuah Pod dengan hostname yang diberi nilai "foo", dan subdomain
yang diberi nilai "bar", pada namespace "my-namespace", akan memiliki fully qualified
domain name (FQDN) "foo.bar.my-namespace.svc.cluster-domain.example".
Contoh:
apiVersion:v1kind:Servicemetadata:name:default-subdomainspec:selector:name:busyboxclusterIP:Noneports:- name:foo# Actually, no port is needed.port:1234targetPort:1234---apiVersion:v1kind:Podmetadata:name:busybox1labels:name:busyboxspec:hostname:busybox-1subdomain:default-subdomaincontainers:- image:busybox:1.28command:- sleep- "3600"name:busybox---apiVersion:v1kind:Podmetadata:name:busybox2labels:name:busyboxspec:hostname:busybox-2subdomain:default-subdomaincontainers:- image:busybox:1.28command:- sleep- "3600"name:busybox
Jika terdapat sebuah Service headless memiliki nama yang sama dengan
subdomain dari suatu Pod pada namespace yang sama, server KubeDNS klaster akan mengembalikan
A record untuk FQDN Pod.
Sebagai contoh, misalnya terdapat sebuah Pod dengan hostname "busybox-1" dan
subdomain "default-subdomain", serta sebuah Service headless dengan nama "default-subdomain" berada pada suatu namespace yang sama, maka Pod tersebut akan menerima FQDN dirinya sendiri
sebagai "busybox-1.default-subdomain.my-namespace.svc.cluster-domain.example". DNS mengembalikan
A record pada nama tersebut dan mengarahkannya pada IP Pod. Baik Pod "busybox1" dan
"busybox2" bisa saja memiliki A record yang berbeda.
Objek Endpoint dapat menspesifikasikan hostname untuk alamat endpoint manapun
beserta dengan alamat IP-nya.
Catatan:
Karena A record tidak dibuat untuk sebuah Pod, maka hostname diperlukan
agar sebuah Pod memiliki A record. Sebuah Pod yang tidak memiliki hostname
tetapi memiliki subdomain hanya akan membuat sebuah A record untuk Service headless
(default-subdomain.my-namespace.svc.cluster-domain.example), yang merujuk pada IP dari
Pod tersebut. Pod juga harus dalam status ready agar dapat memiliki A record kecuali
fieldpublishNotReadyAddresses=True diaktifkan pada Service.
Kebijakan DNS Pod
Kebijakan DNS dapat diaktifkan untuk setiap Pod. Kubernetes saat ini mendukung
kebijakan DNS spesifik Pod (pod-specific DNS policies). Kebijakan ini
dispesifikasikan pada fielddnsPolicy yang ada pada spek Pod.
"Default": Pod akan mewarisi konfigurasi resolusi yang berasal dari Node
dimana Pod tersebut dijalankan.
Silakan baca diskusi terkait
untuk detailnya.
"ClusterFirst": Query DNS apa pun yang tidak sesuai dengan sufiks domain klaster yang sudah dikonfigurasi
misalnya "www.kubernetes.io", akan di-forward ke nameserverupstream yang diwarisi dari Node.
Administrator klaster bisa saja memiliki stub-domain atau DNS usptream lain yang sudah dikonfigurasi.
Silakan lihat diskusi terkait
untuk detail lebih lanjut mengenai bagaimana query DNS melakukan hal tersebut.
"ClusterFirstWithHostNet": Untuk Pod yang dijalankan dengan menggunakan hostNetwork, kamu harus
secara eksplisit mengaktifkan kebijakan DNS-nya menjadi "ClusterFirstWithHostNet".
"None": Hal ini mengisikan sebuah Pod untuk mengabaikan konfigurasi DNS dari environment Kubernetes
Semua pengaturan DNS disediakan menngunakan fielddnsConfig yang ada pada spek Pod.
Silakan lihat konfigurasi DNS Pod di bawah.
Catatan:
"Default" bukan merupakan nilai default kebijakan DNS.
Jika dnsPolicy tidak secara eksplisit dispesifikasikan, maka “ClusterFirst” akan digunakan.
Contoh di bawah ini menunjukkan sebuah Pod dengan kebijakan
DNS yang diubah menjadi "ClusterFirstWithHostNet" karena fieldhostNetwork
diubah menjadi true.
Konfigurasi DNS Pod mengizinkan pengguna untuk memiliki
lebih banyak kontrol terhadap pengaturan DNS pada Pod.
FielddnsConfig bersifat opsional dan dapat digunakan dengan
pengaturan dnsPolicy apa pun.
Meskipun begitu, ketika fielddnsPolicy pada sebuah Pod diubah menjadi "None",
maka fielddnsConfig harus dispesifikasikan.
Berikut merupakan properti yang dapat dispesifikasikan oleh pengguna
pada fielddnsConfig:
nameservers: serangkaian alamat IP yang akan digunakan sebagai server DNS bagi Pod.
Jumlah maksimum dari IP yang dapat didaftarkan pada field ini adalah tiga buah IP.
Ketika sebuah dnsPolicy pada Pod diubah menjadi "None", maka list ini setidaknya
harus mengandung sebuah alamat IP, selain kasus tersebut properti ini bersifat opsional.
Server yang didaftarkan akan digabungkan di dalam nameserver dasar yang dihasilkan dari
kebijakan DNS yang dispesifikasikan, apabila terdapat duplikat terhadap alamat yang didaftarkan
maka alamat tersebut akan dihapus.
searches: merupakan serangkaian domain pencarian DNS yang digunakan untuk proses lookup pada Pod.
Properti ini bersifat opsional. Ketika dispesifikasikan, list yang disediakan akan digabungkan dengan
nama domain pencarian dasar yang dihasilkan dari kebijakan DNS yang dipilih. Alamat yang duplikat akan dihapus.
Nilai maksimum domain pencarian yang dapat didaftarkan adalah 6 domain.
options: merupakan sebuah list opsional yang berisikan objek dimana setiap objek
bisa saja memiliki properti name (yang bersifat wajib). Isi dari properti ini
akan digabungkan dengan opsi yang dihasilkan kebijakan DNS yang digunakan.
Alamat yang duplikat akan dihapus.
Di bawah ini merupakan contoh sebuah Pod dengan pengaturan DNS kustom:
Sekarang kamu memiliki aplikasi yang telah direplikasi, kamu dapat mengeksposnya di jaringan. Sebelum membahas pendekatan jaringan di Kubernetes, akan lebih baik jika kamu paham bagaimana jaringan bekerja di dalam Docker.
Secara default, Docker menggunakan jaringan host, jadi kontainer dapat berkomunikasi dengan kontainer lainnya jika mereka berada di dalam node yang sama. Agar kontainer Docker dapat berkomunikasi antar node, masing-masing kontainer tersebut harus diberikan port yang berbeda di alamat IP node tersebut, yang akan diteruskan (proxied) ke dalam kontainer. Artinya adalah para kontainer di dalam sebuah node harus berkoordinasi port mana yang akan digunakan atau dialokasikan secara otomatis.
Akan sulit untuk mengkoordinasikan port yang digunakan oleh banyak pengembang. Kubernetes mengasumsikan bahwa Pod dapat berkomunikasi dengan Pod lain, terlepas di Node mana Pod tersebut di deploy. Kubernetes memberikan setiap Pod alamat ClusterIP sehingga kamu tidak perlu secara explisit membuat jalur antara Pod ataupun memetakan port kontainer ke dalam port di dalam Node tersebut. Ini berarti kontainer di dalam sebuah Pod dapat berkomunikasi dengan localhost via port, dan setiap Pod di dalam klaster dapat berkomunikasi tanpa NAT. Panduan ini akan membahas bagaimana kamu dapat menjalankan sebuah layanan atau aplikasi di dalam model jaringan di atas.
Panduan ini menggunakan server nginx sederhana untuk mendemonstrasikan konsepnya. Konsep yang sama juga ditulis lebih lengkap di Aplikasi Jenkins CI.
Mengekspos Pod ke dalam klaster
Kita melakukan ini di beberapa contoh sebelumnya, tetapi mari kita lakukan sekali lagi dan berfokus pada prespektif jaringannya. Buat sebuah nginx Pod, dan perhatikan bahwa templat tersebut mempunyai spesifikasi port kontainer:
Kamu dapat melakukan akses dengan ssh ke dalam node di dalam klaster dan mengakses IP Pod tersebut menggunakan curl. Perlu dicatat bahwa kontainer tersebut tidak menggunakan port 80 di dalam node, atau aturan NAT khusus untuk merutekan trafik ke dalam Pod. Ini berarti kamu dapat menjalankan banyak nginx Pod di node yang sama dimana setiap Pod dapat menggunakan containerPort yang sama, kamu dapat mengakses semua itu dari Pod lain ataupun dari node di dalam klaster menggunakan IP. Seperti Docker, port masih dapat di publikasi ke dalam * interface node*, tetapi kebutuhan seperti ini sudah berkurang karena model jaringannya.
Kita mempunyai Pod yang menjalankan nginx di dalam klaster. Teorinya, kamu dapat berkomunikasi ke Pod tersebut secara langsung, tapi apa yang terjadi jika sebuah node mati? Pod di dalam node tersebut ikut mati, dan Deployment akan membuat Pod baru, dengan IP yang berbeda. Ini adalah masalah yang Service selesaikan.
Service Kubernetes adalah sebuah abstraksi yang mendefinisikan sekumpulan Pod yang menyediakan fungsi yang sama dan berjalan di dalam klaster. Saat dibuat, setiap Service diberikan sebuah alamat IP (disebut juga ClusterIP). Alamat ini akan terus ada, dan tidak akan pernah berubah selama Service hidup. Pod dapat berkomunikasi dengan Service dan trafik yang menuju Service tersebut akan otomatis dilakukan mekanisme load balancing ke Pod yang merupakan anggota dari Service tersebut.
Kamu dapat membuat Service untuk replika 2 nginx dengan kubectl explose:
kubectl expose deployment/my-nginx
service/my-nginx exposed
Perintah di atas sama dengan kubectl apply -f dengan yaml sebagai berikut:
Spesifikasi ini akan membuat Service yang membuka TCP port 80 di setiap Pod dengan label run: my-nginx dan mengeksposnya ke dalam port Service (targetPort: adalah port kontainer yang menerima trafik, port adalah service port yang dapat berupa port apapun yang digunakan Pod lain untuk mengakses Service).
Lihat Service
objek API untuk melihat daftar field apa saja yang didukung di definisi Service. Cek Service kamu:
kubectl get svc my-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx ClusterIP 10.0.162.149 <none> 80/TCP 21s
Seperti yang disebutkan sebelumnya, sebuah Service berisi sekumpulan Pod. Pod diekspos melalui endpoints. Service selector akan mengecek Pod secara terus-menerus dan hasilnya akan dikirim (POSTed) ke objek endpoint yang bernama my-nginx. Saat sebuah Pod mati, IP Pod di dalam endpoint tersebut akan otomatis dihapus, dan Pod baru yang sesuai dengan Service selector akan otomatis ditambahkan ke dalam endpoint. Cek endpoint dan perhatikan bahwa IP sama dengan Pod yang dibuat di langkah pertama:
NAME ENDPOINTS AGE
my-nginx 10.244.2.5:80,10.244.3.4:80 1m
Kamu sekarang dapat melakukan curl ke dalam nginx Service di <CLUSTER-IP>:<PORT> dari node manapun di klaster. Perlu dicatat bahwa Service IP adalah IP virtual, IP tersebut tidak pernah ada di interface node manapun. Jika kamu penasaran bagaimana konsep ini bekerja, kamu dapat membaca lebih lanjut tentang service proxy.
Mengakses Service
Kubernetes mendukung 2 mode utama untuk menemukan sebuah Service - variabel environment dan DNS.
DNS membutuhkan tambahan CoreDNS di dalam klaster.
Variabel Environment
Saat sebuah Pod berjalan di Node, kubelet akan menambahkan variabel environment untuk setiap Service yang aktif ke dalam Pod. Ini menimbulkan beberapa masalah. Untuk melihatnya, periksa environment dari Pod nginx yang telah kamu buat (nama Pod-mu akan berbeda-beda):
kubectl exec my-nginx-3800858182-jr4a2 -- printenv | grep SERVICE
Perlu dicatat tidak ada variabel environment yang menunjukan Service yang kamu buat. Ini terjadi karena kamu membuat replika terlebih dahulu sebelum membuat Service. Kerugian lain ditimbulkan adalah bahwa komponen scheduler mungkin saja bisa menempatkan semua Pod di dalam satu Node, yang akan membuat keseluruhan Service mati jika Node tersebut mati. Kita dapat menyelesaikan masalah ini dengan menghapus 2 Pod tersebut dan menunggu Deployment untuk membuat Pod kembali. Kali ini Service ada sebelum replika Pod tersebut ada. Ini akan memberikan kamu scheduler-level Service (jika semua Node kamu mempunyai kapasitas yang sama), serta variabel environment yang benar:
Kubernetes menawarkan sebuah layanan DNS klaster tambahan yang secara otomatis memberikan sebuah nama dns pada Service. Kamu dapat mengecek jika DNS berjalan di dalam klaster Kubernetes:
kubectl get services kube-dns --namespace=kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.0.0.10 <none> 53/UDP,53/TCP 8m
Sisa panduan ini mengasumsikan kamu mempunyai Service dengan IP (my-nginx), dan sebuah server DNS yang memberikan nama ke dalam IP tersebut (CoreDNS klaster), jadi kamu dapat berkomunikasi dengan Service dari Pod lain di dalam klaster menggunakan metode standar (contohnya gethostbyname). Jalankan aplikasi curl lain untuk melakukan pengujian ini:
kubectl run curl --image=radial/busyboxplus:curl -i --tty --rm
Waiting for pod default/curl-131556218-9fnch to be running, status is Pending, pod ready: false
Hit enter for command prompt
Hingga sekarang kita hanya mengakses nginx server dari dalam klaster. Sebelum mengekspos Service ke internet, kamu harus memastikan bahwa kanal komunikasi aman. Untuk melakukan hal tersebut, kamu membutuhkan:
Self signed certificates untuk https (kecuali jika kamu sudah mempunyai identity certificate)
Sebuah server nginx yang terkonfigurasi untuk menggunakan certificate tersebut
Sebuah secret yang membuat setifikat tersebut dapat diakses oleh pod
Kamu dapat melihat semua itu di contoh nginx https. Contoh ini mengaharuskan kamu melakukan instalasi go dan make. Jika kamu tidak ingin melakukan instalasi tersebut, ikuti langkah-langkah manualnya nanti, singkatnya:
NAME TYPE DATA AGE
default-token-il9rc kubernetes.io/service-account-token 1 1d
nginxsecret Opaque 2 1m
Berikut ini adalah langkah-langkah manual yang harus diikuti jika kamu mengalami masalah menjalankan make (pada windows contohnya):
#membuat sebuah key-pair public privateopenssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /d/tmp/nginx.key -out /d/tmp/nginx.crt -subj "/CN=my-nginx/O=my-nginx"#rubah key tersebut ke dalam pengkodean base64cat /d/tmp/nginx.crt | base64
cat /d/tmp/nginx.key | base64
Gunakan hasil keluaran dari perintah sebelumnya untuk membuat sebuah file yaml seperti berikut. Nilai yang dikodekan base64 harus berada di dalam satu baris.
apiVersion:"v1"kind:"Secret"metadata:name:"nginxsecret"namespace:"default"data:# CATATAN: Ganti nilai berikut dengan sertifikat dan kunci hasil encoding base64 milik Anda sendiri.nginx.crt:"REPLACE_WITH_BASE64_CERT"nginx.key:"REPLACE_WITH_BASE64_KEY"
Sekarang buat secrets menggunakan file tersebut:
kubectl apply -f nginxsecrets.yaml
kubectl get secrets
NAME TYPE DATA AGE
default-token-il9rc kubernetes.io/service-account-token 1 1d
nginxsecret Opaque 2 1m
Sekarang modifikasi replika nginx untuk menjalankan server https menggunakan certificate di dalam secret dan Service untuk mengekspos semua port (80 dan 443):
Pada tahapan ini, kamu dapat berkomunikasi dengan server nginx dari node manapun.
kubectl get pods -l run=my-nginx -o custom-columns=POD_IP:.status.podIPs
POD_IP
[map[ip:10.244.3.5]]
node $ curl -k https://10.244.3.5
...
<h1>Welcome to nginx!</h1>
Perlu dicatat bahwa kita menggunakan parameter -k saat menggunakan curl, ini karena kita tidak tau apapun tentang Pod yang menjalankan nginx saat pembuatan seritifikat, jadi kita harus memberitahu curl untuk mengabaikan ketidakcocokan CName. Dengan membuat Service, kita menghubungkan CName yang digunakan pada certificate dengan nama pada DNS yang digunakan Pod. Lakukan pengujian dari sebuah Pod (secret yang sama digunakan untuk agar mudah, Pod tersebut hanya membutuhkan nginx.crt untuk mengakses Service)
Kamu mungkin ingin mengekspos Service ke alamat IP eksternal. Kubernetes mendukung dua cara untuk melakukan ini: NodePort dan LoadBalancer. Service yang dibuat tadi sudah menggunakan NodePort, jadi replika nginx sudah siap untuk menerima trafik dari internet jika Node kamu mempunyai IP publik.
Mari coba membuat ulang Service menggunakan cloud load balancer, ubah saja typeServicemy-nginx dari NodePort ke LoadBalancer:
kubectl edit svc my-nginx
kubectl get svc my-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx ClusterIP 10.0.162.149 162.222.184.144 80/TCP,81/TCP,82/TCP 21s
curl https://<EXTERNAL-IP> -k
...
<title>Welcome to nginx!</title>
IP address pada kolom EXTERNAL-IP menunjukan IP yang tersedia di internet. Sedangkan kolom CLUSTER-IP merupakan IP yang hanya tersedia di dalam klaster kamu (IP private).
Perhatikan pada AWS, tipe LoadBalancer membuat sebuah ELB, yang menggunakan hostname yang panjang, bukan IP. Karena tidak semua keluar pada standar keluaran kubectl get svc. Jadi kamu harus menggunakan kubectl describe service my-nginx untuk melihatnya. Kamu akan melihat seperti ini:
kubectl describe service my-nginx
...
LoadBalancer Ingress: a320587ffd19711e5a37606cf4a74574-1142138393.us-east-1.elb.amazonaws.com
...
Selanjutnya
Kubernetes juga mendukung Federated Service, yang bisa mempengaruhi banyak klaster dan penyedia layanan cloud, untuk meningkatkan ketersediaan, peningkatan toleransi kesalahan, dan pengembangan dari Service kamu. Lihat Panduan Federated Service untuk informasi lebih lanjut.
5.6 - Ingress
Sebuah obyek API yang mengatur akses eksternal terhadap Service yang ada di dalam klaster, biasanya dalam bentuk request HTTP.
Ingress juga menyediakan load balancing, terminasi SSL, serta name-based virtual hosting.
Terminologi
Untuk memudahkan, di awal akan dijelaskan beberapa terminologi yang sering dipakai:
Node: Sebuah mesin fisik atau virtual yang berada di dalam klaster Kubernetes.
Klaster: Sekelompok node yang merupakan resource komputasi primer yang diatur oleh Kubernetes, biasanya diproteksi dari internet dengan menggunakan firewall.
Edge router: Sebuah router mengatur policy firewall pada klaster kamu. Router ini bisa saja berupa gateway yang diatur oleh penyedia layanan cloud maupun perangkat keras.
Jaringan klaster: Seperangkat links baik logis maupus fisik, yang memfasilitasi komunikasi di dalam klaster berdasarkan model jaringan Kubernetes.
Service: Sebuah Service yang mengidentifikasi beberapa Pod dengan menggunakan selector label. Secara umum, semua Service diasumsikan hanya memiliki IP virtual yang hanya dapat diakses dari dalam jaringan klaster.
Apakah Ingress itu?
Ingress ditambahkan sejak Kubernetes v1.1, mengekspos rute HTTP dan HTTPS ke berbagai
services di dalam klaster.
Mekanisme routing trafik dikendalikan oleh aturan-aturan yang didefinisikan pada Ingress.
internet
|
[ Ingress ]
--|-----|--
[ Services ]
Sebuah Ingress dapat dikonfigurasi agar berbagai Service memiliki URL yang dapat diakses dari eksternal (luar klaster), melakukan load balance pada trafik, terminasi SSL, serta Virtual Host berbasis Nama.
Sebuah kontroler Ingress bertanggung jawab untuk menjalankan fungsi Ingress yaitu sebagai loadbalancer, meskipun dapat juga digunakan untuk mengatur edge router atau frontend tambahan untuk menerima trafik.
Sebuah Ingress tidak mengekspos sembarang port atau protokol. Mengekspos Service untuk protokol selain HTTP ke HTTPS internet biasanya dilakukan dengan menggunakan
service dengan tipe Service.Type=NodePort atau
Service.Type=LoadBalancer.
Prasyarat
FEATURE STATE:Kubernetes v1.1 [beta]
Sebelum kamu mulai menggunakan Ingress, ada beberapa hal yang perlu kamu ketahui sebelumnya. Ingress merupakan resource dengan tipe beta.
Catatan:
Kamu harus terlebih dahulu memiliki kontroler Ingress untuk dapat memenuhi Ingress. Membuat sebuah Ingress tanpa adanya kontroler Ingres tidak akan berdampak apa pun.
GCE/Google Kubernetes Engine melakukan deploy kontroler Ingress pada master. Perhatikan laman berikut
keterbatasan versi beta
kontroler ini jika kamu menggunakan GCE/GKE.
Seperti layaknya resource Kubernetes yang lain, sebuah Ingress membutuhkan fieldapiVersion, kind, dan metadata.
Untuk informasi umum soal bagaimana cara bekerja dengan menggunakan berkas konfigurasi, silahkan merujuk pada melakukan deploy aplikasi, konfigurasi kontainer, mengatur resource.
Ingress seringkali menggunakan anotasi untuk melakukan konfigurasi beberapa opsi yang ada bergantung pada kontroler Ingress yang digunakan, sebagai contohnya
adalah anotasi rewrite-target.
Kontroler Ingress yang berbeda memiliki jenis anotasi yang berbeda. Pastikan kamu sudah terlebih dahulu memahami dokumentasi
kontroler Ingress yang akan kamu pakai untuk mengetahui jenis anotasi apa sajakah yang disediakan.
Spesifikasi Ingress
memiliki segala informasi yang dibutuhkan untuk melakukan proses konfigurasi loadbalancer atau server proxy. Hal yang terpenting adalah
bagian inilah yang mengandung semua rules yang nantinya akan digunakan untuk menyesuaikan trafik yang masuk. Resource Ingress hanya menyediakan
fitur rules untuk mengarahkan trafik dengan protokol HTTP.
Rule Ingress
Setiap rule HTTP mengandung informasi berikut:
Host opsional. Di dalam contoh ini, tidak ada host yang diberikan, dengan kata lain, semua rules berlaku untuk inbound
trafik HTTP bagi alamat IP yang dispesifikasikan. JIka sebuah host dispesifikasikan (misalnya saja,
foo.bar.com), maka rules yang ada akan berlaku bagi host tersebut.
Sederetan path (misalnya, /testpath), setiap path ini akan memiliki pasangan berupa sebuah backend yang didefinisikan dengan serviceName
dan servicePort. Baik host dan path harus sesuai dengan konten dari request yang masuk sebelum
loadbalancer akan mengarahkan trafik pada service yang sesuai.
Suatu backend adalah kombinasi service dan port seperti yang dideskripsikan di
dokumentasi Service. Request HTTP (dan HTTPS) yang sesuai dengan
host dan path yang ada pada rule akan diteruskan pada backend terkait.
Backend default seringkali dikonfigurasi pada kontroler kontroler Ingress, tugas backend default ini adalah
mengarahkan request yang tidak sesuai dengan path yang tersedia pada spesifikasi.
Backend Default
Sebuah Ingress yang tidak memiliki rules akan mengarahkan semua trafik pada sebuah backend default. Backend default inilah yang
biasanya bisa dimasukkan sebagai salah satu opsi konfigurasi dari kontroler Ingress dan tidak dimasukkan dalam spesifikasi resource Ingress.
Jika tidak ada host atau path yang sesuai dengan request HTTP pada objek Ingress, maka trafik tersebut
akan diarahkan pada backend default.
Jenis Ingress
Ingress dengan satu Service
Terdapat konsep Kubernetes yang memungkinkan kamu untuk mengekspos sebuah Service, lihat alternatif lain.
Kamu juga bisa membuat spesifikasi Ingress dengan backend default yang tidak memiliki rules.
Jika kamu menggunakan kubectl apply -f kamu dapat melihat:
kubectl get ingress test-ingress
NAME HOSTS ADDRESS PORTS AGE
test-ingress * 107.178.254.228 80 59s
Dimana 107.178.254.228 merupakan alamat IP yang dialokasikan oleh kontroler Ingress untuk
memenuhi Ingress ini.
Catatan:
Kontroler Ingress dan load balancer membutuhkan waktu sekitar satu hingga dua menit untuk mengalokasikan alamat IP.
Hingga alamat IP berhasil dialokasikan, kamu akan melihat tampilan kolom ADDRESS sebagai <pending>.
Fanout sederhana
Sebuah konfigurasi fanout akan melakukan route trafik dari sebuah alamat IP ke banyak Service,
berdasarkan URI HTTP yang diberikan. Sebuah Ingress memungkinkan kamu untuk memiliki jumlah loadbalancer minimum.
Contohnya, konfigurasi seperti di bawah ini:
foo.bar.com -> 178.91.123.132 -> / foo service1:4200
/ bar service2:8080
Kontroler Ingress akan menyediakan loadbalancer (implementasinya tergantung dari jenis Ingress yang digunakan), selama service-service yang didefinisikan (s1, s2) ada.
Apabila Ingress selesai dibuat, maka kamu dapat melihat alamat IP dari berbagai loadbalancer
pada kolom address.
Catatan:
Kamu mungkin saja membutuhkan konfigurasi default-http-backend Service
bergantung pada kontroler Ingress yang kamu pakai.
Virtual Host berbasis Nama
Virtual Host berbasis Nama memungkinkan mekanisme routing berdasarkan trafik HTTP ke beberapa host name dengan alamat IP yang sama.
Jika kamu membuat sebuah Ingress tanpa mendefinisikan host apa pun, maka
trafik web ke alamat IP dari kontroler Ingress tetap dapat dilakukan tanpa harus
menyesuaikan aturan name based virtual host. Sebagai contoh,
resource Ingress di bawah ini akan melakukan pemetaan trafik
dari first.bar.com ke service1, second.foo.com ke service2, dan trafik lain
ke alamat IP tanpa host name yang didefinisikan di dalam request (yang tidak memiliki request header) ke service3.
Kamu dapat mengamankan Ingress yang kamu miliki dengan memberikan spesifikasi secret
yang mengandung private key dan sertifikat TLS. Saat ini, Ingress hanya
memiliki fitur untuk melakukan konfigurasi single TLS port, yaitu 443, serta melakukan terminasi TLS.
Jika section TLS pada Ingress memiliki spesifikasi host yang berbeda,
rules yang ada akan dimultiplekskan pada port yang sama berdasarkan
hostname yang dispesifikasikan melalui ekstensi TLS SNI. Secret TLS harus memiliki
key bernama tls.crt dan tls.key yang mengandung private key dan sertifikat TLS, contohnya:
Ketika kamu menambahkan secret pada Ingress maka kontroler Ingress akan memberikan perintah untuk
memproteksi channel dari klien ke loadbalancer menggunakan TLS.
Kamu harus memastikan secret TLS yang digunakan memiliki sertifikat yang mengandung
CN untuk sslexample.foo.com.
Terdapat perbedaan di antara beberapa fitur TLS
yang disediakan oleh berbagai kontroler Ingress. Perhatikan dokumentasi
nginx,
GCE, atau
kontroler Ingress spesifik platform lainnya untuk memahami cara kerja TLS
pada environment yang kamu miliki.
Loadbalancing
Sebuah kontroler Ingress sudah dibekali dengan beberapa policy terkait mekanisme load balance
yang nantinya akan diterapkan pada semua Ingress, misalnya saja algoritma load balancing, backend
weight scheme, dan lain sebagainya. Beberapa konsep load balance yang lebih advance
(misalnya saja persistent sessions, dynamic weights) belum diekspos melalui Ingress.
Meskipun begitu, kamu masih bisa menggunakan fitur ini melalui
loadbalancer service.
Perlu diketahui bahwa meskipun health check tidak diekspos secara langsung
melalui Ingress, terdapat beberapa konsep di Kubernetes yang sejalan dengan hal ini, misalnya
readiness probes
yang memungkinkan kamu untuk memperoleh hasil yang sama. Silahkan pelajari lebih lanjut dokumentasi
kontroler yang kamu pakai untuk mengetahui bagaimana implementasi health checks pada kontroler yang kamu pilih (nginx,
GCE).
Mengubah Ingress
Untuk mengubah Ingress yang sudah ada dan menambahkan host baru, kamu dapat mengubahnya dengan mode edit:
kubectl describe ingress test
Name: testNamespace: default
Address: 178.91.123.132
Default backend: default-http-backend:80 (10.8.2.3:8080)Rules:
Host Path Backends
---- ---- --------
foo.bar.com
/foo s1:80 (10.8.0.90:80)Annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ADD 35s loadbalancer-controller default/test
kubectl edit ingress test
Sebuah editor akan muncul dan menampilkan konfigurasi Ingress kamu
dalam format YAML apabila kamu telah menjalankan perintah di atas.
Ubah untuk menambahkan host:
Menyimpan konfigurasi dalam bentuk YAML ini akan mengubah resource pada API server,
yang kemudian akan memberi tahu kontroler Ingress untuk mengubah konfigurasi loadbalancer.
Kamu juga dapat mengubah Ingress dengan menggunakan perintah kubectl replace -f pada berkas konfigurasi
Ingress yang ingin diubah.
Mekanisme failing pada beberapa zona availability
Teknik untuk menyeimbangkan persebaran trafik pada failure domain berbeda antar penyedia layanan cloud.
Kamu dapat mempelajari dokumentasi yang relevan bagi kontoler Ingress
untuk informasi yang lebih detail. Kamu juga dapat mempelajari dokumentasi federasi
untuk informasi lebih detail soal bagaimana melakukan deploy untuk federasi klaster.
Pengembangan selanjutnya
Silahkan amati SIG Network
untuk detail lebih lanjut mengenai perubahan Ingress dan resource terkait lainnya. Kamu juga bisa melihat
repositori Ingress untuk informasi yang lebih detail
soal perubahan berbagai kontroler.
Alternatif lain
Kamu dapat mengekspos sebuah Service dalam berbagai cara, tanpa harus menggunakan resource Ingress, dengan menggunakan:
Agar Ingress dapat bekerja sebagaimana mestinya,
sebuah klaster harus memiliki paling tidak sebuah kontroler Ingress.
Berbeda dengan kontroler-kontroler lainnya yang dijalankan
sebagai bagian dari binarykube-controller-manager, kontroler Ingress
tidak secara otomatis dijalankan di dalam klaster. Kamu bisa menggunakan
laman ini untuk memilih implementasi kontroler Ingress yang kamu pikir
paling sesuai dengan kebutuhan kamu.
Kubernetes sebagai sebuah proyek, saat ini, mendukung dan memaintain kontroler-kontroler GCE dan
nginx.
Gloo adalah sebuah proyek kontroler Ingress open source berbasis Envoy yang menawarkan fungsionalitas API Gateway dengan dukungan enterprise dari solo.io.
Traefik adalah sebuah kontroler Ingress yang menyediakan semua fitur secara lengkap (fully featured)
(Let's Encrypt, secrets, http2, websocket), dengan tambahan dukungan
komersial oleh Containous.
Menggunakan beberapa jenis kontroler Ingress sekaligus
Kamu dapat melakukan deployberapa pun banyaknya kontroler Ingress
dalam sebuah klaster. Jika kamu ingin membuat Ingress, kamu tinggal memberikan anotasi setiap Ingress sesuai dengan
ingress.class
yang sesuai untuk menandai kontroler Ingress mana yang digunakan jika terdapat lebih dari satu kontroler Ingress yang ada di
klaster kamu.
Apabila kamu tidak mendefinisikan class yang dipakai, penyedia layanan cloud kamu akan menggunakan kontroler Ingress default yang mereka miliki.
Idealnya, semua ingress harus memenuhi spesifikasi ini, tetapi berbagai jenis
kontroler Ingress bisa saja memiliki sedikit perbedaan cara kerja.
Catatan:
Pastikan kamu sudah terlebih dahulu memahami dokumentasi kontroler Ingress yang akan kamu pakai sebelum memutuskan untuk memakai kontroler tersebut.
Sebuah NetworkPolicy adalah spesifikasi dari sekelompok Pod atau endpoint yang diizinkan untuk saling berkomunikasi.
NetworkPolicy menggunakan label untuk memilih Pod serta mendefinisikan serangkaian rule yang digunakan
untuk mendefinisikan trafik yang diizinkan untuk suatu Pod tertentu.
Prasyarat
NetworkPolicy diimplementasikan dengan menggunakan plugin jaringan,
dengan demikian kamu harus memiliki penyedia jaringan yang mendukung NetworkPolicy -
membuat resource tanpa adanya controller tidak akan berdampak apa pun.
Pod yang terisolasi dan tidak terisolasi
Secara default, Pod bersifat tidak terisolasi; Pod-Pod tersebut
menerima trafik dari resource apa pun.
Pod menjadi terisolasi apabila terdapat NetworkPolicy yang dikenakan pada Pod-Pod tersebut.
Apabila terdapat NetworkPolicy di dalam namespace yang dikenakan pada suatu Pod, Pod tersebut
akan menolak koneksi yang tidak diizinkan NetworkPolicy. (Pod lain dalam namespace
yang tidak dikenakan NetworkPolicy akan tetap menerima trafik dari semua resource.)
ResourceNetworkPolicy
Lihat NetworkPolicy untuk definisi lengkap resource.
Sebuah contoh NetworkPolicy akan terlihat seperti berikut:
Mengirimkan ini ke API server dengan metode POST tidak akan berdampak apa pun
kecuali penyedia jaringan mendukung network policy.
Field-field yang bersifat wajib: Sama dengan seluruh config Kubernetes lainnya, sebuah NetworkPolicy
membutuhkan field-fieldapiVersion, kind, dan metadata. Informasi generik mengenai
bagaimana bekerja dengan fileconfig, dapat dilihat di
Konfigurasi Kontainer menggunakan ConfigMap,
serta Manajemen Objek.
spec: NetworkPolicyspec memiliki semua informasi yang harus diberikan untuk memberikan definisi network policy yang ada pada namespace tertentu.
podSelector: Setiap NetworkPolicy memiliki sebuah podSelector yang bertugas memfilter Pod-Pod yang dikenai policy tersebut. Contoh yang ada memfilter Pod dengan label "role=db". Sebuah podSelector yang empty akan memilih semua Pod yang ada di dalam namespace.
policyTypes: Setiap NetworkPolicy memiliki sebuah daftar policyTypes yang dapat berupa Ingress, Egress, atau keduanya. FieldpolicyTypes mengindikasikan apakah suatu policy diberikan pada trafik ingress, egress, atau camputan ingress dan egress pada Pod tertentu. Jika tidak ada policyTypes tyang diberikan pada NetworkPolicy maka Ingressdefault akan diterapkan dan Egress akan diterapkan apabila policy tersebut memberikan spesifikasi egress.
ingress: Setiap NetworkPolicy bisa saja memberikan serangkaian whitelist rule-ruleingress. Setiap rule mengizinkan trafik yang sesuai dengan sectionfrom dan ports. Contoh policy yang diberikan memiliki sebuah rule, yang sesuai dengan trafik pada sebuah portsingle, bagian pertama dispesifikasikan melalui ipBlock, yang kedua melalui namespaceSelector dan yang ketiga melalui podSelector.
egress: Setiap NetworkPolicy bisa saja meliputi serangkaian whitelistrule-ruleegress. Setiap rule mengizinkan trafik yang sesuai dengan sectionto dan ports. Contoh policy yang diberikan memiliki sebuah rule, yang sesuai dengan portsingle pada destinasi 10.0.0.0/24.
Pada contoh, NetworkPolicy melakukan hal berikut:
Mengisolasi Pod-Pod dengan label "role=db" pada namespace"default" baik untuk ingress atau egress.
(RuleIngress) mengizinkan koneksi ke semua Pod pada namespace“default” dengan label “role=db” untuk protokol TCP port6379 dari:
semua Pod pada namespace"default" dengan label "role=frontend"
semua Pod dalam sebuah namespace dengan label "project=myproject"
alamat IP pada range172.17.0.0–172.17.0.255 dan 172.17.2.0–172.17.255.255 (yaitu, semua 172.17.0.0/16 kecuali 172.17.1.0/24)
(Rule Egress) mengizinkan koneksi dari semua Pod pada namespace"default" dengan label "role=db" ke CIDR 10.0.0.0/24 untuk protokol TCP pada port5978
Terdapat empat jenis selektor yang dapat dispesifikasikan dalam sectioningressfrom atau sectionegressto:
podSelector: Ini digunakan untuk memfilter Pod tertentu pada namespace dimana NetworkPolicy berada yang akan mengatur destinasi ingress atau egress.
namespaceSelector: Ini digunakan untuk memfilter namespace tertentu dimana semua Pod diperbolehkan sebagai sourceingress atau destinasi egress.
namespaceSelectorandpodSelector: Sebuah entri to/from yang memberikan spesifikasi namespaceSelector dan podSelector serta memilih Pod-Pod tertentu yang ada di dalam namespace. Pastikan kamu menggunakan sintaks YAML yang tepat; policy ini:
mengandung sebuah elemen from yang mengizinkan koneksi dari Pod-Pod dengan label role=client di namespace dengan label user=alice. Akan tetapi, policyini:
mengandung dua elemen pada arrayfrom, dan mengizinkan koneksi dari Pod pada Namespace lokal dengan label
role=client, atau dari Pod di namespace apa pun dengan label user=alice.
Ketika kamu merasa ragu, gunakan kubectl describe untuk melihat bagaimana Kubernetes
menginterpretasikan policy tersebut.
ipBlock: Ini digunakan untuk memilih range IP CIDR tertentu untuk berperan sebagai
sourceingress atau destinasi egress. Alamat yang digunakan harus merupakan
alamat IP eksternal klaster, karena alamat IP Pod bersifat ephemeral dan tidak dapat ditebak.
Mekanisme ingress dan egress klaster seringkali membutuhkan mekanisme rewrite alamat IP source dan destinasi
paket. Pada kasus-kasus dimana hal ini, tidak dapat dipastikan bahwa apakah hal ini
terjadi sebelum atau setelah pemrosesan NetworkPolicy, dan perilaku yang ada mungkin saja berbeda
untuk kombinasi plugin jaringan, penyedia layanan cloud, serta implementasi Service yang berbeda.
Pada ingress, artinya bisa saja kamu melakukan filter paket yang masuk berdasarkan source IP,
sementara di kasus lain "source IP" yang digunakan oleh Network Policy adalah alamat IP LoadBalancer,
node dimana Pod berada, dsb.
Pada egress, bisa saja sebuah koneksi dari Pod ke IP Service di-rewrite ke IP eksternal klaster
atau bahkan tidak termasuk di dalam ipBlockpolicy.
PolicyDefault
Secara default, jika tidak ada policy yang ada dalam suatu namespace, maka semua trafik ingress dan egress yang diizinkan ke atau dari Pod dalam namespace.
Contoh di bawah ini akan memberikan gambaran bagaimana kamu dapat mengubah perilaku default pada sebuah namespace.
Default: tolak semua trafik ingress
Kamu dapat membuat policy isolasi "default" untuk sebuah namespace
dengan membuat sebuah NetworkPolicy yang memilih semua Pod tapi tidak mengizinkan
trafik ingress masuk ke Pod-Pod tersebut.
Hal ini menjamin bahwa bahkan Pod yang tidak dipilih oleh NetworkPolicy lain masih terisolasi.
Policy ini tidak mengubah perilaku default dari egress.
Default: izinkan semua trafik ingress
Jika kamu ingin mengizinkan semua trafik ingress pada semua Pod dalam sebuah namespace
(bahkan jika policy ditambahkan dan menyebabkan beberapa Pod menjadi terisolasi), kamu
dapat secara eksplisit mengizinkan semua trafik bagi namespace tersebut.
Kamu dapat membuat policy isolasi "default" untuk sebuah namespace
dengan membuat sebuah NetworkPolicy yang memilih semua Pod tapi tidak mengizinkan
trafik egress keluar dari Pod-Pod tersebut.
Hal ini menjamin bahwa bahkan Pod yang tidak dipilih oleh NetworkPolicy lain masih terisolasi.
Policy ini tidak mengubah perilaku default dari ingress.
Default: izinkan semua trafik egress
Jika kamu ingin mengizinkan semua trafik egress pada semua Pod dalam sebuah namespace
(bahkan jika policy ditambahkan dan menyebabkan beberapa Pod menjadi terisolasi), kamu
dapat secara eksplisit mengizinkan semua trafik bagi namespace tersebut.
Hal ini menjamin bahwa bahkan Pod yang tidak dipilih oleh NetworkPolicy tidak akan mengizinkan trafik ingress atau egress.
Dukungan terhadap SCTP
FEATURE STATE:Kubernetes v1.12 [alpha]
Kubernetes mendukung SCTP sebagai valueprotocol pada definisi NetworkPolicy sebagai fitur alpha. Untuk mengaktifkan fitur ini, administrator klaster harus mengaktifkan gerbang fitur SCTPSupport pada apiserver, contohnya “--feature-gates=SCTPSupport=true,...”. Ketika gerbang fitur ini diaktifkan, pengguna dapat menerapkan value dari fieldprotocol pada NetworkPolicy menjadi SCTP. Kubernetes akan mengatur jaringan sesuai dengan SCTP, seperti halnya koneksi TCP.
Plugin CNI harus mendukung SCTP sebagai value dari protocol pada NetworkPolicy.
Baca lebih lanjut soal panduan bagi skenario generik resourceNetworkPolicy.
5.9 - Gateway API
Gateway API merupakan bagian dari API yang menyediakan penyediaan infrastruktur dinamis dan pengaturan trafik lanjutan.
Gateway API menyediakan layanan jaringan dengan menggunakan mekanisme konfigurasi yang mudah di-extend, berorientasi role, dan mengerti konsep protokol. Gateway API adalah sebuah add-on yang berisi jenis-jenis API yang menyediakan penyediaan infrastruktur dinamis dan pengaturan trafik tingkat lanjut.
Prinsip Desain
Prinsip-prinsip berikut membentuk desain dan arsitektur Gateway API:
Berorientasi role: Gateway API dimodelkan sesuai dengan role organisasi yang bertanggung jawab untuk mengelola jaringan layanan Kubernetes:
Penyedia Infrastruktur: Mengelola infrastruktur yang memungkinkan beberapa klaster terisolasi untuk melayani beberapa tenant, misalnya penyedia layanan cloud.
Operator klaster: Mengelola klaster dan biasanya memperhatikan kebijakan, akses jaringan, izin aplikasi, dll.
Pengembang Aplikasi: Mengelola aplikasi yang berjalan di dalam klaster dan biasanya memperhatikan konfigurasi tingkat aplikasi dan komposisi Service.
Portabel: Spesifikasi Gateway API didefinisikan sebagai Custom Resource dan didukung oleh banyak implementasi.
Ekspresif: Jenis-jenis Gateway API mendukung fungsi untuk kasus penggunaan routing trafik pada umumnya, seperti pencocokan berbasis header, pembobotan trafik, dan lainnya yang sebelumnya hanya mungkin dilakukan di Ingress dengan menggunakan anotasi kustom.
Dapat diperluas: Gateway memungkinkan sumber daya kustom untuk dihubungkan pada berbagai lapisan API. Ini memungkinkan penyesuaian yang lebih detail pada tempat yang tepat dalam struktur API.
Model Sumber Daya (Resource)
Gateway API memiliki tiga jenis API stabil:
GatewayClass: Mendefinisikan satu set gateway dengan konfigurasi umum dan dikelola oleh pengendali yang mengimplementasikan kelas tersebut.
HTTPRoute: Mendefinisikan aturan khusus HTTP untuk memetakan trafik dari pendengar (listener) Gateway ke representasi titik akhir (endpoint) jaringan backend. Titik akhir ini sering diwakili sebagai sebuah Service.
Gateway API diatur ke dalam berbagai jenis API yang memiliki hubungan saling ketergantungan untuk mendukung sifat berorientasi role dari organisasi. Objek Gateway dikaitkan dengan tepat satu GatewayClass; GatewayClass menggambarkan pengendali gateway yang bertanggung jawab untuk mengelola Gateway dari kelas ini. Satu atau lebih jenis rute seperti HTTPRoute, kemudian dikaitkan dengan Gateway. Sebuah Gateway dapat memfilter rute yang mungkin akan dilampirkan pada listeners-nya, membentuk model kepercayaan dua arah dengan rute.
Gambar berikut mengilustrasikan hubungan dari tiga jenis Gateway API yang stabil:
Gateway
Gateway menggambarkan sebuah instans infrastruktur penanganan trafik. Ini mendefinisikan titik akhir jaringan yang dapat digunakan untuk memproses trafik, seperti penyaringan (filter), penyeimbangan (balancing), pemisahan (splitting), dll. untuk backend seperti sebuah Service. Sebagai contoh, Gateway dapat mewakili penyeimbang beban (load balancer) cloud atau server proksi dalam klaster yang dikonfigurasikan untuk menerima trafik HTTP.
Dalam contoh ini, sebuah instans dari infrastruktur penanganan trafik diprogram untuk mendengarkan trafik HTTP pada port 80. Karena fieldaddresses tidak ditentukan, sebuah alamat atau nama host ditugaskan ke Gateway oleh pengendali implementasi. Alamat ini digunakan sebagai titik akhir jaringan untuk memproses trafik titik akhir jaringan backend yang didefinisikan dalam rute.
Lihat Gateway referensi untuk definisi lengkap dari API ini.
HTTPRoute
Jenis HTTPRoute menentukan perilaku routing dari permintaan HTTP dari listener Gateway ke titik akhir jaringan backend. Untuk backend Service, implementasi dapat mewakili titik akhir jaringan backend sebagai IP Service atau Endpoints pendukung dari Service tersebut. HTTPRoute mewakili konfigurasi yang diterapkan pada implementasi Gateway yang mendasarinya. Sebagai contoh, mendefinisikan HTTPRoute baru dapat mengakibatkan pengaturan rute trafik tambahan pada penyeimbang beban cloud atau server proksi dalam klaster.
Dalam contoh ini, trafik HTTP dari Gateway example-gateway dengan header Host: yang disetel ke www.example.com dan jalur permintaan yang ditentukan sebagai /login akan diarahkan ke Service example-svc pada port 8080.
Lihat referensi HTTPRoute untuk definisi lengkap dari API ini.
Aliran Permintaan (Request Flow)
Berikut adalah contoh sederhana dari trafik HTTP yang diarahkan ke sebuah Service menggunakan Gateway dan HTTPRoute:
Dalam contoh ini, aliran permintaan untuk Gateway yang diimplementasikan sebagai reverse proxy adalah:
Klien mulai mempersiapkan permintaan HTTP untuk URL http://www.example.com
Resolver DNS klien melakukan query untuk nama tujuan dan mengetahui pemetaan ke satu atau lebih alamat IP yang terkait dengan Gateway.
Klien mengirimkan permintaan ke alamat IP Gateway; reverse proxy menerima permintaan HTTP dan menggunakan header Host: untuk mencocokkan konfigurasi yang berasal dari Gateway dan HTTPRoute yang terlampir.
Secara opsional, reverse proxy dapat melakukan pencocokan header permintaan dan/atau jalur berdasarkan aturan pencocokan dari HTTPRoute.
Secara opsional, reverse proxy dapat memodifikasi permintaan; sebagai contoh, untuk menambah atau menghapus header, berdasarkan aturan filter dari HTTPRoute.
Terakhir, reverse proxy meneruskan permintaan ke satu atau lebih backend.
Kesesuaian (Conformance)
Gateway API mencakup beragam fitur dan diimplementasikan secara luas. Kombinasi ini memerlukan definisi dan pengujian kesesuaian yang jelas untuk memastikan bahwa API memberikan pengalaman yang konsisten di mana pun digunakan.
Lihat dokumentasi conformance untuk memahami rincian seperti saluran rilis (release channel), tingkat dukungan, dan menjalankan tes kesesuaian (conformance test).
Migrasi dari Ingress
Gateway API adalah penerus API Ingress tapi tidak termasuk dalam jenis Ingress. Akibatnya, konversi satu kali dari sumber daya Ingress yang ada ke sumber daya Gateway API diperlukan.
Referensi panduan migrasi ingress untuk rincian tentang migrasi sumber daya Ingress ke sumber daya Gateway API.
Selanjutnya
Alih-alih sumber daya Gateway API yang diimplementasikan secara natif oleh Kubernetes, spesifikasinya didefinisikan sebagai Custom Resource Definition yang didukung oleh berbagai implementasi.
Instal CRD Gateway API atau ikuti petunjuk instalasi dari implementasi yang kamu pilih. Setelah menginstal sebuah implementasi, gunakan panduan Memulai untuk membantu kamu segera memulai bekerja dengan Gateway API.
Catatan:
Pastikan untuk meninjau dokumentasi dari implementasi yang kamu pilih untuk memahami hal-hal yang perlu diperhatikan.
Referensi spesifikasi API untuk rincian tambahan dari semua jenis Gateway API.
5.10 - Menambahkan Entry pada /etc/hosts Pod dengan HostAliases
Menambahkan entri pada berkas /etc/hosts Pod akan melakukan override
resolusi hostname pada level Pod ketika DNS dan opsi lainnya tidak tersedia.
Pada versi 1.7, pengguna dapat menambahkan entri yang diinginkan beserta field HostAliases
pada PodSpec.
Modifikasi yang dilakukan tanpa menggunakan HostAliases tidaklah disarankan
karena berkas ini diatur oleh Kubelet dan dapat di-override ketika Pod dibuat/di-restart.
Isi Default pada Berkas Hosts
Misalnya saja kamu mempunyai sebuah Pod Nginx yang memiliki sebuah IP Pod:
kubectl run nginx --image nginx --generator=run-pod/v1
pod/nginx created
Perhatikan IP Pod tersebut:
kubectl get pods --output=wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx 1/1 Running 0 13s 10.200.0.4 worker0
Secara default, berkas hosts hanya berisikan boilerplate alamat IP IPv4 and IPv6 seperti
localhost dan hostname dari Pod itu sendiri.
Menambahkan Entri Tambahan dengan HostAliases
Selain boilerplate default, kita dapat menambahkan entri pada berkas
hosts untuk melakukan resolusi foo.local, bar.local pada 127.0.0.1 dan foo.remote,
bar.remote pada 10.1.2.3, kita dapat melakukannya dengan cara menambahkan
HostAliases pada Pod di bawah field.spec.hostAliases:
Dengan tambahan entri yang telah dispesifikasikan sebelumnya.
Kenapa Kubelet Melakukan Mekanisme Manajemen Berkas Hosts?
Kubelet melakukan proses manajemen
berkas hosts untuk setiap container yang ada pada Pod untuk mencegah Docker melakukan
modifikasi pada berkas tersebut
setelah kontainer dihidupkan.
Karena sifat dari berkas tersebut yang secara otomatis di-manage,
semua hal yang didefinisikan oleh pengguna akan ditimpa (overwrite) ketika berkas
hosts di-mount kembali oleh Kubelet ketika ada kontainer yang di-restart
atau Pod di-schedule ulang. Dengan demikian tidak dianjurkan untuk
memodifikasi berkas tersebut secara langsung.
5.11 - Dual-stack IPv4/IPv6
FEATURE STATE:Kubernetes v1.16 [alpha]
Dual-stack IPv4/IPv6 memungkinkan pengalokasian alamat IPv4 dan IPv6 untuk
Pod dan Service.
Jika kamu mengaktifkan jaringan dual-stack IPv4/IPv6 untuk klaster Kubernetes
kamu, klaster akan mendukung pengalokasian kedua alamat IPv4 dan IPv6 secara
bersamaan.
Fitur-fitur yang didukung
Mengaktifkan dual-stack IPv4 / IPv6 pada klaster Kubernetes kamu untuk
menyediakan fitur-fitur berikut ini:
Jaringan Pod dual-stack (pengalokasian sebuah alamat IPv4 dan IPv6 untuk setiap Pod)
Service yang mendukung IPv4 dan IPv6 (setiap Service hanya untuk satu keluarga alamat)
Perutean Pod ke luar klaster (misalnya Internet) melalui antarmuka IPv4 dan IPv6
Prasyarat
Prasyarat berikut diperlukan untuk menggunakan dual-stack IPv4/IPv6 pada
klaster Kubernetes :
Kubernetes versi 1.16 atau yang lebih baru
Dukungan dari penyedia layanan untuk jaringan dual-stack (Penyedia layanan cloud atau yang lainnya harus dapat menyediakan antarmuka jaringan IPv4/IPv6 yang dapat dirutekan) untuk Node Kubernetes
Sebuah plugin jaringan yang mendukung dual-stack (seperti Kubenet atau Calico)
Kube-proxy yang berjalan dalam mode IPVS
Mengaktifkan dual-stack IPv4/IPv6
Untuk mengaktifkan dual-stack IPv4/IPv6, aktifkan gerbang fitur (feature gate)IPv6DualStack
untuk komponen-komponen yang relevan dari klaster kamu, dan tetapkan jaringan
dual-stack pada klaster:
kube-controller-manager:
--feature-gates="IPv6DualStack=true"
--cluster-cidr=<IPv4 CIDR>,<IPv6 CIDR> misalnya --cluster-cidr=10.244.0.0/16,fc00::/24
--node-cidr-mask-size-ipv4|--node-cidr-mask-size-ipv6 nilai bawaannya adalah /24
untuk IPv4 dan /64 untuk IPv6
kubelet:
--feature-gates="IPv6DualStack=true"
kube-proxy:
--proxy-mode=ipvs
--cluster-cidr=<IPv4 CIDR>,<IPv6 CIDR>
--feature-gates="IPv6DualStack=true"
Perhatian:
Jika kamu menentukan blok alamat IPv6 yang lebih besar dari /24 melalui
--cluster-cidr pada baris perintah, maka penetapan tersebut akan gagal.
Service
Jika klaster kamu mengaktifkan jaringan dual-stack IPv4/IPv6, maka kamu dapat
membuat Service dengan
alamat IPv4 atau IPv6. Kamu dapat memilih keluarga alamat untuk clusterIP Service kamu dengan mengatur bagian, .spec.ipFamily, pada Service tersebut.
Kamu hanya dapat mengatur bagian ini saat membuat Service baru. Mengatur bagian
.spec.ipFamily bersifat opsional dan hanya boleh digunakan jika kamu berencana
untuk mengaktifkan Service dan Ingress IPv4 dan IPv6
pada klaster kamu. Konfigurasi bagian ini bukanlah syarat untuk lalu lintas
[egress] (#lalu-lintas-egress).
Catatan:
Keluarga alamat bawaan untuk klaster kamu adalah keluarga alamat dari rentang
clusterIP Service pertama yang dikonfigurasi melalui opsi
--service-cluster-ip-range pada kube-controller-manager.
Kamu dapat mengatur .spec.ipFamily menjadi salah satu dari:
IPv4: Dimana server API akan mengalokasikan IP dari service-cluster-ip-range yaitu ipv4
IPv6: Dimana server API akan mengalokasikan IP dari service-cluster-ip-range yaitu ipv6
Spesifikasi Service berikut ini tidak memasukkan bagian ipFamily.
Kubernetes akan mengalokasikan alamat IP (atau yang dikenal juga sebagai
"cluster IP") dari service-cluster-ip-range yang dikonfigurasi pertama kali
untuk Service ini.
Spesifikasi Service berikut memasukkan bagian ipFamily. Sehingga Kubernetes
akan mengalokasikan alamat IPv6 (atau yang dikenal juga sebagai "cluster IP")
dari service-cluster-ip-range yang dikonfigurasi untuk Service ini.
Sebagai perbandingan, spesifikasi Service berikut ini akan dialokasikan sebuah alamat
IPv4 (atau yang dikenal juga sebagai "cluster IP") dari service-cluster-ip-range
yang dikonfigurasi untuk Service ini.
Penyedia layanan cloud yang mendukung IPv6 untuk pengaturan beban eksternal,
Mengatur bagian type menjadi LoadBalancer sebagai tambahan terhadap mengatur bagian
ipFamily menjadi IPv6 menyediakan sebuah cloud load balancer untuk Service kamu.
Lalu lintas egress
Penggunaan blok alamat IPv6 yang dapat dirutekan dan yang tidak dapat dirutekan
secara publik diperbolehkan selama CNI
dari penyedia layanan dapat mengimplementasikan transportasinya. Jika kamu memiliki
Pod yang menggunakan IPv6 yang dapat dirutekan secara publik dan ingin agar Pod
mencapai tujuan di luar klaster (misalnya Internet publik), kamu harus mengatur
IP samaran untuk lalu lintas keluar dan balasannya. ip-masq-agent
bersifat dual-stack aware, jadi kamu bisa menggunakan ip-masq-agent untuk
masquerading IP dari klaster dual-stack.
Masalah-masalah yang diketahui
Kubenet memaksa pelaporan posisi IP untuk IPv4,IPv6 IP (--cluster-cidr)
5.12 - _Topology Aware Routing_ (Routing yang Mempertimbangkan Topologi)
Topology Aware Routing (Routing yang Mempertimbangkan Topologi) menyediakan mekanisme untuk membantu menjaga trafik jaringan tetap berada di dalam zona tempat asalnya. Memprioritaskan trafik antar Pod yang berada di zona yang sama dalam klaster kamu dapat membantu meningkatkan keandalan, performa (latensi dan throughput jaringan), serta mengurangi biaya.
FEATURE STATE:Kubernetes v1.23 [beta]
Catatan:
Sebelum Kubernetes versi 1.27, fitur ini dikenal dengan nama Topology Aware Hints.
Topology Aware Routing mengatur perilaku routing untuk memprioritaskan menjaga trafik tetap berada di zona asalnya. Dalam beberapa kasus, hal ini dapat membantu mengurangi biaya atau meningkatkan performa jaringan.
Motivasi
Kluster Kubernetes semakin sering diterapkan di lingkungan multi-zona.
Topology Aware Routing menyediakan mekanisme untuk membantu menjaga trafik tetap berada di zona asalnya. Saat menghitung endpoint untuk sebuah Service, kontroler EndpointSlice mempertimbangkan topologi (wilayah dan zona) dari setiap endpoint dan mengisi fieldhints untuk mengalokasikannya ke suatu zona. Komponen klaster seperti kube-proxy kemudian dapat menggunakan hints tersebut dan memanfaatkannya untuk mempengaruhi cara trafik diarahkan (dengan memprioritaskan endpoint yang secara topologis lebih dekat).
Mengaktifkan Topology Aware Routing
Catatan:
Sebelum Kubernetes versi 1.27, perilaku ini dikendalikan menggunakan anotasi
service.kubernetes.io/topology-aware-hints.
Kamu dapat mengaktifkan Topology Aware Routing untuk sebuah Service dengan mengatur anotasi
service.kubernetes.io/topology-mode ke Auto. Ketika terdapat cukup banyak endpoint yang tersedia di setiap zona, Topology Hints akan diisi pada EndpointSlices untuk mengalokasikan endpoint secara individual ke zona tertentu, sehingga trafik diarahkan lebih dekat ke tempat asalnya.
Kapan Fitur ini Bekerja dengan Baik
Fitur ini bekerja paling baik ketika:
1. Trafik masuk didistribusikan secara merata
Jika sebagian besar trafik berasal dari satu zona saja, trafik tersebut dapat membebani sebagian endpoint yang dialokasikan ke zona tersebut. Fitur ini tidak direkomendasikan jika trafik masuk diperkirakan berasal dari satu zona saja.
2. Service memiliki 3 atau lebih endpoint per zona
Dalam klaster dengan tiga zona, ini berarti 9 atau lebih endpoint. Jika ada kurang dari 3 endpoint per zona, kemungkinan besar (≈50%) kontroler EndpointSlice tidak dapat mengalokasikan endpoint secara merata dan akan kembali menggunakan pendekatan routing bawaan yang berlaku di seluruh klaster.
Cara Kerjanya
Heuristik "Auto" berusaha mengalokasikan sejumlah endpoint secara proporsional ke setiap zona. Perlu dicatat bahwa heuristik ini bekerja paling baik untuk Service yang memiliki jumlah endpoint yang signifikan.
Kontroler EndpointSlice
Kontroler EndpointSlice bertanggung jawab untuk mengatur hints pada EndpointSlices ketika heuristik ini diaktifkan. Kontroler mengalokasikan jumlah endpoint secara proporsional ke setiap zona. Proporsi ini didasarkan pada
core CPU tersedia yang dialokasikan untuk Node yang berjalan di zona tersebut. Misalnya, jika satu zona memiliki 2 core CPU dan zona lain hanya memiliki 1 core CPU, kontroler akan mengalokasikan dua kali lebih banyak endpoint ke zona dengan 2 core CPU.
Contoh berikut menunjukkan seperti apa EndpointSlice ketika hints telah diisi:
Komponen kube-proxy memfilter endpoint yang diarahkan berdasarkan hints yang diatur oleh kontroler EndpointSlice. Dalam sebagian besar kasus, ini berarti kube-proxy mampu mengarahkan trafik ke endpoint yang berada di zona yang sama. Namun terkadang kontroler mengalokasikan endpoint dari zona berbeda untuk memastikan distribusi endpoint yang lebih merata antar zona. Hal ini akan menyebabkan sebagian trafik diarahkan ke zona lain.
Pengamanan (Safeguard)
Control plane Kubernetes dan kube-proxy pada setiap Node menerapkan aturan pengamanan sebelum menggunakan Topology Aware Hints. Jika aturan ini tidak terpenuhi, kube-proxy akan memilih endpoint dari mana saja dalam klaster kamu, tanpa memperhatikan zona.
Jumlah endpoint tidak mencukupi: Jika jumlah endpoint lebih sedikit daripada jumlah zona dalam klaster, kontroler tidak akan memberikan hints apa pun.
Tidak mungkin mencapai alokasi yang seimbang: Dalam beberapa kasus, tidak mungkin mencapai alokasi endpoint yang seimbang antar zona. Misalnya, jika zona-a dua kali lebih besar dari zona-b, tetapi hanya ada 2 endpoint, endpoint yang dialokasikan ke zona-a mungkin menerima dua kali lebih banyak trafik dibanding zona-b. Kontroler tidak memberikan hints jika nilai "kelebihan beban kerja (expected overload)" ini tidak bisa ditekan di bawah ambang batas yang dapat diterima untuk setiap zona. Penting untuk dicatat bahwa ini bukan berdasarkan umpan balik waktu nyata. Masih mungkin bagi endpoint individu untuk mengalami kelebihan beban kerja.
Satu atau lebih Node kekurangan informasi: Jika ada Node yang tidak memiliki label topology.kubernetes.io/zone atau tidak melaporkan nilai CPU yang dapat dialokasikan, control plane tidak akan mengatur hintsendpoint yang mempertimbangkan topologi, sehingga kube-proxy tidak memfilter endpoint berdasarkan zona.
Satu atau lebih endpoint tidak memiliki hint zona: Jika ini terjadi, kube-proxy menganggap sedang terjadi transisi dari atau ke Topology Aware Hints. Memfilter endpoint untuk Service dalam kondisi ini berisiko, sehingga kube-proxy kembali menggunakan semua endpoint.
Sebuah zona tidak terwakili dalam hints: Jika kube-proxy tidak dapat menemukan setidaknya satu endpoint dengan hint yang menargetkan zona tempatnya berjalan, kube-proxy akan kembali menggunakan endpoint dari semua zona. Ini biasanya terjadi saat kamu menambahkan zona baru ke klaster yang sudah ada.
Batasan (Constraint)
Topology Aware Hints tidak digunakan ketika internalTrafficPolicy diatur ke Local pada sebuah Service. Kamu bisa menggunakan kedua fitur ini dalam satu klaster pada Service yang berbeda, tetapi tidak pada Service yang sama.
Pendekatan ini tidak akan bekerja dengan baik untuk Service yang memiliki sebagian besar trafik berasal dari sebagian zona tertentu. Pendekatan ini mengasumsikan bahwa trafik masuk akan kira-kira proporsional dengan kapasitas Node di setiap zona.
Kontroler EndpointSlice mengabaikan Node yang belum siap (NotReady) saat menghitung proporsi tiap zona. Ini bisa menimbulkan konsekuensi yang tidak diinginkan jika sebagian besar Node dalam keadaan belum siap.
Kontroler EndpointSlice mengabaikan Node yang memiliki label node-role.kubernetes.io/control-plane atau node-role.kubernetes.io/master. Ini bisa menjadi masalah jika beban kerja juga berjalan di Node-Node tersebut.
Kontroler EndpointSlice tidak mempertimbangkan tolerations saat men-deploy atau menghitung proporsi tiap zona. Jika Pod yang mendukung sebuah Service terbatas pada sebagian Node dalam klaster, hal ini tidak akan diperhitungkan.
Fitur ini mungkin tidak bekerja dengan baik bersama autoscaling. Misalnya, jika sebagian besar trafik berasal dari satu zona, hanya endpoint yang dialokasikan ke zona tersebut yang akan menangani trafik itu. Hal ini dapat menyebabkan Horizontal Pod Autoscaler tidak mendeteksi kejadian ini, atau Pod baru yang ditambahkan justru mulai di zona berbeda.
Heuristik Kustom
Kubernetes diterapkan dalam berbagai cara yang berbeda, sehingga tidak ada satu heuristik tunggal untuk mengalokasikan
endpoint ke zona yang akan cocok untuk setiap kasus penggunaan. Salah satu tujuan utama fitur ini adalah
memungkinkan pengembangan heuristik kustom jika heuristik bawaan tidak sesuai dengan kebutuhan kasus penggunaan kamu.
Langkah awal untuk mengaktifkan heuristik kustom telah disertakan dalam rilis 1.27. Ini adalah implementasi terbatas
yang mungkin belum mencakup beberapa situasi relevan dan masuk akal.
Pelajari tentang fieldtrafficDistribution
yang sangat terkait dengan anotasi service.kubernetes.io/topology-mode dan menyediakan opsi fleksibel untuk
routing trafik dalam Kubernetes.
5.13 - Alokasi ClusterIP pada servis (Service ClusterIP allocation)
Dalam Kubernetes, Service adalah cara abstrak untuk mengekspos aplikasi yang berjalan pada sekumpulan Pod. Service dapat memiliki alamat IP virtual yang berlaku dalam skala klaster (menggunakan Service dengan type: ClusterIP). Klien dapat terhubung menggunakan alamat IP virtual tersebut, dan Kubernetes kemudian mendistribusikan lalu lintas ke Service tersebut di antara berbagai Pod yang menjadi backend-nya.
Bagaimana ClusterIP pada Service dialokasikan?
Ketika Kubernetes perlu menetapkan alamat IP virtual untuk sebuah Service, penetapan tersebut dapat dilakukan dengan dua cara:
dinamis
Control plane klaster secara otomatis memilih alamat IP yang tersedia dari dalam rentang IP yang telah dikonfigurasi untuk Service dengan type: ClusterIP.
statis
Kamu yang menentukan sendiri alamat IP yang diinginkan, asalkan berada dalam rentang IP yang telah dikonfigurasi untuk Service.
Di seluruh klaster kamu, setiap ClusterIP untuk Service harus unik. Mencoba membuat Service dengan ClusterIP tertentu yang telah dialokasikan sebelumnya akan menghasilkan error.
Mengapa Kamu Perlu Menetapkan Alamat IP Cluster Service?
Kamu terkadang ingin memiliki Service yang berjalan dengan alamat IP yang telah dikenal (well-known IP addresses), sehingga komponen lain dan pengguna dalam klaster dapat menggunakannya.
Contoh terbaiknya adalah Service DNS untuk klaster. Sebagai konvensi lunak, beberapa installer Kubernetes menetapkan alamat IP ke-10 dari rentang IP Service untuk Service DNS. Misalnya, jika kamu mengonfigurasi klaster kamu dengan rentang IP Service 10.96.0.0/16 dan ingin alamat IP Service DNS kamu menjadi 10.96.0.10, kamu harus membuat Service seperti berikut:
Namun, seperti yang telah dijelaskan sebelumnya, alamat IP 10.96.0.10 belum digunakan (reserved). Jika Service lain dibuat sebelum atau pararel dengan alokasi dinamis, ada kemungkinan mereka dapat menggunakan alamat IP ini. Akibatnya, kamu tidak akan dapat membuat Service DNS karena akan gagal dengan error konflik.
Bagaimana Cara Menghindari Konflik Alamat IP ClusterIP pada Service?
Implementasi alokasi dalam Kubernetes untuk menetapkan ClusterIP ke Service mengurangi risiko konflik.
rentang IP ClusterIP dibagi, berdasarkan rumus min(max(16, cidrSize / 16), 256),
yang dijelaskan sebagai tidak kurang dari 16 atau lebih dari 256 dengan tahap bertingkat di antara keduanya.
Alokasi IP dinamis menggunakan pita atas secara default, setelah ini habis, akan menggunakan pita bawah. Ini akan memungkinkan pengguna untuk menggunakan alokasi statis pada pita bawah dengan risiko konflik yang rendah.
Contoh
Contoh 1
Contoh ini menggunakan rentang alamat IP: 10.96.0.0/24 (notasi CIDR) untuk alamat IP
dari Service.
Ukuran Rentang: 28 - 2 = 254
Offset Pita (band): min(max(16, 256/16), 256) = min(16, 256) = 16
Awal pita statis: 10.96.0.1
Akhir pita statis: 10.96.0.16
Akhir Rentang: 10.96.0.254
pie showData
title 10.96.0.0/24
"Static" : 16
"Dynamic" : 238
Contoh 2
Contoh ini menggunakan rentang alamat IP: 10.96.0.0/20 (notasi CIDR) untuk alamat IP
dari Service.
Ukuran Rentang: 212 - 2 = 4094 Offset Pita (band): min(max(16, 4096/16), 256) = min(256, 256) = 256 Awal pita statis: 10.96.0.1 Akhir pita statis: 10.96.1.0 Akhir Rentang: 10.96.15.254
pie showData
title 10.96.0.0/20
"Static" : 256
"Dynamic" : 3838
Contoh 3
Contoh ini menggunakan rentang alamat IP: 10.96.0.0/16 (notasi CIDR) untuk alamat IP
dari Service.
Ukuran Rentang: 216 - 2 = 65534 Offset Pita (band): min(max(16, 65536/16), 256) = min(4096, 256) = 256 Awal pita statis: 10.96.0.1 Akhir pita statis: 10.96.1.0 Akhir Rentang: 10.96.255.254
pie showData
title 10.96.0.0/16
"Static" : 256
"Dynamic" : 65278
Berkas-berkas yang disimpan di disk di dalam Container bersifat tidak permanen (akan terhapus seiring dengan dihapusnya Container/Pod), yang menimbulkan beberapa masalah untuk aplikasi biasa saat berjalan di dalam Container. Pertama, saat sebuah Container mengalami kegagalan, Kubelet akan memulai kembali Container tersebut, tetapi semua berkas di dalamnya akan hilang - Container berjalan dalam kondisi yang bersih. Kedua, saat menjalankan banyak Container bersamaan di dalam sebuah Pod, biasanya diperlukan untuk saling berbagi berkas-berkas di antara Container-container tersebut. Kedua masalah tersebut dipecahkan oleh abstraksi Volume pada Kubernetes.
Docker juga memiliki konsep volume, walaupun konsepnya Docker agak lebih fleksibel dan kurang dikelola. Pada Docker, sebuah volume adalah sesederhana sebuah direktori pada disk atau di dalam Container lainnya. Lifetime tidak dikelola dan hingga baru-baru ini hanya ada volume yang didukung disk lokal. Docker sekarang menyediakan driver untuk volume, namun fungsionalitasnya masih sangat terbatas (misalnya hingga Docker 1.7 hanya ada satu driver volume yang diizinkan untuk setiap Container, dan tidak ada cara untuk menyampaikan parameter kepada volume).
Sebaliknya, sebuah Volume Kubernetes memiliki lifetime yang gamblang - sama dengan lifetime Pod yang berisi Volume tersebut. Oleh karena itu, sebuah Volume bertahan lebih lama dari Container-container yang berjalan di dalam Pod tersebut, dan data di Volum tersebut juga dipertahankan melewati diulangnya Container. Tentu saja, saat sebuah Pod berakhir, Volume tersebut juga akan berakhir/terhapus. Dan mungkin lebih penting lagi, Kubernetes mendukung banyak jenis Volume, dan sebuah Pod dapat menggunakan sebanyak apapun Volume secara bersamaan.
Pada intinya, sebuah volume hanyalah sebuah direktori, dan mungkin berisi data, yang dapat diakses oleh Container-container di dalam Pod. Bagaimana direktori tersebut dibuat, medium yang menyokongnya, dan isinya ditentukan oleh jenis volume yang digunakan.
Untuk menggunakan sebuah volume, sebuah Pod memerinci volume-volume yang akan disediakan untuk Pod tersebut (kolom .spec.volumes) dan di mana volume-volume tersebut akan ditambatkan (di-mount) di dalam Container-container di Pod (kolom .spec.containers.volumeMounts).
Sebuah proses di dalam Container memiliki sudut pandang filesystem yang disusun dari image dan volume Dockernya. Docker Image berada pada bagian teratas hierarki filesystem, dan volume manapun yang ditambatkan pada path yang diperinci di dalam Image tersebut. Volume tidak dapat ditambatkan pada volume lain atau memiliki hard link ke volume lain. Setiap Container di dalam Pod harus secara independen memerinci di mana tiap Volume ditambatkan.
Sebuah Volume awsElasticBlockStore menambatkan sebuah Volume EBS Amazon Web Services (AWS) ke dalam Pod kamu. Hal ini berarti bahwa sebuah Volume EBS dapat sebelumnya diisi terlebih dahulu dengan data, dan data dapat "dipindahkan" diantara banyak Pod.
Perhatian:
Kamu harus membuat sebuah volume EBS menggunakan awscli dengan perintah aws ec2 create-volume atau menggunakan AWS API sebelum kamu dapat menggunakannya.
Ada beberapa batasan saat menggunakan Volume awsElasticBlockStore:
Node di mana Pod berjalan haruslah merupakan instance AWS EC2.
Instance tersebut mesti berada pada regiondanavailability-zone yang sama dengan volume EBS.
EBS hanya mendukung penambatan pada satu instance EC2 pada saat yang bersamaan.
Membuat sebuah Volume EBS
Sebelum kamu dapat menggunakan sebuah volume EBS pada sebuah Pod, kamu harus membuatnya pada AWS terlebih dahulu.
Pastikan availability zone yang kamu masukkan sama dengan availability zone klaster kamu. (Dan pastikan juga ukuran dan jenis EBSnya sesuai dengan penggunaan yang kamu butuhkan!)
Contoh Konfigurasi AWS EBS
apiVersion:v1kind:Podmetadata:name:test-ebsspec:containers:- image:registry.k8s.io/test-webservername:test-containervolumeMounts:- mountPath:/test-ebsname:test-volumevolumes:- name:test-volume# volume EBS ini harus sudah dibuat di AWSawsElasticBlockStore:volumeID:<volume-id>fsType:ext4
Migrasi CSI awsElasticBlocStore
FEATURE STATE:Kubernetes v1.14 [alpha]
Pada saat fitur migrasi CSI (Container Storage Interface) untuk awsElasticBlockStore diaktifkan, fitur ini akan menterjemahkan semua operasi plugin dari plugin yang sudah ada di kode inti Kubernetes ke bentuk Driver CSI ebs.csi.aws.com. Untuk menggunakan fitur ini, Driver CSI AWS EBS harus dinstal di klaster dan fitur Alpha CSIMigration serta CSIMigrationAWS harus diaktifkan.
azureDisk
Sebuah azureDisk digunakan untuk menambatkan sebuah Data Disk Microsoft Azure ke dalam sebuah Pod.
Pada saat fitur migrasi CSI untuk azureDisk diaktifkan, fitur ini akan menterjemahkan semua operasi plugin dari plugin yang sudah ada di kode inti Kubernetes ke bentuk Driver CSI disk.csi.azure.com. Untuk menggunakan fitur ini, Driver CSI Azure Disk harus dinstal di klaster dan fitur Alpha CSIMigration serta CSIMigrationAzureDisk harus diaktifkan.
azureFile
Sebuah azureFile digunakan untuk menambatkan sebuah Microsoft Azure File Volume (SMB 2.1 dan 3.0) ke dalam sebuah Pod.
Pada saat fitur migrasi CSI untuk azureFile diaktifkan, fitur ini akan menterjemahkan semua operasi plugin dari plugin yang sudah ada di kode inti Kubernetes ke bentuk Driver CSI file.csi.azure.com. Untuk menggunakan fitur ini, Driver CSI Azure File harus dinstal di klaster dan fitur Alpha CSIMigration serta CSIMigrationAzureFile harus diaktifkan.
cephfs
Sebuah Volume cephfs memungkinkan sebuah volume CephFS yang sudah ada untuk ditambatkan ke dalam Pod kamu. Berbeda dengan emptyDir, yang juga ikut dihapus saat Pod dihapus, isi data di dalam sebuah volume CephFS akan dipertahankan dan Volume tersebut hanya dilepaskan tambatannya (mount-nya). Hal ini berarti bahwa sebuah Volume CephFS dapat sebelumnya diisi terlebih dahulu dengan data, dan data dapat "dipindahkan" diantara banyak Pod.
Perhatian:
Kamu harus memiliki server Ceph sendiri dan mengekspor share-nya sebelum kamu dapat menggunakannya.
Prasyarat: Kubernetes dengan penyedia layanan cloud OpenStack yang telah dikonfigurasikan. Untuk konfigurasi penyedia layanan cloud, silahkan lihat penyedia layanan cloud openstack.
cinder digunakan untuk menambatkan Volume Cinder ke dalam Pod kamu.
Contoh Konfigurasi Volume Cinder
apiVersion:v1kind:Podmetadata:name:test-cinderspec:containers:- image:registry.k8s.io/test-webservername:test-cinder-containervolumeMounts:- mountPath:/test-cindername:test-volumevolumes:- name:test-volume# Volume OpenStack ini harus sudah ada sebelumnya.cinder:volumeID:<volume-id>fsType:ext4
Migrasi CSI Cinder
FEATURE STATE:Kubernetes v1.14 [alpha]
Pada saat fitur migrasi CSI untuk Cinder diaktifkan, fitur ini akan menterjemahkan semua operasi plugin dari plugin yang sudah ada di kode inti Kubernetes ke bentuk Driver CSI cinder.csi.openstack.com. Untuk menggunakan fitur ini, Driver CSI Openstack Cinder harus dinstal di klaster dan fitur Alpha CSIMigration serta CSIMigrationOpenStack harus diaktifkan.
configMap
Sumber daya configMap memungkinkan kamu untuk menyuntikkan data konfigurasi ke dalam Pod.
Data yang ditaruh di dalam sebuah objek ConfigMap dapat dirujuk dalam sebuah Volume dengan tipe configMap dan kemudian digunakan oleh aplikasi/container yang berjalan di dalam sebuah Pod.
Saat mereferensikan sebuah objek configMap, kamu tinggal memasukkan nama ConfigMap tersebut ke dalam rincian Volume yang bersangkutan. Kamu juga dapat mengganti path spesifik yang akan digunakan pada ConfigMap. Misalnya, untuk menambatkan ConfigMap log-config pada Pod yang diberi nama configmap-pod, kamu dapat menggunakan YAML ini:
ConfigMap log-config ditambatkan sebagai sebuah Volume, dan semua isinya yang ditaruh di dalam entri log_level-nya ditambatkan dalam Pod tersebut pada path "/etc/config/log_level.conf".
Perlu dicatat bahwa path tersebut berasal dari isian mountPath pada Volume, dan path yang ditunjuk dengan key bernama log_level.
Perhatian:
Kamu harus membuat sebuah ConfigMap sebelum kamu dapat menggunakannya.
Catatan:
Sebuah Container yang menggunakan sebuah ConfigMap sebagai tambatan Volume subPath tidak akan menerima pembaruan ConfigMap.
downwardAPI
Sebuah Volume downwardAPI digunakan untuk menyediakan data downward API kepada aplikasi.
Volume ini menambatkan sebuah direktori dan menulis data yang diminta pada berkas-berkas teks biasa.
Catatan:
Sebuah Container yang menggunakan Downward API sebagai tambatan Volume subPath tidak akan menerima pembaruan Downward API.
Sebuah Volume emptyDir pertama kali dibuat saat sebuah Pod dimasukkan ke dalam sebuah Node, dan akan terus ada selama Pod tersebut berjalan di Node tersebut. Sesuai dengan namanya, Volume ini awalnya kosong. Container-container di dalam Pod dapat membaca dan menulis berkas-berkas yang sama di dalam Volume emptyDir, walaupun Volume tersebut dapat ditambatkan pada path yang sama maupun berbeda pada setiap Container. Saat sebuah Pod dihapus dari sebuah Node untuk alasan apapun, data di dalam emptyDir tersebut dihapus untuk selamanya.
Catatan:
Sebuah Container yang gagal TIDAK AKAN menghapus sebuah Pod dari sebuah Node, sehingga data di dalam sebuah emptyDir akan aman jika Container di dalam Podnya gagal.
Beberapa kegunaan emptyDir adalah sebagai berikut:
Scratch space, misalnya untuk merge sort menggunakan berkas-berkas di disk
Checkpointing untuk komputasi panjang yang dipulihkan dari proses yang sebelumnya mengalami kegagalan
Menyimpan berkas-berkas yang diambil oleh Container aplikasi Content Manager saat sebuah peladen web melayani data tersebut
Secara bawaan, emptyDir ditaruh pada media penyimpanan apapun yang menyokong Node yang bersangkuta - mungkin sebuah disk atau SSD atau penyimpanan berbasis jaringan, tergantung lingkungan Node yang kamu miliki. Tetapi, kamu juga dapat menyetel bagian emptyDir.medium menjadi "Memory" untuk memberitahukan pada Kubernetes untuk menggunakan sebuah tmpfs (filesystem berbasis RAM) sebagai gantinya. tmpfs memang sangan cepat, tetapi kamu harus sadar bahwa ia tidak seperti disk, data di tmpfs akan terhapus saat Node tersebut diulang kembali. Selain itu, berkas apapun yang kamu tulis akan dihitung terhadap limitmemory milik Container kamu.
Sebuah Volume fc memunginkan sebuah volumefibre channel yang sudah ada untuk ditambatkan ke sebuah Pod.
Kamu dapat menentukan satu atau banyak target World Wide Names menggunakan parameter targetWWNs pada konfigurasi Volume kamu. Jika banyak WWN ditentukan, maka targetWWNs mengharapkan bahwa WWN tersebut berasal dari koneksi multi-path.
Perhatian:
Sebelumnya, kamu harus mengkonfigurasikan FC SAN Zoning untuk mengalokasikan dan melakukan masking terhadap LUN (volume) tersebut terhadap target WWN sehingga Node-node Kubernetes dapat mengakses mereka.
Flocker adalah sebuah proyek open-source yg berfungsi sebagai pengatur volume data Container yang diklasterkan. Flocker menyediakan pengelolaan dan orkestrasi volume yang disokong oleh banyak jenis media penyimpanan.
Sebuah Volume flockere memungkinkan sebuah dataset Flocker untuk ditambatkan ke dalam sebuah Pod. Jika dataset tersebut belum ada di dalam Flocker, maka ia harus dibuat terlebih dahulu dengan menggunakan Flocker CLI atau menggunakan Flocker API. Jika dataset tersebut sudah ada, ia akan ditambatkan kembali oleh Flocker ke Node di mana Pod tersebut dijadwalkan. Hal ini berarti data dapat dioper diantara Pod-pod sesuai dengan kebutuhan.
Perhatian:
Kamu harus memiliki instalasi Flocker yang sudah berjalan sebelum kamu dapat menggunakannya.
Sebuah volumegcePersistentDisk menambatkan sebuah PersistentDisk Google Compute Engine (GCE) ke dalam Pod kamu. Tidak seperti emptyDir yang ikut dihapus saat Pod dihapus, isi dari sebuah PD dipertahankan dan volume-nya hanya dilepaskan tambatannya. Hal ini berarti sebuah PD dapat diisi terlebih dahulu dengan data, dan data tersebut dapat "dioper" diantara Pod-pod.
Perhatian:
Kamu harus membuat sebuah PD menggunakan gcloud atau GCE API atau GCP UI sebelum kamu dapat menggunakannya.
Ada beberapa batasan saat menggunakan sebuah gcePersistentDisk:
Node-node di mana Pod-pod berjalan haruslah GCE VM.
VM tersebut harus berada pada proyek GCE yang sama dan zone yang sama dengan PD tersebut
Sebuah fitur PD yaitu mereka dapat ditambatkan sebagai read-only secara bersamaan oleh beberapa pengguna. Hal ini berarti kamu dapat mengisi data terlebih dahulu dan menyediakan data tersebut secara paralel untuk sebanyak apapun Pod yang kamu butuhkan. Sayangnya, PD hanya dapat ditambatkan kepada satu pengguna saja pada mode read-write - yaitu, tidak boleh ada banyak penulis secara bersamaan.
Menggunakan sebuah PD pada sebuah Pod yang diatur oleh sebuah ReplicationController akan gagal, kecuali jika PD tersebut berada pada mode read-only, atau jumlah replica-nya adalah 0 atau 1.
Membuat sebuah PD
Sebelum kamu dapat menggunakan sebuah PD dengan sebuah Pod, kamu harus membuat PD tersebut terlebih dahulu.
apiVersion:v1kind:Podmetadata:name:test-pdspec:containers:- image:registry.k8s.io/test-webservername:test-containervolumeMounts:- mountPath:/test-pdname:test-volumevolumes:- name:test-volume# GCE PD ini harus sudah ada.gcePersistentDisk:pdName:my-data-diskfsType:ext4
Regional Persistent Disks
FEATURE STATE:Kubernetes v1.10 [beta]
Fitur Regional Persistent Disks memungkinkan pembuatan Persistent Disk yang berada pada beberapa zone pada region yang sama. Untuk menggunakan fitur ini, Volume tersebut harus dibuat sebagai sebuah PersistentVolume; mereferensikan Volume tersebut langsung dari sebuah Pod tidak didukung.
Menyediakan sebuah Regional PD PersistentVolume Secara Manual
Penyediaan secara dinamis mungkin dilakukan dengan sebuah StorageClass untuk GCE PD.
Sebelum membuat sebuah PersistentVolume, kamu harus membuat PD-nya:
Pada saat fitur migrasi CSI untuk GCE PD diaktifkan, fitur ini akan menterjemahkan semua operasi plugin dari plugin yang sudah ada di kode inti Kubernetes ke bentuk Driver CSI pd.csi.storage.gke.io. Untuk menggunakan fitur ini, Driver CSI GCE PD harus dinstal di klaster dan fitur Alpha CSIMigration serta CSIMigrationGCE harus diaktifkan.
gitRepo (kedaluwarsa)
Peringatan:
Tipe Volume gitRepo telah kedaluwarsa. Untuk membuat sebuah Container dengan sebuah git repo, tambatkan sebuah EmptyDir ke dalam sebuah InitContainer yang akan mengklon repo tersebut menggunakan git, dan kemudian tambatkan EmptyDir tersebut ke dalam Container Pod tersebut.
Sebuah Volume gitRepo adalah sebuah percontohan yang menunjukkan apa yang dapat dilakukan dengan plugin volume. Ia menambatkan sebuah direktori kosong dan mengklon sebuah repository git ke dalamnya untuk digunakan oleh Pod kamu. Ke depannya, Volume seperti ini dapat dipindahkan ke model yang bahkan lebih terpisah, daripada melakukan ekstensi pada Kubernetes API untuk setiap kasus serupa.
Sebuah Volume glusterfs memungkinkan sebuah volume Glusterfs (sebuah proyek open-sourcefilesystem berbasis jaringan) untuk ditambatkan ke dalam Pod kamu.
Tidak seperti emptyDir yang ikut dihapus saat Pod dihapus, isi dari sebuah glusterfs dipertahankan dan volume-nya hanya dilepaskan tambatannya. Hal ini berarti sebuah glusterfs dapat diisi terlebih dahulu dengan data, dan data tersebut dapat "dioper" diantara Pod-pod. GlusterFS dapat ditambatkan kepada beberapa penulis secara bersamaan.
Perhatian:
Kamu harus mempunyai instalasi GlusterFS terlebih dahulu sebelum dapat kamu gunakan.
Sebuah Volume hostPath menambatkan sebuah berkas atau direktori dari filesystem Node di mana Pod kamu berjalan ke dalam Pod kamu.
Hal ini bukanlah sesuatu yang dibutuhkan oleh sebagian besar Pod kamu, tetapi hal ini menawarkan sebuah mekanisme pintu darurat untuk beberapa aplikasi.
Contohnya, beberapa kegunaan hostPath adalah sebagai berikut:
Menjalankan sebuah Container yang membutuhkan akses terhadap sistem dalaman Docker; misalnya menggunakan hostPath dari /var/lib/docker
Menjalankan cAdvisor di dalam sebuah Container; menggunakan hostPath dari /sys
Memungkinkan sebuah Pod untuk merinci apakah hostPath harus sudah ada sebelum dijalankannya Pod, apakah ia harus dibuat, dan sebagai apa ia harus dibuat.
Sebagai tambahan pada path yang dibutuhkan, pengguna dapat secara opsional merinci type untuk sebuah hostPath.
Nilai yang didukung untuk kolom type adalah:`
Nilai
Perilaku
String kosong (bawaan) adalah untuk kecocokan dengan versi-versi bawah, yang berarti bahwa tidak ada pemeriksaan yang dilakukan sebelum menambatkan Volume hostPath.
DirectoryOrCreate
Jika tidak ada yang tersedia pada path yang dirinci, sebuah direktori kosong akan dibuat sesuai kebutuhan, dengan permission yang disetel menjadi 0755, dan mempunyai grup dan kepemilikan yang sama dengan Kubelet.
Directory
Sebuah direktori harus sudah tersedia pada path yang dirinci
FileOrCreate
Jika tidak ada yang tersedia pada path yang dirinci, maka sebuah berkas kosong akan dibuat sesuai kebutuhan dengan permission yang disetel menjadi 0644, dan mempunyai grup dan kepemilikan yang sama dengan Kubelet.
File
Sebuah berkas harus sudah tersedia pada path yang dirinci
Socket
Sebuah socket UNIX harus sudah tersedia pada path yang dirinci
CharDevice
Sebuah character device sudah tersedia pada path yang dirinci
BlockDevice
Sebuah block device harus sudah tersedia pada path yang dirinci
Berhati-hatilah saat menggunakan tipe volume ini, karena:
Pod-pod dengan konfigurasi identik (misalnya dibuat dari podTemplate) mungkin berperilaku berbeda pada Node-node yang berbeda oleh karena berkas-berkas yang berbeda pada Node-node tersebut.
Saat Kubernetes menambahkan penjadwalan yang sadar terhadap sumber-daya klaster, sesuai yang telah direncanakan, ia tidak dapat melakukan perhitungan terhadap sumber daya yang digunakan oleh sebuah hostPath
Berkas-berkas atau direktori-direktori yang dibuat pada host-host bersangkutan hanya dapat ditulis oleh root. Kamu butuh antara menjalankan proses aplikasi kamu sebagai root pada sebuah privileged Container atau mengubah permission berkas kamu pada host tersebut agar dapat menulis pada Volume hostPath
Contoh Pod
apiVersion:v1kind:Podmetadata:name:test-pdspec:containers:- image:registry.k8s.io/test-webservername:test-containervolumeMounts:- mountPath:/test-pdname:test-volumevolumes:- name:test-volumehostPath:# Lokasi direktori pada hostpath:/data# kolom ini bersifat opsionaltype:Directory
iscsi
Sebuah Volume iscsi memungkinkan sebuah volume iSCSI (SCSI over IP) yang sudah ada untuk ditambatkan ke dalam Pod kamu.
Tidak seperti emptyDir yang ikut dihapus saat Pod dihapus, isi dari sebuah iscsi dipertahankan dan volume-nya hanya dilepaskan tambatannya. Hal ini berarti sebuah iscsi dapat diisi terlebih dahulu dengan data, dan data tersebut dapat "dioper" diantara Pod-pod.
Perhatian:
Kamu harus memiliki peladen iSCSI yang berjalan dengan volume iSCSI yang telah dibuat terlebih dahulu untuk dapat menggunakannya.
Salah satu fitur iSCSI yaitu mereka dapat ditambatkan sebagai read-only secara bersamaan oleh beberapa pengguna. Hal ini berarti kamu dapat mengisi data terlebih dahulu dan menyediakan data tersebut secara paralel untuk sebanyak apapun Pod yang kamu butuhkan. Sayangnya, iSCSI hanya dapat ditambatkan kepada satu pengguna saja pada mode read-write - yaitu, tidak boleh ada banyak penulis secara bersamaan.
Sebuah Volume local merepresentasikan sebuah media penyimpanan lokal yang ditambatkan, seperti disk, partisi, atau direktori.
Volume local hanya dapat digunakan sebagai PersistentVolume yang dibuat secara statis. Dynamic provisioning belum didukung untuk Volume local.
Dibandingkan dengan Volume hostPath, Volume local dapat digunakan secara durable dan portabel tanpa harus menjadwalkan Pod ke Node secara manual, dikarenakan sistem mengetahui pembatasan yang berlaku terhadap Volume pada Node tersebut, dengan cara melihat node affinity pada PersistentVolume-nya.
Tetapi, Volume local masih bergantung pada ketersediaan Node yang bersangkutan, dan tidak semua aplikasi cocok menggunakannya. Jika sebuah Node tiba-tiba gagal, maka Volume local pada Node tersebut menjadi tidak dapat diakses juga, dan Pod yang menggunakannya tidak dapat dijalankan. Aplikasi yang menggunakan Volumelocal harus dapat mentoleransi hal ini dan juga potensi kehilangan data, tergantung pada karakteristik ketahanan disk yang digunakan.
Berikut sebuah contoh spesifikasi PersistentVolume menggunakan sebuah Volume local dan nodeAffinity:
Kolom nodeAffinity ada PersistentVolue dibutuhkan saat menggunakan Volume local. Ia memungkinkan Kubernetes Scheduler untuk menjadwalkan Pod-pod dengan tepat menggunakan Volume local pada Node yang tepat.
Kolom volumeMode pada PersistentVolume sekarang dapat disetel menjadi "Block" (menggantikan nilai bawaan "Filesystem") untuk membuka Volume local tersebut sebagai media penyimpanan blok mentah. Hal ini membutuhkan diaktifkannya Alpha feature gateBlockVolume.
Saat menggunakan Volume local, disarankan untuk membuat sebuah StorageClass dengan volumeBindingMode yang disetel menjadi WaitForFirstConsumer. Lihatcontohnya. Menunda pengikatan Volume memastikan bahwa keputusan pengikatan PersistentVolumeClaim juga akan dievaluasi terhadap batasan-batasan Node yang berlaku pada Pod, seperti kebutuhan sumber daya Node, nodeSelector, podAffinity, dan podAntiAffinity.
Sebuah penyedia statis eksternal dapat berjalan secara terpisah untuk memperbaik pengaturan siklus hidup Volume local. Perlu dicatat bahwa penyedia ini belum mendukung dynamic provisioning. Untuk contoh bagaimana menjalankan penyedia Volume local eksternal, lihat petunjuk penggunaannya.
Catatan:
PersistentVolume lokal membutuhkan pembersihan dan penghapusan secara manual oleh pengguna jika penyedia eksternal tidak digunakan untuk mengatur siklus hidup Volume lokal tersebut.
nfs
Sebuah Volume nfs memungkinkan sebuah NFS (Network File System) yang sudah ada untuk ditambatkan ke dalam Pod kamu.
Tidak seperti emptyDir yang ikut dihapus saat Pod dihapus, isi dari sebuah nfs dipertahankan dan volume-nya hanya dilepaskan tambatannya. Hal ini berarti sebuah nfs dapat diisi terlebih dahulu dengan data, dan data tersebut dapat "dioper" diantara Pod-pod. NFS juga dapat ditambatkan oleh beberapa penulis secara sekaligus.
Perhatian:
Kamu harus memiliki peladen NFS yang berjalan dengan share yang diekspor sebelum kamu dapat menggunakannya.
Sebuah Volume persistentVolumeClaim digunakan untuk menambatkan sebuah PersistentVolume ke dalam sebuag Pod. PersistentVolume adalah sebuah cara bagi pengguna untuk "mengklaim" penyimpanan yang durable (seperti sebuah GCE PD atau sebuah volume iSCSI) tanpa mengetahui detil lingkungan cloud yang bersangkutan.
Semua sumber harus berada pada namespace yang sama dengan Pod yang menggunakannya. Untuk lebih lanjut, lihat dokumen desain Volume.
Proyeksi serviceAccountToken adalah fitur yang diperkenalkan pada Kubernetes 1.11 dan dipromosikan menjadi Beta pada 1.12.
Untuk mengaktifkan fitur inipada 1.11, kamu harus menyetel feature gateTokenRequestProjection secara eksplisit menjadi True.
Contoh Pod dengan sebuah Secret, Downward API, dan ConfigMap.
Setiap sumber Volume projected terdaftar pada spesifikasi di kolom sources. Parameter-parameter tersebut hampir sama persis dengan dua pengecualian berikut:
Untuk Secret, kolom secretName telah diganti menjadi name agar konsisten dengan penamaan ConfigMap.
Kolom defaultMode hanya dapat dispesifikasikan pada tingkat projected dan tidak untuk setiap sumber Volume. Tetapi, seperti yang ditunjukkan di atas, kamu dapat secara eksplisit menyetel mode untuk setiap proyeksi.
Saat fitur TokenRequestProjection diaktifkan, kamu dapat menyuntikkan token untuk ServiceAccount yang bersangkutan ke dalam Pod pada path yang diinginkan. Berikut contohnya:
Contoh Pod tersebut memiliki Volume projected yang berisi token ServiceAccount yang disuntikkan. Token ini dapat digunakan oleh Container dalam Pod untuk mengakses Kubernetes API Server misalnya. Kolom audience berisi audiensi token yang dituju. Sebuah penerima token tersebut harus mengidentifikasikan dirinya dengan tanda pengenal yang dispesifikasikan pada audience token tersebut, atau jika tidak, harus menolak token tersebut. Kolom ini bersifat opsional dan secara bawaan akan berisi tanda pengenal API Server.
Kolom expirationSeconds adalah masa berlaku yang diinginkan untuk token ServiceAccount tersebut. Secara bawaan, nilainya adalah 1 jam dan harus paling singkat bernilai 10 menit (600 detik). Seorang administrator juga dapat membatasi nilai maksimumnya dengan menyetel opsi --service-account-max-token-expiration pada API Server. Kolom path menunjukkan relative path untuk menambatkan Volume projected tersebut.
Catatan:
Sebuah Container yang menggunakan sebuah sumber Volume projected sebagai tambatan Volume subPath tidak akan menerima pembaruan pada sumber Volume tersebut.
portworxVolume
Sebuah portworxVolume adalah sebuah penyimpanan blok elastis yang berjalan secara hyperconverged dengan Kubernetes. Portworx mengambil sidik jari media penyimpanan pada sebuah server, mengklasifikasikannya berdasarkan kemampuannya, dan mengagregasikan kapasitasnya di banyak server. Portworx berjalan secara in-guest pada mesin virtual atau pada Node Linux bare metal.
Sebuah portworxVolume dapat dibuat secara dinamis melalui Kubernetes, atau ia juga dapat disediakan terlebih dahulu dan dirujuk dari dalam Pod Kubernetes. Berikut contoh sebuah Pod yang mereferensikan PortworxVolume yang telah disediakan terlebih dahulu:
apiVersion:v1kind:Podmetadata:name:test-portworx-volume-podspec:containers:- image:registry.k8s.io/test-webservername:test-containervolumeMounts:- mountPath:/mntname:pxvolvolumes:- name:pxvol# Volume Portworx ini harus sudah tersedia.portworxVolume:volumeID:"pxvol"fsType:"<fs-type>"
Perhatian:
Pastikan kamu sudah memiliki PortworxVolume dengan nama pxvol sebelum dapat menggunakannya pada Pod.
Sebuah Volume quobyte memungkinkan sebuah volume Quobyte yang sudah tersedia untuk ditambatkan ke dalam Pod kamu.
Perhatian:
Kamu harus sudah memiliki instalasi Quobyte dengan volume yang sudah disediakan terlebih dahulu untuk dapat menggunakannya.
Quobyte mendukung Container Storage Interface.
CSI adalah plugin yang direkomendasikan untuk menggunakan Volume Quobyte di dalam Kubernetes. Ada petunjuk dan contoh untuk menggunakan Quobyte menggunakan CSI pada proyek GitHub Quobyte.j
rbd
Sebuah Volume rbd memungkinkan sebuah volume Rados Block Device ditambatkan ke dalam Pod kamu.
Tidak seperti emptyDir yang ikut dihapus saat Pod dihapus, isi dari sebuah rbd dipertahankan dan volume-nya hanya dilepaskan tambatannya. Hal ini berarti sebuah rbd dapat diisi terlebih dahulu dengan data, dan data tersebut dapat "dioper" diantara Pod-pod.
Perhatian:
Kamu harus memiliki instalasi Ceph yang berjalan sebelum kamu dapat menggunakan RBD.
Sebuah fitur RBD yaitu mereka dapat ditambatkan sebagai read-only secara bersamaan oleh beberapa pengguna. Hal ini berarti kamu dapat mengisi data terlebih dahulu dan menyediakan data tersebut secara paralel untuk sebanyak apapun Pod yang kamu butuhkan. Sayangnya, RBD hanya dapat ditambatkan kepada satu pengguna saja pada mode read-write - yaitu, tidak boleh ada banyak penulis secara bersamaan.
ScaleIO adalah platform penyimpanan berbasis perangkat lunak yang dapat menggunakan perangkat keras yang sudah tersedia untuk membuat klaster-klaster media penyimpanan terhubung jaringan yang scalable. Plugin Volume scaleIO memungkinkan Pod-pod yang di-deploy untuk mengakses Volume-volume ScaleIO yang telah tersedia (atau dapat menyediakan volume-volume untuk PersistentVolumeClaim secara dinamis, lihat Persistent Volume ScaleIO).
Perhatian:
Kamu harus memiliki klaster ScaleIO yang berjalan dengan volume-volume yang sudah dibuat sebelum kamu dapat menggunakannya.
Berikut contoh konfigurasi sebuah Pod yang menggunakan ScaleIO:
Sebuah Volume secret digunakan untuk memberikan informasi yang bersifat sensitif, seperti kata sandi, kepada Pod-pod. Kamu dapat menaruh secret dalam Kubernetes API dan menambatkan mereka sebagai berkas-berkas untuk digunakan oleh Pod-pod tanpa harus terikat pada Kubernetes secara langsung. Volume secret didukung oleh tmpfs (filesystem yang didukung oleh RAM) sehingga mereka tidak pernah ditulis pada media penyimpanan yang non-volatile.
Perhatian:
Kamu harus membuat sebuah secret di dalam Kubernetes API sebelum kamu dapat menggunakannya.
Catatan:
Sebuah Container yang menggunakan sebuah Secret sebagai sebuah Volume subPath tidak akan mendapatkan pembaruan terhadap Secret.
Sebuah Volume storageos memungkinkan volume StorageOS yang sudah tersedia untuk ditambatkan ke dalam Pod kamu.
StorageOS berjalan sebagai sebuah COntainer di dalam lingkungan Kubernetes kamu, membuat penyimpanan yang lokal atau penyimpanan yang sedang dipasang untuk diakses dari Node manapun di dalam klaster Kubernetes.
Data dapat direplikasikan untuk melindungi dari kegagalan Node. Thin provisioning dan kompresi dapat meningkatkan utilisasi dan mengurangi biaya.
Di dalam intinya, StorageOS menyediakan penyimpanan blok kepada Container-container, yang dapat diakses melalui sebuah filesystem.
Container StorageOS membutuhkan Linux 64-bit dan tidak memiliki ketergantungan tambahan apapun.
Tersedia pula sebuah lisensi gratis untuk developer.
Perhatian:
Kamu harus menjalankan Container StorageOS pada setiap Node yang ingin mengakses volume-volume StorageOS atau yang akan berkontribusi pada kapasitas penyimpanan di klaster StorageOS. Untuk petunjuk instalasi, lihat dokumentasi StorageOS.
apiVersion:v1kind:Podmetadata:labels:name:redisrole:mastername:test-storageos-redisspec:containers:- name:masterimage:kubernetes/redis:v1env:- name:MASTERvalue:"true"ports:- containerPort:6379volumeMounts:- mountPath:/redis-master-dataname:redis-datavolumes:- name:redis-datastorageos:# Volume `redis-vol01` harus sudah tersedia di dalam StorageOS pada Namespace `default`volumeName:redis-vol01fsType:ext4
Untuk lebih lanjut, termasuk Dynamic Provisioning dan Persistent Volume Claim, lihat contoh-contoh StorageOS.
vsphereVolume
Catatan:
Prasyarat: Kubernetes dengan Cloud Provider vSphere yang telah dikonfigurasikan. Untuk konfigurasi cloudprovider, silahkan lihat petunjuk memulai vSphere.
Sebuah vsphereVolume digunakan untuk menambatkan sebuah Volume VMDK vSphere ke dalam Pod kamu. Isi dari sebuah volume dipertahankan pada saat tambatannya dilepas. Ia mendukung penyimpanan data VMFS dan VSAN.
Perhatian:
Kamu harus membuat VMDK menggunakan satu dari cara-cara berikut sebelum menggunakannya dengan Pod.
Membuat sebuah Volume VMDK
Pilih satu dari beberapa cara berikut untuk membuat sebuah VMDK.
Pertama-tama, ssh ke dalam ESX, kemudian gunakan perintah berikut untuk membuat sebuah VMDK:
Gunakan perintah berikut untuk membuat sebuah VMDK:
vmware-vdiskmanager -c -t 0 -s 40GB -a lsilogic myDisk.vmdk
Contoh Konfigurasi vSphere VMDK
apiVersion:v1kind:Podmetadata:name:test-vmdkspec:containers:- image:registry.k8s.io/test-webservername:test-containervolumeMounts:- mountPath:/test-vmdkname:test-volumevolumes:- name:test-volume# Volume VMDK ini harus sudah tersedia.vsphereVolume:volumePath:"[DatastoreName] volumes/myDisk"fsType:ext4
Terkadang, diperlukan untuk membagi sebuah Volume untuk banyak kegunaan berbeda pada sebuah Pod. Kolom volumeMounts[*].subPath dapat digunakan untuk merinci sebuah sub-path di dalam Volume yang dimaksud, menggantikan root path-nya.
Berikut contoh sebuah Pod dengan stack LAMP (Linux Apache Mysql PHP) menggunakan sebuah Volume yang dibagi-bagi.
Isi HTML-nya dipetakan ke dalam direktori html-nya, dan database-nya akan disimpan di dalam direktori mysql-nya.
Menggunakan subPath dengan environment variable yang diekspansi
FEATURE STATE:Kubernetes v1.15 [beta]
Gunakan kolom subPathExpr untuk membuat nama-nama direktori subPath dari environment variable Downward API.
Sebelum kamu menggunakan fitur ini, kamu harus mengaktifkan feature gateVolumeSubpathEnvExpansion. Kolom subPath dan subPathExpr bersifat mutually exclusive.
Pada contoh ini, sebuah Pod menggunakan subPathExpr untuk membuat sebuah direktori pod1 di dalam Volume hostPath /var/log/pods, menggunakan nama Pod dari Downward API. Direktori host/var/log/pods/pod1 ditambatkan pada /logs di dalam Container-nya.
apiVersion:v1kind:Podmetadata:name:pod1spec:containers:- name:container1env:- name:POD_NAMEvalueFrom:fieldRef:apiVersion:v1fieldPath:metadata.nameimage:busyboxcommand:["sh","-c","while [ true ]; do echo 'Hello'; sleep 10; done | tee -a /logs/hello.txt"]volumeMounts:- name:workdir1mountPath:/logssubPathExpr:$(POD_NAME)restartPolicy:Nevervolumes:- name:workdir1hostPath:path:/var/log/pods
Sumber-sumber
Media penyimpanan (Disk, SSD, dll.) dari sebuah Volume emptyDir ditentukan oleh medium dari filesystem yang menyimpan direktori root dari Kubelet (biasanya /var/lib/kubelet). Tidak ada batasan berapa banyak ruang yang dapat digunakan oleh Volume emptyDir dan hostPath, dan tidak ada isolasi antara Container-container atau antara Pod-pod.
Ke depannya, kita mengharapkan Volume emptyDir dan hostPath akan dapat meminta jumlah ruangan penyimpanan tertentu dengan mengunakan spesifikasi [resource]resource, dan memilih tipe media penyimpanan yang akan digunakan, untuk klaster yang memiliki beberapa jenis media penyimpanan.
Plugin Volume yang Out-of-Tree
Plugin Volume yang Out-of-tree termasuk Container Storage Interface (CSI) dan Flexvolume. Mereka memungkinkan vendor penyimpanan untuk membuat plugin penyimpanan buatan tanpa perlu menambahkannya pada repository Kubernetes.
Sebelum dikenalkannya CSI dan Flexvolume, semua plugin volume (seperti jenis-jenis volume yang terdaftar di atas) berada pada "in-tree", yang berarti bahwa mereka dibangun, di-link, di-compile, dan didistribusikan bersama-sama dengan kode inti Kubernetes dan mengekstensi inti dari Kubernetes API. Hal ini berarti menambah sistem penyimpanan baru ke dalam Kubernetes (sebuah plugin volume) membutukan penambahan kode tersebut ke dalam repository kode inti Kubernetes.
CSI dan Flexvolume memungkinkan plugin volume untuk dikembangkan secara terpisah dari kode inti Kubernetes, dan diinstal pada klaster Kubernetes sebagai ekstensi.
Bagi vendor-vendor penyimpanan yang ingin membuat sebuah plugin volume yang out-of-tree, lihat FAQ ini.
CSI
Container Storage Interface (CSI) mendefinisikan standar antarmuka untuk sistem orkestrasi (seperti Kubernetes) untuk mengekspos sistem penyimpanan apapun ke dalam beban kerja Container mereka.
Dukungan untuk CSI dikenalkan sebagai Alpha pada Kubernetes v1.9, dan menjadi Beta pada Kubernetes v1.10, dan menjadi GA pada Kubernetes v1.13.
Catatan:
Dukungan untuk spesifikasi CSI pada versi 0.2 dan 0.3 telah kedaluwarsa pada Kubernetes v1.13 dan akan dihapus pada rilis-rilis di masa depan.
Catatan:
Driver-driver CSI mungkin tidak cocok pada semua rilis Kubernetes.
Silahkan lihat dokumentasi driver CSI yang bersangkutan untuk petunjuk penggunaan yang didukung untuk setiap rilis Kubernetes, dan untuk melihat matriks kompabilitasnya.
Saat sebuah driver volume CSI dipasang pada klaster Kubernetes, pengguna dapat menggunakan tipe Volume csi untuk menambatkan volume-volume yang diekspos oleh driver CSI tersebut.
Tipe Volume csi tidak mendukung referensi secara langsung dari Pod dan hanya dapat dirujuk di dalam sebuah Pod melalui sebuah objek PersistentVolumeClaim.
Kolom-kolom berikut tersedia untuk administrator-administrator penyimpanan untuk mengkonfigurasi sebuah Persistent Volume CSI.
driver: Sebuah nilai string yang merinci nama dari driver volume yang akan digunakan.
Nilai ini harus sesuai dengan nilai yang dikembalikan oleh GetPluginInfoResponse dari _driver_CSI seperti yang didefinisikan pada spesifikasi CSI.
Ia digunakan oleh Kubernetes untuk mengidentifikasikan driver CSI mana yang akan dipanggil, dan oleh komponen driver CSI untuk mengidentifikasikan objek PersistentVolume mana yang dimiliki oleh driver CSI tersebut.
volumeHandle: Sebuah nilai string yang secara unik mengidentifikasikan volume tersebut.
Nilai ini harus sesuai dengan nilai yang dikembalikan oleh kolom volume.id dari CreateVolumeResponse dari driver CSI seperti yang didefinisikan pada spesifikasi CSI.
Nilai tersebut dioper sebagai volume_id pada semua panggilan terhadap driver volume CSI saat mereferensikan volume yang bersangkutan.
readOnly: Sebuah nilai boolean bersifat opsional yang mengindikasikan jika sebuah volume akan dijadikan sebagai "ControllerPublished" (ditambatkan) sebagai read-only.
Nilai bawaannya adalah false. Nilai ini dioper ke driver CSI melalui kolom readonly pada ControllerPublishVolumeRequest.
fsType: Jika nilai VolumeMode milik PV adalah FileSystem, maka kolom ini dapat digunakan untuk menunjukkan filesystem yang akan digunakan untu menambatkan volume tersebut.
Jika volume tersebut belum diformat dan memformat tidak didukung, maka nilai ini akan digunakan untuk memformat volume tersebut. Nilai ini dioper kepada driver CSI melalui kolom VolumeCapability dari ControllerPublishVolumeRequest, NodeStageVolumeRequest, dan NodePublishVolumeRequest.
volumeAttributes: Sebuah map dari string kepada string yang merinci properti statis dari sebuah volume.
Nilai map ini harus sesuai dengan map yang dikembalikan di dalam kolom volume.attributes pada CreateVolumeResponse dari driver CSI seperti yang didefinisikan pada spesifikasi CSI.
Map tersebut dioper kepada driver CSI melalui kolom volume_attributes padaControllerPublishVolumeRequest, NodeStageVolumeRequests, dan NodePublishVolumeRequest.
controllerPublishSecretRef: Sebuah referensi ke objek Secret yang berisi informasi sensitif untuk diberikan pada driver CSI untuk menyelesaikan panggilan ControllerPublishVolume dan ControllerUnpublishVolume.
Kolom ini bersifat opsional, dan dapat bernilai kosong jika tidak ada Secret yang dibutuhkan. Jika objek Secret berisi lebih dari satu secret, maka semua secret tersebut akan diberikan.
nodeStageSecretRef: Sebuah referensi ke objek Secret yang berisi informasi sensitif untuk diberikan pada driver CSI untuk menyelesaikan panggilan NodeStageVolume. Kolom ini bersifat opsional, dan dapat bernilai kosong jika tidak ada Secret yang dibutuhkan. Jika objek Secret berisi lebih dari satu secret, maka semua secret tersebut akan diberikan.
nodePublishSecretRef: Sebuah referensi ke objek Secret yang berisi informasi sensitif untuk diberikan pada driver CSI untuk menyelesaikan panggilan NodePublishVolume. Kolom ini bersifat opsional, dan dapat bernilai kosong jika tidak ada Secret yang dibutuhkan. Jika objek Secret berisi lebih dari satu secret, maka semua secret tersebut akan diberikan.
Dukungan CSI untuk volume blok raw
FEATURE STATE:Kubernetes v1.14 [beta]
Dimulai pada versi 1.11, CSI memperkenalkan dukungak untuk volume blok raw, yang bergantung pada fitur volume blok raw yang dikenalkan pada versi Kubernetes sebelumnya. Fitur ini akan memungkinkan vendor-vendor dengan driver CSI eksternal untuk mengimplementasi dukungan volume blok raw pada beban kerja Kubernetes.
Dukungan untuk volume blok CSI bersifat feature-gate, tapi secara bawaan diaktifkan. Kedua feature-gate yang harus diaktifkan adalah BlockVolume dan CSIBlockVolume.
FItur ini memungkinkan volume CSI untuk dipasang secara langsung pada spesifikasi Pod, menggantikan spesifikasi pada PersistentVolume. Volume yang dirinci melalui cara ini bersifat sementara tidak akan dipertahankan saat Pod diulang kembali.
Fitur CSI Migration, saat diaktifkan, akan mengarahkan operasi-operasi terhadap plugin-plugin in-tree yang sudah ada ke plugin-plugin CSI yang sesuai (yang diharap sudah dipasang dan dikonfigurasi). Fitur ini mengimplementasi logika translasi dan terjemahan yang dibutuhkan untuk mengarahkan ulang operasi-operasi bersangkutan dengan mulus. Hasilnya, operator-operator tidak perlu membuat perubahan konfigurasi apapun pada StorageClass, PV, atau PVC yang sudah ada (mengacu pada plugin in-tree) saat melakukan transisi pada driver CSI yang menggantikan plugin in-tree yang bersangkutan.
Pada keadaan Alpha, operasi-operasi dan fitur-fitur yang didukung termasuk provisioning/delete, attach/detach, mount/unmount, dan mengubah ukuran volume-volume.
Plugin-plugin in-tree yang mendukung CSI Migration dan mempunyai driver CSI yang sesuai yang telah diimplementasikan terdaftar pada bagian "Jenis-jenis Volume" di atas.
Flexvolume
Flexvolume adalah antarmuka plugin out-of-tree yang telah ada sejak Kubernetes versi 1.2 (sebelum CSI). Ia menggunakan model berbasis exec untuk berhubungan dengan driver-driver. Program driver Flexvolume harus dipasan pada volume plugin path yang telah didefinisikan sebelumnya pada setiap Node (dan pada beberapa kasus, di Master).
Pod-pod berinteraksi dengan driver-driver Flexvolume melalui plugin in-tree flexvolume.
Untuk lebih lanjut, dapat ditemukan di sini.
Mount Propagation
Mount propagation memungkinkan berbagi volume-volume yang ditambatkan oleh sebuah Container kepada Container-container lain di dalam Pod yang sama, atau bahkan pada Pod lainnya di dalam Node yang sama.
Mount propagation dari sebuah volume diatur oleh kolom mountPropagation di dalam containers[*].volumeMounts.
Nilai-nilainya adalah sebagai berikut:
None - Tambatan volume ini tidak akan menerima apapun tambatan selanjutnya yang ditambatkan pada volume ini atau apapun sub-direktori yang dimilikinya oleh host.
Dengan cara yang sama, tidak ada tambatan yang dibuat oleh Container yang dapat terlihat pada host. Ini adalah mode bawaan.
Mode ini setara dengan mount propagationprivate, seperti yang dideskripsikan pada dokumentasi kernel Linux
HostToContainer - Tambatan volume ini akan menerima semua tambatan selanjutnya yang ditambatkan pada volume ini atau pada apapun sub-direktori yang dimilikinya.
Dalam kata lain, jika host yang bersangkutan menambatkan apapun di dalam tambatan volume, Container akan melihatnya ditambatkan di sana.
Secara serupa, jika ada Pod dengan mount propagationBidirectional terhadap volume yang sama menambatkan apapun ke situ, maka Container dengan mount propagationHostToContainer akan melihatnya.
Mode ini setara dengan mount propagationrslave, seperti yang dideskripsikan pada dokumentasi kernel Linux
Bidirectional - Tambatan volume ini memiliki perilaku yang sama dengan tambatan HostToContainer.
Sebagai tambahannya, semua tambatan volume yang dibuat oleh Container akan dipropagasi kembali kepada host yang bersangkutan dan ke semua Container dari semua Pod yang menggunakan volume yang sama.
Contoh kasus umum untuk mode ini adalah Pod dengan sebuah Flexvolume atau driver CSI atau sebuah Pod yang perlu menambatkan sesuatu pada host-nya dengan menggunakan Volume hostPath.
Mode ini setara dengan mount propagationrshared, seperti yang dideskripsikan pada dokumentasi kernel Linux
Perhatian:
Mount propagationBidirectional bisa jadi berbahaya. Ia dapat merusak sistem operasi host-nya, sehingga hanya diizinkan pada Container yang privileged. Keterbiasaan dengan perilaku kernel Linux sangat dianjurkan.
Sebagai tambahan, tambatan volume apapun yang dibuat oleh Container-container di dalam Pod-pod harus dihancurkan (dilepaskan tambatannya) oleh Container-container pada saat terminasi.
Konfigurasi
Sebelum mount propagation dapat bekerja dengan baik pada beberapa instalasi (CoreOS, RedHat/Centos, Ubuntu), mount share harus dikonfigurasi dengan benar pada Docker, seperti yang ditunjukkan di bawah.
Sunting berkas servis systemd Docker kamu. Setel MountFlags sebagai berikut:
MountFlags=shared
Atau, hapus MountFlags=slave jika ada. Kemudian, ulang kembali daemon Docker-nya:
Dokumen ini menjelaskan kondisi terkini dari PersistentVolumes pada Kubernetes. Disarankan telah memiliki familiaritas dengan volume.
Pengenalan
Mengelola penyimpanan adalah hal yang berbeda dengan mengelola komputasi. Sub-sistem PersistentVolume (PV) menyediakan API untuk para pengguna dan administrator yang mengabstraksi detail-detail tentang bagaimana penyimpanan disediakan dari bagaimana penyimpanan dikonsumsi. Untuk melakukan ini, kami mengenalkan dua sumber daya API baru: PersistentVolume (PV) dan PersistentVolumeClaim (PVC).
Sebuah PersistentVolume (PV) adalah suatu bagian dari penyimpanan pada klaster yang telah disediakan oleh seorang administrator. PV merupakan sebuah sumber daya pada klaster sama halnya dengan node yang juga merupakan sumber daya klaster. PV adalah volume plugin seperti Volumes, tetapi memiliki siklus hidup yang independen dari pod individual yang menggunakan PV tersebut. Objek API ini menangkap detail-detail implementasi dari penyimpanan, seperti NFS, iSCSI, atau sistem penyimpanan yang spesifik pada penyedia layanan cloud.
Sebuah PersistentVolumeClaim (PVC) merupakan permintaan penyimpanan oleh pengguna. PVC mirip dengan sebuah pod. Pod mengonsumsi sumber daya node dan PVC mengonsumsi sumber daya PV. Pods dapat meminta taraf-taraf spesifik dari sumber daya (CPU dan Memory). Klaim dapat meminta ukuran dan mode akses yang spesifik (seperti, dapat dipasang sekali sebagai read/write atau lain kali sebagai read-only).
Meskipun PersistentVolumeClaims mengizinkan pengguna untuk mengkonsumsi sumber daya penyimpanan
abstrak, pada umumnya para pengguna membutuhkan PersistentVolumes dengan properti yang
bermacam-macam, seperti performa, untuk mengatasi masalah yang berbeda. Para administrator klaster
harus dapat menawarkan berbagai macam PersistentVolumes yang berbeda tidak hanya pada ukuran dan
mode akses, tanpa memaparkan detail-detail bagaimana cara volume tersebut diimplementasikan
kepada para pengguna. Untuk mengatasi hal ini maka dibutuhkan sumber daya
StorageClass.
PV adalah sumber daya dalam sebuah klaster. PVC adalah permintaan terhadap sumber daya tersebut dan juga berperan sebagai pemeriksaan klaim dari sumber daya yang diminta. Interaksi antara PV dan PVC mengikuti siklus hidup berikut ini:
Penyediaan
Ada dua cara untuk menyediakan PV: secara statis atau dinamis.
Statis
Seorang administrator klaster membuat beberapa PV. PV yang telah dibuat membawa detail-detail dari penyimpanan yang sesungguhnya tersedia untuk digunakan oleh pengguna klaster. PV tersebut ada pada Kubernetes API dan siap untuk digunakan.
Dinamis
Ketika tidak ada PV statis yang dibuat oleh administrator yang sesuai dengan PersistentVolumeClaim (PVC) yang dibuat oleh pengguna, klaster akan mencoba untuk menyediakan volume khusus sesuai permintaan PVC.
Penyediaan dinamis ini berbasis StorageClass: artinya PVC harus meminta sebuah storage class dan storage class tersebut harus sudah dibuat dan dikonfigurasi oleh administrator agar penyediaan dinamis bisa terjadi. Klaim yang meminta PV dengan storage class"" secara efektif telah menonaktifkan penyediaan dinamis.
Untuk mengaktifkan penyediaan storage dinamis berdasarkan storage class, administrator klaster harus mengaktifkan admission controllerDefaultStorageClass pada API server. Hal ini dapat dilakukan, dengan cara memastikan DefaultStorageClass ada di antara urutan daftar value yang dibatasi koma untuk flag--enable-admission-plugins pada komponen API server. Untuk informasi lebih lanjut mengenai flag perintah pada API server, silakan cek dokumentasi,
kube-apiserver.
Pengikatan
Seorang pengguna membuat, atau telah membuat (dalam kasus penyediaan dinamis), sebuah PersistentVolumeClaim (PVC) dengan jumlah penyimpanan spesifik yang diminta dan dengan mode akses tertentu. Sebuah control loop pada master akan melihat adanya PVC baru, mencari PV yang cocok (jika memungkinkan), dan mengikat PVC dengan PV tersebut. Jika sebuah PV disediakan secara dinamis untuk sebuah PVC baru, loop tersebut akan selalu mengikat PV tersebut pada PVC yang baru dibuat itu. Jika tidak, pengguna akan selalu mendapatkan setidaknya apa yang dimintanya, tetapi volume tersebut mungkin lebih dari apa yang diminta sebelumnya. Setelah terikat, ikatan PersistentVolumeClaim (PVC) bersifat eksklusif, terlepas dari bagaimana caranya mereka bisa terikat. Sebuah ikatan PVC ke PV merupakan pemetaan satu ke satu.
Klaim akan berada dalam kondisi tidak terikat tanpa kepastian jika tidak ada volume yang cocok. Klaim akan terikat dengan volume yang cocok ketika ada volume yang cocok. Sebagai contoh, sebuah klaster yang sudah menyediakan banyak PV berukuran 50Gi tidak akan cocok dengan PVC yang meminta 100Gi. PVC hanya akan terikat ketika ada PV 100Gi yang ditambahkan ke klaster.
Penggunaan
Pod menggunakan klaim sebagai volume. Klaster menginspeksi klaim untuk menemukan volume yang terikat dengan klaim tersebut dan memasangkan volume tersebut ke pada pod. Untuk volume yang mendukung banyak mode akses, pengguna yang menentukan mode yang diinginkan ketika menggunakan klaim sebagai volume dalam sebuah pod.
Ketika pengguna memiliki klaim dan klaim tersebut telah terikat, PV yang terikat menjadi hak penggunanya selama yang dibutuhkan. Pengguna menjadwalkan pod dan mengakses PV yang sudah diklaim dengan menambahkan persistentVolumeClaim pada blok volume pada Pod miliknya. Lihat pranala di bawah untuk detail-detail mengenai sintaks.
Object Penyimpanan dalam Perlindungan Penggunaan
Tujuan dari Objek Penyimpanan dalam Perlindungan Penggunan adalah untuk memastikan Persistent Volume Claim (PVC) yang sedang aktif digunakan oleh sebuah pod dan Persistent Volume (PV) yang terikat pada PVC tersebut tidak dihapus dari sistem karena hal ini dapat menyebabkan kehilangan data.
Catatan:
PVC dikatakan aktif digunakan oleh sebuah pod ketika sebuah objek pod ada yang menggunakan PVC tersebut.
Jika seorang pengguna menghapus PVC yang sedang aktif digunakan oleh sebuah pod, PVC tersebut tidak akan langsung dihapus. Penghapusan PVC akan ditunda sampai PVC tidak lagi aktif digunakan oleh pod manapun, dan juga ketika admin menghapus sebuah PV yang terikat dengan sebuah PVC, PV tersebut tidak akan langsung dihapus. Penghapusan PV akan ditunda sampai PV tidak lagi terikat dengan sebuah PVC.
Kamu dapat melihat PVC yang dilindungi ketika status PVC berisi Terminating dan daftar Finalizers meliputi kubernetes.io/pvc-protection:
Ketika seorang pengguna telah selesai dengan volumenya, ia dapat menghapus objek PVC dari API yang memungkinkan untuk reklamasi dari sumber daya tersebut. Kebijakan reklaim dari sebuah PersistentVolume (PV) menyatakan apa yang dilakukan klaster setelah volume dilepaskan dari klaimnya. Saat ini, volume dapat dipertahankan (Retained), didaur ulang (Recycled), atau dihapus (Deleted).
Retain
Retain merupakan kebijakan reklaim yang mengizinkan reklamasi manual dari sebuah sumber daya. Ketika PersistentVolumeClaim (PVC) dihapus, PersistentVolume (PV) masih akan tetap ada dan volume tersebut dianggap "terlepas" . Tetapi PV tersebut belum tersedia untuk klaim lainnya karena data milik pengklaim sebelumnya masih terdapat pada volume. Seorang administrator dapat mereklaim volume secara manual melalui beberapa langkah.
Menghapus PersistentVolume (PV). Aset storage yang terasosiasi dengan infrastruktur eksternal (seperti AWS EBS, GCE PD, Azure Disk, atau Cinder Volume) akan tetap ada setelah PV dihapus.
Secara manual membersihkan data pada aset storage terkait.
Secara manual menghapus aset storage, atau jika kamu ingin menggunakan aset storage yang sama, buatlah sebuah PersistentVolume baru dengan definisi aset storage tersebut.
Delete
Untuk volume plugin yang mendukung kebijakan reklaim Delete, penghapusan akan menghilangkan kedua objek dari Kubernetes, PersistentVolume (PV) dan juga aset storage yang terasosiasi pada infrastruktur eksternal seperti, AWS EBS, GCE PD, Azure Disk, atau Cinder Volume. Volume yang disediakan secara dinamis mewarisi kebijakan reklaim dari StorageClass miliknya, yang secara bawaan adalah Delete. Administrator harus mengkonfigurasi StorageClass sesuai ekspektasi pengguna, jika tidak maka PV tersebut harus diubah atau ditambal setelah dibuat nanti. Lihat Mengganti Kebijakan Reklaim pada PersistentVolume.
Recycle
Peringatan:
Kebijakan reklaim Recycle sudah ditinggalkan. Sebagai gantinya, pendekatan yang direkomendasikan adalah menggunakan penyediaan dinamis.
Jika didukung oleh plugin volume yang berada di baliknya, kebijakan reklaim Recycle melakukan penghapusan dasar (rm -rf /thevolume/*) pada volume dan membuatnya kembali tersedia untuk klaim baru.
Namun, seorang administrator dapat mengkonfigurasi templat recycler pod kustom menggunakan argumen baris perintah controller manager Kubernetes sebagaimana dijelaskan di sini. Templat reycler pod kustom harus memiliki spesifikasi volumes, seperti yang ditunjukkan pada contoh di bawah:
Untuk meminta volume yang lebih besar pada sebuah PVC, ubah objek PVC dan spesifikasikan ukuran yang lebih
besar. Hal ini akan memicu perluasan dari volume yang berada di balik PersistentVolume (PV). Sebuah
PersistentVolume (PV) baru tidak akan dibuat untuk memenuhi klaim tersebut. Sebaliknya, volume yang sudah ada akan diatur ulang ukurannya.
Perluasan Volume CSI
FEATURE STATE:Kubernetes v1.14 [alpha]
Perluasan volume CSI mengharuskan kamu untuk mengaktifkan gerbang fitur ExpandCSIVolumes dan juga membutuhkan driver CSI yang spesifik untuk mendukung perluasan volume. Silakan merujuk pada dokumentasi driver spesifik CSI untuk informasi lebih lanjut.
Mengubah ukuran sebuah volume yang memiliki file system
Kamu hanya dapat mengubah ukuran volume yang memiliki file system jika file system tersebut adalah XFS, Ext3, atau Ext4.
Ketika sebuah volume memiliki file system, file system tersebut hanya akan diubah ukurannya ketika sebuah pod baru dinyalakan menggunakan
PersistentVolumeClaim (PVC) dalam mode ReadWrite. Maka dari itu, jika sebuah pod atau deployment menggunakan sebuah volume dan
kamu ingin memperluasnya, kamu harus menghapus atau membuat ulang pod tersebut setelah volume selesai diperluas oleh penyedia cloud dalam controller-manager. Kamu dapat melihat status dari operasi pengubahan ukuran dengan menjalankan perintah kubectl describe pvc:
kubectl describe pvc <pvc_name>
Jika PersistentVolumeClaim (PVC) memiliki status FileSystemResizePending, maka berarti aman untuk membuat ulang pod menggunakan PersistentVolumeClaim (PVC) tersebut.
FlexVolumes mengizinkan pengubahan ukuran jika driver diatur dengan kapabilitas RequiresFSResize menjadi "true".
FlexVolume dapat diubah ukurannya pada saat pod mengalami restart.
FEATURE STATE:Kubernetes v1.11 [alpha]
Mengubah ukuran PersistentVolumeClaim (PVC) yang sedang digunakan
Memperluas PVC yang sedang digunakan merupakan fitur alfa. Untuk menggunakannya, aktifkan gerbang fitur ExpandInUsePersistentVolumes.
Pada kasus ini, kamu tidak perlu menghapus dan membuat ulang sebuah Pod atau deployment yang menggunakan PVC yang telah ada.
PVC manapun yang sedang digunakan secara otomatis menjadi tersedia untuk pod yang menggunakannya segera setelah file system miliknya diperluas.
Fitur ini tidak memiliki efek pada PVC yang tidak sedang digunakan oleh Pod atau deployment. Kamu harus membuat sebuah Pod yang
menggunakan PVC sebelum perluasan dapat selesai dilakukan.
Memperluas PVC yang sedang digunakan sudah ditambahkan pada rilis 1.13. Untuk mengaktifkan fitur ini gunakan ExpandInUsePersistentVolumes dan gerbang fitur ExpandPersistentVolumes. Gerbang fitur ExpandPersistentVolumes sudah diaktifkan sejak awal. Jika ExpandInUsePersistentVolumes sudah terpasang, FlexVolume dapat diubah ukurannya secara langsung tanpa perlu melakukan restart pada pod.
Catatan:
Pengubahan ukuran FlexVolume hanya mungkin dilakukan ketika driver yang menjalankannya mendukung pengubahan ukuran.
Catatan:
Memperluas volume EBS merupakan operasi yang memakan waktu. Terlebih lagi, ada kuota per volume untuk satu kali modifikasi setiap 6 jam.
Tipe-tipe Persistent Volume
Tipe-tipe PersistentVolume (PV) diimplementasikan sebagai plugin. Kubernetes saat ini mendukung plugin berikut:
GCEPersistentDisk
AWSElasticBlockStore
AzureFile
AzureDisk
FC (Fibre Channel)
FlexVolume
Flocker
NFS
iSCSI
RBD (Ceph Block Device)
CephFS
Cinder (OpenStack block storage)
Glusterfs
VsphereVolume
Quobyte Volumes
HostPath (Hanya untuk pengujian single node -- penyimpanan lokal tidak didukung dan TIDAK AKAN BEKERJA pada klaster multi-node)
Portworx Volumes
ScaleIO Volumes
StorageOS
Persistent Volume
Setiap PV memiliki sebuah spec dan status, yang merupakan spesifikasi dan status dari volume tersebut.
Program pembantu yang berkaitan dengan tipe volume bisa saja diperlukan untuk mengonsumsi sebuah PersistentVolume di dalam klaster. Contoh ini menggunakan PersistentVolume dengan tipe NFS dan program pembantu /sbin/mount.nfs diperlukan untuk mendukung proses mounting sistem berkas (filesystem) NFS.
Kapasitas
Secara umum, sebuah PV akan memiliki kapasitas storage tertentu. Hal ini ditentukan menggunakan atribut capacity pada PV. Lihat Model Sumber Daya Kubernetes untuk memahami satuan yang diharapkan pada atribut capacity.
Saat ini, ukuran storage merupakan satu-satunya sumber daya yang dapat ditentukan atau diminta. Atribut-atribut lainnya di masa depan dapat mencakup IOPS, throughput, dsb.
Mode Volume
FEATURE STATE:Kubernetes v1.13 [beta]
Sebelum Kubernetes 1.9, semua volume plugin akan membuat sebuah filesystem pada PersistentVolume (PV).
Sekarang, kamu dapat menentukan nilai dari volumeMode menjadi block untuk menggunakan perangkat raw block, atau filesystem
untuk menggunakan sebuah filesystem. filesystem menjadi standar yang digunakan jika nilainya dihilangkan. Hal ini merupakan parameter API
opsional.
Mode Akses
Sebuah PersistentVolume (PV) dapat dipasangkan pada sebuah host dengan cara apapun yang didukung oleh penyedia sumber daya. Seperti ditunjukkan pada tabel di bawah, para penyedia akan memiliki kapabilitas yang berbeda-beda dan setiap mode akses PV akan ditentukan menjadi mode-mode spesifik yang didukung oleh tiap volume tersebut. Sebagai contoh, NFS dapat mendukung banyak klien read/write, tetapi sebuah NFS PV tertentu mungkin diekspor pada server sebagai read-only. Setiap PV memilik seperangkat mode aksesnya sendiri yang menjelaskan kapabilitas dari PV tersebut.
Beberapa mode akses tersebut antara lain:
ReadWriteOnce -- volume dapat dipasang sebagai read-write oleh satu node
ReadOnlyMany -- volume dapat dipasang sebagai read-only oleh banyak node
ReadWriteMany -- volume dapat dipasang sebagai read-write oleh banyak node
Pada CLI, mode-mode akses tersebut disingkat menjadi:
RWO - ReadWriteOnce
ROX - ReadOnlyMany
RWX - ReadWriteMany
Penting! Sebuah volume hanya dapat dipasang menggunakan satu mode akses dalam satu waktu, meskipun volume tersebut mendukung banyak mode. Sebagai contoh, sebuah GCEPersistentDisk dapat dipasangkan sebagai ReadWriteOnce oleh satu node atau ReadOnlyMany oleh banyak node, tetapi tidak dalam waktu yang bersamaan.
Volume Plugin
ReadWriteOnce
ReadOnlyMany
ReadWriteMany
AWSElasticBlockStore
✓
-
-
AzureFile
✓
✓
✓
AzureDisk
✓
-
-
CephFS
✓
✓
✓
Cinder
✓
-
-
FC
✓
✓
-
FlexVolume
✓
✓
depends on the driver
Flocker
✓
-
-
GCEPersistentDisk
✓
✓
-
Glusterfs
✓
✓
✓
HostPath
✓
-
-
iSCSI
✓
✓
-
Quobyte
✓
✓
✓
NFS
✓
✓
✓
RBD
✓
✓
-
VsphereVolume
✓
-
- (works when pods are collocated)
PortworxVolume
✓
-
✓
ScaleIO
✓
✓
-
StorageOS
✓
-
-
Kelas
Sebuah PV bisa memiliki sebuah kelas, yang dispesifikasi dalam pengaturan atribut
storageClassName menjadi nama
StorageClass.
Sebuah PV dari kelas tertentu hanya dapat terikat dengan PVC yang meminta
kelas tersebut. Sebuah PV tanpa storageClassName tidak memiliki kelas dan hanya dapat terikat
dengan PVC yang tidak meminta kelas tertentu.
Dahulu, anotasi volume.beta.kubernetes.io/storage-class digunakan sebagai ganti
atribut storageClassName. Anotasi ini masih dapat bekerja, namun
akan dihilangkan sepenuhnya pada rilis Kubernetes mendatang.
Kebijakan Reklaim
Kebijakan-kebijakan reklaim saat ini antara lain:
Retain -- reklamasi manual
Recycle -- penghapusan dasar (rm -rf /thevolume/*)
Delete -- aset storage terasosiasi seperti AWS EBS, GCE PD, Azure Disk, atau OpenStack Cinder volume akan dihapus
Saat ini, hanya NFS dan HostPath yang mendukung daur ulang. AWS EBS, GCE PD, Azure Disk, dan Cinder Volume mendukung penghapusan.
Opsi Pemasangan
Seorang administrator Kubernetes dapat menspesifikasi opsi pemasangan tambahan untuk ketika sebuah Persistent Volume dipasangkan pada sebuah node.
Catatan:
Tidak semua tipe Persistent Volume mendukung opsi pemasanagan.
Tipe-tipe volume yang mendukung opsi pemasangan antara lain:
AWSElasticBlockStore
AzureDisk
AzureFile
CephFS
Cinder (OpenStack block storage)
GCEPersistentDisk
Glusterfs
NFS
Quobyte Volumes
RBD (Ceph Block Device)
StorageOS
VsphereVolume
iSCSI
Opsi pemasangan tidak divalidasi, sehingga pemasangan akan gagal jika salah satunya tidak valid.
Dahulu, anotasi volume.beta.kubernetes.io/mount-options digunakan sebagai ganti
atribut mountOptions. Anotasi ini masih dapat bekerja, namun
akan dihilangkan sepenuhnya pada rilis Kubernetes mendatang.
Afinitas Node
Catatan:
Untuk kebanyakan tipe volume, kamu tidak perlu memasang kolom ini. Kolom ini secara otomatis terisi untuk tipe blok volume AWS EBS, GCE PD dan Azure Disk. Kamu harus mengaturnya secara eksplisit untuk volume lokal.
Sebuah PV dapat menspesifikasi afinitas node untuk mendefinisikan batasan yang membatasi node mana saja yang dapat mengakses volume tersebut. Pod yang menggunakan sebuah PV hanya akan bisa dijadwalkan ke node yang dipilih oleh afinitas node.
Fase
Sebuah volume akan berada dalam salah satu fase di bawah ini:
Available -- sumber daya bebas yang belum terikat dengan sebuah klaim
Bound -- volume sudah terikat dengan sebuah klaim
Released -- klaim sudah dihapus, tetapi sumber daya masih belum direklaim oleh klaster
Failed -- volume gagal menjalankan reklamasi otomatis
CLI akan menunjukkan nama dari PVC yang terikat pada PV.
PersistentVolumeClaims
Setiap PVC memiliki spec dan status, yang merupakan spesifikasi dan status dari klaim.
apiVersion:v1kind:PersistentVolumeClaimmetadata:name:myclaimspec:accessModes:- ReadWriteOncevolumeMode:Filesystemresources:requests:storage:8GistorageClassName:slowselector:matchLabels:release:"stable"matchExpressions:- {key: environment, operator: In, values:[dev]}
Mode Akses
Klaim menggunakan penulisan yang sama dengan volume ketika meminta storage dengan mode akses tertentu.
Mode Volume
Klaim menggunakan penulisan yang sama dengan volume untuk mengindikasikan konsumsi dari volume sebagai filesystem ataupun perangkat block.
Sumber daya
Klaim, seperti pod, bisa meminta sumber daya dengan jumlah tertentu. Pada kasus ini, permintaan untuk storage. Model sumber daya yang sama berlaku untuk baik volume maupun klaim.
Selector
Klaim dapat menspesifikasi label selector untuk memilih serangkaian volume lebih jauh. Hanya volume yang cocok labelnya dengan selector yang dapat terikat dengan klaim. Selector dapat terdiri dari dua kolom:
matchLabels - volume harus memiliki label dengan nilai ini
matchExpressions - daftar dari persyaratan yang dibuat dengan menentukan kunci, daftar nilai, dan operator yang menghubungkan kunci dengan nilai. Operator yang valid meliputi In, NotIn, Exists, dan DoesNotExist.
Semua persyaratan tersebut, dari matchLabels dan matchExpressions akan dilakukan operasi AND bersama – semuanya harus dipenuhi untuk mendapatkan kecocokan.
Kelas
Sebuah klaim dapat meminta kelas tertentu dengan menspesifikasi nama dari
StorageClass
menggunakan atribut storageClassName.
Hanya PV dari kelas yang diminta, yang memiliki storageClassName yang sama dengan PVC, yang dapat
terikat dengan PVC.
PVC tidak harus meminta sebuah kelas. Sebuah PVC dengan storageClassName miliknya bernilai
"" akan selalu diinterpretasikan sebagai meminta PV tanpa kelas, jadi PVC
hanya bisa terikat ke PV tanpa kelas (tanpa anotasi atau bernilai
""). Sebuah PVC tanpa storageClassName tidaklah sama dan diperlakukan berbeda
oleh klaster tergantung apakah
admission pluginDefaultStorageClass
dinyalakan.
Jika admission plugin dinyalakan, administrator bisa menspesifikasi
StorageClass standar. Seluruh PVC yang tidak memiliki storageClassName dapat terikat hanya ke
PVs standar. Menspesifikasikan StorageClass standar dapat dilakukan dengan mengatur
anotasi storageclass.kubernetes.io/is-default-class menjadi "true" pada
sebuah objek StorageClass. Jika administrator tidak menspesifikasikan standar apapun,
klaster menanggapi pembuatan PVC sekan-akan admission plugin dimatikan. Jika
ada lebih dari satu setelan standar dispesifikasikan, admission plugin melarang pembuatan seluruh
PVC.
Jika admission plugin dimatikan, tidak ada pilihan menggunakan
StorageClass standar. Semua PVC yang tidak memiliki storageClassName hanya dapat diikat ke PV yang
tidak memiliki kelas. Pada kasus ini, PVC yang tidak memiliki storageClassName diperlakukan
sama seperti PVC yang memiliki storageClassName bernilai "".
Tergantung metode instalasi, sebuah StorageClass dari setelan standar dapat dibuat
ke klaster Kubernetes oleh addon manager pada saat instalasi.
Ketika sebuah PVC menspesifikasi sebuah selector selain meminta StorageClass,
kebutuhan tersebut akan digabungkan dengan operasi AND bersama: hanya PV dari kelas yang diminta dan dengan
label yang diminta yang dapat terikat ke PVC.
Catatan:
Saat ini, sebuah PVC dengan selector yang tak kosong tidak dapat memiliki PV yang disediakan secara dinamis untuknya.
Dahulu, anotasi volume.beta.kubernetes.io/storage-class digunakan sebagai ganti
atribut storageClassName. Anotasi ini masih dapat bekerja, namun
akan dihilangkan sepenuhnya pada rilis Kubernetes mendatang.
Klaim sebagai Volume
Pod mengakses storage dengan menggunakan klaim sebagai volume. Klaim harus berada pada namespace yang sama dengan pod yang menggunakan klaim tersebut. Klaster menemukan klaim pada namespace yang sama dengan pod dan menggunakannya untuk mendapatkan PersistentVolume (PV) yang ada di baliknya. Volume tersebut kemudian dipasangkan ke host dan lalu ke pod.
Ikatan PersistentVolumes bersifat eksklusif, dan karena PersistentVolumeClaims merupakan objek yang berada pada namespace, pemasangan klaim dengan "banyak" mode (ROX, RWX) hanya dimungkinkan jika berada dalam satu namespace yang sama.
Dukungan Volume Raw Block
FEATURE STATE:Kubernetes v1.13 [beta]
Volume plugins berikut mendukung volume raw block, termasuk penyediaan dinamis jika
mungkin diterapkan.
AWSElasticBlockStore
AzureDisk
FC (Fibre Channel)
GCEPersistentDisk
iSCSI
Local volume
RBD (Ceph Block Device)
VsphereVolume (alpha)
Catatan:
Hanya FC dan volume iSCSI yang mendukung volume raw block pada Kubernetes 1.9.
Dukungan untuk plugin lainnya ditambahkan pada 1.10.
Ketika menambahkan sebuah perangkat raw block untuk sebuah Pod, kita menspesifikasi alamat perangkat dalam kontainer alih-alih alamat pemasangan.
Mengikat Block Volume
Jika seorang pengguna meminta sebuah volume raw block dengan mengindikasikannya menggunakan kolom volumeMode pada specPersistentVolumeClaim (PVC), aturan pengikatannya sedikit berbeda dibanding rilis-rilis sebelumnya yang tidak memerhatikan mode ini sebagai bagian dari spec.
Di bawah merupakan tabel dari kemungkinan kombinasi yang pengguna dan admin dapat spesifikasikan untuk meminta sebuah perangkat raw block. Tabel tersebut mengindikasikan apakah volume akan terikat atau tidak jika dikombinasikan dengan cara tertentu:
Matriks pengikatan volume untuk volume yang disediakan secara statis:
PV volumeMode
PVC volumeMode
Hasil
unspecified
unspecified
TERIKAT
unspecified
Block
TIDAK TERIKAT
unspecified
Filesystem
TERIKAT
Block
unspecified
TIDAK TERIKAT
Block
Block
TERIKAT
Block
Filesystem
TIDAK TERIKAT
Filesystem
Filesystem
TERIKAT
Filesystem
Block
TIDAK TERIKAT
Filesystem
unspecified
TERIKAT
Catatan:
Hanya volume yang disediakan secara statis yang didukung untuk rilis alfa. Administrator harus memperhatikan nilai-nilai tersebut ketika mengerjakan perangkat-perangkat raw block.
Volume Snapshot dan Dukungan Pemulihan Volume dari Snapshot
FEATURE STATE:Kubernetes v1.12 [alpha]
Fitur volume snapshot ditambahkan hanya untuk mendukung CSI Volume Plugins. Untuk lebih detail, lihat volume snapshots.
Untuk mengaktifkan dukungan pemulihan sebuah volume dari sebuah sumber data volume snapshot, aktifkan
gerbang fitur VolumeSnapshotDataSource pada apiserver dan controller-manager.
Membuat Persistent Volume Claim dari Volume Snapshot
Jika kamu menulis templat konfigurasi atau contoh yang dapat berjalan pada berbagai macam klaster
dan membutuhkan persistent storage, kami merekomendasikan agar kamu menggunakan pola berikut:
Masukkan objek PersistentVolumeClaim (PVC) pada kumpulan config (bersamaan dengan
Deployments, ConfigMaps, dsb).
Jangan memasukkan objek PersistentVolume (PV) pada config, karena pengguna yang menginstantiasi
config tersebut kemungkinan tidak memiliki izin untuk membuat PersistentVolume (PV).
Berikan pengguna opsi untuk menyediakan nama storage class ketika menginstantiasi
templat.
Jika pengguna menyediakan nama storage class, taruh nilai tersebut pada
kolom persistentVolumeClaim.storageClassName.
Hal ini akan membuat PVC agar sesuai dengan storage class
yang tepat jika klaster memiliki banyak StorageClass yang diaktifkan oleh admin.
Jika pengguna tidak menyediakan nama storage class, biarkan
kolom persistentVolumeClaim.storageClassName kosong.
Hal ini kakan membuat sebuah PV disediakan secara otomatis untuk pengguna dengan
StorageClass standar pada klaster. Banyak lingkungan klaster memiliki
StorageClass standar yang sudah terpasang, atau administrator dapat membuat
StorageClass standar sendiri.
Dalam pembuatan, perhatikan PVC yang tidak kunjung terikat setelah beberapa lama
dan beritahukan hal ini pada pengguna, karena hal ini dapat mengindikasikan klaster tidak
memiliki dukungan penyimpanan dinamis (di mana pengguna harus membuat PV yang sesuai)
atau klaster tidak memiliki sistem penyimpanan (di mana penggun tidak dapat membuat
PVC yang membutuhkan config).
6.3 - VolumeSnapshot
FEATURE STATE:Kubernetes v1.12 [alpha]
Laman ini menjelaskan tentang fitur VolumeSnapshot pada Kubernetes. Sebelum lanjut membaca, sangat disarankan untuk memahami PersistentVolume terlebih dahulu.
Pengenalan
Seperti halnya sumber daya API PersistentVolume dan PersistentVolumeClaim yang digunakan oleh para pengguna dan administrator untuk menyediakan volume, sumber daya API VolumeSnapshotContent dan VolumeSnapshot digunakan mereka untuk membuat snapshot volume.
VolumeSnapshotContent merupakan suatu snapshot yang diambil dari sebuah volume dari dalam klaster yang telah disediakan oleh administrator. Sepert layaknya PersistentVolume, VolumeSnapshotContent juga merupakan bagian dari sumber daya klaster.
VolumeSnapshot merupakan suatu permintaan snapshot dari volume oleh pengguna. Mirip seperti halnya PersistentVolumeClaim.
Walaupun VolumeSnapshot membuat pengguna bisa mengonsumsi abstraksi dari sumber daya penyimpanan, administrator klaster tetap perlu
menawarkan berbagai macam tipe VolumeSnapshotContent, tanpa perlu mengekspos pengguna pada detail bagaimana snapshot
volume tersebut harus tersediakan. Bagi yang memerlukan hal ini, ada yang namanya sumber daya VolumeSnapshotClass.
Para pengguna tetap perlu mengetahui beberapa hal di bawah ketika menggunakan fitur ini:
Objek API VolumeSnapshot, VolumeSnapshotContent, dan VolumeSnapshotClass adalah CRD, bukan bagian dari API inti.
Fitur VolumeSnapshot hanya tersedia untuk CSI driver.
Sebagai bagian dari proses deploy, tim Kubernetes menyediakan Container sidecar bantuan untuk controller snapshot berrnama external-snapshotter. Container ini melakukan watch pada objek VolumeSnapshot dan memicu operasi CreateSnapshot dan DeleteSnapshot terhadap sebuah endpoint CSI.
Driver CSI ada yang telah implementasi fitur VolumeSnapshot, ada juga yang belum. Driver CSI yang telah menyediakan dukungan terhadap fitur VolumeSnapshot kemungkinan besar menggunakan external-snapshotter.
Driver CSI yang mendukung VolumeSnapshot akan secara otomatis melakukan instalasi CRD untuk VolumeSnapshot.
Siklus hidup VolumeSnapshot dan VolumeSnapshotContent
VolumeSnapshotContent merupakan bagian dari sumber daya klaster. VolumeSnapshot merupakan permintaan terhadap sumber daya tersebut. Interaksi antara VolumeSnapshotContent dan VolumeSnapshot mengikuti siklus hidup berikut ini:
Penyediaan VolumeSnapshot
Ada dua cara untuk menyediakan snapshot: secara statis maupun dinamis.
Statis
Seorang administrator klaster membuat beberapa VolumeSnapshotContent, yang masing-masing memiliki detail tentang penyimpanan sebenarnya yang dapat dipergunakan oleh para pengguna. VolumeSnapshotContent tersebut dapat dikonsumsi melalui API Kubernetes.
Dinamis
Ketika VolumeSnapshotContent yang dibuat oleh administrator tidak ada yang sesuai dengan VolumeSnapshot yang dibuat pengguna, klaster bisa saja
mencoba untuk menyediakan sebuah VolumeSnapshot secara dinamis, khususnya untuk objek VolumeSnapshot.
Proses penyediaan ini berdasarkan VolumeSnapshotClasses: VolumeSnapshot harus meminta sebuah VolumeSnapshotClass
dan administrator harus membuat serta mengatur class tersebut supaya penyediaan dinamis bisa terjadi.
Ikatan (Binding)
Seorang pengguna akan membuat (atau telah membuat, dalam kasus penyediaan dinamis) sebuah VolumeSnapshot dengan ukuran penyimpanan yang diminta beserta mode akses tertentu. Suatu loop kontrol melakukan watch terhadap VolumeSnapshot baru, mencari VolumeSnapshotContent yang sesuai (jika memungkinkan), dan mengikat (bind) keduanya. Jika VolumeSnapshotContent secara dinamis disediakan untuk VolumeSnapshot yang baru,
loop akan terus mengikat VolumeSnapshotContent dengan VolumeSnapshot. Ketika telah terikat (bound), VolumeSnapshot bind bersifat eksklusif, terlepas dari bagaimana proses bind dilakukan. Ikatan (binding) antara suatu VolumeSnapshot dengan VolumeSnapshotContent bersifat 1:1 mapping.
VolumeSnapshot akan tetap tidak terikat (unbound) tanpa ada batas waktu, jika VolumeSnapshotContent yang sesuai tidak ditemukan. VolumeSnapshot akan menjadi terikat (bound) ketika VolumeSnapshotContent yang sesuai menjadi ada.
PersistentVolumeClaim dengan in-Use Protection
Tujuan dari objek PersistentVolumeClaim dengan fitur in Use Protection adalah memastikan objek API PVC yang masih dalam penggunaan (in-use) tidak akan dihilangkan dari sistem (penghilangan akan menyebabkan hilangnya data).
Jika sebuah PVC sedang digunakan secara aktif oleh proses snapshot yang digunakan sebagai sumbernya (source), artinya PVC sedang dalam penggunaan (in-use). Jika seorang pengguna menghapus suatu objek API PVC saat dalam penggunaan sebagai sumber snapshot, objek PVC tidak akan dihilangkan segera. Namun, penghapusan objek PVC akan ditunda sampai PVCC tidak lagi secara aktif digunakan oleh proses snapshot manapun. Suatu PVC tidak lagi diguunakan sebagai suumber snapshot ketika ReadyToUse dari Statussnapshot menjadi true.
Penghapusan
Proses penghapusan akan menghilangkan objek VolumeSnapshot dari API Kubernetes, beserta aset penyimpanan terkait pada infrastruktur eksternal.
VolumeSnapshotContent
Setiap VolumeSnapshotContent memiliki sebuah spec, yang merepresentasikan spesifikasi dari snapshot volume tersebut.
Suatu VolumeSnapshotContent dapat memiliki suatu class, yang didapat dengan mengatur atribut
snapshotClassName dengan nama dari VolumeSnapshotClass.
VolumeSnapshotContent dari class tertentu hanya dapat terikat (bound) dengan VolumeSnapshot yang
"meminta" class tersebut. VolumeSnapshotContent tanpa snapshotClassName tidak memiliki class dan hanya dapat
terikat (bound) dengan VolumeSnapshot yang "meminta" untuk tidak menggunakan class.
VolumeSnapshot
Masing-masing VolumeSnapshot memiliki sebuah spec dan status, yang merepresentasikan spesifikasi dan status dari snapshot volume tersebut.
Suatu VolumeSnapshot dapat meminta sebuah class tertentu dengan mengatur nama dari
VolumeSnapshotClass
menggunakan atribut snapshotClassName.
Hanya VolumeSnapshotContent dari class yang diminta, memiliki snapshotClassName yang sama
dengan VolumeSnapshot, dapat terikat (bound) dengan VolumeSnapshot tersebut.
Penyediaan (Provisioning) Volume dari Snapshot
Kamu dapat menyediakan sebuah volume baru, yang telah terisi dengan data dari suatu snapshot, dengan
menggunakan fielddataSource pada objek PersistentVolumeClaim.
Dokumen ini mendeskripsikan konsep pengklonaan Volume CSI yang telah tersedia di dalam Kubernetes. Pengetahuan tentang Volume disarankan.
Introduction
Fitur CSI Volume Cloning menambahkan dukungan untuk merinci PVC yang telah tersedia pada kolom dataSource untuk mengindikasikan bahwa seorang pengguna ingin melakukan pengklonaan terhadap sebuah Volume.
Sebuah klona didefinisikan sebagai sebuah duplikat dari sebuah Volume Kubernetes yang telah tersedia yang dapat digunakan sebagai sebuah Volume standar. Perbedaannya hanyalah pada saat penyediaannya, daripada membuat sebuah Volume kosong yang "baru", peranti penyokongnya membuat sebuah duplikat sama persis dari Volume yang dirinci.
Implementasi dari pengklonaan, dari sudut pandang API Kubernetes, secara sederhana menambahkan kemampuan untuk merinci sebuah PVC yang telah tersedia sebagai sebuah dataSource saat pembuatan PVC. PVC sumber harus tertambat (bound) dan tersedia (tidak sedang digunakan).
Pengguna-pengguna mesti menyadari hal-hal berikut saat menggunakan fitur ini:
Dukungan pengklonaan (VolumePVCDataSource) hanya tersedia untuk driver-driver CSI.
Dukungan pengklonaan hanya tersedia untuk penyedia-penyedia dinamis.
Driver-driver CSI mungkin telah atau belum mengimplementasi fungsi pengklonaan Volume.
Kamu hanya dapat mengklonakan sebuah PVC saat ia tersedia pada Namespace yang sama dengan PVC tujuan (sumber dan tujuan harus berada pada Namespace yang sama).
Pengklonaan hanya didukung pada Storage Class yang sama.
Volume tujuan harus memiliki Storage Class yang sama dengan sumbernya.
Storage Class bawaan dapat digunakan dan storageClassName dihilangkan dari spec
Penyediaan
Klona-klona disediakan sama seperti PVC lainnya dengan pengecualian dengan penambahan sebuah dataSource yang merujuk pada sebuah PVC yang telah tersedia pada Namespace yang sama.
Hasilnya adalah sebuah PVC baru dengan nama clone-of-pvc-1 yang memiliki isi yang sama dengan sumber yang dirinci pvc-1.
Penggunaan
Setelah tersedianya PVC baru tersebut, PVC baru yang diklonakan tersebut digunakan sama seperti PVC lainnya. Juga diharapkan pada titik ini bahwa PVC baru tersebut adalah sebuah objek terpisah yang independen. Ia dapat digunakan, diklonakan, di-snapshot, atau dihapus secara terpisah dan tanpa perlu memikirkan PVC dataSource aslinya. Hal ini juga berarti bahwa sumber tidak terikat sama sekali dengan klona yang baru dibuat tersebut, dan dapat diubah atau dihapus tanpa memengaruhi klona yang baru dibuat tersebut.
6.5 - StorageClass
Dokumen ini mendeskripsikan konsep StorageClass yang ada pada Kubernetes.
Sebelum lanjut membaca, sangat dianjurkan untuk memiliki pengetahuan terhadap
volumes dan
peristent volume terlebih dahulu.
Pengenalan
Sebuah StorageClass menyediakan cara bagi administrator untuk
mendeskripsikan "kelas" dari penyimpanan yang mereka sediakan.
Kelas yang berbeda bisa saja memiliki perbedaan dari segi kualitas
servis yang disediakan, pemulihan (backup) kebijakan, atau kebijakan lain yang ditentukan
oleh administrator klaster. Kubernetes sendiri tidak dipengaruhi oleh
kelas apakah yang digunakan pada mekanisme penyimpanan yang digunakan.
Mekanisme ini seringkali disebut sebagai "profiles" pada sistem penyimpanan
yang lain.
Sumber daya StorageClass
Setiap StorageClass (kelas penyimpanan) memiliki field-field mendasar seperti
provisioner, parameters, dan reclaimPolicy, yang digunakan ketika
PersistentVolume yang dimiliki oleh kelas tersebut perlu disediakan (di-provision).
Nama yang digunakan oleh suatu StorageClass sifatnya penting, karena
ini merupakan cara yang digunakan oleh pengguna untuk meminta
penyimpanan dengan kelas tertentu. Administrator dapat menentukan
nama dan parameter lain dari suatu kelas ketika membuat suatu objek StorageClass,
dan objek yang sudah dibuat tidak dapat diubah lagi definisinya.
Administrator dapat memberikan spesifikasi StorageClass default bagi
PVC yang tidak membutuhkan kelas tertentu untuk dapat melakukan mekanisme bind:
kamu dapat membaca bagian PersistentVolumeClaim
untuk penjelasan lebih lanjut.
Setiap kelas penyimpanan (storage class) memiliki sebuah provisioner yang
menentukan plugin manakah yang digunakan ketika sebuah PV disediakan (di-provision).
Field ini haruslah didefinisikan.
Kamu tidak dibatasi untuk hanya menggunakan provisioner internal yang disediakan
pada list yang tersedia (yang memiliki nama dengan prefix "kubernetes.io" dan
didistribusikan bersamaan dengan Kubernetes). Kamu juga dapat menjalankan dan
mendefinisikan provisioner eksternal yang merupakan program independen selama
program tersebut menerapkan spesifikasi
yang didefinisikan oleh Kubernetes. Penulis dari provisioner eksternal Kubernetes
memiliki kuasa penuh akan tempat dimana kode sumber yang mereka tulis, bagaimana
mekanisme penyediaan (provisioning) dilakukan, serta bagaimana hal tersebut dapat dijalankan,
serta plugin volume apakah yang digunakan (termasuk Flex), dkk.
Repositori kubernetes-incubator/external-storage
menyimpan library yang dibutukan untuk menulis provisioner eksternal
yang mengimplementasi spesifikasi serta beberapa provisioner eksternal yang
dipelihara oleh komunitas.
Sebagai contoh, NFS tidak menyediakan provisioner internal, tetapi
sebuah provisioner eksternal dapat digunakan. Beberapa provisioner eksternal
dapat ditemukan di bawah repositori kubernetes-incubator/external-storage.
Di sana juga terdapat beberapa kasus dimana vendor penyimpanan 3rd party
menyediakan provisioner eksternal yang mereka sediakan sendiri.
Perolehan Kembali untuk Kebijakan (Reclaim Policy)
Persistent Volumes yang secara dinamis dibuat oleh sebuah kelas penyimpanan
akan memiliki reclaim policy yang didefinisikan di dalam fieldreclaimPolicy
dari kelas tersebut, yang nilainya dapat diisi dengan Delete atau Retain.
Jika tidak terdapat reclaimPolicy yang dispesifikasikan ketika sebuah objek
StorageClass dibuat, maka nilai default bagi kelas tersebut adalah Delete.
PersistentVolume yang dibuat secara manual dan diatur dengan menggunakan
kelas penyimpanan akan menggunakan reclaim policy apapun yang diberikan
pada saat objek tersebut dibuat.
Pilihan Mount
PersistentVolume yang secara dinamis dibuat oleh sebuah kelas penyimpanan
akan memiliki pilihan mount yang dapat dispesifikasikan pada fieldmountOptions dari kelas tersebut.
Jika sebuah plugin volume tidak mendukung pilihan mount
yang dispesifikasikan, mekanisme penyediaan (provision) akan digagalkan. Pilihan mount
yang akan divalidasi pada kelas penyimpanan maupun PV, maka mount tersebut
akan gagal apabila salah satu dari keduanya bersifat invalid.
Secara default, ketika mode Immediate yang mengindikasikan
terjadinya volume binding dan provisioning dinamis terjadi ketika
PersistentVolumeClaim dibuat. Untuk backend penyimpanan yang dibatasi oleh
topologi tertentu dan tidak dapat diakses secara global dari semua Node
yang ada di klaster, PersistentVolume akan di-bound atau di-provision
tanpa perlu memenuhi persyaratan scheduling dari Pod. Hal ini dapat menyebabkan
adanya Pod yang tidak mendapatkan mekanisme scheduling.
Seorang administrator klaster dapat mengatasi hal tersebut dengan cara memberikan
spesifikasi mode WaitForFirstConsumer yang akan memperlambat mekanisme provisioning
dan binding dari sebuah PersistentVolume hingga sebuah Pod yang menggunakan
PersistentVolumeClaim dibuat. PersistentVolume akan dipilih atau di-provisioning
sesuai dengan topologi yang dispesifikasikan oleh limitasi yang diberikan
oleh mekanisme scheduling Pod. Hal ini termasuk, tetapi tidak hanya terbatas pada,
persyaratan sumber daya,
node selector,
afinitas dan
anti-afinitas Pod,
serta taint dan toleration.
Beberapa plugin di bawah ini mendukung WaitForFirstConsumer dengan provisioning
dinamis:
Volume-volume CSI juga didukung
dengan adanya provisioning dinamis serta PV yang telah terlebih dahulu dibuat,
meskipun demikian, akan lebih baik apabila kamu melihat dokumentasi
untuk driver spesifik CSI untuk melihat topologi key yang didukung
beserta contoh penggunaannya. Feature gateCSINodeInfo haruslah diaktifkan.
Topologi yang Diizinkan
Ketika sebuah operator klaster memberikan spesifikasi WaitForFirstConsumer pada
mode binding volume, mekanisme pembatasan (restriksi) provisioning tidak lagi dibutuhkan
pada sebagian besar kasus. Meskipun begitu, apabila hal tersebut masih dibutuhkan,
fieldallowedTopologies dapat dispesifikasikan.
Contoh ini memberikan demonstrasi bagaimana cara membatasi topologi
dari volume yang di-provision pada suatu zona spesifik serta harus digunakan
sebagai pengganti parameter zone dam zones untuk plugin yang akan digunakan.
Kelas-kelas penyimpanan memiliki parameter yang mendeskripsikan
volume yang dimiliki oleh kelas penyimpanan tersebut. Parameter yang berbeda
bisa saja diterima bergantung pada provisioner. Sebagai contohnya, nilai io1,
untuk parameter type, dan parameter iopsPerGB spesifik terhadap EBS.
Ketika sebuah parameter diabaikan, beberapa nilai default akan digunakan sebagai
gantinya.
type: io1, gp2, sc1, st1. Lihat
dokumentasi AWS
untuk detail lebih lanjut. Nilai default: gp2.
zone (deprecated): zona AWS. Jika tidak terdapat nilai zone atau zones
yang dispesifikasikan, volume secara generik dijadwalkan dengan menggunakan
penjadwalan round-robin-ed pada semua zona aktif yang ada pada klaster Kubernetes
yang memiliki node.
zones (deprecated): Nilai terpisahkan koma yang merupakan barisan zona pada AWS.
Jika tidak terdapat nilai zone atau zones yang dispesifikasikan,
volume secara generik dijadwalkan dengan menggunakan penjadwalan
round-robin-ed pada semua zona aktif yang ada pada klaster Kubernetes
yang memiliki node.
iopsPerGB: hanya untuk volume io1. Operasi per detik per GiB. Volume plugin
AWS mengalikan nilai ini dengan ukuran volume yang dibutuhkan untuk menghitung IOPS
dari volume (nilai maksimum yang didukung adalah 20,000 IOPS baca dokumentasi
AWS.
Nilai masukan yang diharapkan merupakan string, misalnya "10", bukan 10.
fsType: fsType yang didukung oleh Kubernetes. Nilai default-nya adalah: "ext4".
encrypted: menyatakan dimana volume EBS harus dienkripsi atau tidak.
Nilai yang valid adalah "true" atau "false" (dalam string bukan boolean i.e. "true", bukan true).
kmsKeyId: opsional. Merupakan nama dari Amazon Resource Name dari key yang digunakan
untuk melakukan enkripsi volume. Jika nilai ini tidak disediakan tetapi nilai dari
fieldencrypted adalah true, sebuah key akan dibuat oleh AWS. Perhatikan dokumentasi AWS
untuk mengetahui nilai yang valid bagi ARN.
Catatan:
Parameter zone dan zones sudah terdeprekasi dan digantikan oleh
allowedTopologies
type: pd-standard atau pd-ssd. Nilai default: pd-standard
zone (deprecated): zona GCE. Jika tidak terdapat nilai zone atau zones
yang dispesifikasikan, volume secara generik dijadwalkan dengan menggunakan
penjadwalan round-robin-ed pada semua zona aktif yang ada pada klaster Kubernetes
yang memiliki node.
zones (deprecated): Nilai terpisahkan koma yang merupakan barisan zona.
Jika tidak terdapat nilai zone atau zones yang dispesifikasikan,
volume secara generik dijadwalkan dengan menggunakan penjadwalan
round-robin-ed pada semua zona aktif yang ada pada klaster Kubernetes
yang memiliki node.
replication-type: none atau regional-pd. Nilai default: none.
Jika replication-type diubah menjadi none, sebuah PD reguler (zonal) akan
di-provisioning.
Jika replication-type diubah menjadi regional-pd, sebuah
Persistent Disk Regional (PD Regional)
akan di-provisioning. Pada kasus ini, pengguna harus menggunakan zones
dan bukan zone untuk menspesifikasikan zona replikasi yang diinginkan. Jika terdapat
tepat dua zona yang dispesifikasikan, PD Regional akan di-provisioning pada
zona replikasi yang diinginkan. Jika terdapat lebih dari 2 zona yang dispesifikasikan,
Kubernetes akan memilih secara acak zona dari zona-zona yang dispesifikasikan. Jika
parameter zones tidak diinisialisasi, Kubernetes akan memilih secara acak dari
zona yang diatur oleh klaster Kubernetes.
Catatan:
Parameter zone dan zones sudah deprecated dan digantikan oleh
allowedTopologies
resturl: Servis REST Gluster/URL servis Heketi yang digunakan untuk
melakukan provisioning volume gluster sesuai dengan kebutuhan. Format secara umum
haruslah dalam bentuk IPaddress:Port dan hal ini merupakan parameter wajib untuk
provisioner dinamis GlusterFS. Jika servis Heketi diekspos sebagai servis yang dapat
melakukan routing pada pengaturan openshift/kubernetes, ini dapat memiliki
format yang sesuai dengan http://heketi-storage-project.cloudapps.mystorage.com
dimana fqdn yang ada merupakan URL servis Heketi yang dapat di-resolve.
restauthenabled : Servis REST Gluster menyediakan nilai boolean yang dapat digunakan
untuk mengajukan authentication untuk server REST yang ada. Jika nilai yang disediakan
adalah "true", dengan kondisi dimana restuser dan restuserkey atau secretNamespace + secretName
harus diisi. Opsi ini sudah_deprecated_, mekanisme otentikasi akan diizinkan apabila
salah satu dari fieldrestuser, restuserkey, secretName atau secretNamespace diterapkan.
restuser : Pengguna servis REST Gluster/Heketi yang memiliki akses
untuk membuat volume di dalam Trusted Pool Gluster.
restuserkey : Password pengguna servis REST Gluster/Heketi
yang digunakan untuk mekanisme otentikasi server REST. Parameter ini deprecated
dan digantikan dengan parameter secretNamespace + secretName.
secretNamespace, secretName : Identifikasi instans Secret yang mengandung
password pengguna yang digunakan untuk berkomunikasi dengan servis REST Gluster.
Parameter ini dianggap opsional, password kosong dapat digunakan ketika
nilai dari secretNamespace dan secretName tidak dispesifikasikan.
Secret yang disediakan haruslah memiliki tipe "kubernetes.io/glusterfs",
yang dapat dibuat dengan menggunakan mekanisme dibawah ini:
clusterid: 630372ccdc720a92c681fb928f27b53f merupakan ID dari klaster
yang akan digunakan oleh Heketi ketikan melakukan provisioning volume. ID ini juga
dapat berupa serangkaian list, misalnya: "8452344e2becec931ece4e33c4674e4e,42982310de6c63381718ccfa6d8cf397".
Parameter ini merupakan parameter opsional.
gidMin, gidMax : Nilai minimum dan maksimum dari GID untuk kelas penyimpanan (storage class).
Sebuah nilai unik dari GID di dalam range ( gidMin-gidMax ) ini akan digunakan untuk melakukan
provisioning volume secara dinamis. Nilai ini bersifat opsional. Jika tidak dispesifikasikan,
volume akan secara default di-provisioning dalam range 2000-2147483647 yang merupakan nilai default
dari gidMin dan gidMax.
volumetype : Tipe volume beserta paremeter-nya dapat diatur dengan menggunakan nilai opsional
berikut. Jika tipe dari volume tidak dispesifikasikan, maka provisioner akan memutuskan tipe
volume apakah yang akan digunakan.
Sebagai contoh:
Volume replika: volumetype: replicate:3 dimana '3' merupakan jumlah replika.
Persebaran (Disperse)/EC volume: volumetype: disperse:4:2 dimana'4' merupakan data dan '2' merupakan jumlah redundansi.
Distribusi volume: volumetype: none
Untuk tipe volume apa saja yang tersedia dan berbagai opsi administrasi yang ada, kamu dapat membaca
Petunjuk Administrasi.
Ketika PersistentVolume di-provisioning secara dinamis, plugin Gluster secara otomatis
akan membuat endpoint serta sebuah servis headless dengan nama gluster-dynamic-<claimname>.
Endpoint dinamis dan servis secara otomatis akan dihapus ketika PVC dihapus.
availability: Zona Availability. Jika tidak dispesifikasikan, secara umum volume akan
diatur dengan menggunakan algoritma round-robin pada semua zona aktif
dimana klaster Kubernetes memiliki sebuah node.
datastore: Pengguna juga dapat menspesifikasikan datastore pada StorageClass.
Volume akan dibuat pada datastore yang dispesifikasikan pada kelas penyimpanan,
dalam hal ini adalah VSANDatastore. Field ini bersifat opsional. Jika datastore
tidak dispesifikasikan, maka volume akan dibuat dengan menggunakan datastore yang dispesifikasikan
pada berkas konfigurasi vSphere yang digunakan untuk menginisialisasi penyedia layanan cloud vSphere.
Manajemen Kebijakan Penyimpanan di dalam Kubernetes
Menggunakan kebijakan (policy) yang ada pada vCenter
Salah satu dari fitur paling penting yang ada pada vSphere untuk manajemen penyimpanan
adalah manajemen bebasis policy. Storage Policy Based Management (SPBM) adalah framework
yang menyediakan sebuah control plane terpadu pada data service yang meluas dan
solusi penyimpanannya yang tersedia. SPBM memungkinkan administrator vSphere menghadapi
permasalahan yang mungkin muncul seperti capacity planning, membedakan level servis, dan
melakukan manajemen headroom capacity.
Policy SPBM dapat dispesifikasikan pada StorageClass menggunakan parameter
storagePolicyName.
Dukungan policy SAN virtual di dalam Kubernetes
Administrator Vsphere Infrastructure (VI) akan memiliki kemampuan
untuk menspesifikasikan Virtual SAN Storage Capabilities khusus
selama masa provisioning volume secara dinamis. Persyaratan kapabilitas
penyimpanan diubah menjadi sebuah policy Virtual SAN yang nantinya akan
dimasukkan ke dalam lapisan Virtual SAN ketika sebuah persitent volume (penyimpanan
virtual) dibuat. Penyimpanan virtual kemudian akan didistribusikan pada semua
datastore Virtual SAN untuk memenuhi kebutuhan ini.
monitors: Monitor Ceph, merupakan nilai yang dipisahkan oleh koma (csv). Parameter ini dibutuhkan.
adminId: ID klien Ceph yang dapat digunakan untuk membuat images di dalam pool.
Nilai default-nya adalah "admin".
adminSecretName: Nama Secret untuk adminId. Parameter ini dibutuhkan.
Secret yang dibutuhkan haruslah memiliki tipe "kubernetes.io/rbd".
adminSecretNamespace: Namespace untuk adminSecretName. Nilai default-nya adalah "default".
pool: Pool Ceph RBD. Nilai default-nya adalah "rbd".
userId: Klien ID Ceph yang digunakan untuk melakukan pemetaan image RBD. Nilai default-nya sama dengan
adminId.
userSecretName: Nama Secret Ceph untuk userId yang digunakan untuk memetakan image RBD.
Secret ini harus berada pada namespace yang sama dengan PVC. Parameter ini dibutuhkan.
Secret yang disediakan haruslah memiliki tipe "kubernetes.io/rbd", dibuat dengan cara:
userSecretNamespace: Namespace untuk userSecretName.
fsType: fsType yang didukung oleh kubernetes. Nilai default-nya adalah: "ext4".
imageFormat: Format image Ceph RBD, nilai yang mungkin adalah "1" atau "2". Nilai default-nya adalah "2".
imageFeatures: Parameter ini bersifat opsional dan hanya dapat digunakan jika kamu mengganti nilai
dari imageFormat ke "2". Saat ini fitur yang didukung hanyalah layering.
Nilai default-nya adalah "", dan tidak ada fitur yang diaktifkan.
quobyteAPIServer: API Server dari Quobyte dalam format
"http(s)://api-server:7860"
registry: Registri Quobyte yang digunakan untuk melakukan mount volume. Kamu dapat menspesifikasikan
registri yang kamu inginkan dengan format pasangan <host>:<port> atau jika kamu ingin mendefinisikan
beberapa registri sekaligus kamu dapat menempatkan koma diantara setiap pasangan <host>:<port> yang ada,
misalnya <host1>:<port>,<host2>:<port>,<host3>:<port>.
Host dapat berupa alamat IP atau DNS.
adminSecretNamespace: Namespace adminSecretName. Nilai default-nya adalah "default".
adminSecretName: Secret yang mengandung informasi mengenai pengguna Quobyte dan
password yang digunakan untuk melakukan otentikasi API server. Secret yang digunakan
haruslah memiliki tipe "kubernetes.io/quobyte", yang dibuat dengan mekanisme berikut:
user: Melakukan pemetaan terhadap semua akses yang dimiliki pengguna.
Nilai default-nya adalah "root".
group: Melakukan pemetaan terhadap semua group. Nilai default-nya adalah "nfsnobody".
quobyteConfig: Menggunakan konfigurasi spesifik untuk membuat volume.
Kamu dapat membuat sebuah file konfigurasi atau melakukan modifikasi terhadap konfigurasi yang sudah ada
dengan menggunakan tatap muka Web atau CLI quobyte. Nilai default-nya adalah "BASE".
quobyteTenant: Menggunakan ID tenant yang dispesifikasikan untuk membuat/menghapus volume.
Tenant Quobyte haruslah sudah berada di dalam Quobyte. Nilai default-nya adalah "DEFAULT".
skuName: Akun penyimpanan Azure yang ada pada tingkatan Sku. Nilai default-nya adalah kosong.
location: Lokasi akun penyimpanan Azure. Nilai default-nya adalah kosong.
storageAccount: Nama akun penyimpanan Azure. Jika sebuan akun penyimpanan disediakan,
akun tersebut haruslah berada pada grup sumber daya yang ada dengan klaster,
dan location akan diabaikan. Jika sebuah akun penyimpanan tidak disediakan, sebuah akun penyimpanan
baru akan dibuat pada grup sumber daya yang ada dengan klaster.
Kelas Penyimpanan Disk Azure yang Baru (mulai versi v1.7.2)
storageaccounttype: Akun penyimpanan Azure yang ada pada tingkatan Sku. Nilai default-nya adalah kosong.
kind: Nilai yang mungkin adalah shared, dedicated, dan managed (default).
Ketika kind yang digunakan adalah shared, semua disk yang tidak di-manage akan
dibuat pada beberapa akun penyimpanan yang ada pada grup sumber daya yang sama dengan klaster.
Ketika kind yang digunakan adalah dedicated, sebuah akun penyimpanan
baru akan dibuat pada grup sumber daya yang ada dengan klaster. Ketika kind yang digunakan adalah
managed, semua disk yang dikelola akan dibuat pada grup sumber daya yang ada dengan klaster.
VM premium dapat di-attach baik pada Standard_LRS dan Premium_LRS disks, sementara Standard
VM hanya dapat di-attach pada disk Standard_LRS.
VM yang dikelola hanya dapat meng-attach disk yang dikelola dan VM yang tidak dikelola hanya dapat
meng-attach disk yang tidak dikelola.
skuName: Akun penyimpanan Azure yang ada pada tingkatan Sku. Nilai default-nya adalah kosong.
location: Lokasi akun penyimpanan Azure. Nilai default-nya adalah kosong.
storageAccount: Nama akun penyimpanan Azure. Nilai default-nya adalah kosong. Jika sebuah penyimpanan
tidak memiliki sebuah akun yang disediakan, semua akun penyimpanan yang diasosiasikan dengan
grup sumber daya yang ada dan kemudian melakukan pencarian terhadap akun yang sesuai dengan
skuName dan location. Jika sebuah akun penyimpanan disediakan, akun tersebut haruslah berada
di dalam grup sumber daya yang sama dengan klaster, serta skuName dan location akan diabaikan.
Selama provision, sebuah secret dibuat untuk menyimpan credentials. Jika klaster
menggunakan konsep RBAC dan
Roles Controller,
menambahkan kapabilitas create untuk sumber daya secret bagi clusterrole
system:controller:persistent-volume-binder.
fs: filesystem yang akan digunakan: none/xfs/ext4 (nilai default-nya: ext4).
block_size: ukuran block dalam Kbytes (nilai default-nya: 32).
repl: jumlah replika synchronous yang dapat disediakan dalam bentuk
faktor replikasi 1..3 (nilai default-nya: 1) Nilai yang diharapkan dalam bentuk String
"1" dan bukan 1.
io_priority: menentukan apakah volume yang dibuat akan dari penyimpanan dengan kualitas
tinggi atau rendah dengan urutan prioritas high/medium/low (nilai default-nya: low).
snap_interval: interval waktu dalam menit yang digunakan untuk melakukan triggersnapshots.
Snapshots dibuat secara inkremen berdasarkan perbedaan yang ada dengan snapshot yang dibuat sebelumnya,
nilai perbedaan 0 akan menonaktifkan pembuatan snapshot (nilai default-nya: 0). Sebuah string merupakan nilai
yang diharapkan "70" dan bukan 70.
aggregation_level: menspesifikasikan jumlah chunks dimana volume akan didistribusikan,
0 mengindikasikan volume yang non-aggregate (nilai default-nya: 0). Sebuah string merupakan nilai
yang diharapkan "0" dan bukan 0.
ephemeral: menentukan apakah volume harus dihapus setelah di-unmount
atau harus tetap ada. Penggunaan emptyDir dapat diubah menjadi true dan penggunaan
persistent volumes untuk basisdata seperti Cassandra harus diubah menjadi false, true/false (nilai default-nya: false). Sebuah string merupakan nilai
yang diharapkan "true" dan bukan true.
provisioner: atribut yang nilainya merupakan kubernetes.io/scaleio
gateway: alamat gateway ScaleIO (wajib)
system: nama sistem ScaleIO (wajib)
protectionDomain: nama domain proteksi ScaleIO (wajib)
storagePool: nama pool volume penyimpanan (wajib)
storageMode: mode provisioning penyimpanan: ThinProvisioned (default) atau
ThickProvisioned
secretRef: penunjuk pada objek Secret yang dikonfigurasi (wajib)
readOnly: menentukan mode akses terhadap volume yang di-mount (nilai default-nya: false)
fsType: filesystem yang digunakan untuk volume (nilai default-nya: ext4)
Plugin volume ScaleIO Kubernetes membutuhkan objek Secret yang suda dikonfigurasi sebelumnya.
Secret ini harus dibuat dengan tipe kubernetes.io/scaleio dan menggunakan namespace yang sama
dengan PVC yang dirujuk, seperti ditunjukkan pada contoh yang ada:
pool: Nama kapasitas distribusi StorageOS yang digunakan untuk melakukan
provisioning volume. Pool default akan digunakan apabila nilainya tidak dispesifikasikan.
description: Deskripsi untuk melakukan assignment volume yang baru dibuat secara dinamis.
Semua deskripsi volume akan bernilai sama untuk kelas penyimpanan yang sama, meskipun begitu
kelas penyimpanan yang berbeda dapat digunakan untuk membuat deskripsi yang berbeda untuk penggunaan
yang berbeda. Nilai default-nya adalah Kubernetes volume.
fsType: Tipe filesystem default yang digunakan. Perhatikan bahwa aturan
yang didefinisikan oleh pengguna di dalam StirageOS dapat meng-override nilai ini.
Nilai default-nya adalah ext4.
adminSecretNamespace: Namespace dimana konfigurasi secret API berada. Hal ini bersifat wajib
apabila adminSecretName diaktifkan.
adminSecretName: Nama secret yang digunakan untuk memperoleh credentials StorageOS
API. Jika tidak dispesifikasikan, nilaidefault akan digunakan.
Plugin volume dapat menggunakan objek Secret untuk menspesifikasikan
endpoint dan kredensial yang digunakan untuk mengakses API StorageOS.
Hal ini hanya akan dibutuhkan apabila terdapat perubahan pada nilai default.
Secret ini harus dibuat dengan tipe kubernetes.io/storageos,
seperti ditunjukkan pada contoh yang ada:
Secret yang digunakan untuk melakukan provisioning volume secara dinamis
dapat dibuat di namespace apapun dan dirujuk dengan menggunakan parameter adminSecretNamespace.
Secret yang digunakan oleh volume yang sedang di-provisioning harus dibuat pada namespace yang sama
dengan PVC yang merujuk secret tersebut.
Volume lokal tidak mendukung adanya provisioning secara dinamis,
meskipun begitu sebuah StorageClass akan tetap dibuat untuk mencegah terjadinya bind volume
sampai scheduling pod dilakukan. Hal ini dispesifikasikan oleh mode binding volume
WaitForFirstConsumer.
Memperlambat binding volume mengizinkan scheduler untuk memastikan
batasan scheduling semua pod ketika memilih PersistentVolume untuk sebuah PersistentVolumeClaim.
6.6 - VolumeSnapshotClass
Laman ini menjelaskan tentang konsep VolumeSnapshotClass pada Kubernetes. Sebelum melanjutkan,
sangat disarankan untuk membaca snapshot volume
dan kelas penyimpanan (storage class) terlebih dahulu.
Pengenalan
Seperti halnya StorageClass yang menyediakan cara bagi admin untuk mendefinisikan
"kelas" penyimpanan yang mereka tawarkan saat proses penyediaan sebuah volume, VolumeSnapshotClass
menyediakan cara untuk mendefinisikan "kelas" penyimpanan saat menyediakan snapshot volume.
Sumber Daya VolumeSnapshotClass
Masing-masing VolumeSnapshotClass terdiri dari fieldsnapshotter dan parameters,
yang digunakan saat sebuah VolumeSnapshot yang dimiliki kelas tersebut perlu untuk
disediakan secara dinamis.
Nama yang dimiliki suatu objek VolumeSnapshotClass sangatlah penting, karena digunakan
oleh pengguna saat meminta sebuah kelas tertentu. Admin dapat mengatur nama dan parameter
lainnya dari sebuah kelas saat pertama kali membuat objek VolumeSnapshotClass. Objek
tidak dapat diubah setelah dibuat.
Admin dapat mengatur VolumeSnapshotClass default untuk VolumeSnapshot yang tidak
memiliki spesifikasi kelas apapun.
VolumeSnapshotClass memiliki sebuah snapshotter yang menentukan plugin volume CSI
apa yang digunakan untuk penyediaan VolumeSnapshot. Field ini wajib diatur.
parameters
VolumeSnapshotClass memiliki parameter-parameter yang menggambarkan snapshot volume
di dalam VolumeSnapshotClass. Parameter-parameter yang berbeda diperbolehkan tergantung
dari shapshotter.
6.7 - Penyediaan Volume Dinamis
Penyediaan volume dinamis memungkinkan volume penyimpanan untuk dibuat sesuai permintaan (on-demand).
Tanpa adanya penyediaan dinamis (dynamic provisioning), untuk membuat volume penyimpanan baru, admin klaster secara manual harus
memanggil penyedia layanan cloud atau layanan penyimpanan, dan kemudian membuat objek PersistentVolume
sebagai representasi di Kubernetes. Fitur penyediaan dinamis menghilangkan kebutuhan admin klaster untuk menyediakan
penyimpanan sebelumnya (pre-provision). Dengan demikian, penyimpanan akan tersedia secara otomatis
ketika diminta oleh pengguna.
Latar Belakang
Penyediaan volume dinamis diimplementasi berdasarkan objek API StorageClass dari
grup API storage.k8s.io. Seorang admin klaster dapat mendefinisikan berbagai macam
objek StorageClass sesuai kebutuhan, masing-masing menentukan plugin volume (disebut
juga provisioner) yang menyediakan sebuah volume beserta kumpulan parameter untuk
diteruskan oleh provisioner ketika proses penyediaan.
Seorang klaster admin dapat mendefinisikan dan mengekspos berbagai templat penyimpanan
(dari sistem penyimpanan yang sama maupun berbeda) di dalam klaster, masing-masing dengan
kumpulan parameter tertentu. Desain ini memastikan bahwa pengguna tidak perlu khawatir betapa
rumitnya mekanisme penyediaan penyimpanan, tapi tetap memiliki kemampuan untuk
memilih berbagai macam pilihan penyimpanan.
Info lebih lanjut mengenai storage class dapat dilihat di sini.
Untuk mengaktifkan penyediaan dinamis, seorang admin klaster perlu untuk
terlebih dahulu membuat (pre-create) satu atau beberapa objek StorageClass
untuk pengguna.
Objek StorageClass mendefinisikan provisioner mana yang seharusnya digunakan
dan parameter apa yang seharusnya diberikan pada provisioner tersebut saat
penyediaan dinamis dipanggil.
Manifestasi berikut ini membuat sebuah StorageClass "slow" yang
menyediakan persistent disk standar.
Pengguna dapat melakukan permintaan untuk penyediaan penyimpanan dinamis dengan
memasukkan StorageClass di dalam PersistentVolumeClaim. Sebelum Kubernetes v1.6,
ini dapat dilakukan melalui anotasi volume.beta.kubernetes.io/storage-class.
Hanya saja, anotasi ini sudah usang sejak v1.6. Pengguna sekarang dapat dan seharusnya
menggunakan fieldstorageClassName dari objek PersistentVolumeClaim. Nilai
dari field ini haruslah sesuai dengan nama StorageClass yang dikonfigurasi oleh
admin (lihat bagian di bawah).
Untuk memilih StorageClass "fast", sebagai contoh, pengguna dapat membuat
PersistentVolumeClaim seperti ini:
Klaim ini menghasilkan persistent disk SSD yang disediakan secara otomatis.
Ketika klaim dihilangkan, volume akan musnah.
Perilaku Default
Penyediaan dinamis dapat diaktifkan pada setiap klaster supaya semua klaim
dapat disediakan secara dinamis jika tidak ada StorageClass yang dispesifikasikan.
Seorang klaster admin dapat mengaktifkan perilaku ini dengan cara:
Seorang admin dapat menandai StorageClass yang spesifik sebagai default dengan menambahkan
anotasi storageclass.kubernetes.io/is-default-class.
Ketika StorageClass default tersebut ada pada klaster dan pengguna membuat PersistentVolumeClaim
tanpa menspesifikasikan storageClassName, admission controllerDefaultStorageClass secara
otomatis menambahkan fieldstorageClassName dengan StorageClass default.
Perhatikan bahwa hanya bisa ada satu default StorageClass pada sebuah klaster,
atau PersistentVolumeClaim tanpa menspesifikasikan storageClassName secara eksplisit
tidak bisa terbuat.
Kesadaran (Awareness) Topologi
Pada klaster Multi-Zona, Pod dapat tersebar di banyak Zona
pada sebuah Region. Penyimpanan dengan backend Zona-Tunggal seharusnya disediakan pada
Zona-Zona dimana Pod dijalankan. Hal ini dapat dicapai dengan mengatur
Mode Volume Binding.
6.8 - Limit Volume yang Spesifik terhadap Node
Laman ini menjelaskan soal jumlah volume maksimal yang dapat dihubungkan
ke sebuah Node untuk berbagai penyedia layanan cloud.
Penyedia layanan cloud seperti Google, Amazon, dan Microsoft pada umumnya memiliki
keterbatasan dalam jumlah volume yang bisa terhubung ke sebuah Node. Keterbatasn ini
sangatlah penting untuk diketahui Kubernetes dalam menentukan keputusan. Jika tidak,
Pod-pod yang telah dijadwalkan pada sebuah Node akan macet dan menunggu terus-menerus
untuk terhubung pada volume.
Limit default pada Kubernetes
Kubernetes scheduler memiliki limit default untuk jumlah volume
yang dapat terhubung pada sebuah Node:
Kamu dapat mengganti limit-limit ini dengan mengkonfigurasi nilai dari
variabel environmentKUBE_MAX_PD_VOLS, lalu menjalankan scheduler.
Berhati-hatilah jika kamu menerapkan limit yang lebih besar dari limit default.
Perhatikan dokumentasi penyedia layanan cloud untuk hal ini, dan pastikan Node
benar-benar dapat mendukung nilai limit yang kamu inginkan.
Limit ini diterapkan untuk seluruh klaster, jadi akan berdampak pada semua Node.
Limit volume dinamis
FEATURE STATE:Kubernetes v1.12 [beta]
Sebagai fitur Alpha, Kubernetes 1.11 memperkenalkan dukungan untuk limit volume yang dinamis berdasarkan tipe Node.
Pada Kubernettes 1.12, fitur ini telah mendapat promosi ke Beta dan akan diaktifkan secara default.
Limit volume dinamis mendukung tipe-tipe volume berikut:
Amazon EBS
Google Persistent Disk
Azure Disk
CSI
Ketika fitur limit volume dinamis diaktifkan, Kubernetes secara otomatis
menentukan tipe Node dan menerapkan jumlah volume dengan tepat, berapa yang bisa
terhubung Node. Sebagai contoh:
Untuk Amazon EBS disk pada tipe instans M5,C5,R5,T3 dan Z1D, Kubernetes hanya memperbolehkan 25
volume dapat terhubung pada sebuah Node. Untuk tipe instans lainnya pada
Amazon Elastic Compute Cloud (EC2),
Kubernetes memperbolehkan 39 jumlah volume dapat terhubung pada sebuah Node.
Pada Azure, maksimal 64 jumlah disk dapat terhubung pada suatu node, tergantung dari tipe node. Untuk perinciannya
bisa dilihat pada Ukuran mesin virtual (VM) di Azure.
Untuk CSI, driver manapun yang memberitahukan (advertise) limit volume terhubung melalui spek CSI akan memiliki limit tersebut yang disediakan
sebagai properti Node dan Scheduler tidak akan menjadwalkan Pod dengan volume pada Node manapun yang sudah penuh kapasitasnya. Untuk penjelasan lebih jauh
lihat spek CSI.
7 - Konfigurasi
7.1 - Konfigurasi dan Penerapan Konsep
Dokumen ini menyoroti dan memperkuat pemahaman konsep konfigurasi yang dikenalkan di seluruh panduan pengguna, dokumentasi Memulai, dan contoh-contoh.
Dokumentasi ini terbuka. Jika Anda menemukan sesuatu yang tidak ada dalam daftar ini tetapi mungkin bermanfaat bagi orang lain, jangan ragu untuk mengajukan issue atau mengirimkan PR.
Tip konfigurasi secara umum
Saat mendefinisikan konfigurasi, tentukan versi API stabil terbaru.
File konfigurasi harus disimpan dalam version control sebelum di push ke cluster. Ini memungkinkan Anda untuk dengan cepat mengembalikan perubahan konfigurasi jika perlu. Ini juga membantu penciptaan dan restorasi cluster.
Tulis file konfigurasi Anda menggunakan YAML tidak dengan JSON. Meskipun format ini dapat digunakan secara bergantian di hampir semua skenario, YAML cenderung lebih ramah pengguna.
Kelompokkan objek terkait ke dalam satu file yang memungkinkan. Satu file seringkali lebih mudah dikelola daripada beberapa file. Lihat pada guestbook-all-in-one.yaml sebagai contoh file sintaks ini.
Perhatikan juga bahwa banyak perintah kubectl dapat dipanggil pada direktori. Misalnya, Anda dapat memanggil kubectl apply pada direktori file konfigurasi.
Jangan tentukan nilai default yang tidak perlu: sederhana, konfigurasi minimal akan membuat kesalahan lebih kecil.
Masukkan deskripsi objek dalam anotasi, untuk memungkinkan introspeksi yang lebih baik.
"Naked" Pods vs ReplicaSets, Deployments, and Jobs
Jangan gunakan Pods naked (artinya, Pods tidak terikat dengan a ReplicaSet a Deployment) jika kamu bisa menghindarinya. Pod naked tidak akan dijadwal ulang jika terjadi kegagalan pada node.
Deployment, yang keduanya menciptakan ReplicaSet untuk memastikan bahwa jumlah Pod yang diinginkan selalu tersedia, dan menentukan strategi untuk mengganti Pods (seperti RollingUpdate), hampir selalu lebih disukai daripada membuat Pods secara langsung, kecuali untuk beberapa yang eksplisit restartPolicy: Never banyak skenario . A Job mungkin juga sesuai.
Services
Buat Service sebelum workloads backend terkait (Penyebaran atau ReplicaSets), dan sebelum workloads apa pun yang perlu mengaksesnya. Ketika Kubernetes memulai sebuah container, ia menyediakan environment variabel yang menunjuk ke semua Layanan yang berjalan ketika container itu dimulai. Misalnya, jika Layanan bernama foo ada, semua container akan mendapatkan variabel berikut di environment awalnya:
FOO_SERVICE_HOST=<the host the Service is running on>
FOO_SERVICE_PORT=<the port the Service is running on>
*Ini menunjukan persyaratan pemesanan * - Service apa pun yang ingin diakses oleh Pod harus dibuat sebelum Pod itu sendiri, atau environment variabel tidak akan diisi. DNS tidak memiliki batasan ini.
Opsional (meskipun sangat disarankan) cluster add-on adalah server DNS.
Server DNS melihat API Kubernetes untuk Service baru dan membuat satu set catatan DNS untuk masing-masing. Jika DNS telah diaktifkan di seluruh cluster maka semua Pods harus dapat melakukan resolusi namaService secara otomatis.
Jangan tentukan hostPort untuk Pod kecuali jika benar-benar diperlukan. Ketika Anda bind Pod ke hostPort, hal itu membatasi jumlah tempat Pod dapat dijadwalkan, karena setiap kombinasi <hostIP, hostPort, protokol> harus unik. Jika Anda tidak menentukan hostIP dan protokol secara eksplisit, Kubernetes akan menggunakan 0.0.0.0 sebagai hostIP dan TCP sebagai default protokol.
Jika Anda secara eksplisit perlu mengekspos port Pod pada node, pertimbangkan untuk menggunakan NodePort Service sebelum beralih ke hostPort.
Hindari menggunakan hostNetwork, untuk alasan yang sama seperti hostPort.
Gunakan [headless Services](/id/docs/concepts/services-networking/service/#headless-
services) (yang memiliki ClusterIP dari None) untuk Service discovery yang mudah ketika Anda tidak membutuhkan kube-proxy load balancing.
Menggunakan label
Deklarasi dan gunakan [labels] (/id/docs/concepts/overview/working-with-objects/labels/) untuk identifikasi semantic attributes aplikasi atau Deployment kamu, seperti { app: myapp, tier: frontend, phase: test, deployment: v3 }. Kamu dapat menggunakan label ini untuk memilih Pod yang sesuai untuk sumber daya lainnya; misalnya, Service yang memilih semua tier: frontend Pods, atau semua komponen phase: test dari app: myapp. Lihat guestbook aplikasi untuk contoh-contoh pendekatan ini.
Service dapat dibuat untuk menjangkau beberapa Penyebaran dengan menghilangkan label khusus rilis dari pemilihnya. Deployments membuatnya mudah untuk memperbarui Service yang sedang berjalan tanpa downtime.
Keadaan objek yang diinginkan dideskripsikan oleh Deployment, dan jika perubahan terhadap spesifikasi tersebut adalah applied, Deployment controller mengubah keadaan aktual ke keadaan yang diinginkan pada tingkat yang terkontrol.
Kamu dapat memanipulasi label untuk debugging. Karena Kubernetes controller (seperti ReplicaSet) dan Service Match dengan Pods menggunakan label pemilih, menghapus label yang relevan dari Pod akan menghentikannya dari dianggap oleh Controller atau dari lalu lintas yang dilayani oleh Service. Jika Anda menghapus label dari Pod yang ada, Controller akan membuat Pod baru untuk menggantikannya. Ini adalah cara yang berguna untuk men-debug Pod yang sebelumnya "live" di Environment "quarantine". Untuk menghapus atau menambahkan label secara interaktif, gunakan kubectl label.
Container Images
Ini imagePullPolicy dan tag dari image mempengaruhi ketika kubelet mencoba menarik image yang ditentukan
imagePullPolicy: IfNotPresent: image ditarik hanya jika belum ada secara lokal.
imagePullPolicy: Always: Image ditarik setiap kali pod dimulai.
imagePullPolicy dihilangkan dan tag imagenya adalah :latest atau dihilangkan:always diterapkan.
imagePullPolicy dihilangkan dan tag image ada tetapi tidak :latest: IfNotPresent diterapkan.
imagePullPolicy: Never: image diasumsikan ada secara lokal. Tidak ada upaya yang dilakukan untuk menarik image.
Catatan:
Untuk memastikan container selalu menggunakan versi image yang sama, Anda bisa menentukannya digest, untuk contoh sha256:45b23dee08af5e43a7fea6c4cf9c25ccf269ee113168c19722f87876677c5cb2. digest mengidentifikasi secara unik versi image tertentu, sehingga tidak pernah diperbarui oleh Kubernetes kecuali Anda mengubah nilai digest.
Catatan:
Anda harus menghindari penggunaan tag : latest saat menempatkan container dalam produksi karena lebih sulit untuk melacak versi image mana yang sedang berjalan dan lebih sulit untuk memutar kembali dengan benar.
Catatan:
Semantik caching dari penyedia gambar yang mendasarinya membuat bahkan imagePullPolicy: Always efisien. Dengan Docker, misalnya, jika image sudah ada, upaya pull cepat karena semua lapisan image di-cache dan tidak perlu mengunduh image.
Menggunakan kubectl
Gunakan kubectl apply -f <directory>. Ini mencari konfigurasi Kubernetes di semua file .yaml, .yml, dan .json di <directory> dan meneruskannya ke apply.
7.2 - Mengatur Sumber Daya Komputasi untuk Container
Saat kamu membuat spesifikasi sebuah Pod, kamu
dapat secara opsional menentukan seberapa banyak CPU dan memori (RAM) yang dibutuhkan
oleh setiap Container. Saat Container-Container menentukan request (permintaan) sumber daya,
scheduler dapat membuat keputusan yang lebih baik mengenai Node mana yang akan dipilih
untuk menaruh Pod-Pod. Dan saat limit (batas) sumber daya Container-Container telah ditentukan,
maka kemungkinan rebutan sumber daya pada sebuah Node dapat dihindari.
Untuk informasi lebih lanjut mengenai perbedaan request dan limit, lihat QoS Sumber Daya.
Jenis-jenis sumber daya
CPU dan memori masing-masing merupakan jenis sumber daya (resource type).
Sebuah jenis sumber daya memiliki satuan dasar. CPU ditentukan dalam satuan jumlah core,
dan memori ditentukan dalam satuan bytes. Jika kamu menggunakan Kubernetes v1.14 keatas,
kamu dapat menentukan sumber daya huge page. Huge page adalah fitur khusus Linux
di mana kernel Node mengalokasikan blok-blok memori yang jauh lebih besar daripada ukuran
page bawaannya.
Sebagai contoh, pada sebuah sistem di mana ukuran page bawaannya adalah 4KiB, kamu
dapat menentukan sebuah limit, hugepages-2Mi: 80Mi. Jika kontainer mencoba mengalokasikan
lebih dari 40 huge page berukuran 20MiB (total 80MiB), maka alokasi tersebut akan gagal.
Catatan:
Kamu tidak dapat melakukan overcommit terhadap sumber daya hugepages-*.
Hal ini berbeda dari sumber daya memory dan cpu (yang dapat di-overcommit).
CPU dan memori secara kolektif disebut sebagai sumber daya komputasi, atau cukup
sumber daya saja. Sumber daya komputasi adalah jumlah yang dapat diminta, dialokasikan,
dan dikonsumsi. Mereka berbeda dengan sumber daya API.
Sumber daya API, seperti Pod dan Service adalah
objek-objek yang dapat dibaca dan diubah melalui Kubernetes API Server.
Request dan Limit Sumber daya dari Pod dan Container
Setiap Container dari sebuah Pod dapat menentukan satu atau lebih dari hal-hal berikut:
Walaupun requests dan limits hanya dapat ditentukan pada Container individual, akan
lebih mudah untuk membahas tentang request dan limit sumber daya dari Pod. Sebuah
request/limit sumber daya Pod untuk jenis sumber daya tertentu adalah jumlah dari
request/limit sumber daya pada jenis tersebut untuk semua Container di dalam Pod tersebut.
Arti dari CPU
Limit dan request untuk sumber daya CPU diukur dalam satuan cpu.
Satu cpu, dalam Kubernetes, adalah sama dengan:
1 vCPU AWS
1 Core GCP
1 vCore Azure
1 vCPU IBM
1 Hyperthread pada sebuah prosesor Intel bare-metal dengan Hyperthreading
Request dalam bentuk pecahan diizinkan. Sebuah Container dengan
spec.containers[].resources.requests.cpu bernilai 0.5 dijamin mendapat
setengah CPU dibandingkan dengan yang meminta 1 CPU. Ekspresi nilai 0.1 ekuivalen
dengan ekspresi nilai 100m, yang dapat dibaca sebagai "seratus milicpu". Beberapa
orang juga membacanya dengan "seratus milicore", dan keduanya ini dimengerti sebagai
hal yang sama. Sebuah request dengan angka di belakang koma, seperti 0.1 dikonversi
menjadi 100m oleh API, dan presisi yang lebih kecil lagi dari 1m tidak dibolehkan.
Untuk alasan ini, bentuk 100m mungkin lebih disukai.
CPU juga selalu diminta dalam jumlah yang mutlak, tidak sebagai jumlah yang relatif;
0.1 adalah jumlah CPU yang sama pada sebuah mesin single-core, dual-core, atau
48-core.
Arti dari Memori
Limit dan request untuk memory diukur dalam satuan bytes. Kamu dapat mengekspresikan
memori sebagai plain integer atau sebagai sebuah fixed-point integer menggunakan
satu dari sufiks-sufiks berikut: E, P, T, G, M, K. Kamu juga dapat menggunakan bentuk
pangkat dua ekuivalennya: Ei, Pi, Ti, Gi, Mi, Ki.
Sebagai contoh, nilai-nilai berikut kurang lebih sama:
128974848, 129e6, 129M, 123Mi
Berikut sebuah contoh.
Pod berikut memiliki dua Container. Setiap Container memiliki request 0.25 cpu dan
64MiB (226 bytes) memori. Setiap Container memiliki limit 0.5 cpu dan
128MiB memori. Kamu dapat berkata bahwa Pod tersebut memiliki request 0.5 cpu dan
128MiB memori, dan memiliki limit 1 cpu dan 265MiB memori.
Bagaimana Pod-Pod dengan request sumber daya dijadwalkan
Saat kamu membuat sebuah Pod, Kubernetes scheduler akan memilih sebuah Node
untuk Pod tersebut untuk dijalankan. Setiap Node memiliki kapasitas maksimum
untuk setiap jenis sumber daya: jumlah CPU dan memori yang dapat disediakan
oleh Node tersebut untuk Pod-Pod. Scheduler memastikan bahwa, untuk setiap
jenis sumber daya, jumlah semua request sumber daya dari Container-Container
yang dijadwalkan lebih kecil dari kapasitas Node tersebut. Perlu dicatat
bahwa walaupun penggunaan sumber daya memori atau CPU aktual/sesungguhnya pada
Node-Node sangat rendah, scheduler tetap akan menolak untuk menaruh sebuah
Pod pada sebuah Node jika pemeriksaan kapasitasnya gagal. Hal ini adalah untuk
menjaga dari kekurangan sumber daya pada sebuah Node saat penggunaan sumber daya
meningkat suatu waktu, misalnya pada saat titik puncak traffic harian.
Bagaimana Pod-Pod dengan limit sumber daya dijalankan
Saat Kubelet menjalankan sebuah Container dari sebuah Pod, Kubelet tersebut
mengoper limit CPU dan memori ke runtime kontainer.
Ketika menggunakan Docker:
spec.containers[].resources.requests.cpu diubah menjadi nilai core-nya,
yang mungkin berbentuk angka pecahan, dan dikalikan dengan 1024. Nilai yang
lebih besar antara angka ini atau 2 digunakan sebagai nilai dari flag--cpu-shares
pada perintah docker run.
spec.containers[].resources.limits.cpu diubah menjadi nilai millicore-nya dan
dikalikan dengan 100. Nilai hasilnya adalah jumlah waktu CPU yang dapat digunakan oleh
sebuah kontainer setiap 100 milidetik. Sebuah kontainer tidak dapat menggunakan lebih
dari jatah waktu CPU-nya selama selang waktu ini.
Catatan:
Periode kuota bawaan adalah 100ms. Resolusi minimum dari kuota CPU adalah 1 milidetik.
spec.containers[].resources.limits.memory diubah menjadi sebuah bilangan bulat, dan
digunakan sebagai nilai dari flag--memory
dari perintah docker run.
Jika sebuah Container melebihi batas memorinya, Container tersebut mungkin akan diterminasi.
Jika Container tersebut dapat diulang kembali, Kubelet akan mengulangnya kembali, sama
seperti jenis kegagalan lainnya.
Jika sebuah Container melebihi request memorinya, kemungkinan Pod-nya akan dipindahkan
kapanpun Node tersebut kehabisan memori.
Sebuah Container mungkin atau mungkin tidak diizinkan untuk melebihi limit CPU-nya
untuk periode waktu yang lama. Tetapi, Container tersebut tidak akan diterminasi karena
penggunaan CPU yang berlebihan.
Untuk menentukan apabila sebuah Container tidak dapat dijadwalkan atau sedang diterminasi
karena limit sumber dayanya, lihat bagian Penyelesaian Masalah.
Memantau penggunaan sumber daya komputasi
Penggunaan sumber daya dari sebuah Pod dilaporkan sebagai bagian dari kondisi Pod.
Jika monitoring opsional diaktifkan pada klaster kamu, maka penggunaan sumber daya Pod dapat diambil
dari sistem monitoring kamu.
Penyelesaian Masalah
Pod-Pod saya berkondisi Pending (tertunda) dengan event message failedScheduling
Jika scheduler tidak dapat menemukan Node manapun yang muat untuk sebuah Pod,
Pod tersebut tidak akan dijadwalkan hingga ditemukannya sebuah tempat yang
muat. Sebuah event akan muncul setiap kali scheduler gagal menemukan tempat
untuk Pod tersebut, seperti berikut:
kubectl describe pod frontend | grep -A 3 Events
Events:
FirstSeen LastSeen Count From Subobject PathReason Message
36s 5s 6 {scheduler } FailedScheduling Failed for reason PodExceedsFreeCPU and possibly others
Pada contoh di atas, Pod bernama "frontend" gagal dijadwalkan karena kekurangan
sumber daya CPU pada Node tersebut. Pesan kesalahan yang serupa dapat juga menunjukkan
kegagalan karena kekurangan memori (PodExceedsFreeMemroy). Secara umum, jika sebuah
Pod berkondisi Pending (tertunda) dengan sebuah pesan seperti ini, ada beberapa hal yang
dapat dicoba:
Tambah lebih banyak Node pada klaster.
Terminasi Pod-Pod yang tidak dibutuhkan untuk memberikan ruangan untuk Pod-Pod yang
tertunda.
Periksa jika nilai request Pod tersebut tidak lebih besar dari Node-node yang ada.
Contohnya, jika semua Node memiliki kapasitas cpu: 1, maka Pod dengan request
cpu: 1.1 tidak akan pernah dijadwalkan.
Kamu dapat memeriksa kapasitas Node-Node dan jumlah-jumlah yang telah dialokasikan
dengan perintah kubectl describe nodes. Contohnya:
kubectl describe nodes e2e-test-node-pool-4lw4
Name: e2e-test-node-pool-4lw4
[ ... lines removed for clarity ...]
Capacity:
cpu: 2
memory: 7679792Ki
pods: 110
Allocatable:
cpu: 1800m
memory: 7474992Ki
pods: 110
[ ... beberapa baris dihapus untuk kejelasan ...]
Non-terminated Pods: (5 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits
--------- ---- ------------ ---------- --------------- -------------
kube-system fluentd-gcp-v1.38-28bv1 100m (5%) 0 (0%) 200Mi (2%) 200Mi (2%)
kube-system kube-dns-3297075139-61lj3 260m (13%) 0 (0%) 100Mi (1%) 170Mi (2%)
kube-system kube-proxy-e2e-test-... 100m (5%) 0 (0%) 0 (0%) 0 (0%)
kube-system monitoring-influxdb-grafana-v4-z1m12 200m (10%) 200m (10%) 600Mi (8%) 600Mi (8%)
kube-system node-problem-detector-v0.1-fj7m3 20m (1%) 200m (10%) 20Mi (0%) 100Mi (1%)
Allocated resources:
(Total limit mungkin melebihi 100 persen, misalnya, karena _overcommit_.)
CPU Requests CPU Limits Memory Requests Memory Limits
------------ ---------- --------------- -------------
680m (34%) 400m (20%) 920Mi (12%) 1070Mi (14%)
Pada keluaran di atas, kamu dapat melihat bahwa jika sebuah Pod meminta lebih dari
1120m CPU atau 6.23Gi memori, Pod tersebut tidak akan muat pada Node tersebut.
Dengan melihat pada bagian Pods, kamu dapat melihat Pod-Pod mana saja yang memakan
sumber daya pada Node tersebut.
Jumlah sumber daya yang tersedia untuk Pod-Pod kurang dari kapasitas Node, karena
daemon sistem menggunakan sebagian dari sumber daya yang ada. Kolom allocatable pada
NodeStatus
memberikan jumlah sumber daya yang tersedia untuk Pod-Pod. Untuk lebih lanjut, lihat
Sumber daya Node yang dapat dialokasikan.
Fitur kuota sumber daya dapat disetel untuk
membatasi jumlah sumber daya yang dapat digunakan. Jika dipakai bersama dengan Namespace,
kuota sumber daya dapat mencegah suatu tim menghabiskan semua sumber daya.
Container saya diterminasi
Container kamu mungkin diterminasi karena Container tersebut melebihi batasnya. Untuk
memeriksa jika sebuah Container diterminasi karena ia melebihi batas sumber dayanya,
gunakan perintah kubectl describe pod pada Pod yang bersangkutan:
kubectl describe pod simmemleak-hra99
Name: simmemleak-hra99
Namespace: default
Image(s): saadali/simmemleak
Node: kubernetes-node-tf0f/10.240.216.66
Labels: name=simmemleak
Status: Running
Reason:
Message:
IP: 10.244.2.75
Replication Controllers: simmemleak (1/1 replicas created)
Containers:
simmemleak:
Image: saadali/simmemleak
Limits:
cpu: 100m
memory: 50Mi
State: Running
Started: Tue, 07 Jul 2015 12:54:41 -0700
Last Termination State: Terminated
Exit Code: 1
Started: Fri, 07 Jul 2015 12:54:30 -0700
Finished: Fri, 07 Jul 2015 12:54:33 -0700
Ready: False
Restart Count: 5
Conditions:
Type Status
Ready False
Events:
FirstSeen LastSeen Count From SubobjectPath Reason Message
Tue, 07 Jul 2015 12:53:51 -0700 Tue, 07 Jul 2015 12:53:51 -0700 1 {scheduler } scheduled Successfully assigned simmemleak-hra99 to kubernetes-node-tf0f
Tue, 07 Jul 2015 12:53:51 -0700 Tue, 07 Jul 2015 12:53:51 -0700 1 {kubelet kubernetes-node-tf0f} implicitly required container POD pulled Pod container image "registry.k8s.io/pause:0.8.0" already present on machine
Tue, 07 Jul 2015 12:53:51 -0700 Tue, 07 Jul 2015 12:53:51 -0700 1 {kubelet kubernetes-node-tf0f} implicitly required container POD created Created with docker id 6a41280f516d
Tue, 07 Jul 2015 12:53:51 -0700 Tue, 07 Jul 2015 12:53:51 -0700 1 {kubelet kubernetes-node-tf0f} implicitly required container POD started Started with docker id 6a41280f516d
Tue, 07 Jul 2015 12:53:51 -0700 Tue, 07 Jul 2015 12:53:51 -0700 1 {kubelet kubernetes-node-tf0f} spec.containers{simmemleak} created Created with docker id 87348f12526a
Pada contoh di atas, Restart Count: 5 menunjukkan bahwa Container simmemleak
pada Pod tersebut diterminasi dan diulang kembali sebanyak lima kali.
Kamu dapat menggunakan perintah kubectl get pod dengan opsi -o go-template=... untuk
mengambil kondisi dari Container-Container yang sebelumnya diterminasi:
kubectl get pod -o go-template='{{range.status.containerStatuses}}{{"Container Name: "}}{{.name}}{{"\r\nLastState: "}}{{.lastState}}{{end}}' simmemleak-hra99
Kamu dapat lihat bahwa Container tersebut diterminasi karena reason:OOM Killed, di mana
OOM merupakan singkatan dari Out Of Memory, atau kehabisan memori.
Penyimpanan lokal sementara
FEATURE STATE:Kubernetes v1.36 [beta]
Kubernetes versi 1.8 memperkenalkan sebuah sumber daya baru, ephemeral-storage untuk mengatur penyimpanan lokal yang bersifat sementara. Pada setiap Node Kubernetes, direktori root dari Kubelet (secara bawaan /var/lib/kubelet) dan direktori log (/var/log) ditaruh pada partisi root dari Node tersebut. Partisi ini juga digunakan bersama oleh Pod-Pod melalui volume emptyDir, log kontainer, lapisan image, dan lapisan kontainer yang dapat ditulis.
Partisi ini bersifat "sementara" dan aplikasi-aplikasi tidak dapat mengharapkan SLA kinerja (misalnya Disk IOPS) dari partisi ini. Pengelolaan penyimpanan lokal sementara hanya berlaku untuk partisi root; partisi opsional untuk lapisan image dan lapisan yang dapat ditulis berada di luar ruang lingkup.
Catatan:
Jika sebuah partisi runtime opsional digunakan, partisi root tidak akan menyimpan lapisan image ataupun lapisan yang dapat ditulis manapun.
Menyetel request dan limit dari penyimpanan lokal sementara
Setiap Container dari sebuah Pod dapat menentukan satu atau lebih dari hal-hal berikut:
Limit dan request untuk ephemeral-storage diukur dalam satuan bytes. Kamu dapat menyatakan
penyimpanan dalam bilangan bulat biasa, atau sebagai fixed-point integer menggunakan satu dari
sufiks-sufiks ini: E, P, T, G, M, K. Kamu jika dapat menggunakan bentuk pangkat dua ekuivalennya:
Ei, Pi, Ti, Gi, Mi, Ki. Contohnya, nilai-nilai berikut kurang lebih sama:
128974848, 129e6, 129M, 123Mi
Contohnya, Pod berikut memiliki dua Container. Setiap Container memiliki request 2GiB untuk penyimpanan lokal sementara. Setiap Container memiliki limit 4GiB untuk penyimpanan lokal sementara. Maka, Pod tersebut memiliki jumlah request 4GiB penyimpanan lokal sementara, dan limit 8GiB.
Bagaimana Pod-Pod dengan request ephemeral-storage dijadwalkan
Saat kamu membuat sebuah Pod, Kubernetes scheduler memilih sebuah Node di mana Pod
tersebut akan dijalankan. Setiap Node memiliki jumlah maksimum penyimpanan lokal sementara yang dapat disediakan.
Untuk lebih lanjut, lihat "Hal-hal yang dapat dialokasikan Node".
Scheduler memastikan bahwa jumlah dari request-request sumber daya dari Container-Container yang dijadwalkan lebih kecil dari kapasitas Node.
Bagaimana Pod-Pod dengan limit ephemeral-storage dijalankan
Untuk isolasi pada tingkat kontainer, jika lapisan yang dapat ditulis dari sebuah Container dan penggunaan log melebihi limit penyimpanannya, maka Pod tersebut akan dipindahkan. Untuk isolasi pada tingkat Pod, jika jumlah dari penyimpanan lokal sementara dari semua Container dan juga volume emptyDir milik Pod melebihi limit, maka Pod teresebut akan dipindahkan.
Memantau penggunaan ephemeral-storage
Saat penyimpanan lokal sementara digunakan, ia dipantau terus-menerus
oleh Kubelet. Pemantauan dilakukan dengan cara memindai setiap volume
emptyDir, direktori log, dan lapisan yang dapat ditulis secara periodik.
Dimulai dari Kubernetes 1.15, volume emptyDir (tetapi tidak direktori log
atau lapisan yang dapat ditulis) dapat, sebagai pilihan dari operator
klaster, dikelola dengan menggunakan project quotas.
Project quotas aslinya diimplementasikan dalam XFS, dan baru-baru ini
telah diubah ke ext4fs. Project quotas dapat digunakan baik untuk
monitoring dan pemaksaan; sejak Kubernetes 1.16, mereka tersedia sebagai
fitur alpha untuk monitoring saja.
Quota lebih cepat dan akurat dibandingkan pemindaian direktori. Saat
sebuah direktori ditentukan untuk sebuah proyek, semua berkas yang dibuat
pada direktori tersebut dibuat untuk proyek tersebut, dan kernel hanya
perlu melacak berapa banyak blok yang digunakan oleh berkas-berkas pada
proyek tersebut. Jika sebuah berkas dibuat dan dihapus, tetapi tetap dengan
sebuah file descriptor yang terbuka, maka berkas tersebut tetap akan
memakan ruangan penyimpanan. Ruangan ini akan dilacak oleh quota tersebut,
tetapi tidak akan terlihat oleh sebuah pemindaian direktori.
Kubernetes menggunakan ID proyek yang dimulai dari 1048576. ID-ID yang
digunakan akan didaftarkan di dalam /etc/projects dan /etc/projid.
Jika ID-ID proyek pada kisaran ini digunakan untuk tujuan lain pada sistem,
ID-ID proyek tersebut harus terdaftar di dalam /etc/projects dan /etc/projid
untuk mencegah Kubernetes menggunakan ID-ID tersebut.
Untuk mengaktifkan penggunaan project quotas, operator klaster
harus melakukan hal-hal berikut:
Aktifkan feature gateLocalStorageCapacityIsolationFSQuotaMonitoring=true
pada konfigurasi Kubelet. Nilainya secara bawaan false pada
Kubernetes 1.16, jadi harus secara eksplisit disetel menjadi true.
Pastikan bahwa partisi root (atau partisi opsional runtime)
telah dibangun (build) dengan mengaktifkan project quotas. Semua sistem berkas (filesystem)
XFS mendukung project quotas, tetapi sistem berkas ext4 harus dibangun
secara khusus untuk mendukungnya
Pastikan bahwa partisi root (atau partisi opsional runtime) ditambatkan (mount)
dengan project quotas yang telah diaktifkan.
Membangun dan menambatkan sistem berkas dengan project quotas yang telah diaktifkan
Sistem berkas XFS tidak membutuhkan tindakan khusus saat dibangun;
mereka secara otomatis telah dibangun dengan project quotas yang
telah diaktifkan.
Sistem berkas ext4fs harus dibangun dengan mengaktifkan quotas,
kemudian mereka harus diaktifkan pada sistem berkas tersebut.
Sumber daya yang diperluas (Extended Resource) adalah nama sumber daya di luar domain kubernetes.io.
Mereka memungkinkan operator klaster untuk menyatakan dan pengguna untuk menggunakan
sumber daya di luar sumber daya bawaan Kubernetes.
Ada dua langkah untuk menggunakan sumber daya yang diperluas. Pertama, operator
klaster harus menyatakan sebuah Extended Resource. Kedua, pengguna harus meminta
sumber daya yang diperluas tersebut di dalam Pod.
Mengelola sumber daya yang diperluas
Sumber daya yang diperluas pada tingkat Node
Sumber daya yang diperluas pada tingkat Node terikat pada Node.
Sumber daya Device Plugin yang dikelola
Lihat Device
Plugin untuk
cara menyatakan sumber daya device plugin yang dikelola pada setiap node.
Sumber daya lainnya
Untuk menyatakan sebuah sumber daya yang diperluas tingkat Node, operator klaster
dapat mengirimkan permintaan HTTP PATCH ke API server untuk menentukan kuantitas
sumber daya yang tersedia pada kolom status.capacity untuk Node pada klaster.
Setelah itu, status.capacity pada Node akan memiliki sumber daya baru tersebut.
Kolom status.allocatable diperbarui secara otomatis dengan sumber daya baru
tersebut secara asynchrounous oleh Kubelet. Perlu dicatat bahwa karena scheduler
menggunakan nilai status.allocatable milik Node saat mengevaluasi muat atau tidaknya
Pod, mungkin ada waktu jeda pendek antara melakukan PATCH terhadap kapasitas Node
dengan sumber daya baru dengan Pod pertama yang meminta sumber daya tersebut untuk
dapat dijadwalkan pada Node tersebut.
Contoh:
Berikut sebuah contoh yang menunjukkan bagaimana cara menggunakan curl untuk
mengirim permintaan HTTP yang menyatakan lima sumber daya "example.com/foo" pada
Node k8s-node-1 yang memiliki master k8s-master.
Pada permintaan HTTP di atas, ~1 adalah encoding untuk karakter / pada jalur (path) patch.
Nilai jalur operasi tersebut di dalam JSON-Patch diinterpretasikan sebagai sebuah JSON-Pointer.
Untuk lebih lanjut, lihat IETF RFC 6901, bagian 3.
Sumber daya yang diperluas pada tingkat klaster
Sumber daya yang diperluas pada tingkat klaster tidak terikat pada Node. Mereka
biasanya dikelola oleh scheduler extender, yang menangani penggunaan sumber daya
dan kuota sumber daya.
Kamu dapat menentukan sumber daya yang diperluas yang ditangani oleh scheduler extender
pada konfigurasi kebijakan scheduler.
Contoh:
Konfigurasi untuk sebuah kebijakan scheduler berikut menunjukkan bahwa
sumber daya yang diperluas pada tingkat klaster "example.com/foo" ditangani
oleh scheduler extender.
Scheduler mengirim sebuah Pod ke scheduler extender hanya jika Pod tersebut
meminta "example.com/foo".
Kolom ignoredByScheduler menentukan bahwa scheduler tidak memeriksa sumber daya
"example.com/foo" pada predikat PodFitsResources miliknya.
Pengguna dapat menggunakan sumber daya yang diperluas di dalam spesifikasi Pod
seperti CPU dan memori. Scheduler menangani akuntansi sumber daya tersebut agar
tidak ada alokasi untuk yang melebihi jumlah yang tersedia.
API server membatasi jumlah sumber daya yang diperluas dalam bentuk
bilangan bulat. Contoh jumlah yang valid adalah 3, 3000m, dan
3Ki. Contoh jumlah yang tidak valid adalah 0.5 dan 1500m.
Catatan:
Sumber daya yang diperluas menggantikan Opaque Integer Resource.
Pengguna dapat menggunakan prefiks nama domain selain kubernetes.io yang sudah dipakai.
Untuk menggunakan sebuah sumber daya yang diperluas di sebuah Pod, masukkan nama
sumber daya tersebut sebagai nilai key dari map spec.containers[].resources.limit
pada spesifikasi Container.
Catatan:
Sumber daya yang diperluas tidak dapat di-overcommit, sehingga
request dan limit nilainya harus sama jika keduanya ada di spesifikasi
sebuah Container.
Sebuah Pod hanya dijadwalkan jika semua request sumber dayanya terpenuhi, termasuk
CPU, memori, dan sumber daya yang diperluas manapun. Pod tersebut akan tetap
berada pada kondisi PENDING selama request sumber daya tersebut tidak terpenuhi.
Contoh:
Pod di bawah meminta 2 CPU dan 1 "example.com/foo" (sebuah sumber daya yang diperluas).
Probe liveness menentukan kapan harus memulai ulang kontainer. Contohnya, Probe liveness dapat menangkap deadlock ketika aplikasi berjalan tetapi tidak dapat membuat progress.
Jika kontainer gagal dalam Probe liveness berulang-ulang, Kubelet akan memulai ulang kontainer tersebut.
Probe liveness tidak menunggu Probe readiness sampai berhasil. Jika kamu ingin menunggu sebelum mengeksekusi Probe liveness, kamu bisa mendefinisikan initialDelaySeconds atau menggunakan
Probe startup.
Probe Readiness
Probe readiness menentukan kapan kontainer akan siap menerima trafik. Ini akan berguna ketika menunggu aplikasi yang memakan waktu lama dalam tugas awalnya, seperti membuat koneksi jaringan, memuat berkas, dan memanaskan(warming) cache.
Jika Probe readiness gagal, Kubernetes akan menghapus semua Pod dari semua endpoint yang cocok.
Probe readiness berjalan selama seluruh siklus hidup kontainer.
Probe Startup
Probe startup memverifikasi apakah aplikasi dalam kontainer sudah dimulai. Ini dapat digunakan untuk mengadopsi cek liveness pada kontainer yang membutuhkan waktu lama untuk memulai, lalu untuk menghindari kontainer tersebut dihentikan oleh Kubelet sebelum siap dan berjalan.
Jika Probe seperti itu telah dikonfigurasi, maka cek liveness dan readiness akan dinonaktifkan sampai Probe tersebut berhasil.
Probe dengan tipe seperti ini hanya akan dieksekusi pada saat startup, tidak seperti Probe liveness dan readiness yang dieksekusi secara periodik.
Objek secret pada Kubernetes mengizinkan kamu menyimpan dan mengatur informasi yang sifatnya sensitif, seperti
password, token OAuth, dan ssh keys. Menyimpan informasi yang sifatnya sensitif ini ke dalam secret
cenderung lebih aman dan fleksible jika dibandingkan dengan menyimpan informasi tersebut secara apa adanya pada definisi Pod atau di dalam container image.
Silahkan lihat Dokumen desain Secret untuk informasi yang sifatnya mendetail.
Ikhtisar Secret
Sebuah Secret merupakan sebuah objek yang mengandung informasi yang sifatnya
sensitif, seperti password, token, atau key. Informasi tersebut sebenarnya bisa saja
disimpan di dalam spesifikasi Pod atau image; meskipun demikian, melakukan penyimpanan
di dalam objek Secret mengizinkan pengguna untuk memiliki kontrol lebih lanjut mengenai
bagaimana Secret ini disimpan, serta mencegah tereksposnya informasi sensitif secara
tidak disengaja.
Baik pengguna dan sistem memiliki kemampuan untuk membuat objek Secret.
Untuk menggunakan Secret, sebuah Pod haruslah merujuk pada Secret tersebut.
Sebuah Secret dapat digunakan di dalam sebuah Pod melalui dua cara:
sebagai file yang ada di dalam volumevolume
yang di-mount pada salah satu container Pod, atau digunakan oleh kubelet
ketika menarik image yang digunakan di dalam Pod.
Secret Built-in
Sebuah Service Account akan Secara Otomatis Dibuat dan Meng-attach Secret dengan Kredensial API
Kubernetes secara otomatis membuat secret yang mengandung kredensial
yang digunakan untuk mengakses API, serta secara otomatis memerintahkan Pod untuk menggunakan
Secret ini.
Mekanisme otomatisasi pembuatan secret dan penggunaan kredensial API dapat di nonaktifkan
atau di-override jika kamu menginginkannya. Meskipun begitu, jika apa yang kamu butuhkan
hanyalah mengakses apiserver secara aman, maka mekanisme default inilah yang disarankan.
Baca lebih lanjut dokumentasi Service Account
untuk informasi lebih lanjut mengenai bagaimana cara kerja Service Account.
Membuat Objek Secret Kamu Sendiri
Membuat Secret dengan Menggunakan kubectl
Misalnya saja, beberapa Pod memerlukan akses ke sebuah basis data. Kemudian username
dan password yang harus digunakan oleh Pod-Pod tersebut berada pada mesin lokal kamu
dalam bentuk file-file./username.txt dan ./password.txt.
# Buatlah berkas yang selanjutnya akan digunakan pada contoh-contoh selanjutnyaecho -n 'admin' > ./username.txt
echo -n '1f2d1e2e67df' > ./password.txt
Perintah kubectl create secret akan mengemas file-file ini menjadi Secret dan
membuat sebuah objek pada Apiserver.
Karakter spesial seperti $, \*, and ! membutuhkan mekanisme escaping.
Jika password yang kamu gunakan mengandung karakter spesial, kamu perlu melakukan escape karakter dengan menggunakan karakter \\. Contohnya, apabila password yang kamu miliki adalah S!B\*d$zDsb, maka kamu harus memanggil perintah kubectl dengan cara berikut:
kubectl create secret generic dev-db-secret --from-literal=username=devuser --from-literal=password=S\!B\\*d\$zDsb
Perhatikan bahwa kamu tidak perlu melakukan escape karakter apabila massukan yang kamu berikan merupakan file (--from-file).
Kamu dapat memastikan apakah suatu Secret sudah dibuat atau belum dengan menggunakan perintah:
Perintah-perintah kubectl get dan kubectl describe secara default akan
mencegah ditampilkannya informasi yang ada di dalam Secret.
Hal ini dilakukan untuk melindungi agar Secret tidak terekspos secara tidak disengaja oleh orang lain,
atau tersimpan di dalam logterminal.
Kamu dapat membuat sebuah Secret dengan terlebih dahulu membuat file yang berisikan
informasi yang ingin kamu jadikan Secret dalam bentuk yaml atau json dan kemudian membuat objek
dengan menggunakan file tersebut. Secret
mengandung dua buah map: data dan stringData. Fielddata digunakan untuk menyimpan sembarang data,
yang di-encode menggunakan base64. Sementara itu stringData disediakan untuk memudahkan kamu untuk menyimpan
informasi sensitif dalam format yang tidak di-encode.
Sebagai contoh, untuk menyimpan dua buah string di dalam Secret dengan menggunakan field data, ubahlah
informasi tersebut ke dalam base64 dengan menggunakan mekanisme sebagai berikut:
Kemudian buatlah Secret menggunakan perintah kubectl apply:
kubectl apply -f ./secret.yaml
secret "mysecret" created
Untuk beberapa skenario, kamu bisa saja ingin menggunakan opsi field stringData.
Field ini mengizinkan kamu untuk memberikan masukan berupa informasi yang belum di-encode secara langsung
pada sebuah Secret, informasi dalam bentuk string ini kemudian akan di-encode ketika Secret dibuat maupun diubah.
Contoh praktikal dari hal ini adalah ketika kamu melakukan proses deploy aplikasi
yang menggunakan Secret sebagai penyimpanan file konfigurasi, dan kamu ingin mengisi
bagian dari konfigurasi file tersebut ketika aplikasi di_deploy_.
Jika kamu ingin aplikasi kamu menggunakan file konfigurasi berikut:
Alat deployment yang kamu gunakan kemudian akan mengubah templat variabel {{username}} dan {{password}}
sebelum menjalankan perintah kubectl apply.
stringData merupakan field yang sifatnya write-only untuk alasan kenyamanan pengguna.
Field ini tidak pernah ditampilkan ketika Secret dibaca. Sebagai contoh, misalkan saja kamu menjalankan
perintah sebagai berikut:
kubectl get secret mysecret -o yaml
Keluaran yang diberikan kurang lebih akan ditampilkan sebagai berikut:
Jika sebuah field dispesifikasikan dalam bentuk data maupun stringData,
maka nilai dari stringData-lah yang akan digunakan. Sebagai contoh, misalkan saja terdapat
definisi Secret sebagai berikut:
Dimana string YWRtaW5pc3RyYXRvcg== akan di-decode sebagai administrator.
Key dari data dan stringData yang boleh tersusun atas karakter alfanumerik,
'-', '_' atau '.'.
Catatan Encoding:Value dari JSON dan YAML yang sudah diseriakisasi dari data Secret
akan di-encode ke dalam string base64. Newline dianggap tidak valid pada string ini dan harus
dihilangkan. Ketika pengguna Darwin/macOS menggunakan alat base64, maka pengguna
tersebut harus menghindari opsi -b yang digunakan untuk memecah baris yang terlalu panjang.
Sebaliknya pengguna Linux harus menambahkan opsi -w 0 pada perintah base64 atau
melakukan mekanisme pipelinebase64 | tr -d '\n' jika tidak terdapat opsi -w.
Membuat Secret dengan Menggunakan Generator
Kubectl mendukung mekanisme manajemen objek dengan menggunakan Kustomize
sejak versi 1.14. Dengan fitur baru ini, kamu juga dapat membuat sebuah Secret dari sebuah generator
dan kemudian mengaplikasikannya untuk membuat sebuah objek pada Apiserver. Generator yang digunakan haruslah
dispesifikasikan di dalam sebuah filekustomization.yaml di dalam sebuah direktori.
Sebagai contoh, untuk menghasilan sebuah Secret dari file-file./username.txt dan ./password.txt
# Membuat sebuah berkas kustomization.yaml dengan SecretGeneratorcat <<EOF >./kustomization.yaml
secretGenerator:
- name: db-user-pass
files:
- username.txt
- password.txt
EOF
Gunakan direktori kustomization untuk membuat objek Secret yang diinginkan.
$ kubectl apply -k .
secret/db-user-pass-96mffmfh4k created
Kamu dapat memastikan Secret tersebut sudah dibuat dengan menggunakan perintah berikut:
$ kubectl get secrets
NAME TYPE DATA AGE
db-user-pass-96mffmfh4k Opaque 2 51s
$ kubectl describe secrets/db-user-pass-96mffmfh4k
Name: db-user-pass
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data====password.txt: 12 bytes
username.txt: 5 bytes
Sebagai contoh, untuk membuat sebuah Secret dari literal username=admin dan password=secret,
kamu dapat menspesifikasikan generator Secret pada filekustomization.yaml sebagai
# Membuat sebuah berkas kustomization.yaml dengan menggunakan SecretGenerator$ cat <<EOF >./kustomization.yaml
secretGenerator:
- name: db-user-pass
literals:
- username=admin
- password=secret
EOF
Aplikasikan direktori kustomization untuk membuat objek Secret.
$ kubectl apply -k .
secret/db-user-pass-dddghtt9b5 created
Catatan:
Secret yang dihasilkan nantinya akan memiliki tambahan sufix dengan cara melakukan teknik hashing
pada isi Secret tersebut. Hal ini dilakukan untuk menjamin dibuatnya sebuah Secret baru setiap kali terjadi
perubahan isi dari Secret tersebut.
Melakukan Proses Decode pada Secret
Secret dapat dibaca dengan menggunakan perintah kubectl get secret.
Misalnya saja, untuk membaca Secret yang dibuat pada bagian sebelumya:
Secret dapat di-mount sebagai volume data atau dapat diekspos sebagai variabel-variabel environment
dapat digunakan di dalam Pod. Secret ini juga dapat digunakan secara langsug
oleh bagian lain dari sistem, tanpa secara langsung berkaitan dengan Pod.
Sebagai contoh, Secret dapat berisikan kredensial bagian suatu sistem lain yang digunakan
untuk berinteraksi dengan sistem eksternal yang kamu butuhkan.
Menggunakan Secret sebagai File melalui Pod
Berikut adalah langkah yang harus kamu penuhi agar kamu dapat menggunakan Secret di dalam volume dalam sebuah Pod:
Buatlah sebuah Secret, atau gunakan sebuah Secret yang sudah kamu buat sebelumnya. Beberapa Pod dapat merujuk pada sebuah Secret yang sama.
Modifikasi definisi Pod kamu dengan cara menambahkan sebuah volume di bawah .spec.volumes[]. Berilah volume tersebut nama, dan pastikan field.spec.volumes[].secret.secretName merujuk pada nama yang sama dengan objek secret.
Tambahkan field.spec.containers[].volumeMounts[] pada setiap container yang membutuhkan Secret. Berikan spesifikasi .spec.containers[].volumeMounts[].readOnly = true dan .spec.containers[].volumeMounts[].mountPath pada direktori dimana Secret tersebut diletakkan.
Modifikasi image dan/atau command line kamu agar program yang kamu miliki merujuk pada file di dalam direktori tersebut. Setiap key pada map data Secret akan menjadi nama dari sebuah file pada mountPath.
Berikut merupakan salah satu contoh dimana sebuah Pod melakukan proses mount Secret pada sebuah volume:
Setiap Secret yang ingin kamu gunakan harus dirujuk pada field.spec.volumes.
Jika terdapat lebih dari satu container di dalam Pod,
maka setiap container akan membutuhkan blok volumeMounts-nya masing-masing,
meskipun demikian hanya sebuah field.spec.volumes yang dibutuhkan untuk setiap Secret.
Kamu dapat menyimpan banyak file ke dalam satu Secret,
atau menggunakan banyak Secret, hal ini tentunya bergantung pada preferensi pengguna.
Proyeksi key Secret pada Suatu Path Spesifik
Kita juga dapat mengontrol path di dalam volume di mana sebuah Secret diproyeksikan.
Kamu dapat menggunakan field.spec.volumes[].secret.items untuk mengubah
path target dari setiap key:
Apa yang akan terjadi jika kita menggunakan definisi di atas:
Secret username akan disimpan pada file/etc/foo/my-group/my-username dan bukan /etc/foo/username.
Secret password tidak akan diproyeksikan.
Jika field.spec.volumes[].secret.items digunakan, hanya key-key yang dispesifikan di dalam
items yang diproyeksikan. Untuk mengonsumsi semua key-key yang ada dari Secret,
semua key yang ada harus didaftarkan pada fielditems.
Semua key yang didaftarkan juga harus ada di dalam Secret tadi.
Jika tidak, volume yang didefinisikan tidak akan dibuat.
PermissionFile-File Secret
Kamu juga dapat menspesifikasikan mode permission dari file Secret yang kamu inginkan.
Jika kamu tidak menspesifikasikan hal tersebut, maka nilai default yang akan diberikan adalah 0644 is used by default.
Kamu dapat memberikan mode default untuk semua Secret yang ada serta melakukan mekanisme overridepermission
pada setiap key jika memang diperlukan.
Sebagai contoh, kamu dapat memberikan spesifikasi mode default sebagai berikut:
Kemudian, sebuah Secret akan di-mount pada /etc/foo, selanjutnya semua file
yang dibuat pada volume secret tersebut akan memiliki permission0400.
Perhatikan bahwa spesifikasi JSON tidak mendukung notasi octal, dengan demikian gunakanlah
value 256 untuk permission 0400. Jika kamu menggunakan format YAML untuk spesifikasi Pod,
kamu dapat menggunakan notasi octal untuk memberikan spesifikasi permission dengan cara yang lebih
natural.
Kamu juga dapat melakukan mekanisme pemetaan, seperti yang sudah dilakukan pada contoh sebelumnya,
dan kemudian memberikan spesifikasi permission yang berbeda untuk file yang berbeda.
Pada kasus tersebut, file yang dihasilkan pada /etc/foo/my-group/my-username akan memiliki
permission0777. Karena terdapat batasan pada representasi JSON, maka kamu
harus memberikan spesifikasi mode permission dalam bentuk notasi desimal.
Perhatikan bahwa permission ini bida saja ditampilkan dalam bentuk notasi desimal,
hal ini akan ditampilkan pada bagian selanjutnya.
Mengonsumsi Value dari Secret melalui Volume
Di dalam sebuah container dimana volume secret di-mount,
key dari Secret akan ditampilkan sebagai file dan value dari Secret yang berada dalam bentuk
base64 ini akan di-decode dam disimpan pada file-file tadi.
Berikut merupakan hasil dari eksekusi perintah di dalam container berdasarkan contoh
yang telah dipaparkan di atas:
ls /etc/foo/
username
password
cat /etc/foo/username
admin
cat /etc/foo/password
1f2d1e2e67df
Program di dalam container bertanggung jawab untuk membaca Secret
dari file-file yang ada.
Secret yang di-mount Akan Diubah Secara Otomatis
Ketika sebuah Secret yang sedang digunakan di dalam volume diubah,
maka key yang ada juga akan diubah. Kubelet akan melakukan mekanisme pengecekan secara periodik
apakah terdapat perubahan pada Secret yang telah di-mount. Meskipun demikian,
proses pengecekan ini dilakukan dengan menggunakan cache lokal untuk mendapatkan value saat ini
dari sebuah Secret. Tipe cache yang ada dapat diatur dengan menggunakan
(fieldConfigMapAndSecretChangeDetectionStrategy pada
KubeletConfiguration).
Mekanisme ini kemudian dapat diteruskan dengan mekanisme watch(default), ttl, atau melakukan pengalihan semua
request secara langsung pada kube-apiserver.
Sebagai hasilnya, delay total dari pertama kali Secret diubah hingga dilakukannya mekanisme
proyeksi key yang baru pada Pod berlangsung dalam jangka waktu sinkronisasi periodik kubelet +
delay propagasi cache, dimana delay propagasi cache bergantung pada jenis cache yang digunakan
(ini sama dengan delay propagasi watch, ttl dari cache, atau nol).
Catatan:
Sebuah container menggunakan Secret sebagai
subPath dari volume
yang di-mount tidak akan menerima perubahan Secret.
Menggunakan Secret sebagai Variabel Environment
Berikut merupakan langkah-langkah yang harus kamu terapkan,
untuk menggunakan secret sebagai variabel _environment_
pada sebuah Pod:
Buatlah sebuah Secret, atau gunakan sebuah Secret yang sudah kamu buat sebelumnya. Beberapa Pod dapat merujuk pada sebuah Secret yang sama.
Modifikasi definisi Pod pada setiap container dimana kamu menginginkan container tersebut dapat mengonsumsi your Pod definition in each container that you wish to consume the value of a secret key to add an environment variabele for each secret key you wish to consume. The environment variabele that consumes the secret key should populate the secret's name and key in env[].valueFrom.secretKeyRef.
Modifikasi image dan/atau command line kamu agar program yang kamu miliki merujuk pada value yang sudah didefinisikan pada variabel environment.
Berikut merupakan contoh dimana sebuah Pod menggunakan Secret sebagai variabel environment:
Di dalam sebuah container yang mengkonsumsi Secret pada sebuah variabel environment, key dari sebuah secret
akan ditampilkan sebagai variabel environment pada umumnya dengan value berupa informasi yang telah di-decode
ke dalam base64. Berikut merupakan hasil yang didapatkan apabila perintah-perintah di bawah ini
dijalankan dari dalam container yang didefinisikan di atas:
echo$SECRET_USERNAME
admin
echo$SECRET_PASSWORD
1f2d1e2e67df
Menggunakan imagePullSecrets
Sebuah imagePullSecret merupakan salah satu cara yang dapat digunakan untuk menempatkan secret
yang mengandung password dari registri Docker (atau registri image lainnya)
pada Kubelet, sehingga Kubelet dapat mengunduh image dan menempatkannya pada Pod.
Memberikan spesifikasi manual dari sebuah imagePullSecret
Penggunaan imagePullSecrets dideskripsikan di dalam dokumentasi image
Mekanisme yang Dapat Diterapkan agar imagePullSecrets dapat Secara Otomatis Digunakan
Kamu dapat secara manual membuat sebuah imagePullSecret, serta merujuk imagePullSecret
yang sudah kamu buat dari sebuah serviceAccount. Semua Pod yang dibuat dengan menggunakan
serviceAccount tadi atau serviceAccount default akan menerima field imagePullSecret dari
serviceAccount yang digunakan.
Bacalah Cara menambahkan ImagePullSecrets pada sebuah service account
untuk informasi lebih detail soal proses yang dijalankan.
Mekanisme Mounting Otomatis dari Secret yang Sudah Dibuat
Secret yang dibuat secara manual (misalnya, secret yang mengandung token yang dapat digunakan
untuk mengakses akun GitHub) dapat di-mount secara otomatis pada sebuah Pod berdasarkan service account
yang digunakan oleh Pod tadi.
Baca Bagaimana Penggunaan PodPreset untuk Memasukkan Informasi ke Dalam Pod untuk informasi lebih lanjut.
Detail
Batasan-Batasan
Sumber dari secret volume akan divalidasi untuk menjamin rujukan pada
objek yang dispesifikasikan mengarah pada objek dengan typeSecret.
Oleh karenanya, sebuah secret harus dibuat sebelum Pod yang merujuk pada secret
tersebut dibuat.
Sebuah objek API Secret berada di dalam sebuah namespace.
Objek-objek ini hanya dapat dirujuk oleh Pod-Pod yang ada pada namespace yang sama.
Secret memiliki batasi dalam hal ukuran maksimalnya yaitu hanya sampai 1MiB per objek.
Oleh karena itulah, pembuatan secret dalam ukuran yang sangat besar tidak dianjurkan
karena dapat menghabiskan sumber daya apiserver dan memori kubelet. Meskipun demikian,
pembuatan banyak secret dengan ukuran kecil juga dapat menhabiskan memori. Pembatasan
sumber daya yang diizinkan untuk pembuatan secret merupakan salah satu fitur tambahan
yang direncanakan kedepannya.
Kubelet hanya mendukung penggunaan secret oleh Pod apabila Pod tersebut
didapatkan melalui apiserver. Hal ini termasuk Pod yang dibuat dengan menggunakan
kubectl, atau secara tak langsung melalui replication controller. Hal ini tidak
termasuk Pod yang dibuat melalui flag--manifest-url yang ada pada kubelet,
maupun REST API yang disediakan (hal ini bukanlah merupakan mekanisme umum yang dilakukan
untuk membuat sebuah Pod).
Secret harus dibuat sebelum digunakan oleh Pod sebagai variabel environment,
kecuali apabila variabel environment ini dianggap opsional. Rujukan pada Secret
yang tidak dapat dipenuhi akan menyebabkan Pod gagal start.
Rujukan melalui secretKeyRef pada key yang tidak ada pada named Secret
akan akan menyebabkan Pod gagal start.
Secret yang digunakan untuk memenuhi variabel environment melalui envFrom yang
memiliki key yang dianggap memiliki penamaan yang tidak valid akan diabaikan.
Hal ini akan akan menyebabkan Pod gagal start. Selanjutnya akan terdapat event
dengan alasan InvalidvariabeleNames dan pesan yang berisikan list dari
key yang diabaikan akibat penamaan yang tidak valid. Contoh yang ada akan menunjukkan
sebuah pod yang merujuk pada secret default/mysecret yang mengandung dua buah key
yang tidak valid, yaitu 1badkey dan 2alsobad.
kubectl get events
LASTSEEN FIRSTSEEN COUNT NAME KIND SUBOBJECT TYPE REASON
0s 0s 1 dapi-test-pod Pod Warning InvalidEnvironmentvariabeleNames kubelet, 127.0.0.1 Keys [1badkey, 2alsobad] from the EnvFrom secret default/mysecret were skipped since they are considered invalid environment variabele names.
Interaksi Secret dan Pod Lifetime
Ketika sebuah pod dibuat melalui API, tidak terdapat mekanisme pengecekan
yang digunakan untuk mengetahui apakah sebuah Secret yang dirujuk sudah dibuat
atau belum. Ketika sebuah Pod di-schedule, kubelet akan mencoba mengambil
informasi mengenai value dari secret tadi. Jika secret tidak dapat diambil
value-nya dengan alasan temporer karena hilangnya koneksi ke API server atau
secret yang dirujuk tidak ada, kubelet akan melakukan mekanisme retry secara periodik.
Kubelet juga akan memberikan laporan mengenai event yang terjadi pada Pod serta alasan
kenapa Pod tersebut belum di-start. Apabila Secret berhasil didapatkan, kubelet
akan membuat dan me-mount volume yang mengandung secret tersebut. Tidak akan ada
container dalam pod yang akan di-start hingga semua volume pod berhasil di-mount.
Contoh-Contoh Penggunaan
Contoh Penggunaan: Pod dengan ssh key
Buatlah sebuah kustomization.yaml dengan SecretGenerator yang mengandung beberapa ssh key:
Pikirkanlah terlebih dahulu sebelum kamu menggunakan ssh key milikmu sendiri: pengguna lain pada klaster tersebut bisa saja memiliki akses pada secret yang kamu definisikan.
Gunakanlah service account untuk membagi informasi yang kamu inginkan di dalam klaster tersebut, dengan demikian kamu dapat membatalkan service account tersebut apabila secret tersebut disalahgunakan.
Sekarang, kita dapat membuat sebuah pod yang merujuk pada secret dengan ssh key yang sudah
dibuat tadi serta menggunakannya melalui sebuah volume yang di-mount:
Karakter spesial seperti $, \*, dan ! membutuhkan mekanisme escaping.
Jika password yang kamu gunakan memiliki karakter spesial, kamu dapat melakukan mekanisme escape
dengan karakter \\ character. Sebagai contohnya, jika password kamu yang sebenarnya adalah
S!B\*d$zDsb, maka kamu harus memanggil perintah eksekusi dengan cara sebagai berikut:
Terapkan semua perubahan pada objek-objek tadi ke Apiserver dengan menggunakan
kubectl apply --k .
Kedua container kemudian akan memiliki file-file berikut ini di dalam
filesystem keduanya dengan value sebagai berikut untuk masing-masing environment:
Perhatikan bahwa specs untuk kedua pod berbeda hanya pada satu field saja;
hal ini bertujuan untuk memfasilitasi adanya kapabilitas yang berbeda dari templat
konfigurasi umum yang tersedia.
Kamu dapat mensimplifikasi spesifikasi dasar Pod dengan menggunakan dua buah service account yang berbeda:
misalnya saja salah satunya disebut sebagai prod-user dengan prod-db-secret, dan satunya lagi disebut
test-user dengan test-db-secret. Kemudian spesifikasi Pod tadi dapat diringkas menjadi:
Dengan tujuan membuat data yang ada 'tersembunyi' (misalnya, di dalam sebuah file dengan nama yang dimulai
dengan karakter titik), kamu dapat melakukannya dengan cara yang cukup sederhana, yaitu cukup dengan membuat
karakter awal key yang kamu inginkan dengan titik. Contohnya, ketika sebuah secret di bawah ini di-mount
pada sebuah volume:
Volume secret-volume akan mengandung sebuah file, yang disebut sebagai .secret-file, serta
container dotfile-test-container akan memiliki file konfigurasinya pada path/etc/secret-volume/.secret-file.
Catatan:
File-file yang diawali dengan karakter titik akan "tersembunyi" dari keluaran perintah ls -l;
kamu harus menggunakan perintah ls -la untuk melihat file-file tadi dari sebuah direktori.
Contoh Penggunaan: Secret yang dapat diakses hanya pada salah satu container di dalam pod
Misalkan terdapat sebuah program yang memiliki kebutuhan untuk menangani request HTTP,
melakukan logika bisnis yang kompleks, serta kemudian menandai beberapa message yang ada
dengan menggunakan HMAC. Karena program ini memiliki logika aplikasi yang cukup kompleks,
maka bisa jadi terdapat beberapa celah terjadinya eksploitasi remotefile pada server,
yang nantinya bisa saja mengekspos private key yang ada pada attacker.
Hal ini dapat dipisah menjadi dua buah proses yang berbeda di dalam dua container:
sebuah container frontend yang menangani interaksi pengguna dan logika bisnis, tetapi
tidak memiliki kapabilitas untuk melihat private key; container lain memiliki kapabilitas
melihat private key yang ada dan memiliki fungsi untuk menandai request yang berasal
dari frontend (melalui jaringan localhost).
Dengan strategi ini, seorang attacker harus melakukan teknik tambahan
untuk memaksa aplikasi melakukan hal yang acak, yang kemudian menyebabkan
mekanisme pembacaan file menjadi lebih susah.
Best practices
Klien yang menggunakan API secret
Ketika men-deploy aplikasi yang berinteraksi dengan API secret, akses yang dilakukan
haruslah dibatasi menggunakan policy autorisasi seperti RBAC.
Secret seringkali menyimpan value yang memiliki jangkauan spektrum
kepentingan, yang mungkin saja dapat menyebabkan terjadinya eskalasi baik
di dalam Kubernetes (misalnya saja token dari sebuah service account) maupun
sistem eksternal. Bahkan apabila setiap aplikasi secara individual memiliki
kapabilitas untuk memahami tingkatan yang dimilikinya untuk berinteraksi dengan secret tertentu,
aplikasi lain dalam namespace itu bisa saja menyebabkan asumsi tersebut menjadi tidak valid.
Karena alasan-alasan yang sudah disebutkan tadi requestwatch dan list untuk sebuah
secret di dalam suatu namespace merupakan kapabilitas yang sebisa mungkin harus dihindari,
karena menampilkan semua secret yang ada berimplikasi pada akses untuk melihat isi yang ada
pada secret yang ada. Kapabilitas untuk melakukan requestwatch dan list pada semua secret di klaster
hanya boleh dimiliki oleh komponen pada sistem level yang paling previleged.
Aplikasi yang membutuhkan akses ke API secret harus melakukan requestget pada
secret yang dibutuhkan. Hal ini memungkinkan administrator untuk membatasi
akses pada semua secret dengan tetap memberikan akses pada instans secret tertentu
yang dibutuhkan aplikasi.
Untuk meningkatkan performa dengan menggunakan iterasi get, klien dapat mendesain
sumber daya yang merujuk pada suatu secret dan kemudian melakukan watch pada secret tersebut,
serta melakukan request secret ketika terjadi perubahan pada rujukan tadi. Sebagai tambahan, API "bulk watch"
yang dapat memberikan kapabilitas watch individual pada sumber daya melalui klien juga sudah direncanakan,
dan kemungkinan akan diimplementasikan dirilis Kubernetes selanjutnya.
Properti Keamanan
Proteksi
Karena objek secret dapat dibuat secara independen dengan pod yang menggunakannya,
risiko tereksposnya secret di dalam workflow pembuatan, pemantauan, serta pengubahan pod.
Sistem yang ada juga dapat memberikan tindakan pencegahan ketika berinteraksi dengan secret,
misalnya saja tidak melakukan penulisan isi secret ke dalam disk apabila hal tersebut
memungkinkan.
Sebuah secret hanya diberikan pada node apabila pod yang ada di dalam node
membutuhkan secret tersebut. Kubelet menyimpan secret yang ada pada tmpfs
sehingga secret tidak ditulis pada disk. Setelah pod yang bergantung pada secret tersebut dihapus,
maka kubelet juga akan menghapus salinan lokal data secret.
Di dalam sebuah node bisa saja terdapat beberapa secret yang dibutuhkan
oleh pod yang ada di dalamnya. Meskipun demikian, hanya secret yang di-request
oleh sebuah pod saja yang dapat dilihat oleh container yang ada di dalamnya.
Dengan demikian, sebuah Pod tidak memiliki akses untuk melihat secret yang ada
pada pod yang lain.
Di dalam sebuah pod bisa jadi terdapat beberapa container.
Meskipun demikian, agar sebuah container bisa mengakses volume secret, container
tersebut haruslah mengirimkan requestvolumeMounts yang ada dapat diakses dari
container tersebut. Pengetahuan ini dapat digunakan untuk membentuk partisi security
pada level pod.
Pada sebagian besar distribusi yang dipelihara projek Kubernetes,
komunikasi antara pengguna dan apiserver serta apisserver dan kubelet dilindungi dengan menggunakan SSL/TLS.
Dengan demikian, secret dalam keadaan dilindungi ketika ditransmisi.
FEATURE STATE:Kubernetes v1.13 [beta]
Kamu dapat mengaktifkan enkripsi pada rest
untuk data secret, sehingga secret yang ada tidak akan ditulis ke dalam etcd
dalam keadaan tidak terenkripsi.
Resiko
Pada API server, data secret disimpan di dalam etcd;
dengan demikian:
Administrator harus mengaktifkan enkripsi pada rest untuk data klaster (membutuhkan versi v1.13 atau lebih)
Administrator harus membatasi akses etcd pada pengguna dengan kapabilitas admin
Administrator bisa saja menghapus data disk yang sudah tidak lagi digunakan oleh etcd
Jika etcd dijalankan di dalam klaster, administrator harus memastikan SSL/TLS
digunakan pada proses komunikasi peer-to-peer etcd.
Jika kamu melakukan konfigurasi melalui sebuah file manifest (JSON or YAML)
yang menyimpan data secret dalam bentuk base64, membagi atau menyimpan secret ini
dalam repositori kode sumber sama artinya dengan memberikan informasi mengenai data secret.
Mekanisme encoding base64 bukanlah merupakan teknik enkripsi dan nilainya dianggap sama saja dengan plain text.
Aplikasi masih harus melindungi value dari secret setelah membaca nilainya dari suatu volume
dengan demikian risiko terjadinya logging secret secara tidak engaja dapat dihindari.
Seorang pengguna yang dapat membuat suatu pod yang menggunakan secret, juga dapat melihat value secret.
Bahkan apabila policy apiserver tidak memberikan kapabilitas untuk membaca objek secret, pengguna
dapat menjalankan pod yang mengekspos secret.
Saat ini, semua orang dengan akses root pada node dapat membaca secret apapun dari apiserver,
dengan cara meniru kubelet. Meskipun begitu, terdapat fitur yang direncanakan pada rilis selanjutnya yang memungkinkan pengiriman secret hanya dapat
mengirimkan secret pada node yang membutuhkan secret tersebut untuk membatasi adanya eksploitasi akses root pada node ini.
Selanjutnya
7.5 - Mengatur Akses Klaster Menggunakan Berkas kubeconfig
Gunakan berkas kubeconfig untuk mengatur informasi mengenai klaster, pengguna,
namespace, dan mekanisme autentikasi. Perintah kubectl menggunakan berkas
kubeconfig untuk mencari informasi yang dibutuhkan untuk memilih klaster dan
berkomunikasi dengan API server dari suatu klaster.
Catatan:
Sebuah berkas yang digunakan untuk mengatur akses pada klaster disebut dengan
berkas kubeconfig. Ini cara yang umum digunakan untuk mereferensikan berkas
konfigurasi. Ini tidak berarti ada berkas dengan nama kubeconfig.
Secara default, kubectl mencari berkas dengan nama config pada direktori
$HOME/.kube. Kamu bisa mengatur lokasi berkas kubeconfig dengan mengatur
nilai KUBECONFIG pada variabel environment atau dengan mengatur menggunakan
tanda --kubeconfig.
Instruksi langkah demi langkah untuk membuat dan menentukan berkas kubeconfig,
bisa mengacu pada [Mengatur Akses Pada Beberapa Klaster]
(/id/docs/tasks/access-application-cluster/configure-access-multiple-clusters).
Mendukung beberapa klaster, pengguna, dan mekanisme autentikasi
Misalkan kamu memiliki beberapa klaster, pengguna serta komponen dapat melakukan
autentikasi dengan berbagai cara. Sebagai contoh:
Kubelet yang berjalan dapat melakukan autentikasi dengan menggunakan sertifikat
Pengguna bisa melakukan autentikasi dengan menggunakan token
Administrator bisa memiliki beberapa sertifikat yang diberikan kepada pengguna
individu.
Dengan berkas kubeconfig, kamu bisa mengatur klaster, pengguna, dan namespace.
Kamu juga bisa menentukan konteks untuk mempercepat dan mempermudah perpindahan
antara klaster dan namespace.
Konteks
Sebuah elemen konteks pada berkas kubeconfig digunakan untuk mengelompokkan
parameter akses dengan nama yang mudah. Setiap konteks akan memiliki 3 parameter:
klaster, pengguna, dan namespace. Secara default, perintah kubectl menggunakan
parameter dari konteks yang aktif untuk berkomunikasi dengan klaster.
Untuk memilih konteks yang aktif, bisa menggunakan perintah berikut:
kubectl config use-context
Variabel environment KUBECONFIG
Variabel environmentKUBECONFIG berisikan beberapa berkas kubeconfig. Untuk
Linux dan Mac, beberapa berkas tersebut dipisahkan dengan tanda titik dua (:).
Untuk Windows, dipisahkan dengan menggunakan tanda titik koma (;). Variabel
environmentKUBECONFIG tidak diwajibkan untuk ada. Jika variabel environmentKUBECONFIG tidak ada, maka kubectl akan menggunakan berkas kubeconfig pada
$HOME/.kube/config.
Jika variabel environmentKUBECONFIG ternyata ada, maka kubectl akan menggunakan
konfigurasi yang merupakan hasil gabungan dari berkas-berkas yang terdapat pada
variabel environmentKUBECONFIG.
Menggabungkan berkas-berkas kubeconfig
Untuk melihat konfigurasimu, gunakan perintah berikut ini:
kubectl config view
Seperti yang dijelaskan sebelumnya, hasil perintah diatas bisa berasal dari sebuah
berkas kubeconfig, atau bisa juga merupakan hasil gabungan dari beberapa berkas kubeconfig.
Berikut adalah aturan yang digunakan kubectl ketika menggabungkan beberapa berkas
kubeconfig:
Jika menggunakan tanda --kubeconfig, maka akan menggunakan berkas yang ditentukan.
Tidak digabungkan. Hanya 1 tanda --kubeconfig yang diperbolehkan.
Sebaliknya, jika variabel environmentKUBECONFIG digunakan, maka akan menggunakan
ini sebagai berkas-berkas yang akan digabungkan. Penggabungan berkas-berkas yang terdapat
pada variabel environmentKUBECONFIG akan mengikuti aturan sebagai berikut:
Mengabaikan berkas tanpa nama.
Mengeluarkan pesan kesalahan untuk berkas dengan isi yang tidak dapat dideserialisasi.
Berkas pertama yang menentukan nilai atau key pada map maka akan digunakan
pada map tersebut.
Tidak pernah mengubah nilai atau key dari suatu map.
Contoh: Pertahankan konteks pada berkas pertama yang mengatur current-context.
Contoh: Jika terdapat dua berkas yang menentukan nilai red-user, maka hanya gunakan
nilai red-user dari berkas pertama.
Meskipun berkas kedua tidak memiliki entri yang bertentangan pada red-user,
abaikan mereka.
Sebaliknya, bisa menggunakan berkas kubeconfig default, $HOME/.kube/config,
tanpa melakukan penggabungan.
Konteks ditentukan oleh yang pertama sesuai dari pilihan berikut:
Menggunakan tanda --context pada perintah
Menggunakan nilai current-context dari hasil gabungan berkas kubeconfig.
Konteks yang kosong masih diperbolehkan pada tahap ini.
Menentukan klaster dan pengguna. Pada tahap ini, mungkin akan ada atau tidak ada konteks.
Menentukan klaster dan pengguna berdasarkan yang pertama sesuai dengan pilihan berikut,
yang mana akan dijalankan dua kali: sekali untuk pengguna dan sekali untuk klaster:
Jika ada, maka gunakan tanda pada perintah: --user atau --cluster.
Jika konteks tidak kosong, maka pengguna dan klaster didapat dari konteks.
Pengguna dan klaster masih diperbolehkan kosong pada tahap ini.
Menentukan informasi klaster sebenarnya yang akan digunakan. Pada tahap ini, mungkin
akan ada atau tidak ada informasi klaster. Membentuk informasi klaster berdasarkan urutan
berikut dan yang pertama sesuai akan digunakan:
Jika ada, maka gunakan tanda pada perintah: --server, --certificate-authority, --insecure-skip-tls-verify.
Jika terdapat atribut informasi klaster dari hasil gabungan berkas kubeconfig,
maka gunakan itu.
Jika tidak terdapat informasi mengenai lokasi server, maka dianggap gagal.
Menentukan informasi pengguna sebenarnya yang akan digunakan. Membentuk informasi
pengguna dengan aturan yang sama dengan pembentukan informasi klaster, namun hanya
diperbolehkan ada satu teknik autentikasi untuk setiap pengguna:
Jika ada, gunakan tanda pada perintah: --client-certificate, --client-key, --username, --password, --token.
Menggunakan fielduser dari hasil gabungan berkas kubeconfig.
Jika terdapat dua teknik yang bertentangan, maka dianggap gagal.
Untuk setiap informasi yang masih belum terisi, akan menggunakan nilai default dan
kemungkinan akan meminta informasi autentikasi.
Referensi berkas
Referensi file dan path pada berkas kubeconfig adalah bernilai relatif terhadap
lokasi dari berkas kubeconfig.
Referensi file pada perintah adalah relatif terhadap direktori kerja saat ini.
Dalam $HOME/.kube/config, relative path akan disimpan secara relatif, dan
absolute path akan disimpan secara mutlak.
Pod dapat memiliki priority (prioritas). Priority mengindikasikan lebih penting atau tidaknya sebuah Pod dibandingkan dengan Pod-pod lainnya. Jika sebuah Pod tidak dapat dijadwalkan (tertunda/pending), penjadwal akan mencoba untuk melakukan preemption/pemindahan (mengusir/evict) Pod-pod dengan prioritas lebih rendah agar penjadwalan Pod yang tertunda sebelumnya dapat dilakukan.
Pada Kubernetes 1.9 dan sesudahnya, Priority juga memengaruhi urutan penjadwalan Pod-pod dan urutan pengusiran Pod-pod dari Node pada kasus kehabisan sumber daya.
Priority dan Pemindahan Pod lulus menjadi beta pada Kubernetes 1.11 dan menjadi GA (Generally Available) pada Kubernetes 1.14. Mereka telah dihidupkan secara bawaan sejak versi 1.11.
Pada versi-versi Kubernetes di mana Priority dan pemindahan Pod masih berada pada tingkat fitur alpha, kamu harus menghidupkannya secara eksplisit. Untuk menggunakan fitur-fitur pada versi-versi lama Kubernetes, ikuti petunjuk di dokumentasi versi Kubernetes kamu, melalui arsip versi dokumentasi untuk versi Kubernetes kamu.
Versi Kubernetes
Keadaan Priority and Pemindahan
Dihidupkan secara Bawaan
1.8
alpha
tidak
1.9
alpha
tidak
1.10
alpha
tidak
1.11
beta
ya
1.14
stable
ya
Peringatan:
Pada sebuah klaster di mana tidak semua pengguna dipercaya, seorang pengguna yang berniat jahat dapat membuat Pod-pod dengan prioritas paling tinggi, membuat Pod-pod lainnya dipindahkan/tidak dapat dijadwalkan. Untuk mengatasi masalah ini, ResourceQuota ditambahkan untuk mendukung prioritas Pod. Seorang admin dapat membuat ResourceQuota untuk pengguna-pengguna pada tingkat prioritas tertentu, mencegah mereka untuk membuat Pod-pod pada prioritas tinggi. Fitur ini telah beta sejak Kubernetes 1.12.
Bagaimana cara menggunakan Priority dan pemindahan Pod
Untuk menggunakan Priority dan pemindahan Pod pada Kubernetes 1.11 dan sesudahnya, ikuti langkah-langkah berikut:
Buat Pod-pod dengan priorityClassName
disetel menjadi salah satu dari PriorityClass yang ditambahkan.
Tentu saja kamu tidak perlu membuat Pod-pod tersebut secara langsung;
Biasanya kamu akan menambahkan priorityClassName pada
template Pod dari sebuah objek kumpulan seperti sebuah Deployment.
Teruslah membaca untuk lebih banyak informasi mengenai langkah-langkah tersebut.
Jika kamu mencoba fitur ini dan memutuskan untuk mematikannya, kamu harus menghapus command-line flag PodPriority atau menyetelnya menjadi false, kemudian melakukan pengulangan kembali terhadap API Server dan Scheduler. Setelah fitur ini dimatikan, Pod-pod yang sudah ada tetap akan memiliki kolom priority mereka, tetapi pemindahan Pod akan dimatikan, dan kolom-kolom priority tersebut diabaikan. Jika fitur tersebut telah dimatikan, kamu tidak dapat menyetel kolom priorityClassName pada Pod-pod baru.
Cara mematikan pemindahan Pod
Catatan:
Pada Kubernetes 1.12 ke atas, Pod-pod yang penting mengandalkan oleh Schneduler agar dapat dijadwalkan saat klaster berada pada kondisi kekurangan sumber daya. Untuk alasan ini, tidak direkomendasikan untuk mematikan fitur pemindahan Pod.
Catatan:
Pada Kubernetes 1.15 ke atas, jika fitur NonPreemptingPriority diaktifkan, PriorityClass memiliki pilihan untuk menyetel preemptionPolicy: Never.
Hal ini akan mencegah Pod-pod dari PriorityClass tersebut untuk memicu pemindahan Pod-pod lainnya.
Pada Kubernetes 1.11 dan sesudahnya, pemindahan Pod dikontrol oleh sebuah flag kube-scheduler yaitu disablePreemption, yang disetel menjadi false secara bawaan. Jika kamu ingin mematikan pemindahan Pod meskipun ada catatan di atas, kamu dapat menyetel disablePreemption menjadi true.
Opsi ini hanya tersedia pada (berkas) konfigurasi komponen saja, dan tidak tersedia pada cara lama melalui command line options. Berikut contoh konfigurasi komponen untuk mematikan pemindahan (preemption) Pod:
Sebuah PriorityClass adalah sebuah objek tanpa Namespace yang mendefinisikan pemetaan dari sebuah nama kelas prioritas menjadi nilai integer dari prioritas tersebut. Nama tersebut dirinci pada kolom name dari metadata objek PriorityClass tersebut. Nilainya dirinci pada kolom value yang diperlukan. Semakin tinggi nilainya, maka semakin tinggi juga prioritasnya.
Sebuah objek PriorityClass dapat memiliki nilai integer 32-bit apa pun yang kurang dari atau sama dengan 1 miliar. Angka-angka yang lebih besar dicadangkan untuk Pod-pod pada sistem yang sangat penting yang secara normal sebaiknya tidak dipindahkan atau diusir. Seorang admin klaster sebaiknya membuat sebuah objek PriorityClass untuk setiap pemetaan seperti ini yang ia inginkan.
PriorityClass juga memiliki dua kolom opsional: globalDefault dan description. Kolom globalDefault mengindikasikan bahwa nilai PriorityClass ini sebaiknya digunakan tanpa sebuah priorityClassName. Hanya sebuah PriorityClass dengan globalDefault disetel menjadi true dapat berada pada sistem/klaster. Jika tidak ada PriorityClass dengan globalDefault yang telah disetel, prioritas Pod-pod tanpa priorityClassName adalah nol.
Kolom description adalah string yang sembarang. Kolom ini diperuntukkan untuk memberitahukan pengguna-pengguna klaster kapan mereka harus menggunakan PriorityClass ini.
Catatan mengenai PodPriority dan Klaster-klaster yang sudah ada
Jika kamu meningkatkan versi klaster kamu dan menghidupkan fitur ini, prioritas
Pod-pod kamu yang sudah ada akan secara efektif menjadi nol.
Penambahan dari sebuah PriorityClass dengan globalDefault yang disetel menjadi
true tidak mengubah prioritas-prioritas Pod-pod yang sudah ada. Nilai dari
PriorityClass semacam ini digunakan hanya untuk Pod-pod yang dibuat setelah
PriorityClass tersebut ditambahkan.
Jika kamu menghapus sebuah PriorityClass, Pod-pod yang sudah ada yang menggunakan
nama dari PriorityClass yang dihapus tersebut tidak akan berubah, tetapi kamu tidak
dapat membuat lebih banyak Pod yang menggunakan nama dari PriorityClass yang telah
dihapus tersebut.
Contoh PriorityClass
apiVersion:scheduling.k8s.io/v1kind:PriorityClassmetadata:name:high-priorityvalue:1000000globalDefault:falsedescription:"Kelas prioritas ini sebaiknya hanya digunakan untuk Pod-pod layanan XYZ saja."
PriorityClass yang Non-preempting (alpha)
Kubernetes 1.15 menambahkan kolom PreemptionPolicy sebagai sebuah fitur alpha. Fitur ini dimatikan secara bawaan pada 1.15, dan membutuhkan diaktifkannya feature gateNonPreemptingPriority.
Pod-pod dengan PreemptionPolicy: Never akan ditaruh pada antrean penjadwalkan mendahului Pod-pod dengan prioritas rendah, tetapi mereka tidak dapat memicu pemindahan Pod-pod lainnya (disebut juga Pod yang non-preempting).
Sebuah Pod yang non-preempting yang sedang menunggu untuk dijadwalkan akan tetap berada pada antrean penjadwalan, hingga sumber daya yang cukup tersedia, dan ia dapat dijadwalkan. Pod yang non-preempting, seperti Pod-pod lainnya, tunduk kepada back-off dari Scheduler. Hal ini berarti bahwa jika Scheduler mencoba untuk menjadwalkan Pod-pod ini dan mereka tidak dapat dijadwalkan, mereka akan dicoba kembali dengan frekuensi (percobaan) yang lebih rendah, memungkinkan Pod-pod lain dengan prioritas yang lebih rendah untuk dijadwalkan sebelum mereka dijadwalkan.
Pod yang non-preempting tetap dapat dipicu untuk dipindahkan oleh Pod lainnya yang memiliki prioritas yang lebih tinggi.
PreemptionPolicy secara bawaan nilainya PreemptionLowerPriority, yang memungkinkan Pod-pod dengan PriorityClass tersebut untuk memicu pemindahan Pod-pod dengan prioritas lebih rendah (sama seperti sifat bawaan). Jika PreemptionPolicy disetel menjadi Never, Pod-pod pada PriorityClass tersebut akan menjadi Pod yang non-preempting.
Sebuah contoh kasus misalnya pada beban kerja data science.
Seorang pengguna dapat memasukkan sebuah beban kerja yang mereka ingin prioritaskan di atas beban kerja lainnya, tetapi tidak ingin menghapus beban kerja yang sudah ada melalui pemicuan pemindahan Pod-pod yang sedang berjalan.
Beban kerja prioritas tinggi dengan PreemptionPolicy: Never akan dijadwalkan mendahului Pod-pod lainnya yang berada dalam antrean, segera setelah sumber daya klaster "secara alami" menjadi cukup.
Contoh PriorityClass yang Non-preempting
apiVersion:scheduling.k8s.io/v1kind:PriorityClassmetadata:name:high-priority-nonpreemptingvalue:1000000preemptionPolicy:NeverglobalDefault:falsedescription:"Kelas prioritas ini tidak akan memicu pemindahan Pod-pod lainnya."
Prioritas Pod
Setelah kamu memiliki satu atau lebih PriorityClass, kamu dapat membuat Pod-pod yang merinci satu dari nama-nama PriorityClass tersebut pada spesifikasi mereka. Admission Controller prioritas menggunakan kolom priorityClassName dan mengumpulkan nilai integer dari prioritasnya. Jika PriorityClass-nya tidak ditemukan, maka Pod tersebut akan ditolak.
YAML berikut adalah contoh sebuah konfigurasi Pod yang menggunakan PriorityClass yang telah dibuat pada contoh sebelumnya. Admission Controller prioritas akan memeriksa spesifikasi tersebut dan memetakan prioritas Pod tersebut menjadi nilai 1000000.
Pada Kubernetes 1.9 dan sesudahnya, saat prioritas Pod dihidupkan, Scheduler mengurutkan Pod-pod yang tertunda berdasarkan prioritas mereka dan sebuah Pod yang tertunda diletakkan mendahului Pod-pod tertunda lainnya yang memiliki prioritas yang lebih rendah pada antrean penjadwalan. Sebagai hasilnya, Pod dengan prioritas lebih tinggi dapat dijadwalkan lebih awal daripada Pod-pod dengan prioritas yang lebih rendah jika syarat penjadwalan terpenuhi. Jika Pod ini tidak dapat dijadwalkan, Scheduler akan melewatkannya dan mencoba untuk menjadwalkan Pod-pod lain dengan prioritas yang lebih rendah.
Pemindahan Pod
Saat Pod-pod dibuat, mereka masuk ke sebuah antrean dan menunggu untuk dijadwalkan. Scheduler memilih sebuah Pod dari antrean dan mencoba untuk menjadwalkannya pada sebuah Node. Jika tidak ditemukan Node yang memenuhi semua kebutuhan Pod tersebut, logika program pemindahan Pod dipicu untuk Pod yang tertunda tersebut. Kita akan menyebut Pod tertunda tersebut dengan P. Logika program pemindahan Pod mencoba untuk menemukan sebuah Node di mana penghapusan dari satu atau lebih Pod dengan prioritas yang lebih rendah daripada P dapat memungkinkan P untuk dijadwalkan pada Node tersebut. Jika Node tersebut ditemukan, satu atau lebih Pod dengan prioritas lebih rendah akan dipindahkan dari Node tersebut. Setelah Pod-pod tersebut dihapus, P dapat dijadwalkan pada Node tersebut.
Informasi yang diekspos pengguna
Saat Pod P memicu pemindahan satu atau lebih Pod pada Node N, kolom nominatedNodeName pada status Pod P disetel menjadi nama dari node N. Kolom ini membantu Scheduler untuk melacak sumber daya yang dicadangkan untuk Pod P dan juga memberikan informasi mengenai pemindahan Pod pada klaster untuk pengguna-pengguna.
Harap catat bahwa Pod P tidak harus dijadwalkan pada "nominated Node" (Node yang dicalonkan) tersebut. Setelah Pod-pod yang terpilih telah dipindahkan, mereka akan mendapatkan periode penghentian secara sopan (graceful) mereka. Jika Node lain menjadi tersedia saat Scheduler sedang menunggu penghentian Pod-pod yang terpilih untuk dipindahkan, Scheduler akan menggunakan Node lain tersebut untuk menjadwalkan Pod P. Sebagai hasilnya nominatedNodeName dan nodeName dari spesifikasi Pod belum tentu selalu sama. Juga, jika Scheduler memindahkan Pod-pod pada Node N, tapi kemudian sebuah Pod lain dengan prioritas lebih tinggi daripada Pod P tiba, Scheduler boleh memberikan Node N kepada Pod dengan prioritas lebih tinggi tersebut. Pada kasus demikian, Scheduler menghapus nominatedPodName dari Pod P. Dengan melakukan ini, Scheduler membuat Pod P berhak untuk memicu pemindahan Pod-pod lain pada Node lain.
Batasan-batasan pemindahan Pod
Penghentian secara sopan dari korban-korban pemindahan Pod
Saat Pod-pod dipindahkan, korban-korbannya mendapatkan periode penghentian secara sopan. Mereka memiliki waktu sebanyak itu untuk menyelesaikan pekerjaan merekan dan berhenti. Jika mereka tidak menyelesaikannya sebelum waktu tersebut, mereka akan dihentikan secara paksa. Periode penghentian secara sopan ini membuat sebuah jarak waktu antara saat di mana Scheduler memindahkan Pod-pod dengan waktu saat Pod yang tertunda tersebut (P) dapat dijadwalkan pada Node tersebut (N). Sementara itu, Scheduler akan terus menjadwalkan Pod-pod lain yang tertunda. Oleh karena itu, biasanya ada jarak waktu antara titik di mana Scheduler memindahkan korban-korban dan titik saat Pod P dijadwalkan. Untuk meminimalkan jarak waktu ini, kamu dapat menyetel periode penghentian secara sopan dari Pod-pod dengan prioritas lebih rendah menjadi nol atau sebuah angka yang kecil.
PodDisruptionBudget didukung, tapi tidak dijamin!
Sebuah Pod Disruption Budget (PDB) memungkinkan pemilik-pemilik aplikasi untuk membatasi jumlah Pod-pod dari sebuah aplikasi yang direplikasi yang mati secara bersamaan dikarenakan disrupsi yang disengaja. Kubernetes 1.9 mendukung PDB saat memindahkan Pod-pod, tetapi penghormatan terhadap PDB ini bersifat "usaha terbaik" (best-effort). Scheduler akan mencoba mencari korban-korban yang PDB-nya tidak dilanggar oleh pemindahan, tetapi jika tidak ada korban yang ditemukan, pemindahan akan tetap terjadi, dan Pod-pod dengan prioritas lebih rendah akan dihapus/dipindahkan meskipun PDB mereka dilanggar.
Afinitas antar-Pod pada Pod-pod dengan prioritas lebih rendah
Sebuah Node akan dipertimbangkan untuk pemindahan Pod hanya jika jawaban pertanyaan berikut adalah "ya": "Jika semua Pod-pod dengan prioritas lebih rendah dari Pod yang tertunda dipindahkan dari Node, dapatkan Pod yang tertunda tersebut dijadwalkan (secara sukses) ke Node tersebut?"
Catatan:
Pemindahan Pod tidak harus memindahkan semua Pod-pod dengan prioritas lebih rendah. Jika Pod yang tertunda dapat dijadwalkan dengan memindahkan lebih sedikit daripada semua Pod-pod dengan prioritas yang lebih rendah, maka hanya sebagian dari Pod-pod dengan prioritas lebih rendah tersebut akan dipindahkan. Meskipun demikian, jawaban untuk pertanyaan sebelumnya haruslah "ya". Jika jawabannya adalah "tidak", maka Node tersebut tidak akan dipertimbangkan untuk pemindahan Pod.
Jika sebuah Pod yang tertunda memiliki afinitas antar-Pod terhadap satu atau lebih dari Pod-pod dengan prioritas lebih rendah pada Node tersebut, maka aturan afinitas antar-Pod tersebut tidak dapat terpenuhi tanpa hadirnya Pod-pod dengan prioritas lebih rendah tersebut. Pada kasus ini, Scheduler tidak melakukan pemindahan terhadap Pod-pod manapun pada Node tersebut. Sebagai gantinya, ia mencari Node lainnya. Scheduler mungkin mendapatkan Node yang cocok atau tidak. Tidak ada jaminan bahwa Pod yang tertunda tersebut dapat dijadwalkan.
Solusi yang direkomendasikan untuk masalah ini adalah dengan cara membuat afinitas antar-Pod hanya terhadap Pod-pod dengan prioritas yang sama atau lebih tinggi.
Pemindahan Pod antar Node
Misalnya sebuah Node N sedang dipertimbangkan untuk pemindahan Pod sehingga sebuah Pod P yang tertunda dapat dijadwalkan pada N. P mungkin menjadi layak untuk N hanya jika sebuah Pod pada Node lain dipindahkan. Berikut sebuah contoh:
Pod P dipertimbangkan untuk Node N.
Pod Q sedang berjalan pada Node lain pada Zona yang sama dengan Node N.
Pod P memiliki anti-afinitas yang berlaku pada seluruh Zona terhadap Pod Q (topologyKey: topology.kubernetes.io/zone).
Tidak ada kasus anti-afinitas lain antara Pod P dengan Pod-pod lainnya pada Zona tersebut.
Untuk dapat menjadwalkan Pod P pada Node N, Pod Q dapat dipindahkan, tetapi
Scheduler tidak melakukan pemindahan Pod antar Node. Jadi, Pod P akan
dianggap tidak dapat dijadwalkan pada Node N.
Jika Pod Q dihapus dari Node-nya, pelanggaran terhadap anti-afinitas Pod tersebut akan hilang, dan Pod P dapat dijadwalkan pada Node N.
Kita mungkin mempertimbangkan untuk menambahkan pemindahan Pod antar Node pada versi-versi yang akan datang jika ada permintaan yang cukup dari pengguna, dan kami menemukan algoritma dengan kinerja yang layak.
Memecahkan masalah pada Prioritas dan Pemindahan Pod
Prioritas dan Pemindahan Pod adalah sebuah fitur besar yang berpotensi dapat mengganggu penjadwalan Pod jika fitur ini memiliki kesalahan (bug).
Masalah yang berpotensi diakibatkan oleh Prioritas dan Pemindahan Pod
Berikut adalah beberapa masalah yang dapat diakibatkan oleh kesalahan-kesalahan pada implementasi fitur ini. Daftar ini tidak lengkap.
Pod-pod dipindahkan secara tidak perlu
Pemindahan Pod menghapus Pod-pod yang sudah ada dari sebuah klaster yang sedang mengalami kekurangan sumber daya untuk menyediakan ruangan untuk Pod-pod tertunda yang memiliki prioritas yang lebih tinggi. Jika seorang pengguna memberikan prioritas-prioritas tinggi untuk Pod-pod tertentu dengan tidak semestinya (karena kesalahan), Pod-pod prioritas tinggi yang tidak disengaja tersebut dapat mengakibatkan pemindahan Pod-pod pada klaster tersebut. Seperti disebutkan di atas, prioritas Pod dispesifikasikan dengan menyetel kolom priorityClassName dari podSpec. Nilai integer dari prioritas tersebut kemudian dipetakan dan diisi pada kolom priority dari podSpec.
Untuk menyelesaikan masalah tersebut, priorityClassName dari Pod-pod tersebut harus diubah untuk menggunakan kelas dengan prioritas yang lebih rendah, atau dibiarkan kosong saja. Kolom priorityClassName yang kosong dipetakan menjadi nol secara bawaan.
Saat sebuah Pod dipindahkan, akan ada Event yang direkam untuk Pod yang dipindahkan tersebut. Pemindahan seharusnya hanya terjadi saat sebuah klaster tidak memiliki sumber daya yang cukup untuk sebuah Pod. Pada kasus seperti ini, pemindahan terjadi hanya saat prioritas dari Pod yang tertunda tersebut lebih tinggi daripada Pod-pod korban. Pemindahan tidak boleh terjadi saat tidak ada Pod yang tertunda (preemptor), atau saat Pod-pod yang tertunda memiliki prioritas yang sama atau lebih rendah dari korban-korbannya. Jika pemindahan terjadi pada skenario demikian, mohon daftarkan sebuah Issue.
Pod-pod dipindahkan, tetapi preemptor tidak dijadwalkan
Saat Pod-pod dijadwalkan, mereka menerima periode penghentian secara sopan mereka, yang secara bawaan bernilai 30 detik, tetapi dapat bernilai apa pun sesuai dengan yang disetel pada PodSpec. Jika Pod-pod korban tidak berhenti sebelum periode ini, mereka akan dihentikan secara paksa. Saat semua korban telah pergi, Pod preemptor dapat dijadwalkan.
Saat Pod preemptor sedang menunggu korban-korban dipindahkan, sebuah Pod dengan prioritas lebih tinggi boleh dibuat jika muat pada Node yang sama. Pada kasus ini, Scheduler akan menjadwalkan Pod dengan prioritas lebih tinggi tersebut alih-alih menjadwalkan Pod preemptor.
Dalam ketidakhadiran Pod dengan prioritas lebih tinggi tersebut, kita mengharapkan Pod preemptor dijadwalkan setelah periode penghentian secara sopan korban-korbannya telah berakhir.
Pod-pod dengan prioritas lebih tinggi dipindahkan karena Pod-pod dengan prioritas lebih rendah
Saat Scheduler mencoba mencari Node-node yang dapat menjalankan sebuah Pod yang tertunda, dan tidak ada Node yang ditemukan, ia akan mencoba untuk memindahkan Pod-pod dengan prioritas lebih rendah dari salah satu Node untuk menyediakan ruangan untuk Pod yang tertunda tersebut. Jika sebuah Node dengan Pod-pod dengan prioritas lebih rendah tidak layak untuk menjalankan Pod yang tertunda tersebut, Scheduler mungkin memilih Node lain dengan Pod yang memiliki prioritas lebih tinggi (dibandingkan dengan Pod-pod pada Node lain tadi) untuk dipindahkan. Korban-korban tersebut harus tetap memiliki prioritas yang lebih rendah dari Pod preemptor.
Saat ada beberapa Node yang tersedia untuk pemindahan, Scheduler mencoba untuk memilih Node dengan kumpulan Pod yang memiliki prioritas paling rendah. Namun, jika Pod-pod tersebut memiliki PodDisruptionBudget yang akan dilanggar apabila mereka dipindahkan, maka Scheduler akan memilih Node lain dengan Pod-pod yang memiliki prioritas lebih tinggi.
Saat ada beberapa Node tersedia untuk pemindahan dan tidak ada satupun skenario di atas yang berlaku, kita mengharapkan Scheduler memilih Node dengan prioritas paling rendah. Apabila hal tersebut tidak terjadi, hal ini mungkin menunjukkan bahwa terdapat kesalahan pada Scheduler.
Interaksi-interaksi prioritas Pod dan QoS
Prioritas Pod dan QoS adalah dua fitur terpisah dengan interaksi yang sedikit dan tidak ada batasan bawaan terhadap penyetelan prioritas Pod berdasarkan kelas QoS-nya. Logika program pemindahan Scheduler tidak mempertimbangkan QoS saat memilih sasaran-sasaran pemindahan. Pemindahan mempertimbangkan prioritas Pod dan mencoba memilih kumpulan sasaran dengan prioritas terendah. Pod-pod dengan prioritas lebih tinggi dipertimbangkan untuk pemindahan hanya jika penghapusan Pod-pod dengan prioritas terendah tidak cukup untuk memungkinkan Scheduler untuk menjadwalkan Pod preemptor, atau jika Pod-pod dengan prioritas terendah tersebut dilindungi oleh PodDisruptionBudget.
Komponen satu-satunya yang mempertimbangkan baik QoS dan prioritas Pod adalah pengusiran oleh Kubelet karena kehabisan sumber daya.
Kubelet menggolongkan Pod-pod untuk pengusiran pertama-tama berdasarkan apakah penggunaan sumber daya mereka melebihi requests mereka atau tidak, kemudian berdasarkan Priority, dan kemudian berdasarkan penggunaan sumber daya yang terbatas tersebut relatif terhadap requests dari Pod-pod tersebut.
Lihat Mengusir Pod-pod pengguna untuk lebih detail. Pengusiran oleh Kubelet karena kehabisan sumber daya tidak mengusir Pod-pod yang memiliki penggunaan sumber daya yang tidak melebihi requests mereka. Jika sebuah Pod dengan prioritas lebih rendah tidak melebihi requests-nya, ia tidak akan diusir. Pod lain dengan prioritas lebih tinggi yang melebihi requests-nya boleh diusir.
8 - Keamanan
Konsep-konsep untuk menjaga cloud-native workload tetap aman.
Bagian dokumentasi Kubernetes ini memiliki tujuan untuk membantu anda
menjalankan workloads lebih aman, dan aspek-aspek mendasar dalam menjaga
klaster Kubernetes tetap aman.
Kubernetes berbasiskan arsitektur cloud-native dan mengambil saran dari
CNCF mengenai praktik yang baik dari cloud native information security.
Baca Cloud Native Security and Kubernetes
untuk konteks yang lebih luas mengenai bagaimana cara mengamankan klaster anda
dan aplikasi yang berjalan di atasnya.
Kubernetes menyarankan anda untuk mengkonfigurasi dan menggunakan TLS dalam menyediakan
enkripsi data saat transit
di dalam control plane, dan di antara control plane dengan client.
Anda juga bisa mengaktifkan encryption at rest
untuk data yang tersimpan di dalam Kubernetes control plane; hal ini terpisah dari
menggunanakan encryption at rest untuk data anda di workload.
Secrets
Secret API menyediakan perlindungan dasar untuk variabel konfigurasi yang konfidensial.
Perlindungan Workload
Terapkan Pod security standards untuk memastikan Pods dan containers terisolasi dengan baik.
Anda juga dapat menggunakan RuntimeClasses untuk mendefinisikan isolasi custom jika dibutuhkan.
Network policies memungkinkan anda mengendalikan
trafik jaringan di antara Pods, atau antara Pods dengan jaringan di luar klaster.
Anda dapat men-deploy security controls dari ekosistem yang lebih besar untuk mengimplementasikan kontrol pencegahan
atau pendeteksian di sekitar Pods, kontainer dan images yang berjalan.
Audit
Kubernetes audit logging menyediakan
sebuah set catatan yang berurutan terkait dengan keamanan, mendokumentasikan
urutan aktivitas dalam suatu cluster. Aktivitas cluster audit dihasilkan
oleh pengguna, aplikasi yang menggunakan Kubernetes API dan control plane.
Keamanan penyedia cloud
Catatan: Items on this page refer to vendors external to Kubernetes. The Kubernetes project authors aren't responsible for those third-party products or projects. To add a vendor, product or project to this list, read the content guide before submitting a change. More information.
Jika anda menjalankan klaster Kubernetes pada perangkat keras anda sendiri atau
pada penyedia layanan komputasi awan, silakan kunjungi halaman dokumentasi untuk melihat saran/tips dalam keamanan.
Berikut ini beberapa tautan ke halaman dokumentasi keamanan dari beberapa
penyedia jasa komputasi awan:
Anda dapat mendefinisikan security policies menggunakan mekanisme Kubernetes-native seperti NetworkPolicy (kontrol deklaratif atas network packet filtering) atau ValidatingAdmissionPolicy
(larangan deklaratif atas perubahan apa yang bisa dibuat seseorang menggunakan Kubernetes API).
Bagaimanapun juga, anda dapat mengandalkan dari implementasi policy dari
ekosistem yang lebih besar di sekitar Kubernetes. Kubernetes menyediakan
mekanisme ekstensi untuk membiarkan ekosistem proyek tersebut mengimplementasikan
policy controls mereka pada peninjauan kode sumber, persetujuan image container,
akses kontrol API, jaringan dan lain-lain.
Untuk informasi lebih lanjut mengenai mekanisme policy dan Kubernetes, silakan
baca Policies.
Selanjutnya
Pelajari lebih lanjut topik terkait keamanan Kubernetes:
Keamanan Kubernetes (dan keamanan secara umum) adalah sebuah topik sangat luas yang memiliki banyak bagian yang sangat berkaitan satu sama lain. Pada masa sekarang ini di mana perangkat lunak open source telah diintegrasi ke dalam banyak sistem yang membantu berjalannya aplikasi web, ada beberapa konsep menyeluruh yang dapat membantu intuisimu untuk berpikir tentang konsep keamanan secara menyeluruh. Panduan ini akan mendefinisikan sebuah cara/model berpikir untuk beberapa konsep umum mengenai Keamanan Cloud Native. Cara berpikir ini sepenuhnya subjektif dan kamu sebaiknya hanya menggunakannya apabila ini membantumu berpikir tentang di mana harus mengamankan stack perangkat lunakmu.
4C pada Keamanan Cloud Native
Mari memulainya dengan sebuah diagram yang dapat membantumu mengerti bagaimana berpikir tentang keamanan dalam bentuk beberapa lapisan.
Catatan:
Pendekatan berlapis ini memperkuat pendekatan defense in depth terhadap keamanan, yang secara luas dianggap sebagai praktik terbaik untuk mengamankan sistem-sistem perangkat lunak. 4C tersebut adalah Cloud, Cluster, Container, dan Code.
The 4C's of Cloud Native Security
Seperti yang dapat kamu lihat dari gambar di atas, setiap dari 4C tersebut bergantung pada keamanan dari kotak yang lebih besar di mana mereka berada. Hampir tidak mungkin untuk mengamankan sistem terhadap standar-standar keamanan yang buruk pada Cloud, Container, dan Code hanya dengan menangani keamanan pada lapisan kode. Akan tetapi, apabila semua area tersebut ditangani dengan baik, maka menambahkan keamanan ke dalam kode kamu akan memperkuat landasan yang sudah kuat. Area-area yang menjadi perhatian ini akan dideskripsikan lebih mendalam di bawah.
Cloud
Dalam banyak hal, Cloud (atau server-server co-located, atau pusat data/data center korporat) adalah trusted computing base (basis komputasi yang dipercaya) dari sebuah klaster Kubernetes. Jika komponen-komponen tersebut rentan secara keamanan (atau dikonfigurasi dengan cara yang rentan), maka sesungguhnya tidak ada cara untuk menjamin keamanan dari komponen-komponen apa pun yang dibangun di atas basis komputasi ini. Memberikan rekomendasi untuk keamanan cloud berada di luar lingkup panduan ini, karena setiap penyedia layanan cloud dan beban kerja pada dasarnya berbeda-beda. Berikut beberapa tautan menuju beberapa dokumentasi penyedia layanan cloud yang populer untuk keamanan maupun untuk memberikan panduan umum untuk mengamankan infrastruktur yang menjadi basis sebuah klaster Kubernetes.
Jika kamu mengoperasikan perangkat keras kamu sendiri, atau penyedia layanan cloud yang berbeda, kamu perlu merujuk pada dokumentasi penyedia layanan cloud yang kamu pakai untuk praktik keamanan terbaik.
Tabel Panduan Umum Infrastruktur
Area yang Menjadi Perhatian untuk Infrastruktur Kubernetes
Rekomendasi
Akses Jaringan terhadap API Server (Master-master)
Secara Ideal, semua akses terhadap Master-master Kubernetes tidak diizinkan secara publik pada internet, dan dikontrol oleh daftar kendali akses (network ACL) yang dibatasi untuk kumpulan alamat IP yang dibutuhkan untuk mengelola klaster.
Akses Jaringan terhadap Node-node (Server-server Worker)
Node-node harus dikonfigurasikan untuk hanya menerima koneksi-koneksi (melalui daftar kendali akses) dari Master-master pada porta-porta (port) yang telah ditentukan, dan menerima koneksi-koneksi dari Service-service Kubernetes dengan tipe NodePort dan LoadBalancer. Apabila memungkinkan, Node-node tersebut sebaiknya tidak diekspos pada internet publik sama sekali.
Akses Kubernetes terhadap API Penyedia Layanan Cloud
Akses terhadap etcd (tempat penyimpanan data Kubernetes) harus dibatasi hanya untuk Master-master saja. Bergantung pada konfigurasimu, kamu sebaiknya juga mengusahakan koneksi etcd menggunakan TLS. Informasi lebih lanjut dapat ditemukan di sini: https://github.com/etcd-io/etcd/tree/master/Documentation#security
Enkripsi etcd
Di mana pun kita dapat melakukannya, mengenkripsi semua data saat diam (at rest) pada semua drive, dan sejak etcd menyimpan keadaan seluruh klaster (termasuk Secret-secret), disk-nya sebaiknya kita enkripsi saat diam.
Cluster
Bagian ini akan memberikan tautan-tautan untuk mengamankan beban-beban kerja di dalam Kubernetes. Ada dua area yang menjadi perhatian untuk mengamankan Kubernetes:
Mengamankan komponen-komponen yang dapat dikonfigurasi yang membentuk klaster
Mengamankan komponen-komponen yang dijalankan di dalam klaster
Komponen-komponen dari Cluster
Jika kamu ingin menjaga klastermu dari akses yang tidak disengaja atau yang bersifat serangan, dan mengadopsi praktik yang baik, baca dan ikutilah nasihat untuk mengamankan klastermu.
Komponen-komponen di dalam Cluster (aplikasimu)
Bergantung pada permukaan yang dapat diserang dari aplikasimu, kamu mungkin ingin berfokus pada aspek keamanan yang spesifik. Sebagai contoh, jika kamu menjalankan sebuah layanan (kita sebut Layanan A) yang kritikal di dalam rantai sumber daya lainnya dan sebuah beban kerja terpisah (kita sebut Layanan B) yang rentan terhadap serangan resource exhaustion, dengan tidak menyetel limit untuk sumber daya maka kamu juga menaruh risiko terhadap Layanan A. Berikut tabel tautan-tautan menuju hal-hal yang perlu diperhatikan untuk mengamankan beban-beban kerja yang berjalan di dalam Kubernetes.
Area yang Menjadi Perhatian untuk Keamanan Beban Kerja
Untuk menjalankan perangkat lunak di dalam Kubernetes, perangkat lunak tersebut haruslah berada di dalam sebuah Container. Karenanya, ada beberapa pertimbangan keamanan yang harus diperhitungkan untuk mengambil manfaat dari fitur-fitur keamanan beban kerja Kubernetes. Keamanan Container berada di luar lingkup panduan ini, tetapi berikut disediakan sebuah tabel rekomendasi-rekomendasi umum dan tautan menuju eksplorasi lebih dalam pada topik ini.
Area yang Menjadi Perhatian untuk Container
Rekomendasi
Pemindaian Kerentanan Container dan Dependensi Keamanan OS
Sebagai bagian dari tahap membangun sebuah image atau dilakukan secara teratur, kamu sebaiknya memindai Container-container terhadap kerentanan yang telah diketahui dengan peralatan seperti CoreOS's Clair
Penandatanganan Image dan Penegakan Aturan
Dua dari Proyek-proyek CNCF (TUF dan Notary) adalah alat-alat yang berguna untuk menandatangani image Container dan memelihara sistem kepercayaan untuk konten dari Container-container kamu. Jika kamu menggunakan Docker, ia dibangun di dalam Docker Engine sebagai Docker Content Trust. Pada bagian penegakan aturan, proyek Portieris dari IBM adalah sebuah alat yang berjalan sebagai sebuah Dynamic Admission Controller Kubernetes untuk memastikan bahwa image-image ditandatangani dengan tepat oleh Notary sebelum dimasukkan ke dalam Cluster.
Larang pengguna-pengguna dengan hak istimewa
Saat membangun Container-container, rujuklah dokumentasimu untuk cara membuat pengguna-pengguna di dalam Container-container yang memiliki hak istimewa sistem operasi yang paling sedikit yang dibutuhkan untuk mencapai tujuan Container tersebut.
Code
Akhirnya pada lapisan kode aplikasi, hal ini adalah satu dari permukaan-permukaan serangan utama yang paling dapat kamu kontrol. Hal ini juga berada di luar lingkup Kubernetes, tetapi berikut beberapa rekomendasi:
Tabel Panduan Umum Keamanan Kode
Area yang Menjadi Perhatian untuk Kode
Rekomendasi
Akses hanya melalui TLS
Jika kode kamu perlu berkomunikasi via TCP, idealnya ia melakukan TLS handshake dengan klien sebelumnya. Dengan pengecualian pada sedikit kasus, kelakuan secara bawaan sebaiknya adalah mengenkripsi semuanya (data) pada saat transit (encryption at transit). Lebih jauh lagi, bahkan "di belakang dinding api" di dalam VPC kita sebaiknya kita melakukan enkripsi lalu lintas jaringan di antara layanan-layanan. Hal ini dapat dilakukan melalui sebuah proses yang dikenal dengan mutual TLS atau mTLS yang melakukan verifikasi dua sisi terhadap komunikasi antara layanan-layanan yang memiliki sertifikat digital. Ada banyak alat-alat yang dapat digunakan untuk mencapai hal ini, seperti Linkerd dan Istio.
Membatasi cakupan porta komunikasi
Rekomendasi ini sepertinya cukup jelas, tetapi di mana pun dapat dilakukan sebaiknya kamu hanya membuka porta-porta pada layananmu yang benar-benar diperlukan untuk komunikasi sistem atau pengambilan metrik.
Keamanan Dependensi Pihak ke-3
Karena aplikasi-aplikasi kita cenderung memiliki dependensi-dependensi di luar kode kita sendiri, merupakan praktik yang baik untuk memastikan hasil pemindaian rutin dependensi-dependensi kode kita masih aman tanpa CVE yang masih ada terhadap mereka. Setiap bahasa pemrograman memiliki alat untuk melakukan pemindaian ini secara otomatis.
Analisis Statis Kode
Kebanyakan bahasa pemrograman menyediakan cara agar potongan kode dapat dianalisis terhadap praktik-praktik penulisan kode yang berpotensi tidak aman. Kapan pun dapat dilakukan, kamu sebaiknya melakukan pemeriksaan menggunakan peralatan otomatis yang dapat memindai kode terhadap kesalahan keamanan yang umum terjadi. Beberapa dari peralatan tersebut dapat ditemukan di sini: https://www.owasp.org/index.php/Source_Code_Analysis_Tools
Serangan Pengamatan (probing) Dinamis
Ada sedikit peralatan otomatis yang dapat dijalankan terhadap layanan/aplikasi kamu untuk mencoba beberapa serangan yang terkenal dan umumnya memengaruhi layanan-layanan. Serangan-serangan tersebut termasuk SQL injection, CSRF, dan XSS. Satu dari alat analisis dinamis yang terkenal adalah OWASP Zed Attack Proxy https://www.owasp.org/index.php/OWASP_Zed_Attack_Proxy_Project
Otomasi yang Kokoh
Kebanyakan dari saran yang disebut di atas dapat diotomasi di dalam delivery pipeline kode kamu sebagai bagian dari rangkaian pemeriksaan keamanan. Untuk mempelajari lebih lanjut tentang pendekatan "Continuous Hacking" terhadap delivery perangkat lunak, artikel ini menyediakan lebih banyak detail.
Konsep untuk menjaga keamanan workload cloud-native Kamu.
Kubernetes berdasarkan pada arsitektur cloud-native dan mengikuti saran dari
CNCF tentang praktik terbaik untuk
keamanan informasi cloud-native.
Baca halaman ini untuk gambaran umum tentang bagaimana Kubernetes dirancang untuk
membantu kamu menerapkan platform cloud-native yang aman.
Keamanan informasi cloud-native
Whitepaper CNCF white paper
tentang keamanan cloud-native yang mendefinisikan kontrol keamanan dan praktik yang
sesuai untuk berbagai fase siklus hidup.
Fase siklus hidup Develop
Pastikan integritas lingkungan pengembangan.
Rancang aplikasi mengikuti praktik terbaik untuk keamanan informasi,
sesuai dengan konteks kamu.
Pertimbangkan keamanan pengguna akhir sebagai bagian dari desain solusi.
Untuk mencapainya, kamu dapat:
Mengadopsi arsitektur, seperti zero trust,
yang meminimalkan permukaan serangan, bahkan untuk ancaman internal.
Mendefinisikan proses tinjauan kode yang mempertimbangkan masalah keamanan.
Membangun model ancaman untuk sistem atau aplikasi kamu yang mengidentifikasi
batas kepercayaan. Gunakan model tersebut untuk mengidentifikasi risiko dan menemukan
cara untuk mengatasinya.
Mengintegrasikan otomatisasi keamanan tingkat lanjut, seperti fuzzing dan
rekayasa kekacauan keamanan,
jika diperlukan.
Fase siklus hidup Distribute
Pastikan keamanan rantai pasokan untuk container image yang kamu jalankan.
Pastikan keamanan rantai pasokan untuk klaster dan komponen lain
yang menjalankan aplikasi kamu. Contohnya adalah database eksternal yang digunakan
oleh aplikasi cloud-native kamu untuk penyimpanan.
Untuk mencapainya, kamu dapat:
Memindai container image dan artefak lainnya untuk kerentanan yang diketahui.
Memastikan distribusi perangkat lunak menggunakan enkripsi dalam transit, dengan
rantai kepercayaan untuk sumber perangkat lunak.
Mengadopsi dan mengikuti proses untuk memperbarui dependensi saat pembaruan tersedia,
terutama sebagai tanggapan terhadap pengumuman keamanan.
Menggunakan mekanisme validasi seperti sertifikat digital untuk memastikan
keamanan rantai pasokan.
Berlangganan feed dan mekanisme lainnya untuk memberi tahu kamu tentang risiko keamanan.
Membatasi akses ke artefak. Tempatkan container image di
registry privat
yang hanya mengizinkan klien yang berwenang untuk menarik image.
Fase siklus hidup Deploy
Pastikan pembatasan yang sesuai pada apa yang dapat diterapkan, siapa yang dapat menerapkannya,
dan di mana itu dapat diterapkan.
kamu dapat menerapkan langkah-langkah dari fase distribute, seperti memverifikasi
identitas kriptografi dari artefak container image.
Saat kamu menerapkan Kubernetes, kamu juga menetapkan fondasi untuk
lingkungan runtime aplikasi kamu: sebuah klaster Kubernetes (atau
beberapa klaster).
Infrastruktur TI tersebut harus memberikan jaminan keamanan yang diharapkan oleh
lapisan yang lebih tinggi.
API Kubernetes adalah inti dari klaster kamu. Melindungi API ini adalah kunci
untuk memberikan keamanan klaster yang efektif.
Halaman lain dalam dokumentasi Kubernetes memiliki detail lebih lanjut tentang cara mengatur
aspek kontrol akses tertentu. Daftar periksa keamanan
memiliki serangkaian pemeriksaan dasar yang disarankan untuk klaster kamu.
Selain itu, mengamankan klaster kamu berarti menerapkan
autentikasi dan
otorisasi yang efektif untuk akses API. Gunakan ServiceAccounts untuk
menyediakan dan mengelola identitas keamanan untuk beban kerja dan komponen klaster.
Kubernetes menggunakan TLS untuk melindungi lalu lintas API; pastikan untuk menerapkan klaster menggunakan
TLS (termasuk untuk lalu lintas antara node dan control plane), dan lindungi
kunci enkripsi. Jika kamu menggunakan API Kubernetes untuk
CertificateSigningRequests,
berikan perhatian khusus untuk membatasi penyalahgunaan di sana.
Perlindungan Runtime: komputasi
Container menyediakan dua
hal: isolasi antara aplikasi yang berbeda, dan mekanisme untuk menggabungkan
aplikasi yang terisolasi tersebut untuk dijalankan pada komputer host yang sama. Kedua
aspek ini, isolasi dan agregasi, berarti bahwa keamanan runtime melibatkan
mengidentifikasi trade-off dan menemukan keseimbangan yang sesuai.
Kubernetes mengandalkan container runtime
untuk benar-benar mengatur dan menjalankan container. Proyek Kubernetes tidak
merekomendasikan runtime container tertentu, dan kamu harus memastikan bahwa
runtime yang kamu pilih memenuhi kebutuhan keamanan informasi kamu.
Untuk melindungi komputasi kamu saat runtime, kamu dapat:
Menerapkan standar keamanan Pod
untuk aplikasi, untuk membantu memastikan mereka berjalan hanya dengan hak istimewa yang diperlukan.
Menjalankan sistem operasi khusus pada node kamu yang dirancang khusus
untuk menjalankan beban kerja yang dikontainerisasi. Biasanya ini berbasis pada sistem operasi
hanya-baca (immutable image) yang hanya menyediakan layanan
penting untuk menjalankan container.
Sistem operasi khusus container membantu mengisolasi komponen sistem dan
menghadirkan permukaan serangan yang lebih kecil jika terjadi pelarian container.
Mendefinisikan ResourceQuotas untuk
mengalokasikan sumber daya bersama secara adil, dan menggunakan
mekanisme seperti LimitRanges
untuk memastikan bahwa Pod menentukan persyaratan sumber daya mereka.
Membagi beban kerja di berbagai node.
Gunakan mekanisme isolasi node,
baik dari Kubernetes itu sendiri atau dari ekosistem, untuk memastikan bahwa
Pod dengan konteks kepercayaan yang berbeda dijalankan pada set node yang terpisah.
Melindungi daya tahan data menggunakan cadangan. Verifikasi bahwa kamu dapat memulihkan data tersebut kapan pun diperlukan.
Mengautentikasi koneksi antara node klaster dan penyimpanan jaringan apa pun yang mereka andalkan.
Menerapkan enkripsi data dalam aplikasi kamu sendiri.
Untuk kunci enkripsi, menghasilkan kunci ini dalam perangkat keras khusus memberikan
perlindungan terbaik terhadap risiko pengungkapan. Sebuah hardware security module
dapat memungkinkan kamu melakukan operasi kriptografi tanpa memungkinkan kunci keamanan
untuk disalin ke tempat lain.
Jaringan dan keamanan
Kamu juga harus mempertimbangkan langkah-langkah keamanan jaringan, seperti
NetworkPolicy atau
service mesh.
Beberapa plugin jaringan untuk Kubernetes menyediakan enkripsi untuk
jaringan klaster kamu, menggunakan teknologi seperti
virtual private network (VPN) overlay.
Secara desain, Kubernetes memungkinkan kamu menggunakan plugin jaringan kamu sendiri untuk
klaster kamu (jika kamu menggunakan Kubernetes yang dikelola, orang atau organisasi
yang mengelola klaster kamu mungkin telah memilih plugin jaringan untuk kamu).
Plugin jaringan yang kamu pilih dan cara kamu mengintegrasikannya dapat memiliki
dampak besar pada keamanan informasi dalam transit.
Observabilitas dan keamanan runtime
Kubernetes memungkinkan kamu memperluas klaster kamu dengan alat tambahan. kamu dapat mengatur solusi pihak ketiga untuk membantu kamu memantau atau memecahkan masalah aplikasi kamu dan klaster tempat mereka berjalan. kamu juga mendapatkan beberapa fitur observabilitas dasar yang sudah ada di Kubernetes itu sendiri. Kode kamu yang berjalan dalam container dapat menghasilkan log, menerbitkan metrik, atau menyediakan data observabilitas lainnya; pada waktu penerapan, kamu perlu memastikan klaster kamu memberikan tingkat perlindungan yang sesuai di sana.
Jika kamu mengatur dasbor metrik atau sesuatu yang serupa, tinjau rantai komponen yang mengisi data ke dalam dasbor tersebut, serta dasbor itu sendiri. Pastikan bahwa seluruh rantai dirancang dengan ketahanan yang cukup dan perlindungan integritas yang cukup sehingga kamu dapat mengandalkannya bahkan selama insiden di mana klaster kamu mungkin mengalami degradasi.
Jika sesuai, terapkan langkah-langkah keamanan di bawah tingkat Kubernetes itu sendiri, seperti boot yang diukur secara kriptografis, atau distribusi waktu yang diautentikasi (yang membantu memastikan keandalan log dan catatan audit).
Untuk lingkungan dengan jaminan tinggi, terapkan perlindungan kriptografi untuk memastikan bahwa log tidak dapat diubah dan tetap rahasia.
Selanjutnya
Keamanan cloud-native
Whitepaper CNCF white paper
tentang keamanan cloud-native.
Whitepaper CNCF white paper
tentang praktik terbaik untuk mengamankan rantai pasokan perangkat lunak.
Informasi tentang opsi autentikasi di Kubernetes dan securityproperties -nya.
Memilih mekanisme autentikasi yang tepat adalah aspek penting dalam mengamankan klaster Anda.
Kubernetes menyediakan beberapa mekanisme bawaan, masing-masing dengan kelebihan dan kekurangannya
yang harus dipertimbangkan dengan hati-hati saat memilih mekanisme autentikasi terbaik untuk klaster Anda.
Secara umum, disarankan untuk mengaktifkan sesedikit mungkin mekanisme autentikasi untuk menyederhanakan
manajemen pengguna dan mencegah kasus di mana pengguna tetap memiliki akses ke klaster yang tidak lagi diperlukan.
Penting untuk dicatat bahwa Kubernetes tidak memiliki basis data pengguna bawaan di dalam klaster.
Sebaliknya, Kubernetes mengambil informasi pengguna dari sistem autentikasi yang dikonfigurasi dan menggunakan
informasi tersebut untuk membuat keputusan otorisasi. Oleh karena itu, untuk mengaudit akses pengguna, Anda perlu
meninjau kredensial dari setiap sumber autentikasi yang dikonfigurasi.
Untuk klaster produksi dengan banyak pengguna yang mengakses API Kubernetes secara langsung, disarankan untuk
menggunakan sumber autentikasi eksternal seperti OIDC. Mekanisme autentikasi internal, seperti sertifikat klien
dan token akun layanan yang dijelaskan di bawah ini, tidak cocok untuk kasus penggunaan ini.
Autentikasi sertifikat klien X.509
Kubernetes memanfaatkan sertifikat klien X.509
untuk komponen sistem, seperti saat kubelet mengautentikasi ke API Server. Meskipun mekanisme ini juga dapat digunakan
untuk autentikasi pengguna, mekanisme ini mungkin tidak cocok untuk penggunaan produksi karena beberapa batasan:
Sertifikat klien tidak dapat dicabut secara individual. Setelah disusupi, sertifikat dapat digunakan oleh penyerang
hingga kedaluwarsa. Untuk mengurangi risiko ini, disarankan untuk mengonfigurasi masa berlaku yang pendek untuk
kredensial autentikasi pengguna yang dibuat menggunakan sertifikat klien.
Jika sertifikat perlu dibatalkan, otoritas sertifikat harus diubah kuncinya, yang dapat memperkenalkan risiko
ketersediaan ke klaster.
Tidak ada catatan permanen tentang sertifikat klien yang dibuat di klaster. Oleh karena itu, semua sertifikat yang
diterbitkan harus dicatat jika Anda perlu melacaknya.
Kunci privat yang digunakan untuk autentikasi sertifikat klien tidak dapat dilindungi dengan kata sandi. Siapa pun
yang dapat membaca file yang berisi kunci tersebut akan dapat menggunakannya.
Menggunakan autentikasi sertifikat klien memerlukan koneksi langsung dari klien ke API server tanpa titik
terminasi TLS yang mengintervensi, yang dapat mempersulit arsitektur jaringan.
Data grup tertanam dalam nilai O dari sertifikat klien, yang berarti keanggotaan grup pengguna tidak dapat diubah
selama masa berlaku sertifikat.
File token statis
Meskipun Kubernetes memungkinkan Anda memuat kredensial dari
berkas token statis yang terletak
di disk node control plane, pendekatan ini tidak disarankan untuk server produksi karena beberapa alasan:
Kredensial disimpan dalam teks biasa di disk node control plane, yang dapat menjadi risiko keamanan.
Mengubah kredensial apa pun memerlukan restart proses API server agar berlaku, yang dapat memengaruhi ketersediaan.
Tidak ada mekanisme yang tersedia untuk memungkinkan pengguna memutar kredensial mereka. Untuk memutar kredensial,
administrator klaster harus memodifikasi token di disk dan mendistribusikannya ke pengguna.
Tidak ada mekanisme penguncian yang tersedia untuk mencegah serangan brute-force.
Token bootstrap
Token bootstrap digunakan untuk menghubungkan
node ke klaster dan tidak disarankan untuk autentikasi pengguna karena beberapa alasan:
Mereka memiliki keanggotaan grup yang dikodekan keras yang tidak cocok untuk penggunaan umum, sehingga tidak cocok
untuk tujuan autentikasi.
Pembuatan token bootstrap secara manual dapat menghasilkan token yang lemah yang dapat ditebak oleh penyerang,
yang dapat menjadi risiko keamanan.
Tidak ada mekanisme penguncian yang tersedia untuk mencegah serangan brute-force, sehingga memudahkan penyerang
untuk menebak atau memecahkan token.
Token rahasia ServiceAccount
Rahasia akun layanan
tersedia sebagai opsi untuk memungkinkan beban kerja yang berjalan di klaster mengautentikasi ke API server.
Di Kubernetes < 1.23, ini adalah opsi default, namun, mereka sedang digantikan dengan token API TokenRequest.
Meskipun rahasia ini dapat digunakan untuk autentikasi pengguna, mereka umumnya tidak cocok karena beberapa alasan:
Mereka tidak dapat diatur dengan masa berlaku dan akan tetap berlaku hingga akun layanan terkait dihapus.
Token autentikasi terlihat oleh pengguna klaster mana pun yang dapat membaca rahasia di namespace tempat mereka
didefinisikan.
Akun layanan tidak dapat ditambahkan ke grup arbitrer, yang mempersulit manajemen RBAC di mana mereka digunakan.
Token API TokenRequest
API TokenRequest adalah alat yang berguna untuk menghasilkan kredensial jangka pendek untuk autentikasi layanan
ke API server atau sistem pihak ketiga. Namun, ini umumnya tidak disarankan untuk autentikasi pengguna karena tidak
ada metode pencabutan yang tersedia, dan mendistribusikan kredensial ke pengguna dengan cara yang aman dapat menjadi
tantangan.
Saat menggunakan token TokenRequest untuk autentikasi layanan, disarankan untuk menerapkan masa berlaku yang pendek
untuk mengurangi dampak token yang disusupi.
Autentikasi token OpenID Connect
Kubernetes mendukung integrasi layanan autentikasi eksternal dengan API Kubernetes menggunakan
OpenID Connect (OIDC).
Ada berbagai macam perangkat lunak yang dapat digunakan untuk mengintegrasikan Kubernetes dengan penyedia identitas.
Namun, saat menggunakan autentikasi OIDC di Kubernetes, penting untuk mempertimbangkan langkah-langkah penguatan berikut:
Perangkat lunak yang diinstal di klaster untuk mendukung autentikasi OIDC harus diisolasi dari beban kerja umum
karena akan berjalan dengan hak istimewa tinggi.
Beberapa layanan Kubernetes yang dikelola memiliki batasan pada penyedia OIDC yang dapat digunakan.
Seperti halnya token TokenRequest, token OIDC harus memiliki masa berlaku yang pendek untuk mengurangi dampak
token yang disusupi.
Autentikasi token Webhook
Autentikasi token Webhook
adalah opsi lain untuk mengintegrasikan penyedia autentikasi eksternal ke Kubernetes. Mekanisme ini memungkinkan
layanan autentikasi, baik yang berjalan di dalam klaster atau di luar, untuk dihubungi untuk keputusan autentikasi
melalui webhook. Penting untuk dicatat bahwa kesesuaian mekanisme ini kemungkinan besar bergantung pada perangkat
lunak yang digunakan untuk layanan autentikasi, dan ada beberapa pertimbangan khusus Kubernetes yang harus diperhatikan.
Untuk mengonfigurasi autentikasi Webhook, akses ke sistem file server control plane diperlukan. Ini berarti bahwa
hal ini tidak akan memungkinkan dengan Kubernetes yang dikelola kecuali penyedia secara khusus membuatnya tersedia.
Selain itu, perangkat lunak apa pun yang diinstal di klaster untuk mendukung akses ini harus diisolasi dari beban
kerja umum, karena akan berjalan dengan hak istimewa tinggi.
Proxy autentikasi
Opsi lain untuk mengintegrasikan sistem autentikasi eksternal ke Kubernetes adalah dengan menggunakan
proxy autentikasi.
Dengan mekanisme ini, Kubernetes mengharapkan menerima permintaan dari proxy dengan nilai header tertentu yang
ditetapkan, menunjukkan nama pengguna dan keanggotaan grup untuk tujuan otorisasi. Penting untuk dicatat bahwa ada
pertimbangan khusus yang harus diperhatikan saat menggunakan mekanisme ini.
Pertama, TLS yang dikonfigurasi dengan aman harus digunakan antara proxy dan API server Kubernetes untuk mengurangi
risiko serangan penyadapan atau pengintaian lalu lintas. Ini memastikan bahwa komunikasi antara proxy dan API server
Kubernetes aman.
Kedua, penting untuk menyadari bahwa penyerang yang dapat memodifikasi header permintaan mungkin dapat memperoleh
akses tidak sah ke sumber daya Kubernetes. Oleh karena itu, penting untuk memastikan bahwa header diamankan dengan
baik dan tidak dapat dirusak.
[Autentikasi dengan Token Akun Layanan](/docs/reference/access-authn-authz/service-accounts-admin/#bound-service-accounfor kens)
8.4 - Daftar Periksa Keamanan
Daftar periksa dasar untuk memastikan keamanan di klaster Kubernetes.
Daftar ini bertujuan memberikan daftar dasar panduan dengan tautan ke
dokumentasi yang lebih lengkap pada setiap topiknya. Daftar ini tidak
berarti sudah final dan masih bisa berubah.
Bagaimana cara membaca dan menggunakan dokumen ini:
Urutan dari topik tidak mencerminkan prioritas
Beberapa daftar, dirincikan dalam paragraf di bawahnya pada setiap bagian.
Perhatian:
Daftar periksa sendiri tidak cukup untuk mendapatkan postur keamanan yang baik.
Postur keamanan yang baik membutuhkan usaha yang terus menerus, dan daftar periksa
bisa menjadi langkah pertama dalam perjalanan panjang dalam keamanan.
Beberapa rekomendasi dalam daftar periksa ini bisa jadi terlalu ketat atau
terlalu longgar untuk kebutuhan spesifik keamanan kamu.
Karena keamanan Kubernetes bukan lah "sama untuk semua", setiap kategori dalam daftar,
harus dievaluasi berdasarkan untung/rugi-nya.
Authentication & Authorization
Autentikasi dan Autorisasi
system:masters group tidak digunakan untuk pengguna atau komponen otentikasi setelah bootstrapping.
kube-controller-manager dijalankan dengan --use-service-account-credentials
aktif.
Sertifikat root terlindungi (baik dengan offline CA, atau online CA dengan akses kontrol yang efektif).
Sertifikat intermediate dan leaf memiliki masa berlaku tidak lebih dari
3 tahun ke depan.
Terdapat sebuah proses untuk me-review akses periodik dan review dilakukan
tidak lebih dari 24 bulan.
Setelah bootstrapping, baik pengguna ataupun komponen harusnya tidak melakukan
otentikasi ke Kubernetes API sebagai system:masters. Mirip dengan, menjalankan
semua kube-controller-manager sebagai system:masters harus dihindari.
Faktanya, system:masters harus digunakan sebagai mekanisme terakhir (pecahkan-kaca), berlawanan dengan pengguna admin.
Keamanan Jaringan
Gunakan plugin CNI untuk mendukung kebijakan jaringan.
CNI plugins in use support network policies.
Kebijakan jaringan ingress dan egress diaplikasikan ke semua workload
di dalam klaster.
Terapkan kebijakan default jaringan setiap namespace, periksa semua pod, dan tolak semua.
Jika memungkinkan, sebuah service mesh digunakan untuk mengenkripsi semua komunikasi di dalam klaster.
Kubernetes API, kubelet API dan etcd tidak terekspos ke Internet.
Akses ke workloads ke cloud metadata API di-filter.
Penggunaan LoadBalancer dan ExternalIPs dilarang.
Sejumlah Container Network Interface (CNI) plugins
menyediakan fungsionalitas untuk membatasi sumber daya jaringan yang
memungkinkan pods berkomunikasi. Hal ini umumnya dilakukan melalui
Network Policies
yang menyediakan sumber daya dengan namespace untuk mendefinisikan aturan.
Kebijakan jaringan default yang mem-blok semua egress dan ingress di setiap
namespace, memilih semua pods, dapat bermanfaat untuk mengadopsi pendekatan daftar
diizinkan untuk memastikan tidak ada workloads yang terlewat.
Tidak semua plugin CNI menyediakan enkripsi saat transit. Jika plugin yang dipilih
tidak memiliki fitur ini, solusi alternatif dapat ditawarkan untuk menggunakan
service mesh yang menyediakan fungsionalitas ini.
Datastore etcd dari control plane harus memiliki kontrol untuk membatasi akses
dan tidak terekspos ke Internet. Lebih jauh, mutual TLS (mTLS) harus digunakan
untuk berkomunikasi dengan aman. Certificate authority untuk ini harus unik ke etcd.
Akses Internet eksternal ke server Kubernetes API harus dibatasi untuk tidak
meng-ekspos API ke publik. Harap hati-hati, banyak managed Kubernetes distributions
yang secara default mengekspos API server. Untuk ini, kamu bisa menggunakan bastion host
untuk mengakses server.
Akses API kubelet
harus dibatasi dan tidak terekspos ke publi, setting default autentikasi dan autorisasi,
saat tidak ada berkas konfigurasi di-spesifikasikan dengan flag --config,
sangat permisif.
Jika penyedia cloud digunakan untuk men-host Kubernetes, akses dari pod ke
cloud metadata API 169.254.169.254 harus dibatasi juga atau diblok jika tidak
dibutuhkan karena ada informasi yang bisa bocor.
Hak RBAC untuk create, update, patch, delete workloads hanya diberikan jika diperlukan.
Kebijakan Pod Security Standards yang sesuai diterapkan untuk semua namespace dan ditegakkan.
Batas memori ditetapkan untuk workloads dengan batas yang sama atau lebih rendah dari permintaan.
Batas CPU dapat ditetapkan pada workloads yang sensitif.
Untuk node yang mendukungnya, Seccomp diaktifkan dengan profil syscalls yang sesuai untuk program.
Untuk node yang mendukungnya, AppArmor atau SELinux diaktifkan dengan profil yang sesuai untuk program.
Otorisasi RBAC sangat penting tetapi
tidak cukup granular untuk memiliki otorisasi pada sumber daya Pods
(atau pada sumber daya apa pun yang mengelola Pods). Granularitas hanya ada pada API verbs
pada sumber daya itu sendiri, misalnya, create pada Pods. Tanpa
admission tambahan, otorisasi untuk membuat sumber daya ini memungkinkan akses langsung
tanpa batas ke node yang dapat dijadwalkan dalam klaster.
Pod Security Standards
mendefinisikan tiga kebijakan berbeda, yaitu privileged, baseline, dan restricted yang membatasi
bagaimana field dapat diatur dalam PodSpec terkait keamanan.
Standar ini dapat ditegakkan di tingkat namespace dengan
Pod Security Admission baru,
yang diaktifkan secara default, atau dengan webhook admission pihak ketiga. Harap dicatat bahwa,
berbeda dengan PodSecurityPolicy admission yang dihapus,
Pod Security Admission
dapat dengan mudah digabungkan dengan webhook admission dan layanan eksternal.
Kebijakan restricted pada Pod Security Admission, kebijakan paling ketat dari
Pod Security Standards,
dapat beroperasi dalam beberapa mode,
warn, audit, atau enforce untuk secara bertahap menerapkan
konteks keamanan
yang paling sesuai sesuai dengan praktik terbaik keamanan. Namun demikian,
konteks keamanan
pada pods harus diselidiki secara terpisah untuk membatasi hak istimewa dan akses yang mungkin dimiliki pods
di luar standar keamanan yang telah ditentukan, untuk kasus penggunaan tertentu.
Batas memori dan CPU
harus ditetapkan untuk membatasi sumber daya memori dan CPU yang dapat dikonsumsi pod pada node,
dan dengan demikian mencegah potensi serangan DoS dari workloads yang berbahaya atau
terkompromi. Kebijakan semacam itu dapat ditegakkan oleh admission controller.
Harap dicatat bahwa batas CPU akan membatasi penggunaan dan dengan demikian dapat memiliki efek yang tidak diinginkan
pada fitur auto-scaling atau efisiensi, misalnya menjalankan proses dalam upaya terbaik dengan sumber daya CPU yang tersedia.
Perhatian:
Batas memori yang lebih tinggi dari permintaan dapat mengekspos seluruh node terhadap masalah OOM.
Mengaktifkan Seccomp
Seccomp adalah singkatan dari secure computing mode dan telah menjadi fitur kernel Linux sejak versi 2.6.12.
Fitur ini dapat digunakan untuk membatasi hak istimewa sebuah proses, dengan membatasi panggilan sistem (syscalls)
yang dapat dilakukan dari ruang pengguna (userspace) ke kernel. Kubernetes memungkinkan Anda untuk secara otomatis
menerapkan profil seccomp yang dimuat ke sebuah node ke Pods dan container Anda.
Seccomp dapat meningkatkan keamanan workloads Anda dengan mengurangi permukaan serangan syscall kernel Linux
yang tersedia di dalam container. Mode filter seccomp memanfaatkan BPF untuk membuat daftar izin atau larangan
terhadap syscall tertentu, yang disebut profil.
Sejak Kubernetes 1.27, Anda dapat mengaktifkan penggunaan RuntimeDefault sebagai profil seccomp default
untuk semua workloads. Sebuah tutorial keamanan tersedia untuk topik ini.
Selain itu, Kubernetes Security Profiles Operator
adalah proyek yang memfasilitasi pengelolaan dan penggunaan seccomp di dalam klaster.
Catatan:
Seccomp hanya tersedia pada node Linux.
Mengaktifkan AppArmor atau SELinux
AppArmor
AppArmor adalah modul keamanan kernel Linux yang dapat
menyediakan cara mudah untuk menerapkan Mandatory Access Control (MAC) dan audit yang lebih baik
melalui log sistem. Profil AppArmor default diterapkan pada node yang mendukungnya, atau profil khusus dapat dikonfigurasi.
Seperti seccomp, AppArmor juga dikonfigurasi melalui profil, di mana setiap profil dapat berjalan dalam mode enforcing,
yang memblokir akses ke sumber daya yang tidak diizinkan, atau mode complain, yang hanya melaporkan pelanggaran.
Profil AppArmor diterapkan pada basis per-container, dengan anotasi, memungkinkan proses untuk mendapatkan hak istimewa yang sesuai.
SELinux juga merupakan
modul keamanan kernel Linux yang dapat menyediakan mekanisme untuk mendukung kebijakan kontrol akses,
termasuk Mandatory Access Controls (MAC). Label SELinux dapat diberikan ke container atau pod
melalui bagian securityContext.
Log audit, jika diaktifkan, dilindungi dari akses umum.
Log audit adalah alat penting untuk melacak aktivitas dalam klaster Kubernetes Anda. Jika log audit diaktifkan, pastikan log tersebut hanya dapat diakses oleh pengguna atau sistem yang berwenang. Hal ini membantu mencegah kebocoran informasi sensitif dan memastikan bahwa log dapat digunakan untuk investigasi keamanan tanpa risiko manipulasi atau akses tidak sah.
Penempatan Pod
Penempatan pod dilakukan sesuai dengan tingkat sensitivitas aplikasi.
Aplikasi sensitif dijalankan secara terisolasi pada node atau dengan runtime sandbox tertentu.
Pod yang berada pada tingkat sensitivitas yang berbeda, misalnya pod aplikasi dan server API Kubernetes, sebaiknya diterapkan pada node yang terpisah. Tujuan dari isolasi node adalah untuk mencegah pelarian container aplikasi yang dapat langsung memberikan akses ke aplikasi dengan tingkat sensitivitas yang lebih tinggi, sehingga memudahkan penyerang untuk berpindah dalam klaster. Pemisahan ini harus ditegakkan untuk mencegah pod secara tidak sengaja diterapkan pada node yang sama. Hal ini dapat ditegakkan dengan fitur berikut:
Pasangan key-value, sebagai bagian dari spesifikasi pod, yang menentukan node mana yang akan digunakan untuk penerapan. Ini dapat ditegakkan pada tingkat namespace dan klaster dengan admission controller PodNodeSelector.
Sebuah admission controller yang memungkinkan administrator membatasi toleransi yang diizinkan dalam sebuah namespace. Pod dalam namespace hanya dapat menggunakan toleransi yang ditentukan pada kunci anotasi objek namespace yang menyediakan serangkaian toleransi default dan yang diizinkan.
RuntimeClass adalah fitur untuk memilih konfigurasi runtime container. Konfigurasi runtime container digunakan untuk menjalankan container dalam pod dan dapat memberikan lebih banyak atau lebih sedikit isolasi dari host dengan biaya overhead kinerja.
Secrets
ConfigMap tidak digunakan untuk menyimpan data rahasia.
Enkripsi saat data tidak aktif (encryption at rest) dikonfigurasi untuk API Secret.
Jika sesuai, mekanisme untuk menyuntikkan secrets yang disimpan di penyimpanan pihak ketiga diterapkan dan tersedia.
Token service account tidak dimasukkan ke dalam pod yang tidak membutuhkannya.
Secrets yang diperlukan untuk pod sebaiknya disimpan dalam Kubernetes Secrets, bukan alternatif seperti ConfigMap. Sumber daya Secret yang disimpan dalam etcd harus dienkripsi saat data tidak aktif.
Pod yang membutuhkan secrets sebaiknya memiliki secrets tersebut secara otomatis dimasukkan melalui volume, yang sebaiknya disimpan di memori seperti dengan opsi emptyDir.medium. Mekanisme juga dapat digunakan untuk menyuntikkan secrets dari penyimpanan pihak ketiga sebagai volume, seperti Secrets Store CSI Driver. Hal ini sebaiknya dilakukan sebagai alternatif dibandingkan memberikan pod akses RBAC service account ke secrets. Dengan cara ini, secrets dapat ditambahkan ke pod sebagai variabel lingkungan atau file. Namun, perlu dicatat bahwa metode variabel lingkungan lebih rentan terhadap kebocoran karena core dump dalam log dan sifat variabel lingkungan di Linux yang tidak bersifat rahasia, dibandingkan dengan mekanisme izin pada file.
Token service account tidak boleh dimasukkan ke dalam pod yang tidak membutuhkannya. Hal ini dapat dikonfigurasi dengan mengatur automountServiceAccountToken ke false, baik di dalam service account untuk diterapkan di seluruh namespace atau secara spesifik untuk sebuah pod. Untuk Kubernetes v1.22 dan yang lebih baru, gunakan Bound Service Accounts untuk kredensial service account yang memiliki batas waktu.
Images
Minimalkan konten yang tidak diperlukan dalam container image.
Container image dikonfigurasi untuk dijalankan sebagai pengguna tanpa hak istimewa.
Referensi ke container image dilakukan menggunakan digest sha256 (bukan tag) atau asal-usul image divalidasi dengan memverifikasi tanda tangan digital image saat waktu penerapan melalui admission control.
Container image secara rutin dipindai selama pembuatan dan penerapan, dan perangkat lunak yang rentan diketahui diperbaiki.
Container image sebaiknya hanya berisi konten minimum yang diperlukan untuk menjalankan program yang dikemas. Sebaiknya hanya program dan dependensinya, dengan membangun image dari base image yang seminimal mungkin. Secara khusus, image yang digunakan di lingkungan produksi sebaiknya tidak mengandung shell atau utilitas debugging, karena ephemeral debug container dapat digunakan untuk pemecahan masalah.
Bangun image agar langsung dijalankan dengan pengguna tanpa hak istimewa menggunakan instruksi USER dalam Dockerfile. Security Context memungkinkan container image dijalankan dengan pengguna dan grup tertentu menggunakan runAsUser dan runAsGroup, bahkan jika tidak ditentukan dalam manifest image. Namun, izin file dalam layer image mungkin membuatnya tidak memungkinkan untuk langsung memulai proses dengan pengguna tanpa hak istimewa tanpa modifikasi image.
Hindari menggunakan tag image untuk mereferensikan image, terutama tag latest, karena image di balik tag dapat dengan mudah dimodifikasi di registry. Sebaiknya gunakan digest lengkap sha256 yang unik untuk manifest image. Kebijakan ini dapat ditegakkan melalui ImagePolicyWebhook. Tanda tangan image juga dapat secara otomatis diverifikasi dengan admission controller saat waktu penerapan untuk memvalidasi keaslian dan integritasnya.
Pemindaian container image dapat mencegah kerentanan kritis diterapkan ke klaster bersama dengan container image. Pemindaian image harus diselesaikan sebelum menerapkan container image ke klaster dan biasanya dilakukan sebagai bagian dari proses penerapan dalam pipeline CI/CD. Tujuan dari pemindaian image adalah untuk mendapatkan informasi tentang kemungkinan kerentanan dan pencegahannya dalam container image, seperti skor Common Vulnerability Scoring System (CVSS). Jika hasil pemindaian image digabungkan dengan aturan kepatuhan pipeline, hanya container image yang telah diperbaiki dengan benar yang akan digunakan di lingkungan produksi.
Admission controllers
Pemilihan admission controller yang sesuai diaktifkan.
Kebijakan keamanan pod ditegakkan oleh Pod Security Admission atau/atau webhook admission controller.
Plugin rantai admission dan webhook dikonfigurasi dengan aman.
Admission controller dapat membantu meningkatkan keamanan klaster. Namun, mereka juga dapat menghadirkan risiko karena memperluas API server dan harus diamankan dengan benar.
Daftar berikut menyajikan sejumlah admission controller yang dapat dipertimbangkan untuk meningkatkan postur keamanan klaster dan aplikasi Anda. Ini mencakup controller yang mungkin dirujuk di bagian lain dokumen ini.
Grup pertama admission controller ini mencakup plugin yang diaktifkan secara default, pertimbangkan untuk tetap mengaktifkannya kecuali Anda tahu apa yang Anda lakukan:
Memungkinkan penggunaan custom controller melalui webhook, controller ini tidak memodifikasi permintaan yang mereka tinjau.
Grup kedua mencakup plugin yang tidak diaktifkan secara default tetapi berada dalam status ketersediaan umum dan direkomendasikan untuk meningkatkan postur keamanan Anda:
Membatasi izin kubelet untuk hanya memodifikasi sumber daya API pod yang mereka miliki atau sumber daya API node yang mewakili mereka sendiri. Ini juga mencegah kubelet menggunakan anotasi node-restriction.kubernetes.io/, yang dapat digunakan oleh penyerang dengan akses ke kredensial kubelet untuk memengaruhi penempatan pod ke node yang dikontrol.
Grup ketiga mencakup plugin yang tidak diaktifkan secara default tetapi dapat dipertimbangkan untuk kasus penggunaan tertentu:
Panduan dasar untuk memastikan keamanan aplikasi di Kubernetes, ditujukan untuk pengembang aplikasi
Daftar ini bertujuan untuk memberikan panduan dasar dalam mengamankan aplikasi
yang berjalan di Kubernetes dari perspektif pengembang.
Daftar ini tidak dimaksudkan untuk menjadi lengkap dan akan terus berkembang seiring waktu.
Cara membaca dan menggunakan dokumen ini:
Urutan topik tidak mencerminkan urutan prioritas.
Beberapa item daftar dijelaskan dalam paragraf di bawah daftar setiap bagian.
Daftar ini mengasumsikan bahwa pengembang adalah pengguna kluster Kubernetes yang
berinteraksi dengan objek dalam lingkup namespace.
Perhatian:
Daftar ini tidak cukup untuk mencapai postur keamanan yang baik dengan sendirinya.
Postur keamanan yang baik membutuhkan perhatian dan peningkatan yang terus-menerus, tetapi daftar ini
dapat menjadi langkah pertama dalam perjalanan tanpa akhir menuju kesiapan keamanan.
Beberapa rekomendasi dalam daftar ini bisa jadi terlalu ketat atau terlalu longgar untuk
kebutuhan keamanan spesifik kamu. Karena keamanan Kubernetes tidak bersifat "satu ukuran untuk semua",
setiap kategori item daftar periksa harus dievaluasi berdasarkan kelebihannya.
Penguatan keamanan dasar
Daftar berikut memberikan rekomendasi penguatan keamanan dasar yang
akan berlaku untuk sebagian besar aplikasi yang di-deploy ke Kubernetes.
Aplikasi dikonfigurasi dengan kelas QoS
yang sesuai melalui permintaan dan batas sumber daya.
Batas memori ditetapkan untuk beban kerja dengan batas yang sama atau lebih besar dari permintaan.
Batas CPU dapat ditetapkan pada beban kerja sensitif.
Akun layanan
Hindari menggunakan default ServiceAccount. Sebagai gantinya, buat ServiceAccount untuk
setiap beban kerja (workloads) atau layanan mikro.
automountServiceAccountToken harus disetel ke false kecuali pod
secara khusus memerlukan akses ke API Kubernetes untuk beroperasi.
Rekomendasi securityContext tingkat pod
Terapkan runAsNonRoot: true.
Konfigurasikan container untuk dijalankan sebagai pengguna dengan hak istimewa lebih rendah
(misalnya, menggunakan runAsUser dan runAsGroup), dan konfigurasikan izin yang sesuai
pada file atau direktori di dalam image container.
Opsional, tambahkan grup tambahan dengan fsGroup untuk mengakses volume persisten.
Aplikasi di-deploy ke namespace yang menerapkan
standar keamanan Pod yang sesuai.
Jika kamu tidak dapat mengontrol penerapan ini untuk kluster tempat aplikasi di-deploy,
pertimbangkan ini melalui dokumentasi atau pertahanan tambahan secara mendalam.
Rekomendasi securityContext tingkat container
Nonaktifkan eskalasi hak istimewa menggunakan allowPrivilegeEscalation: false.
Konfigurasikan sistem file root agar hanya dapat dibaca dengan readOnlyRootFilesystem: true.
Hindari menjalankan container dengan hak istimewa (atur privileged: false).
Hapus semua kemampuan dari container dan tambahkan kembali hanya yang spesifik
yang diperlukan untuk operasi container.
Kontrol Akses Berbasis Peran (RBAC)
Izin seperti create, patch, update, dan delete
hanya boleh diberikan jika diperlukan.
Hindari membuat izin RBAC untuk membuat atau memperbarui peran yang dapat menyebabkan
eskalasi hak istimewa.
Tinjau binding untuk grup system:unauthenticated dan hapus jika memungkinkan,
karena ini memberikan akses kepada siapa saja yang dapat menghubungi server API pada tingkat jaringan.
Untuk beban kerja sensitif, pertimbangkan untuk menyediakan ValidatingAdmissionPolicy yang direkomendasikan
yang lebih membatasi tindakan tulis yang diizinkan.
Keamanan image
Gunakan alat pemindaian image untuk memindai image sebelum mendepoy container di kluster Kubernetes.
Gunakan penandatanganan container untuk memvalidasi tanda tangan image container sebelum men-deploy ke kluster Kubernetes.
Kebijakan jaringan
Konfigurasikan NetworkPolicies
untuk hanya mengizinkan lalu lintas masuk dan keluar yang diharapkan dari pod.
Pastikan bahwa kluster kamu menyediakan dan menerapkan NetworkPolicy.
Jika kamu menulis aplikasi yang akan di-deploy pengguna ke kluster yang berbeda,
pertimbangkan apakah kamu dapat mengasumsikan bahwa NetworkPolicy tersedia dan diterapkan.
Penguatan keamanan tingkat lanjut
Bagian ini mencakup beberapa poin penguatan keamanan tingkat lanjut
yang mungkin berharga berdasarkan pengaturan lingkungan Kubernetes yang berbeda.
Konfigurasikan kelas runtime yang sesuai untuk container.
Catatan: Bagian ini tertaut ke proyek-proyek pihak ketiga yang menyediakan fungsionalitas yang dibutuhkan oleh Kubernetes. Pencipta proyek Kubernetes tidak bertanggung jawab atas proyek-proyek tersebut. Laman ini mengikuti pedoman website CNCF dengan membuat daftar proyek menurut abjad. Untuk menambakan proyek ke dalam daftar ini, bacalah panduan sebelum mengirimkan perubahan.
Beberapa container mungkin memerlukan tingkat isolasi yang berbeda dari yang disediakan oleh
runtime default kluster. runtimeClassName dapat digunakan dalam podspec
untuk mendefinisikan kelas runtime yang berbeda.
Untuk beban kerja sensitif, pertimbangkan menggunakan alat emulasi kernel seperti
gVisor, atau isolasi virtual menggunakan mekanisme
seperti kata-containers.
Dalam lingkungan dengan tingkat kepercayaan tinggi, pertimbangkan menggunakan
mesin virtual rahasia
untuk lebih meningkatkan keamanan kluster.
9 - Penjadwalan dan Pengusiran
9.1 - Bin Packing Sumber Daya untuk Sumber Daya Tambahan
FEATURE STATE:Kubernetes 1.16 [alpha]
Kube-scheduler dapat dikonfigurasikan untuk mengaktifkan pembungkusan rapat
(bin packing) sumber daya bersama dengan sumber daya tambahan melalui fungsi prioritas
RequestedToCapacityRatioResourceAllocation. Fungsi-fungsi prioritas dapat digunakan
untuk menyempurnakan kube-scheduler sesuai dengan kebutuhan.
Mengaktifkan Bin Packing menggunakan RequestedToCapacityRatioResourceAllocation
Sebelum Kubernetes 1.15, kube-scheduler digunakan untuk memungkinkan mencetak
skor berdasarkan rasio permintaan terhadap kapasitas sumber daya utama seperti
CPU dan Memori. Kubernetes 1.16 menambahkan parameter baru ke fungsi prioritas
yang memungkinkan pengguna untuk menentukan sumber daya beserta dengan bobot
untuk setiap sumber daya untuk memberi nilai dari Node berdasarkan rasio
permintaan terhadap kapasitas. Hal ini memungkinkan pengguna untuk bin pack
sumber daya tambahan dengan menggunakan parameter yang sesuai untuk meningkatkan
pemanfaatan sumber daya yang langka dalam klaster yang besar. Perilaku
RequestedToCapacityRatioResourceAllocation dari fungsi prioritas dapat
dikontrol melalui pilihan konfigurasi yang disebut RequestToCapacityRatioArguments.
Argumen ini terdiri dari dua parameter yaitu shape dan resources. Shape
memungkinkan pengguna untuk menyempurnakan fungsi menjadi yang paling tidak
diminta atau paling banyak diminta berdasarkan nilai utilization dan score.
Sumber daya terdiri dari name yang menentukan sumber daya mana yang dipertimbangkan
selama penilaian dan weight yang menentukan bobot masing-masing sumber daya.
Di bawah ini adalah contoh konfigurasi yang menetapkan requestedToCapacityRatioArguments
pada perilaku bin packing untuk sumber daya tambahan intel.com/foo dan intel.com/bar
Argumen di atas memberikan Node nilai 0 jika utilisasi 0% dan 10 untuk utilisasi 100%,
yang kemudian mengaktfikan perilaku bin packing. Untuk mengaktifkan dari paling
yang tidak diminta, nilainya harus dibalik sebagai berikut.
Parameter weight adalah opsional dan diatur ke 1 jika tidak ditentukan.
Selain itu, weight tidak dapat diatur ke nilai negatif.
Bagaimana Fungsi Prioritas RequestedToCapacityRatioResourceAllocation Menilai Node
Bagian ini ditujukan bagi kamu yang ingin memahami secara detail internal
dari fitur ini.
Di bawah ini adalah contoh bagaimana nilai dari Node dihitung untuk satu kumpulan
nilai yang diberikan.
Ketika kamu menjalankan Pod pada Node, Pod itu akan mengambil sejumlah sumber daya sistem. Sumber daya ini adalah tambahan terhadap sumber daya yang diperlukan untuk menjalankan Container di dalam Pod (overhead).
Pod Overhead adalah fitur yang berfungsi untuk menghitung sumber daya digunakan oleh infrastruktur Pod selain permintaan dan limit Container.
Overhead Pod
Pada Kubernetes, Overhead Pod ditentukan pada
saat admisi sesuai dengan Overhead yang ditentukan di dalam
RuntimeClass milik Pod.
Ketika Overhead Pod diaktifkan, Overhead akan dipertimbangkan sebagai tambahan terhadap jumlah permintaan sumber daya Container
saat menjadwalkan Pod. Begitu pula Kubelet, yang akan memasukkan Overhead Pod saat menentukan ukuran
cgroup milik Pod, dan saat melakukan pemeringkatan pengusiran (eviction) Pod.
Yang perlu disiapkan
Kamu harus memastikan bahwa
feature gatePodOverhead telah diaktifkan (secara bawaan dinonaktifkan)
di seluruh klaster kamu, yang berarti:
Pada peladen API khusus (custom) apa pun yang menggunakan feature gate
Catatan:
Pengguna yang dapat mengubah sumber daya RuntimeClass dapat memengaruhi kinerja beban kerja klaster secara keseluruhan. Kamu dapat membatasi akses terhadap kemampuan ini dengan kontrol akses Kubernetes.
Lihat Ringkasan Otorisasi untuk lebih lanjut.
Kamu dapat memaksa sebuah pod untuk hanya dapat berjalan pada node tertentu atau mengajukannya agar berjalan pada node tertentu. Ada beberapa cara untuk melakukan hal tersebut. Semua cara yang direkomendasikan adalah dengan menggunakan selector label untuk menetapkan pilihan yang kamu inginkan. Pada umumnya, pembatasan ini tidak dibutuhkan, sebagaimana scheduler akan melakukan penempatan yang proporsional dengan otomatis (seperti contohnya menyebar pod di node-node, tidak menempatkan pod pada node dengan sumber daya yang tidak memadai, dst.) tetapi ada keadaan-keadaan tertentu yang membuat kamu memiliki kendali lebih terhadap node yang menjadi tempat pod dijalankan, contohnya untuk memastikan pod dijalankan pada mesin yang telah terpasang SSD, atau untuk menempatkan pod-pod dari dua servis yang berbeda yang sering berkomunikasi bersamaan ke dalam zona ketersediaan yang sama.
Penggunaan nodeSelector adalah cara pembatasan pemilihan node paling sederhana yang direkomendasikan. nodeSelector adalah sebuah field pada PodSpec. nodeSelector memerinci sebuah map berisi pasangan kunci-nilai. Agar pod dapat dijalankan pada sebuah node yang memenuhi syarat, node tersebut harus memiliki masing-masing dari pasangan kunci-nilai yang dinyatakan sebagai label (namun node juga dapat memiliki label tambahan diluar itu). Penggunaan paling umum adalah satu pasang kunci-nilai.
Mari kita telusuri contoh dari penggunaan nodeSelector.
Langkah Nol: Prasyarat
Contoh ini mengasumsikan bahwa kamu memiliki pemahaman dasar tentang pod Kubernetes dan kamu telah membuat klaster Kubernetes.
Langkah Satu: Menyematkan label pada node
Jalankan kubectl get nodes untuk mendapatkan nama dari node-node yang ada dalam klaster kamu. Temukan node yang akan kamu tambahkan label, kemudian jalankan perintah kubectl label nodes <node-name> <label-key>=<label-value> untuk menambahkan label pada node yang telah kamu pilih. Sebagai contoh, jika nama node yang saya pilih adalah 'kubernetes-foo-node-1.c.a-robinson.internal' dan label yang ingin saya tambahkan adalah 'disktype=ssd', maka saya dapat menjalankan kubectl label nodes kubernetes-foo-node-1.c.a-robinson.internal disktype=ssd.
Kamu dapat memastikan perintah telah berhasil dengan menjalankan ulang perintah kubectl get nodes --show-labels and memeriksa bahwa node yang dipilih sekarang sudah memiliki label yang ditambahkan. Kamu juga dapat menggunakan kubectl describe node "nodename" untuk melihat daftar lengkap label yang dimiliki sebuah node.
Langkah Dua: Menambahkan sebuah nodeSelector ke konfigurasi pod kamu
Ambil berkas konfigurasi pod manapun yang akan kamu jalankan, dan tambahkan sebuah bagian nodeSelector pada berkas tersebut, seperti berikut. Sebagai contoh, jika berikut ini adalah konfigurasi pod saya:
Ketika kamu menjalankan perintah kubectl apply -f https://k8s.io/examples/pods/pod-nginx.yaml, pod tersebut akan dijadwalkan pada node yang memiliki label yang dirinci. Kamu dapat memastikan penambahan nodeSelector berhasil dengan menjalankan kubectl get pods -o wide dan melihat "NODE" tempat Pod ditugaskan.
Selingan: label node built-in
Sebagai tambahan dari label yang kamu sematkan, node sudah terisi dengan satu set label standar. Pada Kubernetes v1.4 label tersebut adalah
kubernetes.io/hostname
failure-domain.beta.kubernetes.io/zone
failure-domain.beta.kubernetes.io/region
beta.kubernetes.io/instance-type
kubernetes.io/os
kubernetes.io/arch
Catatan:
Nilai dari label-label tersebut spesifik untuk setiap penyedia layanan cloud dan tidak dijamin reliabilitasnya.
Contohnya, nilai dari kubernetes.io/hostname bisa saja sama dengan nama node pada beberapa lingkungan dan berbeda pada lingkungan lain.
Isolasi/pembatasan Node
Menambahkan label pada objek node memungkinkan penargetan pod pada node atau grup node yang spesifik. Penambahan label ini dapat digunakan untuk memastikan pod yang spesifik hanya berjalan pada node dengan isolasi, keamanan, atau pengaturan tertentu. Saat menggunakan label untuk tujuan tersebut, memilih kunci label yang tidak bisa dimodifikasi oleh proses kubelet pada node sangat direkomendasikan. Hal ini mencegah node yang telah diubah untuk menggunakan kredensial kubelet-nya untuk mengatur label-label pada objek nodenya sediri, dan mempengaruhi scheduler untuk menjadwalkan workload ke node yang telah diubah tersebut.
Plugin penerimaan NodeRestriction mencegah kubeletes untuk megatur atau mengubah label dengan awalan node-restriction.kubernetes.io/.
Untuk memanfaatkan awalan label untuk isolasi node:
Pastikan kamu menggunakan authorizer node dan mengaktifkan [plugin admission NodeRestriction(/docs/reference/access-authn-authz/admission-controllers/#noderestriction).
Tambah label dengan awalan node-restriction.kubernetes.io/ ke objek node kamu, dan gunakan label tersebut pada node selector kamu. Contohnya, example.com.node-restriction.kubernetes.io/fips=true or example.com.node-restriction.kubernetes.io/pci-dss=true.
Afinitas dan anti-afinitas
_Field_ nodeSelector menyediakan cara yang sangat sederhana untuk membatasi pod ke node dengan label-label tertentu. Fitur afinitas/anti-afinitas saat ini bersifat beta dan memperluas tipe pembatasan yang dapat kamu nyatakan. Peningkatan kunci dari fitur ini adalah
Bahasa yang lebih ekspresif (tidak hanya "AND of exact match")
Kamu dapat memberikan indikasi bahwa aturan yang dinyatakan bersifat rendah/preferensi dibanding dengan persyaratan mutlak sehingga jika scheduler tidak dapat memenuhinya, pod tetap akan dijadwalkan
Kamu dapat membatasi dengan label pada pod-pod lain yang berjalan pada node (atau domain topological lain), daripada dengan label pada node itu sendiri, yang memungkinkan pengaturan tentang pod yang dapat dan tidak dapat dilokasikan bersama.
Fitur afinitas terdiri dari dua tipe afinitas yaitu "node afinitas" dan "inter-pod afinitas/anti-afinitas"
Node afinitas adalah seperti nodeSelector yang telah ada (tetapi dengam dua kelebihan pertama yang terdaftar di atas), sementara inter-pod afinitas/anti-afinitas membatasi pada label pod daripada label node, seperti yang dijelaskan pada item ketiga pada daftar di atas, sebagai tambahan dari item pertama dan kedua.
FieldnodeSelector tetap berjalan seperti biasa, namun pada akhirnya akan ditinggalkan karena afinitas node dapat menyatakan semua yang nodeSelector dapat nyatakan.
Afinitas node (fitur beta)
Afinitas node diperkenalkan sebagai fitur alfa pada Kubernetes 1.2.
Afinitas node secara konseptual mirip dengan nodeSelector yang memungkinkan kamu untuk membatasi node yang memenuhi syarat untuk penjadwalan pod, berdasarkan label pada node.
Saat ini ada dia tipe afinitas node, yaitu requiredDuringSchedulingIgnoredDuringExecution dan
preferredDuringSchedulingIgnoredDuringExecution. Kamu dapat menganggap dua tipe ini sebagai "kuat" dan "lemah" secara berurutan, dalam arti tipe pertama menyatakan peraturan yang harus dipenuhi agar pod dapat dijadwalkan pada node (sama seperti nodeSelector tetapi menggunakan sintaksis yang lebih ekpresif), sementara tipe kedua menyatakan preferensi yang akan dicoba dilaksanakan tetapi tidak akan dijamin oleh scheduler. Bagian "IgnoredDuringExecution" dari nama tipe ini berarti, mirip dengan cara kerja nodeSelector, jika label pada node berubah pada runtime yang menyebabkan aturan afinitas pada pod tidak lagi terpenuhi, pod akan tetap berjalan pada node. Pada masa yang akan datang kami berencana menawarkan requiredDuringSchedulingRequiredDuringExecution yang akan berjalan seperti requiredDuringSchedulingIgnoredDuringExecution hanya saja tipe ini akan mengeluarkan pod dari node yang gagal untuk memenuhi persyaratan afinitas node pod.
Dengan denikian, contoh dari requiredDuringSchedulingIgnoredDuringExecution adalah "hanya jalankan pod pada node dengan Intel CPU" dan contoh dari preferredDuringSchedulingIgnoredDuringExecution adalah "coba jalankan set pod ini dalam zona ketersediaan XYZ, tetapi jika tidak memungkinkan, maka biarkan beberapa pod berjalan di tempat lain".
Afinitas node dinyatakan sebagai fieldnodeAffinity dari fieldaffinity pada PodSpec.
Berikut ini contoh dari pod yang menggunakan afinitas node:
Aturan afinitas node tersebut menyatakan pod hanya bisa ditugaskan pada node dengan label yang memiliki kunci kubernetes.io/e2e-az-name dan bernilai e2e-az1 atau e2e-az2. Selain itu, dari semua node yang memenuhi kriteria tersebut, mode dengan label dengan kunci another-node-label-key and bernilai another-node-label-value harus lebih diutamakan.
Kamu dapat meilhat operator In digunakan dalam contoh berikut. Sitaksis afinitas node yang baru mendukung operator-operator berikut: In, NotIn, Exists, DoesNotExist, Gt, Lt. Kamu dapat menggunakan NotIn dan DoesNotExist untuk mewujudkan perilaku node anti-afinitas, atau menggunakan node taints untuk menolak pod dari node tertentu.
Jika kamu menyatakan nodeSelector dan nodeAffinity. keduanya harus dipenuhi agar pod dapat dijadwalkan pada node kandidat.
Jika kamu menyatakan beberapa nodeSelectorTerms yang terkait dengan tipe nodeAffinity, maka pod akan dijadwalkan pada node jika salah satu dari nodeSelectorTerms dapat terpenuhi.
Jika kamu menyatakan beberapa matchExpressions yang terkait dengan nodeSelectorTerms, makan pod dapat dijadwalkan pada node hanya jika semuamatchExpressions dapat terpenuhi.
Jika kamu menghapus atau mengubah label pada node tempat pod dijadwalkan, pod tidak akan dihapus. Dengan kata lain, pemilihan afinitas hanya bekerja pada saat waktu penjadwalan pod.
Fieldweight pada preferredDuringSchedulingIgnoredDuringExecution berada pada rentang nilai 1-100. Untuk setiap node yang memenuhi semua persyaratan penjadwalan (permintaan sumber daya, pernyataan afinitas RequiredDuringScheduling, dll.), scheduler akan menghitung nilai jumlah dengan melakukan iterasi pada elemen-elemen dari field ini dan menambah "bobot" pada jumlah jika node cocok dengan MatchExpressions yang sesuai. Nilai ini kemudian digabungkan dengan nilai dari fungsi prioritas lain untuk node. Node dengan nilai tertinggi adalah node lebih diutamakan.
Untuk informasi lebih lanjut tentang afinitas node kamu dapat melihat design doc.
Afinitas and anti-afinitas antar pod (fitur beta)
Afinitas and anti-afinitas antar pod diperkenalkan pada Kubernetes 1.4. Afinitas and anti-afinitas antar pod memungkinkan kamu untuk membatasi node yang memenuhi syarat untuk penjadwalan pod berdasarkan label-label pada pod yang sudah berjalan pada node daripada berdasarkan label-label pada node. Aturan tersebut berbentuk "pod ini harus (atau, dalam kasus
anti-afinitas, tidak boleh) berjalan dalam X jika X itu sudah menjalankan satu atau lebih pod yang memenuhi aturan Y". Y dinyatakan sebagai sebuah LabelSelector dengan daftar namespace terkait; tidak seperti node, karena pod are namespaced (maka dari itu label-label pada pod diberi namespace secara implisit), sebuah label selector di atas label-label pod harus menentukan namespace yang akan diterapkan selector. Secara konsep X adalah domain topologi seperti node, rack, zona penyedia cloud, daerah penyedia cloud, dll. Kamu dapat menyatakannya menggunakan topologyKey yang merupakan kunci untuk label node yang digunakan sistem untuk menunjukkan domain topologi tersebut, contohnya lihat kunci label yang terdaftar di atas pada bagian Selingan: label node built-in.
Catatan:
Afinitas and anti-afinitas antar pod membutuhkan jumlah pemrosesan yang substansial yang dapat memperlambat penjadwalan pada klaster berukuran besar secara signifikan. Kami tidak merekomendasikan penggunaan mereka pada klaster yang berukuran lebih besar dari beberapa ratus node.
Catatan:
Anti-afinitas pod mengharuskan node untuk diberi label secara konsisten, misalnya setiap node dalam klaster harus memiliki label sesuai yang cocok dengan topologyKey. Jika sebagian atau semua node tidak memiliki label topologyKey yang dinyatakan, hal ini dapat menyebabkan perilaku yang tidak diinginkan.
Seperti afinitas node, ada dua tipe afinitas dan anti-afinitas pod, yaitu requiredDuringSchedulingIgnoredDuringExecution dan
preferredDuringSchedulingIgnoredDuringExecution yang menunjukan persyaratan "kuat" vs. "lemah". Lihat deskripsi pada bagian afinitas node sebelumnya.
Sebuah contoh dari afinitas requiredDuringSchedulingIgnoredDuringExecution adalah "Tempatkan bersamaan pod layanan A dan layanan B di zona yang sama, karena mereka banyak berkomunikasi satu sama lain"
dan contoh preferDuringSchedulingIgnoredDuringExecution anti-afinitas akan menjadi "sebarkan pod dari layanan ini di seluruh zona" (persyaratan kuat tidak masuk akal, karena kamu mungkin memiliki lebih banyak pod daripada zona).
Afinitas antar pod dinyatakan sebagai fieldpodAffinity dari fieldaffinity pada PodSpec dan anti-afinitas antar pod dinyatakan sebagai fieldpodAntiAffinity dari fieldaffinity pada PodSpec.
Afinitas pada pod tersebut menetapkan sebuah aturan afinitas pod dan aturan anti-afinitas pod. Pada contoh ini, podAffinity adalah requiredDuringSchedulingIgnoredDuringExecution
sementara podAntiAffinity adalah preferredDuringSchedulingIgnoredDuringExecution. Aturan afinitas pod menyatakan bahwa pod dapat dijadwalkan pada node hanya jika node tersebut berada pada zona yang sama dengan minimal satu pod yang sudah berjalan yang memiliki label dengan kunci "security" dan bernilai "S1". (Lebih detail, pod dapat berjalan pada node N jika node N memiliki label dengan kunci failure-domain.beta.kubernetes.io/zonedan nilai V sehingga ada minimal satu node dalam klaster dengan kunci failure-domain.beta.kubernetes.io/zone dan bernilai V yang menjalankan pod yang memiliki label dengan kunci "security" dan bernilai "S1".) Aturan anti-afinitas pod menyatakan bahwa pod memilih untuk tidak dijadwalkan pada sebuah node jika node tersebut sudah menjalankan pod yang memiliki label dengan kunci "security" dan bernilai "S2". (Jika topologyKey adalah failure-domain.beta.kubernetes.io/zone maka dapat diartikan bahwa pod tidak dapat dijadwalkan pada node jika node berada pada zona yang sama dengan pod yang memiliki label dengan kunci "security" dan bernilai "S2".) Lihat design doc untuk lebih banyak contoh afinitas dan anti-afinitas pod, baik requiredDuringSchedulingIgnoredDuringExecution
maupun preferredDuringSchedulingIgnoredDuringExecution.
Operator yang sah untuk afinitas dan anti-afinitas pod adalah In, NotIn, Exists, DoesNotExist.
Pada dasarnya, topologyKey dapat berupa label-kunci apapun yang sah. Namun, untuk alasan performa dan keamanan, ada beberapa batasan untuk topologyKey:
Untuk afinitas and anti-afinitas pod requiredDuringSchedulingIgnoredDuringExecution, topologyKey tidak boleh kosong.
Untuk anti-afinitas pod requiredDuringSchedulingIgnoredDuringExecution, pengontrol penerimaan LimitPodHardAntiAffinityTopology diperkenalkan untuk membatasi topologyKey pada kubernetes.io/hostname. Jika kamu menginginkan untuk membuatnya tersedia untuk topologi khusus, kamu dapat memodifikasi pengontrol penerimaan, atau cukup menonaktifkannya saja.
Untuk anti-afinitas pod preferredDuringSchedulingIgnoredDuringExecution, topologyKey yang kosong diinterpretasikan sebagai "semua topologi" ("semua topologi" sekarang dibatasi pada kombinasi dari kubernetes.io/hostname, failure-domain.beta.kubernetes.io/zone dan failure-domain.beta.kubernetes.io/region).
Kecuali untuk kasus-kasus di atas, topologyKey dapat berupa label-kunci apapun yang sah.
Sebagai tambahan untuk labelSelector and topologyKey, kamu secara opsional dapat menyatakan daftar namespaces dari namespaces yang akan digunakan untuk mencocokan labelSelector (daftar ini berjalan pada level definisi yang sama dengan labelSelector dan topologyKey)
Jika dihilangkan atau kosong, daftar ini sesuai standar akan merujuk pada namespace dari pod tempat definisi afinitas/anti-afinitas dinyatakan.
Semua matchExpressions berkaitan dengan afinitas and anti-afinitas requiredDuringSchedulingIgnoredDuringExecution harus dipenuhi agar pod dapat dijadwalkan pada node.
Penggunaan yang lebih praktikal
Afinitas and anti-afinitas antar pod dapat menjadi lebih berguna saat digunakan bersamaan dengan koleksi dengan level yang lebih tinggi seperti ReplicaSets, StatefulSets, Deployments, dll. Pengguna dapat dengan mudah mengkonfigurasi bahwa satu set workload harus
ditempatkan bersama dalam topologi yang didefinisikan sama, misalnya, node yang sama.
Selalu ditempatkan bersamaan pada node yang sama
Dalam klaster berisi 3 node, sebuah aplikasi web memiliki in-memory cache seperti redis. Kita menginginkan agar web-server dari aplikasi ini sebisa mungkin ditempatkan bersamaan dengan cache.
Berikut ini kutipan yaml dari deployment redis sederhana dengan 3 replika dan label selector app=store, Deployment memiliki konfigurasi PodAntiAffinity untuk memastikan scheduler tidak menempatkan replika bersamaan pada satu node.
Kutipan yaml dari deployment webserver berikut ini memiliki konfigurasi podAntiAffinity dan podAffinity. Konfigurasi ini menginformasikan scheduler bahwa semua replika harus ditempatkan bersamaan dengan pod yang memiliki label selector app=store. Konfigurasi ini juga memastikan bahwa setiap replika webserver tidak ditempatkan bersamaan pada satu node.
Tidak akan pernah ditempatkan bersamaan dalam node yang sama
Contoh di atas menggunakan aturan PodAntiAffinity dengan topologyKey: "kubernetes.io/hostname" untuk melakukan deploy klaster redis sehingga tidak ada dua instance terletak pada hos yang sama.
Lihat tutorial ZooKeeper untuk contoh dari konfigurasi StatefulSet dengan anti-afinitas untuk ketersediaan tinggi, menggunakan teknik yang sama.
Untuk informasi lebih lanjut tentang afinitas/anti-afinitas antar pod, lihat design doc.
Kamu juga dapat mengecek Taints, yang memungkinkan sebuah node untuk menolak sekumpulan pod.
nodeName
nodeName adalah bentuk paling sederhana dari pembatasan pemilihan node, tetapi karena
keterbatasannya biasanya tidak digunakan. nodeName adalah sebuah field dari
PodSpec. Jika tidak kosong, scheduler mengabaikan pod dan
kubelet yang berjalan pada node tersebut yang mencoba menjalankan pod. Maka, jika
nodeName disediakan dalam PodSpec, ia memiliki hak yang lebih tinggi dibanding metode-metode di atas untuk pemilihan node.
Beberapa keterbatasan dari penggunaan nodeName untuk memilih node adalah:
Jika node yang disebut tidak ada, maka pod tidak akan dijalankan, dan dalam beberapa kasus akan
dihapus secara otomatis.
Jika node yang disebut tidak memiliki resource yang cukup untuk mengakomodasi pod, pod akan gagal
dan alasannya akan mengindikasikan sebab kegagalan, misalnya OutOfmemory atau OutOfcpu.
Nama node pada lingkungan cloud tidak selalu dapat diprediksi atau stabil.
Berikut ini contoh konfigurasi pod menggunakan fieldnodeName:
Afinitas Node, seperti yang dideskripsikan di sini,
adalah salah satu properti dari Pod yang menyebabkan pod tersebut memiliki preferensi
untuk ditempatkan di sekelompok Node tertentu (preferensi ini dapat berupa soft constraints atau
hard constraints yang harus dipenuhi). Taint merupakan kebalikan dari afinitas --
properti ini akan menyebabkan Pod memiliki preferensi untuk tidak ditempatkan pada sekelompok Node tertentu.
Taint dan toleration bekerja sama untuk memastikan Pod dijadwalkan pada Node
yang sesuai. Satu atau lebih taint akan diterapkan pada suatu node; hal ini akan menyebabkan
node tidak akan menerima pod yang tidak mengikuti taint yang sudah diterapkan.
Konsep
Kamu dapat menambahkan taint pada sebuah node dengan menggunakan perintah kubectl taint.
Misalnya,
kubectl taint nodes node1 key=value:NoSchedule
akan menerapkan taint pada nodenode1. Taint tersebut memiliki keykey, valuevalue,
dan effecttaintNoSchedule. Hal ini artinya pod yang ada tidak akan dapat dijadwalkan pada node1
kecuali memiliki taint yang sesuai.
Untuk menghilangkan taint yang ditambahkan dengan perintah di atas, kamu dapat menggunakan
perintah di bawah ini:
kubectl taint nodes node1 key:NoSchedule-
Kamu dapat memberikan spesifikasi toleration untuk pod pada bagian PodSpec.
Kedua toleration yang diterapkan di bawa ini "sesuai" dengan taint yang
taint yang dibuat dengan perintah kubectl taint di atas, sehingga sebuah pod
dengan toleration yang sudah didefinisikan akan mampu di-schedule ke node node:
Sebuah toleration "sesuai" dengan sebuah taint jika key dan efek yang
ditimbulkan sama:
operator dianggap Exists (pada kasus dimana tidak ada value yang diberikan), atau
operator dianggap Equal dan value yang ada sama
Operator bernilai Equal secara default jika tidak diberikan spesifikasi khusus.
Catatan:
Terdapat dua kasus khusus:
Sebuah key dengan operator Exists akan sesuai dengan semua key, value, dan effect yang ada.
Dengan kata lain, tolaration ini akan menerima semua hal yang diberikan.
tolerations:- operator:"Exists"
Sebuah effect yang kosong akan dianggap sesuai dengan semua effect dengan keykey.
tolerations:- key:"key"operator:"Exists"
Contoh yang diberikan di atas menggunakan effect untuk NoSchedule.
Alternatif lain yang dapat digunakan adalah effect untuk PreferNoSchedule.
PreferNoSchedule merupakan "preferensi" yang lebih fleksibel dari NoSchedule --
sistem akan mencoba untuk tidak menempatkan pod yang tidak menoleransi taint
pada node, tapi hal ini bukan merupakan sesuatu yang harus dipenuhi. Jenis ketiga
dari effect adalah NoExecute, akan dijelaskan selanjutnya.
Kamu dapat menerapkan beberapa taint sekaligus pada node atau
beberapa toleration sekaligus pada sebuah pod. Mekanisme Kubernetes dapat
memproses beberapa taint dan toleration sekaligus sama halnya seperti sebuah
filter: memulai dengan taint yang ada pada node, kemudian mengabaikan
taint yang sesuai pada pod yang memiliki toleration yang sesuai; kemudian
taint yang diterapkan pada pod yang sudah disaring tadi akan menghasilkan suatu
effect pada pod. Secara khusus:
jika terdapat taint yang tidak tersaring dengan effectNoSchedule maka Kubernetes tidak akan menempatkan
pod pada node tersebut
jika tidak terdapat taint yang tidak tersaring dengan effectNoSchedule
tapi terdapat setidaknya satu taint yang tidak tersaring dengan
effectPreferNoSchedule maka Kubernetes akan mencoba untuk tidak akan menempatkan
pod pada node tersebut
jika terdapat taint yang tidak tersaring dengan effectNoExecute maka pod akan
berada dalam kondisi evicted dari node (jika pod tersebut sudah terlanjur ditempatkan pada node
tersebut), dan tidak akan di-schedule lagi pada node tersebut.
Sebagai contoh, bayangkan kamu memberikan taint pada node sebagai berikut:
Pada kasus ini, pod tidak akan di-schedule pada node, karena tidak ada
toleration yang sesuai dengan taint ketiga. Akan tetapi, pod yang sebelumnya
sudah dijalankan di node dimana taint ditambahkan akan tetap jalan, karena taint
ketiga merupakan taint yang tidak ditoleransi oleh pod.
Pada umumnya, jika sebuah taint memiliki effectNoExecute ditambahkan pada node,
maka semua pod yang tidak menoleransi taint tersebut akan berada dalam stateevicted secara langsung, dan semua pod yang menoleransi taint tersebut
tidak akan berjalan seperti biasanya (tidak dalam stateevicted). Meskipun demikian,
toleration dengan effectNoExecute dapat dispesfikasikan sebagai field opsional
tolerationSeconds yang memberikan perintah berapa lama suatu pod akan berada
pada node apabila sebuah taint ditambahkan. Contohnya:
ini berarti apabila sebuah pod sedang dalam berada dalam staterunning,
kemudian sebuah taint yang sesuai ditambahkan pada node, maka pod tersebut
akan tetap berada di dalam node untuk periode 3600 detik sebelum state-nya
berubah menjadi evicted. Jika taint dihapus sebelum periode tersebut, maka pod
tetap berjalan sebagaimana mestinya.
Contoh Penggunaan
Taint dan toleration adalah mekanisme fleksibel yang digunakan untuk
memaksa pod agar tidak dijadwalkan pada node-node tertentu atau
mengubah statepod menjadi evicted. Berikut adalah beberapa contoh penggunaannya:
Node-Node yang Sifatnya Dedicated: Jika kamu ingin menggunakan
sekumpulan node dengan penggunaan eksklusif dari sekumpulan pengguna,
kamu dapat menambahkan taint pada node-node tersebut (misalnya,
kubectl taint nodes nodename dedicated=groupName:NoSchedule) dan kemudian
menambahkan toleration yang sesuai pada pod-pod yang berada di dalamnya (hal ini
dapat dilakukan dengan mudah dengan cara menulis
admission controller yang
bersifat khusus). Pod-pod dengan toleration nantinya akan diperbolehkannya untuk menggunakan
node yang sudah di-taint (atau dengan kata lain didedikasikan penggunaannya) maupun
node lain yang ada di dalam klaster. Jika kamu ingin mendedikasikan node khusus
yang hanya digunakan oleh pod-pod tadi serta memastikan pod-pod tadi hanya menggunakan
node yang didedikasikan, maka kamu harus menambahkan sebuah label yang serupa dengan
taint yang diberikan pada sekelompok node (misalnya, dedicated=groupName), dan
admission controller sebaiknya menambahkan afininitas node untuk memastikan pod-pod
tadi hanya dijadwalkan pada node dengan labeldedicated=groupName.
Node-Node dengan Perangkat Keras Khusus: Pada suatu klaster dimana
sebagian kecuali node memiliki perangkat keras khusus (misalnya GPU), kita ingin
memastikan hanya pod-pod yang membutuhkan GPU saja yang dijadwalkan di node dengan GPU.
Hal ini dapat dilakukan dengan memberikan taint pada node yang memiliki perangkat keras
khusus (misalnya, kubectl taint nodes nodename special=true:NoSchedule atau
kubectl taint nodes nodename special=true:PreferNoSchedule) serta menambahkan toleration
yang sesuai pada pod yang menggunakan node dengan perangkat keras khusus. Seperti halnya pada
kebutuhan dedicatednode, hal ini dapat dilakukan dengan mudah dengan cara menulis
admission controller yang
bersifat khusus. Misalnya, kita dapat menggunakan Extended Resource
untuk merepresentasikan perangkat keras khusus, kemudian taintnode dengan perangkat keras khusus
dengan nama extended resource dan jalankan admission controllerExtendedResourceToleration.
Setelah itu, karena node yang ada sudah di-taint, maka tidak akan ada pod yang
tidak memiliki toleration yang akan dijadwalkan pada node tersebut_.
Meskipun begitu, ketika kamu membuat suatu pod yang membutuhkan extended resource,
maka admission controller dari ExtendedResourceToleration akan mengoreksi
toleration sehingga pod tersebut dapat dijadwalkan pada node dengan perangkat keras khusus.
Dengan demikian, kamu tidak perlu menambahkan toleration secara manual pada pod yang ada.
Eviction berbasis Taint (fitur beta): Konfigurasi eviction per pod
yang terjadi ketika pod mengalami gangguan, hal ini akan dibahas lebih lanjut di bagian
selanjutnya.
Eviction berbasis Taint
Sebelumnya, kita sudah pernah membahas soal effecttaintNoExecute,
yang memengaruhi pod yang sudah dijalankan dengan cara sebagai berikut:
pod yang tidak menoleransi taint akan segera diubah state-nya menjadi evicted
pod yang menoleransi taint yang tidak menspesifikasikan tolerationSeconds pada
spesifikasi toleration yang ada akan tetap berada di dalam node tanpa adanya batas waktu tertentu
pod yang menoleransi taint yang menspesifikasikan tolerationSeconds
spesifikasi toleration yang ada akan tetap berada di dalam node hingga batas waktu tertentu
Sebagai tambahan, Kubernetes 1.6 memperkenalkan dukungan alfa untuk merepresentasikan
node yang bermasalah. Dengan kata lain, node controller akan secara otomatis memberikan taint
pada sebuah node apabila node tersebut memenuhi kriteria tertentu. Berikut merupakan taint
yang secara default disediakan:
node.kubernetes.io/not-ready: Node berada dalam statenot ready. Hal ini terjadi apabila
value dari NodeConditionReady adalah "False".
node.kubernetes.io/unreachable: Node berada dalam stateunreachable dari node controller
Hal ini terjadi apabila value dari NodeConditionReady adalah "Unknown".
node.kubernetes.io/memory-pressure: Node berada diambang kapasitas memori.
node.kubernetes.io/disk-pressure: Node berada diambang kapasitas disk.
node.kubernetes.io/network-unavailable: Jaringan pada Node bersifat unavailable.
node.kubernetes.io/unschedulable: Node tidak dapat dijadwalkan.
node.cloudprovider.kubernetes.io/uninitialized: Ketika kubelet dijalankan dengan
penyedia layanan cloud "eksternal", taint ini akan diterapkan pada node untuk menandai
node tersebut tidak digunakan. Setelah kontroler dari cloud-controller-manager melakukan
inisiasi node tersebut, maka kubelet akan menghapus taint yang ada.
Pada versi 1.13, fitur TaintBasedEvictions diubah menjadi beta dan diaktifkan secara default,
dengan demikian taint-taint tersebut secara otomatis ditambahkan oleh NodeController (atau kubelet)
dan logika normal untuk melakukan eviction pada pod dari suatu node tertentu berdasarkan value
dari Ready yang ada pada NodeCondition dinonaktifkan.
Catatan:
Untuk menjaga perilaku rate limiting yang
ada pada evictionpod apabila node mengalami masalah, sistem sebenarnya menambahkan
taint dalam bentuk rate limiter. Hal ini mencegah eviction besar-besaran pada pod
pada skenario dimana master menjadi terpisah dari node lainnya.
Fitur beta ini, bersamaan dengan tolerationSeconds, mengizinkan sebuah pod
untuk menspesifikasikan berapa lama pod harus tetap sesuai dengan sebuah node
apabila node tersebut bermasalah.
Misalnya, sebuah aplikasi dengan banyak state lokal akan lebih baik untuk tetap
berada di suatu node pada saat terjadi partisi jaringan, dengan harapan partisi jaringan
tersebut dapat diselesaikan dan mekanisme evictionpod tidak akan dilakukan.
Toleration yang ditambahkan akan berbentuk sebagai berikut:
Perhatikan bahwa Kubernetes secara otomatis menambahkan toleration untuk
node.kubernetes.io/not-ready dengan tolerationSeconds=300
kecuali konfigurasi lain disediakan oleh pengguna.
Kubernetes juga secara otomatis menambahkan toleration untuk
node.kubernetes.io/unreachable dengan tolerationSeconds=300
kecuali konfigurasi lain disediakan oleh pengguna.
Toleration yang ditambahkan secara otomatis ini menjamin bahwa
perilaku default dari suatu pod adalah tetap bertahan selama 5 menit pada
node apabila salah satu masalah terdeteksi.
Kedua tolerationdefault tadi ditambahkan oleh DefaultTolerationSeconds
admission controller.
Pod-pod pada DaemonSet dibuat dengan tolerationNoExecute untuk taint tanpa tolerationSeconds:
node.kubernetes.io/unreachable
node.kubernetes.io/not-ready
Hal ini menjamin pod-pod yang merupakan bagian dari DaemonSet tidak pernah berada di dalam
stateevicted apabila terjadi permasalahan pada node.
Taint pada Node berdasarkan Kondisi Tertentu
Pada versi 1.12, fitur TaintNodesByCondition menjadi fitur beta, dengan demikian lifecycle
dari kontroler node akan secara otomatis menambahkan taint sesuai dengan kondisi node.
Hal yang sama juga terjadi pada scheduler, scheduler tidak bertugas memeriksa kondisi node
tetapi kondisi taint. Hal ini memastikan bahwa kondisi node tidak memengaruhi apa
yang dijadwalkan di node. Pengguna dapat memilih untuk mengabaikan beberapa permasalahan yang
ada pada node (yang direpresentasikan oleh kondisi Node) dengan menambahkan tolerationPodNoSchedule.
Sedangkan taint dengan effectNoExecute dikendalikan oleh TaintBasedEviction yang merupakan
fitur beta yang diaktifkan secara default oleh Kubernetes sejak versi 1.13.
Sejak Kubernetes versi 1.8, kontroler DaemonSet akan secara otomatis
menambahkan tolerationNoSchedule pada semua daemon untuk menjaga
fungsionalitas DaemonSet.
node.kubernetes.io/memory-pressure
node.kubernetes.io/disk-pressure
node.kubernetes.io/out-of-disk (hanya untuk pod yang bersifat critical)
node.kubernetes.io/unschedulable (versi 1.10 atau yang lebih baru)
node.kubernetes.io/network-unavailable (hanya untuk jaringan host)
Menambahkan toleration ini menjamin backward compatibility.
Kamu juga dapat menambahkan toleration lain pada DaemonSet.
9.5 - Penjadwal Kubernetes
Dalam Kubernetes, scheduling atau penjadwalan ditujukan untuk memastikan
Pod mendapatkan
Node sehingga
Kubelet dapat menjalankannya.
Ikhtisar Penjadwalan
Sebuah penjadwal mengawasi Pod yang baru saja dibuat dan belum ada Node yang
dialokasikan untuknya. Untuk setiap Pod yang ditemukan oleh penjadwal, maka
penjadwal tersebut bertanggung jawab untuk menemukan Node terbaik untuk
menjalankan Pod. Penjadwal dapat menetapkan keputusan penempatan ini dengan
mempertimbangkan prinsip-prinsip penjadwalan yang dijelaskan di bawah ini.
Jika kamu ingin memahami mengapa Pod ditempatkan pada Node tertentu, atau jika
kamu berencana untuk mengimplementasikan penjadwal kustom sendiri, halaman ini
akan membantu kamu belajar tentang penjadwalan.
Kube-scheduler
Kube-scheduler
adalah penjadwal standar untuk Kubernetes dan dijalankan sebagai bagian dari
_control plane_.
Kube-scheduler dirancang agar jika kamu mau dan perlu, kamu bisa menulis
komponen penjadwalan kamu sendiri dan menggunakannya.
Untuk setiap Pod yang baru dibuat atau Pod yang tak terjadwal lainnya,
kube-scheduler memilih Node yang optimal untuk menjalankannya. Namun, setiap
kontainer masuk Pod memiliki persyaratan sumber daya yang berbeda dan setiap Pod
juga memiliki persyaratan yang berbeda juga. Oleh karena itu, Node yang ada
perlu dipilih sesuai dengan persyaratan khusus penjadwalan.
Dalam sebuah Klaster, Node yang memenuhi persyaratan penjadwalan untuk suatu Pod
disebut Node feasible. Jika tidak ada Node yang cocok, maka Pod tetap tidak
terjadwal sampai penjadwal yang mampu menempatkannya.
Penjadwal menemukan Node-Node yang layak untuk sebuah Pod dan kemudian
menjalankan sekumpulan fungsi untuk menilai Node-Node yang layak dan mengambil
satu Node dengan skor tertinggi di antara Node-Node yang layak untuk menjalankan
Pod. Penjadwal kemudian memberi tahu server API tentang keputusan ini dalam
proses yang disebut dengan binding.
Beberapa faktor yang perlu dipertimbangkan untuk keputusan penjadwalan termasuk
persyaratan sumber daya individu dan kolektif, aturan kebijakan / perangkat keras /
lunak, spesifikasi persamaan dan anti-persamaan, lokalitas data, interferensi
antar Workloads, dan sebagainya.
Pemilihan node pada kube-scheduler
Kube-scheduler memilih node untuk pod dalam 2 langkah operasi:
Filtering
Scoring
Langkah filtering menemukan sekumpulan Nodes yang layak untuk menjadwalkan
Pod. Misalnya, penyarin PodFitsResources memeriksa apakah Node kandidat
memiliki sumber daya yang cukup untuk memenuhi permintaan spesifik sumber daya dari
Pod. Setelah langkah ini, daftar Node akan berisi Node-node yang sesuai;
seringkali, akan terisi lebih dari satu. Jika daftar itu kosong, maka Pod itu
tidak (belum) dapat dijadwalkan.
Pada langkah scoring, penjadwal memberi peringkat pada Node-node yang tersisa
untuk memilih penempatan paling cocok untuk Pod. Penjadwal memberikan skor
untuk setiap Node yang sudah tersaring, memasukkan skor ini pada aturan
penilaian yang aktif.
Akhirnya, kube-scheduler memberikan Pod ke Node dengan peringkat tertinggi.
Jika ada lebih dari satu node dengan skor yang sama, maka kube-scheduler
memilih salah satunya secara acak.
Ada dua cara yang didukung untuk mengkonfigurasi perilaku penyaringan dan
penilaian oleh penjadwal:
Aturan Penjadwalan yang memungkinkan
kamu untuk mengkonfigurasi Predicates untuk pemfilteran dan Priorities
untuk penilaian.
Profil Penjadwalan yang memungkinkan
kamu mengkonfigurasi Plugin yang menerapkan tahapan penjadwalan berbeda,
termasuk: QueueSort, Filter, Score, Bind, Reserve, Permit, dan
lainnya. Kamu juga bisa mengonfigurasi kube-scheduler untuk menjalankan
profil yang berbeda.
9.6 - Kerangka Kerja Penjadwalan (Scheduling Framework)
FEATURE STATE:Kubernetes 1.15 [alpha]
Kerangka kerja penjadwalan (Scheduling Framework) adalah arsitektur yang dapat
dipasang (pluggable) pada penjadwal Kubernetes untuk membuat kustomisasi
penjadwal lebih mudah. Hal itu dilakukan dengan menambahkan satu kumpulan "plugin"
API ke penjadwal yang telah ada. Plugin dikompilasi ke dalam penjadwal.
Beberapa API memungkinkan sebagian besar fitur penjadwalan diimplementasikan
sebagai plugin, sambil tetap mempertahankan penjadwalan "inti" sederhana dan
terpelihara. Silahkan merujuk pada [proposal desain dari kerangka penjadwalan]
kep untuk informasi teknis lebih lanjut tentang desain kerangka kerja
tersebut.
Alur kerja kerangka kerja
Kerangka kerja penjadwalan mendefinisikan beberapa titik ekstensi. Plugin penjadwal
mendaftar untuk dipanggil di satu atau lebih titik ekstensi. Beberapa plugin ini
dapat mengubah keputusan penjadwalan dan beberapa hanya bersifat informasi.
Setiap upaya untuk menjadwalkan satu Pod dibagi menjadi dua fase, Siklus Penjadwalan (Scheduling Cycle) dan Siklus Pengikatan (Binding Cycle).
Siklus Penjadwalan dan Siklus Pengikatan
Siklus penjadwalan memilih sebuah Node untuk Pod, dan siklus pengikatan menerapkan
keputusan tersebut ke klaster. Secara bersama-sama, siklus penjadwalan dan siklus
pengikatan diartikan sebagai sebuah "konteks penjadwalan (scheduling context)".
Siklus penjadwalan dijalankan secara serial, sementara siklus pengikatan dapat
berjalan secara bersamaan.
Siklus penjadwalan atau pengikatan dapat dibatalkan jika Pod telah ditentukan
untuk tidak terjadwalkan atau jika terdapat kesalahan internal. Pod akan
dikembalikan ke antrian dan dicoba lagi.
Titik-titik ekstensi
Gambar berikut menunjukkan konteks penjadwalan Pod dan titik-titik ekstensi
yang diperlihatkan oleh kerangka penjadwalan. Dalam gambar ini "Filter"
setara dengan "Predicate" dan "Scoring" setara dengan "Priority Function".
Satu plugin dapat mendaftar di beberapa titik ekstensi untuk melakukan pekerjaan
yang lebih kompleks atau stateful.
Titik-titik ekstensi dari kerangka kerja Penjadwalan
QueueSort
Plugin ini digunakan untuk mengurutkan Pod-Pod dalam antrian penjadwalan. Plugin
QueueSort pada dasarnya menyediakan fungsi Less (Pod1, Pod2). Hanya satu jenis
plugin QueueSort yang dapat diaktifkan dalam waktu yang bersamaan.
PreFilter
Plugin ini digunakan untuk melakukan pra-proses informasi tentang Pod, atau untuk
memeriksa tertentu kondisi yang harus dipenuhi oleh klaster atau Pod. Jika
plugin PreFilter menghasilkan hasil yang salah, siklus penjadwalan dibatalkan.
Filter
Plugin ini digunakan untuk menyaring Node yang tidak dapat menjalankan Pod.
Untuk setiap Node, penjadwal akan memanggil plugin Filter sesuai dengan urutan
mereka dikonfigurasi. Jika ada plugin Filter menandai Node menjadi infeasible,
maka plugin yang lainnya tidak akan dipanggil untuk Node itu. Node-Node dapat dievaluasi
secara bersamaan.
PostFilter
Plugin ini disebut setelah fase Filter, tetapi hanya ketika tidak ada node yang layak
ditemukan untuk pod. Plugin dipanggil dalam urutan yang dikonfigurasi. Jika
plugin postFilter menandai node sebagai 'Schedulable', plugin yang tersisa
tidak akan dipanggil. Implementasi PostFilter yang khas adalah preemption, yang
mencoba membuat pod dapat di menjadwalkan dengan mendahului Pod lain.
PreScore
Plugin ini digunakan untuk melakukan pekerjaan "pra-penilaian", yang
menghasilkan keadaan yang dapat dibagi untuk digunakan oleh plugin-plugin Score.
Jika plugin PreScore mengeluarkan hasil salah, maka siklus penjadwalan dibatalkan.
Score
Plugin ini digunakan untuk menentukan peringkat Node yang telah melewati fase
penyaringan. Penjadwal akan memanggil setiap plugin Score untuk setiap Node.
Akan ada kisaran bilangan bulat yang telah ditetapkan untuk mewakili skor
minimum dan maksimum. Setelah fase NormalizeScore,
penjadwal akan menggabungkan skor Node dari semua plugin sesuai dengan bobot
plugin yang telah dikonfigurasi.
NormalizeScore
Plugin ini digunakan untuk memodifikasi skor sebelum penjadwal menghitung
peringkat akhir Node-Node. Plugin yang mendaftar untuk titik ekstensi ini akan
dipanggil dengan hasil Score dari plugin yang sama. Hal ini dilakukan
sekali untuk setiap plugin dan setiap siklus penjadwalan.
Sebagai contoh, anggaplah sebuah pluginBlinkingLightScorer memberi peringkat
pada Node-Node berdasarkan berapa banyak kedipan lampu yang mereka miliki.
Namun, jumlah maksimum kedipan lampu mungkin kecil jika dibandingkan dengan
NodeScoreMax. Untuk memperbaikinya, BlinkingLightScorer juga harus mendaftar
untuk titik ekstensi ini.
Jika ada plugin NormalizeScore yang menghasilkan hasil yang salah, maka siklus
penjadwalan dibatalkan.
Catatan:
Plugin yang ingin melakukan pekerjaan "pra-pemesanan" harus menggunakan
titik ekstensi NormalizeScore.
Reserve
Ini adalah titik ekstensi yang bersifat informasi. Plugin yang mempertahankan
keadaan runtime (alias "stateful plugins") harus menggunakan titik ekstensi ini
untuk diberitahukan oleh penjadwal ketika sumber daya pada suatu Node dicadangkan
untuk Pod yang telah disiapkan. Proses ini terjadi sebelum penjadwal benar-benar
mengikat Pod ke Node, dan itu ada untuk mencegah kondisi balapan (race conditions)
ketika penjadwal menunggu agar pengikatan berhasil.
Ini adalah langkah terakhir dalam siklus penjadwalan. Setelah Pod berada dalam
status dicadangkan, maka itu akan memicu pluginUnreserve
(apabila gagal) atau pluginPostBind (apabila sukses)
di akhir siklus pengikatan.
Permit
Plugin Permit dipanggil pada akhir siklus penjadwalan untuk setiap Pod
untuk mencegah atau menunda pengikatan ke Node kandidat. Plugin Permit dapat
melakukan salah satu dari ketiga hal ini:
approve Setelah semua plugin Permit menyetujui sebuah Pod, Pod tersebut akan dikirimkan untuk diikat.
deny Jika ada plugin Permit yang menolak sebuah Pod, Pod tersebut akan dikembalikan ke
antrian penjadwalan. Hal ini akan memicu pluginUnreserve.
wait (dengan batas waktu) Jika plugin Permit menghasilkan "wait", maka Pod disimpan dalam
daftar Pod "yang menunggu" internal, dan siklus pengikatan Pod ini dimulai tetapi akan langsung diblokir
sampai mendapatkan approved. Jika waktu tunggu habis, ** wait ** menjadi ** deny **
dan Pod dikembalikan ke antrian penjadwalan, yang memicu pluginUnreserve.
Catatan:
Ketika setiap plugin dapat mengakses daftar Pod-Pod "yang menunggu" dan menyetujuinya
(silahkan lihat FrameworkHandle), kami hanya mengharapkan
plugin Permit untuk menyetujui pengikatan Pod dalam kondisi "menunggu" yang
telah dipesan. Setelah Pod disetujui, akan dikirim ke fase PreBind.
PreBind
Plugin ini digunakan untuk melakukan pekerjaan apa pun yang diperlukan sebelum
Pod terikat. Sebagai contoh, plugin PreBind dapat menyediakan network volume
dan melakukan mounting pada Node target sebelum mengizinkan Pod berjalan di
sana.
Jika ada plugin PreBind yang menghasilkan kesalahan, maka Pod ditolak
dan kembali ke antrian penjadwalan.
Bind
Plugin ini digunakan untuk mengikat Pod ke Node. Plugin-plugin Bind tidak akan
dipanggil sampai semua plugin PreBind selesai. Setiap plugin Bind dipanggil
sesuai urutan saat dikonfigurasi. Plugin Bind dapat memilih untuk menangani
atau tidak Pod yang diberikan. Jika plugin Bind memilih untuk menangani Pod,
** plugin Bind yang tersisa dilewati **.
PostBind
Ini adalah titik ekstensi bersifat informasi. Plugin-plugin PostBind dipanggil
setelah sebuah Pod berhasil diikat. Ini adalah akhir dari siklus pengikatan, dan
dapat digunakan untuk membersihkan sumber daya terkait.
Unreserve
Ini adalah titik ekstensi bersifat informasi. Jika sebuah Pod telah dipesan dan
kemudian ditolak di tahap selanjutnya, maka plugin-plugin Unreserve akan
diberitahu. Plugin Unreserve harus membersihkan status yang terkait dengan Pod
yang dipesan.
Plugin yang menggunakan titik ekstensi ini sebaiknya juga harus digunakan
Reserve.
Plugin API
Ada dua langkah untuk plugin API. Pertama, plugin harus mendaftar dan mendapatkan
konfigurasi, kemudian mereka menggunakan antarmuka titik ekstensi. Antarmuka (interface)
titik ekstensi memiliki bentuk sebagai berikut.
Kamu dapat mengaktifkan atau menonaktifkan plugin dalam konfigurasi penjadwal.
Jika kamu menggunakan Kubernetes v1.18 atau yang lebih baru, kebanyakan
plugin-plugin penjadwalan
sudah digunakan dan diaktifkan secara bawaan.
Selain plugin-plugin bawaan, kamu juga dapat mengimplementasikan plugin-plugin penjadwalan
kamu sendiri dan mengonfigurasinya bersama-sama dengan plugin-plugin bawaan.
Kamu bisa mengunjungi plugin-plugin penjadwalan
untuk informasi lebih lanjut.
Jika kamu menggunakan Kubernetes v1.18 atau yang lebih baru, kamu dapat
mengonfigurasi sekumpulan plugin sebagai profil penjadwal dan kemudian menetapkan
beberapa profil agar sesuai dengan berbagai jenis beban kerja. Pelajari lebih
lanjut di multi profil.
9.7 - Alokasi Sumber Daya Dinamis
FEATURE STATE:Kubernetes v1.35 [stable](enabled by default)
Alokasi sumber daya dinamis (dynamic resource allocation) adalah API untuk meminta dan berbagi sumber daya antara Pod dan kontainer di dalam sebuah Pod. Ini merupakan generalisasi dari API PersistentVolume untuk sumber daya generik. Biasanya, sumber daya tersebut bisa berupa perangkat seperti GPU.
Driver sumber daya pihak ketiga bertanggung jawab untuk melacak dan mempersiapkan sumber daya, dengan alokasi sumber daya yang ditangani oleh Kubernetes melalui parameter terstruktur (diperkenalkan pada Kubernetes 1.30). Berbagai jenis sumber daya mendukung parameter sembarang untuk mendefinisikan kebutuhan dan inisialisasi.
Kubernetes versi 1.26 hingga 1.31 menyertakan implementasi (alpha) dari DRA (Dynamic Resource Allocation) klasik, yang sekarang sudah tidak didukung lagi. Dokumentasi ini yang ditujukan untuk Kubernetes versi 1.36, menjelaskan pendekatan terkini untuk alokasi sumber daya dinamis dalam Kubernetes.
Sebelum kamu memulai
Kubernetes versi 1.36 menyertakan dukungan API tingkat klaster untuk alokasi sumber daya dinamis, tetapi harus diaktifkan secara eksplisit. Kamu juga harus menginstal driver sumber daya untuk sumber daya tertentu yang akan dikelola menggunakan API ini. Jika kamu tidak menggunakan Kubernetes versi 1.36, periksa dokumentasi untuk versi Kubernetes tersebut.
API
resource.k8s.io/v1beta1 dan resource.k8s.io/v1beta2API groups menyediakan tipe-tipe berikut:
ResourceClaim
Menggambarkan permintaan akses ke sumber daya di dalam klaster untuk digunakan oleh beban kerja (workload). Misalnya, jika sebuah beban kerja membutuhkan perangkat akselerator dengan properti tertentu, permintaan tersebut diekspresikan melalui tipe ini. Bagian status melacak apakah klaim ini telah terpenuhi dan sumber daya spesifik apa yang telah dialokasikan.
ResourceClaimTemplate
Mendefinisikan spesifikasi dan beberapa metadata untuk membuat ResourceClaim. Dibuat oleh pengguna saat menerapkan beban kerja. ResourceClaim untuk setiap Pod kemudian dibuat dan dihapus secara otomatis oleh Kubernetes.
DeviceClass
Berisi kriteria seleksi yang telah ditentukan untuk perangkat tertentu serta konfigurasi untuk perangkat tersebut. DeviceClass dibuat oleh administrator klaster saat menginstal driver sumber daya. Setiap permintaan untuk mengalokasikan perangkat dalam ResourceClaim harus merujuk tepat satu DeviceClass.
ResourceSlice
Digunakan oleh driver DRA untuk mempublikasikan informasi tentang sumber daya (biasanya perangkat) yang tersedia di klaster.
DeviceTaintRule
Digunakan oleh administrator atau komponen control plane untuk menambahkan taint perangkat pada perangkat yang dijelaskan dalam ResourceSlice.
Semua parameter yang memilih perangkat didefinisikan dalam ResourceClaim dan DeviceClass menggunakan tipe in-tree. Parameter konfigurasi dapat disematkan di sana. Parameter konfigurasi yang valid bergantung pada driver DRA -- Kubernetes hanya meneruskannya tanpa memprosesnya.
PodSpec dari core/v1 mendefinisikan ResourceClaim yang diperlukan untuk sebuah Pod dalam fieldresourceClaims. Entri dalam daftar tersebut merujuk pada ResourceClaim atau ResourceClaimTemplate. Ketika merujuk pada ResourceClaim, semua Pod yang menggunakan PodSpec ini (misalnya, di dalam Deployment atau StatefulSet) berbagi instance ResourceClaim yang sama. Ketika merujuk pada ResourceClaimTemplate, setiap Pod mendapatkan instance tersendiri.
Daftar resources.claims untuk sumber daya kontainer mendefinisikan apakah sebuah kontainer mendapatkan akses ke instance sumber daya tersebut, yang memungkinkan berbagi sumber daya antara satu atau lebih kontainer.
Berikut adalah contoh untuk driver sumber daya fiksi. Dua objek ResourceClaim akan dibuat untuk Pod ini, dan setiap kontainer mendapatkan akses ke salah satu dari mereka.
Scheduler bertanggung jawab untuk mengalokasikan sumber daya ke ResourceClaim setiap kali sebuah Pod membutuhkannya. Scheduler melakukan ini dengan mengambil daftar lengkap sumber daya yang tersedia dari objek ResourceSlice, melacak sumber daya mana yang sudah dialokasikan ke ResourceClaim yang ada, dan kemudian memilih dari sumber daya yang masih tersisa.
Saat ini, satu-satunya jenis sumber daya yang didukung adalah perangkat. Sebuah instance perangkat memiliki nama, beberapa atribut, dan kapasitas. Perangkat dipilih melalui ekspresi CEL (Common Expression Language) yang memeriksa atribut dan kapasitas tersebut. Selain itu, perangkat yang dipilih juga dapat dibatasi pada kumpulan perangkat yang memenuhi batasan tertentu.
Sumber daya yang dipilih dicatat dalam status ResourceClaim bersama dengan konfigurasi spesifik vendor, sehingga ketika sebuah pod akan dijalankan pada sebuah Node, driver sumber daya di Node tersebut memiliki semua informasi yang diperlukan untuk mempersiapkan sumber daya tersebut.
Dengan menggunakan parameter terstruktur, scheduler dapat mengambil keputusan tanpa berkomunikasi dengan driver sumber daya DRA. Scheduler juga dapat menjadwalkan beberapa Pod dengan cepat dengan menyimpan informasi tentang alokasi ResourceClaim di memori dan menuliskan informasi ini ke objek ResourceClaim di latar belakang sambil secara bersamaan mengikat pod ke sebuah Node.
Memantau Sumber Daya
Kubelet menyediakan layanan gRPC untuk memungkinkan penemuan sumber daya dinamis dari Pod yang sedang berjalan. Untuk informasi lebih lanjut tentang endpoint gRPC, lihat pelaporan alokasi sumber daya.
Pod yang Sudah Dijadwalkan Sebelumnya
Ketika kamu - atau klien API lainnya - membuat sebuah Pod dengan spec.nodeName yang sudah diatur, scheduler akan dilewati. Jika ada ResourceClaim yang dibutuhkan oleh Pod tersebut tetapi belum ada, belum dialokasikan, atau belum dipesan untuk Pod tersebut, maka kubelet akan gagal menjalankan Pod dan akan memeriksa ulang secara berkala karena persyaratan tersebut mungkin masih dapat dipenuhi di kemudian waktu.
Situasi semacam ini juga dapat terjadi ketika dukungan untuk alokasi sumber daya dinamis tidak diaktifkan di scheduler pada saat Pod dijadwalkan (karena perbedaan versi, konfigurasi, feature gate, dll.). kube-controller-manager mendeteksi hal ini dan mencoba membuat Pod dapat dijalankan dengan memesan ResourceClaim yang diperlukan. Namun, ini hanya berhasil jika ResourceClaim tersebut telah dialokasikan oleh scheduler untuk Pod lain.
Lebih baik untuk menghindari melewati scheduler karena Pod yang ditugaskan ke sebuah Node akan memblokir sumber daya normal (RAM, CPU) yang tidak dapat digunakan untuk Pod lain sementara Pod tersebut terhenti. Untuk membuat sebuah Pod berjalan di Node tertentu sambil tetap melalui alur penjadwalan normal, buatlah Pod dengan nodeSelector yang secara tepat cocok dengan Node yang diinginkan:
Kamu juga dapat memodifikasi Pod yang masuk, pada saat admission, untuk menghapus field.spec.nodeName dan menggunakan nodeSelector sebagai gantinya.
Akses Admin
FEATURE STATE:Kubernetes v1.36 [stable](enabled by default)
Kamu dapat menandai sebuah permintaan dalam ResourceClaim atau ResourceClaimTemplate sebagai memiliki fitur istimewa untuk tugas pemeliharaan dan pemecahan masalah. Permintaan dengan akses admin memberikan akses ke perangkat yang sedang digunakan dan mungkin mengaktifkan izin tambahan saat membuat perangkat tersedia di dalam sebuah kontainer:
Jika fitur ini dinonaktifkan, fieldadminAccess akan secara otomatis dihapus saat membuat ResourceClaim semacam itu.
Akses admin adalah mode istimewa dan tidak boleh diberikan kepada pengguna biasa dalam klaster multi-tenant. Mulai dari Kubernetes v1.33, hanya pengguna yang memiliki otorisasi untuk membuat objek ResourceClaim atau ResourceClaimTemplate di namespace yang diberi label resource.k8s.io/admin-access: "true" (case-sensitive) yang dapat menggunakan fieldadminAccess. Hal ini memastikan bahwa pengguna non-admin tidak dapat menyalahgunakan fitur tersebut.
Status Perangkat ResourceClaim
FEATURE STATE:Kubernetes v1.33 [beta](enabled by default)
Driver dapat melaporkan data status perangkat spesifik driver untuk setiap perangkat yang dialokasikan dalam sebuah ResourceClaim. Misalnya, IP yang diberikan ke perangkat antarmuka jaringan dapat dilaporkan dalam status ResourceClaim.
Driver yang menetapkan status, keakuratan informasi bergantung pada implementasi driver DRA tersebut. Oleh karena itu, status perangkat yang dilaporkan mungkin tidak selalu mencerminkan perubahan waktu nyata dari keadaan perangkat.
Ketika fitur ini dinonaktifkan, field tersebut secara otomatis akan dihapus saat menyimpan ResourceClaim.
Status perangkat ResourceClaim didukung ketika memungkinkan, dari driver DRA, untuk memperbarui ResourceClaim yang ada di mana fieldstatus.devices diatur.
Daftar Prioritas
FEATURE STATE:Kubernetes v1.36 [stable](enabled by default)
Kamu dapat menyediakan daftar prioritas sub-permintaan untuk permintaan dalam sebuah ResourceClaim. Scheduler kemudian akan memilih sub-permintaan pertama yang dapat dialokasikan. Ini memungkinkan pengguna untuk menentukan perangkat alternatif yang dapat digunakan oleh beban kerja jika pilihan utama tidak tersedia.
Dalam contoh di bawah ini, ResourceClaimTemplate meminta perangkat dengan warna hitam dan ukuran besar. Jika perangkat dengan atribut tersebut tidak tersedia, Pod tidak dapat dijadwalkan. Dengan fitur daftar prioritas, alternatif kedua dapat ditentukan, yang meminta dua perangkat dengan warna putih dan ukuran kecil. Perangkat hitam besar akan dialokasikan jika tersedia. Namun, jika tidak tersedia dan dua perangkat putih kecil tersedia, Pod masih dapat berjalan.
FEATURE STATE:Kubernetes v1.36 [beta](enabled by default)
Perangkat yang direpresentasikan dalam DRA tidak harus berupa satu unit yang terhubung ke satu mesin, tetapi juga dapat berupa perangkat logis yang terdiri dari beberapa perangkat yang terhubung ke beberapa mesin. Perangkat-perangkat ini mungkin menggunakan sumber daya yang saling tumpang tindih dari perangkat fisik yang mendasarinya, yang berarti bahwa ketika satu perangkat logis dialokasikan, perangkat lainnya tidak akan lagi tersedia.
Dalam API ResourceSlice, ini direpresentasikan sebagai daftar CounterSet yang diberi nama, masing-masing berisi satu set counter yang juga diberi nama. Counter ini merepresentasikan sumber daya yang tersedia pada perangkat fisik yang digunakan oleh perangkat logis yang diiklankan melalui DRA.
Perangkat logis dapat menentukan daftar ConsumesCounters. Setiap entri berisi referensi ke sebuah CounterSet dan satu set counter yang diberi nama dengan jumlah yang akan mereka konsumsi. Jadi, agar sebuah perangkat dapat dialokasikan, set counter yang direferensikan harus memiliki jumlah yang cukup untuk counter yang direferensikan oleh perangkat tersebut.
Berikut adalah contoh dua perangkat, masing-masing mengonsumsi 6Gi memori dari sebuah counter bersama yang memiliki 8Gi memori. Dengan demikian, hanya satu dari perangkat tersebut yang dapat dialokasikan pada satu waktu. Scheduler menangani ini, dan hal ini transparan bagi konsumen karena API ResourceClaim tidak terpengaruh.
FEATURE STATE:Kubernetes v1.35 [stable](enabled by default)
Taint perangkat mirip dengan taint pada Node: sebuah taint memiliki kunci string, nilai string, dan efek. Efek ini diterapkan pada ResourceClaim yang menggunakan perangkat yang telah ditaint dan pada semua Pod yang merujuk ke ResourceClaim tersebut. Efek "NoSchedule" mencegah penjadwalan Pod-Pod tersebut. Perangkat yang ditaint akan diabaikan saat mencoba mengalokasikan ResourceClaim karena penggunaannya akan mencegah penjadwalan Pod.
Efek "NoExecute" menyiratkan "NoSchedule" dan, selain itu, menyebabkan pengusiran semua Pod yang telah dijadwalkan sebelumnya. Pengusiran ini diimplementasikan dalam pengontrol pengusiran taint perangkat di kube-controller-manager dengan cara menghapus Pod yang terpengaruh.
ResourceClaim dapat mentoleransi taint. Jika sebuah taint ditoleransi, efeknya tidak berlaku. Toleransi kosong cocok dengan semua taint. Toleransi dapat dibatasi pada efek tertentu dan/atau cocok dengan pasangan kunci/nilai tertentu. Toleransi dapat memeriksa keberadaan kunci tertentu, terlepas dari nilai apa yang dimilikinya, atau dapat memeriksa nilai spesifik dari sebuah kunci. Untuk informasi lebih lanjut tentang pencocokan ini, lihat konsep taint pada Node.
Pengusiran dapat ditunda dengan mentoleransi taint untuk durasi tertentu. Penundaan tersebut dimulai saat taint ditambahkan ke perangkat, yang dicatat dalam sebuah field pada taint.
Taint berlaku seperti yang dijelaskan di atas juga untuk ResourceClaim yang mengalokasikan "semua" perangkat pada sebuah Node. Semua perangkat harus tidak ditaint atau semua taint mereka harus ditoleransi. Mengalokasikan perangkat dengan akses admin (dijelaskan di atas) juga tidak dikecualikan. Seorang admin yang menggunakan mode tersebut harus secara eksplisit mentoleransi semua taint untuk mengakses perangkat yang ditaint.
Taint dapat ditambahkan ke perangkat dengan dua cara berbeda:
Taint yang Ditetapkan oleh Driver
Driver DRA dapat menambahkan taint ke informasi perangkat yang dipublikasikan dalam ResourceSlice. Konsultasikan dokumentasi driver DRA untuk mengetahui apakah driver menggunakan taint dan apa kunci serta nilainya.
Taint yang Ditetapkan oleh Admin
Seorang admin atau komponen control plane dapat menaint perangkat tanpa harus meminta driver DRA untuk menyertakan taint dalam informasi perangkatnya di ResourceSlice. Mereka melakukannya dengan membuat DeviceTaintRules. Setiap DeviceTaintRule menambahkan satu taint ke perangkat yang cocok dengan selector perangkat. Tanpa selector semacam itu, tidak ada perangkat yang ditaint. Hal ini membuat lebih sulit untuk secara tidak sengaja mengusir semua Pod yang menggunakan ResourceClaim karena kesalahan dalam menentukan selector.
Perangkat dapat dipilih dengan memberikan nama DeviceClass, driver, pool, dan/atau perangkat. DeviceClass memilih semua perangkat yang dipilih oleh selector dalam DeviceClass tersebut. Dengan hanya nama driver, seorang admin dapat melakukan taint semua perangkat yang dikelola oleh driver tersebut, misalnya saat melakukan pemeliharaan driver di seluruh klaster. Menambahkan nama pool dapat membatasi taint ke satu Node, jika driver mengelola perangkat lokal Node.
Terakhir, menambahkan nama perangkat dapat memilih satu perangkat spesifik. Nama perangkat dan nama pool juga dapat digunakan sendiri, jika diinginkan. Misalnya, driver untuk perangkat lokal Node didorong untuk menggunakan nama Node sebagai nama pool mereka. Maka, melakukan taint dengan nama pool tersebut secara otomatis melakukan taint semua perangkat pada sebuah Node.
Driver mungkin menggunakan nama stabil seperti "gpu-0" yang menyembunyikan perangkat spesifik mana yang saat ini ditugaskan ke nama tersebut. Untuk mendukung perlakuan taint ubstabs perangkat keras tertentu, selector CEL dapat digunakan dalam DeviceTaintRule untuk mencocokkan atribut ID unik spesifik vendor, jika driver mendukungnya untuk perangkat kerasnya.
Taint berlaku selama DeviceTaintRule ada. taint dapat dimodifikasi dan dihapus kapan saja. Berikut adalah contoh DeviceTaintRule untuk driver DRA fiksi:
apiVersion:resource.k8s.io/v1alpha3kind:DeviceTaintRulemetadata:name:examplespec:# The entire hardware installation for this# particular driver is broken.# Evict all pods and don't schedule new ones.deviceSelector:driver:dra.example.com_taint_:key:dra.example.com/unhealthyvalue:Brokeneffect:NoExecute
Mengaktifkan Alokasi Sumber Daya Dinamis
Alokasi sumber daya dinamis adalah fitur beta yang secara default tidak diaktifkan dan hanya dapat diaktifkan jika feature gateDynamicResourceAllocation serta API groupsresource.k8s.io/v1beta1 dan resource.k8s.io/v1beta2 diaktifkan. Untuk detail lebih lanjut, lihat parameter --feature-gates dan --runtime-config pada kube-apiserver. Selain itu, kube-scheduler, kube-controller-manager, dan kubelet juga memerlukan feature gate ini.
Ketika driver sumber daya melaporkan status perangkat, maka feature gateDRAResourceClaimDeviceStatus harus diaktifkan selain DynamicResourceAllocation.
Cara cepat untuk memeriksa apakah klaster Kubernetes mendukung fitur ini adalah dengan daftar objek DeviceClass menggunakan perintah berikut:
kubectl get deviceclasses
Jika klaster kamu mendukung alokasi sumber daya dinamis, respon-nya adalah daftar objek DeviceClass atau:
No resources found
Jika tidak didukung, kesalahan berikut akan dicetak:
error: the server doesn't have a resource type "deviceclasses"
Konfigurasi default kube-scheduler mengaktifkan plugin "DynamicResources" hanya jika feature gate diaktifkan dan menggunakan API konfigurasi v1. Konfigurasi kustom mungkin perlu dimodifikasi untuk menyertakannya.
Selain mengaktifkan fitur di klaster, driver sumber daya juga harus diinstal. Silakan merujuk ke dokumentasi driver untuk detail lebih lanjut.
Mengaktifkan Akses Admin
Akses Admin adalah fitur alpha dan hanya dapat diaktifkan jika feature gateDRAAdminAccess diaktifkan di kube-apiserver dan kube-scheduler.
Daftar prioritas adalah fitur alpha dan hanya dapat diaktifkan jika feature gateDRAPrioritizedList diaktifkan di kube-apiserver dan kube-scheduler. Fitur ini juga memerlukan feature gateDynamicResourceAllocation diaktifkan.
Taint dan toleransi perangkat adalah fitur alpha dan hanya dapat diaktifkan jika feature gateDRADevice_Taint_s diaktifkan di kube-apiserver, kube-controller-manager, dan kube-scheduler. Untuk menggunakan DeviceTaintRules, versi API resource.k8s.io/v1alpha3 harus diaktifkan.
kube-scheduler
merupakan penjadwal (scheduler) Kubernetes bawaan yang bertanggung jawab
terhadap penempatan Pod-Pod pada seluruh Node di dalam sebuah klaster.
Node-Node di dalam klaster yang sesuai dengan syarat-syarat penjadwalan dari
sebuah Pod disebut sebagai Node-Node layak (feasible). Penjadwal mencari Node-Node
layak untuk sebuah Pod dan kemudian menjalankan fungsi-fungsi untuk menskor Node-Node tersebut, memilih sebuah Node dengan skor tertinggi di antara
Node-Node layak lainnya, di mana Pod akan dijalankan. Penjadwal kemudian memberitahu
API server soal keputusan ini melalui sebuah proses yang disebut Binding.
Laman ini menjelaskan optimasi penyetelan (tuning) kinerja yang relevan
untuk klaster Kubernetes berskala besar.
Pada klaster berskala besar, kamu bisa menyetel perilaku penjadwal
untuk menyeimbangkan hasil akhir penjadwalan antara latensi (seberapa cepat Pod-Pod baru ditempatkan)
dan akurasi (seberapa akurat penjadwal membuat keputusan penjadwalan yang tepat).
Kamu bisa mengonfigurasi setelan ini melalui pengaturan percentageOfNodesToScore pada kube-scheduler.
Pengaturan KubeSchedulerConfiguration ini menentukan sebuah ambang batas untuk
penjadwalan Node-Node di dalam klaster kamu.
Pengaturan Ambang Batas
Opsi percentageOfNodesToScore menerima semua angka numerik antara 0 dan 100.
Angka 0 adalah angka khusus yang menandakan bahwa kube-scheduler harus menggunakan
nilai bawaan.
Jika kamu mengatur percentageOfNodesToScore dengan angka di atas 100, kube-scheduler
akan membulatkan ke bawah menjadi 100.
Untuk mengubah angkanya, sunting berkas konfigurasi kube-scheduler (biasanya /etc/kubernetes/config/kube-scheduler.yaml),
lalu ulang kembali kube-scheduler.
Setelah kamu selesai menyunting, jalankan perintah
kubectl get componentstatuses
untuk memverifikasi komponen kube-scheduler berjalan dengan baik (healthy). Keluarannya kira-kira seperti ini:
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
...
Ambang Batas Penskoran Node
Untuk meningkatan kinerja penjadwalan, kube-scheduler dapat berhenti mencari
Node-Node yang layak saat sudah berhasil menemukannya. Pada klaster berskala besar,
hal ini menghemat waktu dibandingkan dengan pendekatan awam yang mengecek setiap Node.
Kamu bisa mengatur ambang batas untuk menentukan berapa banyak jumlah Node minimal yang dibutuhkan, sebagai
persentase bagian dari seluruh Node di dalam klaster kamu. kube-scheduler akan mengubahnya menjadi
bilangan bulat berisi jumlah Node. Saat penjadwalan, jika kube-scheduler mengidentifikasi
cukup banyak Node-Node layak untuk melewati jumlah persentase yang diatur, maka kube-scheduler
akan berhenti mencari Node-Node layak dan lanjut ke [fase penskoran] (/id/docs/concepts/scheduling-eviction/kube-scheduler/#kube-scheduler-implementation).
Jika kamu tidak mengatur sebuah ambang batas, maka Kubernetes akan
menghitung sebuah nilai menggunakan pendekatan linier, yaitu 50% untuk klaster dengan 100 Node,
serta 10% untuk klaster dengan 5000 Node.
Artinya, kube-scheduler selalu menskor paling tidak 5% dari klaster kamu, terlepas dari
seberapa besar klasternya, kecuali kamu secara eksplisit mengatur percentageOfNodesToScore
menjadi lebih kecil dari 5.
Jika kamu ingin penjadwal untuk memasukkan seluruh Node di dalam klaster ke dalam penskoran,
maka aturlah percentageOfNodesToScore menjadi 100.
Contoh
Contoh konfigurasi di bawah ini mengatur percentageOfNodesToScore menjadi 50%.
percentageOfNodesToScore merupakan angka 1 sampai 100 dengan
nilai bawaan yang dihitung berdasarkan ukuran klaster. Di sini juga terdapat
batas bawah yang telah ditetapkan, yaitu 100 Node.
Catatan:
Pada klaster dengan kurang dari 100 Node layak, penjadwal masih
terus memeriksa seluruh Node karena Node-Node layak belum mencukupi supaya
penjadwal dapat menghentikan proses pencarian lebih awal.
Pada klaster kecil, jika kamu mengatur percentageOfNodesToScore dengan angka kecil,
pengaturan ini hampir atau sama sekali tidak berpengaruh, karena alasan yang sama.
Jika klaster kamu punya ratusan Node, gunakan angka bawaan untuk opsi konfigurasi ini.
Mengubah angkanya kemungkinan besar tidak akan mengubah kinerja penjadwal secara berarti.
Sebuah catatan penting yang perlu dipertimbangkan saat mengatur angka ini adalah
ketika klaster dengan jumlah Node sedikit diperiksa untuk kelayakan, beberapa Node
tidak dikirim untuk diskor bagi sebuah Pod. Hasilnya, sebuah Node yang mungkin memiliki
nilai lebih tinggi untuk menjalankan Pod tersebut bisa saja tidak diteruskan ke fase penskoran.
Hal ini berdampak pada penempatan Pod yang kurang ideal.
Kamu sebaiknya menghindari pengaturan percentageOfNodesToScore menjadi sangat rendah,
agar kube-scheduler tidak seringkali membuat keputusan penempatan Pod yang buruk.
Hindari pengaturan persentase di bawah 10%, kecuali throughput penjadwal sangat penting
untuk aplikasi kamu dan skor dari Node tidak begitu penting. Dalam kata lain, kamu
memilih untuk menjalankan Pod pada Node manapun selama Node tersebut layak.
Bagaimana Penjadwal Mengecek Node
Bagian ini ditujukan untuk kamu yang ingin mengerti bagaimana fitur ini bekerja secara internal.
Untuk memberikan semua Node di dalam klaster sebuah kesempatan yang adil untuk
dipertimbangkan dalam menjalankan Pod, penjadwal mengecek Node satu persatu
secara round robin. Kamu dapat membayangkan Node-Node ada di dalam sebuah array.
Penjadwal mulai dari indeks array pertama dan mengecek kelayakan dari Node sampai
jumlahnya telah mencukupi sesuai dengan percentageOfNodesToScore. Untuk Pod berikutnya,
penjadwal melanjutkan dari indeks array Node yang terhenti ketika memeriksa
kelayakan Node-Node untuk Pod sebelumnya.
Jika Node-Node berada di beberapa zona, maka penjadwal akan mengecek Node satu persatu
pada seluruh zona untuk memastikan bahwa Node-Node dari zona berbeda masuk dalam pertimbangan
kelayakan. Sebagai contoh, ada 6 Node di dalam 2 zona:
Zona 1: Node 1, Node 2, Node 3, Node 4
Zona 2: Node 5, Node 6
Penjadwal mempertimbangkan kelayakan dari Node-Node tersebut dengan urutan berikut:
Node 1, Node 5, Node 2, Node 6, Node 3, Node 4
Setelah semua Node telah dicek, penjadwal akan kembali pada Node 1.
10 - Policies
10.1 - LimitRange
Secara bawaan, Container berjalan dengan sumber daya komputasi tanpa batas pada klaster Kubernetes.
Dengan ResourceQuota (kuota sumber daya), administrator klaster dapat membatasi konsumsi dan pembuatan sumber daya berbasis Namespace.
Di dalam Namespace, Pod atau Container dapat mengkonsumsi CPU dan memori sesuai dengan yang ditentukan oleh ResourceQuota pada Namespace tersebut.
Ada kekhawatiran bahwa satu Pod atau Container dapat memonopoli semua sumber daya yang tersedia.
LimitRange (Batas Rentang) adalah kebijakan untuk membatasi alokasi sumber daya (bagi Pod atau Container) pada Namespace.
LimitRange memberikan batasan (limit) yang dapat:
Menerapkan penggunaan sumber daya komputasi minimum dan maksimum untuk setiap Pod atau Container dalam Namespace.
Menerapkan permintaan (request) tempat penyimpanan minimum dan maksimum untuk setiap PersistentVolumeClaim dalam Namespace.
Menerapkan rasio antara permintaan dan batas untuk sumber daya dalam Namespace.
Menetapkan permintaan/batas bawaan untuk menghitung sumber daya dalam Namespace dan memasukkannya secara otomatis ke Container pada runtime.
Mengaktifkan LimitRange
Dukungan LimitRange diaktifkan secara bawaan untuk banyak distribusi Kubernetes. Hal ini
diaktifkan ketika tanda --enable-admission-plugins= pada apiserver memiliki admission controllerLimitRanger sebagai
salah satu argumennya.
LimitRange diberlakukan pada Namespace tertentu ketika ada sebuah objek LimitRange pada Namespace tersebut.
Administrator membuat sebuah LimitRange dalam sebuah Namespace.
Pengguna membuat sumber daya seperti Pod, Container, dan PersistentVolumeClaim pada namespace.
Admission controllerLimitRanger memberlakukan bawaan dan batas untuk semua Pod dan Container yang tidak menetapkan persyaratan sumber daya komputasi dan melacak penggunaannya untuk memastikan agar tidak melebihi minimum, maksimum dan rasio sumber daya yang ditentukan dalam LimitRange yang ada pada Namespace.
Apabila permintaan membuat atau memperbarui sumber daya (Pod, Container, PersistentVolumeClaim) yang melanggar batasan LimitRange, maka permintaan ke server API akan gagal dengan kode status HTTP 403 FORBIDDEN dan sebuah pesan yang menjelaskan batasan yang telah dilanggar.
Apabila LimitRange diaktifkan pada Namespace untuk menghitung sumber daya seperti cpu dan memory, pengguna harus menentukan permintaan atau batasan untuk nilai-nilai itu. Jika tidak, sistem dapat menolak pembuatan Pod.
Pelanggaran terhadap LimitRange hanya terjadi pada tahap penerimaan Pod, bukan pada saat Pod sedang berjalan.
Contoh dari kebijakan yang dapat dibuat dengan menggunakan LimitRange yaitu:
Dalam klaster dua Node dengan kapasitas 8 GiB RAM dan 16 core, batasan Pod dalam Namespace meminta 100m untuk CPU dengan batas maksimum 500m untuk CPU dan minta 200Mi untuk Memori dengan batas maksimum 600Mi untuk Memori.
Tetapkan batas bawaan dan permintaan pada 150m untuk CPU dan permintaan standar memori pada 300Mi untuk Container yang dimulai tanpa cpu dan permintaan memori dalam spesifikasi mereka.
Dalam kasus di mana batas total Namespace kurang dari jumlah batas Pod/Container,
mungkin akan ada perebutan untuk sumber daya. Dalam hal ini, maka Container atau Pod tidak akan dibuat.
Baik perebutan maupun perubahan pada LimitRange tidak akan mempengaruhi sumber daya yang sudah dibuat.
Saat beberapa pengguna atau tim berbagi sebuah klaster dengan jumlah Node yang tetap,
ada satu hal yang perlu diperhatikan yaitu suatu tim dapat menggunakan sumber daya
lebih dari jatah yang mereka perlukan.
Resource Quota (kuota sumber daya) adalah sebuah alat yang dapat digunakan oleh
administrator untuk mengatasi hal ini.
Sebuah Resource Quota, didefinisikan oleh objek API ResourceQuota, menyediakan batasan-batasan
yang membatasi konsumsi gabungan sumber daya komputasi untuk tiap Namespace. Resource Quota dapat
membatasi jumlah objek yang dapat dibuat dalam sebuah Namespace berdasarkan tipenya, maupun jumlah
seluruh sumber daya komputasi yang dapat dipakai oleh sumber daya API (misalnya Pod) di Namespace
tersebut.
Resource Quota bekerja sebagai berikut:
Tim-tim berbeda bekerja pada Namespace yang berbeda pula. Sekarang hal ini belum diwajibkan,
tetapi dukungan untuk mewajibkannya melalui ACL sedang direncanakan.
Administrator membuat sebuah ResourceQuota untuk setiap Namespace.
Para pengguna membuat sumber daya (Pod, Service, dll.) di dalam Namespace tersebut, kemudian
sistem kuota memantau penggunaan untuk memastikan bahwa penggunaannya tidak melebihi batas
sumber daya yang ditentukan di ResourceQuota.
Jika pembuatan atau pembaruan sebuah sumber daya melanggar sebuah batasan kuota, maka permintaan
tersebut akan gagal dengan kode status 403 FORBIDDEN dengan sebuah pesan yang menjelaskan batasan
yang akan dilanggar.
Jika kuota diaktifkan di sebuah Namespace untuk sumber daya komputasi seperti cpu dan memory,
pengguna-pengguna harus menentukan requests atau limits untuk sumber daya tersebut; atau sistem
kuota akan menolak pembuatan Pod tersebut. Petunjuk: Gunakan Admission Controller LimitRanger untuk
memaksa nilai-nilai bawaan untuk Pod-Pod yang tidak menentukan kebutuhan sumber daya komputasi.
Lihat petunjuknya untuk contoh bagaimana
cara menghindari masalah ini.
Contoh-contoh kebijakan yang dapat dibuat menggunakan Namespace dan kuota adalah:
Dalam sebuah klaster dengan kapasitas RAM 32 GiB, dan CPU 16 core, misalkan tim A menggunakan 20GiB
dan 10 core, dan tim B menggunakan 10GiB dan 4 core, dan menyimpan 2GiB dan 2 core untuk cadangan
penggunaan di masa depan.
Batasi Namespace "testing" dengan batas 1 core dan RAM 1GiB. Biarkan Namespace "production" menggunakan
berapapun jumlah yang diinginkan.
Pada kasus di mana total kapasitas klaster lebih sedikit dari jumlah seluruh kuota di seluruh Namespace,
dapat terjadi perebutan sumber daya komputasi. Masalah ini akan ditangani dengan cara siapa-cepat-dia-dapat.
Perebutan sumber daya komputasi maupun perubahan kuota tidak akan memengaruhi sumber daya yang sudah dibuat
sebelumnya.
Mengaktifkan Resource Quota
Dukungan untuk Resource Quota diaktifkan secara bawaan pada banyak distribusi Kubernetes. Resource Quota
diaktifkan saat flag--enable-admission-plugins= pada apiserver memiliki ResourceQuota sebagai
salah satu nilainya.
Sebuah Resource Quota akan dipaksakan pada sebuah Namespace tertentu saat ada sebuah objek ResourceQuota
di dalam Namespace tersebut.
Resource Quota Komputasi
Kamu dapat membatasi jumlah total sumber daya komputasi yang dapat
diminta di dalam sebuah Namespace.
Berikut jenis-jenis sumber daya yang didukung:
Nama Sumber Daya
Deskripsi
limits.cpu
Pada seluruh Pod yang berada pada kondisi non-terminal, jumlah limits CPU tidak dapat melebihi nilai ini.
limits.memory
Pada seluruh Pod yang berada pada kondisi non-terminal, jumlah limits memori tidak dapat melebihi nilai ini.
limits.cpu
Pada seluruh Pod yang berada pada kondisi non-terminal, jumlah requests CPU tidak dapat melebihi nilai ini.
limits.memory
Pada seluruh Pod yang berada pada kondisi non-terminal, jumlah requests memori tidak dapat melebihi nilai ini.
Resource Quota untuk sumber daya yang diperluas
Sebagai tambahan untuk sumber daya yang disebutkan di atas, pada rilis 1.10, dukungan kuota untuk
sumber daya yang diperluas ditambahkan.
Karena overcommit tidak diperbolehkan untuk sumber daya yang diperluas, tidak masuk akal untuk menentukan
keduanya; requests dan limits untuk sumber daya yang diperluas yang sama pada sebuah kuota. Jadi, untuk
sumber daya yang diperluas, hanya kuota dengan prefiks requests. saja yang diperbolehkan untuk sekarang.
Mari kita ambil contoh sumber daya GPU. Jika nama sumber dayanya adalah nvidia.com/gpu, dan kamu ingin
membatasi jumlah total GPU yang diminta pada sebuah Namespace menjadi 4, kamu dapat menentukan sebuah kuota
sebagai berikut:
Pada seluruh Persistent Volume Claim yang dikaitkan dengan sebuah nama storage-class (melalui kolom storageClassName), jumlah permintaan penyimpanan tidak dapat melebihi nilai ini.
Pada seluruh Persistent Volume Claim yang dikaitkan dengan sebuah nama storage-class (melalui kolom storageClassName), jumlah kuantitas Persistent Volume Claim yang dapat ada di dalam sebuah Namespace.
Sebagai contoh, jika sebuah operator ingin membatasi penyimpanan dengan Storage Class gold yang berbeda dengan Storage Class bronze, maka operator tersebut dapat menentukan kuota sebagai berikut:
Pada rilis 1.8, dukungan kuota untuk penyimpanan lokal sementara (local ephemeral storage) ditambahkan sebagai
sebuah fitur alpha:
Nama Sumber Daya
Deskripsi
requests.ephemeral-storage
Pada seluruh Pod di sebuah Namespace, jumlah requests penyimpanan lokal sementara tidak dapat melebihi nilai ini.
limits.ephemeral-storage
Pada seluruh Pod di sebuah Namespace, jumlah limits penyimpanan lokal sementara tidak dapat melebihi nilai ini.
Kuota Kuantitas Objek
Rilis 1.9 menambahkan dukungan untuk membatasi semua jenis sumber daya standar yang berada pada sebuah Namespace dengan sintaksis sebagai berikut:
count/<sumber-daya>.<grup>
Berikut contoh-contoh sumber daya yang dapat ditentukan pengguna pada kuota kuantitas objek:
count/persistentvolumeclaims
count/services
count/secrets
count/configmaps
count/replicationcontrollers
count/deployments.apps
count/replicasets.apps
count/statefulsets.apps
count/jobs.batch
count/cronjobs.batch
count/deployments.extensions
Rilis 1.15 menambahkan dukungan untuk sumber daya custom menggunakan sintaksis yang sama.
Contohnya, untuk membuat kuota pada sumber daya customwidgets pada grup API example.com, gunakan
count/widgets.example.com.
Saat menggunakan Resource Quota count/*, sebuah objek akan menggunakan kuotanya jika ia berada pada penyimpanan Apiserver.
Tipe-tipe kuota ini berguna untuk menjaga dari kehabisan sumber daya penyimpanan. Misalnya, kamu mungkin
ingin membatasi kuantitas objek Secret pada sebuah Apiserver karena ukuran mereka yang besar. Terlalu banyak
Secret pada sebuah klaster bahkan dapat membuat Server dan Controller tidak dapat dijalankan! Kamu dapat membatasi
jumlah Job untuk menjaga dari CronJob yang salah dikonfigurasi sehingga membuat terlalu banyak Job pada sebuah
Namespace yang mengakibatkan denial of service.
Sebelum rilis 1.9, kita tidak dapat melakukan pembatasan kuantitas objek generik pada kumpulan sumber daya yang terbatas.
Sebagai tambahan, kita dapat membatasi lebih lanjut sumber daya tertentu dengan kuota berdasarkan jenis mereka.
Berikut jenis-jenis yang telah didukung:
Nama Sumber Daya
Deskripsi
configmaps
Jumlah total ConfigMap yang dapat berada pada suatu Namespace.
persistentvolumeclaims
Jumlah total PersistentVolumeClaimpersistent volume claims yang dapat berada pada suatu Namespace.
pods
Jumlah total Pod yang berada pada kondisi non-terminal yang dapat berada pada suatu Namespace. Sebuah Pod berada kondisi terminal yaitu jika .status.phase in (Failed, Succeded) adalah true.
replicationcontrollers
Jumlah total ReplicationController yang dapat berada pada suatu Namespace.
resourcequotas
Jumlah total ResourceQuota yang dapat berada pada suatu Namespace.
services
Jumlah total Service yang dapat berada pada suatu Namespace.
services.loadbalancers
Jumlah total Service dengan tipe LoadBalancer yang dapat berada pada suatu Namespace.
services.nodeports
Jumlah total Service dengan tipe NodePort yang dapat berada pada suatu Namespace.
secrets
Jumlah total Secret yang dapat berada pada suatu Namespace.
Sebagai contoh, pods membatasi kuantitas dan memaksa kuantitas maksimum pods yang
berada pada kondisi non-terminal yang dibuat pada sebuah Namespace. Kamu mungkin ingin
menyetel kuota pods pada sebuah Namespace untuk menghindari kasus di mana pengguna membuat
banyak Pod kecil dan menghabiskan persediaan alamat IP Pod pada klaster.
Lingkup Kuota
Setiap kuota dapat memiliki kumpulan lingkup yang dikaitkan. Sebuah kuota hanya akan mengukur penggunaan sebuah
sumber daya jika sumber daya tersebut cocok dengan irisan dari lingkup-lingkup yang ditentukan.
Saat sebuah lingkup ditambahkan kepada kuota, lingkup itu akan membatasi kuantitas sumber daya yang didukung menjadi yang berkaitan dengan lingkup tersebut.
Sumber daya yang ditentukan pada kuota di luar kumpulan yang diizinkan akan menghasilkan kesalahan validasi.
Lingkup
Deskripsi
Terminating
Mencocokkan dengan Pod-Pod yang memiliki .spec.activeDeadlineSeconds >= 0
NotTerminating
Mencocokkan dengan Pod-Pod yang memiliki .spec.activeDeadlineSeconds is nil
BestEffort
Mencocokkan dengan Pod-Pod yang memiliki quality of service bertipe best effort.
NotBestEffort
Mencocokkan dengan Pod-Pod yang tidak memiliki quality of service bertipe best effort.
Lingkup BestEffort membatasi sebuah kuota untuk memantau sumber daya berikut: pods
Lingkup Terminating, NotTerminating, dan NotBestEffort membatasi sebuah kuota untuk memantau sumber daya berikut:
cpu
limits.cpu
limits.memory
memory
pods
requests.cpu
requests.memory
Resource Quota Per PriorityClass
FEATURE STATE:Kubernetes 1.12 [beta]
Pod-Pod dapat dibuat dengan sebuah Priority (prioritas) tertentu.
Kamu dapat mengontrol konsumsi sumber daya sistem sebuah Pod berdasarkan Priority Pod tersebut, menggunakan
kolom scopeSelector pada spesifikasi kuota tersebut.
Sebuah kuota dicocokkan dan digunakan hanya jika scopeSelector pada spesifikasi kuota tersebut memilih Pod tersebut.
Contoh ini membuat sebuah objek kuota dan mencocokkannya dengan Pod-Pod pada Priority tertentu. Contoh tersebut
bekerja sebagai berikut:
Pod-Pod di dalam klaster memiliki satu dari tiga Priority Class, "low", "medium", "high".
Satu objek kuota dibuat untuk setiap Priority.
Simpan YAML berikut ke sebuah berkas bernama quota.yml.
resourcequota/pods-high created
resourcequota/pods-medium created
resourcequota/pods-low created
Pastikan bahwa kuota Used adalah 0 dengan kubectl describe quota.
kubectl describe quota
Name: pods-high
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 1k
memory 0 200Gi
pods 010Name: pods-low
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 05memory 0 10Gi
pods 010Name: pods-medium
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 010memory 0 20Gi
pods 010
Buat sebuah Pod dengan Priority "high". Simpan YAML berikut ke sebuah
berkas bernama high-priority-pod.yml.
apiVersion:v1kind:Podmetadata:name:high-priorityspec:containers:- name:high-priorityimage:ubuntucommand:["/bin/sh"]args:["-c","while true; do echo hello; sleep 10;done"]resources:requests:memory:"10Gi"cpu:"500m"limits:memory:"10Gi"cpu:"500m"priorityClassName:high
Terapkan dengan kubectl create.
kubectl create -f ./high-priority-pod.yml
Pastikan bahwa status "Used" untuk kuota dengan Priority "high", pods-high, telah berubah
dan dua kuota lainnya tidak berubah.
kubectl describe quota
Name: pods-high
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 500m 1k
memory 10Gi 200Gi
pods 110Name: pods-low
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 05memory 0 10Gi
pods 010Name: pods-medium
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 010memory 0 20Gi
pods 010
scopeSelector mendukung nilai-nilai berikut pada kolom operator:
In
NotIn
Exist
DoesNotExist
Request vs Limit
Saat mengalokasikan sumber daya komputasi, setiap Container dapat menentukan sebuah nilai request (permintaan) dan limit untuk CPU atau memori.
Kuota tersebut dapat dikonfigurasi untuk membatasi nilai salah satunya.
Jika kuota tersebut memiliki sebuah nilai yang ditentukan untuk requests.cpu atau requests.memory, maka kuota
tersebut mengharuskan setiap Container yang akan dibuat untuk menentukan request eksplisit untuk sumber daya tersebut.
Jika kuota tersebut memiliki sebuah nilai yang ditentukan untuk limits.cpu atau limits.memory, maka kuota tersebut
mengharuskan setiap Container yang akan dibuat untuk menentukan limit eksplisit untuk sumber daya tersebut.
Melihat dan Menyetel kuota
Kubectl mendukung membuat, membarui, dan melihat kuota:
Name: object-counts
Namespace: myspace
Resource Used Hard
-------- ---- ----
configmaps 010persistentvolumeclaims 04pods 04replicationcontrollers 020secrets 110services 010services.loadbalancers 02
Kubectl juga mendukung kuota kuantitas objek untuk semua sumber daya standar yang berada pada Namespace
menggunakan sintaksis count/<resource>.<group>:
kubectl create namespace myspace
kubectl create quota test --hard=count/deployments.extensions=2,count/replicasets.extensions=4,count/pods=3,count/secrets=4 --namespace=myspace
kubectl run nginx --image=nginx --replicas=2 --namespace=myspace
kubectl describe quota --namespace=myspace
Name: testNamespace: myspace
Resource Used Hard
-------- ---- ----
count/deployments.extensions 12count/pods 23count/replicasets.extensions 14count/secrets 14
Kuota dan Kapasitas Klaster
ResourceQuota tidak tergantung pada kapasitas klaster. ResourceQuota ditentukan dalam
satuan-satuan absolut. Jadi, jika kamu menambahkan Node ke klaster kamu, penambahan ini
bukan berarti secara otomatis memberikan setiap Namespace kemampuan untuk menggunakan
lebih banyak sumber daya.
Terkadang kebijakan yang lebih kompleks mungkin lebih diinginkan, seperti:
Secara proporsional membagi sumber daya total klaster untuk beberapa tim.
Mengizinkan setiap tim untuk meningkatkan penggunaan sumber daya sesuai kebutuhan,
tetapi tetap memiliki batas yang cukup besar untuk menghindari kehabisan sumber daya.
Mendeteksi permintaan dari sebuah Namespace, menambah Node, kemudian menambah kuota.
Kebijakan-kebijakan seperti itu dapat diterapkan dengan ResourceQuota sebagai dasarnya,
dengan membuat sebuah "pengontrol" yang memantau penggunaan kuota dan menyesuaikan batas
keras kuota untuk setiap Namespace berdasarkan sinyal-sinyal lainnya.
Perlu dicatat bahwa Resource Quota membagi agregat sumber daya klaster, tapi Resource Quota
tidak membuat batasan-batasan terhadap Node: Pod-Pod dari beberapa Namespace boleh berjalan
di Node yang sama.
Membatasi konsumsi Priority Class secara bawaan
Mungkin saja diinginkan untuk Pod-Pod pada kelas prioritas tertentu, misalnya "cluster-services", sebaiknya diizinkan pada sebuah Namespace, jika dan hanya jika terdapat sebuah objek kuota yang cocok.
Dengan mekanisme ini, operator-operator dapat membatasi penggunaan Priority Class dengan prioritas tinggi pada Namespace-Namespace tertentu saja dan tidak semua Namespace dapat menggunakan Priority Class tersebut secara bawaan.
Untuk memaksa aturan ini, flag kube-apiserver --admission-control-config-file sebaiknya digunakan untuk memberikan path menuju berkas konfigurasi berikut:
# Kedaluwarsa pada v1.17 digantikan oleh apiserver.config.k8s.io/v1apiVersion:apiserver.k8s.io/v1alpha1kind:AdmissionConfigurationplugins:- name:"ResourceQuota"configuration:# Kedaluwarsa pada v1.17 digantikan oleh apiserver.config.k8s.io/v1, ResourceQuotaConfigurationapiVersion:resourcequota.admission.k8s.io/v1beta1kind:ConfigurationlimitedResources:- resource:podsmatchScopes:- scopeName:PriorityClassoperator:Invalues:["cluster-services"]
Sekarang, Pod-Pod "cluster-services" akan diizinkan hanya pada Namespace di mana ada sebuah objek kuota dengan sebuah scopeSelector yang cocok.
Pod Security Policies (kebijakan keamanan Pod) memungkinkan otorisasi secara detil dari pembuatan dan pembaruan Pod.
Apa itu Pod Security Policy?
Pod Security Policy adalah sebuah sumber daya pada tingkat klaster yang mengatur aspek-aspek spesifikasi Pod yang sensitif terhadap keamanan. Objek-objek PodSecurityPolicy mendefinisikan sebuah kumpulan kondisi yang harus dijalankan oleh Pod untuk dapat diterima oleh sistem, dan juga sebagai nilai-nilai bawaan untuk kolom-kolom yang bersangkutan. Mereka memungkinkan administrator untuk mengatur hal-hal berikut:
Pengaturan Pod Security Policy diimplementasi sebagai sebuah opsi (tapi direkomendasikan untuk digunakan) dari admission controller. PodSecurityPolicy dilaksanakan dengan mengaktifkan admission controller-nya, tetapi melakukan hal ini tanpa mengizinkan kebijakan apapun akan menghalangi Pod apapun untuk dibuat di dalam klaster.
Sejak API dari Pod Security Policy (policy/v1beta1/podsecuritypolicy) diaktifkan secara independen dari admission controller, untuk klaster-klaster yang sudah ada direkomendasikan untuk menambahkan dan mengizinkan kebijakan yang bersangkutan sebelum mengaktifkan admission controller tersebut.
Mengizinkan Kebijakan
Saat sebuah sumber daya PodSecurityPolicy dibuat, ia tidak melakukan apa-apa. Untuk menggunakannya, Service Account dari pengguna yang memintanya atau target Pod-nya harus diizinkan terlebih dahulu untuk menggunakan kebijakan tersebut, dengan membolehkan kata kerja use terhadap kebijakan tersebut.
Kebanyakan Pod Kubernetes tidak dibuat secara langsung oleh pengguna. Sebagai gantinya, mereka biasanya dibuat secara tidak langsung sebagai bagian dari sebuah Deployment, ReplicaSet, atau pengontrol yang sudah ditemplat lainnya melalui Controller Manager. Memberikan akses untuk pengontrol terhadap kebijakan tersebut akan mengizinkan akses untuk semua Pod yang dibuat oleh pengontrol tersebut, sehingga metode yang lebih baik untuk mengizinkan kebijakan adalah dengan memberikan akses pada Service Account milik Pod (lihat contohnya).
Melalui RBAC
RBAC adalah mode otorisasi standar Kubernetes, dan dapat digunakan dengan mudah untuk mengotorisasi penggunaan kebijakan-kebijakan.
Pertama-tama, sebuah Role atau ClusterRole perlu memberikan akses pada kata kerja use terhadap kebijakan-kebijakan yang diinginkan. rules yang digunakan untuk memberikan akses tersebut terlihat seperti berikut:
apiVersion:rbac.authorization.k8s.io/v1kind:ClusterRolemetadata:name:<role name>rules:- apiGroups:['policy']resources:['podsecuritypolicies']verbs:['use']resourceNames:- <list of policies to authorize>
Kemudian, Role atau ClusterRole tersebut diikat ke pengguna-pengguna yang diberikan otoritas.
apiVersion:rbac.authorization.k8s.io/v1kind:ClusterRoleBindingmetadata:name:<binding name>roleRef:kind:ClusterRolename:<role name>apiGroup:rbac.authorization.k8s.iosubjects:# Mengotorisasi ServiceAccount spesifik- kind:ServiceAccountname:<authorized service account name>namespace:<authorized pod namespace># Mengotorisasi User spesifik (tidak direkomendasikan)- kind:UserapiGroup:rbac.authorization.k8s.ioname:<authorized user name>
Jika sebuah RoleBinding (bukan ClusterRoleBinding) digunakan, maka ia hanya akan memberi akses penggunaan untuk Pod-Pod yang dijalankan pada Namespace yang sama dengan RoleBinding tersebut. Hal ini dapat dipasangkan dengan grup sistem untuk memberi akses pada semua Pod yang berjalan di Namespace tersebut:
# Mengotorisasi semua ServiceAccount di dalam sebuah Namespace- kind:GroupapiGroup:rbac.authorization.k8s.ioname:system:serviceaccounts# Atau secara ekuivalen, semua pengguna yang telah terotentikasi pada sebuah Namespace- kind:GroupapiGroup:rbac.authorization.k8s.ioname:system:authenticated
Untuk lebih banyak contoh pengikatan RBAC, lihat Contoh Role Binding.
Untuk contoh lengkap untuk mengotorisasi sebuah PodSecurityPolicy, lihat di bawah.
Mengatasi Masalah
Controller Manager harus dijalankan terhadap port API yang telah diamankan, dan tidak boleh memiliki izin superuser, atau semua permintaan akan melewati modul-modul otentikasi dan otorisasi, semua objek PodSecurityPolicy tidak akan diizinkan, dan semua pengguna dapat membuat Container-container yang privileged. Untuk lebih detil tentang mengkonfigurasi otorisasi Controller Manager, lihat Controller Roles.
Urutan Kebijakan
Sebagai tambahan terhadap membatasi pembuatan dan pembaruan Pod, Pod Security Policy dapat digunakan juga untuk menyediakan nilai-nilai bawaan untuk banyak kolom yang dikontrol olehnya. Saat banyak kebijakan tersedia, pengatur Pod Security Policy memilih kebijakan-kebijakan berdasarkan kriteria berikut:
PodSecurityPolicy yang mengizinkan Pod apa adanya, tanpa mengganti nilai-nilai bawaan atau memutasi Pod tersebut, akan lebih dipilih. Urutan PodSecurityPolicy yang tidak mengubah Pod ini tidak dipermasalahkan.
Jika Pod-nya harus diberi nilai bawaan atau dimutasi, maka PodSecurityPolicy pertama (diurutkan berdasarkan namanya) untuk mengizinkan Pod tersebut akan dipilih.
Catatan:
Saat operasi pembaruan (saat ini mutasi terhadap spesifikasi Pod tidak diizinkan) hanya PodSecurityPolicy yang tidak mengubah Pod yang akan digunakan untuk melakukan validasi terhadap Pod tersebut.
Contoh
Contoh ini mengasumsikan kamu telah memiliki klaster yang berjalan dengan admission controller PodSecurityPolicy diaktifkan, dan kamu mempunyai akses admin.
Persiapan
Mempersiapkan sebuah Namespace dan ServiceAccount untuk digunakan pada contoh ini. Kita akan menggunakan ServiceAccount ini untuk meniru sebuah pengguna bukan admin.
apiVersion:policy/v1beta1kind:PodSecurityPolicymetadata:name:examplespec:privileged:false# Jangan izinkan Pod-Pod yang _privileged_!# Sisanya isi kolom-kolom yang dibutuhkanseLinux:rule:RunAsAnysupplementalGroups:rule:RunAsAnyrunAsUser:rule:RunAsAnyfsGroup:rule:RunAsAnyvolumes:- '*'
Dan buatlah PodSecurityPolicy tersebut dengan kubectl:
kubectl-admin create -f example-psp.yaml
Sekarang, sebagai pengguna bukan admin, cobalah membuat Pod sederhana:
kubectl-user create -f- <<EOF
apiVersion: v1
kind: Pod
metadata:
name: pause
spec:
containers:
- name: pause
image: registry.k8s.io/pause
EOFError from server (Forbidden): error when creating "STDIN": pods "pause" is forbidden: unable to validate against any pod security policy: []
Apa yang terjadi? Walaupun PodSecurityPolicy tersebut telah dibuat, ServiceAccount dari Pod tersebut maupun fake-user tidak memikiki izin untuk menggunakan kebijakan tersebut:
kubectl-user auth can-i use podsecuritypolicy/example
no
Membuat RoleBinding untuk memberikan fake-user akses terhadap kata kerja use pada kebijakan contoh kita:
Catatan:
Ini bukan cara yang direkomendasikan! Lihat bagian selanjutnya untuk cara yang lebih baik.
kubectl-admin create role psp:unprivileged \
--verb=use \
--resource=podsecuritypolicy \
--resource-name=example
role "psp:unprivileged" created
kubectl-admin create rolebinding fake-user:psp:unprivileged \
--role=psp:unprivileged \
--serviceaccount=psp-example:fake-user
rolebinding "fake-user:psp:unprivileged" created
kubectl-user auth can-i use podsecuritypolicy/example
yes
Bekerja seperti yang diharapkan! Tapi percobaan apapun untuk membuat Pod yang privileged seharusnya masih ditolak:
kubectl-user create -f- <<EOF
apiVersion: v1
kind: Pod
metadata:
name: privileged
spec:
containers:
- name: pause
image: registry.k8s.io/pause
securityContext:
privileged: true
EOFError from server (Forbidden): error when creating "STDIN": pods "privileged" is forbidden: unable to validate against any pod security policy: [spec.containers[0].securityContext.privileged: Invalid value: true: Privileged containers are not allowed]
Hapus Pod tersebut sebelum melanjutkan:
kubectl-user delete pod pause
Menjalankan Pod lainnya
Mari coba lagi, dengan cara yang sedikit berbeda:
kubectl-user run pause --image=registry.k8s.io/pause
deployment "pause" created
kubectl-user get pods
No resources found.
kubectl-user get events | head -n 2LASTSEEN FIRSTSEEN COUNT NAME KIND SUBOBJECT TYPE REASON SOURCE MESSAGE
1m 2m 15 pause-7774d79b5 ReplicaSet Warning FailedCreate replicaset-controller Error creating: pods "pause-7774d79b5-" is forbidden: no providers available to validate pod request
Apa yang terjadi? Kita telah mengikat Role psp:unprivileged untuk fake-user kita, kenapa kita mendapatkan kesalahan Error creating: pods "pause-7774d79b5-" is forbidden: no providers available to validate pod request? Jawabannya berada pada sumbernya - replicaset-controller. Fake-user berhasil membuat Deployment tersebut (yang berhasil membuat sebuah ReplicaSet), tetapi saat ReplicaSet tersebut akan membuat Pod, ia tidak terotorisasi untuk menggunakan PodSecurityPolicy contoh tersebut.
Untuk memperbaikinya, ikatlah Role psp:unprivileged pada ServiceAccount Pod tersebut. Pada kasus ini (karena kita tidak menspesifikasikannya) ServiceAccount-nya adalah default:
Perlu diperhatikan bahwa sumber daya PodSecurityPolicy tidak diberi Namespace, dan harus dibersihkan secara terpisah:
kubectl-admin delete psp example
podsecuritypolicy "example" deleted
Contoh-contoh Kebijakan
Berikut adalah kebijakan dengan batasan paling sedikit yang dapat kamu buat, ekuivalen dengan tidak menggunakan admission controller Pod Security Policy:
Berikut adalah sebuah contoh kebijakan yang restriktif yang mengharuskan pengguna-pengguna untuk berjalan sebagai pengguna yang unprivileged, memblokir kemungkinan eskalasi menjadi root, dan mengharuskan penggunaan beberapa mekanisme keamanan.
apiVersion:policy/v1beta1kind:PodSecurityPolicymetadata:name:restrictedannotations:seccomp.security.alpha.kubernetes.io/allowedProfileNames:'docker/default,runtime/default'apparmor.security.beta.kubernetes.io/allowedProfileNames:'runtime/default'seccomp.security.alpha.kubernetes.io/defaultProfileName:'runtime/default'apparmor.security.beta.kubernetes.io/defaultProfileName:'runtime/default'spec:privileged:false# Dibutuhkan untuk menghindari eskalasi ke _root_.allowPrivilegeEscalation:false# Hal ini berlebihan dengan _non-root_ + melarang eskalasi _privilege_,# tetapi kita dapat menyediakannya untuk _defense in depth_requiredDropCapabilities:- ALL# Izinkan tipe-tipe volume inti.volumes:- 'configMap'- 'emptyDir'- 'projected'- 'secret'- 'downwardAPI'# Berasumsi bahwa persistentVolumes yang disetel oleh admin klaster aman untuk digunakan.- 'persistentVolumeClaim'hostNetwork:falsehostIPC:falsehostPID:falserunAsUser:# Mengharuskan container untuk berjalan tanpa hak sebagai _root_.rule:'MustRunAsNonRoot'seLinux:# Kebijakan ini mengasumsikan bahwa node-node menggunakan AppArmor daripada SELinux.rule:'RunAsAny'supplementalGroups:rule:'MustRunAs'ranges:# Larang menambahkan grup _root_.- min:1max:65535fsGroup:rule:'MustRunAs'ranges:# Larang menambahkan grup _root_.- min:1max:65535readOnlyRootFilesystem:false
Referensi Kebijakan
Privileged
Privileged - menentukan bila Container manapun di dalam sebuah Pod dapat mengaktifkan mode privileged. Secara bawaan, sebuah Container tidak diizinkan untuk mengakses perangkat apapun pada host-nya, tapi sebuah Container yang "privileged" akan diberikan akses untuk semua perangkat pada host-nya. Hal ini mengizinkan hampir semua akses yang sama dengan proses yang berjalan pada host kepada Container tersebut. Hal ini berfungsi untuk Container-container yang ingin menggunakan kemampuan Linux seperti memanipulasi network stack atau mengakses perangkat-perangkat.
determines if any container in a pod can enable privileged mode.
Namespace Host
HostPID - Mengatur jika Container-container pada Pod dapat berbagi namespace process ID pada host. Catatlah bahwa saat dipasangkan dengan ptrace, hal ini dapat digunakan untuk eskalasi privilege di luar kontainer (ptrace secara bawaan tidak diizinkan).
HostIPC - Mengatur jika container-container pada Pod dapat berbagi namespace IPC pada host.
HostNetwork - Mengatur jika Pod dapat menggunakan namespace jaringan pada host. Melakukan hal ini akan memberikan Pod akses pada perangkat loopback, service yang sedang listening pada localhost, dan dapat digunakan untuk mengintai aktivitas jaringan pada Pod-Pod lain pada Node yang sama.
HostPorts - Memberikan daftar putih dari berbagai port yang diizinkan pada namespace jaringan pada host. Hal ini didefinisikan sebagai sebuah daftar HostPortRange, dengan min(inklusif) dan max(inklusif). Nilai bawaannya adalah tidak ada host port yang diizinkan.
Volume - Menyediakan sebuah daftar putih dari tipe-tipe Volume yang diizinkan. Nilai-nilai yang diizinkan sesuai dengan sumber Volume yang didefinisikan saat membuat sebuah Volume. Untuk daftar lengkap tipe-tipe Volume, lihat tipe-tipe Volume. Sebagai tambahan, * dapat digunakan untuk mengizinkan semua tipe Volume.
Kumpulan Volume-volume minimal yang direkomendasikan untuk PodSecurityPolicy baru adalah sebagai berikut:
configMap
downwardAPI
emptyDir
persistentVolumeClaim
secret
projected
Peringatan:
PodSecurityPolicy tidak membatasi tipe-tipe objek PersistentVolume yang dapat direferensikan oleh PersistentVolumeClaim. Hanya pengguna-pengguna yang dipercaya yang boleh diberikan izin untuk membuat objek-objek PersistentVolume.
FSGroup - Mengatur grup tambahan yang dipasang ke beberapa volume.
MustRunAs - Membutuhkan setidaknya satu range untuk dapat ditentukan. Menggunakan semua nilai minimum dari range yang pertama sebagai nilai bawaannya. Memvalidasikan terhadap semua range.
MayRunAs - Membutuhkan setidaknya satu range untuk dapat ditentukan. Mengizinkan FSGroups dibiarkan kosong tanpa memberikan nilai bawaan. Memvalidasikan terhadap semua range jika nilai FSGroups disetel.
RunAsAny - Tidak ada nilai bawaan yang diberikan. Mengizinkan ID fsGroup apapun untuk digunakan.
AllowedHostPaths - Memperinci sebuah daftar putih dari host path yang diizinkan untuk digunakan oleh volume-volume hostPath. Sebuah daftar kosong berarti tidak ada pembatasan pada host path yang digunakan. Hal ini didefinisikan sebagai sebuah daftar objek-objek dengan sebuah kolom pathPrefix, yang mengizinkan volume-volume hostPath untuk menambatkan sebuah path yang dimulai dengan sebuah prefiks yang diizinkan, dan sebuah kolom readOnly yang menunjukkan bahwa ia harus ditambatkan sebagai read-only.
Misalnya:
allowedHostPaths:# Hal ini mengizinkan "/foo", "/foo/", "/foo/bar" dll., tetapi# melarang "/fool", "/etc/foo" dll.# "/foo/../" tidak sah.- pathPrefix:"/foo"readOnly:true# Izinkan hanya tambatan _read-only_
Peringatan:
Ada banyak cara bagi sebuah Container dengan akses yang tidak dibatasi terhadap host filesystem-nya untuk dapat melakukan eskalasi privilege, termasuk membaca data dari Container-container lain, dan menyalahgunakan kredensial dari service-service sistem, misalnya Kubelet.
Direktori volume hostPath yang dapat ditulis mengizinkan container-container untuk menulis ke filesystem melalui cara-cara yang membiarkan mereka melintasi host filesystem di luar pathPrefix yang bersangkutan.
readOnly: true, tersedia pada Kubernetes 1.11 ke atas, harus digunakan pada semuaallowedHostPaths untuk secara efektif membatasi akses terhadap pathPrefix yang diperinci.
ReadOnlyRootFilesystem - Mengharuskan container-container berjalan dengan sebuah root filesystem yang bersifat read-only (yaitu, tanpa lapisan yang dapat ditulis)
Driver-driver Flexvolume
Hal ini memperinci sebuah daftar putih dari driver-driver Flexvolume yang diizinkan untuk digunakan oleh Flexvolume. Sebuah daftar kosong atau nil berarti tidak ada batasan terhadap driver-driver tersebut.
Pastikan kolom volumes berisi tipe volumenya; Jika tidak, tidak ada driver Flexvolume yang diizinkan.
RunAsUser - Mengatur ID pengguna mana yang digunakan untuk menjalankan container-container.
MustRunAs - Membutuhkan setidaknya satu range untuk dapat ditentukan. Menggunakan semua nilai minimum dari range yang pertama sebagai nilai bawaannya. Memvalidasikan terhadap semua range.
MustRunAsNonRoot - Mengharuskan Pod diajukan dengan nilai runAsUser yang bukan nol, atau memiliki petunjuk USER didefinisikan (dengan UID numerik) di dalam image. Pod-Pod yang belum memperinci runAsNonRoot atau runAsUser akan dimutasikan untuk menyetel runAsNonRoot=true sehingga membutuhkan petunjuk USER dengan nilai numerik bukan nol di dalam Container. Tidak ada nilai bawaan yang diberikan. Menyetel allowPrivilegeEscalation=false sangat disarankan dengan strategi ini.
RunAsAny - Tidak ada nilai bawaan yang diberikan. Mengizinkan runAsUser apapun untuk digunakan.
RunAsGroup - Mengatur ID grup primer mana yang digunakan untuk menjalankan Container-container.
MustRunAs - Membutuhkan setidaknya satu range untuk dapat ditentukan. Menggunakan semua nilai minimum dari range yang pertama sebagai nilai bawaannya. Memvalidasikan terhadap semua range.
MayRunAs - Tidak memerlukan RunAsGroup untuk diperinci. Tetapi, saat RunAsGroup diperinci, mereka harus berada pada range yang didefinisikan.
RunAsAny - Tidak ada nilai bawaan yang diberikan. Mengizinkan runAsGroup apapun untuk digunakan.
SupplementalGroups - Mengatur ID grup mana saja yang ditambah ke Container-container.
MustRunAs - Membutuhkan setidaknya satu range untuk dapat ditentukan. Menggunakan semua nilai minimum dari range yang pertama sebagai nilai bawaannya. Memvalidasikan terhadap semua range.
MayRunAs - Membutuhkan setidaknya satu range untuk dapat ditentukan. Mengizinkan supplementalGroups dibiarkan kosong tanpa memberikan nilai bawaan. Memvalidasikan terhadap semua range jika nilai supplementalGroup disetel.
RunAsAny - Tidak ada nilai bawaan yang diberikan. Mengizinkan ID supplementalGroups apapun untuk digunakan.
Eskalasi Privilege
Opsi ini mengatur opsi Container allowPrivilegeEscalation. Nilai bool ini secara langsung mengatur apakah flagno_new_privs disetel pada proses Container tersebut. Flag ini akan mencegah program setuid mengganti ID pengguna efektif, dan mencegah berkas-berkas untuk memungkinkan kemampuan tambahan (misalnya, ini akan mencagah penggunaan peralatan ping). Perilaku ini dibutuhkan untuk memaksakan MustRunAsNonRoot.
AllowPrivilegeEscalation - Membatasi apakah seorang pengguna diizinkan untuk menyetel konteks keamanan dari sebuah Container menjadi allowPrivilegeEscalation=true. Hal ini memiliki nilai bawaan untuk diizinkan, agar tidak merusak program setuid. Menyetel ini menjadi false memastikan bahwa tidak ada proses child dari sebuah Container dapat memperoleh lebih banyak privilege dari parent-nya.
DefaultAllowPrivilegeEscalation - Menyetel nilai bawaan untuk opsi allowPrivilegeEscalation. Perilaku bawaan tanpa hal ini adalah untuk mengizinkan eskalasi privilege agar tidak merusak program setuid. Jika perilaku ini tidak diinginkan, kolom ini dapat digunakan untuk menyetel nilai bawaan allowPrivilegeEscalation agar melarang eskalasi, sementara masih mengizinkan Pod-Pod untuk meminta allowPrivilegeEscalation secara eksplisit.
Kemampuan-kemampuan
Kemampuan-kemampuan Linux menyediakan perincian yang detail dari privilege-privilege yang biasa dikaitkan dengan superuser. Beberapa dari kemampuan-kemampuan ini dapat digunakan untuk mengeskalasi privilege-privilege atau untuk container breakout, dan dapat dibatasi oleh PodSecurityPolicy. Untuk lebih lanjut tentang kemampuan-kemampuan Linux, lihat capabilities(7).
Kolom-kolom berikut mengambil daftar kemampuan-kemampuan, diperincikan sebagai nama kemampuannya dalam ALL_CAPS tanpa awalan CAP_.
AllowedCapabilities - Menyediakan sebuah daftar putih dari kemampuan-kemampuan yang dapat ditambahkan pada sebuah Container. Kumpulan kemampuan bawaan secara implisit diizinkan. Kumpulan kosong berarti tidak ada kemampuan tambahan yang dapat ditambahkan selain bawaannya. * dapat digunakan untuk mengizinkan semua kemampuan.
RequiredDropCapabilities - Kemampuan-kemampuan yang harus dihapus dari Container-container. Kemampuan-kemampuan ini dihapus dari kumpulan bawaan, dan tidak boleh ditambahkan. Kemampuan-kemampuan yang terdaftar di RequiredDropCapabilities tidak boleh termasuk di dalam AllowedCapabilities atau DefaultAddCapabilities.
DefaultAddCapabilities - Kemampuan-kemampuan yang ditambahkan pada Container-container secara bawaan, sebagai tambahan untuk bawaan runtime. Lihat dokumentasi Docker untuk daftar kemampuan bawaan saat menggunakan runtime Docker.
SELinux
MustRunAs - Mengharuskan penyetelan seLinuxOptions. Menggunakan seLinuxOptions sebagai nilai bawaannya. Memvalidasi terhadap seLinuxOptions.
RunAsAny - Tidak ada nilai bawaan yang disediakan. Mengizinkan nilai seLinuxOptions apapun untuk diberikan.
AllowedProcMountTypes
allowedProcMountTypes adalah sebuah daftar putih dari ProcMountType yang diizinkan. Nilai kosong atau nil menunjukkan bahwa hanya DefaultProcMountType yang boleh digunakan.
DefaultProcMount menggunakan nilai bawaan container runtime untuk readonly dan masked paths untuk /proc. Kebanyakan runtime Container melakukan mask terhadap beberapa path di dalam /proc untuk menghindari security exposure dari perangkat-perangkat atau informasi khusus yang tidak disengaja. Hal ini ditandai dengan nilai stringDefault.
Satu-satunya ProcMountType lainnya adalah UnmaskedProcMount, yang melangkahi perilaku masking bawaan dari runtime Container dan memastikan bahwa /proc yang baru dibuat tetap utuh tanpa perubahan. Hal ini ditandai dengan nilai stringUnmasked.
Penggunaan profil-profil seccomp di dalam Pod-Pod dapat diatur melalui anotasi pada PodSecurityPolicy.
Seccomp adalah fitur Alpha di Kubernetes.
seccomp.security.alpha.kubernetes.io/defaultProfileName - Anotasi yang menunjukkan profil seccomp bawaan untuk diterapkan kepada container-container. Nilai-nilai yang mungkin adalah:
unconfined - Seccomp tidak diterapkan pada proses-proses di container (ini adalah bawaan di Kubernetes), jika tidak ada alternatif yang diberikan.
docker/default - Profil bawaan seccomp Docker digunakan. Sudah kedaluwarsa sejak Kubernetes 1.11. Gunakan runtime/default sebagai gantinya.
localhost/<path> - Menentukan sebuah profil sebagai sebuah berkas pada Node yang berlokasi pada <seccomp_root>/<path>, di mana <seccomp_root> didefinisikan melalui flag--seccomp-profile-root pada Kubelet.
seccomp.security.alpha.kubernetes.io/allowedProfileNames - Anotasi yang menunjukkan nilai-nilai mana yang diizinkan untuk anotasi seccomp pada Pod. Ditentukan sebagai sebuah daftar nilai yang diizinkan yang dibatasi dengan tanda koma. Nilai-nilai yang dimungkinkan adalah yang terdaftar di atas, ditambah dengan * untuk mengizinkan semua profil. Ketiadaan anotasi ini berarti nilai bawaannya tidak dapat diubah.
Sysctl
Secara bawaan, semua sysctl yang aman diizinkan.
forbiddenSysctls - mengecualikan sysctl-sysctl tertentu. Kamu dapat melarang kombinasi dari sysctl-sysctl yang aman maupun tidak aman pada daftar ini. Untuk melarang menyetel sysctl apapun, gunakan nilai *.
allowedUnsafeSysctls - mengizinkan sysctl-sysctl tertentu yang telah dilarang oleh daftar bawaan, selama nilainya tidak terdaftar di dalam forbiddenSysctls.
Ikhtisar administrasi klaster ini ditujukan untuk siapapun yang akan membuat atau mengelola klaster Kubernetes.
Diharapkan untuk memahami beberapa konsep dasar Kubernetes sebelumnya.
Perencanaan Klaster
Lihat panduan di Persiapan untuk mempelajari beberapa contoh tentang bagaimana merencanakan, mengatur dan mengonfigurasi klaster Kubernetes. Solusi yang akan dipaparkan di bawah ini disebut distro.
Sebelum memilih panduan, berikut adalah beberapa hal yang perlu dipertimbangkan:
Apakah kamu hanya ingin mencoba Kubernetes pada komputermu, atau kamu ingin membuat sebuah klaster dengan high-availability, multi-node? Pilihlah distro yang paling sesuai dengan kebutuhanmu.
Jika kamu merencanakan klaster dengan high-availability, pelajari bagaimana cara mengonfigurasi klaster pada multiple zone.
Apakah kamu akan menggunakan Kubernetes klaster di hosting, seperti Google Kubernetes Engine, atau hosting sendiri klastermu?
Apakah klastermu berada pada on-premises, atau di cloud (IaaS)? Kubernetes belum mendukung secara langsung klaster hibrid. Sebagai gantinya, kamu dapat membuat beberapa klaster.
Jika kamu ingin mengonfigurasi Kubernetes on-premises, pertimbangkan model jaringan yang paling sesuai.
Apakah kamu ingin menjalankan Kubernetes pada "bare metal" hardware atau pada virtual machines (VM)?
Apakah kamu hanya ingin mencoba klaster Kubernetes, atau kamu ingin ikut aktif melakukan pengembangan kode dari proyek Kubernetes? Jika jawabannya yang terakhir, pilihlah distro yang aktif dikembangkan. Beberapa distro hanya menggunakan rilis binary, namun menawarkan lebih banyak variasi pilihan.
Pastikan kamu paham dan terbiasa dengan beberapa komponen yang dibutuhkan untuk menjalankan sebuah klaster.
Catatan: Tidak semua distro aktif dikelola. Pilihlah distro yang telah diuji dengan versi terkini dari Kubernetes.
Mengelola Klaster
Mengelola klaster akan menjabarkan beberapa topik terkait lifecycle dari klaster: membuat klaster baru, melakukan upgrade pada node master dan worker, melakukan pemeliharaan node (contoh: upgrade kernel), dan melakukan upgrade versi Kubernetes API pada klaster yang sedang berjalan.
Autentikasi akan menjelaskan autentikasi di Kubernetes, termasuk ragam pilihan autentikasi.
Otorisasi dibedakan dari autentikasi, digunakan untuk mengontrol bagaimana HTTP call ditangani.
Menggunakan Admission Controllers akan menjelaskan plug-in yang akan melakukan intersep permintaan sebelum menuju ke server Kubernetes API, setelah autentikasi dan otorisasi dilakukan.
Hasilkan sertifikat dan kunci server.
Argumen --subject-alt-name digunakan untuk mengatur alamat IP dan nama DNS yang dapat diakses
oleh server API. MASTER_CLUSTER_IP biasanya merupakan IP pertama dari CIDR service cluster
yang diset dengan argumen --service-cluster-ip-range untuk server API dan
komponen manajer pengontrol. Argumen --days digunakan untuk mengatur jumlah hari
masa berlaku sertifikat.
Sampel di bawah ini juga mengasumsikan bahwa kamu menggunakan cluster.local sebagai nama
domain DNS default.
Buat file konfigurasi untuk menghasilkan Certificate Signing Request (CSR).
Pastikan untuk mengganti nilai yang ditandai dengan kurung sudut (mis. <MASTER_IP>)
dengan nilai sebenarnya sebelum menyimpan ke file (mis. csr.conf).
Perhatikan bahwa nilai MASTER_CLUSTER_IP adalah layanan IP klaster untuk
server API seperti yang dijelaskan dalam subbagian sebelumnya.
Sampel di bawah ini juga mengasumsikan bahwa kamu menggunakan cluster.local
sebagai nama domain DNS default.
Terakhir, tambahkan parameter yang sama ke dalam parameter mulai server API.
cfssl
cfssl adalah alat lain untuk pembuatan sertifikat.
Unduh, buka paket dan siapkan command line tools seperti yang ditunjukkan di bawah ini.
Perhatikan bahwa kamu mungkin perlu menyesuaikan contoh perintah berdasarkan arsitektur
perangkat keras dan versi cfssl yang kamu gunakan.
Buat file konfigurasi JSON untuk CA certificate signing request (CSR), misalnya,
ca-csr.json. Pastikan untuk mengganti nilai yang ditandai dengan kurung sudut
dengan nilai sebenarnya yang ingin kamu gunakan.
Hasilkan kunci CA (ca-key.pem) dan sertifikat (ca.pem):
../cfssl gencert -initca ca-csr.json | ../cfssljson -bare ca
Buat file konfigurasi JSON untuk menghasilkan kunci dan sertifikat untuk API
server, misalnya, server-csr.json. Pastikan untuk mengganti nilai dalam kurung sudut
dengan nilai sebenarnya yang ingin kamu gunakan. MASTER_CLUSTER_IP adalah layanan
klaster IP untuk server API seperti yang dijelaskan dalam subbagian sebelumnya.
Sampel di bawah ini juga mengasumsikan bahwa kamu menggunakan cluster.local sebagai
nama domain DNS default.
Node klien dapat menolak untuk mengakui sertifikat CA yang ditandatangani sendiri sebagai valid.
Untuk deployment non-produksi, atau untuk deployment yang berjalan di belakang firewall perusahaan,
kamu dapat mendistribusikan sertifikat CA yang ditandatangani sendiri untuk semua klien dan refresh
daftar lokal untuk sertifikat yang valid.
Updating certificates in /etc/ssl/certs...
1 added, 0 removed; done.
Running hooks in /etc/ca-certificates/update.d....
done.
Sertifikat API
Kamu dapat menggunakan API Certificate.k8s.io untuk menyediakan
sertifikat x509 yang digunakan untuk autentikasi seperti yang didokumentasikan
di sini.
11.3 - Penyedia Layanan Cloud
Laman ini akan menjelaskan bagaimana cara mengelola Kubernetes yang berjalan pada penyedia layanan cloud tertentu.
Kubeadm
Kubeadm merupakan salah satu cara yang banyak digunakan untuk membuat klaster Kubernetes.
Kubeadm memiliki beragam opsi untuk mengatur konfigurasi spesifik untuk penyedia layanan cloud. Salah satu contoh yang biasa digunakan pada penyedia cloud in-tree yang dapat diatur dengan kubeadm adalah sebagai berikut:
Penyedia layanan cloud in-tree biasanya membutuhkan --cloud-provider dan --cloud-config yang ditentukan sebelumnya pada command lines untuk kube-apiserver, kube-controller-manager dan
kubelet. Konten dari file yang ditentukan pada --cloud-config untuk setiap provider akan dijabarkan di bawah ini.
Untuk semua penyedia layanan cloud eksternal, silakan ikuti instruksi pada repositori masing-masing penyedia layanan.
AWS
Bagian ini akan menjelaskan semua konfigurasi yang dapat diatur saat menjalankan Kubernetes pada Amazon Web Services.
Nama Node
Penyedia layanan cloud AWS menggunakan nama DNS privat dari instance AWS sebagai nama dari objek Kubernetes Node.
Load Balancer
Kamu dapat mengatur load balancers eksternal sehingga dapat menggunakan fitur khusus AWS dengan mengatur anotasi seperti di bawah ini.
apiVersion:v1kind:Servicemetadata:name:examplenamespace:kube-systemlabels:run:exampleannotations:service.beta.kubernetes.io/aws-load-balancer-ssl-cert:arn:aws:acm:xx-xxxx-x:xxxxxxxxx:xxxxxxx/xxxxx-xxxx-xxxx-xxxx-xxxxxxxxx#ganti nilai iniservice.beta.kubernetes.io/aws-load-balancer-backend-protocol:httpspec:type:LoadBalancerports:- port:443targetPort:5556protocol:TCPselector:app:example
Pengaturan lainnya juga dapat diaplikasikan pada layanan load balancer di AWS dengan menggunakan anotasi-anotasi. Berikut ini akan dijelaskan anotasi yang didukung oleh AWS ELB:
service.beta.kubernetes.io/aws-load-balancer-access-log-emit-interval: Digunakan untuk menentukan interval pengeluaran log akses.
service.beta.kubernetes.io/aws-load-balancer-access-log-enabled: Digunakan untuk mengaktifkan atau menonaktifkan log akses.
service.beta.kubernetes.io/aws-load-balancer-access-log-s3-bucket-name: Digunakan untuk menentukan nama bucket S3 log akses.
service.beta.kubernetes.io/aws-load-balancer-access-log-s3-bucket-prefix: Digunakan untuk menentukan prefix bucket S3 log akses.
service.beta.kubernetes.io/aws-load-balancer-additional-resource-tags: Digunakan untuk menentukan daftar tag tambahan pada ELB dengan menggunakan parameter key-value. Contoh: "Key1=Val1,Key2=Val2,KeyNoVal1=,KeyNoVal2".
service.beta.kubernetes.io/aws-load-balancer-backend-protocol: Digunakan untuk menentukan protokol yang digunakan oleh backend (pod) di belakang listener. Jika diset ke http (default) atau https, maka akan dibuat HTTPS listener yang akan mengakhiri koneksi dan meneruskan header. Jika diset ke ssl atau tcp, maka akan digunakan "raw" SSL listener. Jika diset ke http dan aws-load-balancer-ssl-cert tidak digunakan, maka akan digunakan HTTP listener.
service.beta.kubernetes.io/aws-load-balancer-ssl-cert: Digunakan untuk meminta securelistener. Nilai yang dimasukkan adalah sertifikat ARN yang valid. Info lebih lanjut lihat ELB Listener Config CertARN merupakan IAM atau CM certificate ARN, contoh: arn:aws:acm:us-east-1:123456789012:certificate/12345678-1234-1234-1234-123456789012.
service.beta.kubernetes.io/aws-load-balancer-connection-draining-enabled: Digunakan untuk mengaktifkan atau menonaktfkan connection draining.
service.beta.kubernetes.io/aws-load-balancer-connection-draining-timeout: Digunakan untuk menentukan connection draining timeout.
service.beta.kubernetes.io/aws-load-balancer-connection-idle-timeout: Digunakan untuk menentukan idle connection timeout.
service.beta.kubernetes.io/aws-load-balancer-cross-zone-load-balancing-enabled: Digunakan untuk mengaktifkan atau menonaktifkan cross-zone load balancing.
service.beta.kubernetes.io/aws-load-balancer-extra-security-groups: Digunakan untuk menentukan grup keamanan yang akan ditambahkan pada ELB yang dibuat.
service.beta.kubernetes.io/aws-load-balancer-internal: Digunakan sebagai indikasi untuk menggunakan internal ELB.
service.beta.kubernetes.io/aws-load-balancer-proxy-protocol: Digunakan untuk mengaktifkan proxy protocol pada ELB. Saat ini hanya dapat menerima nilai * yang berarti mengaktifkan proxy protocol pada semua ELB backends. Di masa mendatang kamu juga dapat mengatur agar proxy protocol hanya aktif pada backends tertentu..
service.beta.kubernetes.io/aws-load-balancer-ssl-ports: Digunakan untuk menentukan daftar port--yang dipisahkan koma-- yang akan menggunakan SSL/HTTPS listeners. Nilai default yaitu * (semua).
Informasi anotasi untuk AWS di atas diperoleh dari komentar pada aws.go
Azure
Nama Node
Penyedia layanan cloud Azure menggunakan hostname dari node (yang ditentukan oleh kubelet atau menggunakan --hostname-override) sebagai nama dari objek Kubernetes Node.
Perlu diperhatikan bahwa nama Kubernetes Node harus sesuai dengan nama Azure VM.
CloudStack
Nama Node
Penyedia layanan cloud CloudStack menggunakan hostname dari node (yang ditentukan kubelet atau menggunakan --hostname-override) sebagai nama dari objek Kubernetes Node.
Perlu diperhatikan bahwa nama Kubernetes Node harus sesuai dengan nama Cloudstack VM.
GCE
Nama Node
Penyedia layanan cloud GCE menggunakan hostname dari node (yang ditentukan kubelet atau menggunakan --hostname-override) sebagai nama dari objek Kubernetes Node.
Perlu diperhatikan bahwa segmen pertama dari nama Kubernetes Node harus sesuai dengan nama instance GCE (contoh: sebuah node dengan nama kubernetes-node-2.c.my-proj.internal harus sesuai dengan instance yang memiliki nama kubernetes-node-2).
OpenStack
Bagian ini akan menjelaskan semua konfigurasi yang dapat diatur saat menggunakan OpenStack dengan Kubernetes.
Nama Node
Penyedia layanan cloud OpenStack menggunakan nama instance (yang diperoleh dari metadata OpenStack) sebagai nama objek Kubernetes Node.
Perlu diperhatikan bahwa nama instance harus berupa nama Kubernetes Node yang valid agar kubelet dapat mendaftarkan objek Node-nya.
Layanan
Penyedia layanan cloud OpenStack menggunakan beragam layanan OpenStack yang tersedia sebagai underlying cloud agar dapat mendukung Kubernetes:
Layanan
Versi API
Wajib
Block Storage (Cinder)
V1†, V2, V3
Tidak
Compute (Nova)
V2
Tidak
Identity (Keystone)
V2‡, V3
Ya
Load Balancing (Neutron)
V1§, V2
Tidak
Load Balancing (Octavia)
V2
Tidak
† Block Storage V1 API tidak lagi didukung, dukungan Block Storage V3 API telah
ditambahkan pada Kubernetes 1.9.
‡ Identity V2 API tidak lagi didukung dan akan dihapus oleh penyedia layanan
pada rilis mendatang. Pada rilis "Queens", OpenStack tidak lagi mengekspos
Identity V2 API.
§ Dukungan Load Balancing V1 API telah dihapus pada Kubernetes 1.9.
Service discovery dilakukan dengan menggunakan katalog layanan/servis (service catalog) yang diatur oleh
OpenStack Identity (Keystone) menggunakan auth-url yang ditentukan pada konfigurasi
penyedia layanan. Penyedia layanan akan menurunkan fungsionalitas secara perlahan saat layanan OpenStack selain Keystone tidak tersedia dan akan menolak dukungan fitur yang terdampak. Beberapa fitur tertentu dapat diaktifkan atau dinonaktfikan tergantung dari ekstensi yang diekspos oleh Neutron pada underlying cloud.
cloud.conf
Kubernetes berinteraksi dengan OpenStack melalui file cloud.conf. File ini akan menyuplai Kubernetes dengan kredensial dan lokasi dari Openstack auth endpoint.
Kamu dapat membuat file cloud.conf dengan menambahkan rincian berikut ini di dalam file:
Konfigurasi pada umumnya
Berikut ini merupakan contoh dan konfigurasi yang biasa digunakan dan akan mencakup semua pilihan yang paling sering dibutuhkan. File ini akan merujuk pada endpoint dari Keystone OpenStack, serta menyediakan rincian bagaimana cara mengautentikasi dengannya, termasuk cara mengatur load balancer:
Konfigurasi untuk penyedia layanan OpenStack berikut ini akan membahas bagian konfigurasi global sehingga harus berada pada bagian [Global] dari filecloud.conf:
auth-url (Wajib): URL dari API keystone digunakan untuk autentikasi. ULR ini dapat ditemukan pada bagian Access dan Security > API Access > Credentials di laman panel kontrol OpenStack.
username (Wajib): Merujuk pada username yang dikelola keystone.
password (Wajib): Merujuk pada kata sandi yang dikelola keystone.
tenant-id (Wajib): Digunakan untuk menentukan id dari project tempat kamu membuat resources.
tenant-name (Opsional): Digunakan untuk menentukan nama dari project tempat kamu ingin membuat resources.
trust-id (Opsional): Digunakan untuk menentukan identifier of the trust untuk digunakan
sebagai otorisasi. Suatu trust merepresentasikan otorisasi dari suatu pengguna (the trustor) untuk didelegasikan
pada pengguna lain (the trustee), dan dapat digunakan oleh trustee
berperan sebagai the trustor. Trust yang tersedia dapat ditemukan pada endpoint/v3/OS-TRUST/trusts dari Keystone API.
domain-id (Opsional): Digunakan untuk menentukan id dari domain tempat user kamu berada.
domain-name (Opsional): Digunakan untuk menentukan nama dari domain tempat user kamu berada.
region (Opsional): Digunakan untuk menentukan identifier dari region saat digunakan pada
multi-region OpenStack cloud. Sebuah region merupakan pembagian secara umum dari deployment OpenStack. Meskipun region tidak wajib berkorelasi secara geografis, suatu deployment dapat menggunakan nama geografis sebagai region identifier seperti
us-east. Daftar region yang tersedia dapat ditemukan pada endpoint/v3/regions
dari Keystone API.
ca-file (Optional): Digunakan untuk menentukan path dari filecustom CA.
Saat menggunakan Keystone V3 - yang mengganti istilah tenant menjadi project - nilai tenant-id
akan secara otomatis dipetakan pada project yang sesuai di API.
Load Balancer
Konfigurasi berikut ini digunakan untuk mengatur load
balancer dan harus berada pada bagian [LoadBalancer] dari filecloud.conf:
lb-version (Opsional): Digunakan untuk menonaktifkan pendeteksian versi otomatis. Nilai
yang valid yaitu v1 atau v2. Jika tidak ditentukan, maka pendeteksian otomatis akan
memilih versi tertinggi yang didukung dari underlying OpenStack
cloud.
use-octavia (Opsional): Digunakan untuk menentukan apakah akan menggunakan endpoint dari layanan Octavia LBaaS. Nilai yang valid yaitu true atau false. Jika diset nilai true namun Octavia LBaaS V2 tidak dapat ditemukan, maka load balancer akan kembali menggunakan endpoint dari Neutron LBaaS V2. Nilai default adalah false.
subnet-id (Opsional): Digunakan untuk menentukan id dari subnet yang ingin kamu
buat load balancer di dalamnya. Nilai id ini dapat dilihat pada Network > Networks. Klik pada
jaringan yang sesuai untuk melihat subnet di dalamnya.
floating-network-id (Opsional): Jika diset, maka akan membuat floating IP
untuk load balancer.
lb-method (Opsional): Digunakan untuk menentukan algoritma pendistribusian
yang akan digunakan. Nilai yang valid yaitu
ROUND_ROBIN, LEAST_CONNECTIONS, atau SOURCE_IP. Jika tidak diset, maka akan
menggunakan algoritma default yaitu ROUND_ROBIN.
lb-provider (Opsional): Digunakan untuk menentukan penyedia dari load balancer.
Jika tidak ditentukan, maka akan menggunakan penyedia default yang ditentukan pada Neutron.
create-monitor (Opsional): Digunakan untuk menentukan apakah akan membuat atau tidak monitor kesehatan
untuk Neutron load balancer. Nilai yang valid yaitu true dan false.
Nilai default adalah false. Jika diset nilai true maka monitor-delay,
monitor-timeout, dan monitor-max-retries juga harus diset.
monitor-delay (Opsional): Waktu antara pengiriman probes ke
anggota dari load balancer. Mohon pastikan kamu memasukkan waktu yang valid. Nilai waktu yang valid yaitu "ns", "us" (atau "µs"), "ms", "s", "m", "h"
monitor-timeout (Opsional): Waktu maksimum dari monitor untuk menunggu
balasan ping sebelum timeout. Nilai ini harus lebih kecil dari nilai delay.
Mohon pastikan kamu memasukkan waktu yang valid. Nilai waktu yang valid yaitu "ns", "us" (atau "µs"), "ms", "s", "m", "h"
monitor-max-retries (Opsional): Jumlah gagal ping yang diizinkan sebelum
mengubah status anggota load balancer menjadi INACTIVE. Harus berupa angka
antara 1 dan 10.
manage-security-groups (Opsional): Digunakan untuk menentukan apakah load balancer
akan mengelola aturan grup keamanan sendiri atau tidak. Nilai yang valid
adalah true dan false. Nilai default adalah false. Saat diset ke true maka
nilai node-security-group juga harus ditentukan.
node-security-group (Opsional): ID dari grup keamanan yang akan dikelola.
Block Storage
Konfigurasi untuk penyedia layanan OpenStack berikut ini digunakan untuk mengatur penyimpanan blok atau block storage
dan harus berada pada bagian [BlockStorage] dari filecloud.conf:
bs-version (Opsional): Digunakan untuk menonaktifkan fitur deteksi versi otomatis. Nilai
yang valid yaitu v1, v2, v3 dan auto. Jika diset ke auto maka pendeteksian versi
otomatis akan memilih versi tertinggi yang didukung oleh underlying
OpenStack cloud. Nilai default jika tidak diset adalah auto.
trust-device-path (Opsional): Pada umumnya nama block device yang ditentukan
oleh Cinder (contoh: /dev/vda) tidak dapat diandalkan. Opsi ini dapat mengatur hal
tersebut. Jika diset ke true maka akan menggunakan nama block device yang ditentukan
oleh Cinder. Nilai default adalah false yang berarti path dari device akan ditentukan
oleh nomor serialnya serta pemetaan dari /dev/disk/by-id, dan ini merupakan
cara yang direkomendasikan.
ignore-volume-az (Opsional): Digunakan untuk mengatur penggunaan availability zone saat
menautkan volumes Cinder. Jika Nova dan Cinder memiliki availability
zones yang berbeda, opsi ini harus diset true. Skenario seperti ini yang umumnya terjadi, yaitu
saat terdapat banyak Nova availability zones namun hanya ada satu Cinder availability zone.
Nilai default yaitu false digunakan untuk mendukung penggunaan pada rilis terdahulu,
tetapi nilai ini dapat berubah pada rilis mendatang.
Jika menjalankan Kubernetes dengan versi <= 1.8 pada OpenStack yang menggunakan paths alih-alih
menggunakan port untuk membedakan antara endpoints, maka mungkin dibutuhkan untuk
secara eksplisit mengatur parameter bs-version. Contoh endpoint yang berdasarkan path yaitu
http://foo.bar/volume sedangkan endpoint yang berdasarkan port memiliki bentuk seperti ini
http://foo.bar:xxx.
Pada lingkungan yang menggunakan endpoint berdasarkan path dan Kubernetes menggunakan logika deteksi-otomatis yang lama, maka errorBS API version autodetection failed. akan muncul saat mencoba
melepaskan volume. Untuk mengatasi isu ini, dimungkinkan
untuk memaksa penggunaan Cinder API versi 2 dengan menambahkan baris berikut ini pada konfigurasi penyedia cloud:
[BlockStorage]bs-version=v2
Metadata
Konfigurasi untuk OpenStack berikut ini digunakan untuk mengatur metadata dan
harus berada pada bagian [Metadata] dari filecloud.conf:
search-order (Opsional): Konfigurasi berikut ini digunakan untuk mengatur bagaimana
cara provider mengambil metadata terkait dengan instance yang dijalankannya. Nilai
default yaitu configDrive,metadataService yang berarti provider akan mengambil
metadata terkait instance dari config drive terlebih dahulu jika tersedia, namun
jika tidak maka akan menggunakan layanan metadata. Nilai alternatif lainnya yaitu:
configDrive - Hanya mengambil metadata instance dari config
drive.
metadataService - Hanya mengambil data instance dari layanan
metadata.
metadataService,configDrive - Mengambil metadata instance dari layanan metadata terlebih
dahulu jika tersedia, jika tidak maka akan mengambil dari config drive.
Pengaturan ini memang sebaiknya dilakukan sebab metadata pada config drive bisa saja lambat laun akan kedaluwarsa, sedangkan layanan metadata akan selalu menyediakan metadata yang paling mutakhir. Tidak semua penyedia layanan cloud OpenStack menyediakan kedua layanan config drive dan layanan metadata dan mungkin hanya salah satu saja
yang tersedia. Oleh sebab itu nilai default diatur agar dapat memeriksa keduanya.
Router
Konfigurasi untuk Openstack berikut ini digunakan untuk mengatur plugin jaringan Kubernetes kubenet
dan harus berada pada bagian [Router] dari filecloud.conf:
router-id (Opsional): Jika Neutron pada underlying cloud mendukung ekstensi
extraroutes maka gunakan router-id untuk menentukan router mana yang akan ditambahkan rute di dalamnya.
Router yang dipilih harus menjangkau jaringan privat tempat node klaster berada
(biasanya hanya ada satu jaringan node, dan nilai ini harus nilai dari default router
pada jaringan node). Nilai ini dibutuhkan untuk dapat menggunakan kubenet pada OpenStack.
OVirt
Nama Node
Penyedia layanan cloud OVirt menggunakan hostname dari node (yang ditentukan kubelet atau menggunakan --hostname-override) sebagai nama dari objek Kubernetes Node.
Perlu diperhatikan bahwa nama Kubernetes Node harus sesuai dengan VM FQDN (yang ditampilkan oleh OVirt di bawah <vm><guest_info><fqdn>...</fqdn></guest_info></vm>)
Photon
Nama Node
Penyedia layanan cloud Photon menggunakan hostname dari node (yang ditentukan kubelet atau menggunakan --hostname-override) sebagai nama dari objek Kubernetes Node.
Perlu diperhatikan bahwa nama Kubernetes Node name harus sesuai dengan nama Photon VM (atau jika overrideIP diset ke true pada --cloud-config, nama Kubernetes Node harus sesuai dengan alamat IP Photon VM).
VSphere
Nama Node
Penyedia layanan cloud VSphere menggunakan hostname yang terdeteksi dari node (yang ditentukan oleh kubelet) sebagai nama dari objek Kubernetes Node.
Parameter --hostname-override diabaikan oleh penyedia layanan cloud VSphere.
IBM Cloud Kubernetes Service
Node Komputasi
Saat menggunakan layanan IBM Cloud Kubernetes Service, kamu dapat membuat klaster yang terdiri dari campuran antara mesin virtual dan fisik (bare metal) sebagai node di single zone atau multiple zones pada satu region. Untuk informasi lebih lanjut, lihat Perencanaan klaster dan pengaturan worker node.
Nama dari objek Kubernetes Node yaitu alamat IP privat dari IBM Cloud Kubernetes Service worker node instance.
Jaringan
Penyedia layanan IBM Cloud Kubernetes Service menyediakan VLAN untuk membuat jaringan node yang terisolasi dengan kinerja tinggi. Kamu juga dapat membuat custom firewall dan policy jaringan Calico untuk menambah lapisan perlindungan ekstra bagi klaster kamu, atau hubungkan klaster kamu dengan on-prem data center via VPN. Untuk informasi lebih lanjut, lihat Perencanaan jaringan privat dan in-cluster.
Untuk membuka aplikasi ke publik atau di dalam klaster, kamu dapat menggunakan NodePort, LoadBalancer, atau Ingress. Kamu juga dapat menyesuaikan aplikasi load balancer Ingress dengan anotasi. Untuk informasi lebih lanjut, lihat Perencanaan untuk membuka aplikasi dengan jaringan eksternal.
Penyimpanan
Penyedia layanan IBM Cloud Kubernetes Service memanfaatkan Kubernetes-native persistent volumes agar pengguna dapat melakukan mountfile, block, dan penyimpanan objek cloud ke aplikasi mereka. Kamu juga dapat menggunakan database-as-a-service dan add-ons pihak ketiga sebagai penyimpanan persistent untuk data kamu. Untuk informasi lebih lanjut, lihat Perencanaan penyimpanan persistent yang selalu tersedia (highly available).
Baidu Cloud Container Engine
Nama Node
Penyedia layanan cloud Baidu menggunakan alamat IP privat dari node (yang ditentukan oleh kubelet atau menggunakan --hostname-override) sebagai nama dari objek Kubernetes Node.
Perlu diperhatikan bahwa nama Kubernetes Node harus sesuai dengan alamat IP privat dari Baidu VM.
11.4 - Mengelola Resource
Kamu telah melakukan deploy pada aplikasimu dan mengeksposnya melalui sebuah service. Lalu? Kubernetes menyediakan berbagai peralatan untuk membantu mengatur mekanisme deploy aplikasi, termasuk pengaturan kapasitas dan pembaruan. Diantara fitur yang akan didiskusikan lebih mendalam yaitu berkas konfigurasi dan label.
Mengelola konfigurasi resource
Banyak aplikasi memerlukan beberapa resource, seperti Deployment dan Service. Pengelolaan beberapa resource dapat disederhanakan dengan mengelompokkannya dalam berkas yang sama (dengan pemisah --- pada YAML). Contohnya:
service/my-nginx-svc created
deployment.apps/my-nginx created
Resource akan dibuat dalam urutan seperti pada berkas. Oleh karena itu, lebih baik menyalakan service lebih dahulu agar menjamin scheduler dapat menyebar pod yang terkait service selagi pod dibangkitkan oleh controller, seperti Deployment.
kubectl apply juga dapat menerima beberapa argumen -f:
kubectl akan membaca berkas apapun yang berakhiran .yaml, .yml, or .json.
Sangat disarankan untuk meletakkan sumber daya yang ada dalam microservice atau tier aplikasi yang sama dalam satu berkas, dan mengelompokkan semua berkas terkait aplikasimu dalam satu direktori. Jika tier masing-masing aplikasi terikat dengan DNS, maka kamu dapat melakukan deploy semua komponen teknologi yang dibutuhkan bersama-sama.
Lokasi konfigurasi dapat juga diberikan dalam bentuk URL. Ini berguna ketika ingin menjalankan berkas konfigurasi dari Github:
Pembuatan resource bukanlah satu-satunya operasi yang bisa dijalankan kubectl secara majemuk. Contoh lainnya adalah mengekstrak nama resource dari berkas konfigurasi untuk menjalankan operasi lainnya, seperti untuk menghapus resource yang telah dibuat:
Namun, untuk resource yang lebih banyak, memasukkan selektor (label query) menggunakan -l atau --selector untuk memfilter resource berdasarkan label akan lebih mudah:
kubectl delete deployment,services -l app=nginx
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
Karena kubectl mengembalikan nama resource yang sama dengan sintaks yang diterima, mudah untuk melanjutkan operasi menggunakan $() atau xargs:
kubectl get $(kubectl create -f docs/concepts/cluster-administration/nginx/ -o name | grep service)
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx-svc LoadBalancer 10.0.0.208 <pending> 80/TCP 0s
Dengan perintah di atas, pertama kita buat resource di dalam examples/application/nginx/. Lalu tampilkan resources yang terbentuk dengan format keluaran -o name (menampilkan tiap resource dalam format resource/nama). Kemudian lakukan grep hanya pada "service", dan tampilkan dengan kubectl get.
Untuk dapat menggunakan perintah di atas pada direktori yang bertingkat, kamu dapat memberi argumen --recursive atau -R bersama dengan argumen --filename,-f.
Misalnya ada sebuah direktori project/k8s/development memuat semua manifests yang berkaitan dengan development environment. Manifest akan tersusun berdasarkan tipe resource:
Secara default, menjalankan operasi majemuk pada project/k8s/development hanya akan terbatas pada direktori terluar saja. Sehingga ketika kita menjalankan operasi pembuatan dengan perintah berikut, kita akan mendapatkan pesan kesalahan:
kubectl apply -f project/k8s/development
error: you must provide one or more resources by argument or filename (.json|.yaml|.yml|stdin)
Solusinya, tambahkan argumen --recursive atau -R bersama dengan --filename,-f, seperti:
namespace/development created
namespace/staging created
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
Jika kamu tertarik mempelajari lebih lanjut tentang kubectl, silahkan baca Ikhtisar kubectl.
Memakai label secara efektif
Contoh yang kita lihat sejauh ini hanya menggunakan paling banyak satu label pada resource. Ada banyak skenario ketika membutuhkan beberapa label untuk membedakan sebuah kelompok dari yang lainnya.
Sebagai contoh, aplikasi yang berbeda akan menggunakan label app yang berbeda, tapi pada aplikasi multitier, seperti pada contoh buku tamu, tiap tier perlu dibedakan. Misal untuk menandai tier frontend bisa menggunakan label:
labels:app:guestbooktier:frontend
sementara itu Redis master dan slave memiliki label tier yang berbeda. Bisa juga menggunakan label tambahan role:
labels:app:guestbooktier:backendrole:master
dan
labels:app:guestbooktier:backendrole:slave
Label memungkinkan kita untuk memilah resource dengan pembeda berupa label:
kubectl apply -f examples/guestbook/all-in-one/guestbook-all-in-one.yaml
kubectl get pods -Lapp -Ltier -Lrole
NAME READY STATUS RESTARTS AGE
guestbook-redis-slave-2q2yf 1/1 Running 0 3m
guestbook-redis-slave-qgazl 1/1 Running 0 3m
Deploy dengan Canary
Skenario lain yang menggunakan beberapa label yaitu saat membedakan deployment komponen yang sama namun dengan rilis atau konfigurasi yang berbeda. Adalah praktik yang umum untuk mendeploy sebuah canary dari rilis aplikasi yang baru (berdasarkan tag image dalam templat pod) bersamaan dengan rilis sebelumnya. Ini memungkinkan rilis yang baru dapat menerima live traffic sebelum benar-benar menggantikan rilis yang lama.
Salah satu alternatif yaitu kamu dapat memakai label track untuk membedakan antar rilis.
Rilis primer dan stabil akan memiliki label track yang berisi stable:
Servis frontend akan meliputi kedua set replika dengan menentukan subset bersama dari para labelnya (tanpa track). Sehingga traffic akan diarahkan ke kedua aplikasi:
selector:app:guestbooktier:frontend
Kamu dapat mengatur jumlah replika rilis stable dan canary untuk menentukan rasio dari tiap rilis yang akan menerima traffic production live (dalam kasus ini 3:1).
Ketika telah yakin, kamu dapat memindahkan track stable ke rilis baru dan menghapus canary.
Kadang, pod dan resource lain yang sudah ada harus dilabeli ulang sebelum membuat resource baru. Hal ini dapat dilakukan dengan perintah kubectl label.
Contohnya jika kamu ingin melabeli ulang semua pod nginx sebagai frontend tier, tinggal jalankan:
Perintah ini melakukan filter pada semua pod dengan label "app=nginx", lalu melabelinya dengan "tier=fe".
Untuk melihat pod yang telah dilabeli, jalankan:
kubectl get pods -l app=nginx -L tier
NAME READY STATUS RESTARTS AGE TIER
my-nginx-2035384211-j5fhi 1/1 Running 0 23m fe
my-nginx-2035384211-u2c7e 1/1 Running 0 23m fe
my-nginx-2035384211-u3t6x 1/1 Running 0 23m fe
Akan muncul semua pod dengan "app=nginx" dan sebuah kolom label tambahan yaitu tier (ditentukan dengan -L atau --label-columns).
Kadang resource perlu ditambahkan anotasi. Anotasi adalah metadata sembarang yang tidak unik, seperti tools, libraries, dsb yang digunakan oleh klien API . Ini dapat dilakukan dengan kubectl annotate. Sebagai contoh:
Saat beban aplikasi naik maupun turun, mudah untuk mengubah kapasitas dengan kubectl. Contohnya, untuk menurunkan jumlah replika nginx dari 3 ke 1, lakukan:
kubectl scale deployment/my-nginx --replicas=1
deployment.apps/my-nginx scaled
Sekarang kamu hanya memiliki satu pod yang dikelola oleh deployment.
kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
my-nginx-2035384211-j5fhi 1/1 Running 0 30m
Agar sistem dapat menyesuaikan jumlah replika nginx yang dibutuhkan secara otomatis dari 1 hingga 3, lakukan:
Kadang kita perlu membuat pembaruan kecil, yang tidak mengganggu pada resource yang telah dibuat.
kubectl apply
Disarankan untuk menyimpan berkas-berkas konfigurasi dalam source control (lihat konfigurasi sebagai kode). Sehingga berkas dapat dipelihara dan diatur dalam versi bersama dengan kode milik resource yang diatur oleh konfigurasi tersebut. Berikutnya, kamu dapat menggunakan kubectl apply untuk membarui perubahan konfigurasi ke klaster.
Perintah ini akan membandingkan versi konfigurasi yang disuplai dengan versi sebelumnya yang telah berjalan dan memasang perubahan yang kamu buat tanpa mengganti properti yang tidak berubah sama sekali.
Perhatikan bahwa kubectl apply memasang anotasi pada resource untuk menentukan perubahan pada konfigurasi sejak terakhir dipanggil. Ketika dijalankan, kubectl apply melakukan pembandingan three-way antara konfigurasi sebelumnya, masukan yang disuplai, dan konfigurasi resource sekarang, untuk dapat menentukan cara memodifikasi resource.
Saat ini, resource dibuat tanpa ada anotasi. Jadi pemanggilan pertama pada kubectl apply akan dikembalikan pada perbandingan two-way antara masukan pengguna dan konfigurasi resource sekarang. Saat pemanggilan pertama ini, tidak ada penghapusan set properti yang terdeteksi saat resource dibuat. Sehingga, tidak ada yang dihapus.
Tiap kubectl apply, atau perintah lain yang memodifikasi konfigurasi seperti kubectl replace dan kubectl edit dijalankan, anotasi akan diperbarui. Sehingga memungkinkan operasi kubectl apply untuk mendeteksi dan melakukan penghapusan secara perbandingan three-way.
kubectl edit
Sebagai alternatif, kamu juga dapat membarui resource dengan kubectl edit:
kubectl edit deployment/my-nginx
Ini sama dengan melakukan get pada resource, mengubahnya di text editor, kemudian menjalankanapply pada resource dengan versi terkini:
kubectl get deployment my-nginx -o yaml > /tmp/nginx.yaml
vi /tmp/nginx.yaml
# lakukan pengubahan, lalu simpan berkaskubectl apply -f /tmp/nginx.yaml
deployment.apps/my-nginx configured
rm /tmp/nginx.yaml
Cara demikian memungkinkan kamu membuat perubahan signifikan dengan mudah. Lihat bahwa kamu juga dapat menentukan editor dengan variabel environment EDITOR atau KUBE_EDITOR.
Untuk informasi tambahan, silahkan lihat laman kubectl edit.
Pada kasus tertentu, kamu mungkin perlu memperbarui field resource yang tidak dapat diperbarui setelah diinisiasi atau kamu ingin membuat perubahan rekursif segera, seperti memperbaiki pod yang rusak saat menjalankan Deployment. Untuk mengubah field seperti itu, gunakan replace --force yang akan menghapus dan membuat ulang resource. Dalam kasus ini kamu dapat mengubah berkas konfigurasi awalnya:
Suatu saat, kamu akan perlu untuk membarui aplikasi yang telah terdeploy, biasanya dengan mengganti image atau tag sebagaimana dalam skenario canary deployment di atas. kubectl mendukung beberapa operasi pembaruan, masing-masing dapat digunakan pada skenario berbeda.
Kami akan memandumu untuk membuat dan membarui aplikasi melalui Deployment.
Misal kamu telah menjalankan nginx versi 1.7.9:
kubectl run my-nginx --image=nginx:1.7.9 --replicas=3
deployment.apps/my-nginx created
Untuk memperbarui versi ke 1.9.1, ganti .spec.template.spec.containers[0].image dari nginx:1.7.9 ke nginx:1.9.1, dengan perintah kubectl yang telah dipelajari di atas.
kubectl edit deployment/my-nginx
Selesai! Deployment akan memperbarui aplikasi nginx yang terdeploy secara berangsur di belakang. Dia akan menjamin hanya ada sekian replika lama yang akan down selagi pembaruan berjalan dan hanya ada sekian replika baru akan dibuat melebihi jumlah pod. Untuk mempelajari lebih lanjut, kunjungi laman Deployment.
Jaringan adalah bagian utama dari Kubernetes, tetapi bisa menjadi sulit
untuk memahami persis bagaimana mengharapkannya bisa bekerja.
Ada 4 masalah yang berbeda untuk diatasi:
Komunikasi antar kontainer yang sangat erat: hal ini diselesaikan oleh
Pod dan komunikasi localhost.
Komunikasi antar Pod: ini adalah fokus utama dari dokumen ini.
Komunikasi Pod dengan Service: ini terdapat di Service.
Komunikasi eksternal dengan Service: ini terdapat di Service.
Kubernetes adalah tentang berbagi mesin antar aplikasi. Pada dasarnya,
saat berbagi mesin harus memastikan bahwa dua aplikasi tidak mencoba menggunakan
port yang sama. Mengkoordinasikan port di banyak pengembang sangat sulit
dilakukan pada skala yang berbeda dan memaparkan pengguna ke masalah
tingkat klaster yang di luar kendali mereka.
Alokasi port yang dinamis membawa banyak komplikasi ke sistem - setiap aplikasi
harus menganggap port sebagai flag, server API harus tahu cara memasukkan
nomor port dinamis ke dalam blok konfigurasi, Service-Service harus tahu cara
menemukan satu sama lain, dll. Sebaliknya daripada berurusan dengan ini,
Kubernetes mengambil pendekatan yang berbeda.
Model jaringan Kubernetes
Setiap Pod mendapatkan alamat IP sendiri. Ini berarti kamu tidak perlu secara langsung membuat tautan antara Pod dan kamu hampir tidak perlu berurusan dengan memetakan port kontainer ke port pada host. Ini menciptakan model yang bersih, kompatibel dengan yang sebelumnya dimana Pod dapat diperlakukan seperti halnya VM atau host fisik dari perspektif alokasi port, penamaan, service discovery, load balancing, konfigurasi aplikasi, dan migrasi.
Kubernetes memberlakukan persyaratan mendasar berikut pada setiap implementasi jaringan (kecuali kebijakan segmentasi jaringan yang disengaja):
Pod pada suatu Node dapat berkomunikasi dengan semua Pod pada semua Node tanpa NAT
agen pada suatu simpul (mis. daemon sistem, kubelet) dapat berkomunikasi dengan semua Pod pada Node itu
Catatan: Untuk platform yang mendukung Pod yang berjalan di jaringan host (mis. Linux):
Pod di jaringan host dari sebuah Node dapat berkomunikasi dengan semua Pod pada semua Node tanpa NAT
Model ini tidak hanya sedikit kompleks secara keseluruhan, tetapi pada prinsipnya kompatibel dengan keinginan Kubernetes untuk memungkinkan low-friction porting dari aplikasi dari VM ke kontainer. Jika pekerjaan kamu sebelumnya dijalankan dalam VM, VM kamu memiliki IP dan dapat berbicara dengan VM lain di proyek yang sama. Ini adalah model dasar yang sama.
Alamat IP Kubernetes ada di lingkup Pod - kontainer dalam Pod berbagi jaringan namespace mereka - termasuk alamat IP mereka. Ini berarti bahwa kontainer dalam Pod semua dapat mencapai port satu sama lain di _localhost_. Ini juga berarti bahwa kontainer dalam Pod harus mengoordinasikan penggunaan port, tetapi ini tidak berbeda dari proses di VM. Ini disebut model "IP-per-pod".
Bagaimana menerapkan model jaringan Kubernetes
Ada beberapa cara agar model jaringan ini dapat diimplementasikan. Dokumen ini bukan studi lengkap tentang berbagai metode, tetapi semoga berfungsi sebagai pengantar ke berbagai teknologi dan berfungsi sebagai titik awal.
Opsi jaringan berikut ini disortir berdasarkan abjad - urutan tidak menyiratkan status istimewa apa pun.
ACI
Infrastruktur Sentral Aplikasi Cisco menawarkan solusi SDN overlay dan underlay terintegrasi yang mendukung kontainer, mesin virtual, dan bare metal server. ACI menyediakan integrasi jaringan kontainer untuk ACI. Tinjauan umum integrasi disediakan di sini.
AOS dari Apstra
AOS adalah sistem Jaringan Berbasis Intent yang menciptakan dan mengelola lingkungan pusat data yang kompleks dari platform terintegrasi yang sederhana. AOS memanfaatkan desain terdistribusi sangat scalable untuk menghilangkan pemadaman jaringan sambil meminimalkan biaya.
Desain Referensi AOS saat ini mendukung host yang terhubung dengan Lapis-3 yang menghilangkan masalah peralihan Lapis-2 yang lama. Host Lapis-3 ini bisa berupa server Linux (Debian, Ubuntu, CentOS) yang membuat hubungan tetangga BGP secara langsung dengan top of rack switches (TORs). AOS mengotomatisasi kedekatan perutean dan kemudian memberikan kontrol yang halus atas route health injections (RHI) yang umum dalam deployment Kubernetes.
AOS memiliki banyak kumpulan endpoint REST API yang memungkinkan Kubernetes dengan cepat mengubah kebijakan jaringan berdasarkan persyaratan aplikasi. Peningkatan lebih lanjut akan mengintegrasikan model Grafik AOS yang digunakan untuk desain jaringan dengan penyediaan beban kerja, memungkinkan sistem manajemen ujung ke ujung untuk layanan cloud pribadi dan publik.
AOS mendukung penggunaan peralatan vendor umum dari produsen termasuk Cisco, Arista, Dell, Mellanox, HPE, dan sejumlah besar sistem white-box dan sistem operasi jaringan terbuka seperti Microsoft SONiC, Dell OPX, dan Cumulus Linux.
AWS VPC CNI menawarkan jaringan AWS Virtual Private Cloud (VPC) terintegrasi untuk klaster Kubernetes. Plugin CNI ini menawarkan throughput dan ketersediaan tinggi, latensi rendah, dan jitter jaringan minimal. Selain itu, pengguna dapat menerapkan jaringan AWS VPC dan praktik keamanan terbaik untuk membangun klaster Kubernetes. Ini termasuk kemampuan untuk menggunakan catatan aliran VPC, kebijakan perutean VPC, dan grup keamanan untuk isolasi lalu lintas jaringan.
Menggunakan plugin CNI ini memungkinkan Pod Kubernetes memiliki alamat IP yang sama di dalam Pod seperti yang mereka lakukan di jaringan VPC. CNI mengalokasikan AWS Elastic Networking Interfaces (ENIs) ke setiap node Kubernetes dan menggunakan rentang IP sekunder dari setiap ENI untuk Pod pada Node. CNI mencakup kontrol untuk pra-alokasi ENI dan alamat IP untuk waktu mulai Pod yang cepat dan memungkinkan klaster besar hingga 2.000 Node.
Big Cloud Fabric adalah arsitektur jaringan asli layanan cloud, yang dirancang untuk menjalankan Kubernetes di lingkungan cloud pribadi / lokal. Dengan menggunakan SDN fisik & virtual terpadu, Big Cloud Fabric menangani masalah yang sering melekat pada jaringan kontainer seperti penyeimbangan muatan, visibilitas, pemecahan masalah, kebijakan keamanan & pemantauan lalu lintas kontainer.
Dengan bantuan arsitektur multi-penyewa Pod virtual pada Big Cloud Fabric, sistem orkestrasi kontainer seperti Kubernetes, RedHat OpenShift, Mesosphere DC/OS & Docker Swarm akan terintegrasi secara alami bersama dengan sistem orkestrasi VM seperti VMware, OpenStack & Nutanix. Pelanggan akan dapat terhubung dengan aman berapa pun jumlah klasternya dan memungkinkan komunikasi antar penyewa di antara mereka jika diperlukan.
Terbaru ini BCF diakui oleh Gartner sebagai visioner dalam Magic Quadrant. Salah satu penyebaran BCF Kubernetes di tempat (yang mencakup Kubernetes, DC/OS & VMware yang berjalan di beberapa DC di berbagai wilayah geografis) juga dirujuk di sini.
Cilium
Cilium adalah perangkat lunak open source untuk menyediakan dan secara transparan mengamankan konektivitas jaringan antar kontainer aplikasi. Cilium mengetahui L7/HTTP dan dapat memberlakukan kebijakan jaringan pada L3-L7 menggunakan model keamanan berbasis identitas yang dipisahkan dari pengalamatan jaringan.
cni-ipvlan-vpc-k8s berisi satu set plugin CNI dan IPAM untuk menyediakan kemudahan, host-lokal, latensi rendah, throughput tinggi , dan tumpukan jaringan yang sesuai untuk Kubernetes dalam lingkungan Amazon Virtual Private Cloud (VPC) dengan memanfaatkan Amazon Elastic Network Interfaces (ENI) dan mengikat IP yang dikelola AWS ke Pod-Pod menggunakan driver IPvlan kernel Linux dalam mode L2.
Plugin ini dirancang untuk secara langsung mengkonfigurasi dan deploy dalam VPC. Kubelet melakukan booting dan kemudian mengkonfigurasi sendiri dan memperbanyak penggunaan IP mereka sesuai kebutuhan tanpa memerlukan kompleksitas yang sering direkomendasikan untuk mengelola jaringan overlay, BGP, menonaktifkan pemeriksaan sumber/tujuan, atau menyesuaikan tabel rute VPC untuk memberikan subnet per instance ke setiap host (yang terbatas hingga 50-100 masukan per VPC). Singkatnya, cni-ipvlan-vpc-k8s secara signifikan mengurangi kompleksitas jaringan yang diperlukan untuk menggunakan Kubernetes yang berskala di dalam AWS.
Contiv
Contiv menyediakan jaringan yang dapat dikonfigurasi (native l3 menggunakan BGP, overlay menggunakan vxlan, classic l2, atau Cisco-SDN / ACI) untuk berbagai kasus penggunaan. Contiv semuanya open sourced.
Contrail / Tungsten Fabric
Contrail, berdasarkan Tungsten Fabric, adalah platform virtualisasi jaringan dan manajemen kebijakan multi-cloud yang benar-benar terbuka. Contrail dan Tungsten Fabric terintegrasi dengan berbagai sistem orkestrasi seperti Kubernetes, OpenShift, OpenStack dan Mesos, dan menyediakan mode isolasi yang berbeda untuk mesin virtual, banyak kontainer / banyak Pod dan beban kerja bare metal.
DANM
[DANM] (https://github.com/nokia/danm) adalah solusi jaringan untuk beban kerja telco yang berjalan di klaster Kubernetes. Dibangun dari komponen-komponen berikut:
Plugin CNI yang mampu menyediakan antarmuka IPVLAN dengan fitur-fitur canggih
Modul IPAM built-in dengan kemampuan mengelola dengan jumlah banyak, cluster-wide, discontinous jaringan L3 dan menyediakan skema dinamis, statis, atau tidak ada permintaan skema IP
Metaplugin CNI yang mampu melampirkan beberapa antarmuka jaringan ke kontainer, baik melalui CNI sendiri, atau mendelegasikan pekerjaan ke salah satu solusi CNI populer seperti SRI-OV, atau Flannel secara paralel
Pengontrol Kubernetes yang mampu mengatur secara terpusat antarmuka VxLAN dan VLAN dari semua host Kubernetes
Pengontrol Kubernetes lain yang memperluas konsep service discovery berbasis servis untuk bekerja di semua antarmuka jaringan Pod
Dengan toolset ini, DANM dapat memberikan beberapa antarmuka jaringan yang terpisah, kemungkinan untuk menggunakan ujung belakang jaringan yang berbeda dan fitur IPAM canggih untuk Pod.
Flannel
[Flannel] (https://github.com/coreos/flannel#flannel) adalah jaringan overlay yang sangat sederhana yang memenuhi persyaratan Kubernetes. Banyak orang telah melaporkan kesuksesan dengan Flannel dan Kubernetes.
Google Compute Engine (GCE)
Untuk skrip konfigurasi klaster Google Compute Engine, perutean lanjutan digunakan untuk menetapkan setiap VM subnet (standarnya adalah /24 - 254 IP). Setiap lalu lintas yang terikat untuk subnet itu akan dialihkan langsung ke VM oleh fabric jaringan GCE. Ini adalah tambahan untuk alamat IP "utama" yang ditugaskan untuk VM, yang NAT'ed untuk akses internet keluar. Sebuah linux bridge (disebut cbr0) dikonfigurasikan untuk ada pada subnet itu, dan diteruskan ke flag-bridge milik docker.
Jembatan ini dibuat oleh Kubelet (dikontrol oleh flag--network-plugin=kubenet) sesuai dengan .spec.podCIDR yang dimiliki oleh Node.
Docker sekarang akan mengalokasikan IP dari blok cbr-cidr. Kontainer dapat menjangkau satu sama lain dan Node di atas jembatan cbr0. IP-IP tersebut semuanya dapat dirutekan dalam jaringan proyek GCE.
GCE sendiri tidak tahu apa-apa tentang IP ini, jadi tidak akan NAT untuk lalu lintas internet keluar. Untuk mencapai itu aturan iptables digunakan untuk menyamar (alias SNAT - untuk membuatnya seolah-olah paket berasal dari lalu lintas Node itu sendiri) yang terikat untuk IP di luar jaringan proyek GCE (10.0.0.0/8).
Terakhir IP forwarding diaktifkan di kernel (sehingga kernel akan memproses paket untuk kontainer yang dijembatani):
sysctl net.ipv4.ip_forward=1
Hasil dari semua ini adalah bahwa semua Pod dapat saling menjangkau dan dapat keluar lalu lintas ke internet.
Jaguar
Jaguar adalah solusi open source untuk jaringan Kubernetes berdasarkan OpenDaylight. Jaguar menyediakan jaringan overlay menggunakan vxlan dan Jaguar CNIPlugin menyediakan satu alamat IP per Pod.
Knitter
Knitter adalah solusi jaringan yang mendukung banyak jaringan di Kubernetes. Solusi ini menyediakan kemampuan manajemen penyewa dan manajemen jaringan. Knitter mencakup satu set solusi jaringan kontainer NFV ujung ke ujung selain beberapa pesawat jaringan, seperti menjaga alamat IP untuk aplikasi, migrasi alamat IP, dll.
Kube-OVN
Kube-OVN adalah fabric jaringan kubernetes berbasis OVN untuk enterprises. Dengan bantuan OVN/OVS, solusi ini menyediakan beberapa fitur jaringan overlay canggih seperti subnet, QoS, alokasi IP statis, mirroring traffic, gateway, kebijakan jaringan berbasis openflow, dan proksi layanan.
Kube-router
Kube-router adalah solusi jaringan yang dibuat khusus untuk Kubernetes yang bertujuan untuk memberikan kinerja tinggi dan kesederhanaan operasional. Kube-router menyediakan Linux LVS/IPVS berbasis proksi layanan, solusi jaringan berbasis penerusan pod-to-pod Linux kernel tanpa overlay, dan penegak kebijakan jaringan berbasis iptables/ipset.
L2 networks and linux bridging
Jika Anda memiliki jaringan L2 yang "bodoh", seperti saklar sederhana di environment "bare-metal", kamu harus dapat melakukan sesuatu yang mirip dengan pengaturan GCE di atas. Perhatikan bahwa petunjuk ini hanya dicoba dengan sangat sederhana - sepertinya berhasil, tetapi belum diuji secara menyeluruh. Jika kamu menggunakan teknik ini dan telah menyempurnakan prosesnya, tolong beri tahu kami.
VMware NSX-T adalah virtualisasi jaringan dan platform keamanan. NSX-T dapat menyediakan virtualisasi jaringan untuk lingkungan multi-cloud dan multi-hypervisor dan berfokus pada kerangka kerja dan arsitektur aplikasi yang muncul yang memiliki titik akhir dan tumpukan teknologi yang heterogen. Selain hypervisor vSphere, lingkungan ini termasuk hypervisor lainnya seperti KVM, wadah, dan bare metal.
NSX-T Container Plug-in (NCP) menyediakan integrasi antara NSX-T dan pembuat wadah seperti Kubernetes, serta integrasi antara NSX-T dan platform CaaS / PaaS berbasis-kontainer seperti Pivotal Container Service (PKS) dan OpenShift.
Nuage Networks VCS (Layanan Cloud Virtual)
Nuage menyediakan platform SDN (Software-Defined Networking) berbasis kebijakan yang sangat skalabel. Nuage menggunakan Open vSwitch open source untuk data plane bersama dengan SDN Controller yang kaya fitur yang dibangun pada standar terbuka.
Platform Nuage menggunakan overlay untuk menyediakan jaringan berbasis kebijakan yang mulus antara Kubernetes Pod-Pod dan lingkungan non-Kubernetes (VM dan server bare metal). Model abstraksi kebijakan Nuage dirancang dengan mempertimbangkan aplikasi dan membuatnya mudah untuk mendeklarasikan kebijakan berbutir halus untuk aplikasi. Mesin analisis real-time platform memungkinkan pemantauan visibilitas dan keamanan untuk aplikasi Kubernetes.
OVN (Open Virtual Networking)
OVN adalah solusi virtualisasi jaringan opensource yang dikembangkan oleh komunitas Open vSwitch. Ini memungkinkan seseorang membuat switch logis, router logis, ACL stateful, load-balancers dll untuk membangun berbagai topologi jaringan virtual. Proyek ini memiliki plugin dan dokumentasi Kubernetes spesifik di ovn-kubernetes.
Project Calico
Project Calico adalah penyedia jaringan wadah sumber terbuka dan mesin kebijakan jaringan.
Calico menyediakan solusi jaringan dan kebijakan kebijakan jaringan yang sangat berskala untuk menghubungkan Pod Kubernetes berdasarkan prinsip jaringan IP yang sama dengan internet, untuk Linux (open source) dan Windows (milik - tersedia dari Tigera). Calico dapat digunakan tanpa enkapsulasi atau overlay untuk menyediakan jaringan pusat data skala tinggi yang berkinerja tinggi. Calico juga menyediakan kebijakan keamanan jaringan berbutir halus, berdasarkan niat untuk Pod Kubernetes melalui firewall terdistribusi.
Calico juga dapat dijalankan dalam mode penegakan kebijakan bersama dengan solusi jaringan lain seperti Flannel, alias kanal, atau jaringan GCE, AWS atau Azure asli.
Romana
Romana adalah jaringan sumber terbuka dan solusi otomasi keamanan yang memungkinkan kamu menggunakan Kubernetes tanpa jaringan hamparan. Romana mendukung Kubernetes Kebijakan Jaringan untuk memberikan isolasi di seluruh ruang nama jaringan.
Weave Net dari Weaveworks
Weave Net adalah jaringan yang tangguh dan mudah digunakan untuk Kubernetes dan aplikasi yang dihostingnya. Weave Net berjalan sebagai plug-in CNI atau berdiri sendiri. Di kedua versi, itu tidak memerlukan konfigurasi atau kode tambahan untuk dijalankan, dan dalam kedua kasus, jaringan menyediakan satu alamat IP per Pod - seperti standar untuk Kubernetes.
Selanjutnya
Desain awal model jaringan dan alasannya, dan beberapa rencana masa depan dijelaskan secara lebih rinci dalam dokumen desain jaringan.
11.6 - Arsitektur Logging
Log aplikasi dan sistem dapat membantu kamu untuk memahami apa yang terjadi di dalam klaster kamu. Log berguna untuk mengidentifikasi dan menyelesaikan masalah serta memonitor aktivitas klaster. Hampir semua aplikasi modern mempunyai sejenis mekanisme log sehingga hampir semua mesin kontainer didesain untuk mendukung suatu mekanisme logging. Metode logging yang paling mudah untuk aplikasi dalam bentuk kontainer adalah menggunakan standard output dan standard error.
Namun, fungsionalitas bawaan dari mesin kontainer atau runtime biasanya tidak cukup memadai sebagai solusi log. Contohnya, jika sebuah kontainer gagal, sebuah pod dihapus, atau suatu node mati, kamu biasanya tetap menginginkan untuk mengakses log dari aplikasimu. Oleh sebab itu, log sebaiknya berada pada penyimpanan dan lifecyle yang terpisah dari node, pod, atau kontainer. Konsep ini dinamakan sebagai logging pada level klaster. Logging pada level klaster ini membutuhkan backend yang terpisah untuk menyimpan, menganalisis, dan mengkueri log. Kubernetes tidak menyediakan solusi bawaan untuk penyimpanan data log, namun kamu dapat mengintegrasikan beragam solusi logging yang telah ada ke dalam klaster Kubernetes kamu.
Arsitektur logging pada level klaster yang akan dijelaskan berikut mengasumsikan bahwa sebuah logging backend telah tersedia baik di dalam maupun di luar klastermu. Meskipun kamu tidak tertarik menggunakan logging pada level klaster, penjelasan tentang bagaimana log disimpan dan ditangani pada node di bawah ini mungkin dapat berguna untukmu.
Hal dasar logging pada Kubernetes
Pada bagian ini, kamu dapat melihat contoh tentang dasar logging pada Kubernetes yang mengeluarkan data pada standard output. Demonstrasi berikut ini menggunakan sebuah spesifikasi pod dengan kontainer yang akan menuliskan beberapa teks ke standard output tiap detik.
Untuk mengambil log, gunakan perintah kubectl logs sebagai berikut:
kubectl logs counter
Keluarannya adalah:
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
Kamu dapat menambahkan parameter --previous pada perintah kubectl logs untuk mengambil log dari kontainer sebelumnya yang gagal atau crash. Jika pod kamu memiliki banyak kontainer, kamu harus menspesifikasikan kontainer mana yang kamu ingin akses lognya dengan menambahkan nama kontainer pada perintah tersebut. Lihat dokumentasi kubectl logs untuk informasi lebih lanjut.
Node-level logging
Semua hal yang ditulis oleh aplikasi dalam kontainer ke stdout dan stderr akan ditangani dan diarahkan ke suatu tempat oleh mesin atau engine kontainer. Contohnya,mesin kontainer Docker akan mengarahkan kedua aliran tersebut ke suatu logging driver, yang akan dikonfigurasi pada Kubernetes untuk menuliskan ke dalam berkas dalam format json.
Catatan:
Logging driver json dari Docker memperlakukan tiap baris sebagai pesan yang terpisah. Saat menggunakan logging driver Docker, tidak ada dukungan untuk menangani pesan multi-line. Kamu harus menangani pesan multi-line pada level agen log atau yang lebih tinggi.
Secara default, jika suatu kontainer restart, kubelet akan menjaga kontainer yang mati tersebut beserta lognya. Namun jika suatu pod dibuang dari node, maka semua hal dari kontainernya juga akan dibuang, termasuk lognya.
Hal lain yang perlu diperhatikan dalam logging pada level node adalah implementasi rotasi log, sehingga log tidak menghabiskan semua penyimpanan yang tersedia pada node. Kubernetes saat ini tidak bertanggung jawab dalam melakukan rotasi log, namun deployment tool seharusnya memberikan solusi terhadap masalah tersebut.
Contohnya, pada klaster Kubernetes, yang di deployed menggunakan kube-up.sh, terdapat alat bernama logrotate yang dikonfigurasi untuk berjalan tiap jamnya. Kamu juga dapat menggunakan runtime kontainer untuk melakukan rotasi log otomatis, misalnya menggunakan log-opt Docker.
Pada kube-up.sh, metode terakhir digunakan untuk COS image pada GCP, sedangkan metode pertama digunakan untuk lingkungan lainnya. Pada kedua metode, secara default akan dilakukan rotasi pada saat berkas log melewati 10MB.
Sebagai contoh, kamu dapat melihat informasi lebih rinci tentang bagaimana kube-up.sh mengatur logging untuk COS image pada GCP yang terkait dengan script.
Saat kamu menjalankan perintah kubectl logs seperti pada contoh tadi, kubelet di node tersebut akan menangani permintaan untuk membaca langsung isi berkas log sebagai respon.
Catatan:
Saat ini, jika suatu sistem eksternal telah melakukan rotasi, hanya konten dari berkas log terbaru yang akan tersedia melalui perintah kubectl logs. Contoh, jika terdapat sebuah berkas 10MB, logrotate akan melakukan rotasi sehingga akan ada dua buah berkas, satu dengan ukuran 10MB, dan satu berkas lainnya yang kosong. Maka kubectl logs akan mengembalikan respon kosong.
Komponen sistem log
Terdapat dua jenis komponen sistem: yaitu yang berjalan di dalam kontainer dan komponen lain yang tidak berjalan di dalam kontainer. Sebagai contoh:
Kubernetes scheduler dan kube-proxy berjalan di dalam kontainer.
Kubelet dan runtime kontainer, contohnya Docker, tidak berjalan di dalam kontainer.
Pada mesin yang menggunakan systemd, kubelet dan runtime runtime menulis ke journald. Jika systemd tidak tersedia, keduanya akan menulis ke berkas .log pada folder /var/log.
Komponen sistem di dalam kontainer akan selalu menuliskan ke folder /var/log, melewati mekanisme default logging. Mereka akan menggunakan logging libraryklog.
Kamu dapat menemukan konvensi tentang tingkat kegawatan logging untuk komponen-komponen tersebut pada dokumentasi development logging.
Seperti halnya pada log kontainer, komponen sistem yang menuliskan log pada folder /var/log juga harus melakukan rotasi log. Pada klaster Kubernetes yang menggunakan kube-up.sh, log tersebut telah dikonfigurasi dan akan dirotasi oleh logrotate secara harian atau saat ukuran log melebihi 100MB.
Arsitektur klaster-level logging
Meskipun Kubernetes tidak menyediakan solusi bawaan untuk logging level klaster, ada beberapa pendekatan yang dapat kamu pertimbangkan. Berikut beberapa diantaranya:
Menggunakan agen logging pada level node yang berjalan pada setiap node.
Menggunakan kontainer sidecar khusus untuk logging aplikasi di dalam pod.
Mengeluarkan log langsung ke backend dari dalam aplikasi
Menggunakan agen node-level logging
Kamu dapat mengimplementasikan klaster-level logging dengan menggunakan agen yang berjalan pada setiap node. Agen logging merupakan perangkat khusus yang akan mengekspos log atau mengeluarkan log ke backend. Umumnya agen logging merupakan kontainer yang memiliki akses langsung ke direktori tempat berkas log berada dari semua kontainer aplikasi yang berjalan pada node tersebut.
Karena agen logging harus berjalan pada setiap node, umumnya dilakukan dengan menggunakan replika DaemonSet, manifest pod, atau menjalankan proses khusus pada node. Namun dua cara terakhir sudah dideprekasi dan sangat tidak disarankan.
Menggunakan agen logging pada level node merupakan cara yang paling umum dan disarankan untuk klaster Kubernetes. Hal ini karena hanya dibutuhkan satu agen tiap node dan tidak membutuhkan perubahan apapun dari sisi aplikasi yang berjalan pada node. Namun, node-level logging hanya dapat dilakukan untuk aplikasi yang menggunakan standard output dan standard error.
Kubernetes tidak menspesifikasikan khusus suatu agen logging, namun ada dua agen logging yang dimasukkan dalam rilis Kubernetes: Stackdriver Logging untuk digunakan pada Google Cloud Platform, dan Elasticsearch. Kamu dapat melihat informasi dan instruksi pada masing-masing dokumentasi. Keduanya menggunakan fluentd dengan konfigurasi kustom sebagai agen pada node.
Menggunakan kontainer sidecar dengan agen logging
Kamu dapat menggunakan kontainer sidecar dengan salah satu cara berikut:
Kontainer sidecar mengeluarkan log aplikasi ke stdout miliknya sendiri.
Kontainer sidecar menjalankan agen logging yang dikonfigurasi untuk mengambil log dari aplikasi kontainer.
Kontainer streamingsidecar
Kamu dapat memanfaatkan kubelet dan agen logging yang telah berjalan pada tiap node dengan menggunakan kontainer sidecar. Kontainer sidecar dapat membaca log dari sebuah berkas, socket atau journald. Tiap kontainer sidecar menuliskan log ke stdout atau stderr mereka sendiri.
Dengan menggunakan cara ini kamu dapat memisahkan aliran log dari bagian-bagian yang berbeda dari aplikasimu, yang beberapa mungkin tidak mendukung log ke stdout dan stderr. Perubahan logika aplikasimu dengan menggunakan cara ini cukup kecil, sehingga hampir tidak ada overhead. Selain itu, karena stdout dan stderr ditangani oleh kubelet, kamu juga dapat menggunakan alat bawaan seperti kubectl logs.
Sebagai contoh, sebuah pod berjalan pada satu kontainer tunggal, dan kontainer menuliskan ke dua berkas log yang berbeda, dengan dua format yang berbeda pula. Berikut ini file konfigurasi untuk Pod:
apiVersion:v1kind:Podmetadata:name:counterspec:containers:- name:countimage:busyboxargs:- /bin/sh- -c- > i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
donevolumeMounts:- name:varlogmountPath:/var/logvolumes:- name:varlogemptyDir:{}
Hal ini akan menyulitkan untuk mengeluarkan log dalam format yang berbeda pada aliran log yang sama, meskipun kamu dapat me-redirect keduanya ke stdout dari kontainer. Sebagai gantinya, kamu dapat menggunakan dua buah kontainer sidecar. Tiap kontainer sidecar dapat membaca suatu berkas log tertentu dari shared volume kemudian mengarahkan log ke stdout-nya sendiri.
Berikut file konfigurasi untuk pod yang memiliki dua buah kontainer sidecard:
Saat kamu menjalankan pod ini, kamu dapat mengakses tiap aliran log secara terpisah dengan menjalankan perintah berikut:
kubectl logs counter count-log-1
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
kubectl logs counter count-log-2
Mon Jan 1 00:00:00 UTC 2001 INFO 0
Mon Jan 1 00:00:01 UTC 2001 INFO 1
Mon Jan 1 00:00:02 UTC 2001 INFO 2
...
Agen node-level yang terpasang di klastermu akan mengambil aliran log tersebut secara otomatis tanpa perlu melakukan konfigurasi tambahan. Bahkan jika kamu mau, kamu dapat mengonfigurasi agen untuk melakukan parse baris log tergantung dari kontainer sumber awalnya.
Sedikit catatan, meskipun menggunakan memori dan CPU yang cukup rendah (sekitar beberapa milicore untuk CPU dan beberapa megabytes untuk memori), penulisan log ke file kemudian mengalirkannya ke stdout dapat berakibat penggunaan disk yang lebih besar. Jika kamu memiliki aplikasi yang menuliskan ke file tunggal, umumnya lebih baik menggunakan /dev/stdout sebagai tujuan daripada menggunakan pendekatan dengan kontainer sidecar.
Kontainer sidecar juga dapat digunakan untuk melakukan rotasi berkas log yang tidak dapat dirotasi oleh aplikasi itu sendiri. Contoh dari pendekatan ini adalah sebuah kontainer kecil yang menjalankan rotasi log secara periodik. Namun, direkomendasikan untuk menggunakan stdout dan stderr secara langsung dan menyerahkan kebijakan rotasi dan retensi pada kubelet.
Kontainer sidecar dengan agen logging
Jika agen node-level logging tidak cukup fleksible untuk kebutuhanmu, kamu dapat membuat kontainer sidecar dengan agen logging yang terpisah, yang kamu konfigurasi spesifik untuk berjalan dengan aplikasimu.
Catatan:
Menggunakan agen logging di dalam kontainer sidecar dapat berakibat penggunaan resource yang signifikan. Selain itu, kamu tidak dapat mengakses log itu dengan menggunakan perintah kubectl logs, karena mereka tidak dikontrol oleh kubelet.
Sebagai contoh, kamu dapat menggunakan Stackdriver,
yang menggunakan fluentd sebagai agen logging. Berikut ini dua file konfigurasi yang dapat kamu pakai untuk mengimplementasikan cara ini. File yang pertama berisi sebuah ConfigMap untuk mengonfigurasi fluentd.
apiVersion:v1kind:ConfigMapmetadata:name:fluentd-configdata:fluentd.conf:| <source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
Catatan:
Konfigurasi fluentd berada diluar cakupan artikel ini. Untuk informasi lebih lanjut tentang cara mengonfigurasi fluentd, silakan lihat dokumentasi resmi fluentd .
File yang kedua mendeskripsikan sebuah pod yang memiliki kontainer sidecar yang menjalankan fluentd. Pod ini melakukan mount sebuah volume yang akan digunakan fluentd untuk mengambil data konfigurasinya.
Setelah beberapa saat, kamu akan mendapati pesan log pada interface Stackdriver.
Ingat, ini hanya contoh saja dan kamu dapat mengganti fluentd dengan agen logging lainnya, yang dapat membaca sumber apa saja dari dalam kontainer aplikasi.
Mengekspos log langsung dari aplikasi
Kamu dapat mengimplementasikan klaster-level logging dengan mengekspos atau mengeluarkan log langsung dari tiap aplikasi; namun cara implementasi mekanisme logging tersebut diluar cakupan dari Kubernetes.
11.7 - Metrik untuk Komponen Sistem Kubernetes
Metrik dari komponen sistem dapat memberikan gambaran yang lebih baik tentang apa
yang sedang terjadi di dalam sistem. Metrik sangat berguna untuk membuat dasbor (dashboard)
dan peringatan (alert).
Komponen Kubernetes mengekspos metrik dalam format Prometheus.
Format ini berupa teks biasa yang terstruktur, dirancang agar orang dan mesin dapat membacanya.
Metrik-metrik dalam Kubernetes
Dalam kebanyakan kasus, metrik tersedia pada endpoint/metrics dari server HTTP.
Untuk komponen yang tidak mengekspos endpoint secara bawaan, endpoint tersebut dapat diaktifkan
dengan menggunakan opsi --bind-address.
Di dalam lingkungan produksi, kamu mungkin ingin mengonfigurasi Server Prometheus
atau pengambil metrik (metrics scraper) lainnya untuk mengumpulkan metrik-metrik ini secara berkala
dan membuatnya tersedia dalam semacam pangkalan data deret waktu (time series database).
Perlu dicatat bahwa kubelet
juga mengekspos metrik pada endpoint-endpoint seperti /metrics/cadvisor,
/metrics/resource dan /metrics/probes. Metrik-metrik tersebut tidak memiliki
siklus hidup yang sama.
Jika klastermu menggunakan RBAC,
maka membaca metrik memerlukan otorisasi melalui user, group, atau
ServiceAccount dengan ClusterRole yang memperbolehkan untuk mengakses /metrics.
Sebagai contoh:
apiVersion:rbac.authorization.k8s.io/v1kind:ClusterRolemetadata:name:prometheusrules:- nonResourceURLs:- "/metrics"verbs:- get
Metrik alfa tidak memiliki jaminan stabilitas. Metrik ini
dapat dimodifikasi atau dihapus kapan saja.
Metrik stabil dijamin tidak akan mengalami perubahan. Hal ini berarti:
Metrik stabil tanpa penanda usang (deprecated signature) tidak akan dihapus ataupun diganti namanya
Jenis metrik stabil tidak akan dimodifikasi
Metrik usang dijadwalkan untuk dihapus, tetapi masih tersedia untuk digunakan.
Metrik ini mencakup anotasi versi di mana metrik ini dianggap menjadi usang.
Sebagai contoh:
Sebelum menjadi usang
# HELP some_counter this counts things
# TYPE some_counter counter
some_counter 0
Setelah menjadi usang
# HELP some_counter (Deprecated since 1.15.0) this counts things
# TYPE some_counter counter
some_counter 0
Metrik tersembunyi tidak lagi dipublikasikan untuk pengambilan metrik (scraping), tetapi masih tersedia untuk digunakan. Untuk menggunakan metrik tersembunyi, lihat bagian Menampilkan metrik tersembunyi.
Metrik yang terhapus tidak lagi dipublikasikan dan tidak dapat digunakan lagi.
Menampilkan metrik tersembunyi
Seperti yang dijelaskan di atas, admin dapat mengaktifkan metrik tersembunyi melalui opsi baris perintah pada biner (program) tertentu. Ini dimaksudkan untuk digunakan sebagai jalan keluar bagi admin jika mereka melewatkan migrasi metrik usang dalam rilis terakhir.
Opsi show-hidden-metrics-for-version menerima input versi yang kamu inginkan untuk menampilkan metrik usang dalam rilis tersebut. Versi tersebut dinyatakan sebagai x.y, di mana x adalah versi mayor, y adalah versi minor. Versi patch tidak diperlukan meskipun metrik dapat menjadi usang dalam rilis patch, alasannya adalah kebijakan penandaan metrik usang dijalankan terhadap rilis minor.
Opsi tersebut hanya dapat menerima input versi minor sebelumnya sebagai nilai. Semua metrik yang disembunyikan di versi sebelumnya akan dikeluarkan jika admin mengatur versi sebelumnya ke show-hidden-metrics-for-version. Versi yang terlalu lama tidak diperbolehkan karena melanggar kebijakan untuk metrik usang.
Ambil metrik A sebagai contoh, di sini diasumsikan bahwa A sudah menjadi usang di versi 1.n. Berdasarkan kebijakan metrik usang, kita dapat mencapai kesimpulan berikut:
Pada rilis 1.n, metrik menjadi usang, dan dapat dikeluarkan secara bawaan.
Pada rilis 1.n+1, metrik disembunyikan secara bawaan dan dapat dikeluarkan dengan baris perintah show-hidden-metrics-for-version=1.n.
Pada rilis 1.n+2, metrik harus dihapus dari codebase. Tidak ada jalan keluar lagi.
Jika kamu meningkatkan versi dari rilis 1.12 ke 1.13, tetapi masih bergantung pada metrik A yang usang di 1.12, kamu harus mengatur metrik tersembunyi melalui baris perintah: --show-hidden-metrics = 1.12 dan ingatlah untuk menghapus ketergantungan terhadap metrik ini sebelum meningkatkan versi rilis ke 1.14.
Menonaktifkan metrik akselerator
kubelet mengumpulkan metrik akselerator melalui cAdvisor. Untuk mengumpulkan metrik ini, untuk akselerator seperti GPU NVIDIA, kubelet membuka koneksi dengan driver GPU. Ini berarti untuk melakukan perubahan infrastruktur (misalnya, pemutakhiran driver), administrator klaster perlu menghentikan agen kubelet.
Pengumpulkan metrik akselerator sekarang menjadi tanggung jawab vendor dibandingkan kubelet. Vendor harus menyediakan sebuah kontainer untuk mengumpulkan metrik dan mengeksposnya ke layanan metrik (misalnya, Prometheus).
Metrik controller manager memberikan gambaran penting
tentang kinerja dan kesehatan controller manager. Metrik ini mencakup metrik
runtime bahasa Go yang umum seperti jumlah go_routine dan metrik khusus
pengontrol seperti latensi permintaan etcd atau latensi API Cloudprovider
(AWS, GCE, OpenStack) yang dapat digunakan untuk mengukur kesehatan klaster.
Mulai dari Kubernetes 1.7, metrik Cloudprovider yang detail tersedia untuk
operasi penyimpanan untuk GCE, AWS, Vsphere, dan OpenStack.
Metrik ini dapat digunakan untuk memantau kesehatan operasi persistent volume.
Misalnya, untuk GCE metrik-metrik berikut ini dipanggil:
Penjadwal mengekspos metrik opsional yang melaporkan sumber daya yang diminta dan limit yang diinginkan dari semua pod yang berjalan. Metrik ini dapat digunakan untuk membangun dasbor perencanaan kapasitas, mengevaluasi limit penjadwalan yang digunakan saat ini atau secara historis, dengan cepat mengidentifikasi beban kerja yang tidak dapat dijadwalkan karena kurangnya sumber daya, dan membandingkan permintaan sumber daya oleh pod dengan penggunaannya yang aktual.
kube-scheduler mengidentifikasi permintaan dan limit sumber daya yang dikonfigurasi untuk setiap Pod; jika permintaan atau limit bukan nol, kube-scheduler akan melaporkan deret waktu (timeseries) metrik. Deret waktu diberi label dengan:
namespace
nama pod
node di mana pod dijadwalkan atau string kosong jika belum dijadwalkan
prioritas
penjadwal yang ditugaskan untuk pod itu
nama dari sumber daya (misalnya, cpu)
satuan dari sumber daya jika diketahui (misalnya, cores)
Setelah pod selesai (memiliki restartPolicyNever atau OnFailure dan berada dalam fase pod Succeeded atau Failed, atau telah dihapus dan semua kontainer dalam keadaan Terminated) deret metrik tidak lagi dilaporkan karena penjadwal sekarang sudah dibebaskan untuk menjadwalkan pod lain untuk dijalankan. Metrik yang dibahas pada bagian ini dikenal sebagai kube_pod_resource_request dan kube_pod_resource_limit.
Metrik diekspos melalui endpoint HTTP /metrics/resources dan memerlukan otorisasi yang sama seperti endpoint /metrics
pada penjadwal. Kamu harus menggunakan opsi --show-hidden-metrics-for-version=1.20 untuk mengekspos metrik-metrik stabilitas alfa ini.
11.8 - Konfigurasi Garbage Collection pada kubelet
Garbage collection merupakan fitur kubelet yang sangat bermanfaat, yang akan membersihkan image-image dan juga kontainer-kontainer
yang tidak lagi digunakan. Kubelet akan melakukan garbage collection untuk kontainer setiap satu menit dan garbage collection untuk
image setiap lima menit.
Perangkat garbage collection eksternal tidak direkomendasikan karena perangkat tersebut berpotensi merusak perilaku kubelet dengan
menghilangkan kontainer-kontainer yang sebenarnya masih diperlukan.
Garbage Collection untuk Image
Kubernetes mengelola lifecycle untuk seluruh image melalui imageManager, dengan bantuan cadvisor.
Policy untuk melakukan garbage collection memperhatikan dua hal: HighThresholdPercent dan LowThresholdPercent.
Penggunaan disk yang melewati batas atas (high threshold) akan men-triggergarbage collection.
Garbage collection akan mulai menghapus dari image-image yang paling jarang digunakan (least recently used)
sampai menemui batas bawah (low threshold) kembali.
Garbage Collection untuk Kontainer
Policy untuk melakukan garbage collection pada kontainer memperhatikan tiga variabel yang ditentukan oleh pengguna (user-defined).
MinAge merupakan umur minimal dimana suatu kontainer dapat terkena garbage collection.
MaxPerPodContainer merupakan jumlah maksimum yang diperbolehkan untuk setiap pod (UID, container name) pair memiliki
kontainer-kontainer yang sudah mati (dead containers). MaxContainers merupakan jumlah maksimal total dari seluruh kontainer yang sudah mati.
Semua variabel ini dapat dinonaktifkan secara individual, dengan mengatur MinAge ke angka nol serta mengatur MaxPerPodContainer dan MaxContainers
ke angka di bawah nol.
Kubelet akan mengambil tindakan untuk kontainer-kontainer yang tidak dikenal, sudah dihapus, atau diluar batasan-batasan yang diatur
sebelumnya melalui flag. Kontainer-kontainer yang paling lama (tertua) biasanya akan dihapus terlebih dahulu. MaxPerPodContainer dan MaxContainer
berpotensi mengalami konflik satu sama lain pada situasi saat menjaga jumlah maksimal kontainer per pod (MaxPerPodContainer) akan melebihi
jumlah kontainer mati (dead containers) yang diperbolehkan (MaxContainers).
MaxPerPodContainer dapat diatur sedemikian rupa dalam situasi ini: Seburuk-buruhknya dengan melakukan downgradeMaxPerPodContainer ke angka 1
dan melakukan evict kontainer-kontainer yang paling lama. Selain itu, kontainer-kontainer milik Pod yang telah dihapus akan dihilangkan
saat umur mereka telah melebihi MinAge.
Kontainer-kontainer yang tidak dikelola oleh kubelet akan terbebas dari garbage collection.
Konfigurasi Pengguna
Para pengguna dapat mengatur threshold-threshold untuk melakukan tuning pada garbage collection image
melalui flag-flag kubelet sebagai berikut:
image-gc-high-threshold, persentase dari penggunaan disk yang men-trigger proses garbage collection untuk image.
Default-nya adalah 85%.
image-gc-low-threshold, persentase dari penggunaan disk dimana garbage collection berusaha menghapus image.
Default-nya adalah 80%.
Kami juga memperbolehkan para pengguna untuk menyesuaikan policy garbage collection melalui
flag-flag kubelet sebagai berikut:
minimum-container-ttl-duration, umur minimal untuk setiap kontainer yang sudah selesai (finished) sebelum
terkena garbage collection. Default-nya adalah 0 menit, yang berarti setiap kontainer yang telah selesai akan
terkena garbage collection.
maximum-dead-containers-per-container, jumlah maksimal dari kontainer-kontainer lama yang diperbolehkan ada
secara global. Default-nya adalah -1, yang berarti tidak ada batasannya untuk global.
Kontainer-kontainer dapat berpotensi terkena garbage collection sebelum kegunaannya telah usang. Kontainer-kontainer
ini memliki log dan data lainnya yang bisa saja berguna saat troubleshoot. Sangat direkomendasikan untuk menetapkan
angka yang cukup besar pada maximum-dead-containers-per-container, untuk memperbolehkan paling tidak 1 kontainer mati
untuk dijaga (retained) per jumlah kontainer yang diharapkan. Angka yang lebih besar untuk maximum-dead-containers
juga direkomendasikan untuk alasan serupa.
Lihat isu ini untuk penjelasan lebih lanjut.
Deprecation
Beberapa fitur Garbage Collection pada kubelet di laman ini akan digantikan oleh fitur eviction nantinya, termasuk:
Flag Existing
Flag Baru
Alasan
--image-gc-high-threshold
--eviction-hard atau --eviction-soft
sinyal eviction yang ada (existing) dapat men-triggergarbage collection
--image-gc-low-threshold
--eviction-minimum-reclaim
hal serupa dapat diperoleh dengan eviction reclaim
--maximum-dead-containers
deprecated saat log yang telah usang tersimpan di luar konteks kontainer
--maximum-dead-containers-per-container
deprecated saat log yang telah usang tersimpan di luar konteks kontainer
--minimum-container-ttl-duration
deprecated saat log yang telah usang tersimpan di luar konteks kontainer
--low-diskspace-threshold-mb
--eviction-hard atau eviction-soft
eviction memberi generalisasi threshold disk untuk resource-resource lainnya
--outofdisk-transition-frequency
--eviction-pressure-transition-period
eviction memberi generalisasi transisi tekanan disk (disk pressure)untuk resource-resource lainnya
Sebuah Proxy/Load-balancer di depan satu atau banyak apiserver:
keberadaan dan implementasinya bervariasi tergantung pada klaster (contohnya nginx)
ada di antara seluruh klien dan satu/banyak apiserver
jika ada beberapa apiserver, berfungsi sebagai load balancer
Cloud Load Balancer pada servis eksternal:
disediakan oleh beberapa penyedia layanan cloud, seperti AWS ELB, Google Cloud Load Balancer
dibuat secara otomatis ketika Service dari Kubernetes dengan tipe LoadBalancer
biasanya hanya tersedia untuk UDP/TCP
support untuk SCTP tergantung pada load balancer yang diimplementasikan oleh penyedia cloud
implementasi bervariasi tergantung pada penyedia cloud
Pengguna Kubernetes biasanya hanya cukup perlu tahu tentang kubectl proxy dan apiserver proxy.
Untuk proxy-proxy lain di luar ini, admin klaster biasanya akan memastikan konfigurasinya dengan benar.
Melakukan request redirect
Proxy telah menggantikan fungsi redirect. Redirect telah terdeprekasi.
11.10 - Metrik controller manager
Metrik controller manager memberikan informasi penting tentang kinerja dan kesehatan dari controller manager.
Tentang metrik controller manager
Metrik controller manager ini berfungsi untuk memberikan informasi penting tentang kinerja dan kesehatan dari controller manager.
Metrik ini juga berisi tentang metrik umum dari runtime bahasa pemrograman Go seperti jumlah go_routine dan metrik spesifik dari controller seperti
latensi dari etcd request atau latensi API dari penyedia layanan cloud (AWS, GCE, OpenStack) yang dapat digunakan untuk mengukur kesehatan dari klaster.
Mulai dari Kubernetes 1.7, metrik yang lebih mendetil tentang operasi penyimpanan dari penyedia layanan cloud juga telah tersedia.
Metrik-metrik ini dapat digunakan untuk memonitor kesehatan dari operasi persistent volume.
Berikut merupakan contoh nama metrik yang disediakan GCE:
Pada sebuah klaster, informasi metrik controller manager dapat diakses melalui http://localhost:10252/metrics
dari host tempat controller manager dijalankan.
Metrik ini dikeluarkan dalam bentuk format prometheus serta mudah untuk dibaca manusia.
Pada environment produksi, kamu mungkin juga ingin mengonfigurasi prometheus atau pengumpul metrik lainnya untuk mengumpulkan metrik-metrik ini secara berkala dalam bentuk basis data time series.
11.11 - Instalasi Add-ons
Add-ons berfungsi untuk menambah serta memperluas fungsionalitas dari Kubernetes.
Laman ini akan menjabarkan beberapa add-ons yang tersedia serta tautan instruksi bagaimana cara instalasi masing-masing add-ons.
Add-ons pada setiap bagian akan diurutkan secara alfabet - pengurutan ini tidak dilakukan berdasarkan status preferensi atau keunggulan.
Jaringan dan Policy Jaringan
ACI menyediakan integrasi jaringan kontainer dan keamanan jaringan dengan Cisco ACI.
Calico merupakan penyedia jaringan L3 yang aman dan policy jaringan.
Canal menggabungkan Flannel dan Calico, menyediakan jaringan serta policy jaringan.
Cilium merupakan plugin jaringan L3 dan policy jaringan yang dapat menjalankan policy HTTP/API/L7 secara transparan. Mendukung mode routing maupun overlay/encapsulation.
CNI-Genie memungkinkan Kubernetes agar dapat terkoneksi dengan beragam plugin CNI, seperti Calico, Canal, Flannel, Romana, atau Weave dengan mulus.
Contiv menyediakan jaringan yang dapat dikonfigurasi (native L3 menggunakan BGP, overlay menggunakan vxlan, klasik L2, dan Cisco-SDN/ACI) untuk berbagai penggunaan serta policy framework yang kaya dan beragam. Proyek Contiv merupakan proyek open source. Laman instalasi ini akan menjabarkan cara instalasi, baik untuk klaster dengan kubeadm maupun non-kubeadm.
Contrail, yang berbasis dari Tungsten Fabric, merupakan sebuah proyek open source yang menyediakan virtualisasi jaringan multi-cloud serta platform manajemen policy. Contrail dan Tungsten Fabric terintegrasi dengan sistem orkestrasi lainnya seperti Kubernetes, OpenShift, OpenStack dan Mesos, serta menyediakan mode isolasi untuk mesin virtual (VM), kontainer/pod dan bare metal.
Flannel merupakan penyedia jaringan overlay yang dapat digunakan pada Kubernetes.
Knitter merupakan solusi jaringan yang mendukung multipel jaringan pada Kubernetes.
Multus merupakan sebuah multi plugin agar Kubernetes mendukung multipel jaringan secara bersamaan sehingga dapat menggunakan semua plugin CNI (contoh: Calico, Cilium, Contiv, Flannel), ditambah pula dengan SRIOV, DPDK, OVS-DPDK dan VPP pada workload Kubernetes.
NSX-T Container Plug-in (NCP) menyediakan integrasi antara VMware NSX-T dan orkestrator kontainer seperti Kubernetes, termasuk juga integrasi antara NSX-T dan platform CaaS/PaaS berbasis kontainer seperti Pivotal Container Service (PKS) dan OpenShift.
Nuage merupakan platform SDN yang menyediakan policy-based jaringan antara Kubernetes Pods dan non-Kubernetes environment dengan monitoring visibilitas dan keamanan.
Romana merupakan solusi jaringan Layer 3 untuk jaringan pod yang juga mendukung NetworkPolicy API. Instalasi Kubeadm add-on ini tersedia di sini.
Weave Net menyediakan jaringan serta policy jaringan, yang akan membawa kedua sisi dari partisi jaringan, serta tidak membutuhkan basis data eksternal.
Service Discovery
CoreDNS merupakan server DNS yang fleksibel, mudah diperluas yang dapat diinstal sebagai in-cluster DNS untuk pod.
Visualisasi & Kontrol
Dashboard merupakan antarmuka web dasbor untuk Kubernetes.
Add-ons Terdeprekasi
Ada beberapa add-on lain yang didokumentasikan pada direktori deprekasi cluster/addons.
Add-on lain yang dipelihara dan dikelola dengan baik dapat ditulis di sini. Ditunggu PR-nya!
11.12 - Prioritas dan Kesetaraan API (API Priority and Fairness)
FEATURE STATE:Kubernetes v1.18 [alpha]
Mengontrol perilaku server API dari Kubernetes pada situasi beban berlebih
merupakan tugas utama dari administrator klaster. kube-apiserver memiliki beberapa kontrol yang tersedia
(seperti opsi --max-request-inflight dan --max-mutating-request-inflight
pada baris perintah atau command-line) untuk membatasi jumlah pekerjaan luar biasa yang akan
diterima, untuk mencegah banjirnya permintaan masuk dari beban berlebih
yang berpotensi untuk menghancurkan server API. Namun opsi ini tidak cukup untuk memastikan
bahwa permintaan yang paling penting dapat diteruskan pada saat kondisi lalu lintas (traffic) yang cukup tinggi.
Fitur Prioritas dan Kesetaraan API atau API Priority and Fairness (APF) adalah alternatif untuk meningkatkan
batasan max-inflight seperti yang disebutkan di atas. APF mengklasifikasi
dan mengisolasi permintaan dengan cara yang lebih halus. Fitur ini juga memperkenalkan
jumlah antrian yang terbatas, sehingga tidak ada permintaan yang ditolak
pada saat terjadi lonjakan permintaan dalam waktu yang sangat singkat. Permintaan dibebaskan dari antrian dengan menggunakan
teknik antrian yang adil (fair queuing) sehingga, sebagai contoh, perilaku buruk dari satu
controller tidak seharusnya
mengakibatkan controller yang lain menderita (meskipun pada tingkat prioritas yang sama).
Perhatian:
Permintaan yang diklasifikasikan sebagai "long running" - terutama watch - tidak
mengikuti filter prioritas dan kesetaraan API. Dimana ini juga berlaku pada
opsi --max-request-inflight tanpa mengaktifkan APF.
Mengaktifkan prioritas dan kesetaraan API
Fitur APF dikontrol oleh sebuah gerbang fitur (feature gate)
dan fitur ini tidak diaktifkan secara bawaan. Silahkan lihat
gerbang fitur
untuk penjelasan umum tentang gerbang fitur dan bagaimana cara mengaktifkan dan menonaktifkannya.
Nama gerbang fitur untuk APF adalah "APIPriorityAndFairness".
Fitur ini melibatkan sebuah Grup API yang harus juga diaktifkan. Kamu bisa melakukan ini dengan
menambahkan opsi pada baris perintah berikut pada permintaan ke kube-apiserver kamu:
kube-apiserver \
--feature-gates=APIPriorityAndFairness=true\
--runtime-config=flowcontrol.apiserver.k8s.io/v1alpha1=true\
# …dan opsi-opsi lainnya seperti biasa
Opsi pada baris perintah --enable-priority-and-fairness=false akan menonaktifkan fitur
APF, bahkan ketika opsi yang lain telah mengaktifkannya.
Konsep
Ada beberapa fitur lainnya yang terlibat dalam fitur APF. Permintaan yang masuk diklasifikasikan berdasarkan atribut permintaan dengan menggunakan
FlowSchema, dan diserahkan ke tingkat prioritas. Tingkat prioritas menambahkan tingkat
isolasi dengan mempertahankan batas konkurensi yang terpisah, sehingga permintaan yang diserahkan
ke tingkat prioritas yang berbeda tidak dapat membuat satu sama lain menderita. Dalam sebuah tingkat prioritas,
algoritma fair-queuing mencegah permintaan dari flows yang berbeda akan memberikan penderitaan
kepada yang lainnya, dan memperbolehkan permintaan untuk dimasukkan ke dalam antrian untuk mencegah pelonjakan lalu lintas
yang akan menyebabkan gagalnya permintaan, walaupun pada saat beban rata-ratanya cukup rendah.
Tingkat prioritas (Priority Level)
Tanpa pengaktifan APF, keseluruhan konkurensi dalam
server API dibatasi oleh opsi pada kube-apiserver--max-request-inflight dan --max-mutating-request-inflight. Dengan pengaktifan APF,
batas konkurensi yang ditentukan oleh opsi ini akan dijumlahkan dan kemudian jumlah tersebut dibagikan
untuk sekumpulan tingkat prioritas (priority level) yang dapat dikonfigurasi. Setiap permintaan masuk diserahkan
ke sebuah tingkat prioritas, dan setiap tingkat prioritas hanya akan meneruskan sebanyak mungkin
permintaan secara bersamaan sesuai dengan yang diijinkan dalam konfigurasi.
Konfigurasi bawaan, misalnya, sudah mencakup tingkat prioritas terpisah untuk
permintaan dalam rangka pemilihan pemimpin (leader-election), permintaan dari controller bawaan, dan permintaan dari
Pod. Hal ini berarti bahwa Pod yang berperilaku buruk, yang bisa membanjiri server API
dengan permintaan, tidak akan mampu mencegah kesuksesan pemilihan pemimpin atau tindakan yang dilakukan oleh controller bawaan.
Antrian (Queuing)
Bahkan dalam sebuah tingkat prioritas mungkin akan ada sumber lalu lintas yang berbeda dalam jumlah besar.
Dalam situasi beban berlebih, sangat penting untuk mencegah satu aliran
permintaan dari penderitaan karena aliran yang lainnya (khususnya, dalam kasus yang relatif umum dari sebuah
klien tunggal bermasalah (buggy) yang dapat membanjiri kube-apiserver dengan permintaan, klien bermasalah itu
idealnya tidak memiliki banyak dampak yang bisa diukur terhadap klien yang lainnya). Hal ini
ditangani dengan menggunakan algoritma fair-queuing untuk memproses permintaan yang diserahkan
oleh tingkat prioritas yang sama. Setiap permintaan diserahkan ke sebuah flow, yang diidentifikasi berdasarkan
nama FlowSchema yang sesuai, ditambah dengan flow distinguisher - yang
bisa saja didasarkan pada pengguna yang meminta, sumber daya Namespace dari target, atau tidak sama sekali - dan
sistem mencoba untuk memberikan bobot yang hampir sama untuk permintaan dalam flow yang berbeda dengan tingkat prioritas yang sama.
Setelah mengklasifikasikan permintaan ke dalam sebuah flow, fitur APF kemudian
dapat menyerahkan permintaan ke dalam sebuah antrian. Penyerahan ini menggunakan
teknik yang dikenal sebagai _shuffle sharding_, yang membuat penggunaan antrian yang relatif efisien
untuk mengisolasi flow dengan intensitas rendah dari flow dengan intensitas tinggi.
Detail dari algoritma antrian dapat disesuaikan untuk setiap tingkat prioritas, dan
memperbolehkan administrator untuk menukar (trade off) dengan penggunaan memori, kesetaraan (properti dimana
flow yang independen akan membuat semua kemajuan ketika total dari lalu lintas sudah melebihi kapasitas),
toleransi untuk lonjakan lalu lintas, dan penambahan latensi yang dihasilkan oleh antrian.
Permintaan yang dikecualikan (Exempt Request)
Beberapa permintaan dianggap cukup penting sehingga mereka tidak akan mengikuti
salah satu batasan yang diberlakukan oleh fitur ini. Pengecualian ini untuk mencegah
konfigurasi flow control yang tidak terkonfigurasi dengan baik sehingga tidak benar-benar menonaktifkan server API.
Bawaan (Default)
Fitur APF dikirimkan dengan konfigurasi yang disarankan
dimana konfigurasi itu seharusnya cukup untuk bereksperimen; jika klaster kamu cenderung
mengalami beban berat maka kamu harus mempertimbangkan konfigurasi apa yang akan bekerja paling baik.
Kelompok konfigurasi yang disarankan untuk semua permintaan terbagi dalam lima prioritas
kelas:
Tingkat prioritas system diperuntukkan bagi permintaan dari grup system:nodes,
mis. Kubelet, yang harus bisa menghubungi server API agar
mendapatkan workload untuk dijadwalkan.
Tingkat prioritas leader-election diperuntukkan bagi permintaan dalam pemilihan pemimpin (leader election)
dari controller bawaan (khususnya, permintaan untuk endpoint, configmaps,
atau leases yang berasal dari system:kube-controller-manager atau pengguna
system:kube-scheduler dan akun Service di Namespace kube-system). Hal ini
penting untuk mengisolasi permintaan ini dari lalu lintas yang lain karena
kegagalan dalam pemilihan pemimpin menyebabkan controller akan gagal dan memulai kembali (restart),
yang pada akhirnya menyebabkan lalu lintas yang lebih mahal karena controller
yang baru perlu menyinkronkan para informannya.
Tingkat prioritas workload-high diperuntukkan bagi permintaan yang lain dari controller bawaan.
Tingkat prioritas workload-low diperuntukkan bagi permintaan dari akun Service yang lain,
yang biasanya mencakup semua permintaan dari controller yang bekerja didalam Pod.
Tingkat prioritas global-default menangani semua lalu lintas lainnya, mis.
perintah interaktif kubectl yang dijalankan oleh pengguna yang tidak memiliki hak khusus.
Kemudian, ada dua PriorityLevelConfiguration dan dua FlowSchema yang telah
dibangun dan tidak mungkin ditimpa ulang:
Tingkat prioritas khusus exempt diperuntukkan bagi permintaan yang tidak akan dikenakan
flow control sama sekali: permintaan itu akan selalu diteruskan sesegera mungkin.
FlowSchema exempt khusus mengklasifikasikan semua permintaan dari kelompok system:masters
ke dalam tingkat prioritas khusus ini. Kamu juga dapat menentukan FlowSchema lain yang mengarahkan
permintaan lain ke tingkat prioritas ini juga, apabila permintaan tersebut sesuai.
Tingkat prioritas khusus catch-all digunakan secara kombinasi dengan spesial
FlowSchema catch-all untuk memastikan bahwa setiap permintaan mendapatkan proses
klasifikasi. Biasanya kamu tidak harus bergantung pada konfigurasi catch-all ini,
dan kamu seharusnya membuat FlowSchema catch-all dan PriorityLevelConfiguration kamu sendiri
(atau gunakan konfigurasi global-default yang sudah diinstal secara bawaan) secara benar.
Untuk membantu menemukan kesalahan konfigurasi yang akan melewatkan beberapa klasifikasi
permintaan, maka tingkat prioritas catch-all hanya wajib mengijinkan satu konkurensi
bersama dan tidak melakukan memasukkan permintaan dalam antrian, sehingga membuat lalu lintas
yang secara relatif hanya sesuai dengan FlowSchema catch-all akan ditolak dengan kode kesalahan HTTP 429.
Sumber daya (Resource)
Flow control API melibatkan dua jenis sumber daya.
PriorityLevelConfiguration
yang menentukan kelas isolasi yang tersedia, bagian dari konkurensi anggaran yang tersedia
yang masing-masing dapat menangani bagian tersebut, dan memperbolehkan untuk melakukan fine-tuning terhadap perilaku antrian.
FlowSchema
yang digunakan untuk mengklasifikasikan permintaan individu yang masuk, mencocokkan masing-masing dengan setiap
PriorityLevelConfiguration.
PriorityLevelConfiguration
Sebuah PriorityLevelConfiguration merepresentasikan sebuah kelas isolasi tunggal. Setiap
PriorityLevelConfiguration memiliki batas independensi dalam hal jumlah
permintaan yang belum diselesaikan, dan batasan dalam hal jumlah permintaan yang mengantri.
Batas konkurensi untuk PriorityLevelConfiguration tidak disebutkan dalam
jumlah permintaan secara mutlak, melainkan dalam "concurrency shares." Total batas konkurensi
untuk server API didistribusikan di antara PriorityLevelConfiguration yang ada
secara proporsional dengan "concurrency shares" tersebut. Ini mengizinkan seorang
administrator klaster untuk meningkatkan atau menurunkan jumlah total lalu lintas ke sebuah
server dengan memulai kembali kube-apiserver dengan nilai opsi
--max-request-inflight (atau --max-mutating-request-inflight) yang berbeda, dan semua
PriorityLevelConfiguration akan melihat konkurensi maksimum yang diizinkan kepadanya untuk menaikkan (atau
menurunkan) dalam fraksi yang sama.
Perhatian:
Dengan fitur Prioritas dan Kesetaraan yang diaktifkan, batas total konkurensi untuk
server diatur pada nilai penjumlahan dari --max-request-inflight dan
--max-mutating-request-inflight. Tidak akan ada lagi perbedaan
antara permintaan yang bermutasi dan permintaan yang tidak bermutasi; jika kamu ingin melayaninya
secara terpisah untuk suatu sumber daya yang ada, maka perlu membuat FlowSchema terpisah yang sesuai dengan
masing-masing kata kerja dari permintaan yang bermutasi dan yang tidak bermutasi tersebut.
Ketika jumlah permintaan masuk yang diserahkan kepada sebuah
PriorityLevelConfiguration melebihi dari tingkat konkurensi yang diizinkan,
bagian type dari spesifikasinya menentukan apa yang akan terjadi pada permintaan selanjutnya.
Tipe Reject berarti bahwa kelebihan lalu lintas akan segera ditolak
dengan kode kesalahan HTTP 429 (yang artinya terlalu banyak permintaan). Tipe Queue berarti permintaan
di atas batas tersebut akan mengantri, dengan teknik sharding shuffle dan fair queuing yang digunakan
untuk menyelaraskan kemajuan antara flow permintaan.
Konfigurasi antrian memungkinkan mengatur algoritma fair queuing untuk sebuah
tingkat prioritas. Detail algoritma dapat dibaca di proposal pembaharuan, namun secara singkat:
Meningkatkan queue (antrian) berarti mengurangi tingkat tabrakan antara flow yang berbeda,
sehingga berakibat pada biaya untuk meningkatkan penggunaan memori. Nilai 1 di sini secara
efektif menonaktifkan logika fair-queuing, tetapi masih mengizinkan permintaan untuk
dimasukkan kedalam antrian.
Meningkatkan queueLengthLimit berarti memperbolehkan lonjakan yang lebih besar dari lalu lintas
untuk berkelanjutan tanpa menggagalkan permintaan apa pun, dengan konsekuensi akan meningkatkan
latensi dan penggunaan memori.
Mengubah handSize berarti memperbolehkan kamu untuk menyesuaikan probabilitas tabrakan antara
flow yang berbeda dan keseluruhan konkurensi yang tersedia untuk satu flow tunggal
dalam situasi beban berlebih.
Catatan:
`HandSize` yang lebih besar membuat dua _flow_ individual berpeluang kecil untuk bertabrakan
(dan dimana _flow_ yang satu bisa membuat _flow_ yang lain menderita), tetapi akan lebih memungkinkan
bahwa _flow_ dalam jumlah kecil akan dapat mendominasi apiserver. `HandSize` yang lebih besar juga
berpotensi meningkatkan jumlah latensi yang diakibatkan oleh satu _flow_ lalu lintas tunggal
yang tinggi. Jumlah maksimum permintaan dalam antrian yang diijinkan dari sebuah _flow_ tunggal
adalah `handSize * queueLengthLimit`.
Berikut ini adalah tabel yang menunjukkan koleksi konfigurasi shuffle sharding
yang menarik, dimana setiap probabilitas mouse (flow dengan intensitas rendah)
yang diberikan akan dimampatkan oleh elephant (flow dengan intensitas tinggi) dalam sebuah koleksi ilustratif
dari jumlah elephant yang berbeda. Silahkan lihat pada
https://play.golang.org/p/Gi0PLgVHiUg, yang digunakan untuk menghitung nilai-nilai dalam tabel ini.
Contoh Konfigurasi Shuffle Sharding
HandSize
Queues
1 elephant
4 elephants
16 elephants
12
32
4.428838398950118e-09
0.11431348830099144
0.9935089607656024
10
32
1.550093439632541e-08
0.0626479840223545
0.9753101519027554
10
64
6.601827268370426e-12
0.00045571320990370776
0.49999929150089345
9
64
3.6310049976037345e-11
0.00045501212304112273
0.4282314876454858
8
64
2.25929199850899e-10
0.0004886697053040446
0.35935114681123076
8
128
6.994461389026097e-13
3.4055790161620863e-06
0.02746173137155063
7
128
1.0579122850901972e-11
6.960839379258192e-06
0.02406157386340147
7
256
7.597695465552631e-14
6.728547142019406e-08
0.0006709661542533682
6
256
2.7134626662687968e-12
2.9516464018476436e-07
0.0008895654642000348
6
512
4.116062922897309e-14
4.982983350480894e-09
2.26025764343413e-05
6
1024
6.337324016514285e-16
8.09060164312957e-11
4.517408062903668e-07
FlowSchema
FlowSchema mencocokkan beberapa permintaan yang masuk dan menetapkan permintaan ke dalam sebuah
tingkat prioritas. Setiap permintaan masuk diuji dengan setiap
FlowSchema secara bergiliran, dimulai dari yang terendah secara numerik ---
yang kita anggap sebagai yang tertinggi secara logis --- matchingPrecedence dan
begitu seterusnya. FlowSchema yang cocok pertama kali akan menang.
Perhatian:
Hanya FlowSchema yang pertama kali cocok untuk permintaan yang diberikan yang akan dianggap penting. Jika ada banyak
FlowSchema yang cocok dengan sebuah permintaan masuk, maka akan ditetapkan berdasarkan salah satu
yang mempunyai matchingPrecedence tertinggi. Jika ada beberapa FlowSchema dengan nilai
matchingPrecedence yang sama dan cocok dengan permintaan yang sama juga, permintaan dengan leksikografis
name yang lebih kecil akan menang, tetapi akan lebih baik untuk tidak mengandalkan metode ini, dan sebaiknya
perlu memastikan bahwa tidak ada dua FlowSchema yang memiliki matchingPrecedence yang sama.
Sebuah FlowSchema dianggap cocok dengan sebuah permintaan yang diberikan jika setidaknya salah satu dari rules nya
ada yang cocok. Sebuah aturan (rule) cocok jika setidaknya satu dari subjectdan
ada salah satu dari resourceRules atau nonResourceRules (tergantung dari apakah permintaan
yang masuk adalah untuk URL sumber daya atau non-sumber daya) yang cocok dengan permintaan tersebut.
Untuk bagian name dalam subjek, dan bagian verbs, apiGroups, resources,
namespaces, dan nonResourceURLs dalam aturan sumber daya dan non-sumber daya,
wildcard* mungkin bisa ditetapkan untuk mencocokkan semua nilai pada bagian yang diberikan,
sehingga secara efektif menghapusnya dari pertimbangan.
Sebuah DistinguisherMethod.type dari FlowSchema menentukan bagaimana permintaan
yang cocok dengan Skema itu akan dipisahkan menjadi flow. Nilai tipe itu bisa jadi ByUser, dalam
hal ini satu pengguna yang meminta tidak akan bisa menghabiskan kapasitas dari pengguna lain,
atau bisa juga ByNamespace, dalam hal ini permintaan sumber daya
di salah satu Namespace tidak akan bisa menyebabkan penderitaan bagi permintaan akan sumber daya
dalam kapasitas Namespace yang lain, atau bisa juga kosong (atau distinguisherMethod
dihilangkan seluruhnya), dalam hal ini semua permintaan yang cocok dengan FlowSchema ini akan
dianggap sebagai bagian dari sebuah flow tunggal. Pilihan yang tepat untuk FlowSchema yang diberikan
akan bergantung pada sumber daya dan lingkungan khusus kamu.
Diagnosis
Setiap respons HTTP dari server API dengan fitur prioritas dan kesetaraan
yang diaktifkan memiliki dua header tambahan: X-Kubernetes-PF-FlowSchema-UID dan
X-Kubernetes-PF-PriorityLevel-UID, yang mencatat skema flow yang cocok dengan permintaan
dan tingkat prioritas masing-masing. Name Objek API tidak termasuk dalam header ini jika pengguna peminta tidak
memiliki izin untuk melihatnya, jadi ketika melakukan debugging kamu dapat menggunakan perintah seperti ini
kubectl get flowschema -o custom-columns="uid:{metadata.uid},name:{metadata.name}"kubectl get prioritylevelconfiguration -o custom-columns="uid:{metadata.uid},name:{metadata.name}"
untuk mendapatkan pemetaan UID ke names baik untuk FlowSchema maupun PriorityLevelConfiguration.
Observabilitas
Saat kamu mengaktifkan fitur Prioritas dan Kesetaraan API atau APF, kube-apiserver
akan mengeluarkan metrik tambahan. Dengan memantau metrik ini dapat membantu kamu untuk menentukan apakah
konfigurasi kamu tidak tepat dalam membatasi lalu lintas yang penting, atau menemukan
beban kerja yang berperilaku buruk yang dapat membahayakan kesehatan dari sistem.
apiserver_flowcontrol_rejected_requests_total menghitung permintaan yang
ditolak, mengelompokkannya berdasarkan nama dari tingkat prioritas yang ditetapkan,
nama FlowSchema yang ditetapkan, dan alasan penolakan tersebut.
Alasan penolakan akan mengambil dari salah satu alasan-alasan berikut:
queue-full, yang mengindikasikan bahwa sudah terlalu banyak permintaan
yang menunggu dalam antrian,
concurrency-limit, yang mengindikasikan bahwa PriorityLevelConfiguration
telah dikonfigurasi untuk menolak, bukan untuk memasukan permintaan berlebih ke
dalam antrian, atau
time-out, yang mengindikasikan bahwa permintaan masih dalam antrian
ketika batas waktu antriannya telah berakhir.
apiserver_flowcontrol_dispatched_requests_total menghitung permintaan
yang sudah mulai dieksekusi, mengelompokkannya berdasarkan nama dari tingkat
prioritas yang ditetapkan, dan nama dari FlowSchema yang ditetapkan.
apiserver_flowcontrol_current_inqueue_requests memberikan
jumlah total sesaat secara instan dari permintaan dalam antrian (bukan yang dieksekusi),
dan mengelompokkannya berdasarkan tingkat prioritas dan FlowSchema.
apiserver_flowcontrol_current_executing_requests memberikan
jumlah total yang instan dari permintaan yang dieksekusi, dan mengelompokkannya
berdasarkan tingkat prioritas dan FlowSchema.
apiserver_flowcontrol_request_queue_length_after_enqueue memberikan
histogram dari panjang antrian untuk semua antrian yang ada, mengelompokkannya berdasarkan
tingkat prioritas dan FlowSchema, berdasarkan pengambilan sampel oleh permintaan
enqueued. Setiap permintaan yang mendapatkan antrian berkontribusi ke satu sampel
dalam histogramnya, pelaporan panjang antrian dilakukan setelah permintaan yang
mengantri tersebut ditambahkan. Perlu dicatat bahwa ini akan menghasilkan statistik
yang berbeda dengan survei yang tidak bias.
Catatan:
Nilai asing atau tidak biasa dalam histogram akan berarti ada kemungkinan sebuah _flow_
(misalnya, permintaan oleh satu pengguna atau untuk satu _namespace_, tergantung pada
konfigurasinya) telah membanjiri server API, dan sedang dicekik. Sebaliknya, jika
histogram dari satu tingkat prioritas menunjukkan bahwa semua antrian dalam prioritas
level itu lebih panjang daripada level prioritas yang lainnya, mungkin akan sesuai
untuk meningkatkan _concurrency shares_ dari PriorityLevelConfiguration itu.
apiserver_flowcontrol_request_concurrency_limit memberikan hasil perhitungan
batas konkurensi (berdasarkan pada batas konkurensi total dari server API dan
concurrency share dari PriorityLevelConfiguration) untuk setiap
PriorityLevelConfiguration.
apiserver_flowcontrol_request_wait_duration_seconds memberikan histogram tentang bagaimana
permintaan yang panjang dihabiskan dalam antrian, mengelompokkannya berdasarkan FlowSchema
yang cocok dengan permintaan, tingkat prioritas yang ditetapkan, dan apakah permintaan
tersebut berhasil dieksekusi atau tidak.
Catatan:
Karena setiap FlowSchema selalu memberikan permintaan untuk satu
PriorityLevelConfiguration, kamu dapat menambahkan histogram untuk semua
FlowSchema dalam satu tingkat prioritas untuk mendapatkan histogram yang efektif
dari permintaan yang ditetapkan ke tingkat prioritas tersebut.
apiserver_flowcontrol_request_execution_seconds memberikan histogram tentang bagaimana
caranya permintaan yang panjang diambil untuk benar-benar dieksekusi, mengelompokkannya
berdasarkan FlowSchema yang cocok dengan permintaan dan tingkat prioritas yang ditetapkan pada
permintaan tersebut.
Selanjutnya
Untuk latar belakang informasi mengenai detail desain dari prioritas dan kesetaraan API, silahkan lihat
proposal pembaharuan.
Kamu juga dapat membuat saran dan permintaan akan fitur melalui SIG API
Machinery.
12 - Memperluas Kubernetes
12.1 - Memperluas Klaster Kubernetes Kamu
Kubernetes sangat mudah dikonfigurasi dan diperluas. Sehingga,
jarang membutuhkan fork atau menambahkan patch ke kode proyek Kubernetes.
Panduan ini menjelaskan pilihan untuk menyesuaikan klaster Kubernetes.
Dokumen ini ditujukan kepada operator klaster yang ingin
memahami bagaimana menyesuaikan klaster Kubernetes dengan kebutuhan lingkungan kerja mereka.
Developer yang prospektif Developer Platform atau Kontributor Proyek Kubernetes juga mendapatkan manfaat dari
dokumen ini sebagai pengantar apa saja poin-poin dan pola-pola perluasan yang ada, untung-rugi, dan batasan-batasannya.
Ikhtisar
Pendekatan-pendekatan kostumisasi secara umum dapat dibagi atas konfigurasi, yang hanya melibatkan perubahan flag, konfigurasi berkas lokal, atau objek-objek sumber daya API; dan perluasan, yang melibatkan berjalannya program atau layanan tambahan. Dokumen ini sebagian besar membahas tentang perluasan.
Konfigurasi
Flag-flag dan berkas-berkas konfigurasi didokumentasikan di bagian Referensi dari dokumentasi daring, didalam setiap binary:
Flag-flag dan berkas-berkas konfigurasi mungkin tidak selalu dapat diubah pada layanan Kubernetes yang hosted atau pada distribusi dengan instalasi yang dikelola. Ketika mereka dapat diubah, mereka biasanya hanya dapat diubah oleh Administrator Klaster. Dan juga, mereka dapat sewaktu-waktu diubah dalam versi Kubernetes di masa depan, dan menyetel mereka mungkin memerlukan proses pengulangan kembali. Oleh karena itu, mereka harus digunakan hanya ketika tidak ada pilihan lain.
API kebijakan bawaan, seperti ResourceQuota, PodSecurityPolicy, NetworkPolicy dan Role-based Access Control (RBAC), adalah API bawaan Kubernetes. API biasanya digunakan oleh layanan Kubernetes yang hosted dan diatur oleh instalasi Kubernetes. Mereka bersifat deklaratif dan menggunakan konvensi yang sama dengan sumber daya Kubernetes lainnya seperti pod-pod, jadi konfigurasi klaster baru dapat diulang-ulang dan dapat diatur dengan cara yang sama dengan aplikasi. Dan, ketika mereka stabil, mereka mendapatkan keuntungan dari kebijakan pendukung yang jelas seperti API Kubernetes lainnya. Oleh karena itu, mereka lebih disukai daripada berkas konfigurasi dan flag-flag saat mereka cocok dengan situasi yang dibutuhkan.
Perluasan
Perluasan adalah komponen perangkat lunak yang memperluas dan berintegrasi secara mendalam dengan Kubernetes.
Mereka mengadaptasi Kubernetes untuk mendukung perangkat keras tipe baru dan jenis baru.
Kebanyakan administrator klaster akan menggunakan instansi Kubernetes yang didistribusikan atau yang hosted.
Sebagai hasilnya, kebanyakan pengguna Kubernetes perlu menginstal perluasan dan lebih sedikit yang perlu untuk membuat perluasan-perluasan yang baru.
Pola-pola Perluasan
Kubernetes didesain untuk dapat diotomasi dengan menulis program-program klien. Program apapun yang membaca dan/atau menulis ke API Kubernetes dapat menyediakan otomasi yang berguna.
Otomasi dapat berjalan di dalam klaster atau di luar klaster. Dengan mengikuti panduan
di dalam dokumen ini, kamu dapat menulis otomasi yang sangat tersedia dan kuat.
Otomasi pada umumnya dapat bekerja dengan berbagai macam klaster Kubernetes, termasuk
klaster yang hosted dan instalasi yang dikelola.
Ada pola spesifik untuk menulis program klien yang bekerja dengan baik bersama Kubernetes yang disebut pola Controller. Controller-controller biasanya membaca kolom .spec milik sebuah objek, kemungkinan melakukan sesuatu, dan kemudian memperbarui objek milik .status.
Controller adalah klien dari Kubernetes. Ketika Kubernetes adalah klien dan memanggil layanan
terpisah, hal tersebut disebut Webhook. Layanan terpisah tersebut disebut sebuah Webhook Backend. Seperti Controller-controller, Webhook-webhook memang menambah sebuah titik untuk terjadinya kegagalan.
Di dalam model Webhook, Kubernetes membuat sebuah network request kepada sebuah layanan terpisah.
Di dalam model Binary Plugin, Kubernetes mengeksekusi sebuah program.
Binary Plugin digunakan oleh kubelet (misalnya Plugin Flex Volume
dan oleh Plugin Jaringan) dan oleh kubectl.
Berikut ini adalah diagram yang menunjukkan bagaimana titik-titik perluasan berinteraksi dengan control plane Kubernetes.
Titik-titik Perluasan
Diagram berikut menunjukkan titik-titik perluasan di sebuah Kubernetes.
Pengguna biasanya berinteraksi dengan API Kubernetes menggunakan kubectl. Plugin-plugin Kubectl memperluas binari kubectl. Mereka hanya memengaruhi lingkungan lokal pengguna, dan tidak dapat memaksakan kebijakan yang menyeluruh di seluruh situs.
apiserver menangani semua permintaan. Beberapa tipe titik perluasan di apiserver memperbolehkan otentikasi permintaan, atau memblokir mereka berdasarkan konten mereka, menyunting konten, dan menangani penghapusan. Hal ini dideskripsikan di bagian Perluasan Akses API
apiserver melayani berbagai macam sumber daya, tipe-tipe sumber daya bawaan, seperti pod, didefinisikan oleh proyek kubernetes dan tidak dapat diubah. kamu juga dapat menambahkan sumber daya yang kamu definisikan sendiri, atau yang proyek lain definisikan, disebut Custom Resources, seperti dijelaskan di bagian Sumber Daya Custom. Sumber daya Custom sering digunakan dengan Perluasan Akses API.
Penjadwal Kubernetes memutuskan ke Node mana Pod akan ditempatkan. Ada beberapa cara untuk memperluas penjadwalan. Hal ini dibahas pada bagian Perluasan-perluasan Penjadwal.
Sebagian besar perilaku Kubernetes diimplementasi oleh program yang disebut Controller-controller yang merupakan klien dari API-Server. Controller-controller sering digunakan bersama dengan Sumber Daya Custom.
Kubelet berjalan di server, dan membantu Pod-pod terlihat seperti server virtual dengan IP mereka sendiri di jaringan klaster. Plugin Jaringan memungkinkan adanya perbedaan implementasi pada jaringan Pod.
Kubelet juga melakukan penambatan dan pelepasan tambatan volume untuk kontainer. Tipe-tipe penyimpanan baru dapat didukung via Plugin Penyimpanan.
Jika kamu tidak yakin untuk memulai dari mana, diagram alir di bawah ini dapat membantu kamu. Ingat lah bahwa beberapa solusi mungkin melibatkan beberapa tipe perluasan.
Perluasan API
Tipe-tipe yang Ditentukan Pengguna
Pertimbangkan untuk menambahkan Sumber Daya Custom ke Kubernetes jika kamu ingin mendefinisikan pengontrol baru, objek konfigurasi aplikasi atau API deklaratif lainnya, dan untuk mengelolanya menggunakan alat Kubernetes, seperti kubectl.
Jangan menggunakan Sumber Daya Custom sebagai penyimpanan data untuk aplikasi, pengguna, atau untuk memonitor data.
Kombinasi antara sebuah API sumber daya custom dan loop kontrol disebut Pola Operator. Pola Operator digunakan untuk mengelola aplikasi yang spesifik dan biasanya stateful. API-API custom dan loop kontrol ini dapat digunakan untuk mengatur sumber daya lainnya, seperti penyimpanan dan kebijakan-kebijakan.
Mengubah Sumber Daya Bawaan
Ketika kamu memperluas API Kubernetes dengan menambahkan sumber daya custom, sumber daya yang ditambahkan akan selalu masuk ke Grup API baru. Kamu tidak dapat mengganti atau mengubah Grup API yang sudah ada. Menambah sebuah API tidak secara langsung membuat kamu memengaruhi perilaku API yang sudah ada (seperti Pod), tetapi Perluasan Akses API dapat memengaruhinya secara langsung.
Perluasan-Perluasan Akses API
Ketika sebuah permintaan sampai ke Server API Kubernetes, permintaan tersebut diotentikasi terlebih dahulu, kemudian diotorisasi, kemudian diarahkan ke berbagai jenis Admission Control. Lihat dokumentasi Mengatur Akses ke API Kubernetes untuk lebih jelasnya tentang alur ini.
Setiap langkah berikut menawarkan titik-titik perluasan.
Kubernetes memiliki beberapa metode otentikasi bawaan yang didukungnya. Metode ini bisa berada di belakang proksi yang mengotentikasi, dan metode ini dapat mengirim sebuah token dari header Otorisasi ke layanan terpisah untuk verifikasi (sebuah webhook). Semua metode ini tercakup dalam Dokumentasi Otentikasi.
Otentikasi
Otentikasi memetakan header atau sertifikat dalam semua permintaan ke username untuk klien yang mebuat permintaan.
Kubernetes menyediakan beberapa metode otentikasi bawaan, dan sebuah metode Webhook Otentikasi jika metode bawaan tersebut tidak mencukupi kebutuhan kamu.
Otorisasi
Otorisasi menentukan apakah pengguna tertentu dapat membaca, menulis, dan melakukan operasi lainnya terhadap sumber daya API. Hal ini hanya bekerja pada tingkat sumber daya secara keseluruhan -- tidak membeda-bedakan berdasarkan field objek sembarang. Jika pilihan otorisasi bawaan tidak mencukupi kebutuhan kamu, Webhook Otorisasi memungkinkan pemanggilan kode yang disediakan pengguna untuk membuat keputusan otorisasi.
Kontrol Admisi Dinamis
Setalah permintaan diotorisasi, jika ini adalah operasi penulisan, permintaan ini akan melalui langkah Kontrol Admisi. Sebagai tambahan untuk step bawaan, ada beberapa perluasan:
Untuk membuat keputusan kontrol admisi sembarang, Webhook Admisi umum dapat digunakan. Webhook Admisi dapat menolak pembuatan atau pembaruan.
Perluasan Infrastruktur
Plugin-plugin Penyimpanan
Flex Volume memungkinkan pengguna untuk memasang tipe-tipe volume tanpa dukungan bawaan dengan cara membiarkan Kubelet memanggil sebuah Plugin Binary untuk menambatkan volume.
Plugin Perangkat
Plugin perangkat memungkinkan sebuah node untuk menemukan sumber daya Node baru (sebagai tambahan dari bawaannya seperti CPU dan memori) melalui sebuah Plugin Perangkat.
Plugin-plugin Jaringan
Struktur-struktur jaringan yang berbeda dapat didukung melalui Plugin Jaringan pada tingkat Node.
Perluasan-perluasan Penjadwal
Penjadwal adalah jenis pengatur spesial yang mengawasi Pod, dan menempatkan Pod ke Node. Penjadwal bawaan dapat digantikan seluruhnya, sementara terus menggunakan komponen Kubernetes lainnya, atau penjadwal ganda dapat berjalan dalam waktu yang bersamaan.
Ini adalah usaha yang signifikan, dan hampir semua pengguna Kubernetes merasa mereka tidak perlu memodifikasi penjadwal tersebut.
Penjadwal juga mendukung webhook yang memperbolehkan sebuah webhook backend (perluasan penjadwal) untuk menyaring dan memprioritaskan Node yang terpilih untuk sebuah Pod.
12.2.1 - Memperluas Kubernetes API dengan Lapisan Agregasi
Lapisan agregasi memungkinkan Kubernetes untuk diperluas dengan API tambahan, selain dari yang ditawarkan oleh API inti Kubernetes.
Ikhtisar
Lapisan agregasi memungkinkan instalasi tambahan beragam API Kubernetes-style di klaster kamu. Tambahan-tambahan ini dapat berupa solusi-solusi yang sudah dibangun (prebuilt) oleh pihak ke-3 yang sudah ada, seperti service-catalog, atau API yang dibuat oleh pengguna seperti apiserver-builder, yang dapat membantu kamu memulainya.
Lapisan agregasi berjalan di dalam proses bersama dengan kube-apiserver. Hingga sebuah sumber daya ekstensi terdaftar, lapisan agregasi tidak akan melakukan apapun. Untuk mendaftarkan sebuah API, pengguna harus menambahkan sebuah objek APIService, yang "mengklaim" jalur URL di API Kubernetes. Pada titik tersebut, lapisan agregasi akan mem-proxy apapun yang dikirim ke jalur API tersebut (misalnya /apis/myextension.mycompany.io/v1/…) ke APIService yang terdaftar.
Biasanya, APIService akan diimplementasikan oleh sebuah ekstensi-apiserver di dalam sebuah Pod yang berjalan di klaster. Ekstensi-apiserver ini biasanya perlu di pasangkan dengan satu atau lebih controller apabila manajemen aktif dari sumber daya tambahan diperlukan. Sebagai hasilnya, apiserver-builder sebenarnya akan memberikan kerangka untuk keduanya. Sebagai contoh lain, ketika service-catalog diinstal, ia menyediakan ekstensi-apiserver dan controller untuk layanan-layanan yang disediakannya.
Ekstensi-apiserver harus memiliki latensi koneksi yang rendah dari dan ke kube-apiserver.
Secara Khusus, permintaan pencarian diperlukan untuk bolak-balik dari kube-apiserver dalam 5 detik atau kurang.
Jika implementasi kamu tidak dapat menyanggupinya, kamu harus mempertimbangkan cara mengubahnya. Untuk sekarang, menyetel
feature-gateEnableAggregatedDiscoveryTimeout=false di kube-apiserver
akan menonaktifkan batasan waktu tersebut. Fitur ini akan dihapus dalam rilis mendatang.
Custom Resource adalah ekstensi dari Kubernetes API. Laman ini mendiskusikan kapan kamu melakukan penambahan sebuah Custom Resource ke klaster Kubernetes dan kapan kamu menggunakan sebuah layanan mandiri. Laman ini mendeskripsikan dua metode untuk menambahkan Custom Resource dan bagaimana cara memilihnya.
Custom Resource
Sebuah sumber daya adalah sebuah endpoint pada Kubernetes API yang menyimpan sebuah koleksi objek API dari sebuah jenis tertentu. Sebagai contoh, sumber daya bawaan Pod mengandung sebuah koleksi objek-objek Pod.
Sebuah Custom Resource adalah sebuah ekstensi dari Kubernetes API yang tidak seharusnya tersedia pada pemasangan default Kubernetes. Namun, banyak fungsi-fungsi inti Kubernetes yang sekarang dibangun menggunakan Custom Resource, membuat Kubernetes lebih modular.
Custom Resource bisa muncul dan menghilang dalam sebuah klaster yang berjalan melalui registrasi dinamis (dynamic registration), dan admin-admin klaster bisa memperbaharui Custom Resource secara independen dari klaster itu sendiri. Ketika sebuah Custom Resource
dipasang, pengguna dapat membuat dan mengakses objek-objek Custom Resource menggunakan kubectl, seperti yang mereka lakukan untuk sumber daya bawaan seperti Pod.
Controller Khusus
Dengan sendirinya, Custom Resource memungkinkan kamu untuk menyimpan dan mengambil data terstruktur. Ketika kamu menggabungkan sebuah Custom Resource dengan controller khusus, Custom Resource akan memberikan sebuah API deklaratif yang sebenarnya.
Sebuah API deklaratif
memungkinkan kamu untuk mendeklarasikan atau menspesifikasikan keadaan dari sumber daya kamu dan mencoba untuk menjaga agar keadaan saat itu tersinkronisasi dengan keadaan yang diinginkan. Controller menginterpretasikan data terstruktur sebagai sebuah rekaman dari keadaan yang diinginkan pengguna, dan secara kontinu menjaga keadaan ini.
Kamu bisa men-deploy dan memperbaharui sebuah controller khusus pada sebuah klaster yang berjalan, secara independen dari siklus hidup klaster itu sendiri. Controller khusus dapat berfungsi dengan sumber daya jenis apapun, tetapi mereka sangat efektif ketika dikombinasikan dengan Custom Resource. Operator pattern mengkombinasikan Custom Resource dan controller khusus. Kamu bisa menggunakan controller khusus untuk menyandi pengetahuan domain untuk aplikasi spesifik menjadi sebuah ekstensi dari Kubernetes API.
Haruskah Custom Resource ditambahkan ke dalam klaster Kubernetes saya?
API kamu terdiri dari sejumlah kecil dari objek yang berukuran relatif kecil (sumber daya).
Objek-objek mendefinisikan pengaturan dari aplikasi atau infrastruktur.
Objek-objek relatif tidak sering diperbaharui.
Manusia sering diperlukan untuk membaca dan menulis objek-objek tersebut.
Operasi utama terhadap objek bersifat CRUD (creating, reading, updating, dan deleting).
Transaksi antar objek tidak dibutuhkan; API merepresentasikan sebuah keadaan yang diinginkan, bukan keadaan yang eksak.
API imperatif bersifat tidak deklaratif.
Tanda-tanda apabila API kamu tidak deklaratif termasuk:
klien berkata "lakukan ini", dan kemudian mendapat sebuah respon serempak ketika selesai.
klien berkata "lakukan ini", dan kemudian mendapat sebuah ID operasi kembali, dan harus melakukan sebuah cek terhadap objek Operation terpisah untuk menentukan selesainya sebuah permintaan.
Kamu berbicara tentang Remote Procedure Call (RPC).
Menyimpan secara langsung sejumlah data (mis. > beberapa kB per objek, atau >1000-an objek).
Membutuhkan akses dengan bandwidth tinggi (10-an permintaan per detik dapat ditopang).
Menyimpan data pengguna (seperti gambar, PII, dll) atau data berskala besar yang diproses oleh aplikasi.
Operasi-operasi natural terhadap objek yang tidak bersifat CRUD.
API yang tidak mudah dimodelkan dengan objek.
Kamu memilih untuk merepresentasikan operasi tertunda dengan sebuah ID operasi atau sebuah objek operasi.
Apakah saya harus menggunakan sebuah ConfigMap atau sebuah Custom Resource?
Gunakan ConfigMap jika salah satu hal berikut berlaku:
Terdapat sebuah format berkas pengaturan yang sudah ada, yang terdokumentasi dengan baik seperti sebuah mysql.cnf atau pom.xml.
Kamu ingin menaruh seluruh berkas pengaturan kedalam sebuah key dari sebuah ConfigMap.
Kegunaan utama dari berkas pengaturan adalah untuk dikonsumsi sebuah program yang berjalan di dalam sebuah Pod di dalam klaster kamu untuk mengatur dirinya sendiri.
Konsumen dari berkas lebih suka untuk mengkonsumsi lewat berkas dalam sebuah Pod atau variabel lingkungan dalam sebuah Pod, dibandingkan melalui Kubernetes API.
Kamu ingin melakukan pembaharuan bergulir lewat Deployment, dll, ketika berkas diperbaharui.
Catatan:
Gunakan sebuah Secret untuk data sensitif, yang serupa dengan ConfigMap tetapi lebih aman.
Gunakan sebuah Custom Resource (CRD atau Aggregated API) jika kebanyakan dari hal berikut berlaku:
Kamu ingin menggunakan pustaka klien Kubernetes dan CLI untuk membuat dan memperbaharui sumber daya baru.
Kamu ingin dukungan tingkat tinggi dari kubectl (sebagai contoh: kubectl get my-object object-name).
Kamu ingin membangun sebuah otomasi baru yang mengawasi pembaharuan terhadap objek baru, dan kemudian melakukan CRUD terhadap objek lainnya, atau sebaliknya.
Kamu ingin menulis otomasi yang menangani pembaharuan untuk objek.
Kamu ingin menggunakan kesepakatan API Kubernetes seperti .spec, .status, dan .metadata.
Kamu ingin objek tersebut untuk menjadi sebuah abstraksi terhadap sebuah kumpulan dari sumber daya terkontrol, atau peringkasan dari sumber daya lainnya.
Menambahkan Custom Resource
Kubernetes menyediakan dua cara untuk menambahkan sumber daya ke klaster kamu:
CRD cukup sederhana dan bisa diciptakan tanpa pemrograman apapun.
Agregasi API membutuhkan pemrograman, tetapi memungkinkan kendali lebih terhadap perilaku API seperti bagaimana data disimpan dan perubahan antar versi API.
Kubernetes menyediakan kedua opsi tersebut untuk memenuhi kebutuhan pengguna berbeda, jadi tidak ada kemudahan penggunaan atau fleksibilitas yang dikompromikan.
Aggregated API adalah bawahan dari APIServer yang duduk dibelakang API server utama, yang bertindak sebagai sebuah proxy. Pengaturan ini disebut Agregasi API (AA). Untuk pengguna, yang terlihat adalah Kubernetes API yang diperluas.
CRD memungkinkan pengguna untuk membuat tipe baru sumber daya tanpa menambahkan APIserver lain. Kamu tidak perlu mengerti Agregasi API untuk menggunakan CRD.
Terlepas dari bagaimana cara mereka dipasang, sumber daya baru disebut sebagai Custom Resource untuk memisahkan mereka dari sumber daya bawaan Kubernetes (seperti Pod).
CustomResourceDefinition
Sumber daya API CustomResourceDefinition memungkinkan kamu untuk medefinisikan Custom Resource. Mendefinisikan sebuah objek CRD akan membuat sebuah Custom Resource dengan sebuah nama dan skema yang kamu spesifikasikan. Kubernetes API melayani dan menangani penyimpanan dari Custom Resource kamu.
Ini membebaskan kamu dari menulis server API kamu sendiri untuk menangani Custom Resource, tetapi sifat dasar dari implementasi menyebabkan kamu memiliki fleksibilitas yang berkurang dibanding agregasi server API).
Lihat contoh controller khusus sebagai sebuah contoh dari bagaimana cara untuk mendaftarkan sebuah Custom Resource, bekerja dengan instans dari tipe baru sumber daya kamu, dan menggunakan sebuah controller untuk menangani event.
Agregasi server API
Biasanya, tiap sumber daya di API Kubernetes membutuhkan kode yang menangani permintaan REST dan mengatur peyimpanan tetap dari objek-objek. Server Kubernetes API utama menangani sumber daya bawaan seperti Pod dan Service, dan juga menangani Custom Resource dalam sebuah cara yang umum melalui CRD.
Lapisan agregasi memungkinkan kamu untuk menyediakan implementasi khusus untuk Custom Resource dengan menulis dan men-deploy API server kamu yang berdiri sendiri. API server utama menlimpahkan permintaan kepada kamu untuk Custom Resource yang kamu tangani, membuat mereka tersedia untuk semua kliennya.
Memilih sebuah metode untuk menambahkan Custom Resource
CRD lebih mudah digunakan. Aggregated API lebih fleksibel. Pilih metode yang paling baik untuk kebutuhan kamu.
Biasanya, CRD cocok jika:
Kamu memiliki field yang banyak
Kamu menggunakan sumber daya dalam perusahaan kamu, atau sebagai bagian dari proyek open-source kecil (berlawanan dengan sebuah produk komersil)
Membandingkan kemudahan penggunaan
CRD lebih mudah dibuat dibandingkan dengan Aggregated API.
CRD
Aggregated API
Tidak membutuhkan pemrograman. Pengguna dapat memilih bahasa apapun untuk sebuah controller CRD.
Membutuhkan pemrograman dalam Go dan membangun binary dan image. Pengguna dapat memilih bahasa apapun untuk sebuah CRD controller.
Tidak ada servis tambahan yang dijalankan; CR ditangani oleh server API.
Sebuah servis tambahan untuk menciptakan dan dapat gagal.
Todal ada dukungan berjalan ketika CRD dibuat. Perbaikan bug apapun akan dianggap sebagai bagian dari peningkatan Kubernetes Master normal.
Mungkin dibutuhkan untuk secara berkala mengambil perbaikan bug dari sumber dan membangun ulang dan memeperbaharui APIserver teragregasi.
Tidak butuh untuk menangani banyak versi dari API kamu. Sebagai contoh: ketika kamu mengendalikan klien untuk sumber daya ini, kamu bisa meningkatkannya selaras dengan API.
Kamu perlu menangani banyak versi dari API kamu, sebagai contoh: ketika mengembangkan sebuah ekstensi untuk dibagikan kepada dunia.
Fitur lanjutan dan fleksibilitas
Aggregated API menawarkan fitur API lebih lanjut dan kustomisasi dari fitur lain, sebagai contoh: lapisan penyimpanan.
Fitur
Deskripsi
CRD
Aggregated API
Validation
Membantu pengguna-pengguna mencegah error dan memungkinkan kamu untuk mengembangkan API kamu secara independen dari klien-klien kamu. Fitur ini sangan berguna ketika ada banyak klien yang tidak semua bisa memperbaharui secara bersamaan pada waktu yang sama.
Ya. Sebagian besar validasi dapat dipesifikasikan di dalam CRD OpenAPI v3.0 validation. Validasi bentuk lainnya didukung dengan penambahan sebuah Validating Webhook.
Ya, cek validasi secara arbitrer
Defaulting
Lihat diatas
Ya, baik melalui OpenAPI v3.0 validationdefault keyword (GA in 1.17), maupun melalui sebuah Mutating Webhook (meskipun tidak akan dijalankan ketika membaca dari etcd untuk objek-objek lama)
Ya
Multi-versioning
Memungkinkan menyajikan objek yang sama lwat dua versi API. Bisa membantu memudahkan perubahan API seperti menamai ulang field-field. Tidak terlalu penting jika kamu mengendalikan versi-versi klien kamu.
Jika kamu membutuhkan penyimpanan dengan sebuah mode performa (sebagai contoh, basis data time-series dibanding penyimpanan key-value) atau isolasi untuk keamanan (sebagau contoh, rahasia penyandian atau berkas berbeda)
Tidak
Ya
Custom Business Logic
Melakukan cek arbitrer atau tindakan-tindakan ketika membuat, membaca, atau memperbaharui sebuah objek
Menambahkan operasi selain CRUD, seperti "logs" atau "exec".
Tidak
Ya
strategic-merge-patch
Endpoint-endpoint baru yang mendukung PATCH dengan Content-Type: application/strategic-merge-patch+json. Berguna untuk memperbaharui objek-objek yang mungkin dapat dimodifikasi baik secara lokal, dan maupun lewat server. Untuk informasi lebih lanjut, lihat "Update API Objects in Place Using kubectl patch"
Tidak
Ya
Protocol Buffers
sumber daya baru mendukung klien-klien yang ingin menggunakan Protocol Buffer
Tidak
Ya
OpenAPI Schema
Apakah ada sebuah skema OpenAPI (swagger) untuk tipe yang bisa secara dinamis diambil dari server? Apakah pengguna terlindungi dari kesalahan pengejaan nama-nama field dengan memastikan bahwa hanya field yang diperbolehkan yang boleh diisi? Apakah tipe-tipe diberlakukan (dengan kata lain, jangan menaruh sebuah int di dalam fieldstring?)
Ketika kamu membuat sebuah Custom Resource, baik melalui sebuah CRD atau sebuah AA, kamu mendapat banyak fitur untuk API kamu, dibandingkan dengan mengimplementasikannya diluar platform Kubernetes.
Fitur
Apa yang dilakukannya
CRUD
Endpoint-endpoint baru yang mendukung operasi dasar melalui HTTP dan kubectl
Watch
Endpoint-endpoint baru yang mendukung operasi Kubernetes Watch melalui HTTP
Discovery
Klien seperti kubectl dan dasbor yang secara otomatis menawarkan operasi list, display, dan pembaharuan field pada sumber daya kamu.
json-patch
Endpoint-endpoint baru yang mendukung PATCH dengan Content-Type: application/json-patch+json
merge-patch
Endpoint-endpoint baru yang mendukung PATCH dengan Content-Type: application/merge-patch+json
HTTPS
Endpoint-endpoint menggunakan HTTPS
Built-in Authentication
Akses ke ekstensi yang menggunakan apiserver inti (lapisan agregasi) untuk otentikasi
Built-in Authorization
Akses ke ekstensi dapat menggunakan ulang otorisasi yang digunakan oleh apiserver inti (mis. RBAC)
Finalizers
Penghapusan blok dari ekstensi sumber daya hingga pembersihan eksternal terjadi.
Admission Webhooks
Menentukan nilai default dan memvalidasi ekstensi sumber daya saat terjadi operasi create/update/delete apapun.
UI/CLI Display
Kubectl, dasbor dapat menampilkan ekstensi sumber daya
Unset vs Empty
Klien-klien dapat membedakan field-field yang tidak diisi dari field-field yang memiliki nilai nol.
Client Libraries Generation
Kubernetes menyediakan pustaka klien dasar, juga alat-alat untuk membuat pustaka klien dengan tipe spesifik.
Labels and annotations
Metadata umum lintas objek yang cara untuk memperbaharui sumber daya inti dan Custom Resource-nya diketahui oleh alat-alat.
Persiapan pemasangan sebuah Custom Resource
Ada beberapa poin yang harus diperhatikan sebelum menambahkan sebuah Custom Resource ke klaster kamu.
Kode pihak ketiga dan poin kegagalan baru
Saat membuat sebuah CRD tidak secara otomatis menambahkan titik-titik kegagalan baru (sebagai contoh, dengan menyebabkan kode pihak ketiga untuk berjalan di API server kamu), paket-paket (sebagai contoh, Chart) atau bundel pemasangan lain seringkali sudah termasuk CRD dan juga sebagai Deployment dari kode pihak ketiga yang mengimplementasi logika bisnis untuk sebuah Custom Resource.
Memasang sebuah APIserver teragregasi selalu melibatkan tindakan menjalankan Deployment baru.
Penyimpanan
Custom Resource mengkonsumsi ruang penyimpanan dengan cara yang sama dengan ConfigMap. Membuat terlalu banyak sumber daya mungkin akan memenuhi ruang penyimpanan server API kamu.
Server Aggregated API dapat menggunakan penyimpanan yang sama dengan server API utama, dimana peringatan yang sama berlaku.
Authentication, authorization, and auditing
CRD selalu menggunakan otentikasi, otorisasi, dan audit pencatatan yang sama sebagai sumber daya bawaan dari server API kamu.
Jika kamu menggunakan RBAC untuk otorisasi, sebagian besar role RBAC tidak akan mengizinkan akses ke sumber daya baru (kecuali role cluster-admin atau role apapun yang dibuat menggunakan aturan wildcard). Kamu akan dibutuhkan untuk secara eksplisit mengizinkan akses ke sumber daya baru. CRD dan Aggregated API seringkali dibundel dengan definisi role baru untuk tipe yang mereka tambahkan.
API server teragregasi dapat atau tidak dapat menggunakan otentikasi, otorisasi, dan pengauditan yang sama dengan server API utama.
Mengakses sebuah Custom Resource
Pustaka klien Kubernetes dapat digunakan untuk mengakses Custom Resource. Tidak semua pustaka klien mendukung Custom Resource. Pustaka klien go dan python melakukannya.
Ketika kamu menambahkan sebuah Custom Resource, kamu dapat mengaksesnya dengan menggunakan:
kubectl
Klien dinamis kubernetes.
Sebuah klien REST yang kamu tulis
Sebuah klien yang dibuat menggunakan Kubernetes client generation tools (membuat satu adalah usaha lanjutan, tetapi beberapa proyek mungkin menyajikan sebuah klien bersama dengan CRD atau AA).
12.3 - Ekstensi Komputasi, Penyimpanan, dan Jaringan
12.3.1 - Plugin Jaringan
FEATURE STATE:Kubernetes v1.36 [alpha]
Peringatan:
Fitur-fitur Alpha berubah dengan cepat.
Plugin jaringan di Kubernetes hadir dalam beberapa varian:
Plugin CNI : mengikuti spesifikasi appc / CNI, yang dirancang untuk interoperabilitas.
Plugin Kubenet : mengimplementasi cbr0 sederhana menggunakan pluginbridge dan host-local CNI
Instalasi
Kubelet memiliki plugin jaringan bawaan tunggal, dan jaringan bawaan umum untuk seluruh klaster. Plugin ini memeriksa plugin-plugin ketika dijalankan, mengingat apa yang ditemukannya, dan mengeksekusi plugin yang dipilih pada waktu yang tepat dalam siklus pod (ini hanya berlaku untuk Docker, karena rkt mengelola plugin CNI sendiri). Ada dua parameter perintah Kubelet yang perlu diingat saat menggunakan plugin:
cni-bin-dir: Kubelet memeriksa direktori ini untuk plugin-plugin saat startup
network-plugin: Plugin jaringan untuk digunakan dari cni-bin-dir. Ini harus cocok dengan nama yang dilaporkan oleh plugin yang diperiksa dari direktori plugin. Untuk plugin CNI, ini (nilainya) hanyalah "cni".
Persyaratan Plugin Jaringan
Selain menyediakan antarmuka NetworkPlugin untuk mengonfigurasi dan membersihkan jaringan Pod, plugin ini mungkin juga memerlukan dukungan khusus untuk kube-proxy. Proksi iptables jelas tergantung pada iptables, dan plugin ini mungkin perlu memastikan bahwa lalu lintas kontainer tersedia untuk iptables. Misalnya, jika plugin menghubungkan kontainer ke bridge Linux, plugin harus mengatur nilai sysctl net/bridge/bridge-nf-call-iptables menjadi 1 untuk memastikan bahwa proksi iptables berfungsi dengan benar. Jika plugin ini tidak menggunakan bridge Linux (melainkan sesuatu seperti Open vSwitch atau mekanisme lainnya), plugin ini harus memastikan lalu lintas kontainer dialihkan secara tepat untuk proksi.
Secara bawaan jika tidak ada plugin jaringan Kubelet yang ditentukan, pluginnoop digunakan, yang menetapkan net/bridge/bridge-nf-call-iptables=1 untuk memastikan konfigurasi sederhana (seperti Docker dengan sebuah bridge) bekerja dengan benar dengan proksi iptables.
CNI
Plugin CNI dipilih dengan memberikan opsi command-line--network-plugin=cni pada Kubelet. Kubelet membaca berkas dari --cni-conf-dir (bawaan /etc/cni/net.d) dan menggunakan konfigurasi CNI dari berkas tersebut untuk mengatur setiap jaringan Pod. Berkas konfigurasi CNI harus sesuai dengan spesifikasi CNI, dan setiap plugin CNI yang diperlukan oleh konfigurasi harus ada di --cni-bin-dir (nilai bawaannya adalah /opt/cni/bin).
Jika ada beberapa berkas konfigurasi CNI dalam direktori, Kubelet menggunakan berkas yang pertama dalam urutan abjad.
Selain plugin CNI yang ditentukan oleh berkas konfigurasi, Kubernetes memerlukan plugin CNI standar loplugin , minimal pada versi 0.2.0.
Dukungan hostPort
Plugin jaringan CNI mendukung hostPort. Kamu dapat menggunakan pluginportmap resmi yang ditawarkan oleh tim plugin CNI atau menggunakan plugin kamu sendiri dengan fungsionalitas portMapping.
Jika kamu ingin mengaktifkan dukungan hostPort, kamu harus menentukan portMappings capability di cni-conf-dir kamu.
Contoh:
Plugin jaringan CNI juga mendukung pembentukan lalu-lintas yang masuk dan keluar dari Pod. Kamu dapat menggunakan plugin resmi bandwidth yang ditawarkan oleh tim plugin CNI atau menggunakan plugin kamu sendiri dengan fungsionalitas kontrol bandwidth.
Jika kamu ingin mengaktifkan pembentukan lalu-lintas, kamu harus menambahkan pluginbandwidth ke berkas konfigurasi CNI kamu (nilai bawaannya adalah /etc/cni/ net.d).
Kubenet adalah plugin jaringan yang sangat mendasar dan sederhana, hanya untuk Linux. Ia, tidak dengan sendirinya, mengimplementasi fitur-fitur yang lebih canggih seperti jaringan cross-node atau kebijakan jaringan. Ia biasanya digunakan bersamaan dengan penyedia layanan cloud yang menetapkan aturan routing untuk komunikasi antar Node, atau dalam lingkungan Node tunggal.
Kubenet membuat bridge Linux bernama cbr0 dan membuat pasangan veth untuk setiap Pod dengan ujung host dari setiap pasangan yang terhubung ke cbr0. Ujung Pod dari pasangan diberi alamat IP yang dialokasikan dari rentang yang ditetapkan untuk Node baik melalui konfigurasi atau oleh controller-manager. cbr0 memiliki MTU yang cocok dengan MTU terkecil dari antarmuka normal yang diaktifkan pada host.
Plugin ini memerlukan beberapa hal:
Plugin CNI bridge, lo dan host-local standar diperlukan, minimal pada versi 0.2.0. Kubenet pertama-tama akan mencari mereka di /opt/cni/bin. Tentukan cni-bin-dir untuk menyediakan lokasi pencarian tambahan. Hasil pencarian pertama akan digunakan.
Kubelet harus dijalankan dengan argumen --network-plugin=kubenet untuk mengaktifkan plugin
Kubelet juga harus dijalankan dengan argumen --non-masquerade-cidr=<clusterCidr> untuk memastikan lalu-lintas ke IP-IP di luar rentang ini akan menggunakan masquerade IP.
Node harus diberi subnet IP melalui perintah kubelet --pod-cidr atau perintah controller-manager --allocate-node-cidrs=true --cluster-cidr=<cidr>.
Menyesuaikan MTU (dengan kubenet)
MTU harus selalu dikonfigurasi dengan benar untuk mendapatkan kinerja jaringan terbaik. Plugin jaringan biasanya akan mencoba membuatkan MTU yang masuk akal, tetapi terkadang logika tidak akan menghasilkan MTU yang optimal. Misalnya, jika bridge Docker atau antarmuka lain memiliki MTU kecil, kubenet saat ini akan memilih MTU tersebut. Atau jika kamu menggunakan enkapsulasi IPSEC, MTU harus dikurangi, dan perhitungan ini di luar cakupan untuk sebagian besar plugin jaringan.
Jika diperlukan, kamu dapat menentukan MTU secara eksplisit dengan opsi network-plugin-mtu kubelet. Sebagai contoh, pada AWS eth0 MTU biasanya adalah 9001, jadi kamu dapat menentukan --network-plugin-mtu=9001. Jika kamu menggunakan IPSEC, kamu dapat menguranginya untuk memungkinkan/mendukung overhead enkapsulasi pada IPSEC, contoh: --network-plugin-mtu=8873.
Opsi ini disediakan untuk plugin jaringan; Saat ini hanya kubenet yang mendukung network-plugin-mtu.
Ringkasan Penggunaan
--network-plugin=cni menetapkan bahwa kita menggunakan plugin jaringan cni dengan binary-binary plugin CNI aktual yang terletak di --cni-bin-dir (nilai bawaannya /opt/cni/bin) dan konfigurasi plugin CNI yang terletak di --cni-conf-dir (nilai bawaannya /etc/cni/net.d).
--network-plugin=kubenet menentukan bahwa kita menggunakan plugin jaringan kubenet dengan bridge CNI dan plugin-pluginhost-local yang terletak di /opt/cni/bin atau cni-bin-dir.
--network-plugin-mtu=9001 menentukan MTU yang akan digunakan, saat ini hanya digunakan oleh plugin jaringan kubenet.
Selanjutnya
12.3.2 - Plugin Perangkat
Gunakan kerangka kerja plugin perangkat Kubernetes untuk mengimplementasikan plugin untuk GPU, NIC, FPGA, InfiniBand, dan sumber daya sejenis yang membutuhkan setelan spesifik vendor.
FEATURE STATE:Kubernetes v1.26 [stable]
Kubernetes menyediakan kerangka kerja plugin perangkat
sehingga kamu dapat memakainya untuk memperlihatkan sumber daya perangkat keras sistem ke dalam Kubelet.
Daripada menkustomisasi kode Kubernetes itu sendiri, vendor dapat mengimplementasikan
plugin perangkat yang di-deploy secara manual atau sebagai DaemonSet.
Perangkat yang dituju termasuk GPU, NIC berkinerja tinggi, FPGA, adaptor InfiniBand,
dan sumber daya komputasi sejenis lainnya yang perlu inisialisasi dan setelan spesifik vendor.
Pendaftaran plugin perangkat
Kubelet mengekspor servis gRPC Registration:
service Registration {
rpc Register(RegisterRequest) returns (Empty) {}
}
Plugin perangkat bisa mendaftarkan dirinya sendiri dengan kubelet melalui servis gRPC.
Dalam pendaftaran, plugin perangkat perlu mengirim:
Nama Unix socket-nya.
Versi API Plugin Perangkat yang dipakai.
ResourceName yang ingin ditunjukkan. ResourceName ini harus mengikuti
skema penamaan sumber daya ekstensi
sebagai vendor-domain/tipe-sumber-daya.
(Contohnya, NVIDIA GPU akan dinamai nvidia.com/gpu.)
Setelah registrasi sukses, plugin perangkat mengirim daftar perangkat yang diatur
ke kubelet, lalu kubelet kemudian bertanggung jawab untuk mengumumkan sumber daya tersebut
ke peladen API sebagai bagian pembaruan status node kubelet.
Contohnya, setelah plugin perangkat mendaftarkan hardware-vendor.example/foo dengan kubelet
dan melaporkan kedua perangkat dalam node dalam kondisi sehat, status node diperbarui
untuk menunjukkan bahwa node punya 2 perangkat “Foo” terpasang dan tersedia.
Kemudian, pengguna dapat meminta perangkat dalam spesifikasi
Kontainer
seperti meminta tipe sumber daya lain, dengan batasan berikut:
Sumber daya ekstensi hanya didukung sebagai sumber daya integer dan tidak bisa overcommitted.
Perangkat tidak bisa dibagikan antar Kontainer.
Semisal klaster Kubernetes menjalankan plugin perangkat yang menunjukkan sumber daya hardware-vendor.example/foo
pada node tertentu. Berikut contoh Pod yang meminta sumber daya itu untuk menjalankan demo beban kerja:
---apiVersion:v1kind:Podmetadata:name:demo-podspec:containers:- name:demo-container-1image:registry.k8s.io/pause:3.8resources:limits:hardware-vendor.example/foo:2## Pod ini perlu 2 perangkat perangkat-vendor.example/foo# dan hanya dapat menjadwalkan ke Node yang bisa memenuhi# kebutuhannya.## Jika Node punya lebih dari 2 perangkat tersedia,# maka kelebihan akan dapat digunakan Pod lainnya.
Implementasi plugin perangkat
Alur kerja umum dari plugin perangkat adalah sebagai berikut:
Inisiasi. Selama fase ini, plugin perangkat melakukan inisiasi spesifik vendor
dan pengaturan untuk memastikan perangkat pada status siap.
Plugin memulai servis gRPC, dengan Unix socket pada lokasi
/var/lib/kubelet/device-plugins/, yang mengimplementasi antarmuka berikut:
service DevicePlugin {
// GetDevicePluginOptions mengembalikan opsi yang akan dikomunikasikan dengan Device Manager.
rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {}
// ListAndWatch mengembalikan aliran dari List of Devices
// Kapanpun Device menyatakan perubahan atau kehilangan Device, ListAndWatch
// mengembalikan daftar baru
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
// Allocate dipanggil saat pembuatan kontainer sehingga Device
// Plugin dapat menjalankan operasi spesifik perangkat dan menyuruh Kubelet
// dari operasi untuk membuat Device tersedia di kontainer
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
// GetPreferredAllocation mengembalikan sekumpulan perangkat yang disukai untuk dialokasikan
// dari daftar yang tersedia. Alokasi yang dihasilkan tidak
// dijamin sebagai alokasi yang pada akhirnya dilakukan oleh
// devicemanager. Ini dirancang hanya untuk membantu devicemanager membuat
// keputusan alokasi yang lebih tepat ketika memungkinkan.
rpc GetPreferredAllocation(PreferredAllocationRequest) returns (PreferredAllocationResponse) {}
// PreStartContainer dipanggil, jika ditunjukkan oleh Plugin Perangkat selama fase pendaftaran,
// sebelum setiap awal kontainer. Plugin perangkat dapat menjalankan operasi spesifik perangkat
// seperti mereset perangkat sebelum membuat perangkat tersedia bagi kontainer.
rpc PreStartContainer(PreStartContainerRequest) returns (PreStartContainerResponse) {}
}
Catatan:
Plugin tidak diwajibkan untuk memberikan implementasi yang fungsional untuk
GetPreferredAllocation() atau PreStartContainer(). Jika ada, indikator mengenai
ketersediaan panggilan ini harus disertakan dalam pesan DevicePluginOptions yang
dikembalikan oleh panggilan ke GetDevicePluginOptions(). Kubelet akan selalu
memanggil GetDevicePluginOptions() untuk memeriksa fungsi opsional mana yang
tersedia sebelum memanggil salah satu fungsi tersebut secara langsung.
Plugin mendaftarkan dirinya sendiri dengan kubelet melalui Unix socket pada lokasi host
/var/lib/kubelet/device-plugins/kubelet.sock.
Catatan:
Urutan alur kerja adalah penting. Sebuah plugin HARUS mulai melayani layanan gRPC
sebelum mendaftarkan dirinya dengan kubelet untuk pendaftaran yang berhasil.
Seteleh sukses mendaftarkan dirinya sendiri, plugin perangkat berjalan dalam mode peladen, dan selama itu
dia tetap mengawasi kesehatan perangkat dan melaporkan balik ke kubelet terhadap perubahan status perangkat.
Dia juga bertanggung jawab untuk melayani request gRPC Allocate. Selama Allocate, plugin perangkat dapat
membuat persiapan spesifik-perangkat; contohnya, pembersihan GPU atau inisiasi QRNG.
Jika operasi berhasil, plugin perangkat mengembalikan AllocateResponse yang memuat konfigurasi
runtime kontainer untuk mengakses perangkat teralokasi. Kubelet memberikan informasi ini ke runtime kontainer.
AllocateResponse berisi nol atau lebih objek ContainerAllocateResponse.
Di dalam objek-objek ini, plugin perangkat mendefinisikan modifikasi yang harus
dilakukan pada definisi kontainer untuk memberikan akses ke perangkat. Modifikasi ini meliputi:
Pemrosesan nama perangkat CDI yang sepenuhnya terqualifikasi oleh Device Manager memerlukan
agar DevicePluginCDIDevicesfeature gate
diaktifkan untuk kubelet dan kube-apiserver. Fitur ini ditambahkan sebagai fitur alpha di Kubernetes
v1.28, meningkat menjadi beta di v1.29 dan menjadi GA di v1.31.
Menangani kubelet yang restart
Plugin perangkat diharapkan dapat mendeteksi kubelet yang restart dan mendaftarkan dirinya sendiri kembali dengan
instance kubelet baru. Pada implementasi sekarang, sebuah instance kubelet baru akan menghapus semua socket Unix yang ada
di dalam /var/lib/kubelet/device-plugins ketika dijalankan. Plugin perangkat dapat mengawasi penghapusan
socket Unix miliknya dan mendaftarkan dirinya sendiri kembali ketika hal tersebut terjadi.
Plugin perangkat dan perangkat yang tidak sehat
Ada kalanya perangkat mengalami kegagalan atau dimatikan. Tanggung jawab Plugin Perangkat dalam
kasus ini adalah memberi tahu kubelet mengenai situasi tersebut menggunakan API ListAndWatchResponse.
Setelah sebuah perangkat ditandai sebagai tidak sehat, kubelet akan mengurangi jumlah yang dapat dialokasikan
untuk sumber daya ini di Node, untuk mencerminkan berapa banyak perangkat yang dapat digunakan untuk
menjadwalkan pod baru. Jumlah kapasitas untuk sumber daya tersebut tidak akan berubah.
Pod yang telah ditugaskan ke perangkat yang gagal akan terus diasosiasikan dengan perangkat ini.
Umumnya, kode yang bergantung pada perangkat akan mulai gagal, dan Pod mungkin akan masuk ke fase Gagal jika
restartPolicy untuk Pod tersebut tidak diatur ke Always, atau bisa juga masuk ke loop crash.
Sebelum Kubernetes v1.31, cara untuk mengetahui apakah sebuah Pod terkait dengan perangkat yang gagal
adalah dengan menggunakan API PodResources.
FEATURE STATE:Kubernetes v1.36 [beta](enabled by default)
Dengan mengaktifkan feature gate ResourceHealthStatus, field allocatedResourcesStatus akan ditambahkan
ke setiap status kontainer, dalam .status untuk setiap Pod. Field allocatedResourcesStatus melaporkan
informasi kesehatan untuk setiap perangkat yang ditugaskan kepada kontainer.
Untuk Pod yang gagal, atau di mana Anda mencurigai adanya kesalahan, Anda dapat menggunakan status ini
untuk memahami apakah perilaku Pod mungkin terkait dengan kegagalan perangkat. Misalnya, jika sebuah
akselerator melaporkan kejadian suhu berlebih, field allocatedResourcesStatus mungkin dapat melaporkan hal ini.
Deployment plugin perangkat
Kamu dapat melakukan deploy sebuah plugin perangkat sebagai DaemonSet, sebagai sebuah paket untuk sistem operasi node-mu,
atau secara manual.
Direktori canonical/var/lib/kubelet/device-plugins membutuhkan akses berprivilese,
sehingga plugin perangkat harus berjalan dalam konteks keamanan dengan privilese.
Jika kamu melakukan deployplugin perangkat sebagai DaemonSet, /var/lib/kubelet/device-plugins
harus dimuat sebagai Volume pada
PodSpec
plugin.
Jika kamu memilih pendekatan DaemonSet, kamu dapat bergantung pada Kubernetes untuk meletakkan Pod
plugin perangkat ke Node, memulai-ulang Pod daemon setelah kegagalan, dan membantu otomasi pembaruan.
Kecocokan API
Sebelumnya, skema pengversian mengharuskan versi API Plugin Perangkat untuk cocok persis dengan
versi kubelet. Sejak lulusnya fitur ini ke tahap Beta di v1.12, ini bukan lagi persyaratan yang ketat.
API telah terversi dan tetap stabil sejak lulusnya fitur ini ke tahap Beta. Karena itu, peningkatan
kubelet seharusnya berjalan lancar, tetapi masih mungkin ada perubahan dalam API sebelum stabilisasi,
yang membuat upgrade tidak dijamin tidak akan mengganggu.
Catatan:
Meskipun komponen Device Manager Kubernetes adalah fitur yang tersedia secara umum, API plugin perangkat tidak stabil.
Untuk informasi lebih lanjut mengenai API plugin perangkat dan kompatibilitas versi,
baca Versi API Plugin Perangkat.
Sebagai proyek, Kubernetes merekomendasikan para developer plugin perangkat:
Mengamati perubahan pada rilis mendatang.
Mendukung versi API plugin perangkat berbeda untuk kompatibilitas-maju/mundur.
Jika kamu menyalakan fitur DevicePlugins dan menjalankan plugin perangkat pada node yang perlu diperbarui
ke rilis Kubernetes dengan versi API plugin yang lebih baru, perbarui plugin perangkatmu
agar mendukung kedua versi sebelum membarui para node ini. Memilih pendekatan demikian akan
menjamin fungsi berkelanjutan dari alokasi perangkat selama pembaruan.
Mengawasi Sumber Daya Plugin Perangkat
FEATURE STATE:Kubernetes v1.28 [stable]
Dalam rangka mengawasi sumber daya yang disediakan plugin perangkat, agen monitoring perlu bisa
menemukan kumpulan perangkat yang terpakai dalam node dan mengambil metadata untuk mendeskripsikan
pada kontainer mana metrik harus diasosiasikan. Metrik prometheus
diekspos oleh agen pengawas perangkat harus mengikuti
Petunjuk Instrumentasi Kubernetes,
mengidentifikasi kontainer dengan label prometheus pod, namespace, dan container.
kubelet menyediakan servis gRPC untuk menyalakan pencarian perangkat yang terpakai, dan untuk menyediakan metadata
untuk perangkat berikut:
// PodResourcesLister adalah layanan yang disediakan kubelet untuk menyediakan informasi tentang
// sumber daya node yang dikonsumsi Pod dan kontainer pada node
service PodResourcesLister {
rpc List(ListPodResourcesRequest) returns (ListPodResourcesResponse) {}
rpc GetAllocatableResources(AllocatableResourcesRequest) returns (AllocatableResourcesResponse) {}
rpc Get(GetPodResourcesRequest) returns (GetPodResourcesResponse) {}
}
Endpoint gRPC List
Endpoint List menyediakan informasi tentang sumber daya dari pod yang sedang berjalan,
dengan rincian seperti ID CPU yang dialokasikan secara eksklusif, ID perangkat sebagaimana
dilaporkan oleh plugin perangkat, dan ID dari node NUMA di mana perangkat ini dialokasikan.
Selain itu, untuk mesin berbasis NUMA, endpoint ini juga mencakup informasi tentang memori
dan hugepages yang diperuntukkan bagi sebuah kontainer.
Mulai dari Kubernetes v1.27, endpoint List dapat memberikan informasi tentang sumber daya
dari pod yang sedang berjalan yang dialokasikan dalam ResourceClaims melalui API DynamicResourceAllocation.
Untuk mengaktifkan fitur ini, kubelet harus dimulai dengan flag berikut:
// ListPodResourcesResponse adalah respons yang dikembalikan oleh fungsi List
message ListPodResourcesResponse {
repeated PodResources pod_resources = 1;
}
// PodResources berisi informasi tentang sumber daya node yang dialokasikan untuk sebuah pod
message PodResources {
string name = 1;
string namespace = 2;
repeated ContainerResources containers = 3;
}
// ContainerResources berisi informasi tentang sumber daya yang dialokasikan untuk sebuah kontainer
message ContainerResources {
string name = 1;
repeated ContainerDevices devices = 2;
repeated int64 cpu_ids = 3;
repeated ContainerMemory memory = 4;
repeated DynamicResource dynamic_resources = 5;
}
// ContainerMemory berisi informasi tentang memori dan hugepages yang dialokasikan untuk sebuah kontainer
message ContainerMemory {
string memory_type = 1;
uint64 size = 2;
TopologyInfo topology = 3;
}
// Topology menjelaskan topologi perangkat keras dari sumber daya
message TopologyInfo {
repeated NUMANode nodes = 1;
}
// Representasi NUMA dari node NUMA
message NUMANode {
int64 ID = 1;
}
// ContainerDevices berisi informasi tentang perangkat yang dialokasikan untuk sebuah kontainer
message ContainerDevices {
string resource_name = 1;
repeated string device_ids = 2;
TopologyInfo topology = 3;
}
// DynamicResource berisi informasi tentang perangkat yang dialokasikan untuk sebuah kontainer oleh Alokasi Sumber Daya Dinamis
message DynamicResource {
string class_name = 1;
string claim_name = 2;
string claim_namespace = 3;
repeated ClaimResource claim_resources = 4;
}
// ClaimResource berisi informasi sumber daya per-plugin
message ClaimResource {
repeated CDIDevice cdi_devices = 1 [(gogoproto.customname) = "CDIDevices"];
}
// CDIDevice mengspesifikasikan informasi perangkat CDI
message CDIDevice {
// Nama perangkat CDI yang sepenuhnya terqualifikasi
// misalnya: vendor.com/gpu=gpudevice1
// lihat detail lebih lanjut dalam spesifikasi CDI:
// https://github.com/container-orchestrated-devices/container-device-interface/blob/main/SPEC.md
string name = 1;
}
Catatan:
cpu_ids dalam ContainerResources pada endpoint List sesuai dengan CPU eksklusif yang
dialokasikan untuk kontainer tertentu. Jika tujuannya adalah untuk mengevaluasi CPU yang
termasuk dalam pool bersama, endpoint List perlu digunakan bersamaan dengan endpoint
GetAllocatableResources seperti yang dijelaskan di bawah ini:
Panggil GetAllocatableResources untuk mendapatkan daftar semua CPU yang dapat dialokasikan.
Panggil GetCpuIds pada semua ContainerResources di sistem.
Kurangi semua CPU dari panggilan GetCpuIds dari panggilan GetAllocatableResources.
Endpoint gRPC GetAllocatableResources
FEATURE STATE:Kubernetes v1.28 [stable]
GetAllocatableResources menyediakan informasi tentang sumber daya yang awalnya tersedia pada node pekerja.
Ini memberikan informasi lebih banyak daripada yang diekspor kubelet ke APIServer.
Catatan:
GetAllocatableResources hanya boleh digunakan untuk mengevaluasi
sumber daya yang dapat dialokasikan
di sebuah node. Jika tujuannya adalah untuk mengevaluasi sumber daya yang bebas/tidak dialokasikan,
maka harus digunakan bersamaan dengan endpoint List(). Hasil yang diperoleh dari GetAllocatableResources
akan tetap sama kecuali ada perubahan pada sumber daya yang mendasarinya yang diekspos ke kubelet.
Hal ini jarang terjadi, tetapi ketika itu terjadi (misalnya: hotplug/hotunplug, perubahan kesehatan perangkat),
klien diharapkan untuk memanggil endpoint GetAllocatableResources.
Namun, memanggil endpoint GetAllocatableResources tidak cukup dalam kasus pembaruan CPU dan/atau memori,
dan Kubelet perlu di-restart untuk mencerminkan kapasitas sumber daya yang benar dan dapat dialokasikan.
// AllocatableResourcesResponses berisi informasi tentang semua perangkat yang diketahui oleh kubelet
message AllocatableResourcesResponse {
repeated ContainerDevices devices = 1;
repeated int64 cpu_ids = 2;
repeated ContainerMemory memory = 3;
}
ContainerDevices memang mengungkapkan informasi topologi yang menyatakan ke sel NUMA mana perangkat
tersebut terasosiasi. Sel NUMA diidentifikasi menggunakan ID integer yang tidak jelas, yang nilainya
konsisten dengan apa yang dilaporkan oleh plugin perangkat
ketika mereka mendaftar ke kubelet.
Servis gRPC dilayani lewat socket unix pada /var/lib/kubelet/pod-resources/kubelet.sock.
Agen pengawas untuk sumber daya plugin perangkat dapat di-deploy sebagai daemon, atau sebagai DaemonSet.
Direktori canonical/var/lib/kubelet/pod-resources perlu akses berprivilese,
sehingga agen pengawas harus berjalan dalam konteks keamanan dengan privilese. Jika agen pengawas perangkat berjalan
sebagai DaemonSet, /var/lib/kubelet/pod-resources harus dimuat sebagai
Volume pada plugin
PodSpec.
Catatan:
Saat mengakses /var/lib/kubelet/pod-resources/kubelet.sock dari DaemonSet
atau aplikasi lain yang diterapkan sebagai kontainer di host, yang memasang socket sebagai
volume, merupakan praktik yang baik untuk memasang direktori /var/lib/kubelet/pod-resources/
daripada /var/lib/kubelet/pod-resources/kubelet.sock. Ini akan memastikan
bahwa setelah kubelet di-restart, kontainer akan dapat terhubung kembali ke socket ini.
Pemasangan kontainer dikelola dengan inode yang mereferensikan socket atau direktori,
tergantung pada apa yang dipasang. Ketika kubelet di-restart, socket dihapus
dan socket baru dibuat, sementara direktori tetap tidak tersentuh.
Jadi inode asli untuk socket menjadi tidak dapat digunakan. Inode ke direktori
akan tetap berfungsi.
Endpoint gRPC Get
FEATURE STATE:Kubernetes v1.27 [alpha]
Endpoint Get menyediakan informasi tentang sumber daya dari Pod yang sedang berjalan.
Ini mengekspos informasi yang mirip dengan yang dijelaskan pada endpoint List.
Endpoint Get memerlukan PodName dan PodNamespace dari Pod yang sedang berjalan.
// GetPodResourcesRequest berisi informasi tentang pod
message GetPodResourcesRequest {
string pod_name = 1;
string pod_namespace = 2;
}
Untuk mengaktifkan fitur ini, Anda harus memulai layanan kubelet Anda dengan flag berikut:
--feature-gates=KubeletPodResourcesGet=true
Endpoint Get dapat memberikan informasi Pod yang berkaitan dengan sumber daya dinamis
yang dialokasikan oleh API alokasi sumber daya dinamis. Untuk mengaktifkan fitur ini,
Anda harus memastikan layanan kubelet Anda dimulai dengan flag berikut:
Integrasi Plugin Perangkat dengan Topology Manager
FEATURE STATE:Kubernetes v1.27 [stable]
Topology Manager adalah komponen Kubelet yang membolehkan sumber daya untuk dikoordinasi
secara selaras dengan Topology. Untuk melakukannya, API Plugin Perangkat telah dikembangkan
untuk memasukkan struct TopologyInfo.
Plugin Perangkat yang ingin memanfaatkan Topology Manager dapat mengembalikan beberapa struct
TopologyInfo sebagai bagian dari pendaftaran perangkat, bersama dengan ID perangkat dan status
kesehatan perangkat. Manajer perangkat akan memakai informasi ini untuk konsultasi dengan
Topology Manager dan membuat keputusan alokasi sumber daya.
TopologyInfo mendukung kolom nodes yang bisa nil (sebagai bawaan) atau daftar node NUMA.
Ini membuat Plugin Perangkat mengumumkan apa saja yang bisa meliputi node NUMA.
Menetapkan TopologyInfo ke nil atau menyediakan daftar sel NUMA yang kosong untuk perangkat tertentu
menunjukkan bahwa Plugin Perangkat tidak memiliki preferensi afinitas NUMA untuk perangkat tersebut.
Contoh structTopologyInfo untuk perangkat yang dipopulate oleh Plugin Perangkat:
Catatan: Bagian ini tertaut ke proyek-proyek pihak ketiga yang menyediakan fungsionalitas yang dibutuhkan oleh Kubernetes. Pencipta proyek Kubernetes tidak bertanggung jawab atas proyek-proyek tersebut. Laman ini mengikuti pedoman website CNCF dengan membuat daftar proyek menurut abjad. Untuk menambakan proyek ke dalam daftar ini, bacalah panduan sebelum mengirimkan perubahan.
Berikut beberapa contoh implementasi plugin perangkat:
Akri, yang memungkinkan Anda dengan mudah
mengekspos perangkat daun heterogen (seperti kamera IP dan perangkat USB).
Pelajari tentang [Topology Manager] (/docs/tasks/adminster-cluster/topology-manager/)
12.4 - Pola Operator
Operator adalah ekstensi perangkat lunak untuk Kubernetes yang memanfaatkan
custom resource
untuk mengelola aplikasi dan komponen-komponennya. Operator mengikuti prinsip
Kubernetes, khususnya dalam hal control loop.
Motivasi
Pola dari Operator bertujuan untuk menangkap tujuan utama dari Operator manusia
yang mengelola layanan atau suatu kumpulan layanan. Operator manusia yang
menjaga spesifik aplikasi dan layanan memiliki pengetahuan yang mendalam tentang
bagaimana sistem harus berperilaku, bagaimana cara menyebarkannya, dan
bagaimana bereaksi jika ada masalah.
Orang-orang yang menjalankan workload-workload di Kubernetes pada umumnya suka
menggunakan otomatisasi untuk menangani tugas-tugas yang berulang. Pola
Operator menangkap bagaimana kamu dapat menulis kode untuk mengotomatiskan
sebuah tugas di luar batas apa yang dapat disediakan oleh Kubernetes itu
sendiri.
Operator di Kubernetes
Kubernetes didesain untuk otomasi. Secara di luar nalar, kamu mendapatkan banyak
otomatisasi bawaan dari komponen inti Kubernetes. Kamu dapat menggunakan
Kubernetes untuk mengotomasikan penyebaran dan menjalankan workload-workload, dan
kamu juga dapat mengotomasikan cara Kubernetes melakukan pekerjaan itu.
Konsep dari controller
Kubernetes memungkinkan kamu memperluas perilaku klaster tanpa harus mengubah
kode dari Kubernetes itu sendiri.
Operator adalah klien API dari Kubernetes yang bertindak sebagai controller
untuk custome resource.
Contoh Operator
Beberapa hal yang dapat kamu gunakan untuk mengotomasi Operator meliputi:
menyebarkan aplikasi sesuai dengan permintaan
mengambil dan memulihkan backup status dari sebuah aplikasi
menangani pembaruan kode aplikasi termasuk dengan perubahan terkait seperti
skema basis data atau pengaturan konfigurasi tambahan
mempublikasikan layanan ke sebuah aplikasi yang tidak mendukung API Kubernetes
untuk menemukan mereka
mensimulasikan kegagalan pada seluruh atau sebagian klaster kamu untuk
menguji resiliensinya
memilih suatu pemimpin untuk aplikasi yang terdistribusi tanpa adanya proses
pemilihan anggota secara internal
Seperti apa sebuah Operator dalam kasus yang lebih terperinci? Berikut ini
adalah contoh yang lebih detail:
Sebuah custom resource bernama SampleDB, bisa kamu konfigurasi ke
dalam klaster.
Sebuah Deployment memastikan sebuah Pod berjalan dimana didalamnya
berisi bagian controller dari Operator.
Kontainer Image dari kode Operator.
Kode controller yang menanyakan pada control-plane untuk mencari tahu
apakah itu sumber daya SampleDB telah dikonfigurasi.
Inti dari Operator adalah kode untuk memberi tahu server API bagaimana
membuatnya kondisi sebenarnya sesuai dengan sumber daya yang dikonfigurasi.
* Jika kamu menambahkan SampleDB baru, Operator menyiapkan
PersistentVolumeClaims untuk menyediakan penyimpanan basis data yang
tahan lama, sebuah StatefulSet untuk menjalankan SampleDB dan pekerjaan
untuk menangani konfigurasi awal.
* Jika kamu menghapusnya, Operator mengambil snapshot, lalu memastikannya
StatefulSet dan Volume juga dihapus.
Operator juga mengelola backup basis data yang reguler. Untuk setiap resource
SampleDB, Operator menentukan kapan membuat Pod yang dapat terhubung
ke database dan mengambil backup. Pod-Pod ini akan bergantung pada ConfigMap
dan / atau sebuah Secret yang memiliki basis data koneksi dan kredensial.
Karena Operator bertujuan untuk menyediakan otomatisasi yang kuat untuk
resource yang dikelola, maka akan ada kode pendukung tambahan. Sebagai contoh
, kode memeriksa untuk melihat apakah basis data menjalankan versi yang
lama dan, jika demikian, kode membuat objek Job yang melakukan pembaruan untuk
kamu.
Menyebarkan Operator
Cara paling umum untuk menyebarkan Operator adalah dengan menambahkan
CustomResourceDefinition dan controller yang berkaitan ke dalam klaster kamu.
Controller biasanya akan berjalan di luar
control plane,
seperti kamu akan menjalankan aplikasi apa pun yang dikontainerisasi.
Misalnya, kamu bisa menjalankan controller di klaster kamu sebagai sebuah
Deployment.
Menggunakan Operator {#menggunakan operator}
Setelah Operator disebarkan, kamu akan menggunakannya dengan menambahkan,
memodifikasi, atau menghapus jenis sumber daya yang digunakan Operator tersebut.
Melanjutkan contoh diatas, kamu akan menyiapkan Deployment untuk Operator itu
sendiri, dan kemudian:
kubectl get SampleDB # find configured databaseskubectl edit SampleDB/example-database # manually change some settings
…dan itu saja! Operator akan berhati-hati dalam menerapkan perubahan
serta menjaga layanan yang ada dalam kondisi yang baik.
Menulis Operator Kamu Sendiri
Jika tidak ada Operator dalam ekosistem yang mengimplementasikan perilaku kamu
inginkan, kamu dapat kode kamu sendiri. Dalam Selanjutnya kamu
akan menemukan beberapa tautan ke library dan perangkat yang dapat kamu gunakan
untuk menulis Operator Cloud Native kamu sendiri.
Kamu juga dapat mengimplementasikan Operator (yaitu, Controller) dengan
menggunakan bahasa / runtime yang dapat bertindak sebagai
klien dari API Kubernetes.
Baca sebuah artikel
dari Google Cloud soal panduan terbaik membangun Operator
12.5 - Service Catalog
Service Catalog adalah sebuah ekstensi API yang memungkinkan aplikasi berjalan pada klaster Kubernetes untuk
mempermudah penggunaan perangkat lunak yang dikelola eksternal, seperti servis penyimpanan
data yang ditawarkan oleh penyedia layanan komputasi awan.
Ini menyediakan cara untuk membuat daftar, melakukan pembuatan, dan mengikat dengan
servis terkelola eksternal
dari makelar servis tanpa membutuhkan
pengetahuan mendalam mengenai cara servis tersebut dibuat dan diatur.
Sebuah makelar servis (service broker), seperti yang didefinisikan oleh [spesifikasi API makelar servis terbuka]
(https://github.com/openservicebrokerapi/servicebroker/blob/v2.13/spec.md), adalah sebuah
endpoint untuk beberapa layanan terkelola yang ditawarkan dan dikelola oleh pihak ketiga,
yang bisa jadi sebuah penyedia layanan cloud seperti AWS, GCP atau Azure.
Beberapa contoh dari servis terkelola adalah Microsoft Azure Cloud Queue, Amazon Simple Queue Service, dan
Google Cloud Pub/Sub, selain itu, bisa juga penawaran perangkat lunak apa pun yang dapat digunakan oleh suatu aplikasi.
Dengan menggunakan Service Catalog,
seorang pengelola klaster dapat melihat
daftar servis terkelola yang ditawarkan oleh makelar servis, melakukan pembuatan terhadap
sebuah servis terkelola, dan menghubungkan (bind) untuk membuat tersedia terhadap aplikasi pada suatu klaster Kubernetes.
Contoh kasus penggunaan
Seorang pengembang aplikasi ingin menggunakan
sistem antrian pesan sebagai bagian dari aplikasinya yang berjalan dalam klaster Kubernetes.
Namun, mereka tidak ingin berurusan dengan kesulitan dalam pengaturan, misalnya menjaga servis tetap
berjalan dan mengatur itu oleh mereka sendiri. Beruntungnya, sudah tersedia penyedia layanan cloud
yang menawarkan sistem antrian pesan sebagai servis terkelola melalui makelar servisnya.
Seorang pengelola klaster dapat membuat Service Catalog dan menggunakannya untuk berkomunikasi dengan
makelar servis milik penyedia layanan cloud untuk menyediakan sebuah servis antrian pesan dan membuat
servis ini tersedia kepada aplikasi dalam klaster Kubernetes.
Seorang pengembang aplikasi tidak perlu memikirkan detail implementasi atau mengatur sistem antrian pesan tersebut.
Aplikasi dapat langsung menggunakan servis tersebut.
Arsitektur
Service Catalog menggunakan API dari Open Service Broker
untuk berkomunikasi dengan makelar servis, bertindak sebagai perantara untuk API Server Kubernetes untuk
merundingkan penyediaan awal dan mengambil kredensial untuk aplikasi bisa menggunakan servis terkelola tersebut.
Ini terimplementasi sebagai ekstensi API Server dan pengontrol, menggunakan etcd sebagai media penyimpanan.
Ini juga menggunakan lapisan agregasi
yang tersedia pada Kubernetes versi 1.7+ untuk menampilkan API-nya.
Sumber Daya API
Service Catalog memasang API servicecatalog.k8s.io dan menyediakan beberapa sumber daya Kubernetes berikut:
ClusterServiceBroker: Sebuah representasi dalam klaster untuk makelar servis, membungkus detail koneksi peladen.
Ini dibuat dan dikelola oleh pengelola klaster yang berharap untuk menggunakan makelar peladen untuk membuat
tipe baru dari sebuah servis terkelola yang tersedia dalam klaster mereka.
ClusterServiceClass: Sebuah servis terkelola ditawarkan oleh beberapa makelar servis.
Ketika sumber daya ClusterServiceBroker ditambahkan ke dalam klaster, kontroler Service Catalog terhubung
ke makelar servis untuk mendapatkan daftar servis terkelola yang tersedia. Kemudian membuat sumber daya
ClusterServiceClass sesuai dengan masing-masing servis terkelola.
ClusterServicePlan: Sebuah penawaran khusus dari servis terkelola. Sebagai contoh, sebuah servis terkelola
bisa memiliki model harga, yaitu gratis atau berbayar, atau ini mungkin juga memiliki konfigurasi pilihan berbeda,
misal menggunakan penyimpanan SSD atau memiliki sumber daya lebih. Mirip dengan ClusterServiceClass, ketika
ClusterServiceBroker baru ditambahkan ke dalam klaster, Service Catalog akan membuat sumber daya
ClusterServicePlan sesuai dengan Service Plan yang tersedia untuk masing-masing servis terkelola.
ServiceInstance: Sebuah objek dari ClusterServiceClass.
Ini dibuat oleh operator klaster untuk membuat bentuk spesifik dari servis terkelola yang tersedia untuk
digunakan oleh salah satu atau lebih aplikasi dalam klaster.
Ketika sumber daya ServiceInstance baru terbuat, pengontrol Service Catalog terhubung ke makelar servis yang
sesuai dan menginstruksikan untuk menyediakan sebuah objek servis.
ServiceBinding: Kredensial untuk mengakses suatu ServiceInstance.
Ini dibuat oleh operator klaster yang ingin aplikasinya untuk menggunakan sebuah ServiceInstance.
Saat dibuat, kontroler Service Catalog membuat sebuah Secret Kubernetes yang berisikan detail koneksi
dan kredensial untuk objek servis, yang bisa dimuat ke dalam Pod.
Autentikasi
Service Catalog mendukung beberapa metode autentikasi, yaitu:
Seorang operator klaster dapat menggunakan API sumber daya Service Catalog untuk membuat servis terkelola
dan membuatnya tersedia dalam klaster Kubernetes. Langkah yang dilalui adalah sebagai berikut:
Membuat daftar servis terkelola dan model pembayaran yang tersedia dari makelar servis.
Membuat sebuah objek dari suatu servis terkelola.
Menghubungkan ke servis terkelola, yang mengembalikan kredensial koneksi.
Memetakan kredensial koneksi ke dalam aplikasi.
Membuat daftar servis terkelola dan model pembayaran
Pertama, seorang operator klaster harus membuat sumber daya ClusterServiceBroker dalam kelompok
servicecatalog.k8s.io. Sumber daya ini memiliki URL dan detail koneksi untuk mengakses makelar servis.
Ini ada contoh dari suatu sumber daya ClusterServiceBroker:
apiVersion:servicecatalog.k8s.io/v1beta1kind:ClusterServiceBrokermetadata:name:cloud-brokerspec:# Merujuk pada titik akhir dari makelar servis. (Ini adalah contoh URL yang tidak nyata)url:https://servicebroker.somecloudprovider.com/v1alpha1/projects/service-catalog/brokers/default###### Nilai tambahan dapat ditambahkan disini, yang mungkin bisa digunakan untuk berkomunikasi# dengan makelar servis, misalnya saja informasi bearer token atau sebuah caBundle untuk TLS.#####
Berikut adalah sebuah diagram urutan yang mengilustrasikan langkah-langkah dalam mendaftarkan
servis terkelola dan model pembayaran yang tersedia dari makelar servis:
Setelah sumber daya ClusterServiceBroker ditambahkan ke dalam Service Catalog, ini membuat panggilan
makelar servis luar untuk membuat daftar servis yang tersedia.
Makelar servis akan mengembalikan daftar servis terkelola yang tersedia dan daftar model pembayaran,
yang akan disimpan sementara sebagai ClusterServiceClass dan ClusterServicePlan.
Seorang operator klaster bisa mendapatkan daftar servis terkelola dengan menggunakan perintah berikut ini:
kubectl get clusterserviceclasses -o=custom-columns=SERVICE\ NAME:.metadata.name,EXTERNAL\ NAME:.spec.externalName
Itu seharusnya memberikan daftar nama servis dengan format yang mirip dengan berikut:
SERVICE NAME EXTERNAL NAME
4f6e6cf6-ffdd-425f-a2c7-3c9258ad2468 cloud-provider-service
... ...
Mereka juga dapat melihat model pembayaran yang tersedia menggunakan perintah berikut:
kubectl get clusterserviceplans -o=custom-columns=PLAN\ NAME:.metadata.name,EXTERNAL\ NAME:.spec.externalName
Itu seharusnya memberikan daftar nama model pembayaran dengan format mirip dengan berikut:
PLAN NAME EXTERNAL NAME
86064792-7ea2-467b-af93-ac9694d96d52 service-plan-name
... ...
Pembuatan sebuah objek
Seorang operator klaster dapat memulai pembuatan sebuah objek dengan membuat sumber daya ServiceInstance.
Ini adalah contoh dari sumber daya ServiceInstance:
apiVersion:servicecatalog.k8s.io/v1beta1kind:ServiceInstancemetadata:name:cloud-queue-instancenamespace:cloud-appsspec:# Referensi untuk salah satu servis yang pernah dikembalikanclusterServiceClassExternalName:cloud-provider-serviceclusterServicePlanExternalName:service-plan-name###### Parameter tambahan dapat ditambahkan disini,# yang mungkin akan digunakan oleh makelar servis.#####
Berikut adalah diagram urutan yang mengilustrasikan langkah-langkah dalam pembuatan sebuah objek dari
servis terkelola:
Ketika sumber daya ServiceInstance sudah terbuat, Service Catalog memulai pemanggilan ke makelar servis
luar untuk membuat sebuah objek dari suatu servis.
Makelar servis membuat sebuah objek baru dari suatu servis terkelola dan mengembalikan sebuah respons HTTP.
Seorang operator klaster dapat mengecek status dari objek untuk melihat apakah sudah siap atau belum.
Menghubungkan ke servis terkelola
Setelah sebuah objek terbuat, klaster operator harus menghubungkan ke servis terkelola untuk mendapatkan
kredensial koneksi dan detail pengguna servis untuk aplikasi bisa mengguakan servis tersebut. Ini dilakukan
dengan membuat sebuah sumber daya ServiceBinding.
Berikut adalah contoh dari sumber daya ServiceBinding:
apiVersion:servicecatalog.k8s.io/v1beta1kind:ServiceBindingmetadata:name:cloud-queue-bindingnamespace:cloud-appsspec:instanceRef:name:cloud-queue-instance###### Informasi tambahan dapat ditambahkan disini, seperti misalnya secretName atau# parameter pengguna servis, yang mungkin akan digunakan oleh makelar servis.#####
Berikut ada diagram urutan yang mengilustrasikan langkah-langkah dalam menghubungkan objek servis terkelola.
Setelah ServiceBinding terbuat, Service Catalog memanggil makelar servis luar untuk meminta
informasi yang dibutuhkan untuk terhubung dengan objek servis.
Makelar servis memberikan izin atau peran kepada aplikasi sesuai dengan pengguna servis.
Makelar servis mengembalikan informasi untuk bisa terhubung dan mengakses servis terkelola.
Ini tergantung pada penyedia layanan dan servis, sehingga informasi yang dikembalikan mungkin berbeda
antara suatu penyedia layanan dan servis terkelolanya.
Memetakan kredensial koneksi
Setelah menghubungkan, langkah terakhir melibatkan pemetaan kredensial koneksi dan informasi spesifik mengenai
servis kedalam aplikasi. Informasi ini disimpan dalam Secrets yang mana aplikasi dalam klaster dapat mengakses
dan menggunakan untuk bisa terkoneksi secara langsung dengan servis terkelola.
Berkas konfigurasi Pod
Salah satu metode untuk melakukan pemetaan ini adalah dengan menggunakan deklarasi konfigurasi Pod.
Berikut adalah contoh yang mendekripsikan bagaimana pemetaan kredensial pengguna servis ke dalam aplikasi.
Sebuah kunci yang disebut sa-key disimpan dalam media bernama provider-cloud-key, dan aplikasi memasang
media ini pada /var/secrets/provider/key.json. Environment variablePROVIDER_APPLICATION_CREDENTIALS
dipetakan dari nilai pada berkas yang dipasang.
Berikut adalah contoh yang mendeskripsikan cara memetakan nilai rahasia ke dalam environment variable aplikasi.
Dalam contoh ini, nama topik dari sistem antrian pesan dipetakan dari secret bernama provider-queue-credentials
dengan nama topic ke dalam environment variableTOPIC.
12.6 - Poseidon-Firmament - Sebuah Penjadwal Alternatif
Rilis saat ini dari Penjadwal Poseidon-Firmament adalah rilis alpha .
Penjadwal Poseidon-Firmament adalah penjadwal alternatif yang dapat digunakan bersama penjadwal Kubernetes bawaan.
Pengenalan
Poseidon adalah sebuah layanan yang berperan sebagai pemersatu antara Penjadwal Firmament dengan Kubernetes. Penjadwal Poseidon-Firmament menambah kapabilitas penjadwal Kubernetes saat ini. Penjadwal ini menggabungkan kemampuan penjadwalan berbasis grafik jaringan grafis (flow network graph) baru bersama penjadwal Kubernetes bawaan. Penjadwal Firmament memodelkan beban-beban kerja dan klaster-klaster sebagai jaringan aliran dan menjalankan optimisasi aliran biaya-minimum kepada jaringan ini untuk membuat keputusan penjadwalan.
Penjadwal ini memodelkan masalah penjadwalan sebagai optimasi berbasis batasan atas grafik jaringan aliran. Hal ini dicapai dengan mengurangi penjadwalan ke masalah optimisasi biaya-minimum aliran-maksimum. Penjadwal Poseidon-Firmament secara dinamis memperbaiki penempatan beban kerja.
Penjadwal Poseidon-Firmament berjalan bersamaan dengan penjadwal Kubernetes bawaan sebagai penjadwal alternatif, sehingga beberapa penjadwal dapat berjalan secara bersamaan.
Keuntungan Utama
Penjadwalan grafik jaringan (network graph) berbasis penjadwalan Poseidon-Firmament memberikan beberapa keuntungan utama sebagai berikut:
Beban kerja (Pod) dijadwalkan secara kolektif untuk memungkinkan penjadwalan dalam skala besar.
Berdasarkan hasil tes kinerja yang ekstensif, skala Poseidon-Firmament jauh lebih baik daripada penjadwal bawaan Kubernetes dilihat dari jumlah node meningkat dalam sebuah klaster. Hal ini disebabkan oleh fakta bahwa Poseidon-Firmament mampu mengamortisasi lebih banyak pekerjaan di seluruh beban kerja.
Penjadwal Poseidon-Firmament mengungguli penjadwal bawaan Kubernetes dengan margin lebar ketika menyangkut jumlah kinerja throughput untuk skenario di mana kebutuhan sumber daya komputasi agak seragam di seluruh pekerjaan (Replicaset / Deployment / Job). Angka kinerja throughputend-to-end penjadwal Poseidon-Firmament , termasuk waktu bind, secara konsisten menjadi lebih baik seiring jumlah Node dalam sebuah klaster meningkat. Misalnya, untuk klaster 2.700 Node (ditampilkan dalam grafik di sini), penjadwal Poseidon-Firmament berhasil mencapai 7X atau lebih throughputend-to-end yang lebih besar dibandingkan dengan penjadwal bawaan Kubernetes, yang mencakup waktu bind.
Tersedianya pembatasan aturan yang kompleks.
Penjadwalan dalam Poseidon-Firmament bersifat dinamis; ini membuat sumber daya klaster dalam keadaan optimal secara global selama setiap berjalannya penjadwalan.
Pemanfaatan sumber daya yang sangat efisien.
Penjadwal Poseidon-Firmament - Bagaimana cara kerjanya
Sebagai bagian dari pendukung penjadwal-penjadwal Kubernetes, setiap Pod baru biasanya dijadwalkan oleh penjadwal bawaan. Kubernetes dapat diinstruksikan untuk menggunakan penjadwal lain dengan menentukan nama penjadwal custom lain ("poseidon" dalam kasus ini) di fieldschedulerName dari PodSpec pada saat pembuatan pod. Dalam kasus ini, penjadwal bawaan akan mengabaikan Pod itu dan memungkinkan penjadwal Poseidon untuk menjadwalkan Pod pada Node yang relevan.
Untuk detail tentang desain proyek ini, lihat dokumen desain.
Kemungkinan Skenario Kasus Penggunaan - Kapan menggunakannya
Seperti yang disebutkan sebelumnya, penjadwal Poseidon-Firmament memungkinkan lingkungan penjadwalan dengan throughput yang sangat tinggi bahkan pada ukuran klaster dengan beban kerja besar, dikarenakan pendekatan penjadwalannya yang sekaligus dalam jumlah besar, dibandingkan dengan pendekatan bawaan pod-at-a-time Kubernetes. Dalam pengujian ekstensif kami, kami telah mengamati manfaat throughput substansial selama kebutuhan sumber daya (CPU / Memori) untuk Pod yang masuk seragam di seluruh tugas (Replicaset / Deployment / Job), terutama karena amortisasi pekerjaan yang efisien di seluruh tugas.
Meskipun penjadwal Poseidon-Firmament mampu menjadwalkan berbagai jenis beban kerja, seperti layanan-layanan, batch, dll., berikut ini adalah beberapa kasus penggunaan yang paling unggul:
Untuk pekerjaan "Big Data / AI" yang terdiri dari sejumlah besar tugas, manfaat dari throughput luar biasa.
Pekerjaan layanan atau batch job di mana kebutuhan sumber dayanya seragam di seluruh pekerjaan (Replicaset / Deployment / Job).
Saat ini, penjadwal Poseidon-Firmament tidak memberikan dukungan untuk ketersediaan tinggi, implementasi kami mengasumsikan bahwa penjadwal tidak mungkin gagal. Dokumen desain menjelaskan cara-cara yang memungkinkan untuk mengaktifkan ketersediaan tinggi, tetapi kami membiarkannya untuk pekerjaan mendatang.
Kami tidak mengetahui adanya production deployment dari penjadwal Poseidon-Firmament saat ini.
Poseidon-Firmament didukung dari rilis Kubernetes 1.6 dan bekerja dengan semua rilis berikutnya.
Proses rilis untuk repo Poseidon dan Firmament berjalan secara serentak. Rilis Poseidon saat ini dapat ditemukan di sini dan rilis Firmament yang sesuai dapat ditemukan di sini.
Matriks Perbandingan Fitur
Fitur
Penjadwal Bawaan Kubernetes
Penjadwal Poseidon-Firmament
Catatan
Node Affinity/Anti-Affinity
Y
Y
Pod Affinity / Anti-Affinity - termasuk dukungan untuk simetri anti-affinity Pod
Y
Y
Saat ini penjadwal bawaan mengungguli penjadwal Poseidon-Firmament Pod dalam segi fungsionalitas affinity/anti-affinity. Kami sedang berupaya menyelesaikan ini.
Taints & Toleration
Y
Y
Kemampuan Penjadwalan Dasar sesuai dengan sumber daya komputasi yang tersedia (CPU & Memori) pada sebuah Node
Y
Y**
Tidak semua Predikat & Prioritas sudah didukung saat ini.
Throughput ekstrim pada skala besar
Y**
Y
Pendekatan penjadwalan massal mengukur atau meningkatkan penempatan beban kerja. Manfaat throughput substansial menggunakan penjadwal Firmament selama persyaratan sumber daya (CPU / Memori) untuk Pod yang masuk seragam di seluruh Replicaset / Deployment / Job. Hal ini terutama disebabkan oleh amortisasi pekerjaan yang efisien di seluruh Replicaset / Deployment / Job. 1) Untuk pekerjaan "Big Data / AI" yang terdiri dari jumlah tugas yang besar, manfaat throughput yang luar biasa. 2) Manfaat throughput substansial juga untuk skenario layanan atau sekumpulan pekerjaan di mana persyaratan sumber daya beban kerja seragam di seluruh Replicaset / Deployment / Job.
Penjadwalan Optimal
Penjadwalan Pod-by-Pod, memproses satu Pod pada satu waktu (dapat mengakibatkan penjadwalan sub-optimal)
Penjadwalan Massal (Penjadwalan optimal)
Penjadwal bawaan Pod-by-Pod Kubernetes dapat menetapkan tugas ke mesin sub-optimal. Sebaliknya, Firmament mempertimbangkan semua tugas yang tidak terjadwal pada saat yang bersamaan bersama dengan batasan lunak dan kerasnya.
Penghindaran Gangguan Kolokasi
N
N**
Direncanakan di Poseidon-Firmament.
Pre-emption Prioritas
Y
N**
Tersedia secara parsial pada Poseidon-Firmament, dibandingkan dengan dukungan ekstensif di penjadwal bawaan Kubernetes.
Penjadwalan Ulang yang Inheren
N
Y**
Penjadwal Poseidon-Firmament mendukung penjadwalan ulang beban kerja. Dalam setiap penjadwalan, penjadwal Poseidon-Firmament mempertimbangkan semua Pod, termasuk Pod yang sedang berjalan, dan sebagai hasilnya dapat melakukan migrasi atau mengeluarkan Pod - sebuah lingkungan penjadwalan yang optimal secara global.
Penjadwalan Berkelompok
N
Y
Dukungan untuk Penjadwalan Volume Persisten Pra-terikat
Y
Y
Dukungan untuk Volume Lokal & Penjadwalan Binding Volume Persisten Dinamis
Y
N**
Direncanakan.
Ketersediaan Tinggi
Y
N**
Direncanakan.
Penjadwalan berbasis metrik real-time
N
Y**
Awalnya didukung menggunakan Heapster (sekarang tidak digunakan lagi) untuk menempatkan Pod menggunakan statistik penggunaan klaster aktual ketimbang reservasi. Rencananya akan dialihkan ke "server metrik".
Dukungan untuk Max-Pod per Node
Y
Y
Penjadwal Poseidon-Firmament secara mulus berdampingan dengan penjadwal bawaan Kubernetes.
Dukungan untuk Penyimpanan Ephemeral, selain CPU / Memori
Y
Y
Instalasi
Untuk instalasi Poseidon dalam-klaster, silakan mulai dari Petunjuk Instalasi.
Penjadwal pod-by-pod, seperti penjadwal bawaan Kubernetes, biasanya memproses satu Pod pada satu waktu. Penjadwal ini memiliki kelemahan penting berikut:
Penjadwal berkomitmen untuk penempatan Pod lebih awal dan membatasi pilihan untuk Pod lain yang menunggu untuk ditempatkan.
Ada peluang terbatas untuk amortisasi pekerjaan lintas Pod karena mereka dipertimbangkan untuk ditempatkan secara individual.
Kelemahan dari penjadwal pod-by-pod ini diatasi dengan penjadwalan secara terkumpul atau dalam jumlah banyak secara bersamaan di penjadwal Poseidon-Firmament. Memproses beberapa Pod dalam satu kumpulan memungkinkan penjadwal untuk bersama-sama mempertimbangkan penempatan mereka, dan dengan demikian untuk menemukan untung-rugi terbaik untuk seluruh kumpulan ketimbang satu Pod saja. Pada saat yang sama, amortisasi berfungsi lintas Pod yang menghasilkan throughput yang jauh lebih tinggi.
Catatan:
Silakan merujuk ke hasil benchmark terbaru untuk hasil uji perbandingan kinerja throughput terperinci antara penjadwal Poseidon-Firmament dan Penjadwal bawaan Kubernetes.