This is the multi-page printable view of this section. Click here to print.
Penjadwalan dan Pengusiran
1 - Bin Packing Sumber Daya untuk Sumber Daya Tambahan
Kubernetes 1.16 [alpha]Kube-scheduler dapat dikonfigurasikan untuk mengaktifkan pembungkusan rapat
(bin packing) sumber daya bersama dengan sumber daya tambahan melalui fungsi prioritas
RequestedToCapacityRatioResourceAllocation. Fungsi-fungsi prioritas dapat digunakan
untuk menyempurnakan kube-scheduler sesuai dengan kebutuhan.
Mengaktifkan Bin Packing menggunakan RequestedToCapacityRatioResourceAllocation
Sebelum Kubernetes 1.15, kube-scheduler digunakan untuk memungkinkan mencetak
skor berdasarkan rasio permintaan terhadap kapasitas sumber daya utama seperti
CPU dan Memori. Kubernetes 1.16 menambahkan parameter baru ke fungsi prioritas
yang memungkinkan pengguna untuk menentukan sumber daya beserta dengan bobot
untuk setiap sumber daya untuk memberi nilai dari Node berdasarkan rasio
permintaan terhadap kapasitas. Hal ini memungkinkan pengguna untuk bin pack
sumber daya tambahan dengan menggunakan parameter yang sesuai untuk meningkatkan
pemanfaatan sumber daya yang langka dalam klaster yang besar. Perilaku
RequestedToCapacityRatioResourceAllocation dari fungsi prioritas dapat
dikontrol melalui pilihan konfigurasi yang disebut RequestToCapacityRatioArguments.
Argumen ini terdiri dari dua parameter yaitu shape dan resources. Shape
memungkinkan pengguna untuk menyempurnakan fungsi menjadi yang paling tidak
diminta atau paling banyak diminta berdasarkan nilai utilization dan score.
Sumber daya terdiri dari name yang menentukan sumber daya mana yang dipertimbangkan
selama penilaian dan weight yang menentukan bobot masing-masing sumber daya.
Di bawah ini adalah contoh konfigurasi yang menetapkan requestedToCapacityRatioArguments
pada perilaku bin packing untuk sumber daya tambahan intel.com/foo dan intel.com/bar
{
"kind" : "Policy",
"apiVersion" : "v1",
...
"priorities" : [
...
{
"name": "RequestedToCapacityRatioPriority",
"weight": 2,
"argument": {
"requestedToCapacityRatioArguments": {
"shape": [
{"utilization": 0, "score": 0},
{"utilization": 100, "score": 10}
],
"resources": [
{"name": "intel.com/foo", "weight": 3},
{"name": "intel.com/bar", "weight": 5}
]
}
}
}
],
}
Fitur ini dinonaktifkan secara default
Tuning RequestedToCapacityRatioResourceAllocation Priority Function
shape digunakan untuk menentukan perilaku dari fungsi RequestedToCapacityRatioPriority.
{"utilization": 0, "score": 0},
{"utilization": 100, "score": 10}
Argumen di atas memberikan Node nilai 0 jika utilisasi 0% dan 10 untuk utilisasi 100%, yang kemudian mengaktfikan perilaku bin packing. Untuk mengaktifkan dari paling yang tidak diminta, nilainya harus dibalik sebagai berikut.
{"utilization": 0, "score": 100},
{"utilization": 100, "score": 0}
resources adalah parameter opsional yang secara default diatur ke:
"resources": [
{"name": "CPU", "weight": 1},
{"name": "Memory", "weight": 1}
]
Ini dapat digunakan untuk menambahkan sumber daya tambahan sebagai berikut:
"resources": [
{"name": "intel.com/foo", "weight": 5},
{"name": "CPU", "weight": 3},
{"name": "Memory", "weight": 1}
]
Parameter weight adalah opsional dan diatur ke 1 jika tidak ditentukan.
Selain itu, weight tidak dapat diatur ke nilai negatif.
Bagaimana Fungsi Prioritas RequestedToCapacityRatioResourceAllocation Menilai Node
Bagian ini ditujukan bagi kamu yang ingin memahami secara detail internal dari fitur ini. Di bawah ini adalah contoh bagaimana nilai dari Node dihitung untuk satu kumpulan nilai yang diberikan.
Sumber daya yang diminta
intel.com/foo : 2
Memory: 256MB
CPU: 2
Bobot dari sumber daya
intel.com/foo : 5
Memory: 1
CPU: 3
FunctionShapePoint {{0, 0}, {100, 10}}
Spesifikasi dari Node 1
Tersedia:
intel.com/foo : 4
Memory : 1 GB
CPU: 8
Digunakan:
intel.com/foo: 1
Memory: 256MB
CPU: 1
Nilai Node:
intel.com/foo = resourceScoringFunction((2+1),4)
= (100 - ((4-3)*100/4)
= (100 - 25)
= 75
= rawScoringFunction(75)
= 7
Memory = resourceScoringFunction((256+256),1024)
= (100 -((1024-512)*100/1024))
= 50
= rawScoringFunction(50)
= 5
CPU = resourceScoringFunction((2+1),8)
= (100 -((8-3)*100/8))
= 37.5
= rawScoringFunction(37.5)
= 3
NodeScore = ((7 * 5) + (5 * 1) + (3 * 3)) / (5 + 1 + 3)
= 5
Spesifikasi dari Node 2
Tersedia:
intel.com/foo: 8
Memory: 1GB
CPU: 8
Digunakan:
intel.com/foo: 2
Memory: 512MB
CPU: 6
Nilai Node:
intel.com/foo = resourceScoringFunction((2+2),8)
= (100 - ((8-4)*100/8)
= (100 - 25)
= 50
= rawScoringFunction(50)
= 5
Memory = resourceScoringFunction((256+512),1024)
= (100 -((1024-768)*100/1024))
= 75
= rawScoringFunction(75)
= 7
CPU = resourceScoringFunction((2+6),8)
= (100 -((8-8)*100/8))
= 100
= rawScoringFunction(100)
= 10
NodeScore = ((5 * 5) + (7 * 1) + (10 * 3)) / (5 + 1 + 3)
= 7
2 - Overhead Pod
Kubernetes v1.16 [alpha]Ketika kamu menjalankan Pod pada Node, Pod itu akan mengambil sejumlah sumber daya sistem. Sumber daya ini adalah tambahan terhadap sumber daya yang diperlukan untuk menjalankan Container di dalam Pod (overhead). Pod Overhead adalah fitur yang berfungsi untuk menghitung sumber daya digunakan oleh infrastruktur Pod selain permintaan dan limit Container.
Overhead Pod
Pada Kubernetes, Overhead Pod ditentukan pada saat admisi sesuai dengan Overhead yang ditentukan di dalam RuntimeClass milik Pod.
Ketika Overhead Pod diaktifkan, Overhead akan dipertimbangkan sebagai tambahan terhadap jumlah permintaan sumber daya Container saat menjadwalkan Pod. Begitu pula Kubelet, yang akan memasukkan Overhead Pod saat menentukan ukuran cgroup milik Pod, dan saat melakukan pemeringkatan pengusiran (eviction) Pod.
Yang perlu disiapkan
Kamu harus memastikan bahwa
feature gate PodOverhead telah diaktifkan (secara bawaan dinonaktifkan)
di seluruh klaster kamu, yang berarti:
- Pada kube-scheduler
- Pada kube-apiserver
- Pada kubelet di setiap Node
- Pada peladen API khusus (custom) apa pun yang menggunakan feature gate
Catatan:
Pengguna yang dapat mengubah sumber daya RuntimeClass dapat memengaruhi kinerja beban kerja klaster secara keseluruhan. Kamu dapat membatasi akses terhadap kemampuan ini dengan kontrol akses Kubernetes. Lihat Ringkasan Otorisasi untuk lebih lanjut.Selanjutnya
3 - Menetapkan Pod ke Node
Kamu dapat memaksa sebuah pod untuk hanya dapat berjalan pada node tertentu atau mengajukannya agar berjalan pada node tertentu. Ada beberapa cara untuk melakukan hal tersebut. Semua cara yang direkomendasikan adalah dengan menggunakan selector label untuk menetapkan pilihan yang kamu inginkan. Pada umumnya, pembatasan ini tidak dibutuhkan, sebagaimana scheduler akan melakukan penempatan yang proporsional dengan otomatis (seperti contohnya menyebar pod di node-node, tidak menempatkan pod pada node dengan sumber daya yang tidak memadai, dst.) tetapi ada keadaan-keadaan tertentu yang membuat kamu memiliki kendali lebih terhadap node yang menjadi tempat pod dijalankan, contohnya untuk memastikan pod dijalankan pada mesin yang telah terpasang SSD, atau untuk menempatkan pod-pod dari dua servis yang berbeda yang sering berkomunikasi bersamaan ke dalam zona ketersediaan yang sama.
Kamu dapat menemukan semua berkas untuk contoh-contoh berikut pada dokumentasi yang kami sediakan di sini
nodeSelector
Penggunaan nodeSelector adalah cara pembatasan pemilihan node paling sederhana yang direkomendasikan. nodeSelector adalah sebuah field pada PodSpec. nodeSelector memerinci sebuah map berisi pasangan kunci-nilai. Agar pod dapat dijalankan pada sebuah node yang memenuhi syarat, node tersebut harus memiliki masing-masing dari pasangan kunci-nilai yang dinyatakan sebagai label (namun node juga dapat memiliki label tambahan diluar itu). Penggunaan paling umum adalah satu pasang kunci-nilai.
Mari kita telusuri contoh dari penggunaan nodeSelector.
Langkah Nol: Prasyarat
Contoh ini mengasumsikan bahwa kamu memiliki pemahaman dasar tentang pod Kubernetes dan kamu telah membuat klaster Kubernetes.
Langkah Satu: Menyematkan label pada node
Jalankan kubectl get nodes untuk mendapatkan nama dari node-node yang ada dalam klaster kamu. Temukan node yang akan kamu tambahkan label, kemudian jalankan perintah kubectl label nodes <node-name> <label-key>=<label-value> untuk menambahkan label pada node yang telah kamu pilih. Sebagai contoh, jika nama node yang saya pilih adalah 'kubernetes-foo-node-1.c.a-robinson.internal' dan label yang ingin saya tambahkan adalah 'disktype=ssd', maka saya dapat menjalankan kubectl label nodes kubernetes-foo-node-1.c.a-robinson.internal disktype=ssd.
Jika terjadi kegagalan dengan kesalahan perintah yang tidak valid ("invalid command"), kemungkinan besar kamu menggunakan kubectl dengan versi lebih lama yang tidak memiliki perintah label. Dalam hal ini, lihat [versi sebelumnya] (https://github.com/kubernetes/kubernetes/blob/a053dbc313572ed60d89dae9821ecab8bfd676dc/examples/node-selection/README.md) dari petunjuk ini untuk instruksi tentang cara menetapkan label pada node.
Kamu dapat memastikan perintah telah berhasil dengan menjalankan ulang perintah kubectl get nodes --show-labels and memeriksa bahwa node yang dipilih sekarang sudah memiliki label yang ditambahkan. Kamu juga dapat menggunakan kubectl describe node "nodename" untuk melihat daftar lengkap label yang dimiliki sebuah node.
Langkah Dua: Menambahkan sebuah nodeSelector ke konfigurasi pod kamu
Ambil berkas konfigurasi pod manapun yang akan kamu jalankan, dan tambahkan sebuah bagian nodeSelector pada berkas tersebut, seperti berikut. Sebagai contoh, jika berikut ini adalah konfigurasi pod saya:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
Kemudian tambahkan sebuah nodeSelector seperti berikut:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
disktype: ssd
Ketika kamu menjalankan perintah kubectl apply -f https://k8s.io/examples/pods/pod-nginx.yaml, pod tersebut akan dijadwalkan pada node yang memiliki label yang dirinci. Kamu dapat memastikan penambahan nodeSelector berhasil dengan menjalankan kubectl get pods -o wide dan melihat "NODE" tempat Pod ditugaskan.
Selingan: label node built-in
Sebagai tambahan dari label yang kamu sematkan, node sudah terisi dengan satu set label standar. Pada Kubernetes v1.4 label tersebut adalah
kubernetes.io/hostnamefailure-domain.beta.kubernetes.io/zonefailure-domain.beta.kubernetes.io/regionbeta.kubernetes.io/instance-typekubernetes.io/oskubernetes.io/arch
Catatan:
Nilai dari label-label tersebut spesifik untuk setiap penyedia layanan cloud dan tidak dijamin reliabilitasnya. Contohnya, nilai darikubernetes.io/hostname bisa saja sama dengan nama node pada beberapa lingkungan dan berbeda pada lingkungan lain.Isolasi/pembatasan Node
Menambahkan label pada objek node memungkinkan penargetan pod pada node atau grup node yang spesifik. Penambahan label ini dapat digunakan untuk memastikan pod yang spesifik hanya berjalan pada node dengan isolasi, keamanan, atau pengaturan tertentu. Saat menggunakan label untuk tujuan tersebut, memilih kunci label yang tidak bisa dimodifikasi oleh proses kubelet pada node sangat direkomendasikan. Hal ini mencegah node yang telah diubah untuk menggunakan kredensial kubelet-nya untuk mengatur label-label pada objek nodenya sediri, dan mempengaruhi scheduler untuk menjadwalkan workload ke node yang telah diubah tersebut.
Plugin penerimaan NodeRestriction mencegah kubeletes untuk megatur atau mengubah label dengan awalan node-restriction.kubernetes.io/.
Untuk memanfaatkan awalan label untuk isolasi node:
Pastikan kamu menggunakan authorizer node dan mengaktifkan [plugin admission NodeRestriction(/docs/reference/access-authn-authz/admission-controllers/#noderestriction).
Tambah label dengan awalan
node-restriction.kubernetes.io/ke objek node kamu, dan gunakan label tersebut pada node selector kamu. Contohnya,example.com.node-restriction.kubernetes.io/fips=trueorexample.com.node-restriction.kubernetes.io/pci-dss=true.
Afinitas dan anti-afinitas
_Field_ nodeSelector menyediakan cara yang sangat sederhana untuk membatasi pod ke node dengan label-label tertentu. Fitur afinitas/anti-afinitas saat ini bersifat beta dan memperluas tipe pembatasan yang dapat kamu nyatakan. Peningkatan kunci dari fitur ini adalah
- Bahasa yang lebih ekspresif (tidak hanya "AND of exact match")
- Kamu dapat memberikan indikasi bahwa aturan yang dinyatakan bersifat rendah/preferensi dibanding dengan persyaratan mutlak sehingga jika scheduler tidak dapat memenuhinya, pod tetap akan dijadwalkan
- Kamu dapat membatasi dengan label pada pod-pod lain yang berjalan pada node (atau domain topological lain), daripada dengan label pada node itu sendiri, yang memungkinkan pengaturan tentang pod yang dapat dan tidak dapat dilokasikan bersama.
Fitur afinitas terdiri dari dua tipe afinitas yaitu "node afinitas" dan "inter-pod afinitas/anti-afinitas"
Node afinitas adalah seperti nodeSelector yang telah ada (tetapi dengam dua kelebihan pertama yang terdaftar di atas), sementara inter-pod afinitas/anti-afinitas membatasi pada label pod daripada label node, seperti yang dijelaskan pada item ketiga pada daftar di atas, sebagai tambahan dari item pertama dan kedua.
Field nodeSelector tetap berjalan seperti biasa, namun pada akhirnya akan ditinggalkan karena afinitas node dapat menyatakan semua yang nodeSelector dapat nyatakan.
Afinitas node (fitur beta)
Afinitas node diperkenalkan sebagai fitur alfa pada Kubernetes 1.2.
Afinitas node secara konseptual mirip dengan nodeSelector yang memungkinkan kamu untuk membatasi node yang memenuhi syarat untuk penjadwalan pod, berdasarkan label pada node.
Saat ini ada dia tipe afinitas node, yaitu requiredDuringSchedulingIgnoredDuringExecution dan
preferredDuringSchedulingIgnoredDuringExecution. Kamu dapat menganggap dua tipe ini sebagai "kuat" dan "lemah" secara berurutan, dalam arti tipe pertama menyatakan peraturan yang harus dipenuhi agar pod dapat dijadwalkan pada node (sama seperti nodeSelector tetapi menggunakan sintaksis yang lebih ekpresif), sementara tipe kedua menyatakan preferensi yang akan dicoba dilaksanakan tetapi tidak akan dijamin oleh scheduler. Bagian "IgnoredDuringExecution" dari nama tipe ini berarti, mirip dengan cara kerja nodeSelector, jika label pada node berubah pada runtime yang menyebabkan aturan afinitas pada pod tidak lagi terpenuhi, pod akan tetap berjalan pada node. Pada masa yang akan datang kami berencana menawarkan requiredDuringSchedulingRequiredDuringExecution yang akan berjalan seperti requiredDuringSchedulingIgnoredDuringExecution hanya saja tipe ini akan mengeluarkan pod dari node yang gagal untuk memenuhi persyaratan afinitas node pod.
Dengan denikian, contoh dari requiredDuringSchedulingIgnoredDuringExecution adalah "hanya jalankan pod pada node dengan Intel CPU" dan contoh dari preferredDuringSchedulingIgnoredDuringExecution adalah "coba jalankan set pod ini dalam zona ketersediaan XYZ, tetapi jika tidak memungkinkan, maka biarkan beberapa pod berjalan di tempat lain".
Afinitas node dinyatakan sebagai field nodeAffinity dari field affinity pada PodSpec.
Berikut ini contoh dari pod yang menggunakan afinitas node:
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/e2e-az-name
operator: In
values:
- e2e-az1
- e2e-az2
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: registry.k8s.io/pause:2.0Aturan afinitas node tersebut menyatakan pod hanya bisa ditugaskan pada node dengan label yang memiliki kunci kubernetes.io/e2e-az-name dan bernilai e2e-az1 atau e2e-az2. Selain itu, dari semua node yang memenuhi kriteria tersebut, mode dengan label dengan kunci another-node-label-key and bernilai another-node-label-value harus lebih diutamakan.
Kamu dapat meilhat operator In digunakan dalam contoh berikut. Sitaksis afinitas node yang baru mendukung operator-operator berikut: In, NotIn, Exists, DoesNotExist, Gt, Lt. Kamu dapat menggunakan NotIn dan DoesNotExist untuk mewujudkan perilaku node anti-afinitas, atau menggunakan node taints untuk menolak pod dari node tertentu.
Jika kamu menyatakan nodeSelector dan nodeAffinity. keduanya harus dipenuhi agar pod dapat dijadwalkan pada node kandidat.
Jika kamu menyatakan beberapa nodeSelectorTerms yang terkait dengan tipe nodeAffinity, maka pod akan dijadwalkan pada node jika salah satu dari nodeSelectorTerms dapat terpenuhi.
Jika kamu menyatakan beberapa matchExpressions yang terkait dengan nodeSelectorTerms, makan pod dapat dijadwalkan pada node hanya jika semua matchExpressions dapat terpenuhi.
Jika kamu menghapus atau mengubah label pada node tempat pod dijadwalkan, pod tidak akan dihapus. Dengan kata lain, pemilihan afinitas hanya bekerja pada saat waktu penjadwalan pod.
Field weight pada preferredDuringSchedulingIgnoredDuringExecution berada pada rentang nilai 1-100. Untuk setiap node yang memenuhi semua persyaratan penjadwalan (permintaan sumber daya, pernyataan afinitas RequiredDuringScheduling, dll.), scheduler akan menghitung nilai jumlah dengan melakukan iterasi pada elemen-elemen dari field ini dan menambah "bobot" pada jumlah jika node cocok dengan MatchExpressions yang sesuai. Nilai ini kemudian digabungkan dengan nilai dari fungsi prioritas lain untuk node. Node dengan nilai tertinggi adalah node lebih diutamakan.
Untuk informasi lebih lanjut tentang afinitas node kamu dapat melihat design doc.
Afinitas and anti-afinitas antar pod (fitur beta)
Afinitas and anti-afinitas antar pod diperkenalkan pada Kubernetes 1.4. Afinitas and anti-afinitas antar pod memungkinkan kamu untuk membatasi node yang memenuhi syarat untuk penjadwalan pod berdasarkan label-label pada pod yang sudah berjalan pada node daripada berdasarkan label-label pada node. Aturan tersebut berbentuk "pod ini harus (atau, dalam kasus
anti-afinitas, tidak boleh) berjalan dalam X jika X itu sudah menjalankan satu atau lebih pod yang memenuhi aturan Y". Y dinyatakan sebagai sebuah LabelSelector dengan daftar namespace terkait; tidak seperti node, karena pod are namespaced (maka dari itu label-label pada pod diberi namespace secara implisit), sebuah label selector di atas label-label pod harus menentukan namespace yang akan diterapkan selector. Secara konsep X adalah domain topologi seperti node, rack, zona penyedia cloud, daerah penyedia cloud, dll. Kamu dapat menyatakannya menggunakan topologyKey yang merupakan kunci untuk label node yang digunakan sistem untuk menunjukkan domain topologi tersebut, contohnya lihat kunci label yang terdaftar di atas pada bagian Selingan: label node built-in.
Catatan:
Afinitas and anti-afinitas antar pod membutuhkan jumlah pemrosesan yang substansial yang dapat memperlambat penjadwalan pada klaster berukuran besar secara signifikan. Kami tidak merekomendasikan penggunaan mereka pada klaster yang berukuran lebih besar dari beberapa ratus node.Catatan:
Anti-afinitas pod mengharuskan node untuk diberi label secara konsisten, misalnya setiap node dalam klaster harus memiliki label sesuai yang cocok dengantopologyKey. Jika sebagian atau semua node tidak memiliki label topologyKey yang dinyatakan, hal ini dapat menyebabkan perilaku yang tidak diinginkan.Seperti afinitas node, ada dua tipe afinitas dan anti-afinitas pod, yaitu requiredDuringSchedulingIgnoredDuringExecution dan
preferredDuringSchedulingIgnoredDuringExecution yang menunjukan persyaratan "kuat" vs. "lemah". Lihat deskripsi pada bagian afinitas node sebelumnya.
Sebuah contoh dari afinitas requiredDuringSchedulingIgnoredDuringExecution adalah "Tempatkan bersamaan pod layanan A dan layanan B di zona yang sama, karena mereka banyak berkomunikasi satu sama lain"
dan contoh preferDuringSchedulingIgnoredDuringExecution anti-afinitas akan menjadi "sebarkan pod dari layanan ini di seluruh zona" (persyaratan kuat tidak masuk akal, karena kamu mungkin memiliki lebih banyak pod daripada zona).
Afinitas antar pod dinyatakan sebagai field podAffinity dari field affinity pada PodSpec dan anti-afinitas antar pod dinyatakan sebagai field podAntiAffinity dari field affinity pada PodSpec.
Contoh pod yang menggunakan pod affinity:
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: failure-domain.beta.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: failure-domain.beta.kubernetes.io/zone
containers:
- name: with-pod-affinity
image: registry.k8s.io/pause:2.0
Afinitas pada pod tersebut menetapkan sebuah aturan afinitas pod dan aturan anti-afinitas pod. Pada contoh ini, podAffinity adalah requiredDuringSchedulingIgnoredDuringExecution
sementara podAntiAffinity adalah preferredDuringSchedulingIgnoredDuringExecution. Aturan afinitas pod menyatakan bahwa pod dapat dijadwalkan pada node hanya jika node tersebut berada pada zona yang sama dengan minimal satu pod yang sudah berjalan yang memiliki label dengan kunci "security" dan bernilai "S1". (Lebih detail, pod dapat berjalan pada node N jika node N memiliki label dengan kunci failure-domain.beta.kubernetes.io/zonedan nilai V sehingga ada minimal satu node dalam klaster dengan kunci failure-domain.beta.kubernetes.io/zone dan bernilai V yang menjalankan pod yang memiliki label dengan kunci "security" dan bernilai "S1".) Aturan anti-afinitas pod menyatakan bahwa pod memilih untuk tidak dijadwalkan pada sebuah node jika node tersebut sudah menjalankan pod yang memiliki label dengan kunci "security" dan bernilai "S2". (Jika topologyKey adalah failure-domain.beta.kubernetes.io/zone maka dapat diartikan bahwa pod tidak dapat dijadwalkan pada node jika node berada pada zona yang sama dengan pod yang memiliki label dengan kunci "security" dan bernilai "S2".) Lihat design doc untuk lebih banyak contoh afinitas dan anti-afinitas pod, baik requiredDuringSchedulingIgnoredDuringExecution
maupun preferredDuringSchedulingIgnoredDuringExecution.
Operator yang sah untuk afinitas dan anti-afinitas pod adalah In, NotIn, Exists, DoesNotExist.
Pada dasarnya, topologyKey dapat berupa label-kunci apapun yang sah. Namun, untuk alasan performa dan keamanan, ada beberapa batasan untuk topologyKey:
- Untuk afinitas and anti-afinitas pod
requiredDuringSchedulingIgnoredDuringExecution,topologyKeytidak boleh kosong. - Untuk anti-afinitas pod
requiredDuringSchedulingIgnoredDuringExecution, pengontrol penerimaanLimitPodHardAntiAffinityTopologydiperkenalkan untuk membatasitopologyKeypadakubernetes.io/hostname. Jika kamu menginginkan untuk membuatnya tersedia untuk topologi khusus, kamu dapat memodifikasi pengontrol penerimaan, atau cukup menonaktifkannya saja. - Untuk anti-afinitas pod
preferredDuringSchedulingIgnoredDuringExecution,topologyKeyyang kosong diinterpretasikan sebagai "semua topologi" ("semua topologi" sekarang dibatasi pada kombinasi darikubernetes.io/hostname,failure-domain.beta.kubernetes.io/zonedanfailure-domain.beta.kubernetes.io/region). - Kecuali untuk kasus-kasus di atas,
topologyKeydapat berupa label-kunci apapun yang sah.
Sebagai tambahan untuk labelSelector and topologyKey, kamu secara opsional dapat menyatakan daftar namespaces dari namespaces yang akan digunakan untuk mencocokan labelSelector (daftar ini berjalan pada level definisi yang sama dengan labelSelector dan topologyKey)
Jika dihilangkan atau kosong, daftar ini sesuai standar akan merujuk pada namespace dari pod tempat definisi afinitas/anti-afinitas dinyatakan.
Semua matchExpressions berkaitan dengan afinitas and anti-afinitas requiredDuringSchedulingIgnoredDuringExecution harus dipenuhi agar pod dapat dijadwalkan pada node.
Penggunaan yang lebih praktikal
Afinitas and anti-afinitas antar pod dapat menjadi lebih berguna saat digunakan bersamaan dengan koleksi dengan level yang lebih tinggi seperti ReplicaSets, StatefulSets, Deployments, dll. Pengguna dapat dengan mudah mengkonfigurasi bahwa satu set workload harus ditempatkan bersama dalam topologi yang didefinisikan sama, misalnya, node yang sama.
Selalu ditempatkan bersamaan pada node yang sama
Dalam klaster berisi 3 node, sebuah aplikasi web memiliki in-memory cache seperti redis. Kita menginginkan agar web-server dari aplikasi ini sebisa mungkin ditempatkan bersamaan dengan cache.
Berikut ini kutipan yaml dari deployment redis sederhana dengan 3 replika dan label selector app=store, Deployment memiliki konfigurasi PodAntiAffinity untuk memastikan scheduler tidak menempatkan replika bersamaan pada satu node.
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-cache
spec:
selector:
matchLabels:
app: store
replicas: 3
template:
metadata:
labels:
app: store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: redis-server
image: redis:3.2-alpine
Kutipan yaml dari deployment webserver berikut ini memiliki konfigurasi podAntiAffinity dan podAffinity. Konfigurasi ini menginformasikan scheduler bahwa semua replika harus ditempatkan bersamaan dengan pod yang memiliki label selector app=store. Konfigurasi ini juga memastikan bahwa setiap replika webserver tidak ditempatkan bersamaan pada satu node.
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-server
spec:
selector:
matchLabels:
app: web-store
replicas: 3
template:
metadata:
labels:
app: web-store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web-store
topologyKey: "kubernetes.io/hostname"
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: web-app
image: nginx:1.12-alpine
Jika kita membuat kedua dployment di atas, klaster berisi 3 node kita seharusnya menjadi seperti berikut.
| node-1 | node-2 | node-3 |
|---|---|---|
| webserver-1 | webserver-2 | webserver-3 |
| cache-1 | cache-2 | cache-3 |
st
Seperti yang kamu lihat, semua 3 replika dari web-server secara otomatis ditempatkan bersama dengan cache seperti yang diharapkan.
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
redis-cache-1450370735-6dzlj 1/1 Running 0 8m 10.192.4.2 kube-node-3
redis-cache-1450370735-j2j96 1/1 Running 0 8m 10.192.2.2 kube-node-1
redis-cache-1450370735-z73mh 1/1 Running 0 8m 10.192.3.1 kube-node-2
web-server-1287567482-5d4dz 1/1 Running 0 7m 10.192.2.3 kube-node-1
web-server-1287567482-6f7v5 1/1 Running 0 7m 10.192.4.3 kube-node-3
web-server-1287567482-s330j 1/1 Running 0 7m 10.192.3.2 kube-node-2
Tidak akan pernah ditempatkan bersamaan dalam node yang sama
Contoh di atas menggunakan aturan PodAntiAffinity dengan topologyKey: "kubernetes.io/hostname" untuk melakukan deploy klaster redis sehingga tidak ada dua instance terletak pada hos yang sama.
Lihat tutorial ZooKeeper untuk contoh dari konfigurasi StatefulSet dengan anti-afinitas untuk ketersediaan tinggi, menggunakan teknik yang sama.
Untuk informasi lebih lanjut tentang afinitas/anti-afinitas antar pod, lihat design doc.
Kamu juga dapat mengecek Taints, yang memungkinkan sebuah node untuk menolak sekumpulan pod.
nodeName
nodeName adalah bentuk paling sederhana dari pembatasan pemilihan node, tetapi karena
keterbatasannya biasanya tidak digunakan. nodeName adalah sebuah field dari
PodSpec. Jika tidak kosong, scheduler mengabaikan pod dan
kubelet yang berjalan pada node tersebut yang mencoba menjalankan pod. Maka, jika
nodeName disediakan dalam PodSpec, ia memiliki hak yang lebih tinggi dibanding metode-metode di atas untuk pemilihan node.
Beberapa keterbatasan dari penggunaan nodeName untuk memilih node adalah:
- Jika node yang disebut tidak ada, maka pod tidak akan dijalankan, dan dalam beberapa kasus akan dihapus secara otomatis.
- Jika node yang disebut tidak memiliki resource yang cukup untuk mengakomodasi pod, pod akan gagal dan alasannya akan mengindikasikan sebab kegagalan, misalnya OutOfmemory atau OutOfcpu.
- Nama node pada lingkungan cloud tidak selalu dapat diprediksi atau stabil.
Berikut ini contoh konfigurasi pod menggunakan field nodeName:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
nodeName: kube-01
Pod di atas akan berjalan pada node kube-01.
Selanjutnya
4 - Taint dan Toleration
Afinitas Node, seperti yang dideskripsikan di sini, adalah salah satu properti dari Pod yang menyebabkan pod tersebut memiliki preferensi untuk ditempatkan di sekelompok Node tertentu (preferensi ini dapat berupa soft constraints atau hard constraints yang harus dipenuhi). Taint merupakan kebalikan dari afinitas -- properti ini akan menyebabkan Pod memiliki preferensi untuk tidak ditempatkan pada sekelompok Node tertentu.
Taint dan toleration bekerja sama untuk memastikan Pod dijadwalkan pada Node yang sesuai. Satu atau lebih taint akan diterapkan pada suatu node; hal ini akan menyebabkan node tidak akan menerima pod yang tidak mengikuti taint yang sudah diterapkan.
Konsep
Kamu dapat menambahkan taint pada sebuah node dengan menggunakan perintah kubectl taint. Misalnya,
kubectl taint nodes node1 key=value:NoSchedule
akan menerapkan taint pada node node1. Taint tersebut memiliki key key, value value,
dan effect taint NoSchedule. Hal ini artinya pod yang ada tidak akan dapat dijadwalkan pada node1
kecuali memiliki taint yang sesuai.
Untuk menghilangkan taint yang ditambahkan dengan perintah di atas, kamu dapat menggunakan perintah di bawah ini:
kubectl taint nodes node1 key:NoSchedule-
Kamu dapat memberikan spesifikasi toleration untuk pod pada bagian PodSpec.
Kedua toleration yang diterapkan di bawa ini "sesuai" dengan taint yang
taint yang dibuat dengan perintah kubectl taint di atas, sehingga sebuah pod
dengan toleration yang sudah didefinisikan akan mampu di-schedule ke node node:
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
tolerations:
- key: "key"
operator: "Exists"
effect: "NoSchedule"
Sebuah toleration "sesuai" dengan sebuah taint jika key dan efek yang ditimbulkan sama:
operatordianggapExists(pada kasus dimana tidak adavalueyang diberikan), atauoperatordianggapEqualdanvalueyang ada sama
Operator bernilai Equal secara default jika tidak diberikan spesifikasi khusus.
Catatan:
Terdapat dua kasus khusus:
- Sebuah
keydengan operatorExistsakan sesuai dengan semua key, value, dan effect yang ada. Dengan kata lain, tolaration ini akan menerima semua hal yang diberikan.
tolerations:
- operator: "Exists"
- Sebuah
effectyang kosong akan dianggap sesuai dengan semua effect dengan keykey.
tolerations:
- key: "key"
operator: "Exists"
Contoh yang diberikan di atas menggunakan effect untuk NoSchedule.
Alternatif lain yang dapat digunakan adalah effect untuk PreferNoSchedule.
PreferNoSchedule merupakan "preferensi" yang lebih fleksibel dari NoSchedule --
sistem akan mencoba untuk tidak menempatkan pod yang tidak menoleransi taint
pada node, tapi hal ini bukan merupakan sesuatu yang harus dipenuhi. Jenis ketiga
dari effect adalah NoExecute, akan dijelaskan selanjutnya.
Kamu dapat menerapkan beberapa taint sekaligus pada node atau beberapa toleration sekaligus pada sebuah pod. Mekanisme Kubernetes dapat memproses beberapa taint dan toleration sekaligus sama halnya seperti sebuah filter: memulai dengan taint yang ada pada node, kemudian mengabaikan taint yang sesuai pada pod yang memiliki toleration yang sesuai; kemudian taint yang diterapkan pada pod yang sudah disaring tadi akan menghasilkan suatu effect pada pod. Secara khusus:
- jika terdapat taint yang tidak tersaring dengan effect
NoSchedulemaka Kubernetes tidak akan menempatkan pod pada node tersebut - jika tidak terdapat taint yang tidak tersaring dengan effect
NoScheduletapi terdapat setidaknya satu taint yang tidak tersaring dengan effectPreferNoSchedulemaka Kubernetes akan mencoba untuk tidak akan menempatkan pod pada node tersebut - jika terdapat taint yang tidak tersaring dengan effect
NoExecutemaka pod akan berada dalam kondisi evicted dari node (jika pod tersebut sudah terlanjur ditempatkan pada node tersebut), dan tidak akan di-schedule lagi pada node tersebut.
Sebagai contoh, bayangkan kamu memberikan taint pada node sebagai berikut:
kubectl taint nodes node1 key1=value1:NoSchedule
kubectl taint nodes node1 key1=value1:NoExecute
kubectl taint nodes node1 key2=value2:NoSchedule
Dan pod memiliki dua toleration:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
Pada kasus ini, pod tidak akan di-schedule pada node, karena tidak ada toleration yang sesuai dengan taint ketiga. Akan tetapi, pod yang sebelumnya sudah dijalankan di node dimana taint ditambahkan akan tetap jalan, karena taint ketiga merupakan taint yang tidak ditoleransi oleh pod.
Pada umumnya, jika sebuah taint memiliki effect NoExecute ditambahkan pada node,
maka semua pod yang tidak menoleransi taint tersebut akan berada dalam state
evicted secara langsung, dan semua pod yang menoleransi taint tersebut
tidak akan berjalan seperti biasanya (tidak dalam state evicted). Meskipun demikian,
toleration dengan effect NoExecute dapat dispesfikasikan sebagai field opsional
tolerationSeconds yang memberikan perintah berapa lama suatu pod akan berada
pada node apabila sebuah taint ditambahkan. Contohnya:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600
ini berarti apabila sebuah pod sedang dalam berada dalam state running, kemudian sebuah taint yang sesuai ditambahkan pada node, maka pod tersebut akan tetap berada di dalam node untuk periode 3600 detik sebelum state-nya berubah menjadi evicted. Jika taint dihapus sebelum periode tersebut, maka pod tetap berjalan sebagaimana mestinya.
Contoh Penggunaan
Taint dan toleration adalah mekanisme fleksibel yang digunakan untuk memaksa pod agar tidak dijadwalkan pada node-node tertentu atau mengubah state pod menjadi evicted. Berikut adalah beberapa contoh penggunaannya:
Node-Node yang Sifatnya Dedicated: Jika kamu ingin menggunakan sekumpulan node dengan penggunaan eksklusif dari sekumpulan pengguna, kamu dapat menambahkan taint pada node-node tersebut (misalnya,
kubectl taint nodes nodename dedicated=groupName:NoSchedule) dan kemudian menambahkan toleration yang sesuai pada pod-pod yang berada di dalamnya (hal ini dapat dilakukan dengan mudah dengan cara menulis admission controller yang bersifat khusus). Pod-pod dengan toleration nantinya akan diperbolehkannya untuk menggunakan node yang sudah di-taint (atau dengan kata lain didedikasikan penggunaannya) maupun node lain yang ada di dalam klaster. Jika kamu ingin mendedikasikan node khusus yang hanya digunakan oleh pod-pod tadi serta memastikan pod-pod tadi hanya menggunakan node yang didedikasikan, maka kamu harus menambahkan sebuah label yang serupa dengan taint yang diberikan pada sekelompok node (misalnya,dedicated=groupName), dan admission controller sebaiknya menambahkan afininitas node untuk memastikan pod-pod tadi hanya dijadwalkan pada node dengan labeldedicated=groupName.Node-Node dengan Perangkat Keras Khusus: Pada suatu klaster dimana sebagian kecuali node memiliki perangkat keras khusus (misalnya GPU), kita ingin memastikan hanya pod-pod yang membutuhkan GPU saja yang dijadwalkan di node dengan GPU. Hal ini dapat dilakukan dengan memberikan taint pada node yang memiliki perangkat keras khusus (misalnya,
kubectl taint nodes nodename special=true:NoScheduleataukubectl taint nodes nodename special=true:PreferNoSchedule) serta menambahkan toleration yang sesuai pada pod yang menggunakan node dengan perangkat keras khusus. Seperti halnya pada kebutuhan dedicated node, hal ini dapat dilakukan dengan mudah dengan cara menulis admission controller yang bersifat khusus. Misalnya, kita dapat menggunakan Extended Resource untuk merepresentasikan perangkat keras khusus, kemudian taint node dengan perangkat keras khusus dengan nama extended resource dan jalankan admission controller ExtendedResourceToleration. Setelah itu, karena node yang ada sudah di-taint, maka tidak akan ada pod yang tidak memiliki toleration yang akan dijadwalkan pada node tersebut_. Meskipun begitu, ketika kamu membuat suatu pod yang membutuhkan extended resource, maka admission controller dariExtendedResourceTolerationakan mengoreksi toleration sehingga pod tersebut dapat dijadwalkan pada node dengan perangkat keras khusus. Dengan demikian, kamu tidak perlu menambahkan toleration secara manual pada pod yang ada.Eviction berbasis Taint (fitur beta): Konfigurasi eviction per pod yang terjadi ketika pod mengalami gangguan, hal ini akan dibahas lebih lanjut di bagian selanjutnya.
Eviction berbasis Taint
Sebelumnya, kita sudah pernah membahas soal effect taint NoExecute,
yang memengaruhi pod yang sudah dijalankan dengan cara sebagai berikut:
- pod yang tidak menoleransi taint akan segera diubah state-nya menjadi evicted
- pod yang menoleransi taint yang tidak menspesifikasikan
tolerationSecondspada spesifikasi toleration yang ada akan tetap berada di dalam node tanpa adanya batas waktu tertentu - pod yang menoleransi taint yang menspesifikasikan
tolerationSecondsspesifikasi toleration yang ada akan tetap berada di dalam node hingga batas waktu tertentu
Sebagai tambahan, Kubernetes 1.6 memperkenalkan dukungan alfa untuk merepresentasikan node yang bermasalah. Dengan kata lain, node controller akan secara otomatis memberikan taint pada sebuah node apabila node tersebut memenuhi kriteria tertentu. Berikut merupakan taint yang secara default disediakan:
node.kubernetes.io/not-ready: Node berada dalam state not ready. Hal ini terjadi apabila value dari NodeConditionReadyadalah "False".node.kubernetes.io/unreachable: Node berada dalam state unreachable dari node controller Hal ini terjadi apabila value dari NodeConditionReadyadalah "Unknown".node.kubernetes.io/out-of-disk: Node kehabisan kapasitas disk.node.kubernetes.io/memory-pressure: Node berada diambang kapasitas memori.node.kubernetes.io/disk-pressure: Node berada diambang kapasitas disk.node.kubernetes.io/network-unavailable: Jaringan pada Node bersifat unavailable.node.kubernetes.io/unschedulable: Node tidak dapat dijadwalkan.node.cloudprovider.kubernetes.io/uninitialized: Ketika kubelet dijalankan dengan penyedia layanan cloud "eksternal", taint ini akan diterapkan pada node untuk menandai node tersebut tidak digunakan. Setelah kontroler dari cloud-controller-manager melakukan inisiasi node tersebut, maka kubelet akan menghapus taint yang ada.
Pada versi 1.13, fitur TaintBasedEvictions diubah menjadi beta dan diaktifkan secara default,
dengan demikian taint-taint tersebut secara otomatis ditambahkan oleh NodeController (atau kubelet)
dan logika normal untuk melakukan eviction pada pod dari suatu node tertentu berdasarkan value
dari Ready yang ada pada NodeCondition dinonaktifkan.
Catatan:
Untuk menjaga perilaku rate limiting yang ada pada eviction pod apabila node mengalami masalah, sistem sebenarnya menambahkan taint dalam bentuk rate limiter. Hal ini mencegah eviction besar-besaran pada pod pada skenario dimana master menjadi terpisah dari node lainnya.Fitur beta ini, bersamaan dengan tolerationSeconds, mengizinkan sebuah pod
untuk menspesifikasikan berapa lama pod harus tetap sesuai dengan sebuah node
apabila node tersebut bermasalah.
Misalnya, sebuah aplikasi dengan banyak state lokal akan lebih baik untuk tetap berada di suatu node pada saat terjadi partisi jaringan, dengan harapan partisi jaringan tersebut dapat diselesaikan dan mekanisme eviction pod tidak akan dilakukan. Toleration yang ditambahkan akan berbentuk sebagai berikut:
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 6000
Perhatikan bahwa Kubernetes secara otomatis menambahkan toleration untuk
node.kubernetes.io/not-ready dengan tolerationSeconds=300
kecuali konfigurasi lain disediakan oleh pengguna.
Kubernetes juga secara otomatis menambahkan toleration untuk
node.kubernetes.io/unreachable dengan tolerationSeconds=300
kecuali konfigurasi lain disediakan oleh pengguna.
Toleration yang ditambahkan secara otomatis ini menjamin bahwa perilaku default dari suatu pod adalah tetap bertahan selama 5 menit pada node apabila salah satu masalah terdeteksi. Kedua toleration default tadi ditambahkan oleh DefaultTolerationSeconds admission controller.
Pod-pod pada DaemonSet dibuat dengan toleration
NoExecute untuk taint tanpa tolerationSeconds:
node.kubernetes.io/unreachablenode.kubernetes.io/not-ready
Hal ini menjamin pod-pod yang merupakan bagian dari DaemonSet tidak pernah berada di dalam state evicted apabila terjadi permasalahan pada node.
Taint pada Node berdasarkan Kondisi Tertentu
Pada versi 1.12, fitur TaintNodesByCondition menjadi fitur beta, dengan demikian lifecycle
dari kontroler node akan secara otomatis menambahkan taint sesuai dengan kondisi node.
Hal yang sama juga terjadi pada scheduler, scheduler tidak bertugas memeriksa kondisi node
tetapi kondisi taint. Hal ini memastikan bahwa kondisi node tidak memengaruhi apa
yang dijadwalkan di node. Pengguna dapat memilih untuk mengabaikan beberapa permasalahan yang
ada pada node (yang direpresentasikan oleh kondisi Node) dengan menambahkan toleration Pod NoSchedule.
Sedangkan taint dengan effect NoExecute dikendalikan oleh TaintBasedEviction yang merupakan
fitur beta yang diaktifkan secara default oleh Kubernetes sejak versi 1.13.
Sejak Kubernetes versi 1.8, kontroler DaemonSet akan secara otomatis
menambahkan toleration NoSchedule pada semua daemon untuk menjaga
fungsionalitas DaemonSet.
node.kubernetes.io/memory-pressurenode.kubernetes.io/disk-pressurenode.kubernetes.io/out-of-disk(hanya untuk pod yang bersifat critical)node.kubernetes.io/unschedulable(versi 1.10 atau yang lebih baru)node.kubernetes.io/network-unavailable(hanya untuk jaringan host)
Menambahkan toleration ini menjamin backward compatibility. Kamu juga dapat menambahkan toleration lain pada DaemonSet.
5 - Penjadwal Kubernetes
Dalam Kubernetes, scheduling atau penjadwalan ditujukan untuk memastikan Pod mendapatkan Node sehingga Kubelet dapat menjalankannya.
Ikhtisar Penjadwalan
Sebuah penjadwal mengawasi Pod yang baru saja dibuat dan belum ada Node yang dialokasikan untuknya. Untuk setiap Pod yang ditemukan oleh penjadwal, maka penjadwal tersebut bertanggung jawab untuk menemukan Node terbaik untuk menjalankan Pod. Penjadwal dapat menetapkan keputusan penempatan ini dengan mempertimbangkan prinsip-prinsip penjadwalan yang dijelaskan di bawah ini.
Jika kamu ingin memahami mengapa Pod ditempatkan pada Node tertentu, atau jika kamu berencana untuk mengimplementasikan penjadwal kustom sendiri, halaman ini akan membantu kamu belajar tentang penjadwalan.
Kube-scheduler
Kube-scheduler adalah penjadwal standar untuk Kubernetes dan dijalankan sebagai bagian dari _control plane_. Kube-scheduler dirancang agar jika kamu mau dan perlu, kamu bisa menulis komponen penjadwalan kamu sendiri dan menggunakannya.
Untuk setiap Pod yang baru dibuat atau Pod yang tak terjadwal lainnya, kube-scheduler memilih Node yang optimal untuk menjalankannya. Namun, setiap kontainer masuk Pod memiliki persyaratan sumber daya yang berbeda dan setiap Pod juga memiliki persyaratan yang berbeda juga. Oleh karena itu, Node yang ada perlu dipilih sesuai dengan persyaratan khusus penjadwalan.
Dalam sebuah Klaster, Node yang memenuhi persyaratan penjadwalan untuk suatu Pod disebut Node feasible. Jika tidak ada Node yang cocok, maka Pod tetap tidak terjadwal sampai penjadwal yang mampu menempatkannya.
Penjadwal menemukan Node-Node yang layak untuk sebuah Pod dan kemudian menjalankan sekumpulan fungsi untuk menilai Node-Node yang layak dan mengambil satu Node dengan skor tertinggi di antara Node-Node yang layak untuk menjalankan Pod. Penjadwal kemudian memberi tahu server API tentang keputusan ini dalam proses yang disebut dengan binding.
Beberapa faktor yang perlu dipertimbangkan untuk keputusan penjadwalan termasuk persyaratan sumber daya individu dan kolektif, aturan kebijakan / perangkat keras / lunak, spesifikasi persamaan dan anti-persamaan, lokalitas data, interferensi antar Workloads, dan sebagainya.
Pemilihan node pada kube-scheduler
Kube-scheduler memilih node untuk pod dalam 2 langkah operasi:
- Filtering
- Scoring
Langkah filtering menemukan sekumpulan Nodes yang layak untuk menjadwalkan Pod. Misalnya, penyarin PodFitsResources memeriksa apakah Node kandidat memiliki sumber daya yang cukup untuk memenuhi permintaan spesifik sumber daya dari Pod. Setelah langkah ini, daftar Node akan berisi Node-node yang sesuai; seringkali, akan terisi lebih dari satu. Jika daftar itu kosong, maka Pod itu tidak (belum) dapat dijadwalkan.
Pada langkah scoring, penjadwal memberi peringkat pada Node-node yang tersisa untuk memilih penempatan paling cocok untuk Pod. Penjadwal memberikan skor untuk setiap Node yang sudah tersaring, memasukkan skor ini pada aturan penilaian yang aktif.
Akhirnya, kube-scheduler memberikan Pod ke Node dengan peringkat tertinggi. Jika ada lebih dari satu node dengan skor yang sama, maka kube-scheduler memilih salah satunya secara acak.
Ada dua cara yang didukung untuk mengkonfigurasi perilaku penyaringan dan penilaian oleh penjadwal:
- Aturan Penjadwalan yang memungkinkan kamu untuk mengkonfigurasi Predicates untuk pemfilteran dan Priorities untuk penilaian.
- Profil Penjadwalan yang memungkinkan
kamu mengkonfigurasi Plugin yang menerapkan tahapan penjadwalan berbeda,
termasuk:
QueueSort,Filter,Score,Bind,Reserve,Permit, dan lainnya. Kamu juga bisa mengonfigurasi kube-scheduler untuk menjalankan profil yang berbeda.
Selanjutnya
- Baca tentang penyetelan performa penjadwal
- Baca tentang pertimbangan penyebarang topologi pod
- Baca referensi dokumentasi untuk kube-scheduler
- Pelajari tentang mengkonfigurasi beberapa penjadwal
- Pelajari tentang aturan manajemen topologi
- Pelajari tentang pengeluaran tambahan Pod
6 - Kerangka Kerja Penjadwalan (Scheduling Framework)
Kubernetes 1.15 [alpha]Kerangka kerja penjadwalan (Scheduling Framework) adalah arsitektur yang dapat dipasang (pluggable) pada penjadwal Kubernetes untuk membuat kustomisasi penjadwal lebih mudah. Hal itu dilakukan dengan menambahkan satu kumpulan "plugin" API ke penjadwal yang telah ada. Plugin dikompilasi ke dalam penjadwal. Beberapa API memungkinkan sebagian besar fitur penjadwalan diimplementasikan sebagai plugin, sambil tetap mempertahankan penjadwalan "inti" sederhana dan terpelihara. Silahkan merujuk pada [proposal desain dari kerangka penjadwalan] kep untuk informasi teknis lebih lanjut tentang desain kerangka kerja tersebut.
Alur kerja kerangka kerja
Kerangka kerja penjadwalan mendefinisikan beberapa titik ekstensi. Plugin penjadwal mendaftar untuk dipanggil di satu atau lebih titik ekstensi. Beberapa plugin ini dapat mengubah keputusan penjadwalan dan beberapa hanya bersifat informasi.
Setiap upaya untuk menjadwalkan satu Pod dibagi menjadi dua fase, Siklus Penjadwalan (Scheduling Cycle) dan Siklus Pengikatan (Binding Cycle).
Siklus Penjadwalan dan Siklus Pengikatan
Siklus penjadwalan memilih sebuah Node untuk Pod, dan siklus pengikatan menerapkan keputusan tersebut ke klaster. Secara bersama-sama, siklus penjadwalan dan siklus pengikatan diartikan sebagai sebuah "konteks penjadwalan (scheduling context)".
Siklus penjadwalan dijalankan secara serial, sementara siklus pengikatan dapat berjalan secara bersamaan.
Siklus penjadwalan atau pengikatan dapat dibatalkan jika Pod telah ditentukan untuk tidak terjadwalkan atau jika terdapat kesalahan internal. Pod akan dikembalikan ke antrian dan dicoba lagi.
Titik-titik ekstensi
Gambar berikut menunjukkan konteks penjadwalan Pod dan titik-titik ekstensi yang diperlihatkan oleh kerangka penjadwalan. Dalam gambar ini "Filter" setara dengan "Predicate" dan "Scoring" setara dengan "Priority Function".
Satu plugin dapat mendaftar di beberapa titik ekstensi untuk melakukan pekerjaan yang lebih kompleks atau stateful.
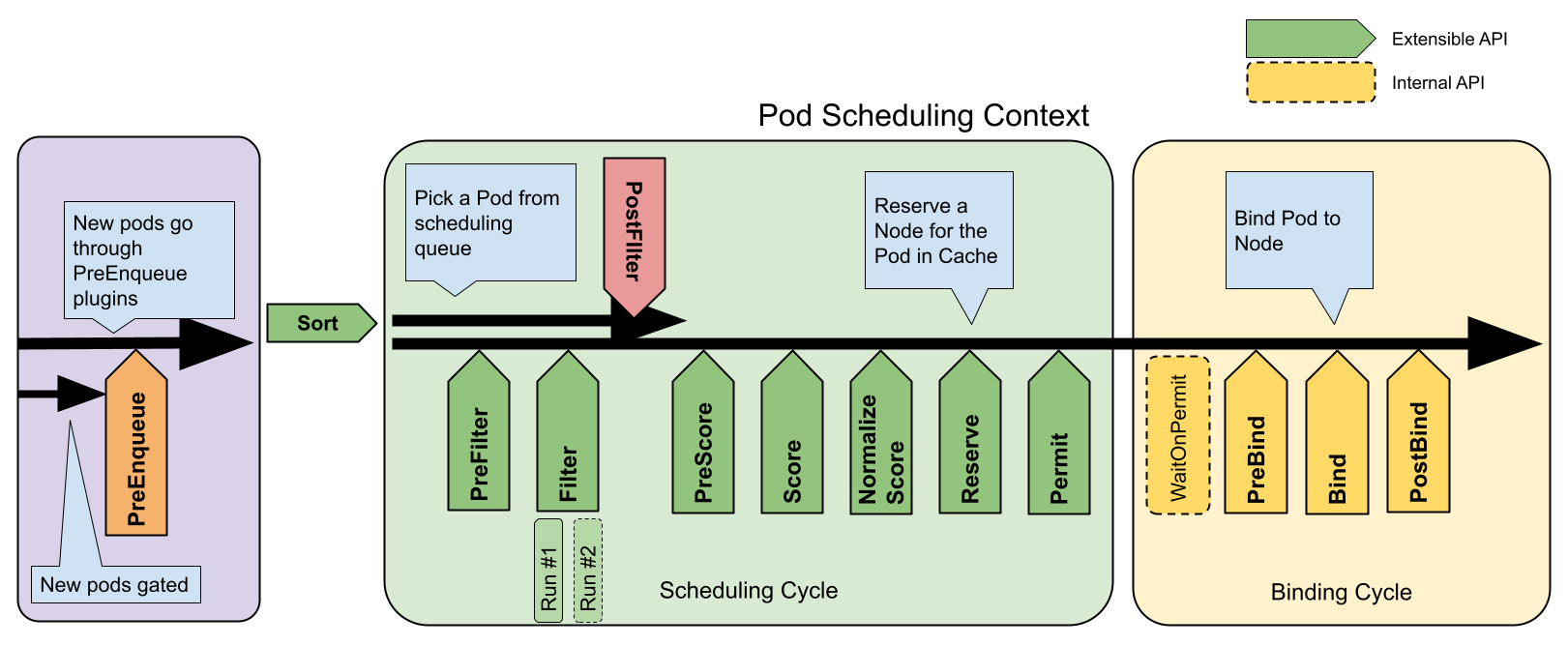
Titik-titik ekstensi dari kerangka kerja Penjadwalan
QueueSort
Plugin ini digunakan untuk mengurutkan Pod-Pod dalam antrian penjadwalan. Plugin
QueueSort pada dasarnya menyediakan fungsi Less (Pod1, Pod2). Hanya satu jenis
plugin QueueSort yang dapat diaktifkan dalam waktu yang bersamaan.
PreFilter
Plugin ini digunakan untuk melakukan pra-proses informasi tentang Pod, atau untuk memeriksa tertentu kondisi yang harus dipenuhi oleh klaster atau Pod. Jika plugin PreFilter menghasilkan hasil yang salah, siklus penjadwalan dibatalkan.
Filter
Plugin ini digunakan untuk menyaring Node yang tidak dapat menjalankan Pod. Untuk setiap Node, penjadwal akan memanggil plugin Filter sesuai dengan urutan mereka dikonfigurasi. Jika ada plugin Filter menandai Node menjadi infeasible, maka plugin yang lainnya tidak akan dipanggil untuk Node itu. Node-Node dapat dievaluasi secara bersamaan.
PostFilter
Plugin ini disebut setelah fase Filter, tetapi hanya ketika tidak ada node yang layak ditemukan untuk pod. Plugin dipanggil dalam urutan yang dikonfigurasi. Jika plugin postFilter menandai node sebagai 'Schedulable', plugin yang tersisa tidak akan dipanggil. Implementasi PostFilter yang khas adalah preemption, yang mencoba membuat pod dapat di menjadwalkan dengan mendahului Pod lain.
PreScore
Plugin ini digunakan untuk melakukan pekerjaan "pra-penilaian", yang menghasilkan keadaan yang dapat dibagi untuk digunakan oleh plugin-plugin Score. Jika plugin PreScore mengeluarkan hasil salah, maka siklus penjadwalan dibatalkan.
Score
Plugin ini digunakan untuk menentukan peringkat Node yang telah melewati fase penyaringan. Penjadwal akan memanggil setiap plugin Score untuk setiap Node. Akan ada kisaran bilangan bulat yang telah ditetapkan untuk mewakili skor minimum dan maksimum. Setelah fase NormalizeScore, penjadwal akan menggabungkan skor Node dari semua plugin sesuai dengan bobot plugin yang telah dikonfigurasi.
NormalizeScore
Plugin ini digunakan untuk memodifikasi skor sebelum penjadwal menghitung peringkat akhir Node-Node. Plugin yang mendaftar untuk titik ekstensi ini akan dipanggil dengan hasil Score dari plugin yang sama. Hal ini dilakukan sekali untuk setiap plugin dan setiap siklus penjadwalan.
Sebagai contoh, anggaplah sebuah plugin BlinkingLightScorer memberi peringkat
pada Node-Node berdasarkan berapa banyak kedipan lampu yang mereka miliki.
func ScoreNode(_ *v1.pod, n *v1.Node) (int, error) {
return getBlinkingLightCount(n)
}
Namun, jumlah maksimum kedipan lampu mungkin kecil jika dibandingkan dengan
NodeScoreMax. Untuk memperbaikinya, BlinkingLightScorer juga harus mendaftar
untuk titik ekstensi ini.
func NormalizeScores(scores map[string]int) {
highest := 0
for _, score := range scores {
highest = max(highest, score)
}
for node, score := range scores {
scores[node] = score*NodeScoreMax/highest
}
}
Jika ada plugin NormalizeScore yang menghasilkan hasil yang salah, maka siklus penjadwalan dibatalkan.
Catatan:
Plugin yang ingin melakukan pekerjaan "pra-pemesanan" harus menggunakan titik ekstensi NormalizeScore.Reserve
Ini adalah titik ekstensi yang bersifat informasi. Plugin yang mempertahankan keadaan runtime (alias "stateful plugins") harus menggunakan titik ekstensi ini untuk diberitahukan oleh penjadwal ketika sumber daya pada suatu Node dicadangkan untuk Pod yang telah disiapkan. Proses ini terjadi sebelum penjadwal benar-benar mengikat Pod ke Node, dan itu ada untuk mencegah kondisi balapan (race conditions) ketika penjadwal menunggu agar pengikatan berhasil.
Ini adalah langkah terakhir dalam siklus penjadwalan. Setelah Pod berada dalam status dicadangkan, maka itu akan memicu plugin Unreserve (apabila gagal) atau plugin PostBind (apabila sukses) di akhir siklus pengikatan.
Permit
Plugin Permit dipanggil pada akhir siklus penjadwalan untuk setiap Pod untuk mencegah atau menunda pengikatan ke Node kandidat. Plugin Permit dapat melakukan salah satu dari ketiga hal ini:
approve
Setelah semua plugin Permit menyetujui sebuah Pod, Pod tersebut akan dikirimkan untuk diikat.deny
Jika ada plugin Permit yang menolak sebuah Pod, Pod tersebut akan dikembalikan ke antrian penjadwalan. Hal ini akan memicu plugin Unreserve.wait (dengan batas waktu)
Jika plugin Permit menghasilkan "wait", maka Pod disimpan dalam daftar Pod "yang menunggu" internal, dan siklus pengikatan Pod ini dimulai tetapi akan langsung diblokir sampai mendapatkan approved. Jika waktu tunggu habis, ** wait ** menjadi ** deny ** dan Pod dikembalikan ke antrian penjadwalan, yang memicu plugin Unreserve.
Catatan:
Ketika setiap plugin dapat mengakses daftar Pod-Pod "yang menunggu" dan menyetujuinya (silahkan lihatFrameworkHandle), kami hanya mengharapkan
plugin Permit untuk menyetujui pengikatan Pod dalam kondisi "menunggu" yang
telah dipesan. Setelah Pod disetujui, akan dikirim ke fase PreBind.PreBind
Plugin ini digunakan untuk melakukan pekerjaan apa pun yang diperlukan sebelum Pod terikat. Sebagai contoh, plugin PreBind dapat menyediakan network volume dan melakukan mounting pada Node target sebelum mengizinkan Pod berjalan di sana.
Jika ada plugin PreBind yang menghasilkan kesalahan, maka Pod ditolak dan kembali ke antrian penjadwalan.
Bind
Plugin ini digunakan untuk mengikat Pod ke Node. Plugin-plugin Bind tidak akan dipanggil sampai semua plugin PreBind selesai. Setiap plugin Bind dipanggil sesuai urutan saat dikonfigurasi. Plugin Bind dapat memilih untuk menangani atau tidak Pod yang diberikan. Jika plugin Bind memilih untuk menangani Pod, ** plugin Bind yang tersisa dilewati **.
PostBind
Ini adalah titik ekstensi bersifat informasi. Plugin-plugin PostBind dipanggil setelah sebuah Pod berhasil diikat. Ini adalah akhir dari siklus pengikatan, dan dapat digunakan untuk membersihkan sumber daya terkait.
Unreserve
Ini adalah titik ekstensi bersifat informasi. Jika sebuah Pod telah dipesan dan kemudian ditolak di tahap selanjutnya, maka plugin-plugin Unreserve akan diberitahu. Plugin Unreserve harus membersihkan status yang terkait dengan Pod yang dipesan.
Plugin yang menggunakan titik ekstensi ini sebaiknya juga harus digunakan Reserve.
Plugin API
Ada dua langkah untuk plugin API. Pertama, plugin harus mendaftar dan mendapatkan konfigurasi, kemudian mereka menggunakan antarmuka titik ekstensi. Antarmuka (interface) titik ekstensi memiliki bentuk sebagai berikut.
type Plugin interface {
Name() string
}
type QueueSortPlugin interface {
Plugin
Less(*v1.pod, *v1.pod) bool
}
type PreFilterPlugin interface {
Plugin
PreFilter(context.Context, *framework.CycleState, *v1.pod) error
}
// ...
Konfigurasi plugin
Kamu dapat mengaktifkan atau menonaktifkan plugin dalam konfigurasi penjadwal. Jika kamu menggunakan Kubernetes v1.18 atau yang lebih baru, kebanyakan plugin-plugin penjadwalan sudah digunakan dan diaktifkan secara bawaan.
Selain plugin-plugin bawaan, kamu juga dapat mengimplementasikan plugin-plugin penjadwalan kamu sendiri dan mengonfigurasinya bersama-sama dengan plugin-plugin bawaan. Kamu bisa mengunjungi plugin-plugin penjadwalan untuk informasi lebih lanjut.
Jika kamu menggunakan Kubernetes v1.18 atau yang lebih baru, kamu dapat mengonfigurasi sekumpulan plugin sebagai profil penjadwal dan kemudian menetapkan beberapa profil agar sesuai dengan berbagai jenis beban kerja. Pelajari lebih lanjut di multi profil.
7 - Alokasi Sumber Daya Dinamis
Kubernetes v1.35 [stable](enabled by default)Alokasi sumber daya dinamis (dynamic resource allocation) adalah API untuk meminta dan berbagi sumber daya antara Pod dan kontainer di dalam sebuah Pod. Ini merupakan generalisasi dari API PersistentVolume untuk sumber daya generik. Biasanya, sumber daya tersebut bisa berupa perangkat seperti GPU.
Driver sumber daya pihak ketiga bertanggung jawab untuk melacak dan mempersiapkan sumber daya, dengan alokasi sumber daya yang ditangani oleh Kubernetes melalui parameter terstruktur (diperkenalkan pada Kubernetes 1.30). Berbagai jenis sumber daya mendukung parameter sembarang untuk mendefinisikan kebutuhan dan inisialisasi.
Kubernetes versi 1.26 hingga 1.31 menyertakan implementasi (alpha) dari DRA (Dynamic Resource Allocation) klasik, yang sekarang sudah tidak didukung lagi. Dokumentasi ini yang ditujukan untuk Kubernetes versi 1.36, menjelaskan pendekatan terkini untuk alokasi sumber daya dinamis dalam Kubernetes.
Sebelum kamu memulai
Kubernetes versi 1.36 menyertakan dukungan API tingkat klaster untuk alokasi sumber daya dinamis, tetapi harus diaktifkan secara eksplisit. Kamu juga harus menginstal driver sumber daya untuk sumber daya tertentu yang akan dikelola menggunakan API ini. Jika kamu tidak menggunakan Kubernetes versi 1.36, periksa dokumentasi untuk versi Kubernetes tersebut.
API
resource.k8s.io/v1beta1 dan resource.k8s.io/v1beta2 API groups menyediakan tipe-tipe berikut:
- ResourceClaim
- Menggambarkan permintaan akses ke sumber daya di dalam klaster untuk digunakan oleh beban kerja (workload). Misalnya, jika sebuah beban kerja membutuhkan perangkat akselerator dengan properti tertentu, permintaan tersebut diekspresikan melalui tipe ini. Bagian status melacak apakah klaim ini telah terpenuhi dan sumber daya spesifik apa yang telah dialokasikan.
- ResourceClaimTemplate
- Mendefinisikan spesifikasi dan beberapa metadata untuk membuat ResourceClaim. Dibuat oleh pengguna saat menerapkan beban kerja. ResourceClaim untuk setiap Pod kemudian dibuat dan dihapus secara otomatis oleh Kubernetes.
- DeviceClass
- Berisi kriteria seleksi yang telah ditentukan untuk perangkat tertentu serta konfigurasi untuk perangkat tersebut. DeviceClass dibuat oleh administrator klaster saat menginstal driver sumber daya. Setiap permintaan untuk mengalokasikan perangkat dalam ResourceClaim harus merujuk tepat satu DeviceClass.
- ResourceSlice
- Digunakan oleh driver DRA untuk mempublikasikan informasi tentang sumber daya (biasanya perangkat) yang tersedia di klaster.
- DeviceTaintRule
- Digunakan oleh administrator atau komponen control plane untuk menambahkan taint perangkat pada perangkat yang dijelaskan dalam ResourceSlice.
Semua parameter yang memilih perangkat didefinisikan dalam ResourceClaim dan DeviceClass menggunakan tipe in-tree. Parameter konfigurasi dapat disematkan di sana. Parameter konfigurasi yang valid bergantung pada driver DRA -- Kubernetes hanya meneruskannya tanpa memprosesnya.
PodSpec dari core/v1 mendefinisikan ResourceClaim yang diperlukan untuk sebuah Pod dalam field resourceClaims. Entri dalam daftar tersebut merujuk pada ResourceClaim atau ResourceClaimTemplate. Ketika merujuk pada ResourceClaim, semua Pod yang menggunakan PodSpec ini (misalnya, di dalam Deployment atau StatefulSet) berbagi instance ResourceClaim yang sama. Ketika merujuk pada ResourceClaimTemplate, setiap Pod mendapatkan instance tersendiri.
Daftar resources.claims untuk sumber daya kontainer mendefinisikan apakah sebuah kontainer mendapatkan akses ke instance sumber daya tersebut, yang memungkinkan berbagi sumber daya antara satu atau lebih kontainer.
Berikut adalah contoh untuk driver sumber daya fiksi. Dua objek ResourceClaim akan dibuat untuk Pod ini, dan setiap kontainer mendapatkan akses ke salah satu dari mereka.
apiVersion: resource.k8s.io/v1beta2
kind: DeviceClass
metadata:
name: resource.example.com
spec:
selectors:
- cel:
expression: device.driver == "resource-driver.example.com"
---
apiVersion: resource.k8s.io/v1beta2
kind: ResourceClaimTemplate
metadata:
name: large-black-cat-claim-template
spec:
spec:
devices:
requests:
- name: req-0
exactly:
deviceClassName: resource.example.com
selectors:
- cel:
expression: |-
device.attributes["resource-driver.example.com"].color == "black" &&
device.attributes["resource-driver.example.com"].size == "large"
---
apiVersion: v1
kind: Pod
metadata:
name: pod-with-cats
spec:
kontainers:
- name: kontainer0
image: ubuntu:20.04
command: ["sleep", "9999"]
resources:
claims:
- name: cat-0
- name: kontainer1
image: ubuntu:20.04
command: ["sleep", "9999"]
resources:
claims:
- name: cat-1
resourceClaims:
- name: cat-0
resourceClaimTemplateName: large-black-cat-claim-template
- name: cat-1
resourceClaimTemplateName: large-black-cat-claim-template
Penjadwalan (Scheduling)
Scheduler bertanggung jawab untuk mengalokasikan sumber daya ke ResourceClaim setiap kali sebuah Pod membutuhkannya. Scheduler melakukan ini dengan mengambil daftar lengkap sumber daya yang tersedia dari objek ResourceSlice, melacak sumber daya mana yang sudah dialokasikan ke ResourceClaim yang ada, dan kemudian memilih dari sumber daya yang masih tersisa.
Saat ini, satu-satunya jenis sumber daya yang didukung adalah perangkat. Sebuah instance perangkat memiliki nama, beberapa atribut, dan kapasitas. Perangkat dipilih melalui ekspresi CEL (Common Expression Language) yang memeriksa atribut dan kapasitas tersebut. Selain itu, perangkat yang dipilih juga dapat dibatasi pada kumpulan perangkat yang memenuhi batasan tertentu. Sumber daya yang dipilih dicatat dalam status ResourceClaim bersama dengan konfigurasi spesifik vendor, sehingga ketika sebuah pod akan dijalankan pada sebuah Node, driver sumber daya di Node tersebut memiliki semua informasi yang diperlukan untuk mempersiapkan sumber daya tersebut.
Dengan menggunakan parameter terstruktur, scheduler dapat mengambil keputusan tanpa berkomunikasi dengan driver sumber daya DRA. Scheduler juga dapat menjadwalkan beberapa Pod dengan cepat dengan menyimpan informasi tentang alokasi ResourceClaim di memori dan menuliskan informasi ini ke objek ResourceClaim di latar belakang sambil secara bersamaan mengikat pod ke sebuah Node.
Memantau Sumber Daya
Kubelet menyediakan layanan gRPC untuk memungkinkan penemuan sumber daya dinamis dari Pod yang sedang berjalan. Untuk informasi lebih lanjut tentang endpoint gRPC, lihat pelaporan alokasi sumber daya.
Pod yang Sudah Dijadwalkan Sebelumnya
Ketika kamu - atau klien API lainnya - membuat sebuah Pod dengan spec.nodeName yang sudah diatur, scheduler akan dilewati. Jika ada ResourceClaim yang dibutuhkan oleh Pod tersebut tetapi belum ada, belum dialokasikan, atau belum dipesan untuk Pod tersebut, maka kubelet akan gagal menjalankan Pod dan akan memeriksa ulang secara berkala karena persyaratan tersebut mungkin masih dapat dipenuhi di kemudian waktu.
Situasi semacam ini juga dapat terjadi ketika dukungan untuk alokasi sumber daya dinamis tidak diaktifkan di scheduler pada saat Pod dijadwalkan (karena perbedaan versi, konfigurasi, feature gate, dll.). kube-controller-manager mendeteksi hal ini dan mencoba membuat Pod dapat dijalankan dengan memesan ResourceClaim yang diperlukan. Namun, ini hanya berhasil jika ResourceClaim tersebut telah dialokasikan oleh scheduler untuk Pod lain.
Lebih baik untuk menghindari melewati scheduler karena Pod yang ditugaskan ke sebuah Node akan memblokir sumber daya normal (RAM, CPU) yang tidak dapat digunakan untuk Pod lain sementara Pod tersebut terhenti. Untuk membuat sebuah Pod berjalan di Node tertentu sambil tetap melalui alur penjadwalan normal, buatlah Pod dengan nodeSelector yang secara tepat cocok dengan Node yang diinginkan:
apiVersion: v1
kind: Pod
metadata:
name: pod-with-cats
spec:
nodeSelector:
kubernetes.io/hostname: name-of-the-intended-node
...
Kamu juga dapat memodifikasi Pod yang masuk, pada saat admission, untuk menghapus field .spec.nodeName dan menggunakan nodeSelector sebagai gantinya.
Akses Admin
Kubernetes v1.36 [stable](enabled by default)Kamu dapat menandai sebuah permintaan dalam ResourceClaim atau ResourceClaimTemplate sebagai memiliki fitur istimewa untuk tugas pemeliharaan dan pemecahan masalah. Permintaan dengan akses admin memberikan akses ke perangkat yang sedang digunakan dan mungkin mengaktifkan izin tambahan saat membuat perangkat tersedia di dalam sebuah kontainer:
apiVersion: resource.k8s.io/v1beta2
kind: ResourceClaimTemplate
metadata:
name: large-black-cat-claim-template
spec:
spec:
devices:
requests:
- name: req-0
exactly:
deviceClassName: resource.example.com
allocationMode: All
adminAccess: true
Jika fitur ini dinonaktifkan, field adminAccess akan secara otomatis dihapus saat membuat ResourceClaim semacam itu.
Akses admin adalah mode istimewa dan tidak boleh diberikan kepada pengguna biasa dalam klaster multi-tenant. Mulai dari Kubernetes v1.33, hanya pengguna yang memiliki otorisasi untuk membuat objek ResourceClaim atau ResourceClaimTemplate di namespace yang diberi label resource.k8s.io/admin-access: "true" (case-sensitive) yang dapat menggunakan field adminAccess. Hal ini memastikan bahwa pengguna non-admin tidak dapat menyalahgunakan fitur tersebut.
Status Perangkat ResourceClaim
Kubernetes v1.33 [beta](enabled by default)Driver dapat melaporkan data status perangkat spesifik driver untuk setiap perangkat yang dialokasikan dalam sebuah ResourceClaim. Misalnya, IP yang diberikan ke perangkat antarmuka jaringan dapat dilaporkan dalam status ResourceClaim.
Driver yang menetapkan status, keakuratan informasi bergantung pada implementasi driver DRA tersebut. Oleh karena itu, status perangkat yang dilaporkan mungkin tidak selalu mencerminkan perubahan waktu nyata dari keadaan perangkat.
Ketika fitur ini dinonaktifkan, field tersebut secara otomatis akan dihapus saat menyimpan ResourceClaim.
Status perangkat ResourceClaim didukung ketika memungkinkan, dari driver DRA, untuk memperbarui ResourceClaim yang ada di mana field status.devices diatur.
Daftar Prioritas
Kubernetes v1.36 [stable](enabled by default)Kamu dapat menyediakan daftar prioritas sub-permintaan untuk permintaan dalam sebuah ResourceClaim. Scheduler kemudian akan memilih sub-permintaan pertama yang dapat dialokasikan. Ini memungkinkan pengguna untuk menentukan perangkat alternatif yang dapat digunakan oleh beban kerja jika pilihan utama tidak tersedia.
Dalam contoh di bawah ini, ResourceClaimTemplate meminta perangkat dengan warna hitam dan ukuran besar. Jika perangkat dengan atribut tersebut tidak tersedia, Pod tidak dapat dijadwalkan. Dengan fitur daftar prioritas, alternatif kedua dapat ditentukan, yang meminta dua perangkat dengan warna putih dan ukuran kecil. Perangkat hitam besar akan dialokasikan jika tersedia. Namun, jika tidak tersedia dan dua perangkat putih kecil tersedia, Pod masih dapat berjalan.
apiVersion: resource.k8s.io/v1beta2
kind: ResourceClaimTemplate
metadata:
name: prioritized-list-claim-template
spec:
spec:
devices:
requests:
- name: req-0
firstAvailable:
- name: large-black
deviceClassName: resource.example.com
selectors:
- cel:
expression: |-
device.attributes["resource-driver.example.com"].color == "black" &&
device.attributes["resource-driver.example.com"].size == "large"
- name: small-white
deviceClassName: resource.example.com
selectors:
- cel:
expression: |-
device.attributes["resource-driver.example.com"].color == "white" &&
device.attributes["resource-driver.example.com"].size == "small"
count: 2
Perangkat yang Dapat Dipartisi
Kubernetes v1.36 [beta](enabled by default)Perangkat yang direpresentasikan dalam DRA tidak harus berupa satu unit yang terhubung ke satu mesin, tetapi juga dapat berupa perangkat logis yang terdiri dari beberapa perangkat yang terhubung ke beberapa mesin. Perangkat-perangkat ini mungkin menggunakan sumber daya yang saling tumpang tindih dari perangkat fisik yang mendasarinya, yang berarti bahwa ketika satu perangkat logis dialokasikan, perangkat lainnya tidak akan lagi tersedia.
Dalam API ResourceSlice, ini direpresentasikan sebagai daftar CounterSet yang diberi nama, masing-masing berisi satu set counter yang juga diberi nama. Counter ini merepresentasikan sumber daya yang tersedia pada perangkat fisik yang digunakan oleh perangkat logis yang diiklankan melalui DRA.
Perangkat logis dapat menentukan daftar ConsumesCounters. Setiap entri berisi referensi ke sebuah CounterSet dan satu set counter yang diberi nama dengan jumlah yang akan mereka konsumsi. Jadi, agar sebuah perangkat dapat dialokasikan, set counter yang direferensikan harus memiliki jumlah yang cukup untuk counter yang direferensikan oleh perangkat tersebut.
Berikut adalah contoh dua perangkat, masing-masing mengonsumsi 6Gi memori dari sebuah counter bersama yang memiliki 8Gi memori. Dengan demikian, hanya satu dari perangkat tersebut yang dapat dialokasikan pada satu waktu. Scheduler menangani ini, dan hal ini transparan bagi konsumen karena API ResourceClaim tidak terpengaruh.
kind: ResourceSlice
apiVersion: resource.k8s.io/v1beta2
metadata:
name: resourceslice
spec:
nodeName: worker-1
pool:
name: pool
generation: 1
resourceSliceCount: 1
driver: dra.example.com
sharedCounters:
- name: gpu-1-counters
counters:
memory:
value: 8Gi
devices:
- name: device-1
consumesCounters:
- counterSet: gpu-1-counters
counters:
memory:
value: 6Gi
- name: device-2
consumesCounters:
- counterSet: gpu-1-counters
counters:
memory:
value: 6Gi
Taint dan Toleransi Perangkat
Kubernetes v1.35 [stable](enabled by default)Taint perangkat mirip dengan taint pada Node: sebuah taint memiliki kunci string, nilai string, dan efek. Efek ini diterapkan pada ResourceClaim yang menggunakan perangkat yang telah ditaint dan pada semua Pod yang merujuk ke ResourceClaim tersebut. Efek "NoSchedule" mencegah penjadwalan Pod-Pod tersebut. Perangkat yang ditaint akan diabaikan saat mencoba mengalokasikan ResourceClaim karena penggunaannya akan mencegah penjadwalan Pod.
Efek "NoExecute" menyiratkan "NoSchedule" dan, selain itu, menyebabkan pengusiran semua Pod yang telah dijadwalkan sebelumnya. Pengusiran ini diimplementasikan dalam pengontrol pengusiran taint perangkat di kube-controller-manager dengan cara menghapus Pod yang terpengaruh.
ResourceClaim dapat mentoleransi taint. Jika sebuah taint ditoleransi, efeknya tidak berlaku. Toleransi kosong cocok dengan semua taint. Toleransi dapat dibatasi pada efek tertentu dan/atau cocok dengan pasangan kunci/nilai tertentu. Toleransi dapat memeriksa keberadaan kunci tertentu, terlepas dari nilai apa yang dimilikinya, atau dapat memeriksa nilai spesifik dari sebuah kunci. Untuk informasi lebih lanjut tentang pencocokan ini, lihat konsep taint pada Node.
Pengusiran dapat ditunda dengan mentoleransi taint untuk durasi tertentu. Penundaan tersebut dimulai saat taint ditambahkan ke perangkat, yang dicatat dalam sebuah field pada taint.
Taint berlaku seperti yang dijelaskan di atas juga untuk ResourceClaim yang mengalokasikan "semua" perangkat pada sebuah Node. Semua perangkat harus tidak ditaint atau semua taint mereka harus ditoleransi. Mengalokasikan perangkat dengan akses admin (dijelaskan di atas) juga tidak dikecualikan. Seorang admin yang menggunakan mode tersebut harus secara eksplisit mentoleransi semua taint untuk mengakses perangkat yang ditaint.
Taint dapat ditambahkan ke perangkat dengan dua cara berbeda:
Taint yang Ditetapkan oleh Driver
Driver DRA dapat menambahkan taint ke informasi perangkat yang dipublikasikan dalam ResourceSlice. Konsultasikan dokumentasi driver DRA untuk mengetahui apakah driver menggunakan taint dan apa kunci serta nilainya.
Taint yang Ditetapkan oleh Admin
Seorang admin atau komponen control plane dapat menaint perangkat tanpa harus meminta driver DRA untuk menyertakan taint dalam informasi perangkatnya di ResourceSlice. Mereka melakukannya dengan membuat DeviceTaintRules. Setiap DeviceTaintRule menambahkan satu taint ke perangkat yang cocok dengan selector perangkat. Tanpa selector semacam itu, tidak ada perangkat yang ditaint. Hal ini membuat lebih sulit untuk secara tidak sengaja mengusir semua Pod yang menggunakan ResourceClaim karena kesalahan dalam menentukan selector.
Perangkat dapat dipilih dengan memberikan nama DeviceClass, driver, pool, dan/atau perangkat. DeviceClass memilih semua perangkat yang dipilih oleh selector dalam DeviceClass tersebut. Dengan hanya nama driver, seorang admin dapat melakukan taint semua perangkat yang dikelola oleh driver tersebut, misalnya saat melakukan pemeliharaan driver di seluruh klaster. Menambahkan nama pool dapat membatasi taint ke satu Node, jika driver mengelola perangkat lokal Node.
Terakhir, menambahkan nama perangkat dapat memilih satu perangkat spesifik. Nama perangkat dan nama pool juga dapat digunakan sendiri, jika diinginkan. Misalnya, driver untuk perangkat lokal Node didorong untuk menggunakan nama Node sebagai nama pool mereka. Maka, melakukan taint dengan nama pool tersebut secara otomatis melakukan taint semua perangkat pada sebuah Node.
Driver mungkin menggunakan nama stabil seperti "gpu-0" yang menyembunyikan perangkat spesifik mana yang saat ini ditugaskan ke nama tersebut. Untuk mendukung perlakuan taint ubstabs perangkat keras tertentu, selector CEL dapat digunakan dalam DeviceTaintRule untuk mencocokkan atribut ID unik spesifik vendor, jika driver mendukungnya untuk perangkat kerasnya.
Taint berlaku selama DeviceTaintRule ada. taint dapat dimodifikasi dan dihapus kapan saja. Berikut adalah contoh DeviceTaintRule untuk driver DRA fiksi:
apiVersion: resource.k8s.io/v1alpha3
kind: DeviceTaintRule
metadata:
name: example
spec:
# The entire hardware installation for this
# particular driver is broken.
# Evict all pods and don't schedule new ones.
deviceSelector:
driver: dra.example.com
_taint_:
key: dra.example.com/unhealthy
value: Broken
effect: NoExecute
Mengaktifkan Alokasi Sumber Daya Dinamis
Alokasi sumber daya dinamis adalah fitur beta yang secara default tidak diaktifkan dan hanya dapat diaktifkan jika feature gate DynamicResourceAllocation serta API groups resource.k8s.io/v1beta1 dan resource.k8s.io/v1beta2 diaktifkan. Untuk detail lebih lanjut, lihat parameter --feature-gates dan --runtime-config pada kube-apiserver. Selain itu, kube-scheduler, kube-controller-manager, dan kubelet juga memerlukan feature gate ini.
Ketika driver sumber daya melaporkan status perangkat, maka feature gate DRAResourceClaimDeviceStatus harus diaktifkan selain DynamicResourceAllocation.
Cara cepat untuk memeriksa apakah klaster Kubernetes mendukung fitur ini adalah dengan daftar objek DeviceClass menggunakan perintah berikut:
kubectl get deviceclasses
Jika klaster kamu mendukung alokasi sumber daya dinamis, respon-nya adalah daftar objek DeviceClass atau:
No resources found
Jika tidak didukung, kesalahan berikut akan dicetak:
error: the server doesn't have a resource type "deviceclasses"
Konfigurasi default kube-scheduler mengaktifkan plugin "DynamicResources" hanya jika feature gate diaktifkan dan menggunakan API konfigurasi v1. Konfigurasi kustom mungkin perlu dimodifikasi untuk menyertakannya.
Selain mengaktifkan fitur di klaster, driver sumber daya juga harus diinstal. Silakan merujuk ke dokumentasi driver untuk detail lebih lanjut.
Mengaktifkan Akses Admin
Akses Admin adalah fitur alpha dan hanya dapat diaktifkan jika feature gate DRAAdminAccess diaktifkan di kube-apiserver dan kube-scheduler.
Mengaktifkan Status Perangkat
Status perangkat ResourceClaim adalah fitur alpha dan hanya dapat diaktifkan jika feature gate DRAResourceClaimDeviceStatus diaktifkan di kube-apiserver.
Mengaktifkan Daftar Prioritas
Daftar prioritas adalah fitur alpha dan hanya dapat diaktifkan jika feature gate DRAPrioritizedList diaktifkan di kube-apiserver dan kube-scheduler. Fitur ini juga memerlukan feature gate DynamicResourceAllocation diaktifkan.
Mengaktifkan Perangkat yang Dapat Dipartisi
Perangkat yang dapat dipartisi adalah fitur alpha dan hanya dapat diaktifkan jika feature gate DRAPartitionableDevices diaktifkan di kube-apiserver dan kube-scheduler.
Mengaktifkan Taint dan Toleransi Perangkat
Taint dan toleransi perangkat adalah fitur alpha dan hanya dapat diaktifkan jika feature gate DRADevice_Taint_s diaktifkan di kube-apiserver, kube-controller-manager, dan kube-scheduler. Untuk menggunakan DeviceTaintRules, versi API resource.k8s.io/v1alpha3 harus diaktifkan.
Selanjutnya
- Untuk informasi lebih lanjut tentang desain, lihat KEP tentang Alokasi Sumber Daya Dinamis dengan Parameter Terstruktur.
8 - Penyetelan Kinerja Penjadwal
Kubernetes v1.14 [beta]kube-scheduler merupakan penjadwal (scheduler) Kubernetes bawaan yang bertanggung jawab terhadap penempatan Pod-Pod pada seluruh Node di dalam sebuah klaster.
Node-Node di dalam klaster yang sesuai dengan syarat-syarat penjadwalan dari sebuah Pod disebut sebagai Node-Node layak (feasible). Penjadwal mencari Node-Node layak untuk sebuah Pod dan kemudian menjalankan fungsi-fungsi untuk menskor Node-Node tersebut, memilih sebuah Node dengan skor tertinggi di antara Node-Node layak lainnya, di mana Pod akan dijalankan. Penjadwal kemudian memberitahu API server soal keputusan ini melalui sebuah proses yang disebut Binding.
Laman ini menjelaskan optimasi penyetelan (tuning) kinerja yang relevan untuk klaster Kubernetes berskala besar.
Pada klaster berskala besar, kamu bisa menyetel perilaku penjadwal untuk menyeimbangkan hasil akhir penjadwalan antara latensi (seberapa cepat Pod-Pod baru ditempatkan) dan akurasi (seberapa akurat penjadwal membuat keputusan penjadwalan yang tepat).
Kamu bisa mengonfigurasi setelan ini melalui pengaturan percentageOfNodesToScore pada kube-scheduler.
Pengaturan KubeSchedulerConfiguration ini menentukan sebuah ambang batas untuk
penjadwalan Node-Node di dalam klaster kamu.
Pengaturan Ambang Batas
Opsi percentageOfNodesToScore menerima semua angka numerik antara 0 dan 100.
Angka 0 adalah angka khusus yang menandakan bahwa kube-scheduler harus menggunakan
nilai bawaan.
Jika kamu mengatur percentageOfNodesToScore dengan angka di atas 100, kube-scheduler
akan membulatkan ke bawah menjadi 100.
Untuk mengubah angkanya, sunting berkas konfigurasi kube-scheduler (biasanya /etc/kubernetes/config/kube-scheduler.yaml),
lalu ulang kembali kube-scheduler.
Setelah kamu selesai menyunting, jalankan perintah
kubectl get componentstatuses
untuk memverifikasi komponen kube-scheduler berjalan dengan baik (healthy). Keluarannya kira-kira seperti ini:
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
...
Ambang Batas Penskoran Node
Untuk meningkatan kinerja penjadwalan, kube-scheduler dapat berhenti mencari Node-Node yang layak saat sudah berhasil menemukannya. Pada klaster berskala besar, hal ini menghemat waktu dibandingkan dengan pendekatan awam yang mengecek setiap Node.
Kamu bisa mengatur ambang batas untuk menentukan berapa banyak jumlah Node minimal yang dibutuhkan, sebagai persentase bagian dari seluruh Node di dalam klaster kamu. kube-scheduler akan mengubahnya menjadi bilangan bulat berisi jumlah Node. Saat penjadwalan, jika kube-scheduler mengidentifikasi cukup banyak Node-Node layak untuk melewati jumlah persentase yang diatur, maka kube-scheduler akan berhenti mencari Node-Node layak dan lanjut ke [fase penskoran] (/id/docs/concepts/scheduling-eviction/kube-scheduler/#kube-scheduler-implementation).
Bagaimana penjadwal mengecek Node menjelaskan proses ini secara detail.
Ambang Batas Bawaan
Jika kamu tidak mengatur sebuah ambang batas, maka Kubernetes akan menghitung sebuah nilai menggunakan pendekatan linier, yaitu 50% untuk klaster dengan 100 Node, serta 10% untuk klaster dengan 5000 Node.
Artinya, kube-scheduler selalu menskor paling tidak 5% dari klaster kamu, terlepas dari
seberapa besar klasternya, kecuali kamu secara eksplisit mengatur percentageOfNodesToScore
menjadi lebih kecil dari 5.
Jika kamu ingin penjadwal untuk memasukkan seluruh Node di dalam klaster ke dalam penskoran,
maka aturlah percentageOfNodesToScore menjadi 100.
Contoh
Contoh konfigurasi di bawah ini mengatur percentageOfNodesToScore menjadi 50%.
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
algorithmSource:
provider: DefaultProvider
...
percentageOfNodesToScore: 50
Menyetel percentageOfNodesToScore
percentageOfNodesToScore merupakan angka 1 sampai 100 dengan
nilai bawaan yang dihitung berdasarkan ukuran klaster. Di sini juga terdapat
batas bawah yang telah ditetapkan, yaitu 100 Node.
Catatan:
Pada klaster dengan kurang dari 100 Node layak, penjadwal masih terus memeriksa seluruh Node karena Node-Node layak belum mencukupi supaya penjadwal dapat menghentikan proses pencarian lebih awal.
Pada klaster kecil, jika kamu mengatur percentageOfNodesToScore dengan angka kecil,
pengaturan ini hampir atau sama sekali tidak berpengaruh, karena alasan yang sama.
Jika klaster kamu punya ratusan Node, gunakan angka bawaan untuk opsi konfigurasi ini. Mengubah angkanya kemungkinan besar tidak akan mengubah kinerja penjadwal secara berarti.
Sebuah catatan penting yang perlu dipertimbangkan saat mengatur angka ini adalah ketika klaster dengan jumlah Node sedikit diperiksa untuk kelayakan, beberapa Node tidak dikirim untuk diskor bagi sebuah Pod. Hasilnya, sebuah Node yang mungkin memiliki nilai lebih tinggi untuk menjalankan Pod tersebut bisa saja tidak diteruskan ke fase penskoran. Hal ini berdampak pada penempatan Pod yang kurang ideal.
Kamu sebaiknya menghindari pengaturan percentageOfNodesToScore menjadi sangat rendah,
agar kube-scheduler tidak seringkali membuat keputusan penempatan Pod yang buruk.
Hindari pengaturan persentase di bawah 10%, kecuali throughput penjadwal sangat penting
untuk aplikasi kamu dan skor dari Node tidak begitu penting. Dalam kata lain, kamu
memilih untuk menjalankan Pod pada Node manapun selama Node tersebut layak.
Bagaimana Penjadwal Mengecek Node
Bagian ini ditujukan untuk kamu yang ingin mengerti bagaimana fitur ini bekerja secara internal.
Untuk memberikan semua Node di dalam klaster sebuah kesempatan yang adil untuk
dipertimbangkan dalam menjalankan Pod, penjadwal mengecek Node satu persatu
secara round robin. Kamu dapat membayangkan Node-Node ada di dalam sebuah array.
Penjadwal mulai dari indeks array pertama dan mengecek kelayakan dari Node sampai
jumlahnya telah mencukupi sesuai dengan percentageOfNodesToScore. Untuk Pod berikutnya,
penjadwal melanjutkan dari indeks array Node yang terhenti ketika memeriksa
kelayakan Node-Node untuk Pod sebelumnya.
Jika Node-Node berada di beberapa zona, maka penjadwal akan mengecek Node satu persatu pada seluruh zona untuk memastikan bahwa Node-Node dari zona berbeda masuk dalam pertimbangan kelayakan. Sebagai contoh, ada 6 Node di dalam 2 zona:
Zona 1: Node 1, Node 2, Node 3, Node 4
Zona 2: Node 5, Node 6
Penjadwal mempertimbangkan kelayakan dari Node-Node tersebut dengan urutan berikut:
Node 1, Node 5, Node 2, Node 6, Node 3, Node 4
Setelah semua Node telah dicek, penjadwal akan kembali pada Node 1.